NetFlow
Материал из Xgu.ru.
Редактор: Игорь Чубин
Оригинал: xgu.ru/wiki/NetFlow
Данная статья рассказывает о том, как организовать сбор, обработку и визуализацию информации о сетевом трафике. Она составлена на основе статей [1] и [2], и их переводов на русский язык [3] и [4] соответственно.
Кроме того, добавлены:
- небольшое введение о терминологии NetFlow, основных элементов и принципах их совместной работы;
- стартовые скрипты для сенсора и коллектора;
- ссылки на свободное программное обеспечение NetFlow;
- небольшие изменения исходных статей.
Рассматривается случай, когда в качестве основной операционной системы используется FreeBSD. При использовании Linux необходимы небольшие изменения в скриптах и именах конфигурационных файлов.
Содержание |
Архитектура NetFlow
Netflow предоставляет возможность анализа сетевого трафика на уровне сеансов, делая запись о каждой транзакции TCP/IP. Информация не столь подробна, как предоставляемая tcpdump'ом, но представляет довольно подробную статистику.
Netflow имеет три основых компонента:
- сенсор;
- коллектор;
- система обработки и представления данных.
Сенсор - демон, который слушает сеть и фиксирует данные сеанса. Также как Snort или любая другая система обнаружения вторжений, коллектор должен иметь возможность подключиться к хабу, "зеркалированному" порту коммутатора или любому другому устройству, для просмотра сетевого трафика. Если вы используете систему пакетной фильтрации на базе BSD или Linux, то это превосходное место для коллектора Netflow, так как весь трафик будет проходить через эту точку. Сенсор будет собирать информацию о сеансах и сбрасывать ее в коллектор.
Коллектор - второй демон, который слушает на UDP порту, указанному вами и осуществляет сбор информации от сенсора. Полученные данные он сбрасывает в файл для дальнейшей обработки. Различные коллекторы сохраняют данные в различных форматах.
Наконец, система обработки читает эти файлы и генерирует отчеты в форме, более удобной для человека. Эта система должна быть совместима с форматом данных, предоставляемых коллектором.
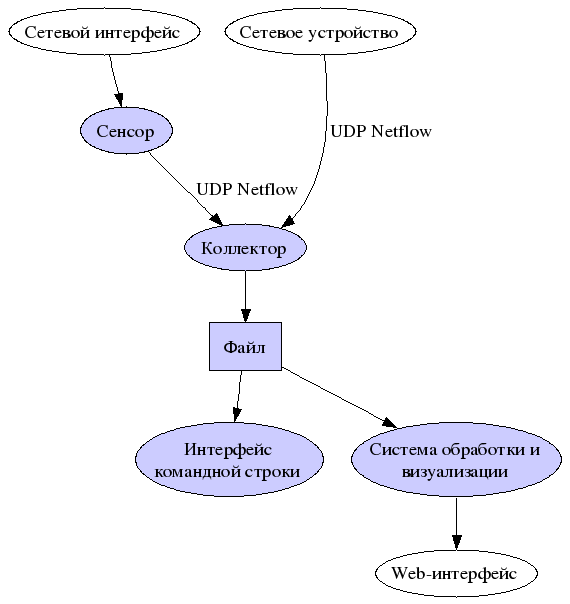
В качестве каждого из элементов системы может использоваться несколько разных вариантов программ. Список доступного программного обеспечения, предназначенного для работы с NetFlow приведен ниже.
Мы рассмотрим свзяку:
- softflowd в качестве сенсора
- flow-capture (из комплекта flow-tools) в качестве коллектора
- flow-stat (из комплекта flow-tools) для анализа в текстовой строке
- flowscan для визуализации и представления в Web
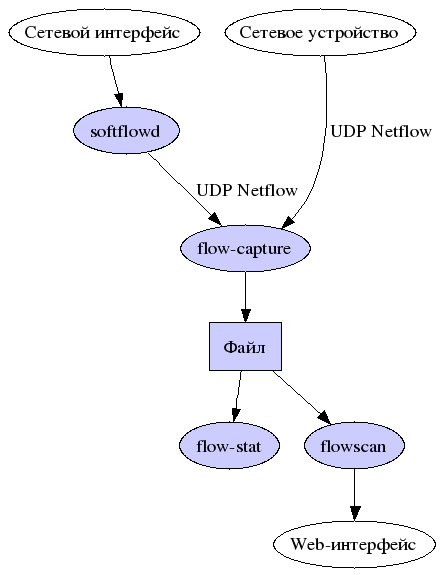
Инсталляция и настройка сенсора
Инсталляция сенсора
В качестве программного обеспечения сенсора будем использовать softflowd [5]. Другое программное обеспечение, которое может использоваться как сенсор, перечислено ниже.
