Рис. 1. Сетевая модель
С развитием информационных технологий гигабитные сетевые адаптеры стали на столько дешевые, что даже небольшие компании могут себе их позволить. К тому же для использования Gigabit Ethernet нет необходимости заменять уже проложенные коммуникации, для него прекрасно подходят существующие: витая пара и оптоволоконный кабель, что описано в 2-х стандартах. Первый, IEEE 802.3ab, использует в качестве среды передачи данных витую пару категории 5e или 6, при работе используются все 4 пары, где данные передаются со скоростью 250 Мбит/сек по каждой паре. Второй стандарт - это IEEE 802.3z, где для передачи данных использует одномодовый или многомодовый оптоволоконный кабель. Как нетрудно догадаться, скорость передачи данных по ним составляет 1 Гбит/с.
На данный момент Gigabit Ethernet используется практически повсеместно - на маршрутизаторах, в качестве межсегментных магистралей, на предприятиях, в вычислительных кластерах и т.д. Исключение могут составлять лишь конечные пользователи, к которым по-прежнему подводится канал 100 Мбит/с, и то не ко всем, некоторые уже могут наслаждаться 1000 Мбит/с каналом. Преимущество Gigabit Ethernet против Fast Ethernet (100 Мбит/с) очевидно - увеличение скорости передачи данных в 10 раз, что позволяет передавать до 125 Мбайт и маршрутизировать около 500.000 пакетов в секунду. Подобный прирост очень важен, ведь теперь Интернет-провайдеры могут улучшить качество предоставляемых услуг, а суперкомпьютеры повысить производительность. Но для того, чтобы работать на такой скорости, для начала необходимо правильно настроить систему. Ведь если для работы с 100 Мбит/с сетевой картой её достаточно просто вставить в компьютер и установить необходимый драйвер, то с 1000 Мбит/с такой номер не пройдет. По умолчанию, операционные системы настроены для работы с 100 Мбит/с, и если ничего не изменять, то вы скорее всего не получите ожидаемого прироста в скорости. Более того, настройки по умолчанию могут привести к тому, что ваша система захлебнется при большом потоке трафика и придет к полной неработоспособности. Поэтому, перед тем как начать передавать данные с гигабитной скоростью, систему нужно корректно настроить, а для этого необходимо полностью понимать работу сетевого стека. Настройка операционной системы для работы на такой скорости схожа с управлением автомобилем - одно неверное движение, и вы можете очутиться в кювете.
В этой статье описывается работа сетевого стека ОС Linux и даются рекомендации по его настройке. Правда, главы "Физический уровень" и "Уровень протоколов" применимы и для других ОС, потому что в них функционирование физической части и TCP/IP протокола, что одинаково работает на многих ОС, особенно, на UNIX подобных. Так же, в приложениях приведены параметры и описание к ним для того.
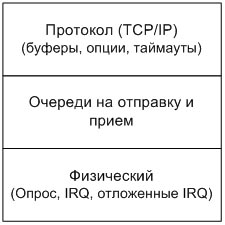
Как известно, для решения сложных задач используется универсальный прием - декомпозиция, т. е. разбиение одной сложной задачи на несколько простых. Например, для описания взаимодействия между узлами в сети используется семиуровневая модель OSI, которая разбивает весь сложный процесс обмена данными на более простые подзадачи. Каждая представляет собой отдельный уровень выполняющий определенную ему функцию. Поэтому взаимодействие компьютера с сетью тоже лучше представить в виде нескольких уровней, а точнее, в виде трехуровневой сетевой модели, в которой различают физический уровень, уровень протоколов и очереди, которые объединяют их (см. рис. 1). Каждый из них имеет свои характеристики и настройки, и хотя они относительно независимы между собой, неправильная настройка одного из них может привести к некорректной работе всей модели. Например, неправильная работа физической части приведет к тому, что при сильном трафике система будет "затоплена" прерываниями, или неверно настроенный TCP/IP может стать причиной низкой производительности протокола. И хотя при этом будут идеально настроены остальные 2 уровня, сетевая подсистема по прежнему не будет работать в полную силу.
Как и в модели OSI, в сетевой модели ОС, каждый уровень выполняет свою функцию. Так, физический уровень занимается тем, что принимает и отправлять пакеты в сеть, а также заботится о размещении их в буферах сетевой карты. Для этого уровня необходимо произвести настройку буферов сетевого адаптера и задать способ обработки событий от него (по прерыванию, отложенное прерывание, режим опроса).
Затем следует уровень очередей, где происходит размещение пакетов в очереди на прием и отправку. Этот уровень выполняют транспортную роль, доставляя пакеты из стека протоколов TCP/IP в физическую часть и наоборот. И хотя настройка здесь тривиальна, однако, при передаче данных на большие расстояния придется немного подумать. И последний, самый высокий - это уровень протоколов, на котором располагается стек TCP/IP. В частности, IP протокол сетевого уровня, отвечающий за доставку пакета от одного хоста к другому. Здесь происходит обработка всех TCP/IP пакетов. В процессе обработки решается дальнейшая судьба пакета. Если узел выполняет роль маршрутизатора и пришедший пакет не предназначается ему, то, скорее всего, пакет будет переправлен дальше в сеть (или отброшен, в зависимости от правил маршрутизации), минуя протоколы более высоких уровней (TCP, UDP). Но, если узел является конечным получателем, то пакет будет передан выше по стеку на транспортный уровень, где подвергнется дальнейшей обработке. И хотя в стеке TCP/IP транспортную роль выполняют 2 протокола, TCP и UDP, в этой статье описывается работа только TCP протокола, так как UDP не нуждается в какой бы то ни было настройке. К тому же, он редко где применяется для надежной передачи данных на большой скорости, одним из немногих примеров является файловая система NFS. В основном, все веб, файл и FTP сервера используют TCP в качестве транспортного протокола, от правильности работы которого зависит очень многое. Обычно настройка TCP сводится к тому, чтобы задать правильные значения буферов, неверный размер которых может стать причиной исчерпания ресурсов на узле или, что менее критично, низкой производительности протокола. К тому же, в TCP присутствует множество различных алгоритмов, которые отягощают его, и зачастую в их использовании нет необходимости, так что их отключение лишь спасет пару тысяч тактов на процессоре.
