FreeBSD Handbook
The FreeBSD Documentation Project
Copyright © 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008 The FreeBSD Documentation Project
Welcome to FreeBSD! This handbook covers the installation and day to day use of FreeBSD 5.5-RELEASE and FreeBSD 6.2-RELEASE. This manual is a work in progress and is the work of many individuals. As such, some sections may become dated and require updating. If you are interested in helping out with this project, send email to the FreeBSD documentation project mailing list. The latest version of this document is always available from the FreeBSD web site (previous versions of this handbook can be obtained from http://docs.FreeBSD.org/doc/). It may also be downloaded in a variety of formats and compression options from the FreeBSD FTP server or one of the numerous mirror sites. If you would prefer to have a hard copy of the handbook, you can purchase one at the FreeBSD Mall. You may also want to search the handbook.
Redistribution and use in source (SGML DocBook) and 'compiled' forms (SGML, HTML, PDF, PostScript, RTF and so forth) with or without modification, are permitted provided that the following conditions are met:
-
Redistributions of source code (SGML DocBook) must retain the above copyright notice, this list of conditions and the following disclaimer as the first lines of this file unmodified.
-
Redistributions in compiled form (transformed to other DTDs, converted to PDF, PostScript, RTF and other formats) must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
Important: THIS DOCUMENTATION IS PROVIDED BY THE FREEBSD DOCUMENTATION PROJECT "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE FREEBSD DOCUMENTATION PROJECT BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS DOCUMENTATION, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
FreeBSD is a registered trademark of the FreeBSD Foundation.
3Com and HomeConnect are registered trademarks of 3Com Corporation.
3ware and Escalade are registered trademarks of 3ware Inc.
ARM is a registered trademark of ARM Limited.
Adaptec is a registered trademark of Adaptec, Inc.
Adobe, Acrobat, Acrobat Reader, and PostScript are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries.
Apple, AirPort, FireWire, Mac, Macintosh, Mac OS, Quicktime, and TrueType are trademarks of Apple Computer, Inc., registered in the United States and other countries.
Corel and WordPerfect are trademarks or registered trademarks of Corel Corporation and/or its subsidiaries in Canada, the United States and/or other countries.
Sound Blaster is a trademark of Creative Technology Ltd. in the United States and/or other countries.
CVSup is a registered trademark of John D. Polstra.
Heidelberg, Helvetica, Palatino, and Times Roman are either registered trademarks or trademarks of Heidelberger Druckmaschinen AG in the U.S. and other countries.
IBM, AIX, EtherJet, Netfinity, OS/2, PowerPC, PS/2, S/390, and ThinkPad are trademarks of International Business Machines Corporation in the United States, other countries, or both.
IEEE, POSIX, and 802 are registered trademarks of Institute of Electrical and Electronics Engineers, Inc. in the United States.
Intel, Celeron, EtherExpress, i386, i486, Itanium, Pentium, and Xeon are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries.
Intuit and Quicken are registered trademarks and/or registered service marks of Intuit Inc., or one of its subsidiaries, in the United States and other countries.
Linux is a registered trademark of Linus Torvalds.
LSI Logic, AcceleRAID, eXtremeRAID, MegaRAID and Mylex are trademarks or registered trademarks of LSI Logic Corp.
M-Systems and DiskOnChip are trademarks or registered trademarks of M-Systems Flash Disk Pioneers, Ltd.
Macromedia, Flash, and Shockwave are trademarks or registered trademarks of Macromedia, Inc. in the United States and/or other countries.
Microsoft, IntelliMouse, MS-DOS, Outlook, Windows, Windows Media and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Netscape and the Netscape Navigator are registered trademarks of Netscape Communications Corporation in the U.S. and other countries.
GateD and NextHop are registered and unregistered trademarks of NextHop in the U.S. and other countries.
Motif, OSF/1, and UNIX are registered trademarks and IT DialTone and The Open Group are trademarks of The Open Group in the United States and other countries.
Oracle is a registered trademark of Oracle Corporation.
PowerQuest and PartitionMagic are registered trademarks of PowerQuest Corporation in the United States and/or other countries.
RealNetworks, RealPlayer, and RealAudio are the registered trademarks of RealNetworks, Inc.
Red Hat, RPM, are trademarks or registered trademarks of Red Hat, Inc. in the United States and other countries.
SAP, R/3, and mySAP are trademarks or registered trademarks of SAP AG in Germany and in several other countries all over the world.
Sun, Sun Microsystems, Java, Java Virtual Machine, JavaServer Pages, JDK, JRE, JSP, JVM, Netra, Solaris, StarOffice, Sun Blade, Sun Enterprise, Sun Fire, SunOS, and Ultra are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries.
Symantec and Ghost are registered trademarks of Symantec Corporation in the United States and other countries.
MATLAB is a registered trademark of The MathWorks, Inc.
SpeedTouch is a trademark of Thomson.
U.S. Robotics and Sportster are registered trademarks of U.S. Robotics Corporation.
VMware is a trademark of VMware, Inc.
Waterloo Maple and Maple are trademarks or registered trademarks of Waterloo Maple Inc.
Mathematica is a registered trademark of Wolfram Research, Inc.
XFree86 is a trademark of The XFree86 Project, Inc.
Ogg Vorbis and Xiph.Org are trademarks of Xiph.Org.
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this document, and the FreeBSD Project was aware of the trademark claim, the designations have been followed by the “™” or the “®” symbol.
- Table of Contents
- Preface
- I. Getting Started
-
- 1 Introduction
-
- 1.1 Synopsis
- 1.2 Welcome to FreeBSD!
- 1.3 About the FreeBSD Project
- 2 Installing FreeBSD
-
- 2.1 Synopsis
- 2.2 Hardware Requirements
- 2.3 Pre-installation Tasks
- 2.4 Starting the Installation
- 2.5 Introducing Sysinstall
- 2.6 Allocating Disk Space
- 2.7 Choosing What to Install
- 2.8 Choosing Your Installation Media
- 2.9 Committing to the Installation
- 2.10 Post-installation
- 2.11 Troubleshooting
- 2.12 Advanced Installation Guide
- 2.13 Preparing Your Own Installation Media
- 3 UNIX Basics
-
- 3.1 Synopsis
- 3.2 Virtual Consoles and Terminals
- 3.3 Permissions
- 3.4 Directory Structure
- 3.5 Disk Organization
- 3.6 Mounting and Unmounting File Systems
- 3.7 Processes
- 3.8 Daemons, Signals, and Killing Processes
- 3.9 Shells
- 3.10 Text Editors
- 3.11 Devices and Device Nodes
- 3.12 Binary Formats
- 3.13 For More Information
- 4 Installing Applications: Packages and Ports
- 5 The X Window System
-
- 5.1 Synopsis
- 5.2 Understanding X
- 5.3 Installing X11
- 5.4 X11 Configuration
- 5.5 Using Fonts in X11
- 5.6 The X Display Manager
- 5.7 Desktop Environments
- II. Common Tasks
-
- 6 Desktop Applications
-
- 6.1 Synopsis
- 6.2 Browsers
- 6.3 Productivity
- 6.4 Document Viewers
- 6.5 Finance
- 6.6 Summary
- 7 Multimedia
-
- 7.1 Synopsis
- 7.2 Setting Up the Sound Card
- 7.3 MP3 Audio
- 7.4 Video Playback
- 7.5 Setting Up TV Cards
- 7.6 Image Scanners
- 8 Configuring the FreeBSD Kernel
- 9 Printing
-
- 9.1 Synopsis
- 9.2 Introduction
- 9.3 Basic Setup
- 9.4 Advanced Printer Setup
- 9.5 Using Printers
- 9.6 Alternatives to the Standard Spooler
- 9.7 Troubleshooting
- 10 Linux Binary Compatibility
-
- 10.1 Synopsis
- 10.2 Installation
- 10.3 Installing Mathematica®
- 10.4 Installing Maple™
- 10.5 Installing MATLAB®
- 10.6 Installing Oracle®
- 10.7 Installing SAP® R/3®
- 10.8 Advanced Topics
- III. System Administration
-
- 11 Configuration and Tuning
-
- 11.1 Synopsis
- 11.2 Initial Configuration
- 11.3 Core Configuration
- 11.4 Application Configuration
- 11.5 Starting Services
- 11.6 Configuring the cron Utility
- 11.7 Using rc under FreeBSD
- 11.8 Setting Up Network Interface Cards
- 11.9 Virtual Hosts
- 11.10 Configuration Files
- 11.11 Tuning with sysctl
- 11.12 Tuning Disks
- 11.13 Tuning Kernel Limits
- 11.14 Adding Swap Space
- 11.15 Power and Resource Management
- 11.16 Using and Debugging FreeBSD ACPI
- 12 The FreeBSD Booting Process
-
- 12.1 Synopsis
- 12.2 The Booting Problem
- 12.3 The Boot Manager and Boot Stages
- 12.4 Kernel Interaction During Boot
- 12.5 Device Hints
- 12.6 Init: Process Control Initialization
- 12.7 Shutdown Sequence
- 13 Users and Basic Account Management
-
- 13.1 Synopsis
- 13.2 Introduction
- 13.3 The Superuser Account
- 13.4 System Accounts
- 13.5 User Accounts
- 13.6 Modifying Accounts
- 13.7 Limiting Users
- 13.8 Groups
- 14 Security
-
- 14.1 Synopsis
- 14.2 Introduction
- 14.3 Securing FreeBSD
- 14.4 DES, Blowfish, MD5, and Crypt
- 14.5 One-time Passwords
- 14.6 TCP Wrappers
- 14.7 KerberosIV
- 14.8 Kerberos5
- 14.9 OpenSSL
- 14.10 VPN over IPsec
- 14.11 OpenSSH
- 14.12 File System Access Control Lists
- 14.13 Monitoring Third Party Security Issues
- 14.14 FreeBSD Security Advisories
- 14.15 Process Accounting
- 15 Jails
-
- 15.1 Synopsis
- 15.2 Terms Related to Jails
- 15.3 Introduction
- 15.4 Creating and Controlling Jails
- 15.5 Fine Tuning and Administration
- 15.6 Application of Jails
- 16 Mandatory Access Control
-
- 16.1 Synopsis
- 16.2 Key Terms in this Chapter
- 16.3 Explanation of MAC
- 16.4 Understanding MAC Labels
- 16.5 Planning the Security Configuration
- 16.6 Module Configuration
- 16.7 The MAC bsdextended Module
- 16.8 The MAC ifoff Module
- 16.9 The MAC portacl Module
- 16.10 The MAC partition Module
- 16.11 The MAC Multi-Level Security Module
- 16.12 The MAC Biba Module
- 16.13 The MAC LOMAC Module
- 16.14 Nagios in a MAC Jail
- 16.15 User Lock Down
- 16.16 Troubleshooting the MAC Framework
- 17 Security Event Auditing
-
- 17.1 Synopsis
- 17.2 Key Terms in this Chapter
- 17.3 Installing Audit Support
- 17.4 Audit Configuration
- 17.5 Administering the Audit Subsystem
- 18 Storage
-
- 18.1 Synopsis
- 18.2 Device Names
- 18.3 Adding Disks
- 18.4 RAID
- 18.5 USB Storage Devices
- 18.6 Creating and Using Optical Media (CDs)
- 18.7 Creating and Using Optical Media (DVDs)
- 18.8 Creating and Using Floppy Disks
- 18.9 Creating and Using Data Tapes
- 18.10 Backups to Floppies
- 18.11 Backup Strategies
- 18.12 Backup Basics
- 18.13 Network, Memory, and File-Backed File Systems
- 18.14 File System Snapshots
- 18.15 File System Quotas
- 18.16 Encrypting Disk Partitions
- 18.17 Encrypting Swap Space
- 19 GEOM: Modular Disk Transformation Framework
-
- 19.1 Synopsis
- 19.2 GEOM Introduction
- 19.3 RAID0 - Striping
- 19.4 RAID1 - Mirroring
- 19.5 GEOM Gate Network Devices
- 19.6 Labeling Disk Devices
- 19.7 UFS Journaling Through GEOM
- 20 The Vinum Volume Manager
-
- 20.1 Synopsis
- 20.2 Disks Are Too Small
- 20.3 Access Bottlenecks
- 20.4 Data Integrity
- 20.5 Vinum Objects
- 20.6 Some Examples
- 20.7 Object Naming
- 20.8 Configuring Vinum
- 20.9 Using Vinum for the Root Filesystem
- 21 Virtualization
-
- 21.1 Synopsis
- 21.2 FreeBSD as a Guest OS
- 21.3 FreeBSD as a Host OS
- 22 Localization - I18N/L10N Usage and Setup
-
- 22.1 Synopsis
- 22.2 The Basics
- 22.3 Using Localization
- 22.4 Compiling I18N Programs
- 22.5 Localizing FreeBSD to Specific Languages
- 23 The Cutting Edge
-
- 23.1 Synopsis
- 23.2 FreeBSD-CURRENT vs. FreeBSD-STABLE
- 23.3 Synchronizing Your Source
- 23.4 Rebuilding “world”
- 23.5 Tracking for Multiple Machines
- IV. Network Communication
-
- 24 Serial Communications
-
- 24.1 Synopsis
- 24.2 Introduction
- 24.3 Terminals
- 24.4 Dial-in Service
- 24.5 Dial-out Service
- 24.6 Setting Up the Serial Console
- 25 PPP and SLIP
-
- 25.1 Synopsis
- 25.2 Using User PPP
- 25.3 Using Kernel PPP
- 25.4 Troubleshooting PPP Connections
- 25.5 Using PPP over Ethernet (PPPoE)
- 25.6 Using PPP over ATM (PPPoA)
- 25.7 Using SLIP
- 26 Electronic Mail
-
- 26.1 Synopsis
- 26.2 Using Electronic Mail
- 26.3 sendmail Configuration
- 26.4 Changing Your Mail Transfer Agent
- 26.5 Troubleshooting
- 26.6 Advanced Topics
- 26.7 SMTP with UUCP
- 26.8 Setting Up to Send Only
- 26.9 Using Mail with a Dialup Connection
- 26.10 SMTP Authentication
- 26.11 Mail User Agents
- 26.12 Using fetchmail
- 26.13 Using procmail
- 27 Network Servers
-
- 27.1 Synopsis
- 27.2 The inetd “Super-Server”
- 27.3 Network File System (NFS)
- 27.4 Network Information System (NIS/YP)
- 27.5 Automatic Network Configuration (DHCP)
- 27.6 Domain Name System (DNS)
- 27.7 Apache HTTP Server
- 27.8 File Transfer Protocol (FTP)
- 27.9 File and Print Services for Microsoft Windows clients (Samba)
- 27.10 Clock Synchronization with NTP
- 28 Firewalls
-
- 28.1 Introduction
- 28.2 Firewall Concepts
- 28.3 Firewall Packages
- 28.4 The OpenBSD Packet Filter (PF) and ALTQ
- 28.5 The IPFILTER (IPF) Firewall
- 28.6 IPFW
- 29 Advanced Networking
-
- 29.1 Synopsis
- 29.2 Gateways and Routes
- 29.3 Wireless Networking
- 29.4 Bluetooth
- 29.5 Bridging
- 29.6 Link Aggregation and Failover
- 29.7 Diskless Operation
- 29.8 ISDN
- 29.9 Network Address Translation
- 29.10 Parallel Line IP (PLIP)
- 29.11 IPv6
- 29.12 Asynchronous Transfer Mode (ATM)
- 29.13 Common Access Redundancy Protocol (CARP)
- V. Appendices
-
- A. Obtaining FreeBSD
-
- A.1 CDROM and DVD Publishers
- A.2 FTP Sites
- A.3 Anonymous CVS
- A.4 Using CTM
- A.5 Using CVSup
- A.6 Using Portsnap
- A.7 CVS Tags
- A.8 AFS Sites
- A.9 rsync Sites
- B. Bibliography
- C. Resources on the Internet
-
- C.1 Mailing Lists
- C.2 Usenet Newsgroups
- C.3 World Wide Web Servers
- C.4 Email Addresses
- C.5 Shell Accounts
- D. PGP Keys
-
- D.1 Officers
- D.2 Core Team Members
- D.3 Developers
- FreeBSD Glossary
- Index
- Colophon
- List of Tables
- 2-1. Sample Device Inventory
- 2-2. Partition Layout for First Disk
- 2-3. Partition Layout for Subsequent Disks
- 2-4. FreeBSD 5.X and 6.X ISO Image Names and Meanings
- 3-1. Disk Device Codes
- 18-1. Physical Disk Naming Conventions
- 20-1. Vinum Plex Organizations
- 24-1. DB-25 to DB-25 Null-Modem Cable
- 24-2. DB-9 to DB-9 Null-Modem Cable
- 24-3. DB-9 to DB-25 Null-Modem Cable
- 24-4. Signal Names
- 29-1. Wiring a Parallel Cable for Networking
- 29-2. Reserved IPv6 addresses
- List of Figures
- 2-1. FreeBSD Boot Loader Menu
- 2-2. Typical Device Probe Results
- 2-3. Selecting Country Menu
- 2-4. Select Sysinstall Exit
- 2-5. Selecting Usage from Sysinstall Main Menu
- 2-6. Selecting Documentation Menu
- 2-7. Sysinstall Documentation Menu
- 2-8. Sysinstall Main Menu
- 2-9. Sysinstall Keymap Menu
- 2-10. Sysinstall Main Menu
- 2-11. Sysinstall Options
- 2-12. Begin Standard Installation
- 2-13. Select Drive for FDisk
- 2-14. Typical Fdisk Partitions before Editing
- 2-15. Fdisk Partition Using Entire Disk
- 2-16. Sysinstall Boot Manager Menu
- 2-17. Exit Select Drive
- 2-18. Sysinstall Disklabel Editor
- 2-19. Sysinstall Disklabel Editor with Auto Defaults
- 2-20. Free Space for Root Partition
- 2-21. Edit Root Partition Size
- 2-22. Choose the Root Partition Type
- 2-23. Choose the Root Mount Point
- 2-24. Sysinstall Disklabel Editor
- 2-25. Choose Distributions
- 2-26. Confirm Distributions
- 2-27. Choose Installation Media
- 2-28. Selecting an Ethernet Device
- 2-29. Set Network Configuration for ed0
- 2-30. Editing inetd.conf
- 2-31. Default Anonymous FTP Configuration
- 2-32. Edit the FTP Welcome Message
- 2-33. Editing exports
- 2-34. System Console Configuration Options
- 2-35. Screen Saver Options
- 2-36. Screen Saver Timeout
- 2-37. System Console Configuration Exit
- 2-38. Select Your Region
- 2-39. Select Your Country
- 2-40. Select Your Time Zone
- 2-41. Select Mouse Protocol Type
- 2-42. Set Mouse Protocol
- 2-43. Configure Mouse Port
- 2-44. Setting the Mouse Port
- 2-45. Enable the Mouse Daemon
- 2-46. Test the Mouse Daemon
- 2-47. Select Package Category
- 2-48. Select Packages
- 2-49. Install Packages
- 2-50. Confirm Package Installation
- 2-51. Select User
- 2-52. Add User Information
- 2-53. Exit User and Group Management
- 2-54. Exit Install
- 2-55. Network Configuration Upper-level
- 2-56. Select a default MTA
- 2-57. Ntpdate Configuration
- 2-58. Network Configuration Lower-level
- 20-1. Concatenated Organization
- 20-2. Striped Organization
- 20-3. RAID-5 Organization
- 20-4. A Simple Vinum Volume
- 20-5. A Mirrored Vinum Volume
- 20-6. A Striped Vinum Volume
- 20-7. A Mirrored, Striped Vinum Volume
- List of Examples
- 2-1. Using an Existing Partition Unchanged
- 2-2. Shrinking an Existing Partition
- 3-1. Sample Disk, Slice, and Partition Names
- 3-2. Conceptual Model of a Disk
- 4-1. Downloading a Package Manually and Installing It Locally
- 11-1. Creating a Swapfile on FreeBSD
- 12-1. boot0 Screenshot
- 12-2. boot2 Screenshot
- 12-3. An Insecure Console in /etc/ttys
- 13-1. Adding a user on FreeBSD
- 13-2. rmuser Interactive Account Removal
- 13-3. Interactive chpass by Superuser
- 13-4. Interactive chpass by Normal User
- 13-5. Changing Your Password
- 13-6. Changing Another User's Password as the Superuser
- 13-7. Adding a Group Using pw(8)
- 13-8. Adding Somebody to a Group Using pw(8)
- 13-9. Using id(1) to Determine Group Membership
- 14-1. Using SSH to Create a Secure Tunnel for SMTP
- 18-1. Using dump over ssh
- 18-2. Using dump over ssh with RSH set
- 18-3. A Script for Creating a Bootable Floppy
- 18-4. Using mdconfig to Mount an Existing File System Image
- 18-5. Creating a New File-Backed Disk with mdconfig
- 18-6. Configure and Mount a File-Backed Disk with mdmfs
- 18-7. Creating a New Memory-Based Disk with mdconfig
- 18-8. Creating a New Memory-Based Disk with mdmfs
- 24-1. Adding Terminal Entries to /etc/ttys
- 26-1. Configuring the sendmail Access Database
- 26-2. Mail Aliases
- 26-3. Example Virtual Domain Mail Map
- 27-1. Reloading the inetd configuration file
- 27-2. Mounting an Export with amd
- 29-1. LACP aggregation with a Cisco switch
- 29-2. Failover mode
- 29-3. Branch Office or Home Network
- 29-4. Head Office or Other LAN
- A-1. Checking Out Something from -CURRENT (ls(1)):
- A-2. Using SSH to check out the src/ tree:
- A-3. Checking Out the Version of ls(1) in the 6-STABLE Branch:
- A-4. Creating a List of Changes (as Unified Diffs) to ls(1)
- A-5. Finding Out What Other Module Names Can Be Used:
Preface
Intended Audience
The FreeBSD newcomer will find that the first section of this book guides the user through the FreeBSD installation process and gently introduces the concepts and conventions that underpin UNIX®. Working through this section requires little more than the desire to explore, and the ability to take on board new concepts as they are introduced.
Once you have traveled this far, the second, far larger, section of the Handbook is a comprehensive reference to all manner of topics of interest to FreeBSD system administrators. Some of these chapters may recommend that you do some prior reading, and this is noted in the synopsis at the beginning of each chapter.
For a list of additional sources of information, please see Appendix B.
Changes from the Second Edition
This third edition is the culmination of over two years of work by the dedicated members of the FreeBSD Documentation Project. The following are the major changes in this new edition:
-
Chapter 11, Configuration and Tuning, has been expanded with new information about the ACPI power and resource management, the cron system utility, and more kernel tuning options.
-
Chapter 14, Security, has been expanded with new information about virtual private networks (VPNs), file system access control lists (ACLs), and security advisories.
-
Chapter 16, Mandatory Access Control (MAC), is a new chapter with this edition. It explains what MAC is and how this mechanism can be used to secure a FreeBSD system.
-
Chapter 18, Storage, has been expanded with new information about USB storage devices, file system snapshots, file system quotas, file and network backed filesystems, and encrypted disk partitions.
-
Chapter 20, Vinum, is a new chapter with this edition. It describes how to use Vinum, a logical volume manager which provides device-independent logical disks, and software RAID-0, RAID-1 and RAID-5.
-
A troubleshooting section has been added to Chapter 25, PPP and SLIP.
-
Chapter 26, Electronic Mail, has been expanded with new information about using alternative transport agents, SMTP authentication, UUCP, fetchmail, procmail, and other advanced topics.
-
Chapter 27, Network Servers, is all new with this edition. This chapter includes information about setting up the Apache HTTP Server, ftpd, and setting up a server for Microsoft® Windows® clients with Samba. Some sections from Chapter 29, Advanced Networking, were moved here to improve the presentation.
-
Chapter 29, Advanced Networking, has been expanded with new information about using Bluetooth® devices with FreeBSD, setting up wireless networks, and Asynchronous Transfer Mode (ATM) networking.
-
A glossary has been added to provide a central location for the definitions of technical terms used throughout the book.
-
A number of aesthetic improvements have been made to the tables and figures throughout the book.
Changes from the First Edition
The second edition was the culmination of over two years of work by the dedicated members of the FreeBSD Documentation Project. The following were the major changes in this edition:
-
A complete Index has been added.
-
All ASCII figures have been replaced by graphical diagrams.
-
A standard synopsis has been added to each chapter to give a quick summary of what information the chapter contains, and what the reader is expected to know.
-
The content has been logically reorganized into three parts: “Getting Started”, “System Administration”, and “Appendices”.
-
Chapter 2 (“Installing FreeBSD”) was completely rewritten with many screenshots to make it much easier for new users to grasp the text.
-
Chapter 3 (“UNIX Basics”) has been expanded to contain additional information about processes, daemons, and signals.
-
Chapter 4 (“Installing Applications”) has been expanded to contain additional information about binary package management.
-
Chapter 5 (“The X Window System”) has been completely rewritten with an emphasis on using modern desktop technologies such as KDE and GNOME on XFree86™ 4.X.
-
Chapter 12 (“The FreeBSD Booting Process”) has been expanded.
-
Chapter 18 (“Storage”) has been written from what used to be two separate chapters on “Disks” and “Backups”. We feel that the topics are easier to comprehend when presented as a single chapter. A section on RAID (both hardware and software) has also been added.
-
Chapter 24 (“Serial Communications”) has been completely reorganized and updated for FreeBSD 4.X/5.X.
-
Chapter 25 (“PPP and SLIP”) has been substantially updated.
-
Many new sections have been added to Chapter 29 (“Advanced Networking”).
-
Chapter 26 (“Electronic Mail”) has been expanded to include more information about configuring sendmail.
-
Chapter 10 (“Linux® Compatibility”) has been expanded to include information about installing Oracle® and SAP® R/3®.
-
The following new topics are covered in this second edition:
-
Configuration and Tuning (Chapter 11).
-
Multimedia (Chapter 7)
-
Organization of This Book
This book is split into five logically distinct sections. The first section, Getting Started, covers the installation and basic usage of FreeBSD. It is expected that the reader will follow these chapters in sequence, possibly skipping chapters covering familiar topics. The second section, Common Tasks, covers some frequently used features of FreeBSD. This section, and all subsequent sections, can be read out of order. Each chapter begins with a succinct synopsis that describes what the chapter covers and what the reader is expected to already know. This is meant to allow the casual reader to skip around to find chapters of interest. The third section, System Administration, covers administration topics. The fourth section, Network Communication, covers networking and server topics. The fifth section contains appendices of reference information.
- Chapter 1, Introduction
-
Introduces FreeBSD to a new user. It describes the history of the FreeBSD Project, its goals and development model.
- Chapter 2, Installation
-
Walks a user through the entire installation process. Some advanced installation topics, such as installing through a serial console, are also covered.
- Chapter 3, UNIX Basics
-
Covers the basic commands and functionality of the FreeBSD operating system. If you are familiar with Linux or another flavor of UNIX then you can probably skip this chapter.
- Chapter 4, Installing Applications
-
Covers the installation of third-party software with both FreeBSD's innovative “Ports Collection” and standard binary packages.
- Chapter 5, The X Window System
-
Describes the X Window System in general and using X11 on FreeBSD in particular. Also describes common desktop environments such as KDE and GNOME.
- Chapter 6, Desktop Applications
-
Lists some common desktop applications, such as web browsers and productivity suites, and describes how to install them on FreeBSD.
- Chapter 7, Multimedia
-
Shows how to set up sound and video playback support for your system. Also describes some sample audio and video applications.
- Chapter 8, Configuring the FreeBSD Kernel
-
Explains why you might need to configure a new kernel and provides detailed instructions for configuring, building, and installing a custom kernel.
- Chapter 9, Printing
-
Describes managing printers on FreeBSD, including information about banner pages, printer accounting, and initial setup.
- Chapter 10, Linux Binary Compatibility
-
Describes the Linux compatibility features of FreeBSD. Also provides detailed installation instructions for many popular Linux applications such as Oracle, SAP R/3, and Mathematica®.
- Chapter 11, Configuration and Tuning
-
Describes the parameters available for system administrators to tune a FreeBSD system for optimum performance. Also describes the various configuration files used in FreeBSD and where to find them.
- Chapter 12, Booting Process
-
Describes the FreeBSD boot process and explains how to control this process with configuration options.
- Chapter 13, Users and Basic Account Management
-
Describes the creation and manipulation of user accounts. Also discusses resource limitations that can be set on users and other account management tasks.
- Chapter 14, Security
-
Describes many different tools available to help keep your FreeBSD system secure, including Kerberos, IPsec and OpenSSH.
- Chapter 15, Jails
-
Describes the jails framework, and the improvements of jails over the traditional chroot support of FreeBSD.
- Chapter 16, Mandatory Access Control
-
Explains what Mandatory Access Control (MAC) is and how this mechanism can be used to secure a FreeBSD system.
- Chapter 17, Security Event Auditing
-
Describes what FreeBSD Event Auditing is, how it can be installed, configured, and how audit trails can be inspected or monitored.
- Chapter 18, Storage
-
Describes how to manage storage media and filesystems with FreeBSD. This includes physical disks, RAID arrays, optical and tape media, memory-backed disks, and network filesystems.
- Chapter 19, GEOM
-
Describes what the GEOM framework in FreeBSD is and how to configure various supported RAID levels.
- Chapter 20, Vinum
-
Describes how to use Vinum, a logical volume manager which provides device-independent logical disks, and software RAID-0, RAID-1 and RAID-5.
- Chapter 21, Virtualization
-
Describes what virtualization systems offer, and how they can be used with FreeBSD.
- Chapter 22, Localization
-
Describes how to use FreeBSD in languages other than English. Covers both system and application level localization.
- Chapter 23, The Cutting Edge
-
Explains the differences between FreeBSD-STABLE, FreeBSD-CURRENT, and FreeBSD releases. Describes which users would benefit from tracking a development system and outlines that process.
- Chapter 24, Serial Communications
-
Explains how to connect terminals and modems to your FreeBSD system for both dial in and dial out connections.
- Chapter 25, PPP and SLIP
-
Describes how to use PPP, SLIP, or PPP over Ethernet to connect to remote systems with FreeBSD.
- Chapter 26, Electronic Mail
-
Explains the different components of an email server and dives into simple configuration topics for the most popular mail server software: sendmail.
- Chapter 27, Network Servers
-
Provides detailed instructions and example configuration files to set up your FreeBSD machine as a network filesystem server, domain name server, network information system server, or time synchronization server.
- Chapter 28, Firewalls
-
Explains the philosophy behind software-based firewalls and provides detailed information about the configuration of the different firewalls available for FreeBSD.
- Chapter 29, Advanced Networking
-
Describes many networking topics, including sharing an Internet connection with other computers on your LAN, advanced routing topics, wireless networking, Bluetooth, ATM, IPv6, and much more.
- Appendix A, Obtaining FreeBSD
-
Lists different sources for obtaining FreeBSD media on CDROM or DVD as well as different sites on the Internet that allow you to download and install FreeBSD.
- Appendix B, Bibliography
-
This book touches on many different subjects that may leave you hungry for a more detailed explanation. The bibliography lists many excellent books that are referenced in the text.
- Appendix C, Resources on the Internet
-
Describes the many forums available for FreeBSD users to post questions and engage in technical conversations about FreeBSD.
- Appendix D, PGP Keys
-
Lists the PGP fingerprints of several FreeBSD Developers.
Conventions used in this book
To provide a consistent and easy to read text, several conventions are followed throughout the book.
Typographic Conventions
- Italic
-
An italic font is used for filenames, URLs, emphasized text, and the first usage of technical terms.
- Monospace
-
A monospaced font is used for error messages, commands, environment variables, names of ports, hostnames, user names, group names, device names, variables, and code fragments.
- Bold
-
A bold font is used for applications, commands, and keys.
User Input
Keys are shown in bold to stand out from other text. Key combinations that are meant to be typed simultaneously are shown with `+' between the keys, such as:
Ctrl+Alt+Del
Meaning the user should type the Ctrl, Alt, and Del keys at the same time.
Keys that are meant to be typed in sequence will be separated with commas, for example:
Ctrl+X, Ctrl+S
Would mean that the user is expected to type the Ctrl and X keys simultaneously and then to type the Ctrl and S keys simultaneously.
Examples
Examples starting with E:\> indicate a MS-DOS® command. Unless otherwise noted, these commands may be executed from a “Command Prompt” window in a modern Microsoft Windows environment.
E:\> tools\fdimage floppies\kern.flp A:
Examples starting with # indicate a command that must be invoked as the superuser in FreeBSD. You can login as root to type the command, or login as your normal account and use su(1) to gain superuser privileges.
# dd if=kern.flp of=/dev/fd0
Examples starting with % indicate a command that should be invoked from a normal user account. Unless otherwise noted, C-shell syntax is used for setting environment variables and other shell commands.
% top
Acknowledgments
The book you are holding represents the efforts of many hundreds of people around the world. Whether they sent in fixes for typos, or submitted complete chapters, all the contributions have been useful.
Several companies have supported the development of this document by paying authors to work on it full-time, paying for publication, etc. In particular, BSDi (subsequently acquired by Wind River Systems) paid members of the FreeBSD Documentation Project to work on improving this book full time leading up to the publication of the first printed edition in March 2000 (ISBN 1-57176-241-8). Wind River Systems then paid several additional authors to make a number of improvements to the print-output infrastructure and to add additional chapters to the text. This work culminated in the publication of the second printed edition in November 2001 (ISBN 1-57176-303-1). In 2003-2004, FreeBSD Mall, Inc, paid several contributors to improve the Handbook in preparation for the third printed edition.
I. Getting Started
This part of the FreeBSD Handbook is for users and administrators who are new to FreeBSD. These chapters:
-
Introduce you to FreeBSD.
-
Guide you through the installation process.
-
Teach you UNIX basics and fundamentals.
-
Show you how to install the wealth of third party applications available for FreeBSD.
-
Introduce you to X, the UNIX windowing system, and detail how to configure a desktop environment that makes you more productive.
We have tried to keep the number of forward references in the text to a minimum so that you can read this section of the Handbook from front to back with the minimum page flipping required.
- Table of Contents
- 1 Introduction
- 2 Installing FreeBSD
- 3 UNIX Basics
- 4 Installing Applications: Packages and Ports
- 5 The X Window System
Chapter 1 Introduction
Restructured, reorganized, and parts rewritten by Jim Mock.1.1 Synopsis
Thank you for your interest in FreeBSD! The following chapter covers various aspects of the FreeBSD Project, such as its history, goals, development model, and so on.
After reading this chapter, you will know:
-
How FreeBSD relates to other computer operating systems.
-
The history of the FreeBSD Project.
-
The goals of the FreeBSD Project.
-
The basics of the FreeBSD open-source development model.
-
And of course: where the name “FreeBSD” comes from.
1.2 Welcome to FreeBSD!
FreeBSD is a 4.4BSD-Lite based operating system for Intel (x86 and Itanium®), AMD64, Alpha™, Sun UltraSPARC® computers. Ports to other architectures are also underway. You can also read about the history of FreeBSD, or the current release. If you are interested in contributing something to the Project (code, hardware, funding), see the Contributing to FreeBSD article.
1.2.1 What Can FreeBSD Do?
FreeBSD has many noteworthy features. Some of these are:
-
Preemptive multitasking with dynamic priority adjustment to ensure smooth and fair sharing of the computer between applications and users, even under the heaviest of loads.
-
Multi-user facilities which allow many people to use a FreeBSD system simultaneously for a variety of things. This means, for example, that system peripherals such as printers and tape drives are properly shared between all users on the system or the network and that individual resource limits can be placed on users or groups of users, protecting critical system resources from over-use.
-
Strong TCP/IP networking with support for industry standards such as SCTP, DHCP, NFS, NIS, PPP, SLIP, IPsec, and IPv6. This means that your FreeBSD machine can interoperate easily with other systems as well as act as an enterprise server, providing vital functions such as NFS (remote file access) and email services or putting your organization on the Internet with WWW, FTP, routing and firewall (security) services.
-
Memory protection ensures that applications (or users) cannot interfere with each other. One application crashing will not affect others in any way.
-
FreeBSD is a 32-bit operating system (64-bit on the Alpha, Itanium, AMD64, and UltraSPARC) and was designed as such from the ground up.
-
The industry standard X Window System (X11R7) provides a graphical user interface (GUI) for the cost of a common VGA card and monitor and comes with full sources.
-
Binary compatibility with many programs built for Linux, SCO, SVR4, BSDI and NetBSD.
-
Thousands of ready-to-run applications are available from the FreeBSD ports and packages collection. Why search the net when you can find it all right here?
-
Thousands of additional and easy-to-port applications are available on the Internet. FreeBSD is source code compatible with most popular commercial UNIX systems and thus most applications require few, if any, changes to compile.
-
Demand paged virtual memory and “merged VM/buffer cache” design efficiently satisfies applications with large appetites for memory while still maintaining interactive response to other users.
-
SMP support for machines with multiple CPUs.
-
A full complement of C, C++, and Fortran development tools. Many additional languages for advanced research and development are also available in the ports and packages collection.
-
Source code for the entire system means you have the greatest degree of control over your environment. Why be locked into a proprietary solution at the mercy of your vendor when you can have a truly open system?
-
Extensive online documentation.
-
And many more!
FreeBSD is based on the 4.4BSD-Lite release from Computer Systems Research Group (CSRG) at the University of California at Berkeley, and carries on the distinguished tradition of BSD systems development. In addition to the fine work provided by CSRG, the FreeBSD Project has put in many thousands of hours in fine tuning the system for maximum performance and reliability in real-life load situations. As many of the commercial giants struggle to field PC operating systems with such features, performance and reliability, FreeBSD can offer them now!
The applications to which FreeBSD can be put are truly limited only by your own imagination. From software development to factory automation, inventory control to azimuth correction of remote satellite antennae; if it can be done with a commercial UNIX product then it is more than likely that you can do it with FreeBSD too! FreeBSD also benefits significantly from literally thousands of high quality applications developed by research centers and universities around the world, often available at little to no cost. Commercial applications are also available and appearing in greater numbers every day.
Because the source code for FreeBSD itself is generally available, the system can also be customized to an almost unheard of degree for special applications or projects, and in ways not generally possible with operating systems from most major commercial vendors. Here is just a sampling of some of the applications in which people are currently using FreeBSD:
-
Internet Services: The robust TCP/IP networking built into FreeBSD makes it an ideal platform for a variety of Internet services such as:
-
FTP servers
-
World Wide Web servers (standard or secure [SSL])
-
IPv4 and IPv6 routing
-
Firewalls and NAT (“IP masquerading”) gateways
-
Electronic Mail servers
-
USENET News or Bulletin Board Systems
-
And more...
With FreeBSD, you can easily start out small with an inexpensive 386 class PC and upgrade all the way up to a quad-processor Xeon with RAID storage as your enterprise grows.
-
-
Education: Are you a student of computer science or a related engineering field? There is no better way of learning about operating systems, computer architecture and networking than the hands on, under the hood experience that FreeBSD can provide. A number of freely available CAD, mathematical and graphic design packages also make it highly useful to those whose primary interest in a computer is to get other work done!
-
Research: With source code for the entire system available, FreeBSD is an excellent platform for research in operating systems as well as other branches of computer science. FreeBSD's freely available nature also makes it possible for remote groups to collaborate on ideas or shared development without having to worry about special licensing agreements or limitations on what may be discussed in open forums.
-
Networking: Need a new router? A name server (DNS)? A firewall to keep people out of your internal network? FreeBSD can easily turn that unused 386 or 486 PC sitting in the corner into an advanced router with sophisticated packet-filtering capabilities.
-
X Window workstation: FreeBSD is a fine choice for an inexpensive X terminal solution, using the freely available X11 server. Unlike an X terminal, FreeBSD allows many applications to be run locally if desired, thus relieving the burden on a central server. FreeBSD can even boot “diskless”, making individual workstations even cheaper and easier to administer.
-
Software Development: The basic FreeBSD system comes with a full complement of development tools including the renowned GNU C/C++ compiler and debugger.
FreeBSD is available in both source and binary form on CDROM, DVD, and via anonymous FTP. Please see Appendix A for more information about obtaining FreeBSD.
1.2.2 Who Uses FreeBSD?
FreeBSD is used to power some of the biggest sites on the Internet, including:
and many more.
1.3 About the FreeBSD Project
The following section provides some background information on the project, including a brief history, project goals, and the development model of the project.
1.3.1 A Brief History of FreeBSD
Contributed by Jordan Hubbard.The FreeBSD project had its genesis in the early part of 1993, partially as an outgrowth of the “Unofficial 386BSD Patchkit” by the patchkit's last 3 coordinators: Nate Williams, Rod Grimes and myself.
Our original goal was to produce an intermediate snapshot of 386BSD in order to fix a number of problems with it that the patchkit mechanism just was not capable of solving. Some of you may remember the early working title for the project being “386BSD 0.5” or “386BSD Interim” in reference to that fact.
386BSD was Bill Jolitz's operating system, which had been up to that point suffering rather severely from almost a year's worth of neglect. As the patchkit swelled ever more uncomfortably with each passing day, we were in unanimous agreement that something had to be done and decided to assist Bill by providing this interim “cleanup” snapshot. Those plans came to a rude halt when Bill Jolitz suddenly decided to withdraw his sanction from the project without any clear indication of what would be done instead.
It did not take us long to decide that the goal remained worthwhile, even without Bill's support, and so we adopted the name “FreeBSD”, coined by David Greenman. Our initial objectives were set after consulting with the system's current users and, once it became clear that the project was on the road to perhaps even becoming a reality, I contacted Walnut Creek CDROM with an eye toward improving FreeBSD's distribution channels for those many unfortunates without easy access to the Internet. Walnut Creek CDROM not only supported the idea of distributing FreeBSD on CD but also went so far as to provide the project with a machine to work on and a fast Internet connection. Without Walnut Creek CDROM's almost unprecedented degree of faith in what was, at the time, a completely unknown project, it is quite unlikely that FreeBSD would have gotten as far, as fast, as it has today.
The first CDROM (and general net-wide) distribution was FreeBSD 1.0, released in December of 1993. This was based on the 4.3BSD-Lite (“Net/2”) tape from U.C. Berkeley, with many components also provided by 386BSD and the Free Software Foundation. It was a fairly reasonable success for a first offering, and we followed it with the highly successful FreeBSD 1.1 release in May of 1994.
Around this time, some rather unexpected storm clouds formed on the horizon as Novell and U.C. Berkeley settled their long-running lawsuit over the legal status of the Berkeley Net/2 tape. A condition of that settlement was U.C. Berkeley's concession that large parts of Net/2 were “encumbered” code and the property of Novell, who had in turn acquired it from AT&T some time previously. What Berkeley got in return was Novell's “blessing” that the 4.4BSD-Lite release, when it was finally released, would be declared unencumbered and all existing Net/2 users would be strongly encouraged to switch. This included FreeBSD, and the project was given until the end of July 1994 to stop shipping its own Net/2 based product. Under the terms of that agreement, the project was allowed one last release before the deadline, that release being FreeBSD 1.1.5.1.
FreeBSD then set about the arduous task of literally re-inventing itself from a completely new and rather incomplete set of 4.4BSD-Lite bits. The “Lite” releases were light in part because Berkeley's CSRG had removed large chunks of code required for actually constructing a bootable running system (due to various legal requirements) and the fact that the Intel port of 4.4 was highly incomplete. It took the project until November of 1994 to make this transition, at which point it released FreeBSD 2.0 to the net and on CDROM (in late December). Despite being still more than a little rough around the edges, the release was a significant success and was followed by the more robust and easier to install FreeBSD 2.0.5 release in June of 1995.
We released FreeBSD 2.1.5 in August of 1996, and it appeared to be popular enough among the ISP and commercial communities that another release along the 2.1-STABLE branch was merited. This was FreeBSD 2.1.7.1, released in February 1997 and capping the end of mainstream development on 2.1-STABLE. Now in maintenance mode, only security enhancements and other critical bug fixes will be done on this branch (RELENG_2_1_0).
FreeBSD 2.2 was branched from the development mainline (“-CURRENT”) in November 1996 as the RELENG_2_2 branch, and the first full release (2.2.1) was released in April 1997. Further releases along the 2.2 branch were done in the summer and fall of '97, the last of which (2.2.8) appeared in November 1998. The first official 3.0 release appeared in October 1998 and spelled the beginning of the end for the 2.2 branch.
The tree branched again on Jan 20, 1999, leading to the 4.0-CURRENT and 3.X-STABLE branches. From 3.X-STABLE, 3.1 was released on February 15, 1999, 3.2 on May 15, 1999, 3.3 on September 16, 1999, 3.4 on December 20, 1999, and 3.5 on June 24, 2000, which was followed a few days later by a minor point release update to 3.5.1, to incorporate some last-minute security fixes to Kerberos. This will be the final release in the 3.X branch.
There was another branch on March 13, 2000, which saw the emergence of the 4.X-STABLE branch. There have been several releases from it so far: 4.0-RELEASE was introduced in March 2000, and the last 4.11-RELEASE came out in January 2005.
The long-awaited 5.0-RELEASE was announced on January 19, 2003. The culmination of nearly three years of work, this release started FreeBSD on the path of advanced multiprocessor and application thread support and introduced support for the UltraSPARC and ia64 platforms. This release was followed by 5.1 in June of 2003. The last 5.X release from the -CURRENT branch was 5.2.1-RELEASE, introduced in February 2004.
The RELENG_5 branch, created in August 2004, was followed by 5.3-RELEASE, which marked the beginning of the 5-STABLE branch releases. The most recent 5.5-RELEASE came out in May 2006. There will be no additional releases from the RELENG_5 branch.
The tree was branched again in July 2005, this time for RELENG_6. 6.0-RELEASE, the first release of the 6.X branch, was released in November 2005. The most recent 6.2-RELEASE came out in Jan 2007. There will be additional releases from the RELENG_6 branch.
For now, long-term development projects continue to take place in the 7.X-CURRENT (trunk) branch, and SNAPshot releases of 7.X on CDROM (and, of course, on the net) are continually made available from the snapshot server as work progresses.
1.3.2 FreeBSD Project Goals
Contributed by Jordan Hubbard.The goals of the FreeBSD Project are to provide software that may be used for any purpose and without strings attached. Many of us have a significant investment in the code (and project) and would certainly not mind a little financial compensation now and then, but we are definitely not prepared to insist on it. We believe that our first and foremost “mission” is to provide code to any and all comers, and for whatever purpose, so that the code gets the widest possible use and provides the widest possible benefit. This is, I believe, one of the most fundamental goals of Free Software and one that we enthusiastically support.
That code in our source tree which falls under the GNU General Public License (GPL) or Library General Public License (LGPL) comes with slightly more strings attached, though at least on the side of enforced access rather than the usual opposite. Due to the additional complexities that can evolve in the commercial use of GPL software we do, however, prefer software submitted under the more relaxed BSD copyright when it is a reasonable option to do so.
1.3.3 The FreeBSD Development Model
Contributed by Satoshi Asami.The development of FreeBSD is a very open and flexible process, being literally built from the contributions of hundreds of people around the world, as can be seen from our list of contributors. FreeBSD's development infrastructure allow these hundreds of developers to collaborate over the Internet. We are constantly on the lookout for new developers and ideas, and those interested in becoming more closely involved with the project need simply contact us at the FreeBSD technical discussions mailing list. The FreeBSD announcements mailing list is also available to those wishing to make other FreeBSD users aware of major areas of work.
Useful things to know about the FreeBSD project and its development process, whether working independently or in close cooperation:
- The CVS repository
-
The central source tree for FreeBSD is maintained by CVS (Concurrent Versions System), a freely available source code control tool that comes bundled with FreeBSD. The primary CVS repository resides on a machine in Santa Clara CA, USA from where it is replicated to numerous mirror machines throughout the world. The CVS tree, which contains the -CURRENT and -STABLE trees, can all be easily replicated to your own machine as well. Please refer to the Synchronizing your source tree section for more information on doing this.
- The committers list
-
The committers are the people who have write access to the CVS tree, and are authorized to make modifications to the FreeBSD source (the term “committer” comes from the cvs(1) commit command, which is used to bring new changes into the CVS repository). The best way of making submissions for review by the committers list is to use the send-pr(1) command. If something appears to be jammed in the system, then you may also reach them by sending mail to the FreeBSD committer's mailing list.
- The FreeBSD core team
-
The FreeBSD core team would be equivalent to the board of directors if the FreeBSD Project were a company. The primary task of the core team is to make sure the project, as a whole, is in good shape and is heading in the right directions. Inviting dedicated and responsible developers to join our group of committers is one of the functions of the core team, as is the recruitment of new core team members as others move on. The current core team was elected from a pool of committer candidates in July 2006. Elections are held every 2 years.
Some core team members also have specific areas of responsibility, meaning that they are committed to ensuring that some large portion of the system works as advertised. For a complete list of FreeBSD developers and their areas of responsibility, please see the Contributors List
Note: Most members of the core team are volunteers when it comes to FreeBSD development and do not benefit from the project financially, so “commitment” should also not be misconstrued as meaning “guaranteed support.” The “board of directors” analogy above is not very accurate, and it may be more suitable to say that these are the people who gave up their lives in favor of FreeBSD against their better judgement!
- Outside contributors
-
Last, but definitely not least, the largest group of developers are the users themselves who provide feedback and bug fixes to us on an almost constant basis. The primary way of keeping in touch with FreeBSD's more non-centralized development is to subscribe to the FreeBSD technical discussions mailing list where such things are discussed. See Appendix C for more information about the various FreeBSD mailing lists.
The FreeBSD Contributors List is a long and growing one, so why not join it by contributing something back to FreeBSD today?
Providing code is not the only way of contributing to the project; for a more complete list of things that need doing, please refer to the FreeBSD Project web site.
In summary, our development model is organized as a loose set of concentric circles. The centralized model is designed for the convenience of the users of FreeBSD, who are provided with an easy way of tracking one central code base, not to keep potential contributors out! Our desire is to present a stable operating system with a large set of coherent application programs that the users can easily install and use -- this model works very well in accomplishing that.
All we ask of those who would join us as FreeBSD developers is some of the same dedication its current people have to its continued success!
1.3.4 The Current FreeBSD Release
FreeBSD is a freely available, full source 4.4BSD-Lite based release for Intel i386™, i486™, Pentium®, Pentium Pro, Celeron®, Pentium II, Pentium III, Pentium 4 (or compatible), Xeon™, DEC Alpha and Sun UltraSPARC based computer systems. It is based primarily on software from U.C. Berkeley's CSRG group, with some enhancements from NetBSD, OpenBSD, 386BSD, and the Free Software Foundation.
Since our release of FreeBSD 2.0 in late 1994, the performance, feature set, and stability of FreeBSD has improved dramatically. The largest change is a revamped virtual memory system with a merged VM/file buffer cache that not only increases performance, but also reduces FreeBSD's memory footprint, making a 5 MB configuration a more acceptable minimum. Other enhancements include full NIS client and server support, transaction TCP support, dial-on-demand PPP, integrated DHCP support, an improved SCSI subsystem, ISDN support, support for ATM, FDDI, Fast and Gigabit Ethernet (1000 Mbit) adapters, improved support for the latest Adaptec controllers, and many thousands of bug fixes.
In addition to the base distributions, FreeBSD offers a ported software collection with thousands of commonly sought-after programs. At the time of this printing, there were over 17,000 ports! The list of ports ranges from http (WWW) servers, to games, languages, editors, and almost everything in between. The entire Ports Collection requires approximately 440 MB of storage, all ports being expressed as “deltas” to their original sources. This makes it much easier for us to update ports, and greatly reduces the disk space demands made by the older 1.0 Ports Collection. To compile a port, you simply change to the directory of the program you wish to install, type make install, and let the system do the rest. The full original distribution for each port you build is retrieved dynamically off the CDROM or a local FTP site, so you need only enough disk space to build the ports you want. Almost every port is also provided as a pre-compiled “package”, which can be installed with a simple command (pkg_add) by those who do not wish to compile their own ports from source. More information on packages and ports can be found in Chapter 4.
A number of additional documents which you may find very helpful in the process of installing and using FreeBSD may now also be found in the /usr/share/doc directory on any recent FreeBSD machine. You may view the locally installed manuals with any HTML capable browser using the following URLs:
- The FreeBSD Handbook
- The FreeBSD FAQ
You can also view the master (and most frequently updated) copies at http://www.FreeBSD.org/.
Chapter 2 Installing FreeBSD
Restructured, reorganized, and parts rewritten by Jim Mock. The sysinstall walkthrough, screenshots, and general copy by Randy Pratt.2.1 Synopsis
FreeBSD is provided with a text-based, easy to use installation program called sysinstall. This is the default installation program for FreeBSD, although vendors are free to provide their own installation suite if they wish. This chapter describes how to use sysinstall to install FreeBSD.
After reading this chapter, you will know:
-
How to create the FreeBSD installation disks.
-
How FreeBSD refers to, and subdivides, your hard disks.
-
How to start sysinstall.
-
The questions sysinstall will ask you, what they mean, and how to answer them.
Before reading this chapter, you should:
-
Read the supported hardware list that shipped with the version of FreeBSD you are installing, and verify that your hardware is supported.
Note: In general, these installation instructions are written for i386 (“PC compatible”) architecture computers. Where applicable, instructions specific to other platforms (for example, Alpha) will be listed. Although this guide is kept as up to date as possible, you may find minor differences between the installer and what is shown here. It is suggested that you use this chapter as a general guide rather than a literal installation manual.
2.2 Hardware Requirements
2.2.1 Minimal Configuration
The minimal configuration to install FreeBSD varies with the FreeBSD version and the hardware architecture.
Information about the minimal configuration is available in the Installation Notes on the Release Information page of the FreeBSD web site. A summary of this information is given in the following sections. Depending on the method you choose to install FreeBSD, you may also need a floppy drive, a supported CDROM drive, and in some case a network adapter. This will be covered by the Section 2.3.7.
2.2.1.1 FreeBSD/i386 and FreeBSD/pc98
Both FreeBSD/i386 and FreeBSD/pc98 require a 486 or better processor and at least 24 MB of RAM. You will need at least 150 MB of free hard drive space for the most minimal installation.
Note: In case of old configurations, most of time, getting more RAM and more hard drive space is more important than getting a faster processor.
2.2.1.2 FreeBSD/alpha
To install FreeBSD/alpha, you will need a supported platform (see Section 2.2.2) and a dedicated disk for FreeBSD. It is not possible to share a disk with another operating system at this time. This disk will need to be attached to a SCSI controller which is supported by the SRM firmware or an IDE disk assuming the SRM in your machine supports booting from IDE disks.
You will need the SRM console firmware for your platform. In some cases, it is possible to switch between AlphaBIOS (or ARC) firmware and SRM. In others it will be necessary to download new firmware from the vendor's Web site.
Note: Support for the Alpha was removed beginning with FreeBSD 7.0. The FreeBSD 6.X series of releases is the last containing support for this architecture.
2.2.1.3 FreeBSD/amd64 Architecture
There are two classes of processors capable of running FreeBSD/amd64. The first are AMD64 processors, including the AMD Athlon™64, AMD Athlon64-FX, AMD Opteron™ or better processors.
The second class of processors that can use FreeBSD/amd64 includes those using the Intel® EM64T architecture. Examples of these processors include the Intel Core™ 2 Duo, Quad, and Extreme processor families and the Intel Xeon 3000, 5000, and 7000 sequences of processors.
If you have a machine based on an nVidia nForce3 Pro-150, you must use the BIOS setup to disable the IO APIC. If you do not have an option to do this, you will likely have to disable ACPI instead. There are bugs in the Pro-150 chipset that we have not found a workaround for yet.
2.2.1.4 FreeBSD/sparc64
To install FreeBSD/sparc64, you will need a supported platform (see Section 2.2.2).
You will need a dedicated disk for FreeBSD/sparc64. It is not possible to share a disk with another operating system at this time.
2.2.2 Supported Hardware
A list of supported hardware is provided with each FreeBSD release in the FreeBSD Hardware Notes. This document can usually be found in a file named HARDWARE.TXT, in the top-level directory of a CDROM or FTP distribution or in sysinstall's documentation menu. It lists, for a given architecture, what hardware devices are known to be supported by each release of FreeBSD. Copies of the supported hardware list for various releases and architectures can also be found on the Release Information page of the FreeBSD Web site.
2.3 Pre-installation Tasks
2.3.1 Inventory Your Computer
Before installing FreeBSD you should attempt to inventory the components in your computer. The FreeBSD installation routines will show you the components (hard disks, network cards, CDROM drives, and so forth) with their model number and manufacturer. FreeBSD will also attempt to determine the correct configuration for these devices, which includes information about IRQ and IO port usage. Due to the vagaries of PC hardware this process is not always completely successful, and you may need to correct FreeBSD's determination of your configuration.
If you already have another operating system installed, such as Windows or Linux, it is a good idea to use the facilities provided by those operating systems to see how your hardware is already configured. If you are not sure what settings an expansion card is using, you may find it printed on the card itself. Popular IRQ numbers are 3, 5, and 7, and IO port addresses are normally written as hexadecimal numbers, such as 0x330.
We recommend you print or write down this information before installing FreeBSD. It may help to use a table, like this:
Table 2-1. Sample Device Inventory
| Device Name | IRQ | IO port(s) | Notes |
|---|---|---|---|
| First hard disk | N/A | N/A | 40 GB, made by Seagate, first IDE master |
| CDROM | N/A | N/A | First IDE slave |
| Second hard disk | N/A | N/A | 20 GB, made by IBM, second IDE master |
| First IDE controller | 14 | 0x1f0 | |
| Network card | N/A | N/A | Intel 10/100 |
| Modem | N/A | N/A | 3Com® 56K faxmodem, on COM1 |
| ... |
Once the inventory of the components in your computer is done, you have to check if they match the hardware requirements of the FreeBSD release you want to install.
2.3.2 Backup Your Data
If the computer you will be installing FreeBSD on contains valuable data, then ensure you have it backed up, and that you have tested the backups before installing FreeBSD. The FreeBSD installation routine will prompt you before writing any data to your disk, but once that process has started it cannot be undone.
2.3.3 Decide Where to Install FreeBSD
If you want FreeBSD to use your entire hard disk, then there is nothing more to concern yourself with at this point -- you can skip this section.
However, if you need FreeBSD to co-exist with other operating systems then you need to have a rough understanding of how data is laid out on the disk, and how this affects you.
2.3.3.1 Disk Layouts for FreeBSD/i386
A PC disk can be divided into discrete chunks. These chunks are called partitions. Since FreeBSD internally also has partitions, the naming can become confusing very quickly, therefore these disk chunks are referred to as disk slices or simply slices in FreeBSD itself. For example, the FreeBSD utility fdisk which operates on the PC disk partitions, refers to slices instead of partitions. By design, the PC only supports four partitions per disk. These partitions are called primary partitions. To work around this limitation and allow more than four partitions, a new partition type was created, the extended partition. A disk may contain only one extended partition. Special partitions, called logical partitions, can be created inside this extended partition.
Each partition has a partition ID, which is a number used to identify the type of data on the partition. FreeBSD partitions have the partition ID of 165.
In general, each operating system that you use will identify partitions in a particular way. For example, DOS, and its descendants, like Windows, assign each primary and logical partition a drive letter, starting with C:.
FreeBSD must be installed into a primary partition. FreeBSD can keep all its data, including any files that you create, on this one partition. However, if you have multiple disks, then you can create a FreeBSD partition on all, or some, of them. When you install FreeBSD, you must have one partition available. This might be a blank partition that you have prepared, or it might be an existing partition that contains data that you no longer care about.
If you are already using all the partitions on all your disks, then you will have to free one of them for FreeBSD using the tools provided by the other operating systems you use (e.g., fdisk on DOS or Windows).
If you have a spare partition then you can use that. However, you may need to shrink one or more of your existing partitions first.
A minimal installation of FreeBSD takes as little as 100 MB of disk space. However, that is a very minimal install, leaving almost no space for your own files. A more realistic minimum is 250 MB without a graphical environment, and 350 MB or more if you want a graphical user interface. If you intend to install a lot of third-party software as well, then you will need more space.
You can use a commercial tool such as PartitionMagic®, or a free tool such as GParted, to resize your partitions and make space for FreeBSD. The tools directory on the CDROM contains two free software tools which can carry out this task, namely FIPS and PResizer. Documentation for both of these is available in the same directory. FIPS, PResizer, and PartitionMagic can resize FAT16 and FAT32 partitions -- used in MS-DOS through Windows ME. Both PartitionMagic and GParted are known to work on NTFS. GParted is available on a number of Live CD Linux distributions, such as SystemRescueCD.
Problems have been reported resizing Microsoft Vista partitions. Having a Vista installation CDROM handy when attempting such an operation is recommended. As with all such disk maintenance tasks, a current set of backups is also strongly advised.
Warning: Incorrect use of these tools can delete the data on your disk. Be sure that you have recent, working backups before using them.
Example 2-1. Using an Existing Partition Unchanged
Suppose that you have a computer with a single 4 GB disk that already has a version of Windows installed, and you have split the disk into two drive letters, C: and D:, each of which is 2 GB in size. You have 1 GB of data on C:, and 0.5 GB of data on D:.
This means that your disk has two partitions on it, one per drive letter. You can copy all your existing data from D: to C:, which will free up the second partition, ready for FreeBSD.
Example 2-2. Shrinking an Existing Partition
Suppose that you have a computer with a single 4 GB disk that already has a version of Windows installed. When you installed Windows you created one large partition, giving you a C: drive that is 4 GB in size. You are currently using 1.5 GB of space, and want FreeBSD to have 2 GB of space.
In order to install FreeBSD you will need to either:
-
Backup your Windows data, and then reinstall Windows, asking for a 2 GB partition at install time.
-
Use one of the tools such as PartitionMagic, described above, to shrink your Windows partition.
2.3.3.2 Disk Layouts for the Alpha
You will need a dedicated disk for FreeBSD on the Alpha. It is not possible to share a disk with another operating system at this time. Depending on the specific Alpha machine you have, this disk can either be a SCSI disk or an IDE disk, as long as your machine is capable of booting from it.
Following the conventions of the Digital / Compaq manuals all SRM input is shown in uppercase. SRM is case insensitive.
To find the names and types of disks in your machine, use the SHOW DEVICE command from the SRM console prompt:
>>>SHOW DEVICE
dka0.0.0.4.0 DKA0 TOSHIBA CD-ROM XM-57 3476
dkc0.0.0.1009.0 DKC0 RZ1BB-BS 0658
dkc100.1.0.1009.0 DKC100 SEAGATE ST34501W 0015
dva0.0.0.0.1 DVA0
ewa0.0.0.3.0 EWA0 00-00-F8-75-6D-01
pkc0.7.0.1009.0 PKC0 SCSI Bus ID 7 5.27
pqa0.0.0.4.0 PQA0 PCI EIDE
pqb0.0.1.4.0 PQB0 PCI EIDE
This example is from a Digital Personal Workstation 433au and shows three disks attached to the machine. The first is a CDROM drive called DKA0 and the other two are disks and are called DKC0 and DKC100 respectively.
Disks with names of the form DKx are SCSI disks. For example DKA100 refers to a SCSI disk with SCSI target ID 1 on the first SCSI bus (A), whereas DKC300 refers to a SCSI disk with SCSI ID 3 on the third SCSI bus (C). Devicename PKx refers to the SCSI host bus adapter. As seen in the SHOW DEVICE output SCSI CDROM drives are treated as any other SCSI hard disk drive.
IDE disks have names similar to DQx, while PQx is the associated IDE controller.
2.3.4 Collect Your Network Configuration Details
If you intend to connect to a network as part of your FreeBSD installation (for example, if you will be installing from an FTP site or an NFS server), then you need to know your network configuration. You will be prompted for this information during the installation so that FreeBSD can connect to the network to complete the install.
2.3.4.1 Connecting to an Ethernet Network or Cable/DSL Modem
If you connect to an Ethernet network, or you have an Internet connection using an Ethernet adapter via cable or DSL, then you will need the following information:
-
IP address
-
IP address of the default gateway
-
Hostname
-
DNS server IP addresses
-
Subnet Mask
If you do not know this information, then ask your system administrator or service provider. They may say that this information is assigned automatically, using DHCP. If so, make a note of this.
2.3.4.2 Connecting Using a Modem
If you dial up to an ISP using a regular modem then you can still install FreeBSD over the Internet, it will just take a very long time.
You will need to know:
-
The phone number to dial for your ISP
-
The COM: port your modem is connected to
-
The username and password for your ISP account
2.3.5 Check for FreeBSD Errata
Although the FreeBSD project strives to ensure that each release of FreeBSD is as stable as possible, bugs do occasionally creep into the process. On very rare occasions those bugs affect the installation process. As these problems are discovered and fixed, they are noted in the FreeBSD Errata, which is found on the FreeBSD web site. You should check the errata before installing to make sure that there are no late-breaking problems which you should be aware of.
Information about all the releases, including the errata for each release, can be found on the release information section of the FreeBSD web site.
2.3.6 Obtain the FreeBSD Installation Files
The FreeBSD installation process can install FreeBSD from files located in any of the following places:
Local Media
-
A CDROM or DVD
-
A DOS partition on the same computer
-
A SCSI or QIC tape
-
Floppy disks
Network
-
An FTP site, going through a firewall, or using an HTTP proxy, as necessary
-
An NFS server
-
A dedicated parallel or serial connection
If you have purchased FreeBSD on CD or DVD then you already have everything you need, and should proceed to the next section (Section 2.3.7).
If you have not obtained the FreeBSD installation files you should skip ahead to Section 2.13 which explains how to prepare to install FreeBSD from any of the above. After reading that section, you should come back here, and read on to Section 2.3.7.
2.3.7 Prepare the Boot Media
The FreeBSD installation process is started by booting your computer into the FreeBSD installer--it is not a program you run within another operating system. Your computer normally boots using the operating system installed on your hard disk, but it can also be configured to use a “bootable” floppy disk. Most modern computers can also boot from a CDROM in the CDROM drive.
Tip: If you have FreeBSD on CDROM or DVD (either one you purchased or you prepared yourself), and your computer allows you to boot from the CDROM or DVD (typically a BIOS option called “Boot Order” or similar), then you can skip this section. The FreeBSD CDROM and DVD images are bootable and can be used to install FreeBSD without any other special preparation.
To create boot floppy images, follow these steps:
-
Acquire the Boot Floppy Images
The boot disks are available on your installation media in the floppies/ directory, and can also be downloaded from the floppies directory, ftp://ftp.FreeBSD.org/pub/FreeBSD/releases/<arch>/<version>-RELEASE/floppies/. Replace <arch> and <version> with the architecture and the version number which you want to install, respectively. For example, the boot floppy images for FreeBSD/i386 6.2-RELEASE are available from ftp://ftp.FreeBSD.org/pub/FreeBSD/releases/i386/6.2-RELEASE/floppies/.
The floppy images have a .flp extension. The floppies/ directory contains a number of different images, and the ones you will need to use depends on the version of FreeBSD you are installing, and in some cases, the hardware you are installing to. In most cases you will need four floppies, boot.flp, kern1.flp, kern2.flp, and kern3.flp. Check README.TXT in the same directory for the most up to date information about these floppy images.
Important: Your FTP program must use binary mode to download these disk images. Some web browsers have been known to use text (or ASCII) mode, which will be apparent if you cannot boot from the disks.
-
Prepare the Floppy Disks
You must prepare one floppy disk per image file you had to download. It is imperative that these disks are free from defects. The easiest way to test this is to format the disks for yourself. Do not trust pre-formatted floppies. The format utility in Windows will not tell about the presence of bad blocks, it simply marks them as “bad” and ignores them. It is advised that you use brand new floppies if choosing this installation route.
Important: If you try to install FreeBSD and the installation program crashes, freezes, or otherwise misbehaves, one of the first things to suspect is the floppies. Try writing the floppy image files to new disks and try again.
-
Write the Image Files to the Floppy Disks
The .flp files are not regular files you copy to the disk. They are images of the complete contents of the disk. This means that you cannot simply copy files from one disk to another. Instead, you must use specific tools to write the images directly to the disk.
If you are creating the floppies on a computer running MS-DOS/Windows, then we provide a tool to do this called fdimage.
If you are using the floppies from the CDROM, and your CDROM is the E: drive, then you would run this:
E:\> tools\fdimage floppies\boot.flp A:Repeat this command for each .flp file, replacing the floppy disk each time, being sure to label the disks with the name of the file that you copied to them. Adjust the command line as necessary, depending on where you have placed the .flp files. If you do not have the CDROM, then fdimage can be downloaded from the tools directory on the FreeBSD FTP site.
If you are writing the floppies on a UNIX system (such as another FreeBSD system) you can use the dd(1) command to write the image files directly to disk. On FreeBSD, you would run:
# dd if=boot.flp of=/dev/fd0On FreeBSD, /dev/fd0 refers to the first floppy disk (the A: drive). /dev/fd1 would be the B: drive, and so on. Other UNIX variants might have different names for the floppy disk devices, and you will need to check the documentation for the system as necessary.
You are now ready to start installing FreeBSD.
2.4 Starting the Installation
Important: By default, the installation will not make any changes to your disk(s) until you see the following message:
Last Chance: Are you SURE you want continue the installation? If you're running this on a disk with data you wish to save then WE STRONGLY ENCOURAGE YOU TO MAKE PROPER BACKUPS before proceeding! We can take no responsibility for lost disk contents!The install can be exited at any time prior to the final warning without changing the contents of the hard drive. If you are concerned that you have configured something incorrectly you can just turn the computer off before this point, and no damage will be done.
2.4.1 Booting
2.4.1.1 Booting for the i386™
-
Start with your computer turned off.
-
Turn on the computer. As it starts it should display an option to enter the system set up menu, or BIOS, commonly reached by keys like F2, F10, Del, or Alt+S. Use whichever keystroke is indicated on screen. In some cases your computer may display a graphic while it starts. Typically, pressing Esc will dismiss the graphic and allow you to see the necessary messages.
-
Find the setting that controls which devices the system boots from. This is usually labeled as the “Boot Order” and commonly shown as a list of devices, such as Floppy, CDROM, First Hard Disk, and so on.
If you needed to prepare boot floppies, then make sure that the floppy disk is selected. If you are booting from the CDROM then make sure that that is selected instead. In case of doubt, you should consult the manual that came with your computer, and/or its motherboard.
Make the change, then save and exit. The computer should now restart.
-
If you needed to prepare boot floppies, as described in Section 2.3.7, then one of them will be the first boot disc, probably the one containing boot.flp. Put this disc in your floppy drive.
If you are booting from CDROM, then you will need to turn on the computer, and insert the CDROM at the first opportunity.
If your computer starts up as normal and loads your existing operating system, then either:
-
The disks were not inserted early enough in the boot process. Leave them in, and try restarting your computer.
-
The BIOS changes earlier did not work correctly. You should redo that step until you get the right option.
-
Your particular BIOS does not support booting from the desired media.
-
-
FreeBSD will start to boot. If you are booting from CDROM you will see a display similar to this (version information omitted):
Booting from CD-Rom... CD Loader 1.2 Building the boot loader arguments Looking up /BOOT/LOADER... Found Relocating the loader and the BTX Starting the BTX loader BTX loader 1.00 BTX version is 1.01 Console: internal video/keyboard BIOS CD is cd0 BIOS drive C: is disk0 BIOS drive D: is disk1 BIOS 639kB/261120kB available memory FreeBSD/i386 bootstrap loader, Revision 1.1 Loading /boot/defaults/loader.conf /boot/kernel/kernel text=0x64daa0 data=0xa4e80+0xa9e40 syms=[0x4+0x6cac0+0x4+0x88e9d] \If you are booting from floppy disc, you will see a display similar to this (version information omitted):
Booting from Floppy... Uncompressing ... done BTX loader 1.00 BTX version is 1.01 Console: internal video/keyboard BIOS drive A: is disk0 BIOS drive C: is disk1 BIOS 639kB/261120kB available memory FreeBSD/i386 bootstrap loader, Revision 1.1 Loading /boot/defaults/loader.conf /kernel text=0x277391 data=0x3268c+0x332a8 | Insert disk labelled "Kernel floppy 1" and press any key...Follow these instructions by removing the boot.flp disc, insert the kern1.flp disc, and press Enter. Boot from first floppy; when prompted, insert the other disks as required.
-
Whether you booted from floppy or CDROM, the boot process will then get to the FreeBSD boot loader menu:
Either wait ten seconds, or press Enter.

2.4.1.2 Booting for the Alpha
-
Start with your computer turned off.
-
Turn on the computer and wait for a boot monitor prompt.
-
If you needed to prepare boot floppies, as described in Section 2.3.7 then one of them will be the first boot disc, probably the one containing boot.flp. Put this disc in your floppy drive and type the following command to boot the disk (substituting the name of your floppy drive if necessary):
>>>BOOT DVA0 -FLAGS '' -FILE ''If you are booting from CDROM, insert the CDROM into the drive and type the following command to start the installation (substituting the name of the appropriate CDROM drive if necessary):
>>>BOOT DKA0 -FLAGS '' -FILE '' -
FreeBSD will start to boot. If you are booting from a floppy disc, at some point you will see the message:
Insert disk labelled "Kernel floppy 1" and press any key...Follow these instructions by removing the boot.flp disc, insert the kern1.flp disc, and press Enter.
-
Whether you booted from floppy or CDROM, the boot process will then get to this point:
Hit [Enter] to boot immediately, or any other key for command prompt. Booting [kernel] in 9 seconds... _Either wait ten seconds, or press Enter. This will then launch the kernel configuration menu.
2.4.1.3 Booting for Sparc64®
Most Sparc64® systems are set up to boot automatically from disk. To install FreeBSD, you need to boot over the network or from a CDROM, which requires you to break into the PROM (OpenFirmware).
To do this, reboot the system, and wait until the boot message appears. It depends on the model, but should look about like:
Sun Blade 100 (UltraSPARC-IIe), Keyboard Present
Copyright 1998-2001 Sun Microsystems, Inc. All rights reserved.
OpenBoot 4.2, 128 MB memory installed, Serial #51090132.
Ethernet address 0:3:ba:b:92:d4, Host ID: 830b92d4.
If your system proceeds to boot from disk at this point, you need to press L1+A or Stop+A on the keyboard, or send a BREAK over the serial console (using for example ~# in tip(1) or cu(1)) to get to the PROM prompt. It looks like this:
ok  ok {0}
ok {0} 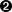
- This is the prompt used on systems with just one CPU.
- This is the prompt used on SMP systems, the digit indicates the number of the active CPU.
At this point, place the CDROM into your drive, and from the PROM prompt, type boot cdrom.
2.4.2 Reviewing the Device Probe Results
The last few hundred lines that have been displayed on screen are stored and can be reviewed.
To review the buffer, press Scroll Lock. This turns on scrolling in the display. You can then use the arrow keys, or PageUp and PageDown to view the results. Press Scroll Lock again to stop scrolling.
Do this now, to review the text that scrolled off the screen when the kernel was carrying out the device probes. You will see text similar to Figure 2-2, although the precise text will differ depending on the devices that you have in your computer.
Figure 2-2. Typical Device Probe Results
avail memory = 253050880 (247120K bytes)
Preloaded elf kernel "kernel" at 0xc0817000.
Preloaded mfs_root "/mfsroot" at 0xc0817084.
md0: Preloaded image </mfsroot> 4423680 bytes at 0xc03ddcd4
md1: Malloc disk
Using $PIR table, 4 entries at 0xc00fde60
npx0: <math processor> on motherboard
npx0: INT 16 interface
pcib0: <Host to PCI bridge> on motherboard
pci0: <PCI bus> on pcib0
pcib1:<VIA 82C598MVP (Apollo MVP3) PCI-PCI (AGP) bridge> at device 1.0 on pci0
pci1: <PCI bus> on pcib1
pci1: <Matrox MGA G200 AGP graphics accelerator> at 0.0 irq 11
isab0: <VIA 82C586 PCI-ISA bridge> at device 7.0 on pci0
isa0: <iSA bus> on isab0
atapci0: <VIA 82C586 ATA33 controller> port 0xe000-0xe00f at device 7.1 on pci0
ata0: at 0x1f0 irq 14 on atapci0
ata1: at 0x170 irq 15 on atapci0
uhci0 <VIA 83C572 USB controller> port 0xe400-0xe41f irq 10 at device 7.2 on pci
0
usb0: <VIA 83572 USB controller> on uhci0
usb0: USB revision 1.0
uhub0: VIA UHCI root hub, class 9/0, rev 1.00/1.00, addr1
uhub0: 2 ports with 2 removable, self powered
pci0: <unknown card> (vendor=0x1106, dev=0x3040) at 7.3
dc0: <ADMtek AN985 10/100BaseTX> port 0xe800-0xe8ff mem 0xdb000000-0xeb0003ff ir
q 11 at device 8.0 on pci0
dc0: Ethernet address: 00:04:5a:74:6b:b5
miibus0: <MII bus> on dc0
ukphy0: <Generic IEEE 802.3u media interface> on miibus0
ukphy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto
ed0: <NE2000 PCI Ethernet (RealTek 8029)> port 0xec00-0xec1f irq 9 at device 10.
0 on pci0
ed0 address 52:54:05:de:73:1b, type NE2000 (16 bit)
isa0: too many dependant configs (8)
isa0: unexpected small tag 14
orm0: <Option ROM> at iomem 0xc0000-0xc7fff on isa0
fdc0: <NEC 72065B or clone> at port 0x3f0-0x3f5,0x3f7 irq 6 drq2 on isa0
fdc0: FIFO enabled, 8 bytes threshold
fd0: <1440-KB 3.5'' drive> on fdc0 drive 0
atkbdc0: <Keyboard controller (i8042)> at port 0x60,0x64 on isa0
atkbd0: <AT Keyboard> flags 0x1 irq1 on atkbdc0
kbd0 at atkbd0
psm0: <PS/2 Mouse> irq 12 on atkbdc0
psm0: model Generic PS/@ mouse, device ID 0
vga0: <Generic ISA VGA> at port 0x3c0-0x3df iomem 0xa0000-0xbffff on isa0
sc0: <System console> at flags 0x100 on isa0
sc0: VGA <16 virtual consoles, flags=0x300>
sio0 at port 0x3f8-0x3ff irq 4 flags 0x10 on isa0
sio0: type 16550A
sio1 at port 0x2f8-0x2ff irq 3 on isa0
sio1: type 16550A
ppc0: <Parallel port> at port 0x378-0x37f irq 7 on isa0
pppc0: SMC-like chipset (ECP/EPP/PS2/NIBBLE) in COMPATIBLE mode
ppc0: FIFO with 16/16/15 bytes threshold
plip0: <PLIP network interface> on ppbus0
ad0: 8063MB <IBM-DHEA-38451> [16383/16/63] at ata0-master UDMA33
acd0: CD-RW <LITE-ON LTR-1210B> at ata1-slave PIO4
Mounting root from ufs:/dev/md0c
/stand/sysinstall running as init on vty0
Check the probe results carefully to make sure that FreeBSD found all the devices you expected. If a device was not found, then it will not be listed. A custom kernel allows you to add in support for devices which are not in the GENERIC kernel, such as sound cards.
For FreeBSD 6.2 and later, after the procedure of device probing, you will see Figure 2-3. Use the arrow key to choose a country, region, or group. Then press Enter, it will set your country and keymap easily. It is also easy to exit the sysinstall program and start over again.
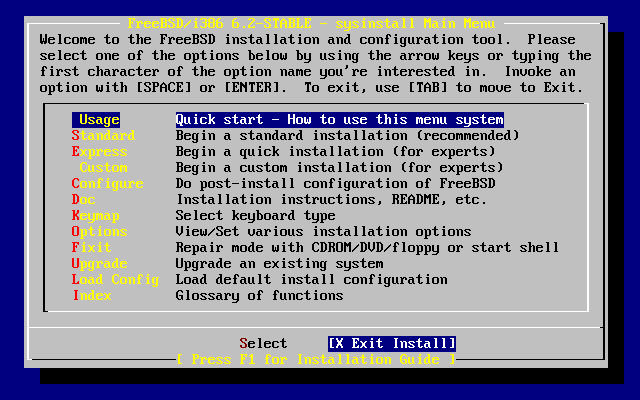
Use the arrow keys to select Exit Install from the Main Install Screen menu. The following message will display:
User Confirmation Requested
Are you sure you wish to exit? The system will reboot
(be sure to remove any floppies/CDs/DVDs from the drives).
[ Yes ] No
The install program will start again if the CDROM is left in the drive and [ Yes ] is selected.
If you are booting from floppies it will be necessary to remove the boot.flp floppy before rebooting.
2.5 Introducing Sysinstall
The sysinstall utility is the installation application provided by the FreeBSD Project. It is console based and is divided into a number of menus and screens that you can use to configure and control the installation process.
The sysinstall menu system is controlled by the arrow keys, Enter, Tab, Space, and other keys. A detailed description of these keys and what they do is contained in sysinstall's usage information.
To review this information, ensure that the Usage entry is highlighted and that the [Select] button is selected, as shown in Figure 2-5, then press Enter.
The instructions for using the menu system will be displayed. After reviewing them, press Enter to return to the Main Menu.
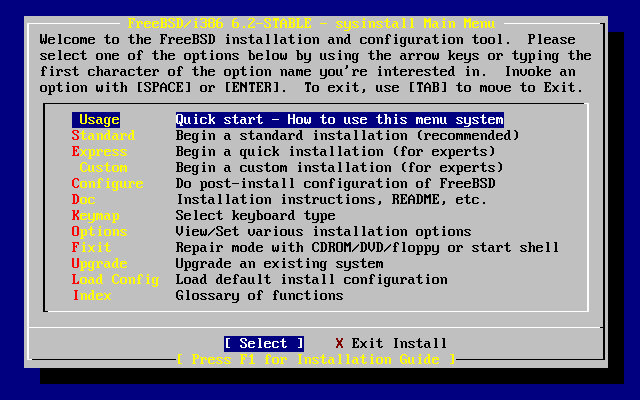
2.5.1 Selecting the Documentation Menu
From the Main Menu, select Doc with the arrow keys and press Enter.
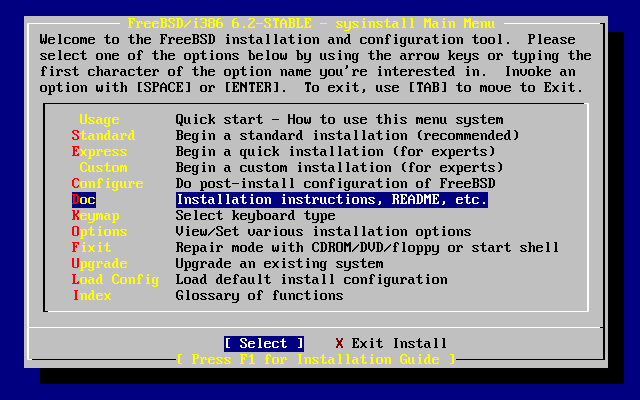
This will display the Documentation Menu.
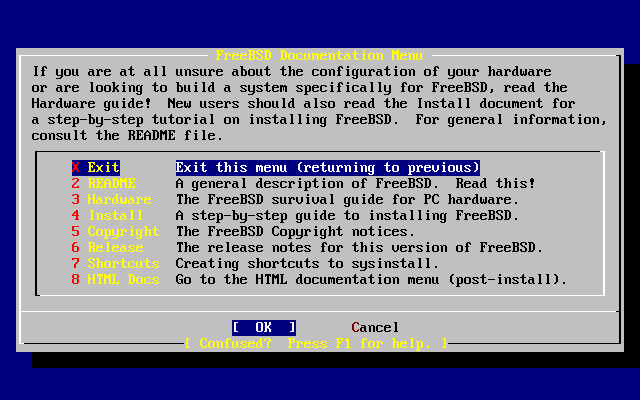
It is important to read the documents provided.
To view a document, select it with the arrow keys and press Enter. When finished reading a document, pressing Enter will return to the Documentation Menu.
To return to the Main Installation Menu, select Exit with the arrow keys and press Enter.
2.5.2 Selecting the Keymap Menu
To change the keyboard mapping, use the arrow keys to select Keymap from the menu and press Enter. This is only required if you are using a non-standard or non-US keyboard.
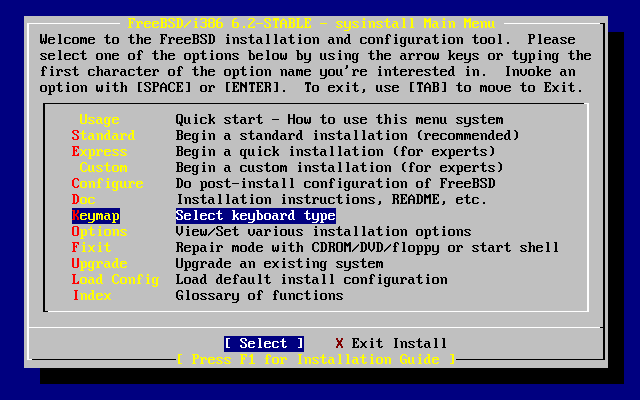
A different keyboard mapping may be chosen by selecting the menu item using up/down arrow keys and pressing Space. Pressing Space again will unselect the item. When finished, choose the [ OK ] using the arrow keys and press Enter.
Only a partial list is shown in this screen representation. Selecting [ Cancel ] by pressing Tab will use the default keymap and return to the Main Install Menu.
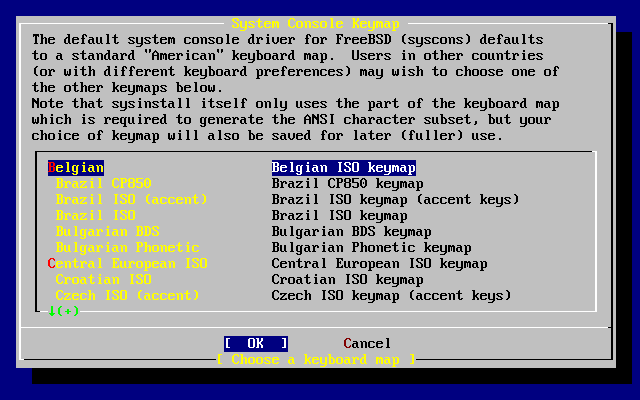
2.5.3 Installation Options Screen
Select Options and press Enter.
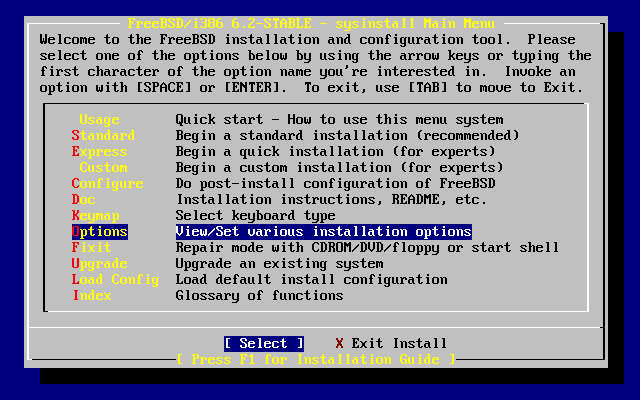
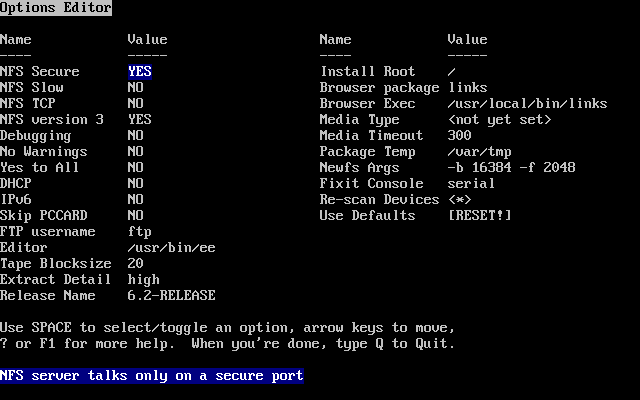
The default values are usually fine for most users and do not need to be changed. The release name will vary according to the version being installed.
The description of the selected item will appear at the bottom of the screen highlighted in blue. Notice that one of the options is Use Defaults to reset all values to startup defaults.
Press F1 to read the help screen about the various options.
Pressing Q will return to the Main Install menu.
2.5.4 Begin a Standard Installation
The Standard installation is the option recommended for those new to UNIX or FreeBSD. Use the arrow keys to select Standard and then press Enter to start the installation.

2.6 Allocating Disk Space
Your first task is to allocate disk space for FreeBSD, and label that space so that sysinstall can prepare it. In order to do this you need to know how FreeBSD expects to find information on the disk.
2.6.1 BIOS Drive Numbering
Before you install and configure FreeBSD on your system, there is an important subject that you should be aware of, especially if you have multiple hard drives.
In a PC running a BIOS-dependent operating system such as MS-DOS or Microsoft Windows, the BIOS is able to abstract the normal disk drive order, and the operating system goes along with the change. This allows the user to boot from a disk drive other than the so-called “primary master”. This is especially convenient for some users who have found that the simplest and cheapest way to keep a system backup is to buy an identical second hard drive, and perform routine copies of the first drive to the second drive using Ghost® or XCOPY . Then, if the first drive fails, or is attacked by a virus, or is scribbled upon by an operating system defect, he can easily recover by instructing the BIOS to logically swap the drives. It is like switching the cables on the drives, but without having to open the case.
More expensive systems with SCSI controllers often include BIOS extensions which allow the SCSI drives to be re-ordered in a similar fashion for up to seven drives.
A user who is accustomed to taking advantage of these features may become surprised when the results with FreeBSD are not as expected. FreeBSD does not use the BIOS, and does not know the “logical BIOS drive mapping”. This can lead to very perplexing situations, especially when drives are physically identical in geometry, and have also been made as data clones of one another.
When using FreeBSD, always restore the BIOS to natural drive numbering before installing FreeBSD, and then leave it that way. If you need to switch drives around, then do so, but do it the hard way, and open the case and move the jumpers and cables.
2.6.2 Creating Slices Using FDisk
Note: No changes you make at this point will be written to the disk. If you think you have made a mistake and want to start again you can use the menus to exit sysinstall and try again or press U to use the Undo option. If you get confused and can not see how to exit you can always turn your computer off.
After choosing to begin a standard installation in sysinstall you will be shown this message:
Message
In the next menu, you will need to set up a DOS-style ("fdisk")
partitioning scheme for your hard disk. If you simply wish to devote
all disk space to FreeBSD (overwriting anything else that might be on
the disk(s) selected) then use the (A)ll command to select the default
partitioning scheme followed by a (Q)uit. If you wish to allocate only
free space to FreeBSD, move to a partition marked "unused" and use the
(C)reate command.
[ OK ]
[ Press enter or space ]
Press Enter as instructed. You will then be shown a list of all the hard drives that the kernel found when it carried out the device probes. Figure 2-13 shows an example from a system with two IDE disks. They have been called ad0 and ad2.
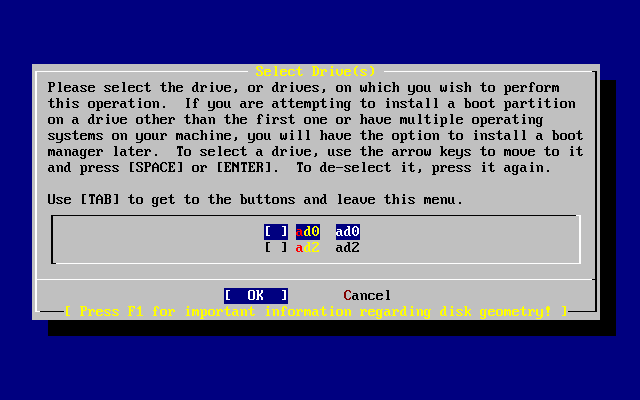
You might be wondering why ad1 is not listed here. Why has it been missed?
Consider what would happen if you had two IDE hard disks, one as the master on the first IDE controller, and one as the master on the second IDE controller. If FreeBSD numbered these as it found them, as ad0 and ad1 then everything would work.
But if you then added a third disk, as the slave device on the first IDE controller, it would now be ad1, and the previous ad1 would become ad2. Because device names (such as ad1s1a) are used to find filesystems, you may suddenly discover that some of your filesystems no longer appear correctly, and you would need to change your FreeBSD configuration.
To work around this, the kernel can be configured to name IDE disks based on where they are, and not the order in which they were found. With this scheme the master disk on the second IDE controller will always be ad2, even if there are no ad0 or ad1 devices.
This configuration is the default for the FreeBSD kernel, which is why this display shows ad0 and ad2. The machine on which this screenshot was taken had IDE disks on both master channels of the IDE controllers, and no disks on the slave channels.
You should select the disk on which you want to install FreeBSD, and then press [ OK ]. FDisk will start, with a display similar to that shown in Figure 2-14.
The FDisk display is broken into three sections.
The first section, covering the first two lines of the display, shows details about the currently selected disk, including its FreeBSD name, the disk geometry, and the total size of the disk.
The second section shows the slices that are currently on the disk, where they start and end, how large they are, the name FreeBSD gives them, and their description and sub-type. This example shows two small unused slices, which are artifacts of disk layout schemes on the PC. It also shows one large FAT slice, which almost certainly appears as C: in MS-DOS / Windows, and an extended slice, which may contain other drive letters for MS-DOS / Windows.
The third section shows the commands that are available in FDisk.
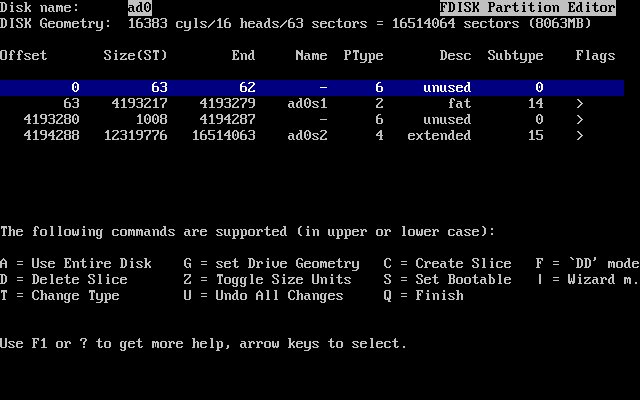
What you do now will depend on how you want to slice up your disk.
If you want to use FreeBSD for the entire disk (which will delete all the other data on this disk when you confirm that you want sysinstall to continue later in the installation process) then you can press A, which corresponds to the Use Entire Disk option. The existing slices will be removed, and replaced with a small area flagged as unused (again, an artifact of PC disk layout), and then one large slice for FreeBSD. If you do this, then you should select the newly created FreeBSD slice using the arrow keys, and press S to mark the slice as being bootable. The screen will then look very similar to Figure 2-15. Note the A in the Flags column, which indicates that this slice is active, and will be booted from.
If you will be deleting an existing slice to make space for FreeBSD then you should select the slice using the arrow keys, and then press D. You can then press C, and be prompted for size of slice you want to create. Enter the appropriate figure and press Enter. The default value in this box represents the largest possible slice you can make, which could be the largest contiguous block of unallocated space or the size of the entire hard disk.
If you have already made space for FreeBSD (perhaps by using a tool such as PartitionMagic) then you can press C to create a new slice. Again, you will be prompted for the size of slice you would like to create.
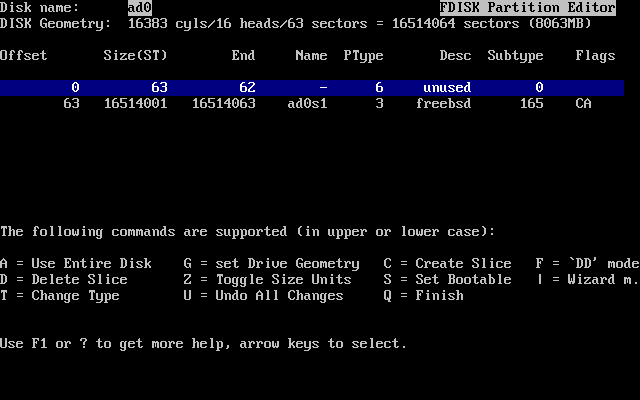
When finished, press Q. Your changes will be saved in sysinstall, but will not yet be written to disk.
2.6.3 Install a Boot Manager
You now have the option to install a boot manager. In general, you should choose to install the FreeBSD boot manager if:
-
You have more than one drive, and have installed FreeBSD onto a drive other than the first one.
-
You have installed FreeBSD alongside another operating system on the same disk, and you want to choose whether to start FreeBSD or the other operating system when you start the computer.
If FreeBSD is going to be the only operating system on this machine, installed on the first hard disk, then the Standard boot manager will suffice. Choose None if you are using a third-party boot manager capable of booting FreeBSD.
Make your choice and press Enter.
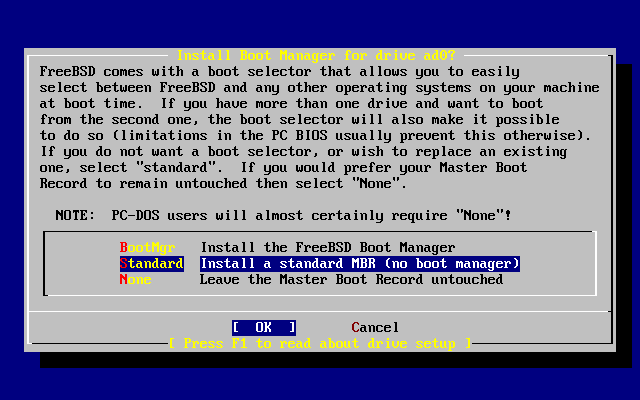
The help screen, reached by pressing F1, discusses the problems that can be encountered when trying to share the hard disk between operating systems.
2.6.4 Creating Slices on Another Drive
If there is more than one drive, it will return to the Select Drives screen after the boot manager selection. If you wish to install FreeBSD on to more than one disk, then you can select another disk here and repeat the slice process using FDisk.
Important: If you are installing FreeBSD on a drive other than your first, then the FreeBSD boot manager needs to be installed on both drives.
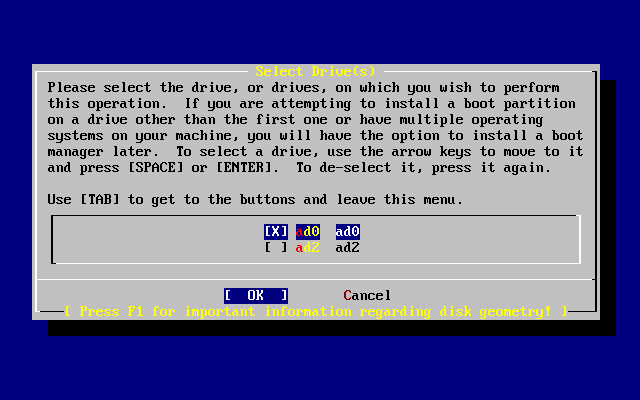
The Tab key toggles between the last drive selected, [ OK ], and [ Cancel ].
Press the Tab once to toggle to the [ OK ], then press Enter to continue with the installation.
2.6.5 Creating Partitions Using Disklabel
You must now create some partitions inside each slice that you have just created. Remember that each partition is lettered, from a through to h, and that partitions b, c, and d have conventional meanings that you should adhere to.
Certain applications can benefit from particular partition schemes, especially if you are laying out partitions across more than one disk. However, for this, your first FreeBSD installation, you do not need to give too much thought to how you partition the disk. It is more important that you install FreeBSD and start learning how to use it. You can always re-install FreeBSD to change your partition scheme when you are more familiar with the operating system.
This scheme features four partitions--one for swap space, and three for filesystems.
Table 2-2. Partition Layout for First Disk
| Partition | Filesystem | Size | Description |
|---|---|---|---|
| a | / | 128 MB | This is the root filesystem. Every other filesystem will be mounted somewhere under this one. 128 MB is a reasonable size for this filesystem. You will not be storing too much data on it, as a regular FreeBSD install will put about 40 MB of data here. The remaining space is for temporary data, and also leaves expansion space if future versions of FreeBSD need more space in /. |
| b | N/A | 2-3 x RAM |
The system's swap space is kept on the b partition. Choosing the right amount of swap space can be a bit of an art. A good rule of thumb is that your swap space should be two or three times as much as the available physical memory (RAM). You should also have at least 64 MB of swap, so if you have less than 32 MB of RAM in your computer then set the swap amount to 64 MB. If you have more than one disk then you can put swap space on each disk. FreeBSD will then use each disk for swap, which effectively speeds up the act of swapping. In this case, calculate the total amount of swap you need (e.g., 128 MB), and then divide this by the number of disks you have (e.g., two disks) to give the amount of swap you should put on each disk, in this example, 64 MB of swap per disk. |
| e | /var | 256 MB | The /var directory contains files that are constantly varying; log files, and other administrative files. Many of these files are read-from or written-to extensively during FreeBSD's day-to-day running. Putting these files on another filesystem allows FreeBSD to optimize the access of these files without affecting other files in other directories that do not have the same access pattern. |
| f | /usr | Rest of disk | All your other files will typically be stored in /usr and its subdirectories. |
If you will be installing FreeBSD on to more than one disk then you must also create partitions in the other slices that you configured. The easiest way to do this is to create two partitions on each disk, one for the swap space, and one for a filesystem.
Table 2-3. Partition Layout for Subsequent Disks
| Partition | Filesystem | Size | Description |
|---|---|---|---|
| b | N/A | See description | As already discussed, you can split swap space across each disk. Even though the a partition is free, convention dictates that swap space stays on the b partition. |
| e | /diskn | Rest of disk | The rest of the disk is taken up with one big partition. This could easily be put on the a partition, instead of the e partition. However, convention says that the a partition on a slice is reserved for the filesystem that will be the root (/) filesystem. You do not have to follow this convention, but sysinstall does, so following it yourself makes the installation slightly cleaner. You can choose to mount this filesystem anywhere; this example suggests that you mount them as directories /diskn, where n is a number that changes for each disk. But you can use another scheme if you prefer. |
Having chosen your partition layout you can now create it using sysinstall. You will see this message:
Message
Now, you need to create BSD partitions inside of the fdisk
partition(s) just created. If you have a reasonable amount of disk
space (200MB or more) and don't have any special requirements, simply
use the (A)uto command to allocate space automatically. If you have
more specific needs or just don't care for the layout chosen by
(A)uto, press F1 for more information on manual layout.
[ OK ]
[ Press enter or space ]
Press Enter to start the FreeBSD partition editor, called Disklabel.
Figure 2-18 shows the display when you first start Disklabel. The display is divided in to three sections.
The first few lines show the name of the disk you are currently working on, and the slice that contains the partitions you are creating (at this point Disklabel calls this the Partition name rather than slice name). This display also shows the amount of free space within the slice; that is, space that was set aside in the slice, but that has not yet been assigned to a partition.
The middle of the display shows the partitions that have been created, the name of the filesystem that each partition contains, their size, and some options pertaining to the creation of the filesystem.
The bottom third of the screen shows the keystrokes that are valid in Disklabel.
Disklabel can automatically create partitions for you and assign them default sizes. Try this now, by Pressing A. You will see a display similar to that shown in Figure 2-19. Depending on the size of the disk you are using, the defaults may or may not be appropriate. This does not matter, as you do not have to accept the defaults.
Note: The default partitioning assigns the /tmp directory its own partition instead of being part of the / partition. This helps avoid filling the / partition with temporary files.
If you choose to not use the default partitions and wish to replace them with your own, use the arrow keys to select the first partition, and press D to delete it. Repeat this to delete all the suggested partitions.
To create the first partition (a, mounted as / -- root), make sure the proper disk slice at the top of the screen is selected and press C. A dialog box will appear prompting you for the size of the new partition (as shown in Figure 2-20). You can enter the size as the number of disk blocks you want to use, or as a number followed by either M for megabytes, G for gigabytes, or C for cylinders.
Note: Beginning with FreeBSD 5.X, users can: select UFS2 (which is default on FreeBSD 5.1 and above) using the Custom Newfs (Z) option, create labels with Auto Defaults and modify them with the Custom Newfs option or add
-O 2during the regular creation period. Do not forget to add-Ufor SoftUpdates if you use the Custom Newfs option!
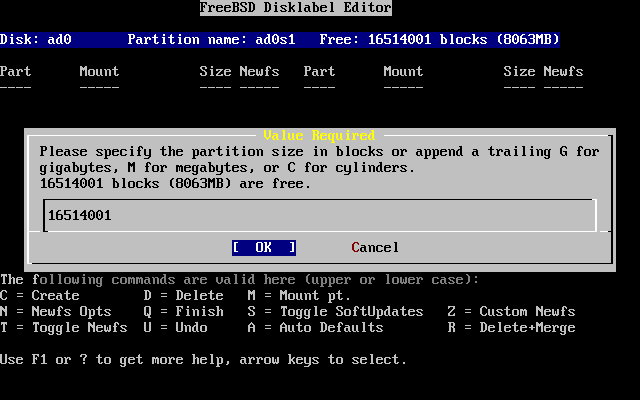
The default size shown will create a partition that takes up the rest of the slice. If you are using the partition sizes described in the earlier example, then delete the existing figure using Backspace, and then type in 128M, as shown in Figure 2-21. Then press [ OK ].
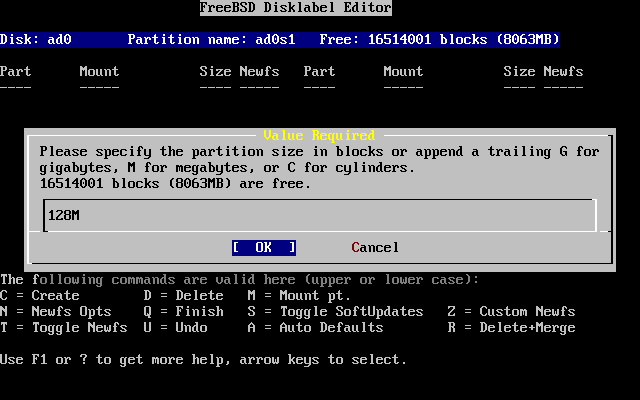
Having chosen the partition's size you will then be asked whether this partition will contain a filesystem or swap space. The dialog box is shown in Figure 2-22. This first partition will contain a filesystem, so check that FS is selected and press Enter.
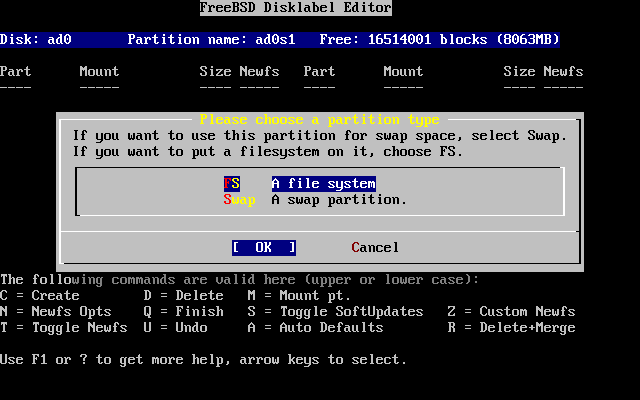
Finally, because you are creating a filesystem, you must tell Disklabel where the filesystem is to be mounted. The dialog box is shown in Figure 2-23. The root filesystem's mount point is /, so type /, and then press Enter.
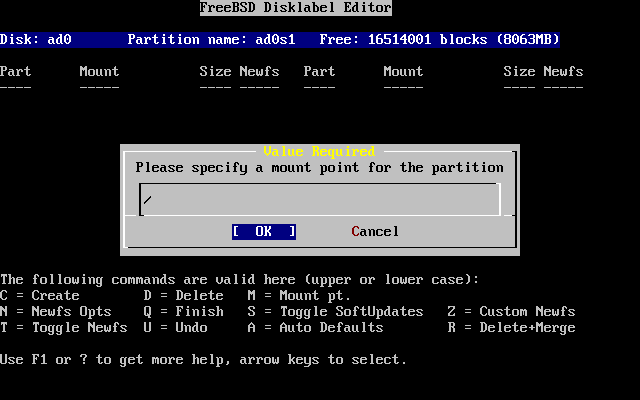
The display will then update to show you the newly created partition. You should repeat this procedure for the other partitions. When you create the swap partition, you will not be prompted for the filesystem mount point, as swap partitions are never mounted. When you create the final partition, /usr, you can leave the suggested size as is, to use the rest of the slice.
Your final FreeBSD DiskLabel Editor screen will appear similar to Figure 2-24, although your values chosen may be different. Press Q to finish.
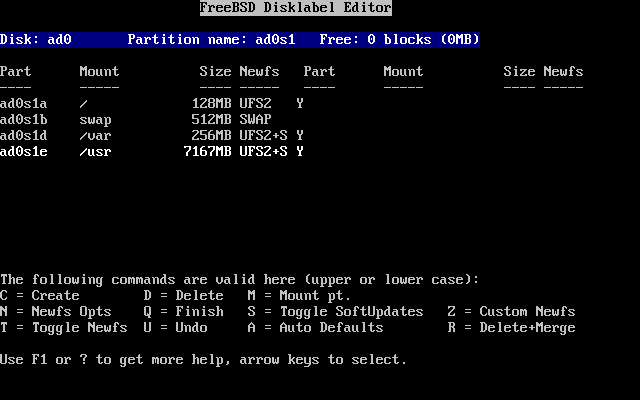
2.7 Choosing What to Install
2.7.1 Select the Distribution Set
Deciding which distribution set to install will depend largely on the intended use of the system and the amount of disk space available. The predefined options range from installing the smallest possible configuration to everything. Those who are new to UNIX and/or FreeBSD should almost certainly select one of these canned options. Customizing a distribution set is typically for the more experienced user.
Press F1 for more information on the distribution set options and what they contain. When finished reviewing the help, pressing Enter will return to the Select Distributions Menu.
If a graphical user interface is desired then a distribution set that is preceded by an X should be chosen. The configuration of the X server and selection of a default desktop must be done after the installation of FreeBSD. More information regarding the configuration of a X server can be found in Chapter 5.
Xorg is the default version of X11 that is installed.
If compiling a custom kernel is anticipated, select an option which includes the source code. For more information on why a custom kernel should be built or how to build a custom kernel, see Chapter 8.
Obviously, the most versatile system is one that includes everything. If there is adequate disk space, select All as shown in Figure 2-25 by using the arrow keys and press Enter. If there is a concern about disk space consider using an option that is more suitable for the situation. Do not fret over the perfect choice, as other distributions can be added after installation.
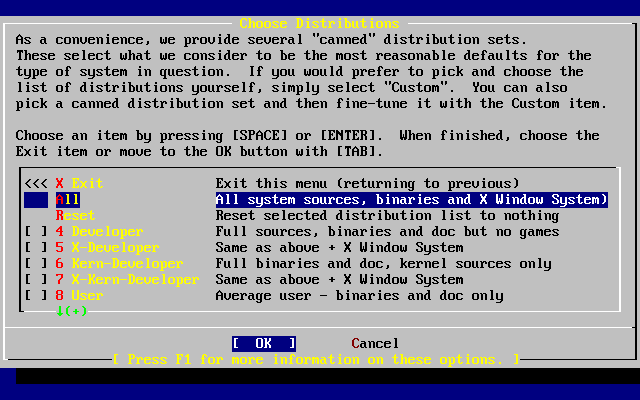
2.7.2 Installing the Ports Collection
After selecting the desired distribution, an opportunity to install the FreeBSD Ports Collection is presented. The ports collection is an easy and convenient way to install software. The Ports Collection does not contain the source code necessary to compile the software. Instead, it is a collection of files which automates the downloading, compiling and installation of third-party software packages. Chapter 4 discusses how to use the ports collection.
The installation program does not check to see if you have adequate space. Select this option only if you have adequate hard disk space. As of FreeBSD 6.2, the FreeBSD Ports Collection takes up about 440 MB of disk space. You can safely assume a larger value for more recent versions of FreeBSD.
User Confirmation Requested
Would you like to install the FreeBSD ports collection?
This will give you ready access to over 17,000 ported software packages,
at a cost of around 440 MB of disk space when "clean" and possibly much
more than that if a lot of the distribution tarballs are loaded
(unless you have the extra CDs from a FreeBSD CD/DVD distribution
available and can mount it on /cdrom, in which case this is far less
of a problem).
The Ports Collection is a very valuable resource and well worth having
on your /usr partition, so it is advisable to say Yes to this option.
For more information on the Ports Collection & the latest ports,
visit:
http://www.FreeBSD.org/ports
[ Yes ] No
Select [ Yes ] with the arrow keys to install the Ports Collection or [ No ] to skip this option. Press Enter to continue. The Choose Distributions menu will redisplay.
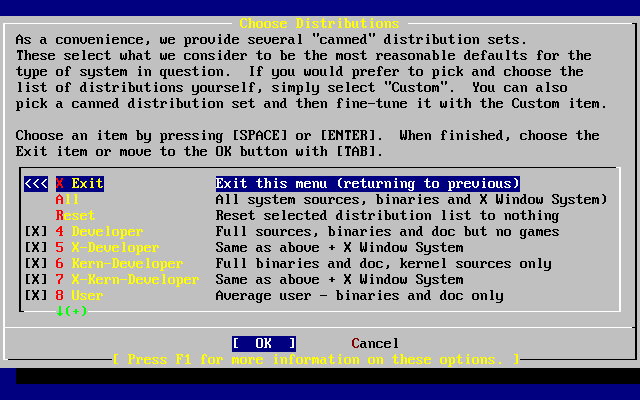
If satisfied with the options, select Exit with the arrow keys, ensure that [ OK ] is highlighted, and pressing Enter to continue.
2.8 Choosing Your Installation Media
If Installing from a CDROM or DVD, use the arrow keys to highlight Install from a FreeBSD CD/DVD. Ensure that [ OK ] is highlighted, then press Enter to proceed with the installation.
For other methods of installation, select the appropriate option and follow the instructions.
Press F1 to display the Online Help for installation media. Press Enter to return to the media selection menu.
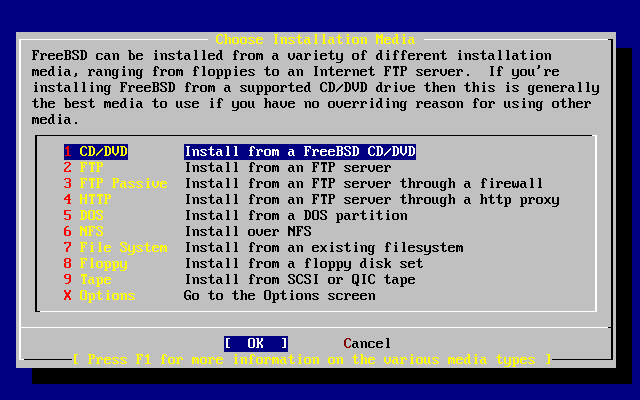
FTP Installation Modes: There are three FTP installation modes you can choose from: active FTP, passive FTP, or via a HTTP proxy.
- FTP Active: Install from an FTP server
This option will make all FTP transfers use “Active” mode. This will not work through firewalls, but will often work with older FTP servers that do not support passive mode. If your connection hangs with passive mode (the default), try active!
- FTP Passive: Install from an FTP server through a firewall
This option instructs sysinstall to use “Passive” mode for all FTP operations. This allows the user to pass through firewalls that do not allow incoming connections on random TCP ports.
- FTP via a HTTP proxy: Install from an FTP server through a http proxy
This option instructs sysinstall to use the HTTP protocol (like a web browser) to connect to a proxy for all FTP operations. The proxy will translate the requests and send them to the FTP server. This allows the user to pass through firewalls that do not allow FTP at all, but offer a HTTP proxy. In this case, you have to specify the proxy in addition to the FTP server.
For a proxy FTP server, you should usually give the name of the server you really want as a part of the username, after an “@” sign. The proxy server then “fakes” the real server. For example, assuming you want to install from ftp.FreeBSD.org, using the proxy FTP server foo.example.com, listening on port 1234.
In this case, you go to the options menu, set the FTP username to ftp@ftp.FreeBSD.org, and the password to your email address. As your installation media, you specify FTP (or passive FTP, if the proxy supports it), and the URL ftp://foo.example.com:1234/pub/FreeBSD.
Since /pub/FreeBSD from ftp.FreeBSD.org is proxied under foo.example.com, you are able to install from that machine (which will fetch the files from ftp.FreeBSD.org as your installation requests them).
2.9 Committing to the Installation
The installation can now proceed if desired. This is also the last chance for aborting the installation to prevent changes to the hard drive.
User Confirmation Requested
Last Chance! Are you SURE you want to continue the installation?
If you're running this on a disk with data you wish to save then WE
STRONGLY ENCOURAGE YOU TO MAKE PROPER BACKUPS before proceeding!
We can take no responsibility for lost disk contents!
[ Yes ] No
Select [ Yes ] and press Enter to proceed.
The installation time will vary according to the distribution chosen, installation media, and the speed of the computer. There will be a series of messages displayed indicating the status.
The installation is complete when the following message is displayed:
Message
Congratulations! You now have FreeBSD installed on your system.
We will now move on to the final configuration questions.
For any option you do not wish to configure, simply select No.
If you wish to re-enter this utility after the system is up, you may
do so by typing: /usr/sbin/sysinstall.
[ OK ]
[ Press enter or space ]
Press Enter to proceed with post-installation configurations.
Selecting [ No ] and pressing Enter will abort the installation so no changes will be made to your system. The following message will appear:
Message
Installation complete with some errors. You may wish to scroll
through the debugging messages on VTY1 with the scroll-lock feature.
You can also choose "No" at the next prompt and go back into the
installation menus to retry whichever operations have failed.
[ OK ]
This message is generated because nothing was installed. Pressing Enter will return to the Main Installation Menu to exit the installation.
2.10 Post-installation
Configuration of various options follows the successful installation. An option can be configured by re-entering the configuration options before booting the new FreeBSD system or after installation using sysinstall (/stand/sysinstall in FreeBSD versions older than 5.2) and selecting Configure.
2.10.1 Network Device Configuration
If you previously configured PPP for an FTP install, this screen will not display and can be configured later as described above.
For detailed information on Local Area Networks and configuring FreeBSD as a gateway/router refer to the Advanced Networking chapter.
User Confirmation Requested
Would you like to configure any Ethernet or SLIP/PPP network devices?
[ Yes ] No
To configure a network device, select [ Yes ] and press Enter. Otherwise, select [ No ] to continue.
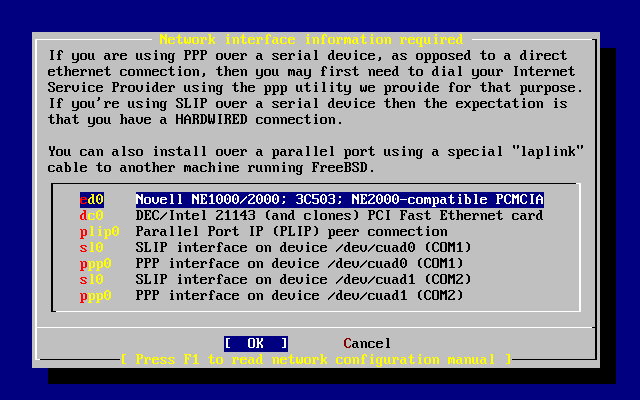
Select the interface to be configured with the arrow keys and press Enter.
User Confirmation Requested
Do you want to try IPv6 configuration of the interface?
Yes [ No ]
In this private local area network, the current Internet type protocol (IPv4) was sufficient and [ No ] was selected with the arrow keys and Enter pressed.
If you are connected to an existing IPv6 network with an RA server, then choose [ Yes ] and press Enter. It will take several seconds to scan for RA servers.
User Confirmation Requested
Do you want to try DHCP configuration of the interface?
Yes [ No ]
If DHCP (Dynamic Host Configuration Protocol) is not required select [ No ] with the arrow keys and press Enter.
Selecting [ Yes ] will execute dhclient, and if successful, will fill in the network configuration information automatically. Refer to Section 27.5 for more information.
The following Network Configuration screen shows the configuration of the Ethernet device for a system that will act as the gateway for a Local Area Network.
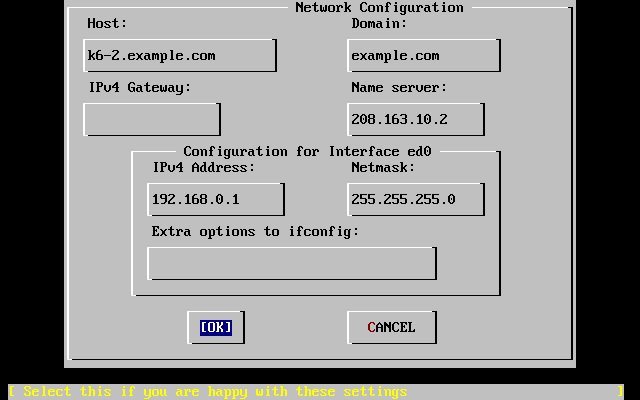
Use Tab to select the information fields and fill in appropriate information:
- Host
-
The fully-qualified hostname, such as k6-2.example.com in this case.
- Domain
-
The name of the domain that your machine is in, such as example.com for this case.
- IPv4 Gateway
-
IP address of host forwarding packets to non-local destinations. You must fill this in if the machine is a node on the network. Leave this field blank if the machine is the gateway to the Internet for the network. The IPv4 Gateway is also known as the default gateway or default route.
- Name server
-
IP address of your local DNS server. There is no local DNS server on this private local area network so the IP address of the provider's DNS server (208.163.10.2) was used.
- IPv4 address
-
The IP address to be used for this interface was 192.168.0.1
- Netmask
-
The address block being used for this local area network is 192.168.0.0 - 192.168.0.255 with a netmask of 255.255.255.0.
- Extra options to ifconfig
-
Any interface-specific options to ifconfig you would like to add. There were none in this case.
Use Tab to select [ OK ] when finished and press Enter.
User Confirmation Requested
Would you like to Bring Up the ed0 interface right now?
[ Yes ] No
Choosing [ Yes ] and pressing Enter will bring the machine up on the network and be ready for use. However, this does not accomplish much during installation, since the machine still needs to be rebooted.
2.10.2 Configure Gateway
User Confirmation Requested
Do you want this machine to function as a network gateway?
[ Yes ] No
If the machine will be acting as the gateway for a local area network and forwarding packets between other machines then select [ Yes ] and press Enter. If the machine is a node on a network then select [ No ] and press Enter to continue.
2.10.3 Configure Internet Services
User Confirmation Requested
Do you want to configure inetd and the network services that it provides?
Yes [ No ]
If [ No ] is selected, various services such telnetd will not be enabled. This means that remote users will not be able to telnet into this machine. Local users will still be able to access remote machines with telnet.
These services can be enabled after installation by editing /etc/inetd.conf with your favorite text editor. See Section 27.2.1 for more information.
Select [ Yes ] if you wish to configure these services during install. An additional confirmation will display:
User Confirmation Requested
The Internet Super Server (inetd) allows a number of simple Internet
services to be enabled, including finger, ftp and telnetd. Enabling
these services may increase risk of security problems by increasing
the exposure of your system.
With this in mind, do you wish to enable inetd?
[ Yes ] No
Select [ Yes ] to continue.
User Confirmation Requested
inetd(8) relies on its configuration file, /etc/inetd.conf, to determine
which of its Internet services will be available. The default FreeBSD
inetd.conf(5) leaves all services disabled by default, so they must be
specifically enabled in the configuration file before they will
function, even once inetd(8) is enabled. Note that services for
IPv6 must be separately enabled from IPv4 services.
Select [Yes] now to invoke an editor on /etc/inetd.conf, or [No] to
use the current settings.
[ Yes ] No
Selecting [ Yes ] will allow adding services by deleting the # at the beginning of a line.
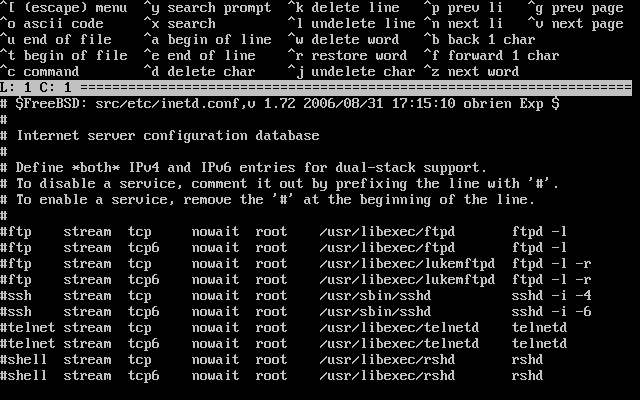
After adding the desired services, pressing Esc will display a menu which will allow exiting and saving the changes.
2.10.4 Enabling SSH login
User Confirmation Requested
Would you like to enable SSH login?
Yes [ No ]
Selecting [ Yes ] will enable sshd(8), the daemon program for OpenSSH. This will allow secure remote access to your machine. For more information about OpenSSH see Section 14.11.
2.10.5 Anonymous FTP
User Confirmation Requested
Do you want to have anonymous FTP access to this machine?
Yes [ No ]
2.10.5.1 Deny Anonymous FTP
Selecting the default [ No ] and pressing Enter will still allow users who have accounts with passwords to use FTP to access the machine.
2.10.5.2 Allow Anonymous FTP
Anyone can access your machine if you elect to allow anonymous FTP connections. The security implications should be considered before enabling this option. For more information about security see Chapter 14.
To allow anonymous FTP, use the arrow keys to select [ Yes ] and press Enter. An additionnal confirmation will display:
User Confirmation Requested
Anonymous FTP permits un-authenticated users to connect to the system
FTP server, if FTP service is enabled. Anonymous users are
restricted to a specific subset of the file system, and the default
configuration provides a drop-box incoming directory to which uploads
are permitted. You must separately enable both inetd(8), and enable
ftpd(8) in inetd.conf(5) for FTP services to be available. If you
did not do so earlier, you will have the opportunity to enable inetd(8)
again later.
If you want the server to be read-only you should leave the upload
directory option empty and add the -r command-line option to ftpd(8)
in inetd.conf(5)
Do you wish to continue configuring anonymous FTP?
[ Yes ] No
This message informs you that the FTP service will also have to be enabled in /etc/inetd.conf if you want to allow anonymous FTP connections, see Section 2.10.3. Select [ Yes ] and press Enter to continue; the following screen will display:
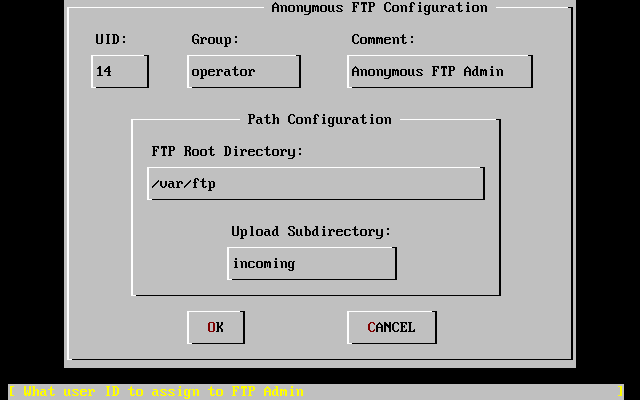
Use Tab to select the information fields and fill in appropriate information:
- UID
-
The user ID you wish to assign to the anonymous FTP user. All files uploaded will be owned by this ID.
- Group
-
Which group you wish the anonymous FTP user to be in.
- Comment
-
String describing this user in /etc/passwd.
- FTP Root Directory
-
Where files available for anonymous FTP will be kept.
- Upload Subdirectory
-
Where files uploaded by anonymous FTP users will go.
The FTP root directory will be put in /var by default. If you do not have enough room there for the anticipated FTP needs, the /usr directory could be used by setting the FTP root directory to /usr/ftp.
When you are satisfied with the values, press Enter to continue.
User Confirmation Requested
Create a welcome message file for anonymous FTP users?
[ Yes ] No
If you select [ Yes ] and press Enter, an editor will automatically start allowing you to edit the message.
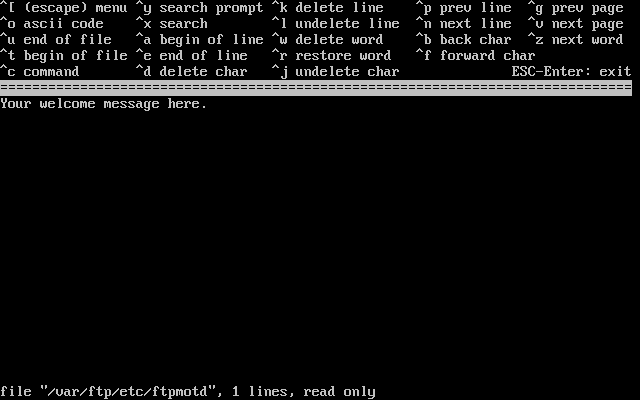
This is a text editor called ee. Use the instructions to change the message or change the message later using a text editor of your choice. Note the file name/location at the bottom of the editor screen.
Press Esc and a pop-up menu will default to a) leave editor. Press Enter to exit and continue. Press Enter again to save changes if you made any.
2.10.6 Configure Network File System
Network File System (NFS) allows sharing of files across a network. A machine can be configured as a server, a client, or both. Refer to Section 27.3 for a more information.
2.10.6.1 NFS Server
User Confirmation Requested
Do you want to configure this machine as an NFS server?
Yes [ No ]
If there is no need for a Network File System server, select [ No ] and press Enter.
If [ Yes ] is chosen, a message will pop-up indicating that the exports file must be created.
Message
Operating as an NFS server means that you must first configure an
/etc/exports file to indicate which hosts are allowed certain kinds of
access to your local filesystems.
Press [Enter] now to invoke an editor on /etc/exports
[ OK ]
Press Enter to continue. A text editor will start allowing the exports file to be created and edited.
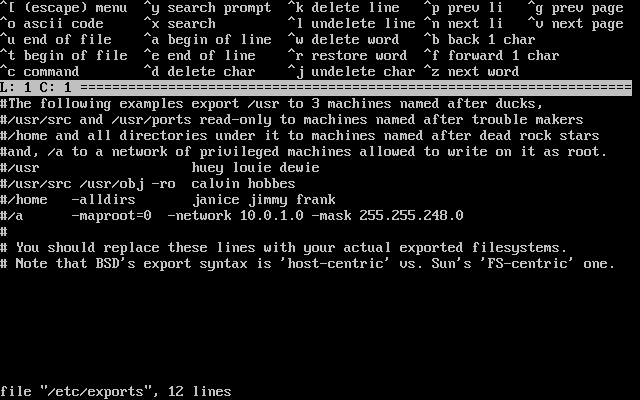
Use the instructions to add the actual exported filesystems now or later using a text editor of your choice. Note the file name/location at the bottom of the editor screen.
Press Esc and a pop-up menu will default to a) leave editor. Press Enter to exit and continue.
2.10.6.2 NFS Client
The NFS client allows your machine to access NFS servers.
User Confirmation Requested
Do you want to configure this machine as an NFS client?
Yes [ No ]
With the arrow keys, select [ Yes ] or [ No ] as appropriate and press Enter.
2.10.7 System Console Settings
There are several options available to customize the system console.
User Confirmation Requested
Would you like to customize your system console settings?
[ Yes ] No
To view and configure the options, select [ Yes ] and press Enter.
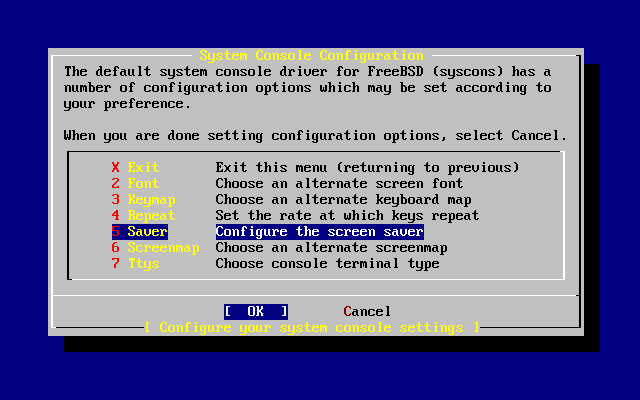
A commonly used option is the screen saver. Use the arrow keys to select Saver and then press Enter.
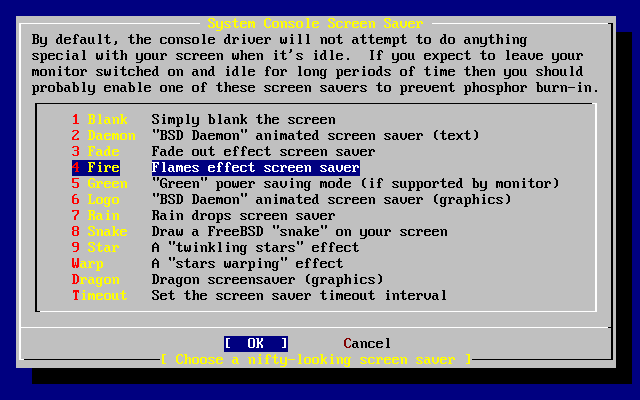
Select the desired screen saver using the arrow keys and then press Enter. The System Console Configuration menu will redisplay.
The default time interval is 300 seconds. To change the time interval, select Saver again. At the Screen Saver Options menu, select Timeout using the arrow keys and press Enter. A pop-up menu will appear:
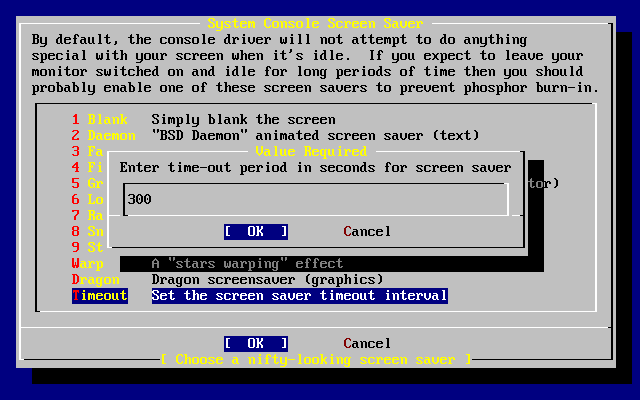
The value can be changed, then select [ OK ] and press Enter to return to the System Console Configuration menu.
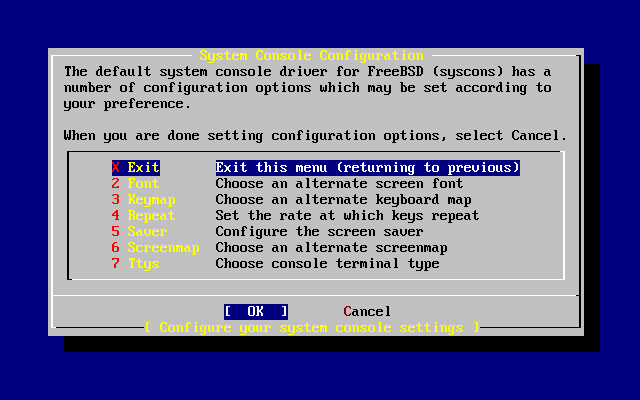
Selecting Exit and pressing Enter will continue with the post-installation configurations.
2.10.8 Setting the Time Zone
Setting the time zone for your machine will allow it to automatically correct for any regional time changes and perform other time zone related functions properly.
The example shown is for a machine located in the Eastern time zone of the United States. Your selections will vary according to your geographical location.
User Confirmation Requested
Would you like to set this machine's time zone now?
[ Yes ] No
Select [ Yes ] and press Enter to set the time zone.
User Confirmation Requested
Is this machine's CMOS clock set to UTC? If it is set to local time
or you don't know, please choose NO here!
Yes [ No ]
Select [ Yes ] or [ No ] according to how the machine's clock is configured and press Enter.
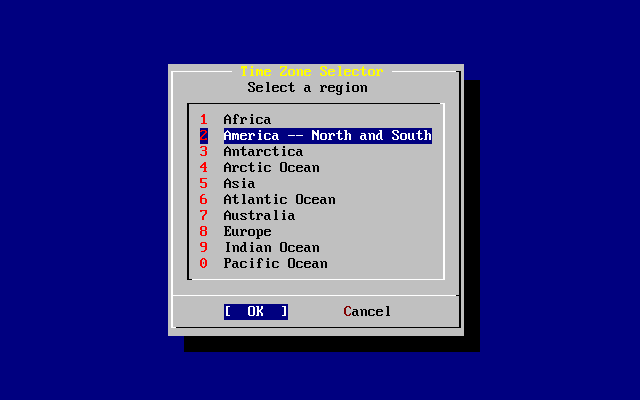
The appropriate region is selected using the arrow keys and then pressing Enter.
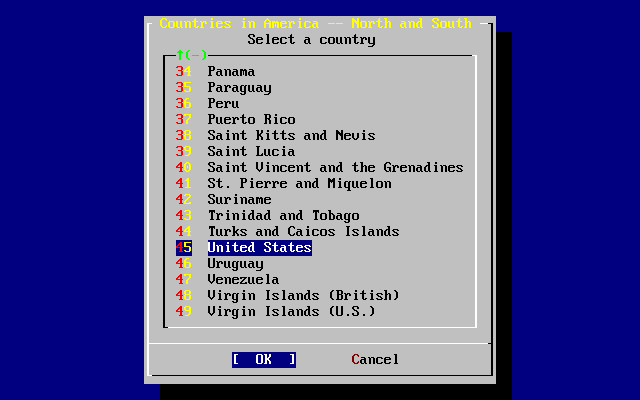
Select the appropriate country using the arrow keys and press Enter.
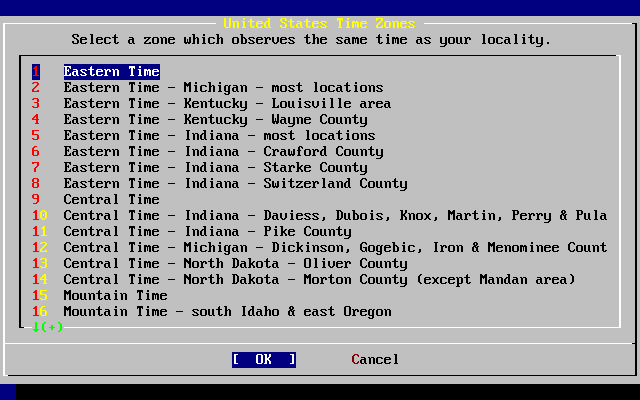
The appropriate time zone is selected using the arrow keys and pressing Enter.
Confirmation
Does the abbreviation 'EDT' look reasonable?
[ Yes ] No
Confirm the abbreviation for the time zone is correct. If it looks okay, press Enter to continue with the post-installation configuration.
2.10.9 Linux Compatibility
User Confirmation Requested
Would you like to enable Linux binary compatibility?
[ Yes ] No
Selecting [ Yes ] and pressing Enter will allow running Linux software on FreeBSD. The install will add the appropriate packages for Linux compatibility.
If installing by FTP, the machine will need to be connected to the Internet. Sometimes a remote ftp site will not have all the distributions like the Linux binary compatibility. This can be installed later if necessary.
2.10.10 Mouse Settings
This option will allow you to cut and paste text in the console and user programs with a 3-button mouse. If using a 2-button mouse, refer to manual page, moused(8), after installation for details on emulating the 3-button style. This example depicts a non-USB mouse configuration (such as a PS/2 or COM port mouse):
User Confirmation Requested
Does this system have a PS/2, serial, or bus mouse?
[ Yes ] No
Select [ Yes ] for a PS/2, serial or bus mouse, or [ No ] for a USB mouse and press Enter.
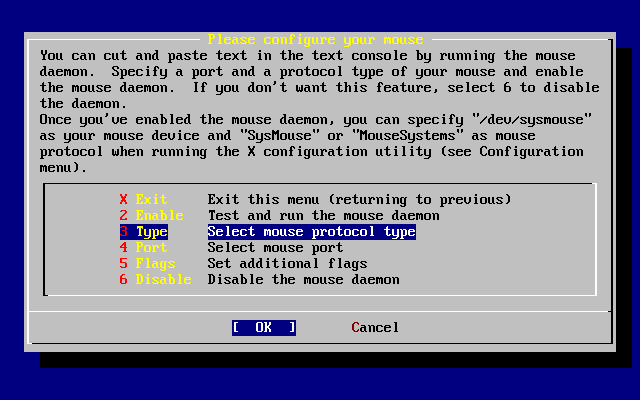
Use the arrow keys to select Type and press Enter.
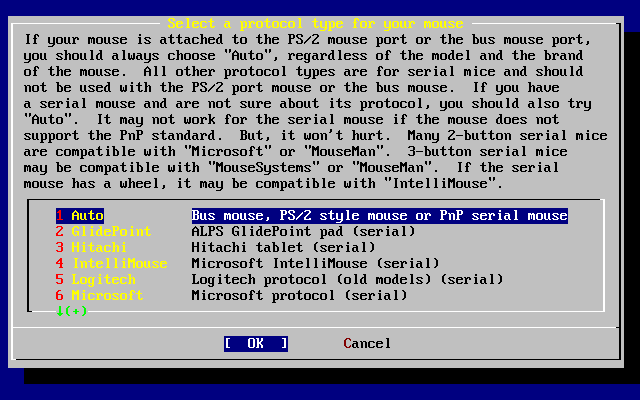
The mouse used in this example is a PS/2 type, so the default Auto was appropriate. To change protocol, use the arrow keys to select another option. Ensure that [ OK ] is highlighted and press Enter to exit this menu.
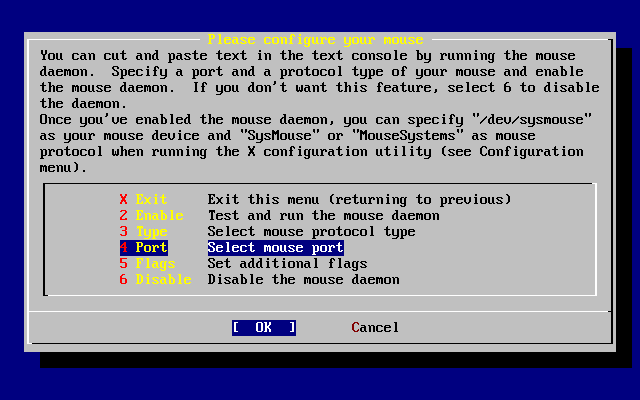
Use the arrow keys to select Port and press Enter.
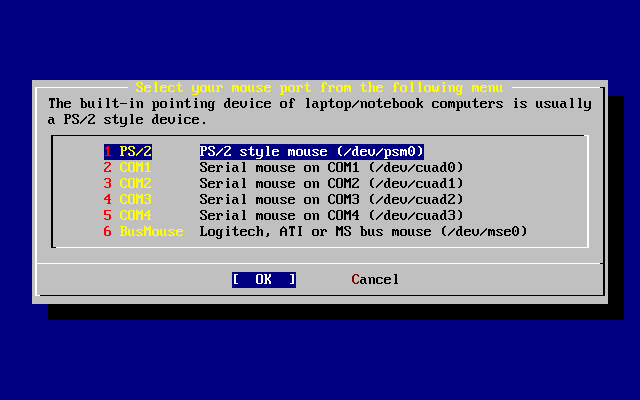
This system had a PS/2 mouse, so the default PS/2 was appropriate. To change the port, use the arrow keys and then press Enter.
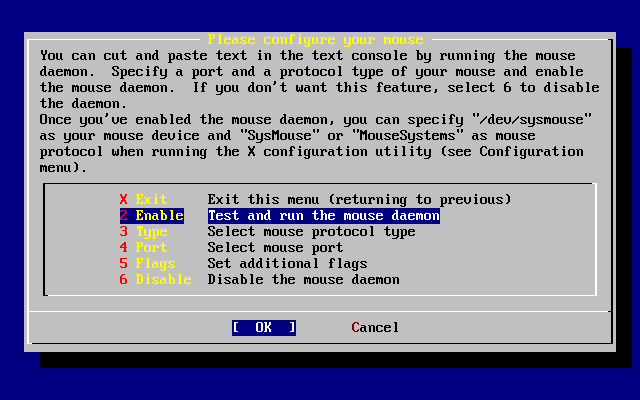
Last, use the arrow keys to select Enable, and press Enter to enable and test the mouse daemon.
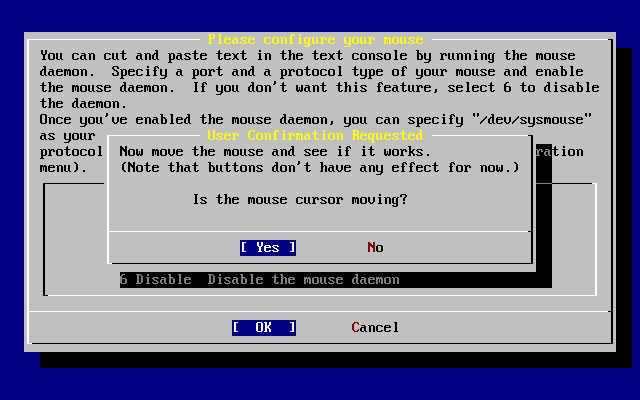
Move the mouse around the screen and verify the cursor shown responds properly. If it does, select [ Yes ] and press Enter. If not, the mouse has not been configured correctly -- select [ No ] and try using different configuration options.
Select Exit with the arrow keys and press Enter to return to continue with the post-installation configuration.
2.10.11 Install Packages
Packages are pre-compiled binaries and are a convenient way to install software.
Installation of one package is shown for purposes of illustration. Additional packages can also be added at this time if desired. After installation sysinstall can be used to add additional packages.
User Confirmation Requested
The FreeBSD package collection is a collection of hundreds of
ready-to-run applications, from text editors to games to WEB servers
and more. Would you like to browse the collection now?
[ Yes ] No
Selecting [ Yes ] and pressing Enter will be followed by the Package Selection screens:
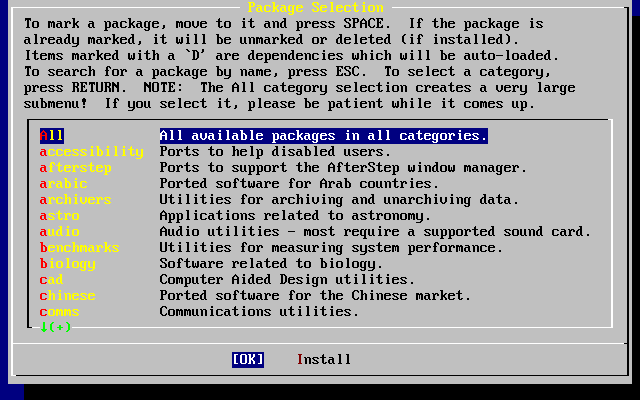
Only packages on the current installation media are available for installation at any given time.
All packages available will be displayed if All is selected or you can select a particular category. Highlight your selection with the arrow keys and press Enter.
A menu will display showing all the packages available for the selection made:
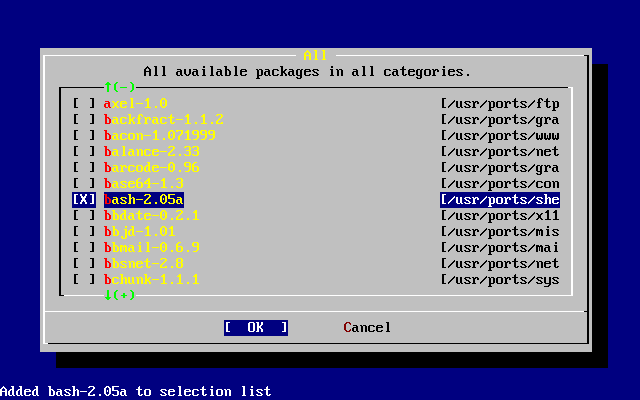
The bash shell is shown selected. Select as many as desired by highlighting the package and pressing the Space key. A short description of each package will appear in the lower left corner of the screen.
Pressing the Tab key will toggle between the last selected package, [ OK ], and [ Cancel ].
When you have finished marking the packages for installation, press Tab once to toggle to the [ OK ] and press Enter to return to the Package Selection menu.
The left and right arrow keys will also toggle between [ OK ] and [ Cancel ]. This method can also be used to select [ OK ] and press Enter to return to the Package Selection menu.
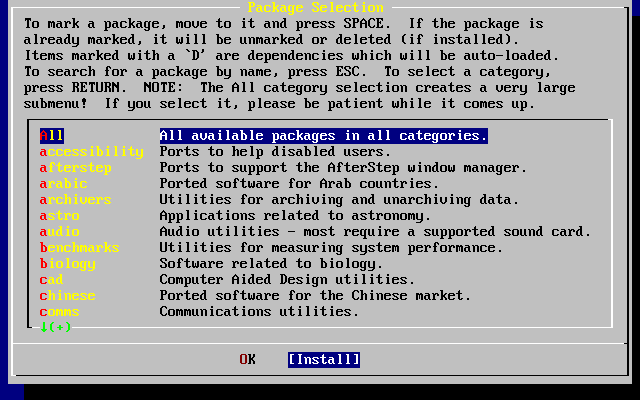
Use the Tab and arrow keys to select [ Install ] and press Enter. You will then need to confirm that you want to install the packages:
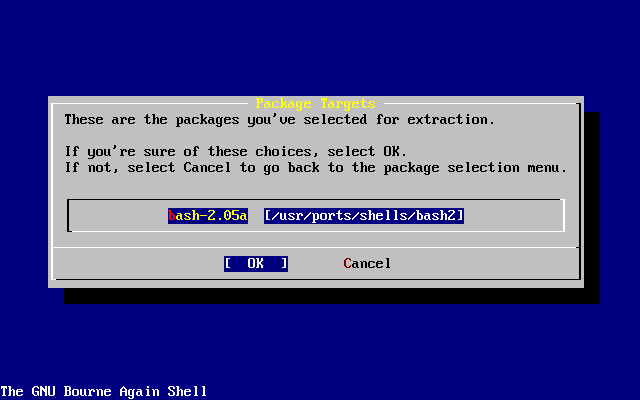
Selecting [ OK ] and pressing Enter will start the package installation. Installing messages will appear until completed. Make note if there are any error messages.
The final configuration continues after packages are installed. If you end up not selecting any packages, and wish to return to the final configuration, select Install anyways.
2.10.12 Add Users/Groups
You should add at least one user during the installation so that you can use the system without being logged in as root. The root partition is generally small and running applications as root can quickly fill it. A bigger danger is noted below:
User Confirmation Requested
Would you like to add any initial user accounts to the system? Adding
at least one account for yourself at this stage is suggested since
working as the "root" user is dangerous (it is easy to do things which
adversely affect the entire system).
[ Yes ] No
Select [ Yes ] and press Enter to continue with adding a user.
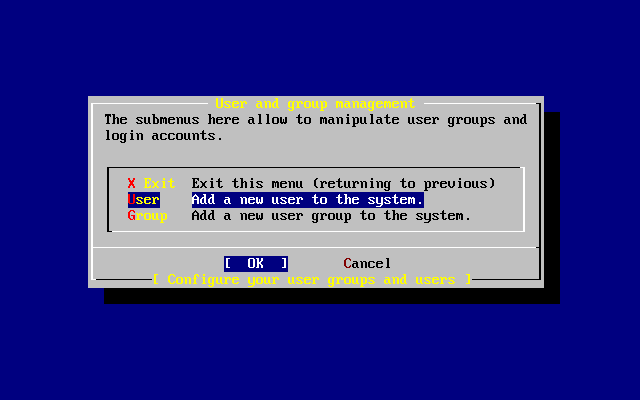
Select User with the arrow keys and press Enter.
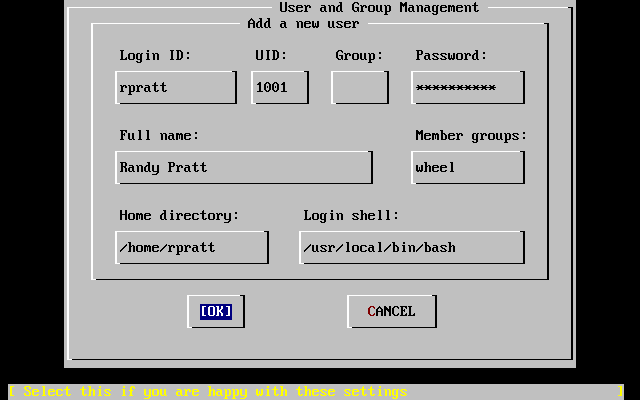
The following descriptions will appear in the lower part of the screen as the items are selected with Tab to assist with entering the required information:
- Login ID
-
The login name of the new user (mandatory).
- UID
-
The numerical ID for this user (leave blank for automatic choice).
- Group
-
The login group name for this user (leave blank for automatic choice).
- Password
-
The password for this user (enter this field with care!).
- Full name
-
The user's full name (comment).
- Member groups
-
The groups this user belongs to (i.e. gets access rights for).
- Home directory
-
The user's home directory (leave blank for default).
- Login shell
-
The user's login shell (leave blank for default, e.g. /bin/sh).
The login shell was changed from /bin/sh to /usr/local/bin/bash to use the bash shell that was previously installed as a package. Do not try to use a shell that does not exist or you will not be able to login. The most common shell used in the BSD-world is the C shell, which can be indicated as /bin/tcsh.
The user was also added to the wheel group to be able to become a superuser with root privileges.
When you are satisfied, press [ OK ] and the User and Group Management menu will redisplay:
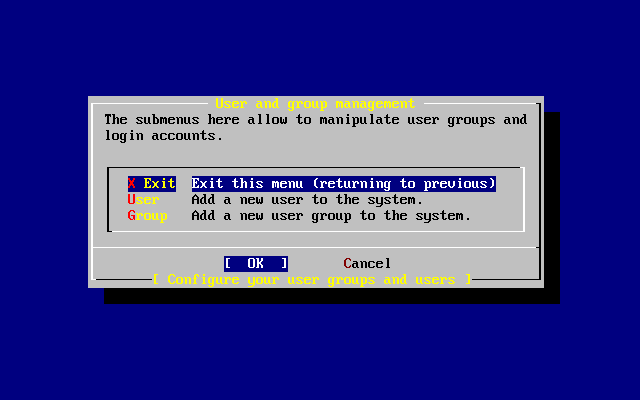
Groups can also be added at this time if specific needs are known. Otherwise, this may be accessed through using sysinstall (/stand/sysinstall in FreeBSD versions older than 5.2) after installation is completed.
When you are finished adding users, select Exit with the arrow keys and press Enter to continue the installation.
2.10.13 Set the root Password
Message
Now you must set the system manager's password.
This is the password you'll use to log in as "root".
[ OK ]
[ Press enter or space ]
Press Enter to set the root password.
The password will need to be typed in twice correctly. Needless to say, make sure you have a way of finding the password if you forget. Notice that the password you type in is not echoed, nor are asterisks displayed.
New password:
Retype new password :
The installation will continue after the password is successfully entered.
2.10.14 Exiting Install
If you need to configure additional network services or any other configuration, you can do it at this point or after installation with sysinstall (/stand/sysinstall in FreeBSD versions older than 5.2).
User Confirmation Requested
Visit the general configuration menu for a chance to set any last
options?
Yes [ No ]
Select [ No ] with the arrow keys and press Enter to return to the Main Installation Menu.
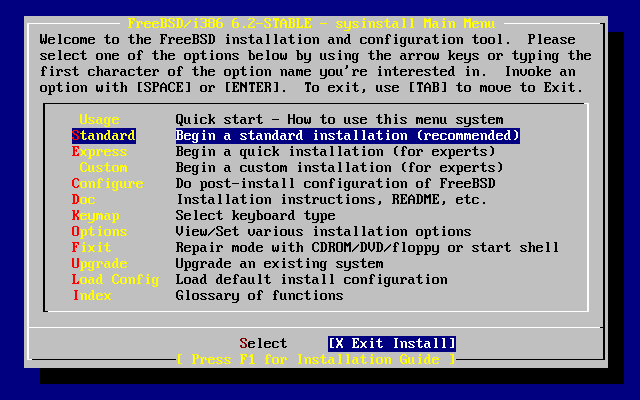
Select [X Exit Install] with the arrow keys and press Enter. You will be asked to confirm exiting the installation:
User Confirmation Requested
Are you sure you wish to exit? The system will reboot (be sure to
remove any floppies/CDs/DVDs from the drives).
[ Yes ] No
Select [ Yes ] and remove the floppy if booting from the floppy. The CDROM drive is locked until the machine starts to reboot. The CDROM drive is then unlocked and the disk can be removed from drive (quickly).
The system will reboot so watch for any error messages that may appear, see Section 2.10.16 for more details.
2.10.15 Configure Additional Network Services
Contributed by Tom Rhodes.Configuring network services can be a daunting task for new users if they lack previous knowledge in this area. Networking, including the Internet, is critical to all modern operating systems including FreeBSD; as a result, it is very useful to have some understanding FreeBSD's extensive networking capabilities. Doing this during the installation will ensure users have some understanding of the various services available to them.
Network services are programs that accept input from anywhere on the network. Every effort is made to make sure these programs will not do anything “harmful”. Unfortunately, programmers are not perfect and through time there have been cases where bugs in network services have been exploited by attackers to do bad things. It is important that you only enable the network services you know that you need. If in doubt it is best if you do not enable a network service until you find out that you do need it. You can always enable it later by re-running sysinstall or by using the features provided by the /etc/rc.conf file.
Selecting the Networking option will display a menu similar to the one below:
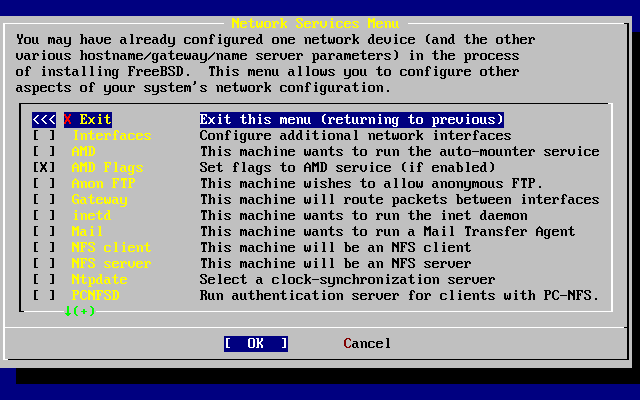
The first option, Interfaces, was previously covered during the Section 2.10.1, thus this option can safely be ignored.
Selecting the AMD option adds support for the BSD automatic mount utility. This is usually used in conjunction with the NFS protocol (see below) for automatically mounting remote file systems. No special configuration is required here.
Next in line is the AMD Flags option. When selected, a menu will pop up for you to enter specific AMD flags. The menu already contains a set of default options:
-a /.amd_mnt -l syslog /host /etc/amd.map /net /etc/amd.map
The -a option sets the default mount location which is
specified here as /.amd_mnt. The -l
option specifies the default log file; however, when syslogd is used all log activity will be sent to the system log
daemon. The /host directory is used to mount an exported file
system from a remote host, while /net directory is used to
mount an exported file system from an IP address. The
/etc/amd.map file defines the default options for AMD exports.
The Anon FTP option permits anonymous FTP connections. Select this option to make this machine an anonymous FTP server. Be aware of the security risks involved with this option. Another menu will be displayed to explain the security risks and configuration in depth.
The Gateway configuration menu will set the machine up to be a gateway as explained previously. This can be used to unset the Gateway option if you accidentally selected it during the installation process.
The Inetd option can be used to configure or completely disable the inetd(8) daemon as discussed above.
The Mail option is used to configure the system's default MTA or Mail Transfer Agent. Selecting this option will bring up the following menu:
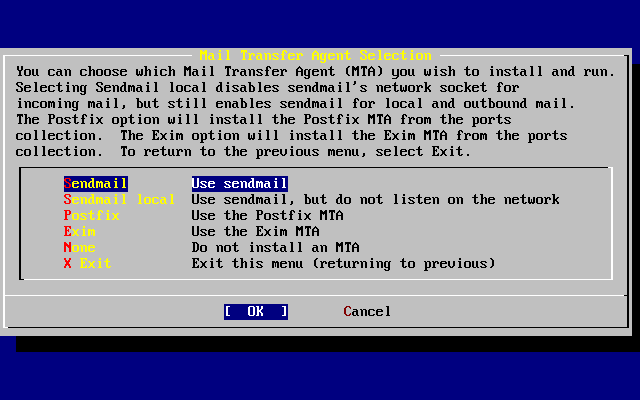
Here you are offered a choice as to which MTA to install and set as the default. An MTA is nothing more than a mail server which delivers email to users on the system or the Internet.
Selecting Sendmail will install the popular sendmail server which is the FreeBSD default. The Sendmail local option will set sendmail to be the default MTA, but disable its ability to receive incoming email from the Internet. The other options here, Postfix and Exim act similar to Sendmail. They both deliver email; however, some users prefer these alternatives to the sendmail MTA.
After selecting an MTA, or choosing not to select an MTA, the network configuration menu will appear with the next option being NFS client.
The NFS client option will configure the system to communicate with a server via NFS. An NFS server makes file systems available to other machines on the network via the NFS protocol. If this is a stand-alone machine, this option can remain unselected. The system may require more configuration later; see Section 27.3 for more information about client and server configuration.
Below that option is the NFS server option, permitting you to set the system up as an NFS server. This adds the required information to start up the RPC remote procedure call services. RPC is used to coordinate connections between hosts and programs.
Next in line is the Ntpdate option, which deals with time synchronization. When selected, a menu like the one below shows up:
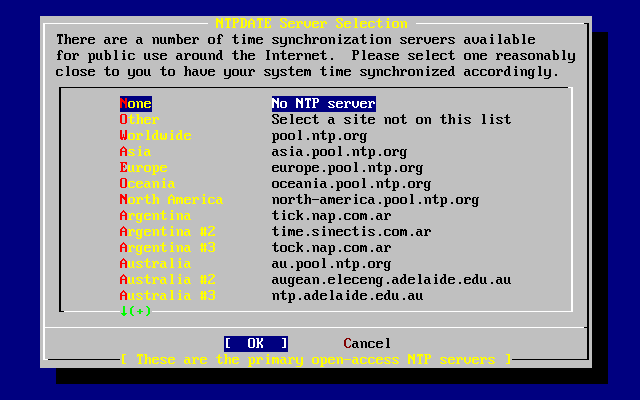
From this menu, select the server which is the closest to your location. Selecting a close one will make the time synchronization more accurate as a server further from your location may have more connection latency.
The next option is the PCNFSD selection. This option will install the net/pcnfsd package from the Ports Collection. This is a useful utility which provides NFS authentication services for systems which are unable to provide their own, such as Microsoft's MS-DOS operating system.
Now you must scroll down a bit to see the other options:
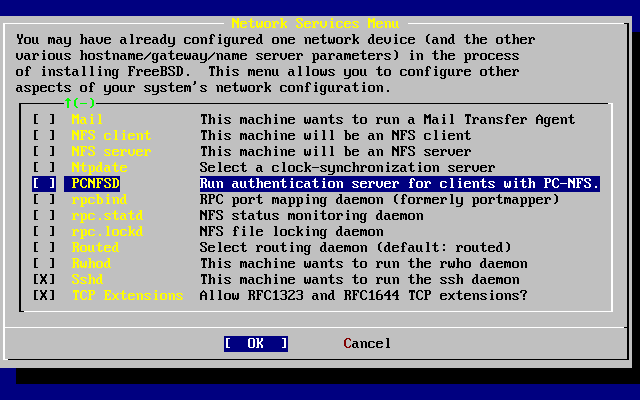
The rpcbind(8), rpc.statd(8), and rpc.lockd(8) utilities are all used for Remote Procedure Calls (RPC). The rpcbind utility manages communication between NFS servers and clients, and is required for NFS servers to operate correctly. The rpc.statd daemon interacts with the rpc.statd daemon on other hosts to provide status monitoring. The reported status is usually held in the /var/db/statd.status file. The next option listed here is the rpc.lockd option, which, when selected, will provide file locking services. This is usually used with rpc.statd to monitor what hosts are requesting locks and how frequently they request them. While these last two options are marvelous for debugging, they are not required for NFS servers and clients to operate correctly.
As you progress down the list the next item here is Routed, which is the routing daemon. The routed(8) utility
manages network routing tables, discovers multicast routers, and supplies a copy of the
routing tables to any physically connected host on the network upon request. This is
mainly used for machines which act as a gateway for the local network. When selected, a
menu will be presented requesting the default location of the utility. The default
location is already defined for you and can be selected with the Enter key. You will then be presented with yet another menu, this time
asking for the flags you wish to pass on to routed. The
default is -q and it should already appear on the screen.
Next in line is the Rwhod option which, when selected, will start the rwhod(8) daemon during system initialization. The rwhod utility broadcasts system messages across the network periodically, or collects them when in “consumer” mode. More information can be found in the ruptime(1) and rwho(1) manual pages.
The next to the last option in the list is for the sshd(8) daemon. This is the secure shell server for OpenSSH and it is highly recommended over the standard telnet and FTP servers. The sshd server is used to create a secure connection from one host to another by using encrypted connections.
Finally there is the TCP Extensions option. This enables the TCP Extensions defined in RFC 1323 and RFC 1644. While on many hosts this can speed up connections, it can also cause some connections to be dropped. It is not recommended for servers, but may be beneficial for stand alone machines.
Now that you have configured the network services, you can scroll up to the very top item which is X Exit and continue on to the next configuration item or simply exit sysinstall in selecting X Exit twice then [X Exit Install].
2.10.16 FreeBSD Bootup
2.10.16.1 FreeBSD/i386 Bootup
If everything went well, you will see messages scroll off the screen and you will arrive at a login prompt. You can view the content of the messages by pressing Scroll-Lock and using PgUp and PgDn. Pressing Scroll-Lock again will return to the prompt.
The entire message may not display (buffer limitation) but it can be viewed from the command line after logging in by typing dmesg at the prompt.
Login using the username/password you set during installation (rpratt, in this example). Avoid logging in as root except when necessary.
Typical boot messages (version information omitted):
Copyright (c) 1992-2002 The FreeBSD Project.
Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994
The Regents of the University of California. All rights reserved.
Timecounter "i8254" frequency 1193182 Hz
CPU: AMD-K6(tm) 3D processor (300.68-MHz 586-class CPU)
Origin = "AuthenticAMD" Id = 0x580 Stepping = 0
Features=0x8001bf<FPU,VME,DE,PSE,TSC,MSR,MCE,CX8,MMX>
AMD Features=0x80000800<SYSCALL,3DNow!>
real memory = 268435456 (262144K bytes)
config> di sn0
config> di lnc0
config> di le0
config> di ie0
config> di fe0
config> di cs0
config> di bt0
config> di aic0
config> di aha0
config> di adv0
config> q
avail memory = 256311296 (250304K bytes)
Preloaded elf kernel "kernel" at 0xc0491000.
Preloaded userconfig_script "/boot/kernel.conf" at 0xc049109c.
md0: Malloc disk
Using $PIR table, 4 entries at 0xc00fde60
npx0: <math processor> on motherboard
npx0: INT 16 interface
pcib0: <Host to PCI bridge> on motherboard
pci0: <PCI bus> on pcib0
pcib1: <VIA 82C598MVP (Apollo MVP3) PCI-PCI (AGP) bridge> at device 1.0 on pci0
pci1: <PCI bus> on pcib1
pci1: <Matrox MGA G200 AGP graphics accelerator> at 0.0 irq 11
isab0: <VIA 82C586 PCI-ISA bridge> at device 7.0 on pci0
isa0: <ISA bus> on isab0
atapci0: <VIA 82C586 ATA33 controller> port 0xe000-0xe00f at device 7.1 on pci0
ata0: at 0x1f0 irq 14 on atapci0
ata1: at 0x170 irq 15 on atapci0
uhci0: <VIA 83C572 USB controller> port 0xe400-0xe41f irq 10 at device 7.2 on pci0
usb0: <VIA 83C572 USB controller> on uhci0
usb0: USB revision 1.0
uhub0: VIA UHCI root hub, class 9/0, rev 1.00/1.00, addr 1
uhub0: 2 ports with 2 removable, self powered
chip1: <VIA 82C586B ACPI interface> at device 7.3 on pci0
ed0: <NE2000 PCI Ethernet (RealTek 8029)> port 0xe800-0xe81f irq 9 at
device 10.0 on pci0
ed0: address 52:54:05:de:73:1b, type NE2000 (16 bit)
isa0: too many dependant configs (8)
isa0: unexpected small tag 14
fdc0: <NEC 72065B or clone> at port 0x3f0-0x3f5,0x3f7 irq 6 drq 2 on isa0
fdc0: FIFO enabled, 8 bytes threshold
fd0: <1440-KB 3.5" drive> on fdc0 drive 0
atkbdc0: <keyboard controller (i8042)> at port 0x60-0x64 on isa0
atkbd0: <AT Keyboard> flags 0x1 irq 1 on atkbdc0
kbd0 at atkbd0
psm0: <PS/2 Mouse> irq 12 on atkbdc0
psm0: model Generic PS/2 mouse, device ID 0
vga0: <Generic ISA VGA> at port 0x3c0-0x3df iomem 0xa0000-0xbffff on isa0
sc0: <System console> at flags 0x1 on isa0
sc0: VGA <16 virtual consoles, flags=0x300>
sio0 at port 0x3f8-0x3ff irq 4 flags 0x10 on isa0
sio0: type 16550A
sio1 at port 0x2f8-0x2ff irq 3 on isa0
sio1: type 16550A
ppc0: <Parallel port> at port 0x378-0x37f irq 7 on isa0
ppc0: SMC-like chipset (ECP/EPP/PS2/NIBBLE) in COMPATIBLE mode
ppc0: FIFO with 16/16/15 bytes threshold
ppbus0: IEEE1284 device found /NIBBLE
Probing for PnP devices on ppbus0:
plip0: <PLIP network interface> on ppbus0
lpt0: <Printer> on ppbus0
lpt0: Interrupt-driven port
ppi0: <Parallel I/O> on ppbus0
ad0: 8063MB <IBM-DHEA-38451> [16383/16/63] at ata0-master using UDMA33
ad2: 8063MB <IBM-DHEA-38451> [16383/16/63] at ata1-master using UDMA33
acd0: CDROM <DELTA OTC-H101/ST3 F/W by OIPD> at ata0-slave using PIO4
Mounting root from ufs:/dev/ad0s1a
swapon: adding /dev/ad0s1b as swap device
Automatic boot in progress...
/dev/ad0s1a: FILESYSTEM CLEAN; SKIPPING CHECKS
/dev/ad0s1a: clean, 48752 free (552 frags, 6025 blocks, 0.9% fragmentation)
/dev/ad0s1f: FILESYSTEM CLEAN; SKIPPING CHECKS
/dev/ad0s1f: clean, 128997 free (21 frags, 16122 blocks, 0.0% fragmentation)
/dev/ad0s1g: FILESYSTEM CLEAN; SKIPPING CHECKS
/dev/ad0s1g: clean, 3036299 free (43175 frags, 374073 blocks, 1.3% fragmentation)
/dev/ad0s1e: filesystem CLEAN; SKIPPING CHECKS
/dev/ad0s1e: clean, 128193 free (17 frags, 16022 blocks, 0.0% fragmentation)
Doing initial network setup: hostname.
ed0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
inet6 fe80::5054::5ff::fede:731b%ed0 prefixlen 64 tentative scopeid 0x1
ether 52:54:05:de:73:1b
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x8
inet6 ::1 prefixlen 128
inet 127.0.0.1 netmask 0xff000000
Additional routing options: IP gateway=YES TCP keepalive=YES
routing daemons:.
additional daemons: syslogd.
Doing additional network setup:.
Starting final network daemons: creating ssh RSA host key
Generating public/private rsa1 key pair.
Your identification has been saved in /etc/ssh/ssh_host_key.
Your public key has been saved in /etc/ssh/ssh_host_key.pub.
The key fingerprint is:
cd:76:89:16:69:0e:d0:6e:f8:66:d0:07:26:3c:7e:2d root@k6-2.example.com
creating ssh DSA host key
Generating public/private dsa key pair.
Your identification has been saved in /etc/ssh/ssh_host_dsa_key.
Your public key has been saved in /etc/ssh/ssh_host_dsa_key.pub.
The key fingerprint is:
f9:a1:a9:47:c4:ad:f9:8d:52:b8:b8:ff:8c:ad:2d:e6 root@k6-2.example.com.
setting ELF ldconfig path: /usr/lib /usr/lib/compat /usr/X11R6/lib
/usr/local/lib
a.out ldconfig path: /usr/lib/aout /usr/lib/compat/aout /usr/X11R6/lib/aout
starting standard daemons: inetd cron sshd usbd sendmail.
Initial rc.i386 initialization:.
rc.i386 configuring syscons: blank_time screensaver moused.
Additional ABI support: linux.
Local package initialization:.
Additional TCP options:.
FreeBSD/i386 (k6-2.example.com) (ttyv0)
login: rpratt
Password:
Generating the RSA and DSA keys may take some time on slower machines. This happens only on the initial boot-up of a new installation. Subsequent boots will be faster.
If the X server has been configured and a Default Desktop chosen, it can be started by typing startx at the command line.
2.10.16.2 FreeBSD/alpha Bootup
Once the install procedure has finished, you will be able to start FreeBSD by typing something like this to the SRM prompt:
>>>BOOT DKC0
This instructs the firmware to boot the specified disk. To make FreeBSD boot automatically in the future, use these commands:
>>> SET BOOT_OSFLAGS A
>>> SET BOOT_FILE ''
>>> SET BOOTDEF_DEV DKC0
>>> SET AUTO_ACTION BOOT
The boot messages will be similar (but not identical) to those produced by FreeBSD booting on the i386.
2.10.17 FreeBSD Shutdown
It is important to properly shutdown the operating system. Do not just turn off power. First, become a superuser by typing su at the command line and entering the root password. This will work only if the user is a member of the wheel group. Otherwise, login as root and use shutdown -h now.
The operating system has halted.
Please press any key to reboot.
It is safe to turn off the power after the shutdown command has been issued and the message “Please press any key to reboot” appears. If any key is pressed instead of turning off the power switch, the system will reboot.
You could also use the Ctrl+Alt+Del key combination to reboot the system, however this is not recommended during normal operation.
2.11 Troubleshooting
The following section covers basic installation troubleshooting, such as common problems people have reported. There are also a few questions and answers for people wishing to dual-boot FreeBSD with MS-DOS or Windows.
2.11.1 What to Do If Something Goes Wrong
Due to various limitations of the PC architecture, it is impossible for probing to be 100% reliable, however, there are a few things you can do if it fails.
Check the Hardware Notes document for your version of FreeBSD to make sure your hardware is supported.
If your hardware is supported and you still experience lock-ups or other problems, you will need to build a custom kernel. This will allow you to add in support for devices which are not present in the GENERIC kernel. The kernel on the boot disks is configured assuming that most hardware devices are in their factory default configuration in terms of IRQs, IO addresses, and DMA channels. If your hardware has been reconfigured, you will most likely need to edit the kernel configuration and recompile to tell FreeBSD where to find things.
It is also possible that a probe for a device not present will cause a later probe for another device that is present to fail. In that case, the probes for the conflicting driver(s) should be disabled.
Note: Some installation problems can be avoided or alleviated by updating the firmware on various hardware components, most notably the motherboard. The motherboard firmware may also be referred to as BIOS and most of the motherboard or computer manufactures have a website where the upgrades and upgrade information may be located.
Most manufacturers strongly advise against upgrading the motherboard BIOS unless there is a good reason for doing so, which could possibly be a critical update of sorts. The upgrade process can go wrong, causing permanent damage to the BIOS chip.
2.11.2 Using MS-DOS® and Windows® File Systems
At this time, FreeBSD does not support file systems compressed with the Double Space™ application. Therefore the file system will need to be uncompressed before FreeBSD can access the data. This can be done by running the Compression Agent located in the Start> Programs > System Tools menu.
FreeBSD can support MS-DOS file systems (sometimes called FAT file systems). The mount_msdosfs(8) command grafts such file systems onto the existing directory hierarchy, allowing the file system's contents to be accessed. mount_msdosfs(8) is not usually invoked directly; instead, it is called by the system through a line in /etc/fstab or by a call to the mount(8) utility with the appropriate parameters.
A typical line in /etc/fstab is:
/dev/ad0sN /dos msdosfs rw 0 0
Note: The /dos directory must already exist for this to work. For details about the format of /etc/fstab, see fstab(5).
A typicall call to mount(8) for a MS-DOS file system looks like:
# mount -t msdosfs /dev/ad0s1 /mnt
In this example, the MS-DOS file system is located on the first partition of the primary hard disk. Your situation may be different, check the output from the dmesg, and mount commands. They should produce enough information to give an idea of the partition layout.
Note: FreeBSD may number disk slices (that is, MS-DOS partitions) differently than other operating systems. In particular, extended MS-DOS partitions are usually given higher slice numbers than primary MS-DOS partitions. The fdisk(8) utility can help determine which slices belong to FreeBSD and which belong to other operating systems.
NTFS partitions can also be mounted in a similar manner using the mount_ntfs(8) command.
2.11.3 Troubleshooting Questions and Answers
- 2.11.3.1. My system hangs while probing hardware during boot, or it behaves strangely during install, or the floppy drive is not probed.
- 2.11.3.2. I go to boot from the hard disk for the first time after installing FreeBSD, the kernel loads and probes my hardware, but stops with messages like:
- 2.11.3.3. I go to boot from the hard disk for the first time after installing FreeBSD, but the Boot Manager prompt just prints F? at the boot menu each time but the boot will not go any further.
- 2.11.3.4. The system finds my ed(4) network card, but I keep getting device timeout errors.
2.11.3.1. My system hangs while probing hardware during boot, or it behaves strangely during install, or the floppy drive is not probed.
FreeBSD 5.0 and above makes extensive use of the system ACPI service on the i386, amd64 and ia64 platforms to aid in system configuration if it is detected during boot. Unfortunately, some bugs still exist in both the ACPI driver and within system motherboards and BIOS. The use of ACPI can be disabled by setting the hint.acpi.0.disabled hint in the third stage boot loader:
set hint.acpi.0.disabled="1"
This is reset each time the system is booted, so it is necessary to add hint.acpi.0.disabled="1" to the file /boot/loader.conf. More information about the boot loader can be found in Section 12.1.
2.11.3.2. I go to boot from the hard disk for the first time after installing FreeBSD, the kernel loads and probes my hardware, but stops with messages like:
changing root device to ad1s1a panic: cannot mount root
What is wrong? What can I do?
What is this bios_drive:interface(unit,partition)kernel_name thing that is displayed with the boot help?
There is a longstanding problem in the case where the boot disk is not the first disk in the system. The BIOS uses a different numbering scheme to FreeBSD, and working out which numbers correspond to which is difficult to get right.
In the case where the boot disk is not the first disk in the system, FreeBSD can need some help finding it. There are two common situations here, and in both of these cases, you need to tell FreeBSD where the root filesystem is. You do this by specifying the BIOS disk number, the disk type and the FreeBSD disk number for that type.
The first situation is where you have two IDE disks, each configured as the master on their respective IDE busses, and wish to boot FreeBSD from the second disk. The BIOS sees these as disk 0 and disk 1, while FreeBSD sees them as ad0 and ad2.
FreeBSD is on BIOS disk 1, of type ad and the FreeBSD disk number is 2, so you would say:
1:ad(2,a)kernel
Note that if you have a slave on the primary bus, the above is not necessary (and is effectively wrong).
The second situation involves booting from a SCSI disk when you have one or more IDE disks in the system. In this case, the FreeBSD disk number is lower than the BIOS disk number. If you have two IDE disks as well as the SCSI disk, the SCSI disk is BIOS disk 2, type da and FreeBSD disk number 0, so you would say:
2:da(0,a)kernel
To tell FreeBSD that you want to boot from BIOS disk 2, which is the first SCSI disk in the system. If you only had one IDE disk, you would use 1: instead.
Once you have determined the correct values to use, you can put the command exactly as you would have typed it in the /boot.config file using a standard text editor. Unless instructed otherwise, FreeBSD will use the contents of this file as the default response to the boot: prompt.
2.11.3.3. I go to boot from the hard disk for the first time after installing FreeBSD, but the Boot Manager prompt just prints F? at the boot menu each time but the boot will not go any further.
The hard disk geometry was set incorrectly in the partition editor when you installed FreeBSD. Go back into the partition editor and specify the actual geometry of your hard disk. You must reinstall FreeBSD again from the beginning with the correct geometry.
If you are failing entirely in figuring out the correct geometry for your machine, here is a tip: Install a small DOS partition at the beginning of the disk and install FreeBSD after that. The install program will see the DOS partition and try to infer the correct geometry from it, which usually works.
The following tip is no longer recommended, but is left here for reference:
If you are setting up a truly dedicated FreeBSD server or workstation where you do not care for (future) compatibility with DOS, Linux or another operating system, you also have got the option to use the entire disk (A in the partition editor), selecting the non-standard option where FreeBSD occupies the entire disk from the very first to the very last sector. This will leave all geometry considerations aside, but is somewhat limiting unless you're never going to run anything other than FreeBSD on a disk.
Your card is probably on a different IRQ from what is specified in the /boot/device.hints file. The ed(4) driver does not use the “soft” configuration by default (values entered using EZSETUP in DOS), but it will use the software configuration if you specify -1 in the hints for the interface.
Either move the jumper on the card to a hard configuration setting (altering the kernel settings if necessary), or specify the IRQ as -1 by setting the hint hint.ed.0.irq="-1" This will tell the kernel to use the soft configuration.
Another possibility is that your card is at IRQ 9, which is shared by IRQ 2 and frequently a cause of problems (especially when you have a VGA card using IRQ 2!). You should not use IRQ 2 or 9 if at all possible.
2.12 Advanced Installation Guide
Contributed by Valentino Vaschetto.This section describes how to install FreeBSD in exceptional cases.
2.12.1 Installing FreeBSD on a System without a Monitor or Keyboard
This type of installation is called a “headless install”, because the machine that you are trying to install FreeBSD on either does not have a monitor attached to it, or does not even have a VGA output. How is this possible you ask? Using a serial console. A serial console is basically using another machine to act as the main display and keyboard for a system. To do this, just follow the steps to create installation floppies, explained in Section 2.3.7.
To modify these floppies to boot into a serial console, follow these steps:
-
Enabling the Boot Floppies to Boot into a Serial Console
If you were to boot into the floppies that you just made, FreeBSD would boot into its normal install mode. We want FreeBSD to boot into a serial console for our install. To do this, you have to mount the boot.flp floppy onto your FreeBSD system using the mount(8) command.
# mount /dev/fd0 /mntNow that you have the floppy mounted, you must change into the /mnt directory:
# cd /mntHere is where you must set the floppy to boot into a serial console. You have to make a file called boot.config containing /boot/loader -h. All this does is pass a flag to the bootloader to boot into a serial console.
# echo "/boot/loader -h" > boot.configNow that you have your floppy configured correctly, you must unmount the floppy using the umount(8) command:
# cd / # umount /mntNow you can remove the floppy from the floppy drive.
-
Connecting Your Null-modem Cable
You now need to connect a null-modem cable between the two machines. Just connect the cable to the serial ports of the 2 machines. A normal serial cable will not work here, you need a null-modem cable because it has some of the wires inside crossed over.
-
Booting Up for the Install
It is now time to go ahead and start the install. Put the boot.flp floppy in the floppy drive of the machine you are doing the headless install on, and power on the machine.
-
Connecting to Your Headless Machine
Now you have to connect to that machine with cu(1):
# cu -l /dev/cuad0On FreeBSD 5.X, use /dev/cuaa0 instead of /dev/cuad0.
That's it! You should now be able to control the headless machine through your cu session. It will ask you to put in the kern1.flp, and then it will come up with a selection of what kind of terminal to use. Select the FreeBSD color console and proceed with your install!
2.13 Preparing Your Own Installation Media
Note: To prevent repetition, “FreeBSD disc” in this context means a FreeBSD CDROM or DVD that you have purchased or produced yourself.
There may be some situations in which you need to create your own FreeBSD installation media and/or source. This might be physical media, such as a tape, or a source that sysinstall can use to retrieve the files, such as a local FTP site, or an MS-DOS partition.
For example:
-
You have many machines connected to your local network, and one FreeBSD disc. You want to create a local FTP site using the contents of the FreeBSD disc, and then have your machines use this local FTP site instead of needing to connect to the Internet.
-
You have a FreeBSD disc, and FreeBSD does not recognize your CD/DVD drive, but MS-DOS/Windows does. You want to copy the FreeBSD installation files to a DOS partition on the same computer, and then install FreeBSD using those files.
-
The computer you want to install on does not have a CD/DVD drive or a network card, but you can connect a “Laplink-style” serial or parallel cable to a computer that does.
-
You want to create a tape that can be used to install FreeBSD.
2.13.1 Creating an Installation CDROM
As part of each release, the FreeBSD project makes available at least two CDROM images (“ISO images”) per supported architecture. These images can be written (“burned”) to CDs if you have a CD writer, and then used to install FreeBSD. If you have a CD writer, and bandwidth is cheap, then this is the easiest way to install FreeBSD.
-
Download the Correct ISO Images
The ISO images for each release can be downloaded from ftp://ftp.FreeBSD.org/pub/FreeBSD/ISO-IMAGES-arch/version or the closest mirror. Substitute arch and version as appropriate.
That directory will normally contain the following images:
Table 2-4. FreeBSD 5.X and 6.X ISO Image Names and Meanings
Filename Contains version-RELEASE-arch-bootonly.iso Everything you need to boot into a FreeBSD kernel and start the installation interface. The installable files have to be pulled over FTP or some other supported source. version-RELEASE-arch-disc1.iso Everything you need to install FreeBSD and a “live filesystem”, which is used in conjunction with the “Repair” facility in sysinstall. version-RELEASE-arch-disc2.iso FreeBSD documentation (prior to FreeBSD 6.2) and as many third-party packages as would fit on the disc. version-RELEASE-arch-docs.iso FreeBSD documentation (for FreeBSD 6.2 and later). You must download one of either the bootonly ISO image (if available), or the image of disc one. Do not download both of them, since the disc one image contains everything that the bootonly ISO image contains.
Use the bootonly ISO if Internet access is cheap for you. It will let you install FreeBSD, and you can then install third-party packages by downloading them using the ports/packages system (see Chapter 4) as necessary.
Use the image of disc one if you want to install a FreeBSD release and want a reasonable selection of third-party packages on the disc as well.
The additional disc images are useful, but not essential, especially if you have high-speed access to the Internet.
-
Write the CDs
You must then write the CD images to disc. If you will be doing this on another FreeBSD system then see Section 18.6 for more information (in particular, Section 18.6.3 and Section 18.6.4).
If you will be doing this on another platform then you will need to use whatever utilities exist to control your CD writer on that platform. The images provided are in the standard ISO format, which many CD writing applications support.
Note: If you are interested in building a customized release of FreeBSD, please see the Release Engineering Article.
2.13.2 Creating a Local FTP Site with a FreeBSD Disc
FreeBSD discs are laid out in the same way as the FTP site. This makes it very easy for you to create a local FTP site that can be used by other machines on your network when installing FreeBSD.
-
On the FreeBSD computer that will host the FTP site, ensure that the CDROM is in the drive, and mounted on /cdrom.
# mount /cdrom -
Create an account for anonymous FTP in /etc/passwd. Do this by editing /etc/passwd using vipw(8) and adding this line:
ftp:*:99:99::0:0:FTP:/cdrom:/nonexistent -
Ensure that the FTP service is enabled in /etc/inetd.conf.
Anyone with network connectivity to your machine can now chose a media type of FTP and type in ftp://your machine after picking “Other” in the FTP sites menu during the install.
Note: If the boot media (floppy disks, usually) for your FTP clients is not precisely the same version as that provided by the local FTP site, then sysinstall will not let you complete the installation. If the versions are not similar and you want to override this, you must go into the Options menu and change distribution name to any.
Warning: This approach is OK for a machine that is on your local network, and that is protected by your firewall. Offering up FTP services to other machines over the Internet (and not your local network) exposes your computer to the attention of crackers and other undesirables. We strongly recommend that you follow good security practices if you do this.
2.13.3 Creating Installation Floppies
If you must install from floppy disk (which we suggest you do not do), either due to unsupported hardware or simply because you insist on doing things the hard way, you must first prepare some floppies for the installation.
At a minimum, you will need as many 1.44 MB floppies as it takes to hold all the files in the base (base distribution) directory. If you are preparing the floppies from DOS, then they must be formatted using the MS-DOS FORMAT command. If you are using Windows, use Explorer to format the disks (right-click on the A: drive, and select “Format”).
Do not trust factory pre-formatted floppies. Format them again yourself, just to be sure. Many problems reported by our users in the past have resulted from the use of improperly formatted media, which is why we are making a point of it now.
If you are creating the floppies on another FreeBSD machine, a format is still not a bad idea, though you do not need to put a DOS filesystem on each floppy. You can use the bsdlabel and newfs commands to put a UFS filesystem on them instead, as the following sequence of commands (for a 3.5" 1.44 MB floppy) illustrates:
# fdformat -f 1440 fd0.1440
# bsdlabel -w fd0.1440 floppy3
# newfs -t 2 -u 18 -l 1 -i 65536 /dev/fd0
Then you can mount and write to them like any other filesystem.
After you have formatted the floppies, you will need to copy the files to them. The distribution files are split into chunks conveniently sized so that five of them will fit on a conventional 1.44 MB floppy. Go through all your floppies, packing as many files as will fit on each one, until you have all of the distributions you want packed up in this fashion. Each distribution should go into a subdirectory on the floppy, e.g.: a:\base\base.aa, a:\base\base.ab, and so on.
Important: The base.inf file also needs to go on the first floppy of the base set since it is read by the installation program in order to figure out how many additional pieces to look for when fetching and concatenating the distribution.
Once you come to the Media screen during the install process, select Floppy and you will be prompted for the rest.
2.13.4 Installing from an MS-DOS Partition
To prepare for an installation from an MS-DOS partition, copy the files from the distribution into a directory called freebsd in the root directory of the partition. For example, c:\freebsd. The directory structure of the CDROM or FTP site must be partially reproduced within this directory, so we suggest using the DOS xcopy command if you are copying it from a CD. For example, to prepare for a minimal installation of FreeBSD:
C:\> md c:\freebsd
C:\> xcopy e:\bin c:\freebsd\bin\ /s
C:\> xcopy e:\manpages c:\freebsd\manpages\ /s
Assuming that C: is where you have free space and E: is where your CDROM is mounted.
If you do not have a CDROM drive, you can download the distribution from ftp.FreeBSD.org. Each distribution is in its own directory; for example, the base distribution can be found in the 6.2/base/ directory.
For as many distributions you wish to install from an MS-DOS partition (and you have the free space for), install each one under c:\freebsd -- the BIN distribution is the only one required for a minimum installation.
2.13.5 Creating an Installation Tape
Installing from tape is probably the easiest method, short of an online FTP install or CDROM install. The installation program expects the files to be simply tarred onto the tape. After getting all of the distribution files you are interested in, simply tar them onto the tape:
# cd /freebsd/distdir
# tar cvf /dev/rwt0 dist1 ... dist2
When you perform the installation, you should make sure that you leave enough room in some temporary directory (which you will be allowed to choose) to accommodate the full contents of the tape you have created. Due to the non-random access nature of tapes, this method of installation requires quite a bit of temporary storage.
Note: When starting the installation, the tape must be in the drive before booting from the boot floppy. The installation probe may otherwise fail to find it.
2.13.6 Before Installing over a Network
There are three types of network installations available. Ethernet (a standard Ethernet controller), Serial port (SLIP or PPP), or Parallel port (PLIP (laplink cable)).
For the fastest possible network installation, an Ethernet adapter is always a good choice! FreeBSD supports most common PC Ethernet cards; a table of supported cards (and their required settings) is provided in the Hardware Notes for each release of FreeBSD. If you are using one of the supported PCMCIA Ethernet cards, also be sure that it is plugged in before the laptop is powered on! FreeBSD does not, unfortunately, currently support hot insertion of PCMCIA cards during installation.
You will also need to know your IP address on the network, the netmask value for your address class, and the name of your machine. If you are installing over a PPP connection and do not have a static IP, fear not, the IP address can be dynamically assigned by your ISP. Your system administrator can tell you which values to use for your particular network setup. If you will be referring to other hosts by name rather than IP address, you will also need a name server and possibly the address of a gateway (if you are using PPP, it is your provider's IP address) to use in talking to it. If you want to install by FTP via a HTTP proxy, you will also need the proxy's address. If you do not know the answers to all or most of these questions, then you should really probably talk to your system administrator or ISP before trying this type of installation.
The SLIP support is rather primitive, and limited primarily to hard-wired links, such as a serial cable running between a laptop computer and another computer. The link should be hard-wired as the SLIP installation does not currently offer a dialing capability; that facility is provided with the PPP utility, which should be used in preference to SLIP whenever possible.
If you are using a modem, then PPP is almost certainly your only choice. Make sure that you have your service provider's information handy as you will need to know it fairly early in the installation process.
If you use PAP or CHAP to connect your ISP (in other words, if you can connect to the ISP in Windows without using a script), then all you will need to do is type in dial at the ppp prompt. Otherwise, you will need to know how to dial your ISP using the “AT commands” specific to your modem, as the PPP dialer provides only a very simple terminal emulator. Please refer to the user-ppp handbook and FAQ entries for further information. If you have problems, logging can be directed to the screen using the command set log local ....
If a hard-wired connection to another FreeBSD (2.0-R or later) machine is available, you might also consider installing over a “laplink” parallel port cable. The data rate over the parallel port is much higher than what is typically possible over a serial line (up to 50 kbytes/sec), thus resulting in a quicker installation.
2.13.6.1 Before Installing via NFS
The NFS installation is fairly straight-forward. Simply copy the FreeBSD distribution files you want onto an NFS server and then point the NFS media selection at it.
If this server supports only “privileged port” (as is generally the default for Sun workstations), you will need to set the option NFS Secure in the Options menu before installation can proceed.
If you have a poor quality Ethernet card which suffers from very slow transfer rates, you may also wish to toggle the NFS Slow flag.
In order for NFS installation to work, the server must support subdir mounts, for example, if your FreeBSD 6.2 distribution directory lives on: ziggy:/usr/archive/stuff/FreeBSD, then ziggy will have to allow the direct mounting of /usr/archive/stuff/FreeBSD, not just /usr or /usr/archive/stuff.
In FreeBSD's /etc/exports file, this is controlled by the
-alldirs options. Other NFS servers may have different
conventions. If you are getting “permission
denied” messages from the server, then it is likely that you do not have this
enabled properly.
Chapter 3 UNIX Basics
Rewritten by Chris Shumway.3.1 Synopsis
The following chapter will cover the basic commands and functionality of the FreeBSD operating system. Much of this material is relevant for any UNIX-like operating system. Feel free to skim over this chapter if you are familiar with the material. If you are new to FreeBSD, then you will definitely want to read through this chapter carefully.
After reading this chapter, you will know:
-
How to use the “virtual consoles” of FreeBSD.
-
How UNIX file permissions work along with understanding file flags in FreeBSD.
-
The default FreeBSD file system layout.
-
The FreeBSD disk organization.
-
How to mount and unmount file systems.
-
What processes, daemons, and signals are.
-
What a shell is, and how to change your default login environment.
-
How to use basic text editors.
-
What devices and device nodes are.
-
What binary format is used under FreeBSD.
-
How to read manual pages for more information.
3.2 Virtual Consoles and Terminals
FreeBSD can be used in various ways. One of them is typing commands to a text terminal. A lot of the flexibility and power of a UNIX operating system is readily available at your hands when using FreeBSD this way. This section describes what “terminals” and “consoles” are, and how you can use them in FreeBSD.
3.2.1 The Console
If you have not configured FreeBSD to automatically start a graphical environment during startup, the system will present you with a login prompt after it boots, right after the startup scripts finish running. You will see something similar to:
Additional ABI support:.
Local package initialization:.
Additional TCP options:.
Fri Sep 20 13:01:06 EEST 2002
FreeBSD/i386 (pc3.example.org) (ttyv0)
login:
The messages might be a bit different on your system, but you will see something similar. The last two lines are what we are interested in right now. The second last line reads:
FreeBSD/i386 (pc3.example.org) (ttyv0)
This line contains some bits of information about the system you have just booted. You are looking at a “FreeBSD” console, running on an Intel or compatible processor of the x86 architecture[1]. The name of this machine (every UNIX machine has a name) is pc3.example.org, and you are now looking at its system console--the ttyv0 terminal.
Finally, the last line is always:
login:
This is the part where you are supposed to type in your “username” to log into FreeBSD. The next section describes how you can do this.
3.2.2 Logging into FreeBSD
FreeBSD is a multiuser, multiprocessing system. This is the formal description that is usually given to a system that can be used by many different people, who simultaneously run a lot of programs on a single machine.
Every multiuser system needs some way to distinguish one “user” from the rest. In FreeBSD (and all the UNIX-like operating systems), this is accomplished by requiring that every user must “log into” the system before being able to run programs. Every user has a unique name (the “username”) and a personal, secret key (the “password”). FreeBSD will ask for these two before allowing a user to run any programs.
Right after FreeBSD boots and finishes running its startup scripts[2], it will present you with a prompt and ask for a valid username:
login:
For the sake of this example, let us assume that your username is john. Type john at this prompt and press Enter. You should then be presented with a prompt to enter a “password”:
login: john
Password:
Type in john's password now, and press Enter. The password is not echoed! You need not worry about this right now. Suffice it to say that it is done for security reasons.
If you have typed your password correctly, you should by now be logged into FreeBSD and ready to try out all the available commands.
You should see the MOTD or message of the day followed by a command prompt (a #, $, or % character). This indicates you have successfully logged into FreeBSD.
3.2.3 Multiple Consoles
Running UNIX commands in one console is fine, but FreeBSD can run many programs at once. Having one console where commands can be typed would be a bit of a waste when an operating system like FreeBSD can run dozens of programs at the same time. This is where “virtual consoles” can be very helpful.
FreeBSD can be configured to present you with many different virtual consoles. You can switch from one of them to any other virtual console by pressing a couple of keys on your keyboard. Each console has its own different output channel, and FreeBSD takes care of properly redirecting keyboard input and monitor output as you switch from one virtual console to the next.
Special key combinations have been reserved by FreeBSD for switching consoles[3]. You can use Alt-F1, Alt-F2, through Alt-F8 to switch to a different virtual console in FreeBSD.
As you are switching from one console to the next, FreeBSD takes care of saving and restoring the screen output. The result is an “illusion” of having multiple “virtual” screens and keyboards that you can use to type commands for FreeBSD to run. The programs that you launch on one virtual console do not stop running when that console is not visible. They continue running when you have switched to a different virtual console.
3.2.4 The /etc/ttys File
The default configuration of FreeBSD will start up with eight virtual consoles. This is not a hardwired setting though, and you can easily customize your installation to boot with more or fewer virtual consoles. The number and settings of the virtual consoles are configured in the /etc/ttys file.
You can use the /etc/ttys file to configure the virtual consoles of FreeBSD. Each uncommented line in this file (lines that do not start with a # character) contains settings for a single terminal or virtual console. The default version of this file that ships with FreeBSD configures nine virtual consoles, and enables eight of them. They are the lines that start with ttyv:
# name getty type status comments
#
ttyv0 "/usr/libexec/getty Pc" cons25 on secure
# Virtual terminals
ttyv1 "/usr/libexec/getty Pc" cons25 on secure
ttyv2 "/usr/libexec/getty Pc" cons25 on secure
ttyv3 "/usr/libexec/getty Pc" cons25 on secure
ttyv4 "/usr/libexec/getty Pc" cons25 on secure
ttyv5 "/usr/libexec/getty Pc" cons25 on secure
ttyv6 "/usr/libexec/getty Pc" cons25 on secure
ttyv7 "/usr/libexec/getty Pc" cons25 on secure
ttyv8 "/usr/X11R6/bin/xdm -nodaemon" xterm off secure
For a detailed description of every column in this file and all the options you can use to set things up for the virtual consoles, consult the ttys(5) manual page.
3.2.5 Single User Mode Console
A detailed description of what “single user mode” is can be found in Section 12.6.2. It is worth noting that there is only one console when you are running FreeBSD in single user mode. There are no virtual consoles available. The settings of the single user mode console can also be found in the /etc/ttys file. Look for the line that starts with console:
# name getty type status comments
#
# If console is marked "insecure", then init will ask for the root password
# when going to single-user mode.
console none unknown off secure
Note: As the comments above the console line indicate, you can edit this line and change secure to insecure. If you do that, when FreeBSD boots into single user mode, it will still ask for the root password.
Be careful when changing this to insecure. If you ever forget the root password, booting into single user mode is a bit involved. It is still possible, but it might be a bit hard for someone who is not very comfortable with the FreeBSD booting process and the programs involved.
3.2.6 Changing Console Video Modes
The FreeBSD console default video mode may be adjusted to 1024x768, 1280x1024, or any other size supported by your graphics chip and monitor. To use a different video mode, you first must recompile your kernel and include two additional options:
options VESA
options SC_PIXEL_MODE
Once the kernel has been recompiled with these two options, you can then determine what video modes are supported by your hardware by using the vidcontrol(1) utility. To get a list of supported video modes issue the following:
# vidcontrol -i mode
The output of this command is a list of video modes that are supported by your hardware. You can then choose to use a new video mode by passing it to vidcontrol(1) in a root console:
# vidcontrol MODE_279
If the new video mode is acceptable, it can be permanently set on boot by setting it in the /etc/rc.conf file:
allscreens_flags="MODE_279"
3.3 Permissions
FreeBSD, being a direct descendant of BSD UNIX, is based on several key UNIX concepts. The first and most pronounced is that FreeBSD is a multi-user operating system. The system can handle several users all working simultaneously on completely unrelated tasks. The system is responsible for properly sharing and managing requests for hardware devices, peripherals, memory, and CPU time fairly to each user.
Because the system is capable of supporting multiple users, everything the system manages has a set of permissions governing who can read, write, and execute the resource. These permissions are stored as three octets broken into three pieces, one for the owner of the file, one for the group that the file belongs to, and one for everyone else. This numerical representation works like this:
| Value | Permission | Directory Listing |
|---|---|---|
| 0 | No read, no write, no execute | --- |
| 1 | No read, no write, execute | --x |
| 2 | No read, write, no execute | -w- |
| 3 | No read, write, execute | -wx |
| 4 | Read, no write, no execute | r-- |
| 5 | Read, no write, execute | r-x |
| 6 | Read, write, no execute | rw- |
| 7 | Read, write, execute | rwx |
You can use the -l command line argument to ls(1) to view a long
directory listing that includes a column with information about a file's permissions for
the owner, group, and everyone else. For example, a ls -l in an
arbitrary directory may show:
% ls -l
total 530
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 myfile
-rw-r--r-- 1 root wheel 512 Sep 5 12:31 otherfile
-rw-r--r-- 1 root wheel 7680 Sep 5 12:31 email.txt
...
Here is how the first column of ls -l is broken up:
-rw-r--r--
The first (leftmost) character tells if this file is a regular file, a directory, a special character device, a socket, or any other special pseudo-file device. In this case, the - indicates a regular file. The next three characters, rw- in this example, give the permissions for the owner of the file. The next three characters, r--, give the permissions for the group that the file belongs to. The final three characters, r--, give the permissions for the rest of the world. A dash means that the permission is turned off. In the case of this file, the permissions are set so the owner can read and write to the file, the group can read the file, and the rest of the world can only read the file. According to the table above, the permissions for this file would be 644, where each digit represents the three parts of the file's permission.
This is all well and good, but how does the system control permissions on devices? FreeBSD actually treats most hardware devices as a file that programs can open, read, and write data to just like any other file. These special device files are stored on the /dev directory.
Directories are also treated as files. They have read, write, and execute permissions. The executable bit for a directory has a slightly different meaning than that of files. When a directory is marked executable, it means it can be traversed into, that is, it is possible to “cd” (change directory) into it. This also means that within the directory it is possible to access files whose names are known (subject, of course, to the permissions on the files themselves).
In particular, in order to perform a directory listing, read permission must be set on the directory, whilst to delete a file that one knows the name of, it is necessary to have write and execute permissions to the directory containing the file.
There are more permission bits, but they are primarily used in special circumstances such as setuid binaries and sticky directories. If you want more information on file permissions and how to set them, be sure to look at the chmod(1) manual page.
3.3.1 Symbolic Permissions
Contributed by Tom Rhodes.Symbolic permissions, sometimes referred to as symbolic expressions, use characters in place of octal values to assign permissions to files or directories. Symbolic expressions use the syntax of (who) (action) (permissions), where the following values are available:
| Option | Letter | Represents |
|---|---|---|
| (who) | u | User |
| (who) | g | Group owner |
| (who) | o | Other |
| (who) | a | All (“world”) |
| (action) | + | Adding permissions |
| (action) | - | Removing permissions |
| (action) | = | Explicitly set permissions |
| (permissions) | r | Read |
| (permissions) | w | Write |
| (permissions) | x | Execute |
| (permissions) | t | Sticky bit |
| (permissions) | s | Set UID or GID |
These values are used with the chmod(1) command just like before, but with letters. For an example, you could use the following command to block other users from accessing FILE:
% chmod go= FILE
A comma separated list can be provided when more than one set of changes to a file must be made. For example the following command will remove the group and “world” write permission on FILE, then it adds the execute permissions for everyone:
% chmod go-w,a+x FILE
3.3.2 FreeBSD File Flags
Contributed by Tom Rhodes.In addition to file permissions discussed previously, FreeBSD supports the use of “file flags.” These flags add an additional level of security and control over files, but not directories.
These file flags add an additional level of control over files, helping to ensure that in some cases not even the root can remove or alter files.
File flags are altered by using the chflags(1) utility, using a simple interface. For example, to enable the system undeletable flag on the file file1, issue the following command:
# chflags sunlink file1
And to disable the system undeletable flag, simply issue the previous command with
“no” in front of the sunlink. Observe:
# chflags nosunlink file1
To view the flags of this file, use the ls(1) command with the
-lo flags:
# ls -lo file1
The output should look like the following:
-rw-r--r-- 1 trhodes trhodes sunlnk 0 Mar 1 05:54 file1
Several flags may only added or removed to files by the root user. In other cases, the file owner may set these flags. It is recommended that administrators read over the chflags(1) and chflags(2) manual pages for more information.
3.4 Directory Structure
The FreeBSD directory hierarchy is fundamental to obtaining an overall understanding of the system. The most important concept to grasp is that of the root directory, “/”. This directory is the first one mounted at boot time and it contains the base system necessary to prepare the operating system for multi-user operation. The root directory also contains mount points for other file systems that are mounted during the transition to multi-user operation.
A mount point is a directory where additional file systems can be grafted onto a
parent file system (usually the root file system). This is further described in Section 3.5. Standard mount points include /usr, /var, /tmp, /mnt, and /cdrom. These directories are usually referenced to entries in the
file /etc/fstab. /etc/fstab is a
table of various file systems and mount points for reference by the system. Most of the
file systems in /etc/fstab are mounted automatically at boot
time from the script rc(8) unless they
contain the noauto option. Details can be found in Section 3.6.1.
A complete description of the file system hierarchy is available in hier(7). For now, a brief overview of the most common directories will suffice.
| Directory | Description |
|---|---|
| / | Root directory of the file system. |
| /bin/ | User utilities fundamental to both single-user and multi-user environments. |
| /boot/ | Programs and configuration files used during operating system bootstrap. |
| /boot/defaults/ | Default bootstrapping configuration files; see loader.conf(5). |
| /dev/ | Device nodes; see intro(4). |
| /etc/ | System configuration files and scripts. |
| /etc/defaults/ | Default system configuration files; see rc(8). |
| /etc/mail/ | Configuration files for mail transport agents such as sendmail(8). |
| /etc/namedb/ | named configuration files; see named(8). |
| /etc/periodic/ | Scripts that are run daily, weekly, and monthly, via cron(8); see periodic(8). |
| /etc/ppp/ | ppp configuration files; see ppp(8). |
| /mnt/ | Empty directory commonly used by system administrators as a temporary mount point. |
| /proc/ | Process file system; see procfs(5), mount_procfs(8). |
| /rescue/ | Statically linked programs for emergency recovery; see rescue(8). |
| /root/ | Home directory for the root account. |
| /sbin/ | System programs and administration utilities fundamental to both single-user and multi-user environments. |
| /tmp/ | Temporary files. The contents of /tmp are usually NOT preserved across a system reboot. A memory-based file system is often mounted at /tmp. This can be automated using the tmpmfs-related variables of rc.conf(5) (or with an entry in /etc/fstab; see mdmfs(8)). |
| /usr/ | The majority of user utilities and applications. |
| /usr/bin/ | Common utilities, programming tools, and applications. |
| /usr/include/ | Standard C include files. |
| /usr/lib/ | Archive libraries. |
| /usr/libdata/ | Miscellaneous utility data files. |
| /usr/libexec/ | System daemons & system utilities (executed by other programs). |
| /usr/local/ | Local executables, libraries, etc. Also used as the default destination for the FreeBSD ports framework. Within /usr/local, the general layout sketched out by hier(7) for /usr should be used. Exceptions are the man directory, which is directly under /usr/local rather than under /usr/local/share, and the ports documentation is in share/doc/port. |
| /usr/obj/ | Architecture-specific target tree produced by building the /usr/src tree. |
| /usr/ports | The FreeBSD Ports Collection (optional). |
| /usr/sbin/ | System daemons & system utilities (executed by users). |
| /usr/share/ | Architecture-independent files. |
| /usr/src/ | BSD and/or local source files. |
| /usr/X11R6/ | X11R6 distribution executables, libraries, etc (optional). |
| /var/ | Multi-purpose log, temporary, transient, and spool files. A memory-based file system is sometimes mounted at /var. This can be automated using the varmfs-related variables of rc.conf(5) (or with an entry in /etc/fstab; see mdmfs(8)). |
| /var/log/ | Miscellaneous system log files. |
| /var/mail/ | User mailbox files. |
| /var/spool/ | Miscellaneous printer and mail system spooling directories. |
| /var/tmp/ | Temporary files. The files are usually preserved across a system reboot, unless /var is a memory-based file system. |
| /var/yp | NIS maps. |
3.5 Disk Organization
The smallest unit of organization that FreeBSD uses to find files is the filename. Filenames are case-sensitive, which means that readme.txt and README.TXT are two separate files. FreeBSD does not use the extension (.txt) of a file to determine whether the file is a program, or a document, or some other form of data.
Files are stored in directories. A directory may contain no files, or it may contain many hundreds of files. A directory can also contain other directories, allowing you to build up a hierarchy of directories within one another. This makes it much easier to organize your data.
Files and directories are referenced by giving the file or directory name, followed by a forward slash, /, followed by any other directory names that are necessary. If you have directory foo, which contains directory bar, which contains the file readme.txt, then the full name, or path to the file is foo/bar/readme.txt.
Directories and files are stored in a file system. Each file system contains exactly one directory at the very top level, called the root directory for that file system. This root directory can then contain other directories.
So far this is probably similar to any other operating system you may have used. There are a few differences; for example, MS-DOS uses \ to separate file and directory names, while Mac OS® uses :.
FreeBSD does not use drive letters, or other drive names in the path. You would not write c:/foo/bar/readme.txt on FreeBSD.
Instead, one file system is designated the root file system. The root file system's root directory is referred to as /. Every other file system is then mounted under the root file system. No matter how many disks you have on your FreeBSD system, every directory appears to be part of the same disk.
Suppose you have three file systems, called A, B, and C. Each file system has one root directory, which contains two other directories, called A1, A2 (and likewise B1, B2 and C1, C2).
Call A the root file system. If you used the ls command to view the contents of this directory you would see two subdirectories, A1 and A2. The directory tree looks like this:
A file system must be mounted on to a directory in another file system. So now suppose that you mount file system B on to the directory A1. The root directory of B replaces A1, and the directories in B appear accordingly:
Any files that are in the B1 or B2 directories can be reached with the path /A1/B1 or /A1/B2 as necessary. Any files that were in /A1 have been temporarily hidden. They will reappear if B is unmounted from A.
If B had been mounted on A2 then the diagram would look like this:
and the paths would be /A2/B1 and /A2/B2 respectively.
File systems can be mounted on top of one another. Continuing the last example, the C file system could be mounted on top of the B1 directory in the B file system, leading to this arrangement:
Or C could be mounted directly on to the A file system, under the A1 directory:
If you are familiar with MS-DOS, this is similar, although not identical, to the join command.
This is not normally something you need to concern yourself with. Typically you create file systems when installing FreeBSD and decide where to mount them, and then never change them unless you add a new disk.
It is entirely possible to have one large root file system, and not need to create any others. There are some drawbacks to this approach, and one advantage.
Benefits of Multiple File Systems
-
Different file systems can have different mount options. For example, with careful planning, the root file system can be mounted read-only, making it impossible for you to inadvertently delete or edit a critical file. Separating user-writable file systems, such as /home, from other file systems also allows them to be mounted nosuid; this option prevents the suid/guid bits on executables stored on the file system from taking effect, possibly improving security.
-
FreeBSD automatically optimizes the layout of files on a file system, depending on how the file system is being used. So a file system that contains many small files that are written frequently will have a different optimization to one that contains fewer, larger files. By having one big file system this optimization breaks down.
-
FreeBSD's file systems are very robust should you lose power. However, a power loss at a critical point could still damage the structure of the file system. By splitting your data over multiple file systems it is more likely that the system will still come up, making it easier for you to restore from backup as necessary.
Benefit of a Single File System
-
File systems are a fixed size. If you create a file system when you install FreeBSD and give it a specific size, you may later discover that you need to make the partition bigger. This is not easily accomplished without backing up, recreating the file system with the new size, and then restoring the backed up data.
Important: FreeBSD features the growfs(8) command, which makes it possible to increase the size of file system on the fly, removing this limitation.
File systems are contained in partitions. This does not have the same meaning as the common usage of the term partition (for example, MS-DOS partition), because of FreeBSD's UNIX heritage. Each partition is identified by a letter from a through to h. Each partition can contain only one file system, which means that file systems are often described by either their typical mount point in the file system hierarchy, or the letter of the partition they are contained in.
FreeBSD also uses disk space for swap space. Swap space provides FreeBSD with virtual memory. This allows your computer to behave as though it has much more memory than it actually does. When FreeBSD runs out of memory it moves some of the data that is not currently being used to the swap space, and moves it back in (moving something else out) when it needs it.
Some partitions have certain conventions associated with them.
| Partition | Convention |
|---|---|
| a | Normally contains the root file system |
| b | Normally contains swap space |
| c | Normally the same size as the enclosing slice. This allows utilities that need to work on the entire slice (for example, a bad block scanner) to work on the c partition. You would not normally create a file system on this partition. |
| d | Partition d used to have a special meaning associated with it, although that is now gone and d may work as any normal partition. |
Each partition-that-contains-a-file-system is stored in what FreeBSD calls a slice. Slice is FreeBSD's term for what the common call partitions, and again, this is because of FreeBSD's UNIX background. Slices are numbered, starting at 1, through to 4.
Slice numbers follow the device name, prefixed with an s, starting at 1. So “da0s1” is the first slice on the first SCSI drive. There can only be four physical slices on a disk, but you can have logical slices inside physical slices of the appropriate type. These extended slices are numbered starting at 5, so “ad0s5” is the first extended slice on the first IDE disk. These devices are used by file systems that expect to occupy a slice.
Slices, “dangerously dedicated” physical drives, and other drives contain partitions, which are represented as letters from a to h. This letter is appended to the device name, so “da0a” is the a partition on the first da drive, which is “dangerously dedicated”. “ad1s3e” is the fifth partition in the third slice of the second IDE disk drive.
Finally, each disk on the system is identified. A disk name starts with a code that indicates the type of disk, and then a number, indicating which disk it is. Unlike slices, disk numbering starts at 0. Common codes that you will see are listed in Table 3-1.
When referring to a partition FreeBSD requires that you also name the slice and disk that contains the partition, and when referring to a slice you must also refer to the disk name. Thus, you refer to a partition by listing the disk name, s, the slice number, and then the partition letter. Examples are shown in Example 3-1.
Example 3-2 shows a conceptual model of the disk layout that should help make things clearer.
In order to install FreeBSD you must first configure the disk slices, then create partitions within the slice you will use for FreeBSD, and then create a file system (or swap space) in each partition, and decide where that file system will be mounted.
Table 3-1. Disk Device Codes
| Code | Meaning |
|---|---|
| ad | ATAPI (IDE) disk |
| da | SCSI direct access disk |
| acd | ATAPI (IDE) CDROM |
| cd | SCSI CDROM |
| fd | Floppy disk |
Example 3-2. Conceptual Model of a Disk
This diagram shows FreeBSD's view of the first IDE disk attached to the system. Assume that the disk is 4 GB in size, and contains two 2 GB slices (MS-DOS partitions). The first slice contains a MS-DOS disk, C:, and the second slice contains a FreeBSD installation. This example FreeBSD installation has three data partitions, and a swap partition.
The three partitions will each hold a file system. Partition a will be used for the root file system, e for the /var directory hierarchy, and f for the /usr directory hierarchy.
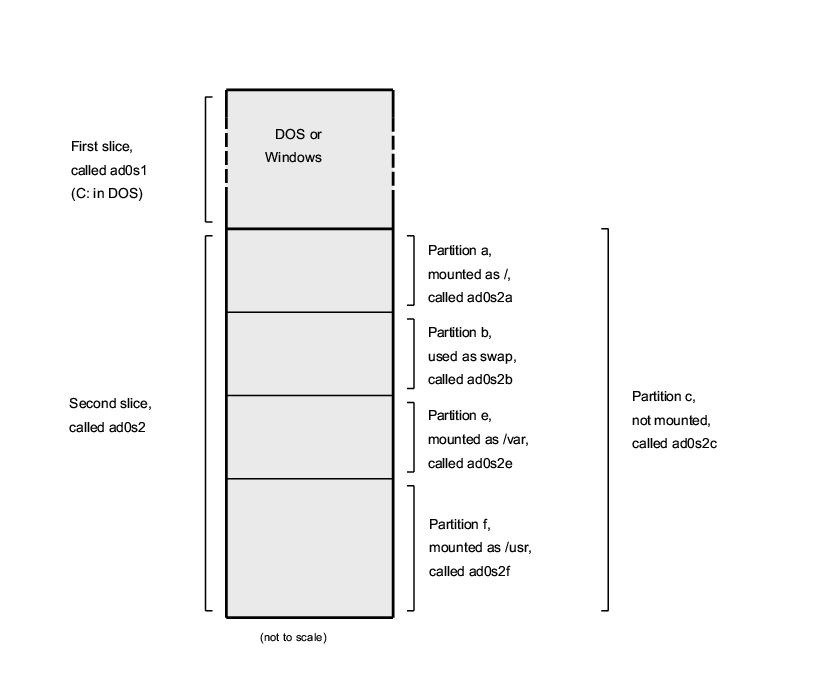
3.6 Mounting and Unmounting File Systems
The file system is best visualized as a tree, rooted, as it were, at /. /dev, /usr, and the other directories in the root directory are branches, which may have their own branches, such as /usr/local, and so on.
There are various reasons to house some of these directories on separate file systems. /var contains the directories log/, spool/, and various types of temporary files, and as such, may get filled up. Filling up the root file system is not a good idea, so splitting /var from / is often favorable.
Another common reason to contain certain directory trees on other file systems is if they are to be housed on separate physical disks, or are separate virtual disks, such as Network File System mounts, or CDROM drives.
3.6.1 The fstab File
During the boot process, file systems listed in /etc/fstab are automatically mounted (unless they are listed with
the noauto option).
The /etc/fstab file contains a list of lines of the following format:
device /mount-point fstype options dumpfreq passno
- device
-
A device name (which should exist), as explained in Section 18.2.
- mount-point
-
A directory (which should exist), on which to mount the file system.
- fstype
-
The file system type to pass to mount(8). The default FreeBSD file system is ufs.
- options
-
Either
rwfor read-write file systems, orrofor read-only file systems, followed by any other options that may be needed. A common option isnoautofor file systems not normally mounted during the boot sequence. Other options are listed in the mount(8) manual page. - dumpfreq
-
This is used by dump(8) to determine which file systems require dumping. If the field is missing, a value of zero is assumed.
- passno
-
This determines the order in which file systems should be checked. File systems that should be skipped should have their passno set to zero. The root file system (which needs to be checked before everything else) should have its passno set to one, and other file systems' passno should be set to values greater than one. If more than one file systems have the same passno then fsck(8) will attempt to check file systems in parallel if possible.
Consult the fstab(5) manual page for more information on the format of the /etc/fstab file and the options it contains.
3.6.2 The mount Command
The mount(8) command is what is ultimately used to mount file systems.
In its most basic form, you use:
There are plenty of options, as mentioned in the mount(8) manual page, but the most common are:
Mount Options
-a-
Mount all the file systems listed in /etc/fstab. Except those marked as “noauto”, excluded by the
-tflag, or those that are already mounted. -d-
Do everything except for the actual mount system call. This option is useful in conjunction with the
-vflag to determine what mount(8) is actually trying to do. -f-
Force the mount of an unclean file system (dangerous), or forces the revocation of write access when downgrading a file system's mount status from read-write to read-only.
-r-
Mount the file system read-only. This is identical to using the
ro(rdonlyfor FreeBSD versions older than 5.2) argument to the-ooption. -tfstype-
Mount the given file system as the given file system type, or mount only file systems of the given type, if given the
-aoption.“ufs” is the default file system type.
-u-
Update mount options on the file system.
-v-
Be verbose.
-w-
Mount the file system read-write.
The -o option takes a comma-separated list of the options,
including the following:
- noexec
-
Do not allow execution of binaries on this file system. This is also a useful security option.
- nosuid
-
Do not interpret setuid or setgid flags on the file system. This is also a useful security option.
3.6.3 The umount Command
The umount(8) command
takes, as a parameter, one of a mountpoint, a device name, or the -a or -A option.
All forms take -f to force unmounting, and -v for verbosity. Be warned that -f is
not generally a good idea. Forcibly unmounting file systems might crash the computer or
damage data on the file system.
-a and -A are used to unmount
all mounted file systems, possibly modified by the file system types listed after -t. -A, however, does not attempt to
unmount the root file system.
3.7 Processes
FreeBSD is a multi-tasking operating system. This means that it seems as though more than one program is running at once. Each program running at any one time is called a process. Every command you run will start at least one new process, and there are a number of system processes that run all the time, keeping the system functional.
Each process is uniquely identified by a number called a process ID, or PID, and, like files, each process also has one owner and group. The owner and group information is used to determine what files and devices the process can open, using the file permissions discussed earlier. Most processes also have a parent process. The parent process is the process that started them. For example, if you are typing commands to the shell then the shell is a process, and any commands you run are also processes. Each process you run in this way will have your shell as its parent process. The exception to this is a special process called init(8). init is always the first process, so its PID is always 1. init is started automatically by the kernel when FreeBSD starts.
Two commands are particularly useful to see the processes on the system, ps(1) and top(1). The ps command is used to show a static list of the currently running processes, and can show their PID, how much memory they are using, the command line they were started with, and so on. The top command displays all the running processes, and updates the display every few seconds, so that you can interactively see what your computer is doing.
By default, ps only shows you the commands that are running and are owned by you. For example:
% ps
PID TT STAT TIME COMMAND
298 p0 Ss 0:01.10 tcsh
7078 p0 S 2:40.88 xemacs mdoc.xsl (xemacs-21.1.14)
37393 p0 I 0:03.11 xemacs freebsd.dsl (xemacs-21.1.14)
48630 p0 S 2:50.89 /usr/local/lib/netscape-linux/navigator-linux-4.77.bi
48730 p0 IW 0:00.00 (dns helper) (navigator-linux-)
72210 p0 R+ 0:00.00 ps
390 p1 Is 0:01.14 tcsh
7059 p2 Is+ 1:36.18 /usr/local/bin/mutt -y
6688 p3 IWs 0:00.00 tcsh
10735 p4 IWs 0:00.00 tcsh
20256 p5 IWs 0:00.00 tcsh
262 v0 IWs 0:00.00 -tcsh (tcsh)
270 v0 IW+ 0:00.00 /bin/sh /usr/X11R6/bin/startx -- -bpp 16
280 v0 IW+ 0:00.00 xinit /home/nik/.xinitrc -- -bpp 16
284 v0 IW 0:00.00 /bin/sh /home/nik/.xinitrc
285 v0 S 0:38.45 /usr/X11R6/bin/sawfish
As you can see in this example, the output from ps(1) is organized into a number of columns. PID is the process ID discussed earlier. PIDs are assigned starting from 1, go up to 99999, and wrap around back to the beginning when you run out (a PID is not reassigned if it is already in use). The TT column shows the tty the program is running on, and can safely be ignored for the moment. STAT shows the program's state, and again, can be safely ignored. TIME is the amount of time the program has been running on the CPU--this is usually not the elapsed time since you started the program, as most programs spend a lot of time waiting for things to happen before they need to spend time on the CPU. Finally, COMMAND is the command line that was used to run the program.
ps(1) supports a
number of different options to change the information that is displayed. One of the most
useful sets is auxww. a displays
information about all the running processes, not just your own. u displays the username of the process' owner, as well as memory
usage. x displays information about daemon processes, and
ww causes ps(1) to display the
full command line for each process, rather than truncating it once it gets too long to
fit on the screen.
The output from top(1) is similar. A sample session looks like this:
% top
last pid: 72257; load averages: 0.13, 0.09, 0.03 up 0+13:38:33 22:39:10
47 processes: 1 running, 46 sleeping
CPU states: 12.6% user, 0.0% nice, 7.8% system, 0.0% interrupt, 79.7% idle
Mem: 36M Active, 5256K Inact, 13M Wired, 6312K Cache, 15M Buf, 408K Free
Swap: 256M Total, 38M Used, 217M Free, 15% Inuse
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
72257 nik 28 0 1960K 1044K RUN 0:00 14.86% 1.42% top
7078 nik 2 0 15280K 10960K select 2:54 0.88% 0.88% xemacs-21.1.14
281 nik 2 0 18636K 7112K select 5:36 0.73% 0.73% XF86_SVGA
296 nik 2 0 3240K 1644K select 0:12 0.05% 0.05% xterm
48630 nik 2 0 29816K 9148K select 3:18 0.00% 0.00% navigator-linu
175 root 2 0 924K 252K select 1:41 0.00% 0.00% syslogd
7059 nik 2 0 7260K 4644K poll 1:38 0.00% 0.00% mutt
...
The output is split into two sections. The header (the first five lines) shows the PID of the last process to run, the system load averages (which are a measure of how busy the system is), the system uptime (time since the last reboot) and the current time. The other figures in the header relate to how many processes are running (47 in this case), how much memory and swap space has been taken up, and how much time the system is spending in different CPU states.
Below that are a series of columns containing similar information to the output from ps(1). As before you can see the PID, the username, the amount of CPU time taken, and the command that was run. top(1) also defaults to showing you the amount of memory space taken by the process. This is split into two columns, one for total size, and one for resident size--total size is how much memory the application has needed, and the resident size is how much it is actually using at the moment. In this example you can see that Netscape® has required almost 30 MB of RAM, but is currently only using 9 MB.
top(1) automatically
updates this display every two seconds; this can be changed with the s option.
3.8 Daemons, Signals, and Killing Processes
When you run an editor it is easy to control the editor, tell it to load files, and so on. You can do this because the editor provides facilities to do so, and because the editor is attached to a terminal. Some programs are not designed to be run with continuous user input, and so they disconnect from the terminal at the first opportunity. For example, a web server spends all day responding to web requests, it normally does not need any input from you. Programs that transport email from site to site are another example of this class of application.
We call these programs daemons. Daemons were characters in Greek mythology: neither good or evil, they were little attendant spirits that, by and large, did useful things for mankind, much like the web servers and mail servers of today do useful things. This is why the BSD mascot has, for a long time, been the cheerful-looking daemon with sneakers and a pitchfork.
There is a convention to name programs that normally run as daemons with a trailing “d”. BIND is the Berkeley Internet Name Domain, but the actual program that executes is called named; the Apache web server program is called httpd; the line printer spooling daemon is lpd and so on. This is a convention, not a hard and fast rule; for example, the main mail daemon for the Sendmail application is called sendmail, and not maild, as you might imagine.
Sometimes you will need to communicate with a daemon process. One way to do so is to send it (or any other running process), what is known as a signal. There are a number of different signals that you can send--some of them have a specific meaning, others are interpreted by the application, and the application's documentation will tell you how that application interprets signals. You can only send a signal to a process that you own. If you send a signal to someone else's process with kill(1) or kill(2), permission will be denied. The exception to this is the root user, who can send signals to everyone's processes.
FreeBSD will also send applications signals in some cases. If an application is badly written, and tries to access memory that it is not supposed to, FreeBSD sends the process the Segmentation Violation signal (SIGSEGV). If an application has used the alarm(3) system call to be alerted after a period of time has elapsed then it will be sent the Alarm signal (SIGALRM), and so on.
Two signals can be used to stop a process, SIGTERM and SIGKILL. SIGTERM is the polite way to kill a process; the process can catch the signal, realize that you want it to shut down, close any log files it may have open, and generally finish whatever it is doing at the time before shutting down. In some cases a process may even ignore SIGTERM if it is in the middle of some task that can not be interrupted.
SIGKILL can not be ignored by a process. This is the “I do not care what you are doing, stop right now” signal. If you send SIGKILL to a process then FreeBSD will stop that process there and then[4].
The other signals you might want to use are SIGHUP, SIGUSR1, and SIGUSR2. These are general purpose signals, and different applications will do different things when they are sent.
Suppose that you have changed your web server's configuration file--you would like to tell the web server to re-read its configuration. You could stop and restart httpd, but this would result in a brief outage period on your web server, which may be undesirable. Most daemons are written to respond to the SIGHUP signal by re-reading their configuration file. So instead of killing and restarting httpd you would send it the SIGHUP signal. Because there is no standard way to respond to these signals, different daemons will have different behavior, so be sure and read the documentation for the daemon in question.
Signals are sent using the kill(1) command, as this example shows.
Sending a Signal to a Process
This example shows how to send a signal to inetd(8). The inetd configuration file is /etc/inetd.conf, and inetd will re-read this configuration file when it is sent SIGHUP.
-
Find the process ID of the process you want to send the signal to. Do this using ps(1) and grep(1). The grep(1) command is used to search through output, looking for the string you specify. This command is run as a normal user, and inetd(8) is run as root, so the
axoptions must be given to ps(1).% ps -ax | grep inetd 198 ?? IWs 0:00.00 inetd -wWSo the inetd(8) PID is 198. In some cases the grep inetd command might also appear in this output. This is because of the way ps(1) has to find the list of running processes.
-
Use kill(1) to send the signal. Because inetd(8) is being run by root you must use su(1) to become root first.
% su Password: # /bin/kill -s HUP 198In common with most UNIX commands, kill(1) will not print any output if it is successful. If you send a signal to a process that you do not own then you will see “kill: PID: Operation not permitted”. If you mistype the PID you will either send the signal to the wrong process, which could be bad, or, if you are lucky, you will have sent the signal to a PID that is not currently in use, and you will see “kill: PID: No such process”.
Why Use /bin/kill?: Many shells provide the kill command as a built in command; that is, the shell will send the signal directly, rather than running /bin/kill. This can be very useful, but different shells have a different syntax for specifying the name of the signal to send. Rather than try to learn all of them, it can be simpler just to use the /bin/kill ... command directly.
Sending other signals is very similar, just substitute TERM or KILL in the command line as necessary.
3.9 Shells
In FreeBSD, a lot of everyday work is done in a command line interface called a shell. A shell's main job is to take commands from the input channel and execute them. A lot of shells also have built in functions to help with everyday tasks such as file management, file globbing, command line editing, command macros, and environment variables. FreeBSD comes with a set of shells, such as sh, the Bourne Shell, and tcsh, the improved C-shell. Many other shells are available from the FreeBSD Ports Collection, such as zsh and bash.
Which shell do you use? It is really a matter of taste. If you are a C programmer you might feel more comfortable with a C-like shell such as tcsh. If you have come from Linux or are new to a UNIX command line interface you might try bash. The point is that each shell has unique properties that may or may not work with your preferred working environment, and that you have a choice of what shell to use.
One common feature in a shell is filename completion. Given the typing of the first few letters of a command or filename, you can usually have the shell automatically complete the rest of the command or filename by hitting the Tab key on the keyboard. Here is an example. Suppose you have two files called foobar and foo.bar. You want to delete foo.bar. So what you would type on the keyboard is: rm fo[Tab].[Tab].
The shell would print out rm foo[BEEP].bar.
The [BEEP] is the console bell, which is the shell telling me it was unable to totally complete the filename because there is more than one match. Both foobar and foo.bar start with fo, but it was able to complete to foo. If you type in ., then hit Tab again, the shell would be able to fill in the rest of the filename for you.
Another feature of the shell is the use of environment variables. Environment variables are a variable/key pair stored in the shell's environment space. This space can be read by any program invoked by the shell, and thus contains a lot of program configuration. Here is a list of common environment variables and what they mean:
| Variable | Description |
|---|---|
| USER | Current logged in user's name. |
| PATH | Colon-separated list of directories to search for binaries. |
| DISPLAY | Network name of the X11 display to connect to, if available. |
| SHELL | The current shell. |
| TERM | The name of the user's type of terminal. Used to determine the capabilities of the terminal. |
| TERMCAP | Database entry of the terminal escape codes to perform various terminal functions. |
| OSTYPE | Type of operating system. e.g., FreeBSD. |
| MACHTYPE | The CPU architecture that the system is running on. |
| EDITOR | The user's preferred text editor. |
| PAGER | The user's preferred text pager. |
| MANPATH | Colon-separated list of directories to search for manual pages. |
Setting an environment variable differs somewhat from shell to shell. For example, in the C-Style shells such as tcsh and csh, you would use setenv to set environment variables. Under Bourne shells such as sh and bash, you would use export to set your current environment variables. For example, to set or modify the EDITOR environment variable, under csh or tcsh a command like this would set EDITOR to /usr/local/bin/emacs:
% setenv EDITOR /usr/local/bin/emacs
Under Bourne shells:
% export EDITOR="/usr/local/bin/emacs"
You can also make most shells expand the environment variable by placing a $ character in front of it on the command line. For example, echo $TERM would print out whatever $TERM is set to, because the shell expands $TERM and passes it on to echo.
Shells treat a lot of special characters, called meta-characters as special representations of data. The most common one is the * character, which represents any number of characters in a filename. These special meta-characters can be used to do filename globbing. For example, typing in echo * is almost the same as typing in ls because the shell takes all the files that match * and puts them on the command line for echo to see.
To prevent the shell from interpreting these special characters, they can be escaped from the shell by putting a backslash (\) character in front of them. echo $TERM prints whatever your terminal is set to. echo \$TERM prints $TERM as is.
3.9.1 Changing Your Shell
The easiest way to change your shell is to use the chsh command. Running chsh will place you into the editor that is in your EDITOR environment variable; if it is not set, you will be placed in vi. Change the “Shell:” line accordingly.
You can also give chsh the -s
option; this will set your shell for you, without requiring you to enter an editor. For
example, if you wanted to change your shell to bash, the
following should do the trick:
% chsh -s /usr/local/bin/bash
Note: The shell that you wish to use must be present in the /etc/shells file. If you have installed a shell from the ports collection, then this should have been done for you already. If you installed the shell by hand, you must do this.
For example, if you installed bash by hand and placed it into /usr/local/bin, you would want to:
# echo "/usr/local/bin/bash" >> /etc/shellsThen rerun chsh.
3.10 Text Editors
A lot of configuration in FreeBSD is done by editing text files. Because of this, it would be a good idea to become familiar with a text editor. FreeBSD comes with a few as part of the base system, and many more are available in the Ports Collection.
The easiest and simplest editor to learn is an editor called ee, which stands for easy editor. To start ee, one would type at the command line ee filename where filename is the name of the file to be edited. For example, to edit /etc/rc.conf, type in ee /etc/rc.conf. Once inside of ee, all of the commands for manipulating the editor's functions are listed at the top of the display. The caret ^ character represents the Ctrl key on the keyboard, so ^e expands to the key combination Ctrl+e. To leave ee, hit the Esc key, then choose leave editor. The editor will prompt you to save any changes if the file has been modified.
FreeBSD also comes with more powerful text editors such as vi as part of the base system, while other editors, like Emacs and vim, are part of the FreeBSD Ports Collection (editors/emacs and editors/vim). These editors offer much more functionality and power at the expense of being a little more complicated to learn. However if you plan on doing a lot of text editing, learning a more powerful editor such as vim or Emacs will save you much more time in the long run.
3.11 Devices and Device Nodes
A device is a term used mostly for hardware-related activities in a system, including disks, printers, graphics cards, and keyboards. When FreeBSD boots, the majority of what FreeBSD displays are devices being detected. You can look through the boot messages again by viewing /var/run/dmesg.boot.
For example, acd0 is the first IDE CDROM drive, while kbd0 represents the keyboard.
Most of these devices in a UNIX operating system must be accessed through special files called device nodes, which are located in the /dev directory.
3.11.1 Creating Device Nodes
When adding a new device to your system, or compiling in support for additional devices, new device nodes must be created.
3.11.1.1 DEVFS (DEVice File System)
The device file system, or DEVFS, provides access to kernel's device namespace in the global file system namespace. Instead of having to create and modify device nodes, DEVFS maintains this particular file system for you.
See the devfs(5) manual page for more information.
3.12 Binary Formats
To understand why FreeBSD uses the elf(5) format, you must first know a little about the three currently “dominant” executable formats for UNIX:
-
The oldest and “classic” UNIX object format. It uses a short and compact header with a magic number at the beginning that is often used to characterize the format (see a.out(5) for more details). It contains three loaded segments: .text, .data, and .bss plus a symbol table and a string table.
-
COFF
The SVR3 object format. The header now comprises a section table, so you can have more than just .text, .data, and .bss sections.
-
The successor to COFF, featuring multiple sections and 32-bit or 64-bit possible values. One major drawback: ELF was also designed with the assumption that there would be only one ABI per system architecture. That assumption is actually quite incorrect, and not even in the commercial SYSV world (which has at least three ABIs: SVR4, Solaris, SCO) does it hold true.
FreeBSD tries to work around this problem somewhat by providing a utility for branding a known ELF executable with information about the ABI it is compliant with. See the manual page for brandelf(1) for more information.
FreeBSD comes from the “classic” camp and used the a.out(5) format, a technology tried and proven through many generations of BSD releases, until the beginning of the 3.X branch. Though it was possible to build and run native ELF binaries (and kernels) on a FreeBSD system for some time before that, FreeBSD initially resisted the “push” to switch to ELF as the default format. Why? Well, when the Linux camp made their painful transition to ELF, it was not so much to flee the a.out executable format as it was their inflexible jump-table based shared library mechanism, which made the construction of shared libraries very difficult for vendors and developers alike. Since the ELF tools available offered a solution to the shared library problem and were generally seen as “the way forward” anyway, the migration cost was accepted as necessary and the transition made. FreeBSD's shared library mechanism is based more closely on Sun's SunOS™ style shared library mechanism and, as such, is very easy to use.
So, why are there so many different formats?
Back in the dim, dark past, there was simple hardware. This simple hardware supported a simple, small system. a.out was completely adequate for the job of representing binaries on this simple system (a PDP-11). As people ported UNIX from this simple system, they retained the a.out format because it was sufficient for the early ports of UNIX to architectures like the Motorola 68k, VAXen, etc.
Then some bright hardware engineer decided that if he could force software to do some sleazy tricks, then he would be able to shave a few gates off the design and allow his CPU core to run faster. While it was made to work with this new kind of hardware (known these days as RISC), a.out was ill-suited for this hardware, so many formats were developed to get to a better performance from this hardware than the limited, simple a.out format could offer. Things like COFF, ECOFF, and a few obscure others were invented and their limitations explored before things seemed to settle on ELF.
In addition, program sizes were getting huge and disks (and physical memory) were still relatively small so the concept of a shared library was born. The VM system also became more sophisticated. While each one of these advancements was done using the a.out format, its usefulness was stretched more and more with each new feature. In addition, people wanted to dynamically load things at run time, or to junk parts of their program after the init code had run to save in core memory and swap space. Languages became more sophisticated and people wanted code called before main automatically. Lots of hacks were done to the a.out format to allow all of these things to happen, and they basically worked for a time. In time, a.out was not up to handling all these problems without an ever increasing overhead in code and complexity. While ELF solved many of these problems, it would be painful to switch from the system that basically worked. So ELF had to wait until it was more painful to remain with a.out than it was to migrate to ELF.
However, as time passed, the build tools that FreeBSD derived their build tools from (the assembler and loader especially) evolved in two parallel trees. The FreeBSD tree added shared libraries and fixed some bugs. The GNU folks that originally wrote these programs rewrote them and added simpler support for building cross compilers, plugging in different formats at will, and so on. Since many people wanted to build cross compilers targeting FreeBSD, they were out of luck since the older sources that FreeBSD had for as and ld were not up to the task. The new GNU tools chain (binutils) does support cross compiling, ELF, shared libraries, C++ extensions, etc. In addition, many vendors are releasing ELF binaries, and it is a good thing for FreeBSD to run them.
ELF is more expressive than a.out and allows more extensibility in the base system. The ELF tools are better maintained, and offer cross compilation support, which is important to many people. ELF may be a little slower than a.out, but trying to measure it can be difficult. There are also numerous details that are different between the two in how they map pages, handle init code, etc. None of these are very important, but they are differences. In time support for a.out will be moved out of the GENERIC kernel, and eventually removed from the kernel once the need to run legacy a.out programs is past.
3.13 For More Information
3.13.1 Manual Pages
The most comprehensive documentation on FreeBSD is in the form of manual pages. Nearly every program on the system comes with a short reference manual explaining the basic operation and various arguments. These manuals can be viewed with the man command. Use of the man command is simple:
% man command
command is the name of the command you wish to learn about. For example, to learn more about ls command type:
% man ls
The online manual is divided up into numbered sections:
-
User commands.
-
System calls and error numbers.
-
Functions in the C libraries.
-
Device drivers.
-
File formats.
-
Games and other diversions.
-
Miscellaneous information.
-
System maintenance and operation commands.
-
Kernel developers.
In some cases, the same topic may appear in more than one section of the online
manual. For example, there is a chmod user command and a chmod() system call. In this case, you can tell the man command which one you want by specifying the section:
% man 1 chmod
This will display the manual page for the user command chmod. References to a particular section of the online manual are traditionally placed in parenthesis in written documentation, so chmod(1) refers to the chmod user command and chmod(2) refers to the system call.
This is fine if you know the name of the command and simply wish to know how to use
it, but what if you cannot recall the command name? You can use man to search for keywords in the command descriptions by using the
-k switch:
% man -k mail
With this command you will be presented with a list of commands that have the keyword “mail” in their descriptions. This is actually functionally equivalent to using the apropos command.
So, you are looking at all those fancy commands in /usr/bin but do not have the faintest idea what most of them actually do? Simply do:
% cd /usr/bin
% man -f *
or
% cd /usr/bin
% whatis *
which does the same thing.
3.13.2 GNU Info Files
FreeBSD includes many applications and utilities produced by the Free Software Foundation (FSF). In addition to manual pages, these programs come with more extensive hypertext documents called info files which can be viewed with the info command or, if you installed emacs, the info mode of emacs.
To use the info(1) command, simply type:
% info
For a brief introduction, type h. For a quick command reference, type ?.
Chapter 4 Installing Applications: Packages and Ports
4.1 Synopsis
FreeBSD is bundled with a rich collection of system tools as part of the base system. However, there is only so much one can do before needing to install an additional third-party application to get real work done. FreeBSD provides two complementary technologies for installing third-party software on your system: the FreeBSD Ports Collection (for installing from source), and packages (for installing from pre-built binaries). Either method may be used to install the newest version of your favorite applications from local media or straight off the network.
After reading this chapter, you will know:
-
How to install third-party binary software packages.
-
How to build third-party software from source by using the ports collection.
-
How to remove previously installed packages or ports.
-
How to override the default values that the ports collection uses.
-
How to find the appropriate software package.
-
How to upgrade your applications.
4.2 Overview of Software Installation
If you have used a UNIX system before you will know that the typical procedure for installing third-party software goes something like this:
-
Download the software, which might be distributed in source code format, or as a binary.
-
Unpack the software from its distribution format (typically a tarball compressed with compress(1), gzip(1), or bzip2(1)).
-
Locate the documentation (perhaps an INSTALL or README file, or some files in a doc/ subdirectory) and read up on how to install the software.
-
If the software was distributed in source format, compile it. This may involve editing a Makefile, or running a configure script, and other work.
-
Test and install the software.
And that is only if everything goes well. If you are installing a software package that was not deliberately ported to FreeBSD you may even have to go in and edit the code to make it work properly.
Should you want to, you can continue to install software the “traditional” way with FreeBSD. However, FreeBSD provides two technologies which can save you a lot of effort: packages and ports. At the time of writing, over 17,000 third-party applications have been made available in this way.
For any given application, the FreeBSD package for that application is a single file which you must download. The package contains pre-compiled copies of all the commands for the application, as well as any configuration files or documentation. A downloaded package file can be manipulated with FreeBSD package management commands, such as pkg_add(1), pkg_delete(1), pkg_info(1), and so on. Installing a new application can be carried out with a single command.
A FreeBSD port for an application is a collection of files designed to automate the process of compiling an application from source code.
Remember that there are a number of steps you would normally carry out if you compiled a program yourself (downloading, unpacking, patching, compiling, installing). The files that make up a port contain all the necessary information to allow the system to do this for you. You run a handful of simple commands and the source code for the application is automatically downloaded, extracted, patched, compiled, and installed for you.
In fact, the ports system can also be used to generate packages which can later be manipulated with pkg_add and the other package management commands that will be introduced shortly.
Both packages and ports understand dependencies. Suppose you want to install an application that depends on a specific library being installed. Both the application and the library have been made available as FreeBSD ports and packages. If you use the pkg_add command or the ports system to add the application, both will notice that the library has not been installed, and automatically install the library first.
Given that the two technologies are quite similar, you might be wondering why FreeBSD bothers with both. Packages and ports both have their own strengths, and which one you use will depend on your own preference.
Package Benefits
-
A compressed package tarball is typically smaller than the compressed tarball containing the source code for the application.
-
Packages do not require any additional compilation. For large applications, such as Mozilla, KDE, or GNOME this can be important, particularly if you are on a slow system.
-
Packages do not require any understanding of the process involved in compiling software on FreeBSD.
Ports Benefits
-
Packages are normally compiled with conservative options, because they have to run on the maximum number of systems. By installing from the port, you can tweak the compilation options to (for example) generate code that is specific to a Pentium 4 or Athlon processor.
-
Some applications have compile-time options relating to what they can and cannot do. For example, Apache can be configured with a wide variety of different built-in options. By building from the port you do not have to accept the default options, and can set them yourself.
In some cases, multiple packages will exist for the same application to specify certain settings. For example, Ghostscript is available as a ghostscript package and a ghostscript-nox11 package, depending on whether or not you have installed an X11 server. This sort of rough tweaking is possible with packages, but rapidly becomes impossible if an application has more than one or two different compile-time options.
-
The licensing conditions of some software distributions forbid binary distribution. They must be distributed as source code.
-
Some people do not trust binary distributions. At least with source code, you can (in theory) read through it and look for potential problems yourself.
-
If you have local patches, you will need the source in order to apply them.
-
Some people like having code around, so they can read it if they get bored, hack it, borrow from it (license permitting, of course), and so on.
To keep track of updated ports, subscribe to the FreeBSD ports mailing list and the FreeBSD ports bugs mailing list.
Warning: Before installing any application, you should check http://vuxml.freebsd.org/ for security issues related to your application.
You can also install ports-mgmt/portaudit which will automatically check all installed applications for known vulnerabilities; a check will be also performed before any port build. Meanwhile, you can use the command portaudit -F -a after you have installed some packages.
The remainder of this chapter will explain how to use packages and ports to install and manage third-party software on FreeBSD.
4.3 Finding Your Application
Before you can install any applications you need to know what you want, and what the application is called.
FreeBSD's list of available applications is growing all the time. Fortunately, there are a number of ways to find what you want:
-
The FreeBSD web site maintains an up-to-date searchable list of all the available applications, at http://www.FreeBSD.org/ports/. The ports are divided into categories, and you may either search for an application by name (if you know it), or see all the applications available in a category.
-
Dan Langille maintains FreshPorts, at http://www.FreshPorts.org/. FreshPorts tracks changes to the applications in the ports tree as they happen, allows you to “watch” one or more ports, and can send you email when they are updated.
-
If you do not know the name of the application you want, try using a site like FreshMeat (http://www.freshmeat.net/) to find an application, then check back at the FreeBSD site to see if the application has been ported yet.
-
If you know the exact name of the port, but just need to find out which category it is in, you can use the whereis(1) command. Simply type whereis file, where file is the program you want to install. If it is found on your system, you will be told where it is, as follows:
# whereis lsof lsof: /usr/ports/sysutils/lsofThis tells us that lsof (a system utility) can be found in the /usr/ports/sysutils/lsof directory.
-
Yet another way to find a particular port is by using the Ports Collection's built-in search mechanism. To use the search feature, you will need to be in the /usr/ports directory. Once in that directory, run make search name=program-name where program-name is the name of the program you want to find. For example, if you were looking for lsof:
# cd /usr/ports # make search name=lsof Port: lsof-4.56.4 Path: /usr/ports/sysutils/lsof Info: Lists information about open files (similar to fstat(1)) Maint: obrien@FreeBSD.org Index: sysutils B-deps: R-deps:The part of the output you want to pay particular attention to is the “Path:” line, since that tells you where to find the port. The other information provided is not needed in order to install the port, so it will not be covered here.
For more in-depth searching you can also use make search key=string where string is some text to search for. This searches port names, comments, descriptions and dependencies and can be used to find ports which relate to a particular subject if you do not know the name of the program you are looking for.
In both of these cases, the search string is case-insensitive. Searching for “LSOF” will yield the same results as searching for “lsof”.
4.4 Using the Packages System
Contributed by Chern Lee.4.4.1 Installing a Package
You can use the pkg_add(1) utility to install a FreeBSD software package from a local file or from a server on the network.
Example 4-1. Downloading a Package Manually and Installing It Locally
# ftp -a ftp2.FreeBSD.org
Connected to ftp2.FreeBSD.org.
220 ftp2.FreeBSD.org FTP server (Version 6.00LS) ready.
331 Guest login ok, send your email address as password.
230-
230- This machine is in Vienna, VA, USA, hosted by Verio.
230- Questions? E-mail freebsd@vienna.verio.net.
230-
230-
230 Guest login ok, access restrictions apply.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> cd /pub/FreeBSD/ports/packages/sysutils/
250 CWD command successful.
ftp> get lsof-4.56.4.tgz
local: lsof-4.56.4.tgz remote: lsof-4.56.4.tgz
200 PORT command successful.
150 Opening BINARY mode data connection for 'lsof-4.56.4.tgz' (92375 bytes).
100% |**************************************************| 92375 00:00 ETA
226 Transfer complete.
92375 bytes received in 5.60 seconds (16.11 KB/s)
ftp> exit
# pkg_add lsof-4.56.4.tgz
If you do not have a source of local packages (such as a FreeBSD CD-ROM set) then it
will probably be easier to use the -r option to pkg_add(1). This will
cause the utility to automatically determine the correct object format and release and
then fetch and install the package from an FTP site.
# pkg_add -r lsof
The example above would download the correct package and add it without any further user intervention. If you want to specify an alternative FreeBSD Packages Mirror, instead of the main distribution site, you have to set the PACKAGESITE environment variable accordingly, to override the default settings. pkg_add(1) uses fetch(3) to download the files, which honors various environment variables, including FTP_PASSIVE_MODE, FTP_PROXY, and FTP_PASSWORD. You may need to set one or more of these if you are behind a firewall, or need to use an FTP/HTTP proxy. See fetch(3) for the complete list. Note that in the example above lsof is used instead of lsof-4.56.4. When the remote fetching feature is used, the version number of the package must be removed. pkg_add(1) will automatically fetch the latest version of the application.
Note: pkg_add(1) will download the latest version of your application if you are using FreeBSD-CURRENT or FreeBSD-STABLE. If you run a -RELEASE version, it will grab the version of the package that was built with your release. It is possible to change this behavior by overriding PACKAGESITE. For example, if you run a FreeBSD 5.4-RELEASE system, by default pkg_add(1) will try to fetch packages from ftp://ftp.freebsd.org/pub/FreeBSD/ports/i386/packages-5.4-release/Latest/. If you want to force pkg_add(1) to download FreeBSD 5-STABLE packages, set PACKAGESITE to ftp://ftp.freebsd.org/pub/FreeBSD/ports/i386/packages-5-stable/Latest/.
Package files are distributed in .tgz and .tbz formats. You can find them at ftp://ftp.FreeBSD.org/pub/FreeBSD/ports/packages/, or on the FreeBSD CD-ROM distribution. Every CD on the FreeBSD 4-CD set (and the PowerPak, etc.) contains packages in the /packages directory. The layout of the packages is similar to that of the /usr/ports tree. Each category has its own directory, and every package can be found within the All directory.
The directory structure of the package system matches the ports layout; they work with each other to form the entire package/port system.
4.4.2 Managing Packages
pkg_info(1) is a utility that lists and describes the various packages installed.
# pkg_info
cvsup-16.1 A general network file distribution system optimized for CV
docbook-1.2 Meta-port for the different versions of the DocBook DTD
...
pkg_version(1) is a utility that summarizes the versions of all installed packages. It compares the package version to the current version found in the ports tree.
# pkg_version
cvsup =
docbook =
...
The symbols in the second column indicate the relative age of the installed version and the version available in the local ports tree.
| Symbol | Meaning |
|---|---|
| = | The version of the installed package matches the one found in the local ports tree. |
| < | The installed version is older than the one available in the ports tree. |
| > | The installed version is newer than the one found in the local ports tree. (The local ports tree is probably out of date.) |
| ? | The installed package cannot be found in the ports index. (This can happen, for instance, if an installed port is removed from the Ports Collection or renamed.) |
| * | There are multiple versions of the package. |
4.4.3 Deleting a Package
To remove a previously installed software package, use the pkg_delete(1) utility.
# pkg_delete xchat-1.7.1
Note that pkg_delete(1) requires the full package name and number; the above command would not work if xchat was given instead of xchat-1.7.1. It is, however, easy to use pkg_version(1) to find the version of the installed package. You could instead simply use a wildcard:
# pkg_delete xchat\*
in this case, all packages whose names start with xchat will be deleted.
4.4.4 Miscellaneous
All package information is stored within the /var/db/pkg directory. The installed file list and descriptions of each package can be found within files in this directory.
4.5 Using the Ports Collection
The following sections provide basic instructions on using the Ports Collection to install or remove programs from your system. The detailed description of available make targets and environment variables is available in ports(7).
4.5.1 Obtaining the Ports Collection
Before you can install ports, you must first obtain the Ports Collection--which is essentially a set of Makefiles, patches, and description files placed in /usr/ports.
When installing your FreeBSD system, sysinstall asked if you would like to install the Ports Collection. If you chose no, you can follow these instructions to obtain the ports collection:
CVSup Method
This is a quick method for getting and keeping your copy of the Ports Collection up to date using CVSup. If you want to learn more about CVSup, see Using CVSup.
Note: The csup utility is a rewrite of the CVSup software in C and is available in FreeBSD 6.2 or later. You can use csup that is included in the base install and skip step #1 and then substitute the cvsup command with csup. For older releases, you can still install csup via the net/csup port/package.
Make sure /usr/ports is empty before you run CVSup for the first time! If you already have the Ports Collection present, obtained from another source, CVSup will not prune removed patch files.
-
Install the net/cvsup-without-gui package:
# pkg_add -r cvsup-without-guiSee CVSup Installation (Section A.5.2) for more details.
-
Run cvsup:
# cvsup -L 2 -h cvsup.FreeBSD.org /usr/share/examples/cvsup/ports-supfileChange cvsup.FreeBSD.org to a CVSup server near you. See CVSup Mirrors (Section A.5.7) for a complete listing of mirror sites.
Note: One may want to use his own ports-supfile, for example to avoid the need of passing the CVSup server on the command line.
-
In this case, as root, copy /usr/share/examples/cvsup/ports-supfile to a new location, such as /root or your home directory.
-
Edit ports-supfile.
-
Change CHANGE_THIS.FreeBSD.org to a CVSup server near you. See CVSup Mirrors (Section A.5.7) for a complete listing of mirror sites.
-
And now to run cvsup, use the following:
# cvsup -L 2 /root/ports-supfile
-
-
Running the cvsup(1) command later will download and apply all the recent changes to your Ports Collection, except actually rebuilding the ports for your own system.
Portsnap Method
Portsnap is an alternative system for distributing the Ports Collection. It was first included in FreeBSD 6.0. On older systems, you can install it from ports-mgmt/portsnap package:
# pkg_add -r portsnap
Please refer to Using Portsnap for a detailed description of all Portsnap features.
-
Since FreeBSD 6.1-RELEASE and with recent versions of the Portsnap port or package, you can safely skip this step. The /usr/ports will be created automatically at first use of the portsnap(8) command. With previous versions of Portsnap, you will have to create an empty directory /usr/ports if it does not exists:
# mkdir /usr/ports -
Download a compressed snapshot of the Ports Collection into /var/db/portsnap. You can disconnect from the Internet after this step, if you wish.
# portsnap fetch -
If you are running Portsnap for the first time, extract the snapshot into /usr/ports:
# portsnap extractIf you already have a populated /usr/ports and you are just updating, run the following command instead:
# portsnap update
Sysinstall Method
This method involves using sysinstall to install the Ports Collection from the installation media. Note that the old copy of Ports Collection from the date of the release will be installed. If you have Internet access, you should always use one of the methods mentioned above.
-
As root, run sysinstall (/stand/sysinstall in FreeBSD versions older than 5.2) as shown below:
# sysinstall -
Scroll down and select Configure, press Enter.
-
Scroll down and select Distributions, press Enter.
-
Scroll down to ports, press Space.
-
Scroll up to Exit, press Enter.
-
Select your desired installation media, such as CDROM, FTP, and so on.
-
Scroll up to Exit and press Enter.
-
Press X to exit sysinstall.
4.5.2 Installing Ports
The first thing that should be explained when it comes to the Ports Collection is what is actually meant by a “skeleton”. In a nutshell, a port skeleton is a minimal set of files that tell your FreeBSD system how to cleanly compile and install a program. Each port skeleton includes:
-
A Makefile. The Makefile contains various statements that specify how the application should be compiled and where it should be installed on your system.
-
A distinfo file. This file contains information about the files that must be downloaded to build the port, and their checksums (using md5(1) and sha256(1)), to verify that files have not been corrupted during the download.
-
A files directory. This directory contains patches to make the program compile and install on your FreeBSD system. Patches are basically small files that specify changes to particular files. They are in plain text format, and basically say “Remove line 10” or “Change line 26 to this ...”. Patches are also known as “diffs” because they are generated by the diff(1) program.
This directory may also contain other files used to build the port.
-
A pkg-descr file. This is a more detailed, often multiple-line, description of the program.
-
A pkg-plist file. This is a list of all the files that will be installed by the port. It also tells the ports system what files to remove upon deinstallation.
Some ports have other files, such as pkg-message. The ports system uses these files to handle special situations. If you want more details on these files, and on ports in general, check out the FreeBSD Porter's Handbook.
The port includes instructions on how to build source code, but does not include the actual source code. You can get the source code from a CD-ROM or from the Internet. Source code is distributed in whatever manner the software author desires. Frequently this is a tarred and gzipped file, but it might be compressed with some other tool or even uncompressed. The program source code, whatever form it comes in, is called a “distfile”. The two methods for installing a FreeBSD port are described below.
Note: You must be logged in as root to install ports.
Warning: Before installing any port, you should be sure to have an up-to-date Ports Collection and you should check http://vuxml.freebsd.org/ for security issues related to your port.
A security vulnerabilities check can be automatically done by portaudit before any new application installation. This tool can be found in the Ports Collection (ports-mgmt/portaudit). Consider running portaudit -F before installing a new port, to fetch the current vulnerabilities database. A security audit and an update of the database will be performed during the daily security system check. For more information read the portaudit(1) and periodic(8) manual pages.
The Ports Collection makes an assumption that you have a working Internet connection. If you do not, you will need to put a copy of the distfile into /usr/ports/distfiles manually.
To begin, change to the directory for the port you want to install:
# cd /usr/ports/sysutils/lsof
Once inside the lsof directory, you will see the port skeleton. The next step is to compile, or “build”, the port. This is done by simply typing make at the prompt. Once you have done so, you should see something like this:
# make
>> lsof_4.57D.freebsd.tar.gz doesn't seem to exist in /usr/ports/distfiles/.
>> Attempting to fetch from ftp://lsof.itap.purdue.edu/pub/tools/unix/lsof/.
===> Extracting for lsof-4.57
...
[extraction output snipped]
...
>> Checksum OK for lsof_4.57D.freebsd.tar.gz.
===> Patching for lsof-4.57
===> Applying FreeBSD patches for lsof-4.57
===> Configuring for lsof-4.57
...
[configure output snipped]
...
===> Building for lsof-4.57
...
[compilation output snipped]
...
#
Notice that once the compile is complete you are returned to your prompt. The next step is to install the port. In order to install it, you simply need to tack one word onto the make command, and that word is install:
# make install
===> Installing for lsof-4.57
...
[installation output snipped]
...
===> Generating temporary packing list
===> Compressing manual pages for lsof-4.57
===> Registering installation for lsof-4.57
===> SECURITY NOTE:
This port has installed the following binaries which execute with
increased privileges.
#
Once you are returned to your prompt, you should be able to run the application you just installed. Since lsof is a program that runs with increased privileges, a security warning is shown. During the building and installation of ports, you should take heed of any other warnings that may appear.
It is a good idea to delete the working subdirectory, which contains all the temporary files used during compilation. Not only does it consume valuable disk space, but it would also cause problems later when upgrading to the newer version of the port.
# make clean
===> Cleaning for lsof-4.57
#
Note: You can save two extra steps by just running make install clean instead of make, make install and make clean as three separate steps.
Note: Some shells keep a cache of the commands that are available in the directories listed in the PATH environment variable, to speed up lookup operations for the executable file of these commands. If you are using one of these shells, you might have to use the rehash command after installing a port, before the newly installed commands can be used. This command will work for shells like tcsh. Use the hash -r command for shells like sh. Look at the documentation for your shell for more information.
Some third-party DVD-ROM products such as the FreeBSD Toolkit from the FreeBSD Mall contain distfiles. They can be used with the Ports Collection. Mount the DVD-ROM on /cdrom. If you use a different mount point, set CD_MOUNTPTS make variable. The needed distfiles will be automatically used if they are present on the disk.
Note: Please be aware that the licenses of a few ports do not allow for inclusion on the CD-ROM. This could be because a registration form needs to be filled out before downloading or redistribution is not allowed, or for another reason. If you wish to install a port not included on the CD-ROM, you will need to be online in order to do so.
The ports system uses fetch(1) to download the files, which honors various environment variables, including FTP_PASSIVE_MODE, FTP_PROXY, and FTP_PASSWORD. You may need to set one or more of these if you are behind a firewall, or need to use an FTP/HTTP proxy. See fetch(3) for the complete list.
For users which cannot be connected all the time, the make fetch option is provided. Just run this command at the top level directory (/usr/ports) and the required files will be downloaded for you. This command will also work in the lower level categories, for example: /usr/ports/net. Note that if a port depends on libraries or other ports this will not fetch the distfiles of those ports too. Replace fetch with fetch-recursive if you want to fetch all the dependencies of a port too.
Note: You can build all the ports in a category or as a whole by running make in the top level directory, just like the aforementioned make fetch method. This is dangerous, however, as some ports cannot co-exist. In other cases, some ports can install two different files with the same filename.
In some rare cases, users may need to acquire the tarballs from a site other than the MASTER_SITES (the location where files are downloaded from). You can override the MASTER_SITES option with the following command:
# cd /usr/ports/directory
# make MASTER_SITE_OVERRIDE= \
ftp://ftp.FreeBSD.org/pub/FreeBSD/ports/distfiles/ fetch
In this example we change the MASTER_SITES option to ftp.FreeBSD.org/pub/FreeBSD/ports/distfiles/.
Note: Some ports allow (or even require) you to provide build options which can enable/disable parts of the application which are unneeded, certain security options, and other customizations. A few which come to mind are www/mozilla, security/gpgme, and mail/sylpheed-claws. A message will be displayed when options such as these are available.
4.5.2.1 Overriding the Default Ports Directories
Sometimes it is useful (or mandatory) to use a different working and target directory. The WRKDIRPREFIX and PREFIX variables can override the default directories. For example:
# make WRKDIRPREFIX=/usr/home/example/ports install
will compile the port in /usr/home/example/ports and install everything under /usr/local.
# make PREFIX=/usr/home/example/local install
will compile it in /usr/ports and install it in /usr/home/example/local.
And of course,
# make WRKDIRPREFIX=../ports PREFIX=../local install
will combine the two (it is too long to completely write on this page, but it should give you the general idea).
Alternatively, these variables can also be set as part of your environment. Read the manual page for your shell for instructions on doing so.
4.5.2.2 Dealing with imake
Some ports that use imake (a part of the X Window System) do not work well with PREFIX, and will insist on installing under /usr/X11R6. Similarly, some Perl ports ignore PREFIX and install in the Perl tree. Making these ports respect PREFIX is a difficult or impossible job.
4.5.2.3 Reconfiguring Ports
When building certain ports, you may be presented with a ncurses-based menu from which you can select certain build options. It is not uncommon for users to wish to revisit this menu to add, remove, or change these options after a port has been built. There are many ways to do this. One option is to go into the directory containing the port and type make config, which will simply present the menu again with the same options selected. Another option is to use make showconfig which will show you all the configuration options for the port. Yet another option is to execute make rmconfig which will remove all selected options and allow you to start over. All of these options, and others, are explained in great detail in in the man page for ports(7).
4.5.3 Removing Installed Ports
Now that you know how to install ports, you are probably wondering how to remove them, just in case you install one and later on decide that you installed the wrong port. We will remove our previous example (which was lsof for those of you not paying attention). Ports are being removed exactly the same as the packages (discussed in the Packages section), using the pkg_delete(1) command:
# pkg_delete lsof-4.57
4.5.4 Upgrading Ports
First, list outdated ports that have a newer version available in the Ports Collection with the pkg_version(1) command:
# pkg_version -v
4.5.4.1 /usr/ports/UPDATING
Once you have updated your Ports Collection, before attempting a port upgrade, you should check /usr/ports/UPDATING. This file describes various issues and additional steps users may encounter and need to perform when updating a port, including such things as file format changes, changes in locations of configuration files, or other such incompatibilities with previous versions.
If UPDATING contradicts something you read here, UPDATING takes precedence.
4.5.4.2 Upgrading Ports using Portupgrade
The portupgrade utility is designed to easily upgrade installed ports. It is available from the ports-mgmt/portupgrade port. Install it like any other port, using the make install clean command:
# cd /usr/ports/ports-mgmt/portupgrade
# make install clean
Scan the list of installed ports with the pkgdb -F command and fix all the inconsistencies it reports. It is a good idea to do this regularly, before every upgrade.
When you run portupgrade -a, portupgrade will begin to upgrade all the outdated ports
installed on your system. Use the -i flag if you want to be
asked for confirmation of every individual upgrade.
# portupgrade -ai
If you want to upgrade only a certain application, not all available ports, use portupgrade pkgname. Include the
-R flag if portupgrade should
first upgrade all the ports required by the given application.
# portupgrade -R firefox
To use packages instead of ports for installation, provide -P flag. With this option portupgrade
searches the local directories listed in PKG_PATH, or fetches
packages from remote site if it is not found locally. If packages can not be found
locally or fetched remotely, portupgrade will use ports. To
avoid using ports, specify -PP.
# portupgrade -PP gnome2
To just fetch distfiles (or packages, if -P is specified)
without building or installing anything, use -F. For further
information see
portupgrade(1).
4.5.4.3 Upgrading Ports using Portmanager
Portmanager is another utility for easy upgrading of installed ports. It is available from the ports-mgmt/portmanager port:
# cd /usr/ports/ports-mgmt/portmanager
# make install clean
All the installed ports can be upgraded using this simple command:
# portmanager -u
You can add the -ui flag to get asked for confirmation of
every step Portmanager will perform. Portmanager can also be used to install new ports on the system.
Unlike the usual make install clean command, it will upgrade all
the dependencies prior to building and installing the selected port.
# portmanager x11/gnome2
If there are any problems regarding the dependencies for the selected port, you can use Portmanager to rebuild all of them in the correct order. Once finished, the problematic port will be rebuilt too.
# portmanager graphics/gimp -f
For further information see portmanager(1).
4.5.5 Ports and Disk Space
Using the Ports Collection will use up disk space over time. After building and installing software from the ports, you should always remember to clean up the temporary work directories using the make clean command. You can sweep the whole Ports Collection with the following command:
# portsclean -C
You will accumulate a lot of old source distribution files in the distfiles directory over time. You can remove them by hand, or you can use the following command to delete all the distfiles that are no longer referenced by any ports:
# portsclean -D
Or to remove all distfiles not referenced by any port currently installed on your system:
# portsclean -DD
Note: The portsclean utility is part of the portupgrade suite.
Do not forget to remove the installed ports once you no longer need them. A nice tool to help automate this task is available from the ports-mgmt/pkg_cutleaves port.
4.6 Post-installation Activities
After installing a new application you will normally want to read any documentation it may have included, edit any configuration files that are required, ensure that the application starts at boot time (if it is a daemon), and so on.
The exact steps you need to take to configure each application will obviously be different. However, if you have just installed a new application and are wondering “What now?” these tips might help:
-
Use pkg_info(1) to find out which files were installed, and where. For example, if you have just installed FooPackage version 1.0.0, then this command
# pkg_info -L foopackage-1.0.0 | lesswill show all the files installed by the package. Pay special attention to files in man/ directories, which will be manual pages, etc/ directories, which will be configuration files, and doc/, which will be more comprehensive documentation.
If you are not sure which version of the application was just installed, a command like this
# pkg_info | grep -i foopackagewill find all the installed packages that have foopackage in the package name. Replace foopackage in your command line as necessary.
-
Once you have identified where the application's manual pages have been installed, review them using man(1). Similarly, look over the sample configuration files, and any additional documentation that may have been provided.
-
If the application has a web site, check it for additional documentation, frequently asked questions, and so forth. If you are not sure of the web site address it may be listed in the output from
# pkg_info foopackage-1.0.0A WWW: line, if present, should provide a URL for the application's web site.
-
Ports that should start at boot (such as Internet servers) will usually install a sample script in /usr/local/etc/rc.d. You should review this script for correctness and edit or rename it if needed. See Starting Services for more information.
4.7 Dealing with Broken Ports
If you come across a port that does not work for you, there are a few things you can do, including:
-
Find out if there is a fix pending for the port in the Problem Report database. If so, you may be able to use the proposed fix.
-
Ask the maintainer of the port for help. Type make maintainer or read the Makefile to find the maintainer's email address. Remember to include the name and version of the port (send the $FreeBSD: line from the Makefile) and the output leading up to the error when you email the maintainer.
Note: Some ports are not maintained by an individual but instead by a mailing list. Many, but not all, of these addresses look like
<freebsd-listname@FreeBSD.org>. Please take this into account when phrasing your questions.In particular, ports shown as maintained by
<freebsd-ports@FreeBSD.org>are actually not maintained by anyone. Fixes and support, if any, come from the general community who subscribe to that mailing list. More volunteers are always needed!If you do not get a response, you can use send-pr(1) to submit a bug report (see Writing FreeBSD Problem Reports).
-
Fix it! The Porter's Handbook includes detailed information on the “Ports” infrastructure so that you can fix the occasional broken port or even submit your own!
-
Grab the package from an FTP site near you. The “master” package collection is on ftp.FreeBSD.org in the packages directory, but be sure to check your local mirror first! These are more likely to work than trying to compile from source and are a lot faster as well. Use the pkg_add(1) program to install the package on your system.
Chapter 5 The X Window System
Updated for X.Org's X11 server by Ken Tom and Marc Fonvieille.5.1 Synopsis
FreeBSD uses X11 to provide users with a powerful graphical user interface. X11 is a freely available version of the X Window System that is implemented in both Xorg and XFree86 (and other software packages not discussed here). FreeBSD versions up to and including FreeBSD 5.2.1-RELEASE will find the default installation to be XFree86, the X11 server released by The XFree86 Project, Inc. As of FreeBSD 5.3-RELEASE, the default and official flavor of X11 was changed to Xorg, the X11 server developed by the X.Org Foundation under a license very similar to the one used by FreeBSD. Commercial X servers for FreeBSD are also available.
This chapter will cover the installation and configuration of X11 with emphasis on Xorg 7.2 release. For information about configuring XFree86 (i.e. on older releases of FreeBSD where XFree86 was the default X11 distribution) or previous releases of Xorg, it is always possible to refer to archived versions of the FreeBSD Handbook at http://docs.FreeBSD.org/doc/.
For more information on the video hardware that X11 supports, check the Xorg web site.
After reading this chapter, you will know:
-
The various components of the X Window System, and how they interoperate.
-
How to install and configure X11.
-
How to install and use different window managers.
-
How to use TrueType® fonts in X11.
-
How to set up your system for graphical logins (XDM).
Before reading this chapter, you should:
-
Know how to install additional third-party software (Chapter 4).
5.2 Understanding X
Using X for the first time can be somewhat of a shock to someone familiar with other graphical environments, such as Microsoft Windows or Mac OS.
While it is not necessary to understand all of the details of various X components and how they interact, some basic knowledge makes it possible to take advantage of X's strengths.
5.2.1 Why X?
X is not the first window system written for UNIX, but it is the most popular of them. X's original development team had worked on another window system prior to writing X. That system's name was “W” (for “Window”). X was just the next letter in the Roman alphabet.
X can be called “X”, “X Window System”, “X11”, and a number of other terms. You may find that using the term “X Windows” to describe X11 can be offensive to some people; for a bit more insight on this, see X(7).
5.2.2 The X Client/Server Model
X was designed from the beginning to be network-centric, and adopts a “client-server” model.
In the X model, the “X server” runs on the computer that has the keyboard, monitor, and mouse attached. The server's responsibility includes tasks such as managing the display, handling input from the keyboard and mouse, and so on. Each X application (such as XTerm, or Netscape) is a “client”. A client sends messages to the server such as “Please draw a window at these coordinates”, and the server sends back messages such as “The user just clicked on the OK button”.
In a home or small office environment, the X server and the X clients commonly run on the same computer. However, it is perfectly possible to run the X server on a less powerful desktop computer, and run X applications (the clients) on, say, the powerful and expensive machine that serves the office. In this scenario the communication between the X client and server takes place over the network.
This confuses some people, because the X terminology is exactly backward to what they expect. They expect the “X server” to be the big powerful machine down the hall, and the “X client” to be the machine on their desk.
It is important to remember that the X server is the machine with the monitor and keyboard, and the X clients are the programs that display the windows.
There is nothing in the protocol that forces the client and server machines to be running the same operating system, or even to be running on the same type of computer. It is certainly possible to run an X server on Microsoft Windows or Apple's Mac OS, and there are various free and commercial applications available that do exactly that.
5.2.3 The Window Manager
The X design philosophy is much like the UNIX design philosophy, “tools, not policy”. This means that X does not try to dictate how a task is to be accomplished. Instead, tools are provided to the user, and it is the user's responsibility to decide how to use those tools.
This philosophy extends to X not dictating what windows should look like on screen, how to move them around with the mouse, what keystrokes should be used to move between windows (i.e., Alt+Tab, in the case of Microsoft Windows), what the title bars on each window should look like, whether or not they have close buttons on them, and so on.
Instead, X delegates this responsibility to an application called a “Window Manager”. There are dozens of window managers available for X: AfterStep, Blackbox, ctwm, Enlightenment, fvwm, Sawfish, twm, Window Maker, and more. Each of these window managers provides a different look and feel; some of them support “virtual desktops”; some of them allow customized keystrokes to manage the desktop; some have a “Start” button or similar device; some are “themeable”, allowing a complete change of look-and-feel by applying a new theme. These window managers, and many more, are available in the x11-wm category of the Ports Collection.
In addition, the KDE and GNOME desktop environments both have their own window managers which integrate with the desktop.
Each window manager also has a different configuration mechanism; some expect configuration file written by hand, others feature GUI tools for most of the configuration tasks; at least one (Sawfish) has a configuration file written in a dialect of the Lisp language.
Focus Policy: Another feature the window manager is responsible for is the mouse “focus policy”. Every windowing system needs some means of choosing a window to be actively receiving keystrokes, and should visibly indicate which window is active as well.
A familiar focus policy is called “click-to-focus”. This is the model utilized by Microsoft Windows, in which a window becomes active upon receiving a mouse click.
X does not support any particular focus policy. Instead, the window manager controls which window has the focus at any one time. Different window managers will support different focus methods. All of them support click to focus, and the majority of them support several others.
The most popular focus policies are:
- focus-follows-mouse
The window that is under the mouse pointer is the window that has the focus. This may not necessarily be the window that is on top of all the other windows. The focus is changed by pointing at another window, there is no need to click in it as well.
- sloppy-focus
This policy is a small extension to focus-follows-mouse. With focus-follows-mouse, if the mouse is moved over the root window (or background) then no window has the focus, and keystrokes are simply lost. With sloppy-focus, focus is only changed when the cursor enters a new window, and not when exiting the current window.
- click-to-focus
The active window is selected by mouse click. The window may then be “raised”, and appear in front of all other windows. All keystrokes will now be directed to this window, even if the cursor is moved to another window.
Many window managers support other policies, as well as variations on these. Be sure to consult the documentation for the window manager itself.
5.2.4 Widgets
The X approach of providing tools and not policy extends to the widgets seen on screen in each application.
“Widget” is a term for all the items in the user interface that can be clicked or manipulated in some way; buttons, check boxes, radio buttons, icons, lists, and so on. Microsoft Windows calls these “controls”.
Microsoft Windows and Apple's Mac OS both have a very rigid widget policy. Application developers are supposed to ensure that their applications share a common look and feel. With X, it was not considered sensible to mandate a particular graphical style, or set of widgets to adhere to.
As a result, do not expect X applications to have a common look and feel. There are several popular widget sets and variations, including the original Athena widget set from MIT, Motif® (on which the widget set in Microsoft Windows was modeled, all bevelled edges and three shades of grey), OpenLook, and others.
Most newer X applications today will use a modern-looking widget set, either Qt, used by KDE, or GTK+, used by the GNOME project. In this respect, there is some convergence in look-and-feel of the UNIX desktop, which certainly makes things easier for the novice user.
5.3 Installing X11
Xorg is the default X11 implementation for FreeBSD. Xorg is the X server of the open source X Window System implementation released by the X.Org Foundation. Xorg is based on the code of XFree86 4.4RC2 and X11R6.6. The version of Xorg currently available in the FreeBSD Ports Collection is 7.2.
To build and install Xorg from the Ports Collection:
# cd /usr/ports/x11/xorg
# make install clean
Note: To build Xorg in its entirety, be sure to have at least 4 GB of free space available.
Alternatively, X11 can be installed directly from packages. Binary packages to use with pkg_add(1) tool are also available for X11. When the remote fetching feature of pkg_add(1) is used, the version number of the package must be removed. pkg_add(1) will automatically fetch the latest version of the application.
So to fetch and install the package of Xorg, simply type:
# pkg_add -r xorg
Note: The examples above will install the complete X11 distribution including the servers, clients, fonts etc. Separate packages and ports of X11 are also available.
The rest of this chapter will explain how to configure X11, and how to set up a productive desktop environment.
5.4 X11 Configuration
Contributed by Christopher Shumway.5.4.1 Before Starting
Before configuration of X11 the following information about the target system is needed:
-
Monitor specifications
-
Video Adapter chipset
-
Video Adapter memory
The specifications for the monitor are used by X11 to determine the resolution and refresh rate to run at. These specifications can usually be obtained from the documentation that came with the monitor or from the manufacturer's website. There are two ranges of numbers that are needed, the horizontal scan rate and the vertical synchronization rate.
The video adapter's chipset defines what driver module X11 uses to talk to the graphics hardware. With most chipsets, this can be automatically determined, but it is still useful to know in case the automatic detection does not work correctly.
Video memory on the graphic adapter determines the resolution and color depth which the system can run at. This is important to know so the user knows the limitations of the system.
5.4.2 Configuring X11
As of version 7.3, Xorg can often work without any configuration file by simply typing at prompt:
% startx
If this does not work, or if the default configuration is not acceptable, then X11 must be configured manually. Configuration of X11 is a multi-step process. The first step is to build an initial configuration file. As the super user, simply run:
# Xorg -configure
This will generate an X11 configuration skeleton file in the /root directory called xorg.conf.new (whether you su(1) or do a direct login affects the inherited supervisor $HOME directory variable). The X11 program will attempt to probe the graphics hardware on the system and write a configuration file to load the proper drivers for the detected hardware on the target system.
The next step is to test the existing configuration to verify that Xorg can work with the graphics hardware on the target system. To perform this task, type:
# Xorg -config xorg.conf.new
If a black and grey grid and an X mouse cursor appear, the configuration was successful. To exit the test, just press Ctrl+Alt+Backspace simultaneously.
Note: If the mouse does not work, you will need to first configure it before proceeding. See Section 2.10.10 in the FreeBSD install chapter.
Next, tune the xorg.conf.new configuration file to taste. Open the file in a text editor such as emacs(1) or ee(1). First, add the frequencies for the target system's monitor. These are usually expressed as a horizontal and vertical synchronization rate. These values are added to the xorg.conf.new file under the "Monitor" section:
Section "Monitor"
Identifier "Monitor0"
VendorName "Monitor Vendor"
ModelName "Monitor Model"
HorizSync 30-107
VertRefresh 48-120
EndSection
The HorizSync and VertRefresh keywords may be missing in the configuration file. If they are, they need to be added, with the correct horizontal synchronization rate placed after the HorizSync keyword and the vertical synchronization rate after the VertRefresh keyword. In the example above the target monitor's rates were entered.
X allows DPMS (Energy Star) features to be used with capable monitors. The xset(1) program controls the time-outs and can force standby, suspend, or off modes. If you wish to enable DPMS features for your monitor, you must add the following line to the monitor section:
Option "DPMS"
While the xorg.conf.new configuration file is still open in an editor, select the default resolution and color depth desired. This is defined in the "Screen" section:
Section "Screen"
Identifier "Screen0"
Device "Card0"
Monitor "Monitor0"
DefaultDepth 24
SubSection "Display"
Viewport 0 0
Depth 24
Modes "1024x768"
EndSubSection
EndSection
The DefaultDepth keyword describes the color depth to run at
by default. This can be overridden with the -depth command
line switch to Xorg(1). The Modes keyword describes the resolution to run at for the given color
depth. Note that only VESA standard modes are supported as defined by the target system's
graphics hardware. In the example above, the default color depth is twenty-four bits per
pixel. At this color depth, the accepted resolution is 1024 by 768 pixels.
Finally, write the configuration file and test it using the test mode given above.
Note: One of the tools available to assist you during troubleshooting process are the X11 log files, which contain information on each device that the X11 server attaches to. Xorg log file names are in the format of /var/log/Xorg.0.log. The exact name of the log can vary from Xorg.0.log to Xorg.8.log and so forth.
If all is well, the configuration file needs to be installed in a common location where Xorg(1) can find it. This is typically /etc/X11/xorg.conf or /usr/local/etc/X11/xorg.conf.
# cp xorg.conf.new /etc/X11/xorg.conf
The X11 configuration process is now complete. Xorg may be now started with the startx(1) utility. The X11 server may also be started with the use of xdm(1).
Note: There is also a graphical configuration tool, xorgcfg(1), which comes with the X11 distribution. It allows you to interactively define your configuration by choosing the appropriate drivers and settings. This program can be invoked from the console, by typing the command xorgcfg -textmode. For more details, refer to the xorgcfg(1) manual page.
Alternatively, there is also a tool called xorgconfig(1). This program is a console utility that is less user friendly, but it may work in situations where the other tools do not.
5.4.3 Advanced Configuration Topics
5.4.3.1 Configuration with Intel® i810 Graphics Chipsets
Configuration with Intel i810 integrated chipsets requires the agpgart AGP programming interface for X11 to drive the card. See the agp(4) driver manual page for more information.
This will allow configuration of the hardware as any other graphics board. Note on systems without the agp(4) driver compiled in the kernel, trying to load the module with kldload(8) will not work. This driver has to be in the kernel at boot time through being compiled in or using /boot/loader.conf.
5.4.3.2 Adding a Widescreen Flatpanel to the Mix
This section assumes a bit of advanced configuration knowledge. If attempts to use the standard configuration tools above have not resulted in a working configuration, there is information enough in the log files to be of use in getting the setup working. Use of a text editor will be necessary.
Current widescreen (WSXGA, WSXGA+, WUXGA, WXGA, WXGA+, et.al.) formats support 16:10 and 10:9 formats or aspect ratios that can be problematic. Examples of some common screen resolutions for 16:10 aspect ratios are:
-
2560x1600
-
1920x1200
-
1680x1050
-
1440x900
-
1280x800
At some point, it will be as easy as adding one of these resolutions as a possible Mode in the Section "Screen" as such:
Section "Screen"
Identifier "Screen0"
Device "Card0"
Monitor "Monitor0"
DefaultDepth 24
SubSection "Display"
Viewport 0 0
Depth 24
Modes "1680x1050"
EndSubSection
EndSection
Xorg is smart enough to pull the resolution information from the widescreen via I2C/DDC information so it knows what the monitor can handle as far as frequencies and resolutions.
If those ModeLines do not exist in the drivers, one might need to give Xorg a little hint. Using /var/log/Xorg.0.log one can extract enough information to manually create a ModeLine that will work. Simply look for information resembling this:
(II) MGA(0): Supported additional Video Mode:
(II) MGA(0): clock: 146.2 MHz Image Size: 433 x 271 mm
(II) MGA(0): h_active: 1680 h_sync: 1784 h_sync_end 1960 h_blank_end 2240 h_border: 0
(II) MGA(0): v_active: 1050 v_sync: 1053 v_sync_end 1059 v_blanking: 1089 v_border: 0
(II) MGA(0): Ranges: V min: 48 V max: 85 Hz, H min: 30 H max: 94 kHz, PixClock max 170 MHz
This information is called EDID information. Creating a ModeLine from this is just a matter of putting the numbers in the correct order:
ModeLine <name> <clock> <4 horiz. timings> <4 vert. timings>
So that the ModeLine in Section "Monitor" for this example would look like this:
Section "Monitor"
Identifier "Monitor1"
VendorName "Bigname"
ModelName "BestModel"
ModeLine "1680x1050" 146.2 1680 1784 1960 2240 1050 1053 1059 1089
Option "DPMS"
EndSection
Now having completed these simple editing steps, X should start on your new widescreen monitor.
5.5 Using Fonts in X11
Contributed by Murray Stokely.5.5.1 Type1 Fonts
The default fonts that ship with X11 are less than ideal for typical desktop publishing applications. Large presentation fonts show up jagged and unprofessional looking, and small fonts in Netscape are almost completely unintelligible. However, there are several free, high quality Type1 (PostScript®) fonts available which can be readily used with X11. For instance, the URW font collection (x11-fonts/urwfonts) includes high quality versions of standard type1 fonts (Times Roman®, Helvetica®, Palatino® and others). The Freefonts collection (x11-fonts/freefonts) includes many more fonts, but most of them are intended for use in graphics software such as the Gimp, and are not complete enough to serve as screen fonts. In addition, X11 can be configured to use TrueType fonts with a minimum of effort. For more details on this, see the X(7) manual page or the section on TrueType fonts.
To install the above Type1 font collections from the ports collection, run the following commands:
# cd /usr/ports/x11-fonts/urwfonts
# make install clean
And likewise with the freefont or other collections. To have the X server detect these fonts, add an appropriate line to the X server configuration file (/etc/X11/xorg.conf), which reads:
FontPath "/usr/local/lib/X11/fonts/URW/"
Alternatively, at the command line in the X session run:
% xset fp+ /usr/local/lib/X11/fonts/URW
% xset fp rehash
This will work but will be lost when the X session is closed, unless it is added to the startup file (~/.xinitrc for a normal startx session, or ~/.xsession when logging in through a graphical login manager like XDM). A third way is to use the new /usr/local/etc/fonts/local.conf file: see the section on anti-aliasing.
5.5.2 TrueType® Fonts
Xorg has built in support for rendering TrueType fonts. There are two different modules that can enable this functionality. The freetype module is used in this example because it is more consistent with the other font rendering back-ends. To enable the freetype module just add the following line to the "Module" section of the /etc/X11/xorg.conf file.
Load "freetype"
Now make a directory for the TrueType fonts (for example, /usr/local/lib/X11/fonts/TrueType) and copy all of the TrueType fonts into this directory. Keep in mind that TrueType fonts cannot be directly taken from a Macintosh®; they must be in UNIX/MS-DOS/Windows format for use by X11. Once the files have been copied into this directory, use ttmkfdir to create a fonts.dir file, so that the X font renderer knows that these new files have been installed. ttmkfdir is available from the FreeBSD Ports Collection as x11-fonts/ttmkfdir.
# cd /usr/local/lib/X11/fonts/TrueType
# ttmkfdir -o fonts.dir
Now add the TrueType directory to the font path. This is just the same as described above for Type1 fonts, that is, use
% xset fp+ /usr/local/lib/X11/fonts/TrueType
% xset fp rehash
or add a FontPath line to the xorg.conf file.
That's it. Now Netscape, Gimp, StarOffice™, and all of the other X applications should now recognize the installed TrueType fonts. Extremely small fonts (as with text in a high resolution display on a web page) and extremely large fonts (within StarOffice) will look much better now.
5.5.3 Anti-Aliased Fonts
Updated by Joe Marcus Clarke.Anti-aliasing has been available in X11 since XFree86 4.0.2. However, font configuration was cumbersome before the introduction of XFree86 4.3.0. Beginning with XFree86 4.3.0, all fonts in X11 that are found in /usr/local/lib/X11/fonts/ and ~/.fonts/ are automatically made available for anti-aliasing to Xft-aware applications. Not all applications are Xft-aware, but many have received Xft support. Examples of Xft-aware applications include Qt 2.3 and higher (the toolkit for the KDE desktop), GTK+ 2.0 and higher (the toolkit for the GNOME desktop), and Mozilla 1.2 and higher.
In order to control which fonts are anti-aliased, or to configure anti-aliasing properties, create (or edit, if it already exists) the file /usr/local/etc/fonts/local.conf. Several advanced features of the Xft font system can be tuned using this file; this section describes only some simple possibilities. For more details, please see fonts-conf(5).
This file must be in XML format. Pay careful attention to case, and make sure all tags are properly closed. The file begins with the usual XML header followed by a DOCTYPE definition, and then the <fontconfig> tag:
<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
As previously stated, all fonts in /usr/local/lib/X11/fonts/ as well as ~/.fonts/ are already made available to Xft-aware applications. If you wish to add another directory outside of these two directory trees, add a line similar to the following to /usr/local/etc/fonts/local.conf:
<dir>/path/to/my/fonts</dir>
After adding new fonts, and especially new font directories, you should run the following command to rebuild the font caches:
# fc-cache -f
Anti-aliasing makes borders slightly fuzzy, which makes very small text more readable and removes “staircases” from large text, but can cause eyestrain if applied to normal text. To exclude font sizes smaller than 14 point from anti-aliasing, include these lines:
<match target="font">
<test name="size" compare="less">
<double>14</double>
</test>
<edit name="antialias" mode="assign">
<bool>false</bool>
</edit>
</match>
<match target="font">
<test name="pixelsize" compare="less" qual="any">
<double>14</double>
</test>
<edit mode="assign" name="antialias">
<bool>false</bool>
</edit>
</match>
Spacing for some monospaced fonts may also be inappropriate with anti-aliasing. This seems to be an issue with KDE, in particular. One possible fix for this is to force the spacing for such fonts to be 100. Add the following lines:
<match target="pattern" name="family">
<test qual="any" name="family">
<string>fixed</string>
</test>
<edit name="family" mode="assign">
<string>mono</string>
</edit>
</match>
<match target="pattern" name="family">
<test qual="any" name="family">
<string>console</string>
</test>
<edit name="family" mode="assign">
<string>mono</string>
</edit>
</match>
(this aliases the other common names for fixed fonts as "mono"), and then add:
<match target="pattern" name="family">
<test qual="any" name="family">
<string>mono</string>
</test>
<edit name="spacing" mode="assign">
<int>100</int>
</edit>
</match>
Certain fonts, such as Helvetica, may have a problem when anti-aliased. Usually this manifests itself as a font that seems cut in half vertically. At worst, it may cause applications such as Mozilla to crash. To avoid this, consider adding the following to local.conf:
<match target="pattern" name="family">
<test qual="any" name="family">
<string>Helvetica</string>
</test>
<edit name="family" mode="assign">
<string>sans-serif</string>
</edit>
</match>
Once you have finished editing local.conf make sure you end the file with the </fontconfig> tag. Not doing this will cause your changes to be ignored.
The default font set that comes with X11 is not very desirable when it comes to anti-aliasing. A much better set of default fonts can be found in the x11-fonts/bitstream-vera port. This port will install a /usr/local/etc/fonts/local.conf file if one does not exist already. If the file does exist, the port will create a /usr/local/etc/fonts/local.conf-vera file. Merge the contents of this file into /usr/local/etc/fonts/local.conf, and the Bitstream fonts will automatically replace the default X11 Serif, Sans Serif, and Monospaced fonts.
Finally, users can add their own settings via their personal .fonts.conf files. To do this, each user should simply create a ~/.fonts.conf. This file must also be in XML format.
One last point: with an LCD screen, sub-pixel sampling may be desired. This basically treats the (horizontally separated) red, green and blue components separately to improve the horizontal resolution; the results can be dramatic. To enable this, add the line somewhere in the local.conf file:
<match target="font">
<test qual="all" name="rgba">
<const>unknown</const>
</test>
<edit name="rgba" mode="assign">
<const>rgb</const>
</edit>
</match>
Note: Depending on the sort of display, rgb may need to be changed to bgr, vrgb or vbgr: experiment and see which works best.
Anti-aliasing should be enabled the next time the X server is started. However, programs must know how to take advantage of it. At present, the Qt toolkit does, so the entire KDE environment can use anti-aliased fonts. GTK+ and GNOME can also be made to use anti-aliasing via the “Font” capplet (see Section 5.7.1.3 for details). By default, Mozilla 1.2 and greater will automatically use anti-aliasing. To disable this, rebuild Mozilla with the -DWITHOUT_XFT flag.
5.6 The X Display Manager
Contributed by Seth Kingsley.5.6.1 Overview
The X Display Manager (XDM) is an optional part of the X Window System that is used for login session management. This is useful for several types of situations, including minimal “X Terminals”, desktops, and large network display servers. Since the X Window System is network and protocol independent, there are a wide variety of possible configurations for running X clients and servers on different machines connected by a network. XDM provides a graphical interface for choosing which display server to connect to, and entering authorization information such as a login and password combination.
Think of XDM as providing the same functionality to the user as the getty(8) utility (see Section 24.3.2 for details). That is, it performs system logins to the display being connected to and then runs a session manager on behalf of the user (usually an X window manager). XDM then waits for this program to exit, signaling that the user is done and should be logged out of the display. At this point, XDM can display the login and display chooser screens for the next user to login.
5.6.2 Using XDM
The XDM daemon program is located in /usr/local/bin/xdm. This program can be run at any time as root and it will start managing the X display on the local machine. If XDM is to be run every time the machine boots up, a convenient way to do this is by adding an entry to /etc/ttys. For more information about the format and usage of this file, see Section 24.3.2.1. There is a line in the default /etc/ttys file for running the XDM daemon on a virtual terminal:
ttyv8 "/usr/local/bin/xdm -nodaemon" xterm off secure
By default this entry is disabled; in order to enable it change field 5 from off to on and restart init(8) using the directions in Section 24.3.2.2. The first field, the name of the terminal this program will manage, is ttyv8. This means that XDM will start running on the 9th virtual terminal.
5.6.3 Configuring XDM
The XDM configuration directory is located in /usr/local/lib/X11/xdm. In this directory there are several files used to change the behavior and appearance of XDM. Typically these files will be found:
| File | Description |
|---|---|
| Xaccess | Client authorization ruleset. |
| Xresources | Default X resource values. |
| Xservers | List of remote and local displays to manage. |
| Xsession | Default session script for logins. |
| Xsetup_* | Script to launch applications before the login interface. |
| xdm-config | Global configuration for all displays running on this machine. |
| xdm-errors | Errors generated by the server program. |
| xdm-pid | The process ID of the currently running XDM. |
Also in this directory are a few scripts and programs used to set up the desktop when XDM is running. The purpose of each of these files will be briefly described. The exact syntax and usage of all of these files is described in xdm(1).
The default configuration is a simple rectangular login window with the hostname of the machine displayed at the top in a large font and “Login:” and “Password:” prompts below. This is a good starting point for changing the look and feel of XDM screens.
5.6.3.1 Xaccess
The protocol for connecting to XDM-controlled displays is called the X Display Manager Connection Protocol (XDMCP). This file is a ruleset for controlling XDMCP connections from remote machines. It is ignored unless the xdm-config is changed to listen for remote connections. By default, it does not allow any clients to connect.
5.6.3.2 Xresources
This is an application-defaults file for the display chooser and login screens. In it, the appearance of the login program can be modified. The format is identical to the app-defaults file described in the X11 documentation.
5.6.3.4 Xsession
This is the default session script for XDM to run after a user has logged in. Normally each user will have a customized session script in ~/.xsession that overrides this script.
5.6.3.5 Xsetup_*
These will be run automatically before displaying the chooser or login interfaces. There is a script for each display being used, named Xsetup_ followed by the local display number (for instance Xsetup_0). Typically these scripts will run one or two programs in the background such as xconsole.
5.6.3.6 xdm-config
This contains settings in the form of app-defaults that are applicable to every display that this installation manages.
5.6.3.7 xdm-errors
This contains the output of the X servers that XDM is trying to run. If a display that XDM is trying to start hangs for some reason, this is a good place to look for error messages. These messages are also written to the user's ~/.xsession-errors file on a per-session basis.
5.6.4 Running a Network Display Server
In order for other clients to connect to the display server, you must edit the access control rules and enable the connection listener. By default these are set to conservative values. To make XDM listen for connections, first comment out a line in the xdm-config file:
! SECURITY: do not listen for XDMCP or Chooser requests
! Comment out this line if you want to manage X terminals with xdm
DisplayManager.requestPort: 0
and then restart XDM. Remember that comments in app-defaults files begin with a “!” character, not the usual “#”. More strict access controls may be desired -- look at the example entries in Xaccess, and refer to the xdm(1) manual page for further information.
5.6.5 Replacements for XDM
Several replacements for the default XDM program exist. One of them, kdm (bundled with KDE) is described later in this chapter. The kdm display manager offers many visual improvements and cosmetic frills, as well as the functionality to allow users to choose their window manager of choice at login time.
5.7 Desktop Environments
Contributed by Valentino Vaschetto.This section describes the different desktop environments available for X on FreeBSD. A “desktop environment” can mean anything ranging from a simple window manager to a complete suite of desktop applications, such as KDE or GNOME.
5.7.1 GNOME
5.7.1.1 About GNOME
GNOME is a user-friendly desktop environment that enables users to easily use and configure their computers. GNOME includes a panel (for starting applications and displaying status), a desktop (where data and applications can be placed), a set of standard desktop tools and applications, and a set of conventions that make it easy for applications to cooperate and be consistent with each other. Users of other operating systems or environments should feel right at home using the powerful graphics-driven environment that GNOME provides. More information regarding GNOME on FreeBSD can be found on the FreeBSD GNOME Project's web site. The web site also contains fairly comprehensive FAQs about installing, configuring, and managing GNOME.
5.7.1.2 Installing GNOME
The software can be easily installed from a package or the Ports Collection:
To install the GNOME package from the network, simply type:
# pkg_add -r gnome2
To build GNOME from source, use the ports tree:
# cd /usr/ports/x11/gnome2
# make install clean
Once GNOME is installed, the X server must be told to start GNOME instead of a default window manager.
The easiest way to start GNOME is with GDM, the GNOME Display Manager. GDM, which is installed as a part of the GNOME desktop (but is disabled by default), can be enabled by adding gdm_enable="YES" to /etc/rc.conf. Once you have rebooted, GNOME will start automatically once you log in -- no further configuration is necessary.
GNOME may also be started from the command-line by properly configuring a file named .xinitrc. If a custom .xinitrc is already in place, simply replace the line that starts the current window manager with one that starts /usr/local/bin/gnome-session instead. If nothing special has been done to the configuration file, then it is enough simply to type:
% echo "/usr/local/bin/gnome-session" > ~/.xinitrc
Next, type startx, and the GNOME desktop environment will be started.
Note: If an older display manager, like XDM, is being used, this will not work. Instead, create an executable .xsession file with the same command in it. To do this, edit the file and replace the existing window manager command with /usr/local/bin/gnome-session:
% echo "#!/bin/sh" > ~/.xsession
% echo "/usr/local/bin/gnome-session" >> ~/.xsession
% chmod +x ~/.xsession
Yet another option is to configure the display manager to allow choosing the window manager at login time; the section on KDE details explains how to do this for kdm, the display manager of KDE.
5.7.1.3 Anti-aliased Fonts with GNOME
X11 supports anti-aliasing via its “RENDER” extension. GTK+ 2.0 and
greater (the toolkit used by GNOME) can make use of this
functionality. Configuring anti-aliasing is described in Section
5.5.3. So, with up-to-date software, anti-aliasing is possible within the GNOME desktop. Just go to Applications->Desktop
Preferences->Font, and select either Best shapes, Best contrast, or
Subpixel smoothing (LCDs). For a GTK+ application that is
not part of the GNOME desktop, set the environment variable
GDK_USE_XFT to 1 before launching
the program.
5.7.2 KDE
5.7.2.1 About KDE
KDE is an easy to use contemporary desktop environment. Some of the things that KDE brings to the user are:
-
A beautiful contemporary desktop
-
A desktop exhibiting complete network transparency
-
An integrated help system allowing for convenient, consistent access to help on the use of the KDE desktop and its applications
-
Consistent look and feel of all KDE applications
-
Standardized menu and toolbars, keybindings, color-schemes, etc.
-
Internationalization: KDE is available in more than 40 languages
-
Centralized, consistent, dialog-driven desktop configuration
-
A great number of useful KDE applications
KDE comes with a web browser called Konqueror, which is a solid competitor to other existing web browsers on UNIX systems. More information on KDE can be found on the KDE website. For FreeBSD specific information and resources on KDE, consult the KDE on FreeBSD team's website.
5.7.2.2 Installing KDE
Just as with GNOME or any other desktop environment, the software can be easily installed from a package or the Ports Collection:
To install the KDE package from the network, simply type:
# pkg_add -r kde
pkg_add(1) will automatically fetch the latest version of the application.
To build KDE from source, use the ports tree:
# cd /usr/ports/x11/kde3
# make install clean
After KDE has been installed, the X server must be told to launch this application instead of the default window manager. This is accomplished by editing the .xinitrc file:
% echo "exec startkde" > ~/.xinitrc
Now, whenever the X Window System is invoked with startx, KDE will be the desktop.
If a display manager such as XDM is being used, the configuration is slightly different. Edit the .xsession file instead. Instructions for kdm are described later in this chapter.
5.7.3 More Details on KDE
Now that KDE is installed on the system, most things can be discovered through the help pages, or just by pointing and clicking at various menus. Windows or Mac® users will feel quite at home.
The best reference for KDE is the on-line documentation. KDE comes with its own web browser, Konqueror, dozens of useful applications, and extensive documentation. The remainder of this section discusses the technical items that are difficult to learn by random exploration.
5.7.3.1 The KDE Display Manager
An administrator of a multi-user system may wish to have a graphical login screen to welcome users. XDM can be used, as described earlier. However, KDE includes an alternative, kdm, which is designed to look more attractive and include more login-time options. In particular, users can easily choose (via a menu) which desktop environment (KDE, GNOME, or something else) to run after logging on.
To enable kdm, the ttyv8 entry in /etc/ttys has to be adapted. The line should look as follows:
ttyv8 "/usr/local/bin/kdm -nodaemon" xterm on secure
5.7.4 XFce
5.7.4.1 About XFce
XFce is a desktop environment based on the GTK+ toolkit used by GNOME, but is much more lightweight and meant for those who want a simple, efficient desktop which is nevertheless easy to use and configure. Visually, it looks very much like CDE, found on commercial UNIX systems. Some of XFce's features are:
-
A simple, easy-to-handle desktop
-
Fully configurable via mouse, with drag and drop, etc.
-
Main panel similar to CDE, with menus, applets and applications launchers
-
Integrated window manager, file manager, sound manager, GNOME compliance module, and more
-
Themeable (since it uses GTK+)
-
Fast, light and efficient: ideal for older/slower machines or machines with memory limitations
More information on XFce can be found on the XFce website.
5.7.4.2 Installing XFce
A binary package for XFce exists (at the time of writing). To install, simply type:
# pkg_add -r xfce4
Alternatively, to build from source, use the ports collection:
# cd /usr/ports/x11-wm/xfce4
# make install clean
Now, tell the X server to launch XFce the next time X is started. Simply type this:
% echo "/usr/local/bin/startxfce4" > ~/.xinitrc
The next time X is started, XFce will be the desktop. As before, if a display manager like XDM is being used, create an .xsession, as described in the section on GNOME, but with the /usr/local/bin/startxfce4 command; or, configure the display manager to allow choosing a desktop at login time, as explained in the section on kdm.
II. Common Tasks
Now that the basics have been covered, this part of the FreeBSD Handbook will discuss some frequently used features of FreeBSD. These chapters:
-
Introduce you to popular and useful desktop applications: browsers, productivity tools, document viewers, etc.
-
Introduce you to a number of multimedia tools available for FreeBSD.
-
Explain the process of building a customized FreeBSD kernel, to enable extra functionality on your system.
-
Describe the print system in detail, both for desktop and network-connected printer setups.
-
Show you how to run Linux applications on your FreeBSD system.
Some of these chapters recommend that you do some prior reading, and this is noted in the synopsis at the beginning of each chapter.
- Table of Contents
- 6 Desktop Applications
- 7 Multimedia
- 8 Configuring the FreeBSD Kernel
- 9 Printing
- 10 Linux Binary Compatibility
Chapter 6 Desktop Applications
Contributed by Christophe Juniet.6.1 Synopsis
FreeBSD can run a wide variety of desktop applications, such as browsers and word processors. Most of these are available as packages or can be automatically built from the ports collection. Many new users expect to find these kinds of applications on their desktop. This chapter will show you how to install some popular desktop applications effortlessly, either from their packages or from the Ports Collection.
Note that when installing programs from the ports, they are compiled from source. This can take a very long time, depending on what you are compiling and the processing power of your machine(s). If building from source takes a prohibitively long amount of time for you, you can install most of the programs of the Ports Collection from pre-built packages.
As FreeBSD features Linux binary compatibility, many applications originally developed for Linux are available for your desktop. It is strongly recommended that you read Chapter 10 before installing any of the Linux applications. Many of the ports using the Linux binary compatibility start with “linux-”. Remember this when you search for a particular port, for instance with whereis(1). In the following text, it is assumed that you have enabled Linux binary compatibility before installing any of the Linux applications.