Инсталляция softflowd:
#make all
#install clean
Для работы softlflowd требуется наличие libpcap. В FreeBSD может использоваться ng_netflow, в этом случае libpcap не обязателен.
Запуск сенсора
После того, как softflowd был установлен, необходимо выбрать интерфейс, мониторинг которого будет производиться, указать IP адрес и UDP порт коллектора. Например, для интерфейса em0 и коллектора 172.16.13.5:8818 запуск softflowd будет выглядеть следующим образом:
# softflowd -i em0 -n 172.16.13.5:8818
Сенсор немедленно начнет слушать сеть и посылать информацию на коллектор.
Для того чтобы программа работала после перезагрузки, необходимо убедиться, что она стартует на этапе начальной загрузки!
Проверка
Softflowd включает в себя программу контроля softflowctl, с помощью которой можно проверить работоспособность softflow:
# softflowctl statistics
softflowd[40475]: Accumulated statistics:
Number of active flows: 2298
Packets processed: 268086
Fragments: 0
Ignored packets: 867 (867 non-IP, 0 too short)
Flows expired: 3103 (0 forced)
Flows exported: 6206 in 214 packets (0 failures)
...
Для того чтобы посмотреть информацию о самих потоках, дайте команду:
# softflowctl dump-flows
softflowd[3716]: Dumping flow data:
ACTIVE seq:2 [192.168.15.21]:57660 <> [192.168.15.254]:18030 proto:6 octets>:3088 packets>:5 octets<:164 packets<:3 start:2006-05-27T06:39:58.098 finish:2006-05-27T06:39:58.098 tcp>:1b tcp<:13 flowlabel>:00000000 flowlabel<:00000000
EXPIRY EVENT for flow 2 in 208 seconds
...
В этом выводе нас будет интересовать число активных потоков (2298) и строка "exported", сообщающая о количестве экспортированных потоков в коллектор.
Проверить, действительно ли данные отправляются и достигают коллектора можно с помощью ethereal, tcpdump или другого анализатора трафика. В случае каких-либо проблем можно использовать флаг -D демона softflowd. Softflowd посылает информацию о потоке после того, как тот будет завершен, например, прекратится FTP-сессия или загрузится web-страница. Это означает, что в любой момент времени у softflowd имеется некий кэш открытых потоков, в связи с чем остановку демона необходимо выполнять командой softflowctl shutdown. В противном случае вы потеряете данные активных потоков, которые еще не были завершены и отправлены на коллектор.
Стартовый скрипт
Для того чтобы softflowd стартовал при загрузке автоматически, необходимо создать скрипт запуска и добавить его в загрузку системы. К сожалению, пока что в порт softflowd такой скрипт не входит, поэтому его прийдётся создать самостоятельно:
