Show Contents Previous Page Next Page
Chapter 2 - A First Module
Instant Modules with Apache::Registry By now, although it may not be obvious, you've seen two of the problems with
using the Apache APIs. The first problem is that you can't make changes to modules
casually. When using the Perl API, you have to restart the server in order to
have your changes take effect. With the C API, you have to rebuild the module
library or completely relink the server executable. Depending on the context,
this can be a minor annoyance (when you're developing a module on a test server
that gets light usage) to a bit of a headache (when you're trying to apply bug
fixes to an installed module on a heavily used production server). The second problem is that Apache API modules don't look anything like CGI
scripts. If you've got a lot of CGI scripts that you want to run faster, porting
them to the Apache API can be a major undertaking. Apache::Registry, an Apache Perl module that is part of the mod_perl
distribution, solves both problems with one stroke. When it runs, it creates
a pseudo-CGI environment that so exactly mimics the real thing that Perl CGI
scripts can run under it unmodified. It also maintains a cache of the scripts
under its control. When you make a change to a script, Apache::Registry
notices that the script's modification date has been updated and recompiles
the script, making the changes take effect immediately without a server restart.
Apache::Registry provides a clean upgrade path for existing CGI
scripts. Running CGI scripts under Apache::Registry gives them
an immediate satisfying performance boost without having to make any source
code changes. Later you can modify the script at your own pace to take advantage
of the nifty features offered only by the Apache API. Be aware that Apache::Registry is intended only for Perl CGI
scripts. CGI scripts written in other languages cannot benefit from the speedup
of having a Perl interpreter embedded in the server. To install Apache::Registry you'll need to create a directory
to hold the scripts that it manages. We recommend a perl directory
within the server root, such as ~www/perl. Now enter the following
directives into perl.conf:
Alias /perl/ /usr/local/apache/perl/
<Location /perl>
SetHandler perl-script
PerlHandler Apache::Registry
PerlSendHeader On
Options +ExecCGI
</Location>
The Alias directive makes URIs beginning with /perl
part of the virtual document tree and associates it with the physical path /usr/local/apache/perl.
Change this as appropriate for your site. The meaning of the various directives
inside <Location> are explained fully in Chapter 4.
Restart the server, and give Apache::Registry a try by creating
the script shown in Example 2-3. Name it hello.pl,
make it executable, and move it into ~www/perl/. With your browser,
fetch http://your.site/perl/hello.pl. You should see the familiar page
that we first saw in Figure 2-1.
Example 2-3. "Hello World" Using Apache::Registry
#!/usr/local/bin/perl
# file: hello.pl
print "Content-Type: text/html\n\n";
print <<END;
<HTML>
<HEAD>
<TITLE>Hello There</TITLE>
</HEAD>
<BODY>
<H1>Hello $ENV{REMOTE_HOST}</H1>
Who would take this book seriously if the first example didn't
say "hello world"?
</BODY>
</HTML>
END
As you can see, hello.pl looks identical to a normal CGI script,
even down to the use of $ENV{REMOTE_HOST} to fetch the CGI environment
variable that contains the name of the remote host. If you make changes to this
script, they will take effect immediately without requiring a server restart.
Plus, if you press the browser's reload button a few times in quick succession,
you may notice that it reloads much faster than a normal Perl CGI script would.
That's because the script's compiled code remains in memory between fetches.
There's none of the usual overhead for loading and running the Perl interpreter.
If you are used to using the CGI.pm module, you'll be heartened to learn that
under Apache::Registry you can create and process fill-out forms
in exactly the way you would in standard CGI scripts. Example 2-4
shows the code for hello_there.pl, another simple-minded example
which creates and processes a short fill-out form.
Example 2-4. Processing a Fill-Out
Form with Apache::Registry and CGI.pm
#!/usr/local/bin/perl
use CGI qw(:standard);
use strict;
my $name = param('name') || 'Anonymous';
print header(),
start_html(-title=>'Yo!',-bgcolor=>'white'),
h1("Hello $name"),
p(
"To change your name, enter it into the text field below and press",
em("change name.")
),
start_form(),
"Name: ",textfield(-name=>'name',-value=>'Anonymous'),
submit(-value=>'Change Name'),
end_form(),
hr(),
end_html();
The script begins by importing CGI.pm's standard group of function definitions.8
It then fetches a CGI parameter named name and stores it in a local
variable, calling CGI.pm's param() function to do the dirty work of
parsing the CGI query string. The script now calls CGI::header() to
produce the HTTP header, and builds up an HTML document in one long print
statement that makes calls to several other CGI functions. Among these calls
are ones to produce the fill-out form, a text field, and a submit button. Figure 2-7 shows a sample page produced by this
script.
Figure 2-7. The Apache::Registry script generates
a fill-out form to accept and process user input. 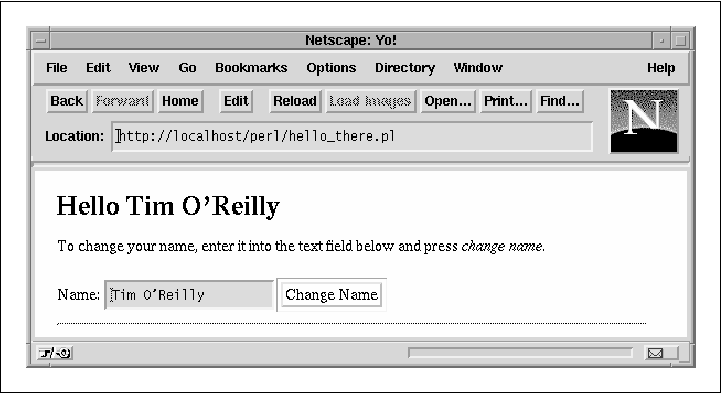 You'll find that most other CGI scripts will work just fine under Apache::Registry.
Those that don't are ones that assume that the process will go away after their
code exits and don't bother to do any cleanup as a result. For example, scripts
that use global variables without initializing them first will be unpleasantly
surprised when the global contains leftover data from a previous invocation
of the script's code. Scripts that use the process ID to create unique filenames
are also in for a shock when they're run again with the same PID. The best way to avoid such problems is by writing clean code. Avoid using
global variables and always use use strict to check for inadvertent
typos. While use strict may be painful at first, it will save you
more time in the long run, along with giving you a warm fuzzy feeling that you
are practicing good code hygiene. Be sure to clean up data structures such as
open filehandles and database handles before your code exits. The Apache::register_cleanup()
method is a handy way to arrange to have a cleanup subroutine called before
control returns to the server. In the short term, another approach is to run legacy scripts with Apache::PerlRun.
Unlike Apache::Registry, this module simply runs the script once
and forgets about it, just like a conventional CGI script. Apache::PerlRun
avoids the overhead of launching the Perl interpreter for each request but still
suffers the compile-time hit from loading each script. Therefore, it realizes
some but not all of the performance increase of Apache::Registry.
More information on Apache::Registry and Apache::PerlRun
scripts can be found in Chapters 3 and 4.
We discuss register_cleanup() and other tricks in Chapter 7.
Footnotes 8 Although it's handy to import function definitions
in this way, there's a significant memory overhead for every symbol you import.
If you have a lot of scripts that import from CGI.pm, your httpd
processes will eventually become too large. You can avoid this by precompiling
and importing CGI.pm's function calls from within the Perl startup script by
using the command use CGI qw(-compile:all). Alternatively, you can use CGI.pm's object-oriented calling
syntax, which does not carry the symbol importation overhead. Show Contents Previous Page Next Page
Copyright © 1999 by O'Reilly & Associates, Inc. | 