Here are the categories covered by this chapter:
-
Browsers (such as Mozilla, Opera, Firefox, Konqueror)
-
Productivity (such as KOffice, AbiWord, The GIMP, OpenOffice.org)
-
Document Viewers (such as Acrobat Reader®, gv, Xpdf, GQview)
-
Finance (such as GnuCash, Gnumeric, Abacus)
Before reading this chapter, you should:
-
Know how to install additional third-party software (Chapter 4).
-
Know how to install additional Linux software (Chapter 10).
For information on how to get a multimedia environment, read Chapter 7. If you want to set up and use electronic mail, please refer to Chapter 26.
6.2 Browsers
FreeBSD does not come with a particular browser pre-installed. Instead, the www directory of the Ports Collection contains a lot of browsers ready to be installed. If you do not have time to compile everything (this can take a very long time in some cases) many of them are available as packages.
KDE and GNOME already provide HTML browsers. Please refer to Section 5.7 for more information on how to set up these complete desktops.
If you are looking for light-weight browsers, you should investigate the Ports Collection for www/dillo, www/links, or www/w3m.
This section covers these applications:
| Application Name | Resources Needed | Installation from Ports | Major Dependencies |
|---|---|---|---|
| Mozilla | heavy | heavy | Gtk+ |
| Opera | light | light | FreeBSD and Linux versions available. The Linux version depends on the Linux Binary Compatibility and linux-openmotif. |
| Firefox | medium | heavy | Gtk+ |
| Konqueror | medium | heavy | KDE Libraries |
6.2.1 Mozilla
Mozilla is a modern, stable browser that is fully ported to FreeBSD: it features a very standards-compliant HTML display engine; it provides a mail and news reader. It even has a HTML composer if you plan to write some web pages yourself. Users of Netscape will recognize the similarities with the Communicator suite, as both browsers share some development history.
On slow machines, with a CPU speed less than 233MHz or with less than 64MB of RAM, Mozilla can be too resource-demanding to be fully usable. You may want to look at the Opera browser instead, described a little later in this chapter.
If you cannot or do not want to compile Mozilla, for whatever reason, the FreeBSD GNOME team has already done this for you. Just install the package from the network by:
# pkg_add -r mozilla
If the package is not available, and you have enough time and disk space, you can get the source for Mozilla, compile it and install it on your system. This is accomplished by:
# cd /usr/ports/www/mozilla
# make install clean
The Mozilla port ensures a correct initialization by running the chrome registry setup with root privileges. However, if you want to fetch some add-ons like mouse gestures, you must run Mozilla as root to get them properly installed.
Once you have completed the installation of Mozilla, you do not need to be root any longer. You can start Mozilla as a browser by typing:
% mozilla
You can start it directly as a mail and news reader as shown below:
% mozilla -mail
6.2.2 Firefox
Firefox is the next-generation browser based on the Mozilla codebase. Mozilla is a complete suite of applications, such as a browser, a mail client, a chat client and much more. Firefox is just a browser, which makes it smaller and faster.
Install the package by typing:
# pkg_add -r firefox
You can also use the Ports Collection if you prefer to compile from source code:
# cd /usr/ports/www/firefox
# make install clean
6.2.3 Firefox, Mozilla and Java™ plugin
Note: In this section and in the next one, we assume you have already installed Firefox or Mozilla.
The FreeBSD Foundation has a license with Sun Microsystems to distribute FreeBSD binaries for the Java Runtime Environment (JRE™) and Java Development Kit (JDK™). Binary packages for FreeBSD are available on the FreeBSD Foundation web site.
To add Java™ support to Firefox or Mozilla, you first have to install the java/javavmwrapper port. Then, download the Diablo JRE package from http://www.freebsdfoundation.org/downloads/java.shtml, and install it with pkg_add(1).
Start your browser, enter about:plugins in the location bar and press Enter. A page listing the installed plugins will be displayed; the Java plugin should be listed there now. If it is not, as root, run the following command:
# ln -s /usr/local/diablo-jre1.5.0/plugin/i386/ns7/libjavaplugin_oji.so \
/usr/local/lib/browser_plugins/
then relaunch your browser.
6.2.4 Firefox, Mozilla and Macromedia® Flash™ plugin
Macromedia® Flash™ plugin is not available for FreeBSD. However, a software layer (wrapper) for running the Linux version of the plugin exists. This wrapper also supports Adobe® Acrobat® plugin, RealPlayer® plugin and more.
Install the www/linuxpluginwrapper port. This port requires emulators/linux_base which is a large port. Follow the instructions displayed by the port to set up your /etc/libmap.conf correctly! Example configurations are installed into /usr/local/share/examples/linuxpluginwrapper/ directory.
The next step is to install the www/linux-flashplugin7 port. Once the plugin is installed, start your browser, enter about:plugins in the location bar and press Enter. A list should appear with all the currently available plugins.
If the Flash plugin is not listed, this is, most of time, caused by a missing symlink. As root, run the following commands:
# ln -s /usr/local/lib/npapi/linux-flashplugin/libflashplayer.so \
/usr/local/lib/browser_plugins/
# ln -s /usr/local/lib/npapi/linux-flashplugin/flashplayer.xpt \
/usr/local/lib/browser_plugins/
If you restart your browser the plugin should now appears in the previously mentioned list.
Note: The linuxpluginwrapper only works on the i386 system architecture.
6.2.5 Opera
Opera is a full-featured and standards-compliant browser. It also comes with a built-in mail and news reader, an IRC client, an RSS/Atom feeds reader and much more. Despite this, Opera is relatively lightweight and very fast. It comes in two flavors: a “native” FreeBSD version and a version that runs under Linux emulation.
To browse the Web with the FreeBSD version of Opera, install the package:
# pkg_add -r opera
Some FTP sites do not have all the packages, but Opera can still be obtained through the Ports Collection by typing:
# cd /usr/ports/www/opera
# make install clean
To install the Linux version of Opera, substitute linux-opera in place of opera in the examples above. The Linux version is useful in situations requiring the use of plug-ins that are only available for Linux, such as Adobe Acrobat Reader. In all other respects, the FreeBSD and Linux versions should be functionally identical.
6.2.6 Konqueror
Konqueror is part of KDE but it can also be used outside of KDE by installing x11/kdebase3. Konqueror is much more than a browser, it is also a file manager and a multimedia viewer.
There is also a set of plugins available for Konqueror, available in misc/konq-plugins.
Konqueror also supports Flash; a “How To” guide for getting Flash support on Konqueror is available at http://freebsd.kde.org/howto.php.
6.3 Productivity
When it comes to productivity, new users often look for a good office suite or a friendly word processor. While some desktop environments like KDE already provide an office suite, there is no default productivity package. FreeBSD can provide all that is needed, regardless of your desktop environment.
This section covers these applications:
| Application Name | Resources Needed | Installation from Ports | Major Dependencies |
|---|---|---|---|
| KOffice | light | heavy | KDE |
| AbiWord | light | light | Gtk+ or GNOME |
| The Gimp | light | heavy | Gtk+ |
| OpenOffice.org | heavy | huge | JDK 1.4, Mozilla |
6.3.1 KOffice
The KDE community has provided its desktop environment with an office suite which can be used outside KDE. It includes the four standard components that can be found in other office suites. KWord is the word processor, KSpread is the spreadsheet program, KPresenter manages slide presentations, and Kontour lets you draw graphical documents.
Before installing the latest KOffice, make sure you have an up-to-date version of KDE.
To install KOffice as a package, issue the following command:
# pkg_add -r koffice
If the package is not available, you can use the ports collection. For instance, to install KOffice for KDE3, do:
# cd /usr/ports/editors/koffice-kde3
# make install clean
6.3.2 AbiWord
AbiWord is a free word processing program similar in look and feel to Microsoft Word. It is suitable for typing papers, letters, reports, memos, and so forth. It is very fast, contains many features, and is very user-friendly.
AbiWord can import or export many file formats, including some proprietary ones like Microsoft's .doc.
AbiWord is available as a package. You can install it by:
# pkg_add -r abiword
If the package is not available, it can be compiled from the Ports Collection. The Ports Collection should be more up to date. It can be done as follows:
# cd /usr/ports/editors/abiword
# make install clean
6.3.3 The GIMP
For image authoring or picture retouching, The GIMP is a very sophisticated image manipulation program. It can be used as a simple paint program or as a quality photo retouching suite. It supports a large number of plug-ins and features a scripting interface. The GIMP can read and write a wide range of file formats. It supports interfaces with scanners and tablets.
You can install the package by issuing this command:
# pkg_add -r gimp
If your FTP site does not have this package, you can use the Ports Collection. The graphics directory of the Ports Collection also contains The Gimp Manual. Here is how to get them installed:
# cd /usr/ports/graphics/gimp
# make install clean
# cd /usr/ports/graphics/gimp-manual-pdf
# make install clean
Note: The graphics directory of the Ports Collection holds the development version of The GIMP in graphics/gimp-devel. An HTML version of The Gimp Manual is available from graphics/gimp-manual-html.
6.3.4 OpenOffice.org
OpenOffice.org includes all of the mandatory applications in a complete office productivity suite: a word processor, a spreadsheet, a presentation manager, and a drawing program. Its user interface is very similar to other office suites, and it can import and export in various popular file formats. It is available in a number of different languages -- internationalization has been extended to interfaces, spell checkers, and dictionaries.
The word processor of OpenOffice.org uses a native XML file format for increased portability and flexibility. The spreadsheet program features a macro language and it can be interfaced with external databases. OpenOffice.org is already stable and runs natively on Windows, Solaris™, Linux, FreeBSD, and Mac OS X. More information about OpenOffice.org can be found on the OpenOffice.org web site. For FreeBSD specific information, and to directly download packages, use the FreeBSD OpenOffice.org Porting Team's web site.
To install OpenOffice.org, do:
# pkg_add -r openoffice.org
Note: When running a -RELEASE version of FreeBSD, this should work. Otherwise, you should look on the FreeBSD OpenOffice.org Porting Team's web site to download and install the appropriate package using pkg_add(1). Both the current release and development version are available for download at this location.
Once the package is installed, you just have to type the following command to run OpenOffice.org:
% openoffice.org
Note: During the first launch, you will be asked some questions and a .openoffice.org2 folder will be created in your home directory.
If the OpenOffice.org packages are not available, you still have the option to compile the port. However, you must bear in mind that it requires a lot of disk space and a fairly long time to compile.
# cd /usr/ports/editors/openoffice.org-2
# make install clean
Note: If you want to build a localized version, replace the previous command line with the following:
# make LOCALIZED_LANG=your_language install cleanYou have to replace your_language with the correct language ISO-code. A list of supported language codes is available in the files/Makefile.localized file, located in the port directory.
Once this is done, OpenOffice.org can be launched with the command:
% openoffice.org
6.4 Document Viewers
Some new document formats have gained popularity since the advent of UNIX; the standard viewers they require may not be available in the base system. We will see how to install such viewers in this section.
This section covers these applications:
| Application Name | Resources Needed | Installation from Ports | Major Dependencies |
|---|---|---|---|
| Acrobat Reader | light | light | Linux Binary Compatibility |
| gv | light | light | Xaw3d |
| Xpdf | light | light | FreeType |
| GQview | light | light | Gtk+ or GNOME |
6.4.1 Acrobat Reader®
Many documents are now distributed as PDF files, which stands for “Portable Document Format”. One of the recommended viewers for these types of files is Acrobat Reader, released by Adobe for Linux. As FreeBSD can run Linux binaries, it is also available for FreeBSD.
To install Acrobat Reader 7 from the Ports collection, do:
# cd /usr/ports/print/acroread7
# make install clean
A package is not available due to licencing restrictions.
6.4.2 gv
gv is a PostScript and PDF viewer. It is originally based on ghostview but it has a nicer look thanks to the Xaw3d library. It is fast and its interface is clean. gv has many features, such as orientation, paper size, scale, and anti-aliasing. Almost any operation can be done with either the keyboard or the mouse.
To install gv as a package, do:
# pkg_add -r gv
If you cannot get the package, you can use the Ports collection:
# cd /usr/ports/print/gv
# make install clean
6.4.3 Xpdf
If you want a small FreeBSD PDF viewer, Xpdf is a light-weight and efficient viewer. It requires very few resources and is very stable. It uses the standard X fonts and does not require Motif or any other X toolkit.
To install the Xpdf package, issue this command:
# pkg_add -r xpdf
If the package is not available or you prefer to use the Ports Collection, do:
# cd /usr/ports/graphics/xpdf
# make install clean
Once the installation is complete, you can launch Xpdf and use the right mouse button to activate the menu.
6.4.4 GQview
GQview is an image manager. You can view a file with a single click, launch an external editor, get thumbnail previews, and much more. It also features a slideshow mode and some basic file operations. You can manage image collections and easily find duplicates. GQview can do full screen viewing and supports internationalization.
If you want to install the GQview package, do:
# pkg_add -r gqview
If the package is not available or you prefer to use the Ports Collection, do:
# cd /usr/ports/graphics/gqview
# make install clean
6.5 Finance
If, for any reason, you would like to manage your personal finances on your FreeBSD Desktop, there are some powerful and easy-to-use applications ready to be installed. Some of them are compatible with widespread file formats, such as the formats used by Quicken® and Excel to store documents.
This section covers these programs:
| Application Name | Resources Needed | Installation from Ports | Major Dependencies |
|---|---|---|---|
| GnuCash | light | heavy | GNOME |
| Gnumeric | light | heavy | GNOME |
| Abacus | light | light | Tcl/Tk |
| KMyMoney | light | heavy | KDE |
6.5.1 GnuCash
GnuCash is part of the GNOME effort to provide user-friendly, yet powerful, applications to end-users. With GnuCash, you can keep track of your income and expenses, your bank accounts, and your stocks. It features an intuitive interface while remaining very professional.
GnuCash provides a smart register, a hierarchical system of accounts, and many keyboard accelerators and auto-completion methods. It can split a single transaction into several more detailed pieces. GnuCash can import and merge Quicken QIF files. It also handles most international date and currency formats.
To install GnuCash on your system, do:
# pkg_add -r gnucash
If the package is not available, you can use the ports collection:
# cd /usr/ports/finance/gnucash
# make install clean
6.5.2 Gnumeric
Gnumeric is a spreadsheet program, part of the GNOME desktop environment. It features convenient automatic “guessing” of user input according to the cell format with an autofill system for many sequences. It can import files in a number of popular formats like those of Excel, Lotus 1-2-3, or Quattro Pro. Gnumeric supports graphs through the math/guppi graphing program. It has a large number of built-in functions and allows all of the usual cell formats such as number, currency, date, time, and much more.
To install Gnumeric as a package, do:
# pkg_add -r gnumeric
If the package is not available, you can use the ports collection by doing:
# cd /usr/ports/math/gnumeric
# make install clean
6.5.3 Abacus
Abacus is a small and easy to use spreadsheet program. It includes many built-in functions useful in several domains such as statistics, finances, and mathematics. It can import and export the Excel file format. Abacus can produce PostScript output.
To install Abacus as a package, do:
# pkg_add -r abacus
If the package is not available, you can use the ports collection by doing:
# cd /usr/ports/deskutils/abacus
# make install clean
6.5.4 KMyMoney
KMyMoney is a personal finance manager built for KDE. KMyMoney intends to provide and incorporate all the important features found in commercial personal finance manager applications. It also highlights ease-of-use and proper double-entry accounting among its features. KMyMoney imports from standard Quicken Interchange Format (QIF) files, tracks investments, handles multiple currencies, and provides a wealth of reports. OFX import capabilities are also available through a separate plugin.
To install KMyMoney as a package, do:
# pkg_add -r kmymoney2
If the package is not available, you can use the Ports Collection by doing:
# cd /usr/ports/finance/kmymoney2
# make install clean
6.6 Summary
While FreeBSD is popular among ISPs for its performance and stability, it is quite ready for day-to-day use as a desktop. With several thousand applications available as packages or ports, you can build a perfect desktop that suits all your needs.
Here is a quick review of all the desktop applications covered in this chapter:
| Application Name | Package Name | Ports Name |
|---|---|---|
| Mozilla | mozilla | www/mozilla |
| Opera | opera | www/opera |
| Firefox | firefox | www/firefox |
| KOffice | koffice-kde3 | editors/koffice-kde3 |
| AbiWord | abiword | editors/abiword |
| The GIMP | gimp | graphics/gimp |
| OpenOffice.org | openoffice | editors/openoffice-1.1 |
| Acrobat Reader | acroread | print/acroread7 |
| gv | gv | print/gv |
| Xpdf | xpdf | graphics/xpdf |
| GQview | gqview | graphics/gqview |
| GnuCash | gnucash | finance/gnucash |
| Gnumeric | gnumeric | math/gnumeric |
| Abacus | abacus | deskutils/abacus |
Chapter 7 Multimedia
Edited by Ross Lippert.7.1 Synopsis
FreeBSD supports a wide variety of sound cards, allowing you to enjoy high fidelity output from your computer. This includes the ability to record and playback audio in the MPEG Audio Layer 3 (MP3), WAV, and Ogg Vorbis formats as well as many other formats. The FreeBSD Ports Collection also contains applications allowing you to edit your recorded audio, add sound effects, and control attached MIDI devices.
With some experimentation, FreeBSD can support playback of video files and DVD's. The number of applications to encode, convert, and playback various video media is more limited than the number of sound applications. For example as of this writing, there is no good re-encoding application in the FreeBSD Ports Collection that could be used to convert between formats, as there is with audio/sox. However, the software landscape in this area is changing rapidly.
This chapter will describe the necessary steps to configure your sound card. The configuration and installation of X11 (Chapter 5) has already taken care of the hardware issues for your video card, though there may be some tweaks to apply for better playback.
After reading this chapter, you will know:
-
How to configure your system so that your sound card is recognized.
-
Methods to test whether your card is working.
-
How to troubleshoot your sound setup.
-
How to playback and encode MP3s and other audio.
-
How video is supported by the X server.
-
Some video player/encoder ports which give good results.
-
How to playback DVD's, .mpg and .avi files.
-
How to rip CD and DVD content into files.
-
How to configure a TV card.
-
How to configure an image scanner.
Before reading this chapter, you should:
-
Know how to configure and install a new kernel (Chapter 8).
Warning: Trying to mount audio CDs with the mount(8) command will result in an error, at least, and a kernel panic, at worst. These media have specialized encodings which differ from the usual ISO-filesystem.
7.2 Setting Up the Sound Card
Contributed by Moses Moore. Enhanced for FreeBSD 5.X by Marc Fonvieille.7.2.1 Configuring the System
Before you begin, you should know the model of the card you have, the chip it uses, and whether it is a PCI or ISA card. FreeBSD supports a wide variety of both PCI and ISA cards. Check the supported audio devices list of the Hardware Notes to see if your card is supported. The Hardware Notes will also mention which driver supports your card.
To use your sound device, you will need to load the proper device driver. This may be accomplished in one of two ways. The easiest way is to simply load a kernel module for your sound card with kldload(8) which can either be done from the command line:
# kldload snd_emu10k1
or by adding the appropriate line to the file /boot/loader.conf like this:
snd_emu10k1_load="YES"
These examples are for a Creative SoundBlaster® Live! sound card. Other available loadable sound modules are listed in /boot/defaults/loader.conf. If you are not sure which driver to use, you may try to load the snd_driver module:
# kldload snd_driver
This is a metadriver loading the most common device drivers at once. This speeds up the search for the correct driver. It is also possible to load all sound drivers via the /boot/loader.conf facility.
If you wish to find out the driver selected for your soundcard after loading the snd_driver metadriver, you may check the /dev/sndstat file with the cat /dev/sndstat command.
A second method is to statically compile in support for your sound card in your kernel. The section below provides the information you need to add support for your hardware in this manner. For more information about recompiling your kernel, please see Chapter 8.
7.2.1.1 Configuring a Custom Kernel with Sound Support
The first thing to do is add the audio framework driver sound(4) to the kernel; for that you will need to add the following line to the kernel configuration file:
device sound
Next, you have to add the support for your sound card. Therefore, you need to know which driver supports the card. Check the supported audio devices list of the Hardware Notes, to determine the correct driver for your sound card. For example, a Creative SoundBlaster Live! sound card is supported by the snd_emu10k1(4) driver. To add the support for this card, use the following:
device snd_emu10k1
Be sure to read the manual page of the driver for the syntax to use. The explicit syntax for the kernel configuration of every supported sound driver can also be found in the /usr/src/sys/conf/NOTES file.
Non-PnP ISA sound cards may require you to provide the kernel with information on the card settings (IRQ, I/O port, etc), as is true of all non-PnP ISA cards. This is done via the /boot/device.hints file. During the boot process, the loader(8) will read this file and pass the settings to the kernel. For example, an old Creative SoundBlaster 16 ISA non-PnP card will use the snd_sbc(4) driver in conjunction with snd_sb16. For this card the following lines must be added to the kernel configuration file:
device snd_sbc
device snd_sb16
and these to /boot/device.hints:
hint.sbc.0.at="isa"
hint.sbc.0.port="0x220"
hint.sbc.0.irq="5"
hint.sbc.0.drq="1"
hint.sbc.0.flags="0x15"
In this case, the card uses the 0x220 I/O port and the IRQ 5.
The syntax used in the /boot/device.hints file is covered in the sound(4) driver manual page and the manual page for the driver in question.
The settings shown above are the defaults. In some cases, you may need to change the IRQ or the other settings to match your card. See the snd_sbc(4) manual page for more information about this card.
7.2.2 Testing the Sound Card
After rebooting with the modified kernel, or after loading the required module, the sound card should appear in your system message buffer (dmesg(8)) as something like:
pcm0: <Intel ICH3 (82801CA)> port 0xdc80-0xdcbf,0xd800-0xd8ff irq 5 at device 31.5 on pci0
pcm0: [GIANT-LOCKED]
pcm0: <Cirrus Logic CS4205 AC97 Codec>
The status of the sound card may be checked via the /dev/sndstat file:
# cat /dev/sndstat
FreeBSD Audio Driver (newpcm)
Installed devices:
pcm0: <Intel ICH3 (82801CA)> at io 0xd800, 0xdc80 irq 5 bufsz 16384
kld snd_ich (1p/2r/0v channels duplex default)
The output from your system may vary. If no pcm devices are listed, go back and review what was done earlier. Go through your kernel configuration file again and make sure the correct device driver was chosen. Common problems are listed in Section 7.2.2.1.
If all goes well, you should now have a functioning sound card. If your CD-ROM or DVD-ROM drive's audio-out pins are properly connected to your sound card, you can put a CD in the drive and play it with cdcontrol(1):
% cdcontrol -f /dev/acd0 play 1
Various applications, such as audio/workman can provide a friendlier interface. You may want to install an application such as audio/mpg123 to listen to MP3 audio files.
Another quick way to test the card is sending data to /dev/dsp, like this:
% cat filename > /dev/dsp
where filename can be any file. This command line should produce some noise, confirming the sound card is actually working.
Sound card mixer levels can be changed via the mixer(8) command. More details can be found in the mixer(8) manual page.
7.2.2.1 Common Problems
| Error | Solution |
|---|---|
| “sb_dspwr(XX) timed out” |
The I/O port is not set correctly. |
| “bad irq XX” |
The IRQ is set incorrectly. Make sure that the set IRQ and the sound IRQ are the same. |
| “xxx: gus pcm not attached, out of memory” |
There is not enough available memory to use the device. |
| “xxx: can't open /dev/dsp!” |
Check with fstat | grep dsp if another application is holding the device open. Noteworthy troublemakers are esound and KDE's sound support. |
7.2.3 Utilizing Multiple Sound Sources
Contributed by Munish Chopra.It is often desirable to have multiple sources of sound that are able to play simultaneously, such as when esound or artsd do not support sharing of the sound device with a certain application.
FreeBSD lets you do this through Virtual Sound Channels, which can be enabled with the sysctl(8) facility. Virtual channels allow you to multiplex your sound card's playback by mixing sound in the kernel.
To set the number of virtual channels, there are two sysctl knobs which, if you are the root user, can be set like this:
# sysctl hw.snd.pcm0.vchans=4
# sysctl hw.snd.maxautovchans=4
The above example allocates four virtual channels, which is a practical number for
everyday use. hw.snd.pcm0.vchans is the number of virtual
channels pcm0 has, and is configurable once a device has been
attached. hw.snd.maxautovchans is the number of virtual channels
a new audio device is given when it is attached using kldload(8). Since the
pcm module can be loaded independently of the hardware
drivers, hw.snd.maxautovchans can store how many virtual
channels any devices which are attached later will be given.
Note: You cannot change the number of virtual channels for a device while it is in use. First close any programs using the device, such as music players or sound daemons.
If you are not using
devfs(5), you
will have to point your applications at /dev/dsp0.x, where x is 0 to 3
if hw.snd.pcm.0.vchans is set to 4 as in the above example.
On a system using
devfs(5), the
above will automatically be allocated transparently to a program that requests /dev/dsp0.
7.2.4 Setting Default Values for Mixer Channels
Contributed by Josef El-Rayes.The default values for the different mixer channels are hardcoded in the sourcecode of the pcm(4) driver. There are many different applications and daemons that allow you to set values for the mixer that are remembered between invocations, but this is not a clean solution. It is possible to set default mixer values at the driver level -- this is accomplished by defining the appropriate values in /boot/device.hints, e.g.:
hint.pcm.0.vol="50"
This will set the volume channel to a default value of 50 when the pcm(4) module is loaded.
7.3 MP3 Audio
Contributed by Chern Lee.MP3 (MPEG Layer 3 Audio) accomplishes near CD-quality sound, leaving no reason to let your FreeBSD workstation fall short of its offerings.
7.3.1 MP3 Players
By far, the most popular X11 MP3 player is XMMS (X Multimedia System). Winamp skins can be used with XMMS since the GUI is almost identical to that of Nullsoft's Winamp. XMMS also has native plug-in support.
XMMS can be installed from the multimedia/xmms port or package.
XMMS's interface is intuitive, with a playlist, graphic equalizer, and more. Those familiar with Winamp will find XMMS simple to use.
The audio/mpg123 port is an alternative, command-line MP3 player.
mpg123 can be run by specifying the sound device and the MP3 file on the command line, as shown below:
# mpg123 -a /dev/dsp1.0 Foobar-GreatestHits.mp3
High Performance MPEG 1.0/2.0/2.5 Audio Player for Layer 1, 2 and 3.
Version 0.59r (1999/Jun/15). Written and copyrights by Michael Hipp.
Uses code from various people. See 'README' for more!
THIS SOFTWARE COMES WITH ABSOLUTELY NO WARRANTY! USE AT YOUR OWN RISK!
Playing MPEG stream from Foobar-GreatestHits.mp3 ...
MPEG 1.0 layer III, 128 kbit/s, 44100 Hz joint-stereo
/dev/dsp1.0 should be replaced with the dsp device entry on your system.
7.3.2 Ripping CD Audio Tracks
Before encoding a CD or CD track to MP3, the audio data on the CD must be ripped onto the hard drive. This is done by copying the raw CDDA (CD Digital Audio) data to WAV files.
The cdda2wav tool, which is a part of the sysutils/cdrtools suite, is used for ripping audio information from CDs and the information associated with them.
With the audio CD in the drive, the following command can be issued (as root) to rip an entire CD into individual (per track) WAV files:
# cdda2wav -D 0,1,0 -B
cdda2wav will support ATAPI (IDE) CDROM drives. To rip from an IDE drive, specify the device name in place of the SCSI unit numbers. For example, to rip track 7 from an IDE drive:
# cdda2wav -D /dev/acd0 -t 7
The -D 0,1,0 indicates
the SCSI device 0,1,0, which corresponds to the output of cdrecord -scanbus.
To rip individual tracks, make use of the -t option as
shown:
# cdda2wav -D 0,1,0 -t 7
This example rips track seven of the audio CDROM. To rip a range of tracks, for example, track one to seven, specify a range:
# cdda2wav -D 0,1,0 -t 1+7
The utility dd(1) can also be used to extract audio tracks on ATAPI drives, read Section 18.6.5 for more information on that possibility.
7.3.3 Encoding MP3s
Nowadays, the mp3 encoder of choice is lame. Lame can be found at audio/lame in the ports tree.
Using the ripped WAV files, the following command will convert audio01.wav to audio01.mp3:
# lame -h -b 128 \
--tt "Foo Song Title" \
--ta "FooBar Artist" \
--tl "FooBar Album" \
--ty "2001" \
--tc "Ripped and encoded by Foo" \
--tg "Genre" \
audio01.wav audio01.mp3
128 kbits seems to be the standard MP3 bitrate in use. Many enjoy the higher
quality 160, or 192. The higher the bitrate, the more disk space the resulting MP3 will
consume--but the quality will be higher. The -h option turns
on the “higher quality but a little slower” mode. The options beginning with
--t indicate ID3 tags, which usually contain song
information, to be embedded within the MP3 file. Additional encoding options can be found
by consulting the lame man page.
7.3.4 Decoding MP3s
In order to burn an audio CD from MP3s, they must be converted to a non-compressed WAV format. Both XMMS and mpg123 support the output of MP3 to an uncompressed file format.
Writing to Disk in XMMS:
-
Launch XMMS.
-
Right-click on the window to bring up the XMMS menu.
-
Select Preference under Options.
-
Change the Output Plugin to “Disk Writer Plugin”.
-
Press Configure.
-
Enter (or choose browse) a directory to write the uncompressed files to.
-
Load the MP3 file into XMMS as usual, with volume at 100% and EQ settings turned off.
-
Press Play -- XMMS will appear as if it is playing the MP3, but no music will be heard. It is actually playing the MP3 to a file.
-
Be sure to set the default Output Plugin back to what it was before in order to listen to MP3s again.
Writing to stdout in mpg123:
-
Run mpg123 -s audio01.mp3 > audio01.pcm
XMMS writes a file in the WAV format, while mpg123 converts the MP3 into raw PCM audio data. Both of these formats can be used with cdrecord to create audio CDs. You have to use raw PCM with burncd(8). If you use WAV files, you will notice a small tick sound at the beginning of each track, this sound is the header of the WAV file. You can simply remove the header of a WAV file with the utility SoX (it can be installed from the audio/sox port or package):
% sox -t wav -r 44100 -s -w -c 2 track.wav track.raw
Read Section 18.6 for more information on using a CD burner in FreeBSD.
7.4 Video Playback
Contributed by Ross Lippert.Video playback is a very new and rapidly developing application area. Be patient. Not everything is going to work as smoothly as it did with sound.
Before you begin, you should know the model of the video card you have and the chip it uses. While Xorg and XFree86 support a wide variety of video cards, fewer give good playback performance. To obtain a list of extensions supported by the X server using your card use the command xdpyinfo(1) while X11 is running.
It is a good idea to have a short MPEG file which can be treated as a test file for evaluating various players and options. Since some DVD players will look for DVD media in /dev/dvd by default, or have this device name hardcoded in them, you might find it useful to make symbolic links to the proper devices:
# ln -sf /dev/acd0 /dev/dvd
# ln -sf /dev/acd0 /dev/rdvd
Note that due to the nature of devfs(5), manually created links like these will not persist if you reboot your system. In order to create the symbolic links automatically whenever you boot your system, add the following lines to /etc/devfs.conf:
link acd0 dvd
link acd0 rdvd
Additionally, DVD decryption, which requires invoking special DVD-ROM functions, requires write permission on the DVD devices.
To enhance the shared memory X11 interface, it is recommended that the values of some sysctl(8) variables should be increased:
kern.ipc.shmmax=67108864
kern.ipc.shmall=32768
7.4.1 Determining Video Capabilities
There are several possible ways to display video under X11. What will really work is largely hardware dependent. Each method described below will have varying quality across different hardware. Secondly, the rendering of video in X11 is a topic receiving a lot of attention lately, and with each version of Xorg, or of XFree86, there may be significant improvement.
A list of common video interfaces:
-
X11: normal X11 output using shared memory.
-
XVideo: an extension to the X11 interface which supports video in any X11 drawable.
-
SDL: the Simple Directmedia Layer.
-
DGA: the Direct Graphics Access.
-
SVGAlib: low level console graphics layer.
7.4.1.1 XVideo
Xorg and XFree86 4.X have an extension called XVideo (aka Xvideo, aka Xv, aka xv) which allows video to be directly displayed in drawable objects through a special acceleration. This extension provides very good quality playback even on low-end machines.
To check whether the extension is running, use xvinfo:
% xvinfo
XVideo is supported for your card if the result looks like:
X-Video Extension version 2.2
screen #0
Adaptor #0: "Savage Streams Engine"
number of ports: 1
port base: 43
operations supported: PutImage
supported visuals:
depth 16, visualID 0x22
depth 16, visualID 0x23
number of attributes: 5
"XV_COLORKEY" (range 0 to 16777215)
client settable attribute
client gettable attribute (current value is 2110)
"XV_BRIGHTNESS" (range -128 to 127)
client settable attribute
client gettable attribute (current value is 0)
"XV_CONTRAST" (range 0 to 255)
client settable attribute
client gettable attribute (current value is 128)
"XV_SATURATION" (range 0 to 255)
client settable attribute
client gettable attribute (current value is 128)
"XV_HUE" (range -180 to 180)
client settable attribute
client gettable attribute (current value is 0)
maximum XvImage size: 1024 x 1024
Number of image formats: 7
id: 0x32595559 (YUY2)
guid: 59555932-0000-0010-8000-00aa00389b71
bits per pixel: 16
number of planes: 1
type: YUV (packed)
id: 0x32315659 (YV12)
guid: 59563132-0000-0010-8000-00aa00389b71
bits per pixel: 12
number of planes: 3
type: YUV (planar)
id: 0x30323449 (I420)
guid: 49343230-0000-0010-8000-00aa00389b71
bits per pixel: 12
number of planes: 3
type: YUV (planar)
id: 0x36315652 (RV16)
guid: 52563135-0000-0000-0000-000000000000
bits per pixel: 16
number of planes: 1
type: RGB (packed)
depth: 0
red, green, blue masks: 0x1f, 0x3e0, 0x7c00
id: 0x35315652 (RV15)
guid: 52563136-0000-0000-0000-000000000000
bits per pixel: 16
number of planes: 1
type: RGB (packed)
depth: 0
red, green, blue masks: 0x1f, 0x7e0, 0xf800
id: 0x31313259 (Y211)
guid: 59323131-0000-0010-8000-00aa00389b71
bits per pixel: 6
number of planes: 3
type: YUV (packed)
id: 0x0
guid: 00000000-0000-0000-0000-000000000000
bits per pixel: 0
number of planes: 0
type: RGB (packed)
depth: 1
red, green, blue masks: 0x0, 0x0, 0x0
Also note that the formats listed (YUV2, YUV12, etc) are not present with every implementation of XVideo and their absence may hinder some players.
If the result looks like:
X-Video Extension version 2.2
screen #0
no adaptors present
Then XVideo is probably not supported for your card.
If XVideo is not supported for your card, this only means that it will be more difficult for your display to meet the computational demands of rendering video. Depending on your video card and processor, though, you might still be able to have a satisfying experience. You should probably read about ways of improving performance in the advanced reading Section 7.4.3.
7.4.1.2 Simple Directmedia Layer
The Simple Directmedia Layer, SDL, was intended to be a porting layer between Microsoft Windows, BeOS, and UNIX, allowing cross-platform applications to be developed which made efficient use of sound and graphics. The SDL layer provides a low-level abstraction to the hardware which can sometimes be more efficient than the X11 interface.
The SDL can be found at devel/sdl12.
7.4.1.3 Direct Graphics Access
Direct Graphics Access is an X11 extension which allows a program to bypass the X server and directly alter the framebuffer. Because it relies on a low level memory mapping to effect this sharing, programs using it must be run as root.
The DGA extension can be tested and benchmarked by dga(1). When dga is running, it changes the colors of the display whenever a key is pressed. To quit, use q.
7.4.2 Ports and Packages Dealing with Video
This section discusses the software available from the FreeBSD Ports Collection which can be used for video playback. Video playback is a very active area of software development, and the capabilities of various applications are bound to diverge somewhat from the descriptions given here.
Firstly, it is important to know that many of the video applications which run on FreeBSD were developed as Linux applications. Many of these applications are still beta-quality. Some of the problems that you may encounter with video packages on FreeBSD include:
-
An application cannot playback a file which another application produced.
-
An application cannot playback a file which the application itself produced.
-
The same application on two different machines, rebuilt on each machine for that machine, plays back the same file differently.
-
A seemingly trivial filter like rescaling of the image size results in very bad artifacts from a buggy rescaling routine.
-
An application frequently dumps core.
-
Documentation is not installed with the port and can be found either on the web or under the port's work directory.
Many of these applications may also exhibit “Linux-isms”. That is, there may be issues resulting from the way some standard libraries are implemented in the Linux distributions, or some features of the Linux kernel which have been assumed by the authors of the applications. These issues are not always noticed and worked around by the port maintainers, which can lead to problems like these:
-
The use of /proc/cpuinfo to detect processor characteristics.
-
A misuse of threads which causes a program to hang upon completion instead of truly terminating.
-
Software not yet in the FreeBSD Ports Collection which is commonly used in conjunction with the application.
So far, these application developers have been cooperative with port maintainers to minimize the work-arounds needed for port-ing.
7.4.2.1 MPlayer
MPlayer is a recently developed and rapidly developing video player. The goals of the MPlayer team are speed and flexibility on Linux and other Unices. The project was started when the team founder got fed up with bad playback performance on then available players. Some would say that the graphical interface has been sacrificed for a streamlined design. However, once you get used to the command line options and the key-stroke controls, it works very well.
7.4.2.1.1 Building MPlayer
MPlayer resides in multimedia/mplayer. MPlayer performs a variety of hardware checks during the build process, resulting in a binary which will not be portable from one system to another. Therefore, it is important to build it from ports and not to use a binary package. Additionally, a number of options can be specified in the make command line, as described in the Makefile and at the start of the build:
# cd /usr/ports/multimedia/mplayer
# make
N - O - T - E
Take a careful look into the Makefile in order
to learn how to tune mplayer towards you personal preferences!
For example,
make WITH_GTK1
builds MPlayer with GTK1-GUI support.
If you want to use the GUI, you can either install
/usr/ports/multimedia/mplayer-skins
or download official skin collections from
http://www.mplayerhq.hu/homepage/dload.html
The default port options should be sufficient for most users. However, if you need the XviD codec, you have to specify the WITH_XVID option in the command line. The default DVD device can also be defined with the WITH_DVD_DEVICE option, by default /dev/acd0 will be used.
As of this writing, the MPlayer port will build its HTML documentation and two executables, mplayer, and mencoder, which is a tool for re-encoding video.
The HTML documentation for MPlayer is very informative. If the reader finds the information on video hardware and interfaces in this chapter lacking, the MPlayer documentation is a very thorough supplement. You should definitely take the time to read the MPlayer documentation if you are looking for information about video support in UNIX.
7.4.2.1.2 Using MPlayer
Any user of MPlayer must set up a .mplayer subdirectory of her home directory. To create this necessary subdirectory, you can type the following:
% cd /usr/ports/multimedia/mplayer
% make install-user
The command options for mplayer are listed in the manual page. For even more detail there is HTML documentation. In this section, we will describe only a few common uses.
To play a file, such as testfile.avi, through one of the various video
interfaces set the -vo option:
% mplayer -vo xv testfile.avi
% mplayer -vo sdl testfile.avi
% mplayer -vo x11 testfile.avi
# mplayer -vo dga testfile.avi
# mplayer -vo 'sdl:dga' testfile.avi
It is worth trying all of these options, as their relative performance depends on many factors and will vary significantly with hardware.
To play from a DVD, replace the testfile.avi with dvd://N -dvd-device DEVICE where N
is the title number to play and DEVICE is the device node for the DVD-ROM. For
example, to play title 3 from /dev/dvd:
# mplayer -vo xv dvd://3 -dvd-device /dev/dvd
Note: The default DVD device can be defined during the build of the MPlayer port via the WITH_DVD_DEVICE option. By default, this device is /dev/acd0. More details can be found in the port Makefile.
To stop, pause, advance and so on, consult the keybindings, which are output by running mplayer -h or read the manual page.
Additional important options for playback are: -fs -zoom
which engages the fullscreen mode and -framedrop which helps
performance.
In order for the mplayer command line to not become too large, the user can create a file .mplayer/config and set default options there:
vo=xv
fs=yes
zoom=yes
Finally, mplayer can be used to rip a DVD title into a .vob file. To dump out the second title from a DVD, type this:
# mplayer -dumpstream -dumpfile out.vob dvd://2 -dvd-device /dev/dvd
The output file, out.vob, will be MPEG and can be manipulated by the other packages described in this section.
7.4.2.1.3 mencoder
Before using mencoder it is a good idea to familiarize yourself with the options from the HTML documentation. There is a manual page, but it is not very useful without the HTML documentation. There are innumerable ways to improve quality, lower bitrate, and change formats, and some of these tricks may make the difference between good or bad performance. Here are a couple of examples to get you going. First a simple copy:
% mencoder input.avi -oac copy -ovc copy -o output.avi
Improper combinations of command line options can yield output files that are
unplayable even by mplayer. Thus, if you just want to rip to a
file, stick to the -dumpfile in mplayer.
To convert input.avi to the MPEG4 codec with MPEG3 audio encoding (audio/lame is required):
% mencoder input.avi -oac mp3lame -lameopts br=192 \
-ovc lavc -lavcopts vcodec=mpeg4:vhq -o output.avi
This has produced output playable by mplayer and xine.
input.avi can be replaced with dvd://1
-dvd-device /dev/dvd and run as root to re-encode a DVD
title directly. Since you are likely to be dissatisfied with your results the first time
around, it is recommended you dump the title to a file and work on the file.
7.4.2.2 The xine Video Player
The xine video player is a project of wide scope aiming not only at being an all in one video solution, but also in producing a reusable base library and a modular executable which can be extended with plugins. It comes both as a package and as a port, multimedia/xine.
The xine player is still very rough around the edges, but it is clearly off to a good start. In practice, xine requires either a fast CPU with a fast video card, or support for the XVideo extension. The GUI is usable, but a bit clumsy.
As of this writing, there is no input module shipped with xine which will play CSS encoded DVD's. There are third party builds which do have modules for this built in them, but none of these are in the FreeBSD Ports Collection.
Compared to MPlayer, xine does more for the user, but at the same time, takes some of the more fine-grained control away from the user. The xine video player performs best on XVideo interfaces.
By default, xine player will start up in a graphical user interface. The menus can then be used to open a specific file:
% xine
Alternatively, it may be invoked to play a file immediately without the GUI with the command:
% xine -g -p mymovie.avi
7.4.2.3 The transcode Utilities
The software transcode is not a player, but a suite of tools for re-encoding video and audio files. With transcode, one has the ability to merge video files, repair broken files, using command line tools with stdin/stdout stream interfaces.
A great number of options can be specified during the build from the multimedia/transcode port, we recommend the following command line to build transcode:
# make WITH_OPTIMIZED_CFLAGS=yes WITH_LIBA52=yes WITH_LAME=yes WITH_OGG=yes \
WITH_MJPEG=yes -DWITH_XVID=yes
The proposed settings should be sufficient for most users.
To illustrate transcode capacities, one example to show how to convert a DivX file into a PAL MPEG-1 file (PAL VCD):
% transcode -i input.avi -V --export_prof vcd-pal -o output_vcd
% mplex -f 1 -o output_vcd.mpg output_vcd.m1v output_vcd.mpa
The resulting MPEG file, output_vcd.mpg, is ready to be played with MPlayer. You could even burn the file on a CD-R media to create a Video CD, in this case you will need to install and use both multimedia/vcdimager and sysutils/cdrdao programs.
There is a manual page for transcode, but you should also consult the transcode wiki for further information and examples.
7.4.3 Further Reading
The various video software packages for FreeBSD are developing rapidly. It is quite possible that in the near future many of the problems discussed here will have been resolved. In the mean time, those who want to get the very most out of FreeBSD's A/V capabilities will have to cobble together knowledge from several FAQs and tutorials and use a few different applications. This section exists to give the reader pointers to such additional information.
The MPlayer documentation is very technically informative. These documents should probably be consulted by anyone wishing to obtain a high level of expertise with UNIX video. The MPlayer mailing list is hostile to anyone who has not bothered to read the documentation, so if you plan on making bug reports to them, RTFM.
The xine HOWTO contains a chapter on performance improvement which is general to all players.
Finally, there are some other promising applications which the reader may try:
-
Avifile which is also a port multimedia/avifile.
-
Ogle which is also a port multimedia/ogle.
-
multimedia/dvdauthor, an open source package for authoring DVD content.
7.5 Setting Up TV Cards
Original contribution by Josef El-Rayes. Enhanced and adapted by Marc Fonvieille.7.5.1 Introduction
TV cards allow you to watch broadcast or cable TV on your computer. Most of them accept composite video via an RCA or S-video input and some of these cards come with a FM radio tuner.
FreeBSD provides support for PCI-based TV cards using a Brooktree Bt848/849/878/879 or a Conexant CN-878/Fusion 878a Video Capture Chip with the bktr(4) driver. You must also ensure the board comes with a supported tuner, consult the bktr(4) manual page for a list of supported tuners.
7.5.2 Adding the Driver
To use your card, you will need to load the bktr(4) driver, this can be done by adding the following line to the /boot/loader.conf file like this:
bktr_load="YES"
Alternatively, you may statically compile the support for the TV card in your kernel, in that case add the following lines to your kernel configuration:
device bktr
device iicbus
device iicbb
device smbus
These additional device drivers are necessary because of the card components being interconnected via an I2C bus. Then build and install a new kernel.
Once the support was added to your system, you have to reboot your machine. During the boot process, your TV card should show up, like this:
bktr0: <BrookTree 848A> mem 0xd7000000-0xd7000fff irq 10 at device 10.0 on pci0
iicbb0: <I2C bit-banging driver> on bti2c0
iicbus0: <Philips I2C bus> on iicbb0 master-only
iicbus1: <Philips I2C bus> on iicbb0 master-only
smbus0: <System Management Bus> on bti2c0
bktr0: Pinnacle/Miro TV, Philips SECAM tuner.
Of course these messages can differ according to your hardware. However you should check if the tuner is correctly detected; it is still possible to override some of the detected parameters with sysctl(8) MIBs and kernel configuration file options. For example, if you want to force the tuner to a Philips SECAM tuner, you should add the following line to your kernel configuration file:
options OVERRIDE_TUNER=6
or you can directly use sysctl(8):
# sysctl hw.bt848.tuner=6
See the bktr(4) manual page and the /usr/src/sys/conf/NOTES file for more details on the available options.
7.5.3 Useful Applications
To use your TV card you need to install one of the following applications:
-
multimedia/fxtv provides TV-in-a-window and image/audio/video capture capabilities.
-
multimedia/xawtv is also a TV application, with the same features as fxtv.
-
misc/alevt decodes and displays Videotext/Teletext.
-
audio/xmradio, an application to use the FM radio tuner coming with some TV cards.
-
audio/wmtune, a handy desktop application for radio tuners.
More applications are available in the FreeBSD Ports Collection.
7.5.4 Troubleshooting
If you encounter any problem with your TV card, you should check at first if the video capture chip and the tuner are really supported by the bktr(4) driver and if you used the right configuration options. For more support and various questions about your TV card you may want to contact and use the archives of the freebsd-multimedia mailing list.
7.6 Image Scanners
Written by Marc Fonvieille.7.6.1 Introduction
In FreeBSD, access to image scanners is provided by the SANE (Scanner Access Now Easy) API available through the FreeBSD Ports Collection. SANE will also use some FreeBSD device drivers to access to the scanner hardware.
FreeBSD supports both SCSI and USB scanners. Be sure your scanner is supported by SANE prior to performing any configuration. SANE has a supported devices list that can provide you with information about the support for a scanner and its status. The uscanner(4) manual page also provides a list of supported USB scanners.
7.6.2 Kernel Configuration
As mentioned above both SCSI and USB interfaces are supported. According to your scanner interface, different device drivers are required.
7.6.2.1 USB Interface
The GENERIC kernel by default includes the device drivers needed to support USB scanners. Should you decide to use a custom kernel, be sure that the following lines are present in your kernel configuration file:
device usb
device uhci
device ohci
device uscanner
Depending upon the USB chipset on your motherboard, you will only need either device uhci or device ohci, however having both in the kernel configuration file is harmless.
If you do not want to rebuild your kernel and your kernel is not the GENERIC one, you can directly load the uscanner(4) device driver module with the kldload(8) command:
# kldload uscanner
To load this module at each system startup, add the following line to /boot/loader.conf:
uscanner_load="YES"
After rebooting with the correct kernel, or after loading the required module, plug in your USB scanner. A line showing the detection of your scanner should appear in the system message buffer (dmesg(8)):
uscanner0: EPSON EPSON Scanner, rev 1.10/3.02, addr 2
This shows that our scanner is using the /dev/uscanner0 device node.
7.6.2.2 SCSI Interface
If your scanner comes with a SCSI interface, it is important to know which SCSI controller board you will use. According to the SCSI chipset used, you will have to tune your kernel configuration file. The GENERIC kernel supports the most common SCSI controllers. Be sure to read the NOTES file and add the correct line to your kernel configuration file. In addition to the SCSI adapter driver, you need to have the following lines in your kernel configuration file:
device scbus
device pass
Once your kernel has been properly compiled and installed, you should be able to see the devices in the system message buffer, when booting:
pass2 at aic0 bus 0 target 2 lun 0
pass2: <AGFA SNAPSCAN 600 1.10> Fixed Scanner SCSI-2 device
pass2: 3.300MB/s transfers
If your scanner was not powered-on at system boot, it is still possible to manually force the detection by performing a SCSI bus scan with the camcontrol(8) command:
# camcontrol rescan all
Re-scan of bus 0 was successful
Re-scan of bus 1 was successful
Re-scan of bus 2 was successful
Re-scan of bus 3 was successful
Then the scanner will appear in the SCSI devices list:
# camcontrol devlist
<IBM DDRS-34560 S97B> at scbus0 target 5 lun 0 (pass0,da0)
<IBM DDRS-34560 S97B> at scbus0 target 6 lun 0 (pass1,da1)
<AGFA SNAPSCAN 600 1.10> at scbus1 target 2 lun 0 (pass3)
<PHILIPS CDD3610 CD-R/RW 1.00> at scbus2 target 0 lun 0 (pass2,cd0)
More details about SCSI devices are available in the scsi(4) and camcontrol(8) manual pages.
7.6.3 SANE Configuration
The SANE system is split in two parts: the backends (graphics/sane-backends) and the frontends (graphics/sane-frontends). The backends part provides access to the scanner itself. The SANE's supported devices list specifies which backend will support your image scanner. It is mandatory to determine the correct backend for your scanner if you want to be able to use your device. The frontends part provides the graphical scanning interface (xscanimage).
The first step is to install the graphics/sane-backends port or package. Then, use the sane-find-scanner command to check the scanner detection by the SANE system:
# sane-find-scanner -q
found SCSI scanner "AGFA SNAPSCAN 600 1.10" at /dev/pass3
The output will show the interface type of the scanner and the device node used to attach the scanner to the system. The vendor and the product model may not appear, it is not important.
Note: Some USB scanners require you to load a firmware, this is explained in the backend manual page. You should also read sane-find-scanner(1) and sane(7) manual pages.
Now we have to check if the scanner will be identified by a scanning frontend. By
default, the SANE backends comes with a command line tool
called
scanimage(1).
This command allows you to list the devices and to perform an image acquisition from the
command line. The -L option is used to list the scanner
devices:
# scanimage -L
device `snapscan:/dev/pass3' is a AGFA SNAPSCAN 600 flatbed scanner
No output or a message saying that no scanners were identified indicates that scanimage(1) is unable to identify the scanner. If this happens, you will need to edit the backend configuration file and define the scanner device used. The /usr/local/etc/sane.d/ directory contains all backends configuration files. This identification problem does appear with certain USB scanners.
For example, with the USB scanner used in the Section 7.6.2.1, sane-find-scanner gives us the following information:
# sane-find-scanner -q
found USB scanner (UNKNOWN vendor and product) at device /dev/uscanner0
The scanner is correctly detected, it uses the USB interface and is attached to the /dev/uscanner0 device node. We can now check if the scanner is correctly identified:
# scanimage -L
No scanners were identified. If you were expecting something different,
check that the scanner is plugged in, turned on and detected by the
sane-find-scanner tool (if appropriate). Please read the documentation
which came with this software (README, FAQ, manpages).
Since the scanner is not identified, we will need to edit the /usr/local/etc/sane.d/epson.conf file. The scanner model used was the EPSON Perfection® 1650, so we know the scanner will use the epson backend. Be sure to read the help comments in the backends configuration files. Line changes are quite simple: comment out all lines that have the wrong interface for your scanner (in our case, we will comment out all lines starting with the word scsi as our scanner uses the USB interface), then add at the end of the file a line specifying the interface and the device node used. In this case, we add the following line:
usb /dev/uscanner0
Please be sure to read the comments provided in the backend configuration file as well as the backend manual page for more details and correct syntax to use. We can now verify if the scanner is identified:
# scanimage -L
device `epson:/dev/uscanner0' is a Epson GT-8200 flatbed scanner
Our USB scanner has been identified. It is not important if the brand and the model do not match the scanner. The key item to be concerned with is the `epson:/dev/uscanner0' field, which give us the right backend name and the right device node.
Once the scanimage -L command is able to see the scanner, the configuration is complete. The device is now ready to scan.
While scanimage(1) does allow us to perform an image acquisition from the command line, it is preferable to use a graphical user interface to perform image scanning. SANE offers a simple but efficient graphical interface: xscanimage (graphics/sane-frontends).
Xsane (graphics/xsane) is another popular graphical scanning frontend. This frontend offers advanced features such as various scanning mode (photocopy, fax, etc.), color correction, batch scans, etc. Both of these applications are usable as a GIMP plugin.
7.6.4 Giving Other Users Access to the Scanner
All previous operations have been done with root privileges. You may however, need other users to have access to the scanner. The user will need read and write permissions to the device node used by the scanner. As an example, our USB scanner uses the device node /dev/uscanner0 which is owned by the operator group. Adding the user joe to the operator group will allow him to use the scanner:
# pw groupmod operator -m joe
For more details read the pw(8) manual page. You also have to set the correct write permissions (0660 or 0664) on the /dev/uscanner0 device node, by default the operator group can only read the device node. This is done by adding the following lines to the /etc/devfs.rules file:
[system=5]
add path uscanner0 mode 660
Then add the following to /etc/rc.conf and reboot the machine:
devfs_system_ruleset="system"
More information regarding these lines can be found in the devfs(8) manual page.
Note: Of course, for security reasons, you should think twice before adding a user to any group, especially the operator group.
Chapter 8 Configuring the FreeBSD Kernel
Updated and restructured by Jim Mock. Originally contributed by Jake Hamby.8.1 Synopsis
The kernel is the core of the FreeBSD operating system. It is responsible for managing memory, enforcing security controls, networking, disk access, and much more. While more and more of FreeBSD becomes dynamically configurable it is still occasionally necessary to reconfigure and recompile your kernel.
After reading this chapter, you will know:
-
Why you might need to build a custom kernel.
-
How to write a kernel configuration file, or alter an existing configuration file.
-
How to use the kernel configuration file to create and build a new kernel.
-
How to install the new kernel.
-
How to troubleshoot if things go wrong.
All of the commands listed within this chapter by way of example should be executed as root in order to succeed.
8.2 Why Build a Custom Kernel?
Traditionally, FreeBSD has had what is called a “monolithic” kernel. This means that the kernel was one large program, supported a fixed list of devices, and if you wanted to change the kernel's behavior then you had to compile a new kernel, and then reboot your computer with the new kernel.
Today, FreeBSD is rapidly moving to a model where much of the kernel's functionality is contained in modules which can be dynamically loaded and unloaded from the kernel as necessary. This allows the kernel to adapt to new hardware suddenly becoming available (such as PCMCIA cards in a laptop), or for new functionality to be brought into the kernel that was not necessary when the kernel was originally compiled. This is known as a modular kernel.
Despite this, it is still necessary to carry out some static kernel configuration. In some cases this is because the functionality is so tied to the kernel that it can not be made dynamically loadable. In others it may simply be because no one has yet taken the time to write a dynamic loadable kernel module for that functionality.
Building a custom kernel is one of the most important rites of passage nearly every BSD user must endure. This process, while time consuming, will provide many benefits to your FreeBSD system. Unlike the GENERIC kernel, which must support a wide range of hardware, a custom kernel only contains support for your PC's hardware. This has a number of benefits, such as:
-
Faster boot time. Since the kernel will only probe the hardware you have on your system, the time it takes your system to boot can decrease dramatically.
-
Lower memory usage. A custom kernel often uses less memory than the GENERIC kernel, which is important because the kernel must always be present in real memory. For this reason, a custom kernel is especially useful on a system with a small amount of RAM.
-
Additional hardware support. A custom kernel allows you to add in support for devices which are not present in the GENERIC kernel, such as sound cards.
8.3 Building and Installing a Custom Kernel
First, let us take a quick tour of the kernel build directory. All directories mentioned will be relative to the main /usr/src/sys directory, which is also accessible through the path name /sys. There are a number of subdirectories here representing different parts of the kernel, but the most important for our purposes are arch/conf, where you will edit your custom kernel configuration, and compile, which is the staging area where your kernel will be built. arch represents one of i386, alpha, amd64, ia64, powerpc, sparc64, or pc98 (an alternative development branch of PC hardware, popular in Japan). Everything inside a particular architecture's directory deals with that architecture only; the rest of the code is machine independent code common to all platforms to which FreeBSD could potentially be ported. Notice the logical organization of the directory structure, with each supported device, file system, and option in its own subdirectory.
This chapter assumes that you are using the i386 architecture in the examples. If this is not the case for your situation, make appropriate adjustments to the path names for your system's architecture.
Note: If there is not a /usr/src/sys directory on your system, then the kernel source has not been installed. The easiest way to do this is by running sysinstall as root, choosing Configure, then Distributions, then src, then base and sys. If you have an aversion to sysinstall and you have access to an “official” FreeBSD CDROM, then you can also install the source from the command line:
# mount /cdrom # mkdir -p /usr/src/sys # ln -s /usr/src/sys /sys # cat /cdrom/src/ssys.[a-d]* | tar -xzvf - # cat /cdrom/src/sbase.[a-d]* | tar -xzvf -
Next, move to the arch/conf directory and copy the GENERIC configuration file to the name you want to give your kernel. For example:
# cd /usr/src/sys/i386/conf
# cp GENERIC MYKERNEL
Traditionally, this name is in all capital letters and, if you are maintaining multiple FreeBSD machines with different hardware, it is a good idea to name it after your machine's hostname. We will call it MYKERNEL for the purpose of this example.
Tip: Storing your kernel configuration file directly under /usr/src can be a bad idea. If you are experiencing problems it can be tempting to just delete /usr/src and start again. After doing this, it usually only takes a few seconds for you to realize that you have deleted your custom kernel configuration file. Also, do not edit GENERIC directly, as it may get overwritten the next time you update your source tree, and your kernel modifications will be lost.
You might want to keep your kernel configuration file elsewhere, and then create a symbolic link to the file in the i386 directory.
For example:
# cd /usr/src/sys/i386/conf # mkdir /root/kernels # cp GENERIC /root/kernels/MYKERNEL # ln -s /root/kernels/MYKERNEL
Now, edit MYKERNEL with your favorite text editor. If you are just starting out, the only editor available will probably be vi, which is too complex to explain here, but is covered well in many books in the bibliography. However, FreeBSD does offer an easier editor called ee which, if you are a beginner, should be your editor of choice. Feel free to change the comment lines at the top to reflect your configuration or the changes you have made to differentiate it from GENERIC.
If you have built a kernel under SunOS or some other BSD operating system, much of this file will be very familiar to you. If you are coming from some other operating system such as DOS, on the other hand, the GENERIC configuration file might seem overwhelming to you, so follow the descriptions in the Configuration File section slowly and carefully.
Note: If you sync your source tree with the latest sources of the FreeBSD project, be sure to always check the file /usr/src/UPDATING before you perform any update steps. This file describes any important issues or areas requiring special attention within the updated source code. /usr/src/UPDATING always matches your version of the FreeBSD source, and is therefore more up to date with new information than this handbook.
You must now compile the source code for the kernel.
Building a Kernel
-
Change to the /usr/src directory:
# cd /usr/src -
Compile the kernel:
# make buildkernel KERNCONF=MYKERNEL -
Install the new kernel:
# make installkernel KERNCONF=MYKERNEL
Note: It is required to have full FreeBSD source tree to build the kernel.
Tip: By default, when you build a custom kernel, all kernel modules will be rebuilt as well. If you want to update a kernel faster or to build only custom modules, you should edit /etc/make.conf before starting to build the kernel:
MODULES_OVERRIDE = linux acpi sound/sound sound/driver/ds1 ntfsThis variable sets up a list of modules to build instead of all of them.
WITHOUT_MODULES = linux acpi sound/sound sound/driver/ds1 ntfsThis variable sets up a list of modules to exclude from the build process. For other variables which you may find useful in the process of building kernel, refer to make.conf(5) manual page.
The new kernel will be copied to the /boot/kernel directory as /boot/kernel/kernel and the old kernel will be moved to /boot/kernel.old/kernel. Now, shutdown the system and reboot to use your new kernel. If something goes wrong, there are some troubleshooting instructions at the end of this chapter that you may find useful. Be sure to read the section which explains how to recover in case your new kernel does not boot.
Note: Other files relating to the boot process, such as the boot loader(8) and configuration are stored in /boot. Third party or custom modules can be placed in /boot/kernel, although users should be aware that keeping modules in sync with the compiled kernel is very important. Modules not intended to run with the compiled kernel may result in instability or incorrectness.
8.4 The Configuration File
Updated for FreeBSD 6.X by Joel Dahl.The general format of a configuration file is quite simple. Each line contains a keyword and one or more arguments. For simplicity, most lines only contain one argument. Anything following a # is considered a comment and ignored. The following sections describe each keyword, in the order they are listed in GENERIC. For an exhaustive list of architecture dependent options and devices, see the NOTES file in the same directory as the GENERIC file. For architecture independent options, see /usr/src/sys/conf/NOTES.
Note: To build a file which contains all available options, as normally done for testing purposes, run the following command as root:
# cd /usr/src/sys/i386/conf && make LINT
The following is an example of the GENERIC kernel configuration file with various additional comments where needed for clarity. This example should match your copy in /usr/src/sys/i386/conf/GENERIC fairly closely.
machine i386
This is the machine architecture. It must be either alpha, amd64, i386, ia64, pc98, powerpc, or sparc64.
cpu I486_CPU
cpu I586_CPU
cpu I686_CPU
The above option specifies the type of CPU you have in your system. You may have multiple instances of the CPU line (if, for example, you are not sure whether you should use I586_CPU or I686_CPU), but for a custom kernel it is best to specify only the CPU you have. If you are unsure of your CPU type, you can check the /var/run/dmesg.boot file to view your boot messages.
ident GENERIC
This is the identification of the kernel. You should change this to whatever you named your kernel, i.e. MYKERNEL if you have followed the instructions of the previous examples. The value you put in the ident string will print when you boot up the kernel, so it is useful to give the new kernel a different name if you want to keep it separate from your usual kernel (e.g., you want to build an experimental kernel).
#To statically compile in device wiring instead of /boot/device.hints
#hints "GENERIC.hints" # Default places to look for devices.
The device.hints(5) is used to configure options of the device drivers. The default location that loader(8) will check at boot time is /boot/device.hints. Using the hints option you can compile these hints statically into your kernel. Then there is no need to create a device.hints file in /boot.
makeoptions DEBUG=-g # Build kernel with gdb(1) debug symbols
The normal build process of FreeBSD includes debugging information when building the
kernel with the the -g option, which enables debugging
information when passed to gcc(1).
options SCHED_4BSD # 4BSD scheduler
The traditional and default system scheduler for FreeBSD. Keep this.
options PREEMPTION # Enable kernel thread preemption
Allows threads that are in the kernel to be preempted by higher priority threads. It helps with interactivity and allows interrupt threads to run sooner rather than waiting.
options INET # InterNETworking
Networking support. Leave this in, even if you do not plan to be connected to a network. Most programs require at least loopback networking (i.e., making network connections within your PC), so this is essentially mandatory.
options INET6 # IPv6 communications protocols
This enables the IPv6 communication protocols.
options FFS # Berkeley Fast Filesystem
This is the basic hard drive file system. Leave it in if you boot from the hard disk.
options SOFTUPDATES # Enable FFS Soft Updates support
This option enables Soft Updates in the kernel, this will help speed up write access on the disks. Even when this functionality is provided by the kernel, it must be turned on for specific disks. Review the output from mount(8) to see if Soft Updates is enabled for your system disks. If you do not see the soft-updates option then you will need to activate it using the tunefs(8) (for existing file systems) or newfs(8) (for new file systems) commands.
options UFS_ACL # Support for access control lists
This option enables kernel support for access control lists. This relies on the use of extended attributes and UFS2, and the feature is described in detail in Section 14.12. ACLs are enabled by default and should not be disabled in the kernel if they have been used previously on a file system, as this will remove the access control lists, changing the way files are protected in unpredictable ways.
options UFS_DIRHASH # Improve performance on big directories
This option includes functionality to speed up disk operations on large directories, at the expense of using additional memory. You would normally keep this for a large server, or interactive workstation, and remove it if you are using FreeBSD on a smaller system where memory is at a premium and disk access speed is less important, such as a firewall.
options MD_ROOT # MD is a potential root device
This option enables support for a memory backed virtual disk used as a root device.
options NFSCLIENT # Network Filesystem Client
options NFSSERVER # Network Filesystem Server
options NFS_ROOT # NFS usable as /, requires NFSCLIENT
The network file system. Unless you plan to mount partitions from a UNIX file server over TCP/IP, you can comment these out.
options MSDOSFS # MSDOS Filesystem
The MS-DOS file system. Unless you plan to mount a DOS formatted hard drive partition at boot time, you can safely comment this out. It will be automatically loaded the first time you mount a DOS partition, as described above. Also, the excellent emulators/mtools software allows you to access DOS floppies without having to mount and unmount them (and does not require MSDOSFS at all).
options CD9660 # ISO 9660 Filesystem
The ISO 9660 file system for CDROMs. Comment it out if you do not have a CDROM drive or only mount data CDs occasionally (since it will be dynamically loaded the first time you mount a data CD). Audio CDs do not need this file system.
options PROCFS # Process filesystem (requires PSEUDOFS)
The process file system. This is a “pretend” file system mounted on /proc which allows programs like ps(1) to give you more information on what processes are running. Use of PROCFS is not required under most circumstances, as most debugging and monitoring tools have been adapted to run without PROCFS: installs will not mount this file system by default.
options PSEUDOFS # Pseudo-filesystem framework
6.X kernels making use of PROCFS must also include support for PSEUDOFS.
options GEOM_GPT # GUID Partition Tables.
This option brings the ability to have a large number of partitions on a single disk.
options COMPAT_43 # Compatible with BSD 4.3 [KEEP THIS!]
Compatibility with 4.3BSD. Leave this in; some programs will act strangely if you comment this out.
options COMPAT_FREEBSD4 # Compatible with FreeBSD4
This option is required on FreeBSD 5.X i386 and Alpha systems to support applications compiled on older versions of FreeBSD that use older system call interfaces. It is recommended that this option be used on all i386 and Alpha systems that may run older applications; platforms that gained support only in 5.X, such as ia64 and Sparc64, do not require this option.
options COMPAT_FREEBSD5 # Compatible with FreeBSD5
This option is required on FreeBSD 6.X and above to support applications compiled on FreeBSD 5.X versions that use FreeBSD 5.X system call interfaces.
options SCSI_DELAY=5000 # Delay (in ms) before probing SCSI
This causes the kernel to pause for 5 seconds before probing each SCSI device in your system. If you only have IDE hard drives, you can ignore this, otherwise you can try to lower this number, to speed up booting. Of course, if you do this and FreeBSD has trouble recognizing your SCSI devices, you will have to raise it again.
options KTRACE # ktrace(1) support
This enables kernel process tracing, which is useful in debugging.
options SYSVSHM # SYSV-style shared memory
This option provides for System V shared memory. The most common use of this is the XSHM extension in X, which many graphics-intensive programs will automatically take advantage of for extra speed. If you use X, you will definitely want to include this.
options SYSVMSG # SYSV-style message queues
Support for System V messages. This option only adds a few hundred bytes to the kernel.
options SYSVSEM # SYSV-style semaphores
Support for System V semaphores. Less commonly used but only adds a few hundred bytes to the kernel.
Note: The
-poption of the ipcs(1) command will list any processes using each of these System V facilities.
options _KPOSIX_PRIORITY_SCHEDULING # POSIX P1003_1B real-time extensions
Real-time extensions added in the 1993 POSIX®. Certain applications in the Ports Collection use these (such as StarOffice).
options KBD_INSTALL_CDEV # install a CDEV entry in /dev
This option is related to the keyboard. It installs a CDEV entry in /dev.
options ADAPTIVE_GIANT # Giant mutex is adaptive.
Giant is the name of a mutual exclusion mechanism (a sleep mutex) that protects a large set of kernel resources. Today, this is an unacceptable performance bottleneck which is actively being replaced with locks that protect individual resources. The ADAPTIVE_GIANT option causes Giant to be included in the set of mutexes adaptively spun on. That is, when a thread wants to lock the Giant mutex, but it is already locked by a thread on another CPU, the first thread will keep running and wait for the lock to be released. Normally, the thread would instead go back to sleep and wait for its next chance to run. If you are not sure, leave this in.
device apic # I/O APIC
The apic device enables the use of the I/O APIC for interrupt delivery. The apic device can be used in both UP and SMP kernels, but is required for SMP kernels. Add options SMP to include support for multiple processors.
Note: The apic device exists only on the i386 architecture, this configuration line should not be used on other architectures.
device eisa
Include this if you have an EISA motherboard. This enables auto-detection and configuration support for all devices on the EISA bus.
device pci
Include this if you have a PCI motherboard. This enables auto-detection of PCI cards and gatewaying from the PCI to ISA bus.
# Floppy drives
device fdc
This is the floppy drive controller.
# ATA and ATAPI devices
device ata
This driver supports all ATA and ATAPI devices. You only need one device ata line for the kernel to detect all PCI ATA/ATAPI devices on modern machines.
device atadisk # ATA disk drives
This is needed along with device ata for ATA disk drives.
device ataraid # ATA RAID drives
This is needed along with device ata for ATA RAID drives.
device atapicd # ATAPI CDROM drives
This is needed along with device ata for ATAPI CDROM drives.
device atapifd # ATAPI floppy drives
This is needed along with device ata for ATAPI floppy drives.
device atapist # ATAPI tape drives
This is needed along with device ata for ATAPI tape drives.
options ATA_STATIC_ID # Static device numbering
This makes the controller number static; without this, the device numbers are dynamically allocated.
# SCSI Controllers
device ahb # EISA AHA1742 family
device ahc # AHA2940 and onboard AIC7xxx devices
options AHC_REG_PRETTY_PRINT # Print register bitfields in debug
# output. Adds ~128k to driver.
device ahd # AHA39320/29320 and onboard AIC79xx devices
options AHD_REG_PRETTY_PRINT # Print register bitfields in debug
# output. Adds ~215k to driver.
device amd # AMD 53C974 (Teckram DC-390(T))
device isp # Qlogic family
#device ispfw # Firmware for QLogic HBAs- normally a module
device mpt # LSI-Logic MPT-Fusion
#device ncr # NCR/Symbios Logic
device sym # NCR/Symbios Logic (newer chipsets + those of `ncr')
device trm # Tekram DC395U/UW/F DC315U adapters
device adv # Advansys SCSI adapters
device adw # Advansys wide SCSI adapters
device aha # Adaptec 154x SCSI adapters
device aic # Adaptec 15[012]x SCSI adapters, AIC-6[23]60.
device bt # Buslogic/Mylex MultiMaster SCSI adapters
device ncv # NCR 53C500
device nsp # Workbit Ninja SCSI-3
device stg # TMC 18C30/18C50
SCSI controllers. Comment out any you do not have in your system. If you have an IDE only system, you can remove these altogether. The *_REG_PRETTY_PRINT lines are debugging options for their respective drivers.
# SCSI peripherals
device scbus # SCSI bus (required for SCSI)
device ch # SCSI media changers
device da # Direct Access (disks)
device sa # Sequential Access (tape etc)
device cd # CD
device pass # Passthrough device (direct SCSI access)
device ses # SCSI Environmental Services (and SAF-TE)
SCSI peripherals. Again, comment out any you do not have, or if you have only IDE hardware, you can remove them completely.
Note: The USB umass(4) driver and a few other drivers use the SCSI subsystem even though they are not real SCSI devices. Therefore make sure not to remove SCSI support, if any such drivers are included in the kernel configuration.
# RAID controllers interfaced to the SCSI subsystem
device amr # AMI MegaRAID
device arcmsr # Areca SATA II RAID
device asr # DPT SmartRAID V, VI and Adaptec SCSI RAID
device ciss # Compaq Smart RAID 5*
device dpt # DPT Smartcache III, IV - See NOTES for options
device hptmv # Highpoint RocketRAID 182x
device rr232x # Highpoint RocketRAID 232x
device iir # Intel Integrated RAID
device ips # IBM (Adaptec) ServeRAID
device mly # Mylex AcceleRAID/eXtremeRAID
device twa # 3ware 9000 series PATA/SATA RAID
# RAID controllers
device aac # Adaptec FSA RAID
device aacp # SCSI passthrough for aac (requires CAM)
device ida # Compaq Smart RAID
device mfi # LSI MegaRAID SAS
device mlx # Mylex DAC960 family
device pst # Promise Supertrak SX6000
device twe # 3ware ATA RAID
Supported RAID controllers. If you do not have any of these, you can comment them out or remove them.
# atkbdc0 controls both the keyboard and the PS/2 mouse
device atkbdc # AT keyboard controller
The keyboard controller (atkbdc) provides I/O services for the AT keyboard and PS/2 style pointing devices. This controller is required by the keyboard driver (atkbd) and the PS/2 pointing device driver (psm).
device atkbd # AT keyboard
The atkbd driver, together with atkbdc controller, provides access to the AT 84 keyboard or the AT enhanced keyboard which is connected to the AT keyboard controller.
device psm # PS/2 mouse
Use this device if your mouse plugs into the PS/2 mouse port.
device kbdmux # keyboard multiplexer
Basic support for keyboard multiplexing. If you do not plan to use more than one keyboard on the system, you can safely remove that line.
device vga # VGA video card driver
The video card driver.
device splash # Splash screen and screen saver support
Splash screen at start up! Screen savers require this too.
# syscons is the default console driver, resembling an SCO console
device sc
sc is the default console driver and resembles a SCO console. Since most full-screen programs access the console through a terminal database library like termcap, it should not matter whether you use this or vt, the VT220 compatible console driver. When you log in, set your TERM variable to scoansi if full-screen programs have trouble running under this console.
# Enable this for the pcvt (VT220 compatible) console driver
#device vt
#options XSERVER # support for X server on a vt console
#options FAT_CURSOR # start with block cursor
This is a VT220-compatible console driver, backward compatible to VT100/102. It works well on some laptops which have hardware incompatibilities with sc. Also set your TERM variable to vt100 or vt220 when you log in. This driver might also prove useful when connecting to a large number of different machines over the network, where termcap or terminfo entries for the sc device are often not available -- vt100 should be available on virtually any platform.
device agp
Include this if you have an AGP card in the system. This will enable support for AGP, and AGP GART for boards which have these features.
# Power management support (see NOTES for more options)
#device apm
Advanced Power Management support. Useful for laptops, although in FreeBSD 5.X and above this is disabled in GENERIC by default.
# Add suspend/resume support for the i8254.
device pmtimer
Timer device driver for power management events, such as APM and ACPI.
# PCCARD (PCMCIA) support
# PCMCIA and cardbus bridge support
device cbb # cardbus (yenta) bridge
device pccard # PC Card (16-bit) bus
device cardbus # CardBus (32-bit) bus
PCMCIA support. You want this if you are using a laptop.
# Serial (COM) ports
device sio # 8250, 16[45]50 based serial ports
These are the serial ports referred to as COM ports in the MS-DOS/Windows world.
Note: If you have an internal modem on COM4 and a serial port at COM2, you will have to change the IRQ of the modem to 2 (for obscure technical reasons, IRQ2 = IRQ 9) in order to access it from FreeBSD. If you have a multiport serial card, check the manual page for sio(4) for more information on the proper values to add to your /boot/device.hints. Some video cards (notably those based on S3 chips) use IO addresses in the form of 0x*2e8, and since many cheap serial cards do not fully decode the 16-bit IO address space, they clash with these cards making the COM4 port practically unavailable.
Each serial port is required to have a unique IRQ (unless you are using one of the multiport cards where shared interrupts are supported), so the default IRQs for COM3 and COM4 cannot be used.
# Parallel port
device ppc
This is the ISA-bus parallel port interface.
device ppbus # Parallel port bus (required)
Provides support for the parallel port bus.
device lpt # Printer
Support for parallel port printers.
Note: All three of the above are required to enable parallel printer support.
device plip # TCP/IP over parallel
This is the driver for the parallel network interface.
device ppi # Parallel port interface device
The general-purpose I/O (“geek port”) + IEEE1284 I/O.
#device vpo # Requires scbus and da
This is for an Iomega Zip drive. It requires scbus and da support. Best performance is achieved with ports in EPP 1.9 mode.
#device puc
Uncomment this device if you have a “dumb” serial or parallel PCI card that is supported by the puc(4) glue driver.
# PCI Ethernet NICs.
device de # DEC/Intel DC21x4x (“Tulip”)
device em # Intel PRO/1000 adapter Gigabit Ethernet Card
device ixgb # Intel PRO/10GbE Ethernet Card
device txp # 3Com 3cR990 (“Typhoon”)
device vx # 3Com 3c590, 3c595 (“Vortex”)
Various PCI network card drivers. Comment out or remove any of these not present in your system.
# PCI Ethernet NICs that use the common MII bus controller code.
# NOTE: Be sure to keep the 'device miibus' line in order to use these NICs!
device miibus # MII bus support
MII bus support is required for some PCI 10/100 Ethernet NICs, namely those which use MII-compliant transceivers or implement transceiver control interfaces that operate like an MII. Adding device miibus to the kernel config pulls in support for the generic miibus API and all of the PHY drivers, including a generic one for PHYs that are not specifically handled by an individual driver.
device bce # Broadcom BCM5706/BCM5708 Gigabit Ethernet
device bfe # Broadcom BCM440x 10/100 Ethernet
device bge # Broadcom BCM570xx Gigabit Ethernet
device dc # DEC/Intel 21143 and various workalikes
device fxp # Intel EtherExpress PRO/100B (82557, 82558)
device lge # Level 1 LXT1001 gigabit ethernet
device msk # Marvell/SysKonnect Yukon II Gigabit Ethernet
device nge # NatSemi DP83820 gigabit ethernet
device nve # nVidia nForce MCP on-board Ethernet Networking
device pcn # AMD Am79C97x PCI 10/100 (precedence over 'lnc')
device re # RealTek 8139C+/8169/8169S/8110S
device rl # RealTek 8129/8139
device sf # Adaptec AIC-6915 (“Starfire”)
device sis # Silicon Integrated Systems SiS 900/SiS 7016
device sk # SysKonnect SK-984x & SK-982x gigabit Ethernet
device ste # Sundance ST201 (D-Link DFE-550TX)
device stge # Sundance/Tamarack TC9021 gigabit Ethernet
device ti # Alteon Networks Tigon I/II gigabit Ethernet
device tl # Texas Instruments ThunderLAN
device tx # SMC EtherPower II (83c170 “EPIC”)
device vge # VIA VT612x gigabit ethernet
device vr # VIA Rhine, Rhine II
device wb # Winbond W89C840F
device xl # 3Com 3c90x (“Boomerang”, “Cyclone”)
Drivers that use the MII bus controller code.
# ISA Ethernet NICs. pccard NICs included.
device cs # Crystal Semiconductor CS89x0 NIC
# 'device ed' requires 'device miibus'
device ed # NE[12]000, SMC Ultra, 3c503, DS8390 cards
device ex # Intel EtherExpress Pro/10 and Pro/10+
device ep # Etherlink III based cards
device fe # Fujitsu MB8696x based cards
device ie # EtherExpress 8/16, 3C507, StarLAN 10 etc.
device lnc # NE2100, NE32-VL Lance Ethernet cards
device sn # SMC's 9000 series of Ethernet chips
device xe # Xircom pccard Ethernet
# ISA devices that use the old ISA shims
#device le
ISA Ethernet drivers. See /usr/src/sys/i386/conf/NOTES for details of which cards are supported by which driver.
# Wireless NIC cards
device wlan # 802.11 support
Generic 802.11 support. This line is required for wireless networking.
device wlan_wep # 802.11 WEP support
device wlan_ccmp # 802.11 CCMP support
device wlan_tkip # 802.11 TKIP support
Crypto support for 802.11 devices. These lines are needed if you intend to use encryption and 802.11i security protocols.
device an # Aironet 4500/4800 802.11 wireless NICs.
device ath # Atheros pci/cardbus NIC's
device ath_hal # Atheros HAL (Hardware Access Layer)
device ath_rate_sample # SampleRate tx rate control for ath
device awi # BayStack 660 and others
device ral # Ralink Technology RT2500 wireless NICs.
device wi # WaveLAN/Intersil/Symbol 802.11 wireless NICs.
#device wl # Older non 802.11 Wavelan wireless NIC.
Support for various wireless cards.
# Pseudo devices
device loop # Network loopback
This is the generic loopback device for TCP/IP. If you telnet or FTP to localhost (a.k.a. 127.0.0.1) it will come back at you through this device. This is mandatory.
device random # Entropy device
Cryptographically secure random number generator.
device ether # Ethernet support
ether is only needed if you have an Ethernet card. It includes generic Ethernet protocol code.
device sl # Kernel SLIP
sl is for SLIP support. This has been almost entirely supplanted by PPP, which is easier to set up, better suited for modem-to-modem connection, and more powerful.
device ppp # Kernel PPP
This is for kernel PPP support for dial-up connections. There is also a version of PPP implemented as a userland application that uses tun and offers more flexibility and features such as demand dialing.
device tun # Packet tunnel.
This is used by the userland PPP software. See the PPP section of this book for more information.
device pty # Pseudo-ttys (telnet etc)
This is a “pseudo-terminal” or simulated login port. It is used by incoming telnet and rlogin sessions, xterm, and some other applications such as Emacs.
device md # Memory “disks”
Memory disk pseudo-devices.
device gif # IPv6 and IPv4 tunneling
This implements IPv6 over IPv4 tunneling, IPv4 over IPv6 tunneling, IPv4 over IPv4 tunneling, and IPv6 over IPv6 tunneling. The gif device is “auto-cloning”, and will create device nodes as needed.
device faith # IPv6-to-IPv4 relaying (translation)
This pseudo-device captures packets that are sent to it and diverts them to the IPv4/IPv6 translation daemon.
# The `bpf' device enables the Berkeley Packet Filter.
# Be aware of the administrative consequences of enabling this!
# Note that 'bpf' is required for DHCP.
device bpf # Berkeley packet filter
This is the Berkeley Packet Filter. This pseudo-device allows network interfaces to be placed in promiscuous mode, capturing every packet on a broadcast network (e.g., an Ethernet). These packets can be captured to disk and or examined with the tcpdump(1) program.
Note: The bpf(4) device is also used by dhclient(8) to obtain the IP address of the default router (gateway) and so on. If you use DHCP, leave this uncommented.
# USB support
device uhci # UHCI PCI->USB interface
device ohci # OHCI PCI->USB interface
device ehci # EHCI PCI->USB interface (USB 2.0)
device usb # USB Bus (required)
#device udbp # USB Double Bulk Pipe devices
device ugen # Generic
device uhid # “Human Interface Devices”
device ukbd # Keyboard
device ulpt # Printer
device umass # Disks/Mass storage - Requires scbus and da
device ums # Mouse
device ural # Ralink Technology RT2500USB wireless NICs
device urio # Diamond Rio 500 MP3 player
device uscanner # Scanners
# USB Ethernet, requires mii
device aue # ADMtek USB Ethernet
device axe # ASIX Electronics USB Ethernet
device cdce # Generic USB over Ethernet
device cue # CATC USB Ethernet
device kue # Kawasaki LSI USB Ethernet
device rue # RealTek RTL8150 USB Ethernet
Support for various USB devices.
# FireWire support
device firewire # FireWire bus code
device sbp # SCSI over FireWire (Requires scbus and da)
device fwe # Ethernet over FireWire (non-standard!)
Support for various Firewire devices.
For more information and additional devices supported by FreeBSD, see /usr/src/sys/i386/conf/NOTES.
8.4.1 Large Memory Configurations (PAE)
Large memory configuration machines require access to more than the 4 gigabyte limit on User+Kernel Virtual Address (KVA) space. Due to this limitation, Intel added support for 36-bit physical address space access in the Pentium Pro and later line of CPUs.
The Physical Address Extension (PAE) capability of
the Intel Pentium Pro and
later CPUs allows memory configurations of up to 64 gigabytes. FreeBSD provides support
for this capability via the PAE kernel configuration option,
available in all current release versions of FreeBSD. Due to the limitations of the Intel
memory architecture, no distinction is made for memory above or below 4 gigabytes. Memory
allocated above 4 gigabytes is simply added to the pool of available memory.
To enable PAE support in the kernel, simply add the following line to your kernel configuration file:
options PAE
Note: The PAE support in FreeBSD is only available for Intel IA-32 processors. It should also be noted, that the PAE support in FreeBSD has not received wide testing, and should be considered beta quality compared to other stable features of FreeBSD.
PAE support in FreeBSD has a few limitations:
-
A process is not able to access more than 4 gigabytes of VM space.
-
KLD modules cannot be loaded into a PAE enabled kernel, due to the differences in the build framework of a module and the kernel.
-
Device drivers that do not use the bus_dma(9) interface will cause data corruption in a PAE enabled kernel and are not recommended for use. For this reason, a PAE kernel configuration file is provided in FreeBSD which excludes all drivers not known to work in a PAE enabled kernel.
-
Some system tunables determine memory resource usage by the amount of available physical memory. Such tunables can unnecessarily over-allocate due to the large memory nature of a PAE system. One such example is the
kern.maxvnodessysctl, which controls the maximum number of vnodes allowed in the kernel. It is advised to adjust this and other such tunables to a reasonable value. -
It might be necessary to increase the kernel virtual address (KVA) space or to reduce the amount of specific kernel resource that is heavily used (see above) in order to avoid KVA exhaustion. The
KVA_PAGESkernel option can be used for increasing the KVA space.
For performance and stability concerns, it is advised to consult the tuning(7) manual page. The pae(4) manual page contains up-to-date information on FreeBSD's PAE support.
8.5 If Something Goes Wrong
There are five categories of trouble that can occur when building a custom kernel. They are:
- config fails:
-
If the config(8) command fails when you give it your kernel description, you have probably made a simple error somewhere. Fortunately, config(8) will print the line number that it had trouble with, so that you can quickly locate the line containing the error. For example, if you see:
config: line 17: syntax errorMake sure the keyword is typed correctly by comparing it to the GENERIC kernel or another reference.
- make fails:
-
If the make command fails, it usually signals an error in your kernel description which is not severe enough for config(8) to catch. Again, look over your configuration, and if you still cannot resolve the problem, send mail to the FreeBSD general questions mailing list with your kernel configuration, and it should be diagnosed quickly.
- The kernel does not boot:
-
If your new kernel does not boot, or fails to recognize your devices, do not panic! Fortunately, FreeBSD has an excellent mechanism for recovering from incompatible kernels. Simply choose the kernel you want to boot from at the FreeBSD boot loader. You can access this when the system boot menu appears. Select the “Escape to a loader prompt” option, number six. At the prompt, type unload kernel and then type boot /boot/kernel.old/kernel, or the filename of any other kernel that will boot properly. When reconfiguring a kernel, it is always a good idea to keep a kernel that is known to work on hand.
After booting with a good kernel you can check over your configuration file and try to build it again. One helpful resource is the /var/log/messages file which records, among other things, all of the kernel messages from every successful boot. Also, the dmesg(8) command will print the kernel messages from the current boot.
Note: If you are having trouble building a kernel, make sure to keep a GENERIC, or some other kernel that is known to work on hand as a different name that will not get erased on the next build. You cannot rely on kernel.old because when installing a new kernel, kernel.old is overwritten with the last installed kernel which may be non-functional. Also, as soon as possible, move the working kernel to the proper /boot/kernel location or commands such as ps(1) may not work properly. To do this, simply rename the directory containing the good kernel:
# mv /boot/kernel /boot/kernel.bad # mv /boot/kernel.good /boot/kernel - The kernel works, but ps(1) does not work any more:
-
If you have installed a different version of the kernel from the one that the system utilities have been built with, for example, a -CURRENT kernel on a -RELEASE, many system-status commands like ps(1) and vmstat(8) will not work any more. You should recompile and install a world built with the same version of the source tree as your kernel. This is one reason it is not normally a good idea to use a different version of the kernel from the rest of the operating system.
Chapter 9 Printing
Contributed by Sean Kelly. Restructured and updated by Jim Mock.9.1 Synopsis
FreeBSD can be used to print with a wide variety of printers, from the oldest impact printer to the latest laser printers, and everything in between, allowing you to produce high-quality printed output from the applications you run.
FreeBSD can also be configured to act as a print server on a network; in this capacity FreeBSD can receive print jobs from a variety of other computers, including other FreeBSD computers, Windows and Mac OS hosts. FreeBSD will ensure that one job at a time is printed, and can keep statistics on which users and machines are doing the most printing, produce “banner” pages showing who's printout is who's, and more.
After reading this chapter, you will know:
-
How to configure the FreeBSD print spooler.
-
How to install print filters, to handle special print jobs differently, including converting incoming documents to print formats that your printers understand.
-
How to enable header, or banner pages on your printout.
-
How to print with printers connected to other computers.
-
How to print with printers connected directly to the network.
-
How to control printer restrictions, including limiting the size of print jobs, and preventing certain users from printing.
-
How to keep printer statistics, and account for printer usage.
-
How to troubleshoot printing problems.
Before reading this chapter, you should:
-
Know how to configure and install a new kernel (Chapter 8).
9.2 Introduction
In order to use printers with FreeBSD, you may set them up to work with the Berkeley line printer spooling system, also known as the LPD spooling system, or just LPD. It is the standard printer control system in FreeBSD. This chapter introduces LPD and will guide you through its configuration.
If you are already familiar with LPD or another printer spooling system, you may wish to skip to section Basic Setup.
LPD controls everything about a host's printers. It is responsible for a number of things:
-
It controls access to attached printers and printers attached to other hosts on the network.
-
It enables users to submit files to be printed; these submissions are known as jobs.
-
It prevents multiple users from accessing a printer at the same time by maintaining a queue for each printer.
-
It can print header pages (also known as banner or burst pages) so users can easily find jobs they have printed in a stack of printouts.
-
It takes care of communications parameters for printers connected on serial ports.
-
It can send jobs over the network to a LPD spooler on another host.
-
It can run special filters to format jobs to be printed for various printer languages or printer capabilities.
-
It can account for printer usage.
Through a configuration file (/etc/printcap), and by providing the special filter programs, you can enable the LPD system to do all or some subset of the above for a great variety of printer hardware.
9.2.1 Why You Should Use the Spooler
If you are the sole user of your system, you may be wondering why you should bother with the spooler when you do not need access control, header pages, or printer accounting. While it is possible to enable direct access to a printer, you should use the spooler anyway since:
-
LPD prints jobs in the background; you do not have to wait for data to be copied to the printer.
-
LPD can conveniently run a job to be printed through filters to add date/time headers or convert a special file format (such as a TeX DVI file) into a format the printer will understand. You will not have to do these steps manually.
-
Many free and commercial programs that provide a print feature usually expect to talk to the spooler on your system. By setting up the spooling system, you will more easily support other software you may later add or already have.
9.3 Basic Setup
To use printers with the LPD spooling system, you will need to set up both your printer hardware and the LPD software. This document describes two levels of setup:
-
See section Simple Printer Setup to learn how to connect a printer, tell LPD how to communicate with it, and print plain text files to the printer.
-
See section Advanced Printer Setup to learn how to print a variety of special file formats, to print header pages, to print across a network, to control access to printers, and to do printer accounting.
9.3.1 Simple Printer Setup
This section tells how to configure printer hardware and the LPD software to use the printer. It teaches the basics:
-
Section Hardware Setup gives some hints on connecting the printer to a port on your computer.
-
Section Software Setup shows how to set up the LPD spooler configuration file (/etc/printcap).
If you are setting up a printer that uses a network protocol to accept data to print instead of a computer's local interfaces, see Printers With Networked Data Stream Interfaces.
Although this section is called “Simple Printer Setup”, it is actually fairly complex. Getting the printer to work with your computer and the LPD spooler is the hardest part. The advanced options like header pages and accounting are fairly easy once you get the printer working.
9.3.1.1 Hardware Setup
This section tells about the various ways you can connect a printer to your PC. It talks about the kinds of ports and cables, and also the kernel configuration you may need to enable FreeBSD to speak to the printer.
If you have already connected your printer and have successfully printed with it under another operating system, you can probably skip to section Software Setup.
9.3.1.1.1 Ports and Cables
Printers sold for use on PC's today generally come with one or more of the following three interfaces:
-
Serial interfaces, also known as RS-232 or COM ports, use a serial port on your computer to send data to the printer. Serial interfaces are common in the computer industry and cables are readily available and also easy to construct. Serial interfaces sometimes need special cables and might require you to configure somewhat complex communications options. Most PC serial ports have a maximum transmission rate of 115200 bps, which makes printing large graphic print jobs with them impractical.
-
Parallel interfaces use a parallel port on your computer to send data to the printer. Parallel interfaces are common in the PC market and are faster than RS-232 serial. Cables are readily available but more difficult to construct by hand. There are usually no communications options with parallel interfaces, making their configuration exceedingly simple.
Parallel interfaces are sometimes known as “Centronics” interfaces, named after the connector type on the printer.
-
USB interfaces, named for the Universal Serial Bus, can run at even faster speeds than parallel or RS-232 serial interfaces. Cables are simple and cheap. USB is superior to RS-232 Serial and to Parallel for printing, but it is not as well supported under UNIX systems. A way to avoid this problem is to purchase a printer that has both a USB interface and a Parallel interface, as many printers do.
In general, Parallel interfaces usually offer just one-way communication (computer to printer) while serial and USB gives you two-way. Newer parallel ports (EPP and ECP) and printers can communicate in both directions under FreeBSD when a IEEE-1284-compliant cable is used.
Two-way communication to the printer over a parallel port is generally done in one of two ways. The first method uses a custom-built printer driver for FreeBSD that speaks the proprietary language used by the printer. This is common with inkjet printers and can be used for reporting ink levels and other status information. The second method is used when the printer supports PostScript.
PostScript jobs are actually programs sent to the printer; they need not produce paper at all and may return results directly to the computer. PostScript also uses two-way communication to tell the computer about problems, such as errors in the PostScript program or paper jams. Your users may be appreciative of such information. Furthermore, the best way to do effective accounting with a PostScript printer requires two-way communication: you ask the printer for its page count (how many pages it has printed in its lifetime), then send the user's job, then ask again for its page count. Subtract the two values and you know how much paper to charge to the user.
9.3.1.1.2 Parallel Ports
To hook up a printer using a parallel interface, connect the Centronics cable between the printer and the computer. The instructions that came with the printer, the computer, or both should give you complete guidance.
Remember which parallel port you used on the computer. The first parallel port is ppc0 to FreeBSD; the second is ppc1, and so on. The printer device name uses the same scheme: /dev/lpt0 for the printer on the first parallel ports etc.
9.3.1.1.3 Serial Ports
To hook up a printer using a serial interface, connect the proper serial cable between the printer and the computer. The instructions that came with the printer, the computer, or both should give you complete guidance.
If you are unsure what the “proper serial cable” is, you may wish to try one of the following alternatives:
-
A modem cable connects each pin of the connector on one end of the cable straight through to its corresponding pin of the connector on the other end. This type of cable is also known as a “DTE-to-DCE” cable.
-
A null-modem cable connects some pins straight through, swaps others (send data to receive data, for example), and shorts some internally in each connector hood. This type of cable is also known as a “DTE-to-DTE” cable.
-
A serial printer cable, required for some unusual printers, is like the null-modem cable, but sends some signals to their counterparts instead of being internally shorted.
You should also set up the communications parameters for the printer, usually through front-panel controls or DIP switches on the printer. Choose the highest bps (bits per second, sometimes baud rate) that both your computer and the printer can support. Choose 7 or 8 data bits; none, even, or odd parity; and 1 or 2 stop bits. Also choose a flow control protocol: either none, or XON/XOFF (also known as “in-band” or “software”) flow control. Remember these settings for the software configuration that follows.
9.3.1.2 Software Setup
This section describes the software setup necessary to print with the LPD spooling system in FreeBSD.
Here is an outline of the steps involved:
-
Configure your kernel, if necessary, for the port you are using for the printer; section Kernel Configuration tells you what you need to do.
-
Set the communications mode for the parallel port, if you are using a parallel port; section Setting the Communication Mode for the Parallel Port gives details.
-
Test if the operating system can send data to the printer. Section Checking Printer Communications gives some suggestions on how to do this.
-
Set up LPD for the printer by modifying the file /etc/printcap. You will find out how to do this later in this chapter.
9.3.1.2.1 Kernel Configuration
The operating system kernel is compiled to work with a specific set of devices. The serial or parallel interface for your printer is a part of that set. Therefore, it might be necessary to add support for an additional serial or parallel port if your kernel is not already configured for one.
To find out if the kernel you are currently using supports a serial interface, type:
# grep sioN /var/run/dmesg.boot
Where N is the number of the serial port, starting from zero. If you see output similar to the following:
sio2 at port 0x3e8-0x3ef irq 5 on isa
sio2: type 16550A
then the kernel supports the port.
To find out if the kernel supports a parallel interface, type:
# grep ppcN /var/run/dmesg.boot
Where N is the number of the parallel port, starting from zero. If you see output similar to the following:
ppc0: <Parallel port> at port 0x378-0x37f irq 7 on isa0
ppc0: SMC-like chipset (ECP/EPP/PS2/NIBBLE) in COMPATIBLE mode
ppc0: FIFO with 16/16/8 bytes threshold
then the kernel supports the port.
You might have to reconfigure your kernel in order for the operating system to recognize and use the parallel or serial port you are using for the printer.
To add support for a serial port, see the section on kernel configuration. To add support for a parallel port, see that section and the section that follows.
9.3.1.3 Setting the Communication Mode for the Parallel Port
When you are using the parallel interface, you can choose whether FreeBSD should use interrupt-driven or polled communication with the printer. The generic printer device driver (lpt(4)) on FreeBSD uses the ppbus(4) system, which controls the port chipset with the ppc(4) driver.
-
The interrupt-driven method is the default with the GENERIC kernel. With this method, the operating system uses an IRQ line to determine when the printer is ready for data.
-
The polled method directs the operating system to repeatedly ask the printer if it is ready for more data. When it responds ready, the kernel sends more data.
The interrupt-driven method is usually somewhat faster but uses up a precious IRQ line. Some newer HP printers are claimed not to work correctly in interrupt mode, apparently due to some (not yet exactly understood) timing problem. These printers need polled mode. You should use whichever one works. Some printers will work in both modes, but are painfully slow in interrupt mode.
You can set the communications mode in two ways: by configuring the kernel or by using the lptcontrol(8) program.
To set the communications mode by configuring the kernel:
-
Edit your kernel configuration file. Look for an ppc0 entry. If you are setting up the second parallel port, use ppc1 instead. Use ppc2 for the third port, and so on.
-
If you want interrupt-driven mode, edit the following line:
hint.ppc.0.irq="N"in the /boot/device.hints file and replace N with the right IRQ number. The kernel configuration file must also contain the ppc(4) driver:
device ppc -
If you want polled mode, remove in your /boot/device.hints file, the following line:
hint.ppc.0.irq="N"In some cases, this is not enough to put the port in polled mode under FreeBSD. Most of time it comes from acpi(4) driver, this latter is able to probe and attach devices, and therefore, control the access mode to the printer port. You should check your acpi(4) configuration to correct this problem.
-
-
Save the file. Then configure, build, and install the kernel, then reboot. See kernel configuration for more details.
To set the communications mode with lptcontrol(8):
-
Type:
# lptcontrol -i -d /dev/lptNto set interrupt-driven mode for lptN.
-
Type:
# lptcontrol -p -d /dev/lptNto set polled-mode for lptN.
You could put these commands in your /etc/rc.local file to set the mode each time your system boots. See lptcontrol(8) for more information.
9.3.1.4 Checking Printer Communications
Before proceeding to configure the spooling system, you should make sure the operating system can successfully send data to your printer. It is a lot easier to debug printer communication and the spooling system separately.
To test the printer, we will send some text to it. For printers that can immediately print characters sent to them, the program lptest(1) is perfect: it generates all 96 printable ASCII characters in 96 lines.
For a PostScript (or other language-based) printer, we will need a more sophisticated test. A small PostScript program, such as the following, will suffice:
%!PS
100 100 moveto 300 300 lineto stroke
310 310 moveto /Helvetica findfont 12 scalefont setfont
(Is this thing working?) show
showpage
The above PostScript code can be placed into a file and used as shown in the examples appearing in the following sections.
Note: When this document refers to a printer language, it is assuming a language like PostScript, and not Hewlett Packard's PCL. Although PCL has great functionality, you can intermingle plain text with its escape sequences. PostScript cannot directly print plain text, and that is the kind of printer language for which we must make special accommodations.
9.3.1.4.1 Checking a Parallel Printer
This section tells you how to check if FreeBSD can communicate with a printer connected to a parallel port.
To test a printer on a parallel port:
-
Become root with su(1).
-
Send data to the printer.
-
If the printer can print plain text, then use lptest(1). Type:
# lptest > /dev/lptNWhere N is the number of the parallel port, starting from zero.
-
If the printer understands PostScript or other printer language, then send a small program to the printer. Type:
# cat > /dev/lptNThen, line by line, type the program carefully as you cannot edit a line once you have pressed RETURN or ENTER. When you have finished entering the program, press CONTROL+D, or whatever your end of file key is.
Alternatively, you can put the program in a file and type:
# cat file > /dev/lptNWhere file is the name of the file containing the program you want to send to the printer.
-
You should see something print. Do not worry if the text does not look right; we will fix such things later.
9.3.1.4.2 Checking a Serial Printer
This section tells you how to check if FreeBSD can communicate with a printer on a serial port.
To test a printer on a serial port:
-
Become root with su(1).
-
Edit the file /etc/remote. Add the following entry:
printer:dv=/dev/port:br#bps-rate:pa=parityWhere port is the device entry for the serial port (ttyd0, ttyd1, etc.), bps-rate is the bits-per-second rate at which the printer communicates, and parity is the parity required by the printer (either even, odd, none, or zero).
Here is a sample entry for a printer connected via a serial line to the third serial port at 19200 bps with no parity:
printer:dv=/dev/ttyd2:br#19200:pa=none -
Connect to the printer with tip(1). Type:
# tip printerIf this step does not work, edit the file /etc/remote again and try using /dev/cuaaN instead of /dev/ttydN.
-
Send data to the printer.
-
If the printer can print plain text, then use lptest(1). Type:
% $lptest -
If the printer understands PostScript or other printer language, then send a small program to the printer. Type the program, line by line, very carefully as backspacing or other editing keys may be significant to the printer. You may also need to type a special end-of-file key for the printer so it knows it received the whole program. For PostScript printers, press CONTROL+D.
Alternatively, you can put the program in a file and type:
% >fileWhere file is the name of the file containing the program. After tip(1) sends the file, press any required end-of-file key.
-
You should see something print. Do not worry if the text does not look right; we will fix that later.
9.3.1.5 Enabling the Spooler: the /etc/printcap File
At this point, your printer should be hooked up, your kernel configured to communicate with it (if necessary), and you have been able to send some simple data to the printer. Now, we are ready to configure LPD to control access to your printer.
You configure LPD by editing the file /etc/printcap. The LPD spooling system reads this file each time the spooler is used, so updates to the file take immediate effect.
The format of the printcap(5) file is straightforward. Use your favorite text editor to make changes to /etc/printcap. The format is identical to other capability files like /usr/share/misc/termcap and /etc/remote. For complete information about the format, see the cgetent(3).
The simple spooler configuration consists of the following steps:
-
Pick a name (and a few convenient aliases) for the printer, and put them in the /etc/printcap file; see the Naming the Printer section for more information on naming.
-
Turn off header pages (which are on by default) by inserting the sh capability; see the Suppressing Header Pages section for more information.
-
Make a spooling directory, and specify its location with the sd capability; see the Making the Spooling Directory section for more information.
-
Set the /dev entry to use for the printer, and note it in /etc/printcap with the lp capability; see the Identifying the Printer Device for more information. Also, if the printer is on a serial port, set up the communication parameters with the ms# capability which is discussed in the Configuring Spooler Communications Parameters section.
-
Install a plain text input filter; see the Installing the Text Filter section for details.
-
Test the setup by printing something with the lpr(1) command. More details are available in the Trying It Out and Troubleshooting sections.
Note: Language-based printers, such as PostScript printers, cannot directly print plain text. The simple setup outlined above and described in the following sections assumes that if you are installing such a printer you will print only files that the printer can understand.
Users often expect that they can print plain text to any of the printers installed on your system. Programs that interface to LPD to do their printing usually make the same assumption. If you are installing such a printer and want to be able to print jobs in the printer language and print plain text jobs, you are strongly urged to add an additional step to the simple setup outlined above: install an automatic plain-text-to-PostScript (or other printer language) conversion program. The section entitled Accommodating Plain Text Jobs on PostScript Printers tells how to do this.
9.3.1.5.1 Naming the Printer
The first (easy) step is to pick a name for your printer. It really does not matter whether you choose functional or whimsical names since you can also provide a number of aliases for the printer.
At least one of the printers specified in the /etc/printcap should have the alias lp. This is the default printer's name. If users do not have the PRINTER environment variable nor specify a printer name on the command line of any of the LPD commands, then lp will be the default printer they get to use.
Also, it is common practice to make the last alias for a printer be a full description of the printer, including make and model.
Once you have picked a name and some common aliases, put them in the /etc/printcap file. The name of the printer should start in the leftmost column. Separate each alias with a vertical bar and put a colon after the last alias.
In the following example, we start with a skeletal /etc/printcap that defines two printers (a Diablo 630 line printer and a Panasonic KX-P4455 PostScript laser printer):
#
# /etc/printcap for host rose
#
rattan|line|diablo|lp|Diablo 630 Line Printer:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:
In this example, the first printer is named rattan and has as aliases line, diablo, lp, and Diablo 630 Line Printer. Since it has the alias lp, it is also the default printer. The second is named bamboo, and has as aliases ps, PS, S, panasonic, and Panasonic KX-P4455 PostScript v51.4.
9.3.1.5.2 Suppressing Header Pages
The LPD spooling system will by default print a header page for each job. The header page contains the user name who requested the job, the host from which the job came, and the name of the job, in nice large letters. Unfortunately, all this extra text gets in the way of debugging the simple printer setup, so we will suppress header pages.
To suppress header pages, add the sh capability to the entry for the printer in /etc/printcap. Here is an example /etc/printcap with sh added:
#
# /etc/printcap for host rose - no header pages anywhere
#
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:sh:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:sh:
Note how we used the correct format: the first line starts in the leftmost column, and subsequent lines are indented. Every line in an entry except the last ends in a backslash character.
9.3.1.5.3 Making the Spooling Directory
The next step in the simple spooler setup is to make a spooling directory, a directory where print jobs reside until they are printed, and where a number of other spooler support files live.
Because of the variable nature of spooling directories, it is customary to put these directories under /var/spool. It is not necessary to backup the contents of spooling directories, either. Recreating them is as simple as running mkdir(1).
It is also customary to make the directory with a name that is identical to the name of the printer, as shown below:
# mkdir /var/spool/printer-name
However, if you have a lot of printers on your network, you might want to put the spooling directories under a single directory that you reserve just for printing with LPD. We will do this for our two example printers rattan and bamboo:
# mkdir /var/spool/lpd
# mkdir /var/spool/lpd/rattan
# mkdir /var/spool/lpd/bamboo
Note: If you are concerned about the privacy of jobs that users print, you might want to protect the spooling directory so it is not publicly accessible. Spooling directories should be owned and be readable, writable, and searchable by user daemon and group daemon, and no one else. We will do this for our example printers:
# chown daemon:daemon /var/spool/lpd/rattan # chown daemon:daemon /var/spool/lpd/bamboo # chmod 770 /var/spool/lpd/rattan # chmod 770 /var/spool/lpd/bamboo
Finally, you need to tell LPD about these directories using the /etc/printcap file. You specify the pathname of the spooling directory with the sd capability:
#
# /etc/printcap for host rose - added spooling directories
#
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:sh:sd=/var/spool/lpd/rattan:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:sh:sd=/var/spool/lpd/bamboo:
Note that the name of the printer starts in the first column but all other entries describing the printer should be indented and each line end escaped with a backslash.
If you do not specify a spooling directory with sd, the spooling system will use /var/spool/lpd as a default.
9.3.1.5.4 Identifying the Printer Device
In the Entries for the Ports section, we identified which entry in the /dev directory FreeBSD will use to communicate with the printer. Now, we tell LPD that information. When the spooling system has a job to print, it will open the specified device on behalf of the filter program (which is responsible for passing data to the printer).
List the /dev entry pathname in the /etc/printcap file using the lp capability.
In our running example, let us assume that rattan is on the first parallel port, and bamboo is on a sixth serial port; here are the additions to /etc/printcap:
#
# /etc/printcap for host rose - identified what devices to use
#
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:sh:sd=/var/spool/lpd/rattan:\
:lp=/dev/lpt0:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:sh:sd=/var/spool/lpd/bamboo:\
:lp=/dev/ttyd5:
If you do not specify the lp capability for a printer in your /etc/printcap file, LPD uses /dev/lp as a default. /dev/lp currently does not exist in FreeBSD.
If the printer you are installing is connected to a parallel port, skip to the section entitled, Installing the Text Filter. Otherwise, be sure to follow the instructions in the next section.
9.3.1.5.5 Configuring Spooler Communication Parameters
For printers on serial ports, LPD can set up the bps rate, parity, and other serial communication parameters on behalf of the filter program that sends data to the printer. This is advantageous since:
-
It lets you try different communication parameters by simply editing the /etc/printcap file; you do not have to recompile the filter program.
-
It enables the spooling system to use the same filter program for multiple printers which may have different serial communication settings.
The following /etc/printcap capabilities control serial communication parameters of the device listed in the lp capability:
- br#bps-rate
-
Sets the communications speed of the device to bps-rate, where bps-rate can be 50, 75, 110, 134, 150, 200, 300, 600, 1200, 1800, 2400, 4800, 9600, 19200, 38400, 57600, or 115200 bits-per-second.
- ms#stty-mode
-
Sets the options for the terminal device after opening the device. stty(1) explains the available options.
When LPD opens the device specified by the lp capability, it sets the characteristics of the device to those specified with the ms# capability. Of particular interest will be the parenb, parodd, cs5, cs6, cs7, cs8, cstopb, crtscts, and ixon modes, which are explained in the stty(1) manual page.
Let us add to our example printer on the sixth serial port. We will set the bps rate to 38400. For the mode, we will set no parity with -parenb, 8-bit characters with cs8, no modem control with clocal and hardware flow control with crtscts:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:sh:sd=/var/spool/lpd/bamboo:\
:lp=/dev/ttyd5:ms#-parenb cs8 clocal crtscts:
9.3.1.5.6 Installing the Text Filter
We are now ready to tell LPD what text filter to use to send jobs to the printer. A text filter, also known as an input filter, is a program that LPD runs when it has a job to print. When LPD runs the text filter for a printer, it sets the filter's standard input to the job to print, and its standard output to the printer device specified with the lp capability. The filter is expected to read the job from standard input, perform any necessary translation for the printer, and write the results to standard output, which will get printed. For more information on the text filter, see the Filters section.
For our simple printer setup, the text filter can be a small shell script that just executes /bin/cat to send the job to the printer. FreeBSD comes with another filter called lpf that handles backspacing and underlining for printers that might not deal with such character streams well. And, of course, you can use any other filter program you want. The filter lpf is described in detail in section entitled lpf: a Text Filter.
First, let us make the shell script /usr/local/libexec/if-simple be a simple text filter. Put the following text into that file with your favorite text editor:
#!/bin/sh
#
# if-simple - Simple text input filter for lpd
# Installed in /usr/local/libexec/if-simple
#
# Simply copies stdin to stdout. Ignores all filter arguments.
/bin/cat && exit 0
exit 2
Make the file executable:
# chmod 555 /usr/local/libexec/if-simple
And then tell LPD to use it by specifying it with the if capability in /etc/printcap. We will add it to the two printers we have so far in the example /etc/printcap:
#
# /etc/printcap for host rose - added text filter
#
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:sh:sd=/var/spool/lpd/rattan:\ :lp=/dev/lpt0:\
:if=/usr/local/libexec/if-simple:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:sh:sd=/var/spool/lpd/bamboo:\
:lp=/dev/ttyd5:ms#-parenb cs8 clocal crtscts:\
:if=/usr/local/libexec/if-simple:
Note: A copy of the if-simple script can be found in the /usr/share/examples/printing directory.
9.3.1.5.7 Turn on LPD
lpd(8) is run from /etc/rc, controlled by the lpd_enable variable. This variable defaults to NO. If you have not done so already, add the line:
lpd_enable="YES"
to /etc/rc.conf, and then either restart your machine, or just run lpd(8).
# lpd
9.3.1.5.8 Trying It Out
You have reached the end of the simple LPD setup. Unfortunately, congratulations are not quite yet in order, since we still have to test the setup and correct any problems. To test the setup, try printing something. To print with the LPD system, you use the command lpr(1), which submits a job for printing.
You can combine lpr(1) with the lptest(1) program, introduced in section Checking Printer Communications to generate some test text.
To test the simple LPD setup:
Type:
# lptest 20 5 | lpr -Pprinter-name
Where printer-name is a the name of a printer (or
an alias) specified in /etc/printcap. To test the default
printer, type lpr(1) without any
-P argument. Again, if you are testing a printer that expects
PostScript, send a PostScript program in that language instead of using lptest(1). You can do
so by putting the program in a file and typing lpr file.
For a PostScript printer, you should get the results of the program. If you are using lptest(1), then your results should look like the following:
!"#$%&'()*+,-./01234
"#$%&'()*+,-./012345
#$%&'()*+,-./0123456
$%&'()*+,-./01234567
%&'()*+,-./012345678
To further test the printer, try downloading larger programs (for language-based printers) or running lptest(1) with different arguments. For example, lptest 80 60 will produce 60 lines of 80 characters each.
If the printer did not work, see the Troubleshooting section.
9.4 Advanced Printer Setup
This section describes filters for printing specially formatted files, header pages, printing across networks, and restricting and accounting for printer usage.
9.4.1 Filters
Although LPD handles network protocols, queuing, access control, and other aspects of printing, most of the real work happens in the filters. Filters are programs that communicate with the printer and handle its device dependencies and special requirements. In the simple printer setup, we installed a plain text filter--an extremely simple one that should work with most printers (section Installing the Text Filter).
However, in order to take advantage of format conversion, printer accounting, specific printer quirks, and so on, you should understand how filters work. It will ultimately be the filter's responsibility to handle these aspects. And the bad news is that most of the time you have to provide filters yourself. The good news is that many are generally available; when they are not, they are usually easy to write.
Also, FreeBSD comes with one, /usr/libexec/lpr/lpf, that works with many printers that can print plain text. (It handles backspacing and tabs in the file, and does accounting, but that is about all it does.) There are also several filters and filter components in the FreeBSD Ports Collection.
Here is what you will find in this section:
-
Section How Filters Work, tries to give an overview of a filter's role in the printing process. You should read this section to get an understanding of what is happening “under the hood” when LPD uses filters. This knowledge could help you anticipate and debug problems you might encounter as you install more and more filters on each of your printers.
-
LPD expects every printer to be able to print plain text by default. This presents a problem for PostScript (or other language-based printers) which cannot directly print plain text. Section Accommodating Plain Text Jobs on PostScript Printers tells you what you should do to overcome this problem. You should read this section if you have a PostScript printer.
-
PostScript is a popular output format for many programs. Some people even write PostScript code directly. Unfortunately, PostScript printers are expensive. Section Simulating PostScript on Non PostScript Printers tells how you can further modify a printer's text filter to accept and print PostScript data on a non PostScript printer. You should read this section if you do not have a PostScript printer.
-
Section Conversion Filters tells about a way you can automate the conversion of specific file formats, such as graphic or typesetting data, into formats your printer can understand. After reading this section, you should be able to set up your printers such that users can type lpr -t to print troff data, or lpr -d to print TeX DVI data, or lpr -v to print raster image data, and so forth. I recommend reading this section.
-
Section Output Filters tells all about a not often used feature of LPD: output filters. Unless you are printing header pages (see Header Pages), you can probably skip that section altogether.
-
Section lpf: a Text Filter describes lpf, a fairly complete if simple text filter for line printers (and laser printers that act like line printers) that comes with FreeBSD. If you need a quick way to get printer accounting working for plain text, or if you have a printer which emits smoke when it sees backspace characters, you should definitely consider lpf.
Note: A copy of the various scripts described below can be found in the /usr/share/examples/printing directory.
9.4.1.1 How Filters Work
As mentioned before, a filter is an executable program started by LPD to handle the device-dependent part of communicating with the printer.
When LPD wants to print a file in a job, it starts a filter program. It sets the filter's standard input to the file to print, its standard output to the printer, and its standard error to the error logging file (specified in the lf capability in /etc/printcap, or /dev/console by default).
Which filter LPD starts and the filter's arguments depend on what is listed in the /etc/printcap file and what arguments the user specified for the job on the lpr(1) command line. For example, if the user typed lpr -t, LPD would start the troff filter, listed in the tf capability for the destination printer. If the user wanted to print plain text, it would start the if filter (this is mostly true: see Output Filters for details).
There are three kinds of filters you can specify in /etc/printcap:
-
The text filter, confusingly called the input filter in LPD documentation, handles regular text printing. Think of it as the default filter. LPD expects every printer to be able to print plain text by default, and it is the text filter's job to make sure backspaces, tabs, or other special characters do not confuse the printer. If you are in an environment where you have to account for printer usage, the text filter must also account for pages printed, usually by counting the number of lines printed and comparing that to the number of lines per page the printer supports. The text filter is started with the following argument list:
filter-name [-c] -wwidth -llength -iindent -n login -h host acct-file
where-c-
appears if the job is submitted with lpr -l
- width
-
is the value from the pw (page width) capability specified in /etc/printcap, default 132
- length
-
is the value from the pl (page length) capability, default 66
- indent
-
is the amount of the indentation from lpr -i, default 0
- login
-
is the account name of the user printing the file
- host
-
is the host name from which the job was submitted
- acct-file
-
is the name of the accounting file from the af capability.
-
A conversion filter converts a specific file format into one the printer can render onto paper. For example, ditroff typesetting data cannot be directly printed, but you can install a conversion filter for ditroff files to convert the ditroff data into a form the printer can digest and print. Section Conversion Filters tells all about them. Conversion filters also need to do accounting, if you need printer accounting. Conversion filters are started with the following arguments:
filter-name -xpixel-width -ypixel-height -n login -h host acct-file
where pixel-width is the value from the px capability (default 0) and pixel-height is the value from the py capability (default 0).
-
The output filter is used only if there is no text filter, or if header pages are enabled. In my experience, output filters are rarely used. Section Output Filters describe them. There are only two arguments to an output filter:
filter-name -wwidth -llength
which are identical to the text filters-wand-larguments.
Filters should also exit with the following exit status:
- exit 0
-
If the filter printed the file successfully.
- exit 1
-
If the filter failed to print the file but wants LPD to try to print the file again. LPD will restart a filter if it exits with this status.
- exit 2
-
If the filter failed to print the file and does not want LPD to try again. LPD will throw out the file.
The text filter that comes with the FreeBSD release, /usr/libexec/lpr/lpf, takes advantage of the page width and length arguments to determine when to send a form feed and how to account for printer usage. It uses the login, host, and accounting file arguments to make the accounting entries.
If you are shopping for filters, see if they are LPD-compatible. If they are, they must support the argument lists described above. If you plan on writing filters for general use, then have them support the same argument lists and exit codes.
9.4.1.2 Accommodating Plain Text Jobs on PostScript® Printers
If you are the only user of your computer and PostScript (or other language-based) printer, and you promise to never send plain text to your printer and to never use features of various programs that will want to send plain text to your printer, then you do not need to worry about this section at all.
But, if you would like to send both PostScript and plain text jobs to the printer, then you are urged to augment your printer setup. To do so, we have the text filter detect if the arriving job is plain text or PostScript. All PostScript jobs must start with %! (for other printer languages, see your printer documentation). If those are the first two characters in the job, we have PostScript, and can pass the rest of the job directly. If those are not the first two characters in the file, then the filter will convert the text into PostScript and print the result.
How do we do this?
If you have got a serial printer, a great way to do it is to install lprps. lprps is a PostScript printer filter which performs two-way communication with the printer. It updates the printer's status file with verbose information from the printer, so users and administrators can see exactly what the state of the printer is (such as “toner low” or “paper jam”). But more importantly, it includes a program called psif which detects whether the incoming job is plain text and calls textps (another program that comes with lprps) to convert it to PostScript. It then uses lprps to send the job to the printer.
lprps is part of the FreeBSD Ports Collection (see The Ports Collection). You can fetch, build and install it yourself, of course. After installing lprps, just specify the pathname to the psif program that is part of lprps. If you installed lprps from the Ports Collection, use the following in the serial PostScript printer's entry in /etc/printcap:
:if=/usr/local/libexec/psif:
You should also specify the rw capability; that tells LPD to open the printer in read-write mode.
If you have a parallel PostScript printer (and therefore cannot use two-way communication with the printer, which lprps needs), you can use the following shell script as the text filter:
#!/bin/sh
#
# psif - Print PostScript or plain text on a PostScript printer
# Script version; NOT the version that comes with lprps
# Installed in /usr/local/libexec/psif
#
IFS="" read -r first_line
first_two_chars=`expr "$first_line" : '\(..\)'`
if [ "$first_two_chars" = "%!" ]; then
#
# PostScript job, print it.
#
echo "$first_line" && cat && printf "\004" && exit 0
exit 2
else
#
# Plain text, convert it, then print it.
#
( echo "$first_line"; cat ) | /usr/local/bin/textps && printf "\004" && exit 0
exit 2
fi
In the above script, textps is a program we installed separately to convert plain text to PostScript. You can use any text-to-PostScript program you wish. The FreeBSD Ports Collection (see The Ports Collection) includes a full featured text-to-PostScript program called a2ps that you might want to investigate.
9.4.1.3 Simulating PostScript on Non PostScript Printers
PostScript is the de facto standard for high quality typesetting and printing. PostScript is, however, an expensive standard. Thankfully, Aladdin Enterprises has a free PostScript work-alike called Ghostscript that runs with FreeBSD. Ghostscript can read most PostScript files and can render their pages onto a variety of devices, including many brands of non-PostScript printers. By installing Ghostscript and using a special text filter for your printer, you can make your non PostScript printer act like a real PostScript printer.
Ghostscript is in the FreeBSD Ports Collection, if you would like to install it from there. You can fetch, build, and install it quite easily yourself, as well.
To simulate PostScript, we have the text filter detect if it is printing a PostScript file. If it is not, then the filter will pass the file directly to the printer; otherwise, it will use Ghostscript to first convert the file into a format the printer will understand.
Here is an example: the following script is a text filter for Hewlett Packard DeskJet
500 printers. For other printers, substitute the -sDEVICE
argument to the gs (Ghostscript) command. (Type gs -h to get a list of devices the current installation of
Ghostscript supports.)
#!/bin/sh
#
# ifhp - Print Ghostscript-simulated PostScript on a DeskJet 500
# Installed in /usr/local/libexec/ifhp
#
# Treat LF as CR+LF (to avoid the "staircase effect" on HP/PCL
# printers):
#
printf "\033&k2G" || exit 2
#
# Read first two characters of the file
#
IFS="" read -r first_line
first_two_chars=`expr "$first_line" : '\(..\)'`
if [ "$first_two_chars" = "%!" ]; then
#
# It is PostScript; use Ghostscript to scan-convert and print it.
#
/usr/local/bin/gs -dSAFER -dNOPAUSE -q -sDEVICE=djet500 \
-sOutputFile=- - && exit 0
else
#
# Plain text or HP/PCL, so just print it directly; print a form feed
# at the end to eject the last page.
#
echo "$first_line" && cat && printf "\033&l0H" &&
exit 0
fi
exit 2
Finally, you need to notify LPD of the filter via the if capability:
:if=/usr/local/libexec/ifhp:
That is it. You can type lpr plain.text and lpr whatever.ps and both should print successfully.
9.4.1.4 Conversion Filters
After completing the simple setup described in Simple Printer Setup, the first thing you will probably want to do is install conversion filters for your favorite file formats (besides plain ASCII text).
9.4.1.4.1 Why Install Conversion Filters?
Conversion filters make printing various kinds of files easy. As an example, suppose we do a lot of work with the TeX typesetting system, and we have a PostScript printer. Every time we generate a DVI file from TeX, we cannot print it directly until we convert the DVI file into PostScript. The command sequence goes like this:
% dvips seaweed-analysis.dvi
% lpr seaweed-analysis.ps
By installing a conversion filter for DVI files, we can skip the hand conversion step each time by having LPD do it for us. Now, each time we get a DVI file, we are just one step away from printing it:
% lpr -d seaweed-analysis.dvi
We got LPD to do the DVI file conversion for us by
specifying the -d option. Section Formatting and Conversion Options lists the
conversion options.
For each of the conversion options you want a printer to support, install a conversion filter and specify its pathname in /etc/printcap. A conversion filter is like the text filter for the simple printer setup (see section Installing the Text Filter) except that instead of printing plain text, the filter converts the file into a format the printer can understand.
9.4.1.4.2 Which Conversion Filters Should I Install?
You should install the conversion filters you expect to use. If you print a lot of DVI data, then a DVI conversion filter is in order. If you have got plenty of troff to print out, then you probably want a troff filter.
The following table summarizes the filters that LPD works with, their capability entries for the /etc/printcap file, and how to invoke them with the lpr command:
| File type | /etc/printcap capability | lpr option |
|---|---|---|
| cifplot | cf | -c |
| DVI | df | -d |
| plot | gf | -g |
| ditroff | nf | -n |
| FORTRAN text | rf | -f |
| troff | tf | -f |
| raster | vf | -v |
| plain text | if | none, -p, or -l |
In our example, using lpr -d means the printer needs a df capability in its entry in /etc/printcap.
Despite what others might contend, formats like FORTRAN text and plot are probably obsolete. At your site, you can give new meanings to these or any of the formatting options just by installing custom filters. For example, suppose you would like to directly print Printerleaf files (files from the Interleaf desktop publishing program), but will never print plot files. You could install a Printerleaf conversion filter under the gf capability and then educate your users that lpr -g mean “print Printerleaf files.”
9.4.1.4.3 Installing Conversion Filters
Since conversion filters are programs you install outside of the base FreeBSD installation, they should probably go under /usr/local. The directory /usr/local/libexec is a popular location, since they are specialized programs that only LPD will run; regular users should not ever need to run them.
To enable a conversion filter, specify its pathname under the appropriate capability for the destination printer in /etc/printcap.
In our example, we will add the DVI conversion filter to the entry for the printer named bamboo. Here is the example /etc/printcap file again, with the new df capability for the printer bamboo.
#
# /etc/printcap for host rose - added df filter for bamboo
#
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:sh:sd=/var/spool/lpd/rattan:\
:lp=/dev/lpt0:\
:if=/usr/local/libexec/if-simple:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:sh:sd=/var/spool/lpd/bamboo:\
:lp=/dev/ttyd5:ms#-parenb cs8 clocal crtscts:rw:\
:if=/usr/local/libexec/psif:\
:df=/usr/local/libexec/psdf:
The DVI filter is a shell script named /usr/local/libexec/psdf. Here is that script:
#!/bin/sh
#
# psdf - DVI to PostScript printer filter
# Installed in /usr/local/libexec/psdf
#
# Invoked by lpd when user runs lpr -d
#
exec /usr/local/bin/dvips -f | /usr/local/libexec/lprps "$@"
This script runs dvips in filter mode (the -f argument) on standard input, which is the job to print. It then
starts the PostScript printer filter lprps (see section Accommodating Plain Text Jobs on PostScript Printers) with the arguments LPD passed to this script. lprps will
use those arguments to account for the pages printed.
9.4.1.4.4 More Conversion Filter Examples
Since there is no fixed set of steps to install conversion filters, let me instead provide more examples. Use these as guidance to making your own filters. Use them directly, if appropriate.
This example script is a raster (well, GIF file, actually) conversion filter for a Hewlett Packard LaserJet III-Si printer:
#!/bin/sh
#
# hpvf - Convert GIF files into HP/PCL, then print
# Installed in /usr/local/libexec/hpvf
PATH=/usr/X11R6/bin:$PATH; export PATH
giftopnm | ppmtopgm | pgmtopbm | pbmtolj -resolution 300 \
&& exit 0 \
|| exit 2
It works by converting the GIF file into a portable anymap, converting that into a portable graymap, converting that into a portable bitmap, and converting that into LaserJet/PCL-compatible data.
Here is the /etc/printcap file with an entry for a printer using the above filter:
#
# /etc/printcap for host orchid
#
teak|hp|laserjet|Hewlett Packard LaserJet 3Si:\
:lp=/dev/lpt0:sh:sd=/var/spool/lpd/teak:mx#0:\
:if=/usr/local/libexec/hpif:\
:vf=/usr/local/libexec/hpvf:
The following script is a conversion filter for troff data from the groff typesetting system for the PostScript printer named bamboo:
#!/bin/sh
#
# pstf - Convert groff's troff data into PS, then print.
# Installed in /usr/local/libexec/pstf
#
exec grops | /usr/local/libexec/lprps "$@"
The above script makes use of lprps again to handle the communication with the printer. If the printer were on a parallel port, we would use this script instead:
#!/bin/sh
#
# pstf - Convert groff's troff data into PS, then print.
# Installed in /usr/local/libexec/pstf
#
exec grops
That is it. Here is the entry we need to add to /etc/printcap to enable the filter:
:tf=/usr/local/libexec/pstf:
Here is an example that might make old hands at FORTRAN blush. It is a FORTRAN-text filter for any printer that can directly print plain text. We will install it for the printer teak:
#!/bin/sh
#
# hprf - FORTRAN text filter for LaserJet 3si:
# Installed in /usr/local/libexec/hprf
#
printf "\033&k2G" && fpr && printf "\033&l0H" &&
exit 0
exit 2
And we will add this line to the /etc/printcap for the printer teak to enable this filter:
:rf=/usr/local/libexec/hprf:
Here is one final, somewhat complex example. We will add a DVI filter to the LaserJet printer teak introduced earlier. First, the easy part: updating /etc/printcap with the location of the DVI filter:
:df=/usr/local/libexec/hpdf:
Now, for the hard part: making the filter. For that, we need a DVI-to-LaserJet/PCL conversion program. The FreeBSD Ports Collection (see The Ports Collection) has one: dvi2xx is the name of the package. Installing this package gives us the program we need, dvilj2p, which converts DVI into LaserJet IIp, LaserJet III, and LaserJet 2000 compatible codes.
dvilj2p makes the filter hpdf quite complex since dvilj2p cannot read from standard input. It wants to work with a filename. What is worse, the filename has to end in .dvi so using /dev/fd/0 for standard input is problematic. We can get around that problem by linking (symbolically) a temporary file name (one that ends in .dvi) to /dev/fd/0, thereby forcing dvilj2p to read from standard input.
The only other fly in the ointment is the fact that we cannot use /tmp for the temporary link. Symbolic links are owned by user and group bin. The filter runs as user daemon. And the /tmp directory has the sticky bit set. The filter can create the link, but it will not be able clean up when done and remove it since the link will belong to a different user.
Instead, the filter will make the symbolic link in the current working directory, which is the spooling directory (specified by the sd capability in /etc/printcap). This is a perfect place for filters to do their work, especially since there is (sometimes) more free disk space in the spooling directory than under /tmp.
Here, finally, is the filter:
#!/bin/sh
#
# hpdf - Print DVI data on HP/PCL printer
# Installed in /usr/local/libexec/hpdf
PATH=/usr/local/bin:$PATH; export PATH
#
# Define a function to clean up our temporary files. These exist
# in the current directory, which will be the spooling directory
# for the printer.
#
cleanup() {
rm -f hpdf$$.dvi
}
#
# Define a function to handle fatal errors: print the given message
# and exit 2. Exiting with 2 tells LPD to do not try to reprint the
# job.
#
fatal() {
echo "$@" 1>&2
cleanup
exit 2
}
#
# If user removes the job, LPD will send SIGINT, so trap SIGINT
# (and a few other signals) to clean up after ourselves.
#
trap cleanup 1 2 15
#
# Make sure we are not colliding with any existing files.
#
cleanup
#
# Link the DVI input file to standard input (the file to print).
#
ln -s /dev/fd/0 hpdf$$.dvi || fatal "Cannot symlink /dev/fd/0"
#
# Make LF = CR+LF
#
printf "\033&k2G" || fatal "Cannot initialize printer"
#
# Convert and print. Return value from dvilj2p does not seem to be
# reliable, so we ignore it.
#
dvilj2p -M1 -q -e- dfhp$$.dvi
#
# Clean up and exit
#
cleanup
exit 0
9.4.1.4.5 Automated Conversion: an Alternative to Conversion Filters
All these conversion filters accomplish a lot for your printing environment, but at the cost forcing the user to specify (on the lpr(1) command line) which one to use. If your users are not particularly computer literate, having to specify a filter option will become annoying. What is worse, though, is that an incorrectly specified filter option may run a filter on the wrong type of file and cause your printer to spew out hundreds of sheets of paper.
Rather than install conversion filters at all, you might want to try having the text filter (since it is the default filter) detect the type of file it has been asked to print and then automatically run the right conversion filter. Tools such as file can be of help here. Of course, it will be hard to determine the differences between some file types--and, of course, you can still provide conversion filters just for them.
The FreeBSD Ports Collection has a text filter that performs automatic conversion called apsfilter. It can detect plain text, PostScript, and DVI files, run the proper conversions, and print.
9.4.1.5 Output Filters
The LPD spooling system supports one other type of filter that we have not yet explored: an output filter. An output filter is intended for printing plain text only, like the text filter, but with many simplifications. If you are using an output filter but no text filter, then:
-
LPD starts an output filter once for the entire job instead of once for each file in the job.
-
LPD does not make any provision to identify the start or the end of files within the job for the output filter.
-
LPD does not pass the user's login or host to the filter, so it is not intended to do accounting. In fact, it gets only two arguments:
filter-name -wwidth -llength
Where width is from the pw capability and length is from the pl capability for the printer in question.
Do not be seduced by an output filter's simplicity. If you would like each file in a job to start on a different page an output filter will not work. Use a text filter (also known as an input filter); see section Installing the Text Filter. Furthermore, an output filter is actually more complex in that it has to examine the byte stream being sent to it for special flag characters and must send signals to itself on behalf of LPD.
However, an output filter is necessary if you want header pages and need to send escape sequences or other initialization strings to be able to print the header page. (But it is also futile if you want to charge header pages to the requesting user's account, since LPD does not give any user or host information to the output filter.)
On a single printer, LPD allows both an output filter and text or other filters. In such cases, LPD will start the output filter to print the header page (see section Header Pages) only. LPD then expects the output filter to stop itself by sending two bytes to the filter: ASCII 031 followed by ASCII 001. When an output filter sees these two bytes (031, 001), it should stop by sending SIGSTOP to itself. When LPD's done running other filters, it will restart the output filter by sending SIGCONT to it.
If there is an output filter but no text filter and LPD is working on a plain text job, LPD uses the output filter to do the job. As stated before, the output filter will print each file of the job in sequence with no intervening form feeds or other paper advancement, and this is probably not what you want. In almost all cases, you need a text filter.
The program lpf, which we introduced earlier as a text filter, can also run as an output filter. If you need a quick-and-dirty output filter but do not want to write the byte detection and signal sending code, try lpf. You can also wrap lpf in a shell script to handle any initialization codes the printer might require.
9.4.1.6 lpf: a Text Filter
The program /usr/libexec/lpr/lpf that comes with FreeBSD binary distribution is a text filter (input filter) that can indent output (job submitted with lpr -i), allow literal characters to pass (job submitted with lpr -l), adjust the printing position for backspaces and tabs in the job, and account for pages printed. It can also act like an output filter.
lpf is suitable for many printing environments. And although it has no capability to send initialization sequences to a printer, it is easy to write a shell script to do the needed initialization and then execute lpf.
In order for lpf to do page accounting correctly, it needs correct values filled in for the pw and pl capabilities in the /etc/printcap file. It uses these values to determine how much text can fit on a page and how many pages were in a user's job. For more information on printer accounting, see Accounting for Printer Usage.
9.4.2 Header Pages
If you have lots of users, all of them using various printers, then you probably want to consider header pages as a necessary evil.
Header pages, also known as banner or burst pages identify to whom jobs belong after they are printed. They are usually printed in large, bold letters, perhaps with decorative borders, so that in a stack of printouts they stand out from the real documents that comprise users' jobs. They enable users to locate their jobs quickly. The obvious drawback to a header page is that it is yet one more sheet that has to be printed for every job, their ephemeral usefulness lasting not more than a few minutes, ultimately finding themselves in a recycling bin or rubbish heap. (Note that header pages go with each job, not each file in a job, so the paper waste might not be that bad.)
The LPD system can provide header pages automatically for your printouts if your printer can directly print plain text. If you have a PostScript printer, you will need an external program to generate the header page; see Header Pages on PostScript Printers.
9.4.2.1 Enabling Header Pages
In the Simple Printer Setup section, we turned off header pages by specifying sh (meaning “suppress header”) in the /etc/printcap file. To enable header pages for a printer, just remove the sh capability.
Sounds too easy, right?
You are right. You might have to provide an output filter to send initialization strings to the printer. Here is an example output filter for Hewlett Packard PCL-compatible printers:
#!/bin/sh
#
# hpof - Output filter for Hewlett Packard PCL-compatible printers
# Installed in /usr/local/libexec/hpof
printf "\033&k2G" || exit 2
exec /usr/libexec/lpr/lpf
Specify the path to the output filter in the of capability. See the Output Filters section for more information.
Here is an example /etc/printcap file for the printer teak that we introduced earlier; we enabled header pages and added the above output filter:
#
# /etc/printcap for host orchid
#
teak|hp|laserjet|Hewlett Packard LaserJet 3Si:\
:lp=/dev/lpt0:sd=/var/spool/lpd/teak:mx#0:\
:if=/usr/local/libexec/hpif:\
:vf=/usr/local/libexec/hpvf:\
:of=/usr/local/libexec/hpof:
Now, when users print jobs to teak, they get a header page with each job. If users want to spend time searching for their printouts, they can suppress header pages by submitting the job with lpr -h; see the Header Page Options section for more lpr(1) options.
Note: LPD prints a form feed character after the header page. If your printer uses a different character or sequence of characters to eject a page, specify them with the ff capability in /etc/printcap.
9.4.2.2 Controlling Header Pages
By enabling header pages, LPD will produce a long header, a full page of large letters identifying the user, host, and job. Here is an example (kelly printed the job named outline from host rose):
k ll ll
k l l
k l l
k k eeee l l y y
k k e e l l y y
k k eeeeee l l y y
kk k e l l y y
k k e e l l y yy
k k eeee lll lll yyy y
y
y y
yyyy
ll
t l i
t l
oooo u u ttttt l ii n nnn eeee
o o u u t l i nn n e e
o o u u t l i n n eeeeee
o o u u t l i n n e
o o u uu t t l i n n e e
oooo uuu u tt lll iii n n eeee
r rrr oooo ssss eeee
rr r o o s s e e
r o o ss eeeeee
r o o ss e
r o o s s e e
r oooo ssss eeee
Job: outline
Date: Sun Sep 17 11:04:58 1995
LPD appends a form feed after this text so the job starts on a new page (unless you have sf (suppress form feeds) in the destination printer's entry in /etc/printcap).
If you prefer, LPD can make a short header; specify sb (short banner) in the /etc/printcap file. The header page will look like this:
rose:kelly Job: outline Date: Sun Sep 17 11:07:51 1995
Also by default, LPD prints the header page first, then the job. To reverse that, specify hl (header last) in /etc/printcap.
9.4.2.3 Accounting for Header Pages
Using LPD's built-in header pages enforces a particular paradigm when it comes to printer accounting: header pages must be free of charge.
Why?
Because the output filter is the only external program that will have control when the header page is printed that could do accounting, and it is not provided with any user or host information or an accounting file, so it has no idea whom to charge for printer use. It is also not enough to just “add one page” to the text filter or any of the conversion filters (which do have user and host information) since users can suppress header pages with lpr -h. They could still be charged for header pages they did not print. Basically, lpr -h will be the preferred option of environmentally-minded users, but you cannot offer any incentive to use it.
It is still not enough to have
each of the filters generate their own header pages (thereby being able to charge for
them). If users wanted the option of suppressing the header pages with lpr -h, they will still get them and be charged for them since LPD does not pass any knowledge of the -h option to any of the filters.
So, what are your options?
You can:
-
Accept LPD's paradigm and make header pages free.
-
Install an alternative to LPD, such as LPRng. Section Alternatives to the Standard Spooler tells more about other spooling software you can substitute for LPD.
-
Write a smart output filter. Normally, an output filter is not meant to do anything more than initialize a printer or do some simple character conversion. It is suited for header pages and plain text jobs (when there is no text (input) filter). But, if there is a text filter for the plain text jobs, then LPD will start the output filter only for the header pages. And the output filter can parse the header page text that LPD generates to determine what user and host to charge for the header page. The only other problem with this method is that the output filter still does not know what accounting file to use (it is not passed the name of the file from the af capability), but if you have a well-known accounting file, you can hard-code that into the output filter. To facilitate the parsing step, use the sh (short header) capability in /etc/printcap. Then again, all that might be too much trouble, and users will certainly appreciate the more generous system administrator who makes header pages free.
9.4.2.4 Header Pages on PostScript Printers
As described above, LPD can generate a plain text header page suitable for many printers. Of course, PostScript cannot directly print plain text, so the header page feature of LPD is useless--or mostly so.
One obvious way to get header pages is to have every conversion filter and the text filter generate the header page. The filters should use the user and host arguments to generate a suitable header page. The drawback of this method is that users will always get a header page, even if they submit jobs with lpr -h.
Let us explore this method. The following script takes three arguments (user login name, host name, and job name) and makes a simple PostScript header page:
#!/bin/sh
#
# make-ps-header - make a PostScript header page on stdout
# Installed in /usr/local/libexec/make-ps-header
#
#
# These are PostScript units (72 to the inch). Modify for A4 or
# whatever size paper you are using:
#
page_width=612
page_height=792
border=72
#
# Check arguments
#
if [ $# -ne 3 ]; then
echo "Usage: `basename $0` <user> <host> <job>" 1>&2
exit 1
fi
#
# Save these, mostly for readability in the PostScript, below.
#
user=$1
host=$2
job=$3
date=`date`
#
# Send the PostScript code to stdout.
#
exec cat <<EOF
%!PS
%
% Make sure we do not interfere with user's job that will follow
%
save
%
% Make a thick, unpleasant border around the edge of the paper.
%
$border $border moveto
$page_width $border 2 mul sub 0 rlineto
0 $page_height $border 2 mul sub rlineto
currentscreen 3 -1 roll pop 100 3 1 roll setscreen
$border 2 mul $page_width sub 0 rlineto closepath
0.8 setgray 10 setlinewidth stroke 0 setgray
%
% Display user's login name, nice and large and prominent
%
/Helvetica-Bold findfont 64 scalefont setfont
$page_width ($user) stringwidth pop sub 2 div $page_height 200 sub moveto
($user) show
%
% Now show the boring particulars
%
/Helvetica findfont 14 scalefont setfont
/y 200 def
[ (Job:) (Host:) (Date:) ] {
200 y moveto show /y y 18 sub def }
forall
/Helvetica-Bold findfont 14 scalefont setfont
/y 200 def
[ ($job) ($host) ($date) ] {
270 y moveto show /y y 18 sub def
} forall
%
% That is it
%
restore
showpage
EOF
Now, each of the conversion filters and the text filter can call this script to first generate the header page, and then print the user's job. Here is the DVI conversion filter from earlier in this document, modified to make a header page:
#!/bin/sh
#
# psdf - DVI to PostScript printer filter
# Installed in /usr/local/libexec/psdf
#
# Invoked by lpd when user runs lpr -d
#
orig_args="$@"
fail() {
echo "$@" 1>&2
exit 2
}
while getopts "x:y:n:h:" option; do
case $option in
x|y) ;; # Ignore
n) login=$OPTARG ;;
h) host=$OPTARG ;;
*) echo "LPD started `basename $0` wrong." 1>&2
exit 2
;;
esac
done
[ "$login" ] || fail "No login name"
[ "$host" ] || fail "No host name"
( /usr/local/libexec/make-ps-header $login $host "DVI File"
/usr/local/bin/dvips -f ) | eval /usr/local/libexec/lprps $orig_args
Notice how the filter has to parse the argument list in order to determine the user and host name. The parsing for the other conversion filters is identical. The text filter takes a slightly different set of arguments, though (see section How Filters Work).
As we have mentioned before, the above scheme, though fairly simple, disables the
“suppress header page” option (the -h option) to
lpr. If users wanted to save a tree (or a few pennies, if you
charge for header pages), they would not be able to do so, since every filter's going to
print a header page with every job.
To allow users to shut off header pages on a per-job basis, you will need to use the trick introduced in section Accounting for Header Pages: write an output filter that parses the LPD-generated header page and produces a PostScript version. If the user submits the job with lpr -h, then LPD will not generate a header page, and neither will your output filter. Otherwise, your output filter will read the text from LPD and send the appropriate header page PostScript code to the printer.
If you have a PostScript printer on a serial line, you can make use of lprps, which comes with an output filter, psof, which does the above. Note that psof does not charge for header pages.
9.4.3 Networked Printing
FreeBSD supports networked printing: sending jobs to remote printers. Networked printing generally refers to two different things:
-
Accessing a printer attached to a remote host. You install a printer that has a conventional serial or parallel interface on one host. Then, you set up LPD to enable access to the printer from other hosts on the network. Section Printers Installed on Remote Hosts tells how to do this.
-
Accessing a printer attached directly to a network. The printer has a network interface in addition (or in place of) a more conventional serial or parallel interface. Such a printer might work as follows:
-
It might understand the LPD protocol and can even queue jobs from remote hosts. In this case, it acts just like a regular host running LPD. Follow the same procedure in section Printers Installed on Remote Hosts to set up such a printer.
-
It might support a data stream network connection. In this case, you “attach” the printer to one host on the network by making that host responsible for spooling jobs and sending them to the printer. Section Printers with Networked Data Stream Interfaces gives some suggestions on installing such printers.
-
9.4.3.1 Printers Installed on Remote Hosts
The LPD spooling system has built-in support for sending jobs to other hosts also running LPD (or are compatible with LPD). This feature enables you to install a printer on one host and make it accessible from other hosts. It also works with printers that have network interfaces that understand the LPD protocol.
To enable this kind of remote printing, first install a printer on one host, the printer host, using the simple printer setup described in the Simple Printer Setup section. Do any advanced setup in Advanced Printer Setup that you need. Make sure to test the printer and see if it works with the features of LPD you have enabled. Also ensure that the local host has authorization to use the LPD service in the remote host (see Restricting Jobs from Remote Printers).
If you are using a printer with a network interface that is compatible with LPD, then the printer host in the discussion below is the printer itself, and the printer name is the name you configured for the printer. See the documentation that accompanied your printer and/or printer-network interface.
Tip: If you are using a Hewlett Packard Laserjet then the printer name text will automatically perform the LF to CRLF conversion for you, so you will not require the hpif script.
Then, on the other hosts you want to have access to the printer, make an entry in their /etc/printcap files with the following:
-
Name the entry anything you want. For simplicity, though, you probably want to use the same name and aliases as on the printer host.
-
Leave the lp capability blank, explicitly (:lp=:).
-
Make a spooling directory and specify its location in the sd capability. LPD will store jobs here before they get sent to the printer host.
-
Place the name of the printer host in the rm capability.
-
Place the printer name on the printer host in the rp capability.
That is it. You do not need to list conversion filters, page dimensions, or anything else in the /etc/printcap file.
Here is an example. The host rose has two printers, bamboo and rattan. We will enable users on the host orchid to print to those printers. Here is the /etc/printcap file for orchid (back from section Enabling Header Pages). It already had the entry for the printer teak; we have added entries for the two printers on the host rose:
#
# /etc/printcap for host orchid - added (remote) printers on rose
#
#
# teak is local; it is connected directly to orchid:
#
teak|hp|laserjet|Hewlett Packard LaserJet 3Si:\
:lp=/dev/lpt0:sd=/var/spool/lpd/teak:mx#0:\
:if=/usr/local/libexec/ifhp:\
:vf=/usr/local/libexec/vfhp:\
:of=/usr/local/libexec/ofhp:
#
# rattan is connected to rose; send jobs for rattan to rose:
#
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:lp=:rm=rose:rp=rattan:sd=/var/spool/lpd/rattan:
#
# bamboo is connected to rose as well:
#
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:lp=:rm=rose:rp=bamboo:sd=/var/spool/lpd/bamboo:
Then, we just need to make spooling directories on orchid:
# mkdir -p /var/spool/lpd/rattan /var/spool/lpd/bamboo
# chmod 770 /var/spool/lpd/rattan /var/spool/lpd/bamboo
# chown daemon:daemon /var/spool/lpd/rattan /var/spool/lpd/bamboo
Now, users on orchid can print to rattan and bamboo. If, for example, a user on orchid typed
% lpr -P bamboo -d sushi-review.dvi
the LPD system on orchid would copy
the job to the spooling directory /var/spool/lpd/bamboo and
note that it was a DVI job. As soon as the host rose has room in
its bamboo spooling directory, the two LPDs would transfer the file to rose. The
file would wait in rose's queue until it was finally printed. It
would be converted from DVI to PostScript (since bamboo is a PostScript printer) on
rose.9.4.3.2 Printers with Networked Data Stream Interfaces
Often, when you buy a network interface card for a printer, you can get two versions: one which emulates a spooler (the more expensive version), or one which just lets you send data to it as if you were using a serial or parallel port (the cheaper version). This section tells how to use the cheaper version. For the more expensive one, see the previous section Printers Installed on Remote Hosts.
The format of the /etc/printcap file lets you specify what serial or parallel interface to use, and (if you are using a serial interface), what baud rate, whether to use flow control, delays for tabs, conversion of newlines, and more. But there is no way to specify a connection to a printer that is listening on a TCP/IP or other network port.
To send data to a networked printer, you need to develop a communications program that can be called by the text and conversion filters. Here is one such example: the script netprint takes all data on standard input and sends it to a network-attached printer. We specify the hostname of the printer as the first argument and the port number to which to connect as the second argument to netprint. Note that this supports one-way communication only (FreeBSD to printer); many network printers support two-way communication, and you might want to take advantage of that (to get printer status, perform accounting, etc.).
#!/usr/bin/perl
#
# netprint - Text filter for printer attached to network
# Installed in /usr/local/libexec/netprint
#
$#ARGV eq 1 || die "Usage: $0 <printer-hostname> <port-number>";
$printer_host = $ARGV[0];
$printer_port = $ARGV[1];
require 'sys/socket.ph';
($ignore, $ignore, $protocol) = getprotobyname('tcp');
($ignore, $ignore, $ignore, $ignore, $address)
= gethostbyname($printer_host);
$sockaddr = pack('S n a4 x8', &AF_INET, $printer_port, $address);
socket(PRINTER, &PF_INET, &SOCK_STREAM, $protocol)
|| die "Can't create TCP/IP stream socket: $!";
connect(PRINTER, $sockaddr) || die "Can't contact $printer_host: $!";
while (<STDIN>) { print PRINTER; }
exit 0;
We can then use this script in various filters. Suppose we had a Diablo 750-N line printer connected to the network. The printer accepts data to print on port number 5100. The host name of the printer is scrivener. Here is the text filter for the printer:
#!/bin/sh
#
# diablo-if-net - Text filter for Diablo printer `scrivener' listening
# on port 5100. Installed in /usr/local/libexec/diablo-if-net
#
exec /usr/libexec/lpr/lpf "$@" | /usr/local/libexec/netprint scrivener 5100
9.4.4 Restricting Printer Usage
This section gives information on restricting printer usage. The LPD system lets you control who can access a printer, both locally or remotely, whether they can print multiple copies, how large their jobs can be, and how large the printer queues can get.
9.4.4.1 Restricting Multiple Copies
The LPD system makes it easy for users to print multiple copies of a file. Users can print jobs with lpr -#5 (for example) and get five copies of each file in the job. Whether this is a good thing is up to you.
If you feel multiple copies cause unnecessary wear and tear on your printers, you can
disable the -# option to lpr(1) by adding the
sc capability to the /etc/printcap
file. When users submit jobs with the -# option, they will
see:
lpr: multiple copies are not allowed
Note that if you have set up access to a printer remotely (see section Printers Installed on Remote Hosts), you need the sc capability on the remote /etc/printcap files as well, or else users will still be able to submit multiple-copy jobs by using another host.
Here is an example. This is the /etc/printcap file for the host rose. The printer rattan is quite hearty, so we will allow multiple copies, but the laser printer bamboo is a bit more delicate, so we will disable multiple copies by adding the sc capability:
#
# /etc/printcap for host rose - restrict multiple copies on bamboo
#
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:sh:sd=/var/spool/lpd/rattan:\
:lp=/dev/lpt0:\
:if=/usr/local/libexec/if-simple:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:sh:sd=/var/spool/lpd/bamboo:sc:\
:lp=/dev/ttyd5:ms#-parenb cs8 clocal crtscts:rw:\
:if=/usr/local/libexec/psif:\
:df=/usr/local/libexec/psdf:
Now, we also need to add the sc capability on the host orchid's /etc/printcap (and while we are at it, let us disable multiple copies for the printer teak):
#
# /etc/printcap for host orchid - no multiple copies for local
# printer teak or remote printer bamboo
teak|hp|laserjet|Hewlett Packard LaserJet 3Si:\
:lp=/dev/lpt0:sd=/var/spool/lpd/teak:mx#0:sc:\
:if=/usr/local/libexec/ifhp:\
:vf=/usr/local/libexec/vfhp:\
:of=/usr/local/libexec/ofhp:
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:lp=:rm=rose:rp=rattan:sd=/var/spool/lpd/rattan:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:lp=:rm=rose:rp=bamboo:sd=/var/spool/lpd/bamboo:sc:
By using the sc capability, we prevent the use of lpr -#, but that still does not prevent users from running lpr(1) multiple times, or from submitting the same file multiple times in one job like this:
% lpr forsale.sign forsale.sign forsale.sign forsale.sign forsale.sign
There are many ways to prevent this abuse (including ignoring it) which you are free to explore.
9.4.4.2 Restricting Access to Printers
You can control who can print to what printers by using the UNIX group mechanism and the rg capability in /etc/printcap. Just place the users you want to have access to a printer in a certain group, and then name that group in the rg capability.
Users outside the group (including root) will be greeted with “lpr: Not a member of the restricted group” if they try to print to the controlled printer.
As with the sc (suppress multiple copies) capability, you need to specify rg on remote hosts that also have access to your printers, if you feel it is appropriate (see section Printers Installed on Remote Hosts).
For example, we will let anyone access the printer rattan, but only those in group artists can use bamboo. Here is the familiar /etc/printcap for host rose:
#
# /etc/printcap for host rose - restricted group for bamboo
#
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:sh:sd=/var/spool/lpd/rattan:\
:lp=/dev/lpt0:\
:if=/usr/local/libexec/if-simple:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:sh:sd=/var/spool/lpd/bamboo:sc:rg=artists:\
:lp=/dev/ttyd5:ms#-parenb cs8 clocal crtscts:rw:\
:if=/usr/local/libexec/psif:\
:df=/usr/local/libexec/psdf:
Let us leave the other example /etc/printcap file (for the host orchid) alone. Of course, anyone on orchid can print to bamboo. It might be the case that we only allow certain logins on orchid anyway, and want them to have access to the printer. Or not.
Note: There can be only one restricted group per printer.
9.4.4.3 Controlling Sizes of Jobs Submitted
If you have many users accessing the printers, you probably need to put an upper limit on the sizes of the files users can submit to print. After all, there is only so much free space on the filesystem that houses the spooling directories, and you also need to make sure there is room for the jobs of other users.
LPD enables you to limit the maximum byte size a file in a job can be with the mx capability. The units are in BUFSIZ blocks, which are 1024 bytes. If you put a zero for this capability, there will be no limit on file size; however, if no mx capability is specified, then a default limit of 1000 blocks will be used.
Note: The limit applies to files in a job, and not the total job size.
LPD will not refuse a file that is larger than the limit you place on a printer. Instead, it will queue as much of the file up to the limit, which will then get printed. The rest will be discarded. Whether this is correct behavior is up for debate.
Let us add limits to our example printers rattan and bamboo. Since those artists' PostScript files tend to be large, we will limit them to five megabytes. We will put no limit on the plain text line printer:
#
# /etc/printcap for host rose
#
#
# No limit on job size:
#
rattan|line|diablo|lp|Diablo 630 Line Printer:\
:sh:mx#0:sd=/var/spool/lpd/rattan:\
:lp=/dev/lpt0:\
:if=/usr/local/libexec/if-simple:
#
# Limit of five megabytes:
#
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\
:sh:sd=/var/spool/lpd/bamboo:sc:rg=artists:mx#5000:\
:lp=/dev/ttyd5:ms#-parenb cs8 clocal crtscts:rw:\
:if=/usr/local/libexec/psif:\
:df=/usr/local/libexec/psdf:
Again, the limits apply to the local users only. If you have set up access to your printers remotely, remote users will not get those limits. You will need to specify the mx capability in the remote /etc/printcap files as well. See section Printers Installed on Remote Hosts for more information on remote printing.
There is another specialized way to limit job sizes from remote printers; see section Restricting Jobs from Remote Printers.
9.4.4.4 Restricting Jobs from Remote Printers
The LPD spooling system provides several ways to restrict print jobs submitted from remote hosts:
- Host restrictions
-
You can control from which remote hosts a local LPD accepts requests with the files /etc/hosts.equiv and /etc/hosts.lpd. LPD checks to see if an incoming request is from a host listed in either one of these files. If not, LPD refuses the request.
The format of these files is simple: one host name per line. Note that the file /etc/hosts.equiv is also used by the ruserok(3) protocol, and affects programs like rsh(1) and rcp(1), so be careful.
For example, here is the /etc/hosts.lpd file on the host rose:
orchid violet madrigal.fishbaum.deThis means rose will accept requests from the hosts orchid, violet, and madrigal.fishbaum.de. If any other host tries to access rose's LPD, the job will be refused.
- Size restrictions
-
You can control how much free space there needs to remain on the filesystem where a spooling directory resides. Make a file called minfree in the spooling directory for the local printer. Insert in that file a number representing how many disk blocks (512 bytes) of free space there has to be for a remote job to be accepted.
This lets you insure that remote users will not fill your filesystem. You can also use it to give a certain priority to local users: they will be able to queue jobs long after the free disk space has fallen below the amount specified in the minfree file.
For example, let us add a minfree file for the printer bamboo. We examine /etc/printcap to find the spooling directory for this printer; here is bamboo's entry:
bamboo|ps|PS|S|panasonic|Panasonic KX-P4455 PostScript v51.4:\ :sh:sd=/var/spool/lpd/bamboo:sc:rg=artists:mx#5000:\ :lp=/dev/ttyd5:ms#-parenb cs8 clocal crtscts:rw:mx#5000:\ :if=/usr/local/libexec/psif:\ :df=/usr/local/libexec/psdf:The spooling directory is given in the sd capability. We will make three megabytes (which is 6144 disk blocks) the amount of free disk space that must exist on the filesystem for LPD to accept remote jobs:
# echo 6144 > /var/spool/lpd/bamboo/minfree - User restrictions
-
You can control which remote users can print to local printers by specifying the rs capability in /etc/printcap. When rs appears in the entry for a locally-attached printer, LPD will accept jobs from remote hosts if the user submitting the job also has an account of the same login name on the local host. Otherwise, LPD refuses the job.
This capability is particularly useful in an environment where there are (for example) different departments sharing a network, and some users transcend departmental boundaries. By giving them accounts on your systems, they can use your printers from their own departmental systems. If you would rather allow them to use only your printers and not your computer resources, you can give them “token” accounts, with no home directory and a useless shell like /usr/bin/false.
9.4.5 Accounting for Printer Usage
So, you need to charge for printouts. And why not? Paper and ink cost money. And then there are maintenance costs--printers are loaded with moving parts and tend to break down. You have examined your printers, usage patterns, and maintenance fees and have come up with a per-page (or per-foot, per-meter, or per-whatever) cost. Now, how do you actually start accounting for printouts?
Well, the bad news is the LPD spooling system does not provide much help in this department. Accounting is highly dependent on the kind of printer in use, the formats being printed, and your requirements in charging for printer usage.
To implement accounting, you have to modify a printer's text filter (to charge for plain text jobs) and the conversion filters (to charge for other file formats), to count pages or query the printer for pages printed. You cannot get away with using the simple output filter, since it cannot do accounting. See section Filters.
Generally, there are two ways to do accounting:
-
Periodic accounting is the more common way, possibly because it is easier. Whenever someone prints a job, the filter logs the user, host, and number of pages to an accounting file. Every month, semester, year, or whatever time period you prefer, you collect the accounting files for the various printers, tally up the pages printed by users, and charge for usage. Then you truncate all the logging files, starting with a clean slate for the next period.
-
Timely accounting is less common, probably because it is more difficult. This method has the filters charge users for printouts as soon as they use the printers. Like disk quotas, the accounting is immediate. You can prevent users from printing when their account goes in the red, and might provide a way for users to check and adjust their “print quotas.” But this method requires some database code to track users and their quotas.
The LPD spooling system supports both methods easily: since you have to provide the filters (well, most of the time), you also have to provide the accounting code. But there is a bright side: you have enormous flexibility in your accounting methods. For example, you choose whether to use periodic or timely accounting. You choose what information to log: user names, host names, job types, pages printed, square footage of paper used, how long the job took to print, and so forth. And you do so by modifying the filters to save this information.
9.4.5.1 Quick and Dirty Printer Accounting
FreeBSD comes with two programs that can get you set up with simple periodic accounting right away. They are the text filter lpf, described in section lpf: a Text Filter, and pac(8), a program to gather and total entries from printer accounting files.
As mentioned in the section on filters (Filters), LPD starts the text and the conversion filters with the name of the accounting file to use on the filter command line. The filters can use this argument to know where to write an accounting file entry. The name of this file comes from the af capability in /etc/printcap, and if not specified as an absolute path, is relative to the spooling directory.
LPD starts lpf with page width and length arguments (from the pw and pl capabilities). lpf uses these arguments to determine how much paper will be used. After sending the file to the printer, it then writes an accounting entry in the accounting file. The entries look like this:
2.00 rose:andy
3.00 rose:kelly
3.00 orchid:mary
5.00 orchid:mary
2.00 orchid:zhang
You should use a separate accounting file for each printer, as lpf has no file locking logic built into it, and two lpfs might corrupt each other's entries if they were to write to the same file at the same time. An easy way to insure a separate accounting file for each printer is to use af=acct in /etc/printcap. Then, each accounting file will be in the spooling directory for a printer, in a file named acct.
When you are ready to charge users for printouts, run the pac(8) program. Just change to the spooling directory for the printer you want to collect on and type pac. You will get a dollar-centric summary like the following:
Login pages/feet runs price
orchid:kelly 5.00 1 $ 0.10
orchid:mary 31.00 3 $ 0.62
orchid:zhang 9.00 1 $ 0.18
rose:andy 2.00 1 $ 0.04
rose:kelly 177.00 104 $ 3.54
rose:mary 87.00 32 $ 1.74
rose:root 26.00 12 $ 0.52
total 337.00 154 $ 6.74
These are the arguments pac(8) expects:
-Pprinter-
Which printer to summarize. This option works only if there is an absolute path in the af capability in /etc/printcap.
-c-
Sort the output by cost instead of alphabetically by user name.
-m-
Ignore host name in the accounting files. With this option, user smith on host alpha is the same user smith on host gamma. Without, they are different users.
-pprice-
Compute charges with price dollars per page or per foot instead of the price from the pc capability in /etc/printcap, or two cents (the default). You can specify price as a floating point number.
-r-
Reverse the sort order.
-s-
Make an accounting summary file and truncate the accounting file.
- name ...
-
Print accounting information for the given user names only.
In the default summary that pac(8) produces, you see the number of pages printed by each user from various hosts. If, at your site, host does not matter (because users can use any host), run pac -m, to produce the following summary:
Login pages/feet runs price
andy 2.00 1 $ 0.04
kelly 182.00 105 $ 3.64
mary 118.00 35 $ 2.36
root 26.00 12 $ 0.52
zhang 9.00 1 $ 0.18
total 337.00 154 $ 6.74
To compute the dollar amount due, pac(8) uses the pc capability in the /etc/printcap file
(default of 200, or 2 cents per page). Specify, in hundredths of cents, the price per
page or per foot you want to charge for printouts in this capability. You can override
this value when you run pac(8) with the -p option. The units for the -p option
are in dollars, though, not hundredths of cents. For example,
# pac -p1.50
makes each page cost one dollar and fifty cents. You can really rake in the profits by
using this option.Finally, running pac -s will save the summary information in a summary accounting file, which is named the same as the printer's accounting file, but with _sum appended to the name. It then truncates the accounting file. When you run pac(8) again, it rereads the summary file to get starting totals, then adds information from the regular accounting file.
9.4.5.2 How Can You Count Pages Printed?
In order to perform even remotely accurate accounting, you need to be able to determine how much paper a job uses. This is the essential problem of printer accounting.
For plain text jobs, the problem is not that hard to solve: you count how many lines are in a job and compare it to how many lines per page your printer supports. Do not forget to take into account backspaces in the file which overprint lines, or long logical lines that wrap onto one or more additional physical lines.
The text filter lpf (introduced in lpf: a Text Filter) takes into account these things when it does accounting. If you are writing a text filter which needs to do accounting, you might want to examine lpf's source code.
How do you handle other file formats, though?
Well, for DVI-to-LaserJet or DVI-to-PostScript conversion, you can have your filter parse the diagnostic output of dvilj or dvips and look to see how many pages were converted. You might be able to do similar things with other file formats and conversion programs.
But these methods suffer from the fact that the printer may not actually print all those pages. For example, it could jam, run out of toner, or explode--and the user would still get charged.
So, what can you do?
There is only one sure way to do accurate accounting. Get a printer that can tell you how much paper it uses, and attach it via a serial line or a network connection. Nearly all PostScript printers support this notion. Other makes and models do as well (networked Imagen laser printers, for example). Modify the filters for these printers to get the page usage after they print each job and have them log accounting information based on that value only. There is no line counting nor error-prone file examination required.
Of course, you can always be generous and make all printouts free.
9.5 Using Printers
This section tells you how to use printers you have set up with FreeBSD. Here is an overview of the user-level commands:
There is also an administrative command, lpc(8), described in the section Administering Printers, used to control printers and their queues.
All three of the commands lpr(1), lprm(1), and lpq(1) accept an
option -P printer-name to
specify on which printer/queue to operate, as listed in the /etc/printcap file. This enables you to submit, remove, and check
on jobs for various printers. If you do not use the -P
option, then these commands use the printer specified in the PRINTER environment variable. Finally, if you do not have a PRINTER environment variable, these commands default to the printer
named lp.
Hereafter, the terminology default printer means the printer named in the PRINTER environment variable, or the printer named lp when there is no PRINTER environment variable.
9.5.1 Printing Jobs
To print files, type:
% lpr filename ...
This prints each of the listed files to the default printer. If you list no files, lpr(1) reads data to print from standard input. For example, this command prints some important system files:
% lpr /etc/host.conf /etc/hosts.equiv
To select a specific printer, type:
% lpr -P printer-name filename ...
This example prints a long listing of the current directory to the printer named rattan:
% ls -l | lpr -P rattan
Because no files were listed for the lpr(1) command, lpr read the data to print from standard input, which was the output of the ls -l command.
The lpr(1) command can also accept a wide variety of options to control formatting, apply file conversions, generate multiple copies, and so forth. For more information, see the section Printing Options.
9.5.2 Checking Jobs
When you print with lpr(1), the data you wish to print is put together in a package called a “print job”, which is sent to the LPD spooling system. Each printer has a queue of jobs, and your job waits in that queue along with other jobs from yourself and from other users. The printer prints those jobs in a first-come, first-served order.
To display the queue for the default printer, type lpq(1). For a specific
printer, use the -P option. For example, the command
% lpq -P bamboo
shows the queue for the printer named bamboo. Here is an example
of the output of the lpq command:
bamboo is ready and printing
Rank Owner Job Files Total Size
active kelly 9 /etc/host.conf, /etc/hosts.equiv 88 bytes
2nd kelly 10 (standard input) 1635 bytes
3rd mary 11 ... 78519 bytes
This shows three jobs in the queue for bamboo. The first job, submitted by user kelly, got assigned “job number” 9. Every job for a printer gets a unique job number. Most of the time you can ignore the job number, but you will need it if you want to cancel the job; see section Removing Jobs for details.
Job number nine consists of two files; multiple files given on the lpr(1) command line are treated as part of a single job. It is the currently active job (note the word active under the “Rank” column), which means the printer should be currently printing that job. The second job consists of data passed as the standard input to the lpr(1) command. The third job came from user mary; it is a much larger job. The pathname of the file she is trying to print is too long to fit, so the lpq(1) command just shows three dots.
The very first line of the output from lpq(1) is also useful: it tells what the printer is currently doing (or at least what LPD thinks the printer is doing).
The lpq(1) command also
support a -l option to generate a detailed long listing. Here
is an example of lpq -l:
waiting for bamboo to become ready (offline ?)
kelly: 1st [job 009rose]
/etc/host.conf 73 bytes
/etc/hosts.equiv 15 bytes
kelly: 2nd [job 010rose]
(standard input) 1635 bytes
mary: 3rd [job 011rose]
/home/orchid/mary/research/venus/alpha-regio/mapping 78519 bytes
9.5.3 Removing Jobs
If you change your mind about printing a job, you can remove the job from the queue with the lprm(1) command. Often, you can even use lprm(1) to remove an active job, but some or all of the job might still get printed.
To remove a job from the default printer, first use lpq(1) to find the job number. Then type:
% lprm job-number
To remove the job from a specific printer, add the -P
option. The following command removes job number 10 from the queue for the printer bamboo:
% lprm -P bamboo 10
The lprm(1) command has a few shortcuts:
- lprm -
-
Removes all jobs (for the default printer) belonging to you.
- lprm user
-
Removes all jobs (for the default printer) belonging to user. The superuser can remove other users' jobs; you can remove only your own jobs.
- lprm
-
With no job number, user name, or
-appearing on the command line, lprm(1) removes the currently active job on the default printer, if it belongs to you. The superuser can remove any active job.
Just use the -P option with the above shortcuts to operate
on a specific printer instead of the default. For example, the following command removes
all jobs for the current user in the queue for the printer named rattan:
% lprm -P rattan -
Note: If you are working in a networked environment, lprm(1) will let you remove jobs only from the host from which the jobs were submitted, even if the same printer is available from other hosts. The following command sequence demonstrates this:
% lpr -P rattan myfile % rlogin orchid % lpq -P rattan Rank Owner Job Files Total Size active seeyan 12 ... 49123 bytes 2nd kelly 13 myfile 12 bytes % lprm -P rattan 13 rose: Permission denied % logout % lprm -P rattan 13 dfA013rose dequeued cfA013rose dequeued
9.5.4 Beyond Plain Text: Printing Options
The lpr(1) command supports a number of options that control formatting text, converting graphic and other file formats, producing multiple copies, handling of the job, and more. This section describes the options.
9.5.4.1 Formatting and Conversion Options
The following lpr(1) options control formatting of the files in the job. Use these options if the job does not contain plain text or if you want plain text formatted through the pr(1) utility.
For example, the following command prints a DVI file (from the TeX typesetting system) named fish-report.dvi to the printer named bamboo:
% lpr -P bamboo -d fish-report.dvi
These options apply to every file in the job, so you cannot mix (say) DVI and ditroff files together in a job. Instead, submit the files as separate jobs, using a different conversion option for each job.
Note: All of these options except
-pand-Trequire conversion filters installed for the destination printer. For example, the-doption requires the DVI conversion filter. Section Conversion Filters gives details.
-c-
Print cifplot files.
-d-
Print DVI files.
-f-
Print FORTRAN text files.
-g-
Print plot data.
-i number-
Indent the output by number columns; if you omit number, indent by 8 columns. This option works only with certain conversion filters.
Note: Do not put any space between the
-iand the number. -l-
Print literal text data, including control characters.
-n-
Print ditroff (device independent troff) data.
- -p
-
Format plain text with pr(1) before printing. See pr(1) for more information.
-T title-
Use title on the pr(1) header instead of the file name. This option has effect only when used with the
-poption. -t-
Print troff data.
-v-
Print raster data.
Here is an example: this command prints a nicely formatted version of the ls(1) manual page on the default printer:
% zcat /usr/share/man/man1/ls.1.gz | troff -t -man | lpr -t
The zcat(1) command
uncompresses the source of the ls(1) manual page and
passes it to the troff(1) command,
which formats that source and makes GNU troff output and passes it to lpr(1), which submits
the job to the LPD spooler. Because we used the -t option to lpr(1), the spooler
will convert the GNU troff output into a format the default printer can understand when
it prints the job.
9.5.4.2 Job Handling Options
The following options to lpr(1) tell LPD to handle the job specially:
- -# copies
-
Produce a number of copies of each file in the job instead of just one copy. An administrator may disable this option to reduce printer wear-and-tear and encourage photocopier usage. See section Restricting Multiple Copies.
This example prints three copies of parser.c followed by three copies of parser.h to the default printer:
% lpr -#3 parser.c parser.h - -m
-
Send mail after completing the print job. With this option, the LPD system will send mail to your account when it finishes handling your job. In its message, it will tell you if the job completed successfully or if there was an error, and (often) what the error was.
- -s
-
Do not copy the files to the spooling directory, but make symbolic links to them instead.
If you are printing a large job, you probably want to use this option. It saves space in the spooling directory (your job might overflow the free space on the filesystem where the spooling directory resides). It saves time as well since LPD will not have to copy each and every byte of your job to the spooling directory.
There is a drawback, though: since LPD will refer to the original files directly, you cannot modify or remove them until they have been printed.
Note: If you are printing to a remote printer, LPD will eventually have to copy files from the local host to the remote host, so the
-soption will save space only on the local spooling directory, not the remote. It is still useful, though. - -r
-
Remove the files in the job after copying them to the spooling directory, or after printing them with the
-soption. Be careful with this option!
9.5.4.3 Header Page Options
These options to lpr(1) adjust the text that normally appears on a job's header page. If header pages are suppressed for the destination printer, these options have no effect. See section Header Pages for information about setting up header pages.
- -C text
-
Replace the hostname on the header page with text. The hostname is normally the name of the host from which the job was submitted.
- -J text
-
Replace the job name on the header page with text. The job name is normally the name of the first file of the job, or stdin if you are printing standard input.
- -h
-
Do not print any header page.
Note: At some sites, this option may have no effect due to the way header pages are generated. See Header Pages for details.
9.5.5 Administering Printers
As an administrator for your printers, you have had to install, set up, and test them. Using the lpc(8) command, you can interact with your printers in yet more ways. With lpc(8), you can
-
Start and stop the printers
-
Enable and disable their queues
-
Rearrange the order of the jobs in each queue.
First, a note about terminology: if a printer is stopped, it will not print anything in its queue. Users can still submit jobs, which will wait in the queue until the printer is started or the queue is cleared.
If a queue is disabled, no user (except root) can submit jobs for the printer. An enabled queue allows jobs to be submitted. A printer can be started for a disabled queue, in which case it will continue to print jobs in the queue until the queue is empty.
In general, you have to have root privileges to use the lpc(8) command. Ordinary users can use the lpc(8) command to get printer status and to restart a hung printer only.
Here is a summary of the lpc(8) commands. Most of the commands take a printer-name argument to tell on which printer to operate. You can use all for the printer-name to mean all printers listed in /etc/printcap.
- abort printer-name
-
Cancel the current job and stop the printer. Users can still submit jobs if the queue is enabled.
- clean printer-name
-
Remove old files from the printer's spooling directory. Occasionally, the files that make up a job are not properly removed by LPD, particularly if there have been errors during printing or a lot of administrative activity. This command finds files that do not belong in the spooling directory and removes them.
- disable printer-name
-
Disable queuing of new jobs. If the printer is running, it will continue to print any jobs remaining in the queue. The superuser (root) can always submit jobs, even to a disabled queue.
This command is useful while you are testing a new printer or filter installation: disable the queue and submit jobs as root. Other users will not be able to submit jobs until you complete your testing and re-enable the queue with the enable command.
- down printer-name message
-
Take a printer down. Equivalent to disable followed by stop. The message appears as the printer's status whenever a user checks the printer's queue with lpq(1) or status with lpc status.
- enable printer-name
-
Enable the queue for a printer. Users can submit jobs but the printer will not print anything until it is started.
- help command-name
-
Print help on the command command-name. With no command-name, print a summary of the commands available.
- restart printer-name
-
Start the printer. Ordinary users can use this command if some extraordinary circumstance hangs LPD, but they cannot start a printer stopped with either the stop or down commands. The restart command is equivalent to abort followed by start.
- start printer-name
-
Start the printer. The printer will print jobs in its queue.
- stop printer-name
-
Stop the printer. The printer will finish the current job and will not print anything else in its queue. Even though the printer is stopped, users can still submit jobs to an enabled queue.
- topq printer-name job-or-username
-
Rearrange the queue for printer-name by placing the jobs with the listed job numbers or the jobs belonging to username at the top of the queue. For this command, you cannot use all as the printer-name.
- up printer-name
-
Bring a printer up; the opposite of the down command. Equivalent to start followed by enable.
lpc(8) accepts the above commands on the command line. If you do not enter any commands, lpc(8) enters an interactive mode, where you can enter commands until you type exit, quit, or end-of-file.
9.6 Alternatives to the Standard Spooler
If you have been reading straight through this manual, by now you have learned just about everything there is to know about the LPD spooling system that comes with FreeBSD. You can probably appreciate many of its shortcomings, which naturally leads to the question: “What other spooling systems are out there (and work with FreeBSD)?”
- LPRng
-
LPRng, which purportedly means “LPR: the Next Generation” is a complete rewrite of PLP. Patrick Powell and Justin Mason (the principal maintainer of PLP) collaborated to make LPRng. The main site for LPRng is http://www.lprng.org/.
- CUPS
-
CUPS, the Common UNIX Printing System, provides a portable printing layer for UNIX-based operating systems. It has been developed by Easy Software Products to promote a standard printing solution for all UNIX vendors and users.
CUPS uses the Internet Printing Protocol (IPP) as the basis for managing print jobs and queues. The Line Printer Daemon (LPD), Server Message Block (SMB), and AppSocket (a.k.a. JetDirect) protocols are also supported with reduced functionality. CUPS adds network printer browsing and PostScript Printer Description (PPD) based printing options to support real-world printing under UNIX.
The main site for CUPS is http://www.cups.org/.
9.7 Troubleshooting
After performing the simple test with lptest(1), you might have gotten one of the following results instead of the correct printout:
- It worked, after awhile; or, it did not eject a full sheet.
-
The printer printed the above, but it sat for awhile and did nothing. In fact, you might have needed to press a PRINT REMAINING or FORM FEED button on the printer to get any results to appear.
If this is the case, the printer was probably waiting to see if there was any more data for your job before it printed anything. To fix this problem, you can have the text filter send a FORM FEED character (or whatever is necessary) to the printer. This is usually sufficient to have the printer immediately print any text remaining in its internal buffer. It is also useful to make sure each print job ends on a full sheet, so the next job does not start somewhere on the middle of the last page of the previous job.
The following replacement for the shell script /usr/local/libexec/if-simple prints a form feed after it sends the job to the printer:
#!/bin/sh # # if-simple - Simple text input filter for lpd # Installed in /usr/local/libexec/if-simple # # Simply copies stdin to stdout. Ignores all filter arguments. # Writes a form feed character (\f) after printing job. /bin/cat && printf "\f" && exit 0 exit 2 - It produced the “staircase effect.”
-
You got the following on paper:
!"#$%&'()*+,-./01234 "#$%&'()*+,-./012345 #$%&'()*+,-./0123456You have become another victim of the staircase effect, caused by conflicting interpretations of what characters should indicate a new line. UNIX style operating systems use a single character: ASCII code 10, the line feed (LF). MS-DOS, OS/2®, and others uses a pair of characters, ASCII code 10 and ASCII code 13 (the carriage return or CR). Many printers use the MS-DOS convention for representing new-lines.
When you print with FreeBSD, your text used just the line feed character. The printer, upon seeing a line feed character, advanced the paper one line, but maintained the same horizontal position on the page for the next character to print. That is what the carriage return is for: to move the location of the next character to print to the left edge of the paper.
Here is what FreeBSD wants your printer to do:
Here are some ways to achieve this:
-
Use the printer's configuration switches or control panel to alter its interpretation of these characters. Check your printer's manual to find out how to do this.
Note: If you boot your system into other operating systems besides FreeBSD, you may have to reconfigure the printer to use a an interpretation for CR and LF characters that those other operating systems use. You might prefer one of the other solutions, below.
-
Have FreeBSD's serial line driver automatically convert LF to CR+LF. Of course, this works with printers on serial ports only. To enable this feature, use the ms# capability and set the onlcr mode in the /etc/printcap file for the printer.
-
Send an escape code to the printer to have it temporarily treat LF characters differently. Consult your printer's manual for escape codes that your printer might support. When you find the proper escape code, modify the text filter to send the code first, then send the print job.
Here is an example text filter for printers that understand the Hewlett-Packard PCL escape codes. This filter makes the printer treat LF characters as a LF and CR; then it sends the job; then it sends a form feed to eject the last page of the job. It should work with nearly all Hewlett Packard printers.
#!/bin/sh # # hpif - Simple text input filter for lpd for HP-PCL based printers # Installed in /usr/local/libexec/hpif # # Simply copies stdin to stdout. Ignores all filter arguments. # Tells printer to treat LF as CR+LF. Ejects the page when done. printf "\033&k2G" && cat && printf "\033&l0H" && exit 0 exit 2Here is an example /etc/printcap from a host called orchid. It has a single printer attached to its first parallel port, a Hewlett Packard LaserJet 3Si named teak. It is using the above script as its text filter:
# # /etc/printcap for host orchid # teak|hp|laserjet|Hewlett Packard LaserJet 3Si:\ :lp=/dev/lpt0:sh:sd=/var/spool/lpd/teak:mx#0:\ :if=/usr/local/libexec/hpif:
-
- It overprinted each line.
-
The printer never advanced a line. All of the lines of text were printed on top of each other on one line.
This problem is the “opposite” of the staircase effect, described above, and is much rarer. Somewhere, the LF characters that FreeBSD uses to end a line are being treated as CR characters to return the print location to the left edge of the paper, but not also down a line.
Use the printer's configuration switches or control panel to enforce the following interpretation of LF and CR characters:
- The printer lost characters.
-
While printing, the printer did not print a few characters in each line. The problem might have gotten worse as the printer ran, losing more and more characters.
The problem is that the printer cannot keep up with the speed at which the computer sends data over a serial line (this problem should not occur with printers on parallel ports). There are two ways to overcome the problem:
-
If the printer supports XON/XOFF flow control, have FreeBSD use it by specifying the ixon mode in the ms# capability.
-
If the printer supports carrier flow control, specify the crtscts mode in the ms# capability. Make sure the cable connecting the printer to the computer is correctly wired for carrier flow control.
-
- It printed garbage.
-
The printer printed what appeared to be random garbage, but not the desired text.
This is usually another symptom of incorrect communications parameters with a serial printer. Double-check the bps rate in the br capability, and the parity setting in the ms# capability; make sure the printer is using the same settings as specified in the /etc/printcap file.
- Nothing happened.
-
If nothing happened, the problem is probably within FreeBSD and not the hardware. Add the log file (lf) capability to the entry for the printer you are debugging in the /etc/printcap file. For example, here is the entry for rattan, with the lf capability:
rattan|line|diablo|lp|Diablo 630 Line Printer:\ :sh:sd=/var/spool/lpd/rattan:\ :lp=/dev/lpt0:\ :if=/usr/local/libexec/if-simple:\ :lf=/var/log/rattan.logThen, try printing again. Check the log file (in our example, /var/log/rattan.log) to see any error messages that might appear. Based on the messages you see, try to correct the problem.
If you do not specify a lf capability, LPD uses /dev/console as a default.
Chapter 10 Linux Binary Compatibility
Restructured and parts updated by Jim Mock. Originally contributed by Brian N. Handy and Rich Murphey.10.1 Synopsis
FreeBSD provides binary compatibility with several other UNIX like operating systems, including Linux. At this point, you may be asking yourself why exactly, does FreeBSD need to be able to run Linux binaries? The answer to that question is quite simple. Many companies and developers develop only for Linux, since it is the latest “hot thing” in the computing world. That leaves the rest of us FreeBSD users bugging these same companies and developers to put out native FreeBSD versions of their applications. The problem is, that most of these companies do not really realize how many people would use their product if there were FreeBSD versions too, and most continue to only develop for Linux. So what is a FreeBSD user to do? This is where the Linux binary compatibility of FreeBSD comes into play.
In a nutshell, the compatibility allows FreeBSD users to run about 90% of all Linux applications without modification. This includes applications such as StarOffice, the Linux version of Netscape, Adobe Acrobat, RealPlayer, VMware™, Oracle, WordPerfect®, Doom, Quake, and more. It is also reported that in some situations, Linux binaries perform better on FreeBSD than they do under Linux.
There are, however, some Linux-specific operating system features that are not supported under FreeBSD. Linux binaries will not work on FreeBSD if they overly use i386 specific calls, such as enabling virtual 8086 mode.
After reading this chapter, you will know:
-
How to enable Linux binary compatibility on your system.
-
How to install additional Linux shared libraries.
-
How to install Linux applications on your FreeBSD system.
-
The implementation details of Linux compatibility in FreeBSD.
Before reading this chapter, you should:
-
Know how to install additional third-party software (Chapter 4).
10.2 Installation
Linux binary compatibility is not turned on by default. The easiest way to enable this functionality is to load the linux KLD object (“Kernel LoaDable object”). You can load this module by typing the following as root:
# kldload linux
If you would like Linux compatibility to always be enabled, then you should add the following line to /etc/rc.conf:
linux_enable="YES"
The kldstat(8) command can be used to verify that the KLD is loaded:
% kldstat
Id Refs Address Size Name
1 2 0xc0100000 16bdb8 kernel
7 1 0xc24db000 d000 linux.ko
If for some reason you do not want to or cannot load the KLD, then you may statically link Linux binary compatibility into the kernel by adding options COMPAT_LINUX to your kernel configuration file. Then install your new kernel as described in Chapter 8.
10.2.1 Installing Linux Runtime Libraries
This can be done one of two ways, either by using the linux_base port, or by installing them manually.
10.2.1.1 Installing Using the linux_base Port
This is by far the easiest method to use when installing the runtime libraries. It is just like installing any other port from the Ports Collection. Simply do the following:
# cd /usr/ports/emulators/linux_base-fc4
# make install distclean
You should now have working Linux binary compatibility. Some programs may complain about incorrect minor versions of the system libraries. In general, however, this does not seem to be a problem.
Note: There may be multiple versions of the emulators/linux_base port available, corresponding to different versions of various Linux distributions. You should install the port most closely resembling the requirements of the Linux applications you would like to install.
10.2.1.2 Installing Libraries Manually
If you do not have the “ports” collection installed, you can install the libraries by hand instead. You will need the Linux shared libraries that the program depends on and the runtime linker. Also, you will need to create a “shadow root” directory, /compat/linux, for Linux libraries on your FreeBSD system. Any shared libraries opened by Linux programs run under FreeBSD will look in this tree first. So, if a Linux program loads, for example, /lib/libc.so, FreeBSD will first try to open /compat/linux/lib/libc.so, and if that does not exist, it will then try /lib/libc.so. Shared libraries should be installed in the shadow tree /compat/linux/lib rather than the paths that the Linux ld.so reports.
Generally, you will need to look for the shared libraries that Linux binaries depend on only the first few times that you install a Linux program on your FreeBSD system. After a while, you will have a sufficient set of Linux shared libraries on your system to be able to run newly imported Linux binaries without any extra work.
10.2.1.3 How to Install Additional Shared Libraries
What if you install the linux_base port and your application still complains about missing shared libraries? How do you know which shared libraries Linux binaries need, and where to get them? Basically, there are 2 possibilities (when following these instructions you will need to be root on your FreeBSD system).
If you have access to a Linux system, see what shared libraries the application needs, and copy them to your FreeBSD system. Look at the following example:
Let us assume you used FTP to get the Linux binary of Doom, and put it on a Linux system you have access to. You then can check which shared libraries it needs by running ldd linuxdoom, like so:
% ldd linuxdoom
libXt.so.3 (DLL Jump 3.1) => /usr/X11/lib/libXt.so.3.1.0
libX11.so.3 (DLL Jump 3.1) => /usr/X11/lib/libX11.so.3.1.0
libc.so.4 (DLL Jump 4.5pl26) => /lib/libc.so.4.6.29
You would need to get all the files from the last column, and put them under /compat/linux, with the names in the first column as symbolic links pointing to them. This means you eventually have these files on your FreeBSD system:
/compat/linux/usr/X11/lib/libXt.so.3.1.0
/compat/linux/usr/X11/lib/libXt.so.3 -> libXt.so.3.1.0
/compat/linux/usr/X11/lib/libX11.so.3.1.0
/compat/linux/usr/X11/lib/libX11.so.3 -> libX11.so.3.1.0
/compat/linux/lib/libc.so.4.6.29
/compat/linux/lib/libc.so.4 -> libc.so.4.6.29
Note: Note that if you already have a Linux shared library with a matching major revision number to the first column of the ldd output, you will not need to copy the file named in the last column to your system, the one you already have should work. It is advisable to copy the shared library anyway if it is a newer version, though. You can remove the old one, as long as you make the symbolic link point to the new one. So, if you have these libraries on your system:
/compat/linux/lib/libc.so.4.6.27 /compat/linux/lib/libc.so.4 -> libc.so.4.6.27and you find a new binary that claims to require a later version according to the output of ldd:
libc.so.4 (DLL Jump 4.5pl26) -> libc.so.4.6.29If it is only one or two versions out of date in the trailing digit then do not worry about copying /lib/libc.so.4.6.29 too, because the program should work fine with the slightly older version. However, if you like, you can decide to replace the libc.so anyway, and that should leave you with:
/compat/linux/lib/libc.so.4.6.29 /compat/linux/lib/libc.so.4 -> libc.so.4.6.29
Note: The symbolic link mechanism is only needed for Linux binaries. The FreeBSD runtime linker takes care of looking for matching major revision numbers itself and you do not need to worry about it.
10.2.2 Installing Linux ELF Binaries
ELF binaries sometimes require an extra step of “branding”. If you attempt to run an unbranded ELF binary, you will get an error message like the following:
% ./my-linux-elf-binary
ELF binary type not known
Abort
To help the FreeBSD kernel distinguish between a FreeBSD ELF binary from a Linux binary, use the brandelf(1) utility.
% brandelf -t Linux my-linux-elf-binary
The GNU toolchain now places the appropriate branding information into ELF binaries automatically, so this step should become increasingly unnecessary in the future.
10.2.3 Configuring the Hostname Resolver
If DNS does not work or you get this message:
resolv+: "bind" is an invalid keyword resolv+:
"hosts" is an invalid keyword
You will need to configure a /compat/linux/etc/host.conf file containing:
order hosts, bind
multi on
The order here specifies that /etc/hosts is searched first and DNS is searched second. When /compat/linux/etc/host.conf is not installed, Linux applications find FreeBSD's /etc/host.conf and complain about the incompatible FreeBSD syntax. You should remove bind if you have not configured a name server using the /etc/resolv.conf file.
10.3 Installing Mathematica®
Updated for Mathematica 5.X by Boris Hollas.This document describes the process of installing the Linux version of Mathematica 5.X onto a FreeBSD system.
The Linux version of Mathematica or Mathematica for Students can be ordered directly from Wolfram at http://www.wolfram.com/.
10.3.1 Running the Mathematica Installer
First, you have to tell FreeBSD that Mathematica's Linux binaries use the Linux ABI. The easiest way to do so is to set the default ELF brand to Linux for all unbranded binaries with the command:
# sysctl kern.fallback_elf_brand=3
This will make FreeBSD assume that unbranded ELF binaries use the Linux ABI and so you should be able to run the installer straight from the CDROM.
Now, copy the file MathInstaller to your hard drive:
# mount /cdrom
# cp /cdrom/Unix/Installers/Linux/MathInstaller /localdir/
and in this file, replace /bin/sh in the first line by /compat/linux/bin/sh. This makes sure that the installer is executed by the Linux version of sh(1). Next, replace all occurrences of Linux) by FreeBSD) with a text editor or the script below in the next section. This tells the Mathematica installer, who calls uname -s to determine the operating system, to treat FreeBSD as a Linux-like operating system. Invoking MathInstaller will now install Mathematica.
10.3.2 Modifying the Mathematica Executables
The shell scripts that Mathematica created during installation have to be modified before you can use them. If you chose /usr/local/bin as the directory to place the Mathematica executables in, you will find symlinks in this directory to files called math, mathematica, Mathematica, and MathKernel. In each of these, replace Linux) by FreeBSD) with a text editor or the following shell script:
#!/bin/sh
cd /usr/local/bin
for i in math mathematica Mathematica MathKernel
do sed 's/Linux)/FreeBSD)/g' $i > $i.tmp
sed 's/\/bin\/sh/\/compat\/linux\/bin\/sh/g' $i.tmp > $i
rm $i.tmp
chmod a+x $i
done
10.3.3 Obtaining Your Mathematica Password
When you start Mathematica for the first time, you will be asked for a password. If you have not yet obtained a password from Wolfram, run the program mathinfo in the installation directory to obtain your “machine ID”. This machine ID is based solely on the MAC address of your first Ethernet card, so you cannot run your copy of Mathematica on different machines.
When you register with Wolfram, either by email, phone or fax, you will give them the “machine ID” and they will respond with a corresponding password consisting of groups of numbers.
10.3.4 Running the Mathematica Frontend over a Network
Mathematica uses some special fonts to display characters not present in any of the standard font sets (integrals, sums, Greek letters, etc.). The X protocol requires these fonts to be install locally. This means you will have to copy these fonts from the CDROM or from a host with Mathematica installed to your local machine. These fonts are normally stored in /cdrom/Unix/Files/SystemFiles/Fonts on the CDROM, or /usr/local/mathematica/SystemFiles/Fonts on your hard drive. The actual fonts are in the subdirectories Type1 and X. There are several ways to use them, as described below.
The first way is to copy them into one of the existing font directories in /usr/X11R6/lib/X11/fonts. This will require editing the fonts.dir file, adding the font names to it, and changing the number of fonts on the first line. Alternatively, you should also just be able to run mkfontdir(1) in the directory you have copied them to.
The second way to do this is to copy the directories to /usr/X11R6/lib/X11/fonts:
# cd /usr/X11R6/lib/X11/fonts
# mkdir X
# mkdir MathType1
# cd /cdrom/Unix/Files/SystemFiles/Fonts
# cp X/* /usr/X11R6/lib/X11/fonts/X
# cp Type1/* /usr/X11R6/lib/X11/fonts/MathType1
# cd /usr/X11R6/lib/X11/fonts/X
# mkfontdir
# cd ../MathType1
# mkfontdir
Now add the new font directories to your font path:
# xset fp+ /usr/X11R6/lib/X11/fonts/X
# xset fp+ /usr/X11R6/lib/X11/fonts/MathType1
# xset fp rehash
If you are using the Xorg server, you can have these font directories loaded automatically by adding them to your xorg.conf file.
Note: For XFree86 servers, the configuration file is XF86Config.
If you do not already have a directory called /usr/X11R6/lib/X11/fonts/Type1, you can change the name of the MathType1 directory in the example above to Type1.
10.4 Installing Maple™
Contributed by Aaron Kaplan. Thanks to Robert Getschmann.Maple™ is a commercial mathematics program similar to Mathematica. You must purchase this software from http://www.maplesoft.com/ and then register there for a license file. To install this software on FreeBSD, please follow these simple steps.
-
Execute the INSTALL shell script from the product distribution. Choose the “RedHat” option when prompted by the installation program. A typical installation directory might be /usr/local/maple.
-
If you have not done so, order a license for Maple from Maple Waterloo Software (http://register.maplesoft.com/) and copy it to /usr/local/maple/license/license.dat.
-
Install the FLEXlm license manager by running the INSTALL_LIC install shell script that comes with Maple. Specify the primary hostname for your machine for the license server.
-
Patch the /usr/local/maple/bin/maple.system.type file with the following:
----- snip ------------------ *** maple.system.type.orig Sun Jul 8 16:35:33 2001 --- maple.system.type Sun Jul 8 16:35:51 2001 *************** *** 72,77 **** --- 72,78 ---- # the IBM RS/6000 AIX case MAPLE_BIN="bin.IBM_RISC_UNIX" ;; + "FreeBSD"|\ "Linux") # the Linux/x86 case # We have two Linux implementations, one for Red Hat and ----- snip end of patch -----Please note that after the "FreeBSD"|\ no other whitespace should be present.
This patch instructs Maple to recognize “FreeBSD” as a type of Linux system. The bin/maple shell script calls the bin/maple.system.type shell script which in turn calls uname -a to find out the operating system name. Depending on the OS name it will find out which binaries to use.
-
Start the license server.
The following script, installed as /usr/local/etc/rc.d/lmgrd.sh is a convenient way to start up lmgrd:
----- snip ------------ #! /bin/sh PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/X11R6/bin PATH=${PATH}:/usr/local/maple/bin:/usr/local/maple/FLEXlm/UNIX/LINUX export PATH LICENSE_FILE=/usr/local/maple/license/license.dat LOG=/var/log/lmgrd.log case "$1" in start) lmgrd -c ${LICENSE_FILE} 2>> ${LOG} 1>&2 echo -n " lmgrd" ;; stop) lmgrd -c ${LICENSE_FILE} -x lmdown 2>> ${LOG} 1>&2 ;; *) echo "Usage: `basename $0` {start|stop}" 1>&2 exit 64 ;; esac exit 0 ----- snip ------------ -
Test-start Maple:
% cd /usr/local/maple/bin % ./xmapleYou should be up and running. Make sure to write Maplesoft to let them know you would like a native FreeBSD version!
10.4.1 Common Pitfalls
-
The FLEXlm license manager can be a difficult tool to work with. Additional documentation on the subject can be found at http://www.globetrotter.com/.
-
lmgrd is known to be very picky about the license file and to core dump if there are any problems. A correct license file should look like this:
# ======================================================= # License File for UNIX Installations ("Pointer File") # ======================================================= SERVER chillig ANY #USE_SERVER VENDOR maplelmg FEATURE Maple maplelmg 2000.0831 permanent 1 XXXXXXXXXXXX \ PLATFORMS=i86_r ISSUER="Waterloo Maple Inc." \ ISSUED=11-may-2000 NOTICE=" Technische Universitat Wien" \ SN=XXXXXXXXXNote: Serial number and key 'X''ed out. chillig is a hostname.
Editing the license file works as long as you do not touch the “FEATURE” line (which is protected by the license key).
10.5 Installing MATLAB®
Contributed by Dan Pelleg.This document describes the process of installing the Linux version of MATLAB® version 6.5 onto a FreeBSD system. It works quite well, with the exception of the Java Virtual Machine™ (see Section 10.5.3).
The Linux version of MATLAB can be ordered directly from The MathWorks at http://www.mathworks.com. Make sure you also get the license file or instructions how to create it. While you are there, let them know you would like a native FreeBSD version of their software.
10.5.1 Installing MATLAB
To install MATLAB, do the following:
-
Insert the installation CD and mount it. Become root, as recommended by the installation script. To start the installation script type:
# /compat/linux/bin/sh /cdrom/installTip: The installer is graphical. If you get errors about not being able to open a display, type setenv HOME ~USER, where USER is the user you did a su(1) as.
-
When asked for the MATLAB root directory, type: /compat/linux/usr/local/matlab.
Tip: For easier typing on the rest of the installation process, type this at your shell prompt: set MATLAB=/compat/linux/usr/local/matlab
-
Edit the license file as instructed when obtaining the MATLAB license.
Tip: You can prepare this file in advance using your favorite editor, and copy it to $MATLAB/license.dat before the installer asks you to edit it.
-
Complete the installation process.
At this point your MATLAB installation is complete. The following steps apply “glue” to connect it to your FreeBSD system.
10.5.2 License Manager Startup
-
Create symlinks for the license manager scripts:
# ln -s $MATLAB/etc/lmboot /usr/local/etc/lmboot_TMW # ln -s $MATLAB/etc/lmdown /usr/local/etc/lmdown_TMW -
Create a startup file at /usr/local/etc/rc.d/flexlm.sh. The example below is a modified version of the distributed $MATLAB/etc/rc.lm.glnx86. The changes are file locations, and startup of the license manager under Linux emulation.
#!/bin/sh case "$1" in start) if [ -f /usr/local/etc/lmboot_TMW ]; then /compat/linux/bin/sh /usr/local/etc/lmboot_TMW -u username && echo 'MATLAB_lmgrd' fi ;; stop) if [ -f /usr/local/etc/lmdown_TMW ]; then /compat/linux/bin/sh /usr/local/etc/lmdown_TMW > /dev/null 2>&1 fi ;; *) echo "Usage: $0 {start|stop}" exit 1 ;; esac exit 0Important: The file must be made executable:
# chmod +x /usr/local/etc/rc.d/flexlm.shYou must also replace username above with the name of a valid user on your system (and not root).
-
Start the license manager with the command:
# /usr/local/etc/rc.d/flexlm.sh start
10.5.3 Linking the Java Runtime Environment
Change the Java Runtime Environment (JRE) link to one working under FreeBSD:
# cd $MATLAB/sys/java/jre/glnx86/
# unlink jre; ln -s ./jre1.1.8 ./jre
10.5.4 Creating a MATLAB Startup Script
-
Place the following startup script in /usr/local/bin/matlab:
#!/bin/sh /compat/linux/bin/sh /compat/linux/usr/local/matlab/bin/matlab "$@" -
Then type the command chmod +x /usr/local/bin/matlab.
Tip: Depending on your version of emulators/linux_base, you may run into errors when running this script. To avoid that, edit the file /compat/linux/usr/local/matlab/bin/matlab, and change the line that says:
if [ `expr "$lscmd" : '.*->.*'` -ne 0 ]; then(in version 13.0.1 it is on line 410) to this line:
if test -L $newbase; then
10.5.5 Creating a MATLAB Shutdown Script
The following is needed to solve a problem with MATLAB not exiting correctly.
-
Create a file $MATLAB/toolbox/local/finish.m, and in it put the single line:
! $MATLAB/bin/finish.shNote: The $MATLAB is literal.
Tip: In the same directory, you will find the files finishsav.m and finishdlg.m, which let you save your workspace before quitting. If you use either of them, insert the line above immediately after the save command.
-
Create a file $MATLAB/bin/finish.sh, which will contain the following:
#!/usr/compat/linux/bin/sh (sleep 5; killall -1 matlab_helper) & exit 0 -
Make the file executable:
# chmod +x $MATLAB/bin/finish.sh
10.6 Installing Oracle®
Contributed by Marcel Moolenaar.10.6.1 Preface
This document describes the process of installing Oracle 8.0.5 and Oracle 8.0.5.1 Enterprise Edition for Linux onto a FreeBSD machine.
10.6.2 Installing the Linux Environment
Make sure you have both emulators/linux_base and devel/linux_devtools from the Ports Collection installed. If you run into difficulties with these ports, you may have to use the packages or older versions available in the Ports Collection.
If you want to run the intelligent agent, you will also need to install the Red Hat Tcl package: tcl-8.0.3-20.i386.rpm. The general command for installing packages with the official RPM port (archivers/rpm) is:
# rpm -i --ignoreos --root /compat/linux --dbpath /var/lib/rpm package
Installation of the package should not generate any errors.
10.6.3 Creating the Oracle Environment
Before you can install Oracle, you need to set up a proper environment. This document only describes what to do specially to run Oracle for Linux on FreeBSD, not what has been described in the Oracle installation guide.
10.6.3.1 Kernel Tuning
As described in the Oracle installation guide, you need to set the maximum size of shared memory. Do not use SHMMAX under FreeBSD. SHMMAX is merely calculated out of SHMMAXPGS and PGSIZE. Therefore define SHMMAXPGS. All other options can be used as described in the guide. For example:
options SHMMAXPGS=10000
options SHMMNI=100
options SHMSEG=10
options SEMMNS=200
options SEMMNI=70
options SEMMSL=61
Set these options to suit your intended use of Oracle.
Also, make sure you have the following options in your kernel configuration file:
options SYSVSHM #SysV shared memory
options SYSVSEM #SysV semaphores
options SYSVMSG #SysV interprocess communication
10.6.3.2 Oracle Account
Create an oracle account just as you would create any other account. The oracle account is special only that you need to give it a Linux shell. Add /compat/linux/bin/bash to /etc/shells and set the shell for the oracle account to /compat/linux/bin/bash.
10.6.3.3 Environment
Besides the normal Oracle variables, such as ORACLE_HOME and ORACLE_SID you must set the following environment variables:
| Variable | Value |
|---|---|
| LD_LIBRARY_PATH | $ORACLE_HOME/lib |
| CLASSPATH | $ORACLE_HOME/jdbc/lib/classes111.zip |
| PATH | /compat/linux/bin /compat/linux/sbin /compat/linux/usr/bin /compat/linux/usr/sbin /bin /sbin /usr/bin /usr/sbin /usr/local/bin $ORACLE_HOME/bin |
It is advised to set all the environment variables in .profile. A complete example is:
ORACLE_BASE=/oracle; export ORACLE_BASE
ORACLE_HOME=/oracle; export ORACLE_HOME
LD_LIBRARY_PATH=$ORACLE_HOME/lib
export LD_LIBRARY_PATH
ORACLE_SID=ORCL; export ORACLE_SID
ORACLE_TERM=386x; export ORACLE_TERM
CLASSPATH=$ORACLE_HOME/jdbc/lib/classes111.zip
export CLASSPATH
PATH=/compat/linux/bin:/compat/linux/sbin:/compat/linux/usr/bin
PATH=$PATH:/compat/linux/usr/sbin:/bin:/sbin:/usr/bin:/usr/sbin
PATH=$PATH:/usr/local/bin:$ORACLE_HOME/bin
export PATH
10.6.4 Installing Oracle
Due to a slight inconsistency in the Linux emulator, you need to create a directory named .oracle in /var/tmp before you start the installer. Let it be owned by the oracle user. You should be able to install Oracle without any problems. If you have problems, check your Oracle distribution and/or configuration first! After you have installed Oracle, apply the patches described in the next two subsections.
A frequent problem is that the TCP protocol adapter is not installed right. As a consequence, you cannot start any TCP listeners. The following actions help solve this problem:
# cd $ORACLE_HOME/network/lib
# make -f ins_network.mk ntcontab.o
# cd $ORACLE_HOME/lib
# ar r libnetwork.a ntcontab.o
# cd $ORACLE_HOME/network/lib
# make -f ins_network.mk install
Do not forget to run root.sh again!
10.6.4.1 Patching root.sh
When installing Oracle, some actions, which need to be performed as root, are recorded in a shell script called root.sh. This script is written in the orainst directory. Apply the following patch to root.sh, to have it use to proper location of chown or alternatively run the script under a Linux native shell.
*** orainst/root.sh.orig Tue Oct 6 21:57:33 1998
--- orainst/root.sh Mon Dec 28 15:58:53 1998
***************
*** 31,37 ****
# This is the default value for CHOWN
# It will redefined later in this script for those ports
# which have it conditionally defined in ss_install.h
! CHOWN=/bin/chown
#
# Define variables to be used in this script
--- 31,37 ----
# This is the default value for CHOWN
# It will redefined later in this script for those ports
# which have it conditionally defined in ss_install.h
! CHOWN=/usr/sbin/chown
#
# Define variables to be used in this script
When you do not install Oracle from CD, you can patch the source for root.sh. It is called rthd.sh and is located in the orainst directory in the source tree.
10.6.4.2 Patching genclntsh
The script genclntsh is used to create a single shared client library. It is used when building the demos. Apply the following patch to comment out the definition of PATH:
*** bin/genclntsh.orig Wed Sep 30 07:37:19 1998
--- bin/genclntsh Tue Dec 22 15:36:49 1998
***************
*** 32,38 ****
#
# Explicit path to ensure that we're using the correct commands
#PATH=/usr/bin:/usr/ccs/bin export PATH
! PATH=/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin export PATH
#
# each product MUST provide a $PRODUCT/admin/shrept.lst
--- 32,38 ----
#
# Explicit path to ensure that we're using the correct commands
#PATH=/usr/bin:/usr/ccs/bin export PATH
! #PATH=/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin export PATH
#
# each product MUST provide a $PRODUCT/admin/shrept.lst
10.6.5 Running Oracle
When you have followed the instructions, you should be able to run Oracle as if it was run on Linux itself.
10.7 Installing SAP® R/3®
Contributed by Holger Kipp. Original version converted to SGML by Valentino Vaschetto.Installations of SAP Systems using FreeBSD will not be supported by the SAP support team -- they only offer support for certified platforms.
10.7.1 Preface
This document describes a possible way of installing a SAP R/3 System with Oracle Database for Linux onto a FreeBSD machine, including the installation of FreeBSD and Oracle. Two different configurations will be described:
-
SAP R/3 4.6B (IDES) with Oracle 8.0.5 on FreeBSD 4.3-STABLE
-
SAP R/3 4.6C with Oracle 8.1.7 on FreeBSD 4.5-STABLE
Even though this document tries to describe all important steps in a greater detail, it is not intended as a replacement for the Oracle and SAP R/3 installation guides.
Please see the documentation that comes with the SAP R/3 Linux edition for SAP and Oracle specific questions, as well as resources from Oracle and SAP OSS.
10.7.2 Software
The following CD-ROMs have been used for SAP installations:
10.7.2.1 SAP R/3 4.6B, Oracle 8.0.5
| Name | Number | Description |
|---|---|---|
| KERNEL | 51009113 | SAP Kernel Oracle / Installation / AIX, Linux, Solaris |
| RDBMS | 51007558 | Oracle / RDBMS 8.0.5.X / Linux |
| EXPORT1 | 51010208 | IDES / DB-Export / Disc 1 of 6 |
| EXPORT2 | 51010209 | IDES / DB-Export / Disc 2 of 6 |
| EXPORT3 | 51010210 | IDES / DB-Export / Disc 3 of 6 |
| EXPORT4 | 51010211 | IDES / DB-Export / Disc 4 of 6 |
| EXPORT5 | 51010212 | IDES / DB-Export / Disc 5 of 6 |
| EXPORT6 | 51010213 | IDES / DB-Export / Disc 6 of 6 |
Additionally, we used the Oracle 8 Server (Pre-production version 8.0.5 for Linux, Kernel Version 2.0.33) CD which is not really necessary, and FreeBSD 4.3-STABLE (it was only a few days past 4.3 RELEASE).
10.7.2.2 SAP R/3 4.6C SR2, Oracle 8.1.7
| Name | Number | Description |
|---|---|---|
| KERNEL | 51014004 | SAP Kernel Oracle / SAP Kernel Version 4.6D / DEC, Linux |
| RDBMS | 51012930 | Oracle 8.1.7/ RDBMS / Linux |
| EXPORT1 | 51013953 | Release 4.6C SR2 / Export / Disc 1 of 4 |
| EXPORT1 | 51013953 | Release 4.6C SR2 / Export / Disc 2 of 4 |
| EXPORT1 | 51013953 | Release 4.6C SR2 / Export / Disc 3 of 4 |
| EXPORT1 | 51013953 | Release 4.6C SR2 / Export / Disc 4 of 4 |
| LANG1 | 51013954 | Release 4.6C SR2 / Language / DE, EN, FR / Disc 1 of 3 |
Depending on the languages you would like to install, additional language CDs might be necessary. Here we are just using DE and EN, so the first language CD is the only one needed. As a little note, the numbers for all four EXPORT CDs are identical. All three language CDs also have the same number (this is different from the 4.6B IDES release CD numbering). At the time of writing this installation is running on FreeBSD 4.5-STABLE (20.03.2002).
10.7.3 SAP Notes
The following notes should be read before installing SAP R/3 and proved to be useful during installation:
10.7.3.1 SAP R/3 4.6B, Oracle 8.0.5
| Number | Title |
|---|---|
| 0171356 | SAP Software on Linux: Essential Comments |
| 0201147 | INST: 4.6C R/3 Inst. on UNIX - Oracle |
| 0373203 | Update / Migration Oracle 8.0.5 --> 8.0.6/8.1.6 LINUX |
| 0072984 | Release of Digital UNIX 4.0B for Oracle |
| 0130581 | R3SETUP step DIPGNTAB terminates |
| 0144978 | Your system has not been installed correctly |
| 0162266 | Questions and tips for R3SETUP on Windows NT / W2K |
10.7.3.2 SAP R/3 4.6C, Oracle 8.1.7
| Number | Title |
|---|---|
| 0015023 | Initializing table TCPDB (RSXP0004) (EBCDIC) |
| 0045619 | R/3 with several languages or typefaces |
| 0171356 | SAP Software on Linux: Essential Comments |
| 0195603 | RedHat 6.1 Enterprise version: Known problems |
| 0212876 | The new archiving tool SAPCAR |
| 0300900 | Linux: Released DELL Hardware |
| 0377187 | RedHat 6.2: important remarks |
| 0387074 | INST: R/3 4.6C SR2 Installation on UNIX |
| 0387077 | INST: R/3 4.6C SR2 Inst. on UNIX - Oracle |
| 0387078 | SAP Software on UNIX: OS Dependencies 4.6C SR2 |
10.7.4 Hardware Requirements
The following equipment is sufficient for the installation of a SAP R/3 System. For production use, a more exact sizing is of course needed:
| Component | 4.6B | 4.6C |
|---|---|---|
| Processor | 2 x 800MHz Pentium III | 2 x 800MHz Pentium III |
| Memory | 1GB ECC | 2GB ECC |
| Hard Disk Space | 50-60GB (IDES) | 50-60GB (IDES) |
For use in production, Xeon Processors with large cache, high-speed disk access (SCSI, RAID hardware controller), USV and ECC-RAM is recommended. The large amount of hard disk space is due to the preconfigured IDES System, which creates 27 GB of database files during installation. This space is also sufficient for initial production systems and application data.
10.7.4.1 SAP R/3 4.6B, Oracle 8.0.5
The following off-the-shelf hardware was used: a dual processor board with 2 800 MHz Pentium III processors, Adaptec® 29160 Ultra160 SCSI adapter (for accessing a 40/80 GB DLT tape drive and CDROM), Mylex® AcceleRAID™ (2 channels, firmware 6.00-1-00 with 32 MB RAM). To the Mylex RAID controller are attached two 17 GB hard disks (mirrored) and four 36 GB hard disks (RAID level 5).
10.7.4.2 SAP R/3 4.6C, Oracle 8.1.7
For this installation a Dell™ PowerEdge™ 2500 was used: a dual processor board with two 1000 MHz Pentium III processors (256 kB Cache), 2 GB PC133 ECC SDRAM, PERC/3 DC PCI RAID Controller with 128 MB, and an EIDE DVD-ROM drive. To the RAID controller are attached two 18 GB hard disks (mirrored) and four 36 GB hard disks (RAID level 5).
10.7.5 Installation of FreeBSD
First you have to install FreeBSD. There are several ways to do this, for more information read the Section 2.13.
10.7.5.1 Disk Layout
To keep it simple, the same disk layout both for the SAP R/3 46B and SAP R/3 46C SR2 installation was used. Only the device names changed, as the installations were on different hardware (/dev/da and /dev/amr respectively, so if using an AMI MegaRAID®, one will see /dev/amr0s1a instead of /dev/da0s1a):
| File system | Size (1k-blocks) | Size (GB) | Mounted on |
|---|---|---|---|
| /dev/da0s1a | 1.016.303 | 1 | / |
| /dev/da0s1b | 6 | swap | |
| /dev/da0s1e | 2.032.623 | 2 | /var |
| /dev/da0s1f | 8.205.339 | 8 | /usr |
| /dev/da1s1e | 45.734.361 | 45 | /compat/linux/oracle |
| /dev/da1s1f | 2.032.623 | 2 | /compat/linux/sapmnt |
| /dev/da1s1g | 2.032.623 | 2 | /compat/linux/usr/sap |
Configure and initialize the two logical drives with the Mylex or PERC/3 RAID software beforehand. The software can be started during the BIOS boot phase.
Please note that this disk layout differs slightly from the SAP recommendations, as SAP suggests mounting the Oracle subdirectories (and some others) separately -- we decided to just create them as real subdirectories for simplicity.
10.7.5.2 make world and a New Kernel
Download the latest -STABLE sources. Rebuild world and your custom kernel after configuring your kernel configuration file. Here you should also include the kernel parameters which are required for both SAP R/3 and Oracle.
10.7.6 Installing the Linux Environment
10.7.6.1 Installing the Linux Base System
First the linux_base port needs to be installed (as root):
# cd /usr/ports/emulators/linux_base
# make install distclean
10.7.6.2 Installing Linux Development Environment
The Linux development environment is needed, if you want to install Oracle on FreeBSD according to the Section 10.6:
# cd /usr/ports/devel/linux_devtools
# make install distclean
The Linux development environment has only been installed for the SAP R/3 46B IDES installation. It is not needed, if the Oracle DB is not relinked on the FreeBSD system. This is the case if you are using the Oracle tarball from a Linux system.
10.7.6.3 Installing the Necessary RPMs
To start the R3SETUP program, PAM support is needed. During the first SAP Installation on FreeBSD 4.3-STABLE we tried to install PAM with all the required packages and finally forced the installation of the PAM package, which worked. For SAP R/3 4.6C SR2 we directly forced the installation of the PAM RPM, which also works, so it seems the dependent packages are not needed:
# rpm -i --ignoreos --nodeps --root /compat/linux --dbpath /var/lib/rpm \
pam-0.68-7.i386.rpm
For Oracle 8.0.5 to run the intelligent agent, we also had to install the RedHat Tcl package tcl-8.0.5-30.i386.rpm (otherwise the relinking during Oracle installation will not work). There are some other issues regarding relinking of Oracle, but that is a Oracle Linux issue, not FreeBSD specific.
10.7.6.4 Some Additional Hints
It might also be a good idea to add linprocfs to /etc/fstab, for more information, see the linprocfs(5) manual page. Another parameter to set is kern.fallback_elf_brand=3 which is done in the file /etc/sysctl.conf.
10.7.7 Creating the SAP R/3 Environment
10.7.7.1 Creating the Necessary File Systems and Mountpoints
For a simple installation, it is sufficient to create the following file systems:
| mount point | size in GB |
|---|---|
| /compat/linux/oracle | 45 GB |
| /compat/linux/sapmnt | 2 GB |
| /compat/linux/usr/sap | 2 GB |
It is also necessary to created some links. Otherwise the SAP Installer will complain, as it is checking the created links:
# ln -s /compat/linux/oracle /oracle
# ln -s /compat/linux/sapmnt /sapmnt
# ln -s /compat/linux/usr/sap /usr/sap
Possible error message during installation (here with System PRD and the SAP R/3 4.6C SR2 installation):
INFO 2002-03-19 16:45:36 R3LINKS_IND_IND SyLinkCreate:200
Checking existence of symbolic link /usr/sap/PRD/SYS/exe/dbg to
/sapmnt/PRD/exe. Creating if it does not exist...
WARNING 2002-03-19 16:45:36 R3LINKS_IND_IND SyLinkCreate:400
Link /usr/sap/PRD/SYS/exe/dbg exists but it points to file
/compat/linux/sapmnt/PRD/exe instead of /sapmnt/PRD/exe. The
program cannot go on as long as this link exists at this
location. Move the link to another location.
ERROR 2002-03-19 16:45:36 R3LINKS_IND_IND Ins_SetupLinks:0
can not setup link '/usr/sap/PRD/SYS/exe/dbg' with content
'/sapmnt/PRD/exe'
10.7.7.2 Creating Users and Directories
SAP R/3 needs two users and three groups. The user names depend on the SAP system ID (SID) which consists of three letters. Some of these SIDs are reserved by SAP (for example SAP and NIX. For a complete list please see the SAP documentation). For the IDES installation we used IDS, for the 4.6C SR2 installation PRD, as that system is intended for production use. We have therefore the following groups (group IDs might differ, these are just the values we used with our installation):
| group ID | group name | description |
|---|---|---|
| 100 | dba | Data Base Administrator |
| 101 | sapsys | SAP System |
| 102 | oper | Data Base Operator |
For a default Oracle installation, only group dba is used. As oper group, one also uses group dba (see Oracle and SAP documentation for further information).
We also need the following users:
| user ID | user name | generic name | group | additional groups | description |
|---|---|---|---|---|---|
| 1000 | idsadm/prdadm | sidadm | sapsys | oper | SAP Administrator |
| 1002 | oraids/oraprd | orasid | dba | oper | Oracle Administrator |
Adding the users with adduser(8) requires the following (please note shell and home directory) entries for “SAP Administrator”:
Name: sidadm
Password: ******
Fullname: SAP Administrator SID
Uid: 1000
Gid: 101 (sapsys)
Class:
Groups: sapsys dba
HOME: /home/sidadm
Shell: bash (/compat/linux/bin/bash)
and for “Oracle Administrator”:
Name: orasid
Password: ******
Fullname: Oracle Administrator SID
Uid: 1002
Gid: 100 (dba)
Class:
Groups: dba
HOME: /oracle/sid
Shell: bash (/compat/linux/bin/bash)
This should also include group oper in case you are using both groups dba and oper.
10.7.7.3 Creating Directories
These directories are usually created as separate file systems. This depends entirely on your requirements. We choose to create them as simple directories, as they are all located on the same RAID 5 anyway:
First we will set owners and rights of some directories (as user root):
# chmod 775 /oracle
# chmod 777 /sapmnt
# chown root:dba /oracle
# chown sidadm:sapsys /compat/linux/usr/sap
# chmod 775 /compat/linux/usr/sap
Second we will create directories as user orasid. These will all be subdirectories of /oracle/SID:
# su - orasid
# cd /oracle/SID
# mkdir mirrlogA mirrlogB origlogA origlogB
# mkdir sapdata1 sapdata2 sapdata3 sapdata4 sapdata5 sapdata6
# mkdir saparch sapreorg
# exit
For the Oracle 8.1.7 installation some additional directories are needed:
# su - orasid
# cd /oracle
# mkdir 805_32
# mkdir client stage
# mkdir client/80x_32
# mkdir stage/817_32
# cd /oracle/SID
# mkdir 817_32
Note: The directory client/80x_32 is used with exactly this name. Do not replace the x with some number or anything.
In the third step we create directories as user sidadm:
# su - sidadm
# cd /usr/sap
# mkdir SID
# mkdir trans
# exit
10.7.7.4 Entries in /etc/services
SAP R/3 requires some entries in file /etc/services, which will not be set correctly during installation under FreeBSD. Please add the following entries (you need at least those entries corresponding to the instance number -- in this case, 00. It will do no harm adding all entries from 00 to 99 for dp, gw, sp and ms). If you are going to use a SAProuter or need to access SAP OSS, you also need 99, as port 3299 is usually used for the SAProuter process on the target system:
sapdp00 3200/tcp # SAP Dispatcher. 3200 + Instance-Number
sapgw00 3300/tcp # SAP Gateway. 3300 + Instance-Number
sapsp00 3400/tcp # 3400 + Instance-Number
sapms00 3500/tcp # 3500 + Instance-Number
sapmsSID 3600/tcp # SAP Message Server. 3600 + Instance-Number
sapgw00s 4800/tcp # SAP Secure Gateway 4800 + Instance-Number
10.7.7.5 Necessary Locales
SAP requires at least two locales that are not part of the default RedHat installation. SAP offers the required RPMs as download from their FTP server (which is only accessible if you are a customer with OSS access). See note 0171356 for a list of RPMs you need.
It is also possible to just create appropriate links (for example from de_DE and en_US ), but we would not recommend this for a production system (so far it worked with the IDES system without any problems, though). The following locales are needed:
de_DE.ISO-8859-1
en_US.ISO-8859-1
Create the links like this:
# cd /compat/linux/usr/share/locale
# ln -s de_DE de_DE.ISO-8859-1
# ln -s en_US en_US.ISO-8859-1
If they are not present, there will be some problems during the installation. If these are then subsequently ignored (by setting the STATUS of the offending steps to OK in file CENTRDB.R3S), it will be impossible to log onto the SAP system without some additional effort.
10.7.7.6 Kernel Tuning
SAP R/3 systems need a lot of resources. We therefore added the following parameters to the kernel configuration file:
# Set these for memory pigs (SAP and Oracle):
options MAXDSIZ="(1024*1024*1024)"
options DFLDSIZ="(1024*1024*1024)"
# System V options needed.
options SYSVSHM #SYSV-style shared memory
options SHMMAXPGS=262144 #max amount of shared mem. pages
#options SHMMAXPGS=393216 #use this for the 46C inst.parameters
options SHMMNI=256 #max number of shared memory ident if.
options SHMSEG=100 #max shared mem.segs per process
options SYSVMSG #SYSV-style message queues
options MSGSEG=32767 #max num. of mes.segments in system
options MSGSSZ=32 #size of msg-seg. MUST be power of 2
options MSGMNB=65535 #max char. per message queue
options MSGTQL=2046 #max amount of msgs in system
options SYSVSEM #SYSV-style semaphores
options SEMMNU=256 #number of semaphore UNDO structures
options SEMMNS=1024 #number of semaphores in system
options SEMMNI=520 #number of semaphore identifiers
options SEMUME=100 #number of UNDO keys
The minimum values are specified in the documentation that comes from SAP. As there is no description for Linux, see the HP-UX section (32-bit) for further information. As the system for the 4.6C SR2 installation has more main memory, the shared segments can be larger both for SAP and Oracle, therefore choose a larger number of shared memory pages.
Note: With the default installation of FreeBSD on i386, leave MAXDSIZ and DFLDSIZ at 1 GB maximum. Otherwise, strange errors like “ORA-27102: out of memory” and “Linux Error: 12: Cannot allocate memory” might happen.
10.7.8 Installing SAP R/3
10.7.8.1 Preparing SAP CDROMs
There are many CDROMs to mount and unmount during the installation. Assuming you have enough CDROM drives, you can just mount them all. We decided to copy the CDROMs contents to corresponding directories:
/oracle/SID/sapreorg/cd-name
where cd-name was one of KERNEL, RDBMS, EXPORT1, EXPORT2, EXPORT3, EXPORT4, EXPORT5 and EXPORT6 for the 4.6B/IDES
installation, and KERNEL, RDBMS, DISK1, DISK2, DISK3, DISK4 and LANG for the 4.6C SR2 installation. All the filenames on the
mounted CDs should be in capital letters, otherwise use the -g option for mounting. So use the following commands:
# mount_cd9660 -g /dev/cd0a /mnt
# cp -R /mnt/* /oracle/SID/sapreorg/cd-name
# umount /mnt
10.7.8.2 Running the Installation Script
First you have to prepare an install directory:
# cd /oracle/SID/sapreorg
# mkdir install
# cd install
Then the installation script is started, which will copy nearly all the relevant files into the install directory:
# /oracle/SID/sapreorg/KERNEL/UNIX/INSTTOOL.SH
The IDES installation (4.6B) comes with a fully customized SAP R/3 demonstration system, so there are six instead of just three EXPORT CDs. At this point the installation template CENTRDB.R3S is for installing a standard central instance (R/3 and database), not the IDES central instance, so one needs to copy the corresponding CENTRDB.R3S from the EXPORT1 directory, otherwise R3SETUP will only ask for three EXPORT CDs.
The newer SAP 4.6C SR2 release comes with four EXPORT CDs. The parameter file that controls the installation steps is CENTRAL.R3S. Contrary to earlier releases there are no separate installation templates for a central instance with or without database. SAP is using a separate template for database installation. To restart the installation later it is however sufficient to restart with the original file.
During and after installation, SAP requires hostname to return the computer name only, not the fully qualified domain name. So either set the hostname accordingly, or set an alias with alias hostname='hostname -s' for both orasid and sidadm (and for root at least during installation steps performed as root). It is also possible to adjust the installed .profile and .login files of both users that are installed during SAP installation.
10.7.8.3 Start R3SETUP 4.6B
Make sure LD_LIBRARY_PATH is set correctly:
# export LD_LIBRARY_PATH=/oracle/IDS/lib:/sapmnt/IDS/exe:/oracle/805_32/lib
Start R3SETUP as root from installation directory:
# cd /oracle/IDS/sapreorg/install
# ./R3SETUP -f CENTRDB.R3S
The script then asks some questions (defaults in brackets, followed by actual input):
| Question | Default | Input |
|---|---|---|
| Enter SAP System ID | [C11] | IDSEnter |
| Enter SAP Instance Number | [00] | Enter |
| Enter SAPMOUNT Directory | [/sapmnt] | Enter |
| Enter name of SAP central host | [troubadix.domain.de] | Enter |
| Enter name of SAP db host | [troubadix] | Enter |
| Select character set | [1] (WE8DEC) | Enter |
| Enter Oracle server version (1) Oracle 8.0.5, (2) Oracle 8.0.6, (3) Oracle 8.1.5, (4) Oracle 8.1.6 | 1Enter | |
| Extract Oracle Client archive | [1] (Yes, extract) | Enter |
| Enter path to KERNEL CD | [/sapcd] | /oracle/IDS/sapreorg/KERNEL |
| Enter path to RDBMS CD | [/sapcd] | /oracle/IDS/sapreorg/RDBMS |
| Enter path to EXPORT1 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT1 |
| Directory to copy EXPORT1 CD | [/oracle/IDS/sapreorg/CD4_DIR] | Enter |
| Enter path to EXPORT2 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT2 |
| Directory to copy EXPORT2 CD | [/oracle/IDS/sapreorg/CD5_DIR] | Enter |
| Enter path to EXPORT3 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT3 |
| Directory to copy EXPORT3 CD | [/oracle/IDS/sapreorg/CD6_DIR] | Enter |
| Enter path to EXPORT4 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT4 |
| Directory to copy EXPORT4 CD | [/oracle/IDS/sapreorg/CD7_DIR] | Enter |
| Enter path to EXPORT5 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT5 |
| Directory to copy EXPORT5 CD | [/oracle/IDS/sapreorg/CD8_DIR] | Enter |
| Enter path to EXPORT6 CD | [/sapcd] | /oracle/IDS/sapreorg/EXPORT6 |
| Directory to copy EXPORT6 CD | [/oracle/IDS/sapreorg/CD9_DIR] | Enter |
| Enter amount of RAM for SAP + DB | 850Enter (in Megabytes) | |
| Service Entry Message Server | [3600] | Enter |
| Enter Group-ID of sapsys | [101] | Enter |
| Enter Group-ID of oper | [102] | Enter |
| Enter Group-ID of dba | [100] | Enter |
| Enter User-ID of sidadm | [1000] | Enter |
| Enter User-ID of orasid | [1002] | Enter |
| Number of parallel procs | [2] | Enter |
If you had not copied the CDs to the different locations, then the SAP installer cannot find the CD needed (identified by the LABEL.ASC file on the CD) and would then ask you to insert and mount the CD and confirm or enter the mount path.
The CENTRDB.R3S might not be error free. In our case, it requested EXPORT4 CD again but indicated the correct key (6_LOCATION, then 7_LOCATION etc.), so one can just continue with entering the correct values.
Apart from some problems mentioned below, everything should go straight through up to the point where the Oracle database software needs to be installed.
10.7.8.4 Start R3SETUP 4.6C SR2
Make sure LD_LIBRARY_PATH is set correctly. This is a different value from the 4.6B installation with Oracle 8.0.5:
# export LD_LIBRARY_PATH=/sapmnt/PRD/exe:/oracle/PRD/817_32/lib
Start R3SETUP as user root from installation directory:
# cd /oracle/PRD/sapreorg/install
# ./R3SETUP -f CENTRAL.R3S
The script then asks some questions (defaults in brackets, followed by actual input):
| Question | Default | Input |
|---|---|---|
| Enter SAP System ID | [C11] | PRDEnter |
| Enter SAP Instance Number | [00] | Enter |
| Enter SAPMOUNT Directory | [/sapmnt] | Enter |
| Enter name of SAP central host | [majestix] | Enter |
| Enter Database System ID | [PRD] | PRDEnter |
| Enter name of SAP db host | [majestix] | Enter |
| Select character set | [1] (WE8DEC) | Enter |
| Enter Oracle server version (2) Oracle 8.1.7 | 2Enter | |
| Extract Oracle Client archive | [1] (Yes, extract) | Enter |
| Enter path to KERNEL CD | [/sapcd] | /oracle/PRD/sapreorg/KERNEL |
| Enter amount of RAM for SAP + DB | 2044 | 1800Enter (in Megabytes) |
| Service Entry Message Server | [3600] | Enter |
| Enter Group-ID of sapsys | [100] | Enter |
| Enter Group-ID of oper | [101] | Enter |
| Enter Group-ID of dba | [102] | Enter |
| Enter User-ID of oraprd | [1002] | Enter |
| Enter User-ID of prdadm | [1000] | Enter |
| LDAP support | 3Enter (no support) | |
| Installation step completed | [1] (continue) | Enter |
| Choose installation service | [1] (DB inst,file) | Enter |
So far, creation of users gives an error during installation in phases OSUSERDBSID_IND_ORA (for creating user orasid) and OSUSERSIDADM_IND_ORA (creating user sidadm).
Apart from some problems mentioned below, everything should go straight through up to the point where the Oracle database software needs to be installed.
10.7.9 Installing Oracle 8.0.5
Please see the corresponding SAP Notes and Oracle Readmes regarding Linux and Oracle DB for possible problems. Most if not all problems stem from incompatible libraries.
For more information on installing Oracle, refer to the Installing Oracle chapter.
10.7.9.1 Installing the Oracle 8.0.5 with orainst
If Oracle 8.0.5 is to be used, some additional libraries are needed for successfully relinking, as Oracle 8.0.5 was linked with an old glibc (RedHat 6.0), but RedHat 6.1 already uses a new glibc. So you have to install the following additional packages to ensure that linking will work:
compat-libs-5.2-2.i386.rpm
compat-glibc-5.2-2.0.7.2.i386.rpm
compat-egcs-5.2-1.0.3a.1.i386.rpm
compat-egcs-c++-5.2-1.0.3a.1.i386.rpm
compat-binutils-5.2-2.9.1.0.23.1.i386.rpm
See the corresponding SAP Notes or Oracle Readmes for further information. If this is no option (at the time of installation we did not have enough time to check this), one could use the original binaries, or use the relinked binaries from an original RedHat system.
For compiling the intelligent agent, the RedHat Tcl package must be installed. If you cannot get tcl-8.0.3-20.i386.rpm, a newer one like tcl-8.0.5-30.i386.rpm for RedHat 6.1 should also do.
Apart from relinking, the installation is straightforward:
# su - oraids
# export TERM=xterm
# export ORACLE_TERM=xterm
# export ORACLE_HOME=/oracle/IDS
# cd $ORACLE_HOME/orainst_sap
# ./orainst
Confirm all screens with Enter until the software is installed, except that one has to deselect the Oracle On-Line Text Viewer, as this is not currently available for Linux. Oracle then wants to relink with i386-glibc20-linux-gcc instead of the available gcc, egcs or i386-redhat-linux-gcc .
Due to time constrains we decided to use the binaries from an Oracle 8.0.5 PreProduction release, after the first attempt at getting the version from the RDBMS CD working, failed, and finding and accessing the correct RPMs was a nightmare at that time.
10.7.9.2 Installing the Oracle 8.0.5 Pre-production Release for Linux (Kernel 2.0.33)
This installation is quite easy. Mount the CD, start the installer. It will then ask for the location of the Oracle home directory, and copy all binaries there. We did not delete the remains of our previous RDBMS installation tries, though.
Afterwards, Oracle Database could be started with no problems.
10.7.10 Installing the Oracle 8.1.7 Linux Tarball
Take the tarball oracle81732.tgz you produced from the installation directory on a Linux system and untar it to /oracle/SID/817_32/.
10.7.11 Continue with SAP R/3 Installation
First check the environment settings of users idsamd (sidadm) and oraids (orasid). They should now both have the files .profile, .login and .cshrc which are all using hostname. In case the system's hostname is the fully qualified name, you need to change hostname to hostname -s within all three files.
10.7.11.1 Database Load
Afterwards, R3SETUP can either be restarted or continued (depending on whether exit was chosen or not). R3SETUP then creates the tablespaces and loads the data (for 46B IDES, from EXPORT1 to EXPORT6, for 46C from DISK1 to DISK4) with R3load into the database.
When the database load is finished (might take a few hours), some passwords are requested. For test installations, one can use the well known default passwords (use different ones if security is an issue!):
| Question | Input |
|---|---|
| Enter Password for sapr3 | sapEnter |
| Confirum Password for sapr3 | sapEnter |
| Enter Password for sys | change_on_installEnter |
| Confirm Password for sys | change_on_installEnter |
| Enter Password for system | managerEnter |
| Confirm Password for system | managerEnter |
At this point We had a few problems with dipgntab during the 4.6B installation.
10.7.11.2 Listener
Start the Oracle Listener as user orasid as follows:
% umask 0; lsnrctl start
Otherwise you might get the error ORA-12546 as the sockets will not have the correct permissions. See SAP Note 072984.
10.7.11.3 Updating MNLS Tables
If you plan to import non-Latin-1 languages into the SAP system, you have to update the Multi National Language Support tables. This is described in the SAP OSS Notes 15023 and 45619. Otherwise, you can skip this question during SAP installation.
Note: If you do not need MNLS, it is still necessary to check the table TCPDB and initializing it if this has not been done. See SAP note 0015023 and 0045619 for further information.
10.7.12 Post-installation Steps
10.7.12.1 Request SAP R/3 License Key
You have to request your SAP R/3 License Key. This is needed, as the temporary license that was installed during installation is only valid for four weeks. First get the hardware key. Log on as user idsadm and call saplicense:
# /sapmnt/IDS/exe/saplicense -get
Calling saplicense without parameters gives a list of options. Upon receiving the license key, it can be installed using:
# /sapmnt/IDS/exe/saplicense -install
You are then required to enter the following values:
SAP SYSTEM ID = SID, 3 chars
CUSTOMER KEY = hardware key, 11 chars
INSTALLATION NO = installation, 10 digits
EXPIRATION DATE = yyyymmdd, usually "99991231"
LICENSE KEY = license key, 24 chars
10.7.12.2 Creating Users
Create a user within client 000 (for some tasks required to be done within client 000, but with a user different from users sap* and ddic). As a user name, We usually choose wartung (or service in English). Profiles required are sap_new and sap_all. For additional safety the passwords of default users within all clients should be changed (this includes users sap* and ddic).
10.7.12.3 Configure Transport System, Profile, Operation Modes, Etc.
Within client 000, user different from ddic and sap*, do at least the following:
| Task | Transaction |
|---|---|
| Configure Transport System, e.g. as Stand-Alone Transport Domain Entity | STMS |
| Create / Edit Profile for System | RZ10 |
| Maintain Operation Modes and Instances | RZ04 |
These and all the other post-installation steps are thoroughly described in SAP installation guides.
10.7.12.4 Edit initsid.sap (initIDS.sap)
The file /oracle/IDS/dbs/initIDS.sap contains the SAP backup profile. Here the size of the tape to be used, type of compression and so on need to be defined. To get this running with sapdba / brbackup, we changed the following values:
compress = hardware
archive_function = copy_delete_save
cpio_flags = "-ov --format=newc --block-size=128 --quiet"
cpio_in_flags = "-iuv --block-size=128 --quiet"
tape_size = 38000M
tape_address = /dev/nsa0
tape_address_rew = /dev/sa0
Explanations:
compress: The tape we use is a HP DLT1 which does
hardware compression.
archive_function: This defines the default behavior for
saving Oracle archive logs: new logfiles are saved to
tape, already saved logfiles are saved again and are then deleted. This prevents lots of
trouble if you need to recover the database, and one of the archive-tapes has gone
bad.
cpio_flags: Default is to use -B which sets block size to 5120 Bytes. For DLT Tapes, HP
recommends at least 32 K block size, so we used --block-size=128 for 64 K. --format=newc is needed because we have inode numbers greater than
65535. The last option --quiet is needed as otherwise brbackup complains as soon as cpio outputs
the numbers of blocks saved.
cpio_in_flags: Flags needed for loading data back from
tape. Format is recognized automatically.
tape_size: This usually gives the raw storage capability
of the tape. For security reason (we use hardware compression), the value is slightly
lower than the actual value.
tape_address: The non-rewindable device to be used with
cpio.
tape_address_rew: The rewindable device to be used with
cpio.
10.7.12.5 Configuration Issues after Installation
The following SAP parameters should be tuned after installation (examples for IDES 46B, 1 GB memory):
| Name | Value |
|---|---|
| ztta/roll_extension | 250000000 |
| abap/heap_area_dia | 300000000 |
| abap/heap_area_nondia | 400000000 |
| em/initial_size_MB | 256 |
| em/blocksize_kB | 1024 |
| ipc/shm_psize_40 | 70000000 |
SAP Note 0013026:
SAP Note 0157246:
Note: With the above parameters, on a system with 1 gigabyte of memory, one may find memory consumption similar to:
Mem: 547M Active, 305M Inact, 109M Wired, 40M Cache, 112M Buf, 3492K Free
10.7.13 Problems during Installation
10.7.13.1 Restart R3SETUP after Fixing a Problem
R3SETUP stops if it encounters an error. If you have looked at the corresponding logfiles and fixed the error, you have to start R3SETUP again, usually selecting REPEAT as option for the last step R3SETUP complained about.
To restart R3SETUP, just start it with the corresponding R3S file:
# ./R3SETUP -f CENTRDB.R3S
for 4.6B, or with
# ./R3SETUP -f CENTRAL.R3S
for 4.6C, no matter whether the error occurred with CENTRAL.R3S or DATABASE.R3S.
Note: At some stages, R3SETUP assumes that both database and SAP processes are up and running (as those were steps it already completed). Should errors occur and for example the database could not be started, you have to start both database and SAP by hand after you fixed the errors and before starting R3SETUP again.
Do not forget to also start the Oracle listener again (as orasid with umask 0; lsnrctl start) if it was also stopped (for example due to a necessary reboot of the system).
10.7.13.2 OSUSERSIDADM_IND_ORA during R3SETUP
If R3SETUP complains at this stage, edit the template file R3SETUP used at that time (CENTRDB.R3S (4.6B) or either CENTRAL.R3S or DATABASE.R3S (4.6C)). Locate [OSUSERSIDADM_IND_ORA] or search for the only STATUS=ERROR entry and edit the following values:
HOME=/home/sidadm (was empty)
STATUS=OK (had status ERROR)
Then you can restart R3SETUP again.
10.7.13.3 OSUSERDBSID_IND_ORA during R3SETUP
Possibly R3SETUP also complains at this stage. The error here is similar to the one in phase OSUSERSIDADM_IND_ORA. Just edit the template file R3SETUP used at that time (CENTRDB.R3S (4.6B) or either CENTRAL.R3S or DATABASE.R3S (4.6C)). Locate [OSUSERDBSID_IND_ORA] or search for the only STATUS=ERROR entry and edit the following value in that section:
STATUS=OK
Then restart R3SETUP.
10.7.13.4 “oraview.vrf FILE NOT FOUND” during Oracle Installation
You have not deselected Oracle On-Line Text Viewer before starting the installation. This is marked for installation even though this option is currently not available for Linux. Deselect this product inside the Oracle installation menu and restart installation.
10.7.13.5 “TEXTENV_INVALID” during R3SETUP, RFC or SAPgui Start
If this error is encountered, the correct locale is missing. SAP Note 0171356 lists the necessary RPMs that need be installed (e.g. saplocales-1.0-3, saposcheck-1.0-1 for RedHat 6.1). In case you ignored all the related errors and set the corresponding STATUS from ERROR to OK (in CENTRDB.R3S) every time R3SETUP complained and just restarted R3SETUP, the SAP system will not be properly configured and you will then not be able to connect to the system with a SAPgui, even though the system can be started. Trying to connect with the old Linux SAPgui gave the following messages:
Sat May 5 14:23:14 2001
*** ERROR => no valid userarea given [trgmsgo. 0401]
Sat May 5 14:23:22 2001
*** ERROR => ERROR NR 24 occured [trgmsgi. 0410]
*** ERROR => Error when generating text environment. [trgmsgi. 0435]
*** ERROR => function failed [trgmsgi. 0447]
*** ERROR => no socket operation allowed [trxio.c 3363]
Speicherzugriffsfehler
This behavior is due to SAP R/3 being unable to correctly assign a locale and also not being properly configured itself (missing entries in some database tables). To be able to connect to SAP, add the following entries to file DEFAULT.PFL (see Note 0043288):
abap/set_etct_env_at_new_mode = 0
install/collate/active = 0
rscp/TCP0B = TCP0B
Restart the SAP system. Now you can connect to the system, even though country-specific language settings might not work as expected. After correcting country settings (and providing the correct locales), these entries can be removed from DEFAULT.PFL and the SAP system can be restarted.
10.7.13.6 ORA-00001
This error only happened with Oracle 8.1.7 on FreeBSD. The reason was that the Oracle database could not initialize itself properly and crashed, leaving semaphores and shared memory on the system. The next try to start the database then returned ORA-00001.
Find them with ipcs -a and remove them with ipcrm.
10.7.13.7 ORA-00445 (Background Process PMON Did Not Start)
This error happened with Oracle 8.1.7. This error is reported if the database is started with the usual startsap script (for example startsap_majestix_00) as user prdadm.
A possible workaround is to start the database as user oraprd instead with svrmgrl:
% svrmgrl
SVRMGR> connect internal;
SVRMGR> startup;
SVRMGR> exit
10.7.13.8 ORA-12546 (Start Listener with Correct Permissions)
Start the Oracle listener as user oraids with the following commands:
# umask 0; lsnrctl start
Otherwise you might get ORA-12546 as the sockets will not have the correct permissions. See SAP Note 0072984.
10.7.13.9 ORA-27102 (Out of Memory)
This error happened whilst trying to use values for MAXDSIZ and DFLDSIZ greater than 1 GB (1024x1024x1024). Additionally, we got “Linux Error 12: Cannot allocate memory”.
10.7.13.10 [DIPGNTAB_IND_IND] during R3SETUP
In general, see SAP Note 0130581 (R3SETUP step DIPGNTAB terminates). During the IDES-specific installation, for some reason the installation process was not using the proper SAP system name “IDS”, but the empty string "" instead. This leads to some minor problems with accessing directories, as the paths are generated dynamically using SID (in this case IDS). So instead of accessing:
/usr/sap/IDS/SYS/...
/usr/sap/IDS/DVMGS00
the following paths were used:
/usr/sap//SYS/...
/usr/sap/D00
To continue with the installation, we created a link and an additional directory:
# pwd
/compat/linux/usr/sap
# ls -l
total 4
drwxr-xr-x 3 idsadm sapsys 512 May 5 11:20 D00
drwxr-x--x 5 idsadm sapsys 512 May 5 11:35 IDS
lrwxr-xr-x 1 root sapsys 7 May 5 11:35 SYS -> IDS/SYS
drwxrwxr-x 2 idsadm sapsys 512 May 5 13:00 tmp
drwxrwxr-x 11 idsadm sapsys 512 May 4 14:20 trans
We also found SAP Notes (0029227 and 0008401) describing this behavior. We did not encounter any of these problems with the SAP 4.6C installation.
10.7.13.11 [RFCRSWBOINI_IND_IND] during R3SETUP
During installation of SAP 4.6C, this error was just the result of another error happening earlier during installation. In this case, you have to look through the corresponding logfiles and correct the real problem.
If after looking through the logfiles this error is indeed the correct one (check the SAP Notes), you can set STATUS of the offending step from ERROR to OK (file CENTRDB.R3S) and restart R3SETUP. After installation, you have to execute the report RSWBOINS from transaction SE38. See SAP Note 0162266 for additional information about phase RFCRSWBOINI and RFCRADDBDIF.
10.7.13.12 [RFCRADDBDIF_IND_IND] during R3SETUP
Here the same restrictions apply: make sure by looking through the logfiles, that this error is not caused by some previous problems.
If you can confirm that SAP Note 0162266 applies, just set STATUS of the offending step from ERROR to OK (file CENTRDB.R3S) and restart R3SETUP. After installation, you have to execute the report RADDBDIF from transaction SE38.
10.7.13.13 sigaction sig31: File size limit exceeded
This error occurred during start of SAP processes disp+work. If starting SAP with the startsap script, subprocesses are then started which detach and do the dirty work of starting all other SAP processes. As a result, the script itself will not notice if something goes wrong.
To check whether the SAP processes did start properly, have a look at the process status with ps ax | grep SID, which will give you a list of all Oracle and SAP processes. If it looks like some processes are missing or if you cannot connect to the SAP system, look at the corresponding logfiles which can be found at /usr/sap/SID/DVEBMGSnr/work/. The files to look at are dev_ms and dev_disp.
Signal 31 happens here if the amount of shared memory used by Oracle and SAP exceed the one defined within the kernel configuration file and could be resolved by using a larger value:
# larger value for 46C production systems:
options SHMMAXPGS=393216
# smaller value sufficient for 46B:
#options SHMMAXPGS=262144
10.7.13.14 Start of saposcol Failed
There are some problems with the program saposcol (version 4.6D). The SAP system is using saposcol to collect data about the system performance. This program is not needed to use the SAP system, so this problem can be considered a minor one. The older versions (4.6B) does work, but does not collect all the data (many calls will just return 0, for example for CPU usage).
10.8 Advanced Topics
If you are curious as to how the Linux binary compatibility works, this is the section
you want to read. Most of what follows is based heavily on an email written to FreeBSD chat
mailing list by Terry Lambert <tlambert@primenet.com> (Message ID:
<199906020108.SAA07001@usr09.primenet.com>).
10.8.1 How Does It Work?
FreeBSD has an abstraction called an “execution class loader”. This is a wedge into the execve(2) system call.
What happens is that FreeBSD has a list of loaders, instead of a single loader with a fallback to the #! loader for running any shell interpreters or shell scripts.
Historically, the only loader on the UNIX platform examined the magic number (generally the first 4 or 8 bytes of the file) to see if it was a binary known to the system, and if so, invoked the binary loader.
If it was not the binary type for the system, the execve(2) call returned a failure, and the shell attempted to start executing it as shell commands.
The assumption was a default of “whatever the current shell is”.
Later, a hack was made for sh(1) to examine the first two characters, and if they were :\n, then it invoked the csh(1) shell instead (we believe SCO first made this hack).
What FreeBSD does now is go through a list of loaders, with a generic #! loader that knows about interpreters as the characters which follow to the next whitespace next to last, followed by a fallback to /bin/sh.
For the Linux ABI support, FreeBSD sees the magic number as an ELF binary (it makes no distinction between FreeBSD, Solaris, Linux, or any other OS which has an ELF image type, at this point).
The ELF loader looks for a specialized brand, which is a comment section in the ELF image, and which is not present on SVR4/Solaris ELF binaries.
For Linux binaries to function, they must be branded as type Linux from brandelf(1):
# brandelf -t Linux file
When this is done, the ELF loader will see the Linux brand on the file.
When the ELF loader sees the Linux brand, the loader replaces a pointer in the proc structure. All system calls are indexed through this pointer (in a traditional UNIX system, this would be the sysent[] structure array, containing the system calls). In addition, the process is flagged for special handling of the trap vector for the signal trampoline code, and several other (minor) fix-ups that are handled by the Linux kernel module.
The Linux system call vector contains, among other things, a list of sysent[] entries whose addresses reside in the kernel module.
When a system call is called by the Linux binary, the trap code dereferences the system call function pointer off the proc structure, and gets the Linux, not the FreeBSD, system call entry points.
In addition, the Linux mode dynamically reroots lookups; this is, in effect, what the union option to file system mounts (not the unionfs file system type!)
does. First, an attempt is made to lookup the file in the /compat/linux/original-path
directory, then only if that fails,
the lookup is done in the /original-path directory. This makes sure that
binaries that require other binaries can run (e.g., the Linux toolchain can all run under
Linux ABI support). It also means that the Linux binaries can load and execute FreeBSD
binaries, if there are no corresponding Linux binaries present, and that you could place
a uname(1) command in
the /compat/linux directory tree to ensure that the Linux
binaries could not tell they were not running on Linux.
In effect, there is a Linux kernel in the FreeBSD kernel; the various underlying functions that implement all of the services provided by the kernel are identical to both the FreeBSD system call table entries, and the Linux system call table entries: file system operations, virtual memory operations, signal delivery, System V IPC, etc... The only difference is that FreeBSD binaries get the FreeBSD glue functions, and Linux binaries get the Linux glue functions (most older OS's only had their own glue functions: addresses of functions in a static global sysent[] structure array, instead of addresses of functions dereferenced off a dynamically initialized pointer in the proc structure of the process making the call).
Which one is the native FreeBSD ABI? It does not matter. Basically the only difference is that (currently; this could easily be changed in a future release, and probably will be after this) the FreeBSD glue functions are statically linked into the kernel, and the Linux glue functions can be statically linked, or they can be accessed via a kernel module.
Yeah, but is this really emulation? No. It is an ABI implementation, not an emulation. There is no emulator (or simulator, to cut off the next question) involved.
So why is it sometimes called “Linux emulation”? To make it hard to sell FreeBSD! Really, it is because the historical implementation was done at a time when there was really no word other than that to describe what was going on; saying that FreeBSD ran Linux binaries was not true, if you did not compile the code in or load a module, and there needed to be a word to describe what was being loaded--hence “the Linux emulator”.
III. System Administration
The remaining chapters of the FreeBSD Handbook cover all aspects of FreeBSD system administration. Each chapter starts by describing what you will learn as a result of reading the chapter, and also details what you are expected to know before tackling the material.
These chapters are designed to be read when you need the information. You do not have to read them in any particular order, nor do you need to read all of them before you can begin using FreeBSD.
- Table of Contents
- 11 Configuration and Tuning
- 12 The FreeBSD Booting Process
- 13 Users and Basic Account Management
- 14 Security
- 15 Jails
- 16 Mandatory Access Control
- 17 Security Event Auditing
- 18 Storage
- 19 GEOM: Modular Disk Transformation Framework
- 20 The Vinum Volume Manager
- 21 Virtualization
- 22 Localization - I18N/L10N Usage and Setup
- 23 The Cutting Edge
Chapter 11 Configuration and Tuning
Written by Chern Lee. Based on a tutorial written by Mike Smith. Also based on tuning(7) written by Matt Dillon.11.1 Synopsis
One of the important aspects of FreeBSD is system configuration. Correct system configuration will help prevent headaches during future upgrades. This chapter will explain much of the FreeBSD configuration process, including some of the parameters which can be set to tune a FreeBSD system.
After reading this chapter, you will know:
-
How to efficiently work with file systems and swap partitions.
-
The basics of rc.conf configuration and /usr/local/etc/rc.d startup systems.
-
How to configure and test a network card.
-
How to configure virtual hosts on your network devices.
-
How to use the various configuration files in /etc.
-
How to tune FreeBSD using sysctl variables.
-
How to tune disk performance and modify kernel limitations.
Before reading this chapter, you should:
11.2 Initial Configuration
11.2.1 Partition Layout
11.2.1.1 Base Partitions
When laying out file systems with bsdlabel(8) or sysinstall(8), remember that hard drives transfer data faster from the outer tracks to the inner. Thus smaller and heavier-accessed file systems should be closer to the outside of the drive, while larger partitions like /usr should be placed toward the inner. It is a good idea to create partitions in a similar order to: root, swap, /var, /usr.
The size of /var reflects the intended machine usage. /var is used to hold mailboxes, log files, and printer spools. Mailboxes and log files can grow to unexpected sizes depending on how many users exist and how long log files are kept. Most users would never require a gigabyte, but remember that /var/tmp must be large enough to contain packages.
The /usr partition holds much of the files required to support the system, the ports(7) collection (recommended) and the source code (optional). Both of which are optional at install time. At least 2 gigabytes would be recommended for this partition.
When selecting partition sizes, keep the space requirements in mind. Running out of space in one partition while barely using another can be a hassle.
Note: Some users have found that sysinstall(8)'s Auto-defaults partition sizer will sometimes select smaller than adequate /var and / partitions. Partition wisely and generously.
11.2.1.2 Swap Partition
As a rule of thumb, the swap partition should be about double the size of system memory (RAM). For example, if the machine has 128 megabytes of memory, the swap file should be 256 megabytes. Systems with less memory may perform better with more swap. Less than 256 megabytes of swap is not recommended and memory expansion should be considered. The kernel's VM paging algorithms are tuned to perform best when the swap partition is at least two times the size of main memory. Configuring too little swap can lead to inefficiencies in the VM page scanning code and might create issues later if more memory is added.
On larger systems with multiple SCSI disks (or multiple IDE disks operating on different controllers), it is recommend that a swap is configured on each drive (up to four drives). The swap partitions should be approximately the same size. The kernel can handle arbitrary sizes but internal data structures scale to 4 times the largest swap partition. Keeping the swap partitions near the same size will allow the kernel to optimally stripe swap space across disks. Large swap sizes are fine, even if swap is not used much. It might be easier to recover from a runaway program before being forced to reboot.
11.2.1.3 Why Partition?
Several users think a single large partition will be fine, but there are several reasons why this is a bad idea. First, each partition has different operational characteristics and separating them allows the file system to tune accordingly. For example, the root and /usr partitions are read-mostly, without much writing. While a lot of reading and writing could occur in /var and /var/tmp.
By properly partitioning a system, fragmentation introduced in the smaller write heavy partitions will not bleed over into the mostly-read partitions. Keeping the write-loaded partitions closer to the disk's edge, will increase I/O performance in the partitions where it occurs the most. Now while I/O performance in the larger partitions may be needed, shifting them more toward the edge of the disk will not lead to a significant performance improvement over moving /var to the edge. Finally, there are safety concerns. A smaller, neater root partition which is mostly read-only has a greater chance of surviving a bad crash.
11.3 Core Configuration
The principal location for system configuration information is within /etc/rc.conf. This file contains a wide range of configuration information, principally used at system startup to configure the system. Its name directly implies this; it is configuration information for the rc* files.
An administrator should make entries in the rc.conf file to override the default settings from /etc/defaults/rc.conf. The defaults file should not be copied verbatim to /etc - it contains default values, not examples. All system-specific changes should be made in the rc.conf file itself.
A number of strategies may be applied in clustered applications to separate site-wide configuration from system-specific configuration in order to keep administration overhead down. The recommended approach is to place site-wide configuration into another file, such as /etc/rc.conf.site, and then include this file into /etc/rc.conf, which will contain only system-specific information.
As rc.conf is read by sh(1) it is trivial to achieve this. For example:
-
rc.conf:
. /etc/rc.conf.site hostname="node15.example.com" network_interfaces="fxp0 lo0" ifconfig_fxp0="inet 10.1.1.1" -
rc.conf.site:
defaultrouter="10.1.1.254" saver="daemon" blanktime="100"
The rc.conf.site file can then be distributed to every system using rsync or a similar program, while the rc.conf file remains unique.
Upgrading the system using sysinstall(8) or make world will not overwrite the rc.conf file, so system configuration information will not be lost.
11.4 Application Configuration
Typically, installed applications have their own configuration files, with their own syntax, etc. It is important that these files be kept separate from the base system, so that they may be easily located and managed by the package management tools.
Typically, these files are installed in /usr/local/etc. In the case where an application has a large number of configuration files, a subdirectory will be created to hold them.
Normally, when a port or package is installed, sample configuration files are also installed. These are usually identified with a .default suffix. If there are no existing configuration files for the application, they will be created by copying the .default files.
For example, consider the contents of the directory /usr/local/etc/apache:
-rw-r--r-- 1 root wheel 2184 May 20 1998 access.conf
-rw-r--r-- 1 root wheel 2184 May 20 1998 access.conf.default
-rw-r--r-- 1 root wheel 9555 May 20 1998 httpd.conf
-rw-r--r-- 1 root wheel 9555 May 20 1998 httpd.conf.default
-rw-r--r-- 1 root wheel 12205 May 20 1998 magic
-rw-r--r-- 1 root wheel 12205 May 20 1998 magic.default
-rw-r--r-- 1 root wheel 2700 May 20 1998 mime.types
-rw-r--r-- 1 root wheel 2700 May 20 1998 mime.types.default
-rw-r--r-- 1 root wheel 7980 May 20 1998 srm.conf
-rw-r--r-- 1 root wheel 7933 May 20 1998 srm.conf.default
The file sizes show that only the srm.conf file has been changed. A later update of the Apache port would not overwrite this changed file.
11.5 Starting Services
Contributed by Tom Rhodes.Many users choose to install third party software on FreeBSD from the Ports Collection. In many of these situations it may be necessary to configure the software in a manner which will allow it to be started upon system initialization. Services, such as mail/postfix or www/apache13 are just two of the many software packages which may be started during system initialization. This section explains the procedures available for starting third party software.
In FreeBSD, most included services, such as cron(8), are started through the system start up scripts. These scripts may differ depending on FreeBSD or vendor version; however, the most important aspect to consider is that their start up configuration can be handled through simple startup scripts.
Before the advent of rc.d, applications would drop a simple start up script into the /usr/local/etc/rc.d directory which would be read by the system initialization scripts. These scripts would then be executed during the latter stages of system start up.
While many individuals have spent hours trying to merge the old configuration style into the new system, the fact remains that some third party utilities still require a script simply dropped into the aforementioned directory. The subtle differences in the scripts depend whether or not rc.d is being used. Prior to FreeBSD 5.1 the old configuration style is used and in almost all cases a new style script would do just fine.
While every script must meet some minimal requirements, most of the time these requirements are FreeBSD version agnostic. Each script must have a .sh extension appended to the end and every script must be executable by the system. The latter may be achieved by using the chmod command and setting the unique permissions of 755. There should also be, at minimal, an option to start the application and an option to stop the application.
The simplest start up script would probably look a little bit like this one:
#!/bin/sh
echo -n ' utility'
case "$1" in
start)
/usr/local/bin/utility
;;
stop)
kill -9 `cat /var/run/utility.pid`
;;
*)
echo "Usage: `basename $0` {start|stop}" >&2
exit 64
;;
esac
exit 0
This script provides for a stop and start option for the application hereto referred simply as utility.
Could be started manually with:
# /usr/local/etc/rc.d/utility.sh start
While not all third party software requires the line in rc.conf, almost every day a new port will be modified to accept this configuration. Check the final output of the installation for more information on a specific application. Some third party software will provide start up scripts which permit the application to be used with rc.d; although, this will be discussed in the next section.
11.5.1 Extended Application Configuration
Now that FreeBSD includes rc.d, configuration of application startup has become easier, and more featureful. Using the key words discussed in the rc.d section, applications may now be set to start after certain other services for example DNS; may permit extra flags to be passed through rc.conf in place of hard coded flags in the start up script, etc. A basic script may look similar to the following:
#!/bin/sh
#
# PROVIDE: utility
# REQUIRE: DAEMON
# KEYWORD: shutdown
#
# DO NOT CHANGE THESE DEFAULT VALUES HERE
# SET THEM IN THE /etc/rc.conf FILE
#
utility_enable=${utility_enable-"NO"}
utility_flags=${utility_flags-""}
utility_pidfile=${utility_pidfile-"/var/run/utility.pid"}
. /etc/rc.subr
name="utility"
rcvar=`set_rcvar`
command="/usr/local/sbin/utility"
load_rc_config $name
pidfile="${utility_pidfile}"
start_cmd="echo \"Starting ${name}.\"; /usr/bin/nice -5 ${command} ${utility_flags} ${command_args}"
run_rc_command "$1"
This script will ensure that the provided utility will be started after the daemon service. It also provides a method for setting and tracking the PID, or process ID file.
This application could then have the following line placed in /etc/rc.conf:
utility_enable="YES"
This method also allows for easier manipulation of the command line arguments, inclusion of the default functions provided in /etc/rc.subr, compatibility with the rcorder(8) utility and provides for easier configuration via the rc.conf file.
11.5.2 Using Services to Start Services
Other services, such as POP3 server daemons, IMAP, etc. could be started using the inetd(8). This involves installing the service utility from the Ports Collection with a configuration line appended to the /etc/inetd.conf file, or uncommenting one of the current configuration lines. Working with inetd and its configuration is described in depth in the inetd section.
In some cases, it may be more plausible to use the cron(8) daemon to start system services. This approach has a number of advantages because cron runs these processes as the crontab's file owner. This allows regular users to start and maintain some applications.
The cron utility provides a unique feature, @reboot, which may be used in place of the time specification. This will cause the job to be run when cron(8) is started, normally during system initialization.
11.6 Configuring the cron Utility
Contributed by Tom Rhodes.One of the most useful utilities in FreeBSD is cron(8). The cron utility runs in the background and constantly checks the /etc/crontab file. The cron utility also checks the /var/cron/tabs directory, in search of new crontab files. These crontab files store information about specific functions which cron is supposed to perform at certain times.
The cron utility uses two different types of configuration files, the system crontab and user crontabs. The only difference between these two formats is the sixth field. In the system crontab, the sixth field is the name of a user for the command to run as. This gives the system crontab the ability to run commands as any user. In a user crontab, the sixth field is the command to run, and all commands run as the user who created the crontab; this is an important security feature.
Note: User crontabs allow individual users to schedule tasks without the need for root privileges. Commands in a user's crontab run with the permissions of the user who owns the crontab.
The root user can have a user crontab just like any other user. This one is different from /etc/crontab (the system crontab). Because of the system crontab, there is usually no need to create a user crontab for root.
Let us take a look at the /etc/crontab file (the system crontab):
# /etc/crontab - root's crontab for FreeBSD
#
# $FreeBSD: src/etc/crontab,v 1.32 2002/11/22 16:13:39 tom Exp $
#
#
SHELL=/bin/sh
PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin
HOME=/var/log
#
#
#minute hour mday month wday who command  #
#
*/5 * * * * root /usr/libexec/atrun
#
#
*/5 * * * * root /usr/libexec/atrun 
- Like most FreeBSD configuration files, the # character represents a comment. A comment can be placed in the file as a reminder of what and why a desired action is performed. Comments cannot be on the same line as a command or else they will be interpreted as part of the command; they must be on a new line. Blank lines are ignored.
- First, the environment must be defined. The equals (=) character is used to define any environment settings, as with this example where it is used for the SHELL, PATH, and HOME options. If the shell line is omitted, cron will use the default, which is sh. If the PATH variable is omitted, no default will be used and file locations will need to be absolute. If HOME is omitted, cron will use the invoking users home directory.
- This line defines a total of seven fields. Listed here are the values minute, hour, mday, month, wday, who, and command. These are almost all self explanatory. minute is the time in minutes the command will be run. hour is similar to the minute option, just in hours. mday stands for day of the month. month is similar to hour and minute, as it designates the month. The wday option stands for day of the week. All these fields must be numeric values, and follow the twenty-four hour clock. The who field is special, and only exists in the /etc/crontab file. This field specifies which user the command should be run as. When a user installs his or her crontab file, they will not have this option. Finally, the command option is listed. This is the last field, so naturally it should designate the command to be executed.
- This last line will define the values discussed above. Notice here we have a */5 listing, followed by several more * characters. These * characters mean “first-last”, and can be interpreted as every time. So, judging by this line, it is apparent that the atrun command is to be invoked by root every five minutes regardless of what day or month it is. For more information on the atrun command, see the atrun(8) manual page.
-
Commands can have any number of flags passed to them; however, commands which extend to multiple lines need to be broken with the backslash “\” continuation character.
This is the basic set up for every crontab file, although there is one thing different about this one. Field number six, where we specified the username, only exists in the system /etc/crontab file. This field should be omitted for individual user crontab files.
11.6.1 Installing a Crontab
Important: You must not use the procedure described here to edit/install the system crontab. Simply use your favorite editor: the cron utility will notice that the file has changed and immediately begin using the updated version. See this FAQ entry for more information.
To install a freshly written user crontab, first use your favorite editor to create a file in the proper format, and then use the crontab utility. The most common usage is:
% crontab crontab-file
In this example, crontab-file is the filename of a crontab that was previously created.
There is also an option to list installed crontab files:
just pass the -l option to crontab
and look over the output.
For users who wish to begin their own crontab file from scratch, without the use of a template, the crontab -e option is available. This will invoke the selected editor with an empty file. When the file is saved, it will be automatically installed by the crontab command.
If you later want to remove your user crontab completely,
use crontab with the -r option.
11.7 Using rc under FreeBSD
Contributed by Tom Rhodes.In 2002 FreeBSD integrated the NetBSD rc.d system for system
initialization. Users should notice the files listed in the /etc/rc.d directory. Many of these files are for basic services
which can be controlled with the start, stop, and restart options. For
instance, sshd(8) can be
restarted with the following command:
# /etc/rc.d/sshd restart
This procedure is similar for other services. Of course, services are usually started automatically at boot time as specified in rc.conf(5). For example, enabling the Network Address Translation daemon at startup is as simple as adding the following line to /etc/rc.conf:
natd_enable="YES"
If a natd_enable="NO" line is already present, then simply
change the NO to YES. The rc
scripts will automatically load any other dependent services during the next reboot, as
described below.
Since the rc.d system is primarily intended to start/stop
services at system startup/shutdown time, the standard start,
stop and restart options will
only perform their action if the appropriate /etc/rc.conf
variables are set. For instance the above sshd restart command
will only work if sshd_enable is set to YES in /etc/rc.conf. To start, stop or restart a service regardless of the settings in /etc/rc.conf, the commands should be prefixed with
“one”. For instance to restart sshd regardless of
the current /etc/rc.conf setting, execute the following
command:
# /etc/rc.d/sshd onerestart
It is easy to check if a service is enabled in /etc/rc.conf
by running the appropriate rc.d script with the option rcvar. Thus, an administrator can check that sshd is in fact enabled in /etc/rc.conf by
running:
# /etc/rc.d/sshd rcvar
# sshd
$sshd_enable=YES
Note: The second line (# sshd) is the output from the sshd command, not a root console.
To determine if a service is running, a status option is
available. For instance to verify that sshd is actually
started:
# /etc/rc.d/sshd status
sshd is running as pid 433.
In some cases it is also possible to reload a service.
This will attempt to send a signal to an individual service, forcing the service to
reload its configuration files. In most cases this means sending the service a SIGHUP signal. Support for this feature is not included for every
service.
The rc.d system is not only used for network services, it also contributes to most of the system initialization. For instance, consider the bgfsck file. When this script is executed, it will print out the following message:
Starting background file system checks in 60 seconds.
Therefore this file is used for background file system checks, which are done only during system initialization.
Many system services depend on other services to function properly. For example, NIS and other RPC-based services may fail to start until after the rpcbind (portmapper) service has started. To resolve this issue, information about dependencies and other meta-data is included in the comments at the top of each startup script. The rcorder(8) program is then used to parse these comments during system initialization to determine the order in which system services should be invoked to satisfy the dependencies. The following words may be included at the top of each startup file:
-
PROVIDE: Specifies the services this file provides.
-
REQUIRE: Lists services which are required for this service. This file will run after the specified services.
-
BEFORE: Lists services which depend on this service. This file will run before the specified services.
By using this method, an administrator can easily control system services without the hassle of “runlevels” like some other UNIX operating systems.
Additional information about the rc.d system can be found in the rc(8) and rc.subr(8) manual pages. If you are interested in writing your own rc.d scripts or improving the existing ones, you may find this article also useful.
11.8 Setting Up Network Interface Cards
Contributed by Marc Fonvieille.Nowadays we can not think about a computer without thinking about a network connection. Adding and configuring a network card is a common task for any FreeBSD administrator.
11.8.1 Locating the Correct Driver
Before you begin, you should know the model of the card you have, the chip it uses, and whether it is a PCI or ISA card. FreeBSD supports a wide variety of both PCI and ISA cards. Check the Hardware Compatibility List for your release to see if your card is supported.
Once you are sure your card is supported, you need to determine the proper driver for the card. /usr/src/sys/conf/NOTES and /usr/src/sys/arch/conf/NOTES will give you the list of network interface drivers with some information about the supported chipsets/cards. If you have doubts about which driver is the correct one, read the manual page of the driver. The manual page will give you more information about the supported hardware and even the possible problems that could occur.
If you own a common card, most of the time you will not have to look very hard for a driver. Drivers for common network cards are present in the GENERIC kernel, so your card should show up during boot, like so:
dc0: <82c169 PNIC 10/100BaseTX> port 0xa000-0xa0ff mem 0xd3800000-0xd38
000ff irq 15 at device 11.0 on pci0
dc0: Ethernet address: 00:a0:cc:da:da:da
miibus0: <MII bus> on dc0
ukphy0: <Generic IEEE 802.3u media interface> on miibus0
ukphy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto
dc1: <82c169 PNIC 10/100BaseTX> port 0x9800-0x98ff mem 0xd3000000-0xd30
000ff irq 11 at device 12.0 on pci0
dc1: Ethernet address: 00:a0:cc:da:da:db
miibus1: <MII bus> on dc1
ukphy1: <Generic IEEE 802.3u media interface> on miibus1
ukphy1: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto
In this example, we see that two cards using the dc(4) driver are present on the system.
If the driver for your NIC is not present in GENERIC, you will need to load the proper driver to use your NIC. This may be accomplished in one of two ways:
-
The easiest way is to simply load a kernel module for your network card with kldload(8), or automatically at boot time by adding the appropriate line to the file /boot/loader.conf. Not all NIC drivers are available as modules; notable examples of devices for which modules do not exist are ISA cards.
-
Alternatively, you may statically compile the support for your card into your kernel. Check /usr/src/sys/conf/NOTES, /usr/src/sys/arch/conf/NOTES and the manual page of the driver to know what to add in your kernel configuration file. For more information about recompiling your kernel, please see Chapter 8. If your card was detected at boot by your kernel (GENERIC) you do not have to build a new kernel.
11.8.1.1 Using Windows NDIS Drivers
Unfortunately, there are still many vendors that do not provide schematics for their drivers to the open source community because they regard such information as trade secrets. Consequently, the developers of FreeBSD and other operating systems are left two choices: develop the drivers by a long and pain-staking process of reverse engineering or using the existing driver binaries available for the Microsoft Windows platforms. Most developers, including those involved with FreeBSD, have taken the latter approach.
Thanks to the contributions of Bill Paul (wpaul), as of FreeBSD 5.3-RELEASE there is “native” support for the Network Driver Interface Specification (NDIS). The FreeBSD NDISulator (otherwise known as Project Evil) takes a Windows driver binary and basically tricks it into thinking it is running on Windows. Because the ndis(4) driver is using a Windows binary, it is only usable on i386 and amd64 systems.
Note: The ndis(4) driver is designed to support mainly PCI, CardBus and PCMCIA devices, USB devices are not yet supported.
In order to use the NDISulator, you need three things:
-
Kernel sources
-
Windows XP driver binary (.SYS extension)
-
Windows XP driver configuration file (.INF extension)
Locate the files for your specific card. Generally, they can be found on the included CDs or at the vendors' websites. In the following examples, we will use W32DRIVER.SYS and W32DRIVER.INF.
Note: You can not use a Windows/i386 driver with FreeBSD/amd64, you must get a Windows/amd64 driver to make it work properly.
The next step is to compile the driver binary into a loadable kernel module. To accomplish this, as root, use ndisgen(8):
# ndisgen /path/to/W32DRIVER.INF /path/to/W32DRIVER.SYS
The ndisgen(8) utility is interactive and will prompt for any extra information it requires; it will produce a kernel module in the current directory which can be loaded as follows:
# kldload ./W32DRIVER.ko
In addition to the generated kernel module, you must load the ndis.ko and if_ndis.ko modules. This should be automatically done when you load any module that depends on ndis(4). If you want to load them manually, use the following commands:
# kldload ndis
# kldload if_ndis
The first command loads the NDIS miniport driver wrapper, the second loads the actual network interface.
Now, check dmesg(8) to see if there were any errors loading. If all went well, you should get output resembling the following:
ndis0: <Wireless-G PCI Adapter> mem 0xf4100000-0xf4101fff irq 3 at device 8.0 on pci1
ndis0: NDIS API version: 5.0
ndis0: Ethernet address: 0a:b1:2c:d3:4e:f5
ndis0: 11b rates: 1Mbps 2Mbps 5.5Mbps 11Mbps
ndis0: 11g rates: 6Mbps 9Mbps 12Mbps 18Mbps 36Mbps 48Mbps 54Mbps
From here you can treat the ndis0 device like any other network interface (e.g., dc0).
You can configure the system to load the NDIS modules at boot time in the same way as with any other module. First, copy the generated module, W32DRIVER.ko, to the /boot/modules directory. Then, add the following line to /boot/loader.conf:
W32DRIVER_load="YES"
11.8.2 Configuring the Network Card
Once the right driver is loaded for the network card, the card needs to be configured. As with many other things, the network card may have been configured at installation time by sysinstall.
To display the configuration for the network interfaces on your system, enter the following command:
% ifconfig
dc0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.1.3 netmask 0xffffff00 broadcast 192.168.1.255
ether 00:a0:cc:da:da:da
media: Ethernet autoselect (100baseTX <full-duplex>)
status: active
dc1: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 10.0.0.1 netmask 0xffffff00 broadcast 10.0.0.255
ether 00:a0:cc:da:da:db
media: Ethernet 10baseT/UTP
status: no carrier
lp0: flags=8810<POINTOPOINT,SIMPLEX,MULTICAST> mtu 1500
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet 127.0.0.1 netmask 0xff000000
tun0: flags=8010<POINTOPOINT,MULTICAST> mtu 1500
Note: Old versions of FreeBSD may require the
-aoption following ifconfig(8), for more details about the correct syntax of ifconfig(8), please refer to the manual page. Note also that entries concerning IPv6 (inet6 etc.) were omitted in this example.
In this example, the following devices were displayed:
-
dc0: The first Ethernet interface
-
dc1: The second Ethernet interface
-
lp0: The parallel port interface
-
lo0: The loopback device
-
tun0: The tunnel device used by ppp
FreeBSD uses the driver name followed by the order in which one the card is detected at the kernel boot to name the network card. For example sis2 would be the third network card on the system using the sis(4) driver.
In this example, the dc0 device is up and running. The key indicators are:
-
UP means that the card is configured and ready.
-
The card has an Internet (inet) address (in this case 192.168.1.3).
-
It has a valid subnet mask (netmask; 0xffffff00 is the same as 255.255.255.0).
-
It has a valid broadcast address (in this case, 192.168.1.255).
-
The MAC address of the card (ether) is 00:a0:cc:da:da:da
-
The physical media selection is on autoselection mode (media: Ethernet autoselect (100baseTX <full-duplex>)). We see that dc1 was configured to run with 10baseT/UTP media. For more information on available media types for a driver, please refer to its manual page.
-
The status of the link (status) is active, i.e. the carrier is detected. For dc1, we see status: no carrier. This is normal when an Ethernet cable is not plugged into the card.
If the ifconfig(8) output had shown something similar to:
dc0: flags=8843<BROADCAST,SIMPLEX,MULTICAST> mtu 1500
ether 00:a0:cc:da:da:da
it would indicate the card has not been configured.
To configure your card, you need root privileges. The network card configuration can be done from the command line with ifconfig(8) but you would have to do it after each reboot of the system. The file /etc/rc.conf is where to add the network card's configuration.
Open /etc/rc.conf in your favorite editor. You need to add a line for each network card present on the system, for example in our case, we added these lines:
ifconfig_dc0="inet 192.168.1.3 netmask 255.255.255.0"
ifconfig_dc1="inet 10.0.0.1 netmask 255.255.255.0 media 10baseT/UTP"
You have to replace dc0, dc1, and so on, with the correct device for your cards, and the addresses with the proper ones. You should read the card driver and ifconfig(8) manual pages for more details about the allowed options and also rc.conf(5) manual page for more information on the syntax of /etc/rc.conf.
If you configured the network during installation, some lines about the network card(s) may be already present. Double check /etc/rc.conf before adding any lines.
You will also have to edit the file /etc/hosts to add the names and the IP addresses of various machines of the LAN, if they are not already there. For more information please refer to hosts(5) and to /usr/share/examples/etc/hosts.
11.8.3 Testing and Troubleshooting
Once you have made the necessary changes in /etc/rc.conf, you should reboot your system. This will allow the change(s) to the interface(s) to be applied, and verify that the system restarts without any configuration errors.
Once the system has been rebooted, you should test the network interfaces.
11.8.3.1 Testing the Ethernet Card
To verify that an Ethernet card is configured correctly, you have to try two things. First, ping the interface itself, and then ping another machine on the LAN.
First test the local interface:
% ping -c5 192.168.1.3
PING 192.168.1.3 (192.168.1.3): 56 data bytes
64 bytes from 192.168.1.3: icmp_seq=0 ttl=64 time=0.082 ms
64 bytes from 192.168.1.3: icmp_seq=1 ttl=64 time=0.074 ms
64 bytes from 192.168.1.3: icmp_seq=2 ttl=64 time=0.076 ms
64 bytes from 192.168.1.3: icmp_seq=3 ttl=64 time=0.108 ms
64 bytes from 192.168.1.3: icmp_seq=4 ttl=64 time=0.076 ms
--- 192.168.1.3 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.074/0.083/0.108/0.013 ms
Now we have to ping another machine on the LAN:
% ping -c5 192.168.1.2
PING 192.168.1.2 (192.168.1.2): 56 data bytes
64 bytes from 192.168.1.2: icmp_seq=0 ttl=64 time=0.726 ms
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.766 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.700 ms
64 bytes from 192.168.1.2: icmp_seq=3 ttl=64 time=0.747 ms
64 bytes from 192.168.1.2: icmp_seq=4 ttl=64 time=0.704 ms
--- 192.168.1.2 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.700/0.729/0.766/0.025 ms
You could also use the machine name instead of 192.168.1.2 if you have set up the /etc/hosts file.
11.8.3.2 Troubleshooting
Troubleshooting hardware and software configurations is always a pain, and a pain which can be alleviated by checking the simple things first. Is your network cable plugged in? Have you properly configured the network services? Did you configure the firewall correctly? Is the card you are using supported by FreeBSD? Always check the hardware notes before sending off a bug report. Update your version of FreeBSD to the latest STABLE version. Check the mailing list archives, or perhaps search the Internet.
If the card works, yet performance is poor, it would be worthwhile to read over the tuning(7) manual page. You can also check the network configuration as incorrect network settings can cause slow connections.
Some users experience one or two “device timeout” messages, which is normal for some cards. If they continue, or are bothersome, you may wish to be sure the device is not conflicting with another device. Double check the cable connections. Perhaps you may just need to get another card.
At times, users see a few “watchdog timeout” errors. The first thing to do here is to check your network cable. Many cards require a PCI slot which supports Bus Mastering. On some old motherboards, only one PCI slot allows it (usually slot 0). Check the network card and the motherboard documentation to determine if that may be the problem.
“No route to host” messages occur if the system is unable to route a packet to the destination host. This can happen if no default route is specified, or if a cable is unplugged. Check the output of netstat -rn and make sure there is a valid route to the host you are trying to reach. If there is not, read on to Chapter 29.
“ping: sendto: Permission denied” error messages are often caused by a misconfigured firewall. If ipfw is enabled in the kernel but no rules have been defined, then the default policy is to deny all traffic, even ping requests! Read on to Chapter 28 for more information.
Sometimes performance of the card is poor, or below average. In these cases it is best to set the media selection mode from autoselect to the correct media selection. While this usually works for most hardware, it may not resolve this issue for everyone. Again, check all the network settings, and read over the tuning(7) manual page.
11.9 Virtual Hosts
A very common use of FreeBSD is virtual site hosting, where one server appears to the network as many servers. This is achieved by assigning multiple network addresses to a single interface.
A given network interface has one “real” address, and may have any number of “alias” addresses. These aliases are normally added by placing alias entries in /etc/rc.conf.
An alias entry for the interface fxp0 looks like:
ifconfig_fxp0_alias0="inet xxx.xxx.xxx.xxx netmask xxx.xxx.xxx.xxx"
Note that alias entries must start with alias0 and proceed upwards in order, (for example, _alias1, _alias2, and so on). The configuration process will stop at the first missing number.
The calculation of alias netmasks is important, but fortunately quite simple. For a given interface, there must be one address which correctly represents the network's netmask. Any other addresses which fall within this network must have a netmask of all 1s (expressed as either 255.255.255.255 or 0xffffffff).
For example, consider the case where the fxp0 interface is connected to two networks, the 10.1.1.0 network with a netmask of 255.255.255.0 and the 202.0.75.16 network with a netmask of 255.255.255.240. We want the system to appear at 10.1.1.1 through 10.1.1.5 and at 202.0.75.17 through 202.0.75.20. As noted above, only the first address in a given network range (in this case, 10.0.1.1 and 202.0.75.17) should have a real netmask; all the rest (10.1.1.2 through 10.1.1.5 and 202.0.75.18 through 202.0.75.20) must be configured with a netmask of 255.255.255.255.
The following /etc/rc.conf entries configure the adapter correctly for this arrangement:
ifconfig_fxp0="inet 10.1.1.1 netmask 255.255.255.0"
ifconfig_fxp0_alias0="inet 10.1.1.2 netmask 255.255.255.255"
ifconfig_fxp0_alias1="inet 10.1.1.3 netmask 255.255.255.255"
ifconfig_fxp0_alias2="inet 10.1.1.4 netmask 255.255.255.255"
ifconfig_fxp0_alias3="inet 10.1.1.5 netmask 255.255.255.255"
ifconfig_fxp0_alias4="inet 202.0.75.17 netmask 255.255.255.240"
ifconfig_fxp0_alias5="inet 202.0.75.18 netmask 255.255.255.255"
ifconfig_fxp0_alias6="inet 202.0.75.19 netmask 255.255.255.255"
ifconfig_fxp0_alias7="inet 202.0.75.20 netmask 255.255.255.255"
11.10 Configuration Files
11.10.1 /etc Layout
There are a number of directories in which configuration information is kept. These include:
| /etc | Generic system configuration information; data here is system-specific. |
| /etc/defaults | Default versions of system configuration files. |
| /etc/mail | Extra sendmail(8) configuration, other MTA configuration files. |
| /etc/ppp | Configuration for both user- and kernel-ppp programs. |
| /etc/namedb | Default location for named(8) data. Normally named.conf and zone files are stored here. |
| /usr/local/etc | Configuration files for installed applications. May contain per-application subdirectories. |
| /usr/local/etc/rc.d | Start/stop scripts for installed applications. |
| /var/db | Automatically generated system-specific database files, such as the package database, the locate database, and so on |
11.10.2 Hostnames
11.10.2.1 /etc/resolv.conf
/etc/resolv.conf dictates how FreeBSD's resolver accesses the Internet Domain Name System (DNS).
The most common entries to resolv.conf are:
| nameserver | The IP address of a name server the resolver should query. The servers are queried in the order listed with a maximum of three. |
| search | Search list for hostname lookup. This is normally determined by the domain of the local hostname. |
| domain | The local domain name. |
A typical resolv.conf:
search example.com
nameserver 147.11.1.11
nameserver 147.11.100.30
Note: Only one of the search and domain options should be used.
If you are using DHCP, dhclient(8) usually rewrites resolv.conf with information received from the DHCP server.
11.10.2.2 /etc/hosts
/etc/hosts is a simple text database reminiscent of the old Internet. It works in conjunction with DNS and NIS providing name to IP address mappings. Local computers connected via a LAN can be placed in here for simplistic naming purposes instead of setting up a named(8) server. Additionally, /etc/hosts can be used to provide a local record of Internet names, reducing the need to query externally for commonly accessed names.
# $FreeBSD$
#
# Host Database
# This file should contain the addresses and aliases
# for local hosts that share this file.
# In the presence of the domain name service or NIS, this file may
# not be consulted at all; see /etc/nsswitch.conf for the resolution order.
#
#
::1 localhost localhost.my.domain myname.my.domain
127.0.0.1 localhost localhost.my.domain myname.my.domain
#
# Imaginary network.
#10.0.0.2 myname.my.domain myname
#10.0.0.3 myfriend.my.domain myfriend
#
# According to RFC 1918, you can use the following IP networks for
# private nets which will never be connected to the Internet:
#
# 10.0.0.0 - 10.255.255.255
# 172.16.0.0 - 172.31.255.255
# 192.168.0.0 - 192.168.255.255
#
# In case you want to be able to connect to the Internet, you need
# real official assigned numbers. PLEASE PLEASE PLEASE do not try
# to invent your own network numbers but instead get one from your
# network provider (if any) or from the Internet Registry (ftp to
# rs.internic.net, directory `/templates').
#
/etc/hosts takes on the simple format of:
[Internet address] [official hostname] [alias1] [alias2] ...
For example:
10.0.0.1 myRealHostname.example.com myRealHostname foobar1 foobar2
Consult hosts(5) for more information.
11.10.3 Log File Configuration
11.10.3.1 syslog.conf
syslog.conf is the configuration file for the syslogd(8) program. It indicates which types of syslog messages are logged to particular log files.
# $FreeBSD$
#
# Spaces ARE valid field separators in this file. However,
# other *nix-like systems still insist on using tabs as field
# separators. If you are sharing this file between systems, you
# may want to use only tabs as field separators here.
# Consult the syslog.conf(5) manual page.
*.err;kern.debug;auth.notice;mail.crit /dev/console
*.notice;kern.debug;lpr.info;mail.crit;news.err /var/log/messages
security.* /var/log/security
mail.info /var/log/maillog
lpr.info /var/log/lpd-errs
cron.* /var/log/cron
*.err root
*.notice;news.err root
*.alert root
*.emerg *
# uncomment this to log all writes to /dev/console to /var/log/console.log
#console.info /var/log/console.log
# uncomment this to enable logging of all log messages to /var/log/all.log
#*.* /var/log/all.log
# uncomment this to enable logging to a remote log host named loghost
#*.* @loghost
# uncomment these if you're running inn
# news.crit /var/log/news/news.crit
# news.err /var/log/news/news.err
# news.notice /var/log/news/news.notice
!startslip
*.* /var/log/slip.log
!ppp
*.* /var/log/ppp.log
Consult the syslog.conf(5) manual page for more information.
11.10.3.2 newsyslog.conf
newsyslog.conf is the configuration file for newsyslog(8), a program that is normally scheduled to run by cron(8). newsyslog(8) determines when log files require archiving or rearranging. logfile is moved to logfile.0, logfile.0 is moved to logfile.1, and so on. Alternatively, the log files may be archived in gzip(1) format causing them to be named: logfile.0.gz, logfile.1.gz, and so on.
newsyslog.conf indicates which log files are to be managed, how many are to be kept, and when they are to be touched. Log files can be rearranged and/or archived when they have either reached a certain size, or at a certain periodic time/date.
# configuration file for newsyslog
# $FreeBSD$
#
# filename [owner:group] mode count size when [ZB] [/pid_file] [sig_num]
/var/log/cron 600 3 100 * Z
/var/log/amd.log 644 7 100 * Z
/var/log/kerberos.log 644 7 100 * Z
/var/log/lpd-errs 644 7 100 * Z
/var/log/maillog 644 7 * @T00 Z
/var/log/sendmail.st 644 10 * 168 B
/var/log/messages 644 5 100 * Z
/var/log/all.log 600 7 * @T00 Z
/var/log/slip.log 600 3 100 * Z
/var/log/ppp.log 600 3 100 * Z
/var/log/security 600 10 100 * Z
/var/log/wtmp 644 3 * @01T05 B
/var/log/daily.log 640 7 * @T00 Z
/var/log/weekly.log 640 5 1 $W6D0 Z
/var/log/monthly.log 640 12 * $M1D0 Z
/var/log/console.log 640 5 100 * Z
Consult the newsyslog(8) manual page for more information.
11.10.4 sysctl.conf
sysctl.conf looks much like rc.conf. Values are set in a variable=value form. The specified values are set after the system goes into multi-user mode. Not all variables are settable in this mode.
To turn off logging of fatal signal exits and prevent users from seeing processes started from other users, the following tunables can be set in sysctl.conf:
# Do not log fatal signal exits (e.g. sig 11)
kern.logsigexit=0
# Prevent users from seeing information about processes that
# are being run under another UID.
security.bsd.see_other_uids=0
11.11 Tuning with sysctl
sysctl(8) is an interface that allows you to make changes to a running FreeBSD system. This includes many advanced options of the TCP/IP stack and virtual memory system that can dramatically improve performance for an experienced system administrator. Over five hundred system variables can be read and set using sysctl(8).
At its core, sysctl(8) serves two functions: to read and to modify system settings.
To view all readable variables:
% sysctl -a
To read a particular variable, for example, kern.maxproc:
% sysctl kern.maxproc
kern.maxproc: 1044
To set a particular variable, use the intuitive variable=value syntax:
# sysctl kern.maxfiles=5000
kern.maxfiles: 2088 -> 5000
Settings of sysctl variables are usually either strings, numbers, or booleans (a boolean being 1 for yes or a 0 for no).
If you want to set automatically some variables each time the machine boots, add them to the /etc/sysctl.conf file. For more information see the sysctl.conf(5) manual page and the Section 11.10.4.
11.11.1 sysctl(8) Read-only
Contributed by Tom Rhodes.In some cases it may be desirable to modify read-only sysctl(8) values. While this is sometimes unavoidable, it can only be done on (re)boot.
For instance on some laptop models the cardbus(4) device will not probe memory ranges, and fail with errors which look similar to:
cbb0: Could not map register memory
device_probe_and_attach: cbb0 attach returned 12
Cases like the one above usually require the modification of some default sysctl(8) settings which are set read only. To overcome these situations a user can put sysctl(8) “OIDs” in their local /boot/loader.conf. Default settings are located in the /boot/defaults/loader.conf file.
Fixing the problem mentioned above would require a user to set hw.pci.allow_unsupported_io_range=1 in the aforementioned file. Now
cardbus(4) will work
properly.
11.12 Tuning Disks
11.12.1 Sysctl Variables
11.12.1.1 vfs.vmiodirenable
The vfs.vmiodirenable sysctl variable may be set to
either 0 (off) or 1 (on); it is 1 by default. This variable controls how directories are
cached by the system. Most directories are small, using just a single fragment (typically
1 K) in the file system and less (typically 512 bytes) in the buffer cache.
With this variable turned off (to 0), the buffer cache will only cache a fixed number of
directories even if you have a huge amount of memory. When turned on (to 1), this sysctl
allows the buffer cache to use the VM Page Cache to cache the directories, making all the
memory available for caching directories. However, the minimum in-core memory used to
cache a directory is the physical page size (typically 4 K) rather than 512
bytes. We recommend keeping this option on if you are running any services which
manipulate large numbers of files. Such services can include web caches, large mail
systems, and news systems. Keeping this option on will generally not reduce performance
even with the wasted memory but you should experiment to find out.
11.12.1.2 vfs.write_behind
The vfs.write_behind sysctl variable defaults to 1 (on). This tells the file system to issue media writes as full
clusters are collected, which typically occurs when writing large sequential files. The
idea is to avoid saturating the buffer cache with dirty buffers when it would not benefit
I/O performance. However, this may stall processes and under certain circumstances you
may wish to turn it off.
11.12.1.3 vfs.hirunningspace
The vfs.hirunningspace sysctl variable determines how
much outstanding write I/O may be queued to disk controllers system-wide at any given
instance. The default is usually sufficient but on machines with lots of disks you may
want to bump it up to four or five megabytes. Note that setting too high a value (exceeding the
buffer cache's write threshold) can lead to extremely bad clustering performance. Do not
set this value arbitrarily high! Higher write values may add latency to reads occurring
at the same time.
There are various other buffer-cache and VM page cache related sysctls. We do not recommend modifying these values, the VM system does an extremely good job of automatically tuning itself.
11.12.1.4 vm.swap_idle_enabled
The vm.swap_idle_enabled sysctl variable is useful in
large multi-user systems where you have lots of users entering and leaving the system and
lots of idle processes. Such systems tend to generate a great deal of continuous pressure
on free memory reserves. Turning this feature on and tweaking the swapout hysteresis (in
idle seconds) via vm.swap_idle_threshold1 and vm.swap_idle_threshold2 allows you to depress the priority of
memory pages associated with idle processes more quickly then the normal pageout
algorithm. This gives a helping hand to the pageout daemon. Do not turn this option on
unless you need it, because the tradeoff you are making is essentially pre-page memory
sooner rather than later; thus eating more swap and disk bandwidth. In a small system
this option will have a determinable effect but in a large system that is already doing
moderate paging this option allows the VM system to stage whole processes into and out of
memory easily.
11.12.1.5 hw.ata.wc
FreeBSD 4.3 flirted with turning off IDE write caching. This reduced write
bandwidth to IDE disks but was considered necessary due to serious data consistency
issues introduced by hard drive vendors. The problem is that IDE drives lie about when a
write completes. With IDE write caching turned on, IDE hard drives not only write data to
disk out of order, but will sometimes delay writing some blocks indefinitely when under
heavy disk loads. A crash or power failure may cause serious file system corruption.
FreeBSD's default was changed to be safe. Unfortunately, the result was such a huge
performance loss that we changed write caching back to on by default after the release.
You should check the default on your system by observing the hw.ata.wc sysctl variable. If IDE write caching is turned off, you
can turn it back on by setting the kernel variable back to 1. This must be done from the
boot loader at boot time. Attempting to do it after the kernel boots will have no
effect.
For more information, please see ata(4).
11.12.1.6 SCSI_DELAY (kern.cam.scsi_delay)
The SCSI_DELAY kernel config may be used to reduce system
boot times. The defaults are fairly high and can be responsible for 15 seconds of delay in the boot process. Reducing it to 5 seconds usually works (especially with modern drives). Newer
versions of FreeBSD (5.0 and higher) should use the kern.cam.scsi_delay boot time tunable. The tunable, and kernel
config option accept values in terms of milliseconds and not seconds.
11.12.2 Soft Updates
The tunefs(8) program can be used to fine-tune a file system. This program has many different options, but for now we are only concerned with toggling Soft Updates on and off, which is done by:
# tunefs -n enable /filesystem
# tunefs -n disable /filesystem
A filesystem cannot be modified with tunefs(8) while it is mounted. A good time to enable Soft Updates is before any partitions have been mounted, in single-user mode.
Soft Updates drastically improves meta-data performance, mainly file creation and deletion, through the use of a memory cache. We recommend to use Soft Updates on all of your file systems. There are two downsides to Soft Updates that you should be aware of: First, Soft Updates guarantees filesystem consistency in the case of a crash but could very easily be several seconds (even a minute!) behind updating the physical disk. If your system crashes you may lose more work than otherwise. Secondly, Soft Updates delays the freeing of filesystem blocks. If you have a filesystem (such as the root filesystem) which is almost full, performing a major update, such as make installworld, can cause the filesystem to run out of space and the update to fail.
11.12.2.1 More Details about Soft Updates
There are two traditional approaches to writing a file systems meta-data back to disk. (Meta-data updates are updates to non-content data like inodes or directories.)
Historically, the default behavior was to write out meta-data updates synchronously. If a directory had been changed, the system waited until the change was actually written to disk. The file data buffers (file contents) were passed through the buffer cache and backed up to disk later on asynchronously. The advantage of this implementation is that it operates safely. If there is a failure during an update, the meta-data are always in a consistent state. A file is either created completely or not at all. If the data blocks of a file did not find their way out of the buffer cache onto the disk by the time of the crash, fsck(8) is able to recognize this and repair the filesystem by setting the file length to 0. Additionally, the implementation is clear and simple. The disadvantage is that meta-data changes are slow. An rm -r, for instance, touches all the files in a directory sequentially, but each directory change (deletion of a file) will be written synchronously to the disk. This includes updates to the directory itself, to the inode table, and possibly to indirect blocks allocated by the file. Similar considerations apply for unrolling large hierarchies (tar -x).
The second case is asynchronous meta-data updates. This is the default for Linux/ext2fs and mount -o async for *BSD ufs. All meta-data updates are simply being passed through the buffer cache too, that is, they will be intermixed with the updates of the file content data. The advantage of this implementation is there is no need to wait until each meta-data update has been written to disk, so all operations which cause huge amounts of meta-data updates work much faster than in the synchronous case. Also, the implementation is still clear and simple, so there is a low risk for bugs creeping into the code. The disadvantage is that there is no guarantee at all for a consistent state of the filesystem. If there is a failure during an operation that updated large amounts of meta-data (like a power failure, or someone pressing the reset button), the filesystem will be left in an unpredictable state. There is no opportunity to examine the state of the filesystem when the system comes up again; the data blocks of a file could already have been written to the disk while the updates of the inode table or the associated directory were not. It is actually impossible to implement a fsck which is able to clean up the resulting chaos (because the necessary information is not available on the disk). If the filesystem has been damaged beyond repair, the only choice is to use newfs(8) on it and restore it from backup.
The usual solution for this problem was to implement dirty region logging, which is also referred to as journaling, although that term is not used consistently and is occasionally applied to other forms of transaction logging as well. Meta-data updates are still written synchronously, but only into a small region of the disk. Later on they will be moved to their proper location. Because the logging area is a small, contiguous region on the disk, there are no long distances for the disk heads to move, even during heavy operations, so these operations are quicker than synchronous updates. Additionally the complexity of the implementation is fairly limited, so the risk of bugs being present is low. A disadvantage is that all meta-data are written twice (once into the logging region and once to the proper location) so for normal work, a performance “pessimization” might result. On the other hand, in case of a crash, all pending meta-data operations can be quickly either rolled-back or completed from the logging area after the system comes up again, resulting in a fast filesystem startup.
Kirk McKusick, the developer of Berkeley FFS, solved this problem with Soft Updates: all pending meta-data updates are kept in memory and written out to disk in a sorted sequence (“ordered meta-data updates”). This has the effect that, in case of heavy meta-data operations, later updates to an item “catch” the earlier ones if the earlier ones are still in memory and have not already been written to disk. So all operations on, say, a directory are generally performed in memory before the update is written to disk (the data blocks are sorted according to their position so that they will not be on the disk ahead of their meta-data). If the system crashes, this causes an implicit “log rewind”: all operations which did not find their way to the disk appear as if they had never happened. A consistent filesystem state is maintained that appears to be the one of 30 to 60 seconds earlier. The algorithm used guarantees that all resources in use are marked as such in their appropriate bitmaps: blocks and inodes. After a crash, the only resource allocation error that occurs is that resources are marked as “used” which are actually “free”. fsck(8) recognizes this situation, and frees the resources that are no longer used. It is safe to ignore the dirty state of the filesystem after a crash by forcibly mounting it with mount -f. In order to free resources that may be unused, fsck(8) needs to be run at a later time. This is the idea behind the background fsck: at system startup time, only a snapshot of the filesystem is recorded. The fsck can be run later on. All file systems can then be mounted “dirty”, so the system startup proceeds in multiuser mode. Then, background fscks will be scheduled for all file systems where this is required, to free resources that may be unused. (File systems that do not use Soft Updates still need the usual foreground fsck though.)
The advantage is that meta-data operations are nearly as fast as asynchronous updates (i.e. faster than with logging, which has to write the meta-data twice). The disadvantages are the complexity of the code (implying a higher risk for bugs in an area that is highly sensitive regarding loss of user data), and a higher memory consumption. Additionally there are some idiosyncrasies one has to get used to. After a crash, the state of the filesystem appears to be somewhat “older”. In situations where the standard synchronous approach would have caused some zero-length files to remain after the fsck, these files do not exist at all with a Soft Updates filesystem because neither the meta-data nor the file contents have ever been written to disk. Disk space is not released until the updates have been written to disk, which may take place some time after running rm. This may cause problems when installing large amounts of data on a filesystem that does not have enough free space to hold all the files twice.
11.13 Tuning Kernel Limits
11.13.1 File/Process Limits
11.13.1.1 kern.maxfiles
kern.maxfiles can be raised or lowered based upon your
system requirements. This variable indicates the maximum number of file descriptors on
your system. When the file descriptor table is full, “file:
table is full” will show up repeatedly in the system message buffer, which can
be viewed with the dmesg command.
Each open file, socket, or fifo uses one file descriptor. A large-scale production server may easily require many thousands of file descriptors, depending on the kind and number of services running concurrently.
In older FreeBSD releases, the default value of kern.maxfiles is derived from the maxusers option in your kernel configuration file. kern.maxfiles grows proportionally to the value of maxusers. When compiling a custom kernel, it is a good idea to set
this kernel configuration option according to the uses of your system. From this number,
the kernel is given most of its pre-defined limits. Even though a production machine may
not actually have 256 users connected at once, the resources needed may be similar to a
high-scale web server.
As of FreeBSD 4.5, kern.maxusers is automatically sized
at boot based on the amount of memory available in the system, and may be determined at
run-time by inspecting the value of the read-only kern.maxusers sysctl. Some sites will require larger or smaller
values of kern.maxusers and may set it as a loader tunable;
values of 64, 128, and 256 are not uncommon. We do not recommend going above 256 unless
you need a huge number of file descriptors; many of the tunable values set to their
defaults by kern.maxusers may be individually overridden at
boot-time or run-time in /boot/loader.conf (see the loader.conf(5) man
page or the /boot/defaults/loader.conf file for some hints) or
as described elsewhere in this document. Systems older than FreeBSD 4.4 must set
this value via the kernel config(8) option maxusers instead.
In older releases, the system will auto-tune maxusers for you if you explicitly set it to 0[5]. When setting this option, you will want to set maxusers to at least 4, especially if you are using the X Window System or compiling software. The reason is that the most important table set by maxusers is the maximum number of processes, which is set to 20 + 16 * maxusers, so if you set maxusers to 1, then you can only have 36 simultaneous processes, including the 18 or so that the system starts up at boot time and the 15 or so you will probably create when you start the X Window System. Even a simple task like reading a manual page will start up nine processes to filter, decompress, and view it. Setting maxusers to 64 will allow you to have up to 1044 simultaneous processes, which should be enough for nearly all uses. If, however, you see the dreaded proc table full error when trying to start another program, or are running a server with a large number of simultaneous users (like ftp.FreeBSD.org), you can always increase the number and rebuild.