Можно заметить, что настройка всех трех уровней требуется далеко не всегда, все зависит от того, какого рода трафик обрабатывается на узле. Условно, по уровню взаимодействия с узлом, весь трафик в сети можно разделить на 2 категории - собственный и маршрутный (рис. 2).

Собственный трафик принадлежит всем 3-м уровням сетевой модели, так как он порождается самым верхним уровнем, а отправляется самым нижним (рис. 2а). Происходит это следующим образом:
При приеме данные движутся по этой же схеме, только в обратном направлении - от сетевого интерфейса к приложению.
Для маршрутного трафика схема (рис. 2б) выглядят несколько иначе:
Как видно, при обработке маршрутного трафика в основном участвуют только 2 нижних уровня, до TCP пакеты попросту не доходит. Поэтому при настройке узла следует учитывать, с каким видом трафика будет вестись работа. Если узел выполняет роль маршрутизатора, то в настройке уровня протокола нет необходимости, ведь TCP так и не будет задействован, но если узел служит файл- или веб-сервером, узлом в кластере либо просто домашней машиной, то для корректной работы необходимо будет правильно настроить все 3 уровня сетевой модели. А для этого необходимо понимать работу каждого уровня более детально.
Начнем с самого низкого уровня, на котором начинает и заканчивает работать сетевой стек. Как уже было сказано выше, физический уровень представлен сетевым интерфейсом. Гигабитный адаптер способен принимать и передавать данные на скорости 1 Гбит/с, другими словами, для передачи одного бита информации ему требуется всего 1 наносекунда. В Ethernet среде максимальный размер кадра, который может быть передан или принят адаптером, составляет 1538 байт (без использования Jumbo Frames). В кадр входят
Контроллер способен принимать и отправлять полные Ethernet кадры каждые 12.3 микросекунды (1538*8) или, примерно, 81000 кадра в секунду (1,000,000,000/1538/8 ~ 81000). Конечно, при нормальной работе сети далеко не все пакеты имеют полный размер, поэтому их реальное количество может составлять до 250 тыс. в секунду и это только в одну сторону, при двухстороннем обмене (Full Duplex) значение удваивается [1]. Обработка пакетов на такой скорости требует много процессорного времени, поэтому от эффективности работы физического уровня зависит не только скорость передачи данных в сеть, но и состояние системы в целом.
Всю работу сетевого интерфейса можно разделить на 2 процесса - это прием/передача пакетов и размещение их в буферах. Оба эти процесса взаимосвязаны между собой - перед тем как пакет будет отправлен в сеть, сначала он помещается в буфер сетевой карты, а в случае приема пакета из сети, наоборот.
Драйвер выделяет буфера в физической памяти компьютера, где сетевая карта сохраняет вновь прибывшие пакеты. Для определения размера выделяемой памяти используются [2, 5], как правило, 2 параметра - это количество буферов (один буфер - один пакет), которые задаются в конфигурации сетевой карты, и максимальный размер передаваемого сегмента (maximum transfer unit, MTU). Последний параметр помогает драйверу определить, сколько памяти необходимо выделить под один буфер. Если MTU не использовать, то может случиться, что выделенный буфер окажется меньше, чем принимаемый пакет, или выделенной памяти окажется слишком много, что тоже неприятно. Как не сложно догадаться, чем больше MTU и/или количество буферов, тем больше памяти будет зарезервировано. Например, сетевые карты от фирмы Intel для MTU 1500 выделяют по 2048 байт. Получается, если выставить количество буферов в 5000 для входящих пакетов, то драйвер выделит примерно 10 Мбайт памяти.
При инициализации драйвера память для входящих пакетов будет выделена статически, и в будущем никто не сможет использовать её, пока работает драйвер. Необходимость такого подхода обусловлена тем, что если сетевая карта будет работать в режиме опроса или отложенных прерываний, о которых речь пойдет чуть ниже, то ей придется последовательно принимать несколько пакетов и размещать их в памяти без уведомления об этом событии центрального процессора (ЦП). А раз так, то и место, куда будут складываться пакеты, должно быть заранее подготовлено.
Для исходящих ситуация выглядит несколько иначе. Для них также задается в конфигурации максимальное количество буферов, но память выделяется динамически, по запросу. В этом случае ЦП так или иначе будет задействован, к тому же размер данных заранее известен, поэтому можно выделить ровно столько памяти, сколько необходимо.
После инициализации адаптер может начинать обрабатывать пакеты. По умолчанию многие сетевые карты работают в режиме простого прерывания, при котором прием и отправка пакетов выглядит следующим образом.
Такой подход обработки событий на сетевом интерфейсе годится лишь при низком трафике. Обрабатывать 5-10 тыс. пакетов в секунду не составляет труда даже для среднего компьютера, но с увеличением потока система начнет все больше и больше времени тратить на обработку прерываний с сетевой карты, что отрицательно скажется на общей производительности ОС. С дальнейшим ростом трафика обрабатывать каждый кадр отдельно станет слишком дорогим удовольствием, если не сказать губительным. Даже для современных процессоров, трафик в 200 тыс. кадров в секунду приведет к тому, что система будет полностью поглощена его обработкой, и на работу пользовательских приложений совершенно не останется времени. Как итог, система станет неуправляемой. Более того, большой трафик станет причиной не только неработающих пользовательских приложений, но и возникновения ошибок на сетевом интерфейсе. Мало кто сможет справиться с гигабитным потоком [1]. Ясно одно, что для нормальной работы сети необходимо снизить количество вызываемых прерываний на сетевой карте, при этом оставляя уровень трафика на должном уровне. Добиться этого можно 2-мя способами - обработкой событий в режиме опроса устройства (polling) и использованием отложенных прерываний. Общий смысл у них один - это уменьшение количества обращений к сетевой карте, но реализации разные. Режим опроса является программной реализаций на уровне операционной системы, а отложенные прерывания - аппаратной.