#!/bin/sh
# Set this rc.conf variables
# * softflowd_enable - enable softflowd?
# * softflowd_interfaces - interfaces to listen
# * softflowd_netflow_host - collector host
# * softflowd_netflow_port - collector port
# in rc.conf variables
# Example:
# softflowd_interfaces="em0 em1 xl0"
# softflowd_netflow_host=
# softflowd_netflow_port=
. /etc/rc.conf
if ! PREFIX=$(expr $0 : "\(/.*\)/etc/rc\.d/$(basename $0)\$"); then
echo "$0: Cannot determine the PREFIX" >&2
exit 1
fi
echo "$softflowd_enable" | grep -qix yes || exit
[ -z "$softflowd_interfaces" ] && exit
case "$1" in
start)
[ -x ${PREFIX}/sbin/softflowd ] || exit
SOFTFLOWD=${PREFIX}/sbin/softflowd
SOFTFLOWCTL=${PREFIX}/sbin/softflowctl
for interface in ${softflowd_interfaces}
do
${SOFTFLOWD} -i ${interface} -n "$softflowd_netflow_host":"$softflowd_netflow_port"
echo -n softflowd[$interface]" "
softflowd_netflow_port="`expr $softflowd_netflow_port + 1`"
done
;;
stop)
${SOFTFLOWCTL} shutdown && echo -n ' softflowd'
;;
*)
echo "Usage: `basename $0` {start|stop}" >&2
;;
esac
exit 0
После того как скрипт создан, необходимо:
- убедиться, что он находится в каталоге /usr/local/etc
- убедиться, что он имеет расширение .sh
- убедиться, что он исполняемый, или дать команду:
# chmod +x /usr/local/etc/rc.d/softflowd.sh
Для запуска скрипта в файле /etc/rc.conf следует установить переменные:
- softflowd_enable - запускать softflowd при старте?
- softflowd_interfaces - какие интерфейсы прослушивать?
- softflowd_netflow_host - IP-адрес хоста коллектора NetFlow
- softflowd_netflow_port - Порт на котором слушает процесс-коллектор NetFlow
Запуск и останов скрипта выполняются командами:
# /usr/local/etc/rc.d/softflowd.sh start
# /usr/local/etc/rc.d/softflowd.sh stop
Инсталляция и настройка коллектора
Коллектор NetFlow предназначен для сбора данных, предоставляемых сенсором и сохранения их на диск для дальнейшего хранения и обработки.
Инсталляция коллектора
В качестве Netflow-коллектора будем использовать flow-capture, очень популярный коллектор Netflow, входящий в состав пакета flow-tools.
В FreeBSD порт flow-tools располагается в каталоге /usr/ports/net-mgmt/flow-tools. Установите его обычным "make all install." Не делайте "make clean", так как, возможно, вам придется устанавливать некоторые компоненты вручную. По этой самой причине не рекомендуется использовать прекомпилированный пакет.
# cd /usr/ports/net-mgmt/flow-tools
# make all install
# # Не делайте make clean !
Создайте каталог в котором flow-capture будет хранить свои данные. Пусть это будет /var/netflow. Убедитесь, что на дисковом разделе, в котором создается каталог, достаточно свободного места: на скоростной сети данные Netflow могут составить несколько гигабайт в неделю.
Для работы системы отображения, необходимо создать каталог saved.
Запуск коллектора
Теперь нам необходимо выполнить стартовый скрипт flow-capture. Выглядит он следующим образом:
# /usr/local/bin/flow-capture -p /var/run/flow-capture.pid -n 287 \
-N 0 -w /var/netflows/ -S 5 0/0/8818
Большинство параметров можно оставить без изменеия. Флаг -w указывает каталог данных, заключительный аргумент обозначает локальный IP, удаленый IP и прослушиваемый UDP порт. В этом случае, значение 0/0/8818 указывает коллектору слушать на всех локальных IP адресах, принимать данные с любых удаленных хостов, порт 8818. В случае, если вы опасаетесь принимать чужие данне, то жестко задайте адрес сенсора.
Параметр -n указывает, сколько раз flow-capture должен создавать новый файл. Параметр -N задает глубину иерархии каталогов, в которых будут храниться файлы с данными NetFlow. Параметр -S указывает размер интервала в минутах, в течение которого flow-capture будет записывать информацию о счетчиках пакетов в файл.
После старта flow-capture данные начинают копиться в рабочем каталоге. Имя файла определяется как версия Netflow, дата и время начала сбора данных. Например, имя файла tmp-v05.2005-04-28.201001-0400 означает временный файл, содержащий данные 5 версии Netflow, собранные 28 апреля 2005 с 20:10:01, временная зона -4 часа от Гринвича. Каждые пять минут flow-capture перемещает временный файл в постоянное местоположение и начинает новый временный файл. В отличии от временного, файл, помещенный на постоянное хранение, начинается на ft, но имеет тот же префикс.
Проверка
Для того, чтобы убедиться, что данные собираются, посмотрите, во-первых, появились ли файлы в каталоге netflow, а во-вторых, увеличивается ли размер временного файла.