Note: maxusers does not limit the number of users which can log into your machine. It simply sets various table sizes to reasonable values considering the maximum number of users you will likely have on your system and how many processes each of them will be running. One keyword which does limit the number of simultaneous remote logins and X terminal windows is pseudo-device pty 16. With FreeBSD 5.X, you do not have to worry about this number since the pty(4) driver is “auto-cloning”; you simply use the line device pty in your configuration file.
11.13.1.2 kern.ipc.somaxconn
The kern.ipc.somaxconn sysctl variable limits the size of
the listen queue for accepting new TCP connections. The default value of 128 is typically too low for robust handling of new connections in a
heavily loaded web server environment. For such environments, it is recommended to
increase this value to 1024 or higher. The service daemon may
itself limit the listen queue size (e.g. sendmail(8), or Apache) but will often have a directive in its configuration file
to adjust the queue size. Large listen queues also do a better job of avoiding Denial of
Service (DoS) attacks.
11.13.2 Network Limits
The NMBCLUSTERS kernel configuration option dictates the
amount of network Mbufs available to the system. A heavily-trafficked server with a low
number of Mbufs will hinder FreeBSD's ability. Each cluster represents approximately
2 K of memory, so a value of 1024 represents 2 megabytes of kernel memory reserved
for network buffers. A simple calculation can be done to figure out how many are needed.
If you have a web server which maxes out at 1000 simultaneous connections, and each
connection eats a 16 K receive and 16 K send buffer, you need approximately
32 MB worth of network buffers to cover the web server. A good rule of thumb is to
multiply by 2, so 2x32 MB / 2 KB =
64 MB / 2 kB = 32768. We recommend values between 4096 and 32768
for machines with greater amounts of memory. Under no circumstances should you specify an
arbitrarily high value for this parameter as it could lead to a boot time crash. The
-m option to netstat(1) may be used
to observe network cluster use.
kern.ipc.nmbclusters loader tunable should be used to
tune this at boot time. Only older versions of FreeBSD will require you to use the NMBCLUSTERS kernel config(8) option.
For busy servers that make extensive use of the sendfile(2) system
call, it may be necessary to increase the number of sendfile(2) buffers
via the NSFBUFS kernel configuration option or by setting its
value in /boot/loader.conf (see loader(8) for
details). A common indicator that this parameter needs to be adjusted is when processes
are seen in the sfbufa state. The sysctl variable kern.ipc.nsfbufs is a read-only glimpse at the kernel configured
variable. This parameter nominally scales with kern.maxusers, however it may be necessary to tune
accordingly.
Important: Even though a socket has been marked as non-blocking, calling sendfile(2) on the non-blocking socket may result in the sendfile(2) call blocking until enough struct sf_buf's are made available.
11.13.2.1 net.inet.ip.portrange.*
The net.inet.ip.portrange.* sysctl variables control the
port number ranges automatically bound to TCP and UDP sockets. There are three ranges: a
low range, a default range, and a high range. Most network programs use the default range
which is controlled by the net.inet.ip.portrange.first and
net.inet.ip.portrange.last, which default to 1024 and 5000,
respectively. Bound port ranges are used for outgoing connections, and it is possible to
run the system out of ports under certain circumstances. This most commonly occurs when
you are running a heavily loaded web proxy. The port range is not an issue when running
servers which handle mainly incoming connections, such as a normal web server, or has a
limited number of outgoing connections, such as a mail relay. For situations where you
may run yourself out of ports, it is recommended to increase net.inet.ip.portrange.last modestly. A value of 10000, 20000 or 30000 may be reasonable. You should also consider firewall effects
when changing the port range. Some firewalls may block large ranges of ports (usually
low-numbered ports) and expect systems to use higher ranges of ports for outgoing
connections -- for this reason it is not recommended that net.inet.ip.portrange.first be lowered.
11.13.2.2 TCP Bandwidth Delay Product
The TCP Bandwidth Delay Product Limiting is similar to TCP/Vegas in NetBSD. It can be
enabled by setting net.inet.tcp.inflight.enable sysctl
variable to 1. The system will attempt to calculate the
bandwidth delay product for each connection and limit the amount of data queued to the
network to just the amount required to maintain optimum throughput.
This feature is useful if you are serving data over modems, Gigabit Ethernet, or even
high speed WAN links (or any other link with a high bandwidth delay product), especially
if you are also using window scaling or have configured a large send window. If you
enable this option, you should also be sure to set net.inet.tcp.inflight.debug to 0 (disable
debugging), and for production use setting net.inet.tcp.inflight.min to at least 6144 may be beneficial. However, note that setting high minimums may
effectively disable bandwidth limiting depending on the link. The limiting feature
reduces the amount of data built up in intermediate route and switch packet queues as
well as reduces the amount of data built up in the local host's interface queue. With
fewer packets queued up, interactive connections, especially over slow modems, will also
be able to operate with lower Round Trip
Times. However, note that this feature only effects data transmission
(uploading / server side). It has no effect on data reception (downloading).
Adjusting net.inet.tcp.inflight.stab is not recommended. This parameter defaults
to 20, representing 2 maximal packets added to the bandwidth delay product window
calculation. The additional window is required to stabilize the algorithm and improve
responsiveness to changing conditions, but it can also result in higher ping times over
slow links (though still much lower than you would get without the inflight algorithm).
In such cases, you may wish to try reducing this parameter to 15, 10, or 5; and may also
have to reduce net.inet.tcp.inflight.min (for example, to
3500) to get the desired effect. Reducing these parameters should be done as a last
resort only.
11.13.3 Virtual Memory
11.13.3.1 kern.maxvnodes
A vnode is the internal representation of a file or directory. So increasing the number of vnodes available to the operating system cuts down on disk I/O. Normally this is handled by the operating system and does not need to be changed. In some cases where disk I/O is a bottleneck and the system is running out of vnodes, this setting will need to be increased. The amount of inactive and free RAM will need to be taken into account.
To see the current number of vnodes in use:
# sysctl vfs.numvnodes
vfs.numvnodes: 91349
To see the maximum vnodes:
# sysctl kern.maxvnodes
kern.maxvnodes: 100000
If the current vnode usage is near the maximum, increasing kern.maxvnodes by a value of 1,000 is probably a good idea. Keep
an eye on the number of vfs.numvnodes. If it climbs up to
the maximum again, kern.maxvnodes will need to be increased
further. A shift in your memory usage as reported by top(1) should be
visible. More memory should be active.
11.14 Adding Swap Space
No matter how well you plan, sometimes a system does not run as you expect. If you find you need more swap space, it is simple enough to add. You have three ways to increase swap space: adding a new hard drive, enabling swap over NFS, and creating a swap file on an existing partition.
For information on how to encrypt swap space, what options for this task exist and why it should be done, please refer to Section 18.17 of the Handbook.
11.14.1 Swap on a New Hard Drive
The best way to add swap, of course, is to use this as an excuse to add another hard drive. You can always use another hard drive, after all. If you can do this, go reread the discussion of swap space in Section 11.2 of the Handbook for some suggestions on how to best arrange your swap.
11.14.2 Swapping over NFS
Swapping over NFS is only recommended if you do not have a local hard disk to swap to; NFS swapping will be limited by the available network bandwidth and puts an additional burden on the NFS server.
11.14.3 Swapfiles
You can create a file of a specified size to use as a swap file. In our example here we will use a 64MB file called /usr/swap0. You can use any name you want, of course.
Example 11-1. Creating a Swapfile on FreeBSD
-
Be certain that your kernel configuration includes the memory disk driver (md(4)). It is default in GENERIC kernel.
device md # Memory "disks" -
Create a swapfile (/usr/swap0):
# dd if=/dev/zero of=/usr/swap0 bs=1024k count=64 -
Set proper permissions on (/usr/swap0):
# chmod 0600 /usr/swap0 -
Enable the swap file in /etc/rc.conf:
swapfile="/usr/swap0" # Set to name of swapfile if aux swapfile desired. -
Reboot the machine or to enable the swap file immediately, type:
# mdconfig -a -t vnode -f /usr/swap0 -u 0 && swapon /dev/md0
11.15 Power and Resource Management
Written by Hiten Pandya and Tom Rhodes.It is important to utilize hardware resources in an efficient manner. Before ACPI was introduced, it was difficult and inflexible for operating systems to manage the power usage and thermal properties of a system. The hardware was managed by the BIOS and thus the user had less control and visibility into the power management settings. Some limited configurability was available via Advanced Power Management (APM). Power and resource management is one of the key components of a modern operating system. For example, you may want an operating system to monitor system limits (and possibly alert you) in case your system temperature increased unexpectedly.
In this section of the FreeBSD Handbook, we will provide comprehensive information about ACPI. References will be provided for further reading at the end.
11.15.1 What Is ACPI?
Advanced Configuration and Power Interface (ACPI) is a standard written by an alliance of vendors to provide a standard interface for hardware resources and power management (hence the name). It is a key element in Operating System-directed configuration and Power Management, i.e.: it provides more control and flexibility to the operating system (OS). Modern systems “stretched” the limits of the current Plug and Play interfaces prior to the introduction of ACPI. ACPI is the direct successor to APM (Advanced Power Management).
11.15.2 Shortcomings of Advanced Power Management (APM)
The Advanced Power Management (APM) facility controls the power usage of a system based on its activity. The APM BIOS is supplied by the (system) vendor and it is specific to the hardware platform. An APM driver in the OS mediates access to the APM Software Interface, which allows management of power levels. APM should still be used for systems manufactured at or before the year 2000.
There are four major problems in APM. Firstly, power management is done by the (vendor-specific) BIOS, and the OS does not have any knowledge of it. One example of this, is when the user sets idle-time values for a hard drive in the APM BIOS, that when exceeded, it (BIOS) would spin down the hard drive, without the consent of the OS. Secondly, the APM logic is embedded in the BIOS, and it operates outside the scope of the OS. This means users can only fix problems in their APM BIOS by flashing a new one into the ROM; which is a very dangerous procedure with the potential to leave the system in an unrecoverable state if it fails. Thirdly, APM is a vendor-specific technology, which means that there is a lot of parity (duplication of efforts) and bugs found in one vendor's BIOS, may not be solved in others. Last but not the least, the APM BIOS did not have enough room to implement a sophisticated power policy, or one that can adapt very well to the purpose of the machine.
Plug and Play BIOS (PNPBIOS) was unreliable in many situations. PNPBIOS is 16-bit technology, so the OS has to use 16-bit emulation in order to “interface” with PNPBIOS methods.
The FreeBSD APM driver is documented in the apm(4) manual page.
11.15.3 Configuring ACPI
The acpi.ko driver is loaded by default at start up by the loader(8) and should not be compiled into the kernel. The reasoning behind this is that modules are easier to work with, say if switching to another acpi.ko without doing a kernel rebuild. This has the advantage of making testing easier. Another reason is that starting ACPI after a system has been brought up often doesn't work well. If you are experiencing problems, you can disable ACPI altogether. This driver should not and can not be unloaded because the system bus uses it for various hardware interactions. ACPI can be disabled by setting hint.acpi.0.disabled="1" in /boot/loader.conf or at the loader(8) prompt.
Note: ACPI and APM cannot coexist and should be used separately. The last one to load will terminate if the driver notices the other running.
ACPI can be used to put the system into a sleep
mode with
acpiconf(8), the
-s flag, and a 1-5 option. Most
users will only need 1 or 3 (suspend to
RAM). Option 5 will do a soft-off which is the same action
as:
# halt -p
Other options are available via sysctl(8). Check out the acpi(4) and acpiconf(8) manual pages for more information.
11.16 Using and Debugging FreeBSD ACPI
Written by Nate Lawson. With contributions from Peter Schultz and Tom Rhodes.ACPI is a fundamentally new way of discovering devices, managing power usage, and providing standardized access to various hardware previously managed by the BIOS. Progress is being made toward ACPI working on all systems, but bugs in some motherboards' ACPI Machine Language (AML) bytecode, incompleteness in FreeBSD's kernel subsystems, and bugs in the Intel ACPI-CA interpreter continue to appear.
This document is intended to help you assist the FreeBSD ACPI maintainers in identifying the root cause of problems you observe and debugging and developing a solution. Thanks for reading this and we hope we can solve your system's problems.
11.16.1 Submitting Debugging Information
Note: Before submitting a problem, be sure you are running the latest BIOS version and, if available, embedded controller firmware version.
For those of you that want to submit a problem right away, please send the following information to freebsd-acpi@FreeBSD.org:
-
Description of the buggy behavior, including system type and model and anything that causes the bug to appear. Also, please note as accurately as possible when the bug began occurring if it is new for you.
-
The dmesg(8) output after boot -v, including any error messages generated by you exercising the bug.
-
The dmesg(8) output from boot -v with ACPI disabled, if disabling it helps fix the problem.
-
Output from sysctl hw.acpi. This is also a good way of figuring out what features your system offers.
-
URL where your ACPI Source Language (ASL) can be found. Do not send the ASL directly to the list as it can be very large. Generate a copy of your ASL by running this command:
# acpidump -dt > name-system.asl(Substitute your login name for name and manufacturer/model for system. Example: njl-FooCo6000.asl)
Most of the developers watch the FreeBSD-CURRENT mailing list but please submit problems to freebsd-acpi to be sure it is seen. Please be patient, all of us have full-time jobs elsewhere. If your bug is not immediately apparent, we will probably ask you to submit a PR via send-pr(1). When entering a PR, please include the same information as requested above. This will help us track the problem and resolve it. Do not send a PR without emailing freebsd-acpi first as we use PRs as reminders of existing problems, not a reporting mechanism. It is likely that your problem has been reported by someone before.
11.16.2 Background
ACPI is present in all modern computers that conform to the ia32 (x86), ia64 (Itanium), and amd64 (AMD) architectures. The full standard has many features including CPU performance management, power planes control, thermal zones, various battery systems, embedded controllers, and bus enumeration. Most systems implement less than the full standard. For instance, a desktop system usually only implements the bus enumeration parts while a laptop might have cooling and battery management support as well. Laptops also have suspend and resume, with their own associated complexity.
An ACPI-compliant system has various components. The BIOS and chipset vendors provide various fixed tables (e.g., FADT) in memory that specify things like the APIC map (used for SMP), config registers, and simple configuration values. Additionally, a table of bytecode (the Differentiated System Description Table DSDT) is provided that specifies a tree-like name space of devices and methods.
The ACPI driver must parse the fixed tables, implement an interpreter for the bytecode, and modify device drivers and the kernel to accept information from the ACPI subsystem. For FreeBSD, Intel has provided an interpreter (ACPI-CA) that is shared with Linux and NetBSD. The path to the ACPI-CA source code is src/sys/contrib/dev/acpica. The glue code that allows ACPI-CA to work on FreeBSD is in src/sys/dev/acpica/Osd. Finally, drivers that implement various ACPI devices are found in src/sys/dev/acpica.
11.16.3 Common Problems
For ACPI to work correctly, all the parts have to work correctly. Here are some common problems, in order of frequency of appearance, and some possible workarounds or fixes.
11.16.3.1 Mouse Issues
In some cases, resuming from a suspend operation will cause the mouse to fail. A known work around is to add hint.psm.0.flags="0x3000" to the /boot/loader.conf file. If this does not work then please consider sending a bug report as described above.
11.16.3.2 Suspend/Resume
ACPI has three suspend to RAM (STR) states, S1-S3, and one suspend to disk state (STD), called S4. S5 is “soft off” and is the normal state your system is in when plugged in but not powered up. S4 can actually be implemented two separate ways. S4BIOS is a BIOS-assisted suspend to disk. S4OS is implemented entirely by the operating system.
Start by checking sysctl hw.acpi for the suspend-related items. Here are the results for a Thinkpad:
hw.acpi.supported_sleep_state: S3 S4 S5
hw.acpi.s4bios: 0
This means that we can use acpiconf -s to test S3, S4OS, and S5. If s4bios was one (1), we would have S4BIOS support instead of S4 OS.
When testing suspend/resume, start with S1, if supported. This state is most likely to work since it does not require much driver support. No one has implemented S2 but if you have it, it is similar to S1. The next thing to try is S3. This is the deepest STR state and requires a lot of driver support to properly reinitialize your hardware. If you have problems resuming, feel free to email the freebsd-acpi list but do not expect the problem to be resolved since there are a lot of drivers/hardware that need more testing and work.
To help isolate the problem, remove as many drivers from your kernel as possible. If
it works, you can narrow down which driver is the problem by loading drivers until it
fails again. Typically binary drivers like nvidia.ko, X11
display drivers, and USB will have the most problems
while Ethernet interfaces usually work fine. If you can properly load/unload the drivers,
you can automate this by putting the appropriate commands in /etc/rc.suspend and /etc/rc.resume. There
is a commented-out example for unloading and loading a driver. Try setting hw.acpi.reset_video to zero (0) if your
display is messed up after resume. Try setting longer or shorter values for hw.acpi.sleep_delay to see if that helps.
Another thing to try is load a recent Linux distribution with ACPI support and test their suspend/resume support on the same hardware. If it works on Linux, it is likely a FreeBSD driver problem and narrowing down which driver causes the problems will help us fix the problem. Note that the ACPI maintainers do not usually maintain other drivers (e.g sound, ATA, etc.) so any work done on tracking down a driver problem should probably eventually be posted to the freebsd-current list and mailed to the driver maintainer. If you are feeling adventurous, go ahead and start putting some debugging printf(3)s in a problematic driver to track down where in its resume function it hangs.
Finally, try disabling ACPI and enabling APM instead. If suspend/resume works with APM, you may be better off sticking with APM, especially on older hardware (pre-2000). It took vendors a while to get ACPI support correct and older hardware is more likely to have BIOS problems with ACPI.
11.16.3.3 System Hangs (temporary or permanent)
Most system hangs are a result of lost interrupts or an interrupt storm. Chipsets have a lot of problems based on how the BIOS configures interrupts before boot, correctness of the APIC (MADT) table, and routing of the System Control Interrupt (SCI).
Interrupt storms can be distinguished from lost interrupts by checking the output of vmstat -i and looking at the line that has acpi0. If the counter is increasing at more than a couple per second, you have an interrupt storm. If the system appears hung, try breaking to DDB (CTRL+ALT+ESC on console) and type show interrupts.
Your best hope when dealing with interrupt problems is to try disabling APIC support with hint.apic.0.disabled="1" in loader.conf.
11.16.3.4 Panics
Panics are relatively rare for ACPI and are the top priority to be fixed. The first step is to isolate the steps to reproduce the panic (if possible) and get a backtrace. Follow the advice for enabling options DDB and setting up a serial console (see Section 24.6.5.3) or setting up a dump(8) partition. You can get a backtrace in DDB with tr. If you have to handwrite the backtrace, be sure to at least get the lowest five (5) and top five (5) lines in the trace.
Then, try to isolate the problem by booting with ACPI disabled. If that works, you can isolate the ACPI subsystem by using various values of debug.acpi.disable. See the acpi(4) manual page
for some examples.
11.16.3.5 System Powers Up After Suspend or Shutdown
First, try setting hw.acpi.disable_on_poweroff="0" in loader.conf(5). This keeps ACPI from disabling various events during the shutdown process. Some systems need this value set to 1 (the default) for the same reason. This usually fixes the problem of a system powering up spontaneously after a suspend or poweroff.
11.16.3.6 Other Problems
If you have other problems with ACPI (working with a docking station, devices not detected, etc.), please email a description to the mailing list as well; however, some of these issues may be related to unfinished parts of the ACPI subsystem so they might take a while to be implemented. Please be patient and prepared to test patches we may send you.
11.16.4 ASL, acpidump, and IASL
The most common problem is the BIOS vendors providing incorrect (or outright buggy!) bytecode. This is usually manifested by kernel console messages like this:
ACPI-1287: *** Error: Method execution failed [\\_SB_.PCI0.LPC0.FIGD._STA] \\
(Node 0xc3f6d160), AE_NOT_FOUND
Often, you can resolve these problems by updating your BIOS to the latest revision. Most console messages are harmless
but if you have other problems like battery status not working, they are a good place to
start looking for problems in the AML. The bytecode,
known as AML, is compiled from a source language
called ASL. The AML
is found in the table known as the DSDT. To get a copy
of your ASL, use acpidump(8). You
should use both the -t (show contents of the fixed tables)
and -d (disassemble AML to
ASL) options. See the Submitting Debugging Information section for an example
syntax.
The simplest first check you can do is to recompile your ASL to check for errors. Warnings can usually be ignored but errors are bugs that will usually prevent ACPI from working correctly. To recompile your ASL, issue the following command:
# iasl your.asl
11.16.5 Fixing Your ASL
In the long run, our goal is for almost everyone to have ACPI work without any user intervention. At this point, however, we are still developing workarounds for common mistakes made by the BIOS vendors. The Microsoft interpreter (acpi.sys and acpiec.sys) does not strictly check for adherence to the standard, and thus many BIOS vendors who only test ACPI under Windows never fix their ASL. We hope to continue to identify and document exactly what non-standard behavior is allowed by Microsoft's interpreter and replicate it so FreeBSD can work without forcing users to fix the ASL. As a workaround and to help us identify behavior, you can fix the ASL manually. If this works for you, please send a diff(1) of the old and new ASL so we can possibly work around the buggy behavior in ACPI-CA and thus make your fix unnecessary.
Here is a list of common error messages, their cause, and how to fix them:
11.16.5.1 _OS dependencies
Some AML assumes the world consists of various Windows versions. You can tell FreeBSD to claim it is any OS to see if this fixes problems you may have. An easy way to override this is to set hw.acpi.osname="Windows 2001" in /boot/loader.conf or other similar strings you find in the ASL.
11.16.5.2 Missing Return statements
Some methods do not explicitly return a value as the standard requires. While ACPI-CA does not handle this, FreeBSD has a workaround that
allows it to return the value implicitly. You can also add explicit Return statements
where required if you know what value should be returned. To force iasl to compile the ASL, use the
-f flag.
11.16.5.3 Overriding the Default AML
After you customize your.asl, you will want to compile it, run:
# iasl your.asl
You can add the -f flag to force creation of the AML, even if there are errors during compilation. Remember that
some errors (e.g., missing Return statements) are automatically worked around by the
interpreter.
DSDT.aml is the default output filename for iasl. You can load this instead of your BIOS's buggy copy (which is still present in flash memory) by editing /boot/loader.conf as follows:
acpi_dsdt_load="YES"
acpi_dsdt_name="/boot/DSDT.aml"
Be sure to copy your DSDT.aml to the /boot directory.
11.16.6 Getting Debugging Output From ACPI
The ACPI driver has a very flexible debugging facility. It allows you to specify a set of subsystems as well as the level of verbosity. The subsystems you wish to debug are specified as “layers” and are broken down into ACPI-CA components (ACPI_ALL_COMPONENTS) and ACPI hardware support (ACPI_ALL_DRIVERS). The verbosity of debugging output is specified as the “level” and ranges from ACPI_LV_ERROR (just report errors) to ACPI_LV_VERBOSE (everything). The “level” is a bitmask so multiple options can be set at once, separated by spaces. In practice, you will want to use a serial console to log the output if it is so long it flushes the console message buffer. A full list of the individual layers and levels is found in the acpi(4) manual page.
Debugging output is not enabled by default. To enable it, add options ACPI_DEBUG to your kernel configuration file if ACPI is compiled into the kernel. You can add ACPI_DEBUG=1 to your /etc/make.conf to enable it globally. If it is a module, you can recompile just your acpi.ko module as follows:
# cd /sys/modules/acpi/acpi
&& make clean &&
make ACPI_DEBUG=1
Install acpi.ko in /boot/kernel and add your desired level and layer to loader.conf. This example enables debug messages for all ACPI-CA components and all ACPI hardware drivers (CPU, LID, etc.). It will only output error messages, the least verbose level.
debug.acpi.layer="ACPI_ALL_COMPONENTS ACPI_ALL_DRIVERS"
debug.acpi.level="ACPI_LV_ERROR"
If the information you want is triggered by a specific event (say, a suspend and then resume), you can leave out changes to loader.conf and instead use sysctl to specify the layer and level after booting and preparing your system for the specific event. The sysctls are named the same as the tunables in loader.conf.
11.16.7 References
More information about ACPI may be found in the following locations:
-
The ACPI Mailing List Archives http://lists.freebsd.org/pipermail/freebsd-acpi/
-
The old ACPI Mailing List Archives http://home.jp.FreeBSD.org/mail-list/acpi-jp/
-
The ACPI 2.0 Specification http://acpi.info/spec.htm
-
FreeBSD Manual pages: acpi(4), acpi_thermal(4), acpidump(8), iasl(8), acpidb(8)
-
DSDT debugging resource. (Uses Compaq as an example but generally useful.)
Chapter 12 The FreeBSD Booting Process
12.1 Synopsis
The process of starting a computer and loading the operating system is referred to as “the bootstrap process”, or simply “booting”. FreeBSD's boot process provides a great deal of flexibility in customizing what happens when you start the system, allowing you to select from different operating systems installed on the same computer, or even different versions of the same operating system or installed kernel.
This chapter details the configuration options you can set and how to customize the FreeBSD boot process. This includes everything that happens until the FreeBSD kernel has started, probed for devices, and started init(8). If you are not quite sure when this happens, it occurs when the text color changes from bright white to grey.
After reading this chapter, you will know:
-
What the components of the FreeBSD bootstrap system are, and how they interact.
-
The options you can give to the components in the FreeBSD bootstrap to control the boot process.
-
The basics of device.hints(5).
x86 Only: This chapter only describes the boot process for FreeBSD running on Intel x86 systems.
12.2 The Booting Problem
Turning on a computer and starting the operating system poses an interesting dilemma. By definition, the computer does not know how to do anything until the operating system is started. This includes running programs from the disk. So if the computer can not run a program from the disk without the operating system, and the operating system programs are on the disk, how is the operating system started?
This problem parallels one in the book The Adventures of Baron Munchausen. A character had fallen part way down a manhole, and pulled himself out by grabbing his bootstraps, and lifting. In the early days of computing the term bootstrap was applied to the mechanism used to load the operating system, which has become shortened to “booting”.
On x86 hardware the Basic Input/Output System (BIOS) is responsible for loading the operating system. To do this, the BIOS looks on the hard disk for the Master Boot Record (MBR), which must be located on a specific place on the disk. The BIOS has enough knowledge to load and run the MBR, and assumes that the MBR can then carry out the rest of the tasks involved in loading the operating system, possibly with the help of the BIOS.
The code within the MBR is usually referred to as a boot manager, especially when it interacts with the user. In this case the boot manager usually has more code in the first track of the disk or within some OS's file system. (A boot manager is sometimes also called a boot loader, but FreeBSD uses that term for a later stage of booting.) Popular boot managers include boot0 (a.k.a. Boot Easy, the standard FreeBSD boot manager), Grub, GAG, and LILO. (Only boot0 fits within the MBR.)
If you have only one operating system installed on your disks then a standard PC MBR will suffice. This MBR searches for the first bootable (a.k.a. active) slice on the disk, and then runs the code on that slice to load the remainder of the operating system. The MBR installed by fdisk(8), by default, is such an MBR. It is based on /boot/mbr.
If you have installed multiple operating systems on your disks then you can install a different boot manager, one that can display a list of different operating systems, and allows you to choose the one to boot from. Two of these are discussed in the next subsection.
The remainder of the FreeBSD bootstrap system is divided into three stages. The first stage is run by the MBR, which knows just enough to get the computer into a specific state and run the second stage. The second stage can do a little bit more, before running the third stage. The third stage finishes the task of loading the operating system. The work is split into these three stages because the PC standards put limits on the size of the programs that can be run at stages one and two. Chaining the tasks together allows FreeBSD to provide a more flexible loader.
The kernel is then started and it begins to probe for devices and initialize them for use. Once the kernel boot process is finished, the kernel passes control to the user process init(8), which then makes sure the disks are in a usable state. init(8) then starts the user-level resource configuration which mounts file systems, sets up network cards to communicate on the network, and generally starts all the processes that usually are run on a FreeBSD system at startup.
12.3 The Boot Manager and Boot Stages
12.3.1 The Boot Manager
The code in the MBR or boot manager is sometimes referred to as stage zero of the boot process. This subsection discusses two of the boot managers previously mentioned: boot0 and LILO.
The boot0 Boot Manager: The MBR installed by FreeBSD's installer or boot0cfg(8), by default, is based on /boot/boot0. (The boot0 program is very simple, since the program in the MBR can only be 446 bytes long because of the slice table and 0x55AA identifier at the end of the MBR.) If you have installed boot0 and multiple operating systems on your hard disks, then you will see a display similar to this one at boot time:
Other operating systems, in particular Windows, have been known to overwrite an existing MBR with their own. If this happens to you, or you want to replace your existing MBR with the FreeBSD MBR then use the following command:
# fdisk -B -b /boot/boot0 device
where device is the device that you boot from, such as ad0 for the first IDE disk, ad2 for the first IDE disk on a second IDE controller, da0 for the first SCSI disk, and so on. Or, if you want a custom configuration of the MBR, use boot0cfg(8).
The LILO Boot Manager: To install this boot manager so it will also boot FreeBSD, first start Linux and add the following to your existing /etc/lilo.conf configuration file:
other=/dev/hdXY
table=/dev/hdX
loader=/boot/chain.b
label=FreeBSD
In the above, specify FreeBSD's primary partition and drive using Linux specifiers,
replacing X with the Linux drive letter and Y with the Linux primary partition number. If you are
using a SCSI drive, you will need to change /dev/hd to read something similar to /dev/sd. The loader=/boot/chain.b line can be omitted if you have both operating
systems on the same drive. Now run /sbin/lilo -v to commit
your new changes to the system; this should be verified by checking its screen
messages.
12.3.2 Stage One, /boot/boot1, and Stage Two, /boot/boot2
Conceptually the first and second stages are part of the same program, on the same area of the disk. Because of space constraints they have been split into two, but you would always install them together. They are copied from the combined file /boot/boot by the installer or bsdlabel (see below).
They are located outside file systems, in the first track of the boot slice, starting with the first sector. This is where boot0, or any other boot manager, expects to find a program to run which will continue the boot process. The number of sectors used is easily determined from the size of /boot/boot.
boot1 is very simple, since it can only be 512 bytes in size, and knows just enough about the FreeBSD bsdlabel, which stores information about the slice, to find and execute boot2.
boot2 is slightly more sophisticated, and understands the FreeBSD file system enough to find files on it, and can provide a simple interface to choose the kernel or loader to run.
Since the loader is much more sophisticated, and provides a nice easy-to-use boot configuration, boot2 usually runs it, but previously it was tasked to run the kernel directly.
If you ever need to replace the installed boot1 and boot2 use bsdlabel(8):
# bsdlabel -B diskslice
where diskslice is the disk and slice you boot from, such as ad0s1 for the first slice on the first IDE disk.
Dangerously Dedicated Mode: If you use just the disk name, such as ad0, in the bsdlabel(8) command you will create a dangerously dedicated disk, without slices. This is almost certainly not what you want to do, so make sure you double check the bsdlabel(8) command before you press Return.
12.3.3 Stage Three, /boot/loader
The loader is the final stage of the three-stage bootstrap, and is located on the file system, usually as /boot/loader.
The loader is intended as a user-friendly method for configuration, using an easy-to-use built-in command set, backed up by a more powerful interpreter, with a more complex command set.
12.3.3.1 Loader Program Flow
During initialization, the loader will probe for a console and for disks, and figure out what disk it is booting from. It will set variables accordingly, and an interpreter is started where user commands can be passed from a script or interactively.
The loader will then read /boot/loader.rc, which by default reads in /boot/defaults/loader.conf which sets reasonable defaults for variables and reads /boot/loader.conf for local changes to those variables. loader.rc then acts on these variables, loading whichever modules and kernel are selected.
Finally, by default, the loader issues a 10 second wait for key presses, and boots the kernel if it is not interrupted. If interrupted, the user is presented with a prompt which understands the easy-to-use command set, where the user may adjust variables, unload all modules, load modules, and then finally boot or reboot.
12.3.3.2 Loader Built-In Commands
These are the most commonly used loader commands. For a complete discussion of all available commands, please see loader(8).
- autoboot seconds
-
Proceeds to boot the kernel if not interrupted within the time span given, in seconds. It displays a countdown, and the default time span is 10 seconds.
- boot [-options] [kernelname]
-
Immediately proceeds to boot the kernel, with the given options, if any, and with the kernel name given, if it is.
- boot-conf
-
Goes through the same automatic configuration of modules based on variables as what happens at boot. This only makes sense if you use unload first, and change some variables, most commonly kernel.
- help [topic]
-
Shows help messages read from /boot/loader.help. If the topic given is index, then the list of available topics is given.
- include filename ...
-
Processes the file with the given filename. The file is read in, and interpreted line by line. An error immediately stops the include command.
- load [
-ttype] filename -
Loads the kernel, kernel module, or file of the type given, with the filename given. Any arguments after filename are passed to the file.
- ls [
-l] [path] -
Displays a listing of files in the given path, or the root directory, if the path is not specified. If
-lis specified, file sizes will be shown too. - lsdev [
-v] -
Lists all of the devices from which it may be possible to load modules. If
-vis specified, more details are printed. - lsmod [
-v] -
Displays loaded modules. If
-vis specified, more details are shown. - more filename
-
Displays the files specified, with a pause at each
LINESdisplayed. - reboot
-
Immediately reboots the system.
- set variable, set variable=value
-
Sets the loader's environment variables.
- unload
-
Removes all loaded modules.
12.3.3.3 Loader Examples
Here are some practical examples of loader usage:
-
To simply boot your usual kernel, but in single-user mode:
boot -s -
To unload your usual kernel and modules, and then load just your old (or another) kernel:
unload load kernel.oldYou can use kernel.GENERIC to refer to the generic kernel that comes on the install disk, or kernel.old to refer to your previously installed kernel (when you have upgraded or configured your own kernel, for example).
Note: Use the following to load your usual modules with another kernel:
unload set kernel="kernel.old" boot-conf -
To load a kernel configuration script (an automated script which does the things you would normally do in the kernel boot-time configurator):
load -t userconfig_script /boot/kernel.conf
12.4 Kernel Interaction During Boot
Once the kernel is loaded by either loader (as usual) or boot2 (bypassing the loader), it examines its boot flags, if any, and adjusts its behavior as necessary.
12.4.1 Kernel Boot Flags
Here are the more common boot flags:
-a-
during kernel initialization, ask for the device to mount as the root file system.
-C-
boot from CDROM.
-c-
run UserConfig, the boot-time kernel configurator
-s-
boot into single-user mode
-v-
be more verbose during kernel startup
Note: There are other boot flags, read boot(8) for more information on them.
12.5 Device Hints
Contributed by Tom Rhodes.Note: This is a FreeBSD 5.0 and later feature which does not exist in earlier versions.
During initial system startup, the boot loader(8) will read the device.hints(5) file. This file stores kernel boot information known as variables, sometimes referred to as “device hints”. These “device hints” are used by device drivers for device configuration.
Device hints may also be specified at the Stage 3 boot loader prompt. Variables can be added using set, removed with unset, and viewed with the show commands. Variables set in the /boot/device.hints file can be overridden here also. Device hints entered at the boot loader are not permanent and will be forgotten on the next reboot.
Once the system is booted, the kenv(1) command can be used to dump all of the variables.
The syntax for the /boot/device.hints file is one variable per line, using the standard hash “#” as comment markers. Lines are constructed as follows:
hint.driver.unit.keyword="value"
The syntax for the Stage 3 boot loader is:
set hint.driver.unit.keyword=value
driver is the device driver name, unit is the device driver unit number, and keyword is the hint keyword. The keyword may consist of the following options:
-
at: specifies the bus which the device is attached to.
-
port: specifies the start address of the I/O to be used.
-
irq: specifies the interrupt request number to be used.
-
drq: specifies the DMA channel number.
-
maddr: specifies the physical memory address occupied by the device.
-
flags: sets various flag bits for the device.
-
disabled: if set to 1 the device is disabled.
Device drivers may accept (or require) more hints not listed here, viewing their manual page is recommended. For more information, consult the device.hints(5), kenv(1), loader.conf(5), and loader(8) manual pages.
12.6 Init: Process Control Initialization
Once the kernel has finished booting, it passes control to the user process init(8), which is located at /sbin/init, or the program path specified in the init_path variable in loader.
12.6.1 Automatic Reboot Sequence
The automatic reboot sequence makes sure that the file systems available on the system are consistent. If they are not, and fsck(8) cannot fix the inconsistencies, init(8) drops the system into single-user mode for the system administrator to take care of the problems directly.
12.6.2 Single-User Mode
This mode can be reached through the automatic reboot
sequence, or by the user booting with the -s option or
setting the boot_single variable in loader.
It can also be reached by calling shutdown(8) without
the reboot (-r) or halt (-h)
options, from multi-user mode.
If the system console is set to insecure in /etc/ttys, then the system prompts for the root password before initiating single-user mode.
Example 12-3. An Insecure Console in /etc/ttys
# name getty type status comments
#
# If console is marked "insecure", then init will ask for the root password
# when going to single-user mode.
console none unknown off insecure
Note: An insecure console means that you consider your physical security to the console to be insecure, and want to make sure only someone who knows the root password may use single-user mode, and it does not mean that you want to run your console insecurely. Thus, if you want security, choose insecure, not secure.
12.6.3 Multi-User Mode
If init(8) finds your file systems to be in order, or once the user has finished in single-user mode, the system enters multi-user mode, in which it starts the resource configuration of the system.
12.6.3.1 Resource Configuration (rc)
The resource configuration system reads in configuration defaults from /etc/defaults/rc.conf, and system-specific details from /etc/rc.conf, and then proceeds to mount the system file systems mentioned in /etc/fstab, start up networking services, start up miscellaneous system daemons, and finally runs the startup scripts of locally installed packages.
The rc(8) manual page is a good reference to the resource configuration system, as is examining the scripts themselves.
12.7 Shutdown Sequence
Upon controlled shutdown, via shutdown(8), init(8) will attempt to run the script /etc/rc.shutdown, and then proceed to send all processes the TERM signal, and subsequently the KILL signal to any that do not terminate timely.
To power down a FreeBSD machine on architectures and systems that support power management, simply use the command shutdown -p now to turn the power off immediately. To just reboot a FreeBSD system, just use shutdown -r now. You need to be root or a member of operator group to run shutdown(8). The halt(8) and reboot(8) commands can also be used, please refer to their manual pages and to shutdown(8)'s one for more information.
Note: Power management requires acpi(4) support in the kernel or loaded as module for.
Chapter 13 Users and Basic Account Management
Contributed by Neil Blakey-Milner.13.1 Synopsis
FreeBSD allows multiple users to use the computer at the same time. Obviously, only one of those users can be sitting in front of the screen and keyboard at any one time [6], but any number of users can log in through the network to get their work done. To use the system every user must have an account.
After reading this chapter, you will know:
-
The differences between the various user accounts on a FreeBSD system.
-
How to add user accounts.
-
How to remove user accounts.
-
How to change account details, such as the user's full name, or preferred shell.
-
How to set limits on a per-account basis, to control the resources such as memory and CPU time that accounts and groups of accounts are allowed to access.
-
How to use groups to make account management easier.
Before reading this chapter, you should:
-
Understand the basics of UNIX and FreeBSD (Chapter 3).
13.2 Introduction
All access to the system is achieved via accounts, and all processes are run by users, so user and account management are of integral importance on FreeBSD systems.
Every account on a FreeBSD system has certain information associated with it to identify the account.
- User name
-
The user name as it would be typed at the login: prompt. User names must be unique across the computer; you may not have two users with the same user name. There are a number of rules for creating valid user names, documented in passwd(5); you would typically use user names that consist of eight or fewer all lower case characters.
- Password
-
Each account has a password associated with it. The password may be blank, in which case no password will be required to access the system. This is normally a very bad idea; every account should have a password.
- User ID (UID)
-
The UID is a number, traditionally from 0 to 65535[7], used to uniquely identify the user to the system. Internally, FreeBSD uses the UID to identify users--any FreeBSD commands that allow you to specify a user name will convert it to the UID before working with it. This means that you can have several accounts with different user names but the same UID. As far as FreeBSD is concerned these accounts are one user. It is unlikely you will ever need to do this.
- Group ID (GID)
-
The GID is a number, traditionally from 0 to 65535[7], used to uniquely identify the primary group that the user belongs to. Groups are a mechanism for controlling access to resources based on a user's GID rather than their UID. This can significantly reduce the size of some configuration files. A user may also be in more than one group.
- Login class
-
Login classes are an extension to the group mechanism that provide additional flexibility when tailoring the system to different users.
- Password change time
-
By default FreeBSD does not force users to change their passwords periodically. You can enforce this on a per-user basis, forcing some or all of your users to change their passwords after a certain amount of time has elapsed.
- Account expiry time
-
By default FreeBSD does not expire accounts. If you are creating accounts that you know have a limited lifespan, for example, in a school where you have accounts for the students, then you can specify when the account expires. After the expiry time has elapsed the account cannot be used to log in to the system, although the account's directories and files will remain.
- User's full name
-
The user name uniquely identifies the account to FreeBSD, but does not necessarily reflect the user's real name. This information can be associated with the account.
- Home directory
-
The home directory is the full path to a directory on the system in which the user will start when logging on to the system. A common convention is to put all user home directories under /home/username or /usr/home/username. The user would store their personal files in their home directory, and any directories they may create in there.
- User shell
-
The shell provides the default environment users use to interact with the system. There are many different kinds of shells, and experienced users will have their own preferences, which can be reflected in their account settings.
There are three main types of accounts: the Superuser, system users, and user accounts. The Superuser account, usually called root, is used to manage the system with no limitations on privileges. System users run services. Finally, user accounts are used by real people, who log on, read mail, and so forth.
13.3 The Superuser Account
The superuser account, usually called root, comes preconfigured to facilitate system administration, and should not be used for day-to-day tasks like sending and receiving mail, general exploration of the system, or programming.
This is because the superuser, unlike normal user accounts, can operate without limits, and misuse of the superuser account may result in spectacular disasters. User accounts are unable to destroy the system by mistake, so it is generally best to use normal user accounts whenever possible, unless you especially need the extra privilege.
You should always double and triple-check commands you issue as the superuser, since an extra space or missing character can mean irreparable data loss.
So, the first thing you should do after reading this chapter is to create an unprivileged user account for yourself for general usage if you have not already. This applies equally whether you are running a multi-user or single-user machine. Later in this chapter, we discuss how to create additional accounts, and how to change between the normal user and superuser.
13.4 System Accounts
System users are those used to run services such as DNS, mail, web servers, and so forth. The reason for this is security; if all services ran as the superuser, they could act without restriction.
Examples of system users are daemon, operator, bind (for the Domain Name Service), news, and www.
nobody is the generic unprivileged system user. However, it is important to keep in mind that the more services that use nobody, the more files and processes that user will become associated with, and hence the more privileged that user becomes.
13.5 User Accounts
User accounts are the primary means of access for real people to the system, and these accounts insulate the user and the environment, preventing the users from damaging the system or other users, and allowing users to customize their environment without affecting others.
Every person accessing your system should have a unique user account. This allows you to find out who is doing what, prevent people from clobbering each others' settings or reading each others' mail, and so forth.
Each user can set up their own environment to accommodate their use of the system, by using alternate shells, editors, key bindings, and language.
13.6 Modifying Accounts
There are a variety of different commands available in the UNIX environment to manipulate user accounts. The most common commands are summarized below, followed by more detailed examples of their usage.
| Command | Summary |
|---|---|
| adduser(8) | The recommended command-line application for adding new users. |
| rmuser(8) | The recommended command-line application for removing users. |
| chpass(1) | A flexible tool to change user database information. |
| passwd(1) | The simple command-line tool to change user passwords. |
| pw(8) | A powerful and flexible tool to modify all aspects of user accounts. |
13.6.1 adduser
adduser(8) is a simple program for adding new users. It creates entries in the system passwd and group files. It will also create a home directory for the new user, copy in the default configuration files (“dotfiles”) from /usr/share/skel, and can optionally mail the new user a welcome message.
Example 13-1. Adding a user on FreeBSD
# adduser
Username: jru
Full name: J. Random User
Uid (Leave empty for default):
Login group [jru]:
Login group is jru. Invite jru into other groups? []: wheel
Login class [default]:
Shell (sh csh tcsh zsh nologin) [sh]: zsh
Home directory [/home/jru]:
Use password-based authentication? [yes]:
Use an empty password? (yes/no) [no]:
Use a random password? (yes/no) [no]:
Enter password:
Enter password again:
Lock out the account after creation? [no]:
Username : jru
Password : ****
Full Name : J. Random User
Uid : 1001
Class :
Groups : jru wheel
Home : /home/jru
Shell : /usr/local/bin/zsh
Locked : no
OK? (yes/no): yes
adduser: INFO: Successfully added (jru) to the user database.
Add another user? (yes/no): no
Goodbye!
#
Note: The password you type in is not echoed, nor are asterisks displayed. Make sure that you do not mistype the password.
13.6.2 rmuser
You can use rmuser(8) to completely remove a user from the system. rmuser(8) performs the following steps:
-
Removes the user's crontab(1) entry (if any).
-
Removes any at(1) jobs belonging to the user.
-
Kills all processes owned by the user.
-
Removes the user from the system's local password file.
-
Removes the user's home directory (if it is owned by the user).
-
Removes the incoming mail files belonging to the user from /var/mail.
-
Removes all files owned by the user from temporary file storage areas such as /tmp.
-
Finally, removes the username from all groups to which it belongs in /etc/group.
Note: If a group becomes empty and the group name is the same as the username, the group is removed; this complements the per-user unique groups created by adduser(8).
rmuser(8) cannot be used to remove superuser accounts, since that is almost always an indication of massive destruction.
By default, an interactive mode is used, which attempts to make sure you know what you are doing.
Example 13-2. rmuser Interactive Account Removal
# rmuser jru
Matching password entry:
jru:*:1001:1001::0:0:J. Random User:/home/jru:/usr/local/bin/zsh
Is this the entry you wish to remove? y
Remove user's home directory (/home/jru)? y
Updating password file, updating databases, done.
Updating group file: trusted (removing group jru -- personal group is empty) done.
Removing user's incoming mail file /var/mail/jru: done.
Removing files belonging to jru from /tmp: done.
Removing files belonging to jru from /var/tmp: done.
Removing files belonging to jru from /var/tmp/vi.recover: done.
#
13.6.3 chpass
chpass(1) changes user database information such as passwords, shells, and personal information.
Only system administrators, as the superuser, may change other users' information and passwords with chpass(1).
When passed no options, aside from an optional username, chpass(1) displays an editor containing user information. When the user exists from the editor, the user database is updated with the new information.
Note: You will be asked for your password after exiting the editor if you are not the superuser.
Example 13-3. Interactive chpass by Superuser
#Changing user database information for jru.
Login: jru
Password: *
Uid [#]: 1001
Gid [# or name]: 1001
Change [month day year]:
Expire [month day year]:
Class:
Home directory: /home/jru
Shell: /usr/local/bin/zsh
Full Name: J. Random User
Office Location:
Office Phone:
Home Phone:
Other information:
The normal user can change only a small subset of this information, and only for themselves.
Example 13-4. Interactive chpass by Normal User
#Changing user database information for jru.
Shell: /usr/local/bin/zsh
Full Name: J. Random User
Office Location:
Office Phone:
Home Phone:
Other information:
Note: chfn(1) and chsh(1) are just links to chpass(1), as are ypchpass(1), ypchfn(1), and ypchsh(1). NIS support is automatic, so specifying the yp before the command is not necessary. If this is confusing to you, do not worry, NIS will be covered in Chapter 27.
13.6.4 passwd
passwd(1) is the usual way to change your own password as a user, or another user's password as the superuser.
Note: To prevent accidental or unauthorized changes, the original password must be entered before a new password can be set.
Example 13-5. Changing Your Password
% passwd
Changing local password for jru.
Old password:
New password:
Retype new password:
passwd: updating the database...
passwd: done
Example 13-6. Changing Another User's Password as the Superuser
# passwd jru
Changing local password for jru.
New password:
Retype new password:
passwd: updating the database...
passwd: done
Note: As with chpass(1), yppasswd(1) is just a link to passwd(1), so NIS works with either command.
13.6.5 pw
pw(8) is a command line utility to create, remove, modify, and display users and groups. It functions as a front end to the system user and group files. pw(8) has a very powerful set of command line options that make it suitable for use in shell scripts, but new users may find it more complicated than the other commands presented here.
13.7 Limiting Users
If you have users, the ability to limit their system use may have come to mind. FreeBSD provides several ways an administrator can limit the amount of system resources an individual may use. These limits are divided into two sections: disk quotas, and other resource limits.
Disk quotas limit disk usage to users, and they provide a way to quickly check that usage without calculating it every time. Quotas are discussed in Section 18.15.
The other resource limits include ways to limit the amount of CPU, memory, and other resources a user may consume. These are defined using login classes and are discussed here.
Login classes are defined in /etc/login.conf. The precise semantics are beyond the scope of this section, but are described in detail in the login.conf(5) manual page. It is sufficient to say that each user is assigned to a login class (default by default), and that each login class has a set of login capabilities associated with it. A login capability is a name=value pair, where name is a well-known identifier and value is an arbitrary string processed accordingly depending on the name. Setting up login classes and capabilities is rather straight-forward and is also described in login.conf(5).
Note: The system does not normally read the configuration in /etc/login.conf directly, but reads the database file /etc/login.conf.db which provides faster lookups. To generate /etc/login.conf.db from /etc/login.conf, execute the following command:
# cap_mkdb /etc/login.conf
Resource limits are different from plain vanilla login capabilities in two ways. First, for every limit, there is a soft (current) and hard limit. A soft limit may be adjusted by the user or application, but may be no higher than the hard limit. The latter may be lowered by the user, but never raised. Second, most resource limits apply per process to a specific user, not the user as a whole. Note, however, that these differences are mandated by the specific handling of the limits, not by the implementation of the login capability framework (i.e., they are not really a special case of login capabilities).
And so, without further ado, below are the most commonly used resource limits (the rest, along with all the other login capabilities, may be found in login.conf(5)).
- coredumpsize
-
The limit on the size of a core file generated by a program is, for obvious reasons, subordinate to other limits on disk usage (e.g., filesize, or disk quotas). Nevertheless, it is often used as a less-severe method of controlling disk space consumption: since users do not generate core files themselves, and often do not delete them, setting this may save them from running out of disk space should a large program (e.g., emacs) crash.
- cputime
-
This is the maximum amount of CPU time a user's process may consume. Offending processes will be killed by the kernel.
Note: This is a limit on CPU time consumed, not percentage of the CPU as displayed in some fields by top(1) and ps(1). A limit on the latter is, at the time of this writing, not possible, and would be rather useless: a compiler--probably a legitimate task--can easily use almost 100% of a CPU for some time.
- filesize
-
This is the maximum size of a file the user may possess. Unlike disk quotas, this limit is enforced on individual files, not the set of all files a user owns.
- maxproc
-
This is the maximum number of processes a user may be running. This includes foreground and background processes alike. For obvious reasons, this may not be larger than the system limit specified by the
kern.maxprocsysctl(8). Also note that setting this too small may hinder a user's productivity: it is often useful to be logged in multiple times or execute pipelines. Some tasks, such as compiling a large program, also spawn multiple processes (e.g., make(1), cc(1), and other intermediate preprocessors). - memorylocked
-
This is the maximum amount a memory a process may have requested to be locked into main memory (e.g., see mlock(2)). Some system-critical programs, such as amd(8), lock into main memory such that in the event of being swapped out, they do not contribute to a system's trashing in time of trouble.
- memoryuse
-
This is the maximum amount of memory a process may consume at any given time. It includes both core memory and swap usage. This is not a catch-all limit for restricting memory consumption, but it is a good start.
- openfiles
-
This is the maximum amount of files a process may have open. In FreeBSD, files are also used to represent sockets and IPC channels; thus, be careful not to set this too low. The system-wide limit for this is defined by the
kern.maxfilessysctl(8). - sbsize
-
This is the limit on the amount of network memory, and thus mbufs, a user may consume. This originated as a response to an old DoS attack by creating a lot of sockets, but can be generally used to limit network communications.
- stacksize
-
This is the maximum size a process' stack may grow to. This alone is not sufficient to limit the amount of memory a program may use; consequently, it should be used in conjunction with other limits.
There are a few other things to remember when setting resource limits. Following are some general tips, suggestions, and miscellaneous comments.
-
Processes started at system startup by /etc/rc are assigned to the daemon login class.
-
Although the /etc/login.conf that comes with the system is a good source of reasonable values for most limits, only you, the administrator, can know what is appropriate for your system. Setting a limit too high may open your system up to abuse, while setting it too low may put a strain on productivity.
-
Users of the X Window System (X11) should probably be granted more resources than other users. X11 by itself takes a lot of resources, but it also encourages users to run more programs simultaneously.
-
Remember that many limits apply to individual processes, not the user as a whole. For example, setting
openfilesto 50 means that each process the user runs may open up to 50 files. Thus, the gross amount of files a user may open is the value of openfiles multiplied by the value of maxproc. This also applies to memory consumption.
For further information on resource limits and login classes and capabilities in general, please consult the relevant manual pages: cap_mkdb(1), getrlimit(2), login.conf(5).
13.8 Groups
A group is simply a list of users. Groups are identified by their group name and GID (Group ID). In FreeBSD (and most other UNIX like systems), the two factors the kernel uses to decide whether a process is allowed to do something is its user ID and list of groups it belongs to. Unlike a user ID, a process has a list of groups associated with it. You may hear some things refer to the “group ID” of a user or process; most of the time, this just means the first group in the list.
The group name to group ID map is in /etc/group. This is a plain text file with four colon-delimited fields. The first field is the group name, the second is the encrypted password, the third the group ID, and the fourth the comma-delimited list of members. It can safely be edited by hand (assuming, of course, that you do not make any syntax errors!). For a more complete description of the syntax, see the group(5) manual page.
If you do not want to edit /etc/group manually, you can use the pw(8) command to add and edit groups. For example, to add a group called teamtwo and then confirm that it exists you can use:
Example 13-7. Adding a Group Using pw(8)
# pw groupadd teamtwo
# pw groupshow teamtwo
teamtwo:*:1100:
The number 1100 above is the group ID of the group teamtwo. Right now, teamtwo has no members, and is thus rather useless. Let's change that by inviting jru to the teamtwo group.
Example 13-8. Adding Somebody to a Group Using pw(8)
# pw groupmod teamtwo -M jru
# pw groupshow teamtwo
teamtwo:*:1100:jru
The argument to the -M option is a comma-delimited list of
users who are members of the group. From the preceding sections, we know that the
password file also contains a group for each user. The latter (the user) is automatically
added to the group list by the system; the user will not show up as a member when using
the groupshow command to pw(8), but will show
up when the information is queried via id(1) or similar tool.
In other words, pw(8) only manipulates
the /etc/group file; it will never attempt to read additionally
data from /etc/passwd.
Example 13-9. Using id(1) to Determine Group Membership
% id jru
uid=1001(jru) gid=1001(jru) groups=1001(jru), 1100(teamtwo)
As you can see, jru is a member of the groups jru and teamtwo.
For more information about pw(8), see its manual page, and for more information on the format of /etc/group, consult the group(5) manual page.
Chapter 14 Security
Much of this chapter has been taken from the security(7) manual page by Matthew Dillon.14.1 Synopsis
This chapter will provide a basic introduction to system security concepts, some general good rules of thumb, and some advanced topics under FreeBSD. A lot of the topics covered here can be applied to system and Internet security in general as well. The Internet is no longer a “friendly” place in which everyone wants to be your kind neighbor. Securing your system is imperative to protect your data, intellectual property, time, and much more from the hands of hackers and the like.
FreeBSD provides an array of utilities and mechanisms to ensure the integrity and security of your system and network.
After reading this chapter, you will know:
-
Basic system security concepts, in respect to FreeBSD.
-
About the various crypt mechanisms available in FreeBSD, such as DES and MD5.
-
How to set up one-time password authentication.
-
How to configure TCP Wrappers for use with inetd.
-
How to set up KerberosIV on FreeBSD releases prior to 5.0.
-
How to set up Kerberos5 on FreeBSD.
-
How to configure IPsec and create a VPN between FreeBSD/Windows machines.
-
How to configure and use OpenSSH, FreeBSD's SSH implementation.
-
What file system ACLs are and how to use them.
-
How to use the Portaudit utility to audit third party software packages installed from the Ports Collection.
-
How to utilize the FreeBSD security advisories publications.
-
Have an idea of what Process Accounting is and how to enable it on FreeBSD.
Before reading this chapter, you should:
-
Understand basic FreeBSD and Internet concepts.
Additional security topics are covered throughout this book. For example, Mandatory Access Control is discussed in Chapter 16 and Internet Firewalls are discussed in Chapter 28.
14.2 Introduction
Security is a function that begins and ends with the system administrator. While all BSD UNIX multi-user systems have some inherent security, the job of building and maintaining additional security mechanisms to keep those users “honest” is probably one of the single largest undertakings of the sysadmin. Machines are only as secure as you make them, and security concerns are ever competing with the human necessity for convenience. UNIX systems, in general, are capable of running a huge number of simultaneous processes and many of these processes operate as servers -- meaning that external entities can connect and talk to them. As yesterday's mini-computers and mainframes become today's desktops, and as computers become networked and inter-networked, security becomes an even bigger issue.
System security also pertains to dealing with various forms of attack, including attacks that attempt to crash, or otherwise make a system unusable, but do not attempt to compromise the root account (“break root”). Security concerns can be split up into several categories:
-
Denial of service attacks.
-
User account compromises.
-
Root compromise through accessible servers.
-
Root compromise via user accounts.
-
Backdoor creation.
A denial of service attack is an action that deprives the machine of needed resources. Typically, DoS attacks are brute-force mechanisms that attempt to crash or otherwise make a machine unusable by overwhelming its servers or network stack. Some DoS attacks try to take advantage of bugs in the networking stack to crash a machine with a single packet. The latter can only be fixed by applying a bug fix to the kernel. Attacks on servers can often be fixed by properly specifying options to limit the load the servers incur on the system under adverse conditions. Brute-force network attacks are harder to deal with. A spoofed-packet attack, for example, is nearly impossible to stop, short of cutting your system off from the Internet. It may not be able to take your machine down, but it can saturate your Internet connection.
A user account compromise is even more common than a DoS attack. Many sysadmins still run standard telnetd, rlogind, rshd, and ftpd servers on their machines. These servers, by default, do not operate over encrypted connections. The result is that if you have any moderate-sized user base, one or more of your users logging into your system from a remote location (which is the most common and convenient way to login to a system) will have his or her password sniffed. The attentive system admin will analyze his remote access logs looking for suspicious source addresses even for successful logins.
One must always assume that once an attacker has access to a user account, the attacker can break root. However, the reality is that in a well secured and maintained system, access to a user account does not necessarily give the attacker access to root. The distinction is important because without access to root the attacker cannot generally hide his tracks and may, at best, be able to do nothing more than mess with the user's files, or crash the machine. User account compromises are very common because users tend not to take the precautions that sysadmins take.
System administrators must keep in mind that there are potentially many ways to break root on a machine. The attacker may know the root password, the attacker may find a bug in a root-run server and be able to break root over a network connection to that server, or the attacker may know of a bug in a suid-root program that allows the attacker to break root once he has broken into a user's account. If an attacker has found a way to break root on a machine, the attacker may not have a need to install a backdoor. Many of the root holes found and closed to date involve a considerable amount of work by the attacker to cleanup after himself, so most attackers install backdoors. A backdoor provides the attacker with a way to easily regain root access to the system, but it also gives the smart system administrator a convenient way to detect the intrusion. Making it impossible for an attacker to install a backdoor may actually be detrimental to your security, because it will not close off the hole the attacker found to break in the first place.
Security remedies should always be implemented with a multi-layered “onion peel” approach and can be categorized as follows:
-
Securing root and staff accounts.
-
Securing root-run servers and suid/sgid binaries.
-
Securing user accounts.
-
Securing the password file.
-
Securing the kernel core, raw devices, and file systems.
-
Quick detection of inappropriate changes made to the system.
-
Paranoia.
The next section of this chapter will cover the above bullet items in greater depth.
14.3 Securing FreeBSD
Command vs. Protocol: Throughout this document, we will use bold text to refer to an application, and a monospaced font to refer to specific commands. Protocols will use a normal font. This typographical distinction is useful for instances such as ssh, since it is a protocol as well as command.
The sections that follow will cover the methods of securing your FreeBSD system that were mentioned in the last section of this chapter.
14.3.1 Securing the root Account and Staff Accounts
First off, do not bother securing staff accounts if you have not secured the root account. Most systems have a password assigned to the root account. The first thing you do is assume that the password is always compromised. This does not mean that you should remove the password. The password is almost always necessary for console access to the machine. What it does mean is that you should not make it possible to use the password outside of the console or possibly even with the su(1) command. For example, make sure that your ptys are specified as being insecure in the /etc/ttys file so that direct root logins via telnet or rlogin are disallowed. If using other login services such as sshd, make sure that direct root logins are disabled there as well. You can do this by editing your /etc/ssh/sshd_config file, and making sure that PermitRootLogin is set to NO. Consider every access method -- services such as FTP often fall through the cracks. Direct root logins should only be allowed via the system console.
Of course, as a sysadmin you have to be able to get to root, so we open up a few holes. But we make sure these holes require additional password verification to operate. One way to make root accessible is to add appropriate staff accounts to the wheel group (in /etc/group). The staff members placed in the wheel group are allowed to su to root. You should never give staff members native wheel access by putting them in the wheel group in their password entry. Staff accounts should be placed in a staff group, and then added to the wheel group via the /etc/group file. Only those staff members who actually need to have root access should be placed in the wheel group. It is also possible, when using an authentication method such as Kerberos, to use Kerberos' .k5login file in the root account to allow a ksu(1) to root without having to place anyone at all in the wheel group. This may be the better solution since the wheel mechanism still allows an intruder to break root if the intruder has gotten hold of your password file and can break into a staff account. While having the wheel mechanism is better than having nothing at all, it is not necessarily the safest option.
An indirect way to secure staff accounts, and ultimately root access is to use an alternative login access method and do what is known as “starring” out the encrypted password for the staff accounts. Using the vipw(8) command, one can replace each instance of an encrypted password with a single “*” character. This command will update the /etc/master.passwd file and user/password database to disable password-authenticated logins.
A staff account entry such as:
foobar:R9DT/Fa1/LV9U:1000:1000::0:0:Foo Bar:/home/foobar:/usr/local/bin/tcsh
Should be changed to this:
foobar:*:1000:1000::0:0:Foo Bar:/home/foobar:/usr/local/bin/tcsh
This change will prevent normal logins from occurring, since the encrypted password will never match “*”. With this done, staff members must use another mechanism to authenticate themselves such as kerberos(1) or ssh(1) using a public/private key pair. When using something like Kerberos, one generally must secure the machines which run the Kerberos servers and your desktop workstation. When using a public/private key pair with ssh, one must generally secure the machine used to login from (typically one's workstation). An additional layer of protection can be added to the key pair by password protecting the key pair when creating it with ssh-keygen(1). Being able to “star” out the passwords for staff accounts also guarantees that staff members can only login through secure access methods that you have set up. This forces all staff members to use secure, encrypted connections for all of their sessions, which closes an important hole used by many intruders: sniffing the network from an unrelated, less secure machine.
The more indirect security mechanisms also assume that you are logging in from a more restrictive server to a less restrictive server. For example, if your main box is running all sorts of servers, your workstation should not be running any. In order for your workstation to be reasonably secure you should run as few servers as possible, up to and including no servers at all, and you should run a password-protected screen blanker. Of course, given physical access to a workstation an attacker can break any sort of security you put on it. This is definitely a problem that you should consider, but you should also consider the fact that the vast majority of break-ins occur remotely, over a network, from people who do not have physical access to your workstation or servers.
Using something like Kerberos also gives you the ability to disable or change the password for a staff account in one place, and have it immediately affect all the machines on which the staff member may have an account. If a staff member's account gets compromised, the ability to instantly change his password on all machines should not be underrated. With discrete passwords, changing a password on N machines can be a mess. You can also impose re-passwording restrictions with Kerberos: not only can a Kerberos ticket be made to timeout after a while, but the Kerberos system can require that the user choose a new password after a certain period of time (say, once a month).
14.3.2 Securing Root-run Servers and SUID/SGID Binaries
The prudent sysadmin only runs the servers he needs to, no more, no less. Be aware that third party servers are often the most bug-prone. For example, running an old version of imapd or popper is like giving a universal root ticket out to the entire world. Never run a server that you have not checked out carefully. Many servers do not need to be run as root. For example, the ntalk, comsat, and finger daemons can be run in special user sandboxes. A sandbox is not perfect, unless you go through a large amount of trouble, but the onion approach to security still stands: If someone is able to break in through a server running in a sandbox, they still have to break out of the sandbox. The more layers the attacker must break through, the lower the likelihood of his success. Root holes have historically been found in virtually every server ever run as root, including basic system servers. If you are running a machine through which people only login via sshd and never login via telnetd or rshd or rlogind, then turn off those services!
FreeBSD now defaults to running ntalkd, comsat, and finger in a sandbox. Another program which may be a candidate for running in a sandbox is named(8). /etc/defaults/rc.conf includes the arguments necessary to run named in a sandbox in a commented-out form. Depending on whether you are installing a new system or upgrading an existing system, the special user accounts used by these sandboxes may not be installed. The prudent sysadmin would research and implement sandboxes for servers whenever possible.
There are a number of other servers that typically do not run in sandboxes: sendmail, popper, imapd, ftpd, and others. There are alternatives to some of these, but installing them may require more work than you are willing to perform (the convenience factor strikes again). You may have to run these servers as root and rely on other mechanisms to detect break-ins that might occur through them.
The other big potential root holes in a system are the suid-root and sgid binaries installed on the system. Most of these binaries, such as rlogin, reside in /bin, /sbin, /usr/bin, or /usr/sbin. While nothing is 100% safe, the system-default suid and sgid binaries can be considered reasonably safe. Still, root holes are occasionally found in these binaries. A root hole was found in Xlib in 1998 that made xterm (which is typically suid) vulnerable. It is better to be safe than sorry and the prudent sysadmin will restrict suid binaries, that only staff should run, to a special group that only staff can access, and get rid of (chmod 000) any suid binaries that nobody uses. A server with no display generally does not need an xterm binary. Sgid binaries can be almost as dangerous. If an intruder can break an sgid-kmem binary, the intruder might be able to read /dev/kmem and thus read the encrypted password file, potentially compromising any passworded account. Alternatively an intruder who breaks group kmem can monitor keystrokes sent through ptys, including ptys used by users who login through secure methods. An intruder that breaks the tty group can write to almost any user's tty. If a user is running a terminal program or emulator with a keyboard-simulation feature, the intruder can potentially generate a data stream that causes the user's terminal to echo a command, which is then run as that user.
14.3.3 Securing User Accounts
User accounts are usually the most difficult to secure. While you can impose draconian access restrictions on your staff and “star” out their passwords, you may not be able to do so with any general user accounts you might have. If you do have sufficient control, then you may win out and be able to secure the user accounts properly. If not, you simply have to be more vigilant in your monitoring of those accounts. Use of ssh and Kerberos for user accounts is more problematic, due to the extra administration and technical support required, but still a very good solution compared to a encrypted password file.
14.3.4 Securing the Password File
The only sure fire way is to star out as many passwords as you can and use ssh or Kerberos for access to those accounts. Even though the encrypted password file (/etc/spwd.db) can only be read by root, it may be possible for an intruder to obtain read access to that file even if the attacker cannot obtain root-write access.
Your security scripts should always check for and report changes to the password file (see the Checking file integrity section below).
14.3.5 Securing the Kernel Core, Raw Devices, and File systems
If an attacker breaks root he can do just about anything, but there are certain conveniences. For example, most modern kernels have a packet sniffing device driver built in. Under FreeBSD it is called the bpf device. An intruder will commonly attempt to run a packet sniffer on a compromised machine. You do not need to give the intruder the capability and most systems do not have the need for the bpf device compiled in.
But even if you turn off the bpf device, you still have
/dev/mem and /dev/kmem to worry
about. For that matter, the intruder can still write to raw disk devices. Also, there is
another kernel feature called the module loader, kldload(8). An
enterprising intruder can use a KLD module to install his own bpf device, or other sniffing device, on a running kernel. To
avoid these problems you have to run the kernel at a higher secure level, at least
securelevel 1. The securelevel can be set with a sysctl on the
kern.securelevel variable. Once you have set the securelevel
to 1, write access to raw devices will be denied and special chflags flags, such as schg, will be
enforced. You must also ensure that the schg flag is set on
critical startup binaries, directories, and script files -- everything that gets run up
to the point where the securelevel is set. This might be overdoing it, and upgrading the
system is much more difficult when you operate at a higher secure level. You may
compromise and run the system at a higher secure level but not set the schg flag for every system file and directory under the sun. Another
possibility is to simply mount / and /usr read-only. It should be noted that being too draconian in what
you attempt to protect may prevent the all-important detection of an intrusion.
14.3.6 Checking File Integrity: Binaries, Configuration Files, Etc.
When it comes right down to it, you can only protect your core system configuration and control files so much before the convenience factor rears its ugly head. For example, using chflags to set the schg bit on most of the files in / and /usr is probably counterproductive, because while it may protect the files, it also closes a detection window. The last layer of your security onion is perhaps the most important -- detection. The rest of your security is pretty much useless (or, worse, presents you with a false sense of security) if you cannot detect potential intrusions. Half the job of the onion is to slow down the attacker, rather than stop him, in order to be able to catch him in the act.
The best way to detect an intrusion is to look for modified, missing, or unexpected files. The best way to look for modified files is from another (often centralized) limited-access system. Writing your security scripts on the extra-secure limited-access system makes them mostly invisible to potential attackers, and this is important. In order to take maximum advantage you generally have to give the limited-access box significant access to the other machines in the business, usually either by doing a read-only NFS export of the other machines to the limited-access box, or by setting up ssh key-pairs to allow the limited-access box to ssh to the other machines. Except for its network traffic, NFS is the least visible method -- allowing you to monitor the file systems on each client box virtually undetected. If your limited-access server is connected to the client boxes through a switch, the NFS method is often the better choice. If your limited-access server is connected to the client boxes through a hub, or through several layers of routing, the NFS method may be too insecure (network-wise) and using ssh may be the better choice even with the audit-trail tracks that ssh lays.
Once you have given a limited-access box at least read access to the client systems it is supposed to monitor, you must write scripts to do the actual monitoring. Given an NFS mount, you can write scripts out of simple system utilities such as find(1) and md5(1). It is best to physically md5 the client-box files at least once a day, and to test control files such as those found in /etc and /usr/local/etc even more often. When mismatches are found, relative to the base md5 information the limited-access machine knows is valid, it should scream at a sysadmin to go check it out. A good security script will also check for inappropriate suid binaries and for new or deleted files on system partitions such as / and /usr.
When using ssh rather than NFS, writing the security script is much more difficult. You essentially have to scp the scripts to the client box in order to run them, making them visible, and for safety you also need to scp the binaries (such as find) that those scripts use. The ssh client on the client box may already be compromised. All in all, using ssh may be necessary when running over insecure links, but it is also a lot harder to deal with.
A good security script will also check for changes to user and staff members access configuration files: .rhosts, .shosts, .ssh/authorized_keys and so forth, files that might fall outside the purview of the MD5 check.
If you have a huge amount of user disk space, it may take too long to run through every file on those partitions. In this case, setting mount flags to disallow suid binaries is a good idea. The nosuid option (see mount(8)) is what you want to look into. You should probably scan them anyway, at least once a week, since the object of this layer is to detect a break-in attempt, whether or not the attempt succeeds.
Process accounting (see accton(8)) is a relatively low-overhead feature of the operating system which might help as a post-break-in evaluation mechanism. It is especially useful in tracking down how an intruder has actually broken into a system, assuming the file is still intact after the break-in has occured.
Finally, security scripts should process the log files, and the logs themselves should be generated in as secure a manner as possible -- remote syslog can be very useful. An intruder will try to cover his tracks, and log files are critical to the sysadmin trying to track down the time and method of the initial break-in. One way to keep a permanent record of the log files is to run the system console to a serial port and collect the information to a secure machine monitoring the consoles.
14.3.7 Paranoia
A little paranoia never hurts. As a rule, a sysadmin can add any number of security features, as long as they do not affect convenience, and can add security features that do affect convenience with some added thought. Even more importantly, a security administrator should mix it up a bit -- if you use recommendations such as those given by this document verbatim, you give away your methodologies to the prospective attacker who also has access to this document.
14.3.8 Denial of Service Attacks
This section covers Denial of Service attacks. A DoS attack is typically a packet attack. While there is not much you can do about modern spoofed packet attacks that saturate your network, you can generally limit the damage by ensuring that the attacks cannot take down your servers by:
-
Limiting server forks.
-
Limiting springboard attacks (ICMP response attacks, ping broadcast, etc.).
-
Overloading the Kernel Route Cache.
A common DoS attack scenario is attacking a forking server and making it spawning so
many child processes that the host system eventually runs out of memory, file
descriptors, etc. and then grinds to a halt. inetd (see inetd(8)) has several
options to limit this sort of attack. It should be noted that while it is possible to
prevent a machine from going down, it is not generally possible to prevent a service from
being disrupted by the attack. Read the inetd manual page
carefully and pay specific attention to the -c, -C, and -R options. Note that
spoofed-IP attacks will circumvent the -C option to inetd, so typically a combination of options must be used. Some
standalone servers have self-fork-limitation parameters.
Sendmail has its -OMaxDaemonChildren option, which tends to work much better than
trying to use Sendmail's load limiting options due to the load
lag. You should specify a MaxDaemonChildren parameter, when you
start sendmail; high enough to handle your expected load, but
not so high that the computer cannot handle that number of Sendmail instances without falling on its face. It is also
prudent to run Sendmail in queued mode (-ODeliveryMode=queued) and to run the daemon (sendmail -bd) separate from the queue-runs (sendmail -q15m). If you still want real-time delivery you can run
the queue at a much lower interval, such as -q1m, but be sure
to specify a reasonable MaxDaemonChildren option for that Sendmail
to prevent cascade failures.
Syslogd can be attacked directly and it is strongly
recommended that you use the -s option whenever possible, and
the -a option otherwise.
You should also be fairly careful with connect-back services such as TCP Wrapper's reverse-identd, which can be attacked directly. You generally do not want to use the reverse-ident feature of TCP Wrapper for this reason.
It is a very good idea to protect internal services from external access by
firewalling them off at your border routers. The idea here is to prevent saturation
attacks from outside your LAN, not so much to protect internal services from
network-based root compromise. Always configure an exclusive
firewall, i.e., “firewall everything except ports A, B, C, D, and M-Z”. This way you can
firewall off all of your low ports except for certain specific services such as named (if you are primary for a zone), ntalkd, sendmail, and other
Internet-accessible services. If you try to configure the firewall the other way -- as an
inclusive or permissive firewall, there is a good chance that you will forget to
“close” a couple of services, or that you will add a new internal service and
forget to update the firewall. You can still open up the high-numbered port range on the
firewall, to allow permissive-like operation, without compromising your low ports. Also
take note that FreeBSD allows you to control the range of port numbers used for dynamic
binding, via the various net.inet.ip.portrange sysctl's (sysctl -a | fgrep portrange),
which can also ease the complexity of your firewall's configuration. For example, you
might use a normal first/last range of 4000 to 5000, and a hiport range of 49152 to
65535, then block off everything under 4000 in your firewall (except for certain specific
Internet-accessible ports, of course).
Another common DoS attack is called a springboard attack -- to attack a server in a manner that causes the server to generate responses which overloads the server, the local network, or some other machine. The most common attack of this nature is the ICMP ping broadcast attack. The attacker spoofs ping packets sent to your LAN's broadcast address with the source IP address set to the actual machine they wish to attack. If your border routers are not configured to stomp on ping packets to broadcast addresses, your LAN winds up generating sufficient responses to the spoofed source address to saturate the victim, especially when the attacker uses the same trick on several dozen broadcast addresses over several dozen different networks at once. Broadcast attacks of over a hundred and twenty megabits have been measured. A second common springboard attack is against the ICMP error reporting system. By constructing packets that generate ICMP error responses, an attacker can saturate a server's incoming network and cause the server to saturate its outgoing network with ICMP responses. This type of attack can also crash the server by running it out of memory, especially if the server cannot drain the ICMP responses it generates fast enough. Use the sysctl variable net.inet.icmp.icmplim to limit these attacks. The last major class of springboard attacks is related to certain internal inetd services such as the udp echo service. An attacker simply spoofs a UDP packet with the source address being server A's echo port, and the destination address being server B's echo port, where server A and B are both on your LAN. The two servers then bounce this one packet back and forth between each other. The attacker can overload both servers and their LANs simply by injecting a few packets in this manner. Similar problems exist with the internal chargen port. A competent sysadmin will turn off all of these inetd-internal test services.
Spoofed packet attacks may also be used to overload the kernel route cache. Refer to
the net.inet.ip.rtexpire, rtminexpire, and rtmaxcache sysctl parameters. A spoofed packet attack that uses a random source
IP will cause the kernel to generate a temporary cached route in the route table,
viewable with netstat -rna | fgrep W3. These routes typically
timeout in 1600 seconds or so. If the kernel detects that the cached route table has
gotten too big it will dynamically reduce the rtexpire but
will never decrease it to less than rtminexpire. There are
two problems:
-
The kernel does not react quickly enough when a lightly loaded server is suddenly attacked.
-
The
rtminexpireis not low enough for the kernel to survive a sustained attack.
If your servers are connected to the Internet via a T3 or better, it may be prudent to
manually override both rtexpire and rtminexpire via sysctl(8). Never set
either parameter to zero (unless you want to crash the machine). Setting both parameters
to 2 seconds should be sufficient to protect the route table from attack.
14.3.9 Access Issues with Kerberos and SSH
There are a few issues with both Kerberos and ssh that need to be addressed if you
intend to use them. Kerberos 5 is an excellent authentication protocol, but there are
bugs in the kerberized telnet and rlogin applications that make them unsuitable for dealing with
binary streams. Also, by default Kerberos does not encrypt a session unless you use the
-x option. ssh encrypts everything
by default.
Ssh works quite well in every respect except that it forwards encryption keys by default. What this means is that if you have a secure workstation holding keys that give you access to the rest of the system, and you ssh to an insecure machine, your keys are usable. The actual keys themselves are not exposed, but ssh installs a forwarding port for the duration of your login, and if an attacker has broken root on the insecure machine he can utilize that port to use your keys to gain access to any other machine that your keys unlock.
We recommend that you use ssh in combination with Kerberos whenever possible for staff logins. Ssh can be compiled with Kerberos support. This reduces your reliance on potentially exposed ssh keys while at the same time protecting passwords via Kerberos. Ssh keys should only be used for automated tasks from secure machines (something that Kerberos is unsuited to do). We also recommend that you either turn off key-forwarding in the ssh configuration, or that you make use of the from=IP/DOMAIN option that ssh allows in its authorized_keys file to make the key only usable to entities logging in from specific machines.
14.4 DES, Blowfish, MD5, and Crypt
Parts rewritten and updated by Bill Swingle.Every user on a UNIX system has a password associated with their account. It seems obvious that these passwords need to be known only to the user and the actual operating system. In order to keep these passwords secret, they are encrypted with what is known as a “one-way hash”, that is, they can only be easily encrypted but not decrypted. In other words, what we told you a moment ago was obvious is not even true: the operating system itself does not really know the password. It only knows the encrypted form of the password. The only way to get the “plain-text” password is by a brute force search of the space of possible passwords.
Unfortunately the only secure way to encrypt passwords when UNIX came into being was based on DES, the Data Encryption Standard. This was not such a problem for users resident in the US, but since the source code for DES could not be exported outside the US, FreeBSD had to find a way to both comply with US law and retain compatibility with all the other UNIX variants that still used DES.
The solution was to divide up the encryption libraries so that US users could install the DES libraries and use DES but international users still had an encryption method that could be exported abroad. This is how FreeBSD came to use MD5 as its default encryption method. MD5 is believed to be more secure than DES, so installing DES is offered primarily for compatibility reasons.
14.4.1 Recognizing Your Crypt Mechanism
Currently the library supports DES, MD5 and Blowfish hash functions. By default FreeBSD uses MD5 to encrypt passwords.
It is pretty easy to identify which encryption method FreeBSD is set up to use. Examining the encrypted passwords in the /etc/master.passwd file is one way. Passwords encrypted with the MD5 hash are longer than those encrypted with the DES hash and also begin with the characters $1$. Passwords starting with $2a$ are encrypted with the Blowfish hash function. DES password strings do not have any particular identifying characteristics, but they are shorter than MD5 passwords, and are coded in a 64-character alphabet which does not include the $ character, so a relatively short string which does not begin with a dollar sign is very likely a DES password.
The password format used for new passwords is controlled by the passwd_format login capability in /etc/login.conf, which takes values of des, md5 or blf. See the login.conf(5) manual page for more information about login capabilities.
14.5 One-time Passwords
By default, FreeBSD includes support for OPIE (One-time Passwords In Everything), which uses the MD5 hash by default.
There are three different sorts of passwords which we will discuss below. The first is your usual UNIX style or Kerberos password; we will call this a “UNIX password”. The second sort is the one-time password which is generated by the OPIE opiekey(1) program and accepted by the opiepasswd(1) program and the login prompt; we will call this a “one-time password”. The final sort of password is the secret password which you give to the opiekey program (and sometimes the opiepasswd programs) which it uses to generate one-time passwords; we will call it a “secret password” or just unqualified “password”.
The secret password does not have anything to do with your UNIX password; they can be the same but this is not recommended. OPIE secret passwords are not limited to 8 characters like old UNIX passwords[8], they can be as long as you like. Passwords of six or seven word long phrases are fairly common. For the most part, the OPIE system operates completely independently of the UNIX password system.
Besides the password, there are two other pieces of data that are important to OPIE. One is what is known as the “seed” or “key”, consisting of two letters and five digits. The other is what is called the “iteration count”, a number between 1 and 100. OPIE creates the one-time password by concatenating the seed and the secret password, then applying the MD5 hash as many times as specified by the iteration count and turning the result into six short English words. These six English words are your one-time password. The authentication system (primarily PAM) keeps track of the last one-time password used, and the user is authenticated if the hash of the user-provided password is equal to the previous password. Because a one-way hash is used it is impossible to generate future one-time passwords if a successfully used password is captured; the iteration count is decremented after each successful login to keep the user and the login program in sync. When the iteration count gets down to 1, OPIE must be reinitialized.
There are a few programs involved in each system which we will discuss below. The opiekey program accepts an iteration count, a seed, and a secret password, and generates a one-time password or a consecutive list of one-time passwords. The opiepasswd program is used to initialize OPIE, and to change passwords, iteration counts, or seeds; it takes either a secret passphrase, or an iteration count, seed, and a one-time password. The opieinfo program will examine the relevant credentials files (/etc/opiekeys) and print out the invoking user's current iteration count and seed.
There are four different sorts of operations we will cover. The first is using opiepasswd over a secure connection to set up one-time-passwords for the first time, or to change your password or seed. The second operation is using opiepasswd over an insecure connection, in conjunction with opiekey over a secure connection, to do the same. The third is using opiekey to log in over an insecure connection. The fourth is using opiekey to generate a number of keys which can be written down or printed out to carry with you when going to some location without secure connections to anywhere.
14.5.1 Secure Connection Initialization
To initialize OPIE for the first time, execute the opiepasswd command:
% opiepasswd -c
[grimreaper] ~ $ opiepasswd -f -c
Adding unfurl:
Only use this method from the console; NEVER from remote. If you are using
telnet, xterm, or a dial-in, type ^C now or exit with no password.
Then run opiepasswd without the -c parameter.
Using MD5 to compute responses.
Enter new secret pass phrase:
Again new secret pass phrase:
ID unfurl OTP key is 499 to4268
MOS MALL GOAT ARM AVID COED
At the Enter new secret pass phrase: or Enter secret password: prompts, you should enter a password or phrase. Remember, this is not the password that you will use to login with, this is used to generate your one-time login keys. The “ID” line gives the parameters of your particular instance: your login name, the iteration count, and seed. When logging in the system will remember these parameters and present them back to you so you do not have to remember them. The last line gives the particular one-time password which corresponds to those parameters and your secret password; if you were to re-login immediately, this one-time password is the one you would use.
14.5.2 Insecure Connection Initialization
To initialize or change your secret password over an insecure connection, you will need to already have a secure connection to some place where you can run opiekey; this might be in the form of a shell prompt on a machine you trust. You will also need to make up an iteration count (100 is probably a good value), and you may make up your own seed or use a randomly-generated one. Over on the insecure connection (to the machine you are initializing), use opiepasswd:
% opiepasswd
Updating unfurl:
You need the response from an OTP generator.
Old secret pass phrase:
otp-md5 498 to4268 ext
Response: GAME GAG WELT OUT DOWN CHAT
New secret pass phrase:
otp-md5 499 to4269
Response: LINE PAP MILK NELL BUOY TROY
ID mark OTP key is 499 gr4269
LINE PAP MILK NELL BUOY TROY
To accept the default seed press Return. Then before entering an access password, move over to your secure connection and give it the same parameters:
% opiekey 498 to4268
Using the MD5 algorithm to compute response.
Reminder: Don't use opiekey from telnet or dial-in sessions.
Enter secret pass phrase:
GAME GAG WELT OUT DOWN CHAT
Now switch back over to the insecure connection, and copy the one-time password generated over to the relevant program.
14.5.3 Generating a Single One-time Password
Once you have initialized OPIE and login, you will be presented with a prompt like this:
% telnet example.com
Trying 10.0.0.1...
Connected to example.com
Escape character is '^]'.
FreeBSD/i386 (example.com) (ttypa)
login: <username>
otp-md5 498 gr4269 ext
Password:
As a side note, the OPIE prompts have a useful feature (not shown here): if you press Return at the password prompt, the prompter will turn echo on, so you can see what you are typing. This can be extremely useful if you are attempting to type in a password by hand, such as from a printout.
At this point you need to generate your one-time password to answer this login prompt. This must be done on a trusted system that you can run opiekey on. (There are versions of these for DOS, Windows and Mac OS as well.) They need the iteration count and the seed as command line options. You can cut-and-paste these right from the login prompt on the machine that you are logging in to.
On the trusted system:
% opiekey 498 to4268
Using the MD5 algorithm to compute response.
Reminder: Don't use opiekey from telnet or dial-in sessions.
Enter secret pass phrase:
GAME GAG WELT OUT DOWN CHAT
Now that you have your one-time password you can continue logging in.
14.5.4 Generating Multiple One-time Passwords
Sometimes you have to go places where you do not have access to a trusted machine or secure connection. In this case, it is possible to use the opiekey command to generate a number of one-time passwords beforehand to be printed out and taken with you. For example:
% opiekey -n 5 30 zz99999
Using the MD5 algorithm to compute response.
Reminder: Don't use opiekey from telnet or dial-in sessions.
Enter secret pass phrase: <secret password>
26: JOAN BORE FOSS DES NAY QUIT
27: LATE BIAS SLAY FOLK MUCH TRIG
28: SALT TIN ANTI LOON NEAL USE
29: RIO ODIN GO BYE FURY TIC
30: GREW JIVE SAN GIRD BOIL PHI
The -n 5 requests five keys in sequence, the 30 specifies what the last iteration number should be. Note that
these are printed out in reverse
order of eventual use. If you are really paranoid, you might want to write the results
down by hand; otherwise you can cut-and-paste into lpr. Note
that each line shows both the iteration count and the one-time password; you may still
find it handy to scratch off passwords as you use them.
14.5.5 Restricting Use of UNIX® Passwords
OPIE can restrict the use of UNIX passwords based on the IP address of a login session. The relevant file is /etc/opieaccess, which is present by default. Please check opieaccess(5) for more information on this file and which security considerations you should be aware of when using it.
Here is a sample opieaccess file:
permit 192.168.0.0 255.255.0.0
This line allows users whose IP source address (which is vulnerable to spoofing) matches the specified value and mask, to use UNIX passwords at any time.
If no rules in opieaccess are matched, the default is to deny non-OPIE logins.
14.6 TCP Wrappers
Written by: Tom Rhodes.Anyone familiar with inetd(8) has probably heard of TCP Wrappers at some point. But few individuals seem to fully comprehend its usefulness in a network environment. It seems that everyone wants to install a firewall to handle network connections. While a firewall has a wide variety of uses, there are some things that a firewall not handle such as sending text back to the connection originator. The TCP software does this and much more. In the next few sections many of the TCP Wrappers features will be discussed, and, when applicable, example configuration lines will be provided.
The TCP Wrappers software extends the abilities of inetd to provide support for every server daemon under its control. Using this method it is possible to provide logging support, return messages to connections, permit a daemon to only accept internal connections, etc. While some of these features can be provided by implementing a firewall, this will add not only an extra layer of protection but go beyond the amount of control a firewall can provide.
The added functionality of TCP Wrappers should not be considered a replacement for a good firewall. TCP Wrappers can be used in conjunction with a firewall or other security enhancements though and it can serve nicely as an extra layer of protection for the system.
Since this is an extension to the configuration of inetd, the reader is expected have read the inetd configuration section.
Note: While programs run by inetd(8) are not exactly “daemons”, they have traditionally been called daemons. This is the term we will use in this section too.
14.6.1 Initial Configuration
The only requirement of using TCP Wrappers in
FreeBSD is to ensure the inetd server is started from rc.conf with the -Ww option; this is
the default setting. Of course, proper configuration of /etc/hosts.allow is also expected, but syslogd(8) will throw
messages in the system logs in these cases.
Note: Unlike other implementations of TCP Wrappers, the use of hosts.deny has been deprecated. All configuration options should be placed in /etc/hosts.allow.
In the simplest configuration, daemon connection policies are set to either be permitted or blocked depending on the options in /etc/hosts.allow. The default configuration in FreeBSD is to allow a connection to every daemon started with inetd. Changing this will be discussed only after the basic configuration is covered.
Basic configuration usually takes the form of daemon : address : action. Where daemon is the daemon name which inetd started. The address can be a valid hostname, an IP address or an IPv6 address enclosed in brackets ([ ]). The action field can be either allow or deny to grant or deny access appropriately. Keep in mind that configuration works off a first rule match semantic, meaning that the configuration file is scanned in ascending order for a matching rule. When a match is found the rule is applied and the search process will halt.
Several other options exist but they will be explained in a later section. A simple configuration line may easily be constructed from that information alone. For example, to allow POP3 connections via the mail/qpopper daemon, the following lines should be appended to hosts.allow:
# This line is required for POP3 connections:
qpopper : ALL : allow
After adding this line, inetd will need restarted. This can
be accomplished by use of the kill(1) command, or
with the restart parameter with /etc/rc.d/inetd.
14.6.2 Advanced Configuration
TCP Wrappers has advanced options too; they will allow for more control over the way connections are handled. In some cases it may be a good idea to return a comment to certain hosts or daemon connections. In other cases, perhaps a log file should be recorded or an email sent to the administrator. Other situations may require the use of a service for local connections only. This is all possible through the use of configuration options known as wildcards, expansion characters and external command execution. The next two sections are written to cover these situations.
14.6.2.1 External Commands
Suppose that a situation occurs where a connection should be denied yet a reason
should be sent to the individual who attempted to establish that connection. How could it
be done? That action can be made possible by using the twist
option. When a connection attempt is made, twist will be
called to execute a shell command or script. An example already exists in the hosts.allow file:
# The rest of the daemons are protected.
ALL : ALL \
: severity auth.info \
: twist /bin/echo "You are not welcome to use %d from %h."
This example shows that the message, “You are not allowed to use daemon from hostname.” will be returned for any daemon not previously configured in the access file. This is extremely useful for sending a reply back to the connection initiator right after the established connection is dropped. Note that any message returned must be wrapped in quote " characters; there are no exceptions to this rule.
Warning: It may be possible to launch a denial of service attack on the server if an attacker, or group of attackers could flood these daemons with connection requests.
Another possibility is to use the spawn option in these
cases. Like twist, the spawn
implicitly denies the connection and may be used to run external shell commands or
scripts. Unlike twist, spawn will
not send a reply back to the individual who established the connection. For an example,
consider the following configuration line:
# We do not allow connections from example.com:
ALL : .example.com \
: spawn (/bin/echo %a from %h attempted to access %d >> \
/var/log/connections.log) \
: deny
This will deny all connection attempts from the *.example.com domain; simultaneously logging the hostname, IP address and the daemon which they attempted to access in the /var/log/connections.log file.
Aside from the already explained substitution characters above, e.g. %a, a few others exist. See the hosts_access(5) manual page for the complete list.
14.6.2.2 Wildcard Options
Thus far the ALL example has been used continuously throughout the examples. Other options exist which could extend the functionality a bit further. For instance, ALL may be used to match every instance of either a daemon, domain or an IP address. Another wildcard available is PARANOID which may be used to match any host which provides an IP address that may be forged. In other words, paranoid may be used to define an action to be taken whenever a connection is made from an IP address that differs from its hostname. The following example may shed some more light on this discussion:
# Block possibly spoofed requests to sendmail:
sendmail : PARANOID : deny
In that example all connection requests to sendmail which have an IP address that varies from its hostname will be denied.
Caution: Using the PARANOID may severely cripple servers if the client or server has a broken DNS setup. Administrator discretion is advised.
To learn more about wildcards and their associated functionality, see the hosts_access(5) manual page.
Before any of the specific configuration lines above will work, the first configuration line should be commented out in hosts.allow. This was noted at the beginning of this section.
14.7 KerberosIV
Contributed by Mark Murray. Based on a contribution by Mark Dapoz.Kerberos is a network add-on system/protocol that allows users to authenticate themselves through the services of a secure server. Services such as remote login, remote copy, secure inter-system file copying and other high-risk tasks are made considerably safer and more controllable.
The following instructions can be used as a guide on how to set up Kerberos as distributed for FreeBSD. However, you should refer to the relevant manual pages for a complete description.
14.7.1 Installing KerberosIV
Kerberos is an optional component of FreeBSD. The easiest way to install this software is by selecting the krb4 or krb5 distribution in sysinstall during the initial installation of FreeBSD. This will install the “eBones” (KerberosIV) or “Heimdal” (Kerberos5) implementation of Kerberos. These implementations are included because they are developed outside the USA/Canada and were thus available to system owners outside those countries during the era of restrictive export controls on cryptographic code from the USA.
Alternatively, the MIT implementation of Kerberos is available from the Ports Collection as security/krb5.
14.7.2 Creating the Initial Database
This is done on the Kerberos server only. First make sure that you do not have any old Kerberos databases around. You should change to the directory /etc/kerberosIV and check that only the following files are present:
# cd /etc/kerberosIV
# ls
README krb.conf krb.realms
If any additional files (such as principal.* or master_key) exist, then use the kdb_destroy command to destroy the old Kerberos database, or if Kerberos is not running, simply delete the extra files.
You should now edit the krb.conf and krb.realms files to define your Kerberos realm. In this case the realm will be EXAMPLE.COM and the server is grunt.example.com. We edit or create the krb.conf file:
# cat krb.conf
EXAMPLE.COM
EXAMPLE.COM grunt.example.com admin server
CS.BERKELEY.EDU okeeffe.berkeley.edu
ATHENA.MIT.EDU kerberos.mit.edu
ATHENA.MIT.EDU kerberos-1.mit.edu
ATHENA.MIT.EDU kerberos-2.mit.edu
ATHENA.MIT.EDU kerberos-3.mit.edu
LCS.MIT.EDU kerberos.lcs.mit.edu
TELECOM.MIT.EDU bitsy.mit.edu
ARC.NASA.GOV trident.arc.nasa.gov
In this case, the other realms do not need to be there. They are here as an example of how a machine may be made aware of multiple realms. You may wish to not include them for simplicity.
The first line names the realm in which this system works. The other lines contain realm/host entries. The first item on a line is a realm, and the second is a host in that realm that is acting as a “key distribution center”. The words admin server following a host's name means that host also provides an administrative database server. For further explanation of these terms, please consult the Kerberos manual pages.
Now we have to add grunt.example.com to the EXAMPLE.COM realm and also add an entry to put all hosts in the .example.com domain in the EXAMPLE.COM realm. The krb.realms file would be updated as follows:
# cat krb.realms
grunt.example.com EXAMPLE.COM
.example.com EXAMPLE.COM
.berkeley.edu CS.BERKELEY.EDU
.MIT.EDU ATHENA.MIT.EDU
.mit.edu ATHENA.MIT.EDU
Again, the other realms do not need to be there. They are here as an example of how a machine may be made aware of multiple realms. You may wish to remove them to simplify things.
The first line puts the specific system into the named realm. The rest of the lines show how to default systems of a particular subdomain to a named realm.
Now we are ready to create the database. This only needs to run on the Kerberos server (or Key Distribution Center). Issue the kdb_init command to do this:
# kdb_init
Realm name [default ATHENA.MIT.EDU ]: EXAMPLE.COM
You will be prompted for the database Master Password.
It is important that you NOT FORGET this password.
Enter Kerberos master key:
Now we have to save the key so that servers on the local machine can pick it up. Use the kstash command to do this:
# kstash
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!
This saves the encrypted master password in /etc/kerberosIV/master_key.
14.7.3 Making It All Run
Two principals need to be added to the database for each system that will be secured with Kerberos. Their names are kpasswd and rcmd. These two principals are made for each system, with the instance being the name of the individual system.
These daemons, kpasswd and rcmd allow other systems to change Kerberos passwords and run commands like rcp(1), rlogin(1) and rsh(1).
Now let us add these entries:
# kdb_edit
Opening database...
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Previous or default values are in [brackets] ,
enter return to leave the same, or new value.
Principal name: passwd
Instance: grunt
<Not found>, Create [y] ? y
Principal: passwd, Instance: grunt, kdc_key_ver: 1
New Password: <---- enter RANDOM here
Verifying password
New Password: <---- enter RANDOM here
Random password [y] ? y
Principal's new key version = 1
Expiration date (enter yyyy-mm-dd) [ 2000-01-01 ] ?
Max ticket lifetime (*5 minutes) [ 255 ] ?
Attributes [ 0 ] ?
Edit O.K.
Principal name: rcmd
Instance: grunt
<Not found>, Create [y] ?
Principal: rcmd, Instance: grunt, kdc_key_ver: 1
New Password: <---- enter RANDOM here
Verifying password
New Password: <---- enter RANDOM here
Random password [y] ?
Principal's new key version = 1
Expiration date (enter yyyy-mm-dd) [ 2000-01-01 ] ?
Max ticket lifetime (*5 minutes) [ 255 ] ?
Attributes [ 0 ] ?
Edit O.K.
Principal name: <---- null entry here will cause an exit
14.7.4 Creating the Server File
We now have to extract all the instances which define the services on each machine. For this we use the ext_srvtab command. This will create a file which must be copied or moved by secure means to each Kerberos client's /etc directory. This file must be present on each server and client, and is crucial to the operation of Kerberos.
# ext_srvtab grunt
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Generating 'grunt-new-srvtab'....
Now, this command only generates a temporary file which must be renamed to srvtab so that all the servers can pick it up. Use the mv(1) command to move it into place on the original system:
# mv grunt-new-srvtab srvtab
If the file is for a client system, and the network is not deemed safe, then copy the client-new-srvtab to removable media and transport it by secure physical means. Be sure to rename it to srvtab in the client's /etc directory, and make sure it is mode 600:
# mv grumble-new-srvtab srvtab
# chmod 600 srvtab
14.7.5 Populating the Database
We now have to add some user entries into the database. First let us create an entry for the user jane. Use the kdb_edit command to do this:
# kdb_edit
Opening database...
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Previous or default values are in [brackets] ,
enter return to leave the same, or new value.
Principal name: jane
Instance:
<Not found>, Create [y] ? y
Principal: jane, Instance: , kdc_key_ver: 1
New Password: <---- enter a secure password here
Verifying password
New Password: <---- re-enter the password here
Principal's new key version = 1
Expiration date (enter yyyy-mm-dd) [ 2000-01-01 ] ?
Max ticket lifetime (*5 minutes) [ 255 ] ?
Attributes [ 0 ] ?
Edit O.K.
Principal name: <---- null entry here will cause an exit
14.7.6 Testing It All Out
First we have to start the Kerberos daemons. Note that if you have correctly edited your /etc/rc.conf then this will happen automatically when you reboot. This is only necessary on the Kerberos server. Kerberos clients will automatically get what they need from the /etc/kerberosIV directory.
# kerberos &
Kerberos server starting
Sleep forever on error
Log file is /var/log/kerberos.log
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Current Kerberos master key version is 1
Local realm: EXAMPLE.COM
# kadmind -n &
KADM Server KADM0.0A initializing
Please do not use 'kill -9' to kill this job, use a
regular kill instead
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Now we can try using the kinit command to get a ticket for the ID jane that we created above:
% kinit jane
MIT Project Athena (grunt.example.com)
Kerberos Initialization for "jane"
Password:
Try listing the tokens using klist to see if we really have them:
% klist
Ticket file: /tmp/tkt245
Principal: jane@EXAMPLE.COM
Issued Expires Principal
Apr 30 11:23:22 Apr 30 19:23:22 krbtgt.EXAMPLE.COM@EXAMPLE.COM
Now try changing the password using passwd(1) to check if the kpasswd daemon can get authorization to the Kerberos database:
% passwd
realm EXAMPLE.COM
Old password for jane:
New Password for jane:
Verifying password
New Password for jane:
Password changed.
14.7.7 Adding su Privileges
Kerberos allows us to give each user who needs root privileges their own separate su(1) password. We could now add an ID which is authorized to su(1) to root. This is controlled by having an instance of root associated with a principal. Using kdb_edit we can create the entry jane.root in the Kerberos database:
# kdb_edit
Opening database...
Enter Kerberos master key:
Current Kerberos master key version is 1.
Master key entered. BEWARE!
Previous or default values are in [brackets] ,
enter return to leave the same, or new value.
Principal name: jane
Instance: root
<Not found>, Create [y] ? y
Principal: jane, Instance: root, kdc_key_ver: 1
New Password: <---- enter a SECURE password here
Verifying password
New Password: <---- re-enter the password here
Principal's new key version = 1
Expiration date (enter yyyy-mm-dd) [ 2000-01-01 ] ?
Max ticket lifetime (*5 minutes) [ 255 ] ? 12 <--- Keep this short!
Attributes [ 0 ] ?
Edit O.K.
Principal name: <---- null entry here will cause an exit
Now try getting tokens for it to make sure it works:
# kinit jane.root
MIT Project Athena (grunt.example.com)
Kerberos Initialization for "jane.root"
Password:
Now we need to add the user to root's .klogin file:
# cat /root/.klogin
jane.root@EXAMPLE.COM
Now try doing the su(1):
% su
Password:
and take a look at what tokens we have:
# klist
Ticket file: /tmp/tkt_root_245
Principal: jane.root@EXAMPLE.COM
Issued Expires Principal
May 2 20:43:12 May 3 04:43:12 krbtgt.EXAMPLE.COM@EXAMPLE.COM
14.7.8 Using Other Commands
In an earlier example, we created a principal called jane with an instance root. This was based on a user with the same name as the principal, and this is a Kerberos default; that a <principal>.<instance> of the form <username>.root will allow that <username> to su(1) to root if the necessary entries are in the .klogin file in root's home directory:
# cat /root/.klogin
jane.root@EXAMPLE.COM
Likewise, if a user has in their own home directory lines of the form:
% cat ~/.klogin
jane@EXAMPLE.COM
jack@EXAMPLE.COM
This allows anyone in the EXAMPLE.COM realm who has authenticated themselves as jane or jack (via kinit, see above) to access to jane's account or files on this system (grunt) via rlogin(1), rsh(1) or rcp(1).
For example, jane now logs into another system using Kerberos:
% kinit
MIT Project Athena (grunt.example.com)
Password:
% rlogin grunt
Last login: Mon May 1 21:14:47 from grumble
Copyright (c) 1980, 1983, 1986, 1988, 1990, 1991, 1993, 1994
The Regents of the University of California. All rights reserved.
FreeBSD BUILT-19950429 (GR386) #0: Sat Apr 29 17:50:09 SAT 1995
Or jack logs into jane's account on the same machine (jane having set up the .klogin file as above, and the person in charge of Kerberos having set up principal jack with a null instance):
% kinit
% rlogin grunt -l jane
MIT Project Athena (grunt.example.com)
Password:
Last login: Mon May 1 21:16:55 from grumble
Copyright (c) 1980, 1983, 1986, 1988, 1990, 1991, 1993, 1994
The Regents of the University of California. All rights reserved.
FreeBSD BUILT-19950429 (GR386) #0: Sat Apr 29 17:50:09 SAT 1995
14.8 Kerberos5
Contributed by Tillman Hodgson. Based on a contribution by Mark Murray.Every FreeBSD release beyond FreeBSD-5.1 includes support only for Kerberos5. Hence Kerberos5 is the only version included, and its configuration is similar in many aspects to that of KerberosIV. The following information only applies to Kerberos5 in post FreeBSD-5.0 releases. Users who wish to use the KerberosIV package may install the security/krb4 port.
Kerberos is a network add-on system/protocol that allows users to authenticate themselves through the services of a secure server. Services such as remote login, remote copy, secure inter-system file copying and other high-risk tasks are made considerably safer and more controllable.
Kerberos can be described as an identity-verifying proxy system. It can also be described as a trusted third-party authentication system. Kerberos provides only one function -- the secure authentication of users on the network. It does not provide authorization functions (what users are allowed to do) or auditing functions (what those users did). After a client and server have used Kerberos to prove their identity, they can also encrypt all of their communications to assure privacy and data integrity as they go about their business.
Therefore it is highly recommended that Kerberos be used with other security methods which provide authorization and audit services.
The following instructions can be used as a guide on how to set up Kerberos as distributed for FreeBSD. However, you should refer to the relevant manual pages for a complete description.
For purposes of demonstrating a Kerberos installation, the various name spaces will be handled as follows:
-
The DNS domain (“zone”) will be example.org.
-
The Kerberos realm will be EXAMPLE.ORG.
Note: Please use real domain names when setting up Kerberos even if you intend to run it internally. This avoids DNS problems and assures inter-operation with other Kerberos realms.
14.8.1 History
Kerberos was created by MIT as a solution to network security problems. The Kerberos protocol uses strong cryptography so that a client can prove its identity to a server (and vice versa) across an insecure network connection.
Kerberos is both the name of a network authentication protocol and an adjective to describe programs that implement the program (Kerberos telnet, for example). The current version of the protocol is version 5, described in RFC 1510.
Several free implementations of this protocol are available, covering a wide range of operating systems. The Massachusetts Institute of Technology (MIT), where Kerberos was originally developed, continues to develop their Kerberos package. It is commonly used in the US as a cryptography product, as such it has historically been affected by US export regulations. The MIT Kerberos is available as a port (security/krb5). Heimdal Kerberos is another version 5 implementation, and was explicitly developed outside of the US to avoid export regulations (and is thus often included in non-commercial UNIX variants). The Heimdal Kerberos distribution is available as a port (security/heimdal), and a minimal installation of it is included in the base FreeBSD install.
In order to reach the widest audience, these instructions assume the use of the Heimdal distribution included in FreeBSD.
14.8.2 Setting up a Heimdal KDC
The Key Distribution Center (KDC) is the centralized authentication service that Kerberos provides -- it is the computer that issues Kerberos tickets. The KDC is considered “trusted” by all other computers in the Kerberos realm, and thus has heightened security concerns.
Note that while running the Kerberos server requires very few computing resources, a dedicated machine acting only as a KDC is recommended for security reasons.
To begin setting up a KDC, ensure that your /etc/rc.conf file contains the correct settings to act as a KDC (you may need to adjust paths to reflect your own system):
kerberos5_server_enable="YES"
kadmind5_server_enable="YES"
Next we will set up your Kerberos config file, /etc/krb5.conf:
[libdefaults]
default_realm = EXAMPLE.ORG
[realms]
EXAMPLE.ORG = {
kdc = kerberos.example.org
admin_server = kerberos.example.org
}
[domain_realm]
.example.org = EXAMPLE.ORG
Note that this /etc/krb5.conf file implies that your KDC will have the fully-qualified hostname of kerberos.example.org. You will need to add a CNAME (alias) entry to your zone file to accomplish this if your KDC has a different hostname.
Note: For large networks with a properly configured BIND DNS server, the above example could be trimmed to:
[libdefaults] default_realm = EXAMPLE.ORGWith the following lines being appended to the example.org zonefile:
_kerberos._udp IN SRV 01 00 88 kerberos.example.org. _kerberos._tcp IN SRV 01 00 88 kerberos.example.org. _kpasswd._udp IN SRV 01 00 464 kerberos.example.org. _kerberos-adm._tcp IN SRV 01 00 749 kerberos.example.org. _kerberos IN TXT EXAMPLE.ORG
Note: For clients to be able to find the Kerberos services, you must have either a fully configured /etc/krb5.conf or a minimally configured /etc/krb5.conf and a properly configured DNS server.
Next we will create the Kerberos database. This database contains the keys of all principals encrypted with a master password. You are not required to remember this password, it will be stored in a file (/var/heimdal/m-key). To create the master key, run kstash and enter a password.
Once the master key has been created, you can initialize the database using the kadmin program with the -l option (standing for “local”). This option instructs kadmin to modify the database files directly rather than going through the kadmind network service. This handles the chicken-and-egg problem of trying to connect to the database before it is created. Once you have the kadmin prompt, use the init command to create your realms initial database.
Lastly, while still in kadmin, create your first principal using the add command. Stick to the defaults options for the principal for now, you can always change them later with the modify command. Note that you can use the ? command at any prompt to see the available options.
A sample database creation session is shown below:
# kstash
Master key: xxxxxxxx
Verifying password - Master key: xxxxxxxx
# kadmin -l
kadmin> init EXAMPLE.ORG
Realm max ticket life [unlimited]:
kadmin> add tillman
Max ticket life [unlimited]:
Max renewable life [unlimited]:
Attributes []:
Password: xxxxxxxx
Verifying password - Password: xxxxxxxx
Now it is time to start up the KDC services. Run /etc/rc.d/kerberos start and /etc/rc.d/kadmind start to bring up the services. Note that you will not have any kerberized daemons running at this point but you should be able to confirm the that the KDC is functioning by obtaining and listing a ticket for the principal (user) that you just created from the command-line of the KDC itself:
% kinit tillman
tillman@EXAMPLE.ORG's Password:
% klist
Credentials cache: FILE:/tmp/krb5cc_500
Principal: tillman@EXAMPLE.ORG
Issued Expires Principal
Aug 27 15:37:58 Aug 28 01:37:58 krbtgt/EXAMPLE.ORG@EXAMPLE.ORG
The ticket can then be revoked when you have finished:
% k5destroy
14.8.3 Kerberos enabling a server with Heimdal services
First, we need a copy of the Kerberos configuration file, /etc/krb5.conf. To do so, simply copy it over to the client computer from the KDC in a secure fashion (using network utilities, such as scp(1), or physically via a floppy disk).
Next you need a /etc/krb5.keytab file. This is the major difference between a server providing Kerberos enabled daemons and a workstation -- the server must have a keytab file. This file contains the server's host key, which allows it and the KDC to verify each others identity. It must be transmitted to the server in a secure fashion, as the security of the server can be broken if the key is made public. This explicitly means that transferring it via a clear text channel, such as FTP, is a very bad idea.
Typically, you transfer to the keytab to the server using the kadmin program. This is handy because you also need to create the host principal (the KDC end of the krb5.keytab) using kadmin.
Note that you must have already obtained a ticket and that this ticket must be allowed to use the kadmin interface in the kadmind.acl. See the section titled “Remote administration” in the Heimdal info pages (info heimdal) for details on designing access control lists. If you do not want to enable remote kadmin access, you can simply securely connect to the KDC (via local console, ssh(1) or Kerberos telnet(1)) and perform administration locally using kadmin -l.
After installing the /etc/krb5.conf file, you can use kadmin from the Kerberos server. The add --random-key command will let you add the server's host principal, and the ext command will allow you to extract the server's host principal to its own keytab. For example:
# kadmin
kadmin> add --random-key host/myserver.example.org
Max ticket life [unlimited]:
Max renewable life [unlimited]:
Attributes []:
kadmin> ext host/myserver.example.org
kadmin> exit
Note that the ext command (short for “extract”) stores the extracted key in /etc/krb5.keytab by default.
If you do not have kadmind running on the KDC (possibly for security reasons) and thus do not have access to kadmin remotely, you can add the host principal (host/myserver.EXAMPLE.ORG) directly on the KDC and then extract it to a temporary file (to avoid over-writing the /etc/krb5.keytab on the KDC) using something like this:
# kadmin
kadmin> ext --keytab=/tmp/example.keytab host/myserver.example.org
kadmin> exit
You can then securely copy the keytab to the server computer (using scp or a floppy, for example). Be sure to specify a non-default keytab name to avoid over-writing the keytab on the KDC.
At this point your server can communicate with the KDC (due to its krb5.conf file) and it can prove its own identity (due to the krb5.keytab file). It is now ready for you to enable some Kerberos services. For this example we will enable the telnet service by putting a line like this into your /etc/inetd.conf and then restarting the inetd(8) service with /etc/rc.d/inetd restart:
telnet stream tcp nowait root /usr/libexec/telnetd telnetd -a user
The critical bit is that the -a (for authentication) type is set to user. Consult the telnetd(8) manual page for more details.
14.8.4 Kerberos enabling a client with Heimdal
Setting up a client computer is almost trivially easy. As far as Kerberos configuration goes, you only need the Kerberos configuration file, located at /etc/krb5.conf. Simply securely copy it over to the client computer from the KDC.
Test your client computer by attempting to use kinit, klist, and kdestroy from the client to obtain, show, and then delete a ticket for the principal you created above. You should also be able to use Kerberos applications to connect to Kerberos enabled servers, though if that does not work and obtaining a ticket does the problem is likely with the server and not with the client or the KDC.
When testing an application like telnet, try using a packet sniffer (such as tcpdump(1)) to confirm that your password is not sent in the clear. Try using telnet with the -x option, which encrypts the entire data stream (similar to ssh).
Various non-core Kerberos client applications are also installed by default. This is where the “minimal” nature of the base Heimdal installation is felt: telnet is the only Kerberos enabled service.
The Heimdal port adds some of the missing client applications: Kerberos enabled versions of ftp, rsh, rcp, rlogin, and a few other less common programs. The MIT port also contains a full suite of Kerberos client applications.
14.8.5 User configuration files: .k5login and .k5users
Users within a realm typically have their Kerberos principal (such as tillman@EXAMPLE.ORG) mapped to a local user account (such as a local account named tillman). Client applications such as telnet usually do not require a user name or a principal.
Occasionally, however, you want to grant access to a local user account to someone who does not have a matching Kerberos principal. For example, tillman@EXAMPLE.ORG may need access to the local user account webdevelopers. Other principals may also need access to that local account.
The .k5login and .k5users files, placed in a users home directory, can be used similar to a powerful combination of .hosts and .rhosts, solving this problem. For example, if a .k5login with the following contents:
tillman@example.org
jdoe@example.org
Were to be placed into the home directory of the local user webdevelopers then both principals listed would have access to that account without requiring a shared password.
Reading the manual pages for these commands is recommended. Note that the ksu manual page covers .k5users.
14.8.6 Kerberos Tips, Tricks, and Troubleshooting
-
When using either the Heimdal or MIT Kerberos ports ensure that your PATH environment variable lists the Kerberos versions of the client applications before the system versions.
-
Do all the computers in your realm have synchronized time settings? If not, authentication may fail. Section 27.10 describes how to synchronize clocks using NTP.
-
MIT and Heimdal inter-operate nicely. Except for kadmin, the protocol for which is not standardized.
-
If you change your hostname, you also need to change your host/ principal and update your keytab. This also applies to special keytab entries like the www/ principal used for Apache's www/mod_auth_kerb.
-
All hosts in your realm must be resolvable (both forwards and reverse) in DNS (or /etc/hosts as a minimum). CNAMEs will work, but the A and PTR records must be correct and in place. The error message is not very intuitive: “Kerberos5 refuses authentication because Read req failed: Key table entry not found”.
-
Some operating systems that may being acting as clients to your KDC do not set the permissions for ksu to be setuid root. This means that ksu does not work, which is a good security idea but annoying. This is not a KDC error.
-
With MIT Kerberos, if you want to allow a principal to have a ticket life longer than the default ten hours, you must use modify_principal in kadmin to change the maxlife of both the principal in question and the krbtgt principal. Then the principal can use the -l option with kinit to request a ticket with a longer lifetime.
-
Note: If you run a packet sniffer on your KDC to add in troubleshooting and then run kinit from a workstation, you will notice that your TGT is sent immediately upon running kinit -- even before you type your password! The explanation is that the Kerberos server freely transmits a TGT (Ticket Granting Ticket) to any unauthorized request; however, every TGT is encrypted in a key derived from the user's password. Therefore, when a user types their password it is not being sent to the KDC, it is being used to decrypt the TGT that kinit already obtained. If the decryption process results in a valid ticket with a valid time stamp, the user has valid Kerberos credentials. These credentials include a session key for establishing secure communications with the Kerberos server in the future, as well as the actual ticket-granting ticket, which is actually encrypted with the Kerberos server's own key. This second layer of encryption is unknown to the user, but it is what allows the Kerberos server to verify the authenticity of each TGT.
-
If you want to use long ticket lifetimes (a week, for example) and you are using OpenSSH to connect to the machine where your ticket is stored, make sure that Kerberos
TicketCleanupis set to no in your sshd_config or else your tickets will be deleted when you log out. -
Remember that host principals can have a longer ticket lifetime as well. If your user principal has a lifetime of a week but the host you are connecting to has a lifetime of nine hours, you will have an expired host principal in your cache and the ticket cache will not work as expected.
-
When setting up a krb5.dict file to prevent specific bad passwords from being used (the manual page for kadmind covers this briefly), remember that it only applies to principals that have a password policy assigned to them. The krb5.dict files format is simple: one string per line. Creating a symbolic link to /usr/share/dict/words might be useful.
14.8.7 Differences with the MIT port
The major difference between the MIT and Heimdal installs relates to the kadmin program which has a different (but equivalent) set of commands and uses a different protocol. This has a large implications if your KDC is MIT as you will not be able to use the Heimdal kadmin program to administer your KDC remotely (or vice versa, for that matter).
The client applications may also take slightly different command line options to accomplish the same tasks. Following the instructions on the MIT Kerberos web site (http://web.mit.edu/Kerberos/www/) is recommended. Be careful of path issues: the MIT port installs into /usr/local/ by default, and the “normal” system applications may be run instead of MIT if your PATH environment variable lists the system directories first.
Note: With the MIT security/krb5 port that is provided by FreeBSD, be sure to read the /usr/local/share/doc/krb5/README.FreeBSD file installed by the port if you want to understand why logins via telnetd and klogind behave somewhat oddly. Most importantly, correcting the “incorrect permissions on cache file” behavior requires that the login.krb5 binary be used for authentication so that it can properly change ownership for the forwarded credentials.
The rc.conf must also be modified to contain the following configuration:
kerberos5_server="/usr/local/sbin/krb5kdc"
kadmind5_server="/usr/local/sbin/kadmind"
kerberos5_server_enable="YES"
kadmind5_server_enable="YES"
This is done because the applications for MIT kerberos installs binaries in the /usr/local hierarchy.
14.8.8 Mitigating limitations found in Kerberos
14.8.8.1 Kerberos is an all-or-nothing approach
Every service enabled on the network must be modified to work with Kerberos (or be otherwise secured against network attacks) or else the users credentials could be stolen and re-used. An example of this would be Kerberos enabling all remote shells (via rsh and telnet, for example) but not converting the POP3 mail server which sends passwords in plain text.
14.8.8.2 Kerberos is intended for single-user workstations
In a multi-user environment, Kerberos is less secure. This is because it stores the tickets in the /tmp directory, which is readable by all users. If a user is sharing a computer with several other people simultaneously (i.e. multi-user), it is possible that the user's tickets can be stolen (copied) by another user.
This can be overcome with the -c filename command-line option or (preferably) the KRB5CCNAME environment variable, but this is rarely done. In principal, storing the ticket in the users home directory and using simple file permissions can mitigate this problem.
14.8.8.3 The KDC is a single point of failure
By design, the KDC must be as secure as the master password database is contained on it. The KDC should have absolutely no other services running on it and should be physically secured. The danger is high because Kerberos stores all passwords encrypted with the same key (the “master” key), which in turn is stored as a file on the KDC.
As a side note, a compromised master key is not quite as bad as one might normally fear. The master key is only used to encrypt the Kerberos database and as a seed for the random number generator. As long as access to your KDC is secure, an attacker cannot do much with the master key.
Additionally, if the KDC is unavailable (perhaps due to a denial of service attack or network problems) the network services are unusable as authentication can not be performed, a recipe for a denial-of-service attack. This can alleviated with multiple KDCs (a single master and one or more slaves) and with careful implementation of secondary or fall-back authentication (PAM is excellent for this).
14.8.8.4 Kerberos Shortcomings
Kerberos allows users, hosts and services to authenticate between themselves. It does not have a mechanism to authenticate the KDC to the users, hosts or services. This means that a trojanned kinit (for example) could record all user names and passwords. Something like security/tripwire or other file system integrity checking tools can alleviate this.
14.9 OpenSSL
Written by: Tom Rhodes.One feature that many users overlook is the OpenSSL toolkit included in FreeBSD. OpenSSL provides an encryption transport layer on top of the normal communications layer; thus allowing it to be intertwined with many network applications and services.
Some uses of OpenSSL may include encrypted authentication of mail clients, web based transactions such as credit card payments and more. Many ports such as www/apache13-ssl, and mail/sylpheed-claws will offer compilation support for building with OpenSSL.
Note: In most cases the Ports Collection will attempt to build the security/openssl port unless the WITH_OPENSSL_BASE make variable is explicitly set to “yes”.
The version of OpenSSL included in FreeBSD supports Secure Sockets Layer v2/v3 (SSLv2/SSLv3), Transport Layer Security v1 (TLSv1) network security protocols and can be used as a general cryptographic library.
Note: While OpenSSL supports the IDEA algorithm, it is disabled by default due to United States patents. To use it, the license should be reviewed and, if the restrictions are acceptable, the MAKE_IDEA variable must be set in make.conf.
One of the most common uses of OpenSSL is to provide certificates for use with software applications. These certificates ensure that the credentials of the company or individual are valid and not fraudulent. If the certificate in question has not been verified by one of the several “Certificate Authorities”, or CAs, a warning is usually produced. A Certificate Authority is a company, such as VeriSign, which will sign certificates in order to validate credentials of individuals or companies. This process has a cost associated with it and is definitely not a requirement for using certificates; however, it can put some of the more paranoid users at ease.
14.9.1 Generating Certificates
To generate a certificate, the following command is available:
# openssl req -new -nodes -out req.pem -keyout cert.pem
Generating a 1024 bit RSA private key
................++++++
.......................................++++++
writing new private key to 'cert.pem'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [AU]:US
State or Province Name (full name) [Some-State]:PA
Locality Name (eg, city) []:Pittsburgh
Organization Name (eg, company) [Internet Widgits Pty Ltd]:My Company
Organizational Unit Name (eg, section) []:Systems Administrator
Common Name (eg, YOUR name) []:localhost.example.org
Email Address []:trhodes@FreeBSD.org
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:SOME PASSWORD
An optional company name []:Another Name
Notice the response directly after the “Common Name” prompt shows a domain name. This prompt requires a server name to be entered for verification purposes; placing anything but a domain name would yield a useless certificate. Other options, for instance expire time, alternate encryption algorithms, etc. are available. A complete list may be obtained by viewing the openssl(1) manual page.
Two files should now exist in the directory in which the aforementioned command was issued. The certificate request, req.pem, may be sent to a certificate authority who will validate the credentials that you entered, sign the request and return the certificate to you. The second file created will be named cert.pem and is the private key for the certificate and should be protected at all costs; if this falls in the hands of others it can be used to impersonate you (or your server).
In cases where a signature from a CA is not required, a self signed certificate can be created. First, generate the RSA key:
# openssl dsaparam -rand -genkey -out myRSA.key 1024
Next, generate the CA key:
# openssl gendsa -des3 -out myca.key myRSA.key
Use this key to create the certificate:
# openssl req -new -x509 -days 365 -key myca.key -out new.crt
Two new files should appear in the directory: a certificate authority signature file, myca.key and the certificate itself, new.crt. These should be placed in a directory, preferably under /etc, which is readable only by root. Permissions of 0700 should be fine for this and they can be set with the chmod utility.
14.9.2 Using Certificates, an Example
So what can these files do? A good use would be to encrypt connections to the Sendmail MTA. This would dissolve the use of clear text authentication for users who send mail via the local MTA.
Note: This is not the best use in the world as some MUAs will present the user with an error if they have not installed the certificate locally. Refer to the documentation included with the software for more information on certificate installation.
The following lines should be placed inside the local .mc file:
dnl SSL Options
define(`confCACERT_PATH',`/etc/certs')dnl
define(`confCACERT',`/etc/certs/new.crt')dnl
define(`confSERVER_CERT',`/etc/certs/new.crt')dnl
define(`confSERVER_KEY',`/etc/certs/myca.key')dnl
define(`confTLS_SRV_OPTIONS', `V')dnl
Where /etc/certs/ is the directory to be used for storing
the certificate and key files locally. The last few requirements are a rebuild of the
local .cf file. This is easily achieved by typing make install within the /etc/mail directory. Follow that up with make restart which should start the
Sendmail daemon.
If all went well there will be no error messages in the /var/log/maillog file and Sendmail will show up in the process list.
For a simple test, simply connect to the mail server using the telnet(1) utility:
# telnet example.com 25
Trying 192.0.34.166...
Connected to example.com.
Escape character is '^]'.
220 example.com ESMTP Sendmail 8.12.10/8.12.10; Tue, 31 Aug 2004 03:41:22 -0400 (EDT)
ehlo example.com
250-example.com Hello example.com [192.0.34.166], pleased to meet you
250-ENHANCEDSTATUSCODES
250-PIPELINING
250-8BITMIME
250-SIZE
250-DSN
250-ETRN
250-AUTH LOGIN PLAIN
250-STARTTLS
250-DELIVERBY
250 HELP
quit
221 2.0.0 example.com closing connection
Connection closed by foreign host.
If the “STARTTLS” line appears in the output then everything is working correctly.
14.10 VPN over IPsec
Written by Nik Clayton.Creating a VPN between two networks, separated by the Internet, using FreeBSD gateways.
14.10.1 Understanding IPsec
Written by Hiten M. Pandya.This section will guide you through the process of setting up IPsec, and to use it in an environment which consists of FreeBSD and Microsoft Windows 2000/XP machines, to make them communicate securely. In order to set up IPsec, it is necessary that you are familiar with the concepts of building a custom kernel (see Chapter 8).
IPsec is a protocol which sits on top of the Internet Protocol (IP) layer. It allows two or more hosts to communicate in a secure manner (hence the name). The FreeBSD IPsec “network stack” is based on the KAME implementation, which has support for both protocol families, IPv4 and IPv6.
Note: FreeBSD contains a “hardware accelerated” IPsec stack, known as “Fast IPsec”, that was obtained from OpenBSD. It employs cryptographic hardware (whenever possible) via the crypto(4) subsystem to optimize the performance of IPsec. This subsystem is new, and does not support all the features that are available in the KAME version of IPsec. However, in order to enable hardware-accelerated IPsec, the following kernel option has to be added to your kernel configuration file:
options FAST_IPSEC # new IPsec (cannot define w/ IPSEC)Note, that it is not currently possible to use the “Fast IPsec” subsystem in lieu of the KAME implementation of IPsec. Consult the fast_ipsec(4) manual page for more information.
Note: To let firewalls properly track state for gif(4) tunnels too, you have to enable the
IPSEC_FILTERGIFin your kernel configuration:options IPSEC_FILTERGIF #filter ipsec packets from a tunnel
IPsec consists of two sub-protocols:
-
Encapsulated Security Payload (ESP), protects the IP packet data from third party interference, by encrypting the contents using symmetric cryptography algorithms (like Blowfish, 3DES).
-
Authentication Header (AH), protects the IP packet header from third party interference and spoofing, by computing a cryptographic checksum and hashing the IP packet header fields with a secure hashing function. This is then followed by an additional header that contains the hash, to allow the information in the packet to be authenticated.
ESP and AH can either be used together or separately, depending on the environment.
IPsec can either be used to directly encrypt the traffic between two hosts (known as Transport Mode); or to build “virtual tunnels” between two subnets, which could be used for secure communication between two corporate networks (known as Tunnel Mode). The latter is more commonly known as a Virtual Private Network (VPN). The ipsec(4) manual page should be consulted for detailed information on the IPsec subsystem in FreeBSD.
To add IPsec support to your kernel, add the following options to your kernel configuration file:
options IPSEC #IP security
options IPSEC_ESP #IP security (crypto; define w/ IPSEC)
If IPsec debugging support is desired, the following kernel option should also be added:
options IPSEC_DEBUG #debug for IP security
14.10.2 The Problem
There is no standard for what constitutes a VPN. VPNs can be implemented using a number of different technologies, each of which have their own strengths and weaknesses. This section presents a scenario, and the strategies used for implementing a VPN for this scenario.
14.10.3 The Scenario: Two networks, connected to the Internet, to behave as one
The premise is as follows:
-
You have at least two sites
-
Both sites are using IP internally
-
Both sites are connected to the Internet, through a gateway that is running FreeBSD.
-
The gateway on each network has at least one public IP address.
-
The internal addresses of the two networks can be public or private IP addresses, it does not matter. You can be running NAT on the gateway machine if necessary.
-
The internal IP addresses of the two networks do not collide. While I expect it is theoretically possible to use a combination of VPN technology and NAT to get this to work, I expect it to be a configuration nightmare.
If you find that you are trying to connect two networks, both of which, internally, use the same private IP address range (e.g. both of them use 192.168.1.x), then one of the networks will have to be renumbered.
The network topology might look something like this:
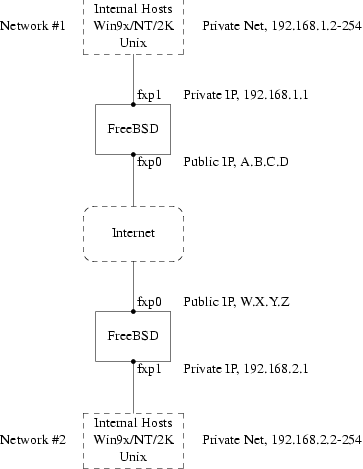
Notice the two public IP addresses. I will use the letters to refer to them in the rest of this article. Anywhere you see those letters in this article, replace them with your own public IP addresses. Note also that internally, the two gateway machines have .1 IP addresses, and that the two networks have different private IP addresses (192.168.1.x and 192.168.2.x respectively). All the machines on the private networks have been configured to use the .1 machine as their default gateway.
The intention is that, from a network point of view, each network should view the machines on the other network as though they were directly attached the same router -- albeit a slightly slow router with an occasional tendency to drop packets.
This means that (for example), machine 192.168.1.20 should be able to run
ping 192.168.2.34
and have it work, transparently. Windows machines should be able to see the machines on the other network, browse file shares, and so on, in exactly the same way that they can browse machines on the local network.
And the whole thing has to be secure. This means that traffic between the two networks has to be encrypted.
Creating a VPN between these two networks is a multi-step process. The stages are as follows:
-
Create a “virtual” network link between the two networks, across the Internet. Test it, using tools like ping(8), to make sure it works.
-
Apply security policies to ensure that traffic between the two networks is transparently encrypted and decrypted as necessary. Test this, using tools like tcpdump(1), to ensure that traffic is encrypted.
-
Configure additional software on the FreeBSD gateways, to allow Windows machines to see one another across the VPN.
14.10.3.1 Step 1: Creating and testing a “virtual” network link
Suppose that you were logged in to the gateway machine on network #1 (with public IP address A.B.C.D, private IP address 192.168.1.1), and you ran ping 192.168.2.1, which is the private address of the machine with IP address W.X.Y.Z. What needs to happen in order for this to work?
-
The gateway machine needs to know how to reach 192.168.2.1. In other words, it needs to have a route to 192.168.2.1.
-
Private IP addresses, such as those in the 192.168.x range are not supposed to appear on the Internet at large. Instead, each packet you send to 192.168.2.1 will need to be wrapped up inside another packet. This packet will need to appear to be from A.B.C.D, and it will have to be sent to W.X.Y.Z. This process is called encapsulation.
-
Once this packet arrives at W.X.Y.Z it will need to “unencapsulated”, and delivered to 192.168.2.1.
You can think of this as requiring a “tunnel” between the two networks. The two “tunnel mouths” are the IP addresses A.B.C.D and W.X.Y.Z, and the tunnel must be told the addresses of the private IP addresses that will be allowed to pass through it. The tunnel is used to transfer traffic with private IP addresses across the public Internet.
This tunnel is created by using the generic interface, or gif devices on FreeBSD. As you can imagine, the gif interface on each gateway host must be configured with four IP addresses; two for the public IP addresses, and two for the private IP addresses.
Support for the gif device must be compiled in to the FreeBSD kernel on both machines. You can do this by adding the line:
device gif
to the kernel configuration files on both machines, and then compile, install, and reboot as normal.
Configuring the tunnel is a two step process. First the tunnel must be told what the outside (or public) IP addresses are, using ifconfig(8). Then the private IP addresses must be configured using ifconfig(8).
On the gateway machine on network #1 you would run the following commands to configure the tunnel.
# ifconfig gif0 create
# ifconfig gif0 tunnel A.B.C.D W.X.Y.Z
# ifconfig gif0 inet 192.168.1.1 192.168.2.1 netmask 0xffffffff
On the other gateway machine you run the same commands, but with the order of the IP addresses reversed.
# ifconfig gif0 create
# ifconfig gif0 tunnel W.X.Y.Z A.B.C.D
# ifconfig gif0 inet 192.168.2.1 192.168.1.1 netmask 0xffffffff
You can then run:
ifconfig gif0
to see the configuration. For example, on the network #1 gateway, you would see this:
# ifconfig gif0
gif0: flags=8051<UP,POINTOPOINT,RUNNING,MULTICAST> mtu 1280
tunnel inet A.B.C.D --> W.X.Y.Z
inet 192.168.1.1 --> 192.168.2.1 netmask 0xffffffff
As you can see, a tunnel has been created between the physical addresses A.B.C.D and W.X.Y.Z, and the traffic allowed through the tunnel is that between 192.168.1.1 and 192.168.2.1.
This will also have added an entry to the routing table on both machines, which you can examine with the command netstat -rn. This output is from the gateway host on network #1.
# netstat -rn
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
...
192.168.2.1 192.168.1.1 UH 0 0 gif0
...
As the “Flags” value indicates, this is a host route, which means that each gateway knows how to reach the other gateway, but they do not know how to reach the rest of their respective networks. That problem will be fixed shortly.
It is likely that you are running a firewall on both machines. This will need to be circumvented for your VPN traffic. You might want to allow all traffic between both networks, or you might want to include firewall rules that protect both ends of the VPN from one another.
It greatly simplifies testing if you configure the firewall to allow all traffic through the VPN. You can always tighten things up later. If you are using ipfw(8) on the gateway machines then a command like
ipfw add 1 allow ip from any to any via gif0
will allow all traffic between the two end points of the VPN, without affecting your other firewall rules. Obviously you will need to run this command on both gateway hosts.
This is sufficient to allow each gateway machine to ping the other. On 192.168.1.1, you should be able to run
ping 192.168.2.1
and get a response, and you should be able to do the same thing on the other gateway machine.
However, you will not be able to reach internal machines on either network yet. This is because of the routing -- although the gateway machines know how to reach one another, they do not know how to reach the network behind each one.
To solve this problem you must add a static route on each gateway machine. The command to do this on the first gateway would be:
route add 192.168.2.0 192.168.2.1 netmask 0xffffff00
This says “In order to reach the hosts on the network 192.168.2.0, send the packets to the host 192.168.2.1”. You will need to run a similar command on the other gateway, but with the 192.168.1.x addresses instead.
IP traffic from hosts on one network will now be able to reach hosts on the other network.
That has now created two thirds of a VPN between the two networks, in as much as it is “virtual” and it is a “network”. It is not private yet. You can test this using ping(8) and tcpdump(1). Log in to the gateway host and run
tcpdump dst host 192.168.2.1
In another log in session on the same host run
ping 192.168.2.1
You will see output that looks something like this:
16:10:24.018080 192.168.1.1 > 192.168.2.1: icmp: echo request
16:10:24.018109 192.168.1.1 > 192.168.2.1: icmp: echo reply
16:10:25.018814 192.168.1.1 > 192.168.2.1: icmp: echo request
16:10:25.018847 192.168.1.1 > 192.168.2.1: icmp: echo reply
16:10:26.028896 192.168.1.1 > 192.168.2.1: icmp: echo request
16:10:26.029112 192.168.1.1 > 192.168.2.1: icmp: echo reply
As you can see, the ICMP messages are going back and forth unencrypted. If you had
used the -s parameter to tcpdump(1) to grab
more bytes of data from the packets you would see more information.
Obviously this is unacceptable. The next section will discuss securing the link between the two networks so that all traffic is automatically encrypted.
Summary:
-
Configure both kernels with “device gif”.
-
Edit /etc/rc.conf on gateway host #1 and add the following lines (replacing IP addresses as necessary).
gif_interfaces="gif0" gifconfig_gif0="A.B.C.D W.X.Y.Z" ifconfig_gif0="inet 192.168.1.1 192.168.2.1 netmask 0xffffffff" static_routes="vpn" route_vpn="192.168.2.0 192.168.2.1 netmask 0xffffff00" -
Edit your firewall script (/etc/rc.firewall, or similar) on both hosts, and add
ipfw add 1 allow ip from any to any via gif0 -
Make similar changes to /etc/rc.conf on gateway host #2, reversing the order of IP addresses.
14.10.3.2 Step 2: Securing the link
To secure the link we will be using IPsec. IPsec provides a mechanism for two hosts to agree on an encryption key, and to then use this key in order to encrypt data between the two hosts.
The are two areas of configuration to be considered here.
-
There must be a mechanism for two hosts to agree on the encryption mechanism to use. Once two hosts have agreed on this mechanism there is said to be a “security association” between them.
-
There must be a mechanism for specifying which traffic should be encrypted. Obviously, you do not want to encrypt all your outgoing traffic -- you only want to encrypt the traffic that is part of the VPN. The rules that you put in place to determine what traffic will be encrypted are called “security policies”.
Security associations and security policies are both maintained by the kernel, and can be modified by userland programs. However, before you can do this you must configure the kernel to support IPsec and the Encapsulated Security Payload (ESP) protocol. This is done by configuring a kernel with:
options IPSEC
options IPSEC_ESP
and recompiling, reinstalling, and rebooting. As before you will need to do this to the kernels on both of the gateway hosts.
You have two choices when it comes to setting up security associations. You can configure them by hand between two hosts, which entails choosing the encryption algorithm, encryption keys, and so forth, or you can use daemons that implement the Internet Key Exchange protocol (IKE) to do this for you.
I recommend the latter. Apart from anything else, it is easier to set up.
Editing and displaying security policies is carried out using setkey(8). By analogy, setkey is to the kernel's security policy tables as route(8) is to the kernel's routing tables. setkey can also display the current security associations, and to continue the analogy further, is akin to netstat -r in that respect.
There are a number of choices for daemons to manage security associations with FreeBSD. This article will describe how to use one of these, racoon -- which is available from security/ipsec-tools in the FreeBSD Ports collection.
The racoon software must be run on both gateway hosts. On each host it is configured with the IP address of the other end of the VPN, and a secret key (which you choose, and must be the same on both gateways).
The two daemons then contact one another, confirm that they are who they say they are (by using the secret key that you configured). The daemons then generate a new secret key, and use this to encrypt the traffic over the VPN. They periodically change this secret, so that even if an attacker were to crack one of the keys (which is as theoretically close to unfeasible as it gets) it will not do them much good -- by the time they have cracked the key the two daemons have chosen another one.
The configuration file for racoon is stored in ${PREFIX}/etc/racoon. You should find a configuration file there, which should not need to be changed too much. The other component of racoon's configuration, which you will need to change, is the “pre-shared key”.
The default racoon configuration expects to find this in the file ${PREFIX}/etc/racoon/psk.txt. It is important to note that the pre-shared key is not the key that will be used to encrypt your traffic across the VPN link, it is simply a token that allows the key management daemons to trust one another.
psk.txt contains a line for each remote site you are dealing with. In this example, where there are two sites, each psk.txt file will contain one line (because each end of the VPN is only dealing with one other end).
On gateway host #1 this line should look like this:
W.X.Y.Z secret
That is, the public IP address of the remote end, whitespace, and a text string that provides the secret. Obviously, you should not use “secret” as your key -- the normal rules for choosing a password apply.
On gateway host #2 the line would look like this
A.B.C.D secret
That is, the public IP address of the remote end, and the same secret key. psk.txt must be mode 0600 (i.e., only read/write to root) before racoon will run.
You must run racoon on both gateway machines. You will also need to add some firewall rules to allow the IKE traffic, which is carried over UDP to the ISAKMP (Internet Security Association Key Management Protocol) port. Again, this should be fairly early in your firewall ruleset.
ipfw add 1 allow udp from A.B.C.D to W.X.Y.Z isakmp
ipfw add 1 allow udp from W.X.Y.Z to A.B.C.D isakmp
Once racoon is running you can try pinging one gateway host from the other. The connection is still not encrypted, but racoon will then set up the security associations between the two hosts -- this might take a moment, and you may see this as a short delay before the ping commands start responding.
Once the security association has been set up you can view it using setkey(8). Run
setkey -D
on either host to view the security association information.
That's one half of the problem. The other half is setting your security policies.
To create a sensible security policy, let's review what's been set up so far. This discussions hold for both ends of the link.
Each IP packet that you send out has a header that contains data about the packet. The header includes the IP addresses of both the source and destination. As we already know, private IP addresses, such as the 192.168.x.y range are not supposed to appear on the public Internet. Instead, they must first be encapsulated inside another packet. This packet must have the public source and destination IP addresses substituted for the private addresses.
So if your outgoing packet started looking like this:
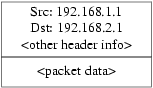
Then it will be encapsulated inside another packet, looking something like this:
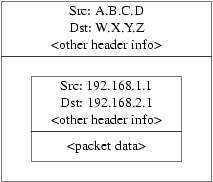
This encapsulation is carried out by the gif device. As you can see, the packet now has real IP addresses on the outside, and our original packet has been wrapped up as data inside the packet that will be put out on the Internet.
Obviously, we want all traffic between the VPNs to be encrypted. You might try putting this in to words, as:
“If a packet leaves from A.B.C.D, and it is destined for W.X.Y.Z, then encrypt it, using the necessary security associations.”
“If a packet arrives from W.X.Y.Z, and it is destined for A.B.C.D, then decrypt it, using the necessary security associations.”
That's close, but not quite right. If you did this, all traffic to and from W.X.Y.Z, even traffic that was not part of the VPN, would be encrypted. That's not quite what you want. The correct policy is as follows
“If a packet leaves from A.B.C.D, and that packet is encapsulating another packet, and it is destined for W.X.Y.Z, then encrypt it, using the necessary security associations.”
“If a packet arrives from W.X.Y.Z, and that packet is encapsulating another packet, and it is destined for A.B.C.D, then decrypt it, using the necessary security associations.”
A subtle change, but a necessary one.
Security policies are also set using setkey(8). setkey(8) features a
configuration language for defining the policy. You can either enter configuration
instructions via stdin, or you can use the -f option to
specify a filename that contains configuration instructions.
The configuration on gateway host #1 (which has the public IP address A.B.C.D) to force all outbound traffic to W.X.Y.Z to be encrypted is:
spdadd A.B.C.D/32 W.X.Y.Z/32 ipencap -P out ipsec esp/tunnel/A.B.C.D-W.X.Y.Z/require;
Put these commands in a file (e.g. /etc/ipsec.conf) and then run
# setkey -f /etc/ipsec.conf
spdadd tells setkey(8) that we want
to add a rule to the secure policy database. The rest of this line specifies which
packets will match this policy. A.B.C.D/32 and W.X.Y.Z/32 are the IP addresses and netmasks that identify the
network or hosts that this policy will apply to. In this case, we want it to apply to
traffic between these two hosts. ipencap tells the kernel
that this policy should only apply to packets that encapsulate other packets. -P out says that this policy applies to outgoing packets, and ipsec says that the packet will be secured.
The second line specifies how this packet will be encrypted. esp is the protocol that will be used, while tunnel indicates that the packet will be further encapsulated in an
IPsec packet. The repeated use of A.B.C.D and W.X.Y.Z is used to select the security association to use, and the
final require mandates that packets must be encrypted if they
match this rule.
This rule only matches outgoing packets. You will need a similar rule to match incoming packets.
spdadd W.X.Y.Z/32 A.B.C.D/32 ipencap -P in ipsec esp/tunnel/W.X.Y.Z-A.B.C.D/require;
Note the in instead of out in
this case, and the necessary reversal of the IP addresses.
The other gateway host (which has the public IP address W.X.Y.Z) will need similar rules.
spdadd W.X.Y.Z/32 A.B.C.D/32 ipencap -P out ipsec esp/tunnel/W.X.Y.Z-A.B.C.D/require;
spdadd A.B.C.D/32 W.X.Y.Z/32 ipencap -P in ipsec esp/tunnel/A.B.C.D-W.X.Y.Z/require;
Finally, you need to add firewall rules to allow ESP and IPENCAP packets back and forth. These rules will need to be added to both hosts.
ipfw add 1 allow esp from A.B.C.D to W.X.Y.Z
ipfw add 1 allow esp from W.X.Y.Z to A.B.C.D
ipfw add 1 allow ipencap from A.B.C.D to W.X.Y.Z
ipfw add 1 allow ipencap from W.X.Y.Z to A.B.C.D
Because the rules are symmetric you can use the same rules on each gateway host.
Outgoing packets will now look something like this:
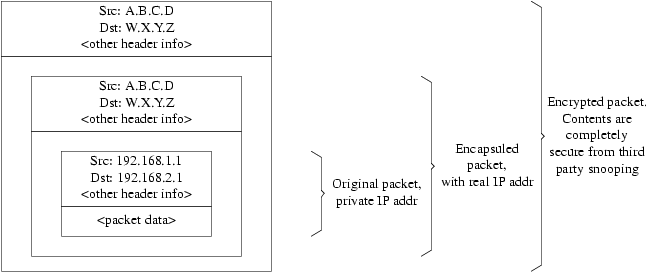
When they are received by the far end of the VPN they will first be decrypted (using the security associations that have been negotiated by racoon). Then they will enter the gif interface, which will unwrap the second layer, until you are left with the innermost packet, which can then travel in to the inner network.
You can check the security using the same ping(8) test from earlier. First, log in to the A.B.C.D gateway machine, and run:
tcpdump dst host 192.168.2.1
In another log in session on the same host run
ping 192.168.2.1
This time you should see output like the following:
XXX tcpdump output
Now, as you can see, tcpdump(1) shows the
ESP packets. If you try to examine them with the -s option
you will see (apparently) gibberish, because of the encryption.
Congratulations. You have just set up a VPN between two remote sites.
Summary
-
Configure both kernels with:
options IPSEC options IPSEC_ESP -
Install security/ipsec-tools. Edit ${PREFIX}/etc/racoon/psk.txt on both gateway hosts, adding an entry for the remote host's IP address and a secret key that they both know. Make sure this file is mode 0600.
-
Add the following lines to /etc/rc.conf on each host:
ipsec_enable="YES" ipsec_file="/etc/ipsec.conf" -
Create an /etc/ipsec.conf on each host that contains the necessary spdadd lines. On gateway host #1 this would be:
spdadd A.B.C.D/32 W.X.Y.Z/32 ipencap -P out ipsec esp/tunnel/A.B.C.D-W.X.Y.Z/require; spdadd W.X.Y.Z/32 A.B.C.D/32 ipencap -P in ipsec esp/tunnel/W.X.Y.Z-A.B.C.D/require;On gateway host #2 this would be:
spdadd W.X.Y.Z/32 A.B.C.D/32 ipencap -P out ipsec esp/tunnel/W.X.Y.Z-A.B.C.D/require; spdadd A.B.C.D/32 W.X.Y.Z/32 ipencap -P in ipsec esp/tunnel/A.B.C.D-W.X.Y.Z/require; -
Add firewall rules to allow IKE, ESP, and IPENCAP traffic to both hosts:
ipfw add 1 allow udp from A.B.C.D to W.X.Y.Z isakmp ipfw add 1 allow udp from W.X.Y.Z to A.B.C.D isakmp ipfw add 1 allow esp from A.B.C.D to W.X.Y.Z ipfw add 1 allow esp from W.X.Y.Z to A.B.C.D ipfw add 1 allow ipencap from A.B.C.D to W.X.Y.Z ipfw add 1 allow ipencap from W.X.Y.Z to A.B.C.D
The previous two steps should suffice to get the VPN up and running. Machines on each network will be able to refer to one another using IP addresses, and all traffic across the link will be automatically and securely encrypted.
14.11 OpenSSH
Contributed by Chern Lee.OpenSSH is a set of network connectivity tools used to access remote machines securely. It can be used as a direct replacement for rlogin, rsh, rcp, and telnet. Additionally, TCP/IP connections can be tunneled/forwarded securely through SSH. OpenSSH encrypts all traffic to effectively eliminate eavesdropping, connection hijacking, and other network-level attacks.
OpenSSH is maintained by the OpenBSD project, and is based upon SSH v1.2.12 with all the recent bug fixes and updates. It is compatible with both SSH protocols 1 and 2.
14.11.1 Advantages of Using OpenSSH
Normally, when using telnet(1) or rlogin(1), data is sent over the network in a clear, un-encrypted form. Network sniffers anywhere in between the client and server can steal your user/password information or data transferred in your session. OpenSSH offers a variety of authentication and encryption methods to prevent this from happening.
14.11.2 Enabling sshd
The sshd is an option presented during a Standard install of FreeBSD. To see if sshd is enabled, check the rc.conf file for:
sshd_enable="YES"
This will load sshd(8), the daemon program for OpenSSH, the next time your system initializes. Alternatively, it is possible to use /etc/rc.d/sshd rc(8) script to start OpenSSH:
/etc/rc.d/sshd start
14.11.3 SSH Client
The ssh(1) utility works similarly to rlogin(1).
# ssh user@example.com
Host key not found from the list of known hosts.
Are you sure you want to continue connecting (yes/no)? yes
Host 'example.com' added to the list of known hosts.
user@example.com's password: *******
The login will continue just as it would have if a session was created using rlogin or telnet. SSH utilizes a key fingerprint system for verifying the authenticity of the server when the client connects. The user is prompted to enter yes only when connecting for the first time. Future attempts to login are all verified against the saved fingerprint key. The SSH client will alert you if the saved fingerprint differs from the received fingerprint on future login attempts. The fingerprints are saved in ~/.ssh/known_hosts, or ~/.ssh/known_hosts2 for SSH v2 fingerprints.
By default, recent versions of the OpenSSH servers only
accept SSH v2 connections. The client will use version 2 if possible and will fall back
to version 1. The client can also be forced to use one or the other by passing it the
-1 or -2 for version 1 or version
2, respectively. The version 1 compatibility is maintained in the client for backwards
compatibility with older versions.
14.11.4 Secure Copy
The scp(1) command works similarly to rcp(1); it copies a file to or from a remote machine, except in a secure fashion.
# scp user@example.com:/COPYRIGHT COPYRIGHT
user@example.com's password: *******
COPYRIGHT 100% |*****************************| 4735
00:00
#
Since the fingerprint was already saved for this host in the previous example, it is verified when using scp(1) here.
The arguments passed to scp(1) are similar to
cp(1), with the file
or files in the first argument, and the destination in the second. Since the file is
fetched over the network, through SSH, one or more of the file arguments takes on the
form user@host:<path_to_remote_file>.
14.11.5 Configuration
The system-wide configuration files for both the OpenSSH daemon and client reside within the /etc/ssh directory.
ssh_config configures the client settings, while sshd_config configures the daemon.
Additionally, the sshd_program (/usr/sbin/sshd by default), and sshd_flags rc.conf options can provide
more levels of configuration.
14.11.6 ssh-keygen
Instead of using passwords, ssh-keygen(1) can be used to generate DSA or RSA keys to authenticate a user:
% ssh-keygen -t dsa
Generating public/private dsa key pair.
Enter file in which to save the key (/home/user/.ssh/id_dsa):
Created directory '/home/user/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/user/.ssh/id_dsa.
Your public key has been saved in /home/user/.ssh/id_dsa.pub.
The key fingerprint is:
bb:48:db:f2:93:57:80:b6:aa:bc:f5:d5:ba:8f:79:17 user@host.example.com
ssh-keygen(1) will create a public and private key pair for use in authentication. The private key is stored in ~/.ssh/id_dsa or ~/.ssh/id_rsa, whereas the public key is stored in ~/.ssh/id_dsa.pub or ~/.ssh/id_rsa.pub, respectively for DSA and RSA key types. The public key must be placed in the ~/.ssh/authorized_keys file of the remote machine for both RSA or DSA keys in order for the setup to work.
This will allow connection to the remote machine based upon SSH keys instead of passwords.
If a passphrase is used in ssh-keygen(1), the user will be prompted for a password each time in order to use the private key. ssh-agent(1) can alleviate the strain of repeatedly entering long passphrases, and is explored in the Section 14.11.7 section below.
Warning: The various options and files can be different according to the OpenSSH version you have on your system; to avoid problems you should consult the ssh-keygen(1) manual page.
14.11.7 ssh-agent and ssh-add
The ssh-agent(1) and ssh-add(1) utilities provide methods for SSH keys to be loaded into memory for use, without needing to type the passphrase each time.
The ssh-agent(1) utility will handle the authentication using the private key(s) that are loaded into it. ssh-agent(1) should be used to launch another application. At the most basic level, it could spawn a shell or at a more advanced level, a window manager.
To use ssh-agent(1) in a shell, first it will need to be spawned with a shell as an argument. Secondly, the identity needs to be added by running ssh-add(1) and providing it the passphrase for the private key. Once these steps have been completed the user will be able to ssh(1) to any host that has the corresponding public key installed. For example:
% ssh-agent csh
% ssh-add
Enter passphrase for /home/user/.ssh/id_dsa:
Identity added: /home/user/.ssh/id_dsa (/home/user/.ssh/id_dsa)
%
To use ssh-agent(1) in X11, a call to ssh-agent(1) will need to be placed in ~/.xinitrc. This will provide the ssh-agent(1) services to all programs launched in X11. An example ~/.xinitrc file might look like this:
exec ssh-agent startxfce4
This would launch ssh-agent(1), which would in turn launch XFCE, every time X11 starts. Then once that is done and X11 has been restarted so that the changes can take effect, simply run ssh-add(1) to load all of your SSH keys.
14.11.8 SSH Tunneling
OpenSSH has the ability to create a tunnel to encapsulate another protocol in an encrypted session.
The following command tells ssh(1) to create a tunnel for telnet:
% ssh -2 -N -f -L 5023:localhost:23 user@foo.example.com
%
The ssh command is used with the following options:
-2-
Forces ssh to use version 2 of the protocol. (Do not use if you are working with older SSH servers)
-N-
Indicates no command, or tunnel only. If omitted, ssh would initiate a normal session.
-f-
Forces ssh to run in the background.
-L-
Indicates a local tunnel in localport:remotehost:remoteport fashion.
user@foo.example.com-
The remote SSH server.
An SSH tunnel works by creating a listen socket on localhost on the specified port. It then forwards any connection received on the local host/port via the SSH connection to the specified remote host and port.
In the example, port 5023 on localhost is being forwarded to port 23 on localhost of the remote machine. Since 23 is telnet, this would create a secure telnet session through an SSH tunnel.
This can be used to wrap any number of insecure TCP protocols such as SMTP, POP3, FTP, etc.
Example 14-1. Using SSH to Create a Secure Tunnel for SMTP
% ssh -2 -N -f -L 5025:localhost:25 user@mailserver.example.com
user@mailserver.example.com's password: *****
% telnet localhost 5025
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
220 mailserver.example.com ESMTP
This can be used in conjunction with an ssh-keygen(1) and additional user accounts to create a more seamless/hassle-free SSH tunneling environment. Keys can be used in place of typing a password, and the tunnels can be run as a separate user.
14.11.8.1 Practical SSH Tunneling Examples
14.11.8.1.1 Secure Access of a POP3 Server
At work, there is an SSH server that accepts connections from the outside. On the same office network resides a mail server running a POP3 server. The network, or network path between your home and office may or may not be completely trustable. Because of this, you need to check your e-mail in a secure manner. The solution is to create an SSH connection to your office's SSH server, and tunnel through to the mail server.
% ssh -2 -N -f -L 2110:mail.example.com:110 user@ssh-server.example.com
user@ssh-server.example.com's password: ******
When the tunnel is up and running, you can point your mail client to send POP3 requests to localhost port 2110. A connection here will be forwarded securely across the tunnel to mail.example.com.
14.11.8.1.2 Bypassing a Draconian Firewall
Some network administrators impose extremely draconian firewall rules, filtering not only incoming connections, but outgoing connections. You may be only given access to contact remote machines on ports 22 and 80 for SSH and web surfing.
You may wish to access another (perhaps non-work related) service, such as an Ogg Vorbis server to stream music. If this Ogg Vorbis server is streaming on some other port than 22 or 80, you will not be able to access it.
The solution is to create an SSH connection to a machine outside of your network's firewall, and use it to tunnel to the Ogg Vorbis server.
% ssh -2 -N -f -L 8888:music.example.com:8000 user@unfirewalled-system.example.org
user@unfirewalled-system.example.org's password: *******
Your streaming client can now be pointed to localhost port 8888, which will be forwarded over to music.example.com port 8000, successfully evading the firewall.
14.11.9 The AllowUsers Users Option
It is often a good idea to limit which users can log in and from where. The AllowUsers option is a good way to accomplish this. For example, to only allow the root user to log in from 192.168.1.32, something like this would be appropriate in the /etc/ssh/sshd_config file:
AllowUsers root@192.168.1.32
To allow the user admin to log in from anywhere, just list the username by itself:
AllowUsers admin
Multiple users should be listed on the same line, like so:
AllowUsers root@192.168.1.32 admin
Note: It is important that you list each user that needs to log in to this machine; otherwise they will be locked out.
After making changes to /etc/ssh/sshd_config you must tell sshd(8) to reload its config files, by running:
# /etc/rc.d/sshd reload
14.12 File System Access Control Lists
Contributed by Tom Rhodes.In conjunction with file system enhancements like snapshots, FreeBSD 5.0 and later offers the security of File System Access Control Lists (ACLs).
Access Control Lists extend the standard UNIX permission model in a highly compatible (POSIX.1e) way. This feature permits an administrator to make use of and take advantage of a more sophisticated security model.
To enable ACL support for UFS file systems, the following:
options UFS_ACL
must be compiled into the kernel. If this option has not been compiled in, a warning message will be displayed when attempting to mount a file system supporting ACLs. This option is included in the GENERIC kernel. ACLs rely on extended attributes being enabled on the file system. Extended attributes are natively supported in the next generation UNIX file system, UFS2.
Note: A higher level of administrative overhead is required to configure extended attributes on UFS1 than on UFS2. The performance of extended attributes on UFS2 is also substantially higher. As a result, UFS2 is generally recommended in preference to UFS1 for use with access control lists.
ACLs are enabled by the mount-time administrative
flag, acls, which may be added to /etc/fstab. The mount-time flag can also be automatically set in a
persistent manner using tunefs(8) to modify a
superblock ACLs flag in the file system header. In
general, it is preferred to use the superblock flag for several reasons:
-
The mount-time ACLs flag cannot be changed by a remount (mount(8)
-u), only by means of a complete umount(8) and fresh mount(8). This means that ACLs cannot be enabled on the root file system after boot. It also means that you cannot change the disposition of a file system once it is in use. -
Setting the superblock flag will cause the file system to always be mounted with ACLs enabled even if there is not an fstab entry or if the devices re-order. This prevents accidental mounting of the file system without ACLs enabled, which can result in ACLs being improperly enforced, and hence security problems.
Note: We may change the ACLs behavior to allow the flag to be enabled without a complete fresh mount(8), but we consider it desirable to discourage accidental mounting without ACLs enabled, because you can shoot your feet quite nastily if you enable ACLs, then disable them, then re-enable them without flushing the extended attributes. In general, once you have enabled ACLs on a file system, they should not be disabled, as the resulting file protections may not be compatible with those intended by the users of the system, and re-enabling ACLs may re-attach the previous ACLs to files that have since had their permissions changed, resulting in other unpredictable behavior.
File systems with ACLs enabled will show a + (plus) sign in their permission settings when viewed. For example:
drwx------ 2 robert robert 512 Dec 27 11:54 private
drwxrwx---+ 2 robert robert 512 Dec 23 10:57 directory1
drwxrwx---+ 2 robert robert 512 Dec 22 10:20 directory2
drwxrwx---+ 2 robert robert 512 Dec 27 11:57 directory3
drwxr-xr-x 2 robert robert 512 Nov 10 11:54 public_html
Here we see that the directory1, directory2, and directory3 directories are all taking advantage of ACLs. The public_html directory is not.
14.12.1 Making Use of ACLs
The file system ACLs can be viewed by the getfacl(1) utility. For instance, to view the ACL settings on the test file, one would use the command:
% getfacl test
#file:test
#owner:1001
#group:1001
user::rw-
group::r--
other::r--
To change the ACL settings on this file, invoke the setfacl(1) utility. Observe:
% setfacl -k test
The -k flag will remove all of the currently defined
ACLs from a file or file system. The more preferable
method would be to use -b as it leaves the basic fields
required for ACLs to work.
% setfacl -m u:trhodes:rwx,group:web:r--,o::--- test
In the aforementioned command, the -m option was used to
modify the default ACL entries. Since there were no
pre-defined entries, as they were removed by the previous command, this will restore the
default options and assign the options listed. Take care to notice that if you add a user
or group which does not exist on the system, an “Invalid
argument” error will be printed to stdout.
14.13 Monitoring Third Party Security Issues
Contributed by Tom Rhodes.In recent years, the security world has made many improvements to how vulnerability assessment is handled. The threat of system intrusion increases as third party utilities are installed and configured for virtually any operating system available today.
Vulnerability assessment is a key factor in security, and while FreeBSD releases advisories for the base system, doing so for every third party utility is beyond the FreeBSD Project's capability. There is a way to mitigate third party vulnerabilities and warn administrators of known security issues. A FreeBSD add on utility known as Portaudit exists solely for this purpose.
The ports-mgmt/portaudit port polls a database, updated and maintained by the FreeBSD Security Team and ports developers, for known security issues.
To begin using Portaudit, one must install it from the Ports Collection:
# cd /usr/ports/ports-mgmt/portaudit && make install clean
During the install process, the configuration files for periodic(8) will be updated, permitting Portaudit output in the daily security runs. Ensure the daily security run emails, which are sent to root's email account, are being read. No more configuration will be required here.
After installation, an administrator can update the database and view known vulnerabilities in installed packages by invoking the following command:
# portaudit -Fda
Note: The database will automatically be updated during the periodic(8) run; thus, the previous command is completely optional. It is only required for the following examples.
To audit the third party utilities installed as part of the Ports Collection at anytime, an administrator need only run the following command:
# portaudit -a
Portaudit will produce something like this for vulnerable packages:
Affected package: cups-base-1.1.22.0_1
Type of problem: cups-base -- HPGL buffer overflow vulnerability.
Reference: <http://www.FreeBSD.org/ports/portaudit/40a3bca2-6809-11d9-a9e7-0001020eed82.html>
1 problem(s) in your installed packages found.
You are advised to update or deinstall the affected package(s) immediately.
By pointing a web browser to the URL shown, an administrator may obtain more information about the vulnerability in question. This will include versions affected, by FreeBSD Port version, along with other web sites which may contain security advisories.
In short, Portaudit is a powerful utility and extremely useful when coupled with the Portupgrade port.
14.14 FreeBSD Security Advisories
Contributed by Tom Rhodes.Like many production quality operating systems, FreeBSD publishes “Security Advisories”. These advisories are usually mailed to the security lists and noted in the Errata only after the appropriate releases have been patched. This section will work to explain what an advisory is, how to understand it, and what measures to take in order to patch a system.
14.14.1 What does an advisory look like?
The FreeBSD security advisories look similar to the one below, taken from the freebsd-security-notifications mailing list.
=============================================================================
FreeBSD-SA-XX:XX.UTIL Security Advisory
The FreeBSD Project
Topic: denial of service due to some problem
Category: core
Module: sys
Announced: 2003-09-23
Credits: Person@EMAIL-ADDRESS Affects: All releases of FreeBSD
Affects: All releases of FreeBSD FreeBSD 4-STABLE prior to the correction date
Corrected: 2003-09-23 16:42:59 UTC (RELENG_4, 4.9-PRERELEASE)
2003-09-23 20:08:42 UTC (RELENG_5_1, 5.1-RELEASE-p6)
2003-09-23 20:07:06 UTC (RELENG_5_0, 5.0-RELEASE-p15)
2003-09-23 16:44:58 UTC (RELENG_4_8, 4.8-RELEASE-p8)
2003-09-23 16:47:34 UTC (RELENG_4_7, 4.7-RELEASE-p18)
2003-09-23 16:49:46 UTC (RELENG_4_6, 4.6-RELEASE-p21)
2003-09-23 16:51:24 UTC (RELENG_4_5, 4.5-RELEASE-p33)
2003-09-23 16:52:45 UTC (RELENG_4_4, 4.4-RELEASE-p43)
2003-09-23 16:54:39 UTC (RELENG_4_3, 4.3-RELEASE-p39)
FreeBSD 4-STABLE prior to the correction date
Corrected: 2003-09-23 16:42:59 UTC (RELENG_4, 4.9-PRERELEASE)
2003-09-23 20:08:42 UTC (RELENG_5_1, 5.1-RELEASE-p6)
2003-09-23 20:07:06 UTC (RELENG_5_0, 5.0-RELEASE-p15)
2003-09-23 16:44:58 UTC (RELENG_4_8, 4.8-RELEASE-p8)
2003-09-23 16:47:34 UTC (RELENG_4_7, 4.7-RELEASE-p18)
2003-09-23 16:49:46 UTC (RELENG_4_6, 4.6-RELEASE-p21)
2003-09-23 16:51:24 UTC (RELENG_4_5, 4.5-RELEASE-p33)
2003-09-23 16:52:45 UTC (RELENG_4_4, 4.4-RELEASE-p43)
2003-09-23 16:54:39 UTC (RELENG_4_3, 4.3-RELEASE-p39) CVE Name: CVE-XXXX-XXXX
CVE Name: CVE-XXXX-XXXX For general information regarding FreeBSD Security Advisories,
including descriptions of the fields above, security branches, and the
following sections, please visit
http://www.FreeBSD.org/security/.
I. Background
For general information regarding FreeBSD Security Advisories,
including descriptions of the fields above, security branches, and the
following sections, please visit
http://www.FreeBSD.org/security/.
I. Background II. Problem Description
II. Problem Description III. Impact
III. Impact IV. Workaround
IV. Workaround V. Solution
V. Solution VI. Correction details
VI. Correction details VII. References
VII. References
- The Topic field indicates exactly what the problem is. It is basically an introduction to the current security advisory and notes the utility with the vulnerability.
- The Category refers to the affected part of the system which may be one of core, contrib, or ports. The core category means that the vulnerability affects a core component of the FreeBSD operating system. The contrib category means that the vulnerability affects software contributed to the FreeBSD Project, such as sendmail. Finally the ports category indicates that the vulnerability affects add on software available as part of the Ports Collection.
- The Module field refers to the component location, for instance sys. In this example, we see that the module, sys, is affected; therefore, this vulnerability affects a component used within the kernel.
- The Announced field reflects the date said security advisory was published, or announced to the world. This means that the security team has verified that the problem does exist and that a patch has been committed to the FreeBSD source code repository.
- The Credits field gives credit to the individual or organization who noticed the vulnerability and reported it.
- The Affects field explains which releases of FreeBSD are affected by this vulnerability. For the kernel, a quick look over the output from ident on the affected files will help in determining the revision. For ports, the version number is listed after the port name in /var/db/pkg. If the system does not sync with the FreeBSD CVS repository and rebuild daily, chances are that it is affected.
- The Corrected field indicates the date, time, time offset, and release that was corrected.
- Reserved for the identification information used to look up vulnerabilities in the Common Vulnerabilities Database system.
- The Background field gives information on exactly what the affected utility is. Most of the time this is why the utility exists in FreeBSD, what it is used for, and a bit of information on how the utility came to be.
- The Problem Description field explains the security hole in depth. This can include information on flawed code, or even how the utility could be maliciously used to open a security hole.
- The Impact field describes what type of impact the problem could have on a system. For example, this could be anything from a denial of service attack, to extra privileges available to users, or even giving the attacker superuser access.
- The Workaround field offers a feasible workaround to system administrators who may be incapable of upgrading the system. This may be due to time constraints, network availability, or a slew of other reasons. Regardless, security should not be taken lightly, and an affected system should either be patched or the security hole workaround should be implemented.
- The Solution field offers instructions on patching the affected system. This is a step by step tested and verified method for getting a system patched and working securely.
- The Correction Details field displays the CVS branch or release name with the periods changed to underscore characters. It also shows the revision number of the affected files within each branch.
- The References field usually offers sources of other information. This can include web URLs, books, mailing lists, and newsgroups.
14.15 Process Accounting
Contributed by Tom Rhodes.Process accounting is a security method in which an administrator may keep track of system resources used, their allocation among users, provide for system monitoring, and minimally track a user's commands.
This indeed has its own positive and negative points. One of the positives is that an intrusion may be narrowed down to the point of entry. A negative is the amount of logs generated by process accounting, and the disk space they may require. This section will walk an administrator through the basics of process accounting.
14.15.1 Enable and Utilizing Process Accounting
Before making use of process accounting, it must be enabled. To do this, execute the following commands:
# touch /var/account/acct
# accton /var/account/acct
# echo 'accounting_enable="YES"' >> /etc/rc.conf
Once enabled, accounting will begin to track CPU stats, commands, etc. All accounting logs are in a non-human readable format and may be viewed using the sa(8) utility. If issued without any options, sa will print information relating to the number of per user calls, the total elapsed time in minutes, total CPU and user time in minutes, average number of I/O operations, etc.
To view information about commands being issued, one would use the lastcomm(1) utility. The lastcomm may be used to print out commands issued by users on specific ttys(5), for example:
# lastcomm ls
trhodes ttyp1
Would print out all known usage of the ls by trhodes on the ttyp1 terminal.
Many other useful options exist and are explained in the lastcomm(1), acct(5) and sa(8) manual pages.
Chapter 15 Jails
Contributed by Matteo Riondato.15.1 Synopsis
This chapter will provide an explanation of what FreeBSD jails are and how to use them. Jails, sometimes referred to as an enhanced replacement of chroot environments, are a very powerful tool for system administrators, but their basic usage can also be useful for advanced users.
After reading this chapter, you will know:
-
What a jail is, and what purpose it may serve in FreeBSD installations.
-
How to build, start, and stop a jail.
-
The basics of jail administration, both from inside and outside the jail.
Other sources of useful information about jails are:
-
The jail(8) manual page. This is the full reference of the jail utility -- the administrative tool which can be used in FreeBSD to start, stop, and control FreeBSD jails.
-
The mailing lists and their archives. The archives of the FreeBSD general questions mailing list and other mailing lists hosted by the FreeBSD list server already contain a wealth of material for jails. It should always be engaging to search the archives, or post a new question to the freebsd-questions mailing list.
15.2 Terms Related to Jails
To facilitate better understanding of parts of the FreeBSD system related to jails, their internals and the way they interact with the rest of FreeBSD, the following terms are used further in this chapter:
- chroot(2) (command)
-
A system call of FreeBSD, which changes the root directory of a process and all its descendants.
- chroot(2) (environment)
-
The environment of processes running in a “chroot”. This includes resources such as the part of the file system which is visible, user and group IDs which are available, network interfaces and other IPC mechanisms, etc.
- jail(8) (command)
-
The system administration utility which allows launching of processes within a jail environment.
- host (system, process, user, etc.)
-
The controlling system of a jail environment. The host system has access to all the hardware resources available, and can control processes both outside of and inside a jail environment. One of the important differences of the host system from a jail is that the limitations which apply to superuser processes inside a jail are not enforced for processes of the host system.
- hosted (system, process, user, etc.)
-
A process, user or other entity, whose access to resources is restricted by an FreeBSD jail.
15.3 Introduction
Since system administration is a difficult and perplexing task, many powerful tools were developed to make life easier for the administrator. These tools mostly provide enhancements of some sort to the way systems are installed, configured and maintained. Part of the tasks which an administrator is expected to do is to properly configure the security of a system, so that it can continue serving its real purpose, without allowing security violations.
One of the tools which can be used to enhance the security of a FreeBSD system are
jails. Jails were introduced in
FreeBSD 4.X by Poul-Henning Kamp <phk@FreeBSD.org>, but were greatly improved
in FreeBSD 5.X to make them a powerful and flexible subsystem. Their development
still goes on, enhancing their usefulness, performance, reliability, and security.
15.3.1 What is a Jail
BSD-like operating systems have had chroot(2) since the time of 4.2BSD. The chroot(8) utility can be used to change the root directory of a set of processes, creating a safe environment, separate from the rest of the system. Processes created in the chrooted environment can not access files or resources outside of it. For that reason, compromising a service running in a chrooted environment should not allow the attacker to compromise the entire system. The chroot(8) utility is good for easy tasks, which do not require a lot of flexibility or complex and advanced features. Since the inception of the chroot concept, however, many ways have been found to escape from a chrooted environment and, although they have been fixed in modern versions of the FreeBSD kernel, it was clear that chroot(2) was not the ideal solution for securing services. A new subsystem had to be implemented.
This is one of the main reasons why jails were developed.
Jails improve on the concept of the traditional chroot(2) environment, in several ways. In a traditional chroot(2) environment, processes are only limited in the part of the file system they can access. The rest of the system resources (like the set of system users, the running processes, or the networking subsystem) are shared by the chrooted processes and the processes of the host system. Jails expand this model by virtualizing not only access to the file system, but also the set of users, the networking subsystem of the FreeBSD kernel and a few other things. A more complete set of fine-grained controls available for tuning the access of a jailed environment is described in Section 15.5.
A jail is characterized by four elements:
-
A directory subtree -- the starting point from which a jail is entered. Once inside the jail, a process is not permitted to escape outside of this subtree. Traditional security issues which plagued the original chroot(2) design will not affect FreeBSD jails.
-
A hostname -- the hostname which will be used within the jail. Jails are mainly used for hosting network services, therefore having a descriptive hostname for each jail can really help the system administrator.
-
An IP address -- this will be assigned to the jail and cannot be changed in any way during the jail's life span. The IP address of a jail is usually an alias address for an existing network interface, but this is not strictly necessary.
-
A command -- the path name of an executable to run inside the jail. This is relative to the root directory of the jail environment, and may vary a lot, depending on the type of the specific jail environment.
Apart from these, jails can have their own set of users and their own root user. Naturally, the powers of the root user are limited within the jail environment and, from the point of view of the host system, the jail root user is not an omnipotent user. In addition, the root user of a jail is not allowed to perform critical operations to the system outside of the associated jail(8) environment. More information about capabilities and restrictions of the root user will be discussed in Section 15.5 below.
15.4 Creating and Controlling Jails
Some administrators divide jails into the following two types: “complete” jails, which resemble a real FreeBSD system, and “service” jails, dedicated to one application or service, possibly running with privileges. This is only a conceptual division and the process of building a jail is not affected by it. The jail(8) manual page is quite clear about the procedure for building a jail:
# setenv D /here/is/the/jail
# mkdir -p $D
# cd /usr/src
# make world DESTDIR=$D
# cd etc/ [9]
# make distribution DESTDIR=$D
# mount_devfs devfs $D/dev
- Selecting a location for a jail is the best starting point. This is where the jail will physically reside within the file system of the jail's host. A good choice can be /usr/jail/jailname, where jailname is the hostname identifying the jail. The /usr/ file system usually has enough space for the jail file system, which for “complete” jails is, essentially, a replication of every file present in a default installation of the FreeBSD base system.
- This command will populate the directory subtree chosen as jail's physical location on the file system with the necessary binaries, libraries, manual pages and so on. Everything is done in the typical FreeBSD style -- first everything is built/compiled, then installed to the destination path.
- The distribution target for make installs every needed configuration file. In simple words, it installs every installable file of /usr/src/etc/ to the /etc directory of the jail environment: $D/etc/.
- Mounting the devfs(8) file system inside a jail is not required. On the other hand, any, or almost any application requires access to at least one device, depending on the purpose of the given application. It is very important to control access to devices from inside a jail, as improper settings could permit an attacker to do nasty things in the jail. Control over devfs(8) is managed through rulesets which are described in the devfs(8) and devfs.conf(5) manual pages.
Once a jail is installed, it can be started by using the jail(8) utility. The
jail(8) utility takes
four mandatory arguments which are described in the Section
15.3.1. Other arguments may be specified too, e.g., to run the jailed process with
the credentials of a specific user. The command argument depends on the type of the jail;
for a virtual system, /etc/rc is a good choice, since it will replicate the startup
sequence of a real FreeBSD system. For a service jail, it depends on the service or application that
will run within the jail.
Jails are often started at boot time and the FreeBSD rc mechanism provides an easy way to do this.
-
A list of the jails which are enabled to start at boot time should be added to the rc.conf(5) file:
jail_enable="YES" # Set to NO to disable starting of any jails jail_list="www" # Space separated list of names of jails -
For each jail listed in
jail_list, a group of rc.conf(5) settings, which describe the particular jail, should be added:jail_www_rootdir="/usr/jail/www" # jail's root directory jail_www_hostname="www.example.org" # jail's hostname jail_www_ip="192.168.0.10" # jail's IP address jail_www_devfs_enable="YES" # mount devfs in the jail jail_www_devfs_ruleset="www_ruleset" # devfs ruleset to apply to jailThe default startup of jails configured in rc.conf(5), will run the /etc/rc script of the jail, which assumes the jail is a complete virtual system. For service jails, the default startup command of the jail should be changed, by setting the
jail_jailname_exec_startoption appropriately.Note: For a full list of available options, please see the rc.conf(5) manual page.
The /etc/rc.d/jail script can be used to start or stop a jail by hand, if an entry for it exists in rc.conf:
# /etc/rc.d/jail start www
# /etc/rc.d/jail stop www
A clean way to shut down a jail(8) is not available at the moment. This is because commands normally used to accomplish a clean system shutdown cannot be used inside a jail. The best way to shut down a jail is to run the following command from within the jail itself or using the jexec(8) utility from outside the jail:
# sh /etc/rc.shutdown
More information about this can be found in the jail(8) manual page.
15.5 Fine Tuning and Administration
There are several options which can be set for any jail, and various ways of combining a host FreeBSD system with jails, to produce higher level applications. This section presents:
-
Some of the options available for tuning the behavior and security restrictions implemented by a jail installation.
-
Some of the high-level applications for jail management, which are available through the FreeBSD Ports Collection, and can be used to implement overall jail-based solutions.
15.5.1 System tools for jail tuning in FreeBSD
Fine tuning of a jail's configuration is mostly done by setting sysctl(8) variables. A
special subtree of sysctl exists as a basis for organizing all the relevant options: the
security.jail.* hierarchy of FreeBSD kernel options. Here is
a list of the main jail-related sysctls, complete with their default value. Names should
be self-explanatory, but for more information about them, please refer to the jail(8) and sysctl(8) manual
pages.
-
security.jail.set_hostname_allowed: 1 -
security.jail.socket_unixiproute_only: 1 -
security.jail.sysvipc_allowed: 0 -
security.jail.enforce_statfs: 2 -
security.jail.allow_raw_sockets: 0 -
security.jail.chflags_allowed: 0 -
security.jail.jailed: 0
These variables can be used by the system administrator of the host system to add or remove some of the
limitations imposed by default on the root user. Note that
there are some limitations which cannot be removed. The root
user is not allowed to mount or unmount file systems from within a jail(8). The root inside a jail may not load or unload devfs(8) rulesets, set
firewall rules, or do many other administrative tasks which require modifications of
in-kernel data, such as setting the securelevel of the
kernel.
The base system of FreeBSD contains a basic set of tools for viewing information about the active jails, and attaching to a jail to run administrative commands. The jls(8) and jexec(8) commands are part of the base FreeBSD system, and can be used to perform the following simple tasks:
-
Print a list of active jails and their corresponding jail identifier (JID), IP address, hostname and path.
-
Attach to a running jail, from its host system, and run a command inside the jail or perform administrative tasks inside the jail itself. This is especially useful when the root user wants to cleanly shut down a jail. The jexec(8) utility can also be used to start a shell in a jail to do administration in it; for example:
# jexec 1 tcsh
15.5.2 High-level administrative tools in FreeBSD Ports Collection
Among the many third-party utilities for jail administration, one of the most complete and useful is sysutils/jailutils. It is a set of small applications that contribute to jail(8) management. Please refer to its web page for more information.
15.6 Application of Jails
15.6.1 Service Jails
Contributed by Daniel Gerzo.This section is based upon an idea originally presented by Simon L. Nielsen <simon@FreeBSD.org>
at http://simon.nitro.dk/service-jails.html, and an updated article
written by Ken Tom <locals@gmail.com>. This section illustrates
how to set up a FreeBSD system that adds an additional layer of security, using the jail(8) feature. It is
also assumed that the given system is at least running RELENG_6_0 and the information
provided earlier in this chapter has been well understood.
15.6.1.1 Design
One of the major problems with jails is the management of their upgrade process. This tends to be a problem because every jail has to be rebuilt from scratch whenever it is updated. This is usually not a problem for a single jail, since the update process is fairly simple, but can be quite time consuming and tedious if a lot of jails are created.
Warning: This setup requires advanced experience with FreeBSD and usage of its features. If the presented steps below look too complicated, it is advised to take a look at a simpler system such as sysutils/ezjail, which provides an easier method of administering FreeBSD jails and is not as sophisticated as this setup.
This idea has been presented to resolve such issues by sharing as much as is possible between jails, in a safe way -- using read-only mount_nullfs(8) mounts, so that updating will be be simpler, and putting single services into individual jails will become more attractive. Additionally, it provides a simple way to add or remove jails as well as a way to upgrade them.
Note: Examples of services in this context are: an HTTP server, a DNS server, a SMTP server, and so forth.
The goals of the setup described in this section are:
-
Create a simple and easy to understand jail structure. This implies not having to run a full installworld on each and every jail.
-
Make it easy to add new jails or remove existing ones.
-
Make it easy to update or upgrade existing jails.
-
Make it possible to run a customized FreeBSD branch.
-
Be paranoid about security, reducing as much as possible the possibility of compromise.
-
Save space and inodes, as much as possible.
As it has been already mentioned, this design relies heavily on having a single master template which is read-only (known as nullfs) mounted into each jail and one read-write device per jail. A device can be a separate physical disc, a partition, or a vnode backed md(4) device. In this example, we will use read-write nullfs mounts.
The file system layout is described in the following list:
-
Each jail will be mounted under the /home/j directory.
-
/home/j/mroot is the template for each jail and the read-only partition for all of the jails.
-
A blank directory will be created for each jail under the /home/j directory.
-
Each jail will have a /s directory, that will be linked to the read-write portion of the system.
-
Each jail shall have its own read-write system that is based upon /home/j/skel.
-
Each jailspace (read-write portion of each jail) shall be created in /home/js.
Note: This assumes that the jails are based under the /home partition. This can, of course, be changed to anything else, but this change will have to be reflected in each of the examples below.
15.6.1.2 Creating the Template
This section will describe the steps needed to create the master template that will be the read-only portion for the jails to use.
It is always a good idea to update the FreeBSD system to the latest -RELEASE branch. Check the corresponding Handbook Chapter to accomplish this task. In the case the update is not feasible, the buildworld will be required in order to be able to proceed. Additionally, the sysutils/cpdup package will be required. We will use the portsnap(8) utility to download the FreeBSD Ports Collection. The Handbook Portsnap Chapter is always good reading for newcomers.
-
First, create a directory structure for the read-only file system which will contain the FreeBSD binaries for our jails, then change directory to the FreeBSD source tree and install the read-only file system to the jail template:
# mkdir /home/j /home/j/mroot # cd /usr/src # make installworld DESTDIR=/home/j/mroot -
Next, prepare a FreeBSD Ports Collection for the jails as well as a FreeBSD source tree, which is required for mergemaster:
# cd /home/j/mroot # mkdir usr/ports # portsnap -p /home/j/mroot/usr/ports fetch extract # cpdup /usr/src /home/j/mroot/usr/src -
Create a skeleton for the read-write portion of the system:
# mkdir /home/j/skel /home/j/skel/home /home/j/skel/usr-X11R6 /home/j/skel/distfiles # mv etc /home/j/skel # mv usr/local /home/j/skel/usr-local # mv tmp /home/j/skel # mv var /home/j/skel # mv root /home/j/skel -
Use mergemaster to install missing configuration files. Then get rid of the extra directories that mergemaster creates:
# mergemaster -t /home/j/skel/var/tmp/temproot -D /home/j/skel -i # cd /home/j/skel # rm -R bin boot lib libexec mnt proc rescue sbin sys usr dev -
Now, symlink the read-write file system to the read-only file system. Please make sure that the symlinks are created in the correct s/ locations. Real directories or the creation of directories in the wrong locations will cause the installation to fail.
# cd /home/j/mroot # mkdir s # ln -s s/etc etc # ln -s s/home home # ln -s s/root root # ln -s ../s/usr-local usr/local # ln -s ../s/usr-X11R6 usr/X11R6 # ln -s ../../s/distfiles usr/ports/distfiles # ln -s s/tmp tmp # ln -s s/var var -
As a last step, create a generic /home/j/skel/etc/make.conf with its contents as shown below:
WRKDIRPREFIX?= /s/portbuildHaving WRKDIRPREFIX set up this way will make it possible to compile FreeBSD ports inside each jail. Remember that the ports directory is part of the read-only system. The custom path for WRKDIRPREFIX allows builds to be done in the read-write portion of every jail.
15.6.1.3 Creating Jails
Now that we have a complete FreeBSD jail template, we can setup and configure the jails in /etc/rc.conf. This example demonstrates the creation of 3 jails: “NS”, “MAIL” and “WWW”.
-
Put the following lines into the /etc/fstab file, so that the read-only template for the jails and the read-write space will be available in the respective jails:
/home/j/mroot /home/j/ns nullfs ro 0 0 /home/j/mroot /home/j/mail nullfs ro 0 0 /home/j/mroot /home/j/www nullfs ro 0 0 /home/js/ns /home/j/ns/s nullfs rw 0 0 /home/js/mail /home/j/mail/s nullfs rw 0 0 /home/js/www /home/j/www/s nullfs rw 0 0Note: Partitions marked with a 0 pass number are not checked by fsck(8) during boot, and partitions marked with a 0 dump number are not backed up by dump(8). We do not want fsck to check nullfs mounts or dump to back up the read-only nullfs mounts of the jails. This is why they are marked with “0 0” in the last two columns of each fstab entry above.
-
Configure the jails in /etc/rc.conf:
jail_enable="YES" jail_set_hostname_allow="NO" jail_list="ns mail www" jail_ns_hostname="ns.example.org" jail_ns_ip="192.168.3.17" jail_ns_rootdir="/usr/home/j/ns" jail_ns_devfs_enable="YES" jail_mail_hostname="mail.example.org" jail_mail_ip="192.168.3.18" jail_mail_rootdir="/usr/home/j/mail" jail_mail_devfs_enable="YES" jail_www_hostname="www.example.org" jail_www_ip="62.123.43.14" jail_www_rootdir="/usr/home/j/www" jail_www_devfs_enable="YES"Warning: The reason why the
jail_name_rootdirvariable is set to /usr/home instead of /home is that the physical path of the /home directory on a default FreeBSD installation is /usr/home. Thejail_name_rootdirvariable must not be set to a path which includes a symbolic link, otherwise the jails will refuse to start. Use the realpath(1) utility to determine a value which should be set to this variable. Please see the FreeBSD-SA-07:01.jail Security Advisory for more information. -
Create the required mount points for the read-only file system of each jail:
# mkdir /home/j/ns /home/j/mail /home/j/www -
Install the read-write template into each jail. Note the use of sysutils/cpdup, which helps to ensure that a correct copy is done of each directory:
# mkdir /home/js # cpdup /home/j/skel /home/js/ns # cpdup /home/j/skel /home/js/mail # cpdup /home/j/skel /home/js/www -
In this phase, the jails are built and prepared to run. First, mount the required file systems for each jail, and then start them using the /etc/rc.d/jail script:
# mount -a # /etc/rc.d/jail start
The jails should be running now. To check if they have started correctly, use the jls(8) command. Its output should be similar to the following:
# jls
JID IP Address Hostname Path
3 192.168.3.17 ns.example.org /home/j/ns
2 192.168.3.18 mail.example.org /home/j/mail
1 62.123.43.14 www.example.org /home/j/www
At this point, it should be possible to log onto each jail, add new users or configure daemons. The JID column indicates the jail identification number of each running jail. Use the following command in order to perform administrative tasks in the jail whose JID is 3:
# jexec 3 tcsh
15.6.1.4 Upgrading
In time, there will be a need to upgrade the system to a newer version of FreeBSD, either because of a security issue, or because new features have been implemented which are useful for the existing jails. The design of this setup provides an easy way to upgrade existing jails. Additionally, it minimizes their downtime, as the jails will be brought down only in the very last minute. Also, it provides a way to roll back to the older versions should any problems occur.
-
The first step is to upgrade the host system in the usual manner. Then create a new temporary read-only template in /home/j/mroot2.
# mkdir /home/j/mroot2 # cd /usr/src # make installworld DESTDIR=/home/j/mroot2 # cd /home/j/mroot2 # cpdup /usr/src usr/src # mkdir sThe installworld run creates a few unnecessary directories, which should be removed:
# chflags -R 0 var # rm -R etc var root usr/local tmp -
Recreate the read-write symlinks for the master file system:
# ln -s s/etc etc # ln -s s/root root # ln -s s/home home # ln -s ../s/usr-local usr/local # ln -s ../s/usr-X11R6 usr/X11R6 # ln -s s/tmp tmp # ln -s s/var var -
The right time to stop the jails is now:
# /etc/rc.d/jail stop -
Unmount the original file systems:
# umount /home/j/ns/s # umount /home/j/ns # umount /home/j/mail/s # umount /home/j/mail # umount /home/j/www/s # umount /home/j/wwwNote: The read-write systems are attached to the read-only system (/s) and must be unmounted first.
-
Move the old read-only file system and replace it with the new one. This will serve as a backup and archive of the old read-only file system should something go wrong. The naming convention used here corresponds to when a new read-only file system has been created. Move the original FreeBSD Ports Collection over to the new file system to save some space and inodes:
# cd /home/j # mv mroot mroot.20060601 # mv mroot2 mroot # mv mroot.20060601/usr/ports mroot/usr -
At this point the new read-only template is ready, so the only remaining task is to remount the file systems and start the jails:
# mount -a # /etc/rc.d/jail start
Use jls(8) to check if the jails started correctly. Do not forget to run mergemaster in each jail. The configuration files will need to be updated as well as the rc.d scripts.
Chapter 16 Mandatory Access Control
Written by Tom Rhodes.16.1 Synopsis
FreeBSD 5.X introduced new security extensions from the TrustedBSD project based on the POSIX.1e draft. Two of the most significant new security mechanisms are file system Access Control Lists (ACLs) and Mandatory Access Control (MAC) facilities. Mandatory Access Control allows new access control modules to be loaded, implementing new security policies. Some provide protections of a narrow subset of the system, hardening a particular service. Others provide comprehensive labeled security across all subjects and objects. The mandatory part of the definition comes from the fact that the enforcement of the controls is done by administrators and the system, and is not left up to the discretion of users as is done with discretionary access control (DAC, the standard file and System V IPC permissions on FreeBSD).
This chapter will focus on the Mandatory Access Control Framework (MAC Framework), and a set of pluggable security policy modules enabling various security mechanisms.
After reading this chapter, you will know:
-
What MAC security policy modules are currently included in FreeBSD and their associated mechanisms.
-
What MAC security policy modules implement as well as the difference between a labeled and non-labeled policy.
-
How to efficiently configure a system to use the MAC framework.
-
How to configure the different security policy modules included with the MAC framework.
-
How to implement a more secure environment using the MAC framework and the examples shown.
-
How to test the MAC configuration to ensure the framework has been properly implemented.
Before reading this chapter, you should:
-
Understand UNIX and FreeBSD basics (Chapter 3).
-
Be familiar with the basics of kernel configuration/compilation (Chapter 8).
-
Have some familiarity with security and how it pertains to FreeBSD (Chapter 14).
Warning: The improper use of the information contained herein may cause loss of system access, aggravation of users, or inability to access the features provided by X11. More importantly, MAC should not be relied upon to completely secure a system. The MAC framework only augments existing security policy; without sound security practices and regular security checks, the system will never be completely secure.
It should also be noted that the examples contained within this chapter are just that, examples. It is not recommended that these particular settings be rolled out on a production system. Implementing the various security policy modules takes a good deal of thought and testing. One who does not fully understand exactly how everything works may find him or herself going back through the entire system and reconfiguring many files or directories.
16.1.1 What Will Not Be Covered
This chapter covers a broad range of security issues relating to the MAC framework. The development of new MAC security policy modules will not be covered. A number of security policy modules included with the MAC framework have specific characteristics which are provided for both testing and new module development. These include the mac_test(4), mac_stub(4) and mac_none(4). For more information on these security policy modules and the various mechanisms they provide, please review the manual pages.
16.2 Key Terms in this Chapter
Before reading this chapter, a few key terms must be explained. This will hopefully clear up any confusion that may occur and avoid the abrupt introduction of new terms and information.
-
compartment: A compartment is a set of programs and data to be partitioned or separated, where users are given explicit access to specific components of a system. Also, a compartment represents a grouping, such as a work group, department, project, or topic. Using compartments, it is possible to implement a need-to-know security policy.
-
high water mark: A high water mark policy is one which permits the raising of security levels for the purpose of accessing higher level information. In most cases, the original level is restored after the process is complete. Currently, the FreeBSD MAC framework does not have a policy for this, but the definition is included for completeness.
-
integrity: Integrity, as a key concept, is the level of trust which can be placed on data. As the integrity of the data is elevated, so does the ability to trust that data.
-
label: A label is a security attribute which can be applied to files, directories, or other items in the system. It could be considered a confidentiality stamp; when a label is placed on a file it describes the security properties for that specific file and will only permit access by files, users, resources, etc. with a similar security setting. The meaning and interpretation of label values depends on the policy configuration: while some policies might treat a label as representing the integrity or secrecy of an object, other policies might use labels to hold rules for access.
-
level: The increased or decreased setting of a security attribute. As the level increases, its security is considered to elevate as well.
-
low water mark: A low water mark policy is one which permits lowering of the security levels for the purpose of accessing information which is less secure. In most cases, the original security level of the user is restored after the process is complete. The only security policy module in FreeBSD to use this is mac_lomac(4).
-
multilabel: The
multilabelproperty is a file system option which can be set in single user mode using the tunefs(8) utility, during the boot operation using the fstab(5) file, or during the creation of a new file system. This option will permit an administrator to apply different MAC labels on different objects. This option only applies to security policy modules which support labeling. -
object: An object or system object is an entity through which information flows under the direction of a subject. This includes directories, files, fields, screens, keyboards, memory, magnetic storage, printers or any other data storage/moving device. Basically, an object is a data container or a system resource; access to an object effectively means access to the data.
-
policy: A collection of rules which defines how objectives are to be achieved. A policy usually documents how certain items are to be handled. This chapter will consider the term policy in this context as a security policy; i.e. a collection of rules which will control the flow of data and information and define whom will have access to that data and information.
-
sensitivity: Usually used when discussing MLS. A sensitivity level is a term used to describe how important or secret the data should be. As the sensitivity level increases, so does the importance of the secrecy, or confidentiality of the data.
-
single label: A single label is when the entire file system uses one label to enforce access control over the flow of data. When a file system has this set, which is any time when the
multilabeloption is not set, all files will conform to the same label setting. -
subject: a subject is any active entity that causes information to flow between objects; e.g. a user, user processor, system process, etc. On FreeBSD, this is almost always a thread acting in a process on behalf of a user.
16.3 Explanation of MAC
With all of these new terms in mind, consider how the MAC framework augments the security of the system as a whole. The various security policy modules provided by the MAC framework could be used to protect the network and file systems, block users from accessing certain ports and sockets, and more. Perhaps the best use of the policy modules is to blend them together, by loading several security policy modules at a time for a multi-layered security environment. In a multi-layered security environment, multiple policy modules are in effect to keep security in check. This is different to a hardening policy, which typically hardens elements of a system that is used only for specific purposes. The only downside is administrative overhead in cases of multiple file system labels, setting network access control user by user, etc.
These downsides are minimal when compared to the lasting effect of the framework; for instance, the ability to pick and choose which policies are required for a specific configuration keeps performance overhead down. The reduction of support for unneeded policies can increase the overall performance of the system as well as offer flexibility of choice. A good implementation would consider the overall security requirements and effectively implement the various security policy modules offered by the framework.
Thus a system utilizing MAC features should at least guarantee that a user will not be permitted to change security attributes at will; all user utilities, programs and scripts must work within the constraints of the access rules provided by the selected security policy modules; and that total control of the MAC access rules are in the hands of the system administrator.
It is the sole duty of the system administrator to carefully select the correct security policy modules. Some environments may need to limit access control over the network; in these cases, the mac_portacl(4), mac_ifoff(4) and even mac_biba(4) policy modules might make good starting points. In other cases, strict confidentiality of file system objects might be required. Policy modules such as mac_bsdextended(4) and mac_mls(4) exist for this purpose.
Policy decisions could be made based on network configuration. Perhaps only certain users should be permitted access to facilities provided by ssh(1) to access the network or the Internet. The mac_portacl(4) would be the policy module of choice for these situations. But what should be done in the case of file systems? Should all access to certain directories be severed from other groups or specific users? Or should we limit user or utility access to specific files by setting certain objects as classified?
In the file system case, access to objects might be considered confidential to some users, but not to others. For an example, a large development team might be broken off into smaller groups of individuals. Developers in project A might not be permitted to access objects written by developers in project B. Yet they might need to access objects created by developers in project C; that is quite a situation indeed. Using the different security policy modules provided by the MAC framework; users could be divided into these groups and then given access to the appropriate areas without fear of information leakage.
Thus, each security policy module has a unique way of dealing with the overall security of a system. Module selection should be based on a well thought out security policy. In many cases, the overall policy may need to be revised and reimplemented on the system. Understanding the different security policy modules offered by the MAC framework will help administrators choose the best policies for their situations.
The default FreeBSD kernel does not include the option for the MAC framework; thus the following kernel option must be added before trying any of the examples or information in this chapter:
options MAC
And the kernel will require a rebuild and a reinstall.
Caution: While the various manual pages for MAC policy modules state that they may be built into the kernel, it is possible to lock the system out of the network and more. Implementing MAC is much like implementing a firewall, care must be taken to prevent being completely locked out of the system. The ability to revert back to a previous configuration should be considered while the implementation of MAC remotely should be done with extreme caution.
16.4 Understanding MAC Labels
A MAC label is a security attribute which may be applied to subjects and objects throughout the system.
When setting a label, the user must be able to comprehend what it is, exactly, that is being done. The attributes available on an object depend on the policy module loaded, and that policy modules interpret their attributes in different ways. If improperly configured due to lack of comprehension, or the inability to understand the implications, the result will be the unexpected and perhaps, undesired, behavior of the system.
The security label on an object is used as a part of a security access control decision by a policy. With some policies, the label by itself contains all information necessary to make a decision; in other models, the labels may be processed as part of a larger rule set, etc.
For instance, setting the label of biba/low on a file will represent a label maintained by the Biba security policy module, with a value of “low”.
A few policy modules which support the labeling feature in FreeBSD offer three specific predefined labels. These are the low, high, and equal labels. Although they enforce access control in a different manner with each policy module, you can be sure that the low label will be the lowest setting, the equal label will set the subject or object to be disabled or unaffected, and the high label will enforce the highest setting available in the Biba and MLS policy modules.
Within single label file system environments, only one label may be used on objects.
This will enforce one set of access permissions across the entire system and in many
environments may be all that is required. There are a few cases where multiple labels may
be set on objects or subjects in the file system. For those cases, the multilabel option may be passed to tunefs(8).
In the case of Biba and MLS, a numeric label may be set to indicate the precise level of hierarchical control. This numeric level is used to partition or sort information into different groups of say, classification only permitting access to that group or a higher group level.
In most cases the administrator will only be setting up a single label to use throughout the file system.
Hey wait, this is similar to DAC! I thought MAC gave control strictly to the administrator. That statement still holds true, to some extent as root is the one in control and who configures the policies so that users are placed in the appropriate categories/access levels. Alas, many policy modules can restrict the root user as well. Basic control over objects will then be released to the group, but root may revoke or modify the settings at any time. This is the hierarchal/clearance model covered by policies such as Biba and MLS.
16.4.1 Label Configuration
Virtually all aspects of label policy module configuration will be performed using the base system utilities. These commands provide a simple interface for object or subject configuration or the manipulation and verification of the configuration.
All configuration may be done by use of the setfmac(8) and setpmac(8) utilities. The setfmac command is used to set MAC labels on system objects while the setpmac command is used to set the labels on system subjects. Observe:
# setfmac biba/high test
If no errors occurred with the command above, a prompt will be returned. The only time these commands are not quiescent is when an error occurred; similarly to the chmod(1) and chown(8) commands. In some cases this error may be a “Permission denied” and is usually obtained when the label is being set or modified on an object which is restricted.[10] The system administrator may use the following commands to overcome this:
# setfmac biba/high test
“Permission denied”
# setpmac biba/low setfmac biba/high test
# getfmac test
test: biba/high
As we see above, setpmac can be used to override the policy
module's settings by assigning a different label to the invoked process. The getpmac utility is usually used with currently running processes,
such as sendmail: although it takes a process ID in place of a
command the logic is extremely similar. If users attempt to manipulate a file not in
their access, subject to the rules of the loaded policy modules, the “Operation not permitted” error will be displayed by the
mac_set_link function.
16.4.1.1 Common Label Types
For the mac_biba(4), mac_mls(4) and mac_lomac(4) policy modules, the ability to assign simple labels is provided. These take the form of high, equal and low, what follows is a brief description of what these labels provide:
-
The low label is considered the lowest label setting an object or subject may have. Setting this on objects or subjects will block their access to objects or subjects marked high.
-
The equal label should only be placed on objects considered to be exempt from the policy.
-
The high label grants an object or subject the highest possible setting.
With respect to each policy module, each of those settings will instate a different information flow directive. Reading the proper manual pages will further explain the traits of these generic label configurations.
16.4.1.1.1 Advanced Label Configuration
Numeric grade labels are used for comparison:compartment+compartment; thus the following:
biba/10:2+3+6(5:2+3-20:2+3+4+5+6)
May be interpreted as:
“Biba Policy Label”/“Grade 10” :“Compartments 2, 3 and 6”: (“grade 5 ...”)
In this example, the first grade would be considered the “effective grade” with “effective compartments”, the second grade is the low grade and the last one is the high grade. In most configurations these settings will not be used; indeed, they offered for more advanced configurations.
When applied to system objects, they will only have a current grade/compartments as opposed to system subjects as they reflect the range of available rights in the system, and network interfaces, where they are used for access control.
The grade and compartments in a subject and object pair are used to construct a relationship referred to as “dominance”, in which a subject dominates an object, the object dominates the subject, neither dominates the other, or both dominate each other. The “both dominate” case occurs when the two labels are equal. Due to the information flow nature of Biba, you have rights to a set of compartments, “need to know”, that might correspond to projects, but objects also have a set of compartments. Users may have to subset their rights using su or setpmac in order to access objects in a compartment from which they are not restricted.
16.4.1.2 Users and Label Settings
Users themselves are required to have labels so that their files and processes may properly interact with the security policy defined on the system. This is configured through the login.conf file by use of login classes. Every policy module that uses labels will implement the user class setting.
An example entry containing every policy module setting is displayed below:
default:\
:copyright=/etc/COPYRIGHT:\
:welcome=/etc/motd:\
:setenv=MAIL=/var/mail/$,BLOCKSIZE=K:\
:path=~/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin:\
:manpath=/usr/share/man /usr/local/man:\
:nologin=/usr/sbin/nologin:\
:cputime=1h30m:\
:datasize=8M:\
:vmemoryuse=100M:\
:stacksize=2M:\
:memorylocked=4M:\
:memoryuse=8M:\
:filesize=8M:\
:coredumpsize=8M:\
:openfiles=24:\
:maxproc=32:\
:priority=0:\
:requirehome:\
:passwordtime=91d:\
:umask=022:\
:ignoretime@:\
:label=partition/13,mls/5,biba/10(5-15),lomac/10[2]:
The label option is used to set the user class default label which will be enforced by MAC. Users will never be permitted to modify this value, thus it can be considered not optional in the user case. In a real configuration, however, the administrator will never wish to enable every policy module. It is recommended that the rest of this chapter be reviewed before any of this configuration is implemented.
Note: Users may change their label after the initial login; however, this change is subject constraints of the policy. The example above tells the Biba policy that a process's minimum integrity is 5, its maximum is 15, but the default effective label is 10. The process will run at 10 until it chooses to change label, perhaps due to the user using the setpmac command, which will be constrained by Biba to the range set at login.
In all cases, after a change to login.conf, the login class capability database must be rebuilt using cap_mkdb and this will be reflected throughout every forthcoming example or discussion.
It is useful to note that many sites may have a particularly large number of users requiring several different user classes. In depth planning is required as this may get extremely difficult to manage.
Future versions of FreeBSD will include a new way to deal with mapping users to labels; however, this will not be available until some time after FreeBSD 5.3.
16.4.1.3 Network Interfaces and Label Settings
Labels may also be set on network interfaces to help control the flow of data across the network. In all cases they function in the same way the policies function with respect to objects. Users at high settings in biba, for example, will not be permitted to access network interfaces with a label of low.
The maclabel may be passed to ifconfig when setting the MAC
label on network interfaces. For example:
# ifconfig bge0 maclabel biba/equal
will set the MAC label of biba/equal on the bge(4) interface. When using a setting similar to biba/high(low-high) the entire label should be quoted; otherwise an error will be returned.
Each policy module which supports labeling has a tunable which may be used to disable
the MAC label on network interfaces. Setting the label
to equal will have a similar effect. Review the output from
sysctl, the policy manual pages, or even the information found
later in this chapter for those tunables.
16.4.2 Singlelabel or Multilabel?
By default the system will use the singlelabel option. But
what does this mean to the administrator? There are several differences which, in their
own right, offer pros and cons to the flexibility in the systems security model.
The singlelabel only permits for one label, for instance
biba/high to be used for each subject or object. It provides for
lower administration overhead but decreases the flexibility of policies which support
labeling. Many administrators may want to use the multilabel
option in their security policy.
The multilabel option will permit each subject or object
to have its own independent MAC label in place of the
standard singlelabel option which will allow only one label
throughout the partition. The multilabel and single label options are only required for the policies which
implement the labeling feature, including the Biba, Lomac, MLS and SEBSD policies.
In many cases, the multilabel may not need to be set at
all. Consider the following situation and security model:
-
FreeBSD web-server using the MAC framework and a mix of the various policies.
-
This machine only requires one label, biba/high, for everything in the system. Here the file system would not require the
multilabeloption as a single label will always be in effect. -
But, this machine will be a web server and should have the web server run at biba/low to prevent write up capabilities. The Biba policy and how it works will be discussed later, so if the previous comment was difficult to interpret just continue reading and return. The server could use a separate partition set at biba/low for most if not all of its runtime state. Much is lacking from this example, for instance the restrictions on data, configuration and user settings; however, this is just a quick example to prove the aforementioned point.
If any of the non-labeling policies are to be used, then the multilabel option would never be required. These include the seeotheruids, portacl and partition policies.
It should also be noted that using multilabel with a
partition and establishing a security model based on multilabel functionality could open the doors for higher
administrative overhead as everything in the file system would have a label. This
includes directories, files, and even device nodes.
The following command will set multilabel on the file
systems to have multiple labels. This may only be done in single user mode:
# tunefs -l enable /
This is not a requirement for the swap file system.
Note: Some users have experienced problems with setting the
multilabelflag on the root partition. If this is the case, please review the Section 16.16 of this chapter.
16.5 Planning the Security Configuration
Whenever a new technology is implemented, a planning phase is always a good idea. During the planning stages, an administrator should in general look at the “big picture”, trying to keep in view at least the following:
-
The implementation requirements;
-
The implementation goals;
For MAC installations, these include:
-
How to classify information and resources available on the target systems.
-
What sorts of information or resources to restrict access to along with the type of restrictions that should be applied.
-
Which MAC module or modules will be required to achieve this goal.
It is always possible to reconfigure and change the system resources and security settings, it is quite often very inconvenient to search through the system and fix existing files and user accounts. Planning helps to ensure a trouble-free and efficient trusted system implementation. A trial run of the trusted system, including the configuration, is often vital and definitely beneficial before a MAC implementation is used on production systems. The idea of just letting loose on a system with MAC is like setting up for failure.
Different environments may have explicit needs and requirements. Establishing an in depth and complete security profile will decrease the need of changes once the system goes live. As such, the future sections will cover the different modules available to administrators; describe their use and configuration; and in some cases provide insight on what situations they would be most suitable for. For instance, a web server might roll out the mac_biba(4) and mac_bsdextended(4) policies. In other cases, a machine with very few local users, the mac_partition(4) might be a good choice.
16.6 Module Configuration
Every module included with the MAC framework may be either compiled into the kernel as noted above or loaded as a run-time kernel module. The recommended method is to add the module name to the /boot/loader.conf file so that it will load during the initial boot operation.
The following sections will discuss the various MAC
modules and cover their features. Implementing them into a specific environment will also
be a consideration of this chapter. Some modules support the use of labeling, which is
controlling access by enforcing a label such as “this is allowed and this is
not”. A label configuration file may control how files may be accessed, network
communication can be exchanged, and more. The previous section showed how the multilabel flag could be set on file systems to enable per-file or
per-partition access control.
A single label configuration would enforce only one label across the system, that is
why the tunefs option is called multilabel.
16.6.1 The MAC seeotheruids Module
Module name: mac_seeotheruids.ko
Kernel configuration line: options MAC_SEEOTHERUIDS
Boot option: mac_seeotheruids_load="YES"
The mac_seeotheruids(4) module mimics and extends the security.bsd.see_other_uids and security.bsd.see_other_gids sysctl tunables. This option does not require any labels to be set before configuration and can operate transparently with the other modules.
After loading the module, the following sysctl tunables may be used to control the features:
-
security.mac.seeotheruids.enabled will enable the module's features and use the default settings. These default settings will deny users the ability to view processes and sockets owned by other users.
-
security.mac.seeotheruids.specificgid_enabled will allow a certain group to be exempt from this policy. To exempt specific groups from this policy, use the security.mac.seeotheruids.specificgid=XXX sysctl tunable. In the above example, the XXX should be replaced with the numeric group ID to be exempted.
-
security.mac.seeotheruids.primarygroup_enabled is used to exempt specific primary groups from this policy. When using this tunable, the security.mac.seeotheruids.specificgid_enabled may not be set.
16.7 The MAC bsdextended Module
Module name: mac_bsdextended.ko
Kernel configuration line: options MAC_BSDEXTENDED
Boot option: mac_bsdextended_load="YES"
The mac_bsdextended(4) module enforces the file system firewall. This module's policy provides an extension to the standard file system permissions model, permitting an administrator to create a firewall-like ruleset to protect files, utilities, and directories in the file system hierarchy. When access to a file system object is attempted, the list of rules is iterated until either a matching rule is located or the end is reached. This behavior may be changed by the use of a sysctl(8) parameter, security.mac.bsdextended.firstmatch_enabled. Similar to other firewall modules in FreeBSD, a file containing access control rules can be created and read by the system at boot time using an rc.conf(5) variable.
The rule list may be entered using a utility, ugidfw(8), that has a syntax similar to that of ipfw(8). More tools can be written by using the functions in the libugidfw(3) library.
Extreme caution should be taken when working with this module; incorrect use could block access to certain parts of the file system.
16.7.1 Examples
After the mac_bsdextended(4) module has been loaded, the following command may be used to list the current rule configuration:
# ugidfw list
0 slots, 0 rules
As expected, there are no rules defined. This means that everything is still completely accessible. To create a rule which will block all access by users but leave root unaffected, simply run the following command:
# ugidfw add subject not uid root new object not uid root mode n
Note: In releases prior to FreeBSD 5.3, the
addparameter did not exist. In those cases thesetshould be used instead. See below for a command example.
This is a very bad idea as it will block all users from issuing even the most simple commands, such as ls. A more patriotic list of rules might be:
# ugidfw set 2 subject uid user1 object uid user2 mode n
# ugidfw set 3 subject uid user1 object gid user2 mode n
This will block any and all access, including directory listings, to user2's home directory from the username user1.
In place of user1, the not uid user2 could be passed. This will enforce the same
access restrictions above for all users in place of just one user.
Note: The root user will be unaffected by these changes.
This should provide a general idea of how the mac_bsdextended(4) module may be used to help fortify a file system. For more information, see the mac_bsdextended(4) and the ugidfw(8) manual pages.
16.8 The MAC ifoff Module
Module name: mac_ifoff.ko
Kernel configuration line: options MAC_IFOFF
Boot option: mac_ifoff_load="YES"
The mac_ifoff(4) module exists solely to disable network interfaces on the fly and keep network interfaces from being brought up during the initial system boot. It does not require any labels to be set up on the system, nor does it have a dependency on other MAC modules.
Most of the control is done through the sysctl tunables listed below.
-
security.mac.ifoff.lo_enabled will enable/disable all traffic on the loopback (lo(4)) interface.
-
security.mac.ifoff.bpfrecv_enabled will enable/disable all traffic on the Berkeley Packet Filter interface (bpf(4))
-
security.mac.ifoff.other_enabled will enable/disable traffic on all other interfaces.
One of the most common uses of mac_ifoff(4) is network monitoring in an environment where network traffic should not be permitted during the boot sequence. Another suggested use would be to write a script which uses security/aide to automatically block network traffic if it finds new or altered files in protected directories.
16.9 The MAC portacl Module
Module name: mac_portacl.ko
Kernel configuration line: MAC_PORTACL
Boot option: mac_portacl_load="YES"
The mac_portacl(4) module is used to limit binding to local TCP and UDP ports using a variety of sysctl variables. In essence mac_portacl(4) makes it possible to allow non-root users to bind to specified privileged ports, i.e. ports fewer than 1024.
Once loaded, this module will enable the MAC policy on all sockets. The following tunables are available:
-
security.mac.portacl.enabled will enable/disable the policy completely.[11]
-
security.mac.portacl.port_high will set the highest port number that mac_portacl(4) will enable protection for.
-
security.mac.portacl.suser_exempt will, when set to a non-zero value, exempt the root user from this policy.
-
security.mac.portacl.rules will specify the actual mac_portacl policy; see below.
The actual mac_portacl policy, as specified in the security.mac.portacl.rules sysctl, is a text string of the form: rule[,rule,...] with as many rules as needed. Each rule is of the
form: idtype:id:protocol:port. The idtype parameter can be uid or gid and used to interpret the id
parameter as either a user id or group id, respectively. The protocol parameter is used to determine if the rule should apply
to TCP or UDP by
setting the parameter to tcp or udp.
The final port parameter is the port number to allow the
specified user or group to bind to.
Note: Since the ruleset is interpreted directly by the kernel only numeric values can be used for the user ID, group ID, and port parameters. I.e. user, group, and port service names cannot be used.
By default, on UNIX-like systems, ports fewer than 1024 can only be used by/bound to privileged processes, i.e. those run as root. For mac_portacl(4) to allow non-privileged processes to bind to ports below 1024 this standard UNIX restriction has to be disabled. This can be accomplished by setting the sysctl(8) variables net.inet.ip.portrange.reservedlow and net.inet.ip.portrange.reservedhigh to zero.
See the examples below or review the mac_portacl(4) manual page for further information.
16.9.1 Examples
The following examples should illuminate the above discussion a little better:
# sysctl security.mac.portacl.port_high=1023
# sysctl net.inet.ip.portrange.reservedlow=0 net.inet.ip.portrange.reservedhigh=0
First we set mac_portacl(4) to cover the standard privileged ports and disable the normal UNIX bind restrictions.
# sysctl security.mac.portacl.suser_exempt=1
The root user should not be crippled by this policy, thus set the security.mac.portacl.suser_exempt to a non-zero value. The mac_portacl(4) module has now been set up to behave the same way UNIX-like systems behave by default.
# sysctl security.mac.portacl.rules=uid:80:tcp:80
Allow the user with UID 80 (normally the www user) to bind to port 80. This can be used to allow the www user to run a web server without ever having root privilege.
# sysctl security.mac.portacl.rules=uid:1001:tcp:110,uid:1001:tcp:995
Permit the user with the UID of 1001 to bind to the TCP ports 110 (“pop3”) and 995 (“pop3s”). This will permit this user to start a server that accepts connections on ports 110 and 995.
16.10 The MAC partition Module
Module name: mac_partition.ko
Kernel configuration line: options MAC_PARTITION
Boot option: mac_partition_load="YES"
The mac_partition(4) policy will drop processes into specific “partitions” based on their MAC label. Think of it as a special type of jail(8), though that is hardly a worthy comparison.
This is one module that should be added to the loader.conf(5) file so that it loads and enables the policy during the boot process.
Most configuration for this policy is done using the setpmac(8) utility which will be explained below. The following sysctl tunable is available for this policy:
-
security.mac.partition.enabled will enable the enforcement of MAC process partitions.
When this policy is enabled, users will only be permitted to see their processes, and any others within their partition, but will not be permitted to work with utilities outside the scope of this partition. For instance, a user in the insecure class above will not be permitted to access the top command as well as many other commands that must spawn a process.
To set or drop utilities into a partition label, use the setpmac utility:
# setpmac partition/13 top
This will add the top command to the label set on users in the insecure class. Note that all processes spawned by users in the insecure class will stay in the partition/13 label.
16.10.1 Examples
The following command will show you the partition label and the process list:
# ps Zax
This next command will allow the viewing of another user's process partition label and that user's currently running processes:
# ps -ZU trhodes
Note: Users can see processes in root's label unless the mac_seeotheruids(4) policy is loaded.
A really crafty implementation could have all of the services disabled in /etc/rc.conf and started by a script that starts them with the proper labeling set.
Note: The following policies support integer settings in place of the three default labels offered. These options, including their limitations, are further explained in the module manual pages.
16.11 The MAC Multi-Level Security Module
Module name: mac_mls.ko
Kernel configuration line: options MAC_MLS
Boot option: mac_mls_load="YES"
The mac_mls(4) policy controls access between subjects and objects in the system by enforcing a strict information flow policy.
In MLS environments, a “clearance” level is set in each subject or objects label, along with compartments. Since these clearance or sensibility levels can reach numbers greater than six thousand; it would be a daunting task for any system administrator to thoroughly configure each subject or object. Thankfully, three “instant” labels are already included in this policy.
These labels are mls/low, mls/equal and mls/high. Since these labels are described in depth in the manual page, they will only get a brief description here:
-
The mls/low label contains a low configuration which permits it to be dominated by all other objects. Anything labeled with mls/low will have a low clearance level and not be permitted to access information of a higher level. In addition, this label will prevent objects of a higher clearance level from writing or passing information on to them.
-
The mls/equal label should be placed on objects considered to be exempt from the policy.
-
The mls/high label is the highest level of clearance possible. Objects assigned this label will hold dominance over all other objects in the system; however, they will not permit the leaking of information to objects of a lower class.
MLS provides for:
-
A hierarchical security level with a set of non hierarchical categories;
-
Fixed rules: no read up, no write down (a subject can have read access to objects on its own level or below, but not above. Similarly, a subject can have write access to objects on its own level or above but not beneath.);
-
Secrecy (preventing inappropriate disclosure of data);
-
Basis for the design of systems that concurrently handle data at multiple sensitivity levels (without leaking information between secret and confidential).
The following sysctl tunables are available for the configuration of special services and interfaces:
-
security.mac.mls.enabled is used to enable/disable the MLS policy.
-
security.mac.mls.ptys_equal will label all pty(4) devices as mls/equal during creation.
-
security.mac.mls.revocation_enabled is used to revoke access to objects after their label changes to a label of a lower grade.
-
security.mac.mls.max_compartments is used to set the maximum number of compartment levels with objects; basically the maximum compartment number allowed on a system.
To manipulate the MLS labels, the setfmac(8) command has been provided. To assign a label to an object, issue the following command:
# setfmac mls/5 test
To get the MLS label for the file test issue the following command:
# getfmac test
This is a summary of the MLS policy's features. Another approach is to create a master policy file in /etc which specifies the MLS policy information and to feed that file into the setfmac command. This method will be explained after all policies are covered.
16.11.1 Planning Mandatory Sensitivity
With the Multi-Level Security Policy Module, an administrator plans for controlling the flow of sensitive information. By default, with its block read up block write down nature, the system defaults everything to a low state. Everything is accessible and an administrator slowly changes this during the configuration stage; augmenting the confidentiality of the information.
Beyond the three basic label options above, an administrator may group users and groups as required to block the information flow between them. It might be easier to look at the information in clearance levels familiarized with words, for instance classifications such as Confidential, Secret, and Top Secret. Some administrators might just create different groups based on project levels. Regardless of classification method, a well thought out plan must exist before implementing such a restrictive policy.
Some example situations for this security policy module could be an e-commerce web server, a file server holding critical company information, and financial institution environments. The most unlikely place would be a personal workstation with only two or three users.
16.12 The MAC Biba Module
Module name: mac_biba.ko
Kernel configuration line: options MAC_BIBA
Boot option: mac_biba_load="YES"
The mac_biba(4) module loads the MAC Biba policy. This policy works much like that of the MLS policy with the exception that the rules for information flow are slightly reversed. This is said to prevent the downward flow of sensitive information whereas the MLS policy prevents the upward flow of sensitive information; thus, much of this section can apply to both policies.
In Biba environments, an “integrity” label is set on each subject or object. These labels are made up of hierarchal grades, and non-hierarchal components. As an object's or subject's grade ascends, so does its integrity.
Supported labels are biba/low, biba/equal, and biba/high; as explained below:
-
The biba/low label is considered the lowest integrity an object or subject may have. Setting this on objects or subjects will block their write access to objects or subjects marked high. They still have read access though.
-
The biba/equal label should only be placed on objects considered to be exempt from the policy.
-
The biba/high label will permit writing to objects set at a lower label, but not permit reading that object. It is recommended that this label be placed on objects that affect the integrity of the entire system.
Biba provides for:
-
Hierarchical integrity level with a set of non hierarchical integrity categories;
-
Fixed rules: no write up, no read down (opposite of MLS). A subject can have write access to objects on its own level or below, but not above. Similarly, a subject can have read access to objects on its own level or above, but not below;
-
Integrity (preventing inappropriate modification of data);
-
Integrity levels (instead of MLS sensitivity levels).
The following sysctl tunables can be used to manipulate the Biba policy.
-
security.mac.biba.enabled may be used to enable/disable enforcement of the Biba policy on the target machine.
-
security.mac.biba.ptys_equal may be used to disable the Biba policy on pty(4) devices.
-
security.mac.biba.revocation_enabled will force the revocation of access to objects if the label is changed to dominate the subject.
To access the Biba policy setting on system objects, use the setfmac and getfmac commands:
# setfmac biba/low test
# getfmac test
test: biba/low
16.12.1 Planning Mandatory Integrity
Integrity, different from sensitivity, guarantees that the information will never be manipulated by untrusted parties. This includes information passed between subjects, objects, and both. It ensures that users will only be able to modify and in some cases even access information they explicitly need to.
The mac_biba(4) security policy module permits an administrator to address which files and programs a user or users may see and invoke while assuring that the programs and files are free from threats and trusted by the system for that user, or group of users.
During the initial planning phase, an administrator must be prepared to partition users into grades, levels, and areas. Users will be blocked access not only to data but programs and utilities both before and after they start. The system will default to a high label once this policy module is enabled, and it is up to the administrator to configure the different grades and levels for users. Instead of using clearance levels as described above, a good planning method could include topics. For instance, only allow developers modification access to the source code repository, source code compiler, and other development utilities. While other users would be grouped into other categories such as testers, designers, or just ordinary users and would only be permitted read access.
With its natural security control, a lower integrity subject is unable to write to a higher integrity subject; a higher integrity subject cannot observe or read a lower integrity object. Setting a label at the lowest possible grade could make it inaccessible to subjects. Some prospective environments for this security policy module would include a constrained web server, development and test machine, and source code repository. A less useful implementation would be a personal workstation, a machine used as a router, or a network firewall.
16.13 The MAC LOMAC Module
Module name: mac_lomac.ko
Kernel configuration line: options MAC_LOMAC
Boot option: mac_lomac_load="YES"
Unlike the MAC Biba policy, the mac_lomac(4) policy permits access to lower integrity objects only after decreasing the integrity level to not disrupt any integrity rules.
The MAC version of the Low-watermark integrity policy, not to be confused with the older lomac(4) implementation, works almost identically to Biba, but with the exception of using floating labels to support subject demotion via an auxiliary grade compartment. This secondary compartment takes the form of [auxgrade]. When assigning a lomac policy with an auxiliary grade, it should look a little bit like: lomac/10[2] where the number two (2) is the auxiliary grade.
The MAC LOMAC policy relies on the ubiquitous labeling of all system objects with integrity labels, permitting subjects to read from low integrity objects and then downgrading the label on the subject to prevent future writes to high integrity objects. This is the [auxgrade] option discussed above, thus the policy may provide for greater compatibility and require less initial configuration than Biba.
16.13.1 Examples
Like the Biba and MLS policies; the setfmac and setpmac utilities may be used to place labels on system objects:
# setfmac /usr/home/trhodes lomac/high[low]
# getfmac /usr/home/trhodes lomac/high[low]
Notice the auxiliary grade here is low, this is a feature provided only by the MAC LOMAC policy.
16.14 Nagios in a MAC Jail
The following demonstration will implement a secure environment using various MAC modules with properly configured policies. This is only a test and should not be considered the complete answer to everyone's security woes. Just implementing a policy and ignoring it never works and could be disastrous in a production environment.
Before beginning this process, the multilabel option must be set on each file system as stated at the beginning of this chapter. Not doing so will result in errors. While at it, ensure that the net-mngt/nagios-plugins, net-mngt/nagios, and www/apache13 ports are all installed, configured, and working correctly.
16.14.1 Create an insecure User Class
Begin the procedure by adding the following user class to the /etc/login.conf file:
insecure:\
:copyright=/etc/COPYRIGHT:\
:welcome=/etc/motd:\
:setenv=MAIL=/var/mail/$,BLOCKSIZE=K:\
:path=~/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin
:manpath=/usr/share/man /usr/local/man:\
:nologin=/usr/sbin/nologin:\
:cputime=1h30m:\
:datasize=8M:\
:vmemoryuse=100M:\
:stacksize=2M:\
:memorylocked=4M:\
:memoryuse=8M:\
:filesize=8M:\
:coredumpsize=8M:\
:openfiles=24:\
:maxproc=32:\
:priority=0:\
:requirehome:\
:passwordtime=91d:\
:umask=022:\
:ignoretime@:\
:label=biba/10(10-10):
And adding the following line to the default user class:
:label=biba/high:
Once this is completed, the following command must be issued to rebuild the database:
# cap_mkdb /etc/login.conf
16.14.2 Boot Configuration
Do not reboot yet, just add the following lines to /boot/loader.conf so the required modules will load during system initialization:
mac_biba_load="YES"
mac_seeotheruids_load="YES"
16.14.3 Configure Users
Set the root user to the default class using:
# pw usermod root -L default
All user accounts that are not root or system users will now require a login class. The login class is required otherwise users will be refused access to common commands such as vi(1). The following sh script should do the trick:
# for x in `awk -F: '($3 >= 1001) && ($3 != 65534) { print $1 }' \
/etc/passwd`; do pw usermod $x -L default; done;
Drop the nagios and www users into the insecure class:
# pw usermod nagios -L insecure
# pw usermod www -L insecure
16.14.4 Create the Contexts File
A contexts file should now be created; the following example file should be placed in /etc/policy.contexts.
# This is the default BIBA policy for this system.
# System:
/var/run biba/equal
/var/run/* biba/equal
/dev biba/equal
/dev/* biba/equal
/var biba/equal
/var/spool biba/equal
/var/spool/* biba/equal
/var/log biba/equal
/var/log/* biba/equal
/tmp biba/equal
/tmp/* biba/equal
/var/tmp biba/equal
/var/tmp/* biba/equal
/var/spool/mqueue biba/equal
/var/spool/clientmqueue biba/equal
# For Nagios:
/usr/local/etc/nagios
/usr/local/etc/nagios/* biba/10
/var/spool/nagios biba/10
/var/spool/nagios/* biba/10
# For apache
/usr/local/etc/apache biba/10
/usr/local/etc/apache/* biba/10
This policy will enforce security by setting restrictions on the flow of information. In this specific configuration, users, root and others, should never be allowed to access Nagios. Configuration files and processes that are a part of Nagios will be completely self contained or jailed.
This file may now be read into our system by issuing the following command:
# setfsmac -ef /etc/policy.contexts /
# setfsmac -ef /etc/policy.contexts /
Note: The above file system layout may be different depending on environment; however, it must be run on every single file system.
The /etc/mac.conf file requires the following modifications in the main section:
default_labels file ?biba
default_labels ifnet ?biba
default_labels process ?biba
default_labels socket ?biba
16.14.5 Enable Networking
Add the following line to /boot/loader.conf:
security.mac.biba.trust_all_interfaces=1
And the following to the network card configuration stored in rc.conf. If the primary Internet configuration is done via DHCP, this may need to be configured manually after every system boot:
maclabel biba/equal
16.14.6 Testing the Configuration
Ensure that the web server and Nagios will not be started on system initialization, and reboot. Ensure the root user cannot access any of the files in the Nagios configuration directory. If root can issue an ls(1) command on /var/spool/nagios, then something is wrong. Otherwise a “permission denied” error should be returned.
If all seems well, Nagios, Apache, and Sendmail can now be started in a way fitting of the security policy. The following commands will make this happen:
# cd /etc/mail && make stop && \
setpmac biba/equal make start && setpmac biba/10\(10-10\) apachectl start && \
setpmac biba/10\(10-10\) /usr/local/etc/rc.d/nagios.sh forcestart
Double check to ensure that everything is working properly. If not, check the log files or error messages. Use the sysctl(8) utility to disable the mac_biba(4) security policy module enforcement and try starting everything again, like normal.
Note: The root user can change the security enforcement and edit the configuration files without fear. The following command will permit the degradation of the security policy to a lower grade for a newly spawned shell:
# setpmac biba/10 cshTo block this from happening, force the user into a range via login.conf(5). If setpmac(8) attempts to run a command outside of the compartment's range, an error will be returned and the command will not be executed. In this case, setting root to biba/high(high-high).
16.15 User Lock Down
This example considers a relatively small, fewer than fifty users, storage system. Users would have login capabilities, and be permitted to not only store data but access resources as well.
For this scenario, the mac_bsdextended(4) mixed with mac_seeotheruids(4) could co-exist and block access not only to system objects but to hide user processes as well.
Begin by adding the following lines to /boot/loader.conf:
mac_seeotheruids_enabled="YES"
The mac_bsdextended(4) security policy module may be activated through the use of the following rc.conf variable:
ugidfw_enable="YES"
Default rules stored in /etc/rc.bsdextended will be loaded at system initialization; however, the default entries may need modification. Since this machine is expected only to service users, everything may be left commented out except the last two. These will force the loading of user owned system objects by default.
Add the required users to this machine and reboot. For testing purposes, try logging in as a different user across two consoles. Run the ps aux command to see if processes of other users are visible. Try to run ls(1) on another users home directory, it should fail.
Do not try to test with the root user unless the specific sysctls have been modified to block super user access.
Note: When a new user is added, their mac_bsdextended(4) rule will not be in the ruleset list. To update the ruleset quickly, simply unload the security policy module and reload it again using the kldunload(8) and kldload(8) utilities.
16.16 Troubleshooting the MAC Framework
During the development stage, a few users reported problems with normal configuration. Some of these problems are listed below:
16.16.1 The multilabel option cannot be enabled on /
The multilabel flag does not stay enabled on my root (/) partition!
It seems that one out of every fifty users has this problem, indeed, we had this problem during our initial configuration. Further observation of this so called “bug” has lead me to believe that it is a result of either incorrect documentation or misinterpretation of the documentation. Regardless of why it happened, the following steps may be taken to resolve it:
-
Edit /etc/fstab and set the root partition at
rofor read-only. -
Reboot into single user mode.
-
Run tunefs
-l enableon /. -
Reboot the system into normal mode.
-
Run mount
-urw/ and change theroback torwin /etc/fstab and reboot the system again. -
Double-check the output from the mount to ensure that
multilabelhas been properly set on the root file system.
16.16.2 Cannot start a X11 server after MAC
After establishing a secure environment with MAC, I am no longer able to start X!
This could be caused by the MAC partition policy or by a mislabeling in one of the MAC labeling policies. To debug, try the following:
-
Check the error message; if the user is in the insecure class, the partition policy may be the culprit. Try setting the user's class back to the default class and rebuild the database with the cap_mkdb command. If this does not alleviate the problem, go to step two.
-
Double-check the label policies. Ensure that the policies are set correctly for the user in question, the X11 application, and the /dev entries.
-
If neither of these resolve the problem, send the error message and a description of your environment to the TrustedBSD discussion lists located at the TrustedBSD website or to the FreeBSD general questions mailing list mailing list.
16.16.3 Error: _secure_path(3) cannot stat .login_conf
When I attempt to switch from the root to another user in the system, the error message “_secure_path: unable to state .login_conf”.
This message is usually shown when the user has a higher label setting then that of
the user whom they are attempting to become. For instance a user on the system, joe, has a default label of biba/low.
The root user, who has a label of biba/high, cannot view joe's home
directory. This will happen regardless if root has used the su command to become joe, or not. In this
scenario, the Biba integrity model will not permit root to view
objects set at a lower integrity level.
16.16.4 The root username is broken!
In normal or even single user mode, the root is not recognized. The whoami command returns 0 (zero) and su returns “who are you?”. What could be going on?
This can happen if a labeling policy has been disabled, either by a sysctl(8) or the
policy module was unloaded. If the policy is being disabled or has been temporarily
disabled, then the login capabilities database needs to be reconfigured with the label option being removed. Double check the login.conf file to ensure that all label options have been removed and rebuild the database with the
cap_mkdb command.
This may also happen if a policy restricts access to the master.passwd file or database. Usually caused by an administrator altering the file under a label which conflicts with the general policy being used by the system. In these cases, the user information would be read by the system and access would be blocked as the file has inherited the new label. Disable the policy via a sysctl(8) and everything should return to normal.
Chapter 17 Security Event Auditing
Written by Tom Rhodes and Robert Watson.17.1 Synopsis
FreeBSD 6.2 and later include support for fine-grained security event auditing. Event auditing allows the reliable, fine-grained, and configurable logging of a variety of security-relevant system events, including logins, configuration changes, and file and network access. These log records can be invaluable for live system monitoring, intrusion detection, and postmortem analysis. FreeBSD implements Sun™'s published BSM API and file format, and is interoperable with both Sun's Solaris and Apple®'s Mac OS X audit implementations.
This chapter focuses on the installation and configuration of Event Auditing. It explains audit policies, and provides an example audit configuration.
After reading this chapter, you will know:
-
What Event Auditing is and how it works.
-
How to configure Event Auditing on FreeBSD for users and processes.
-
How to review the audit trail using the audit reduction and review tools.
Before reading this chapter, you should:
-
Understand UNIX and FreeBSD basics (Chapter 3).
-
Be familiar with the basics of kernel configuration/compilation (Chapter 8).
-
Have some familiarity with security and how it pertains to FreeBSD (Chapter 14).
Warning: The audit facility in FreeBSD 6.2 is experimental, and production deployment should occur only after careful consideration of the risks of deploying experimental software. Known limitations include that not all security-relevant system events are currently auditable, and that some login mechanisms, such as X11-based display managers and third party daemons, do not properly configure auditing for user login sessions.
Warning: The security event auditing facility is able to generate very detailed logs of system activity: on a busy system, trail file data can be very large when configured for high detail, exceeding gigabytes a week in some configurations. Administrators should take into account disk space requirements associated with high volume audit configurations. For example, it may be desirable to dedicate a file system to the /var/audit tree so that other file systems are not affected if the audit file system becomes full.
17.2 Key Terms in this Chapter
Before reading this chapter, a few key audit-related terms must be explained:
-
event: An auditable event is any event that can be logged using the audit subsystem. Examples of security-relevant events include the creation of a file, the building of a network connection, or a user logging in. Events are either “attributable”, meaning that they can be traced to an authenticated user, or “non-attributable” if they cannot be. Examples of non-attributable events are any events that occur before authentication in the login process, such as bad password attempts.
-
class: Event classes are named sets of related events, and are used in selection expressions. Commonly used classes of events include “file creation” (fc), “exec” (ex) and “login_logout” (lo).
-
record: A record is an audit log entry describing a security event. Records contain a record event type, information on the subject (user) performing the action, date and time information, information on any objects or arguments, and a success or failure condition.
-
trail: An audit trail, or log file, consists of a series of audit records describing security events. Typically, trails are in roughly chronological order with respect to the time events completed. Only authorized processes are allowed to commit records to the audit trail.
-
selection expression: A selection expression is a string containing a list of prefixes and audit event class names used to match events.
-
preselection: The process by which the system identifies which events are of interest to the administrator in order to avoid generating audit records describing events that are not of interest. The preselection configuration uses a series of selection expressions to identify which classes of events to audit for which users, as well as global settings that apply to both authenticated and unauthenticated processes.
-
reduction: The process by which records from existing audit trails are selected for preservation, printing, or analysis. Likewise, the process by which undesired audit records are removed from the audit trail. Using reduction, administrators can implement policies for the preservation of audit data. For example, detailed audit trails might be kept for one month, but after that, trails might be reduced in order to preserve only login information for archival purposes.
17.3 Installing Audit Support
User space support for Event Auditing is installed as part of the base FreeBSD operating system. In FreeBSD 6.3 and later, kernel support for Event Auditing is compiled in by default. In FreeBSD 6.2, support must be explicitly compiled into the kernel by adding the following lines to the kernel configuration file:
options AUDIT
Rebuild and reinstall the kernel via the normal process explained in Chapter 8.
Once an audit-enabled kernel is built, installed, and the system has been rebooted, enable the audit daemon by adding the following line to rc.conf(5):
auditd_enable="YES"
Audit support must then be started by a reboot, or by manually starting the audit daemon:
/etc/rc.d/auditd start
17.4 Audit Configuration
All configuration files for security audit are found in /etc/security. The following files must be present before the audit daemon is started:
-
audit_class - Contains the definitions of the audit classes.
-
audit_control - Controls aspects of the audit subsystem, such as default audit classes, minimum disk space to leave on the audit log volume, maximum audit trail size, etc.
-
audit_event - Textual names and descriptions of system audit events, as well as a list of which classes each event in.
-
audit_user - User-specific audit requirements, which are combined with the global defaults at login.
-
audit_warn - A customizable shell script used by auditd to generate warning messages in exceptional situations, such as when space for audit records is running low or when the audit trail file has been rotated.
Warning: Audit configuration files should be edited and maintained carefully, as errors in configuration may result in improper logging of events.
17.4.1 Event Selection Expressions
Selection expressions are used in a number of places in the audit configuration to determine which events should be audited. Expressions contain a list of event classes to match, each with a prefix indicating whether matching records should be accepted or ignored, and optionally to indicate if the entry is intended to match successful or failed operations. Selection expressions are evaluated from left to right, and two expressions are combined by appending one onto the other.
The following list contains the default audit event classes present in audit_class:
-
all - all - Match all event classes.
-
ad - administrative - Administrative actions performed on the system as a whole.
-
ap - application - Application defined action.
-
cl - file close - Audit calls to the
closesystem call. -
ex - exec - Audit program execution. Auditing of command line arguments and environmental variables is controlled via audit_control(5) using the argv and envv parameters to the policy setting.
-
fa - file attribute access - Audit the access of object attributes such as stat(1), pathconf(2) and similar events.
-
fc - file create - Audit events where a file is created as a result.
-
fd - file delete - Audit events where file deletion occurs.
-
fm - file attribute modify - Audit events where file attribute modification occurs, such as chown(8), chflags(1), flock(2), etc.
-
fr - file read - Audit events in which data is read, files are opened for reading, etc.
-
fw - file write - Audit events in which data is written, files are written or modified, etc.
-
io - ioctl - Audit use of the ioctl(2) system call.
-
ip - ipc - Audit various forms of Inter-Process Communication, including POSIX pipes and System V IPC operations.
-
lo - login_logout - Audit login(1) and logout(1) events occurring on the system.
-
na - non attributable - Audit non-attributable events.
-
no - invalid class - Match no audit events.
-
nt - network - Audit events related to network actions, such as connect(2) and accept(2).
-
ot - other - Audit miscellaneous events.
-
pc - process - Audit process operations, such as exec(3) and exit(3).
These audit event classes may be customized by modifying the audit_class and audit_event configuration files.
Each audit class in the list is combined with a prefix indicating whether successful/failed operations are matched, and whether the entry is adding or removing matching for the class and type.
-
(none) Audit both successful and failed instances of the event.
-
+ Audit successful events in this class.
-
- Audit failed events in this class.
-
^ Audit neither successful nor failed events in this class.
-
^+ Do not audit successful events in this class.
-
^- Do not audit failed events in this class.
The following example selection string selects both successful and failed login/logout events, but only successful execution events:
lo,+ex
17.4.2 Configuration Files
In most cases, administrators will need to modify only two files when configuring the audit system: audit_control and audit_user. The first controls system-wide audit properties and policies; the second may be used to fine-tune auditing by user.
17.4.2.1 The audit_control File
The audit_control file specifies a number of defaults for the audit subsystem. Viewing the contents of this file, we see the following:
dir:/var/audit
flags:lo
minfree:20
naflags:lo
policy:cnt
filesz:0
The dir option is used to set one or more directories
where audit logs will be stored. If more than one directory entry appears, they will be
used in order as they fill. It is common to configure audit so that audit logs are stored
on a dedicated file system, in order to prevent interference between the audit subsystem
and other subsystems if the file system fills.
The flags field sets the system-wide default preselection
mask for attributable events. In the example above, successful and failed login and
logout events are audited for all users.
The minfree option defines the minimum percentage of free
space for the file system where the audit trail is stored. When this threshold is
exceeded, a warning will be generated. The above example sets the minimum free space to
twenty percent.
The naflags option specifies audit classes to be audited
for non-attributed events, such as the login process and system daemons.
The policy option specifies a comma-separated list of
policy flags controlling various aspects of audit behavior. The default cnt flag indicates that the system should continue running despite
an auditing failure (this flag is highly recommended). Another commonly used flag is argv, which causes command line arguments to the execve(2) system call
to be audited as part of command execution.
The filesz option specifies the maximum size in bytes to
allow an audit trail file to grow to before automatically terminating and rotating the
trail file. The default, 0, disables automatic log rotation. If the requested file size
is non-zero and below the minimum 512k, it will be ignored and a log message will be
generated.
17.4.2.2 The audit_user File
The audit_user file permits the administrator to specify further audit requirements for specific users. Each line configures auditing for a user via two fields: the first is the alwaysaudit field, which specifies a set of events that should always be audited for the user, and the second is the neveraudit field, which specifies a set of events that should never be audited for the user.
The following example audit_user file audits login/logout events and successful command execution for the root user, and audits file creation and successful command execution for the www user. If used with the example audit_control file above, the lo entry for root is redundant, and login/logout events will also be audited for the www user.
root:lo,+ex:no
www:fc,+ex:no
17.5 Administering the Audit Subsystem
17.5.1 Viewing Audit Trails
Audit trails are stored in the BSM binary format, so tools must be used to modify or convert to text. The praudit(1) command converts trail files to a simple text format; the auditreduce(1) command may be used to reduce the audit trail file for analysis, archiving, or printing purposes. auditreduce supports a variety of selection parameters, including event type, event class, user, date or time of the event, and the file path or object acted on.
For example, the praudit utility will dump the entire contents of a specified audit log in plain text:
# praudit /var/audit/AUDITFILE
Where AUDITFILE is the audit log to dump.
Audit trails consist of a series of audit records made up of tokens, which praudit prints sequentially one per line. Each token is of a specific type, such as header holding an audit record header, or path holding a file path from a name lookup. The following is an example of an execve event:
header,133,10,execve(2),0,Mon Sep 25 15:58:03 2006, + 384 msec
exec arg,finger,doug
path,/usr/bin/finger
attribute,555,root,wheel,90,24918,104944
subject,robert,root,wheel,root,wheel,38439,38032,42086,128.232.9.100
return,success,0
trailer,133
This audit represents a successful execve call, in which the command finger doug has been run. The arguments token contains both the processed command line presented by the shell to the kernel. The path token holds the path to the executable as looked up by the kernel. The attribute token describes the binary, and in particular, includes the file mode which can be used to determine if the application was setuid. The subject token describes the subject process, and stores in sequence the audit user ID, effective user ID and group ID, real user ID and group ID, process ID, session ID, port ID, and login address. Notice that the audit user ID and real user ID differ: the user robert has switched to the root account before running this command, but it is audited using the original authenticated user. Finally, the return token indicates the successful execution, and the trailer concludes the record.
In FreeBSD 6.3 and later, praudit also supports an XML output
format, which can be selected using the -x argument.
17.5.2 Reducing Audit Trails
Since audit logs may be very large, an administrator will likely want to select a subset of records for using, such as records associated with a specific user:
# auditreduce -u trhodes /var/audit/AUDITFILE | praudit
This will select all audit records produced for the user trhodes stored in the AUDITFILE file.
17.5.3 Delegating Audit Review Rights
Members of the audit group are given permission to read audit trails in /var/audit; by default, this group is empty, so only the root user may read audit trails. Users may be added to the audit group in order to delegate audit review rights to the user. As the ability to track audit log contents provides significant insight into the behavior of users and processes, it is recommended that the delegation of audit review rights be performed with caution.
17.5.4 Live Monitoring Using Audit Pipes
Audit pipes are cloning pseudo-devices in the device file system which allow applications to tap the live audit record stream. This is primarily of interest to authors of intrusion detection and system monitoring applications. However, for the administrator the audit pipe device is a convenient way to allow live monitoring without running into problems with audit trail file ownership or log rotation interrupting the event stream. To track the live audit event stream, use the following command line:
# praudit /dev/auditpipe
By default, audit pipe device nodes are accessible only to the root user. To make them accessible to the members of the audit group, add a devfs rule to devfs.rules:
add path 'auditpipe*' mode 0440 group audit
See devfs.rules(5) for more information on configuring the devfs file system.
Warning: It is easy to produce audit event feedback cycles, in which the viewing of each audit event results in the generation of more audit events. For example, if all network I/O is audited, and praudit(1) is run from an SSH session, then a continuous stream of audit events will be generated at a high rate, as each event being printed will generate another event. It is advisable to run praudit on an audit pipe device from sessions without fine-grained I/O auditing in order to avoid this happening.
17.5.5 Rotating Audit Trail Files
Audit trails are written to only by the kernel, and managed only by the audit daemon, auditd. Administrators should not attempt to use newsyslog.conf(5) or other tools to directly rotate audit logs. Instead, the audit management tool may be used to shut down auditing, reconfigure the audit system, and perform log rotation. The following command causes the audit daemon to create a new audit log and signal the kernel to switch to using the new log. The old log will be terminated and renamed, at which point it may then be manipulated by the administrator.
# audit -n
Warning: If the auditd daemon is not currently running, this command will fail and an error message will be produced.
Adding the following line to /etc/crontab will force the rotation every twelve hours from cron(8):
0 */12 * * * root /usr/sbin/audit -n
The change will take effect once you have saved the new /etc/crontab.
Automatic rotation of the audit trail file based on file size is possible via the
filesz option in audit_control(5), and
is described in the configuration files section of this chapter.
17.5.6 Compressing Audit Trails
As audit trail files can become very large, it is often desirable to compress or otherwise archive trails once they have been closed by the audit daemon. The audit_warn script can be used to perform customized operations for a variety of audit-related events, including the clean termination of audit trails when they are rotated. For example, the following may be added to the audit_warn script to compress audit trails on close:
#
# Compress audit trail files on close.
#
if [ "$1" = closefile ]; then
gzip -9 $2
fi
Other archiving activities might include copying trail files to a centralized server, deleting old trail files, or reducing the audit trail to remove unneeded records. The script will be run only when audit trail files are cleanly terminated, so will not be run on trails left unterminated following an improper shutdown.
Chapter 18 Storage
18.1 Synopsis
This chapter covers the use of disks in FreeBSD. This includes memory-backed disks, network-attached disks, standard SCSI/IDE storage devices, and devices using the USB interface.
After reading this chapter, you will know:
-
The terminology FreeBSD uses to describe the organization of data on a physical disk (partitions and slices).
-
How to add additional hard disks to your system.
-
How to configure FreeBSD to use USB storage devices.
-
How to set up virtual file systems, such as memory disks.
-
How to use quotas to limit disk space usage.
-
How to encrypt disks to secure them against attackers.
-
How to create and burn CDs and DVDs on FreeBSD.
-
The various storage media options for backups.
-
How to use backup programs available under FreeBSD.
-
How to backup to floppy disks.
-
What file system snapshots are and how to use them efficiently.
Before reading this chapter, you should:
-
Know how to configure and install a new FreeBSD kernel (Chapter 8).
18.2 Device Names
The following is a list of physical storage devices supported in FreeBSD, and the device names associated with them.
Table 18-1. Physical Disk Naming Conventions
| Drive type | Drive device name |
|---|---|
| IDE hard drives | ad |
| IDE CDROM drives | acd |
| SCSI hard drives and USB Mass storage devices | da |
| SCSI CDROM drives | cd |
| Assorted non-standard CDROM drives | mcd for Mitsumi CD-ROM and scd for Sony CD-ROM devices |
| Floppy drives | fd |
| SCSI tape drives | sa |
| IDE tape drives | ast |
| Flash drives | fla for DiskOnChip® Flash device |
| RAID drives | aacd for Adaptec AdvancedRAID, mlxd and mlyd for Mylex, amrd for AMI MegaRAID, idad for Compaq Smart RAID, twed for 3ware® RAID. |
18.3 Adding Disks
Originally contributed by David O'Brien.Lets say we want to add a new SCSI disk to a machine that currently only has a single drive. First turn off the computer and install the drive in the computer following the instructions of the computer, controller, and drive manufacturer. Due to the wide variations of procedures to do this, the details are beyond the scope of this document.
Login as user root. After you have installed the drive, inspect /var/run/dmesg.boot to ensure the new disk was found. Continuing with our example, the newly added drive will be da1 and we want to mount it on /1 (if you are adding an IDE drive, the device name will be ad1).
FreeBSD runs on IBM-PC compatible computers, therefore it must take into account the PC BIOS partitions. These are different from the traditional BSD partitions. A PC disk has up to four BIOS partition entries. If the disk is going to be truly dedicated to FreeBSD, you can use the dedicated mode. Otherwise, FreeBSD will have to live within one of the PC BIOS partitions. FreeBSD calls the PC BIOS partitions slices so as not to confuse them with traditional BSD partitions. You may also use slices on a disk that is dedicated to FreeBSD, but used in a computer that also has another operating system installed. This is a good way to avoid confusing the fdisk utility of other, non-FreeBSD operating systems.
In the slice case the drive will be added as /dev/da1s1e. This is read as: SCSI disk, unit number 1 (second SCSI disk), slice 1 (PC BIOS partition 1), and e BSD partition. In the dedicated case, the drive will be added simply as /dev/da1e.
Due to the use of 32-bit integers to store the number of sectors, bsdlabel(8) is limited to 2^32-1 sectors per disk or 2TB in most cases. The fdisk(8) format allows a starting sector of no more than 2^32-1 and a length of no more than 2^32-1, limiting partitions to 2TB and disks to 4TB in most cases. The sunlabel(8) format is limited to 2^32-1 sectors per partition and 8 partitions for a total of 16TB. For larger disks, gpt(8) partitions may be used.
18.3.1 Using sysinstall(8)
-
Navigating Sysinstall
You may use sysinstall to partition and label a new disk using its easy to use menus. Either login as user root or use the su command. Run sysinstall and enter the Configure menu. Within the FreeBSD Configuration Menu, scroll down and select the Fdisk option.
-
fdisk Partition Editor
Once inside fdisk, typing A will use the entire disk for FreeBSD. When asked if you want to “remain cooperative with any future possible operating systems”, answer YES. Write the changes to the disk using W. Now exit the FDISK editor by typing q. Next you will be asked about the “Master Boot Record”. Since you are adding a disk to an already running system, choose None.
-
Disk Label Editor
Next, you need to exit sysinstall and start it again. Follow the directions above, although this time choose the Label option. This will enter the Disk Label Editor. This is where you will create the traditional BSD partitions. A disk can have up to eight partitions, labeled a-h. A few of the partition labels have special uses. The a partition is used for the root partition (/). Thus only your system disk (e.g, the disk you boot from) should have an a partition. The b partition is used for swap partitions, and you may have many disks with swap partitions. The c partition addresses the entire disk in dedicated mode, or the entire FreeBSD slice in slice mode. The other partitions are for general use.
sysinstall's Label editor favors the e partition for non-root, non-swap partitions. Within the Label editor, create a single file system by typing C. When prompted if this will be a FS (file system) or swap, choose FS and type in a mount point (e.g, /mnt). When adding a disk in post-install mode, sysinstall will not create entries in /etc/fstab for you, so the mount point you specify is not important.
You are now ready to write the new label to the disk and create a file system on it. Do this by typing W. Ignore any errors from sysinstall that it could not mount the new partition. Exit the Label Editor and sysinstall completely.
-
Finish
The last step is to edit /etc/fstab to add an entry for your new disk.
18.3.2 Using Command Line Utilities
18.3.2.1 Using Slices
This setup will allow your disk to work correctly with other operating systems that might be installed on your computer and will not confuse other operating systems' fdisk utilities. It is recommended to use this method for new disk installs. Only use dedicated mode if you have a good reason to do so!
# dd if=/dev/zero of=/dev/da1 bs=1k count=1
# fdisk -BI da1 #Initialize your new disk
# bsdlabel -B -w da1s1 auto #Label it.
# bsdlabel -e da1s1 # Edit the bsdlabel just created and add any partitions.
# mkdir -p /1
# newfs /dev/da1s1e # Repeat this for every partition you created.
# mount /dev/da1s1e /1 # Mount the partition(s)
# vi /etc/fstab # Add the appropriate entry/entries to your /etc/fstab.
If you have an IDE disk, substitute ad for da.
18.3.2.2 Dedicated
If you will not be sharing the new drive with another operating system, you may use the dedicated mode. Remember this mode can confuse Microsoft operating systems; however, no damage will be done by them. IBM's OS/2 however, will “appropriate” any partition it finds which it does not understand.
# dd if=/dev/zero of=/dev/da1 bs=1k count=1
# bsdlabel -Bw da1 auto
# bsdlabel -e da1 # create the `e' partition
# newfs -d0 /dev/da1e
# mkdir -p /1
# vi /etc/fstab # add an entry for /dev/da1e
# mount /1
An alternate method is:
# dd if=/dev/zero of=/dev/da1 count=2
# bsdlabel /dev/da1 | bsdlabel -BR da1 /dev/stdin
# newfs /dev/da1e
# mkdir -p /1
# vi /etc/fstab # add an entry for /dev/da1e
# mount /1
18.4 RAID
18.4.1 Software RAID
18.4.1.1 Concatenated Disk Driver (CCD) Configuration
Original work by Christopher Shumway. Revised by Jim Brown.When choosing a mass storage solution the most important factors to consider are speed, reliability, and cost. It is rare to have all three in balance; normally a fast, reliable mass storage device is expensive, and to cut back on cost either speed or reliability must be sacrificed.
In designing the system described below, cost was chosen as the most important factor, followed by speed, then reliability. Data transfer speed for this system is ultimately constrained by the network. And while reliability is very important, the CCD drive described below serves online data that is already fully backed up on CD-R's and can easily be replaced.
Defining your own requirements is the first step in choosing a mass storage solution. If your requirements prefer speed or reliability over cost, your solution will differ from the system described in this section.
18.4.1.1.1 Installing the Hardware
In addition to the IDE system disk, three Western Digital 30GB, 5400 RPM IDE disks form the core of the CCD disk described below providing approximately 90GB of online storage. Ideally, each IDE disk would have its own IDE controller and cable, but to minimize cost, additional IDE controllers were not used. Instead the disks were configured with jumpers so that each IDE controller has one master, and one slave.
Upon reboot, the system BIOS was configured to automatically detect the disks attached. More importantly, FreeBSD detected them on reboot:
ad0: 19574MB <WDC WD205BA> [39770/16/63] at ata0-master UDMA33
ad1: 29333MB <WDC WD307AA> [59598/16/63] at ata0-slave UDMA33
ad2: 29333MB <WDC WD307AA> [59598/16/63] at ata1-master UDMA33
ad3: 29333MB <WDC WD307AA> [59598/16/63] at ata1-slave UDMA33
Note: If FreeBSD does not detect all the disks, ensure that you have jumpered them correctly. Most IDE drives also have a “Cable Select” jumper. This is not the jumper for the master/slave relationship. Consult the drive documentation for help in identifying the correct jumper.
Next, consider how to attach them as part of the file system. You should research both vinum(8) (Chapter 20) and ccd(4). In this particular configuration, ccd(4) was chosen.
18.4.1.1.2 Setting Up the CCD
The ccd(4) driver allows you to take several identical disks and concatenate them into one logical file system. In order to use ccd(4), you need a kernel with ccd(4) support built in. Add this line to your kernel configuration file, rebuild, and reinstall the kernel:
device ccd
The ccd(4) support can also be loaded as a kernel loadable module.
To set up ccd(4), you must first use bsdlabel(8) to label the disks:
bsdlabel -w ad1 auto
bsdlabel -w ad2 auto
bsdlabel -w ad3 auto
This creates a bsdlabel for ad1c, ad2c and ad3c that spans the entire disk.
The next step is to change the disk label type. You can use bsdlabel(8) to edit the disks:
bsdlabel -e ad1
bsdlabel -e ad2
bsdlabel -e ad3
This opens up the current disk label on each disk with the editor specified by the EDITOR environment variable, typically vi(1).
An unmodified disk label will look something like this:
8 partitions:
# size offset fstype [fsize bsize bps/cpg]
c: 60074784 0 unused 0 0 0 # (Cyl. 0 - 59597)
Add a new e partition for ccd(4) to use. This
can usually be copied from the c partition, but the fstype must
be 4.2BSD. The disk label should now look something like
this:
8 partitions:
# size offset fstype [fsize bsize bps/cpg]
c: 60074784 0 unused 0 0 0 # (Cyl. 0 - 59597)
e: 60074784 0 4.2BSD 0 0 0 # (Cyl. 0 - 59597)
18.4.1.1.3 Building the File System
Now that you have all the disks labeled, you must build the ccd(4). To do that, use ccdconfig(8), with options similar to the following:
ccdconfig ccd0 32 0 /dev/ad1e /dev/ad2e /dev/ad3e
The use and meaning of each option is shown below:
- The first argument is the device to configure, in this case, /dev/ccd0c. The /dev/ portion is optional.
- The interleave for the file system. The interleave defines the size of a stripe in disk blocks, each normally 512 bytes. So, an interleave of 32 would be 16,384 bytes.
- Flags for ccdconfig(8). If you want to enable drive mirroring, you can specify a flag here. This configuration does not provide mirroring for ccd(4), so it is set at 0 (zero).
- The final arguments to ccdconfig(8) are the devices to place into the array. Use the complete pathname for each device.
After running ccdconfig(8) the ccd(4) is configured. A file system can be installed. Refer to newfs(8) for options, or simply run:
newfs /dev/ccd0c
18.4.1.1.4 Making it All Automatic
Generally, you will want to mount the ccd(4) upon each reboot. To do this, you must configure it first. Write out your current configuration to /etc/ccd.conf using the following command:
ccdconfig -g > /etc/ccd.conf
During reboot, the script /etc/rc runs ccdconfig -C if /etc/ccd.conf exists. This automatically configures the ccd(4) so it can be mounted.
Note: If you are booting into single user mode, before you can mount(8) the ccd(4), you need to issue the following command to configure the array:
ccdconfig -C
To automatically mount the ccd(4), place an entry for the ccd(4) in /etc/fstab so it will be mounted at boot time:
/dev/ccd0c /media ufs rw 2 2
18.4.1.2 The Vinum Volume Manager
The Vinum Volume Manager is a block device driver which implements virtual disk drives. It isolates disk hardware from the block device interface and maps data in ways which result in an increase in flexibility, performance and reliability compared to the traditional slice view of disk storage. vinum(8) implements the RAID-0, RAID-1 and RAID-5 models, both individually and in combination.
See Chapter 20 for more information about vinum(8).
18.4.2 Hardware RAID
FreeBSD also supports a variety of hardware RAID controllers. These devices control a RAID subsystem without the need for FreeBSD specific software to manage the array.
Using an on-card BIOS, the card controls most of the disk operations itself. The following is a brief setup description using a Promise IDE RAID controller. When this card is installed and the system is started up, it displays a prompt requesting information. Follow the instructions to enter the card's setup screen. From here, you have the ability to combine all the attached drives. After doing so, the disk(s) will look like a single drive to FreeBSD. Other RAID levels can be set up accordingly.
18.4.3 Rebuilding ATA RAID1 Arrays
FreeBSD allows you to hot-replace a failed disk in an array. This requires that you catch it before you reboot.
You will probably see something like the following in /var/log/messages or in the dmesg(8) output:
ad6 on monster1 suffered a hard error.
ad6: READ command timeout tag=0 serv=0 - resetting
ad6: trying fallback to PIO mode
ata3: resetting devices .. done
ad6: hard error reading fsbn 1116119 of 0-7 (ad6 bn 1116119; cn 1107 tn 4 sn 11)\\
status=59 error=40
ar0: WARNING - mirror lost
Using atacontrol(8), check for further information:
# atacontrol list
ATA channel 0:
Master: no device present
Slave: acd0 <HL-DT-ST CD-ROM GCR-8520B/1.00> ATA/ATAPI rev 0
ATA channel 1:
Master: no device present
Slave: no device present
ATA channel 2:
Master: ad4 <MAXTOR 6L080J4/A93.0500> ATA/ATAPI rev 5
Slave: no device present
ATA channel 3:
Master: ad6 <MAXTOR 6L080J4/A93.0500> ATA/ATAPI rev 5
Slave: no device present
# atacontrol status ar0
ar0: ATA RAID1 subdisks: ad4 ad6 status: DEGRADED
-
You will first need to detach the ata channel with the failed disk so you can safely remove it:
# atacontrol detach ata3 -
Replace the disk.
-
Reattach the ata channel:
# atacontrol attach ata3 Master: ad6 <MAXTOR 6L080J4/A93.0500> ATA/ATAPI rev 5 Slave: no device present -
Add the new disk to the array as a spare:
# atacontrol addspare ar0 ad6 -
Rebuild the array:
# atacontrol rebuild ar0 -
It is possible to check on the progress by issuing the following command:
# dmesg | tail -10 [output removed] ad6: removed from configuration ad6: deleted from ar0 disk1 ad6: inserted into ar0 disk1 as spare # atacontrol status ar0 ar0: ATA RAID1 subdisks: ad4 ad6 status: REBUILDING 0% completed -
Wait until this operation completes.
18.5 USB Storage Devices
Contributed by Marc Fonvieille.A lot of external storage solutions, nowadays, use the Universal Serial Bus (USB): hard drives, USB thumbdrives, CD-R burners, etc. FreeBSD provides support for these devices.
18.5.1 Configuration
The USB mass storage devices driver, umass(4), provides the support for USB storage devices. If you use the GENERIC kernel, you do not have to change anything in your configuration. If you use a custom kernel, be sure that the following lines are present in your kernel configuration file:
device scbus
device da
device pass
device uhci
device ohci
device usb
device umass
The umass(4) driver uses the SCSI subsystem to access to the USB storage devices, your USB device will be seen as a SCSI device by the system. Depending on the USB chipset on your motherboard, you only need either device uhci or device ohci, however having both in the kernel configuration file is harmless. Do not forget to compile and install the new kernel if you added any lines.
Note: If your USB device is a CD-R or DVD burner, the SCSI CD-ROM driver, cd(4), must be added to the kernel via the line:
device cdSince the burner is seen as a SCSI drive, the driver atapicam(4) should not be used in the kernel configuration.
Support for USB 2.0 controllers is provided on FreeBSD; however, you must add:
device ehci
to your configuration file for USB 2.0 support. Note uhci(4) and ohci(4) drivers are still needed if you want USB 1.X support.
18.5.2 Testing the Configuration
The configuration is ready to be tested: plug in your USB device, and in the system message buffer (dmesg(8)), the drive should appear as something like:
umass0: USB Solid state disk, rev 1.10/1.00, addr 2
GEOM: create disk da0 dp=0xc2d74850
da0 at umass-sim0 bus 0 target 0 lun 0
da0: <Generic Traveling Disk 1.11> Removable Direct Access SCSI-2 device
da0: 1.000MB/s transfers
da0: 126MB (258048 512 byte sectors: 64H 32S/T 126C)
Of course, the brand, the device node (da0) and other details can differ according to your configuration.
Since the USB device is seen as a SCSI one, the camcontrol command can be used to list the USB storage devices attached to the system:
# camcontrol devlist
<Generic Traveling Disk 1.11> at scbus0 target 0 lun 0 (da0,pass0)
If the drive comes with a file system, you should be able to mount it. The Section 18.3 will help you to format and create partitions on the USB drive if needed.
To make this device mountable as a normal user, certain steps have to be taken. First, the devices that are created when a USB storage device is connected need to be accessible by the user. A solution is to make all users of these devices a member of the operator group. This is done with pw(8). Second, when the devices are created, the operator group should be able to read and write them. This is accomplished by adding these lines to /etc/devfs.rules:
[localrules=1]
add path 'da*' mode 0660 group operator
Note: If there already are SCSI disks in the system, it must be done a bit different. E.g., if the system already contains disks da0 through da2 attached to the system, change the second line as follows:
add path 'da[3-9]*' mode 0660 group operatorThis will exclude the already existing disks from belonging to the operator group.
You also have to enable your devfs.rules(5) ruleset in your /etc/rc.conf file:
devfs_system_ruleset="localrules"
Next, the kernel has to be configured to allow regular users to mount file systems. The easiest way is to add the following line to /etc/sysctl.conf:
vfs.usermount=1
Note that this only takes effect after the next reboot. Alternatively, one can also use sysctl(8) to set this variable.
The final step is to create a directory where the file system is to be mounted. This directory needs to be owned by the user that is to mount the file system. One way to do that is for root to create a subdirectory owned by that user as /mnt/$USER (replace $USER by the login name of the actual user):
# mkdir /mnt/$USER
# chown $USER:$USER /mnt/$USER
Suppose a USB thumbdrive is plugged in, and a device /dev/da0s1 appears. Since these devices usually come preformatted with a FAT file system, one can mount them like this:
% mount -t msdosfs -m 644 -M 755 /dev/da0s1 /mnt/$USER
If you unplug the device (the disk must be unmounted before), you should see, in the system message buffer, something like the following:
umass0: at uhub0 port 1 (addr 2) disconnected
(da0:umass-sim0:0:0:0): lost device
(da0:umass-sim0:0:0:0): removing device entry
GEOM: destroy disk da0 dp=0xc2d74850
umass0: detached
18.5.3 Further Reading
Beside the Adding Disks and Mounting and Unmounting File Systems sections, reading various manual pages may be also useful: umass(4), camcontrol(8), and usbdevs(8).
18.6 Creating and Using Optical Media (CDs)
Contributed by Mike Meyer.18.6.1 Introduction
CDs have a number of features that differentiate them from conventional disks. Initially, they were not writable by the user. They are designed so that they can be read continuously without delays to move the head between tracks. They are also much easier to transport between systems than similarly sized media were at the time.
CDs do have tracks, but this refers to a section of data to be read continuously and not a physical property of the disk. To produce a CD on FreeBSD, you prepare the data files that are going to make up the tracks on the CD, then write the tracks to the CD.
The ISO 9660 file system was designed to deal with these differences. It unfortunately codifies file system limits that were common then. Fortunately, it provides an extension mechanism that allows properly written CDs to exceed those limits while still working with systems that do not support those extensions.
The sysutils/cdrtools port includes mkisofs(8), a program that you can use to produce a data file containing an ISO 9660 file system. It has options that support various extensions, and is described below.
Which tool to use to burn the CD depends on whether your CD burner is ATAPI or something else. ATAPI CD burners use the burncd program that is part of the base system. SCSI and USB CD burners should use cdrecord from the sysutils/cdrtools port. It is also possible to use cdrecord and other tools for SCSI drives on ATAPI hardware with the ATAPI/CAM module.
If you want CD burning software with a graphical user interface, you may wish to take a look at either X-CD-Roast or K3b. These tools are available as packages or from the sysutils/xcdroast and sysutils/k3b ports. X-CD-Roast and K3b require the ATAPI/CAM module with ATAPI hardware.
18.6.2 mkisofs
The mkisofs(8) program, which is part of the sysutils/cdrtools port, produces an ISO 9660 file system that is an image of a directory tree in the UNIX file system name space. The simplest usage is:
# mkisofs -o imagefile.iso /path/to/tree
This command will create an imagefile.iso containing an ISO 9660 file system that is a copy of the tree at /path/to/tree. In the process, it will map the file names to names that fit the limitations of the standard ISO 9660 file system, and will exclude files that have names uncharacteristic of ISO file systems.
A number of options are available to overcome those restrictions. In particular, -R enables the Rock Ridge extensions common to UNIX systems, -J enables Joliet
extensions used by Microsoft systems, and -hfs can be used to
create HFS file systems used by Mac OS.
For CDs that are going to be used only on FreeBSD systems, -U can be used to disable all filename restrictions. When used with
-R, it produces a file system image that is identical to the
FreeBSD tree you started from, though it may violate the ISO 9660 standard in a number of
ways.
The last option of general use is -b. This is used to
specify the location of the boot image for use in producing an “El Torito”
bootable CD. This option takes an argument which is the path to a boot image from the top
of the tree being written to the CD. By default,
mkisofs(8)
creates an ISO image in the so-called “floppy disk emulation” mode, and thus
expects the boot image to be exactly 1200, 1440 or 2880 KB in size. Some boot
loaders, like the one used by the FreeBSD distribution disks, do not use emulation mode;
in this case, the -no-emul-boot option should be used. So, if
/tmp/myboot holds a bootable FreeBSD system with the boot image
in /tmp/myboot/boot/cdboot, you could produce the image of an
ISO 9660 file system in /tmp/bootable.iso like so:
# mkisofs -R -no-emul-boot -b boot/cdboot -o /tmp/bootable.iso /tmp/myboot
Having done that, if you have md configured in your kernel, you can mount the file system with:
# mdconfig -a -t vnode -f /tmp/bootable.iso -u 0
# mount -t cd9660 /dev/md0 /mnt
At which point you can verify that /mnt and /tmp/myboot are identical.
There are many other options you can use with mkisofs(8) to fine-tune its behavior. In particular: modifications to an ISO 9660 layout and the creation of Joliet and HFS discs. See the mkisofs(8) manual page for details.
18.6.3 burncd
If you have an ATAPI CD burner, you can use the burncd command to burn an ISO image onto a CD. burncd is part of the base system, installed as /usr/sbin/burncd. Usage is very simple, as it has few options:
# burncd -f cddevice data imagefile.iso fixate
Will burn a copy of imagefile.iso on cddevice. The default device is /dev/acd0. See burncd(8) for options to set the write speed, eject the CD after burning, and write audio data.
18.6.4 cdrecord
If you do not have an ATAPI CD burner, you will have to use cdrecord to burn your CDs. cdrecord is not part of the base system; you must install it from either the port at sysutils/cdrtools or the appropriate package. Changes to the base system can cause binary versions of this program to fail, possibly resulting in a “coaster”. You should therefore either upgrade the port when you upgrade your system, or if you are tracking -STABLE, upgrade the port when a new version becomes available.
While cdrecord has many options, basic usage is even simpler than burncd. Burning an ISO 9660 image is done with:
# cdrecord dev=device imagefile.iso
The tricky part of using cdrecord is finding the dev to use. To find the proper setting, use the -scanbus flag of cdrecord, which might
produce results like this:
# cdrecord -scanbus
Cdrecord-Clone 2.01 (i386-unknown-freebsd7.0) Copyright (C) 1995-2004 Jörg Schilling
Using libscg version 'schily-0.1'
scsibus0:
0,0,0 0) 'SEAGATE ' 'ST39236LW ' '0004' Disk
0,1,0 1) 'SEAGATE ' 'ST39173W ' '5958' Disk
0,2,0 2) *
0,3,0 3) 'iomega ' 'jaz 1GB ' 'J.86' Removable Disk
0,4,0 4) 'NEC ' 'CD-ROM DRIVE:466' '1.26' Removable CD-ROM
0,5,0 5) *
0,6,0 6) *
0,7,0 7) *
scsibus1:
1,0,0 100) *
1,1,0 101) *
1,2,0 102) *
1,3,0 103) *
1,4,0 104) *
1,5,0 105) 'YAMAHA ' 'CRW4260 ' '1.0q' Removable CD-ROM
1,6,0 106) 'ARTEC ' 'AM12S ' '1.06' Scanner
1,7,0 107) *
This lists the appropriate dev value for the devices on
the list. Locate your CD burner, and use the three numbers separated by commas as the
value for dev. In this case, the CRW device is 1,5,0, so the
appropriate input would be dev=1,5,0. There are easier ways
to specify this value; see
cdrecord(1) for
details. That is also the place to look for information on writing audio tracks,
controlling the speed, and other things.
18.6.5 Duplicating Audio CDs
You can duplicate an audio CD by extracting the audio data from the CD to a series of files, and then writing these files to a blank CD. The process is slightly different for ATAPI and SCSI drives.
SCSI Drives
-
Use cdda2wav to extract the audio.
% cdda2wav -v255 -D2,0 -B -Owav -
Use cdrecord to write the .wav files.
% cdrecord -v dev=2,0 -dao -useinfo *.wavMake sure that 2,0 is set appropriately, as described in Section 18.6.4.
ATAPI Drives
-
The ATAPI CD driver makes each track available as /dev/acddtnn, where d is the drive number, and nn is the track number written with two decimal digits, prefixed with zero as needed. So the first track on the first disk is /dev/acd0t01, the second is /dev/acd0t02, the third is /dev/acd0t03, and so on.
Make sure the appropriate files exist in /dev. If the entries are missing, force the system to retaste the media:
# dd if=/dev/acd0 of=/dev/null count=1 -
Extract each track using dd(1). You must also use a specific block size when extracting the files.
# dd if=/dev/acd0t01 of=track1.cdr bs=2352 # dd if=/dev/acd0t02 of=track2.cdr bs=2352 ... -
Burn the extracted files to disk using burncd. You must specify that these are audio files, and that burncd should fixate the disk when finished.
# burncd -f /dev/acd0 audio track1.cdr track2.cdr ... fixate
18.6.6 Duplicating Data CDs
You can copy a data CD to a image file that is functionally equivalent to the image file created with mkisofs(8), and you can use it to duplicate any data CD. The example given here assumes that your CDROM device is acd0. Substitute your correct CDROM device.
# dd if=/dev/acd0 of=file.iso bs=2048
Now that you have an image, you can burn it to CD as described above.
18.6.7 Using Data CDs
Now that you have created a standard data CDROM, you probably want to mount it and read the data on it. By default, mount(8) assumes that a file system is of type ufs. If you try something like:
# mount /dev/cd0 /mnt
you will get a complaint about “Incorrect super
block”, and no mount. The CDROM is not a UFS file
system, so attempts to mount it as such will fail. You just need to tell mount(8) that the file
system is of type ISO9660, and everything will work. You do this
by specifying the -t cd9660 option mount(8). For example,
if you want to mount the CDROM device, /dev/cd0, under /mnt, you would execute:
# mount -t cd9660 /dev/cd0 /mnt
Note that your device name (/dev/cd0 in this example) could
be different, depending on the interface your CDROM uses. Also, the -t cd9660 option just executes mount_cd9660(8). The
above example could be shortened to:
# mount_cd9660 /dev/cd0 /mnt
You can generally use data CDROMs from any vendor in this way. Disks with certain ISO
9660 extensions might behave oddly, however. For example, Joliet disks store all
filenames in two-byte Unicode characters. The FreeBSD kernel does not speak Unicode, but
the FreeBSD CD9660 driver is able to convert Unicode characters on the fly. If some
non-English characters show up as question marks you will need to specify the local
charset you use with the -C option. For more information,
consult the mount_cd9660(8) manual
page.
Note: To be able to do this character conversion with the help of the
-Coption, the kernel will require the cd9660_iconv.ko module to be loaded. This can be done either by adding this line to loader.conf:cd9660_iconv_load="YES"and then rebooting the machine, or by directly loading the module with kldload(8).
Occasionally, you might get “Device not configured” when trying to mount a CDROM. This usually means that the CDROM drive thinks that there is no disk in the tray, or that the drive is not visible on the bus. It can take a couple of seconds for a CDROM drive to realize that it has been fed, so be patient.
Sometimes, a SCSI CDROM may be missed because it did not have enough time to answer the bus reset. If you have a SCSI CDROM please add the following option to your kernel configuration and rebuild your kernel.
options SCSI_DELAY=15000
This tells your SCSI bus to pause 15 seconds during boot, to give your CDROM drive every possible chance to answer the bus reset.
18.6.8 Burning Raw Data CDs
You can choose to burn a file directly to CD, without creating an ISO 9660 file system. Some people do this for backup purposes. This runs more quickly than burning a standard CD:
# burncd -f /dev/acd1 -s 12 data archive.tar.gz fixate
In order to retrieve the data burned to such a CD, you must read data from the raw device node:
# tar xzvf /dev/acd1
You cannot mount this disk as you would a normal CDROM. Such a CDROM cannot be read under any operating system except FreeBSD. If you want to be able to mount the CD, or share data with another operating system, you must use mkisofs(8) as described above.
18.6.9 Using the ATAPI/CAM Driver
Contributed by Marc Fonvieille.This driver allows ATAPI devices (CD-ROM, CD-RW, DVD drives etc...) to be accessed through the SCSI subsystem, and so allows the use of applications like sysutils/cdrdao or cdrecord(1).
To use this driver, you will need to add the following line to the /boot/loader.conf file:
atapicam_load="YES"
then, reboot your machine.
Note: If you prefer to statically compile the atapicam(4) support in your kernel, you will have to add this line to your kernel configuration file:
device atapicamYou also need the following lines in your kernel configuration file:
device ata device scbus device cd device passwhich should already be present. Then rebuild, install your new kernel, and reboot your machine.
During the boot process, your burner should show up, like so:
acd0: CD-RW <MATSHITA CD-RW/DVD-ROM UJDA740> at ata1-master PIO4
cd0 at ata1 bus 0 target 0 lun 0
cd0: <MATSHITA CDRW/DVD UJDA740 1.00> Removable CD-ROM SCSI-0 device
cd0: 16.000MB/s transfers
cd0: Attempt to query device size failed: NOT READY, Medium not present - tray closed
The drive could now be accessed via the /dev/cd0 device name, for example to mount a CD-ROM on /mnt, just type the following:
# mount -t cd9660 /dev/cd0 /mnt
As root, you can run the following command to get the SCSI address of the burner:
# camcontrol devlist
<MATSHITA CDRW/DVD UJDA740 1.00> at scbus1 target 0 lun 0 (pass0,cd0)
So 1,0,0 will be the SCSI address to use with cdrecord(1) and other SCSI application.
For more information about ATAPI/CAM and SCSI system, refer to the atapicam(4) and cam(4) manual pages.
18.7 Creating and Using Optical Media (DVDs)
Contributed by Marc Fonvieille. With inputs from Andy Polyakov.18.7.1 Introduction
Compared to the CD, the DVD is the next generation of optical media storage technology. The DVD can hold more data than any CD and is nowadays the standard for video publishing.
Five physical recordable formats can be defined for what we will call a recordable DVD:
-
DVD-R: This was the first DVD recordable format available. The DVD-R standard is defined by the DVD Forum. This format is write once.
-
DVD-RW: This is the rewritable version of the DVD-R standard. A DVD-RW can be rewritten about 1000 times.
-
DVD-RAM: This is also a rewritable format supported by the DVD Forum. A DVD-RAM can be seen as a removable hard drive. However, this media is not compatible with most DVD-ROM drives and DVD-Video players; only a few DVD writers support the DVD-RAM format. Read the Section 18.7.9 for more information on DVD-RAM use.
-
DVD+RW: This is a rewritable format defined by the DVD+RW Alliance. A DVD+RW can be rewritten about 1000 times.
-
DVD+R: This format is the write once variation of the DVD+RW format.
A single layer recordable DVD can hold up to 4,700,000,000 bytes which is actually 4.38 GB or 4485 MB (1 kilobyte is 1024 bytes).
Note: A distinction must be made between the physical media and the application. For example, a DVD-Video is a specific file layout that can be written on any recordable DVD physical media: DVD-R, DVD+R, DVD-RW etc. Before choosing the type of media, you must be sure that both the burner and the DVD-Video player (a standalone player or a DVD-ROM drive on a computer) are compatible with the media under consideration.
18.7.2 Configuration
The program growisofs(1) will be used to perform DVD recording. This command is part of the dvd+rw-tools utilities (sysutils/dvd+rw-tools). The dvd+rw-tools support all DVD media types.
These tools use the SCSI subsystem to access to the devices, therefore the ATAPI/CAM support must be added to your kernel. If your burner uses the USB interface this addition is useless, and you should read the Section 18.5 for more details on USB devices configuration.
You also have to enable DMA access for ATAPI devices, this can be done in adding the following line to the /boot/loader.conf file:
hw.ata.atapi_dma="1"
Before attempting to use the dvd+rw-tools you should consult the dvd+rw-tools' hardware compatibility notes for any information related to your DVD burner.
Note: If you want a graphical user interface, you should have a look to K3b (sysutils/k3b) which provides a user friendly interface to growisofs(1) and many other burning tools.
18.7.3 Burning Data DVDs
The growisofs(1) command is a frontend to mkisofs, it will invoke mkisofs(8) to create the file system layout and will perform the write on the DVD. This means you do not need to create an image of the data before the burning process.
To burn onto a DVD+R or a DVD-R the data from the /path/to/data directory, use the following command:
# growisofs -dvd-compat -Z /dev/cd0 -J -R /path/to/data
The options -J -R are passed to
mkisofs(8) for
the file system creation (in this case: an ISO 9660 file system with Joliet and Rock
Ridge extensions), consult the
mkisofs(8)
manual page for more details.
The option -Z is used for the initial session recording in
any case: multiple sessions or not. The DVD device, /dev/cd0, must be changed according to your
configuration. The -dvd-compat parameter will close the disk,
the recording will be unappendable. In return this should provide better media
compatibility with DVD-ROM drives.
It is also possible to burn a pre-mastered image, for example to burn the image imagefile.iso, we will run:
# growisofs -dvd-compat -Z /dev/cd0=imagefile.iso
The write speed should be detected and automatically set according to the media and
the drive being used. If you want to force the write speed, use the -speed= parameter. For more information, read the
growisofs(1)
manual page.
18.7.4 Burning a DVD-Video
A DVD-Video is a specific file layout based on ISO 9660 and the micro-UDF (M-UDF) specifications. The DVD-Video also presents a specific data structure hierarchy, it is the reason why you need a particular program such as multimedia/dvdauthor to author the DVD.
If you already have an image of the DVD-Video file system, just burn it in the same way as for any image, see the previous section for an example. If you have made the DVD authoring and the result is in, for example, the directory /path/to/video, the following command should be used to burn the DVD-Video:
# growisofs -Z /dev/cd0 -dvd-video /path/to/video
The -dvd-video option will be passed down to
mkisofs(8) and
will instruct it to create a DVD-Video file system layout. Beside this, the -dvd-video option implies -dvd-compat
growisofs(1)
option.
18.7.5 Using a DVD+RW
Unlike CD-RW, a virgin DVD+RW needs to be formatted before first use. The growisofs(1) program will take care of it automatically whenever appropriate, which is the recommended way. However you can use the dvd+rw-format command to format the DVD+RW:
# dvd+rw-format /dev/cd0
You need to perform this operation just once, keep in mind that only virgin DVD+RW medias need to be formatted. Then you can burn the DVD+RW in the way seen in previous sections.
If you want to burn new data (burn a totally new file system not append some data) onto a DVD+RW, you do not need to blank it, you just have to write over the previous recording (in performing a new initial session), like this:
# growisofs -Z /dev/cd0 -J -R /path/to/newdata
DVD+RW format offers the possibility to easily append data to a previous recording. The operation consists in merging a new session to the existing one, it is not multisession writing, growisofs(1) will grow the ISO 9660 file system present on the media.
For example, if we want to append data to our previous DVD+RW, we have to use the following:
# growisofs -M /dev/cd0 -J -R /path/to/nextdata
The same mkisofs(8) options we used to burn the initial session should be used during next writes.
Note: You may want to use the
-dvd-compatoption if you want better media compatibility with DVD-ROM drives. In the DVD+RW case, this will not prevent you from adding data.
If for any reason you really want to blank the media, do the following:
# growisofs -Z /dev/cd0=/dev/zero
18.7.6 Using a DVD-RW
A DVD-RW accepts two disc formats: the incremental sequential one and the restricted overwrite. By default DVD-RW discs are in sequential format.
A virgin DVD-RW can be directly written without the need of a formatting operation, however a non-virgin DVD-RW in sequential format needs to be blanked before to be able to write a new initial session.
To blank a DVD-RW in sequential mode, run:
# dvd+rw-format -blank=full /dev/cd0
Note: A full blanking (
-blank=full) will take about one hour on a 1x media. A fast blanking can be performed using the-blankoption if the DVD-RW will be recorded in Disk-At-Once (DAO) mode. To burn the DVD-RW in DAO mode, use the command:# growisofs -use-the-force-luke=dao -Z /dev/cd0=imagefile.isoThe
-use-the-force-luke=daooption should not be required since growisofs(1) attempts to detect minimally (fast blanked) media and engage DAO write.In fact one should use restricted overwrite mode with any DVD-RW, this format is more flexible than the default incremental sequential one.
To write data on a sequential DVD-RW, use the same instructions as for the other DVD formats:
# growisofs -Z /dev/cd0 -J -R /path/to/data
If you want to append some data to your previous recording, you will have to use the
growisofs(1)
-M option. However, if you perform data addition on a DVD-RW
in incremental sequential mode, a new session will be created on the disc and the result
will be a multi-session disc.
A DVD-RW in restricted overwrite format does not need to be blanked before a new
initial session, you just have to overwrite the disc with the -Z option, this is similar to the DVD+RW case. It is also possible
to grow an existing ISO 9660 file system written on the disc in a same way as for a
DVD+RW with the -M option. The result will be a one-session
DVD.
To put a DVD-RW in the restricted overwrite format, the following command must be used:
# dvd+rw-format /dev/cd0
To change back to the sequential format use:
# dvd+rw-format -blank=full /dev/cd0
18.7.7 Multisession
Very few DVD-ROM drives support multisession DVDs, they will most of time, hopefully, only read the first session. DVD+R, DVD-R and DVD-RW in sequential format can accept multiple sessions, the notion of multiple sessions does not exist for the DVD+RW and the DVD-RW restricted overwrite formats.
Using the following command after an initial (non-closed) session on a DVD+R, DVD-R, or DVD-RW in sequential format, will add a new session to the disc:
# growisofs -M /dev/cd0 -J -R /path/to/nextdata
Using this command line with a DVD+RW or a DVD-RW in restricted overwrite mode, will append data in merging the new session to the existing one. The result will be a single-session disc. This is the way used to add data after an initial write on these medias.
Note: Some space on the media is used between each session for end and start of sessions. Therefore, one should add sessions with large amount of data to optimize media space. The number of sessions is limited to 154 for a DVD+R, about 2000 for a DVD-R, and 127 for a DVD+R Double Layer.
18.7.8 For More Information
To obtain more information about a DVD, the dvd+rw-mediainfo /dev/cd0 command can be ran with the disc in the drive.
More information about the dvd+rw-tools can be found in the growisofs(1) manual page, on the dvd+rw-tools web site and in the cdwrite mailing list archives.
Note: The dvd+rw-mediainfo output of the resulting recording or the media with issues is mandatory for any problem report. Without this output, it will be quite impossible to help you.
18.7.9 Using a DVD-RAM
18.7.9.1 Configuration
DVD-RAM writers come with either SCSI or ATAPI interface. DMA access for ATAPI devices has to be enabled, this can be done by adding the following line to the /boot/loader.conf file:
hw.ata.atapi_dma="1"
18.7.9.2 Preparing the Medium
As previously mentioned in the chapter introduction, a DVD-RAM can be seen as a removable hard drive. As any other hard drive the DVD-RAM must be “prepared” before the first use. In the example, the whole disk space will be used with a standard UFS2 file system:
# dd if=/dev/zero of=/dev/acd0 count=2
# bsdlabel -Bw acd0
# newfs /dev/acd0
The DVD device, acd0, must be changed according to the configuration.
18.7.9.3 Using the Medium
Once the previous operations have been performed on the DVD-RAM, it can be mounted as a normal hard drive:
# mount /dev/acd0 /mnt
After this the DVD-RAM will be both readable and writeable.
18.8 Creating and Using Floppy Disks
Original work by Julio Merino. Rewritten by Martin Karlsson.Storing data on floppy disks is sometimes useful, for example when one does not have any other removable storage media or when one needs to transfer small amounts of data to another computer.
This section will explain how to use floppy disks in FreeBSD. It will primarily cover formatting and usage of 3.5inch DOS floppies, but the concepts are similar for other floppy disk formats.
18.8.1 Formatting Floppies
18.8.1.1 The Device
Floppy disks are accessed through entries in /dev, just like other devices. To access the raw floppy disk, simply use /dev/fdN.
18.8.1.2 Formatting
A floppy disk needs to be low-level formated before it can be used. This is usually done by the vendor, but formatting is a good way to check media integrity. Although it is possible to force larger (or smaller) disk sizes, 1440kB is what most floppy disks are designed for.
To low-level format the floppy disk you need to use fdformat(1). This utility expects the device name as an argument.
Make note of any error messages, as these can help determine if the disk is good or bad.
18.8.1.2.1 Formatting Floppy Disks
Use the /dev/fdN devices to format the floppy. Insert a new 3.5inch floppy disk in your drive and issue:
# /usr/sbin/fdformat -f 1440 /dev/fd0
18.8.2 The Disk Label
After low-level formatting the disk, you will need to place a disk label on it. This disk label will be destroyed later, but it is needed by the system to determine the size of the disk and its geometry later.
The new disk label will take over the whole disk, and will contain all the proper information about the geometry of the floppy. The geometry values for the disk label are listed in /etc/disktab.
You can run now bsdlabel(8) like so:
# /sbin/bsdlabel -B -w /dev/fd0 fd1440
18.8.3 The File System
Now the floppy is ready to be high-level formated. This will place a new file system on it, which will let FreeBSD read and write to the disk. After creating the new file system, the disk label is destroyed, so if you want to reformat the disk, you will have to recreate the disk label.
The floppy's file system can be either UFS or FAT. FAT is generally a better choice for floppies.
To put a new file system on the floppy, issue:
# /sbin/newfs_msdos /dev/fd0
The disk is now ready for use.
18.8.4 Using the Floppy
To use the floppy, mount it with mount_msdosfs(8). One can also use emulators/mtools from the ports collection.
18.9 Creating and Using Data Tapes
The major tape media are the 4mm, 8mm, QIC, mini-cartridge and DLT.
18.9.1 4mm (DDS: Digital Data Storage)
4mm tapes are replacing QIC as the workstation backup media of choice. This trend accelerated greatly when Conner purchased Archive, a leading manufacturer of QIC drives, and then stopped production of QIC drives. 4mm drives are small and quiet but do not have the reputation for reliability that is enjoyed by 8mm drives. The cartridges are less expensive and smaller (3 x 2 x 0.5 inches, 76 x 51 x 12 mm) than 8mm cartridges. 4mm, like 8mm, has comparatively short head life for the same reason, both use helical scan.
Data throughput on these drives starts ~150 kB/s, peaking at ~500 kB/s. Data capacity starts at 1.3 GB and ends at 2.0 GB. Hardware compression, available with most of these drives, approximately doubles the capacity. Multi-drive tape library units can have 6 drives in a single cabinet with automatic tape changing. Library capacities reach 240 GB.
The DDS-3 standard now supports tape capacities up to 12 GB (or 24 GB compressed).
4mm drives, like 8mm drives, use helical-scan. All the benefits and drawbacks of helical-scan apply to both 4mm and 8mm drives.
Tapes should be retired from use after 2,000 passes or 100 full backups.
18.9.2 8mm (Exabyte)
8mm tapes are the most common SCSI tape drives; they are the best choice of exchanging tapes. Nearly every site has an Exabyte 2 GB 8mm tape drive. 8mm drives are reliable, convenient and quiet. Cartridges are inexpensive and small (4.8 x 3.3 x 0.6 inches; 122 x 84 x 15 mm). One downside of 8mm tape is relatively short head and tape life due to the high rate of relative motion of the tape across the heads.
Data throughput ranges from ~250 kB/s to ~500 kB/s. Data sizes start at 300 MB and go up to 7 GB. Hardware compression, available with most of these drives, approximately doubles the capacity. These drives are available as single units or multi-drive tape libraries with 6 drives and 120 tapes in a single cabinet. Tapes are changed automatically by the unit. Library capacities reach 840+ GB.
The Exabyte “Mammoth” model supports 12 GB on one tape (24 GB with compression) and costs approximately twice as much as conventional tape drives.
Data is recorded onto the tape using helical-scan, the heads are positioned at an angle to the media (approximately 6 degrees). The tape wraps around 270 degrees of the spool that holds the heads. The spool spins while the tape slides over the spool. The result is a high density of data and closely packed tracks that angle across the tape from one edge to the other.
18.9.3 QIC
QIC-150 tapes and drives are, perhaps, the most common tape drive and media around. QIC tape drives are the least expensive “serious” backup drives. The downside is the cost of media. QIC tapes are expensive compared to 8mm or 4mm tapes, up to 5 times the price per GB data storage. But, if your needs can be satisfied with a half-dozen tapes, QIC may be the correct choice. QIC is the most common tape drive. Every site has a QIC drive of some density or another. Therein lies the rub, QIC has a large number of densities on physically similar (sometimes identical) tapes. QIC drives are not quiet. These drives audibly seek before they begin to record data and are clearly audible whenever reading, writing or seeking. QIC tapes measure 6 x 4 x 0.7 inches (152 x 102 x 17 mm).
Data throughput ranges from ~150 kB/s to ~500 kB/s. Data capacity ranges from 40 MB to 15 GB. Hardware compression is available on many of the newer QIC drives. QIC drives are less frequently installed; they are being supplanted by DAT drives.
Data is recorded onto the tape in tracks. The tracks run along the long axis of the tape media from one end to the other. The number of tracks, and therefore the width of a track, varies with the tape's capacity. Most if not all newer drives provide backward-compatibility at least for reading (but often also for writing). QIC has a good reputation regarding the safety of the data (the mechanics are simpler and more robust than for helical scan drives).
Tapes should be retired from use after 5,000 backups.
18.9.4 DLT
DLT has the fastest data transfer rate of all the drive types listed here. The 1/2" (12.5mm) tape is contained in a single spool cartridge (4 x 4 x 1 inches; 100 x 100 x 25 mm). The cartridge has a swinging gate along one entire side of the cartridge. The drive mechanism opens this gate to extract the tape leader. The tape leader has an oval hole in it which the drive uses to “hook” the tape. The take-up spool is located inside the tape drive. All the other tape cartridges listed here (9 track tapes are the only exception) have both the supply and take-up spools located inside the tape cartridge itself.
Data throughput is approximately 1.5 MB/s, three times the throughput of 4mm, 8mm, or QIC tape drives. Data capacities range from 10 GB to 20 GB for a single drive. Drives are available in both multi-tape changers and multi-tape, multi-drive tape libraries containing from 5 to 900 tapes over 1 to 20 drives, providing from 50 GB to 9 TB of storage.
With compression, DLT Type IV format supports up to 70 GB capacity.
Data is recorded onto the tape in tracks parallel to the direction of travel (just like QIC tapes). Two tracks are written at once. Read/write head lifetimes are relatively long; once the tape stops moving, there is no relative motion between the heads and the tape.
18.9.5 AIT
AIT is a new format from Sony, and can hold up to 50 GB (with compression) per tape. The tapes contain memory chips which retain an index of the tape's contents. This index can be rapidly read by the tape drive to determine the position of files on the tape, instead of the several minutes that would be required for other tapes. Software such as SAMS:Alexandria can operate forty or more AIT tape libraries, communicating directly with the tape's memory chip to display the contents on screen, determine what files were backed up to which tape, locate the correct tape, load it, and restore the data from the tape.
Libraries like this cost in the region of $20,000, pricing them a little out of the hobbyist market.
18.9.6 Using a New Tape for the First Time
The first time that you try to read or write a new, completely blank tape, the operation will fail. The console messages should be similar to:
sa0(ncr1:4:0): NOT READY asc:4,1
sa0(ncr1:4:0): Logical unit is in process of becoming ready
The tape does not contain an Identifier Block (block number 0). All QIC tape drives since the adoption of QIC-525 standard write an Identifier Block to the tape. There are two solutions:
-
mt fsf 1 causes the tape drive to write an Identifier Block to the tape.
-
Use the front panel button to eject the tape.
Re-insert the tape and dump data to the tape.
dump will report “DUMP: End of tape detected” and the console will show: “HARDWARE FAILURE info:280 asc:80,96”.
rewind the tape using: mt rewind.
Subsequent tape operations are successful.
18.10 Backups to Floppies
18.10.1 Can I Use Floppies for Backing Up My Data?
Floppy disks are not really a suitable media for making backups as:
-
The media is unreliable, especially over long periods of time.
-
Backing up and restoring is very slow.
-
They have a very limited capacity (the days of backing up an entire hard disk onto a dozen or so floppies has long since passed).
However, if you have no other method of backing up your data then floppy disks are better than no backup at all.
If you do have to use floppy disks then ensure that you use good quality ones. Floppies that have been lying around the office for a couple of years are a bad choice. Ideally use new ones from a reputable manufacturer.
18.10.2 So How Do I Backup My Data to Floppies?
The best way to backup to floppy disk is to use tar(1) with the -M (multi volume) option, which allows backups to span multiple
floppies.
To backup all the files in the current directory and sub-directory use this (as root):
# tar Mcvf /dev/fd0 *
When the first floppy is full tar(1) will prompt you to insert the next volume (because tar(1) is media independent it refers to volumes; in this context it means floppy disk).
Prepare volume #2 for /dev/fd0 and hit return:
This is repeated (with the volume number incrementing) until all the specified files have been archived.
18.10.3 Can I Compress My Backups?
Unfortunately, tar(1) will not allow
the -z option to be used for multi-volume archives. You
could, of course, gzip(1) all the files,
tar(1) them to the
floppies, then gunzip(1) the files
again!
18.10.4 How Do I Restore My Backups?
To restore the entire archive use:
# tar Mxvf /dev/fd0
There are two ways that you can use to restore only specific files. First, you can start with the first floppy and use:
# tar Mxvf /dev/fd0 filename
The utility tar(1) will prompt you to insert subsequent floppies until it finds the required file.
Alternatively, if you know which floppy the file is on then you can simply insert that floppy and use the same command as above. Note that if the first file on the floppy is a continuation from the previous one then tar(1) will warn you that it cannot restore it, even if you have not asked it to!
18.11 Backup Strategies
Original work by Lowell Gilbert.The first requirement in devising a backup plan is to make sure that all of the following problems are covered:
-
Disk failure
-
Accidental file deletion
-
Random file corruption
-
Complete machine destruction (e.g. fire), including destruction of any on-site backups.
It is perfectly possible that some systems will be best served by having each of these problems covered by a completely different technique. Except for strictly personal systems with very low-value data, it is unlikely that one technique would cover all of them.
Some of the techniques in the toolbox are:
-
Archives of the whole system, backed up onto permanent media offsite. This actually provides protection against all of the possible problems listed above, but is slow and inconvenient to restore from. You can keep copies of the backups onsite and/or online, but there will still be inconveniences in restoring files, especially for non-privileged users.
-
Filesystem snapshots. This is really only helpful in the accidental file deletion scenario, but it can be very helpful in that case, and is quick and easy to deal with.
-
Copies of whole filesystems and/or disks (e.g. periodic rsync(1) of the whole machine). This is generally most useful in networks with unique requirements. For general protection against disk failure, it is usually inferior to RAID. For restoring accidentally deleted files, it can be comparable to UFS snapshots, but that depends on your preferences.
-
RAID. Minimizes or avoids downtime when a disk fails. At the expense of having to deal with disk failures more often (because you have more disks), albeit at a much lower urgency.
-
Checking fingerprints of files. The mtree(8) utility is very useful for this. Although it is not a backup technique, it helps guarantee that you will notice when you need to resort to your backups. This is particularly important for offline backups, and should be checked periodically.
It is quite easy to come up with even more techniques, many of them variations on the ones listed above. Specialized requirements will usually lead to specialized techniques (for example, backing up a live database usually requires a method particular to the database software as an intermediate step). The important thing is to know what dangers you want to protect against, and how you will handle each.
18.12 Backup Basics
The three major backup programs are dump(8), tar(1), and cpio(1).
18.12.1 Dump and Restore
The traditional UNIX backup programs are dump and restore. They operate on the drive as a collection of disk blocks, below the abstractions of files, links and directories that are created by the file systems. dump backs up an entire file system on a device. It is unable to backup only part of a file system or a directory tree that spans more than one file system. dump does not write files and directories to tape, but rather writes the raw data blocks that comprise files and directories.
Note: If you use dump on your root directory, you would not back up /home, /usr or many other directories since these are typically mount points for other file systems or symbolic links into those file systems.
dump has quirks that remain from its early days in Version 6 of AT&T UNIX (circa 1975). The default parameters are suitable for 9-track tapes (6250 bpi), not the high-density media available today (up to 62,182 ftpi). These defaults must be overridden on the command line to utilize the capacity of current tape drives.
It is also possible to backup data across the network to a tape drive attached to another computer with rdump and rrestore. Both programs rely upon rcmd(3) and ruserok(3) to access the remote tape drive. Therefore, the user performing the backup must be listed in the .rhosts file on the remote computer. The arguments to rdump and rrestore must be suitable to use on the remote computer. When rdumping from a FreeBSD computer to an Exabyte tape drive connected to a Sun called komodo, use:
# /sbin/rdump 0dsbfu 54000 13000 126 komodo:/dev/nsa8 /dev/da0a 2>&1
Beware: there are security implications to allowing .rhosts authentication. Evaluate your situation carefully.
It is also possible to use dump and restore in a more secure fashion over ssh.
Example 18-1. Using dump over ssh
# /sbin/dump -0uan -f - /usr | gzip -2 | ssh -c blowfish \
targetuser@targetmachine.example.com dd of=/mybigfiles/dump-usr-l0.gz
Or using dump's built-in method, setting the environment variable RSH:
18.12.2 tar
tar(1) also dates back to Version 6 of AT&T UNIX (circa 1975). tar operates in cooperation with the file system; it writes files and directories to tape. tar does not support the full range of options that are available from cpio(1), but it does not require the unusual command pipeline that cpio uses.
On FreeBSD 5.3 and later, both GNU tar and the default bsdtar are available. The GNU version can be invoked with gtar. It supports remote devices using the same syntax as rdump. To tar to an Exabyte tape drive connected to a Sun called komodo, use:
# /usr/bin/gtar cf komodo:/dev/nsa8 . 2>&1
The same could be accomplished with bsdtar by using a pipeline and rsh to send the data to a remote tape drive.
# tar cf - . | rsh hostname dd of=tape-device obs=20b
If you are worried about the security of backing up over a network you should use the ssh command instead of rsh.
18.12.3 cpio
cpio(1) is the original UNIX file interchange tape program for magnetic media. cpio has options (among many others) to perform byte-swapping, write a number of different archive formats, and pipe the data to other programs. This last feature makes cpio an excellent choice for installation media. cpio does not know how to walk the directory tree and a list of files must be provided through stdin.
cpio does not support backups across the network. You can use a pipeline and rsh to send the data to a remote tape drive.
# for f in directory_list; do
find $f >> backup.list
done
# cpio -v -o --format=newc < backup.list | ssh user@host "cat > backup_device"
Where directory_list is the list of directories you want to back up, user@host is the user/hostname combination that will be performing the backups, and backup_device is where the backups should be written to (e.g., /dev/nsa0).
18.12.4 pax
pax(1) is IEEE/POSIX's answer to tar and cpio. Over the years the various versions of tar and cpio have gotten slightly incompatible. So rather than fight it out to fully standardize them, POSIX created a new archive utility. pax attempts to read and write many of the various cpio and tar formats, plus new formats of its own. Its command set more resembles cpio than tar.
18.12.5 Amanda
Amanda (Advanced Maryland Network Disk Archiver) is a client/server backup system, rather than a single program. An Amanda server will backup to a single tape drive any number of computers that have Amanda clients and a network connection to the Amanda server. A common problem at sites with a number of large disks is that the length of time required to backup to data directly to tape exceeds the amount of time available for the task. Amanda solves this problem. Amanda can use a “holding disk” to backup several file systems at the same time. Amanda creates “archive sets”: a group of tapes used over a period of time to create full backups of all the file systems listed in Amanda's configuration file. The “archive set” also contains nightly incremental (or differential) backups of all the file systems. Restoring a damaged file system requires the most recent full backup and the incremental backups.
The configuration file provides fine control of backups and the network traffic that Amanda generates. Amanda will use any of the above backup programs to write the data to tape. Amanda is available as either a port or a package, it is not installed by default.
18.12.6 Do Nothing
“Do nothing” is not a computer program, but it is the most widely used backup strategy. There are no initial costs. There is no backup schedule to follow. Just say no. If something happens to your data, grin and bear it!