Одним из способов обработки событий на сетевой карте является её опрос (polling). Вместо того, что бы генерировать прерывание (IRQ) при каждом событии, система сама, время от времени, осуществляет проверки на наличие принятых или отправленных пакетов. Когда сетевая карта работает в режиме прерывания, то ЦП приходится при каждом вызове прерывания сохранять свое текущее состояние и переключатся на обработку событий с сетевой карты, а по завершению - обратно. Такое насильственное переключение контекста не позволяет системе контролировать себя, да и само по себе переключение занимает определенные ресурсы. Режим опроса предполагает отключение прерываний на устройстве, что позволяет операционной системе самой осуществлять контроль над ресурсами. Раз нет прерывания, которое в любой момент может переключить работу процессора, то система теперь сама способна решать, когда и сколько ресурсов она может уделить сетевой карте. Если пакетов придет слишком много и система не будет успевать обработать их все, то она может оставить некоторую часть в буфере и уделит больше времени пользовательским приложениям и ядру. По крайней мере, в этом случае система будет управляема. Одним из условий работы сетевой карты в режиме опроса является поддержка работы с DMA и возможность отключать прерывания.
Недостатком использования метода опроса перед прерыванием - это высокая латентность и угроза переполнения буфера. В случае с отключенными прерываниями, система никогда не сможет узнать, когда и сколько пакетов было получено сетевой картой. Очевидно, если система не будет достаточно часто проверять карту, то может произойти ситуация (и часто так и бывает), когда буфер на прием или отправку пакетов будет полностью заполнен и тогда сетевая карта начнет отбрасывать вновь поступившие пакеты (некоторые сетевые карты не отбрасывают пакеты, а просто заново перезаписывают буфер). Когда прерывания отключены, то узнать был ли отброшен пакет невозможно, так как никто об этом не сигнализирует. Но современные сетевые карты не так глупы, многие из них имеют внутренние регистры, которые хранят информацию об ошибках. Например, они могут хранить информацию о количестве принятых/отправленных пакетов, байт, количество отброшенных пакетов, причину по который пакет не был принят и т.д. Используя эту информацию можно определить, достаточно ли буферов выделено или нет. Посмотреть статистику по работе сетевого интерфейса можно при помощи команды netstat с параметром -i (netstat -i). После того, как очередной пакет был размещен в буфере, он не отправляется немедленно на обработку, как это было при работе по прерыванию, вместо этого, он ожидает, пока система не проверит сетевую карту и от того на сколько часто или редко будет происходить эта проверка зависит, сколько времени пакет будет просто лежать в буфере. Поэтому при настройке режима опроса всегда приходится выбирать между высокой латентностью с угрозой переполнения буфера и частотой опроса сетевой карты. Стоит заметить, что откладывая обработку пакетов становится проблематично связать (bonding) два и более гигабитных канала [20].
В различных UNIX системах, режим опроса для сетевой карты и реализован и называется по-разному (стоит отметить, что на данный момент Microsoft Windows не имеет поддержки режима опроса). Но общий смысл у них одни - уменьшить количество обращений к сетевой карте и позволить ОС успешно обрабатывать даже большой поток трафика.
Начнем с ОС Linux, где реализация метода опроса называется NAPI (New API). Так как основной проблемой является не отправка пакетов, а их прием, то NAPI, как утверждают сами разработчики, был задуман и реализован только для входящих пакетов, но никто не мешает использовать NAPI и для исходящих пакетов [6]. На данный момент некоторые драйвера сетевых карт, такие как e1000 и tulip, имеют поддержку NAPI как для входящих, так и для исходящих пакетов. Посмотреть, как драйвер сетевой карты работает с NAPI можно из документации к драйверу. Общий принцип работы NAPI следующий:
Как видно, на самом деле, карточка работает в смешанном режиме опрос/прерывание, это позволяет избежать лишних обращений к сетевой карте. Если за определенный таймаут ни одного пакет не было принято, то и обращаться к ней нет смысла. Что касается настройки NAPI, то их попросту нет. NAPI автоматически подстраивается под текущую загрузку системы. Если трафик не велик и система без особой нагрузки может его обработать, то обращение к сетевой карте происходят довольно часто, что позволяет уменьшить латентность, но при увеличении трафика, обращения начинают происходить реже, это позволяет сохранить систему в управляемом состоянии и позволить ей успешно обрабатывать трафик [2, 4, 7]. Поэтому, для корректной работы сетевой карты достаточно просто вставить её в слот, скомпилировать драйвер с поддержкой NAPI и можно наслаждаться жизнью. Единственное о чем не следует забывать, так это о размере буферов. Хотя NAPI и берет на себя всю работу, он все же не следит за тем, на сколько заполняются буфера. Узнать в этом случае необходимое количество буферов можно только эмпирическим путем. В качестве тестовых программ хорошо использовать NetPiPe, NetPerf или TTCP [17, 18].
Как уже упоминалось раньше, в каждой реализации UNIX режим опроса называется по-разному. В *BSD системах режим опроса так и называется - polling (опрос) [8]. Реализован он несколько иначе, нежели в Linux:
Даже после того, как все пакеты были обработаны, прерывания на карточке не включаются, как это происходит с NAPI, она будет находиться в poll списке все время работы. И в отличие от NAPI, polling имеет много настроек, которые помогут довольно четко настроить систему для работы с сетевым интерфейсом. В частности, в polling имеется возможность задавать частоту опроса устройства. Выставив этот параметр и зная количество пакетов, которые может получить сетевая карта за это время можно довольно точно определить размер буфера. Параметры и их описания для настройки режима опроса под FreeBSD представлены в приложении 1.
Режим опроса под FreeBSD и NAPI под Linux позволяют существенно снизить загрузку системы при обработке большого трафика и ускорить работу с сетью [6, 7, 8]. И хотя они существуют достаточно давно (по IT меркам), по-прежнему можно столкнуться с сетевыми картами, которые не поддерживают их работу.