Стартовый скрипт
Точно также как и для softflowd, для того чтобы коллектор стартовал автоматически, необходимо создать скрипт запуска и добавить его в загрузку системы. В порт flow-tools такой скрипт не входит, поэтому его прийдётся создать самостоятельно:
#!/bin/sh
# Set this rc.conf variables
# * flowcapture_enable - enable flow-capture?
# * flowcapture_port - port to listen to netflow data [optional]
# * flowcapture_dir - directory to place netflow statistics files to [optional]
# * flowcapture_flags - override default specified in the script
# and port and dir variables [optional]
flowcapture_port=8818
flowcapture_dir=/var/netflow
flowcapture_pid=/var/run/flow-capture.pid
. /etc/rc.conf
if ! PREFIX=$(expr $0 : "\(/.*\)/etc/rc\.d/$(basename $0)\$"); then
echo "$0: Cannot determine the PREFIX" >&2
exit 1
fi
echo "$flowcapture_enable" | grep -qix yes || exit
case "$1" in
start)
[ -x ${PREFIX}/bin/flow-capture ] || exit
FLOWCAPTURE=${PREFIX}/bin/flow-capture
port="$flowcapture_port"
for dir in $flowcapture_dir
do
[ -z "$flowcapture_flags" ] && \
flags="-p ${flowcapture_pid} -n 287 -N 0 -w ${dir} -S 5 0/0/${port}"
${FLOWCAPTURE} ${flags}
port="`expr $port + 1`"
done
;;
stop)
port="$flowcapture_port"
for dir in $flowcapture_dir
do
[ -e "${flowcapture_pid}.${port}" ] || { echo NetFlow collector flow-capture is not running on port $port; exit ; }
kill "`cat ${flowcapture_pid}.${port}`" 2> /dev/null && echo -n ' flow-capture:'$port' '
port="`expr $port + 1`"
done
;;
*)
echo "Usage: `basename $0` {start|stop}" >&2
;;
esac
exit 0
После того как скрипт создан, необходимо:
- убедиться, что он находится в каталоге /usr/local/etc
- убедиться, что он имеет расширение .sh
- убедиться, что он исполняемый, или дать команду:
# chmod +x /usr/local/etc/rc.d/flowcapture.sh
Для запуска скрипта в файле /etc/rc.conf следует установить переменные:
- flowcapture_enable - Запускать flow-capture при старте?
- flowcapture_port - Порт, на котором должен слушать коллектор NetFlow (опционально; по умолчанию 8818)
- flowcapture_dir - Имя каталога, в который должны складываться файлы данных коллектора NetFlow (опционально; по умолчанию /var/netflow)
- flowcapture_flags - указать флаги для запуска flow-capture вручную. Перекрывает остальные переменные. Флаг нужно указывать только в том случае, если необходимо перекрыть значения, использующиеся в скрипте
Если нужно запустить несколько копий flow-capture, необходимо задать несколько каталогов для записи данных в переменной flowcapture_dir. Прослушиваемый порт, в этом случае, будет автоматически увеличиваться на 1 для каждой копии flow-capture. Например, пусть:
flowcapture_dir="/var/netflow/in /var/netflow/out"
flowcapture_port=8818
Тогда данные, поступающие на порт 8818 буду попадать в каталог /var/netflow/in, а, поступающие на порт 8819 - в каталог /var/netflow/out.
Запуск и останов скрипта выполняются командами:
# /usr/local/etc/rc.d/flowcapture.sh start
# /usr/local/etc/rc.d/flowcapture.sh stop
Инсталляция модуля Cflow.pm
Информация в этих файлах находится в бинарном формате, требующем для просмотра специальных инструментальных средств. Многие из тех инструментальных средств используют модуль Cflow.pm.
Cflow это perl-модуль, предоставляющий API для чтения двоичнх файлов данных NetFlow-коллекторов, таких как argus, cflowd, flow-tools и lfapd.
Большое количество программ составления отчетов Netflow используют perl модуль Cflow.pm для чтения файлов Netflow. Этот модуль включает в себя библиотеки и утилиты командной строки, необходимые для просмотра и редактирования файлов данных. Каждый коллектор имеет собственный формат хранения файлов и хотя Cflow.pm изначально создавался для чтения файлов cflowd(8), сейчас он способен обрабатывать и другие форматы.