If your time and your data is worth little to nothing, then “Do nothing” is the most suitable backup program for your computer. But beware, UNIX is a useful tool, you may find that within six months you have a collection of files that are valuable to you.
“Do nothing” is the correct backup method for /usr/obj and other directory trees that can be exactly recreated by your computer. An example is the files that comprise the HTML or PostScript version of this Handbook. These document formats have been created from SGML input files. Creating backups of the HTML or PostScript files is not necessary. The SGML files are backed up regularly.
18.12.7 Which Backup Program Is Best?
dump(8) Period. Elizabeth D. Zwicky torture tested all the backup programs discussed here. The clear choice for preserving all your data and all the peculiarities of UNIX file systems is dump. Elizabeth created file systems containing a large variety of unusual conditions (and some not so unusual ones) and tested each program by doing a backup and restore of those file systems. The peculiarities included: files with holes, files with holes and a block of nulls, files with funny characters in their names, unreadable and unwritable files, devices, files that change size during the backup, files that are created/deleted during the backup and more. She presented the results at LISA V in Oct. 1991. See torture-testing Backup and Archive Programs.
18.12.8 Emergency Restore Procedure
18.12.8.1 Before the Disaster
There are only four steps that you need to perform in preparation for any disaster that may occur.
First, print the bsdlabel from each of your disks (e.g. bsdlabel da0 | lpr), your file system table (/etc/fstab) and all boot messages, two copies of each.
Second, determine that the boot and fix-it floppies (boot.flp and fixit.flp) have all your devices. The easiest way to check is to reboot your machine with the boot floppy in the floppy drive and check the boot messages. If all your devices are listed and functional, skip on to step three.
Otherwise, you have to create two custom bootable floppies which have a kernel that can mount all of your disks and access your tape drive. These floppies must contain: fdisk, bsdlabel, newfs, mount, and whichever backup program you use. These programs must be statically linked. If you use dump, the floppy must contain restore.
Third, create backup tapes regularly. Any changes that you make after your last backup may be irretrievably lost. Write-protect the backup tapes.
Fourth, test the floppies (either boot.flp and fixit.flp or the two custom bootable floppies you made in step two.) and backup tapes. Make notes of the procedure. Store these notes with the bootable floppy, the printouts and the backup tapes. You will be so distraught when restoring that the notes may prevent you from destroying your backup tapes (How? In place of tar xvf /dev/sa0, you might accidentally type tar cvf /dev/sa0 and over-write your backup tape).
For an added measure of security, make bootable floppies and two backup tapes each time. Store one of each at a remote location. A remote location is NOT the basement of the same office building. A number of firms in the World Trade Center learned this lesson the hard way. A remote location should be physically separated from your computers and disk drives by a significant distance.
Example 18-3. A Script for Creating a Bootable Floppy
#!/bin/sh
#
# create a restore floppy
#
# format the floppy
#
PATH=/bin:/sbin:/usr/sbin:/usr/bin
fdformat -q fd0
if [ $? -ne 0 ]
then
echo "Bad floppy, please use a new one"
exit 1
fi
# place boot blocks on the floppy
#
bsdlabel -w -B /dev/fd0c fd1440
#
# newfs the one and only partition
#
newfs -t 2 -u 18 -l 1 -c 40 -i 5120 -m 5 -o space /dev/fd0a
#
# mount the new floppy
#
mount /dev/fd0a /mnt
#
# create required directories
#
mkdir /mnt/dev
mkdir /mnt/bin
mkdir /mnt/sbin
mkdir /mnt/etc
mkdir /mnt/root
mkdir /mnt/mnt # for the root partition
mkdir /mnt/tmp
mkdir /mnt/var
#
# populate the directories
#
if [ ! -x /sys/compile/MINI/kernel ]
then
cat << EOM
The MINI kernel does not exist, please create one.
Here is an example config file:
#
# MINI -- A kernel to get FreeBSD onto a disk.
#
machine "i386"
cpu "I486_CPU"
ident MINI
maxusers 5
options INET # needed for _tcp _icmpstat _ipstat
# _udpstat _tcpstat _udb
options FFS #Berkeley Fast File System
options FAT_CURSOR #block cursor in syscons or pccons
options SCSI_DELAY=15 #Be pessimistic about Joe SCSI device
options NCONS=2 #1 virtual consoles
options USERCONFIG #Allow user configuration with -c XXX
config kernel root on da0 swap on da0 and da1 dumps on da0
device isa0
device pci0
device fdc0 at isa? port "IO_FD1" bio irq 6 drq 2 vector fdintr
device fd0 at fdc0 drive 0
device ncr0
device scbus0
device sc0 at isa? port "IO_KBD" tty irq 1 vector scintr
device npx0 at isa? port "IO_NPX" irq 13 vector npxintr
device da0
device da1
device da2
device sa0
pseudo-device loop # required by INET
pseudo-device gzip # Exec gzipped a.out's
EOM
exit 1
fi
cp -f /sys/compile/MINI/kernel /mnt
gzip -c -best /sbin/init > /mnt/sbin/init
gzip -c -best /sbin/fsck > /mnt/sbin/fsck
gzip -c -best /sbin/mount > /mnt/sbin/mount
gzip -c -best /sbin/halt > /mnt/sbin/halt
gzip -c -best /sbin/restore > /mnt/sbin/restore
gzip -c -best /bin/sh > /mnt/bin/sh
gzip -c -best /bin/sync > /mnt/bin/sync
cp /root/.profile /mnt/root
chmod 500 /mnt/sbin/init
chmod 555 /mnt/sbin/fsck /mnt/sbin/mount /mnt/sbin/halt
chmod 555 /mnt/bin/sh /mnt/bin/sync
chmod 6555 /mnt/sbin/restore
#
# create minimum file system table
#
cat > /mnt/etc/fstab <<EOM
/dev/fd0a / ufs rw 1 1
EOM
#
# create minimum passwd file
#
cat > /mnt/etc/passwd <<EOM
root:*:0:0:Charlie &:/root:/bin/sh
EOM
cat > /mnt/etc/master.passwd <<EOM
root::0:0::0:0:Charlie &:/root:/bin/sh
EOM
chmod 600 /mnt/etc/master.passwd
chmod 644 /mnt/etc/passwd
/usr/sbin/pwd_mkdb -d/mnt/etc /mnt/etc/master.passwd
#
# umount the floppy and inform the user
#
/sbin/umount /mnt
echo "The floppy has been unmounted and is now ready."
18.12.8.2 After the Disaster
The key question is: did your hardware survive? You have been doing regular backups so there is no need to worry about the software.
If the hardware has been damaged, the parts should be replaced before attempting to use the computer.
If your hardware is okay, check your floppies. If you are using a custom boot floppy, boot single-user (type -s at the boot: prompt). Skip the following paragraph.
If you are using the boot.flp and fixit.flp floppies, keep reading. Insert the boot.flp floppy in the first floppy drive and boot the computer. The original install menu will be displayed on the screen. Select the Fixit--Repair mode with CDROM or floppy. option. Insert the fixit.flp when prompted. restore and the other programs that you need are located in /mnt2/rescue (/mnt2/stand for FreeBSD versions older than 5.2).
Recover each file system separately.
Try to mount (e.g. mount /dev/da0a /mnt) the root partition of your first disk. If the bsdlabel was damaged, use bsdlabel to re-partition and label the disk to match the label that you printed and saved. Use newfs to re-create the file systems. Re-mount the root partition of the floppy read-write (mount -u -o rw /mnt). Use your backup program and backup tapes to recover the data for this file system (e.g. restore vrf /dev/sa0). Unmount the file system (e.g. umount /mnt). Repeat for each file system that was damaged.
Once your system is running, backup your data onto new tapes. Whatever caused the crash or data loss may strike again. Another hour spent now may save you from further distress later.
18.13 Network, Memory, and File-Backed File Systems
Reorganized and enhanced by Marc Fonvieille.Aside from the disks you physically insert into your computer: floppies, CDs, hard drives, and so forth; other forms of disks are understood by FreeBSD - the virtual disks.
These include network file systems such as the Network File System and Coda, memory-based file systems and file-backed file systems.
According to the FreeBSD version you run, you will have to use different tools for creation and use of file-backed and memory-based file systems.
Note: Use devfs(5) to allocate device nodes transparently for the user.
18.13.1 File-Backed File System
The utility mdconfig(8) is used to configure and enable memory disks, md(4), under FreeBSD. To use mdconfig(8), you have to load md(4) module or to add the support in your kernel configuration file:
device md
The mdconfig(8) command supports three kinds of memory backed virtual disks: memory disks allocated with malloc(9), memory disks using a file or swap space as backing. One possible use is the mounting of floppy or CD images kept in files.
To mount an existing file system image:
Example 18-4. Using mdconfig to Mount an Existing File System Image
# mdconfig -a -t vnode -f diskimage -u 0
# mount /dev/md0 /mnt
To create a new file system image with mdconfig(8):
Example 18-5. Creating a New File-Backed Disk with mdconfig
# dd if=/dev/zero of=newimage bs=1k count=5k
5120+0 records in
5120+0 records out
# mdconfig -a -t vnode -f newimage -u 0
# bsdlabel -w md0 auto
# newfs md0a
/dev/md0a: 5.0MB (10224 sectors) block size 16384, fragment size 2048
using 4 cylinder groups of 1.25MB, 80 blks, 192 inodes.
super-block backups (for fsck -b #) at:
160, 2720, 5280, 7840
# mount /dev/md0a /mnt
# df /mnt
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/md0a 4710 4 4330 0% /mnt
If you do not specify the unit number with the -u option,
mdconfig(8) will use
the md(4) automatic
allocation to select an unused device. The name of the allocated unit will be output on
stdout like md4. For more details about mdconfig(8), please
refer to the manual page.
The utility mdconfig(8) is very useful, however it asks many command lines to create a file-backed file system. FreeBSD also comes with a tool called mdmfs(8), this program configures a md(4) disk using mdconfig(8), puts a UFS file system on it using newfs(8), and mounts it using mount(8). For example, if you want to create and mount the same file system image as above, simply type the following:
Example 18-6. Configure and Mount a File-Backed Disk with mdmfs
# dd if=/dev/zero of=newimage bs=1k count=5k
5120+0 records in
5120+0 records out
# mdmfs -F newimage -s 5m md0 /mnt
# df /mnt
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/md0 4718 4 4338 0% /mnt
If you use the option md without unit number, mdmfs(8) will use md(4) auto-unit
feature to automatically select an unused device. For more details about mdmfs(8), please refer
to the manual page.
18.13.2 Memory-Based File System
For a memory-based file system the “swap backing” should normally be used. Using swap backing does not mean that the memory disk will be swapped out to disk by default, but merely that the memory disk will be allocated from a memory pool which can be swapped out to disk if needed. It is also possible to create memory-based disk which are malloc(9) backed, but using malloc backed memory disks, especially large ones, can result in a system panic if the kernel runs out of memory.
Example 18-7. Creating a New Memory-Based Disk with mdconfig
# mdconfig -a -t swap -s 5m -u 1
# newfs -U md1
/dev/md1: 5.0MB (10240 sectors) block size 16384, fragment size 2048
using 4 cylinder groups of 1.27MB, 81 blks, 192 inodes.
with soft updates
super-block backups (for fsck -b #) at:
160, 2752, 5344, 7936
# mount /dev/md1 /mnt
# df /mnt
Filesystem 1K-blocks Used Avail Capacity Mounted on
/dev/md1 4718 4 4338 0% /mnt
18.13.3 Detaching a Memory Disk from the System
When a memory-based or file-based file system is not used, you should release all resources to the system. The first thing to do is to unmount the file system, then use mdconfig(8) to detach the disk from the system and release the resources.
For example to detach and free all resources used by /dev/md4:
# mdconfig -d -u 4
It is possible to list information about configured md(4) devices in using the command mdconfig -l.
18.14 File System Snapshots
Contributed by Tom Rhodes.FreeBSD offers a feature in conjunction with Soft Updates: File system snapshots.
Snapshots allow a user to create images of specified file systems, and treat them as a file. Snapshot files must be created in the file system that the action is performed on, and a user may create no more than 20 snapshots per file system. Active snapshots are recorded in the superblock so they are persistent across unmount and remount operations along with system reboots. When a snapshot is no longer required, it can be removed with the standard rm(1) command. Snapshots may be removed in any order, however all the used space may not be acquired because another snapshot will possibly claim some of the released blocks.
The un-alterable snapshot file flag is set by mksnap_ffs(8) after
initial creation of a snapshot file. The unlink(1) command
makes an exception for snapshot files since it allows them to be removed.
Snapshots are created with the mount(8) command. To place a snapshot of /var in the file /var/snapshot/snap use the following command:
# mount -u -o snapshot /var/snapshot/snap /var
Alternatively, you can use mksnap_ffs(8) to create a snapshot:
# mksnap_ffs /var /var/snapshot/snap
One can find snapshot files on a file system (e.g. /var) by using the find(1) command:
# find /var -flags snapshot
Once a snapshot has been created, it has several uses:
-
Some administrators will use a snapshot file for backup purposes, because the snapshot can be transfered to CDs or tape.
-
The file system integrity checker, fsck(8), may be run on the snapshot. Assuming that the file system was clean when it was mounted, you should always get a clean (and unchanging) result. This is essentially what the background fsck(8) process does.
-
Run the dump(8) utility on the snapshot. A dump will be returned that is consistent with the file system and the timestamp of the snapshot. dump(8) can also take a snapshot, create a dump image and then remove the snapshot in one command using the
-Lflag. -
mount(8) the snapshot as a frozen image of the file system. To mount(8) the snapshot /var/snapshot/snap run:
# mdconfig -a -t vnode -f /var/snapshot/snap -u 4 # mount -r /dev/md4 /mnt
You can now walk the hierarchy of your frozen /var file system mounted at /mnt. Everything will initially be in the same state it was during the snapshot creation time. The only exception is that any earlier snapshots will appear as zero length files. When the use of a snapshot has delimited, it can be unmounted with:
# umount /mnt
# mdconfig -d -u 4
For more information about softupdates and file system
snapshots, including technical papers, you can visit Marshall Kirk McKusick's website at
http://www.mckusick.com/.
18.15 File System Quotas
Quotas are an optional feature of the operating system that allow you to limit the amount of disk space and/or the number of files a user or members of a group may allocate on a per-file system basis. This is used most often on timesharing systems where it is desirable to limit the amount of resources any one user or group of users may allocate. This will prevent one user or group of users from consuming all of the available disk space.
18.15.1 Configuring Your System to Enable Disk Quotas
Before attempting to use disk quotas, it is necessary to make sure that quotas are configured in your kernel. This is done by adding the following line to your kernel configuration file:
options QUOTA
The stock GENERIC kernel does not have this enabled by default, so you will have to configure, build and install a custom kernel in order to use disk quotas. Please refer to Chapter 8 for more information on kernel configuration.
Next you will need to enable disk quotas in /etc/rc.conf. This is done by adding the line:
enable_quotas="YES"
For finer control over your quota startup, there is an additional configuration variable available. Normally on bootup, the quota integrity of each file system is checked by the quotacheck(8) program. The quotacheck(8) facility insures that the data in the quota database properly reflects the data on the file system. This is a very time consuming process that will significantly affect the time your system takes to boot. If you would like to skip this step, a variable in /etc/rc.conf is made available for the purpose:
check_quotas="NO"
Finally you will need to edit /etc/fstab to enable disk quotas on a per-file system basis. This is where you can either enable user or group quotas or both for all of your file systems.
To enable per-user quotas on a file system, add the userquota option to the options field in the /etc/fstab entry for the file system you want to enable quotas on.
For example:
/dev/da1s2g /home ufs rw,userquota 1 2
Similarly, to enable group quotas, use the groupquota
option instead of userquota. To enable both user and group
quotas, change the entry as follows:
/dev/da1s2g /home ufs rw,userquota,groupquota 1 2
By default, the quota files are stored in the root directory of the file system with the names quota.user and quota.group for user and group quotas respectively. See fstab(5) for more information. Even though the fstab(5) manual page says that you can specify an alternate location for the quota files, this is not recommended because the various quota utilities do not seem to handle this properly.
At this point you should reboot your system with your new kernel. /etc/rc will automatically run the appropriate commands to create the initial quota files for all of the quotas you enabled in /etc/fstab, so there is no need to manually create any zero length quota files.
In the normal course of operations you should not be required to run the quotacheck(8), quotaon(8), or quotaoff(8) commands manually. However, you may want to read their manual pages just to be familiar with their operation.
18.15.2 Setting Quota Limits
Once you have configured your system to enable quotas, verify that they really are enabled. An easy way to do this is to run:
# quota -v
You should see a one line summary of disk usage and current quota limits for each file system that quotas are enabled on.
You are now ready to start assigning quota limits with the edquota(8) command.
You have several options on how to enforce limits on the amount of disk space a user or group may allocate, and how many files they may create. You may limit allocations based on disk space (block quotas) or number of files (inode quotas) or a combination of both. Each of these limits are further broken down into two categories: hard and soft limits.
A hard limit may not be exceeded. Once a user reaches his hard limit he may not make any further allocations on the file system in question. For example, if the user has a hard limit of 500 kbytes on a file system and is currently using 490 kbytes, the user can only allocate an additional 10 kbytes. Attempting to allocate an additional 11 kbytes will fail.
Soft limits, on the other hand, can be exceeded for a limited amount of time. This period of time is known as the grace period, which is one week by default. If a user stays over his or her soft limit longer than the grace period, the soft limit will turn into a hard limit and no further allocations will be allowed. When the user drops back below the soft limit, the grace period will be reset.
The following is an example of what you might see when you run the edquota(8) command. When the edquota(8) command is invoked, you are placed into the editor specified by the EDITOR environment variable, or in the vi editor if the EDITOR variable is not set, to allow you to edit the quota limits.
# edquota -u test
Quotas for user test:
/usr: kbytes in use: 65, limits (soft = 50, hard = 75)
inodes in use: 7, limits (soft = 50, hard = 60)
/usr/var: kbytes in use: 0, limits (soft = 50, hard = 75)
inodes in use: 0, limits (soft = 50, hard = 60)
You will normally see two lines for each file system that has quotas enabled. One line for the block limits, and one line for inode limits. Simply change the value you want updated to modify the quota limit. For example, to raise this user's block limit from a soft limit of 50 and a hard limit of 75 to a soft limit of 500 and a hard limit of 600, change:
/usr: kbytes in use: 65, limits (soft = 50, hard = 75)
to:
/usr: kbytes in use: 65, limits (soft = 500, hard = 600)
The new quota limits will be in place when you exit the editor.
Sometimes it is desirable to set quota limits on a range of UIDs. This can be done by
use of the -p option on the edquota(8) command.
First, assign the desired quota limit to a user, and then run edquota
-p protouser startuid-enduid. For example, if user test
has the desired quota limits, the following command can be used to duplicate those quota
limits for UIDs 10,000 through 19,999:
# edquota -p test 10000-19999
For more information see edquota(8) manual page.
18.15.3 Checking Quota Limits and Disk Usage
You can use either the quota(1) or the repquota(8) commands to check quota limits and disk usage. The quota(1) command can be used to check individual user or group quotas and disk usage. A user may only examine his own quota, and the quota of a group he is a member of. Only the super-user may view all user and group quotas. The repquota(8) command can be used to get a summary of all quotas and disk usage for file systems with quotas enabled.
The following is some sample output from the quota -v command for a user that has quota limits on two file systems.
Disk quotas for user test (uid 1002):
Filesystem usage quota limit grace files quota limit grace
/usr 65* 50 75 5days 7 50 60
/usr/var 0 50 75 0 50 60
On the /usr file system in the above example, this user is currently 15 kbytes over the soft limit of 50 kbytes and has 5 days of the grace period left. Note the asterisk * which indicates that the user is currently over his quota limit.
Normally file systems that the user is not using any disk space on will not show up in
the output from the quota(1) command, even
if he has a quota limit assigned for that file system. The -v
option will display those file systems, such as the /usr/var
file system in the above example.
18.15.4 Quotas over NFS
Quotas are enforced by the quota subsystem on the NFS server. The rpc.rquotad(8) daemon makes quota information available to the quota(1) command on NFS clients, allowing users on those machines to see their quota statistics.
Enable rpc.rquotad in /etc/inetd.conf like so:
rquotad/1 dgram rpc/udp wait root /usr/libexec/rpc.rquotad rpc.rquotad
Now restart inetd:
# kill -HUP `cat /var/run/inetd.pid`
18.16 Encrypting Disk Partitions
Contributed by Lucky Green.FreeBSD offers excellent online protections against unauthorized data access. File permissions and Mandatory Access Control (MAC) (see Chapter 16) help prevent unauthorized third-parties from accessing data while the operating system is active and the computer is powered up. However, the permissions enforced by the operating system are irrelevant if an attacker has physical access to a computer and can simply move the computer's hard drive to another system to copy and analyze the sensitive data.
Regardless of how an attacker may have come into possession of a hard drive or powered-down computer, both GEOM Based Disk Encryption (gbde) and geli cryptographic subsystems in FreeBSD are able to protect the data on the computer's file systems against even highly-motivated attackers with significant resources. Unlike cumbersome encryption methods that encrypt only individual files, gbde and geli transparently encrypt entire file systems. No cleartext ever touches the hard drive's platter.
18.16.1 Disk Encryption with gbde
-
Become root
Configuring gbde requires super-user privileges.
% su - Password: -
Add gbde(4) Support to the Kernel Configuration File
Add the following line to the kernel configuration file:
options GEOM_BDE
Rebuild the kernel as described in Chapter 8.
Reboot into the new kernel.
-
An alternative to recompiling the kernel is to use kldload to load gbde(4):
# kldload geom_bde
18.16.1.1 Preparing the Encrypted Hard Drive
The following example assumes that you are adding a new hard drive to your system that will hold a single encrypted partition. This partition will be mounted as /private. gbde can also be used to encrypt /home and /var/mail, but this requires more complex instructions which exceed the scope of this introduction.
-
Add the New Hard Drive
Install the new drive to the system as explained in Section 18.3. For the purposes of this example, a new hard drive partition has been added as /dev/ad4s1c. The /dev/ad0s1* devices represent existing standard FreeBSD partitions on the example system.
# ls /dev/ad* /dev/ad0 /dev/ad0s1b /dev/ad0s1e /dev/ad4s1 /dev/ad0s1 /dev/ad0s1c /dev/ad0s1f /dev/ad4s1c /dev/ad0s1a /dev/ad0s1d /dev/ad4 -
Create a Directory to Hold gbde Lock Files
# mkdir /etc/gbdeThe gbde lock file contains information that gbde requires to access encrypted partitions. Without access to the lock file, gbde will not be able to decrypt the data contained in the encrypted partition without significant manual intervention which is not supported by the software. Each encrypted partition uses a separate lock file.
-
Initialize the gbde Partition
A gbde partition must be initialized before it can be used. This initialization needs to be performed only once:
# gbde init /dev/ad4s1c -i -L /etc/gbde/ad4s1cgbde(8) will open your editor, permitting you to set various configuration options in a template. For use with UFS1 or UFS2, set the sector_size to 2048:
$FreeBSD: src/sbin/gbde/template.txt,v 1.1 2002/10/20 11:16:13 phk Exp $ # # Sector size is the smallest unit of data which can be read or written. # Making it too small decreases performance and decreases available space. # Making it too large may prevent filesystems from working. 512 is the # minimum and always safe. For UFS, use the fragment size # sector_size = 2048 [...]gbde(8) will ask you twice to type the passphrase that should be used to secure the data. The passphrase must be the same both times. gbde's ability to protect your data depends entirely on the quality of the passphrase that you choose. [12]
The gbde init command creates a lock file for your gbde partition that in this example is stored as /etc/gbde/ad4s1c.
Caution: gbde lock files must be backed up together with the contents of any encrypted partitions. While deleting a lock file alone cannot prevent a determined attacker from decrypting a gbde partition, without the lock file, the legitimate owner will be unable to access the data on the encrypted partition without a significant amount of work that is totally unsupported by gbde(8) and its designer.
-
Attach the Encrypted Partition to the Kernel
# gbde attach /dev/ad4s1c -l /etc/gbde/ad4s1cYou will be asked to provide the passphrase that you selected during the initialization of the encrypted partition. The new encrypted device will show up in /dev as /dev/device_name.bde:
# ls /dev/ad* /dev/ad0 /dev/ad0s1b /dev/ad0s1e /dev/ad4s1 /dev/ad0s1 /dev/ad0s1c /dev/ad0s1f /dev/ad4s1c /dev/ad0s1a /dev/ad0s1d /dev/ad4 /dev/ad4s1c.bde -
Create a File System on the Encrypted Device
Once the encrypted device has been attached to the kernel, you can create a file system on the device. To create a file system on the encrypted device, use newfs(8). Since it is much faster to initialize a new UFS2 file system than it is to initialize the old UFS1 file system, using newfs(8) with the
-O2option is recommended.# newfs -U -O2 /dev/ad4s1c.bdeNote: The newfs(8) command must be performed on an attached gbde partition which is identified by a *.bde extension to the device name.
-
Mount the Encrypted Partition
Create a mount point for the encrypted file system.
# mkdir /privateMount the encrypted file system.
# mount /dev/ad4s1c.bde /private -
Verify That the Encrypted File System is Available
The encrypted file system should now be visible to df(1) and be available for use.
% df -H Filesystem Size Used Avail Capacity Mounted on /dev/ad0s1a 1037M 72M 883M 8% / /devfs 1.0K 1.0K 0B 100% /dev /dev/ad0s1f 8.1G 55K 7.5G 0% /home /dev/ad0s1e 1037M 1.1M 953M 0% /tmp /dev/ad0s1d 6.1G 1.9G 3.7G 35% /usr /dev/ad4s1c.bde 150G 4.1K 138G 0% /private
18.16.1.2 Mounting Existing Encrypted File Systems
After each boot, any encrypted file systems must be re-attached to the kernel, checked for errors, and mounted, before the file systems can be used. The required commands must be executed as user root.
-
Attach the gbde Partition to the Kernel
# gbde attach /dev/ad4s1c -l /etc/gbde/ad4s1cYou will be asked to provide the passphrase that you selected during initialization of the encrypted gbde partition.
-
Check the File System for Errors
Since encrypted file systems cannot yet be listed in /etc/fstab for automatic mounting, the file systems must be checked for errors by running fsck(8) manually before mounting.
# fsck -p -t ffs /dev/ad4s1c.bde -
Mount the Encrypted File System
# mount /dev/ad4s1c.bde /privateThe encrypted file system is now available for use.
18.16.1.2.1 Automatically Mounting Encrypted Partitions
It is possible to create a script to automatically attach, check, and mount an encrypted partition, but for security reasons the script should not contain the gbde(8) password. Instead, it is recommended that such scripts be run manually while providing the password via the console or ssh(1).
As an alternative, an rc.d script is provided. Arguments for this script can be passed via rc.conf(5), for example:
gbde_autoattach_all="YES"
gbde_devices="ad4s1c"
This will require that the gbde passphrase be entered at boot time. After typing the correct passphrase, the gbde encrypted partition will be mounted automatically. This can be very useful when using gbde on notebooks.
18.16.1.3 Cryptographic Protections Employed by gbde
gbde(8) encrypts the sector payload using 128-bit AES in CBC mode. Each sector on the disk is encrypted with a different AES key. For more information on gbde's cryptographic design, including how the sector keys are derived from the user-supplied passphrase, see gbde(4).
18.16.1.4 Compatibility Issues
sysinstall(8) is incompatible with gbde-encrypted devices. All *.bde devices must be detached from the kernel before starting sysinstall(8) or it will crash during its initial probing for devices. To detach the encrypted device used in our example, use the following command:
# gbde detach /dev/ad4s1c
Also note that, as vinum(4) does not use the geom(4) subsystem, you cannot use gbde with vinum volumes.
18.16.2 Disk Encryption with geli
Contributed by Daniel Gerzo.A new cryptographic GEOM class is available as of FreeBSD 6.0 - geli. It is currently being developed by Pawel Jakub Dawidek <pjd@FreeBSD.org>. The
geli utility is different to gbde; it
offers different features and uses a different scheme for doing cryptographic work.
The most important features of geli(8) are:
-
Utilizes the crypto(9) framework -- when cryptographic hardware is available, geli will use it automatically.
-
Supports multiple cryptographic algorithms (currently AES, Blowfish, and 3DES).
-
Allows the root partition to be encrypted. The passphrase used to access the encrypted root partition will be requested during the system boot.
-
Allows the use of two independent keys (e.g. a “key” and a “company key”).
-
geli is fast - performs simple sector-to-sector encryption.
-
Allows backup and restore of Master Keys. When a user has to destroy his keys, it will be possible to get access to the data again by restoring keys from the backup.
-
Allows to attach a disk with a random, one-time key -- useful for swap partitions and temporary file systems.
More geli features can be found in the geli(8) manual page.
The next steps will describe how to enable support for geli in the FreeBSD kernel and will explain how to create and use a geli encryption provider.
In order to use geli, you must be running FreeBSD 6.0-RELEASE or later. Super-user privileges will be required since modifications to the kernel are necessary.
-
Adding geli Support to the Kernel
Add the following lines to the kernel configuration file:
options GEOM_ELI device cryptoRebuild the kernel as described in Chapter 8.
Alternatively, the geli module can be loaded at boot time. Add the following line to the /boot/loader.conf:
geom_eli_load="YES"geli(8) should now be supported by the kernel.
-
Generating the Master Key
The following example will describe how to generate a key file, which will be used as part of the Master Key for the encrypted provider mounted under /private. The key file will provide some random data used to encrypt the Master Key. The Master Key will be protected by a passphrase as well. Provider's sector size will be 4kB big. Furthermore, the discussion will describe how to attach the geli provider, create a file system on it, how to mount it, how to work with it, and finally how to detach it.
It is recommended to use a bigger sector size (like 4kB) for better performance.
The Master Key will be protected with a passphrase and the data source for key file will be /dev/random. The sector size of /dev/da2.eli, which we call provider, will be 4kB.
# dd if=/dev/random of=/root/da2.key bs=64 count=1 # geli init -s 4096 -K /root/da2.key /dev/da2 Enter new passphrase: Reenter new passphrase:It is not mandatory that both a passphrase and a key file are used; either method of securing the Master Key can be used in isolation.
If key file is given as “-”, standard input will be used. This example shows how more than one key file can be used.
# cat keyfile1 keyfile2 keyfile3 | geli init -K - /dev/da2 -
Attaching the Provider with the generated Key
# geli attach -k /root/da2.key /dev/da2 Enter passphrase:The new plaintext device will be named /dev/da2.eli.
# ls /dev/da2* /dev/da2 /dev/da2.eli -
Creating the new File System
# dd if=/dev/random of=/dev/da2.eli bs=1m # newfs /dev/da2.eli # mount /dev/da2.eli /privateThe encrypted file system should be visible to df(1) and be available for use now:
# df -H Filesystem Size Used Avail Capacity Mounted on /dev/ad0s1a 248M 89M 139M 38% / /devfs 1.0K 1.0K 0B 100% /dev /dev/ad0s1f 7.7G 2.3G 4.9G 32% /usr /dev/ad0s1d 989M 1.5M 909M 0% /tmp /dev/ad0s1e 3.9G 1.3G 2.3G 35% /var /dev/da2.eli 150G 4.1K 138G 0% /private -
Unmounting and Detaching the Provider
Once the work on the encrypted partition is done, and the /private partition is no longer needed, it is prudent to consider unmounting and detaching the geli encrypted partition from the kernel.
# umount /private # geli detach da2.eli
More information about the use of geli(8) can be found in the manual page.
18.16.2.1 Using the geli rc.d Script
geli comes with a rc.d script which can be used to simplify the usage of geli. An example of configuring geli through rc.conf(5) follows:
geli_devices="da2"
geli_da2_flags="-p -k /root/da2.key"
This will configure /dev/da2 as a geli provider of which the Master Key file is located in /root/da2.key, and geli will not use a
passphrase when attaching the provider (note that this can only be used if -P was given during the geli init phase).
The system will detach the geli provider from the kernel before
the system shuts down.
More information about configuring rc.d is provided in the rc.d section of the Handbook.
18.17 Encrypting Swap Space
Written by Christian Brüffer.Swap encryption in FreeBSD is easy to configure and has been available since FreeBSD 5.3-RELEASE. Depending on which version of FreeBSD is being used, different options are available and configuration can vary slightly. From FreeBSD 6.0-RELEASE onwards, the gbde(8) or geli(8) encryption systems can be used for swap encryption. With earlier versions, only gbde(8) is available. Both systems use the encswap rc.d script.
The previous section, Encrypting Disk Partitions, includes a short discussion on the different encryption systems.
18.17.1 Why should Swap be Encrypted?
Like the encryption of disk partitions, encryption of swap space is done to protect sensitive information. Imagine an application that e.g. deals with passwords. As long as these passwords stay in physical memory, all is well. However, if the operating system starts swapping out memory pages to free space for other applications, the passwords may be written to the disk platters unencrypted and easy to retrieve for an adversary. Encrypting swap space can be a solution for this scenario.
18.17.2 Preparation
Note: For the remainder of this section, ad0s1b will be the swap partition.
Up to this point the swap has been unencrypted. It is possible that there are already passwords or other sensitive data on the disk platters in cleartext. To rectify this, the data on the swap partition should be overwritten with random garbage:
# dd if=/dev/random of=/dev/ad0s1b bs=1m
18.17.3 Swap Encryption with gbde(8)
If FreeBSD 6.0-RELEASE or newer is being used, the .bde suffix should be added to the device in the respective /etc/fstab swap line:
# Device Mountpoint FStype Options Dump Pass#
/dev/ad0s1b.bde none swap sw 0 0
For systems prior to FreeBSD 6.0-RELEASE, the following line in /etc/rc.conf is also needed:
gbde_swap_enable="YES"
18.17.4 Swap Encryption with geli(8)
Alternatively, the procedure for using geli(8) for swap encryption is similar to that of using gbde(8). The .eli suffix should be added to the device in the respective /etc/fstab swap line:
# Device Mountpoint FStype Options Dump Pass#
/dev/ad0s1b.eli none swap sw 0 0
geli(8) uses the AES algorithm with a key length of 256 bit by default.
Optionally, these defaults can be altered using the geli_swap_flags option in /etc/rc.conf. The following line tells the encswap rc.d script to create geli(8) swap partitions using the Blowfish algorithm with a key length of 128 bit, a sectorsize of 4 kilobytes and the “detach on last close” option set:
geli_swap_flags="-e blowfish -l 128 -s 4096 -d"
For systems prior to FreeBSD 6.2-RELEASE, use the following line:
geli_swap_flags="-a blowfish -l 128 -s 4096 -d"
Please refer to the description of the onetime command in the geli(8) manual page for a list of possible options.
18.17.5 Verifying that it Works
Once the system has been rebooted, proper operation of the encrypted swap can be verified using the swapinfo command.
If gbde(8) is being used:
% swapinfo
Device 1K-blocks Used Avail Capacity
/dev/ad0s1b.bde 542720 0 542720 0%
If geli(8) is being used:
% swapinfo
Device 1K-blocks Used Avail Capacity
/dev/ad0s1b.eli 542720 0 542720 0%
Chapter 19 GEOM: Modular Disk Transformation Framework
Written by Tom Rhodes.19.1 Synopsis
This chapter covers the use of disks under the GEOM framework in FreeBSD. This includes the major RAID control utilities which use the framework for configuration. This chapter will not go into in depth discussion on how GEOM handles or controls I/O, the underlying subsystem, or code. This information is provided through the geom(4) manual page and its various SEE ALSO references. This chapter is also not a definitive guide to RAID configurations. Only GEOM-supported RAID classifications will be discussed.
After reading this chapter, you will know:
-
What type of RAID support is available through GEOM.
-
How to use the base utilities to configure, maintain, and manipulate the various RAID levels.
-
How to mirror, stripe, encrypt, and remotely connect disk devices through GEOM.
-
How to troubleshoot disks attached to the GEOM framework.
Before reading this chapter, you should:
-
Understand how FreeBSD treats disk devices (Chapter 18).
-
Know how to configure and install a new FreeBSD kernel (Chapter 8).
19.2 GEOM Introduction
GEOM permits access and control to classes -- Master Boot Records, BSD labels, etc -- through the use of providers, or the special files in /dev. Supporting various software RAID configurations, GEOM will transparently provide access to the operating system and operating system utilities.
19.3 RAID0 - Striping
Written by Tom Rhodes and Murray Stokely.Striping is a method used to combine several disk drives into a single volume. In many cases, this is done through the use of hardware controllers. The GEOM disk subsystem provides software support for RAID0, also known as disk striping.
In a RAID0 system, data are split up in blocks that get written across all the drives in the array. Instead of having to wait on the system to write 256k to one disk, a RAID0 system can simultaneously write 64k to each of four different disks, offering superior I/O performance. This performance can be enhanced further by using multiple disk controllers.
Each disk in a RAID0 stripe must be of the same size, since I/O requests are interleaved to read or write to multiple disks in parallel.
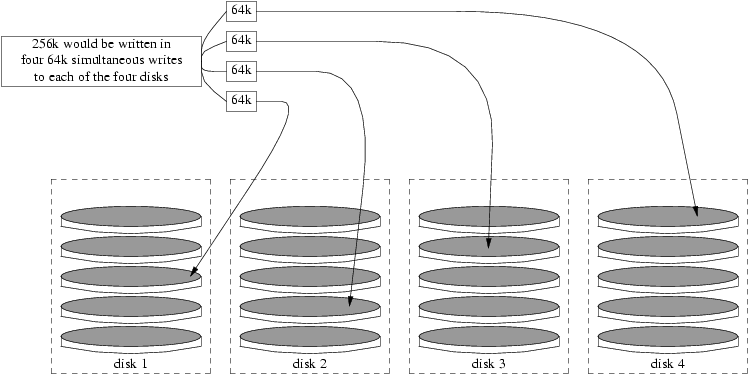
Creating a stripe of unformatted ATA disks
-
Load the geom_stripe module:
# kldload geom_stripe -
Ensure that a suitable mount point exists. If this volume will become a root partition, then temporarily use another mount point such as /mnt:
# mkdir /mnt -
Determine the device names for the disks which will be striped, and create the new stripe device. For example, to stripe two unused and unpartitioned ATA disks, for example /dev/ad2 and /dev/ad3:
# gstripe label -v st0 /dev/ad2 /dev/ad3 -
Write a standard label, also known as a partition table, on the new volume and install the default bootstrap code:
# bsdlabel -wB /dev/stripe/st0 -
This process should have created two other devices in the /dev/stripe directory in addition to the st0 device. Those include st0a and st0c. At this point a file system may be created on the st0a device with the newfs utility:
# newfs -U /dev/stripe/st0aMany numbers will glide across the screen, and after a few seconds, the process will be complete. The volume has been created and is ready to be mounted.
To manually mount the created disk stripe:
# mount /dev/stripe/st0a /mnt
To mount this striped file system automatically during the boot process, place the volume information in /etc/fstab file:
# echo "/dev/stripe/st0a /mnt ufs rw 2 2" \
>> /etc/fstab
The geom_stripe module must also be automatically loaded during system initialization, by adding a line to /boot/loader.conf:
# echo 'geom_stripe_load="YES"' >> /boot/loader.conf
19.4 RAID1 - Mirroring
Mirroring is a technology used by many corporations and home users to back up data without interruption. When a mirror exists, it simply means that diskB replicates diskA. Or, perhaps diskC+D replicates diskA+B. Regardless of the disk configuration, the important aspect is that information on one disk or partition is being replicated. Later, that information could be more easily restored, backed up without causing service or access interruption, and even be physically stored in a data safe.
To begin, ensure the system has two disk drives of equal size, this exercise assumes they are direct access (da(4)) SCSI disks.
Begin by installing FreeBSD on the first disk with only two partitions. One should be a swap partition, double the RAM size and all remaining space devoted to the root (/) file system. It is possible to have separate partitions for other mount points; however, this will increase the difficulty level ten fold due to manual alteration of the bsdlabel(8) and fdisk(8) settings.
Reboot and wait for the system to fully initialize. Once this process has completed, log in as the root user.
Create the /dev/mirror/gm device and link it with /dev/da1:
# gmirror label -vnb round-robin gm0 /dev/da1
The system should respond with:
Metadata value stored on /dev/da1.
Done.
Initialize GEOM, this will load the /boot/kernel/geom_mirror.ko kernel module:
# gmirror load
Note: This command should have created the gm0, device node under the /dev/mirror directory.
Install a generic fdisk label and boot code to new gm0 device:
# fdisk -vBI /dev/mirror/gm0
Now install generic bsdlabel information:
# bsdlabel -wB /dev/mirror/gm0s1
Note: If multiple slices and partitions exist, the flags for the previous two commands will require alteration. They must match the slice and partition size of the other disk.
Use the newfs(8) utility to construct a default UFS file system on the gm0s1a device node:
# newfs -U /dev/mirror/gm0s1a
This should have caused the system to spit out some information and a bunch of numbers. This is good. Examine the screen for any error messages and mount the device to the /mnt mount point:
# mount /dev/mirror/gm0s1a /mnt
Now move all data from the boot disk over to this new file system. This example uses the dump(8) and restore(8) commands; however, dd(1) would also work with this scenario.
# dump -L -0 -f- / |(cd /mnt && restore -r -v -f-)
This must be done for each file system. Simply place the appropriate file system in the correct location when running the aforementioned command.
Now edit the replicated /mnt/etc/fstab file and remove or comment out the swap file [13]. Change the other file system information to use the new disk as shown in the following example:
# Device Mountpoint FStype Options Dump Pass#
#/dev/da0s2b none swap sw 0 0
/dev/mirror/gm0s1a / ufs rw 1 1
Now create a boot.config file on both the current and new root partitions. This file will “help” the system BIOS boot the correct drive:
# echo "1:da(1,a)/boot/loader" > /boot.config
# echo "1:da(1,a)/boot/loader" > /mnt/boot.config
Note: We have placed it on both root partitions to ensure proper boot up. If for some reason the system cannot read from the new root partition, a failsafe is available.
Ensure the geom_mirror.ko module will load on boot by running the following command:
# echo 'geom_mirror_load="YES"' >> /mnt/boot/loader.conf
Reboot the system:
# shutdown -r now
If all has gone well, the system should have booted from the gm0s1a device and a login prompt should be waiting. If something went wrong, see review the forthcoming troubleshooting section. Now add the da0 disk to gm0 device:
# gmirror configure -a gm0
# gmirror insert gm0 /dev/da0
The -a flag tells gmirror(8) to use
automatic synchronization; i.e., mirror the disk writes automatically. The manual page
explains how to rebuild and replace disks, although it uses data in place of gm0.
19.4.1 Troubleshooting
19.4.1.1 System refuses to boot
If the system boots up to a prompt similar to:
ffs_mountroot: can't find rootvp
Root mount failed: 6
mountroot>
Reboot the machine using the power or reset button. At the boot menu, select option six (6). This will drop the system to a loader(8) prompt. Load the kernel module manually:
OK? load geom_mirror
OK? boot
If this works then for whatever reason the module was not being loaded properly. Place:
options GEOM_MIRROR
in the kernel configuration file, rebuild and reinstall. That should remedy this issue.
19.5 GEOM Gate Network Devices
GEOM supports the remote use of devices, such as disks, CD-ROMs, files, etc. through the use of the gate utilities. This is similar to NFS.
To begin, an exports file must be created. This file specifies who is permitted to access the exported resources and what level of access they are offered. For example, to export the fourth slice on the first SCSI disk, the following /etc/gg.exports is more than adequate:
192.168.1.0/24 RW /dev/da0s4d
It will allow all hosts inside the private network access the file system on the da0s4d partition.
To export this device, ensure it is not currently mounted, and start the ggated(8) server daemon:
# ggated
Now to mount the device on the client machine, issue the following commands:
# ggatec create -o rw 192.168.1.1 /dev/da0s4d
ggate0
# mount /dev/ggate0 /mnt
From here on, the device may be accessed through the /mnt mount point.
Note: It should be pointed out that this will fail if the device is currently mounted on either the server machine or any other machine on the network.
When the device is no longer needed, it may be safely unmounted with the umount(8) command, similar to any other disk device.
19.6 Labeling Disk Devices
During system initialization, the FreeBSD kernel will create device nodes as devices are found. This method of probing for devices raises some issues, for instance what if a new disk device is added via USB? It is very likely that a flash device may be handed the device name of da0 and the original da0 shifted to da1. This will cause issues mounting file systems if they are listed in /etc/fstab, effectively, this may also prevent the system from booting.
One solution to this issue is to chain the SCSI devices in order so a new device added to the SCSI card will be issued unused device numbers. But what about USB devices which may replace the primary SCSI disk? This happens because USB devices are usually probed before the SCSI card. One solution is to only insert these devices after the system has been booted. Another method could be to use only a single ATA drive and never list the SCSI devices in /etc/fstab.
A better solution is available. By using the glabel utility, an administrator or user may label their disk devices and use these labels in /etc/fstab. Because glabel stores the label in the last sector of a given provider, the label will remain persistent across reboots. By using this label as a device, the file system may always be mounted regardless of what device node it is accessed through.
Note: This goes without saying that a label be permanent. The glabel utility may be used to create both a transient and permanent label. Only the permanent label will remain consistent across reboots. See the glabel(8) manual page for more information on the differences between labels.
19.6.1 Label Types and Examples
There are two types of labels, a generic label and a file system label. The difference between the labels is the auto detection associated with permanent labels, and the fact that this type of label will be persistent across reboots. These labels are given a special directory in /dev, which will be named based on their file system type. For example, UFS2 file system labels will be created in the /dev/ufs2 directory.
A generic label will go away with the next reboot. These labels will be created in the /dev/label directory and are perfect for experimentation.
Permanent labels may be placed on the file system using the tunefs or newfs utilities. To create a permanent label for a UFS2 file system without destroying any data, issue the following command:
# tunefs -L home /dev/da3
Warning: If the file system is full, this may cause data corruption; however, if the file system is full then the main goal should be removing stale files and not adding labels.
A label should now exist in /dev/ufs2 which may be added to /etc/fstab:
/dev/ufs2/home /home ufs rw 2 2
Note: The file system must not be mounted while attempting to run tunefs.
Now the file system may be mounted like normal:
# mount /home
From this point on, so long as the geom_label.ko kernel module is loaded at boot with /boot/loader.conf or the GEOM_LABEL kernel option is present, the device node may change without any ill effect on the system.
File systems may also be created with a default label by using the -L flag with newfs. See the newfs(8) manual page
for more information.
The following command can be used to destroy the label:
# glabel destroy home
19.7 UFS Journaling Through GEOM
With the release of FreeBSD 7.0, the long awaited feature of UFS journals has been implemented. The implementation itself is provided through the GEOM subsystem and is easily configured via the gjournal(8) utility.
What is journaling? Journaling capability stores a log of file system transactions, i.e.: changes that make up a complete disk write operation, before meta-data and file writes are committed to the disk proper. This transaction log can later be replayed to redo file system transactions, preventing file system inconsistencies.
This method is yet another mechanism to protect against data loss and inconsistencies of the file system. Unlike Soft Updates which tracks and enforces meta-data updates and Snapshots which is an image of the file system, an actual log is stored at the end sector and, in some cases, may be stored on another disk entirely.
Unlike other file system journaling implementations, the gjournal method is block based and not implemented as part of the file system - only as a GEOM extension.
To enable support for gjournal, the FreeBSD kernel must have the following option - which is the default on 7.X systems:
options UFS_GJOURNAL
Creating a journal on a free file system may now be done using the following steps, considering that the da4 is a new SCSI disk:
# gjournal label /dev/da4
# gjournal load
At this point, there should be a /dev/da4 device node and a /dev/da4.journal device node. A file system may now be created on this device:
# newfs -O 2 -J /dev/da4.journal
The previously issued command will create a UFS2 file system with journaling being made active.
Effectively mount the device at the desired point with:
# mount /dev/da4.journal /mnt
Note: In the case of several slices, a journal will be created for each individual slice. For instance, if ad4s1 and ad4s2 are both slices, then gjournal will create ad4s1.journal and ad4s2.journal. In the case of the command being run twice, the result will be “journals”.
Under some circumstances, keeping the journal on another disk may be desired. For these cases, the journal provider or storage device should be listed after the device to enable journaling on. Journaling may also be enabled on current file systems by using tunefs; however, always make a backup before attempting to alter a file system. In most cases, the gjournal will fail if it is unable to create the actual journal but this does not protect against data loss incurred as a result of misusing tunefs.
Chapter 20 The Vinum Volume Manager
Originally written by Greg Lehey.20.1 Synopsis
No matter what disks you have, there are always potential problems:
-
They can be too small.
-
They can be too slow.
-
They can be too unreliable.
Various solutions to these problems have been proposed and implemented. One way some users safeguard themselves against such issues is through the use of multiple, and sometimes redundant, disks. In addition to supporting various cards and controllers for hardware RAID systems, the base FreeBSD system includes the Vinum Volume Manager, a block device driver that implements virtual disk drives. Vinum is a so-called Volume Manager, a virtual disk driver that addresses these three problems. Vinum provides more flexibility, performance, and reliability than traditional disk storage, and implements RAID-0, RAID-1, and RAID-5 models both individually and in combination.
This chapter provides an overview of potential problems with traditional disk storage, and an introduction to the Vinum Volume Manager.
Note: Starting with FreeBSD 5, Vinum has been rewritten in order to fit into the GEOM architecture (Chapter 19), retaining the original ideas, terminology, and on-disk metadata. This rewrite is called gvinum (for GEOM vinum). The following text usually refers to Vinum as an abstract name, regardless of the implementation variant. Any command invocations should now be done using the gvinum command, and the name of the kernel module has been changed from vinum.ko to geom_vinum.ko, and all device nodes reside under /dev/gvinum instead of /dev/vinum. As of FreeBSD 6, the old Vinum implementation is no longer available in the code base.
20.2 Disks Are Too Small
Disks are getting bigger, but so are data storage requirements. Often you will find you want a file system that is bigger than the disks you have available. Admittedly, this problem is not as acute as it was ten years ago, but it still exists. Some systems have solved this by creating an abstract device which stores its data on a number of disks.
20.3 Access Bottlenecks
Modern systems frequently need to access data in a highly concurrent manner. For example, large FTP or HTTP servers can maintain thousands of concurrent sessions and have multiple 100 Mbit/s connections to the outside world, well beyond the sustained transfer rate of most disks.
Current disk drives can transfer data sequentially at up to 70 MB/s, but this value is of little importance in an environment where many independent processes access a drive, where they may achieve only a fraction of these values. In such cases it is more interesting to view the problem from the viewpoint of the disk subsystem: the important parameter is the load that a transfer places on the subsystem, in other words the time for which a transfer occupies the drives involved in the transfer.
In any disk transfer, the drive must first position the heads, wait for the first sector to pass under the read head, and then perform the transfer. These actions can be considered to be atomic: it does not make any sense to interrupt them.
Consider a typical transfer of about 10 kB: the current generation of high-performance disks can position the heads in an average of 3.5 ms. The fastest drives spin at 15,000 rpm, so the average rotational latency (half a revolution) is 2 ms. At 70 MB/s, the transfer itself takes about 150 μs, almost nothing compared to the positioning time. In such a case, the effective transfer rate drops to a little over 1 MB/s and is clearly highly dependent on the transfer size.
The traditional and obvious solution to this bottleneck is “more spindles”: rather than using one large disk, it uses several smaller disks with the same aggregate storage space. Each disk is capable of positioning and transferring independently, so the effective throughput increases by a factor close to the number of disks used.
The exact throughput improvement is, of course, smaller than the number of disks involved: although each drive is capable of transferring in parallel, there is no way to ensure that the requests are evenly distributed across the drives. Inevitably the load on one drive will be higher than on another.
The evenness of the load on the disks is strongly dependent on the way the data is shared across the drives. In the following discussion, it is convenient to think of the disk storage as a large number of data sectors which are addressable by number, rather like the pages in a book. The most obvious method is to divide the virtual disk into groups of consecutive sectors the size of the individual physical disks and store them in this manner, rather like taking a large book and tearing it into smaller sections. This method is called concatenation and has the advantage that the disks are not required to have any specific size relationships. It works well when the access to the virtual disk is spread evenly about its address space. When access is concentrated on a smaller area, the improvement is less marked. Figure 20-1 illustrates the sequence in which storage units are allocated in a concatenated organization.
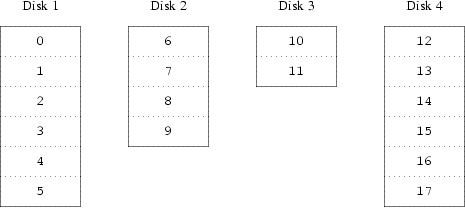
An alternative mapping is to divide the address space into smaller, equal-sized components and store them sequentially on different devices. For example, the first 256 sectors may be stored on the first disk, the next 256 sectors on the next disk and so on. After filling the last disk, the process repeats until the disks are full. This mapping is called striping or RAID-0 [14]. Striping requires somewhat more effort to locate the data, and it can cause additional I/O load where a transfer is spread over multiple disks, but it can also provide a more constant load across the disks. Figure 20-2 illustrates the sequence in which storage units are allocated in a striped organization.
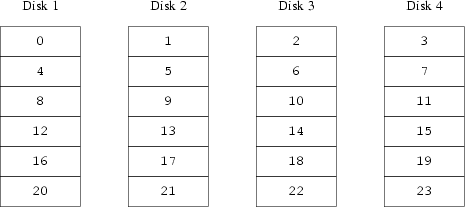
20.4 Data Integrity
The final problem with current disks is that they are unreliable. Although disk drive reliability has increased tremendously over the last few years, they are still the most likely core component of a server to fail. When they do, the results can be catastrophic: replacing a failed disk drive and restoring data to it can take days.
The traditional way to approach this problem has been mirroring, keeping two copies of the data on different physical hardware. Since the advent of the RAID levels, this technique has also been called RAID level 1 or RAID-1. Any write to the volume writes to both locations; a read can be satisfied from either, so if one drive fails, the data is still available on the other drive.
Mirroring has two problems:
-
The price. It requires twice as much disk storage as a non-redundant solution.
-
The performance impact. Writes must be performed to both drives, so they take up twice the bandwidth of a non-mirrored volume. Reads do not suffer from a performance penalty: it even looks as if they are faster.
An alternative solution is parity, implemented in the RAID levels 2, 3, 4 and 5. Of these, RAID-5 is the most interesting. As implemented in Vinum, it is a variant on a striped organization which dedicates one block of each stripe to parity of the other blocks. As implemented by Vinum, a RAID-5 plex is similar to a striped plex, except that it implements RAID-5 by including a parity block in each stripe. As required by RAID-5, the location of this parity block changes from one stripe to the next. The numbers in the data blocks indicate the relative block numbers.
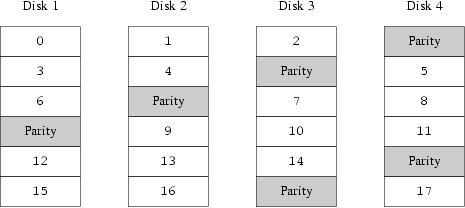
Compared to mirroring, RAID-5 has the advantage of requiring significantly less storage space. Read access is similar to that of striped organizations, but write access is significantly slower, approximately 25% of the read performance. If one drive fails, the array can continue to operate in degraded mode: a read from one of the remaining accessible drives continues normally, but a read from the failed drive is recalculated from the corresponding block from all the remaining drives.
20.5 Vinum Objects
In order to address these problems, Vinum implements a four-level hierarchy of objects:
-
The most visible object is the virtual disk, called a volume. Volumes have essentially the same properties as a UNIX disk drive, though there are some minor differences. They have no size limitations.
-
Volumes are composed of plexes, each of which represent the total address space of a volume. This level in the hierarchy thus provides redundancy. Think of plexes as individual disks in a mirrored array, each containing the same data.
-
Since Vinum exists within the UNIX disk storage framework, it would be possible to use UNIX partitions as the building block for multi-disk plexes, but in fact this turns out to be too inflexible: UNIX disks can have only a limited number of partitions. Instead, Vinum subdivides a single UNIX partition (the drive) into contiguous areas called subdisks, which it uses as building blocks for plexes.
-
Subdisks reside on Vinum drives, currently UNIX partitions. Vinum drives can contain any number of subdisks. With the exception of a small area at the beginning of the drive, which is used for storing configuration and state information, the entire drive is available for data storage.
The following sections describe the way these objects provide the functionality required of Vinum.
20.5.1 Volume Size Considerations
Plexes can include multiple subdisks spread over all drives in the Vinum configuration. As a result, the size of an individual drive does not limit the size of a plex, and thus of a volume.
20.5.2 Redundant Data Storage
Vinum implements mirroring by attaching multiple plexes to a volume. Each plex is a representation of the data in a volume. A volume may contain between one and eight plexes.
Although a plex represents the complete data of a volume, it is possible for parts of the representation to be physically missing, either by design (by not defining a subdisk for parts of the plex) or by accident (as a result of the failure of a drive). As long as at least one plex can provide the data for the complete address range of the volume, the volume is fully functional.
20.5.3 Performance Issues
Vinum implements both concatenation and striping at the plex level:
-
A concatenated plex uses the address space of each subdisk in turn.
-
A striped plex stripes the data across each subdisk. The subdisks must all have the same size, and there must be at least two subdisks in order to distinguish it from a concatenated plex.
20.5.4 Which Plex Organization?
The version of Vinum supplied with FreeBSD 6.2 implements two kinds of plex:
-
Concatenated plexes are the most flexible: they can contain any number of subdisks, and the subdisks may be of different length. The plex may be extended by adding additional subdisks. They require less CPU time than striped plexes, though the difference in CPU overhead is not measurable. On the other hand, they are most susceptible to hot spots, where one disk is very active and others are idle.
-
The greatest advantage of striped (RAID-0) plexes is that they reduce hot spots: by choosing an optimum sized stripe (about 256 kB), you can even out the load on the component drives. The disadvantages of this approach are (fractionally) more complex code and restrictions on subdisks: they must be all the same size, and extending a plex by adding new subdisks is so complicated that Vinum currently does not implement it. Vinum imposes an additional, trivial restriction: a striped plex must have at least two subdisks, since otherwise it is indistinguishable from a concatenated plex.
Table 20-1 summarizes the advantages and disadvantages of each plex organization.
20.6 Some Examples
Vinum maintains a configuration database which describes the objects known to an individual system. Initially, the user creates the configuration database from one or more configuration files with the aid of the gvinum(8) utility program. Vinum stores a copy of its configuration database on each disk slice (which Vinum calls a device) under its control. This database is updated on each state change, so that a restart accurately restores the state of each Vinum object.
20.6.1 The Configuration File
The configuration file describes individual Vinum objects. The definition of a simple volume might be:
drive a device /dev/da3h
volume myvol
plex org concat
sd length 512m drive a
This file describes four Vinum objects:
-
The drive line describes a disk partition (drive) and its location relative to the underlying hardware. It is given the symbolic name a. This separation of the symbolic names from the device names allows disks to be moved from one location to another without confusion.
-
The volume line describes a volume. The only required attribute is the name, in this case myvol.
-
The plex line defines a plex. The only required parameter is the organization, in this case concat. No name is necessary: the system automatically generates a name from the volume name by adding the suffix .px, where x is the number of the plex in the volume. Thus this plex will be called myvol.p0.
-
The sd line describes a subdisk. The minimum specifications are the name of a drive on which to store it, and the length of the subdisk. As with plexes, no name is necessary: the system automatically assigns names derived from the plex name by adding the suffix .sx, where x is the number of the subdisk in the plex. Thus Vinum gives this subdisk the name myvol.p0.s0.
After processing this file, gvinum(8) produces the following output:
# gvinum -> create config1
Configuration summary
Drives: 1 (4 configured)
Volumes: 1 (4 configured)
Plexes: 1 (8 configured)
Subdisks: 1 (16 configured)
D a State: up Device /dev/da3h Avail: 2061/2573 MB (80%)
V myvol State: up Plexes: 1 Size: 512 MB
P myvol.p0 C State: up Subdisks: 1 Size: 512 MB
S myvol.p0.s0 State: up PO: 0 B Size: 512 MB
This output shows the brief listing format of gvinum(8). It is represented graphically in Figure 20-4.
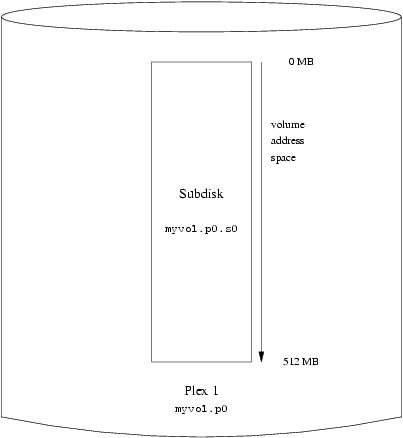
This figure, and the ones which follow, represent a volume, which contains the plexes, which in turn contain the subdisks. In this trivial example, the volume contains one plex, and the plex contains one subdisk.
This particular volume has no specific advantage over a conventional disk partition. It contains a single plex, so it is not redundant. The plex contains a single subdisk, so there is no difference in storage allocation from a conventional disk partition. The following sections illustrate various more interesting configuration methods.
20.6.2 Increased Resilience: Mirroring
The resilience of a volume can be increased by mirroring. When laying out a mirrored volume, it is important to ensure that the subdisks of each plex are on different drives, so that a drive failure will not take down both plexes. The following configuration mirrors a volume:
drive b device /dev/da4h
volume mirror
plex org concat
sd length 512m drive a
plex org concat
sd length 512m drive b
In this example, it was not necessary to specify a definition of drive a again, since Vinum keeps track of all objects in its configuration database. After processing this definition, the configuration looks like:
Drives: 2 (4 configured)
Volumes: 2 (4 configured)
Plexes: 3 (8 configured)
Subdisks: 3 (16 configured)
D a State: up Device /dev/da3h Avail: 1549/2573 MB (60%)
D b State: up Device /dev/da4h Avail: 2061/2573 MB (80%)
V myvol State: up Plexes: 1 Size: 512 MB
V mirror State: up Plexes: 2 Size: 512 MB
P myvol.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p1 C State: initializing Subdisks: 1 Size: 512 MB
S myvol.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p1.s0 State: empty PO: 0 B Size: 512 MB
Figure 20-5 shows the structure graphically.
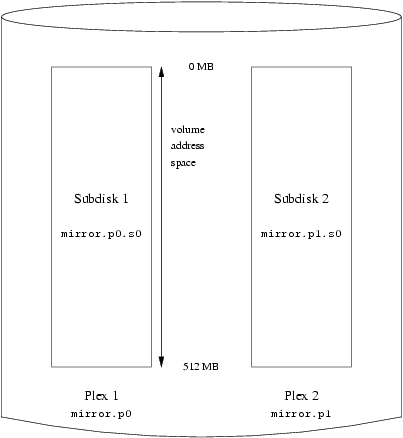
In this example, each plex contains the full 512 MB of address space. As in the previous example, each plex contains only a single subdisk.
20.6.3 Optimizing Performance
The mirrored volume in the previous example is more resistant to failure than an unmirrored volume, but its performance is less: each write to the volume requires a write to both drives, using up a greater proportion of the total disk bandwidth. Performance considerations demand a different approach: instead of mirroring, the data is striped across as many disk drives as possible. The following configuration shows a volume with a plex striped across four disk drives:
drive c device /dev/da5h
drive d device /dev/da6h
volume stripe
plex org striped 512k
sd length 128m drive a
sd length 128m drive b
sd length 128m drive c
sd length 128m drive d
As before, it is not necessary to define the drives which are already known to Vinum. After processing this definition, the configuration looks like:
Drives: 4 (4 configured)
Volumes: 3 (4 configured)
Plexes: 4 (8 configured)
Subdisks: 7 (16 configured)
D a State: up Device /dev/da3h Avail: 1421/2573 MB (55%)
D b State: up Device /dev/da4h Avail: 1933/2573 MB (75%)
D c State: up Device /dev/da5h Avail: 2445/2573 MB (95%)
D d State: up Device /dev/da6h Avail: 2445/2573 MB (95%)
V myvol State: up Plexes: 1 Size: 512 MB
V mirror State: up Plexes: 2 Size: 512 MB
V striped State: up Plexes: 1 Size: 512 MB
P myvol.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p0 C State: up Subdisks: 1 Size: 512 MB
P mirror.p1 C State: initializing Subdisks: 1 Size: 512 MB
P striped.p1 State: up Subdisks: 1 Size: 512 MB
S myvol.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p0.s0 State: up PO: 0 B Size: 512 MB
S mirror.p1.s0 State: empty PO: 0 B Size: 512 MB
S striped.p0.s0 State: up PO: 0 B Size: 128 MB
S striped.p0.s1 State: up PO: 512 kB Size: 128 MB
S striped.p0.s2 State: up PO: 1024 kB Size: 128 MB
S striped.p0.s3 State: up PO: 1536 kB Size: 128 MB
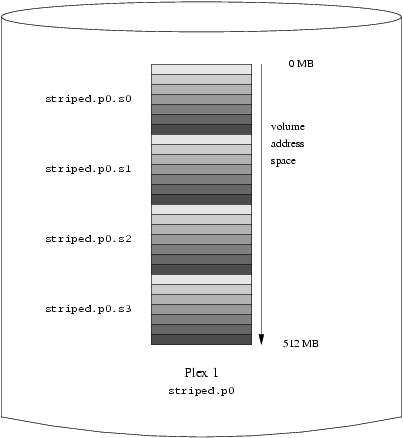
This volume is represented in Figure 20-6. The darkness of the stripes indicates the position within the plex address space: the lightest stripes come first, the darkest last.
20.6.4 Resilience and Performance
With sufficient hardware, it is possible to build volumes which show both increased resilience and increased performance compared to standard UNIX partitions. A typical configuration file might be:
volume raid10
plex org striped 512k
sd length 102480k drive a
sd length 102480k drive b
sd length 102480k drive c
sd length 102480k drive d
sd length 102480k drive e
plex org striped 512k
sd length 102480k drive c
sd length 102480k drive d
sd length 102480k drive e
sd length 102480k drive a
sd length 102480k drive b
The subdisks of the second plex are offset by two drives from those of the first plex: this helps ensure that writes do not go to the same subdisks even if a transfer goes over two drives.
Figure 20-7 represents the structure of this volume.
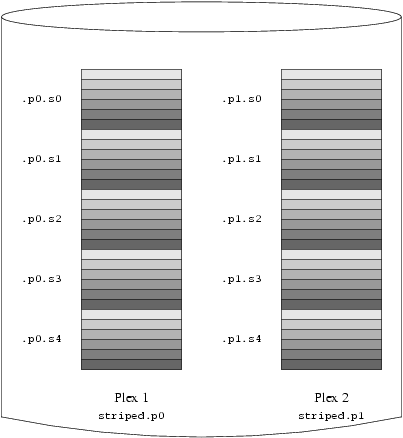
20.7 Object Naming
As described above, Vinum assigns default names to plexes and subdisks, although they may be overridden. Overriding the default names is not recommended: experience with the VERITAS volume manager, which allows arbitrary naming of objects, has shown that this flexibility does not bring a significant advantage, and it can cause confusion.
Names may contain any non-blank character, but it is recommended to restrict them to letters, digits and the underscore characters. The names of volumes, plexes and subdisks may be up to 64 characters long, and the names of drives may be up to 32 characters long.
Vinum objects are assigned device nodes in the hierarchy /dev/gvinum. The configuration shown above would cause Vinum to create the following device nodes:
-
Note: This only applies to the historic Vinum implemenation.
The control devices /dev/vinum/control and /dev/vinum/controld, which are used by gvinum(8) and the Vinum daemon respectively.
-
Device entries for each volume. These are the main devices used by Vinum. Thus the configuration above would include the devices /dev/gvinum/myvol, /dev/gvinum/mirror, /dev/gvinum/striped, /dev/gvinum/raid5 and /dev/gvinum/raid10.
-
Note: This only applies to the historic Vinum implemenation.
A directory /dev/vinum/drive with entries for each drive. These entries are in fact symbolic links to the corresponding disk nodes.
-
All volumes get direct entries under /dev/gvinum/.
-
The directories /dev/gvinum/plex, and /dev/gvinum/sd, which contain device nodes for each plex and for each subdisk, respectively.
For example, consider the following configuration file:
drive drive1 device /dev/sd1h
drive drive2 device /dev/sd2h
drive drive3 device /dev/sd3h
drive drive4 device /dev/sd4h
volume s64 setupstate
plex org striped 64k
sd length 100m drive drive1
sd length 100m drive drive2
sd length 100m drive drive3
sd length 100m drive drive4
After processing this file, gvinum(8) creates the following structure in /dev/gvinum:
drwxr-xr-x 2 root wheel 512 Apr 13 16:46 plex
crwxr-xr-- 1 root wheel 91, 2 Apr 13 16:46 s64
drwxr-xr-x 2 root wheel 512 Apr 13 16:46 sd
/dev/vinum/plex:
total 0
crwxr-xr-- 1 root wheel 25, 0x10000002 Apr 13 16:46 s64.p0
/dev/vinum/sd:
total 0
crwxr-xr-- 1 root wheel 91, 0x20000002 Apr 13 16:46 s64.p0.s0
crwxr-xr-- 1 root wheel 91, 0x20100002 Apr 13 16:46 s64.p0.s1
crwxr-xr-- 1 root wheel 91, 0x20200002 Apr 13 16:46 s64.p0.s2
crwxr-xr-- 1 root wheel 91, 0x20300002 Apr 13 16:46 s64.p0.s3
Although it is recommended that plexes and subdisks should not be allocated specific names, Vinum drives must be named. This makes it possible to move a drive to a different location and still recognize it automatically. Drive names may be up to 32 characters long.
20.7.1 Creating File Systems
Volumes appear to the system to be identical to disks, with one exception. Unlike UNIX drives, Vinum does not partition volumes, which thus do not contain a partition table. This has required modification to some disk utilities, notably newfs(8), which previously tried to interpret the last letter of a Vinum volume name as a partition identifier. For example, a disk drive may have a name like /dev/ad0a or /dev/da2h. These names represent the first partition (a) on the first (0) IDE disk (ad) and the eighth partition (h) on the third (2) SCSI disk (da) respectively. By contrast, a Vinum volume might be called /dev/gvinum/concat, a name which has no relationship with a partition name.
Normally, newfs(8) interprets the name of the disk and complains if it cannot understand it. For example:
# newfs /dev/gvinum/concat
newfs: /dev/gvinum/concat: can't figure out file system partition
In order to create a file system on this volume, use newfs(8):
# newfs /dev/gvinum/concat
Note: On FreeBSD versions prior to 5.0 newfs(8) requires an additional -v flag and the old device naming scheme:
# newfs -v /dev/vinum/concat
20.8 Configuring Vinum
The GENERIC kernel does not contain Vinum. It is possible to build a special kernel which includes Vinum, but this is not recommended. The standard way to start Vinum is as a kernel module (kld). You do not even need to use kldload(8) for Vinum: when you start gvinum(8), it checks whether the module has been loaded, and if it is not, it loads it automatically.
20.8.1 Startup
Vinum stores configuration information on the disk slices in essentially the same form as in the configuration files. When reading from the configuration database, Vinum recognizes a number of keywords which are not allowed in the configuration files. For example, a disk configuration might contain the following text:
volume myvol state up
volume bigraid state down
plex name myvol.p0 state up org concat vol myvol
plex name myvol.p1 state up org concat vol myvol
plex name myvol.p2 state init org striped 512b vol myvol
plex name bigraid.p0 state initializing org raid5 512b vol bigraid
sd name myvol.p0.s0 drive a plex myvol.p0 state up len 1048576b driveoffset 265b plexoffset 0b
sd name myvol.p0.s1 drive b plex myvol.p0 state up len 1048576b driveoffset 265b plexoffset 1048576b
sd name myvol.p1.s0 drive c plex myvol.p1 state up len 1048576b driveoffset 265b plexoffset 0b
sd name myvol.p1.s1 drive d plex myvol.p1 state up len 1048576b driveoffset 265b plexoffset 1048576b
sd name myvol.p2.s0 drive a plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 0b
sd name myvol.p2.s1 drive b plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 524288b
sd name myvol.p2.s2 drive c plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 1048576b
sd name myvol.p2.s3 drive d plex myvol.p2 state init len 524288b driveoffset 1048841b plexoffset 1572864b
sd name bigraid.p0.s0 drive a plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 0b
sd name bigraid.p0.s1 drive b plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 4194304b
sd name bigraid.p0.s2 drive c plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 8388608b
sd name bigraid.p0.s3 drive d plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 12582912b
sd name bigraid.p0.s4 drive e plex bigraid.p0 state initializing len 4194304b driveoff set 1573129b plexoffset 16777216b
The obvious differences here are the presence of explicit location information and naming (both of which are also allowed, but discouraged, for use by the user) and the information on the states (which are not available to the user). Vinum does not store information about drives in the configuration information: it finds the drives by scanning the configured disk drives for partitions with a Vinum label. This enables Vinum to identify drives correctly even if they have been assigned different UNIX drive IDs.
20.8.1.1 Automatic Startup
Note: This information only relates to the historic Vinum implementation. Gvinum always features an automatic startup once the kernel module is loaded.
In order to start Vinum automatically when you boot the system, ensure that you have the following line in your /etc/rc.conf:
start_vinum="YES" # set to YES to start vinum
If you do not have a file /etc/rc.conf, create one with this content. This will cause the system to load the Vinum kld at startup, and to start any objects mentioned in the configuration. This is done before mounting file systems, so it is possible to automatically fsck(8) and mount file systems on Vinum volumes.
When you start Vinum with the vinum start command, Vinum reads the configuration database from one of the Vinum drives. Under normal circumstances, each drive contains an identical copy of the configuration database, so it does not matter which drive is read. After a crash, however, Vinum must determine which drive was updated most recently and read the configuration from this drive. It then updates the configuration if necessary from progressively older drives.
20.9 Using Vinum for the Root Filesystem
For a machine that has fully-mirrored filesystems using Vinum, it is desirable to also mirror the root filesystem. Setting up such a configuration is less trivial than mirroring an arbitrary filesystem because:
-
The root filesystem must be available very early during the boot process, so the Vinum infrastructure must already be available at this time.
-
The volume containing the root filesystem also contains the system bootstrap and the kernel, which must be read using the host system's native utilities (e. g. the BIOS on PC-class machines) which often cannot be taught about the details of Vinum.
In the following sections, the term “root volume” is generally used to describe the Vinum volume that contains the root filesystem. It is probably a good idea to use the name "root" for this volume, but this is not technically required in any way. All command examples in the following sections assume this name though.
20.9.1 Starting up Vinum Early Enough for the Root Filesystem
There are several measures to take for this to happen:
-
Vinum must be available in the kernel at boot-time. Thus, the method to start Vinum automatically described in Section 20.8.1.1 is not applicable to accomplish this task, and the start_vinum parameter must actually not be set when the following setup is being arranged. The first option would be to compile Vinum statically into the kernel, so it is available all the time, but this is usually not desirable. There is another option as well, to have /boot/loader (Section 12.3.3) load the vinum kernel module early, before starting the kernel. This can be accomplished by putting the line:
geom_vinum_load="YES"into the file /boot/loader.conf.
-
Note: For Gvinum, all startup is done automatically once the kernel module has been loaded, so the procedure described above is all that is needed. The following text documents the behaviour of the historic Vinum system, for the sake of older setups.
Vinum must be initialized early since it needs to supply the volume for the root filesystem. By default, the Vinum kernel part is not looking for drives that might contain Vinum volume information until the administrator (or one of the startup scripts) issues a vinum start command.
Note: The following paragraphs are outlining the steps needed for FreeBSD 5.X and above. The setup required for FreeBSD 4.X differs, and is described below in Section 20.9.5.
By placing the line:
vinum.autostart="YES"into /boot/loader.conf, Vinum is instructed to automatically scan all drives for Vinum information as part of the kernel startup.
Note that it is not necessary to instruct the kernel where to look for the root filesystem. /boot/loader looks up the name of the root device in /etc/fstab, and passes this information on to the kernel. When it comes to mount the root filesystem, the kernel figures out from the device name provided which driver to ask to translate this into the internal device ID (major/minor number).
20.9.2 Making a Vinum-based Root Volume Accessible to the Bootstrap
Since the current FreeBSD bootstrap is only 7.5 KB of code, and already has the burden of reading files (like /boot/loader) from the UFS filesystem, it is sheer impossible to also teach it about internal Vinum structures so it could parse the Vinum configuration data, and figure out about the elements of a boot volume itself. Thus, some tricks are necessary to provide the bootstrap code with the illusion of a standard "a" partition that contains the root filesystem.
For this to be possible at all, the following requirements must be met for the root volume:
-
The root volume must not be striped or RAID-5.
-
The root volume must not contain more than one concatenated subdisk per plex.
Note that it is desirable and possible that there are multiple plexes, each containing one replica of the root filesystem. The bootstrap process will, however, only use one of these replica for finding the bootstrap and all the files, until the kernel will eventually mount the root filesystem itself. Each single subdisk within these plexes will then need its own "a" partition illusion, for the respective device to become bootable. It is not strictly needed that each of these faked "a" partitions is located at the same offset within its device, compared with other devices containing plexes of the root volume. However, it is probably a good idea to create the Vinum volumes that way so the resulting mirrored devices are symmetric, to avoid confusion.
In order to set up these "a" partitions, for each device containing part of the root volume, the following needs to be done:
-
The location (offset from the beginning of the device) and size of this device's subdisk that is part of the root volume need to be examined, using the command:
# gvinum l -rv rootNote that Vinum offsets and sizes are measured in bytes. They must be divided by 512 in order to obtain the block numbers that are to be used in the bsdlabel command.
-
Run the command:
# bsdlabel -e devnamefor each device that participates in the root volume. devname must be either the name of the disk (like da0) for disks without a slice (aka. fdisk) table, or the name of the slice (like ad0s1).
If there is already an "a" partition on the device (presumably, containing a pre-Vinum root filesystem), it should be renamed to something else, so it remains accessible (just in case), but will no longer be used by default to bootstrap the system. Note that active partitions (like a root filesystem currently mounted) cannot be renamed, so this must be executed either when being booted from a “Fixit” medium, or in a two-step process, where (in a mirrored situation) the disk that has not been currently booted is being manipulated first.
Then, the offset of the Vinum partition on this device (if any) must be added to the offset of the respective root volume subdisk on this device. The resulting value will become the "offset" value for the new "a" partition. The "size" value for this partition can be taken verbatim from the calculation above. The "fstype" should be 4.2BSD. The "fsize", "bsize", and "cpg" values should best be chosen to match the actual filesystem, though they are fairly unimportant within this context.
That way, a new "a" partition will be established that overlaps the Vinum partition on this device. Note that the bsdlabel will only allow for this overlap if the Vinum partition has properly been marked using the "vinum" fstype.
-
That's all! A faked "a" partition does exist now on each device that has one replica of the root volume. It is highly recommendable to verify the result again, using a command like:
# fsck -n /dev/devnamea
It should be remembered that all files containing control information must be relative to the root filesystem in the Vinum volume which, when setting up a new Vinum root volume, might not match the root filesystem that is currently active. So in particular, the files /etc/fstab and /boot/loader.conf need to be taken care of.
At next reboot, the bootstrap should figure out the appropriate control information from the new Vinum-based root filesystem, and act accordingly. At the end of the kernel initialization process, after all devices have been announced, the prominent notice that shows the success of this setup is a message like:
Mounting root from ufs:/dev/gvinum/root
20.9.3 Example of a Vinum-based Root Setup
After the Vinum root volume has been set up, the output of gvinum l -rv root could look like:
...
Subdisk root.p0.s0:
Size: 125829120 bytes (120 MB)
State: up
Plex root.p0 at offset 0 (0 B)
Drive disk0 (/dev/da0h) at offset 135680 (132 kB)
Subdisk root.p1.s0:
Size: 125829120 bytes (120 MB)
State: up
Plex root.p1 at offset 0 (0 B)
Drive disk1 (/dev/da1h) at offset 135680 (132 kB)
The values to note are 135680 for the offset (relative to partition /dev/da0h). This translates to 265 512-byte disk blocks in bsdlabel's terms. Likewise, the size of this root volume is 245760 512-byte blocks. /dev/da1h, containing the second replica of this root volume, has a symmetric setup.
The bsdlabel for these devices might look like:
...
8 partitions:
# size offset fstype [fsize bsize bps/cpg]
a: 245760 281 4.2BSD 2048 16384 0 # (Cyl. 0*- 15*)
c: 71771688 0 unused 0 0 # (Cyl. 0 - 4467*)
h: 71771672 16 vinum # (Cyl. 0*- 4467*)
It can be observed that the "size" parameter for the faked "a" partition matches the value outlined above, while the "offset" parameter is the sum of the offset within the Vinum partition "h", and the offset of this partition within the device (or slice). This is a typical setup that is necessary to avoid the problem described in Section 20.9.4.3. It can also be seen that the entire "a" partition is completely within the "h" partition containing all the Vinum data for this device.
Note that in the above example, the entire device is dedicated to Vinum, and there is no leftover pre-Vinum root partition, since this has been a newly set-up disk that was only meant to be part of a Vinum configuration, ever.
20.9.4 Troubleshooting
If something goes wrong, a way is needed to recover from the situation. The following list contains few known pitfalls and solutions.
20.9.4.1 System Bootstrap Loads, but System Does Not Boot
If for any reason the system does not continue to boot, the bootstrap can be interrupted with by pressing the space key at the 10-seconds warning. The loader variables (like vinum.autostart) can be examined using the show, and manipulated using set or unset commands.
If the only problem was that the Vinum kernel module was not yet in the list of modules to load automatically, a simple load geom_vinum will help.
When ready, the boot process can be continued with a boot
-as. The options -as will request the kernel to ask for
the root filesystem to mount (-a), and make the boot process
stop in single-user mode (-s), where the root filesystem is
mounted read-only. That way, even if only one plex of a multi-plex volume has been
mounted, no data inconsistency between plexes is being risked.
At the prompt asking for a root filesystem to mount, any device that contains a valid root filesystem can be entered. If /etc/fstab had been set up correctly, the default should be something like ufs:/dev/gvinum/root. A typical alternate choice would be something like ufs:da0d which could be a hypothetical partition that contains the pre-Vinum root filesystem. Care should be taken if one of the alias "a" partitions are entered here that are actually reference to the subdisks of the Vinum root device, because in a mirrored setup, this would only mount one piece of a mirrored root device. If this filesystem is to be mounted read-write later on, it is necessary to remove the other plex(es) of the Vinum root volume since these plexes would otherwise carry inconsistent data.
20.9.4.2 Only Primary Bootstrap Loads
If /boot/loader fails to load, but the primary bootstrap still loads (visible by a single dash in the left column of the screen right after the boot process starts), an attempt can be made to interrupt the primary bootstrap at this point, using the space key. This will make the bootstrap stop in stage two, see Section 12.3.2. An attempt can be made here to boot off an alternate partition, like the partition containing the previous root filesystem that has been moved away from "a" above.
20.9.4.3 Nothing Boots, the Bootstrap Panics
This situation will happen if the bootstrap had been destroyed by the Vinum installation. Unfortunately, Vinum accidentally currently leaves only 4 KB at the beginning of its partition free before starting to write its Vinum header information. However, the stage one and two bootstraps plus the bsdlabel embedded between them currently require 8 KB. So if a Vinum partition was started at offset 0 within a slice or disk that was meant to be bootable, the Vinum setup will trash the bootstrap.
Similarly, if the above situation has been recovered, for example by booting from a “Fixit” medium, and the bootstrap has been re-installed using bsdlabel -B as described in Section 12.3.2, the bootstrap will trash the Vinum header, and Vinum will no longer find its disk(s). Though no actual Vinum configuration data or data in Vinum volumes will be trashed by this, and it would be possible to recover all the data by entering exact the same Vinum configuration data again, the situation is hard to fix at all. It would be necessary to move the entire Vinum partition by at least 4 KB off, in order to have the Vinum header and the system bootstrap no longer collide.
20.9.5 Differences for FreeBSD 4.X
Under FreeBSD 4.X, some internal functions required to make Vinum automatically scan all disks are missing, and the code that figures out the internal ID of the root device is not smart enough to handle a name like /dev/vinum/root automatically. Therefore, things are a little different here.
Vinum must explicitly be told which disks to scan, using a line like the following one in /boot/loader.conf:
vinum.drives="/dev/da0 /dev/da1"
It is important that all drives are mentioned that could possibly contain Vinum data. It does not harm if more drives are listed, nor is it necessary to add each slice and/or partition explicitly, since Vinum will scan all slices and partitions of the named drives for valid Vinum headers.
Since the routines used to parse the name of the root filesystem, and derive the device ID (major/minor number) are only prepared to handle “classical” device names like /dev/ad0s1a, they cannot make any sense out of a root volume name like /dev/vinum/root. For that reason, Vinum itself needs to pre-setup the internal kernel parameter that holds the ID of the root device during its own initialization. This is requested by passing the name of the root volume in the loader variable vinum.root. The entry in /boot/loader.conf to accomplish this looks like:
vinum.root="root"
Now, when the kernel initialization tries to find out the root device to mount, it sees whether some kernel module has already pre-initialized the kernel parameter for it. If that is the case, and the device claiming the root device matches the major number of the driver as figured out from the name of the root device string being passed (that is, "vinum" in our case), it will use the pre-allocated device ID, instead of trying to figure out one itself. That way, during the usual automatic startup, it can continue to mount the Vinum root volume for the root filesystem.
However, when boot -a has been requesting to ask for entering the name of the root device manually, it must be noted that this routine still cannot actually parse a name entered there that refers to a Vinum volume. If any device name is entered that does not refer to a Vinum device, the mismatch between the major numbers of the pre-allocated root parameter and the driver as figured out from the given name will make this routine enter its normal parser, so entering a string like ufs:da0d will work as expected. Note that if this fails, it is however no longer possible to re-enter a string like ufs:vinum/root again, since it cannot be parsed. The only way out is to reboot again, and start over then. (At the “askroot” prompt, the initial /dev/ can always be omitted.)
Chapter 21 Virtualization
Contributed by Murray Stokely.21.1 Synopsis
Virtualization software allows multiple operating systems to run simultaneously on the same computer. Such software systems for PCs often involve a host operating system which runs the virtualization software and supports any number of guest operating systems.
After reading this chapter, you will know:
-
The difference between a host operating system and a guest operating system.
-
How to install FreeBSD on an Intel-based Apple Macintosh computer.
-
How to install FreeBSD on Linux with Xen™.
-
How to install FreeBSD on Microsoft Windows with Virtual PC.
-
How to tune a FreeBSD system for best performance under virtualization.
Before reading this chapter, you should:
-
Understand the basics of UNIX and FreeBSD (Chapter 3).
-
Know how to install FreeBSD (Chapter 2).
-
Know how to set up your network connection (Chapter 29).
-
Know how to install additional third-party software (Chapter 4).
21.2 FreeBSD as a Guest OS
21.2.1 Parallels on MacOS
Parallels Desktop for Mac is a commercial software product available for Intel based Apple Mac computers running Mac OS 10.4.6 or higher. FreeBSD is a fully supported guest operating system. Once Parallels has been installed on Mac OS X, the user must configure a virtual machine and then install the desired guest operating system.
21.2.1.1 Installing FreeBSD on Parallels/Mac OS® X
The first step in installing FreeBSD on Mac OS X/Parallels is to create a new virtual machine for installing FreeBSD. Select FreeBSD as the Guest OS Type when prompted:
And choose a reasonable amount of disk and memory depending on your plans for this virtual FreeBSD instance. 4GB of disk space and 512MB of RAM work well for most uses of FreeBSD under Parallels:
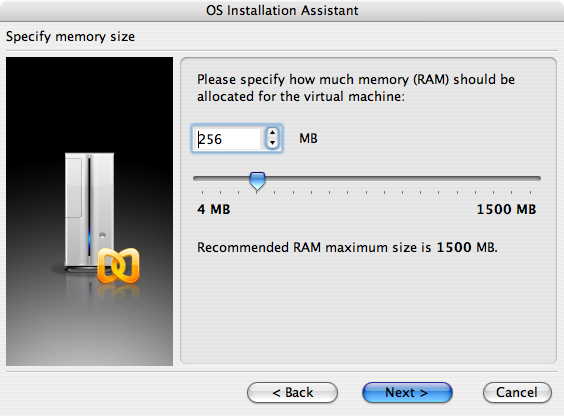
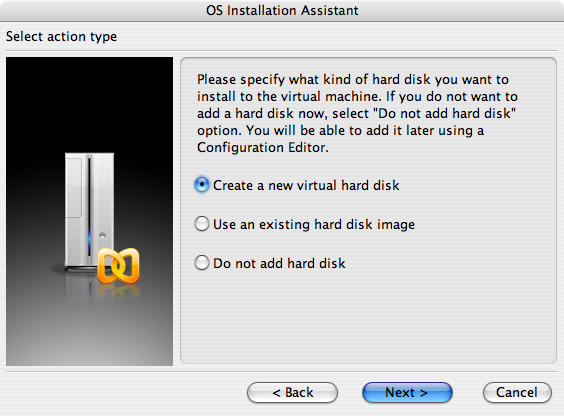
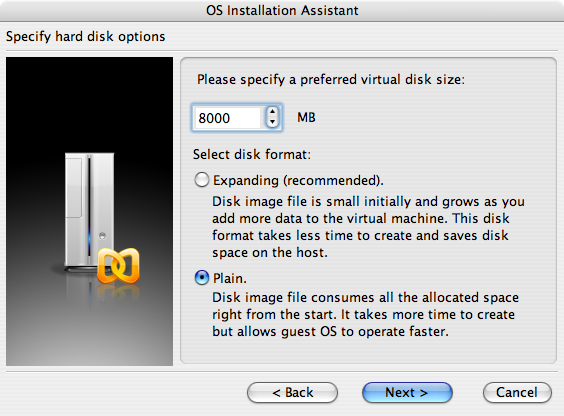
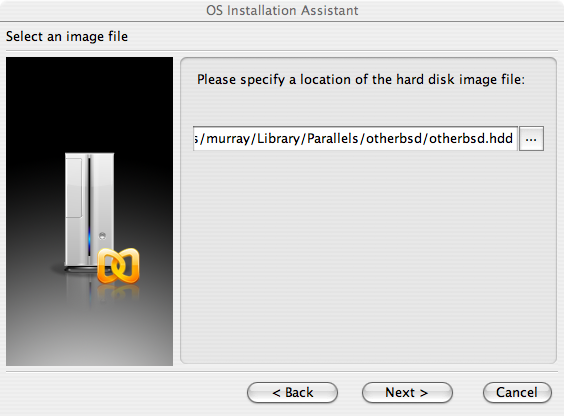
Select the type of networking and a network interface:
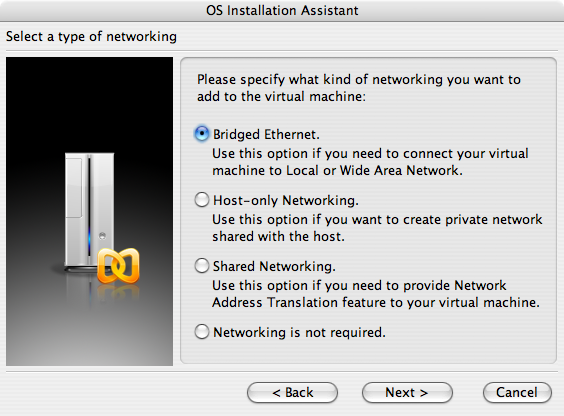
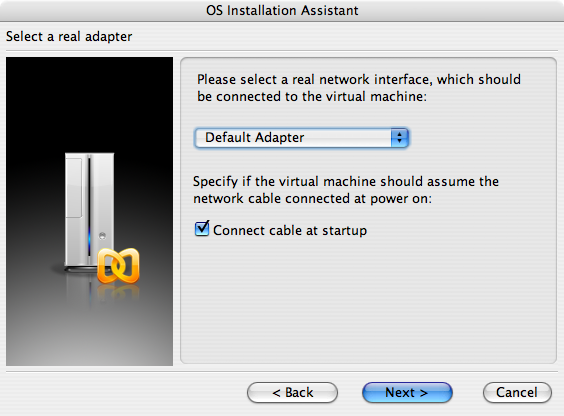
Save and finish the configuration:
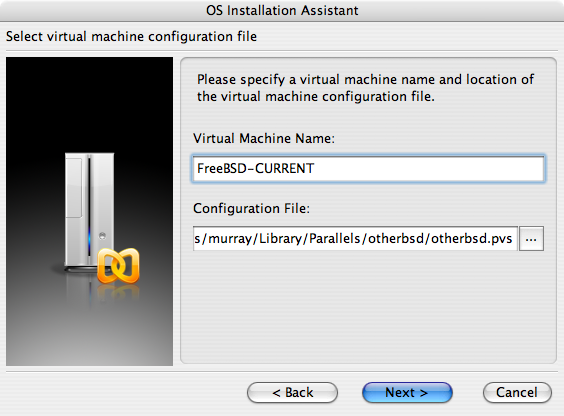
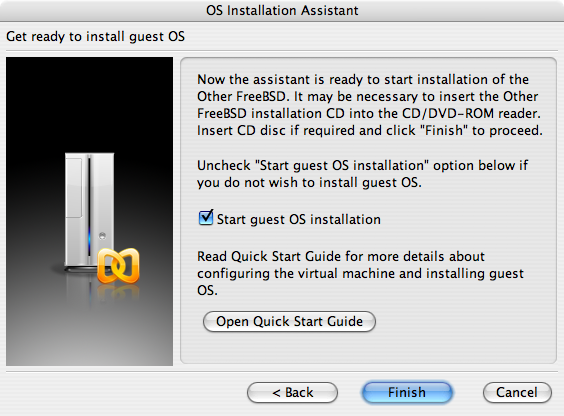
After your FreeBSD virtual machine has been created, you will need to install FreeBSD on it. This is best done with an official FreeBSD CDROM or with an ISO image downloaded from an official FTP site. When you have the appropriate ISO image on your local Mac filesystem or a CDROM in your Mac's CD drive, click on the disc icon in the bottom right corner of your FreeBSD Parallels window. This will bring up a window that allows you to associate the CDROM drive in your virtual machine with an ISO file on disk or with your real CDROM drive.
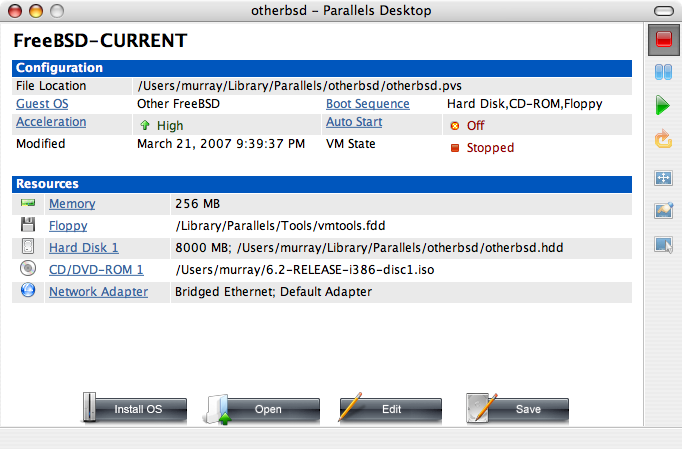
Once you have made this association with your CDROM source, reboot your FreeBSD virtual machine as normal by clicking the reboot icon. Parallels will reboot with a special BIOS that first checks if you have a CDROM just as a normal BIOS would do.
In this case it will find the FreeBSD installation media and begin a normal sysinstall based installation as described in Chapter 2. You may install, but do not attempt to configure X11 at this time.
When you have finished the installation, reboot into your newly installed FreeBSD virtual machine.
21.2.1.2 Configuring FreeBSD on Mac OS X/Parallels
After FreeBSD has been successfully installed on Mac OS X with Parallels, there are a number of configuration steps that can be taken to optimize the system for virtualized operation.
-
Set boot loader variables
The most important step is to reduce the
kern.hztunable to reduce the CPU utilization of FreeBSD under the Parallels environment. This is accomplished by adding the following line to /boot/loader.conf:kern.hz=100Without this setting, an idle FreeBSD Parallels guest OS will use roughly 15% of the CPU of a single processor iMac®. After this change the usage will be closer to a mere 5%.
-
Create a new kernel configuration file
You can remove all of the SCSI, FireWire, and USB device drivers. Parallels provides a virtual network adapter used by the ed(4) driver, so all other network devices except for ed(4) and miibus(4) can be removed from the kernel.
-
Setup networking
The most basic networking setup involves simply using DHCP to connect your virtual machine to the same local area network as your host Mac. This can be accomplished by adding ifconfig_ed0="DHCP" to /etc/rc.conf. More advanced networking setups are described in Chapter 29.
21.2.2 FreeBSD with Xen™ on Linux
Contributed by Fukang Chen (Loader).The Xen hypervisor is an open source paravirtualization product which is now supported by the commercial XenSource company. Guest operating systems are known as domU domains, and the host operating system is known as dom0. The first step in running a virtual FreeBSD instance under Linux is to install Xen for Linux dom0. The host operating system will be a Slackware Linux distribution.
21.2.2.1 Setup Xen 3 on Linux dom0
-
Download Xen 3.0 from XenSource
Download xen-3.0.4_1-src.tgz from http://www.xensource.com/.
-
Unpack the tarball
# cd xen-3.0.4_1-src # KERNELS="linux-2.6-xen0 linux-2.6-xenU" make world # make installNote: To re-compile the kernel for dom0:
# cd xen-3.0.4_1-src/linux-2.6.16.33-xen0 # make menuconfig # make # make installOlder version of Xen may need to specify make ARCH=xen menuconfig
-
Add a menu entry into Grub menu.lst
Edit /boot/grub/menu.lst and add the following lines:
title Xen-3.0.4 root (hd0,0) kernel /boot/xen-3.0.4-1.gz dom0_mem=262144 module /boot/vmlinuz-2.6.16.33-xen0 root=/dev/hda1 ro -
Reboot your computer into Xen
First, edit /etc/xen/xend-config.sxp, and add the following line:
(network-script 'network-bridge netdev=eth0')Then, we can launch Xen:
# /etc/init.d/xend start # /etc/init.d/xendomains startOur dom0 is running:
# xm list Name ID Mem VCPUs State Time(s) Domain-0 0 256 1 r----- 54452.9
21.2.2.2 FreeBSD 7-CURRENT domU
Download the FreeBSD domU kernel for Xen 3.0 and disk image from http://www.fsmware.com/
Put the configuration file xmexample1.bsd into /etc/xen/ and modify the related entries about where the kernel and the disk image are stored. It should look like the following:
kernel = "/opt/kernel-current"
memory = 256
name = "freebsd"
vif = [ '' ]
disk = [ 'file:/opt/mdroot-7.0,hda1,w' ]
#on_crash = 'preserve'
extra = "boot_verbose"
extra += ",boot_single"
extra += ",kern.hz=100"
extra += ",vfs.root.mountfrom=ufs:/dev/xbd769a"
The mdroot-7.0.bz2 file should be uncompressed.
Next, the __xen_guest section in kernel-current needs to be altered to add the VIRT_BASE that Xen 3.0.3 requires:
# objcopy kernel-current -R __xen_guest
# perl -e 'print "LOADER=generic,GUEST_OS=freebsd,GUEST_VER=7.0,XEN_VER=xen-3.0,BSD_SYMTAB,VIRT_BASE=0xC0000000\x00"' > tmp
# objcopy kernel-current --add-section __xen_guest=tmp
# objdump -j __xen_guest -s kernel-current
kernel-current: file format elf32-i386
Contents of section __xen_guest:
0000 4c4f4144 45523d67 656e6572 69632c47 LOADER=generic,G
0010 55455354 5f4f533d 66726565 6273642c UEST_OS=freebsd,
0020 47554553 545f5645 523d372e 302c5845 GUEST_VER=7.0,XE
0030 4e5f5645 523d7865 6e2d332e 302c4253 N_VER=xen-3.0,BS
0040 445f5359 4d544142 2c564952 545f4241 D_SYMTAB,VIRT_BA
0050 53453d30 78433030 30303030 3000 SE=0xC0000000.
We are, now, ready to create and launch our domU:
# xm create /etc/xen/xmexample1.bsd -c
Using config file "/etc/xen/xmexample1.bsd".
Started domain freebsd
WARNING: loader(8) metadata is missing!
Copyright (c) 1992-2006 The FreeBSD Project.
Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994
The Regents of the University of California. All rights reserved.
FreeBSD 7.0-CURRENT #113: Wed Jan 4 06:25:43 UTC 2006
kmacy@freebsd7.gateway.2wire.net:/usr/home/kmacy/p4/freebsd7_xen3/src/sys/i386-xen/compile/XENCONF
WARNING: DIAGNOSTIC option enabled, expect reduced performance.
Xen reported: 1796.927 MHz processor.
Timecounter "ixen" frequency 1796927000 Hz quality 0
CPU: Intel(R) Pentium(R) 4 CPU 1.80GHz (1796.93-MHz 686-class CPU)
Origin = "GenuineIntel" Id = 0xf29 Stepping = 9
Features=0xbfebfbff<FPU,VME,DE,PSE,TSC,MSR,PAE,MCE,CX8,APIC,SEP,MTRR,PGE,MCA,CMOV,PAT,PSE36,CLFLUSH,
DTS,ACPI,MMX,FXSR,SSE,SSE2,SS,HTT,TM,PBE>
Features2=0x4400<CNTX-ID,<b14>>
real memory = 265244672 (252 MB)
avail memory = 255963136 (244 MB)
xc0: <Xen Console> on motherboard
cpu0 on motherboard
Timecounters tick every 10.000 msec
[XEN] Initialising virtual ethernet driver.
xn0: Ethernet address: 00:16:3e:6b:de:3a
[XEN]
Trying to mount root from ufs:/dev/xbd769a
WARNING: / was not properly dismounted
Loading configuration files.
No suitable dump device was found.
Entropy harvesting: interrupts ethernet point_to_point kickstart.
Starting file system checks:
/dev/xbd769a: 18859 files, 140370 used, 113473 free (10769 frags, 12838 blocks, 4.2% fragmentation)
Setting hostname: demo.freebsd.org.
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x2
inet 127.0.0.1 netmask 0xff000000
Additional routing options:.
Mounting NFS file systems:.
Starting syslogd.
/etc/rc: WARNING: Dump device does not exist. Savecore not run.
ELF ldconfig path: /lib /usr/lib /usr/lib/compat /usr/X11R6/lib /usr/local/lib
a.out ldconfig path: /usr/lib/aout /usr/lib/compat/aout /usr/X11R6/lib/aout
Starting usbd.
usb: Kernel module not available: No such file or directory
Starting local daemons:.
Updating motd.
Starting sshd.
Initial i386 initialization:.
Additional ABI support: linux.
Starting cron.
Local package initialization:.
Additional TCP options:.
Starting background file system checks in 60 seconds.
Sun Apr 1 02:11:43 UTC 2007
FreeBSD/i386 (demo.freebsd.org) (xc0)
login:
The domU should run the FreeBSD 7.0-CURRENT kernel:
# uname -a
FreeBSD demo.freebsd.org 7.0-CURRENT FreeBSD 7.0-CURRENT #113: Wed Jan 4 06:25:43 UTC 2006
kmacy@freebsd7.gateway.2wire.net:/usr/home/kmacy/p4/freebsd7_xen3/src/sys/i386-xen/compile/XENCONF i386
The network can now be configured on the domU. The FreeBSD domU will use a specific interface called xn0:
# ifconfig xn0 10.10.10.200 netmask 255.0.0.0
# ifconfig
xn0: flags=843<UP,BROADCAST,RUNNING,SIMPLEX> mtu 1500
inet 10.10.10.200 netmask 0xff000000 broadcast 10.255.255.255
ether 00:16:3e:6b:de:3a
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x2
inet 127.0.0.1 netmask 0xff000000
On dom0 Slackware, some Xen dependant network interfaces should show up:
# ifconfig
eth0 Link encap:Ethernet HWaddr 00:07:E9:A0:02:C2
inet addr:10.10.10.130 Bcast:0.0.0.0 Mask:255.0.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:815 errors:0 dropped:0 overruns:0 frame:0
TX packets:1400 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:204857 (200.0 KiB) TX bytes:129915 (126.8 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:99 errors:0 dropped:0 overruns:0 frame:0
TX packets:99 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:9744 (9.5 KiB) TX bytes:9744 (9.5 KiB)
peth0 Link encap:Ethernet HWaddr FE:FF:FF:FF:FF:FF
UP BROADCAST RUNNING NOARP MTU:1500 Metric:1
RX packets:1853349 errors:0 dropped:0 overruns:0 frame:0
TX packets:952923 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:2432115831 (2.2 GiB) TX bytes:86528526 (82.5 MiB)
Base address:0xc000 Memory:ef020000-ef040000
vif0.1 Link encap:Ethernet HWaddr FE:FF:FF:FF:FF:FF
UP BROADCAST RUNNING NOARP MTU:1500 Metric:1
RX packets:1400 errors:0 dropped:0 overruns:0 frame:0
TX packets:815 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:129915 (126.8 KiB) TX bytes:204857 (200.0 KiB)
vif1.0 Link encap:Ethernet HWaddr FE:FF:FF:FF:FF:FF
UP BROADCAST RUNNING NOARP MTU:1500 Metric:1
RX packets:3 errors:0 dropped:0 overruns:0 frame:0
TX packets:2 errors:0 dropped:157 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:140 (140.0 b) TX bytes:158 (158.0 b)
xenbr1 Link encap:Ethernet HWaddr FE:FF:FF:FF:FF:FF
UP BROADCAST RUNNING NOARP MTU:1500 Metric:1
RX packets:4 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:112 (112.0 b) TX bytes:0 (0.0 b)
# brctl show
bridge name bridge id STP enabled interfaces
xenbr1 8000.feffffffffff no vif0.1
peth0
vif1.0
21.2.3 Virtual PC on Windows
Virtual PC for Windows is a Microsoft software product available for free download. See system requirements. Once Virtual PC has been installed on Microsoft Windows, the user must configure a virtual machine and then install the desired guest operating system.
21.2.3.1 Installing FreeBSD on Virtual PC/Microsoft® Windows
The first step in installing FreeBSD on Microsoft Windows /Virtual PC is to create a new virtual machine for installing FreeBSD. Select Create a virtual machine when prompted:
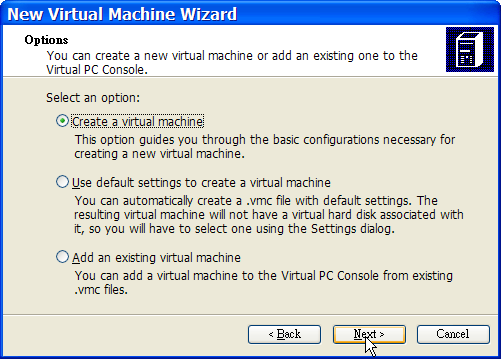
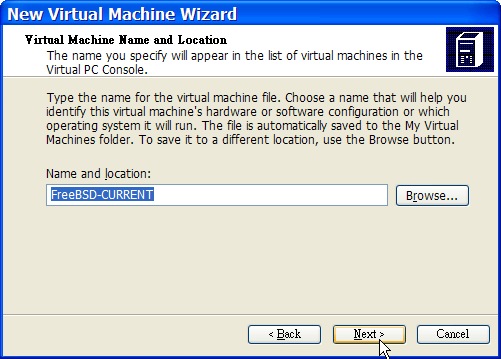
And select Other as the Operating system when prompted:
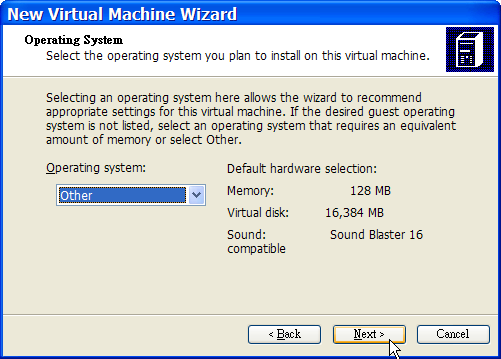
Then, choose a reasonable amount of disk and memory depending on your plans for this virtual FreeBSD instance. 4GB of disk space and 512MB of RAM work well for most uses of FreeBSD under Virtual PC:
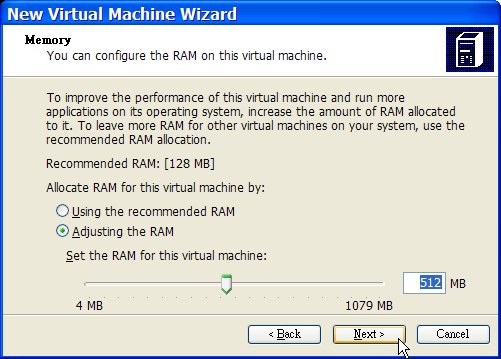
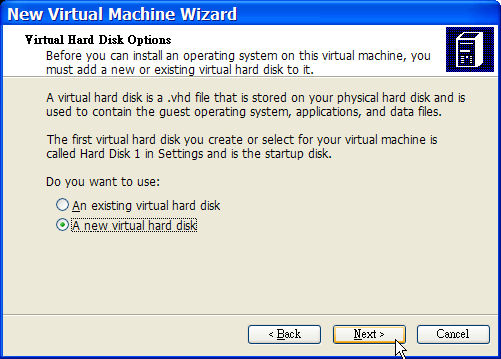
Save and finish the configuration:
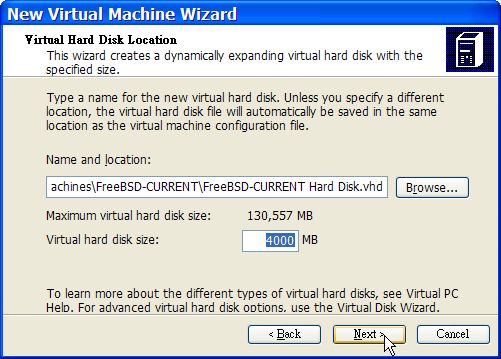
Select your FreeBSD virtual machine and click Settings, then set the type of networking and a network interface:
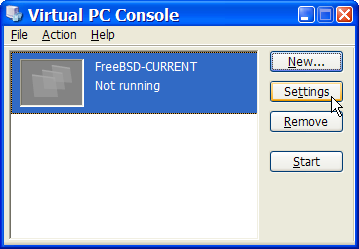
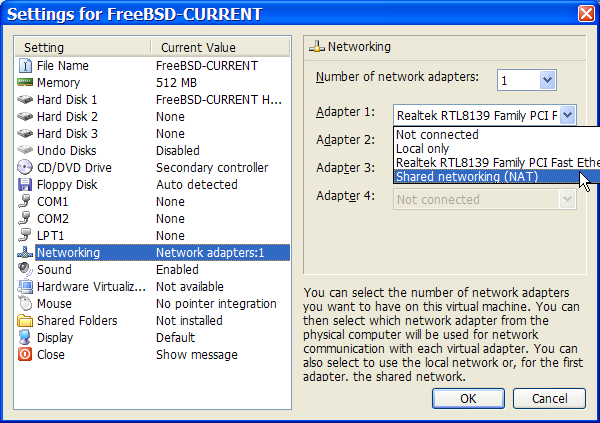
After your FreeBSD virtual machine has been created, you will need to install FreeBSD on it. This is best done with an official FreeBSD CDROM or with an ISO image downloaded from an official FTP site. When you have the appropriate ISO image on your local Windows filesystem or a CDROM in your CD drive, double click on your FreeBSD virtual machine to boot. Then, click CD and choose Capture ISO Image... on Virtual PC window. This will bring up a window that allows you to associate the CDROM drive in your virtual machine with an ISO file on disk or with your real CDROM drive.
Once you have made this association with your CDROM source, reboot your FreeBSD virtual machine as normal by clicking the Action and Reset. Virtual PC will reboot with a special BIOS that first checks if you have a CDROM just as a normal BIOS would do.
In this case it will find the FreeBSD installation media and begin a normal sysinstall based installation as described in Chapter 2. You may install, but do not attempt to configure X11 at this time.
When you have finished the installation, remember to eject CDROM or release ISO image. Finally, reboot into your newly installed FreeBSD virtual machine.
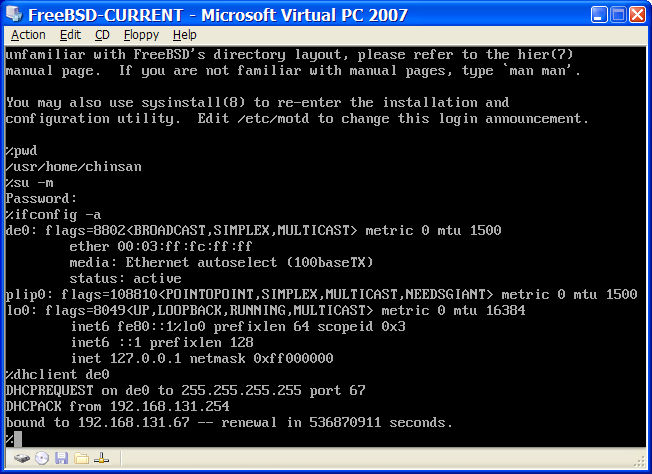
21.2.3.2 Configuring FreeBSD on Microsoft Windows/Virtual PC
After FreeBSD has been successfully installed on Microsoft Windows with Virtual PC, there are a number of configuration steps that can be taken to optimize the system for virtualized operation.
-
Set boot loader variables
The most important step is to reduce the
kern.hztunable to reduce the CPU utilization of FreeBSD under the Virtual PC environment. This is accomplished by adding the following line to /boot/loader.conf:kern.hz=100Without this setting, an idle FreeBSD Virtual PC guest OS will use roughly 40% of the CPU of a single processor computer. After this change the usage will be closer to a mere 3%.
-
Create a new kernel configuration file
You can remove all of the SCSI, FireWire, and USB device drivers. Virtual PC provides a virtual network adapter used by the de(4) driver, so all other network devices except for de(4) and miibus(4) can be removed from the kernel.
-
Setup networking
The most basic networking setup involves simply using DHCP to connect your virtual machine to the same local area network as your host Microsoft Windows. This can be accomplished by adding ifconfig_de0="DHCP" to /etc/rc.conf. More advanced networking setups are described in Chapter 29.
21.3 FreeBSD as a Host OS
FreeBSD is not officially supported by any virtualization package as a host operating system at this time, but many people use older versions of VMware in this capacity. Work is also ongoing in getting Xen to work as a host environment on FreeBSD.
Chapter 22 Localization - I18N/L10N Usage and Setup
Contributed by Andrey Chernov. Rewritten by Michael C. Wu.22.1 Synopsis
FreeBSD is a very distributed project with users and contributors located all over the world. This chapter discusses the internationalization and localization features of FreeBSD that allow non-English speaking users to get real work done. There are many aspects of the i18n implementation in both the system and application levels, so where applicable we refer the reader to more specific sources of documentation.
After reading this chapter, you will know:
-
How different languages and locales are encoded on modern operating systems.
-
How to set the locale for your login shell.
-
How to configure your console for non-English languages.
-
How to use X Window System effectively with different languages.
-
Where to find more information about writing i18n-compliant applications.
Before reading this chapter, you should:
-
Know how to install additional third-party applications (Chapter 4).
22.2 The Basics
22.2.1 What Is I18N/L10N?
Developers shortened internationalization into the term I18N, counting the number of letters between the first and the last letters of internationalization. L10N uses the same naming scheme, coming from “localization”. Combined together, I18N/L10N methods, protocols, and applications allow users to use languages of their choice.
I18N applications are programmed using I18N kits under libraries. It allows for developers to write a simple file and translate displayed menus and texts to each language. We strongly encourage programmers to follow this convention.
22.2.2 Why Should I Use I18N/L10N?
I18N/L10N is used whenever you wish to either view, input, or process data in non-English languages.
22.2.3 What Languages Are Supported in the I18N Effort?
I18N and L10N are not FreeBSD specific. Currently, one can choose from most of the major languages of the World, including but not limited to: Chinese, German, Japanese, Korean, French, Russian, Vietnamese and others.
22.3 Using Localization
In all its splendor, I18N is not FreeBSD-specific and is a convention. We encourage you to help FreeBSD in following this convention.
Localization settings are based on three main terms: Language Code, Country Code, and Encoding. Locale names are constructed from these parts as follows:
LanguageCode_CountryCode.Encoding
22.3.1 Language and Country Codes
In order to localize a FreeBSD system to a specific language (or any other I18N-supporting UNIX like systems), the user needs to find out the codes for the specify country and language (country codes tell applications what variation of given language to use). In addition, web browsers, SMTP/POP servers, web servers, etc. make decisions based on them. The following are examples of language/country codes:
22.3.2 Encodings
Some languages use non-ASCII encodings that are 8-bit, wide or multibyte characters, see multibyte(3) for more details. Older applications do not recognize them and mistake them for control characters. Newer applications usually do recognize 8-bit characters. Depending on the implementation, users may be required to compile an application with wide or multibyte characters support, or configure it correctly. To be able to input and process wide or multibyte characters, the FreeBSD Ports Collection has provided each language with different programs. Refer to the I18N documentation in the respective FreeBSD Port.
Specifically, the user needs to look at the application documentation to decide on how to configure it correctly or to pass correct values into the configure/Makefile/compiler.
Some things to keep in mind are:
-
Language specific single C chars character sets (see multibyte(3)), e.g. ISO8859-1, ISO8859-15, KOI8-R, CP437.
-
Wide or multibyte encodings, e.g. EUC, Big5.
You can check the active list of character sets at the IANA Registry.
Note: FreeBSD use X11-compatible locale encodings instead.
22.3.3 I18N Applications
In the FreeBSD Ports and Package system, I18N applications have been named with I18N in their names for easy identification. However, they do not always support the language needed.
22.3.4 Setting Locale
Usually it is sufficient to export the value of the locale name as LANG in the login shell. This could be done in the user's ~/.login_conf file or in the startup file of the user's shell (~/.profile, ~/.bashrc, ~/.cshrc). There is no need to set the locale subsets such as LC_CTYPE, LC_CTIME. Please refer to language-specific FreeBSD documentation for more information.
You should set the following two environment variables in your configuration files:
-
LANG for POSIX setlocale(3) family functions
-
MM_CHARSET for applications' MIME character set
This includes the user shell configuration, the specific application configuration, and the X11 configuration.
22.3.4.1 Setting Locale Methods
There are two methods for setting locale, and both are described below. The first (recommended one) is by assigning the environment variables in login class, and the second is by adding the environment variable assignments to the system's shell startup file.
22.3.4.1.1 Login Classes Method
This method allows environment variables needed for locale name and MIME character sets to be assigned once for every possible shell instead of adding specific shell assignments to each shell's startup file. User Level Setup can be done by an user himself and Administrator Level Setup require superuser privileges.
22.3.4.1.1.1 User Level Setup
Here is a minimal example of a .login_conf file in user's home directory which has both variables set for Latin-1 encoding:
me:\
:charset=ISO-8859-1:\
:lang=de_DE.ISO8859-1:
Here is an example of a .login_conf that sets the variables for Traditional Chinese in BIG-5 encoding. Notice the many more variables set because some software does not respect locale variables correctly for Chinese, Japanese, and Korean.
#Users who do not wish to use monetary units or time formats
#of Taiwan can manually change each variable
me:\
:lang=zh_TW.Big5:\
:setenv=LC_ALL=zh_TW.Big:\
:setenv=LC_COLLATE=zh_TW.Big5:\
:setenv=LC_CTYPE=zh_TW.Big5:\
:setenv=LC_MESSAGES=zh_TW.Big5:\
:setenv=LC_MONETARY=zh_TW.Big5:\
:setenv=LC_NUMERIC=zh_TW.Big5:\
:setenv=LC_TIME=zh_TW.Big5:\
:charset=big5:\
:xmodifiers="@im=gcin": #Set gcin as the XIM Input Server
See Administrator Level Setup and login.conf(5) for more details.
22.3.4.1.1.2 Administrator Level Setup
Verify that the user's login class in /etc/login.conf sets the correct language. Make sure these settings appear in /etc/login.conf:
language_name:accounts_title:\
:charset=MIME_charset:\
:lang=locale_name:\
:tc=default:
So sticking with our previous example using Latin-1, it would look like this:
german:German Users Accounts:\
:charset=ISO-8859-1:\
:lang=de_DE.ISO8859-1:\
:tc=default:
Before changing users Login Classes execute the following command:
# cap_mkdb /etc/login.conf
to make new configuration in /etc/login.conf visible to the system.
Changing Login Classes with vipw(8)
Use vipw to add new users, and make the entry look like this:
user:password:1111:11:language:0:0:User Name:/home/user:/bin/sh
Changing Login Classes with adduser(8)
Use adduser to add new users, and do the following:
-
Set defaultclass = language in /etc/adduser.conf. Keep in mind you must enter a default class for all users of other languages in this case.
-
An alternative variant is answering the specified language each time that
Enter login class: default []:appears from adduser(8).
-
Another alternative is to use the following for each user of a different language that you wish to add:
# adduser -class language
Changing Login Classes with pw(8)
If you use pw(8) for adding new users, call it in this form:
# pw useradd user_name -L language
22.3.4.1.2 Shell Startup File Method
Note: This method is not recommended because it requires a different setup for each possible shell program chosen. Use the Login Class Method instead.
To add the locale name and MIME character set, just set the two environment variables shown below in the /etc/profile and/or /etc/csh.login shell startup files. We will use the German language as an example below:
In /etc/profile:
LANG=de_DE.ISO8859-1; export LANG
MM_CHARSET=ISO-8859-1; export MM_CHARSET
Or in /etc/csh.login:
setenv LANG de_DE.ISO8859-1
setenv MM_CHARSET ISO-8859-1
Alternatively, you can add the above instructions to /usr/share/skel/dot.profile (similar to what was used in /etc/profile above), or /usr/share/skel/dot.login (similar to what was used in /etc/csh.login above).
For X11:
In $HOME/.xinitrc:
LANG=de_DE.ISO8859-1; export LANG
Or:
setenv LANG de_DE.ISO8859-1
Depending on your shell (see above).
22.3.5 Console Setup
For all single C chars character sets, set the correct console fonts in /etc/rc.conf for the language in question with:
font8x16=font_name
font8x14=font_name
font8x8=font_name
The font_name here is taken from the /usr/share/syscons/fonts directory, without the .fnt suffix.
Also be sure to set the correct keymap and screenmap for your single C chars character set through sysinstall (/stand/sysinstall in FreeBSD versions older than 5.2). Once inside sysinstall, choose Configure, then Console. Alternatively, you can add the following to /etc/rc.conf:
scrnmap=screenmap_name
keymap=keymap_name
keychange="fkey_number sequence"
The screenmap_name here is taken from the /usr/share/syscons/scrnmaps directory, without the .scm suffix. A screenmap with a corresponding mapped font is usually needed as a workaround for expanding bit 8 to bit 9 on a VGA adapter's font character matrix in pseudographics area, i.e., to move letters out of that area if screen font uses a bit 8 column.
If you have the moused daemon enabled by setting the following in your /etc/rc.conf:
moused_enable="YES"
then examine the mouse cursor information in the next paragraph.
By default the mouse cursor of the syscons(4) driver occupies the 0xd0-0xd3 range in the character set. If your language uses this range, you need to move the cursor's range outside of it. To enable the workaround for FreeBSD, add the following line to /etc/rc.conf:
mousechar_start=3
The keymap_name here is taken from the /usr/share/syscons/keymaps directory, without the .kbd suffix. If you are uncertain which keymap to use, you use can kbdmap(1) to test keymaps without rebooting.
The keychange is usually needed to program function keys to match the selected terminal type because function key sequences cannot be defined in the key map.
Also be sure to set the correct console terminal type in /etc/ttys for all ttyv* entries. Current pre-defined correspondences are:
| Character Set | Terminal Type |
|---|---|
| ISO8859-1 or ISO8859-15 | cons25l1 |
| ISO8859-2 | cons25l2 |
| ISO8859-7 | cons25l7 |
| KOI8-R | cons25r |
| KOI8-U | cons25u |
| CP437 (VGA default) | cons25 |
| US-ASCII | cons25w |
For wide or multibyte characters languages, use the correct FreeBSD port in your /usr/ports/language directory. Some ports appear as console while the system sees it as serial vtty's, hence you must reserve enough vtty's for both X11 and the pseudo-serial console. Here is a partial list of applications for using other languages in console:
| Language | Location |
|---|---|
| Traditional Chinese (BIG-5) | chinese/big5con |
| Japanese | japanese/kon2-16dot or japanese/mule-freewnn |
| Korean | korean/han |
22.3.6 X11 Setup
Although X11 is not part of the FreeBSD Project, we have included some information here for FreeBSD users. For more details, refer to the Xorg web site or whichever X11 Server you use.
In ~/.Xresources, you can additionally tune application specific I18N settings (e.g., fonts, menus, etc.).
22.3.6.1 Displaying Fonts
Install Xorg server (x11-servers/xorg-server) or XFree86 server (x11-servers/XFree86-4-Server), then install the language TrueType fonts. Setting the correct locale should allow you to view your selected language in menus and such.
22.3.6.2 Inputting Non-English Characters
The X11 Input Method (XIM) Protocol is a new standard for all X11 clients. All X11 applications should be written as XIM clients that take input from XIM Input servers. There are several XIM servers available for different languages.
22.3.7 Printer Setup
Some single C chars character sets are usually hardware coded into printers. Wide or multibyte character sets require special setup and we recommend using apsfilter. You may also convert the document to PostScript or PDF formats using language specific converters.
22.3.8 Kernel and File Systems
The FreeBSD fast filesystem (FFS) is 8-bit clean, so it can be used with any single C chars character set (see multibyte(3)), but there is no character set name stored in the filesystem; i.e., it is raw 8-bit and does not know anything about encoding order. Officially, FFS does not support any form of wide or multibyte character sets yet. However, some wide or multibyte character sets have independent patches for FFS enabling such support. They are only temporary unportable solutions or hacks and we have decided to not include them in the source tree. Refer to respective languages' web sites for more information and the patch files.
The FreeBSD MS-DOS filesystem has the configurable ability to convert between MS-DOS, Unicode character sets and chosen FreeBSD filesystem character sets. See mount_msdosfs(8) for details.
22.4 Compiling I18N Programs
Many FreeBSD Ports have been ported with I18N support. Some of them are marked with -I18N in the port name. These and many other programs have built in support for I18N and need no special consideration.
However, some applications such as MySQL need to be have the Makefile configured with the specific charset. This is usually done in the Makefile or done by passing a value to configure in the source.
22.5 Localizing FreeBSD to Specific Languages
22.5.1 Russian Language (KOI8-R Encoding)
Originally contributed by Andrey Chernov.For more information about KOI8-R encoding, see the KOI8-R References (Russian Net Character Set).
22.5.1.1 Locale Setup
Put the following lines into your ~/.login_conf file:
me:My Account:\
:charset=KOI8-R:\
:lang=ru_RU.KOI8-R:
See earlier in this chapter for examples of setting up the locale.
22.5.1.2 Console Setup
-
Add the following line to your /etc/rc.conf file:
mousechar_start=3 -
Also, use following settings in /etc/rc.conf:
keymap="ru.koi8-r" scrnmap="koi8-r2cp866" font8x16="cp866b-8x16" font8x14="cp866-8x14" font8x8="cp866-8x8" -
For each ttyv* entry in /etc/ttys, use cons25r as the terminal type.
See earlier in this chapter for examples of setting up the console.
22.5.1.3 Printer Setup
Since most printers with Russian characters come with hardware code page CP866, a special output filter is needed to convert from KOI8-R to CP866. Such a filter is installed by default as /usr/libexec/lpr/ru/koi2alt. A Russian printer /etc/printcap entry should look like:
lp|Russian local line printer:\
:sh:of=/usr/libexec/lpr/ru/koi2alt:\
:lp=/dev/lpt0:sd=/var/spool/output/lpd:lf=/var/log/lpd-errs:
See printcap(5) for a detailed description.
22.5.1.4 MS-DOS FS and Russian Filenames
The following example fstab(5) entry enables support for Russian filenames in mounted MS-DOS filesystems:
/dev/ad0s2 /dos/c msdos rw,-Wkoi2dos,-Lru_RU.KOI8-R 0 0
The option -L selects the locale name used, and -W sets the character conversion table. To use the -W option, be sure to mount /usr before
the MS-DOS partition because the conversion tables are
located in /usr/libdata/msdosfs. For more information, see the
mount_msdosfs(8)
manual page.
22.5.1.5 X11 Setup
-
Do non-X locale setup first as described.
-
If you use Xorg, install x11-fonts/xorg-fonts-cyrillic package.
Check the "Files" section in your /etc/X11/xorg.conf file. The following lines must be added before any other FontPath entries:
FontPath "/usr/X11R6/lib/X11/fonts/cyrillic/misc" FontPath "/usr/X11R6/lib/X11/fonts/cyrillic/75dpi" FontPath "/usr/X11R6/lib/X11/fonts/cyrillic/100dpi"If you use a high resolution video mode, swap the 75 dpi and 100 dpi lines.
Note: See ports for more cyrillic fonts.
-
To activate a Russian keyboard, add the following to the "Keyboard" section of your xorg.conf file:
Option "XkbLayout" "us,ru" Option "XkbOptions" "grp:toggle"Also make sure that XkbDisable is turned off (commented out) there.
For grp:caps_toggle the RUS/LAT switch will be Right Alt, for grp:ctrl_shift_toggle switch will be Ctrl+Shift. The old CapsLock function is still available via Shift+CapsLock (in LAT mode only). For grp:toggle the RUS/LAT switch will be Right Alt. grp:caps_toggle does not work in Xorg for unknown reason.
If you have “Windows” keys on your keyboard, and notice that some non-alphabetical keys are mapped incorrectly in RUS mode, add the following line in your xorg.conf file:
Option "XkbVariant" ",winkeys"Note: The Russian XKB keyboard may not work with non-localized applications.
Note: Minimally localized applications should call a
XtSetLanguageProc (NULL, NULL, NULL);function early in the program.See KOI8-R for X Window for more instructions on localizing X11 applications.
22.5.2 Traditional Chinese Localization for Taiwan
The FreeBSD-Taiwan Project has an Chinese HOWTO for FreeBSD at http://netlab.cse.yzu.edu.tw/~statue/freebsd/zh-tut/ using many Chinese
ports. Current editor for the FreeBSD Chinese HOWTO is Shen
Chuan-Hsing <statue@freebsd.sinica.edu.tw>.
Chuan-Hsing Shen <statue@freebsd.sinica.edu.tw>
has created the Chinese
FreeBSD Collection (CFC) using FreeBSD-Taiwan's zh-L10N-tut.
The packages and the script files are available at ftp://freebsd.csie.nctu.edu.tw/pub/taiwan/CFC/.
22.5.3 German Language Localization (for All ISO 8859-1 Languages)
Slaven Rezic <eserte@cs.tu-berlin.de> wrote a
tutorial how to use umlauts on a FreeBSD machine. The tutorial is written in German and
available at http://user.cs.tu-berlin.de/~eserte/FreeBSD/doc/umlaute/umlaute.html.
22.5.4 Japanese and Korean Language Localization
For Japanese, refer to http://www.jp.FreeBSD.org/, and for Korean, refer to http://www.kr.FreeBSD.org/.
22.5.5 Non-English FreeBSD Documentation
Some FreeBSD contributors have translated parts of FreeBSD to other languages. They are available through links on the main site or in /usr/share/doc.
Chapter 23 The Cutting Edge
Restructured, reorganized, and parts updated by Jim Mock. Original work by Jordan Hubbard, Poul-Henning Kamp, John Polstra, and Nik Clayton.23.1 Synopsis
FreeBSD is under constant development between releases. For people who want to be on the cutting edge, there are several easy mechanisms for keeping your system in sync with the latest developments. Be warned--the cutting edge is not for everyone! This chapter will help you decide if you want to track the development system, or stick with one of the released versions.
After reading this chapter, you will know:
-
The difference between the two development branches: FreeBSD-STABLE and FreeBSD-CURRENT.
-
How to keep your system up to date with CVSup, CVS, or CTM.
-
How to rebuild and reinstall the entire base system with make buildworld (etc).
Before reading this chapter, you should:
-
Properly set up your network connection (Chapter 29).
-
Know how to install additional third-party software (Chapter 4).
23.2 FreeBSD-CURRENT vs. FreeBSD-STABLE
There are two development branches to FreeBSD: FreeBSD-CURRENT and FreeBSD-STABLE. This section will explain a bit about each and describe how to keep your system up-to-date with each respective tree. FreeBSD-CURRENT will be discussed first, then FreeBSD-STABLE.
23.2.1 Staying Current with FreeBSD
As you read this, keep in mind that FreeBSD-CURRENT is the “bleeding edge” of FreeBSD development. FreeBSD-CURRENT users are expected to have a high degree of technical skill, and should be capable of solving difficult system problems on their own. If you are new to FreeBSD, think twice before installing it.
23.2.1.1 What Is FreeBSD-CURRENT?
FreeBSD-CURRENT is the latest working sources for FreeBSD. This includes work in progress, experimental changes, and transitional mechanisms that might or might not be present in the next official release of the software. While many FreeBSD developers compile the FreeBSD-CURRENT source code daily, there are periods of time when the sources are not buildable. These problems are resolved as expeditiously as possible, but whether or not FreeBSD-CURRENT brings disaster or greatly desired functionality can be a matter of which exact moment you grabbed the source code in!
23.2.1.2 Who Needs FreeBSD-CURRENT?
FreeBSD-CURRENT is made available for 3 primary interest groups:
-
Members of the FreeBSD community who are actively working on some part of the source tree and for whom keeping “current” is an absolute requirement.
-
Members of the FreeBSD community who are active testers, willing to spend time solving problems in order to ensure that FreeBSD-CURRENT remains as sane as possible. These are also people who wish to make topical suggestions on changes and the general direction of FreeBSD, and submit patches to implement them.
-
Those who merely wish to keep an eye on things, or to use the current sources for reference purposes (e.g. for reading, not running). These people also make the occasional comment or contribute code.
23.2.1.3 What Is FreeBSD-CURRENT Not?
-
A fast-track to getting pre-release bits because you heard there is some cool new feature in there and you want to be the first on your block to have it. Being the first on the block to get the new feature means that you are the first on the block to get the new bugs.
-
A quick way of getting bug fixes. Any given version of FreeBSD-CURRENT is just as likely to introduce new bugs as to fix existing ones.
-
In any way “officially supported”. We do our best to help people genuinely in one of the 3 “legitimate” FreeBSD-CURRENT groups, but we simply do not have the time to provide tech support. This is not because we are mean and nasty people who do not like helping people out (we would not even be doing FreeBSD if we were). We simply cannot answer hundreds messages a day and work on FreeBSD! Given the choice between improving FreeBSD and answering lots of questions on experimental code, the developers opt for the former.
23.2.1.4 Using FreeBSD-CURRENT
-
Join the freebsd-current and the cvs-all lists. This is not just a good idea, it is essential. If you are not on the freebsd-current list, you will not see the comments that people are making about the current state of the system and thus will probably end up stumbling over a lot of problems that others have already found and solved. Even more importantly, you will miss out on important bulletins which may be critical to your system's continued health.
The cvs-all list will allow you to see the commit log entry for each change as it is made along with any pertinent information on possible side-effects.
To join these lists, or one of the others available go to http://lists.FreeBSD.org/mailman/listinfo and click on the list that you wish to subscribe to. Instructions on the rest of the procedure are available there.
-
Grab the sources from a FreeBSD mirror site. You can do this in one of two ways:
-
Use the cvsup program with the supfile named standard-supfile available from /usr/share/examples/cvsup. This is the most recommended method, since it allows you to grab the entire collection once and then only what has changed from then on. Many people run cvsup from cron and keep their sources up-to-date automatically. You have to customize the sample supfile above, and configure cvsup for your environment.
-
Use the CTM facility. If you have very bad connectivity (high price connections or only email access) CTM is an option. However, it is a lot of hassle and can give you broken files. This leads to it being rarely used, which again increases the chance of it not working for fairly long periods of time. We recommend using CVSup for anybody with a 9600 bps modem or faster connection.
-
-
If you are grabbing the sources to run, and not just look at, then grab all of FreeBSD-CURRENT, not just selected portions. The reason for this is that various parts of the source depend on updates elsewhere, and trying to compile just a subset is almost guaranteed to get you into trouble.
Before compiling FreeBSD-CURRENT, read the Makefile in /usr/src carefully. You should at least install a new kernel and rebuild the world the first time through as part of the upgrading process. Reading the FreeBSD-CURRENT mailing list and /usr/src/UPDATING will keep you up-to-date on other bootstrapping procedures that sometimes become necessary as we move toward the next release.
-
Be active! If you are running FreeBSD-CURRENT, we want to know what you have to say about it, especially if you have suggestions for enhancements or bug fixes. Suggestions with accompanying code are received most enthusiastically!
23.2.2 Staying Stable with FreeBSD
23.2.2.1 What Is FreeBSD-STABLE?
FreeBSD-STABLE is our development branch from which major releases are made. Changes go into this branch at a different pace, and with the general assumption that they have first gone into FreeBSD-CURRENT for testing. This is still a development branch, however, and this means that at any given time, the sources for FreeBSD-STABLE may or may not be suitable for any particular purpose. It is simply another engineering development track, not a resource for end-users.
23.2.2.2 Who Needs FreeBSD-STABLE?
If you are interested in tracking or contributing to the FreeBSD development process, especially as it relates to the next “point” release of FreeBSD, then you should consider following FreeBSD-STABLE.
While it is true that security fixes also go into the FreeBSD-STABLE branch, you do not need to track FreeBSD-STABLE to do this. Every security advisory for FreeBSD explains how to fix the problem for the releases it affects [15] , and tracking an entire development branch just for security reasons is likely to bring in a lot of unwanted changes as well.
Although we endeavor to ensure that the FreeBSD-STABLE branch compiles and runs at all times, this cannot be guaranteed. In addition, while code is developed in FreeBSD-CURRENT before including it in FreeBSD-STABLE, more people run FreeBSD-STABLE than FreeBSD-CURRENT, so it is inevitable that bugs and corner cases will sometimes be found in FreeBSD-STABLE that were not apparent in FreeBSD-CURRENT.
For these reasons, we do not recommend that you blindly track FreeBSD-STABLE, and it is particularly important that you do not update any production servers to FreeBSD-STABLE without first thoroughly testing the code in your development environment.
If you do not have the resources to do this then we recommend that you run the most recent release of FreeBSD, and use the binary update mechanism to move from release to release.
23.2.2.3 Using FreeBSD-STABLE
-
Join the freebsd-stable list. This will keep you informed of build-dependencies that may appear in FreeBSD-STABLE or any other issues requiring special attention. Developers will also make announcements in this mailing list when they are contemplating some controversial fix or update, giving the users a chance to respond if they have any issues to raise concerning the proposed change.
The cvs-all list will allow you to see the commit log entry for each change as it is made along with any pertinent information on possible side-effects.
To join these lists, or one of the others available go to http://lists.FreeBSD.org/mailman/listinfo and click on the list that you wish to subscribe to. Instructions on the rest of the procedure are available there.
-
If you are going to install a new system and want it to run monthly snapshot built from FreeBSD-STABLE, please check the Snapshots web page for more information. Alternatively, it is possible to install the most recent FreeBSD-STABLE release from the mirror sites and follow the instructions below to upgrade your system to the most up to date FreeBSD-STABLE source code.
If you are already running a previous release of FreeBSD and wish to upgrade via sources then you can easily do so from FreeBSD mirror site. This can be done in one of two ways:
-
Use the cvsup program with the supfile named stable-supfile from the directory /usr/share/examples/cvsup. This is the most recommended method, since it allows you to grab the entire collection once and then only what has changed from then on. Many people run cvsup from cron to keep their sources up-to-date automatically. You have to customize the sample supfile above, and configure cvsup for your environment.
-
Use the CTM facility. If you do not have a fast and inexpensive connection to the Internet, this is the method you should consider using.
-
-
Essentially, if you need rapid on-demand access to the source and communications bandwidth is not a consideration, use cvsup or ftp. Otherwise, use CTM.
-
Before compiling FreeBSD-STABLE, read the Makefile in /usr/src carefully. You should at least install a new kernel and rebuild the world the first time through as part of the upgrading process. Reading the FreeBSD-STABLE mailing list and /usr/src/UPDATING will keep you up-to-date on other bootstrapping procedures that sometimes become necessary as we move toward the next release.
23.3 Synchronizing Your Source
There are various ways of using an Internet (or email) connection to stay up-to-date with any given area of the FreeBSD project sources, or all areas, depending on what interests you. The primary services we offer are Anonymous CVS, CVSup, and CTM.
Warning: While it is possible to update only parts of your source tree, the only supported update procedure is to update the entire tree and recompile both userland (i.e., all the programs that run in user space, such as those in /bin and /sbin) and kernel sources. Updating only part of your source tree, only the kernel, or only userland will often result in problems. These problems may range from compile errors to kernel panics or data corruption.
Anonymous CVS and CVSup use the pull model of updating sources. In the case of CVSup the user (or a cron script) invokes the cvsup program, and it interacts with a cvsupd server somewhere to bring your files up-to-date. The updates you receive are up-to-the-minute and you get them when, and only when, you want them. You can easily restrict your updates to the specific files or directories that are of interest to you. Updates are generated on the fly by the server, according to what you have and what you want to have. Anonymous CVS is quite a bit more simplistic than CVSup in that it is just an extension to CVS which allows it to pull changes directly from a remote CVS repository. CVSup can do this far more efficiently, but Anonymous CVS is easier to use.
CTM, on the other hand, does not interactively compare the sources you have with those on the master archive or otherwise pull them across. Instead, a script which identifies changes in files since its previous run is executed several times a day on the master CTM machine, any detected changes being compressed, stamped with a sequence-number and encoded for transmission over email (in printable ASCII only). Once received, these “CTM deltas” can then be handed to the ctm_rmail(1) utility which will automatically decode, verify and apply the changes to the user's copy of the sources. This process is far more efficient than CVSup, and places less strain on our server resources since it is a push rather than a pull model.
There are other trade-offs, of course. If you inadvertently wipe out portions of your archive, CVSup will detect and rebuild the damaged portions for you. CTM will not do this, and if you wipe some portion of your source tree out (and do not have it backed up) then you will have to start from scratch (from the most recent CVS “base delta”) and rebuild it all with CTM or, with Anonymous CVS, simply delete the bad bits and resync.
23.4 Rebuilding “world”
Once you have synchronized your local source tree against a particular version of FreeBSD (FreeBSD-STABLE, FreeBSD-CURRENT, and so on) you can then use the source tree to rebuild the system.
Make a Backup: It cannot be stressed enough how important it is to make a backup of your system before you do this. While rebuilding the world is (as long as you follow these instructions) an easy task to do, there will inevitably be times when you make mistakes, or when mistakes made by others in the source tree render your system unbootable.
Make sure you have taken a backup. And have a fixit floppy or bootable CD at hand. You will probably never have to use it, but it is better to be safe than sorry!
Subscribe to the Right Mailing List: The FreeBSD-STABLE and FreeBSD-CURRENT branches are, by their nature, in development. People that contribute to FreeBSD are human, and mistakes occasionally happen.
Sometimes these mistakes can be quite harmless, just causing your system to print a new diagnostic warning. Or the change may be catastrophic, and render your system unbootable or destroy your file systems (or worse).
If problems like these occur, a “heads up” is posted to the appropriate mailing list, explaining the nature of the problem and which systems it affects. And an “all clear” announcement is posted when the problem has been solved.
If you try to track FreeBSD-STABLE or FreeBSD-CURRENT and do not read the FreeBSD-STABLE mailing list or the FreeBSD-CURRENT mailing list respectively, then you are asking for trouble.
Do not use make world: A lot of older documentation recommends using make world for this. Doing that skips some important steps and should only be used if you are sure of what you are doing. For almost all circumstances make world is the wrong thing to do, and the procedure described here should be used instead.
23.4.1 The Canonical Way to Update Your System
To update your system, you should check /usr/src/UPDATING for any pre-buildworld steps necessary for your version of the sources and then use the following procedure:
# make buildworld
# make buildkernel
# make installkernel
# reboot
Note: There are a few rare cases when an extra run of mergemaster -p is needed before the buildworld step. These are described in UPDATING. In general, though, you can safely omit this step if you are not updating across one or more major FreeBSD versions.
After installkernel finishes successfully, you should boot in single user mode (i.e. using boot -s from the loader prompt). Then run:
# mergemaster -p
# make installworld
# mergemaster
# reboot
Read Further Explanations: The sequence described above is only a short resume to help you getting started. You should however read the following sections to clearly understand each step, especially if you want to use a custom kernel configuration.
23.4.2 Read /usr/src/UPDATING
Before you do anything else, read /usr/src/UPDATING (or the equivalent file wherever you have a copy of the source code). This file should contain important information about problems you might encounter, or specify the order in which you might have to run certain commands. If UPDATING contradicts something you read here, UPDATING takes precedence.
Important: Reading UPDATING is not an acceptable substitute for subscribing to the correct mailing list, as described previously. The two requirements are complementary, not exclusive.
23.4.3 Check /etc/make.conf
Examine the files /usr/share/examples/etc/make.conf and /etc/make.conf. The first contains some default defines - most of which are commented out. To make use of them when you rebuild your system from source, add them to /etc/make.conf. Keep in mind that anything you add to /etc/make.conf is also used every time you run make, so it is a good idea to set them to something sensible for your system.
A typical user will probably want to copy the CFLAGS and NO_PROFILE lines found in /usr/share/examples/etc/make.conf to /etc/make.conf and uncomment them.
Examine the other definitions (COPTFLAGS, NOPORTDOCS and so on) and decide if they are relevant to you.
23.4.4 Update the Files in /etc
The /etc directory contains a large part of your system's configuration information, as well as scripts that are run at system startup. Some of these scripts change from version to version of FreeBSD.
Some of the configuration files are also used in the day to day running of the system. In particular, /etc/group.
There have been occasions when the installation part of make installworld has expected certain usernames or groups to exist. When performing an upgrade it is likely that these users or groups did not exist. This caused problems when upgrading. In some cases make buildworld will check to see if these users or groups exist.
An example of this is when the smmsp user was added. Users had the installation process fail for them when mtree(8) was trying to create /var/spool/clientmqueue.
The solution is to run mergemaster(8) in
pre-buildworld mode by providing the -p option. This will
compare only those files that are essential for the success of buildworld or installworld. If your
old version of mergemaster does not support -p, use the new version in the source tree when running for the
first time:
# cd /usr/src/usr.sbin/mergemaster
# ./mergemaster.sh -p
Tip: If you are feeling particularly paranoid, you can check your system to see which files are owned by the group you are renaming or deleting:
# find / -group GID -printwill show all files owned by group GID (which can be either a group name or a numeric group ID).
23.4.5 Drop to Single User Mode
You may want to compile the system in single user mode. Apart from the obvious benefit of making things go slightly faster, reinstalling the system will touch a lot of important system files, all the standard system binaries, libraries, include files and so on. Changing these on a running system (particularly if you have active users on the system at the time) is asking for trouble.
Another method is to compile the system in multi-user mode, and then drop into single user mode for the installation. If you would like to do it this way, simply hold off on the following steps until the build has completed. You can postpone dropping to single user mode until you have to installkernel or installworld.
As the superuser, you can execute:
# shutdown now
from a running system, which will drop it to single user mode.
Alternatively, reboot the system, and at the boot prompt, select the “single user” option. The system will then boot single user. At the shell prompt you should then run:
# fsck -p
# mount -u /
# mount -a -t ufs
# swapon -a
This checks the file systems, remounts / read/write, mounts all the other UFS file systems referenced in /etc/fstab and then turns swapping on.
Note: If your CMOS clock is set to local time and not to GMT (this is true if the output of the date(1) command does not show the correct time and zone), you may also need to run the following command:
# adjkerntz -iThis will make sure that your local time-zone settings get set up correctly -- without this, you may later run into some problems.
23.4.6 Remove /usr/obj
As parts of the system are rebuilt they are placed in directories which (by default) go under /usr/obj. The directories shadow those under /usr/src.
You can speed up the make buildworld process, and possibly save yourself some dependency headaches by removing this directory as well.
Some files below /usr/obj may have the immutable flag set (see chflags(1) for more information) which must be removed first.
# cd /usr/obj
# chflags -R noschg *
# rm -rf *
23.4.7 Recompile the Base System
23.4.7.1 Saving the Output
It is a good idea to save the output you get from running make(1) to another file. If something goes wrong you will have a copy of the error message. While this might not help you in diagnosing what has gone wrong, it can help others if you post your problem to one of the FreeBSD mailing lists.
The easiest way to do this is to use the script(1) command, with a parameter that specifies the name of the file to save all output to. You would do this immediately before rebuilding the world, and then type exit when the process has finished.
# script /var/tmp/mw.out
Script started, output file is /var/tmp/mw.out
# make TARGET
... compile, compile, compile ...
# exit
Script done, ...
If you do this, do not save the output in /tmp. This directory may be cleared next time you reboot. A better place to store it is in /var/tmp (as in the previous example) or in root's home directory.
23.4.7.2 Compile the Base System
You must be in the /usr/src directory:
# cd /usr/src
(unless, of course, your source code is elsewhere, in which case change to that directory instead).
To rebuild the world you use the make(1) command. This command reads instructions from the Makefile, which describes how the programs that comprise FreeBSD should be rebuilt, the order in which they should be built, and so on.
The general format of the command line you will type is as follows:
# make -x -DVARIABLE target
In this example, -x is
an option that you would pass to make(1). See the make(1) manual page
for an example of the options you can pass.
-DVARIABLE passes a
variable to the Makefile. The behavior of the Makefile is controlled by these variables. These are the same
variables as are set in /etc/make.conf, and this provides
another way of setting them.
# make -DNO_PROFILE target
is another way of specifying that profiled libraries should not be built, and corresponds with the
NO_PROFILE= true # Avoid compiling profiled libraries
line in /etc/make.conf.
target tells make(1) what you want to do. Each Makefile defines a number of different “targets”, and your choice of target determines what happens.
Some targets are listed in the Makefile, but are not meant for you to run. Instead, they are used by the build process to break out the steps necessary to rebuild the system into a number of sub-steps.
Most of the time you will not need to pass any parameters to make(1), and so your command like will look like this:
# make target
Where target will be one of many build options. The first target should always be buildworld.
As the names imply, buildworld builds a complete new tree under /usr/obj, and installworld, another target, installs this tree on the current machine.
Having separate options is very useful for two reasons. First, it allows you to do the build safe in the knowledge that no components of your running system will be affected. The build is “self hosted”. Because of this, you can safely run buildworld on a machine running in multi-user mode with no fear of ill-effects. It is still recommended that you run the installworld part in single user mode, though.
Secondly, it allows you to use NFS mounts to upgrade multiple machines on your network. If you have three machines, A, B and C that you want to upgrade, run make buildworld and make installworld on A. B and C should then NFS mount /usr/src and /usr/obj from A, and you can then run make installworld to install the results of the build on B and C.
Although the world target still exists, you are strongly encouraged not to use it.
Run
# make buildworld
It is possible to specify a -j option to make which will cause it to spawn several simultaneous processes.
This is most useful on multi-CPU machines. However, since much of the compiling process
is IO bound rather than CPU bound it is also useful on single CPU machines.
On a typical single-CPU machine you would run:
# make -j4 buildworld
make(1) will then have up to 4 processes running at any one time. Empirical evidence posted to the mailing lists shows this generally gives the best performance benefit.
If you have a multi-CPU machine and you are using an SMP configured kernel try values between 6 and 10 and see how they speed things up.
23.4.7.3 Timings
Many factors influence the build time, but fairly recent machines may only take a one or two hours to build the FreeBSD-STABLE tree, with no tricks or shortcuts used during the process. A FreeBSD-CURRENT tree will take somewhat longer.
23.4.8 Compile and Install a New Kernel
To take full advantage of your new system you should recompile the kernel. This is practically a necessity, as certain memory structures may have changed, and programs like ps(1) and top(1) will fail to work until the kernel and source code versions are the same.
The simplest, safest way to do this is to build and install a kernel based on GENERIC. While GENERIC may not have all the necessary devices for your system, it should contain everything necessary to boot your system back to single user mode. This is a good test that the new system works properly. After booting from GENERIC and verifying that your system works you can then build a new kernel based on your normal kernel configuration file.
On FreeBSD it is important to build world before building a new kernel.
Note: If you want to build a custom kernel, and already have a configuration file, just use KERNCONF=MYKERNEL like this:
# cd /usr/src # make buildkernel KERNCONF=MYKERNEL # make installkernel KERNCONF=MYKERNEL
Note that if you have raised kern.securelevel above 1 and you have set either the noschg or similar flags to your kernel binary, you might find it necessary to drop into single user mode to use installkernel. Otherwise you should be able to run both these commands from multi user mode without problems. See init(8) for details about kern.securelevel and chflags(1) for details about the various file flags.
23.4.9 Reboot into Single User Mode
You should reboot into single user mode to test the new kernel works. Do this by following the instructions in Section 23.4.5.
23.4.10 Install the New System Binaries
If you were building a version of FreeBSD recent enough to have used make buildworld then you should now use installworld to install the new system binaries.
Run
# cd /usr/src
# make installworld
Note: If you specified variables on the make buildworld command line, you must specify the same variables in the make installworld command line. This does not necessarily hold true for other options; for example,
-jmust never be used with installworld.For example, if you ran:
# make -DNO_PROFILE buildworldyou must install the results with:
# make -DNO_PROFILE installworldotherwise it would try to install profiled libraries that had not been built during the make buildworld phase.
23.4.11 Update Files Not Updated by make installworld
Remaking the world will not update certain directories (in particular, /etc, /var and /usr) with new or changed configuration files.
The simplest way to update these files is to use mergemaster(8), though it is possible to do it manually if you would prefer to do that. Regardless of which way you choose, be sure to make a backup of /etc in case anything goes wrong.
23.4.11.1 mergemaster
Contributed by Tom Rhodes.The mergemaster(8) utility is a Bourne script that will aid you in determining the differences between your configuration files in /etc, and the configuration files in the source tree /usr/src/etc. This is the recommended solution for keeping the system configuration files up to date with those located in the source tree.
To begin simply type mergemaster at your prompt, and watch it
start going. mergemaster will then build a temporary root
environment, from / down, and populate it with various system
configuration files. Those files are then compared to the ones currently installed in
your system. At this point, files that differ will be shown in diff(1) format, with
the + sign representing added or modified lines, and - representing lines that will be either removed completely, or
replaced with a new line. See the diff(1) manual page
for more information about the diff(1) syntax and how
file differences are shown.
mergemaster(8) will then show you each file that displays variances, and at this point you will have the option of either deleting the new file (referred to as the temporary file), installing the temporary file in its unmodified state, merging the temporary file with the currently installed file, or viewing the diff(1) results again.
Choosing to delete the temporary file will tell mergemaster(8) that we wish to keep our current file unchanged, and to delete the new version. This option is not recommended, unless you see no reason to change the current file. You can get help at any time by typing ? at the mergemaster(8) prompt. If the user chooses to skip a file, it will be presented again after all other files have been dealt with.
Choosing to install the unmodified temporary file will replace the current file with the new one. For most unmodified files, this is the best option.
Choosing to merge the file will present you with a text editor, and the contents of both files. You can now merge them by reviewing both files side by side on the screen, and choosing parts from both to create a finished product. When the files are compared side by side, the l key will select the left contents and the r key will select contents from your right. The final output will be a file consisting of both parts, which can then be installed. This option is customarily used for files where settings have been modified by the user.
Choosing to view the diff(1) results again will show you the file differences just like mergemaster(8) did before prompting you for an option.
After mergemaster(8) is done with the system files you will be prompted for other options. mergemaster(8) may ask if you want to rebuild the password file and will finish up with an option to remove left-over temporary files.
23.4.11.2 Manual Update
If you wish to do the update manually, however, you cannot just copy over the files from /usr/src/etc to /etc and have it work. Some of these files must be “installed” first. This is because the /usr/src/etc directory is not a copy of what your /etc directory should look like. In addition, there are files that should be in /etc that are not in /usr/src/etc.
If you are using mergemaster(8) (as recommended), you can skip forward to the next section.
The simplest way to do this by hand is to install the files into a new directory, and then work through them looking for differences.
Backup Your Existing /etc: Although, in theory, nothing is going to touch this directory automatically, it is always better to be sure. So copy your existing /etc directory somewhere safe. Something like:
# cp -Rp /etc /etc.old
-Rdoes a recursive copy,-ppreserves times, ownerships on files and suchlike.
You need to build a dummy set of directories to install the new /etc and other files into. /var/tmp/root is a reasonable choice, and there are a number of subdirectories required under this as well.
# mkdir /var/tmp/root
# cd /usr/src/etc
# make DESTDIR=/var/tmp/root distrib-dirs distribution
This will build the necessary directory structure and install the files. A lot of the subdirectories that have been created under /var/tmp/root are empty and should be deleted. The simplest way to do this is to:
# cd /var/tmp/root
# find -d . -type d | xargs rmdir 2>/dev/null
This will remove all empty directories. (Standard error is redirected to /dev/null to prevent the warnings about the directories that are not empty.)
/var/tmp/root now contains all the files that should be placed in appropriate locations below /. You now have to go through each of these files, determining how they differ with your existing files.
Note that some of the files that will have been installed in /var/tmp/root have a leading “.”. At the time of writing the only files like this are shell startup files in /var/tmp/root/ and /var/tmp/root/root/, although there may be others (depending on when you are reading this). Make sure you use ls -a to catch them.
The simplest way to do this is to use diff(1) to compare the two files:
# diff /etc/shells /var/tmp/root/etc/shells
This will show you the differences between your /etc/shells file and the new /var/tmp/root/etc/shells file. Use these to decide whether to merge in changes that you have made or whether to copy over your old file.
Name the New Root Directory (/var/tmp/root) with a Time Stamp, so You Can Easily Compare Differences Between Versions: Frequently rebuilding the world means that you have to update /etc frequently as well, which can be a bit of a chore.
You can speed this process up by keeping a copy of the last set of changed files that you merged into /etc. The following procedure gives one idea of how to do this.
Make the world as normal. When you want to update /etc and the other directories, give the target directory a name based on the current date. If you were doing this on the 14th of February 1998 you could do the following:
# mkdir /var/tmp/root-19980214 # cd /usr/src/etc # make DESTDIR=/var/tmp/root-19980214 \ distrib-dirs distributionMerge in the changes from this directory as outlined above.
Do not remove the /var/tmp/root-19980214 directory when you have finished.
When you have downloaded the latest version of the source and remade it, follow step 1. This will give you a new directory, which might be called /var/tmp/root-19980221 (if you wait a week between doing updates).
You can now see the differences that have been made in the intervening week using diff(1) to create a recursive diff between the two directories:
# cd /var/tmp # diff -r root-19980214 root-19980221Typically, this will be a much smaller set of differences than those between /var/tmp/root-19980221/etc and /etc. Because the set of differences is smaller, it is easier to migrate those changes across into your /etc directory.
You can now remove the older of the two /var/tmp/root-* directories:
# rm -rf /var/tmp/root-19980214Repeat this process every time you need to merge in changes to /etc.
You can use date(1) to automate the generation of the directory names:
# mkdir /var/tmp/root-`date "+%Y%m%d"`
23.4.12 Rebooting
You are now done. After you have verified that everything appears to be in the right place you can reboot the system. A simple shutdown(8) should do it:
# shutdown -r now
23.4.13 Finished
You should now have successfully upgraded your FreeBSD system. Congratulations.
If things went slightly wrong, it is easy to rebuild a particular piece of the system. For example, if you accidentally deleted /etc/magic as part of the upgrade or merge of /etc, the file(1) command will stop working. In this case, the fix would be to run:
# cd /usr/src/usr.bin/file
# make all install
23.4.14 Questions
- 23.4.14.1. Do I need to re-make the world for every change?
- 23.4.14.2. My compile failed with lots of signal 11 (or other signal number) errors. What has happened?
- 23.4.14.3. Can I remove /usr/obj when I have finished?
- 23.4.14.4. Can interrupted builds be resumed?
- 23.4.14.5. How can I speed up making the world?
- 23.4.14.6. What do I do if something goes wrong?
There is no easy answer to this one, as it depends on the nature of the change. For example, if you just ran CVSup, and it has shown the following files as being updated:
src/games/cribbage/instr.c
src/games/sail/pl_main.c
src/release/sysinstall/config.c
src/release/sysinstall/media.c
src/share/mk/bsd.port.mk
it probably is not worth rebuilding the entire world. You could just go to the appropriate sub-directories and make all install, and that's about it. But if something major changed, for example src/lib/libc/stdlib then you should either re-make the world, or at least those parts of it that are statically linked (as well as anything else you might have added that is statically linked).
At the end of the day, it is your call. You might be happy re-making the world every fortnight say, and let changes accumulate over that fortnight. Or you might want to re-make just those things that have changed, and be confident you can spot all the dependencies.
And, of course, this all depends on how often you want to upgrade, and whether you are tracking FreeBSD-STABLE or FreeBSD-CURRENT.
23.4.14.2. My compile failed with lots of signal 11 (or other signal number) errors. What has happened?
This is normally indicative of hardware problems. (Re)making the world is an effective way to stress test your hardware, and will frequently throw up memory problems. These normally manifest themselves as the compiler mysteriously dying on receipt of strange signals.
A sure indicator of this is if you can restart the make and it dies at a different point in the process.
In this instance there is little you can do except start swapping around the components in your machine to determine which one is failing.
The short answer is yes.
/usr/obj contains all the object files that were produced during the compilation phase. Normally, one of the first steps in the make buildworld process is to remove this directory and start afresh. In this case, keeping /usr/obj around after you have finished makes little sense, and will free up a large chunk of disk space (currently about 340 MB).
However, if you know what you are doing you can have make buildworld skip this step. This will make subsequent builds run much faster, since most of sources will not need to be recompiled. The flip side of this is that subtle dependency problems can creep in, causing your build to fail in odd ways. This frequently generates noise on the FreeBSD mailing lists, when one person complains that their build has failed, not realizing that it is because they have tried to cut corners.
This depends on how far through the process you got before you found a problem.
In general (and this is not a hard and fast rule) the make buildworld process builds new copies of essential tools (such as gcc(1), and make(1)) and the system libraries. These tools and libraries are then installed. The new tools and libraries are then used to rebuild themselves, and are installed again. The entire system (now including regular user programs, such as ls(1) or grep(1)) is then rebuilt with the new system files.
If you are at the last stage, and you know it (because you have looked through the output that you were storing) then you can (fairly safely) do:
... fix the problem ...
# cd /usr/src
# make -DNO_CLEAN all
This will not undo the work of the previous make buildworld.
If you see the message:
--------------------------------------------------------------
Building everything..
--------------------------------------------------------------
in the make buildworld output then it is probably fairly safe to do so.
If you do not see that message, or you are not sure, then it is always better to be safe than sorry, and restart the build from scratch.
-
Run in single user mode.
-
Put the /usr/src and /usr/obj directories on separate file systems held on separate disks. If possible, put these disks on separate disk controllers.
-
Better still, put these file systems across multiple disks using the ccd(4) (concatenated disk driver) device.
-
Turn off profiling (set “NO_PROFILE=true” in /etc/make.conf). You almost certainly do not need it.
-
Also in /etc/make.conf, set CFLAGS to something like
-O -pipe. The optimization-O2is much slower, and the optimization difference between-Oand-O2is normally negligible.-pipelets the compiler use pipes rather than temporary files for communication, which saves disk access (at the expense of memory). -
Pass the
-jnoption to make(1) to run multiple processes in parallel. This usually helps regardless of whether you have a single or a multi processor machine. -
The file system holding /usr/src can be mounted (or remounted) with the
noatimeoption. This prevents the file system from recording the file access time. You probably do not need this information anyway.# mount -u -o noatime /usr/srcWarning: The example assumes /usr/src is on its own file system. If it is not (if it is a part of /usr for example) then you will need to use that file system mount point, and not /usr/src.
-
The file system holding /usr/obj can be mounted (or remounted) with the
asyncoption. This causes disk writes to happen asynchronously. In other words, the write completes immediately, and the data is written to the disk a few seconds later. This allows writes to be clustered together, and can be a dramatic performance boost.Warning: Keep in mind that this option makes your file system more fragile. With this option there is an increased chance that, should power fail, the file system will be in an unrecoverable state when the machine restarts.
If /usr/obj is the only thing on this file system then it is not a problem. If you have other, valuable data on the same file system then ensure your backups are fresh before you enable this option.
# mount -u -o async /usr/objWarning: As above, if /usr/obj is not on its own file system, replace it in the example with the name of the appropriate mount point.
Make absolutely sure your environment has no extraneous cruft from earlier builds. This is simple enough.
# chflags -R noschg /usr/obj/usr
# rm -rf /usr/obj/usr
# cd /usr/src
# make cleandir
# make cleandir
Yes, make cleandir really should be run twice.
Then restart the whole process, starting with make buildworld.
If you still have problems, send the error and the output of uname -a to FreeBSD general questions mailing list. Be prepared to answer other questions about your setup!
23.5 Tracking for Multiple Machines
Contributed by Mike Meyer.If you have multiple machines that you want to track the same source tree, then having all of them download sources and rebuild everything seems like a waste of resources: disk space, network bandwidth, and CPU cycles. It is, and the solution is to have one machine do most of the work, while the rest of the machines mount that work via NFS. This section outlines a method of doing so.
23.5.1 Preliminaries
First, identify a set of machines that is going to run the same set of binaries, which we will call a build set. Each machine can have a custom kernel, but they will be running the same userland binaries. From that set, choose a machine to be the build machine. It is going to be the machine that the world and kernel are built on. Ideally, it should be a fast machine that has sufficient spare CPU to run make buildworld and make buildkernel. You will also want to choose a machine to be the test machine, which will test software updates before they are put into production. This must be a machine that you can afford to have down for an extended period of time. It can be the build machine, but need not be.
All the machines in this build set need to mount /usr/obj and /usr/src from the same machine, and at the same point. Ideally, those are on two different drives on the build machine, but they can be NFS mounted on that machine as well. If you have multiple build sets, /usr/src should be on one build machine, and NFS mounted on the rest.
Finally make sure that /etc/make.conf on all the machines in the build set agrees with the build machine. That means that the build machine must build all the parts of the base system that any machine in the build set is going to install. Also, each build machine should have its kernel name set with KERNCONF in /etc/make.conf, and the build machine should list them all in KERNCONF, listing its own kernel first. The build machine must have the kernel configuration files for each machine in /usr/src/sys/arch/conf if it is going to build their kernels.
23.5.2 The Base System
Now that all that is done, you are ready to build everything. Build the kernel and world as described in Section 23.4.7.2 on the build machine, but do not install anything. After the build has finished, go to the test machine, and install the kernel you just built. If this machine mounts /usr/src and /usr/obj via NFS, when you reboot to single user you will need to enable the network and mount them. The easiest way to do this is to boot to multi-user, then run shutdown now to go to single user mode. Once there, you can install the new kernel and world and run mergemaster just as you normally would. When done, reboot to return to normal multi-user operations for this machine.
After you are certain that everything on the test machine is working properly, use the same procedure to install the new software on each of the other machines in the build set.
23.5.3 Ports
The same ideas can be used for the ports tree. The first critical step is mounting /usr/ports from the same machine to all the machines in the build set. You can then set up /etc/make.conf properly to share distfiles. You should set DISTDIR to a common shared directory that is writable by whichever user root is mapped to by your NFS mounts. Each machine should set WRKDIRPREFIX to a local build directory. Finally, if you are going to be building and distributing packages, you should set PACKAGES to a directory similar to DISTDIR.
IV. Network Communication
FreeBSD is one of the most widely deployed operating systems for high performance network servers. The chapters in this part cover:
-
Serial communication
-
PPP and PPP over Ethernet
-
Electronic Mail
-
Running Network Servers
-
Firewalls
-
Other Advanced Networking Topics
These chapters are designed to be read when you need the information. You do not have to read them in any particular order, nor do you need to read all of them before you can begin using FreeBSD in a network environment.
- Table of Contents
- 24 Serial Communications
- 25 PPP and SLIP
- 26 Electronic Mail
- 27 Network Servers
- 28 Firewalls
- 29 Advanced Networking
Chapter 24 Serial Communications
24.1 Synopsis
UNIX has always had support for serial communications. In fact, the very first UNIX machines relied on serial lines for user input and output. Things have changed a lot from the days when the average “terminal” consisted of a 10-character-per-second serial printer and a keyboard. This chapter will cover some of the ways in which FreeBSD uses serial communications.
After reading this chapter, you will know:
-
How to connect terminals to your FreeBSD system.
-
How to use a modem to dial out to remote hosts.
-
How to allow remote users to login to your system with a modem.
-
How to boot your system from a serial console.
Before reading this chapter, you should:
24.2 Introduction
24.2.1 Terminology
- bps
-
Bits per Second -- the rate at which data is transmitted
- DTE
-
Data Terminal Equipment -- for example, your computer
- DCE
-
Data Communications Equipment -- your modem
- RS-232
-
EIA standard for hardware serial communications
When talking about communications data rates, this section does not use the term “baud”. Baud refers to the number of electrical state transitions that may be made in a period of time, while “bps” (bits per second) is the correct term to use (at least it does not seem to bother the curmudgeons quite as much).
24.2.2 Cables and Ports
To connect a modem or terminal to your FreeBSD system, you will need a serial port on your computer and the proper cable to connect to your serial device. If you are already familiar with your hardware and the cable it requires, you can safely skip this section.
24.2.2.1 Cables
There are several different kinds of serial cables. The two most common types for our purposes are null-modem cables and standard (“straight”) RS-232 cables. The documentation for your hardware should describe the type of cable required.
24.2.2.1.1 Null-modem Cables
A null-modem cable passes some signals, such as “Signal Ground”, straight through, but switches other signals. For example, the “Transmitted Data” pin on one end goes to the “Received Data” pin on the other end.
You can also construct your own null-modem cable for use with terminals (e.g., for quality purposes). This table shows the RS-232C signals and the pin numbers on a DB-25 connector. Note that the standard also calls for a straight-through pin 1 to pin 1 Protective Ground line, but it is often omitted. Some terminals work OK using only pins 2, 3 and 7, while others require different configurations than the examples shown below.
Table 24-1. DB-25 to DB-25 Null-Modem Cable
| Signal | Pin # | Pin # | Signal | |
|---|---|---|---|---|
| SG | 7 | connects to | 7 | SG |
| TD | 2 | connects to | 3 | RD |
| RD | 3 | connects to | 2 | TD |
| RTS | 4 | connects to | 5 | CTS |
| CTS | 5 | connects to | 4 | RTS |
| DTR | 20 | connects to | 6 | DSR |
| DTR | 20 | connects to | 8 | DCD |
| DSR | 6 | connects to | 20 | DTR |
| DCD | 8 | connects to | 20 | DTR |
Here are two other schemes more common nowadays.
Table 24-2. DB-9 to DB-9 Null-Modem Cable
| Signal | Pin # | Pin # | Signal | |
|---|---|---|---|---|
| RD | 2 | connects to | 3 | TD |
| TD | 3 | connects to | 2 | RD |
| DTR | 4 | connects to | 6 | DSR |
| DTR | 4 | connects to | 1 | DCD |
| SG | 5 | connects to | 5 | SG |
| DSR | 6 | connects to | 4 | DTR |
| DCD | 1 | connects to | 4 | DTR |
| RTS | 7 | connects to | 8 | CTS |
| CTS | 8 | connects to | 7 | RTS |
Table 24-3. DB-9 to DB-25 Null-Modem Cable
| Signal | Pin # | Pin # | Signal | |
|---|---|---|---|---|
| RD | 2 | connects to | 2 | TD |
| TD | 3 | connects to | 3 | RD |
| DTR | 4 | connects to | 6 | DSR |
| DTR | 4 | connects to | 8 | DCD |
| SG | 5 | connects to | 7 | SG |
| DSR | 6 | connects to | 20 | DTR |
| DCD | 1 | connects to | 20 | DTR |
| RTS | 7 | connects to | 5 | CTS |
| CTS | 8 | connects to | 4 | RTS |
Note: When one pin at one end connects to a pair of pins at the other end, it is usually implemented with one short wire between the pair of pins in their connector and a long wire to the other single pin.
The above designs seems to be the most popular. In another variation (explained in the book RS-232 Made Easy) SG connects to SG, TD connects to RD, RTS and CTS connect to DCD, DTR connects to DSR, and vice-versa.
24.2.2.1.2 Standard RS-232C Cables
A standard serial cable passes all of the RS-232C signals straight through. That is, the “Transmitted Data” pin on one end of the cable goes to the “Transmitted Data” pin on the other end. This is the type of cable to use to connect a modem to your FreeBSD system, and is also appropriate for some terminals.
24.2.2.2 Ports
Serial ports are the devices through which data is transferred between the FreeBSD host computer and the terminal. This section describes the kinds of ports that exist and how they are addressed in FreeBSD.
24.2.2.2.1 Kinds of Ports
Several kinds of serial ports exist. Before you purchase or construct a cable, you need to make sure it will fit the ports on your terminal and on the FreeBSD system.
Most terminals will have DB-25 ports. Personal computers, including PCs running FreeBSD, will have DB-25 or DB-9 ports. If you have a multiport serial card for your PC, you may have RJ-12 or RJ-45 ports.
See the documentation that accompanied the hardware for specifications on the kind of port in use. A visual inspection of the port often works too.
24.2.2.2.2 Port Names
In FreeBSD, you access each serial port through an entry in the /dev directory. There are two different kinds of entries:
-
Call-in ports are named /dev/ttydN where N is the port number, starting from zero. Generally, you use the call-in port for terminals. Call-in ports require that the serial line assert the data carrier detect (DCD) signal to work correctly.
-
Call-out ports are named /dev/cuadN. You usually do not use the call-out port for terminals, just for modems. You may use the call-out port if the serial cable or the terminal does not support the carrier detect signal.
Note: Call-out ports are named /dev/cuaaN in FreeBSD 5.X and older.
If you have connected a terminal to the first serial port (COM1 in MS-DOS), then you will use /dev/ttyd0 to refer to the terminal. If the terminal is on the second serial port (also known as COM2), use /dev/ttyd1, and so forth.
24.2.3 Kernel Configuration
FreeBSD supports four serial ports by default. In the MS-DOS world, these are known as COM1, COM2, COM3, and COM4. FreeBSD currently supports “dumb” multiport serial interface cards, such as the BocaBoard 1008 and 2016, as well as more intelligent multi-port cards such as those made by Digiboard and Stallion Technologies. However, the default kernel only looks for the standard COM ports.
To see if your kernel recognizes any of your serial ports, watch for messages while the kernel is booting, or use the /sbin/dmesg command to replay the kernel's boot messages. In particular, look for messages that start with the characters sio.
Tip: To view just the messages that have the word sio, use the command:
# /sbin/dmesg | grep 'sio'
For example, on a system with four serial ports, these are the serial-port specific kernel boot messages:
sio0 at 0x3f8-0x3ff irq 4 on isa
sio0: type 16550A
sio1 at 0x2f8-0x2ff irq 3 on isa
sio1: type 16550A
sio2 at 0x3e8-0x3ef irq 5 on isa
sio2: type 16550A
sio3 at 0x2e8-0x2ef irq 9 on isa
sio3: type 16550A
If your kernel does not recognize all of your serial ports, you will probably need to configure your kernel in the /boot/device.hints file. You can also comment-out or completely remove lines for devices you do not have.
Please refer to the sio(4) manual page for more information on serial ports and multiport boards configuration. Be careful if you are using a configuration file that was previously used for a different version of FreeBSD because the device flags and the syntax have changed between versions.
Note: port IO_COM1 is a substitution for port 0x3f8, IO_COM2 is 0x2f8, IO_COM3 is 0x3e8, and IO_COM4 is 0x2e8, which are fairly common port addresses for their respective serial ports; interrupts 4, 3, 5, and 9 are fairly common interrupt request lines. Also note that regular serial ports cannot share interrupts on ISA-bus PCs (multiport boards have on-board electronics that allow all the 16550A's on the board to share one or two interrupt request lines).
24.2.4 Device Special Files
Most devices in the kernel are accessed through “device special files”, which are located in the /dev directory. The sio devices are accessed through the /dev/ttydN (dial-in) and /dev/cuadN (call-out) devices. FreeBSD also provides initialization devices (/dev/ttydN.init and /dev/cuadN.init on FreeBSD 6.X, /dev/ttyidN and /dev/cuaiaN on FreeBSD 5.X) and locking devices (/dev/ttydN.lock and /dev/cuadN.lock on FreeBSD 6.X, /dev/ttyldN and /dev/cualaN on FreeBSD 5.X). The initialization devices are used to initialize communications port parameters each time a port is opened, such as crtscts for modems which use RTS/CTS signaling for flow control. The locking devices are used to lock flags on ports to prevent users or programs changing certain parameters; see the manual pages termios(4), sio(4), and stty(1) for information on the terminal settings, locking and initializing devices, and setting terminal options, respectively.
24.2.5 Serial Port Configuration
The ttydN (or cuadN) device is the regular device you will want to open for your applications. When a process opens the device, it will have a default set of terminal I/O settings. You can see these settings with the command
# stty -a -f /dev/ttyd1
When you change the settings to this device, the settings are in effect until the
device is closed. When it is reopened, it goes back to the default set. To make changes
to the default set, you can open and adjust the settings of the “initial
state” device. For example, to turn on CLOCAL mode, 8
bit communication, and XON/XOFF flow control by default for
ttyd5, type:
# stty -f /dev/ttyd5.init clocal cs8 ixon ixoff
System-wide initialization of the serial devices is controlled in /etc/rc.d/serial. This file affects the default settings of serial devices.
To prevent certain settings from being changed by an application, make adjustments to the “lock state” device. For example, to lock the speed of ttyd5 to 57600 bps, type:
# stty -f /dev/ttyd5.lock 57600
Now, an application that opens ttyd5 and tries to change the speed of the port will be stuck with 57600 bps.
Naturally, you should make the initial state and lock state devices writable only by the root account.
24.3 Terminals
Contributed by Sean Kelly.Terminals provide a convenient and low-cost way to access your FreeBSD system when you are not at the computer's console or on a connected network. This section describes how to use terminals with FreeBSD.
24.3.1 Uses and Types of Terminals
The original UNIX systems did not have consoles. Instead, people logged in and ran programs through terminals that were connected to the computer's serial ports. It is quite similar to using a modem and terminal software to dial into a remote system to do text-only work.
Today's PCs have consoles capable of high quality graphics, but the ability to establish a login session on a serial port still exists in nearly every UNIX style operating system today; FreeBSD is no exception. By using a terminal attached to an unused serial port, you can log in and run any text program that you would normally run on the console or in an xterm window in the X Window System.
For the business user, you can attach many terminals to a FreeBSD system and place them on your employees' desktops. For a home user, a spare computer such as an older IBM PC or a Macintosh can be a terminal wired into a more powerful computer running FreeBSD. You can turn what might otherwise be a single-user computer into a powerful multiple user system.
For FreeBSD, there are three kinds of terminals:
The remaining subsections describe each kind.
24.3.1.1 Dumb Terminals
Dumb terminals are specialized pieces of hardware that let you connect to computers over serial lines. They are called “dumb” because they have only enough computational power to display, send, and receive text. You cannot run any programs on them. It is the computer to which you connect them that has all the power to run text editors, compilers, email, games, and so forth.
There are hundreds of kinds of dumb terminals made by many manufacturers, including Digital Equipment Corporation's VT-100 and Wyse's WY-75. Just about any kind will work with FreeBSD. Some high-end terminals can even display graphics, but only certain software packages can take advantage of these advanced features.
Dumb terminals are popular in work environments where workers do not need access to graphical applications such as those provided by the X Window System.
24.3.1.2 PCs Acting as Terminals
If a dumb terminal has just enough ability to display, send, and receive text, then certainly any spare personal computer can be a dumb terminal. All you need is the proper cable and some terminal emulation software to run on the computer.
Such a configuration is popular in homes. For example, if your spouse is busy working on your FreeBSD system's console, you can do some text-only work at the same time from a less powerful personal computer hooked up as a terminal to the FreeBSD system.
There are at least two utilities in the base-system of FreeBSD that can be used to work through a serial connection: cu(1) and tip(1).
To connect from a client system that runs FreeBSD to the serial connection of another system, you can use:
# cu -l serial-port-device
Where “serial-port-device” is the name of a special device file denoting a serial port of your system. These device files are called /dev/cuaaN for FreeBSD versions older than 6.0, and /dev/cuadN for 6.0 and later versions.
The “N”-part of a device name is the serial port number.
Note: Note that device numbers in FreeBSD start from zero and not one (like they do, for instance in MS-DOS-derived systems). This means that what MS-DOS-based systems call “COM1” is usually /dev/cuad0 in FreeBSD.
Note: Some people prefer to use other programs, available through the Ports Collection. The Ports include quite a few utilities which can work in ways similar to cu(1) and tip(1), i.e. comms/minicom.
24.3.1.3 X Terminals
X terminals are the most sophisticated kind of terminal available. Instead of connecting to a serial port, they usually connect to a network like Ethernet. Instead of being relegated to text-only applications, they can display any X application.
We introduce X terminals just for the sake of completeness. However, this chapter does not cover setup, configuration, or use of X terminals.
24.3.2 Configuration
This section describes what you need to configure on your FreeBSD system to enable a login session on a terminal. It assumes you have already configured your kernel to support the serial port to which the terminal is connected--and that you have connected it.
Recall from Chapter 12 that the init process is responsible for all process control and initialization at system startup. One of the tasks performed by init is to read the /etc/ttys file and start a getty process on the available terminals. The getty process is responsible for reading a login name and starting the login program.
Thus, to configure terminals for your FreeBSD system the following steps should be taken as root:
-
Add a line to /etc/ttys for the entry in the /dev directory for the serial port if it is not already there.
-
Specify that /usr/libexec/getty be run on the port, and specify the appropriate getty type from the /etc/gettytab file.
-
Specify the default terminal type.
-
Set the port to “on.”
-
Specify whether the port should be “secure.”
-
Force init to reread the /etc/ttys file.
As an optional step, you may wish to create a custom getty type for use in step 2 by making an entry in /etc/gettytab. This chapter does not explain how to do so; you are encouraged to see the gettytab(5) and the getty(8) manual pages for more information.
24.3.2.1 Adding an Entry to /etc/ttys
The /etc/ttys file lists all of the ports on your FreeBSD system where you want to allow logins. For example, the first virtual console ttyv0 has an entry in this file. You can log in on the console using this entry. This file also contains entries for the other virtual consoles, serial ports, and pseudo-ttys. For a hardwired terminal, just list the serial port's /dev entry without the /dev part (for example, /dev/ttyv0 would be listed as ttyv0).
A default FreeBSD install includes an /etc/ttys file with support for the first four serial ports: ttyd0 through ttyd3. If you are attaching a terminal to one of those ports, you do not need to add another entry.
Example 24-1. Adding Terminal Entries to /etc/ttys
Suppose we would like to connect two terminals to the system: a Wyse-50 and an old 286 IBM PC running Procomm terminal software emulating a VT-100 terminal. We connect the Wyse to the second serial port and the 286 to the sixth serial port (a port on a multiport serial card). The corresponding entries in the /etc/ttys file would look like this:
ttyd1 "/usr/libexec/getty std.38400" wy50 on insecure
ttyd5 "/usr/libexec/getty std.19200" vt100 on insecure
- The first field normally specifies the name of the terminal special file as it is found in /dev.
- The second field is the command to execute for this line, which is usually getty(8). getty initializes and opens the line, sets the speed, prompts for a user name and then executes the login(1) program.
-
The getty program accepts one (optional) parameter on its command line, the getty type. A getty type configures characteristics on the terminal line, like bps rate and parity. The getty program reads these characteristics from the file /etc/gettytab.
-
The file /etc/gettytab contains lots of entries for terminal lines both old and new. In almost all cases, the entries that start with the text std will work for hardwired terminals. These entries ignore parity. There is a std entry for each bps rate from 110 to 115200. Of course, you can add your own entries to this file. The gettytab(5) manual page provides more information.
-
When setting the getty type in the /etc/ttys file, make sure that the communications settings on the terminal match.
-
For our example, the Wyse-50 uses no parity and connects at 38400 bps. The 286 PC uses no parity and connects at 19200 bps.
- The third field is the type of terminal usually connected to that tty line. For dial-up ports, unknown or dialup is typically used in this field since users may dial up with practically any type of terminal or software. For hardwired terminals, the terminal type does not change, so you can put a real terminal type from the termcap(5) database file in this field.
-
For our example, the Wyse-50 uses the real terminal type while the 286 PC running Procomm will be set to emulate at VT-100.
- The fourth field specifies if the port should be enabled. Putting on here will have the init process start the program in the second field, getty. If you put off in this field, there will be no getty, and hence no logins on the port.
- The final field is used to specify whether the port is secure. Marking a port as secure means that you trust it enough to allow the root account (or any account with a user ID of 0) to login from that port. Insecure ports do not allow root logins. On an insecure port, users must login from unprivileged accounts and then use su(1) or a similar mechanism to gain superuser privileges.
-
It is highly recommended that you use “insecure” even for terminals that are behind locked doors. It is quite easy to login and use su if you need superuser privileges.
24.3.2.2 Force init to Reread /etc/ttys
After making the necessary changes to the /etc/ttys file you should send a SIGHUP (hangup) signal to the init process to force it to re-read its configuration file. For example:
# kill -HUP 1
Note: init is always the first process run on a system, therefore it will always have PID 1.
If everything is set up correctly, all cables are in place, and the terminals are powered up, then a getty process should be running on each terminal and you should see login prompts on your terminals at this point.
24.3.3 Troubleshooting Your Connection
Even with the most meticulous attention to detail, something could still go wrong while setting up a terminal. Here is a list of symptoms and some suggested fixes.
24.3.3.1 No Login Prompt Appears
Make sure the terminal is plugged in and powered up. If it is a personal computer acting as a terminal, make sure it is running terminal emulation software on the correct serial port.
Make sure the cable is connected firmly to both the terminal and the FreeBSD computer. Make sure it is the right kind of cable.
Make sure the terminal and FreeBSD agree on the bps rate and parity settings. If you have a video display terminal, make sure the contrast and brightness controls are turned up. If it is a printing terminal, make sure paper and ink are in good supply.
Make sure that a getty process is running and serving the terminal. For example, to get a list of running getty processes with ps, type:
# ps -axww|grep getty
You should see an entry for the terminal. For example, the following display shows that a getty is running on the second serial port ttyd1 and is using the std.38400 entry in /etc/gettytab:
22189 d1 Is+ 0:00.03 /usr/libexec/getty std.38400 ttyd1
If no getty process is running, make sure you have enabled the port in /etc/ttys. Also remember to run kill -HUP 1 after modifying the ttys file.
If the getty process is running but the terminal still does not display a login prompt, or if it displays a prompt but will not allow you to type, your terminal or cable may not support hardware handshaking. Try changing the entry in /etc/ttys from std.38400 to 3wire.38400 (remember to run kill -HUP 1 after modifying /etc/ttys). The 3wire entry is similar to std, but ignores hardware handshaking. You may need to reduce the baud rate or enable software flow control when using 3wire to prevent buffer overflows.
24.3.3.2 If Garbage Appears Instead of a Login Prompt
Make sure the terminal and FreeBSD agree on the bps rate and parity settings. Check the getty processes to make sure the correct getty type is in use. If not, edit /etc/ttys and run kill -HUP 1.
24.3.3.3 Characters Appear Doubled; the Password Appears When Typed
Switch the terminal (or the terminal emulation software) from “half duplex” or “local echo” to “full duplex.”
24.4 Dial-in Service
Contributed by Guy Helmer. Additions by Sean Kelly.Configuring your FreeBSD system for dial-in service is very similar to connecting terminals except that you are dealing with modems instead of terminals.
24.4.1 External vs. Internal Modems
External modems seem to be more convenient for dial-up, because external modems often can be semi-permanently configured via parameters stored in non-volatile RAM and they usually provide lighted indicators that display the state of important RS-232 signals. Blinking lights impress visitors, but lights are also very useful to see whether a modem is operating properly.
Internal modems usually lack non-volatile RAM, so their configuration may be limited only to setting DIP switches. If your internal modem has any signal indicator lights, it is probably difficult to view the lights when the system's cover is in place.
24.4.1.1 Modems and Cables
If you are using an external modem, then you will of course need the proper cable. A standard RS-232C serial cable should suffice as long as all of the normal signals are wired:
Table 24-4. Signal Names
| Acronyms | Names |
|---|---|
| RD | Received Data |
| TD | Transmitted Data |
| DTR | Data Terminal Ready |
| DSR | Data Set Ready |
| DCD | Data Carrier Detect (RS-232's Received Line Signal Detector) |
| SG | Signal Ground |
| RTS | Request to Send |
| CTS | Clear to Send |
FreeBSD needs the RTS and CTS signals for flow control at speeds above 2400 bps, the CD signal to detect when a call has been answered or the line has been hung up, and the DTR signal to reset the modem after a session is complete. Some cables are wired without all of the needed signals, so if you have problems, such as a login session not going away when the line hangs up, you may have a problem with your cable.
Like other UNIX like operating systems, FreeBSD uses the hardware signals to find out when a call has been answered or a line has been hung up and to hangup and reset the modem after a call. FreeBSD avoids sending commands to the modem or watching for status reports from the modem. If you are familiar with connecting modems to PC-based bulletin board systems, this may seem awkward.
24.4.2 Serial Interface Considerations
FreeBSD supports NS8250-, NS16450-, NS16550-, and NS16550A-based EIA RS-232C (CCITT V.24) communications interfaces. The 8250 and 16450 devices have single-character buffers. The 16550 device provides a 16-character buffer, which allows for better system performance. (Bugs in plain 16550's prevent the use of the 16-character buffer, so use 16550A's if possible). Because single-character-buffer devices require more work by the operating system than the 16-character-buffer devices, 16550A-based serial interface cards are much preferred. If the system has many active serial ports or will have a heavy load, 16550A-based cards are better for low-error-rate communications.
24.4.3 Quick Overview
As with terminals, init spawns a getty process for each configured serial port for dial-in connections. For example, if a modem is attached to /dev/ttyd0, the command ps ax might show this:
4850 ?? I 0:00.09 /usr/libexec/getty V19200 ttyd0
When a user dials the modem's line and the modems connect, the CD (Carrier Detect) line is reported by the modem. The kernel notices that carrier has been detected and completes getty's open of the port. getty sends a login: prompt at the specified initial line speed. getty watches to see if legitimate characters are received, and, in a typical configuration, if it finds junk (probably due to the modem's connection speed being different than getty's speed), getty tries adjusting the line speeds until it receives reasonable characters.
After the user enters his/her login name, getty executes /usr/bin/login, which completes the login by asking for the user's password and then starting the user's shell.
24.4.4 Configuration Files
There are three system configuration files in the /etc directory that you will probably need to edit to allow dial-up access to your FreeBSD system. The first, /etc/gettytab, contains configuration information for the /usr/libexec/getty daemon. Second, /etc/ttys holds information that tells /sbin/init what tty devices should have getty processes running on them. Lastly, you can place port initialization commands in the /etc/rc.d/serial script.
There are two schools of thought regarding dial-up modems on UNIX. One group likes to configure their modems and systems so that no matter at what speed a remote user dials in, the local computer-to-modem RS-232 interface runs at a locked speed. The benefit of this configuration is that the remote user always sees a system login prompt immediately. The downside is that the system does not know what a user's true data rate is, so full-screen programs like Emacs will not adjust their screen-painting methods to make their response better for slower connections.
The other school configures their modems' RS-232 interface to vary its speed based on the remote user's connection speed. For example, V.32bis (14.4 Kbps) connections to the modem might make the modem run its RS-232 interface at 19.2 Kbps, while 2400 bps connections make the modem's RS-232 interface run at 2400 bps. Because getty does not understand any particular modem's connection speed reporting, getty gives a login: message at an initial speed and watches the characters that come back in response. If the user sees junk, it is assumed that they know they should press the Enter key until they see a recognizable prompt. If the data rates do not match, getty sees anything the user types as “junk”, tries going to the next speed and gives the login: prompt again. This procedure can continue ad nauseam, but normally only takes a keystroke or two before the user sees a good prompt. Obviously, this login sequence does not look as clean as the former “locked-speed” method, but a user on a low-speed connection should receive better interactive response from full-screen programs.
This section will try to give balanced configuration information, but is biased towards having the modem's data rate follow the connection rate.
24.4.4.1 /etc/gettytab
/etc/gettytab is a termcap(5)-style file of configuration information for getty(8). Please see the gettytab(5) manual page for complete information on the format of the file and the list of capabilities.
24.4.4.1.1 Locked-speed Config
If you are locking your modem's data communications rate at a particular speed, you probably will not need to make any changes to /etc/gettytab.
24.4.4.1.2 Matching-speed Config
You will need to set up an entry in /etc/gettytab to give getty information about the speeds you wish to use for your modem. If you have a 2400 bps modem, you can probably use the existing D2400 entry.
#
# Fast dialup terminals, 2400/1200/300 rotary (can start either way)
#
D2400|d2400|Fast-Dial-2400:\
:nx=D1200:tc=2400-baud:
3|D1200|Fast-Dial-1200:\
:nx=D300:tc=1200-baud:
5|D300|Fast-Dial-300:\
:nx=D2400:tc=300-baud:
If you have a higher speed modem, you will probably need to add an entry in /etc/gettytab; here is an entry you could use for a 14.4 Kbps modem with a top interface speed of 19.2 Kbps:
#
# Additions for a V.32bis Modem
#
um|V300|High Speed Modem at 300,8-bit:\
:nx=V19200:tc=std.300:
un|V1200|High Speed Modem at 1200,8-bit:\
:nx=V300:tc=std.1200:
uo|V2400|High Speed Modem at 2400,8-bit:\
:nx=V1200:tc=std.2400:
up|V9600|High Speed Modem at 9600,8-bit:\
:nx=V2400:tc=std.9600:
uq|V19200|High Speed Modem at 19200,8-bit:\
:nx=V9600:tc=std.19200:
This will result in 8-bit, no parity connections.
The example above starts the communications rate at 19.2 Kbps (for a V.32bis connection), then cycles through 9600 bps (for V.32), 2400 bps, 1200 bps, 300 bps, and back to 19.2 Kbps. Communications rate cycling is implemented with the nx= (“next table”) capability. Each of the lines uses a tc= (“table continuation”) entry to pick up the rest of the “standard” settings for a particular data rate.
If you have a 28.8 Kbps modem and/or you want to take advantage of compression on a 14.4 Kbps modem, you need to use a higher communications rate than 19.2 Kbps. Here is an example of a gettytab entry starting a 57.6 Kbps:
#
# Additions for a V.32bis or V.34 Modem
# Starting at 57.6 Kbps
#
vm|VH300|Very High Speed Modem at 300,8-bit:\
:nx=VH57600:tc=std.300:
vn|VH1200|Very High Speed Modem at 1200,8-bit:\
:nx=VH300:tc=std.1200:
vo|VH2400|Very High Speed Modem at 2400,8-bit:\
:nx=VH1200:tc=std.2400:
vp|VH9600|Very High Speed Modem at 9600,8-bit:\
:nx=VH2400:tc=std.9600:
vq|VH57600|Very High Speed Modem at 57600,8-bit:\
:nx=VH9600:tc=std.57600:
If you have a slow CPU or a heavily loaded system and do not have 16550A-based serial ports, you may receive “sio” “silo” errors at 57.6 Kbps.
24.4.4.2 /etc/ttys
Configuration of the /etc/ttys file was covered in Example 24-1. Configuration for modems is similar but we must pass a different argument to getty and specify a different terminal type. The general format for both locked-speed and matching-speed configurations is:
ttyd0 "/usr/libexec/getty xxx" dialup on
The first item in the above line is the device special file for this entry -- ttyd0 means /dev/ttyd0 is the file that this getty will be watching. The second item, "/usr/libexec/getty xxx" (xxx will be replaced by the initial gettytab capability) is the process init will run on the device. The third item, dialup, is the default terminal type. The fourth parameter, on, indicates to init that the line is operational. There can be a fifth parameter, secure, but it should only be used for terminals which are physically secure (such as the system console).
The default terminal type (dialup in the example above) may depend on local preferences. dialup is the traditional default terminal type on dial-up lines so that users may customize their login scripts to notice when the terminal is dialup and automatically adjust their terminal type. However, the author finds it easier at his site to specify vt102 as the default terminal type, since the users just use VT102 emulation on their remote systems.
After you have made changes to /etc/ttys, you may send the init process a HUP signal to re-read the file. You can use the command
# kill -HUP 1
to send the signal. If this is your first time setting up the system, you may want to
wait until your modem(s) are properly configured and connected before signaling init. 24.4.4.2.1 Locked-speed Config
For a locked-speed configuration, your ttys entry needs to have a fixed-speed entry provided to getty. For a modem whose port speed is locked at 19.2 Kbps, the ttys entry might look like this:
ttyd0 "/usr/libexec/getty std.19200" dialup on
If your modem is locked at a different data rate, substitute the appropriate value for std.speed instead of std.19200. Make sure that you use a valid type listed in /etc/gettytab.
24.4.4.2.2 Matching-speed Config
In a matching-speed configuration, your ttys entry needs to reference the appropriate beginning “auto-baud” (sic) entry in /etc/gettytab. For example, if you added the above suggested entry for a matching-speed modem that starts at 19.2 Kbps (the gettytab entry containing the V19200 starting point), your ttys entry might look like this:
ttyd0 "/usr/libexec/getty V19200" dialup on
24.4.4.3 /etc/rc.d/serial
High-speed modems, like V.32, V.32bis, and V.34 modems, need to use hardware (RTS/CTS) flow control. You can add stty commands to /etc/rc.d/serial to set the hardware flow control flag in the FreeBSD kernel for the modem ports.
For example to set the termios flag crtscts on serial port #1's (COM2)
dial-in and dial-out initialization devices, the following lines could be added to /etc/rc.d/serial:
# Serial port initial configuration
stty -f /dev/ttyd1.init crtscts
stty -f /dev/cuad1.init crtscts
24.4.5 Modem Settings
If you have a modem whose parameters may be permanently set in non-volatile RAM, you will need to use a terminal program (such as Telix under MS-DOS or tip under FreeBSD) to set the parameters. Connect to the modem using the same communications speed as the initial speed getty will use and configure the modem's non-volatile RAM to match these requirements:
-
CD asserted when connected
-
DTR asserted for operation; dropping DTR hangs up line and resets modem
-
CTS transmitted data flow control
-
Disable XON/XOFF flow control
-
RTS received data flow control
-
Quiet mode (no result codes)
-
No command echo
Please read the documentation for your modem to find out what commands and/or DIP switch settings you need to give it.
For example, to set the above parameters on a U.S. Robotics® Sportster® 14,400 external modem, one could give these commands to the modem:
ATZ
AT&C1&D2&H1&I0&R2&W
You might also want to take this opportunity to adjust other settings in the modem, such as whether it will use V.42bis and/or MNP5 compression.
The U.S. Robotics Sportster 14,400 external modem also has some DIP switches that need to be set; for other modems, perhaps you can use these settings as an example:
-
Switch 1: UP -- DTR Normal
-
Switch 2: N/A (Verbal Result Codes/Numeric Result Codes)
-
Switch 3: UP -- Suppress Result Codes
-
Switch 4: DOWN -- No echo, offline commands
-
Switch 5: UP -- Auto Answer
-
Switch 6: UP -- Carrier Detect Normal
-
Switch 7: UP -- Load NVRAM Defaults
-
Switch 8: N/A (Smart Mode/Dumb Mode)
Result codes should be disabled/suppressed for dial-up modems to avoid problems that can occur if getty mistakenly gives a login: prompt to a modem that is in command mode and the modem echoes the command or returns a result code. This sequence can result in a extended, silly conversation between getty and the modem.
24.4.5.1 Locked-speed Config
For a locked-speed configuration, you will need to configure the modem to maintain a constant modem-to-computer data rate independent of the communications rate. On a U.S. Robotics Sportster 14,400 external modem, these commands will lock the modem-to-computer data rate at the speed used to issue the commands:
ATZ
AT&B1&W
24.4.5.2 Matching-speed Config
For a variable-speed configuration, you will need to configure your modem to adjust its serial port data rate to match the incoming call rate. On a U.S. Robotics Sportster 14,400 external modem, these commands will lock the modem's error-corrected data rate to the speed used to issue the commands, but allow the serial port rate to vary for non-error-corrected connections:
ATZ
AT&B2&W
24.4.5.3 Checking the Modem's Configuration
Most high-speed modems provide commands to view the modem's current operating parameters in a somewhat human-readable fashion. On the U.S. Robotics Sportster 14,400 external modems, the command ATI5 displays the settings that are stored in the non-volatile RAM. To see the true operating parameters of the modem (as influenced by the modem's DIP switch settings), use the commands ATZ and then ATI4.
If you have a different brand of modem, check your modem's manual to see how to double-check your modem's configuration parameters.
24.4.6 Troubleshooting
Here are a few steps you can follow to check out the dial-up modem on your system.
24.4.6.1 Checking Out the FreeBSD System
Hook up your modem to your FreeBSD system, boot the system, and, if your modem has status indication lights, watch to see whether the modem's DTR indicator lights when the login: prompt appears on the system's console -- if it lights up, that should mean that FreeBSD has started a getty process on the appropriate communications port and is waiting for the modem to accept a call.
If the DTR indicator does not light, login to the FreeBSD system through the console and issue a ps ax to see if FreeBSD is trying to run a getty process on the correct port. You should see lines like these among the processes displayed:
114 ?? I 0:00.10 /usr/libexec/getty V19200 ttyd0
115 ?? I 0:00.10 /usr/libexec/getty V19200 ttyd1
If you see something different, like this:
114 d0 I 0:00.10 /usr/libexec/getty V19200 ttyd0
and the modem has not accepted a call yet, this means that getty has completed its open on the communications port. This could indicate a problem with the cabling or a mis-configured modem, because getty should not be able to open the communications port until CD (carrier detect) has been asserted by the modem.
If you do not see any getty processes waiting to open the desired ttydN port, double-check your entries in /etc/ttys to see if there are any mistakes there. Also, check the log file /var/log/messages to see if there are any log messages from init or getty regarding any problems. If there are any messages, triple-check the configuration files /etc/ttys and /etc/gettytab, as well as the appropriate device special files /dev/ttydN, for any mistakes, missing entries, or missing device special files.
24.4.6.2 Try Dialing In
Try dialing into the system; be sure to use 8 bits, no parity, and 1 stop bit on the remote system. If you do not get a prompt right away, or get garbage, try pressing Enter about once per second. If you still do not see a login: prompt after a while, try sending a BREAK. If you are using a high-speed modem to do the dialing, try dialing again after locking the dialing modem's interface speed (via AT&B1 on a U.S. Robotics Sportster modem, for example).
If you still cannot get a login: prompt, check /etc/gettytab again and double-check that
-
The initial capability name specified in /etc/ttys for the line matches a name of a capability in /etc/gettytab
-
Each nx= entry matches another gettytab capability name
-
Each tc= entry matches another gettytab capability name
If you dial but the modem on the FreeBSD system will not answer, make sure that the modem is configured to answer the phone when DTR is asserted. If the modem seems to be configured correctly, verify that the DTR line is asserted by checking the modem's indicator lights (if it has any).
If you have gone over everything several times and it still does not work, take a break and come back to it later. If it still does not work, perhaps you can send an electronic mail message to the FreeBSD general questions mailing list describing your modem and your problem, and the good folks on the list will try to help.
24.5 Dial-out Service
The following are tips for getting your host to be able to connect over the modem to another computer. This is appropriate for establishing a terminal session with a remote host.
This is useful to log onto a BBS.
This kind of connection can be extremely helpful to get a file on the Internet if you have problems with PPP. If you need to FTP something and PPP is broken, use the terminal session to FTP it. Then use zmodem to transfer it to your machine.
24.5.1 My Stock Hayes Modem Is Not Supported, What Can I Do?
Actually, the manual page for tip is out of date. There is a generic Hayes dialer already built in. Just use at=hayes in your /etc/remote file.
The Hayes driver is not smart enough to recognize some of the advanced features of newer modems--messages like BUSY, NO DIALTONE, or CONNECT 115200 will just confuse it. You should turn those messages off when you use tip (using ATX0&W).
Also, the dial timeout for tip is 60 seconds. Your modem should use something less, or else tip will think there is a communication problem. Try ATS7=45&W.
Note: As shipped, tip does not yet support Hayes modems fully. The solution is to edit the file tipconf.h in the directory /usr/src/usr.bin/tip/tip. Obviously you need the source distribution to do this.
Edit the line #define HAYES 0 to #define HAYES 1. Then make and make install. Everything works nicely after that.
24.5.2 How Am I Expected to Enter These AT Commands?
Make what is called a “direct” entry in your /etc/remote file. For example, if your modem is hooked up to the first serial port, /dev/cuad0, then put in the following line:
cuad0:dv=/dev/cuad0:br#19200:pa=none
Use the highest bps rate your modem supports in the br capability. Then, type tip cuad0 and you will be connected to your modem.
Or use cu as root with the following command:
# cu -lline -sspeed
line is the serial port (e.g./dev/cuad0) and speed is the speed (e.g.57600). When you are done entering the AT commands hit ~. to exit.
24.5.3 The @ Sign for the pn Capability Does Not Work!
The @ sign in the phone number capability tells tip to look in /etc/phones for a phone number. But the @ sign is also a special character in capability files like /etc/remote. Escape it with a backslash:
pn=\@
24.5.4 How Can I Dial a Phone Number on the Command Line?
Put what is called a “generic” entry in your /etc/remote file. For example:
tip115200|Dial any phone number at 115200 bps:\
:dv=/dev/cuad0:br#115200:at=hayes:pa=none:du:
tip57600|Dial any phone number at 57600 bps:\
:dv=/dev/cuad0:br#57600:at=hayes:pa=none:du:
Then you can do things like:
# tip -115200 5551234
If you prefer cu over tip, use a generic cu entry:
cu115200|Use cu to dial any number at 115200bps:\
:dv=/dev/cuad1:br#57600:at=hayes:pa=none:du:
and type:
# cu 5551234 -s 115200
24.5.5 Do I Have to Type in the bps Rate Every Time I Do That?
Put in an entry for tip1200 or cu1200, but go ahead and use whatever bps rate is appropriate with the br capability. tip thinks a good default is 1200 bps which is why it looks for a tip1200 entry. You do not have to use 1200 bps, though.
24.5.6 I Access a Number of Hosts Through a Terminal Server
Rather than waiting until you are connected and typing CONNECT <host> each time, use tip's cm capability. For example, these entries in /etc/remote:
pain|pain.deep13.com|Forrester's machine:\
:cm=CONNECT pain\n:tc=deep13:
muffin|muffin.deep13.com|Frank's machine:\
:cm=CONNECT muffin\n:tc=deep13:
deep13:Gizmonics Institute terminal server:\
:dv=/dev/cuad2:br#38400:at=hayes:du:pa=none:pn=5551234:
will let you type tip pain or tip muffin to connect to the hosts pain or muffin, and tip deep13 to get to the terminal server.
24.5.7 Can Tip Try More Than One Line for Each Site?
This is often a problem where a university has several modem lines and several thousand students trying to use them.
Make an entry for your university in /etc/remote and use @ for the pn capability:
big-university:\
:pn=\@:tc=dialout
dialout:\
:dv=/dev/cuad3:br#9600:at=courier:du:pa=none:
Then, list the phone numbers for the university in /etc/phones:
big-university 5551111
big-university 5551112
big-university 5551113
big-university 5551114
tip will try each one in the listed order, then give up. If you want to keep retrying, run tip in a while loop.
24.5.8 Why Do I Have to Hit Ctrl+P Twice to Send Ctrl+P Once?
Ctrl+P is the default “force” character, used to tell tip that the next character is literal data. You can set the force character to any other character with the ~s escape, which means “set a variable.”
Type ~sforce=single-char followed by a newline. single-char is any single character. If you leave out single-char, then the force character is the nul character, which you can get by typing Ctrl+2 or Ctrl+Space. A pretty good value for single-char is Shift+Ctrl+6, which is only used on some terminal servers.
You can have the force character be whatever you want by specifying the following in your $HOME/.tiprc file:
force=<single-char>
24.5.9 Suddenly Everything I Type Is in Upper Case??
You must have pressed Ctrl+A, tip's “raise character,” specially designed for people with broken caps-lock keys. Use ~s as above and set the variable raisechar to something reasonable. In fact, you can set it to the same as the force character, if you never expect to use either of these features.
Here is a sample .tiprc file perfect for Emacs users who need to type Ctrl+2 and Ctrl+A a lot:
force=^^
raisechar=^^
The ^^ is Shift+Ctrl+6.
24.5.10 How Can I Do File Transfers with tip?
If you are talking to another UNIX system, you can send and receive files with ~p (put) and ~t (take). These commands run cat and echo on the remote system to accept and send files. The syntax is:
~p local-file [remote-file]
~t remote-file [local-file]
There is no error checking, so you probably should use another protocol, like zmodem.
24.5.11 How Can I Run zmodem with tip?
To receive files, start the sending program on the remote end. Then, type ~C rz to begin receiving them locally.
To send files, start the receiving program on the remote end. Then, type ~C sz files to send them to the remote system.
24.6 Setting Up the Serial Console
Contributed by Kazutaka YOKOTA. Based on a document by Bill Paul.24.6.1 Introduction
FreeBSD has the ability to boot on a system with only a dumb terminal on a serial port as a console. Such a configuration should be useful for two classes of people: system administrators who wish to install FreeBSD on machines that have no keyboard or monitor attached, and developers who want to debug the kernel or device drivers.
As described in Chapter 12, FreeBSD employs a three stage bootstrap. The first two stages are in the boot block code which is stored at the beginning of the FreeBSD slice on the boot disk. The boot block will then load and run the boot loader (/boot/loader) as the third stage code.
In order to set up the serial console you must configure the boot block code, the boot loader code and the kernel.
24.6.2 Serial Console Configuration, Terse Version
This section assumes that you are using the default setup and just want a fast overview of setting up the serial console.
-
Connect the serial cable to COM1 and the controlling terminal.
-
To see all boot messages on the serial console, issue the following command while logged in as the superuser:
# echo 'console="comconsole"' >> /boot/loader.conf -
Edit /etc/ttys and change off to on and dialup to vt100 for the ttyd0 entry. Otherwise a password will not be required to connect via the serial console, resulting in a potential security hole.
-
Reboot the system to see if the changes took effect.
If a different configuration is required, a more in depth configuration explanation exists in Section 24.6.3.
24.6.3 Serial Console Configuration
-
Prepare a serial cable.
You will need either a null-modem cable or a standard serial cable and a null-modem adapter. See Section 24.2.2 for a discussion on serial cables.
-
Unplug your keyboard.
Most PC systems probe for the keyboard during the Power-On Self-Test (POST) and will generate an error if the keyboard is not detected. Some machines complain loudly about the lack of a keyboard and will not continue to boot until it is plugged in.
If your computer complains about the error, but boots anyway, then you do not have to do anything special. (Some machines with Phoenix BIOS installed merely say “Keyboard failed” and continue to boot normally.)
If your computer refuses to boot without a keyboard attached then you will have to configure the BIOS so that it ignores this error (if it can). Consult your motherboard's manual for details on how to do this.
Tip: Set the keyboard to “Not installed” in the BIOS setup. You will still be able to use your keyboard. All this does is tell the BIOS not to probe for a keyboard at power-on. Your BIOS should not complain if the keyboard is absent. You can leave the keyboard plugged in even with this flag set to “Not installed” and the keyboard will still work.
Note: If your system has a PS/2® mouse, chances are very good that you may have to unplug your mouse as well as your keyboard. This is because PS/2 mice share some hardware with the keyboard and leaving the mouse plugged in can fool the keyboard probe into thinking the keyboard is still there. It is said that a Gateway 2000 Pentium 90 MHz system with an AMI BIOS that behaves this way. In general, this is not a problem since the mouse is not much good without the keyboard anyway.
-
Plug a dumb terminal into COM1 (sio0).
If you do not have a dumb terminal, you can use an old PC/XT with a modem program, or the serial port on another UNIX box. If you do not have a COM1 (sio0), get one. At this time, there is no way to select a port other than COM1 for the boot blocks without recompiling the boot blocks. If you are already using COM1 for another device, you will have to temporarily remove that device and install a new boot block and kernel once you get FreeBSD up and running. (It is assumed that COM1 will be available on a file/compute/terminal server anyway; if you really need COM1 for something else (and you cannot switch that something else to COM2 (sio1)), then you probably should not even be bothering with all this in the first place.)
-
Make sure the configuration file of your kernel has appropriate flags set for COM1 (sio0).
Relevant flags are:
- 0x10
-
Enables console support for this unit. The other console flags are ignored unless this is set. Currently, at most one unit can have console support; the first one (in config file order) with this flag set is preferred. This option alone will not make the serial port the console. Set the following flag or use the
-hoption described below, together with this flag. - 0x20
-
Forces this unit to be the console (unless there is another higher priority console), regardless of the
-hoption discussed below. The flag 0x20 must be used together with the0x10flag. - 0x40
-
Reserves this unit (in conjunction with 0x10) and makes the unit unavailable for normal access. You should not set this flag to the serial port unit which you want to use as the serial console. The only use of this flag is to designate the unit for kernel remote debugging. See The Developer's Handbook for more information on remote debugging.
Example:
device sio0 at isa? port IO_COM1 flags 0x10 irq 4See the sio(4) manual page for more details.
If the flags were not set, you need to run UserConfig (on a different console) or recompile the kernel.
-
Create boot.config in the root directory of the a partition on the boot drive.
This file will instruct the boot block code how you would like to boot the system. In order to activate the serial console, you need one or more of the following options--if you want multiple options, include them all on the same line:
-h-
Toggles internal and serial consoles. You can use this to switch console devices. For instance, if you boot from the internal (video) console, you can use
-hto direct the boot loader and the kernel to use the serial port as its console device. Alternatively, if you boot from the serial port, you can use the-hto tell the boot loader and the kernel to use the video display as the console instead. -D-
Toggles single and dual console configurations. In the single configuration the console will be either the internal console (video display) or the serial port, depending on the state of the
-hoption above. In the dual console configuration, both the video display and the serial port will become the console at the same time, regardless of the state of the-hoption. However, note that the dual console configuration takes effect only during the boot block is running. Once the boot loader gets control, the console specified by the-hoption becomes the only console. -P-
Makes the boot block probe the keyboard. If no keyboard is found, the
-Dand-hoptions are automatically set.Note: Due to space constraints in the current version of the boot blocks, the
-Poption is capable of detecting extended keyboards only. Keyboards with less than 101 keys (and without F11 and F12 keys) may not be detected. Keyboards on some laptop computers may not be properly found because of this limitation. If this is the case with your system, you have to abandon using the-Poption. Unfortunately there is no workaround for this problem.
Use either the
-Poption to select the console automatically, or the-hoption to activate the serial console.You may include other options described in boot(8) as well.
The options, except for
-P, will be passed to the boot loader (/boot/loader). The boot loader will determine which of the internal video or the serial port should become the console by examining the state of the-hoption alone. This means that if you specify the-Doption but not the-hoption in /boot.config, you can use the serial port as the console only during the boot block; the boot loader will use the internal video display as the console. -
Boot the machine.
When you start your FreeBSD box, the boot blocks will echo the contents of /boot.config to the console. For example:
/boot.config: -P Keyboard: noThe second line appears only if you put
-Pin /boot.config and indicates presence/absence of the keyboard. These messages go to either serial or internal console, or both, depending on the option in /boot.config.Options Message goes to none internal console -hserial console -Dserial and internal consoles -Dhserial and internal consoles -P, keyboard presentinternal console -P, keyboard absentserial console After the above messages, there will be a small pause before the boot blocks continue loading the boot loader and before any further messages printed to the console. Under normal circumstances, you do not need to interrupt the boot blocks, but you may want to do so in order to make sure things are set up correctly.
Hit any key, other than Enter, at the console to interrupt the boot process. The boot blocks will then prompt you for further action. You should now see something like:
>> FreeBSD/i386 BOOT Default: 0:ad(0,a)/boot/loader boot:Verify the above message appears on either the serial or internal console or both, according to the options you put in /boot.config. If the message appears in the correct console, hit Enter to continue the boot process.
If you want the serial console but you do not see the prompt on the serial terminal, something is wrong with your settings. In the meantime, you enter
-hand hit Enter/Return (if possible) to tell the boot block (and then the boot loader and the kernel) to choose the serial port for the console. Once the system is up, go back and check what went wrong.
After the boot loader is loaded and you are in the third stage of the boot process you can still switch between the internal console and the serial console by setting appropriate environment variables in the boot loader. See Section 24.6.6.
24.6.4 Summary
Here is the summary of various settings discussed in this section and the console eventually selected.
24.6.4.1 Case 1: You Set the Flags to 0x10 for sio0
device sio0 at isa? port IO_COM1 flags 0x10 irq 4
| Options in /boot.config | Console during boot blocks | Console during boot loader | Console in kernel |
|---|---|---|---|
| nothing | internal | internal | internal |
-h |
serial | serial | serial |
-D |
serial and internal | internal | internal |
-Dh |
serial and internal | serial | serial |
-P, keyboard present |
internal | internal | internal |
-P, keyboard absent |
serial and internal | serial | serial |
24.6.4.2 Case 2: You Set the Flags to 0x30 for sio0
device sio0 at isa? port IO_COM1 flags 0x30 irq 4
| Options in /boot.config | Console during boot blocks | Console during boot loader | Console in kernel |
|---|---|---|---|
| nothing | internal | internal | serial |
-h |
serial | serial | serial |
-D |
serial and internal | internal | serial |
-Dh |
serial and internal | serial | serial |
-P, keyboard present |
internal | internal | serial |
-P, keyboard absent |
serial and internal | serial | serial |
24.6.5 Tips for the Serial Console
24.6.5.1 Setting a Faster Serial Port Speed
By default, the serial port settings are: 9600 baud, 8 bits, no parity, and 1 stop bit. If you wish to change the default console speed, you have the following options:
-
Recompile the boot blocks with BOOT_COMCONSOLE_SPEED set to the new console speed. See Section 24.6.5.2 for detailed instructions about building and installing new boot blocks.
If the serial console is configured in some other way than by booting with
-h, or if the serial console used by the kernel is different from the one used by the boot blocks, then you must also add the following option to the kernel configuration file and compile a new kernel:options CONSPEED=19200 -
Use the
-Sboot option of the kernel. The-Scommand line option can be added to /boot.config. See the boot(8) manual page for a description of how to add options to /boot.config and a list of the supported options. -
Enable the
comconsole_speedoption in your /boot/loader.conf file.This option depends on
console,boot_serial, andboot_multiconsbeing set in /boot/loader.conf too. An example of usingcomconsole_speedto change the serial console speed is:boot_multicons="YES" boot_serial="YES" comconsole_speed="115200" console="comconsole,vidconsole"
Note: FreeBSD versions before 6.1-RELEASE do not support the
-Sor thecomconsole_speedoption in /boot/loader.conf, so you will have to recompile the boot blocks if you are using such a version of FreeBSD.
24.6.5.2 Using Serial Port Other Than sio0 for the Console
Using a port other than sio0 as the console requires some recompiling. If you want to use another serial port for whatever reasons, recompile the boot blocks, the boot loader and the kernel as follows.
-
Get the kernel source. (See Chapter 23)
-
Edit /etc/make.conf and set BOOT_COMCONSOLE_PORT to the address of the port you want to use (0x3F8, 0x2F8, 0x3E8 or 0x2E8). Only sio0 through sio3 (COM1 through COM4) can be used; multiport serial cards will not work. No interrupt setting is needed.
-
Create a custom kernel configuration file and add appropriate flags for the serial port you want to use. For example, if you want to make sio1 (COM2) the console:
device sio1 at isa? port IO_COM2 flags 0x10 irq 3or
device sio1 at isa? port IO_COM2 flags 0x30 irq 3The console flags for the other serial ports should not be set.
-
Recompile and install the boot blocks and the boot loader:
# cd /sys/boot # make clean # make # make install -
Rebuild and install the kernel.
-
Write the boot blocks to the boot disk with bsdlabel(8) and boot from the new kernel.
24.6.5.3 Entering the DDB Debugger from the Serial Line
If you wish to drop into the kernel debugger from the serial console (useful for remote diagnostics, but also dangerous if you generate a spurious BREAK on the serial port!) then you should compile your kernel with the following options:
options BREAK_TO_DEBUGGER
options DDB
24.6.5.4 Getting a Login Prompt on the Serial Console
While this is not required, you may wish to get a login prompt over the serial line, now that you can see boot messages and can enter the kernel debugging session through the serial console. Here is how to do it.
Open the file /etc/ttys with an editor and locate the lines:
ttyd0 "/usr/libexec/getty std.9600" unknown off secure
ttyd1 "/usr/libexec/getty std.9600" unknown off secure
ttyd2 "/usr/libexec/getty std.9600" unknown off secure
ttyd3 "/usr/libexec/getty std.9600" unknown off secure
ttyd0 through ttyd3 corresponds to COM1 through COM4. Change off to on for the desired port. If you have changed the speed of the serial port, you need to change std.9600 to match the current setting, e.g. std.19200.
You may also want to change the terminal type from unknown to the actual type of your serial terminal.
After editing the file, you must kill -HUP 1 to make this change take effect.
24.6.6 Changing Console from the Boot Loader
Previous sections described how to set up the serial console by tweaking the boot block. This section shows that you can specify the console by entering some commands and environment variables in the boot loader. As the boot loader is invoked at the third stage of the boot process, after the boot block, the settings in the boot loader will override the settings in the boot block.
24.6.6.1 Setting Up the Serial Console
You can easily specify the boot loader and the kernel to use the serial console by writing just one line in /boot/loader.rc:
set console="comconsole"
This will take effect regardless of the settings in the boot block discussed in the previous section.
You had better put the above line as the first line of /boot/loader.rc so as to see boot messages on the serial console as early as possible.
Likewise, you can specify the internal console as:
set console="vidconsole"
If you do not set the boot loader environment variable console,
the boot loader, and subsequently the kernel, will use whichever console indicated by the
-h option in the boot block.
In versions 3.2 or later, you may specify the console in /boot/loader.conf.local or /boot/loader.conf, rather than in /boot/loader.rc. In this method your /boot/loader.rc should look like:
include /boot/loader.4th
start
Then, create /boot/loader.conf.local and put the following line there.
console=comconsole
or
console=vidconsole
See loader.conf(5) for more information.
Note: At the moment, the boot loader has no option equivalent to the
-Poption in the boot block, and there is no provision to automatically select the internal console and the serial console based on the presence of the keyboard.
24.6.6.2 Using a Serial Port Other Than sio0 for the Console
You need to recompile the boot loader to use a serial port other than sio0 for the serial console. Follow the procedure described in Section 24.6.5.2.
24.6.7 Caveats
The idea here is to allow people to set up dedicated servers that require no graphics hardware or attached keyboards. Unfortunately, while most systems will let you boot without a keyboard, there are quite a few that will not let you boot without a graphics adapter. Machines with AMI BIOSes can be configured to boot with no graphics adapter installed simply by changing the “graphics adapter” setting in the CMOS configuration to “Not installed.”
However, many machines do not support this option and will refuse to boot if you have no display hardware in the system. With these machines, you will have to leave some kind of graphics card plugged in, (even if it is just a junky mono board) although you will not have to attach a monitor. You might also try installing an AMI BIOS.
Chapter 25 PPP and SLIP
Restructured, reorganized, and updated by Jim Mock.25.1 Synopsis
FreeBSD has a number of ways to link one computer to another. To establish a network or Internet connection through a dial-up modem, or to allow others to do so through you, requires the use of PPP or SLIP. This chapter describes setting up these modem-based communication services in detail.
After reading this chapter, you will know:
-
How to set up user PPP.
-
How to set up kernel PPP.
-
How to set up PPPoE (PPP over Ethernet).
-
How to set up PPPoA (PPP over ATM).
-
How to configure and set up a SLIP client and server.
Before reading this chapter, you should:
-
Be familiar with basic network terminology.
-
Understand the basics and purpose of a dialup connection and PPP and/or SLIP.
You may be wondering what the main difference is between user PPP and kernel PPP. The answer is simple: user PPP processes the inbound and outbound data in userland rather than in the kernel. This is expensive in terms of copying the data between the kernel and userland, but allows a far more feature-rich PPP implementation. User PPP uses the tun device to communicate with the outside world whereas kernel PPP uses the ppp device.
Note: Throughout in this chapter, user PPP will simply be referred to as ppp unless a distinction needs to be made between it and any other PPP software such as pppd. Unless otherwise stated, all of the commands explained in this chapter should be executed as root.
25.2 Using User PPP
Updated and enhanced by Tom Rhodes. Originally contributed by Brian Somers. With input from Nik Clayton, Dirk Frömberg, and Peter Childs.25.2.1 User PPP
25.2.1.1 Assumptions
This document assumes you have the following:
-
An account with an Internet Service Provider (ISP) which you connect to using PPP.
-
You have a modem or other device connected to your system and configured correctly which allows you to connect to your ISP.
-
The dial-up number(s) of your ISP.
-
Your login name and password. (Either a regular UNIX style login and password pair, or a PAP or CHAP login and password pair.)
-
The IP address of one or more name servers. Normally, you will be given two IP addresses by your ISP to use for this. If they have not given you at least one, then you can use the enable dns command in ppp.conf and ppp will set the name servers for you. This feature depends on your ISPs PPP implementation supporting DNS negotiation.
The following information may be supplied by your ISP, but is not completely necessary:
-
The IP address of your ISP's gateway. The gateway is the machine to which you will connect and will be set up as your default route. If you do not have this information, we can make one up and your ISP's PPP server will tell us the correct value when we connect.
This IP number is referred to as HISADDR by ppp.
-
The netmask you should use. If your ISP has not provided you with one, you can safely use 255.255.255.255.
-
If your ISP provides you with a static IP address and hostname, you can enter it. Otherwise, we simply let the peer assign whatever IP address it sees fit.
If you do not have any of the required information, contact your ISP.
Note: Throughout this section, many of the examples showing the contents of configuration files are numbered by line. These numbers serve to aid in the presentation and discussion only and are not meant to be placed in the actual file. Proper indentation with tab and space characters is also important.
25.2.1.2 Automatic PPP Configuration
Both ppp and pppd (the kernel level implementation of PPP) use the configuration files located in the /etc/ppp directory. Examples for user ppp can be found in /usr/share/examples/ppp/.
Configuring ppp requires that you edit a number of files, depending on your requirements. What you put in them depends to some extent on whether your ISP allocates IP addresses statically (i.e., you get given one IP address, and always use that one) or dynamically (i.e., your IP address changes each time you connect to your ISP).
25.2.1.2.1 PPP and Static IP Addresses
You will need to edit the /etc/ppp/ppp.conf configuration file. It should look similar to the example below.
Note: Lines that end in a : start in the first column (beginning of the line)-- all other lines should be indented as shown using spaces or tabs.
1 default:
2 set log Phase Chat LCP IPCP CCP tun command
3 ident user-ppp VERSION (built COMPILATIONDATE)
4 set device /dev/cuaa0
5 set speed 115200
6 set dial "ABORT BUSY ABORT NO\\sCARRIER TIMEOUT 5 \
7 \"\" AT OK-AT-OK ATE1Q0 OK \\dATDT\\T TIMEOUT 40 CONNECT"
8 set timeout 180
9 enable dns
10
11 provider:
12 set phone "(123) 456 7890"
13 set authname foo
14 set authkey bar
15 set login "TIMEOUT 10 \"\" \"\" gin:--gin: \\U word: \\P col: ppp"
16 set timeout 300
17 set ifaddr x.x.x.x y.y.y.y 255.255.255.255 0.0.0.0
18 add default HISADDR
- Line 1:
-
Identifies the default entry. Commands in this entry are executed automatically when ppp is run.
- Line 2:
-
Enables logging parameters. When the configuration is working satisfactorily, this line should be reduced to saying
set log phase tunin order to avoid excessive log file sizes.
- Line 3:
-
Tells PPP how to identify itself to the peer. PPP identifies itself to the peer if it has any trouble negotiating and setting up the link, providing information that the peers administrator may find useful when investigating such problems.
- Line 4:
-
Identifies the device to which the modem is connected. COM1 is /dev/cuaa0 and COM2 is /dev/cuaa1.
- Line 5:
-
Sets the speed you want to connect at. If 115200 does not work (it should with any reasonably new modem), try 38400 instead.
- Line 6 & 7:
-
The dial string. User PPP uses an expect-send syntax similar to the chat(8) program. Refer to the manual page for information on the features of this language.
Note that this command continues onto the next line for readability. Any command in ppp.conf may do this if the last character on the line is a ``\'' character.
- Line 8:
-
Sets the idle timeout for the link. 180 seconds is the default, so this line is purely cosmetic.
- Line 9:
-
Tells PPP to ask the peer to confirm the local resolver settings. If you run a local name server, this line should be commented out or removed.
- Line 10:
-
A blank line for readability. Blank lines are ignored by PPP.
- Line 11:
-
Identifies an entry for a provider called “provider”. This could be changed to the name of your ISP so that later you can use the
load ISPto start the connection. - Line 12:
-
Sets the phone number for this provider. Multiple phone numbers may be specified using the colon (:) or pipe character (|)as a separator. The difference between the two separators is described in ppp(8). To summarize, if you want to rotate through the numbers, use a colon. If you want to always attempt to dial the first number first and only use the other numbers if the first number fails, use the pipe character. Always quote the entire set of phone numbers as shown.
You must enclose the phone number in quotation marks (") if there is any intention on using spaces in the phone number. This can cause a simple, yet subtle error.
- Line 13 & 14:
-
Identifies the user name and password. When connecting using a UNIX style login prompt, these values are referred to by the set login command using the \U and \P variables. When connecting using PAP or CHAP, these values are used at authentication time.
- Line 15:
-
If you are using PAP or CHAP, there will be no login at this point, and this line should be commented out or removed. See PAP and CHAP authentication for further details.
The login string is of the same chat-like syntax as the dial string. In this example, the string works for a service whose login session looks like this:
J. Random Provider login: foo password: bar protocol: pppYou will need to alter this script to suit your own needs. When you write this script for the first time, you should ensure that you have enabled “chat” logging so you can determine if the conversation is going as expected.
- Line 16:
-
Sets the default idle timeout (in seconds) for the connection. Here, the connection will be closed automatically after 300 seconds of inactivity. If you never want to timeout, set this value to zero or use the
-ddialcommand line switch. - Line 17:
-
Sets the interface addresses. The string x.x.x.x should be replaced by the IP address that your provider has allocated to you. The string y.y.y.y should be replaced by the IP address that your ISP indicated for their gateway (the machine to which you connect). If your ISP has not given you a gateway address, use 10.0.0.2/0. If you need to use a “guessed” address, make sure that you create an entry in /etc/ppp/ppp.linkup as per the instructions for PPP and Dynamic IP addresses. If this line is omitted, ppp cannot run in
-automode. - Line 18:
-
Adds a default route to your ISP's gateway. The special word HISADDR is replaced with the gateway address specified on line 17. It is important that this line appears after line 17, otherwise HISADDR will not yet be initialized.
If you do not wish to run ppp in
-auto, this line should be moved to the ppp.linkup file.
It is not necessary to add an entry to ppp.linkup when you
have a static IP address and are running ppp in -auto mode as
your routing table entries are already correct before you connect. You may however wish
to create an entry to invoke programs after connection. This is explained later with the
sendmail example.
Example configuration files can be found in the /usr/share/examples/ppp/ directory.
25.2.1.2.2 PPP and Dynamic IP Addresses
If your service provider does not assign static IP addresses, ppp can be configured to negotiate the local and remote addresses. This is done by “guessing” an IP address and allowing ppp to set it up correctly using the IP Configuration Protocol (IPCP) after connecting. The ppp.conf configuration is the same as PPP and Static IP Addresses, with the following change:
17 set ifaddr 10.0.0.1/0 10.0.0.2/0 255.255.255.255
Again, do not include the line number, it is just for reference. Indentation of at least one space is required.
- Line 17:
-
The number after the / character is the number of bits of the address that ppp will insist on. You may wish to use IP numbers more appropriate to your circumstances, but the above example will always work.
The last argument (0.0.0.0) tells PPP to start negotiations using address 0.0.0.0 rather than 10.0.0.1 and is necessary for some ISPs. Do not use 0.0.0.0 as the first argument to set ifaddr as it prevents PPP from setting up an initial route in
-automode.
If you are not running in -auto mode, you will need to
create an entry in /etc/ppp/ppp.linkup. ppp.linkup is used after a connection has been established. At this
point, ppp will have assigned the interface addresses and it
will now be possible to add the routing table entries:
1 provider:
2 add default HISADDR
- Line 1:
-
On establishing a connection, ppp will look for an entry in ppp.linkup according to the following rules: First, try to match the same label as we used in ppp.conf. If that fails, look for an entry for the IP address of our gateway. This entry is a four-octet IP style label. If we still have not found an entry, look for the MYADDR entry.
- Line 2:
-
This line tells ppp to add a default route that points to HISADDR. HISADDR will be replaced with the IP number of the gateway as negotiated by the IPCP.
See the pmdemand entry in the files /usr/share/examples/ppp/ppp.conf.sample and /usr/share/examples/ppp/ppp.linkup.sample for a detailed example.
25.2.1.2.3 Receiving Incoming Calls
When you configure ppp to receive incoming calls on a machine connected to a LAN, you must decide if you wish to forward packets to the LAN. If you do, you should allocate the peer an IP number from your LAN's subnet, and use the command enable proxy in your /etc/ppp/ppp.conf file. You should also confirm that the /etc/rc.conf file contains the following:
gateway_enable="YES"
25.2.1.2.4 Which getty?
Configuring FreeBSD for Dial-up Services provides a good description on enabling dial-up services using getty(8).
An alternative to getty is mgetty, a smarter version of getty designed with dial-up lines in mind.
The advantages of using mgetty is that it actively talks to modems, meaning if port is turned off in /etc/ttys then your modem will not answer the phone.
Later versions of mgetty (from 0.99beta onwards) also support the automatic detection of PPP streams, allowing your clients script-less access to your server.
Refer to Mgetty and AutoPPP for more information on mgetty.
25.2.1.2.5 PPP Permissions
The ppp command must normally be run as the root user. If however, you wish to allow ppp to run in server mode as a normal user by executing ppp as described below, that user must be given permission to run ppp by adding them to the network group in /etc/group.
You will also need to give them access to one or more sections of the configuration file using the allow command:
allow users fred mary
If this command is used in the default section, it gives the specified users access to everything.
25.2.1.2.6 PPP Shells for Dynamic-IP Users
Create a file called /etc/ppp/ppp-shell containing the following:
#!/bin/sh
IDENT=`echo $0 | sed -e 's/^.*-\(.*\)$/\1/'`
CALLEDAS="$IDENT"
TTY=`tty`
if [ x$IDENT = xdialup ]; then
IDENT=`basename $TTY`
fi
echo "PPP for $CALLEDAS on $TTY"
echo "Starting PPP for $IDENT"
exec /usr/sbin/ppp -direct $IDENT
This script should be executable. Now make a symbolic link called ppp-dialup to this script using the following commands:
# ln -s ppp-shell /etc/ppp/ppp-dialup
You should use this script as the shell for all of your dialup users. This is an example from /etc/passwd for a dialup PPP user with username pchilds (remember do not directly edit the password file, use vipw(8)).
pchilds:*:1011:300:Peter Childs PPP:/home/ppp:/etc/ppp/ppp-dialup
Create a /home/ppp directory that is world readable containing the following 0 byte files:
-r--r--r-- 1 root wheel 0 May 27 02:23 .hushlogin
-r--r--r-- 1 root wheel 0 May 27 02:22 .rhosts
which prevents /etc/motd from being displayed.
25.2.1.2.7 PPP Shells for Static-IP Users
Create the ppp-shell file as above, and for each account with statically assigned IPs create a symbolic link to ppp-shell.
For example, if you have three dialup customers, fred, sam, and mary, that you route /24 CIDR networks for, you would type the following:
# ln -s /etc/ppp/ppp-shell /etc/ppp/ppp-fred
# ln -s /etc/ppp/ppp-shell /etc/ppp/ppp-sam
# ln -s /etc/ppp/ppp-shell /etc/ppp/ppp-mary
Each of these users dialup accounts should have their shell set to the symbolic link created above (for example, mary's shell should be /etc/ppp/ppp-mary).
25.2.1.2.8 Setting Up ppp.conf for Dynamic-IP Users
The /etc/ppp/ppp.conf file should contain something along the lines of:
default:
set debug phase lcp chat
set timeout 0
ttyd0:
set ifaddr 203.14.100.1 203.14.100.20 255.255.255.255
enable proxy
ttyd1:
set ifaddr 203.14.100.1 203.14.100.21 255.255.255.255
enable proxy
Note: The indenting is important.
The default: section is loaded for each session. For each dialup line enabled in /etc/ttys create an entry similar to the one for ttyd0: above. Each line should get a unique IP address from your pool of IP addresses for dynamic users.
25.2.1.2.9 Setting Up ppp.conf for Static-IP Users
Along with the contents of the sample /usr/share/examples/ppp/ppp.conf above you should add a section for each of the statically assigned dialup users. We will continue with our fred, sam, and mary example.
fred:
set ifaddr 203.14.100.1 203.14.101.1 255.255.255.255
sam:
set ifaddr 203.14.100.1 203.14.102.1 255.255.255.255
mary:
set ifaddr 203.14.100.1 203.14.103.1 255.255.255.255
The file /etc/ppp/ppp.linkup should also contain routing information for each static IP user if required. The line below would add a route for the 203.14.101.0/24 network via the client's ppp link.
fred:
add 203.14.101.0 netmask 255.255.255.0 HISADDR
sam:
add 203.14.102.0 netmask 255.255.255.0 HISADDR
mary:
add 203.14.103.0 netmask 255.255.255.0 HISADDR
25.2.1.2.10 mgetty and AutoPPP
Configuring and compiling mgetty with the AUTO_PPP option enabled allows mgetty to detect the LCP phase of PPP connections and automatically spawn off a ppp shell. However, since the default login/password sequence does not occur it is necessary to authenticate users using either PAP or CHAP.
This section assumes the user has successfully configured, compiled, and installed a version of mgetty with the AUTO_PPP option (v0.99beta or later).
Make sure your /usr/local/etc/mgetty+sendfax/login.config file has the following in it:
/AutoPPP/ - - /etc/ppp/ppp-pap-dialup
This will tell mgetty to run the ppp-pap-dialup script for detected PPP connections.
Create a file called /etc/ppp/ppp-pap-dialup containing the following (the file should be executable):
#!/bin/sh
exec /usr/sbin/ppp -direct pap$IDENT
For each dialup line enabled in /etc/ttys, create a corresponding entry in /etc/ppp/ppp.conf. This will happily co-exist with the definitions we created above.
pap:
enable pap
set ifaddr 203.14.100.1 203.14.100.20-203.14.100.40
enable proxy
Each user logging in with this method will need to have a username/password in /etc/ppp/ppp.secret file, or alternatively add the following option to authenticate users via PAP from the /etc/passwd file.
enable passwdauth
If you wish to assign some users a static IP number, you can specify the number as the third argument in /etc/ppp/ppp.secret. See /usr/share/examples/ppp/ppp.secret.sample for examples.
25.2.1.2.11 MS Extensions
It is possible to configure PPP to supply DNS and NetBIOS nameserver addresses on demand.
To enable these extensions with PPP version 1.x, the following lines might be added to the relevant section of /etc/ppp/ppp.conf.
enable msext
set ns 203.14.100.1 203.14.100.2
set nbns 203.14.100.5
And for PPP version 2 and above:
accept dns
set dns 203.14.100.1 203.14.100.2
set nbns 203.14.100.5
This will tell the clients the primary and secondary name server addresses, and a NetBIOS nameserver host.
In version 2 and above, if the set dns line is omitted, PPP will use the values found in /etc/resolv.conf.
25.2.1.2.12 PAP and CHAP Authentication
Some ISPs set their system up so that the authentication part of your connection is done using either of the PAP or CHAP authentication mechanisms. If this is the case, your ISP will not give a login: prompt when you connect, but will start talking PPP immediately.
PAP is less secure than CHAP, but security is not normally an issue here as passwords, although being sent as plain text with PAP, are being transmitted down a serial line only. There is not much room for crackers to “eavesdrop”.
Referring back to the PPP and Static IP addresses or PPP and Dynamic IP addresses sections, the following alterations must be made:
13 set authname MyUserName
14 set authkey MyPassword
15 set login
- Line 13:
-
This line specifies your PAP/CHAP user name. You will need to insert the correct value for MyUserName.
- Line 14:
-
This line specifies your PAP/CHAP password. You will need to insert the correct value for MyPassword. You may want to add an additional line, such as:
16 accept PAPor
16 accept CHAPto make it obvious that this is the intention, but PAP and CHAP are both accepted by default.
- Line 15:
-
Your ISP will not normally require that you log into the server if you are using PAP or CHAP. You must therefore disable your “set login” string.
25.2.1.2.13 Changing Your ppp Configuration on the Fly
It is possible to talk to the ppp program while it is running in the background, but only if a suitable diagnostic port has been set up. To do this, add the following line to your configuration:
set server /var/run/ppp-tun%d DiagnosticPassword 0177
This will tell PPP to listen to the specified UNIX domain socket, asking clients for the specified password before allowing access. The %d in the name is replaced with the tun device number that is in use.
Once a socket has been set up, the pppctl(8) program may be used in scripts that wish to manipulate the running program.
25.2.1.3 Using PPP Network Address Translation Capability
PPP has ability to use internal NAT without kernel diverting capabilities. This functionality may be enabled by the following line in /etc/ppp/ppp.conf:
nat enable yes
Alternatively, PPP NAT may be enabled by command-line option -nat. There is also /etc/rc.conf knob named ppp_nat, which is enabled by default.
If you use this feature, you may also find useful the following /etc/ppp/ppp.conf options to enable incoming connections forwarding:
nat port tcp 10.0.0.2:ftp ftp
nat port tcp 10.0.0.2:http http
or do not trust the outside at all
nat deny_incoming yes
25.2.1.4 Final System Configuration
You now have ppp configured, but there are a few more things to do before it is ready to work. They all involve editing the /etc/rc.conf file.
Working from the top down in this file, make sure the hostname= line is set, e.g.:
hostname="foo.example.com"
If your ISP has supplied you with a static IP address and name, it is probably best that you use this name as your host name.
Look for the network_interfaces variable. If you want to configure your system to dial your ISP on demand, make sure the tun0 device is added to the list, otherwise remove it.
network_interfaces="lo0 tun0"
ifconfig_tun0=
Note: The ifconfig_tun0 variable should be empty, and a file called /etc/start_if.tun0 should be created. This file should contain the line:
ppp -auto mysystemThis script is executed at network configuration time, starting your ppp daemon in automatic mode. If you have a LAN for which this machine is a gateway, you may also wish to use the
-aliasswitch. Refer to the manual page for further details.
Make sure that the router program is set to NO with the following line in your /etc/rc.conf:
router_enable="NO"
It is important that the routed daemon is not started, as routed tends to delete the default routing table entries created by ppp.
It is probably a good idea to ensure that the sendmail_flags
line does not include the -q option, otherwise sendmail will attempt to do a network lookup every now and then,
possibly causing your machine to dial out. You may try:
sendmail_flags="-bd"
The downside of this is that you must force sendmail to re-examine the mail queue whenever the ppp link is up by typing:
# /usr/sbin/sendmail -q
You may wish to use the !bg command in ppp.linkup to do this automatically:
1 provider:
2 delete ALL
3 add 0 0 HISADDR
4 !bg sendmail -bd -q30m
If you do not like this, it is possible to set up a “dfilter” to block SMTP traffic. Refer to the sample files for further details.
All that is left is to reboot the machine. After rebooting, you can now either type:
# ppp
and then dial provider to start the PPP session, or, if you want ppp to establish sessions automatically when there is outbound traffic (and you have not created the start_if.tun0 script), type:
# ppp -auto provider
25.2.1.5 Summary
To recap, the following steps are necessary when setting up ppp for the first time:
Client side:
-
Ensure that the tun device is built into your kernel.
-
Ensure that the tunN device file is available in the /dev directory.
-
Create an entry in /etc/ppp/ppp.conf. The pmdemand example should suffice for most ISPs.
-
If you have a dynamic IP address, create an entry in /etc/ppp/ppp.linkup.
-
Update your /etc/rc.conf file.
-
Create a start_if.tun0 script if you require demand dialing.
Server side:
-
Ensure that the tun device is built into your kernel.
-
Ensure that the tunN device file is available in the /dev directory.
-
Create an entry in /etc/passwd (using the vipw(8) program).
-
Create a profile in this users home directory that runs ppp -direct direct-server or similar.
-
Create an entry in /etc/ppp/ppp.conf. The direct-server example should suffice.
-
Create an entry in /etc/ppp/ppp.linkup.
-
Update your /etc/rc.conf file.
25.3 Using Kernel PPP
Parts originally contributed by Gennady B. Sorokopud and Robert Huff.25.3.1 Setting Up Kernel PPP
Before you start setting up PPP on your machine, make sure that pppd is located in /usr/sbin and the directory /etc/ppp exists.
pppd can work in two modes:
-
As a “client” -- you want to connect your machine to the outside world via a PPP serial connection or modem line.
-
As a “server” -- your machine is located on the network, and is used to connect other computers using PPP.
In both cases you will need to set up an options file (/etc/ppp/options or ~/.ppprc if you have more than one user on your machine that uses PPP).
You will also need some modem/serial software (preferably comms/kermit), so you can dial and establish a connection with the remote host.
25.3.2 Using pppd as a Client
Based on information provided by Trev Roydhouse.The following /etc/ppp/options might be used to connect to a Cisco terminal server PPP line.
crtscts # enable hardware flow control
modem # modem control line
noipdefault # remote PPP server must supply your IP address
# if the remote host does not send your IP during IPCP
# negotiation, remove this option
passive # wait for LCP packets
domain ppp.foo.com # put your domain name here
:<remote_ip> # put the IP of remote PPP host here
# it will be used to route packets via PPP link
# if you didn't specified the noipdefault option
# change this line to <local_ip>:<remote_ip>
defaultroute # put this if you want that PPP server will be your
# default router
To connect:
-
Dial to the remote host using Kermit (or some other modem program), and enter your user name and password (or whatever is needed to enable PPP on the remote host).
-
Exit Kermit (without hanging up the line).
-
Enter the following:
# /usr/src/usr.sbin/pppd.new/pppd /dev/tty01 19200Be sure to use the appropriate speed and device name.
Now your computer is connected with PPP. If the connection fails, you can add the
debug option to the /etc/ppp/options file, and check console messages to track the
problem.
Following /etc/ppp/pppup script will make all 3 stages automatic:
#!/bin/sh
ps ax |grep pppd |grep -v grep
pid=`ps ax |grep pppd |grep -v grep|awk '{print $1;}'`
if [ "X${pid}" != "X" ] ; then
echo 'killing pppd, PID=' ${pid}
kill ${pid}
fi
ps ax |grep kermit |grep -v grep
pid=`ps ax |grep kermit |grep -v grep|awk '{print $1;}'`
if [ "X${pid}" != "X" ] ; then
echo 'killing kermit, PID=' ${pid}
kill -9 ${pid}
fi
ifconfig ppp0 down
ifconfig ppp0 delete
kermit -y /etc/ppp/kermit.dial
pppd /dev/tty01 19200
/etc/ppp/kermit.dial is a Kermit script that dials and makes all necessary authorization on the remote host (an example of such a script is attached to the end of this document).
Use the following /etc/ppp/pppdown script to disconnect the PPP line:
#!/bin/sh
pid=`ps ax |grep pppd |grep -v grep|awk '{print $1;}'`
if [ X${pid} != "X" ] ; then
echo 'killing pppd, PID=' ${pid}
kill -TERM ${pid}
fi
ps ax |grep kermit |grep -v grep
pid=`ps ax |grep kermit |grep -v grep|awk '{print $1;}'`
if [ "X${pid}" != "X" ] ; then
echo 'killing kermit, PID=' ${pid}
kill -9 ${pid}
fi
/sbin/ifconfig ppp0 down
/sbin/ifconfig ppp0 delete
kermit -y /etc/ppp/kermit.hup
/etc/ppp/ppptest
Check to see if pppd is still running by executing /usr/etc/ppp/ppptest, which should look like this:
#!/bin/sh
pid=`ps ax| grep pppd |grep -v grep|awk '{print $1;}'`
if [ X${pid} != "X" ] ; then
echo 'pppd running: PID=' ${pid-NONE}
else
echo 'No pppd running.'
fi
set -x
netstat -n -I ppp0
ifconfig ppp0
To hang up the modem, execute /etc/ppp/kermit.hup, which should contain:
set line /dev/tty01 ; put your modem device here
set speed 19200
set file type binary
set file names literal
set win 8
set rec pack 1024
set send pack 1024
set block 3
set term bytesize 8
set command bytesize 8
set flow none
pau 1
out +++
inp 5 OK
out ATH0\13
echo \13
exit
Here is an alternate method using chat instead of kermit:
The following two files are sufficient to accomplish a pppd connection.
/etc/ppp/options:
/dev/cuaa1 115200
crtscts # enable hardware flow control
modem # modem control line
connect "/usr/bin/chat -f /etc/ppp/login.chat.script"
noipdefault # remote PPP serve must supply your IP address
# if the remote host doesn't send your IP during
# IPCP negotiation, remove this option
passive # wait for LCP packets
domain <your.domain> # put your domain name here
: # put the IP of remote PPP host here
# it will be used to route packets via PPP link
# if you didn't specified the noipdefault option
# change this line to <local_ip>:<remote_ip>
defaultroute # put this if you want that PPP server will be
# your default router
/etc/ppp/login.chat.script:
Note: The following should go on a single line.
ABORT BUSY ABORT 'NO CARRIER' "" AT OK ATDT<phone.number>
CONNECT "" TIMEOUT 10 ogin:-\\r-ogin: <login-id>
TIMEOUT 5 sword: <password>
Once these are installed and modified correctly, all you need to do is run pppd, like so:
# pppd
25.3.3 Using pppd as a Server
/etc/ppp/options should contain something similar to the following:
crtscts # Hardware flow control
netmask 255.255.255.0 # netmask (not required)
192.114.208.20:192.114.208.165 # IP's of local and remote hosts
# local ip must be different from one
# you assigned to the Ethernet (or other)
# interface on your machine.
# remote IP is IP address that will be
# assigned to the remote machine
domain ppp.foo.com # your domain
passive # wait for LCP
modem # modem line
The following /etc/ppp/pppserv script will tell pppd to behave as a server:
#!/bin/sh
ps ax |grep pppd |grep -v grep
pid=`ps ax |grep pppd |grep -v grep|awk '{print $1;}'`
if [ "X${pid}" != "X" ] ; then
echo 'killing pppd, PID=' ${pid}
kill ${pid}
fi
ps ax |grep kermit |grep -v grep
pid=`ps ax |grep kermit |grep -v grep|awk '{print $1;}'`
if [ "X${pid}" != "X" ] ; then
echo 'killing kermit, PID=' ${pid}
kill -9 ${pid}
fi
# reset ppp interface
ifconfig ppp0 down
ifconfig ppp0 delete
# enable autoanswer mode
kermit -y /etc/ppp/kermit.ans
# run ppp
pppd /dev/tty01 19200
Use this /etc/ppp/pppservdown script to stop the server:
#!/bin/sh
ps ax |grep pppd |grep -v grep
pid=`ps ax |grep pppd |grep -v grep|awk '{print $1;}'`
if [ "X${pid}" != "X" ] ; then
echo 'killing pppd, PID=' ${pid}
kill ${pid}
fi
ps ax |grep kermit |grep -v grep
pid=`ps ax |grep kermit |grep -v grep|awk '{print $1;}'`
if [ "X${pid}" != "X" ] ; then
echo 'killing kermit, PID=' ${pid}
kill -9 ${pid}
fi
ifconfig ppp0 down
ifconfig ppp0 delete
kermit -y /etc/ppp/kermit.noans
The following Kermit script (/etc/ppp/kermit.ans) will enable/disable autoanswer mode on your modem. It should look like this:
set line /dev/tty01
set speed 19200
set file type binary
set file names literal
set win 8
set rec pack 1024
set send pack 1024
set block 3
set term bytesize 8
set command bytesize 8
set flow none
pau 1
out +++
inp 5 OK
out ATH0\13
inp 5 OK
echo \13
out ATS0=1\13 ; change this to out ATS0=0\13 if you want to disable
; autoanswer mode
inp 5 OK
echo \13
exit
A script named /etc/ppp/kermit.dial is used for dialing and authenticating on the remote host. You will need to customize it for your needs. Put your login and password in this script; you will also need to change the input statement depending on responses from your modem and remote host.
;
; put the com line attached to the modem here:
;
set line /dev/tty01
;
; put the modem speed here:
;
set speed 19200
set file type binary ; full 8 bit file xfer
set file names literal
set win 8
set rec pack 1024
set send pack 1024
set block 3
set term bytesize 8
set command bytesize 8
set flow none
set modem hayes
set dial hangup off
set carrier auto ; Then SET CARRIER if necessary,
set dial display on ; Then SET DIAL if necessary,
set input echo on
set input timeout proceed
set input case ignore
def \%x 0 ; login prompt counter
goto slhup
:slcmd ; put the modem in command mode
echo Put the modem in command mode.
clear ; Clear unread characters from input buffer
pause 1
output +++ ; hayes escape sequence
input 1 OK\13\10 ; wait for OK
if success goto slhup
output \13
pause 1
output at\13
input 1 OK\13\10
if fail goto slcmd ; if modem doesn't answer OK, try again
:slhup ; hang up the phone
clear ; Clear unread characters from input buffer
pause 1
echo Hanging up the phone.
output ath0\13 ; hayes command for on hook
input 2 OK\13\10
if fail goto slcmd ; if no OK answer, put modem in command mode
:sldial ; dial the number
pause 1
echo Dialing.
output atdt9,550311\13\10 ; put phone number here
assign \%x 0 ; zero the time counter
:look
clear ; Clear unread characters from input buffer
increment \%x ; Count the seconds
input 1 {CONNECT }
if success goto sllogin
reinput 1 {NO CARRIER\13\10}
if success goto sldial
reinput 1 {NO DIALTONE\13\10}
if success goto slnodial
reinput 1 {\255}
if success goto slhup
reinput 1 {\127}
if success goto slhup
if < \%x 60 goto look
else goto slhup
:sllogin ; login
assign \%x 0 ; zero the time counter
pause 1
echo Looking for login prompt.
:slloop
increment \%x ; Count the seconds
clear ; Clear unread characters from input buffer
output \13
;
; put your expected login prompt here:
;
input 1 {Username: }
if success goto sluid
reinput 1 {\255}
if success goto slhup
reinput 1 {\127}
if success goto slhup
if < \%x 10 goto slloop ; try 10 times to get a login prompt
else goto slhup ; hang up and start again if 10 failures
:sluid
;
; put your userid here:
;
output ppp-login\13
input 1 {Password: }
;
; put your password here:
;
output ppp-password\13
input 1 {Entering SLIP mode.}
echo
quit
:slnodial
echo \7No dialtone. Check the telephone line!\7
exit 1
; local variables:
; mode: csh
; comment-start: "; "
; comment-start-skip: "; "
; end:
25.4 Troubleshooting PPP Connections
Contributed by Tom Rhodes.This section covers a few issues which may arise when using PPP over a modem connection. For instance, perhaps you need to know exactly what prompts the system you are dialing into will present. Some ISPs present the ssword prompt, and others will present password; if the ppp script is not written accordingly, the login attempt will fail. The most common way to debug ppp connections is by connecting manually. The following information will walk you through a manual connection step by step.
25.4.1 Check the Device Nodes
If you reconfigured your kernel then you recall the sio device. If you did not configure your kernel, there is no reason to worry. Just check the dmesg output for the modem device with:
# dmesg | grep sio
You should get some pertinent output about the sio devices. These are the COM ports we need. If your modem acts like a standard serial port then you should see it listed on sio1, or COM2. If so, you are not required to rebuild the kernel. When matching up sio modem is on sio1 or COM2 if you are in DOS, then your modem device would be /dev/cuaa1.
25.4.2 Connecting Manually
Connecting to the Internet by manually controlling ppp is quick, easy, and a great way to debug a connection or just get information on how your ISP treats ppp client connections. Lets start PPP from the command line. Note that in all of our examples we will use example as the hostname of the machine running PPP. You start ppp by just typing ppp:
# ppp
We have now started ppp.
ppp ON example> set device /dev/cuaa1
We set our modem device, in this case it is cuaa1.
ppp ON example> set speed 115200
Set the connection speed, in this case we are using 115,200 kbps.
ppp ON example> enable dns
Tell ppp to configure our resolver and add the nameserver lines to /etc/resolv.conf. If ppp cannot determine our hostname, we can set one manually later.
ppp ON example> term
Switch to “terminal” mode so that we can manually control the modem.
deflink: Entering terminal mode on /dev/cuaa1
type '~h' for help
at
OK
atdt123456789
Use at to initialize the modem, then use atdt and the number for your ISP to begin the dial in process.
CONNECT
Confirmation of the connection, if we are going to have any connection problems, unrelated to hardware, here is where we will attempt to resolve them.
ISP Login:myusername
Here you are prompted for a username, return the prompt with the username that was provided by the ISP.
ISP Pass:mypassword
This time we are prompted for a password, just reply with the password that was provided by the ISP. Just like logging into FreeBSD, the password will not echo.
Shell or PPP:ppp
Depending on your ISP this prompt may never appear. Here we are being asked if we wish to use a shell on the provider, or to start ppp. In this example, we have chosen to use ppp as we want an Internet connection.
Ppp ON example>
Notice that in this example the first p has been
capitalized. This shows that we have successfully connected to the ISP.
PPp ON example>
We have successfully authenticated with our ISP and are waiting for the assigned IP address.
PPP ON example>
We have made an agreement on an IP address and successfully completed our connection.
PPP ON example>add default HISADDR
Here we add our default route, we need to do this before we can talk to the outside
world as currently the only established connection is with the peer. If this fails due to
existing routes you can put a bang character ! in front of the
add. Alternatively, you can set this before making the actual
connection and it will negotiate a new route accordingly.
If everything went good we should now have an active connection to the Internet, which could be thrown into the background using CTRL+z If you notice the PPP return to ppp then we have lost our connection. This is good to know because it shows our connection status. Capital P's show that we have a connection to the ISP and lowercase p's show that the connection has been lost for whatever reason. ppp only has these 2 states.
25.4.2.1 Debugging
If you have a direct line and cannot seem to make a connection, then turn hardware
flow CTS/RTS to off with the set
ctsrts off. This is mainly the case if you are connected to some PPP capable terminal servers, where PPP hangs when it tries to write data to your communication link,
so it would be waiting for a CTS, or Clear To Send
signal which may never come. If you use this option however, you should also use the
set accmap option, which may be required to defeat hardware
dependent on passing certain characters from end to end, most of the time XON/XOFF. See
the ppp(8) manual page for
more information on this option, and how it is used.
If you have an older modem, you may need to use the set parity
even. Parity is set at none be default, but is used for error checking (with a
large increase in traffic) on older modems and some ISPs. You may need this option for the Compuserve ISP.
PPP may not return to the command mode, which is usually a negotiation error where the ISP is waiting for your side to start negotiating. At this point, using the ~p command will force ppp to start sending the configuration information.
If you never obtain a login prompt, then most likely you need to use PAP or CHAP authentication instead of the UNIX style in the example above. To use PAP or CHAP just add the following options to PPP before going into terminal mode:
ppp ON example> set authname myusername
Where myusername should be replaced with the username that was assigned by the ISP.
ppp ON example> set authkey mypassword
Where mypassword should be replaced with the password that was assigned by the ISP.
If you connect fine, but cannot seem to find any domain name, try to use ping(8) with an
IP address and see if you can get any return
information. If you experience 100 percent (100%) packet loss, then it is most likely
that you were not assigned a default route. Double check that the option add default HISADDR was set during the connection. If you can
connect to a remote IP address then it is possible
that a resolver address has not been added to the /etc/resolv.conf. This file should look like:
domain example.com
nameserver x.x.x.x
nameserver y.y.y.y
Where x.x.x.x and y.y.y.y should be replaced with the IP address of your ISP's DNS servers. This information may or may not have been provided when you signed up, but a quick call to your ISP should remedy that.
You could also have syslog(3) provide a logging function for your PPP connection. Just add:
!ppp
*.* /var/log/ppp.log
to /etc/syslog.conf. In most cases, this functionality already exists.
25.5 Using PPP over Ethernet (PPPoE)
Contributed (from http://node.to/freebsd/how-tos/how-to-freebsd-pppoe.html) by Jim Mock.This section describes how to set up PPP over Ethernet (PPPoE).
25.5.1 Configuring the Kernel
No kernel configuration is necessary for PPPoE any longer. If the necessary netgraph support is not built into the kernel, it will be dynamically loaded by ppp.
25.5.2 Setting Up ppp.conf
Here is an example of a working ppp.conf:
default:
set log Phase tun command # you can add more detailed logging if you wish
set ifaddr 10.0.0.1/0 10.0.0.2/0
name_of_service_provider:
set device PPPoE:xl1 # replace xl1 with your Ethernet device
set authname YOURLOGINNAME
set authkey YOURPASSWORD
set dial
set login
add default HISADDR
25.5.4 Starting ppp at Boot
Add the following to your /etc/rc.conf file:
ppp_enable="YES"
ppp_mode="ddial"
ppp_nat="YES" # if you want to enable nat for your local network, otherwise NO
ppp_profile="name_of_service_provider"
25.5.5 Using a PPPoE Service Tag
Sometimes it will be necessary to use a service tag to establish your connection. Service tags are used to distinguish between different PPPoE servers attached to a given network.
You should have been given any required service tag information in the documentation provided by your ISP. If you cannot locate it there, ask your ISP's tech support personnel.
As a last resort, you could try the method suggested by the Roaring Penguin PPPoE program which can be found in the Ports Collection. Bear in mind however, this may de-program your modem and render it useless, so think twice before doing it. Simply install the program shipped with the modem by your provider. Then, access the System menu from the program. The name of your profile should be listed there. It is usually ISP.
The profile name (service tag) will be used in the PPPoE configuration entry in ppp.conf as the provider part of the set device command (see the ppp(8) manual page for full details). It should look like this:
set device PPPoE:xl1:ISP
Do not forget to change xl1 to the proper device for your Ethernet card.
Do not forget to change ISP to the profile you have just found above.
For additional information, see:
-
Cheaper Broadband with FreeBSD on DSL by Renaud Waldura.
-
Nutzung von T-DSL und T-Online mit FreeBSD by Udo Erdelhoff (in German).
25.5.6 PPPoE with a 3Com® HomeConnect® ADSL Modem Dual Link
This modem does not follow RFC 2516 (A Method for transmitting PPP over Ethernet (PPPoE), written by L. Mamakos, K. Lidl, J. Evarts, D. Carrel, D. Simone, and R. Wheeler). Instead, different packet type codes have been used for the Ethernet frames. Please complain to 3Com if you think it should comply with the PPPoE specification.
In order to make FreeBSD capable of communicating with this device, a sysctl must be set. This can be done automatically at boot time by updating /etc/sysctl.conf:
net.graph.nonstandard_pppoe=1
or can be done immediately with the command:
# sysctl net.graph.nonstandard_pppoe=1
Unfortunately, because this is a system-wide setting, it is not possible to talk to a normal PPPoE client or server and a 3Com HomeConnect® ADSL Modem at the same time.
25.6 Using PPP over ATM (PPPoA)
The following describes how to set up PPP over ATM (PPPoA). PPPoA is a popular choice among European DSL providers.
25.6.1 Using PPPoA with the Alcatel SpeedTouch™ USB
PPPoA support for this device is supplied as a port in FreeBSD because the firmware is distributed under Alcatel's license agreement and can not be redistributed freely with the base system of FreeBSD.
To install the software, simply use the Ports Collection. Install the net/pppoa port and follow the instructions provided with it.
Like many USB devices, the Alcatel SpeedTouch™ USB needs to download firmware from the host computer to operate properly. It is possible to automate this process in FreeBSD so that this transfer takes place whenever the device is plugged into a USB port. The following information can be added to the /etc/usbd.conf file to enable this automatic firmware transfer. This file must be edited as the root user.
device "Alcatel SpeedTouch USB"
devname "ugen[0-9]+"
vendor 0x06b9
product 0x4061
attach "/usr/local/sbin/modem_run -f /usr/local/libdata/mgmt.o"
To enable the USB daemon, usbd, put the following the line into /etc/rc.conf:
usbd_enable="YES"
It is also possible to set up ppp to dial up at startup. To do this add the following lines to /etc/rc.conf. Again, for this procedure you will need to be logged in as the root user.
ppp_enable="YES"
ppp_mode="ddial"
ppp_profile="adsl"
For this to work correctly you will need to have used the sample ppp.conf which is supplied with the net/pppoa port.
25.6.2 Using mpd
You can use mpd to connect to a variety of services, in particular PPTP services. You can find mpd in the Ports Collection, net/mpd. Many ADSL modems require that a PPTP tunnel is created between the modem and computer, one such modem is the Alcatel SpeedTouch Home.
First you must install the port, and then you can configure mpd to suit your requirements and provider settings. The port places a set of sample configuration files which are well documented in PREFIX/etc/mpd/. Note here that PREFIX means the directory into which your ports are installed, this defaults to /usr/local/. A complete guide to configure mpd is available in HTML format once the port has been installed. It is placed in PREFIX/share/doc/mpd/. Here is a sample configuration for connecting to an ADSL service with mpd. The configuration is spread over two files, first the mpd.conf:
default:
load adsl
adsl:
new -i ng0 adsl adsl
set bundle authname username
set bundle password password
set bundle disable multilink
set link no pap acfcomp protocomp
set link disable chap
set link accept chap
set link keep-alive 30 10
set ipcp no vjcomp
set ipcp ranges 0.0.0.0/0 0.0.0.0/0
set iface route default
set iface disable on-demand
set iface enable proxy-arp
set iface idle 0
open
- The username used to authenticate with your ISP.
- The password used to authenticate with your ISP.
The mpd.links file contains information about the link, or links, you wish to establish. An example mpd.links to accompany the above example is given beneath:
adsl:
set link type pptp
set pptp mode active
set pptp enable originate outcall
set pptp self 10.0.0.1
set pptp peer 10.0.0.138
- The IP address of your FreeBSD computer which you will be using mpd from.
- The IP address of your ADSL modem. For the Alcatel SpeedTouch Home this address defaults to 10.0.0.138.
It is possible to initialize the connection easily by issuing the following command as root:
# mpd -b adsl
You can see the status of the connection with the following command:
% ifconfig ng0
ng0: flags=88d1<UP,POINTOPOINT,RUNNING,NOARP,SIMPLEX,MULTICAST> mtu 1500
inet 216.136.204.117 --> 204.152.186.171 netmask 0xffffffff
Using mpd is the recommended way to connect to an ADSL service with FreeBSD.
25.6.3 Using pptpclient
It is also possible to use FreeBSD to connect to other PPPoA services using net/pptpclient.
To use net/pptpclient to connect to a DSL service, install the port or package and edit your /etc/ppp/ppp.conf. You will need to be root to perform both of these operations. An example section of ppp.conf is given below. For further information on ppp.conf options consult the ppp manual page, ppp(8).
adsl:
set log phase chat lcp ipcp ccp tun command
set timeout 0
enable dns
set authname username
set authkey password
set ifaddr 0 0
add default HISADDR
- The username of your account with the DSL provider.
- The password for your account.
Warning: Because you must put your account's password in the ppp.conf file in plain text form you should make sure than nobody can read the contents of this file. The following series of commands will make sure the file is only readable by the root account. Refer to the manual pages for chmod(1) and chown(8) for further information.
# chown root:wheel /etc/ppp/ppp.conf # chmod 600 /etc/ppp/ppp.conf
This will open a tunnel for a PPP session to your DSL router. Ethernet DSL modems have a preconfigured LAN IP address which you connect to. In the case of the Alcatel SpeedTouch Home this address is 10.0.0.138. Your router documentation should tell you which address your device uses. To open the tunnel and start a PPP session execute the following command:
# pptp address adsl
Tip: You may wish to add an ampersand (“&”) to the end of the previous command because pptp will not return your prompt to you otherwise.
A tun virtual tunnel device will be created for interaction between the pptp and ppp processes. Once you have been returned to your prompt, or the pptp process has confirmed a connection you can examine the tunnel like so:
% ifconfig tun0
tun0: flags=8051<UP,POINTOPOINT,RUNNING,MULTICAST> mtu 1500
inet 216.136.204.21 --> 204.152.186.171 netmask 0xffffff00
Opened by PID 918
If you are unable to connect, check the configuration of your router, which is usually accessible via telnet or with a web browser. If you still cannot connect you should examine the output of the pptp command and the contents of the ppp log file, /var/log/ppp.log for clues.
25.7 Using SLIP
Originally contributed by Satoshi Asami. With input from Guy Helmer and Piero Serini.25.7.1 Setting Up a SLIP Client
The following is one way to set up a FreeBSD machine for SLIP on a static host network. For dynamic hostname assignments (your address changes each time you dial up), you probably need to have a more complex setup.
First, determine which serial port your modem is connected to. Many people set up a symbolic link, such as /dev/modem, to point to the real device name, /dev/cuaaN (or /dev/cuadN under FreeBSD 6.X). This allows you to abstract the actual device name should you ever need to move the modem to a different port. It can become quite cumbersome when you need to fix a bunch of files in /etc and .kermrc files all over the system!
Note: /dev/cuaa0 (or /dev/cuad0 under FreeBSD 6.X) is COM1, cuaa1 (or /dev/cuad1) is COM2, etc.
Make sure you have the following in your kernel configuration file:
device sl
It is included in the GENERIC kernel, so this should not be a problem unless you have deleted it.
25.7.1.1 Things You Have to Do Only Once
-
Add your home machine, the gateway and nameservers to your /etc/hosts file. Ours looks like this:
127.0.0.1 localhost loghost 136.152.64.181 water.CS.Example.EDU water.CS water 136.152.64.1 inr-3.CS.Example.EDU inr-3 slip-gateway 128.32.136.9 ns1.Example.EDU ns1 128.32.136.12 ns2.Example.EDU ns2 -
Make sure you have hosts before bind in your /etc/host.conf on FreeBSD versions prior to 5.0. Since FreeBSD 5.0, the system uses the file /etc/nsswitch.conf instead, make sure you have files before dns in the
hostsline of this file. Without these parameters funny things may happen. -
Edit the /etc/rc.conf file.
-
Set your hostname by editing the line that says:
hostname="myname.my.domain"Your machine's full Internet hostname should be placed here.
-
Designate the default router by changing the line:
defaultrouter="NO"to:
defaultrouter="slip-gateway"
-
-
Make a file /etc/resolv.conf which contains:
domain CS.Example.EDU nameserver 128.32.136.9 nameserver 128.32.136.12As you can see, these set up the nameserver hosts. Of course, the actual domain names and addresses depend on your environment.
-
Set the password for root and toor (and any other accounts that do not have a password).
-
Reboot your machine and make sure it comes up with the correct hostname.
25.7.1.2 Making a SLIP Connection
-
Dial up, type slip at the prompt, enter your machine name and password. What is required to be entered depends on your environment. If you use Kermit, you can try a script like this:
# kermit setup set modem hayes set line /dev/modem set speed 115200 set parity none set flow rts/cts set terminal bytesize 8 set file type binary # The next macro will dial up and login define slip dial 643-9600, input 10 =>, if failure stop, - output slip\x0d, input 10 Username:, if failure stop, - output silvia\x0d, input 10 Password:, if failure stop, - output ***\x0d, echo \x0aCONNECTED\x0aOf course, you have to change the username and password to fit yours. After doing so, you can just type slip from the Kermit prompt to connect.
Note: Leaving your password in plain text anywhere in the filesystem is generally a bad idea. Do it at your own risk.
-
Leave the Kermit there (you can suspend it by Ctrl-z) and as root, type:
# slattach -h -c -s 115200 /dev/modemIf you are able to ping hosts on the other side of the router, you are connected! If it does not work, you might want to try
-ainstead of-cas an argument to slattach.
25.7.1.3 How to Shutdown the Connection
Do the following:
# kill -INT `cat /var/run/slattach.modem.pid`
to kill slattach. Keep in mind you must be root to do the above. Then go back to kermit (by running fg if you suspended it) and exit from it (q).
The slattach(8) manual page says you have to use ifconfig sl0 down to mark the interface down, but this does not seem to make any difference. (ifconfig sl0 reports the same thing.)
Some times, your modem might refuse to drop the carrier. In that case, simply start kermit and quit it again. It usually goes out on the second try.
25.7.1.4 Troubleshooting
If it does not work, feel free to ask on freebsd-net mailing list. The things that people tripped over so far:
-
Not using
-cor-ain slattach (This should not be fatal, but some users have reported that this solves their problems.) -
Using
s10instead ofsl0(might be hard to see the difference on some fonts). -
Try ifconfig sl0 to see your interface status. For example, you might get:
# ifconfig sl0 sl0: flags=10<POINTOPOINT> inet 136.152.64.181 --> 136.152.64.1 netmask ffffff00 -
If you get “no route to host” messages from ping(8), there may be a problem with your routing table. You can use the netstat -r command to display the current routes :
# netstat -r Routing tables Destination Gateway Flags Refs Use IfaceMTU Rtt Netmasks: (root node) (root node) Route Tree for Protocol Family inet: (root node) => default inr-3.Example.EDU UG 8 224515 sl0 - - localhost.Exampl localhost.Example. UH 5 42127 lo0 - 0.438 inr-3.Example.ED water.CS.Example.E UH 1 0 sl0 - - water.CS.Example localhost.Example. UGH 34 47641234 lo0 - 0.438 (root node)The preceding examples are from a relatively busy system. The numbers on your system will vary depending on network activity.
25.7.2 Setting Up a SLIP Server
This document provides suggestions for setting up SLIP Server services on a FreeBSD system, which typically means configuring your system to automatically start up connections upon login for remote SLIP clients.
25.7.2.1 Prerequisites
This section is very technical in nature, so background knowledge is required. It is assumed that you are familiar with the TCP/IP network protocol, and in particular, network and node addressing, network address masks, subnetting, routing, and routing protocols, such as RIP. Configuring SLIP services on a dial-up server requires a knowledge of these concepts, and if you are not familiar with them, please read a copy of either Craig Hunt's TCP/IP Network Administration published by O'Reilly & Associates, Inc. (ISBN Number 0-937175-82-X), or Douglas Comer's books on the TCP/IP protocol.
It is further assumed that you have already set up your modem(s) and configured the appropriate system files to allow logins through your modems. If you have not prepared your system for this yet, please see Section 24.4 for details on dialup services configuration. You may also want to check the manual pages for sio(4) for information on the serial port device driver and ttys(5), gettytab(5), getty(8), & init(8) for information relevant to configuring the system to accept logins on modems, and perhaps stty(1) for information on setting serial port parameters (such as clocal for directly-connected serial interfaces).
25.7.2.2 Quick Overview
In its typical configuration, using FreeBSD as a SLIP server works as follows: a SLIP user dials up your FreeBSD SLIP Server system and logs in with a special SLIP login ID that uses /usr/sbin/sliplogin as the special user's shell. The sliplogin program browses the file /etc/sliphome/slip.hosts to find a matching line for the special user, and if it finds a match, connects the serial line to an available SLIP interface and then runs the shell script /etc/sliphome/slip.login to configure the SLIP interface.
25.7.2.2.1 An Example of a SLIP Server Login
For example, if a SLIP user ID were Shelmerg, Shelmerg's entry in /etc/master.passwd would look something like this:
Shelmerg:password:1964:89::0:0:Guy Helmer - SLIP:/usr/users/Shelmerg:/usr/sbin/sliplogin
When Shelmerg logs in, sliplogin will search /etc/sliphome/slip.hosts for a line that had a matching user ID; for example, there may be a line in /etc/sliphome/slip.hosts that reads:
Shelmerg dc-slip sl-helmer 0xfffffc00 autocomp
sliplogin will find that matching line, hook the serial line into the next available SLIP interface, and then execute /etc/sliphome/slip.login like this:
/etc/sliphome/slip.login 0 19200 Shelmerg dc-slip sl-helmer 0xfffffc00 autocomp
If all goes well, /etc/sliphome/slip.login will issue an ifconfig for the SLIP interface to which sliplogin attached itself (SLIP interface 0, in the above example, which was the first parameter in the list given to slip.login) to set the local IP address (dc-slip), remote IP address (sl-helmer), network mask for the SLIP interface (0xfffffc00), and any additional flags (autocomp). If something goes wrong, sliplogin usually logs good informational messages via the syslogd daemon facility, which usually logs to /var/log/messages (see the manual pages for syslogd(8) and syslog.conf(5) and perhaps check /etc/syslog.conf to see to what syslogd is logging and where it is logging to).
25.7.2.3 Kernel Configuration
FreeBSD's default kernel (GENERIC) comes with SLIP (sl(4)) support; in case of a custom kernel, you have to add the following line to your kernel configuration file:
device sl
By default, your FreeBSD machine will not forward packets. If you want your FreeBSD
SLIP Server to act as a router, you will have to edit the /etc/rc.conf file and change the setting of the gateway_enable variable to YES.
You will then need to reboot for the new settings to take effect.
Please refer to Chapter 8 on Configuring the FreeBSD Kernel for help in reconfiguring your kernel.
25.7.2.4 Sliplogin Configuration
As mentioned earlier, there are three files in the /etc/sliphome directory that are part of the configuration for /usr/sbin/sliplogin (see sliplogin(8) for the actual manual page for sliplogin): slip.hosts, which defines the SLIP users and their associated IP addresses; slip.login, which usually just configures the SLIP interface; and (optionally) slip.logout, which undoes slip.login's effects when the serial connection is terminated.
25.7.2.4.1 slip.hosts Configuration
/etc/sliphome/slip.hosts contains lines which have at least four items separated by whitespace:
-
SLIP user's login ID
-
Local address (local to the SLIP server) of the SLIP link
-
Remote address of the SLIP link
-
Network mask
The local and remote addresses may be host names (resolved to IP addresses by /etc/hosts or by the domain name service, depending on your specifications in the file /etc/nsswitch.conf), and the network mask may be a name that can be resolved by a lookup into /etc/networks. On a sample system, /etc/sliphome/slip.hosts looks like this:
#
# login local-addr remote-addr mask opt1 opt2
# (normal,compress,noicmp)
#
Shelmerg dc-slip sl-helmerg 0xfffffc00 autocomp
At the end of the line is one or more of the options:
-
normal-- no header compression -
compress-- compress headers -
autocomp-- compress headers if the remote end allows it -
noicmp-- disable ICMP packets (so any “ping” packets will be dropped instead of using up your bandwidth)
Your choice of local and remote addresses for your SLIP links depends on whether you are going to dedicate a TCP/IP subnet or if you are going to use “proxy ARP” on your SLIP server (it is not “true” proxy ARP, but that is the terminology used in this section to describe it). If you are not sure which method to select or how to assign IP addresses, please refer to the TCP/IP books referenced in the SLIP Prerequisites (Section 25.7.2.1) and/or consult your IP network manager.
If you are going to use a separate subnet for your SLIP clients, you will need to allocate the subnet number out of your assigned IP network number and assign each of your SLIP client's IP numbers out of that subnet. Then, you will probably need to configure a static route to the SLIP subnet via your SLIP server on your nearest IP router.
Otherwise, if you will use the “proxy ARP” method, you will need to assign your SLIP client's IP addresses out of your SLIP server's Ethernet subnet, and you will also need to adjust your /etc/sliphome/slip.login and /etc/sliphome/slip.logout scripts to use arp(8) to manage the proxy-ARP entries in the SLIP server's ARP table.
25.7.2.4.2 slip.login Configuration
The typical /etc/sliphome/slip.login file looks like this:
#!/bin/sh -
#
# @(#)slip.login 5.1 (Berkeley) 7/1/90
#
# generic login file for a slip line. sliplogin invokes this with
# the parameters:
# 1 2 3 4 5 6 7-n
# slipunit ttyspeed loginname local-addr remote-addr mask opt-args
#
/sbin/ifconfig sl$1 inet $4 $5 netmask $6
This slip.login file merely runs ifconfig for the appropriate SLIP interface with the local and remote addresses and network mask of the SLIP interface.
If you have decided to use the “proxy ARP” method (instead of using a separate subnet for your SLIP clients), your /etc/sliphome/slip.login file will need to look something like this:
#!/bin/sh -
#
# @(#)slip.login 5.1 (Berkeley) 7/1/90
#
# generic login file for a slip line. sliplogin invokes this with
# the parameters:
# 1 2 3 4 5 6 7-n
# slipunit ttyspeed loginname local-addr remote-addr mask opt-args
#
/sbin/ifconfig sl$1 inet $4 $5 netmask $6
# Answer ARP requests for the SLIP client with our Ethernet addr
/usr/sbin/arp -s $5 00:11:22:33:44:55 pub
The additional line in this slip.login, arp -s $5 00:11:22:33:44:55 pub, creates an ARP entry in the SLIP server's ARP table. This ARP entry causes the SLIP server to respond with the SLIP server's Ethernet MAC address whenever another IP node on the Ethernet asks to speak to the SLIP client's IP address.
When using the example above, be sure to replace the Ethernet MAC address (00:11:22:33:44:55) with the MAC address of your system's Ethernet card, or your “proxy ARP” will definitely not work! You can discover your SLIP server's Ethernet MAC address by looking at the results of running netstat -i; the second line of the output should look something like:
ed0 1500 <Link>0.2.c1.28.5f.4a 191923 0 129457 0 116
This indicates that this particular system's Ethernet MAC address is 00:02:c1:28:5f:4a -- the periods in the Ethernet MAC address given by netstat -i must be changed to colons and leading zeros should be added to each single-digit hexadecimal number to convert the address into the form that arp(8) desires; see the manual page on arp(8) for complete information on usage.
Note: When you create /etc/sliphome/slip.login and /etc/sliphome/slip.logout, the “execute” bit (i.e., chmod 755 /etc/sliphome/slip.login /etc/sliphome/slip.logout) must be set, or sliplogin will be unable to execute it.
25.7.2.4.3 slip.logout Configuration
/etc/sliphome/slip.logout is not strictly needed (unless you are implementing “proxy ARP”), but if you decide to create it, this is an example of a basic slip.logout script:
#!/bin/sh -
#
# slip.logout
#
# logout file for a slip line. sliplogin invokes this with
# the parameters:
# 1 2 3 4 5 6 7-n
# slipunit ttyspeed loginname local-addr remote-addr mask opt-args
#
/sbin/ifconfig sl$1 down
If you are using “proxy ARP”, you will want to have /etc/sliphome/slip.logout remove the ARP entry for the SLIP client:
#!/bin/sh -
#
# @(#)slip.logout
#
# logout file for a slip line. sliplogin invokes this with
# the parameters:
# 1 2 3 4 5 6 7-n
# slipunit ttyspeed loginname local-addr remote-addr mask opt-args
#
/sbin/ifconfig sl$1 down
# Quit answering ARP requests for the SLIP client
/usr/sbin/arp -d $5
The arp -d $5 removes the ARP entry that the “proxy ARP” slip.login added when the SLIP client logged in.
It bears repeating: make sure /etc/sliphome/slip.logout has the execute bit set after you create it (i.e., chmod 755 /etc/sliphome/slip.logout).
25.7.2.5 Routing Considerations
If you are not using the “proxy ARP” method for routing packets between your SLIP clients and the rest of your network (and perhaps the Internet), you will probably have to add static routes to your closest default router(s) to route your SLIP clients subnet via your SLIP server.
25.7.2.5.1 Static Routes
Adding static routes to your nearest default routers can be troublesome (or impossible if you do not have authority to do so...). If you have a multiple-router network in your organization, some routers, such as those made by Cisco and Proteon, may not only need to be configured with the static route to the SLIP subnet, but also need to be told which static routes to tell other routers about, so some expertise and troubleshooting/tweaking may be necessary to get static-route-based routing to work.
25.7.2.5.2 Running GateD®
Note: GateD is proprietary software now and will not be available as source code to the public anymore (more info on the GateD website). This section only exists to ensure backwards compatibility for those that are still using an older version.
An alternative to the headaches of static routes is to install GateD on your FreeBSD SLIP server and configure it to use the appropriate routing protocols (RIP/OSPF/BGP/EGP) to tell other routers about your SLIP subnet. You will need to write a /etc/gated.conf file to configure your GateD; here is a sample, similar to what the author used on a FreeBSD SLIP server:
#
# gated configuration file for dc.dsu.edu; for gated version 3.5alpha5
# Only broadcast RIP information for xxx.xxx.yy out the ed Ethernet interface
#
#
# tracing options
#
traceoptions "/var/tmp/gated.output" replace size 100k files 2 general ;
rip yes {
interface sl noripout noripin ;
interface ed ripin ripout version 1 ;
traceoptions route ;
} ;
#
# Turn on a bunch of tracing info for the interface to the kernel:
kernel {
traceoptions remnants request routes info interface ;
} ;
#
# Propagate the route to xxx.xxx.yy out the Ethernet interface via RIP
#
export proto rip interface ed {
proto direct {
xxx.xxx.yy mask 255.255.252.0 metric 1; # SLIP connections
} ;
} ;
#
# Accept routes from RIP via ed Ethernet interfaces
import proto rip interface ed {
all ;
} ;
The above sample gated.conf file broadcasts routing information regarding the SLIP subnet xxx.xxx.yy via RIP onto the Ethernet; if you are using a different Ethernet driver than the ed driver, you will need to change the references to the ed interface appropriately. This sample file also sets up tracing to /var/tmp/gated.output for debugging GateD's activity; you can certainly turn off the tracing options if GateD works correctly for you. You will need to change the xxx.xxx.yy's into the network address of your own SLIP subnet (be sure to change the net mask in the proto direct clause as well).
Once you have installed and configured GateD on your system, you will need to tell the FreeBSD
startup scripts to run GateD in
place of routed. The easiest way to accomplish this is to set
the router and router_flags
variables in /etc/rc.conf. Please see the manual page for GateD for information on
command-line parameters.
Chapter 26 Electronic Mail
Original work by Bill Lloyd. Rewritten by Jim Mock.26.1 Synopsis
“Electronic Mail”, better known as email, is one of the most widely used forms of communication today. This chapter provides a basic introduction to running a mail server on FreeBSD, as well as an introduction to sending and receiving email using FreeBSD; however, it is not a complete reference and in fact many important considerations are omitted. For more complete coverage of the subject, the reader is referred to the many excellent books listed in Appendix B.
After reading this chapter, you will know:
-
What software components are involved in sending and receiving electronic mail.
-
Where basic sendmail configuration files are located in FreeBSD.
-
The difference between remote and local mailboxes.
-
How to block spammers from illegally using your mail server as a relay.
-
How to install and configure an alternate Mail Transfer Agent on your system, replacing sendmail.
-
How to troubleshoot common mail server problems.
-
How to use SMTP with UUCP.
-
How to set up the system to send mail only.
-
How to use mail with a dialup connection.
-
How to configure SMTP Authentication for added security.
-
How to install and use a Mail User Agent, such as mutt to send and receive email.
-
How to download your mail from a remote POP or IMAP server.
-
How to automatically apply filters and rules to incoming email.
Before reading this chapter, you should:
-
Properly set up your network connection (Chapter 29).
-
Properly set up the DNS information for your mail host (Chapter 27).
-
Know how to install additional third-party software (Chapter 4).
26.2 Using Electronic Mail
There are five major parts involved in an email exchange. They are: the user program, the server daemon, DNS, a remote or local mailbox, and of course, the mailhost itself.
26.2.1 The User Program
This includes command line programs such as mutt, pine, elm, and mail, and GUI programs such as balsa, xfmail to name a few, and something more “sophisticated” like a WWW browser. These programs simply pass off the email transactions to the local “mailhost”, either by calling one of the server daemons available, or delivering it over TCP.
26.2.2 Mailhost Server Daemon
FreeBSD ships with sendmail by default, but also support numerous other mail server daemons, just some of which include:
-
exim;
-
postfix;
-
qmail.
The server daemon usually has two functions--it is responsible for receiving incoming mail as well as delivering outgoing mail. It is not responsible for the collection of mail using protocols such as POP or IMAP to read your email, nor does it allow connecting to local mbox or Maildir mailboxes. You may require an additional daemon for that.
Warning: Older versions of sendmail have some serious security issues which may result in an attacker gaining local and/or remote access to your machine. Make sure that you are running a current version to avoid these problems. Optionally, install an alternative MTA from the FreeBSD Ports Collection.
26.2.3 Email and DNS
The Domain Name System (DNS) and its daemon named play a large role in the delivery of email. In order to deliver mail from your site to another, the server daemon will look up the remote site in the DNS to determine the host that will receive mail for the destination. This process also occurs when mail is sent from a remote host to your mail server.
DNS is responsible for mapping hostnames to IP addresses, as well as for storing information specific to mail delivery, known as MX records. The MX (Mail eXchanger) record specifies which host, or hosts, will receive mail for a particular domain. If you do not have an MX record for your hostname or domain, the mail will be delivered directly to your host provided you have an A record pointing your hostname to your IP address.
You may view the MX records for any domain by using the host(1) command, as seen in the example below:
% host -t mx FreeBSD.org
FreeBSD.org mail is handled (pri=10) by mx1.FreeBSD.org
26.2.4 Receiving Mail
Receiving mail for your domain is done by the mail host. It will collect all mail sent to your domain and store it either in mbox (the default method for storing mail) or Maildir format, depending on your configuration. Once mail has been stored, it may either be read locally using applications such as mail(1) or mutt, or remotely accessed and collected using protocols such as POP or IMAP. This means that should you only wish to read mail locally, you are not required to install a POP or IMAP server.
26.2.4.1 Accessing remote mailboxes using POP and IMAP
In order to access mailboxes remotely, you are required to have access to a POP or IMAP server. These protocols allow users to connect to their mailboxes from remote locations with ease. Though both POP and IMAP allow users to remotely access mailboxes, IMAP offers many advantages, some of which are:
-
IMAP can store messages on a remote server as well as fetch them.
-
IMAP supports concurrent updates.
-
IMAP can be extremely useful over low-speed links as it allows users to fetch the structure of messages without downloading them; it can also perform tasks such as searching on the server in order to minimize data transfer between clients and servers.
In order to install a POP or IMAP server, the following steps should be performed:
-
Choose an IMAP or POP server that best suits your needs. The following POP and IMAP servers are well known and serve as some good examples:
-
qpopper;
-
teapop;
-
imap-uw;
-
courier-imap;
-
-
Install the POP or IMAP daemon of your choosing from the ports collection.
-
Where required, modify /etc/inetd.conf to load the POP or IMAP server.
Warning: It should be noted that both POP and IMAP transmit information, including username and password credentials in clear-text. This means that if you wish to secure the transmission of information across these protocols, you should consider tunneling sessions over ssh(1). Tunneling sessions is described in Section 14.11.8.
26.2.4.2 Accessing local mailboxes
Mailboxes may be accessed locally by directly utilizing MUAs on the server on which the mailbox resides. This can be done using applications such as mutt or mail(1).
26.2.5 The Mail Host
The mail host is the name given to a server that is responsible for delivering and receiving mail for your host, and possibly your network.
26.3 sendmail Configuration
Contributed by Christopher Shumway.sendmail(8) is the default Mail Transfer Agent (MTA) in FreeBSD. sendmail's job is to accept mail from Mail User Agents (MUA) and deliver it to the appropriate mailer as defined by its configuration file. sendmail can also accept network connections and deliver mail to local mailboxes or deliver it to another program.
sendmail uses the following configuration files:
| Filename | Function |
|---|---|
| /etc/mail/access | sendmail access database file |
| /etc/mail/aliases | Mailbox aliases |
| /etc/mail/local-host-names | Lists of hosts sendmail accepts mail for |
| /etc/mail/mailer.conf | Mailer program configuration |
| /etc/mail/mailertable | Mailer delivery table |
| /etc/mail/sendmail.cf | sendmail master configuration file |
| /etc/mail/virtusertable | Virtual users and domain tables |
26.3.1 /etc/mail/access
The access database defines what host(s) or IP addresses have access to the local mail
server and what kind of access they have. Hosts can be listed as OK, REJECT, RELAY or simply passed to sendmail's
error handling routine with a given mailer error. Hosts that are listed as OK, which is the default, are allowed to send mail to this host as
long as the mail's final destination is the local machine. Hosts that are listed as REJECT are rejected for all mail connections. Hosts that have the
RELAY option for their hostname are allowed to send mail for
any destination through this mail server.
Example 26-1. Configuring the sendmail Access Database
cyberspammer.com 550 We do not accept mail from spammers
FREE.STEALTH.MAILER@ 550 We do not accept mail from spammers
another.source.of.spam REJECT
okay.cyberspammer.com OK
128.32 RELAY
In this example we have five entries. Mail senders that match the left hand side of the table are affected by the action on the right side of the table. The first two examples give an error code to sendmail's error handling routine. The message is printed to the remote host when a mail matches the left hand side of the table. The next entry rejects mail from a specific host on the Internet, another.source.of.spam. The next entry accepts mail connections from a host okay.cyberspammer.com, which is more exact than the cyberspammer.com line above. More specific matches override less exact matches. The last entry allows relaying of electronic mail from hosts with an IP address that begins with 128.32. These hosts would be able to send mail through this mail server that are destined for other mail servers.
When this file is updated, you need to run make in /etc/mail/ to update the database.
26.3.2 /etc/mail/aliases
The aliases database contains a list of virtual mailboxes that are expanded to other user(s), files, programs or other aliases. Here are a few examples that can be used in /etc/mail/aliases:
Example 26-2. Mail Aliases
root: localuser
ftp-bugs: joe,eric,paul
bit.bucket: /dev/null
procmail: "|/usr/local/bin/procmail"
The file format is simple; the mailbox name on the left side of the colon is expanded
to the target(s) on the right. The first example simply expands the mailbox root to the mailbox localuser, which is
then looked up again in the aliases database. If no match is found, then the message is
delivered to the local user localuser. The next example shows a
mail list. Mail to the mailbox ftp-bugs is expanded to the
three local mailboxes joe, eric, and
paul. Note that a remote mailbox could be specified as <user@example.com>. The next example shows writing mail to a
file, in this case /dev/null. The last example shows sending
mail to a program, in this case the mail message is written to the standard input of /usr/local/bin/procmail through a UNIX pipe.
When this file is updated, you need to run make in /etc/mail/ to update the database.
26.3.3 /etc/mail/local-host-names
This is a list of hostnames sendmail(8) is to accept as the local host name. Place any domains or hosts that sendmail is to be receiving mail for. For example, if this mail server was to accept mail for the domain example.com and the host mail.example.com, its local-host-names might look something like this:
example.com
mail.example.com
When this file is updated, sendmail(8) needs to be restarted to read the changes.
26.3.4 /etc/mail/sendmail.cf
sendmail's master configuration file, sendmail.cf controls the overall behavior of sendmail, including everything from rewriting e-mail addresses to printing rejection messages to remote mail servers. Naturally, with such a diverse role, this configuration file is quite complex and its details are a bit out of the scope of this section. Fortunately, this file rarely needs to be changed for standard mail servers.
The master sendmail configuration file can be built from m4(1) macros that define the features and behavior of sendmail. Please see /usr/src/contrib/sendmail/cf/README for some of the details.
When changes to this file are made, sendmail needs to be restarted for the changes to take effect.
26.3.5 /etc/mail/virtusertable
The virtusertable maps mail addresses for virtual domains and mailboxes to real mailboxes. These mailboxes can be local, remote, aliases defined in /etc/mail/aliases or files.
Example 26-3. Example Virtual Domain Mail Map
root@example.com root
postmaster@example.com postmaster@noc.example.net
@example.com joe
In the above example, we have a mapping for a domain example.com. This file is processed in a first match order down the
file. The first item maps <root@example.com> to the
local mailbox root. The next entry maps <postmaster@example.com> to the mailbox postmaster on the host noc.example.net.
Finally, if nothing from example.com has matched so far, it will
match the last mapping, which matches every other mail message addressed to someone at
example.com. This will be mapped to the local mailbox joe.
26.4 Changing Your Mail Transfer Agent
Written by Andrew Boothman. Information taken from e-mails written by Gregory Neil Shapiro.As already mentioned, FreeBSD comes with sendmail already installed as your MTA (Mail Transfer Agent). Therefore by default it is in charge of your outgoing and incoming mail.
However, for a variety of reasons, some system administrators want to change their system's MTA. These reasons range from simply wanting to try out another MTA to needing a specific feature or package which relies on another mailer. Fortunately, whatever the reason, FreeBSD makes it easy to make the change.
26.4.1 Install a New MTA
You have a wide choice of MTAs available. A good starting point is the FreeBSD Ports Collection where you will be able to find many. Of course you are free to use any MTA you want from any location, as long as you can make it run under FreeBSD.
Start by installing your new MTA. Once it is installed it gives you a chance to decide if it really fulfills your needs, and also gives you the opportunity to configure your new software before getting it to take over from sendmail. When doing this, you should be sure that installing the new software will not attempt to overwrite system binaries such as /usr/bin/sendmail. Otherwise, your new mail software has essentially been put into service before you have configured it.
Please refer to your chosen MTA's documentation for information on how to configure the software you have chosen.
26.4.2 Disable sendmail
The procedure used to start sendmail changed significantly between 4.5-RELEASE, 4.6-RELEASE, and later releases. Therefore, the procedure used to disable it is subtly different.
Warning: If you disable sendmail's outgoing mail service, it is important that you replace it with an alternative mail delivery system. If you choose not to, system functions such as periodic(8) will be unable to deliver their results by e-mail as they would normally expect to. Many parts of your system may expect to have a functional sendmail-compatible system. If applications continue to use sendmail's binaries to try to send e-mail after you have disabled them, mail could go into an inactive sendmail queue, and never be delivered.
26.4.2.1 FreeBSD 4.5-STABLE before 2002/4/4 and Earlier (Including 4.5-RELEASE and Earlier)
Enter:
sendmail_enable="NO"
into /etc/rc.conf. This will disable sendmail's incoming mail service, but if /etc/mail/mailer.conf (see below) is not changed, sendmail will still be used to send e-mail.
26.4.2.2 FreeBSD 4.5-STABLE after 2002/4/4 (Including 4.6-RELEASE and Later)
In order to completely disable sendmail, including the outgoing mail service, you must use
sendmail_enable="NONE"
in /etc/rc.conf.
If you only want to disable sendmail's incoming mail service, you should set
sendmail_enable="NO"
in /etc/rc.conf. However, if incoming mail is disabled, local delivery will still function. More information on sendmail's startup options is available from the rc.sendmail(8) manual page.
26.4.2.3 FreeBSD 5.0-STABLE and Later
In order to completely disable sendmail, including the outgoing mail service, you must use
sendmail_enable="NO"
sendmail_submit_enable="NO"
sendmail_outbound_enable="NO"
sendmail_msp_queue_enable="NO"
in /etc/rc.conf.
If you only want to disable sendmail's incoming mail service, you should set
sendmail_enable="NO"
in /etc/rc.conf. More information on sendmail's startup options is available from the rc.sendmail(8) manual page.
26.4.3 Running Your New MTA on Boot
You may have a choice of two methods for running your new MTA on boot, again depending on what version of FreeBSD you are running.
26.4.3.1 FreeBSD 4.5-STABLE before 2002/4/11 (Including 4.5-RELEASE and Earlier)
Add a script to /usr/local/etc/rc.d/ that ends in .sh and is executable by root. The script should accept start and stop parameters. At startup time the system scripts will execute the command
/usr/local/etc/rc.d/supermailer.sh start
which you can also use to manually start the server. At shutdown time, the system scripts will use the stop option, running the command
/usr/local/etc/rc.d/supermailer.sh stop
which you can also use to manually stop the server while the system is running.
26.4.3.2 FreeBSD 4.5-STABLE after 2002/4/11 (Including 4.6-RELEASE and Later)
With later versions of FreeBSD, you can use the above method or you can set
mta_start_script="filename"
in /etc/rc.conf, where filename is the name of some script that you want executed at boot to start your MTA.
26.4.4 Replacing sendmail as the System's Default Mailer
The program sendmail is so ubiquitous as standard software on UNIX systems that some software just assumes it is already installed and configured. For this reason, many alternative MTA's provide their own compatible implementations of the sendmail command-line interface; this facilitates using them as “drop-in” replacements for sendmail.
Therefore, if you are using an alternative mailer, you will need to make sure that software trying to execute standard sendmail binaries such as /usr/bin/sendmail actually executes your chosen mailer instead. Fortunately, FreeBSD provides a system called mailwrapper(8) that does this job for you.
When sendmail is operating as installed, you will find something like the following in /etc/mail/mailer.conf:
sendmail /usr/libexec/sendmail/sendmail
send-mail /usr/libexec/sendmail/sendmail
mailq /usr/libexec/sendmail/sendmail
newaliases /usr/libexec/sendmail/sendmail
hoststat /usr/libexec/sendmail/sendmail
purgestat /usr/libexec/sendmail/sendmail
This means that when any of these common commands (such as sendmail itself) are run, the system actually invokes a copy of mailwrapper named sendmail, which checks mailer.conf and executes /usr/libexec/sendmail/sendmail instead. This system makes it easy to change what binaries are actually executed when these default sendmail functions are invoked.
Therefore if you wanted /usr/local/supermailer/bin/sendmail-compat to be run instead of sendmail, you could change /etc/mail/mailer.conf to read:
sendmail /usr/local/supermailer/bin/sendmail-compat
send-mail /usr/local/supermailer/bin/sendmail-compat
mailq /usr/local/supermailer/bin/mailq-compat
newaliases /usr/local/supermailer/bin/newaliases-compat
hoststat /usr/local/supermailer/bin/hoststat-compat
purgestat /usr/local/supermailer/bin/purgestat-compat
26.4.5 Finishing
Once you have everything configured the way you want it, you should either kill the sendmail processes that you no longer need and start the processes belonging to your new software, or simply reboot. Rebooting will also give you the opportunity to ensure that you have correctly configured your system to start your new MTA automatically on boot.
26.5 Troubleshooting
- 26.5.1. Why do I have to use the FQDN for hosts on my site?
- 26.5.2. sendmail says “mail loops back to myself”
- 26.5.3. How can I run a mail server on a dial-up PPP host?
- 26.5.4. Why do I keep getting “Relaying Denied” errors when sending mail from other hosts?
You will probably find that the host is actually in a different domain; for example, if you are in foo.bar.edu and you wish to reach a host called mumble in the bar.edu domain, you will have to refer to it by the fully-qualified domain name, mumble.bar.edu, instead of just mumble.
Traditionally, this was allowed by BSD BIND resolvers. However the current version of BIND that ships with FreeBSD no longer provides default abbreviations for non-fully qualified domain names other than the domain you are in. So an unqualified host mumble must either be found as mumble.foo.bar.edu, or it will be searched for in the root domain.
This is different from the previous behavior, where the search continued across mumble.bar.edu, and mumble.edu. Have a look at RFC 1535 for why this was considered bad practice, or even a security hole.
As a good workaround, you can place the line:
search foo.bar.edu bar.edu
instead of the previous:
domain foo.bar.edu
into your /etc/resolv.conf. However, make sure that the search
order does not go beyond the “boundary between local and public
administration”, as RFC 1535 calls it.This is answered in the sendmail FAQ as follows:
I'm getting these error messages:
553 MX list for domain.net points back to relay.domain.net
554 <user@domain.net>... Local configuration error
How can I solve this problem?
You have asked mail to the domain (e.g., domain.net) to be
forwarded to a specific host (in this case, relay.domain.net)
by using an MX record, but the relay machine does not recognize
itself as domain.net. Add domain.net to /etc/mail/local-host-names
[known as /etc/sendmail.cw prior to version 8.10]
(if you are using FEATURE(use_cw_file)) or add “Cw domain.net”
to /etc/mail/sendmail.cf.
The sendmail FAQ can be found at http://www.sendmail.org/faq/ and is recommended reading if you want to do any “tweaking” of your mail setup.
You want to connect a FreeBSD box on a LAN to the Internet. The FreeBSD box will be a mail gateway for the LAN. The PPP connection is non-dedicated.
There are at least two ways to do this. One way is to use UUCP.
Another way is to get a full-time Internet server to provide secondary MX services for your domain. For example, if your company's domain is example.com and your Internet service provider has set example.net up to provide secondary MX services to your domain:
example.com. MX 10 example.com.
MX 20 example.net.
Only one host should be specified as the final recipient (add Cw example.com in /etc/mail/sendmail.cf on example.com).
When the sending sendmail is trying to deliver the mail it will try to connect to you (example.com) over the modem link. It will most likely time out because you are not online. The program sendmail will automatically deliver it to the secondary MX site, i.e. your Internet provider (example.net). The secondary MX site will then periodically try to connect to your host and deliver the mail to the primary MX host (example.com).
You might want to use something like this as a login script:
#!/bin/sh
# Put me in /usr/local/bin/pppmyisp
( sleep 60 ; /usr/sbin/sendmail -q ) &
/usr/sbin/ppp -direct pppmyisp
If you are going to create a separate login script for a user you could use sendmail -qRexample.com instead in the script above. This will force all mail in your queue for example.com to be processed immediately.
A further refinement of the situation is as follows:
Message stolen from the FreeBSD Internet service provider's mailing list.
> we provide the secondary MX for a customer. The customer connects to
> our services several times a day automatically to get the mails to
> his primary MX (We do not call his site when a mail for his domains
> arrived). Our sendmail sends the mailqueue every 30 minutes. At the
> moment he has to stay 30 minutes online to be sure that all mail is
> gone to the primary MX.
>
> Is there a command that would initiate sendmail to send all the mails
> now? The user has not root-privileges on our machine of course.
In the “privacy flags” section of sendmail.cf, there is a
definition Opgoaway,restrictqrun
Remove restrictqrun to allow non-root users to start the queue processing.
You might also like to rearrange the MXs. We are the 1st MX for our
customers like this, and we have defined:
# If we are the best MX for a host, try directly instead of generating
# local config error.
OwTrue
That way a remote site will deliver straight to you, without trying
the customer connection. You then send to your customer. Only works for
“hosts”, so you need to get your customer to name their mail
machine “customer.com” as well as
“hostname.customer.com” in the DNS. Just put an A record in
the DNS for “customer.com”.
In default FreeBSD installations, sendmail is configured to only send mail from the host it is running on. For example, if a POP server is available, then users will be able to check mail from school, work, or other remote locations but they still will not be able to send outgoing emails from outside locations. Typically, a few moments after the attempt, an email will be sent from MAILER-DAEMON with a “5.7 Relaying Denied” error message.
