Использование службы директорий LDAP для представления метаинформации
в глобальных вычислительных системах
|
|
objectClass: organization o: Keldysh Institute for Applied Mathematics o: KIAM postalAddress: Miusskaya sq. 4, Moscow, Russia domainName: keldysh.ru domainName: kiam.ru |
objectClass: computeResource hn: spp1600.keldysh.ru manufacturer: Convex processorCount: 8 OSType: unix OSVersion: hp ux 10.01 |
Для каждого объекта директории устанавливается, к какому классу или классам он принадлежит. Эта принадлежность отображается в форме задания обязательного атрибута с именем objectClass, значениями которого являются имена классов.
Классы объектов определяются в схеме директории. В объявлении класса задается его имя и перечисляются атрибуты, которые используются в объектах данного класса, а также фиксируются те из них, задание значений в которых обязательно. Кроме того, могут быть указаны один или несколько родительских классов, определения которых будут наследоваться. Все атрибуты, упоминаемые как обязательные в родительских классах, становятся обязательными и в порождаемом классе. То же самое относится и к опциональным (необязательным) атрибутам.
Особенностью представления схемы в LDAP является то, что здесь определение атрибутов (устанавливающее соответствие между именем атрибута и типом допустимых для него значений) не включается в объявления классов, а дается самостоятельно. Таким образом в схеме сначала определяется набор атрибутов, который затем используется при построении классов объектов. Такой способ определения схемы принят в LDAP для того, чтобы исключить ситуацию появления в классах одинаково поименованных атрибутов с различными типами значений.
Как было отмечено выше, объект может принадлежать к нескольким классам одновременно. Обязательными атрибутами такого объекта считаются все те, которые объявлены обязательными хотя бы в одном из этих классов. Соответствено, опциональным атрибутом является тот, который объявлен как необязательный во всех классах, включенных в объявление объекта.
Для иллюстрации сказанного рассмотрим следующий пример, в котором объявляются три класса, показанные на следующей диаграмме: person (человек) и organizationalPerson (должностное лицо) и internetPerson (пользователь Интернет).
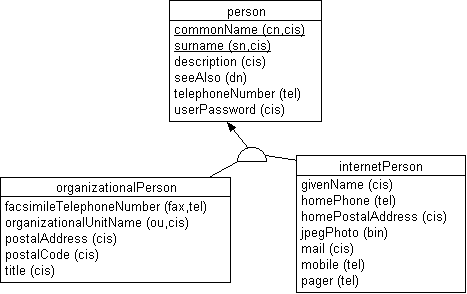
Класс person определяет наиболее общие атрибуты, которые присущи любому человеку: полное имя (commonName, например, фамилия и имя); фамилия (surname); произвольное текстовое описание (description); DN-ссылка на другие объекты, представляющие этого человека в директории (seeAlso); телефонный номер (telephoneNumber); пароль для входа в директорию, в зашифрованном виде (userPassword). Атрибуты commonName и surname являются обязательными (выделены на диаграмме подчеркиванием).
Класс person является родительским для двух производных от него классов. Класс organizationalPerson добавляет дополнительные атрибуты, характеризующие человека как должностное лицо: номер факса, наименование подразделения организации где он работает, почтовый адрес и код, должность. С другой стороны класс internetPerson характеризует человека как пользователя Интернет, вводя атрибуты: имя (givenName), домашние адрес и телефон, фотография, адрес электронной почты, номера мобильного телефона и пейджера.
Как можно заметить, схема определяет структуру представления информации в директории, номенклатуру отображаемых понятий, а также атрибутный состав информационных объектов. Таким образом схема играет важную роль, позволяя создателям директории ограничить круг представимой в ней информации. Одновременно, для пользователей директории схема полезна в информационном плане - как словарь терминов, которыми можно оперировать при поиске информации в директории. Ниже (в заключительной части раздела 1.3 ) мы вернемся к понятию схемы еще раз, чтобы описать принятый в LDAP подход к реализации схемы в случае распределенной директории.
1.2 Модель информационного дерева директории
Объекты директории организуются в виде древовидной структуры, называемой информационным деревом директории. Подчиненность объектов в дереве директории, как правило, отражает географическую, организационную, политическую или иную подчиненность сущностей реального мира, соответствующих объектам директории. Например, дерево директории, где будет храниться информация об организациях, может иметь следующую структуру. На первом уровне дерева располагаются объекты, представляющие страны мира. На втором уровне располагаются объекты, отображающие организации. На более глубоких уровнях идут подразделения организаций, работающий в них персонал, имеющиеся у организаций и их подразделений вычислительные ресурсы.
При создании нового объекта в директории необходимо определить его атрибуты (задав имена и значения), указать существующий объект, которому он будет подчинен, а также зафиксировать относительное уникальное имя (RDN - relative distinguished name) этого объекта. Относительное имя задается посредством указания одного или нескольких атрибутов и их значений, имеющихся у объекта. Если атрибут обладает несколькими значениями, то выбирается одно из них. Например, если организация имеет два наименования - полное и сокращенное, Keldysh Institute for Applied Mathematics и KIAM, то в RDN может войти только одно из них. Относительное имя должно быть уникальным по отношению к относительным именам других объектов, подчиненных тому же родителю.
Уникальные имена объектов (DN - distinguished name), позволяющие идентифицировать объекты в директории, вне зависимости от их подчиненности, образуются посредством конкатенации относительных уникальных имен объектов на пути от корня до идентифицируемого объекта (аналогично полному имени файла в иерерхической файловой системе). Синтаксически уникальные имена записываются обратной последовательности - от объекта к корню. Для разделения RDN'ов в уникальном имени используется запятая.
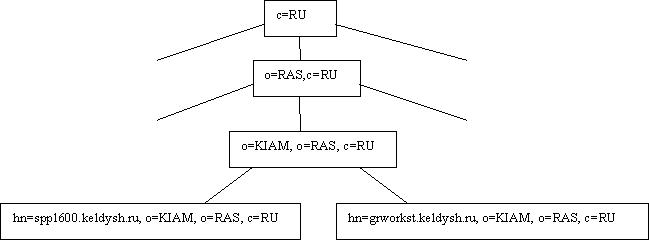
На приведенной схеме представлен пример фрагмента информационного дерева, в котором присутствуют следующие объекты. На верхнем уровне иерархии находится объект с DN-именем cn=RU, используемый для группирования организаций по территориальной принадлежности (в данном случае - Российских организаций). На следующих уровнях располагается объект, представляющий РАН и, в подчинении ему, объект - ИПМ. В поддереве ИПМ содержится два объекта, описывающие принадлежащие ИПМ вычислители.
1.3 Модель распределенной директории
Одним из основных достоинств LDAP является возможность организации распределенных директорий. В распределенной директории различные фрагменты информационного дерева физически размещаются и обслуживаются разными LDAP-серверами. Такая архитектура позволяет распределять между организациями, заинтересованными в размещении в директории своей информации, накладные расходы по установке и администрированию LDAP-серверов. Например, в зависимости от имеющихся организационных договоренностей, информация об организациях, входящих в систему Российской Академии Наук, может быть размещена на центральном сервере РАН, либо на собственных серверах организаций.
Для идентификации LDAP-серверов используется их Интернет-адрес, представляемый в формате ldap:// URL:port, где URL задает IP-адрес или DNS-адрес серевера, а port - номер порта (обычно 389). Например, сервер ИПМ может иметь адрес ldap://ldap.keldysh.ru:389.
Добавление к идентификатору LDAP-сервера уникального имени (DN) объекта директории, например, ldap://ldap.keldysh.ru:389/o=KIAM, o=RAS, c=RU используется для идентифицикации объектов распределенной директории с учетом мест их размещения.
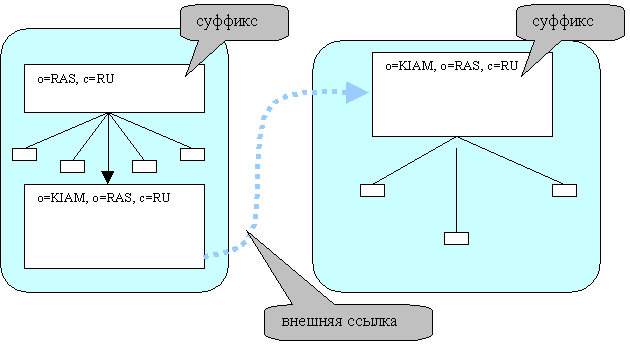
Каждый LDAP-сервер обладает собственной внутренней базой данных, в которой непосредственно хранится один или несколько фрагментов директории. Логически каждый фрагмент представляет собой поддерево информационного дерева директории. Идентификация каждого поддерева осуществляется при помощи задания суффикса - уникального имени (DN) объекта, являющегося корнем этого поддерева. Определение набора суффиксов (т.е. обслуживаемых сервером фрагментов директории) входит в обязанности администратора LDAP-сервера.
Каждое поддерево, определяемое своим суффиксом, может содержать фиктивные вершины типа внешних ссылок (referrals), адресующих объекты, размещенные на других LDAP-серверах. По смыслу, с помощью внешних ссылок можно исключить из хранимого фрагмента одно или несколько поддеревьев, предоставив при этом адреса тех LDAP-серверов, которые реально отвечают за ведение этих поддеревьев. Таким образом, внешние ссылки LDAP позволяют представить единое, в концептуальном смысле, информационное дерево директории. Внешняя ссылка оформляется в виде специального объекта, принадлежащего к классу Referral. Объекты этого класса обладают атрибутом ref, в котором и задается адрес объекта на соответствующем сервере в виде ldap:// URL:port/DN.
Для иллюстрации определенных выше понятий: суффиксов и ссылок, рассмотрим следующий пример. Предположим, что в распределенную директорию, где будет размещаться информация о научных организациях, должны быть включены два сервера, один из которых имеет адрес ldap://ldap.keldysh.ru и принадлежит ИПМ им. Келдыша, а другой, с адресом ldap://ldap.ras.ru - Российской академии наук. Тогда, администратор сервера РАН должен определить на своем сервере суффикс o=RAS, c=RU, а администратор сервера ИПМ - суффикс o=KIAM, o=RAS, c=RU. Поскольку ИПМ собирается размещать информацию о своих ресурсах на собственном сервере, то администратор сервера РАН должен создать у себя объект типа Referral с DN o=KIAM, o=RAS, c=RU, указав в качестве атрибута ref адрес ldap://ldap.keldysh.ru:389 /o=KIAM, o=RAS, c=RU. Описанная конфигурация изображена на следующей схеме.