В последних версиях FreeBSD /usr/ports/net-mgmt/p5-Cflow автоматически обнаруживает библиотеки flow-tools. Cflow вызывает их как -lnsl и в случае ошибки выдается предупреждение.
Note (probably harmless): No library found for -lnsl
Если вы увидели это предупреждение, то самая пора начать волноваться - это означает, что Cflow работать не будет! В этом случае необходимо деинсталлировать пакет и установить его как рассказано ниже.
Если предупреждения не
появилось, необходимо выполнить проверку работоспособности. Cflow
включает в себя утилиту flowdumper(1), которая читает файлы данных из
командной строки. Воспользуемся ей.
#flowdumper -s ft-v05.2005-04-28.201501-0400 | more
2005/04/28 19:14:01 172.16.30.247.80 -> 216.98.200.250.63647 6(SYN|ACK) 3 144
2005/04/28 19:14:01 216.98.200.250.63647 -> 172.16.30.247.80 6(SYN) 1 48
2005/04/28 19:14:01 172.16.30.247.80 -> 216.98.200.250.63648 6(SYN|ACK) 3 144
2005/04/28 19:14:01 216.98.200.250.63648 -> 172.16.30.247.80 6(SYN) 1 48
...
В коротком(short, -s) режиме каждая строка - поток. Она включает в себя адрес источника и назначения, тип транзакции и количество пакетов и байтов в этом потоке в следующем формате:
- дата;
- время;
- IP-адрес.порт отправителя;
- IP-адрес.порт получателя;
- флаги;
- количество пакетов в потоке;
- количество байтов в потоке.
В показанном выше примере представлено две TCP/IP сессии - первая строка указывает на трафик, исходящий с 172.16.30.247, порт 80, на хост 216.98.200.25. Следующая строка показывает трафик, идущий в обратном направлении.
Если инсталляция прошла успешно, можно перейти к следующему разделу. В противном случае необходимо выполнить действия, описанные ниже.
Установка Cflow из flow-tools/contribs
В случае некорректной установки, flowdumper выведет ошибку или ничего не выведет.
$ flowdumper -v ft-v05.2006-05-24.150001+0300
ft-v05.2006-05-24.150001+0300: Invalid index in cflowd flow file: 0xCF100103!
Version 5 flow-export is required with *all* fields being saved.
Если такая ситуация произошла, продолжать работу не получится. Необходимо деинсталлировать p5-Cflow и попытаться установить его другим способом.
В каталоге исходных текстов flow-tools должен находиться каталог contrib. В подкаталоге contrib у нас усть другой архив Cflow. Распакуем его:
# cd /usr/ports/net-mgmt/flow-tools/work/flow-tools-0.67/contrib
# tar -xzvf Cflow-1.051.tar.gz
#
Cflow часто собирает правильную библиотеку, когда устанавливается flow-tools. Выполним сборку модуля:
# perl Makefile.PL
# make
# make install
Пробуйте flowdumper снова, все должно работать.
В противном случае, применим решение "в лоб". Flow-tools устанавливает libft.a в каталог /usr/local/lib. Отредактируем Makefile.PL модуля Cflow.pm в части, касающейся библиотек flow-tools:
sub find_flow_tools {
my($ver, $dir);
my($libdir, $incdir);
if (-f '../../lib/libft.a') {
$dir = '../../lib';
$incdir = "-I$dir -I$dir/..";
$libdir = "-L$dir";
}
Заменим
if (-f '../../lib/libft.a') {
на
if (-f '/usr/local/lib/libft.a') {
После выполнения make и make install чего мы работоспособный flow-tools должен быть установлен.
С помощью CFlow можно написать множество разнообразных скриптов, решающих самые разные задачи обработки и визуализации.
Обработка и визуализация данных NetFlow
FlowScan является скриптом, написанным на Perl и, анализируя записи
NetFlow, сохраняет их в базе данных RRD, Round Robin Database.
RRD предназначен для хранения постоянно изменяющихся данных,
наиболее важными из которых являются последние данные,
а более старые имеют не такое важное значение, и поэтому могут храниться не целиком,
а в усреднённом виде.