There are several ways to get around this. The most straightforward solution is to put your ISP's address in a relay-domains file at /etc/mail/relay-domains. A quick way to do this would be:
# echo "your.isp.example.com" > /etc/mail/relay-domains
After creating or editing this file you must restart sendmail. This works great if you are a server administrator and do not wish to send mail locally, or would like to use a point and click client/system on another machine or even another ISP. It is also very useful if you only have one or two email accounts set up. If there is a large number of addresses to add, you can simply open this file in your favorite text editor and then add the domains, one per line:
your.isp.example.com
other.isp.example.net
users-isp.example.org
www.example.org
Now any mail sent through your system, by any host in this list (provided the user has an account on your system), will succeed. This is a very nice way to allow users to send mail from your system remotely without allowing people to send SPAM through your system.
26.6 Advanced Topics
The following section covers more involved topics such as mail configuration and setting up mail for your entire domain.
26.6.1 Basic Configuration
Out of the box, you should be able to send email to external hosts as long as you have set up /etc/resolv.conf or are running your own name server. If you would like to have mail for your host delivered to the MTA (e.g., sendmail) on your own FreeBSD host, there are two methods:
-
Run your own name server and have your own domain. For example, FreeBSD.org
-
Get mail delivered directly to your host. This is done by delivering mail directly to the current DNS name for your machine. For example, example.FreeBSD.org.
Regardless of which of the above you choose, in order to have mail delivered directly to your host, it must have a permanent static IP address (not a dynamic address, as with most PPP dial-up configurations). If you are behind a firewall, it must pass SMTP traffic on to you. If you want to receive mail directly at your host, you need to be sure of either of two things:
-
Make sure that the (lowest-numbered) MX record in your DNS points to your host's IP address.
-
Make sure there is no MX entry in your DNS for your host.
Either of the above will allow you to receive mail directly at your host.
Try this:
# hostname
example.FreeBSD.org
# host example.FreeBSD.org
example.FreeBSD.org has address 204.216.27.XX
If that is what you see, mail directly to <yourlogin@example.FreeBSD.org> should work without problems
(assuming sendmail is running correctly on example.FreeBSD.org).
If instead you see something like this:
# host example.FreeBSD.org
example.FreeBSD.org has address 204.216.27.XX
example.FreeBSD.org mail is handled (pri=10) by hub.FreeBSD.org
All mail sent to your host (example.FreeBSD.org) will end up being collected on hub under the same username instead of being sent directly to your host.
The above information is handled by your DNS server. The DNS record that carries mail routing information is the Mail eXchange entry. If no MX record exists, mail will be delivered directly to the host by way of its IP address.
The MX entry for freefall.FreeBSD.org at one time looked like this:
freefall MX 30 mail.crl.net
freefall MX 40 agora.rdrop.com
freefall MX 10 freefall.FreeBSD.org
freefall MX 20 who.cdrom.com
As you can see, freefall had many MX entries. The lowest MX number is the host that receives mail directly if available; if it is not accessible for some reason, the others (sometimes called “backup MXes”) accept messages temporarily, and pass it along when a lower-numbered host becomes available, eventually to the lowest-numbered host.
Alternate MX sites should have separate Internet connections from your own in order to be most useful. Your ISP or another friendly site should have no problem providing this service for you.
26.6.2 Mail for Your Domain
In order to set up a “mailhost” (a.k.a. mail server) you need to have any mail sent to various workstations directed to it. Basically, you want to “claim” any mail for any hostname in your domain (in this case *.FreeBSD.org) and divert it to your mail server so your users can receive their mail on the master mail server.
To make life easiest, a user account with the same username should exist on both machines. Use adduser(8) to do this.
The mailhost you will be using must be the designated mail exchanger for each workstation on the network. This is done in your DNS configuration like so:
example.FreeBSD.org A 204.216.27.XX ; Workstation
MX 10 hub.FreeBSD.org ; Mailhost
This will redirect mail for the workstation to the mailhost no matter where the A record points. The mail is sent to the MX host.
You cannot do this yourself unless you are running a DNS server. If you are not, or cannot run your own DNS server, talk to your ISP or whoever provides your DNS.
If you are doing virtual email hosting, the following information will come in handy. For this example, we will assume you have a customer with his own domain, in this case customer1.org, and you want all the mail for customer1.org sent to your mailhost, mail.myhost.com. The entry in your DNS should look like this:
customer1.org MX 10 mail.myhost.com
You do not need an A record for customer1.org if you only want to handle email for that domain.
Note: Be aware that pinging customer1.org will not work unless an A record exists for it.
The last thing that you must do is tell sendmail on your mailhost what domains and/or hostnames it should be accepting mail for. There are a few different ways this can be done. Either of the following will work:
-
Add the hosts to your /etc/mail/local-host-names file if you are using the FEATURE(use_cw_file). If you are using a version of sendmail earlier than 8.10, the file is /etc/sendmail.cw.
-
Add a Cwyour.host.com line to your /etc/sendmail.cf or /etc/mail/sendmail.cf if you are using sendmail 8.10 or higher.
26.7 SMTP with UUCP
The sendmail configuration that ships with FreeBSD is designed for sites that connect directly to the Internet. Sites that wish to exchange their mail via UUCP must install another sendmail configuration file.
Tweaking /etc/mail/sendmail.cf manually is an advanced topic. sendmail version 8 generates config files via m4(1) preprocessing, where the actual configuration occurs on a higher abstraction level. The m4(1) configuration files can be found under /usr/share/sendmail/cf. The file README in the cf directory can serve as a basic introduction to m4(1) configuration.
The best way to support UUCP delivery is to use the mailertable feature. This creates a database that sendmail can use to make routing decisions.
First, you have to create your .mc file. The directory /usr/share/sendmail/cf/cf contains a few examples. Assuming you have named your file foo.mc, all you need to do in order to convert it into a valid sendmail.cf is:
# cd /etc/mail
# make foo.cf
# cp foo.cf /etc/mail/sendmail.cf
A typical .mc file might look like:
VERSIONID(`Your version number') OSTYPE(bsd4.4)
FEATURE(accept_unresolvable_domains)
FEATURE(nocanonify)
FEATURE(mailertable, `hash -o /etc/mail/mailertable')
define(`UUCP_RELAY', your.uucp.relay)
define(`UUCP_MAX_SIZE', 200000)
define(`confDONT_PROBE_INTERFACES')
MAILER(local)
MAILER(smtp)
MAILER(uucp)
Cw your.alias.host.name
Cw youruucpnodename.UUCP
The lines containing accept_unresolvable_domains, nocanonify, and confDONT_PROBE_INTERFACES features will prevent any usage of the DNS during mail delivery. The UUCP_RELAY clause is needed to support UUCP delivery. Simply put an Internet hostname there that is able to handle .UUCP pseudo-domain addresses; most likely, you will enter the mail relay of your ISP there.
Once you have this, you need an /etc/mail/mailertable file. If you have only one link to the outside that is used for all your mails, the following file will suffice:
#
# makemap hash /etc/mail/mailertable.db < /etc/mail/mailertable
. uucp-dom:your.uucp.relay
A more complex example might look like this:
#
# makemap hash /etc/mail/mailertable.db < /etc/mail/mailertable
#
horus.interface-business.de uucp-dom:horus
.interface-business.de uucp-dom:if-bus
interface-business.de uucp-dom:if-bus
.heep.sax.de smtp8:%1
horus.UUCP uucp-dom:horus
if-bus.UUCP uucp-dom:if-bus
. uucp-dom:
The first three lines handle special cases where domain-addressed mail should not be sent out to the default route, but instead to some UUCP neighbor in order to “shortcut” the delivery path. The next line handles mail to the local Ethernet domain that can be delivered using SMTP. Finally, the UUCP neighbors are mentioned in the .UUCP pseudo-domain notation, to allow for a uucp-neighbor !recipient override of the default rules. The last line is always a single dot, matching everything else, with UUCP delivery to a UUCP neighbor that serves as your universal mail gateway to the world. All of the node names behind the uucp-dom: keyword must be valid UUCP neighbors, as you can verify using the command uuname.
As a reminder that this file needs to be converted into a DBM database file before use. The command line to accomplish this is best placed as a comment at the top of the mailertable file. You always have to execute this command each time you change your mailertable file.
Final hint: if you are uncertain whether some particular mail routing would work,
remember the -bt option to sendmail. It starts sendmail in address test mode; simply enter 3,0, followed by the address you wish to test for the mail routing.
The last line tells you the used internal mail agent, the destination host this agent
will be called with, and the (possibly translated) address. Leave this mode by typing Ctrl+D.
% sendmail -bt
ADDRESS TEST MODE (ruleset 3 NOT automatically invoked)
Enter <ruleset> <address>
> 3,0 foo@example.com
canonify input: foo @ example . com
...
parse returns: $# uucp-dom $@ your.uucp.relay $: foo < @ example . com . >
> ^D
26.8 Setting Up to Send Only
Contributed by Bill Moran.There are many instances where you may only want to send mail through a relay. Some examples are:
-
Your computer is a desktop machine, but you want to use programs such as send-pr(1). To do so, you should use your ISP's mail relay.
-
The computer is a server that does not handle mail locally, but needs to pass off all mail to a relay for processing.
Just about any MTA is capable of filling this particular niche. Unfortunately, it can be very difficult to properly configure a full-featured MTA just to handle offloading mail. Programs such as sendmail and postfix are largely overkill for this use.
Additionally, if you are using a typical Internet access service, your agreement may forbid you from running a “mail server”.
The easiest way to fulfill those needs is to install the mail/ssmtp port. Execute the following commands as root:
# cd /usr/ports/mail/ssmtp
# make install replace clean
Once installed, mail/ssmtp can be configured with a four-line file located at /usr/local/etc/ssmtp/ssmtp.conf:
root=yourrealemail@example.com
mailhub=mail.example.com
rewriteDomain=example.com
hostname=_HOSTNAME_
Make sure you use your real email address for root. Enter your ISP's outgoing mail relay in place of mail.example.com (some ISPs call this the “outgoing mail server” or “SMTP server”).
Make sure you disable sendmail, including the outgoing mail service. See Section 26.4.2 for details.
mail/ssmtp has some other options available. See the example configuration file in /usr/local/etc/ssmtp or the manual page of ssmtp for some examples and more information.
Setting up ssmtp in this manner will allow any software on your computer that needs to send mail to function properly, while not violating your ISP's usage policy or allowing your computer to be hijacked for spamming.
26.9 Using Mail with a Dialup Connection
If you have a static IP address, you should not need to adjust anything from the defaults. Set your host name to your assigned Internet name and sendmail will do the rest.
If you have a dynamically assigned IP number and use a dialup PPP connection to the Internet, you will probably have a mailbox on your ISPs mail server. Let's assume your ISP's domain is example.net, and that your user name is user, you have called your machine bsd.home, and your ISP has told you that you may use relay.example.net as a mail relay.
In order to retrieve mail from your mailbox, you must install a retrieval agent. The fetchmail utility is a good choice as it supports many different protocols. This program is available as a package or from the Ports Collection (mail/fetchmail). Usually, your ISP will provide POP. If you are using user PPP, you can automatically fetch your mail when an Internet connection is established with the following entry in /etc/ppp/ppp.linkup:
MYADDR:
!bg su user -c fetchmail
If you are using sendmail (as shown below) to deliver mail to non-local accounts, you probably want to have sendmail process your mailqueue as soon as your Internet connection is established. To do this, put this command after the fetchmail command in /etc/ppp/ppp.linkup:
!bg su user -c "sendmail -q"
Assume that you have an account for user on bsd.home. In the home directory of user on bsd.home, create a .fetchmailrc file:
poll example.net protocol pop3 fetchall pass MySecret
This file should not be readable by anyone except user as it contains the password MySecret.
In order to send mail with the correct from: header, you must
tell sendmail to use <user@example.net> rather than <user@bsd.home>. You may also wish to tell sendmail to send all mail via relay.example.net, allowing quicker mail transmission.
The following .mc file should suffice:
VERSIONID(`bsd.home.mc version 1.0')
OSTYPE(bsd4.4)dnl
FEATURE(nouucp)dnl
MAILER(local)dnl
MAILER(smtp)dnl
Cwlocalhost
Cwbsd.home
MASQUERADE_AS(`example.net')dnl
FEATURE(allmasquerade)dnl
FEATURE(masquerade_envelope)dnl
FEATURE(nocanonify)dnl
FEATURE(nodns)dnl
define(`SMART_HOST', `relay.example.net')
Dmbsd.home
define(`confDOMAIN_NAME',`bsd.home')dnl
define(`confDELIVERY_MODE',`deferred')dnl
Refer to the previous section for details of how to turn this .mc file into a sendmail.cf file. Also, do not forget to restart sendmail after updating sendmail.cf.
26.10 SMTP Authentication
Written by James Gorham.Having SMTP Authentication in place on your mail server has a number of benefits. SMTP Authentication can add another layer of security to sendmail, and has the benefit of giving mobile users who switch hosts the ability to use the same mail server without the need to reconfigure their mail client settings each time.
-
Install security/cyrus-sasl2 from the ports. You can find this port in security/cyrus-sasl2. The security/cyrus-sasl2 port supports a number of compile-time options. For the SMTP Authentication method we will be using here, make sure that the
LOGINoption is not disabled. -
After installing security/cyrus-sasl2, edit /usr/local/lib/sasl2/Sendmail.conf (or create it if it does not exist) and add the following line:
pwcheck_method: saslauthd -
Next, install security/cyrus-sasl2-saslauthd, edit /etc/rc.conf to add the following line:
saslauthd_enable="YES"and finally start the saslauthd daemon:
# /usr/local/etc/rc.d/saslauthd startThis daemon serves as a broker for sendmail to authenticate against your FreeBSD passwd database. This saves the trouble of creating a new set of usernames and passwords for each user that needs to use SMTP authentication, and keeps the login and mail password the same.
-
Now edit /etc/make.conf and add the following lines:
SENDMAIL_CFLAGS=-I/usr/local/include/sasl -DSASL SENDMAIL_LDFLAGS=-L/usr/local/lib SENDMAIL_LDADD=-lsasl2These lines will give sendmail the proper configuration options for linking to cyrus-sasl2 at compile time. Make sure that cyrus-sasl2 has been installed before recompiling sendmail.
-
Recompile sendmail by executing the following commands:
# cd /usr/src/lib/libsmutil # make cleandir && make obj && make # cd /usr/src/lib/libsm # make cleandir && make obj && make # cd /usr/src/usr.sbin/sendmail # make cleandir && make obj && make && make installThe compile of sendmail should not have any problems if /usr/src has not been changed extensively and the shared libraries it needs are available.
-
After sendmail has been compiled and reinstalled, edit your /etc/mail/freebsd.mc file (or whichever file you use as your .mc file. Many administrators choose to use the output from hostname(1) as the .mc file for uniqueness). Add these lines to it:
dnl set SASL options TRUST_AUTH_MECH(`GSSAPI DIGEST-MD5 CRAM-MD5 LOGIN')dnl define(`confAUTH_MECHANISMS', `GSSAPI DIGEST-MD5 CRAM-MD5 LOGIN')dnlThese options configure the different methods available to sendmail for authenticating users. If you would like to use a method other than pwcheck, please see the included documentation.
-
Finally, run make(1) while in /etc/mail. That will run your new .mc file and create a .cf file named freebsd.cf (or whatever name you have used for your .mc file). Then use the command make install restart, which will copy the file to sendmail.cf, and will properly restart sendmail. For more information about this process, you should refer to /etc/mail/Makefile.
If all has gone correctly, you should be able to enter your login information into the
mail client and send a test message. For further investigation, set the LogLevel of sendmail to 13 and watch /var/log/maillog for any errors.
For more information, please see the sendmail page regarding SMTP authentication.
26.11 Mail User Agents
Contributed by Marc Silver.A Mail User Agent (MUA) is an application that is used to send and receive email. Furthermore, as email “evolves” and becomes more complex, MUA's are becoming increasingly powerful in the way they interact with email; this gives users increased functionality and flexibility. FreeBSD contains support for numerous mail user agents, all of which can be easily installed using the FreeBSD Ports Collection. Users may choose between graphical email clients such as evolution or balsa, console based clients such as mutt, pine or mail, or the web interfaces used by some large organizations.
26.11.1 mail
mail(1) is the default Mail User Agent (MUA) in FreeBSD. It is a console based MUA that offers all the basic functionality required to send and receive text-based email, though it is limited in interaction abilities with attachments and can only support local mailboxes.
Although mail does not natively support interaction with POP or IMAP servers, these mailboxes may be downloaded to a local mbox file using an application such as fetchmail, which will be discussed later in this chapter (Section 26.12).
In order to send and receive email, simply invoke the mail command as per the following example:
% mail
The contents of the user mailbox in /var/mail are automatically read by the mail utility. Should the mailbox be empty, the utility exits with a message indicating that no mails could be found. Once the mailbox has been read, the application interface is started, and a list of messages will be displayed. Messages are automatically numbered, as can be seen in the following example:
Mail version 8.1 6/6/93. Type ? for help.
"/var/mail/marcs": 3 messages 3 new
>N 1 root@localhost Mon Mar 8 14:05 14/510 "test"
N 2 root@localhost Mon Mar 8 14:05 14/509 "user account"
N 3 root@localhost Mon Mar 8 14:05 14/509 "sample"
Messages can now be read by using the t mail command, suffixed by the message number that should be displayed. In this example, we will read the first email:
& t 1
Message 1:
From root@localhost Mon Mar 8 14:05:52 2004
X-Original-To: marcs@localhost
Delivered-To: marcs@localhost
To: marcs@localhost
Subject: test
Date: Mon, 8 Mar 2004 14:05:52 +0200 (SAST)
From: root@localhost (Charlie Root)
This is a test message, please reply if you receive it.
As can be seen in the example above, the t key will cause the message to be displayed with full headers. To display the list of messages again, the h key should be used.
If the email requires a response, you may use mail to reply, by using either the R or r mail keys. The R key instructs mail to reply only to the sender of the email, while r replies not only to the sender, but also to other recipients of the message. You may also suffix these commands with the mail number which you would like make a reply to. Once this has been done, the response should be entered, and the end of the message should be marked by a single . on a new line. An example can be seen below:
& R 1
To: root@localhost
Subject: Re: test
Thank you, I did get your email.
.
EOT
In order to send new email, the m key should be used, followed by the recipient email address. Multiple recipients may also be specified by separating each address with the , delimiter. The subject of the message may then be entered, followed by the message contents. The end of the message should be specified by putting a single . on a new line.
& mail root@localhost
Subject: I mastered mail
Now I can send and receive email using mail ... :)
.
EOT
While inside the mail utility, the ? command may be used to display help at any time, the mail(1) manual page should also be consulted for more help with mail.
Note: As previously mentioned, the mail(1) command was not originally designed to handle attachments, and thus deals with them very poorly. Newer MUAs such as mutt handle attachments in a much more intelligent way. But should you still wish to use the mail command, the converters/mpack port may be of considerable use.
26.11.2 mutt
mutt is a small yet very powerful Mail User Agent, with excellent features, just some of which include:
-
The ability to thread messages;
-
PGP support for digital signing and encryption of email;
-
MIME Support;
-
Maildir Support;
-
Highly customizable.
All of these features help to make mutt one of the most advanced mail user agents available. See http://www.mutt.org for more information on mutt.
The stable version of mutt may be installed using the mail/mutt port, while the current development version may be installed via the mail/mutt-devel port. After the port has been installed, mutt can be started by issuing the following command:
% mutt
mutt will automatically read the contents of the user mailbox in /var/mail and display the contents if applicable. If no mails are found in the user mailbox, then mutt will wait for commands from the user. The example below shows mutt displaying a list of messages:
In order to read an email, simply select it using the cursor keys, and press the Enter key. An example of mutt displaying email can be seen below:
As with the mail(1) command, mutt allows users to reply only to the sender of the message as well as to all recipients. To reply only to the sender of the email, use the r keyboard shortcut. To send a group reply, which will be sent to the original sender as well as all the message recipients, use the g shortcut.
Note: mutt makes use of the vi(1) command as an editor for creating and replying to emails. This may be customized by the user by creating or editing their own .muttrc file in their home directory and setting the editor variable or by setting the EDITOR environment variable. See http://www.mutt.org/ for more information about configuring mutt.
In order to compose a new mail message, press m. After a valid subject has been given, mutt will start vi(1) and the mail can be written. Once the contents of the mail are complete, save and quit from vi and mutt will resume, displaying a summary screen of the mail that is to be delivered. In order to send the mail, press y. An example of the summary screen can be seen below:
mutt also contains extensive help, which can be accessed from most of the menus by pressing the ? key. The top line also displays the keyboard shortcuts where appropriate.
26.11.3 pine
pine is aimed at a beginner user, but also includes some advanced features.
Warning: The pine software has had several remote vulnerabilities discovered in the past, which allowed remote attackers to execute arbitrary code as users on the local system, by the action of sending a specially-prepared email. All such known problems have been fixed, but the pine code is written in a very insecure style and the FreeBSD Security Officer believes there are likely to be other undiscovered vulnerabilities. You install pine at your own risk.
The current version of pine may be installed using the mail/pine4 port. Once the port has installed, pine can be started by issuing the following command:
% pine
The first time that pine is run it displays a greeting page with a brief introduction, as well as a request from the pine development team to send an anonymous email message allowing them to judge how many users are using their client. To send this anonymous message, press Enter, or alternatively press E to exit the greeting without sending an anonymous message. An example of the greeting page can be seen below:
Users are then presented with the main menu, which can be easily navigated using the cursor keys. This main menu provides shortcuts for the composing new mails, browsing of mail directories, and even the administration of address book entries. Below the main menu, relevant keyboard shortcuts to perform functions specific to the task at hand are shown.
The default directory opened by pine is the inbox. To view the message index, press I, or select the MESSAGE INDEX option as seen below:
The message index shows messages in the current directory, and can be navigated by using the cursor keys. Highlighted messages can be read by pressing the Enter key.
In the screenshot below, a sample message is displayed by pine. Keyboard shortcuts are displayed as a reference at the bottom of the screen. An example of one of these shortcuts is the r key, which tells the MUA to reply to the current message being displayed.
Replying to an email in pine is done using the pico editor, which is installed by default with pine. The pico utility makes it easy to navigate around the message and is slightly more forgiving on novice users than vi(1) or mail(1). Once the reply is complete, the message can be sent by pressing Ctrl+X. The pine application will ask for confirmation.
The pine application can be customized using the SETUP option from the main menu. Consult http://www.washington.edu/pine/ for more information.
26.12 Using fetchmail
Contributed by Marc Silver.fetchmail is a full-featured IMAP and POP client which allows users to automatically download mail from remote IMAP and POP servers and save it into local mailboxes; there it can be accessed more easily. fetchmail can be installed using the mail/fetchmail port, and offers various features, some of which include:
-
Support of POP3, APOP, KPOP, IMAP, ETRN and ODMR protocols.
-
Ability to forward mail using SMTP, which allows filtering, forwarding, and aliasing to function normally.
-
May be run in daemon mode to check periodically for new messages.
-
Can retrieve multiple mailboxes and forward them based on configuration, to different local users.
While it is outside the scope of this document to explain all of fetchmail's features, some basic features will be explained. The fetchmail utility requires a configuration file known as .fetchmailrc, in order to run correctly. This file includes server information as well as login credentials. Due to the sensitive nature of the contents of this file, it is advisable to make it readable only by the owner, with the following command:
% chmod 600 .fetchmailrc
The following .fetchmailrc serves as an example for downloading a single user mailbox using POP. It tells fetchmail to connect to example.com using a username of joesoap and a password of XXX. This example assumes that the user joesoap is also a user on the local system.
poll example.com protocol pop3 username "joesoap" password "XXX"
The next example connects to multiple POP and IMAP servers and redirects to different local usernames where applicable:
poll example.com proto pop3:
user "joesoap", with password "XXX", is "jsoap" here;
user "andrea", with password "XXXX";
poll example2.net proto imap:
user "john", with password "XXXXX", is "myth" here;
The fetchmail utility can be run in daemon mode by running
it with the -d flag, followed by the interval (in seconds)
that fetchmail should poll servers listed in the .fetchmailrc file. The following example would cause fetchmail to poll every 600 seconds:
% fetchmail -d 600
More information on fetchmail can be found at http://fetchmail.berlios.de/.
26.13 Using procmail
Contributed by Marc Silver.The procmail utility is an incredibly powerful application used to filter incoming mail. It allows users to define “rules” which can be matched to incoming mails to perform specific functions or to reroute mail to alternative mailboxes and/or email addresses. procmail can be installed using the mail/procmail port. Once installed, it can be directly integrated into most MTAs; consult your MTA documentation for more information. Alternatively, procmail can be integrated by adding the following line to a .forward in the home directory of the user utilizing procmail features:
"|exec /usr/local/bin/procmail || exit 75"
The following section will display some basic procmail rules, as well as brief descriptions on what they do. These rules, and others must be inserted into a .procmailrc file, which must reside in the user's home directory.
The majority of these rules can also be found in the procmailex(5) manual page.
Forward all mail from <user@example.com> to an
external address of <goodmail@example2.com>:
:0
* ^From.*user@example.com
! goodmail@example2.com
Forward all mails shorter than 1000 bytes to an external address of <goodmail@example2.com>:
:0
* < 1000
! goodmail@example2.com
Send all mail sent to <alternate@example.com> into
a mailbox called alternate:
:0
* ^TOalternate@example.com
alternate
Send all mail with a subject of “Spam” to /dev/null:
:0
^Subject:.*Spam
/dev/null
A useful recipe that parses incoming FreeBSD.org mailing lists and places each list in its own mailbox:
:0
* ^Sender:.owner-freebsd-\/[^@]+@FreeBSD.ORG
{
LISTNAME=${MATCH}
:0
* LISTNAME??^\/[^@]+
FreeBSD-${MATCH}
}
Chapter 27 Network Servers
Reorganized by Murray Stokely.27.1 Synopsis
This chapter will cover some of the more frequently used network services on UNIX systems. We will cover how to install, configure, test, and maintain many different types of network services. Example configuration files are included throughout this chapter for you to benefit from.
After reading this chapter, you will know:
-
How to manage the inetd daemon.
-
How to set up a network file system.
-
How to set up a network information server for sharing user accounts.
-
How to set up automatic network settings using DHCP.
-
How to set up a domain name server.
-
How to set up the Apache HTTP Server.
-
How to set up a File Transfer Protocol (FTP) Server.
-
How to set up a file and print server for Windows clients using Samba.
-
How to synchronize the time and date, and set up a time server, with the NTP protocol.
Before reading this chapter, you should:
-
Understand the basics of the /etc/rc scripts.
-
Be familiar with basic network terminology.
-
Know how to install additional third-party software (Chapter 4).
27.2 The inetd “Super-Server”
Contributed by Chern Lee. Updated for FreeBSD 6.1-RELEASE by The FreeBSD Documentation Project.27.2.1 Overview
inetd(8) is sometimes referred to as the “Internet Super-Server” because it manages connections for several services. When a connection is received by inetd, it determines which program the connection is destined for, spawns the particular process and delegates the socket to it (the program is invoked with the service socket as its standard input, output and error descriptors). Running inetd for servers that are not heavily used can reduce the overall system load, when compared to running each daemon individually in stand-alone mode.
Primarily, inetd is used to spawn other daemons, but several trivial protocols are handled directly, such as chargen, auth, and daytime.
This section will cover the basics in configuring inetd through its command-line options and its configuration file, /etc/inetd.conf.
27.2.2 Settings
inetd is initialized through the rc(8) system. The inetd_enable option is set to NO by default, but may be turned on by sysinstall during installation, depending on the configuration chosen by the user. Placing:
inetd_enable="YES"
or
inetd_enable="NO"
into /etc/rc.conf will enable or disable inetd starting at boot time. The command:
# /etc/rc.d/inetd rcvar
can be run to display the current effective setting.
Additionally, different command-line options can be passed to inetd via the inetd_flags option.
27.2.3 Command-Line Options
Like most server daemons, inetd has a number of options that it can be passed in order to modify its behaviour. The full list of options reads:
inetd [-d] [-l] [-w] [-W] [-c maximum]
[-C rate] [-a address | hostname] [-p filename] [-R rate] [-s maximum] [configuration
file]
Options can be passed to inetd using the inetd_flags option in /etc/rc.conf. By default, inetd_flags is set to -wW -C 60, which turns on TCP wrapping for inetd's services, and prevents any single IP address from requesting any service more than 60 times in any given minute.
Novice users may be pleased to note that these parameters usually do not need to be modified, although we mention the rate-limiting options below as they be useful should you find that you are receiving an excessive amount of connections. A full list of options can be found in the inetd(8) manual.
- -c maximum
-
Specify the default maximum number of simultaneous invocations of each service; the default is unlimited. May be overridden on a per-service basis with the
max-childparameter. - -C rate
-
Specify the default maximum number of times a service can be invoked from a single IP address in one minute; the default is unlimited. May be overridden on a per-service basis with the
max-connections-per-ip-per-minuteparameter. - -R rate
-
Specify the maximum number of times a service can be invoked in one minute; the default is 256. A rate of 0 allows an unlimited number of invocations.
- -s maximum
-
Specify the maximum number of times a service can be invoked from a single IP address at any one time; the default is unlimited. May be overridden on a per-service basis with the
max-child-per-ipparameter.
27.2.4 inetd.conf
Configuration of inetd is done via the file /etc/inetd.conf.
When a modification is made to /etc/inetd.conf, inetd can be forced to re-read its configuration file by running the command:
Each line of the configuration file specifies an individual daemon. Comments in the file are preceded by a “#”. The format of each entry in /etc/inetd.conf is as follows:
service-name
socket-type
protocol
{wait|nowait}[/max-child[/max-connections-per-ip-per-minute[/max-child-per-ip]]]
user[:group][/login-class]
server-program
server-program-arguments
An example entry for the ftpd(8) daemon using IPv4 might read:
ftp stream tcp nowait root /usr/libexec/ftpd ftpd -l
- service-name
-
This is the service name of the particular daemon. It must correspond to a service listed in /etc/services. This determines which port inetd must listen to. If a new service is being created, it must be placed in /etc/services first.
- socket-type
-
Either stream, dgram, raw, or seqpacket. stream must be used for connection-based, TCP daemons, while dgram is used for daemons utilizing the UDP transport protocol.
- protocol
-
One of the following:
- {wait|nowait}[/max-child[/max-connections-per-ip-per-minute[/max-child-per-ip]]]
-
wait|nowaitindicates whether the daemon invoked from inetd is able to handle its own socket or not.dgramsocket types must use thewaitoption, while stream socket daemons, which are usually multi-threaded, should usenowait.waitusually hands off multiple sockets to a single daemon, whilenowaitspawns a child daemon for each new socket.The maximum number of child daemons inetd may spawn can be set using the
max-childoption. If a limit of ten instances of a particular daemon is needed, a /10 would be placed afternowait. Specifying /0 allows an unlimited number of childrenIn addition to
max-child, two other options which limit the maximum connections from a single place to a particular daemon can be enabled.max-connections-per-ip-per-minutelimits the number of connections from any particular IP address per minutes, e.g. a value of ten would limit any particular IP address connecting to a particular service to ten attempts per minute.max-child-per-iplimits the number of children that can be started on behalf on any single IP address at any moment. These options are useful to prevent intentional or unintentional excessive resource consumption and Denial of Service (DoS) attacks to a machine.In this field, either of
waitornowaitis mandatory.max-child,max-connections-per-ip-per-minuteandmax-child-per-ipare optional.A stream-type multi-threaded daemon without any
max-child,max-connections-per-ip-per-minuteormax-child-per-iplimits would simply be: nowait.The same daemon with a maximum limit of ten daemons would read: nowait/10.
The same setup with a limit of twenty connections per IP address per minute and a maximum total limit of ten child daemons would read: nowait/10/20.
These options are utilized by the default settings of the fingerd(8) daemon, as seen here:
finger stream tcp nowait/3/10 nobody /usr/libexec/fingerd fingerd -sFinally, an example of this field with a maximum of 100 children in total, with a maximum of 5 for any one IP address would read: nowait/100/0/5.
- user
-
This is the username that the particular daemon should run as. Most commonly, daemons run as the root user. For security purposes, it is common to find some servers running as the daemon user, or the least privileged nobody user.
- server-program
-
The full path of the daemon to be executed when a connection is received. If the daemon is a service provided by inetd internally, then
internalshould be used. - server-program-arguments
-
This works in conjunction with
server-programby specifying the arguments, starting with argv[0], passed to the daemon on invocation. If mydaemon -d is the command line, mydaemon -d would be the value ofserver-program-arguments. Again, if the daemon is an internal service, useinternalhere.
27.2.5 Security
Depending on the choices made at install time, many of inetd's services may be enabled by default. If there is no apparent need for a particular daemon, consider disabling it. Place a “#” in front of the daemon in question in /etc/inetd.conf, and then reload the inetd configuration. Some daemons, such as fingerd, may not be desired at all because they provide information that may be useful to an attacker.
Some daemons are not security-conscious and have long, or non-existent, timeouts for
connection attempts. This allows an attacker to slowly send connections to a particular
daemon, thus saturating available resources. It may be a good idea to place max-connections-per-ip-per-minute, max-child or max-child-per-ip
limitations on certain daemons if you find that you have too many connections.
By default, TCP wrapping is turned on. Consult the hosts_access(5) manual page for more information on placing TCP restrictions on various inetd invoked daemons.
27.2.6 Miscellaneous
daytime, time, echo, discard, chargen, and auth are all internally provided services of inetd.
The auth service provides identity network services, and is configurable to a certain degree, whilst the others are simply on or off.
Consult the inetd(8) manual page for more in-depth information.
27.3 Network File System (NFS)
Reorganized and enhanced by Tom Rhodes. Written by Bill Swingle.Among the many different file systems that FreeBSD supports is the Network File System, also known as NFS. NFS allows a system to share directories and files with others over a network. By using NFS, users and programs can access files on remote systems almost as if they were local files.
Some of the most notable benefits that NFS can provide are:
-
Local workstations use less disk space because commonly used data can be stored on a single machine and still remain accessible to others over the network.
-
There is no need for users to have separate home directories on every network machine. Home directories could be set up on the NFS server and made available throughout the network.
-
Storage devices such as floppy disks, CDROM drives, and Zip® drives can be used by other machines on the network. This may reduce the number of removable media drives throughout the network.
27.3.1 How NFS Works
NFS consists of at least two main parts: a server and one or more clients. The client remotely accesses the data that is stored on the server machine. In order for this to function properly a few processes have to be configured and running.
The server has to be running the following daemons:
| Daemon | Description |
|---|---|
| nfsd | The NFS daemon which services requests from the NFS clients. |
| mountd | The NFS mount daemon which carries out the requests that nfsd(8) passes on to it. |
| rpcbind | This daemon allows NFS clients to discover which port the NFS server is using. |
The client can also run a daemon, known as nfsiod. The nfsiod daemon services the requests from the NFS server. This is optional, and improves performance, but is not required for normal and correct operation. See the nfsiod(8) manual page for more information.
27.3.2 Configuring NFS
NFS configuration is a relatively straightforward process. The processes that need to be running can all start at boot time with a few modifications to your /etc/rc.conf file.
On the NFS server, make sure that the following options are configured in the /etc/rc.conf file:
rpcbind_enable="YES"
nfs_server_enable="YES"
mountd_flags="-r"
mountd runs automatically whenever the NFS server is enabled.
On the client, make sure this option is present in /etc/rc.conf:
nfs_client_enable="YES"
The /etc/exports file specifies which file systems NFS should export (sometimes referred to as “share”). Each line in /etc/exports specifies a file system to be exported and which machines have access to that file system. Along with what machines have access to that file system, access options may also be specified. There are many such options that can be used in this file but only a few will be mentioned here. You can easily discover other options by reading over the exports(5) manual page.
Here are a few example /etc/exports entries:
The following examples give an idea of how to export file systems, although the
settings may be different depending on your environment and network configuration. For
instance, to export the /cdrom directory to three example
machines that have the same domain name as the server (hence the lack of a domain name
for each) or have entries in your /etc/hosts file. The -ro flag makes the exported file system read-only. With this flag,
the remote system will not be able to write any changes to the exported file system.
/cdrom -ro host1 host2 host3
The following line exports /home to three hosts by IP
address. This is a useful setup if you have a private network without a DNS server configured. Optionally the /etc/hosts file could be configured for internal hostnames; please
review hosts(5) for more
information. The -alldirs flag allows the subdirectories to
be mount points. In other words, it will not mount the subdirectories but permit the
client to mount only the directories that are required or needed.
/home -alldirs 10.0.0.2 10.0.0.3 10.0.0.4
The following line exports /a so that two clients from
different domains may access the file system. The -maproot=root flag allows the root user
on the remote system to write data on the exported file system as root. If the -maproot=root flag is not
specified, then even if a user has root access on the remote
system, he will not be able to modify files on the exported file system.
/a -maproot=root host.example.com box.example.org
In order for a client to access an exported file system, the client must have permission to do so. Make sure the client is listed in your /etc/exports file.
In /etc/exports, each line represents the export information for one file system to one host. A remote host can only be specified once per file system, and may only have one default entry. For example, assume that /usr is a single file system. The following /etc/exports would be invalid:
# Invalid when /usr is one file system
/usr/src client
/usr/ports client
One file system, /usr, has two lines specifying exports to the same host, client. The correct format for this situation is:
/usr/src /usr/ports client
The properties of one file system exported to a given host must all occur on one line. Lines without a client specified are treated as a single host. This limits how you can export file systems, but for most people this is not an issue.
The following is an example of a valid export list, where /usr and /exports are local file systems:
# Export src and ports to client01 and client02, but only
# client01 has root privileges on it
/usr/src /usr/ports -maproot=root client01
/usr/src /usr/ports client02
# The client machines have root and can mount anywhere
# on /exports. Anyone in the world can mount /exports/obj read-only
/exports -alldirs -maproot=root client01 client02
/exports/obj -ro
The mountd daemon must be forced to recheck the /etc/exports file whenever it has been modified, so the changes can take effect. This can be accomplished either by sending a HUP signal to the running daemon:
# kill -HUP `cat /var/run/mountd.pid`
or by invoking the mountd rc(8) script with the appropriate parameter:
# /etc/rc.d/mountd onereload
Please refer to Section 11.7 for more information about using rc scripts.
Alternatively, a reboot will make FreeBSD set everything up properly. A reboot is not necessary though. Executing the following commands as root should start everything up.
On the NFS server:
# rpcbind
# nfsd -u -t -n 4
# mountd -r
On the NFS client:
# nfsiod -n 4
Now everything should be ready to actually mount a remote file system. In these examples the server's name will be server and the client's name will be client. If you only want to temporarily mount a remote file system or would rather test the configuration, just execute a command like this as root on the client:
# mount server:/home /mnt
This will mount the /home directory on the server at /mnt on the client. If everything is set up correctly you should be able to enter /mnt on the client and see all the files that are on the server.
If you want to automatically mount a remote file system each time the computer boots, add the file system to the /etc/fstab file. Here is an example:
server:/home /mnt nfs rw 0 0
The fstab(5) manual page lists all the available options.
27.3.3 Locking
Some applications (e.g. mutt) require file locking to operate correctly. In the case of NFS, rpc.lockd can be used for file locking. To enable it, add the following to the /etc/rc.conf file on both client and server (it is assumed that the NFS client and server are configured already):
rpc_lockd_enable="YES"
rpc_statd_enable="YES"
Start the application by using:
# /etc/rc.d/nfslocking start
If real locking between the NFS clients and
NFS server is not required, it is possible to let the
NFS client do locking locally by passing -L to mount_nfs(8). Refer to
the mount_nfs(8) manual
page for further details.
27.3.4 Practical Uses
NFS has many practical uses. Some of the more common ones are listed below:
-
Set several machines to share a CDROM or other media among them. This is cheaper and often a more convenient method to install software on multiple machines.
-
On large networks, it might be more convenient to configure a central NFS server in which to store all the user home directories. These home directories can then be exported to the network so that users would always have the same home directory, regardless of which workstation they log in to.
-
Several machines could have a common /usr/ports/distfiles directory. That way, when you need to install a port on several machines, you can quickly access the source without downloading it on each machine.
27.3.5 Automatic Mounts with amd
Contributed by Wylie Stilwell. Rewritten by Chern Lee.amd(8) (the automatic mounter daemon) automatically mounts a remote file system whenever a file or directory within that file system is accessed. Filesystems that are inactive for a period of time will also be automatically unmounted by amd. Using amd provides a simple alternative to permanent mounts, as permanent mounts are usually listed in /etc/fstab.
amd operates by attaching itself as an NFS server to the /host and /net directories. When a file is accessed within one of these directories, amd looks up the corresponding remote mount and automatically mounts it. /net is used to mount an exported file system from an IP address, while /host is used to mount an export from a remote hostname.
An access to a file within /host/foobar/usr would tell amd to attempt to mount the /usr export on the host foobar.
Example 27-2. Mounting an Export with amd
You can view the available mounts of a remote host with the showmount command. For example, to view the mounts of a host named foobar, you can use:
% showmount -e foobar
Exports list on foobar:
/usr 10.10.10.0
/a 10.10.10.0
% cd /host/foobar/usr
As seen in the example, the showmount shows /usr as an export. When changing directories to /host/foobar/usr, amd attempts to resolve the hostname foobar and automatically mount the desired export.
amd can be started by the startup scripts by placing the following lines in /etc/rc.conf:
amd_enable="YES"
Additionally, custom flags can be passed to amd from the
amd_flags option. By default, amd_flags is set to:
amd_flags="-a /.amd_mnt -l syslog /host /etc/amd.map /net /etc/amd.map"
The /etc/amd.map file defines the default options that exports are mounted with. The /etc/amd.conf file defines some of the more advanced features of amd.
Consult the amd(8) and amd.conf(5) manual pages for more information.
27.3.6 Problems Integrating with Other Systems
Contributed by John Lind.Certain Ethernet adapters for ISA PC systems have limitations which can lead to serious network problems, particularly with NFS. This difficulty is not specific to FreeBSD, but FreeBSD systems are affected by it.
The problem nearly always occurs when (FreeBSD) PC systems are networked with high-performance workstations, such as those made by Silicon Graphics, Inc., and Sun Microsystems, Inc. The NFS mount will work fine, and some operations may succeed, but suddenly the server will seem to become unresponsive to the client, even though requests to and from other systems continue to be processed. This happens to the client system, whether the client is the FreeBSD system or the workstation. On many systems, there is no way to shut down the client gracefully once this problem has manifested itself. The only solution is often to reset the client, because the NFS situation cannot be resolved.
Though the “correct” solution is to get a higher performance and capacity
Ethernet adapter for the FreeBSD system, there is a simple workaround that will allow
satisfactory operation. If the FreeBSD system is the server, include the option -w=1024 on the mount from the client. If the FreeBSD system is the
client, then mount the NFS file
system with the option -r=1024. These options may be
specified using the fourth field of the fstab entry on the
client for automatic mounts, or by using the -o parameter of
the mount(8) command for
manual mounts.
It should be noted that there is a different problem, sometimes mistaken for this one, when the NFS servers and clients are on different networks. If that is the case, make certain that your routers are routing the necessary UDP information, or you will not get anywhere, no matter what else you are doing.
In the following examples, fastws is the host (interface) name
of a high-performance workstation, and freebox is the host
(interface) name of a FreeBSD system with a lower-performance Ethernet adapter. Also, /sharedfs will be the exported NFS file system (see exports(5)), and /project will be the mount point on the client for the exported
file system. In all cases, note that additional options, such as hard or soft and bg may be desirable in your application.
Examples for the FreeBSD system (freebox) as the client in /etc/fstab on freebox:
fastws:/sharedfs /project nfs rw,-r=1024 0 0
As a manual mount command on freebox:
# mount -t nfs -o -r=1024 fastws:/sharedfs /project
Examples for the FreeBSD system as the server in /etc/fstab on fastws:
freebox:/sharedfs /project nfs rw,-w=1024 0 0
As a manual mount command on fastws:
# mount -t nfs -o -w=1024 freebox:/sharedfs /project
Nearly any 16-bit Ethernet adapter will allow operation without the above restrictions on the read or write size.
For anyone who cares, here is what happens when the failure occurs, which also explains why it is unrecoverable. NFS typically works with a “block” size of 8 K (though it may do fragments of smaller sizes). Since the maximum Ethernet packet is around 1500 bytes, the NFS “block” gets split into multiple Ethernet packets, even though it is still a single unit to the upper-level code, and must be received, assembled, and acknowledged as a unit. The high-performance workstations can pump out the packets which comprise the NFS unit one right after the other, just as close together as the standard allows. On the smaller, lower capacity cards, the later packets overrun the earlier packets of the same unit before they can be transferred to the host and the unit as a whole cannot be reconstructed or acknowledged. As a result, the workstation will time out and try again, but it will try again with the entire 8 K unit, and the process will be repeated, ad infinitum.
By keeping the unit size below the Ethernet packet size limitation, we ensure that any complete Ethernet packet received can be acknowledged individually, avoiding the deadlock situation.
Overruns may still occur when a high-performance workstations is slamming data out to a PC system, but with the better cards, such overruns are not guaranteed on NFS “units”. When an overrun occurs, the units affected will be retransmitted, and there will be a fair chance that they will be received, assembled, and acknowledged.
27.4 Network Information System (NIS/YP)
Written by Bill Swingle. Enhanced by Eric Ogren and Udo Erdelhoff.27.4.1 What Is It?
NIS, which stands for Network Information Services, was developed by Sun Microsystems to centralize administration of UNIX (originally SunOS) systems. It has now essentially become an industry standard; all major UNIX like systems (Solaris, HP-UX, AIX®, Linux, NetBSD, OpenBSD, FreeBSD, etc) support NIS.
NIS was formerly known as Yellow Pages, but because of trademark issues, Sun changed the name. The old term (and yp) is still often seen and used.
It is a RPC-based client/server system that allows a group of machines within an NIS domain to share a common set of configuration files. This permits a system administrator to set up NIS client systems with only minimal configuration data and add, remove or modify configuration data from a single location.
It is similar to the Windows NT® domain system; although the internal implementation of the two are not at all similar, the basic functionality can be compared.
27.4.2 Terms/Processes You Should Know
There are several terms and several important user processes that you will come across when attempting to implement NIS on FreeBSD, whether you are trying to create an NIS server or act as an NIS client:
| Term | Description |
|---|---|
| NIS domainname | An NIS master server and all of its clients (including its slave servers) have a NIS domainname. Similar to an Windows NT domain name, the NIS domainname does not have anything to do with DNS. |
| rpcbind | Must be running in order to enable RPC (Remote Procedure Call, a network protocol used by NIS). If rpcbind is not running, it will be impossible to run an NIS server, or to act as an NIS client. |
| ypbind | “Binds” an NIS client to its NIS server. It will take the NIS domainname from the system, and using RPC, connect to the server. ypbind is the core of client-server communication in an NIS environment; if ypbind dies on a client machine, it will not be able to access the NIS server. |
| ypserv | Should only be running on NIS servers; this is the NIS server process itself. If ypserv(8) dies, then the server will no longer be able to respond to NIS requests (hopefully, there is a slave server to take over for it). There are some implementations of NIS (but not the FreeBSD one), that do not try to reconnect to another server if the server it used before dies. Often, the only thing that helps in this case is to restart the server process (or even the whole server) or the ypbind process on the client. |
| rpc.yppasswdd | Another process that should only be running on NIS master servers; this is a daemon that will allow NIS clients to change their NIS passwords. If this daemon is not running, users will have to login to the NIS master server and change their passwords there. |
27.4.3 How Does It Work?
There are three types of hosts in an NIS environment: master servers, slave servers, and clients. Servers act as a central repository for host configuration information. Master servers hold the authoritative copy of this information, while slave servers mirror this information for redundancy. Clients rely on the servers to provide this information to them.
Information in many files can be shared in this manner. The master.passwd, group, and hosts files are commonly shared via NIS. Whenever a process on a client needs information that would normally be found in these files locally, it makes a query to the NIS server that it is bound to instead.
27.4.3.1 Machine Types
-
A NIS master server. This server, analogous to a Windows NT primary domain controller, maintains the files used by all of the NIS clients. The passwd, group, and other various files used by the NIS clients live on the master server.
Note: It is possible for one machine to be an NIS master server for more than one NIS domain. However, this will not be covered in this introduction, which assumes a relatively small-scale NIS environment.
-
NIS slave servers. Similar to the Windows NT backup domain controllers, NIS slave servers maintain copies of the NIS master's data files. NIS slave servers provide the redundancy, which is needed in important environments. They also help to balance the load of the master server: NIS Clients always attach to the NIS server whose response they get first, and this includes slave-server-replies.
-
NIS clients. NIS clients, like most Windows NT workstations, authenticate against the NIS server (or the Windows NT domain controller in the Windows NT workstations case) to log on.
27.4.4 Using NIS/YP
This section will deal with setting up a sample NIS environment.
27.4.4.1 Planning
Let us assume that you are the administrator of a small university lab. This lab, which consists of 15 FreeBSD machines, currently has no centralized point of administration; each machine has its own /etc/passwd and /etc/master.passwd. These files are kept in sync with each other only through manual intervention; currently, when you add a user to the lab, you must run adduser on all 15 machines. Clearly, this has to change, so you have decided to convert the lab to use NIS, using two of the machines as servers.
Therefore, the configuration of the lab now looks something like:
| Machine name | IP address | Machine role |
|---|---|---|
| ellington | 10.0.0.2 | NIS master |
| coltrane | 10.0.0.3 | NIS slave |
| basie | 10.0.0.4 | Faculty workstation |
| bird | 10.0.0.5 | Client machine |
| cli[1-11] | 10.0.0.[6-17] | Other client machines |
If you are setting up a NIS scheme for the first time, it is a good idea to think through how you want to go about it. No matter what the size of your network, there are a few decisions that need to be made.
27.4.4.1.1 Choosing a NIS Domain Name
This might not be the “domainname” that you are used to. It is more accurately called the “NIS domainname”. When a client broadcasts its requests for info, it includes the name of the NIS domain that it is part of. This is how multiple servers on one network can tell which server should answer which request. Think of the NIS domainname as the name for a group of hosts that are related in some way.
Some organizations choose to use their Internet domainname for their NIS domainname. This is not recommended as it can cause confusion when trying to debug network problems. The NIS domainname should be unique within your network and it is helpful if it describes the group of machines it represents. For example, the Art department at Acme Inc. might be in the “acme-art” NIS domain. For this example, assume you have chosen the name test-domain.
However, some operating systems (notably SunOS) use their NIS domain name as their Internet domain name. If one or more machines on your network have this restriction, you must use the Internet domain name as your NIS domain name.
27.4.4.1.2 Physical Server Requirements
There are several things to keep in mind when choosing a machine to use as a NIS server. One of the unfortunate things about NIS is the level of dependency the clients have on the server. If a client cannot contact the server for its NIS domain, very often the machine becomes unusable. The lack of user and group information causes most systems to temporarily freeze up. With this in mind you should make sure to choose a machine that will not be prone to being rebooted regularly, or one that might be used for development. The NIS server should ideally be a stand alone machine whose sole purpose in life is to be an NIS server. If you have a network that is not very heavily used, it is acceptable to put the NIS server on a machine running other services, just keep in mind that if the NIS server becomes unavailable, it will affect all of your NIS clients adversely.
27.4.4.2 NIS Servers
The canonical copies of all NIS information are stored on a single machine called the NIS master server. The databases used to store the information are called NIS maps. In FreeBSD, these maps are stored in /var/yp/[domainname] where [domainname] is the name of the NIS domain being served. A single NIS server can support several domains at once, therefore it is possible to have several such directories, one for each supported domain. Each domain will have its own independent set of maps.
NIS master and slave servers handle all NIS requests with the ypserv daemon. ypserv is responsible for receiving incoming requests from NIS clients, translating the requested domain and map name to a path to the corresponding database file and transmitting data from the database back to the client.
27.4.4.2.1 Setting Up a NIS Master Server
Setting up a master NIS server can be relatively straight forward, depending on your needs. FreeBSD comes with support for NIS out-of-the-box. All you need is to add the following lines to /etc/rc.conf, and FreeBSD will do the rest for you.
-
nisdomainname="test-domain"This line will set the NIS domainname to test-domain upon network setup (e.g. after reboot).
-
nis_server_enable="YES"This will tell FreeBSD to start up the NIS server processes when the networking is next brought up.
-
nis_yppasswdd_enable="YES"This will enable the rpc.yppasswdd daemon which, as mentioned above, will allow users to change their NIS password from a client machine.
Note: Depending on your NIS setup, you may need to add further entries. See the section about NIS servers that are also NIS clients, below, for details.
Now, all you have to do is to run the command /etc/netstart as superuser. It will set up everything for you, using the values you defined in /etc/rc.conf.
27.4.4.2.2 Initializing the NIS Maps
The NIS maps are database files, that are kept in the /var/yp directory. They are generated from configuration files in the /etc directory of the NIS master, with one exception: the /etc/master.passwd file. This is for a good reason, you do not want to propagate passwords to your root and other administrative accounts to all the servers in the NIS domain. Therefore, before we initialize the NIS maps, you should:
# cp /etc/master.passwd /var/yp/master.passwd
# cd /var/yp
# vi master.passwd
You should remove all entries regarding system accounts (bin, tty, kmem, games, etc), as well as any accounts that you do not want to be propagated to the NIS clients (for example root and any other UID 0 (superuser) accounts).
Note: Make sure the /var/yp/master.passwd is neither group nor world readable (mode 600)! Use the chmod command, if appropriate.
When you have finished, it is time to initialize the NIS maps! FreeBSD includes a
script named ypinit to do this for you (see its manual page for
more information). Note that this script is available on most UNIX Operating Systems, but not on all. On Digital UNIX/Compaq
Tru64 UNIX it is called ypsetup. Because we are generating maps
for an NIS master, we are going to pass the -m option to ypinit. To generate the NIS maps, assuming you already performed the
steps above, run:
ellington# ypinit -m test-domain
Server Type: MASTER Domain: test-domain
Creating an YP server will require that you answer a few questions.
Questions will all be asked at the beginning of the procedure.
Do you want this procedure to quit on non-fatal errors? [y/n: n] n
Ok, please remember to go back and redo manually whatever fails.
If you don't, something might not work.
At this point, we have to construct a list of this domains YP servers.
rod.darktech.org is already known as master server.
Please continue to add any slave servers, one per line. When you are
done with the list, type a <control D>.
master server : ellington
next host to add: coltrane
next host to add: ^D
The current list of NIS servers looks like this:
ellington
coltrane
Is this correct? [y/n: y] y
[..output from map generation..]
NIS Map update completed.
ellington has been setup as an YP master server without any errors.
ypinit should have created /var/yp/Makefile from /var/yp/Makefile.dist. When created, this file assumes that you are operating in a single server NIS environment with only FreeBSD machines. Since test-domain has a slave server as well, you must edit /var/yp/Makefile:
ellington# vi /var/yp/Makefile
You should comment out the line that says
NOPUSH = "True"
(if it is not commented out already).
27.4.4.2.3 Setting up a NIS Slave Server
Setting up an NIS slave server is even more simple than setting up the master. Log on
to the slave server and edit the file /etc/rc.conf as you did
before. The only difference is that we now must use the -s
option when running ypinit. The -s
option requires the name of the NIS master be passed to it as well, so our command line
looks like:
coltrane# ypinit -s ellington test-domain
Server Type: SLAVE Domain: test-domain Master: ellington
Creating an YP server will require that you answer a few questions.
Questions will all be asked at the beginning of the procedure.
Do you want this procedure to quit on non-fatal errors? [y/n: n] n
Ok, please remember to go back and redo manually whatever fails.
If you don't, something might not work.
There will be no further questions. The remainder of the procedure
should take a few minutes, to copy the databases from ellington.
Transferring netgroup...
ypxfr: Exiting: Map successfully transferred
Transferring netgroup.byuser...
ypxfr: Exiting: Map successfully transferred
Transferring netgroup.byhost...
ypxfr: Exiting: Map successfully transferred
Transferring master.passwd.byuid...
ypxfr: Exiting: Map successfully transferred
Transferring passwd.byuid...
ypxfr: Exiting: Map successfully transferred
Transferring passwd.byname...
ypxfr: Exiting: Map successfully transferred
Transferring group.bygid...
ypxfr: Exiting: Map successfully transferred
Transferring group.byname...
ypxfr: Exiting: Map successfully transferred
Transferring services.byname...
ypxfr: Exiting: Map successfully transferred
Transferring rpc.bynumber...
ypxfr: Exiting: Map successfully transferred
Transferring rpc.byname...
ypxfr: Exiting: Map successfully transferred
Transferring protocols.byname...
ypxfr: Exiting: Map successfully transferred
Transferring master.passwd.byname...
ypxfr: Exiting: Map successfully transferred
Transferring networks.byname...
ypxfr: Exiting: Map successfully transferred
Transferring networks.byaddr...
ypxfr: Exiting: Map successfully transferred
Transferring netid.byname...
ypxfr: Exiting: Map successfully transferred
Transferring hosts.byaddr...
ypxfr: Exiting: Map successfully transferred
Transferring protocols.bynumber...
ypxfr: Exiting: Map successfully transferred
Transferring ypservers...
ypxfr: Exiting: Map successfully transferred
Transferring hosts.byname...
ypxfr: Exiting: Map successfully transferred
coltrane has been setup as an YP slave server without any errors.
Don't forget to update map ypservers on ellington.
You should now have a directory called /var/yp/test-domain. Copies of the NIS master server's maps should be in this directory. You will need to make sure that these stay updated. The following /etc/crontab entries on your slave servers should do the job:
20 * * * * root /usr/libexec/ypxfr passwd.byname
21 * * * * root /usr/libexec/ypxfr passwd.byuid
These two lines force the slave to sync its maps with the maps on the master server. Although these entries are not mandatory, since the master server attempts to ensure any changes to its NIS maps are communicated to its slaves and because password information is vital to systems depending on the server, it is a good idea to force the updates. This is more important on busy networks where map updates might not always complete.
Now, run the command /etc/netstart on the slave server as well, which again starts the NIS server.
27.4.4.3 NIS Clients
An NIS client establishes what is called a binding to a particular NIS server using the ypbind daemon. ypbind checks the system's default domain (as set by the domainname command), and begins broadcasting RPC requests on the local network. These requests specify the name of the domain for which ypbind is attempting to establish a binding. If a server that has been configured to serve the requested domain receives one of the broadcasts, it will respond to ypbind, which will record the server's address. If there are several servers available (a master and several slaves, for example), ypbind will use the address of the first one to respond. From that point on, the client system will direct all of its NIS requests to that server. ypbind will occasionally “ping” the server to make sure it is still up and running. If it fails to receive a reply to one of its pings within a reasonable amount of time, ypbind will mark the domain as unbound and begin broadcasting again in the hopes of locating another server.
27.4.4.3.1 Setting Up a NIS Client
Setting up a FreeBSD machine to be a NIS client is fairly straightforward.
-
Edit the file /etc/rc.conf and add the following lines in order to set the NIS domainname and start ypbind upon network startup:
nisdomainname="test-domain" nis_client_enable="YES" -
To import all possible password entries from the NIS server, remove all user accounts from your /etc/master.passwd file and use vipw to add the following line to the end of the file:
+:::::::::Note: This line will afford anyone with a valid account in the NIS server's password maps an account. There are many ways to configure your NIS client by changing this line. See the netgroups section below for more information. For more detailed reading see O'Reilly's book on Managing NFS and NIS.
Note: You should keep at least one local account (i.e. not imported via NIS) in your /etc/master.passwd and this account should also be a member of the group wheel. If there is something wrong with NIS, this account can be used to log in remotely, become root, and fix things.
-
To import all possible group entries from the NIS server, add this line to your /etc/group file:
+:*::
After completing these steps, you should be able to run ypcat passwd and see the NIS server's passwd map.
27.4.5 NIS Security
In general, any remote user can issue an RPC to ypserv(8) and retrieve the contents of your NIS maps, provided the remote user knows your domainname. To prevent such unauthorized transactions, ypserv(8) supports a feature called “securenets” which can be used to restrict access to a given set of hosts. At startup, ypserv(8) will attempt to load the securenets information from a file called /var/yp/securenets.
Note: This path varies depending on the path specified with the
-poption. This file contains entries that consist of a network specification and a network mask separated by white space. Lines starting with “#” are considered to be comments. A sample securenets file might look like this:
# allow connections from local host -- mandatory
127.0.0.1 255.255.255.255
# allow connections from any host
# on the 192.168.128.0 network
192.168.128.0 255.255.255.0
# allow connections from any host
# between 10.0.0.0 to 10.0.15.255
# this includes the machines in the testlab
10.0.0.0 255.255.240.0
If ypserv(8) receives a request from an address that matches one of these rules, it will process the request normally. If the address fails to match a rule, the request will be ignored and a warning message will be logged. If the /var/yp/securenets file does not exist, ypserv will allow connections from any host.
The ypserv program also has support for Wietse Venema's TCP Wrapper package. This allows the administrator to use the TCP Wrapper configuration files for access control instead of /var/yp/securenets.
Note: While both of these access control mechanisms provide some security, they, like the privileged port test, are vulnerable to “IP spoofing” attacks. All NIS-related traffic should be blocked at your firewall.
Servers using /var/yp/securenets may fail to serve legitimate NIS clients with archaic TCP/IP implementations. Some of these implementations set all host bits to zero when doing broadcasts and/or fail to observe the subnet mask when calculating the broadcast address. While some of these problems can be fixed by changing the client configuration, other problems may force the retirement of the client systems in question or the abandonment of /var/yp/securenets.
Using /var/yp/securenets on a server with such an archaic implementation of TCP/IP is a really bad idea and will lead to loss of NIS functionality for large parts of your network.
The use of the TCP Wrapper package increases the latency of your NIS server. The additional delay may be long enough to cause timeouts in client programs, especially in busy networks or with slow NIS servers. If one or more of your client systems suffers from these symptoms, you should convert the client systems in question into NIS slave servers and force them to bind to themselves.
27.4.6 Barring Some Users from Logging On
In our lab, there is a machine basie that is supposed to be a faculty only workstation. We do not want to take this machine out of the NIS domain, yet the passwd file on the master NIS server contains accounts for both faculty and students. What can we do?
There is a way to bar specific users from logging on to a machine, even if they are present in the NIS database. To do this, all you must do is add -username to the end of the /etc/master.passwd file on the client machine, where username is the username of the user you wish to bar from logging in. This should preferably be done using vipw, since vipw will sanity check your changes to /etc/master.passwd, as well as automatically rebuild the password database when you finish editing. For example, if we wanted to bar user bill from logging on to basie we would:
basie# vipw
[add -bill to the end, exit]
vipw: rebuilding the database...
vipw: done
basie# cat /etc/master.passwd
root:[password]:0:0::0:0:The super-user:/root:/bin/csh
toor:[password]:0:0::0:0:The other super-user:/root:/bin/sh
daemon:*:1:1::0:0:Owner of many system processes:/root:/sbin/nologin
operator:*:2:5::0:0:System &:/:/sbin/nologin
bin:*:3:7::0:0:Binaries Commands and Source,,,:/:/sbin/nologin
tty:*:4:65533::0:0:Tty Sandbox:/:/sbin/nologin
kmem:*:5:65533::0:0:KMem Sandbox:/:/sbin/nologin
games:*:7:13::0:0:Games pseudo-user:/usr/games:/sbin/nologin
news:*:8:8::0:0:News Subsystem:/:/sbin/nologin
man:*:9:9::0:0:Mister Man Pages:/usr/share/man:/sbin/nologin
bind:*:53:53::0:0:Bind Sandbox:/:/sbin/nologin
uucp:*:66:66::0:0:UUCP pseudo-user:/var/spool/uucppublic:/usr/libexec/uucp/uucico
xten:*:67:67::0:0:X-10 daemon:/usr/local/xten:/sbin/nologin
pop:*:68:6::0:0:Post Office Owner:/nonexistent:/sbin/nologin
nobody:*:65534:65534::0:0:Unprivileged user:/nonexistent:/sbin/nologin
+:::::::::
-bill
basie#
27.4.7 Using Netgroups
Contributed by Udo Erdelhoff.The method shown in the previous section works reasonably well if you need special rules for a very small number of users and/or machines. On larger networks, you will forget to bar some users from logging onto sensitive machines, or you may even have to modify each machine separately, thus losing the main benefit of NIS: centralized administration.
The NIS developers' solution for this problem is called netgroups. Their purpose and semantics can be compared to the normal groups used by UNIX file systems. The main differences are the lack of a numeric ID and the ability to define a netgroup by including both user accounts and other netgroups.
Netgroups were developed to handle large, complex networks with hundreds of users and machines. On one hand, this is a Good Thing if you are forced to deal with such a situation. On the other hand, this complexity makes it almost impossible to explain netgroups with really simple examples. The example used in the remainder of this section demonstrates this problem.
Let us assume that your successful introduction of NIS in your laboratory caught your superiors' interest. Your next job is to extend your NIS domain to cover some of the other machines on campus. The two tables contain the names of the new users and new machines as well as brief descriptions of them.
| User Name(s) | Description |
|---|---|
| alpha, beta | Normal employees of the IT department |
| charlie, delta | The new apprentices of the IT department |
| echo, foxtrott, golf, ... | Ordinary employees |
| able, baker, ... | The current interns |
| Machine Name(s) | Description |
|---|---|
| war, death, famine, pollution | Your most important servers. Only the IT employees are allowed to log onto these machines. |
| pride, greed, envy, wrath, lust, sloth | Less important servers. All members of the IT department are allowed to login onto these machines. |
| one, two, three, four, ... | Ordinary workstations. Only the real employees are allowed to use these machines. |
| trashcan | A very old machine without any critical data. Even the intern is allowed to use this box. |
If you tried to implement these restrictions by separately blocking each user, you would have to add one -user line to each system's passwd for each user who is not allowed to login onto that system. If you forget just one entry, you could be in trouble. It may be feasible to do this correctly during the initial setup, however you will eventually forget to add the lines for new users during day-to-day operations. After all, Murphy was an optimist.
Handling this situation with netgroups offers several advantages. Each user need not be handled separately; you assign a user to one or more netgroups and allow or forbid logins for all members of the netgroup. If you add a new machine, you will only have to define login restrictions for netgroups. If a new user is added, you will only have to add the user to one or more netgroups. Those changes are independent of each other: no more “for each combination of user and machine do...” If your NIS setup is planned carefully, you will only have to modify exactly one central configuration file to grant or deny access to machines.
The first step is the initialization of the NIS map netgroup. FreeBSD's ypinit(8) does not create this map by default, but its NIS implementation will support it once it has been created. To create an empty map, simply type
ellington# vi /var/yp/netgroup
and start adding content. For our example, we need at least four netgroups: IT employees, IT apprentices, normal employees and interns.
IT_EMP (,alpha,test-domain) (,beta,test-domain)
IT_APP (,charlie,test-domain) (,delta,test-domain)
USERS (,echo,test-domain) (,foxtrott,test-domain) \
(,golf,test-domain)
INTERNS (,able,test-domain) (,baker,test-domain)
IT_EMP, IT_APP etc. are the names of the netgroups. Each bracketed group adds one or more user accounts to it. The three fields inside a group are:
-
The name of the host(s) where the following items are valid. If you do not specify a hostname, the entry is valid on all hosts. If you do specify a hostname, you will enter a realm of darkness, horror and utter confusion.
-
The name of the account that belongs to this netgroup.
-
The NIS domain for the account. You can import accounts from other NIS domains into your netgroup if you are one of the unlucky fellows with more than one NIS domain.
Each of these fields can contain wildcards. See netgroup(5) for details.
Note: Netgroup names longer than 8 characters should not be used, especially if you have machines running other operating systems within your NIS domain. The names are case sensitive; using capital letters for your netgroup names is an easy way to distinguish between user, machine and netgroup names.
Some NIS clients (other than FreeBSD) cannot handle netgroups with a large number of entries. For example, some older versions of SunOS start to cause trouble if a netgroup contains more than 15 entries. You can circumvent this limit by creating several sub-netgroups with 15 users or less and a real netgroup that consists of the sub-netgroups:
BIGGRP1 (,joe1,domain) (,joe2,domain) (,joe3,domain) [...] BIGGRP2 (,joe16,domain) (,joe17,domain) [...] BIGGRP3 (,joe31,domain) (,joe32,domain) BIGGROUP BIGGRP1 BIGGRP2 BIGGRP3You can repeat this process if you need more than 225 users within a single netgroup.
Activating and distributing your new NIS map is easy:
ellington# cd /var/yp
ellington# make
This will generate the three NIS maps netgroup, netgroup.byhost and netgroup.byuser. Use ypcat(1) to check if your new NIS maps are available:
ellington% ypcat -k netgroup
ellington% ypcat -k netgroup.byhost
ellington% ypcat -k netgroup.byuser
The output of the first command should resemble the contents of /var/yp/netgroup. The second command will not produce output if you have not specified host-specific netgroups. The third command can be used to get the list of netgroups for a user.
The client setup is quite simple. To configure the server war, you only have to start vipw(8) and replace the line
+:::::::::
with
+@IT_EMP:::::::::
Now, only the data for the users defined in the netgroup IT_EMP is imported into war's password database and only these users are allowed to login.
Unfortunately, this limitation also applies to the ~ function of the shell and all routines converting between user names and numerical user IDs. In other words, cd ~user will not work, ls -l will show the numerical ID instead of the username and find . -user joe -print will fail with “No such user”. To fix this, you will have to import all user entries without allowing them to login onto your servers.
This can be achieved by adding another line to /etc/master.passwd. This line should contain:
+:::::::::/sbin/nologin, meaning “Import all entries but replace the shell with /sbin/nologin in the imported entries”. You can replace any field in the passwd entry by placing a default value in your /etc/master.passwd.
Warning: Make sure that the line +:::::::::/sbin/nologin is placed after +@IT_EMP:::::::::. Otherwise, all user accounts imported from NIS will have /sbin/nologin as their login shell.
After this change, you will only have to change one NIS map if a new employee joins the IT department. You could use a similar approach for the less important servers by replacing the old +::::::::: in their local version of /etc/master.passwd with something like this:
+@IT_EMP:::::::::
+@IT_APP:::::::::
+:::::::::/sbin/nologin
The corresponding lines for the normal workstations could be:
+@IT_EMP:::::::::
+@USERS:::::::::
+:::::::::/sbin/nologin
And everything would be fine until there is a policy change a few weeks later: The IT department starts hiring interns. The IT interns are allowed to use the normal workstations and the less important servers; and the IT apprentices are allowed to login onto the main servers. You add a new netgroup IT_INTERN, add the new IT interns to this netgroup and start to change the configuration on each and every machine... As the old saying goes: “Errors in centralized planning lead to global mess”.
NIS' ability to create netgroups from other netgroups can be used to prevent situations like these. One possibility is the creation of role-based netgroups. For example, you could create a netgroup called BIGSRV to define the login restrictions for the important servers, another netgroup called SMALLSRV for the less important servers and a third netgroup called USERBOX for the normal workstations. Each of these netgroups contains the netgroups that are allowed to login onto these machines. The new entries for your NIS map netgroup should look like this:
BIGSRV IT_EMP IT_APP
SMALLSRV IT_EMP IT_APP ITINTERN
USERBOX IT_EMP ITINTERN USERS
This method of defining login restrictions works reasonably well if you can define groups of machines with identical restrictions. Unfortunately, this is the exception and not the rule. Most of the time, you will need the ability to define login restrictions on a per-machine basis.
Machine-specific netgroup definitions are the other possibility to deal with the policy change outlined above. In this scenario, the /etc/master.passwd of each box contains two lines starting with “+”. The first of them adds a netgroup with the accounts allowed to login onto this machine, the second one adds all other accounts with /sbin/nologin as shell. It is a good idea to use the “ALL-CAPS” version of the machine name as the name of the netgroup. In other words, the lines should look like this:
+@BOXNAME:::::::::
+:::::::::/sbin/nologin
Once you have completed this task for all your machines, you will not have to modify the local versions of /etc/master.passwd ever again. All further changes can be handled by modifying the NIS map. Here is an example of a possible netgroup map for this scenario with some additional goodies:
# Define groups of users first
IT_EMP (,alpha,test-domain) (,beta,test-domain)
IT_APP (,charlie,test-domain) (,delta,test-domain)
DEPT1 (,echo,test-domain) (,foxtrott,test-domain)
DEPT2 (,golf,test-domain) (,hotel,test-domain)
DEPT3 (,india,test-domain) (,juliet,test-domain)
ITINTERN (,kilo,test-domain) (,lima,test-domain)
D_INTERNS (,able,test-domain) (,baker,test-domain)
#
# Now, define some groups based on roles
USERS DEPT1 DEPT2 DEPT3
BIGSRV IT_EMP IT_APP
SMALLSRV IT_EMP IT_APP ITINTERN
USERBOX IT_EMP ITINTERN USERS
#
# And a groups for a special tasks
# Allow echo and golf to access our anti-virus-machine
SECURITY IT_EMP (,echo,test-domain) (,golf,test-domain)
#
# machine-based netgroups
# Our main servers
WAR BIGSRV
FAMINE BIGSRV
# User india needs access to this server
POLLUTION BIGSRV (,india,test-domain)
#
# This one is really important and needs more access restrictions
DEATH IT_EMP
#
# The anti-virus-machine mentioned above
ONE SECURITY
#
# Restrict a machine to a single user
TWO (,hotel,test-domain)
# [...more groups to follow]
If you are using some kind of database to manage your user accounts, you should be able to create the first part of the map with your database's report tools. This way, new users will automatically have access to the boxes.
One last word of caution: It may not always be advisable to use machine-based netgroups. If you are deploying a couple of dozen or even hundreds of identical machines for student labs, you should use role-based netgroups instead of machine-based netgroups to keep the size of the NIS map within reasonable limits.
27.4.8 Important Things to Remember
There are still a couple of things that you will need to do differently now that you are in an NIS environment.
-
Every time you wish to add a user to the lab, you must add it to the master NIS server only, and you must remember to rebuild the NIS maps. If you forget to do this, the new user will not be able to login anywhere except on the NIS master. For example, if we needed to add a new user jsmith to the lab, we would:
# pw useradd jsmith # cd /var/yp # make test-domainYou could also run adduser jsmith instead of pw useradd jsmith.
-
Keep the administration accounts out of the NIS maps. You do not want to be propagating administrative accounts and passwords to machines that will have users that should not have access to those accounts.
-
Keep the NIS master and slave secure, and minimize their downtime. If somebody either hacks or simply turns off these machines, they have effectively rendered many people without the ability to login to the lab.
This is the chief weakness of any centralized administration system. If you do not protect your NIS servers, you will have a lot of angry users!
27.4.9 NIS v1 Compatibility
FreeBSD's ypserv has some support for serving NIS v1 clients. FreeBSD's NIS implementation only uses the NIS v2 protocol, however other implementations include support for the v1 protocol for backwards compatibility with older systems. The ypbind daemons supplied with these systems will try to establish a binding to an NIS v1 server even though they may never actually need it (and they may persist in broadcasting in search of one even after they receive a response from a v2 server). Note that while support for normal client calls is provided, this version of ypserv does not handle v1 map transfer requests; consequently, it cannot be used as a master or slave in conjunction with older NIS servers that only support the v1 protocol. Fortunately, there probably are not any such servers still in use today.
27.4.10 NIS Servers That Are Also NIS Clients
Care must be taken when running ypserv in a multi-server domain where the server machines are also NIS clients. It is generally a good idea to force the servers to bind to themselves rather than allowing them to broadcast bind requests and possibly become bound to each other. Strange failure modes can result if one server goes down and others are dependent upon it. Eventually all the clients will time out and attempt to bind to other servers, but the delay involved can be considerable and the failure mode is still present since the servers might bind to each other all over again.
You can force a host to bind to a particular server by running ypbind with the -S flag. If you do not
want to do this manually each time you reboot your NIS server, you can add the following
lines to your /etc/rc.conf:
nis_client_enable="YES" # run client stuff as well
nis_client_flags="-S NIS domain,server"
See ypbind(8) for further information.
27.4.11 Password Formats
One of the most common issues that people run into when trying to implement NIS is password format compatibility. If your NIS server is using DES encrypted passwords, it will only support clients that are also using DES. For example, if you have Solaris NIS clients in your network, then you will almost certainly need to use DES encrypted passwords.
To check which format your servers and clients are using, look at /etc/login.conf. If the host is configured to use DES encrypted passwords, then the default class will contain an entry like this:
default:\
:passwd_format=des:\
:copyright=/etc/COPYRIGHT:\
[Further entries elided]
Other possible values for the passwd_format capability include blf and md5 (for Blowfish and MD5 encrypted passwords, respectively).
If you have made changes to /etc/login.conf, you will also need to rebuild the login capability database, which is achieved by running the following command as root:
# cap_mkdb /etc/login.conf
Note: The format of passwords already in /etc/master.passwd will not be updated until a user changes his password for the first time after the login capability database is rebuilt.
Next, in order to ensure that passwords are encrypted with the format that you have chosen, you should also check that the crypt_default in /etc/auth.conf gives precedence to your chosen password format. To do this, place the format that you have chosen first in the list. For example, when using DES encrypted passwords, the entry would be:
crypt_default = des blf md5
Having followed the above steps on each of the FreeBSD based NIS servers and clients, you can be sure that they all agree on which password format is used within your network. If you have trouble authenticating on an NIS client, this is a pretty good place to start looking for possible problems. Remember: if you want to deploy an NIS server for a heterogenous network, you will probably have to use DES on all systems because it is the lowest common standard.
27.5 Automatic Network Configuration (DHCP)
Written by Greg Sutter.27.5.1 What Is DHCP?
DHCP, the Dynamic Host Configuration Protocol, describes the means by which a system can connect to a network and obtain the necessary information for communication upon that network. FreeBSD versions prior to 6.0 use the ISC (Internet Software Consortium) DHCP client (dhclient(8)) implementation. Later versions use the OpenBSD dhclient taken from OpenBSD 3.7. All information here regarding dhclient is for use with either of the ISC or OpenBSD DHCP clients. The DHCP server is the one included in the ISC distribution.
27.5.2 What This Section Covers
This section describes both the client-side components of the ISC and OpenBSD DHCP client and server-side components of the ISC DHCP system. The client-side program, dhclient, comes integrated within FreeBSD, and the server-side portion is available from the net/isc-dhcp3-server port. The dhclient(8), dhcp-options(5), and dhclient.conf(5) manual pages, in addition to the references below, are useful resources.
27.5.3 How It Works
When dhclient, the DHCP client, is executed on the client machine, it begins broadcasting requests for configuration information. By default, these requests are on UDP port 68. The server replies on UDP 67, giving the client an IP address and other relevant network information such as netmask, router, and DNS servers. All of this information comes in the form of a DHCP “lease” and is only valid for a certain time (configured by the DHCP server maintainer). In this manner, stale IP addresses for clients no longer connected to the network can be automatically reclaimed.
DHCP clients can obtain a great deal of information from the server. An exhaustive list may be found in dhcp-options(5).
27.5.4 FreeBSD Integration
FreeBSD fully integrates the ISC or OpenBSD DHCP client, dhclient (according to the FreeBSD version you run). DHCP client support is provided within both the installer and the base system, obviating the need for detailed knowledge of network configurations on any network that runs a DHCP server. dhclient has been included in all FreeBSD distributions since 3.2.
DHCP is supported by sysinstall. When configuring a network interface within sysinstall, the second question asked is: “Do you want to try DHCP configuration of the interface?”. Answering affirmatively will execute dhclient, and if successful, will fill in the network configuration information automatically.
There are two things you must do to have your system use DHCP upon startup:
-
Make sure that the bpf device is compiled into your kernel. To do this, add device bpf to your kernel configuration file, and rebuild the kernel. For more information about building kernels, see Chapter 8.
The bpf device is already part of the GENERIC kernel that is supplied with FreeBSD, so if you do not have a custom kernel, you should not need to create one in order to get DHCP working.
Note: For those who are particularly security conscious, you should be warned that bpf is also the device that allows packet sniffers to work correctly (although they still have to be run as root). bpf is required to use DHCP, but if you are very sensitive about security, you probably should not add bpf to your kernel in the expectation that at some point in the future you will be using DHCP.
-
Edit your /etc/rc.conf to include the following:
ifconfig_fxp0="DHCP"Note: Be sure to replace fxp0 with the designation for the interface that you wish to dynamically configure, as described in Section 11.8.
If you are using a different location for dhclient, or if you wish to pass additional flags to dhclient, also include the following (editing as necessary):
dhcp_program="/sbin/dhclient" dhcp_flags=""
The DHCP server, dhcpd, is included as part of the net/isc-dhcp3-server port in the ports collection. This port contains the ISC DHCP server and documentation.
27.5.5 Files
-
/etc/dhclient.conf
dhclient requires a configuration file, /etc/dhclient.conf. Typically the file contains only comments, the defaults being reasonably sane. This configuration file is described by the dhclient.conf(5) manual page.
-
/sbin/dhclient
dhclient is statically linked and resides in /sbin. The dhclient(8) manual page gives more information about dhclient.
-
/sbin/dhclient-script
dhclient-script is the FreeBSD-specific DHCP client configuration script. It is described in dhclient-script(8), but should not need any user modification to function properly.
-
/var/db/dhclient.leases
The DHCP client keeps a database of valid leases in this file, which is written as a log. dhclient.leases(5) gives a slightly longer description.
27.5.6 Further Reading
The DHCP protocol is fully described in RFC 2131. An informational resource has also been set up at http://www.dhcp.org/.
27.5.7 Installing and Configuring a DHCP Server
27.5.7.1 What This Section Covers
This section provides information on how to configure a FreeBSD system to act as a DHCP server using the ISC (Internet Software Consortium) implementation of the DHCP server.
The server is not provided as part of FreeBSD, and so you will need to install the net/isc-dhcp3-server port to provide this service. See Chapter 4 for more information on using the Ports Collection.
27.5.7.2 DHCP Server Installation
In order to configure your FreeBSD system as a DHCP server, you will need to ensure that the bpf(4) device is compiled into your kernel. To do this, add device bpf to your kernel configuration file, and rebuild the kernel. For more information about building kernels, see Chapter 8.
The bpf device is already part of the GENERIC kernel that is supplied with FreeBSD, so you do not need to create a custom kernel in order to get DHCP working.
Note: Those who are particularly security conscious should note that bpf is also the device that allows packet sniffers to work correctly (although such programs still need privileged access). bpf is required to use DHCP, but if you are very sensitive about security, you probably should not include bpf in your kernel purely because you expect to use DHCP at some point in the future.
The next thing that you will need to do is edit the sample dhcpd.conf which was installed by the net/isc-dhcp3-server port. By default, this will be /usr/local/etc/dhcpd.conf.sample, and you should copy this to /usr/local/etc/dhcpd.conf before proceeding to make changes.
27.5.7.3 Configuring the DHCP Server
dhcpd.conf is comprised of declarations regarding subnets and hosts, and is perhaps most easily explained using an example :
option domain-name "example.com";
option domain-name-servers 192.168.4.100;
option subnet-mask 255.255.255.0;
default-lease-time 3600;
max-lease-time 86400;
ddns-update-style none;
subnet 192.168.4.0 netmask 255.255.255.0 {
range 192.168.4.129 192.168.4.254;
option routers 192.168.4.1;
}
host mailhost {
hardware ethernet 02:03:04:05:06:07;
fixed-address mailhost.example.com;
}
- This option specifies the domain that will be provided to clients as the default search domain. See resolv.conf(5) for more information on what this means.
- This option specifies a comma separated list of DNS servers that the client should use.
- The netmask that will be provided to clients.
- A client may request a specific length of time that a lease will be valid. Otherwise the server will assign a lease with this expiry value (in seconds).
- This is the maximum length of time that the server will lease for. Should a client request a longer lease, a lease will be issued, although it will only be valid for max-lease-time seconds.
- This option specifies whether the DHCP server should attempt to update DNS when a lease is accepted or released. In the ISC implementation, this option is required.
- This denotes which IP addresses should be used in the pool reserved for allocating to clients. IP addresses between, and including, the ones stated are handed out to clients.
- Declares the default gateway that will be provided to clients.
- The hardware MAC address of a host (so that the DHCP server can recognize a host when it makes a request).
- Specifies that the host should always be given the same IP address. Note that using a hostname is correct here, since the DHCP server will resolve the hostname itself before returning the lease information.
Once you have finished writing your dhcpd.conf, you should enable the DHCP server in /etc/rc.conf, i.e. by adding:
dhcpd_enable="YES"
dhcpd_ifaces="dc0"
Replace the dc0 interface name with the interface (or interfaces, separated by whitespace) that your DHCP server should listen on for DHCP client requests.
Then, you can proceed to start the server by issuing the following command:
# /usr/local/etc/rc.d/isc-dhcpd.sh start
Should you need to make changes to the configuration of your server in the future, it is important to note that sending a SIGHUP signal to dhcpd does not result in the configuration being reloaded, as it does with most daemons. You will need to send a SIGTERM signal to stop the process, and then restart it using the command above.
27.5.7.4 Files
-
/usr/local/sbin/dhcpd
dhcpd is statically linked and resides in /usr/local/sbin. The dhcpd(8) manual page installed with the port gives more information about dhcpd.
-
/usr/local/etc/dhcpd.conf
dhcpd requires a configuration file, /usr/local/etc/dhcpd.conf before it will start providing service to clients. This file needs to contain all the information that should be provided to clients that are being serviced, along with information regarding the operation of the server. This configuration file is described by the dhcpd.conf(5) manual page installed by the port.
-
/var/db/dhcpd.leases
The DHCP server keeps a database of leases it has issued in this file, which is written as a log. The manual page dhcpd.leases(5), installed by the port gives a slightly longer description.
-
/usr/local/sbin/dhcrelay
dhcrelay is used in advanced environments where one DHCP server forwards a request from a client to another DHCP server on a separate network. If you require this functionality, then install the net/isc-dhcp3-relay port. The dhcrelay(8) manual page provided with the port contains more detail.
27.6 Domain Name System (DNS)
Contributed by Chern Lee, Tom Rhodes, and Daniel Gerzo.27.6.1 Overview
FreeBSD utilizes, by default, a version of BIND (Berkeley Internet Name Domain), which is the most common implementation of the DNS protocol. DNS is the protocol through which names are mapped to IP addresses, and vice versa. For example, a query for www.FreeBSD.org will receive a reply with the IP address of The FreeBSD Project's web server, whereas, a query for ftp.FreeBSD.org will return the IP address of the corresponding FTP machine. Likewise, the opposite can happen. A query for an IP address can resolve its hostname. It is not necessary to run a name server to perform DNS lookups on a system.
FreeBSD currently comes with BIND9 DNS server software by default. Our installation provides enhanced security features, a new file system layout and automated chroot(8) configuration.
DNS is coordinated across the Internet through a somewhat complex system of authoritative root, Top Level Domain (TLD), and other smaller-scale name servers which host and cache individual domain information.
Currently, BIND is maintained by the Internet Software Consortium http://www.isc.org/.
27.6.2 Terminology
To understand this document, some terms related to DNS must be understood.
| Term | Definition |
|---|---|
| Forward DNS | Mapping of hostnames to IP addresses. |
| Origin | Refers to the domain covered in a particular zone file. |
| named, BIND, name server | Common names for the BIND name server package within FreeBSD. |
| Resolver | A system process through which a machine queries a name server for zone information. |
| Reverse DNS | The opposite of forward DNS; mapping of IP addresses to hostnames. |
| Root zone | The beginning of the Internet zone hierarchy. All zones fall under the root zone, similar to how all files in a file system fall under the root directory. |
| Zone | An individual domain, subdomain, or portion of the DNS administered by the same authority. |
Examples of zones:
-
. is the root zone.
-
org. is a Top Level Domain (TLD) under the root zone.
-
example.org. is a zone under the org. TLD.
-
1.168.192.in-addr.arpa is a zone referencing all IP addresses which fall under the 192.168.1.* IP space.
As one can see, the more specific part of a hostname appears to its left. For example, example.org. is more specific than org., as org. is more specific than the root zone. The layout of each part of a hostname is much like a file system: the /dev directory falls within the root, and so on.
27.6.3 Reasons to Run a Name Server
Name servers usually come in two forms: an authoritative name server, and a caching name server.
An authoritative name server is needed when:
-
One wants to serve DNS information to the world, replying authoritatively to queries.
-
A domain, such as example.org, is registered and IP addresses need to be assigned to hostnames under it.
-
An IP address block requires reverse DNS entries (IP to hostname).
-
A backup or second name server, called a slave, will reply to queries.
A caching name server is needed when:
-
A local DNS server may cache and respond more quickly than querying an outside name server.
When one queries for www.FreeBSD.org, the resolver usually queries the uplink ISP's name server, and retrieves the reply. With a local, caching DNS server, the query only has to be made once to the outside world by the caching DNS server. Every additional query will not have to look to the outside of the local network, since the information is cached locally.
27.6.4 How It Works
In FreeBSD, the BIND daemon is called named for obvious reasons.
| File | Description |
|---|---|
| named(8) | The BIND daemon. |
| rndc(8) | Name server control utility. |
| /etc/namedb | Directory where BIND zone information resides. |
| /etc/namedb/named.conf | Configuration file of the daemon. |
Depending on how a given zone is configured on the server, the files related to that zone can be found in the master, slave, or dynamic subdirectories of the /etc/namedb directory. These files contain the DNS information that will be given out by the name server in response to queries.
27.6.5 Starting BIND
Since BIND is installed by default, configuring it all is relatively simple.
The default named configuration is that of a basic resolving name server, ran in a chroot(8) environment. To start the server one time with this configuration, use the following command:
# /etc/rc.d/named forcestart
To ensure the named daemon is started at boot each time, put the following line into the /etc/rc.conf:
named_enable="YES"
There are obviously many configuration options for /etc/namedb/named.conf that are beyond the scope of this document. However, if you are interested in the startup options for named on FreeBSD, take a look at the named_* flags in /etc/defaults/rc.conf and consult the rc.conf(5) manual page. The Section 11.7 section is also a good read.
27.6.6 Configuration Files
Configuration files for named currently reside in /etc/namedb directory and will need modification before use, unless all that is needed is a simple resolver. This is where most of the configuration will be performed.
27.6.6.1 Using make-localhost
To configure a master zone for the localhost visit the /etc/namedb directory and run the following command:
# sh make-localhost
If all went well, a new file should exist in the master subdirectory. The filenames should be localhost.rev for the local domain name and localhost-v6.rev for IPv6 configurations. As the default configuration file, required information will be present in the named.conf file.
27.6.6.2 /etc/namedb/named.conf
// $FreeBSD$
//
// Refer to the named.conf(5) and named(8) man pages, and the documentation
// in /usr/share/doc/bind9 for more details.
//
// If you are going to set up an authoritative server, make sure you
// understand the hairy details of how DNS works. Even with
// simple mistakes, you can break connectivity for affected parties,
// or cause huge amounts of useless Internet traffic.
options {
directory "/etc/namedb";
pid-file "/var/run/named/pid";
dump-file "/var/dump/named_dump.db";
statistics-file "/var/stats/named.stats";
// If named is being used only as a local resolver, this is a safe default.
// For named to be accessible to the network, comment this option, specify
// the proper IP address, or delete this option.
listen-on { 127.0.0.1; };
// If you have IPv6 enabled on this system, uncomment this option for
// use as a local resolver. To give access to the network, specify
// an IPv6 address, or the keyword "any".
// listen-on-v6 { ::1; };
// In addition to the "forwarders" clause, you can force your name
// server to never initiate queries of its own, but always ask its
// forwarders only, by enabling the following line:
//
// forward only;
// If you've got a DNS server around at your upstream provider, enter
// its IP address here, and enable the line below. This will make you
// benefit from its cache, thus reduce overall DNS traffic in the Internet.
/*
forwarders {
127.0.0.1;
};
*/
Just as the comment says, to benefit from an uplink's cache, forwarders can be enabled here. Under normal circumstances, a name server will recursively query the Internet looking at certain name servers until it finds the answer it is looking for. Having this enabled will have it query the uplink's name server (or name server provided) first, taking advantage of its cache. If the uplink name server in question is a heavily trafficked, fast name server, enabling this may be worthwhile.
Warning: 127.0.0.1 will not work here. Change this IP address to a name server at your uplink.
/*
* If there is a firewall between you and nameservers you want
* to talk to, you might need to uncomment the query-source
* directive below. Previous versions of BIND always asked
* questions using port 53, but BIND versions 8 and later
* use a pseudo-random unprivileged UDP port by default.
*/
// query-source address * port 53;
};
// If you enable a local name server, don't forget to enter 127.0.0.1
// first in your /etc/resolv.conf so this server will be queried.
// Also, make sure to enable it in /etc/rc.conf.
zone "." {
type hint;
file "named.root";
};
zone "0.0.127.IN-ADDR.ARPA" {
type master;
file "master/localhost.rev";
};
// RFC 3152
zone "1.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.IP6.ARPA" {
type master;
file "master/localhost-v6.rev";
};
// NB: Do not use the IP addresses below, they are faked, and only
// serve demonstration/documentation purposes!
//
// Example slave zone config entries. It can be convenient to become
// a slave at least for the zone your own domain is in. Ask
// your network administrator for the IP address of the responsible
// primary.
//
// Never forget to include the reverse lookup (IN-ADDR.ARPA) zone!
// (This is named after the first bytes of the IP address, in reverse
// order, with ".IN-ADDR.ARPA" appended.)
//
// Before starting to set up a primary zone, make sure you fully
// understand how DNS and BIND works. There are sometimes
// non-obvious pitfalls. Setting up a slave zone is simpler.
//
// NB: Don't blindly enable the examples below. :-) Use actual names
// and addresses instead.
/* An example master zone
zone "example.net" {
type master;
file "master/example.net";
};
*/
/* An example dynamic zone
key "exampleorgkey" {
algorithm hmac-md5;
secret "sf87HJqjkqh8ac87a02lla==";
};
zone "example.org" {
type master;
allow-update {
key "exampleorgkey";
};
file "dynamic/example.org";
};
*/
/* Examples of forward and reverse slave zones
zone "example.com" {
type slave;
file "slave/example.com";
masters {
192.168.1.1;
};
};
zone "1.168.192.in-addr.arpa" {
type slave;
file "slave/1.168.192.in-addr.arpa";
masters {
192.168.1.1;
};
};
*/
In named.conf, these are examples of slave entries for a forward and reverse zone.
For each new zone served, a new zone entry must be added to named.conf.
For example, the simplest zone entry for example.org can look like:
zone "example.org" {
type master;
file "master/example.org";
};
The zone is a master, as indicated by the type statement,
holding its zone information in /etc/namedb/master/example.org
indicated by the file statement.
zone "example.org" {
type slave;
file "slave/example.org";
};
In the slave case, the zone information is transferred from the master name server for the particular zone, and saved in the file specified. If and when the master server dies or is unreachable, the slave name server will have the transferred zone information and will be able to serve it.
27.6.6.3 Zone Files
An example master zone file for example.org (existing within /etc/namedb/master/example.org) is as follows:
$TTL 3600 ; 1 hour
example.org. IN SOA ns1.example.org. admin.example.org. (
2006051501 ; Serial
10800 ; Refresh
3600 ; Retry
604800 ; Expire
86400 ; Minimum TTL
)
; DNS Servers
IN NS ns1.example.org.
IN NS ns2.example.org.
; MX Records
IN MX 10 mx.example.org.
IN MX 20 mail.example.org.
IN A 192.168.1.1
; Machine Names
localhost IN A 127.0.0.1
ns1 IN A 192.168.1.2
ns2 IN A 192.168.1.3
mx IN A 192.168.1.4
mail IN A 192.168.1.5
; Aliases
www IN CNAME @
Note that every hostname ending in a “.” is an exact hostname, whereas everything without a trailing “.” is referenced to the origin. For example, www is translated into www.origin. In our fictitious zone file, our origin is example.org., so www would translate to www.example.org.
The format of a zone file follows:
recordname IN recordtype value
The most commonly used DNS records:
- SOA
-
start of zone authority
- NS
-
an authoritative name server
- A
-
a host address
- CNAME
-
the canonical name for an alias
- MX
-
mail exchanger
- PTR
-
a domain name pointer (used in reverse DNS)
example.org. IN SOA ns1.example.org. admin.example.org. (
2006051501 ; Serial
10800 ; Refresh after 3 hours
3600 ; Retry after 1 hour
604800 ; Expire after 1 week
86400 ) ; Minimum TTL of 1 day
- example.org.
-
the domain name, also the origin for this zone file.
- ns1.example.org.
-
the primary/authoritative name server for this zone.
- admin.example.org.
-
the responsible person for this zone, email address with “@” replaced. (
<admin@example.org>becomes admin.example.org) - 2006051501
-
the serial number of the file. This must be incremented each time the zone file is modified. Nowadays, many admins prefer a yyyymmddrr format for the serial number. 2006051501 would mean last modified 05/15/2006, the latter 01 being the first time the zone file has been modified this day. The serial number is important as it alerts slave name servers for a zone when it is updated.
IN NS ns1.example.org.
This is an NS entry. Every name server that is going to reply authoritatively for the zone must have one of these entries.
localhost IN A 127.0.0.1
ns1 IN A 192.168.1.2
ns2 IN A 192.168.1.3
mx IN A 192.168.1.4
mail IN A 192.168.1.5
The A record indicates machine names. As seen above, ns1.example.org would resolve to 192.168.1.2.
IN A 192.168.1.1
This line assigns IP address 192.168.1.1 to the current origin, in this case example.org.
www IN CNAME @
The canonical name record is usually used for giving aliases to a machine. In the example, www is aliased to the “master” machine which name equals to domain name example.org (192.168.1.1). CNAMEs can be used to provide alias hostnames, or round robin one hostname among multiple machines.
IN MX 10 mail.example.org.
The MX record indicates which mail servers are responsible for handling incoming mail for the zone. mail.example.org is the hostname of the mail server, and 10 being the priority of that mail server.
One can have several mail servers, with priorities of 10, 20 and so on. A mail server attempting to deliver to example.org would first try the highest priority MX (the record with the lowest priority number), then the second highest, etc, until the mail can be properly delivered.
For in-addr.arpa zone files (reverse DNS), the same format is used, except with PTR entries instead of A or CNAME.
$TTL 3600
1.168.192.in-addr.arpa. IN SOA ns1.example.org. admin.example.org. (
2006051501 ; Serial
10800 ; Refresh
3600 ; Retry
604800 ; Expire
3600 ) ; Minimum
IN NS ns1.example.org.
IN NS ns2.example.org.
1 IN PTR example.org.
2 IN PTR ns1.example.org.
3 IN PTR ns2.example.org.
4 IN PTR mx.example.org.
5 IN PTR mail.example.org.
This file gives the proper IP address to hostname mappings of our above fictitious domain.
27.6.7 Caching Name Server
A caching name server is a name server that is not authoritative for any zones. It simply asks queries of its own, and remembers them for later use. To set one up, just configure the name server as usual, omitting any inclusions of zones.
27.6.8 Security
Although BIND is the most common implementation of DNS, there is always the issue of security. Possible and exploitable security holes are sometimes found.
While FreeBSD automatically drops named into a chroot(8) environment; there are several other security mechanisms in place which could help to lure off possible DNS service attacks.
It is always good idea to read CERT's security advisories and to subscribe to the FreeBSD security notifications mailing list to stay up to date with the current Internet and FreeBSD security issues.
Tip: If a problem arises, keeping sources up to date and having a fresh build of named would not hurt.
27.7 Apache HTTP Server
Contributed by Murray Stokely.27.7.1 Overview
FreeBSD is used to run some of the busiest web sites in the world. The majority of web servers on the Internet are using the Apache HTTP Server. Apache software packages should be included on your FreeBSD installation media. If you did not install Apache when you first installed FreeBSD, then you can install it from the www/apache13 or www/apache22 port.
Once Apache has been installed successfully, it must be configured.
Note: This section covers version 1.3.X of the Apache HTTP Server as that is the most widely used version for FreeBSD. Apache 2.X introduces many new technologies but they are not discussed here. For more information about Apache 2.X, please see http://httpd.apache.org/.
27.7.2 Configuration
The main Apache HTTP Server configuration file is installed as /usr/local/etc/apache/httpd.conf on FreeBSD. This file is a typical UNIX text configuration file with comment lines beginning with the # character. A comprehensive description of all possible configuration options is outside the scope of this book, so only the most frequently modified directives will be described here.
- ServerRoot "/usr/local"
-
This specifies the default directory hierarchy for the Apache installation. Binaries are stored in the bin and sbin subdirectories of the server root, and configuration files are stored in etc/apache.
- ServerAdmin you@your.address
-
The address to which problems with the server should be emailed. This address appears on some server-generated pages, such as error documents.
- ServerName www.example.com
-
ServerName allows you to set a host name which is sent back to clients for your server if it is different to the one that the host is configured with (i.e., use www instead of the host's real name).
- DocumentRoot "/usr/local/www/data"
-
DocumentRoot: The directory out of which you will serve your documents. By default, all requests are taken from this directory, but symbolic links and aliases may be used to point to other locations.
It is always a good idea to make backup copies of your Apache configuration file before making changes. Once you are satisfied with your initial configuration you are ready to start running Apache.
27.7.3 Running Apache
Apache does not run from the inetd super server as many other network servers do. It is configured to run standalone for better performance for incoming HTTP requests from client web browsers. A shell script wrapper is included to make starting, stopping, and restarting the server as simple as possible. To start up Apache for the first time, just run:
# /usr/local/sbin/apachectl start
You can stop the server at any time by typing:
# /usr/local/sbin/apachectl stop
After making changes to the configuration file for any reason, you will need to restart the server:
# /usr/local/sbin/apachectl restart
To restart Apache without aborting current connections, run:
# /usr/local/sbin/apachectl graceful
Additional information available at apachectl(8) manual page.
To launch Apache at system startup, add the following line to /etc/rc.conf:
apache_enable="YES"
or for Apache 2.2:
apache22_enable="YES"
If you would like to supply additional command line options for the Apache httpd program started at system boot, you may specify them with an additional line in rc.conf:
apache_flags=""
Now that the web server is running, you can view your web site by pointing a web browser to http://localhost/. The default web page that is displayed is /usr/local/www/data/index.html.
27.7.4 Virtual Hosting
Apache supports two different types of Virtual Hosting. The first method is Name-based Virtual Hosting. Name-based virtual hosting uses the clients HTTP/1.1 headers to figure out the hostname. This allows many different domains to share the same IP address.
To setup Apache to use Name-based Virtual Hosting add an entry like the following to your httpd.conf:
NameVirtualHost *
If your webserver was named www.domain.tld and you wanted to setup a virtual domain for www.someotherdomain.tld then you would add the following entries to httpd.conf:
<VirtualHost *>
ServerName www.domain.tld
DocumentRoot /www/domain.tld
</VirtualHost>
<VirtualHost *>
ServerName www.someotherdomain.tld
DocumentRoot /www/someotherdomain.tld
</VirtualHost>
Replace the addresses with the addresses you want to use and the path to the documents with what you are using.
For more information about setting up virtual hosts, please consult the official Apache documentation at: http://httpd.apache.org/docs/vhosts/.
27.7.5 Apache Modules
There are many different Apache modules available to add functionality to the basic server. The FreeBSD Ports Collection provides an easy way to install Apache together with some of the more popular add-on modules.
27.7.5.1 mod_ssl
The mod_ssl module uses the OpenSSL library to provide strong cryptography via the Secure Sockets Layer (SSL v2/v3) and Transport Layer Security (TLS v1) protocols. This module provides everything necessary to request a signed certificate from a trusted certificate signing authority so that you can run a secure web server on FreeBSD.
If you have not yet installed Apache, then a version of Apache 1.3.X that includes mod_ssl may be installed with the www/apache13-modssl port. SSL support is also available for Apache 2.X in the www/apache22 port, where it is enabled by default.
27.7.5.2 Dynamic Websites with Perl & PHP
In the past few years, more businesses have turned to the Internet in order to enhance their revenue and increase exposure. This has also increased the need for interactive web content. While some companies, such as Microsoft, have introduced solutions into their proprietary products, the open source community answered the call. Two options for dynamic web content include mod_perl & mod_php.
27.7.5.2.1 mod_perl
The Apache/Perl integration project brings together the full power of the Perl programming language and the Apache HTTP Server. With the mod_perl module it is possible to write Apache modules entirely in Perl. In addition, the persistent interpreter embedded in the server avoids the overhead of starting an external interpreter and the penalty of Perl start-up time.
mod_perl is available a few different ways. To use mod_perl remember that mod_perl 1.0 only works with Apache 1.3 and mod_perl 2.0 only works with Apache 2.X. mod_perl 1.0 is available in www/mod_perl and a statically compiled version is available in www/apache13-modperl. mod_perl 2.0 is avaliable in www/mod_perl2.
27.7.5.2.2 mod_php
Written by Tom Rhodes.PHP, also known as “PHP: Hypertext Preprocessor” is a general-purpose scripting language that is especially suited for Web development. Capable of being embedded into HTML its syntax draws upon C, Java, and Perl with the intention of allowing web developers to write dynamically generated webpages quickly.
To gain support for PHP5 for the Apache web server, begin by installing the lang/php5 port.
If the lang/php5 port is being installed for the first time, available OPTIONS will be displayed automatically. If a menu is not displayed, i.e. because the lang/php5 port has been installed some time in the past, it is always possible to bring the options dialog up again by running:
# make config
in the port directory.
In the options dialog, check the APACHE option to build mod_php5 as a loadable module for the Apache web server.
Note: A lot of sites are still using PHP4 for various reasons (i.e. compatibility issues or already deployed web applications). If the mod_php4 is needed instead of mod_php5, then please use the lang/php4 port. The lang/php4 port supports many of the configuration and build-time options of the lang/php5 port.
This will install and configure the modules required to support dynamic PHP applications. Check to ensure the following sections have been added to /usr/local/etc/apache/httpd.conf:
LoadModule php5_module libexec/apache/libphp5.so
AddModule mod_php5.c
<IfModule mod_php5.c>
DirectoryIndex index.php index.html
</IfModule>
<IfModule mod_php5.c>
AddType application/x-httpd-php .php
AddType application/x-httpd-php-source .phps
</IfModule>
Once completed, a simple call to the apachectl command for a graceful restart is needed to load the PHP module:
# apachectl graceful
For future upgrades of PHP, the make config command will not be required; the selected OPTIONS are saved automatically by the FreeBSD Ports framework.
The PHP support in FreeBSD is extremely modular so the base install is very limited. It is very easy to add support using the lang/php5-extensions port. This port provides a menu driven interface to PHP extension installation. Alternatively, individual extensions can be installed using the appropriate port.
For instance, to add support for the MySQL database server to PHP5, simply install the databases/php5-mysql port.
After installing an extension, the Apache server must be reloaded to pick up the new configuration changes:
# apachectl graceful
27.8 File Transfer Protocol (FTP)
Contributed by Murray Stokely.27.8.1 Overview
The File Transfer Protocol (FTP) provides users with a simple way to transfer files to and from an FTP server. FreeBSD includes FTP server software, ftpd, in the base system. This makes setting up and administering an FTP server on FreeBSD very straightforward.
27.8.2 Configuration
The most important configuration step is deciding which accounts will be allowed access to the FTP server. A normal FreeBSD system has a number of system accounts used for various daemons, but unknown users should not be allowed to log in with these accounts. The /etc/ftpusers file is a list of users disallowed any FTP access. By default, it includes the aforementioned system accounts, but it is possible to add specific users here that should not be allowed access to FTP.
You may want to restrict the access of some users without preventing them completely from using FTP. This can be accomplished with the /etc/ftpchroot file. This file lists users and groups subject to FTP access restrictions. The ftpchroot(5) manual page has all of the details so it will not be described in detail here.
If you would like to enable anonymous FTP access to your server, then you must create a user named ftp on your FreeBSD system. Users will then be able to log on to your FTP server with a username of ftp or anonymous and with any password (by convention an email address for the user should be used as the password). The FTP server will call chroot(2) when an anonymous user logs in, to restrict access to only the home directory of the ftp user.
There are two text files that specify welcome messages to be displayed to FTP clients. The contents of the file /etc/ftpwelcome will be displayed to users before they reach the login prompt. After a successful login, the contents of the file /etc/ftpmotd will be displayed. Note that the path to this file is relative to the login environment, so the file ~ftp/etc/ftpmotd would be displayed for anonymous users.
Once the FTP server has been configured properly, it must be enabled in /etc/inetd.conf. All that is required here is to remove the comment symbol “#” from in front of the existing ftpd line :
ftp stream tcp nowait root /usr/libexec/ftpd ftpd -l
As explained in Example 27-1, the inetd configuration must be reloaded after this configuration file is changed.
You can now log on to your FTP server by typing:
% ftp localhost
27.8.3 Maintaining
The ftpd daemon uses syslog(3) to log messages. By default, the system log daemon will put messages related to FTP in the /var/log/xferlog file. The location of the FTP log can be modified by changing the following line in /etc/syslog.conf:
ftp.info /var/log/xferlog
Be aware of the potential problems involved with running an anonymous FTP server. In particular, you should think twice about allowing anonymous users to upload files. You may find that your FTP site becomes a forum for the trade of unlicensed commercial software or worse. If you do need to allow anonymous FTP uploads, then you should set up the permissions so that these files can not be read by other anonymous users until they have been reviewed.
27.9 File and Print Services for Microsoft Windows clients (Samba)
Contributed by Murray Stokely.27.9.1 Overview
Samba is a popular open source software package that provides file and print services for Microsoft Windows clients. Such clients can connect to and use FreeBSD filespace as if it was a local disk drive, or FreeBSD printers as if they were local printers.
Samba software packages should be included on your FreeBSD installation media. If you did not install Samba when you first installed FreeBSD, then you can install it from the net/samba3 port or package.
27.9.2 Configuration
A default Samba configuration file is installed as /usr/local/share/examples/smb.conf.default. This file must be copied to /usr/local/etc/smb.conf and customized before Samba can be used.
The smb.conf file contains runtime configuration information for Samba, such as definitions of the printers and “file system shares” that you would like to share with Windows clients. The Samba package includes a web based tool called swat which provides a simple way of configuring the smb.conf file.
27.9.2.1 Using the Samba Web Administration Tool (SWAT)
The Samba Web Administration Tool (SWAT) runs as a daemon from inetd. Therefore, the following line in /etc/inetd.conf should be uncommented before swat can be used to configure Samba:
swat stream tcp nowait/400 root /usr/local/sbin/swat swat
As explained in Example 27-1, the inetd configuration must be reloaded after this configuration file is changed.
Once swat has been enabled in inetd.conf, you can use a browser to connect to http://localhost:901. You will first have to log on with the system root account.
Once you have successfully logged on to the main Samba configuration page, you can browse the system documentation, or begin by clicking on the Globals tab. The Globals section corresponds to the variables that are set in the [global] section of /usr/local/etc/smb.conf.
27.9.2.2 Global Settings
Whether you are using swat or editing /usr/local/etc/smb.conf directly, the first directives you are likely to encounter when configuring Samba are:
- workgroup
-
NT Domain-Name or Workgroup-Name for the computers that will be accessing this server.
- netbios name
-
This sets the NetBIOS name by which a Samba server is known. By default it is the same as the first component of the host's DNS name.
- server string
-
This sets the string that will be displayed with the net view command and some other networking tools that seek to display descriptive text about the server.
27.9.2.3 Security Settings
Two of the most important settings in /usr/local/etc/smb.conf are the security model chosen, and the backend password format for client users. The following directives control these options:
- security
-
The two most common options here are security = share and security = user. If your clients use usernames that are the same as their usernames on your FreeBSD machine then you will want to use user level security. This is the default security policy and it requires clients to first log on before they can access shared resources.
In share level security, client do not need to log onto the server with a valid username and password before attempting to connect to a shared resource. This was the default security model for older versions of Samba.
- passdb backend
-
Samba has several different backend authentication models. You can authenticate clients with LDAP, NIS+, a SQL database, or a modified password file. The default authentication method is smbpasswd, and that is all that will be covered here.
Assuming that the default smbpasswd backend is used, the /usr/local/private/smbpasswd file must be created to allow Samba to authenticate clients. If you would like to give your UNIX user accounts access from Windows clients, use the following command:
# smbpasswd -a username
Please see the Official Samba HOWTO for additional information about configuration options. With the basics outlined here, you should have everything you need to start running Samba.
27.9.3 Starting Samba
The net/samba3 port adds a new startup script, which can be used to control Samba. To enable this script, so that it can be used for example to start, stop or restart Samba, add the following line to the /etc/rc.conf file:
samba_enable="YES"
Or, for fine grain control:
nmbd_enable="YES"
smbd_enable="YES"
Note: This will also configure Samba to automatically start at system boot time.
It is possible then to start Samba at any time by typing:
# /usr/local/etc/rc.d/samba start
Starting SAMBA: removing stale tdbs :
Starting nmbd.
Starting smbd.
Please refer to Section 11.7 for more information about using rc scripts.
Samba actually consists of three separate daemons. You should see that both the nmbd and smbd daemons are started by the samba script. If you enabled winbind name resolution services in smb.conf, then you will also see that the winbindd daemon is started.
You can stop Samba at any time by typing :
# /usr/local/etc/rc.d/samba stop
Samba is a complex software suite with functionality that allows broad integration with Microsoft Windows networks. For more information about functionality beyond the basic installation described here, please see http://www.samba.org.
27.10 Clock Synchronization with NTP
Contributed by Tom Hukins.27.10.1 Overview
Over time, a computer's clock is prone to drift. The Network Time Protocol (NTP) is one way to ensure your clock stays accurate.
Many Internet services rely on, or greatly benefit from, computers' clocks being accurate. For example, a web server may receive requests to send a file if it has been modified since a certain time. In a local area network environment, it is essential that computers sharing files from the same file server have synchronized clocks so that file timestamps stay consistent. Services such as cron(8) also rely on an accurate system clock to run commands at the specified times.
FreeBSD ships with the ntpd(8) NTP server which can be used to query other NTP servers to set the clock on your machine or provide time services to others.
27.10.2 Choosing Appropriate NTP Servers
In order to synchronize your clock, you will need to find one or more NTP servers to use. Your network administrator or ISP may have set up an NTP server for this purpose--check their documentation to see if this is the case. There is an online list of publicly accessible NTP servers which you can use to find an NTP server near to you. Make sure you are aware of the policy for any servers you choose, and ask for permission if required.
Choosing several unconnected NTP servers is a good idea in case one of the servers you are using becomes unreachable or its clock is unreliable. ntpd(8) uses the responses it receives from other servers intelligently--it will favor unreliable servers less than reliable ones.
27.10.3 Configuring Your Machine
27.10.3.1 Basic Configuration
If you only wish to synchronize your clock when the machine boots up, you can use ntpdate(8). This may be appropriate for some desktop machines which are frequently rebooted and only require infrequent synchronization, but most machines should run ntpd(8).
Using ntpdate(8) at boot time is also a good idea for machines that run ntpd(8). The ntpd(8) program changes the clock gradually, whereas ntpdate(8) sets the clock, no matter how great the difference between a machine's current clock setting and the correct time.
To enable ntpdate(8) at boot
time, add ntpdate_enable="YES" to /etc/rc.conf. You will also need to specify all servers you wish to
synchronize with and any flags to be passed to ntpdate(8) in ntpdate_flags.
27.10.3.2 General Configuration
NTP is configured by the /etc/ntp.conf file in the format described in ntp.conf(5). Here is a simple example:
server ntplocal.example.com prefer
server timeserver.example.org
server ntp2a.example.net
driftfile /var/db/ntp.drift
The server option specifies which servers are to be used, with one server listed on each line. If a server is specified with the prefer argument, as with ntplocal.example.com, that server is preferred over other servers. A response from a preferred server will be discarded if it differs significantly from other servers' responses, otherwise it will be used without any consideration to other responses. The prefer argument is normally used for NTP servers that are known to be highly accurate, such as those with special time monitoring hardware.
The driftfile option specifies which file is used to store the system clock's frequency offset. The ntpd(8) program uses this to automatically compensate for the clock's natural drift, allowing it to maintain a reasonably correct setting even if it is cut off from all external time sources for a period of time.
The driftfile option specifies which file is used to store information about previous responses from the NTP servers you are using. This file contains internal information for NTP. It should not be modified by any other process.
27.10.3.3 Controlling Access to Your Server
By default, your NTP server will be accessible to all hosts on the Internet. The restrict option in /etc/ntp.conf allows you to control which machines can access your server.
If you want to deny all machines from accessing your NTP server, add the following line to /etc/ntp.conf:
restrict default ignore
Note: This will also prevent access from your server to any servers listed in your local configuration. If you need to synchronise your NTP server with an external NTP server you should allow the specific server. See the ntp.conf(5) manual for more information.
If you only want to allow machines within your own network to synchronize their clocks with your server, but ensure they are not allowed to configure the server or used as peers to synchronize against, add
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
instead, where 192.168.1.0 is an IP address on your network and 255.255.255.0 is your network's netmask.
/etc/ntp.conf can contain multiple restrict options. For more details, see the Access Control Support subsection of ntp.conf(5).
27.10.4 Running the NTP Server
To ensure the NTP server is started at boot time, add the line ntpd_enable="YES" to /etc/rc.conf. If you
wish to pass additional flags to ntpd(8), edit the
ntpd_flags parameter in /etc/rc.conf.
To start the server without rebooting your machine, run ntpd
being sure to specify any additional parameters from ntpd_flags in /etc/rc.conf. For
example:
# ntpd -p /var/run/ntpd.pid
27.10.5 Using ntpd with a Temporary Internet Connection
The ntpd(8) program does not need a permanent connection to the Internet to function properly. However, if you have a temporary connection that is configured to dial out on demand, it is a good idea to prevent NTP traffic from triggering a dial out or keeping the connection alive. If you are using user PPP, you can use filter directives in /etc/ppp/ppp.conf. For example:
set filter dial 0 deny udp src eq 123
# Prevent NTP traffic from initiating dial out
set filter dial 1 permit 0 0
set filter alive 0 deny udp src eq 123
# Prevent incoming NTP traffic from keeping the connection open
set filter alive 1 deny udp dst eq 123
# Prevent outgoing NTP traffic from keeping the connection open
set filter alive 2 permit 0/0 0/0
For more details see the PACKET FILTERING section in ppp(8) and the examples in /usr/share/examples/ppp/.
Note: Some Internet access providers block low-numbered ports, preventing NTP from functioning since replies never reach your machine.
27.10.6 Further Information
Documentation for the NTP server can be found in /usr/share/doc/ntp/ in HTML format.
Chapter 28 Firewalls
Contributed by Joseph J. Barbish. Converted to SGML and updated by Brad Davis.28.1 Introduction
Firewalls make it possible to filter incoming and outgoing traffic that flows through your system. A firewall can use one or more sets of “rules” to inspect the network packets as they come in or go out of your network connections and either allows the traffic through or blocks it. The rules of a firewall can inspect one or more characteristics of the packets, including but not limited to the protocol type, the source or destination host address, and the source or destination port.
Firewalls can greatly enhance the security of a host or a network. They can be used to do one or more of the following things:
-
To protect and insulate the applications, services and machines of your internal network from unwanted traffic coming in from the public Internet.
-
To limit or disable access from hosts of the internal network to services of the public Internet.
-
To support network address translation (NAT), which allows your internal network to use private IP addresses and share a single connection to the public Internet (either with a single IP address or by a shared pool of automatically assigned public addresses).
After reading this chapter, you will know:
-
How to properly define packet filtering rules.
-
The differences between the firewalls built into FreeBSD.
-
How to use and configure the OpenBSD PF firewall.
-
How to use and configure IPFILTER.
-
How to use and configure IPFW.
Before reading this chapter, you should:
-
Understand basic FreeBSD and Internet concepts.
28.2 Firewall Concepts
There are two basic ways to create firewall rulesets: “inclusive” or “exclusive”. An exclusive firewall allows all traffic through except for the traffic matching the ruleset. An inclusive firewall does the reverse. It only allows traffic matching the rules through and blocks everything else.
Inclusive firewalls are generally safer than exclusive firewalls because they significantly reduce the risk of allowing unwanted traffic to pass through the firewall.
Security can be tightened further using a “stateful firewall”. With a stateful firewall the firewall keeps track of which connections are opened through the firewall and will only allow traffic through which either matches an existing connection or opens a new one. The disadvantage of a stateful firewall is that it can be vulnerable to Denial of Service (DoS) attacks if a lot of new connections are opened very fast. With most firewalls it is possible to use a combination of stateful and non-stateful behavior to make an optimal firewall for the site.
28.3 Firewall Packages
FreeBSD has three different firewall packages built into the base system. They are: IPFILTER (also known as IPF), IPFIREWALL (also known as IPFW), and OpenBSD's PacketFilter (also known as PF). FreeBSD also has two built in packages for traffic shaping (basically controlling bandwidth usage): altq(4) and dummynet(4). Dummynet has traditionally been closely tied with IPFW, and ALTQ with IPF/PF. IPF, IPFW, and PF all use rules to control the access of packets to and from your system, although they go about it different ways and have different rule syntaxes.
The reason that FreeBSD has multiple built in firewall packages is that different people have different requirements and preferences. No single firewall package is the best.
The author prefers IPFILTER because its stateful rules are much less complicated to use in a NAT environment and it has a built in ftp proxy that simplifies the rules to allow secure outbound FTP usage.
Since all firewalls are based on inspecting the values of selected packet control fields, the creator of the firewall rulesets must have an understanding of how TCP/IP works, what the different values in the packet control fields are and how these values are used in a normal session conversation. For a good explanation go to: http://www.ipprimer.com/overview.cfm.
28.4 The OpenBSD Packet Filter (PF) and ALTQ
As of July 2003 the OpenBSD firewall software application known as PF was ported to FreeBSD and was made available in the FreeBSD Ports Collection; the first release that contained PF as an integrated part of the base system was FreeBSD 5.3 in November 2004. PF is a complete, fully featured firewall that has optional support for ALTQ (Alternate Queuing). ALTQ provides Quality of Service (QoS) bandwidth shaping that allows guaranteeing bandwidth to different services based on filtering rules. The OpenBSD Project does an outstanding job of maintaining the PF User's Guide that it will not be made part of this handbook firewall section as that would just be duplicated effort.
More info can be found at the PF for FreeBSD web site: http://pf4freebsd.love2party.net/.
28.4.1 Enabling PF
PF is included in the basic FreeBSD install for versions newer than 5.3 as a separate run time loadable module. The system will dynamically load the PF kernel loadable module when the rc.conf statement pf_enable="YES" is used. The loadable module was created with pflog(4) logging enabled.
Note: The module assumes the presence of options INET and device bpf. Unless NOINET6 for FreeBSD prior to 6.0-RELEASE and NO_INET6 for later releases (for example in make.conf(5)) was defined during the build, it also requires options INET6.
Once the kernel module is loaded or the kernel is statically built with PF support, it is possible to enable or disable pf with the pfctl command.
This example demonstrates how to enable pf:
# pfctl -e
The pfctl command provides a way to work with the pf firewall. It is a good idea to check the pfctl(8) manual page to find out more information about using it.
28.4.2 Kernel options
It is not a mandatory requirement that you enable PF by compiling the following options into the FreeBSD kernel. It is only presented here as background information. Compiling PF into the kernel causes the loadable module to never be used.
Sample kernel config PF option statements are in the /usr/src/sys/conf/NOTES kernel source and are reproduced here:
device pf
device pflog
device pfsync
device pf enables support for the “Packet Filter” firewall.
device pflog enables the optional pflog(4) pseudo network device which can be used to log traffic to a bpf(4) descriptor. The pflogd(8) daemon can be used to store the logging information to disk.
device pfsync enables the optional pfsync(4) pseudo network device that is used to monitor “state changes”. As this is not part of the loadable module one has to build a custom kernel to use it.
These settings will take effect only after you have built and installed a kernel with them set.
28.4.3 Available rc.conf Options
You need the following statements in /etc/rc.conf to activate PF at boot time:
pf_enable="YES" # Enable PF (load module if required)
pf_rules="/etc/pf.conf" # rules definition file for pf
pf_flags="" # additional flags for pfctl startup
pflog_enable="YES" # start pflogd(8)
pflog_logfile="/var/log/pflog" # where pflogd should store the logfile
pflog_flags="" # additional flags for pflogd startup
If you have a LAN behind this firewall and have to forward packets for the computers in the LAN or want to do NAT, you have to enable the following option as well:
gateway_enable="YES" # Enable as LAN gateway
28.4.4 Enabling ALTQ
ALTQ is only available by compiling the options into the FreeBSD Kernel. ALTQ is not supported by all of the available network card drivers. Please see the altq(4) manual page for a list of drivers that are supported in your release of FreeBSD. The following options will enable ALTQ and add additional functionality.
options ALTQ
options ALTQ_CBQ # Class Bases Queuing (CBQ)
options ALTQ_RED # Random Early Detection (RED)
options ALTQ_RIO # RED In/Out
options ALTQ_HFSC # Hierarchical Packet Scheduler (HFSC)
options ALTQ_PRIQ # Priority Queuing (PRIQ)
options ALTQ_NOPCC # Required for SMP build
options ALTQ enables the ALTQ framework.
options ALTQ_CBQ enables Class Based Queuing (CBQ). CBQ allows you to divide a connection's bandwidth into different classes or queues to prioritize traffic based on filter rules.
options ALTQ_RED enables Random Early Detection (RED). RED is used to avoid network congestion. RED does this by measuring the length of the queue and comparing it to the minimum and maximum thresholds for the queue. If the queue is over the maximum all new packets will be dropped. True to its name, RED drops packets from different connections randomly.
options ALTQ_RIO enables Random Early Detection In and Out.
options ALTQ_HFSC enables the Hierarchical Fair Service Curve Packet Scheduler. For more information about HFSC see: http://www-2.cs.cmu.edu/~hzhang/HFSC/main.html.
options ALTQ_PRIQ enables Priority Queuing (PRIQ). PRIQ will always pass traffic that is in a higher queue first.
options ALTQ_NOPCC enables SMP support for ALTQ. This option is required on SMP systems.
28.4.5 Creating Filtering Rules
The Packet Filter reads its configuration rules from the pf.conf(5) file and it modifies, drops or passes packets according to the rules or definitions specified there. The FreeBSD installation comes with a default /etc/pf.conf which contains useful examples and explanations.
Although FreeBSD has its own /etc/pf.conf the syntax is the same as one used in OpenBSD. A great resource for configuring the pf firewall has been written by OpenBSD team and is available at http://www.openbsd.org/faq/pf/.
Warning: When browsing the pf user's guide, please keep in mind that different versions of FreeBSD contain different versions of pf. The pf firewall in FreeBSD 5.X is at the level of OpenBSD version 3.5 and in FreeBSD 6.X is at the level of OpenBSD version 3.7.
The FreeBSD packet filter mailing list is a good place to ask questions about configuring and running the pf firewall. Do not forget to check the mailing list archives before asking questions.
28.5 The IPFILTER (IPF) Firewall
Note: This section is work in progress. The contents might not be accurate at all times.
The author of IPFILTER is Darren Reed. IPFILTER is not operating system dependent: it is an open source application and has been ported to FreeBSD, NetBSD, OpenBSD, SunOS, HP/UX, and Solaris operating systems. IPFILTER is actively being supported and maintained, with updated versions being released regularly.
IPFILTER is based on a kernel-side firewall and NAT mechanism that can be controlled and monitored by userland interface programs. The firewall rules can be set or deleted with the ipf(8) utility. The NAT rules can be set or deleted with the ipnat(1) utility. The ipfstat(8) utility can print run-time statistics for the kernel parts of IPFILTER. The ipmon(8) program can log IPFILTER actions to the system log files.
IPF was originally written using a rule processing logic of “the last matching rule wins” and used only stateless type of rules. Over time IPF has been enhanced to include a “quick” option and a stateful “keep state” option which drastically modernized the rules processing logic. IPF's official documentation covers the legacy rule coding parameters and the legacy rule file processing logic. The modernized functions are only included as additional options, completely understating their benefits in producing a far superior secure firewall.
The instructions contained in this section are based on using rules that contain the “quick” option and the stateful “keep state” option. This is the basic framework for coding an inclusive firewall rule set.
An inclusive firewall only allows packets matching the rules to pass through. This way you can control what services can originate behind the firewall destined for the public Internet and also control the services which can originate from the public Internet accessing your private network. Everything else is blocked and logged by default design. Inclusive firewalls are much, much more secure than exclusive firewall rule sets and is the only rule set type covered herein.
For detailed explanation of the legacy rules processing method see: http://www.obfuscation.org/ipf/ipf-howto.html#TOC_1 and http://coombs.anu.edu.au/~avalon/ip-filter.html.
The IPF FAQ is at http://www.phildev.net/ipf/index.html.
A searchable archive of the open-source IPFilter mailing list is available at http://marc.theaimsgroup.com/?l=ipfilter.
28.5.1 Enabling IPF
IPF is included in the basic FreeBSD install as a separate run time loadable module. The system will dynamically load the IPF kernel loadable module when the rc.conf statement ipfilter_enable="YES" is used. The loadable module was created with logging enabled and the default pass all options. You do not need to compile IPF into the FreeBSD kernel just to change the default to block all, you can do that by just coding a block all rule at the end of your rule set.
28.5.2 Kernel options
It is not a mandatory requirement that you enable IPF by compiling the following options into the FreeBSD kernel. It is only presented here as background information. Compiling IPF into the kernel causes the loadable module to never be used.
Sample kernel config IPF option statements are in the /usr/src/sys/conf/NOTES kernel source and are reproduced here:
options IPFILTER
options IPFILTER_LOG
options IPFILTER_DEFAULT_BLOCK
options IPFILTER enables support for the “IPFILTER” firewall.
options IPFILTER_LOG enables the option to have IPF log traffic by writing to the ipl packet logging pseudo--device for every rule that has the log keyword.
options IPFILTER_DEFAULT_BLOCK changes the default behavior so any packet not matching a firewall pass rule gets blocked.
These settings will take effect only after you have built and installed a kernel with them set.
28.5.3 Available rc.conf Options
You need the following statements in /etc/rc.conf to activate IPF at boot time:
ipfilter_enable="YES" # Start ipf firewall
ipfilter_rules="/etc/ipf.rules" # loads rules definition text file
ipmon_enable="YES" # Start IP monitor log
ipmon_flags="-Ds" # D = start as daemon
# s = log to syslog
# v = log tcp window, ack, seq
# n = map IP & port to names
If you have a LAN behind this firewall that uses the reserved private IP address ranges, then you need to add the following to enable NAT functionality:
gateway_enable="YES" # Enable as LAN gateway
ipnat_enable="YES" # Start ipnat function
ipnat_rules="/etc/ipnat.rules" # rules definition file for ipnat
28.5.4 IPF
The ipf command is used to load your rules file. Normally you create a file containing your custom rules and use this command to replace in mass the currently running firewall internal rules:
# ipf -Fa -f /etc/ipf.rules
-Fa means flush all internal rules tables.
-f means this is the file to read for the rules to
load.
This gives you the ability to make changes to your custom rules file, run the above IPF command, and thus update the running firewall with a fresh copy of all the rules without having to reboot the system. This method is very convenient for testing new rules as the procedure can be executed as many times as needed.
See the ipf(8) manual page for details on the other flags available with this command.
The ipf(8) command expects the rules file to be a standard text file. It will not accept a rules file written as a script with symbolic substitution.
There is a way to build IPF rules that utilizes the power of script symbolic substitution. For more information, see Section 28.5.9.
28.5.5 IPFSTAT
The default behavior of ipfstat(8) is to retrieve and display the totals of the accumulated statistics gathered as a result of applying the user coded rules against packets going in and out of the firewall since it was last started, or since the last time the accumulators were reset to zero by the ipf -Z command.
See the ipfstat(8) manual page for details.
The default ipfstat(8) command output will look something like this:
input packets: blocked 99286 passed 1255609 nomatch 14686 counted 0
output packets: blocked 4200 passed 1284345 nomatch 14687 counted 0
input packets logged: blocked 99286 passed 0
output packets logged: blocked 0 passed 0
packets logged: input 0 output 0
log failures: input 3898 output 0
fragment state(in): kept 0 lost 0
fragment state(out): kept 0 lost 0
packet state(in): kept 169364 lost 0
packet state(out): kept 431395 lost 0
ICMP replies: 0 TCP RSTs sent: 0
Result cache hits(in): 1215208 (out): 1098963
IN Pullups succeeded: 2 failed: 0
OUT Pullups succeeded: 0 failed: 0
Fastroute successes: 0 failures: 0
TCP cksum fails(in): 0 (out): 0
Packet log flags set: (0)
When supplied with either -i for inbound or -o for outbound, it will retrieve and display the appropriate list
of filter rules currently installed and in use by the kernel.
ipfstat -in displays the inbound internal rules table with rule number.
ipfstat -on displays the outbound internal rules table with the rule number.
The output will look something like this:
@1 pass out on xl0 from any to any
@2 block out on dc0 from any to any
@3 pass out quick on dc0 proto tcp/udp from any to any keep state
ipfstat -ih displays the inbound internal rules table, prefixing each rule with a count of how many times the rule was matched.
ipfstat -oh displays the outbound internal rules table, prefixing each rule with a count of how many times the rule was matched.
The output will look something like this:
2451423 pass out on xl0 from any to any
354727 block out on dc0 from any to any
430918 pass out quick on dc0 proto tcp/udp from any to any keep state
One of the most important functions of the ipfstat command is
the -t flag which displays the state table in a way similar
to the way top(1) shows the
FreeBSD running process table. When your firewall is under attack this function gives you
the ability to identify, drill down to, and see the attacking packets. The optional
sub-flags give the ability to select the destination or source IP, port, or protocol that
you want to monitor in real time. See the ipfstat(8) manual page
for details.
28.5.6 IPMON
In order for ipmon to work properly, the kernel option
IPFILTER_LOG must be turned on. This command has two different modes that it can be used
in. Native mode is the default mode when you type the command on the command line without
the -D flag.
Daemon mode is for when you want to have a continuous system log file available so
that you can review logging of past events. This is how FreeBSD and IPFILTER are
configured to work together. FreeBSD has a built in facility to automatically rotate
system logs. That is why outputting the log information to syslogd is better than the
default of outputting to a regular file. In the default rc.conf
file you see the ipmon_flags statement uses the -Ds
flags:
ipmon_flags="-Ds" # D = start as daemon
# s = log to syslog
# v = log tcp window, ack, seq
# n = map IP & port to names
The benefits of logging are obvious. It provides the ability to review, after the fact, information such as which packets had been dropped, what addresses they came from and where they were going. These all give you a significant edge in tracking down attackers.
Even with the logging facility enabled, IPF will not generate any rule logging on its own. The firewall administrator decides what rules in the rule set he wants to log and adds the log keyword to those rules. Normally only deny rules are logged.
It is very customary to include a default deny everything rule with the log keyword included as your last rule in the rule set. This way you get to see all the packets that did not match any of the rules in the rule set.
28.5.7 IPMON Logging
Syslogd uses its own special method for segregation of log
data. It uses special groupings called “facility” and “level”.
IPMON in -Ds mode uses security as
the “facility” name. All IPMON logged data goes to security The following levels can be used to further segregate the
logged data if desired:
LOG_INFO - packets logged using the "log" keyword as the action rather than pass or block.
LOG_NOTICE - packets logged which are also passed
LOG_WARNING - packets logged which are also blocked
LOG_ERR - packets which have been logged and which can be considered short
To setup IPFILTER to log all data to /var/log/ipfilter.log, you will need to create the file. The following command will do that:
# touch /var/log/ipfilter.log
The syslog function is controlled by definition statements in the /etc/syslog.conf file. The syslog.conf file offers considerable flexibility in how syslog will deal with system messages issued by software applications like IPF.
Add the following statement to /etc/syslog.conf:
security.* /var/log/ipfilter.log
The security.* means to write all the logged messages to the coded file location.
To activate the changes to /etc/syslog.conf you can reboot or bump the syslog task into re-reading /etc/syslog.conf by running /etc/rc.d/syslogd reload
Do not forget to change /etc/newsyslog.conf to rotate the new log you just created above.
28.5.8 The Format of Logged Messages
Messages generated by ipmon consist of data fields separated by white space. Fields common to all messages are:
-
The date of packet receipt.
-
The time of packet receipt. This is in the form HH:MM:SS.F, for hours, minutes, seconds, and fractions of a second (which can be several digits long).
-
The name of the interface the packet was processed on, e.g. dc0.
-
The group and rule number of the rule, e.g. @0:17.
These can be viewed with ipfstat -in.
-
The action: p for passed, b for blocked, S for a short packet, n did not match any rules, L for a log rule. The order of precedence in showing flags is: S, p, b, n, L. A capital P or B means that the packet has been logged due to a global logging setting, not a particular rule.
-
The addresses. This is actually three fields: the source address and port (separated by a comma), the -> symbol, and the destination address and port. 209.53.17.22,80 -> 198.73.220.17,1722.
-
PR followed by the protocol name or number, e.g. PR tcp.
-
len followed by the header length and total length of the packet, e.g. len 20 40.
If the packet is a TCP packet, there will be an additional field starting with a hyphen followed by letters corresponding to any flags that were set. See the ipmon(8) manual page for a list of letters and their flags.
If the packet is an ICMP packet, there will be two fields at the end, the first always being “ICMP”, and the next being the ICMP message and sub-message type, separated by a slash, e.g. ICMP 3/3 for a port unreachable message.
28.5.9 Building the Rule Script with Symbolic Substitution
Some experienced IPF users create a file containing the rules and code them in a manner compatible with running them as a script with symbolic substitution. The major benefit of doing this is that you only have to change the value associated with the symbolic name and when the script is run all the rules containing the symbolic name will have the value substituted in the rules. Being a script, you can use symbolic substitution to code frequently used values and substitute them in multiple rules. You will see this in the following example.
The script syntax used here is compatible with the sh, csh, and tcsh shells.
Symbolic substitution fields are prefixed with a dollar sign: $.
Symbolic fields do not have the $ prefix.
The value to populate the symbolic field must be enclosed with double quotes (").
Start your rule file with something like this:
############# Start of IPF rules script ########################
oif="dc0" # name of the outbound interface
odns="192.0.2.11" # ISP's DNS server IP address
myip="192.0.2.7" # my static IP address from ISP
ks="keep state"
fks="flags S keep state"
# You can choose between building /etc/ipf.rules file
# from this script or running this script "as is".
#
# Uncomment only one line and comment out another.
#
# 1) This can be used for building /etc/ipf.rules:
#cat > /etc/ipf.rules << EOF
#
# 2) This can be used to run script "as is":
/sbin/ipf -Fa -f - << EOF
# Allow out access to my ISP's Domain name server.
pass out quick on $oif proto tcp from any to $odns port = 53 $fks
pass out quick on $oif proto udp from any to $odns port = 53 $ks
# Allow out non-secure standard www function
pass out quick on $oif proto tcp from $myip to any port = 80 $fks
# Allow out secure www function https over TLS SSL
pass out quick on $oif proto tcp from $myip to any port = 443 $fks
EOF
################## End of IPF rules script ########################
That is all there is to it. The rules are not important in this example; how the symbolic substitution fields are populated and used are. If the above example was in a file named /etc/ipf.rules.script, you could reload these rules by entering the following command:
# sh /etc/ipf.rules.script
There is one problem with using a rules file with embedded symbolics: IPF does not understand symbolic substitution, and cannot read such scripts directly.
This script can be used in one of two ways:
-
Uncomment the line that begins with cat, and comment out the line that begins with /sbin/ipf. Place ipfilter_enable="YES" into /etc/rc.conf as usual, and run script once after each modification to create or update /etc/ipf.rules.
-
Disable IPFILTER in system startup scripts by adding ipfilter_enable="NO" (this is default value) into /etc/rc.conf file.
Add a script like the following to your /usr/local/etc/rc.d/ startup directory. The script should have an obvious name like ipf.loadrules.sh. The .sh extension is mandatory.
#!/bin/sh sh /etc/ipf.rules.scriptThe permissions on this script file must be read, write, execute for owner root.
# chmod 700 /usr/local/etc/rc.d/ipf.loadrules.sh
Now, when your system boots, your IPF rules will be loaded.
28.5.10 IPF Rule Sets
A rule set is a group of ipf rules coded to pass or block packets based on the values contained in the packet. The bi-directional exchange of packets between hosts comprises a session conversation. The firewall rule set processes the packet two times, once on its arrival from the public Internet host and again as it leaves for its return trip back to the public Internet host. Each TCP/IP service (i.e. telnet, www, mail, etc.) is predefined by its protocol, source and destination IP address, or the source and destination port number. This is the basic selection criteria used to create rules which will pass or block services.
IPF was originally written using a rules processing logic of “the last matching rule wins” and used only stateless rules. Over time IPF has been enhanced to include a “quick” option and a stateful “keep state” option which drastically modernized the rule processing logic.
The instructions contained in this section are based on using rules that contain the “quick” option and the stateful “keep state” option. This is the basic framework for coding an inclusive firewall rule set.
An inclusive firewall only allows services matching the rules through. This way you can control what services can originate behind the firewall destined for the public Internet and also control the services which can originate from the public Internet accessing your private network. Everything else is blocked and logged by default design. Inclusive firewalls are much, much securer than exclusive firewall rule sets and is the only rule set type covered herein.
Warning: When working with the firewall rules, be very careful. Some configurations will lock you out of the server. To be on the safe side, you may wish to consider performing the initial firewall configuration from the local console rather than doing it remotely e.g. via ssh.
28.5.11 Rule Syntax
The rule syntax presented here has been simplified to only address the modern stateful rule context and “first matching rule wins” logic. For the complete legacy rule syntax description see the ipf(8) manual page.
A # character is used to mark the start of a comment and may appear at the end of a rule line or on its own line. Blank lines are ignored.
Rules contain keywords. These keywords have to be coded in a specific order from left to right on the line. Keywords are identified in bold type. Some keywords have sub-options which may be keywords themselves and also include more sub-options. Each of the headings in the below syntax has a bold section header which expands on the content.
ACTION IN-OUT OPTIONS SELECTION STATEFUL PROTO SRC_ADDR,DST_ADDR OBJECT PORT_NUM TCP_FLAG STATEFUL
ACTION = block | pass
IN-OUT = in | out
OPTIONS = log | quick | on interface-name
SELECTION = proto value | source/destination IP | port = number | flags flag-value
PROTO = tcp/udp | udp | tcp | icmp
SRC_ADD,DST_ADDR = all | from object to object
OBJECT = IP address | any
PORT_NUM = port number
TCP_FLAG = S
STATEFUL = keep state
28.5.11.1 ACTION
The action indicates what to do with the packet if it matches the rest of the filter rule. Each rule must have a action. The following actions are recognized:
block indicates that the packet should be dropped if the selection parameters match the packet.
pass indicates that the packet should exit the firewall if the selection parameters match the packet.
28.5.11.2 IN-OUT
A mandatory requirement is that each filter rule explicitly state which side of the I/O it is to be used on. The next keyword must be either in or out and one or the other has to be coded or the rule will not pass syntax checks.
in means this rule is being applied against an inbound packet which has just been received on the interface facing the public Internet.
out means this rule is being applied against an outbound packet destined for the interface facing the public Internet.
28.5.11.3 OPTIONS
Note: These options must be used in the order shown here.
log indicates that the packet header will be written to the ipl log (as described in the LOGGING section below) if the selection parameters match the packet.
quick indicates that if the selection parameters match the packet, this rule will be the last rule checked, allowing a “short-circuit” path to avoid processing any following rules for this packet. This option is a mandatory requirement for the modernized rules processing logic.
on indicates the interface name to be incorporated into the selection parameters. Interface names are as displayed by ifconfig(8). Using this option, the rule will only match if the packet is going through that interface in the specified direction (in/out). This option is a mandatory requirement for the modernized rules processing logic.
When a packet is logged, the headers of the packet are written to the IPL packet logging pseudo-device. Immediately following the log keyword, the following qualifiers may be used (in this order):
body indicates that the first 128 bytes of the packet contents will be logged after the headers.
first If the log keyword is being used in conjunction with a “keep state” option, it is recommended that this option is also applied so that only the triggering packet is logged and not every packet which thereafter matches the “keep state” information.
28.5.11.4 SELECTION
The keywords described in this section are used to describe attributes of the packet to be interrogated when determining whether rules match or not. There is a keyword subject, and it has sub-option keywords, one of which has to be selected. The following general-purpose attributes are provided for matching, and must be used in this order:
28.5.11.5 PROTO
proto is the subject keyword and must be coded along with one of its corresponding keyword sub-option values. The value allows a specific protocol to be matched against. This option is a mandatory requirement for the modernized rules processing logic.
tcp/udp | udp | tcp | icmp or any protocol names found in /etc/protocols are recognized and may be used. The special protocol keyword tcp/udp may be used to match either a TCP or a UDP packet, and has been added as a convenience to save duplication of otherwise identical rules.
28.5.11.6 SRC_ADDR/DST_ADDR
The all keyword is essentially a synonym for “from any to any” with no other match parameters.
from src to dst: the from and to keywords are used to match against IP addresses. Rules must specify BOTH source and destination parameters. any is a special keyword that matches any IP address. Examples of use: “from any to any” or “from 0.0.0.0/0 to any” or “from any to 0.0.0.0/0” or “from 0.0.0.0 to any” or “from any to 0.0.0.0”.
IP addresses may be specified as a dotted IP address numeric form/mask-length, or as single dotted IP address numeric form.
There is no way to match ranges of IP addresses which do not express themselves easily as mask-length. See this web page for help on writing mask-length: http://jodies.de/ipcalc.
28.5.11.7 PORT
If a port match is included, for either or both of source and destination, then it is only applied to TCP and UDP packets. When composing port comparisons, either the service name from /etc/services or an integer port number may be used. When the port appears as part of the from object, it matches the source port number; when it appears as part of the to object, it matches the destination port number. The use of the port option with the to object is a mandatory requirement for the modernized rules processing logic. Example of use: “from any to any port = 80”
Port comparisons may be done in a number of forms, with a number of comparison operators, or port ranges may be specified.
port "=" | "!=" | "<" | ">" | "<=" | ">=" | "eq" | "ne" | "lt" | "gt" | "le" | "ge".
To specify port ranges, port "<>" | "><"
Warning: Following the source and destination matching parameters, the following two parameters are mandatory requirements for the modernized rules processing logic.
28.5.11.8 TCP_FLAG
Flags are only effective for TCP filtering. The letters represents one of the possible flags that can be interrogated in the TCP packet header.
The modernized rules processing logic uses the flags S parameter to identify the tcp session start request.
28.5.11.9 STATEFUL
keep state indicates that on a pass rule, any packets that match the rules selection parameters should activate the stateful filtering facility.
Note: This option is a mandatory requirement for the modernized rules processing logic.
28.5.12 Stateful Filtering
Stateful filtering treats traffic as a bi-directional exchange of packets comprising a session conversation. When activated, keep-state dynamically generates internal rules for each anticipated packet being exchanged during the bi-directional session conversation. It has the interrogation abilities to determine if the session conversation between the originating sender and the destination are following the valid procedure of bi-directional packet exchange. Any packets that do not properly fit the session conversation template are automatically rejected as impostors.
Keep state will also allow ICMP packets related to a TCP or UDP session through. So if you get ICMP type 3 code 4 in response to some web surfing allowed out by a keep state rule, they will be automatically allowed in. Any packet that IPF can be certain is part of an active session, even if it is a different protocol, will be let in.
What happens is:
Packets destined to go out the interface connected to the public Internet are first checked against the dynamic state table, if the packet matches the next expected packet comprising in a active session conversation, then it exits the firewall and the state of the session conversation flow is updated in the dynamic state table, the remaining packets get checked against the outbound rule set.
Packets coming in to the interface connected to the public Internet are first checked against the dynamic state table, if the packet matches the next expected packet comprising a active session conversation, then it exits the firewall and the state of the session conversation flow is updated in the dynamic state table, the remaining packets get checked against the inbound rule set.
When the conversation completes it is removed from the dynamic state table.
Stateful filtering allows you to focus on blocking/passing new sessions. If the new session is passed, all its subsequent packets will be allowed through automatically and any impostors automatically rejected. If a new session is blocked, none of its subsequent packets will be allowed through. Stateful filtering has technically advanced interrogation abilities capable of defending against the flood of different attack methods currently employed by attackers.
28.5.13 Inclusive Rule Set Example
The following rule set is an example of how to code a very secure inclusive type of firewall. An inclusive firewall only allows services matching pass rules through and blocks all other by default. All firewalls have at the minimum two interfaces which have to have rules to allow the firewall to function.
All UNIX flavored systems including FreeBSD are designed to use interface lo0 and IP address 127.0.0.1 for internal communication within the operating system. The firewall rules must contain rules to allow free unmolested movement of these special internally used packets.
The interface which faces the public Internet is the one where you place your rules to authorize and control access out to the public Internet and access requests arriving from the public Internet. This can be your user PPP tun0 interface or your NIC that is connected to your DSL or cable modem.
In cases where one or more NICs are cabled to private LANs behind the firewall, those interfaces must have a rule coded to allow free unmolested movement of packets originating from those LAN interfaces.
The rules should be first organized into three major sections: all the free unmolested interfaces, the public interface outbound, and the public interface inbound.
The rules in each of the public interface sections should have the most frequently matched rules placed before less commonly matched rules, with the last rule in the section blocking and logging all packets on that interface and direction.
The Outbound section in the following rule set only contains 'pass' rules which contain selection values that uniquely identify the service that is authorized for public Internet access. All the rules have the 'quick', 'on', 'proto', 'port', and 'keep state' option coded. The 'proto tcp' rules have the 'flag' option included to identify the session start request as the triggering packet to activate the stateful facility.
The Inbound section has all the blocking of undesirable packets first, for two different reasons. The first is that these things being blocked may be part of an otherwise valid packet which may be allowed in by the later authorized service rules. The second reason is that by having a rule that explicitly blocks selected packets that I receive on an infrequent basis and that I do not want to see in the log, they will not be caught by the last rule in the section which blocks and logs all packets which have fallen through the rules. The last rule in the section which blocks and logs all packets is how you create the legal evidence needed to prosecute the people who are attacking your system.
Another thing you should take note of, is there is no response returned for any of the undesirable stuff, their packets just get dropped and vanish. This way the attacker has no knowledge if his packets have reached your system. The less the attackers can learn about your system, the more time they must invest before actually doing something bad. The inbound 'nmap OS fingerprint' attempts rule I log the first occurrence because this is something a attacker would do.
Any time you see log messages on a rule with 'log first'. You should do an ipfstat -hio command to see the number of times the rule has been matched so you know if you are being flooded, i.e. under attack.
When you log packets with port numbers you do not recognize, look it up in /etc/services or go to http://www.securitystats.com/tools/portsearch.php and do a port number lookup to find what the purpose of that port number is.
Check out this link for port numbers used by Trojans http://www.simovits.com/trojans/trojans.html.
The following rule set is a complete very secure 'inclusive' type of firewall rule set that I have used on my system. You can not go wrong using this rule set for your own. Just comment out any pass rules for services that you do not want to authorize.
If you see messages in your log that you want to stop seeing just add a block rule in the inbound section.
You have to change the dc0 interface name in every rule to the interface name of the Nic card that connects your system to the public Internet. For user PPP it would be tun0.
Add the following statements to /etc/ipf.rules:
#################################################################
# No restrictions on Inside LAN Interface for private network
# Not needed unless you have LAN
#################################################################
#pass out quick on xl0 all
#pass in quick on xl0 all
#################################################################
# No restrictions on Loopback Interface
#################################################################
pass in quick on lo0 all
pass out quick on lo0 all
#################################################################
# Interface facing Public Internet (Outbound Section)
# Interrogate session start requests originating from behind the
# firewall on the private network
# or from this gateway server destine for the public Internet.
#################################################################
# Allow out access to my ISP's Domain name server.
# xxx must be the IP address of your ISP's DNS.
# Dup these lines if your ISP has more than one DNS server
# Get the IP addresses from /etc/resolv.conf file
pass out quick on dc0 proto tcp from any to xxx port = 53 flags S keep state
pass out quick on dc0 proto udp from any to xxx port = 53 keep state
# Allow out access to my ISP's DHCP server for cable or DSL networks.
# This rule is not needed for 'user ppp' type connection to the
# public Internet, so you can delete this whole group.
# Use the following rule and check log for IP address.
# Then put IP address in commented out rule & delete first rule
pass out log quick on dc0 proto udp from any to any port = 67 keep state
#pass out quick on dc0 proto udp from any to z.z.z.z port = 67 keep state
# Allow out non-secure standard www function
pass out quick on dc0 proto tcp from any to any port = 80 flags S keep state
# Allow out secure www function https over TLS SSL
pass out quick on dc0 proto tcp from any to any port = 443 flags S keep state
# Allow out send & get email function
pass out quick on dc0 proto tcp from any to any port = 110 flags S keep state
pass out quick on dc0 proto tcp from any to any port = 25 flags S keep state
# Allow out Time
pass out quick on dc0 proto tcp from any to any port = 37 flags S keep state
# Allow out nntp news
pass out quick on dc0 proto tcp from any to any port = 119 flags S keep state
# Allow out gateway & LAN users non-secure FTP ( both passive & active modes)
# This function uses the IPNAT built in FTP proxy function coded in
# the nat rules file to make this single rule function correctly.
# If you want to use the pkg_add command to install application packages
# on your gateway system you need this rule.
pass out quick on dc0 proto tcp from any to any port = 21 flags S keep state
# Allow out secure FTP, Telnet, and SCP
# This function is using SSH (secure shell)
pass out quick on dc0 proto tcp from any to any port = 22 flags S keep state
# Allow out non-secure Telnet
pass out quick on dc0 proto tcp from any to any port = 23 flags S keep state
# Allow out FBSD CVSUP function
pass out quick on dc0 proto tcp from any to any port = 5999 flags S keep state
# Allow out ping to public Internet
pass out quick on dc0 proto icmp from any to any icmp-type 8 keep state
# Allow out whois for LAN PC to public Internet
pass out quick on dc0 proto tcp from any to any port = 43 flags S keep state
# Block and log only the first occurrence of everything
# else that's trying to get out.
# This rule enforces the block all by default logic.
block out log first quick on dc0 all
#################################################################
# Interface facing Public Internet (Inbound Section)
# Interrogate packets originating from the public Internet
# destine for this gateway server or the private network.
#################################################################
# Block all inbound traffic from non-routable or reserved address spaces
block in quick on dc0 from 192.168.0.0/16 to any #RFC 1918 private IP
block in quick on dc0 from 172.16.0.0/12 to any #RFC 1918 private IP
block in quick on dc0 from 10.0.0.0/8 to any #RFC 1918 private IP
block in quick on dc0 from 127.0.0.0/8 to any #loopback
block in quick on dc0 from 0.0.0.0/8 to any #loopback
block in quick on dc0 from 169.254.0.0/16 to any #DHCP auto-config
block in quick on dc0 from 192.0.2.0/24 to any #reserved for docs
block in quick on dc0 from 204.152.64.0/23 to any #Sun cluster interconnect
block in quick on dc0 from 224.0.0.0/3 to any #Class D & E multicast
##### Block a bunch of different nasty things. ############
# That I do not want to see in the log
# Block frags
block in quick on dc0 all with frags
# Block short tcp packets
block in quick on dc0 proto tcp all with short
# block source routed packets
block in quick on dc0 all with opt lsrr
block in quick on dc0 all with opt ssrr
# Block nmap OS fingerprint attempts
# Log first occurrence of these so I can get their IP address
block in log first quick on dc0 proto tcp from any to any flags FUP
# Block anything with special options
block in quick on dc0 all with ipopts
# Block public pings
block in quick on dc0 proto icmp all icmp-type 8
# Block ident
block in quick on dc0 proto tcp from any to any port = 113
# Block all Netbios service. 137=name, 138=datagram, 139=session
# Netbios is MS/Windows sharing services.
# Block MS/Windows hosts2 name server requests 81
block in log first quick on dc0 proto tcp/udp from any to any port = 137
block in log first quick on dc0 proto tcp/udp from any to any port = 138
block in log first quick on dc0 proto tcp/udp from any to any port = 139
block in log first quick on dc0 proto tcp/udp from any to any port = 81
# Allow traffic in from ISP's DHCP server. This rule must contain
# the IP address of your ISP's DHCP server as it's the only
# authorized source to send this packet type. Only necessary for
# cable or DSL configurations. This rule is not needed for
# 'user ppp' type connection to the public Internet.
# This is the same IP address you captured and
# used in the outbound section.
pass in quick on dc0 proto udp from z.z.z.z to any port = 68 keep state
# Allow in standard www function because I have apache server
pass in quick on dc0 proto tcp from any to any port = 80 flags S keep state
# Allow in non-secure Telnet session from public Internet
# labeled non-secure because ID/PW passed over public Internet as clear text.
# Delete this sample group if you do not have telnet server enabled.
#pass in quick on dc0 proto tcp from any to any port = 23 flags S keep state
# Allow in secure FTP, Telnet, and SCP from public Internet
# This function is using SSH (secure shell)
pass in quick on dc0 proto tcp from any to any port = 22 flags S keep state
# Block and log only first occurrence of all remaining traffic
# coming into the firewall. The logging of only the first
# occurrence stops a .denial of service. attack targeted
# at filling up your log file space.
# This rule enforces the block all by default logic.
block in log first quick on dc0 all
################### End of rules file #####################################
28.5.14 NAT
NAT stands for Network Address Translation. To those familiar with Linux, this concept is called IP Masquerading; NAT and IP Masquerading are the same thing. One of the many things the IPF NAT function enables is the ability to have a private Local Area Network (LAN) behind the firewall sharing a single ISP assigned IP address on the public Internet.
You may ask why would someone want to do this. ISPs normally assign a dynamic IP address to their non-commercial users. Dynamic means that the IP address can be different each time you dial in and log on to your ISP, or for cable and DSL modem users when you power off and then power on your modems you can get assigned a different IP address. This IP address is how you are known to the public Internet.
Now lets say you have five PCs at home and each one needs Internet access. You would have to pay your ISP for an individual Internet account for each PC and have five phone lines.
With NAT you only need a single account with your ISP, then cable your other four PCs to a switch and the switch to the NIC in your FreeBSD system which is going to service your LAN as a gateway. NAT will automatically translate the private LAN IP address for each separate PC on the LAN to the single public IP address as it exits the firewall bound for the public Internet. It also does the reverse translation for returning packets.
NAT is most often accomplished without the approval, or knowledge, of your ISP and in most cases is grounds for your ISP terminating your account if found out. Commercial users pay a lot more for their Internet connection and usually get assigned a block of static IP address which never change. The ISP also expects and consents to their Commercial customers using NAT for their internal private LANs.
There is a special range of IP addresses reserved for NATed private LAN IP address. According to RFC 1918, you can use the following IP ranges for private nets which will never be routed directly to the public Internet:
28.5.15 IPNAT
NAT rules are loaded by using the ipnat command. Typically the NAT rules are stored in /etc/ipnat.rules. See ipnat(1) for details.
When changing the NAT rules after NAT has been started, make your changes to the file containing
the NAT rules, then run ipnat command with the -CF flags to
delete the internal in use NAT rules and flush the
contents of the translation table of all active entries.
To reload the NAT rules issue a command like this:
# ipnat -CF -f /etc/ipnat.rules
To display some statistics about your NAT, use this command:
# ipnat -s
To list the NAT table's current mappings, use this command:
# ipnat -l
To turn verbose mode on, and display information relating to rule processing and active rules/table entries:
# ipnat -v
28.5.16 IPNAT Rules
NAT rules are very flexible and can accomplish many different things to fit the needs of commercial and home users.
The rule syntax presented here has been simplified to what is most commonly used in a non-commercial environment. For a complete rule syntax description see the ipnat(5) manual page.
The syntax for a NAT rule looks something like this:
map IF LAN_IP_RANGE -> PUBLIC_ADDRESS
The keyword map starts the rule.
Replace IF with the external interface.
The LAN_IP_RANGE is what your internal clients use for IP Addressing, usually this is something like 192.168.1.0/24.
The PUBLIC_ADDRESS can either be the external IP address or the special keyword 0/32, which means to use the IP address assigned to IF.
28.5.17 How NAT works
A packet arrives at the firewall from the LAN with a public destination. It passes through the outbound filter rules, NAT gets his turn at the packet and applies its rules top down, first matching rule wins. NAT tests each of its rules against the packets interface name and source IP address. When a packets interface name matches a NAT rule then the [source IP address, i.e. private LAN IP address] of the packet is checked to see if it falls within the IP address range specified to the left of the arrow symbol on the NAT rule. On a match the packet has its source IP address rewritten with the public IP address obtained by the 0/32 keyword. NAT posts a entry in its internal NAT table so when the packet returns from the public Internet it can be mapped back to its original private IP address and then passed to the filter rules for processing.
28.5.18 Enabling IPNAT
To enable IPNAT add these statements to /etc/rc.conf.
To enable your machine to route traffic between interfaces:
gateway_enable="YES"
To start IPNAT automatically each time:
ipnat_enable="YES"
To specify where to load the IPNAT rules from:
ipnat_rules="/etc/ipnat.rules"
28.5.19 NAT for a very large LAN
For networks that have large numbers of PC's on the LAN or networks with more than a single LAN, the process of funneling all those private IP addresses into a single public IP address becomes a resource problem that may cause problems with the same port numbers being used many times across many NATed LAN PC's, causing collisions. There are two ways to relieve this resource problem.
28.5.19.1 Assigning Ports to Use
A normal NAT rule would look like:
map dc0 192.168.1.0/24 -> 0/32
In the above rule the packet's source port is unchanged as the packet passes through IPNAT. By adding the portmap keyword you can tell IPNAT to only use source ports in a range. For example the following rule will tell IPNAT to modify the source port to be within that range:
map dc0 192.168.1.0/24 -> 0/32 portmap tcp/udp 20000:60000
Additionally we can make things even easier by using the auto keyword to tell IPNAT to determine by itself which ports are available to use:
map dc0 192.168.1.0/24 -> 0/32 portmap tcp/udp auto
28.5.19.2 Using a pool of public addresses
In very large LANs there comes a point where there are just too many LAN addresses to fit into a single public address. If a block of public IP addresses is available, you can use these addresses as a “pool”, and let IPNAT pick one of the public IP addresses as packet-addresses are mapped on their way out.
For example, instead of mapping all packets through a single public IP address, as in:
map dc0 192.168.1.0/24 -> 204.134.75.1
A range of public IP addresses can be specified either with a netmask:
map dc0 192.168.1.0/24 -> 204.134.75.0/255.255.255.0
or using CIDR notation:
map dc0 192.168.1.0/24 -> 204.134.75.0/24
28.5.20 Port Redirection
A very common practice is to have a web server, email server, database server and DNS server each segregated to a different PC on the LAN. In this case the traffic from these servers still have to be NATed, but there has to be some way to direct the inbound traffic to the correct LAN PCs. IPNAT has the redirection facilities of NAT to solve this problem. Lets say you have your web server on LAN address 10.0.10.25 and your single public IP address is 20.20.20.5 you would code the rule like this:
rdr dc0 20.20.20.5/32 port 80 -> 10.0.10.25 port 80
or:
rdr dc0 0.0.0.0/0 port 80 -> 10.0.10.25 port 80
or for a LAN DNS Server on LAN address of 10.0.10.33 that needs to receive public DNS requests:
rdr dc0 20.20.20.5/32 port 53 -> 10.0.10.33 port 53 udp
28.5.21 FTP and NAT
FTP is a dinosaur left over from the time before the Internet as it is known today, when research universities were leased lined together and FTP was used to share files among research Scientists. This was a time when data security was not a consideration. Over the years the FTP protocol became buried into the backbone of the emerging Internet and its username and password being sent in clear text was never changed to address new security concerns. FTP has two flavors, it can run in active mode or passive mode. The difference is in how the data channel is acquired. Passive mode is more secure as the data channel is acquired be the ordinal ftp session requester. For a real good explanation of FTP and the different modes see http://www.slacksite.com/other/ftp.html.
28.5.21.1 IPNAT Rules
IPNAT has a special built in FTP proxy option which can be specified on the NAT map rule. It can monitor all outbound packet traffic for FTP active or passive start session requests and dynamically create temporary filter rules containing only the port number really in use for the data channel. This eliminates the security risk FTP normally exposes the firewall to from having large ranges of high order port numbers open.
This rule will handle all the traffic for the internal LAN:
map dc0 10.0.10.0/29 -> 0/32 proxy port 21 ftp/tcp
This rule handles the FTP traffic from the gateway:
map dc0 0.0.0.0/0 -> 0/32 proxy port 21 ftp/tcp
This rule handles all non-FTP traffic from the internal LAN:
map dc0 10.0.10.0/29 -> 0/32
The FTP map rule goes before our regular map rule. All packets are tested against the first rule from the top. Matches on interface name, then private LAN source IP address, and then is it a FTP packet. If all that matches then the special FTP proxy creates temp filter rules to let the FTP session packets pass in and out, in addition to also NATing the FTP packets. All LAN packets that are not FTP do not match the first rule and fall through to the third rule and are tested, matching on interface and source IP, then are NATed.
28.5.21.2 IPNAT FTP Filter Rules
Only one filter rule is needed for FTP if the NAT FTP proxy is used.
Without the FTP Proxy you will need the following three rules:
# Allow out LAN PC client FTP to public Internet
# Active and passive modes
pass out quick on rl0 proto tcp from any to any port = 21 flags S keep state
# Allow out passive mode data channel high order port numbers
pass out quick on rl0 proto tcp from any to any port > 1024 flags S keep state
# Active mode let data channel in from FTP server
pass in quick on rl0 proto tcp from any to any port = 20 flags S keep state
28.6 IPFW
Note: This section is work in progress. The contents might not be accurate at all times.
The IPFIREWALL (IPFW) is a FreeBSD sponsored firewall software application authored and maintained by FreeBSD volunteer staff members. It uses the legacy stateless rules and a legacy rule coding technique to achieve what is referred to as Simple Stateful logic.
The IPFW sample rule set (found in /etc/rc.firewall) in the standard FreeBSD install is rather simple and it is not expected that it used directly without modifications. The example does not use stateful filtering, which is beneficial in most setups, so it will not be used as base for this section.
The IPFW stateless rule syntax is empowered with technically sophisticated selection capabilities which far surpasses the knowledge level of the customary firewall installer. IPFW is targeted at the professional user or the advanced technical computer hobbyist who have advanced packet selection requirements. A high degree of detailed knowledge into how different protocols use and create their unique packet header information is necessary before the power of the IPFW rules can be unleashed. Providing that level of explanation is out of the scope of this section of the handbook.
IPFW is composed of seven components, the primary component is the kernel firewall filter rule processor and its integrated packet accounting facility, the logging facility, the 'divert' rule which triggers the NAT facility, and the advanced special purpose facilities, the dummynet traffic shaper facilities, the 'fwd rule' forward facility, the bridge facility, and the ipstealth facility.
28.6.1 Enabling IPFW
IPFW is included in the basic FreeBSD install as a separate run time loadable module. The system will dynamically load the kernel module when the rc.conf statement firewall_enable="YES" is used. You do not need to compile IPFW into the FreeBSD kernel unless you want NAT function enabled.
After rebooting your system with firewall_enable="YES" in rc.conf the following white highlighted message is displayed on the screen as part of the boot process:
ipfw2 initialized, divert disabled, rule-based forwarding disabled, default to deny, logging disabled
The loadable module does have logging ability compiled in. To enable logging and set the verbose logging limit, there is a knob you can set in /etc/sysctl.conf by adding these statements, logging will be enabled on future reboots:
net.inet.ip.fw.verbose=1
net.inet.ip.fw.verbose_limit=5
28.6.2 Kernel Options
It is not a mandatory requirement that you enable IPFW by compiling the following options into the FreeBSD kernel unless you need NAT function. It is presented here as background information.
options IPFIREWALL
This option enables IPFW as part of the kernel
options IPFIREWALL_VERBOSE
Enables logging of packets that pass through IPFW and have the 'log' keyword specified in the rule set.
options IPFIREWALL_VERBOSE_LIMIT=5
Limits the number of packets logged through syslogd(8) on a per entry basis. You may wish to use this option in hostile environments which you want to log firewall activity. This will close a possible denial of service attack via syslog flooding.
options IPFIREWALL_DEFAULT_TO_ACCEPT
This option will allow everything to pass through the firewall by default, which is a good idea when you are first setting up your firewall.
options IPV6FIREWALL
options IPV6FIREWALL_VERBOSE
options IPV6FIREWALL_VERBOSE_LIMIT
options IPV6FIREWALL_DEFAULT_TO_ACCEPT
These options are exactly the same as the IPv4 options but they are for IPv6. If you do not use IPv6 you might want to use IPV6FIREWALL without any rules to block all IPv6
options IPDIVERT
This enables the use of NAT functionality.
Note: If you do not include IPFIREWALL_DEFAULT_TO_ACCEPT or set your rules to allow incoming packets you will block all packets going to and from this machine.
28.6.3 /etc/rc.conf Options
Enable the firewall:
firewall_enable="YES"
To select one of the default firewall types provided by FreeBSD, select one by reading the /etc/rc.firewall file and place it in the following:
firewall_type="open"
Available values for this setting are:
-
open -- pass all traffic.
-
client -- will protect only this machine.
-
simple -- protect the whole network.
-
closed -- entirely disables IP traffic except for the loopback interface.
-
UNKNOWN -- disables the loading of firewall rules.
-
filename -- absolute path of file containing firewall rules.
It is possible to use two different ways to load custom rules for ipfw firewall. One is by setting firewall_type variable to absolute path of file, which contains firewall rules without any command-line options for ipfw(8) itself. A simple example of ruleset file can be following:
add block in all
add block out all
On the other hand, it is possible to set firewall_script variable to absolute path of executable script that includes ipfw commands being executed at system boot time. A valid ruleset script that would be equivalent to the ruleset file shown above would be following:
#!/bin/sh
ipfw -q flush
ipfw add block in all
ipfw add block out all
Note: If firewall_type is set to either client or simple, the default rules found in /etc/rc.firewall should be reviewed to fit to the configuration of the given machine. Also note that the examples used in this chapter expect that the firewall_script is set to /etc/ipfw.rules.
Enable logging:
firewall_logging="YES"
Warning: The only thing that the
firewall_loggingvariable will do is setting thenet.inet.ip.fw.verbosesysctl variable to the value of 1 (see Section 28.6.1). There is no rc.conf variable to set log limitations, but it can be set via sysctl variable, manually or from the /etc/sysctl.conf file:net.inet.ip.fw.verbose_limit=5
If your machine is acting as a gateway, i.e. providing Network Address Translation (NAT) via natd(8), please refer to Section 29.9 for information regarding the required /etc/rc.conf options.
28.6.4 The IPFW Command
The ipfw command is the normal vehicle for making manual single rule additions or deletions to the firewall active internal rules while it is running. The problem with using this method is once your system is shutdown or halted all the rules you added or changed or deleted are lost. Writing all your rules in a file and using that file to load the rules at boot time, or to replace in mass the currently running firewall rules with changes you made to the files content is the recommended method used here.
The ipfw command is still a very useful to display the running firewall rules to the console screen. The IPFW accounting facility dynamically creates a counter for each rule that counts each packet that matches the rule. During the process of testing a rule, listing the rule with its counter is the one of the ways of determining if the rule is functioning.
To list all the rules in sequence:
# ipfw list
To list all the rules with a time stamp of when the last time the rule was matched:
# ipfw -t list
To list the accounting information, packet count for matched rules along with the rules themselves. The first column is the rule number, followed by the number of outgoing matched packets, followed by the number of incoming matched packets, and then the rule itself.
# ipfw -a list
List the dynamic rules in addition to the static rules:
# ipfw -d list
Also show the expired dynamic rules:
# ipfw -d -e list
Zero the counters:
# ipfw zero
Zero the counters for just rule NUM:
# ipfw zero NUM
28.6.5 IPFW Rule Sets
A rule set is a group of ipfw rules coded to allow or deny packets based on the values contained in the packet. The bi-directional exchange of packets between hosts comprises a session conversation. The firewall rule set processes the packet twice: once on its arrival from the public Internet host and again as it leaves for its return trip back to the public Internet host. Each tcp/ip service (i.e. telnet, www, mail, etc.) is predefined by its protocol, and port number. This is the basic selection criteria used to create rules which will allow or deny services.
When a packet enters the firewall it is compared against the first rule in the rule set and progress one rule at a time moving from top to bottom of the set in ascending rule number sequence order. When the packet matches a rule selection parameters, the rules action field value is executed and the search of the rule set terminates for that packet. This is referred to as “the first match wins” search method. If the packet does not match any of the rules, it gets caught by the mandatory ipfw default rule, number 65535 which denies all packets and discards them without any reply back to the originating destination.
Note: The search continues after count, skipto and tee rules.
The instructions contained here are based on using rules that contain the stateful 'keep state', 'limit', 'in'/'out', and via options. This is the basic framework for coding an inclusive type firewall rule set.
An inclusive firewall only allows services matching the rules through. This way you can control what services can originate behind the firewall destine for the public Internet and also control the services which can originate from the public Internet accessing your private network. Everything else is denied by default design. Inclusive firewalls are much, much more secure than exclusive firewall rule sets and is the only rule set type covered here in.
Warning: When working with the firewall rules be careful, you can end up locking your self out.
28.6.5.1 Rule Syntax
The rule syntax presented here has been simplified to what is necessary to create a standard inclusive type firewall rule set. For a complete rule syntax description see the ipfw(8) manual page.
Rules contain keywords: these keywords have to be coded in a specific order from left to right on the line. Keywords are identified in bold type. Some keywords have sub-options which may be keywords them selves and also include more sub-options.
# is used to mark the start of a comment and may appear at the end of a rule line or on its own lines. Blank lines are ignored.
CMD RULE_NUMBER ACTION LOGGING SELECTION STATEFUL
28.6.5.1.3 ACTION
A rule can be associated with one of the following actions, which will be executed when the packet matches the selection criterion of the rule.
allow | accept | pass | permit
These all mean the same thing which is to allow packets that match the rule to exit the firewall rule processing. The search terminates at this rule.
check-state
Checks the packet against the dynamic rules table. If a match is found, execute the action associated with the rule which generated this dynamic rule, otherwise move to the next rule. The check-state rule does not have selection criterion. If no check-state rule is present in the rule set, the dynamic rules table is checked at the first keep-state or limit rule.
deny | drop
Both words mean the same thing which is to discard packets that match this rule. The search terminates.
28.6.5.1.4 Logging
log or logamount
When a packet matches a rule with the log keyword, a message will be logged to syslogd with a facility name of SECURITY. The logging only occurs if the number of packets logged so far for that particular rule does not exceed the logamount parameter. If no logamount is specified, the limit is taken from the sysctl variable net.inet.ip.fw.verbose_limit. In both cases, a value of zero removes the logging limit. Once the limit is reached, logging can be re-enabled by clearing the logging counter or the packet counter for that rule, see the ipfw reset log command.
Note: Logging is done after all other packet matching conditions have been successfully verified, and before performing the final action (accept, deny) on the packet. It is up to you to decide which rules you want to enable logging on.
28.6.5.1.5 Selection
The keywords described in this section are used to describe attributes of the packet to be interrogated when determining whether rules match the packet or not. The following general-purpose attributes are provided for matching, and must be used in this order:
udp | tcp | icmp
or any protocol names found in /etc/protocols are recognized and may be used. The value specified is protocol to be matched against. This is a mandatory requirement.
from src to dst
The from and to keywords are used to match against IP addresses. Rules must specify BOTH source and destination parameters. any is a special keyword that matches any IP address. me is a special keyword that matches any IP address configured on an interface in your FreeBSD system to represent the PC the firewall is running on (i.e. this box) as in 'from me to any' or 'from any to me' or 'from 0.0.0.0/0 to any' or 'from any to 0.0.0.0/0' or 'from 0.0.0.0 to any' or 'from any to 0.0.0.0' or 'from me to 0.0.0.0'. IP addresses are specified as a dotted IP address numeric form/mask-length, or as single dotted IP address numeric form. This is a mandatory requirement. See this link for help on writing mask-lengths. http://jodies.de/ipcalc
port number
For protocols which support port numbers (such as TCP and UDP). It is mandatory that you code the port number of the service you want to match on. Service names (from /etc/services) may be used instead of numeric port values.
in | out
Matches incoming or outgoing packets, respectively. The in and out are keywords and it is mandatory that you code one or the other as part of your rule matching criterion.
via IF
Matches packets going through the interface specified by exact name. The via keyword causes the interface to always be checked as part of the match process.
setup
This is a mandatory keyword that identifies the session start request for TCP packets.
keep-state
This is a mandatory> keyword. Upon a match, the firewall will create a dynamic rule, whose default behavior is to match bidirectional traffic between source and destination IP/port using the same protocol.
limit {src-addr | src-port | dst-addr | dst-port}
The firewall will only allow N connections with the same set of parameters as specified in the rule. One or more of source and destination addresses and ports can be specified. The 'limit' and 'keep-state' can not be used on same rule. Limit provides the same stateful function as 'keep-state' plus its own functions.
28.6.5.2 Stateful Rule Option
Stateful filtering treats traffic as a bi-directional exchange of packets comprising a session conversation. It has the interrogation abilities to determine if the session conversation between the originating sender and the destination are following the valid procedure of bi-directional packet exchange. Any packets that do not properly fit the session conversation template are automatically rejected as impostors.
'check-state' is used to identify where in the IPFW rules set the packet is to be tested against the dynamic rules facility. On a match the packet exits the firewall to continue on its way and a new rule is dynamic created for the next anticipated packet being exchanged during this bi-directional session conversation. On a no match the packet advances to the next rule in the rule set for testing.
The dynamic rules facility is vulnerable to resource depletion from a SYN-flood attack which would open a huge number of dynamic rules. To counter this attack, FreeBSD added another new option named limit. This option is used to limit the number of simultaneous session conversations by interrogating the rules source or destinations fields as directed by the limit option and using the packet's IP address found there, in a search of the open dynamic rules counting the number of times this rule and IP address combination occurred, if this count is greater that the value specified on the limit option, the packet is discarded.
28.6.5.3 Logging Firewall Messages
The benefits of logging are obvious: it provides the ability to review after the fact the rules you activated logging on which provides information like, what packets had been dropped, what addresses they came from, where they were going, giving you a significant edge in tracking down attackers.
Even with the logging facility enabled, IPFW will not generate any rule logging on it's own. The firewall administrator decides what rules in the rule set he wants to log and adds the log verb to those rules. Normally only deny rules are logged, like the deny rule for incoming ICMP pings. It is very customary to duplicate the ipfw default deny everything rule with the log verb included as your last rule in the rule set. This way you get to see all the packets that did not match any of the rules in the rule set.
Logging is a two edged sword, if you are not careful, you can lose yourself in the over abundance of log data and fill your disk up with growing log files. DoS attacks that fill up disk drives is one of the oldest attacks around. These log message are not only written to syslogd, but also are displayed on the root console screen and soon become very annoying.
The IPFIREWALL_VERBOSE_LIMIT=5 kernel option limits the number of consecutive messages sent to the system logger syslogd, concerning the packet matching of a given rule. When this option is enabled in the kernel, the number of consecutive messages concerning a particular rule is capped at the number specified. There is nothing to be gained from 200 log messages saying the same identical thing. For instance, five consecutive messages concerning a particular rule would be logged to syslogd, the remainder identical consecutive messages would be counted and posted to the syslogd with a phrase like this:
last message repeated 45 times
All logged packets messages are written by default to /var/log/security file, which is defined in the /etc/syslog.conf file.
28.6.5.4 Building a Rule Script
Most experienced IPFW users create a file containing the rules and code them in a manner compatible with running them as a script. The major benefit of doing this is the firewall rules can be refreshed in mass without the need of rebooting the system to activate the new rules. This method is very convenient in testing new rules as the procedure can be executed as many times as needed. Being a script, you can use symbolic substitution to code frequent used values and substitution them in multiple rules. You will see this in the following example.
The script syntax used here is compatible with the 'sh', 'csh', 'tcsh' shells. Symbolic substitution fields are prefixed with a dollar sign $. Symbolic fields do not have the $ prefix. The value to populate the Symbolic field must be enclosed to "double quotes".
Start your rules file like this:
############### start of example ipfw rules script #############
#
ipfw -q -f flush # Delete all rules
# Set defaults
oif="tun0" # out interface
odns="192.0.2.11" # ISP's DNS server IP address
cmd="ipfw -q add " # build rule prefix
ks="keep-state" # just too lazy to key this each time
$cmd 00500 check-state
$cmd 00502 deny all from any to any frag
$cmd 00501 deny tcp from any to any established
$cmd 00600 allow tcp from any to any 80 out via $oif setup $ks
$cmd 00610 allow tcp from any to $odns 53 out via $oif setup $ks
$cmd 00611 allow udp from any to $odns 53 out via $oif $ks
################### End of example ipfw rules script ############
That is all there is to it. The rules are not important in this example, how the Symbolic substitution field are populated and used are.
If the above example was in /etc/ipfw.rules file, you could reload these rules by entering on the command line.
# sh /etc/ipfw.rules
The /etc/ipfw.rules file could be located anywhere you want and the file could be named any thing you would like.
The same thing could also be accomplished by running these commands by hand:
# ipfw -q -f flush
# ipfw -q add check-state
# ipfw -q add deny all from any to any frag
# ipfw -q add deny tcp from any to any established
# ipfw -q add allow tcp from any to any 80 out via tun0 setup keep-state
# ipfw -q add allow tcp from any to 192.0.2.11 53 out via tun0 setup keep-state
# ipfw -q add 00611 allow udp from any to 192.0.2.11 53 out via tun0 keep-state
28.6.5.5 Stateful Ruleset
The following non-NATed rule set is an example of how to code a very secure 'inclusive' type of firewall. An inclusive firewall only allows services matching pass rules through and blocks all other by default. All firewalls have at the minimum two interfaces which have to have rules to allow the firewall to function.
All UNIX flavored operating systems, FreeBSD included, are designed to use interface lo0 and IP address 127.0.0.1 for internal communication with in the operating system. The firewall rules must contain rules to allow free unmolested movement of these special internally used packets.
The interface which faces the public Internet, is the one which you code your rules to authorize and control access out to the public Internet and access requests arriving from the public Internet. This can be your ppp tun0 interface or your NIC that is connected to your DSL or cable modem.
In cases where one or more than one NIC are connected to a private LANs behind the firewall, those interfaces must have rules coded to allow free unmolested movement of packets originating from those LAN interfaces.
The rules should be first organized into three major sections, all the free unmolested interfaces, public interface outbound, and the public interface inbound.
The order of the rules in each of the public interface sections should be in order of the most used rules being placed before less often used rules with the last rule in the section being a block log all packets on that interface and direction.
The Outbound section in the following rule set only contains 'allow' rules which contain selection values that uniquely identify the service that is authorized for public Internet access. All the rules have the, proto, port, in/out, via and keep state option coded. The 'proto tcp' rules have the 'setup' option included to identify the start session request as the trigger packet to be posted to the keep state stateful table.
The Inbound section has all the blocking of undesirable packets first for two different reasons. First is these things being blocked may be part of an otherwise valid packet which may be allowed in by the later authorized service rules. Second reason is that by having a rule that explicitly blocks selected packets that I receive on an infrequent bases and do not want to see in the log, this keeps them from being caught by the last rule in the section which blocks and logs all packets which have fallen through the rules. The last rule in the section which blocks and logs all packets is how you create the legal evidence needed to prosecute the people who are attacking your system.
Another thing you should take note of, is there is no response returned for any of the undesirable stuff, their packets just get dropped and vanish. This way the attackers has no knowledge if his packets have reached your system. The less the attackers can learn about your system the more secure it is. When you log packets with port numbers you do not recognize, look the numbers up in /etc/services/ or go to http://www.securitystats.com/tools/portsearch.php and do a port number lookup to find what the purpose of that port number is. Check out this link for port numbers used by Trojans: http://www.simovits.com/trojans/trojans.html.
28.6.5.6 An Example Inclusive Ruleset
The following non-NATed rule set is a complete inclusive type ruleset. You can not go wrong using this rule set for you own. Just comment out any pass rules for services you do not want. If you see messages in your log that you want to stop seeing just add a deny rule in the inbound section. You have to change the 'dc0' interface name in every rule to the interface name of the NIC that connects your system to the public Internet. For user ppp it would be 'tun0'.
You will see a pattern in the usage of these rules.
-
All statements that are a request to start a session to the public Internet use keep-state.
-
All the authorized services that originate from the public Internet have the limit option to stop flooding.
-
All rules use in or out to clarify direction.
-
All rules use via interface name to specify the interface the packet is traveling over.
The following rules go into /etc/ipfw.rules.
################ Start of IPFW rules file ###############################
# Flush out the list before we begin.
ipfw -q -f flush
# Set rules command prefix
cmd="ipfw -q add"
pif="dc0" # public interface name of NIC
# facing the public Internet
#################################################################
# No restrictions on Inside LAN Interface for private network
# Not needed unless you have LAN.
# Change xl0 to your LAN NIC interface name
#################################################################
#$cmd 00005 allow all from any to any via xl0
#################################################################
# No restrictions on Loopback Interface
#################################################################
$cmd 00010 allow all from any to any via lo0
#################################################################
# Allow the packet through if it has previous been added to the
# the "dynamic" rules table by a allow keep-state statement.
#################################################################
$cmd 00015 check-state
#################################################################
# Interface facing Public Internet (Outbound Section)
# Interrogate session start requests originating from behind the
# firewall on the private network or from this gateway server
# destine for the public Internet.
#################################################################
# Allow out access to my ISP's Domain name server.
# x.x.x.x must be the IP address of your ISP.s DNS
# Dup these lines if your ISP has more than one DNS server
# Get the IP addresses from /etc/resolv.conf file
$cmd 00110 allow tcp from any to x.x.x.x 53 out via $pif setup keep-state
$cmd 00111 allow udp from any to x.x.x.x 53 out via $pif keep-state
# Allow out access to my ISP's DHCP server for cable/DSL configurations.
# This rule is not needed for .user ppp. connection to the public Internet.
# so you can delete this whole group.
# Use the following rule and check log for IP address.
# Then put IP address in commented out rule & delete first rule
$cmd 00120 allow log udp from any to any 67 out via $pif keep-state
#$cmd 00120 allow udp from any to x.x.x.x 67 out via $pif keep-state
# Allow out non-secure standard www function
$cmd 00200 allow tcp from any to any 80 out via $pif setup keep-state
# Allow out secure www function https over TLS SSL
$cmd 00220 allow tcp from any to any 443 out via $pif setup keep-state
# Allow out send & get email function
$cmd 00230 allow tcp from any to any 25 out via $pif setup keep-state
$cmd 00231 allow tcp from any to any 110 out via $pif setup keep-state
# Allow out FBSD (make install & CVSUP) functions
# Basically give user root "GOD" privileges.
$cmd 00240 allow tcp from me to any out via $pif setup keep-state uid root
# Allow out ping
$cmd 00250 allow icmp from any to any out via $pif keep-state
# Allow out Time
$cmd 00260 allow tcp from any to any 37 out via $pif setup keep-state
# Allow out nntp news (i.e. news groups)
$cmd 00270 allow tcp from any to any 119 out via $pif setup keep-state
# Allow out secure FTP, Telnet, and SCP
# This function is using SSH (secure shell)
$cmd 00280 allow tcp from any to any 22 out via $pif setup keep-state
# Allow out whois
$cmd 00290 allow tcp from any to any 43 out via $pif setup keep-state
# deny and log everything else that.s trying to get out.
# This rule enforces the block all by default logic.
$cmd 00299 deny log all from any to any out via $pif
#################################################################
# Interface facing Public Internet (Inbound Section)
# Interrogate packets originating from the public Internet
# destine for this gateway server or the private network.
#################################################################
# Deny all inbound traffic from non-routable reserved address spaces
$cmd 00300 deny all from 192.168.0.0/16 to any in via $pif #RFC 1918 private IP
$cmd 00301 deny all from 172.16.0.0/12 to any in via $pif #RFC 1918 private IP
$cmd 00302 deny all from 10.0.0.0/8 to any in via $pif #RFC 1918 private IP
$cmd 00303 deny all from 127.0.0.0/8 to any in via $pif #loopback
$cmd 00304 deny all from 0.0.0.0/8 to any in via $pif #loopback
$cmd 00305 deny all from 169.254.0.0/16 to any in via $pif #DHCP auto-config
$cmd 00306 deny all from 192.0.2.0/24 to any in via $pif #reserved for docs
$cmd 00307 deny all from 204.152.64.0/23 to any in via $pif #Sun cluster interconnect
$cmd 00308 deny all from 224.0.0.0/3 to any in via $pif #Class D & E multicast
# Deny public pings
$cmd 00310 deny icmp from any to any in via $pif
# Deny ident
$cmd 00315 deny tcp from any to any 113 in via $pif
# Deny all Netbios service. 137=name, 138=datagram, 139=session
# Netbios is MS/Windows sharing services.
# Block MS/Windows hosts2 name server requests 81
$cmd 00320 deny tcp from any to any 137 in via $pif
$cmd 00321 deny tcp from any to any 138 in via $pif
$cmd 00322 deny tcp from any to any 139 in via $pif
$cmd 00323 deny tcp from any to any 81 in via $pif
# Deny any late arriving packets
$cmd 00330 deny all from any to any frag in via $pif
# Deny ACK packets that did not match the dynamic rule table
$cmd 00332 deny tcp from any to any established in via $pif
# Allow traffic in from ISP's DHCP server. This rule must contain
# the IP address of your ISP.s DHCP server as it.s the only
# authorized source to send this packet type.
# Only necessary for cable or DSL configurations.
# This rule is not needed for .user ppp. type connection to
# the public Internet. This is the same IP address you captured
# and used in the outbound section.
#$cmd 00360 allow udp from any to x.x.x.x 67 in via $pif keep-state
# Allow in standard www function because I have apache server
$cmd 00400 allow tcp from any to me 80 in via $pif setup limit src-addr 2
# Allow in secure FTP, Telnet, and SCP from public Internet
$cmd 00410 allow tcp from any to me 22 in via $pif setup limit src-addr 2
# Allow in non-secure Telnet session from public Internet
# labeled non-secure because ID & PW are passed over public
# Internet as clear text.
# Delete this sample group if you do not have telnet server enabled.
$cmd 00420 allow tcp from any to me 23 in via $pif setup limit src-addr 2
# Reject & Log all incoming connections from the outside
$cmd 00499 deny log all from any to any in via $pif
# Everything else is denied by default
# deny and log all packets that fell through to see what they are
$cmd 00999 deny log all from any to any
################ End of IPFW rules file ###############################
28.6.5.7 An Example NAT and Stateful Ruleset
There are some additional configuration statements that need to be enabled to activate the NAT function of IPFW. The kernel source needs 'option divert' statement added to the other IPFIREWALL statements compiled into a custom kernel.
In addition to the normal IPFW options in /etc/rc.conf, the following are needed.
natd_enable="YES" # Enable NATD function
natd_interface="rl0" # interface name of public Internet NIC
natd_flags="-dynamic -m" # -m = preserve port numbers if possible
Utilizing stateful rules with divert natd rule (Network Address Translation) greatly complicates the rule set coding logic. The positioning of the check-state, and 'divert natd' rules in the rule set becomes very critical. This is no longer a simple fall-through logic flow. A new action type is used, called 'skipto'. To use the skipto command it is mandatory that you number each rule so you know exactly where the skipto rule number is you are really jumping to.
The following is an uncommented example of one coding method, selected here to explain the sequence of the packet flow through the rule sets.
The processing flow starts with the first rule from the top of the rule file and progress one rule at a time deeper into the file until the end is reach or the packet being tested to the selection criteria matches and the packet is released out of the firewall. It is important to take notice of the location of rule numbers 100 101, 450, 500, and 510. These rules control the translation of the outbound and inbound packets so their entries in the keep-state dynamic table always register the private LAN IP address. Next notice that all the allow and deny rules specified the direction the packet is going (IE outbound or inbound) and the interface. Also notice that all the start outbound session requests all skipto rule 500 for the network address translation.
Lets say a LAN user uses their web browser to get a web page. Web pages use port 80 to communicate over. So the packet enters the firewall, It does not match 100 because it is headed out not in. It passes rule 101 because this is the first packet so it has not been posted to the keep-state dynamic table yet. The packet finally comes to rule 125 a matches. It is outbound through the NIC facing the public Internet. The packet still has it's source IP address as a private LAN IP address. On the match to this rule, two actions take place. The keep-state option will post this rule into the keep-state dynamic rules table and the specified action is executed. The action is part of the info posted to the dynamic table. In this case it is "skipto rule 500". Rule 500 NATs the packet IP address and out it goes. Remember this, this is very important. This packet makes its way to the destination and returns and enters the top of the rule set. This time it does match rule 100 and has it destination IP address mapped back to its corresponding LAN IP address. It then is processed by the check-state rule, it's found in the table as an existing session conversation and released to the LAN. It goes to the LAN PC that sent it and a new packet is sent requesting another segment of the data from the remote server. This time it gets checked by the check-state rule and its outbound entry is found, the associated action, 'skipto 500', is executed. The packet jumps to rule 500 gets NATed and released on it's way out.
On the inbound side, everything coming in that is part of an existing session conversation is being automatically handled by the check-state rule and the properly placed divert natd rules. All we have to address is denying all the bad packets and only allowing in the authorized services. Lets say there is a apache server running on the firewall box and we want people on the public Internet to be able to access the local web site. The new inbound start request packet matches rule 100 and its IP address is mapped to LAN IP for the firewall box. The packet is them matched against all the nasty things we want to check for and finally matches against rule 425. On a match two things occur. The packet rule is posted to the keep-state dynamic table but this time any new session requests originating from that source IP address is limited to 2. This defends against DoS attacks of service running on the specified port number. The action is allow so the packet is released to the LAN. On return the check-state rule recognizes the packet as belonging to an existing session conversation sends it to rule 500 for NATing and released to outbound interface.
Example Ruleset #1:
#!/bin/sh
cmd="ipfw -q add"
skip="skipto 500"
pif=rl0
ks="keep-state"
good_tcpo="22,25,37,43,53,80,443,110,119"
ipfw -q -f flush
$cmd 002 allow all from any to any via xl0 # exclude LAN traffic
$cmd 003 allow all from any to any via lo0 # exclude loopback traffic
$cmd 100 divert natd ip from any to any in via $pif
$cmd 101 check-state
# Authorized outbound packets
$cmd 120 $skip udp from any to xx.168.240.2 53 out via $pif $ks
$cmd 121 $skip udp from any to xx.168.240.5 53 out via $pif $ks
$cmd 125 $skip tcp from any to any $good_tcpo out via $pif setup $ks
$cmd 130 $skip icmp from any to any out via $pif $ks
$cmd 135 $skip udp from any to any 123 out via $pif $ks
# Deny all inbound traffic from non-routable reserved address spaces
$cmd 300 deny all from 192.168.0.0/16 to any in via $pif #RFC 1918 private IP
$cmd 301 deny all from 172.16.0.0/12 to any in via $pif #RFC 1918 private IP
$cmd 302 deny all from 10.0.0.0/8 to any in via $pif #RFC 1918 private IP
$cmd 303 deny all from 127.0.0.0/8 to any in via $pif #loopback
$cmd 304 deny all from 0.0.0.0/8 to any in via $pif #loopback
$cmd 305 deny all from 169.254.0.0/16 to any in via $pif #DHCP auto-config
$cmd 306 deny all from 192.0.2.0/24 to any in via $pif #reserved for docs
$cmd 307 deny all from 204.152.64.0/23 to any in via $pif #Sun cluster
$cmd 308 deny all from 224.0.0.0/3 to any in via $pif #Class D & E multicast
# Authorized inbound packets
$cmd 400 allow udp from xx.70.207.54 to any 68 in $ks
$cmd 420 allow tcp from any to me 80 in via $pif setup limit src-addr 1
$cmd 450 deny log ip from any to any
# This is skipto location for outbound stateful rules
$cmd 500 divert natd ip from any to any out via $pif
$cmd 510 allow ip from any to any
######################## end of rules ##################
The following is pretty much the same as above, but uses a self documenting coding style full of description comments to help the inexperienced IPFW rule writer to better understand what the rules are doing.
Example Ruleset #2:
#!/bin/sh
################ Start of IPFW rules file ###############################
# Flush out the list before we begin.
ipfw -q -f flush
# Set rules command prefix
cmd="ipfw -q add"
skip="skipto 800"
pif="rl0" # public interface name of NIC
# facing the public Internet
#################################################################
# No restrictions on Inside LAN Interface for private network
# Change xl0 to your LAN NIC interface name
#################################################################
$cmd 005 allow all from any to any via xl0
#################################################################
# No restrictions on Loopback Interface
#################################################################
$cmd 010 allow all from any to any via lo0
#################################################################
# check if packet is inbound and nat address if it is
#################################################################
$cmd 014 divert natd ip from any to any in via $pif
#################################################################
# Allow the packet through if it has previous been added to the
# the "dynamic" rules table by a allow keep-state statement.
#################################################################
$cmd 015 check-state
#################################################################
# Interface facing Public Internet (Outbound Section)
# Interrogate session start requests originating from behind the
# firewall on the private network or from this gateway server
# destine for the public Internet.
#################################################################
# Allow out access to my ISP's Domain name server.
# x.x.x.x must be the IP address of your ISP's DNS
# Dup these lines if your ISP has more than one DNS server
# Get the IP addresses from /etc/resolv.conf file
$cmd 020 $skip tcp from any to x.x.x.x 53 out via $pif setup keep-state
# Allow out access to my ISP's DHCP server for cable/DSL configurations.
$cmd 030 $skip udp from any to x.x.x.x 67 out via $pif keep-state
# Allow out non-secure standard www function
$cmd 040 $skip tcp from any to any 80 out via $pif setup keep-state
# Allow out secure www function https over TLS SSL
$cmd 050 $skip tcp from any to any 443 out via $pif setup keep-state
# Allow out send & get email function
$cmd 060 $skip tcp from any to any 25 out via $pif setup keep-state
$cmd 061 $skip tcp from any to any 110 out via $pif setup keep-state
# Allow out FreeBSD (make install & CVSUP) functions
# Basically give user root "GOD" privileges.
$cmd 070 $skip tcp from me to any out via $pif setup keep-state uid root
# Allow out ping
$cmd 080 $skip icmp from any to any out via $pif keep-state
# Allow out Time
$cmd 090 $skip tcp from any to any 37 out via $pif setup keep-state
# Allow out nntp news (i.e. news groups)
$cmd 100 $skip tcp from any to any 119 out via $pif setup keep-state
# Allow out secure FTP, Telnet, and SCP
# This function is using SSH (secure shell)
$cmd 110 $skip tcp from any to any 22 out via $pif setup keep-state
# Allow out whois
$cmd 120 $skip tcp from any to any 43 out via $pif setup keep-state
# Allow ntp time server
$cmd 130 $skip udp from any to any 123 out via $pif keep-state
#################################################################
# Interface facing Public Internet (Inbound Section)
# Interrogate packets originating from the public Internet
# destine for this gateway server or the private network.
#################################################################
# Deny all inbound traffic from non-routable reserved address spaces
$cmd 300 deny all from 192.168.0.0/16 to any in via $pif #RFC 1918 private IP
$cmd 301 deny all from 172.16.0.0/12 to any in via $pif #RFC 1918 private IP
$cmd 302 deny all from 10.0.0.0/8 to any in via $pif #RFC 1918 private IP
$cmd 303 deny all from 127.0.0.0/8 to any in via $pif #loopback
$cmd 304 deny all from 0.0.0.0/8 to any in via $pif #loopback
$cmd 305 deny all from 169.254.0.0/16 to any in via $pif #DHCP auto-config
$cmd 306 deny all from 192.0.2.0/24 to any in via $pif #reserved for docs
$cmd 307 deny all from 204.152.64.0/23 to any in via $pif #Sun cluster
$cmd 308 deny all from 224.0.0.0/3 to any in via $pif #Class D & E multicast
# Deny ident
$cmd 315 deny tcp from any to any 113 in via $pif
# Deny all Netbios service. 137=name, 138=datagram, 139=session
# Netbios is MS/Windows sharing services.
# Block MS/Windows hosts2 name server requests 81
$cmd 320 deny tcp from any to any 137 in via $pif
$cmd 321 deny tcp from any to any 138 in via $pif
$cmd 322 deny tcp from any to any 139 in via $pif
$cmd 323 deny tcp from any to any 81 in via $pif
# Deny any late arriving packets
$cmd 330 deny all from any to any frag in via $pif
# Deny ACK packets that did not match the dynamic rule table
$cmd 332 deny tcp from any to any established in via $pif
# Allow traffic in from ISP's DHCP server. This rule must contain
# the IP address of your ISP's DHCP server as it's the only
# authorized source to send this packet type.
# Only necessary for cable or DSL configurations.
# This rule is not needed for 'user ppp' type connection to
# the public Internet. This is the same IP address you captured
# and used in the outbound section.
$cmd 360 allow udp from x.x.x.x to any 68 in via $pif keep-state
# Allow in standard www function because I have Apache server
$cmd 370 allow tcp from any to me 80 in via $pif setup limit src-addr 2
# Allow in secure FTP, Telnet, and SCP from public Internet
$cmd 380 allow tcp from any to me 22 in via $pif setup limit src-addr 2
# Allow in non-secure Telnet session from public Internet
# labeled non-secure because ID & PW are passed over public
# Internet as clear text.
# Delete this sample group if you do not have telnet server enabled.
$cmd 390 allow tcp from any to me 23 in via $pif setup limit src-addr 2
# Reject & Log all unauthorized incoming connections from the public Internet
$cmd 400 deny log all from any to any in via $pif
# Reject & Log all unauthorized out going connections to the public Internet
$cmd 450 deny log all from any to any out via $pif
# This is skipto location for outbound stateful rules
$cmd 800 divert natd ip from any to any out via $pif
$cmd 801 allow ip from any to any
# Everything else is denied by default
# deny and log all packets that fell through to see what they are
$cmd 999 deny log all from any to any
################ End of IPFW rules file ###############################
Chapter 29 Advanced Networking
29.1 Synopsis
This chapter will cover a number of advanced networking topics.
After reading this chapter, you will know:
-
The basics of gateways and routes.
-
How to set up IEEE 802.11 and Bluetooth devices.
-
How to make FreeBSD act as a bridge.
-
How to set up network booting on a diskless machine.
-
How to set up network address translation.
-
How to connect two computers via PLIP.
-
How to set up IPv6 on a FreeBSD machine.
-
How to configure ATM.
-
How to enable and utilize the features of CARP, the Common Access Redundancy Protocol in FreeBSD
Before reading this chapter, you should:
29.2 Gateways and Routes
Contributed by Coranth Gryphon.For one machine to be able to find another over a network, there must be a mechanism in place to describe how to get from one to the other. This is called routing. A “route” is a defined pair of addresses: a “destination” and a “gateway”. The pair indicates that if you are trying to get to this destination, communicate through this gateway. There are three types of destinations: individual hosts, subnets, and “default”. The “default route” is used if none of the other routes apply. We will talk a little bit more about default routes later on. There are also three types of gateways: individual hosts, interfaces (also called “links”), and Ethernet hardware addresses (MAC addresses).
29.2.1 An Example
To illustrate different aspects of routing, we will use the following example from netstat:
% netstat -r
Routing tables
Destination Gateway Flags Refs Use Netif Expire
default outside-gw UGSc 37 418 ppp0
localhost localhost UH 0 181 lo0
test0 0:e0:b5:36:cf:4f UHLW 5 63288 ed0 77
10.20.30.255 link#1 UHLW 1 2421
example.com link#1 UC 0 0
host1 0:e0:a8:37:8:1e UHLW 3 4601 lo0
host2 0:e0:a8:37:8:1e UHLW 0 5 lo0 =>
host2.example.com link#1 UC 0 0
224 link#1 UC 0 0
The first two lines specify the default route (which we will cover in the next section) and the localhost route.
The interface (Netif column) that this routing table specifies to use for localhost is lo0, also known as the loopback device. This says to keep all traffic for this destination internal, rather than sending it out over the LAN, since it will only end up back where it started.
The next thing that stands out are the addresses beginning with 0:e0:. These are Ethernet hardware addresses, which are also known as MAC addresses. FreeBSD will automatically identify any hosts (test0 in the example) on the local Ethernet and add a route for that host, directly to it over the Ethernet interface, ed0. There is also a timeout (Expire column) associated with this type of route, which is used if we fail to hear from the host in a specific amount of time. When this happens, the route to this host will be automatically deleted. These hosts are identified using a mechanism known as RIP (Routing Information Protocol), which figures out routes to local hosts based upon a shortest path determination.
FreeBSD will also add subnet routes for the local subnet (10.20.30.255 is the broadcast address for the subnet 10.20.30, and example.com is the domain name associated with that subnet). The designation link#1 refers to the first Ethernet card in the machine. You will notice no additional interface is specified for those.
Both of these groups (local network hosts and local subnets) have their routes automatically configured by a daemon called routed. If this is not run, then only routes which are statically defined (i.e. entered explicitly) will exist.
The host1 line refers to our host, which it knows by Ethernet address. Since we are the sending host, FreeBSD knows to use the loopback interface (lo0) rather than sending it out over the Ethernet interface.
The two host2 lines are an example of what happens when we use an ifconfig(8) alias (see the section on Ethernet for reasons why we would do this). The => symbol after the lo0 interface says that not only are we using the loopback (since this address also refers to the local host), but specifically it is an alias. Such routes only show up on the host that supports the alias; all other hosts on the local network will simply have a link#1 line for such routes.
The final line (destination subnet 224) deals with multicasting, which will be covered in another section.
Finally, various attributes of each route can be seen in the Flags column. Below is a short table of some of these flags and their meanings:
| U | Up: The route is active. |
| H | Host: The route destination is a single host. |
| G | Gateway: Send anything for this destination on to this remote system, which will figure out from there where to send it. |
| S | Static: This route was configured manually, not automatically generated by the system. |
| C | Clone: Generates a new route based upon this route for machines we connect to. This type of route is normally used for local networks. |
| W | WasCloned: Indicated a route that was auto-configured based upon a local area network (Clone) route. |
| L | Link: Route involves references to Ethernet hardware. |
29.2.2 Default Routes
When the local system needs to make a connection to a remote host, it checks the routing table to determine if a known path exists. If the remote host falls into a subnet that we know how to reach (Cloned routes), then the system checks to see if it can connect along that interface.
If all known paths fail, the system has one last option: the “default” route. This route is a special type of gateway route (usually the only one present in the system), and is always marked with a c in the flags field. For hosts on a local area network, this gateway is set to whatever machine has a direct connection to the outside world (whether via PPP link, DSL, cable modem, T1, or another network interface).
If you are configuring the default route for a machine which itself is functioning as the gateway to the outside world, then the default route will be the gateway machine at your Internet Service Provider's (ISP) site.
Let us look at an example of default routes. This is a common configuration:

The hosts Local1 and Local2 are at your site. Local1 is connected to an ISP via a dial up PPP connection. This PPP server computer is connected through a local area network to another gateway computer through an external interface to the ISPs Internet feed.
The default routes for each of your machines will be:
A common question is “Why (or how) would we set the T1-GW to be the default gateway for Local1, rather than the ISP server it is connected to?”.
Remember, since the PPP interface is using an address on the ISP's local network for your side of the connection, routes for any other machines on the ISP's local network will be automatically generated. Hence, you will already know how to reach the T1-GW machine, so there is no need for the intermediate step of sending traffic to the ISP server.
It is common to use the address X.X.X.1 as the gateway address for your local network. So (using the same example), if your local class-C address space was 10.20.30 and your ISP was using 10.9.9 then the default routes would be:
| Host | Default Route |
|---|---|
| Local2 (10.20.30.2) | Local1 (10.20.30.1) |
| Local1 (10.20.30.1, 10.9.9.30) | T1-GW (10.9.9.1) |
You can easily define the default route via the /etc/rc.conf file. In our example, on the Local2 machine, we added the following line in /etc/rc.conf:
defaultrouter="10.20.30.1"
It is also possible to do it directly from the command line with the route(8) command:
# route add default 10.20.30.1
For more information on manual manipulation of network routing tables, consult route(8) manual page.
29.2.3 Dual Homed Hosts
There is one other type of configuration that we should cover, and that is a host that sits on two different networks. Technically, any machine functioning as a gateway (in the example above, using a PPP connection) counts as a dual-homed host. But the term is really only used to refer to a machine that sits on two local-area networks.
In one case, the machine has two Ethernet cards, each having an address on the separate subnets. Alternately, the machine may only have one Ethernet card, and be using ifconfig(8) aliasing. The former is used if two physically separate Ethernet networks are in use, the latter if there is one physical network segment, but two logically separate subnets.
Either way, routing tables are set up so that each subnet knows that this machine is the defined gateway (inbound route) to the other subnet. This configuration, with the machine acting as a router between the two subnets, is often used when we need to implement packet filtering or firewall security in either or both directions.
If you want this machine to actually forward packets between the two interfaces, you need to tell FreeBSD to enable this ability. See the next section for more details on how to do this.
29.2.4 Building a Router
A network router is simply a system that forwards packets from one interface to another. Internet standards and good engineering practice prevent the FreeBSD Project from enabling this by default in FreeBSD. You can enable this feature by changing the following variable to YES in rc.conf(5):
gateway_enable=YES # Set to YES if this host will be a gateway
This option will set the sysctl(8) variable
net.inet.ip.forwarding to 1. If you
should need to stop routing temporarily, you can reset this to 0
temporarily.
Your new router will need routes to know where to send the traffic. If your network is simple enough you can use static routes. FreeBSD also comes with the standard BSD routing daemon routed(8), which speaks RIP (both version 1 and version 2) and IRDP. Support for BGP v4, OSPF v2, and other sophisticated routing protocols is available with the net/zebra package. Commercial products such as GateD are also available for more complex network routing solutions.
29.2.5 Setting Up Static Routes
Contributed by Al Hoang.29.2.5.1 Manual Configuration
Let us assume we have a network as follows:
In this scenario, RouterA is our FreeBSD machine that is acting as a router to the rest of the Internet. It has a default route set to 10.0.0.1 which allows it to connect with the outside world. We will assume that RouterB is already configured properly and knows how to get wherever it needs to go. (This is simple in this picture. Just add a default route on RouterB using 192.168.1.1 as the gateway.)
If we look at the routing table for RouterA we would see something like the following:
% netstat -nr
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default 10.0.0.1 UGS 0 49378 xl0
127.0.0.1 127.0.0.1 UH 0 6 lo0
10.0.0/24 link#1 UC 0 0 xl0
192.168.1/24 link#2 UC 0 0 xl1
With the current routing table RouterA will not be able to reach our Internal Net 2. It does not have a route for 192.168.2.0/24. One way to alleviate this is to manually add the route. The following command would add the Internal Net 2 network to RouterA's routing table using 192.168.1.2 as the next hop:
# route add -net 192.168.2.0/24 192.168.1.2
Now RouterA can reach any hosts on the 192.168.2.0/24 network.
29.2.5.2 Persistent Configuration
The above example is perfect for configuring a static route on a running system. However, one problem is that the routing information will not persist if you reboot your FreeBSD machine. The way to handle the addition of a static route is to put it in your /etc/rc.conf file:
# Add Internal Net 2 as a static route
static_routes="internalnet2"
route_internalnet2="-net 192.168.2.0/24 192.168.1.2"
The static_routes configuration variable is a list of strings separated by a space. Each string references to a route name. In our above example we only have one string in static_routes. This string is internalnet2. We then add a configuration variable called route_internalnet2 where we put all of the configuration parameters we would give to the route(8) command. For our example above we would have used the command:
# route add -net 192.168.2.0/24 192.168.1.2
so we need "-net 192.168.2.0/24 192.168.1.2".
As said above, we can have more than one string in static_routes. This allows us to create multiple static routes. The following lines shows an example of adding static routes for the 192.168.0.0/24 and 192.168.1.0/24 networks on an imaginary router:
static_routes="net1 net2"
route_net1="-net 192.168.0.0/24 192.168.0.1"
route_net2="-net 192.168.1.0/24 192.168.1.1"
29.2.6 Routing Propagation
We have already talked about how we define our routes to the outside world, but not about how the outside world finds us.
We already know that routing tables can be set up so that all traffic for a particular address space (in our examples, a class-C subnet) can be sent to a particular host on that network, which will forward the packets inbound.
When you get an address space assigned to your site, your service provider will set up their routing tables so that all traffic for your subnet will be sent down your PPP link to your site. But how do sites across the country know to send to your ISP?
There is a system (much like the distributed DNS information) that keeps track of all assigned address-spaces, and defines their point of connection to the Internet Backbone. The “Backbone” are the main trunk lines that carry Internet traffic across the country, and around the world. Each backbone machine has a copy of a master set of tables, which direct traffic for a particular network to a specific backbone carrier, and from there down the chain of service providers until it reaches your network.
It is the task of your service provider to advertise to the backbone sites that they are the point of connection (and thus the path inward) for your site. This is known as route propagation.
29.2.7 Troubleshooting
Sometimes, there is a problem with routing propagation, and some sites are unable to connect to you. Perhaps the most useful command for trying to figure out where routing is breaking down is the traceroute(8) command. It is equally useful if you cannot seem to make a connection to a remote machine (i.e. ping(8) fails).
The traceroute(8) command is run with the name of the remote host you are trying to connect to. It will show the gateway hosts along the path of the attempt, eventually either reaching the target host, or terminating because of a lack of connection.
For more information, see the manual page for traceroute(8).
29.2.8 Multicast Routing
FreeBSD supports both multicast applications and multicast routing natively. Multicast applications do not require any special configuration of FreeBSD; applications will generally run out of the box. Multicast routing requires that support be compiled into the kernel:
options MROUTING
In addition, the multicast routing daemon, mrouted(8) must be configured to set up tunnels and DVMRP via /etc/mrouted.conf. More details on multicast configuration may be found in the manual page for mrouted(8).
29.3 Wireless Networking
Loader, Marc Fonvieille, and Murray Stokely.29.3.1 Wireless Networking Basics
Most wireless networks are based on the IEEE 802.11 standards. A basic wireless network consists of multiple stations communicating with radios that broadcast in either the 2.4GHz or 5GHz band (though this varies according to the locale and is also changing to enable communication in the 2.3GHz and 4.9GHz ranges).
802.11 networks are organized in two ways: in infrastructure mode one station acts as a master with all the other stations associating to it; the network is known as a BSS and the master station is termed an access point (AP). In a BSS all communication passes through the AP; even when one station wants to communicate with another wireless station messages must go through the AP. In the second form of network there is no master and stations communicate directly. This form of network is termed an IBSS and is commonly known as an ad-hoc network.
802.11 networks were first deployed in the 2.4GHz band using protocols defined by the IEEE 802.11 and 802.11b standard. These specifications include the operating frequencies, MAC layer characteristics including framing and transmission rates (communication can be done at various rates). Later the 802.11a standard defined operation in the 5GHz band, including different signalling mechanisms and higher transmission rates. Still later the 802.11g standard was defined to enable use of 802.11a signalling and transmission mechanisms in the 2.4GHz band in such a way as to be backwards compatible with 802.11b networks.
Separate from the underlying transmission techniques 802.11 networks have a variety of security mechanisms. The original 802.11 specifications defined a simple security protocol called WEP. This protocol uses a fixed pre-shared key and the RC4 cryptographic cipher to encode data transmitted on a network. Stations must all agree on the fixed key in order to communicate. This scheme was shown to be easily broken and is now rarely used except to discourage transient users from joining networks. Current security practice is given by the IEEE 802.11i specification that defines new cryptographic ciphers and an additional protocol to authenticate stations to an access point and exchange keys for doing data communication. Further, cryptographic keys are periodically refreshed and there are mechanisms for detecting intrusion attempts (and for countering intrusion attempts). Another security protocol specification commonly used in wireless networks is termed WPA. This was a precursor to 802.11i defined by an industry group as an interim measure while waiting for 802.11i to be ratified. WPA specifies a subset of the requirements found in 802.11i and is designed for implementation on legacy hardware. Specifically WPA requires only the TKIP cipher that is derived from the original WEP cipher. 802.11i permits use of TKIP but also requires support for a stronger cipher, AES-CCM, for encrypting data. (The AES cipher was not required in WPA because it was deemed too computationally costly to be implemented on legacy hardware.)
Other than the above protocol standards the other important standard to be aware of is 802.11e. This defines protocols for deploying multi-media applications such as streaming video and voice over IP (VoIP) in an 802.11 network. Like 802.11i, 802.11e also has a precursor specification termed WME (later renamed WMM) that has been defined by an industry group as a subset of 802.11e that can be deployed now to enable multi-media applications while waiting for the final ratification of 802.11e. The most important thing to know about 802.11e and WME/WMM is that it enables prioritized traffic use of a wireless network through Quality of Service (QoS) protocols and enhanced media access protocols. Proper implementation of these protocols enable high speed bursting of data and prioritized traffic flow.
Since the 6.0 version, FreeBSD supports networks that operate using 802.11a, 802.11b, and 802.11g. The WPA and 802.11i security protocols are likewise supported (in conjunction with any of 11a, 11b, and 11g) and QoS and traffic prioritization required by the WME/WMM protocols are supported for a limited set of wireless devices.
29.3.2 Basic Setup
29.3.2.1 Kernel Configuration
To use wireless networking you need a wireless networking card and to configure the kernel with the appropriate wireless networking support. The latter is separated into multiple modules so that you only need to configure the software you are actually going to use.
The first thing you need is a wireless device. The most commonly used devices are those that use parts made by Atheros. These devices are supported by the ath(4) driver and require the following line to be added to the /boot/loader.conf file:
if_ath_load="YES"
The Atheros driver is split up into three separate pieces: the driver proper (ath(4)), the hardware support layer that handles chip-specific functions (ath_hal(4)), and an algorithm for selecting which of several possible rates for transmitting frames (ath_rate_sample here). When you load this support as modules these dependencies are automatically handled for you. If instead of an Atheros device you had another device you would select the module for that device; e.g.:
if_wi_load="YES"
for devices based on the Intersil Prism parts (wi(4) driver).
Note: In the rest of this document, we will use an ath(4) device, the device name in the examples must be changed according to your configuration. A list of available wireless drivers can be found at the beginning of the wlan(4) manual page. If a native FreeBSD driver for your wireless device does not exist, it may be possible to directly use the Windows driver with the help of the NDIS driver wrapper.
With a device driver configured you need to also bring in the 802.11 networking support required by the driver. For the ath(4) driver this is at least the wlan(4) module; this module is automatically loaded with the wireless device driver. With that you will need the modules that implement cryptographic support for the security protocols you intend to use. These are intended to be dynamically loaded on demand by the wlan(4) module but for now they must be manually configured. The following modules are available: wlan_wep(4), wlan_ccmp(4) and wlan_tkip(4). Both wlan_ccmp(4) and wlan_tkip(4) drivers are only needed if you intend to use the WPA and/or 802.11i security protocols. If your network is to run totally open (i.e., with no encryption) then you do not even need the wlan_wep(4) support. To load these modules at boot time, add the following lines to /boot/loader.conf:
wlan_wep_load="YES"
wlan_ccmp_load="YES"
wlan_tkip_load="YES"
With this information in the system bootstrap configuration file (i.e., /boot/loader.conf), you have to reboot your FreeBSD box. If you do not want to reboot your machine for the moment, you can just load the modules by hand using kldload(8).
Note: If you do not want to use modules, it is possible to compile these drivers into the kernel by adding the following lines to your kernel configuration file:
device ath # Atheros IEEE 802.11 wireless network driver device ath_hal # Atheros Hardware Access Layer device ath_rate_sample # John Bicket's SampleRate control algorithm. device wlan # 802.11 support (Required) device wlan_wep # WEP crypto support for 802.11 devices device wlan_ccmp # AES-CCMP crypto support for 802.11 devices device wlan_tkip # TKIP and Michael crypto support for 802.11 devicesWith this information in the kernel configuration file, recompile the kernel and reboot your FreeBSD machine.
When the system is up, we could find some information about the wireless device in the boot messages, like this:
ath0: <Atheros 5212> mem 0xff9f0000-0xff9fffff irq 17 at device 2.0 on pci2
ath0: Ethernet address: 00:11:95:d5:43:62
ath0: mac 7.9 phy 4.5 radio 5.6
29.3.3 Infrastructure Mode
The infrastructure mode or BSS mode is the mode that is typically used. In this mode, a number of wireless access points are connected to a wired network. Each wireless network has its own name, this name is called the SSID of the network. Wireless clients connect to the wireless access points.
29.3.3.1 FreeBSD Clients
29.3.3.1.1 How to Find Access Points
To scan for networks, use the ifconfig command. This request may take a few moments to complete as it requires that the system switches to each available wireless frequency and probes for available access points. Only the super-user can initiate such a scan:
# ifconfig ath0 up scan
SSID BSSID CHAN RATE S:N INT CAPS
dlinkap 00:13:46:49:41:76 6 54M 29:3 100 EPS WPA WME
freebsdap 00:11:95:c3:0d:ac 1 54M 22:1 100 EPS WPA
Note: You must mark the interface
upbefore you can scan. Subsequent scan requests do not require you to mark the interface up again.
The output of a scan request lists each BSS/IBSS network found. Beside the name of the network, SSID, we find the BSSID which is the MAC address of the access point. The CAPS field identifies the type of each network and the capabilities of the stations operating there:
- E
-
Extended Service Set (ESS). Indicates that the station is part of an infrastructure network (in contrast to an IBSS/ad-hoc network).
- I
-
IBSS/ad-hoc network. Indicates that the station is part of an ad-hoc network (in contrast to an ESS network).
- P
-
Privacy. Data confidentiality is required for all data frames exchanged within the BSS. This means that this BSS requires the station to use cryptographic means such as WEP, TKIP or AES-CCMP to encrypt/decrypt data frames being exchanged with others.
- S
-
Short Preamble. Indicates that the network is using short preambles (defined in 802.11b High Rate/DSSS PHY, short preamble utilizes a 56 bit sync field in contrast to a 128 bit field used in long preamble mode).
- s
-
Short slot time. Indicates that the 802.11g network is using a short slot time because there are no legacy (802.11b) stations present.
One can also display the current list of known networks with:
# ifconfig ath0 list scan
This information may be updated automatically by the adapter or manually with a scan request. Old data is automatically removed from the cache, so
over time this list may shrink unless more scans are done.
29.3.3.1.2 Basic Settings
This section provides a simple example of how to make the wireless network adapter work in FreeBSD without encryption. After you are familiar with these concepts, we strongly recommend using WPA to set up your wireless network.
There are three basic steps to configure a wireless network: selecting an access point, authenticating your station, and configuring an IP address. The following sections discuss each step.
29.3.3.1.2.1 Selecting an Access Point
Most of time it is sufficient to let the system choose an access point using the builtin heuristics. This is the default behaviour when you mark an interface up or otherwise configure an interface by listing it in /etc/rc.conf, e.g.:
ifconfig_ath0="DHCP"
If there are multiple access points and you want to select a specific one, you can select it by its SSID:
ifconfig_ath0="ssid your_ssid_here DHCP"
In an environment where there are multiple access points with the same SSID (often done to simplify roaming) it may be necessary to associate to one specific device. In this case you can also specify the BSSID of the access point (you can also leave off the SSID):
ifconfig_ath0="ssid your_ssid_here bssid xx:xx:xx:xx:xx:xx DHCP"
There are other ways to constrain the choice of an access point such as limiting the
set of frequencies the system will scan on. This may be useful if you have a multi-band
wireless card as scanning all the possible channels can be time-consuming. To limit
operation to a specific band you can use the mode parameter;
e.g.:
ifconfig_ath0="mode 11g ssid your_ssid_here DHCP"
will force the card to operate in 802.11g which is defined only for 2.4GHz frequencies
so any 5GHz channels will not be considered. Other ways to do this are the channel parameter, to lock operation to one specific frequency, and
the chanlist parameter, to specify a list of channels for
scanning. More information about these parameters can be found in the ifconfig(8) manual
page.
29.3.3.1.2.2 Authentication
Once you have selected an access point your station needs to authenticate before it can pass data. Authentication can happen in several ways. The most common scheme used is termed open authentication and allows any station to join the network and communicate. This is the authentication you should use for test purpose the first time you set up a wireless network. Other schemes require cryptographic handshakes be completed before data traffic can flow; either using pre-shared keys or secrets, or more complex schemes that involve backend services such as RADIUS. Most users will use open authentication which is the default setting. Next most common setup is WPA-PSK, also known as WPA Personal, which is described below.
Note: If you have an Apple AirPort® Extreme base station for an access point you may need to configure shared-key authentication together with a WEP key. This can be done in the /etc/rc.conf file or using the wpa_supplicant(8) program. If you have a single AirPort base station you can setup access with something like:
ifconfig_ath0="authmode shared wepmode on weptxkey 1 wepkey 01234567 DHCP"In general shared key authentication is to be avoided because it uses the WEP key material in a highly-constrained manner making it even easier to crack the key. If WEP must be used (e.g., for compatibility with legacy devices) it is better to use WEP with open authentication. More information regarding WEP can be found in the Section 29.3.3.1.4.
29.3.3.1.2.3 Getting an IP Address with DHCP
Once you have selected an access point and set the authentication parameters, you will have to get an IP address to communicate. Most of time you will obtain your wireless IP address via DHCP. To achieve that, simply edit /etc/rc.conf and add DHCP to the configuration for your device as shown in various examples above:
ifconfig_ath0="DHCP"
At this point, you are ready to bring up the wireless interface:
# /etc/rc.d/netif start
Once the interface is running, use ifconfig to see the status of the interface ath0:
# ifconfig ath0
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::211:95ff:fed5:4362%ath0 prefixlen 64 scopeid 0x1
inet 192.168.1.100 netmask 0xffffff00 broadcast 192.168.1.255
ether 00:11:95:d5:43:62
media: IEEE 802.11 Wireless Ethernet autoselect (OFDM/54Mbps)
status: associated
ssid dlinkap channel 6 bssid 00:13:46:49:41:76
authmode OPEN privacy OFF txpowmax 36 protmode CTS bintval 100
The status: associated means you are connected to the wireless network (to the dlinkap network in our case). The bssid 00:13:46:49:41:76 part is the MAC address of your access point; the authmode line informs you that the communication is not encrypted (OPEN).
29.3.3.1.2.4 Static IP Address
In the case you cannot obtain an IP address from a DHCP server, you can set a fixed IP address. Replace the DHCP keyword shown above with the address information. Be sure to retain any other parameters you have set up for selecting an access point:
ifconfig_ath0="ssid your_ssid_here inet 192.168.1.100 netmask 255.255.255.0"
29.3.3.1.3 WPA
WPA (Wi-Fi Protected Access) is a security protocol used together with 802.11 networks to address the lack of proper authentication and the weakness of WEP. WPA leverages the 802.1X authentication protocol and uses one of several ciphers instead of WEP for data integrity. The only cipher required by WPA is TKIP (Temporary Key Integrity Protocol) which is a cipher that extends the basic RC4 cipher used by WEP by adding integrity checking, tamper detection, and measures for responding to any detected intrusions. TKIP is designed to work on legacy hardware with only software modification; it represents a compromise that improves security but is still not entirely immune to attack. WPA also specifies the AES-CCMP cipher as an alternative to TKIP and that is preferred when possible; for this specification the term WPA2 (or RSN) is commonly used.
WPA defines authentication and encryption protocols. Authentication is most commonly done using one of two techniques: by 802.1X and a backend authentication service such as RADIUS, or by a minimal handshake between the station and the access point using a pre-shared secret. The former is commonly termed WPA Enterprise with the latter known as WPA Personal. Since most people will not set up a RADIUS backend server for wireless network, WPA-PSK is by far the most commonly encountered configuration for WPA.
The control of the wireless connection and the authentication (key negotiation or authentication with a server) is done with the wpa_supplicant(8) utility. This program requires a configuration file, /etc/wpa_supplicant.conf, to run. More information regarding this file can be found in the wpa_supplicant.conf(5) manual page.
29.3.3.1.3.1 WPA-PSK
WPA-PSK also known as WPA-Personal is based on a pre-shared key (PSK) generated from a given password and that will be used as the master key in the wireless network. This means every wireless user will share the same key. WPA-PSK is intended for small networks where the use of an authentication server is not possible or desired.
Warning: Always use strong passwords that are sufficiently long and made from a rich alphabet so they will not be guessed and/or attacked.
The first step is the configuration of the /etc/wpa_supplicant.conf file with the SSID and the pre-shared key of your network:
network={
ssid="freebsdap"
psk="freebsdmall"
}
Then, in /etc/rc.conf, we indicate that the wireless device configuration will be done with WPA and the IP address will be obtained with DHCP:
ifconfig_ath0="WPA DHCP"
Then, we can bring up the interface:
# /etc/rc.d/netif start
Starting wpa_supplicant.
DHCPDISCOVER on ath0 to 255.255.255.255 port 67 interval 5
DHCPDISCOVER on ath0 to 255.255.255.255 port 67 interval 6
DHCPOFFER from 192.168.0.1
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPACK from 192.168.0.1
bound to 192.168.0.254 -- renewal in 300 seconds.
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::211:95ff:fed5:4362%ath0 prefixlen 64 scopeid 0x1
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
ether 00:11:95:d5:43:62
media: IEEE 802.11 Wireless Ethernet autoselect (OFDM/36Mbps)
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode WPA privacy ON deftxkey UNDEF TKIP 2:128-bit txpowmax 36
protmode CTS roaming MANUAL bintval 100
Or you can try to configure it manually using the same /etc/wpa_supplicant.conf above, and run:
# wpa_supplicant -i ath0 -c /etc/wpa_supplicant.conf
Trying to associate with 00:11:95:c3:0d:ac (SSID='freebsdap' freq=2412 MHz)
Associated with 00:11:95:c3:0d:ac
WPA: Key negotiation completed with 00:11:95:c3:0d:ac [PTK=TKIP GTK=TKIP]
The next operation is the launch of the dhclient command to get the IP address from the DHCP server:
# dhclient ath0
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPACK from 192.168.0.1
bound to 192.168.0.254 -- renewal in 300 seconds.
# ifconfig ath0
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::211:95ff:fed5:4362%ath0 prefixlen 64 scopeid 0x1
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
ether 00:11:95:d5:43:62
media: IEEE 802.11 Wireless Ethernet autoselect (OFDM/48Mbps)
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode WPA privacy ON deftxkey UNDEF TKIP 2:128-bit txpowmax 36
protmode CTS roaming MANUAL bintval 100
Note: If the /etc/rc.conf is set up with the line ifconfig_ath0="DHCP" then it is no need to run the dhclient command manually, dhclient will be launched after wpa_supplicant plumbs the keys.
In the case where the use of DHCP is not possible, you can set a static IP address after wpa_supplicant has authenticated the station:
# ifconfig ath0 inet 192.168.0.100 netmask 255.255.255.0
# ifconfig ath0
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::211:95ff:fed5:4362%ath0 prefixlen 64 scopeid 0x1
inet 192.168.0.100 netmask 0xffffff00 broadcast 192.168.0.255
ether 00:11:95:d5:43:62
media: IEEE 802.11 Wireless Ethernet autoselect (OFDM/36Mbps)
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode WPA privacy ON deftxkey UNDEF TKIP 2:128-bit txpowmax 36
protmode CTS roaming MANUAL bintval 100
When DHCP is not used, you also have to manually set up the default gateway and the nameserver:
# route add default your_default_router
# echo "nameserver your_DNS_server" >> /etc/resolv.conf
29.3.3.1.3.2 WPA with EAP-TLS
The second way to use WPA is with an 802.1X backend authentication server, in this case WPA is called WPA-Enterprise to make difference with the less secure WPA-Personal with its pre-shared key. The authentication in WPA-Enterprise is based on EAP (Extensible Authentication Protocol).
EAP does not come with an encryption method, it was decided to embed EAP inside an encrypted tunnel. Many types of EAP authentication methods have been designed, the most common methods are EAP-TLS, EAP-TTLS and EAP-PEAP.
EAP-TLS (EAP with Transport Layer Security) is a very well-supported authentication protocol in the wireless world since it was the first EAP method to be certified by the Wi-Fi alliance. EAP-TLS will require three certificates to run: the CA certificate (installed on all machines), the server certificate for your authentication server, and one client certificate for each wireless client. In this EAP method, both authentication server and wireless client authenticate each other in presenting their respective certificates, and they verify that these certificates were signed by your organization's certificate authority (CA).
As previously, the configuration is done via /etc/wpa_supplicant.conf:
network={
ssid="freebsdap"
proto=RSN
key_mgmt=WPA-EAP
eap=TLS
identity="loader"
ca_cert="/etc/certs/cacert.pem"
client_cert="/etc/certs/clientcert.pem"
private_key="/etc/certs/clientkey.pem"
private_key_passwd="freebsdmallclient"
}
- This field indicates the network name (SSID).
- Here, we use RSN (IEEE 802.11i) protocol, i.e., WPA2.
- The key_mgmt line refers to the key management protocol we use. In our case it is WPA using EAP authentication: WPA-EAP.
- In this field, we mention the EAP method for our connection.
- The identity field contains the identity string for EAP.
- The ca_cert field indicates the pathname of the CA certificate file. This file is needed to verify the server certificat.
- The client_cert line gives the pathname to the client certificate file. This certificate is unique to each wireless client of the network.
- The private_key field is the pathname to the client certificate private key file.
- The private_key_passwd field contains the passphrase for the private key.
Then add the following line to /etc/rc.conf:
ifconfig_ath0="WPA DHCP"
The next step is to bring up the interface with the help of the rc.d facility:
# /etc/rc.d/netif start
Starting wpa_supplicant.
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPACK from 192.168.0.20
bound to 192.168.0.254 -- renewal in 300 seconds.
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::211:95ff:fed5:4362%ath0 prefixlen 64 scopeid 0x1
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
ether 00:11:95:d5:43:62
media: IEEE 802.11 Wireless Ethernet autoselect (DS/11Mbps)
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode WPA2/802.11i privacy ON deftxkey UNDEF TKIP 2:128-bit
txpowmax 36 protmode CTS roaming MANUAL bintval 100
As previously shown, it is also possible to bring up the interface manually with both wpa_supplicant and ifconfig commands.
29.3.3.1.3.3 WPA with EAP-TTLS
With EAP-TLS both the authentication server and the client need a certificate, with EAP-TTLS (EAP-Tunneled Transport Layer Security) a client certificate is optional. This method is close to what some secure web sites do , where the web server can create a secure SSL tunnel even if the visitors do not have client-side certificates. EAP-TTLS will use the encrypted TLS tunnel for safe transport of the authentication data.
The configuration is done via the /etc/wpa_supplicant.conf file:
network={
ssid="freebsdap"
proto=RSN
key_mgmt=WPA-EAP
eap=TTLS
identity="test"
password="test"
ca_cert="/etc/certs/cacert.pem"
phase2="auth=MD5"
}
- In this field, we mention the EAP method for our connection.
- The identity field contains the identity string for EAP authentication inside the encrypted TLS tunnel.
- The password field contains the passphrase for the EAP authentication.
- The ca_cert field indicates the pathname of the CA certificate file. This file is needed to verify the server certificat.
- In this field, we mention the authentication method used in the encrypted TLS tunnel. In our case, EAP with MD5-Challenge has been used. The “inner authentication” phase is often called “phase2”.
You also have to add the following line to /etc/rc.conf:
ifconfig_ath0="WPA DHCP"
The next step is to bring up the interface:
# /etc/rc.d/netif start
Starting wpa_supplicant.
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPACK from 192.168.0.20
bound to 192.168.0.254 -- renewal in 300 seconds.
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::211:95ff:fed5:4362%ath0 prefixlen 64 scopeid 0x1
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
ether 00:11:95:d5:43:62
media: IEEE 802.11 Wireless Ethernet autoselect (DS/11Mbps)
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode WPA2/802.11i privacy ON deftxkey UNDEF TKIP 2:128-bit
txpowmax 36 protmode CTS roaming MANUAL bintval 100
29.3.3.1.3.4 WPA with EAP-PEAP
PEAP (Protected EAP) has been designed as an alternative to EAP-TTLS. There are two types of PEAP methods, the most common one is PEAPv0/EAP-MSCHAPv2. In the rest of this document, we will use the PEAP term to refer to that EAP method. PEAP is the most used EAP standard after EAP-TLS, in other words if you have a network with mixed OSes, PEAP should be the most supported standard after EAP-TLS.
PEAP is similar to EAP-TTLS: it uses a server-side certificate to authenticate clients by creating an encrypted TLS tunnel between the client and the authentication server, which protects the ensuing exchange of authentication information. In term of security the difference between EAP-TTLS and PEAP is that PEAP authentication broadcasts the username in clear, only the password is sent in the encrypted TLS tunnel. EAP-TTLS will use the TLS tunnel for both username and password.
We have to edit the /etc/wpa_supplicant.conf file and add the EAP-PEAP related settings:
network={
ssid="freebsdap"
proto=RSN
key_mgmt=WPA-EAP
eap=PEAP
identity="test"
password="test"
ca_cert="/etc/certs/cacert.pem"
phase1="peaplabel=0"
phase2="auth=MSCHAPV2"
}
- In this field, we mention the EAP method for our connection.
- The identity field contains the identity string for EAP authentication inside the encrypted TLS tunnel.
- The password field contains the passphrase for the EAP authentication.
- The ca_cert field indicates the pathname of the CA certificate file. This file is needed to verify the server certificat.
- This field contains the parameters for the first phase of the authentication (the TLS tunnel). According to the authentication server used, you will have to specify a specific label for the authentication. Most of time, the label will be “client EAP encryption” which is set by using peaplabel=0. More information can be found in the wpa_supplicant.conf(5) manual page.
- In this field, we mention the authentication protocol used in the encrypted TLS tunnel. In the case of PEAP, it is auth=MSCHAPV2.
The following must be added to /etc/rc.conf:
ifconfig_ath0="WPA DHCP"
Then, we can bring up the interface:
# /etc/rc.d/netif start
Starting wpa_supplicant.
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPREQUEST on ath0 to 255.255.255.255 port 67
DHCPACK from 192.168.0.20
bound to 192.168.0.254 -- renewal in 300 seconds.
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::211:95ff:fed5:4362%ath0 prefixlen 64 scopeid 0x1
inet 192.168.0.254 netmask 0xffffff00 broadcast 192.168.0.255
ether 00:11:95:d5:43:62
media: IEEE 802.11 Wireless Ethernet autoselect (DS/11Mbps)
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode WPA2/802.11i privacy ON deftxkey UNDEF TKIP 2:128-bit
txpowmax 36 protmode CTS roaming MANUAL bintval 100
29.3.3.1.4 WEP
WEP (Wired Equivalent Privacy) is part of the original 802.11 standard. There is no authentication mechanism, only a weak form of access control, and it is easily to be cracked.
WEP can be set up with ifconfig:
# ifconfig ath0 ssid my_net wepmode on weptxkey 3 wepkey 3:0x3456789012 \
inet 192.168.1.100 netmask 255.255.255.0
-
The weptxkey means which WEP key will be used in the transmission. Here we used the third key. This must match the setting in the access point.
-
The wepkey means setting the selected WEP key. It should in the format index:key, if the index is not given, key 1 is set. That is to say we need to set the index if we use keys other than the first key.
Note: You must replace the 0x3456789012 with the key configured for use on the access point.
You are encouraged to read ifconfig(8) manual page for further information.
The wpa_supplicant facility also can be used to configure your wireless interface with WEP. The example above can be set up by adding the following lines to /etc/wpa_supplicant.conf:
network={
ssid="my_net"
key_mgmt=NONE
wep_key3=3456789012
wep_tx_keyidx=3
}
Then:
# wpa_supplicant -i ath0 -c /etc/wpa_supplicant.conf
Trying to associate with 00:13:46:49:41:76 (SSID='dlinkap' freq=2437 MHz)
Associated with 00:13:46:49:41:76
29.3.4 Ad-hoc Mode
IBSS mode, also called ad-hoc mode, is designed for point to point connections. For example, to establish an ad-hoc network between the machine A and the machine B we will just need to choose two IP adresses and a SSID.
On the box A:
# ifconfig ath0 ssid freebsdap mediaopt adhoc inet 192.168.0.1 netmask 255.255.255.0
# ifconfig ath0
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
inet6 fe80::211:95ff:fec3:dac%ath0 prefixlen 64 scopeid 0x4
ether 00:11:95:c3:0d:ac
media: IEEE 802.11 Wireless Ethernet autoselect <adhoc> (autoselect <adhoc>)
status: associated
ssid freebsdap channel 2 bssid 02:11:95:c3:0d:ac
authmode OPEN privacy OFF txpowmax 36 protmode CTS bintval 100
The adhoc parameter indicates the interface is running in the IBSS mode.
On B, we should be able to detect A:
# ifconfig ath0 up scan
SSID BSSID CHAN RATE S:N INT CAPS
freebsdap 02:11:95:c3:0d:ac 2 54M 19:3 100 IS
The I in the output confirms the machine A is in ad-hoc mode. We just have to configure B with a different IP address:
# ifconfig ath0 ssid freebsdap mediaopt adhoc inet 192.168.0.2 netmask 255.255.255.0
# ifconfig ath0
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::211:95ff:fed5:4362%ath0 prefixlen 64 scopeid 0x1
inet 192.168.0.2 netmask 0xffffff00 broadcast 192.168.0.255
ether 00:11:95:d5:43:62
media: IEEE 802.11 Wireless Ethernet autoselect <adhoc> (autoselect <adhoc>)
status: associated
ssid freebsdap channel 2 bssid 02:11:95:c3:0d:ac
authmode OPEN privacy OFF txpowmax 36 protmode CTS bintval 100
Both A and B are now ready to exchange informations.
29.3.5 FreeBSD Host Access Points
FreeBSD can act as an Access Point (AP) which eliminates the need to buy a hardware AP or run an ad-hoc network. This can be particularly useful when your FreeBSD machine is acting as a gateway to another network (e.g., the Internet).
29.3.5.1 Basic Settings
Before configuring your FreeBSD machine as an AP, the kernel must be configured with the appropriate wireless networking support for your wireless card. You also have to add the support for the security protocols you intend to use. For more details, see Section 29.3.2.
Note: The use of the NDIS driver wrapper and the Windows drivers do not allow currently the AP operation. Only native FreeBSD wireless drivers support AP mode.
Once the wireless networking support is loaded, you can check if your wireless device supports the host-based access point mode (also know as hostap mode):
# ifconfig ath0 list caps
ath0=783ed0f<WEP,TKIP,AES,AES_CCM,IBSS,HOSTAP,AHDEMO,TXPMGT,SHSLOT,SHPREAMBLE,MONITOR,TKIPMIC,WPA1,WPA2,BURST,WME>
This output displays the card capabilities; the HOSTAP word confirms this wireless card can act as an Access Point. Various supported ciphers are also mentioned: WEP, TKIP, WPA2, etc., these informations are important to know what security protocols could be set on the Access Point.
The wireless device can now be put into hostap mode and configured with the correct SSID and IP address:
# ifconfig ath0 ssid freebsdap mode 11g mediaopt hostap inet 192.168.0.1 netmask 255.255.255.0
Use again ifconfig to see the status of the ath0 interface:
# ifconfig ath0
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
inet6 fe80::211:95ff:fec3:dac%ath0 prefixlen 64 scopeid 0x4
ether 00:11:95:c3:0d:ac
media: IEEE 802.11 Wireless Ethernet autoselect mode 11g <hostap>
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode OPEN privacy OFF txpowmax 38 bmiss 7 protmode CTS burst dtimperiod 1 bintval 100
The hostap parameter indicates the interface is running in the host-based access point mode.
The interface configuration can be done automatically at boot time by adding the following line to /etc/rc.conf:
ifconfig_ath0="ssid freebsdap mode 11g mediaopt hostap inet 192.168.0.1 netmask 255.255.255.0"
29.3.5.2 Host-based Access Point without Authentication or Encryption
Although it is not recommended to run an AP without any authentication or encryption, this is a simple way to check if your AP is working. This configuration is also important for debugging client issues.
Once the AP configured as previously shown, it is possible from another wireless machine to initiate a scan to find the AP:
# ifconfig ath0 up scan
SSID BSSID CHAN RATE S:N INT CAPS
freebsdap 00:11:95:c3:0d:ac 1 54M 22:1 100 ES
The client machine found the Access Point and can be associated with it:
# ifconfig ath0 ssid freebsdap inet 192.168.0.2 netmask 255.255.255.0
# ifconfig ath0
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet6 fe80::211:95ff:fed5:4362%ath0 prefixlen 64 scopeid 0x1
inet 192.168.0.2 netmask 0xffffff00 broadcast 192.168.0.255
ether 00:11:95:d5:43:62
media: IEEE 802.11 Wireless Ethernet autoselect (OFDM/54Mbps)
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode OPEN privacy OFF txpowmax 36 protmode CTS bintval 100
29.3.5.3 WPA Host-based Access Point
This section will focus on setting up FreeBSD Access Point using the WPA security protocol. More details regarding WPA and the configuration of WPA-based wireless clients can be found in the Section 29.3.3.1.3.
The hostapd daemon is used to deal with client authentication and keys management on the WPA enabled Access Point.
In the following, all the configuration operations will be performed on the FreeBSD machine acting as AP. Once the AP is correctly working, hostapd should be automatically enabled at boot with the following line in /etc/rc.conf:
hostapd_enable="YES"
Before trying to configure hostapd, be sure you have done the basic settings introduced in the Section 29.3.5.1.
29.3.5.3.1 WPA-PSK
WPA-PSK is intended for small networks where the use of an backend authentication server is not possible or desired.
The configuration is done in the /etc/hostapd.conf file:
interface=ath0
debug=1
ctrl_interface=/var/run/hostapd
ctrl_interface_group=wheel
ssid=freebsdap
wpa=1
wpa_passphrase=freebsdmall
wpa_key_mgmt=WPA-PSK
wpa_pairwise=CCMP TKIP
- This field indicates the wireless interface used for the Access Point.
- This field sets the level of verbosity during the execution of hostapd. A value of 1 represents the minimal level.
- The ctrl_interface field gives the pathname of the directory used by hostapd to stores its domain socket files for the communication with external programs such as hostapd_cli(8). The default value is used here.
- The ctrl_interface_group line sets the group (here, it is the wheel group) allowed to access to the control interface files.
- This field sets the network name.
- The wpa field enables WPA and specifies which WPA authentication protocol will be required. A value of 1 configures the AP for WPA-PSK.
- The wpa_passphrase field contains the ASCII passphrase for the WPA authentication.
-
Warning: Always use strong passwords that are sufficiently long and made from a rich alphabet so they will not be guessed and/or attacked.
- The wpa_key_mgmt line refers to the key management protocol we use. In our case it is WPA-PSK.
- The wpa_pairwise field indicates the set of accepted encryption algorithms by the Access Point. Here both TKIP (WPA) and CCMP (WPA2) ciphers are accepted. CCMP cipher is an alternative to TKIP and that is strongly preferred when possible; TKIP should be used solely for stations incapable of doing CCMP.
The next step is to start hostapd:
# /etc/rc.d/hostapd forcestart
# ifconfig ath0
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 2290
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
inet6 fe80::211:95ff:fec3:dac%ath0 prefixlen 64 scopeid 0x4
ether 00:11:95:c3:0d:ac
media: IEEE 802.11 Wireless Ethernet autoselect mode 11g <hostap>
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode WPA2/802.11i privacy MIXED deftxkey 2 TKIP 2:128-bit txpowmax 36 protmode CTS dtimperiod 1 bintval 100
The Access Point is running, the clients can now be associated with it, see Section 29.3.3.1.3 for more details. It is possible to see the stations associated with the AP using the ifconfig ath0 list sta command.
29.3.5.4 WEP Host-based Access Point
It is not recommended to use WEP for setting up an Access Point since there is no authentication mechanism and it is easily to be cracked. Some legacy wireless cards only support WEP as security protocol, these cards will only allow to set up AP without authentication or encryption or using the WEP protocol.
The wireless device can now be put into hostap mode and configured with the correct SSID and IP address:
# ifconfig ath0 ssid freebsdap wepmode on weptxkey 3 wepkey 3:0x3456789012 mode 11g mediaopt hostap \
inet 192.168.0.1 netmask 255.255.255.0
-
The weptxkey means which WEP key will be used in the transmission. Here we used the third key (note that the key numbering starts with 1). This parameter must be specified to really encrypt the data.
-
The wepkey means setting the selected WEP key. It should in the format index:key, if the index is not given, key 1 is set. That is to say we need to set the index if we use keys other than the first key.
Use again ifconfig to see the status of the ath0 interface:
# ifconfig ath0
ath0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 192.168.0.1 netmask 0xffffff00 broadcast 192.168.0.255
inet6 fe80::211:95ff:fec3:dac%ath0 prefixlen 64 scopeid 0x4
ether 00:11:95:c3:0d:ac
media: IEEE 802.11 Wireless Ethernet autoselect mode 11g <hostap>
status: associated
ssid freebsdap channel 1 bssid 00:11:95:c3:0d:ac
authmode OPEN privacy ON deftxkey 3 wepkey 3:40-bit txpowmax 36 protmode CTS dtimperiod 1 bintval 100
From another wireless machine, it is possible to initiate a scan to find the AP:
# ifconfig ath0 up scan
SSID BSSID CHAN RATE S:N INT CAPS
freebsdap 00:11:95:c3:0d:ac 1 54M 22:1 100 EPS
The client machine found the Access Point and can be associated with it using the correct parameters (key, etc.), see Section 29.3.3.1.4 for more details.
29.3.6 Troubleshooting
If you are having trouble with wireless networking, there are a number of steps you can take to help troubleshoot the problem.
-
If you do not see the access point listed when scanning be sure you have not configured your wireless device to a limited set of channels.
-
If you cannot associate to an access point verify the configuration of your station matches the one of the access point. This includes the authentication scheme and any security protocols. Simplify your configuration as much as possible. If you are using a security protocol such as WPA or WEP configure the access point for open authentication and no security to see if you can get traffic to pass.
-
Once you can associate to the access point diagnose any security configuration using simple tools like ping(8).
The wpa_supplicant has much debugging support; try running it manually with the
-ddoption and look at the system logs. -
There are also many lower-level debugging tools. You can enable debugging messages in the 802.11 protocol support layer using the wlandebug program found in /usr/src/tools/tools/net80211. For example:
# wlandebug -i ath0 +scan+auth+debug+assoc net.wlan.0.debug: 0 => 0xc80000<assoc,auth,scan>can be used to enable console messages related to scanning for access points and doing the 802.11 protocol handshakes required to arrange communication.
There are also many useful statistics maintained by the 802.11 layer; the wlanstats tool will dump these informations. These statistics should identify all errors identified by the 802.11 layer. Beware however that some errors are identified in the device drivers that lie below the 802.11 layer so they may not show up. To diagnose device-specific problems you need to refer to the drivers' documentation.
If the above information does not help to clarify the problem, please submit a problem report and include output from the above tools.
29.4 Bluetooth
Written by Pav Lucistnik.29.4.1 Introduction
Bluetooth is a wireless technology for creating personal networks operating in the 2.4 GHz unlicensed band, with a range of 10 meters. Networks are usually formed ad-hoc from portable devices such as cellular phones, handhelds and laptops. Unlike the other popular wireless technology, Wi-Fi, Bluetooth offers higher level service profiles, e.g. FTP-like file servers, file pushing, voice transport, serial line emulation, and more.
The Bluetooth stack in FreeBSD is implemented using the Netgraph framework (see netgraph(4)). A broad variety of Bluetooth USB dongles is supported by the ng_ubt(4) driver. The Broadcom BCM2033 chip based Bluetooth devices are supported via the ubtbcmfw(4) and ng_ubt(4) drivers. The 3Com Bluetooth PC Card 3CRWB60-A is supported by the ng_bt3c(4) driver. Serial and UART based Bluetooth devices are supported via sio(4), ng_h4(4) and hcseriald(8). This section describes the use of the USB Bluetooth dongle.
29.4.2 Plugging in the Device
By default Bluetooth device drivers are available as kernel modules. Before attaching a device, you will need to load the driver into the kernel:
# kldload ng_ubt
If the Bluetooth device is present in the system during system startup, load the module from /boot/loader.conf:
ng_ubt_load="YES"
Plug in your USB dongle. The output similar to the following will appear on the console (or in syslog):
ubt0: vendor 0x0a12 product 0x0001, rev 1.10/5.25, addr 2
ubt0: Interface 0 endpoints: interrupt=0x81, bulk-in=0x82, bulk-out=0x2
ubt0: Interface 1 (alt.config 5) endpoints: isoc-in=0x83, isoc-out=0x3,
wMaxPacketSize=49, nframes=6, buffer size=294
Note: The Bluetooth stack has to be started manually on FreeBSD 6.0, and on FreeBSD 5.X before 5.5. It is done automatically from devd(8) on FreeBSD 5.5, 6.1 and newer.
Copy /usr/share/examples/netgraph/bluetooth/rc.bluetooth into some convenient place, like /etc/rc.bluetooth. This script is used to start and stop the Bluetooth stack. It is a good idea to stop the stack before unplugging the device, but it is not (usually) fatal. When starting the stack, you will receive output similar to the following:
# /etc/rc.bluetooth start ubt0 BD_ADDR: 00:02:72:00:d4:1a Features: 0xff 0xff 0xf 00 00 00 00 00 <3-Slot> <5-Slot> <Encryption> <Slot offset> <Timing accuracy> <Switch> <Hold mode> <Sniff mode> <Park mode> <RSSI> <Channel quality> <SCO link> <HV2 packets> <HV3 packets> <u-law log> <A-law log> <CVSD> <Paging scheme> <Power control> <Transparent SCO data> Max. ACL packet size: 192 bytes Number of ACL packets: 8 Max. SCO packet size: 64 bytes Number of SCO packets: 8
29.4.3 Host Controller Interface (HCI)
Host Controller Interface (HCI) provides a command interface to the baseband controller and link manager, and access to hardware status and control registers. This interface provides a uniform method of accessing the Bluetooth baseband capabilities. HCI layer on the Host exchanges data and commands with the HCI firmware on the Bluetooth hardware. The Host Controller Transport Layer (i.e. physical bus) driver provides both HCI layers with the ability to exchange information with each other.
A single Netgraph node of type hci is created for a single Bluetooth device. The HCI node is normally connected to the Bluetooth device driver node (downstream) and the L2CAP node (upstream). All HCI operations must be performed on the HCI node and not on the device driver node. Default name for the HCI node is “devicehci”. For more details refer to the ng_hci(4) manual page.
One of the most common tasks is discovery of Bluetooth devices in RF proximity. This operation is called inquiry. Inquiry and other HCI related operations are done with the hccontrol(8) utility. The example below shows how to find out which Bluetooth devices are in range. You should receive the list of devices in a few seconds. Note that a remote device will only answer the inquiry if it put into discoverable mode.
% hccontrol -n ubt0hci inquiry
Inquiry result, num_responses=1
Inquiry result #0
BD_ADDR: 00:80:37:29:19:a4
Page Scan Rep. Mode: 0x1
Page Scan Period Mode: 00
Page Scan Mode: 00
Class: 52:02:04
Clock offset: 0x78ef
Inquiry complete. Status: No error [00]
BD_ADDR is unique address of a Bluetooth device, similar to MAC addresses of a network card. This address is needed for further communication with a device. It is possible to assign human readable name to a BD_ADDR. The /etc/bluetooth/hosts file contains information regarding the known Bluetooth hosts. The following example shows how to obtain human readable name that was assigned to the remote device:
% hccontrol -n ubt0hci remote_name_request 00:80:37:29:19:a4
BD_ADDR: 00:80:37:29:19:a4
Name: Pav's T39
If you perform an inquiry on a remote Bluetooth device, it will find your computer as “your.host.name (ubt0)”. The name assigned to the local device can be changed at any time.
The Bluetooth system provides a point-to-point connection (only two Bluetooth units involved), or a point-to-multipoint connection. In the point-to-multipoint connection the connection is shared among several Bluetooth devices. The following example shows how to obtain the list of active baseband connections for the local device:
% hccontrol -n ubt0hci read_connection_list
Remote BD_ADDR Handle Type Mode Role Encrypt Pending Queue State
00:80:37:29:19:a4 41 ACL 0 MAST NONE 0 0 OPEN
A connection handle is useful when termination of the baseband connection is required. Note, that it is normally not required to do it by hand. The stack will automatically terminate inactive baseband connections.
# hccontrol -n ubt0hci disconnect 41
Connection handle: 41
Reason: Connection terminated by local host [0x16]
Refer to hccontrol help for a complete listing of available HCI commands. Most of the HCI commands do not require superuser privileges.
29.4.4 Logical Link Control and Adaptation Protocol (L2CAP)
Logical Link Control and Adaptation Protocol (L2CAP) provides connection-oriented and connectionless data services to upper layer protocols with protocol multiplexing capability and segmentation and reassembly operation. L2CAP permits higher level protocols and applications to transmit and receive L2CAP data packets up to 64 kilobytes in length.
L2CAP is based around the concept of channels. Channel is a logical connection on top of baseband connection. Each channel is bound to a single protocol in a many-to-one fashion. Multiple channels can be bound to the same protocol, but a channel cannot be bound to multiple protocols. Each L2CAP packet received on a channel is directed to the appropriate higher level protocol. Multiple channels can share the same baseband connection.
A single Netgraph node of type l2cap is created for a single Bluetooth device. The L2CAP node is normally connected to the Bluetooth HCI node (downstream) and Bluetooth sockets nodes (upstream). Default name for the L2CAP node is “devicel2cap”. For more details refer to the ng_l2cap(4) manual page.
A useful command is l2ping(8), which can be used to ping other devices. Some Bluetooth implementations might not return all of the data sent to them, so 0 bytes in the following example is normal.
# l2ping -a 00:80:37:29:19:a4
0 bytes from 0:80:37:29:19:a4 seq_no=0 time=48.633 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=1 time=37.551 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=2 time=28.324 ms result=0
0 bytes from 0:80:37:29:19:a4 seq_no=3 time=46.150 ms result=0
The l2control(8) utility is used to perform various operations on L2CAP nodes. This example shows how to obtain the list of logical connections (channels) and the list of baseband connections for the local device:
% l2control -a 00:02:72:00:d4:1a read_channel_list
L2CAP channels:
Remote BD_ADDR SCID/ DCID PSM IMTU/ OMTU State
00:07:e0:00:0b:ca 66/ 64 3 132/ 672 OPEN
% l2control -a 00:02:72:00:d4:1a read_connection_list
L2CAP connections:
Remote BD_ADDR Handle Flags Pending State
00:07:e0:00:0b:ca 41 O 0 OPEN
Another diagnostic tool is btsockstat(1). It does a job similar to as netstat(1) does, but for Bluetooth network-related data structures. The example below shows the same logical connection as l2control(8) above.
% btsockstat
Active L2CAP sockets
PCB Recv-Q Send-Q Local address/PSM Foreign address CID State
c2afe900 0 0 00:02:72:00:d4:1a/3 00:07:e0:00:0b:ca 66 OPEN
Active RFCOMM sessions
L2PCB PCB Flag MTU Out-Q DLCs State
c2afe900 c2b53380 1 127 0 Yes OPEN
Active RFCOMM sockets
PCB Recv-Q Send-Q Local address Foreign address Chan DLCI State
c2e8bc80 0 250 00:02:72:00:d4:1a 00:07:e0:00:0b:ca 3 6 OPEN
29.4.5 RFCOMM Protocol
The RFCOMM protocol provides emulation of serial ports over the L2CAP protocol. The protocol is based on the ETSI standard TS 07.10. RFCOMM is a simple transport protocol, with additional provisions for emulating the 9 circuits of RS-232 (EIATIA-232-E) serial ports. The RFCOMM protocol supports up to 60 simultaneous connections (RFCOMM channels) between two Bluetooth devices.
For the purposes of RFCOMM, a complete communication path involves two applications running on different devices (the communication endpoints) with a communication segment between them. RFCOMM is intended to cover applications that make use of the serial ports of the devices in which they reside. The communication segment is a Bluetooth link from one device to another (direct connect).
RFCOMM is only concerned with the connection between the devices in the direct connect case, or between the device and a modem in the network case. RFCOMM can support other configurations, such as modules that communicate via Bluetooth wireless technology on one side and provide a wired interface on the other side.
In FreeBSD the RFCOMM protocol is implemented at the Bluetooth sockets layer.
29.4.6 Pairing of Devices
By default, Bluetooth communication is not authenticated, and any device can talk to any other device. A Bluetooth device (for example, cellular phone) may choose to require authentication to provide a particular service (for example, Dial-Up service). Bluetooth authentication is normally done with PIN codes. A PIN code is an ASCII string up to 16 characters in length. User is required to enter the same PIN code on both devices. Once user has entered the PIN code, both devices will generate a link key. After that the link key can be stored either in the devices themselves or in a persistent storage. Next time both devices will use previously generated link key. The described above procedure is called pairing. Note that if the link key is lost by any device then pairing must be repeated.
The hcsecd(8) daemon is responsible for handling of all Bluetooth authentication requests. The default configuration file is /etc/bluetooth/hcsecd.conf. An example section for a cellular phone with the PIN code arbitrarily set to “1234” is shown below:
device {
bdaddr 00:80:37:29:19:a4;
name "Pav's T39";
key nokey;
pin "1234";
}
There is no limitation on PIN codes (except length). Some devices (for example
Bluetooth headsets) may have a fixed PIN code built in. The -d switch forces the hcsecd(8) daemon to
stay in the foreground, so it is easy to see what is happening. Set the remote device to
receive pairing and initiate the Bluetooth connection to the remote device. The remote
device should say that pairing was accepted, and request the PIN code. Enter the same PIN
code as you have in hcsecd.conf. Now your PC and the remote
device are paired. Alternatively, you can initiate pairing on the remote device.
On FreeBSD 5.5, 6.1 and newer, the following line can be added to the /etc/rc.conf file to have hcsecd started automatically on system start:
hcsecd_enable="YES"
The following is a sample of the hcsecd daemon output:
hcsecd[16484]: Got Link_Key_Request event from 'ubt0hci', remote bdaddr 0:80:37:29:19:a4
hcsecd[16484]: Found matching entry, remote bdaddr 0:80:37:29:19:a4, name 'Pav's T39', link key doesn't exist
hcsecd[16484]: Sending Link_Key_Negative_Reply to 'ubt0hci' for remote bdaddr 0:80:37:29:19:a4
hcsecd[16484]: Got PIN_Code_Request event from 'ubt0hci', remote bdaddr 0:80:37:29:19:a4
hcsecd[16484]: Found matching entry, remote bdaddr 0:80:37:29:19:a4, name 'Pav's T39', PIN code exists
hcsecd[16484]: Sending PIN_Code_Reply to 'ubt0hci' for remote bdaddr 0:80:37:29:19:a4
29.4.7 Service Discovery Protocol (SDP)
The Service Discovery Protocol (SDP) provides the means for client applications to discover the existence of services provided by server applications as well as the attributes of those services. The attributes of a service include the type or class of service offered and the mechanism or protocol information needed to utilize the service.
SDP involves communication between a SDP server and a SDP client. The server maintains a list of service records that describe the characteristics of services associated with the server. Each service record contains information about a single service. A client may retrieve information from a service record maintained by the SDP server by issuing a SDP request. If the client, or an application associated with the client, decides to use a service, it must open a separate connection to the service provider in order to utilize the service. SDP provides a mechanism for discovering services and their attributes, but it does not provide a mechanism for utilizing those services.
Normally, a SDP client searches for services based on some desired characteristics of the services. However, there are times when it is desirable to discover which types of services are described by an SDP server's service records without any a priori information about the services. This process of looking for any offered services is called browsing.
The Bluetooth SDP server sdpd(8) and command line client sdpcontrol(8) are included in the standard FreeBSD installation. The following example shows how to perform a SDP browse query.
% sdpcontrol -a 00:01:03:fc:6e:ec browse
Record Handle: 00000000
Service Class ID List:
Service Discovery Server (0x1000)
Protocol Descriptor List:
L2CAP (0x0100)
Protocol specific parameter #1: u/int/uuid16 1
Protocol specific parameter #2: u/int/uuid16 1
Record Handle: 0x00000001
Service Class ID List:
Browse Group Descriptor (0x1001)
Record Handle: 0x00000002
Service Class ID List:
LAN Access Using PPP (0x1102)
Protocol Descriptor List:
L2CAP (0x0100)
RFCOMM (0x0003)
Protocol specific parameter #1: u/int8/bool 1
Bluetooth Profile Descriptor List:
LAN Access Using PPP (0x1102) ver. 1.0
... and so on. Note that each service has a list of attributes (RFCOMM channel for example). Depending on the service you might need to make a note of some of the attributes. Some Bluetooth implementations do not support service browsing and may return an empty list. In this case it is possible to search for the specific service. The example below shows how to search for the OBEX Object Push (OPUSH) service:
% sdpcontrol -a 00:01:03:fc:6e:ec search OPUSH
Offering services on FreeBSD to Bluetooth clients is done with the sdpd(8) server. On FreeBSD 5.5, 6.1 and newer, the following line can be added to the /etc/rc.conf file:
sdpd_enable="YES"
Then the sdpd daemon can be started with:
# /etc/rc.d/sdpd start
On FreeBSD 6.0, and on FreeBSD 5.X before 5.5, sdpd is not integrated into the system startup scripts. It has to be started manually with:
# sdpd
The local server application that wants to provide Bluetooth service to the remote clients will register service with the local SDP daemon. The example of such application is rfcomm_pppd(8). Once started it will register Bluetooth LAN service with the local SDP daemon.
The list of services registered with the local SDP server can be obtained by issuing SDP browse query via local control channel:
# sdpcontrol -l browse
29.4.8 Dial-Up Networking (DUN) and Network Access with PPP (LAN) Profiles
The Dial-Up Networking (DUN) profile is mostly used with modems and cellular phones. The scenarios covered by this profile are the following:
-
use of a cellular phone or modem by a computer as a wireless modem for connecting to a dial-up Internet access server, or using other dial-up services;
-
use of a cellular phone or modem by a computer to receive data calls.
Network Access with PPP (LAN) profile can be used in the following situations:
-
LAN access for a single Bluetooth device;
-
LAN access for multiple Bluetooth devices;
-
PC to PC (using PPP networking over serial cable emulation).
In FreeBSD both profiles are implemented with ppp(8) and rfcomm_pppd(8) - a wrapper that converts RFCOMM Bluetooth connection into something PPP can operate with. Before any profile can be used, a new PPP label in the /etc/ppp/ppp.conf must be created. Consult rfcomm_pppd(8) manual page for examples.
In the following example rfcomm_pppd(8) will be used to open RFCOMM connection to remote device with BD_ADDR 00:80:37:29:19:a4 on DUN RFCOMM channel. The actual RFCOMM channel number will be obtained from the remote device via SDP. It is possible to specify RFCOMM channel by hand, and in this case rfcomm_pppd(8) will not perform SDP query. Use sdpcontrol(8) to find out RFCOMM channel on the remote device.
# rfcomm_pppd -a 00:80:37:29:19:a4 -c -C dun -l rfcomm-dialup
In order to provide Network Access with PPP (LAN) service the sdpd(8) server must be running. A new entry for LAN clients must be created in the /etc/ppp/ppp.conf file. Consult rfcomm_pppd(8) manual page for examples. Finally, start RFCOMM PPP server on valid RFCOMM channel number. The RFCOMM PPP server will automatically register Bluetooth LAN service with the local SDP daemon. The example below shows how to start RFCOMM PPP server.
# rfcomm_pppd -s -C 7 -l rfcomm-server
29.4.9 OBEX Object Push (OPUSH) Profile
OBEX is a widely used protocol for simple file transfers between mobile devices. Its main use is in infrared communication, where it is used for generic file transfers between notebooks or PDAs, and for sending business cards or calendar entries between cellular phones and other devices with PIM applications.
The OBEX server and client are implemented as a third-party package obexapp, which is available as comms/obexapp port.
OBEX client is used to push and/or pull objects from the OBEX server. An object can, for example, be a business card or an appointment. The OBEX client can obtain RFCOMM channel number from the remote device via SDP. This can be done by specifying service name instead of RFCOMM channel number. Supported service names are: IrMC, FTRN and OPUSH. It is possible to specify RFCOMM channel as a number. Below is an example of an OBEX session, where device information object is pulled from the cellular phone, and a new object (business card) is pushed into the phone's directory.
% obexapp -a 00:80:37:29:19:a4 -C IrMC
obex> get telecom/devinfo.txt devinfo-t39.txt
Success, response: OK, Success (0x20)
obex> put new.vcf
Success, response: OK, Success (0x20)
obex> di
Success, response: OK, Success (0x20)
In order to provide OBEX Object Push service, sdpd(8) server must be running. A root folder, where all incoming objects will be stored, must be created. The default path to the root folder is /var/spool/obex. Finally, start OBEX server on valid RFCOMM channel number. The OBEX server will automatically register OBEX Object Push service with the local SDP daemon. The example below shows how to start OBEX server.
# obexapp -s -C 10
29.4.10 Serial Port Profile (SPP)
The Serial Port Profile (SPP) allows Bluetooth devices to perform RS232 (or similar) serial cable emulation. The scenario covered by this profile deals with legacy applications using Bluetooth as a cable replacement, through a virtual serial port abstraction.
The rfcomm_sppd(1) utility implements the Serial Port profile. A pseudo tty is used as a virtual serial port abstraction. The example below shows how to connect to a remote device Serial Port service. Note that you do not have to specify a RFCOMM channel - rfcomm_sppd(1) can obtain it from the remote device via SDP. If you would like to override this, specify a RFCOMM channel on the command line.
# rfcomm_sppd -a 00:07:E0:00:0B:CA -t /dev/ttyp6
rfcomm_sppd[94692]: Starting on /dev/ttyp6...
Once connected, the pseudo tty can be used as serial port:
# cu -l ttyp6
29.4.11 Troubleshooting
29.4.11.1 A remote device cannot connect
Some older Bluetooth devices do not support role switching. By default, when FreeBSD is accepting a new connection, it tries to perform a role switch and become master. Devices, which do not support this will not be able to connect. Note that role switching is performed when a new connection is being established, so it is not possible to ask the remote device if it does support role switching. There is a HCI option to disable role switching on the local side:
# hccontrol -n ubt0hci write_node_role_switch 0
29.4.11.2 Something is going wrong, can I see what exactly is happening?
Yes, you can. Use the third-party package hcidump, which is available as comms/hcidump port. The hcidump utility is similar to tcpdump(1). It can be used to display the content of the Bluetooth packets on the terminal and to dump the Bluetooth packets to a file.
29.5 Bridging
Written by Andrew Thompson.29.5.1 Introduction
It is sometimes useful to divide one physical network (such as an Ethernet segment) into two separate network segments without having to create IP subnets and use a router to connect the segments together. A device that connects two networks together in this fashion is called a “bridge”. A FreeBSD system with two network interface cards can act as a bridge.
The bridge works by learning the MAC layer addresses (Ethernet addresses) of the devices on each of its network interfaces. It forwards traffic between two networks only when its source and destination are on different networks.
In many respects, a bridge is like an Ethernet switch with very few ports.
29.5.2 Situations Where Bridging Is Appropriate
There are many common situations in which a bridge is used today.
29.5.2.1 Connecting Networks
The basic operation of a bridge is to join two or more network segments together. There are many reasons to use a host based bridge over plain networking equipment such as cabling constraints, firewalling or connecting pseudo networks such as a Virtual Machine interface. A bridge can also connect a wireless interface running in hostap mode to a wired network and act as an access point.
29.5.2.2 Filtering/Traffic Shaping Firewall
A common situation is where firewall functionality is needed without routing or network address translation (NAT).
An example is a small company that is connected via DSL or ISDN to their ISP. They have a 13 globally-accessible IP addresses from their ISP and have 10 PCs on their network. In this situation, using a router-based firewall is difficult because of subnetting issues.
A bridge-based firewall can be configured and dropped into the path just downstream of their DSL/ISDN router without any IP numbering issues.
29.5.2.3 Network Tap
A bridge can join two network segments and be used to inspect all Ethernet frames that pass between them. This can either be from using bpf(4)/tcpdump(1) on the bridge interface or by sending a copy of all frames out an additional interface (span port).
29.5.2.4 Layer 2 VPN
Two Ethernet networks can be joined across an IP link by bridging the networks to an EtherIP tunnel or a tap(4) based solution such as OpenVPN.
29.5.2.5 Layer 2 Redundancy
A network can be connected together with multiple links and use the Spanning Tree Protocol to block redundant paths. For an Ethernet network to function properly only one active path can exist between two devices, Spanning Tree will detect loops and put the redundant links into a blocked state. Should one of the active links fail then the protocol will calculate a different tree and reenable one of the blocked paths to restore connectivity to all points in the network.
29.5.3 Kernel Configuration
This section covers if_bridge(4) bridge implementation, a netgraph bridging driver is also available, for more information see ng_bridge(4) manual page.
The bridge driver is a kernel module and will be automatically loaded by ifconfig(8) when creating a bridge interface. It is possible to compile the bridge in to the kernel by adding device if_bridge to your kernel configuration file.
Packet filtering can be used with any firewall package that hooks in via the pfil(9) framework. The firewall can be loaded as a module or compiled into the kernel.
The bridge can be used as a traffic shaper with altq(4) or dummynet(4).
29.5.4 Enabling the Bridge
The bridge is created using interface cloning. To create a bridge use ifconfig(8), if the bridge driver is not present in the kernel then it will be loaded automatically.
# ifconfig bridge create
bridge0
# ifconfig bridge0
bridge0: flags=8802<BROADCAST,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 96:3d:4b:f1:79:7a
id 00:00:00:00:00:00 priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 100 timeout 1200
root id 00:00:00:00:00:00 priority 0 ifcost 0 port 0
A bridge interface is created and is automatically assigned a randomly generated Ethernet address. The maxaddr and timeout parameters control how many MAC addresses the bridge will keep in its forwarding table and how many seconds before each entry is removed after it is last seen. The other parameters control how Spanning Tree operates.
Add the member network interfaces to the bridge. For the bridge to forward packets all member interfaces and the bridge need to be up:
# ifconfig bridge0 addm fxp0 addm fxp1 up
# ifconfig fxp0 up
# ifconfig fxp1 up
The bridge is now forwarding Ethernet frames between fxp0 and fxp1. The equivalent configuration in /etc/rc.conf so the bridge is created at startup is:
cloned_interfaces="bridge0"
ifconfig_bridge0="addm fxp0 addm fxp1 up"
ifconfig_fxp0="up"
ifconfig_fxp1="up"
If the bridge host needs an IP address then the correct place to set this is on the bridge interface itself rather than one of the member interfaces. This can be set statically or via DHCP:
# ifconfig bridge0 inet 192.168.0.1/24
It is also possible to assign an IPv6 address to a bridge interface.
29.5.5 Firewalling
When packet filtering is enabled, bridged packets will pass through the filter inbound on the originating interface, on the bridge interface and outbound on the appropriate interfaces. Either stage can be disabled. When direction of the packet flow is important it is best to firewall on the member interfaces rather than the bridge itself.
The bridge has several configurable settings for passing non-IP and ARP packets, and layer2 firewalling with IPFW. See if_bridge(4) for more information.
29.5.6 Spanning Tree
The bridge driver implements the Rapid Spanning Tree Protocol (RSTP or 802.1w) with backwards compatibility with the legacy Spanning Tree Protocol (STP). Spanning Tree is used to detect and remove loops in a network topology. RSTP provides faster Spanning Tree convergence than legacy STP, the protocol will exchange information with neighbouring switches to quickly transition to forwarding without creating loops.
The following table shows the supported operating modes:
| OS Version | STP Modes | Default Mode |
|---|---|---|
| FreeBSD 5.4--FreeBSD 6.2 | STP | STP |
| FreeBSD 6.3+ | RSTP or STP | STP |
| FreeBSD 7.0+ | RSTP or STP | RSTP |
Spanning Tree can be enabled on member interfaces using the stp command. For a bridge with fxp0 and fxp1 as the current interfaces, enable STP with the following:
# ifconfig bridge0 stp fxp0 stp fxp1
bridge0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether d6:cf:d5:a0:94:6d
id 00:01:02:4b:d4:50 priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 100 timeout 1200
root id 00:01:02:4b:d4:50 priority 32768 ifcost 0 port 0
member: fxp0 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 3 priority 128 path cost 200000 proto rstp
role designated state forwarding
member: fxp1 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 4 priority 128 path cost 200000 proto rstp
role designated state forwarding
This bridge has a spanning tree ID of 00:01:02:4b:d4:50 and a priority of 32768. As the root id is the same it indicates that this is the root bridge for the tree.
Another bridge on the network also has spanning tree enabled:
bridge0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
ether 96:3d:4b:f1:79:7a
id 00:13:d4:9a:06:7a priority 32768 hellotime 2 fwddelay 15
maxage 20 holdcnt 6 proto rstp maxaddr 100 timeout 1200
root id 00:01:02:4b:d4:50 priority 32768 ifcost 400000 port 4
member: fxp0 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 4 priority 128 path cost 200000 proto rstp
role root state forwarding
member: fxp1 flags=1c7<LEARNING,DISCOVER,STP,AUTOEDGE,PTP,AUTOPTP>
port 5 priority 128 path cost 200000 proto rstp
role designated state forwarding
The line root id 00:01:02:4b:d4:50 priority 32768 ifcost 400000 port 4 shows that the root bridge is 00:01:02:4b:d4:50 as above and has a path cost of 400000 from this bridge, the path to the root bridge is via port 4 which is fxp0.
29.5.7 Advanced Bridging
29.5.7.1 Reconstruct Traffic Flows
The bridge supports monitor mode, where the packets are discarded after bpf(4) processing, and are not processed or forwarded further. This can be used to multiplex the input of two or more interfaces into a single bpf(4) stream. This is useful for reconstructing the traffic for network taps that transmit the RX/TX signals out through two separate interfaces.
To read the input from four network interfaces as one stream:
# ifconfig bridge0 addm fxp0 addm fxp1 addm fxp2 addm fxp3 monitor up
# tcpdump -i bridge0
29.5.7.2 Span Ports
A copy of every Ethernet frame received by the bridge will be transmitted out a designated span port. The number of span ports configured on a bridge is unlimited, if an interface is designated as a span port then it may not also be used as a regular bridge port. This is most useful for snooping a bridged network passively on another host connected to one of the span ports of the bridge.
To send a copy of all frames out the interface named fxp4:
# ifconfig bridge0 span fxp4
29.5.7.3 Private Interfaces
A private interface does not forward any traffic to any other port that is also a private interface. The traffic is blocked unconditionally so no Ethernet frames will be forwarded, including ARP. If traffic needs to be selectively blocked then a firewall should be used instead.
29.5.7.4 Sticky Interfaces
If a bridge member interface is marked as sticky then dynamically learned address entries are treated at static once entered into the forwarding cache. Sticky entries are never aged out of the cache or replaced, even if the address is seen on a different interface. This gives the benefit of static address entries without the need to pre-populate the forwarding table, clients learnt on a particular segment of the bridge can not roam to another segment.
Another example of using sticky addresses would be to combine the bridge with VLANs to create a router where customer networks are isolated without wasting IP address space. Consider that CustomerA is on vlan100 and CustomerB is on vlan101. The bridge has the address 192.168.0.1 and is also an internet router.
# ifconfig bridge0 addm vlan100 sticky vlan100 addm vlan101 sticky vlan101
# ifconfig bridge0 inet 192.168.0.1/24
Both clients see 192.168.0.1 as their default gateway and since the bridge cache is sticky they can not spoof the MAC address of the other customer to intercept their traffic.
Any communication between the VLANs can be blocked using private interfaces (or a firewall):
# ifconfig bridge0 private vlan100 private vlan101
The customers are completely isolated from each other, the full /24 address range can be allocated without subnetting.
29.5.7.5 Address limits
The number of unique source MAC addresses behind an interface can limited. Once the limit is reached packets with unknown source addresses are dropped until an existing host cache entry expires or is removed.
The following example sets the maximum number of Ethernet devices for CustomerA on vlan100 to 10.
# ifconfig bridge0 ifmaxaddr vlan100 10
29.5.7.6 SNMP Monitoring
The bridge interface and STP parameters can be monitored via the SNMP daemon which is included in the FreeBSD base system. The exported bridge MIBs conform to the IETF standards so any SNMP client or monitoring package can be used to retrieve the data.
On the bridge machine uncomment the begemotSnmpdModulePath."bridge" = "/usr/lib/snmp_bridge.so" line from /etc/snmp.config and start the bsnmpd daemon. Other configuration such as community names and access lists may need to be modified. See bsnmpd(1) and snmp_bridge(3) for more information.
The following examples use the Net-SNMP software (net-mgmt/net-snmp) to query a bridge, the net-mgmt/bsnmptools port can also be used. From the SNMP client host add to $HOME/.snmp/snmp.conf the following lines to import the bridge MIB definitions in to Net-SNMP:
mibdirs +/usr/share/snmp/mibs
mibs +BRIDGE-MIB:RSTP-MIB:BEGEMOT-MIB:BEGEMOT-BRIDGE-MIB
To monitor a single bridge via the IETF BRIDGE-MIB (RFC4188) do
% snmpwalk -v 2c -c public bridge1.example.com mib-2.dot1dBridge
BRIDGE-MIB::dot1dBaseBridgeAddress.0 = STRING: 66:fb:9b:6e:5c:44
BRIDGE-MIB::dot1dBaseNumPorts.0 = INTEGER: 1 ports
BRIDGE-MIB::dot1dStpTimeSinceTopologyChange.0 = Timeticks: (189959) 0:31:39.59 centi-seconds
BRIDGE-MIB::dot1dStpTopChanges.0 = Counter32: 2
BRIDGE-MIB::dot1dStpDesignatedRoot.0 = Hex-STRING: 80 00 00 01 02 4B D4 50
...
BRIDGE-MIB::dot1dStpPortState.3 = INTEGER: forwarding(5)
BRIDGE-MIB::dot1dStpPortEnable.3 = INTEGER: enabled(1)
BRIDGE-MIB::dot1dStpPortPathCost.3 = INTEGER: 200000
BRIDGE-MIB::dot1dStpPortDesignatedRoot.3 = Hex-STRING: 80 00 00 01 02 4B D4 50
BRIDGE-MIB::dot1dStpPortDesignatedCost.3 = INTEGER: 0
BRIDGE-MIB::dot1dStpPortDesignatedBridge.3 = Hex-STRING: 80 00 00 01 02 4B D4 50
BRIDGE-MIB::dot1dStpPortDesignatedPort.3 = Hex-STRING: 03 80
BRIDGE-MIB::dot1dStpPortForwardTransitions.3 = Counter32: 1
RSTP-MIB::dot1dStpVersion.0 = INTEGER: rstp(2)
The dot1dStpTopChanges.0 value is two which means that the STP bridge topology has changed twice, a topology change means that one or more links in the network have changed or failed and a new tree has been calculated. The dot1dStpTimeSinceTopologyChange.0 value will show when this happened.
To monitor multiple bridge interfaces one may use the private BEGEMOT-BRIDGE-MIB:
% snmpwalk -v 2c -c public bridge1.example.com
enterprises.fokus.begemot.begemotBridge
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseName."bridge0" = STRING: bridge0
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseName."bridge2" = STRING: bridge2
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseAddress."bridge0" = STRING: e:ce:3b:5a:9e:13
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseAddress."bridge2" = STRING: 12:5e:4d:74:d:fc
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseNumPorts."bridge0" = INTEGER: 1
BEGEMOT-BRIDGE-MIB::begemotBridgeBaseNumPorts."bridge2" = INTEGER: 1
...
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTimeSinceTopologyChange."bridge0" = Timeticks: (116927) 0:19:29.27 centi-seconds
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTimeSinceTopologyChange."bridge2" = Timeticks: (82773) 0:13:47.73 centi-seconds
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTopChanges."bridge0" = Counter32: 1
BEGEMOT-BRIDGE-MIB::begemotBridgeStpTopChanges."bridge2" = Counter32: 1
BEGEMOT-BRIDGE-MIB::begemotBridgeStpDesignatedRoot."bridge0" = Hex-STRING: 80 00 00 40 95 30 5E 31
BEGEMOT-BRIDGE-MIB::begemotBridgeStpDesignatedRoot."bridge2" = Hex-STRING: 80 00 00 50 8B B8 C6 A9
To change the bridge interface being monitored via the mib-2.dot1dBridge subtree do:
% snmpset -v 2c -c private bridge1.example.com
BEGEMOT-BRIDGE-MIB::begemotBridgeDefaultBridgeIf.0 s bridge2
29.6 Link Aggregation and Failover
Written by Andrew Thompson.29.6.1 Introduction
The lagg(4) interface allows aggregation of multiple network interfaces as one virtual interface for the purpose of providing fault-tolerance and high-speed links.
29.6.2 Operating Modes
- failover
-
Sends and receives traffic only through the master port. If the master port becomes unavailable, the next active port is used. The first interface added is the master port; any interfaces added after that are used as failover devices.
- fec
-
Supports Cisco EtherChannel. This is a static setup and does not negotiate aggregation with the peer or exchange frames to monitor the link, if the switch supports LACP then that should be used instead.
Balances outgoing traffic across the active ports based on hashed protocol header information and accepts incoming traffic from any active port. The hash includes the Ethernet source and destination address, and, if available, the VLAN tag, and the IPv4/IPv6 source and destination address.
- lacp
-
Supports the IEEE 802.3ad Link Aggregation Control Protocol (LACP) and the Marker Protocol. LACP will negotiate a set of aggregable links with the peer in to one or more Link Aggregated Groups. Each LAG is composed of ports of the same speed, set to full-duplex operation. The traffic will be balanced across the ports in the LAG with the greatest total speed, in most cases there will only be one LAG which contains all ports. In the event of changes in physical connectivity, Link Aggregation will quickly converge to a new configuration.
Balances outgoing traffic across the active ports based on hashed protocol header information and accepts incoming traffic from any active port. The hash includes the Ethernet source and destination address, and, if available, the VLAN tag, and the IPv4/IPv6 source and destination address.
- loadbalance
-
This is an alias of fec mode.
- roundrobin
-
Distributes outgoing traffic using a round-robin scheduler through all active ports and accepts incoming traffic from any active port. This mode will violate Ethernet frame ordering and should be used with caution.
29.6.3 Examples
Example 29-1. LACP aggregation with a Cisco switch
This example connects two interfaces on a FreeBSD machine to the switch as a single load balanced and fault tolerant link. More interfaces can be added to increase throughput and fault tolerance. Since frame ordering is mandatory on Ethernet links then any traffic between two stations always flows over the same physical link limiting the maximum speed to that of one interface. The transmit algorithm attempts to use as much information as it can to distinguish different traffic flows and balance across the available interfaces.
On the Cisco switch add the interfaces to the channel group.
interface FastEthernet0/1
channel-group 1 mode active
channel-protocol lacp
!
interface FastEthernet0/2
channel-group 1 mode active
channel-protocol lacp
!
On the FreeBSD machine create the lagg interface.
# ifconfig lagg0 create
# ifconfig lagg0 up laggproto lacp laggport fxp0 laggport fxp1
View the interface status from ifconfig; ports marked as ACTIVE are part of the active aggregation group that has been negotiated with the remote switch and traffic will be transmitted and received. Use the verbose output of ifconfig(8) to view the LAG identifiers.
lagg0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8<VLAN_MTU>
ether 00:05:5d:71:8d:b8
media: Ethernet autoselect
status: active
laggproto lacp
laggport: fxp1 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
laggport: fxp0 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
The switch will show which ports are active. For more detail use show lacp neighbor detail.
switch# show lacp neighbor
Flags: S - Device is requesting Slow LACPDUs
F - Device is requesting Fast LACPDUs
A - Device is in Active mode P - Device is in Passive mode
Channel group 1 neighbors
Partner's information:
LACP port Oper Port Port
Port Flags Priority Dev ID Age Key Number State
Fa0/1 SA 32768 0005.5d71.8db8 29s 0x146 0x3 0x3D
Fa0/2 SA 32768 0005.5d71.8db8 29s 0x146 0x4 0x3D
Example 29-2. Failover mode
Failover mode can be used to switch over to another interface if the link is lost on the master.
# ifconfig lagg0 create
# ifconfig lagg0 up laggproto failover laggport fxp0 laggport fxp1
lagg0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=8<VLAN_MTU>
ether 00:05:5d:71:8d:b8
media: Ethernet autoselect
status: active
laggproto failover
laggport: fxp1 flags=0<>
laggport: fxp0 flags=5<MASTER,ACTIVE>
Traffic will be transmitted and received on fxp0. If the link is lost on fxp0 then fxp1 will become the active link. If the link is restored on the master interface then it will once again become the active link.
29.7 Diskless Operation
Updated by Jean-François Dockès. Reorganized and enhanced by Alex Dupre.A FreeBSD machine can boot over the network and operate without a local disk, using file systems mounted from an NFS server. No system modification is necessary, beyond standard configuration files. Such a system is relatively easy to set up because all the necessary elements are readily available:
-
There are at least two possible methods to load the kernel over the network:
-
PXE: The Intel Preboot eXecution Environment system is a form of smart boot ROM built into some networking cards or motherboards. See pxeboot(8) for more details.
-
The Etherboot port (net/etherboot) produces ROM-able code to boot kernels over the network. The code can be either burnt into a boot PROM on a network card, or loaded from a local floppy (or hard) disk drive, or from a running MS-DOS system. Many network cards are supported.
-
-
A sample script (/usr/share/examples/diskless/clone_root) eases the creation and maintenance of the workstation's root file system on the server. The script will probably require a little customization but it will get you started very quickly.
-
Standard system startup files exist in /etc to detect and support a diskless system startup.
-
Swapping, if needed, can be done either to an NFS file or to a local disk.
There are many ways to set up diskless workstations. Many elements are involved, and most can be customized to suit local taste. The following will describe variations on the setup of a complete system, emphasizing simplicity and compatibility with the standard FreeBSD startup scripts. The system described has the following characteristics:
-
The diskless workstations use a shared read-only / file system, and a shared read-only /usr.
The root file system is a copy of a standard FreeBSD root (typically the server's), with some configuration files overridden by ones specific to diskless operation or, possibly, to the workstation they belong to.
The parts of the root which have to be writable are overlaid with md(4) file systems. Any changes will be lost when the system reboots.
-
The kernel is transferred and loaded either with Etherboot or PXE as some situations may mandate the use of either method.
Caution: As described, this system is insecure. It should live in a protected area of a network, and be untrusted by other hosts.
All the information in this section has been tested using FreeBSD 5.2.1-RELEASE.
29.7.1 Background Information
Setting up diskless workstations is both relatively straightforward and prone to errors. These are sometimes difficult to diagnose for a number of reasons. For example:
-
Compile time options may determine different behaviors at runtime.
-
Error messages are often cryptic or totally absent.
In this context, having some knowledge of the background mechanisms involved is very useful to solve the problems that may arise.
Several operations need to be performed for a successful bootstrap:
-
The machine needs to obtain initial parameters such as its IP address, executable filename, server name, root path. This is done using the DHCP or BOOTP protocols. DHCP is a compatible extension of BOOTP, and uses the same port numbers and basic packet format.
It is possible to configure a system to use only BOOTP. The bootpd(8) server program is included in the base FreeBSD system.
However, DHCP has a number of advantages over BOOTP (nicer configuration files, possibility of using PXE, plus many others not directly related to diskless operation), and we will describe mainly a DHCP configuration, with equivalent examples using bootpd(8) when possible. The sample configuration will use the ISC DHCP software package (release 3.0.1.r12 was installed on the test server).
-
The machine needs to transfer one or several programs to local memory. Either TFTP or NFS are used. The choice between TFTP and NFS is a compile time option in several places. A common source of error is to specify filenames for the wrong protocol: TFTP typically transfers all files from a single directory on the server, and would expect filenames relative to this directory. NFS needs absolute file paths.
-
The possible intermediate bootstrap programs and the kernel need to be initialized and executed. There are several important variations in this area:
-
PXE will load pxeboot(8), which is a modified version of the FreeBSD third stage loader. The loader(8) will obtain most parameters necessary to system startup, and leave them in the kernel environment before transferring control. It is possible to use a GENERIC kernel in this case.
-
Etherboot, will directly load the kernel, with less preparation. You will need to build a kernel with specific options.
PXE and Etherboot work equally well; however, because kernels normally let the loader(8) do more work for them, PXE is the preferred method.
If your BIOS and network cards support PXE, you should probably use it.
-
-
Finally, the machine needs to access its file systems. NFS is used in all cases.
See also diskless(8) manual page.
29.7.2 Setup Instructions
29.7.2.1 Configuration Using ISC DHCP
The ISC DHCP server can answer both BOOTP and DHCP requests.
ISC DHCP 3.0 is not part of the base system. You will first need to install the net/isc-dhcp3-server port or the corresponding package.
Once ISC DHCP is installed, it needs a configuration file to run (normally named /usr/local/etc/dhcpd.conf). Here follows a commented example, where host margaux uses Etherboot and host corbieres uses PXE:
default-lease-time 600;
max-lease-time 7200;
authoritative;
option domain-name "example.com";
option domain-name-servers 192.168.4.1;
option routers 192.168.4.1;
subnet 192.168.4.0 netmask 255.255.255.0 {
use-host-decl-names on;
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.4.255;
host margaux {
hardware ethernet 01:23:45:67:89:ab;
fixed-address margaux.example.com;
next-server 192.168.4.4;
filename "/data/misc/kernel.diskless";
option root-path "192.168.4.4:/data/misc/diskless";
}
host corbieres {
hardware ethernet 00:02:b3:27:62:df;
fixed-address corbieres.example.com;
next-server 192.168.4.4;
filename "pxeboot";
option root-path "192.168.4.4:/data/misc/diskless";
}
}
- This option tells dhcpd to send the value in the host declarations as the hostname for the diskless host. An alternate way would be to add an option host-name margaux inside the host declarations.
- The next-server directive designates the TFTP or NFS server to use for loading loader or kernel file (the default is to use the same host as the DHCP server).
- The filename directive defines the file that Etherboot or PXE will load for the next execution step. It must be specified according to the transfer method used. Etherboot can be compiled to use NFS or TFTP. The FreeBSD port configures NFS by default. PXE uses TFTP, which is why a relative filename is used here (this may depend on the TFTP server configuration, but would be fairly typical). Also, PXE loads pxeboot, not the kernel. There are other interesting possibilities, like loading pxeboot from a FreeBSD CD-ROM /boot directory (as pxeboot(8) can load a GENERIC kernel, this makes it possible to use PXE to boot from a remote CD-ROM).
- The root-path option defines the path to the root file system, in usual NFS notation. When using PXE, it is possible to leave off the host's IP as long as you do not enable the kernel option BOOTP. The NFS server will then be the same as the TFTP one.
29.7.2.2 Configuration Using BOOTP
Here follows an equivalent bootpd configuration (reduced to one client). This would be found in /etc/bootptab.
Please note that Etherboot must be compiled with the non-default option NO_DHCP_SUPPORT in order to use BOOTP, and that PXE needs DHCP. The only obvious advantage of bootpd is that it exists in the base system.
.def100:\
:hn:ht=1:sa=192.168.4.4:vm=rfc1048:\
:sm=255.255.255.0:\
:ds=192.168.4.1:\
:gw=192.168.4.1:\
:hd="/tftpboot":\
:bf="/kernel.diskless":\
:rp="192.168.4.4:/data/misc/diskless":
margaux:ha=0123456789ab:tc=.def100
29.7.2.3 Preparing a Boot Program with Etherboot
Etherboot's Web site contains extensive documentation mainly intended for Linux systems, but nonetheless containing useful information. The following will just outline how you would use Etherboot on a FreeBSD system.
You must first install the net/etherboot package or port.
You can change the Etherboot configuration (i.e. to use TFTP instead of NFS) by editing the Config file in the Etherboot source directory.
For our setup, we shall use a boot floppy. For other methods (PROM, or MS-DOS program), please refer to the Etherboot documentation.
To make a boot floppy, insert a floppy in the drive on the machine where you installed Etherboot, then change your current directory to the src directory in the Etherboot tree and type:
# gmake bin32/devicetype.fd0
devicetype depends on the type of the Ethernet card in the diskless workstation. Refer to the NIC file in the same directory to determine the right devicetype.
29.7.2.4 Booting with PXE
By default, the pxeboot(8) loader loads the kernel via NFS. It can be compiled to use TFTP instead by specifying the LOADER_TFTP_SUPPORT option in /etc/make.conf. See the comments in /usr/share/examples/etc/make.conf for instructions.
There are two other make.conf options which may be useful for setting up a serial console diskless machine: BOOT_PXELDR_PROBE_KEYBOARD, and BOOT_PXELDR_ALWAYS_SERIAL.
To use PXE when the machine starts, you will usually need to select the Boot from network option in your BIOS setup, or type a function key during the PC initialization.
29.7.2.5 Configuring the TFTP and NFS Servers
If you are using PXE or Etherboot configured to use TFTP, you need to enable tftpd on the file server:
-
Create a directory from which tftpd will serve the files, e.g. /tftpboot.
-
Add this line to your /etc/inetd.conf:
tftp dgram udp wait root /usr/libexec/tftpd tftpd -l -s /tftpbootNote: It appears that at least some PXE versions want the TCP version of TFTP. In this case, add a second line, replacing dgram udp with stream tcp.
-
Tell inetd to reread its configuration file. The
inetd_enable="YES"must be in the /etc/rc.conf file for this command to execute correctly:# /etc/rc.d/inetd restart
You can place the tftpboot directory anywhere on the server. Make sure that the location is set in both inetd.conf and dhcpd.conf.
In all cases, you also need to enable NFS and export the appropriate file system on the NFS server.
-
Add this to /etc/rc.conf:
nfs_server_enable="YES" -
Export the file system where the diskless root directory is located by adding the following to /etc/exports (adjust the volume mount point and replace margaux corbieres with the names of the diskless workstations):
/data/misc -alldirs -ro margaux corbieres -
Tell mountd to reread its configuration file. If you actually needed to enable NFS in /etc/rc.conf at the first step, you probably want to reboot instead.
# /etc/rc.d/mountd restart
29.7.2.6 Building a Diskless Kernel
If using Etherboot, you need to create a kernel configuration file for the diskless client with the following options (in addition to the usual ones):
options BOOTP # Use BOOTP to obtain IP address/hostname
options BOOTP_NFSROOT # NFS mount root file system using BOOTP info
You may also want to use BOOTP_NFSV3, BOOT_COMPAT and BOOTP_WIRED_TO (refer to NOTES).
These option names are historical and slightly misleading as they actually enable indifferent use of DHCP and BOOTP inside the kernel (it is also possible to force strict BOOTP or DHCP use).
Build the kernel (see Chapter 8), and copy it to the place specified in dhcpd.conf.
Note: When using PXE, building a kernel with the above options is not strictly necessary (though suggested). Enabling them will cause more DHCP requests to be issued during kernel startup, with a small risk of inconsistency between the new values and those retrieved by pxeboot(8) in some special cases. The advantage of using them is that the host name will be set as a side effect. Otherwise you will need to set the host name by another method, for example in a client-specific rc.conf file.
Note: In order to be loadable with Etherboot, a kernel needs to have the device hints compiled in. You would typically set the following option in the configuration file (see the NOTES configuration comments file):
hints "GENERIC.hints"
29.7.2.7 Preparing the Root Filesystem
You need to create a root file system for the diskless workstations, in the location listed as root-path in dhcpd.conf.
29.7.2.7.1 Using make world to populate root
This method is quick and will install a complete virgin system (not only the root file system) into DESTDIR. All you have to do is simply execute the following script:
#!/bin/sh
export DESTDIR=/data/misc/diskless
mkdir -p ${DESTDIR}
cd /usr/src; make buildworld && make buildkernel
cd /usr/src/etc; make distribution
Once done, you may need to customize your /etc/rc.conf and /etc/fstab placed into DESTDIR according to your needs.
29.7.2.8 Configuring Swap
If needed, a swap file located on the server can be accessed via NFS.
29.7.2.8.1 NFS Swap
The kernel does not support enabling NFS swap at boot time. Swap must be enabled by the startup scripts, by mounting a writable file system and creating and enabling a swap file. To create a swap file of appropriate size, you can do like this:
# dd if=/dev/zero of=/path/to/swapfile bs=1k count=1 oseek=100000
To enable it you have to add the following line to your rc.conf:
swapfile=/path/to/swapfile
29.7.2.9 Miscellaneous Issues
29.7.2.9.1 Running with a Read-only /usr
If the diskless workstation is configured to run X, you will have to adjust the XDM configuration file, which puts the error log on /usr by default.
29.7.2.9.2 Using a Non-FreeBSD Server
When the server for the root file system is not running FreeBSD, you will have to create the root file system on a FreeBSD machine, then copy it to its destination, using tar or cpio.
In this situation, there are sometimes problems with the special files in /dev, due to differing major/minor integer sizes. A solution to this problem is to export a directory from the non-FreeBSD server, mount this directory onto a FreeBSD machine, and use devfs(5) to allocate device nodes transparently for the user.
29.8 ISDN
A good resource for information on ISDN technology and hardware is Dan Kegel's ISDN Page.
A quick simple road map to ISDN follows:
-
If you live in Europe you might want to investigate the ISDN card section.
-
If you are planning to use ISDN primarily to connect to the Internet with an Internet Provider on a dial-up non-dedicated basis, you might look into Terminal Adapters. This will give you the most flexibility, with the fewest problems, if you change providers.
-
If you are connecting two LANs together, or connecting to the Internet with a dedicated ISDN connection, you might consider the stand alone router/bridge option.
Cost is a significant factor in determining what solution you will choose. The following options are listed from least expensive to most expensive.
29.8.1 ISDN Cards
Contributed by Hellmuth Michaelis.FreeBSD's ISDN implementation supports only the DSS1/Q.931 (or Euro-ISDN) standard using passive cards. Some active cards are supported where the firmware also supports other signaling protocols; this also includes the first supported Primary Rate (PRI) ISDN card.
The isdn4bsd software allows you to connect to other ISDN routers using either IP over raw HDLC or by using synchronous PPP: either by using kernel PPP with isppp, a modified sppp(4) driver, or by using userland ppp(8). By using userland ppp(8), channel bonding of two or more ISDN B-channels is possible. A telephone answering machine application is also available as well as many utilities such as a software 300 Baud modem.
Some growing number of PC ISDN cards are supported under FreeBSD and the reports show that it is successfully used all over Europe and in many other parts of the world.
The passive ISDN cards supported are mostly the ones with the Infineon (formerly Siemens) ISAC/HSCX/IPAC ISDN chipsets, but also ISDN cards with chips from Cologne Chip (ISA bus only), PCI cards with Winbond W6692 chips, some cards with the Tiger300/320/ISAC chipset combinations and some vendor specific chipset based cards such as the AVM Fritz!Card PCI V.1.0 and the AVM Fritz!Card PnP.
Currently the active supported ISDN cards are the AVM B1 (ISA and PCI) BRI cards and the AVM T1 PCI PRI cards.
For documentation on isdn4bsd, have a look at /usr/share/examples/isdn/ directory on your FreeBSD system or at the homepage of isdn4bsd which also has pointers to hints, erratas and much more documentation such as the isdn4bsd handbook.
In case you are interested in adding support for a different ISDN protocol, a
currently unsupported ISDN PC card or otherwise enhancing isdn4bsd, please get in touch with Hellmuth Michaelis <hm@FreeBSD.org>.
For questions regarding the installation, configuration and troubleshooting isdn4bsd, a freebsd-isdn mailing list is available.
29.8.2 ISDN Terminal Adapters
Terminal adapters (TA), are to ISDN what modems are to regular phone lines.
Most TA's use the standard Hayes modem AT command set, and can be used as a drop in replacement for a modem.
A TA will operate basically the same as a modem except connection and throughput speeds will be much faster than your old modem. You will need to configure PPP exactly the same as for a modem setup. Make sure you set your serial speed as high as possible.
The main advantage of using a TA to connect to an Internet Provider is that you can do Dynamic PPP. As IP address space becomes more and more scarce, most providers are not willing to provide you with a static IP anymore. Most stand-alone routers are not able to accommodate dynamic IP allocation.
TA's completely rely on the PPP daemon that you are running for their features and stability of connection. This allows you to upgrade easily from using a modem to ISDN on a FreeBSD machine, if you already have PPP set up. However, at the same time any problems you experienced with the PPP program and are going to persist.
If you want maximum stability, use the kernel PPP option, not the userland PPP.
The following TA's are known to work with FreeBSD:
-
Motorola BitSurfer and Bitsurfer Pro
-
Adtran
Most other TA's will probably work as well, TA vendors try to make sure their product can accept most of the standard modem AT command set.
The real problem with external TA's is that, like modems, you need a good serial card in your computer.
You should read the FreeBSD Serial Hardware tutorial for a detailed understanding of serial devices, and the differences between asynchronous and synchronous serial ports.
A TA running off a standard PC serial port (asynchronous) limits you to 115.2 Kbs, even though you have a 128 Kbs connection. To fully utilize the 128 Kbs that ISDN is capable of, you must move the TA to a synchronous serial card.
Do not be fooled into buying an internal TA and thinking you have avoided the synchronous/asynchronous issue. Internal TA's simply have a standard PC serial port chip built into them. All this will do is save you having to buy another serial cable and find another empty electrical socket.
A synchronous card with a TA is at least as fast as a stand-alone router, and with a simple 386 FreeBSD box driving it, probably more flexible.
The choice of synchronous card/TA v.s. stand-alone router is largely a religious issue. There has been some discussion of this in the mailing lists. We suggest you search the archives for the complete discussion.
29.8.3 Stand-alone ISDN Bridges/Routers
ISDN bridges or routers are not at all specific to FreeBSD or any other operating system. For a more complete description of routing and bridging technology, please refer to a networking reference book.
In the context of this section, the terms router and bridge will be used interchangeably.
As the cost of low end ISDN routers/bridges comes down, it will likely become a more and more popular choice. An ISDN router is a small box that plugs directly into your local Ethernet network, and manages its own connection to the other bridge/router. It has built in software to communicate via PPP and other popular protocols.
A router will allow you much faster throughput than a standard TA, since it will be using a full synchronous ISDN connection.
The main problem with ISDN routers and bridges is that interoperability between manufacturers can still be a problem. If you are planning to connect to an Internet provider, you should discuss your needs with them.
If you are planning to connect two LAN segments together, such as your home LAN to the office LAN, this is the simplest lowest maintenance solution. Since you are buying the equipment for both sides of the connection you can be assured that the link will work.
For example to connect a home computer or branch office network to a head office network the following setup could be used:
Example 29-3. Branch Office or Home Network
Network uses a bus based topology with 10 base 2 Ethernet (“thinnet”). Connect router to network cable with AUI/10BT transceiver, if necessary.
If your home/branch office is only one computer you can use a twisted pair crossover cable to connect to the stand-alone router directly.
