14.2. Чтение XML-документов с помощью DOM.
DOM -- это стандарт API, для разбора XML-документов, разработанный в недрах World Wide Web Consortium (W3C). Qt предоставляет реализацию DOM Level 2 для чтения, изменения и записи XML-документов.
DOM представляет XML-файл в памяти, в виде древовидной структуры. У приложения имеется возможность перемещаться по этой структуре, как ему заблагорассудится. Программа может изменить содержимое дерева и сохранить его обратно в файл.
Рассмотрим следующий XML-документ:
<doc>
<quote>Errare humanum est</quote>
<translation>To err is human</translation>
</doc>
Соответствующее ему дерево DOM:

В Qt, имена классов узлов начинаются с префикса QDom. Таким образом, класс QDomElement представляет узел Element, а QDomText -- узел Text.
Различные типы узлов могут включать в себя различные типы дочерних узлов. Например, узел Element может содержать другие узлы типа Element, а так же Entity Reference, Text, CDATA Section, Processing Instruction и Comment. На рисунке 14.3 показано, какие типы узлов, в состав каких типов могут входить.
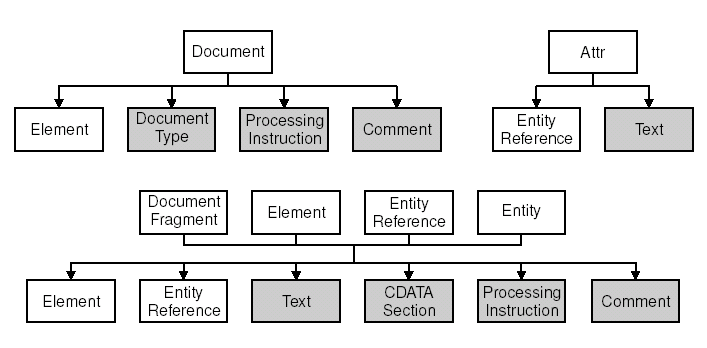
Рисунок 14.3. Взаимоотношения между типами узлов в DOM.
Для демонстрации работы с XML-документами через API DOM, мы напишем парсер, который будет анализировать XML-файл, представленный выше.
class DomParser
{
public:
DomParser(QIODevice *device, QListView *view);
private:
void parseEntry(const QDomElement &element,
QListViewItem *parent);
QListView *listView;
};
Наш класс DomParser будет производить
анализ XML-файла и выводить его содержимое в QListView. Этот класс не имеет предка.
DomParser::DomParser(QIODevice *device, QListView *view)
{
listView = view;
QString errorStr;
int errorLine;
int errorColumn;
QDomDocument doc;
if (!doc.setContent(device, true, &errorStr, &errorLine,
&errorColumn)) {
qWarning("Line %d, column %d: %s", errorLine, errorColumn,
errorStr.ascii());
return;
}
QDomElement root = doc.documentElement();
if (root.tagName() != "bookindex") {
qWarning("The file is not a bookindex file");
return;
}
QDomNode node = root.firstChild();
while (!node.isNull()) {
if (node.toElement().tagName() == "entry")
parseEntry(node.toElement(), 0);
node = node.nextSibling();
}
}
В конструкторе создается объект QDomDocument и вызывается его метод setContent(), чтобы прочитать XML-документ из
QIODevice. Она автоматически открывает
устройство. Затем вызывается documentElement(), чтобы получить корневой узел (со
всеми дочерними узлами), и проверяется -- является ли этот элемент
тегом <bookindex>. После этого выполняются итерации по всем
дочерним узлам и если встречен тег <entry>, вызывается
parseEntry() для его анализа.Класс QDomNode может хранить узлы любого типа. Если вы собираетесь обрабатывать узлы какого-то конкретного типа, нужно сначала выполнить соответствующее преобразование. В этом примере нас интересуют только узлы типа Element, поэтому мы выполняем преобразование вызовом метода toElement(), чтобы получить узел типа QDomElement, и затем вызываем tagName(), чтобы прочитать имя тега. Если узел относится к другому типу, то функция toElement() вернет пустой объект QDomElement, с пустым именем тега.
void DomParser::parseEntry(const QDomElement &element,
QListViewItem *parent)
{
QListViewItem *item;
if (parent) {
item = new QListViewItem(parent);
} else {
item = new QListViewItem(listView);
}
item->setOpen(true);
item->setText(0, element.attribute("term"));
QDomNode node = element.firstChild();
while (!node.isNull()) {
if (node.toElement().tagName() == "entry") {
parseEntry(node.toElement(), item);
} else if (node.toElement().tagName() == "page") {
QDomNode childNode = node.firstChild();
while (!childNode.isNull()) {
if (childNode.nodeType() == QDomNode::TextNode) {
QString page = childNode.toText().data();
QString allPages = item->text(1);
if (!allPages.isEmpty())
allPages += ", ";
allPages += page;
item->setText(1, allPages);
break;
}
childNode = childNode.nextSibling();
}
}
node = node.nextSibling();
}
}
В функции parseEntry() создается
элемент списка QListView. Если тег вложен в
другой тег <entry>, то
создается вложенный элемент списка. В противном случае создается
элемент списка верхнего уровня. Чтобы открыть элемент списка,
вызывается setOpen(true) и затем в него
записывается текст, отображаемый в первой колонке списка, вызовом
функции setText() (содержимое атрибута
term).После инициализации QListViewItem, выполняются итерации по всем вложенным узлам, соответствующим данному тегу <entry>.
Если встречен тег <entry>, вызывается функция parseEntry(), которой, в качестве второго аргумента передается, текущий элемент списка. В результате будет создан новый элемент списка, вложенный в текущий.
Если встречен тег <page>, выполняется поиск узла Text. После того как он будет найден, выполняется преобразование узла, функцией toText(), в QDomText и из него извлекается текст в виде QString. Полученный таким образом текст добавляется в список номеров страниц, который отображается во второй колонке QListViewItem.
Теперь покажем, как можно использовать полученный класс DomParser:
void parseFile(const QString &fileName) {
QListView *listView = new QListView(0);
listView->setCaption(QObject::tr("DOM Parser"));
listView->setRootIsDecorated(true);
listView->setResizeMode(QListView::AllColumns);
listView->addColumn(QObject::tr("Terms"));
listView->addColumn(QObject::tr("Pages"));
listView->show();
QFile file(fileName);
DomParser(&file, listView);
}
Сначала создается и настраивается QListView. Затем создаются QFile и DomParser. Во время
создания, DomParser выполняет разбор
XML-документа и заполняет список.Как показывает пример, навигация по DOM-дереву может оказаться весьма громоздкой. Простое извлечение текста, заключенного между тегами <page> и </page> потребовало от нас выполнения итераций по всему списку дочерних узлов, с помощью функций firstChild() и nextSibling(). Программисты, которые часто сталкиваются с необходимостью выполнения синтаксического анализа XML-документов, нередко пишут свои высокоуровневые классы-обертки, упрощающие выполнение наиболее часто используемых операций, таких как извлечение текста, заключенного между тегами.