За счёт этого RRD не требует много дискового пространства даже для хранения информации
о больших промежутках времени.
FlowScan позволяет сторонним модулям использовать свои процессы, для генерирования собственных отчетов. Ниже рассматривается один из таких модулей -- CUFlow и CGI-скрипт CUGrapher.pl, который позволяет получить доступ к нему через Web-интерфейс.
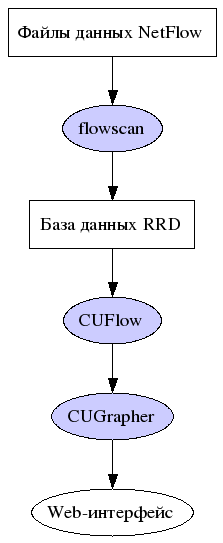
Установка FlowScan
Установку flowscan мы будем делать из системы портов, каталог программы находится в /usr/ports/net-mgmt/flowscan. Таже будут установлениы несколько модулей Perl в качестве зависимостей. Весь инструментарий FlowScan будет по умолчанию установлен в /usr/local/var/db/flows/bin. Учтите, что сразу после установки FlowScan не работоспособен!
Сначала, нам необходимо обновить модуль FlowScan, так как официальный дистрибутив долгое время не обновлялся и не способен обрабатывать записи потока. Автор написал обновленный модуль flowscan.pm, но не включил его в состав дистрибутива. Получите FlowScan.pm версии [6] и скопируйте ее в каталог /usr/local/var/db/flows/bin, перезаписав модуль версии 1.5.
В Этом же самом каталоге находится образцовый файл конфигурации FlowScan flowscan.cf.sample. В первую очередь необходимо указать FlowScan, где искать файлы потока. FlowScan будет пытаться обработать каждый файл в каталоге, если вы не укажите регулярное выражение, описывающее необходимые файлы, включая временные файли и вложенные каталоги. В следующем примере мы обрабатываем только завершенные файлы потока, хранящиеся в каталоге /var/netflows:
FlowFileGlob /var/netflows/ft-v*[0-9]
В ReportClasses перечисляются все используемые для вывода отчетов модули. FlowScan поставляется с двумя модулями: CampusIO и SubNetIO. Возможно, они впоследтсвии окажутся кому-то полезными, но сейчас будет использоваться CUFlow.
ReportClasses CUFlow
Параметр WaitSeconds задает интервал ожидания между попытками FlowScan проверить каталог. Довольно много инструментальных средств используют пятиминутный интервал и могут некорректно работать с меньшим значением.
WaitSeconds 300
В заключение, включим отладку для проверки правильности установки:
Verbose 1
Конфигурирование FlowScan закончено, но нам все еще необходимо настроить модуль отчетов для правильного отображения информации.
Конфигурирование CUFlow
Скачайте [7], распакуйте и скопируйте CUFlow.pm и CUFlow.cf в /usr/local/var/db/flows/bin. Сам модуль можно оставить без изменений, но необходимо отредактировать cuflow.cf, чтобы он соответствовал вашим настройкам Perl.
Инструкция Subnet указывает принадлежащие вам сети. На основании этих данных CUFlow будет различать входящий и исходящий трафик.
Subnet 192.168.2/23
Инструкция Network описывает сети, которые вы хотите обрабатывать отдельно друг от друга. Каждая инструкция будет отображаться как вариант в CGI скрипте. Как вы видите в этом примере, диапазоны могут перекрываться:
Network 192.168.2.3,192.168.2.5,192.168.3.80 webservers
Network 192.168.2.9,192.168.3.1 mailservers
Network 192.168.2.0/25 infrastructure
Network 192.168.2.128/25 dmz
Network 192.168.3.0/25 administration
Network 192.168.3.128/25 development
Директивой OutputDir указывается, где сохранять отчеты. Не храните их в доступном по сети месте или в каталоге flow-capture.