Example 29-4. Head Office or Other LAN
Network uses a star topology with 10 base T Ethernet (“Twisted Pair”).
One large advantage of most routers/bridges is that they allow you to have 2 separate independent PPP connections to 2 separate sites at the same time. This is not supported on most TA's, except for specific (usually expensive) models that have two serial ports. Do not confuse this with channel bonding, MPP, etc.
This can be a very useful feature if, for example, you have an dedicated ISDN connection at your office and would like to tap into it, but do not want to get another ISDN line at work. A router at the office location can manage a dedicated B channel connection (64 Kbps) to the Internet and use the other B channel for a separate data connection. The second B channel can be used for dial-in, dial-out or dynamically bonding (MPP, etc.) with the first B channel for more bandwidth.
An Ethernet bridge will also allow you to transmit more than just IP traffic. You can also send IPX/SPX or whatever other protocols you use.
29.9 Network Address Translation
Contributed by Chern Lee.29.9.1 Overview
FreeBSD's Network Address Translation daemon, commonly known as natd(8) is a daemon that accepts incoming raw IP packets, changes the source to the local machine and re-injects these packets back into the outgoing IP packet stream. natd(8) does this by changing the source IP address and port such that when data is received back, it is able to determine the original location of the data and forward it back to its original requester.
The most common use of NAT is to perform what is commonly known as Internet Connection Sharing.
29.9.2 Setup
Due to the diminishing IP space in IPv4, and the increased number of users on high-speed consumer lines such as cable or DSL, people are increasingly in need of an Internet Connection Sharing solution. The ability to connect several computers online through one connection and IP address makes natd(8) a reasonable choice.
Most commonly, a user has a machine connected to a cable or DSL line with one IP address and wishes to use this one connected computer to provide Internet access to several more over a LAN.
To do this, the FreeBSD machine on the Internet must act as a gateway. This gateway machine must have two NICs--one for connecting to the Internet router, the other connecting to a LAN. All the machines on the LAN are connected through a hub or switch.
Note: There are many ways to get a LAN connected to the Internet through a FreeBSD gateway. This example will only cover a gateway with at least two NICs.
A setup like this is commonly used to share an Internet connection. One of the LAN machines is connected to the Internet. The rest of the machines access the Internet through that “gateway” machine.
29.9.3 Configuration
The following options must be in the kernel configuration file:
options IPFIREWALL
options IPDIVERT
Additionally, at choice, the following may also be suitable:
options IPFIREWALL_DEFAULT_TO_ACCEPT
options IPFIREWALL_VERBOSE
The following must be in /etc/rc.conf:
gateway_enable="YES"
firewall_enable="YES"
firewall_type="OPEN"
natd_enable="YES"
natd_interface="fxp0"
natd_flags=""
- Sets up the machine to act as a gateway. Running sysctl net.inet.ip.forwarding=1 would have the same effect.
- Enables the firewall rules in /etc/rc.firewall at boot.
- This specifies a predefined firewall ruleset that allows anything in. See /etc/rc.firewall for additional types.
- Indicates which interface to forward packets through (the interface connected to the Internet).
- Any additional configuration options passed to natd(8) on boot.
Having the previous options defined in /etc/rc.conf would run natd -interface fxp0 at boot. This can also be run manually.
Note: It is also possible to use a configuration file for natd(8) when there are too many options to pass. In this case, the configuration file must be defined by adding the following line to /etc/rc.conf:
natd_flags="-f /etc/natd.conf"The /etc/natd.conf file will contain a list of configuration options, one per line. For example the next section case would use the following file:
redirect_port tcp 192.168.0.2:6667 6667 redirect_port tcp 192.168.0.3:80 80For more information about the configuration file, consult the natd(8) manual page about the
-foption.
Each machine and interface behind the LAN should be assigned IP address numbers in the private network space as defined by RFC 1918 and have a default gateway of the natd machine's internal IP address.
For example, client A and B behind the LAN have IP addresses of 192.168.0.2 and 192.168.0.3, while the natd machine's LAN interface has an IP address of 192.168.0.1. Client A and B's default gateway must be set to that of the natd machine, 192.168.0.1. The natd machine's external, or Internet interface does not require any special modification for natd(8) to work.
29.9.4 Port Redirection
The drawback with natd(8) is that the LAN clients are not accessible from the Internet. Clients on the LAN can make outgoing connections to the world but cannot receive incoming ones. This presents a problem if trying to run Internet services on one of the LAN client machines. A simple way around this is to redirect selected Internet ports on the natd machine to a LAN client.
For example, an IRC server runs on client A, and a web server runs on client B. For this to work properly, connections received on ports 6667 (IRC) and 80 (web) must be redirected to the respective machines.
The -redirect_port must be passed to natd(8) with the
proper options. The syntax is as follows:
-redirect_port proto targetIP:targetPORT[-targetPORT]
[aliasIP:]aliasPORT[-aliasPORT]
[remoteIP[:remotePORT[-remotePORT]]]
In the above example, the argument should be:
-redirect_port tcp 192.168.0.2:6667 6667
-redirect_port tcp 192.168.0.3:80 80
This will redirect the proper tcp ports to the LAN client machines.
The -redirect_port argument can be used to indicate port
ranges over individual ports. For example, tcp
192.168.0.2:2000-3000 2000-3000 would redirect all connections received on ports
2000 to 3000 to ports 2000 to 3000 on client A.
These options can be used when directly running natd(8), placed within the natd_flags="" option in /etc/rc.conf, or passed via a configuration file.
For further configuration options, consult natd(8)
29.9.5 Address Redirection
Address redirection is useful if several IP addresses are available, yet they must be on one machine. With this, natd(8) can assign each LAN client its own external IP address. natd(8) then rewrites outgoing packets from the LAN clients with the proper external IP address and redirects all traffic incoming on that particular IP address back to the specific LAN client. This is also known as static NAT. For example, the IP addresses 128.1.1.1, 128.1.1.2, and 128.1.1.3 belong to the natd gateway machine. 128.1.1.1 can be used as the natd gateway machine's external IP address, while 128.1.1.2 and 128.1.1.3 are forwarded back to LAN clients A and B.
The -redirect_address syntax is as follows:
-redirect_address localIP publicIP
| localIP | The internal IP address of the LAN client. |
| publicIP | The external IP address corresponding to the LAN client. |
In the example, this argument would read:
-redirect_address 192.168.0.2 128.1.1.2
-redirect_address 192.168.0.3 128.1.1.3
Like -redirect_port, these arguments are also placed
within the natd_flags="" option of /etc/rc.conf, or passed via a configuration file. With address
redirection, there is no need for port redirection since all data received on a
particular IP address is redirected.
The external IP addresses on the natd machine must be active and aliased to the external interface. Look at rc.conf(5) to do so.
29.10 Parallel Line IP (PLIP)
PLIP lets us run TCP/IP between parallel ports. It is useful on machines without network cards, or to install on laptops. In this section, we will discuss:
-
Creating a parallel (laplink) cable.
-
Connecting two computers with PLIP.
29.10.1 Creating a Parallel Cable
You can purchase a parallel cable at most computer supply stores. If you cannot do that, or you just want to know how it is done, the following table shows how to make one out of a normal parallel printer cable.
Table 29-1. Wiring a Parallel Cable for Networking
| A-name | A-End | B-End | Descr. | Post/Bit |
|---|---|---|---|---|
|
DATA0 |
2 |
15 |
Data |
0/0x01 |
|
DATA1 |
3 |
13 |
Data |
0/0x02 |
|
DATA2 |
4 |
12 |
Data |
0/0x04 |
|
DATA3 |
5 |
10 |
Strobe |
0/0x08 |
|
DATA4 |
6 |
11 |
Data |
0/0x10 |
| GND | 18-25 | 18-25 | GND | - |
29.10.2 Setting Up PLIP
First, you have to get a laplink cable. Then, confirm that both computers have a kernel with lpt(4) driver support:
# grep lp /var/run/dmesg.boot
lpt0: <Printer> on ppbus0
lpt0: Interrupt-driven port
The parallel port must be an interrupt driven port, you should have lines similar to the following in your in the /boot/device.hints file:
hint.ppc.0.at="isa"
hint.ppc.0.irq="7"
Then check if the kernel configuration file has a device plip line or if the plip.ko kernel module is loaded. In both cases the parallel networking interface should appear when you use the ifconfig(8) command to display it:
# ifconfig plip0
plip0: flags=8810<POINTOPOINT,SIMPLEX,MULTICAST> mtu 1500
Plug the laplink cable into the parallel interface on both computers.
Configure the network interface parameters on both sites as root. For example, if you want to connect the host host1 with another machine host2:
host1 <-----> host2
IP Address 10.0.0.1 10.0.0.2
Configure the interface on host1 by doing:
# ifconfig plip0 10.0.0.1 10.0.0.2
Configure the interface on host2 by doing:
# ifconfig plip0 10.0.0.2 10.0.0.1
You now should have a working connection. Please read the manual pages lp(4) and lpt(4) for more details.
You should also add both hosts to /etc/hosts:
127.0.0.1 localhost.my.domain localhost
10.0.0.1 host1.my.domain host1
10.0.0.2 host2.my.domain
To confirm the connection works, go to each host and ping the other. For example, on host1:
# ifconfig plip0
plip0: flags=8851<UP,POINTOPOINT,RUNNING,SIMPLEX,MULTICAST> mtu 1500
inet 10.0.0.1 --> 10.0.0.2 netmask 0xff000000
# netstat -r
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
host2 host1 UH 0 0 plip0
# ping -c 4 host2
PING host2 (10.0.0.2): 56 data bytes
64 bytes from 10.0.0.2: icmp_seq=0 ttl=255 time=2.774 ms
64 bytes from 10.0.0.2: icmp_seq=1 ttl=255 time=2.530 ms
64 bytes from 10.0.0.2: icmp_seq=2 ttl=255 time=2.556 ms
64 bytes from 10.0.0.2: icmp_seq=3 ttl=255 time=2.714 ms
--- host2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/stddev = 2.530/2.643/2.774/0.103 ms
29.11 IPv6
Originally Written by Aaron Kaplan. Restructured and Added by Tom Rhodes. Extended by Brad Davis.IPv6 (also known as IPng “IP next generation”) is the new version of the well known IP protocol (also known as IPv4). Like the other current *BSD systems, FreeBSD includes the KAME IPv6 reference implementation. So your FreeBSD system comes with all you will need to experiment with IPv6. This section focuses on getting IPv6 configured and running.
In the early 1990s, people became aware of the rapidly diminishing address space of IPv4. Given the expansion rate of the Internet there were two major concerns:
-
Running out of addresses. Today this is not so much of a concern anymore since RFC1918 private address space (10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16) and Network Address Translation (NAT) are being employed.
-
Router table entries were getting too large. This is still a concern today.
IPv6 deals with these and many other issues:
-
128 bit address space. In other words theoretically there are 340,282,366,920,938,463,463,374,607,431,768,211,456 addresses available. This means there are approximately 6.67 * 10^27 IPv6 addresses per square meter on our planet.
-
Routers will only store network aggregation addresses in their routing tables thus reducing the average space of a routing table to 8192 entries.
There are also lots of other useful features of IPv6 such as:
-
Address autoconfiguration (RFC2462)
-
Anycast addresses (“one-out-of many”)
-
Mandatory multicast addresses
-
IPsec (IP security)
-
Simplified header structure
-
Mobile IP
-
IPv6-to-IPv4 transition mechanisms
For more information see:
-
IPv6 overview at playground.sun.com
29.11.1 Background on IPv6 Addresses
There are different types of IPv6 addresses: Unicast, Anycast and Multicast.
Unicast addresses are the well known addresses. A packet sent to a unicast address arrives exactly at the interface belonging to the address.
Anycast addresses are syntactically indistinguishable from unicast addresses but they address a group of interfaces. The packet destined for an anycast address will arrive at the nearest (in router metric) interface. Anycast addresses may only be used by routers.
Multicast addresses identify a group of interfaces. A packet destined for a multicast address will arrive at all interfaces belonging to the multicast group.
Note: The IPv4 broadcast address (usually xxx.xxx.xxx.255) is expressed by multicast addresses in IPv6.
Table 29-2. Reserved IPv6 addresses
| IPv6 address | Prefixlength (Bits) | Description | Notes |
|---|---|---|---|
| :: | 128 bits | unspecified | cf. 0.0.0.0 in IPv4 |
| ::1 | 128 bits | loopback address | cf. 127.0.0.1 in IPv4 |
| ::00:xx:xx:xx:xx | 96 bits | embedded IPv4 | The lower 32 bits are the IPv4 address. Also called “IPv4 compatible IPv6 address” |
| ::ff:xx:xx:xx:xx | 96 bits | IPv4 mapped IPv6 address | The lower 32 bits are the IPv4 address. For hosts which do not support IPv6. |
| fe80:: - feb:: | 10 bits | link-local | cf. loopback address in IPv4 |
| fec0:: - fef:: | 10 bits | site-local | |
| ff:: | 8 bits | multicast | |
| 001 (base 2) | 3 bits | global unicast | All global unicast addresses are assigned from this pool. The first 3 bits are “001”. |
29.11.2 Reading IPv6 Addresses
The canonical form is represented as: x:x:x:x:x:x:x:x, each “x” being a 16 Bit hex value. For example FEBC:A574:382B:23C1:AA49:4592:4EFE:9982
Often an address will have long substrings of all zeros therefore one such substring per address can be abbreviated by “::”. Also up to three leading “0”s per hexquad can be omitted. For example fe80::1 corresponds to the canonical form fe80:0000:0000:0000:0000:0000:0000:0001.
A third form is to write the last 32 Bit part in the well known (decimal) IPv4 style with dots “.” as separators. For example 2002::10.0.0.1 corresponds to the (hexadecimal) canonical representation 2002:0000:0000:0000:0000:0000:0a00:0001 which in turn is equivalent to writing 2002::a00:1.
By now the reader should be able to understand the following:
# ifconfig
rl0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> mtu 1500
inet 10.0.0.10 netmask 0xffffff00 broadcast 10.0.0.255
inet6 fe80::200:21ff:fe03:8e1%rl0 prefixlen 64 scopeid 0x1
ether 00:00:21:03:08:e1
media: Ethernet autoselect (100baseTX )
status: active
fe80::200:21ff:fe03:8e1%rl0 is an auto configured link-local address. It is generated from the MAC address as part of the auto configuration.
For further information on the structure of IPv6 addresses see RFC3513.
29.11.3 Getting Connected
Currently there are four ways to connect to other IPv6 hosts and networks:
-
Getting an IPv6 network from your upstream provider. Talk to your Internet provider for instructions.
-
Tunnel via 6-to-4 (RFC3068)
-
Use the net/freenet6 port if you are on a dial-up connection.
29.11.4 DNS in the IPv6 World
There used to be two types of DNS records for IPv6. The IETF has declared A6 records obsolete. AAAA records are the standard now.
Using AAAA records is straightforward. Assign your hostname to the new IPv6 address you just received by adding:
MYHOSTNAME AAAA MYIPv6ADDR
To your primary zone DNS file. In case you do not serve your own DNS zones ask your DNS provider. Current versions of bind (version 8.3 and 9) and dns/djbdns (with the IPv6 patch) support AAAA records.
29.11.5 Applying the needed changes to /etc/rc.conf
29.11.5.1 IPv6 Client Settings
These settings will help you configure a machine that will be on your LAN and act as a client, not a router. To have rtsol(8) autoconfigure your interface on boot all you need to add is:
ipv6_enable="YES"
To statically assign an IP address such as 2001:471:1f11:251:290:27ff:fee0:2093, to your fxp0 interface, add:
ipv6_ifconfig_fxp0="2001:471:1f11:251:290:27ff:fee0:2093"
To assign a default router of 2001:471:1f11:251::1 add the following to /etc/rc.conf:
ipv6_defaultrouter="2001:471:1f11:251::1"
29.11.5.2 IPv6 Router/Gateway Settings
This will help you take the directions that your tunnel provider has given you and convert it into settings that will persist through reboots. To restore your tunnel on startup use something like the following in /etc/rc.conf:
List the Generic Tunneling interfaces that will be configured, for example gif0:
gif_interfaces="gif0"
To configure the interface with a local endpoint of MY_IPv4_ADDR to a remote endpoint of REMOTE_IPv4_ADDR:
gifconfig_gif0="MY_IPv4_ADDR REMOTE_IPv4_ADDR"
To apply the IPv6 address you have been assigned for use as your IPv6 tunnel endpoint, add:
ipv6_ifconfig_gif0="MY_ASSIGNED_IPv6_TUNNEL_ENDPOINT_ADDR"
Then all you have to do is set the default route for IPv6. This is the other side of the IPv6 tunnel:
ipv6_defaultrouter="MY_IPv6_REMOTE_TUNNEL_ENDPOINT_ADDR"
29.11.5.3 IPv6 Tunnel Settings
If the server is to route IPv6 between the rest of your network and the world, the following /etc/rc.conf setting will also be needed:
ipv6_gateway_enable="YES"
29.11.6 Router Advertisement and Host Auto Configuration
This section will help you setup rtadvd(8) to advertise the IPv6 default route.
To enable rtadvd(8) you will need the following in your /etc/rc.conf:
rtadvd_enable="YES"
It is important that you specify the interface on which to do IPv6 router solicitation. For example to tell rtadvd(8) to use fxp0:
rtadvd_interfaces="fxp0"
Now we must create the configuration file, /etc/rtadvd.conf. Here is an example:
fxp0:\
:addrs#1:addr="2001:471:1f11:246::":prefixlen#64:tc=ether:
Replace fxp0 with the interface you are going to be using.
Next, replace 2001:471:1f11:246:: with the prefix of your allocation.
If you are dedicated a /64 subnet you will not need to change anything else. Otherwise, you will need to change the prefixlen# to the correct value.
29.12 Asynchronous Transfer Mode (ATM)
Contributed by Harti Brandt.29.12.1 Configuring classical IP over ATM (PVCs)
Classical IP over ATM (CLIP) is the simplest method to use Asynchronous Transfer Mode (ATM) with IP. It can be used with switched connections (SVCs) and with permanent connections (PVCs). This section describes how to set up a network based on PVCs.
29.12.1.1 Fully meshed configurations
The first method to set up a CLIP with PVCs is to connect each machine to each other machine in the network via a dedicated PVC. While this is simple to configure it tends to become impractical for a larger number of machines. The example supposes that we have four machines in the network, each connected to the ATM network with an ATM adapter card. The first step is the planning of the IP addresses and the ATM connections between the machines. We use the following:
To build a fully meshed net we need one ATM connection between each pair of machines:
| Machines | VPI.VCI couple |
|---|---|
| hostA - hostB | 0.100 |
| hostA - hostC | 0.101 |
| hostA - hostD | 0.102 |
| hostB - hostC | 0.103 |
| hostB - hostD | 0.104 |
| hostC - hostD | 0.105 |
The VPI and VCI values at each end of the connection may of course differ, but for simplicity we assume that they are the same. Next we need to configure the ATM interfaces on each host:
hostA# ifconfig hatm0 192.168.173.1 up
hostB# ifconfig hatm0 192.168.173.2 up
hostC# ifconfig hatm0 192.168.173.3 up
hostD# ifconfig hatm0 192.168.173.4 up
assuming that the ATM interface is hatm0 on all hosts. Now the PVCs need to be configured on hostA (we assume that they are already configured on the ATM switches, you need to consult the manual for the switch on how to do this).
hostA# atmconfig natm add 192.168.173.2 hatm0 0 100 llc/snap ubr
hostA# atmconfig natm add 192.168.173.3 hatm0 0 101 llc/snap ubr
hostA# atmconfig natm add 192.168.173.4 hatm0 0 102 llc/snap ubr
hostB# atmconfig natm add 192.168.173.1 hatm0 0 100 llc/snap ubr
hostB# atmconfig natm add 192.168.173.3 hatm0 0 103 llc/snap ubr
hostB# atmconfig natm add 192.168.173.4 hatm0 0 104 llc/snap ubr
hostC# atmconfig natm add 192.168.173.1 hatm0 0 101 llc/snap ubr
hostC# atmconfig natm add 192.168.173.2 hatm0 0 103 llc/snap ubr
hostC# atmconfig natm add 192.168.173.4 hatm0 0 105 llc/snap ubr
hostD# atmconfig natm add 192.168.173.1 hatm0 0 102 llc/snap ubr
hostD# atmconfig natm add 192.168.173.2 hatm0 0 104 llc/snap ubr
hostD# atmconfig natm add 192.168.173.3 hatm0 0 105 llc/snap ubr
Of course other traffic contracts than UBR can be used given the ATM adapter supports those. In this case the name of the traffic contract is followed by the parameters of the traffic. Help for the atmconfig(8) tool can be obtained with:
# atmconfig help natm add
or in the atmconfig(8) manual page.
The same configuration can also be done via /etc/rc.conf. For hostA this would look like:
network_interfaces="lo0 hatm0"
ifconfig_hatm0="inet 192.168.173.1 up"
natm_static_routes="hostB hostC hostD"
route_hostB="192.168.173.2 hatm0 0 100 llc/snap ubr"
route_hostC="192.168.173.3 hatm0 0 101 llc/snap ubr"
route_hostD="192.168.173.4 hatm0 0 102 llc/snap ubr"
The current state of all CLIP routes can be obtained with:
hostA# atmconfig natm show
29.13 Common Access Redundancy Protocol (CARP)
Contributed by Tom Rhodes.The Common Access Redundancy Protocol, or CARP allows multiple hosts to share the same IP address. In some configurations, this may be used for availability or load balancing. Hosts may use separate IP addresses as well, as in the example provided here.
To enable support for CARP, the FreeBSD kernel must be rebuilt with the following option:
device carp
CARP functionality should now be available and may be tuned via several sysctl OIDs. Devices themselves may be loaded via the ifconfig command:
# ifconfig carp0 create
In a real environment, these interfaces will need unique identification numbers known as a VHID. This VHID or Virtual Host Identification will be used to distinguish the host on the network.
29.13.1 Using CARP For Server Availability (CARP)
One use of CARP, as noted above, is for server availability. This example will provide failover support for three hosts, all with unique IP addresses and providing the same web content. These machines will act in conjunction with a Round Robin DNS configuration. The failover machine will have two additional CARP interfaces, one for each of the content server's IPs. When a failure occurs, the failover server should pick up the failed machine's IP address. This means the failure should go completely unnoticed to the user. The failover server requires identical content and services as the other content servers it is expected to pick up load for.
The two machines should be configured identically other than their issued hostnames and VHIDs. This example calls these machines hosta.example.org and hostb.example.org respectively. First, the required lines for a CARP configuration have to be added to rc.conf. For hosta.example.org, the rc.conf file should contain the following lines:
hostname="hosta.example.org"
ifconfig_fxp0="inet 192.168.1.3 netmask 255.255.255.0"
cloned_interfaces="carp0"
ifconfig_carp0="vhid 1 pass testpast 192.168.1.50/24"
On hostb.example.org the following lines should be in rc.conf:
hostname="hostb.example.org"
ifconfig_fxp0="inet 192.168.1.4 netmask 255.255.255.0"
cloned_interfaces="carp0"
ifconfig_carp0="vhid 2 pass testpass 192.168.1.51/24"
Note: It is very important that the passwords, specified by the
passoption to ifconfig, are identical. The carp devices will only listen to and accept advertisements from machines with the correct password. The VHID must also be different for each machine.
The third machine, provider.example.org, should be prepared so that it may handle failover from either host. This machine will require two carp devices, one to handle each host. The appropriate rc.conf configuration lines will be similar to the following:
hostname="provider.example.org"
ifconfig_fxp0="inet 192.168.1.5 netmask 255.255.255.0"
cloned_interfaces="carp0 carp1"
ifconfig_carp0="vhid 1 advskew 100 pass testpass 192.168.1.50/24"
ifconfig_carp1="vhid 2 advskew 100 pass testpass 192.168.1.51/24"
Having the two carp devices will allow provider.example.org to notice and pick up the IP address of either machine should it stop responding.
Note: The default FreeBSD kernel may have preemption enabled. If so, provider.example.org may not relinquish the IP address back to the original content server. In this case, an administrator may “nudge” the interface. The following command should be issued on provider.example.org:
# ifconfig carp0 down && ifconfig carp0 upThis should be done on the carp interface which corresponds to the correct host.
At this point, CARP should be completely enabled and available for testing. For testing, either networking has to be restarted or the machines need to be rebooted.
More information is always available in the carp(4) manual page.
V. Appendices
- Table of Contents
- A. Obtaining FreeBSD
- B. Bibliography
- C. Resources on the Internet
- D. PGP Keys
Appendix A. Obtaining FreeBSD
A.1 CDROM and DVD Publishers
A.1.1 Retail Boxed Products
FreeBSD is available as a boxed product (FreeBSD CDs, additional software, and printed documentation) from several retailers:
-
CompUSA
WWW: http://www.compusa.com/
-
Frys Electronics
WWW: http://www.frys.com/
A.1.2 CD and DVD Sets
FreeBSD CD and DVD sets are available from many online retailers:
-
BSD Mall by Daemon News
PO Box 161
Nauvoo, IL 62354
USA
Phone: +1 866 273-6255
Fax: +1 217 453-9956
Email:<sales@bsdmall.com>
WWW: http://www.bsdmall.com/
-
BSD-Systems
Email:<info@bsd-systems.co.uk>
WWW: http://www.bsd-systems.co.uk
-
FreeBSD Mall, Inc.
3623 Sanford Street
Concord, CA 94520-1405
USA
Phone: +1 925 240-6652
Fax: +1 925 674-0821
Email:<info@freebsdmall.com>
WWW: http://www.freebsdmall.com/
-
Dr. Hinner EDV
St. Augustinus-Str. 10
D-81825 München
Germany
Phone: (089) 428 419
WWW: http://www.hinner.de/linux/freebsd.html
-
Ikarios
22-24 rue Voltaire
92000 Nanterre
France
WWW: http://ikarios.com/form/#freebsd
-
JMC Software
Ireland
Phone: 353 1 6291282
WWW: http://www.thelinuxmall.com
-
Linux CD Mall
Private Bag MBE N348
Auckland 1030
New Zealand
Phone: +64 21 866529
WWW: http://www.linuxcdmall.co.nz/
-
The Linux Emporium
Hilliard House, Lester Way
Wallingford
OX10 9TA
United Kingdom
Phone: +44 1491 837010
Fax: +44 1491 837016
WWW: http://www.linuxemporium.co.uk/products/freebsd/
-
Linux+ DVD Magazine
Lewartowskiego 6
Warsaw
00-190
Poland
Phone: +48 22 860 18 18
Email:<editors@lpmagazine.org>
WWW: http://www.lpmagazine.org/
-
Linux System Labs Australia
21 Ray Drive
Balwyn North
VIC - 3104
Australia
Phone: +61 3 9857 5918
Fax: +61 3 9857 8974
WWW: http://www.lsl.com.au
-
LinuxCenter.Ru
Galernaya Street, 55
Saint-Petersburg
190000
Russia
Phone: +7-812-3125208
Email:<info@linuxcenter.ru>
WWW: http://linuxcenter.ru/freebsd
A.1.3 Distributors
If you are a reseller and want to carry FreeBSD CDROM products, please contact a distributor:
-
Cylogistics
809B Cuesta Dr., #2149
Mountain View, CA 94040
USA
Phone: +1 650 694-4949
Fax: +1 650 694-4953
Email:<sales@cylogistics.com>
WWW: http://www.cylogistics.com/
-
Ingram Micro
1600 E. St. Andrew Place
Santa Ana, CA 92705-4926
USA
Phone: 1 (800) 456-8000
WWW: http://www.ingrammicro.com/
-
Kudzu, LLC
7375 Washington Ave. S.
Edina, MN 55439
USA
Phone: +1 952 947-0822
Fax: +1 952 947-0876
Email:<sales@kudzuenterprises.com>
-
LinuxCenter.Ru
Galernaya Street, 55
Saint-Petersburg
190000
Russia
Phone: +7-812-3125208
Email:<info@linuxcenter.ru>
WWW: http://linuxcenter.ru/freebsd
-
Navarre Corp
7400 49th Ave South
New Hope, MN 55428
USA
Phone: +1 763 535-8333
Fax: +1 763 535-0341
WWW: http://www.navarre.com/
A.2 FTP Sites
The official sources for FreeBSD are available via anonymous FTP from a worldwide set of mirror sites. The site ftp://ftp.FreeBSD.org/pub/FreeBSD/ is well connected and allows a large number of connections to it, but you are probably better off finding a “closer” mirror site (especially if you decide to set up some sort of mirror site).
The FreeBSD mirror sites database is more accurate than the mirror listing in the Handbook, as it gets its information from the DNS rather than relying on static lists of hosts.
Additionally, FreeBSD is available via anonymous FTP from the following mirror sites. If you choose to obtain FreeBSD via anonymous FTP, please try to use a site near you. The mirror sites listed as “Primary Mirror Sites” typically have the entire FreeBSD archive (all the currently available versions for each of the architectures) but you will probably have faster download times from a site that is in your country or region. The regional sites carry the most recent versions for the most popular architecture(s) but might not carry the entire FreeBSD archive. All sites provide access via anonymous FTP but some sites also provide access via other methods. The access methods available for each site are provided in parentheses after the hostname.
Central Servers, Primary Mirror Sites, Argentina, Armenia, Australia, Austria, Brazil, Bulgaria, Canada, China, Croatia, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hong Kong, Hungary, Iceland, Indonesia, Ireland, Israel, Italy, Japan, Korea, Latvia, Lithuania, Netherlands, New Zealand, Norway, Poland, Portugal, Romania, Russia, Saudi Arabia, Singapore, Slovak Republic, Slovenia, South Africa, Spain, Sweden, Switzerland, Taiwan, Turkey, Ukraine, United Kingdom, USA.
(as of 2007/07/17 10:11:16 UTC)
- Central Servers
- Primary Mirror Sites
-
In case of problems, please contact the hostmaster
<mirror-admin@FreeBSD.org>for this domain. - Argentina
-
In case of problems, please contact the hostmaster
<hostmaster@ar.FreeBSD.org>for this domain. - Armenia
-
In case of problems, please contact the hostmaster
<hostmaster@am.FreeBSD.org>for this domain. - Australia
-
In case of problems, please contact the hostmaster
<hostmaster@au.FreeBSD.org>for this domain. - Austria
-
In case of problems, please contact the hostmaster
<hostmaster@at.FreeBSD.org>for this domain.-
ftp://ftp2.at.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
- Brazil
-
In case of problems, please contact the hostmaster
<hostmaster@br.FreeBSD.org>for this domain.-
ftp://ftp3.br.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
- Bulgaria
-
In case of problems, please contact the hostmaster
<hostmaster@bg.FreeBSD.org>for this domain.-
ftp://ftp.bg.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
-
ftp://ftp2.bg.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
-
- Canada
-
In case of problems, please contact the hostmaster
<hostmaster@ca.FreeBSD.org>for this domain. - China
-
In case of problems, please contact the hostmaster
<hostmaster@cn.FreeBSD.org>for this domain. - Croatia
-
In case of problems, please contact the hostmaster
<hostmaster@hr.FreeBSD.org>for this domain. - Czech Republic
-
In case of problems, please contact the hostmaster
<hostmaster@cz.FreeBSD.org>for this domain.-
ftp://ftp.cz.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
- Denmark
-
In case of problems, please contact the hostmaster
<hostmaster@dk.FreeBSD.org>for this domain.-
ftp://ftp.dk.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6 / http)
-
- Estonia
-
In case of problems, please contact the hostmaster
<hostmaster@ee.FreeBSD.org>for this domain. - Finland
-
In case of problems, please contact the hostmaster
<hostmaster@fi.FreeBSD.org>for this domain. - France
-
In case of problems, please contact the hostmaster
<hostmaster@fr.FreeBSD.org>for this domain. - Germany
-
In case of problems, please contact the hostmaster
<de-bsd-hubs@de.FreeBSD.org >for this domain.-
ftp://ftp2.de.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
ftp://ftp4.de.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
- Greece
-
In case of problems, please contact the hostmaster
<hostmaster@gr.FreeBSD.org>for this domain. - Hong Kong
- Hungary
-
In case of problems, please contact the hostmaster
<mohacsi@ik.bme.hu>for this domain.-
ftp://ftp.hu.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
- Iceland
-
In case of problems, please contact the hostmaster
<hostmaster@is.FreeBSD.org>for this domain.-
ftp://ftp.is.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
-
- Indonesia
-
In case of problems, please contact the hostmaster
<hostmaster@id.FreeBSD.org>for this domain.-
ftp://ftp.id.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
- Ireland
-
In case of problems, please contact the hostmaster
<hostmaster@ie.FreeBSD.org>for this domain.-
ftp://ftp2.ie.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
ftp://ftp3.ie.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
- Israel
-
In case of problems, please contact the hostmaster
<hostmaster@il.FreeBSD.org>for this domain.-
ftp://ftp.il.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6)
-
- Italy
-
In case of problems, please contact the hostmaster
<hostmaster@it.FreeBSD.org>for this domain. - Japan
-
In case of problems, please contact the hostmaster
<hostmaster@jp.FreeBSD.org>for this domain. - Korea
-
In case of problems, please contact the hostmaster
<hostmaster@kr.FreeBSD.org>for this domain.-
ftp://ftp.kr.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
-
- Latvia
-
In case of problems, please contact the hostmaster
<hostmaster@lv.FreeBSD.org>for this domain. - Lithuania
-
In case of problems, please contact the hostmaster
<hostmaster@lt.FreeBSD.org>for this domain. - Netherlands
-
In case of problems, please contact the hostmaster
<hostmaster@nl.FreeBSD.org>for this domain.-
ftp://ftp.nl.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
- New Zealand
- Norway
-
In case of problems, please contact the hostmaster
<hostmaster@no.FreeBSD.org>for this domain.-
ftp://ftp.no.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
-
- Poland
-
In case of problems, please contact the hostmaster
<hostmaster@pl.FreeBSD.org>for this domain. - Portugal
-
In case of problems, please contact the hostmaster
<hostmaster@pt.FreeBSD.org>for this domain. - Romania
-
In case of problems, please contact the hostmaster
<hostmaster@ro.FreeBSD.org>for this domain.-
ftp://ftp1.ro.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6)
- Russia
-
In case of problems, please contact the hostmaster
<hostmaster@ru.FreeBSD.org>for this domain.-
ftp://ftp2.ru.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
ftp://ftp5.ru.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
- Saudi Arabia
-
In case of problems, please contact the hostmaster
<ftpadmin@isu.net.sa>for this domain. - Singapore
-
In case of problems, please contact the hostmaster
<hostmaster@sg.FreeBSD.org>for this domain.-
ftp://ftp.sg.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
- Slovak Republic
-
In case of problems, please contact the hostmaster
<hostmaster@sk.FreeBSD.org>for this domain.-
ftp://ftp.sk.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6 / http / httpv6)
-
- Slovenia
-
In case of problems, please contact the hostmaster
<hostmaster@si.FreeBSD.org>for this domain. - South Africa
-
In case of problems, please contact the hostmaster
<hostmaster@za.FreeBSD.org>for this domain. - Spain
-
In case of problems, please contact the hostmaster
<hostmaster@es.FreeBSD.org>for this domain. - Sweden
-
In case of problems, please contact the hostmaster
<hostmaster@se.FreeBSD.org>for this domain. - Switzerland
-
In case of problems, please contact the hostmaster
<hostmaster@ch.FreeBSD.org>for this domain. - Taiwan
-
In case of problems, please contact the hostmaster
<hostmaster@tw.FreeBSD.org>for this domain.-
ftp://ftp.tw.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6 / rsync / rsyncv6)
-
ftp://ftp2.tw.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6 / http / httpv6 / rsync / rsyncv6)
-
ftp://ftp6.tw.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
- Turkey
-
-
ftp://ftp.tr.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
ftp://ftp2.tr.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
-
- Ukraine
- United Kingdom
-
In case of problems, please contact the hostmaster
<hostmaster@uk.FreeBSD.org>for this domain. - USA
-
In case of problems, please contact the hostmaster
<hostmaster@us.FreeBSD.org>for this domain.-
ftp://ftp4.us.FreeBSD.org/pub/FreeBSD/ (ftp / ftpv6)
-
ftp://ftp5.us.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
-
ftp://ftp7.us.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
-
ftp://ftp12.us.FreeBSD.org/pub/FreeBSD/ (ftp / rsync)
-
ftp://ftp13.us.FreeBSD.org/pub/FreeBSD/ (ftp / http / rsync)
A.3 Anonymous CVS
A.3.1 Introduction
Anonymous CVS (or, as it is otherwise known, anoncvs) is a feature provided by the CVS utilities bundled with FreeBSD for synchronizing with a remote CVS repository. Among other things, it allows users of FreeBSD to perform, with no special privileges, read-only CVS operations against one of the FreeBSD project's official anoncvs servers. To use it, one simply sets the CVSROOT environment variable to point at the appropriate anoncvs server, provides the well-known password “anoncvs” with the cvs login command, and then uses the cvs(1) command to access it like any local repository.
Note: The cvs login command, stores the passwords that are used for authenticating to the CVS server in a file called .cvspass in your HOME directory. If this file does not exist, you might get an error when trying to use cvs login for the first time. Just make an empty .cvspass file, and retry to login.
While it can also be said that the CVSup and anoncvs services both perform essentially the same function, there are various trade-offs which can influence the user's choice of synchronization methods. In a nutshell, CVSup is much more efficient in its usage of network resources and is by far the most technically sophisticated of the two, but at a price. To use CVSup, a special client must first be installed and configured before any bits can be grabbed, and then only in the fairly large chunks which CVSup calls collections.
Anoncvs, by contrast, can be used to examine anything from an individual file to a specific program (like ls or grep) by referencing the CVS module name. Of course, anoncvs is also only good for read-only operations on the CVS repository, so if it is your intention to support local development in one repository shared with the FreeBSD project bits then CVSup is really your only option.
A.3.2 Using Anonymous CVS
Configuring cvs(1) to use an Anonymous CVS repository is a simple matter of setting the CVSROOT environment variable to point to one of the FreeBSD project's anoncvs servers. At the time of this writing, the following servers are available:
-
Austria: :pserver:anoncvs@anoncvs.at.FreeBSD.org:/home/ncvs (Use cvs login and enter any password when prompted.)
-
France: :pserver:anoncvs@anoncvs.fr.FreeBSD.org:/home/ncvs (pserver (password “anoncvs”), ssh (no password))
-
Germany: :pserver:anoncvs@anoncvs.de.FreeBSD.org:/home/ncvs (rsh, pserver, ssh, ssh/2022)
-
Japan: :pserver:anoncvs@anoncvs.jp.FreeBSD.org:/home/ncvs (Use cvs login and enter the password “anoncvs” when prompted.)
-
Taiwan: :pserver:anoncvs@anoncvs.tw.FreeBSD.org:/home/ncvs (pserver (use cvs login and enter any password when prompted), ssh (no password))
SSH2 HostKey: 1024 e8:3b:29:7b:ca:9f:ac:e9:45:cb:c8:17:ae:9b:eb:55 /etc/ssh/ssh_host_dsa_key.pub -
USA: freebsdanoncvs@anoncvs.FreeBSD.org:/home/ncvs (ssh only - no password)
SSH HostKey: 1024 a1:e7:46:de:fb:56:ef:05:bc:73:aa:91:09:da:f7:f4 root@sanmateo.ecn.purdue.edu SSH2 HostKey: 1024 52:02:38:1a:2f:a8:71:d3:f5:83:93:8d:aa:00:6f:65 ssh_host_dsa_key.pub -
USA: anoncvs@anoncvs1.FreeBSD.org:/home/ncvs (ssh2 only - no password)
SSH2 HostKey: 2048 53:1f:15:a3:72:5c:43:f6:44:0e:6a:e9:bb:f8:01:62 /etc/ssh/ssh_host_dsa_key.pub
Since CVS allows one to “check out” virtually any version of the FreeBSD
sources that ever existed (or, in some cases, will exist), you need to be familiar with
the revision (-r) flag to cvs(1) and what some
of the permissible values for it in the FreeBSD Project repository are.
There are two kinds of tags, revision tags and branch tags. A revision tag refers to a specific revision. Its meaning stays the same from day to day. A branch tag, on the other hand, refers to the latest revision on a given line of development, at any given time. Because a branch tag does not refer to a specific revision, it may mean something different tomorrow than it means today.
Section A.7 contains revision tags that users might be interested in. Again, none of these are valid for the Ports Collection since the Ports Collection does not have multiple branches of development.
When you specify a branch tag, you normally receive the latest versions of the files
on that line of development. If you wish to receive some past version, you can do so by
specifying a date with the -D date flag. See the cvs(1) manual page for
more details.
A.3.3 Examples
While it really is recommended that you read the manual page for cvs(1) thoroughly before doing anything, here are some quick examples which essentially show how to use Anonymous CVS:
Example A-1. Checking Out Something from -CURRENT (ls(1)):
% setenv CVSROOT :pserver:anoncvs@anoncvs.tw.FreeBSD.org:/home/ncvs
% cvs login
At the prompt, enter any word for “password”.
% cvs co ls
Example A-2. Using SSH to check out the src/ tree:
% cvs -d freebsdanoncvs@anoncvs.FreeBSD.org:/home/ncvs co src
The authenticity of host 'anoncvs.freebsd.org (128.46.156.46)' can't be established.
DSA key fingerprint is 52:02:38:1a:2f:a8:71:d3:f5:83:93:8d:aa:00:6f:65.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'anoncvs.freebsd.org' (DSA) to the list of known hosts.
Example A-3. Checking Out the Version of ls(1) in the 6-STABLE Branch:
% setenv CVSROOT :pserver:anoncvs@anoncvs.tw.FreeBSD.org:/home/ncvs
% cvs login
At the prompt, enter any word for “password”.
% cvs co -rRELENG_6 ls
A.3.4 Other Resources
The following additional resources may be helpful in learning CVS:
-
CVS Tutorial from Cal Poly.
-
CVS Home, the CVS development and support community.
-
CVSweb is the FreeBSD Project web interface for CVS.
A.4 Using CTM
CTM is a method for keeping a remote directory tree in sync with a central one. It has been developed for usage with FreeBSD's source trees, though other people may find it useful for other purposes as time goes by. Little, if any, documentation currently exists at this time on the process of creating deltas, so contact the ctm-users mailing list for more information and if you wish to use CTM for other things.
A.4.1 Why Should I Use CTM?
CTM will give you a local copy of the FreeBSD source trees. There are a number of “flavors” of the tree available. Whether you wish to track the entire CVS tree or just one of the branches, CTM can provide you the information. If you are an active developer on FreeBSD, but have lousy or non-existent TCP/IP connectivity, or simply wish to have the changes automatically sent to you, CTM was made for you. You will need to obtain up to three deltas per day for the most active branches. However, you should consider having them sent by automatic email. The sizes of the updates are always kept as small as possible. This is typically less than 5K, with an occasional (one in ten) being 10-50K and every now and then a large 100K+ or more coming around.
You will also need to make yourself aware of the various caveats related to working directly from the development sources rather than a pre-packaged release. This is particularly true if you choose the “current” sources. It is recommended that you read Staying current with FreeBSD.
A.4.2 What Do I Need to Use CTM?
You will need two things: The CTM program, and the initial deltas to feed it (to get up to “current” levels).
The CTM program has been part of FreeBSD ever since version 2.0 was released, and lives in /usr/src/usr.sbin/ctm if you have a copy of the source available.
The “deltas” you feed CTM can be had two ways, FTP or email. If you have general FTP access to the Internet then the following FTP sites support access to CTM:
ftp://ftp.FreeBSD.org/pub/FreeBSD/CTM/
or see section mirrors.
FTP the relevant directory and fetch the README file, starting from there.
If you wish to get your deltas via email:
Subscribe to one of the CTM distribution lists. ctm-cvs-cur supports the entire CVS tree. ctm-src-cur supports the head of the development branch. ctm-src-4 supports the 4.X release branch, etc.. (If you do not know how to subscribe yourself to a list, click on the list name above or go to http://lists.FreeBSD.org/mailman/listinfo and click on the list that you wish to subscribe to. The list page should contain all of the necessary subscription instructions.)
When you begin receiving your CTM updates in the mail, you may use the ctm_rmail program to unpack and apply them. You can actually use the ctm_rmail program directly from a entry in /etc/aliases if you want to have the process run in a fully automated fashion. Check the ctm_rmail manual page for more details.
Note: No matter what method you use to get the CTM deltas, you should subscribe to the ctm-announce mailing list. In the future, this will be the only place where announcements concerning the operations of the CTM system will be posted. Click on the list name above and follow the instructions to subscribe to the list.
A.4.3 Using CTM for the First Time
Before you can start using CTM deltas, you will need to get to a starting point for the deltas produced subsequently to it.
First you should determine what you already have. Everyone can start from an “empty” directory. You must use an initial “Empty” delta to start off your CTM supported tree. At some point it is intended that one of these “started” deltas be distributed on the CD for your convenience, however, this does not currently happen.
Since the trees are many tens of megabytes, you should prefer to start from something already at hand. If you have a -RELEASE CD, you can copy or extract an initial source from it. This will save a significant transfer of data.
You can recognize these “starter” deltas by the X appended to the number (src-cur.3210XEmpty.gz for instance). The designation following the X corresponds to the origin of your initial “seed”. Empty is an empty directory. As a rule a base transition from Empty is produced every 100 deltas. By the way, they are large! 70 to 80 Megabytes of gzip'd data is common for the XEmpty deltas.
Once you have picked a base delta to start from, you will also need all deltas with higher numbers following it.
A.4.4 Using CTM in Your Daily Life
To apply the deltas, simply say:
# cd /where/ever/you/want/the/stuff
# ctm -v -v /where/you/store/your/deltas/src-xxx.*
CTM understands deltas which have been put through gzip, so you do not need to gunzip them first, this saves disk space.
Unless it feels very secure about the entire process, CTM
will not touch your tree. To verify a delta you can also use the -c flag and CTM will not actually touch
your tree; it will merely verify the integrity of the delta and see if it would apply
cleanly to your current tree.
There are other options to CTM as well, see the manual pages or look in the sources for more information.
That is really all there is to it. Every time you get a new delta, just run it through CTM to keep your sources up to date.
Do not remove the deltas if they are hard to download again. You just might want to keep them around in case something bad happens. Even if you only have floppy disks, consider using fdwrite to make a copy.
A.4.5 Keeping Your Local Changes
As a developer one would like to experiment with and change files in the source tree. CTM supports local modifications in a limited way: before checking for the presence of a file foo, it first looks for foo.ctm. If this file exists, CTM will operate on it instead of foo.
This behavior gives us a simple way to maintain local changes: simply copy the files you plan to modify to the corresponding file names with a .ctm suffix. Then you can freely hack the code, while CTM keeps the .ctm file up-to-date.
A.4.6 Other Interesting CTM Options
A.4.6.1 Finding Out Exactly What Would Be Touched by an Update
You can determine the list of changes that CTM will make on
your source repository using the -l option to CTM.
This is useful if you would like to keep logs of the changes, pre- or post- process the modified files in any manner, or just are feeling a tad paranoid.
A.4.6.2 Making Backups Before Updating
Sometimes you may want to backup all the files that would be changed by a CTM update.
Specifying the -B backup-file option causes CTM to backup all files that would be touched by a given CTM delta to backup-file.
A.4.6.3 Restricting the Files Touched by an Update
Sometimes you would be interested in restricting the scope of a given CTM update, or may be interested in extracting just a few files from a sequence of deltas.
You can control the list of files that CTM would operate on
by specifying filtering regular expressions using the -e and
-x options.
For example, to extract an up-to-date copy of lib/libc/Makefile from your collection of saved CTM deltas, run the commands:
# cd /where/ever/you/want/to/extract/it/
# ctm -e '^lib/libc/Makefile' ~ctm/src-xxx.*
For every file specified in a CTM delta, the -e and -x options are applied in the
order given on the command line. The file is processed by CTM
only if it is marked as eligible after all the -e and -x options are applied to it.
A.4.7 Future Plans for CTM
Tons of them:
-
Use some kind of authentication into the CTM system, so as to allow detection of spoofed CTM updates.
-
Clean up the options to CTM, they became confusing and counter intuitive.
A.4.8 Miscellaneous Stuff
There is a sequence of deltas for the ports collection too, but interest has not been all that high yet.
A.4.9 CTM Mirrors
CTM/FreeBSD is available via anonymous FTP from the following mirror sites. If you choose to obtain CTM via anonymous FTP, please try to use a site near you.
In case of problems, please contact the ctm-users mailing list.
- California, Bay Area, official source
- South Africa, backup server for old deltas
- Taiwan/R.O.C.
If you did not find a mirror near to you or the mirror is incomplete, try to use a search engine such as alltheweb.
A.5 Using CVSup
A.5.1 Introduction
CVSup is a software package for distributing and updating source trees from a master CVS repository on a remote server host. The FreeBSD sources are maintained in a CVS repository on a central development machine in California. With CVSup, FreeBSD users can easily keep their own source trees up to date.
CVSup uses the so-called pull model of updating. Under the pull model, each client asks the server for updates, if and when they are wanted. The server waits passively for update requests from its clients. Thus all updates are instigated by the client. The server never sends unsolicited updates. Users must either run the CVSup client manually to get an update, or they must set up a cron job to run it automatically on a regular basis.
The term CVSup, capitalized just so, refers to the entire software package. Its main components are the client cvsup which runs on each user's machine, and the server cvsupd which runs at each of the FreeBSD mirror sites.
As you read the FreeBSD documentation and mailing lists, you may see references to sup. Sup was the predecessor of CVSup, and it served a similar purpose. CVSup is used much in the same way as sup and, in fact, uses configuration files which are backward-compatible with sup's. Sup is no longer used in the FreeBSD project, because CVSup is both faster and more flexible.
Note: The csup utility is a rewrite of the CVSup software in C. Its biggest advantage is, that it is faster and does not depend on the Modula-3 language, thus you do not need to install it as a requirement. Moreover, if you are using FreeBSD 6.2 or later, you can use it out-of-the-box, since it is included in the base system. Older FreeBSD versions do not have csup(1) in their base system but you can easily install the net/csup port, or a precompiled package. The csup utility does not support CVS mode, though. If you want to mirror complete repositories, you will still need to use CVSup. If you decided to use csup, just skip the steps on the installation of CVSup and substitute the references of CVSup with csup while following the remainder of this article.
A.5.2 Installation
The easiest way to install CVSup is to use the precompiled net/cvsup package from the FreeBSD packages collection. If you prefer to build CVSup from source, you can use the net/cvsup port instead. But be forewarned: the net/cvsup port depends on the Modula-3 system, which takes a substantial amount of time and disk space to download and build.
Note: If you are going to be using CVSup on a machine which will not have XFree86 or Xorg installed, such as a server, be sure to use the port which does not include the CVSup GUI, net/cvsup-without-gui.
If you want to install csup on FreeBSD 6.1 or earlier, you can use the precompiled net/csup package from the FreeBSD packages collection. If you prefer to build csup from source, you can use the net/csup port instead.
A.5.3 CVSup Configuration
CVSup's operation is controlled by a configuration file called the supfile. There are some sample supfiles in the directory /usr/share/examples/cvsup/.
The information in a supfile answers the following questions for CVSup:
In the following sections, we will construct a typical supfile by answering each of these questions in turn. First, we describe the overall structure of a supfile.
A supfile is a text file. Comments begin with # and extend to the end of the line. Lines that are blank and lines that contain only comments are ignored.
Each remaining line describes a set of files that the user wishes to receive. The line begins with the name of a “collection”, a logical grouping of files defined by the server. The name of the collection tells the server which files you want. After the collection name come zero or more fields, separated by white space. These fields answer the questions listed above. There are two types of fields: flag fields and value fields. A flag field consists of a keyword standing alone, e.g., delete or compress. A value field also begins with a keyword, but the keyword is followed without intervening white space by = and a second word. For example, release=cvs is a value field.
A supfile typically specifies more than one collection to receive. One way to structure a supfile is to specify all of the relevant fields explicitly for each collection. However, that tends to make the supfile lines quite long, and it is inconvenient because most fields are the same for all of the collections in a supfile. CVSup provides a defaulting mechanism to avoid these problems. Lines beginning with the special pseudo-collection name *default can be used to set flags and values which will be used as defaults for the subsequent collections in the supfile. A default value can be overridden for an individual collection, by specifying a different value with the collection itself. Defaults can also be changed or augmented in mid-supfile by additional *default lines.
With this background, we will now proceed to construct a supfile for receiving and updating the main source tree of FreeBSD-CURRENT.
-
Which files do you want to receive?
The files available via CVSup are organized into named groups called “collections”. The collections that are available are described in the following section. In this example, we wish to receive the entire main source tree for the FreeBSD system. There is a single large collection src-all which will give us all of that. As a first step toward constructing our supfile, we simply list the collections, one per line (in this case, only one line):
src-all -
Which version(s) of them do you want?
With CVSup, you can receive virtually any version of the sources that ever existed. That is possible because the cvsupd server works directly from the CVS repository, which contains all of the versions. You specify which one of them you want using the tag= and
date=value fields.Warning: Be very careful to specify any tag= fields correctly. Some tags are valid only for certain collections of files. If you specify an incorrect or misspelled tag, CVSup will delete files which you probably do not want deleted. In particular, use only tag=. for the ports-* collections.
The tag= field names a symbolic tag in the repository. There are two kinds of tags, revision tags and branch tags. A revision tag refers to a specific revision. Its meaning stays the same from day to day. A branch tag, on the other hand, refers to the latest revision on a given line of development, at any given time. Because a branch tag does not refer to a specific revision, it may mean something different tomorrow than it means today.
Section A.7 contains branch tags that users might be interested in. When specifying a tag in CVSup's configuration file, it must be preceded with tag= (RELENG_4 will become tag=RELENG_4). Keep in mind that only the tag=. is relevant for the Ports Collection.
Warning: Be very careful to type the tag name exactly as shown. CVSup cannot distinguish between valid and invalid tags. If you misspell the tag, CVSup will behave as though you had specified a valid tag which happens to refer to no files at all. It will delete your existing sources in that case.
When you specify a branch tag, you normally receive the latest versions of the files on that line of development. If you wish to receive some past version, you can do so by specifying a date with the
date=value field. The cvsup(1) manual page explains how to do that.For our example, we wish to receive FreeBSD-CURRENT. We add this line at the beginning of our supfile:
*default tag=.There is an important special case that comes into play if you specify neither a tag= field nor a date= field. In that case, you receive the actual RCS files directly from the server's CVS repository, rather than receiving a particular version. Developers generally prefer this mode of operation. By maintaining a copy of the repository itself on their systems, they gain the ability to browse the revision histories and examine past versions of files. This gain is achieved at a large cost in terms of disk space, however.
-
Where do you want to get them from?
We use the host= field to tell cvsup where to obtain its updates. Any of the CVSup mirror sites will do, though you should try to select one that is close to you in cyberspace. In this example we will use a fictional FreeBSD distribution site, cvsup99.FreeBSD.org:
*default host=cvsup99.FreeBSD.orgYou will need to change the host to one that actually exists before running CVSup. On any particular run of cvsup, you can override the host setting on the command line, with
-h hostname. -
Where do you want to put them on your own machine?
The prefix= field tells cvsup where to put the files it receives. In this example, we will put the source files directly into our main source tree, /usr/src. The src directory is already implicit in the collections we have chosen to receive, so this is the correct specification:
*default prefix=/usr -
Where should cvsup maintain its status files?
The CVSup client maintains certain status files in what is called the “base” directory. These files help CVSup to work more efficiently, by keeping track of which updates you have already received. We will use the standard base directory, /var/db:
*default base=/var/dbIf your base directory does not already exist, now would be a good time to create it. The cvsup client will refuse to run if the base directory does not exist.
-
Miscellaneous supfile settings:
There is one more line of boiler plate that normally needs to be present in the supfile:
*default release=cvs delete use-rel-suffix compressrelease=cvs indicates that the server should get its information out of the main FreeBSD CVS repository. This is virtually always the case, but there are other possibilities which are beyond the scope of this discussion.
delete gives CVSup permission to delete files. You should always specify this, so that CVSup can keep your source tree fully up-to-date. CVSup is careful to delete only those files for which it is responsible. Any extra files you happen to have will be left strictly alone.
use-rel-suffix is ... arcane. If you really want to know about it, see the cvsup(1) manual page. Otherwise, just specify it and do not worry about it.
compress enables the use of gzip-style compression on the communication channel. If your network link is T1 speed or faster, you probably should not use compression. Otherwise, it helps substantially.
-
Putting it all together:
Here is the entire supfile for our example:
*default tag=. *default host=cvsup99.FreeBSD.org *default prefix=/usr *default base=/var/db *default release=cvs delete use-rel-suffix compress src-all
A.5.3.1 The refuse File
As mentioned above, CVSup uses a pull method. Basically, this means that you connect to the CVSup server, and it says, “Here is what you can download from me...”, and your client responds “OK, I will take this, this, this, and this.” In the default configuration, the CVSup client will take every file associated with the collection and tag you chose in the configuration file. However, this is not always what you want, especially if you are synching the doc, ports, or www trees -- most people cannot read four or five languages, and therefore they do not need to download the language-specific files. If you are CVSuping the Ports Collection, you can get around this by specifying each collection individually (e.g., ports-astrology, ports-biology, etc instead of simply saying ports-all). However, since the doc and www trees do not have language-specific collections, you must use one of CVSup's many nifty features: the refuse file.
The refuse file essentially tells CVSup that it should not take every single file from a collection; in other words, it tells the client to refuse certain files from the server. The refuse file can be found (or, if you do not yet have one, should be placed) in base/sup/. base is defined in your supfile; our defined base is /var/db, which means that by default the refuse file is /var/db/sup/refuse.
The refuse file has a very simple format; it simply contains the names of files or directories that you do not wish to download. For example, if you cannot speak any languages other than English and some German, and you do not feel the need to read the German translation of documentation, you can put the following in your refuse file:
doc/bn_*
doc/da_*
doc/de_*
doc/el_*
doc/es_*
doc/fr_*
doc/hu_*
doc/it_*
doc/ja_*
doc/mn_*
doc/nl_*
doc/no_*
doc/pl_*
doc/pt_*
doc/ru_*
doc/sr_*
doc/tr_*
doc/zh_*
and so forth for the other languages (you can find the full list by browsing the FreeBSD CVS repository).
With this very useful feature, those users who are on slow links or pay by the minute for their Internet connection will be able to save valuable time as they will no longer need to download files that they will never use. For more information on refuse files and other neat features of CVSup, please view its manual page.
A.5.4 Running CVSup
You are now ready to try an update. The command line for doing this is quite simple:
# cvsup supfile
where supfile is of course the name of the supfile you have just created. Assuming you are running under X11, cvsup will display a GUI window with some buttons to do the usual things. Press the go button, and watch it run.
Since you are updating your actual /usr/src tree in this example, you will need to run the program as root so that cvsup has the permissions it needs to update your files. Having just created your configuration file, and having never used this program before, that might understandably make you nervous. There is an easy way to do a trial run without touching your precious files. Just create an empty directory somewhere convenient, and name it as an extra argument on the command line:
# mkdir /var/tmp/dest
# cvsup supfile /var/tmp/dest
The directory you specify will be used as the destination directory for all file updates. CVSup will examine your usual files in /usr/src, but it will not modify or delete any of them. Any file updates will instead land in /var/tmp/dest/usr/src. CVSup will also leave its base directory status files untouched when run this way. The new versions of those files will be written into the specified directory. As long as you have read access to /usr/src, you do not even need to be root to perform this kind of trial run.
If you are not running X11 or if you just do not like GUIs, you should add a couple of options to the command line when you run cvsup:
# cvsup -g -L 2 supfile
The -g tells CVSup not to use
its GUI. This is automatic if you are not running X11, but otherwise you have to specify
it.
The -L 2 tells CVSup to print
out the details of all the file updates it is doing. There are three levels of verbosity,
from -L 0 to -L 2. The default is
0, which means total silence except for error messages.
There are plenty of other options available. For a brief list of them, type cvsup -H. For more detailed descriptions, see the manual page.
Once you are satisfied with the way updates are working, you can arrange for regular runs of CVSup using cron(8). Obviously, you should not let CVSup use its GUI when running it from cron(8).
A.5.5 CVSup File Collections
The file collections available via CVSup are organized hierarchically. There are a few large collections, and they are divided into smaller sub-collections. Receiving a large collection is equivalent to receiving each of its sub-collections. The hierarchical relationships among collections are reflected by the use of indentation in the list below.
The most commonly used collections are src-all, and ports-all. The other collections are used only by small groups of people for specialized purposes, and some mirror sites may not carry all of them.
- cvs-all release=cvs
-
The main FreeBSD CVS repository, including the cryptography code.
- distrib release=cvs
-
Files related to the distribution and mirroring of FreeBSD.
- doc-all release=cvs
-
Sources for the FreeBSD Handbook and other documentation. This does not include files for the FreeBSD web site.
- ports-all release=cvs
-
The FreeBSD Ports Collection.
Important: If you do not want to update the whole of ports-all (the whole ports tree), but use one of the subcollections listed below, make sure that you always update the ports-base subcollection! Whenever something changes in the ports build infrastructure represented by ports-base, it is virtually certain that those changes will be used by “real” ports real soon. Thus, if you only update the “real” ports and they use some of the new features, there is a very high chance that their build will fail with some mysterious error message. The very first thing to do in this case is to make sure that your ports-base subcollection is up to date.
Important: If you are going to be building your own local copy of ports/INDEX, you must accept ports-all (the whole ports tree). Building ports/INDEX with a partial tree is not supported. See the FAQ.
- ports-accessibility release=cvs
-
Software to help disabled users.
- ports-arabic release=cvs
-
Arabic language support.
- ports-archivers release=cvs
-
Archiving tools.
- ports-astro release=cvs
-
Astronomical ports.
- ports-audio release=cvs
-
Sound support.
- ports-base release=cvs
-
The Ports Collection build infrastructure - various files located in the Mk/ and Tools/ subdirectories of /usr/ports.
Note: Please see the important warning above: you should always update this subcollection, whenever you update any part of the FreeBSD Ports Collection!
- ports-benchmarks release=cvs
-
Benchmarks.
- ports-biology release=cvs
-
Biology.
- ports-cad release=cvs
-
Computer aided design tools.
- ports-chinese release=cvs
-
Chinese language support.
- ports-comms release=cvs
-
Communication software.
- ports-converters release=cvs
-
character code converters.
- ports-databases release=cvs
-
Databases.
- ports-deskutils release=cvs
-
Things that used to be on the desktop before computers were invented.
- ports-devel release=cvs
-
Development utilities.
- ports-dns release=cvs
-
DNS related software.
- ports-editors release=cvs
-
Editors.
- ports-emulators release=cvs
-
Emulators for other operating systems.
- ports-finance release=cvs
-
Monetary, financial and related applications.
- ports-ftp release=cvs
-
FTP client and server utilities.
- ports-games release=cvs
-
Games.
- ports-german release=cvs
-
German language support.
- ports-graphics release=cvs
-
Graphics utilities.
- ports-hebrew release=cvs
-
Hebrew language support.
- ports-hungarian release=cvs
-
Hungarian language support.
- ports-irc release=cvs
-
Internet Relay Chat utilities.
- ports-japanese release=cvs
-
Japanese language support.
- ports-java release=cvs
-
Java utilities.
- ports-korean release=cvs
-
Korean language support.
- ports-lang release=cvs
-
Programming languages.
- ports-mail release=cvs
-
Mail software.
- ports-math release=cvs
-
Numerical computation software.
- ports-mbone release=cvs
-
MBone applications.
- ports-misc release=cvs
-
Miscellaneous utilities.
- ports-multimedia release=cvs
-
Multimedia software.
- ports-net release=cvs
-
Networking software.
- ports-net-im release=cvs
-
Instant messaging software.
- ports-net-mgmt release=cvs
-
Network management software.
- ports-net-p2p release=cvs
-
Peer to peer networking.
- ports-news release=cvs
-
USENET news software.
- ports-palm release=cvs
-
Software support for Palm™ series.
- ports-polish release=cvs
-
Polish language support.
- ports-ports-mgmt release=cvs
-
Utilities to manage ports and packages.
- ports-portuguese release=cvs
-
Portuguese language support.
- ports-print release=cvs
-
Printing software.
- ports-russian release=cvs
-
Russian language support.
- ports-science release=cvs
-
Science.
- ports-security release=cvs
-
Security utilities.
- ports-shells release=cvs
-
Command line shells.
- ports-sysutils release=cvs
-
System utilities.
- ports-textproc release=cvs
-
text processing utilities (does not include desktop publishing).
- ports-ukrainian release=cvs
-
Ukrainian language support.
- ports-vietnamese release=cvs
-
Vietnamese language support.
- ports-www release=cvs
-
Software related to the World Wide Web.
- ports-x11 release=cvs
-
Ports to support the X window system.
- ports-x11-clocks release=cvs
-
X11 clocks.
- ports-x11-drivers release=cvs
-
X11 drivers.
- ports-x11-fm release=cvs
-
X11 file managers.
- ports-x11-fonts release=cvs
-
X11 fonts and font utilities.
- ports-x11-toolkits release=cvs
-
X11 toolkits.
- ports-x11-servers release=cvs
-
X11 servers.
- ports-x11-themes release=cvs
-
X11 themes.
- ports-x11-wm release=cvs
-
X11 window managers.
- projects-all release=cvs
-
Sources for the FreeBSD projects repository.
- src-all release=cvs
-
The main FreeBSD sources, including the cryptography code.
- src-base release=cvs
-
Miscellaneous files at the top of /usr/src.
- src-bin release=cvs
-
User utilities that may be needed in single-user mode (/usr/src/bin).
- src-cddl release=cvs
-
Utilities and libraries covered by the CDDL license (/usr/src/cddl).
- src-contrib release=cvs
-
Utilities and libraries from outside the FreeBSD project, used relatively unmodified (/usr/src/contrib).
- src-crypto release=cvs
-
Cryptography utilities and libraries from outside the FreeBSD project, used relatively unmodified (/usr/src/crypto).
- src-eBones release=cvs
-
Kerberos and DES (/usr/src/eBones). Not used in current releases of FreeBSD.
- src-etc release=cvs
-
System configuration files (/usr/src/etc).
- src-games release=cvs
-
Games (/usr/src/games).
- src-gnu release=cvs
-
Utilities covered by the GNU Public License (/usr/src/gnu).
- src-include release=cvs
-
Header files (/usr/src/include).
- src-kerberos5 release=cvs
-
Kerberos5 security package (/usr/src/kerberos5).
- src-kerberosIV release=cvs
-
KerberosIV security package (/usr/src/kerberosIV).
- src-lib release=cvs
-
Libraries (/usr/src/lib).
- src-libexec release=cvs
-
System programs normally executed by other programs (/usr/src/libexec).
- src-release release=cvs
-
Files required to produce a FreeBSD release (/usr/src/release).
- src-rescue release=cvs
-
Statically linked programs for emergency recovery; see rescue(8) (/usr/src/rescue).
- src-sbin release=cvs
-
System utilities for single-user mode (/usr/src/sbin).
- src-secure release=cvs
-
Cryptographic libraries and commands (/usr/src/secure).
- src-share release=cvs
-
Files that can be shared across multiple systems (/usr/src/share).
- src-sys release=cvs
-
The kernel (/usr/src/sys).
- src-sys-crypto release=cvs
-
Kernel cryptography code (/usr/src/sys/crypto).
- src-tools release=cvs
-
Various tools for the maintenance of FreeBSD (/usr/src/tools).
- src-usrbin release=cvs
-
User utilities (/usr/src/usr.bin).
- src-usrsbin release=cvs
-
System utilities (/usr/src/usr.sbin).
- www release=cvs
-
The sources for the FreeBSD WWW site.
- distrib release=self
-
The CVSup server's own configuration files. Used by CVSup mirror sites.
- gnats release=current
-
The GNATS bug-tracking database.
- mail-archive release=current
-
FreeBSD mailing list archive.
- www release=current
-
The pre-processed FreeBSD WWW site files (not the source files). Used by WWW mirror sites.
A.5.6 For More Information
For the CVSup FAQ and other information about CVSup, see The CVSup Home Page.
Most FreeBSD-related discussion of CVSup takes place on the FreeBSD technical discussions mailing list. New versions of the software are announced there, as well as on the FreeBSD announcements mailing list.
For questions or bug reports about CVSup take a look at the CVSup FAQ.
A.5.7 CVSup Sites
CVSup servers for FreeBSD are running at the following sites:
Central Servers, Primary Mirror Sites, Argentina, Armenia, Australia, Austria, Brazil, Bulgaria, Canada, China, Costa Rica, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Iceland, Indonesia, Ireland, Israel, Italy, Japan, Korea, Kuwait, Kyrgyzstan, Latvia, Lithuania, Netherlands, New Zealand, Norway, Philippines, Poland, Portugal, Romania, Russia, San Marino, Singapore, Slovak Republic, Slovenia, South Africa, Spain, Sweden, Switzerland, Taiwan, Thailand, Turkey, Ukraine, United Kingdom, USA.
(as of 2007/07/17 10:11:16 UTC)
- Central Servers
-
-
cvsup.FreeBSD.org
-
- Primary Mirror Sites
-
-
cvsup1.FreeBSD.org
-
cvsup2.FreeBSD.org
-
cvsup3.FreeBSD.org
-
cvsup4.FreeBSD.org
-
cvsup5.FreeBSD.org
-
cvsup6.FreeBSD.org
-
cvsup7.FreeBSD.org
-
cvsup8.FreeBSD.org
-
cvsup9.FreeBSD.org
-
cvsup10.FreeBSD.org
-
cvsup11.FreeBSD.org
-
cvsup12.FreeBSD.org
-
cvsup13.FreeBSD.org
-
cvsup14.FreeBSD.org
-
cvsup15.FreeBSD.org
-
cvsup16.FreeBSD.org
-
cvsup18.FreeBSD.org
-
- Argentina
-
-
cvsup.ar.FreeBSD.org
-
- Armenia
-
-
cvsup1.am.FreeBSD.org
-
- Australia
-
-
cvsup.au.FreeBSD.org
-
cvsup2.au.FreeBSD.org
-
cvsup3.au.FreeBSD.org
-
cvsup4.au.FreeBSD.org
-
cvsup5.au.FreeBSD.org
-
cvsup6.au.FreeBSD.org
-
cvsup7.au.FreeBSD.org
-
- Austria
-
-
cvsup.at.FreeBSD.org
-
cvsup2.at.FreeBSD.org
-
- Brazil
-
-
cvsup.br.FreeBSD.org
-
cvsup2.br.FreeBSD.org
-
cvsup3.br.FreeBSD.org
-
cvsup4.br.FreeBSD.org
-
cvsup5.br.FreeBSD.org
-
- Bulgaria
-
-
cvsup.bg.FreeBSD.org
-
- Canada
-
-
cvsup1.ca.FreeBSD.org
-
- China
-
-
cvsup.cn.FreeBSD.org
-
cvsup2.cn.FreeBSD.org
-
cvsup3.cn.FreeBSD.org
-
cvsup4.cn.FreeBSD.org
-
cvsup5.cn.FreeBSD.org
-
- Costa Rica
-
-
cvsup1.cr.FreeBSD.org
-
- Czech Republic
-
-
cvsup.cz.FreeBSD.org
-
- Denmark
-
-
cvsup.dk.FreeBSD.org
-
cvsup2.dk.FreeBSD.org
-
cvsup3.dk.FreeBSD.org
-
- Estonia
-
-
cvsup.ee.FreeBSD.org
-
- Finland
-
-
cvsup.fi.FreeBSD.org
-
cvsup2.fi.FreeBSD.org
-
- France
-
-
cvsup.fr.FreeBSD.org
-
cvsup2.fr.FreeBSD.org
-
cvsup3.fr.FreeBSD.org
-
cvsup4.fr.FreeBSD.org
-
cvsup5.fr.FreeBSD.org
-
cvsup8.fr.FreeBSD.org
-
- Germany
-
-
cvsup.de.FreeBSD.org
-
cvsup2.de.FreeBSD.org
-
cvsup3.de.FreeBSD.org
-
cvsup4.de.FreeBSD.org
-
cvsup5.de.FreeBSD.org
-
cvsup6.de.FreeBSD.org
-
cvsup7.de.FreeBSD.org
-
cvsup8.de.FreeBSD.org
-
- Greece
-
-
cvsup.gr.FreeBSD.org
-
cvsup2.gr.FreeBSD.org
-
- Hungary
-
-
cvsup.hu.FreeBSD.org
-
- Iceland
-
-
cvsup.is.FreeBSD.org
-
- Indonesia
-
-
cvsup.id.FreeBSD.org
-
- Ireland
-
-
cvsup.ie.FreeBSD.org
-
cvsup2.ie.FreeBSD.org
-
- Israel
-
-
cvsup.il.FreeBSD.org
-
- Italy
-
-
cvsup.it.FreeBSD.org
-
- Japan
-
-
cvsup.jp.FreeBSD.org
-
cvsup2.jp.FreeBSD.org
-
cvsup3.jp.FreeBSD.org
-
cvsup4.jp.FreeBSD.org
-
cvsup5.jp.FreeBSD.org
-
cvsup6.jp.FreeBSD.org
-
- Korea
-
-
cvsup.kr.FreeBSD.org
-
cvsup2.kr.FreeBSD.org
-
cvsup3.kr.FreeBSD.org
-
- Kuwait
-
-
cvsup1.kw.FreeBSD.org
-
- Kyrgyzstan
-
-
cvsup.kg.FreeBSD.org
-
- Latvia
-
-
cvsup.lv.FreeBSD.org
-
cvsup2.lv.FreeBSD.org
-
- Lithuania
-
-
cvsup.lt.FreeBSD.org
-
cvsup2.lt.FreeBSD.org
-
cvsup3.lt.FreeBSD.org
-
- Netherlands
-
-
cvsup.nl.FreeBSD.org
-
cvsup2.nl.FreeBSD.org
-
cvsup3.nl.FreeBSD.org
-
- New Zealand
-
-
cvsup.nz.FreeBSD.org
-
cvsup2.nz.FreeBSD.org
-
- Norway
-
-
cvsup.no.FreeBSD.org
-
- Philippines
-
-
cvsup1.ph.FreeBSD.org
-
- Poland
-
-
cvsup.pl.FreeBSD.org
-
cvsup2.pl.FreeBSD.org
-
cvsup3.pl.FreeBSD.org
-
- Portugal
-
-
cvsup.pt.FreeBSD.org
-
cvsup2.pt.FreeBSD.org
-
cvsup3.pt.FreeBSD.org
-
- Romania
-
-
cvsup.ro.FreeBSD.org
-
cvsup1.ro.FreeBSD.org
-
cvsup2.ro.FreeBSD.org
-
cvsup3.ro.FreeBSD.org
-
- Russia
-
-
cvsup.ru.FreeBSD.org
-
cvsup2.ru.FreeBSD.org
-
cvsup3.ru.FreeBSD.org
-
cvsup4.ru.FreeBSD.org
-
cvsup5.ru.FreeBSD.org
-
cvsup6.ru.FreeBSD.org
-
cvsup7.ru.FreeBSD.org
-
- San Marino
-
-
cvsup.sm.FreeBSD.org
-
- Singapore
-
-
cvsup.sg.FreeBSD.org
-
- Slovak Republic
-
-
cvsup.sk.FreeBSD.org
-
- Slovenia
-
-
cvsup.si.FreeBSD.org
-
cvsup2.si.FreeBSD.org
-
- South Africa
-
-
cvsup.za.FreeBSD.org
-
cvsup2.za.FreeBSD.org
-
- Spain
-
-
cvsup.es.FreeBSD.org
-
cvsup2.es.FreeBSD.org
-
cvsup3.es.FreeBSD.org
-
- Sweden
-
-
cvsup.se.FreeBSD.org
-
cvsup3.se.FreeBSD.org
-
- Switzerland
-
-
cvsup.ch.FreeBSD.org
-
- Taiwan
-
-
cvsup.tw.FreeBSD.org
-
cvsup3.tw.FreeBSD.org
-
cvsup4.tw.FreeBSD.org
-
cvsup5.tw.FreeBSD.org
-
cvsup6.tw.FreeBSD.org
-
cvsup7.tw.FreeBSD.org
-
cvsup8.tw.FreeBSD.org
-
cvsup9.tw.FreeBSD.org
-
cvsup10.tw.FreeBSD.org
-
cvsup11.tw.FreeBSD.org
-
cvsup12.tw.FreeBSD.org
-
cvsup13.tw.FreeBSD.org
-
cvsup14.tw.FreeBSD.org
-
- Thailand
-
-
cvsup.th.FreeBSD.org
-
- Turkey
-
-
cvsup.tr.FreeBSD.org
-
cvsup2.tr.FreeBSD.org
-
- Ukraine
-
-
cvsup2.ua.FreeBSD.org
-
cvsup3.ua.FreeBSD.org
-
cvsup4.ua.FreeBSD.org
-
cvsup5.ua.FreeBSD.org
-
cvsup6.ua.FreeBSD.org
-
cvsup7.ua.FreeBSD.org
-
- United Kingdom
-
-
cvsup.uk.FreeBSD.org
-
cvsup2.uk.FreeBSD.org
-
cvsup3.uk.FreeBSD.org
-
cvsup4.uk.FreeBSD.org
-
- USA
-
-
cvsup1.us.FreeBSD.org
-
cvsup2.us.FreeBSD.org
-
cvsup3.us.FreeBSD.org
-
cvsup4.us.FreeBSD.org
-
cvsup5.us.FreeBSD.org
-
cvsup6.us.FreeBSD.org
-
cvsup7.us.FreeBSD.org
-
cvsup8.us.FreeBSD.org
-
cvsup9.us.FreeBSD.org
-
cvsup10.us.FreeBSD.org
-
cvsup11.us.FreeBSD.org
-
cvsup12.us.FreeBSD.org
-
cvsup13.us.FreeBSD.org
-
cvsup14.us.FreeBSD.org
-
cvsup15.us.FreeBSD.org
-
cvsup16.us.FreeBSD.org
-
cvsup18.us.FreeBSD.org
-
A.6 Using Portsnap
A.6.1 Introduction
Portsnap is a system for securely distributing the FreeBSD ports tree. Approximately once an hour, a “snapshot” of the ports tree is generated, repackaged, and cryptographically signed. The resulting files are then distributed via HTTP.
Like CVSup, Portsnap uses a pull model of updating: The packaged and signed ports trees are placed on a web server which waits passively for clients to request files. Users must either run portsnap(8) manually to download updates or set up a cron(8) job to download updates automatically on a regular basis.
For technical reasons, Portsnap does not update the “live” ports tree in /usr/ports/ directly; instead, it works via a compressed copy of the ports tree stored in /var/db/portsnap/ by default. This compressed copy is then used to update the live ports tree.
Note: If Portsnap is installed from the FreeBSD Ports Collection, then the default location for its compressed snapshot will be /usr/local/portsnap/ instead of /var/db/portsnap/.
A.6.2 Installation
On FreeBSD 6.0 and more recent versions, Portsnap is contained in the FreeBSD base system. On older versions of FreeBSD, it can be installed using the ports-mgmt/portsnap port.
A.6.3 Portsnap Configuration
Portsnap's operation is controlled by the /etc/portsnap.conf configuration file. For most users, the default configuration file will suffice; for more details, consult the portsnap.conf(5) manual page.
Note: If Portsnap is installed from the FreeBSD Ports Collection, it will use the configuration file /usr/local/etc/portsnap.conf instead of /etc/portsnap.conf. This configuration file is not created when the port is installed, but a sample configuration file is distributed; to copy it into place, run the following command:
# cd /usr/local/etc && cp portsnap.conf.sample portsnap.conf
A.6.4 Running Portsnap for the First Time
The first time portsnap(8) is run, it will need to download a compressed snapshot of the entire ports tree into /var/db/portsnap/ (or /usr/local/portsnap/ if Portsnap was installed from the Ports Collection). For the beginning of 2006 this is approximately a 41 MB download.
# portsnap fetch
Once the compressed snapshot has been downloaded, a “live” copy of the ports tree can be extracted into /usr/ports/. This is necessary even if a ports tree has already been created in that directory (e.g., by using CVSup), since it establishes a baseline from which portsnap can determine which parts of the ports tree need to be updated later.
# portsnap extract
Note: In the default installation /usr/ports is not created. If you run FreeBSD 6.0-RELEASE, it should be created before portsnap is used. On more recent versions of FreeBSD or Portsnap, this operation will be done automatically at first use of the portsnap command.
A.6.5 Updating the Ports Tree
After an initial compressed snapshot of the ports tree has been downloaded and extracted into /usr/ports/, updating the ports tree consists of two steps: fetching updates to the compressed snapshot, and using them to update the live ports tree. These two steps can be specified to portsnap as a single command:
# portsnap fetch update
Note: Some older versions of portsnap do not support this syntax; if it fails, try instead the following:
# portsnap fetch # portsnap update
A.6.6 Running Portsnap from cron
In order to avoid problems with “flash crowds” accessing the Portsnap servers, portsnap fetch will not run from a cron(8) job. Instead, a special portsnap cron command exists, which waits for a random duration up to 3600 seconds before fetching updates.
In addition, it is strongly recommended that portsnap update
not be run from a cron job, since it is liable to cause major
problems if it happens to run at the same time as a port is being built or installed.
However, it is safe to update the ports' INDEX files, and this
can be done by passing the -I flag to portsnap. (Obviously, if portsnap -I update
is run from cron, then it will be necessary to run portsnap update without the -I flag at a
later time in order to update the rest of the tree.)
Adding the following line to /etc/crontab will cause portsnap to update its compressed snapshot and the INDEX files in /usr/ports/, and will send an email if any installed ports are out of date:
0 3 * * * root portsnap -I cron update && pkg_version -vIL=
Note: If the system clock is not set to the local time zone, please replace 3 with a random value between 0 and 23, in order to spread the load on the Portsnap servers more evenly.
Note: Some older versions of portsnap do not support listing multiple commands (e.g., cron update) in the same invocation of portsnap. If the line above fails, try replacing portsnap -I cron update with portsnap cron && portsnap -I update.
A.7 CVS Tags
When obtaining or updating sources using cvs or CVSup, a revision tag must be specified. A revision tag refers to either a particular line of FreeBSD development, or a specific point in time. The first type are called “branch tags”, and the second type are called “release tags”.
A.7.1 Branch Tags
All of these, with the exception of HEAD (which is always a valid tag), only apply to the src/ tree. The ports/, doc/, and www/ trees are not branched.
- HEAD
-
Symbolic name for the main line, or FreeBSD-CURRENT. Also the default when no revision is specified.
In CVSup, this tag is represented by a . (not punctuation, but a literal . character).
Note: In CVS, this is the default when no revision tag is specified. It is usually not a good idea to checkout or update to CURRENT sources on a STABLE machine, unless that is your intent.
- RELENG_7
-
The line of development for FreeBSD-7.X, also known as FreeBSD 7-STABLE
- RELENG_7_0
-
The release branch for FreeBSD-7.0, used only for security advisories and other critical fixes.
- RELENG_6
-
The line of development for FreeBSD-6.X, also known as FreeBSD 6-STABLE
- RELENG_6_3
-
The release branch for FreeBSD-6.3, used only for security advisories and other critical fixes.
- RELENG_6_2
-
The release branch for FreeBSD-6.2, used only for security advisories and other critical fixes.
- RELENG_6_1
-
The release branch for FreeBSD-6.1, used only for security advisories and other critical fixes.
- RELENG_6_0
-
The release branch for FreeBSD-6.0, used only for security advisories and other critical fixes.
- RELENG_5
-
The line of development for FreeBSD-5.X, also known as FreeBSD 5-STABLE.
- RELENG_5_5
-
The release branch for FreeBSD-5.5, used only for security advisories and other critical fixes.
- RELENG_5_4
-
The release branch for FreeBSD-5.4, used only for security advisories and other critical fixes.
- RELENG_5_3
-
The release branch for FreeBSD-5.3, used only for security advisories and other critical fixes.
- RELENG_5_2
-
The release branch for FreeBSD-5.2 and FreeBSD-5.2.1, used only for security advisories and other critical fixes.
- RELENG_5_1
-
The release branch for FreeBSD-5.1, used only for security advisories and other critical fixes.
- RELENG_5_0
-
The release branch for FreeBSD-5.0, used only for security advisories and other critical fixes.
- RELENG_4
-
The line of development for FreeBSD-4.X, also known as FreeBSD 4-STABLE.
- RELENG_4_11
-
The release branch for FreeBSD-4.11, used only for security advisories and other critical fixes.
- RELENG_4_10
-
The release branch for FreeBSD-4.10, used only for security advisories and other critical fixes.
- RELENG_4_9
-
The release branch for FreeBSD-4.9, used only for security advisories and other critical fixes.
- RELENG_4_8
-
The release branch for FreeBSD-4.8, used only for security advisories and other critical fixes.
- RELENG_4_7
-
The release branch for FreeBSD-4.7, used only for security advisories and other critical fixes.
- RELENG_4_6
-
The release branch for FreeBSD-4.6 and FreeBSD-4.6.2, used only for security advisories and other critical fixes.
- RELENG_4_5
-
The release branch for FreeBSD-4.5, used only for security advisories and other critical fixes.
- RELENG_4_4
-
The release branch for FreeBSD-4.4, used only for security advisories and other critical fixes.
- RELENG_4_3
-
The release branch for FreeBSD-4.3, used only for security advisories and other critical fixes.
- RELENG_3
-
The line of development for FreeBSD-3.X, also known as 3.X-STABLE.
- RELENG_2_2
-
The line of development for FreeBSD-2.2.X, also known as 2.2-STABLE. This branch is mostly obsolete.
A.7.2 Release Tags
These tags refer to a specific point in time when a particular version of FreeBSD was released. The release engineering process is documented in more detail by the Release Engineering Information and Release Process documents. The src tree uses tag names that start with RELENG_ tags. The ports and doc trees use tags whose names begin with RELEASE tags. Finally, the www tree is not tagged with any special name for releases.
- RELENG_7_0_0_RELEASE
-
FreeBSD 7.0
- RELENG_6_3_0_RELEASE
-
FreeBSD 6.3
- RELENG_6_2_0_RELEASE
-
FreeBSD 6.2
- RELENG_6_1_0_RELEASE
-
FreeBSD 6.1
- RELENG_6_0_0_RELEASE
-
FreeBSD 6.0
- RELENG_5_5_0_RELEASE
-
FreeBSD 5.5
- RELENG_5_4_0_RELEASE
-
FreeBSD 5.4
- RELENG_4_11_0_RELEASE
-
FreeBSD 4.11
- RELENG_5_3_0_RELEASE
-
FreeBSD 5.3
- RELENG_4_10_0_RELEASE
-
FreeBSD 4.10
- RELENG_5_2_1_RELEASE
-
FreeBSD 5.2.1
- RELENG_5_2_0_RELEASE
-
FreeBSD 5.2
- RELENG_4_9_0_RELEASE
-
FreeBSD 4.9
- RELENG_5_1_0_RELEASE
-
FreeBSD 5.1
- RELENG_4_8_0_RELEASE
-
FreeBSD 4.8
- RELENG_5_0_0_RELEASE
-
FreeBSD 5.0
- RELENG_4_7_0_RELEASE
-
FreeBSD 4.7
- RELENG_4_6_2_RELEASE
-
FreeBSD 4.6.2
- RELENG_4_6_1_RELEASE
-
FreeBSD 4.6.1
- RELENG_4_6_0_RELEASE
-
FreeBSD 4.6
- RELENG_4_5_0_RELEASE
-
FreeBSD 4.5
- RELENG_4_4_0_RELEASE
-
FreeBSD 4.4
- RELENG_4_3_0_RELEASE
-
FreeBSD 4.3
- RELENG_4_2_0_RELEASE
-
FreeBSD 4.2
- RELENG_4_1_1_RELEASE
-
FreeBSD 4.1.1
- RELENG_4_1_0_RELEASE
-
FreeBSD 4.1
- RELENG_4_0_0_RELEASE
-
FreeBSD 4.0
- RELENG_3_5_0_RELEASE
-
FreeBSD-3.5
- RELENG_3_4_0_RELEASE
-
FreeBSD-3.4
- RELENG_3_3_0_RELEASE
-
FreeBSD-3.3
- RELENG_3_2_0_RELEASE
-
FreeBSD-3.2
- RELENG_3_1_0_RELEASE
-
FreeBSD-3.1
- RELENG_3_0_0_RELEASE
-
FreeBSD-3.0
- RELENG_2_2_8_RELEASE
-
FreeBSD-2.2.8
- RELENG_2_2_7_RELEASE
-
FreeBSD-2.2.7
- RELENG_2_2_6_RELEASE
-
FreeBSD-2.2.6
- RELENG_2_2_5_RELEASE
-
FreeBSD-2.2.5
- RELENG_2_2_2_RELEASE
-
FreeBSD-2.2.2
- RELENG_2_2_1_RELEASE
-
FreeBSD-2.2.1
- RELENG_2_2_0_RELEASE
-
FreeBSD-2.2.0
A.8 AFS Sites
AFS servers for FreeBSD are running at the following sites:
- Sweden
-
The path to the files are: /afs/stacken.kth.se/ftp/pub/FreeBSD/
stacken.kth.se # Stacken Computer Club, KTH, Sweden 130.237.234.43 #hot.stacken.kth.se 130.237.237.230 #fishburger.stacken.kth.se 130.237.234.3 #milko.stacken.kth.seMaintainer
<ftp@stacken.kth.se>
A.9 rsync Sites
The following sites make FreeBSD available through the rsync protocol. The rsync utility works in much the same way as the rcp(1) command, but has more options and uses the rsync remote-update protocol which transfers only the differences between two sets of files, thus greatly speeding up the synchronization over the network. This is most useful if you are a mirror site for the FreeBSD FTP server, or the CVS repository. The rsync suite is available for many operating systems, on FreeBSD, see the net/rsync port or use the package.
- Czech Republic
-
rsync://ftp.cz.FreeBSD.org/
Available collections:
-
ftp: A partial mirror of the FreeBSD FTP server.
-
FreeBSD: A full mirror of the FreeBSD FTP server.
-
- Germany
-
rsync://grappa.unix-ag.uni-kl.de/
Available collections:
-
freebsd-cvs: The full FreeBSD CVS repository.
This machine also mirrors the CVS repositories of the NetBSD and the OpenBSD projects, among others.
-
- Netherlands
-
rsync://ftp.nl.FreeBSD.org/
Available collections:
-
vol/4/freebsd-core: A full mirror of the FreeBSD FTP server.
-
- Taiwan
-
rsync://ftp.tw.FreeBSD.org/
rsync://ftp2.tw.FreeBSD.org/
rsync://ftp6.tw.FreeBSD.org/
Available collections:
-
FreeBSD: A full mirror of the FreeBSD FTP server.
-
- United Kingdom
-
rsync://rsync.mirror.ac.uk/
Available collections:
-
ftp.FreeBSD.org: A full mirror of the FreeBSD FTP server.
-
- United States of America
-
rsync://ftp-master.FreeBSD.org/
This server may only be used by FreeBSD primary mirror sites.
Available collections:
-
FreeBSD: The master archive of the FreeBSD FTP server.
-
acl: The FreeBSD master ACL list.
rsync://ftp13.FreeBSD.org/
Available collections:
-
FreeBSD: A full mirror of the FreeBSD FTP server.
-
Appendix B. Bibliography
While the manual pages provide the definitive reference for individual pieces of the FreeBSD operating system, they are notorious for not illustrating how to put the pieces together to make the whole operating system run smoothly. For this, there is no substitute for a good book on UNIX system administration and a good users' manual.
B.1 Books & Magazines Specific to FreeBSD
International books & Magazines:
-
Using FreeBSD (in Traditional Chinese), published by Drmaster , 1997. ISBN 9-578-39435-7.
-
FreeBSD Unleashed (Simplified Chinese translation), published by China Machine Press. ISBN 7-111-10201-0.
-
FreeBSD From Scratch First Edition (in Simplified Chinese), published by China Machine Press. ISBN 7-111-07482-3.
-
FreeBSD From Scratch Second Edition (in Simplified Chinese), published by China Machine Press. ISBN 7-111-10286-X.
-
FreeBSD Handbook Second Edition (Simplified Chinese translation), published by Posts & Telecom Press. ISBN 7-115-10541-3.
-
FreeBSD 3.x Internet (in Simplified Chinese), published by Tsinghua University Press. ISBN 7-900625-66-6.
-
FreeBSD & Windows (in Simplified Chinese), published by China Railway Publishing House. ISBN 7-113-03845-X
-
FreeBSD Internet Services HOWTO (in Simplified Chinese), published by China Railway Publishing House. ISBN 7-113-03423-3
-
FreeBSD for PC 98'ers (in Japanese), published by SHUWA System Co, LTD. ISBN 4-87966-468-5 C3055 P2900E.
-
FreeBSD (in Japanese), published by CUTT. ISBN 4-906391-22-2 C3055 P2400E.
-
Complete Introduction to FreeBSD (in Japanese), published by Shoeisha Co., Ltd. ISBN 4-88135-473-6 P3600E.
-
Personal UNIX Starter Kit FreeBSD (in Japanese), published by ASCII. ISBN 4-7561-1733-3 P3000E.
-
FreeBSD Handbook (Japanese translation), published by ASCII. ISBN 4-7561-1580-2 P3800E.
-
FreeBSD mit Methode (in German), published by Computer und Literatur Verlag/Vertrieb Hanser, 1998. ISBN 3-932311-31-0.
-
FreeBSD 4 - Installieren, Konfigurieren, Administrieren (in German), published by Computer und Literatur Verlag, 2001. ISBN 3-932311-88-4.
-
FreeBSD 5 - Installieren, Konfigurieren, Administrieren (in German), published by Computer und Literatur Verlag, 2003. ISBN 3-936546-06-1.
-
FreeBSD de Luxe (in German), published by Verlag Modere Industrie, 2003. ISBN 3-8266-1343-0.
-
FreeBSD Install and Utilization Manual (in Japanese), published by Mainichi Communications Inc., 1998. ISBN 4-8399-0112-0.
-
Onno W Purbo, Dodi Maryanto, Syahrial Hubbany, Widjil Widodo Building Internet Server with FreeBSD (in Indonesia Language), published by Elex Media Komputindo.
-
Absolute BSD: The Ultimate Guide to FreeBSD (Traditional Chinese translation), published by GrandTech Press, 2003. ISBN 986-7944-92-5.
-
The FreeBSD 6.0 Book (in Traditional Chinese), published by Drmaster, 2006. ISBN 9-575-27878-X.
English language books & Magazines:
-
Absolute BSD: The Ultimate Guide to FreeBSD, published by No Starch Press, 2002. ISBN: 1886411743
-
The Complete FreeBSD, published by O'Reilly, 2003. ISBN: 0596005164
-
The FreeBSD Corporate Networker's Guide, published by Addison-Wesley, 2000. ISBN: 0201704811
-
FreeBSD: An Open-Source Operating System for Your Personal Computer, published by The Bit Tree Press, 2001. ISBN: 0971204500
-
Teach Yourself FreeBSD in 24 Hours, published by Sams, 2002. ISBN: 0672324245
-
FreeBSD 6 Unleashed, published by Sams, 2006. ISBN: 0672328755
-
FreeBSD: The Complete Reference, published by McGrawHill, 2003. ISBN: 0072224096
B.2 Users' Guides
-
Computer Systems Research Group, UC Berkeley. 4.4BSD User's Reference Manual. O'Reilly & Associates, Inc., 1994. ISBN 1-56592-075-9
-
Computer Systems Research Group, UC Berkeley. 4.4BSD User's Supplementary Documents. O'Reilly & Associates, Inc., 1994. ISBN 1-56592-076-7
-
UNIX in a Nutshell. O'Reilly & Associates, Inc., 1990. ISBN 093717520X
-
Mui, Linda. What You Need To Know When You Can't Find Your UNIX System Administrator. O'Reilly & Associates, Inc., 1995. ISBN 1-56592-104-6
-
Ohio State University has written a UNIX Introductory Course which is available online in HTML and PostScript format.
An Italian translation of this document is available as part of the FreeBSD Italian Documentation Project.
-
Jpman Project, Japan FreeBSD Users Group. FreeBSD User's Reference Manual (Japanese translation). Mainichi Communications Inc., 1998. ISBN4-8399-0088-4 P3800E.
-
Edinburgh University has written an Online Guide for newcomers to the UNIX environment.
B.3 Administrators' Guides
-
Albitz, Paul and Liu, Cricket. DNS and BIND, 4th Ed. O'Reilly & Associates, Inc., 2001. ISBN 1-59600-158-4
-
Computer Systems Research Group, UC Berkeley. 4.4BSD System Manager's Manual. O'Reilly & Associates, Inc., 1994. ISBN 1-56592-080-5
-
Costales, Brian, et al. Sendmail, 2nd Ed. O'Reilly & Associates, Inc., 1997. ISBN 1-56592-222-0
-
Frisch, Æleen. Essential System Administration, 2nd Ed. O'Reilly & Associates, Inc., 1995. ISBN 1-56592-127-5
-
Hunt, Craig. TCP/IP Network Administration, 2nd Ed. O'Reilly & Associates, Inc., 1997. ISBN 1-56592-322-7
-
Nemeth, Evi. UNIX System Administration Handbook. 3rd Ed. Prentice Hall, 2000. ISBN 0-13-020601-6
-
Stern, Hal Managing NFS and NIS O'Reilly & Associates, Inc., 1991. ISBN 0-937175-75-7
-
Jpman Project, Japan FreeBSD Users Group. FreeBSD System Administrator's Manual (Japanese translation). Mainichi Communications Inc., 1998. ISBN4-8399-0109-0 P3300E.
-
Dreyfus, Emmanuel. Cahiers de l'Admin: BSD 2nd Ed. (in French), Eyrolles, 2004. ISBN 2-212-11463-X
B.4 Programmers' Guides
-
Asente, Paul, Converse, Diana, and Swick, Ralph. X Window System Toolkit. Digital Press, 1998. ISBN 1-55558-178-1
-
Computer Systems Research Group, UC Berkeley. 4.4BSD Programmer's Reference Manual. O'Reilly & Associates, Inc., 1994. ISBN 1-56592-078-3
-
Computer Systems Research Group, UC Berkeley. 4.4BSD Programmer's Supplementary Documents. O'Reilly & Associates, Inc., 1994. ISBN 1-56592-079-1
-
Harbison, Samuel P. and Steele, Guy L. Jr. C: A Reference Manual. 4th ed. Prentice Hall, 1995. ISBN 0-13-326224-3
-
Kernighan, Brian and Dennis M. Ritchie. The C Programming Language. 2nd Ed. PTR Prentice Hall, 1988. ISBN 0-13-110362-8
-
Lehey, Greg. Porting UNIX Software. O'Reilly & Associates, Inc., 1995. ISBN 1-56592-126-7
-
Plauger, P. J. The Standard C Library. Prentice Hall, 1992. ISBN 0-13-131509-9
-
Spinellis, Diomidis. Code Reading: The Open Source Perspective. Addison-Wesley, 2003. ISBN 0-201-79940-5
-
Spinellis, Diomidis. Code Quality: The Open Source Perspective. Addison-Wesley, 2006. ISBN 0-321-16607-8
-
Stevens, W. Richard and Stephen A. Rago. Advanced Programming in the UNIX Environment. 2nd Ed. Reading, Mass. : Addison-Wesley, 2005. ISBN 0-201-43307-9
-
Stevens, W. Richard. UNIX Network Programming. 2nd Ed, PTR Prentice Hall, 1998. ISBN 0-13-490012-X
-
Wells, Bill. “Writing Serial Drivers for UNIX”. Dr. Dobb's Journal. 19(15), December 1994. pp68-71, 97-99.
B.5 Operating System Internals
-
Andleigh, Prabhat K. UNIX System Architecture. Prentice-Hall, Inc., 1990. ISBN 0-13-949843-5
-
Jolitz, William. “Porting UNIX to the 386”. Dr. Dobb's Journal. January 1991-July 1992.
-
Leffler, Samuel J., Marshall Kirk McKusick, Michael J Karels and John Quarterman The Design and Implementation of the 4.3BSD UNIX Operating System. Reading, Mass. : Addison-Wesley, 1989. ISBN 0-201-06196-1
-
Leffler, Samuel J., Marshall Kirk McKusick, The Design and Implementation of the 4.3BSD UNIX Operating System: Answer Book. Reading, Mass. : Addison-Wesley, 1991. ISBN 0-201-54629-9
-
McKusick, Marshall Kirk, Keith Bostic, Michael J Karels, and John Quarterman. The Design and Implementation of the 4.4BSD Operating System. Reading, Mass. : Addison-Wesley, 1996. ISBN 0-201-54979-4
(Chapter 2 of this book is available online as part of the FreeBSD Documentation Project, and chapter 9 here.)
-
Marshall Kirk McKusick, George V. Neville-Neil The Design and Implementation of the FreeBSD Operating System. Boston, Mass. : Addison-Wesley, 2004. ISBN 0-201-70245-2
-
Stevens, W. Richard. TCP/IP Illustrated, Volume 1: The Protocols. Reading, Mass. : Addison-Wesley, 1996. ISBN 0-201-63346-9
-
Schimmel, Curt. Unix Systems for Modern Architectures. Reading, Mass. : Addison-Wesley, 1994. ISBN 0-201-63338-8
-
Stevens, W. Richard. TCP/IP Illustrated, Volume 3: TCP for Transactions, HTTP, NNTP and the UNIX Domain Protocols. Reading, Mass. : Addison-Wesley, 1996. ISBN 0-201-63495-3
-
Vahalia, Uresh. UNIX Internals -- The New Frontiers. Prentice Hall, 1996. ISBN 0-13-101908-2
-
Wright, Gary R. and W. Richard Stevens. TCP/IP Illustrated, Volume 2: The Implementation. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-63354-X
B.6 Security Reference
-
Cheswick, William R. and Steven M. Bellovin. Firewalls and Internet Security: Repelling the Wily Hacker. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-63357-4
-
Garfinkel, Simson and Gene Spafford. Practical UNIX & Internet Security. 2nd Ed. O'Reilly & Associates, Inc., 1996. ISBN 1-56592-148-8
-
Garfinkel, Simson. PGP Pretty Good Privacy O'Reilly & Associates, Inc., 1995. ISBN 1-56592-098-8
B.7 Hardware Reference
-
Anderson, Don and Tom Shanley. Pentium Processor System Architecture. 2nd Ed. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-40992-5
-
Ferraro, Richard F. Programmer's Guide to the EGA, VGA, and Super VGA Cards. 3rd ed. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-62490-7
-
Intel Corporation publishes documentation on their CPUs, chipsets and standards on their developer web site, usually as PDF files.
-
Shanley, Tom. 80486 System Architecture. 3rd ed. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-40994-1
-
Shanley, Tom. ISA System Architecture. 3rd ed. Reading, Mass. : Addison-Wesley, 1995. ISBN 0-201-40996-8
-
Shanley, Tom. PCI System Architecture. 4th ed. Reading, Mass. : Addison-Wesley, 1999. ISBN 0-201-30974-2
-
Van Gilluwe, Frank. The Undocumented PC, 2nd Ed. Reading, Mass: Addison-Wesley Pub. Co., 1996. ISBN 0-201-47950-8
-
Messmer, Hans-Peter. The Indispensable PC Hardware Book, 4th Ed. Reading, Mass: Addison-Wesley Pub. Co., 2002. ISBN 0-201-59616-4
B.8 UNIX History
-
Lion, John Lion's Commentary on UNIX, 6th Ed. With Source Code. ITP Media Group, 1996. ISBN 1573980137
-
Raymond, Eric S. The New Hacker's Dictionary, 3rd edition. MIT Press, 1996. ISBN 0-262-68092-0. Also known as the Jargon File
-
Salus, Peter H. A quarter century of UNIX. Addison-Wesley Publishing Company, Inc., 1994. ISBN 0-201-54777-5
-
Simon Garfinkel, Daniel Weise, Steven Strassmann. The UNIX-HATERS Handbook. IDG Books Worldwide, Inc., 1994. ISBN 1-56884-203-1. Out of print, but available online.
-
Don Libes, Sandy Ressler Life with UNIX -- special edition. Prentice-Hall, Inc., 1989. ISBN 0-13-536657-7
-
The BSD family tree. http://www.FreeBSD.org/cgi/cvsweb.cgi/src/share/misc/bsd-family-tree or /usr/share/misc/bsd-family-tree on a FreeBSD machine.
-
The BSD Release Announcements collection. 1997. http://www.de.FreeBSD.org/de/ftp/releases/
-
Networked Computer Science Technical Reports Library. http://www.ncstrl.org/
-
Old BSD releases from the Computer Systems Research group (CSRG). http://www.mckusick.com/csrg/: The 4CD set covers all BSD versions from 1BSD to 4.4BSD and 4.4BSD-Lite2 (but not 2.11BSD, unfortunately). The last disk also holds the final sources plus the SCCS files.
B.9 Magazines and Journals
-
The C/C++ Users Journal. R&D Publications Inc. ISSN 1075-2838
-
Sys Admin -- The Journal for UNIX System Administrators Miller Freeman, Inc., ISSN 1061-2688
-
freeX -- Das Magazin für Linux - BSD - UNIX (in German) Computer- und Literaturverlag GmbH, ISSN 1436-7033
Appendix C. Resources on the Internet
The rapid pace of FreeBSD progress makes print media impractical as a means of following the latest developments. Electronic resources are the best, if not often the only, way stay informed of the latest advances. Since FreeBSD is a volunteer effort, the user community itself also generally serves as a “technical support department” of sorts, with electronic mail and USENET news being the most effective way of reaching that community.
The most important points of contact with the FreeBSD user community are outlined below. If you are aware of other resources not mentioned here, please send them to the FreeBSD documentation project mailing list so that they may also be included.
C.1 Mailing Lists
Though many of the FreeBSD development members read USENET, we cannot always guarantee that we will get to your questions in a timely fashion (or at all) if you post them only to one of the comp.unix.bsd.freebsd.* groups. By addressing your questions to the appropriate mailing list you will reach both us and a concentrated FreeBSD audience, invariably assuring a better (or at least faster) response.
The charters for the various lists are given at the bottom of this document. Please read the charter before joining or sending mail to any list. Most of our list subscribers now receive many hundreds of FreeBSD related messages every day, and by setting down charters and rules for proper use we are striving to keep the signal-to-noise ratio of the lists high. To do less would see the mailing lists ultimately fail as an effective communications medium for the project.
Note: If you wish to test your ability to send to FreeBSD lists, send a test message to freebsd-test. Please do not send test messages to any other list.
When in doubt about what list to post a question to, see How to get best results from the FreeBSD-questions mailing list.
Before posting to any list, please learn about how to best use the mailing lists, such as how to help avoid frequently-repeated discussions, by reading the Mailing List Frequently Asked Questions (FAQ) document.
Archives are kept for all of the mailing lists and can be searched using the FreeBSD World Wide Web server. The keyword searchable archive offers an excellent way of finding answers to frequently asked questions and should be consulted before posting a question.
C.1.1 List Summary
General lists: The following are general lists which anyone is free (and encouraged) to join:
| List | Purpose |
|---|---|
| cvs-all | Changes made to the FreeBSD source tree |
| freebsd-advocacy | FreeBSD Evangelism |
| freebsd-announce | Important events and project milestones |
| freebsd-arch | Architecture and design discussions |
| freebsd-bugbusters | Discussions pertaining to the maintenance of the FreeBSD problem report database and related tools |
| freebsd-bugs | Bug reports |
| freebsd-chat | Non-technical items related to the FreeBSD community |
| freebsd-current | Discussion concerning the use of FreeBSD-CURRENT |
| freebsd-isp | Issues for Internet Service Providers using FreeBSD |
| freebsd-jobs | FreeBSD employment and consulting opportunities |
| freebsd-policy | FreeBSD Core team policy decisions. Low volume, and read-only |
| freebsd-questions | User questions and technical support |
| freebsd-security-notifications | Security notifications |
| freebsd-stable | Discussion concerning the use of FreeBSD-STABLE |
| freebsd-test | Where to send your test messages instead of one of the actual lists |
Technical lists: The following lists are for technical discussion. You should read the charter for each list carefully before joining or sending mail to one as there are firm guidelines for their use and content.
| List | Purpose |
|---|---|
| freebsd-acpi | ACPI and power management development |
| freebsd-afs | Porting AFS to FreeBSD |
| freebsd-aic7xxx | Developing drivers for the Adaptec AIC 7xxx |
| freebsd-alpha | Porting FreeBSD to the Alpha |
| freebsd-amd64 | Porting FreeBSD to AMD64 systems |
| freebsd-apache | Discussion about Apache related ports |
| freebsd-arm | Porting FreeBSD to ARM® processors |
| freebsd-atm | Using ATM networking with FreeBSD |
| freebsd-audit | Source code audit project |
| freebsd-binup | Design and development of the binary update system |
| freebsd-bluetooth | Using Bluetooth technology in FreeBSD |
| freebsd-cluster | Using FreeBSD in a clustered environment |
| freebsd-cvsweb | CVSweb maintenance |
| freebsd-database | Discussing database use and development under FreeBSD |
| freebsd-doc | Creating FreeBSD related documents |
| freebsd-drivers | Writing device drivers for FreeBSD |
| freebsd-eclipse | FreeBSD users of Eclipse IDE, tools, rich client applications and ports. |
| freebsd-embedded | Using FreeBSD in embedded applications |
| freebsd-eol | Peer support of FreeBSD-related software that is no longer supported by the FreeBSD project. |
| freebsd-emulation | Emulation of other systems such as Linux/MS-DOS/Windows |
| freebsd-firewire | FreeBSD FireWire® (iLink, IEEE 1394) technical discussion |
| freebsd-fs | File systems |
| freebsd-geom | GEOM-specific discussions and implementations |
| freebsd-gnome | Porting GNOME and GNOME applications |
| freebsd-hackers | General technical discussion |
| freebsd-hardware | General discussion of hardware for running FreeBSD |
| freebsd-i18n | FreeBSD Internationalization |
| freebsd-ia32 | FreeBSD on the IA-32 (Intel x86) platform |
| freebsd-ia64 | Porting FreeBSD to Intel's upcoming IA64 systems |
| freebsd-ipfw | Technical discussion concerning the redesign of the IP firewall code |
| freebsd-isdn | ISDN developers |
| freebsd-jail | Discussion about the jail(8) facility |
| freebsd-java | Java developers and people porting JDKs to FreeBSD |
| freebsd-kde | Porting KDE and KDE applications |
| freebsd-lfs | Porting LFS to FreeBSD |
| freebsd-libh | The second generation installation and package system |
| freebsd-mips | Porting FreeBSD to MIPS® |
| freebsd-mobile | Discussions about mobile computing |
| freebsd-mozilla | Porting Mozilla to FreeBSD |
| freebsd-multimedia | Multimedia applications |
| freebsd-new-bus | Technical discussions about bus architecture |
| freebsd-net | Networking discussion and TCP/IP source code |
| freebsd-openoffice | Porting OpenOffice.org and StarOffice to FreeBSD |
| freebsd-performance | Performance tuning questions for high performance/load installations |
| freebsd-perl | Maintenance of a number of Perl-related ports |
| freebsd-pf | Discussion and questions about the packet filter firewall system |
| freebsd-platforms | Concerning ports to non Intel architecture platforms |
| freebsd-ports | Discussion of the Ports Collection |
| freebsd-ports-bugs | Discussion of the ports bugs/PRs |
| freebsd-ppc | Porting FreeBSD to the PowerPC® |
| freebsd-proliant | Technical discussion of FreeBSD on HP ProLiant server platforms |
| freebsd-python | FreeBSD-specific Python issues |
| freebsd-qa | Discussion of Quality Assurance, usually pending a release |
| freebsd-rc | Discussion related to the rc.d system and its development |
| freebsd-realtime | Development of realtime extensions to FreeBSD |
| freebsd-scsi | The SCSI subsystem |
| freebsd-security | Security issues affecting FreeBSD |
| freebsd-small | Using FreeBSD in embedded applications (obsolete; use freebsd-embedded instead) |
| freebsd-smp | Design discussions for [A]Symmetric MultiProcessing |
| freebsd-sparc64 | Porting FreeBSD to Sparc® based systems |
| freebsd-standards | FreeBSD's conformance to the C99 and the POSIX standards |
| freebsd-sun4v | Porting FreeBSD to UltraSPARC T1 based systems |
| freebsd-threads | Threading in FreeBSD |
| freebsd-testing | FreeBSD Performance and Stability Tests |
| freebsd-tokenring | Support Token Ring in FreeBSD |
| freebsd-usb | Discussing FreeBSD support for USB |
| freebsd-vuxml | Discussion on VuXML infrastructure |
| freebsd-x11 | Maintenance and support of X11 on FreeBSD |
Limited lists: The following lists are for more specialized (and demanding) audiences and are probably not of interest to the general public. It is also a good idea to establish a presence in the technical lists before joining one of these limited lists so that you will understand the communications etiquette involved.
| List | Purpose |
|---|---|
| freebsd-hubs | People running mirror sites (infrastructural support) |
| freebsd-user-groups | User group coordination |
| freebsd-vendors | Vendors pre-release coordination |
| freebsd-www | Maintainers of www.FreeBSD.org |
Digest lists: All of the above lists are available in a digest format. Once subscribed to a list, you can change your digest options in your account options section.
CVS lists: The following lists are for people interested in seeing the log messages for changes to various areas of the source tree. They are Read-Only lists and should not have mail sent to them.
| List | Source area | Area Description (source for) |
|---|---|---|
| cvs-all | /usr/(CVSROOT|doc|ports|projects|src) | All changes to any place in the tree (superset of other CVS commit lists) |
| cvs-doc | /usr/(doc|www) | All changes to the doc and www trees |
| cvs-ports | /usr/ports | All changes to the ports tree |
| cvs-projects | /usr/projects | All changes to the projects tree |
| cvs-src | /usr/src | All changes to the src tree |
C.1.2 How to Subscribe
To subscribe to a list, click on the list name above or go to http://lists.FreeBSD.org/mailman/listinfo and click on the list that you are interested in. The list page should contain all of the necessary subscription instructions.
To actually post to a given list you simply send mail to <listname@FreeBSD.org>. It will then be
redistributed to mailing list members world-wide.
To unsubscribe yourself from a list, click on the URL found at the bottom of every
email received from the list. It is also possible to send an email to <listname-unsubscribe@FreeBSD.org> to
unsubscribe yourself.
Again, we would like to request that you keep discussion in the technical mailing lists on a technical track. If you are only interested in important announcements then it is suggested that you join the FreeBSD announcements mailing list, which is intended only for infrequent traffic.
C.1.3 List Charters
All FreeBSD mailing lists have
certain basic rules which must be adhered to by anyone using them. Failure to comply with
these guidelines will result in two (2) written warnings from the FreeBSD Postmaster
<postmaster@FreeBSD.org>, after which,
on a third offense, the poster will removed from all FreeBSD mailing lists and filtered
from further posting to them. We regret that such rules and measures are necessary at
all, but today's Internet is a pretty harsh environment, it would seem, and many fail to
appreciate just how fragile some of its mechanisms are.
Rules of the road:
-
The topic of any posting should adhere to the basic charter of the list it is posted to, e.g. if the list is about technical issues then your posting should contain technical discussion. Ongoing irrelevant chatter or flaming only detracts from the value of the mailing list for everyone on it and will not be tolerated. For free-form discussion on no particular topic, the FreeBSD chat mailing list is freely available and should be used instead.
-
No posting should be made to more than 2 mailing lists, and only to 2 when a clear and obvious need to post to both lists exists. For most lists, there is already a great deal of subscriber overlap and except for the most esoteric mixes (say “-stable & -scsi”), there really is no reason to post to more than one list at a time. If a message is sent to you in such a way that multiple mailing lists appear on the Cc line then the Cc line should also be trimmed before sending it out again. You are still responsible for your own cross-postings, no matter who the originator might have been.
-
Personal attacks and profanity (in the context of an argument) are not allowed, and that includes users and developers alike. Gross breaches of netiquette, like excerpting or reposting private mail when permission to do so was not and would not be forthcoming, are frowned upon but not specifically enforced. However, there are also very few cases where such content would fit within the charter of a list and it would therefore probably rate a warning (or ban) on that basis alone.
-
Advertising of non-FreeBSD related products or services is strictly prohibited and will result in an immediate ban if it is clear that the offender is advertising by spam.
Individual list charters:
- freebsd-acpi
-
ACPI and power management development
- freebsd-afs
-
Andrew File System
This list is for discussion on porting and using AFS from CMU/Transarc
- freebsd-announce
-
Important events / milestones
This is the mailing list for people interested only in occasional announcements of significant FreeBSD events. This includes announcements about snapshots and other releases. It contains announcements of new FreeBSD capabilities. It may contain calls for volunteers etc. This is a low volume, strictly moderated mailing list.
- freebsd-arch
-
Architecture and design discussions
This list is for discussion of the FreeBSD architecture. Messages will mostly be kept strictly technical in nature. Examples of suitable topics are:
-
How to re-vamp the build system to have several customized builds running at the same time.
-
What needs to be fixed with VFS to make Heidemann layers work.
-
How do we change the device driver interface to be able to use the same drivers cleanly on many buses and architectures.
-
How to write a network driver.
-
- freebsd-audit
-
Source code audit project
This is the mailing list for the FreeBSD source code audit project. Although this was originally intended for security-related changes, its charter has been expanded to review any code changes.
This list is very heavy on patches, and is probably of no interest to the average FreeBSD user. Security discussions not related to a particular code change are held on freebsd-security. Conversely, all developers are encouraged to send their patches here for review, especially if they touch a part of the system where a bug may adversely affect the integrity of the system.
- freebsd-binup
-
FreeBSD Binary Update Project
This list exists to provide discussion for the binary update system, or binup. Design issues, implementation details, patches, bug reports, status reports, feature requests, commit logs, and all other things related to binup are fair game.
- freebsd-bluetooth
-
Bluetooth in FreeBSD
This is the forum where FreeBSD's Bluetooth users congregate. Design issues, implementation details, patches, bug reports, status reports, feature requests, and all matters related to Bluetooth are fair game.
- freebsd-bugbusters
-
Coordination of the Problem Report handling effort
The purpose of this list is to serve as a coordination and discussion forum for the Bugmeister, his Bugbusters, and any other parties who have a genuine interest in the PR database. This list is not for discussions about specific bugs, patches or PRs.
- freebsd-bugs
-
Bug reports
This is the mailing list for reporting bugs in FreeBSD. Whenever possible, bugs should be submitted using the send-pr(1) command or the WEB interface to it.
- freebsd-chat
-
Non technical items related to the FreeBSD community
This list contains the overflow from the other lists about non-technical, social information. It includes discussion about whether Jordan looks like a toon ferret or not, whether or not to type in capitals, who is drinking too much coffee, where the best beer is brewed, who is brewing beer in their basement, and so on. Occasional announcements of important events (such as upcoming parties, weddings, births, new jobs, etc) can be made to the technical lists, but the follow ups should be directed to this -chat list.
- freebsd-core
-
FreeBSD core team
This is an internal mailing list for use by the core members. Messages can be sent to it when a serious FreeBSD-related matter requires arbitration or high-level scrutiny.
- freebsd-current
-
Discussions about the use of FreeBSD-CURRENT
This is the mailing list for users of FreeBSD-CURRENT. It includes warnings about new features coming out in -CURRENT that will affect the users, and instructions on steps that must be taken to remain -CURRENT. Anyone running “CURRENT” must subscribe to this list. This is a technical mailing list for which strictly technical content is expected.
- freebsd-cvsweb
-
FreeBSD CVSweb Project
Technical discussions about use, development and maintenance of FreeBSD-CVSweb.
- freebsd-doc
-
Documentation project
This mailing list is for the discussion of issues and projects related to the creation of documentation for FreeBSD. The members of this mailing list are collectively referred to as “The FreeBSD Documentation Project”. It is an open list; feel free to join and contribute!
- freebsd-drivers
-
Writing device drivers for FreeBSD
This is a forum for technical discussions related to device drivers on FreeBSD. It is primarily a place for device driver writers to ask questions about how to write device drivers using the APIs in the FreeBSD kernel.
- freebsd-eclipse
-
FreeBSD users of Eclipse IDE, tools, rich client applications and ports.
The intention of this list is to provide mutual support for everything to do with choosing, installing, using, developing and maintaining the Eclipse IDE, tools, rich client applications on the FreeBSD platform and assisting with the porting of Eclipse IDE and plugins to the FreeBSD environment.
The intention is also to facilitate exchange of information between the Eclipse community and the FreeBSD community to the mutual benefit of both.
Although this list is focused primarily on the needs of Eclipse users it will also provide a forum for those who would like to develop FreeBSD specific applications using the Eclipse framework.
- freebsd-embedded
-
Using FreeBSD in embedded applications
This list discusses topics related to using FreeBSD in embedded systems. This is a technical mailing list for which strictly technical content is expected. For the purpose of this list we define embedded systems as those computing devices which are not desktops and which usually serve a single purpose as opposed to being general computing environments. Examples include, but are not limited to, all kinds of phone handsets, network equipment such as routers, switches and PBXs, remote measuring equipment, PDAs, Point Of Sale systems, and so on.
- freebsd-emulation
-
Emulation of other systems such as Linux/MS-DOS/Windows
This is a forum for technical discussions related to running programs written for other operating systems on FreeBSD.
- freebsd-eol
-
Peer support of FreeBSD-related software that is no longer supported by the FreeBSD project.
This list is for those interested in providing or making use of peer support of FreeBSD-related software for which the FreeBSD project no longer provides official support (e.g., in the form of security advisories and patches).
- freebsd-firewire
-
FireWire (iLink, IEEE 1394)
This is a mailing list for discussion of the design and implementation of a FireWire (aka IEEE 1394 aka iLink) subsystem for FreeBSD. Relevant topics specifically include the standards, bus devices and their protocols, adapter boards/cards/chips sets, and the architecture and implementation of code for their proper support.
- freebsd-fs
-
File systems
Discussions concerning FreeBSD file systems. This is a technical mailing list for which strictly technical content is expected.
- freebsd-geom
-
GEOM
Discussions specific to GEOM and related implementations. This is a technical mailing list for which strictly technical content is expected.
- freebsd-gnome
-
GNOME
Discussions concerning The GNOME Desktop Environment for FreeBSD systems. This is a technical mailing list for which strictly technical content is expected.
- freebsd-ipfw
-
IP Firewall
This is the forum for technical discussions concerning the redesign of the IP firewall code in FreeBSD. This is a technical mailing list for which strictly technical content is expected.
- freebsd-ia64
-
Porting FreeBSD to IA64
This is a technical mailing list for individuals actively working on porting FreeBSD to the IA-64 platform from Intel, to bring up problems or discuss alternative solutions. Individuals interested in following the technical discussion are also welcome.
- freebsd-isdn
-
ISDN Communications
This is the mailing list for people discussing the development of ISDN support for FreeBSD.
- freebsd-java
-
Java Development
This is the mailing list for people discussing the development of significant Java applications for FreeBSD and the porting and maintenance of JDKs.
- freebsd-jobs
-
Jobs offered and sought
This is a forum for posting employment notices and resumes specifically related to FreeBSD, e.g. if you are seeking FreeBSD-related employment or have a job involving FreeBSD to advertise then this is the right place. This is not a mailing list for general employment issues since adequate forums for that already exist elsewhere.
Note that this list, like other FreeBSD.org mailing lists, is distributed worldwide. Thus, you need to be clear about location and the extent to which telecommuting or assistance with relocation is available.
Email should use open formats only -- preferably plain text, but basic Portable Document Format (PDF), HTML, and a few others are acceptable to many readers. Closed formats such as Microsoft Word (.doc) will be rejected by the mailing list server.
- freebsd-kde
-
KDE
Discussions concerning KDE on FreeBSD systems. This is a technical mailing list for which strictly technical content is expected.
- freebsd-hackers
-
Technical discussions
This is a forum for technical discussions related to FreeBSD. This is the primary technical mailing list. It is for individuals actively working on FreeBSD, to bring up problems or discuss alternative solutions. Individuals interested in following the technical discussion are also welcome. This is a technical mailing list for which strictly technical content is expected.
- freebsd-hardware
-
General discussion of FreeBSD hardware
General discussion about the types of hardware that FreeBSD runs on, various problems and suggestions concerning what to buy or avoid.
- freebsd-hubs
-
Mirror sites
Announcements and discussion for people who run FreeBSD mirror sites.
- freebsd-isp
-
Issues for Internet Service Providers
This mailing list is for discussing topics relevant to Internet Service Providers (ISPs) using FreeBSD. This is a technical mailing list for which strictly technical content is expected.
- freebsd-openoffice
-
OpenOffice.org
Discussions concerning the porting and maintenance of OpenOffice.org and StarOffice.
- freebsd-performance
-
Discussions about tuning or speeding up FreeBSD
This mailing list exists to provide a place for hackers, administrators, and/or concerned parties to discuss performance related topics pertaining to FreeBSD. Acceptable topics includes talking about FreeBSD installations that are either under high load, are experiencing performance problems, or are pushing the limits of FreeBSD. Concerned parties that are willing to work toward improving the performance of FreeBSD are highly encouraged to subscribe to this list. This is a highly technical list ideally suited for experienced FreeBSD users, hackers, or administrators interested in keeping FreeBSD fast, robust, and scalable. This list is not a question-and-answer list that replaces reading through documentation, but it is a place to make contributions or inquire about unanswered performance related topics.
- freebsd-pf
-
Discussion and questions about the packet filter firewall system
Discussion concerning the packet filter (pf) firewall system in terms of FreeBSD. Technical discussion and user questions are both welcome. This list is also a place to discuss the ALTQ QoS framework.
- freebsd-platforms
-
Porting to Non Intel platforms
Cross-platform FreeBSD issues, general discussion and proposals for non Intel FreeBSD ports. This is a technical mailing list for which strictly technical content is expected.
- freebsd-policy
-
Core team policy decisions
This is a low volume, read-only mailing list for FreeBSD Core Team Policy decisions.
- freebsd-ports
-
Discussion of “ports”
Discussions concerning FreeBSD's “ports collection” (/usr/ports), ports infrastructure, and general ports coordination efforts. This is a technical mailing list for which strictly technical content is expected.
- freebsd-ports-bugs
-
Discussion of “ports” bugs
Discussions concerning problem reports for FreeBSD's “ports collection” (/usr/ports), proposed ports, or modifications to ports. This is a technical mailing list for which strictly technical content is expected.
- freebsd-proliant
-
Technical discussion of FreeBSD on HP ProLiant server platforms
This mailing list is to be used for the technical discussion of the usage of FreeBSD on HP ProLiant servers, including the discussion of ProLiant-specific drivers, management software, configuration tools, and BIOS updates. As such, this is the primary place to discuss the hpasmd, hpasmcli, and hpacucli modules.
- freebsd-python
-
Python on FreeBSD
This is a list for discussions related to improving Python-support on FreeBSD. This is a technical mailing list. It is for individuals working on porting Python, its 3rd party modules and Zope stuff to FreeBSD. Individuals interested in following the technical discussion are also welcome.
- freebsd-questions
-
User questions
This is the mailing list for questions about FreeBSD. You should not send “how to” questions to the technical lists unless you consider the question to be pretty technical.
- freebsd-scsi
-
SCSI subsystem
This is the mailing list for people working on the SCSI subsystem for FreeBSD. This is a technical mailing list for which strictly technical content is expected.
- freebsd-security
-
Security issues
FreeBSD computer security issues (DES, Kerberos, known security holes and fixes, etc). This is a technical mailing list for which strictly technical discussion is expected. Note that this is not a question-and-answer list, but that contributions (BOTH question AND answer) to the FAQ are welcome.
- freebsd-security-notifications
-
Security Notifications
Notifications of FreeBSD security problems and fixes. This is not a discussion list. The discussion list is FreeBSD-security.
- freebsd-small
-
Using FreeBSD in embedded applications
This list discusses topics related to unusually small and embedded FreeBSD installations. This is a technical mailing list for which strictly technical content is expected.
Note: This list has been obsoleted by freebsd-embedded.
- freebsd-stable
-
Discussions about the use of FreeBSD-STABLE
This is the mailing list for users of FreeBSD-STABLE. It includes warnings about new features coming out in -STABLE that will affect the users, and instructions on steps that must be taken to remain -STABLE. Anyone running “STABLE” should subscribe to this list. This is a technical mailing list for which strictly technical content is expected.
- freebsd-standards
-
C99 & POSIX Conformance
This is a forum for technical discussions related to FreeBSD Conformance to the C99 and the POSIX standards.
- freebsd-usb
-
Discussing FreeBSD support for USB
This is a mailing list for technical discussions related to FreeBSD support for USB.
- freebsd-user-groups
-
User Group Coordination List
This is the mailing list for the coordinators from each of the local area Users Groups to discuss matters with each other and a designated individual from the Core Team. This mail list should be limited to meeting synopsis and coordination of projects that span User Groups.
- freebsd-vendors
-
Vendors
Coordination discussions between The FreeBSD Project and Vendors of software and hardware for FreeBSD.
C.1.4 Filtering on the Mailing Lists
The FreeBSD mailing lists are filtered in multiple ways to avoid the distribution of spam, viruses, and other unwanted emails. The filtering actions described in this section do not include all those used to protect the mailing lists.
Only certain types of attachments are allowed on the mailing lists. All attachments with a MIME content type not found in the list below will be stripped before an email is distributed on the mailing lists.
-
application/octet-stream
-
application/pdf
-
application/pgp-signature
-
application/x-pkcs7-signature
-
message/rfc822
-
multipart/alternative
-
multipart/related
-
multipart/signed
-
text/html
-
text/plain
-
text/x-diff
-
text/x-patch
Note: Some of the mailing lists might allow attachments of other MIME content types, but the above list should be applicable for most of the mailing lists.
If an email contains both an HTML and a plain text version, the HTML version will be removed. If an email contains only an HTML version, it will be converted to plain text.
C.2 Usenet Newsgroups
In addition to two FreeBSD specific newsgroups, there are many others in which FreeBSD
is discussed or are otherwise relevant to FreeBSD users. Keyword
searchable archives are available for some of these newsgroups from courtesy of
Warren Toomey <wkt@cs.adfa.edu.au>.
C.2.1 BSD Specific Newsgroups
-
de.comp.os.unix.bsd (German)
-
fr.comp.os.bsd (French)
-
it.comp.os.freebsd (Italian)
-
tw.bbs.comp.386bsd (Traditional Chinese)
C.3 World Wide Web Servers
Central Servers, Argentina, Armenia, Australia, Austria, Belgium, Brazil, Bulgaria, Canada, China, Costa Rica, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hong Kong, Hungary, Iceland, Indonesia, Ireland, Italy, Japan, Korea, Kuwait, Kyrgyzstan, Latvia, Lithuania, Netherlands, New Zealand, Norway, Philippines, Poland, Portugal, Romania, Russia, San Marino, Singapore, Slovak Republic, Slovenia, South Africa, Spain, Sweden, Switzerland, Taiwan, Thailand, Turkey, Ukraine, United Kingdom, USA.
(as of 2007/07/17 10:11:16 UTC)
-
Central Servers
-
Argentina
-
Armenia
-
http://www1.am.FreeBSD.org/ (IPv6)
-
-
Australia
-
Austria
-
Belgium
-
Brazil
-
Bulgaria
-
Canada
-
China
-
Costa Rica
-
Czech Republic
-
Denmark
-
Estonia
-
Finland
-
France
-
Germany
-
Greece
-
Hong Kong
-
Hungary
-
Iceland
-
Indonesia
-
Ireland
-
Italy
-
Japan
-
Korea
-
Kuwait
-
Kyrgyzstan
-
Latvia
-
Lithuania
-
Netherlands
-
New Zealand
-
Norway
-
Philippines
-
Poland
-
Portugal
-
Romania
-
Russia
-
San Marino
-
Singapore
-
Slovak Republic
-
Slovenia
-
South Africa
-
Spain
-
Sweden
-
Switzerland
-
Taiwan
-
Thailand
-
Turkey
-
Ukraine
-
United Kingdom
-
USA
C.4 Email Addresses
The following user groups provide FreeBSD related email addresses for their members. The listed administrator reserves the right to revoke the address if it is abused in any way.
| Domain | Facilities | User Group | Administrator |
|---|---|---|---|
| ukug.uk.FreeBSD.org | Forwarding only | <freebsd-users@uk.FreeBSD.org> |
Lee Johnston <lee@uk.FreeBSD.org> |
C.5 Shell Accounts
The following user groups provide shell accounts for people who are actively supporting the FreeBSD project. The listed administrator reserves the right to cancel the account if it is abused in any way.
| Host | Access | Facilities | Administrator |
|---|---|---|---|
| dogma.freebsd-uk.eu.org | Telnet/FTP/SSH | Email, Web space, Anonymous FTP | Lee Johnston <lee@uk.FreeBSD.org> |
Appendix D. PGP Keys
In case you need to verify a signature or send encrypted email to one of the officers or developers a number of keys are provided here for your convenience. A complete keyring of FreeBSD.org users is available for download from http://www.FreeBSD.org/doc/pgpkeyring.txt.
D.1 Officers
D.1.1
Security Officer Team <security-officer@FreeBSD.org>
pub 1024D/CA6CDFB2 2002-08-27 FreeBSD Security Officer <security-officer@FreeBSD.org>
Key fingerprint = C374 0FC5 69A6 FBB1 4AED B131 15D6 8804 CA6C DFB2
sub 2048g/A3071809 2002-08-27
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD1rpGQRBACJ1CQS7VnTTvH3wjscXQed2RoeVi+n3HtxaF9ApJbxb77dXk+/
DL1ZR0bcZ8s7uQ1D5BkrqSHevoA9FlEN02MM9qyIerXter2/ZEporVOG+/XMkIiV
rd3AgVwUnawhOMKTlYmttcOpADKr9RkYvCT6QMqFDXJssbW7gPlEqOzhYwCgoIdD
ygZ5RdfXm/hBnp+oTWadeIED/2WvL/Iy0YheRTSmTvEdK+Cd4xPhmY2SrrvF2+lE
oFIn94C0fJhqKhJp+wGXmQ/h3yF0gcr1NfFBm6y1iztEz2n0ciaEmMf1tu0Y+u+Y
E0/1Igpoj9Kj5xxRJD5wYyDi0qzxP8BhvJ6sKJtO+f6/OIgZ0ITYWakim7d3RrNV
0ditA/0XUvDgdEB0hm7iqR8FbwKNmS8DVKGs+CYrFwSBJ0vUH65WFapbdWbi2uwm
8CDKgSWpS16/PVr/ql84ePWdiVhHYmkkjuWPUFHSUcDiYL8YG9rnymw6Enx3Nyyr
ewiUOJFzWN6/u3O4x2M9ljrQQ1FmmAbw9R4KT/KHOyBC0W+xHbQ3RnJlZUJTRCBT
ZWN1cml0eSBPZmZpY2VyIDxzZWN1cml0eS1vZmZpY2VyQEZyZWVCU0Qub3JnPoha
BBMRAgAaBQI9a6RkBQsHAwIBAxUCAwMWAgECHgECF4AACgkQFdaIBMps37J/wQCg
je4X7iqjNbVDgwpk+98vc+/HoE4An1usSnfAlNcEcd+05ksTw1gPh+h2iEYEExEC
AAYFAj1rq0oACgkQjDKM/xYG25XUdgCfU5F3sYm41Hf28rIlSZzQMat0thcAoI9g
CvTZQ9bKEQbwtFVWIk2weU8ViJwEEwEBAAYFAj1rq2sACgkQVS4eLnPSiKWIFQP/
UYR/wbAka7y0ck0ILV1RRdG2XSnmcb4MSWf/LZwMfmaQ53MC+pHbRWbMZqZVlwrI
RSown9qRvmFT0p47RdJ5ToKS8G8HI9vVJ/tjNU2bYfdtelrwZPvjOJ6Mn4+rzkbL
3OzUOZLqJC0LKvPoBMmTNzsW7Q2gyEMfIujBbnhvz3aJARwEEwEBAAYFAj1rr20A
CgkQZ8KAjzPBYnu5NQf/eSvFPfkLpwQ2HGG5/2n3dfecW+U2FBHh1eULNkREtX+/
AixPveY5wJ6Nl3z1vYqelZN2xw/+ujE92bjEIZPQWM8y2xGZ2ynJPcIsITob2mOQ
v+UePgCun3E3xPRCo+Ob0jhuT45MSoSFYeTw1xgMLbCGN7LowTAG3gzytyJALGGu
awv+V9dUgp6H5GVv7ukTN0OODFg9G9ePbLnkr2/TSjZP9KIth4AYLAOmYqHcssuW
/UCHbzQvoDmo7LZ3lSwlmoTjZ6/Z6QCbHvX0vdP0mDGx/PwXEaVR0+kxtScKHun1
noBBA48AwMNNtZrEHPRVH1vxaSTGYqLtnBV1z+b6UohGBBIRAgAGBQI9a+m2AAoJ
EGxj2gSE0Nfn5VUAoMSonGArly+4U9yM/4uWCvL8mcv2AJ0acJM2ymhDJ1czJ7Jn
hTE8Xo7HsYhGBBMRAgAGBQI9bIKkAAoJEIQ2twt/hoJob64An1BABq6aK4reFRv8
XXTX9984uYxSAJ4gnZLCSdA4U3pHyBsQTr8KtDYdb4hGBBMRAgAGBQI9bVVoAAoJ
EDm2huD+gXpQmA0AoJ8lWlK+7PzyYSWKcItueryfx2uBAJ9Sm0elnPCWc7+gYfol
5MD+X74FYIkAlQMFED3TIstNVigheQUMEQEBa+YD/15yHDEuNRD+6KAeUNLYe0Eg
bSxQmrkQqIm+7ipjjOUX37UJUlar5yzpKyBXv/WvYkvUxklK6YSRd3c7XL7ad9Fc
7II2efTUSOzZYP/xUeK3tFBSn94Lx5cmGjHf4WHPDODQz2nAKqEo2zMMlwCCh1Kz
2GY/hCzqmltplrERjUFAiJwEEwECAAYFAj3dTLAACgkQ4clLRt8d1HE69AP+PDOt
c2wCs5idJB2fkOrLF7QW9QnfGEglBqpa+4vi78iYHQfnm8lM81xPCjnpLSI8Y8tE
7VU4LGRPGC1vxHaCyqGumcPgUCi7lMR/8RGs+5Wt5DsK11zlZ5gN81qys1xRU2qm
hX/HXXQm+Yif39GmnwTXaHGlKYUsqCWcMlaOGdmIRgQTEQIABgUCQJLfKQAKCRDr
gN4di3HTpALjAKCgs/Erpp8mQn9U9Qt6zHW5m2DZAQCfWAjRdsf3T0bMUnim7kpg
Wh5T2B+IRQQTEQIABgUCP22XMwAKCRDevFcampZ5sEmjAJ9Zf9wSUM0nVsCnedWv
cfpMQHLUcgCYurObAik7/aKS/Vo/a1q2/WT494hGBBMRAgAGBQI/YtlRAAoJEE8s
09gnk88tG7YAoNwXHjLvISrUQltenwHdL7R6EqdbAJ0S7ybg5sqRzt5oL4N0xGO4
GDbBM4hGBBMRAgAGBQI/YhfZAAoJEMiGpCvVsvD7qiAAoJo94KW34j6ZMf7RuGH+
5sc6uI7hAJ93C2JScC/nXGdO+MGNqV33e3BzZYhGBBMRAgAGBQI+HF0GAAoJENjD
uVLpGrm5WAEAoIEQ6U0Ape36VJ7pwMcScytHzrltAKCI0W26DZ4pTi9qOH5rdU2g
kcadI4hGBBMRAgAGBQI+HFq8AAoJEG2U2yGkQUVxyYwAnj0gw7Zt4yJXs68Srhfk
UaOMPtzpAJ9QakRJURlrvB6xvcYTvXRNIyBtC4hGBBIRAgAGBQJAUefhAAoJEDjt
bfJDXByagZ0AniB6cV/GYN2WGuorwSXuQCmYlnfDAJ9p6fRiYvQTE0y019rC/HpA
tpc42ohGBBIRAgAGBQJAPsK7AAoJEKodfLASZ/CSHHEAn00ztGSHSKeQgKpYWna0
rjYVOPMoAKDJgeZl1JXGlfHnv1ZS6krqRKiedYhGBBIRAgAGBQI/Yef3AAoJENjK
MXFboFLDNr0AoK7JeaCLQ+qHTNE5H0mMdu9z+1ghAKCQ8sSe2918uu7Dn9cT4RV2
8JijmohGBBIRAgAGBQI/PgbjAAoJENs/1fd/fjFjCLcAn02bEWSbo7xohWAk9/CV
2GNdAzhOAKCD3B71tVr4DC6LYXWBi7kgA5Fq0ohGBBIRAgAGBQI+u3osAAoJEO9q
yAAdy8+3shMAoL+Vl04RGsc+H57yqXvDPcQtaiYbAJoCcTv2rPDWo33oGJluLhsM
be+9m4hGBBERAgAGBQJAR7JmAAoJEDBLkEqH0c4P1GsAoJRfd7AFxc1BYKzwIQCZ
XbepeX5FAJoClbmiVVeXpvJKUf+Ys++1ldk7CohFBBARAgAGBQJAIqrwAAoJENYQ
7uRow9plvlYAoMT7IenrxfJT+ZvajgPA8NN0jlTlAJdFLsMF6E5SIuedLT3WeGqc
Q6RciEYEEBECAAYFAj/j+n4ACgkQk+9jXsWyW9OyOQCfYOY/C1Hsp53PEHWmt9vx
C77IDMYAoJgIpZtDmlfhiOla1jMK2vqMuAlOiEYEEBECAAYFAj998hIACgkQ50IL
eLrbjhGsUwCgjAOu/z1COtiXysFLqMP+jS9ultoAoJzLYU5SwEz8M9rTXi/hJIN6
PoReiEYEEBECAAYFAj9x7b0ACgkQTazywsMSOx8bsgCff2tCn386VsNoNZQE+D+3
PXg+9PcAoJHEdIMqQODz6jZZlpcAFsnC29PPiEYEEBECAAYFAj7hmoUACgkQxQkl
fg8wGi5/SQCglieAaHunWoNrpAuoxboJ2HJaCwwAn3eZ04xo9poyYr9eqz+nrCgJ
M+JbiEYEEBECAAYFAj5ipOsACgkQbsTLOUwlm0c76ACeKwU+FKbJ7klx5vlux2dQ
9sH9cK8AoMtGZwVE93xTndVQg0iS1KUq2xPFiEYEEBECAAYFAj5inQoACgkQ4amb
D6mmD+MnLgCcC+5+3K4uDcwvcr6lvRpfZ2abaVAAn3SEc2KgWpmW8juKzmuiZboR
/CQGiEYEEBECAAYFAj5cWPMACgkQ52ZAyG9FrmnG0ACfe83QHt/+VV/negPLyv5H
iW5CnCQAn0u3tskQaeov1QuRu26mb2GasSmBiEYEEBECAAYFAj5H+/sACgkQfpJ9
hXZBmGNkjwCdFmVgtnzX3aunC2T5IlhlZy2Pz7sAoPrdeN4o4ykI+tSBqFN3IYUZ
GJe8iEYEEBECAAYFAkA3lS0ACgkQKm1dqesZmawCSQCdFPgwlahsZHUgHH24JoZE
sVvcrmQAnAzfPPyOrU0pt/5f6HHLje5kBjojiEYEExECAAYFAkB/iiQACgkQNZ4V
AYLNnkMySgCfYS1HqCdSoc75kn7cRSAHY6MmgfkAn0GelA2Q5LHVGBEtB8mWjC6B
JzbEiEYEExECAAYFAkEnhKsACgkQP6DeCKDTkWjhTwCghO0gYDrroDvTjquy1584
ihzfz5QAn0urR2W8reAOR0H8IfBumsuN/+zdiEYEExECAAYFAkC2EcwACgkQ90UN
cjm0VUF5rQCfTT/2vWmDSeqC8dK5ZsSLiuqtHs4AnR4PvkIx+TknhKU2EwcVE5CV
pHw6iEYEExECAAYFAkCyKFwACgkQeQODqXRm5lPuwgCgovBJrJlj1B1WMwpLISS+
q43AuCMAnjXaQynGIjqo6wRpgV2CxzethYGFiEYEExECAAYFAkCq6TcACgkQFRup
lBF1wuM0OgCcCY3os6OZ5wmdEM3qOJHgtVz5FKUAn38/6pIytOz0RhHz9xRPJjrl
GCMliEYEExECAAYFAkCqp6QACgkQB2FzsZKExFKx7gCfd72iIOvpiV9xw0m9n77i
UIkdgB4AnR3fslT+bKmFxnmfq2oKS/bD+iu/iEYEExECAAYFAkCqgn8ACgkQD1ro
JTQ4LlGNTQCeMHMlCHwkDF70O8Kk6AB9rCVCxSQAoKpVBTtRqF0Ck7xuCRp359AP
A/1riEYEExECAAYFAkCo4G8ACgkQcc6vrOyiitthMACeNnk2DTydmxBy+W4J5frI
MQwsehkAn1yBV/gIBvXeUzFX+6o/ySg0F1PSiEYEExECAAYFAkCo36YACgkQoO/5
4HmnyHB4UQCfVbeWVRZ6rLaBez0vkpfZsm4g3YAAoIJueunliyY5Wse7+GIA1T/N
K/JeiEYEExECAAYFAkCoS58ACgkQ/f+PWOTbRPLVawCdFKEX6aGMxhWn6OcTp7Qp
eoo6eBEAoNLQFWF57hOHoCBD0Qeb7U7ouWS+iEYEExECAAYFAkCoS5wACgkQ0g/U
BcrVCcb/PwCfX04XG82U4ib+vPovQq1nmXSFGPYAn2wWaB7Gl9xqFkL1S16M4FMU
A9ToiEYEExECAAYFAkCn7qYACgkQfb0Lle2MIEJyUgCeJgzbC36/KwSWYCmpLM72
/Vux0RYAoJhTdSOuAp46/4BE9GtOVy0lqZzeiEYEExECAAYFAkCnfJwACgkQ3+43
lGvsmAqwvgCeNtww51G092rjInFoLAU0YqBThwQAn3v++9yqDcPTAPtDRcoEMSkt
PlmJiJwEEwECAAYFAkCpwMAACgkQH3+pCANY/L3U0wP/VM4QrWAnOLxZQ/Cg6ZuI
xsXxscuNtLvlXcrQzCXaSlsYhkx+5iqvOyhiis7EZYu5vwHnssuqns8PC4B5XAJA
uR/+N/EH8t4KnP/yqIc0wp4KfpVYfwPNqu9XvmqjOmXav6qYOGSHDcsysiATeNzE
rDFbmQKT6EeHnMjF4HZZbfqIRgQSEQIABgUCQORLhwAKCRA/Es89ZBWVCcOtAJ4g
5m3rJQlQEGSTcSbMWbNhOJFdGQCfUI44eXdXJtOXEwI4zsxFdki16WyIRgQSEQIA
BgUCQLDsygAKCRB+t5LfGR/NisDbAKCpGbs/t/Gyfetfy3M2RfdsdIXcSACfWBzP
Pxs3lmRtM6vVx3r7om633cmIRQQSEQIABgUCQKrr5AAKCRBLs6ZvfrNSQOfEAJdg
T76wMqMiHDDgzH8/NF3A/1fUAJ46iOdx3bxyhLrI1oHgRc9izBbYmYhGBBIRAgAG
BQJAqPivAAoJEDOEg8QL/Ll+B/QAniYZXQqD0PIzy1y3hb6CBSyNjOTsAJ9eEPp/
oh+acl2VDuPnK34IQtQeFYhGBBIRAgAGBQJAqAuxAAoJEAzLfv4LMKk7RPMAnjmL
+rAjQx9S0tPNSKNfuFnXUzNmAJ9FF3fmiLde7kqoDSQ/t9Zm6ZXRHYhGBBIRAgAG
BQJAp90zAAoJEElFpTfXe0P7QaAAoIR2WkzaiFdNzVUj1veIYnx1x+mfAKCF2eNy
qQpoJOHBSPHcxmrgdoIGa4hGBBIRAgAGBQJApvwJAAoJEBeO4nT4FnLFn4cAnA3Y
IMTwPRTWvQhVGXqEUIM+761IAKCCGiAt3+Qov35ZOCyKQ/vDk5BEyYhGBBERAgAG
BQJAptgxAAoJEOkmLZBjtZhfsKAAn1/SJa31Ot4kfi70/EVDuMIVLoP0AJ9nNAJT
OcLEkFFWJ0ZexOSqYUijUohKBBARAgAKBQJAptP4AwUIeAAKCRD2HMi1rvM4RzSJ
AJ9MYcvRIwT1EVBTurXokwfcHMJ6OgCghsJdl1GvU8qynJ6TZR0dp1obxJGIRgQQ
EQIABgUCQKrpHwAKCRAVG6mUEXXC4wJ9AJ9E3RqbicSB6JCH9FTCNpFy3P+n3gCf
Vhd6zUdv83P35PabKh6XW/VuiLSIRgQQEQIABgUCQKljGwAKCRBpapuqFtak+PBw
AJ9HaxTQRCf6ve9KJhWMKbQajWevCQCaAiecCM2CprcrRLnNH4JizkEfP8q5Ag0E
PWukaRAIAPJl4g1DI4Cw9fI6Q9Hk46Pwtpgiz4jDe+Yqd0bSUoP4kFD7D6PO4cgL
qOz619lMszKVsO1PDzXm1p2tSJPjIauknqJ4pbUWEhIB7+CkK0B8inVbzY3zDXh1
U8ENUrIBrzDkG92TWIQqTIto0y31gVW+S8HUMqBvKotmnBgTq8I+BWzI+4LGoMnO
D57ZwwdKI6Vjn0NJ6wCvRRwNjBWfErSnlv8JrFcoIsBiTUQkgru/lJYc6x4i07Bq
5Lz4R+ug0Ns5/H0crwBpt0vK7YEHmAGFUiNKZuyUBSWzbiYxhEYec6vKx72AIbnr
GxFa8vpjsm1+fOfyVQJdzpxnr2de2qMAAwUH/0hStQ91RUSp3KwQJ3U0GgnUO0hw
RkZEJs40LWkpwblAZW36IUBteNmQd7KTDaPcNH2PBF5wcu2Ag6+DtIp/zDX3nyJ9
naw+arzKHf5vyrGLAEaqrIonrm/29v1TylFjGpFemOH9JnKHGJ6o95ZSgtl7JYXR
D/vSfGNznnMeoJnrlsvECcxYutNO+qFGbVpgvOeufMrhWg9ye/bNMGtJOqO/FrZl
3kR6/TaTI83lbK5HsSqUQ3zUjIIwUOKKxRglBQyy6rqDp4zBV18V9kdrb30Q23qU
WHmX244nQTZTk/V69V9tW3Gx1hEkC5kWbztBLWBHEYae0begIT/y+94EeC2IRgQY
EQIABgUCPWukaQAKCRAV1ogEymzfsrpOAJ4oQy5hHzOhKmce9YvLgdzcTNl93QCe
KRrlaWusbYfqZn4BQsSpYw90evo=
=BvhO
-----END PGP PUBLIC KEY BLOCK-----
D.1.2 Core
Team Secretary <core-secretary@FreeBSD.org>
pub 1024R/FF8AE305 2002-01-08 core-secretary@FreeBSD.org
Key fingerprint = CE EF 8A 48 70 00 B5 A9 55 69 DE 87 E3 9A E1 CD
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzw7fN4AAAEEALL1ENfbFYcAEmS6Hrb7CV7sWrbG+HlIwYvUUuqvr8+D3axd
XuRJGFaWk8zNrTrwWROnlMMlctG3iXNsKzQNxAE6N64rbrUbKI5PzihfEsJW5/io
XGXrRGdXvwob/Qdnd6mIlm3IJduChV7Nf3K2WbimUNkFeXrrh/ymwUj/iuMFAAUR
tBpjb3JlLXNlY3JldGFyeUBGcmVlQlNELm9yZ4kAlQMFEDw7fN78psFI/4rjBQEB
U4ID/1N6haUd+k+tzwNpX6pKnlCuTCJvJ619Lp83T8pRDGZom/uSLrfMrzvmKPeE
abXGnreM41JRLAbGOclsONVBCLvwc/v+VVXTm24J1rdS1qY/SD+LE87pxPL6Ncyt
Ug2sxPSo8fDVKu+MdcGK5zwP5ekNHDl+DB1mMsYDkZHTp9FMiQCVAwUQPDt+RafG
T4fq3uQJAQFKvAQAl6+XaXQ1GzfqJoGqaTVW2O1OaodyBJjLxgRsVv7ps5Z4M4nl
uYoe5ih+Lk3BVD9Y18QKUrnAPlbXDr1Ld0arq8uFkFsVzNDb2asg6tgcQe7mQ9lA
QZPgVOU+siTmEuolSvxwsjxn/szBYBPv5EnU6lSmGf/RDJnbFXC9Z/LgPFU=
=tMn4
-----END PGP PUBLIC KEY BLOCK-----
D.1.3
Ports Management Team Secretary <portmgr-secretary@FreeBSD.org>
pub 1024D/7414629C 2005-11-30
Key fingerprint = D50C BA61 8DC6 C42E 4C05 BF9A 79F6 E071 7414 629C
uid FreeBSD portmgr secretary <portmgr-secretary@FreeBSD.org>
sub 2048g/80B696E6 2005-11-30
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEONy/ARBAC4Ke7ijFSAiNZ8eKGENunAPSCm5Q75nmJrc9QW3DKQydseMYn5
kRPzybZ3IMTzIMkB4kydWoOFb5xlyQ2NLsf0nrn0Kc4DbnpmwFi+2Owv48XIoJ80
4tTHkog+pC+3kMOmAbikOgHfT5DZCu0Vz4k343yg06uFB5RZkFDV3qdr6wCgp8ye
cBFzt6Qnf7baiKC87mSy46ED/2Kw/sUT40JT57u5SL5rgrAt15Q/PdCbFlBX9N8f
y0CA7KUL82ISxFwmuFESIi8zD4IOmx2ow4EBczVCVmbAw04GNKyVL4X3KdcZdLxr
d5BEdu3WcEs9FfbHiJgpPonNQ7UHeaG/Oos0N/LZqGM5kjaopSjNX9QTZXnYtIeX
v5WRA/9un7HooV6yVf/o6lhjpLg0Dgu/nGPwTVt6mz0dS2sg7FwuWwefnYMo1Hte
YRJHhP8wR8MeRai5uwUHkn9OINTu2a1WSHxfjL0T8JGI2XWppqwg21llvBlJ9HDZ
vlnpvG8vsD5+2HLvJe/tHQOXEaKqnlWGRt+6eeKLc2pTOeRrhbQ5RnJlZUJTRCBw
b3J0bWdyIHNlY3JldGFyeSA8cG9ydG1nci1zZWNyZXRhcnlARnJlZUJTRC5vcmc+
iGAEExECACAFAkONy/ACGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRB59uBx
dBRinOoSAJ9dmofaKia2PRYmFrJ6VRV1qMEDiACbB/A1Qwv2jl5ra+Q/G28nrR4N
IJGIRgQQEQIABgUCQ43N5QAKCRCrL1pbFSVpkP9bAKDpJAKn7gPuU+2dGxSh+O/q
dkmPVwCg1nFrGigvTij6agMfoYAhqDmeIRmIRgQQEQIABgUCQ43Q1QAKCRCH2lwN
JzWaUfzfAJ4xutImfjEERePh5E/p2WPRoYZWNgCbBZTRqSz9zuMM1fsvrMcFmCQs
FPyIRgQQEQIABgUCQ43ROwAKCRAV1ogEymzfssaIAKCWan2+HILTdb2mgFu9aZkI
tXUXlwCeP+W80VRiM6lGr6VjJFbkDqD6ak+5Ag0EQ43MFRAIALjm7U1vf218XrDD
rO6ztZdMSoQfLnbqDB/RyNr6CnnFrgIaT4/hBABT7S9Hmb5rPiN3UOTDsgHUq7tC
eGnf+9K8KA45KclMcayVhttyGlwAtO0kZebxZEAlWAhl4ixfejAwKdrjGe66b2up
VFEmR6W7GhPitJDyWKK4/57fe3tSEs3yC2iJEbFpzYnVGK4DPUEsbSQ0Gv+COS1q
l7QQW7H09dWt443r125I1Viv3nrIXlpmR5KFS0MvQ4bZyyAo4k2t0BxmAXNyxLh+
1HZe5bh3dkk1XbJlooNwfr+WhqSlLsTGQsj1/9HmjVMWyzH6tA5tZ42Fu1ZGTA6D
nc7BBLMAAwUH/jt/r2iJDiKFpjay4DIICXeKrKUP+mzYQJGJXX+Mls+TjDLFpm0Q
ng/wUCjZH8+GQStKSiaY7Lqnt1V0aKpw74CznHzgu4+ve9QG1+O5ald61Yy7dPGH
+9Adr3jYJzdMhojjzPSKxIuDkHYOvjka/VGPtYDBuCaVPGDHGvWT4YZiVvpDg/zB
ucCAWF55WKphZXh7v7ZPvdfCj6DeZ+wQBF10d9HXlWulitc+27gQiBhA2JFXG2p6
Qg6Zj1E4AUdK5Hpjx+HgqGATq3GqzyQdUxvhR6VoV1OjmQvz1paLT3V0ch3mvRNi
Md/oNJsHCSL9yhmtonSaprKG51OboDbVOFqISQQYEQIACQUCQ43MFQIbDAAKCRB5
9uBxdBRinHoLAKCLZP7CvMzL2+hGwUqJZFGEbJvdBwCgpcmwzwPPes0zlJdBdwJw
JXoktV0=
=AmvS
-----END PGP PUBLIC KEY BLOCK-----
D.2 Core Team Members
D.2.1 Wilko Bulte <wilko@FreeBSD.org>
pub 1024D/186B8DBD 2006-07-29
Key fingerprint = 07C2 6CB3 9C18 D290 6C5F 8879 CF83 EC86 186B 8DBD
uid Wilko Bulte (wilko@FreeBSD.org) <wilko@FreeBSD.org>
sub 2048g/1C4683F1 2006-07-29
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.4.2 (FreeBSD)
mQGiBETLtf8RBAD12xaszO99wnMaNtuoyE3dIfsv4ijnLmKeFwXXGGe40tf5lDu1
0X1DrI4wX6emUgSTsuxgZh4OJOuCz/YOLwO1AqL0v8Emjxa1VicZmoQ2zjMPY1GD
6rWOIvgRC+6M3LstE7h0N49uouNANFHAaAfCNxyWw2EvZxnqc85TMd1BcwCgnEOe
lHdj9PehNMRSp2TkNpcS5SUEAOEw+rs/vMXeqXHP910nd4U5DmBxIaoA7ARIqAS5
F+SvNtDxlNeeLSMY7l64kCgB/RO4NGYxMTPklFMAm4cr0ri8s6+v/Y4vdoWsDluW
MbzKsxBHVmPxr9WEU9iZxexbSlDdeJ2l19xgty4Jp3xPJ0iSo8Tip8w00kSN9cN3
ULs1BADKhXiy9B2tfDUAQCstSr/04ZB015u1CZEAMxOfIZ97Y1RjSTdAAshqB/sX
coKlQ5Sanx5shV4xARen/8d1EftgIfX1s0hL2QhA9xCHdHob/9Ok8SbpMq+H3WDj
VEqpf9dJieU/IFE4wLc1y5M61jw5kX5bqbXPWtIuCJqC0DB9qLQzV2lsa28gQnVs
dGUgKHdpbGtvQEZyZWVCU0Qub3JnKSA8d2lsa29ARnJlZUJTRC5vcmc+iGEEExEC
ACEFAkTLtf8CGwMHCwkIBwMCAQQVAggDBBYCAwECHgECF4AACgkQz4Pshhhrjb07
2gCfb5LcR2MiNHfyP2FEgQ2NphUkXDcAnREV1tDLlJy7KxOlub01Px8NhNkfiJwE
EAECAAYFAkTLuj8ACgkQ/KbBSP+K4wXTDwQAjdsoW8icjSXo/hl8OBEeQfQCPtuu
0MU4hJM4TRf6QCHXxtJPpMgGGqp6HbMEwmxO58yhKOLCZk5Xyo8rsVJG23pQvGqW
UmphE6+9e8RuwneZiJ/yvbn7cOaS9EuUIHnIZnvNYTqLboIG1XaYwq8YqwNhsHVb
8H1Jvx9fVSo9RGq5Ag0ERMu2DRAIANuJ6ZjYQnDhZFSVColje5oXGEmn3BBIeyLo
TjzbmLo41iPlPPedLnnG7bGcWlwb8Y6CvsniC2+9Tf79O8rpGglQZQFAKS4qSToA
CMWBlKPF2yaCLOlKezzn5Xo3D61WYs3z74ak+CKznqdFDkXYU7c428XprqqLnuzk
jUQyfrNOCg9jjODB6eXVS0nkYlYhsfBe9Mh3xmaf8QGocH01dCaXNJASKbSgUtWJ
aD0fXWexf6p04DX/84359mtOquZe4NCEy/o2RpKoHxaN8cggO3NUfsLkDBODQ1vr
RS/H2sixVLbfNPx4XzIYc525ISyGGk1WJ0hxUPDaJeMtlUVE2HMAAwUH/AuwxkpX
QT49Q3+kZf7hHcvR5fzaRKUcK/lIdPAhJBTZZQjZxH5Qo1MfDftizkIg4O9FcN3w
eR7AKVhjVGLPna10Tb7PuNByKehsCMJM089OTJNEwRKu5AzpgE+pvkBeKTWwoGUE
7hkaunpFXGv8TglO25G1hxKgryB3CBu6n4jN4pnlUtwBBQ6jTC+YRd5zeCiDJYvY
R89ibrdmvFsI6Cy7K0iSFBFaJREOakXPTdmcWSxC71MMuefPrUhMsys0SN/EPd3g
n/LDvcBtismvo8FAUKTHPlJhvXM87V7sDfCmtzG79NzlwjJto4pJoHyJg57T3kJy
cQ2qe/WZTvl9OFeISQQYEQIACQUCRMu2DQIbDAAKCRDPg+yGGGuNvdVZAJsErSAN
uN92IOQQttYydXNGTCUC4gCeOaQSjL1nW1ZwEJt2HuwEJ8LI8Bk=
=RrPJ
-----END PGP PUBLIC KEY BLOCK-----
D.2.2 Brooks Davis <brooks@FreeBSD.org>
pub 1024D/F2381AD4 2001-02-10 Brooks Davis (The Aerospace Corporation) <brooks@aero.org>
Key fingerprint = 655D 519C 26A7 82E7 2529 9BF0 5D8E 8BE9 F238 1AD4
uid Brooks Davis <brooks@one-eyed-alien.net>
uid Brooks Davis <brooks@FreeBSD.org>
uid Brooks Davis <brooks@aero.org>
sub 2048g/CFDACA7A 2003-01-25 [expires: 2008-01-24]
sub 1024g/42921194 2001-02-10 [expires: 2009-02-08]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDqEiCoRBADwWLn5/i7UKtPtYhqlnae4bL5gq5hNreZ0/iAlCf0AS9Q0z11H
Kyl3jI80pHNoNXrjBYtbeLv3u8Wz4kqSOM24ucJyEL1ZM5zh9TOM3FEnk4462gZj
e1MSZROiYg5m4RPkFPsVlDsVEVt1aniEY5kFokbpTamUW7eBMsYDNaHEYwCg6Iwl
Hq7RDo+mVvxaFWbimI+64vkD/iptrVjjQmdXeGD5PTv5D5xOlvDJDQt4Kw7SD3Wl
dpaKF1wZQ13n1a8s1GBnNwBQl4eSgbaPan/Bam1wnOhBwfp807I/aXgS1HCBlCLs
VJNvNuftEKNTVhIDw01APzkndiRwPfHjkEnZ6Ff8UBxFyCe/U48vXUcijj+i05ZI
yXuGBADppRc6BpUq28RLl0HVBnJq6+njKhLUS2++AD/Gy5PlRfKS0RscPOeJLfSU
aw/HykDjp7tM9Be4pMbfUQ9mFvh/ZBxWHZPR12xElVCGxj2D5tvjTCNmUAbkB/5L
lkKd4GsbzUvSceYRyV/t8BxF2dgm8lhvWcxDvAteMyNyoV+0BrQ6QnJvb2tzIERh
dmlzIChUaGUgQWVyb3NwYWNlIENvcnBvcmF0aW9uKSA8YnJvb2tzQGFlcm8ub3Jn
PohMBBIRAgAMBQI9B7DYBYMBJ3SlAAoJEBj1A4AkwngCeSYAoPJZ5vE9UAYPW6vW
yvsAprLmopuNAKC6S5zXelLVFDUrLi+MVgeSfIqgXYhGBBMRAgAGBQI9B6m9AAoJ
ECAVMdWEXf7dAUoAn2tNprMHQ3GowRSBVHMYfDsVwMOWAKCMeVAeOT2f+UOaoBwl
r7YuDCLwi4hMBBIRAgAMBQI9B7EQBYMBJ3RtAAoJECH5xbz3apv1L4AAn01CIvO7
8iQxayGebFC+ZGNYZev9AKDIqruLMqqfTCqTW0CjeskH4byWYIhMBBMRAgAMBQI9
B9z7BYMBJ0iCAAoJEEbtrfQ1fWX7i3MAn0jRvwud4ZOitTB3daUtv5wZzk0KAJ9+
+7Np6yTi/m6MXLx9eYLfWbI+rohcBBMRAgAcBQI+MetzAhsDBAsHAwIDFQIDAxYC
AQIeAQIXgAAKCRBdjovp8jga1NhRAJ4kZXwuJkRJ1PCvJH9j4feh9gDXzgCfRtPC
3wF/cYDxw+gv0CLdpditsPuIogQSAQEADAUCPQew9wWDASd0hgAKCRB8S2dtoA4V
Y7yaBACBwlZHVEwE0iSzIUptxfxeDAtspPDj/dcH/TT2CL+a7yveZDVWzw0tSEaw
NBrKNOlYDoJ+dfHIwEF+fzrpF4W6MwhaQzSnZl4BnFDYqFHOoy25Au+aI4CxIbE+
ASUjAxyxB8ARHqlzkuKvzw1Ufz26k8BZCoR1jZgWgOhH3KdvA4hGBBARAgAGBQI9
B6RXAAoJELTXEKIORR994ekAoLGmzFNdRd8ssJ/m/I5Cu2hvk5inAJ9wZcou0zdI
dx+6mZxHgbQrAVTLR4iiBBMBAQAMBQI9B7niBYMBJ2ubAAoJELaE8XzBCodNdbsE
AI9rmSqZPo8pCDz6IRrG3Zur/bCHCmbNnIUbtEfof6zdktbTGxpWKW6Ky7DgASxc
5AGl/oERjl++mqcK2JDg75frSiN5m1fnPYyYHfC0CAoCYnqjNWu+X/kmx+legDAW
lhe0CKrtP6gfr8p9hpnDfAXpn+FwztAnSrvg9AYMWX87iKIEEgEBAAwFAj0HsQQF
gwEndHkACgkQ1uCh/k++Kt2gBAP/VLf3jn8CUwPjnQexU0Zmvsp56uz3znIYgwMw
Odssf/+6ZAkmD4+nWfpqNe8E8sSVfkB2lubwHLdaNoryw8uQcxBvmvv3n0QYqihS
/24tSv0aGMzLtxTMamCSenYDanrbNMTjgKR15HqYWkrfw3sEWZLRNuSjKIx0T3JJ
90w0gZCITAQSEQIADAUCPQgdBgWDAScIdwAKCRDYyjFxW6BSw7lzAKCkXgeuY5T2
1JwAvvurVuvl0al+/gCgktsWG0/EDeFm+ZVKBYoqSTtnuWuIRgQTEQIABgUCP9pE
QQAKCRAiNF4LttI9kC4+AKCIVGprdR3oDkDpXcep0a5BMugqVACfWiQco8m564A1
Tu5Ak+RCJrBNimeIXQQTEQIAHQUCOzgO0wUJAeEzgAULBwoDBAMVAwIDFgIBAheA
AAoJEF2Oi+nyOBrUTUwAoLZTi0Wu//gC4jHxa0X5RlreItPNAJ9OhNie9uaq1sb7
a/2om2YJd3uvmYhcBBMRAgAcBQJAKQ9xAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAAK
CRBdjovp8jga1PPZAJ9VOelxNVxCn25U4ZgyowWLYpXFrQCeJkxBOOcgOdJDmLZH
Pj8Oiyx0z+KIXAQTEQIAHAUCQCkPcQIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQ
XY6L6fI4GtTz2QCfYALdSOXIJdXNE4lAT8mmtrLWh8MAoNapfZGR1sNnfIPAwfpz
YDiP2xcitChCcm9va3MgRGF2aXMgPGJyb29rc0BvbmUtZXllZC1hbGllbi5uZXQ+
iFwEExECABwFAj4x63ECGwMECwcDAgMVAgMDFgIBAh4BAheAAAoJEF2Oi+nyOBrU
+X4AoKj80vPx7x7Y9aXTX0XUrWwuF/8vAKCxvPCOjA6/vW+H0Md/X1nn99/rxIhM
BBIRAgAMBQI9B7DYBYMBJ3SlAAoJEBj1A4AkwngC5F4An1GOggEGiro0D9KquwEH
d0yIcgQsAJ4+7SFjd37yzg+oLyaJL7iYTiQtdYhGBBMRAgAGBQI9B6m7AAoJECAV
MdWEXf7dGuIAoIYn5mcbcU59IE7A3AE/wFgtGcN2AJ4zoA+ZvZZaXF7DhjWcz12d
R5RrHohMBBIRAgAMBQI9B7EQBYMBJ3RtAAoJECH5xbz3apv1E9IAniYLWbuPvksA
Z1Vq4QH0y9K/hpxJAKCrwCwulTPRhVtZfBRPMK6c2z26FIhMBBIRAgAMBQI82YBF
BYMBVaU4AAoJECo2sboILs/FoN0AniSZVrHoQMKn2wiQ7dXQtxi3gJyYAJ9j88tT
vHQs0uh815eEOzoEB/fEh4hMBBMRAgAMBQI9B9z7BYMBJ0iCAAoJEEbtrfQ1fWX7
kQ0AnjG6tE9kmXj4FEL1gReYNFb2M9TIAJ9iBPkjK+iEUunZ4TEVMLcKLbKRnoii
BBIBAQAMBQI9B7D3BYMBJ3SGAAoJEHxLZ22gDhVj3BED/AsIDqJ5AJwNfUCPfbzJ
jfAiTDBkeg9lqe0TtQvoZsy10c/j7HHJm3Ep5ZxvDF8EcgxwzlNTBVgLgHKoFE7y
Ld/YoM6t4UfsyRr7fJsgY1ImOrctdushSVNZtpglHhvxoIQEtjRhl8qJaE9JVlcW
TTp+Bs9TVgA7cfSjXoLxeraCiEYEEBECAAYFAj0HpFQACgkQtNcQog5FH32gswCf
dUGafaD2nIy8Y5P9NHhYKpF8OIIAoIR74egvKAtgh82Gj8o9y6gRChDMiEYEEBEC
AAYFAj0HrZUACgkQtVKwQ3c5Bdaw7wCfbIMCNWdRWWoxc0Vap70fUe2QicsAn2Wz
JQnaUzMhc4B6RKScPB7EXK39iKIEEwEBAAwFAj0HueIFgwEna5sACgkQtoTxfMEK
h034tAP/ZUfFxR5PYlJors/0LaC//7dAIuUHOiiOTHMRzlRH84qSazmfxfdTtNnA
S0WrTnrHIu+QDvYhEoLW7t3F8xySVCwrynTekfJjxMDz/mgh6YFUt95ocBBly1Gi
Sh72OXG1o/+pGE6kH3j4jDmcCc9m8WEb3Q/rHBd1N28Dg7s5xQ+IogQSAQEADAUC
PQexBAWDASd0eQAKCRDW4KH+T74q3f+5A/998FWLIHjneIyxLye6gura1MCo2r8U
ppVWxP8Dxd9WKfrRmeVFBxxmYLTqVeE6P1SLF7HpyNWX2LYUvz0aInGyDO5gvxGz
AWIXLf8YhxqTRobI6DkZ5u5qqVdAI79rLCigqlJxmUhNLB1rEggIDIFQ8rhoA1bh
lTaNm25k09iQP4hMBBIRAgAMBQI9CB0GBYMBJwh3AAoJENjKMXFboFLDZcYAoMvH
hqGefQvwVSx53snZm8tXXLbuAJ9/n12p/f9KNWGu5xZHPlUwnfSFf4hGBBARAgAG
BQI8TfKvAAoJEF2Oi+nyOBrUEj0An04klgcanatMV4YxA2i7cIvtyp8FAKC/Qp6+
vFInWLVkptCJhCrjjIDZ3YhGBBARAgAGBQI9B6RXAAoJELTXEKIORR99nv0AoLLh
csQo0sPOYbb19V2LPBCsluCNAJ0XfyVsKF+VRbAr34VFEiW+F8WQhIiiBBIBAQAM
BQI9B7D3BYMBJ3SGAAoJEHxLZ22gDhVjRLQD/RHgcbsVjud71s5KUMAYeNy3X+aU
SOnWQTZBX+ueFw1vqADjryMIZvruxUJONyelJMst3oyS7qEZ3Ei+6RrPgqCfJAVu
Z1T3blE5/mSuJ4R+FOPWp5oLhpXHNJDtix+cGDlbEp7WpZ6M5bItcZCyXDzC3BSJ
wOFKbmZ0F++X20eYiKIEEgEBAAwFAj0HsQQFgwEndHkACgkQ1uCh/k++Kt3SXQP/
Xjx2N2KhEZR3ae87wfnlyIxwdBh2tM9ymaNvrQBiKJrjgMyZ7fvGWfM0ViHvjUrR
vQYgTXlJKA3pJXlePMLraYzQLA7jaKSlRnPp9Z/1/wMtXAAgCCZSPaqc3TBhpsBC
F4/izBHzmDzuVjPprcB5ux4fzMxQgd1kwJwb804BAveITAQSEQIADAUCPNWacwWD
AVmLCgAKCRAqNrG6CC7PxbLxAKCSWSeeoGca9t1d8N/uSDcZhD08uACeMIlz/KhI
HG3KA7ZoU2TpCTktWjGITAQSEQIADAUCPQew2AWDASd0pQAKCRAY9QOAJMJ4AuvI
AKD/UsvHBAaQHEoSV6kzhd536LozwwCglQ14mfrb15r6NeEnd55NxJNIeLOITAQS
EQIADAUCPQexEAWDASd0bQAKCRAh+cW892qb9bEnAJ9vjJvV+X06hPbh+aLeV/Co
crzcxQCeOoYlaeBVFqN5DJb5/QH01VpBfgeITAQSEQIADAUCPQgdBgWDAScIdwAK
CRDYyjFxW6BSw6QzAJsEQ+qCl9TNAUNozkCZVMOov9YbwACfVsdfrwpWoTGj3gQD
ewytLTT/TuyIogQTAQEADAUCPQe54gWDASdrmwAKCRC2hPF8wQqHTb43A/9s2Kzk
nSEPLId1sdUCyrkmaUDsn41LPAt3qCPrKlUwMmQiGtKFaiAwLqcG8aPdHcyfbdK5
iFPPYFC8q6jP6IBJx3Qka+zKpRAfiQEQP2YxryI2ULuYJSIJkrVqOb3WrOtTwJOI
6Kgu3M5RC2OtDVuB/6OWP/vgbtYUB882tlXzy4hGBBMRAgAGBQI9B6m9AAoJECAV
MdWEXf7doioAn2RLiv6/weSU9TJ7I7dxlww0Ee4iAJ9PZO3DCo4WYt4/R8m4XzLm
tNDukIhGBBMRAgAGBQI/2kRBAAoJECI0Xgu20j2QhEsAn3RsNpmkxXIqd/sLFEbK
rDimYvWmAKCfpLCk4ALJ/SKeQY9S95Es+4AQyYhMBBMRAgAMBQI9B9z7BYMBJ0iC
AAoJEEbtrfQ1fWX7q+4AoKXQwhGMe3CXyDTDNcyXFmCBawc8AJ9bA62P3t+9EC65
kL1SI2xNrg2M5YhcBBMRAgAcBQI+MetzAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAAK
CRBdjovp8jga1KrmAJwOxEBtOdatahaOuYA6ACQHlLwTkgCeMqUW77vrgkasL7bi
MkkGvHwmMo+IXQQTEQIAHQUCOoSIKgUJAeEzgAULBwoDBAMVAwIDFgIBAheAAAoJ
EF2Oi+nyOBrUF6YAoNMKImiZJ1bAx7aTQ4DB70xJZhAdAKDSKh0tX4RTgx40wbQM
b+U0mWiaE4hdBBMRAgAdBQI8TfIBBQkDqp1TBQsHCgMEAxUDAgMWAgECF4AACgkQ
XY6L6fI4GtRLkwCgjMFcyYK8yWRTQLtdRAaCaWuRYOMAoIpnNstQiVqxrru+izm2
aQ6gY2VKiFwEExECABwFAkApD24CGwMECwcDAgMVAgMDFgIBAh4BAheAAAoJEF2O
i+nyOBrUsY0Anj7/RSzntPtb5KercoXgEpOzPrTrAJ4mbBurAmPs6AzVed2qkErd
vJglUIhcBBMRAgAcBQJAKQ9xAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRBdjovp
8jga1LC5AKCkA8d/+zcW+hVQJ7AIFOp7ql/8/QCeNXlsoRfoJQoh9Ju8TEotyFfR
LQ+IXAQTEQIAHAUCQCkPcQIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQXY6L6fI4
GtSwuQCgqRSyOpCKwmFPX/Tlv+yqHVJxBVcAoNJ01MdO7LxSyIxx5+RWIqtlEh/l
tCFCcm9va3MgRGF2aXMgPGJyb29rc0BGcmVlQlNELm9yZz6IXAQTEQIAHAUCPjHr
cwIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQXY6L6fI4GtSq5gCcDsRAbTnWrWoW
jrmAOgAkB5S8E5IAnjKlFu+764JGrC+24jJJBrx8JjKPiEwEEhECAAwFAj0HsNgF
gwEndKUACgkQGPUDgCTCeALryACg/1LLxwQGkBxKElepM4Xed+i6M8MAoJUNeJn6
29ea+jXhJ3eeTcSTSHiziEYEExECAAYFAj0Hqb0ACgkQIBUx1YRd/t2iKgCfZEuK
/r/B5JT1Mnsjt3GXDDQR7iIAn09k7cMKjhZi3j9HybhfMua00O6QiEwEEhECAAwF
Aj0HsRAFgwEndG0ACgkQIfnFvPdqm/WxJwCfb4yb1fl9OoT24fmi3lfwqHK83MUA
njqGJWngVRajeQyW+f0B9NVaQX4HiEwEEhECAAwFAjzVmnMFgwFZiwoACgkQKjax
ugguz8Wy8QCgklknnqBnGvbdXfDf7kg3GYQ9PLgAnjCJc/yoSBxtygO2aFNk6Qk5
LVoxiEwEExECAAwFAj0H3PsFgwEnSIIACgkQRu2t9DV9Zfur7gCgpdDCEYx7cJfI
NMM1zJcWYIFrBzwAn1sDrY/e370QLrmQvVIjbE2uDYzliKIEEgEBAAwFAj0HsPcF
gwEndIYACgkQfEtnbaAOFWNEtAP9EeBxuxWO53vWzkpQwBh43Ldf5pRI6dZBNkFf
654XDW+oAOOvIwhm+u7FQk43J6Ukyy3ejJLuoRncSL7pGs+CoJ8kBW5nVPduUTn+
ZK4nhH4U49anmguGlcc0kO2LH5wYOVsSntalnozlsi1xkLJcPMLcFInA4UpuZnQX
75fbR5iIRgQQEQIABgUCPQekVwAKCRC01xCiDkUffZ79AKCy4XLEKNLDzmG29fVd
izwQrJbgjQCdF38lbChflUWwK9+FRRIlvhfFkISIogQTAQEADAUCPQe54gWDASdr
mwAKCRC2hPF8wQqHTb43A/9s2KzknSEPLId1sdUCyrkmaUDsn41LPAt3qCPrKlUw
MmQiGtKFaiAwLqcG8aPdHcyfbdK5iFPPYFC8q6jP6IBJx3Qka+zKpRAfiQEQP2Yx
ryI2ULuYJSIJkrVqOb3WrOtTwJOI6Kgu3M5RC2OtDVuB/6OWP/vgbtYUB882tlXz
y4iiBBIBAQAMBQI9B7EEBYMBJ3R5AAoJENbgof5Pvird0l0D/148djdioRGUd2nv
O8H55ciMcHQYdrTPcpmjb60AYiia44DMme37xlnzNFYh741K0b0GIE15SSgN6SV5
XjzC62mM0CwO42ikpUZz6fWf9f8DLVwAIAgmUj2qnN0wYabAQheP4swR85g87lYz
6a3AebseH8zMUIHdZMCcG/NOAQL3iEwEEhECAAwFAj0IHQYFgwEnCHcACgkQ2Mox
cVugUsOkMwCbBEPqgpfUzQFDaM5AmVTDqL/WG8AAn1bHX68KVqExo94EA3sMrS00
/07siEYEExECAAYFAj/aREEACgkQIjReC7bSPZCQlgCfWfvjbQPos3dVyGnehGU0
xKEEk30An3PeNtnErBOYeX59F0dOX3cwLQ3+iFwEExECAB0FAjs4DqQFCQHhM4AF
CwcKAwQDFQMCAxYCAQIXgAAKCRBdjovp8jga1Km6AJjeuXr+8VTlrtHzjwqsvhZl
NrGxAKDLY4IAo8Z2xmwHeTD8S7x1hj3qsIhdBBMRAgAdBQI8TfIBBQkDqp1TBQsH
CgMEAxUDAgMWAgECF4AACgkQXY6L6fI4GtRLkwCgjMFcyYK8yWRTQLtdRAaCaWuR
YOMAoIpnNstQiVqxrru+izm2aQ6gY2VKiFwEExECABwFAkApD3ECGwMECwcDAgMV
AgMDFgIBAh4BAheAAAoJEF2Oi+nyOBrU9N8AnRDzezWDu+DsR1q+wK78ep2gnNwW
AKC0uRKXBbs6D1VALWV2690idpfbNohcBBMRAgAcBQJAKQ9xAhsDBAsHAwIDFQID
AxYCAQIeAQIXgAAKCRBdjovp8jga1PTfAKCnyLAIgULiie3gWB+Z5X17Ija30QCg
kkP+JO7KC8mbJqK7478evOJKR7iIXAQTEQIAHAUCQCkPcQIbAwQLBwMCAxUCAwMW
AgECHgECF4AACgkQXY6L6fI4GtT03wCg47kLnbj0v4pNrBuKXQldrHvbvXUAn1F7
nu4Y7Lxqg3cpKPcf0fM060R9tB5Ccm9va3MgRGF2aXMgPGJyb29rc0BhZXJvLm9y
Zz6IXAQTEQIAHAUCPjHrcwIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQXY6L6fI4
GtSQRQCgvVneiEcT6L3KYQW2TvwB6U0YRt4An2+RwT8Ai76g/vIYJbAWb3PytaoC
iEwEEhECAAwFAj0HsNgFgwEndKUACgkQGPUDgCTCeAI7FACfQ521ekmJna2rhBXB
OXfXW2AJPm4AoPSafeA4kIkkMDFS0rdkTelaESUUiEYEExECAAYFAj0Hqb0ACgkQ
IBUx1YRd/t0m0ACfUwk2I88VNI8pjx60KyGCpEY30KIAnicrAiGQ38xyOhiNul+3
IKs2KuERiEwEEhECAAwFAj0HsRAFgwEndG0ACgkQIfnFvPdqm/Vw0gCfSX8yaiqq
pKnguj2Cs71Ta9fnBBAAoPI2YeyD9bZ38w641WUqZD6Mv7GliEwEEhECAAwFAjzZ
gEUFgwFVpTgACgkQKjaxugguz8Wm7gCfYwZHdphh9wBDm3L7QzNncjqbGtsAnjp3
eKrGZyRJ7SgllZZ8Yz3/e61qiEwEExECAAwFAj0H3PsFgwEnSIIACgkQRu2t9DV9
Zfs+lgCfb4kk2AEQQo9ww2CZeSaAxCkRBJYAn0f31/OSCDqlHgvHje3Y+8sma3TS
iKIEEgEBAAwFAj0HsPcFgwEndIYACgkQfEtnbaAOFWNYOQP+MqOYaF8aLTFd2ooE
MDUpdu/LLdlVrpcpimjx7ejrsvMPYPWwD2TO4t+1rtcuGH3JSMHvEbPSy4QOSdgJ
SNNw+DRgmrKmfB5DBzQH9Km5c51Ay+4K9U3H3W0RbxrdTFvXlf2h2I4dlNzkeaf3
oeKW/Yc9cpClPsIChpZb5lHdqluIRgQQEQIABgUCPQekVwAKCRC01xCiDkUffc01
AKCOW85ZzD9ab94Qp5E1PdgXx129QgCgzgf+v4JKu7qKlCMtu4/tpeeomXWIogQT
AQEADAUCPQe54gWDASdrmwAKCRC2hPF8wQqHTTg3BACByOMJkusuWyagEQd1TFrd
SnJOPmXFgSpajolbJvuN4rkrEA663bMr/wfA+irQEz9dKjYBj1aoLJYj7Jhnn9kf
NGbIfThVMZa2H99xBmqFbRzgQJQLszykNV6wgWvVDZJNuC+CsAQZepvGG8/wRGRi
na0V7tpJ4kBVOEwlo3rlK4iiBBIBAQAMBQI9B7EEBYMBJ3R5AAoJENbgof5Pvird
Oo4D/RE0H17FW+gssO+poM2x3yerNuwAmlluxSAeiSUduqDPnMEwIP0UOIxlQPHN
jdm0njWtr1Zmr3ix6dLjK2OIgJf48KPIfXS77nd/ZbUHWBq1bK2xeKv7Oq5Srm2W
/uSrMlkXOAJufQ8F/gbD9SBC29n6888KaK6eGS4NQ1u90umHiEwEEhECAAwFAj0I
HQYFgwEnCHcACgkQ2MoxcVugUsNu8ACfaVQVorE9d8ANS8YFY/0lQMUO5s4AoKMo
ObbfFA4aqc1YWrw8wqqIKjjdiEYEExECAAYFAj/aRD4ACgkQIjReC7bSPZDtuwCc
CiZH9qbbbpILyeyfjo0dntKXucgAmQE5qrWH2Er33sFYYIho/7LzmzG9iF0EExEC
AB0FAjxN8gEFCQOqnVMFCwcKAwQDFQMCAxYCAQIXgAAKCRBdjovp8jga1FpEAKCy
syTI58GyJB5AHHC7TElmy5+0aACgsCF+cD1se9Thvrhb2+udSJJT3mmIXAQTEQIA
HAUCQCkPcQIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQXY6L6fI4GtQYTwCfTHWD
qsjlLLvuITJuhdlfHhmraT8AnAz1wZjrPijvGQvvvfW20dfstxORiFwEExECABwF
AkApD3ECGwMECwcDAgMVAgMDFgIBAh4BAheAAAoJEF2Oi+nyOBrUGE8AoMLdeqh0
zokwYa/qMGcvbd1DKaaYAJ9mMZ0+ZGig70Cx2RK4vEPIsA81KLkCDQQ+MeyLEAgA
+kEja1erzDxR0YgK2CtGExFiwSpWdqMyLS93x0PO1wRaOKe47f0tMFsWXgKVxy6C
CNxQBoMBQJleTUM4UmKEu1Meal+aiBn5oxtF6kLzT7jZbjVCrcFpkWYCcnbYZSCR
ZO+sS0aoC2KG10nUzQ9Oj7ftsFs/3xPRGstBf17ou/is5bhRieK1IfDOBOKmtaZT
d92/73+7Nb6idOz/TSEQkimRA3Vq76DoFCuC7qFB6B8sTBhd+94M01Yrzdjs9oYq
mlZrSQLsqZXP38NNsvNiqRoI+hOSn8HDSua7e9RRi4/w16Y55Rnt41ZXIXG6ohe+
WS2eU/X32EsReRVUrb3XEwADBQf/Vs4+GUp2vpkSs+8FjN3M/LP78auKGAqyiXet
FoIWq4NaC4C7tlU6l3t6SAxrQj0H9KWEUFVe/Jbd7xCK60Zq9vK+POyf5Tl7wt2+
SGODc/0JAE+J3SLY0RUcBYtCOdeCSxA7fRMcPCHm4niJDCllug2QJ2jwWzAn71vK
JQ9PECh0zQrivOG0L9by5gVqmVRuyh4wyBf1XeuL9XUxIZ1XpIlcXNRnV0dO7wjc
xznp2P55ZDV4A7e+NaDxz6C/mnbs6xNsc+eBn5IcSo5bOYypz1RYm06GXW6hdtpT
lSwnodCP5HOlQQoQ/Bj8rtGLmxg5f4EOP/idplTd19iIJl0DLIhMBBgRAgAMBQI+
MeyLBQkJZgGAAAoJEF2Oi+nyOBrUomMAn0oFmuLZdXYeZPW+ruuUy8uqnFsqAJ9+
Bz+Ra0Wk3jmDN7W5ugCMEEStK7kBDQQ6hIgtEAQAtXZi01HjJynbyJWBOHoZ017b
keassLMjavVUa9WSeQZn9mUegKAGaq3PgsbNePIfsU+h2W8d4Q1Vp+0ki5eVfpQY
qvreD5DlCHZkwTEDYtauTOZAQBlXfrO44bUsfv7DCdRNwnvEwakHHxgjNcYeGDiZ
9QgRY1C1xooMAqQffzsAAwUD/jqxtm0WEuFPpufFnSUHekm1HTu5QitDxeMydBJg
lQMWAi4gGI9zXL4G+Km6FFOsk6hADE0ltZ4UirU3o2kJtudwfm7gHSiWdSOC6lUv
8AbhgkGi+yCfFIN9Q3NxhesvPpgBjkXMFxZsxKuLzMX7UTzv6LK2d84yrV2aCW0h
AmUUiEwEGBECAAwFAkApGvcFCQ8KlEoACgkQXY6L6fI4GtTY8ACdHaAvyohLtTBf
tGTlxgFaGWLm6EYAnjyYaPrEbgXEaMGKuaOGdHh4fW5+
=k1pm
-----END PGP PUBLIC KEY BLOCK-----
D.2.3 Giorgos Keramidas
<keramida@FreeBSD.org>
pub 1024D/318603B6 2001-09-21
Key fingerprint = C1EB 0653 DB8B A557 3829 00F9 D60F 941A 3186 03B6
uid Giorgos Keramidas <keramida@FreeBSD.org>
uid Giorgos Keramidas <keramida@ceid.upatras.gr>
uid Giorgos Keramidas <keramida@hellug.gr>
uid Giorgos Keramidas <keramida@linux.gr>
sub 1024g/50FDBAD1 2001-09-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDuqmfwRBACakPfvtnWVymPgHktoM/fjtoJT49oIkRG6DWXLzr6M6E6ReOAJ
LCTCo42xgy6vndGb/GUTYIS8JMZSZB0qkTEvPorP70Y0RpD32z+51UYrDtMykohW
lnTGjSS/+IwT8cTePzu2C+RTAcvlMktOZ4xHRRZHzi6iEZrrok24cRXLSwCgx1/D
GsEQB415mu3t9REREVaPehkD+gMQ2EYZQSj7ZChSghDR3p8hHvzNmN0MgrxNWSbq
KID+pO3kBT58SMhOdf206jRAPchoq8aF6Y1h7sZpZCarA1g5M5vomWKdWRde7j4i