Альтернативой режима опроса являются отложенные прерывания (в англ. Литературе встречаются разные названия: interrupt moderation, adaptive interrupt или interrupt coalescence). В отличие от опроса, который является реализацией на уровне операционной системы, отложенные прерывания реализованы на самой сетевой карте, что дает возможность использовать их с любыми системами. Схема работы сетевой карты с отложенными прерываниями почти такая же, как и с простыми прерываниями, за дополнением одного пункта:
Откладывая генерацию прерывания, сетевая карта может продолжать собирать события, которые на ней происходят, и по завершению таймера, когда сработает прерывание, она может передать сразу несколько событий. Плюсы и минусы такого поведения описаны выше. Уменьшение количества обращений к сетевой карте увеличивает общую производительность системы, но при этом, увеличивается и латентность.
Что касается настройки отложенных прерываний, то они чем то схожи с NAPI и с Polling под *BSD. Их настройка может происходить 2-мя путями: автоматическая и ручная. В автоматическом режиме карточка сама регулирует частоту генерации прерывания в зависимости от потока трафика. При низком трафике прерывания генерируются довольно часто, таким образом, уменьшая латентность. С увеличением потока сетевая карта начинает откладывать генерацию прерывания, тем самым уменьшая их количество. Если она поддерживает режим автоматической настройки отложенных прерываний, то лучше выбрать его. Но если его нет или по каким либо причина не устраивает его работа, то можно воспользоваться ручной настройкой. Как правило, при ручной настройке отложенных прерываний доступны 2 параметра, абсолютный и пакетный таймер (у разных производителей эти параметры могут называться по-разному), каждый их этих таймеров может быть установлен как на прием, так и на передачу. Абсолютный таймер используется при большом уровне трафика, он позволяет отложить вызов прерывания и продолжать получать или отправлять пакеты (см. рис 3).
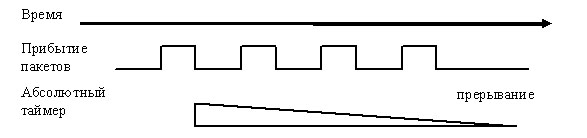
Абсолютный таймер стартует после получения первого пакета и последующие пакеты, если таковы будут, не изменят его состояния. После истечения таймаута контролером будет сгенерированно прерывание, и система займется обработкой событий с сетевой карты. Недостаток этого метода в том, что если придет только один пакет, он все равно будет находиться в буфере до тех пор, пока не закончится таймаут. И в случае с небольшим или низким трафиком абсолютный таймер заметно увеличит латентность. Для решения этой проблемы применяется второй таймер пакетный (см. рис. 4).
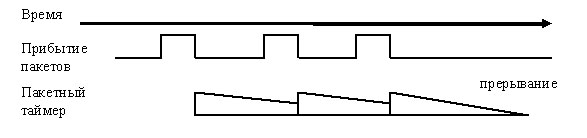
Он стартует каждый раз, когда принимается или отправляется пакет. Если контролер успевает обработать ещё один пакет во время таймаута, то таймер стартует снова. По истечению таймаута генерируется прерывание. В отличие от абсолютного таймера пакетный должен быть гораздо меньше, в 2-5 пакетов. Это позволяет снизить латентность при небольшом уровне трафика. Но недостаток использования этого таймера в том, что при большом трафике он может работать до тех пор, пока контролер не исчерпает все свои ресурсы [1, 5, 9].
Для лучшей производительности рекомендуется совмещать работу абсолютного и пакетного таймера. Таким образом, при большом трафике можно быть уверенным, что абсолютный таймер прервет работу и сгенерирует прерывание, а при среднем и низком пакетный таймер ускорит обработку пакетов и снизит латентность. Поддержку обоих таймеров можно найти у сетевых карточек от Intel, Broadcom и других производителей. Чтобы узнать, поддерживает ли сетевая карта отложенные прерывания, смотрите документацию к ней. Использования отложенных прерываний позволяет снизить загрузку процессора на 15-20 % [1].
Обработка гигабитного трафика вызывает большую нагрузку на систему. Многочисленные вызовы прерываний не дают ей нормально заниматься другими задачами. Режим опроса и отложенные прерывания, позволяют уменьшить количество обращений к сетевой карте и успешно обрабатывать трафик на большой скорости. Хотя опрос реализован на уровне операционной системы, а отложенные прерывания на сетевом интерфейсе, вместе они работать не могут, необходимо делать выбор в пользу одного или другого. Если используется UNIX, то лучше выбирать карточку, с которой ОС может работать в режиме опроса. Если же в качестве операционной системы используется Microsoft Windows, тогда лучше смотреть в сторону отложенных прерываний, потому как Windows пока не поддерживает режим опроса.
После того, как пакет был получен сетевой картой, он поступает на обработку в ядро, в IP модуль, где решается его дальнейшая судьба. Как уже было упомянуто выше, на уровне протокола происходит маршрутизация пакета, поэтому приходящий пакет будет либо переправлен дальше, минуя уровень приложения, либо передан выше по стеку. Связь IP модуля с физическим уровнем, т.е. с сетевой картой, осуществляется при помощи двух очередей. Одна из них называется backlog и служит для входящих пакетов, другая - txqueue, для исходящих [2].
В ОС Linux прием пакетов с сетевой карты может проходить в двух режимах - это режим прерывания и опроса (NAPI). В зависимости от того, в каком режиме происходит работа с устройством, зависит, как функционирует backlog. Когда обработка событий на сетевом интерфейсе происходит по прерыванию (а так же по отложенному прерыванию), backlog работает следующим образом (см. рис. 5).