Понятно, что отдельный LDAP-сервер может отработать только такие запросы пользователей, которые относятся к обслуживаемым им фрагментам директории.
Если поступивший запрос относится к другим фрагментам и, следовательно, не может быть выполнен данным сервером, то в ответ на такой запрос сообщается адрес вышестоящего в иерархии серверов LDAP-сервера. Эта возможность обеспечивается за счет указания умалчиваемой внешней ссылки на LDAP-сервере, в которой фиксируется адрес вышестоящего сервера. Например, на сервере ИПМ следует установить умалчиваемую ссылку ldap://ldap.ras.ru:389. В результате сервер ИМП будет перенаправлять серверу РАН все те запросы, которые касаются других организаций.
В распределенных информационных системах, базирующихся на модели LDAP, для обеспечения эффективности поиска информации используется репликация данных. Репликация - это механизм, посредством которого фрагменты директории, расположенные на одних серверах, автоматически копируются на другие. Использование репликации позволяет существенно повысить доступность данных, обеспечивая устойчивость к сбоям, более высокую производительность, сбалансированную загрузку серверов и т.п. Например, установление взаимной репликации между серверами РАН и ИПМ, в результате которой сервер РАН будет иметь копию данных с сервера ИПМ и наоборот, позволит каждому из них обрабатыватывать без переадресации все запросы, относящиеся к информации об организациях РАН. При такой организации выход одного из серверов из строя не будет иметь критических последствий.
При установке репликационного механизма различают сервер-поставщик данных и сервер-получатель. Любой LDAP-сервер может одновременно выступать как в роли поставщика, так и в роли получателя. Для того, чтобы сервер мог использоваться как поставщик, на нем устанавливается специальный журнал, в котором фиксируются все изменения, происходящие в данных. С помощью журналов минимизируются объемы пересылаемых данных - не вся директория, а только изменения, произошедшие со времени предыдущей репликации.
Существуют два варианта инициализации репликации - со стороны сервера-поставщика, и со стороны сервера-получателя. В первом случае, на поставщике заводится список рассылки, в котором указываются адреса серверов получателей и суффиксы реплицируемых фрагментов директории. Во втором случае, когда репликация инициализируется со стороны сервера-получателя, сам получатель будет обращаться к поставщику, считывая из журнала соответствующие изменения. С точки зрения администрирования репликации оба варианта подобны друг другу, позволяя в конечном итоге обновлять данные на серверах-получателях по истечении определенного временного интервала. Однако, при инициализации репликации со стороны сервера-поставщика возможна установка такого режима репликации, когда каждое изменение в поставляемых данных немедленно рассылается всем получателям. Такой режим важен в случаях, когда необходима актуализация данных в режиме реального времени.
Каждый реплицируемый объект, размещаемый на сервере-получателе, помечается как объект-копия. При этом в объекте-копии фиксируется адрес LDAP-сервера, который является хозяином этого объекта - т.е. сервера, на котором объект был создан и который обладает исключительным правом его изменения. При попытке пользователя выполнить операции по изменению или удалению объекта-копии, такой запрос всегда пересылается серверу - хозяину объекта. Эта парадигма (у объекта всегда один хозяин) позволяет организовать достаточно сложные схемы репликации, например каскадную репликацию.
В завершение остановимся на вопросах реализации схемы в распределенной директории. На каждом LDAP- сервере в специальном объекте с DN- именем cn=schema перечисляются определения типов атрибутов и классов объектов, составляющие схему директории, поддерживаемую данным LDAP-сервером. При установке сервера в качестве начальной схемы загружается общепринятая схема (common schema), определенная в стандарте [RFC2256]. Администратору сервера предоставляется возможность модификации схемы, путем: добавления новых атрибутов и классов; модификации существующих классов; удаления атрибутов и классов (при этом рекомендуется воздержаться от изменения атрибутов и классов общепринятой, начальной схемы). Эта возможность позволяет администратору расширять общепринятую схему, обеспечивая представление объектов, не поддерживаемых в общепринятой схеме (например, описание вычислительных ресурсов организации).
С целью облегчения модели LDAP в службе директорий не введены какие-либо штатные механизмы, обеспечивающие синхронизацию схем, установленных на различных LDAP- серверах распределенной директории. Результатом такого рассогласования схемы может стать снижение качества представления хранящейся в директории информации (например, одно и то же понятие будет отображено разными классами или атрибутами с разными именами), что естественно повлечет за собой снижение эффективности поиска в директории. В связи с этим общепринятая практика, обеспечивающая успешное создание распределенных информационных приложений на базе службы директорий LDAP, заключается в том, чтобы на начальном этапе разработки зафиксировать схему, отражающую понятия предметной области. Дальнейшая эволюция схемы предполагает согласованное внесение изменений на всех LDAP-серверах, входящих в состав прикладной системы.
1.4 Функциональная модель
Функциональные операции, поддерживаемые службой директорий LDAP, базируются на клиент-серверной архитектуре и позволяют: открыть соединение клиента с сервером, произвести аутентификацию клиента, выполнить поиск и модификацию объектов в директории, закрыть соединение при завершении работы. Для большинства современных систем программирования (С++, Perl, Java и т.д.) имеются прикладные программные интерфейсы (API), реализующие вышеназванные базовые функции клиента LDAP.
Отметим, что сами по себе операции поиска и модификации данных не являются распределенными, т.е. область их действия ограничивается фрагментом директории, размещенном на том LDAP- сервере, с которым у клиента открыто соединение. При этом в интерфейс этих операций заложена возможность перенаправления запросов клиента на другие LDAP- сервера, которая реализуется за счет использования возвращаемых сервером перенаправляющих ссылок (continuation references). Подобный механизм позволяет создавать клиентские приложения, обеспечивающие прозрачность при выполнении операции поиска и модификации в распределенной директории.
Из имеющихся в настоящий момент клиентских приложений следует отметить набор командных утилит (ldapsearch, ldapmodif y и др.), реализованный в большинстве операционных систем (Unix, Windows), которые позволяют осуществлять поиск и модификацию данных в распределенной директории. Кроме того, имеются специализированные LDAP-броузеры, позволяющие в графическом режиме осуществлять навигацию и поиск в директориях, а также выполнять операции модификации. В последние версии Интернет-броузеров (Netscape Navigator, Microsoft Explorer) также встроены возможности поиска в распределенных директориях LDAP.
В следующей таблице приведен список наиболее важных операций в LDAP, утилит и дана их краткая характеристика в соответствии с [RFC1823]. Отметим, что все операции могут выполняться как в синхронном, так и в асинхронном режимах.
| Операция | Утилита | Описание |
| Search | ldapsearch | Осуществляет поиск в директории и возвращает результат в виде списка найденных объектов |
| Add | ldapadd | Обеспечивает возможность добавления новых объектов в директорию. При добавлении объекта задаются его атрибуты и их значения, а также определяется уникальное имя (DN) объекта. Добавлять можно только листовые объекты. |
| Delete | ldapdelete | Выполняет удаление объектов из директории. При этом возможно удаление только листовых объектов. Удаление поддерева может быть реализовано только путем последовательного применения этой операции. |
| Modify | ldapmodify | Обеспечивает возможность модификации (добавления, удаления, замены) атрибутов и значений атрибутов у существующих объектов директории. |
| Bind | Выполняет открытие сессии соединения клиента с сервером. При открытии сессии клиент может предоставить данные, аутентифицирующие его на сервере. | |
| Unbind | Закрывает соединение между клиентом и сервером | |
| Abandon | Завершает выполнение асинхронной операции, запущеной на сервере. |
В настоящем разделе подробно рассматривается операция поиска, которая интересна ввиду особенностей модели директорий, связанных с их иерархической организацией, и представляется нам далеко не тривиальной. Для выполнения поиска необходимо задать три обязательных параметра: базовый DN, глубину поиска и фильтр. Запросы клиента выполняются на том LDAP-сервере, с которым предварительно установлено соединение при помощи операции Вind.
Базовый DN и глубина поиска, указанные в запросе, определяют фрагмент директории, в котором будет выполняться поиск. Базовый DN задает уникальное имя объекта, принимаемого в качестве начальной вершины поискового фрагмента (поддерева) в информационном дереве директории. Глубина поиска определяет количество уровней в поисковом поддереве, на которых будет выполняться запрос. Допустимы три варианта задания значения этого параметра: SUBTREE (поиск во всем поддереве), SINGLE (поиск среди всех объектов, непосредственно подчиненных базовому) и BASE (только базовый объект). Задание глубины BASE, чаще всего, используется для получения конкретного объекта директории.
Фильтр специфицирует тот критерий, которому должны удовлетворить все объекты, возвращаемые в качестве результата поиска. Фильтр представляет собой набор элементарных предикатов, соединенных при помощи булевых операторов. Элементарный предикат имеет вид имя-атрибута оператор значение. Например, чтобы найти организацию с названием KIAM, можно задать предикат o=KIAM.
В качестве операторов используются = (совпадение), >= (больше или равно), <= (меньше или равно). Значение, указываемое в предикате =, может содержать специальный символ *. В этом случае проверяется не точное равенство значений, а их сопоставимость. Например, предикату o=K*M* удовлетворяют организации, название которых начинается с буквы K и включает букву M. Если атрибут какого-либо объекта обладает несколькими значениями, то такой объект будет включен в результирующее множество, если хотя бы одно из его значений удовлетворяет предикату.
Предикаты в фильтре могут соединяться посредством булевых операторов - отрицания (НЕ - !), логического объединения (ИЛИ - |) и пересечения (И - &). Для записи операторов используется префиксная нотация, имеющая следующее синтаксическое определение.