kRsAa5ntUbW1wIQV+cTO2SVcynlP8sZ/1RHapzy4GD3mH1qspJTAKdfSzjNMUMZJ
zB80A/93O5RBrYqnZUW6TfUbCdSNudb+FYYyEF7/0YFf2BfgCn+HWpp6a9hHgbjM
zvy4DkkjLu0UjoNeIRGbkLUgZwY0JpMZ1qQZSdQHy13Vt3LkG9I3qnBXqzKRdxQv
Hl6+vHUIagar1tGZNK6sTvbGt7TRhy8RDLV+wSvU4YTvAGtqWLQoR2lvcmdvcyBL
ZXJhbWlkYXMgPGtlcmFtaWRhQEZyZWVCU0Qub3JnPohiBBMRAgAaBQsHCgMEAxUD
AgMWAgECF4ACGQEFAju+Q6EAEgdlR1BHAAEBCRDWD5QaMYYDtn/gAJ0UcfvNt0XL
oA4TlfYpDdslz2LJewCcDxASNUAzOJcGn6FPUfhol5nzT5u0LEdpb3Jnb3MgS2Vy
YW1pZGFzIDxrZXJhbWlkYUBjZWlkLnVwYXRyYXMuZ3I+iF8EExECABcFAjuqmoUF
CwcKAwQDFQMCAxYCAQIXgAASCRDWD5QaMYYDtgdlR1BHAAEB+h8AoI3v1fOoyqR4
/u72yFxQDEzbUACQAKC66iQb18quWS3QRNcFzbiTI8ifMohGBBARAgAGBQI7rKO8
AAoJEGHjIVoOe1PRGvcAoKuKIaRiUHnSWzt7SGL7YtQzKHqMAJsGj5pBOcXj82xF
xfy3hpK7jSu3B7QmR2lvcmdvcyBLZXJhbWlkYXMgPGtlcmFtaWRhQGhlbGx1Zy5n
cj6IXAQTEQIAHAUCPdQL6QIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQ1g+UGjGG
A7ZKTwCfW+//cB8QAM3n3rFthG39VZeMEp0An2AV3OOQaKayX4MMx9Mr5rzGmkzj
tCVHaW9yZ29zIEtlcmFtaWRhcyA8a2VyYW1pZGFAbGludXguZ3I+iFwEExECABwF
Aj3UDA4CGwMECwcDAgMVAgMDFgIBAh4BAheAAAoJENYPlBoxhgO2MEsAoMOehdZO
6Vq06MYhzxLVwGSUSL/NAKC4YjRI3M07BhDNEiBCTTLd6V2kN7kBDQQ7qpooEAQA
oMOrDFI6w41FpGo1SaaeyF87ItkOZJNOZo05sNGK1xkb0A+/N047+QnoNq1wKp1M
MJJ6hV5N7BfoWjyqwdR0Au2+EGbyMC3VC3Ttq1fJ5xvQ7L/d5yBePYr2Kci7f8vP
H7yrsqm12B9MyJa8rTRzIiHT56MZosjaXJEn/rbqOKMAAwYD/3iCHaPl0tihQhDK
pLLGMpNvFrhrIUnf/AQgN3Ez2VchSJubuTms4ybNsS3jr1cvd4iyoYIqln7iRFMQ
/BQdgUhkKIOFW0E+wNRRUDob28ed/rz4cR4HEMmOf3uiCw7egrsdou3nkV8gmI42
w9H5p+/qpxBRJX10xEeLOs/LVCKSiE4EGBECAAYFAjuqmigAEgkQ1g+UGjGGA7YH
ZUdQRwABAUnQAKCU1zwyCX9rKsiYRORPjK5G1mkVcwCeKAOtsSjWx31CViTq5Z8v
mEgj0aY=
=cDvT
-----END PGP PUBLIC KEY BLOCK-----
D.2.4 Warner Losh <imp@FreeBSD.org>
pub 1024D/1EF6D8A7 2006-08-15
Key fingerprint = AEC9 99C1 3212 1A86 93A6 A96B DB9F 6F12 1EF6 D8A7
uid M. Warner Losh <imp@bsdimp.com>
sub 4096g/34FC5B17 2006-08-15
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBETiNtkRBAD+0dRgNX15oiBnZZyPj5Hwtyz0YbT179dXB5CMh07im35NV8gX
8Lg84tBOuVuefpuNn3DeF84J8acijg7VWtE4achX8yNZ7iWxVKh3xg1BANnXrIzE
1lsrc5KMrlmjnTs4GwKZF2OmfkuTFKTJVz5M7GkQB1sCGa5udBpOmHxmwwCg0Nnh
9QsizYrhCxR1kkfYmEbfbd8D/iA4aah6rf5Hn8OMNFayw6g4olks2gtb70i2W9Dn
mxsJugj6eg94gobUpI8XmO1OlB+1OGrCmIZJZcpOYjV9iRBPyFL8nht7NkqcHonT
B7fMBCBuiYVHc18mC94f1hGEES+7QRSWjB7gade5Yz+SOSBFayiDD+hLQjUiWAeC
/FEpA/438gLLi+WLUgs45q/11sMjesaRDRuTqTaQ5vgfVKRnoxqALHlotmEQBhTR
b247KBQTYG8JrCBUnyJlghYbHrTqri76YtAMS2joKdG6MKqC80Ph8Uf6ZRZ9Esp4
14WQSmzmz0+F6INrVB0bBvVmI3wVLvKEbYi6QVLb27ru4dcph7QfTS4gV2FybmVy
IExvc2ggPGltcEBic2RpbXAuY29tPohgBBMRAgAgBQJE4jbZAhsDBgsJCAcDAgQV
AggDBBYCAwECHgECF4AACgkQ259vEh722KfcDQCgto2j2W1wyQFkr/3SdYqnGMSo
vIIAoLJcYTiLLjeq5XDjQwTwbiXHZd5huQQNBETiN5EQEAD7HLggXwvghaPuncfE
Bat4NgZQhXZYDn7f58o4NrANA2tQGtWs2XJ2JcUnOoZxPam3v6OTs5ImfGZxfpgL
5wec7hA1CdPbp/hKGAf0+XpLgkGt3v5icio4NFCMy+dUvySlOrSGPriuYRnJHgvQ
U8PlTOfNj1EN+ezK18bswu06FkZBqzKBLIF6lVfT9HQnMt6dKFH2Ms9wSubsEdq5
TThlCm0e2W5e3F+fDcmNOA19GCHbmyQ7MYtgB8wS06c9AO84epwwu4ot8bqoJh8C
OeS6Br6310/cG55gTS6N2vnIEnjUC1gW6HxIeOkshp1ImkaLwhH0Yjk2fQJusWh4
8G/5IRh3PaBXKzZZH48eX2Z7k+ZBWRN2QVLh7JnvFW2MrU6POkF7lqyIUA4DCOTS
cNxWMpXlRg8lE/AecN/TXHg1IXaie6PyEVGmry9U4s/W3KrLxSoLkFD7clrqUrAT
/OkEd8VEMxQtm5RV9Ijq8Wxf4IKo/a7tZ22GA3RthfsCYTlpiKZOvEdr6bLHtWyj
n26jiCu0oDs6SIIZ+YYU5cPqkA084g/8H0GYCTl8XwsCPl364P7OeaQl5omcK5dt
qL0V7Ys5Uq403IlKXbG5PQzr59uuwAxOH+ep7902yVESzrnVdg1moEcHvow8bo1e
qZbpoVSt41Wu1L+XVcndJmZNlwADBQ//UjPmAOE44IUMPrcscW87Od/XxG/gA5dc
MvlC5AuhdB4w3sDhIQPZ2ZpsYum7dlZQlqdIozcRVfVy7gUOBnGDBWhM9f+MTGTA
Z1Rhuz5jFyFAeGrrEmega+BD4ggt4kNhkO/1DV21Rts8smizA/2fYxlEfG8R27GK
vZxIaipJX8bGS3rlu+56KSdQ1nnYOyz1ybXitz2l6ntkIyX38vexXbow4nReSSNc
VWvPcZj9CswE6WxLF2v01g7kh/3oWb03KlIDCFsk+8WRz0gkkw/MSMvbj75iv31R
YeEAjr8rnlRwiSEBr2Ywq6G9oiCutesqhWg3jzFNtMp4YgZK3gKbm9Kwca58q+/d
/Xcycke5OcCKIYUZV5fzEyBOGOzgPpy7zZhOF5Bqr29TwYruzoJxkS2qnD/u3AGw
AWvQP7uuu3zBu0ximnTlMA6/C+cmX+bSCN8ReAVCK7heg6TGDUZivzmcy7NkS2iw
AEpeWH1Krsm6wNc8pI17HchnLwpl4vhmAcmLWQ4BgxZjEYaUjY78GqusvMQdgPLD
H+IX2q6+oxGK62l8OgOIdN8nbBEtneWM3+sJyCX5D8pPHGdwzjcvhahrDQ2KYv/a
YcAlVIcGqzD/k0J5sMi82tTEV2hh/bgexLJ/ZFqJH9V0G9OdRSbEeq3UW9YN2esT
GgNbeLg20VOISQQYEQIACQUCROI3kQIbDAAKCRDbn28SHvbYp7w1AJ9lSOzsQDMa
I61JMex7wnCq+pcxbACgqyYAo/+08YYuVkrJsaoxMhSQIcQ=
=b6Wd
-----END PGP PUBLIC KEY BLOCK-----
D.2.5 George V. Neville-Neil <gnn@FreeBSD.org>
pub 1024D/440A33D2 2002-09-17
Key fingerprint = AF66 410F CC8D 1FC9 17DB 6225 61D8 76C1 440A 33D2
uid George V. Neville-Neil <gnn@freebsd.org>
uid George V. Neville-Neil <gnn@neville-neil.com>
sub 2048g/95A74F6E 2002-09-17
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD2Gwe4RBACw78PVfE2fA9U0mISJrV1ohjdkzVTly0WQ/YwMgyB/J/Z/M35G
zIc8yKi8YR/6QYGqgEzeKAhrUIDyBfudhaJ527gyR3Xi+QHgWMQDvd41NlqM5DBn
yIVKj10DmDYjcHm29M1OHAkXKZT6tHCqp1dKFD7EXtY1bOakvN7TIKld7wCg6AS/
iPmIvGE7wpFlcFkYIjjL4ksD/iKpKneEwB7dEksyDQX8l18v58x0lH334WDgRO5a
X3Wlc4He8b3kWzBWK0z81XE8Z7ip0Io13LHhamLp1P1eDX4sWKQpJmdRtHziC9R6
4GwW9P7aCUCCf91XxaYEU2j755u1Zby3gF1tbookwO1iXQERYuo3ZHezH1bkdRk2
HNecA/9+HCfVESjRFPfOEVqljx+Lm5atTx5VX/D/6iprDUARn0YgW5xrwM8doeNI
UxkBOUszEUPDpXPnMI5RWB+0siQhZl3yX+lUPtASrEj84rpOSXZtNPAkHit/iwva
pW75gZjt9yN7IhVQVw8O2OMTRGNoWsshzKzznqxNP3p1JYYq/rQtR2VvcmdlIFYu
IE5ldmlsbGUtTmVpbCA8Z25uQG5ldmlsbGUtbmVpbC5jb20+iFkEExECABkFAj2G
we4ECwcDAgMVAgMDFgIBAh4BAheAAAoJEGHYdsFECjPS6hUAni/U8Zbrr+TFHLt3
cLg0VWnWxCI/AKCNqxRmA/HlZLPRzhVCQODgfbOG4LQoR2VvcmdlIFYuIE5ldmls
bGUtTmVpbCA8Z25uQGZyZWVic2Qub3JnPohgBBMRAgAgBQJDtkW7AhsjBgsJCAcD
AgQVAggDBBYCAwECHgECF4AACgkQYdh2wUQKM9LtQACfTi75crWjtxxVJUmGSn2+
CDnlCesAnRqM+XSv9/KnZ3O/GRtpkNwT9NCJuQINBD2GwgUQCACvJfoCKfRo3y1J
kaisLLtSVsqCeF1mlwfBGyvD0Lu0VnDGuy9aHExafNEbUaW+OQe0YXtZeX70CUPF
nizBcDEsHEj1pC9HoZCSoYXtqORBa3ZIUwz+jJbjHJErs7XM/EshhAollC14rXKt
K7+UVCw5JkCmialF7LAyWgqeBilwtKUBpIaXquf0/qws+uOikcZb3UttamQFUW0Y
l4KKHP24cvCOXSlx8Kl9l2rQzfedjQPXI98zkcR3SEjZ07cDs+mQOTax2OgVS3F2
nDUEqLQmAiftHFWQ0h3RBpEYLGTNd3gXXxJPxZdR7YIBnxvJ7RZM5qGgZfTc0Jm4
aM5s+As3AAMFB/0dVB40Fvk74U6mwHLMwEkzHiZoVVZPBUMsuqb3FlgZrMYmwa3q
APNhPhWSO9pLQlPJ99nFFj1lRUU7OO/oihsdKLEfT2CT5tqa6fAWoiSQIKBBbkrm
bQedeXPWtvJezS0FY17rOfK8242Lnq+djS8ihBxSKpCVbwWO1DPktu6hGzWQz+x2
B91jbMfM9/n00xEkZ4Z2H0dSZNY2WKqK+MkqAiYf6uJBs7BZV391WWQ1fagCP/Tf
HPM0gDnwFfqSJmxJzPm3upTmYgoSRqri7NH3Wec5pY15b67JFHMpMFbgauEsiDSi
CCk4YxHfge4SMe6noPICAjN6PCkIMDldxi+ZiEYEGBECAAYFAj2GwgUACgkQYdh2
wUQKM9KJgACgwzfFmUB4diy5sTzLVLE3TCqwnJYAn39ByQnv/FeLGSY/blYrVsQK
aCpC
=SotO
-----END PGP PUBLIC KEY BLOCK-----
D.2.6 Wes Peters <wes@FreeBSD.org>
pub 1024D/AD10C6C4 2000-10-19 Wes Peters <wes@freebsd.org>
Key fingerprint = 76C4 753C 83FF D982 C57D 3A2A 7387 E292 AD10 C6C4
uid Wes Peters <wes@softweyr.com>
sub 1024g/237A5EF9 2000-10-19
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDnubLMRBACzBJP6rUq+ruNhVttH8vMFy3IQIWgoMNbzGsa6O26y3wFXV6xr
gLGYo0Yb621CWKpO5/bfRbfPobcgVbInsx0cVJITNeLwLbvZP8Yd9GkUy5B8DomW
ptrKd61NRG4NjGoXNG3Z1KaPYEmbQG7hOeilq2cIcNlSDhILrpRlzbboSwCg+cbC
zRXEcCiGUKUgwD9E/58vKFkD+wdbVXdjRlAZ0uzs9+B1zTuR4CqFe7mOE2ZwEz+0
eI1X639jr5CFNlruWXbT4ZzcqPdAe4Z5G1SqucG8a+hOqfzybi4D04fsnM99f6IK
P4M4ejwmKQnrsUXuoyEOGhxtziXbuX7AfftDd9CcmFJi9ix4MT8JNVCmf2AnG3oU
+/WPA/9RmCW9XrnKGFzuJPrj5f+FlF0yyOfnGBtCluDg0bGWlncOoVdaHajdpTzk
2es8vDDn17vX4KDGJhai4/lgvdoIIu6VZ9gbDvjkhBPRZID2PBtRA3PqJrHAe8OK
PkP78wceHncrjH7PGOvB6K7zgkolBhbigBQxxqyJpiwlLsJYmrQdV2VzIFBldGVy
cyA8d2VzQHNvZnR3ZXlyLmNvbT6IVgQTEQIAFgUCOe5sswQLCgQDAxUDAgMWAgEC
F4AACgkQc4fikq0QxsRqSgCg5U4czx4fZBpgKXkSUwqN12NUTDgAoN6nLEpYOwax
3CZSxOHKIM0OaQaCiEYEEBECAAYFAjnuga8ACgkQXVIcjOaxUBbcsQCfU7yEZGRh
fd27HoAoCaoesLs3DDAAoNFYihZhlddiaAsSRFEdl5YLRXMKtBxXZXMgUGV0ZXJz
IDx3ZXNAZnJlZWJzZC5vcmc+iFcEExECABcFAj2QxXYFCwcKAwQDFQMCAxYCAQIX
gAAKCRBzh+KSrRDGxPC2AKDE+pC6kiHzVt/N+O+J887lxRi+MACggx0g0bc+XakU
F9uTA/Mem/EGc9S5AQ0EOe5svRAEAK6sihIm3ua+pbbXwHBq/3KP1mnR5TumcuqY
VMJH0h+Snaps/seA5332YrlYlzGZot7u/yK+oNj9HAt1b3bqRjxVpcQkkVqO5beN
vtJ2l0VDVtdynNL/p6pIj/w/tQlbMYjwDtEbner76IG0RZvwrREz5Dr5FUEcSJuN
l4sOaJ3nAAMFBACCbceKau0sxw7mymEgXlCQmj/uF4e8DaPmgPJxncccbv78GEeV
NQbLYsKKxts43vmhHKNQI0SUSN3kpqIGAP/Z1FwaxsL2UAZvGzL+o2Eb0mhfe9iI
N8MPaxLWFZevSE/e9EWsb5o3d6xZJqhuaLzMGi0yqR18ZUAUMhAeIK1hAYhGBBgR
AgAGBQI57my9AAoJEHOH4pKtEMbEIHkAn2jVNUFiT5HelooOTkOL36zXxALOAJ9K
ni2QSv6GouiphI2WO/b+d0STFg==
=oTDt
-----END PGP PUBLIC KEY BLOCK-----
D.2.7 Hiroki Sato <hrs@FreeBSD.org>
pub 1024D/2793CF2D 2001-06-12
Key fingerprint = BDB3 443F A5DD B3D0 A530 FFD7 4F2C D3D8 2793 CF2D
uid Hiroki Sato <hrs@allbsd.org>
uid Hiroki Sato <hrs@eos.ocn.ne.jp>
uid Hiroki Sato <hrs@ring.gr.jp>
uid Hiroki Sato <hrs@FreeBSD.org>
uid Hiroki Sato <hrs@jp.FreeBSD.org>
uid Hiroki Sato <hrs@vlsi.ee.noda.tus.ac.jp>
uid Hiroki Sato <hrs@jp.NetBSD.org>
uid Hiroki Sato <hrs@NetBSD.org>
sub 1024g/8CD251FF 2001-06-12
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDsmLLMRBACzChIgYTqLMuheXTZHCAY+wFm4wOcjUhx5PkzCsb1H2qGO5/3p
LNv7Z1zaGRXQMUSGphxM+Sipe5EQV+/1OGAGcN5Lz2sOd7otDbCdwR92QIzYnyfn
35pkS/rabz+UFKEwh+ccBQDKZg6oDRD8DtsLDzAvBag+fauln2uqlDlKSwCg4AGc
ke9KiRL+VZJgD7laVQMT600D/0WAnR8FgnA5oEDqLRDP1tZErGiU7TPUVkq7ZkpR
ViQsJTYQIzxWXF8wkD9j0QqC6KgkChYifW9r5+GJuEh857G7NMDh5CnGcFsr/9uh
wn1LH1iJkG5FPb6Zx1HaMPqEbvSwp50DF/8kHaQlAqjQfzABW+BKcsHAZiTV00Bu
S7yEA/wLmej2UdFb+CvoZC4qDTwj/Fy6xO3ME3D6hCBLCR4KeYT5IT/J70G56g1/
Ic/Itdj3cOf/RaqsYXizK9GMvsEFRJiMJTNKREpH5sztAyyCVkhDAGAA73lOf9y4
sGq5vZ6h6veFEQzFTMToaV5acMRMEJK/ugaJkTEGq3Gn2tQjabQfSGlyb2tpIFNh
dG8gPGhyc0Blb3Mub2NuLm5lLmpwPohcBBMRAgAcAhsDBAsHAwIDFQIDAxYCAQIe
AQIXgAUCPzY1pwAKCRBPLNPYJ5PPLQxsAKCipc7Tk4QPfaTnZAc3J1H+Vmc7OwCg
y1xlg6kRmKFhWobRRX03sG5heIWIRgQTEQIABgUCP2IanQAKCRDIhqQr1bLw+53v
AJ9rm3jlMF5wNeAnlKSxdcP8YcLFzACffliwvDb5nO50lTnN5/T0XM8PUGWIRgQS
EQIABgUCP2f41wAKCRDuPE27/jtZzTFDAJ9qWdy39KMcSSJuYMq1BNyiHhVc5ACf
eRVaMEO3K3NHh+UiKfAccQXwLceIRgQSEQIABgUCP20rzQAKCRAY9QOAJMJ4Aqwo
AJ0QrVuTX9Vd2BXnuGftHXcJVW+KUwCgwModml8nDy8nA/qod6rhCUb/VAGIRgQS
EQIABgUCP20r2QAKCRAh+cW892qb9fKtAKCPwzRMmAhiWWTPAYaiNtSSjycqGACb
Bv2jPZVD+6UxJD4ZcOunhInjNbeIRgQQEQIABgUCQLQzJgAKCRAvsXjH5Mut+dR1
AJ41IZ30UOvIwi6XCdcNkFegS4C45ACfeLcyKr6Kb1lqLJVZGeFvKfLNno+IXAQT
EQIAHAUCPfra/wIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQTyzT2CeTzy2oQACg
moJ5n4P6uEHj7D6WF1DEe0DV050An01CvJaR9UDTKyd7WbPq6BVKtcZuiEYEExEC
AAYFAkCy6TwACgkQK6gmAsLOgJlSIwCfaRw9Wmb0/e6ZgTf/lKiFEA23RiIAoKSj
/3r/xu7BWHvzSpuYUJj3sI/BiQEcBBMBAgAGBQJAswv4AAoJENVYvCoVl065JZQH
/1pATGg6L65NaGoFci6Uq25lJl+F6s4jjLlAuwO3xP/p0Ch8BW/9v/6lbCPmztME
9jVcr4Q9ERU/vHbqGmGS1S5T0eeUwwbfoIsztnDi6TFiKprvZ66nczp0cH1Gxvuj
QZ1MZkxPcqiXwZkOzhzCguROknT5TuUVSTYXKN3rQ9OCrr5zKO7cq3kaf+RyhteF
C1Efpf3G0tyHKYeAu0R14h88OQfw9JoYmQfxljkdyRpAU1PLjnxzw17eJ2YqYnSZ
AgnPeg6nVvzS6cLkTnJ2op4uQEGXTGdylTy5R97Xv8pGBJazy+Mgcb/3IykH0pqQ
kWnbcQEC4IUes0piX5pZKniJARwEEwECAAYFAkCzDmoACgkQscybBm85tqSCowgA
8Vplv49XWBOrn40BjY3R9Mfw+l90ch+JZ81XDkrA9De7d7ptlEHl/P+FPgvSANbW
0u1zJE8YiAzk5UxqKnDjjp/cbyFQU3EBhXjT7VZcj18x/f6s2rzm6fjjBCX9Mrr/
Iz1x2bBL3ULeStaAtMKUR/bRj1K5cZHeGPXvLdP0IxRH4TIHT28UIE0rzy+BjtNN
0P7W2ZxlDatb0gwXyVh8ynbOibgEMAM3uVpKWLIRpRtahpaB0jIKu4PpvMW0JGcx
Do6as1LMfaONCfDMKC4TVd8V4G9hymFd2L6LerIAXm3IKn5TodxgJ/FeC3L/Ssza
vbXjxtTHbfM8vpm8eI6of4kBHAQTAQIABgUCQLMxZwAKCRBSm6PEYwEaYguDCADa
PrepShWS+4of+TFUhGLYl9SHf8boBcrFfW52JgDHsF2u0XOYxJhes/JjCxcd3OkM
YAoBqaEUMtgLtCyIWqg7gX8Aed2u2ycrXKgonUqKuPqjvN2tirCjzNbSJvytsRYd
0U5iBUHrpVPLglRkUQUTWIkNmAFUvO8ab4n21sl1CXI/u26wyf0EH8qt71Ga63bT
Q8T7mrtHNOO3GQOtf5XpLHphq7K9GPCfuUHJmDCGAwSqfTO5tqS/W3GjdhDBjoVj
LELJgIes/miRYlEQ9HjlMOIaoVjGpipT8FEFTUsqD3su7Tpva97GYGcAVWAmnQnR
mGFrs9yy7vR3UnL/NgYviQEcBBMBAgAGBQJAs0hDAAoJEE/xZ7ZF/0/GVIAIAIpb
71fS1EEmoZ4nZrWLfJhs9H1IUBATP9zws/a2ugzYT6nZ5SAGajyTEBaCFpLWXS0U
Amccvw2PQiM/rwFiwIR25Nrd163C8CFtZQIKS4iJ1Ljqpx64/1YFAL8Nfca3XViM
+5sM9x25j1NaTcwKSwd0OZtPm33qzqGStLQMxlW6WpV8Ekq1gCoFLHloBU6E46uz
IT2bL9uFQCC9MIS53ftnLRz2h5QA7F0DDVMZrfAmJEjL1TXmaDeKPiRj20/8HrbB
2biZi0F3IhrL07RFzrhbK+J4qMrRkw6yuFp3LzNxY5KqnpCO/0iy7gxLbG9VkajS
5Q9ZucY8WUsRpRN+uhCJARwEEwECAAYFAkCzoX0ACgkQmvBY4t/4H8uKDgf/YIJz
ICAsSlLWAX00gRAunBCoEaHo+cF2QzBs1mVb1Q4VMBear/zkwE7fjp6v6fKHXxsU
UJkkjZGNa+JLOYoDoOihugfxu5od8qmU1cIojjlXIceetTlvHM2tILAXpOyd1TnN
yHArObUPYIqeeLrLivXCT7/A0ONsxYbBoWD5qqQR/3vlVmCxG2tdDEoFv0VgZWLy
S6ktixGsEtEvWHgumQiq7gnQcZYnhf8NWGZWCGol0aj2snxpccCjspuT3zU5PVky
uMjr8757bd+a4bytFTpk7x2VJZGbYuCRuOrDx5v1TSkGsqaKFF/sJ2fjt8MEqzDx
i/VHes4x+punL/B+fokBHAQTAQIABgUCQLRViAAKCRAjA56Z3Rqi9Lk5B/4k2OII
2fT8eUOy4BvtAA3oWc5vgMIfDNG0clBAHvtOeKeqiJgsERnvhbgDkVylwJOSNC3u
NerNzdQjhWqw6U9FEnWvOYbJiyptyQ0cHqsQhttrasNOwdQvDa4jXeUFHLJuQYqq
fot9vUdfHzrCns1Tc3DylzD6+zhGm75Cw8Zen7I0ScjFLVzYjWYA6hg30Gw6GtBS
aAfKo5Odi928kTotEs+HdB6zM5b+Y+vJh+LOFVbktUEVZKX+/3sgMv246Uw/CzFN
+5dPBah9hCVQBmPNDniMRJEJ6cdB9ksFqCNP7c4yMyYZnd/b/RTriaO3lTNCZt8F
olXZur3ucseJ+28oiQEcBBMBAgAGBQJAtKVUAAoJEO7DExhmwa8um1MIAJ1QN+wN
kN4amtejZAFYJE9AtP3kPr56DWGxdMJcY8KEv0H7vU7iz58aaP0X+gn1TLpjPqK8
ohUzrJsVSO42U1TpoqiGW9V5UYAx2YKw41ZfZLo9Ybwg4egrM/UdIg6FJNmhK7oe
NlP+NUXWvZQUUtfWIW48wyGJLMD1HMxc2TAWKWgj97QQ1/dby2FXpmmbxB+csFqs
BhpmnNP/s1iAD4iprYdeZlMRBGCaoG3kEKhwJC4vDuzphzQYpSK67X8SedKEGl1f
0oAySC3DDlLoO1wPIBSVvYvbRieKhnByuAMwmGK88pcyTUTt0G+r1IcLE3QMTyMK
KyxivrRdCrHxjtCIRgQTEQIABgUCQLNQOwAKCRC7Q5vMFLL3474/AJ9JzkE+rw4U
kcbXfQHkl59mC/RYOwCdE25Je1JBFQDlQemvKzSlM8e5GKCJARwEEwECAAYFAkC5
w9EACgkQUVq9X6lcyubt4gf/e5pUqdbKZ41+kE6Ui9KS2N0ZqBBugyYLCacNxfoY
kZjOopIZkkkP47RViY5inPiraDPxzsG/6C79Zvt/yEhMFrS5KXu9s1D5bvYVakeJ
6IwU6dx7eYibcsRKXmmWNd6UPk9WBJ28AqxQ/alRGQz5sLaaPdn1qv0TV2p0LH5b
j4WoG/NA5CnqNzcdc2y8GN4trFklJPZ87sMrvjm0c0teLP0TdRLGeOWkKgGK+k9M
DP5QHbmyCkCH13wMwBOXlSuiSPdb3JE9Jzk+4YYClSQkpwNUy30r7MPEBJg2zgc3
ufKFvZoLthsfh55ZUn7GQv7EKaAsaZNORJ2EaY+l526P/IkBHAQTAQIABgUCQMMO
LAAKCRB+XEPmt2iGAl7XCACA9k/kuoB/UKAt2MyisnYmwXcOwbsPLOcFzi7xsAWb
6sKg6KvKo/RxVdyT+tkxx/obOBItUuTsowkHc/rFcByFRq9kuxE7WCBzPSCxL28S
rxoKVChfdb/SuECInWrVN4VoG6jFnH1OnerjtpZxdXh0Y+UZmP8CWW6ZygrXG5zX
ipVVOqCKJ/pPhKami+wCvdYGT3kX6MCDrs7P3lzNDRbfMJNQgZ21vHqpITbdS3fs
HTXXiy9C5gkhMSx1GgBACB84s4Z/J3f+6x5KdHbdGdkVC8/ehslkJ780BMVWf08M
42hBEdTqSWeEUVcEFJS+bHmm3ZXp+mVEqCf6eUThlLAriQEcBBMBAgAGBQJAxU4z
AAoJEL5Kg/C+npPiQcgIAL4THYYFL2+YLmE009FxZpxZMzoSYBwqpfZa+rW6XgsU
i93pLUDjXi3q4tXMCj9uEbTIr/vXNAaTxN+xZFhppi0sRhGRSC4ITXgdaKk1POG1
9sCbT9yjr7QA+i93cHewGfAvVJEs+ATfxuubZgNbEdBGd/1Ri+eINgZbrpqoh3Ar
yNkoKrPi6Q3T+rCF7gBXLb4qFoRyRpiepyzbYM748BLUXTsT0rYgIiGJlk8KprKb
azK1QK9HYl0rocqSWQSpouqLI/rUjZKn7iJPDi9dISApf9mK+gcXwvMpJUdC4YFT
RlfbHARx6A9CqzxuvTJzw2n6ogKICQYNSJHSj2O569eJARwEEwECAAYFAkGeN2AA
CgkQsqstIGq2NOWfUwf6AxWjwx7+cI8+fKZ+2ChmcD9TDUdsJ8UoCs1eedrkeDwZ
PXEN0eAz1J+FkcrR2y5GgShb/7n52OO0vPqYKmzjamvJrgqT0wVD1X+tClnMam1i
Tnq0SKFglvS1DM89Xl2GfEnpLv8/EI93axXSa0KXq27tnv5E+TZ8r6caH0rSzI4S
AFXAseSq3ftRhvxAiDrdreChkJsVxaiUX22KFD0EkRhxCCybN6RjIGZL0/fIwwYF
a1L2jGWr8mgCAc4LBtnNdrktDYrqwz1/h+kc0e6RYJqo6ntQc2xGbUGU9YiGaOsK
rtyV9AdmIJ0wGTdYEd8fMhrYf9XE4WBiF8u1aUhJJrQcSGlyb2tpIFNhdG8gPGhy
c0ByaW5nLmdyLmpwPoheBBMRAgAeBQI/NjP8AhsDBgsJCAcDAgMVAgMDFgIBAh4B
AheAAAoJEE8s09gnk88tuwMAnR65rFqhkPBpogVS2hkBCFvVX1LzAKCwtgpaYLqG
JrCrUZwfHz2RQOgVL4hGBBMRAgAGBQI/YhqdAAoJEMiGpCvVsvD7iw0AoJWnr7IQ
YBy6hCFX56yGIRUWmZ+RAKC3j8EkR+m/9+awiCoiYeatigCw7ohGBBIRAgAGBQI/
bSvNAAoJEBj1A4AkwngCSSEAoOe4zoTpjUABdjwneqEWACMqwmZ0AKCPalZ55dBL
0Sq0peJfnDc9KnksUYhGBBIRAgAGBQI/bSvZAAoJECH5xbz3apv1fFcAoK4/sizJ
v/rZ+W1NglHt9tm14hyMAKD/esdnQJtfwdF+5xJh1VUilzPP0ohGBBARAgAGBQJA
tDMlAAoJEC+xeMfky635ysIAniSKbYLQhy3dUnlvCUriOKwFfCTUAJ0XOyhV8fT2
Shqs9O2FeX+oTcGBGohGBBMRAgAGBQJAsuk8AAoJECuoJgLCzoCZwNcAn0sIddq2
esx4P4xfWLYfvYsokZ+0AKCcxkf4i/GlhSHxs0LT+BDKyWzpc4kBHAQTAQIABgUC
QLML9wAKCRDVWLwqFZdOuWsCCACX8pUlEb6bIbIyUqsYEBeY0oMwWdD+gRdjF7Wz
BnBoR3z5uGJJTFKws3Ydmp2scXP/7xjrPhHGgDnMWj4Txm8vHQeL9AxyR3T+d6Pt
8J7c9KGEtlhcYD5HWx6p4LtlUv2zqxNBrfFBuRFMUO1kzF8tFwhsvPMVTtkciugd
Qbu7VGTVplowmHY8TmRNYKjoEiY2WCWqhPeXQ4o3M0nHrv+PF9KTHhEAoesNDwHS
gz4KFiTPaN2N6r1cxuluatDu7eggfa8Ks1KT5YLCqZcuT+Y04zUWlrKBDVC1Akw6
rmY6cy/dJjA2m6gq1vKs4UYhpZN0oNnTPmIJrLca9fCA40pXiQEcBBMBAgAGBQJA
sw5pAAoJELHMmwZvObak/cIIANBoIezbWvzay1QUYePdjzHQPOMT4AlHGYOqZxv7
9pUcM5H0WuNnMQ6JSycOuZVg+McmgN+tIvmTMfcbDvXJze3Yu7rY8U+BzBZ1dzAy
XivxcjSuftGGAgBG+FF0eEJyzfYwDF17ohF2dIazLKpapQhnH547/xeicwsqCD22
a1RGbFB9urMX2g+mlBdD6eu8NpeNn+v0uR5arBi3Icy0JClgmMYOhBpTYkGnuIxl
8bz781Wg4qorJct+c3zLPBTkF4W6ouOyn66kBVyfoijIlChf9RFPQc7Vy5yKHdn6
p1eZdQ1kQ02LrEWQkzMtOt4cY+b1aTNCAhkg15QcKXaCyKeJARwEEwECAAYFAkCz
MWcACgkQUpujxGMBGmJz0wgAhseUPK4ge6iQcnyfSNV6uAMtFAw2Kh+Em4qMUiBL
E1aURYiteS4iOqTqhYqX9QNMXumVs7Koa0gQFn5NPhYYpqt32vn2+v0PXCldwbck
WARZoTjHE960KjY/lJPGgMimXzTf2RMayqRz2Itri1kfkD5Ws9NBFf8SHSjS4W7s
vceidxpAYAHsoEUCdnrrKMvEvY8YEz1qkxzpnHd8yCR4v0wf2bNrSjnMQLijiRRq
p31s03Qbiu1r4Xx8UO91jqj4S8USTwk2gjPJavFrJ/0SaetxRfLQ9oq4O4RqFTxu
mcenlEdxkD1ewpWx9n3vP/w8FZeAHhw9qpQrPKwXmf12YokBHAQTAQIABgUCQLNI
QwAKCRBP8We2Rf9PxkHtCACTPFGqKwdToKiRmoIrTNDB2h2v6ulCXCb0ZR3hJtbd
7LMc0MEDBtwTcKBqInWY8Pm5cRPHaBs4PUVHdd2yfNZ49hcTFioSeNXcLy1apUE2
VHEHY/NxxyzQV3dlknAjNMdzMClflact0XJ04XlxsUhUqy5f3ptyH8dkuUUzj+tC
w7lCJ98VtebI1vvXHzj+DI37b89zptJkHSjyVuIPe8qS9T820/a/4h1kprDG/U0x
s/F1HoeclKa3yXVEOtp/4ZumtyPq8eZF7hz3Qf6stb4m4YKR3ZnLXZJM30OpJ6KZ
gEBunBnmqhbRNm37XJbcHAmAjsdff2l+FnnZ/FwgRqHGiQEcBBMBAgAGBQJAs6F9
AAoJEJrwWOLf+B/LCdkIAJ7jPDrvd+NvsJYXiqyHgkJRA46oRqOMeJeabQS9c3HJ
HSCMvxZ1JWRKmIVMQc7WMMQ58OpN3jMgH/Qk03edO8olkgJa4cGdM7ESmR9QFsYJ
9nO96CBK+D28h/HLgoT8VsFLHMBZbXApqnTrn3DLzAHSdUG1AyEa/a10OizuA0Nk
P4gB5D0qRlWjD8OGRhRRsVIwNmi+XT6/rnJnycWeglxLaq+L7BOUUbf/AmzjYSsT
1s1G8DPfZsumo7Axf2mql0plpVkY10bmoEBV5unb+yDkQDcPz5R/4Jrs2BgFofz9
GLdzSPW9toQzybst0DXT5jhIhMGMpX+hbhInd561nZ2JARwEEwECAAYFAkC0VYcA
CgkQIwOemd0aovS8awf7BZqwZSMurqtGbcpbOLmZ0ZNz4oSRXn09oSQeIU88qjYm
HmEUS84SxmE77pokRdmjFwxP72Ld92j7DsjfCrrhFYYZ+RKlylKQvmQ631jWM3YH
JcUWxERWKgqpsakuhWbgUlwagMUvNUvXJ2ZKUMf1kd5dBS1VUPheq4CUKyi5DaqM
9C9bYIoi0NFHYb3nsXYe1l8UhGEJiqdy2myBDujOIbUPT/JqN9MG71moCtP+ioe+
0Eb6j5Zj4XzU1zT/Nnt6rIsUBbuq6OnIb++p1gkryWJDheDvFQelvosZsMxHF7FF
ndleZ04FBUCHwcnoYLwcAJpUstEj3gG2Dnro1iH1XYkBHAQTAQIABgUCQLSlUwAK
CRDuwxMYZsGvLtcKB/9Hg8/vtnRmmuST4NXCI+CR1lMLILUcYZxTE0l6JvHghJch
MfWuvFNWyAwdSOMplJtFM/EII6XvGNUY4JwYNI1pPWPuJlKfUfTSjpTJCpL9VdmG
rgABbP03akgg3sTM7yzUjlMUMvbEzbfUwDkddxBk5kBSR+SdnJYNOWAsftiC9H/f
DSLs2feh6Vw50K8H3RljA3bfg/Ph7qMKncdJ+aXa6Ll22BXTUqq9Yv9Lg9ZF3Oa/
lFeTLVn4J/4C9ODQOc/IR5twLFuQcZTITj4305sF9k3e067BQjSaegAcmbPy2z5b
z+b8RqKDGMx+12pmSzXC6G/gRNAXv8ulxafP3cn9iEYEExECAAYFAkCzUDsACgkQ
u0ObzBSy9+N3ogCeKzZQ67tklSSuK4gEmVZTyemmgN4AoLqKa0hsDnCRDMpl/E+5
ThW6onE1iQEcBBMBAgAGBQJAucPSAAoJEFFavV+pXMrmR1kH/jgAMsHoMZUAd/rJ
U0n0nnAPqqMQ3DdIOWSOz/u2EkDADUb2Q/4UzzsrnbNvZvR2ci4XzEKII0UBYpVP
bJeTmmLYBjlYT9C5+2yAFJVUsbfP+7ctLXTvfMrODXUl8Ztd0KxZgbVYMC78GjDK
HxLChz7fchFMJcza1fxwRdKu17nbR4zUw1MzzwOccTbT6FMc/OXr8v5vLlltZFGl
Bazyz2EKnw1mcHIzwapRwGgWjxuppm32mxUkkzgOQaxK2NHQLnJlaYDHhFK2Jlpe
qoXwnMGqWrCDGKUz4y4WTnUkd/X8LXLqMSYhM+CGjQwdKiOb5nCz4vCYPTKV9aoh
BdPhljyJARwEEwECAAYFAkDDDi0ACgkQflxD5rdohgJYqQf/Y9F+jLmoHMjSLXWg
JWh9bW55JTt6DYofmbIEx8KPD+ANmxfZ52YoLfzPif3WCC5HY+kBHz4d93dxscYg
6SNIYQ8tZeUtUyaJL1rwXDmqf42Xwx9Gz63p/drGixirohHCcZQKht1btZEyfjxr
dsb2qGFQBgRgh14PVWCQTshVskbkvTyCb8lpqrzlwieFeqi773VKdY3+2+g5k39y
uf/UYdDnprd4THt1W4Tyjc8JQEMY8tgUqhibrkHO6uqfdaOcsGX4mo76ou7TnSDy
bg6IXqIcMnk+dhb4z16W0oI0+zksTg8hCcY+azbsv9UJ6IodbTrnp0M3Zdm8QfHx
vdeO0IkBHAQTAQIABgUCQMVOMwAKCRC+SoPwvp6T4mHXB/43978B6YGrqi4NpR+d
Q/ozbme2CuolEXGN6SMBrBtNCh1mnek9W5+VmGk8B+0hPsoXSJJjq3AgUGgGO5oT
bjl/RWZcdAUgdzgKLOVnPqkHbcktQQmbMQ8qnaGcZKyIvSthaQdLtz52amh2HK4K
YZrrwdcdd3UkJhRAcBUsx+O98gntz2Q1wzsT+vV8qjLNR0m2OulzDzdcUr2spLue
LSs+JBOBDP8IbsfIl/n1ZLEZZe2HlQvTqlD2dk54ecbD/Dls7Bxsi+HN+g6Ync/P
jkH18DDkCdrY5ynGiyX2UFUXB01j46Al/dkVbsC1rmhMP2GBNsp4RAKaoYC8tTv9
DVKsiQEcBBMBAgAGBQJBnjdgAAoJELKrLSBqtjTlIOQH/2g3UvCc4NJrD7cS6NcX
9uN3MUrKpWuLaCMAMp1MiFkYnWZYeohijSLL44A8ysfNhBsOi4/qxHvucpADrLwC
MiQG2ZLlunjztjWHf/z3RSPXNiPqxPLBOxNYUXOWisjrH56rNJfgkWxmeOZxLayp
R0WU47FnsmBiI6F667XCiuy7OGVWM8WuZxBPE9X58eFxQW3fF/xid6s4B+bblK78
W5/BEBWFyTy0qs/cFAt6ygEocUWfCAFeRlozOUqq7VxTqcuNT7VKmegNcx9nn8Gj
Jm8qH04OGh7YhdlvXSVJ8kNokVhI8aReYCh/fTngo+fnTwnSQFqCH4+YI1Ez3dHO
WAy0HUhpcm9raSBTYXRvIDxocnNARnJlZUJTRC5vcmc+iFcEExECABcFAjsmLLMF
CwcKAwQDFQMCAxYCAQIXgAAKCRBPLNPYJ5PPLWYPAJ9dKxYSQigmtLX3LwEQcfCa
/GvtgwCg2sCQAQsuE0HibUhUUMx+9uxg+m+IRgQTEQIABgUCP2IamgAKCRDIhqQr
1bLw+8N1AJ4jFrKHiTKV+PmL45FruuUur/J7MACfTSL3Sb2z0gCxVT5pyl5XxWLS
AeaIRgQTEQIABgUCP2HlbQAKCRDYyjFxW6BSw8hgAJ9I+xN1LGJBIeClEpsO6UM+
8W9/KACgq7N5/as6KSen3dyYsgNH0JGe0kSIRgQSEQIABgUCP2f41wAKCRDuPE27
/jtZzf/tAJ4ioUxYBFl3MhLupzF05UG8wmyYfQCdHOCxLxIT/xAKNWlzV+/rX0xS
Yh+IRgQSEQIABgUCP20rzQAKCRAY9QOAJMJ4AnJQAJ9hxHdHDdVSJoGgwx0d72rl
SKkRVACfW/xliG7Gf5G8YvPBmiGzfrtAGZKIRgQSEQIABgUCP20r2QAKCRAh+cW8
92qb9bhyAKCjWV0dApN9JZGvJY+QLbvvWGEgQQCfWSz9x934L9vGiezGFCeQ3Lkr
UvmIRgQQEQIABgUCQLQzJQAKCRAvsXjH5Mut+ayrAJ9sz9NMTQThkgZTRh7PSbl+
S6YQdgCcDS8F7KEN0Nmd7U0PKbVjLX9LqMaIRgQTEQIABgUCQLLpPAAKCRArqCYC
ws6AmcZHAKCAwkZiO2xbYA8gR2K/M8FEK/wdtQCfb9rRzgfJ2YT8ojTE9r7BFZEA
TmCJARwEEwECAAYFAkCzC/gACgkQ1Vi8KhWXTrnm+wf/dyQB9i44KyJCvbtLqVzp
E/pdy29IOzpxeoU5UZquA6Sg3LiTXu4UeqnwNgxwkMQhjVLtL26nWDqON0oQeWE1
ZC9CfY/pF/XsSq69qaVMGs+qJ4DUzIS+zDj8YPoizjbygLihaJ8MKX91+Uus3UMK
OGHXYdSow73HdnaNX2vCm+DHwmQO4t/XWOfx+W+ZjBDq1NzgzMoq+dIqoZHZR9EJ
GkGUR4i0a5aRRdu7mnPMK4Svoc8qWso9ZOeOZk8PNi70uj/9ho5tJ8q1daesjito
qFfo6lkt76BDtjTwCzxZ2AXUhjGWlBbdJgLvkjk45ZKF2RESHuqHbIXXH/PlEpg+
6YkBHAQTAQIABgUCQLMOagAKCRCxzJsGbzm2pEByB/wI67OIo9Eg5W1vVByP/mXA
v/1x9RWxOMpm+iELdOuOXccBG+FJ6kgG5sJOfK03vUqs2ds145yf1wZgHmk9Brgu
tCuwtYRyROPHIVa2UcRj8PEXINLlzFDXww198GHiV+cz3skkllzDwjpjJ/8e5HZX
bUPz74bPOyJmHQmiJ1z5O9D8GedCdk5PympsQaPxXcFFmzjZsrfSJJIxrumzhqqa
f5Ps7NYa6aZ/ocpa51KliQGYXilFEy7b2CZWLg6CzgsXgDXvEGVVVJO5fWgpvUqI
5TRmS0Ciu96PpxF1EnHbevbrLRCwTvadR2pcY4fzU1gwJQrDBvnj+ozxvLbi5LQd
iQEcBBMBAgAGBQJAszFnAAoJEFKbo8RjARpiDoUIAK7lonFHzvrpAH5/iC3chpiB
e4QfaijAv3B1B3UJ2aRfKu9HfKjjBgKkoxGGnzunbrhLXDc8pC2BMq0A6pJYiST+
Y9dZC301x41P0i7NMZ2TBRXFGPmjsrvwI6Xo5TA9l6j/hpgvO49BYHDW3XT5RdwS
GAHNKabyZosRN03Im5D68KzfaWf+4+r4prf8rZH//J8WTrjIZAmekJGghnKsEn/F
FdhGgfBjAtuUoMTVuaQvIUFzz3kJmV2iYtM5yqSip33lmvFQNRgIueXzCMXFTrOh
GB+/rQ0qdqdVednBCHXvtm/HXttSvKevFBOcMZahL4llLvyOAUbrgFB2uRweaACJ
ARwEEwECAAYFAkCzSEMACgkQT/FntkX/T8Zrsgf+PvULY5hVauXtCO/0Y2pmsszV
0LPCM081aaJ9wL76SGB0xJ3UUobGP6SGsiNU0lT6NNcMeSZPkVJQWzg5Yd92VBRv
FTdNGAO4CfQlkoVRAxMGpmg9mZ1AQaagaZtoPSmKO2+hfufmK0jxkY2DBMQTLvjH
7aIR6x8/hQ9ZOYutNoem201BCwhsBQ+70vXGCge/6IZ0ETSid9XvnXOdOU6zciHW
Dtwd7WwMegCwxh0I9aV7MdvlbDdGN51DVLGXW4xIH+9Y9yqZfGG8OSHd3tv1HJjE
PDYrNppts9z/MVBIpQMR+iqiMbqYDFonC+mcn4WVrLMTJrJCa5vAzXwBJCEanYkB
HAQTAQIABgUCQLOhfQAKCRCa8Fji3/gfy6U3B/4mSu+ldrMriDFVxRZ4Qv/m7rQm
gyPbc0B95A7bqUSbJn8v+uUqx8uToBz1jpCm54NgB/foOwHXAleinAl2cOt7wBRK
BY3Ec23YZtKAiZkpW9fnfFg0KdeSlJbzPxAnED2RAkaAYpK3WeoLlGyr2flJRRCH
WhG94fiZ8dnTJ9FCTbQMeaX1xensKxWJFAyrxPkliVBAD4BabqlA2DcuRA7au4pu
lGHkvkH/FRz6A2E7NrsgIwTsLO2e7Ab+EzCXu1s6YFi70Z9OO3/F9tlP3Vi6k7t0
Fd/nogLEiZjm8yBed/Wc57loGAm8lgsnGNtWj9IFSeGk9ITpSDF2U2i0tP9OiQEc
BBMBAgAGBQJAtFWIAAoJECMDnpndGqL09KEH/0UUSK/k1Zs5fAiLuckr2po64asv
ovj0bie4EassGGLcQkGpnNhSBZdmPsvRC3Pr7B31IYt9X19+YV9OPt1rTXkG8iWd
Quscw9kXSX2xrQF9efEVcsC+/mHUKc9itqJ0gPE441SHOngaX5TOoyZ8wENHtkpY
p/sJ4LZMGESS1JHv9FSx81L1pn6vkoz3vjcgVo2y2wBnY0u3xHoYE3eLxBEx2THK
13tNFpfWmfr/oRxlr9l4+K333g+ShEJCVZyZlLp6EwIDZTL3T8qXhU3o7HG9fBVJ
2xlicpd4jlt3IoJmOK0PzWNbVRmEoQZHEpGD6R4XpiX0OObkEQZa6WkfKviJARwE
EwECAAYFAkC0pVQACgkQ7sMTGGbBry7tpAgAsdC4ug73SdZdJ+ssRXvHgK2HHFl1
P1HjMhjc5p/CSwaIeX7a1ZpyvUz4MzJ8y4oFXVGJ0JvSztm7vM96QXoSqwIKMpFi
aZRGHEN3P4OrV6IrDYmodNQtxlqty82q5lSi5O6M6nPAc67ryEKOQCZgQ5LIJaoK
Nl6vlDxX/BjpItLxXM0gQeq0+haJGC7Ked7seaqWqkHV+TegOdY9AL5C0bZog4Tq
dyikL+o73YUU3meyPt+d7rAQ4t39n4wbbPe+LeKEtyAcYwMv/1gQpaDroSw2WqPU
zNziJNLIyoDk5sFpC9NOPPJEWug4oIDjnTkLE9NtoT2lV2xTgF7QrK583YhGBBMR
AgAGBQJAs1A7AAoJELtDm8wUsvfjifIAnRMw/QklCgallzTsoRm2aI75TGPIAJ4j
2NEdfLR4N2naJrJefImCspKj84kBHAQTAQIABgUCQLnD0gAKCRBRWr1fqVzK5mXg
CACby5FtoNR+2WyOQ7nb0B4S6MTzYM/9MVeFHLBqH702O8HklHUkKhOicXvOclyp
eU6ZJnzrR2sTRZ72RQtj8DGxn1I3fdJgzh26elkDHC6jVNASRyRj8TM9Ga6Ufjgi
ZXGBCcsG1WPKACCEwAn6odlmJcD5QHSSrTHe5urMoFxW2tfOo8gTYAoi62/PrN8a
+TOj4fHgUdPFST5UtkAa2RSjuYygUtkk+5xXbRzG9cnCIFil88j6Mr/gU55X31x+
5gxujN1eTuikimKccFHozxF9Cvjp7SzKSXb1QPOg53vTyNxcZN9yD61aC/Ma0Zwn
15Mw0kcM6hLNJjYxjsxzSbuSiQEcBBMBAgAGBQJAww4tAAoJEH5cQ+a3aIYCfLsH
+gOGXM3nmtWT3F7JN2EDI3GZ+5FkDtkfUndiz/P6qd4Sovvu4EgOIavsqc5Orgt3
uXlDSksgh8N02bps85XPRdzbvMZ/AkFNdDDyvGLCuHY7w6T3JVnY/InnQTykTuY7
kUDCBX/YcQdIaHirejVof2X88ixjJ6AFjQ4NvKkfxqwuCUqySXKZED8b68EufMoQ
luGo8XVVPOM2tpw048AqQQ7+VIxyZvLz6gvAdz2BfhOMgDkcl2U61asgRQwsDO0o
YhIBFBeUPgf0wGTpQyuTcTFXEGyBSDM2N+K8mkebatT6FnsYdNvkcL7Ctrt+PISG
004LdNp/IgpMsVV3X3u3rbaJARwEEwECAAYFAkDFTjMACgkQvkqD8L6ek+KDVggA
uIOXMC2LClB8cUrbBFCbFKwKetAjo6LVn8kuRYAsp37RjPeE66PAoXezQ83XnWhn
HY2Fk/Alg9IYACyy0/GJ9vCNv4o59lq1VKYvFJuYbMeOOozOf0Ii25Mizdkj7Kwx
UnOIAWQ16+N7QGCBurXD/+qAvGTaQakX4sNO7iLdUxCI7oDWtura8MOzxMOg8KFr
Pkv+j6ApjBTFROe9Wo9uPA7Tc6wdm75Q9BE5uQ2Pz68fQskDx9PSG2aQ5d4MZPV4
kM/Qzd9a50fVwuJzCaHyFnalpzP4KMHdyQhREW9wmLDGnAHIPFHQpHdLXSZdoJAp
+mH06M71F6znD4svVxbl/okBHAQTAQIABgUCQZ43YAAKCRCyqy0garY05QQWB/4x
X4HilqFUXQkz0SWufFk8ZXN8hh8D9Go63LBqFFdl6rtSqzPfmaBee0T735QnjxI8
0YKZGoLNVG4R8X0x0EdZeZSlhWZzmBWqRMoOExyLsyZ3IIW5NsTdggc5OQV1NkYX
xxBUsBMPgfoQ07UBd07FZF38jJE0CAiDHrYjSiy+/bFEg8N+Em/X1i+o1ZUvjA8l
WQjnw7/j95g8wrdwOESPGeDbu/ORcyjbgR7XjUQxmckUcfB3+J66u9zDetCJqqMp
9GDM4QqOZY22Vzuk8r5tnJi0J3u7gQTbOL+P8JX+uRHlODcCDjZBKpKoMw6vzasZ
4Z74yaN/hrRYOo+hgJ5EtCBIaXJva2kgU2F0byA8aHJzQGpwLkZyZWVCU0Qub3Jn
PohcBBMRAgAcBQI9+tqqAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRBPLNPYJ5PP
LSI9AJ9bQ+mm0NWi7hmF0fJtK7fapH4zoACeI6dlsx4hywLFXj2xROmwbjPLF3CI
RgQTEQIABgUCP2IanQAKCRDIhqQr1bLw+0X0AKCL+fwnOLK7iDy8qhPIdLEHnrse
bQCg6u7UT6HqjiJx8Nhe8qQXrSYwJXeIRgQTEQIABgUCP2HlcAAKCRDYyjFxW6BS
wxvuAKDpV3SYMNaKcw03aaYiaIwCn8yPiACgrtwxFyDKk7daX9YrWi7mgzTB6/KI
RgQSEQIABgUCP2f41wAKCRDuPE27/jtZzabcAJsFLNv0cA199S1JIBzaxB7gQ9lv
DgCgqHaJhbS0UXANsN58dDW0mOiR726IRgQSEQIABgUCP20rzQAKCRAY9QOAJMJ4
AgsIAKCUtIUJ+mcL3luf7okhhrirhiHLqACgto0zmqOr0lZDx1O9Wt+U3Nw7qpSI
RgQSEQIABgUCP20r2QAKCRAh+cW892qb9aUKAJ4qTxYZMvr9hbPD5S4X2bFU7jiM
7ACfYtk4Xf5yYT7nGCqUmchfypWdEveIRgQQEQIABgUCQLQzJgAKCRAvsXjH5Mut
+Z7TAJ9lPA2k0EmOlR7ZRgznx+hKsk6/+QCfffa/jLrs3i5diJCjQ14qnyKu/mmI
RgQTEQIABgUCQLLpPAAKCRArqCYCws6AmVGCAKCFvVn4ivY2uQvZjTmOU9z0xT9l
CwCeJcLhRNvVc0vaIFcTAOP0re0bfwWJARwEEwECAAYFAkCzC/kACgkQ1Vi8KhWX
TrlsWwgAzJlqcX6oqoYNUjkPu3cFAxzaEwyo2nEu7ol2kuPpsPFIfMvYt3Q+vwu8
Z5nKH2kIIK+BF/yOU3eoGffjLxgIeDK6c6gO0jae0zHenGUeNDuzTonfVzssGtzq
n3kHOOksB59xCbz9JGuFOsPrX8JXScgNyJob5Vz+UdRIV+cYlj9+3qH9Mkq+tnFS
auBDhGEN8Ff0NJIooD6NYZgnE97fbQnjhFZdzIOcPOM95kI01WSj7435x3EU5IDW
Ae44M0Zh4TIpLUhHPOMk8QSHIzG3Lz3QmhG1g+PV0ZouzZbym3PE94DX4kdxAbxA
SvEZ5UekKrozWA/CJOznXXlnDHPosYkBHAQTAQIABgUCQLMObAAKCRCxzJsGbzm2
pBl7CADp7nkXyO7plC1d8cvZFoEC+C15dZlp9/zBpJPcNiXiu5VvYtcOlTrgMOnv
NZ8/1hZY2gTCVSy8db8wFwlBcrHCICJJJR+etv/dhncpEZGNH5VHRR37F4GT9zyS
02qVq48Ye2013e3FJgzd53YIvbVlVAUnPc1u/M+AXIts6FlSAcOg7XBv3lUY1Y8A
6rJTlDSh0OZ7WxhHAXgphOxg0AYUbSk9MsDOKFTU75+X5Kk+4QnMXvhiOMgq9/kX
rFDPcVYtzOeD5dttI5UiwMxXgjLnq6IpIIMFS95TZsifrX+CIvdQ7lZ4PA7QAJP0
WoLYmrtWJZd0JNtolpimIdKTMTO9iQEcBBMBAgAGBQJAszFnAAoJEFKbo8RjARpi
BUoIALnckJAZZ3cWUXHE3Tf55s0u+CdodcFsSGzQvxb31ecGR5+GRWFvSFbIxqpU
CyInwjvUkSUyLdeJLzkBub4ftsEi/KDx9+eRVNmWnwVJFf6ut9OEGc/GADbs8AMf
oT2QO1U2fe2SgR/gb648lfDRpAgf1rSa07wPlxTzD9RwvdptzWtv6uX/LZrgkoZv
MBbFY/SXazETkGBTqE6WSHZLJPcAA8MnSZ86iLoOxYiZXnsWCruwvCb9/5Ib0tof
ktzy79QWKuIy9yO6I57bGpyOdUQl9qfIk/Lwi5aTU00dEZNxhFSGTRin7VpoPXnY
IudCk5a8G+b39jpaxwQxoqmT7tOJARwEEwECAAYFAkCzSEQACgkQT/FntkX/T8ZR
/gf+ODOktgyeJEHU9qNa5PDL5Iwt7aAwQtpnqoaGZl0/7P/a7pilHgvSq1iPQM41
41KJV9ZttIR8PTivnlkKbGvV4/R719ug7Fam+32LGsvizeKKRhIqSbBQgK/SL/gZ
qm0WT77YsRdk9k7zn2wMUEM2O3lz3E4yxSieO6Ot3hbxvLrjGf3thCoKF+ke42yD
DQA3K+jwdtgsP7fcQQjlhK7R7usEF3vqR9H2xw7HNHJVLFFAxpPsizTIu6MaEc/N
pr4u8qlU2+XyZUhsYttTbv2u5uSVJ0r3Zgki+C0bqyO1F1tdsUnbIbAqWMDg9rlG
fMe2NT6ZxFspeTab+AbbJI+o0okBHAQTAQIABgUCQLOhfQAKCRCa8Fji3/gfy626
B/9WO+bKaHhyFrUgtdwcxUI4cB0Sv7nxGHLUJD/9sO5pj3CFR8Q7nDpWKmlq2mfI
mj5g6v7hFoGHjqnwr11Vot/xVOPteRCilAlxMgbqzBUgxVbgp1Zj1t0H4ukrMmh7
kPR0w1mFBHJ340msYJTdVz0LrJxPgA4SyB5DXmPgo+n1uCRTzI5gKhDirUQrYhj1
RcBy8WTWg6itlN9GiYm/aeZ71fauiu9Ic0+O6rl3Zobw7uWZDoXrrPl9c1F2fyn7
xU2Ct7Hbs8iGnokBA4opMyA6vC9zebYwNMLzhtVIDI/yMiTlI8qqebnraXCWHHw9
V73Vjq+INWxSWP0Rn8PTaVhaiQEcBBMBAgAGBQJAtFWIAAoJECMDnpndGqL0wT8H
/2mDmbMvwL8ziq6JwOZRvk98ZxNd02JKuyrSbxMc6zKihV9+fCrFbYzhT6AxGUah
QqML2CA9P2prpZiGSD7SyoHs6t2vATGH4L8mE3n+R/jQqh+YPmLzCTuHMNS7J49H
t9dmSgo2LOWj6LIjLJiUNW8+XwAAcAmjwuH3RpNazN7R49XnUDnSaPNMBVGHecu3
s780HFw1J7KcU4qWFrvb3PnwyPu/mLIys0YZuFoWcxMrnXmIvHAMNDwU5EzDVBSN
WNsZUo2HUbCqn0e4FAcb8/sV6AgKl4XX5BuaOdxkURcqOB9WtR5cOg2idMwtKIGM
KJzEvkyCKGXVQ9L1RtEMh3iJARwEEwECAAYFAkC0pVQACgkQ7sMTGGbBry7+hQgA
gFwpg6wPpLAY3BENmNvt9uG0MVEURRTYZLWB5WmIJUgDAfuY4Ndab5kQfeqZOlKl
9+COqpnBerNl9G3aWrbk+D+jB33ysAnhxf51qkRsXVteI1AmOFUc8jGliJ4r0ta9
5o4i+tptjsd6bYhtNsf9wpxB6VZPfwrNZCslqtqm2rLMXB/Mb6JCtGd9w4jB3IMg
TAgox0KkY5/8T56LxLGnJ3ok2ALNPGv90co9Vtu8ESw6bkW3wHnP+vqkbi8WjztA
mih0TvFJUkpyRC+NHjYnjs5omIgcEAU08gsrW9jyQ4VhZgoncG56UFHnn1C2beXU
zQjAId+zCjb3HjtHDbDFw4hGBBMRAgAGBQJAs1A7AAoJELtDm8wUsvfj2RkAn1xw
q2yuXfm0WpwLWi97znM+ZbWgAKCFSlkiRicGDnu+78bvF2RzOYQAMYkBHAQTAQIA
BgUCQLnD0gAKCRBRWr1fqVzK5jA8CACbZbjAmtERYpHR1zxMZnDra3U1+1H1WPez
xJvWDz1xZZfEW444LfCPkGMp5zgUVyTcRd8Mu5FQWmLrygOs3/Ld7r7Yb3CYIZPY
o8MBwF70LY4Em6eNTGQNkojIdA/ei6OAMB4u5W6NMwveWZThIlEuCQgFVzKoiStb
awUYWDJx+BvQn8l9Mro7huKKll0psJbFUfma7SmfwEMK6WmiTh8RgOE9UA62nUPv
eeCMzUf5PpacGQU9+0UsFHeR897uM+3J6Vss6Eu+jKUGEaKVZxqhlmaqp3hgdbEo
ZyRGKlHE7a6LMHkgOD0UXOiQnT2KciX5Z/Y2I9dO7cWHIh1J/T5QiQEcBBMBAgAG
BQJAww4uAAoJEH5cQ+a3aIYCnggH/2sx8H88waPdhsY7cwRHWbcSv7JKZY22Ik6S
rJEqRCZ3gG4xIu62c9pJzxfCnIX0mkCNkAe0tSb+ekoUWkYEq+SBjXUIhv0mwRo0
U96mR28MO5b9q9t4OSNIo0JSGKLrNlrG4swg6m+XTsxI//p0C5qritmwWi7HwjZt
KXYZ6oIT8YETsvglB8BK/6PmcDzrLiufy24PSl9XQpJlnFYX7bVxHJb/xhS/KWqB
a5V83yUwelLSrQZbrlFf/4yvZsN9u84yjkN6+AI1634NmB31Ui/XxW+DtKQObiQ1
2hHPpZsjoJNgxQxo6bNOXnN9dvoznAdnMN/LsWbWJJNayNrcG8aJARwEEwECAAYF
AkDFTjMACgkQvkqD8L6ek+LJEAf/Zgnsj1SlrWn2uAMWDsFrBZfoZPk9iS8ig25K
47HxIdSHAiXWmYGrCRG36nrwB7RMWmbGFNtpoB8nEOmJfo68McswoznLah8H2/v4
YTMLE8VAjLwqfBSfZ3YA42BPTEh+Vh54eEd6cBFejCKLXprFWV5XY0zINxM2Pd8m
htGhR88c7Xg49VcWmfqo36PQxXZKuF1MFbIJqFGGCShnD5EEfYItuO085rLbafTL
5IPfH+eiJfPR0y3bEsbXrerogjBZLDq4fvd/V0othiLyVatrI+aCSexPucqgiFAr
s1eNWXz4kuf+IhMoeGIiN4BLoz14g1w0+/To/7vqzwPeb9peMYkBHAQTAQIABgUC
QZ43YAAKCRCyqy0garY05WqeB/wMgeyfyiIZmQ6T/uv2t19pYmH4TubB3/OhTkRy
UM0I+xF803NkNgtqTqmE3UjsGzgzdoEkCZygz6u5EwoFLlL9QzSBCt6iqLYkE6R7
E1kMwTii9Qqt3zvvWwpSo26JIqY0jYVds9FZ72MpINhKGaY5jWTwJsNCOCq2TX6i
AfbUqc+/A34yR0160UhCwxLodMmDkI7ppMFcbld5HZcRJFK644segf3TeHFCfwK+
bNGP1uk1w2FsXK55ZGPOIK+lonIG4VfTGHZ6bftJQzAG9cMUs3HGrUo7pVfP5g/y
Z3XYPrmpWpkc9wWcASZU0TvH+3P/Z0IOcxOdM9rASaWDsc/6tBxIaXJva2kgU2F0
byA8aHJzQGFsbGJzZC5vcmc+iF8EExECAB8CGwMECwcDAgMVAgMDFgIBAh4BAheA
BQI/NjWqAhkBAAoJEE8s09gnk88tn2gAoKarj2gNlCNw7K8VTz8oOZ9ufgENAKC+
hznVbdygdVKcInaF1nXhvLChoIhGBBMRAgAGBQI/YnUAAAoJEMiGpCvVsvD7stUA
oKreo/3/C3RkAgaypY6NQXPeFDaoAKDvxc9H0bh2asnzjpixWGCtA2bDR4hGBBIR
AgAGBQI/Z/jNAAoJEO48Tbv+O1nNqEQAoJWkR79ANI5/k1oxbCGCbATQDC61AKDb
Jaxa2LvzLIdPg/ZBujIDXSZu5IhGBBIRAgAGBQI/bSvKAAoJEBj1A4AkwngCQMcA
oOfJXwzGRG84GkacRosFUibNeNvXAJ9ofuO6fNcfNncZx3cgUWZwYcmfIohGBBIR
AgAGBQI/bSvWAAoJECH5xbz3apv1f00AoIxRcbCYP6W0kKsm5NnCtdLHW4IZAJ45
1oB2oRr6UIfPnDaqwEJjx3+U7ohGBBARAgAGBQJAtDMiAAoJEC+xeMfky635MHgA
n1nb3FI6ikG8ZCWFSSW3N9cO3DIVAJ9/hXmKkcAjQprHxg75edkWVdzLG4hcBBMR
AgAcBQI9+trCAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRBPLNPYJ5PPLeI1AJ0b
nQFyT8fgHUPBe9kZ3BZWHMgo/wCfcZ09QeF8A/OUMJ0pMFh53CQN0F6IRgQTEQIA
BgUCQLLpNwAKCRArqCYCws6AmcIaAKCSXS2qZlR+7hYXt6IjyHBrgtVqWACeNXaG
d2bPdGN8/4VgTs9WUKa2yneJARwEEwECAAYFAkCzC+8ACgkQ1Vi8KhWXTrnZLwgA
0jhmtvztYsNgjWpzq3cXNmqxR+bD/uB7HlfmoxMqh3tj6OB97XegncJtmZ1bwCV/
Y3aeSE7y0O+crMsaHM95DAw+SPjJoWZ/aLxLRC7mVxs31dVZS9JnMZWddZ7zJbzw
aJzdLfwJPGKU7BzSKC0eK1FiNk7h2outFeZwIHR9vofQdj8o3lw895qYUYdVy9jg
uwoSCg0wWB5tFj7XDiaDk/oGKyTX6WR5CEtvtr2xAQVhehkMGJtwMtVyivdlszb7
TRHmM/kImtSqqydrll1MLO3n5pS6jsrro8H4vvblPTP48XV4c61aEuHcHav1h8jw
EqMkwJnJpupfw6XEu5NlY4kBHAQTAQIABgUCQLMOYQAKCRCxzJsGbzm2pPF+CACZ
SLDx+InSN54WaXdcI4/z+l1mUVvaCHhw3pDjFRdpWEvqmIHXa3IK/9RHz+cXe9C0
T9Kj6CZHUuekWA8h7aRNeb78rtkDPQqsMzzuczneCdd+WjGqARHS34Bl6ciGNIgn
vR+/gwY75ZZ6kwqcBM0Wtc6zDdZrd8YhkvzZpfD1PIH2c70icec9GHoKhcTxbNM8
I0zQzrsIsdsWY8QNZdtPPMDnw4pu8R87yc/zeT7FRPnGK8UZwUbpQ/4ESI2poo4l
n8Ua01cpCSpwelKWIYNBVi6A2Q9Xq95jfIVJSdAbQ+7uvC/4giucpVbOcVuZdFPa
/KZDHQLXUoNEuumI+Hv1iQEcBBMBAgAGBQJAszFlAAoJEFKbo8RjARpifkwH/RC7
M2rC76UiMGowc6IdOR2lngIp0RrA6bga5dy3vg0QcNq2aXxIcnRkNvijFVeY9BT/
uv1sMjEnQsoj2CZ6FANQKjuWxD61DXq4fn07lGMEXoaE07ShQUHvEtCY2ESECYaL
DtXl6gGYueB7v+V77NNeStAS2oqbsekX3cAGKOhMECfdOMj46xvD4xrpFxo1M6mc
/aZ3NKRJQv8mIO2uhAYv8TEdFheGK4v4QfX+AuE3uiikOPeNTYxzqh5wnQUPBMlb
+g7tSK+0RTEAhXG1AIdz3E8k3bz+iQhrSi98DVStu72HDq9sg0N2APAaotwv11pp
P9KEJvHcX5TQWOfzRUCJARwEEwECAAYFAkCzSEEACgkQT/FntkX/T8ZHQAf/QtLW
KOh72UgHPE6jl4iqj0rmw80FmY2vgiUhs0rW2vr7zFHNvECjF/vVMPgyixaaFysR
susXQHnJ400jgHR/vBV8Je7aU0ipsKnXSKZdY3wZv5ZiH3I34FPIg2flHbCXwt3Y
U6I9ivMf3QYNSRUbo3JHPQWOA8+H3MxcxLSqRpC2py9rZsEGSBXkmQSwFGb8qhwF
9A6dxqpUqBM0and8Hm8T4fHDhoIV8pByPruOFsnTV4yqOQo1991rKyUrey9l9VS3
YdM4RpEu659PN0RNQeOj0NKQAtdmc5c3GTavvSKrvwNrIaSI0s0ZL44p4Fr1gzwa
VILlKL1S0mETR4zPXYkBHAQTAQIABgUCQLN41AAKCRDPprRiULKHC5xsB/9dVt2l
MNrnucY6l+v/vHjgpY1Sd2aPy7ag04yWe+OAzJY+dGWasfESHgncatLY5iKGzYaM
EJ8p6fBT+Ulzpijf+N4JDxhHlqomEc9PJCSPbRqQu6Pq7fhTNNJO6cF5MqW0G39p
Uf30VUzj/aVwmWAl+trwrESjgTtXLSKJCorMIj1iVoox6Nt63BU/P84QzOqHO3xH
Vk7KQNjdR4wtnT4IWZvso5gb2soXJAvSTcJNe1H7jtP0yWixuvlwG79gaCrgOvOD
Nx1B8a6tzDA9m+OfKjpuLsDwof0xwEbxuAK+klbmJ5Uc0lL97yPO/gMEYH3bLHrH
QXPtMTzlAQlU43pWiQEcBBMBAgAGBQJAs6F3AAoJEJrwWOLf+B/LC5IH/ReoS4R4
CFSUowHW9EXdRaGNZmjkJAuP47wtVbB1U05YfK7wCe0q9n0H28E17p6ja5zII0Bj
R3bPPT0RLH4+4J88zVto+rgREdLZorSVQcTpQYEnKfc/rbm9zdGjTdTVQzEXIZQk
1jC41Theeem56WRlTFij1CF2VhLKxL4QGQd5wUGskF08+lXS9QhS3mZeiGW6Gmlt
0ONLsVjmKCFDaTMZLUpkt5m5kgxwsTdeJPP1ZWN411ULXmqQ80zzWclhnIisU8Qd
T6KA0dX8xg0alIJsYkIKGAz7FFeUr4XMeyoVPEYdSxSyA1TpJSl3VKWe+/8qlRnJ
uj3yRWiKjEyMCmWJARwEEwECAAYFAkC0VYUACgkQIwOemd0aovS37QgAkKZ+qznx
hH52JrOMd4q0rsSKFDck8xGKnDZLKq2cL1TX9/Tot4Y8BylRYPJ5TkvHAgsYwDmb
JExx51URGHh7f7nacSQ++SBa8I4sNER+vndbk5prWLrtnlo4/qztz7KrOrGxoMMC
zSD3j4BeUJUDn/ipZTqwgoOwGjwXiT8rc+AZp9L7rBi7u8yHbDwkU56tQ+sY0m3n
wdH24h5HJmO+pb+qajzM7wg9lu8LkBkBHHx5YAo0JpNpknoWQkE+eL/sUsCDYovN
nryJzUCvA6khwny6ecq01fk82otQjq3Ogde9IpTWew9LReqq8CHXAHvsctknRVYY
u5pWzh1qDiBdCokBHAQTAQIABgUCQLSlUAAKCRDuwxMYZsGvLgZ/CACvRDAMHf0j
+COgYtjgJDMy7V9tXPPwgDWF6DeJJRuMisAffO9pd7UBlG0rgKD0ci1JUdb6VxWz
PrlBWLplGlEzPItG9AlaBrE8AizxgGWTuPn/bCV084FT2W+PGwFY+uAHpBVUiRa5
X6hswvCw0hkAqx95V+uFD8hWlEBJwLrQCHcsBaKCH4tMQjc+bjEfn0I6bMsbyThr
I70NEXA6kd9CMJmTDvigIR3z4qV5iHzbZxK5WBzPLbkcWKc55J2tI2M4C/XLpGMb
NfYBBOmJf8jJNcVoX54SdikxMIXASE9ME6fJ4upsjL3EOBA9J29/oeaOs/9bFT4c
GGaMj0cT0TjliEYEExECAAYFAkCzUDkACgkQu0ObzBSy9+OzJgCeOtNti9brEpD8
72W3UYI66FBkFSEAn3aPCGqzPwbuzqLW2FBxeoQKiMAAiQEcBBMBAgAGBQJAucPQ
AAoJEFFavV+pXMrm9s4H/jSeno9mxTozq+5XdUbLjx1QkbQbUSr02ysJGZMG6ryY
MWPEtMaHMbcJQtgClpiUWQFtbjdqZW+8vqOjc1vdxphJH4JzgSU7xQcxryF8foK+
2yMEIpSbvG60Qd6JsBTVwQ35dTHP4PkSUzw5xpYcheZHcw2E0xffAD0GqfTBCRBs
KQQWg/FGYo1meK/W57NUpSlONOvYq1ud5MEkOzlqRFSo9a/SVhmdJJ6Y6IrxvmU/
P+N2XS0Z1eTUZcmiorxV9ntT/1bG+gxzs7xjJ6HTMeIVvgSrCZSNoPPSwyXiWUvy
f4rgRWT7u0944TYEKIrRy57D/U7hr6Dh+Y+IPVoIlWWJARwEEwECAAYFAkDDDigA
CgkQflxD5rdohgInNQgAquuLfBHSUP8ltbezxGAGJO+oSIDPhTQa/pjmslno1y3b
5sZzRognnLPpA+5Rc8WjhmU1xhDm+D9K9N77s9kPD5o2BpFZUM9skBxMzu6phQzo
XsxNnj8E5uABZSYLsnKUW9vGERyW+kyjTgNHTcRgCVAiXT0dMQ3U+P6QT5+g6ttK
H5Jf6XhkiLoj9EQVuA3TfCbNpoNyorM20gb4sFv8VpkUPorCQ/A51hUj2bucxwsm
6jh4grawmOzs3jc+MV35uIPEKTrHJzZIDnPbee0udFV6E3hDjP782pc87Rk+xCxJ
NLNkP2k1/SUVDBeuQ8ldeHHfWx/FQjCQonUf3HtvaokBHAQTAQIABgUCQMVOLAAK
CRC+SoPwvp6T4phSB/9t+cACeUyjpl3fMBU/JVL+nWbVfpQ/GbcT6CSzOXV8VKsW
lm07Jo8dnsiqS3uOF2TIx++mYcpFsTrY2QYHWDjgF+wwHCKEKY0P1vIFGJ92lmf4
X4T5Rj1q6UlFbRp6FvRXZfBiuBSES3porD90nWXKpv1liVpBzywqrG0dAbUIrQ+/
jOjDHPSjO26lfyv/gxgeWamoCPAquwgQ20TeloC30hjzix4aeSu+zNjrC3NVfcJo
DIyvUDfajTdci1n170vzshTNvI63EDe7WC2DxmSrNgC1LZJUo3Q1f3wYEqPTaOwU
wE0WeQ7APCGJCHHznKywBoa26EU8iRny1D2nJoSyiQEcBBMBAgAGBQJBnjdZAAoJ
ELKrLSBqtjTlg90H/1pMMdEWoBhKP9/H+xwVAehlil0lMPno0HxqANxHsQL5ee1A
2Qo57q8/7AgH/KAWVCRmn56/WO3cdy6hAvucp2e7DcOInF9whtkSykTAff4c5yTj
ygMvEqt8Rel0Wi5ebmMsj4ZCI+HPbcAwBH5aM6ACq/XHttkrYUu1ejAxIdKaWdEZ
FnOtbghYGNXR2oe6nAHXbGn7OMCcyztwBmslGsXLAbtzWU380AjDGhB4dYTHZkdN
jjHL71WstXqPSTgechA4zbEHvYVC2UU2V+lvsQOkve7ikZvJbZ2WP2da0jcqttqa
/5w0D9Ccev8ihTqlrrR6NtWviVByEehExWF6laO0KEhpcm9raSBTYXRvIDxocnNA
dmxzaS5lZS5ub2RhLnR1cy5hYy5qcD6IXAQTEQIAHAUCPfra1gIbAwQLBwMCAxUC
AwMWAgECHgECF4AACgkQTyzT2CeTzy2vSACaA9NzC8lloD/hJicT4dUgvF61CpAA
oLGalbhtBKr0NMoDud6MOZw6p2i+iEYEExECAAYFAj9iGp0ACgkQyIakK9Wy8Pvn
XQCfQ5/FPuRYelyUPkwUTcrOMWRVkOAAoIEdBVXdbONMBfEG2I1F+fPrtgMuiEYE
EhECAAYFAj9tK80ACgkQGPUDgCTCeALA5QCfTgzj2jtnfnOfuXIcd4iU0WF/NhQA
n1WmFvbzJbsFivHcLlENDbrgxiNoiEYEEhECAAYFAj9tK9kACgkQIfnFvPdqm/VD
EACfQA5cn36fFwE8ae81VUvB0RoU89oAoPOj9Rr1TQ882dknXaj30S5Zm9ALiEYE
EBECAAYFAkC0MyYACgkQL7F4x+TLrfkHeACeLAluTYpmlh/DLpRE66fkeUTt9JEA
nAipNTdFXLfUaOZXBzaPQzi9Z0q+iEYEExECAAYFAkCy6TwACgkQK6gmAsLOgJnJ
RACfSlSXUf9r64qwfFLcsbgg88LI9FQAoI8hc0ES+8qxwQ8TrPb7Wffjj6dkiQEc
BBMBAgAGBQJAswv5AAoJENVYvCoVl0650a8IAOIUtAR1ly/Hz1kpL24RwRCZ4AU+
Q1Q6j+efiqqF7inCNbbEfVUG0mZYWNbRTsvP2Ro2VNRWkObhwzi577ZoEt9/j6DF
5RyLg9ygrW0Ecde1NzlDBb/jQG/ktTzdGCVFPXfIwgRA24hVaaVSYKbgDYdcLIsL
YzcQ3jrBlTiSsYt2TB9lQzZ9GZ8sFWTbORr67FtSKioLsGBYpkHoh0CpJmKsryts
Tfr5A5bC7Km5zS9+LBOqJ0OaKRuDr3feRdHLdH+Y5Jll7vAPTPJfbFVDcNX0116y
LQzhkyReIWgVPLqp+Osz+CP3lr489BG+tM8q0HQpt4uUYMpP6FNoYSym4bKJARwE
EwECAAYFAkCzDmwACgkQscybBm85tqSrCwgAwYs4LPFjr7UQkBnfZPxU2rpdKscr
Iy5FxALAhwixtKAnkttVGfrAlzcC3X9eXFgbvSyX5fm/8xZ/rByxK7fAKjx2Lolw
wFMSxTzTgDjO/VQXeMJusE8cLsDwKSDKX12cRSnHs97jVXQRYscgW7fG0bMQ8U4n
4DvuyE99iOvgxdvMf1l5wYEakB4GWbvYKPcrcezh8WZejEGYzVSNDsJ4VNPxbGcj
6Xmyrgl6DxgACUdKx8+rpZiffe6eU1zPczXUJt3cT9SlxOgjdg97PBD+oG2suoDq
f4OJgywnlS98pYxrMT3yv+KHbzxf8+bnrxjvCRcenEhqa9JZFjk4pwuaRokBHAQT
AQIABgUCQLMxZwAKCRBSm6PEYwEaYl3GB/9PSezuN3Fi//MaRDXjCv+JV7X6K4op
ZE+od8ijON35Bd5vZy0xpFU/OARMiQp6WzUDS/4LiVSBmZhZTon4Q2xmQq8ldI5q
Oil7JTzcJfswvHeih7/7prwQdOpGS+SpT9Q5qcR0PLbneIYwUOgTvnLMNWPvTyC0
TS4B8xT7B/3QZQyQyvs9wSAB6VHOOLEn3oPyZBKnwwBB0doEzOhvUUDj0Rzj5EkQ
cE1RaErLrudAO+oNgnFM1+GFoN/JVJniDiFaBEWfvsNX1ryf00clQ056FadRLMcS
nFnUigVZZ815NqJ7p4gobuO7XQ1bsAKouvTjv2LGFHLcUfRByrauZpueiQEcBBMB
AgAGBQJAs0hEAAoJEE/xZ7ZF/0/G3U0H/0EI1QitVx32y5e8CXF/ZxRjUSmH6PJT
ASon0SVDye5z8klsWWFApAm8Eg0J8gizMHsezPVbYCdM06gNcgdsLnSSi6mX1PnU
8T60WfMZsoZxyVwue0ZzJNjdrahhU7mT0bs/MxY0GabCaXAfK8EzjcDgKDaZxFLB
x33ZU9Njeb35iUF90duvnVHA8MZcqtONfYt9a4izvwq8ThQdO/Sv46zp8LDQWQnN
GMfzcz+P2VxWqn3UDxafLcaAOJJ5Rxsi7wlXFRSVZO5ddLDycGHg7yf/DfXf3LjS
AJOHvNv70Qf6NRba4g2mUdnzSIndBwGctuubrT+0F0FafDYYycaiIl2JARwEEwEC
AAYFAkCzoX0ACgkQmvBY4t/4H8t+KAf/bKM3JvLmjOZDi+NoCKA6E+nLqb+CBVTb
fh3sGpgRAwkwLNq4zAy35g2UUEcHa4FhQIUytyyfHIVCncfaXVJ9zMQfvL/iAxee
fChIHQk3X0WJgToPb+zMq+ASjPFy3CiT+yE8gg+ABsb7kyiOLWSGN72M9sjFG0gO
pgEAUuuFNb6Lzls4UnJ27yWXIm7dnMohafxglvGRYM1EluNPuoOLBkMgLsiwO4kl
p906bTfgjKT4d8+hG9vOcXRUQvHGxAJfbSTm6LxCPHDFZP02WLNBg3SS/YHrUOe7
cEQkpIeKK/6MaShEoIRwOIvMr68teS8znCEkkrGTt6DLb65iEoIGuIkBHAQTAQIA
BgUCQLRViAAKCRAjA56Z3Rqi9BTiCACL9piPHnfpotSayUoMGLPxkeJ5BqNA5b0A
sJQuejS1EoXYBFimuiPYJp9MhCXS70M73ZjtNdpktV9zfl996esqfWHmeATAbKvs
6s6NIDRZP7dB+9cMguNAXLTkmlMRiDT7nsr/jExd/8+gw672MafsfFxvJuVMHG2p
qAWZrxAczOIjDwoVaK+th4Ep/8L/s1SrI0U9ysG1Z6gA2aP7ES7pbIQw+jCvcyXh
lkKcUVHMC9lQHM6HeNPdCihq+BmNJhN8bo2SZAlvMTZ7G1o/MB4wT9Iq4/N7NdBc
ld7ekFrtm6mtblnKCs41xjIp0h57f8JgbtKEvczPKsBds2+A0iE7iQEcBBMBAgAG
BQJAtKVUAAoJEO7DExhmwa8ueY4H/3EjbkzE84Ak1iUrc/0ZkvorX205EQqpYme8
zVloptpZ8MYWMFwr44YIj2DWnUuNlQp546A1K9OXN+8Rvux9dN1xiql1G6AZEjMu
I5Sz9IvnSYvznFWmaAs0NBAhObtOSfcUCod7ClQIgRIG7O3U/mq3zXn3v7YQdyRB
wAuix+fQW/rLfyjLX5I2Jgvi4eU0j6OsSQK080LQkFuJwzfte3fd7FkkkFM/tLza
AVawXysybf8Mt73VChEwUKZSib3M1OYdlceoNi7GkY7aBiXZAPLrBsQmvqXslR2j
YPYY7+I3L2tmWYGmrJkn7qsWQ2yPEMOIkjC7HJBDLjZD0MzdFxmIRgQTEQIABgUC
QLNQOwAKCRC7Q5vMFLL349GXAJ9GzvkatBkda6oifmfPLl+56YLVCACgpGX47mjF
o/g8naw7sjT3fakQhMaJARwEEwECAAYFAkC5w9IACgkQUVq9X6lcyuaiUAf+I4Cf
7DvVsrZ10VwEmJuOXx0N9fo2tDAR8PRFfUGDOyDn8OgOGh86YfYQW2n2PYXl0oMc
6egPODv/SiAhWgNKuC4pY6do9fmow9A9I7zHD7XrvUJ/NO74tDfa3weFqkwyq9Fj
PIibRPkNxW9tzr2hNUrCrBuONOUdIJFWy0UT8CXR7OsIHlIFAEly5CRHb/ZcvDhm
SIo68zyklOsFUR/2CZRyvu7SkD9MsgT8qg2FZYFIz5zcD30qfUwluYu9puHpc5do
R7V20o26wXB3vzy0TE35zeNtSY02JxPEiTKOXu4v2ELx56KJyaXoyZOj5KJxMcTB
vGug4WtLBW60ZBxrsokBHAQTAQIABgUCQMMOLgAKCRB+XEPmt2iGAuhQCACj3ny8
hAEPSO94yUSh8FOZvCs9vyyYgi2IHucXy5QaCATO7KywunAeg4mDQTqNRursm713
7XfIdbf9YD42WOwFAzjSZnwlXLyJMfIELXjweNJUXBWscZ6VX/6zXdalAUZmsulU
EkndsVjBjDqoGZhOTtEGWTIZMgWlYlGRV8MkM5NEGmA2TOOwvAZItx838EYVsSH0
mmYaRSRQOmwomSS66ShxPFmthtd+5l37qNfRiS8ydbrrUkZbArImFlYJYYaehqWT
gvYRRZuJ9fFSzR+fPOgKEYuFTaHLDfi1D3gQ3mmvFflYJDFF39KTtZ8HJ3ZvyBdd
lLM1DkgwOsERESBbiQEcBBMBAgAGBQJAxU4zAAoJEL5Kg/C+npPi2oAIAL21RBF4
5DHEcRJIKkPjX/gl5yF5a8br627PZJ7JTLD470VmNMb7MFGbscRSgHRx0pQza7Wd
3f+m9ybubo/OQFntQwtpiv3yBie/451Ra5OhGXlVX67LN/xqGAoiSTOcPBTsZpka
SZO97mcRd0A3YL8mj3y8MZ8KYnWycX6fk1Vyi60kW7heKuafmsQD2nGKlsPtsZii
tiSjKKECt/XyYpKlR5Fr7MUrSOu5APU8VcjIQs1lOobpnLwEkj96EdRyoKpBFcv/
eDMrLYDTSWVZym7VLeCMQeVYjVl+MPhnu8qPRMEXSAoEvqRwa3KDft8vG28Llwxy
9N5G1I431id6H2CJARwEEwECAAYFAkGeN2AACgkQsqstIGq2NOWLRQf/axx/TnCL
3hrreHZMCn82jxKQhVfN0rARDBihF8yLvCX0+rUlKQZ0HNNPCZSu0m4VoW6PC9p3
/AVW2+w84Ov/MElR5vK9JNgbeul05R4w6wqTQHvN2LX+qE97rgN316W+LOZVgITS
i7FC3Dy9pa9FChFs4irGbnAuEy5Txj99Xuf3YF4bIllhu/Vrm++VW4/cXS5fvJzO
sb63vSCRWIWW/Y5x476lGG5sHutrwYLzrUj2vfr58r+aASj2xiPXDPSMu5yzOQsN
mmi8v9ZN49y6Cc4Moc9X7+wO9A5ifW0sdYlHogDVxp0bcjM88kGEHLARHABaSkyr
bSr7YEMLr+ziHbQfSGlyb2tpIFNhdG8gPGhyc0BqcC5OZXRCU0Qub3JnPoheBBMR
AgAeBQI/NjOgAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEE8s09gnk88tZpoA
nRatVk/nA/GFTUsqxedgdeENn3tpAJ4rIoxSYJ3wtCRvaFLEfnGwoMFctIhGBBMR
AgAGBQI/YhqdAAoJEMiGpCvVsvD7zpYAoPVoJ4Jw96f/YnrN9XLS2IivmwT5AKCT
HFEgmLRgQ4cD2qC/47z7+bAq7YhGBBIRAgAGBQI/Z/jXAAoJEO48Tbv+O1nNqSoA
oILBW6SsRHWWoJNRKBVwpbGY0YDQAKCEetLMleCGgPU1PP6Nh3KYiuRe1IhGBBIR
AgAGBQI/bSvNAAoJEBj1A4AkwngC3/gAoNjQ9eDq3nsz6+8+ewX8/Qg8rXI2AJ9b
KJdMllj1nr+PwnDrCsyadP3J0ohGBBIRAgAGBQI/bSvZAAoJECH5xbz3apv1SXsA
mgJk8iPo32qlH0cPHsE5vjHa3kBtAKDXxg77aS9eBtdtDg8xkn6Xh+71s4hGBBAR
AgAGBQJAtDMmAAoJEC+xeMfky635XoEAoJDe9cyLjHgdeIareG/a+Dnvy0CnAJ94
bRd1N7gPP07iMjYoPtpxroCLP4hGBBMRAgAGBQJAsuk8AAoJECuoJgLCzoCZjk8A
n3wATeWa+zpUCCa3GqNP5hCDNSHSAJ4+CvtUI/9QGytl9uaKH2b6E1VMiYkBHAQT
AQIABgUCQLML+AAKCRDVWLwqFZdOuR0OCACNAOJum9BORlC7N3TBsifMLZL5XFH2
j+uH6idZ89GNLn0lRDcYlhPRy+why880pP6tRhiZw1Jb50Fgf8HeawtbNuB+nPz3
eYzEwNihocJTpIi3Iv7DTnDZCRl8QTsPN5FJQciXoa+2dIQkrUOZcQlx+catYmkC
md7ur0xaFNWB+nMD725xT6LI+9zUVZSRUSWEvu/If6fMsdmNdotHb/UQD+Esk1Nm
hIc5hY1RbC70kuSxbl5NiG71bX/KuK7IvFe4kHyASRKst6zDIG9g/s+FV3KNlk73
XceL/ym3MP8ABMJgvgdmsYx2GuxYM9uiscZyahoHfHXpDGRjkTed5ZhdiQEcBBMB
AgAGBQJAsw5rAAoJELHMmwZvObakuusH/0ZkAoJWjWHz2WscWb+DN+rD1UsDSZW2
O0QhJCmm6I5mPnpf/WiRAfXbu/C5eYuQSae2wnGkR9sRlhhlzkTDhz7Ff0JdXIBm
csRo16fWl4PBDmv1H44KJTX+GpGdeoKs95euGHgZvsIYCYaBaqedhh3CjB+L+i9r
V6JXHQMDhHK/1IuXA8PL0JS4yINZNrDP+bXyiz+p9O60AqMWloiTkU+cPn5b4aMu
1LlTmq3qrm+ym7SHLhY1OSzAT5GiybZvNT2cV1h9Eume0QJUmhmrf3IZLqQuXzCl
moxKzp5WdEdELIn4MqJ29LkW7gE+zJLNE/2K137RoNNFlbQHZVZFIjqJARwEEwEC
AAYFAkCzMWcACgkQUpujxGMBGmJT9AgAj0UgYHcptbJ6SGRi8eC6gMEAK2rG/DyA
pAtZGTKCeISLU1y9IKGouyXMAK3ugmQG8dPi6TlILTudLu0JFy7kgML5KGUpOEnn
EwBKABjyL1Kxr3nsP0fGR34wD74JkUk32GuCo7UgwHEFb1BAY/UqSEmZsL8yfyzI
wocv5mN9H1Rct9kPO1lQOCxRkUo85rDoI+u3iNU7c8OtaOCHUyFSyKQknL72KASF
Ph6R9Bu92w6oSe4zPIVfxPnUPkHuXtPjSlcBei0B40lDTG7WjuxI3kqsDzQFxmzp
7/R2fou/dw7Lv5+etWqzsecxBSbfSGqPZVpNf3I9jJvYHmlAM4M3XokBHAQTAQIA
BgUCQLNIRAAKCRBP8We2Rf9Pxnh/CAC/qYMVZ9TLw3pilgs6let7mhFMUfQ8nMGP
QJI2VqZCoQ7YrCVyvpWZgv7zfguAvpn/kZKVfCgvs3yZ3AJRRZCiQxbMbRBa/IP6
CJLconNt0ZO65D82El0ibvBzs4MDLi4GyvJ6mYkm5psoaqrYahYBCDX7Ej6WDi4U
pTqd+KjXJQAtbonwjHV0OmwxuMlh0hi8Qx4PNXi3rwc3JgmxHmVLDJqHvTDctakO
bMQ29Vcn/IlC3AfW+vurw43wLpuGOaN6TqZu2sjw37uSIn920Kzhd5JuHncHJy13
9Wxs7GScTbbi9f1H/paeUffUZcNb8HvON588meezNESY+5Sm0LrAiQEcBBMBAgAG
BQJAs6F9AAoJEJrwWOLf+B/LS90H/RFpd1vGGy5DUC2o/gsqmE+c7l5737dZ2oWF
J57R6nWyAsmnQAunXplsfh94IOZokbRZ+EW8bTIeIMdHgR/9XSIuk3XYbuP5XVwY
fGnvbiZnsW2TkUQhRqp8n6KZoQjFKU1avjcK74MLUv0Jt7DEqs0844E4ltW+LoAA
YOhW01Ai2FUQ6y915bqzdh2fRDmv9uFjWbXc5VHDUZqBz4DPR5q3FtxCvvdKpeEP
MRmbQ6E9lml7cMYgUdAhPU0tetx6iBw1nXAWHnD65xxNDrFQpOUQA043qw5kPHvP
KrPd/k690iuYK3ibakfsUO8QPggHqkdV09Iwauy8MHUCwEMJAlyJARwEEwECAAYF
AkC0VYgACgkQIwOemd0aovRDUgf/ZNq6+PmuVsUMJVbbMDIkxxoUAU0V6tHuyMi5
DlRHYAjisyjgll5xu6cameMp8C3+2hQ1T/Szg0DX/4EFxoaiFZ2jXAjmJDJ/czdA
38S5scAdw4c561+VBRr18HHLsW6T1UGhPd3BmZGcbZ0MfM2fKpBrUPL0xfuKBgYn
rfa8whtdIsTqB5+mmmC2f092fnHkbrth30NJyHFAH14c40vSp80BclVGR0cNopDX
ifLMNw4AWH3UKihOe2WDklwkGydCZa0DMOUECIkqueDCKH7xk8AnhiAR4eEn9Ewl
2BDZcp8xVtXWEHasqqG26uq8RSFhAgefbHDnn4HhKK4zSvphOIkBHAQTAQIABgUC
QLSlVAAKCRDuwxMYZsGvLiQkB/4u4LsHpm4KqAH+H1ysn/08FMO5UX0+OwxG2NXa
CGuxyadKvqub4MZoBDAKNY/SPKecHuYEp/h2xZSuKbZQsKJhHFQseXeMJ0aGEWP/
MOo5rCS3ZmET3G3j3MH8zQj3sdqfK5HOoQ32AME/jkpSZahQpk48QRfTj3XqumPq
z9MkbDAjycXN7O2hqyWAGdNZDIM3o6bvhA6T384plXnnhTSgdD5ysA9k3tdOeOLz
lzzcYQ/HlEn8DUJIpdK9IRB0fqylzf+bOoDz83N3hP0AJGRgbg+Sn3oKe9aA3uqB
g71qRKdcENGIcxkzVj4JjFeo7G1C0cdDCAw07K4fjyj92hM7iEYEExECAAYFAkCz
UDsACgkQu0ObzBSy9+O9lACgnedlaRAKKUlpBbsIMSNZAMx8tXgAoLZGbDsV7TRD
w7MARY9BPH4LTKNyiQEcBBMBAgAGBQJAucPSAAoJEFFavV+pXMrmuC8H/il276jG
EbOhWmxp1ou04GFXgWIpKwInV/iKNKnhd53WQ2/cq/BpB1hczByATMmaNVElN7cy
FGQ2jPJZn7VQGat6NGnLmR5mFGaw4bf9Jxwepzsi6XXsWhCbG2dWu//e0ugOJvCM
Lkn9Z2Vjqkc8YDSTc/naK4o160h0Kv3Khb9WFuIwV4iQ0q1GIM5XrXZApt+o5OKm
ywwC0vOAWgSRRWjB5UJhAHQKRyAoDaPiCLZczVoLZqWxFpYiSryfHXEIAUNvwdC1
EcY97ygNW1t6eRvVCDMkHnH7uv4ZDdDA+yRow2zDLiaDmvtytT30r2zKFSaeLSRo
ajTgd29cLSf0yDuJARwEEwECAAYFAkDDDi0ACgkQflxD5rdohgJXrQf+Od529a6F
RedmYPutv/VvsX7WwMKPgesWdK2zBlW+xAqXJBdIKcBPBnaDK8DQINZXDvjlZzYu
OLG/Yv8WCZxE2kTsGjmEWH8ulmU6Z7cHiFUFe+pPiLNnyE8JqFCg8DNlDDK12WRI
tRGWEN+wQTXQMXEAUbb6lZvY8svN9zWL9VpRWBCrutZaU0xSlUEu2ncbrcrfPyI/
nl4VUHArNFmozHGEYozeCHebe+wzztnpu/rH7WUb1q4ffvzqAMHRoB3Ic1DuG+Uk
tYgQAxQnjrYbnArpJl4E+KLKSy+d1XgDGl2GAANYNL9IYE8vYc1jSCa+cH+NkLME
0hNmsI5pu3KDbIkBHAQTAQIABgUCQMVOMwAKCRC+SoPwvp6T4r3GB/4o6m8mU7sC
6D0GmQHoKN++NKmLdGgTnfp052/7x0NQVGygKEFcHt1MRrAuCwb9oepRR4T9AJB7
WLut5PWqtB+YUgD7BzwmJ5Pj0XjWiVaIjMkUrCp8RIyHqMU3MKImtbt2xxkveisJ
cxEC5F9nEolC/RQsPBVNedhSSS8s2rDmmqVTkgDHT3Hi4XRcz3BWFgS81e+oUCPH
iFFPpsgkh9nRZsOaXfJ0vTf826bVBM2Cxzs+/DSdUPi0kVbQmdm1geQ1azWiA1Sl
klwXuJt2NGcY5DqQ1uQXCMv587xVwGFj4BQgBm17aOmrPFqJtDnZTUk5yfndylDE
P7PeX7tZzF7SiQEcBBMBAgAGBQJBnjdgAAoJELKrLSBqtjTlTeIH/3lixyhMlWNX
K3/xHMzP5nkUBX73e01TTdUdDmTIzjE33V8gmRf0NHPG4SS7oUpgwbb8gSagWw66
hfjuFZ60q3KiZxh772cb2hetHlHIhnLWqAGk5FSFcY6dPYvLtWNd8Mfhs43L+DJX
KtEXcoyDSV8MRdnhkVa565Wrwn3rieERoJkZ2Eos18taEzJZ7vz1qIpPODT/Dn+s
ZJ+MMOBEnM3s+Cu1+NKTrZp065fKK8vSxg+MI3O65Ly4BJKr6Oda/pfANCYOIAOF
eQiyjMoKqswk6YglilhzuTtA1+60AQ+MqCa73gIzhJy/ZaLjEh81+NZ+l0VQimDE
GLdleapuici0HEhpcm9raSBTYXRvIDxocnNATmV0QlNELm9yZz6IXgQTEQIAHgUC
PzYztQIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRBPLNPYJ5PPLSUBAKCatyv+
yZ0cGQiOijsVZB+7tJRVpACeIy/3CmDGzZom6+r4Bo9mp/Lb4teIRgQTEQIABgUC
P2IanQAKCRDIhqQr1bLw+xpFAJ9N686zePqYaQWk/HepMSOWTxSWAgCgrl/e68yu
eI+F7R7PpODN3XHXcseIRgQSEQIABgUCP2f41wAKCRDuPE27/jtZzfFnAJ9M558P
mQdiAbGb+/gfJOkBQMOqNACfcjQx0SRpxDSvO+xFeZy5e2XKp1qIRgQSEQIABgUC
P20rzQAKCRAY9QOAJMJ4AtHQAKC3pyZY/YdXPKweCSM39h2i44i0PQCdHrSV+1GV
EpqhDdfXstI4LVZupISIRgQSEQIABgUCP20r2QAKCRAh+cW892qb9QG0AKDn1HKo
6TSNlxjR0CsC0EPMaAjVfACdGZsPxuu4XxV1S91wGrgxwAifP1OIRgQQEQIABgUC
QLQzJQAKCRAvsXjH5Mut+TkdAJ9AzcQqwyKbXPs4cQjC7k1dPhAy3QCfakldtifV
uPB4rO4WZSJ2eD77AY+IRgQTEQIABgUCQLLpPAAKCRArqCYCws6Amb/qAKCN6OaV
fOSaJr5Q4Dxkq4xF4FAg0ACfT5fXPEN3ebjWLS0JUX/qDEqoK2WJARwEEwECAAYF
AkCzC/cACgkQ1Vi8KhWXTrlJAgf9H1M03L1qeSfQCmBuFUxfG5DaQ/2pHSRN3dmH
5ljWBdl8R4VgrvP0QUs4w5d6bsmcjxkS57PifVD+t175RpWUTuI8t26V28RR9Cpv
O1Fw2xT4XaLQgSe4xbHmvfMvocRgg3TfgqGSiRHsQxYwPwPxMhj2lSXDSaTHsXl3
8cxRZ8AAVd1S7/9oJ6I2toYIa6hTpGC+MFEA0SbLm6r9cAg34suh7mLhtzRn4XSw
mLbpAiWcIYu5NnaYxDVe8V1HK5jGMtC9nKfLt/w1FHppKRTu82CXvxk7Fn1LTXZR
SNb0OdDlXKRllA3ANXNukS7Sw2qtJhqDaDAAqp0inEfumRVN1IkBHAQTAQIABgUC
QLMOaQAKCRCxzJsGbzm2pEWbCADu+BulQN6y0fk5xHHxBLYPO8b5UfVe2o9BhNa4
KkiBUFWa+Gkr1FBvdnS5x235ftkvQiKGfWYYuTdevOCjCSjZy0iaoGgdc76VLpyp
qfPIvHfnnYDwCijZmzeoRzhPbTR4HXILRgbBJ1qOEn4zkt8p7fNyFZqYuYPGVzZr
9m8moHGPdhod02nrp6u7CaLBVpfcHcKLhNPt5f7OCmL/6DUkxAmgy8x68V02ZwVX
hgMM5sy67pHRfBub6prwn/smkOCOfDxptxmLc+7kGA5Tc/jUfhiKedeMwhA0IRRq
VleTH8wfg/pL8bipGbICLrB7X+OE6RBLowJp3YjoAwDDi8u/iQEcBBMBAgAGBQJA
szFnAAoJEFKbo8RjARpih38H/RkYT+tk8NxlfpHQY01nbPc6AAUzEARge0j7Bjkg
2ghiugTlLdEXERci5+xJVwsep7Z2QIDnIPVQBN6L2Vsxnm4J3+9oOYJhiZ+DnP2Z
aA7Q704iuTLG1GmywnACWSGrwk/t3wj6oDE7PTCfV4SU4Ctf1AfM/Ix3iyTQiR8W
DQLgS5A38Mu+mwNEeUBpfuZeN1i5jssVVZGirNM93Ui2Yv73pDCx1izcXD+UqgBR
HUzbbBk6i/hztoqjVKfHBzUIbwQ+iKbHEvg6WGoQqd/PQarpqEONE0HyLQkjmLEK
aoQ+ZtmM6xGtbFQxRvrshgMrZodqEwDRHJU72hNIcyYLE7aJARwEEwECAAYFAkCz
SEMACgkQT/FntkX/T8YhCwgAw4ZZ+jvaXUqi0sENdiPdiBmwZFYDSOgf6TQVZ+/f
T7Vp7RenpwQlILAuPQDRfAagzc7ldgTLrN2SrjPc863IjE3XTAiTy4rC0gAEjEiO
6aQl2kOhZKwLG6sPqju9bKjOTrYmows3ody+zLKlYMstm0egL38hyZuxdx9so0a4
lNVUIIqJ7GuBytX2WSWdzt0a6sRYkbxb65TXKLw5YdMHEoTAgsuAXAAy1xEommH6
svRkd7rdq5E0WnX42BKJUNevQw5d0qtZqqnfbtfzuYihNJ3k1U4/kizXVOltvQ7B
z+XBMkt6LkmGx3JaRrECK9hUFUaj3Y/grpVmQJnE9l8O7okBHAQTAQIABgUCQLOh
fQAKCRCa8Fji3/gfyyP0CACQ30ZrNr5J+PURv21IyX3gh0drTSsEOIv1qtdqv8pS
x9st/2HU7kCt05AAnJMV+T7IsWSy0QgAh9puyvWcKLXdm3iSzyxJB7UcFxEcFhxd
MxJhvDtajLWJoBc8iDVynt7R6SbsUULP+GCr1/oWzbwsUVcnAjY2lEzyU5n9Ka8Q
kjhugf6wHebgrNXFYux20blt9sLbMDdJoxuF9l3+UDxXdf4gA7bqo4S6KDSKI6Rc
DMGLZLdKqHTsVQl67IqttlvKHL1LJNrQZV6Govn83uDyPl1JTzjNVEAVSKSwyPKv
PAzhtjDLI2w0HNTOyTXMA7pFiaRAqZOyQyh7K2Vach0tiQEcBBMBAgAGBQJAtFWH
AAoJECMDnpndGqL07XkH/1DB98vnqmMLaP8fGtbduIKcYEe9K9xM9c4Wp0TBvVTv
D7xqKVi92IDHAHMa01xmg0bEHP4odCLvw9wxXCl9Cr7yyIfPInMVBasRffkUAYD9
QPOQIktejVOzA7T3Sg53lYo6+RXSrd2vPWV2MO8Wjb90AElCKXALXHcSfhILZFLh
T1ISVhgrjfXvV2zUuLax5yvmW0l8kbtMyPpvCtbWbjfH77USV50u6c3pLuMrfMzt
mt23f5Ax9Zx/Fuv7IK35W3fXVoLIzxEJF4V2/Wop6SGOKYucg3r3/yb5vVG3VPfJ
moaCayD2/7oG5YoX5IS0TUkK4Q9e0IeE4qr4KaBzX8yJARwEEwECAAYFAkC0pVMA
CgkQ7sMTGGbBry6OeAf/Q2lM49O8E7e3Pm1rFlFsZiEBAuvM21kIdgISNRdK1df/
IAg4/URFJ1TYaTIuYVu3sjFg9gDgMgfbdtN2HMgfbmtKf3fBfCceMAPok5mE2bfd
ernjQmKeRxNPR2hfDr0JlvC9ptZWcl5/skjNmBn0SJ727V1AYi4mG3zeNnxY5su/
bZ8mVGKTUcPPxndtUuwmKVeMO204iWMzaueRuM3lE/Gna6a7sLOAG9qYsS95hvRq
GMf03/BmJbA3mz24ZlGnRiKUyzNXO+R8eYMl+EHB3IxV8ewEBa/yG6x7xgl+e+AR
4jdvDjdo58Gf/PEl7JjtUaxE/h30gHp3V89CIIOhqIhGBBMRAgAGBQJAs1A7AAoJ
ELtDm8wUsvfjMewAn2IHIGjUpsIw/LNVuVSEF9Oz2fRGAJ9OpytK1FQMMNFkDbhk
wvN9rjFgG4kBHAQTAQIABgUCQLnD0gAKCRBRWr1fqVzK5vLOB/4jocx9ubvvuBGb
hjzpLNFr0lg630qETI8FbPwdNpfRcM9piNg8SEBQReNtcm82o33W+3pRC2WSLWns
Zbc+UDfqZLqaMAFWe+mFh4HjQXDxy8xylYpWFXMEvhwN3cpvzbVm7wCx4bDD76Bp
mxhGr1jgkWnRNV9y75GxoWbRH52/+jEdvCqK1IaDHlhDjPaWGe0NmUVjG2wx/H+/
YtE+xnDsnOnUypYgPR/lPO/HKDm5elNYMYkbUgOZBnXhhCS3Me5GBn5qGaclIP5R
MxemXeLTH+nxxAAgyXp4z7f/47NVCosS63QIp+TPFlv8B+b2TSHI702ZQCh17pNq
Hqm5sILqiQEcBBMBAgAGBQJAww4tAAoJEH5cQ+a3aIYCRlwH/2FWPlSsnEnYqbjv
MJ8GA05FQJEusciVq8W7dv8LLL4HPmiwLtaI4Arh+GxL7TIL0YEzdAMys+Wnusd6
A1qVj7IjZxzHim3G6RPuUoXUIu+kyBAUy7uGdKuyeIV3pN5xg5utSSnpDgPQhS+K
3K2KUrdV2PLs0I4Y++mN3YYmdf4rpqBhRyd0709Z4sL7WO+BmFrW41vDtv3R1whG
jEg8Cn/0zdOIuqo6H4IA4g6duwWE4Rzq4xyoQ14zhsP/MpnEvwvTDxxv6IkGGT1t
AJCn3nYKsh0f59H4LiPKsMsLS3c/R2HuaFxAj+p2nRqT9pGGys4CI4mNUC2y69/p
B2So4oaJARwEEwECAAYFAkDFTjMACgkQvkqD8L6ek+L2KAf/ej9glZQkHYb0CADh
/Fkv226K97lUOaXfiWbDpiveC/iwT1UjFPlL9JX1Zl+uxVSz6nZE1NDWaR8tU5aM
FqedI32uVtT+zpYg35TtXULIMsKpnqsgpsQ1w0QYNem0uWb9zf8pTDgOgQD2pQn6
Y2UqQVRGVwgS2RH8190xyKKFyyFvBH7ol5KFM5ceJuv7KNH0MJ3AKMsLxVdnRopH
QKQMVrEl3XDVWwXZo7MvDt/zOHdWWwUEuuL3uN0RgVCmTD+71FZo+g6m5SpXb+py
+4QemA8TSQfeyBG82GIsG7yB99PEo7vEYmRiHnyurOrBm/PQiag2RpPwvip/Jk76
WFaWhokBHAQTAQIABgUCQZ43YAAKCRCyqy0garY05acLB/91HDMx+v2nF6hthq7O
O659cESMBPOiBxiy7ce7XNjJ/wt7bbOqcn+odwWUYEsc5YZGrBdgC0MYovFraUHC
Vo1lV3opVVZoALDNL3wtXQOC0dXRoUj2aSrZkpp+WxT9rsDnGLv0KcmFM3UcpKWv
BSwIvRpg9/NBzeEirnoh9bQXHkfMmn/UysOfC5Jn7KzTIj5wWg/Y26uBZHeudG2x
xHrIwe8xSpAX53VizIBPEd50DARuy38OVQrQ6h+6mJsEDFhnSvbFVwEOt/ZjyhRZ
pkkNasXvBxtFWv9IyiIv/tcOSADUJCleryIzQWlBJUpq4e5HrCgM8buQTimB8Z4q
6+SRuQENBDsmLM0QBADx1OyHXOriU8+yIZEAq5uVFfOSf+WpjMwsr/m+ZPCKxvMV
gQTfgGy/591XuO6upJ3N6Jc+XEq/fJQtaNI2fP7uViSHPjCXJycDS5kYiGK0USf7
Z8wk7txq/FnIaHRtD9o24XrHFkFi4TutLSbQjvh/Du72jHQBdAeMcCgMnKyXHwAE
DQP+OusHspKiVZbXgA/S0UNdHGPu9xkUbzjEPHP096X7cdFugYYP8TrArSNvQlIW
My96QbgC2WW4yCBc09MVR5jLGpBX11d9rNGjorbJtdWEoYbDhE+jd2tvUvi1OLdp
srOb3LJA7dC+966Lb7Wp+Vh6iPqRfs4+7IveWc+9SKY5rk2IRgQYEQIABgUCOyYs
zQAKCRBPLNPYJ5PPLTHoAJ41BFtRWr51zPq1YC59HnY1tPhAVACfa9wBW5B8JtRP
OGg0F7Gi41lcFhA=
=wurQ
-----END PGP PUBLIC KEY BLOCK-----
D.2.8 Murray Stokely <murray@FreeBSD.org>
pub 1024D/0E451F7D 2001-02-12 Murray Stokely <murray@freebsd.org>
Key fingerprint = E2CA 411D DD44 53FD BB4B 3CB5 B4D7 10A2 0E45 1F7D
sub 1024g/965A770C 2001-02-12
-----BEGIN PGP PUBLIC KEY BLOCK-----
Comment: For info see http://www.gnupg.org
mQGiBDqHuqsRBACMfFOo/NFWEADUNcCq/6yvGLAZL1V4okeB+zTlIf/NJCiA/AT2
AKiFNd4T3lYLlUjm44/OcPhelAqFSrtgmBLovWJibt7nva0dlOIXStQQSikzMOzV
4tgtiQF2ONXIqFlGcEfKo5/fcxrsJ2EpQqNX7ujGtsKHpsZpkqrcL74GowCgzuwK
PxnD+AHoa6YiX6LIhZA3ciMEAIS1vMlXFQJD1m7831ej8gBtdRVqYVHS3RohJmyY
91eGsVdDnDtywmWUA3sg/LTRRU77zx36MbAp40XZJJeSfLUp3UeKrcxSoxpI3L/V
C/V6BBnOLDQ5GcUiRwQTSClh8Ck2Hyi1msA00FZJxTdgPpa+CJANwAM5M+y3DJ6+
uZSpA/9/CNa8aRcI/OPfs5SeTA/m9SSV+ITSAIfcaVYflquqQwnNh+c7SJ+3Poys
BUahaTVcFHRrRmrVGUytek18i77cNe4ZItlUn1qu/yZwbVyTdGek8Zbv3pGIzP8r
8r57HwL8Gi252Yv5ovCRThzsshEfN5yQizbKgHiWWmr/1FEyUbQjTXVycmF5IFN0
b2tlbHkgPG11cnJheUBmcmVlYnNkLm9yZz6JAJUDBRA7PNuWDu2852ZqdCEBAbUv
A/9SDqoqWGmNNtNG9prUMqe+Rx3HqkukymKicFzvEkCjULQa1sH2TeM7ZxfqDh86
hbtJEzF2/AsbYIhk6fg7adEV4+8WfZs3TRCHxBlWY2BXEW/9zWmSL/4YNox+BQSQ
yo7ue4S2K2wfk2JgJeh1e/rEuBk1oR+G9NxfT7eKNT8W4IhGBBARAgAGBQI7cIWo
AAoJEA9QMphcQTsIRsEAn0QX5oqWK3a6wPhbNHPjkhUH6jfFAJ9+kLllZ+J8AkVl
LwTQ+owZAVuSA4hGBBARAgAGBQI6r/ZnAAoJECAVMdWEXf7dtnoAnj373ngJc4AU
WJ+B6QXGhLmBJ988AJ4+qzDA2FJQqDUr+u+iW50y0QAYAIhGBBARAgAGBQI8XEdU
AAoJECjR4s8DTnOXdFcAoO9z1mz2n/TRMnWu9TbnOBEoWxDZAJ912Q+CPxILPTWf
0vZNhA/86cW354kAlQMFEDqeC5tlYKmsNPn51QEB+cMEAKc0MMTo/JO7QRQEqBTi
VWRLXfCjPaA0XCXtw8/oc1OY2wpECRg8baemNZKnpXy1y6iQdUfJGXU8UfiK0Tvg
e10Rr7v7AdLugriggcElksLLYhgfALy8C6dr5yCcT/gcQN6qCJ4/144eBIry8EaZ
MYdxqIM7/5Exb8E7wK2gY2wviEYEEBECAAYFAjtNN/gACgkQbCk0DjIZ+YLIQACd
Fk/ofe08SuTTYiTGHY0lCeSfIicAn2WzGB3b8n2lcA2q6xZhFVGCjXbUiD8DBRA7
PMC4d84pxY+hLiARAncDAKC/Ote5mlNMwt/N6uJAJEnVLk6fMgCfXXwjERQ4uNfT
btsBo3oR93gSuLOIRgQQEQIABgUCOzub0QAKCRCTqAdkLDfjdVI2AJ0QHSmZV7v+
Vf5ZL/iydysCTabdpgCeP3/6CAiw7KjlAYhMatYRwIUSpFCIVwQTEQIAFwUCOoe6
qwULBwoDBAMVAwIDFgIBAheAAAoJELTXEKIORR995IcAniQ+bgl1JAocyhGbknOz
z55c9i+XAJ0Q4/tU3vPZ3TkrU8xK8Zct2qvkNIhGBBARAgAGBQI7jq3rAAoJEMiT
/MUn0FXbpeoAnA3VZSq+WIMQWoBffOxa3qQ4gZaqAKDVf3cq9j8JxhINE55bNjpw
6HLiAohGBBARAgAGBQI7c/gUAAoJEOd14yTbQbOH8ksAnR4yNm3N9dlHZzG8SG2h
6jVXStWgAKCFQPVqEYS072jmEQc+pwhoKE5aN4kAlQMFEDqdf131FVv7jlQtXQEB
YWQD/jEXwixBkuVVuLboFETpUCdMeVc6BpPzrHdfa52aPFKHqt416fAeeeXRly6l
AxMDdJPxU2ZG3abR4iiaqDKWwiluFkEwLBL0AE2Qx2R/nNZqEYNB0BSUQNPH/Q//
kG6mLOAVVvRLAL5R3MEeK/Y0ErH/7JXn8JPrl/rKqwCbIsL1iQCVAwUQPMskr22D
N4pRurLtAQGBKwQAiXOCEjXh0ItyqSJltkb/6Z2DYJw6ypRikRJ+yTypNHD1EobE
s1wOQS0EHzyXyIu7y2lj9pMhf4aVdYnMObBarg2IDx20qUkCKVEr+evccPxIsXt6
CZh9Q6D5eaSyjziS0RuHpEubzVPY+raR0u90VJKU4YNzmht9D+ZNKRuTupiIRgQQ
EQIABgUCPMskzAAKCRDTST7w0perjoE8AJ4uqL6O5gfCXSPKxcGF4scxAu9nQACc
DpJ7Vx5Y7fMJMmDWAiox1+uHE9m5AQ0EOoe6rRAEAPF15Mz5Kg25Az3g+7OB37Qf
ZukClm8gdjR9ziTS+rkjYxeP+j+BmrQNyqdyM+dNGiEk+TgJiBy6otjE3RSQHuVw
xin9yMIuTxa6xh0PX+sV5aW03YUViglWkevdMDLTAaEUwc0y2fZv1as6Huk4k5LK
NanNMRnU2giytGuCTyq7AAMFA/wMMI9Px5Q0/p3iNDXZ5YQ6zbDR/aC/q2lxN38F
UJOEnMaSpZvD/EE/gpmI2naHQuGS5C3RrCrX3/7IGGEVE9U0dl+krreVDDxz/yXY
hX2D+5ZvriekJZHPmek20gT9i9gm3xLl2e0zS1zQ6BcYCtX5kVwIW5PTs09/MVvw
scShNohGBBgRAgAGBQI6h7qtAAoJELTXEKIORR99rLsAn2+OxqxPJK8ZmYPKX1JK
qN+IdvKuAKC6p9c3lJBbYHFlhxPDhBvgBaSOKw==
=WyeV
-----END PGP PUBLIC KEY BLOCK-----
D.3 Developers
D.3.1 Ariff Abdullah <ariff@FreeBSD.org>
pub 1024D/C5304CDA 2005-10-01
Key fingerprint = 5C7C 6BF4 8293 DE76 27D9 FD57 96BF 9D78 C530 4CDA
uid Ariff Abdullah <skywizard@MyBSD.org.my>
uid Ariff Abdullah <ariff@MyBSD.org.my>
uid Ariff Abdullah <ariff@FreeBSD.org>
sub 2048g/8958C1D3 2005-10-01
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEM+MioRBACP2lgLXXL1cIqZ8sdgUMaon8gBQWTn40tjTV3N6GtR+NUYbQI2
Fcg43aopA9VVoeVyBlCSAyaiLTzZkyg1XRDqsjz9BnRWotwTX2e26ndVgsUzmXs6
NjBcCYYNfVQ09BN3B05FRlPRpveMzCkZCFmWJCzjAYBMg/60fSia2In4twCg6Pr9
Bp/eR5Ny9z4WzpIsynAt6rMD/1pDoV+FbZ6iw80Zq7pdyspPdPCRIzXhYsoe5uTX
kjWRWixctbphxgvMheQWZNPNhDyDo/YvuPa2qtrHCDqRYSgmAHPC+NWfyoJhCMjG
WMjcW9wWZ0j2Oc2uCTvficrGKF8U9ol6E+x6tlc5Cw2jjrPkwJCd70W9SByrgIdv
51bNA/4nBw7S9grYcnKChYu9mGMsAixCXzMeIVc043Y2SD1NBg59ZNiaSkmRyD6E
dCYRDhQeF2CePV3ZhlXDxOm6vD2l4H+9sQ1TRlEP/ARejwJrPPRO+plCf8pLDgj+
78Kj2OlEwC+ziMdXyk8W91FhtCCDXQgDnf3ND/h4IWTzrVD0dbQjQXJpZmYgQWJk
dWxsYWggPGFyaWZmQE15QlNELm9yZy5teT6IYAQTEQIAIAIbAwIeAQIXgAUCQ1EY
kQYLCQgHAwIEFQIIAwQWAgMBAAoJEJa/nXjFMEza1FsAnjbSH6NqUl+VC42MGNYG
6xGCfJoxAJ93L2Zf9C/ug6afFr4Bh/HoJbFiOrQiQXJpZmYgQWJkdWxsYWggPGFy
aWZmQEZyZWVCU0Qub3JnPohgBBMRAgAgAhsDAh4BAheABQJDURiFBgsJCAcDAgQV
AggDBBYCAwEACgkQlr+deMUwTNqW7wCeLHdcpasWMJgoqfLIM8PTJ/UlZ28AoLF0
V2UMd0CdWCANmPNdZcME6jietCdBcmlmZiBBYmR1bGxhaCA8c2t5d2l6YXJkQE15
QlNELm9yZy5teT6IYAQTEQIAIAIbAwIeAQIXgAUCQ1EYnQYLCQgHAwIEFQIIAwQW
AgMBAAoJEJa/nXjFMEzaMs0An0gHq10v/5mnLWBYqnwZ+SnZNCYbAKDaTpCa6ddQ
7jdr/lmi8XwK+blRqLkCDQRDPjIxEAgAudaX6QqmUT7UjXmxjlNr6wdDT0BDCu9H
ZJuYt9Nf5V0Yd9ExfhRKh2YoYoW0790gka92R7uvrs7FJiu35KrYvOUjmwbouVf8
Cg2fQqDcw0Lj/CD0meEduZOS4moxv/5GcJc2vsQ1BDsRwX0DmLQYXIaqIsRSo4U4
KxWi/zZC5TF1Iwo7JyGY1Gc1SMZuWeZC/qx8bQxvkLx1q3qyZybjUtE2WkfqH0bI
/XCpN5kxDciq/U1IP0H2pU/Md/OAvylKID6uR9yPh9kaOOhcvmOID9oWIMbE8a7x
eAQ0QkEVpoexA+5DbUarPzjfqUprpZCydaE8s7Gzy/ocegAYqiGQKwADBQf/fxph
6IW/Be5YFg15+9wZ+1MlEszXw9pZnkLU4Ypwz6ksNjrbpHcEbBdK45kw17pOL+WW
Yie5tA/b8ndzoga/qyaOa7lH3b4pA78GMhGd7gSzrziNkuE7Yc3WNqjpRVYmVgH+
9K0rjJaK55hhKDdEGj1jMXNXAXtXra70DNWZt88HLs85goWm7vnnsiPBgOVquYEB
/q5ExD/E46TkxF5/Kl02LyHTcyhWsUjksmoEi1O/wxXOAxi/GM3QRrkbF7voaC+d
Og5pxQXsftoXsk5fBEDBD1iCqqs1m2IJIUwuMxVlcc+IvD/eYejrtNlkzh5NLash
evj4a81s2LLPh5qd3YhJBBgRAgAJBQJDPjIxAhsMAAoJEJa/nXjFMEzaXHkAoLi5
OZgXddFLJYSXXnK3iwzYho2tAJ0Ze7tHvJd2md4VSth52CSBYDEemA==
=2tPN
-----END PGP PUBLIC KEY BLOCK-----
D.3.2 Shaun Amott <shaun@FreeBSD.org>
pub 1024D/6B387A9A 2001-03-19
Key fingerprint = B506 E6C7 74A1 CC11 9A23 5C13 9268 5D08 6B38 7A9A
uid Shaun Amott <shaun@inerd.com>
uid Shaun Amott <shaun@FreeBSD.org>
uid Shaun Amott <shaun@coder.net>
sub 2048g/26FA8703 2001-03-19
sub 2048R/7FFF5151 2005-11-06
sub 2048R/27C54137 2005-11-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDq2bMERBAD+HhpI3J/ftblnkB3BKL4SlcPuRgpzd+qdEZpVFBW9TF4RwZhq
uVvuhTwcLsTlv8QBoCkUU2Wf508RnG14EtW1hoqciHRSKyKmCOOz5GNYQB9z0VkL
n/KH3yxYtCVqcr/ZJPXSyGGSzLUuCxX8SgaByYOV8XWJbqlE44nmvTEqNwCg9CV9
+Ifdl4ohYfPhvQGAQ0Z51JcD/0YNZMWcWruqawPYwQmzIiS5FB7bZa2etPkBzA+/
EYVdO5L/8CfRy/QTsuF5w9OkRTVGzicjP5j8T0aGziARA7T7LdPGYdQQ8bR9cAWt
TGeZmlGas4vbz22FN5mEMU1xO6EArt3RFq4uL2ePWM/nmRiTGWVWfZN9ps0qL0VV
PPd4A/9oa3eSYuJs9bzyFtm4h0rAyQyr7koNIia3757kMQr1L/OmBXUiPS6r51EX
WISBLslMksGtfLdzlprd21x7Y+iRhwysjX9fyoul5Tzn9HENbZdp5ACeEjFFX7LX
K1sI6ZVeFDMfwex+TMBmWfv66HGzRgBCpjN3TtcOwHPNo6x6g7QdU2hhdW4gQW1v
dHQgPHNoYXVuQGluZXJkLmNvbT6IYwQTEQIAIwIbAwIeAQIXgAIZAQUCRK2r0QYL
CQgHAwIEFQIIAwQWAgMBAAoJEJJoXQhrOHqa4A8AoLpKui3MGaN7QoP7+ABKFjar
IVzkAJ0XMx2qfpovyhKEaD5mIVmE/HPdm7QfU2hhdW4gQW1vdHQgPHNoYXVuQEZy
ZWVCU0Qub3JnPohgBBMRAgAgAhsDAh4BAheABQJEravfBgsJCAcDAgQVAggDBBYC
AwEACgkQkmhdCGs4eppDtwCg5tYU74gBC7sqeDhEXKimC/7Tz0MAnjduBqG32uxo
mc/IV69B0JSmJr6qtB1TaGF1biBBbW90dCA8c2hhdW5AY29kZXIubmV0PohZBBMR
AgAZBQI6tmzBBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRCSaF0Iazh6muq5AJwPh0yT
t5nRFrEKqikW55V1FlD5ewCcDIyBiHTW+QgEtFh3Pfc9PKARI3e5Ag0EOrZs4BAI
AMt5nMPpvbWK9kwuRnwUPuC2RQrXHQIhyDMhbLImB09hzX3CiWhGDqjK1EOat1o4
jg3DvHUGqCiyHfehrAMv0Mbxn4SWdc0jHbG8BCkClZ99T4IcqmTaUvrqFm0AY4zc
fHdIaTSzbklqa2xPBqjVkShhOciye69MQXiPzgIA8QwhNcrE43l+dybrLVodlVtj
L7DN+PtN3Ppi8uZqwAxgT9hzD2rW7yzsCblQA8v83tct8PvxYgDAq4tA4iQ2Mccw
DgRafE7L54PLkTDodh5sX6YSFfY2HtfS/RrvLuKexEkYsJtqk1HlLFfifOB53Dst
AIdQEo2U7GkUAtHJev7WiecABREH/2XHn5dHOUn+M3a8hApXUV2f+N0VI3fYuGOO
9M6VryDyEyC92RrA6JyUIogLxfxJm1eHAz6FMePQ69iwkTV+77Ew4ou0wP5rIPB/
anFMrkYogYuy+yKBROUzpqwQG1Cy9bIwBN4+tqjbQGvF0Rhv3F8SZ0QaeZ9d1sc3
Q9XsS8ETpR67KJF1RxW1ZoZpBevTLDSd/WE79WO4QiGOdlBjGPCuD5hjsS8dRYYh
rb3jlmlOXhKEY2PLUxAexKsHmQ3cPo3TC7N9TXALVtLJoj6Fy4Ra+avv2LqwXTp3
t+9u1nceS++MuZ1jlbQZiXPEjGHPBTkVetZ9KMht34nL+XQj6GKIRgQYEQIABgUC
OrZs4AAKCRCSaF0Iazh6mvinAKDgFnBWM6lARAMJfnHyFA672uMbBwCcDtev208c
PUMaKeawyHRzessLlwW5AQsEQ21itAEIAOY/8K4N1uiSS0i0MXnCOmiPWhnXPDvq
41mdioUPxseOifG5RIlIdGCl8bVsSClUuhNl3HnKolYj58859NRy0ByKqIS3tkXH
ai6NJ76c6nEO32U3zXjy1W8GeEuvLAVyGfVaDDiBlUgSMBwOknjMxuU0kTx2yQAr
56I79QqRovP0Co4tmuyUJLEBPC3w/e1IsWs9vIznaC00cVxSuIqgrKf7YoNLQTNg
Y8Y8cjgsD7aQILN7Z5hNMIpbg+AxijFxjO43Yzom0dJ8chQqzEGICTjV8f7xi501
lTH5KRk1sXduePqLtQdi4ak9lU4Sm3QeGi4YULMxTUWFZK4Xp2187FEABimISQQY
EQIACQUCQ21itAIbAgAKCRCSaF0Iazh6mlh6AKC9ChkRNDsKAHpJ5gqqlN2F/ZLj
/wCfdZCfKPTmNG26LpwbDrEce2zyVsS5AQsEQ21i2AEIANik3CxXBWA8nYnGckTS
i9FAiuSsoNakPjrOqb79k7SIlDtbzZL1g0rTAKyEdqjo12dVrPZOYZh5XN0bsAFe
K25b4Uql0cFxnk7ByNeoLTleowraGaxtFd0UpxeBRm7oImFQZrSxSxnxZuHamLDw
SV7BbAQCiQX8Flar10RVKwYCVthwGddam4U5JCQ2JNwqVXEVV7Ma9uvMjqVM+vyp
d2KVGF5zABW7YUb0HjJ9KsWrlSdOAjVBe0FAxgucCbX0nbh8UPHPobzCenXh5bsp
ImANLsDelnC/NdoL2zTn2JnziY46yyB/xwF7Aj9NE5aNmF3mhod6SeJ4eimWu+8s
KFcABimISQQYEQIACQUCQ21i2AIbDAAKCRCSaF0Iazh6moOxAJ9ygGn22aYARUZD
V2ySs9vnvqun9ACg7ECGM+wxsRdNrqrWXEY2c2sXEpk=
=Hf4Z
-----END PGP PUBLIC KEY BLOCK-----
D.3.3 Henrik Brix Andersen <brix@FreeBSD.org>
pub 1024D/54E278F8 2003-04-09
Key fingerprint = 7B63 EF32 7831 A704 220D 7E61 BFE4 387E 54E2 78F8
uid Henrik Brix Andersen <henrik@brixandersen.dk>
uid Henrik Brix Andersen <brix@pil.dk>
uid Henrik Brix Andersen <brix@aauug.dk>
uid Henrik Brix Andersen <brix@FreeBSD.org>
sub 1024g/3B13C209 2003-04-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD6UQlgRBAChxRQ81Vmb8AMxEG+meT1euB3fDPtkvtSc+HdWDnpNWCTnkyq/
IVuG1c23Hi410K+MVwRn/IXaUGHANhsIL6408dHX3QuvTCWW/RYx3bPU2gxjbuw8
4ZT/dw1vsbR/dnjz2PaX9Hhq5boAy0IXkpsRqLh5ys+pW96idnfCW8VCewCgyFTR
+GTaKsSAJ6mFEIo6Q9NbsH0D/1M0Rtj1teZbJIitnYkRK8l5YH6AD1swOEdZTvUY
AccQjQOwn/9EWO4nYdOknoogXLYMMsz1Pkw/X5IoABeH9AHRcxhhkG9B2SVzaxyI
BB0VH5J8ks2zkf0o5yKieBtIobPw5lcgLjwhALVrsV4FjV3G0+lS/cb08wlID1sI
nqHcA/9ibS8Omf/xFQLlD9KebW87FadmrPsBS0qPOZzOkMqdCaFZsJ9UZie+RcMR
qDFZZLHZjAh71J1czn7qbK+BCv+LRhzERTWevw7fgL/41m0DO8JqzMkLZr9EneRL
7ZJ5NtBPS5WoWzMpoydaQEA2sjCnMmTxBtJpCenR26LynXmdmLQtSGVucmlrIEJy
aXggQW5kZXJzZW4gPGhlbnJpa0Bicml4YW5kZXJzZW4uZGs+iGEEExECACECGwMG
CwkIBwMCAxUCAwMWAgECHgECF4AFAkUMaR0CGQEACgkQv+Q4flTiePjlBgCgqa2K
xi/J9ln8BULtheJ4PzDhp48An0OnhLfiWDsn1XoS9KQ38XzrSimbiEYEEBECAAYF
AkPMcpwACgkQN0y+n1M3mo2P+QCdH5NSpHYikhVD41PPaSNg1SY9rm0An2LXs/aT
06Tz69gBoWoWeLMnkfrGiJwEEAECAAYFAkQMD3YACgkQH3+pCANY/L2ZaAP/cCpR
TmyTqgIA9Q4CguB07gdlm02Ak8TVubuvBylM9JrZpPR+bqSrjocEi+rgUFJn/e6b
IrQ41WnPrP7K050DpQelGx1WxnKwGgssNzGP96y+babR/1jGUTO1fLyD+cZQ3GTy
CxCOa0YIHpyB89icVeAcYUaOmlUTkYoInY+0+7eIRgQQEQIABgUCRAycfgAKCRAJ
xOeJkBbvUD4gAKCJPc2v59Heoxo+HNEElroGNuQrFwCginDoNFpG0imu5WleEhJc
EesQGrSIRgQQEQIABgUCRDFIzQAKCRDz3nmC81+kz3ZpAJ9FW6NzbeeOnXXDwT9s
tdEZm7c6swCgle3IfXIKYd18RtxqMWxfxpFTQvOIRgQQEQIABgUCRMz8SAAKCRBd
Vo7rtLWu26v2AJ9RGgGOcs1/9XfklMYo0UrzeMml/QCgsNXw9k3E3kkCE3c7SVBi
klYWP72IRgQTEQIABgUCRQ1LqQAKCRCfd8Csb3oRX/o9AKDoN7obVo8CjEUaarVv
I/6COPYj9QCgw1IlrO3dyh6lLJbgdci9Xg55Ry2IRgQQEQIABgUCRSzZpwAKCRDV
CFOpIhPncu8hAJ4niDTm5vUWx5FHeAkbkey7zYV79QCdGJOrDToSQIDoDv/wv6xf
x7xNMjmJAkgEEAECADIFAkVXKukrGmh0dHA6Ly93d3cucGFlcHMuY3gvZ3BnL3Np
Z25pbmctcG9saWN5LmFzYwAKCRAmSeYoxdNNBYjyD/9uK1PGmlM7TEI8A+oMUQYL
OHao0/EdKdQnbuoCX5EC2HtW6ITXytHxzDoisCFOVQS3YpN73vth9IZRXPM7JaBQ
+uG5ndUqprNIWyon/LC85R1S5iK2Q5KIHyEcntBDDqzzYVWig0+Pm83kzJspM4Va
8btXk05rFIzi09xcL3Yew2a84YDCwifWEs0TRhsUtsht2mO01hS8XjmyJvzdNebI
HOwL8kQVDZbNIPReCpCmgk7p6AerphHjbrzTrby/BdkM7vKukvOIX9uJXIFr9s/6
VdiupUWJ2i0H+zRD0eLdpTtmPMe0Yy2SUrIuqkq2TUm+bLLm8jIIypoSz69hUfhH
M+koasJ3wrz+LriUORK3vUCOxIhuMFUKL/oIWsMNzi0onnTaEoD2YwUS5Xd3i5Nl
PQHinaGAp5c4/05/fqFzEvplik/9gK8SDC67SZcEm85BmyrGe1JUuivemB45PEJ1
o5MKkPyxE2oFEvpFjJwRlHa/8Xd+b6hBVZqNDk+ACTqsdi/+i73TCDC0Tc5H1yy0
OICxowaYtXvoMBolZBgDM30d1PfFLULowpqHQLQnCrgF+QfKEooKIxgUqgs2HxJz
T+6EJGbO+NwT6GClosbAaQk3cRcvR4bZ3oRaSA5E2LySTu8Vifs4nH0cc86OAmCO
Mau10ikzd9Ewyv+/z4lbzIhGBBARAgAGBQJFWOY9AAoJEK6UZT1dE6xFELEAnRBP
hI3AwYWMDdxL+b7td3vGI2c0AJ9/e+cOTjDM7Jg9w6XxPIbVCAe5KIhGBBARAgAG
BQJFWhAaAAoJEBRll9zcw5nH7lwAoLBj35DUAC1Ftv5GNrOUakRuC4l4AKCgKP3M
GsROrLP5b0qgIcLBWRzfUohGBBARAgAGBQJFWuFiAAoJEBdynXf0qFEvckkAnjCt
0FiAGhaXlAHW1LODtjrdejmNAJ9qaPTihxJrExSUQ0pYPwahDkWPo4hGBBARAgAG
BQJG7wWGAAoJEJ7XWD/BTrKCgooAoMlrxw5Ai6Qa9mA+zLdnpNLRMiJiAJ0WL6Vd
gF7oQof3A/3lrQN48xdNR4hGBBARAgAGBQJG739QAAoJECGmRpvR77qmomMAniZl
uTilewm9oM6i1322xHr1GKWVAKCHF8tSCL1z1y98piDoOBPzBXsJB4hrBBARAgAr
BQJG8YqxBYMB4oUAHhpodHRwOi8vd3d3LmNhY2VydC5vcmcvY3BzLnBocAAKCRDS
uw0BZdD9WIwvAJ4xQw3xp+9xfdhKDoNrSALnqzmwEQCfcvsMnu3g5qEkhPmTmDqg
Mq0twzOIXgQTEQIAHgUCQ0JEDwIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRC/
5Dh+VOJ4+JyVAKCW3JS2DvDpr+TlD5qYSHb64OKbPwCfda1O1FIElnQNw1YnZ6op
4NYf0GWIcwQQEQIAMwUCQ/8J+wWDAeEzgCYaaHR0cDovL3d3dy5jYWNlcnQub3Jn
L2luZGV4LnBocD9pZD0xMAAKCRDSuw0BZdD9WJv1AKCeEY8AF53YFwkwiQBXbR84
jlXVRwCfcT0zhAl57VR4Ijt1D4cJ6g3A8qW0IkhlbnJpayBCcml4IEFuZGVyc2Vu
IDxicml4QHBpbC5kaz6IXgQTEQIAHgUCQgFQNgIbAwYLCQgHAwIDFQIDAxYCAQIe
AQIXgAAKCRC/5Dh+VOJ4+BwWAJ0XDcS0nTWbWGS0/J65xCBT3sirHACfaTWqV/4z
+J5UUY0jaFyAVDPacoaIRgQTEQIABgUCQgoIZgAKCRDVCFOpIhPncp82AJwOTmRd
hjhBNF0rbozKDAfzm9kpyACdFr78039yVcjhacuJ9TryX+sP/PaIRgQTEQIABgUC
QiyUOwAKCRDuniwkh809vTUBAJ4tRY6maegjAvifM9Sx3lRmOElxUQCfUlNXI32J
yF11laaBw2lemWR8osSIRgQQEQIABgUCQmvCJQAKCRCrL1pbFSVpkFpIAJ9gE6av
LyOYKPShubfQtzDcvk1FPQCgsGqOWEWjBDcILsEjSAZf2s15YaSIRgQQEQIABgUC
Q8xynAAKCRA3TL6fUzeajR6QAJ9EJ+inLsddYSrMzPjUIg5KN/NS0ACffc6FKBmE
xNgfb0fDWhWo6CzlZqeInAQQAQIABgUCRAwPdgAKCRAff6kIA1j8vQQkA/4hBEQU
moD7f9qCtcthstfHJatafSdgGt/+ZUdA+L+nSVBBV+w/lQn9Quh78Dch8n3RRi1j
odco95NelcMGGw2RcbycCj8YhMYelBgvOtvb70siUOm/dvEXUGqfG70tEbyTZARV
nPyObvJ7cKsWsPwKDP5PYsdBlJrVGAkkIsMPdIhGBBARAgAGBQJEDJx+AAoJEAnE
54mQFu9QbDQAn3yrCh2cVJ6Q7xusvvbCsjOhT754AJsEEQjfk7n0WUuIiR217JSU
3WV7QIhGBBARAgAGBQJEMUjJAAoJEPPeeYLzX6TPZpYAn1diR1oFxnftj+Xvj7az
wnMU+bONAJ9vsUccKZArvPjiUMHN62Jyk9/N7IhGBBARAgAGBQJEzPxIAAoJEF1W
juu0ta7br0YAn1e+UFgxNqCNoL3pk3JWnGdDR0/KAJ4h32cbcVycxt3cai3+8xJu
IfanLIhGBBMRAgAGBQJFDUupAAoJEJ93wKxvehFf7+AAoKr10orISa6VpbVLtB8b
q7yifos6AJwMyQi25YY/+89ucuuj5D/ENOdJJohGBBIRAgAGBQJDEWGEAAoJEPNM
8i8UkicnL+0Ani1X8NQYrQwLNUqddTQaPjU2kFhUAKDRh4aU40EjT/awjFaoL1QS
cRaD2okCSAQQAQIAMgUCRVcq8SsaaHR0cDovL3d3dy5wYWVwcy5jeC9ncGcvc2ln
bmluZy1wb2xpY3kuYXNjAAoJECZJ5ijF000FI/EP/2CKJioV5P2l3B9Y00u5N/9/
lRVujKoOh1HcOFndNi7tZpKOiBxP5nQRvVGH8O9qSdsYAUA0/1KK7+FAgUrPL91s
/d6cG0srtAGMFd+0lxy8nvfYPn0AKAuuumCXjclZsm7H2zoMsaAP0TGO5zGq8tKJ
oIhA2jZyR6qUYc6UmcrTTTLMJEcPNoQtk6WOehpZ6+ZXok9O3Oj/lKTeIOfxMVlW
lZK9fc0ErL0umNp1n2lYmzub0cAtPOLpLN659BfPc7p30oGyavg7YcmstUSH7KcX
aHL2EBFE03iY7p2tVRRkuWgTwZQL7OJ2i7p81XTHNwt43G2PR6sVrwcAJaBCzG+5
nFLt9B/9ZFZSO7Al+2X741vAHMpeSpPrZs/jCYypJ56xvOWLgyGqjoJ7iuftTrI2
KUijZpR3yc+EQT0TMbKkMmH0Fwmc6lMriokw5Uv0MTbmQryAOrDmmI3EW+bn4c1W
xyprujfzXNckuvoCP7cO+PMaw62/MiVTubjjahuzyjyBBDBDnv+AcHtFYEvI79Pp
5A4tN7KwO2VfNyeiiMboHZo/e1z/ftb9yE6CPPfJ8trbRD+BYiI2pXNsd2WZOWJi
OQLjnQGNWIDDiGLDQkuCFapP/9GPE+2wnGUPFpzCl61TmhPFytA/ktMbrSvAdeO4
ZG+A+uffHw3bvx7Io18kiEYEEBECAAYFAkVY5j0ACgkQrpRlPV0TrEW1qgCfcXyz
F96vs56ANzRmKDYIRUdaRM8An2dlIMNig/8QOZiQMlWttQW18FQwiEYEEBECAAYF
AkVaEA0ACgkQFGWX3NzDmcfKhQCeOLI4ezcjAFLpx6yi6IhzhuIHmxMAoK6FE9S5
NTnBHNVE8E03DhHDBj8piEYEEBECAAYFAkVjZ/IACgkQF3Kdd/SoUS/85ACZAb6T
KVDKJfYeUujPSjT8oMluXOEAoIvwHipR6LSx62c0IIRtPvjGRJk+iEYEEBECAAYF
AkbvBYYACgkQntdYP8FOsoK0cQCfVwXURwpyhvvRovOqCeg7KSOvLVIAn2I8XtcA
KxViE70DShYy7fDV+5DQiEYEEBECAAYFAkbvf1AACgkQIaZGm9HvuqZCsgCghy8K
FNI13rJZQx9HYRWYomYOvQoAnR330uULJKZ3OXoEFl8cxBSL/kCwiGsEEBECACsF
AkbxirEFgwHihQAeGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9jcHMucGhwAAoJENK7
DQFl0P1YDMcAnA1nZbi9QGODZxTjjFrSHj5mrXSBAJ4gY3iMB9HESMIXNmJvQQ/O
7IJrYIhGBBARAgAGBQJFWOY5AAoJEK6UZT1dE6xFcTAAniEErsWgnAb4i0ZcxL/v
novt79NBAKCJEJqzGFauU0MYKCHmh64FbdwN94hzBBARAgAzBQJCVxbXBYMB4TOA
JhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5kZXgucGhwP2lkPTEwAAoJENK7DQFl
0P1YrSQAn2OAkKvtEH72NjoIzkZfT0mLcyFsAJ4hEiR0DQGTBRklTgzoZoC0CWh3
k4icBBABAgAGBQJEDA9yAAoJEB9/qQgDWPy99QED/jNAIt5GmHGuD6OnZ2dIhpl5
8zhucqJ+xbCvp8NFvhOjBJNX+sAaI/S1OmPgaI1LefnvSDjDYQ7+Ou1357t3HFAH
I6uRI/kABJDYUEV29YEc2acvIw0dAY95F2DEUYBTJF1C6mUpl1CkyYjrg+Cn2NNH
GbFV1iphNo526dVizkH7tCRIZW5yaWsgQnJpeCBBbmRlcnNlbiA8YnJpeEBhYXV1
Zy5kaz6IXgQTEQIAHgUCQ0JEJQIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRC/
5Dh+VOJ4+EHrAJ0SX5TjZM6JK8DH0QJNIpHakTJigQCePQ74xyOwLGB5Y4CIfGQf
pLUxIDmIRgQQEQIABgUCQ8xynAAKCRA3TL6fUzeajcljAKC8lebtK/fRJIX++RQD
uVhmcxemTgCgmGr1vSItbirCA2GCthhsETpz7qmInAQQAQIABgUCRAwPdgAKCRAf
f6kIA1j8vX7lA/sHHMOfH5JgCqYBa52Y7mCpHPCEHgv2eu09reEaRY0Qy7EmMEKQ
kkehf+vExiRHZl1IUgVf77tjeqwjt3YZQIwGAKo3zN1/Ba+umMEE2ktJWWI3C8S6
MCLUGZOLENuKrgIrBqLqDGwUQNiwDTlxfY2ODVthtf9eNFwak1A8q6drwYhGBBAR
AgAGBQJEDJx+AAoJEAnE54mQFu9Q3okAn18cdHUyzT2tjJqMytrRpf7tdpSzAJwK
M2hrJlCV/7oOQkFpAWIaL8UxMIhGBBARAgAGBQJEMUjNAAoJEPPeeYLzX6TPb7QA
niksYFwY0wFYAg66Nql5hB8qJ/ZNAJwKByscvCbtu1RNtoccPWDkszClp4hGBBAR
AgAGBQJEzPxIAAoJEF1Wjuu0ta7bwbgAn3ZNw8fR8zrz816sYlEDlC2xib0LAJ0c
K5pvfwwBa/XXnC9utctBkrgdw4hGBBMRAgAGBQJFDUupAAoJEJ93wKxvehFfe08A
oIy56uksH0GiHf2GyZxV/DwxmOWCAKDuQyGvkwjr9rbPagu9qRejYCgzkohGBBAR
AgAGBQJFLNmpAAoJENUIU6kiE+dyj3AAn3d94rNoE4x+U0SlkfgH6O03lub2AKCu
2GedBOgw1mXdvlFa8uI/R/SkDIkCSAQQAQIAMgUCRVcq8SsaaHR0cDovL3d3dy5w
YWVwcy5jeC9ncGcvc2lnbmluZy1wb2xpY3kuYXNjAAoJECZJ5ijF000FcHgP+wW0
iY6h1ZRpHZBpwSIVR24gro1LkOF+JbZ9e0RQB0WiHYgTwjCVzrUNUox/WNIWQgVo
yzg51Odi6IzvTbH0JbZetPmk7g5ExcAKmYKmoslThGhQqkTZjkAGvCK3cyoZQWjK
6d5ueFz0iAi2snrbRqwebRF8jAjksLp9X7rC5KIRLXOGyD/M9nxpOdhN8YKH+8K2
2rEOa7FQSxUr0TtPXtdkkIt5X49H3csuswO9VLJHAks5KSkKqAYv+Dr9qy/D+UZf
SDwbhaYeZBbjYWu2l8EkX6FHA7Z32Itnm5vOpx1GTJ3A4HH/He3M+PEKOr5Tfa2d
ILKzVgCj2ZhoJ9hBy69prQ/iF2K00DKkAlg5HEH6KTvC1eiKgPTylRwDYGHGAqNR
7cPWv4LzHueNnyVZLAZ4lo3FSGaxGi7lIjWcb1wbhuUdYw0aD+OcZcCjOZxrlVEf
NAmhNpsGDzhMhd1sHNNAQI8FQmnSvr2uhicXdGanKi/iIcd7mC0hD0eBbYDtcMw3
INV4S1geLw6qE49WLZz+xT+ZZMw/mfnDXv4f4Ac+tk/6IVFJESchwS6cGUqDdN8G
AhP6KwxW0bUdwQY25BBMdWCvH8lKMu7BRbF3I6DbcoVqcEzaBj6nplhCeDzFrZ8Y
LivNCYj7/jGgCJ7LzEShgtTYPKkS6Elp0VSFJTHhiEYEEBECAAYFAkVY5j0ACgkQ
rpRlPV0TrEXlKgCghOznZkB/pJUHwUFP94ufHk2LYrUAnjaspyPwcxs1B/hs6NqY
k2uWjtgdiEYEEBECAAYFAkVaEBkACgkQFGWX3NzDmcdDxwCcD32/HX9Mh23+vaHV
vIesKA+81NoAn3M/Kj0jNmUnmhKIYOjRyv9GTDXniEYEEBECAAYFAkVjaB0ACgkQ
F3Kdd/SoUS+OIwCdEoOP88LbrbrpP6x0tl9LJGeBvWgAnitvFrIQiq7reKBG4IGy
4C86u1MGiEYEEBECAAYFAkbvBYYACgkQntdYP8FOsoKxAgCfYvCf2XlS0MRxWTkT
aSdm1V8NfnMAnAx8jBXy73bXM3KlyCnNLCQt2uYoiEYEEBECAAYFAkbvf1AACgkQ
IaZGm9HvuqaFzwCgrjOxhu4iFit1hX4d8HnGK/DO5HQAmwQ7f8U3Ac6d6ICRGpQ/
mjQO2qtciGsEEBECACsFAkbxirEFgwHihQAeGmh0dHA6Ly93d3cuY2FjZXJ0Lm9y
Zy9jcHMucGhwAAoJENK7DQFl0P1YJcUAoI33Kbgxo8muXWtc8sfueEjfyJJSAJ9e
LfzoaS/Aopm5nN46KJvNxuOdq4hzBBARAgAzBQJD/wn7BYMB4TOAJhpodHRwOi8v
d3d3LmNhY2VydC5vcmcvaW5kZXgucGhwP2lkPTEwAAoJENK7DQFl0P1YuVcAniY/
d5PXyWwSKNmxCjrlxcJPGcJsAJ9i9rsXp67YTZ0bZPMwNv97xNNOD7QjSGVucmlr
IEJyaXggQW5kZXJzZW4gPDAxMDc5QGloYS5kaz6ISQQwEQIACQUCRLk+yQIdIAAK
CRC/5Dh+VOJ4+PgHAJ0RbR1AKKcMZ1K+9Uu5aUXXSZy/UwCgp5XdCZ70Y4bcogOL
b7RhhV8AtYyIRgQQEQIABgUCQ8xynAAKCRA3TL6fUzeajf2TAJ4tiHqqMvvmm8Ji
c+W7twBpaWgg+wCgrNWuHKtY9q+kM6mNQc0rpo6NHieIRgQQEQIABgUCRAycfgAK
CRAJxOeJkBbvUAUzAJ9mWE5KXCnIqms2+D2g2AztwOmjvQCgjPb/+uy3IHeEGYXu
b8cO0NHMDP2IRgQQEQIABgUCRDFIzQAKCRDz3nmC81+kz44hAJ4v2+3Vtzbru10N
tLEVa9JS7VZ44gCeP4S0HP5DjKL05TqzTU44DfXKMfqIRgQQEQIABgUCRVjmPQAK
CRCulGU9XROsRS/AAJ9+iYvEwRhECR3HMSRwCEvNLfUX6wCgjAIUN0d/NuAxuw/i
zlbZ8JfUtYKIXgQTEQIAHgUCQ00DIgIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAK
CRC/5Dh+VOJ4+FC0AJ9TM8beIF/8EwtCXXsLqGX1tI4oAwCdEqAaIpaL76R5ZbF8
Hn+oM1XE3OaIcwQQEQIAMwUCQ/8J+wWDAeEzgCYaaHR0cDovL3d3dy5jYWNlcnQu
b3JnL2luZGV4LnBocD9pZD0xMAAKCRDSuw0BZdD9WGlLAJ9rRFhM8qgeHo6CybaH
tJwcdRheiwCfT1DsbGR81tGDvjnNaA+RG3kcRWCInAQQAQIABgUCRAwPdgAKCRAf
f6kIA1j8vdG1A/4g8kULXJSrk+CbcsRpQMHyeDEVg/Yg9DcofR6GZt7g4dTRz0Tn
KHVWI2VgpYrFNSFQo9Qwk+M4RIp2ZTRYEeudDkUpmavwr+4YJ0dT6WFhDDOAxiSN
OfsBLjhi6RkuRDj3Rk/mWFUy0VYsl1URkYrWg7RtJ5FwHREzCtP7PWA1h7QkSGVu
cmlrIEJyaXggQW5kZXJzZW4gPGJyaXhAZ2ltcC5vcmc+iEkEMBECAAkFAkIKBUwC
HSAACgkQv+Q4flTiePgzugCfcsChoTb1941q9SnD+GoPR/iec+QAn01l6uhmRfT2
GUYO8DiWILfgM9EjiEYEEBECAAYFAkPMcpwACgkQN0y+n1M3mo3M7gCfUhjb2cPR
swP/mHEO0lS3yo7XHe8An12Utvjjx2B2nEtR0MJ/dp4c6WaliEYEEhECAAYFAkHZ
UikACgkQrp/nBQgMTKXuhwCghy925sEUUKbGbDB4aFeBTZJfqVAAmwRibqOg4xna
04sDxZwrOCEyQYMEiFkEExECABkFAj6UQlgECwcDAgMVAgMDFgIBAh4BAheAAAoJ
EL/kOH5U4nj48x4An0LnxAzLNAGALlIZSKR4UDnrorR2AJ0SIyC4nQLSrC2MRHOd
2ayJjsM6YoheBBMRAgAeBQJCCgUXAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJ
EL/kOH5U4nj4Gk0AnAkHLv4180NBzFZT7oMoeRYAii8rAJ9Y+T7RLvg4E7HT41Rc
7G1yr+YIRLQmSGVucmlrIEJyaXggQW5kZXJzZW4gPGJyaXhAZ2VudG9vLm9yZz6I
SQQwEQIACQUCRQxpeAIdIAAKCRC/5Dh+VOJ4+FYZAKCWWIFlZr8dT7Sq1Bme3+sh
GfVv4gCeKJO0XQuX3QDvvSkwiOwnxxd7wB+IRgQQEQIABgUCQmvCIQAKCRCrL1pb
FSVpkGWCAKDgKn6UeT4zocpuGgQAcrlezNUdCgCgj7jbaiEViejDhukf7ewlcA3I
dzqIRgQQEQIABgUCQ8xymQAKCRA3TL6fUzeaje2CAJ4v45rjjRbhRWbPYIe9SWjL
SiJFSACgtEdrjTqIQEKARJ2yXkj0tbD3mlGIRgQQEQIABgUCRAycdwAKCRAJxOeJ
kBbvUOuKAJ0V+IrjlZOvnhHuQYUnwJt2/ku0OQCfYUnN2CWCXpkk+ezU5ZmWKl45
qCiIRgQQEQIABgUCRDFIBQAKCRDz3nmC81+kzyeLAJ46G4BwFYY9A+7ECwaPZPN7
5uwILwCfbp2Qz1rkSQOSMXf7aUn0NTfVID2IRgQQEQIABgUCRMz8RwAKCRBdVo7r
tLWu23XNAKDUqB1ZMQgPxYz5QMVrkFygywg/9gCg9ZAMqutTl7SJlnpTI+/8K8bB
ReOIRgQQEQIABgUCRVjmOQAKCRCulGU9XROsRXEwAJ4hBK7FoJwG+ItGXMS/756L
7e/TQQCgiRCasxhWrlNDGCgh5oeuBW3cDfeIRgQSEQIABgUCQdlSKAAKCRCun+cF
CAxMpQF6AKCNLiuIdY8oyJuqGF0LW7nQNtV2jgCffbfz1ocIJJQg84/FQPeqAPQB
WH6IRgQSEQIABgUCQxFhhAAKCRDzTPIvFJInJ0sRAJ40qmXNWNcdjuqoML3ELFsa
b9oShQCfdyuTHnzRdQpFRM/nHSZObwNtTbOIRgQTEQIABgUCQgoIaAAKCRDVCFOp
IhPnciQ+AJ0ak5LIn6akWvMZkWCH8uPwGfE1qwCeLXE95w87H+Nsy8yPOQMX+1Op
gcWIRgQTEQIABgUCQiyUOAAKCRDuniwkh809vSgnAJ9wSk0FBhjWP5b2awAWWRIy
LodwMwCgrsGH0702X3E8dTuyv8gMi7pH5LiIXgQTEQIAHgIbAwYLCQgHAwIDFQID
AxYCAQIeAQIXgAUCRQxpGgAKCRC/5Dh+VOJ4+Ig8AJsHy23a7eityD/kfEiZGdqi
ZztMswCdG/Q8hR0WIR8rWX6BLa7BJeKNrTSIXgQTEQIAHgUCQVbLjAIbAwYLCQgH
AwIDFQIDAxYCAQIeAQIXgAAKCRC/5Dh+VOJ4+LwxAKDGhPJUUfBYrGGdIqkVP9C5
keY2PQCgv6Qv/cIHjQPnImdXyWD7C9AgavyIYQQTEQIAIQIbAwYLCQgHAwIDFQID
AxYCAQIeAQIXgAUCQgoLDwIZAQAKCRC/5Dh+VOJ4+HQIAJ9Q8GLp70kleUuYOagN
T5gNxSz55ACeIWoWHJI66pXlf89rery2AK0cNOOIcwQQEQIAMwUCQlcW1wWDAeEz
gCYaaHR0cDovL3d3dy5jYWNlcnQub3JnL2luZGV4LnBocD9pZD0xMAAKCRDSuw0B
ZdD9WKvGAJ9a9MkNFi0AS/AE6ZYdZPbHYMhqtwCfXzkVUX+7dtH4QIuq2xP6INnP
jP+InAQQAQIABgUCRAwPcgAKCRAff6kIA1j8vfUBA/4zQCLeRphxrg+jp2dnSIaZ
efM4bnKifsWwr6fDRb4TowSTV/rAGiP0tTpj4GiNS3n570g4w2EO/jrtd+e7dxxQ
ByOrkSP5AASQ2FBFdvWBHNmnLyMNHQGPeRdgxFGAUyRdQuplKZdQpMmI64Pgp9jT
RxmxVdYqYTaOdunVYs5B+7QnSGVucmlrIEJyaXggQW5kZXJzZW4gPGJyaXhARnJl
ZUJTRC5vcmc+iGAEExECACAFAkcpBP4CGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIX
gAAKCRC/5Dh+VOJ4+Gp5AJ9bHRWLLALFKQTHKqBpKpU1cfz5WwCguhErOQMUYMYz
y2H9yhvL1y7vdh65AQ0EPpRCXxAEAPrtI7bQ5JzA/f+gmvW2OY0VMgEFOjXQm3X+
YEyUWniuQRvKy9yO/a+mlFhGNsbsTC5jJ9F5sDpcsX6X0r5kIirkgIyq2jtQo3I2
damPD3AvCI+R4xyTlCuZcLz9sfU8dcLDybo3FKJFh3Zhstg78StKEN8ytkmL3C3S
lj3uzquTAAMGA/46ARDbChaPCTez0Dr5wagYIP83ziY1IEWXotU6qIBOSAXOb1V6
cOxXUu5Vu93x381Rn6ObYA0AsXGWArF6q2EmEVktdkhySnkZU9GqtQkpq4XTh9Bn
zD0kjoqnduudo3rBrSfELempjBl0GMNSNo616zbtSqqVNhfSxBoMszQBEYhGBBgR
AgAGBQI+lEJfAAoJEL/kOH5U4nj49GcAnin5+1aKIIFGp8edGF/elOXPEYNRAKDD
4mSrC96PYoIx+3Zdq9zvDaphVQ==
=Sa4u
-----END PGP PUBLIC KEY BLOCK-----
D.3.4 Will Andrews <will@FreeBSD.org>
pub 1024D/F81672C5 2000-05-22 Will Andrews (Key for official matters) <will@FreeBSD.org>
Key fingerprint = 661F BBF7 9F5D 3D02 C862 5F6C 178E E274 F816 72C5
uid Will Andrews <will@physics.purdue.edu>
uid Will Andrews <will@puck.firepipe.net>
uid Will Andrews <will@c-60.org>
uid Will Andrews <will@csociety.org>
uid Will Andrews <will@csociety.ecn.purdue.edu>
uid Will Andrews <will@telperion.openpackages.org>
sub 1024g/55472804 2000-05-22
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDkpEQ4RBAC9OidsAMYXkcTy2/Vb0/YO4X06+pwtKVPbYRHt0wSvmoeUhr8k
W7YIZpORNycc4v/0p4U/vD3fNL4bb07gnkijJWC+RrLVsxp/HkAy+XPy1TlBg/g9
rgT+eNnmIudIbIFGgfNYR9pcjdBvDYYzn0rKCxZ3bUqQv1iY1Szd6XBVYwCgmRt/
TtV14iuuWTXcCB9ZM118W/sEAKxMqiMnqr4VZ43Dr2EPOjmWTU+rqWhLQsfPj0MO
r1Fm3kCr2kf+k5o8o/Ry6a9bNaufrO9LsR7yvPEia/J8ofAAonWM5VHywK5V/+D2
ZSXqscdpGN74cRu33vAs8V5Wcnc2EaRk7t3yBk8Cdek2If9pOTVWD7Jjhmaqxp59
rCh6A/9NNpxhBQkCRaixGrqNae9ASQdtZAe32+ZxQ3cvhfNb8y11dHVWG6ft3vZi
lUgBKCwWJ8y7rcpmUg0mQEGgGLpA0pdtOn0r20Re+WgeBiO1afi80JYbpICjtToN
+9bK1GWwkyoXcHDCoCyGkk3ZJx486YjlZ+g8CqbYjqclisBRALQ6V2lsbCBBbmRy
ZXdzIChLZXkgZm9yIG9mZmljaWFsIG1hdHRlcnMpIDx3aWxsQEZyZWVCU0Qub3Jn
PohWBBMRAgAWBQI5KREOBAsKBAMDFQMCAxYCAQIXgAAKCRAXjuJ0+BZyxXK9AJ98
8qcbCXD8dbu5UElIXyVgtCpSxQCePH23d1468zNXLosSjAM/9h0liSyJAJUDBRA5
74f6TVYoIXkFDBEBAUkXA/4vTZbVHINxXv8ibNOwc8zRT08qo/+Iw9bk+VZT1Xjn
A87pDJyH1k5TlikkMcTZvuKgssosymef60Nmn2/De+PBO8zvKHcTVu05aNVa73tg
trwTl7ENt+W1DapWy13F/tX+STmZJpwJyNnc9LXe/purKQeNvcm5tOg4F/YG8d2e
fohGBBARAgAGBQI5+H4QAAoJEK9FHtaSnhLg6gsAniX8LUlfBDyl91aWd2NRUzbg
N5WhAKCCLiFZq9VNOkWvvDgjZzgAXj76W4hGBBARAgAGBQI6ouoFAAoJEFfKvVMG
TqYaWVkAnAmGUup4WCbHu8c4wXvGswYDyYNXAJ0XIIJCKOFyKlof+v2Rm/J5IbP0
NYhGBBARAgAGBQI6omaOAAoJEH5rTE5yo9FXsNcAoJHYIQi/k1v0FlYAZnYikG94
LV67AJ9bb+qeiYkHgnAYqMLuk8pv1So6e4hGBBARAgAGBQI6oZ+kAAoJEFZ+so+o
kYHJj8MAnAz2IpK9Bt3Kf+5tMZZar8GyciAnAJ4nbeQGuBXTZd1dtAAHCsHPvDpo
TYhGBBARAgAGBQI6oY8UAAoJENuTRJDtZOBHC3UAoKJGpnx5MKT07nrg/tLcHDIr
RILoAJ9WNsiSA+a4Pk8RXN7TT8NMXR1PDYhGBBARAgAGBQI6oYMLAAoJEGThPMPL
m56Bj9EAn06SAivn1Ll5AOjpHcv+lyHu3Y2LAKCVY9ejgWzNsAXkyk1zzr/w65m6
2IhGBBARAgAGBQI6oVEPAAoJENHLaIZZSoFYtqEAn1fiWA5C6foEV71UnZ9jAslP
zFulAKCmyH5S32XA2oZiXOO2dh87tD3ku4hGBBARAgAGBQI6oVWbAAoJEH2lYKC2
NiUF8WIAn2ov1kKivbanjlmkhqUfhJ4UgnmaAKCKbDev7w9A/x165BOa0gY4lsuo
jYhGBBARAgAGBQI6YhEMAAoJEH7GRFHr0ksD+6EAn3xlIX9koN/aZmgzghEn01dV
L5QVAJ9vHUwP4LTEYVe+oYPzFNW9Dx9fm4hGBBARAgAGBQI6YhIuAAoJEKU/65aE
ev7dTGQAnRFFYj6VafoBDbi7cuuNddL4viwTAJ9Auv+fan1RWaUIVZzq5qgXsrcQ
B4hGBBARAgAGBQI6oV6FAAoJEMPcgjWRkSGbbHgAnjXsGyCZ3Lf0MAq7ZzWZYQP9
YjeqAJwKtrO440YlW1IyuYXQ6Ysgj76MF4hGBBARAgAGBQI6tTL5AAoJEIiAJody
7R5edJ8An3LrnEhtPiweCq2cVStw0PSJb/brAJ45SNjE11cqZSYlPMd3z2S8UtEH
OIhGBBARAgAGBQI6wMZ3AAoJEMiQcw+j+eMOCOMAnjkJqTQn42X9UHkPkTj/eGCk
5qzbAJ9nPnHucrIC+M88X15gKCatzhgJTohGBBARAgAGBQI6wLzDAAoJENyUJSW9
K5HzWmEAn1Xgz5P2xkoKTi/ng+UQHNPuhKIuAJ0VF4FFlwV7lEm0a/JiXObAJ64L
x4hGBBARAgAGBQI6wqe7AAoJEAEFOAfY6XLYVyoAn0yPuCPxhW+LvRHxgtHGhEGn
ZzacAJ4j5x2xiI/yL73mtapioHK7VGa2+4hGBBARAgAGBQI7PSb7AAoJECAVMdWE
Xf7d+EgAn0uuy0W4Yd23i/d4EaKimiMQIreuAJwMc6Fb32PczOVi54KAtQJN2mAd
VohGBBARAgAGBQI7XVoIAAoJECAVMdWEXf7doRQAnjUgJRPvmV3Ypl3KdWmZbRpA
Or3oAJ9FoKRpWLZ8coLzWm52jwn5q6TF/4hGBBARAgAGBQI8eyOqAAoJEH/lKgSH
iFdAeZYAnRG3/rF2zgf0VIWy6gtxsehrLZMuAJ93v/XsLOlRGGkrDCgTsaXcBUeQ
1YhGBBARAgAGBQI8IRwJAAoJEMXJoI90uRz9C9sAn388rJipCduesilA9+rfHl5x
lILFAKCd8Y9nI0E0eAdan/dFAd05lvMEeIhGBBMRAgAGBQI9ubeJAAoJEE6gdPxu
EezdzjsAn05V6e4xnR99HmcZbm88uPZY94E1AJ9CnZraQWa/MLijO4d7V2kCADQ1
wohGBBMRAgAGBQJAPskcAAoJEKodfLASZ/CS+PoAn3Xj17WyndOSAEh+8w8u33G2
1+MCAKCw7gfCCtb8itISfpkgd/8n8TBv3ohGBBMRAgAGBQJAKaqPAAoJEHLf1wFG
g1ZMRSIAn3kmBtVaLFxnXkhS2kMkSqNKmXgXAJ9JOnxKvZd8kQnlOdiGzC5c8dxu
OYhKBBARAgAKBQJAptP3AwUIeAAKCRD2HMi1rvM4R7pKAJ0RflZSvdplvh3yhU5I
wzaFs1AhcwCfbmdWD8xBPyuT8FDRKzeYPSO4zyKIRgQSEQIABgUCQKbRZwAKCRDp
Ji2QY7WYX9MtAJ0TcgkUONYFfMpb0k9wJ12iGYqIyQCggoU+NDH15Q0DGNJ+b+6o
fW9UILSIRgQSEQIABgUCQKfYrgAKCRBJRaU313tD+5jnAKCa/FQhomau5NtKYDht
xKJO608eswCfQr7oZcePU20Zxgqb1uoi0LDF98KJARwEEgECAAYFAkCnJCwACgkQ
TCWvuGAugxkMbAf/T6goFajYP5YBLYUP578PfNfwSoSczlAQpLINIFCtNncsQ1Y8
YjCshMdaL1/lNawo8AGY7RRTnOUoGa0ZrUKNsePCELstkJYCBTouXcco66cQwDM2
I55nBc+jbdY97wIRYVcZnM9xKvGpFAJiy0irqTC4v3wPX1ycdazb9Q5RgLwjL4oh
BnJZqHWeoFTBIGO7zdxskSyRxZ5AwHYa9SKlYct7gcIWSrK8YZRw+jtNwA0UKAjn
3hlbMgV6143fmpj1o8A+ViYxA7n3tvAOi7UK8WIxNHyrgBoThYzt9S9+7+llTUkJ
rJRYp/vBDgPmapUyJAwH4QVIHWGFKCbnNpllmohGBBIRAgAGBQJAp4LZAAoJECIY
yB6OfAP/C58AnjIZRmz9zWqXSAXaWJRnqi7E2RCLAJ4x/BSOwbSc3jaiNCmNyJP4
DXELNYhGBBMRAgAGBQJApsl3AAoJEGxj2gSE0NfnyLcAoIDjUnRf1GIwQUYw7iUw
WgseVBBGAJ9L6cXjA7iABnQa5xX6Lp9mYgCl9IhGBBMRAgAGBQJAp8QxAAoJEAzL
fv4LMKk77yMAnREfcGLguywNK5MpEoJx72caIs7bAJ9FJtOy5iovjZ6/t/ryYmLg
Limr3ohGBBIRAgAGBQJAqPWaAAoJEDOEg8QL/Ll+cysAoLM1cUJD7v3KJbkRwVN5
e/jRBt/yAKCQ6lxy+q4Ra61ekM+sGCjMvM5VbIhGBBIRAgAGBQJAqpxkAAoJEAdh
c7GShMRSKkIAn1YD8qG6HNYnWQG34qRV9ovwVBTPAJ0ZiIM4kw9a/R2pVKBOsYYn
5CShKIkBHAQTAQIABgUCQKivYQAKCRBnwoCPM8Fiew3hCACXkEA3YbztUSXHsmXC
iZ0WlT7rqB9wN3P+fpU81HTMsgKObYWzciekkJssJz4fidJImTjMqbjvx4Wm/Rx7
+TUoQUxyrwMW5E/DTDi6SwlqiYqKsgAKECJWYNtoZcvpm0QRbbFlNd70Aj+6R1eU
Xi8o4eyR3iTJomTayMWnpoMjwkKNUmVEBnQ5nFLoTDF8at25nIWVIs+pUEnIkrz5
TUDA851oKH4SryQ/ogFboTZsLEJayjsp4S/7Q7s0dBoV3skWsOFCAWg8LYIlKVBN
ogacgzkG+VRYDV+hHjUzOmmReUAMeVLgwRRH3eadrfsJ6r0sRGjraVGcWddpT7jT
MAkRiJwEEwECAAYFAkCpvP4ACgkQH3+pCANY/L09xQP7BbreEbzRT5xjynMbRNBL
7jQU8eJ36xsZBAg0Ndmy3RPgKoTLM8W2bpPftPFfZQG4/tVJED710NmLpITF+519
JZIrHDF5n6/WZnmvILjXcFAqSBmpPLIRGl4/lEdJ75JtMI2uwsPTWGTF8CyTlIK8
u44i1XoNPHEc2Fh8/gp14DaIRgQTEQIABgUCQKd3uwAKCRDf7jeUa+yYCkbPAJ9s
TWrX+NsYCmuRgMk0arKpw3dNrACfYcUnPqJkab+3Gdb0LynqibVT98yIRgQTEQIA
BgUCQKhJWwAKCRDSD9QFytUJxrYiAJ9rlZoQFz3Se8SMgeVRtKE4H7jmHwCfVh39
ejQHc3lcoKaGUeubOZJKizyIRgQTEQIABgUCQKhJeAAKCRD9/49Y5NtE8t2MAJ9v
HJFHe+n9G0Jfm0vxBDmDYPz2wACglJEIRYayc9jSNEexx/n4xE0PY3eIRgQTEQIA
BgUCQKivVQAKCRCMMoz/FgbblffVAJ0S6RhPkC5JLRGh+6JCO5j0Jgh5lwCfc25a
TmXjiYFC9gXMS9cEjOKWofyIRgQTEQIABgUCQKivcQAKCRAV1ogEymzfsuRJAKCT
VaxRHsr+eOwUk9mDZMz/tLkjZwCghfShD1CsquqswE/Kn9TqWljuF26IRgQTEQIA
BgUCQKje2gAKCRCg7/ngeafIcK1HAJ0QMkuMvtpqxUX4sqx0GZ/qVQTpFQCdEpJC
z0qbaYDHkmvRFyxpXkJp5c+IRgQTEQIABgUCQKl7egAKCRC3Mfr7JqXQZpumAKCn
nmhKM5jX48VRtjmUeleqhncu7wCbBAkU0WW9uJ99d8jnb3tPnZtcPS+IRgQTEQIA
BgUCQKp9aQAKCRAPWuglNDguUU30AJkB0XkN5uwPl60D/sf5dDGJdla8lgCgqI08
h2IFzUhFfRe4JebGanhIK32IWQQTEQIAGQQLCgQDAxUDAgMWAgECF4AFAkCo5NwC
GQEACgkQF47idPgWcsVwGQCeOeAnXAJa2hPSdnhbvUFzbPDoGKoAn1boTxqp75so
Cyf1GI4q11Z3Uo+ziEYEEhECAAYFAkCq6woACgkQS7Omb36zUkDsQACfbiy50uw4
G7Yi4pJcsmpAkY4U31sAn1NL++CSAbFffvoh6Grk6oEommdJiEYEEhECAAYFAkCw
62sACgkQfreS3xkfzYoIkACePCKVtKrannuu8pmYU19wIyweEwgAn38Y0deNl7+o
hyKf2tfhLYUtwugKiEYEEBECAAYFAkCsifEACgkQK9nNvBpGp+iYqgCfarwUJaQU
VNUbtdA6b95XQ9Iw+YAAmwdXZkcH8rHp0EZmNyHe02JL8k9diEYEEBECAAYFAkC5
EM4ACgkQ+wPnfyoZ1wfFxQCghcWGMdiKo5NQQxbU3EJEaDvrkPoAn1zKhaLkQhoB
1BgU7QyxyUT9vy87iEYEEhECAAYFAkC2DFsACgkQ90UNcjm0VUFoUwCgz7WNpAED
7lb30Epp79Z7RiAxO6kAnA9r8/9p4dPg/ANSNGrY4ne/0crOiJwEEwECAAYFAkCy
Nq0ACgkQd9KrJbDIcT06aAQArNCe9coJqJXFoZZ1LslBDRQN41rIdo7DyRoySq9a
ndz6XGq6LYwtzieOlM8pH0bPQLd88ThJn/9M9rYMRHqL3zhlc/IZTzB4KNn62Og2
6ajDeY0CV3Ldibu2I2nVFNYwcjeluUr6b6mt2DtodxfqAWW4f1JOiV59ASUvK0Zr
PPmIRgQTEQIABgUCQKmWXAAKCRAVG6mUEXXC40x1AJ9a7Q64WiwmC49MeHnlTrnC
27iRJgCfVo/NXKcofncDAlZslEdzDuIXM1GIRgQTEQIABgUCQLIQJAAKCRB5A4Op
dGbmU+hmAJsEH2zv8ouX2EiGPmUYnu9IFleLzQCeP9yVuy1bSsKplENQP9wP9Qme
jRa0JldpbGwgQW5kcmV3cyA8d2lsbEBwaHlzaWNzLnB1cmR1ZS5lZHU+iFcEExEC
ABcFAjphXNQFCwcKAwQDFQMCAxYCAQIXgAAKCRAXjuJ0+BZyxVI6AJ9CrOgJcDfB
9YvIpskNVAxBacXt2gCeOIYZf02v2eSoIiqDVFIPKETUBRWIRgQQEQIABgUCOqLq
FgAKCRBXyr1TBk6mGskJAKCEsPn1r9ORImEPcZMCbuV7U6JI1gCeNmQo4K1wE7l/
XElc0zGWPxSyqJaIRgQQEQIABgUCOqJmlAAKCRB+a0xOcqPRV5zQAKDINyVjCAdr
rfvpliwZQLhCDiIoSwCguxNEk9M3h+TZ7GG9+vlgKy0+Qo2IRgQQEQIABgUCOqGf
pwAKCRBWfrKPqJGByd6sAJ9xvRCtS5T3jaGjg3OLLyqHIAkmjwCcCA+FZ1ZrdX8u
31cBJibREhBXtHuIRgQQEQIABgUCOqGPIwAKCRDbk0SQ7WTgR/0GAKC4BkhREOCi
jRaNqAda7TF4/9sFRQCgk+Q7HHIh8axLJzF374uB4MqoHW+IRgQQEQIABgUCOqGD
EAAKCRBk4TzDy5uegTfTAJ9v/7KNKqOT+u5T9p5UpoVJlP2pNwCfY9T++GURQiMM
us9J2viqcWxBIJCIRgQQEQIABgUCOqFRHgAKCRDRy2iGWUqBWPJdAKCpBvHUcwfB
RBD4L+xTE/jOT4rlFwCg7NBt232yTk6CxTuB8AeNtzXgmNqIRgQQEQIABgUCOqFe
iQAKCRDD3II1kZEhm+SdAKCbz1QkgPNkp4NHP+Qi/dHgf/VLOgCfTGVU7rSYvdAO
HRI9ibtR6IzXwK2IRgQQEQIABgUCOrUzBwAKCRCIgCaHcu0eXnT5AKCMp6C0si8m
dt1UseMITlhxwJzzCQCdFAKw3j/oZd6ReY4jqN0OpoEhnyyIRgQQEQIABgUCOsDG
fwAKCRDIkHMPo/njDtjlAJ4yyggZsBhyZjmOLISQ9bhLwEUq0ACdF3jsvJLGi/Re
lBmsnvQJ3tvxps+IRgQQEQIABgUCOsC8ywAKCRDclCUlvSuR80yWAJwK22xGQchL
JA07usb/cOhHlr/6rACeMmel2vJvjpteJPfNEpYyK9e/bBmIRgQQEQIABgUCOsKn
vwAKCRABBTgH2Oly2E7TAKCLTu4cmCQx3mp4359cMe5sZPomYwCfcW9nEmIQqrVF
adgRFF/YRAacXqiIRgQQEQIABgUCOz0m/gAKCRAgFTHVhF3+3ct1AJ42ZYLyilBY
J1XpELp4HriH7dInTwCfX8gr5YHO/Mi8oO14Jw33fMJvSjqIRQQQEQIABgUCO11a
DAAKCRAgFTHVhF3+3cG9AJY7coLpkNMHTfg3XMB040JQTa2gAJ9gGPDxNKQywzk5
H1GrG170K5xwZYhGBBARAgAGBQI8eyPGAAoJEH/lKgSHiFdAQIkAnjGGWhCyD8eU
+XP2VH6GDHnHKcHeAKCoGrIdw/oKFsf7/9K0U2WnghWpUIhGBBARAgAGBQI8IRwM
AAoJEMXJoI90uRz9siQAoKB9gwa9U7mcnVPuKK/ulExpaZ+uAJsGQ0124T9qOcIC
Y33iZiHZlpCUsIhGBBMRAgAGBQJAPskcAAoJEKodfLASZ/CS41oAn3fT/QxhSmGY
6kInC+N+lktAF8kOAJ43QH1wX1qTRAXfx5r76JWauKvLmohGBBMRAgAGBQJAKaqP
AAoJEHLf1wFGg1ZM6jkAn1VhhaP5EVLnG1SC4JqDhfdVwjkAAJ9PSwjiePNSsYDR
mzXNwGHKFHo8aohGBBIRAgAGBQJAptFnAAoJEOkmLZBjtZhffp4AnieKV15xnSdu
T4y27Fn8jzx/L/A5AJ0aFnxoY5nUQicQB494EvoiZn2mIohGBBIRAgAGBQJAp9iu
AAoJEElFpTfXe0P7QeMAn1dLn13Nmpq29v6GDkiiEXwp6UxOAKCSwGD0zvqwTgXI
soMcNAAM+YtFDokBHAQSAQIABgUCQKckLQAKCRBMJa+4YC6DGRCBCADMu8QGRaF5
a66IdejmuT+tQP5oDMRPYfrmMntjbM4DcTrDElEKTMdz+7c/Dv1jOXWJP8WxlJRg
lX7pBGDHtknLxsO0f02FsPE8trICMwn5wEjI+IrNDYxQA6bjP22eP+Nry/lEErB+
HsHBOVfDaM0mmPmq1z5hnHlR3dQNFyjPhchPrTbNBnncUFLTL+AJKVy24h1w752M
ChaEDzEfx217sk4okhlwnXgSwdGc+080p+hEk5XwmZJ28xhLicjYG1bSQtIxjaLe
XNHMnAvL5X8q2in5zEcqlPzEtz9+UC6pT8fAbwUqgFcQ72x+Gdc9QY01lpLsbmDe
t/kk3Iv8f/xYiEYEEhECAAYFAkCngtkACgkQIhjIHo58A/86CQCfSjxh5SEJOPa2
ozO9Aqao50xFKOEAnRrjbsdxBj1Wcu6UTtqmwnnRTt2XiEYEExECAAYFAkCmyXcA
CgkQbGPaBITQ1+cT9ACg1Ai7Yd/0h3dYstPdtgU8rO4qvnEAoLvxt78QsvpeOXOA
MiQH16PMsLskiEYEExECAAYFAkCnxDEACgkQDMt+/gswqTsQqACgjuFs8g1nOn+a
OXMqBtwNk+Jj/y4AnjGwT0MDCr5czAUzZQCvgSFTIotjiEYEEhECAAYFAkCo9ZoA
CgkQM4SDxAv8uX7aYwCgqbJnrIjkkIpzB7ZAY9nbJYUVDPgAnidDkYoh3c3itpno
UEbpy671CGTsiEYEEhECAAYFAkCqnGoACgkQB2FzsZKExFLS6wCfU6Etf+2IgB1C
+I0uryQlg/WB9ysAn0HBWsqnIkFbghnU6I8ov/65znBtiQEcBBMBAgAGBQJAqK9h
AAoJEGfCgI8zwWJ7OXUIALF/cycXWLbUeUJ/tzA0mQ6nD8twYMa7tOnpSuFg3aga
3h/mOEYwI5QQYYz9Dt+M8/YAT8DDj1grwxjpXnmtRwJvZPhZ1VusWeFcChYNaA6/
G+WPmUY4h6z+/hOQd7vv8K98eKJTe2NZLaV9+LdPYe7lixJjvo7ohDVxERCZJ+UH
ASS3+mhLEHhKcPFGZ8LLWmE/1W+z4X0R7AE+xUJYvS3DDUqxXYHjFZHYBHXeWnJD
S2awXj1JdqCgS87ov0roFvH8mPijZhT8j+hmR5vl6BhOMAxsP0MpDyboiEPW1JZ7
z0LPr8Bd8JNlV5mv0QpnNqO5Ib3x+hStRpZAzl4Th3CInAQTAQIABgUCQKm9AgAK
CRAff6kIA1j8vedLA/91VS/llLBRsCyFqJRHBsXFnA5aIn4RtI6Sb76UY6pH10XW
7hsGbe7dznXJDPtWiwBodyXHQ54iY/BMxhGaX5JOVj7xQwg+bTZO5d6p1bTrJOAt
Hqp8O+yrPK2llJ9e68jabyUCzuN1/cTxikxETlYS8kw4hu+1Ac4thM6Pvgm0kYhG
BBMRAgAGBQJAp3e7AAoJEN/uN5Rr7JgKP2cAoJCscGxLN3j7A1o/kuM32G3d35d+
AKCIxhHSG7S9wNxiv8N9QIwx/+2gDYhGBBMRAgAGBQJAqElbAAoJENIP1AXK1QnG
l9sAmwRZaOmIwMvJ18aTt6qBZkUHsbDmAJ97LU7Ul54r2W0s9aNjQkprFGHEbYhG
BBMRAgAGBQJAqEl4AAoJEP3/j1jk20Tye0AAoLEc6JHbfoE9jIWSAUVd/g87gLY9
AKCLIfhAFLDKcCUclkpFB/sg9ZxmzIhGBBMRAgAGBQJAqK9VAAoJEIwyjP8WBtuV
ctQAnR24oAfEZRpn9qtCWQhRVmI6kcl/AJ95my3HpbD1ipLyuzhd4dekOimZMYhG
BBMRAgAGBQJAqK9xAAoJEBXWiATKbN+yCL4An0cPFSzkkKzAgSiBs1qlhOwZokKP
AJ9fE6lot1sXphqp1MORszCK+bKSoohGBBMRAgAGBQJAqN7aAAoJEKDv+eB5p8hw
oWEAn1VoA8SG7uyj9eRY/X+84GbWej9NAJ0biaL1SSHNoMATebMgr6rvmQ0C7ohG
BBMRAgAGBQJAqXt+AAoJELcx+vsmpdBmWmoAmgMEpaziA8bKVOJA8vA5qCAIIVJE
AJsF8ciJ0a37vP+CI5XLqAfO94xBX4hGBBMRAgAGBQJAqn1sAAoJEA9a6CU0OC5R
4AoAn0tNJTF3Ss1PJk9S2n7rtxQR/NNAAJ9JoTOzwBrKhkvTDEBOxghNMQWxy4hG
BBIRAgAGBQJAqusLAAoJEEuzpm9+s1JAZJ0AniChjfzpZu507E4bt5EtK1xd7WJW
AKCEyQWtM7n64YeFZGYJ648yMq9jqIhGBBIRAgAGBQJAsOtvAAoJEH63kt8ZH82K
ZRMAn3Id7c9G6pNhGQY9oGY3bdc0QLn4AKCkM3xLol83pzvW/czGfZ9Ag6fXi4hG
BBARAgAGBQJArInxAAoJECvZzbwaRqfoGosAoJjHhULArgsJW4RvOGZQxFYwJu0r
AJ9kPQzV0Sm8KAYa9A9cv3TqlGagh4hGBBARAgAGBQJAuRDMAAoJEPsD538qGdcH
+N0Anj90SSPx48+Wet5CfOVPQ2X8bfYjAJ9zTRzOvxHhzNSySQn0wvnM1zKSM4hG
BBIRAgAGBQJAtgxbAAoJEPdFDXI5tFVB4HwAn1BFz9AerYJvF9ynEHJsXwc8kNem
AKC34NoI+3vL4sCigygjuefRbCsdwYicBBMBAgAGBQJAsjauAAoJEHfSqyWwyHE9
RLYEALYUI0rxFZiutb1ugeylu6lBzRxcUds+taqP3aZgRoVJmwQV7iPSmx3y1Bpp
F7sCuOeftNK9Cfm2o4/nbTbggodECobaVurhY3+cJtYtBsAc83oR5PrbL+7T5DqG
6e4ameIrl8VM2QS4GRaOPwLaqEyamWtNRQGrDAISrNAaMCysiEUEExECAAYFAkCp
llwACgkQFRuplBF1wuM2TwCY7h1YKmKJ4oTSK+ZvVq6DKgVTDQCdE4IPBzderPEC
vtEFZqDRlJ5aW0SIRgQTEQIABgUCQLIQJAAKCRB5A4OpdGbmUwgGAJ9NruE1wByH
2L33EL6NjQjpDe2VSgCgiujhM6vX8jsH14WihpE6wMb3jUq0JVdpbGwgQW5kcmV3
cyA8d2lsbEBwdWNrLmZpcmVwaXBlLm5ldD6IVwQTEQIAFwUCOmHtvgULBwoDBAMV
AwIDFgIBAheAAAoJEBeO4nT4FnLFpJkAnjreO//xK1JLqxMYcl54UJoyOOw/AJ9L
Veo5+H3jG2G5sle70lVcuKGvwYhGBBARAgAGBQI6ouoWAAoJEFfKvVMGTqYamfIA
nRoi+6SmRpfFfj5ht6bNm0vfl7yiAJ9cOfgB8cfalxSKTnUcnO0A/i4yNYhGBBAR
AgAGBQI6omaTAAoJEH5rTE5yo9FXvR0AnjhKPTkxZFd6OalScIN9O9JgM6XUAKDE
EKqPkdT2r3fAJZKbuOTJAJ3KpYhGBBARAgAGBQI6oZ+nAAoJEFZ+so+okYHJWawA
oJJHqy1njq2/ocfxPhRtVnUPdqErAJ9zDRtn2LBabXdcoeCw+CDqhNKRYohGBBAR
AgAGBQI6oY8jAAoJENuTRJDtZOBHLpEAoKFJ9UlklSSuJI9BjK8zIjO/xy7/AJ0U
lUaJXo0kRuqbfOCoFlTp+ZlvxohGBBARAgAGBQI6oYMQAAoJEGThPMPLm56BPmYA
oI5iJbpHv3hybp6C7jtrcXVOEW9IAKDStNhXi5SVG+HMxunzL/zeaJLbB4hGBBAR
AgAGBQI6oVEeAAoJENHLaIZZSoFYtYkAoKn1tJPS+d5DjY/EphjkibVehScZAJ9t
UxyhhDj0snPGijERlFLClSdb1ohGBBARAgAGBQI6oV6JAAoJEMPcgjWRkSGb1+oA
ni2D1MVkJRVMjs/F2CR2Ocy2D3PvAKCx0tfjs2jXlDhe82s4Xm8BYVWxDIhGBBAR
AgAGBQI6tTMHAAoJEIiAJody7R5e7rgAmwYpQNbANj9iYnxOgGT4h4iLPVy1AKCa
GEVRPVD9rJy/U6Use5ac7EiKMIhGBBARAgAGBQI6wMZ/AAoJEMiQcw+j+eMO3JwA
n1Y2UJxMVwL+LAFtRrisM2LbxhD5AJ9k0WyBVvgtixgyTZf9c0HkpQy1pIhGBBAR
AgAGBQI6wLzLAAoJENyUJSW9K5HzTFMAoLfCeKcPKsIllTVA0VgBrIb/70SVAJ9z
FNvcfPJHlCTOEvaFr8ONWCPOT4hGBBARAgAGBQI6wqe/AAoJEAEFOAfY6XLYFpkA
nRpZXa8HmbVJ6pfhQ0viO2iIMazYAJ9j3lj8knIAC1HFCjk5LxDkB9k9JYhGBBAR
AgAGBQI7PSb+AAoJECAVMdWEXf7dv5oAn1RwfjiP/aVsVUMdeKWOSLHbs7xbAJ94
pSDrSXvKYmzwrkn+kyBk7bwa54hGBBARAgAGBQI7XVoMAAoJECAVMdWEXf7duzMA
njS0IYU8wVvXFUVFXPCalpMrSvKYAJ9g359xNB7RGfN0UhlDFEHKjmxEwYhGBBAR
AgAGBQI8eyPGAAoJEH/lKgSHiFdA7dYAoIk/gGBdVNaP0k2YnU9nxBkrsT9XAJoD
4sZEYEX5l7TIsrre5SMogmaU/IhGBBARAgAGBQI8IRwMAAoJEMXJoI90uRz9lE4A
n3Er9KDBlpH4L79o4XOWbuo0VLLvAKCQDZMMU1SkN3GLgaCt2F8LOFsOhYhGBBMR
AgAGBQJAPskcAAoJEKodfLASZ/CSqw4An2aeUQ6mKJGarVXJ5iAjBvxGh1DmAJ0R
1q9yrK2EYDAL5t3SjSmDP5qzD4hGBBMRAgAGBQJAKaqPAAoJEHLf1wFGg1ZMSnAA
mgM8aeE+CqdwltsfVM2zCqJ0NOmLAJ40LeUHNIS/xp2x4twHJP/yVzXySohGBBIR
AgAGBQJAptFnAAoJEOkmLZBjtZhfLjYAn04IhFbUmWVMCmUMs2rYlmorwrMrAJoC
yIlVUQXTGNxtAEfpob1sS8bZXIhGBBIRAgAGBQJAp9iuAAoJEElFpTfXe0P7f7YA
n3VmL7rYifFoBSyw0P3srV6z6/PwAJ4kNfkLrmzzyIHeoSi0QHDAS8XnzYkBHAQS
AQIABgUCQKckLAAKCRBMJa+4YC6DGXh5B/wMa3NG83RG9BDI/JMUtSnMLdAyRPQH
72lgI6QRym769knkD/GlyURshfw3MQOrN5QOPyFKae5c132xqG0ruYnlxAjlxK49
LNZoC5MKLnxU1aXbBI/5H62PBxTjQnp2kdBgOsY47TJ4BZXPhfDTVVOoJrIROjmM
0ooJhq1thCSv0T2GfQxL3O1xx0kP4ekESwKwb/hQcPrh69XifG1u023XevWOZyC0
em4XQN1E5YoPETGK220dzQVp3FT0hX17FkEjujK5MiwogiLJ6lBS/ZInc2QSw4YC
jsVkfw1F8KXsF12R2TlJasQYT9NzSCQkybU95PdgMYJe5sNNZjg/RsDriEYEEhEC
AAYFAkCngtkACgkQIhjIHo58A//AJQCfetOM9xR3zWHVfWjsd+J09Ww6VioAn0ap
5pgMfoUJhrOa/eO3R0JsXCRZiEYEExECAAYFAkCmyXcACgkQbGPaBITQ1+cANwCg
pjn2wU4YlhrDmiKxcV9L78uOyu8An1tUdKXN2mgl1qorTJ1OnlMZs1rBiEYEExEC
AAYFAkCnxDEACgkQDMt+/gswqTvkRwCgopcposBSeSTAnl/FGufgF2Ba1aYAnAjz
61jwqsjYXjS2GzoaDVFF3mG9iEYEEhECAAYFAkCo9ZoACgkQM4SDxAv8uX6ofwCg
qxD5jBXvqAVjEh1grkeA8GNS+EwAoMyhVmUrGO/vepvIvtx/4JaIK/MNiEYEEhEC
AAYFAkCqnGoACgkQB2FzsZKExFKw1gCfaExLB7vjElicKyV6V7cNBIX5X9EAoIXO
66MtKVzqQ7U0GzJdCVIMX+t2iQEcBBMBAgAGBQJAqK9hAAoJEGfCgI8zwWJ71uoH
/3KtvzqE6mUZ5EaouxqpozRwRaSB+UphYzdUuu7iRW5sPge7mGythYFynTGqOT8+
wr4xk5QJYR4aFzdWfaox2y8xB54Pn4lO07iV0U89W9sOLEuJdxQdvMLtqsgaZ/FN
K9UICacu9EJ8QDPX08h6xhBGtjh3VkDn+yAGiGfZYrjom/4RncrfD0zomVTHYWEj
KzNqd2u6i8yu8NmNMgjnBfkF3NkRrhD34MPtlkWPPYMphPwOLNr2WA53shyZjtsc
G+ojRG3ATYXQweUozdQA4oWRNUqdmO4omKTLOKU5OYIpXOQTRiTzM2me+J2C4vB4
QSCQQPP1LPWV0MmXVRVQqUOInAQTAQIABgUCQKm9AgAKCRAff6kIA1j8vaRzA/9s
yU2v7PGgrq1yfvkhOglPB4v5MKykOK/VGuFFpiJTVsUY+D5/XtzXu3KD9vSY+Yz+
yPCK3oSS64B9NY9btRso6a6YMlZj2bAtWtdo3Ku4IIABW+om1xfE1gEk2vSFLdYJ
uPfyBMuAl07eZZzlprstmnY1WUk37XtVp9F0m3FZ/IhGBBMRAgAGBQJAp3e7AAoJ
EN/uN5Rr7JgKM9gAn2chzrEJ4vb2ewj5/dbauidMLsz6AKCg+PlmUc6jeYkBU8ug
0qw6E1UlzYhGBBMRAgAGBQJAqElbAAoJENIP1AXK1QnGnVgAniaN9iUJByKJU+kt
aVUFmNszZBrwAJ9zY8jfVD7YzVLB437DQ6e4qzkrAYhGBBMRAgAGBQJAqEl4AAoJ
EP3/j1jk20TyQTAAnRGr9dB+InpMSGArRK4AfuyUoeZCAJ957AjnVjpB1ZLnFOM6
bkbNw+nyo4hGBBMRAgAGBQJAqK9VAAoJEIwyjP8WBtuVUTQAoJ7FNtbASWxESis7
RJx8w367chscAKCdCfGhyUpsFg0Lno4nytF242WT7IhGBBMRAgAGBQJAqK9xAAoJ
EBXWiATKbN+yfygAn0g8YlNEMvhhcJmDP9kG0gpgsK+JAJ42cN9MlIZpIOXHXvf8
ere9b5BUn4hGBBMRAgAGBQJAqN7ZAAoJEKDv+eB5p8hwfoYAn2Ph/NQk3qy8KQJ3
tRYnxM7Aao7wAJ9a2+cmOtMP4+lkUKtmdJuX8QeMHIhGBBMRAgAGBQJAqXt+AAoJ
ELcx+vsmpdBmc4AAoKf5PPQbhoKqezJRKpWVMtDEElnrAKCTtTOinfz7YSKnh4iM
H8NaU9vp+ohGBBMRAgAGBQJAqn1sAAoJEA9a6CU0OC5RTKUAn2n3V8PFOtYlzOB7
yoKZRKf6or4YAJ4jtx3QD2Z3u/bV85opXG6WHZdt+IhGBBIRAgAGBQJAqusLAAoJ
EEuzpm9+s1JA7mIAni2SqErea7IVC1xbD7A7dkb5MKvgAJ9CZS8R9I5mZz14jQm4
+AwjLQ0Gl4hGBBIRAgAGBQJAsOtuAAoJEH63kt8ZH82KsfcAnRk2EauQAjcihowT
qrV2QomwTqjeAJ40rR+8SiNzn9idi7eyPdg3qYKaGohGBBARAgAGBQJArInxAAoJ
ECvZzbwaRqfoI2gAoIJIJZJJw2SqKhdcTO0nvBXaTDAJAKCAZHCw6+HnF5ApijVG
wjA7kOHMKYhGBBARAgAGBQJAuRDMAAoJEPsD538qGdcHn+YAoJKL9fB+OMEAxZYZ
7zh5XmStmXeuAKCtHtDupKp6cCUGul+vBIHktu4jkIhGBBIRAgAGBQJAtgxbAAoJ
EPdFDXI5tFVBZBoAn0G+tqcyPH0Snpe4YHKOZshgV8cUAJ9g15qDPlxf4HACqiGf
Vz0f3PlRy4icBBMBAgAGBQJAsjauAAoJEHfSqyWwyHE9cBQEAI/sAelqU8snYXOM
fNvRlrzm0GYUW5YEzUHoeT4a9IOq+pjekTKdMgW+dq2lPuBNi9MNgeEZDNfxDPFf
PNuAOWixYYWu9EyhN5Mh4Jk3PMGeS2z1oZBGSuW2YxW+qBhGKei/V2gl5IVw4roQ
bQkvMKvWQDDMQW2Z7nt4EUgJ1NxoiEYEExECAAYFAkCpllwACgkQFRuplBF1wuMd
NwCffvCN6bO7LOSBbZCc0x3crEi+qtwAnRzjQ7yLA05E39y/U9hEOBtJuA8qiEYE
ExECAAYFAkCyECQACgkQeQODqXRm5lNhTwCfThJVogz/N0DodXnFNklSiEVKgZ8A
oK1z7RG0Aq0uoNf4iafbHRqwmeCRtBxXaWxsIEFuZHJld3MgPHdpbGxAYy02MC5v
cmc+iFcEExECABcFAjph7wsFCwcKAwQDFQMCAxYCAQIXgAAKCRAXjuJ0+BZyxWir
AJoD39/0AZK6FltXjv1oLpJmslLdLQCeKm28Uyv4HysxhC0zufVBST9hK9yIRgQQ
EQIABgUCOqGfpwAKCRBWfrKPqJGBye6oAJ9Jvu+ro1c8MA/7vROD4WhH5A5kAACd
HZFVILpqZKY5PX6airLJkFNyRSSIRgQQEQIABgUCOqLqFgAKCRBXyr1TBk6mGqUw
AJ4wl2pFeL0BkLLQGErwIyAgS8puowCfVXp68uMriB/F56Fd4iHF3O8+ZuKIRgQQ
EQIABgUCOqGDEAAKCRBk4TzDy5uegZv4AJ0bElzl89dUg0ONgUO7qOu7xiCmfQCf
RFH77CcMiX9uxTswP3F9C7nDS3qIRgQQEQIABgUCOqJmkwAKCRB+a0xOcqPRV2/5
AJ9ZnjjHsDi8uhGg2lyGHsGg41NIbwCfS9qKfHJjFFszID1T4ja4nHsMtmmIRgQQ
EQIABgUCOrUzBwAKCRCIgCaHcu0eXjIKAJsHv49nIBSfOcGLIRePTGMiOLFI6wCf
XDzpKFyX+dxOZt3qT6jujiQpZTeIRgQQEQIABgUCOqFeiQAKCRDD3II1kZEhm4I4
AKC5vwsD8Rslq2HhgbOmlS3rvV9mQQCgjbd+fsO91t+F+3Q0LuaUbzEaoBWIRgQQ
EQIABgUCOsDGfwAKCRDIkHMPo/njDkp5AJ42DzStyPGD7eEMaS+RW6IeNDWeswCf
SaSvXA2PvSex7qMyzVe6xJNwDwSIRgQQEQIABgUCOqFRHgAKCRDRy2iGWUqBWIuN
AKDXSqkEFxqdZWv4NU48hUB+D8d5nwCgvKsz1yfRxvCyIFkbGxHV3zNJEqWIRgQQ
EQIABgUCOqGPIwAKCRDbk0SQ7WTgRz9NAJ94uuOt9pDheNfbnFIJLQemikkrzACf
WAEnQjhw6hHNX7dioOuR+UgshySIRgQQEQIABgUCOsC8ywAKCRDclCUlvSuR868/
AJ4t/KSyTGzZUVjwSrRQYByuKnrBNgCeMwVMvH879zborpgXUqBkls3YOR2IRgQQ
EQIABgUCOsKnvwAKCRABBTgH2Oly2JQBAJ9C05vcUlCEfPqULebk64CoR+f6ZgCe
NgDqAxQCZs9z4QfsNlbsy8/vZLCIRgQQEQIABgUCOz0m/gAKCRAgFTHVhF3+3dAD
AJ47gvmOQwW35Yad/chONZ72/GZAbgCfT34oZiJ7YeoP9hN45kKGGlvhQxqIRgQQ
EQIABgUCO11aDAAKCRAgFTHVhF3+3Q+UAJ9kqUWwUEhv90q4FdSv93gzYapSGwCf
Rj8V4oNxYUqis06to2eDlyInTxKIRgQQEQIABgUCPHsjwgAKCRB/5SoEh4hXQMQ7
AJ9vzSRX/1iUiVUAeIafPSM0Y4LYhQCfcLoVxoBbNPwQTFgATNlCx7eKwPeIRgQQ
EQIABgUCPCEcDAAKCRDFyaCPdLkc/RKAAJ0R3dcxEpBoeqFYqsaxfuYkXMygPACg
0fu5QmNQRg9F7Bxg1T7ypggL6HCIRgQTEQIABgUCQD7JHAAKCRCqHXywEmfwku24
AJwI+naTYrY6U2qPORstbIPmkzZvlACgtFwQIyGoM719MyNEwtbB0MMXD32IRgQT
EQIABgUCQCmqjAAKCRBy39cBRoNWTIvXAJ9siqYSVyvIp93DuNz33B8oLBc9jQCe
PBDNZoVm9YFLOJsiZyTlyhrtWhyIRgQSEQIABgUCQKbRZAAKCRDpJi2QY7WYX0ya
AJ9ZLFKsK70l/LeUFhxitulPVRUfagCdHvonQKEuJnPcKkGQtgFyfWpY1o+IRgQT
EQIABgUCQKfELgAKCRAMy37+CzCpO3WgAJ0aX++QnuZm0QiN2hmP0MJgtxb9UgCf
VH3U8cu9K+fxTfrc9S6FDzCVFCaIRgQTEQIABgUCQKbJcgAKCRBsY9oEhNDX530l
AJ90znmCSMhWvud2M43uD4Tnnf3TNwCgl4XVZZBDNS7yR71URE6uVPzHCl2IRgQS
EQIABgUCQKeC2QAKCRAiGMgejnwD/+P0AJ9ISaMl/swpqdbSiGb0mQgPrqm01gCf
f97B/utdvkdiG0lhBhjn9Qx0qHyJARwEEgECAAYFAkCnJCkACgkQTCWvuGAugxkt
OQf/YPsNxsXueLXaEXFMaON3hx0JXoQUne6RKl7aCH7cXSGgTG6R5E0iJPfsYIX+
gOUPBq5/BlE+5+zw7c5+gf8PY+Aw8NJTgrJiQqon8B+WVh7C1ivsnQjNgJEFDzfV
PAC2hx/Sj3W9XipcHWj5agWpNcSZPo4cN0YoXWnItLKf0euQmjypvdwGYGD3c7m0
/stbskARb8ai06q9z3uwdasafUjxSuFJe6YRGXStXe8/i2RtKfpsxlTUE66zgjhq
HpsC5RygiU0tr27tlimUTR6/O4PAngvIgyYZ7ivNh4wElbUgb2iCPfVuicoNOgV3
OpC1YYMSlNPra13xZ7fNM1/+m4hGBBIRAgAGBQJAp9iuAAoJEElFpTfXe0P7PCsA
mwbInTmX5XB9VrHkXoWGCuROTvfvAJ9bZ3iGSO4vnYyxeJf4TeovCD2JBohGBBIR
AgAGBQJAqPWXAAoJEDOEg8QL/Ll+rssAnA3lbMPkeWeat+sNawADRltOipzsAJsE
pJUfNx+ein73C+3R3wHA6kihaYhGBBARAgAGBQJAqLnEAAoJEGlqm6oW1qT48MsA
n0bvEHEkpBMkZM3jLUhUEVssO6QxAJ935ljkFRJA9S+hLU9ziuSqgeYWxYhGBBIR
AgAGBQJAp1XXAAoJEH29C5XtjCBCF9gAoJmg+axvgOW6yOGvuGUJMjJHDPZoAKCn
PQLsOZf/4snJOugIfUAY8PcyTohGBBIRAgAGBQJAqpxqAAoJEAdhc7GShMRSYDwA
mwaKGk+RGc/P3H89tPJ6I4M44Ly7AJ9P2BZ8bpEAyWqH1NUL0b6GkJPY5okBHAQT
AQIABgUCQKivYQAKCRBnwoCPM8Fie7+IB/9Pc/CvXmjlyuVLCDDSPNrOOPVp1vsv
j7kp6BBZ2aSxkA25BgFJBVqrLF1JhdMQ3cEjV6wAc+l1iMg2c3MVs4Cq88TMkOaZ
hjQi3BhGVfoRYrwcUwfEcuyN2ldECpeV/dMhrtudKF1tS5ofVqtqv61MlifYHkKW
U1YBITzspnj8JYWqCKZhxJcwxCfkwpnULWqXh+sU4DlW2fo7kXau6NlZvLNoj0xf
L9ksQZIgEddx+DOWU+Zu6U/Rfr+ul0mRKeuGEaR2Aq0SjZvNT5ZVElrPiFcVRADn
/I92R/SU3TLy2c1sFMfgIxI9XQE/zkv0Ruki2Kp2DwBcOfxecrx3gjk7iJwEEwEC
AAYFAkCpvQIACgkQH3+pCANY/L1AKAP9Gzf7he+XQLSsZBZlvyHaHgWP2YOB4BoR
mAx1cZJmZz/fVGJtFX59kgZZgNUnkwdV2wjf+463LEEIPVoTPMAPZhffc3Kznk8Q
abTSxudWxueh6cAjQOinMHKA0DFeIkgUM2njzSfUd8odbuleOw3gjY81kUjSnDPX
NbN53Ip0dcGIRgQTEQIABgUCQKd3twAKCRDf7jeUa+yYCk6IAJ9F4cTWo97ahVFe
nVkAGzqz5t3m6wCdETnVfbbt0lVrlu8Sfb2oZi6TMgOIRgQTEQIABgUCQKhJWgAK
CRDSD9QFytUJxhiTAJoCLyCccGi7l1t+bSXYIjm5ZZkEPACeMVC6S99O417dMBSc
6T2Vk35OfuiIRgQTEQIABgUCQKhJdwAKCRD9/49Y5NtE8l0JAKCCuv5C2hX0CoyG
5w5zgXAzWALLkACdFJhxCwAbvWcZWtxw/fIGsWLKsX6IRgQTEQIABgUCQKivVQAK
CRCMMoz/FgbblfK7AJ90l7SlpJixzH2qzEQv/iPqLpnv+wCfadob0jDr7I7p/aNu
YoXgR33tmFSIRgQTEQIABgUCQKivcQAKCRAV1ogEymzfsmgUAJ0Z7M2LQ+AbEgJI
1UuIxSO5tmMw/wCfetFRpwjYvxeiIwqtoAy8ZcKhPFeIRgQTEQIABgUCQKjSPAAK
CRBgZdUz/cIFueCTAJ9QQsvBlCtuhKUezCe4TjERyGbTSQCgw3mYUK2P5FkeUp4K
4qgiKVi7WjmIRgQTEQIABgUCQKje2AAKCRCg7/ngeafIcFRdAJ95xls+xlurbRtp
Rt7ZGQEukBfqUACghqjdh0c0MsTkcTixxvbmnSqBoLWIRgQTEQIABgUCQKl7fgAK
CRC3Mfr7JqXQZrEVAJ4kvplZXBbPG0a9hNxK/k8yXr17TACgjEk2gEGOOMTbsKXV
dBLiKIXFIu2IRgQTEQIABgUCQKp9bAAKCRAPWuglNDguUd3PAJ9l/irj8YGRkNzu
1l7jua6yQq0hrwCgq5z8txmIgTfkU1noh8h7uauk8yqIRgQSEQIABgUCQKrrCwAK
CRBLs6ZvfrNSQHvfAJsFx3zBDlONN89fSuyejuBe4lvlFACeLF45X3FS0Hnb36Bw
ZrrryVZyjJuIRgQSEQIABgUCQLDrbgAKCRB+t5LfGR/NivevAJ4zXfKUidygcIns
sPbO5+Ymo0VAOACcCqJ4LSllyeVh71V+5Qa70AzbHmGIRgQQEQIABgUCQKyJ7wAK
CRAr2c28Gkan6JmYAJwI8QCRQIdW7OtkjMkUaMnOENA+OgCfXFj5ZCyJAtZFWK4z
EwFCPJrCumeIRgQQEQIABgUCQLkQtQAKCRD7A+d/KhnXB4o4AJ9+gAGPGx9Jruij
Hw4oTD3LhB3LOwCdGk49zHiSG3qkegApm/K/cJ6bl8mIRgQSEQIABgUCQLYMUgAK
CRD3RQ1yObRVQQlQAJ0UK41DFOQgcO/leNzDRKdxP7JkDwCgn3d+pa6EMmzSO+4S
pHx5lZURcjSInAQTAQIABgUCQLI2rQAKCRB30qslsMhxPUpZA/9bpKi6s12KJ4K1
grdUxPLoSbPupejASnMGC8r5/4KzhZHZzOTNI5voaHMEeItAMx+E/Xf39rbnUxRX
gYvjuYflG4kcnA8ZufA/REdiNgrUMB20A5lnHmB+YhZVZdP3f+iuwwB+3ksZt50Q
kN164rpo8wWKfg8F9i4P4tfG6qWZfIhGBBMRAgAGBQJAqZZcAAoJEBUbqZQRdcLj
nlsAn1yEFi1W6Xwn9sPsZEf2m6gavcLlAJ9J4+r+2YdIbg6Sj/Ai/hZEtM3o+4hG
BBMRAgAGBQJAshAgAAoJEHkDg6l0ZuZTr4wAn3YTPooQJDMwizbbkFyfzoG50On1
AJ9PlqOY8KszGuzGLp7A7ec0jryQ3LQgV2lsbCBBbmRyZXdzIDx3aWxsQGNzb2Np
ZXR5Lm9yZz6IVwQTEQIAFwUCOmFc7gULBwoDBAMVAwIDFgIBAheAAAoJEBeO4nT4
FnLFeNIAn0jJNx9gOHkPCXJ5ueGr0WiKLiAEAJ0dN6NV0N8is6tSO1DhNYPKm2HK
FohGBBARAgAGBQI6oZ+nAAoJEFZ+so+okYHJ2BUAnRwvqQw5OlaTZJCWRvmZT+wm
BfkyAJ9Yco39ExUfBqTzB0DT0ASAJANPgohGBBARAgAGBQI6ouoWAAoJEFfKvVMG
TqYaKMUAnjn/BmkLBi/q0Wz6iV50XPqlTAu1AJwMdJJLkHvzwJ0rimQ0vkF+ts4D
t4hGBBARAgAGBQI6oYMQAAoJEGThPMPLm56BH60AoNoc7tB9hvUeV1v/k3L35/Go
tSjQAKDL2FeS5sU0qqlEFaHIQGL48IACW4hGBBARAgAGBQI6omaTAAoJEH5rTE5y
o9FXjQEAoOFJ9wV70Iz9lSfF2gc59DMP37+oAJ9QeqL/M5y1haDv7HvqHlJdxXuq
SohGBBARAgAGBQI6tTMHAAoJEIiAJody7R5eCuAAoKNrzURee2AeAmGT/yxKAhRO
9vuAAKC2PjEgfp5BJRwfOrRd3waUSDbuf4hGBBARAgAGBQI6oV6JAAoJEMPcgjWR
kSGbH1YAmwdWIXIYO7OeuHdpUx/IPuoXoMUyAJ0YvqNh002VQ2s/k86up0JAj+5q
1ohGBBARAgAGBQI6wMZ/AAoJEMiQcw+j+eMO25sAnRXeJ6f+MgI3LAnZGmQBdMM1
LbVHAJ9ZWI7dR0UOqxjMoKmQDOvu60l2KohGBBARAgAGBQI6oVEeAAoJENHLaIZZ
SoFYFXwAoJVxEgk+U2tsxgqIUsr+KBQF6y8KAKDimhL1XO6yORKFYCpU2f3RrLEi
2YhGBBARAgAGBQI6oY8jAAoJENuTRJDtZOBHgh8An1EVP8YjI5k44QilkCBigExy
dCDOAKC8/fnk89hOt6pajQUOBLE5p8NZlohGBBARAgAGBQI6wLzLAAoJENyUJSW9
K5HzQZkAnAw0AYfxkuwDJswn+T3GWhrNh2wrAJ9HpvXlVycXIEG1YhmJ3TBQk8X/
nIhGBBARAgAGBQI6wqe/AAoJEAEFOAfY6XLYYxkAn2yy6cAVPsGTzc/dGJtipV3K
b7I5AJ464mj5s+at+r/ntf+TYKinH43rSIhGBBARAgAGBQI7PSb+AAoJECAVMdWE
Xf7dycoAnAsdGVVqoPQZc1aEIE/ks4+pHlkmAJ0Tm3rkqSRYyvjb5FWYudgfO+Ou
qYhGBBARAgAGBQI7XVoMAAoJECAVMdWEXf7dOBcAn2iSn3oYdU9nYw40pmCUyPyh
5mO3AJ9fCb1cAK6Gkx/qzO4nkslQnS4V7YhGBBARAgAGBQI8eyPGAAoJEH/lKgSH
iFdAKYoAoLSrCwMB9VgRZCKlxzgcd6T3wsvJAKCOnOhNR1LhFQy3+GP7zapiHEKv
dYhGBBARAgAGBQI8IRwMAAoJEMXJoI90uRz9EtkAn21xyvfcuhe7mMDlPyEYLf43
Nj0HAKDtAb0yt4SZ5LsUnoq0rPYZ3UpD/ohGBBMRAgAGBQI9ubeLAAoJEE6gdPxu
Eezd7tAAn3NOriOwQ2d6wDKUMhtWSfmCdV9oAJ9qWibW9qNuEavltFZGrfzuwLo+
qYhGBBMRAgAGBQJAPskcAAoJEKodfLASZ/CSdHQAoMEj+drpESATh9N0dWrgattt
vplkAJ9I9PxBu+aXsHXS77jzh2GTFN3qlIhGBBMRAgAGBQJAKaqPAAoJEHLf1wFG
g1ZMc5YAn1RaGPR/v1ATiCpQ/4hCBiqDXKbAAJ0VtPUaOarnc8J/pcNkoQsd3WLI
MYhGBBIRAgAGBQJAptFnAAoJEOkmLZBjtZhfaI8An1BXGywAiQab5M1D/DArOmwx
Z4ZFAJ4+ZButjJ10BjyKqqimaROd2QJkn4hGBBIRAgAGBQJAp9iuAAoJEElFpTfX
e0P7EU8AnRc9tbsXRDQoLRj2zPxaVKMau0m0AKCEOara95GaGxRY32B/tnzt9mc0
ZokBHAQSAQIABgUCQKckLAAKCRBMJa+4YC6DGek7CACPkXOYH5iX29wOgRS+V4gC
1sYrnDGSzmzHikfBWl2ZHsAscZ/N5Q/yTHrvpK08IjyUe5JaMnIz3FlzZRB0pJ/K
mowAILVTIvOGAwLPQjHiOFYLxtLMlBhdEVItfHs73nw3hLXljRjoug6CRYKZ4pud
WKxxJAXpzP4Ks0U+oOhKefwujGYXXfZcV1ryB60dFFoGWR0QTvnfwRewlQA4G4Lh
JjdSDoXjmwyxVCh4AJGmFZXNKDYNHtkhEQk9YRxT9sQfqa/c/ACUK5L014Pwm5r3
In77Ip8V4U3axem+bfxoCh/QohQrZcS0hbrTN2iwDacWOoGEBF3/f+XwF9BqHOzY
iEYEEhECAAYFAkCngtkACgkQIhjIHo58A/+FXwCgpd9bWAu20TpgcTuVQ7IZzMRS
Yx0An02jCRPBwqgrg1S/JxBVGSsleUF2iEYEExECAAYFAkCmyXcACgkQbGPaBITQ
1+cpUwCgxdnZj5U5yTGNb06NYZYLfx5xTnQAoIkdP2nNqEW1Y+1uJ1w8e7pNJsQb
iEYEExECAAYFAkCnxDEACgkQDMt+/gswqTucpwCfbsjVB3hdLEZFRk+xtsovu++s
DCkAnjg1lo6WVlNy/WYKM7gRJWWBoxqniEYEEhECAAYFAkCo9ZoACgkQM4SDxAv8
uX4B5gCfcJQYy7mlaI5Amm4gyqLrm4OUfxgAoLhRij406pLwSitkx8I6P7cxKez6
iEYEEhECAAYFAkCqnGoACgkQB2FzsZKExFKL9ACffVa3vUpZ5TxdyLcFx/RYbuKy
bY4AnRMySZuUt81LpEDqyOaaE7wfc4BaiQEcBBMBAgAGBQJAqK9hAAoJEGfCgI8z
wWJ7eDEIAKapwodpfBbfPx4CjIksvjcA47u18Gi3RE9P1+UYMowOoOUgITHTshZ+
mlASH3jf0SId/e2Wfde+WIpRQZkcKAQ/B9UZAr/54xW7JIXGmOYjj/mqaQWJMDdq
p2sJfdOVqT8izo6ksITdHvCU5jVmqFAaMLvhlpBn1RjXyoVuUNk2d5HVa77cIJrj
BCW8M3u113MF6Ga6eHpXINbZw9A3FGHbC3g7SbaWwwhGT9Ar0+JmLQK3XT+LKjGS
BMsyt7+tiU8Y3rB5owGdZ3gf0B1RjlLImz8dJ0PAGDXrxOsx9AuB0P+SK2oL7AFz
HoGcIWT7Uerivsm6TlJuwzCTCTrwHg2InAQTAQIABgUCQKm9AgAKCRAff6kIA1j8
vb5BA/0eZllqTS+EXiu4kIaAm9dRABDCz5awuYMgezWEFwSsfLxNGioMJkn1CB1f
iFZY7RBhDSdW/aQjC9mtJgwhiLbRRJQd9Vi+3h0SAwgBby8Qib3+UnDZfgAIIjb/
WjiYxqoEg9VQRJ3VdryBi8cQvnqqWl/FbX2w/dpmw697I4Pq2ohGBBMRAgAGBQJA
p3e7AAoJEN/uN5Rr7JgKLHIAnjV99qI5ZpjmJda6D6LpgbtgLWXyAJwMaOQO8Aky
vdufbfI12XE8pFCvJ4hGBBMRAgAGBQJAqElbAAoJENIP1AXK1QnGcwAAoJZgtBkP
+rV01H1pLbbWJe+OV8uxAJ9lFkis/hmsRxSE9ra2R8oGv/AIIohGBBMRAgAGBQJA
qEl4AAoJEP3/j1jk20TyG5UAoJBZ3oMAnYpcYmNLjtiDrh7wzn2LAJsE6cyza/Dd
q+qJQEi3l205TVLcdIhGBBMRAgAGBQJAqK9VAAoJEIwyjP8WBtuVCMYAniIDWgT0
pxCmpyOzMd/BSVTuvmPtAJ9KMOxnp6xOflxvSZ89H9LojLOELYhGBBMRAgAGBQJA
qK9xAAoJEBXWiATKbN+yiCUAnRcuOPIEhrgTpJAAmHMeW/vXpTv/AJ9sao5el5JS
EISY7K+MC9qDthjgVYhGBBMRAgAGBQJAqN7ZAAoJEKDv+eB5p8hwG7AAnRxmeriM
a28OysIRD8S9YJTBvbBKAJ0RD8UMyA7St9TchJ5Zla3z1KUdCIhGBBMRAgAGBQJA
qXt+AAoJELcx+vsmpdBmQ6gAn0a+jh3z0LL5ANdT2jtHsU/O06WiAJ4oe1Tt0gUv
LkANDuuF3Lf+hRqrwIhGBBMRAgAGBQJAqn1sAAoJEA9a6CU0OC5R7JsAn0u+0xJw
2ETFapx7UaNGNekiwB0PAJ9l8Z/lhNaWDSO8scexAEdk5yfOOYhGBBIRAgAGBQJA
qusLAAoJEEuzpm9+s1JAdH8Ani/vu3j/Fy7PSOJbwLtpFLOEEYgrAJ9TahITNYvJ
3JT0DJcugfcXvVcng4hGBBIRAgAGBQJAsOtuAAoJEH63kt8ZH82KCAgAn2valkSE
Ma+TR8LMkimHwXxAW+MyAJ9OXeKNQG6eLmJM1QjH1HPUeKvZCIhGBBARAgAGBQJA
rInxAAoJECvZzbwaRqfo1/0An3N9D8cNItLmLTtRueKGqgkxWwWVAJ99Dw3X//ja
vDXuHCS2IavQSw5tOYhGBBARAgAGBQJAuRDLAAoJEPsD538qGdcHZI4AnRvTrIMd
s9dWX8fvLo0XCwL4D6/fAJsESrU7T+NRagzEoPqKTx+5oCOgl4hGBBIRAgAGBQJA
tgxbAAoJEPdFDXI5tFVBEX4An0HwVeuS5HLj/FoOm4HorIFr3bFTAJ9MAJPrJRbs
2yjngH2NluuEK+uS7oicBBMBAgAGBQJAsjatAAoJEHfSqyWwyHE9hDkD/jYM7yIb
CiwMKhAbVQPoDgBdqDSoALG23TzstQQ9FU7ayPgsXETmfuZBYsNuGs0JY0XYdWHm
CPy8t2UfhLUqQw5aYNx662ZYKngUfqtnNWLqCRaRwzB7dqLZd+6/keAoMmss4Gnd
47ADXaWWz2eDMx5Q+Mz/LIuLFC075/BFAEHLiEYEExECAAYFAkCpllwACgkQFRup
lBF1wuNKrACeNNIc94dDUnTrEPfFOST8j12MkE4AoIG+bgIcuh/2hsFM5O/IuKB2
r/SciEYEExECAAYFAkCyECQACgkQeQODqXRm5lPpvgCeLTerNPaa9y/OnYKp3rht
zvWVgWQAoKpveqAo5EyuphnBI9zAD6l+DgT7tCtXaWxsIEFuZHJld3MgPHdpbGxA
Y3NvY2lldHkuZWNuLnB1cmR1ZS5lZHU+iFcEExECABcFAjphXOAFCwcKAwQDFQMC
AxYCAQIXgAAKCRAXjuJ0+BZyxXx5AJ4tkMDCcd6LKqw+v3XZX3T1WaLxMQCfYMp8
6ixcy//vupQn3Y9AAE/FWEaIRgQQEQIABgUCOqGfpwAKCRBWfrKPqJGByVkiAJwN
BGEpI2aXmQ5AbqZINpfIFXMwiACeIwn/TokvsKFenAcKlaBKxGhz/TuIRgQQEQIA
BgUCOqLqFgAKCRBXyr1TBk6mGu5qAKCnckRx7752fAF7UybYs8JsMFDNPwCgou8R
aQlJCFZQW61yOPh//0hXYZ2IRgQQEQIABgUCOqGDEAAKCRBk4TzDy5uegS6MAKC8
2aHJKv+Whl7aGXfWW3lyH+569gCdHfzYTNkhAQuxxpUjf44l0C+XEVmIRgQQEQIA
BgUCOqJmlAAKCRB+a0xOcqPRV8KKAKDbNqcadCcjc4PFu5ZWypt4WU/dfQCg1Ndc
C9lP3N4xAU83bPAYGDlfb3CIRgQQEQIABgUCOrUzBwAKCRCIgCaHcu0eXpx3AJ9l
4NWdb4o1P3qV0pDxRnVM1Ej9UQCfSuwsLb5glNiHjNtTn8XNtTeGkgWIRgQQEQIA
BgUCOqFeiQAKCRDD3II1kZEhmyoNAKCfCtP+oYsFuMz5gxBMls/xXQxVfQCdHU5L
Qp+QRbHPxhLRaAE/GWONVJ6IRgQQEQIABgUCOsDGfwAKCRDIkHMPo/njDkbtAJ9s
neVuzwes3KiZw1J2Uu6+Mcf6zQCcCSG4cp/K2BfoBUeQD17gSGkiZ02IRgQQEQIA
BgUCOqFRHwAKCRDRy2iGWUqBWDbJAJ4j60cztwp+5Lzhafr69XBqHONQGwCdGHTN
59M5Vy4C/hCQ2aGV2vhVx5yIRgQQEQIABgUCOqGPIwAKCRDbk0SQ7WTgR8JaAKCe
jMLA2xZhWWzhFzEemgOoktbr7ACaAkbAzmndpr1e7ihpvFloPbsOJbCIRgQQEQIA
BgUCOsC8ywAKCRDclCUlvSuR85FwAKC0Jq0XkGTgWTiSHWCC+57PAx0c/wCfT2EE
E6/8qIyzQKMZzKSE7ajTC+2IRgQQEQIABgUCOsKnvwAKCRABBTgH2Oly2MoLAKCN
CLfouQ3CrqOZDfj4npCW0zpr0gCfYfSzYyPT3RulJEwYIyg3dZeUUbiIRgQQEQIA
BgUCOz0m/gAKCRAgFTHVhF3+3UvIAJ4uDAHFQpJXR1oX4Cg5kRu+QcLobgCfcXTJ
IBqs1OXqyGmoHlkRUAdrNK2IRgQQEQIABgUCO11aDAAKCRAgFTHVhF3+3SWSAJ9R
CM1acE15CRCC4NjUpVACTIW06wCfVYmShOE7HL7EURqzDfMvqsJIeh6IRgQQEQIA
BgUCPHsjxgAKCRB/5SoEh4hXQDHtAKCfjoa6UPXWnppzc672TLe1zaY+wACfQ09+
MKFDM+hTdq2UXaz1RYy+19iIRgQQEQIABgUCPCEcDAAKCRDFyaCPdLkc/QnBAKD3
x85EFCQuwW4nvJ/ZtOdLzq5OQACeNpK+Gw99BDSDPvIITUrrQkH90jeIRgQTEQIA
BgUCPbm3iwAKCRBOoHT8bhHs3XYAAJ9m9oxdK6ibWGHBQkDmSu/9x2ksYACfbI8H
NJ+nvBF/lupcuXMZMk1mzIKIRgQTEQIABgUCQD7JHAAKCRCqHXywEmfwksydAKC9
8vyj3LHQXjOaGYyr7EVVx887GwCgr8x5EShe3UahdwAunxNn3xZj9gOIRgQTEQIA
BgUCQCmqjwAKCRBy39cBRoNWTEfVAJ4qGVg2p0W4WWUm+v4BFhoHqUKCTgCdHUuj
Bp9emccVaCkf4IyC7fUna4SIRgQSEQIABgUCQKbRZwAKCRDpJi2QY7WYX94KAJ4o
Eiy6Q/qn2KPOEKsJy0/ug4y7tACfUoPrIm+8Rc4Zj4wc0bSVZlHgKByIRgQSEQIA
BgUCQKfYrgAKCRBJRaU313tD+1tRAJ4k/JIkw3p0brmL5g0qsA7k7U/brwCfdrjT
8WBiRqgTu/e/tchcpgzMgJmJARwEEgECAAYFAkCnJC0ACgkQTCWvuGAugxl+CwgA
gbMGNVf3Lv7uI0qizMUVLj0LrjItUZFemB8P+699GQjAYqCq7iCWCn2KVO4KZIHm
F+mI6axAwBeRxrY0fVqssk/kyttjwR1ltnj5W3Grq5G7zEwXsyTccfCEnYcKN4Ho
DuYw5DCzycHjJoKizFalOCG1wSEcwHOjEmZsbsbbcYqylvtmg6oh4JoUuVcnpi9t
aj49wExFnzjKtp+yGfdIpIMAlxXQhovoTfSfcyKQp20ttXIsp7KQcwBKAuyWFZAB
DygmLBWy242PRjar1vBo1cRz9ire6KG5ZYKMeDQXp4gcuMQNtOMuMLb9qb2wN9FZ
rt9Z1z0/a8vWZetPEQCmv4hGBBIRAgAGBQJAp4LZAAoJECIYyB6OfAP/RkoAnjk1
pnACKUbTR+sPpSYW/HslmJGJAJ0S9dPJtstlreTC8K8XxaYefpKJCohGBBMRAgAG
BQJApsl3AAoJEGxj2gSE0NfnaqsAn13dU4GwZQvZBPzGPZU2GFXOr52qAJ9qbmV7
MscUkEpCdob5aS6IEoeovohGBBMRAgAGBQJAp8QxAAoJEAzLfv4LMKk7WQEAn1WG
P7L8ZSmdKLphoaro+hYJmf5sAJsEMCPbXwSi55waTAmgYuKTR769hohGBBIRAgAG
BQJAqPWaAAoJEDOEg8QL/Ll+uqgAnjjL/stN6COheM+GWxmWsmO46Gn4AKDFWOjn
o7mT/qPpXcP7Q8Gp/aHTPIhGBBIRAgAGBQJAqpxqAAoJEAdhc7GShMRS1h0AoI0O
qRyR8Gt8suQ/HVSj3D24b88DAJ4u79WZltpS6EzEKPUQN+i03GPZHokBHAQTAQIA
BgUCQKivYQAKCRBnwoCPM8Fie9KlB/0ZT+yhSGMukshehXWwPiHt9BvbTJNeTIs8
xtSLnz3Uf9iYvEvCoccBpbNZOzD1ows/7igKnX3T0vccDmdo9RD55uyRKZMugXke
o6gJ0omcjL1mEh/1jyhOzhAp1ewPciN0Zkd0cDeFsiI91YwXbEo+xriDHl2eDm5V
tznZDjszBm1s3yVxW+JZSBAS17W+Qu0HbnhaUR35MGIam6YSveBfbtJUdiUdk5bJ
CVzXi2GlXx9xLe4xRxJfR4T5wOYjelXKj1AEqS9J5fMOi+ofYEB548HDbK7X0+JG
EBIl8dFDkGO+w4SrpSUgkvKjV1JLORyDBgurRYQwlCR8P/pReb0riJwEEwECAAYF
AkCpvQIACgkQH3+pCANY/L1KDQQAqieTHgyrSOHd8C6E2mILg43qXwOkLjKAiaoa
s6KbxuERSjT6B8G7/olqKDnYwY1/5LoFSrXuHurCcg7OR6EiIQBI3XUvRz5v/HyW
oUKYtelpx9FbWz5oWk7sqJD/axRThQh8yBM6w+Sjfvq7pDrJykCQtgyEgz9FJPql
WN1EDruIRgQTEQIABgUCQKd3uwAKCRDf7jeUa+yYCms2AJ91ZzafXQtRr2iSkGUA
jNHfBVryIwCfbfKYBwbyHPdvhC193+idU8rUOVOIRgQTEQIABgUCQKhJWwAKCRDS
D9QFytUJxigPAJ4y0x3WTkH1ux8uQLVq4ZityiTrCwCaA77OvXDR/GKVM33DU0Mw
UAda4r6IRgQTEQIABgUCQKhJeAAKCRD9/49Y5NtE8qfAAJ4ysyF4RCIma/vghpxJ
ME+e6eJsUwCffpPPQ90ROgCF6f9lE9DwV8i45E2IRgQTEQIABgUCQKivVQAKCRCM
Moz/FgbbldITAKCBZYMyaNFAJtlzL7FtHrbiCdKhMACdEsQtN73NIh1lErTG9a1c
4M6fkniIRgQTEQIABgUCQKivcQAKCRAV1ogEymzfsnzWAJsHJ581uCIJYpJUSs2p
poQfk0knpQCePduFiOHYJ3vDcAz0dyN99yiF0WiIRgQTEQIABgUCQKje2gAKCRCg
7/ngeafIcINmAJ42FF7EfodtLk7m3Em1TDCaxGVsBQCgmsZUr1uNi9G//dIJNjOY
dXfI0CWIRgQTEQIABgUCQKl7fgAKCRC3Mfr7JqXQZi1FAJ9Vav/F5TY6gM30GYZG
jfjTKk1E3QCfdnMA9mCXgEtgzkYleHtA+BfJ39OIRgQTEQIABgUCQKp9bAAKCRAP
WuglNDguUa+TAKCpUr+i7ThzzqoiuxU66ikW4pOcEACfXkFIF5pW4LGbYj+VEPTD
r4mWpOaIRgQSEQIABgUCQKrrCwAKCRBLs6ZvfrNSQCLLAJ4xor9VMZKM1kDSAHbg
Rfs0/U4zqQCfS2h8TjWprDxe1PcjwFk/+zuTsNGIRgQSEQIABgUCQLDrbwAKCRB+
t5LfGR/Nihq3AJ9VCO+8bpky5AIscqqNl6Fr3DtpdwCfZLe9+6mVUkhQd3mqovUz
kbAY14aIRgQQEQIABgUCQKyJ8QAKCRAr2c28Gkan6DWIAJ0XhKRBBSompfxeB00v
TC0Spos12gCbB7Thq2Ly8uyf19Ydk0lYe+IyEQeIRgQQEQIABgUCQLkQzQAKCRD7
A+d/KhnXB/iIAKCs/pTWCzFDvb4+DgVWgKvUJCkxtACfYWuXvADTC6PYBVgkVnwj
UNz5d9KIRgQSEQIABgUCQLYMWwAKCRD3RQ1yObRVQbwnAJ0VZs2CBINmIgefxAbN
AT1R7loQ8wCgky448QCc10Ak+JXp4YGUgR1EACeInAQTAQIABgUCQLI2rgAKCRB3
0qslsMhxPWheA/4jgsNiBg6YESHBhio9kUHd0iIfPfmgoSNavfqxhQGWvagmRTtf
w8NYpq7zKjiFXnXL4IMGY9bdI/ltSXbC2tCyLLd0NguZXz1IJmkzE3cA4QGaox8i
ucypPqfzgM6l1kRc/VJjJwT51sg0/gr8Eobytm1KXm+I88GPV2z2300L6YhGBBMR
AgAGBQJAqZZcAAoJEBUbqZQRdcLj56UAnj4my3C6dzziSrZ41VLpWo4UCesFAJ9g
yEG/ZhXhlahY8R2/sjs06uDXuohGBBMRAgAGBQJAshAkAAoJEHkDg6l0ZuZT158A
nRkrV4sFeuN/FDnTysGUGmPYvR0rAJ0RcRtE3ZhoiaLdtiBQYVHLlH3xxrQuV2ls
bCBBbmRyZXdzIDx3aWxsQHRlbHBlcmlvbi5vcGVucGFja2FnZXMub3JnPohWBBMR
AgAXBQI6YV0CBQsHCgMEAxUDAgMWAgECF4AACgkQF47idPgWcsUZ+QCfcXuWqcLI
MugVU+hNb4ksM7Wh0swAmKZdOHxGuPnEzZLxANd1mh+oZUGIRgQQEQIABgUCOqGf
qAAKCRBWfrKPqJGByatIAJ4kOWmxRB8Gp0Qt5CuAqICXh+b6bgCfePafenjj4MlN
nA9XL/33Lr7YIvWIRgQQEQIABgUCOqLqFgAKCRBXyr1TBk6mGmZ3AJ9bP3hyoiJg
2FKZj67d+QJEXtbvxwCfbIxRLs0QPtGcWGNp1a9hRsjLXj+IRgQQEQIABgUCOqGD
EAAKCRBk4TzDy5uegbLoAJ0Y6fVacc5uTXGC2A8Ldwu2qF0SvACgmGT5HX3LRXfK
SYiXnPHeiCOwf62IRgQQEQIABgUCOqJmlAAKCRB+a0xOcqPRV+DhAKCXj3DwhUwi
r1Mo05ZcN4rQmm4AsACgpIxLZILww0P1ikrzVC4QcT5rQxaIRgQQEQIABgUCOrUz
CAAKCRCIgCaHcu0eXjLzAKDPBxBKmmwFYa00EzqUkONo0k39OwCeOgHBWuaixXaX
kxeuEcxZ7c/HrqqIRgQQEQIABgUCOqFeiQAKCRDD3II1kZEhm8pmAJ9viHoD2kio
ajxmUz/mYUFeJsFnDQCgqF8FSS5u/Snz5e78tMkQ6QB41bqIRgQQEQIABgUCOsDG
fwAKCRDIkHMPo/njDt9uAJ9VBB6VTOV6UANVTH7m/nllFl8/ZACfZoFfRRQ2+UUn
xypk5HD2Qd8Cu22IRgQQEQIABgUCOqFRHwAKCRDRy2iGWUqBWGW6AJ9mplLKda7e
/wiuaL8jz9/4jwb5yQCdFIJBPw6T22iRHZsQ3K3t7s2OxeGIRgQQEQIABgUCOqGP
IwAKCRDbk0SQ7WTgRw8IAKCs/k4pzfAwcmgsSWQFG1jlnjBzDwCgi8CWjy9BOEwo
UGgMiNQMd7BFYVCIRgQQEQIABgUCOsC8ywAKCRDclCUlvSuR81sqAJ9vSIXHYAFe
G0HzIQhFKnxgHHOADgCgl3X+eogcl7NS50eG6sZP+RktH5aIRgQQEQIABgUCOsKn
vwAKCRABBTgH2Oly2FbEAJsEe64ctQhCe6lk7j/k7DIy3R4bTACcDw5bTmQp11lw
XksUwh8IWU+ItFuIRgQQEQIABgUCOz0m/gAKCRAgFTHVhF3+3Q5qAJ0ai4bxn6Cx
W2y8iZuQQDReAU73TQCfYT47yqqkRWwTHScnVKXipv/ta0yIRgQQEQIABgUCO11a
DAAKCRAgFTHVhF3+3TlnAJwK7E8/m+ituR5rqZUcrIxZrV31OACdGNOTm5GLMrO7
L4y4U08KvRgKLh+IRgQQEQIABgUCPCEcDAAKCRDFyaCPdLkc/ZGIAJ43/0amQlEy
GRmI03WrpQf/UpvFuQCfUQYkG5hJstXL+U1eJNhhykvroliIRgQTEQIABgUCPbNZ
6gAKCRB/5SoEh4hXQDRoAJ0TgAgjwEwj+flg26Pw0u9TLowR7gCePmF2LOBk13km
pJEIljdYwiy9NFuIRgQTEQIABgUCQD7JHAAKCRCqHXywEmfwkkJ1AJ9aFHkD63O8
KMHw6Ya67bQ16BRzjQCfTejGAlrbCeEgZgYOCg753kYDvkeIRgQTEQIABgUCQCmq
jwAKCRBy39cBRoNWTHhhAJ42ubYX51+H+p4f9vUoDV7xwClLhwCcD80jD/cZgrei
nRjuUEdEIfDFsAaIRgQSEQIABgUCQKbRZwAKCRDpJi2QY7WYX557AJ4ntkoDx0sD
3WWPmRRzWKTskgDjGgCdE9lID3H6APoyPkUcWEmBBin41NeIRgQSEQIABgUCQKfY
rgAKCRBJRaU313tD+37KAJ9P7TRQYiRZAVRzMPvl89Hlt7sbiQCeOD34frlxFn8e
bJYHVoqCa8Qi5RiJARwEEgECAAYFAkCnJC0ACgkQTCWvuGAugxkFGgf+Pp1R2rzZ
Y6qiyY60TEudtc5DL1CsP9xBNCRwkvv3NcXLgkpe3USKYxh6jrTX8rgIap0Ew4nK
5H8lgdXv8nkX1ObmqPZwLMNg66mvDAuSzjpGwCt4FvHEC0V12FzSPdMJlLMCgIKZ
o0ZHFLH827T6jE0E3rnGXWWDkvvSyVB08I0GqjLh6XJ3ZbPKjsrWYaKUflsjNMSw
XnQsp956lOgFSD+W2gxMJ+907B2JArmX6bWJbvwURZEqdTDAdRDuuYiZ1M6z97La
LQHWRtQoQ7wG8Us66YyjS+V5oQAcTFpCLn8rHd2vde+z4TZFA58uy78GQbfXsdf+
i9Z/PZ2R55r1x4hGBBIRAgAGBQJAp4LZAAoJECIYyB6OfAP/CbAAoKB6HYTpl89I
7s/PcJTADMdySqNXAJ9bV2Ft4SmYNYEO9KoJEBVXiuKr9ohGBBMRAgAGBQJApsl3
AAoJEGxj2gSE0Nfn/O0AoMCTade7zRMH0ujNJryQSjxUsYZlAKDUzgk7tPnEKK5D
liSefRxKmnjO04hGBBMRAgAGBQJAp8QxAAoJEAzLfv4LMKk7VP4An0UoScHUtD08
7HmhBOgsF3HHgIktAJ9votVwjrL5gH/uKj8Cm23VKQ68+4hGBBIRAgAGBQJAqPWa
AAoJEDOEg8QL/Ll+pHcAn0v538D24VoOhMDkrDBpIBSsvfDEAJkBE+YJMQ+JFHKI
IejL3YLI1GXinohGBBIRAgAGBQJAqpxqAAoJEAdhc7GShMRSlrgAn0YO4ANEVcIl
kqwmB4xswLX3DIb+AJ9KvG002bsaylRXSGTiMUgos4fmx4kBHAQTAQIABgUCQKiv
YQAKCRBnwoCPM8Fie+EuB/9bvSX69czID06weCzvrpIGceYts6QSaTZryvsKT1Ap
zjSdPHvnTw5RxwC0btaAllqQWTJjMYcame5LGBU66e9fg4iEQcgI+3Vcu7sHmwR1
Aj/X1clPV+bPu6OGbzCk0rsVdEiVRLEl0KqemPnAYcCvyopSqa41e9YC3gDs7Vh8
BLU2jwEMOLG5hhGj1gKzdRd+abHmYc5i59M3DcXY9w09cTAadDLPxIw82asQ/q8I
zQ949c0wDeoRThRK49m7alxK/bEP7PQz1WFcEDUzu31vd4Gk8D70nVgjCEyeixnd
Sua+1CHw+ZDNOLSn5hAKEww+rg0M1z6Czfs5KQw1Gqb8iJwEEwECAAYFAkCpvQIA
CgkQH3+pCANY/L2UyQQAhiidH+YYKSA/XCc0KqEmFHj3O6zmFDWcjX/ZgiW4wzVI
Fy9Yk13swDCv0xnZwtNgjbCEI66avTCYIXL+CUwPRcefvizsXfwzfnkQGKxRajpX
y9x00+NYm7dZIUi4kI4RsP3tw7uTpVQcdG0Wnbw8B7wCo+UWCzeTkT550m+FrbSI
RgQTEQIABgUCQKd3uwAKCRDf7jeUa+yYCqxtAJwMu59kka1su0wm4QscTXyYHonB
SQCgplPW3tyiHs7mcQlxmmsPUb0gx9GIRgQTEQIABgUCQKhJWwAKCRDSD9QFytUJ
xqMKAJ9jqLMAPmwaYRcP2FY98G9mTBIRNwCggZ8NG29qMUBFBGV15AVkEnAA1SaI
RgQTEQIABgUCQKhJeAAKCRD9/49Y5NtE8nPlAJ9Vm6HpmO63OCUtYGOTTx/n9hCe
CACfdW8VWOTDB9FTA6RZZ5lrWNWACPCIRgQTEQIABgUCQKivVQAKCRCMMoz/Fgbb
leQyAJ9weje1QUfCvsX6/0HTE9s+i8xnCACfXPGzGaRLQDbX0gMiCXDzFoZUXlqI
RgQTEQIABgUCQKivcQAKCRAV1ogEymzfspHUAJ9zEbdggH120b719tnTHnOJvwBL
RQCgkW8M/YLAIpr4TcW62Q/36sEtEMOIRgQTEQIABgUCQKje2gAKCRCg7/ngeafI
cGj7AJ9nGQg2x5NehEY03fbgvnHP+s6R8QCgqkJdAv97LTv6DzUe8qb8WTSD4z2I
RgQTEQIABgUCQKl7fgAKCRC3Mfr7JqXQZp31AKCBmzmCaKYFSzq4NdhJSeerW3hD
PgCfRSD4aI6qIMeD6iIh4p3//6qH7UuIRgQTEQIABgUCQKp9bAAKCRAPWuglNDgu
UQIdAJ0UMMhgp0fPCpjvbg3DrxIYct4iGgCeMCaX+ewwINPMz/L5fHMlctfrN4SI
RgQSEQIABgUCQKrrCwAKCRBLs6ZvfrNSQM7FAJ4g2HoWeTEY3FVC5DYzbaKwuYAt
QgCfbDdgQH71a5LI0IhnhdENfmuuSheIRgQSEQIABgUCQLDrbwAKCRB+t5LfGR/N
ilFzAKCpk31uqK89ljjNTcr8cHokV76nXgCgi5cP9xMl2fLO9zYhZzTi8ftNo+mI
RgQQEQIABgUCQKyJ8QAKCRAr2c28Gkan6PYtAKCbMAW22Zs0XEnUrRLtcZmBsUWA
GQCfcIap53s8vvPvhF/YwpbASVzJkNmIRgQQEQIABgUCQLkQzQAKCRD7A+d/KhnX
B1cQAJ9lwvFMZGPRigSiM9E9ixrpO9DZYQCff2vVrMpJhVpI2FIn4WPO5iBlnpSI
RgQSEQIABgUCQLYMWwAKCRD3RQ1yObRVQXsyAJ9ZZPFswPyE4oPwC/SVeUXaQQ1g
sQCfWEHzeoHuiwbBTz4PK7+tYS1pH/aInAQTAQIABgUCQLI2rgAKCRB30qslsMhx
PbzpA/4oqsinFpcjsb9HG4VB1hbUzdAxJn+zJCLt6oeLiXRshjmL5MA7Fb6nBkdu
J7HAOY9pdNL46UqdX2CXDshzObwVk8AMYfmr7V/xhNbOsoVzZOJRbtQtZlkrVW1C
Q5Fdvdi2aKL0OrixaQWUUBKTMsk090DIfdZfyjmpGS3ZfAzCUIhFBBMRAgAGBQJA
qZZcAAoJEBUbqZQRdcLj6UcAniVZ4OYkDBkKqIGKj+4VxuxN/bTNAJjB/pIcftA3
9Pt1Hw8F7qs4ORD3iEYEExECAAYFAkCyECQACgkQeQODqXRm5lOK9ACeMy9qsXdg
niu9NUJuvT/FNPIrw78AnjmCkUBkxqsAG/BrQv/qx6VsgZVluQENBDkpESUQBACf
5xwEwzcieacHwPrjzAiAJ1X04qaEmVSgGAKuMGTcJDk5s9yUhlRuWBizV+wmTx3I
Yx+Od2M8PzhN8Ckx1WAcshIB3I8oblx1+sjoefD8cIuEtmksdpnLr5fNkEamxvO8
RyH8Czivyi3k6y3/xqZFSujdcoVrHPY+khBk2bczYwADBQQAiUPd1TVIIdfDR0Fa
+j/amW+W+gbbbK3i90sDBEDxKOTBr00ih3y2OnOJ70AGT3yaT2zu5800i+kZhaA3
0Pm43CNvP2v1OeAl78xS6sktO/KWHhrWX2sRrX9mgbw04InnDNB5QOj2Ju9FIO5w
w1cwEbsfGRfg2RM+lN9qNaCKzMSIRgQYEQIABgUCOSkRJQAKCRAXjuJ0+BZyxex6
AJ4tc3hmnPfGlqNmOpLI6wVHjx+HdACfWiZBPiYZxeZIN7rYYE5kZOQ7cX8=
=inzo
-----END PGP PUBLIC KEY BLOCK-----
D.3.5 Eric Anholt <anholt@FreeBSD.org>
pub 1024D/6CF0EAF7 2003-09-08
Key fingerprint = 76FE 2475 820B B75F DCA4 0F3E 1D47 6F60 6CF0 EAF7
uid Eric Anholt <eta@lclark.edu>
uid Eric Anholt <anholt@FreeBSD.org>
sub 1024g/80B404C1 2003-09-08
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD9dFQARBACzmGtuaKFqQwoRV32TI4ANBPHPlXkKXJ1WYQQkahzP/VfzNOUH
VbjIMQqrNPawOcrFyEFuI/FJLWXewhrcrM+of831BXWqnQ7ketGqKUO3xT18N1MG
BVCx7F1wpPW42YkhFVAubZ5tyHLOVSc+iJZVGgZ5mUi57odqZ1l+rnqpjwCgnXx5
tas++vGBPk70vcIP+ZmswGMEAI0Lfr7Qy42P6hbYJZpk/NVAvXMZMUyK7fti2lR8
BCOQr8lSdFUZMAqOhlGSfr75Lp8YhR4R4qCSISPXIbtkpYpS5A4YOk22qljLfyrC
vki3U3Qum1eO2L67jswb+hQ7pCeaddNm9Jmsg+CJOZl6nfDIJpC8yoXH76W8tXAm
1DgiA/96RKTseIR0z79ahlxX5HDr2A5bPM5CZBdPba4tSuFIwd28HVUdLhJmsGpC
uVnQ5VnhBh5coNBhcb+ngZCOr9NvvyvwrxdYYGvuABeWS3v2UGx7XnJQmBQubWYq
CEk3wScZWhEoFchvPEVfXtzNBjI6sF1FWMYkAhHaYiH4M7rBiLQgRXJpYyBBbmhv
bHQgPGFuaG9sdEBGcmVlQlNELm9yZz6IWQQTEQIAGQUCP10VAAQLBwMCAxUCAwMW
AgECHgECF4AACgkQHUdvYGzw6veNhgCgij4I47kRmhRkdzJeftLig2TG8/gAnRcb
r7ah3d3nPKNLRN+nQDTp0uxctBxFcmljIEFuaG9sdCA8ZXRhQGxjbGFyay5lZHU+
iF4EExECAB4FAj/CqF0CGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQHUdvYGzw
6vfvYgCeIy1G5U6YPFK2QZNhB7SazQXwvjgAoJmxWRZr8zKOmcMiYFf1tj05UDhC
uQENBD9dFQEQBACpBlENAalxZonZ7K2NU6xiH/qz+XI+ZU6WQh58iUlM0QPUU8ta
Ot8uQUL5DT6G5myFDZufYomYrdzaLxuZbzpWzDOFGqb9aWLlHC16ydWbIRvPif0D
ar9wFJX3b5DFkVICUYXTKTx/O/VqcpGHH7tLInuipYRapOBrUw1LU87qLwADBQP+
KbuF41ujgb7QfPX5x5Cdg9D9SZAQyxu5TbsSXmc4fuel10QFMdWyMEUW2rMLixYn
cWw7AfziHCy3uWOOm1qxm8npYCIRp0jG3M/Jydc8iQTqL59v0/UBOxPQ1pYZxE/8
EOmbHRHe9BQt4pfouuLVKXGzxg3NW6nXXNQVEeOyqFaIRgQYEQIABgUCP10VAQAK
CRAdR29gbPDq9y8MAJ0dP1d27SdsNNU4d8nFpwrXfXXa2wCfRvgv8i7ziyodkgwl
B8LNmWvWUn8=
=2V8B
-----END PGP PUBLIC KEY BLOCK-----
D.3.6 Mathieu Arnold <mat@FreeBSD.org>
pub 1024D/FE6D850F 2005-04-25
Key fingerprint = 2771 11F4 0A7E 73F9 ADDD A542 26A4 7C6A FE6D 850F
uid Mathieu Arnold <mat@FreeBSD.org>
uid Mathieu Arnold <mat@mat.cc>
uid Mathieu Arnold <mat@cpan.org>
uid Mathieu Arnold <m@absolight.fr>
uid Mathieu Arnold <m@absolight.net>
uid Mathieu Arnold <mat@club-internet.fr>
uid Mathieu Arnold <marnold@april.org>
uid Mathieu Arnold <paypal@mat.cc>
sub 2048g/EAD18BD9 2005-04-25
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEJs9i0RBADoZqZbz9Vl/0QuM9+PCmS1nEA2k89ZRqPA8C+b2peJb0j0I616
Qa+SOJIyRIBWGIk+zxhDRxZ/GN2mMW2Q5QksDxPl2dGYbN33LiCWKXxNdVhbsAFG
0DzGwkjMRagiUitaJD6yopBkpyCGmpEUMiYyjK5HShg82XTMIfpsGKL/vwCg+WhB
13MxjhKRKBpV9l2qSufcpCsEALPFvpDP2sc63v30ljbH8vEGHFyaq27E50H+V1FR
eYJarsudpG0LvwcrqJsFEe6afz5urMCnFeHN23Sd6WQY0Mf6GPWd4EBqgl8NdM18
kREA60gAPpP23vYSFTyZs4CgMC7VbzAQlIeb/gRMRIqsR8lIuJr9x+DIBRdm0UMp
DmTzA/9+bhe3AK0dYblCod/brugDfUFzu5KNFpdnXmfphJFdUgFtyGoqSmN/M27r
gV1eA7PKWR/mKCD8JilQ09k52yHK/W0IFNVQ2q39gpGXhCW5oHgW2iKATd3XR0lr
AWbfrOsL4usfgddQARJKsQgIqwsL6LeALf4G6F4hC2PeSG3fN7QgTWF0aGlldSBB
cm5vbGQgPG1hdEBGcmVlQlNELm9yZz6IRgQQEQIABgUCQmz5pAAKCRCphinMbP++
Z8BbAJ9I/EyakF2BOIO6ZnQJ1hEqFMKgDwCgk4kBiHkzmrhTmP+rgcNxac/zRhOI
RgQQEQIABgUCQnIkXQAKCRCgT/sbfcrp0x+5AKDU+ijbet8rXUdmI+C9udcOT2xq
lQCeNwk6GAuzU5v9EVIpB7P3jI7QI/6IRgQQEQIABgUCQoiqGQAKCRAMy37+CzCp
O2zgAKCJVfxjMFBMwVlNNrSwa9y8vqSgAgCeIzOhEwHTwFNZpmuNQ9dPp/hvI++I
RgQQEQIABgUCQpnnGAAKCRCH2lwNJzWaUbsbAKCBq5Sk9XH7DcL1sL+s6gSfSmTw
sACgvpGprYIPeu8byEee5uDFM9Et6imIRgQQEQIABgUCQwMO8wAKCRCNe42EaOyD
lLFjAJ92fYiuvgcty5higoarBc/GGxKMJQCeImBQbK7s9vBGeXSbWsr3PSggGjqI
RgQQEQIABgUCQ6VuFAAKCRC9I1l/mlC1/qqnAJ4iBh31o/strzn6bYNJEy1yzDsL
DACgkTZRShR//I9TkX9qBDEQfUL7kUiIRgQQEQIABgUCRDkpSAAKCRB0bJ/+pXPx
DzSRAJ9V/DPFLvkBSqVYsSEPItyh9aeKggCfXLYrGCkY1QcH8dQPZswFK00sh56I
SgQQEQIACgUCQoaQVQMFATwACgkQ1wPoPfOWTTQWvwCgjn1Cr+idP1Sbh+PXoldb
vNIYE8wAn0BOTEjOLfQvSe6NnTCWEEzIZCH1iHMEEBECADMFAkJtAA4FgwHhM4Am
Gmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9pbmRleC5waHA/aWQ9MTAACgkQ0rsNAWXQ
/VjVUACgnUimWsV1n2hmqNJ7F/WFvEvNoz0An1NewfpyuOoXH5P/YgIwK0m0agRV
iEYEEhECAAYFAkJtEbMACgkQktwjcC7SSBIdYACfWu+rS/h4Ww6jsG7HZmsruOd4
x7YAoKuvPVwRJVmDV2klKrt8gMwV1u5siEYEEhECAAYFAkKKkdYACgkQIhjIHo58
A/9iDgCgoa+NcTAAb+SX5p/DdKHNbyfj0bwAnjwJyhoIBwyygoRlWBnjyPG7g/Zv
iJwEEwECAAYFAkKLGf8ACgkQH3+pCANY/L1T7QP/XIUnVmyMYt6hc/fPt6jcjGHq
mhSIFimxO3Fs0NPuMzhL9tfRbBSS8i+G5gNXGz9U9RiU8jgGw0uDorRlIJxd3+Oh
+iIvG3DyJlAqPj24ng1YeZTacoQf3HkDsP81LrieYGcCryzI8EV9lXZBA0vyqp+g
7BBuXSSotHE+xPE9kVeIRgQTEQIABgUCQnFLmQAKCRCNSU00xw69UGyNAJ91yYo9
7PA5b3IAINWGN0klfkTDhQCfQ4Lfi+RUWYCoSHpoR6CyuJkPxUWIRgQTEQIABgUC
QnYo2AAKCRC1yGyEMX0o1qkCAKCnb0OJSl8BwyBId0BhwbPa2Q6IxACgtMmTq2g6
cOM1Vm57qoBT9QULJz6IRgQTEQIABgUCQobwEQAKCRBgZdUz/cIFuUpWAJ9Vrnvc
Uuq4ngfqF3A2SdGGvpRsqQCfdTDdhZjiZPnqT/t8UumqJQS0teCIRgQTEQIABgUC
Q6gbjwAKCRCkqrO0wJU1sepsAJ9tNoc9L9BVwxeElWGk169dGCSmbwCeIXwT1p2r
Z0Oy7Qf3w3wcmYwXVnyIYgQTEQIAIgIbAwcLCQgHAwIBAxUCAwMWAgECHgECF4AF
AkJs+fYCGQEACgkQJqR8av5thQ9IJgCgm8SiQlyHfTLXW1o0KPvMzjN5b6AAnRLV
3Zsj8mhwfmslRt2KjtYkKMztiH0EExECAD0CGwMCHgECF4ACGQEGCwkIBwMCBBUC
CAMEFgIDAQUCRkndMRkYaGtwOi8vd3d3a2V5cy5ldS5wZ3AubmV0AAoJECakfGr+
bYUPBF0AniwyVHKHoYQ78eJjaxZta14mJHMAAJwI5GH/DyaEWmP0+dyEtrGV5G8w
64icBBMBAgAGBQJDpajpAAoJEFViUQuqeigOx6ID/1VabIv21Ed7zSxnapgDkrqi
lx3l9jUEo/eIOQMrGpYYu5E7gpmTPzi2ij+MENvE893YP/rKE3JV9BEYwksDsTXy
h/qn+YnLIJLNBkLqzC6XIFhJ8iGcBsxEGTWvFPdQG8vbzQnZV92ichwoXZp+NCRV
qxuRe7wsrwvF/rs+gr/miF8EExECAB8FAkJs9i0CGwMHCwkIBwMCAQMVAgMDFgIB
Ah4BAheAAAoJECakfGr+bYUP+OkAoNkfDw1UBJ3c4tSo3nwhaB86VZsKAJ4gSnCy
DT9uxvgjD9UHHz8EUtSiCYhGBBARAgAGBQJErt/IAAoJEEY0I5Nj9gwsgBgAoKl+
viNkeVRNml2woRJLLIYE/7uzAJ9EeFDmjzvetRpbLTEwIJGSFJ+O04hGBBARAgAG
BQJErRyLAAoJEFhgc7NAI3AvXSwAn16vWce2WvrYi/RBOirHr8Gbu8ILAJ4hbN29
I2NPEGlR4JZgWqhfqI6ZD4hGBBARAgAGBQJEs9I2AAoJEFZOnwVRvFhBirwAnRUR
ohYfZHwhGhJw+Kn+4Zibc70NAJ4pJKkBXEXsmpjBsmDF1eb+UFCMYYhGBBARAgAG
BQJEsUZRAAoJEJTDy2TSbRi8/1sAoJmBCzFPf2UDnHPtY19FYvDKo5T7AJ9oDfTk
5hbM2wRpw/HeURVvr4LomIhGBBARAgAGBQJEsOa2AAoJEM8opP8z1LbGcOsAoPCS
o1HJhWEmtzsgdfCE7dRX7JlUAJ96PFoDvf3wB7NlB68um+sPsR4d04hGBBIRAgAG
BQJErOYeAAoJEHeRQ9mfGs6ck3EAoOpmFYvnoiTr/bRfeNpWCFnLBfJ7AKCP8MxH
76ozrgCypKGjomF2b7h8wYhGBBARAgAGBQJEsThUAAoJEPHPFQgJyXlayMEAoLO1
/o+D6UEphiArMz6sSd+v/vbRAKC28P+1byFq9b+A89sZ+XnKVzmp9IhGBBARAgAG
BQJEsj0KAAoJEGwxx7NpBHVSYuQAn1uVl5Ss91CU+wzW95n+Vg1z6Ao8AKCKqkUA
BCKD0Zy3K1wt5b8lIhWBrYhGBBARAgAGBQJEs+eMAAoJEEU8RUkCMNYCXx8AoPq5
xsmid7M6852Agjo8/pLCl30mAJ43jCYOZAUrtZqD2mVRhzPJdm+lxYhGBBARAgAG
BQJEsOwyAAoJEFkymUKhHnTsqWsAnRyUKfyZNdlYMtXckhEfKAQYQbvcAJkBiyoF
R48WMLZNzEHAGYxgoqVhq4hGBBERAgAGBQJEt4jSAAoJEDRNtjiDUpwqzb4An1vt
mYtRxl0wg7i+QNqJisf/NKI+AJ4k1Bz6t3+5vKIhhGJj7BR32lTp7ohGBBMRAgAG
BQJEt4+FAAoJEDRNtjiDUpwqOlcAoIv1A7stRdMgoLewPUTlb40N/A0+AJ0Xw9mz
6OQsgd8rU4n5aqtrhELoB4kCHAQQAQIABgUCRTyUHgAKCRAmSeYoxdNNBcjVD/49
QWGwFAs/12jjUFNhOHuvMyke0Qc93Lg5K+BtCCqh5Z2XE7w0HrvcKTy3ZCa4nnUE
0t7XmqWnGeYTfqQiNT0ROIxdnlHucQQO/knk12rraJ5u9F8BdyqbF5KDzkZYD4ky
rdxE8QMWTwumvzDb38XNgcFdsvLu8NB32rjoW16+8rFnuVL3gcQ3VV+zW0oozieh
T3YOI7JRlGzmDitg2X5lGgtJX7ipChXqG5NS32y0/KQ+Cksa0kxRGIP1UdXnSRjr
ChH211A65RPLSV8fjfhLiqnlVBmWqcfkOYg0RXfL7+IbR38Wv9QrWXpTFr8xJsac
X4Ww8xB9rqL3X2Nyr/OY8dK8fmI8r2OFrbCL+HuIblHRMrjeMaOKbGQA3bz0lYb3
Rm0m56fASGxvOhXXMTq8DHmyn6LqtEAAnqNHhWaigIFwphM0zUV6O03viB/HM+kj
q994/r4oDd2f63jG1EVMxwA41hZoWCh5ycdHvDvhzT4/Mk7dCqOFmgIVixxXzQrh
yERZ2vmUWUVJQzyBJuDPDKHG/79MmZBHb7r2D+4s4o0UnV6AR56XTuqSyPNCutEG
hFDviPPeNWn1woCqdIYf0HYg/IeXXdXL6ZvrPKb7dc9wyHJFbmzQwTWFORkAGU7u
UpCS5ofBoNcuZJ+qBvfT2lmYoS5jLfWlfckr04lstohGBBMRAgAGBQJFr+q/AAoJ
EFaK6ScFFSqpfzgAn20c8xGOt4rbbn54MevHMdWExZuQAJ91x72T8XbU0MVzub5u
ED5RSjCKo4hGBBIRAgAGBQJF2a1VAAoJENXkzjzP+fsLYNcAoIMHE4eSmYUnqIlO
+rkvfIWBwpweAKCuiOBvcimQG9p7xmCNVDd/5V9IoohrBBARAgArBQJGC47CBYMB
4oUAHhpodHRwOi8vd3d3LmNhY2VydC5vcmcvY3BzLnBocAAKCRDSuw0BZdD9WOQk
AJ9tcXXZ/KedC7b29iDeZz/ndnR2iACbBDOAZtENvEk/u9jI36HWoGihuKiIYwQT
EQIAIwIbAwIeAQIXgAIZAQUCQ6f7LAYLCQgHAwIEFQIIAwQWAgMBAAoJECakfGr+
bYUPHtoAn3I0Dtz1V3SJgri49XGkWGJ+KjyrAJ4n+CfAxsUXUOTL1ruH/CF85h6a
fIh9BBMRAgA9AhsDAh4BAheAAhkBBgsJCAcDAgQVAggDBBYCAwEFAkX6ou8ZGGhr
cDovL3d3d2tleXMuZXUucGdwLm5ldAAKCRAmpHxq/m2FD7zVAJ44aQkKVoSqMTV0
lH4WjYN7t8DddwCeL6sqwWlYbwIXJ+yXQn92XaWF7hy0G01hdGhpZXUgQXJub2xk
IDxtYXRAbWF0LmNjPohGBBARAgAGBQJCbPmkAAoJEKmGKcxs/75nLGoAn0aZH7AF
GIrp0RzcxsHUHuqg7UKnAJoDIZE2o+NflGAVCYIZDqprxxifJ4hGBBARAgAGBQJC
ciRiAAoJEKBP+xt9yunTIIAAnR2SwmgiKUf/gr0LB7ByNGAE5wWsAJ4/GcHj/wMA
c8v7orM1IX0BJ86VnohGBBARAgAGBQJCiKocAAoJEAzLfv4LMKk7g7sAnAtGIcxl
lnB0ysEiCS8r1HoS+25QAJ9OMIs8SG2o1DuCzKvMUSd1zbgIk4hGBBARAgAGBQJC
mecaAAoJEIfaXA0nNZpRyNcAoMP+uOEtT9iWbHiuFb2Zt9wWCtbaAJ99Gb73DuDW
zAaoO5FM70hq62CYZYhGBBARAgAGBQJDAw7+AAoJEI17jYRo7IOUPwUAoJsNLu3M
ve2b+xuQJU2JKVaFiyfqAKCDQyKNy2aPrX1o9R4sFO9BVbtVYohGBBARAgAGBQJD
pW4ZAAoJEL0jWX+aULX+5VwAnjFM7jF5W/wepLIih9XVJPFveHQJAJ0ZaLAY/fhD
aJCkd4BM+O2C5K4ipIhGBBARAgAGBQJEOSlbAAoJEHRsn/6lc/EPL1kAn33Ruexp
7UsBxT0tO1XcPhcJv6JfAJ9vCWZd2fl4fBlZYtpZOxP9JIxtPIhzBBARAgAzBQJC
bQAOBYMB4TOAJhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5kZXgucGhwP2lkPTEw
AAoJENK7DQFl0P1YQPwAnjCk6+JguNQDHvquwGD1MQ50Lp8/AKCXwwyfNewKS3ft
lJ36x06Z9CbomohGBBIRAgAGBQJCbRG2AAoJEJLcI3Au0kgS3AQAoIfwoqk8zlX1
M3hJ8SQzO341ytG5AJ9D4M8xvyz+6hCO+hQJbHOH++URYYhGBBIRAgAGBQJCipHX
AAoJECIYyB6OfAP/QyIAnA8JR8C+ScTT61Z4im89hqgvRlzbAJ9MWA/FZ6PV1Br5
thTYWyK0+wQatYicBBMBAgAGBQJCixoCAAoJEB9/qQgDWPy9DAUD/1C7Bntuxrz4
R6plO0P7FyG2rTI6kgJ954OwH1qDgqSZwtzioBvhPg6eMzTFOGAeQldslIqoO1YE
PPUnndpT3ppu3TiEJB1VxbRoOlS54elTzBTqsiLPHZsPlv69YXAN4BwN93IhadeI
PXuZatNMWGHrIkXw/KbDtaZuRoCdKcZAiEYEExECAAYFAkJxe7oACgkQjUlNNMcO
vVDx0wCfRpDnDUTw5+90xx7ft/i332tJAdoAoNQjb31NHFU66ilhc3gBOMTobSg/
iEYEExECAAYFAkJ2KNsACgkQtchshDF9KNazJwCghgmoy7tPAo0Ict/cwRZd149W
Up4An1cqWwPI+63crwlmPB0YPLb17gReiEYEExECAAYFAkOoG5oACgkQpKqztMCV
NbHamQCbB53N589ZAELg9+BexJARwUjenEoAnjnzscRGg2LnthknsXXW+nhnYImg
iF8EExECAB8FAkJs9zECGwMHCwkIBwMCAQMVAgMDFgIBAh4BAheAAAoJECakfGr+
bYUPDt4AoLJxDDziXy6ER41W50gzeELTrOByAJ49GMf0N0sjhtH43pF+apWpM5wI
F4h6BBMRAgA6AhsDAh4BAheABgsJCAcDAgQVAggDBBYCAwEFAkZJ3TMZGGhrcDov
L3d3d2tleXMuZXUucGdwLm5ldAAKCRAmpHxq/m2FD0O8AKDY6Ck9+w2LPaOyn9lS
zKvemya/lwCeLuRnLhsoDzHyDlktUJgh9+fQNGuInAQTAQIABgUCQ6Wo7QAKCRBV
YlELqnooDnunA/9LMBVFiAiJn90rXezC4QwmutNza/mwlOKjQ1jkRlbR8seMlGxn
5m8XeypfRNexeJvYweHfMBSOHnaLpEnu9Ylw1s3RCRmP0P0sAV3DcQ9TtyRTz97e
UpOoRYLr6+vDezhIKWIIkTKx5F8t36OmG3z/nNXI+83E19pKDNFiJ2Va64hGBBAR
AgAGBQJErt/LAAoJEEY0I5Nj9gwssyAAn3Ofd7PY3Rlcwtq+fqNHIYYoMOMHAJ4q
PzKDvTmIj093d5Lncf/+sZiEWIhGBBMRAgAGBQJEr5bUAAoJEHyOr3aQJLyoRJIA
njHp5TkZGFaChdZQdOts7XeVQg8AAJ4mnEByhJbcqPuPGe1OibrPXA7bgIhGBBAR
AgAGBQJEsUZXAAoJEJTDy2TSbRi8R5QAoKh/oMzElYeT3mK1Bl1jJjWByab8AJ4i
EI6zslz5bw7PCd2jB/gIWszug4hGBBARAgAGBQJEsOa7AAoJEM8opP8z1LbGW1QA
n1frW1EzTqiQb7nFXtO7AmuGzgaKAJ42CxgDPHK6FuTE9/DZF76FHFUW3IhGBBAR
AgAGBQJEsThWAAoJEPHPFQgJyXla4EwAn39VFFBaC2r3qkC8yLbQNrTf/HblAJwO
QbQB5hd03JKVZFnGU3AtvUpw64hGBBARAgAGBQJEsj0NAAoJEGwxx7NpBHVSmfMA
nRxMMAf/ZL2OwGm+DGYrhCwQvZuoAKCXXPi3NYOSaqT3S4DkFlrTCgEyQYhGBBAR
AgAGBQJEs+eOAAoJEEU8RUkCMNYCIvQAoI3hh1gUgTHR71r81kAknCd2UGVpAJ9h
an2IyrorHyh9HhYpccE7YxJqt4hGBBARAgAGBQJEsOw3AAoJEFkymUKhHnTs0s0A
oN8HGhufHKV/6jhqXbi6HnyCw5fKAJ9cBhtXO5beagMrk3saNHh0/atfT4hGBBMR
AgAGBQJEt4+VAAoJEDRNtjiDUpwqXsIAn2neZa4QHjGa1mCQQcapF6GgjB4xAKCs
ghDUAktU9O8E5L3JexWl1xplwIkCHAQQAQIABgUCRTyUJgAKCRAmSeYoxdNNBeyB
D/94LKYa3P0YEf0imAe14WUtXiOGTtQItnqMV0qiuxBFtaa7wv+9Umfe2MGg5VUb
kVGA35fgO0ecICumj9639h9AWiT7pIue+iynOU0t2OeJt4ieJbs/ZdtOABPp9GDU
S0X/q4iwB/373TQWqzdtEfwXHJKGZOaivjmWkOWXAJd/joQsUAJKTYHO2LNf8WNq
i6MKLBCNloIb3WZn7da1PtR9IRlrGurExj/RThbv1fzsYC2T19woK2IUtXcPtWg7
M2ncXtpjzMDYzYoYGrvrFSG+cyMV7RYz2EkRzIYOZA+6GaKifE0FvVS+URowhjly
lsk6fLd2I8fEu2fnOLGkhGQ8OwQBzlfcYDXFxtGdApSxZFaD3EAOMr7KBkQzac3M
oaAz6LXonj6Kt95xiBP9Mgb4jqpBXEDdbiIJqooftSp+f1EJpwrxO+J6THNaaYIY
PqvzvOjyjGiyWRNbQNxLngBnciD292weTkpu8GJJDDq3LabXxD6XiEITIQy+9/79
ug3R4PJG8AGM8nFq1faeOCn3l9U622lXbayFGciKXx60nGTCcUnyncnccJthk7uQ
wwE7Lh0ow5FIr6kt5vCUy8IunQw0rAogF+YEi6l6t0m/8JW1xxj4aBX2wiSbh1s3
3K9aK4ZdikJ+jhqvIUVQT6b3/5pP1h7kXp7VOnH1V8kG94hGBBMRAgAGBQJFr+q/
AAoJEFaK6ScFFSqpxhYAoI4A/orsTorfnEy7slNIuBDd11ayAJ0f9TfrWNalwd8f
0bd0OAL5JfbxD4hGBBIRAgAGBQJF2a1bAAoJENXkzjzP+fsL1RcAoI4mx3weRnJy
AfKpOGCaO/423y1xAKCQGvGgSyrIDOss5ZMlZ+6U05rzmIhrBBARAgArBQJGC47C
BYMB4oUAHhpodHRwOi8vd3d3LmNhY2VydC5vcmcvY3BzLnBocAAKCRDSuw0BZdD9
WCfMAKCX5WqsS4x/3RfUc/n/K/T6PIh6pwCgh5J+s6rnnuoyq1tUT2SBNM5YwOeI
YAQTEQIAIAIbAwIeAQIXgAUCQ6f7MAYLCQgHAwIEFQIIAwQWAgMBAAoJECakfGr+
bYUPhLMAoLY8pjGwHPYwmtUqoTcJFAL4R0MVAKCDvvs92MHXjZMbgFob3lY/RlnU
gYh6BBMRAgA6AhsDAh4BAheABgsJCAcDAgQVAggDBBYCAwEFAkX6ovEZGGhrcDov
L3d3d2tleXMuZXUucGdwLm5ldAAKCRAmpHxq/m2FD8vLAKCFI3qK1z+aOr4RB42L
Fpidico8GQCgnqEtyrl7CZ4ytVc8MyMziTeUaum0HU1hdGhpZXUgQXJub2xkIDxt
YXRAY3Bhbi5vcmc+iEYEEBECAAYFAkJs+aQACgkQqYYpzGz/vmf+JwCeNx248vmc
AD7/7yEQaWXlsRnemxoAn271IgFSZmP1L6b8Qb6j8djBU7DeiEYEEBECAAYFAkJy
JGIACgkQoE/7G33K6dOUTwCgl73BuAoLpsj/uISyhE7ivzxSb/kAoOBRC/Q6Uqxg
eS0Z9zDi+bn/61CWiEYEEBECAAYFAkKIqhwACgkQDMt+/gswqTu8TgCbBoDq06ku
qCMVhWENKOO1jPns7mMAn1u5sUkizWpW8TkGwWAkXdiyZIT1iEYEEBECAAYFAkKZ
5xoACgkQh9pcDSc1mlGtegCgs/H1SunkY/jVPy1q/3/nEY7ZAqUAoKlOVpQo4A/h
XiftmF6D3/Okt4pTiEYEEBECAAYFAkMDDv4ACgkQjXuNhGjsg5RX+QCcChlOhX9G
oDXUvD6y7x9qwGN0hqUAoIXyVvv/xsl1QN+8fL6Qj5D0P62niEYEEBECAAYFAkOl
bhkACgkQvSNZf5pQtf4jIACgkbn50dNjQinBGWO0oFKtEDhCSv8An1RWCu46g/dt
FIdDSf2gnNgJE+OeiEYEEBECAAYFAkQ5KVsACgkQdGyf/qVz8Q9o/ACfXaFjrGel
f4mqvv/M9i4uIyJ3RcgAoJeUUaNXs8J+WF86LTkHUPMaLF0diHMEEBECADMFAkJt
AA4FgwHhM4AmGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9pbmRleC5waHA/aWQ9MTAA
CgkQ0rsNAWXQ/VhCeACgg0Kb6jGZexqttiOC7LMgFtaHSOIAnjQR+WE93s7eE4ux
E3hMI7nPXRQaiEYEEhECAAYFAkJtEbYACgkQktwjcC7SSBJFGACfQQBk3IaOZKkC
e7HDF54HURXyDvYAoJrRdQQ/BtL/V/69NTzPWiSD0tdRiEYEEhECAAYFAkKKkdcA
CgkQIhjIHo58A/+4fwCgnV3jdlOwR97i3AIp2k5k9oOIyoUAmgNl48teoILQc0TH
F2Fd//KC3WFJiJwEEwECAAYFAkKLGgIACgkQH3+pCANY/L0yngQAiGVjhe3/OlbJ
clB+aMfG0spu35YpWQfRXjVfidspy2Q2ktEHxWixpNEi+KTwVvQLKIXcp8FKXwG3
DpOHIIYI88IVekKyvC9nBFFO/wBUDhgZqh5hmOGDAwp8ju9dUsOm6p7+5IQ7xUU/
5JZdwTN+pHIQVvujbbeiHvIaqtNLyuiIRgQTEQIABgUCQnF74wAKCRCNSU00xw69
UPBtAKDqs8NIXRJui2LPJV2UXpp7GySNEgCggInwEuHY0dHnr57Nzo8pnVFsjcKI
RgQTEQIABgUCQnYo2wAKCRC1yGyEMX0o1qrqAJ9kOWEyTV9TyckpHCynLzWOIWA+
SwCaAuIRdCTmZKl5RIR541yYXr9SOcKIRgQTEQIABgUCQ6gbmgAKCRCkqrO0wJU1
sbfoAKCshfw3tSgEYd/X30nqLUyN86r2HACfUUBVZSsEdSDjfbzlq6+oYSml4beI
XwQTEQIAHwUCQmz3WAIbAwcLCQgHAwIBAxUCAwMWAgECHgECF4AACgkQJqR8av5t
hQ/vPACgmLCZt7fj7d34RceIP7La8T8KQT4An3Jg3AnRj0EDDvkocqt6903RqgWy
iHoEExECADoCGwMCHgECF4AGCwkIBwMCBBUCCAMEFgIDAQUCRkndMxkYaGtwOi8v
d3d3a2V5cy5ldS5wZ3AubmV0AAoJECakfGr+bYUPAzMAn2PQjsp6CmAyN3qOBKD6
Tqpb/ET/AKCnw5sAraX5lFBkDEDAHiVEepQPB4icBBMBAgAGBQJDpajtAAoJEFVi
UQuqeigOJ4AD/RlnKOhsxc4sbNJ6sllLaKf3SzcZcc7A1y50vDPk2MwRVMQ6unwD
AkpAunZsg9YTrtOvjY/G6d6E91T8CJXrgdrxl5wgpk/rHpT7V1mn+DK7jemEvIgT
BqnBU1skldNulXTdk26YmIyrKWwLtE1CccodKsbMd/iqIho/vsDq1IgDiEYEEBEC
AAYFAkSu38wACgkQRjQjk2P2DCy9HwCfYOkX15vnQ/oe9weSZ42EWdYVNHgAn13K
/hGWDGlQtabjoXfqpsGvVv6xiEYEEBECAAYFAkSxRlcACgkQlMPLZNJtGLzWWACg
33QsBMvPV9fjE6bsjJ9xbGFo1+YAniMksN7BjMhdgjJi+YzmghT4RpgHiEYEEBEC
AAYFAkSw5rsACgkQzyik/zPUtsaMDQCg0dKgGHcb8A1ktRKqi44uHz13sOQAniHY
pYr0veuJVSd87ainH7sP9ldOiEYEEhECAAYFAkSs5iEACgkQd5FD2Z8azpxtPgCf
a3Z7gM0c2dG4o0ODdHdh3AnB0o8AoJiD4d9miGmlEFADrnpte9plthSgiEYEEBEC
AAYFAkSxOFYACgkQ8c8VCAnJeVrIAwCfRSBbW1am5QUsFBe22ZqLLAsdopAAnRdj
vb9VzOyMUcr4kyvgyFTkbjgXiEYEEBECAAYFAkSyPQ0ACgkQbDHHs2kEdVJ6RQCf
cCgDGj7fjsWi5zS92TL3+l5eduEAoIDauVwSz8Qk10hIeOGz5Z9OCAExiEYEEBEC
AAYFAkSz544ACgkQRTxFSQIw1gJX0gCg9CWTuDEOdEPZmVif3LNP++tHoS4AoMkr
DrUl/tN3N/GXXPiPDgF3i9VniEYEEBECAAYFAkSw7DcACgkQWTKZQqEedOw02gCd
HrizfGczWy6USELcwV68mGzBk8sAn2Is4nOCkNHpDSe8mYnKRJSjIx0hiEYEExEC
AAYFAkS3j6UACgkQNE22OINSnCqa4wCePqO6/S4F559x+Q24mVpXrsIuP+oAoImx
g42x5cieXM05JhD3vW1scBD9iQIcBBABAgAGBQJFPJQmAAoJECZJ5ijF000FA+gP
/0J4H1mPcTk0p/PCtIzGjNY1mtsAJtAgCyAcd4ueXXU226a5J5QwXwkLb/7RJ+d9
tPr1EWO5tR1n319nyonYxJVP3XzoZTKbrCZmtiFnbwEQXoeqT/njW5iONIDlVrb4
RfevdTugqetVA19pTif5pGr9i9nXPlDx3188Y/IoIsF+r6VQE8HCRksXymnKAxm8
GAoGnRIDK2Odk8OK2V72vff1v61z31sIm0P1AoESCRCJSLyUp1BvKnUu4ZkJKK3h
QpmqcjoU73jDMH2Sli9B5R4ujZdDJv+cZJvlhJb88IaJImF4lDebKmN+8GXLyST+
55CIMBoUsS1wN3OJm+Y2pM+bV7aze8OU/fkFiO/zunDaQg7cJtaGxdQ6FMsAngPA
vuDxwbAI6/IscUtrVcwSSX8Nh6/6sN399aj549ipyH3x4mukjlrz6NJJZs0J6tvz
haHu63pAZSXpf/4TcRFMHw8Lz7o6GQWJ4HO4mJMpfzvHvKE1gLAdSvJ3IWgzPpsv
Lwzws7M0/HejGx95hHExLaPGeStkcglhQxFpx3BwAmdz7WOS+d+fplI565O127rY
LQeyRKS9wABTDDG4ZpjRDKiO4NTctADS3TbrTQkP2WKaJBuNF5CdJyZ7HbTednHW
Z21o/tAyF8Sdmw9qmVqjUiTDwzQDpUlg/CmonXocJW18iEYEExECAAYFAkWv6r8A
CgkQVorpJwUVKqlkBgCZAfmCVmePqFLhQLQLh2+Y6XHQFxUAn2JrekH/llrLlEmb
gpGWWd0Fjs+IiEYEEhECAAYFAkXZrVsACgkQ1eTOPM/5+wudXwCfVMnPgesuCNKT
Ule3nmMxSDkoXGMAn0q4Mgrl9xrF1ySJJVtTttDAOXSBiGsEEBECACsFAkYLjsIF
gwHihQAeGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9jcHMucGhwAAoJENK7DQFl0P1Y
NgMAnApKvTJGh3piM/pia3OAsrdY3pp0AJ4uRT54MUr6Jje0QLOIBZDN++917Ihg
BBMRAgAgAhsDAh4BAheABQJDp/swBgsJCAcDAgQVAggDBBYCAwEACgkQJqR8av5t
hQ9z5wCfZRJfMJh7JjNA0BIWoI+M1yxvpmMAoJHefiX7d/xLUB2sHAKLuEAgWhPz
iHoEExECADoCGwMCHgECF4AGCwkIBwMCBBUCCAMEFgIDAQUCRfqi8RkYaGtwOi8v
d3d3a2V5cy5ldS5wZ3AubmV0AAoJECakfGr+bYUPen0Amwe3Z/uxbTFsOuTZvcYw
F9KkesM/AJ9jl+Y4KhwNxjL/zQfQgZZOrQij7rQfTWF0aGlldSBBcm5vbGQgPG1A
YWJzb2xpZ2h0LmZyPohGBBARAgAGBQJCbPmiAAoJEKmGKcxs/75nZ4QAn0R7l8BN
i5igOxFg/TJAjEl+snqXAJ4rf0W8DFLlbYmYoKNjvFkZlqiQdYhGBBARAgAGBQJC
ciRiAAoJEKBP+xt9yunTIfwAn2VSNgAzBtlHCFVqfR2jRl7MuhJVAKDmnPXQP7jj
DMac+LchJmrEuAB2n4hGBBARAgAGBQJCiKocAAoJEAzLfv4LMKk74joAn0kO2C0E
P5tWD+Y7qWKcP8h95TpyAJ9VQwAnMyZSU4wgxEEVPUfj07yP0YhGBBARAgAGBQJC
mecaAAoJEIfaXA0nNZpRDqEAoLoc/XXs6xMrtHSaUioN+EB3kR6iAJ4sSbrR2HtY
CNQ8q22LmEc1rxTwtYhGBBARAgAGBQJDAw7+AAoJEI17jYRo7IOU7E0Ani5eZ6Za
i49Yz52SOnGNkZ1Xg+wOAJwJJJx/PtZQE6HiQ2OpBO6iFLys+4hGBBARAgAGBQJD
pW4ZAAoJEL0jWX+aULX+aU8An3j26teCEZqaD17rokv4ZQb7fSyPAKCQ3Ap0uAG1
J3IJ06COBmC1FbcC94hGBBARAgAGBQJEOSlcAAoJEHRsn/6lc/EPiSQAn1Pstyxg
jwyw4cKKV2uW4vufViFGAJ9eUSjbtkvlFz5piBsQwYHPRSTEs4hzBBARAgAzBQJC
bQAOBYMB4TOAJhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5kZXgucGhwP2lkPTEw
AAoJENK7DQFl0P1YFz8AmwR0Xs87uTTptm2mnE5VY4ku4IigAJ9YxuJUl190fJTD
uRUs2aEw0vgrlYhGBBIRAgAGBQJCbRG2AAoJEJLcI3Au0kgSEzcAn3xNN0bLAMz0
ZpwiKD0vUtnOgQ1ZAJ90dVpM6CiUHxMx1JACpWXJerjgfYhGBBIRAgAGBQJCipHX
AAoJECIYyB6OfAP/zZoAmgM2L19Ep9FzBd4iMz9/3kLfcQ3FAKCLfdgQ3N+NAFPn
/BUHK4p38WddUIicBBMBAgAGBQJCixoCAAoJEB9/qQgDWPy9TM4D/i66hWMxV4RS
GpwMxqZXjxoo4vxp+ebtC8L9CDwHo0cJvjI+SjVfbD/515obqAwIUzNh7YqmImYv
VqYzEPtFVRsSHfm+5YpXD9ArmTSw5q0zCSbwjVxUSgI6mfz2fjUVeLlWpe02Rqnj
LMWXsxuBLe88/VliFCIPrHI0M7/QHrdKiEYEExECAAYFAkJxe+YACgkQjUlNNMcO
vVAZCQCffEidzBqAilm2heJeow0sYCNphS8AmwQezJRJnQONrQHKCkXCz7javnOd
iEYEExECAAYFAkJ2KNsACgkQtchshDF9KNb8KACgvadRI0iaLpshFL7QUlpjiUAN
T24AoMr+gUjQ9wHwvUGALlCmwG7+Gk5PiEYEExECAAYFAkOoG5oACgkQpKqztMCV
NbHbsACgmW9H1YQHoKYX43bCYm6h94+qoFkAoLXjvWleNUmZ8jfIARmUx6sxvZ2P
iF8EExECAB8FAkJs93wCGwMHCwkIBwMCAQMVAgMDFgIBAh4BAheAAAoJECakfGr+
bYUPWUgAoJ+bfzVQE4GTv4zERx5oUv5U42XHAJsEDChyaKIuCKnpEdF41zC3NIsC
BYh6BBMRAgA6AhsDAh4BAheABgsJCAcDAgQVAggDBBYCAwEFAkZJ3TMZGGhrcDov
L3d3d2tleXMuZXUucGdwLm5ldAAKCRAmpHxq/m2FD/guAJ4rLMHUNINIK6X9KmUx
W6LarTaD5wCgxLlSsT/mvtBzp8CwvvB5secXkqiInAQTAQIABgUCQ6Wo7QAKCRBV
YlELqnooDkHWA/9RyFfw1zXreSRmZR30ffSp9eThRkg6KoybpY5/DgupRTW8qgxm
KiIgHi5TKikpwUZoKj64RuB07LAk0LzyxTNk6sY90+HNUc1ZHYJV5rRG+yYn1xHP
xEErbkRnsppPgzu2J95CBfbQgt0dM7jyktzyYAG47e72jkOrkOxzzECNPIhGBBAR
AgAGBQJErt/MAAoJEEY0I5Nj9gwsZLoAniQyqdhjedzDXYrwXeFF4fq+MLpFAJ4y
wzWIPxiPS/3u7frcmJ2jT0c1oohGBBARAgAGBQJEsUZXAAoJEJTDy2TSbRi8IwsA
nAyek7uDf4Bhi27e0KRw2grnc9a6AJ9QrZCqg46tJTVkwIiuIw8UnRmoLIhGBBAR
AgAGBQJEsOa7AAoJEM8opP8z1LbGQncAoJcv/cUdiPyDNywU3iht/VJjDLcVAJ42
Z7DM/C3H3iMCLq3XRvzmjJtMmohGBBARAgAGBQJEsThWAAoJEPHPFQgJyXlaTB0A
nip2COgcfBIkUpoiCXt0er1Ndk89AJ93PNfOBrO0NOiIAMBO4b3dQn/LsohGBBAR
AgAGBQJEsj0NAAoJEGwxx7NpBHVSLJQAnjOwNF3UkbnrkDTmY4IRuGsm0ogQAJ9o
2jnNfuTcfF5QL+CPqUAJ11ZttYhGBBARAgAGBQJEs+eOAAoJEEU8RUkCMNYCmZIA
nR9UWJ8siJUp/IyQ+3NSHDP/9e34AKCXIs7YmLufzX0XFQ1g7qj1N9Pm4ohGBBAR
AgAGBQJEsOw3AAoJEFkymUKhHnTsHAgAoJDXDqDsEQrgJJti57lbq7ar3MA9AJ4t
Zxp//d2FrkxvvfJVViaE1jjqgohGBBMRAgAGBQJEt4+2AAoJEDRNtjiDUpwqOYoA
oLTwk2y87noQJmMyI6L4k+q+zfrcAJ9yYWPqy5HD2Z9GH2BHPN3jmiVJH4kCHAQQ
AQIABgUCRTyUJwAKCRAmSeYoxdNNBWajD/0TsUjlyyoNYzkSTUKglVwKd9bx4+dk
Cvl7lgjhKDtPvyhEeukOlwfxNY2KO/H4cQe4F3MuevNHLxf+3ydxfdnx/QO9USoQ
ZhDxTObocyLjNlKrDSBqKWJ+s84CMgCyKW1BuTzFyOq7rLXWxoQZYGSfNY3DjjnP
yfvoVbG6rRRLD6BBjMpapGGfMXBoAbs8IgcfApwoVFLrR4BcvylCS4jgH2eyim4J
j510XZTqURQLrJBvCo+fxEmxYfzl2ipHf7AKXlx/zzST46dHGkRSIYMqEjsRpTNR
BqvqRBU+IvIAeUXqfUImSeZJQCKfcWpbA5kORu4ZQt1OcX/q95mlq5cWXfNdKqqW
x5RO3kCpgz/IyFdCMFjasP1brQUHg8TapPB0Al1Kilm7tRzU+OIsE7YNBub7IwB/
8gE0BBtkcMFE9zfv5C4y7wPMlFu7t6qS8Xk5WcZ9MjkN714mi6wcRn1MocfeUnq1
+Zho4IiiNzJPp4TMjHYtjm9xX2+bUP5x998GaH8420wAtO8T8JtvU/K1kWLaNfyx
OkGV2obFA/0MXNvDu40VSJykaBaOAFy9ITcK6Iab/K93ppvnTNnW3W5qO+YvGUoK
cW8zZM7x7JkaZVwgVh7225YqxbER9tfYdHGCGliEeKhl7YQnYBCR96mTFmcrmGeG
I3arj891FC20q4hGBBMRAgAGBQJFr+q/AAoJEFaK6ScFFSqp52MAnjMjbcLtaUDJ
cW2/kTj1MeYM58IcAJ9zQOF3bv8n5vsOO8FcmLFH39IS0IhGBBIRAgAGBQJF2a1b
AAoJENXkzjzP+fsLtY0AnRkwaB8Uf4H6JDUPE87iv/t1w7e+AJ9RbddbphHb2/wI
1JORfx9Li0K154hrBBARAgArBQJGC47DBYMB4oUAHhpodHRwOi8vd3d3LmNhY2Vy
dC5vcmcvY3BzLnBocAAKCRDSuw0BZdD9WOiJAJ0VJO99RhSWPRi/lj68Mvfqyilr
hQCfTOVqrVG2n6b3g+KHig2KnYiH6COIYAQTEQIAIAIbAwIeAQIXgAUCQ6f7MAYL
CQgHAwIEFQIIAwQWAgMBAAoJECakfGr+bYUPXY4AoNXuw+zuMj2rxTsruKMcF2Ij
KJ3CAJ0VP6J8KzHFlMfBpdEEuI3V5d4PnYh6BBMRAgA6AhsDAh4BAheABgsJCAcD
AgQVAggDBBYCAwEFAkX6ovEZGGhrcDovL3d3d2tleXMuZXUucGdwLm5ldAAKCRAm
pHxq/m2FD0vaAJ4hK6sOxT5l+3jMlTXVj+xy9+zmcwCg5af+ISeWnNS0EjAmrPP+
Zwct/lq0IE1hdGhpZXUgQXJub2xkIDxtQGFic29saWdodC5uZXQ+iEYEEBECAAYF
AkJs+aQACgkQqYYpzGz/vmf7XQCeJHjP6NyAbrXDisGNDcBJSipBI3oAn1Co1zkO
5NUKBT4u7taXoeKai5YfiEYEEBECAAYFAkJyJGIACgkQoE/7G33K6dN3AgCgpvhV
iYYrAm0LudK+xcyM5u6UMZsAn1/u78652P0baaF4AJc8+kqDYgrOiEYEEBECAAYF
AkKIqhwACgkQDMt+/gswqTvoBwCeOH+dXSfx8OOqiPvsJGtkITyfZlsAoJfWTEGV
8HlxStoZmDVXSr5oCYJtiEYEEBECAAYFAkKZ5xoACgkQh9pcDSc1mlFNpwCfRCaC
6HV4kn41/QhiafH255fqEZkAnA75h9SBEPBuG8y+J8ORWGceCKjriEYEEBECAAYF
AkMDDv4ACgkQjXuNhGjsg5TTjgCfU7lncHHMN+c1HvDvWtoNEmNrgtgAn15qBmaq
FMFI1yu1ZEfebGUsqy3kiEYEEBECAAYFAkOlbhkACgkQvSNZf5pQtf4dmACfZHjl
UewODZBCPTgFc1l9veRKO5gAn17K+aAAxjz4akIVRI50aS/22u4WiEYEEBECAAYF
AkQ5KVwACgkQdGyf/qVz8Q84TwCdHDI+1X1YreWOv2I/ocz5nMtSn00AoIqwaxrj
tXGrq4/cA+e59Ux3/fCriHMEEBECADMFAkJtAA4FgwHhM4AmGmh0dHA6Ly93d3cu
Y2FjZXJ0Lm9yZy9pbmRleC5waHA/aWQ9MTAACgkQ0rsNAWXQ/Vi9CwCeMngv2djr
LTWBYLopHC49d4kcxIEAn3BGDvpTUcTNlY7LXZGGAXL1tLrhiEYEEhECAAYFAkJt
EbYACgkQktwjcC7SSBInMgCgtUspLyQebmmH9rdW7WKt2ZiflrMAoJEkib/cnPJ5
jaekU0I0WaEXobmKiEYEEhECAAYFAkKKkdcACgkQIhjIHo58A/96zACfV2mhAAVE
x8qkUf0zqjokg1XOD2cAnAg1kIcaKXNWMz4cb1yywp3pH08oiJwEEwECAAYFAkKL
GgIACgkQH3+pCANY/L1fqAQAjKlRczzgB+qq3CUajoUxRqvfRhVgyk3Q5PDMA53e
fTh5EQqpBzxNlMBdPJcGnS+zpV8/ywKUNtmhO3wT8IAQ0LYfTzD4kVXzPgTdcc4v
3tzZO3HYCn3w3xVGpE6+pK7ebj7Y9g8zNlze+aphGyohRA8A1avid7tUCRX0kotX
vLGIRgQTEQIABgUCQnF75gAKCRCNSU00xw69UDSiAKDIL1c5vwNWFqbzbt4ubmO4
GLx6zACfdKNpZPtHU2kqQzGRE6VNHCxGspyIRgQTEQIABgUCQnYo2wAKCRC1yGyE
MX0o1r/QAJ0UQtGyTZ/n1O6xRmumidA12LTW5ACfco/smbIfWaVjkiqVn3/us+78
4fGIRgQTEQIABgUCQ6gbmgAKCRCkqrO0wJU1seq5AJ4sBKT3LDZxYM1qw4BDnkEq
f8p+JwCgr4WQtloaxOpkzJvAFtqDqmTQX2+IXwQTEQIAHwUCQmz3EAIbAwcLCQgH
AwIBAxUCAwMWAgECHgECF4AACgkQJqR8av5thQ97awCg68Y9wA0K9MlXfEOMQSjP
vi6JVBoAoJ7etnPIVdOJb9XSpHOCnaB32xv5iHoEExECADoCGwMCHgECF4AGCwkI
BwMCBBUCCAMEFgIDAQUCRkndMxkYaGtwOi8vd3d3a2V5cy5ldS5wZ3AubmV0AAoJ
ECakfGr+bYUPI/oAoNtAz5cMhToAaUUlQX9yTOj9n6i9AJ9kQTLmXqtI2nQoesOa
hUdOqaItm4icBBMBAgAGBQJDpajtAAoJEFViUQuqeigOg00EALa9dlfQrwQQeNz8
cQz1xSVqaMo0niMqOT67y48X8s3ZMgLfOku7N0jyvffG3XvO/8WIXIMg2NV1eFBA
KZdy6DSekXV5DxM9+LOnDMocUcbgK3jy3jLQ70TH+8wWZkeJCa3lVo3FgEXYoIDh
fNsqcoo4cr95D1ZiyGHEutnpbXyBiEYEEBECAAYFAkSu38wACgkQRjQjk2P2DCxd
vgCePGkzymsz99Qunf+qkvuUyNfRa1cAn3VKsQOiaVIStNEFnRRnXe12uciviEYE
EBECAAYFAkSxRlcACgkQlMPLZNJtGLw7awCgoF/lmgCMCq5X1Vfbf+rma64+JjYA
n1tfgMWY5M+B04/TI0AK1dO+NtoiiEYEEBECAAYFAkSw5rsACgkQzyik/zPUtsaa
UgCguQ8iNfeLGTHAU19C7XOV73YyP1wAnjignGKLOdOxpTBWCCWAU7e3lP/IiEYE
EBECAAYFAkSxOFYACgkQ8c8VCAnJeVr2NACfev0jm8oXxD2Rq3cwJkp6UkIwFSIA
nRkbGmuP/ftwRrGifKnHB7pZevMAiEYEEBECAAYFAkSyPQ0ACgkQbDHHs2kEdVL1
4ACfRxdIC3tUJzIA77U9jl+oH/yh6iIAnRn/g+Vb47eGNKe0XxIr4+LEDIdqiEYE
EBECAAYFAkSz544ACgkQRTxFSQIw1gLNVgCg+NAnyXBe+SvocVEfUKUZ9LxOfKMA
oMaB+EDrYQp/fHOXJ9dfsbk7xujdiEYEEBECAAYFAkSw7DcACgkQWTKZQqEedOz+
/wCgkWuhE1xwiS/2rJywaKmZ2mRzhsIAnj9MdXSHP94wj/Qc7gXmB94aV3kYiEYE
ExECAAYFAkS3j8YACgkQNE22OINSnCp8eQCeKJrANbQj7O+twULYX+mFLhabif0A
oJJ39ssJgq268MAus6njYYL1enrKiQIcBBABAgAGBQJFPJQnAAoJECZJ5ijF000F
JqwQALVcYYVbv9N6Fr32x0W218Lw0IEMRP9+juSUdgWZv8DrBqCnNE0AdqNBwGjq
krbfoNpCqYYkZtsrg1NJ6AngP0/mktqgzad0438blrYivGoabhXliawXcr++ciBi
B4G9PlIm3NqmG8K43NWVDVSn6o0GBoefCPzHaRkaSDPNFx/OzycNApdSI2juZ+H4
Vhqwja8G2kg1t4WiFmZ+5Q8ZXwIuLEl/vmij/mrC3K4fXETzDs/vaKCpF/MgaB2T
xYssNaRaNGCqNWo/UhKxGzCz+ub/IH57l3bLOK7dSVRFD5D8EB1rd+WXbtF/K5ri
OKRk/SnyzpTE9I++2FbAsUBMZU2+DLwyHpeYmcapKxIpECpRV7XEJEUIQaGmEex2
GaklfrLLDSaPXQ5vJeBmAcvtpobnLTFNAtOnikIbNVjpS8biMzFOgQpwVvzAScSW
wxLG06ZhW6yBhoJSNUzu4nq4P6OvsYqOGFOeqqX7gPrlkxHOBV4Ta8uN7g6uvkzy
bTJ7RuaAoa8Y2S7u3ZCYZPKZ2w1nyUP5o1855JEgr7jDbqQP2T6I6tEgK4g8iSA8
b7NawybxE9drpGSCOXbchQZOwjvfMfKRtL0A/SC9zjONN1a/Gg9HrF6sh2dZyD3w
mbVEZi966oLli864lv7UzJ/PktgRpcAJgX4L+04+iXPdiMqsiEYEExECAAYFAkWv
6r8ACgkQVorpJwUVKqkmMgCdFmcd+4Tvxw5IZW75ouVrXAUsyoAAn1xEFgtHvtFT
k5XWI0L3IroV19UoiEYEEhECAAYFAkXZrVsACgkQ1eTOPM/5+wv1SgCcDlMdRo9O
hJ5rgxvS1uolzcTA/RIAn2bbx/7q6vo1vjeSvoD2wjfxgu6eiGsEEBECACsFAkYL
jsMFgwHihQAeGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9jcHMucGhwAAoJENK7DQFl
0P1YYgwAniCdxrs/ueyLNLArYvY7/wp4DqFxAJ9/jcr1eGXAPTQrQOsd5Y5sWW9A
SohgBBMRAgAgAhsDAh4BAheABQJDp/swBgsJCAcDAgQVAggDBBYCAwEACgkQJqR8
av5thQ+TtwCfX0TnBmmltkHOJIIGneo61GchpkoAnjgKQ4nklchEnRELbfOGlP7l
87ExiHoEExECADoCGwMCHgECF4AGCwkIBwMCBBUCCAMEFgIDAQUCRfqi8RkYaGtw
Oi8vd3d3a2V5cy5ldS5wZ3AubmV0AAoJECakfGr+bYUPyBQAniQXQMNmettxevYA
4JWn6hhFKHpVAKDLkDOWh6eSeaQ68zog4wXJs2KGErQkTWF0aGlldSBBcm5vbGQg
PGFybi1tYXRAbWljcm9uZXQuZnI+iEYEEBECAAYFAkJs+aQACgkQqYYpzGz/vme6
2QCeNXYLIg1iwtHH5/yWu2kV96rj9KYAn38UmcOODF/G7dAgIFvL00kTGnSAiEYE
EhECAAYFAkJtEbYACgkQktwjcC7SSBIKlgCeL5mCRJJqY8ft/YEB7+XvAcls7/sA
nRH5oVDQ/VvTv1QNWlNKTfqu4/7CiF8EExECAB8FAkJs9yICGwMHCwkIBwMCAQMV
AgMDFgIBAh4BAheAAAoJECakfGr+bYUP7MAAn0bwnX2/cQASBpczElxQtnXp4s2I
AKCMEMvO6N7Kqrg73GhPpeziH0r7EohbBDARAgAcBQJCcJUXFR0gSVNQIG91dCBv
ZiBidXNpbmVzcwAKCRAmpHxq/m2FDwzxAKCAFVstFv3/0CCrtINfrOisCKRg4QCW
OzAa51YBIrpb6JG9O/XRiz/Y9LQpTWF0aGlldSBBcm5vbGQgPGFybl9tYXRAY2x1
Yi1pbnRlcm5ldC5mcj6IRgQQEQIABgUCQmz5pAAKCRCphinMbP++Z5HCAJ9qY5tZ
hao8cJ50UCuK3UUPqhUmFQCfa37pemBs4kGyYC8qDT1tKaraoyWIRgQQEQIABgUC
QnIkYgAKCRCgT/sbfcrp020CAKDuoLoaXrpX5waE86fRV3PrHDRxxQCdF0nTzpgS
ZBtYyqKY39KMFIX+CrqIRgQQEQIABgUCQoiqHAAKCRAMy37+CzCpO/ixAJ4+Jeuq
aLmLwWXdvla3M9EO1QjvYQCfVtnYoy0wc4OWbtK2WzynjhRNde2IRgQQEQIABgUC
QpnnGgAKCRCH2lwNJzWaUcMqAJ9Wk1v10JfnvVxFrf1BV8i+w9OpuACeP5ZoC6Vi
vXlwfT96OsyXrD6vuR6IRgQQEQIABgUCQwMO/gAKCRCNe42EaOyDlBAWAJ9VYmvb
OiduYq39vCqu/LNX85/sZACZAY+aIRnbrGR15SVFm62JHoB8T9iIRgQQEQIABgUC
Q6VuGQAKCRC9I1l/mlC1/gtPAJwLdv2D/ex805/V2ahHbun+eYV3mACaAtCQkOKV
S5ThfyfaFIIbThyr+nCIRgQQEQIABgUCRDkpXAAKCRB0bJ/+pXPxD5phAKCbRXHJ
/d3EWDj7qSgLYpvsVAJEOwCfaZD2Xy2kzFQdP+HUnn3OwAeJ1dSIcwQQEQIAMwUC
Qm0ADgWDAeEzgCYaaHR0cDovL3d3dy5jYWNlcnQub3JnL2luZGV4LnBocD9pZD0x
MAAKCRDSuw0BZdD9WJi7AJ0aQqClPgeROgqq62AnUuqh67VIkwCfd8LrDAtnYBsj
+BsTHvCnRKrcyhiIRgQSEQIABgUCQm0RtgAKCRCS3CNwLtJIEjgjAJ4hi6LVd9VS
FLl8h/5g4hFRw80hUACgpSRiW4/ERFsf386mBs0bIn8PCciIRgQSEQIABgUCQoqR
1wAKCRAiGMgejnwD/9i/AJ9exHLfgknKMURry/damhIzFao7WgCfaDgyQRjUoojN
cBHsRzz8bIM/g+CInAQTAQIABgUCQosaAgAKCRAff6kIA1j8vc2kBACkXmPTkesu
WmQ8WlphgMqqg1XmMEZqFfev/gZZ5iYQ3IJ7ggqedc7MROd7Tn57DtGohiqlKdrp
etmc9KrUb0PMWXDMJ/L84wE4Rb2H/Z9mAuNY/n0IoMA/Z0Tx8IHrnE3DBtENl9BB
KE78ZwUfW3N+ev4dduDsGfm4w/NkSlKazIhGBBMRAgAGBQJCcXvmAAoJEI1JTTTH
Dr1QY1YAoLYf8h33mnENvmfO8+L9GiJpWuBnAJ4oJdYoNVlY7xblXAXtAWr0JL1S
BYhGBBMRAgAGBQJCdijbAAoJELXIbIQxfSjWyxUAn1t0NBAvclSBfPY5nC85auTM
2IHGAJ4/XWbiqS1PAXeQ04hYuDli1oqSWohGBBMRAgAGBQJDqBuaAAoJEKSqs7TA
lTWxmWEAnj1z+DapdZtRFzR93ksOkuV4h8kTAJwP3cVV5lYWQUGVMQbea2BIf/jv
z4hfBBMRAgAfBQJCbPdFAhsDBwsJCAcDAgEDFQIDAxYCAQIeAQIXgAAKCRAmpHxq
/m2FD/gRAKC+z4vclxbUBtadk3nVEZmWkthG6gCgmvLc5nIjaMWpQSYythSaAcBb
LKiIYAQTEQIAIAIbAwIeAQIXgAUCQ6f7MAYLCQgHAwIEFQIIAwQWAgMBAAoJECak
fGr+bYUP4gwAn2fMeUqcVwZwvtRqnIEPlw9I6CSzAJ0f2in+KxQSuwNo1YBd2UT5
RT2gkoicBBMBAgAGBQJDpajtAAoJEFViUQuqeigOhbgD/jwtx+EV385xk/fdQliH
fp4dX2TViwKRASSvBhAr/4UdJCGYu/LCfzkduQg3Di0d5ueMI13NqE+QMGhRSuW9
l/ANR2qE/dCW3PZFWBJdMoG9l80ACuOSOxx6EDHJZrywCivVp5lIwTG1dacHh5Og
eQkuO3UjvJ6cFR4bZoahZ343iEYEEBECAAYFAkSu38wACgkQRjQjk2P2DCwMIQCf
emqfBpXYe7pONtMKyyoY3mZUvWoAn09wtyYziFiVlOsAZB73wlfiRdEciEYEEBEC
AAYFAkStJ8QACgkQ32vf+TG6PzrQtgCgk6LeXX+085udsDUtN+gwoE8r+IIAnR7k
w0tXFS8TpGRync5Wsg12CptSiEYEEBECAAYFAkSw7DcACgkQWTKZQqEedOx+XgCe
NT9NHtZudylYbEymKXET/Mta28EAniv71H9DBWK5BdkkkNT2IWN5dcMQiEYEEBEC
AAYFAkSxRlcACgkQlMPLZNJtGLx1vgCeNU604WQJlA/TaSH79dPBbRDx8CEAn09p
urvt1UOsoFd9kHsOh36jyL5niEYEEBECAAYFAkSw5rsACgkQzyik/zPUtsZLjACf
TFw6lnGNT/kPXsXx31KI8ff2kjAAoNFBEpY4Y0R1dQFDFdBp3DebJd2FiEYEEhEC
AAYFAkSs5iQACgkQd5FD2Z8azpwF2wCeLLO2OHrAhFXznJYkRx3Ga8P5u74AnRsd
oiTEahiexlo93SOZRM/eC1dMiEYEEBECAAYFAkSxOFYACgkQ8c8VCAnJeVr24QCd
GeG2zQpCGyOGvAJM7b+mAnksycQAoJffqvhKwGPSYsQYhZkwWnghoBdpiEYEEBEC
AAYFAkSyPQ0ACgkQbDHHs2kEdVIDTACeP+HVMA5ZqpvU7vq7vbTpR056ydEAn1kR
F388sbun8NmiTapQ35QYAR5niEYEEBECAAYFAkSz544ACgkQRTxFSQIw1gIBEQCf
dF/CpcdY4bL7lva5UaNFo81gNJAAoIkZtXKiIY/OGl6t8zn9/r47S7MQiEYEExEC
AAYFAkS3j9YACgkQNE22OINSnCoFcgCggZ9dGPfpD0EtVKdhujFBIpqGtYoAn3RZ
f/8WScZOdN2Q9V5ug0FVrAnQiGQEMBECACQFAkXMXpIdHSBJU1AgZG9lcyBub3Qg
ZXhpc3QgYW55IG1vcmUACgkQJqR8av5thQ+HiACfSj/2igKujqCY3/5dgXZiIdAj
smoAniz+OverdxAmzIR1RkSCAk15zmEEtCtNYXRoaWV1IEFybm9sZCA8bWF0aGll
dS5hcm5vbGRAdC1vbmxpbmUuZnI+iEYEEBECAAYFAkJs+aQACgkQqYYpzGz/vmeb
3gCdGw8eQjbSFxpCn6PJQN77PtGN2BIAoJvcTv3Z02B3OpWwGQNX4W2fHqeOiEYE
EBECAAYFAkJyJGIACgkQoE/7G33K6dPXqgCgkPH6rXMsInhb0XVJ0JDPeccXZr4A
n0pVNyceImW0CYbuoeSc7sCxAo4hiEYEEBECAAYFAkKIqhwACgkQDMt+/gswqTus
eACbBlJkdNQOKkhyjGQa8iTkS0As0pQAnjdql3cAqCn2w6EPlSK5QvbUHZMWiEYE
EBECAAYFAkKZ5xoACgkQh9pcDSc1mlFy0wCfb98Iqu4f8/pdlco5IdGx6FGEkB4A
n1ldaOcrJZhcTpZWhnfavU6Hu8+xiEYEEBECAAYFAkMDDv4ACgkQjXuNhGjsg5QZ
nACfc+DBF8F6kDF8rxuxkClzHCspE8sAoIFOg4WRtzyMXKcoh5LZwLlOkrLliEYE
EBECAAYFAkOlbhkACgkQvSNZf5pQtf7FgQCgmlYxMrfkfV7xaysUgj4qs6qXXGoA
n2q7nMNle0D6hwMIPge/pNBNImJjiEYEEBECAAYFAkQ5KVwACgkQdGyf/qVz8Q+d
mACffJbZDYvwJLXUDCw4mgtL2vlqHEEAoJ5Xb3VR3HckiSod3oh/XAZEACjgiHME
EBECADMFAkJtAA4FgwHhM4AmGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9pbmRleC5w
aHA/aWQ9MTAACgkQ0rsNAWXQ/Vg6zQCeNBsTRdIF6CQsLk03AZKsaF3kS4gAn1lO
kbM542r0gca3RieVcbE1b5eaiEYEEhECAAYFAkJtEbYACgkQktwjcC7SSBJ1PQCg
nSByb5tOv8j0RyyDZy4uPOSMY1EAn16z7t9/gDqEk2oy0NRQKVGxbuTgiEYEEhEC
AAYFAkKKkdcACgkQIhjIHo58A/9IcACeNxBQTO/HIjcAZuNvjkV2z11xDAsAnRGH
5CggYGwKftlm2JNUxnGTQnBSiJwEEwECAAYFAkKLGgMACgkQH3+pCANY/L2hJwP9
GKPczI3zkokkuODjmL+wZyF9eOMacRHkQjEYRmY99Sf+UphCdTdNVps1W3XSYiMM
6Xs7C3tNlyobVwmraECt5POexo6b0yeQafTwKgPqFOGeymNrfHxL0orJ1ATOjLSm
KU3cBPP0ReWt7fKvPHHvs8+drjTAteDOCrR5Ugmuit2IRgQTEQIABgUCQnF75gAK
CRCNSU00xw69UMF4AJ9Ox8L+aM97fKHcnwh1/Ne3Ca1A7QCdGsBi9zo1eCzgrT0G
LhP3xsFIObmIRgQTEQIABgUCQnYo2wAKCRC1yGyEMX0o1ihVAKC43u9KWCGWdAkR
f43eOPnRm1MrtwCeKvvXMyGZfxaYwK391I4ztiZbrvOIRgQTEQIABgUCQ6gbmgAK
CRCkqrO0wJU1scceAKCaFE83vDirMo3eaE4WvoQlek9daQCggu+UIoR0z0CrGBX5
Fk5N/W/7u8iIXwQTEQIAHwUCQmz3bAIbAwcLCQgHAwIBAxUCAwMWAgECHgECF4AA
CgkQJqR8av5thQ9vnwCdGHYpFtCdxp4iVPSL/oCsbk7yryQAn1atFWAL0Eav9rUy
M/jJCRGh1GajiGAEExECACACGwMCHgECF4AFAkOn+zAGCwkIBwMCBBUCCAMEFgID
AQAKCRAmpHxq/m2FD71MAKDYqDTJTNpCUXCnfxREG88g8o5lugCeIlPJ4b9f8kaV
JOA2qJGYb3VSoFOInAQTAQIABgUCQ6Wo7QAKCRBVYlELqnooDhwQBACxTupc3ke1
BoADXRzUxXsc2Jzt15U8uCAdYUJFiMJgfgRUqh0PuZ8SZm0uFQdKM9P6A8Esk1WX
aHrbefPVXpJhwdeD8GS2LrQQaSLqOLe9R1YzerU8phUE0TKFUJkcQsdw8Yd/GP9C
DlTDd1PARYfl1xuGybDbjGDQKtHHa7IoHohGBBARAgAGBQJErt/MAAoJEEY0I5Nj
9gwsIPcAnRuauCNkuWfLisSWtNEcfK3s5nynAJ0eZ5MnAJuxb8p3eW485Uwu0Ble
GohGBBARAgAGBQJEsUZXAAoJEJTDy2TSbRi8avoAoPFx4qtJP7nvgpYB2n9W6tC6
rAixAKDWWTx4A86IzY9gR/VLhc/5WqCaR4hGBBARAgAGBQJEsOa7AAoJEM8opP8z
1LbGXYQAnjo/N+oNXHRQygu1CIjBKwsGf7SkAJ9J4Cq+wVC82DXPp5AxTBaahg00
u4hGBBIRAgAGBQJErOYmAAoJEHeRQ9mfGs6cjukAoMdqiaqtlE0uUXVnroQd6pg1
HJ34AJ45jdlLHGLYEmbNxvSQ2e7yzqe4gohGBBARAgAGBQJEsThWAAoJEPHPFQgJ
yXla8gIAoI9FRVDVJK2RkBDUS/R1DmZ3ZMJ4AKDPFBtzZrofyVGntnzi45zzZu4v
14hGBBARAgAGBQJEsj0NAAoJEGwxx7NpBHVSFh0An2v81CSoE6501Lmj4VTWUZm9
TJsvAJ9zBk76w+Jan1XveclgaIYeCmoTfIhGBBARAgAGBQJEs+eOAAoJEEU8RUkC
MNYCSHoAoJON/H1AEPSEAvJJegdVSbHdl3tGAJ9U5cKG8rti9tk4TWBjNSdSq+rw
aIhGBBARAgAGBQJEsOw3AAoJEFkymUKhHnTss3EAnR2K1wF4eMkABWhjTpELqky0
FAAXAKDcUF88mZ5AsmqYACNMb4MCS4JDxYhGBBMRAgAGBQJEt4/kAAoJEDRNtjiD
UpwqGCoAoKLpCy62tlx1+DZeaVkHSXu/659UAKCx27DWy+M+FjlaMTrRbZywOHkP
24hWBDARAgAWBQJFzF57Dx0gTGVmdCB0aGF0IGpvYgAKCRAmpHxq/m2FD5IAAKCJ
JTUVHsiyFCL5vaQM0iJdxGfQJwCg6U3ms82fMWec+dUePM7eTaVB/fa0JU1hdGhp
ZXUgQXJub2xkIDxtYXRAY2x1Yi1pbnRlcm5ldC5mcj6IegQTEQIAOgIbAwYLCQgH
AwIEFQIIAwQWAgMBAh4BAheABQJGSd0zGRhoa3A6Ly93d3drZXlzLmV1LnBncC5u
ZXQACgkQJqR8av5thQ8Y+wCg42FZmm6rQFzbwVy5t9f9SFkLTr8An2Yg9LSIXMnY
LdazHhbfXmsK760ZiEYEEhECAAYFAkXZrVsACgkQ1eTOPM/5+wt6MwCfWA4sZbaj
GgwH3ot0nqklS+D7WeAAniOHV1AgRErMe5jQzF8vrRs/L4TfiGsEEBECACsFAkYL
jsMFgwHihQAeGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9jcHMucGhwAAoJENK7DQFl
0P1YGFcAn1C4XpMp5EQufwPD67C2XgS4P7EyAJ9zKKT69jixkzthNZfSlNjeaTDf
D4hgBBMRAgAgBQJFzF+yAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQJqR8
av5thQ9ofgCg5+jjtmG+bAjwjXvNtgM8N2pFAOQAoIZgLSFRaN//ahkyMiNZAax/
yd2biHoEExECADoCGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAUCRfqi8RkYaGtw
Oi8vd3d3a2V5cy5ldS5wZ3AubmV0AAoJECakfGr+bYUP4lIAn2/wDtGoJm7Yxb/v
FDnOBKPmt0+lAJ9MMDP8jSzD0NTXD/InlAoOd7C/FLQiTWF0aGlldSBBcm5vbGQg
PG1hcm5vbGRAYXByaWwub3JnPoh6BBMRAgA6AhsDBgsJCAcDAgQVAggDBBYCAwEC
HgECF4AFAkZJ3TMZGGhrcDovL3d3d2tleXMuZXUucGdwLm5ldAAKCRAmpHxq/m2F
D9phAKCGAUL9wta0YiysQoCJwcag/us7IQCeJnkKQxslHXozayQEbCeCqbjZFb6I
awQQEQIAKwUCRguOwwWDAeKFAB4aaHR0cDovL3d3dy5jYWNlcnQub3JnL2Nwcy5w
aHAACgkQ0rsNAWXQ/VjJ1gCfdRgZSGhsTMjzuljcqwMQ3kVDCjIAn3mZdhGEWIRM
xbCLCuUANeuGpGHciGAEExECACAFAkXY47ACGwMGCwkIBwMCBBUCCAMEFgIDAQIe
AQIXgAAKCRAmpHxq/m2FD3mFAKD0lCha/IHk098f6DgHMFYtI/VAIQCdHvgVQ36Q
YXZtwXa1khlVgLEYbOOIegQTEQIAOgIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheA
BQJF+qLxGRhoa3A6Ly93d3drZXlzLmV1LnBncC5uZXQACgkQJqR8av5thQ8spgCg
vWBMjXSV3D8gyfwr8y9y2yU17iEAoPOmxhAfO4jCu+8U/3gGQWScKee7tB5NYXRo
aWV1IEFybm9sZCA8cGF5cGFsQG1hdC5jYz6IegQTEQIAOgIbAwYLCQgHAwIEFQII
AwQWAgMBAh4BAheABQJGSd0zGRhoa3A6Ly93d3drZXlzLmV1LnBncC5uZXQACgkQ
JqR8av5thQ+V9QCg7MTUBoxGLoB2Uk3wmhxCWWp5F5oAoKTE65leYuwM6MyDwDUA
2ja6hiMBiGAEExECACAFAkZJ3NgCGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAK
CRAmpHxq/m2FD9ZIAKDViBlYTpOxw3GVl86Y1SYOngPubACgkkA/QrUfQ5vnffwG
AThakLLO0R25Ag0EQmz2URAIAMd0clI1gYopRRg1DlUYfHDActVaDNo0kY7p1Lrg
Ib7P/HRcQ5vR2BC/DIfqBWrbzOJGG5jXFXcka+1ZRs2vbv778jHcixXSXaP28ej+
XxH3bERqJvWulRrFKYM8mEkG3SVNIMAfZeeUGlUX+Msyx6EVoJ9z8sVPa/p6ts9U
vVeBhYq9FAnW3szvuGENHUUqS96nA4php5QPwfsnMknMQd9rNjZsIbANzW6wLmIR
Jw9chZmEawYCi78umAEpTK7cVHaLfolaJHi2BR3gYvUcszEmF3CFi6DZtMr0s1bt
GH0frLXnrmgpq8zVvgF5TRrLjNC0CKe8Yn1C5pvTDXVXHbMAAwUIALQpboqByzh1
lEUNx6Q9OaVbfRtzv52YWqBJp0tdSBGAEGEL1sgurd//BiqERzLhnGptxSnHKdsP
3ZtOY9K3YmdRCWhyVZtt1nPEzomkOn/t2UBtIbrVcM6geVS+dsfwTgiiXReSuu2k
uot4Nk04KHSetDtxfm15933jJaHroQZeQKhYimlR1EuPzciPus40PzlSIHBsNoFK
z6qvgz3Puf3nnmafOdskh4aV7ogTIjvlnBYra7wuLcIpSLC7BQXuc69JVqP+5cG3
3hmj5Ool4Mfh5AIYb0Lj9D0yyJqo1UyCqbPeWo1lzj5xaspclMiCzoE77Hqd4LI0
54VOXzsXVYKISQQYEQIACQUCQmz2UQIbDAAKCRAmpHxq/m2FDy8qAKDsXVlB5MDt
ydMjrsBH+qwhoiGI8wCfdTd4ZU99kETGpnFIfO7mDHd1VEE=
=vtoU
-----END PGP PUBLIC KEY BLOCK-----
D.3.7 Satoshi Asami <asami@FreeBSD.org>
pub 1024R/1E08D889 1997-07-23 Satoshi Asami <asami@cs.berkeley.edu>
Key fingerprint = EB 3C 68 9E FB 6C EB 3F DB 2E 0F 10 8F CE 79 CA
uid Satoshi Asami <asami@FreeBSD.ORG>
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzPVyoQAAAEEAL7W+kipxB171Z4SVyyL9skaA7hG3eRsSOWk7lfvfUBLtPog
f3OKwrApoc/jwLf4+Qpdzv5DLEt/6Hd/clskhJ+q1gMNHyZ5ABmUxrTRRNvJMTrb
3fPU3oZj7sL/MyiFaT1zF8EaMP/iS2ZtcFsbYOqGeA8E/58uk4NA0SoeCNiJAAUR
tCVTYXRvc2hpIEFzYW1pIDxhc2FtaUBjcy5iZXJrZWxleS5lZHU+iQCVAwUQM/AT
+EqGN2HYnOMZAQF11QP/eSXb2FuTb1yX5yoo1Im8YnIk1SEgCGbyEbOMMBznVNDy
5g2TAD0ofLxPxy5Vodjg8rf+lfMVtO5amUH6aNcORXRncE83T10JmeM6JEp0T6jw
zOHKz8jRzygYLBayGsNIJ4BGxa4LeaGxJpO1ZEvRlNkPH/YEXK5oQmq9/DlrtYOJ
AEUDBRAz42JT8ng6GBbVvu0BAU8nAYCsJ8PiJpRUGlrz6rxjX8hqM1v3vqFHLcG+
G52nVMBSy+RZBgzsYIPwI5EZtWAKb22JAJUDBRAz4QBWdbtuOHaj97EBAaQPA/46
+NLUp+Wubl90JoonoXocwAg88tvAUVSzsxPXj0lvypAiSI2AJKsmn+5PuQ+/IoQy
lywRsxiQ5GD7C72SZ1yw2WI9DWFeAi+qa4b8n9fcLYrnHpyCY+zxEpu4pam8FJ7H
JocEUZz5HRoKKOLHErzXDiuTkkm72b1glmCqAQvnB4kAlQMFEDPZ3gyDQNEqHgjY
iQEBFfUEALu2C0uo+1Z7C5+xshWRYY5xNCzK20O6bANVJ+CO2fih96KhwsMof3lw
fDso5HJSwgFd8WT/sR+Wwzz6BAE5UtgsQq5GcsdYQuGI1yIlCYUpDp5sgswNm+OA
bX5a+r4F/ZJqrqT1J56Mer0VVsNfe5nIRsjd/rnFAFVfjcQtaQmjiQCVAwUQM9uV
mcdm8Q+/vPRJAQELHgP9GqNiMpLQlZig17fDnCJ73P0e5t/hRLFehZDlmEI2TK7j
Yeqbw078nZgyyuljZ7YsbstRIsWVCxobX5eH1kX+hIxuUqCAkCsWUY4abG89kHJr
XGQn6X1CX7xbZ+b6b9jLK+bJKFcLSfyqR3M2eCyscSiZYkWKQ5l3FYvbUzkeb6K0
IVNhdG9zaGkgQXNhbWkgPGFzYW1pQEZyZWVCU0QuT1JHPg==
=39SC
-----END PGP PUBLIC KEY BLOCK-----
D.3.8 Timur I. Bakeyev <timur@FreeBSD.org>
pub 1024D/60BA1F47 2002-04-27
Key fingerprint = 84BF EAD1 607D 362F 210E 69B3 0BF0 6412 60BA 1F47
uid Timur I. Bakeyev (BaT) <timur@bat.ru>
uid Timur I. Bakeyev <timur@gnu.org>
uid Timur I. Bakeyev (BaT) <bat@cpan.org>
uid Timur I. Bakeyev (BaT) <timur@FreeBSD.org>
uid Timur I. Bakeyev (BaT) <timur@gnome.org>
uid Timur I. Bakeyev <timur@gnome.org>
sub 2048g/8A5B0042 2002-04-27
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDzKgVMRBACCnaqx4HadaPu6wiCHEsqGN0ldtLmfgYzxBPDr/QDLxAxa5/DF
cfJhxx3x/ZwxOVPVqNlmXY+ZbD8RujRJYNkgP4gsFumQIvhMiUcM0ViR+6MNIm18
F+gjYKjUuME5GUyRXFtuPzb6HQdgOzKhwSVMyiKoAFmjqhVLqGOYUbMxQwCg/dQ7
7SWczXhbKDhLL7s9FIMSbLUD/3iz0fHSftOIFPSRrVPA6bvpKNIfv/XPlXTlVvqe
I2bsCFBhFDo6GA/jeOdhPRLiBpHQETXl3RsL9BQSuKNHitcnc0n4KSL8k1RjDcj/
cY2tqoW/WYA8W4vYWn3e9pjgsyHtOt1FbCjsm6bGdoKIZtJ4ezHyUu1u2cUNe7rd
xtIGA/9M49n/nXPTZ1EHnme6XIqGcsBoJnQ4IUxCFWZWe2Ng5l/QJUHnjDHjXam3
XO0trwOxgyybt9rlpwbRhS5M4oUVx3TWS7AZiU+FxPaYNbbEoOE7KmXORJ06tIZ/
EHPr2Ktt4gNsn4z2qla9VEDNfC+c6EdkzS6FbldUie+UJV6Wm7QlVGltdXIgSS4g
QmFrZXlldiAoQmFUKSA8dGltdXJAYmF0LnJ1PohaBBMRAgAaBQsHCgMEAxUDAgMW
AgECF4ACGQEFAjzKgVQACgkQC/BkEmC6H0edkACg8MpADILdNHD635oFbCq9i/Nm
YrMAn1kmJEQSo+pfb9oP/1G3YNZ6IOaOiEYEEhECAAYFAj42vX0ACgkQhdRQRWtp
GwPyRwCfegowGN8yOL/wA6dJ4WmCOdbzMwUAn2PYx4bZKjOcr08Abawzk4J4R1Hv
iEYEExECAAYFAj4asrgACgkQtN/ca3YJIodGTgCguz9TjADQ+fm+qmXUa3i6iWBb
hz0An1ltnB0X+kq92F7Gf5Zv/BVkRQHgiEYEEhECAAYFAj48BK4ACgkQ7PDpCywX
IIOsQwCfZ/4dnUM94rZwGS15W0pReflUm8UAnR9gX8nnu8tcXeUbPk4egPRW5iY8
iEYEExECAAYFAj9XV2sACgkQ99Q+k88Bfle5cwCgs1LBXAPXu/+IG13QY69ifLpy
2PAAnAwdijdGVaetTn9pIHNt6cqBalA7iJwEEwECAAYFAj9XV3cACgkQIkYMagPC
+y0PIQP+Ktorj9CX5t6Fl+kV4gjfT3wWIFIEPWuByoB96uJRyY9tHwELgYPb+etX
FdzBtE3KFUNS9+7yBWJeoQrd8sX8EjYBMxCtIqFWogx9A1fqrbgiKI3GtNOJ6AIS
j18XgaiTmtmJ8Js7vAfPVaM69wQI4wi2f/Gk16DG5vZlReUYzXWIRgQTEQIABgUC
P1dXJgAKCRBrasbbmnN0e4mWAKCA79XFhiNXVdUYg9HN+25KMsXZqACgtSQh3PjH
wWcIclf91rD6uGpdd0iIRgQSEQIABgUCQLhXTwAKCRA27/mqpwtSBzIbAJ4sb24/
rbGSyctwdFPQmjxKEbrNJACeKhP6gJSL4KvEvCDtlS4hEQ0R0IqIRgQTEQIABgUC
QVusZwAKCRAiylhMenujwNC6AKCkDYcLLeUZ2reDeqgOBEBf1GmemACePdwTXycL
08f68bsB19NOZmrubj2IRgQTEQIABgUCQVuvyQAKCRAhpkab0e+6pjWaAJ0ePfmN
IZgNPm/5xTiOsZnHrwQxBgCghM61JdvNmLFlZFAF1HIPLQlQEr+IRgQQEQIABgUC
QlgsvQAKCRCe11g/wU6ygpZ4AKC9AwM5iuGI2HwlZ8HwOX3DY287ugCdEDKabswb
sku4CgquIVaHLoNOTMuJASIEEAECAAwFAkLtYjQFAwASdQAACgkQlxC4m8pXrXyE
UggAob0tk0KxlIaayTnIPYQWwdqOiuzSezvDAAHnLLuOWop8PMsc8SXs/TeI/7US
LkP84ftLgQBYVVRJ+NuibqS+hXQTawryx67SqyxDVLyQf3VGoab+xTxvXt9z5JYe
dNuGjfRsx852BBj6biQidYkNjSpNQxJDpOs28gaL36oxHdt2F96MRg49ufWPXT9N
E2pIYP1IO6LO/XHeGLoyg9CxdSrtokX3DQO2+RKKC3LADfNnmoAcrGEgIy6aTVmG
tMNyWN/9scieBQmy+WJbYfSIXm6hirlk59rI66Rimg8Xl2Fje4y+ucO6LpIw0KTB
IU/BHyrnFyt2/Ub2b1Az3Sk3lIkBIgQQAQIADAUCQkcQ2QUDABJ1AAAKCRCXELib
yletfM2jCACXTZeu/NkIuSyTUi2MhgWQz8SeKPL/4zWqt+cKO48Cn0/eaX8ec7jH
RKqovzJsiNiLtszs5wGfZ/z3olWHuhMkQ+w1TUSpFqxfOIJg9vzvhbdmRSh/9cPl
6jD9s4shxK57snEasdWhun79mzKN9NGBv/Pgg9MtnUn7gWFS6pbVi4hjDQQWAQeO
ewQtgdlsq3m+Svp3KEIWsk33ywRqPNtBsojbWPVcIss/zbqoEJZ+cI0QL495odjn
/dcBTYywvBAAN6gg7hmwz4CPA16Tn/9XIO8r7RDMtKl4IeR+LNz5IyGzvIxkIzyB
zGktTCVLUrLVUWRyhsCm78Oe+KHkkt48iQEiBBABAgAMBQJCWM+eBQMAEnUAAAoJ
EJcQuJvKV6180WgH/2CZ3kKKM9XFIYriPIuqEDghwzH/TJ8DB+eZVDQr4O9Pw/JT
2lD5AXMpRsuI8StNeZT7B7Rn2t6lA1g2TeST/XItU1r9WJM8PdKJwM1Q7gemECv/
QNGYqxKw8ETLK/A34juu7ZRLPoDgxZgQK5MjasFPFb7h+D/8yDahSB5NIFqlN1UZ
fce46AXMflbTGqiQd/rnaw1/SstzlYtNhrFUv1lH0e/6MDQV7xvSrLD/RJYzt1Pj
Mzx5xBCktVGJmkEcQ+G3nQmRbMGljyeX7Xy+qNGcaLpjaC15ENSJOs97i69lZ/pL
pAXhN+IGpo1z8mY6hRTx8rW6VxoGaA/2whhfcUmJASIEEAECAAwFAkJp9GUFAwAS
dQAACgkQlxC4m8pXrXzotQgAhfcwyaKF3RfHj1ksALEMUNIgLcXyLf+60j96nkXA
5sjXohsWE2by7VvjUTDP2FZHv9NdiSKDU60BUGwTGWmjUVy+rHM8o82NdjtaKK3T
up4+HSg1hTiFsVBbjiNKUsgwnB4CuXy2+CXKPTKqwOQCiczda+t8UD6zhZKVv+yF
CKWNyXGmCt8mSYwh744DbQJbFM4cXrnCFweFzy9AaVXIpizy2UGq9muIEluQyTCn
8L1oelm6Gde85nSkBa4aHJnZ0lyUFe5HDscNRvLIRsiZRHICuIlyKzjgwAOa0k+y
++4W/h661q3TziTpFo9ABxI3gd0RYMiZjF/13T2xNWiVRIkBIgQQAQIADAUCQnxp
IgUDABJ1AAAKCRCXELibyletfNuXCAC1f9+6w5t44mL4c4uuUXvOKZHFj16Zalhi
SI2gxImhSxzHfWUchg9K5FN9KcStTi0JSSH8JXrkZ3kYYDwWBhE9xcuhdzUO+AOv
EEezKb6hKM2Ai7X+KOaRcfvaAwhrCYXTgk3Q/udumv5Q291d+8IqcRIJFhpOmu1c
Y1u5TotfhdQ7bIsWaedYz2uj3vLAVCIcHD0YAsroY+xeWCjrLdDqzDbKxsw0mqog
1uW0eolQ5aLKaQAgtcLjtmTDcJf4wSaDwxg3WGvBTEB0i0I1zwwdEq3ZQ2xIeFHu
Y3Zd/yF34D2ZasJ4UAlporLcggpZv/SGNrIAK6r7lbuoMQAGC1+1iQEiBBABAgAM
BQJCjY6FBQMAEnUAAAoJEJcQuJvKV618zgEIAIP63Uv83jw8UpI6LM+rr6bwPq37
W0oywF0CL77xP2KpwGj0R7lVfZFcaBcSsyjNnp7OeLZhQWEopup2Gzh7gcmUlUK6
UtKztjWMrhMb9lS1R7pTsISCn89Ysl5HKquBhEXAhtOkIGIeWUAE1C1QPm08VPnk
/GMlAdNsSs/MLD8039oPSXMBNIHc/K+Z9y49lMHCznETe0/zZ7ONma761PztwZhU
XLz2XjLhs9LfzC9pGAWkAE4bnB9QY/3UYC7y/+9QlD1Cdop8df37X1gxjctQdJNF
mx75XNPIY0uOBfmUaJ6uTddc2FKGTO//IoEuLxt3zoGNL8CHNpSaTDqN0yOJASIE
EAECAAwFAkKfWqgFAwASdQAACgkQlxC4m8pXrXznLAf/VdlZ5aoRCPIF3suttNzD
ZN+X7DJhrweNVjGFjPUcM1AXqH6dc8/PB4MDPSt+TpcjbVhi2M6lLkwqwFY9vRzr
Txg2ttYfWlECfvo6pPYUy0fG0lMpmWGucTio1Ze3x8P9Mzb1hrFDj0Y0sf+1Qj+s
Kfa4iDqR7hwuBXDX6NvQ8QxqLXynSx9cBn1xSKFdvo1l6g30bz+lmAq9ITYIc/a0
tNuUyNaR0EfMLFrD4IoT5u7mCwgykiLcMIOgKAnXHU1KzI+0eJ/94rC9+jbBXonk
9Kqm29MAkYN5HJi1YAfIAOqk5wkuJFUXk8k7+AiwJ7oq8d4YdAysd9bHcK+UjlAQ
EokBIgQQAQIADAUCQrKEJgUDABJ1AAAKCRCXELibyletfOWAB/sF4ym7oOoZw6t9
KYq6AVQclYG5rRZCtzbX0rNx7cSHs9jVU+tZgQkC8Cy73BS/x0YH4X0ghKguAZBX
9xllDHUOYtt61tURxXIFxFF8tHwarRSVbdS/K0S9dFh8Kq5D5RZZp8W6zKElr3nE
9cgRm3bJoWoTzXZtEBluhfyanKLcQ52jlocrvflC8a64xy2JdIbanmOcukZG1A0+
IcraRbANGJhNAxUwuw6+sEgmxdFu6jCyykxl0+xF97l7urnH/3697v0QTh9VxENb
GQS0gqTxo98DkqykT7KOwf6dT5Pjwa8XmJLltiUBHlx2QphxogK6ng2Ib5ztjzQX
ZfDNtxP+iQEiBBABAgAMBQJCtSlnBQMAEnUAAAoJEJcQuJvKV618OrMH/0RuHwcc
hYLPaxLOeyuVzsEg1VOwaB8y1SXRsjZCXtrMPO8sRXFmAvbDPC9/MeTa1Wr6mP4Q
gBxBWiqN5O2pEpaiXF5mcudxbZVCtITYtJVc0oEpPexNcsZT1eAr2iLEI3Zwf1Tf
ooQlksZmhuW2lGwx+zLdeHPkRLob3j55by89jCAUmwhbWwDzJtkA8EP4DenfLGjT
pD+7c04fVTRxJu52oEZHDpf7oAOm2m3xr5lHfj7KUDELvsK7hVREpW3yy6Mr20dA
aVtTDbI0BNfj89rCdtF5YSxs0DO8f/A9mIuF32EGzLoeU2LkNJxdGW0FGfgiLkdJ
qlt0K8JKPS2RdKmJASIEEAECAAwFAkK3JIcFAwASdQAACgkQlxC4m8pXrXxhDAf+
JRBguqmRrxC5OMjaKlYM0/+VfclrsSRDH4mk1u+WmshkxapWzFV8qNjLG9CcFGVu
cVwUpWNzPXPkboQDvrKJ5dUP+K6Jcu7f4E9KMAGJq4Drpi1ttMwUzSahG52mb5kW
rpLsmGrKqiO3wUsyyXCGC0nBiDp7/gLh69hZVstLEyq37jF0w3zIKiObQIPiHMGU
rHT3ACkChLGoFbaVyQpUd7DLBBwdH2ugqRp0nZ17vvN95gzgj1gzamav+ofVdpFM
2F8AGQK0SqwqC4UIhcToQIKmqLotWEOeKg6CHc63pFEq8fvyVubT2LX+6BoHTUqE
5Ch+XxYAjgJ/QSsnbSkOGokBIgQQAQIADAUCQsj0IQUDABJ1AAAKCRCXELibylet
fCcxCADDI247XgstIOK6XzvADRDaHkj4ePk9sBZA4HXUb2WUIYsVS5Tng1qLcrUY
SRKL7GF+1C7nH2/axKtOvarV/I9US5k0dLkgcDT6qooHaEimxQ3py2q9rOca3BGr
KLjNW1h77rirEUt+ZVnHKDjTzxx+7lTVg1iXZJJhGDAa1LZ44kDeaMlxkSqapIhi
MbVc/sH6xgaMN8kqKbyqAy0MEA4IuUONol1OeyjEGEVXXE9P7gtcOjvNGDlFvEi5
P9w7RGDVI6KsGYp/udkiXirCQFBhVXkvj5/bOtL4J94pGFCe6cVHwnrR0pX1JXLv
vFY+Elqv4AN48dgOufttI4cylPC5iQEiBBABAgAMBQJCzD+pBQMAEnUAAAoJEJcQ
uJvKV618pGAH/2GwExKNF+RGhwN3ZwwHfq0tAytzRE9wiLSZ81z3/hmHWHkSwFGO
80/HOJpmTO5ed+nbftZsQFbQeKkrpSh5MmhEr60wkuQaabg1wDNnC5E2A2j0mzJK
t09BtTRT88Z1PrQ4kYNJr+PjffYf/M4nKJWhWqjNXL1zcqUtzfTW5IWbjpvSXrn+
T4TtnSuuYp0oYTqXkzuIdvmf6itGcAch923BrrriUTWa42QcN0sihXVYJKb4M1A3
apvivAfbEXfYMiLe4tiSHvgB8TgRMBf1zXXR6s7Ndz/3t3pVsKJljtwC7bBsNuVK
KrGd+zUGWgKjgjz0kuGnBo7jUxpeYbNXSC+JASIEEAECAAwFAkLRh1oFAwASdQAA
CgkQlxC4m8pXrXzAVwf8CtfxrZrpnFe2zOfbX8VYp9gEN8qw/9wiqpZHNDg8kGUi
gnNXf9qcnYANJowI1ACbQc2FuaLVy7ZMo5TbqY7o/gjh3JdMOQ52kNXDnNV0AMuD
+CGUybShCb4toOATMESW2D4USLj3JOD4mCRara6doAbNv/MVkk+KztpipuQSJYi+
Bw47P+UOqAii4aAYLDajVY/lHuuNPCjJNyK2DfgNPrxsp3Mh1R/SSlyXW/WkbHrT
wq3kAHyCX+K6DZOeF89xo6GdwF3SnaQGWPY3HM4zoQHK1N2Obn7Aa1fXid1WeL0L
UjKbR1fIwgVihiQmMPPoR4KzFpgLYzs9y+95A3aMcokBIgQQAQIADAUCQuy8BAUD
ABJ1AAAKCRCXELibyletfH5DB/0VWr+m4wCxWyppcJ4xQSmuzbJCIf/DlmeDKTuU
VoDEP5AQyXUQAqycW9ZMONnxnqtFIAXfUtxwsmbCasxn03BgPgQXkmv99QI4R9bG
780G5ZA3n0WnRDVNf2nm2A63EpRYOMHQlYzv2Yjr6UTjaVyeYP2fHycZOmZDY090
1w9/WR6F/d+8YmPCfciDkpvU1jp0cqIwl+NB3SHjitYusH0uENEwPmeRURv6W9cE
Tw1Szji8XZIzpEa/NEBg6wNsv5ML9+X15+/8OczeaY2JCH5H7MZaeu1zTE62svEU
7GF0uUVwrv+wqku0s3kPdY5ViWI6MaAnDBqu3pYNLyqTukHwiEYEEBECAAYFAj9X
VmAACgkQa2rG25pzdHvmMgCfWf+qd5DM4iIdhmp8JDZDgLOhtwAAniv18InDXQUF
EBLeLV+cayvW2OmoiFcEExECABcFAjzKgVMFCwcKAwQDFQMCAxYCAQIXgAAKCRAL
8GQSYLofR94WAKC5q8jfxmxsyhnZwTmtyTZ2FOgQnwCfbGopQpkOjDTVChafwety
Yvr7KwK0IFRpbXVyIEkuIEJha2V5ZXYgPHRpbXVyQGdudS5vcmc+iFcEExECABcF
Aj4bPngFCwcKAwQDFQMCAxYCAQIXgAAKCRAL8GQSYLofRyIxAKCoNYZHTaDHSs79
uXnC/ncU5avLvwCg6ZdSGBsaMR3vfbkQ8TgikhQaS1KIRgQSEQIABgUCPja9ggAK
CRCF1FBFa2kbA0OaAJ9sxdhm4B67VM8hyojrNx//sEBxOQCgjop2qQBHTwvIwSsA
5KC7Wuy7vhqIRgQSEQIABgUCPjwEsgAKCRDs8OkLLBcgg9woAJ9NQ/0aD31aVOhK
BMrYxqsXFsXxHgCglAMN45m14w3tXTMKu8dWJCFHV5aIRgQTEQIABgUCP1dXbgAK
CRD31D6TzwF+VwfPAJ9CNV8q+WP2K8jMojwOotnDmJOSgwCeI1nlUb/HlLALB8Wz
GacyQGx3Gb+InAQTAQIABgUCP1dXegAKCRAiRgxqA8L7LSs7BACjTDJG0wDABcwb
0B7Cm0OgWovvMUvj0YGF7rbLqg7NjRbynlaAPy0zBsiPh9GUT9/c1S5ddppzRXWo
IZoaiEr+qAUQrxgF6wT8EUfsoOWP8NB5yIIsmsLHVjGrdN13tqYkVmz4PttTqnlL
Qi5kAEZC6rYEi0afP4qlpQQRQ45SqIhGBBMRAgAGBQI/V1cmAAoJEGtqxtuac3R7
kNcAnR3ofQZU4RyKzPZIUWQ2MWlrgdJBAJ4ip/P6Tth1j+OMe9adQ37cJr769YhG
BBIRAgAGBQJAuFdSAAoJEDbv+aqnC1IHP4QAoOR3E7hCKvga5CncXMgmUJBApOp2
AKCNTiRhFlqeQK84kXyzlYazHZtzoIhGBBMRAgAGBQJBW6xtAAoJECLKWEx6e6PA
gQoAn1DJHActISXIcxz4uOgq+5VSDk4tAKCEvDMLQaC+esVqlnalxoRt180ow4hG
BBMRAgAGBQJBW6/MAAoJECGmRpvR77qmbgEAniYZLs65OXMwUhMtngCotG7sgEfs
AKC+XoymkU57EX/SfiLt6kDO+4Rc/IhGBBARAgAGBQJCWCzBAAoJEJ7XWD/BTrKC
jq4AniPcxMxogyNgCQKdYhQpAPGOSvC2AKCYyNvxz97vih2MxFl7cx/yTk+yN4kB
IgQQAQIADAUCQu1iNAUDABJ1AAAKCRCXELibyletfLeMB/9raHxdvPtMAzXKgKUr
PNJ2RdULowsfLoMu9hrMfUumoW2tBPvR2r0olltVF1Q1oPKZOc6nY+Lb6XxH5EBs
hyedak/bwUeTvNYaA+yZ0aeF6MSsCgrm08VtoqndgBaIlkvJGTKrkJ0WD5ww2c4Y
DaH7oN7f/R5XUSNVQFAD2EQkmGnLYnEmeA2TzUEr6Jb1HSeXYdva7kLGLcVdvwHm
cNi+lMBFiDQDmBaAWpG+ldDFc314kxah54imtJcY3kN/jvV1tyaU5p6j2vnFNPXR
mJAisJuVvLQJgyqAHpeq5xCo0X9uYgCju3v/8t7B0WpeL4kC2UeEy3TpUJRHtY9q
fk/FiQEiBBABAgAMBQJCRxDZBQMAEnUAAAoJEJcQuJvKV618j3wH/0LubsehIcdZ
qjZUamOWEjf6puWzjWctmgVVlxOfwNeyyrlf5x7GGNIse+uQqPZa1Tlk+LoUeB2C
zJLCw4xjxVSgOmXIi0bNk9MKLhLwnM3B/j2UFZO1WftIJEV3u4Ps0jh0vrvIfoX6
5+78IroSBDBqYugtt0N5sTu9t16fbqbh9VlQvnioKpTV/Evde//ie6EsRuZE/2do
c5RPsObi9jUJhz6bcFrPI7uJeNRLmX5WQ42C+nQO8NItZX8CgayRs0J3AFS3tSnm
5iBL9wMnRqKsNNxfM6yWwpSQ6PRh3GApbYY15N9HViUigfHFyOfg2n7NBsQB79aP
HRGiuwmIabyJASIEEAECAAwFAkJYz54FAwASdQAACgkQlxC4m8pXrXwLIAf+McSJ
ND6Sh6qrPw3A8rUQKpxN3ONycT6wuGFCz4npzyQKwzZ47bp98hZBSRT9iZMVIHRj
QOURfj1FDZyBzVIXHUzkWkimk2u3cVari0X1KC4I8PtH7Sj9AYHEHOQwB1G2J1Au
2iz03XoADBUPjUUQ6pPpfsadeaGTo85Ufff96UPPALaCvVc6IlUJ/2zrQTJ6LtLX
1g9c61h/wGikHq/1LaZ7gX2ahTjX04xh6r5k72oaaT3mOkmZM3WurFTaRpJoAFBZ
S15l1jnL18Aix4NsbITCNlvsajTiHuyvwh7zUz2ETZFkqAzu1h4KxBQ6D0BG7FI5
OGUTLDzkI8ex34iiJokBIgQQAQIADAUCQmn0ZQUDABJ1AAAKCRCXELibyletfMIB
B/4tb2rWNxc0EGy2VLPjMtipGNRn4ewmMP6BdGYUNWeuFwbNZmpVeXmbSQiQ9U+f
VbHZF40I6pCZ9lIiFTID5EnnsPN2pYihimwoPsyzPdGzgoWrN7U7K14HyNXhprdf
H0uSx3zWmtc2tz0U8si+6Isefmxu9zVcRyi4MeJ21+BsUoEcjqtXu2RaRi6Ak/ci
exneEE9BILLYBnt1HYtvJKr/BWExCsv4W2Lna+6HrPdq0GR/nkxs5fCXwRiOldyj
tQXrCeE8ciUE4HS1CaqUf5k2IA1m0rFA26pY8aJOvzAUwJjkhI5ZpeRzw6i0n6lG
lqbjN9HaKs3PyH0TLb2H3Sa0iQEiBBABAgAMBQJCfGkiBQMAEnUAAAoJEJcQuJvK
V618y0AH/jI+KjrfOqFyC1oJG64qRnIUk2TwDCoVPHS+qqfzuntr/x+XQN09/CxK
cMTnB5L/Rk387qHucfvSDkgBFnIeZCUCU58Rtd1u7TaUfL561xBzjtanqfeF3DbV
QW8NYSDn1TYbAj89wZiL1q7OcSxHgda7xUWHokrfjb94mpDHijFtW4BM3rD6BWGO
4X9PMkruzKC74sPmJnngtAwOffRbdkNot2xlo3KMmhiAeOYQGGbVqYB3BxnjLru1
f7HharnVrsKCq3eDSokPODn//CXVVYx0GEAjiElwq9jgN2DL57cbcpWNEXMXB2gs
DUEnmI7KGth5AUkEBP1Xd68yg3+PVQWJASIEEAECAAwFAkJ8aSIFAwASdQAACgkQ
lxC4m8pXrXzblwgAtX/fusObeOJi+HOLrlF7zimRxY9emWpYYkiNoMSJoUscx31l
HIYPSuRTfSnErU4tCUkh/CV65Gd5GGA8FgYRPcXLoXc1DvgDrxBHsym+oSjNgIu1
/ijmkXH72gMIawmF04JN0P7nbpr+UNvdXfvCKnESCRYaTprtXGNbuU6LX4XUO2yL
FmnnWM9ro97ywFQiHBw9GALK6GPsXlgo6y3Q6sw2ysbMNJqqINbltHqJUOWiymkA
ILXC47Zkw3CX+MEmg8MYN1hrwUxAdItCNc8MHRKt2UNsSHhR7mN2Xf8hd+A9mWrC
eFAJaaKy3IIKWb/0hjayACuq+5W7qDEABgtftYkBIgQQAQIADAUCQo2OhQUDABJ1
AAAKCRCXELibyletfGDcB/wPuGNNVE3xSr4w/fngaIY+J3whKm38cAroMvXFkQev
B3mjXruEa9TGGMQDJDoGrl/ZnGBGeIcfb3FxD2+i9qn7yL9erRUBhhBSX+TGrcE2
M6VsECq2FrgQU6HchWV2v1apmmQ1V+H0Y3JGukYFQXU/PZUWHepjOgualJJYwCA+
HU9ENQPpEjiPgZ0QaP0PdDO5ayAHe0+swSRJnRP0w70k2eVM+nfnh9xERHsZFH3c
jSlJmhhSfx2hveeGG6O/rE2bgPYiDdBEg286X17Qki5au6IkZvYtG4dgcF0VRdUx
toKtkGJ+icOBzRcxVU0AR/HR+KU9QpSoPR7lds0XDCd1iQEiBBABAgAMBQJCjY6F
BQMAEnUAAAoJEJcQuJvKV618zgEIAIP63Uv83jw8UpI6LM+rr6bwPq37W0oywF0C
L77xP2KpwGj0R7lVfZFcaBcSsyjNnp7OeLZhQWEopup2Gzh7gcmUlUK6UtKztjWM
rhMb9lS1R7pTsISCn89Ysl5HKquBhEXAhtOkIGIeWUAE1C1QPm08VPnk/GMlAdNs
Ss/MLD8039oPSXMBNIHc/K+Z9y49lMHCznETe0/zZ7ONma761PztwZhUXLz2XjLh
s9LfzC9pGAWkAE4bnB9QY/3UYC7y/+9QlD1Cdop8df37X1gxjctQdJNFmx75XNPI
Y0uOBfmUaJ6uTddc2FKGTO//IoEuLxt3zoGNL8CHNpSaTDqN0yOJASIEEAECAAwF
AkKfWqgFAwASdQAACgkQlxC4m8pXrXw50Qf/ZAnqSLD21fNnyZ2YgoD8SIs4ssqy
z+cA3PSb8tELIyRdU+Nid50K7VCscJ2xUlWzarrs/og9msglLtq9fWf3WgMs2IO+
FbRwDH8siokXzzeea0bM/CJ+QhuCGYwGMdhrhPEJBMBjU/STaz2ROy+2+SaKuG57
diLdFqEjp7x6GB+la3iZa1v6au85U1NdbvKb3KHHipimtUMI59XwVjoN1JMXdbyY
oqVLSlnglQ31IJzLiP3JP5HDVmXfLVbWzZhaOh+fw36n59yyZ1MVyCdZy3UN+w4w
/tjhjiXeP6vjXL+5C/BUKa4yMRdTgMl6l6/mmeNijseAD+/SOMSJPSD80IkBIgQQ
AQIADAUCQp9aqAUDABJ1AAAKCRCXELibyletfOcsB/9V2VnlqhEI8gXey6203MNk
35fsMmGvB41WMYWM9RwzUBeofp1zz88HgwM9K35OlyNtWGLYzqUuTCrAVj29HOtP
GDa21h9aUQJ++jqk9hTLR8bSUymZYa5xOKjVl7fHw/0zNvWGsUOPRjSx/7VCP6wp
9riIOpHuHC4FcNfo29DxDGotfKdLH1wGfXFIoV2+jWXqDfRvP6WYCr0hNghz9rS0