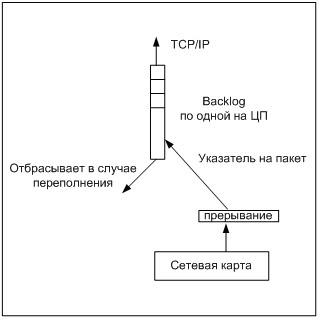
Если при попытке расположить очередной указатель на пакет, окажется, что очередь полная, то пакет просто отбрасывается. Это будет происходить до тех пор, пока очередь не освободится. По умолчанию, размер backlog очереди равен 300 пакетов, что при скорости в 1000 Мбит/с. очень мало. Минимальный размер очереди должен быть не меньше количества буферов на сетевой карте, чтобы иметь возможность принять все пакеты. Рекомендуемое значение длинны backlog очереди около 3000. Более точное значение можно выставить после проведения тестов на производительность. Во время работы очередь ведет статистику: количество обработанных пакетов, сколько раз очередь была переполнена и т.д., которую можно посмотреть через /proc/net/softnet_stat (инструкции по настройке backlog приведены в Приложении 2).
В случае, когда система работает с сетевой картой в режиме опроса, backlog очередь просто отсутствует, таким образом, пакеты поступают на обработку в TCP/IP стек напрямую. Правда, вместо этого появляется очередь для устройств, в которой регистрируются устройства, работающие в режиме опроса (см. рис. 6). В этом случае, прием пакетов происходит по следующей схеме.
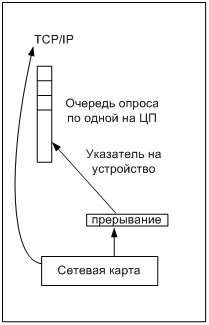
При обработке пакетов в режиме опроса отсутствует возможность потери пакетов на этом уровне, так как теперь нет backlog очереди, а так же отсутствует их неупорядоченность. Поэтому, если работа с устройством производится в режиме опроса, то в настройке backlog очереди просто нет необходимости.
Схема отправки пакетов, как в режиме NAPI, прерываний и отложенных прерываний выглядит одинаково (см. рис. 7). Очередь на отправку называется txqueue и регулируется через команду ifconfig. По своему принципу работы txqueue схожи с очередью backlog, в неё также помещаются только указатели на пакет, и в случае переполнения очереди отбрасывается [2]. Отправка пакетов через эту очередь выглядит следующим образом.
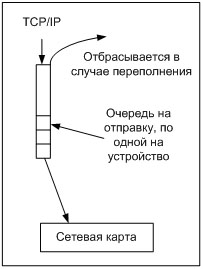
По умолчанию, очередь для отправки пакетов тоже мала, но необходимый размер рассчитывается не так, как у backlog. Здесь большую роль играют скорость передачи данных и расстояние, на которое данные передаются. Если используется медленное устройство, например, модем, тогда размер txqueue очереди должен быть небольшим, чтобы предотвратить передачу большого количества пакетов на устройство, иначе можно вызвать переполнение буферов, а следовательно, потерю пакетов. Когда же используется быстрый канал, да ещё и на большое расстояние, например, спутниковый канал, то размер очереди должен быть достаточно большим, примерно 20000-30000. В основном это необходимо для TCP протокола. Дело в том, что размер очереди txqueue влияет на "окно переполнения" (congestion window) в TCP протоколе, которое влияет на скорость передачи данных [3]. Если очередь не будет достаточно велика, то она станет узким местом в производительности TCP протокола. Маленькая очередь не позволит окну полностью раскрыться, а значит, скорость передачи не будет максимальна. Но если расстояние не большое, как например, в вычислительном кластере или канал, соединяющий 2 маршрутизатора в пределах города, то очереди в 5000-10000 вполне хватит. Конечно, для того чтобы точного узнать, какого размера должна быть очередь txqueue, необходимо будет провести серию тестов. Но, в отличие от backlog, статистика по работе txqueue недоступна, что делает её настройку несколько затруднительной.
В современном Internet основой для передачи данных является стек протоколов TCP/IP. Он обеспечивает весь набор инструментов для доставки данных от одного приложения к другому. В него входят один протокол сетевого уровня, который отвечает за доставку пакетов от одного хоста к другому и два протокола транспортного уровня, TCP и UDP, ответственные за доставку данных от приложения к приложению. В стеке TCP/IP за надежность доставки данных отвечает только TCP протокол, и, хотя UDP тоже является транспортным протоколом, он не берет на себя подобных обязательств, благодаря чему всегда работает максимально быстро, чего не скажешь о TCP [10].
В работе TCP участвует множество различных алгоритмов: контроль потока, расчет внутренних переменных (RTT, RTO.), таймеры и опции [11, 3, 4]. Все они необходимы, что бы обеспечить быструю и надежную доставку данных с контролем состояния канала. Но нас интересует лишь те, которые влияют на скорость передачи данных - это контроль потока и опции.
Для контроля потока в TCP используется 2 параметра это "скользящее окно" (sliding window) и "окно переполнения" (congestion window). Первое из них сообщает отправляющей стороне, сколько байт может принять получатель на данный момент. Другими словами, оно отображает текущее состояние TCP буфера для приема. Зная его, отправитель следит за тем, чтобы в сеть не было послано больше данных, чем указано в окне, иначе буфер получателя может оказаться переполненным. Чем больше буфер, тем больше TCP пакетов можно послать без ожидания подтверждения. Но вся проблема в том, что размер этого поля в TCP заголовке равен 16 битам, а это значит, что максимальный размер передаваемого значения не может быть больше, чем 216=65536 байт, и даже если размер буфера на принимающей стороне будет несколько мегабайт это никак не поможет, так как максимальное значение, которое можно передать в окне, это 65536. Таким образом, без подтверждения в сети может находиться примерно 44 полных Ethernet пакета и этого явно мало для 1000 Мбит/с., в следствии чего канал будет простаивать, особенно, если расстояние между удаленными точками велико (см. рис. 8). Передав 44 пакета в сеть, TCP больше не сможем посылать данные, пока не получит подтверждения в котором будет объявлен новый размер окна. Для того, что бы иметь возможность пересылать размер окна больше, чем 2 16, было решено использовать масштабирование TCP окна (window scaling), RFC 1323.