фильтр := ( предикат) | ( ! фильтр ) | ( & фильтр ...) | ( | фильтр ... )
Для иллюстрации понятий, описанных выше, рассмотрим следующий пример. Допустим, мы хотим найти в РАН и ее организациях вычислители с числом процессоров больше трех, на которых установлена операционная система UNIX. Это можно сделать при помощи следующего запроса.
БАЗА: o=RAS, c=RU
ГЛУБИНА: SUBTREE
ФИЛЬТР: (& (objectClass=computeResource) (processorCount >= 4) (OSType=unix))
Результаты поиска оформляются в виде списка найденных объектов. В список включаются DN объектов, атрибуты и их значения. Для уменьшения размеров выдачи, при вызове функции поиска можно указать перечень возвращаемых атрибутов. Если такой перечень не задается, то по-умолчанию возвращаются все атрибуты найденных объектов. Другим способом органичения размеров выдачи является возможность указания максимально допустимого числа объектов в результирующем списке.
Если поисковый фрагмент на LDAP-сервере, к которому изначально адресован запрос, содержит объекты класса Referral (внешняя ссылка), то помимо списка результатов сервер возвращает клиенту все обнаруженные им внешние ссылки. Таким образом, клиенту дается возможность продолжить поиск на других LDAP-серверах, с использованием того же критерия. Современные утилиты, устанавливаемые на клиентских местах, реализуют механизм автоматической переадресации запросов в случаях получения в ответ внешних ссылок. Формируемый ими список результатов образуется путем объединения ответов от всех серверов, опрошенных при выполнении подобного распределенного запроса. Для предотвращения зацикливания обычно устанавливается предел числа переходов по внешним ссылкам. Подобный подход позволяет обеспечить необходимую прозрачность поиска в распределенных директориях.
Для иллюстрации механизма выполнения запросов обратимся к примеру распределенной директории, приведенному в предыдущем разделе. Напомним, что в примере использовалось два LDAP-сервера: сервер РАН с суффиксом o=RAS,c=RU и сервер ИПМ с суффиксом o=KIAM,o=RAS,c=RU. На сервере РАН объект с DN-именем o=KIAM,o=RAS,c=RU представлен ссылкой на сервер ИПМ. В свою очередь сервер ИПМ имеет умалчиваемую внешнюю ссылку на сервер РАН.
Если к серверу PAH адресуется запрос по базе o=RAS,c=RU с глубиной SUBTREE, то в ответ возвращается множество найденных на сервере объектов, а также перенаправляющая ссылка на сервер ИПМ. Клиент перенаправляет запрос на сервер ИПМ, указывая в качестве базы o=KIAM,o=RAS,c=RU. Множество объектов, найденных на сервере ИПМ, добавляется к результирующему множеству, полученному на предыдущем шаге от сервера РАН. С другой стороны, если к серверу РАН адресуется запрос по базе o=KIAM,o=RAS,c=RU, то он просто возвращает ссылку, перенаправляющую поиск на сервер ИПМ.
Рассмотрим другую ситуацию, когда запрос по базе o=RAS,c=RU адресуется к серверу ИПМ. В этом случае сервер ИПМ возвращает клиенту свою умалчиваемую внешнюю ссылку, т.е. запрос переадресуется серверу РАН, где выполняется по описанной выше схеме. Наконец, если к серверу ИПМ адресуется запрос по базе o=KIAM,o=RAS,c=RU, то он выполняет его, возвращая точное результирующее множество (без перенаправляющих ссылок).
Отметим, что независимо от того, с какого из двух серверов начинается выполнение одного и того же запроса (с одинаковой базой, глубиной и фильтром), результирующее множество всегда будет одинаковым.
1.5 Модель обеспечения безопасности
Обеспечение безопасности в LDAP имеет две основных стороны. Во-первых, LDAP определяет протокол взаимодействия клиента и сервера. Для обеспечения безопасности этого протокола принят традиционный подход, основанный на использовании механизмов Secure Socket Layer (SSL). Слой SSL обеспечивает взаимную аутентификацию клиента и сервера; гарантирует отсутствие искажений в информации, передаваемой по сети; а также позволяет сохранить приватность информации при передаче. В целом, использование SSL в LDAP постороено по аналогии с другими безопасными сетевыми протоколами, например https и ftps. В настоящей работе этот аспект модели безопасности LDAP подробно рассматриваться не будет.
С другой стороны, служба директорий LDAP представляет собой инструмент для реализации информационных систем и, поэтому, она должна обеспечивать безопасность хранящейся в системе информации, защищая ее от несанкционированного доступа. Разграничение доступа в LDAP в настоящий момент не стандартизовано и различные реализации LDAP могут иметь существенные отличия в этом аспекте. Однако существуют общие принципы разграничения доступа, которые прослеживаются во всех реализациях. При изложении этих принципов мы будем основываться на механизме обеспечения безопасности, принятом в службе директорий LDAP компании Netscape. Разграничение доступа базируется на следующих понятиях:
- представление пользователей и групп пользователей
- способы аутентификации пользователей в момент входа в систему
- представление правил разграничения доступа и используемая схема авторизации действий, выполняемых пользователями
Пользователи и группы пользователей в LDAP представляются в виде объектов директории. По большому счету эти объекты ничем не отличаются от прочих, информационных объектов. Для представления пользователей используется класс person или производные от него классы inetOrgPerson, organizationalPerson и др. Объекты этих классов используются для представления людей и могут, помимо прочей информации, иметь атрибуты userPassword и userCertificate. Если какой-либо из этих атрибутов у объекта задан (или заданы оба), то такой объект LDAP рассматривает как зарегистрированного пользователя. Уникальное имя (DN) этого объекта выполняет роль имени для входа (login name).
В атрибуте userPassword можно в зашифрованном виде задать пароль в формате "(способ-шифрования) зашифрованный-пароль", например userPassword: {sha}FTSLQhxXpA05. В атрибуте userCertificate можно сохранить пользовательский сертификат в бинарном формате. С помощью этих атрибутов LDAP-сервер аутентифицирует пользователя в момент открытия соединения (операция Bind). При этом имеется два варианта аутентификации. Простая аутентификация требует указания DN пользователя и пароля в момент соединения. При этом проверяется совпадение заданного при соединении пароля с паролем в атрибуте userPassword соответствующего объекта. Сложная аутентификация основана на использовании механизмов SSL. При сложной аутентификации проверяется наличие у пользователя инициирующего соединение закрытого ключа, соответствующего сертификату в атрибуте userCertifica te.
В соответствии с общепринятыми соглашениями для представления администраторов директории, обладающих правами изменения закрепленных за ними фрагментов, используют объекты с RDN cn=Directory Manager. Эти объекты размещаются непосредственно в том фрагменте, за ведение которого администратор отвечает. Например, администратор фрагмента директории РАН будет иметь DN cn=Directory Manager,o=RAS,c=RU, а администратор ИПМ - имя cn=Directory Manager,o=KIAM,o=RAS,c=RU.
Группы пользователей представляются при помощи объектов класса groupOfNames или производных классов, которые обладают атрибутом cn (commonName), используемом для задания имени группы, а также множественным атрибутом member, в котором перечисляются уникальные имена (DN) пользователей - членов группы. Для идентификации группы, аналогичным образом, используется DN соответствующего ей объекта.
Информация, определяющая правила разграничения доступа, представляется в директориях LDAP с помощью специальных атрибутов aci (Access Control Information instruction), которые могут быть добавлены к любому объекту директории. Атрибут aci является множественным, т.е. может принимать несколько значений, каждое из которых определяет самостоятельную инструкцию разрешающего или запрещающего характера.
Инструкция aci имеет следующий формат:
< target >(<permission><bind rule>)(<permission><bind rule>)...
Выражение target определяет некоторое множество объектов директории, составляющих область действия данной инструкции. При этом в target можно включать только объекты, входящие в поддерево, вершиной которого является объект с данным aci. Область действия можно задать посредством прямого указания DN объекта, либо шаблона DN'ов с использованием символа *. Например target="o=*,o=RAS,c=RU" задает все организации, входящие в РАН. Другой способ задания области действия инструкции основан на указании поискового фильтра в формате, принятом в операции поиска (Search), в виде targetfilter=фильтр. В target могут быть также перечислены атрибуты объектов, к которым относится инструкция. Для этого используется нотация targetattr=список-атрибутов.
Выражение permission определяет тип инструкции (разрешить или запретить) и вид операции (read, write, add, delete, search). Например, запрет на модификацию задается в виде deny(write,add,delete).
При определении прав доступа к директории учитывается ряд параметров, которые характеризуют текущее соединение (в результате выполнения операции Bind) клиента с сервером. В aci-инструкции в части bind rule (правила соединения) могут быть введены ограничения на параметры соединения, при удовлетворении которых доступ к директории будет разрешен или запрещен. Правила соединения могут быть простыми, например, такое правило может разрешать доступ к директории всем пользователям, принадлежащим к определенной группе. С другой стороны, правила соединения могут быть более сложными. Например, доступ к директории может быть предоставлен пользователям определенной группы в период времени с 8 утра до 5 вечера, при этом допускается обращение к директории только с компьютеров с определенными IP-адресами. Формально, в части bind rule можно задать следующие виды ограничений или их комбинацию:
- ограничение на идентификаторы пользователей, которое принимает вид userdn=DN или userdn != DN, где DN - уникальное имя, шаблон имен (с символом *) или одно из специальных имен: Anyone - любой, в том числе анонимный, пользователь; All - любой зарегистрированный пользователь; и др.
- ограничение группы, к которой должен принадлежать пользователь, установивший соединение. Имеет вид groupdn = DN или groupdn != DN, где DN - имя группы или шаблон.
- ограничение сетевого адреса компьютера, с которого устанавливается соединение, которое задается в виде ip = IP -адрес (ip != IP -адрес) или dns = DNS- адрес (dns = DNS- адрес). В позиции адреса можно указывать точный адрес либо шаблон.
- ограничение даты соединения dateofweek и времени соединения timeofday. Например, dayofweek = "Sun, Mon, Tue" или timeofday >= "1200".
- ограничение на используемый при соединении способ аутентификации: простая аутентификация authmethod = "simple" или сложная authmethod = "ssl".
