| United States-English |
|
|
|
Arbitration For Data Integrity in Serviceguard Clusters: > Chapter 1 Arbitration
for Data Integrity in Serviceguard ClustersArbitration in Disaster-Tolerant Clusters |
|
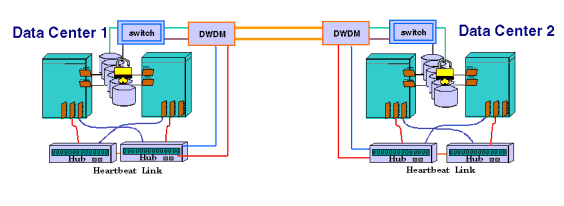
Disaster-tolerant clusters are those which are intended to survive the loss of a data center that contains multiple resources. Examples are an extended distance cluster where nodes may be separated into different data centers on one site; metropolitan clusters, where the nodes are separated into equal-sized groups located a significant distance apart; and continental clusters, in which the geographically separate data centers provide a home for entirely separate clusters, complete with storage devices. In extended distance (campus) clusters, the nodes are divided into two separate data centers in different buildings, which can be as far as 100 km apart. A dual cluster lock disk may be used for arbitration, with the two lock disks located in the two different data centers. This affords protection against the loss of one of the data centers. If a quorum server is used, it must be in a different location from either of the two data centers, thus providing additional protection against data center loss. Similarly, if arbitrator nodes are used, they must be in a different location from the two data centers. An extended distance cluster is no different from a standard Serviceguard cluster except that components are subdivided by data center. This means that groups of nodes are located in different buildings, and storage units with mirrored data are placed in separate facilities as well. Arbitration in a MetroCluster configuration has traditionally followed a different model than that of the single arbitrator device (originally this was a lock disk). Because a MetroCluster configuration contains two distinct data centers at some distance from one another, the main protection has been against a partition that separates the two data centers into equal-sized groups of nodes. A lock disk is not possible in this type of cluster, since metropolitan clusters use a specialized data replication method rather than LVM mirroring. Since LVM is not used with shared data, there is no one disk that is actually connected to both data centers that could act as a lock disk. Arbitration in this case can be obtained by using arbitrator nodes or a quorum server. For example, a metropolitan cluster with three nodes in Data Center A and three nodes in Data Center B could be partitioned such that two equal-sized groups remain up and running, trying to re-form. To address this problem, the supported configurations included one or two arbitrator nodes located in a third data center. These nodes are configured into the cluster for the purpose of providing a majority of nodes when combined with one half the nodes in an equal partition. In other words, if the metropolitan cluster should lose one data center, the surviving data center would still remain connected to the arbitrator nodes, so the surviving group would be larger than 50% of the previously running nodes in the cluster. It could therefore obtain the quorum and re-form the cluster. Note that in a metropolitan cluster, it is the simple existence of the node(s) in the third data center that provides arbitration combined with the requirement that the configuration have an equal number of nodes in Data Center A and Data Center B. The arbitrator nodes located in Data Center C may do useful work, but they are not attached to the storage devices used by the main nodes in the cluster. They are fully configured as cluster nodes, but their main job is to provide arbitration. With the advent of the quorum server, another MetroCluster configuration is now possible. A quorum server process, located in a third data center, can be used for arbitration. The third data center is needed, as it was in the case of arbitrator nodes, to provide the appropriate degree of disaster tolerance. That is, the QS could arbitrate cluster re-formation if either of the other two entire sites should be destroyed. One advantage of the quorum server is that additional cluster nodes do not have to be configured for arbitration. There are no special arbitration requirements or configurations for the separate clusters within a continental cluster. Each cluster must provide its own arbitration separately, according to the applicable rules for a standard Serviceguard cluster. In other words, the continental cluster can employ any supported method of arbitration for its component clusters. ContinentalClusters provides semi-automatic failover via commands which must be issued by a human operator. Between the member clusters of a continental cluster, the arbitrator is the system administrator on the recovery site, who must verify that it is appropriate to issue the cmrecovercl command. Lock disks are not supported in metropolitan clusters, but they can be used in an extended distance cluster, which employs mirrored LVM over a FibreChannel disk link.
For an extended distance cluster, there should be one lock disk in each of the data centers; all nodes have access to both lock disks via the disk link. In the event of a failure of one of the data centers, the nodes in the remaining data center will be able to acquire their local lock disk, allowing them to successfully reform a new cluster. In a dual lock disk configuration, there is an extremely slight chance of split-brain in dual lock disk configuration. The use of dual locks is as follows in an extended distance cluster:
A dual lock disk configuration is shown in Figure 9. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||