Масштабирование окна позволяет передавать в сеть большее количество пакетов без подтверждения. Включается данная опция вот так.
С другой стороны, отправитель тоже должен контролировать поток, что бы на промежуточном маршрутизаторе не произошло переполнения. Для этого используется окно переполнения "congestion window" [10]. Оно находится в самом стеке протокола и его значение не передается в заголовке пакета. Это окно определяет максимальное количество пакетов, которое можно отправить в сеть без подтверждения. При этом, размер "окна переполнения" не может превышать размер "скользящего окна", иначе отправитель переполнит буфер получателя. Таким образом, при помощи этих двух окон, отправитель и получатель могу контролировать поток. Размеры этих окон напрямую зависят от выделяемого буферного пространства. Буфер на прием ответственен за скользящее окно, а буфер на отправку за окно переполнения.
Как упоминалось раньше, по умолчанию системы настроены на оптимальную работу со 100 Мбит/с., поэтому для работы с 1000 Мбит/с. желательно изменить значение буферов. Но увеличивать их вслепую нельзя, так как они размещаются в памяти ядра, и слишком большое значение может привести к большему потреблению памяти и к общему спаду производительности системы.
В Linux и FreeBSD структура TCP буфера выглядит следующим образом (см. рис. 9). Существует 2 буфера, это общий (для всех сетевых соединений) и TCP буфер (для конкретного TCP соединения).
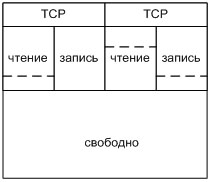
Как видно, общий буфер всегда должен быть больше, чем TCP буфер, так как возможно несколько TCP соединений одновременно. Слишком малое значение общего буфера по отношению к TCP буферу может привести к очень медленной работе всего TCP/IP стека. При вычислении размера буферов стоит руководствоваться следующими параметрами:
Если количество одновременных подключений превышает 10, то нет необходимости увеличивать TCP буфера, так как каждое соединения максимально получит по 100 Мбит/с. Более того, при большом количестве подключений можно понизить размер TCP буферов, чтобы не занимать много памяти. Такая ситуация может возникнуть у провайдеров, предоставляющих доступ в Интернет через NAT, proxy, на веб серверах, на публичных FTP серверах и т.д. Но, оставляя неизменным или понижая TCP буфер, все же необходимо скорректировать общий буфер, так как он предоставляет место для всех подключений. Подсчитать его размер довольно просто, для этого нужно среднее количество одновременных соединений умножить на размер TCP буферов (прием + отправка). Например, для web сервера, который обслуживает 1000 одновременных подключений, где на каждое соединение выделено по 16К на прием и на отправку, необходимо затратить 32М общего буфера (2*16К*1000=32000К). Хорошим тоном считается увеличение полученного значения на 2, т.е. 64 Мб. Для современных компьютеров это небольшой объем памяти [12, 13, 14]. Если же количество одновременных подключений невелико (2-5), как например, в кластерах, промышленных компьютерах или на выделенных серверах, то помимо расчета общего буфера необходимо установить и TCP буфера. Во многих источниках для расчета TCP буфера приводиться формула:
Но для расчета TCP буфера её нельзя не рекомендуется. Эта формула определяет максимальное количество данных, которые можно отправить до того момента, как будет получено подтверждение (ACK). Это было бы верным при условии, что в сети не происходило бы никаких дополнительных задержек, и что ACK будет отсылаться немедленно после получения первого пакета. Но TCP не отправляет ACK сразу по прибытию пакета. Для того, что бы не засорять канал, TCP ожидает небольшой таймаут, на случай, если ещё придут данные и тогда уже отправляет ACK с подтверждением нескольких пакетов, это называется отложенным ACK. Размер таймаута постоянно изменяется, поэтому точно рассчитать его нельзя. Но даже если последовать примеру хорошего тона и удвоить размер буфера, все равно он может оказаться слишком маленьким, так как в сети существуют свои задержки. Например, если сетевая карта работает в режиме polling или отложенных прерываний, то пакет какое-то время проведет в буфере сетевой карты. Поэтому для хорошей настройки TCP буфера придется поиграть с настройками, постепенно повышая размер буфера и проверяя скорость работы при помощи специальных программ. Для начала, если расстояние между удаленными точками невелико, то размер буфера для отправки в 2 Мб, а на прием в 4 Мб должно вполне хватить. Ещё одним правилом хорошего тона считается установка приемного буфера равным двум размерам буфера для отправки. И не стоит забывать о расчете внутреннего буфера. Команды для настройки ОС см. приложения 2.
И на последок, стоит упомянуть об опциях и алгоритмах TCP протокола. Во время работы они занимают определенные вычислительные ресурсы, а также место в передаваемых по сети пакетах, что далеко не всегда необходимо. Отключение некоторых опций не приведет к существенному увеличению скорости передачи данных, но зато позволит сэкономить немало ресурсов системы. Так, например, если канал передачи данных достаточно надежный, с минимальными потерями, то можно отключить использование "Выборочных подтверждений" (SACK - Selective ACKnowledgement), а вместе с ним DSACK и FACK. Эти алгоритмы обеспечивают быстрое восстановление соединения, если произошла потеря пакета и в случае с надежным каналом их присутствие излишне [12, 13]. И даже если произойдет потеря, TCP и без SACK достаточно лихо восстановит соединение.
Для корректной работы гигабит необходима правильная настройка всех 3-х уровней сетевой модели. И хотя они друг от друга не зависимы, сбой на одном из них может привести к плохой работе всего стека. Как видно, потеря пакетов или узкое место может возникать на любом из уровней, поэтому каждый из них должен быть настроен корректно. Проверить настройки можно при помощи утилит NetPiPe, NetPerf и TTCP [16, 17, 18], а используя системные утилиты (ifconfig, netstat, /proc/net/softnet_stat) всегда можно посмотреть статистику того или иного уровня и сделать заключение о корректности его работы. Правильная настройка Gigabit Ethernet позволит не только лучше использовать его возможности на 100%, но и сэкономить немало вычислительных ресурсов в системе.