Для иллюстрации управления доступом к директории LDAP рассмотрим следующий пример. Чтобы разрешить всем пользователям директории, включая анонимных, доступ на чтение и поиск в фрагменте директории, представляющем информацию об ИПМ и, одновременно, предоставить право ведения этой информации администратору директории, нужно установить следующие aci-инструкции у объекта с dn "o=KIAM,o=RAS,c=RU":
aci: (target = "ldap:///o=KIAM,o=RAS,c=RU ") (targetattr=*) allow (read,search)
userdn = ldap:///anyone"
aci: (target = "ldap:///o= o=KIAM,o=RAS,c=RU") (targetattr=*) allow (add,modify,delete)
userdn = "ldap:///cn=Directory Manager,o=KIAM,o=RAS,c=RU "
При авторизации доступа клиента к определенному объекту директории LDAP-сервер использует следующую схему. Сначала суммируются все aci-инструкции, приписанные к самому объекту, а также ко всем объектам, расположенным в информационном дереве директории на пути, соединяющем данный объект с корнем директории. После этого рассматриваются все aci-инструкции, запрещающие выполнение авторизуемого действия. Если находится хотя бы одна запрещающая инструкция, то выполнение действия блокируется. Далее рассмариваются все разрешающие aci-инструкции. Если не находится ни одной инструкция, разрешающей это действие, то его выполнение также блокируется. Таким образом, запрещающие инструкции имеют безусловный приоритет по отношению к разрешающим инструкциям.
2. Организация метаданных в глобальной вычислительной системе Globus
Система MDS представляет собой реально действующий прототип метакомпьютерной информационной службы, разработанной и эксплуатируемой в рамках проекта Globus. На сегодняшний день в MDS аккумулирована информация о вычислительных ресурсах метакомпьютера, предоставленных более 100 вычислительными центрами из различных стран мира. К достоинствам MDS следует отнести, что помимо данных о вычислительных ресурсах как таковых (серверах, рабочих станциях, кластерах), в системе также представлена информация о сетевых ресурсах (конфигурация сети и параметры, описывающие ее производительность). Наличие этой информации позволяет существенно оптимизировать распределенные вычисления, поскольку дает возможность учитывать пропускную способность сети при предварительном планировании размещения вычислительных заданий.
В основе реализации MDS лежит служба директорий LDAP. Для представления метаинформации в Globus организована автономная директория (MDS-директория), которая отличается от обычной директории собственной схемой, расширяющей стандартную схему LDAP набором классов, необходимых для представления элементов глобальной вычислительной системы. Схема MDS будет подробно рассмотрена нами в первой части настоящего раздела.
С технической точки зрения любой LDAP-сервер, на котором установлена схема MDS, может использоваться как MDS-сервер. Верхние уровни директории MDS построены по тому же принципу, что и соответствующие уровни LDAP-директории. На первом уровне расположен объект c именем c=US, а на втором - объект o=Globus,c=US. Оба этих объекта являются по сути фиктивными, поскольку не хранят никакой полезной информации. Все реальные объекты, представляющие метаинформацию, подчинены вершине o=Globus,c=US информационного дерева. Такая организация обеспечивает возможность в будущем интегрировать M DS-директорию в глобальную директорию LDAP.
Поскольку система MDS является приложением над LDAP, она наследует все программное обеспеспечение, имеющееся в службе директорий. В частности ее разработчикам не пришлось тратить дополнительные усилия на реализацию операций поиска, модификации данных, аутентификацию и авторизацию пользователей и т.п. Для этих целей в MDS применяются страндартные пользовательские утилиты и API, принятые в LDAP.
Принципиальное значение имеет то, что основной объем информации в MDS собирается и актуализируется в автоматическом режиме. Для этого реализована необходимая инфраструктура, которая базируется на взаимодействии MDS-сервера и комплекса резидентных программ (демонов), которые устанавливаются на вычислителях, подключаемых к системе Globus. Этот аспект системы MDS рассматривается во второй части раздела, где будет также проиллюстрирована технология подключения к метакомпьютерной системе Globus вычислительных ресурсов новых организаций.
2.1 Схема директории MDS
На представленной ниже схеме приведены основные классы, которые используются в MDS.
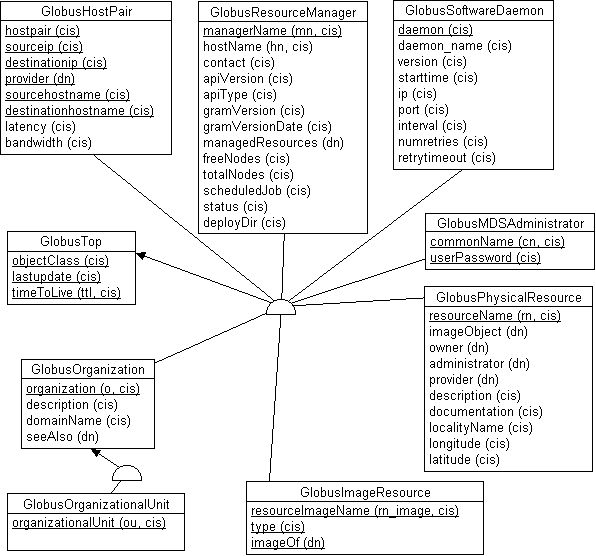
Все классы объектов, определяемые в схеме MDS, наследуют атрибуты от абстрактного класса GlobusTop. Класс GlobusTop имеет три обязательных атрибута (обозначенных подчеркиванием): имя класса объекта (objectClass), дата и время последнего обновления объекта (lastupdate) и служебный атрибут, определяющий время жизни объекта (timeToLive, ttl). Два последних атрибута, которые имеют все объекты MDS, определяют правила автоматического удаления объектов из директории. Значение ttl может быть задано либо как constant, тогда на объект не распространяется автоматическое удаление, либо как dd:hh:mm, тогда он будет удален, если величина lastupdate+ttl больше чем текущая дата. Например, если ttl имеет значение 04:00:00, то это означает, что объект будет удален, если он не обновлялся в течение четырех дней.
Для представления организаций и их подразделений используются классы GlobusOrganization и GlobusOrganizationalUnit. Атрибутный состав этих классов аналогичен стандартному, принятому в LDAP для описания организаций (на схеме приведена только часть атрибутов, которые реально используются в MDS). Для представления администраторов MDS используется класс GlobusMDSAdministrator, который содержит атрибуты: общепринятое имя (cn, обычно здесь указывается Directory Manager) и зашифрованный пароль (userPassword).
Подключение вычислительных ресурсов организации к системе Globus требует установки одного или нескольких менеджеров ресурсов, которые отвечают за взаимодействие с клиентскими приложениями и выполняют операции резервирования вычислительных ресурсов, запуска заданий и т.п. Существуют менеджеры нескольких типов - штатный менеджер fork (включенный в состав ОС UNIX), а также специализированные менеджеры для различных кластерных систем (pbs, condor и др.). Менеджеры ресурсов представляются в MDS при помощи класса GlobusResourceManager, в котором объявляются следующие атрибуты: имя менеджера (managerName), представляемое строкой в формате DNSимяХоста-ТипМенеджера (например, "grworkst.keldysh.ru-fork" - менеджер с DNS-именем grworkst.keldysh.ru типа fork); имя хоста, на котором установлен менеджер (hostName); адрес, по которому производится соединение с менеджером в формате DNSимяХоста:Порт (contact); ссылки (DN) на обслуживаемые менеджером вычислительные ресурвы (managedResources); общее число обслуживаемых узлов и число свободных узлов (totalNodes, freeNodes); список выполняемых в текущий момент заданий (sheduledJob); а также прочая служебная информация.
В системе Globus реализованы операции мониторинга сети, который осуществляется при помощи демонов, выполняющих периодическое измерение задержки и пропускной способности соединения между парами хостов. Для представления получаемой демонами информации используются объекты класса GlobusHostPair, в которых отражаются: адреса пары хостов IP и DNS (sourceip, destinationip и sourcehostname, destinationhostname); уникальное имя пары, образуемое конкатенацией sourceip и destinationip (hostpair); DN-имя демона, предоставившего информацию (provider), а также полученные демоном результаты измерения (latency - задержка, bandwidth - пропускная способность). В MDS также представляется информация и о самих демонах-измерителях. Для этого используется класс GlobusSoftwareDaemon со следующими атрибутами: имя демона (daemon и daemon_name); время запуска демона (starttime); IP-адрес и порт, на котором выполняется демон (ip, port); временной интервал, через которые возобновляются измерения (interval); а также настроечная информация (numretri e s - число попыток соединения, retrytimeout - контрольное время для обрыва соединения).
Для представления реальных физических ресурсов в MDS вводится абстрактный класс GlobusPhysicalResource, который является родительским для трех производных классов: GlobusComputeResource - описание вычислительного ресурса, GlobusNetwork - описание сети, GlobusNetworkInterface - описание сетевого интерфейса (сетевой платы) компьютера. В свою очередь от класса GlobusComputeResource порождается набор дочерних классов, описывающих различные аспекты вычислительных ресурсов метакомпьютера, как показано на приведенной ниже диаграмме.
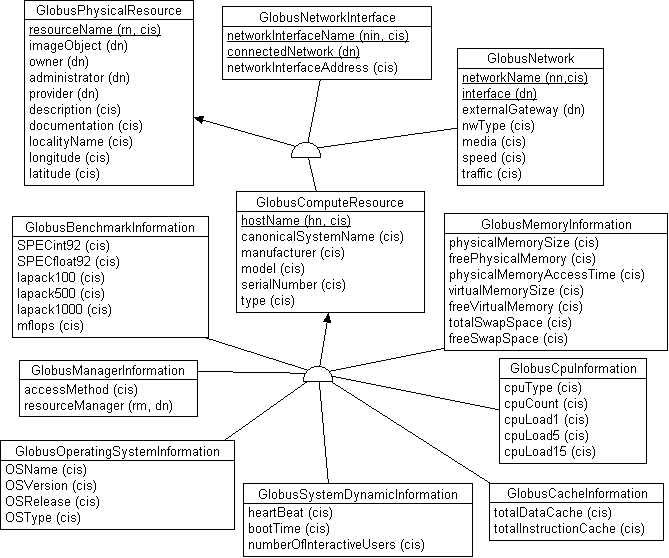
Класс GlobusPhysicalResource имеет следующие атрибуты: имя ресурса (resourceName, например "Host grworkst.keldysh.ru" или "Network 194.226.56.0"); ссылки на организацию-владельца, администратора и провайдера ресурса (owner, administrator, provider); текстовое описание и ссылки на документацию (description, documentation); характеристики географического местоположения ресурса (localityName - штат, город и т.п., longitude - географическая долгота, latitude - широта); а также ссылка на образ ресурса (imageObject). Смысл последнего атрибута будет раскрыт несколько позже.