OutputDir /var/log/cuflow
CUFlow также вычисляет самые активные сайты и строит "хит-парад" IP адресов, передавших большее количество трафика в течении 5 минут. За этот параметр отвечает опция Scoreboard. Эта опция использует три аргумента: число IP в "хит-параде", имя каталога для хранения старых списков и имя файла текущего списка. В следующем примере указывается вести "Top 10" IP адресов, сохранять отчеты в /usr/local/www/data/scoreboard и текущим считать файл /usr/local/www/data/scoreboard/topten.html:
Scoreboard 10 /usr/local/www/data/scoreboard \
/usr/local/www/data/scoreboard/topten.html
В то время как список самых больших потребителей/генераторов трафика в данный пятиминутный период полезен для предотвращения проблем, так же был бы полезен список самых активных хостов. Опция AggregateScore позволяет вам сделать это:
AggregateScore 10 /var/log/cuflow/agg.dat /usr/local/www/data/overall.html
Если у вас довольно сложная сеть, то может возникнуть необходимость в нескольких сенсорах Netflow. CUFlow может отделять данные от разных сенсоров, при этом различные маршрутизаторы буду доступны в CUFlow CGI.
Router 192.168.2.1 fred
Router 192.168.3.1 barney
Директива Services предназначена для указания TCP/IP портов, которые вы хотите отслеживать отдельно. Эта директива позволяет вам делать такие выводы как "80% нашего трафика приходится на HTTP" и тому подобное. Учтите, что это повышает нагрузку на сервер, поэтому не стоит здесь указывать весь /etc/services. Не стоит указывать сервисы, которые заблокированы, например Gnutella, Edonkey и т.д:
Service 20-21/tcp ftp
Service 22/tcp ssh
Service 23/tcp telnet
Директива Protocol очень похожа на Services, только вместо Layer 4
используется Layer 4 модели OSI. Я рекомендую указывать Protocol 1
(ICMP), Protocol 6 (UDP) и Protocol 17 (TCP) в качестве базового
минимума. Если есть много пользователей VPN то стоит отслеживать IPSec
и GRE.
Protocol 1 icmp
Protocol 6 tcp
Protocol 17 udp
Так как Netflow был разработан в Cisco, то неудивительно, что много
Netflow датчиков включают информацию BGP. CUFlow может отображать
информацию о трафике к/от различных AS, используя для этого номер AS
(опция ASNumber), softflowd не предосталяет информацию о номере
автономной системы. В случае использования softflowd закомментируйте
опцию ASNumber.
Сохранение записей Netflow из FlowScan
По умолчанию, FlowScan удаляет записи после обработки. Можно сохранять эти записи в течении нескольких месяцев или пока позволяет дисковое пространство. Создайте подкаталог saved в директории Netflow и тогда FlowScan автоматически будет сохранять там обработанные файлы. Даже если вы не планируете хранение старых файлов потока, я рекомендую делать это хотябы первое время, пока вы не убедитесь, что FlowScan работает правильно. В случае, если что-то пойдет не так, наличие этих данны облегчит поиск и устранение неисправности.
Запуск FlowScan
Теоретически у нас все готово к запуску:
# /usr/local/var/db/flows/bin/flowscan
FlowScan должен запуститься, выводя подобные сообщения:
2004/09/02 11:35:18 flowscan-1.020 CUFlow: Cflow::find took 1 wallclock secs
( 0.60 usr + 0.02 sys = 0.62 CPU) for 43011 flow file bytes, flow hit ratio: 2759/2760
2004/09/02 11:35:18 flowscan-1.020 CUFlow: report took 0 wallclock secs
( 0.15 usr 0.19 sys + 0.02 cusr 0.09 csys = 0.44 CPU)
FlowScan анализирует все старые файлы потока, при этом процесс можеть
занять довольно продолжительное время, все зависит от того, сколько
файлов накопилось в системе. Достойной упоминания вещью здесь является
"flow hit ratio", котороя указывает на количество файлов, не
соответствующих формату FlowScan и это очень хороший показатель. Если
этот параметр равен 0, то скорее всего вы неправильно указали параметр
Subnet.