Аппаратный уровень: на котором производится настройка сетевой карты. В отличии от NAPI под Linux, имеет множество параметров позволяющие произвести точную настройку. Перед тем как использовать режим опроса, необходимо проверить, может ли система работать с сетевой картой в этом режиме, для этого достаточно посмотреть man polling. Что бы иметь возможность использовать режим опроса (polling) на FreeBSD необходимо пересобрать ядро с его поддержкой, а так же выставить частоту опроса, например:
options DEVICE_POLLING
options HZ=1000 # частота опроса
после этого, появляется возможность использовать его в системе. Все остальные настройки производятся путем изменения переменных ядра через sysctl:
kern.polling.enable - включает или отключает использование polling в системе. (0 - отключен, 1 - включен). При включении, все устройства, поддерживающие режим опроса, автоматически переводятся в режим опроса.
kern.polling.user_frac - определяет использование процессорного времени между ядром и пользовательскими процессами. Чем меньше значение, тем меньше времени будет уделено пользовательским процессам и больше ядру. Стоит заметить, что если у одного из уровней задач (пользовательский) не имеет достаточно работы, то остатки процессорного времени переходят другому (ядру), так что процессорное время не теряется. По умолчанию, значение этой переменной - 50. Меньшее значение стоит выставлять на маршрутизаторах. Допустимый предел значений от 1 до 99.
kern.polling.handlers - определяет количество устройств, которые могут быть зарегистрированы как polling.
kern.polling.burst - максимальное количество пакетов, которое может быть обработано с одного устройства за каждый проход. Это значение подстраивается ядром, основываясь на текучем уровне загрузки, мощности процессора, потока трафика и т.д.
kern.polling.burst_max - определяет верхнюю границу kern.polling.burst.
kern.polling.reg_frac - в процессе опроса не проверяется состояние регистров на ошибки, текущее состояние связи и.т.д., это значение указывает, как часто (каждые reg_frac / HZ секунд) проводить подобные проверки. Значение по умолчанию - 20.
kern.polling.idle_poll - определяет, использовать ли опрос устройств в свободное время. Нет причин отключать его, разве что для проведения тестов или при возникновении ошибок. По умолчанию включено.
Как правило, в работе используют только kern.polling.enable и kern.polling.user_frac. Более подробную информацию о параметрах polling можно посмотреть в "man polling".
Уровень ядра:intr_queue_maxlen - очередь для входящих пакетов (аналогична backlog под Linux). Изменяется при помощи sysctl: net.inet.ip.intr_queue_maxlen. Значение по умолчанию = 50, что очень мало.
intr_queue_drops - статистика по работе intr_queue_maxlen, отображает количество отброшенных пакетов из очереди. Посмотреть её можно через sysctl: net.inet.ip.intr_queue_drops.
Уровень протокола:Все параметры выставляются через sysctl:
net.inet.tcp.rfc1323 - контролирует работу временной марки и масштабируемого окна. (0 - выключено, 1 - включено)
kern.ipc.maxsockbuf - максимальный размер TCP буфера.
net.inet.tcp.recvspace - размер TCP буфера для приема. Влияет на размер "скользящего окна".
net.inet.tcp.sendspace - размер TCP буфера для отправки. Влияет на размер "окна переполнения".
Для того, что бы выставлять значения при загрузке их следует прописать в /etc/sysctl.conf. Пример использования /etc/sysctl.conf:
kern.polling.enable=1
net.inet.ip.intr_queue_maxlen=5000
kern.ipc.maxsockbuf=8388608
net.inet.tcp.sendspace=3217968
net.inet.tcp.recvspace=3217968
net.inet.tcp.rfc1323=1
Аппаратный уровень: на аппаратном уровне в Linux возможно использование polling (NAPI). Для того, что бы сетевая карта могла работать в режиме NAPI, необходимо скомпилировать драйвера с его поддержкой. На данный момент NAPI не конфигурируемый. Для настройки отложенных прерываний читайте документацию к сетевому адаптеру.
Ошибки которые возникают на сетевом интерфейсе можно посмотреть при помощи команды ifconfig.
eth0 Link encap:Ethernet HWaddr 00:30:48:27:4E:F0
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:830338155 errors:862 dropped:862 overruns:862 frame:0
TX packets:734455967 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:240093669 (228.9 Mb) TX bytes:856927884 (817.2 Mb)
Interrupt:54 Base address:0x3000 Memory:fc200000-fc220000
RX packets - полученные пакеты.
TX packets - отправленные пакеты.
На этом примере видно, что при приеме, 862 пакета были отброшены (dropped), в связи с переполнением буфера. (overruns).
Уровень ядра:Backlog: длина очереди для входящих пакетов. Выставить значение можно через /proc/sys/net/core/netdev_max_backlog и/или через sysctl -w net.core.netdev_max_backlog. Значение по умолчанию 300. Минимальное значение должно быть равным количеству буферов на сетевом интерфейсе, что бы не вызвать переполнение. Рекомендуемое значение от 3000. Не используется при NAPI.
softnet_stat: Отображает статистику работы backlog очереди. Просмотреть её можно через /proc/net/softnet_stat. Колонки означают следующее:
Txqueuelen: длина очереди для исходящих пакетов. Настраивается через ifconfig. Например, ifconfig eth0 txqueuelen 3000. Значение по умолчанию 1000. Минимальное значение должно быть равным количеству буферов для отправки на сетевом адаптере иначе можно вызвать переполнить. Рекомендуется использовать очередь размером от 3000. При передаче данных на большие расстояния длина очереди должна быть соответственно увеличена.