Класс GlobusComputeResource наследует перечисленные в GlobusPhysicalResource атрибуты и вводит описание хоста с использованием следующих атрибутов: DNS-имя хоста (hostname); каноническое имя системы, которое образуется конкатенацией типа процессора, производителя и версии операционной системы (canonicalSystemName, например, "hppa1.1 hp h pux 10.20"); производитель компьютера (manufacturer, например, hp или sun); модель и серийный номер (model, serialNumber); тип хоста (type, обычно принимает значения workstation или server). Как видно из диаграммы, от класса GlobusComputeResource порождается семь дочерних классов.
Класс GlobusCpuInformation отражает информацию о процессорах, используемых хостом. Этот класс имеет следующие атрибуты: тип процессора (cpuType); количество процессоров (cpuCount); средняя загруженность процессоров за последние 1, 5 и 15 минут (cpuLoad1, cpuLoad5 и cpuLoad15). Характеристика имеющегося у хоста кеша дается в классе GlobusCacheInformation, где отражается общий размер кеша данных и кеша инструкций (totalDataCache и totalInstructionCache).
Характеристика имеющейся оперативной памяти представляется классом GlobusMemoryInformation, где приводится: общий и свободный размеры физической памяти (physicalMemorySize и freePhysicalMemory); время доступа к физической памяти (physicalMemoryAccessTime); общий и свободный размеры виртуальной памяти (virtualMemorySize и freeVirtualMemory); общий и свободный размеры области своппинга (totalSwapSpace и freeSwapSpace).
Для представления динамики изменений состояния вычислителя используется класс GlobusSystemDynamicInformation, в котором отражается: дата и время последней перезагрузки системы (bootTime); дата и время последней проверки, выявившей работоспособность вычислителя (heartBeat); количество пользователей, подключенных в момент последней проверки к вычислителю в интерактивном режиме (numberOfInteractiveUsers).
Характеристики операционной системы, установленной на вычислителе, отражаются в классе GlobusOperatingSystemInformation, где указывается наименование, версия, номер выпуска и тип операционной системы (OSName, OSVersion, OSRelease и OSType). Номинальная производительность вычислителя представляется классом GlobusBenchmarkInformation, где фиксируются характеристики, полученные в результате выполнения стандартных тестов: SPECint92, SPECfloat92, LAPACK, mflops.
Описание вычислительного ресурса завершает класс GlobusManagerInformation, в котором устанавливается ссылка на менеджер ресурсов, обслуживающий данный вычислитель (resourceManager) и, кроме того, здесь можно задать расписание для доступа и резервирования вычислителя (accessMethod).
Как было сказано выше, помимо вычислительных ресурсов в MDS отражается информация о сетевых ресурсах, для чего введены два класса: GlobusNetwork и GlobusNetworkInterface. В классе GlobusNetwork описывается сегмент сети. При этом делается акцент на описание физических характеристик сегмента: идентификатор сегмента (networkName, например, имеющиеся в ИПМ два сегмента можно идентифицировать как 194.226.56.0 и 194.226.57.0); ссылка на вышестоящий внешний сегмент, если такой сегмент представлен в MDS (externalGateway); тип сети (nwType, например, ethernet или ATM); вид кабеля (media, например, cooper или fiber-optic); номинальная пропускная способность сегмента (speed); средняя загруженность сегмента (traffic); ссылки на сетевые интерфейсы компьютеров (объекты класса GlobusNetworkInterface), подключенных к сегменту (interface).
В объектах класса GlobusNetworkInterface отображаются характеристики сетевых плат, через которые компьютеры подключаются в сегмент. Здесь представляется следующая информация: логическое имя порта компьютера, в котором установлена плата (networkInterfaceName, например, lan0 или COM1); ссылка на сегмент сети (connectedNetwork); аппаратный адрес сетевой карты (networkInterfaceAddress, например, в случае Ethernet - 48-битовый адрес карты, устанавливаемый изготовителем).
Помимо физических характеристик сетевых ресурсов (конфигурации и параметров сети), для спецификации которых достаточно описаных выше классов GlobusComputeResource, GlobusNetwork и GlobusNetworkInterface, необходимо также каким-то образом представить информацию логического характера, которая отражала бы какие семейства протоколов (IP, IPX, OSI и т.п.) поддерживаются в рамках конкретной физической сети. При этом для каждого протокола необходимо зафиксировать систему логических адресов, посредством которых в рамках данного протокола идентифицируются узлы сети.
В принципе, для представления этой информации можно было бы расширить атрибутный состав классов, описывающих физические ресурсы. Например, добавить к классу GlobusNetworkInterface атрибут IPaddress, присутствие значения в котором определяло бы, во-первых, что данный интерфейс поддерживает IP-стек и, во-вторых, само значение сообщало необходимый для соединения IP-адрес. Такое простое решение имеет один принципиальный недостаток. В схеме должен быть перечислен весь спектр используемых сетевых протоколов, причем появление новых неизбежно приводило бы к необходимости расширения схемы, доопределению атрибутного состава классов.
В MDS используется другой, более сложный подход к представлению логической информации о сети, в основе которого лежат идеи, изложенные в [RFC1609]. Физический взгляд на сетевые ресурсы, который реализуется объектами классов GlobusComputeResource, GlobusNetwork и GlobusNetworkInterface, дополняется несколькими логическими взглядами (views). Для представления логических взглядов вводится класс GlobusImageResource (образ физического ресурса), от которого путем наследования порождается три подкласса: GlobusComputeResourceImage, GlobusNetworkImage и GlobusNetworkInterfaceImage, представленные на следующей диаграмме.
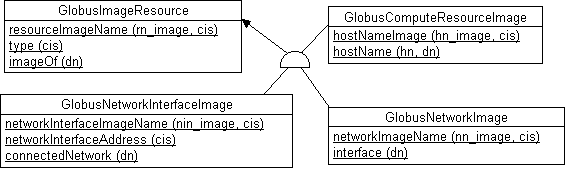
Класс GlobusImageResource содержит три обязательных атрибута, которые наследуются всеми подклассами: имя образа ресурса (resourceImageName, например, "Host Image grworkst.keldysh.ru" или "Network Image 194.226.57.0"); наименование сетевого протокола, который поддерживает данный объект (type, например, IP или IPX); DN-ссылка на соответствующий физический объект, образом которого является данный объект (imageOf).
Класс GlobusComputeResourceImage, используемый для представления образов вычислительных ресурсов, фактически не содержит новых атрибутов, поскольку имя образа вычислителя (hostNameImage, например "Host Image grworkst.keldysh.ru") совпадает с именем образа ресурса, а DN-ссылка на физический хост(hostName) совпадает со ссылкой в imageOf. Класс GlobusNetworkImage, используемый для представления образов сетевых сегментов, обладает атрибутом networkImageName, значение которого совпадает с resourceImageName, а также атрибутом interface, где представляются ссылки на объекты- образы сетевых карт. Класс GlobusNetworkInterfaceImage обладает атрибутом networkInterfaceImageName, значение которого также совпадает с resourceImageName; атрибутом networkInterfaceAddress, который определяет логический адрес узла, соответствующий протоколу; и наконец атрибутом connectedNetwork, который содержит DN-ссылку на соответствующий образ сетевого сегмента.
Из сказанного видно, что между физическими и логическими объектами устанавливаются перекрестные ссылки (атрибуты imageObject у физических объектов и атрибуты imageOf у логических). Описание структуры сети, представленное посредством атрибутов connectedNetwork и interface у объектов NetworkInterface и Network, соответственно, дублируется в объектах-образах. Описанные понятия будут проиллюстрированы в следующей части настоящего раздела.
2.2 Организация сбора и актуализации информации в MDS
В системе Globus предусмотрена достаточно простая технология подключения новых вычислительных ресурсов, к достоинствам которой следует отнести минимизацию трудозатрат административного персонала (администратора центрального MDS-сервера и администраторов, выделенных организациями) на этапе настройки и дальнейшего ведения процедуры сбора метаинформации в MDS-директории. В настоящем разделе мы рассмотрим как производится подключение к Globus ресурсов организации, используя в качестве примера Институт прикладной математики.
На начальном этапе подключения к системе Globus новой огранизации требуется провести регистрацию, заполнив сооветствующую форму (HTML-форму на Web-сервере [WWWGlo]). В этой форме указываются: наименование организации (полное и краткое), почтовый адрес, телефон, факс, доменное имя (DNS-имя) и пр., а также адрес электронной почты локального администратора, отвечающего в рамках данной организации за подключение ресурсов к системе Globus. Получив такое уведомление от новой организации администратор MDS-сервера производит ее регистрацию в директории MDS, создавая два новых объекта. Первый из которых представляет информацию об организации и размещается в информационном дереве директории в непосредственном подчинении вершине o=Globys, c=US. Второй объект представляет локального администратора Globus для данной организации и становится дочерней вершиной объекта-организации. Этому объекту приписывается зашифрованный пароль, который используется для входа в директорию и дает право администрировать поддерево, соответствующее данной организации. Приведенные ниже объекты представляют ИПМ и его администратора в MDS, после регистрации.
dn: o=KIAM, o=Globus, c=US
objectclass: GlobusOrganization
o: Keldysh Institute for Applied Mathematics
o: KIAM
domainname: keldysh.ru
domainname: kiam.ru
lastupdate: Fri Feb 19 22:20:19 GMT 1999
ttl: constant
dn: cn=Directory Manager, o=KIAM, o=Globus, c=US
objectclass: GlobusMDSAdministrator
cn: Directory Manager
o: Keldysh Institute for Applied Mathematics
o: KIAM
userpassword: {SHA}La2UsBWJSjCcvP5yUUg85G8P3I4=
lastupdate: Fri Feb 19 22:20:19 GMT 1999
ttl: constant
Следующим шагом для подключения к Globus является установка программного обеспечения на компьютере, выделяемом под шлюз (gatekeeper). Именно с этой машины будет в дальнейшем выполняться обновление фрагмента MDS-директории данной организации. Для этого на шлюзовой машине запускается демон обновления MDS, который по истечении определенных интервалов времени отгружает на MDS-сервер обновленное состояние ресурсов данной организации, включенных в метакомпьютер. Отметим, что шлюзовая машина может также использоваться и как вычислитель, доступный пользователям Globus.