Если FlowScan выдает ошибку "Invalid index in cflowd flow file", то скорее всего, вы не установили новую версию модуля Flowscan.pm . После обработки всех файлов FlowScan выведет сообщение "sleep 300...", в течении этого времени вы можете проверить появление новых файлов потока. Вы можете нажать Ctrl-C для выхода из FlowScan. Вероятно вы захотите запускать FlowScan на этапе начальной загрузки. Для этого перейдите в каталог /usr/local/etc/rc.d и скопируйте туда образцово-показательный скрипт flowscan.sh. Для его работы вовсе необязательно его редактировать, но можно изменить параметр logfile в случае, если вы используете другой каталог.
Если FlowScan выдает ошибку "ERROR updating /var/netflow/...: unknown option", необходимо внести исправления в файл FlowScan.pm, описанные в [8].
Стартовый скрипт flowscan.sh:
#!/bin/sh
# Set this rc.conf variables
# * flowscan_enable - directory to place netflow statistics files to [optional]
# * flowscan_dir - directory to place netflow statistics files to [optional]
flowscan_dir=/usr/local/var/db/flows
. /etc/rc.conf
echo "$flowscan_enable" | grep -qix yes || exit
case "$1" in
start)
echo Starting Flowscan from ...
for dir in $flowscan_dir/*
do
[ -x $dir/flowscan ] || continue
echo $dir
nohup $dir/flowscan > /dev/null 2>&1 &
done
echo Ok
;;
stop)
kill `ps aux | grep perl.*flowscan| grep -v grep | awk '{print $2}'` && echo -n flowscan
;;
*)
echo "Usage: `basename $0` {start|stop}" >&2
;;
esac
exit 0
Построение графиков
К счастью, построение графиков из RRD файлов является довольно тривиальной задачей. В состав CUFlow входит CGI скрипт, CUGrapher.pl. Скопируйте его в каталог cgi-bin вашего web-сервера. Необходимо установить две переменные: $rrddir и $organization. Параметр $rrddir указывает на каталог, где CUFlow хранит файлы RRD.
my $rrddir = "/var/log/cuflow";
Для вывода имени организации вверху страницы используется переменная $organization:
my $organization = "Your Company Name";
Теперь перейдем на URL и выберем, для примера, сеть. Вы должны будете увидеть массив раскрывающихся меню. Выберете любой и нажмите "Generate graph".
Интеграция средств визуализации Netflow и Cacti
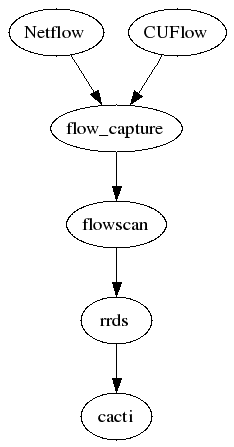
Дополнительная информация
При написании этого раздела использовались следующие материалы:
- Cacti Netflow Howto
- HowTo use externally updated rrd files in cacti - Как добавить в кактус внешние графики
Смотрите также:
Программное обеспечение
Сенсоры NetFlow:
- softflowd - Netflow-сенсор для Linux и FreeBSD
- fprobe - NetFlow-сенсор для Linux, базирующийся на libpcap
- nProbe - Расширяемый NetFlow-сенсор под Linux/FreeBSD и Windows
Коллекторы NetFlow:
- argus by Carter Bullard
- flow-tools by Mark Fullmer (with NetFlow v1, v5, v6, or v7)
- CAIDA's cflowd 2.x by Daniel McRobb (with Cisco's NetFlow v5); см. также [9]
- lfapd by Steve Premeau (with Riverstone's LFAPv4):
- flowc by Uninet Ltd. and Taras Shevchenko Kiev University
- nfdump
Программы визуализации данных NetFlow:
- FlowScan
- CUFlow
- NfSen - NetFlow Sensor, Web-фронтенд для nfdump
Источники
При написании использовались материалы статей:
- Monitoring Network Traffic with Netflow - Статья о NetFlow на ONLamp
- Visualizing Network Traffic with Netflow and FlowScan - Статья о том как сделать графическое представление информации NetFlow
- Building Detailed Network Reports with Netflow
- Мониторинг сетевого трафика с помощью Netflow - Перевод статьи "Monitoring Network Traffic with Netflow" на русский язык
- Визуализация сетевого трафика с помощью NetFlow и FlowScan - Перевод статьи "Visualizing Network Traffic with Netflow and FlowScan" на русский язык