Уровень протокола:tcp_mem: Задаются 3 значения, определяющие общий объем памяти, который может быть использован стеком TCP. Значения измеряются в страницах памяти. Размер одной страницы зависит от аппаратуры и конфигурации ядра. Для архитектуры i386 размер одной страницы составляет 4Кб, или 4096 байт. Некоторые, более новые аппаратные реализации, имеют размер страницы равный 16, 32 или даже 64 Кб. Все три значения по-умолчанию рассчитываются во время загрузки. Первое число задает нижний порог. Ниже этого порога, стек TCP вообще никак не беспокоится об управлении памятью, используемой различными TCP сокетами. Когда объем используемой памяти достигает второго предела (числа), то TCP начинает более энергично "расталкивать" память, стремясь освободить ее как можно быстрее. Этот процесс продолжается до тех пор, пока объем используемой памяти не достигнет нижнего предела. И последнее число - максимальный объем памяти, который может использоваться для нужд TCP. Если используемый объем памяти достигнет этого порога, то TCP просто начинает "терять" пакеты и соединения до тех пор, пока объем используемой памяти не уменьшится. Установить ее значение можно через /proc/sys/net/ipv4/tcp_mem или sysctl net.ipv4.tcp_mem. По умолчанию значение этой переменной достаточно большое (не забывайте, она измеряется в страницах памяти!), так что о нем можно особо не беспокоиться.
tcp_rmem: Переменная содержит три числа, которые используются при управлении размерами приемных буферов (измеряется в байтах!). Эта переменная используется при расчете размера скользящего окна. Первое число - минимальный размер приемного буфера, который выделяется для каждого сокета. Этот размер буфера выделяется всегда, даже при очень высоких нагрузках на систему. Значение по-умолчанию - 4096 байт, или 4 Кб. Второе число - размер приемного буфера по-умолчанию, который выделяется для каждого сокета. Это значение перекрывается переменной /proc/sys/net/core/rmem_default, которая используется другими протоколами. Значение по-умолчанию - 87380 байт, или 85 Кб. Третье, и последнее, число - максимально возможный размер приемного буфера, который может быть размещен для каждого сокета. Это значение перекрывается переменной /proc/sys/net/core/rmem_max, если значение в ipv4 оказывается больше. Установить значение tcp_rmem можно через: /proc/sys/net/ipv4/tcp_rmem или sysctl net.ipv4.tcp_rmem
tcp_wmem: Размер буфера передачи выделяемый для каждого TCP соединения. Первое значение - минимальный размер буфера передачи для каждого сокета. Системой гарантируется выделение этого пространства при открытии сокета. Обычно это значение равно 4096 байт. Второе значение - размер передающего буфера по умолчанию. Значение по умолчанию - 16384 байт, или 16 Кб. Это значение перекрывается переменной /proc/sys/net/core/wmem_default>, которая используется другими протоколами и, как правило, tcp_wmem должна быть меньше чем /proc/sys/net/core/wmem_default. Третье значение - максимальный размер буфера передачи для отдельного сокета. По-умолчанию - 131072 байт, или 128 Кб. Но при установке 3-его значения помните о /proc/sys/net/core/wmem_max, которая перекрывает его. Выставить правильные значения tcp_wmem можно либо через /proc/sys/net/ipv4/tcp_wmem либо через sysctl net.ipv4.tcp_wmem. Размер этого буфера влияет на "окно переполнения" которое определяет максимальное количество пакетов, которое можно послать без подтверждения.
rmem_default и wmem_default: Размер буфера по умолчанию который выделяется для каждого соединения. Установить значения можно через /proc:
echo "значение" > /proc/sys/net/core/rmem_default>
echo "значение" > /proc/sys/net/core/wmem_default
или через sysctl:
sysctl -w net.core.rmem_default=значение
sysctl -w net.core.wmem_default=значение
rmem_max и wmem_max: Максимальный размер буфера, который выделит система под одно соединение. Не обязательно TCP соединение, это может быть любой другой протокол. Верхняя граница размера буфера. Если буфер заполнится полностью, то последующие пакеты будут отбрасываться. Устанавливается значение для этих
переменных так же как для rmem_default и wmem_default:
echo "значение" > /proc/sys/net/core/rmem_max
echo "значение" > /proc/sys/net/core/wmem_max
или через sysctl:
sysctl -w net.core.rmem_max=значение
sysctl -w net.core.wmem_max=значение
tcp_dsack: Поддержка дублированных SACK, включено по умолчанию. Устанавливается через sysctl -w net.ipv4.tcp_dsack или /proc/sys/net/ipv4/tcp_dsack (0 - выключен, 1 - включен)
tcp_fack: Поддержка TCP Forward Acknowledgement, включена по умолчанию. Работает вместе с SACK. Устанавливается через sysctl -w net.ipv4.tcp_fack или /proc/sys/net/ipv4/tcp_fack (0 - выключен, 1- включен)
tcp_sack: Разрешает Selective Acknowledgements (SACK -- Выборочное Подтверждение). Устанавливается через sysctl -w net.ipv4.tcp_sack или /proc/sys/net/ipv4/tcp_sack (0 - выключен, 1 - включен)
tcp_window_scaling: Разрешает/запрещает масштабирование TCP-окна, как определено в RFC 1323. Включить можно sysctl -w net.ipv4.tcp_window_scaling или /proc/sys/net/ipv4/tcp_window_scaling (0 - выключен, 1 - включен)
tcp_timestamps: Вставляет временную марку, как описано в RFC1323. По умолчанию включено. Изменить настроку можно через sysctl -w net.ipv4.tcp_timestamps или /proc/sys/net/ipv4/tcp_timestamps (0 - выключен, 1 - включен)
Пример настройки TCP протокола для узла, где количество одновременных соединений очень мало 1-3 и расстояние между узлами не более 2-х метров. Все настройки записаны в файл /etc/sysctl.conf:
net.ipv4.tcp_fack = 0
net.ipv4.tcp_sack = 0
net.core.wmem_max = 33554432
net.core.rmem_max = 33554432
net.core.rmem_default = 8388608
net.core.wmem_default = 4194394
net.ipv4.tcp_rmem = 4096 8388608 16777216
net.ipv4.tcp_wmem = 4096 4194394 16777216
Более подробно о настройках TCP можно посмотреть в "man tcp".