Список вычислителей, выделенных организацией в распоряжение метакомпьютерной системы, фиксируется в соответствующем конфигурационном файле, размещенном на шлюзовой машине. Этот файл автоматически модифицируется при подключении новых вычислителей или исключении каких-то из них. При подключении вычислителя на нем устанавливается необходимое программное обеспечение и запускается демон - менеджер ресурса (ResourceManager) соответствующего типа.
Демон обновления MDS, запущенный на шлюзовой машине, выполняет опрос вычислителей из списка, который представлен в конфигурационном файле, и автоматически формирует фрагмент поддерева организации. В этот фрагмент попадают следующие объекты. Для каждого вычислителя создается два объекта. Первый объект, класса GlobusComputeResource, отображает этот вычислитель как физический ресурс, а второй, класса GlobusResourceManager, описывает менеджер ресурса, запущенный на данном вычислителе. Например, рабочая станция grworkst.keldysh.ru представляется в MDS объектами:
dn: hn=grworkst.keldysh.ru, o=KIAM, o=Globus, c=US
objectclass: GlobusComputeResource
objectclass: GlobusOperatingSystemInformation
objectclass: GlobusCacheInformation
objectclass: GlobusMemoryInformation
objectclass: GlobusManagerInformation
objectclass: GlobusCpuInformation
objectclass: GlobusSystemDynamicInformation
objectclass: GlobusBenchmarkInformation
hn: grworkst.keldysh.ru
rn: Host grworkst.keldysh.ru
canonicalsystemname: hppa1.1 hp hpux 10.20
manufacturer: hp
machinehardwarename: hppa1.1
type: workstation
osname: hpux
osversion: hppa1.1 hp hpux 10.20
osrelease: 10.20
ostype: hpux
cpuload1: 3.77
cpuload5: 3.29
cpuload15: 3.40
lastupdate: Fri Apr 2 16:35:02 GMT 1999
ttl: 04:00:00
dn: cn=grworkst.keldysh.ru-fork, o=KIAM, o=Globus, c=US
objectclass: GlobusResourceManager
cn: grworkst.keldysh.ru-fork
mn: grworkst.keldysh.ru-fork
hn: grworkst.keldysh.ru
apiversion: 0.1
apitype: fork
deploydir: /opt/globus
managedresources: hn=grworkst.keldysh.ru, o=KIAM, o=Globus, c=US
gramversion: 1.15
gramversiondate: 1998/09/1901:13:02
gramsecurity: ssleay
lastupdate: Mon Apr 5 18:48:22 GMT 1999
ttl: 00:01:00
Оба объекта располагаются в информационном дереве в непосредственном подчинении вершины, соответствующей организации (для ИПМ - o=KIAM, o=Globus, c=US). Далее, демон обновления MDS автоматически формирует объекты, отображающие сетевые ресурсы организации, которые связывают вычислители, перечисленные в конфигурационном файле. В представленном ниже примере приведены объекты, которые были порождены демоном обновления для хоста grworkst.keldysh.ru.
dn: nn=194.226.57.0, o=KIAM, o=Globus, c=US
objectclass: GlobusNetwork
nn: 194.226.57.0
rn: Network 194.226.57.0
imageobject: nn_image=194.226.57.0, o=KIAM, o=Globus, c=US
interface: nin=lan0, hn=grworkst.keldysh.ru, o=KIAM, o=Globus, c=US
lastupdate: Mon Apr 5 16:54:42 GMT 1999
ttl: 04:00:00
dn: nin=lan0, hn=grworkst.keldysh.ru, o=KIAM, o=Globus, c=US
objectclass: GlobusNetworkInterface
nin: lan0
rn: Interface lan0
imageobject: nin_image=194.226.57.39, hn_image=grworkst.keldysh.ru, nn_image=194.226.57.0,
o=KIAM, o=Globus, c=US
connectednetwork: nn=194.226.57.0, o=KIAM, o=Globus, c=US
type: IP
lastupdate: Mon Apr 5 16:54:36 GMT 1999
ttl: 04:00:00
dn: nn_image=194.226.57.0, o=KIAM, o=Globus, c=US
objectclass: GlobusNetworkImage
nn_image: 194.226.57.0
rn_image: Network Image 194.226.57.0
imageof: nn=194.226.57.0, o=KIAM, o=Globus, c=US
type: IP
lastupdate: Mon Apr 5 16:54:44 GMT 1999
ttl: 04:00:00
dn: hn_image=grworkst.keldysh.ru, nn_image=194.226.57.0, o=KIAM, o=Globus, c=US
objectclass: GlobusComputeResourceImage
hn_image: grworkst.keldysh.ru
rn_image: Host Image grworkst.keldysh.ru
hn: grworkst.keldysh.ru
imageof: hn=grworkst.keldysh.ru, o=KIAM, o=Globus, c=US
lastupdate: Mon Apr 5 16:54:33 GMT 1999
ttl: 04:00:00
dn: nin_image=194.226.57.39, hn_image=grworkst.keldysh.ru, nn_image=194.226.57.0,
o=KIAM, o=Globus, c=US
objectclass: GlobusNetworkInterfaceImage
nin_image: 194.226.57.39
rn_image: Interface Image 194.226.57.39
type: IP
imageof: nin=lan0, hn=grworkst.keldysh.ru, o=KIAM, o=Globus, c=US
networkinterfaceaddress: 194.226.57.39
connectednetwork: nn_image=194.226.57.0, o=KIAM, o=Globus, c=US
lastupdate: Mon Apr 5 16:54:39 GMT 1999
ttl: 04:00:00
На следующей диаграмме представлена структура информационного дерева директории, соответствующего организации ИПМ, в том простом случае, когда к метакомпьютерной системе Globus подключена одна рабочая станция. Из диаграммы легко представить, во что будет результироваться подключение новых вычислителей ИПМ, если учесть, что подчиненность объектов соответствующих классов, отражаемая в их DN-именах, является предопределенной в MDS.
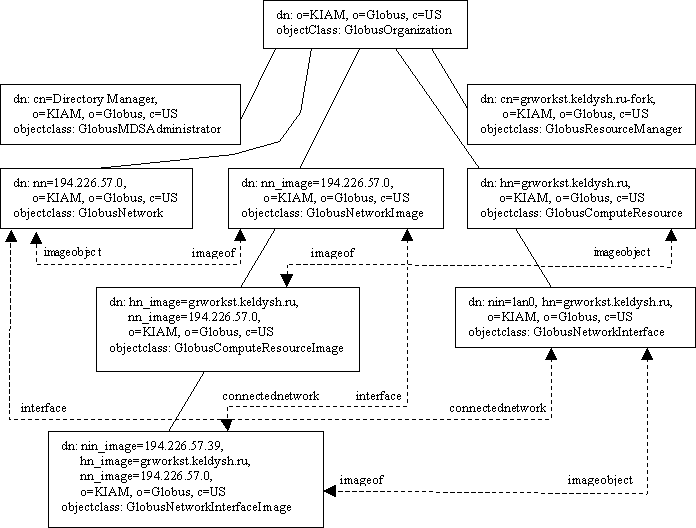
Как видно из схемы, в непосредственном подчинении вершины, представляющей организацию в информационном дереве, располагаются объекты, отображающие: вычислители (класса GlobusComputeResource), менеджеры ресурсов, установленные на этих вычислителях (GlobusResourceManager), сегменты сети (GlobusNetwork) и образы сегментов сети (GlobusNetworkImage). В подчинении объектов-вычислителей (класса GlobusComputeResource) располагаются объекты, отображающие сетевые карты, установленные в портах вычислителя (класс GlobusNetworkInterface). Последние связываются с объектами-сегментами сети посредством атрибута connectedNetwork (обратная связь устанавливается атрибутом interface). В объекты-образы сетевых сегментов (класса GlobusNetworkIm a ge) вкладываются образы вычислителей (класса GlobusComputeResourceImage), которым, в свою очередь, подчиняются образы сетевых соединений (класса GlobusNetworkInterfaceImage). Каждый объект-образ связывается с соответствующим объектом, представляющим физический ресурс, при помощи атрибута imageOf (обратная связь устанавливается атрибутом imageObject).
Приведенный пример показывает содержание фрагмента MDS-директории, который формируется автоматически на этапе установки системы Globus. Содержание этого фрагмента может быть далее расширено полезной информацией, за счет установки дополнительных компонент Globus. Например, на grworkst.keldysh.ru может быть установлен демон, выполняющий тестирование номинальной производительности и определение текущего состояния (загруженности и работоспособности) компьютера, результаты которых дополнят описание соответствующего объекта-вычислителя, означивая атрибуты классов GlobusBenchmarkInformation и GlobusSystemDynamicInformation. Кроме того, можно настроить демоны, выполняющие мониторинг сети, указывая те хосты, соединение с которыми должно измеряться. В результате этого в фрагменте директории появляются объекты класса GlobusHostPair, сообщающие полученную метрическую информацию. Объекты класса GlobusHostPair располагаются в информационном дереве на том же уровне, что и объекты-вычислители.
Наконец, некоторые параметры, которые в принципе не могут быть определены автоматически (например, вид кабеля, задаваемый атрибутом media в классе GlobusNetwork), можно указать вручную. Для этого в системе имеются специальные текстовые файлы-шаблоны, редактирование которых входит в обязанности администратора сайта.
3. Использование ИСМ для поиска вычислительных ресурсов и планирования выполнения заданий
Основными потребителями метаинформации в глобальной вычислительной системе являются приложения, которые используют эти данные для обнаружения необходимых ресурсов, выбора оптимальных ресурсов, планирования вычислений и т.п. В метакомпьютерной среде необходимо поддерживать разнообразные схемы запуска и выполнения приложений, отвечающие различиям в структуре приложений и определенному для них регламенту выполнения, например: приложение может состоять из нескольких заданий, которые требуется разместить на конкретном вычислителе; либо на нескольких вычислителях, но в рамках одного сайта; либо допускается вариант размещения на вычислителях из нескольких сайтов.
В настоящем разделе дается представление об основных способах использования ИСМ для различных схем запуска и выполнения приложений, начиная с простейшего случая, когда при запуске задания явно указываются вычислительные ресурсы, на которых оно должно быть размещено, и переходя к более сложными вариантам, которые включают поиск ресурсов в метакомпьютере (с учетом конфигурации и параметров сети или без их учета) и динамическое размещение заданий. Те аспекты выполнения заданий, которые непосредственно не касаются ИСМ (различные политики планирования, устройство очередей, взаимодействие глобальной среды с локальными кластерами и т.д.) в настоящей работе не обсуждаются. Обзор многих методов планирования вычислений для метакомпьютерной среды содержится в [Ber98].
Основное применение ИСМ - это планирование распределенных вычислений. При этом планирование нужно понимать в более широком смысле чем обычное планирование на многопроцессорных компьютерах. А именно, планирование в метакомпьютерной среде включает в себя по крайней мере:
- нахождение свободных ресурсов в сети, удовлетворяющих определенным требованиям (производительность, объем памяти, необходимые операционные системы и другое программное обеспечение и т.д.);
- выяснение и оценка коммуникационных возможностей между этими ресурсами;
- распределение компонент приложений (программ и./или данных) по найденным ресурсам.
Обратим внимание, что каждое из этих действий требует значительной информации о ресурсах и конфигурации сети, которую может предоставить ИСМ.
Хотя наиболее значимый эффект от проименения ИСМ достигается в задачах, связанных с поиском и планированием необходимых ресурсов в сети, однако некоторую пользу из ИСМ можно извлечь и в случае, когда адреса тех ресурсов, которые будут использоваться приложением, заранее известны. В частности, такое применение ИСМ заложено в клиентской программе globusrun системы Globus. Программа globusrun имеет два основных варианта вызова:
globusrun [options] -r resource singleRSLstring
globusrun [options] multipleRSLstring.
Рассмотрим сначала первый вариант. В этом случае формируется одинарный запрос на выполнение некоторого задания, параметры которого (исполняемая программа, размещение данных и т.д.) задаются в строке singleRSLstring (на языке описания заданий RSL), используя менеджер ресурсов, задаваемый в параметре resource. При этом значением параметра resource может быть так называемая контактная строка некоторого менеджера ресурсов (содержащая имя менеджера, номер порта и контактное имя менеджера ) или просто DN-имя менеджера. В первом случае globusrun напрямую передает задание менеджеру ресурса. Во втором случае дополнительная информация о менеджере, которая необходима для передачи ему задания и должна быть включена в его контактную строку, определяется путем обращения к MDS.
Второй вариант формирует кратный запрос на одновременное выполнение нескольких заданий на нескольких компьютерах. В этом случае multipleRSLstring фактически содержит несколько одинарных запросов с указанием для каждого из них того менеджера ресурсов, который должен исполнить этот запрос. При этом, если в запросе используются DN-имена менеджеров, то программа globusrun сначала определяет контактные строки для них (так же как выше, используя MDS) и после этого передает всю информацию модулю DUROC коаллокирования ресурсов, который дальше занимается размещением заданий по вычислителям и их исполнением.
После выполнения исходного размещения заданий и их запуска происходит регулярное обновление информации о текущем состоянии вычислителей и запущенных на них заданиях в MDS. Планировшик или само приложение могут использовать эту динамически актуализируемую информацию для отслеживания состояния заданий и при необходимости принять решение о снятия задания с перегруженного вычислителя и передачи задания другому вычислителю и т.п.
Перейдем к рассмотрению более сложного случая, когда фиксированное заранее выделение необходимых ресурсов невозможно или нежелательно. В этом случае наиболее простым вариантом является ручное планирование вычислений. А именно, пользователь, которому для выполнения своего приложения нужны удаленные ресурсы, запускает команду поиска ldapsearch с указанием параметров нужных ему ресурсов. На основе полученной из MDS-сервера информации пользователь вручную размещает в сети задания с помощью, например, FTP или rcp (или запускает globusrun с соответствующими параметрами RSLstring и/или менеджера ресурсов). Производимая при этом работа, конечно, сильно зависит от типа рассматриваемого приложения. Если приложение не является распределенным, и требуется просто найти для его выполнения свободный компьютер, например, с определенной операционной системой, быстродействием и объемом оперативной памяти, то команда поиска может быть задана в следующем виде:
ldapsearch -h mds.globus.org -b "o=globus, c=us", -s SUBTREE
"(&(osname=hpux) &
(osversion:=hppa1.1 hp hpux 10.20) &(osrelease:=10.20)&(ostype= hpux)&
(freePhysicalMemory >10Mb)& (mflops>100M.) &(cpuload1> 0)) "
Назначение атрибутов, по которым производится поиск в представленных здесь примерах, описано в предыдущем разделе работы. Результаты поиска будут представлены пользователю в виде списка DN-имен найденных вычислителей, на которых установлена операционная ситема HP UX (указанной версии), имеющих более 10Mb свободной оперативной памяти, с производительностью процессоров более 100Mflops и находящихся в рабочем состоянии (cpuload1> 0).
Другой пример команды поиска выдает для всех пар взаимосвязанных в сети компьютеров (sourcehostname и destinationhostname) значения пропускной способности и задержки канала между ними, определенные в моменты времени (modifytimestamp), начиная с полуночи 25 октября 1999 г.
ldapsearch -b 'o=Globus, c=US' -h mds.globus.org -p 389
"(& (modifytimestamp>=19991025000000Z)
(& (sourcehostname=*)
(destinationhostname=*)))"
bandwidth latency modifytimestamp
Конечно, в обоих случаях в качестве ответа можно получить очень большой объем информации, в которой трудно будет разобраться. Существенное сокращение объема результатов поиска может быть достигнуто за счет указания в поисковом фильтре дополнительных критериев отбора. Например, учитывая, что пользователя интересуют только те вычислители, на котороых он реально может запустить свои задания, в запросе полезно было бы использовать уточняющий критерий вида allowedUser = <имя-пользователя>. К сожалению, в текущей версии MDS в описании вычислителей не предусмотрен атрибут, перечисляющий пользователей метакомпьютера, которым разрешен доступ. Этот очевидный недостаток видимо будет устранен в последующих версиях системы.
Другая возможность сократить объем результирующей информации связана с сужением базы поиска. Например, указание в предыдущих запросах в качестве базового DN "o=KIAM, o=Globus, c=US" вместо "o=Globus, c=US" сужает область поиска вычислительного ресурса, ограничивая его рамками конкретной организации (в данном случае - ИПМ). Развитием этой идеи является выполнение поиска по заданному пользователем списку организаций, либо поиск по признаку географической близости (например, по организациям России). Поскольку такие операции в общем случае трудоемки для исполнения вручную (требуют нескольких запросов ldapsearch и интегрирования полученных результатов), то для их эффективной реализации создаются соответствующие клиентские программы.
В оставшейся части настоящего раздела будут рассмотрены несколько прототипов клиентских программ, предназначенных для автоматизации процесса запуска и выполнения приложений в среде метакомпьютера, которые включают в себя возможности нетривиального поиска ресурсов, планирования вычислений, мониторинга хода вычислений и т.п.
Одна из таких систем, называемая Graphical Resource Selector (GRS), объявлена авторами проекта Globus [CFK98] (программа установки системы Globus даже содержит параметр включения GRS в установку, однако в распространяемую версию GRS не включена). GRS основана на сопоставлении двух графов G1 и G2, изображающих фрагменты сети. Граф G1 является шаблоном, который определяется пользователем и представляет конфигурацию, требуемую для выполнения приложения. В узлах графа указывается информация о компьютерах: тип, ОС, модуль, который будет исполняться на данном компьютере, и т.д. На ребрах графа указываются требования на необходимые коммуникационные характеристики между данными узлами: тип протокола, пропускная способность, задержка и т.д. Используя информацию из MDS, система GRS строит граф G2, сопоставимый с G1. В графе G2 отображаются конкретные доступные в данный момент физические ресурсы, на которые можно распределить модули приложения. Граф G2 представляет собой фактический план размещения заданий по вычислителям, на основании которого действует подсистема коаллокирования DUROC.
Как видно, система GRS задумана как универсальная программа запуска распределенного приложения, базирующаяся на достаточно распространенном подходе к представлению приложений в форме графа. Следует обратить внимание, что сопоставление графов, лежащее в основе размещения вычислений в GRS, является довольно сложно реализуемой операцией. В процессе выполнения сопоставления может потребоваться многократное обращение к MDS, соединение (JOIN) полученных результатов, агрегирование результатов и т.п.
Другой подход к автоматизации запуска распределенных вычислений в метакомпьютере связан с построением планировщиков для конкретных приложений или типов приложений. На практике во многих случаях разработчики приложения реализуют собственный планировщик (брокер приложения), отвечающий за запуск и выполнение данного приложения. Использование знания об архитектуре приложения и других его специфических особенностей дает возможность создавать достаточно простые и эффективные брокеры. Такая специализация позволяет существенно более эффективно использовать информацию из ИСМ и более глубоко и многосторонне управлять всем процессом выполнения заданий (по сравнению с системами планирования общего назначения).
Более общий подход состоит в создании планировщиков, ориентированных на приложения определенного типа. Один из важных классов приложений, для которых такой подход является полезным, составляют приложения типа "хозяин-слуги". В таких приложениях "хозяин" распределяет некоторый набор независимо обрабатываемых задач между "слугами", результаты работы которых передаются обратно "хозяину" (этот процесс может выполняться в цикле). Независимость обрабатываемых "слугами" задач позволяет более свободно обращаться с ними при планировании.
Одной из известных систем обработки приложений типа "хозяин-слуги" является система Nimrod. Эта система разработана для выполнения вычислительных экспериментов следующего типа. Имеется некоторое параметризованное приложение, которое нужно выполнить для большого числа значений параметров (например, решение некоторой системы дифференциальных уравнений с различными граничными условиями) с последующим сравнением результатов вычислений и их визуализацией. Система Nimrod предназначена для распределенного выполнения такого вычислительного эксперимента. Однако Nimrod не содержит средств автоматического планирования: она выбирает компьютеры (или кластерные системы) из фиксированного заранее списка (хранимого в файле) и передает им задания. При этом пользователю не гарантируется завершение работы его приложения за какое-то определенное время. Если ожидание ответа превосходит разумные пределы, то пользователь может принудительно снять задание с выполнения.
В настоящее время на базе системы Nimrod разрабатывается система Nimrod-G [AG97], использующая для обнаружения подходящих ресурсов и планирования запуска вычислений средства системы Globus. Пользователь системы Nimrod-G может задавать ограничения на окончательный срок завершения вычислительного эксперимента или на общую стоимость его выполнения. При этом система должна либо выполнить эксперимент в рамках заданных ограничений, либо сообщить пользователю, что при имеющихся ресурсах это невозможно. Эта функция системы обеспечивается с помощью соответствующей информации из ИСМ. Однако, так как значительная часть информации в ИСМ динамична и отражает действительное положение дел в метакомпьютере только с известной долей приближения, перспектива завершения вычислительного эксперимента в рамках данных ограничений не может быть абсолютно гарантирована. Для повышения степени гарантии можно использовать те или иные эвристические приемы.
С другой стороны, динамичность состояния метакомпьютера вызывает необходимость мониторинга (с помощью регулярного обращения к ИСМ) состояния выполнения отдельных задач эксперимента. В частности, в некоторый момент может выясниться, что обстановка на каком-либо из вычислителей (компьютеров или кластеров) изменилась настолько, что дальнейшее выполнение каких-то заданий вызовет выход за пределы критических ограничений на время или стоимость эксперимента. В этом случае задания забираются из вычислителя с тем, чтобы передать их в дальнейшем на другие подходящие вычислители.
Некоторый подход к построению инструментальной системы для создания планировщиков, ориентированных на приложения, предлагается в [BW97].
Можно заметить, что для более успешного планирования вычислений в метакомпьютерной среде важную роль играет такой механизм как предварительное резервирование ресурсов. При использовании этого механизма планировщик не только формирует план размещения заданий по ресурсам, но и гарантирует получение этих ресурсов в соответствии с заранее составленным расписанием. Однако, резервирование в метакомпьютерной среде представляет собой весьма сложную проблему. По сравнению с обычными системами резервирования оно осложняется, в частности, непредсказумостью времени выполнения многих приложений и, соответственно, трудностью предсказания моментов освобождения тех или иных ресурсов. В настоящее время вопросы резервирования исследуются в рамках проекта системы коаллокирования и резервирования ресурсов GARA. [FKL99], расширяющей возможности системы Globus.
Заключение
Метаинформация играет важную роль для организации высокопроизводительных вычислений в глобальных вычислительных средах. В работе были рассмотрены связанные с этим аспекты представления и использования метаинформации. Были названы основные классы объектов вычислительной среды, информация о состоянии которых должна отображаться в виде метаданных. Введено понятие информационной службы метакомпьютера (ИСМ) и описаны основные операции, которые эта служба должна поддерживать. Рассмотрены вопросы использования ИСМ с целью обеспечения различных схем оптимального запуска приложений и планирования вычислений в метакомпьютерной среде.
Значительная часть работы была посвящена вопросам реализации ИСМ. Показано, что достаточно адекватным инструментом для реализации ИСМ является служба директорий LDAP. Было дано подробное описание LDAP, включая важные технические аспекты, связанные с организацией распределенных директорий, администрированием пользователей и разграничением доступа. Описана система MDS, представляющая собой экспериментальную реализацию ИСМ, выполненную в рамках проекта Globus. Подробно рассмотрена система классов, составляющих схему MDS, а также поддерживаемые в MDS процедуры организации сбора и автоматической актуализации метаинформации.
Рассмотренные в работе вопросы являются частью обширной проблематики, возникающей в рамках задачи создания глобальных распределенных вычислительных систем. В настоящее время эта область активно развивается, привлекая внимание большого числа исследователей. По нашему мнению, к числу наиболее актуальных проблем, связанных с совершенствованием ИСМ, принадлежат следующие.
Небходимо дальнейшее развитие модели директорий в направлении поддержки истории изменений состояния вычислительных ресурсов, что должно позволить строить прогнозы для более эффективного планирования выполнения заданий. В описание ресурса должно быть включено представление о стоимости использования этого ресурса, а также информацию о его доступности для конкретных пользователей или групп пользователей.
К недостаткам модели LDAP, которые должны быть устранены в будущем, следует отнести отсутствие четких правил обеспечения корректной эволюции схемы директории, а также соответствующих механизмов синхронизации схемы в случае распределенных директорий. Также необходимо совершенствование языковых конструкций для задания запросов к директории в сторону большей выразительности и декларативности. При этом для обеспечения эффективной реализации алгоритмов планирования явно не хватает конструкции соединения (типа реляционного JOIN), агрегативных операций (типа COUNT, MIN, MAX и т.д.), а также операций сортировки и группирования (типа ORDER BY и GROUP BY).
В процессе эволюции метакомпьютерных систем возникает необходимость интегрирования в ИСМ информации из внешних источников, например, собираемых службами мониторинга сетей данных. Для обеспечения интеграции подобной внешней информации, должны быть разработаны соответствующие шлюзовые интерфейсы, предоставляющие доступ как к внешним LDAP- директориям, так и к другим типам баз данных. Примером такой интеграции является проект RIB-Globus [WWWRib], направленный на аккумулирование в MDS информации из распределенной реляционной базы данных RIB. В этой базе собрана ценная информация о программном обеспечении, установленном на компьютерах по всему миру.
Еще одним перспективным направлением в метакомпьютинге является дальнейшее совершенствование клиентских рабочих мест, с целью создания дружелюбного пользовательского интерфейса, а также реализации интеллектуальных брокеров и планировщиков, способных эффективно организовать выполнение заданий, оптимизировать стоимостные и временные характеристики, обеспечить устойчивое прохождение заданий в случае сбоев.
Список литературы
[AG97] D.Abramson, and J.Giddy, "Scheduling Large Parametric Modelling Experiments on a Distributed Meta-computer", PCW '97, September 25 and 26, 1997, Australian National University, Canberra, pp P2-H-1 - P2-H-8.
[Ber98] F.Berman, "High-Performance Scheduling", a chapter from the book "The Grid - Blueprint for a New Computing Infrastructure", July 1998.
http://www.mkp.com/books_catalog/1-55860-475-8.asp
[BW97] F.Berman, and R.Wolski, "The AppLeS Project: A Status Report", Proceedings of the 8th NEC Research Symposium, Berlin, Germany, May 1997.
http://www.cs.ucsd.edu/groups/hpcl/apples/pubs/nec97.ps
[CFK98] K.Czajkowski, I.Foster, C.Kesselman, S.Martin, W.Smith, and S.Tuecke, "A Resource Management Architecture for Metacomputing Systems", In Proc. IPPS/SPDP '98 Workshop on Job Scheduling Strategies for Parallel Processing,1998
[FFK97] S.Fitzgerald, I.Foster, C.Kesselman, G.von Laszewski, W.Smith, and S.Tuecke, "A Directory Service for Configuring High-Performance Distributed Computations", In Proc 6th IEEE Symp. on High Performance Distributed Computing, pp.365-375, IEEE Computer Society Press, 1997
[FK97] I. Foster, and C.Kesselman, "Globus: A Metacomputing Infrastructure Toolkit.", Intl J. Supercomputer Applications, 11(2):115-128, 1997.
[FKL99] I. Foster, C. Kesselman, C. Lee, R. Lindell, K. Nahrstedt, A. Roy, "A Distributed Resource Management Architecture that Supports Advance Reservations and Co-Allocation", Intl Workshop on Quality of Service, 1999.
[JBH98] H.Johner, L.Brown, F.-S. Hinner, W.Reis, and J.Westman, "Understanding LDAP", ITSO Redbook SG24-4986-00, June 1998
[JLM99] H.V.Jagadish, L.V.S.Lakshmanan, T.Milo, D.Srivastava, and D.Vista, "Querying Network Directories", In Proc. ACM SIGMOD Int.Conf. on Management of Data, June 1999
[RFC1609] G.Mansfield, T.Johannsen, and M.Knopper, "Charting networks in the X.500 directory", RFC1609, March 1994, (Experimental)
[RFC1823] T.Howes, and M.Smith, "The LDAP Application Program Interface", RFC1823, August 1995
[RFC2251] M.Wahl, T.Howes, and S.Kille, "Lightweight Directory Access Protocol (v3)", RFC2251, December 1997
[RFC2252] M.Wahl, A. Coulbeck, T.Howes, and S.Kille, "Lightweight Directory Access Protocol (v3): Attribute Syntax Definitions", RFC2252, December 1997
[RFC2253] M.Wahl, T.Howes, and S.Kille, "Lightweight Directory Access Protocol (v3): UTF-8 String Representation of Distinguished Names", RFC2253, December 1997
[RFC2254] T.Howes, "The String Representation of LDAP Search Filters", RFC2254, December 1997
[RFC2255] T.Howes, and M.Smith, "The LDAP URL Format", RFC2255, December 1997
[RFC2256] M.Wahl, "A Summary of the X.500(96) User Schema for use with LDAPv3", RFC2256, December 1997
[Smi96] M.Smith, "Definition of the inetOrgPerson Object Class", Internet Draft (work in progress), November 1996
[WWWGlo] http://www.globus.org