25TI1pHQR8wsWsPgihPm7uYLCDKSItwwg6AoCdcdTUrMj7R4n/3isL36NsFeieT0
qqbb0wCRg3kcmLVgB8gA6qTnCS4kVReTyTv4CLAnuirx3hh0DKx31sdwr5SOUBAS
iQEiBBABAgAMBQJCsoQmBQMAEnUAAAoJEJcQuJvKV618bD8IAKny62FOW3YP0UJ4
jNGsKfefmR/jVd4Lg96XnuDHhApvpmQ35lvzEJTwVGk+tUPpqn0kA0e/j3eC21oe
Tk4KXSPC82xXvZ/+eGXvoUm1u0eS01nkvLA3rDx8gMFvqmNvv2kKgI9Q2LPKSAR2
tgB9CVTijbRHgto+/QzU7O/W+Evf68kVpErGXLa7/ArtlS/C3gTWtb3josNLU9Qh
DE0Lda31fF8s8szTd9XwsLqMDZyw84XWjR+cUhQyQRgdSO0dtOFjqmCivz+JxAn6
Yud3u9ySDArI61tcf1+h+H7BNaXY9mx/K+E3Byti/LNeIY1dPOsWnkx4Gp5kc6vs
WhfdYYeJASIEEAECAAwFAkKyhCYFAwASdQAACgkQlxC4m8pXrXzlgAf7BeMpu6Dq
GcOrfSmKugFUHJWBua0WQrc219Kzce3Eh7PY1VPrWYEJAvAsu9wUv8dGB+F9IISo
LgGQV/cZZQx1DmLbetbVEcVyBcRRfLR8Gq0UlW3UvytEvXRYfCquQ+UWWafFusyh
Ja95xPXIEZt2yaFqE812bRAZboX8mpyi3EOdo5aHK735QvGuuMctiXSG2p5jnLpG
RtQNPiHK2kWwDRiYTQMVMLsOvrBIJsXRbuowsspMZdPsRfe5e7q5x/9+ve79EE4f
VcRDWxkEtIKk8aPfA5KspE+yjsH+nU+T48GvF5iS5bYlAR5cdkKYcaICup4NiG+c
7Y80F2XwzbcT/okBIgQQAQIADAUCQrUpZwUDABJ1AAAKCRCXELibyletfDqzB/9E
bh8HHIWCz2sSznsrlc7BINVTsGgfMtUl0bI2Ql7azDzvLEVxZgL2wzwvfzHk2tVq
+pj+EIAcQVoqjeTtqRKWolxeZnLncW2VQrSE2LSVXNKBKT3sTXLGU9XgK9oixCN2
cH9U36KEJZLGZobltpRsMfsy3Xhz5ES6G94+eW8vPYwgFJsIW1sA8ybZAPBD+A3p
3yxo06Q/u3NOH1U0cSbudqBGRw6X+6ADptpt8a+ZR34+ylAxC77Cu4VURKVt8suj
K9tHQGlbUw2yNATX4/PawnbReWEsbNAzvH/wPZiLhd9hBsy6HlNi5DScXRltBRn4
Ii5HSapbdCvCSj0tkXSpiQEiBBABAgAMBQJCtSlnBQMAEnUAAAoJEJcQuJvKV618
dzYH/iru/DPAUvViLWw5NbaP+Q/6HvD1qAfpsGat3063Cs3I1bJv6Dxkl9TIL1bH
PdMu4i7Snzogl0KjxYs61JxagYJIqG3ceVCB9fw8INx4hc2AHFdmFi1uzI/12d1L
uuXYMkECL/AgTtFNkMjgL4DqSec8IPVm53yPZ84aWmFKtZI5xgzjETMXxfd/PpeZ
cE1if17MvhvBzoEB03oisInFyUI1zUz9nVBQx591qOctN8wn5ePYS2CW3FKPQT1l
UBba1jp2UZo2R5PHybj5Moq4gZ7QXPKn8fHGXdF9OTXDSB9CPkUtKVq+mvJLuMXF
At2DTh2i1yLkue2V/LHw4EjFb2WJASIEEAECAAwFAkK3JIcFAwASdQAACgkQlxC4
m8pXrXzz9Qf+IUc55Z5BBhcio42hyH2EkkJMwZ96PeqNg8cA/nqtWEBf5Y8w6yY7
RU0dbR6PJm8srpdZ9nQiMFZHU8/7FYI0Izm/1EmZQ9TOq4jAHINvrhUMyF58m9et
1zVDdpFLCwg+HO3Y8WQy1ZNcLfO5Wu5qa9z8jR85QZ13OyC/V38wBPS3YIQygr0X
WZToanT+s523BxohTO2Q00Da/Cy0Rr+YTgHB6skThLQRkaX0LIt990PSm82RQ8tv
aSsP1P9818ABzlzFSDpTgP/RgDzSmCggveU7rGhOtHH9MJEgWiwdwu/Q4qV8C0BM
FWHHme6nyN5ws5kCVEpZMPkBubEwUaSkuokBIgQQAQIADAUCQsj0IQUDABJ1AAAK
CRCXELibyletfCcxCADDI247XgstIOK6XzvADRDaHkj4ePk9sBZA4HXUb2WUIYsV
S5Tng1qLcrUYSRKL7GF+1C7nH2/axKtOvarV/I9US5k0dLkgcDT6qooHaEimxQ3p
y2q9rOca3BGrKLjNW1h77rirEUt+ZVnHKDjTzxx+7lTVg1iXZJJhGDAa1LZ44kDe
aMlxkSqapIhiMbVc/sH6xgaMN8kqKbyqAy0MEA4IuUONol1OeyjEGEVXXE9P7gtc
OjvNGDlFvEi5P9w7RGDVI6KsGYp/udkiXirCQFBhVXkvj5/bOtL4J94pGFCe6cVH
wnrR0pX1JXLvvFY+Elqv4AN48dgOufttI4cylPC5iQEiBBABAgAMBQJCyPQhBQMA
EnUAAAoJEJcQuJvKV618S/wH/jCOVe/Vco4vHAQoWshAPNfYEBKR23hEnJC2Njy+
qWlfio3g/9W4GymZIefYU5/t5QTLM5VB+jf6YweXh8YdH3nPHNEItpRynAz3MeqG
+A36my4UkIthxZJ35uMsHt+Xd14SE0FxbWUI5FxE8f9H/VWvZEmgKmNH0VeE7U0u
kXshVHQ1XDp4SoeZf/xIC+ZO33G43FhtYvi0i3pz9ZbVTCNxNa0y5uhDddkHHOaz
7o3FITPKvi/ZKwVSEA77fHDUcI8eCoqEJzpjcklf5NETFXyS6qMLGQmE7CNaeOS/
/89UXn8zrLHyJXycQk9/sCyTZkPm6AWquECe1XYp4eJP7XKJASIEEAECAAwFAkLM
P6kFAwASdQAACgkQlxC4m8pXrXyN9Qf/SaUiREp76VFFad7yODdp3hoL6Ykp4Ecv
loppwDGU5CFOrir06YVXadGeACk6VAIxxJsDM6seRYQbQVvLHy4DIydZSW8UNVG9
EFMmmsScyKj1zQ/a5XZRvZ+g8n7GZzkis/rU566fBGVm1UKN3Rka84H96D6gsaue
hx7+NMqWRt5Bf67XAKBEEU5UOAF5NRsnUmvbSrX6WWDxm0LF4+rWvp64Ff89DIO2
79YulE2QnGv1Hb/5mPhoJjx+jMBn29WtvuzTF54O3Ue9TazmKyabCfjIzb6Lk/ub
oyaEHpuJFXQdd3yT26AfpKj/8oKRtDzm+l8aBqXZqdBzdiSxFBl5hYkBIgQQAQIA
DAUCQsw/qQUDABJ1AAAKCRCXELibyletfKRgB/9hsBMSjRfkRocDd2cMB36tLQMr
c0RPcIi0mfNc9/4Zh1h5EsBRjvNPxziaZkzuXnfp237WbEBW0HipK6UoeTJoRK+t
MJLkGmm4NcAzZwuRNgNo9JsySrdPQbU0U/PGdT60OJGDSa/j4332H/zOJyiVoVqo
zVy9c3KlLc301uSFm46b0l65/k+E7Z0rrmKdKGE6l5M7iHb5n+orRnAHIfdtwa66
4lE1muNkHDdLIoV1WCSm+DNQN2qb4rwH2xF32DIi3uLYkh74AfE4ETAX9c110erO
zXc/97d6VbCiZY7cAu2wbDblSiqxnfs1BloCo4I89JLhpwaO41MaXmGzV0gviQEi
BBABAgAMBQJC0YdaBQMAEnUAAAoJEJcQuJvKV618Z1EIAMJhy3TMTZVcCeiBxZFF
ybfoOQivK2bw3ANNn2ajWh7L/jVg/QV6Gr6mW6cyJvbcqQQzFSVDKZPJsolq2ZP1
BlDXmSfAfshkOVt1mOLZqhFDoLIXZPYg2CjhtmWCtX+Bn9bVRtTcwOnAE/IfJOkg
JDurYylZenHj1Rx+ENI/cCi04gq43XRNS1OxDUX8WaOpUgGUgB2HIRSPdpSsp8Nx
JUtvuAGyL1/bPFofwqauOcwMSS4d++DhvdaWqjxlIwZraH6AAtZohkr/5E6L3qVK
uL209pI3ODRgkQJkIlxnzcdZz+X26I2qKzdUvs5kzHedaTBKUXCWtSnbIC2+LG3A
i2mJASIEEAECAAwFAkLRh1oFAwASdQAACgkQlxC4m8pXrXzAVwf8CtfxrZrpnFe2
zOfbX8VYp9gEN8qw/9wiqpZHNDg8kGUignNXf9qcnYANJowI1ACbQc2FuaLVy7ZM
o5TbqY7o/gjh3JdMOQ52kNXDnNV0AMuD+CGUybShCb4toOATMESW2D4USLj3JOD4
mCRara6doAbNv/MVkk+KztpipuQSJYi+Bw47P+UOqAii4aAYLDajVY/lHuuNPCjJ
NyK2DfgNPrxsp3Mh1R/SSlyXW/WkbHrTwq3kAHyCX+K6DZOeF89xo6GdwF3SnaQG
WPY3HM4zoQHK1N2Obn7Aa1fXid1WeL0LUjKbR1fIwgVihiQmMPPoR4KzFpgLYzs9
y+95A3aMcokBIgQQAQIADAUCQuy8BAUDABJ1AAAKCRCXELibyletfH5DB/0VWr+m
4wCxWyppcJ4xQSmuzbJCIf/DlmeDKTuUVoDEP5AQyXUQAqycW9ZMONnxnqtFIAXf
UtxwsmbCasxn03BgPgQXkmv99QI4R9bG780G5ZA3n0WnRDVNf2nm2A63EpRYOMHQ
lYzv2Yjr6UTjaVyeYP2fHycZOmZDY0901w9/WR6F/d+8YmPCfciDkpvU1jp0cqIw
l+NB3SHjitYusH0uENEwPmeRURv6W9cETw1Szji8XZIzpEa/NEBg6wNsv5ML9+X1
5+/8OczeaY2JCH5H7MZaeu1zTE62svEU7GF0uUVwrv+wqku0s3kPdY5ViWI6MaAn
DBqu3pYNLyqTukHwiQEiBBABAgAMBQJC7LwEBQMAEnUAAAoJEJcQuJvKV618t4gH
/j964zrhCIQYFtps4tDJW20XBtmfyjium22h1ZQwsF1WlnhTUiWRaEpdDhxCHE8i
U3ykQXZH9BzO7cWm/Eq2K20+xx9aWCYH02k+eFZVFED2vDEkfXUndvI3SEwYdQoa
qfMkoUZPWir2quyRH82gtfEToPOJamNn6X/uXFTCPmG0/uL3s+fe1XDkB+wD+Evb
108ODifY6bN4kNpDPoy05InXWj6eU+5r1yg78yv0+O4lTqzbPqnD1zV7klIFa7it
1hmzKSHi6bTCUVGCgee6shKJVaXHAIpS+nWKx+W6UyzmL2zk63F1nRvif6Z9sFY/
IFh5I8zKyuw6M24CW6Pp4jKJASIEEAECAAwFAkLtYjQFAwASdQAACgkQlxC4m8pX
rXyEUggAob0tk0KxlIaayTnIPYQWwdqOiuzSezvDAAHnLLuOWop8PMsc8SXs/TeI
/7USLkP84ftLgQBYVVRJ+NuibqS+hXQTawryx67SqyxDVLyQf3VGoab+xTxvXt9z
5JYedNuGjfRsx852BBj6biQidYkNjSpNQxJDpOs28gaL36oxHdt2F96MRg49ufWP
XT9NE2pIYP1IO6LO/XHeGLoyg9CxdSrtokX3DQO2+RKKC3LADfNnmoAcrGEgIy6a
TVmGtMNyWN/9scieBQmy+WJbYfSIXm6hirlk59rI66Rimg8Xl2Fje4y+ucO6LpIw
0KTBIU/BHyrnFyt2/Ub2b1Az3Sk3lIhGBBARAgAGBQI/V1aYAAoJEGtqxtuac3R7
VLIAn2XO/Wp/VMaTKPzENzeoZF+szflfAKCcPlJy5cD4EqftpbtpgzGlLwCnQrQl
VGltdXIgSS4gQmFrZXlldiAoQmFUKSA8YmF0QGNwYW4ub3JnPohXBBMRAgAXBQI+
Gz7KBQsHCgMEAxUDAgMWAgECF4AACgkQC/BkEmC6H0cB8gCcDzhfcY3z4ToxHgpR
wjUuwPKgEeYAoIe79JpDq1CFwOr/xF88fF5p7AnYiEYEEhECAAYFAj42vYIACgkQ
hdRQRWtpGwOYfQCfRGF5b7MBwB3mHt2iMI33+QTlpcMAoJ0N11O4oEkc/nJp4WlC
N46YvznCiEYEEhECAAYFAj48BLIACgkQ7PDpCywXIIOHPACgh4AFMZ82/Mh1V1db
O/ApG1pmC+cAninZ1bZD/sjsqBAsIL9ZcERMxX9XiEYEExECAAYFAj9XV24ACgkQ
99Q+k88Bfle/awCgnkDx3BVjkRePbyrUe1DSeWN4lFsAn2/ZiqfIx5WwCowrWdfU
V4qIJH9TiJwEEwECAAYFAj9XV3oACgkQIkYMagPC+y1SRgQAhkZD9kyXO+sIhwgG
8mf9ktrbcxYiq8D8UJ5gI7sBAds/8rkIrGIkJAoz9SAf5tvl11nfZ4FjTfY63qWv
3aiOVnTl+hmSowkfyJfUtWyqT2eF+sfGQsmpTpLublo7rBlEBe+7sTsTRhBE0omi
3hCzg0IUx/RIps37TT/6HBT65dCIRgQTEQIABgUCP1dXJgAKCRBrasbbmnN0e1tI
AKCmxrkdZWzBekJq/cFzBPgz8r/7ngCcCtmQQPvlwrpp5MHnEs+zI5TeEcGIRgQS
EQIABgUCQLhXUgAKCRA27/mqpwtSBxjbAKDRysZih7AZOXVioOHHW8V384YS2wCe
LhNCGpel7EC1gLQZKVM8SUbiPoiIRgQTEQIABgUCQVusbQAKCRAiylhMenujwME/
AJ9GGxP3oqPN9Lf8GaGeGNPZOZKJNACghDNLEfLguVzVJ5tkY+J1UND/nrOIRgQT
EQIABgUCQVuvzAAKCRAhpkab0e+6pia7AJ9PMUUoMEOJnPPbjWYGvjzHo6V41gCf
QgzJo11LPJN3FmqFnmT6f/FlN/CIRgQQEQIABgUCQlgswQAKCRCe11g/wU6ygnv3
AJ9lM9P4mGLm8dUjxcXhJx9HYf9AlQCdE5GUagE/sRwbo66GdHZ9Y+dI0uOJASIE
EAECAAwFAkLtYjQFAwASdQAACgkQlxC4m8pXrXzEQAf/WuZGG/jtTR1GHjGjBTQi
H8BTrmaq3BIjEG8oeenaQdXJbelg2qwH1dVoTLD3+F9yh3M6FzxUqWvPlu+6+7oI
QCDZDB18mHKnZVIouXZD0GrxqOtV0N+mTTzmInMigAgDietB4ztmTX8aXxCzXuK6
rTwYbm/HRyr2euJpPLt/zIY44RlUMD5eEiSR+G4TKmfz4sU7aFsBGYyLKA4hdHS0
v/lK2Wei9irjQQlAVhlfVeVxNrsuCzp3xP98iRwvMyKgzFNa+O2J5wroJ7dbzRTj
nmvdy5gFJ0VOj7BTzmUS0E4GQF56J6aBQExVDfVWEV37OWIJkOAd/bbnipGfZGOb
5IkBIgQQAQIADAUCQkcQ2QUDABJ1AAAKCRCXELibyletfBrYB/9YL/2mk+JEugdi
HhJKBpXMRtYaoBmkg/ZTQ3+2AHfyGcfC/I7v+HUqtZWHyCWX31/MYU4UHQZzgVcm
KMoVnGHxUJnVtGE+mCP7an0F0hSw9jY9bsUb5TDAwW/OOUwPT9N9V/smImTmLu7S
aI65dv3NrrANZRVFv1lIRi2xTwu5TzoPUz6eagTpzyO0o32AaGam+ishHuLH4nia
nWywVg4U7S6a8A1NKTM/ycam5As+tqF9kdSfME9PCrtDSdPdWtCqqcLHxzhGhBVX
nYExnyk0k5TMqlcd+rlt1jZS6zgjkxmY5xFcD5vcSa+w19h9JecEIH/9FdvxLU9J
WpGK0w8BiQEiBBABAgAMBQJCWM+eBQMAEnUAAAoJEJcQuJvKV618dWEIAIumv/q0
nGtILrAVoVxeF6rr29labesv6Q/D3Vp40DY8RpYp8yvJM5wS+l/7UMvMpHaf5JfK
JycDqIe+nySvphNqQkaUDQuFm/JHe0SXToKdT0mpngqw1NfM4pi26qefADVOEm85
fMncdkMfSOgXixW/qWVcrCKiF5SHawDq5S8L9v3QbsvVvLrcWUldJu5ZYJG/Qaz7
gHY5L7HeTr4bnh2Qx11mhSkXi6T+wODhhXucQAhs/MF6pSuRSzC185lX6b7GLNRq
5dcXBQ5hpGkUnxXj2SR+jc0WWPx57Y/doF+BgIdc4ZeGrspqs1jPPVcEqxCkfNuy
qjPggyaIiWF7oDiJASIEEAECAAwFAkJp9GUFAwASdQAACgkQlxC4m8pXrXxxQggA
t8JbktxgC6tshG3jugsr7MTCHxEq9Z8ZZ22rVc7Ia8aINiSJOnDwp1G4Vl8albEK
7SqxTSa8bEsgA2SDobE24vZPCm7zJzHaLJp7Qs57XnmUownUGdr7Oyg9ywzU1nG+
oGx/19pxSQ4rI5g1Cbl/lfxUU+1fsZXbexDeNHhkE50pBwBZMI7xtuvP58pVghTl
a1X5jIDH0u3+E557fU+KTGZ7GtIKvjhDRxd4H8M6uQFtmkiudkBugqmy45YVXPzh
+xoRhJUKVieKgPnpTSmgfCpvVF0fIHXPQF6z4Ln5VR8CqFbfDj2nQipDW14gEZVX
Etq9/FZHxsjG1R/3BnuLTokBIgQQAQIADAUCQnxpIgUDABJ1AAAKCRCXELibylet
fBe1B/wLr1SsrExlkk+Z5sVrfwW5AUs0KWLxIdgPLPmmiYC3VmygK7tcXUTRz1mb
+yORyfdbanfqbmmhgsE/bOf95OsuIeG2WV2AY2shsnCTltlOTcB3L0T7JXFrxOgn
KqWFCxjSJe6n5waFXgHO7s8kgWbQ+2yhWdIomWZUclJDOiUQ2p6+STR2JnJmN4W0
DKSVvM5JCldlHSji4Wrh26rrLTnIfbuzUiQCP5LRwVXTrIz9Q8TM9SEvIpnzEL9z
jPtdTjGaWKU12L692Ly/NKAdQWlbjMp8ZmHzlorqx8Tdm6KEudvA/GapZC7k4lii
K4cGLyNysQJfL0Cezv2osWlK36mriQEiBBABAgAMBQJCjY6FBQMAEnUAAAoJEJcQ
uJvKV618blkIAJDbVS/cW/4dOIpvCCF5a7IlG2uBSn03+0rLvgcE61Bk6VZgGFSp
+TkD0G0gvipBGCSXjSHLMfStLpCvZxnhR0C5rwE1sS423uAv+1BXGR/+TcT4er41
sFuPqFHu3yDLNlbnnKYXkfhfhBuQKU9QKn0N7V7aHGlnDNL0xhGpaTqcVs+jvGJR
iocGW7LABqgp7Ay/30o4S9HttsS0Xc9QgiiAXSMoX4SPu/v6/xJPDSsM+GL0H3p/
Cu+EIuMIQAkDS8pHWufMfu14APTvWTzGCR+67tkxN/DL7otej0UcGRSj5rpp5nBv
CMa4CxqFNvsUBjE/VKcpF1l3vJ5n2XBty4mJASIEEAECAAwFAkKfWqgFAwASdQAA
CgkQlxC4m8pXrXxhuAf/UgezCBP0jyarCikqrCBq/hyJIoyYpNi0eN2OnaT8TA2J
1fhfQ7s4Bga5IEnnaBCSp4w6pxlGmBIFj3LLHLfiX7B4Lh1EFpM4VsmHjHOBzVNE
oa0zdmwsOhz6P7oRDdCxt9hPtiicAKYqdFhG171oXNtC6raeR0HuQ348YM9TD7BS
W0UNJLsB+TtthNWCMJH7XNu12ryVdo+rpiCqbDNoCf6hrE3IecqWLHxknHj8aMFg
S1744lTTk2hhe2kY4/9yQfcLoBQnVjQqfYtveJ4AdqOtrvupqf7MNIiahJ2I7ey2
6+q0WIH6CRnPOE5O0KP1z/UbcLP8rhRU2/kvMlopeYkBIgQQAQIADAUCQrKEJgUD
ABJ1AAAKCRCXELibyletfJt5B/wPnQb8BeA6VoLTIRi7fJCScuZQMNOisbGNR+9z
tc4y7HVLNEV/m41lfD0zEOyb/VKdpIoxN/YRfCJiRbqDKO8waNTdzGTc1+8+rYsC
/wdh3fcHjo9AjJHUPej++wwPbev4m0/JG7510jFg2uhzrLAOSyuzJuedD12HoTyk
O6FfEMw7UUutsZNPG66krftrUcLDk2bmEDSDnJQ4Kz6EmRnGfRc0cRY/qugMJ2wU
DPbfdaqrDbcuDYktgsy88wTMCXNioWr+j5BuyCKUYpVxq5DB2bPAuRkQYIgpxI4h
XzSvo/2X9FYIhcvvOLN1zvrzBNtbSUygJluXIif1MVk5iKZHiQEiBBABAgAMBQJC
tSlnBQMAEnUAAAoJEJcQuJvKV6186sUIAI67K9iDMx1rMBGvpr1a2KMvs8B8lk0k
vO+z8EHLDznCtN2ajfCfpvAYD/B4nu848kmB5tWvP5TfV3FDamM0Eake4QQotXL9
jVJn0XYf8m71zW0sn1LzYzpYW1u/lkIctQ/ESZCBLtkXSpeE8aQj08AIPLVTVROY
qq6i2qgVvPgs5VA8p8NKMfffuVCKR9bOUODD8QyOjTZWNQ+9Nr97E7VX2k46l2Vr
HgZtwBZk8jy7bb0sI/MGJgru5JiibUThUBNdruOwpJzq+7T7NSPxr//dNDTaWSTx
wl1QclQYOuNTl94nWkzWlO4Dg+2mkGZTi8D8ExrYfVDB9IiLWDpx+0KJASIEEAEC
AAwFAkK3JIcFAwASdQAACgkQlxC4m8pXrXy+WwgAuF92mI6tsfsOnl4S14fOMHbp
BFYou4yGHWMi0GB/EP77mJu1XY5vKXWnbnltnEbyuboskqRghEpCf/NSH7yKL2X0
2O1+59SOOb4SI2W7DzkK5ysdHuT9WjTvyZPksGOxnwQkxtVgp0p5EBfXDEtUiv2h
7AVvOARKjuj2VFoiKXsTW/P/wD3i7BMu6eGBhJIyqBzCgUZPP3dDZgIAW+N6Cn+d
PQwEOXMKndgkOpxDCKS9WVJQvDhFMjDA1uNXfsyQw8XwFDQA0pD7A4TW1Os0R53D
egb5a6OviCLF2NagVt3cwVdKo8fZBB7IWPBB5PjpxjAjl/9HgORSU7Hjvx5r2okB
IgQQAQIADAUCQsj0IQUDABJ1AAAKCRCXELibyletfMySB/9e9SK81Fk0f95Ve9Pq
Et8NFBdz07YOsqPVec7FiCihgP9I6fAuq8Mg1dCgzhvyCNyb5NQvX3wi6lNZ4kgR
yzuMmg9hYkbLTq+S5apLOnmdRlxhsMUU5+YbZ9v+rIffoXT4E/ZhYQMqLMkoIk9u
asJK3mdD/HkHpQGXJDRC1FNclx5zMiU+w8oJqg67lpMv7VYVHaqHtj0xK3C0/ODA
nDzDWOYms0OZJeJ4XdGUWL+fTmwtJFEov4Z7Uh0FSk4D1FIHCENH/4+ZdVzaP9Kq
0TRXNuo0hLPT/52mvWMf8fi6pODQcKE7N2T8aimCMsf4Y/QAA2/YbQi84UeajdMR
oV2YiQEiBBABAgAMBQJCzD+pBQMAEnUAAAoJEJcQuJvKV618exsH/3S3PlLAy+2V
PS1lTHuVOEk0YsLYc/CpQuEfKDQmLvPHL5QOOj44pXcugw8azToacifKcsZsQNcK
q6mBzf5EonC0TLDWKia2bRBbGPqvlwFVwc3U3GjXpmrgBvOHVq79nhquQ8uTy7vi
MFUKWYuwuMiE1cXgPDZm9CLiK4KHl8mX9gDyBb+LOyItQ4hLzRbz1BpN3J2l7fy+
xiCrUsGm0o8w/f2yMYTb9JQ3kWuRhUy6SAFdXGibQId2/58ez0tdfemL3k7MFLeY
4rdCJHnXIoiFj5XDzz4ImkveojcyR3NQa1VgH3IZ/u7BHLyhHSkLsw1ENBS1scIB
xXtvSyEtiLiJASIEEAECAAwFAkLRh1oFAwASdQAACgkQlxC4m8pXrXzA3wgAhWjG
Ejq0P0pXN9YZNSzBx1NYemQ8aDL4dCDbgK8CDfVBXkOW/2DrrgjcABamjzSyKsIP
N7SJVIaqL414jw/YScXXMhNlJBtZG6KEE4g8ChO71vL8CE0s4WBGi3GgdIzDpQBU
hN8Rl31DsUO8derRQkbV7APSiT+mWVN1DyLoh4SlW04noqpFk9kO4VU/2Yue4DXo
uCD8A9MpJThIDwqisfCMl3BuUJA/lcRAW6rWGbcx5+18aV7RiX0PYqZQFfLOgmEI
WEArTr9HcOFrTCHDcev002vQf99tk34g7wh4gD36Z6Z1EHW2jAhC9GFjU/o/HI7z
nEMiitcDK2lS5n4fXokBIgQQAQIADAUCQuy8BAUDABJ1AAAKCRCXELibyletfJ3f
CACy3oLduJ3ctEv06khfEUvZyfapzOClzHhvyYweSEgJcz7t9A83F9/fhk16ebmJ
1OX/o1ACZkHdUtBJ+H+Z4YHXioER1J0/oFB5VIxxv+Fnp+yJBCdlIyB0B5V2qN03
qry+L0AEuQdoJbP3y3CHnrzClmk2FoJx1HmO24azmiDcnXdA/rrz6KB20m0ZHyNT
FBZ6FsT9CJ/tgfTEh7hlR7v4bDJZ9sUrbLv5TsQ2NTFM9dzhzGit8RlVDslEy7I+
IT3MrHeRzX7skqu7Gbbot/nG2gZRDQIL8pp+wMljRQV7aCw/KY6BfmGrhL0f2XtT
U9k83bfn6kXVnhaVhJAyirDDiEYEEBECAAYFAj9XVp4ACgkQa2rG25pzdHtJPQCb
BdDITfqiE78TK38CnBhxheMuokwAoI+iB1ZISJnGs/yEsBeiDpCMLGwrtCpUaW11
ciBJLiBCYWtleWV2IChCYVQpIDx0aW11ckBGcmVlQlNELm9yZz6IYAQTEQIAIAUC
Rmv6OgIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEAvwZBJguh9HwKgAoNgO
4jfdn99TldOw5nmbCDhoIlBQAKCjeCH4rtxwjfuohls4UDMGvvizMLQoVGltdXIg
SS4gQmFrZXlldiAoQmFUKSA8dGltdXJAZ25vbWUub3JnPohgBBMRAgAgBQJGa/qg
AhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQC/BkEmC6H0ciXQCfaLDgVYoB
AhALXpSaiCTIes6LtjwAnA0Z3Bz53BhIZVgRYmX4h8KrMUKrtCJUaW11ciBJLiBC
YWtleWV2IDx0aW11ckBnbm9tZS5vcmc+iEYEEBECAAYFAkJYLMEACgkQntdYP8FO
soKJ9wCgxl+jp2g5sORP6iPzlzfKPVarKZYAniAFJjD5EbtiBZ0NgDdF7If86iRo
iEYEExECAAYFAkFbrG0ACgkQIspYTHp7o8AVLwCeO34Uy7VOGdRyi1GiYELYpXze
C80An3UiZy9WsyF0Ipo3qmPJcu1/OAURiEYEExECAAYFAkFbr8wACgkQIaZGm9Hv
uqa9gQCg1dOu8uYVsz16ssIRGdqg94FKdoEAoOvi1FUa777JSHmpn9DFewEU72G4
iF4EExECAB4FAkFE2EACGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQC/BkEmC6
H0euxQCfXzAjPx9rcpwiKCbQmYT46FAiFaQAoIU/wLHhk0P2tPsypbH7d4FHmuhx
tCxUaW11ciBJLiBCYWtleWV2IChSSVBFIE5DQykgPHRpbXVyQHJpcGUubmV0Poht
BDARAgAtBQJGa/3vJh0gSSdtIG5vdCB3b3JraW5nIGZvciBSSVBFIE5DQyBhbnlt
b3JlAAoJEAvwZBJguh9HFhYAnRODziCK9941utLK2rDXA43JljXTAKCmccNmG3gp
iAQ05TPn6EJpgILHyokBIgQQAQIADAUCQkcQ2QUDABJ1AAAKCRCXELibyletfAr/
B/4lF26+op/jSSheUuQhkc0JnqY1fed9bSgon5HpKuoFWwURHrf0F79lY69Z/Cqm
suC249GoAmZFtrNdp+BzjpwzV+VMXE/2VGhGhE6HNlOGXUd9nAJ3Cb5VLJnWQ2U/
OvV1sm17v144U1KzWTg24YdRBBmWS1r/8VoJTBweevQK6UbRtt5w4cuIoeHlpBZI
6d18sxxfD1Y1/BS0d/v8dQYqqk0ZtFA/WGXNTa71LCSpjIwvOSP82p/W1U8NhnlA
qDBYHLkHqvGkcS+WJUkKz7hCGDiAm7/wgQMyWEzODVBQu6V4kpSy+EuF5Rflo8aX
CYbs9nkHydMuUglOcSRd0Jo5iQEiBBABAgAMBQJCWM+eBQMAEnUAAAoJEJcQuJvK
V618BFEIAKQ4PJv4KBXRrNXG8NX2AhGl0PI/EzNg64zBhKH+dwHp5IVgX/f6oO1y
/8ePRmSY2qI7D7eCiWjAnSkx7TQ9jyZxOKvo9VzTgfWT0oHod8suBMM/DAsDuvmf
s0k+bWmi2Vf0A2frNCL1UWF8bGt7LFGRI62cq/hQC4OFAjvxpIkr1CHAqC1MKhfz
f4dQ28OS5vbpUR8uFS4LlfPlRJCkKWHYJk8ju95HAXCXr2o6QuoOdtZxS7gA7+65
frLUs6SzW1Q0IyebzR0jniKlJhZFTF0usd1sbdOzofSnup/uIEktU70PSkrFDvGK
uXhrUn+36+7jRNzefrcapzsRFf3B5Y6JASIEEAECAAwFAkJp9GUFAwASdQAACgkQ
lxC4m8pXrXzzJgf+NhiK8dfBYwdQknv0aE48gI6kMapxK6uJPxfkGr+u91eD73Ol
gUQvRrLHqSMasoXEbr4iORyho2XWngTfrXDeOZpOthAKY5fI871yiulIeevQI+dk
XO6eHfaRaDSxbjIWdmcQoQEjJfCtfVLI/3x/AkUPilFRoPNdc9XsbtS43pxA+cgk
lIiX+HhhCwnILMbkSNIhDO98RDeSeGMr6PXGzpM5bovYre1hiRBe4EfBK7fW3iuJ
ymfGj+1Hidk+2kGYBk0Aj31DD/nwMVwTWHWXW/J2KuDkm82z5ZUsvU4FmKPczHkR
MPd42u88c/5HazFSWUkFkQD+z7oyuFxs/ixHaYkBIgQQAQIADAUCQnxpIgUDABJ1
AAAKCRCXELibyletfISVB/0WzMcD1eH0KGqQMpAwUA3+wD7AR8w74HjlDBERsLs2
MYGB+3F2vHzUYdFj7wEb1zlFW18t4E5GJx+Owj/rG5cx+zl7TeSnxohwxgodKzPh
gWeEFnuFwFOGPbBcCoqfSasmaRs7kiGAaBA/VToUdA9o46LSSsY3O8CW9c4ZVe3/
cuI9Qd7k1hJWdLOWpUhOi03zPB46+uAWYM+si8syZ01uVNWFcp7Rlcg8JgDZ5Qxq
dLmyWxbdwqVjLpt2aVjIEmiRQMYTLY0Kn0dJHR8BKWrMqV5yCcBbPIF1z+yR/On9
WgfH1k6/9a/wbtcauHC+/tjWFB0iqGc8+JYv3ckpMZiCiQEiBBABAgAMBQJCjY6G
BQMAEnUAAAoJEJcQuJvKV618hFYH/iDSc0+noWX1n8JEjjvDx8d4ojHJYF/mqw2l
ryNJfkphluYy3joPlLLqLET+pAm5hxCtd+CGS64m04+eq7QbVsreTqlKMqrdLaC/
TcUq0Ys8XfxlXJ0Bn5Gb3FeI94SFBAx4BCFtpdQbZ8urMBGEoNAFMSiNgd+oW83e
u5DM/hjxhKWUfa/b01NSK/1SNjx9RiIv+4/mpLuNVnfKtzdie3MO/uL/7KoZGCXy
FjI7q8zxu9POackSVbaUdxfdX/wMmqm6Ua0ZX6Nz57PzGL7V3F1NZRS77dL32WQ3
OSpzJWdxVmzFGwmiPLl2QR1JZ1Pqtst3Ix6szMaGQPCRdWGec7uJASIEEAECAAwF
AkKfWqgFAwASdQAACgkQlxC4m8pXrXzl5Qf+Mn0NUER6mVy8Cwnaug0G2gckzJXx
frdfQ07Vz/V0EjROJLsyw1bKIflxiRnmv2tuYwZtFTAsTDIBnRg3dWkWq52lbXKT
TeMP4cANUv/bEJ12xhZAiKPXRSowbfYl2XSErK3j9IYESavbb3NcMFMJYkzSZtjD
vlDpQmOYcAcashlJerd0thYzyyZDlDXtOWYF+uVoIlprFArHQlkTHjT6j+GHnbFD
uMQee+QaCgo8yPXKvQaknJ4pj21y9L/5P14Fgl1DrWUm8oEvhKcA2L81mINHFoJA
eN3i6Jb8esWa2FBTZwGlGSEyw0iLS5CxjR7HVuxaQwAeKy7Blr2aCSjZnYkBIgQQ
AQIADAUCQrKEJgUDABJ1AAAKCRCXELibyletfHgjB/9ryx6ouX2K++7BwzQSpdaz
guyR47JWP/JBEKJk9EpGZRyJyM+/RlaGJjlN/5F5Yg+7Fuw/Y5+fOW1EyXyyOaSm
u9JYxXhvJz+VezcbjigFNgGQKBXcmvXSva+1+b+U3qH5edCB38UAhBKzF1wvCuir
D6nfpglaKtiYqhcesygXNaoVUWuFly60TBGHnK+SicyWvBgV+Oq7fhQ2CLqBBIg5
o7YwkqiwoWOCdTmVe69OrlE3xibNUh/q5ppFauRzgjOmkiXNFI6qxSJVmrWSxOCP
uSDB73NX8MuWe0YpjveFoC9MuN9CupL/aAAuESlDI4UMpxRVjjzurpABtuSaGaTH
iQEiBBABAgAMBQJCtSlnBQMAEnUAAAoJEJcQuJvKV618sxcH/jHYK4jLXBr4Syv8
8NSm8+0+bZNAtjxmHIJTj5djuAanP05gljB32q+uK1JJqOMxa8dTz17icx9sV3S+
F4CLfGUxZeAyWHYPPGKH1CgzG5V58PUQcezucP2G9QjPOeOJFOBYjMg/5mtnN9I2
dJAgggalAbwsmbSK5MwKwE5WTw39xbcyMupAP5pG8ZAa/PfH2K8jTMiwh7ssIEoJ
pNiLsqi5aDw+IhZv0XmrtjZIIfkRk0T1ZNcRzLfar4m6aZZkleW4ZhwfMl6j+MSd
nUgEh0sH9N4iB6UZdDTnFh+GU5JJ8yDHU174jhp4RtliTOs9i2OyPpqHX1Ed6DVK
EU3ueWyJASIEEAECAAwFAkK3JIcFAwASdQAACgkQlxC4m8pXrXxIVwf+P/aMahox
tmRhgJCWhqcsWGbYx0z5I4gzhq6+6nnuj/6riJrdApw3qGahHqx+qH9uhaUP+j41
82YAxGoY0CcsOVcEjLZxtLQSFCrgkW2opZZiYCrKE7Nqu+/qlhPmFUobrNSz7HTe
G5wSRW79r/FrH3Qj0MsoQsKw1kaYHiwIs+GpJhhdvK3nuNlDwQhIPdH1fZWBzGBc
b52BrggjpXN299fdGDEyDfbztvCfigTP9VPA26Nvkt0FECbZnDL+Szv1FBNUtuj0
iNW2jYnaw4I9l7EfA04YwWKJMrEQASO1Q8NMh1fG7CThLJ2HJF2SGYPq5ScgKd8S
NpVPQ25led5cS4kBIgQQAQIADAUCQsj0IQUDABJ1AAAKCRCXELibyletfLecCACY
t+1IQ/6YFhQsXjOeY+80CiFh5eCmv79sQV1UC1+S8PslgZqOQrKT+Ij/k3oERNrl
CXFPql48pLJo2POFAzOONNOuNaxIjvXxWdoezeHSULEwOu5/ilTwpPGPcSbYqlPq
30rguRqFxWyHrRx6D5iBY65uGDenb+2qY8d6xKAUijD1YFCinfzKIyWmmUHClxxw
BDASWGhc8L+1VQ4h5WC9jcMALaFJwqcFSf8hoUPdIR8E5qUJo1mptZtLptnTs0zj
mw9dZUVY9Rx8fojmFDKxvaqvbYzqEHuTqSX4oCDeWCDtsO1TRSK2m2V7c/DAalrL
6uYQekkP/37S9TbEixQSiQEiBBABAgAMBQJCzD+pBQMAEnUAAAoJEJcQuJvKV618
0DsH/0hU3FFmYwoeitMF915zRpzqeZjCB70Egw5Nt9+lt4fCce+IFyiH2owlbpRl
2eQXEV8coSK4d5nggsnd0WoUViJyGBkjOuo4G8Fx47eRizg9oAOLj8+a5cfLInOc
xojfv3URlNSlPosHLWgYKQe+6rMk4bCJJHsreKulu+MEAIo0BcystzN4551MH/kh
wWCT3gRQvfXMpQpEUPc3g7cx1eZa5n2R3/eQHIdPyWLbqVzfLoHycatSC0hZUmtg
8uKuyEV9Gd9b0SS4umBd3y6j4lsB+Lyk7F6Nzx8+DGteFeWtt5Px/TnXco4/9R+W
N7GOMr8U9j8NtURHkBKsWVvSVCKJASIEEAECAAwFAkLRh1oFAwASdQAACgkQlxC4
m8pXrXwSxwf/TyVtcaHWXqO9KLbLEPTLfXjAIqWBjzTrpX59Gpf2Kjrx74SonG+2
267M/Q7yyzbGnwhwEKLX+xwNe+KN0m0yM6b4MdOw8lUQg/Qo0SwVQDWqpb43x5fB
hyRKXqkLLZx0OOinSKvK9WXc63qXEhbXFv0gl/rdfs8eQF3ZmU1RI+cjFVorupMN
3s+OCaciTR04vgJT4/6A9iLujIYLTCLk5I1RGK7l42JQUzv4F+n4IAEmjSfCOqm2
+gIPQQzlcgYNY72HtHECfJI72jrY/qLGvNJ8+GIyrtfSsY08/rG4FK/UH7ggJ1vk
GsPZQoqOjcnbaq+RSdwSIU1uSowh1gqYV4kBIgQQAQIADAUCQuy8BAUDABJ1AAAK
CRCXELibyletfEjFCADJpplFbznx839sgqYSa9HTkO43FLbji+xvk9UkBCNyBcuF
zXZnNzrx36aHScIFonoUYu00Xnv9Xak3z9hySr/8q7ioJIwan0JVsEV2JHwKieE6
PQ8uHe/svlE20+sY+1xL4XvZbbQ0up6ynnxdFiNQ3h8h1CVKrlEeELijMezW3M27
5gdqdqozxwG5W3LDj7aG0wQH33QUkjoVRozQH20Mg+ubC0cu/PzOAXBk5uh+fbgQ
IMNw/bNj5bXvwoptkSp7CHjYcXiG3OhdEB6UFRUO4KbC4+NNlgsXHFAHC9gSJ9a3
tFqC+GeQNkiBfqlD2yJQqaHTSRMi5Wz4E4C0nwONiQEiBBABAgAMBQJC7WI0BQMA
EnUAAAoJEJcQuJvKV618lp8IAIAA5TEnRVObgOQfkP5R1uvmz0d094pQQt+7CU2Q
//7w0R5AvIs1ePqM0IDzVQ0KfTU7VzJFYSWTQE0fZ8yhn+vtg8bsiFP0XPKAjUmc
oWqsFx1/qRgrsi4n3cZU+Kfdwt+xqUhW4RX4McxVfPN6gcxHVa3qNr8v7pqjm/Dl
VHHx+osTcZMQCpGT734qEuFhF8wbupeJCi410ULF0Xqf9WrQ6JOBjvTCsJRJ2c0I
D4bMKjkUP7+G0BBH0HKiobtWQDm0tFy04wG3BWaIar0zEiTFVl/ChkTKILLJZVDf
wDZBgkP2LQ5SxwkaZ4esJyYuWM/4fff+HFPN9OJhuXdcbjmIRgQQEQIABgUCP1dW
pQAKCRBrasbbmnN0e8qNAKC8gC01p34Zu+S5sA+Lvalfk2z2bQCgwCUk83bD2MVX
M8yIJkFMAEcLbF6IRgQQEQIABgUCQlgswQAKCRCe11g/wU6ygolCAKCV7DoJ3IWV
+2rkU60rZ0F74SH4qACgzEUAFOwERR1ani43VVbRVt1FalyIRgQSEQIABgUCPja9
ggAKCRCF1FBFa2kbA3MxAJ9y+xuvY+HKTxHdMjjQVcZQoJ6f+gCeMBwdUM/iqcw4
kGoMtUYkwOKUkOGIRgQSEQIABgUCPjwEswAKCRDs8OkLLBcgg8c+AKCBfl9YEpyV
Wct1a0clhZYaXGsA0ACfXQpZRGmyS2/XY33ycPhKBc+DOzKIRgQSEQIABgUCQLhX
UgAKCRA27/mqpwtSB3OdAJoCdyMKzshLPDSEtQ5OfFcszAVwvQCg1uhrbo13Beso
A1TVw0eD7Vmc9a6InAQTAQIABgUCP1dXegAKCRAiRgxqA8L7Lax5A/wLCoxU/LdE
j0ASaGbZT6et8m4lBzi7lFVyuRNCTGLstcSWS6ebRcAKU5TneU43gAkhq2u4+yEc
9D43E23qlP4gLAipDYiDB95Z7TdayYBVWZkiSuNL/KoIW3EXOuKf4kUdKVZjD93G
Cm93qaUe4J3XBQqxZ6+Rij8Qho1DCzTAkIhGBBMRAgAGBQI/V1cmAAoJEGtqxtua
c3R7bo0An1P41fXK5SLyNo52THgS0uI72KvfAKCHtL4XF42674KiQE7oPyXrvXu8
fIhGBBMRAgAGBQI/V1duAAoJEPfUPpPPAX5XwboAoJiSEgMTJVeBtzUrCCUHXxbv
SxrsAJ9FNZsm9w8us5spA/Z7AVB18Q03jIhGBBMRAgAGBQJBW6xtAAoJECLKWEx6
e6PA3WsAoIlcyrqT/mjSh0U4lPg4kdCn5BVJAJ43Cs2wPgtZ3TivzW60Hpb9GwI6
pIhGBBMRAgAGBQJBW6/MAAoJECGmRpvR77qmHJcAn2cIFvGeximMk8rn7wosqT4k
lToPAKDskukcV3USoFqM0op1pflj4qd46IhXBBMRAgAXBQI+G0AoBQsHCgMEAxUD
AgMWAgECF4AACgkQC/BkEmC6H0cSwwCeJKfu/H4R63MQTDDjC0vE/WSVBaoAoKv1
X5j1EhMKnenQt1sbqxL0GgSXuQINBDzKgZEQCADbERrRz38HJOplktZBQipl4KrL
/pc0lQylol34RPGJ8rnzeWxnHw7dHVtqZRJ1MImATGubXGtK4+RToyPveXrY3f4U
dvRz8GQew9bvaD6PFY28A3Dec2jCSnQPCA+0DVWmFg1dSOYd0nQIFuKUBDqcAbmn
hI0/PKQRmjCP9G5eqUZcEEfmKm68JiqMwRRTYI+jMcTIeHeXBkrJTJH7myyCpByb
aHo6M9IPeI8U9mJAoQdwPHjhcl1ZIj6/ub/o86yzAYH2+ozG+CmMR6+1GnuJl8Jq
Q9ka0FHRFzoBga8Gwp6+bibZG/IOvUy8iqDul/7yZuZ+WstLmIUeKmEIBNTvAAMF
CADZM1ZQfJKfIl4GGx1Kn4ZsBEz+GMUMfcO37gB2QPcOEowpr+rlAwUlwNVLyfeB
JyoEPv9PJVLU0JSViuTljl6R+sabm1BLhsCggXiMzfS4HaA0NscuNdBlJ4t/jkAG
186u0fezEIxQmgdrzLeZhE2mDXflpHtv/rQBaiB3UvcPG4GSq65zjzoRf/QbKrwX
eiIFtSTBZPpMPzlJkMmiTMA4jUdUKjpjXluRxn9l1ouan2WT/w6KcpcFRDXaPtn4
o1INmTWyGVZr0U94fFgX/+yNNgFb/q9ONJBFL7rYotvpVLGL+IGzHv5xLHWiym6x
emtWpksVppW8BtYI8cnQOT2ViEYEGBECAAYFAjzKgZEACgkQC/BkEmC6H0eiKQCg
0I7kYcd8hY9Z7akRmB7QZbKLRukAn1figHfNRdbksZ1MgA42+z1QS/fv
=r3u1
-----END PGP PUBLIC KEY BLOCK-----
D.3.9 John Baldwin <jhb@FreeBSD.org>
pub 1024R/C10A874D 1999-01-13 John Baldwin <jbaldwin@weather.com>
Key fingerprint = 43 33 1D 37 72 B1 EF 5B 9B 5F 39 F8 BD C1 7C B5
uid John Baldwin <john@baldwin.cx>
uid John Baldwin <jhb@FreeBSD.org>
uid John Baldwin <jobaldwi@vt.edu>
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQCNAzadDAUAAAEEAJqqRE8GJe9Pyxrn7PmCX7n5MWUYrawt3ycvHBYPIRbV7e64
fFPR8BI06mr28/UVWEOQmGl1Pr6FIvpiwWq2Vj7rpdw5waAswIanpt2haw4gt7DO
Ao6bwBSK0zZwj/lnmKdM9VH6ZhPwO35xd/YC0vRs7tcoVRMRs7aE8XzBCodNAAUR
tCNKb2huIEJhbGR3aW4gPGpiYWxkd2luQHdlYXRoZXIuY29tPokAlQMFEz0CFAS2
hPF8wQqHTQEBIOUEAJZmaiJ5jYb8+SSCB/rBVjCH0rcjn6lIMAqAw5OtfrQe9OYt
S66sifX291nCdkONr2dANCd+qCMQU2x593EFlGfM5o/g1ZzPDFN2SfK/d3x15cBU
9Ab3HV+7bGH1Jy4qpcusD5Ygakk5/bZmP2EMDHgzqAEccpP4HfpVfVBDMAFQiEYE
ExECAAYFAj0HoFEACgkQIBUx1YRd/t1h4ACcCZAL/VJVPBCa7X2+6iyuhHfaLcsA
n2n/7gwjK8dBiaBzfLUPJK/K9+CtiEYEEhECAAYFAj0HrW8ACgkQGPUDgCTCeAIJ
ngCfTjCf3tGDkHHlS/q7pTi/XzL1mwYAnRS6IuKuKxxwf131PIo5F0VamSakiEYE
EhECAAYFAj0HrZAACgkQIfnFvPdqm/VpMgCfXwdg2Ou8n1S83UsaqwY1N4oto04A
oPcC8GkdlHUx5ildiKH9PKBIQr2NiEYEExECAAYFAj0HqH4ACgkQRu2t9DV9Zfta
HQCfeU/G9AL7UA/QzdhOW6le407IfB0AoKt1cYzcC1ZL8+lYi56BQ2e1Dy/AiEYE
ExECAAYFAj0HrDYACgkQXY6L6fI4GtRDIACfZlJuVxLQf3lLEZJhBzxBXve+IXsA
oJfin1JSKQaOoiazs344s2NfuY3kiQCVAwUSPQete3xLZ22gDhVjAQHoKgP/RFRC
XizNHsRN6TahiIS9hlYYoqhLub2SEkOAZzMUFFshyMfA/jNfCizTTpYtf2PjKwj6
u7JEuWcyF+pHkQ0mWJHIE6YEQLa8RK2n6JWD8KS1nD4XM250m2Sx7IPWT4Rub4If
tmqF2Trvd+6GS8GNAwyG4CMSrcEpLZzZL2ROsjCJAJUDBRI9B62G1uCh/k++Kt0B
ATqWA/4y+I5HNckCfbYFd7Ak+ZnQR9UaAhWHiC81HpYzzmQqD1yWugE0zXm8Kajo
ZT091rzNzIzx+p/B5uJuu99cfq9fdcYxZXRDuceHWIO9YScqmRgikJVejORWDScz
jtKMRzcWHonKodM7BflCPOeyfR70XuJwf9Xqh83P/XjCQnwjvYhGBBARAgAGBQI9
B6pUAAoJELVSsEN3OQXWMX8AnivKuGg8RwxaAHrRlJsd9Ye1BrfCAJ9MEj3DnhVV
jYYq7y8kUQ570neiTohGBBIRAgAGBQI9CBaKAAoJENjKMXFboFLDOvQAoLtw4wFZ
B00wRL2Aci/jYPZBSQXsAJ4ta392+gPoR8c8YJdZEYJMiZaRh7QeSm9obiBCYWxk
d2luIDxqb2huQGJhbGR3aW4uY3g+iQCVAwUTPPZJpLaE8XzBCodNAQHezwP8DVDh
2LR62STWkikj5YAKMR21AK653FKGz+GQ2F62J0IZr50BDdkoTNU1AxiZ8IaQ8o6s
MIrwhUrEgqTKGk8OX2eUjg4XZ7Q/ZM4WqQ2oPbF5w4LdD2X961CvmUwB9XQAnauw
gUYZB7WRkDhLlujiecgLg0dPfJ+uwwsIpDTxWEiIRgQSEQIABgUCPQgWigAKCRDY
yjFxW6BSwytyAKDiQAdFnsDA7dQiBLCM3jndCRsAfgCg/I13xOarvWXzCfaR7iMp
toewhy20HkpvaG4gQmFsZHdpbiA8amhiQEZyZWVCU0Qub3JnPokAlQMFEzz2SbW2
hPF8wQqHTQEBkRsD/j6xByZbBXayf0nTk4P0Ca0qARxXBiCM3MfWtv5h/Sd5riOL
n/d0R2X2qiO/zsTj4JX/KTUAaXnJ0a2ydE5El636pUUZ4Ec0ZG30rP4ZkZEEcHE8
QW31o4BI2sqKsVyC3CSHqw7l2WLGlA8Cy5dKUcnoJ+wfsMxv3NudAdIGgMm1iEYE
ExECAAYFAj0HoE0ACgkQIBUx1YRd/t0bagCfahFaLA6H2zPzr68eyNk9Uno0r90A
n3knjIB2Q1rSvdvDVi2NttHYVxJLiEYEEhECAAYFAj0HrWYACgkQGPUDgCTCeAKE
kQCgzgQhhLTbGpe2bDsWxo0CfRldu38An25D1vJBYBW1xDlcLElzrSizhhAJiEYE
EhECAAYFAj0HrY0ACgkQIfnFvPdqm/U/4wCg8WKCObKK8tocSxNnAWP4hZADY68A
oMJvVnQ1GH69z5CGCkDGLyEJ1nRxiEYEExECAAYFAj0HqCIACgkQRu2t9DV9ZfvH
fQCff3clrAIQ7/FqIGC01p7nt6QDlvMAoMzVBHA1wPEBhtaVO5ER7COF9qYfiEYE
ExECAAYFAj0HrDMACgkQXY6L6fI4GtTu2wCfXVHd0LhgEk3Qm0FxzCtDoZiyLXwA
njMHH6JVt1h9FC2Kb6K+xFSF/vZtiQCVAwUSPQeteHxLZ22gDhVjAQGFpAQArCb2
RrgK5GWKxZYHENR+FcObOVOf04HBbs3KF/yUymUd9UAGjeqAbTAPnURBK08SkkLp
WBichGlkktKibhE14qFhMmbiOnwGzWPMmkEK+4+5h+SxHTboDxAUWYAAnGlcnjek
PttKfKXBqIU83oTGIJLWZV3XDP4T1aJ5tzt24lGJAJUDBRI9B62E1uCh/k++Kt0B
AVSoA/9PRLVhEI2zbyjUfONL8WbZPonkTkk95356m/WxkxF/RcbQkrJeODpGjr99
24Pl1hYE8MrouUBIizKfZHxHDUmJB9tkZW2y5A5pG+AerZwuedojzRnZLKOcMujt
+1v+fnIwsNW+uzd7Cdpq1YqAeuMcwKAQ6PqAAPZ4uUNem2C0hIhGBBARAgAGBQI9
B6pQAAoJELVSsEN3OQXWo6IAnjcnqYNmtLJYHtQSe5TAF5r9cOsPAJ9qVvLEIUw7
A9yVxH+9eIkP2QmxTohGBBIRAgAGBQI9CBaEAAoJENjKMXFboFLDmnYAoNc7x6cP
3FP5SVK3B+BzINN4U/pEAKCrjaz6zO7Fi6Ech3tZN1XvqfSJvbQeSm9obiBCYWxk
d2luIDxqb2JhbGR3aUB2dC5lZHU+iQCVAwUQNp0ZWraE8XzBCodNAQF3AgP8Dobg
60W8YLjNK9d6QI0WMLqS5t4IarSCKvj0dmCv2mAQS9v19rAXIV25KN22JxI4jE+d
sJD3xrGbV0XDQvxJqqDS39u4T9DRiacc3CG2471lr8R+xe2nJy8v7aM8yUjHv13d
h+Bx2rtcC1CFNSd+ZBrLxH4Uh9qu12AmE6a8xf6JAJUDBRI9B617fEtnbaAOFWMB
AdFNBACAiYoaFlmX/tUWO9JzHJE8vlLdgzg6XSv806lgrm/r8OYxSsWQLdhIqreK
F/Q5EwYA73lgpgb6wArWsUN6a6h9YjJZKSJpuFrvHjScSXVRQw8vVVXyrddUT+rK
nrBcLx5pe3KILCM87rZCS5NvnnjvtjJDmpdYuMdWOyK6GGiyOYkAlQMFEj0HrYbW
4KH+T74q3QEBAPgD/iPYCwqtIpqtiiKiSOHLbj90ffngiWVMJdJfQX3UUEOlnCvn
PIv5B+MyknkGnKifmBTyk5qrdU5Fnb0Gl2rkSp7ZkWHPQP1gz0kKvQyP/cDNomqp
D6yivJ30llpTUyLwMAmrF9fa0hhzyzzAUO/ID5hWTTxtUgo1+ef7mr/VRN1ciEYE
EBECAAYFAjq3efgACgkQwqUsK9IvFbHYMACeMmDl3LhzvrVCc85dRbT3gA4wNccA
n293Cz5RbqOtpe06dFPH5AprYh7liEYEEBECAAYFAj0HqlQACgkQtVKwQ3c5BdZb
MQCfWEdoTE+GiJ+X4K5yMMuAIOiRTXYAn2iK6OcjPw+DAEcboef4LpE6Hj8WiEYE
EhECAAYFAj0HrW8ACgkQGPUDgCTCeAKcuQCfTRlZ9SJBW883Q+jMgcNrTBpGRWgA
oKWtVGiPiitV0vY3OjqK/eWQ0xQdiEYEEhECAAYFAj0HrZAACgkQIfnFvPdqm/Uz
dACgs8VNTtrRld+h2ToPM2jo1EmGM9UAn3AwOUKQf4qbA+F4L6ZcWKhGvgpUiEYE
EhECAAYFAj0IFooACgkQ2MoxcVugUsMbVwCgg7bRPW4qUB0mC1u3u4CeEGTXZMAA
n0LVjCotR4s7tLQplT5RLvI6PTC0iEYEExECAAYFAj0HoFEACgkQIBUx1YRd/t1G
BACfbrg60vKIfBvKUidp6UNN2y1F4EUAmQHN0mDDu7hdZGwxTT0P7+fnNI1riEYE
ExECAAYFAj0HqH4ACgkQRu2t9DV9ZfsxhQCfUX7HUMhcwttdYpEt8YjVN5m405gA
n0uxQ5hCOtiTY1vE3++dV5WH70OiiEYEExECAAYFAj0HrDYACgkQXY6L6fI4GtRj
hgCgyeoQeBNyA+PLgTBCCxIe3ZWk76AAniWmPw4V03t2C1QciwbnvxfFrr+S
=BVS/
-----END PGP PUBLIC KEY BLOCK-----
D.3.10 Simon Barner <barner@FreeBSD.org>
pub 1024D/EBADA82A 2000-11-10
Key fingerprint = 67D1 3562 9A2F 3177 E46A 35ED 0A49 FEFD EBAD A82A
uid Simon Barner <barner@FreeBSD.org>
uid Simon Barner <barner@in.tum.de>
uid Simon Barner <barner@informatik.tu-muenchen.de>
uid Simon Barner <barner@gmx.de>
sub 2048g/F63052DE 2000-11-10
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDoMJEMRBAD9C2z1pr1D+V0OgztcnlU7sBqGQyjYFmzWhEDPquPdMQwIDtMs
FH1QeE/90uc8J35Y2Ba1/O9b9zG13t2rSXz9zenGo89thgcaptTY527UAoNJZXqO
1UbBsq+wfOuVTAnFSue9bdgyzqx6jmJpIqvm8J06iesBrXyB70U1oSF2AQCg/zR4
QTdnrmfpDoC2vLpYdd/emmMEAJgbd14BbLebVrxUiS85dGbrWon1SxjxTza3vR1+
3npc+VMpeoEOiCXaBwpMAq7dzbzalaU1dgkr031x98ZpXPIyEi9KkBLZ9kPZRzIV
okH+XIZ3IU+eUFuLKuGg9xWtweOq4xL9X0Epe7uU3DouGaVN6i099zP9w2e2eLPk
07grBADECiS7ejh3pYFwe9dSOKN5iI1SlAqNH69mvMEsPOPYVbsJmYU6dhPdEWa3
O7o6CCho3gUejhdl+z7dnrsxHOHRHFAIr5o1gvIGkmKCn4H02KIr+S7cI11pqjJO
mofEJ5w21I7Lr1fL7AA/7pZgnWePZaPeh9fXlQ8kAoJ/0UTemLQfU2ltb24gQmFy
bmVyIDxiYXJuZXJAaW4udHVtLmRlPohTBBARAgALBQI6DCRWBAsDAQIAEgkQCkn+
/eutqCoHZUdQRwABATxcAJ0ZfEhRc3q0UIY9eZtY2L+s7glyMgCg/UjC7MEKC1xq
oHWkz5Zjz1oaXCKIPwMFEDqOp3zb0kX8s7KhLBECxOwAoLku1efxcFzT9B3loRuu
lISktrZEAKD37jQuRlMyWf20uU13gSfJtCeLl7QvU2ltb24gQmFybmVyIDxiYXJu
ZXJAaW5mb3JtYXRpay50dS1tdWVuY2hlbi5kZT6IUwQQEQIACwUCOgwkQwQLAwEC
ABIJEApJ/v3rragqB2VHUEcAAQEnzwCfYt2w8JvMG7FD8Ae+sBa6bUpaB6cAoIQM
0d25+IpshigRTM3djVgabwtGiD8DBRA6jqdN29JF/LOyoSwRAq9mAJ99N2SXxuOh
SDt1dd3axBQS7U1dSACgjX8LFHWBZ75KSLNr22LMKuSEk1y0HFNpbW9uIEJhcm5l
ciA8YmFybmVyQGdteC5kZT6IUwQQEQIACwUCOgwkTQQLAwECABIJEApJ/v3rragq
B2VHUEcAAQFxcACfQfBW95c31MHGvSanzCk+D245McMAoI8nSI4dqDbGIPppKK92
cq098ZyxiD8DBRA6jqds29JF/LOyoSwRAnNHAKDvjMCXb8PXP0zufz/nEksQwwaw
4wCg0Li4kAQhbnKgLXOFq1sVB2GtfqW0IVNpbW9uIEJhcm5lciA8YmFybmVyQEZy
ZWVCU0Qub3JnPoheBBMRAgAeBQJCHMdDAhsjBgsJCAcDAgMVAgMDFgIBAh4BAheA
AAoJEApJ/v3rragqCKMAoM5MXsScnfdD/rKoHkyfIWAOrHQSAKDDLfdDG1pMsfMa
/4O0QPY3LN9hFbkCDQQ6DCRDEAgA9kJXtwh/CBdyorrWqULzBej5UxE5T7bxbrlL
OCDaAadWoxTpj0BV89AHxstDqZSt90xkhkn4DIO9ZekX1KHTUPj1WV/cdlJPPT2N
286Z4VeSWc39uK50T8X8dryDxUcwYc58yWb/Ffm7/ZFexwGq01uejaClcjrUGvC/
RgBYK+X0iP1YTknbzSC0neSRBzZrM2w4DUUdD3yIsxx8Wy2O9vPJI8BD8KVbGI2O
u1WMuF040zT9fBdXQ6MdGGzeMyEstSr/POGxKUAYEY18hKcKctaGxAMZyAcpesqV
DNmWn6vQClCbAkbTCD1mpF1Bn5x8vYlLIhkmuquiXsNV6TILOwACAgf/bGaz5lw7
KGb1+Yl0n+GXfFF/OwDbujxVoGn1KM+dKbColaX44Sr/L60px4cQ56ZxX1e6hxJi
TaLrrtx3bxZSTUlJuzuNdOA0vfcw4yQzrPql12op9K2DVeoo/WzBwZecM1eeg+VU
s4vlQuG46c3NbeTvXpuSyoHzDVgf5XMtwI/qTditup1g6tlViur0BMrUNJ6WZSpO
TLAgN1DKjuEi1FGVEs2n+BSEGBk2dM2325j6qYQtE6iXEEc18s/xyT+CSEQYfAP3
4/4UsCOi4pmuy/+OlBXYEv7rg8O0EpUqT4Po0BbhrMCdwzlhbb3LpMHyTwYSPdEi
A9+h9Mv9c0QK9og/AwUYOgwkQwpJ/v3rragqEQIJBACg27m44rBDabiRWXVEGny1
8o9/o+UAoI65F9bRERosGt0m0f0q1WwwdGcz
=HMUk
-----END PGP PUBLIC KEY BLOCK-----
D.3.11 Doug Barton <DougB@FreeBSD.org>
pub 1024D/D5B2F0FB 2003-01-16
Key fingerprint = 9DD1 E44C 8660 ADA6 580F 83B6 C886 A42B D5B2 F0FB
uid Doug Barton <DougB@DougBarton.us>
uid Doug Barton <DougB@DougBarton.net>
uid Doug Barton <DougB@FreeBSD.org>
sub 4096g/2DBB3F89 2003-01-16
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.4.7 (FreeBSD)
Comment: Public key for DougB@{DougBarton.{us|net}|FreeBSD.org}
mQGiBD4mlDMRBAC0iRjdwnYWGl2pP6W8MbxLHnZpBNAnEUaz8VfC5w3HAyFUV3jp
t5Lwerd6Xfxl9YziXC9yI3nQNMJtGLlHpAv6kgGAO581PPzS5ruXS5LBwsts7ioe
KFBv2QKVxVPgZfgowqAW7EBZN+PclrApi5e61evbr+CYFiR4OISrvo0N7wCg/sqB
X9yb5NjWLtEDEPeFWOcz1rcD/RcW6Hu0Pm6UWHmT9QT/43yC2MD/8CHpeMO2tKGx
H04nbWZIt26ViSdt6jniIDau+H9/gzshTB+rghLzuvHpupiUp0uwuAHd00bAkB5E
lBXXvDEDlI1w4EBdoRFWpnLRYtNbHmYelCFWntvgrlgw8sm7KFneZQWbK68RLHAs
vRcLBACNaC55OuDz5GqhMLp8q3pFI06a7jsTnRtH2DoMxbgkFbktNuu/yWWan8Jb
QddYcrRxZIiOq2yu0deZHAyoRpGQg8Xa0lHQrrU3APMA2m1CTUviLTb2X1SNitJI
ukkOxPlx4uM0yxYTjHJx950WxmdVCBWdEdOx7YFa5xZTkYrxVLQhRG91ZyBCYXJ0
b24gPERvdWdCQERvdWdCYXJ0b24udXM+iIQEExECAEQCGwMCHgECF4ACGQEGCwkI
BwMCBBUIAwIEFgMCAQUCRzrMwCAYeC1oa3A6Ly9wb29sLnNrcy1rZXlzZXJ2ZXJz
Lm5ldAAKCRDIhqQr1bLw+0C3AKCyxfTbZOf+/vaFniYfIBaQtHcVYgCfU3m2622B
J0PmbLDXLAHJ1/7SsXyIRgQTEQIABgUCQ4O+cwAKCRDC0M/JN6wFjJd6AJ977E2k
J88bmDdhbrt7F9L4uZjmGgCgkNcHGuPrMMx9VIDEcHVuaJWyYtCIRgQQEQIABgUC
RVJ92wAKCRDHibNcwXWxw/mhAKCOFUhlbJT3XoxASHR8iV0LWsGZzQCgokks/a5B
o4XzGhzk+gAsqMzO1IqInAQQAQIABgUCRVKTuwAKCRDFndaSjlfOma+/A/47UDdJ
OVLkdFH9rmHCXT6UTYAasV4wZBFnFJC4IkxgDxKIL7ecxnjX8ms4C7SLdRfLnW8c
5udS7HYigKIG0QdWYBjbtQzCH+irVud+0cO/OjeEB3kYSoh8zZ7PKeUOoR1OyOiZ
Glj0erF3OwRtqCUnuVKmHygo74ue3MxqGj/3t4hGBBARAgAGBQJFUoU6AAoJEDTw
bqaaJAtdvRoAoKYFKyZTpNVYl+N++cfBU5le7O+SAJ9EBMZdH3SULRnyd+5qRd1t
hwB1ZYhGBBARAgAGBQJFWaEAAAoJENWMny3eufZHKykAn2PF8XYOZ9vZ+cluvISJ
mVSDq/jsAJ4lX3EoI2X5J8g8sU8u6sOutoFP84hGBBARAgAGBQJFWsY9AAoJEGJA
5uuW058LvloAoM0r6+3VpLWtSbrsmLOaatO12bZuAJ454LJZVwtUC3qe8P4mA8UJ
tDoQk4kBMAQQAQIABgUCRVpx3gAKCRBvM1bf/KFvkFkGCKDJ3zOr9UfXfvZc6Ppj
752/dvGXtgvjoLCxtMltNxX+FFXmD0qBxPw2u1TYn2K+lq1/Nq9W0BjYYYkT07UL
hKRQ501vCBbrqnNgrD2f/6o4BE23nVsgYgGnFOklAjz288yX2AbAaMu7wguHMqGb
yBQnlD8165azIWyfrHsGs7i+kWLqdAmLCKV8O1pAzm1E4AGrDfK76/z8p2EEODBH
iBSHKAqdex0aRGlpfpcGJfKJPyU/1cPD2UxtWth+oPunVn3KZDsWWv31xqZsOVhb
Zrv10sZyip1ghJfOXc39BWQ6pRbQONmcyp/4mxbVHHLxFOPSW8tDfbLr7ux/rQXf
uIsaAVJMPbKn/0BoimehWLBn7AXLta2JASIEEAECAAwFAkbfqdQFAwASdQAACgkQ
lxC4m8pXrXw+1ggAjxFn474LUz1JAbBpYBShcl7Pn15Kt1ApFNtGR4hYdSXtNcUr
9apUmHzF1HkhSPODQEIlBeiBxBf0O2/FD8zj7nXVA4ELsH3YQym39Rb5vUmGakqf
R/o0I0tBQX97i/oZBdVDEcxgezYoNVNSCQNdQvl0qDSp/eF928HeAf01u0yYW0by
UPiKSejEiQ4Yg5kYyaRTC4elqBXRtUYPB/pkSHJCt32fsudGqEbZJYq++JOEiANN
5oWMH4+ifNIi98Nc2tME3wpauw3Ww17+FpN5rirEM3fzpg4xDwyPsmcA0q5y1JNW
Vu13XMh4GJtq4sBkQyAGVdqUvC0aQ5AWyt7d7ohGBBARAgAGBQJHLQW+AAoJEN/a
zsY7+ZIlEyMAoO93GBmUCW+XvbPpN5vslTY7NOx9AJ45xnaN80Cd4mv5pQlgm00S
w2jRHIhGBBARAgAGBQJHLW1wAAoJEJhXkSdLYyMRJtEAoIjld/sArPh3Cym0PMAB
Z+PYh9RdAJ4rt0IUwg3YKvddmnXIuc2U2eSwuIhGBBARAgAGBQJHL5D8AAoJEOd8
mMQSCOrvE/QAoMd956pIAxtoZsFAMds3xC5CndXcAJ9/TRUgvt5ataxaNwZdxT+b
mzpL0YhGBBARAgAGBQJHL18LAAoJECv7augiY2UCPk0AnjFzfVsP0xyjslGu8wlF
oGthuewZAJ4mNTyy0xt7y+EtTfdFLMdSGi5pNIhGBBMRAgAGBQJHL7SoAAoJEFoo
wZVaGo9/6SEAoMrn/lChZfdTr5rnSMpHLybGUZFuAJ9W0U2FvZ7VBHoC2ZycBeGk
pggDz4hGBBMRAgAGBQJHL8KhAAoJEFsqkax3EFk5JeIAn07XFG0xO208xD0rv0zl
NT1AIbJ2AJ9ILYyk6EcUFO3wCzPiZEjkDOv1R4hGBBARAgAGBQJHMbRVAAoJEHcC
6rsPWinK844An1v6pODEqczam/9m2j5hJr3+VhPNAJ42/MT+yDNBZ7bUI1H2buNg
JGJw1YhGBBARAgAGBQJHOimRAAoJEOTCQBfopvGFtH8An2uhsFLGptujcCUnGjrl
+XGEQILIAJ9i8JTQHUFbDvZyFmxPRvlSovICBIkCHAQQAQIABgUCRVKCwwAKCRCw
sicTFbkGmd2iEACYun8xXmYQkt/6ZrycLja0iPepjZmpknTWKAyiqvnGwR4bhYrL
XHN6QiiIJqRJW/+v9dF9xWA4TkJA1ceuq2m0wBki3+gNudh0QqkerGtVWvReK5Jp
KTps6YOGXmKSx23k+u8rp3eVDkskg0LFbZtvpsM4RbFeRpan0y11pNIzZ5ZhWk1u
rFsWeTjHXBnVGnMxSfGENhB4eMrfBXVuBMzAZmDxp3jXnn/rTAjz/eS9ntW8DeDq
jpvzgCuCpcSOEMGQQz7G+hZjogDxJwxAHoU8hbX0EkLbWnxvHh1JTPUAoso3QsMo
i6m8xDg5MbtV0MBKNZfaGDppWBh8rQf/9NARhquRGN7B5ZwUeqf6u3Fvbht/oXMA
TRQjTo3bPa26KvHYQy3X+rYCNF+3fTG1OkiHmIDj4GvHbQT8LNIYVwHFGPDoW6h/
BWHKR6LdKwdjsQI4Asl9D3+EUned0NHhe6T91wboxzg26oeUfj0HLGMn+/rYOCIr
EmPvxsWbFJnYfFQQNj3w5r+zsy20OjeLyO3OP/HGfbOrvSLTdDSqHzf6GdRP1yNe
BEuwkK9ZGrB1YaCBn5a1mHtC4q+YcWdzeD87c/j9JVfKdy08DHa7uTUvLGp0I2Al
eOiZBn+tQMPyjKLPkSBkMfkw/gbuUAlttRbCollQCagAulvwj+mQMGb0o4kCHAQQ
AQIABgUCRVKC3AAKCRA+arEaVtUZlR15EAC+KvJ/npr3tRtG5cmfrph3o1nilNrB
a5bhWkdAms9c9yDg9kKOeBzxryyHmjQlVAZ2ogg7SFMbSyECOMh5w16CTTWTnsXN
qp8joovy0qU9mi55jW0VleLqGy2Cb/eDNh8DUR2YA3kx0RT+LT+fn7mZg9n8M7M1
3+untEzz3ye3HRtsLhsd5x1bJdrsQChbUDP1fm1USmfB4CFB0gCZ8kuwNB3JI45s
f7mLvLppZz0FLoJjmmMjO7stDScXJ8agCBu3/wLKjJFFUJSjMZ46HWeGzUMIvkiK
M8d6sWWrCRorQVGg5ALeg/7T337mY+qVK40CSsqaa66QzWe57BBTCVc9v+M5w5ca
b8wjXFjLxJGLALsO4Bq9PLxXYc5zBipxl6XJ7JDjMQRN4cpUI9FzkD+4jWtQhrM7
ocsac9lDzP0Gm+PjIdFoFOtC0HS/6TY4yDBv/3TYEOhQq+Xpmh4nSI3DAleMTrkl
2aadYitmYvhNs7gN6XjQLkrEVgWsPluxkxWw/gB2NfZspD/pZV9bjdV+Rc6lRL1J
mVX8eW0aUfl45Ng7rnbUrUp2BVIe+1QjC0/DFotEGJB3qxgdIUeX9ZB1p0FlWBB1
rgCStqEQ3to+s9Qhnx9bF6ZFRerOvVLikUnmHrb1bTZ/6QywZj3qqAIiNsRrhB9T
AObqPcZAfL+tI7QiRG91ZyBCYXJ0b24gPERvdWdCQERvdWdCYXJ0b24ubmV0PohG
BBMRAgAGBQI/YttzAAoJEE8s09gnk88tKHcAoIVay7s13kDlqmSgqpDfNHBdMmXx
AJ41QYp+1ag8YPz06JA3eo5zcLU4BIhGBBMRAgAGBQI/YeYiAAoJENjKMXFboFLD
qDEAoLni/47DO1Rf6nppktM76PZPy8weAKDcmKB939Tnnf11mxbbuhx/2gYXBYhG
BBARAgAGBQJAKAXDAAoJEPerh6Os1SBBGr8AoNHN4f8z2OqFoTI876j/fk6TzAzQ
AKCBj/LwQBjMkuVVoyJ0+4Ocer1fo4hGBBARAgAGBQJAResoAAoJECcqJO3H3cgW
gggAoLhsEslV9n2f5bo+yJqn9ItsLHnQAJ9yTPqt1X5RB9Nkt/lh9tTF9/wMNYkC
HAQQAQIABgUCQEXrXwAKCRAWcgy00nqd1DMMD/0YQcpwhjS4Y2Q2DzCoGoO/gLa5
WbAt05f5HvtbuX+MzlPJ3h4RAPmfMqA12veDmFECCGqdE8fMRAOSnIpmO8J/mE5Y
QRszsA4/stL4Pyg5EvGZfLqE+G5cUN2+PrGExt7lNtr3RCd7rxdqVtnsbXbi2Bwr
Cmf92JzT933oTejvHD9p6vl4bQYXKY70QUakpGy2EO0cvplOsZifUGYL5Dy930Ce
kG6u4nMW3DY3V1FKVrCc9PbM+dDLREEeP+piq9Sws/sfZ7cfHPMt+hGEAnMdP/9z
5ivs/A+r9FlLp1/AH2rJVYjm8Xrn4KXVPNgQ1KCI9YcjK+SkeukZ6WQVHSuxNa6I
6PRf3O+RFwaSnKKkuHw8KoUbjIMXcsDBICQM3Mfsm0Jk0056LfP/1YGTTAa+QSXo
O9OxtZJxW2gyzZjt//pIWDxFCrXJu5zhwgWrSBuctvIx84LLWc8rk8IzW4fEKW7+
efRou8p9N4S2WLdd5iz7Uwt36p7+YHSRHOADoElfoSk5ork+eDVRyNoW0yo/1qo9
l+6IizrZVRCTRiinNakz82gaIqNuqD+1gOH1QJC1jF/YJjXayXh5BtaCttmWfRHs
IgFB4Y6CexQNaV/20OP3v+Mti10QndB/ThmKV3u0meKkVhN4a3ScxF62wP6RpoNe
u6qNqHD/9R1u266+p4hGBBARAgAGBQJAJBaoAAoJEASBw5fnLV8wRXgAoNdHWFkP
L55D32wrK3GkQ/UIb1cIAJ4p9EGPmVTBL54xC25jFEiU76/bqYhGBBMRAgAGBQI+
M7epAAoJEM0LijX7V9eTnmkAnimeIl/H8AVO6ML7IpABxQJZiEtyAJ92nW0bPyOm
NemuCU9hXcjra8GlM4hGBBMRAgAGBQJBNsTFAAoJEBPuCY+OXB/B0DIAn3VUDRNr
iw3rjqnSHzft0q+HN8GNAJoDCxtQgK4LEyNOZ3DG6zp1Y6wSf4hGBBMRAgAGBQJB
N3lrAAoJENIP1AXK1QnGuIIAniZVE4/k/oKaYnP4ny89iS/FT+xzAJ9J6W2vlle7
/y2ozeWaQ86htb2C1IhGBBMRAgAGBQJBN3mkAAoJEKxZSaYHOGuZ/nYAoKRJQz9W
rP9G8isFjFdgz7/Tk/c7AJ9r30MZhkZegSTgqzIbxef+nNFwzYhGBBMRAgAGBQJB
N3m7AAoJEP3/j1jk20Tygr0AoLnnaw6mlz+TPHOKyHIOOSlw4kD3AJ9vimFP3XHV
9F8lfLtNcvEUiNn444hGBBIRAgAGBQJBL62GAAoJEEouP6ZaRCq02V4AoMpYDuLc
MzIVbiLGPZoxgc51IKsHAJ9N7deAyqTfD4DNjB/dIp+IWJENg4kAlQMFEEE7TDj7
wj+NsTMUOQEBqBwD/AhvoI+lZIaTGVbIsvXAKW+UF1tjswQxK4gv1NQkxSzkMbKf
IiXN0sIv9JxoFXM49UGRDFj1C0rH7hFBjyzoKvjNSfNTIf5N83hujTc27wTVUhQ3
7Di0olmdi1y/A1ASzLUMBZiOMu0zArFLBf6uqJFi+g0GzBp4u+k18tFoBQf+iEYE
ExECAAYFAkFE9xkACgkQwtDPyTesBYyF8gCePBUlmkT2JJWB0eA1cz7x5r50HikA
n31saKyqwkn5VJlT6ZD19Pz/v6pgiEYEExECAAYFAkGS82YACgkQuFXdJW0mnu2d
ZACePkzmB6aVw/HHvmh5NPmWMcTpQm4AoJIhVpaahpswYG9yzXrZO0a5ICsyiEYE
EhECAAYFAkGUVZAACgkQEC8OJ8ylIRp90QCeLTsKubcYGvsJbsJuKtRn5vFyJGkA
n2GDQMol+ORlewSdJW3kofbBf+Z9iIEEExECAEECGwMCHgECF4AGCwkIBwMCBBUI
AwIEFgMCAQUCRzrMwyAYeC1oa3A6Ly9wb29sLnNrcy1rZXlzZXJ2ZXJzLm5ldAAK
CRDIhqQr1bLw+0+dAKDf18TT8xAziwSuUdLI5lAwXr0qFQCgjGU89SNNvPC80uZq
1CFtEFsboxOIRgQQEQIABgUCRVJ94wAKCRDHibNcwXWxw14uAKCYZ1NXvJ8mzMux
MQ4b5hJpuQQUdACg/ISj44b+vrpVg7GGMaFGvX63n3mInAQQAQIABgUCRVKTvAAK
CRDFndaSjlfOmXJWBACMcnKP/El2pLJuWg5eEGriZII+81RBlTa7qNzwQRo1vsTC
dlnXAekfEh9Jhbz2poockISOsXpQAnxIH/bNTaVPAlW9OYXDMH9rM1jGUWmE2hFo
myAlQXi9AFQRNn1F2P0iJ8tEr3H8cjHFvvaTquZobH6M54OJw3vjVIxBOGC0yohG
BBARAgAGBQJFUoU6AAoJEDTwbqaaJAtdl2EAn0jHucscRHI/psVdy31JtZXwhvkz
AJwOsZmKIFimRRQyNpoQvJPEZA+/BohGBBARAgAGBQJFWaEFAAoJENWMny3eufZH
ZIkAoLg0QE9XGaqUaGGz2Wt6I0mRGJC7AKDCxxF6zUdMbRrkl+CaU4s1kHK5AohG
BBARAgAGBQJBlXh6AAoJEGJA5uuW058L3eIAnA0YRRsumio7/0QfEpSIyFQY9Y+C
AKCGAW+rhVjGYCHg+ACU0w0l8JQalYkBMAQQAQIABgUCRVpx4wAKCRBvM1bf/KFv
kF/mCKCjzjzCZk6+LL9/1BFnEpf85lxIAL3ER9KvRTLeqpPNOBXgCHTlPCO2nutx
Iky8ZuaeNgsOEKANq5q0W/wbUyCYQKYX/G05mUrg0aPdq82n3uW0n1tRP1agXwJ7
Xk1gRJibE/vT1BUEa0Vrc6ujo9j4+bbZQLxNdRDbtzjEFCn5Bi4u0rOBHtwvoRj4
AU5Wlp3xpE6+YHFe9oYY72BltWIp1QT6L+4KjDAzgRDztRr8Ci01aaleVpEGgmnq
JOZwHeCAi5tiVAnl5ZOyXibKe9TX2whkInG5U9lgG7Siljk+2FJflLsJBbrI7Uzq
qxFxHGPH5mT7xyc20PJOTwejXYwHoHa28idV6xvaZ5DElK+L0ufz4N2JASIEEAEC
AAwFAkbfqdUFAwASdQAACgkQlxC4m8pXrXz5/AgArmj11Q/WboJUXfgWLPJLw5rP
SErX+s291UuJCJIt5jiLNzHpcaj7uKxzq32i0luFicnh5gPfQv70WmEYuaSw+ehc
zntaCVQqq7MwYvterGo3+0wUZyfSyroG+ufIYlS9jJdctiXL3xNiH4hUlZU3kq0f
uK0EpiQ1w9C4nT+llc5YQFTXRXKjBbq+4jgIW2tilY0dqmJvnMBH5RvIcyUvuzVI
7lAvekh7P9zFm7EVnIk/NHUYRblllCTgqrDfpOYYZUYqO/TEGlVETzY5TYWkhv7Z
o+5NanXiN+n8ajW9L7EPVdcC3X4zH4L2jO6j9P/MU/8vkOxsh3mTMdQbkXLYd4hG
BBARAgAGBQJHLQW+AAoJEN/azsY7+ZIlypgAoLu76k+mPUvns8w4MHGRPJ9gb4/Y
AJ992ytcwm39VgH52j5a5biFutkFYohGBBARAgAGBQJHLW1zAAoJEJhXkSdLYyMR
a8gAn185pg6aLK1LWZFgVHUOhvsTImw5AJ4npBkMHZ7ZnF/hCK/WtLJG1sZZGYhG
BBARAgAGBQJHL5D8AAoJEOd8mMQSCOrv4rwAoNLy24E7KtbOMl9eAHQI10JysKtU
AJsGWMmCcC5anKBVdQySsJud5WdkPohGBBARAgAGBQJHL18PAAoJECv7augiY2UC
r/gAn01HmsTmdgahAcbW/RBGwBGY/9g1AJ0VmC4XntgqGqGCeSVCRxZkgj+9aYhG
BBMRAgAGBQJHL7SoAAoJEFoowZVaGo9/IckAoNqDtisMl50Mt20AQ9p/q6j9KQPz
AKDdA45U/JWu40WWsCABDNmXPtKGtYhGBBMRAgAGBQJHL8KhAAoJEFsqkax3EFk5
qcAAnjKbm82tgEjmWnVF2pTtgG3TQMGOAJ4jNqgn9NOK3qg4Dxz4v20dOer7fIhG
BBARAgAGBQJHMbRVAAoJEHcC6rsPWinKXugAn3X9C/6rJBq7naR2+Ap9S7zYlmDS
AJ0QKoBMbTmfyGgjuoDsM5lbf2SpIIhGBBARAgAGBQJHOimRAAoJEOTCQBfopvGF
jwYAni3sKAWg+TqZ8Ay2Gi9pW/ZA+ZSNAJ9ZEhRp2tdnznkxrJ69siHRUyL2AYkC
HAQQAQIABgUCRVKCzAAKCRCwsicTFbkGmcOBD/9Ba1thA0MktakX6Zb3kUstS/z5
2ilJKcZKBn7xYbq89SlEFapln8bg6NwUiUIGke1WwuW7iSj10WtVNYjorUAVx5gR
8+qQkE1V82MWPbQBWU7Bk5tevpNwx7f3KabNit+XtFEr48cho+pshFSyHFKqr1Vf
XTiCBIPRLmmv5L8TrLFQGNYdqWMizTPJuBByQA0iFNxR92GN9CUgUOcN2eKUjdrv
F91CHylsEW0uD3m6u6FdlGvoY0yAO682UdReJb9FXuiOJLKP1lEYXOUlu6A6ZL9C
EDOccw/54tckX/bpE1Hx5G0kUIiaE8mMJ6zbzibhy0onHZrQw1aGdHH4PuhsazmQ
DMX7Y7x4RvpVLyLZXWhbbiGhjmAX93QzJEj+i0F8KfAh4XCt4N8C15nPUD9BfWN5
zuT+xQ//U4XUe+o9xJWsgeGmRXc8/G0PWuQKSDOG6Mi98Cyoesc/r2j+ijYt7Mho
p94aNWKsBukLI//JN0tEr+dtHxPrCDB6xVxgJDjvDfe/WnDF04/eJld8AhsGwIz7
D1S9zyJ9wte8NrA726I6QCIunZYyCMmTwwWJ3vSJJBZQjyODCz98FDB15blYIOql
6gKHxjfBPisWS74vxWPyHcrP7AnRPRarb0ZraMqyqrP2iJByB5vGEjgRGvAI68PH
PNlNJnGJAk9W44QMWokCHAQQAQIABgUCRVKC3wAKCRA+arEaVtUZlf1tD/9Tahp1
avDXviDgmVgrO6t9CL1o2bMS6t9tBSq5sKgBMW0GQpU2l4vSQA18GLOFrW6Fb2pV
aMIQgIPg6jbpuPOQaGEn0s0HfSknIpft9CaHOvmYF1Y6PFcxJueJvI0sQy2AXCWR
7kngzczEJpaqnlDfg0+RT6iQkwspuq6S3/EGMscNs230BE5Qq0g8PadEMwccvEz2
V4RC84NnDAG4uX1AD5OneVj9h93gK0n9HDekzkcG8q8Aa07HwJSdomLRg9wHvnZF
053AQcjAVBP6rr4ApTI7Qrif/sfDd/jC62DJee2m04fZnNi+Rok21mMvj5Em/j76
zeiGc/CWr8xTK37tIMJeTp3yBHjStIOC7/F1EMVxXxmooWpcq2DZkXyfLX1ycRJ+
b9LJVqu3qoiPoxlfmjZMZRe7/pQ7FExqesI8Qt5vBnDlyzGsSj7Q68YoGRK1on3D
oekp0tkhdltOJwQ/o5oAyTDDxdn5agqYLrPBgmUkRF2THmLwccFY3ltOg1t63cDu
fTqT0t7H7gWpNCyg6XCROxpTNaTTcMDUsclJHLKwR2j1V2zbkl2xaoXX/hug9b6q
cRBvcFLGWCPEDQYaZTInI/PRZEPh16O9zJiuDV1R4GOPdD7rRTG11Zotdr5F/4sq
nUk4bDuwpZ+N4sZMSPc5gjCuyiYT4eY6JJ7DkbQfRG91ZyBCYXJ0b24gPERvdWdC
QEZyZWVCU0Qub3JnPohGBBMRAgAGBQI/Ytt1AAoJEE8s09gnk88t9/IAoLRaSLKf
t9yw+FBwDLz9htPYdUiSAKCdytbnv+MC6gHHDd7SH87zorw9gIhGBBMRAgAGBQI/
YeYlAAoJENjKMXFboFLDK1oAoJIsopxBwKHN9qiGmSEx9YaEgTP8AKDlc7oOrDpS
p9QJBWFoVsH22CahxIhGBBARAgAGBQJAKAXeAAoJEPerh6Os1SBBQAEAoNLJfByO
r5Z6aigTLQIDosJRg34sAJ0eravBLsHN10ls0ROUvf5qUX1yDIhGBBARAgAGBQJA
ResrAAoJECcqJO3H3cgW/wcAnj8Tjjl60+36miVm8ArFFo1xfEenAJ9pffEI3cdQ
YH9oNm53cG7hufkcCYkCHAQQAQIABgUCQEXrYQAKCRAWcgy00nqd1CybD/9Qi7t8
b2KhL9q5uxDLDJOYgq62s7fXDsOmHuT4pgAyGqIhBUUSRUUZ2BFBplzVSQeKC0bM
4aEOfK/O6ULMlUuBDjXEsIfWPSZfy9xCEbJ/MEsB9eJJScyEj4+eAvlSLcobIeym
sY9/6P2d7tLbFL+rDh0rjcnva0hzXDKJ2AU9Vpd7WYyNNc3wMgqYXHO/N06wWRHL
hVeqtGlg5t4MxxHR3KwlAhscFxs/xGPvtQpSJW5Fk3uQGnKMihNsa0DgOmkkQf5Y
omV+04X+jz3fd7KqgbxRDW19djlua6AMHneGaXGQjSDk6TGigbTrDMyqAhphwRI0
JG5fzfYuUOHsLobj6G8NELiZ9yxfKRvpBGwcsGiU6U0TF1IydgunZY/jUciVSRHY
2o7oqUEIthfomsDC1XvGpp8Ir7Rv/uTesxDyzHFFrc3ObhG86+5a1MGzjLKg0rzb
84CHlt29tNJWyh5p8aE6OXNm/ImiQD5I0yi7MEU9Kjult8xNCcRqKP2t2EkLqojC
/XpPs30BT2z6hBPIx1qdy1tU9Gyy3pvRp9bJsKGQP8WOb3biKw8z7Khc21/KhVLI
QvIdaPu7CdfxUnFmZ0kksVoFxzP0AA868T4tKoZ09sP0EOeA5z3Kqmm7SPuZT4ds
cEBmbFcso6pcdDE+M9jTXDPkD8yBtLV2hSeAeohGBBARAgAGBQJAJDHqAAoJEASB
w5fnLV8wM1EAoOOlCKwW+4qJDoXxYoJvqYcMOiTIAKC9GXZu7Nf6+USCIJ7hztoX
WG1rc4hGBBMRAgAGBQI+M7ewAAoJEM0LijX7V9eTOPUAoLs6VfqYwhtidx0Tyt3E
i0F/ogRSAKCqqmYlU8CzbQdEvM1fJWJeqVPH2IhGBBMRAgAGBQJBNsTLAAoJEBPu
CY+OXB/Bq8kAn3cFkbZJxgLS6ZJQI4uVs9BCpL7iAJ968P0xR+0E+w8P2jFrc/KF
seSVmohGBBMRAgAGBQJBN3luAAoJENIP1AXK1QnGVUkAmQGSmsdhLaMptrIJZEbY
UkAUGGhEAJ4vwRvwSXkUJY50bOuio9WVZAfDPYhGBBMRAgAGBQJBN3mlAAoJEKxZ
SaYHOGuZuxsAnRp9hkP+/86VtY0t71Xw+WxBjFC6AKCrERqUn9ZTXKfNisQFK9TO
XFVrIYhGBBMRAgAGBQJBN3m8AAoJEP3/j1jk20Ty23IAoL+hNDRE4MhpxRhDsP+L
wuyaxECTAKChzN8uXP6KTXdZAAWBzgq0Am9fwohGBBIRAgAGBQJBL62GAAoJEEou
P6ZaRCq0Cz8An16ULaVqvOL8wTUJF37IyMsNLJkhAJ9HU5ddvopjOWqNdy9+mh1x
BI95+IkAlQMFEEE7TEf7wj+NsTMUOQEBoycD/0f5MY9tFSw/SVWP52uW8yztvqcc
epCibnhsd6iAPBjRmk9/C63rTSHgAdlcm0F78RgwTkecT++2/uZJPgKH0kIV/Tkp
sa9rcjCr/ygSgS0l4RtV5hTbdJm3mXwyIl4HBfnKBHZGXzuB5nzMepPxXsRvMs7j
jlCeHPuXuH2/fKUxiEYEExECAAYFAkFE9xsACgkQwtDPyTesBYy1zwCfSxB7A0EI
23pgWUzzjoRR7mQ2p8gAn1HFLYxb8/FDAXvr6o7guP4RI4fViEYEExECAAYFAkGS
82gACgkQuFXdJW0mnu2TFwCgpC9Eku3Um7i8wS+IWJYrql6wWXoAn3uK5E/2X3yq
k5O6x+TJ1YlUmljOiEYEEhECAAYFAkGUVZUACgkQEC8OJ8ylIRq8pQCfd3cgjAm3
iJqdBkixY0chjNgOiMYAnj9cvFRraOkyJ2ERiGo6N/M2xPZDiIEEExECAEECGwMC
HgECF4AGCwkIBwMCBBUIAwIEFgMCAQUCRzrMwyAYeC1oa3A6Ly9wb29sLnNrcy1r
ZXlzZXJ2ZXJzLm5ldAAKCRDIhqQr1bLw+8oHAJ9m6ds3FWr18kIvFFGVwLFXo01L
ywCg6ZZvHf95mQ7t5L6qZsEabhMnj7qJASIEEAECAAwFAkODuY4FAwASdQAACgkQ
lxC4m8pXrXwkvAf+K10jpWpCs+XPlVzOpQZN62QP8KfMcaoFzpWScld0f9ak76Vg
XUgZmbWzbq3eEU2U9Z2tYy5LTW6SK0Gx92InZmPO6PiTLmq+0HaE/EQZTRVScitf
wpDJ2NPoUsWo4/Y94gyefJG+ZJ4Q442LtrodvDMRB7cda+q1UkIy2cPv0NrmmTrp
soC2sX3whwgovyRCfXMwRlMN9oo2VBpxsOdrYP7HxKxSlkX3GHqdlpxwEvE/94Gs
yEHjhCRQIyncVmWGSVACIh1qkbra2d8bxifjiQgid2/rFPg2J9/tgqLW66lFS+4K
8lAnr2VBt/gT3hEfFyj7pzBDew1PqR3r8p5VzIhGBBARAgAGBQJFUn3jAAoJEMeJ
s1zBdbHDbisAn3iskSQ5IOuej/9HqjbXZ2nrjJKCAKDCJj3G/+Lwsy7cVJoWo+Rw
p8hPOYicBBABAgAGBQJFUpO8AAoJEMWd1pKOV86Z4gkD/jgRGdVdZUUOw13xFe6J
De2eofvsKbYZxak/oVY25YQXcyu2uUhj6ssb0r48aal9EN80SR8KusqhohFzzEeC
hcbrVNBwOJxDxx3ahSN8CdH1bG7n8PrhD2Kvt7kjin6dpDvfB8gyjs3RfmiEEs0T
dzwcVEaPfvm8wZf43pTh21ehiEYEEBECAAYFAkVShToACgkQNPBuppokC10yiACd
EV7be/WP6WJEYwwTVlRjen3Cvl4AnjmG2Se2MqCF8V3YP9FogvpsNmNciEYEEBEC
AAYFAkVZoQUACgkQ1YyfLd659kdPiACg9gqTEJQkP5vsX+lE93rEpyR3HNsAoP0v
FoLjzFWYVY5DAk+2qqVdTd8giEYEEBECAAYFAkGVeNMACgkQYkDm65bTnwvXKQCe
OQGWcWPpKnEgSzAGMvmrYlkWYe8An0vdxRCgQtXubeLNrBq+Mphjm8faiQEwBBAB
AgAGBQJFWnHjAAoJEG8zVt/8oW+QTjMIn3aTUFaqK5Nwf5EGCVNCLW45hYZbcaGi
Wg1oTUt3jSX47O/icy9ctNKxTQnHyVA54BPGZi4kJU3MPtjGah/z5pbH3DLP9x2n
+2dtvb994Ek0H5S0AbcDforreTvF0XVd6du590XNX/x0xVA2fS3Sj9qTV9ujwHUO
oeCVhm4S6JohJyOWdx7bVqH/dlHa/p7FyX7W4Os9AQ1MQivkGuvJrV/ACcfDmsc8
jGtctyqjTnMMLH56mtjYh7t8m2s3itQ/lWoTEGhKLnSPT6yqoQtSGlvYyGXQi+bH
V/KLbrx6O4GiUBCR3fPyIBsbW153+vkjg6VeDbefflqLAHuzruvMVqDcAwPNEJNv
ef3b5XGm6//OA5GULohGBBARAgAGBQJHLW1zAAoJEJhXkSdLYyMRF1gAn3MlKsa+
CpoQltUceK7gBpt16xsJAJ9QRTys+LlsS1E/bX/BG6hCq2pgMIhFBBARAgAGBQJH
L5D8AAoJEOd8mMQSCOrvnowAl0y95c415zfloXS+FF9IhThdFX8AoLtl7FtPVMXr
8hsV1ewjgSuplccNiEYEEBECAAYFAkcvXw8ACgkQK/tq6CJjZQLiFwCff6m2seeJ
+pWeEnG7DC5I8lmX70QAn0q4W2W2cQwILF2vXnZrI1GrUpcNiEYEExECAAYFAkcv
tKgACgkQWijBlVoaj38J1wCgoPqUtXktagdqkO2akmzZfAXejmIAn0r29+dMyxLa
p0xkb3lXPRbXd2itiEYEExECAAYFAkcvwqEACgkQWyqRrHcQWTlZiwCfURKKyRFj
A+mgBTwcLmxDzRJ890cAn2IOcqfd3AkdTQpdi3tDeJFKkrLDiEYEEBECAAYFAkc4
MwIACgkQ39rOxjv5kiXtXgCfdxwj71/mwAyD29x8hHWnGlo5obgAn1IR75BdzHXl
iq/wTy1YIagdBPsXiEUEEBECAAYFAkcxtFYACgkQdwLquw9aKcohwQCXXfb0zlnA
xRr8hnjXzLzfR001jACghjTzC/Z7QhMg7onuGa7drmun5HaIRgQQEQIABgUCRzop
kQAKCRDkwkAX6KbxhSvZAKDLw5eQT/l1ZJxYRvsnXeh3+oHUTACfdGmM9KptsMz6
4byYoiKUl0Zj/8KJAhwEEAECAAYFAkVSgswACgkQsLInExW5BplKQA//X5gpsXVJ
wNyVLcKVshtwM6VDmFxbfUttbVzcC2y8qojPBak2ylRCmUN1uCr4vA0wJnqpBdNP
cUXVSYsFQShhvuNgOzFt5jxX68oZKPCniD40uKf2VW1VYrk8DAGibXh1OIaTxKK2
JRRhlhzQNS1Tiz/XjibBBaZBJxqXNv5JIdCKhNQHDSiDRfP/VAMpqm+8W3y9Y7eJ
YosS8IRpGDoyEBcTSofan/lQQAtjpG8/5XhUyjxBaTY694MK/9LvNTdOidDFMkyV
Pn6yt3Ez5C3vHPeP656+j3LiEdSBs3Il8c53xJY+QriPs4QJH5ySgA7tOIHFsYPy
G+cDlccUtFvz1z2pqW5TY1NM8g3NQs1gnyBtNp+Kw2O5NFKdF21fvIhW0O5X4S94
tdvyQgzB/C0Zs/+hg/YKNjLBzMvdlADYGEkp95C5Lue4sn0UIhH48np+ByIrMbcI
lK+dUs6BLxEanl4niHap4JFODINa4drN3ntQOfJeZfWPANTtn7yNjHqbQXNoHZtf
1ITU0p5lGczrLdkE7ntvTIwpDayCZY4G3D+hsGRppI3QTy0QVm0Ki7YayOAOigUw
VJ+l5xH9FZOC9Y8cKbIa8NBd2z72z3ACofZVCOmlCuLg9Z3BDAboTAG9tPnmuSum
xWXvt95dreiUiBhqf/RhIGkHQs6J/5rpYnKJAhwEEAECAAYFAkVSgt8ACgkQPmqx
GlbVGZVLWg/9GhZ3Px9mIEaC1W9mtlzsPlECGpXiN3q0pSF8+tyyODnHx9pGyUaE
ZQkkYRDPn7j5AiMp4ftWg40NeTGXSjPdaPJjG/zQR3+o7WHVaoOBFzCpQpNBi7Nm
mmi7TgFuBIzrXydf+mbjJMf7QAZB3Mv8bLXQpozv4utqto1xap+iTcd4tLxATOb/
lib+z8jS1htCidhMVJYBDCSb2oOUv5oyb86EaPl3AEhxtiql0WMp4WFj8mcNL0re
IwbSH3lf7Plo3+sbDT6VWF79v+/UmvuHWOGFfSlo62iUKxUT2rtLL1YdBpwJbkcF
U6tpJ44JF3OAS9FS1avFlsvRbrYwciLt0VV2tr/Cd7BD01Tj+ZsrSo9sNEWDzzmF
qXSruyXFnfuI6xOqkK5veMxse4h3TCCs0vcEfuVB98BACqf8FBd3yZ906vGi9CAL
B2873C2N39QfKQqzghSOtaWQZns+lwOSRe0ryZlm7PY6h7CAOOtxAY7CAeX78bYw
VcB45Iqo0/hVMz/oSIXor1hrQhCX/gKzTtGt6egxmaABr5F8yeTliwUV7LrFOKlY
OnYqJAQGmuzjd3xhj/HFhF3dH528cZuMGoO2xub3NepD/bERA1W9vq+jb4ZF++4E
9Yjo+XEro7HVj5018s9r/j7vC/g5pvw5spZYot6D4HbiRysO93S/nPy5BA0EPiab
qxAQAN7PSlKsOr6r4fEeKmCz3mMRfxQnRH4Oe5i15TK+VlhN3AnFSRnaVy4eqHMW
GsOQ5Qs+mrbHKv8OC06DKHczaNZ3mL+qUA+9EfIdLOlFkidZH/JL8OKuewUZwtmo
re/u+6I06AvNBO1blAKPySUKZFHEibxVPkdcJwUoeJGC1i7SntNC8x9JcggpoFIg
xWmgkZDsVuBdTcm/isWKd2zPIjI0OagNQjjipFdrW9j54ujbUz6kqpkMYjH1rMTv
XR/3SXIuu3BjZLDxwkePz2kYbVakKlDna+wnYsAjpP+ufM7LUdlmw4OHUK3irnF+
ynN/sJu20D6g87e6NiXe2Tf42eNZU5EGonRDtAktUBhfqohjLxC3kWHmWQ6SDV5p
aOV5qmpiMFnHVVIhH2DKZr65aEBtMG5UHm3SaEZPYQaz81ePQC6jLYqd5vH+oB6H
riQ3pYZ9XHry+ktuNGha0jV1ssrBwm+kWDFsS2i6w6pAB/YDHvMsbOBH5fPGpCfq
iJM4gsdZSM69Uls1ccfjtXN3rRSs9cpYx4Yk43LvTOoftv3GGAFA/Gnx9NGXL6yy
gE/RAHSD10UiEjuNLLCTLNF5JeSkxQzZL77rscGu5dmQr3WywV2RPCkuwk7qE/F4
dvDshxNYunZ1FcCKojcXmsAsfofINjClBjt/xHWo2gE96i6fAAQLD/wN6jE7AUUS
Uo6k2qxh4A1RRycAHFrRy+8jjq/W0g11y02INuqRbVj1+ohaPvDWwI4vXzPU+YHh
8bJ3IqPp/bXPB7DHlB8IUdQnIP0RyI1iRunAlrcZPao8CM6+FvKJVqtqf3J48oH7
cksCfROMuF7j8JVecocOz9U3pLxXQxmNzOyvwuxBMKDtkAFJB6289pR7Hf8I1+x8
rMJLCVx3jmiVgoXr1LBeTPToWANoLCJW0ZKTt39DtS2vCN4ode6ICDPoaTHZwg+a
uc+ZM9Fo3EYHZtSfLS5q9c90DqebPmOSxzlTTkrAM+ulKqWjQY8NHa8/JjvZiI+D
P4vy+tJuO/RsQz1PUkTum4qcEEPVlQPGEKDz96zrOxtm8cTXkRj4z/pbJfftgj3e
wJoyAlahV08mTl5RKVDwsiUpS6rH3wQUC/iWsJnu6V17bjzjjWcZiD/aO1m+0725
fhqwffJGJxeKu/sR7slKf+c0pihBPEMHvEIBs5SfcER3+MFKH5mewAzn+YZwndcR
De1NC4Us1jN/9LZ13vjZBW+1Z12OPi3j0uVdYEzBsmDEclchJv91SBQ0IYBpS4fx
0GKkJuncKPsRbaUDc/L8a43m9pEEUE4Y/e1TvYfHJGFtA0/obNIU4MwsXx8IY2wY
M6h0fqBuMDNIo0sEOCZF2t8vAzIMP9pjP4hGBBgRAgAGBQI+JpurAAoJEMiGpCvV
svD7YRkAniN8zA4YNKBoDfVkKRJ9kF4QfRjpAKC2/TfdpMED//hCeSWUk1o/hhli
nQ==
=McJg
-----END PGP PUBLIC KEY BLOCK-----
D.3.12 Vitaly Bogdanov <bvs@FreeBSD.org>
pub 1024D/B32017F7 2005-10-02 Vitaly Bogdanov <gad@gad.glazov.net>
Key fingerprint = 402E B8E4 53CB 22FF BE62 AE35 A0BF B077 B320 17F7
uid Vitaly Bogdanov <bvs@freebsd.org>
sub 1024g/0E88C62E 2005-10-02
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEM/sJgRBAD26RM3o9QC+V5JO6/zr3ffRnNb08Bc6YIvpTd8yUhc4AIa1Zbg
QHoUNZ0pOLffeZ3i0wnqV3lMV1cPMtvSRWlvh+XSiSg8hYlnh7+oAwmqs0Zev1r7
w/In683ytXREuidcak8qWq4GAkET20sIICV7Ye56HJDlKrtOjUWDhVQJvwCg8jUp
CDtJ8V6Cw6GgjxH1iaNR1X0EAMKCUJwZgIoh2Rpqfrbwv92AD7dmaJJLVfnUSMCE
GvjcZ+O41PpvWi3PkxmgA3Zb0sJ3OSfgPi3Tnj3Nllyhqnf3WO1Yumzq3myBg+F/
qH9a8BXvVJlk/2cbYUC6uJeGMCC971X3hceu51J41k0ano7/ALIWeoUC1HhkAOaP
f7IoBADkQCDuIvdJ7KebBMgXIHwAJnycVZsXXQPlOx0gty4+OVMY9PfpEm7T+1DM
mWwuckntM9tSYuInbUPco70LBxuHHBNnhiUOTkijZ5GK/VF+WPnqOEopkjL7LD2q
wSYqGaBPbl/noAoEb3Nx7h8D94kJUF7Gchs9fCH6UxHd+/Q8jbQhVml0YWx5IEJv
Z2Rhbm92IDxidnNAZnJlZWJzZC5vcmc+iF4EExECAB4FAkM/sJgCGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQoL+wd7MgF/cbhwCghoShm9pCHbiUjXin1mR+0HaU
XvAAniOPVmeKUuBBKCc3KLPIhfCCKt9viEYEEBECAAYFAkM/zzcACgkQhdRQRWtp
GwOrjACfRJUhoojMI3sBMsjH9IuCwj8CikoAn3RlHMmCAx7JIiAMmg2gC1qjIUsU
tCRWaXRhbHkgQm9nZGFub3YgPGdhZEBnYWQuZ2xhem92Lm5ldD6IXgQTEQIAHgUC
Qz+yTQIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRCgv7B3syAX91XMAKDJ89F+
46BctXCALIn53c89waWDrQCgmCHSVr/rVUMU6fnyHtoNvYXtkFuIRgQQEQIABgUC
Qz/PMwAKCRCF1FBFa2kbA/bwAJ4mwlXag5w3scB7heyAtqr7w6491QCghh/fVv3t
EOFNlmwonrudaMSIYTm5AQ0EQz+wmRAEAKke9/e3jLaDx8i86+J0eTOAypCQy7WU
QajhZDFqBHbBQTDRbcYG1dLYd/sC9oUwqgaLe+yEYw3JdfsiaiHsE2yZ/S4S2wTL
7MrUqOc1aVPu95c3Xcef13DKCMx36B4EbMwJa00bU5ut6/7tHly5Edb8nkn5vKP4
00TbjMa/3ZCHAAMFA/9OffxCzJmwUjCOxAg2GBberPxovtCtwAw7goKZzuga9+9Q
dZBICMIc4l/I+zjDlphF/k9I5CQGOwoKTo+OCsZN7SSAB94NV9BEoA1MX9drWv0y
CZJlD1bSrcPFVjWajXqC6NpAAiCdQapvV1sJK0F09v/RTHdPAZcRnpg/YS2jDohJ
BBgRAgAJBQJDP7CZAhsMAAoJEKC/sHezIBf3nP8AoNBIM6JqCrnzQealKln3Tc+t
HMPIAJ9td+R2zFqwuX+IMk135J0T/PXeaw==
=bBFz
-----END PGP PUBLIC KEY BLOCK-----
D.3.13 Renato Botelho <garga@FreeBSD.org>
pub 1024D/2244EDA9 2003-12-16 [expires: 2010-03-22]
uid Renato Botelho <garga@FreeBSD.org>
uid Renato Botelho <renato@galle.com.br>
uid Renato Botelho <garga@brainsoft.com.br>
uid Renato Botelho <freebsd@galle.com.br>
sub 1024g/7B295760 2003-12-16
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.4.0 (FreeBSD)
mQGiBD/fJGwRBAC/raNISTKpkhGpJA6iYgLgHzfbJU8uwiej3s+7psND31ZYSEhH
VkSxq10pHFeVCsbeyh/FMsru+pDJXRcsACkPTJR4CzC1VW/FmsDTKAbaZPFty433
xbSU83u3XAqv7JQBtsTs8o7RBlJtiiAuFbtDcsotEASJ8UGKFVxdRSlHwwCgsspa
c9VFTt28MSnF23UKv32YA5cD/iLUNRgZqkZHjdGHxaMcpEwVDWFC8nrygNNQ5LBo
cfb+NAVT3vSIc5NDeuP7XPSdJcWqCkH0+XUTqzuspo9NIYyjHoOj+JulZtW7CFB8
vFWjjbeajKlp6X4EisvdNdwfpzivp5UanNmNjDGth3caN3oPowyVDpZITeTYgRd7
zUIyA/9Mx44O+40mpbYbyn0tatgeb7KYUKV7SZgrPwew0Pt10VzwzqXEQFbP2jS+
AvO3A/zrEr1xUwMij++E7rvW/IgE6lEE+KYCI7y1Xg4wHo8WieVCn8PGNZWM+bEj
UnUxRSH5l9fgHsJmcOauc1x0a+opNcMtvZmqPTjbZvAPjBhv3rQkUmVuYXRvIEJv
dGVsaG8gPHJlbmF0b0BnYWxsZS5jb20uYnI+iGQEExECACQGCwkIBwMCAxUCAwMW
AgECHgECF4ACGQEFAkDF+tIFCQpM1+IACgkQ6CRbiSJE7aloZgCfdHg8C56QVcS+
jQilNr4jhyQTMNkAn3e7AqwEpcLnPsWnklvVhehq7JvriGQEExECACQGCwkIBwMC
AxUCAwMWAgECHgECF4ACGQEFAkDF+tIFCQpM1+IACgkQ6CRbiSJE7aloZgCfblhT
phi9f1UhQvQoveo33aYDYaAAoKdDYdy5AMkoXE2KgtgPR/3ifKSLiFoEExECABsF
Aj/fJGwGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQ6CRbiSJE7akT0ACgkeOd/u5g
JG833xM+oiRdjKYlzyEAmPgpMzDyTDJeLRNGxyDb0HsWIa6IYQQTEQIAIQYLCQgH
AwIDFQIDAxYCAQIeAQIXgAUCQD5AfgUJBCGDEgAKCRDoJFuJIkTtqU7FAJ9+ORyf
52+toIQaIn/7fJoM4EPo8QCfXWD9EqIVxIbnhKp5nVHRRaTINam0J1JlbmF0byBC
b3RlbGhvIDxnYXJnYUBicmFpbnNvZnQuY29tLmJyPohkBBMRAgAkAhsDBgsJCAcD
AgMVAgMDFgIBAh4BAheABQJAxfrOBQkKTNfiAAoJEOgkW4kiRO2pr9kAn2eAuMiP
WZgAu6udufUcWg9x/MrSAKCqMcUfE9ywTkzPIHl4rVF7NZni+4hkBBMRAgAkBQJA
xfajAhsDBQkEIYMSBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEOgkW4kiRO2pdO4A
n0EeP6NKXMxuuyYGznhbrjy1i3O/AJ47i8d5H4wNnXSOKi8rNErYc2ldFrQiUmVu
YXRvIEJvdGVsaG8gPHJiZ2FyZ2FAZ21haWwuY29tPohkBBMRAgAkBQJA4wTGAhsD
BQkKTNfiBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEOgkW4kiRO2pU+AAn1o76JDl
XxlE0klr6jrmwzwxg74mAKCubxTs2QGcWa21XGt3JnjPLENz4LkBDQQ/3yRtEAQA
pbe0v2n44Ryi3dUr3dZ6HruyCEj/5GuW8F7yz2CyZjsKcnkUC+nnsUn18YOBQhGB
ei1aMvjs4j9xk8dORKxNcm6gsfAoApKS3TYUasaW2QmToJJRSFDVbMo9Bg4Ul/Nb
vlU1b81pu0Zww1OcJn3BctuKqG7mKGPIjA3KOYUfSH8AAwUEAIXm/DCsHGGIwJCH
GDmEAsGIYJk9g2NWh2ObW/2uUblHbDd6h63gVWxd5Y4n1Ql9lNDqhaiJl4BRAVEa
oW4tK0JNZOhtf2drAPZsrOm3/Jc29D74T55lgOILJd2GQ9a4sy+OzzXfrYsB77C2
1vkIUi/pYZfTz/f/Ar1MT1mVj3/uiEYEGBECAAYFAj/fJG0ACgkQ6CRbiSJE7amG
agCgsHfJXA4PvaIw/d2hHS9VlAh5Z6cAoKPyew4gQHo/5fCeBunSpIQbAanR
=FjxJ
-----END PGP PUBLIC KEY BLOCK-----
D.3.14 Konstantin Belousov <kib@FreeBSD.org>
pub 1024D/DD4C6F88 2004-07-29
Key fingerprint = 39DA E615 A45C 111D 777B 3AD0 0B7F 8C04 DD4C 6F88
uid Konstantin Belousov <kib@freebsd.org>
uid Konstantin Belousov <konstantin.belousov@zoral.com.ua>
uid Kostik Belousov <kostikbel@ukr.net>
uid Kostik Belousov <kostikbel@gmail.com>
sub 2048g/18488597 2004-07-29
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEEIq/MRBADOl8+kLZyTRb2xRJmgwq0a0xIPuQxBvUa3Ac7T2d3r0mCXQAni
MG6IoSxnTGhZd8JRMya03RNAEFDFIxozgBh7tWOBfCxWB5KHS6F2PfXoWpHz6APL
9d1eSu8qMMJ0aHCk5icZdhMWlviFMwyl2x+VhJKsxpRbrU1hbWd27x6ouwCg+AD7
cPohqZoWEAlbS9Pc0elxsq0EAJw4lcIrlUCc7Z9G0e92HXc4IyeTswv5is/yDz9g
7LUyp1qJbqggV2LGtjTqit1ldccIB4D4N7afokMQiye1zAyntpPcef+oIBf4zFr0
KmSnG0IgaUm8fpZJ/qumOkU8GX2SYiKUQtMQ1xdbnCQaRdOjC796C7PKgK7QDD7+
qbLhBAC2ysSQZ824HHS1EN48NlV25vV9HBIag1VwUVmO7IVGHdxZKFfnyXrtiQmq
wpb3okcsCls5x1QQsT54095kP20UrYDHho8yndB1bPRlLnAhtJQpGVTQ7P44ab1A
SxIcp+gvgIoHFKRVsj949uhn7vcbzJEe15whWTj06WckVmuCL7Q2S29uc3RhbnRp
biBCZWxvdXNvdiA8a29uc3RhbnRpbi5iZWxvdXNvdkB6b3JhbC5jb20udWE+iGAE
ExECACAFAkM9SpYCGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRALf4wE3Uxv
iJ7ZAKCj7lMo10TeSyCYE3Y6/dr9RnqAtwCfZro6JLEIqa60+ef1NyHxscvQ0ce0
I0tvc3RpayBCZWxvdXNvdiA8a29zdGlrYmVsQHVrci5uZXQ+iF4EExECAB4FAkEI
q/MCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQC3+MBN1Mb4jQewCeJmg8ftV4
x7l2AoSAPsIDoQgXZFkAn0v/zBXhfjFoDcMK0cJTyPhYm4vptCVLb3N0aWsgQmVs
b3Vzb3YgPGtvc3Rpa2JlbEBnbWFpbC5jb20+iGAEExECACAFAkM9SmQCGwMGCwkI
BwMCBBUCCAMEFgIDAQIeAQIXgAAKCRALf4wE3UxviMLdAKD2lvxZqIpK4J8s7f5g
HZ/BeoqkLgCeMoiVpODH3W1jp7WmIAcPTX27OEe0JUtvbnN0YW50aW4gQmVsb3Vz
b3YgPGtpYkBmcmVlYnNkLm9yZz6IYAQTEQIAIAUCRIECYwIbAwYLCQgHAwIEFQII
AwQWAgMBAh4BAheAAAoJEAt/jATdTG+IhlkAoIR7laQrFh1QrZlIG95dj2oFOwDa
AJ9rpiIgeCaPJZKediKAWDCaJ81IXLkCDQRBCKwAEAgAksTzLKLHecQ1G1mHaw0D
5E4YmadGDnx/K4abjzzINUP033VgKdMXe3ocJOI4YeALGzhoFAjj3s5VvFqgUL8B
8xBn5r2vSGLe1WZCZmq5kzfls7E1I6TSQSRqIm2CRBYzSAFaqs5uaOPGMZ+fSfYO
W11wtIChNJBDVhO5YgRKJlxhMCaLTTH6qB1ZCrSswIFLgApssTUHcHW32eh9qxQW
U7XD7MjMbkbr1Ig1scaGkjUGLoIHboqFYDS8sLMaJp/RUyflAbzizL3vI7G3i4jP
zBLPrWnnhVDPWGJptuPedyFU2ZtgX4E+txP9yDoOrcjBgJEj5JAO+nTMIoabxtXR
lwADBQf+JdFUtGznzSmMgjfjW1N1cuM8xe2JBA1TRx6Bg3Kn6bVixmpRBOxQ3gtl
k+o2dOHZtPtB22J9IMsc72fAFHpDqogm5ADN+PdtHsjWYS4U64Pg008VYc+IWSXx
fqLLRK3luwDFn9mpvgcWc8yue8Di4jZ+SojNtmvSSRofm8ruf+6uJS6EPUz9dzH2
PcMqhI0+nJMn20Zeq4g84g4G2KUEo1Y+ruL4iUUQcVRTWIBHw4jkFdGdMG5z/2Ao
myeZ35IoHFJF3NoY/H6/ZrBe2D2qbY4CsrvCutUEKIKtJqTHSB80pJS7hdlSH269
3SSIuof00KCuWbrWQvGp3Mpx9kp76IhJBBgRAgAJBQJBCKwAAhsMAAoJEAt/jATd
TG+I/pEAnA+MZs48oSlZF452F1xW9q75hhGVAKCzW5aFbJsAnJClz8JS27TynnPd
CQ==
=EJ3p
-----END PGP PUBLIC KEY BLOCK-----
D.3.15 Anton Berezin <tobez@FreeBSD.org>
pub 1024D/7A7BA3C0 2000-05-25 Anton Berezin <tobez@catpipe.net>
Key fingerprint = CDD8 560C 174B D8E5 0323 83CE 22CA 584C 7A7B A3C0
uid Anton Berezin <tobez@tobez.org>
uid Anton Berezin <tobez@FreeBSD.org>
sub 1024g/ADC71E87 2000-05-25
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDks22ERBACsqOob/YoPnaI/xubQKn/CCUFsaEMqL14TZ+FSlCphq3uZ7Y0W
Qg2eqaTp97lG2NTVNEzF7K0yr/C3ofEQmTINQTd7DmEj04DDlR+t8BMFe6Xz2sBI
WlEPD54ZfJVqhEX5P6T0xe9hiqjXKwQHHl1skKniKeO07o3K/4bCDDMfKwCg5DY1
/2j/Gid0YmxsJCIlg9kzRGMD/1lkSkQ0KrPH3RVPMrkRWE3rvvMES/F7jYNfKDQj
X5lJDKoIQyWh1JwAmW/O10V+24Vl6JEFNQ4QJ7ix9hlkI59YS4TERxCUGGDpl3jr
Lae6FFxYc1D5H8LLpiTSApmZcLxUE8CFoZJLySHgjp8qzvA60wMOjkfkWMgw3BpE
N8DVA/9UF+5ue4bLHsPn7Jv5NzOkzaTgC/9O3UZUj/jYOp/vkI+0wPnP0U5f304P
iLpYl1tlCEpciWF88MS5k3+8zsk8trqorss/XQfFzhHVtvRtgVxj87V0Z01E2ZZr
YlqrnzHKQZOAKM2X9FiRZOAkndkkpeB+7SSeXDP62I56B+690LQfQW50b24gQmVy
ZXppbiA8dG9iZXpAdG9iZXoub3JnPohWBBMRAgAWBQI5LNthBAsKBAMDFQMCAxYC
AQIXgAAKCRAiylhMenujwBepAKCCtVcVRS40E9SY4Su8GTOBVoH4UwCgu3gK3zMy
/QhZnnhmTKaguG6XopqIRgQQEQIABgUCOSz5ngAKCRCBvdPEDh+beRnEAJ9xU+6P
TJrLGk8PKtO+UY8Zt7MTxgCdHYzFsXZ81j9HY0Z4EaHkQBXv1JmITAQQEQIADAUC
OS6PpwUDCWdTAAAKCRDXjLzlZqdLMXMaAJwOE+6Jh5PnfHc09x3JKN4/a0v63wCg
6GdysmObSBQXATzYBuhy/0eFCCC0IUFudG9uIEJlcmV6aW4gPHRvYmV6QEZyZWVC
U0Qub3JnPohXBBMRAgAXBQI7JNTmBQsHCgMEAxUDAgMWAgECF4AACgkQIspYTHp7
o8CQ3wCeI+P8VsHzHpfmUMa5kCzjBeqj3zcAoKYmyZUSxhV9TBQPo2WQ7zF3zcoB
tCFBbnRvbiBCZXJlemluIDx0b2JlekBjYXRwaXBlLm5ldD6IVwQTEQIAFwUCOyTV
DwULBwoDBAMVAwIDFgIBAheAAAoJECLKWEx6e6PATIsAn3clXqExEiP/Q/IDQb7e
/yolgMrRAKDPw+6ZxTOJFba2HWEto0PwQ/COE7kBDQQ5LNt+EAQAjHltp9g75EOw
pEDSUvK/B0aRUsjoIyAokRuW9Tg8S0xIhtV8ogcklvcXjQbjiEsAiO13hX7zmdmb
yH7xLiSjea/m/whmNr9K094BS1K5i7mmUqNEFOyPB7VkPbRs5gF0dCkHT5uVgqFJ
HSbss3zPyGYEBi8uDokIfOt4o5CEMYsAAwUD/269N/UwZkO4+NYivNX0ZpcUouqV
YDPQ8YLwSrkwWpG7UNvNHd1HS43OWwAOy585SkLpZkjlW58NqyXJuWVC0xJtdTrI
MKTZ3IJNXMK2wdK+nBuTL4IvJwkf04pwFel80F2NtgUjR3ZgIlRNvFtvtCkNPg0j
t7J8pPvL2vU5hz7HiEYEGBECAAYFAjks234ACgkQIspYTHp7o8Bj7wCfSZsld8vv
iM02pWobJy/VvsBJKU8An2auT0HLmVLClDph/fQa+k1R2qsR
=ISZ3
-----END PGP PUBLIC KEY BLOCK-----
D.3.16 Damien Bergamini
<damien@FreeBSD.org>
pub 2048R/D129F093 2005-03-02
Key fingerprint = D3AB 28C3 1A4A E219 3145 54FE 220A 7486 D129 F093
uid Damien Bergamini <damien.bergamini@free.fr>
uid Damien Bergamini <damien@FreeBSD.org>
sub 2048R/9FBA73A4 2005-03-02
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQELBEIlmIgBCAC0YtqJTRZ/ri1bBd6NyFd3r4fWx/M5NeqIYOa7S1x/b3wjlAdD
Q6/mPMkGYqtUiQx9kMhrmZJHz/nC6SFxw0nSxKOfsvOQZgyJbeKZ7NS3SReOzUD1
Xao0pt6yPH9eeLduI9R5AL+XMvWvPfWgh/kZbOoC25F3TrQQkp+lbmu//cxzn6Y5
OybyTKiF0heYOcBOrmtp5AU9LZWdsEH2rDXBnEIFLTL3qK/HuJariizqUnPjDb1y
OfNldKLkcq3Cs8QNpSGrrbWMoLvCtIXAY1kYRywKfT0BgTH6JOoGz6n1dLQHKubZ
WCsyqzO07M43O5vhSLDXS3L4St2srV1XblaVAAYptCVEYW1pZW4gQmVyZ2FtaW5p
IDxkYW1pZW5ARnJlZUJTRC5vcmc+iQE0BBMBAgAeBQJCJZiIAhsDBgsJCAcDAgMV
AgMDFgIBAh4BAheAAAoJECIKdIbRKfCTKlMIAJmIx4DZmHkbpSHxERQyN4kQizY/
x+7L2CuwuAtjabo1wlcE/XacMx01qN7FL931PGi9UEWxdp3FTu2MMH4e7DmY0F8A
7oEbFecE1bjDRKLkRBFo+R6yHvZ9YjGB7dFlsTwaM4FpTfrgg81j3MSIHdg5i8G6
OA5eBJSiL7IN3ftcxIoutYXfPnrOksba7ThEZ9631ft3athczyaISAtdQkIIO7J8
pBBTkE4wbh1AzPRDmeN8DDU9h/pH9W0uVTOCqhAXnSE9C5kZ3SBhvXBPeN9vtHa6
pyR6uqg2+N5FSJ5lENvCeRKC2W80m/an8n/1WCK6QuFTr02uVuGShksBTdy0K0Rh
bWllbiBCZXJnYW1pbmkgPGRhbWllbi5iZXJnYW1pbmlAZnJlZS5mcj6JATQEEwEC
AB4FAkIlo0sCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQIgp0htEp8JOVTQgA
nah0cBkhmPhPVVKNGTQScbdPgu7TTLcAB4SVJHN4Je8ml/OeWrIaNXeQDD8wdfJZ
svlddxvxB8r6ScJ3ZtLsSHQnGLejgiEsHEO+Fi/xmt1D+pn0l2dK+GMC4E8dPd5w
ZGLg9nFDZolgLQP664eqzx3A+NSgh5A6IteAtrRDg+3uzlquhJNWqup01pymcery
Cv0rnMaZJTjE2IsMyzc6hw9CQ9AC3YVfXT/xMlSe9cB3C1EDtmHkKQOpzarheQOT
Xi4rqScHJTevKT4Pz50uYwoAC8B793ZRKJ5cYH0G3YuDB4lhPaOeAxOi4Ftt97De
HTeeIqXmrDV2kOu3t7ifTrkBCwRCJZi8AQgAzF1fU7BHdNHHTFTmT9f/TWIoEhsv
4oKue/cyAmVGjeg4jEFn6001JWjojzxe8IZzdYwAgOwHGRbfxiirvd1nzxJlOBVg
8BfrplMcRAMh61IprrU310cd6tVDyxvFqENLM9fgCnAwWAEldZoOSBBgPmiV5+Cp
xZJu959KpsoG6TuAn2PYUXdttjvdGgzU0lyji43GHZ58yJYtruFfikWoXJXlXvuh
9GjNqFk28vKi4b7HBR79zvtyQLT+xkRLcGMbQemLeCQmi/O4umDpkVovDn/FgaPB
iEZmtRbHtCAODO1vW4YrYvMYGlB224hQcUuiOiEMn8P/oMkg8dXe52xFEQAGKYkB
HwQYAQIACQUCQiWYvAIbDAAKCRAiCnSG0Snwk/baCACJ3Ed4SX2BTo+jqt5f0hZx
OO4s1B3MAD7y8LzL85QySYdr/3e5i1IrgLTVOH1UQQ2Bvpk/Ly3M40FBUapHzuOa
TpOfqk3nHwj+o7HuFQr3yzVl5o50fQPkXhwf2PMr0iQLuwHdFzmF/A5aNW9lunsT
ICRXApvEEQU/eq2nSUrIINxSYbzuXHfkNWjcFX0DIv3V/ZKBxCnVQknc7YFXmqXC
PEjAsMS6mj7fzkr2c+JDH+AK7Y1gexDyjoSqZb7HeTiy1c4x+UXDs4605XAwKpZK
757qxfG/ThAKmn2/xiy3bCYmHR9PQ0lBCCkXdNeRgdklUkawzZQdcqrO8ElYJERp
=uQuq
-----END PGP PUBLIC KEY BLOCK-----
D.3.17 Tim Bishop <tdb@FreeBSD.org>
pub 1024D/5AE7D984 2000-10-07
Key fingerprint = 1453 086E 9376 1A50 ECF6 AE05 7DCE D659 5AE7 D984
uid Tim Bishop <tim@bishnet.net>
uid Tim Bishop <T.D.Bishop@kent.ac.uk>
uid Tim Bishop <tdb@i-scream.org>
uid Tim Bishop <tdb@FreeBSD.org>
sub 4096g/7F886031 2000-10-07
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDnfszMRBAD4i2R+XBC9TXuDnhbclf08am1QA0dZs8dAZoPuRr0gmdTrQiGQ
STg1kHkHR4ErsF8CFcxw5bvB1U9fmDnRRhHNoD3GAtlroN8YLDTefs4KbvK26V0E
bbVf236zxSV7N3EfqqCGRM5sfD9h7m/muL7M29p8wkPiwhqei7Ic/QXifQCg/zTk
9Vqp/TNPTruTVJjqujgIFC8D/AzpkXRzaTATBg/Nqysjva+sOmLEzr9B7uUVfY0y
rWvc3+QiR4Gx6+VhwwmbBH9Jnq7eg2zLTKrtS4wWKGSWnISU2+AHGYzMa5Lth3QN
20yDmybOj2qepoLx/9PTSrUcsWJScKCLIVkWQdhiNm0G7XOUh/WNn4UZZrk8U1L9
3H7OBACzb16QVMYcVmud3FLNJWS6HCv5wWF5DEKBI5LOZrAFcmmAjCNe3HSHFSGD
JFXNJIn1I4rG7rtudAGtUWYMAU0l1MPSjh3Dvq9Wh3bs4Pa1kZmTl1qGKLTElhN5
DC9NBlu0pdXQcbBnhonEshX7EJKcoXmcV/QcjFegjTZ91Xgc6IhhBB8RAgAhBQI5
37tkAgcAFwyAEWWofENeCLsU7YuIEDES9ZhE/P7UAAoJEH3O1lla59mE8PMAn2NF
0lKRNhxBiOrxOgOfJ2m8Bj3cAJ92sTs7/EaIuXnyy1yLexmw59EdEbQcVGltIEJp
c2hvcCA8dGltQGJpc2huZXQubmV0PohmBBARAgAmBRsDAAAAAhkBBQJDaQtmBgsJ
CAcDAgQVAggDBBYCAwECHgECF4AACgkQfc7WWVrn2YTLOACfSKneVG4B3EoFM/fP
Il6rJN/LrgIAoMcsYZe4FXjI8TgDoHy+Xtu2ZXPgiEYEEBECAAYFAjnfti0ACgkQ
MRL1mET8/tRKdACgjizhpGPXZyKfg02rHRjv3HI939cAoPqij9xXHG7XkxyX+yem
4WK8oLNeiEYEEBECAAYFAjtfEtMACgkQW3YaO5gYTxn4SACfWTe72dgrWfC1xrbi
Hjtol+WAf0UAn0TTr2uRjIi7vR8rg9Bnjefjouo+iEYEEBECAAYFAjth+5wACgkQ
6vqDvLlNLpVrPwCeMttJ6ad8vifJy6luMJMzIbiWJhUAn3vU1yVqWpL7qL+PWGHE
kytuaOC/iEYEEBECAAYFAjti0w8ACgkQF7ttEUnfsrL75gCg9WCn37lGhN4+R8i1
lrtn4s4GH0YAoL0JurG7CvAv6iHnjwaNUk3qQWd5iEYEEBECAAYFAjw5kBoACgkQ
QffKHSlQv/gsNgCg50C6odjVC+6WNU28bNSjwO6TzmoAn1nB0T7kwnf0iBmuUcWy
EnOXwjw/iEYEExECAAYFAkG3SLcACgkQIWeMYbU/1OVOfQCcDr0EPQenBwscxHHa
QjLaNEEeuEsAn2IX5XWulgyVpcFS4nbF62bn/6yUiEYEExECAAYFAkG3StQACgkQ
2nKnhxYOZOU81gCfa7Rs5AnqStlQjGEyL2zkMK7OiSMAn2bSIoA9aN0HYxaCV5Ly
JX8tgfJ5iEYEExECAAYFAkDYCBsACgkQEp1WLmJavCBWJwCeIXvriDUS2TUdT77g
kISc2PRdapgAoKHxc5ZX2iork8KNmM3o0/aJu0mSiEYEExECAAYFAkG3YlAACgkQ
eR7zsjPVKg3yKgCgywPbTx4R021b1T4eGSL/3z1XFPcAmQGhMzCC0+HPa3s+cWDR
n+2YkJcYiEYEExECAAYFAkG3ZwEACgkQfnhAL+snBNB9zwCgr2w4FGWlzA+2huI3
lTFmViFTarMAn3e3wZD13RdhNgKI9XbvXkuFu9JciEYEExECAAYFAkG4DUoACgkQ
A+OhltVdZ9pTtQCdEEjGARcAPhfFN7vlTWK9kVljIJsAoIANUmYsoWPosNagfVTd
tNov59MGiEYEEhECAAYFAkG4RYoACgkQw6usuxzEM0WIvACeMv3Lk6/Miuc10rOC
+a7ExAXteWUAmwQjrMBs9QD251r/QnyBODzQcFHsiEYEExECAAYFAkG5hw8ACgkQ
li3ES4mncmbuswCfaWIIeMyzNL8DipU6BZ4x0IX8ONYAmwYbz60U17cNkMuVQsVb
oZhXXksviEYEEBECAAYFAkHtDqwACgkQpQ4p2TvRQNAW1QCggPLI6W6bxEXPqK9w
5dGfRP7FTtkAniSMjrmWTP4ZBVs6rDxshjXVgTBtiEYEEBECAAYFAkMA9K8ACgkQ
WzzNBFs5gIBp0QCgrG6omGHaBpDoMIyP6/LKvfoGX5wAoJrr2mUTEqXlIbEIE7HM
oOwrPmzciEYEEhECAAYFAkHdoGgACgkQ57/k9Wdwtz8sFACg6wW5rtAUM3lbNRPH
C6TVbyGwZqwAoM/RBEgyUDbs195hyu2w2l8ZHqajiQEiBBABAgAMBQJDjczqBQMA
EnUAAAoJEJcQuJvKV6184jIIAKweV4Q/y/D9zZDPd4qmTgWd+42+gIZKgHT+zisx
pOz3z93KwScw9/ZG/sIzfrUxqFPUsym6RnErZH1+2qtBxd46KDMmqWuzCKnNsb54
bQy9Xgj7R0C309L4gDnjk5jl7aW4RSX+sECqMuik3pQWZR8sOZk43ai3g5T/XpdY
oBgTniwJot16HcDEvvevPYtcjigc7vZ12nKfI1NMicK8cxAkxLdzUBPBXkEPnCR7
FigZsdkoxo1JVNJHef+Px5ErNFxDthjV41aO7o9BbHPnlvMklIeM7EmTVQDwcOh2
WYHoiA6iUlUTFVn0wPaoOiUmyhz85tzo5DXseX6IC6yMxge0IlRpbSBCaXNob3Ag
PFQuRC5CaXNob3BAa2VudC5hYy51az6IYAQTEQIAIAIbAwIeAQIXgAUCQ2kLbwYL
CQgHAwIEFQIIAwQWAgMBAAoJEH3O1lla59mEPugAoJYJuWPF4LxsVVxOhwcMOX+K
Jmv4AJ9PSfpJSWE91h+fkbYzLBxM1XUSiYhGBBMRAgAGBQJBt0eUAAoJEOr6g7y5
TS6VWzwAoJARK/wdjecAWUZPJZzFKDsSnNJZAJ9vn+bgj8z5UxyiQ9CqQVtnZ3Sz
mIhGBBMRAgAGBQJBt0i5AAoJECFnjGG1P9TlVsoAoJH0SYwjAndlcqLjaRWgNK4D
pJbuAJsHtcoMvhHyt5Vl+aAVH+zc6GEgxYhGBBMRAgAGBQJBt0rfAAoJENpyp4cW
DmTlh/UAnjMzSCWqSdQxkXnRadXe5SQApVPqAJ9srI7o2wYqHPl8mwX+jkVXCK7M
C4hGBBMRAgAGBQJBt2JTAAoJEHke87Iz1SoN8eQAoJtBRqO40tbTL/wrZCCb5zDa
B+6QAKCGJoUt9GQ8EXuixWLYNyvJRiof54hGBBMRAgAGBQJBt2cLAAoJEH54QC/r
JwTQ2t0AoNI/83A67Fw4elk+9SvZEoh0rObGAJ95sDMn8QGx/m+plqsV9PERFxzf
oIhGBBMRAgAGBQJBt2fHAAoJEBKdVi5iWrwgCAwAni6lOIjTxxJmnDu+ishxoE5p
f5HkAKCgD7lX/2Xia5Swd2zNAAUX+ibp/ohGBBMRAgAGBQJBt6d8AAoJEFt2GjuY
GE8ZyHAAn3pa0VCvG8y1uKboc/l5ctGvejyEAJ9KohndTigNPpT4Nm+wxz72wbtx
I4hGBBMRAgAGBQJBuA1NAAoJEAPjoZbVXWfazksAoNIlcv1JHTS0nkDNiODmeon4
qBvHAKCGj3wgV/lZytNRoxwiL4UNGbaByohGBBIRAgAGBQJBuEWOAAoJEMOrrLsc
xDNFSaYAnjuKi9/xYpb7ihnnxIGp8Afd1m9VAKDWlidfrwLpT4rSrjJ/EuFiV1u6
h4hGBBMRAgAGBQJBuYcSAAoJEJYtxEuJp3Jmm4YAoJpzQDRZu+3waFE7wwNfA40Q
D/sMAJ9qv9RJzu5LKY8IiGeLso3zdBtF24hGBBARAgAGBQJB7Q6wAAoJEKUOKdk7
0UDQ+cQAnA34pLhpoJaahezczByKkdl7zw35AJ4u/JFnq8F2xfjXrHKbFsq8hE0G
5ohGBBARAgAGBQJDAPSyAAoJEFs8zQRbOYCA+ZEAn2znyZcKP6GpWc+Mk9tjhExW
OvhaAJ43j2w/U5u93WNIVkKn5CgY+UTzqohGBBIRAgAGBQJB3aBtAAoJEOe/5PVn
cLc/tSgAoLNj/SHxc4EPTI4vO0JAEA2QZC7hAKCP/yglIlWTZkm/EvXwrcxnLmtp
c4kBIgQQAQIADAUCQ43M6gUDABJ1AAAKCRCXELibyletfGXkCADAm0Md1D9ryYKO
g7Rn9u9z3A5gRYCndWouZ3qCvYX5df3dY51VU7EOuTAF3cvkXDmMkJ57RQ95l6Yw
OPBEFhrFsNZ0+lzXZFvx4oLmeEYj6w2lDO+NGsy1GbxrWejqApzqqHYOFQXBkv2P
0wH+wNZFfO949LtG4wwLLSk0Xi4xKlffBWjPH4Mdhr+KH5lMC0/t6jkPpsBOdytt
MT4GqrBDIXrR6u8wGSBhL/vbbgt0qs8LFrGzJqJl1vOeo/es5zW2nF/RwcoBxCme
KeriDNJhspOEfuqE+UWYrFBOCTpNw72OQGyk90vps0314XRjRVYQ1dzJEB/fsvYw
w0Y+w/hGtB1UaW0gQmlzaG9wIDx0ZGJAaS1zY3JlYW0ub3JnPohgBBMRAgAgAhsD
Ah4BAheABQJDaQtvBgsJCAcDAgQVAggDBBYCAwEACgkQfc7WWVrn2YQoSACg03bx
S9swvRJ+WzrnYwVUhWUXDxwAmwShlDBq4ZseuA89Tk354AbzJCtRiEYEExECAAYF
AkG3R5QACgkQ6vqDvLlNLpWuLwCeJpUPvGn/83H9CePaqY0RBRMu/pQAn10RKC6g
A+PZhg2IUna4knYrV7lxiEYEExECAAYFAkG3SLkACgkQIWeMYbU/1OVc6gCeMWXh
THikzJg0DPjrq5puqYwqXxAAnjtCpOQUeXc7j2lO6WiSuNge3EtHiEYEExECAAYF
AkG3St4ACgkQ2nKnhxYOZOWgHwCggEQXoann+N3idBx+0h3VpsJse98Anjb96nkH
Joa4xW3H6YJrtWhfe+I3iEYEExECAAYFAkG3YlMACgkQeR7zsjPVKg0rmACgjUgu
anZ3SG5bpmnJDf21BWoLh5oAoKSIsqP5FSBwtny6KLylzG7MW7siiEYEExECAAYF
AkG3ZwsACgkQfnhAL+snBNAsHACghamTnLNDk0ZAspHmKBHI1GMeYfYAn1ub+VfG
hd5WeJkkiWOlpk/FBlFOiEYEExECAAYFAkG3Z8QACgkQEp1WLmJavCAOGwCgr3IS
1UYOGPM+bM+n7Cjp2u5945gAoI0m7S6GXYl5jsaE1iCMw6ElzoBYiEYEExECAAYF
AkG3p3wACgkQW3YaO5gYTxn/RgCeLV03juwyipL15IcOQNKiBqHz1g4Ani548Rdp
Q3FL3bhwdYC+IvGKup6EiEYEExECAAYFAkG4DU0ACgkQA+OhltVdZ9q9FgCglfvb
AzUpu44ZXRjzhQbNDsUrQTgAn2FDAiaT94CtgAEzGUjg3Dtxc7dkiEYEEhECAAYF
AkG4RY4ACgkQw6usuxzEM0WKJACgjuZlgKF24+RxhxYAzL4g0u0AQ+QAoI76AEBh
wsOKjXy87b6oaxy5QqOyiEYEExECAAYFAkG5hxIACgkQli3ES4mncmZagwCg3CLJ
XqmgOfFjVQZuWADxTINu72sAoOsLdwTIpWyv1OW3E8uzC61GBPTqiEYEEBECAAYF
AkHtDrAACgkQpQ4p2TvRQNAwhgCgxzho0VEbzY4/ECVbVtNSssEp46cAoNGduxph
wNjvIROXlXZfgP+vmHbOiEYEEBECAAYFAkMA9LIACgkQWzzNBFs5gICEoACdFShC
qE6i31Hry6NPdWBgDNPUbKUAn2W7KJH6yL5GkQScL8gjTR/bSMNEiEYEEhECAAYF
AkHdoGwACgkQ57/k9Wdwtz9btQCZAbcfQ+C0H46jtc+TlbbpfaSx+gkAnRz3xMFe
Xny1x7hJqsnMyss4r6ZHiQEiBBABAgAMBQJDjczqBQMAEnUAAAoJEJcQuJvKV618
s3QH/iHO1U+LZF3eylEcpJnbmwuoLQgJRV9DfdlPbIcUnPskw1MyQiZUX6gmI4X1
vXbT7/bS+od64Nf/PVabeLpLZCQELVrMcLNcFt5BuX518RA9I6Lldhl8MgXsXqfv
rJIqVaUhIli18Tc7KRnVx0a0djchcudq3no2lLwu7yOpJXYnbAT+21i6plhfZceg
8Yv+PJfs7par1x4RcsNJ3x9jTow2DeIKTVjz664c1RJA22qcwsZA+3FOWEkTrM+i
jZ09HZDvuqT0Bigtx2sAZwDf0+Mw8f8lWm2CNun9uBvqyD0mtJkb8p0IvjT0V6wZ
NlyXAfw8VaCxapzQ1gyhE35iV3+0HFRpbSBCaXNob3AgPHRkYkBGcmVlQlNELm9y
Zz6IYAQTEQIAIAUCQ43KZwIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEH3O
1lla59mEh3EAoPBwl/6Ei9LAWGWutHMSO2T0BTUnAKDBsMVsdDcPpjJUMbZocXZR
F8E9pIkBIgQQAQIADAUCQ43M6gUDABJ1AAAKCRCXELibyletfHkwB/9tTnUSuRlb
LfLBcv6KoKR1AQcvC4GuvFuap6vCeIlTc2YpJO2U4H9+4tDJZ23AumzUgZN6T/Sp
WKLV+1wciqCPoPieCtcq36PwYHuReUBWyXodOg2eAL2T5YndFy3f3GvFHutmmxEv
gIOELoEJbQIVhd6uBWiIcSOoJAYOzulk105i0Hj6pM6gF+tWK5HsXEBHMkl705+S
upknwAHbH2Y273ZZglx2FtibtzDFwOpdHQfzQdx2Cp9E7Dk6Cixkr/wU0FseioK4
e+zKk1ClblJXEzxMUb0zDQgNdRV8+hTJ9saYPHchnRXCBg5QJj+lxCtIQ+WU1MAB
Atd793HT5F65uQQNBDnfszMQEAD5GKB+WgZhekOQldwFbIeG7GHszUUfDtjgo3nG
ydx6C6zkP+NGlLYwSlPXfAIWSIC1FeUpmamfB3TT/+OhxZYgTphluNgN7hBdq7YX
HFHYUMoiV0MpvpXoVis4eFwL2/hMTdXjqkbM+84X6CqdFGHjhKlP0YOEqHm274+n
Q0YIxswdd1ckOErixPDojhNnl06SE2H22+slDhf99pj3yHx5sHIdOHX79sFzxIMR
JitDYMPj6NYK/aEoJguuqa6zZQ+iAFMBoHzWq6MSHvoPKs4fdIRPyvMX86RA6dfS
d7ZCLQI2wSbLaF6dfJgJCo1+Le3kXXn11JJPmxiO/CqnS3wy9kJXtwh/CBdyorrW
qULzBej5UxE5T7bxbrlLOCDaAadWoxTpj0BV89AHxstDqZSt90xkhkn4DIO9ZekX
1KHTUPj1WV/cdlJPPT2N286Z4VeSWc39uK50T8X8dryDxUcwYc58yWb/Ffm7/ZFe
xwGq01uejaClcjrUGvC/RgBYK+X0iP1YTknbzSC0neSRBzZrM2w4DUUdD3yIsxx8
Wy2O9vPJI8BD8KVbGI2Ou1WMuF040zT9fBdXQ6MdGGzeMyEstSr/POGxKUAYEY18
hKcKctaGxAMZyAcpesqVDNmWn6vQClCbAkbTCD1mpF1Bn5x8vYlLIhkmuquiXsNV
6z3WFwACAg/9Gs7SRDkdcrrYwzGJMLiJglFQq9dv3bSghtwmAwhw1HS184+uxhnr
ZQoV1JuZpLJQ/gEQTCi2QN+7k76C8cqVb5Y3bvtfpFjSOVkRCPYDQTluM8yOXvKO
8A7tRpQMjvn3SnnT8IF6wEBxEu52YxLSxEESNHv4N+BNGZZaBhNrj6mdl7vAdkwB
vY8xxuoiB3ww8pc0LQKhQsRg/ePPhCDLtedDrKxN033ucmgm8V4u3CEENwk1mdmF
ha1GOGlhyDfKJL4nIUNYlLpx0VO+mH0ocSNKQauPzLidFWDddavvfnbnEVq8f2u5
xfcTxL9QinQHSL0QQvsPtv31OGG9HQ02gnLZ669UMYVl6KoNSjPZEuPi7xgJU7TK
yDuYVd+FkVzaaVrUZxl1MfNqfMU7oCIw6Lw9Kfm/mJJB0HzxBW2VvH+Z3Q35bJ/b
3WgOSBnA8XfkZae3vVrlHcnWjnjQ/76QPRrcMPa6DNoUvQ+U+BjUUrKAoQOw9DWm
oPjmogFlesFHZl2FiBp+2gStUmNwGlS2wdnvk+nrGrxoJd0s/7iLj6nRVIPLVbID
fNcLL8O5phxUw3Y59CL5uI9KrzHtan0pgQArgP6FMYppRERiinAqJLQ9Yp/1li0P
9puxK0/zG8MxMkL6sXUA9Q1KpXRkOz5NOvlX2WFgoXxDZUTdlid8tCeITAQYEQIA
DAUCOd+zMwUbDAAAAAAKCRB9ztZZWufZhBwyAJ9GfDyIbcgdnMe0CjuPin9UobRo
5ACdHjn4iuMiXZA8cDDPAi8VybndPak=
=F66Y
-----END PGP PUBLIC KEY BLOCK-----
D.3.18 Martin Blapp <mbr@FreeBSD.org>
pub 1024D/D300551E 2001-12-20 Martin Blapp <mb@imp.ch>
Key fingerprint = B434 53FC C87C FE7B 0A18 B84C 8686 EF22 D300 551E
sub 1024g/998281C8 2001-12-20
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDwhwB0RBACelK3FYxd6cT5ukbiSdVLHPLfzgH3F34JfS6Q4FMXgEAPtx7iy
U4Lc8A4Z2gCq1ZHBZTzKc61U+nzHe+eUWtAj0h3qDP4DOd7JCZbh4SW6dMIC7MAM
/9J5br6e2fIIn3rzbROXSW7CJPox2D/zZcT1b727Wgy5NHUob3qej/zhwwCgrZ0o
KBapUXgnKhesQzKlH2wWCJkD/3njAzJsFS7nDdTssMtd7ip9W97uNOFLuJ1/Sg5S
332BUby73hNzSXlS4rhtQB6NVBRLfGASuEYBJQIEz6aao/lDprIxTusCTrO/EGqa
Dy5y4XE1ClIyZ0yVw05UJiTOZ7Mu/kUTBBzQ2i15lxjzXBt9pNifvtcKBhcDmdzQ
zepQA/9Jio4IBFmjPDsl3kpvA8KqP7VXKFMMBVT9SztYVIeiFgbvff/YCqzkE5RD
0PWUFPF3o8rzsCovlpySfUNLUlfqxEZ+5+/5ky7AbJ6Vmyn7Tl+mBSZs4mTV7ktN
526ngUaW2j+aO2SdWao/di+sRutrgRjJqyvgGn1YGnrSoKbMJ7QYTWFydGluIEJs
YXBwIDxtYkBpbXAuY2g+iFcEExECABcFAjwhwB0FCwcKAwQDFQMCAxYCAQIXgAAK
CRCGhu8i0wBVHh3IAKCDMueq8RCcRO+3Lc+uQyXqDKCf3QCgpVWa7oS6lTiNxwSP
enZ7+4g+TkK5AQ0EPCHAIhAEAI3iAhZEDBjyJvPS74CXq1ypWvXfQUCYADCc/Cuv
3xrr1p4ff3oYc+IIVdeOQktKWRP1dK7v1JLmqFsNQQIs+NtgHyO+azyX5vJGVRTg
aCIuMMTnrDBC7VbAnWXtTHF5VKmmd891Y+nk68p5YVnRPc/fReXEY6dA9lqW0bN2
f2jLAAMGA/9rMbPpnRy+uvaAQChkHvOV1RnDAhN2R+U9u3d0uNnv7sWa/TJrcdig
KNUsUvXqIXVkqEMrYHTbCVC4mLMd51MLARiIKOaHeynRZYkEmdi5X7EiBLS9dCUe
7+vMz4jV6MRIGyr8TBy3CEFIdAnpY6EIVd326PzYIgx8UZw3oEvjGIhGBBgRAgAG
BQI8IcAiAAoJEIaG7yLTAFUetM4AoJg56qwlr8E1iEs0F33G6POGCWnCAJ4mW9E3
25TD51pcom8Plwy1BkuBSw==
=oE+K
-----END PGP PUBLIC KEY BLOCK-----
D.3.19 Roman Bogorodskiy <novel@FreeBSD.org>
pub 1024R/1DAACA46 2004-05-25 [expires: 2008-01-10]
Key fingerprint = AC27 CF29 5E51 E53F 8C8D DB90 8074 5B38 1DAA CA46
uid Roman Bogorodskiy <novel@FreeBSD.org>
uid Roman Bogorodskiy <bogorodskiy@gmail.com>
uid Roman Bogorodskiy <bogorodskiy@inbox.ru>
uid Roman Bogorodskiy <novel@clublife.ru>
-----BEGIN PGP PUBLIC KEY BLOCK-----
mIsEQLMkmwEEAM4cQe1CNDdIWcOlb8221icriocsnJOWZ4XMX1Ww7CTUfPZU31Ho
boNl3sK/+KsJxwt6frqOBnnvtQYQEYzIQNJ4pMKC2Mz15jMYndwsuxg6L09e6+R1
7RfIEFEXU7p6YWQFLoBFUW16XF7ye8YrjFJxAEfTa4jnXF27ERopVpUFAAYptCVS
b21hbiBCb2dvcm9kc2tpeSA8bm92ZWxARnJlZUJTRC5vcmc+iL0EEwECACcCGwMG
CwkIBwMCAxUCAwMWAgECHgECF4ACGQEFAkWk7H0FCQbS+2IACgkQgHRbOB2qykaY
TgP/aTl0A12yrwFi6sQE/2hzrK6qQ1HL4qmz3UETXZSHcKbZwXYLbGO2Qvs5dMZv
FCw50QbLh+3I2fn3kFU/IaupD3wwIoTdRJiLM+vl+EU/H3ClZ0fgC7iEnroHCbL4
OZW+L6SEx+eT508pQm36SOJKGkS/++wrbUGuG50JiKOKihG0KVJvbWFuIEJvZ29y
b2Rza2l5IDxib2dvcm9kc2tpeUBnbWFpbC5jb20+iLoEEwECACQCGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AFAkWk7IEFCQbS+2IACgkQgHRbOB2qykZlpgP/Vr9cnLEF
iijzgyHXBhfo3Y8dmO7+8r1LDd7zEBfFIVQWmmquOZBcHOdJ7kOWe+X7e56yBCpb
DboNUiXgYJ728UfDvk3ida5Mj4OiQjOKlW1pyiwNhNE8/X1ngoVIdZ/mafv8141Q
nkIINIC7dcB27+QKDuzQJ2FMI+4azR1a3Ee0KFJvbWFuIEJvZ29yb2Rza2l5IDxi
b2dvcm9kc2tpeUBpbmJveC5ydT6IugQTAQIAJAIbAwYLCQgHAwIDFQIDAxYCAQIe
AQIXgAUCRaTsgQUJBtL7YgAKCRCAdFs4HarKRvzvBADDlwy0yK1iSQNKx1z7kkoL
+JVzXfzDmJ4uOw3T6XwUNuXzNENslgNd2UQJgEm8ag5Bxsx9sXY2xbq7OwIoeULl
gc6Dde8MgLUZdlFLfUIzRz8Bw6Mw2cxTp5IM2EL1Q7Khj55toRplzkM3rzIU8YEf
lT21C1tFsk6SZHVLROG3n4i0BBMBAgAeBQJAsySbAhsDBgsJCAcDAgMVAgMDFgIB
Ah4BAheAAAoJEIB0WzgdqspG/3kD/0isk4pKJTMKCcoaGcZsGW6C3e5CZw8Mr+OW
AsxHGh/Iv3iGB7gGoO07R/I+uAMNR2VbPQAvYPlMwrIhubNzUZRzkdlBu7QQyT7C
lyEIAn/ikUzfmxvD2U0D0SrHguz7YcSH1Vjb9R7J8dc+qlPJBRXIX6saNG6+FbSk
KN+J8hOBtCVSb21hbiBCb2dvcm9kc2tpeSA8bm92ZWxAY2x1YmxpZmUucnU+iLwE
EwECACYCGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAUCRaTsgQUJBtL7YgAKCRCA
dFs4HarKRuscA/972/PGOvl0zijaqyAQ8p4vIQU9/0MTOvjSJ7h1F2R77B4SI7lK
afbO87vBPo1QugRmJ/j3bD4pOg9G2CNXOFyUENrV47E0BVGCQURph9/CPGw0wdUm
s/AcBfDoCsqIA71O+p/5d7STbtIatKdoUePi89QIjI0HQjpXV/l5Py1SEw==
=0bTH
-----END PGP PUBLIC KEY BLOCK-----
D.3.20 Alexander
Botero-Lowry <alexbl@FreeBSD.org>
pub 1024D/12A95A7B 2006-09-13
Key fingerprint = D0C3 47F8 AE87 C829 0613 3586 24DF F52B 12A9 5A7B
uid Alexander Botero-Lowry <alexbl@FreeBSD.org>
sub 2048g/CA287923 2006-09-13
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEUHm3YRBAC/bBl9E1saFAVuS5wtnBQ7BbXPOr21SBExZ3t+f8k2PG2SsKYL
xNMAn1drC9UdbUVcQDzlGcWQONYRKj4kWoYSYNDOElwa7Rv/f4z4NnIhOxxT6G+M
qQTFWj6MjrCVPZh+b5Y3DTdmNxuJq+Yf9+DFsxc0i+xhMrbbjuokWRFdxwCgvb8Y
fLNYJqjf9V5hhnvt3K2/L9sD/2frMKR7o1Ie3CgQbhZgYLkGlMmAlyrKLamdRzRl
AmjJ35mkIQ9iu36BpsUmVL9WPjy2sdep0FyRLRgu5/q9qhJxy31GsVYv5y9m9+px
X+00CN1a/5g1d6gxLUY30KsOL8OXSqwmq36iJHEsRxFfs9NJ/dBui1cFW0dDNmdg
nE9xA/0aX+9BPSiu/hXFa5A2Q8fCB1wOcaru+QzgbY7nWnse2PQ7Nsv0xEMkaYdT
AqA9I/UyssYeRygD7H8edd24xy39EBAVLLCD57Tjye2fCOyWBIGJU7Jtc4b/DJgm
6bP2bSscB44ybBmlWdza2sgui9D4beWQvEVZGgpsnqnCjJQDOLQrQWxleGFuZGVy
IEJvdGVyby1Mb3dyeSA8YWxleGJsQEZyZWVCU0Qub3JnPohgBBMRAgAgBQJFB5t2
AhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQJN/1KxKpWntZ4wCfWY5pLq6V
rCpsAiGcIniMBUoueTYAn0b5suADC5pawqBP/Xbv95e69gDWuQINBEUHm5sQCADC
7ynjQmBXd8q2Ei9ab6oO6Q4XbEu2eMLcm1C4b1cu8Riyb0bYI8fQ0JkYPWBDdgvG
iVuDGHjLRCJm8LDV4VAhpkn6obPaDW2ZVf3urkAsCszSmv0jlEO+grOj48c7sLeR
NpZX76FCKFtgHClQOSfR/9eoKFQh5jveWgSQ0gEW95gGQShy1cTi1XUdJdxilL6G
GNBfSNgAFwQBkepgzjR853bVysoZEF0Z9MF/PZgmAXoPYTs54tA24LSETmBo5BjA
yUTI6Dv4+jKXqmDphX6BjxeJkYxlKAyVBgNrKZahPoyOPd0FvMINn4MpOJdpq3sv
PSXwbexIrroMJQz7nR9vAAQLB/95AIR3oGIOhDCAUwf18K0Uv+v2cKVhClHqyAGy
zHjyoyEoSnhApWVXD2hNvqfxy37t5/5EzaU0mvC0GMpv0trBa9uBRk8GrXgILnzh
dYjhbSPZStx3D/0lFBLHt9qYjFFQweKNun9coOV0TzdXigH5PFxiks90Qc/sfr6N
v6hXA4MAe81zeEdQafBkreHDo9fL4i+GwxF9novXNZ0C+YNJ6+3wOIJwacCZ1bdy
gWTM8pTa7vtvtA0Pk4CZpGKSICg/jDq9dZT+vaNGFnKvQOQv1RPNLs/QqfvUo4ZF
khopn5yHXGJjLZp0Zds4MdqXLddUNHXW20Yki11eZ9NXK1KdiEkEGBECAAkFAkUH
m5sCGwwACgkQJN/1KxKpWnuSYgCeOgBV4svD8sqNBVN467Le6aLzPxIAoKsNXerk
njcpzY8FzVuY52JnLNP4
=CUqZ
-----END PGP PUBLIC KEY BLOCK-----
D.3.21 Hartmut Brandt <harti@FreeBSD.org>
pub 1024D/5920099F 2003-01-29 Hartmut Brandt <brandt@fokus.fraunhofer.de>
Key fingerprint = F60D 09A0 76B7 31EE 794B BB91 082F 291D 5920 099F
uid Hartmut Brandt <harti@freebsd.org>
sub 1024g/21D30205 2003-01-29
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.1 (FreeBSD)
mQGiBD43wzYRBACpuUuayKjLpf+tMndpkOwxmpaPkLFxiA/dI1iWjY8I9ItDLZyM
LqgYXemOOga6vbTvIUq7Bjzl3oR72kjNX3J1EljsMj7dxksoY5lflEMdxAyzdVoI
+/cu+cWiP0Z9unKpYmTk8S13sUTtZc0+ixioaUvHzSJ0nxQMpIW7dqCDewCgmSVR
6i2aK4oImAa9+ZbCxg7fCxcD/2xgAAwJSmaiaV/0As3A6IO0eSkbkzFSkMF+ms7C
OtrHr1zmdM7h8MaGg/jw0Z6eZalYD7AclLvXDW0rxCMFwh06SC2axUTk+aE+vcys
fuSk/HJtnktHUxZDgb28jf4X6zfcdTKE5dt5a9w3XHHPgdTXjGn7+sQNR4CWDcvq
1qNQBACOqNxJdCC9tDLycRoupNSwzldMKVBZ2/JdQjfCIq6d8HPMNVLU8PGlDjoy
RN4QkMZLbwV9Gaigk2DR6vvi8meARADt53x4OjS4W3O/Pc/Aj8rsUcF2mRU/wiJC
8VkQsnaci5GuaYAssgKroOTZQzxHkOjbk4FeQ70C+wxovRsTh7QrSGFydG11dCBC
cmFuZHQgPGJyYW5kdEBmb2t1cy5mcmF1bmhvZmVyLmRlPohfBBMRAgAfAhsDBAsH
AwIDFQIDAxYCAQIeAQIXgAIZAQUCPjlTfwAKCRAILykdWSAJnxpyAJ9eHCdgiEt/
+Z5Ms8Qe3ekWTYTy1gCfdVWLF2MrZNL/MYOgBhhex70gKzu0IkhhcnRtdXQgQnJh
bmR0IDxoYXJ0aUBmcmVlYnNkLm9yZz6IXAQTEQIAHAUCPjlT2QIbAwQLBwMCAxUC
AwMWAgECHgECF4AACgkQCC8pHVkgCZ+BBQCeMpgFMMm4siEtrzqdisrRaxJJvosA
nA7UDwOVoHDZaAkFD0HNcUsTkO3KuQENBD43wzcQBADsEH8o/9tD01ScNfhoMbK4
N7GsIJNFwQf0+MQuplpXQx4eBpI9ST1ZoAUXeM1j4jk5PIAMJzt8w6BAGgcU4iUG
Un0R/QMTTXVkfovdSe9FW7/QtUjRtTQz3QOfZTkekYauFIiW+lSmH3BDwRXhpKgM
e19eQZYOPRfLCnLLwqdr9wADBQQA5tIdzlDS80CNZxxoFDKlvOghtrIzPG/wIwGV
at2clZMLhXESxDxDkpwT7XP1GRLyN/Plh/4k2vwxni7nOJ8BIch7rRh3E48TJat1
iZ99SFc9iibED5hY/HrKlc/kphFnUuEr/kk82UCv9p4/d2V1+8v1N+Cy2jCGvrip
IQ6v2fOIRgQYEQIABgUCPjfDNwAKCRAILykdWSAJn0J4AJwMsjovUA6jCJRMEzOS
kIakJgqJvgCeNLKyNEkyJZh0wZUcEg1zYLRYp/w=
=+h/9
-----END PGP PUBLIC KEY BLOCK-----
D.3.22 Oliver Braun <obraun@FreeBSD.org>
pub 1024D/EF25B1BA 2001-05-06 Oliver Braun <obraun@unsane.org>
Key fingerprint = 6A3B 042A 732E 17E4 B6E7 3EAF C0B1 6B7D EF25 B1BA
uid Oliver Braun <obraun@obraun.net>
uid Oliver Braun <obraun@freebsd.org>
uid Oliver Braun <obraun@haskell.org>
sub 1024g/09D28582 2001-05-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDr1p9kRBADrTCmhk/+XY9Jc34z36wp8zy1rbxGBy80enJM+aFPHks/iYPxR
WA1tB8BEdGPJliUMYcNGeo+ZX3As1+xxo7NJCc7Zd7Gfs1+fMOXPwKGt02mr+Nje
+nF9XMfdGPP0IcK9lzkVeEdH2JP41pS2SmrMwsTE/eGv9pFEnnmRxeuFcwCg1RYc
f8freOk8v68+J99mCUUAGl8EANePcxWbRYgH5KulTzE5nYIt9WBn247T7goE3yn1
R2VddSXXGhs0byRxXpNAcrysyGshIQY0nnZSB5AUt27tZJucoT1p/BtBFQ6hLCQe
kaIRL0sdXrVJZn3/Q1G7vJWD6wwS35dro5PsYYPDI+qL1tISlWHZNQ2Y6jGdqhc4
Len0A/4nV78yB7cLvHksxwvbdtVVn8eVo1B2U+/b4cXhevHAl8AmNN+usmEodxxe
8FYWV8jY323xiYSMrCpYT9FuD3r2qORMOGWpg0zth6BkhdgH1z2i7koKkGIfc4mV
6oea3ep5uaU82r1sGe7/cVzMGUwzZq9xizwODfbmSW6E+vdAjLQgT2xpdmVyIEJy
YXVuIDxvYnJhdW5AdW5zYW5lLm9yZz6IXwQTEQIAHwIbAwQLBwMCAxUCAwMWAgEC
HgECF4ACGQEFAj4YDoEACgkQwLFrfe8lsbr7rgCg1K0Zl8CPgrQG7BEaZqzSiIM6
IZAAnjz5ifN2xHJSOJiLYloidZsikNFQtCBPbGl2ZXIgQnJhdW4gPG9icmF1bkBv
YnJhdW4ubmV0PohcBBMRAgAcBQI9Y1sqAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAAK
CRDAsWt97yWxuv0CAJ9lUDzKKdaCp/8mJjlXLjlSZaaJTgCfXIqQr58p5MSFkVdL
hLbK1P1l8FK0IU9saXZlciBCcmF1biA8b2JyYXVuQGZyZWVic2Qub3JnPohcBBMR
AgAcBQI9Y1tFAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRDAsWt97yWxukHLAJ9u
oP9cIdBXldt7XfQ/5xK2fUsHPgCdFIR7cK0l0spO2xjzbzhoPPVShbq0IU9saXZl
ciBCcmF1biA8b2JyYXVuQGhhc2tlbGwub3JnPoheBBMRAgAeBQJAViQBAhsDBgsJ
CAcDAgMVAgMDFgIBAh4BAheAAAoJEMCxa33vJbG6MhIAoJ3dqHVStQdGzLPTGbtP
Zq8wG0jmAKCzMo+si/LFBZAnOqYN3g2yVOOc6rkBDQQ69afaEAQAlaNzX3ql+XfL
obAAIWW/TdY9Yh6r0fFFoK2Mdt6vungWhzSWb63DprREXyW1k6QbPQxL+pAfeCYZ
oXQuNBmsUpO1Xn6ViEGRd53D07sNJfBrE/5w3hwL+c9lWSJlt0vHKzFtPAmqenBd
fA0fs9afiew2sHhk/jz/FAwWcnF4aC8AAwUD/0upFaHEZsf8sVmSEew5tAtZ6i3x
zaBjhaDv3sYobza57S8mXYhscK+nNHx3bP036wJ0z8ypqb5oCqGzWUkj9OpYZs0u
Tbpla/MoCI9N1Ch8LfQkWPuvYjHF6LSY3wpZKaNWfeZPCmMT5XPqjuxDB1pCmnAU
OizLyimZU2Y8tfQWiEYEGBECAAYFAjr1p9oACgkQwLFrfe8lsbqmfgCffgEhvau1
1EUoZmkdnzUg2rbKYnQAn1fVK9TjWnJWQ/YDOn9hmMZWYjib
=wrrS
-----END PGP PUBLIC KEY BLOCK-----
D.3.23 Diane Bruce <db@FreeBSD.org>
pub 1024D/E08F5B15 2007-01-18
Key fingerprint = A5FB 296B 5771 C1CD 6183 0FAB 77FF DCBE E08F 5B15
uid Diane Bruce <db@db.net>
uid Diane Bruce <db@FreeBSD.org>
sub 2048g/73281702 2007-01-18
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEWvrjsRBADPHOAUGtAny5WUa+5+6EFo83DOSCxMWqECyfgGcX0fLdQFTlNC
oQwjuDPJoUX3l2U8+Pr0PbCnU9dAv/nfR4mefBYaSYKrOkKR2JMCUu6Z551wJIOo
G65q410cwz3scHJ9m52iGRbZoz99+AjGymA/V4zHYV3phF+hXJKamS/DLwCghPo6
Osexk+odFXJ+Yq8fz9MdvaMEAKPsHsY9gWyzmVtQ8toM3yudoZcjILTsNbX7oDM4
Q0MWURvY1JkyH5vQ0l/BbJH50CGzFHb1CvDHDyR9wx74U4q58eRnx+HzSC/UukBT
e/SOBwXM2MHv0D6fHgm7Tepwiy2uc7St5SawiJXEW5XdY2bleovVDanPvFhv2pSz
z56IA/9O+rsGqWmgutoU97HyoIrHkY1aMAbcVkBocooeioXdm+V4AF+nlIp3pZQ+
7YS0X7JkyQTRoxvGsGawjktbDGAzBFTYazAS2eKhBE3wyWME/14VR1OVG6EAvli+
fL4tVUi3xBHDdb8Pd3PzWt1CduBW6RIs2NCrv5baMO35RQo71bQcRGlhbmUgQnJ1
Y2UgPGRiQEZyZWVCU0Qub3JnPohgBBMRAgAgBQJFr647AhsDBgsJCAcDAgQVAggD
BBYCAwECHgECF4AACgkQd//cvuCPWxUTzwCfcKKh+vsTusry/Ait8DtdpUse8YMA
n2URXcmflBA8OQ1JrFFjiW/5N3iwtBdEaWFuZSBCcnVjZSA8ZGJAZGIubmV0Pohg
BBMRAgAgBQJFr7DmAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQd//cvuCP
WxVIvwCdFGub9b6qt+L50ePcYnLy5sthiZIAn3PPdYTUPdXV6DfOtKFPcx6ArSHm
uQINBEWvrlEQCAC5N9u/zG1ahYsV+kiytZ5Mgt+I+yi5aSCAQPThSGXsVptfZRW6
0LVElbLL2v+r6ETRK92QrtZLSqM51sKWY+lyJfxRjuW2AsVAL6/NgV7bTuYs2etL
vo347XX2ff7DrA07mGOAPrer9naBlaLPwWggWO9bU8HzphbL+kI15T0aUXLwIdeM
LjHOQAypJ9iFsv/OY2A7epAw8zK4LCPA0boBQY6CKcFV9gxDl/kmsqobvBeyAru2
jFAgeFytIJsP3O1kA1aKEFDolcoPwlVUQiAsFvNtUSX8k8r1HKfQpnjuSCXLU7jE
82X5VWSAcoX/PyaXDY7AmHJFLpZGyGIs5sLrAAMFCACQPyOQmX0iDjJW8OCpmgE5
yDv3Jedc/w4546OLOC4aT1wclNZh+iHR2meuFgm6J1bv9h78R6dCkGDJeh8MTCtn
d9J/IDc/QElCqqndnn5XmXjtGqukXIlIg7iGF71T74K/Nb0Lepb9p9BQpiNqudHJ
L+KqSAjFT03vfpJab65EpyeOq1ZIswDIWMRb2BFQs/El8rX8cXOSzTrKfWSamRw/
6l1aBwsmqi8sW23GSBYCd7FKQADVKIu7EN68QT6Diyd9CB0s4U2DjHrr7snncyUF
A9c6FTX+tIE8NXJ7ku40g7T0WnX8jpuoagdWpjlu/NS2cgaK3n8MwrL5kYYLc6+O
iEkEGBECAAkFAkWvrlECGwwACgkQd//cvuCPWxWcygCbBuZU/pJ2tZXVsUrFSRts
8Cvwa9MAn25/zFXyrtEDo+1imX3MjKZrdJC/
=vYnO
-----END PGP PUBLIC KEY BLOCK-----
D.3.24 Jonathan M. Bresler <jmb@FreeBSD.org>
pub 1024R/97E638DD 1996-06-05 Jonathan M. Bresler <jmb@Bresler.org>
Key fingerprint = 31 57 41 56 06 C1 40 13 C5 1C E3 E5 DC 62 0E FB
uid Jonathan M. Bresler <jmb@FreeBSD.ORG>
uid Jonathan M. Bresler
uid Jonathan M. Bresler <Jonathan.Bresler@USi.net>
uid Jonathan M. Bresler <jmb@Frb.GOV>
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzG2GToAAAEEANI6+4SJAAgBpl53XcfEr1M9wZyBqC0tzpie7Zm4vhv3hO8s
o5BizSbcJheQimQiZAY4OnlrCpPxijMFSaihshs/VMAz1qbisUYAMqwGEO/T4QIB
nWNo0Q/qOniLMxUrxS1RpeW5vbghErHBKUX9GVhxbiVfbwc4wAHbXdKX5jjdAAUR
tCVKb25hdGhhbiBNLiBCcmVzbGVyIDxqbWJARnJlZUJTRC5PUkc+iQCVAwUQNbtI
gAHbXdKX5jjdAQHamQP+OQr10QRknamIPmuHmFYJZ0jU9XPIvTTMuOiUYLcXlTdn
GyTUuzhbEywgtOldW2V5iA8platXThtqC68NsnN/xQfHA5xmFXVbayNKn8H5stDY
2s/4+CZ06mmJfqYmONF1RCbUk/M84rVT3Gn2tydsxFh4Pm32lf4WREZWRiLqmw+J
AJUDBRA44g2RH3+pCANY/L0BASF9A/0apMb/yMyQgcBLRPI+MO1QjiLxIXeh1nsK
jWpqSUojzNmosasXU9WnY3AaYv1tkXGHd031Jlhooi7W9Cr8y2Ou8cYF3kZmxTN/
cDkSWAijoduK3209QjpzdkfNZQyeWrXewRBohgt2b1jKuz3CMtmu8yV187vdITBQ
/m1Ed/uONog/AwUQNd6r4j1NsS003qvIEQJxcQCffcdAPWYz04JfuMnTVGiOAbvF
CnYAoPCa7zqkrz4C+NNZWv6naUq28Z1TiQCVAwUQNAtxKFUuHi5z0oilAQEm/gP/
eYOsPQwz0Rg5W7JeKTdQZUjyq5g0D0StVwt23XQ2NhzXpUjYc6dhWA9FqDda3tbz
CVdKGmiR8L+8I23t/kmBF/yHZrX8yNDG2UP7j8mzyTsYtrneguifphBiTfYgQp7G
gs/AhE7gvYEdZrcbMcklI/ZpNH8Sn3T+kt0A67+gkNSJAJUDBRA4uR++V8m5SpXB
F3EBARc5A/9jtM4Ds4ppcEwOyn5+QbncmqIZ1pkolASMWypkOb0sRVB4rw4Qcufv
cq9NFy7cOVzMGqU7t6Xt+JwBSAXhT6ftkgqz4Z3z9X/uDXXLNl9xwG+prcioHysJ
AuuPhyUgaQCICTf1+2LKxV11aVfNn1eVJ5NNHg6+CIVl+We/7Iyt3ohGBBARAgAG
BQI2CQVCAAoJEGNKpdi6XK7SitoAnjShEqJHD2ALvwkUBGlEUhskuHxkAKDexPfc
e6H7zFSdQXvddPpvU3Lec4kAlQMFEDWiXlNlYKmsNPn51QEBPNcD/2H9lS6GhEpN
ZWJqKy0Yl9aLboUH8qbmcNAGv8SvDdeSxAIzBMvIS6CDp1qFDW71jkTm0o/FsHr1
4X7sldUcT/PfOLNHpUvex1HHvhM9pw+x2FlGMKERBzSG0stgA+QmsU9UDMCVKWbu
p34xd/x8mi9CzrE+1kle6RC6Q82WGpn3iD8DBRA0h/5BeLVyoGs5bW8RAn5OAKDv
lWhVX4LlJFl9dKT0kn7z8jyqogCeMZ/EUiHtbbZp6pJAzIS4dNJio5SIRgQQEQIA
BgUCOEVR4AAKCRCWrNRNg2cM0c1qAKCtP5zsLVfZQTruoogvyp25ocJ6sACgsF7c
v4sg8sPgs4HE3EVogHl1VhmJAJUDBRAyrIvQs1pi61mfMj0BAXblA/0YVeEGvPa2
JbPb7SBZulwY2fJlt+xWMXqiMYN2ayMkzJYIbDj1dH+88pgglj0Riji3j0YhqNGQ
hJA02IjPbZ8ECNPa5j1iW+dMn00mV4x8evh3JujugQpgxZaKNDMaOp/abzB/05pq
h8QrAFfqfFxFsqzGb8FUspzMZiXde2ORy4kAlQMFEDQN8X31FVv7jlQtXQEBxnQE
AILJ2JJQbVVHRrkMFwd22KfaJkw+wlQ9Gom1a8/pV4jw4Wk1ZDgtboRMC+ffkfFX
aQJxAzKG3WQwP4oQnPuvxVv3hNLsq1mc2+TYPVdTHwuhyPrF6Xlz8ufOWeensGnV
dsmPa783MJplDR5gF0/+TtEtgFgdBCWfnHsE66JEk1VTiEYEEBECAAYFAjnufrgA
CgkQI+eG6b7tlG7qMwCeKE+mmecBnRdF6KTmUNRuf/xMANIAni8Wju9074WOiUlj
wCBWrvBMtwafiQCVAwUQOe6AHU1WKCF5BQwRAQEBBAP/REth5Qb//1T+a6jvv+Rw
VayyzlE24W/McZRyL1pXDzbRuRx9wPiMS9yq8kwwozFQZbeHLLJkxSO661W6Fn1t
LA3+Rn02ooZ8uvrqk1GM6TvlLdzOU/2pOcUkFICu8xTPCSySVjQgFr811YwHYVZK
1uhessQyqlFROgdQ4lcJo2eIRgQQEQIABgUCOe57PAAKCRBdUhyM5rFQFtNqAKCQ
iOJTUg+XEzw4kJT6GrBjmb1MNQCdHo/p1MhqvDg8W5f2yEVWsshuvvSIRgQQEQIA
BgUCOe6DBQAKCRAgFTHVhF3+3ScPAJ9XLuCarFLgNYtc5XuT2jN0nLq5GwCfXwmK
wiwnzbOFlbSITRfBDXnbAVeJAJUDBRA57pqgfEtnbaAOFWMBAV8YBADLjY62KZgj
XJyLSkZtvJzgnKUCzeUAA/mO0i0aQd4QrlU4lvORGX49CzfWpPUoEIz6/slj9IrS
w5x4+W6/F2wgWneOMKkmkROtrxfkK/JiDF17cC+zA6W4MSZj3WfcZ1Cx5czh1zS7
KZt4X+AALhlgP9IdoYZ6aYguva44haoyUYhGBBARAgAGBQI57ppjAAoJEML8hqol
OUaLZC0AoPIjsOAF9TVLJH+n0uWKzSiQ6tPrAJ4+fHCwBQbZ+HcjeP5yNaWsxlZ3
S4kAlQMFEDnumqzW4KH+T74q3QEBZvsEALkknigcjnZcLz4q86YQIPSwinmLiEgW
cggrYVCUC3J246VCaJKcsJF03W2Yhp2MJuFhElcOZEfRSozk3O9QsuaAx+hmB/Ww
mrQD7Aq7KleNSEoNLeao8vB1VlWVRSWjmtwtDj7kLo0DwJQPwr7RbsrkTKMC/DXr
evAR8Q+V37bEiEYEEBECAAYFAjxI8Y4ACgkQDJkTa5SHS1Q7ogCgk/vN0Ojp2f5r
vJSCuMXnfbwMQcAAn3h3QmTwBFLyExCGnRqGgkiyJNtOtBNKb25hdGhhbiBNLiBC
cmVzbGVyiQCVAwUQMbYtYQHbXdKX5jjdAQHEHwP/fEaQoTi7zKD1U/5kW2YPIBUy
MTpLiO9QOr4stYjJvhHh4EjwfGvMIhbFrPKtxSNH1s3m4jAXKXiQBDCz17IIzL4n
8dlunxNGE5MHcsmpWzggyIg4zbPqPOcg4gLFEWsEkr2o0akwzIGa3tbCvC+ITaX/
rdlWV1jaQjTqSNyPZBOIPwMFEDSH/lx4tXKgazltbxECmXgAoLaWM3SvE67viXkq
S2MMO8UHqG1MAKCsCyhLvqh9cmQDKs8hwJ6MBzoRPYhGBBARAgAGBQI57ns/AAoJ
EF1SHIzmsVAWAxoAoMaEEZ9kUqSwFm6sPsslETsnrHy6AKDgNz2bZ8N+X8MGwFZh
vuLIlymSHYhGBBARAgAGBQI57oLRAAoJECAVMdWEXf7dc9YAn3hfo8kvuWZA2YuT
BE6mPp0DKY9pAKCFzsfQRhqdZhPaK5MqochPkd3Mq4kAlQMFEDnumqV8S2dtoA4V
YwEB0JID/0r92+qOLTZns+hFzAfi1vdqJ7nSNsG8ESIVMq4wVNVUf+b0A+5pNLAY
ZgrQjL8CbgQT1h03uvvudmMwNY7nhRKYbkdtwIOUId+9XCLkepo0aScRhL4esuSC
jcWI+MgSzZxJeyqsavoCx5L+rLe1l1s1+vvazq8liQeSyXlcU1VwiEYEEBECAAYF
AjnummUACgkQwvyGqiU5Rou3UQCeLAOGkBiAovJemwQx0gTc3qhxdoYAnj+x/ACW
iaekxgwmyTmG0lLxFnuBiQCVAwUQOe6ardbgof5PvirdAQFRUgQAstd65wbZWxGF
VDmMVmJNR62SZGburDLq8SvX/vvjoac6/2zBg/u6sZaji7DJCcAto8MCKj6pbvq3
fTZdfwve52XhDk6EMM50i5Hqc2fPWJYB6JuOjCWyutnTXj9odg8Y1o5cUSuaxsOh
TGmDXmmyT1vsf7j3FMDDzYuWXAfEWp6IRgQQEQIABgUCPEjxlgAKCRAMmRNrlIdL
VAYsAJ9R5CD4T/m59oJ5fZDFZBDEqxyAQQCggPB/NYegHZZFqe8UvIwDawvzRp+0
LkpvbmF0aGFuIE0uIEJyZXNsZXIgPEpvbmF0aGFuLkJyZXNsZXJAVVNpLm5ldD6J
AJUDBRA123UpAdtd0pfmON0BAVf+A/0SyTU67QKidQE8V1r/YPAq9/2BdBk5seXS
KyTqQbqe3kkpojPwS/SLOGDLKFW1wiP/E6gOu0zCAr6t+T2VOMG6EAfA6gQK/oEP
Oe/DOxJMNTgBeiV2OgBdj/JO4THFQXFTgAhCz0/zcjzQchuUEQ6DZpbKJCWllP9p
bOEEgWWZW4g/AwUQNhlqDT1NsS003qvIEQK37wCbB3PS9GfrxsuQ4AkE011KsdYz
tnkAn1lv/gOBbRuI7cpzaugzUXAXTvaniEYEEBECAAYFAjYJB1kACgkQY0ql2Lpc
rtK/kgCgsUMJ5Te8teWc5975HtaCbsFBymkAoNl01D0GgAqY2RcVUdm8HwqkB1oI
iEYEEBECAAYFAjkGAQgACgkQf0/uBDn7eUQ4EQCfQZlhYxtvbvpKk/xxMf8E1uZT
kW8AnAhzff+mTJ1odLahcdnZj3RCLog6iD8DBRA2ikVNsmH2M6yqReURAvvgAKDm
eL5BkG+s9r7u4EynZlHsLsZ8RwCcC9556M1OwODG8ONZ1G1ylBSeBUSJAJUDBRA5
7oAxTVYoIXkFDBEBAfM1A/9RzuGwZkpx7fusQBmiLkDdNuLq3bNqWRdpEsrBB6qH
YxZgQ2egYS1UNLPkISVHd2aJjLnaE53pq1fEMig3wnhnIGkHdb9w9HPIbFklOej2
0VJEocEc46pPxa3gx8SK696JDoXS0dWiYHX77Do/ro73U5hJJWeIZnXNufKsE4BG
u4hGBBARAgAGBQI57ns/AAoJEF1SHIzmsVAWB+4AoOrr1fhnul1zpfTLn/iN/n1K
jWl0AKDHMaBsSOUgNPueiB7HNZt1aqZhiohGBBARAgAGBQI57oMIAAoJECAVMdWE
Xf7dbB4AoI3GO8yAvh0uF66bD9B+NlHpUal3AKCGaHKa0Q5j1EZBFI+4bSney4Pw
qIkAlQMFEDnumqV8S2dtoA4VYwEB8zcEAKpk/Dz50tcyMH5Rf6fsqOJEEavuWiIT
ghf3qyI99E5L7gi1Tiy2aJmLbgbKK2p2uSMoV3H+p9dGEaVpCIxHrAn77iljw3uX
9M/5jhO8dcDOxXBbDTUEYkGHe2oU3af+/JbyX8a4jQLLHQtQmW/9j5H/QKQC4IVT
+wEQAQpqGG7LiEYEEBECAAYFAjnummUACgkQwvyGqiU5RotGwACfezC2rPY51SLA
SP5vQrMpQVkYvbcAoIYINz1Bpz9OXuyHpi4AqaDnR58RiQCVAwUQOe6ardbgof5P
virdAQFfWQP8C+ciH9S5Zm0parEgVPGjn3/uBCOJuz8aiiCY7SaFZxjcjRdHU1m4
rNqwmPlsMZlqrqo7JRJOQ76cCW0jSscicqCfeKWuc8RhtIxjPL3C80l3WMrSS5Qf
cq8nXga6FFOx8XQgS/gBLcqSb1RM1Jf46WlgAOMU8i8CSjEjHV2zn02IRgQQEQIA
BgUCPEjxlgAKCRAMmRNrlIdLVDRTAKCHydMKzwB7GwbQJiGmYl2kQOwdRwCeIgjs
m13E8ArGGqGUkA6SuQqv0Gm0IUpvbmF0aGFuIE0uIEJyZXNsZXIgPGptYkBGcmIu
R09WPokAlQMFEDWiXnxlYKmsNPn51QEBzcMD/3UZQwz2npbOtOvX3tJmmiPS6zyN
0lzCWUiKYrK2wGEVnqXbsDD67eH7yRPHfrRPlQOSa+UC9ssNYwzI7qcTqDruDcMp
Sn9jH40fhl2YGli9wcPoNy4B6uKXd9N/AgOiQTDEn4xs4C/NlG1o93lU3QCY5SXG
xAKWyCtePWVY6BrGiD8DBRA0h/51eLVyoGs5bW8RAtMpAJ487dbxFRAtp/MptpJC
6PBxXBvKsACg1EIMJZw9fB2Te+bKPT53vnxjt6q0JUpvbmF0aGFuIE0uIEJyZXNs
ZXIgPGptYkBCcmVzbGVyLm9yZz6JAJUDBRA7OHatAdtd0pfmON0BAaNEA/9VjhJZ
kBrKgKtuLzzLcPnMVWDM41ZCyCCy7brN01DTLwaEVpl966PRqt+uOs3onanWI3wG
/EP95akELBsrgcwG58huk7PjVNYNaCrJYMiSKY95bGxYUGXInU9mH1dSzvksZ6iR
pX25BMHqkEMHAxahVagzguPetlTIHxHGRSH3lg==
=ttzj
-----END PGP PUBLIC KEY BLOCK-----
D.3.25 Christian
Brüffer <brueffer@FreeBSD.org>
pub 1024D/A0ED982D 2002-10-14 Christian Brueffer <chris@unixpages.org>
Key fingerprint = A5C8 2099 19FF AACA F41B B29B 6C76 178C A0ED 982D
uid Christian Brueffer <brueffer@hitnet.rwth-aachen.de>
uid Christian Brueffer <brueffer@FreeBSD.org>
sub 4096g/1DCC100F 2002-10-14
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD2rQOwRBADLcEUFT8eaPCGT7y4xMjj7DY6CTI7t3TNjgTPj2tATbxOo3No8
R0E8PR4MMMpccKTG71n1aNMag5r6y7FtbDyO5sgGKnoCOz8H5/kDVPoEAw8fKYI/
Q/j05sLuNUShvV+IEHDx4aGdaQOZEnFMyxpXXxsaPIfI/rJ5K8i73+31JwCg/7rr
OjDVEnXDNUZx12ujNyD9vq0D/jVhCxyKm6f7V6u2Lq3lKUmFFQsYBJmh2p1Inwsq
tMMdYdT5onCi2EHhBw0nW4ysn7XfdN+Cri7Yk/EAx1DOwIem8mEQG2FcCJ5yOqVV
p7sz3+bp7vmUzwOmXe1E8QWwcqyRFX+yqcGGxrD6ehgr9llVD3pCApD6N+e9d0vl
ORy4A/46IvrNPVYlDiDekeQLH4MzXlnVGhX98Lq1o9LIFwl7hUPhqVpG6UatA24B
K/azip0AMUeD3MeMsKuxFb0qqn/rZ85dW5SSz9cg3rVzmhuYfBdEm6xEWg+BoZpL
8tFeoCVcX95q4lqjiHgE/d3/VQSRwoWVVG8DmmZFMnnmIt1WoLQoQ2hyaXN0aWFu
IEJydWVmZmVyIDxjaHJpc0B1bml4cGFnZXMub3JnPohYBBARAgAYBQI9q0DtCAsJ
CAcDAgEKAhkBBRsDAAAAAAoJEGx2F4yg7Zgt9tgAniNgDKTb5ZAQjBL/doFKFT7m
s6c7AJ49RwfYfT4be7obYp2ZZ7aEJr+tmIhGBBIRAgAGBQI9tHFTAAoJED4s35lZ
GelGqJEAoI8CT8/26OAozq7WpOpDQZLH2aI/AKCGizY0oJBtzMdEyYj303NFClV0
IohGBBMRAgAGBQI9tIqxAAoJENSNEHJ4+KjUFf0AoOcwwaNv48o0G9OvnKVVGY9b
edo+AJ9UCnX+rTiQOahO/tCiOOVnHgZEM4hGBBIRAgAGBQI99O1xAAoJEJcogidD
tsgARQsAoNBxaBPOUhAN34qG6g9C+0oXHTC1AJ9vt7I/GfQcGCtPNnHxEm3AoXwh
5YhGBBARAgAGBQI99RB+AAoJEKZaJJONqkR/Mi0AnRn/99VRozdca285prO+NPkA
Cg/TAKDdL5bQLQei1SyloKlTqkuWAfVdIohGBBMRAgAGBQI99PpWAAoJEN+hCDdk
3bohrC8AoKj1SB884tTunr9OdnKrfCtVVeQaAJ9QTSJf6yg0JMPYUI7T06zP0L/f
B4hGBBARAgAGBQI99SgwAAoJELxQScEjmqjoyjsAoLPAcXFZOhXru+oOE465+lLq
bgv0AJ44FB8ZXbw6u9neEPX7G1beX7yJV4hGBBARAgAGBQI99mg6AAoJEIMfett9
H+vdYTUAoMeEBU2FdOB475V7CNUwpYJT+bRzAJ4/r+Q0qv8BVF1qJmokm0E+Bg/8
YohGBBARAgAGBQI+QCnWAAoJEJWnRNJ6HmtfIP8AoOCcpXoIDXIOTZNckhICJQan
s3wQAJwPyYCVxDZU+WQbNR8upItgo7s1fIhGBBMRAgAGBQI+QCWlAAoJEGxG8ZwW
/bKYF6gAn3bT7wTVBIj8qdi7lspqagL4a285AJ4wJNnmqSOHaxGn/4c5p5DaAaJT
hIkBHAQSAQEABgUCPkA0WAAKCRC1rDlKuf8qEU6sB/0RUUYV6tktIznR7MmiSTGn
EEEdT/t//Il4ivTZorHBI1ULXaprpHFannSSB6KHUxj8aTOdTcnfTGY5fviuJ1X6
cqL8vMMH+rKSohOfOzyvwS5Zl23cnNSrbCBr/nQnt1ml1yLDn0JSGf4bky9cso8u
zqVcD+K3YlMhaEE3Zw+9j7bVB7EGTvagdEP7c+GnhOeL2bVsW/7BzKlfA6lMMkfb
tw1ugYkNPvqON2ginJ5p+CAHytlcN/Hnh6jXchVkS4Xqinjg3pNeBlHeJE/mt9cE
cZFa1iRo83INwXo2rRhhyXIE7AFYWpbhj4rRqGYPsQgwsv2luCeUSINxXj/vi6Cs
iEYEExECAAYFAj5AStgACgkQlI/WoOEPUC6I7wCg0LPlcqHSoNJ8qnb/krs/TRvf
N8MAn3JxT01fwnIbPsn3NUpPGxublJ5hiEYEEBECAAYFAj5ARsgACgkQHI0nZIQ3
4x9UaACgqYp8Zm9oEGLlqJKl0jme36AD+9wAnjMSyiirb8IPdfTNakxbjzjQiQ1q
iEYEEBECAAYFAj5AVSkACgkQgGcShyMVr6O0CACghtDd/756Qt8yRdA0fhiyER3k
UzYAoMY4QyfLBvOTIaVLdg82XQjpUc5XiJwEEwECAAYFAj5AWbcACgkQhqAIGyKy
lR0OSwQAsSzI3Jcqcv1cjX0IXh0h7SyUUDO8mxmeyv1YVk8Y/zuer8yclgrI8WXs
DdoUpekxLcyDxlbVZTiP8Ou0/gbege4PZk+j1LXQMUK0QREtkFXDYkqoe9T8AfH4
jHzPrE8oxZv5tEiH1DXGui1FVgYu43dj3iiPTXlGYfIXWaVkaQuIRgQTEQIABgUC
PkCsmwAKCRBiSEuPG0iN6mH5AJ9TgzqSmdJwKuI8vs0JJX+NB4DeXgCg4836cQM5
r4MHlS1cUdr+72vNxTSIRgQTEQIABgUCPkCqBgAKCRCuUcxBI0Z68Q2IAKCaIreJ
/zUexMSd4HK0yFHuqNCixgCgnzFQgJGDnHTgvuXD4vP4Okd085mIRgQTEQIABgUC
PkDJGQAKCRDVVqZgiOPvV2XRAJ4uhqgTVrMnAUY8Gp1HESewRT+IrQCfbgB5zcul
S/zWaJxOOrl0eB2B9MWIRgQTEQIABgUCPkDghQAKCRA5o8lM/cSo/edaAJ9KGbXK
FC8ndJQvQWaoFvePYu6cmQCfSQqYvPij62WG+toaZIhM6Ea9Y4SIRgQTEQIABgUC
PkFUywAKCRC0deIHurWCKaWyAKCyeLFGK0Ng2gtDju8JFu9oXBqtRwCg5k/sK1St
bay9MSi0Mb3iqtiroc2ITAQQEQIADAUCPkFeMwUDAeEzgAAKCRBPg4y3JqCoFhqY
AJ9XaocRc8QsdRtLa17x6DRTPvUEkwCgkE8NaLHnYXtI3fSlv0QIO9s//qmIRgQT
EQIABgUCPkGUsQAKCRDwJO+CNVGeqEl6AJ9kAk5RKEbYfC1KmMGR9jiZgfRylQCe
KrhgE4mRczH0/gfRv4Q410kSPuCIRgQTEQIABgUCPkEWygAKCRDcNnQ35arLNExK
AJ4npmE4HzSiX9hRypiUrpvFiAV2KQCeL1zn1FXYoHJb9o7QxPZPorixJyWIRgQT
EQIABgUCPkFcSgAKCRAHJZTVR7A166TAAJoD4/EEobBLgMWcyjBkzzsQt61CcQCf
eDUP4YPiXnOMWEHb6niniX2QMh6IRgQTEQIABgUCPkFcXQAKCRA/V8xvnmt231O1
AKCUP6yVSLTUYArTYUDhbOtSK2EtpQCfS0jDuX3itbNFWAfY3IY1sBNJAveIRgQT
EQIABgUCPkF1zQAKCRBBGPb8lSbpxfkTAJ4tO5Vy+EQue6JCYXIR8Apm9ox//ACb
Bvt28q0wHMHKDRn6F39wutTcegOIRgQTEQIABgUCPkFzRQAKCRDQ5Ee9ESjyXz+K
AJ4lZEVUWgVtQdna0Q1pvBLN/wXpMACfSSGBnPibuFJHmk5WAcJ0gExg4XSIRgQT
EQIABgUCPkFzXQAKCRBrphakwVE7DH5IAJ9pLWlp71EvtZpk2KEvSceTQDX6swCg
sMVAUl9aS57pfF0Z/bgDjsLdTUOIRgQTEQIABgUCPkEMYQAKCRDHON/LNYa6cfMR
AKC66PdcgDznO/cpgjHPU8h5f4/9iACdETmErSDKXiqZpIR7b3RpXMaO/72IRgQQ
EQIABgUCPkF6lgAKCRBueUUCoBl5wGR2AJ98AT0VpUCAg+qzzzT9aOuN42y53gCg
37700zFkeQQoKMM4RRMnjNwTwaSIRgQQEQIABgUCPkF6pQAKCRCjGM7Esm5qufhS
AJ9qt0EDKCtGjnXJqE+erVgLtbt2ogCdHke6r3Zky8VQFgh9fdfpiBIeV0GITAQQ
EQIADAUCPkDKfgUDAeEzgAAKCRB1E6I2ExAs9WO5AKDnENHrOy8mgyRfgTIbMaHj
sHKb1ACfWcSnEa8ABNE3v1mWS4zrSCAmBzqIRgQTEQIABgUCPkKmEAAKCRBADB62
okjOY9vnAKCWd3f7VJFj3ffKNIqM63buaBFWagCfbshGLwLcdDyNhGE+aF16xY99
neeIRgQTEQIABgUCPkQyogAKCRCwxLn3mg2CqeOMAJwLwFHjq4esWWMvVF9D9PUe
7SZ5UQCdEOo13vMqocdwfRcKsv8gw1y4B9+InAQTAQIABgUCPkRPHgAKCRAS6T6J
P9G2taeABACXK/ImUOOyX019EStwiXtS1HguI+Z4TjPJrxlSFWu6vdE+DhAREDSr
OLFKAAmgHN2exOYGzJy54TwB3+Ka3FWVGicP3v0atQAmqkvF6v0z/LMdm6NNMOuc
Kgn2L0aT4jEUwXuvC2+YNDhpRXnpNQiDSg6BYwpkuJrEJ77QZtDNCohGBBARAgAG
BQI+RYMeAAoJEFv8diRAZaHa9YQAoI2Zih3rCykaUGKYBWvLS0TqawPCAKDboE5E
U8y4Q5uRvqEfwIHxcgOc7ohGBBMRAgAGBQI+QY9dAAoJEC9KXfQQ64+oHEUAn2wo
Kp8h/4YDJtM9Dnnoc+eXcLJuAJ4tWRDvtGyVAAnBP4tqRCUrWGuENIhGBBARAgAG
BQI+RsZ1AAoJEJ71dopqzj+soRMAn1xrXwJJyYciiAa/UPfE0Vr9bhxZAJ92lOJS
Hwe1fjxJcPv8eYYbYU3FeIhGBBARAgAGBQI+QFwRAAoJEGoCMg2CoDJeZ10An0mx
yh+/gaAPt7s4yHch7b/7dVErAKDDfVJBxaLinkOYKDSXYYWHGZVH4IhGBBMRAgAG
BQI+RsY3AAoJEOpKzVz2XGjNPxgAn3h2DoQFHXt140bwi9SR7SKDHcMqAKC97iDJ
Xt550JBePnL4eGJH0j1lG4icBBMBAgAGBQI+Rs/1AAoJEEC/HpEdDdC5pVcD/3UD
+r2NORap3l00GJgf63ljEgRH58o2u8909YF9BokreuY3s2mm5p8wljqe/4HkzLgK
MFofakrriI71hYLwrxF4WHEc8jqU1m3fKTcRSFhFRkuAUJiiFwyMVLUdC9XJELZR
oZhAl8KO4evsBisQPDQLgGYFeRfBUWvChNc/eiJ6iEYEEBECAAYFAj5H0HgACgkQ
EMun3/wGpS3BbwCfajF2ODH35UF9TQS48rWxreb/Dz4AoKuT3EUMOUS4RVWj4Q0Z
2UYmF7tJiEYEExECAAYFAj5IZ7kACgkQmpTNb38U76TgbgCfQlKPRZ4RBZfWlSjX
B20sJlbYSUcAoIjHZYrroyuwb17VTh81Uf2iBip3iEYEExECAAYFAj5IaS8ACgkQ
v7s1Bo4lI/2YkQCfR6M2yrdGc+79fKnSQpiD5sn63B8An1zzPpAh5HHqdtW01745
j362VSmniEYEExECAAYFAj5JZJ0ACgkQ3uEZ6Jp2yaOK9ACeJ2bfNOX07BwChMzW
UCZNyTS0h9sAnjLV+ObIWS57lTNwGdbVMPXgplBWiEYEExECAAYFAj5PlXMACgkQ
cieKIj7SkS6LzwCeJPx3d2X5PXxmAsVIwF80r67SMhYAoII7hB+XhLyHAT5PW/BQ
pCScXc6MiEkEExECAAkFAj7wz8ICBwAACgkQDbEkl9DbWrbO9QCfT4U7xi30Vt0A
MPo8H8c0Lba+GWkAnR9vF6/1TzSu4EagOAtCSAIaWOd2iEYEEhECAAYFAj8IRKUA
CgkQnIUccvEtoGX6CQCglL9GYYqEZbyv5dny2bEc6xNqj00AoK2EyoGeh7/cs29t
G4vEa8anP6QDiEYEEBECAAYFAj8QSoMACgkQ1vr63ZUvP/+aFQCgrQmu2/c478cK
KjkPMrlCzdZx+NoAoO5J+QmjnQDUekLYWwDB8i3TOsieiQEcBBMBAQAGBQI/EH+U
AAoJEEAGFQ5ACertVIUH/Azn8fXwLlzayHQT3wQVmCHw6YfrZApvwVVLoeJI+8a6
M9jpoNqNzljPNAeTjB37q7dlZvxnzFwl4BotfPAm4ngNUwXwlmKv3K+KEcvbRofW
Mx/zJ8cn31LELBKbt+Qllppj1cWXQ5ChdOmGTu6lUPQLcwkh+e27DXHgf55XwuQg
TtrhGQ+bq6oJags1XK2UHF2tByX9uZC/hLIu636ihUCglVWHYuyNhopQXiAT4sVf
t9I7W/e08tqAwmk5iuMCYEcYh1sKg2JuceGyekW5KYGigZUEfpN3RYD6zuHdviwW
QuZB1Xwq+Y1kkvYS1xu6QPNcVsd/CG+FPb7Vww0bSxOIRgQTEQIABgUCPw2/zQAK
CRB8IsOfgHrFOkY9AJ96QFRLl+sl+pFfu2JJave2fV649QCfadnfBkTUPA6StFMA
EDWvJ1ICzySIRgQTEQIABgUCPw6kogAKCRBN/6N0Q4ZdAUH0AKDp5kvDex6HCAnq
fmybUAR9whYLQgCfbKFsDSX+qZL4Qq2HvUliDmwKJw6IRgQTEQIABgUCPxAeRgAK
CRDhhSLXfHEryzoEAJ984Gzh3bKTkdDH08s2SWAJkCMMkQCfRNjYGcZNIUzYue/1
7APruMSC5R+IRgQTEQIABgUCPxAotQAKCRCzNNMIli/S3m98AKC19CVUObRp4qR2
JkYj09bxYFr/lACglnLd6Gz/LyTPGA9rvms+3KbIkcGIRgQTEQIABgUCPxD7LAAK
CRDFwMXHIY0Y13QlAJ4xY/2Y+xuXIBbqhZl6Y+Jx7ZwS1ACdGIyyvrlPboGw4lqv
KgpGA8TsLh6IRgQTEQIABgUCPxFJKAAKCRDqIZlBJHfK+J6bAJ4geeSsc4JL60AZ
bkM1YN7A7FZB4wCgoiZScishDdFGVjb+QrBzc8sXu2eIRgQTEQIABgUCPxFcuAAK
CRAZ/tg84r6jQUSoAJwN0bCkjnYRW6DWGGZWqSO8glSZCQCfft+I/6HvKRUuRdGf
29xsLRTFNjaJARwEEAECAAYFAj8RQWQACgkQCen5CopyTkXXDwf/QiR+bCozEnSd
Vi9DlLAaZzp7S8g0Vp+5xSd8e6Jq4/DqjNPx+r7Z6VtPt0sjcPb+d21NO3G+/wWg
IfNc793nC3ICFVMb7oOiCLVZIy1N3gOT4hDB8p8lRxkfGjxUzHsMMAZi3Y2iGYUo
jECY4N/mJC3UtJEwOKIAowkeB2U/wfHltDEaTI/SzbnkHykOChGIRIeih/E1/lA1
q42ID3Zjsj2m4lUWkT91bb0AoZBlO6Ok01MC+2JgLUG4fBl36+ZsG28P8gv13SVy
55R78N9A7tuUtITJ0OYTPPhlsrc0gFSGbTmY35pQtdsZEc5QkTO5E9pg47al8+hq
s4MuStvIN4hGBBARAgAGBQI/EScLAAoJEPVrJqOmOZ5zz64Anj3t4jqCRQVOEm3T
RuemkVOyeP83AKDHv8q6JjDeaEIi9oHd7aNTAoYTM4hGBBMRAgAGBQI/El8bAAoJ
EKCQ+9OXGZ/Du/YAn129Pm1Iqj4Krj6OUM02FUP/79EjAKCL564QetVLIRjdb7dt
mt+z9R0Fx4hGBBMRAgAGBQI/Eo7JAAoJEFZtNizuCXfoB4UAnAl1zmeSu4RDdxlb
mqwZ5FBYW49pAKCfoRrxG+zqOPJUxiRWM7KL5QvabIhGBBMRAgAGBQI/EpRGAAoJ
EI+5mXFO6zHxS1oAoNu5slCe2MxIcTOGSDq33CWkDB+eAJ9UvHRA9+FEL6QnGDDa
f7cKLXGAn4hGBBARAgAGBQI/ErtaAAoJEEbMXGPzGKVqBKwAoIWVZi26MWxq91G7
ytgdk+IAo1ljAJ4oxOjd8ktAxzpngemiQba6fcODhIhGBBARAgAGBQI/Eo1CAAoJ
ENQ8swWV/so0IGsAoLgQbXksT3ky1H6PZT84riVZIYIhAJ9fhEFvggy+mk1c7Q83
F4siBXPdo4hGBBIRAgAGBQI/EvrmAAoJEL9BWVtzcqKlY/EAn1jS/jDdL6Jt22bf
kEumd6bXkybmAJ4k1h9wjnMJbO1e77abv/qEI+SpWYhGBBMRAgAGBQI/ExELAAoJ
ELmCy9XA4x8d5moAnipVnLkzFFinxEI5FPryPZIZOSPlAJ9nL00dJBHPmdq+/aNX
2uiG9o2vC4icBBMBAgAGBQI/EyqqAAoJELRrkjttir5xzgQD/Rx6E+XnZYugX81T
gusbMr+3Nqvidy7sRITxcpdp4P/KEZ7TqgDYPiM2pcndmJ4H9cGgYjdOQPCXBnT1
bgt8YrPR17UaD5SEHRHkCSrq+kArqhXzRyi1fHDp+y/tuW9LYwQwJtADBlzewVJI
lAu4i/YhYnrIbqSslK8RbuPMFGSSiEYEEhECAAYFAj8TLZsACgkQNfZhfFE679nk
3wCeLdsBGmcMlV2/Fq5bvg9n3sZEib8An29knbRciT9i2YiYFHy3biaWWeT2iEYE
ExECAAYFAj8S58IACgkQklW9n+aETbmJFgCgsX2fJUE0P1sSyBNv1vGns5SsZyMA
oIHA4TSpCkuIBkXuw/zccPUsK8ZEiEYEEBECAAYFAj8TQ0MACgkQrews0RqVN+dj
oQCcCt3DtSKMn0jxKoFS2yNKFg/fwOEAn2miXA/DS14nMD2/8Xo+twofkN9xiJwE
EAECAAYFAj8TXYAACgkQ722CQfCBGV2UugP/Ry/90QFKOTobYclldwH6/Sz8FbfW
cv+7MehDTGDwpdaEDEBpBmcQOTgSAX58B8Pp+pCxzrMBMj0+X4IKOFGxv3qAVqgg
pEdYwOOAAFIuL7ZijYd5dzIE4js2D6CT2L3hYFoV0e3+OtJ8cZTSliRsdT/FZNnm
zM+3T5Zk2GzSMf2IRgQTEQIABgUCPxGixQAKCRAoxvVrgXw1aC/4AJ96fwHv2e3+
UfXBq8PYyVhfUlyRHQCfZwSwcBi72xgw48PYLUnrtJ4d68GIRgQTEQIABgUCPxQj
DgAKCRBRrPatdb6Al0noAJ9YIZEaWBg8wW3eaufla8kBM/FkjQCgqmKGpsT5MADz
sQPYnVmKOPczbfmIRgQTEQIABgUCPxRZnwAKCRCELNt6RHeeGLS9AKCGcRi1Ga3I
jSTwa8Ixg+NfqReVQgCfShNW3daI34t7bSXgmN/hHZ6mLraIRgQTEQIABgUCPxRS
GQAKCRBYKVdQBQCDi8ojAJ4h8c0qO9HoaQ8mqFKA9qVBSIB9ggCgs0O7CNw39RtJ
a7iPBSGikcpQat2IRgQQEQIABgUCPxRgmwAKCRB3+BUzuw7ox2t4AJ9QxWGJLAbw
NchwY3fZGJ4nSDcqqQCfS/yf2Of/6auZaKWcaM/6oTMMzE2IRgQSEQIABgUCPxUO
mgAKCRDVTq5LyZhwscJ7AKCbv7SLVqf2T8EapBaReRaL5NcoNACbBqnuJh8Pc/3t
48Fog112zOqkxyGIRgQQEQIABgUCPxUqvgAKCRCJzUshYHVZ5uKiAKCtW4l39m7T
IqF8u8pfqkgpz8Z2DgCdFiBCMi/FyPfVULc//LVKwwcZaciIRgQTEQIABgUCPxUq
9AAKCRDTW7yZvH0CCv8DAJ9hWSxUcOEVML9AaFJ5+3fkXlUSaACfRyvdPSRAHcfo
bjdv8BmWsH7WYJKIRgQTEQIABgUCPxVegwAKCRCe0HjvSzoTXFEHAJ9s5QrMG7TV
B7mWxE+O/VwCRKNHOACfYuq+wytbP9pFJkZQwX1rW0lWgvuIRgQTEQIABgUCPxVe
hQAKCRDwI/gLJoQdW+9AAJ9VvvZW5R7ppcZfYrJ1SZChveCnvQCfR2sWHPSbzGrp
sii0DbkB3x4GE6GIRgQTEQIABgUCPxWL9AAKCRBTtrgdwTzuB+GUAJ4yxAtvBEqG
tDKsySqR2Ywv7xcRzwCfRQBmGdzar/OeLVHUziwduAoeShWIRgQTEQIABgUCPxPz
IQAKCRBL7yYkIt9Ah2GWAJ4kpQG83TGrnIR0p6Web4T1QZjBsACgiBqEfjSGxngU
cTRrQxx/bs8TX6iIRgQTEQIABgUCPxPzKAAKCRCVZB9rJT5Y45ftAJ9fNjIStddg
GjgMs3jcGo6oak8QjQCgq4Q7ivzJ2HJUawLk0hOM1p8BT3eIRgQTEQIABgUCPxXW
bwAKCRBBufToW3E98CEaAKCAodx0EjodNg5VE5AF3oPAVPlZSgCgrIh3fheMXgTy
32bqzny8BV5yjhSJAdcEEwECAMEFAj8V9CqGFIAAAAAAGgBjc2lnbmF0dXJlLW5v
dGVzQHBlbmd1aW4uZGUiaHR0cDovL3d3dy5wZW5ndWluLmRlL35iYi9jb250YWN0
L3BncC9zaWduaW5ncy9ub3Rlcy5BNUM4MjA5OTE5RkZBQUNBRjQxQkIyOUI2Qzc2
MTc4Q0EwRUQ5ODJELmFzYyIzGmh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+YmIvY29u
dGFjdC9wZ3AvcG9saWN5L3YxLjEvAAoJEBmiaAmIOP2URR0IANjcbSgJNDnmGxUg
lEcaoUk6QEeo9iNa11OJP4+Uv1XXEEbHiyWpvALvzQ6v7Vwhofo2KGLVCTEhZHz7
MVIl+0c/zbCd7v99iOPySRRN3DhJvqPnD22Kc2KTM7WknZSW2WOKd1fU29vENFr7
7Z59UPqiB55zbXIobObbJOwu3x/vRNC/5bE4t2H7zLNRxmeNKt3S/ch6odJdCM/B
lYy0Df2REc2s2EVLcOYsL+RXwWQp33BFt4/YqmGJQUus2nxz6GraY4J925p2S4Y7
3RcTDcWZTAeexwpxHSw4VmJ5Vupa9Jll/vAdurLUVCDd4Dd1pGJAnsHsLqD5/zdX
YIxNST2JAQEEExECAMEFAj8V9DuGFIAAAAAAGgBjc2lnbmF0dXJlLW5vdGVzQHBl
bmd1aW4uZGUiaHR0cDovL3d3dy5wZW5ndWluLmRlL35iYi9jb250YWN0L3BncC9z
aWduaW5ncy9ub3Rlcy5BNUM4MjA5OTE5RkZBQUNBRjQxQkIyOUI2Qzc2MTc4Q0Ew
RUQ5ODJELmFzYyIzGmh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+YmIvY29udGFjdC9w
Z3AvcG9saWN5L3YxLjEvAAoJEKseS2BGdWse/3oAn297V8QlgeWSsvqfNYPKpqWp
OGRhAKCIuuT96Pn38WtlGOBa7zZrECTNvohGBBMRAgAGBQI/E7DoAAoJEOfJ26/j
Vu/ApXcAn0Czyiw503iLkF53c2qHJ2HUelW7AKDDiDT1zAGHdsdcaH9svMxWOa0l
dIhGBBMRAgAGBQI/Ft47AAoJEDu/z3e9iwUNnssAoK6lcUf4GkqjwYYqH08P1J+r
HaJHAJ9c9pAx86VmCaV6wQ26cKLBKUNdgohGBBARAgAGBQI/EaO3AAoJENAZ9e+Q
J6uIx6UAn11HUO9dUXyAcUXqx8lyaEa20cW7AJ9kMTvSqDHkvci2MhcUkGzjpUv6
xYhGBBIRAgAGBQI/ERsxAAoJEPS0sMx5fr+r/m0AmwT/dtstpPJs7wEOejhbgGqm
vc/PAJ9Ynh+eN+noydvRINXMXigzuuoX1YhGBBMRAgAGBQI/F9G0AAoJEJEfSuaG
oRjmlD0Anj1mLd5E3VlkwvE2/tjgs6fQ7Zy4AJ0Z7vIFQjFnMIGJwhFqYsLbKsy4
+ohGBBMRAgAGBQI/GE0WAAoJEBp0fkUw4LnYvPgAoIUWj1ZA98QOQqcjUoC2XYom
fJl+AJ9O71OiZXEgbccf2oQeY0B9mD00IIhGBBMRAgAGBQI/GX6nAAoJEGZmcXrb
g1Z57xIAoNUVFg9YL70dNJk6t9ktEEjzb2QrAJoCbcLt/dEXOcWXWbY6hDrpkKro
oohGBBMRAgAGBQI/GX7LAAoJEA2WS2ZXDm3qO3MAniLwLC8Yy9QYRDWNfPNgkOhO
L9lVAJ9AL3wmTAeNsmupBo6rUaw+gFw4sohGBBMRAgAGBQI/GX74AAoJEE4CrK4d
1rOArlMAn31ZFiAi9SPYMbK4MUgJjmVvF0znAKCPp7dwDl1Xi4hTigwPlgC+aqvF
o4hGBBMRAgAGBQI/GNSkAAoJEM6KedeYAW3H84gAnAu3PMqTcX+JptdB37ZOmijC
gihkAJ9ENGWYLfe60LF5xG8/57lUSswxQIhGBBMRAgAGBQI/GvN1AAoJECyYPlrS
ilXWFAUAoNEZuH54IwKv3HKqwdTb5DL08dJvAKCVsuNiCCrAadVPkmIPOHcC7Xpm
lIhGBBMRAgAGBQI/HE8FAAoJEHFe1qB+e4rJehgAn12rQA8HsCAuMgIlZfE4HtGe
atjYAJ9ceEBHVmJxsAF3FcCr38hxW2PwfohGBBARAgAGBQI/FbTNAAoJECole3fG
NyjSnukAn3LkrAAgqj9XTzCauqMRDJwY0EN+AJ4pUAViilJ4+l0xkiB8G6w9zBVj
mohGBBIRAgAGBQI/HGcmAAoJEMgPdFmtwp7NMGIAnRZpcoAfoNrvzFIoGcY2d1fu
9GTSAJ92cH6IuV1sargAc0JD/vUrzQpfp4hGBBARAgAGBQI/HanrAAoJEIsCZlm2
jV9/Sf8AoMAQDmyuP/iKKZERTcP02ZCXv3JHAKDcHVMd7wFzEZ9qNnJuUEAQ6ovZ
uohGBBMRAgAGBQI/HasEAAoJEN56r26UwJx/7UEAoMz4FRCmX3fCjNNDk0gmwLYQ
c40RAKDjnf8D9EUTbvCCJvxQ+O7kEYnnM4hGBBARAgAGBQI/HaguAAoJECjdsP0Z
yba6H7MAnAvGz3+gipApA92/b+SK1uVpFGwsAJ9yH+kNzOTDXwo175VGLAmURBWO
LYiOBBMRAgBOBQI/FzFmRxpodHRwOi8vd3d3Lm1hdGhlbWF0aWsudW5pLWJpZWxl
ZmVsZC5kZS9+bW11dHovc2lnbi1wb2xpY3ktMjAwMy0wNy5odG1sAAoJEN6Fg/i9
v+g45T0AoMBLmZPru2CgFojMenlKza7YIMThAKC4Wiu1jnPKUwLOp5/MB2MvmHx/
RohGBBMRAgAGBQI/HsRyAAoJEPhZkLAkiutz3TAAniyoHpHInn/2jUtEPN3jGkCN
6pD5AJwKClQwZX+WmC4aX+jzP1zamQa4G4hGBBARAgAGBQI/HoSMAAoJEG8ji8JP
2loMBSwAnAvu0OawaAa/YM3/4qajHNr+X2JnAKCGtUpISQdh/E/IrZ7edx/qUnE6
+ohGBBMRAgAGBQI/Hvd7AAoJEDPN5fiITHpBKh8AoLE1re+oa04pjBTtTf3/36Nl
gcaSAJ0QbazVwe0lBE8ETg50Kg49prwSdIhGBBMRAgAGBQI/HuFUAAoJEJSbJewH
RHJSjP0Anje106ckc1DIxXY1P5fBawny3A6qAKChKf9GrwfT4n8KhfofgMVIO43M
gohGBBIRAgAGBQI/Hw1YAAoJEOdNKbgr4W0BL6oAnRnMjBLoSTryzhH9RbgEvzqP
b5TNAKCNwTLxRmyFK0ggzoWc54Dj7vecOIhGBBIRAgAGBQI/I5jRAAoJEBigzI1X
BqS0aykAoM97S+RAuCp1fMZwVTKxpeRmaB7wAKCoq/P79PiPTdc1Dx+jXWsZJuE4
IohGBBMRAgAGBQI/JXRrAAoJEPK1Kl0KX7aHiREAoJCYlW13RsXkN2h9+wnnxfxH
NCm4AJ48N1o5SqnLkoH1RbaGNSCLzemZaYhGBBMRAgAGBQI/JuGpAAoJEIkhtdzN
FaiDH+cAnRQdXLaRinzhypYKixILJ/kqbM1FAKCD71d5zuec12xpIdpTIGSHS//X
p4hGBBMRAgAGBQI/JuG0AAoJEAcXdOAA2M0W5HAAn2nCP4ChajePMo13UgUhBAdj
WEDcAJ9OxZ8RWnV4/woi4cJzI8ecYdZKW4iNBBMRAgBNBQI/J8icRhpodHRwOi8v
d3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9jcnlwdG8va2V5c2lnbmluZy9rZXlzaWdu
aW5nLnZlcjEuMC50eHQACgkQpHnNxFq0YGqQqwCgmC3Bor+yZOdWCVMPcU4UJwme
4nwAn1ogianeyFlIdSmXdVyAKZCI8yDoiQFjBBMBAgBNBQI/J8inRhpodHRwOi8v
d3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9jcnlwdG8va2V5c2lnbmluZy9rZXlzaWdu
aW5nLnZlcjEuMC50eHQACgkQ+Xz54zpLf10zZgf/USp4QHtIfkjZzwcTZ9A8ZshL
o2F/+u2E+rs83afTmFHPZWVQeQOakPceaQXkHq99yVERNTr2btJs17LroQDg/DRT
spuMOnWpU1HqiaFDsHXJi0/An2aDg51nEDzzdiH/aIL2B9rQAk8ZkdaOEns1VwdI
7pr5gBW3DGwIwMxkIU5bagzuTYe/DYqwQr1WJgdh30IaX3N/u/7rLnGCkkuoTnPJ
pSLHBdnWCnXvS3zj7Ky22Xi2YdQSGxqvMHvaPp2vvwUFLC/plnyZFi8SpEptncFY
gohdU+awfkZMLWs2lJ1uQmb6Ce3Miw3k3DYVrGsKSF+S0cEfCyprlPjPG8e3oIiN
BBMRAgBNBQI/J8iyRhpodHRwOi8vd3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9jcnlw
dG8va2V5c2lnbmluZy9rZXlzaWduaW5nLnZlcjEuMC50eHQACgkQeQV2j3WE9dg3
qgCgkNm7eLMfVxKfRmxc4KAYg2Z09W4AnRSC551xVi3FQAiT1MK4AtAzsP/FiEYE
ExECAAYFAj8nyMIACgkQ+dAU8DjJhY390ACePZsJNaxFOT73pg8KEoDXD4UxGMEA
oNvNIjre4i2MZZbM0Wmhft72hbxXiEYEExECAAYFAj8nyMsACgkQXQ9/SeDknzRW
xQCg3oqo0keERowG1CDWB61hzWVzZbYAnjz59v8q0it2nMI6bdoW+k5cexb/iJwE
EwECAAYFAj8nyNUACgkQG7CLvyqSMiUw+gQAmw3DUvljjS//6vm+fqSQoOiNoD1e
UwCM88Ug3tacEEuI6/mHTghuuvnuJ7Q/PbIxmJEFtNDMCAZV3zto8+FjuoI0DiaB
u3xdn8qWQOn662XZ6bNvS7eog93fk+Hxk0LWocw0aEu2pVM7FNegRsjzx9qtzkVq
5ow533SVeHBkqJOIRgQTEQIABgUCPyfKvgAKCRApvl0iaP1Un4bEAKCWhOwKmCW4
jvrqNdkAE7IQZhe/BwCgiLRIrNBxcRXUj1bSFg78IbgSGjuIRgQSEQIABgUCPyfh
MgAKCRCfzyzNPz5kJvp5AJ9SNJGpZkQ/6j1+Fmde6tmo3j3APACdFSsB5Ydr1lVo
JlIx/hzh5cRlzhyIRgQSEQIABgUCPyheRQAKCRCWJIPhVmLHNLs+AJ9E2uMLZOqL
9YVFPi+b5fw7hijHVwCgnXLQuv8mfVjc+j2Kb5FWmnlptuKIRgQTEQIABgUCPykS
RAAKCRAC1u0h4yxPS45aAJ91+p06ngZRvjfEXEBLD3P3L+NRyQCgpHNju63uXD4k
tz+IDW1mB5tKQvSIRgQTEQIABgUCPy5JvwAKCRA5Ig1uDBr/u8XoAJsH1kfPDKp9
K5QF8+CQMdbRfWsOlwCcCwJvCLfXTlONYE57Ymm14pKrEaWIRgQTEQIABgUCPy6P
mgAKCRDKDhacKPo4im0HAJ4wFWktr3ddxLyObSvsgTWkvWpIEQCgq+2w2ZcTMaZI
+9DORKLz3i7XaFKJARwEEAECAAYFAj8wMdwACgkQC3gy83PWLUG+qQgAjlu0+Nuc
UMGjGsjAzDj91vdQQSY3tnr5xN3Q8ThElsieaTlsktZdu9FBe6yS0acUnQ1TvXlD
ub+KTpc3AJmG4dlm0EhHtK7Cg8l416jZ+zNFlIitSdY7mZADS8LLVOkjPetpPVol
R/o1zGrLO3XZhZ8kCWUXI7DyVgz2Y+VleAiD5YkZ0jqEC6JQlbQf2fpyQdqJnCgk
86oHMAG5u3Ue62mn2OSWBGYGS4FP7Kauap+E8HnRFz0yMPhBXGkxy6juoMz1y9WZ
CaDlsMZ+4QjRLuj+371oZwNeL5IsadEfiFmgE0pmrF55dzELaUQx+9cmN9d3YCmj
nijFrYNUWHZKQIkBHAQQAQIABgUCPzAx6gAKCRAZq6/sHbI0q3zSB/4gASNN4W7l
BSyZ9hbzoRlVoE0UqQr6U6OlOov0fkyGC2v8pYmcz1M1Cbjjq5G68cd+qurDzqzG
4Qj4ZHI1rSwQFT8T68owL/Z/h2loUn9rpDZEBts2Vx1lUCa05t+b+znFtGjDgZYT
fhMsd+3GQg3nx5E2rMfnyj+bSlNLzyvtBbZ4KPQshEBvn8YoUtZtnQFGXKiVRULF
tv/laXPkxA06e8pwFshv9ZcVztM2JrY28bm4AeIxV+lXltXzuRuhaNIQk5HMrQpw
zOyNqLMmk+AsHV1aO2LcTF6uILyS73/T0cXpnnUXfMooZ7d0au9HCqawssGqL1e0
EoDj5fTiXx0AiEYEEBECAAYFAj8wMfgACgkQeF8wZf69S9yHpQCfe5VHuI3+Jd3y
QrO2Y1GdG4JX+38AoPfazoV9u8oHnlT8xFr83Zif6IQFiQIcBBABAgAGBQI/MDIG
AAoJEHw5el/KZtCx7DMP/2aRTGoRvfamj8ruS+USMF/jDl6/S6AWvsxIziqYOmh+
fv7CsqJL8h4yvoDcAjQcm9fEOguVhQi7juWU5RsrFHzAjzB8Pts527S7UZlnSKUs
SZLq6rINSu/LvXjXFDErXyPTQWFPq3k+SPbq9zbYjd9FzHO657rGFGM2zLkLSme1
zevAtOZZM4nXXb+lZACnMlayETDG62KBGbpEkyCDx20ciBKnc1O0gt80pb6BZvyt
Feuveqrzjv8llbz0yS8c6WwZCIRSGL+SSk8GMoVAlUnc+n40YzWDqFE2nyhI3OpT
QuukUPkim6YpyHw7U0kKHv90NNKA8v7/AiI6enBfN0omIiAccr2obWhlhbOt9nS9
npXvmCDnC2oOjE145GfC+7FdbuTE6dL7tPbuDhZ5vT8tpqV+9Gj9EJK2H6ztMY5r
ecjgHddf3rbjQXE6PG+/uIoVmjh3Rsmx63clIulEAU8lLwrQbb2CqIcsY/Zl9TBv
sDOV5iuusLrV27LJHvzxNiMnDI917GBQWlsvj0w2LoTdJDCKgcHCJq3v6SOQsqoP
n9ijvj2xZGWoRjUTizy3F932aHPMQhyTUVTA87/IxF61jCvcDCy3YUJ6EuHkuF1G
151efg9w46e8u1+KF38KunEYrwo0sOuU6GU+v79ZFOhgJY12awEulbFn5TGZZ86d
iEYEEBECAAYFAj8wMhYACgkQlYRRoq3PfpSW5ACfdMKPaOquZzmWviuXWfoMFzAo
IE8AniVwalnJp5JljCxr1OWr0PaDaKoOiJwEEAECAAYFAj8wMicACgkQ/Uo43Ch2
DT20JQP+NFxgVD2xrfjN/PCN7ZatwGT4eEe+j7FE4lDYGpYJ830Q57xpxzDfrsGv
fIDVqQezmdVZoGuOECA09sD/DJ8fVb7HtlUcE3zCMk9nMVfhJAe+JLIZVOkVedWd
rwbYtx54TqmCYduaP5X/IlMqSa5HL9lsAgTwCZLr7sOt24LAf0qIRgQTEQIABgUC
Pzal8AAKCRC7xxTRnGfNlrxGAJ4hwZ4KAbBORIrkTlQprQXaTfgf0ACeI47PZfdu
Mn1iZ7Xg4ejlKigPz2WIRgQTEQIABgUCPzflcgAKCRCAdScAZahB7eQoAJ0SZt2o
HMBiSE0gbG+hMu2lJ4nrngCgpEtvcDkdvk3/Qy4JEm3fLR7Cpo6IRgQTEQIABgUC
Pzf4IwAKCRBFwCFHaavdVMhDAJ4rhdl/bKvFlu/ahFADLZTtwR6/3ACeNtWb6fVA
llBaFCOxSBtaICz5W9mIRgQTEQIABgUCP0konwAKCRCPubcPpM/JbgEmAJ9PIP8H
bg278jI1avE1N+C9VjFV2ACgmGrFTHsIWGgFfrw7Sqj/vMmrywCIRgQQEQIABgUC
PzVMUwAKCRBp0qYd4mP81C9HAJ0R3iCefYja6RA+/Cv5F6Wu9alUTQCfW5oZ48dh
YdoS82hxs4YpaESrFEqIRgQTEQIABgUCP42/OQAKCRB54pxgsAY/569TAJ0aMIZp
chsYwsi5lJRIF+NuAxSfUACeNC4MqwSQt7Y7ASJaUDvWMfbsF3yIRgQTEQIABgUC
P42/mgAKCRDGBDxWcgdxN1OOAJ9XMeDw2w6IQsmHJQiSk50HbraJ5gCfZAC78xmU
cUAq6uadZORzKW/treqIRgQQEQIABgUCP45vGQAKCRAKYuU0N6eRSfzUAJwM7g0P
CTUtY/jUu7f/1Xd2cXtc6ACghx0WLvVgrMSZtmfEQhTkW/R+/6qJARwEEgECAAYF
Aj+OYUwACgkQFTlqeTPrBZqT9QgAgkOtXIH8SrLanPSf9REu/P8YAn3B7ko0bwAR
UFLegLX6ZRPKGw12VZclHFJh8hd2J+0O/2cjbQ2xIC9LOznW76OC4lbT1HxrgWD3
2eLDtNlzq7FM1xGUdGXM7XuFLozTttgfwormTstmaFllHN4kmGdcwMJRtW8pjP6t
uLLf7CE6HisrtFK5R+QO+TFEHO+dO748aSoXfO7TT93s6A5MV7YI9oISCBE4rPjP
B5AdHZQ4L/QIm7qiLSl1PGveqnp10x+cFzNzmQiChtMYIINAuMEuuBxAzrMwS3z4
cV8+5zqCpRslbEHPhFJyMXkL2ZJOgAcJyLkIxG/9aL2AqbHDSYhGBBIRAgAGBQI/
j8NxAAoJEMVYWQiVq/UMlL4An280i47DSt+sNxi1OM4cCUpa5i8cAJwJzqUx08nq
7GMTxEsSPZafQBWO4ohGBBMRAgAGBQI/kCDZAAoJEF7HvjcDzgGe4REAoKFoV63s
c/My06+doCJycybMf6AjAJ9V+TcIEGkOdByE3+r0Ys4jF911fIhGBBMRAgAGBQI/
kRkiAAoJEOOmjcqmmNqZMoUAnijL+0qgDAksgXoA3xr3Tk/I4L82AJ0b4TTxGood
FhRNwGCM93EGIzicB4hGBBIRAgAGBQI/lDULAAoJEJ0IqAztkI1q+OYAnAuqbpE+
rJLs9+bpc/UsBFj1ghG6AKDGggzTlbJJqSgxaEvYhv6ahfu9SIhGBBMRAgAGBQI/
lEHkAAoJEIMpe+qmIxHWFlwAn3rI+WFl5+1e5afy1Xx9qLbeOhDQAJ0SokGwXAo1
0QqhxJ3WGf1jjpYhJ4hGBBERAgAGBQI/lW0DAAoJEJUsViNsp2z0GrYAn0rJEMdQ
aDRWKPrqdCacx8hDZdjqAKCLNoLPU5GfK20xku1/dNMpxHmvLIhGBBMRAgAGBQI/
nDGzAAoJEDYCVlOr4LEGS4IAn3PAcXTHD+ulTndaeWCQ0WrmHuKEAJ9HzGp3rPEH
JfZQd+3UrpWd30dzl4hGBBMRAgAGBQI+NyJlAAoJEG2U2yGkQUVx5K0An1lgdEfX
UV1yQ+6tuL6akEVsCW1KAJ9AO9JSGybVAti4LF8Wz/VRtueY7IiQBDARAgBQBQI/
ncHeSR0ATXlzdGVyeSBzaWduaW5nLS0tbm90IHN1cmUgaG93IHRoaXMgaGFwcGVu
ZWQgKGl0IHdhc24ndCBkb25lIG1hbnVhbGx5KS4ACgkQbZTbIaRBRXHQLwCeK15w
ST/D72fydZqlVmn/kEx9KFUAnjWmzOsXrlp6d66eqxDBwac2iOIziEYEEBECAAYF
Aj/MHs0ACgkQoL6dujuIbn2o5QCfRi2oW0yE3L2sc4OTWso1uoWv5ZcAn1/mG+ds
kC4bAX9qWWJXIQeB7fbiiEYEExECAAYFAj+iix4ACgkQ8vvXZt12fkp93gCg533A
7EQLLS7C0Jun0O14QhwwPCEAoNrmvM93m/60hKJSRMy/ZG/qaRy4iEYEEBECAAYF
Aj/TW9kACgkQkdi6ijTVyg2CuACfWPKZQaGJhxec8ZAhelwl/ij1jOUAoLR6i3Ov
uUSuLVjDDFF/ZndakMCLiEYEExECAAYFAj/TjhoACgkQrxRSXsoHIeblXgCgwDvP
keczgmorK6z3bU+p39gDsHsAoM7TELHu74vRESjbvdoJkTyrTztPiEYEEBECAAYF
Aj/TwFEACgkQYb5H+9Ze2NeAEACePETsGDvQX3v0ZWJRSrGqSiDL0HsAn0aobcvD
mux581zlq3281LYA6cnmiEYEEBECAAYFAj5/IZIACgkQzfT3onTsQylJ3QCcDAYG
QikUQF4jHn5PJjXQXUgZMSkAn3ZIoX0rA6Y4fGH5rbzELL12wuJviEkEExECAAkF
Aj/UxMwCBwAACgkQBy76KTKckK4AuQCeJoe/0QQEbco/h5PENyg128pvm9sAnivX
VaV2x/hTlOIw6qER8fG7z9KqiEYEEBECAAYFAj/XiH0ACgkQNQqtfCuFneOytwCf
fIhyhSxYlVSOfu078TuT569qRYcAnRlOh3WqMiQzIuTaQi+Agg2ykeE3iEYEEBEC
AAYFAj/Xcq4ACgkQ9aLWrfOU0PhCnACgj1PXRLZNYXBI4P+Vw4t5wlUCeF4AoMf4
gUUp1XCfNY5CmAC4CBt1YFUGiEYEEBECAAYFAj/XpgEACgkQ/aHb+2190pFugQCe
LOn9kYcdItEqoGu4JOc9Ngtoi18AnRo0XHS4rSRelq+oAMHqSLZS8alciEYEExEC
AAYFAj/Xv9gACgkQcC9qbtgxVkOxSwCeJ3GErMbLA/p6vM4NDYKhorpt17YAoKgO
967C8mLAwv7/+czvVW7WBupViEYEEBECAAYFAj/XoWEACgkQzCIUKbtGVYKX4ACg
qPyYzWRc+5JdIlkpmxMUACnCH8cAnRGKXQVG3z7TB32znSiTm63cyJHsiEYEEBEC
AAYFAj/Yo84ACgkQDq3Sz9XRqj610QCeJEC5udCic5fLfbz9/GAsWyAM680AoILo
AIJhn1PeJhKqKteTaT5MdPpFiEYEExECAAYFAj/Y37kACgkQJPQmYjmxi4EZDACe
MA20l3YUKhPghr0wGa7MnteVj5oAn3hU9hlBh4h8GRZqnClnAXG3qDXIiEYEExEC
AAYFAj/XuFAACgkQ+KSYvZS8wB8izACeMpPY5ZqTUTdUA05qsZ0ErNVm2oQAnjLp
jG6yPrUmwHvT8O17ltWL8CXHiEYEExECAAYFAj/XvtcACgkQAeqShO1JBbuVQwCe
JAAMb7eC56pSbWlNhv9xDu4td4EAnjPJmALDSNQFalSSdbxUV4iBWsmDiEYEEBEC
AAYFAj/XnWwACgkQh11XSMrLwHRnCACghxsOwhJbXBlGXgxvaTPeA1GKM04AoL92
50nCHy2KZJmxR1Oe4DZTikJoiEwEEBECAAwFAj/XiA0FAwHihQAACgkQdROiNhMQ
LPW4HQCfUG3UFks3osXfD4hHkFcRoGJyabYAoM6U8m3qVOwTTfJSNnXFqyugz8lD
iEYEEBECAAYFAj/cWVIACgkQelwNae19I7g7xQCgrtq/h4ozaL3TxqA9D49Odfqk
cf0An0Ot5vzBp7skl9Bp3sgaWA0RgUThiEYEEBECAAYFAj/d5ncACgkQj73eiy+k
MR7NqgCfc/X3fbd6U93u2tD2xA6tK2gKz7oAn3rDEur36q90L53IZP5w5mQ2t15w
iEYEEhECAAYFAj/e/FQACgkQLgAJRlBWnRjPIQCfawWWupHHRIxGwduV2uZxouq1
kz0An0NxU2dfjJILCfYLYjurG1aObzrdiEYEEhECAAYFAj/fLOcACgkQgzvwJ1ry
ljDGkQCeKX8Ar3yFXfwq6h6B4KLd+bzhabsAoIOHzTm8/bsOsm7cbYoeXNEBZQnV
iEYEExECAAYFAj/Y7VgACgkQZzP420x1p2vsZgCcDiGSliKdQP6UUiUca0dzUebE
qbwAoOmSJ9pWaXD4icy8EUkfusBhj+PPiEYEEhECAAYFAj/vPLkACgkQ3zaE8GN4
8xviggCg1s0K3hlt6Bw4PliKTEfs3g0EM7kAn0H/+wkWTSa1xErpUZjgl9vKdB/n
iEYEEhECAAYFAj/vaxsACgkQyQMBxhAreU10HACg2WiblLSaNXyTsQF/zi8CO3Fy
SNIAnRiR2fTN8iibKASxXQT5gLCRiFc7iEYEExECAAYFAj/wRzAACgkQiwjDDlS8
cmMR8QCdFLDD1LshZdd9y++AcXXAd8JFYH0An3CkEQYVMD61/ZDPvzW6SBdeJpjd
iEYEExECAAYFAj/xNU4ACgkQSUvu2wE5EjsiSACglWzNcc+rkv4bWgIW5SLvo83v
ShYAn0r+cbn67GOxFdm905jxAJM+QAGziEYEEBECAAYFAj/x6dIACgkQvBVic1oT
sEhgDQCfQIz7/ZmYWGqn2/wm+tSNCU3E3D8AnAjBgX9jyj4T79cXZjhpaVhzSonf
iEYEEhECAAYFAj/x+gEACgkQCY7iyqpOgLYWBgCfWtVXlPVraUfLDnzlbOMZgXRJ
k8cAmgKnXNFwReO0Bz60WpJnNGPhsA87iEYEEhECAAYFAj/yEZEACgkQ0+ZxvPFT
Y6Gi8gCfXeQNg1avmlYbRCr9Ity2kRbVvAoAn0AGrC5XevRxByhpf9/wKv9trCLC
iEYEEhECAAYFAj/x/nMACgkQifW7lGXJEoUbDQCeLEcBerNwNut03XfWmOg9xodr
YXIAoK2Dq3KnWWRjENnSgl6s/pRF7SFIiEYEExECAAYFAj/zKTgACgkQEfTEHrP7
rjNYWACggHYsjpybsAmKHpayy0b11LiDmsQAn3bEIjIFOAfWvCFxToatp1OgnhuR
iEYEExECAAYFAj/0V/gACgkQ9PcicYLJuilDmACeIgnpFaxO0ZiBBBN1aeiT2V1m
NxIAnRUPWPJwV7dKd3i3c10WMaSB1s/RiEYEExECAAYFAj/09Y4ACgkQ4Wmz+z2I
PqDwgACcDmwo5RkikTERrC+6sTJ0uhdbXK0An2YekNp0yrRguk+SzAhROHEoVN8Z
iEYEExECAAYFAj/1JiIACgkQLst0AlVuMNfGFACfSf4dFqSHOPaaSYRF0ck3fNgu
jC4An2EKObjjVlVj36gmWLRUrnl0Fw/YiEYEEhECAAYFAj/1sWwACgkQnNo+exDK
ny15VACg5gem120WJOG3MKHKjbNoVrl3sdAAoIkZQ6kCVkRpyUL3ov3hzO9xjNow
iEYEEhECAAYFAj/2GVoACgkQKLKVw/RurbsAtACdHa3VY+v+AgtD/Nuvx+DBQxc0
JJ4AnjNUqkn8WIJ5mS0jRsPEhmJ81VdxiEYEExECAAYFAj/5ow0ACgkQRusmgsje
DU0XsQCgiXkZfz0DZ8Cgu0nOkd/I2S2LklIAnRaT5vooiSlsvxq3n31OYeafRc7Y
iEYEExECAAYFAj/8GhIACgkQjO6yWbPCgfQlbQCZAbXll/YNK4GXvxsD/ICWgvVB
j1MAn3EdI9xHFGIqHIJ6KPn59v1ZOFAhiEYEExECAAYFAkAFrx4ACgkQuQ3Xye1h
lT26iwCdGEaXzeUFd/X6OOkncdf20Z5cWs4An16X6Ut6+9owKE1iHJHyjBsZplMk
iEYEExECAAYFAkAGEqYACgkQRCBj41UDsd950QCg2RdqiQ20WSkcWf9T13yIENz4
/z8An1oJ7q4ls5d9+s2UREP9yh1AkeiJiEYEEhECAAYFAkBCeEgACgkQmHaJYZ7R
Ab8ekwCgsH2bZTUWGY+HBimDdY4B7asGzMAAoIjsf/izTitOdz4na4+S7PxYo6B0
iEYEExECAAYFAkBMc2kACgkQr2QksT29OyAF3gCgo85r90z+byzUjM57KXmvESf9
O68An2+u8+AIWxV9+i1agskqPPFdAOgBiEYEExECAAYFAkBiITcACgkQKljOqlJp
jp8S/gCfRmCcHfOoEGZUf/ICbOY1VGTZEK0AoJhoFFGHpLQu44Iq6tZJHZs2ODnf
iEYEEBECAAYFAkEM6rYACgkQXeJJllsDWKL45gCcDJx+4zD0hVXi3ez8BkyXnMfN
wCoAn1xHtocmnkTag1jl1ke/2Z96litviEYEExECAAYFAkGE4h0ACgkQqy9aWxUl
aZBj8ACg5EqhFkBmwZ8L7RvOlHuY93Y63DMAn3fcIDDXcOFCBsAQAbIh573SDq6f
iEYEEhECAAYFAkFA71MACgkQBylq0S4AzzwtcQCggPEERYPfPAEE+z+DvdNPeyVy
ZjsAnixUDnQ8UUuydV7XIeAVuP1wPrmViEYEExECAAYFAkGEziwACgkQP6DeCKDT
kWiWVACfanXL546V4NPJI3z1YAqlDlkUy58AnR2YSnfJdQP4STnEPGRP9uwmmMnS
iEYEEBECAAYFAkFNVNgACgkQSyDnAOeswYdIVgCg0VoGbAdWCETg+AkQsV0dRflg
6H0AoIHQyhYlKCArNqFiiooRj998Kp7iiEYEExECAAYFAkGaleUACgkQXY6L6fI4
GtS4QgCfS+eEP/ntPztpxxXJy6+hTcT2WLYAoJv9l0ngKxapQM2e8HV6/uiz46Vs
iEYEExECAAYFAkHlLtcACgkQ/H2Ek1xrBMkgiACfXIEMqCHfqUxwCDPy44RlfBIS
8j0AoLcEbVKi9yIm9yXnLLyvSP0avHgmiEYEEBECAAYFAkInm+EACgkQX4f0Vv2/
Nxy9AgCg0+fWpsicamBgYJM98yx2UCXEBhsAn3sq76QB4Tl/G1tuibRsFXtUJypH
iEYEExECAAYFAkJZlcwACgkQcBdD8e7nfkWWdgCdFFgUXM5Rww975q3EAHMCZTBI
uf0AnRJeHh71RmqheKknxhV/BLZQO3NviJwEEAECAAYFAkIcKQQACgkQ5RUoJTMc
2l0gAAP/SkBt3+QJ9AWv841/a3OXNuoK9tbJ4ZGQhkGYVqgREYT2WhLQcukCbsl7
hnhj3hIsvFQ2Ibq5OqkDIVFHHIZy8EDNBZpoX5RhzaQMHRkXsf0+zuMR5EpEB+H9
9AaapTx6mmCqrpCYQbRMDX3qIZx7yfm28v9dGJKT+R8fliXr9Bi0M0NocmlzdGlh
biBCcnVlZmZlciA8YnJ1ZWZmZXJAaGl0bmV0LnJ3dGgtYWFjaGVuLmRlPohPBBAR
AgAPBQI9q0EkCAsJCAcDAgEKAAoJEGx2F4yg7Zgt74oAnjGE1c1jdTHTGEYhWgUj
YeHee0U5AJ9cmeMgr5XSuF6B6H4saaaL8C0yGYhGBBIRAgAGBQI9tHFYAAoJED4s
35lZGelGshoAoKjcIBjSAQvs7qs1YPobVnCtXk5DAJ4+aucRPTSAjG53Oi3UufOD
5EMoXYhGBBMRAgAGBQI9tIq7AAoJENSNEHJ4+KjUn5cAn3QIeyeEcztJAG/g0TDn
O9G4Fti+AJ4oKRxI9s+mC0ZKTLxVGNA/VvSfs4hGBBARAgAGBQI99RB+AAoJEKZa
JJONqkR/xGEAn2hhwbXcGFeyaAfu8NAIgewXfofyAJ96u5jnfMiUnI5M0IZ85j0p
CE+enIhGBBMRAgAGBQI99PpZAAoJEN+hCDdk3bohHrcAoJg1hl0wWn36eWkeR3Sz
7Wl+t2eZAKCmfeJTPxD15DuoRzwTHjgI2LRixIhGBBARAgAGBQI99mhTAAoJEIMf
ett9H+vdkRIAniOZxKBze0MfDYjUFqpU8Mkmi/2uAKDXtq7qNVR+8BHyZHzO3Rce
QQzL1ohGBBARAgAGBQI+QCnWAAoJEJWnRNJ6HmtffAMAnRtBAMYtiRm34zmTfkBG
MhPHNXkYAKDsI4vO3pPN4yHL3zg7Im2Vtt8LOYhGBBMRAgAGBQI+QCWnAAoJEGxG
8ZwW/bKYHmcAnRaexQEkpH/weZuhhWFd3k4NfcgqAJ9sIjBlBgYfZ4/K0MizocDV
UYqHb4kBHAQSAQEABgUCPkA0XQAKCRC1rDlKuf8qEQxuB/40ondanrBbsEFNEdnG
HzOZzxUB1hG0jAomkbO3gv79qiTxizq9t8weQB4fVh0AhZ0KJVxeJr86Z4iPSz46
1S2IXRyi4VCdhZ0zWtw6s7+cVGF47egcyMOPe4cESgeJn6Macp/vVwbyf44EJ+KX
9o9Qn0iV2aW/J4bL0fKpV3p8a90LIJtmK2agLk4V3fZMfOPOV+15oytmO4Pmrxum
fcvgpIA5vfqM0dTL+ZpBIWITMU0e85vl+WPx2zok8xt7Ly84hS+gLnRDwrNKYm7G
12viTJOUDg9mcfxCOyV7z5EmVjfMzQbinsatgZ9BBK1HjGak7RfCLn5zmF/WXam7
xF+MiEYEExECAAYFAj5ASuEACgkQlI/WoOEPUC4B9wCfQdt6bD3cg67q6NapMzl8
tVkvwfkAniHumuOtEoPxjxOiz838H+VvlH34iEYEEBECAAYFAj5ARsgACgkQHI0n
ZIQ34x8BWQCgnZQ0SvlZny3U7nM6yPIcEiiBUH4AoMWc4PpBTJDQicAXi1sho54z
wZA/iEYEEBECAAYFAj5AVSkACgkQgGcShyMVr6PzqACg6CVGOLFGtw5Q8sAJ+Ujq
qOFgJ5cAoLqBYBwb8zBaaqZRYB8OK18U18TZiJwEEwECAAYFAj5AWbgACgkQhqAI
GyKylR1OggP/bTrJNeOtMd+C0YdFEjOUvaxLRtXP8ga2rVi5b8UwdQSDTHmtq7iE
+b10Jkgj6eaUhmDyKgknezBIQLRPzu/7aDjM0+3BSPmkW4CTI7UWxECQJwqiCu2R
AnrduAllRG3z2Zgur87l9zoH+IOguERmIfawU3c+VIt6Fj9euNFOgE2IRgQTEQIA
BgUCPkCsngAKCRBiSEuPG0iN6omYAKDnbWbx4mPpI69Wor6B6OOaAQTjtACfc/WA
J38X3O0OENnb/K5IgGL2f6uIRgQTEQIABgUCPkCqFAAKCRCuUcxBI0Z68dlvAKCP
XIuDufIzJSMMljNAq4nAErw0IgCfRt6GmlkPjnhtid3uaJC4A+iOqyWIRgQTEQIA
BgUCPkDJGwAKCRDVVqZgiOPvV8CdAJ48OwRI/e2sAAlBxKC9zRFKg6wbVwCfWSCp
GA2L39tMexAn55CpdKR2K5aIRgQTEQIABgUCPkDglwAKCRA5o8lM/cSo/f/UAJ0Q
dEZSxgWIIwUE4dneT/oDNtIZrwCfb76Kr9o4RaKQjAaHDlViEeqHt6aIRgQTEQIA
BgUCPkFU0wAKCRC0deIHurWCKQ5AAKCRN4ozZTbwVoDDKUE8/5gWpPQeQgCgquc4
oMK47BicU2CzTOwJWCMcq2WITAQQEQIADAUCPkFeMwUDAeEzgAAKCRBPg4y3JqCo
FlhuAKCO0wWTLknRQLNlwlUa8qk8ES7lmwCg+MdIinFHkKQG4T4NveGx3M2sKBaI
RgQTEQIABgUCPkGUwgAKCRDwJO+CNVGeqFRuAJ4vbA3s4Bc1BCMAYE+oxtCEvBqQ
bgCeMDgyFQPET6ZFKZ0cHIeKcJJiHOGIRgQTEQIABgUCPkEW2AAKCRDcNnQ35arL
NJHYAJ9KKBN4skVd0f9eap/dTZLkEz19jQCgrmFeW1esQbrvvrJfndRDt6DlEN2I
RgQTEQIABgUCPkFcTwAKCRAHJZTVR7A165/kAJoCAXm2/WMWCnkeSDGueKYBEu6l
DgCgnJSZhVZvaKwnomv1W1KtlRjl+BWIRgQTEQIABgUCPkFcYwAKCRA/V8xvnmt2
3/l5AJ41iWNVTfcuWAS8nIzzhYTDVWnPTwCg19SZ3hZXkFlHVks4VLGAAiwPBsiI
RgQTEQIABgUCPkF10AAKCRBBGPb8lSbpxbM0AJ9zUihZu04IpPRZPSz9LiG2dgHO
MgCgnrll692/wGopjsYCE8aRzlJuFDiIRgQTEQIABgUCPkFzRQAKCRDQ5Ee9ESjy
X+dBAJ9OroeixjCx/bDMDoBSCYqB321S1ACeJ2H9NHd3KGXZ8JvMELMvmS/RxgWI
RgQTEQIABgUCPkFzXQAKCRBrphakwVE7DK/9AJ4kYBvBO0OKLPbjsWBcZ+F7e7sN
ZACfencb2FyQneCzhX78tjjrWraRIBqIRgQTEQIABgUCPkEMZgAKCRDHON/LNYa6
cUkHAJoD517olE6O5piUrvw+yoZzF8++4ACfWOCLwyh2DEVl+Y8PZYnCIsB1TvOI
RgQQEQIABgUCPkF7XwAKCRBueUUCoBl5wB6ZAJ40y6v+9Wr/Me0lEsg4VwhoVW8y
NgCgj+5cl3eEEX+Ou8vR16ATBdlgnH+IRgQQEQIABgUCPkF7bAAKCRCjGM7Esm5q
ucvYAJ4ulBIZxcnftwKEhfBzSbGNCJyrpwCfXxX7ISVFgqeqkSESFZW+JHwfipWI
TAQQEQIADAUCPkDKfgUDAeEzgAAKCRB1E6I2ExAs9SkMAJ9W5y4x0CHyg8GSL0s/
CUVmJJ6MIQCg0Jw7lN4t3LtFCjScjeDU+IabpmSIRgQTEQIABgUCPkKmEAAKCRBA
DB62okjOYyvHAJ4zV/6Z+/o2g1z45eEWeGaqqwP/5gCfc7Dfa6RiCQDsGOnWNA5m
bwAGnMeIRgQTEQIABgUCPkQyqwAKCRCwxLn3mg2CqcvwAJ42iDFNJbmM+g2Ah7hT
IuBjsey8BACgkCMQxNDIRObSJZD7t1fqO3NdCvOInAQTAQIABgUCPkRPKgAKCRAS
6T6JP9G2tSTaA/44qliNYgOZfKeTRzhDzwX3IRZlVmDX6PhGAHPb1ju/ClUJN+Qs
i1Meq8qOxJ7EmxWdhVaicvPQuSUP/9zKWBF7xT5DOmBFwruK5TB4azgixsEnqTbn
E2Ueqqba74xTFO2+jfj/9r+rNwYxsprNhh1yKV+oClgoMOg18UiQiYWzxYhGBBAR
AgAGBQI+RYMeAAoJEFv8diRAZaHa8p4An2BVlKsaa7mOkTfotelp+kStgveQAJ4y
nhx0QrwelwDFlnMLAb/hJhNwEohGBBMRAgAGBQI+QY9hAAoJEC9KXfQQ64+oVo0A
n0BHI9vdu8OYdVeI8Nqy4O7w+MJ0AJ9cLRVTXawC0XC45h6LxJ+KqiNrdIhGBBAR
AgAGBQI+RsZ1AAoJEJ71dopqzj+sNkoAnAgmXXhMgwAtbLhbAhgVOMFlRRUmAJ0X
Y7tvPh8CFXT6fOb6xf8qozpem4hGBBMRAgAGBQI+RsY3AAoJEOpKzVz2XGjNJgQA
oKfu2aKW7fSiH5z4ZBrPjqA1moWbAKC4GRKnvliFWw7nqg69xNmffHVu/oicBBMB
AgAGBQI+Rs/1AAoJEEC/HpEdDdC5rUEEANq8aUuaMlZ1aw6oCTlFDhxSOu+Gpkcx
grlziYDwKXUjR2OFUZaq/wohbjrJGTGR3DBdOe2NYaTudbFNehl9nfAEAdw1bxTE
rDuDydm96FSYVh4XpKBCdndNjF5TIyT3miwkCyE/AIvWpa7tJVZzwTfyiPpX+BWW
jTpu3Hl2rDNFiEYEEBECAAYFAj5Hr40ACgkQagIyDYKgMl6dvgCg47NneegMxMG7
biK/VPBZDwP1YfEAoLxxEAkHSDkeNBg+lkmB+HlbJaiAiEYEEBECAAYFAj5H0HgA
CgkQEMun3/wGpS2VhACgypTumsugt1rogDj6n9vS403AesoAn3f5F9gcRmo5x5iJ
WRQGkyqDn9e6iEYEExECAAYFAj5IZ7wACgkQmpTNb38U76Q0gACeMWM0+Zlma8mL
sVBYvy+sFl24pegAoICrdVi0Vp0d1S8PlhnLfVBmJkMOiEYEExECAAYFAj5IaTEA
CgkQv7s1Bo4lI/3jBwCfWhLWZlO1s087n/FfB4pC1v4/n5UAn1zTvthQ8iEaXlGb
97ycKkGRTq80iEYEExECAAYFAj5JZJ4ACgkQ3uEZ6Jp2yaN5hwCfVmppO2o1alnw
VuglKbdXjOE1rpgAoJwOiXq5tuE4pSjdbQi/b+8/YMLgiEYEExECAAYFAj5PlXUA
CgkQcieKIj7SkS4XSACfWqEMG5JG2di4ScIs4bBuTC/i7ZUAoI5f3vVGq2ZgjoCg
ZT0GNuCT8yFbiEkEExECAAkFAj7wz8YCBwAACgkQDbEkl9DbWrZlIACfQst10m5i
3W/Zw1IhTGymFHr5lz0An3+3+EQGY4rktVDTvAkI+GOp/qJ8iEYEEhECAAYFAj8I
RKsACgkQnIUccvEtoGVYnwCdHtQFnSIRNHApNkvDCTXjaBvlvgkAnjwDaZGVW2cv
i7HMcnCem6zK0qfIiEYEEBECAAYFAj8QVQkACgkQ1vr63ZUvP/+6cwCg8MI1AMI7
aWXiVHhsevxtmKb8K8UAoIfduASaeW1jfkIQJjKvnSAJCUOfiQEcBBMBAQAGBQI/
EH+ZAAoJEEAGFQ5ACertyh4H/jpXvk+I6jjf6yoHT76hbi7X22fBJoacEJDQr+W3
qESSANtS0QS2ha8e6sIMXvoZb9lCDdGMOOf8v7+h58kpwVzCrwP6bvk5HboORULF
bP+AQnzuWIY5I7URtFviqbZDUtcTnUine5Bnr9EgE+IsT04G4Bdra2tTF8NywrWn
zB7L8KW5fgGEjx8FuCMl3xhHKLVGTAFbGEUG0p7bIcszKmL9skXZfOR2BBwOei2r
PcUkFhVrAFnbYZDOzH0dOU9XNyYC/sciS1uRunhJgbvhlEy/3/z8B+REOTO6SoOW
ShQmVpHF1L+RM2vbgaA7n4Lm1M0fD1cuFFeecOCxr5WbyB+IRgQTEQIABgUCPw2/
zwAKCRB8IsOfgHrFOjHXAKCQMiaglcYaiOJzpMlWsI2g9OUSLgCeMxJubKw4zbte
Ay0EwHn1XOzDkt+IRgQTEQIABgUCPw6kqgAKCRBN/6N0Q4ZdAd8kAJwPB1+MBBya
+I6+FZBA0F6+hwH8nQCgu8br/qRVO/37nWKXcBrdovqMrymIRgQTEQIABgUCPxAe
SAAKCRDhhSLXfHEry8HKAJ4j5xQM6HBjgGS2m6QGiUmNR5dOqQCePZXu5A6YWe8x
eXbi8r6vPwhaFtyIRgQTEQIABgUCPxAotQAKCRCzNNMIli/S3necAKD6pZHPYzJR
QCvCthKRLehSscHijwCgynfSZuATXmj4Dw9ujUs0LwCCoJWIRgQTEQIABgUCPxD7
LAAKCRDFwMXHIY0Y12OOAKDx2DUpUt1R3qsn3sVmLb213OiBbQCdFT21Q5ZVNjyi
0Du0TF4s9HcqnKuIRgQTEQIABgUCPxFJLAAKCRDqIZlBJHfK+O94AJ9Jhf6DOhk6
SNTMc3vcxW6oja7gVgCdESo1tGfX5eNioP1a78vlE9Td+92IRgQTEQIABgUCPxFc
uAAKCRAZ/tg84r6jQV0gAJ4nGDM3FYzIfwc7/OWNGgt/Jnky9ACgr+5vwUI2+s3m
H0mM7oAGKxXzg5iJARwEEAECAAYFAj8RQWYACgkQCen5CopyTkUtQgf6AzTMbzqi
7dNRiblJ+3p4r993zSDGeiPMeS6iM62Ab6yGHbCJWDXS3N/AV3AY31H9zg1kfnYb
hUmIpKnoML1V5vXND2+a0feC8eg6YaFUzATZbA1LJxQgsukEoGPjUutuzHrdTUme
aWEvcEjrqjit32/r2/Ii72IJLp46EUHT3arMe86yyH/ui/SO/kNUe78rgM6QmKOf
KVImKee+0lsU8y+H/v+81YUgxXqFjjpIW1MxFLtuinug53dOYworXhOLKUFg7JOn
Y1OWxdNNLmjP5+hCDvEJeFobKUJeneFJHBzq/x+YJdqrcwRpdP76W4Oy1uZJMTNy
T7kr7VzxhgIie4hGBBARAgAGBQI/EScQAAoJEPVrJqOmOZ5zDWAAn18TasWrwIRv
55y1GIsgYByCbytNAJ97Mi2X1jbcQ9Glyl3GQPd0a6teKohGBBMRAgAGBQI/El8f
AAoJEKCQ+9OXGZ/DEBgAn3J/H+TnOg/+twcFz6qlzvTMx3sfAJ4g2GwIEU4QslyL
S6OLz3JUgyphFIhGBBMRAgAGBQI/Eo7MAAoJEFZtNizuCXfoIZcAoJmG/mmltkyw
EK8fHmc0EV6gyRd9AJ42LmhI63aCOjf1th67+LqsHaZg44hGBBMRAgAGBQI/EpRG
AAoJEI+5mXFO6zHxsV8AniK2jiSurdSQWdixPZoV2eUXulpGAKCYrtNkuLP4s5Ej
cx+54hmyhyRKqYhGBBARAgAGBQI/ErtgAAoJEEbMXGPzGKVqeVQAoIc5qKO5Q6GE
vLUe8dFWWjoPZn2YAJ9LBBPFsQxIGavFNMCtEfaVGICOUohGBBARAgAGBQI/Eo1F
AAoJENQ8swWV/so0wwYAoL0ynA9cDZlRVk1WKRCx0U3MWsmVAKDDkTQxbcVhx4Y4
wNPp/9+bLQbcRYhGBBIRAgAGBQI/EvroAAoJEL9BWVtzcqKlDjcAn07iDymtatbZ
1A4lzxgP9J+LUNKBAKCBmNvdGEgB3NStaioG1ykK38WJ64hGBBMRAgAGBQI/ExEL
AAoJELmCy9XA4x8d2ekAniL9GJ18995gauA8HIZfGs1+AHBEAJ9x4by7OYz6s1p4
X58cYM5EJqRVJ4icBBMBAgAGBQI/EyqtAAoJELRrkjttir5xQ1UD/3qEX2rdoUfy
BnnicW1Wlj9xCzi8tjpeawzjf2lSKW4UlwfSoZvPBTTnyp9gVrtWKI+Ore9pdCQq
qOzbAAjEJIjiWRkRNRSyj401W7nEB0v0cUsxdyh3ajScAdZsG86OpqmLHIPZg2TQ
hdFiBJAI0jRQ6haTY7Vc+3C4kgF4jfKriEYEEhECAAYFAj8TLaEACgkQNfZhfFE6
79kzhwCcCcGP7VtaWt+vXh8i2p9QdJLXFwwAmgMz496wZkvq6AtXvPc3rv4dKRJe
iEYEExECAAYFAj8S58QACgkQklW9n+aETbkOtwCgiV7F6uPAkVhyniYK47lrplJp
WUMAnRrc7filMie3WQ6KoIYMc58AFUneiEYEEBECAAYFAj8TQ5YACgkQrews0RqV
N+eIFQCfZv0mqPt9yfoTIf0iEHFL7+nRIHUAoJHd2euw2J6ivJXwDnYTJQvg17FW
iJwEEAECAAYFAj8TXYUACgkQ722CQfCBGV0MxgQAo/5lTYhqACyuXP6o1yZBTBOL
yOB5jQ4hXSJEefy0P0iIwZGFOxXE1BVfgA272XqgU2wByxFe8BPMrkNdlgoxmgpo
/H1nvcUMINwFbixM3loOgy4NpDSxfg3/i4wrSn6flqJ0X/aNDlUcwaxRyo0XVX8J
WxDPob7rLd/tMjgshZeIRgQTEQIABgUCPxGixQAKCRAoxvVrgXw1aF/WAKCuLcvb
sIDc/yIOJ4L/PwetJqz65wCgv14ZUzkr2byfbxWqB0x9Pe8Z4ZyIRgQTEQIABgUC
PxQjDwAKCRBRrPatdb6Al1zHAJ9HRP0Qei3JEyXz4WwigmOCxGzCLgCdEz0mS8ca
K0YGTruexNKnVz4c3S+IRgQTEQIABgUCPxRZoQAKCRCELNt6RHeeGJgJAJ0eBH2p
BiN/er2jDaR65lwk7GHsMACfXCSInkBPdcRrmDx4qjBVMPh7c0SIRgQTEQIABgUC
PxRSGQAKCRBYKVdQBQCDi0/PAKCUqyyZnTffFI0Cc6XXIxLcSc+l5QCgyKOzD0UP
F3LyejZLMXoE6HNHsJaIRgQQEQIABgUCPxRgnAAKCRB3+BUzuw7oxx3MAKCRkneT
Fl4GmlPR9PimSByE28Z/WwCghDzNUCmnkgwl67jbtpZAJNuSPcmIRgQSEQIABgUC
PxUOmwAKCRDVTq5LyZhwsf6bAJ9P7azN7qGk4buXQ7CIhQ3a2pHb7ACeJSF9Qdn2
8nkdMM7G6u8jb96wBaKIRgQQEQIABgUCPxUqvwAKCRCJzUshYHVZ5tNZAKCwYW7A
KNF1Jl5WF8YrLZdQXqfmIQCglwELvUiyJWOMzPqFR0YPx0n1u5qIRgQTEQIABgUC
PxUq+QAKCRDTW7yZvH0CCpsoAJsHOkTbpuzsvGTvNrrYNPSwXAhvkQCeNinhCKOS
jjiIUbUIHDsOz8sIAYCIRgQTEQIABgUCPxVegwAKCRCe0HjvSzoTXCvGAJ9w31Zv
azal4I/N1CX9sOu/2R/ABgCeMyo5M0vG06uLFkVKidTP0t838QOIRgQTEQIABgUC
PxVehQAKCRDwI/gLJoQdWzvhAJ90ieEwIPKGXlPEmCnLlaCfGAhpCgCg9H/SGzS4
V+jAaEqmSIvltHTf/c+IRgQTEQIABgUCPxWL+QAKCRBTtrgdwTzuByH/AJ9S0n5U
egb5DNIUMt05ImWfQ+uWEQCfTRu3SC9Yn/YGW18W65mSeoGEkqmIRgQTEQIABgUC
PxPzIgAKCRBL7yYkIt9Ah08pAJwMs9tctTxNv/QGhPmlonaQ6ugxcACfcTmKFWST
9tpWQGJYMdPIymVW3+SIRgQTEQIABgUCPxPzKQAKCRCVZB9rJT5Y4xYwAJsEa4Zi
Ib+DJ3f1K3KX7ofvADBQ7ACgkAR1nIokfD6rFzMhfWGCIfmgXU2IRgQTEQIABgUC
PxXWdAAKCRBBufToW3E98CnFAKCH+yj3Fo+mwbSpXoHJmDk9pd+BfQCfXgANpSPQ
qib0Wtteoo2PPtgiMi2JAdcEEwECAMEFAj8V9DCGFIAAAAAAGgBjc2lnbmF0dXJl
LW5vdGVzQHBlbmd1aW4uZGUiaHR0cDovL3d3dy5wZW5ndWluLmRlL35iYi9jb250
YWN0L3BncC9zaWduaW5ncy9ub3Rlcy5BNUM4MjA5OTE5RkZBQUNBRjQxQkIyOUI2
Qzc2MTc4Q0EwRUQ5ODJELmFzYyIzGmh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+YmIv
Y29udGFjdC9wZ3AvcG9saWN5L3YxLjEvAAoJEBmiaAmIOP2UEw0H/RVZqajm10VQ
cFpumvPC/qvWRIxZdQASPdMGKAASqPnrNQmfqHo/3rnU3BoquWWlZikwn22BGkuR
aytvAI+AAyrrkA3R5HgwlIgtCQpTzljJPVEOA261BDlXLvttZipW6DvjZ8+s7QWW
fKZYwbRCm5mcri1JQAmxtjZkK3E1K7yfDL7onLrHDx6H1d0njgN1j5K/82m3e6eF
YOoi0Qpq17yH1HggGXx04rGgn9yaBOTmP0fJPsfnzWo4+GIfmQjfG0rrJhdakRgW
a1JO4aI+goaxu6KSTFhpOnd2Rw34bkQICL6jZC6G4MtVSao0IsVtNiP1YcBbv2Bs
0ueQduyvaJiJAQEEExECAMEFAj8V9D2GFIAAAAAAGgBjc2lnbmF0dXJlLW5vdGVz
QHBlbmd1aW4uZGUiaHR0cDovL3d3dy5wZW5ndWluLmRlL35iYi9jb250YWN0L3Bn
cC9zaWduaW5ncy9ub3Rlcy5BNUM4MjA5OTE5RkZBQUNBRjQxQkIyOUI2Qzc2MTc4
Q0EwRUQ5ODJELmFzYyIzGmh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+YmIvY29udGFj
dC9wZ3AvcG9saWN5L3YxLjEvAAoJEKseS2BGdWseZeQAoIz9KlFMtajFGHN2dxGK
sG6mO3oCAJ0X8Z4DETXm/K8ILQ1Z/pP4RodIP4hGBBMRAgAGBQI/E7DrAAoJEOfJ
26/jVu/Aw+4AoO4wBXNHbVE/rPsMbKPufe7Ec31YAJ4/1ioDRk5fR5TEb+vvXSW8
nofiqohGBBMRAgAGBQI/Ft48AAoJEDu/z3e9iwUNDfQAn2WxsohG5n9Aq43Ct95k
koqBFturAJ9+96R3ERPGKh9swWnJ9rBlkUFGZ4hGBBARAgAGBQI/EaO6AAoJENAZ
9e+QJ6uI8fYAn2tnCEZv5HogN3Abkr0XrmYL+7KPAJ9H4zrNiI2xha68apWA5qlV
LqyHPohGBBIRAgAGBQI/ERszAAoJEPS0sMx5fr+r7kYAnRw1oK6hqhlDWUHxmPRW
VbnYP5NxAJ9GDLHgyWasYFj4rFsBHleIAmu+yYhGBBMRAgAGBQI/GE0WAAoJEBp0
fkUw4LnYihIAoMSxOoAUqwrOSZZfAT1PN5tnh7X6AJ4pe0/QNg+zIB9/mvZAJbvg
bSHfsIhGBBMRAgAGBQI/GX6qAAoJEGZmcXrbg1Z5GsoAoNPTcGZB/zlLarfBlJdN
cyTkaTN+AKDAj9c7kZqVwQRvfgO19viKFqOuEIhGBBMRAgAGBQI/GX7NAAoJEA2W
S2ZXDm3qNhcAn16xPNxTE4U9eqCCT26dCf7VqAyzAJ9RT4KTUEUGKseS8f13FzTo
T1ueoIhGBBMRAgAGBQI/GX76AAoJEE4CrK4d1rOA1O0An1WBdZaCJRIthN1/ymMm
Q6HnRPotAJ955kGEkWDp8s5SL6NDI0zBBkGvVohGBBMRAgAGBQI/GNSpAAoJEM6K
edeYAW3H1z4AnjSEKHleKRyOb/kG37ko+eIB9FD2AJ9GQ/q0P754ZtxqaFUiqHAJ
NHkKI4hGBBMRAgAGBQI/GvN9AAoJECyYPlrSilXWwDYAoKUwfgKjZAsl0coktJZv
14OHy3tRAJ9VAy9BEUSWIFSaKPsC8WCrs4eXjohGBBMRAgAGBQI/HE8FAAoJEHFe
1qB+e4rJ2f8AnjihYtaFRbsEwGtuE9C+5wjKZYkEAKCGJ8lgK5447GtFvs9sc0Kk
OcJyxIhGBBARAgAGBQI/FbTZAAoJECole3fGNyjSTqQAnjzG6RQUZB2fHuOOv97X
PEUxf6VyAKCAu1JdTxOl7uvOSgzX/l5hhZ9SHYhGBBIRAgAGBQI/HGcoAAoJEMgP
dFmtwp7NENYAn1wYpBppW2AV2J+LS+4UqyzwUgx+AJ4rmKBgfE8OkM1QHOiYqpy0
MTkL0YhGBBARAgAGBQI/HanwAAoJEIsCZlm2jV9/1N4AoI19E9A4I1vz5at3XRlR
EbRDIA+dAKC8ih/vVhLc8dZ49H56mvqPO4ZIjYhGBBMRAgAGBQI/HasHAAoJEN56
r26UwJx/dQsAnAisenAR0GJXx2M1KEZqOEVN81+IAKDi4FQbYnuBNYkp3mmut5CX
SSpeKYhGBBARAgAGBQI/HagwAAoJECjdsP0Zyba6/0AAn0j5wJOnIcQfDKStVSoi
QcKv3qxEAJ47GNt06E1oPDpBFSyHaX0EicKupIiOBBMRAgBOBQI/FzFmRxpodHRw
Oi8vd3d3Lm1hdGhlbWF0aWsudW5pLWJpZWxlZmVsZC5kZS9+bW11dHovc2lnbi1w
b2xpY3ktMjAwMy0wNy5odG1sAAoJEN6Fg/i9v+g48LIAoJ9sjzxj49V+IkmTST5q
N1rn2aueAKDSswvpJjjC4WCe0fCZk8NvnCOLP4hGBBMRAgAGBQI/HsRyAAoJEPhZ
kLAkiutzRcgAni/Tdya62QESUwbPY192zUnpZCUZAJ4p0eMJaTtAFgfUz6k1s9nx
B9hHEohGBBARAgAGBQI/HoSRAAoJEG8ji8JP2loMP8UAnRgUejZZNVhjDeuOy3cH
M8UQ2fNgAKCbpsSxJs6JFR+yS/N9jx8xcWKvyIhGBBMRAgAGBQI/HuFWAAoJEJSb
JewHRHJS5fIAoIvtsVi2+q1/HNomoog68sSbV3/8AJ9lafbGsCje3wLB59bdpLx6
bfvcCYhGBBIRAgAGBQI/Hw1dAAoJEOdNKbgr4W0B8hkAoILgUU+r59s3zs7CL83+
W27m+AxgAJ9gnOZb4OFx0xRKGXWI26XyL6cQFIhGBBIRAgAGBQI/I5jUAAoJEBig
zI1XBqS0N0wAnA1VvaIzKG9Sx1YRKvtT6Y7kGhjTAKDbqwjDwn0D3Fzf7NYSs2LV
icJVAIhGBBMRAgAGBQI/JXRuAAoJEPK1Kl0KX7aHFCgAn09gsKJwPCNoEwVSnGy5
UDc/sVfSAJ9cc/IJ1M0xWIddrgpzP2O5+V+4W4hGBBMRAgAGBQI/JuGsAAoJEIkh
tdzNFaiDmcQAnRQnqsobCou74MLykzwtmFlZUZbhAJ0dmMVtHYC74K2zt+lJvz49
/G1YfIhGBBMRAgAGBQI/JuG3AAoJEAcXdOAA2M0WDRAAoILMsRMzn0aCdR/d7TVe
39qvyzLMAKCpgKEyrjeLLn85zYQt/mEHlJBF+oiNBBMRAgBNBQI/J8ifRhpodHRw
Oi8vd3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9jcnlwdG8va2V5c2lnbmluZy9rZXlz
aWduaW5nLnZlcjEuMC50eHQACgkQpHnNxFq0YGrGIQCgpqtvf2JAIBFJj2ZEAjar
xQHUk8sAnR1PKOzaTtbULulLAfboR5j38Jg+iQFjBBMBAgBNBQI/J8iqRhpodHRw
Oi8vd3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9jcnlwdG8va2V5c2lnbmluZy9rZXlz
aWduaW5nLnZlcjEuMC50eHQACgkQ+Xz54zpLf11CkQf+L6ndlBkMOsXAHSRpruI8
FEip58dRE3PEWCR5Cs3Zj/TrV9mF0pCnbU+5wlfCBz2Ieuj2ddNwI+9kWicCF4Xs
9avqRAasSO5sUSgpq405nKmNu7KdJEQG33expmPz/AX+agHOwTKpniohjlEa67Qd
TG2ewcKvmLEQW0LjY0Rq2gRJ4cGFYkSmynOBp6agg6bITiwXPNQZKQ5VafjOQVUR
tXtQTjInZ8gJGVdkrGD46D5a8yznX/KQU4ZEgRmDb6vl9POybhOihDvszahBfwzs
c5QBZPHEXCdeCNA3rdCYbaqkxohS+y5PjcYchfO12YOaOB0Gg8SWOnow/M0FFmFc
FYiNBBMRAgBNBQI/J8i1RhpodHRwOi8vd3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9j
cnlwdG8va2V5c2lnbmluZy9rZXlzaWduaW5nLnZlcjEuMC50eHQACgkQeQV2j3WE
9dg9VACfcYe3EhS4Nh/EaOlsxtBPfa8k5jUAniNbDyUG3T3TZv9p6fCzIMIoG569
iEYEExECAAYFAj8nyMUACgkQ+dAU8DjJhY3c5gCfTaZQqM+jRp21JyZUdMM+9lii
SVIAnA58fijG8f9ytFnVu2v+60w/0cEqiEYEExECAAYFAj8nyM4ACgkQXQ9/SeDk
nzTt+wCfdlDeiOXOMP5OlGd9mobCgiIbzfcAoOSkTiIY5k/iyi0W1ajOo89HcoaE
iJwEEwECAAYFAj8nyNgACgkQG7CLvyqSMiV/bAP/TXflvf1U6ypKOg90Kd4++x0s
0jm0gC+pMsFOedx2G4V7mFdCU5O86MVc+M4J5ztBFR+phYaHTtIfREkgggFCFovP
lykzZxTDc4FD/qQmLmMvHVjwb0pVYI9zPEcL2U7ZcvZEQog94lRxwcoIhEWFOdvK
nyjM9KEAsk3yqmAa2fmIRgQTEQIABgUCPyfKwAAKCRApvl0iaP1Un0XaAJ0eKoSA
oyzjyNbxkxPLqhyptAq0WwCfXd4vilC3Rv2Jy6bITLFqiWLNUAyIRgQSEQIABgUC
PyfhNQAKCRCfzyzNPz5kJs5vAKCBDTvRUTDkXEedWjYkkRLcyRGY9QCfViuaISw/
9ypRk755ZGohUNkzqamIRgQSEQIABgUCPyheSQAKCRCWJIPhVmLHNEPbAJ0ea8Dp
Xtr3VBTWI57Ph1y9S9sXaACeJKs/hNYnEIkOrh4Vv+dSMBhFom2IRgQTEQIABgUC
PykSSAAKCRAC1u0h4yxPS93SAJkBXNMPqDHBuSJCdvunTRZ6dfHrqwCgnJuM/d4I
Kque1PwGKAgVr7K/VMSIRgQTEQIABgUCPy5KqwAKCRA5Ig1uDBr/u0+wAKCuQ2qK
LXzGsqgrONq1Nc/Q4eRJcQCgkrxWXt0TsjDNRZCXZ7phpuQ7mSeIRgQTEQIABgUC
Py6PmgAKCRDKDhacKPo4iuhHAJ9pftPW+2A+h0pIORtiS1hm6wzYCwCg6gUZjYQz
N+aMeImP3AJl20vOPnWJARwEEAECAAYFAj8wMXwACgkQC3gy83PWLUEMIgf/avZz
1HowES/LgWuGufamC94UJckVdAw0DN2O5rxGmgqA5TfqwL0g02rfllJRjIYBPT4M
uwr50BdVALJ9XLmyGq5Rm6grB4F2HYI04EiU+e38Kr8B5W/rbV2rpEzWYS1bmMbC
iEDDydGTfaDIgG4Qgghk9JyTIhoCXIwZ+glPaa1HSAhTIcNhJq2LfulcqPVvt+C+
Zj6A7DgB0OWqccz2+vxMCVYLq7aEVpwcgdPvegYLA1CJ+RiDWKTNkJCWalN9GIzB
21H8XP1fnIqRlnwhpu9qou374BVO+b5l2aRDRz7WNXDFWK/MsZSpiPicIkmykZBY
mOC3dMNwgmJrl8Ijg4kBHAQQAQIABgUCPzAxiQAKCRAZq6/sHbI0q+O2B/9k95vb
VU+jRLlZOW19HGWGOaIFlZ0lS49SPc3GJN5HutFyj0QLQOyR5ttDWgJ9oCdbQZun
/AoTcaVn1KPV65cmXi0AmUfawDNMsHRA+onlVSUttF6Z9FVRJEr37/r2U1uThIQD
h6Xv3U+3OFZeCspo0mVWS+lQ+i0c+n3yc6+X+5SIMUOwqe332qTeP/smiGsoN1Gp
V6TVJlWHDtTPrAPu89C4/b3rokhVATNVoBm5zk/5aotT5hqf2v7t1nKUlWu06iUO
7VUeeWxyV0+wDnzo9uwDlDCU1PtOu4bSNwCTB2WrUqQLzbD3EIz+9km4ysNWNARb
Ub8CcRIm8OUq2oCfiEYEEBECAAYFAj8wMZcACgkQeF8wZf69S9wgFwCgh6pV0QC6
nGUvV5gh6kpq2m86WosAoK9BWccENWzlZPN5FrKAZhsy0phJiQIcBBABAgAGBQI/
MDGlAAoJEHw5el/KZtCx0PUP/jrWCrxFkGmigxc/+hLB9XwwM/Mx01OopeE+vpx/
+GUyrGpSsuhYP2Pvhq7VTFsGqOzIWs6pBpm51/zEZ+43RExafIICRTQ5a4J2dRMC
rgLH2Smlkz766klepK1pNFamixWsWopmtsWZ2YX/91G6U6IPASvLLcV+lFuQEZxC
kL0GlLk89iOm/Fzyu7r7xG0DOzI4sFdo7W6LQAGhwxTWEqfIpRqTIPH/IYqLeXxE
gROe6gCGkpSsk7+S2kG8oKmFPd+AWI8LFhHpBL/NksLTW/Vad2lCHejWe4us1nKD
O0lrIdNgjs0W4+p2y/TFH/pUFiOUbBdEqRvzPPMQaUp5kDAbZbG7Eydg+CKImPMd
90xMGWRHs7e60m6aMDwmx43eIdTjFsnBuCuGfic3+ydJ9QeL7IGjhT7wWUGQjpas
hbumPKEjhhphIUJtaJFDC6NOLp7o1DgdlQ806OgU3KzmDM5i6QO3noeRA4en6XHc
ds/D93quTOXsw9Ex6S6m9AdT1XmPkYN1SUNQr3S0BxYzXiZuuZkdQ4sFigwmYljq
u19A7d97XfIe9cRcuOuV3eSJInljG8XP5zx5rAgQNqAU5RoKLl9kik0qmLVkk8Re
8UCAvFVkklZicYR2kLe/YmXTsckT9od6Je5LOpVe++y4+la48vtCKXuP3JL+Rqqa
ZxZZiEYEEBECAAYFAj8wMbUACgkQlYRRoq3PfpQZUgCeJbkFjCtAGLhiePn1uRM9
SuRi7sQAn3QdlR7RiyDXyO8GoAT0/ODhdcAliJwEEAECAAYFAj8wMcUACgkQ/Uo4
3Ch2DT3PxAP+L98q7LvobV7AtOIZY13z/wKHCLzrHUeiOOd+I3l8hit6fIzsqmTH
sCcSu/wVt7oFaTwt4+TN2epunVFV74J0nB82Bew7J2CXD19ZsQy9qTqeNvLvmJD8
FmWC6LYIqkN3IwVVB330sZQYVcNSNl4hCy4wntNLGWPY37XmG7nOi9uIRgQTEQIA
BgUCPzal+QAKCRC7xxTRnGfNlhX6AJ9zfXvNPU17VpgdCyF9L4tw7Gvz5wCdG0dT
1Wfl599fDBZ07pZYdU3fGj2IRgQTEQIABgUCPzflcgAKCRCAdScAZahB7bOWAKCB
UB7pH58orpwn4kam34h0S4U1fQCgvh/QHkfYznXxW4PLZjHFzg47eiGIRgQTEQIA
BgUCPzf4KQAKCRBFwCFHaavdVI8lAJ90ZPmZVgVr13U6xu8J/QJF0Ah5QgCdGXhO
FWEyuY+1IMswfRS9DXffJd6IRgQTEQIABgUCP0konwAKCRCPubcPpM/JbmcVAJ4v
xU32w0zWpHtxvY1M9bKwjay5dwCg2PFIpqfUrd3Tt5sfIizXsfwhIyWIRgQQEQIA
BgUCPzVMUwAKCRBp0qYd4mP81Kv5AJ42Yx1ASL78rhDVdaBNU2/Y1dKOqACeJdCJ
UqJ1H5ToCAJTRTHOeEqG4SaIRgQTEQIABgUCP42/PQAKCRB54pxgsAY/5/CIAKCo
l3I4e61OU01kWV8xKx4LkYDIaQCfRKFeoCAMtEaCxpsg1pBHnCisJa+IRgQTEQIA
BgUCP42/nAAKCRDGBDxWcgdxN4ZxAJ9eDJmhY+uLrkHbceesEom/jLccMgCeJC64
Yq58dSgFA6YUEdKnDReMw8KIRgQQEQIABgUCP45vGwAKCRAKYuU0N6eRSdCvAJwP
4vLFAOUAcCd1BQR6AQZ0O/SkDQCfRrqr0qbUI+JwPCsgyT7I3tTTSQ+JARwEEgEC
AAYFAj+OYU8ACgkQFTlqeTPrBZrRwgf/ZKubbJqGC3UX4ed1XV3gbWMgnp2P76x6
AdRKzMXyo2OisVNQEe0HeW3xKnJa56FMF0qDziybKY6+KxAbURbw5gtNGs/N4/Hw
WWwd5G33ZoFFXOQm2N3GUg+98hqmmqipcgtNDWBXh/WQ7oKNcJGu4pcd7I8zHHD1
wzjUrFaETAQhPH9e2IZHnpkF18L5GJUIazwbc0oD8Mq7mkZVUecTXnt7wnwAp/Df
7Ix5jeCQkeQB8hNchslF3vUvDm89dU8XLHwTWPquBIXt0/wDFeDgjfyRw82OjyjQ
R3niJ6WHAECnVTkmkR/nBkrQMj/BGFopvcEUg87BXHaR1b0LgfUieIhGBBIRAgAG
BQI/j8N2AAoJEMVYWQiVq/UMPDIAn0q90rhCABcqV87OrVSUKLNlpNOjAJ4nyVwh
GBSNxYmncdRy0pRlqteeg4hGBBMRAgAGBQI/kCDdAAoJEF7HvjcDzgGeXXgAn33N
/7nmO6dooe3A3IwL+KqHe+8+AJ43UeYDXw2wPwMSJ2VY1WFXC8oS6ohGBBMRAgAG
BQI/kRkjAAoJEOOmjcqmmNqZsd0AoK0wBPCZWa5I2rXl78GnC7PR+KHVAKCYNcZV
c40GH/6Za+v6Tumh2gHOFohGBBIRAgAGBQI/lDUOAAoJEJ0IqAztkI1qlGMAniIs
K64nE6FCAoDOW2RtzVihd/S8AJ96MLTd83xZobZy2Or6WUqSPX19W4hGBBMRAgAG
BQI/lEHrAAoJEIMpe+qmIxHWoiYAn0OP5sE1dShF4C/yK/xdRmYMTt/cAJ0fv3lX
KPA7/qKsZGTdrp9rq6Np24hGBBERAgAGBQI/lW0HAAoJEJUsViNsp2z0ufYAnjxk
+57rxIA3qkkxmd7JtusUFZlDAKCYo1y4XzEXUAoF9+mH+Jz+PqAss4hGBBMRAgAG
BQI/nDG1AAoJEDYCVlOr4LEGgCUAn2nV6DTZm+Kf9zniWY4ZuI2jUazXAKDeQys6
EhMQp9SWwduoajYatT6OxIhGBBMRAgAGBQI+NyJoAAoJEG2U2yGkQUVxohoAn2VY
P1vR6UKqe+eVtiKvLvppkdx5AJ4mTUyRiMQB/zTosBIg+XNK0UETIoiQBDARAgBQ
BQI/ncHiSR0ATXlzdGVyeSBzaWduaW5nLS0tbm90IHN1cmUgaG93IHRoaXMgaGFw
cGVuZWQgKGl0IHdhc24ndCBkb25lIG1hbnVhbGx5KS4ACgkQbZTbIaRBRXH+1ACf
XWYn1p2HoizDLdw+iwRVO84lTYoAnit4RRnVZSGea/WVhblSOX6goQxsiEYEEBEC
AAYFAj/MHtEACgkQoL6dujuIbn22AwCfdjB/V9Sdi5wdaW7CS7VIbS9RwLQAni56
8dJQar1j0wNmXbE5Xfj8XwR6iEYEExECAAYFAj+iix4ACgkQ8vvXZt12fkoj6ACf
Zgas1+pCwq0vTrlLSsJ/2FezbAgAoO9ow3Rf8prgbXkGZHtw2W++GYcziEYEEBEC
AAYFAj/TW9sACgkQkdi6ijTVyg2RdACggXb0RV8mxMqjMEuE1gPMBZQkIUAAniu7
Ef0yG2oxmX9P0HbPJMWbfiKriEYEExECAAYFAj/Tjh8ACgkQrxRSXsoHIeaAHgCe
MlxY0DqFe6If827ellDd7AuYz8sAoNBF4vsAZVj3+Sq5JvtztYYhaHW/iEYEEBEC
AAYFAj/TwGAACgkQYb5H+9Ze2NckCACZAYI/Sua+imgs+lBloApb63SqvQMAnjlz
PgbRW0g33NwZyCRJ6UBQlA8qiEYEExECAAYFAj/UFwcACgkQzfT3onTsQykjTgCg
s6m4JzgSm/sRtThBSrucGrJFv7wAn1R7Ag7wl5gRWMO3f3f5ChyHevhxiEkEExEC
AAkFAj/UxMwCBwAACgkQBy76KTKckK4HfQCfesYSGD9uNXV8JaPNCBHe1MHsdhIA
mwZ69GW/iauucCuNSUaLIQgFUlz8iEYEEBECAAYFAj/XiH0ACgkQNQqtfCuFneNb
GACfbZIcctfTfOj1c073/2IjdILsZFsAnAqKONkeyL3Wcu9GV0KFD3gz108diEYE
EBECAAYFAj/Xcq4ACgkQ9aLWrfOU0PiEQwCeNLY95/5hUOocoFpxY6oXvXkjkvEA
n29v0j5n6QQnndXCTIMUeIJMAk4AiEYEEBECAAYFAj/XpgUACgkQ/aHb+2190pHu
dACfdUqf8Wj0F1ie233+IBIikobs/qsAn2L3StgUl6Y8jB52DSp7aVgJy2jtiEYE
ExECAAYFAj/Xv+AACgkQcC9qbtgxVkOFMQCfbOu1HBGGNWFBFFk9cXHPrthzoo4A
n2bfdbDLYStoUgCwRjBS1CJZZWTuiEYEEBECAAYFAj/XoWkACgkQzCIUKbtGVYLS
4gCdFzJwV7QofoXGXogHRfYPdzzQ2DMAniIEHofyr/VP4uuI35cj6EKUTv5WiEYE
EBECAAYFAj/YpB4ACgkQDq3Sz9XRqj4fHQCgl2bz+XiGHWLW92k0SAQyu2+v6nMA
oIV2DUC/8BGXcLASPlkYuItOMFM6iEYEExECAAYFAj/Y38QACgkQJPQmYjmxi4ET
xgCgjzeFT9+TpPcD1URii38arKnRtSoAnAnHMqiOy0VYg/M10gv2e4Cvqy3giEYE
ExECAAYFAj/XuFAACgkQ+KSYvZS8wB93xQCeIIV54ff2TtO3EbThvSVrbfHudioA
n2KzEeLl2WpbK2EqXTU17SVy5jERiEYEExECAAYFAj/XvtcACgkQAeqShO1JBbuQ
QgCglcqvpwWZ26QnW7Y3trjj9J7/wXIAn233CK2a8fDM0mlPOFdWeiix6f+tiEYE
EBECAAYFAj/XnWwACgkQh11XSMrLwHSWNQCcDPZp+80dOy7KMJXhM53O2gdotcQA
n2WtX8MPq8JIir/FVxBOGRIoTQMgiEwEEBECAAwFAj/XiA0FAwHihQAACgkQdROi
NhMQLPUpbQCbB8hbodxjMNo4dcLjfIbY4J5iGg4An1EAIv00YOE31DXaG48PLDBq
B0wgiEYEEBECAAYFAj/cWVUACgkQelwNae19I7gNPACfRWOyKnHacjD7rWBdNy2i
6ayslEgAoMKdZ3FpbeLtwZY37bWI/eSIXQE+iEYEEBECAAYFAj/d5nsACgkQj73e
iy+kMR4XOgCeIzGhKxsVEvBUUHNoWOPmeXpKz1cAmwV6zprqvfkjHkHzaaHIZ0k9
vXa3iEYEEhECAAYFAj/e/GEACgkQLgAJRlBWnRhiygCfeU2+IkLEVetQjjgv6xlz
UY/jz14AnAokmecPv9MD/fXocBCeNBNmHsbziEYEEhECAAYFAj/fLOcACgkQgzvw
J1ryljCf5wCfUZPMFsuj6M1pgH7eTWShAfa6IgAAnjWgtE+Wtt2huIEFLU3Ue4xr
2vByiEYEExECAAYFAj/Y7VgACgkQZzP420x1p2tUBgCg0Ne6b338FI2iYZMOfpW4
QJoMJp4An0vtWvlXx6I2yYz4uvdHdNf74dWciEYEEhECAAYFAj/vPLwACgkQ3zaE
8GN48xvAPQCfeXQFRykZwoDnJxZRrbsMuNdX/pIAnjDKK44pLTm1tXubPLOwoW6j
tPgSiEYEEhECAAYFAj/vayIACgkQyQMBxhAreU1pOwCfRk/rb5Tj65Fu6rLAnG7c
x7ugGtEAoI+Oj6yNuPAuUFtvNq3UXicXUpYDiEYEExECAAYFAj/wRzYACgkQiwjD
DlS8cmN30wCfV0oT4G7ZzHahe30z6BQnSrWCKMUAmwTXnFPMc6xKukz3tT0G23eS
rPh4iEYEExECAAYFAj/xNU4ACgkQSUvu2wE5EjvT+ACglXXJjkV9Q+FLfL8c300X
PTaF72oAnA7OPAHN0hY20vTev/d11D8ERRabiEYEEBECAAYFAj/x6dUACgkQvBVi
c1oTsEiqfwCePNZqs2jGRorP1rNwarv6TEwIDx4AnjIS8RzUVBN+xdQwkbrGzGnN
PCS9iEYEEhECAAYFAj/x+gUACgkQCY7iyqpOgLa2rgCbByTLSpUPjYdJHWafbvAh
jfVpumgAnjqFyycwkXiVxqBwbOunkwDDWwswiEYEEhECAAYFAj/yEZUACgkQ0+Zx
vPFTY6EXQQCgiKnhP7W32TAfrXEcMY57kIxdc7YAnjOFG/fZkEb+suBcQjM35jU6
yTyCiEYEEhECAAYFAj/x/nUACgkQifW7lGXJEoUxoQCfX/Uzi+Z/MEIuKtugYWsz
29DtpEgAniQkFUIKcazMsjHYMhu0P53Yxb2DiEYEExECAAYFAj/zKT4ACgkQEfTE
HrP7rjPClACgiU7qn0gyQGbgcPEDIoV7/iElsoEAoIwdiCCo8/fDYwKZJzH0ic6Z
QYX9iEYEExECAAYFAj/0V/sACgkQ9PcicYLJuinfUACfbfARX3S434I4di1KmQDJ
Cho67j0AoI55EvMrfZqOYvX89Pqxfvn4kH2DiEYEExECAAYFAj/09ZEACgkQ4Wmz
+z2IPqCAwgCfenqkn+38y4Rl31FB34ADe7s0slAAn1yhVL+2PX5Bnof4iMi2JdKB
kSVbiEYEExECAAYFAj/1JicACgkQLst0AlVuMNeJjACfWzqMUDu3J+Vm6voXol9n
jTqqXWsAn0Skh066ZAL/JD8Jz3gWRu3yY+dCiEYEEhECAAYFAj/1sW4ACgkQnNo+
exDKny0nYwCeMl0Nd/wd+qxe9fQiK6gBLpOcmZ0AoJjAuyyLG09ohUXVjBSPulgv
iRnNiEYEEhECAAYFAj/2GVoACgkQKLKVw/Rurbs4nACfRgNCI6+2XU7vQ0TuUxrc
yUC6W54An0BjKyxPtz04iwkBr1+4QWGfaBvLiEYEExECAAYFAj/5oxEACgkQRusm
gsjeDU0uIACgxMoHD6V9c1JK9sJf+nUU3MTslrQAn0MBbVlBXhgzOEwuHCLXfyjx
WmXWiEYEExECAAYFAj/8GhUACgkQjO6yWbPCgfQ/AgCeP2AmiYnXpXrEPFc34vfm
vIE2LHAAn2+3opBvEMpbJZHi61TbkdiwskoCiEYEExECAAYFAkAFryQACgkQuQ3X
ye1hlT26fgCg2R4UWJu3NcLjP1yM/ME8RGTrTg4An3AfYTAqWT11safSh8P3Bp+b
DBX4iEYEExECAAYFAkAGEqsACgkQRCBj41UDsd/mQwCfQxivxS3uk5qPUms1rlaZ
ortwF9oAoInKBAxQe8ArmnxreB14YDowUK7BiEYEEhECAAYFAkBCeEoACgkQmHaJ
YZ7RAb9aGwCePCImHjDatX93iZNuD42ke3oSYIsAoJfssZTjjRRntJgqY/KUmyoE
uaPuiEYEExECAAYFAkBMc2wACgkQr2QksT29OyDJbgCgibgPVr6fRXvDYUDct3DS
l/L9tjQAnAunmZTq5rfaK4gGEaFpvM/fhN8DiEYEExECAAYFAkBiIT0ACgkQKljO
qlJpjp93EQCg0IXwhDrFGg0+pSHtYWkrbK76dAYAn3w4uI5HPkR/EPUCelCIoota
HAkziEYEEBECAAYFAkEM6sIACgkQXeJJllsDWKJB2QCgu5C5Z/xi8kxD9Y3HIHZ2
i65aD7QAniZxuCBSEsTUrUFQa14JXjpOigS/iEYEExECAAYFAkGE4iEACgkQqy9a
WxUlaZDrDACgie5dsv4FtXyqaGQx1KeIg5MgsysAn2wD6sUUho8L+aLUtch0mCDa
sLptiEYEEhECAAYFAkFA71QACgkQBylq0S4Azzw5LwCeKPCrHyToXmAhIAFapS3W
XFtENAwAnj8NbIq//frXLu+MFFgNuVWs1yo4iEYEExECAAYFAkGEzjUACgkQP6De
CKDTkWjBXACgi4VgWJC+6SHQKT763qnhT42o/Z8AmgNnndmcd+6COISqKDC0t6cu
yRgliEYEExECAAYFAkGalesACgkQXY6L6fI4GtT0xgCfRBpt301zvBQPNtR5KWrV
TYKd4BIAn1C1Hj35ZmPGY1ErpJ7/OlvRaEkYiEYEExECAAYFAkHlLtcACgkQ/H2E
k1xrBMnCdwCfSTfAeH71fmicdpo0WyQtDJGbLKcAoJQvIh/dJCcTRzehMoikepB4
0VVJiEYEEBECAAYFAkInm+YACgkQX4f0Vv2/Nxw4UwCfcyR6UVmqk6V1MpMcnwqk
EUIFt34AoJ02pIwEObvB1gyVQtpP6Jof8CYziEYEExECAAYFAkJZlc8ACgkQcBdD
8e7nfkUQkgCgvVSUG/qMQSzRM8eZoC+cMv8jAV8An2iWuvuyK9WpYkZkN5dYTqmK
XIE+iJwEEAECAAYFAkIcKQcACgkQ5RUoJTMc2l32ZQP+I/nbPkxTJDqhjh+SPB+P
9ansJYa7ZkXaPd8I7P1nENYQ7WEDS9Wc4b8AnOdtd4EI3OQK5UmswjMGJyipsa5h
NblzAbdnI053tY7RDpfs352TvoBm47aipuMoRJctSIkWfRlex/HytYlygV/6gwyI
+C9zkG9I02U1OpDzENTR4yC0KUNocmlzdGlhbiBCcnVlZmZlciA8YnJ1ZWZmZXJA
RnJlZUJTRC5vcmc+iFwEExECABwFAj4irWgCGwMECwcDAgMVAgMDFgIBAh4BAheA
AAoJEGx2F4yg7ZgtTl8AoIozE3IKJSq8armihwVbsb423M18AJ9u80NA9CxL7GkS
rCvatNOzJjNf7YhGBBMRAgAGBQI+JLCgAAoJENSNEHJ4+KjUHPsAnjsf26YTRwAQ
Lsj9ep/LkNuiyoJGAKC8XX4asaznd7jeU0qeJQ3Xohcj04hGBBMRAgAGBQI+LG6/
AAoJED4s35lZGelG8uoAoKOXTvFfJ3RkByeKGVvKu+o7XPdaAJ4/2bXepNLqNEDg
Usl7hkak7FRZ0ohGBBARAgAGBQI+QCnWAAoJEJWnRNJ6Hmtf0MUAnA37LFsdr2rC
AcQM1bxrTb41Ap++AKCTtJ/NK3bVL3hbxM7q9r8JNfntEYhGBBMRAgAGBQI+QCWn
AAoJEGxG8ZwW/bKYPGwAn1CbytJ94xED5anIuEUuV807YSD/AJ0VjiIKBDWZN/+x
rEd4WaHVDKuDJIkBHAQSAQEABgUCPkA0XQAKCRC1rDlKuf8qEaljCACsCiPSrFAx
yz1saPmjan+RBm2i2HxUJe9XP+wODZ+EtMbqedUkCg0NMTXByyh6bcuBUgKn1pG4
PTOZvJMxEHLfsCDvzwp/NxHXIDN+yiGBr0e9WeqiV9zDLFQWPmiSc9AOyoiUavNK
mYzgzmLvCKZnSLmP/GA+BfLIoUJuZwt8BsLXgqyaSs3LNT9GooZi8aVByq8Cgytt
RZVGOB5EQDlmBYHoy+ifTCWkRfhSIx7Oa0uP9ybPR0/RwjVxp6nk1DUMySFb25A5
gVfhiQ+IvgOBwXWQ8O5ykoWdBccJYkGRI/4rLYY2nQQ+Z+MoxiStKzNvrJtshxj+
ESVTaS8TcZh0iEYEExECAAYFAj5ASuEACgkQlI/WoOEPUC47WwCePdtefQKkwfQo
f0vmDb8Qc2Kxq4gAoMwKA9A0fXTG8Pp24ikc1c3+5UB7iEYEEBECAAYFAj5ARsgA
CgkQHI0nZIQ34x81cwCdEYnjuBXMswEj+iBabubPYYuRrKUAoOntf4ZBIMkaPyw2
jE5wQ3IVnLtUiEYEEBECAAYFAj5AVSkACgkQgGcShyMVr6NFQQCeIM3GKLD+VPMK
T/BTEvHJU4pSuAIAnA5XMGZaiudfhDLmrlqVpqTpb/tEiJwEEwECAAYFAj5AWbgA
CgkQhqAIGyKylR3pZgQAkGSMVHpz3PiArTQNZ+rMF6CsSBpsp+Rs0CyLlG5Nsqrl
he0qW0QZkC/7OvgfGn+WHzO2O44vbPjpgsE/Ex0VOZeuBYpTJZQQz8MbiNjixwyp
iHBWXBp3e0CbHSq26z6/fAqhVQeDqCQZETAfrROeyNIp3vzzfvqdUkmof8c/34SI
RgQTEQIABgUCPkCsngAKCRBiSEuPG0iN6s71AJ4g22uWyjB8uU9gSzu8Vfdgolyi
PQCeP7+bfvgRhTVagTOc7sjGOEp5bB6IRgQTEQIABgUCPkCqFAAKCRCuUcxBI0Z6
8fToAKCa/NyunXgzy2O3hJbgASRFYkkF2QCdHAK1a99O4O3+zQjJWh/q9fXC2kmI
RgQTEQIABgUCPkDJGwAKCRDVVqZgiOPvVyT3AJ9idyqUM1cUQoTx9vy7G4ITEnVn
5ACbBqQ0Ndq/Cp6PDPESlT6gXbEl0BOIRgQTEQIABgUCPkDglwAKCRA5o8lM/cSo
/Y97AJ4hsp9zg6qM3M3Yu97Q4oBTDdZ7HACcDtBISlliQarPWwt4mHRctma26+2I
RgQTEQIABgUCPkFU0wAKCRC0deIHurWCKSPRAKC51dPMqkgVeoeC2hMvgmQlLHHt
NgCeKy8boiFAHHezYS7maFRCMsrlNLKITAQQEQIADAUCPkFeMwUDAeEzgAAKCRBP
g4y3JqCoFvJSAKDBbykzsluQJ0mV9s0jQFMBtPsfqACgvr4s+/MxbUJjSpDqEQ1Z
NxI8Yt6IRgQTEQIABgUCPkGUwgAKCRDwJO+CNVGeqNE1AJsEfE/svURDc6ClzGTB
b2XKekuxuwCfVwuku5/SDcB0IvRijwXTxA4t51WIRgQTEQIABgUCPkEW2AAKCRDc
NnQ35arLNNiKAKCyu+jjTP2kF2zsFRZJ4OLiptzuGwCg2E8G0lPX9hMzRFN0nYYe
vRlUfWaIRgQTEQIABgUCPkFcTwAKCRAHJZTVR7A163zjAKCeyLsZqYxPLe/XomuC
gCQOd8u2bwCfYt4iCLPcx0yMt7Nb48QOVGOdxn+IRgQTEQIABgUCPkFcYwAKCRA/
V8xvnmt23y0HAKC90+rYGPDvyXXmAx+Kj3QEV2fl/gCeLQH2EXuHRfJyJKzxt4jy
vp9CwXOIRgQTEQIABgUCPkF10AAKCRBBGPb8lSbpxfNUAKCHY5RVSETfgloHO2bA
iahBDgFPSgCdGfQaKBrD92CKSYdeMNNOjNxhKnqIRgQTEQIABgUCPkFzRQAKCRDQ
5Ee9ESjyX1ObAKCWaptXNj4ISu67NT4hEEDGIfUSXQCfVznMDC/hyeOL2BwfRTGr
sY35frWIRgQTEQIABgUCPkFzXQAKCRBrphakwVE7DNXiAJwLv7OBvfZYVGh1aCRw
qXrGB7X8gQCeI6szoysJKsw8oQUxuZS7ME9kPLiIRgQTEQIABgUCPkEMZgAKCRDH
ON/LNYa6cYhBAKCaX9Ofy/81DQWMQfRIiGPoSf/PHACdHErqKXUCB5SBl7ylZhse
rKncHa+IRgQQEQIABgUCPkF7fwAKCRBueUUCoBl5wKwUAJ4sz30UjqeOnDRBjd6m
3VDHk173EQCeLoMTVar27qYR1TdMt8LBZqU0LbSIRgQQEQIABgUCPkF7igAKCRCj
GM7Esm5quXMTAKCjxNkNzck8JF9O8jsRlT8vgh98dgCgjN+sxGrCkMktXiHZOa9T
VbdMfSWITAQQEQIADAUCPkDKfgUDAeEzgAAKCRB1E6I2ExAs9UbFAJ9Ed8MZ6F7n
J+wQ8eUAKbVarTKDwwCfSF4ed0z7231cWJ9ODYuIIfiFwcmIRgQTEQIABgUCPkKm
EAAKCRBADB62okjOY4nVAJ4kHn7Lcj762BaXyMH4zYFNLeh8WgCfU5ZdUpFTjB6o
zFGXDPz6grIlrqGIRgQTEQIABgUCPkQyqwAKCRCwxLn3mg2CqabxAJ9DetdwesQd
SCga1zBvSZ95ZpfxTwCggFwmSkqD8Kvh7ap7P2yTYetXAyaInAQTAQIABgUCPkRP
KgAKCRAS6T6JP9G2tUOGBACm8D9SO0e9TBUQfXrq1XfW1EV+GqdPCN17J/YAVp1N
QCqlLHYF3+/VIsaT42ioM5QQcy263L+aFVx2Yi4R3zEeolbGfFBTgvn28odrreZp
uAFgjO76PX0eSFv7vvWntHLPgZ0M9rHplKuGs6kb5GlJxr/VHiHWFKvQnYZsvT/t
g4hGBBARAgAGBQI+RYMeAAoJEFv8diRAZaHa+a0An2tACMMhZoxiOeQxm2v/587Z
68EVAJ0SIMqmBEUP8pu4idR4Wq/2zGWWyYhGBBMRAgAGBQI+QY9hAAoJEC9KXfQQ
64+oUaMAnR4qJpGEXFPEIkj16B0DmNOaPeh6AJ9NSY/3VohzNVc6CSQKZtvAtKh2
H4hGBBARAgAGBQI+RsZ1AAoJEJ71dopqzj+sFVEAn1ZE05x0HC+y1mk4U8Z9cxzs
aZxaAKCCVWIs8JTIrKIkMfJLZlAMZHLpfYhGBBMRAgAGBQI+RsY3AAoJEOpKzVz2
XGjNpz0AnRNN1YcShhvf77WeO041Gmb6eyu9AKC/eibZjNysFFd/aJFigvZ3trLN
lIicBBMBAgAGBQI+Rs/1AAoJEEC/HpEdDdC5rSoEANMcRBg9Y2PKFTtgS72hP1j1
Wse6+MOIRw8W8rt5sFMH21hwIhcDa0nBFDXuNJgNfXYp44AexcRB5BK9EYQWt2pU
g+R335AEVTa39sXl6BSU3K3xnBqBMyNFz6acjZ++cjKAXYfIp3jAS+CoIZ4RN7rk
d/gmKSivEYp4rTiTbrK2iEYEEBECAAYFAj5Hr40ACgkQagIyDYKgMl4cFQCeNw45
uJggp0nNoq9STTZv4sEQurkAnAjxHHZtm1X7SeUL0Xj/cSOk/DC0iEYEEBECAAYF
Aj5H0HgACgkQEMun3/wGpS0wXACdHsxbYdzNvBZiKZjmshdpfSCK/2AAoM+6H8QQ
uFoB/L26N+Xw5SiZ1Z30iEYEExECAAYFAj5IZ7wACgkQmpTNb38U76Q0fgCgiwEH
FgMDHri4LJPoy7nHRlrDGDUAniBp2UFcQwZa2Llw9YsFLMCk6DeLiEYEExECAAYF
Aj5IaTEACgkQv7s1Bo4lI/0/aACgifSFyPzrEtJlX4orbUUwUVXdebsAnRty6E9O
kRzBB2Ka+xl2gXLMVySUiEYEExECAAYFAj5JZJ4ACgkQ3uEZ6Jp2yaNZUQCdFpZG
J83wRl9/ndVyDYvefxq7q5QAmwfd6brtJlAuDkesUDkJBZN5NbgwiEYEExECAAYF
Aj5PlXUACgkQcieKIj7SkS5bUgCeMYJadtePbjOFfoKeERLaFgm9COwAn2w8t4Uz
ywpeSNF6BFaCU0NNlWSAiEkEExECAAkFAj7wz8YCBwAACgkQDbEkl9DbWra3VQCf
ZB5blsydcC31ITmvk+Nvb1lO8fsAnRbkIRgOWfPYQ4jZ1gEivjYV7PJEiEYEEhEC
AAYFAj8L5ygACgkQnIUccvEtoGW3lwCfWZsK3sNJ7YvcszKxAMMKuzwAuIAAoLm5
wgjvmtLqcq6bFMljnWchBQ5KiEYEEBECAAYFAj8QVQkACgkQ1vr63ZUvP/8vcgCf
TI3DqqaXacjWQNGUE4Gnu3VL2fEAn2s4632/qa6krXU5wCWrV47P41uXiQEcBBMB
AQAGBQI/EH+ZAAoJEEAGFQ5ACert3KgIAKnjwK5NIpuqBE9K6PlNG5hi+B8O4q6m
Zw1pm305lmdUWJwGXzr9JHzaOyJPYXMq92LfUA6v3kwkKZq192hONxdKc0OJo6gJ
I4tc5dpcLHW+iA/YwBADPvKZArwoQYCYH5aiYthCT4+MCqkm6ZBMTmdFrUuvw0t2
/5zlGR6JHaPhs1wDE4j0WFe/F704EgqrOa1EWu68ailpDmBWeoPiEVjeBTw117RV
gKI1GhBjoGN2pde+qtO3+lAz48eC5CtH5omwTVhjpk4VPdoln8eKWv2ap3FIy7Ei
K22TWwLeNWmE+5oxEUQt0gCnIfQJbbd95ljxNtSthJ61ZkZg7jWHxPmIRgQTEQIA
BgUCPw2/zwAKCRB8IsOfgHrFOhxwAJ9U6Yb7IGqCjCI77N+zq8411u06jACgj3Ls
Qf9OhNKc33AGUfc0sHtN5QaIRgQTEQIABgUCPw6kqgAKCRBN/6N0Q4ZdAQ77AKDD
AXNgH7xMSn91PWMiV6ym7Rye4gCg2PRVP3qsB7lJF40Xcg7y6juwijOIRQQTEQIA
BgUCPxAeSAAKCRDhhSLXfHEry5ZlAJ9ADR0K82x34rlDUegL6GGOyLti4QCRATLo
x+QxRJzusucNkQLUeVszn4hGBBMRAgAGBQI/ECi1AAoJELM00wiWL9LekvEAoO/z
MbtjaJqlcSNXD91aCn6Lk93pAKDAeVhyrUz1hbjbavCbrdy4DLL+yohGBBMRAgAG
BQI/EPssAAoJEMXAxcchjRjXqEoAoIN9qyLfnNPIdmPEp+5K8i9wdYMxAJ0fjRmQ
oDjRpXggm+lxM0iBHHozHohGBBMRAgAGBQI/EUksAAoJEOohmUEkd8r4n+4AoJ7a
9dbf+AY38ytohtsRezz5YJjGAKChRm9oi4NEvkRrKzpNVleolqeMb4hGBBMRAgAG
BQI/EVy4AAoJEBn+2DzivqNBHeYAoNh3Qz3P0MDqDZq/2enn4PI+nHbQAKDSGflE
K2t2/ytDfTnYQnD/lw0mO4kBHAQQAQIABgUCPxFBZQAKCRAJ6fkKinJORQvPB/9t
lEMYInNoVIK6zLBr9N6NrzoykHSaknZWMwzJOuWm2Cg7pT8smDpyURnA0i0mTGC5
+dLf59SGxCwpvRReAhiZViNKnX9x/GWCqICV5CMbbELzS2RO7XR3PWR+3F0QWBHe
0p/HbbhE6CIUTwOUlLS+ZlthI4YEx54EGLZRWWqs0RE8N4V7hoPm9NWoB9mW+ORs
YmOqsrWU0LEfexyRgeYWQYQwNIoOQGjEwFGm2SxG3I4mExCY6szHkHeK5dGaVsuV
bPji+ayO5u9xoSc5qhwchM7VzadpL9kcp2Vgo4Vv36nL1pS4i0SzZOTkt7+oPKG7
h72yvsWwPW7o1CHxexEKiEYEEBECAAYFAj8RJxAACgkQ9Wsmo6Y5nnMjRQCgreH+
6SoH9RQ0c/X1lZGa9p1mbVEAoLZ7x9Pba7Su84vTeBNvQMhWxalSiEYEExECAAYF
Aj8SXx8ACgkQoJD705cZn8NJyACghdLLiRgMdfUt8tHzGaW5TECGr2IAnionmDmO
S3Aoc4Tbu5iogQ93WxskiEYEExECAAYFAj8SjswACgkQVm02LO4Jd+hzaQCeLky+
oyXD5dSQJIOLkn4/agg87EkAniv1iwRLJxXOCRNAREm9tEnKVxK/iEYEExECAAYF
Aj8SlEYACgkQj7mZcU7rMfGTkACghx4WqwAb0nJnqVDLK1/hyCAltpUAn2oqc67Q
8beMOiWqSEGMfCKHfamAiEYEEBECAAYFAj8Su2AACgkQRsxcY/MYpWoiVACgq1NL
o1I7oTsD7cRFAAi9G7EkaU8AnjEAGb6BvnLdiOKiGY+80sTGU2ykiEYEEBECAAYF
Aj8SjUUACgkQ1DyzBZX+yjTLEQCeLajUmemRkgmpsquVkEUkn4tCHRYAoKzJ5/8w
f+5hS6fUhz9rHQBnTTJ3iEYEEhECAAYFAj8S+ugACgkQv0FZW3NyoqXKkgCdGtpv
7qnPjtW9VewBQ+Me3zQY1ycAoJLK2WQbPL57M06GEuqsxCIolst4iEYEExECAAYF
Aj8TEQsACgkQuYLL1cDjHx2StACdGDHjGgoQMPakN+pxWCe6CjJhDb8AniZ2P3p2
61uAGe2SvR/O7JiY4VhBiJwEEwECAAYFAj8TKqwACgkQtGuSO22KvnEGKAQAicKN
rwvinh0b4AmDFx6rfxdBRcF6oETbnW0Czhz9Ub9m3FEKzRmER/4JidpMJENJs0s7
OdGQjkZRTxHoYp8jGNO8pnj0UVQGghGzp94ugdahOQUWZm7YVg3+ykXQ2MBnuOeu
fmuMK9k0IIgXIucz8Qe2ReGuPMctcD3VQbUiXaWIRgQSEQIABgUCPxMtoQAKCRA1
9mF8UTrv2SK9AJwNYzbE5aP0s426BCj9PclRi43vEwCdF3X0LWoFc3WWrtU2BQDu
myowwGiIRgQTEQIABgUCPxLnxAAKCRCSVb2f5oRNuQRJAJ9vcjKc8FJkgrjizELr
PPzYtL7xWgCdG4PioIfrU26tG95qO3Z3RbldRjeIRgQQEQIABgUCPxNDbAAKCRCt
7CzRGpU358JLAKCdFud7Fadntmb8gbSugCAlayKu+ACeOdXIHn9KTKRsFf+lay/M
FJkuv5SInAQQAQIABgUCPxNdhQAKCRDvbYJB8IEZXdpHBACzum/QB8hUm73zvfbt
g8kryWZupfhnr8eyg5iW4NKteLWTcYYGc1uoQIWxdBAvtRn3hxE1IRM/0HsuByha
nO6dqWditfHyFzYCWB9BdvVCj3244qAbfPr8ZrM0Qen4PXMgUwSKhEvhjDe5y1Cd
Oumn292TTVrKGmYYPMqm/xhpUohGBBMRAgAGBQI/EaLFAAoJECjG9WuBfDVoSFEA
oOyMY2PmIBHy1xsS+19UwvGALJXaAJ4wMEwOUoAvULyJRHe2lHKAxP70HIhGBBMR
AgAGBQI/FCMPAAoJEFGs9q11voCXV5kAoJRknzUcLVG05Yr/+uPie1eCzd2hAJ9x
KrzXTXH0UYBDRtDxtrePXR3xGIhGBBMRAgAGBQI/FFmhAAoJEIQs23pEd54Y6DIA
n3bIXtmTPR77OSN7xWiCRHi/C24xAJ4++/3c+oMrFS15+vXcUdtVvCFks4hGBBMR
AgAGBQI/FFIZAAoJEFgpV1AFAIOL5uEAmgNuz24Nklg8Z0YZZuJJ4KZ6MAtsAJ4x
nx+0TqHlKV6QpVY5LK/EUuIF34hGBBARAgAGBQI/FGCcAAoJEHf4FTO7DujHYg4A
nRqJi+N5xvmJLFBtc/Fwg/4tZrk1AJ4z1G2F+8xdFOW4HAEMvpM4DIhp9YhGBBIR
AgAGBQI/FQ6bAAoJENVOrkvJmHCxEJEAniyqkEscT5Pb1U4/YsBjlOKT3BFnAKDe
gRTwyuQZ5Fv4nVjQ4PqZX3GoGIhGBBARAgAGBQI/FSq/AAoJEInNSyFgdVnmFvIA
n1ZPAm4K+PVEiQO61qCfMn+ChxtOAKCS/X79h4HhU1u4nrdXZHIhAbmzNYhGBBMR
AgAGBQI/FSr5AAoJENNbvJm8fQIKhgsAnjccO2D3BzBrHQC0PkG2IonxKDVCAKCZ
tyTDYdhtFUwDmt+Uc4uxRnfAJIhGBBMRAgAGBQI/FV6DAAoJEJ7QeO9LOhNcdRsA
niNNCWCT3t/EosNju1EPYDaK9t/eAJ4kdChYqxvVu2svHHxQnP42VC1zf4hGBBMR
AgAGBQI/FV6FAAoJEPAj+AsmhB1b6/UAmwU7MIhoLC7bmh7l36761YwzQksxAKDO
WIJW/wXBbulL8Gw6XXMJvtRrCohGBBMRAgAGBQI/FYv5AAoJEFO2uB3BPO4Hw5kA
oMGOp6M8HsCoWqOer0DSsNwxViHRAJ9s55WWSjqlWBoz2l23y6643Bz3AohGBBMR
AgAGBQI/E/MiAAoJEEvvJiQi30CHnt8An3HUfqUqQriyiTZN2WMHIk9hRDe5AJ9a
dB5xQdh4wBZnNSSSo9nlL62/T4hGBBMRAgAGBQI/E/MpAAoJEJVkH2slPljj6BIA
niMNct9yBdxXiOMCVJl0HjACq6lPAKDGNnzpHdoqODj83NcmyXJVWETt6IhGBBMR
AgAGBQI/FdZ0AAoJEEG59OhbcT3wPJAAoLuaK8k/Ql+BzeTWzCrvnV/WsuM1AJ9B
E8/KPWvRl/CZanwDgSAZ+3Ha3okB1wQTAQIAwQUCPxX0L4YUgAAAAAAaAGNzaWdu
YXR1cmUtbm90ZXNAcGVuZ3Vpbi5kZSJodHRwOi8vd3d3LnBlbmd1aW4uZGUvfmJi
L2NvbnRhY3QvcGdwL3NpZ25pbmdzL25vdGVzLkE1QzgyMDk5MTlGRkFBQ0FGNDFC
QjI5QjZDNzYxNzhDQTBFRDk4MkQuYXNjIjMaaHR0cDovL3d3dy5wZW5ndWluLmRl
L35iYi9jb250YWN0L3BncC9wb2xpY3kvdjEuMS8ACgkQGaJoCYg4/ZT6JAgAvfif
YdKHBnC3Ezv483f2fsdF/jbUNa+1iz77iFI1dRa+SRWKRVbglKeznpT8GYbw6+82
gxWZ7Xotbn3s5yGLXNYP0vBhek1YG0zYig498ROlIc8OPwNgCEVUHj962FFfQSwF
2CQ+2e7h5PRll2PRpZNQCzm+c5Xj9p/tslSBWQ23/1p1U7eI3bvfMLVRx9tC/nyP
sQo/V/yhIYPi4Ys1anBCl0Gin9g+eg4ghhWl7ksOZqG/Oc6c6viQsgVME4eKVHpl
jdOj9WCpWIYar2Jsf16ITOMlYnGB4a3SJ1kxfXVR4lhZCaZ7PhVAaEH/GZC1ElPz
jbKLNdvCTfe3GMNTBokBAQQTEQIAwQUCPxX0PYYUgAAAAAAaAGNzaWduYXR1cmUt
bm90ZXNAcGVuZ3Vpbi5kZSJodHRwOi8vd3d3LnBlbmd1aW4uZGUvfmJiL2NvbnRh
Y3QvcGdwL3NpZ25pbmdzL25vdGVzLkE1QzgyMDk5MTlGRkFBQ0FGNDFCQjI5QjZD
NzYxNzhDQTBFRDk4MkQuYXNjIjMaaHR0cDovL3d3dy5wZW5ndWluLmRlL35iYi9j
b250YWN0L3BncC9wb2xpY3kvdjEuMS8ACgkQqx5LYEZ1ax7SjwCgmoUN3NUQ0fQw
bmHqkVnBCc/jL8YAmweyJNMQNKsDC0frsHFyejRnNGumiEYEExECAAYFAj8TsOsA
CgkQ58nbr+NW78AkMACfWs9ycteAylXk2RTrD5RHIYXgrVQAn0VpM3W6vemovNt5
zQWuHwUHKMELiEYEExECAAYFAj8W3jwACgkQO7/Pd72LBQ2EJgCgqRYVlay6OEUR
eBS4I1Rj2wKtZrcAnidL9ET5crzLbhC9Gx6/tHWhhPPriEYEEBECAAYFAj8Ro7oA
CgkQ0Bn175Anq4jOzACeLP5omUoyFcsNXRdWv/IYPBW3jLIAn1Vg4cqudANdKnKB
SoTDTh0YxC60iEYEEhECAAYFAj8RGzMACgkQ9LSwzHl+v6vvzACfaVizS3TQYJEA
P8o1Qaz/KbQaVmwAnj5l/c+7wA/YOzu5sJpArDrXZ+CRiEYEExECAAYFAj8X0bUA
CgkQkR9K5oahGOZPrACfaQI+NCA28YYgnl2gjmoI1mLl2/QAn38tDQ910otKemZf
9Eie7p/zTbGZiEYEExECAAYFAj8ZfqoACgkQZmZxetuDVnl0pACgiUtNtNoOd0Wb
siifl8jXtNOzkGMAn0WikIoLoN6BlIzYMWjJNhnttKt+iEYEExECAAYFAj8Zfs0A
CgkQDZZLZlcOberQGQCfV4ZlNvw3wH/9ta7BKKgKBzVHj4MAnj++kNQTiMn7F28N
rqv7oavDW8DyiEYEExECAAYFAj8ZfvoACgkQTgKsrh3Ws4DaHACdG3J2dN/Ht7In
qFmFAp+bsPIGxKMAn349vGOvuO3WGqcfgmM+8BDNoVzJiEYEExECAAYFAj8Y1KkA
CgkQzop515gBbcepuwCfUEZxQi8amnQKl1RS/2Z4MasB/YgAnjxMNuDjHxEIjhwy
Y8Mk+JtdWmVpiEYEExECAAYFAj8a830ACgkQLJg+WtKKVdZ+rACfXkoiYy82nK/i
YRGzPYcBV0hjwLkAoMGxpR1weQQwjgLYea8VDeSU66ZfiEYEExECAAYFAj8cTwUA
CgkQcV7WoH57isn++QCfbhjBUzU5EfBMOxwXHd80vwRWTFsAoJMp0cfimpqtBYRe
uwaCgUmuHV+EiEYEEBECAAYFAj8VtNkACgkQKiV7d8Y3KNLBkwCgoA0kZroWq8B+
ag+qFhwgFfTUGGgAmwcQ/qJN0IO0d1Zu7m7ex9OCUxfIiEYEEhECAAYFAj8cZygA
CgkQyA90Wa3Cns0OegCfUFBDn9FBailXpLIoksAsZ27NSkgAnRI70vpPjFvb880q
bgF3TkMQuVJ2iEYEEBECAAYFAj8dqfAACgkQiwJmWbaNX3/9/gCbBaaHT1TQNSp6
Y/EoRyYqBAel8IcAoKWvO/u8TwpNruMH+WH11TB67cDXiEYEExECAAYFAj8dqwcA
CgkQ3nqvbpTAnH+negCfcddCOdcCmF8AxieobFEgaFM5SzAAoJLWt4QuQQMb+5LG
i6HOfseqhvH3iEYEEBECAAYFAj8dqDAACgkQKN2w/RnJtroclgCfTWrG2BkWpeG0
peOeyfnmeBWI64AAoNYCOG5EA+52XuU69JjeIqszZf0eiEYEEBECAAYFAj8ehJEA
CgkQbyOLwk/aWgz09gCfZWcalQyB0a4G0QHSD7VxkWFTXyUAniqUNQKvts2I18wQ
zH7F306DZe4ciEYEExECAAYFAj8e4VYACgkQlJsl7AdEclLTGgCggsUlLw5yEf2M
1Cnaaw6N0Ad/l1AAnjB8UZ5fTPJSKPUgFpP/hfflfCvNiEYEEhECAAYFAj8fDVoA
CgkQ500puCvhbQHOOQCeJlrssgsQVNCb42WxqaBp6e7Omq4AniuERsB6p23quHNG
l3tkpA77MRtAiEYEEhECAAYFAj8jmNQACgkQGKDMjVcGpLQElwCePTqpW7AWzc+f
jU4u1sObSP9kOkcAoOX/pYt05VCXzkKaIDiQsitAW1zgiEYEExECAAYFAj8kSI8A
CgkQ+FmQsCSK63OKnQCfYoWfh8UGrL+Yc9UkH5fLdVLSpGsAnA87zg5HQWV9VKgk
wjA7Q1gk/o+TiEYEExECAAYFAj8ldG0ACgkQ8rUqXQpftod80ACcCIEO/NksTr12
Ka3M+xwdwR8APPwAnik0OuGabOoH1cdM9ucb1c2TuVyTiEYEExECAAYFAj8m4awA
CgkQiSG13M0VqIOS9wCfYTFqZOjyXShszGT/5n1P2BnHAXMAn1laYpV9MlJZZ433
TunwfmXAaW8KiEYEExECAAYFAj8m4bcACgkQBxd04ADYzRb/QQCeIYeWMEtqYONp
EFShsdv9jT3NQp0AniNQSdgk02WKnIrgU7BdKwqV3/6piI0EExECAE0FAj8nyJ9G
Gmh0dHA6Ly93d3cudHJhc2gubmV0L350aG9tYXNiL2NyeXB0by9rZXlzaWduaW5n
L2tleXNpZ25pbmcudmVyMS4wLnR4dAAKCRCkec3EWrRgaumsAJ49yYODSjXTHdF4
uogHi2icoLyOkACfaqc1xnyfvxNnr8hYGn1HHh5nXyWJAWMEEwECAE0FAj8nyKpG
Gmh0dHA6Ly93d3cudHJhc2gubmV0L350aG9tYXNiL2NyeXB0by9rZXlzaWduaW5n
L2tleXNpZ25pbmcudmVyMS4wLnR4dAAKCRD5fPnjOkt/Xa3sCACEx/OEdlEQQArf
alLWO4GlbfrBTrhzUMc5gmOFxPbTTu0HBg7xFNtPV9tcTfs2sUikM9OnzZo6DBPs
teKvF793G//Dt10s74WvJB1E6+K6PM2fYUancvcqGt61wSx1DiP1gTlh5ifNNJxo
azU6tMseWp34UtWT6Jzh6cciUAnKQEIi1Updi3CuoUnPL8s+tv30CdXnQOY5eCSk
ymCEOicjXgHgIyAsAYdmybd4fsl0wJbXeiinGf8Fpp3AKsbqQXNaiGUV6ghXTNND
NRDd7bkdIjrSpjWdqQy8eA+3VVU6YvM3GWpeLBHGo/6egjk2oymEpjOno4M7KVG8
xyCWcG9CiI0EExECAE0FAj8nyLVGGmh0dHA6Ly93d3cudHJhc2gubmV0L350aG9t
YXNiL2NyeXB0by9rZXlzaWduaW5nL2tleXNpZ25pbmcudmVyMS4wLnR4dAAKCRB5
BXaPdYT12AqQAJ9olcgtXD9q6blGQ9oMBzTO8qaLtQCfeTuMjvpcK9qgry2qOxz4
c6j7nlCIRgQTEQIABgUCPyfIxQAKCRD50BTwOMmFjVDVAJ9+NLIHcNgIlrfSYvT1
wSSkr5lKgwCgjktXHVXa4ED+qK4zwnE/iGEaRZ+IRgQTEQIABgUCPyfIzgAKCRBd
D39J4OSfNJhWAKD9qwn9gmx4l6sm6S2UHvKv+9OA3gCglkqjc52se5S7rxkZUG3M
Ol5PhDaInAQTAQIABgUCPyfI2AAKCRAbsIu/KpIyJTG7BADYnvRfP3BEmDAn3gzO
5xxWc+Sud2OcAX5VTq9p43X9YY/I4+ziJfDt4rw+nsqncykJS//9q5g1aYIp+6Ca
JYbwMUE59aRuUwA7hCFKPXYThA/ZKs7Z7SziE88OrED4DepXNUSQOHWF7a7OtLz9
fMLhsKmFQ41IEn9V3kv5b0Ffv4hGBBMRAgAGBQI/J8rAAAoJECm+XSJo/VSfjPAA
n2Lalf12Ql+HKytgVbyZqe9zgXQgAJ9EMknNdmFIlW+m6xCHsdCJVVbGaYhGBBIR
AgAGBQI/J+E1AAoJEJ/PLM0/PmQm+nIAn1+OSW2iFCAHLltzx1HhCjjb9qUfAJ0V
wVDDriT7AyFpxZK0KjxwBk4X24hGBBIRAgAGBQI/KF5JAAoJEJYkg+FWYsc0JaoA
n0xQCU5ZKSxpn6S/jQ3ibIuy6FpkAJ487HCwK6/iIQADjZ6PA1wZv9VkmYhGBBMR
AgAGBQI/KRJIAAoJEALW7SHjLE9LVswAnjYbOD95v8Af1QDnZJRQ8z5Dgh+gAJ9U
rmQoearNZM43GDJNYuGFaCZNcIhGBBMRAgAGBQI/LkpUAAoJEDkiDW4MGv+7/FkA
nRLppa2/GDsYIcx8t+XWFVKw7LkxAJ90TrDbg/Ku9/cNYe/pjwwV/hMp0YkBHAQQ
AQIABgUCPzAw6gAKCRALeDLzc9YtQWc1B/wNPdo9LSVmAU/Wap4lf/BgSVVhHfiH
pE1HCJF9J8Xx1+9ZamYwFHNMoeuSdAjluz6sDWHQY7igY4gjfpKzLv4YoQcS4I6Q
EzQTbZfDgXBjkJUtY0ZyJpGMehDLrmPJOF2gpYnwehadzF+kI+YW0or1cwia+2G/
Aym8VyofL4MXm2Hws6Ym4NjoYMqhWPPI26OUSXBjD4aw3frX0LAhAhhvc/C9QfWx
BzxQSyZcmonPvwGvi37tNBhNUJE5sRcEioGJSVhFDjZ85AFDRgwSRAypHXWUT6Ho
QbQgPjPDVcbxEqNsqShpqfgh65ptFEyIj1vkbxmyFA0eHVyH0tZR1lSDiQEcBBAB
AgAGBQI/MDEXAAoJEBmrr+wdsjSrrfQIAMSp3UhvfocyuTylAJr6v7PiT1Pbdhck
GmFYOsk5O+zUho9Z70ETbWqIuba5ssjldIUmnCvc45TRneCAKMLRnNnNTDWKn0Bu
+kvHeQdZq7aEkg7q6pufJe9lc/bf3aCzOLbTfuyMNLovL4a18QdiJkACiArhcW45
qpjtFmOpDDYADY1qBcJ9bIf9dFpFvccPqkStHEbYYC5pNc1GtY8ky7tE+Og1en10
AXmIxoB0fjvXpFEukrasz4rhsdqsMkQI+XoHAWpDWMi/x/+lCr3tpu2Gry/Jah5B
zZhj8ui8ETIz+zk4+D3AmeBVqgtqZdCUEzaN9VUa8tjCFKHEVa02+LGIRgQQEQIA
BgUCPzAxKwAKCRB4XzBl/r1L3ECIAJ0eCiux15E4V+VJhAI9VYWmZODttwCdGaqG
/Y/sybsl4PHNZ9NpUBh/FkKJAhwEEAECAAYFAj8wMUEACgkQfDl6X8pm0LFl2w/9
HQERgH/7URJy9Kkjdni9uJN2goE8XsbJIKCt6WyTB2F7p7bwPjf+SnZF3vQCQ4wG
/SeR5hc+24vS6g7OpstJ55S+rACIzUgeFynkUSZV83cE7c1fuhoS+V2wh/FOjL0J
P6idaNgQzf5joOhE0zpMUIywqyqH+T7JDpWYgwU6s0M981WBIa4Smdvb99KIjBOU
JCm0usouGvUUuNW16lwzzkfJ/qEKUiY5vpQNv0Lv8fKlCL/wM15UX1wqEPkvc4Ib
BtBLTVbT5k9tqU5e0SduyGzNVwSybT4fxbWI94GejQd3RPuPP6IoYhvoncY4ho2Y
EixbKFBX348sRgPc2wls4Kqj7dCo73bB0ibbOI7DN8J824BuXbuKu5C+ZdCQM7zA
+E2K+ZfJSktgHuXq6W/Taeqs10UiGLkG394vzwVJID27FqgafRKSoCYyIU9/j480
brojzcXRfdOUVXfnqMY8Ss/xO+NfmiWwVk2pEiMNNyFQU+5oQ3r3+INXfY36gz8e
/bYovv5qmwdgQ94bOU+V/j+xC63UgFAXA/N9UweWeW1XhLHGPP7rdgFzTyIWomPA
/DrsGkI2B9PK48uGbkcTKYl7bGrqh+ANPN4gLVohp/56Dmsk/oNvLHstVDNuRk2k
/YV/WTT5q7+X7JiRpcfytFCrZOP8WU+4AEi7gdpIcE+IRgQQEQIABgUCPzAxVAAK
CRCVhFGirc9+lBXbAKDBJmrdE3DxoHK0bJwsN5EckOTu9gCdFMulMvpPbmDlySI+
hL9Gx7L/g+WInAQQAQIABgUCPzAxZwAKCRD9SjjcKHYNPYJhA/4nqee92MZijuG2
5X1KAF9DA8soZ+dP1rzb1bLyc2DRQBPxUDFnvCi8t86eP129nuBEjRio0fJVBva8
2wHvylQGOd5XBxyBtMgX9ZtaIj2JZiDb4RrYuUwpmsuB7uKOhKt6NmZ9lhveDT46
9CXrFMMSQqcDkQTiLe0eQIbMi9hcFYhGBBMRAgAGBQI/NqX5AAoJELvHFNGcZ82W
D/UAnRExqoFW3L3j+Aoxsw5CHx224HfRAJwJerLot2mcAIfNB7npjxdZk2yK24hG
BBMRAgAGBQI/N+VyAAoJEIB1JwBlqEHtM+0An1k+PgllLDTk88Z1kzNfwHSxOnvf
AKCHWseWvQWd6Uk3//whXYKV4ot9aohGBBMRAgAGBQI/N/gpAAoJEEXAIUdpq91U
71IAnRo1KMe0RMD6M4JjuIri7Zy2mstBAJ0Vpg2C+YGXvd5YZ+mnPTKN9WXPM4hG
BBMRAgAGBQI/SSifAAoJEI+5tw+kz8luQUwAoOOKJaJO6SjfsxiOm5NZfF2pw6sj
AJ9SlkPdSyqD58xJwxlb2xAs58WT+4hGBBARAgAGBQI/NUxTAAoJEGnSph3iY/zU
O0kAnAl3RxhXu/wYrZf5ctYg4+2SzzGwAJ4yU/n5w45/eAe8D8UGHpobqHEKg4hG
BBMRAgAGBQI/jb89AAoJEHninGCwBj/nSVkAoIL3Ab36kDrxCdNbXMjpk6P1c3Rz
AKCUHLn2aWUpnAeAegsLnBajoH41qYhGBBMRAgAGBQI/jb+cAAoJEMYEPFZyB3E3
Ea8AnR7u9awHvpFa3GY4qUDp+7VEgMTJAJ9tOR51tuXusrWNV6yx2++nV/rjLohG
BBARAgAGBQI/jm8bAAoJEApi5TQ3p5FJAE8AoKwSSlwTiVCZi3N/2meTpJU1oat+
AJ9+z+XZyJtnJjucUC/izFVbl04+qokBHAQSAQIABgUCP45hTwAKCRAVOWp5M+sF
mjeNCACIaGM4pyfLZQiOCUK7FZSgHx0lFTpgs5pwH3SBcZGKV7QQqYsfzCL2Zrtj
/wjfu9i/JK3Sj6HIKiGoS//JrAO76tj3oaSVS7tWfXoISTfQScWL9ptE9ZAPhbfy
kZju+37HDgqVbz0svvF9SqpRIbKwhHf/MFnoGhhbfTU48VbMBJqX1CHycWuSUG7k
tAaToJMAXUzWaAonLqR434r+CKSHBC47tt5kk2135E/goUqpe3PsNxPvXooA5wN0
2BTfhFydGHTBOb9p3/IMZR6t6FoRGHuMiEe820QXOHM+fMYxFUAaIedjqu7dww4q
TJxO42wvbAyY9obZxp3dXR+nEjVviEYEEhECAAYFAj+Pw3YACgkQxVhZCJWr9Qy2
UACeLxedd4vqG5XVdoIS01n+76o3DDsAn2hyLlvfZVikM1P3PmC4QBEH2kkeiEYE
ExECAAYFAj+QIN0ACgkQXse+NwPOAZ7eIgCeJkRZTx6pHGwuKB9R4KjsTVcB5kUA
n0nOi57LKtxGWf+li6J69oHvgcugiEYEExECAAYFAj+RGSMACgkQ46aNyqaY2pnW
6wCfdCy8jZ3DEW+W9Hakp2ler6iIdo8AnAojg532UYtlykBDf0Q6m3MsQdE/iEYE
EhECAAYFAj+UNQ4ACgkQnQioDO2QjWq8fACeKiLVJ6IFGRb9JbXnkCO90VrHUqQA
n282TAi+qgTgM7dHOheLzsEyKxDriEYEExECAAYFAj+UQecACgkQgyl76qYjEdZU
WwCbBUbR/gk/Uhcek7avclOtrQVrIIAAn0qpM1m1XUL7ixgmtdennvoiCNeuiEYE
ERECAAYFAj+VbQcACgkQlSxWI2ynbPTjUgCbB4KpAPDi4QagoP1TD9NW8iX0E6IA
oIAPYV97iIqcpDtYJUDpMXjbON7giEYEExECAAYFAj+cMbUACgkQNgJWU6vgsQZo
4wCfQc/5xH+dyqrjVGdhWMPd0FQm9TgAn0Qc5w2LZae33c/w719es5x9JZSliEYE
EBECAAYFAj/MHtEACgkQoL6dujuIbn02QACfSJtqsGWZOtgpML/VSW3RDSP1XHMA
oIGyEKajsYJrQNpGdzS+tRho6Pq/iEYEExECAAYFAj+iix4ACgkQ8vvXZt12fkok
XwCeIQla46p2LNJoMKmZCTW9HBxYOfcAoNMLxSOuxcyZNyPTM+NhNwDgF1uQiEYE
EBECAAYFAj/TW9sACgkQkdi6ijTVyg343wCbBSH2dPWbpCqYD4omdshxDEI1FMEA
n1eFHJemWi3pGocyh+fyEYJfMP5ziEYEExECAAYFAj/Tjh8ACgkQrxRSXsoHIeYN
LACcCZaXkN8BlR46SWC71qVYMsm53qsAoM76dKYoTaA8CdaS4GbB0W66rd2siEYE
EBECAAYFAj/TwGAACgkQYb5H+9Ze2NfDuwCeNXsqExTieZcI2eIUez4kWhh9ymkA
n0V2Mnj3FmpGaZvdXg65IN+9Tr5viEYEExECAAYFAj/UFwAACgkQzfT3onTsQyny
RQCgj5bFoIb/wfXBjD/R1gS/AKIYdvMAoKKGAfp9/A1Rz7an7AQ4oTvYYm9eiEkE
ExECAAkFAj/UxMwCBwAACgkQBy76KTKckK6qowCdHF8ZRa7YRkAknNOCuvznq00X
CKgAnArMww69/mIB3eBPEwkZsDhp3FQjiEYEEBECAAYFAj/XiH0ACgkQNQqtfCuF
neOScACeIaxrzXRm+hcUBqt20gjmY79Z9f0An1XFQNpkwdjl2EUc+5bm23eSl/hG
iEYEEBECAAYFAj/Xcq4ACgkQ9aLWrfOU0Ph+ewCfeFti16lB5A4sHItngExL66kx
O7gAnRm8mjMBtUuqpRCBx7INcdEWuUAIiEYEEBECAAYFAj/XpgUACgkQ/aHb+219
0pFxOQCggwOUQaonajrYVJ9sjpAV9cwvBjUAn2fdSGhIIrpAh4yqRq/R6ZWNIREf
iEYEExECAAYFAj/Xv+AACgkQcC9qbtgxVkMFPgCePvZowhAxOSDHnw9f5l0+6HqJ
IVAAoJM8h96F8pD0P31AkyFo+qodJdOUiEYEEBECAAYFAj/XoWkACgkQzCIUKbtG
VYIdVwCgyA3X6St8uQuLk5NqGQmfxoIupl0AoNwW+p6/xkVwk7i+vYNejgc4mXqW
iEYEEBECAAYFAj/YpB4ACgkQDq3Sz9XRqj6ILQCcCb5YSf+tgCZwKhkQW7dLG/Q5
uN4An1CuhFSX1Re/bWXnPNqB75vA9olAiEYEExECAAYFAj/Y38QACgkQJPQmYjmx
i4FnvgCgh5t5z9lZRj+bKqs6U9oX9/78Ez0AoIH8uVRGPErq4kvzbpC6UUmsYtR7
iEYEExECAAYFAj/XuFAACgkQ+KSYvZS8wB9DpACffLxLgKArAgSe+5v8JY+0I+S/
lrEAn1zE0csYp8+u+gFGLsBHyMQKDhqGiEYEExECAAYFAj/XvtcACgkQAeqShO1J
BbvW4gCeIa1JnXdnd6LAvwQr+36bvWUu7wsAn36jHN0o/+Tbyj2QN7YYAa+gYept
iEYEEBECAAYFAj/XnWwACgkQh11XSMrLwHQlJgCcCdRD3EUOL8OsjjK5N1vPnUob
NgEAn03ghR+B+mIsgAVFES1LtgLExrSZiEwEEBECAAwFAj/XiA0FAwHihQAACgkQ
dROiNhMQLPVEHQCg5yjQ46yGPV/f3IzMSnukdxsJ4ykAmwTxZNo2QYHy7XorN+Or
Hd32s6CQiEYEEBECAAYFAj/cWVUACgkQelwNae19I7hnoQCgjHPwlkB1qPfYO6ra
psHejUNxzHQAn2oZtPFh+hv87UTj6gDfuq3n2o3CiEYEEBECAAYFAj/d5nsACgkQ
j73eiy+kMR5UtgCeNX28gshCUcouiyLGrmOd2YwMSC0AnibfMx9aCqtqIeOjASNn
MBFzKY3iiEYEEhECAAYFAj/e/GsACgkQLgAJRlBWnRh1VQCfWlhVyLnyHWQjtNg7
TaTfemcfGBUAnjMDr9mwygAmejudhpkITSBzrwoIiEYEEhECAAYFAj/fLOcACgkQ
gzvwJ1ryljAGkgCePOfIerD2DXKN/TQPZSVaN1ZmiokAn106i/qfhQSzb+Q4mMXd
8W7cGFSwiEYEExECAAYFAj/Y7VgACgkQZzP420x1p2t+8wCfZEAl8wfTcU/5uHMV
qW3os+hgnAQAoI9h7QIYR0QodAZa9IH3KYS7tmGsiEYEExECAAYFAj/mQ1wACgkQ
GnR+RTDgudirrgCeJX/yn02mailchnH3d3JU2jtRIyEAoI70nHxlvWxsNFYmCl3z
4VoOrW4YiEYEEhECAAYFAj/vPLwACgkQ3zaE8GN48xvn1QCfQss+3kXi8X29t6wP
a/cRp4beIV4AoKcBgGMzqqIjjkWY/HFs3wH6xFcZiEYEEhECAAYFAj/vayIACgkQ
yQMBxhAreU0bVQCfb3mCqIlHn7ZElS+wn826yhBOmPoAnj1WgD3eC0NmN3RuYoMx
cH+PU4EOiEYEExECAAYFAj/wRzYACgkQiwjDDlS8cmMeVgCfZzXplPy/cMDzQgGu
Vw6xFauSPScAoJCrOY82iK2x5l2AeUHgZLbojXZDiEYEExECAAYFAj/xNU4ACgkQ
SUvu2wE5EjuI3ACgiv3k4RqBEIUss5RvpepAK4Y3rZgAniVupZfQ/r68I2rqi1I+
AvOijuOWiEYEEBECAAYFAj/x6dUACgkQvBVic1oTsEiB6gCfenXdk7gGBkdUBXlg
LTPC0HDomo4AniprCUw813XbLcsLmZuvq7B1S4ANiEYEEhECAAYFAj/x+gUACgkQ
CY7iyqpOgLZztgCgpU046MI/UGnUqLvDrUDMJ/ekUNwAnRvpxtlZ8vrQwz7BkegV
tDEL/EB9iEYEEhECAAYFAj/yEZUACgkQ0+ZxvPFTY6ET5ACeL5K9erZny9Fn+sph
Urujs81JoLsAn0ZY7a7bwsJmKcGo2WIxvKZYpru3iEYEEhECAAYFAj/x/nUACgkQ
ifW7lGXJEoXSjwCeN23wVo5QMXvHuRybSW0P9xaOlJkAmwQZzrqv3bccOPn2ElSG
9CVeR8PtiEYEExECAAYFAj/zKT4ACgkQEfTEHrP7rjNvagCfQfIxhFnT9SG+GwRE
mGzDjTSS0AsAoKYG4lqU8G0uxzaLKxIXfBSDqH63iEYEExECAAYFAj/0V/sACgkQ
9PcicYLJuikMCgCgpsrWYvma/TT/z1SN1bakeboTsIMAoK40cDvcjh8dmBgFFzer
V7zFE1DbiEYEExECAAYFAj/09ZEACgkQ4Wmz+z2IPqD4GACgulNNmi+P8uuVfBZf
Vu6tTVUi+nAAnihwwaspuMHRmwhRq/odU092ukruiEYEExECAAYFAj/1JicACgkQ
Lst0AlVuMNeqNQCeJnB6tTtOGy2ds9Wf+hjWz+/FG4YAn0wM3Sy6EyhP89WC7uMf
K73QbeH+iEYEEhECAAYFAj/1sW4ACgkQnNo+exDKny1iBgCg0UmG9Hg4N/IFiYB7
wXPDppwNXM4An2F+XXvbwOujAi3OE2S6plVuNTt9iEYEEhECAAYFAj/2GVoACgkQ
KLKVw/Rurbtu0ACgmtoTOXHwAD9Zu15BVxHb67UXYpoAnjzRra4Z2Z3SiJnzF83a
9Uxcd4x8iEYEExECAAYFAj/5oxEACgkQRusmgsjeDU2RhgCfcRKpJ1bq/ymHtui2
1j3Ufn6UUF8An3rizHdyEjpDdpUQ9u1eRfqMsPb+iEYEExECAAYFAj/8GhUACgkQ
jO6yWbPCgfROwwCdH3Ws5B9iesex/7R+/YWBD+M0jiwAn3/eVFdelF0T0Utzv1Ke
eNQwVyv0iEYEExECAAYFAkAFryQACgkQuQ3Xye1hlT2AswCgtKMVir1GSuv8Rocy
RNC107VTmKgAn3MteSt70GWM/nS239p8l1BCh7esiEYEExECAAYFAkAGEqsACgkQ
RCBj41UDsd9xLgCcDIDSlanmS96ZVrMacoMGCh0HNmEAn3Lo4X3MVBR5SiU0gb3x
LPo5CoDMiEYEEhECAAYFAkBCeEoACgkQmHaJYZ7RAb9gzQCfVa+qGad+Zkq3Zx18
9GSZaVTdroMAnRP9xE+TFb+HI6vzemB1iif6g4BwiEYEExECAAYFAkBMc2wACgkQ
r2QksT29OyBpgQCeOD2lTaqwx6lcbCm6wnrgi2h3/x4AoJ5hpBI6yNCviCS98xI/
D0BHM/xziEYEExECAAYFAkBiIT0ACgkQKljOqlJpjp9upACeIoPnG/ikGvzJqIt1
uaSZgZhLgEYAoL3B3xaitxopYNChyQMMsDkJqSCQiEYEEBECAAYFAkEM6sIACgkQ
XeJJllsDWKKrKACeNFxuWsAZ9Z0MYh+3Nrar7xZIQr0AoK4gNulVz45VWEprn1Ls
W9CAZHgHiEYEExECAAYFAkGE4iEACgkQqy9aWxUlaZCpeACgx3Rd8oeXCxZQ9AnK
aXydlAcEBjsAnRul8Qx6J497R36LPRjMcozPSDQniEYEEhECAAYFAkFA71QACgkQ
Bylq0S4AzzxPxgCfXyT6YMYhkuJV5R5ZhTVjzpaRfI4AmwaASBOAO8WQG00kfjoN
8lEDQRRUiEYEExECAAYFAkGEzjUACgkQP6DeCKDTkWgquACghQCx33B4V97w8hYw
0ZJiVG5R6lYAnA/LjmnEXXQ6VbkqrNhRDbMWuOLRiEYEExECAAYFAkGalesACgkQ
XY6L6fI4GtQYVQCgkaUgKPC9J/ghbEGH17tKZy5iAJgAn3qCoFUWERhP3Ws6fDRg
lfnALMneiEYEExECAAYFAkHlLtcACgkQ/H2Ek1xrBMmz4wCgoN5+t/5mZZBT63uH
RQOSzxhQySoAmwRs+Yon6K05ds8ssnVxr7TTy1QBiEYEEBECAAYFAkInm+YACgkQ
X4f0Vv2/NxzBTQCg0bVg4f/8sD+F0ljinZi/LxclIpcAnAmAhAjI4fCM/GVlO0cc
amx3VVxeiEYEExECAAYFAkJZlc8ACgkQcBdD8e7nfkVGVgCbBZVJ7UqpEGGOQlGz
pF1qhwhPRYoAn1xjePg7u8yp1odhfQ5iy6wDmTrViJwEEAECAAYFAkIcKQcACgkQ
5RUoJTMc2l2e6QQAmwapMcggHaXF7ghSTI25YdBGuY5Mq7T1+OP5lVO59FGTbZUH
4/U/7HZm+P/OsO8m67jZs3gXlwa+ry1XNdTKbUvbleNulZm2dUtnFCjT4uhVVh0R
G6W1pjLa1zI33Dk89EX7M9yqao9bLf/oo/xJtHnk234x/V2nlk7lD2f+D365BA0E
PatA7RAQAPkYoH5aBmF6Q5CV3AVsh4bsYezNRR8O2OCjecbJ3HoLrOQ/40aUtjBK
U9d8AhZIgLUV5SmZqZ8HdNP/46HFliBOmGW42A3uEF2rthccUdhQyiJXQym+lehW
Kzh4XAvb+ExN1eOqRsz7zhfoKp0UYeOEqU/Rg4Soebbvj6dDRgjGzB13VyQ4SuLE
8OiOE2eXTpITYfbb6yUOF/32mPfIfHmwch04dfv2wXPEgxEmK0Ngw+Po1gr9oSgm
C66prrNlD6IAUwGgfNaroxIe+g8qzh90hE/K8xfzpEDp19J3tkItAjbBJstoXp18
mAkKjX4t7eRdefXUkk+bGI78KqdLfDL2Qle3CH8IF3KiutapQvMF6PlTETlPtvFu
uUs4INoBp1ajFOmPQFXz0AfGy0OplK33TGSGSfgMg71l6RfUodNQ+PVZX9x2Uk89
PY3bzpnhV5JZzf24rnRPxfx2vIPFRzBhznzJZv8V+bv9kV7HAarTW56NoKVyOtQa
8L9GAFgr5fSI/VhOSdvNILSd5JEHNmszbDgNRR0PfIizHHxbLY7288kjwEPwpVsY
jY67VYy4XTjTNP18F1dDox0YbN4zISy1Kv884bEpQBgRjXyEpwpy1obEAxnIByl6
ypUM2Zafq9AKUJsCRtMIPWakXUGfnHy9iUsiGSa6q6Jew1XrPdYXAAICD/452SqR
qgEr6leAU7Ls2WJ5CqMIlPLRlMm0jvXzPAjiQN0HwA84KwcAJ+qTA7B5VTpG37AW
yr3GvEjqzl5rzUxF3K6+NOP0CaExn34N89XpoytviumgnEvfIhP/1t5jRrhboS2Z
B+HKBYHYIF1VJ1yQt1FpirLwCRHtl8T3ZCj2IGD3u3qUJ7YOhqQGZ5yxiKi4yUCL
occ0tWu9PX8XH7ENIeJABvjpGZnSzDNZVddF4Jwsg/NMx48dbzY2ooxJoL4i+B/s
YOHMV+YWAHdlD4WpoRinCx5k7+XY8Q7fH0nB97LgWn/Noujch53eRIKxKMoPs+VG
VbKmdyN7qb5EB8vmiIx+giISjO9bnvr4O1negFZ47Wwqt8SEO835CSKIVnygkpp/
LwQYiRIvxfasjV9g/fdlfr99HPv6BsC/1by/TsfQjqLlb31upyX+lSjDcA8u702I
DEqexk89AjVtNi2kwc4wbC3YzJrAgCl0zgPZXXFlUrFx/oei0rCw/5yfTgg+ijLp
SLF3CliUK7yi6jR9U3SoBEclJ/6fw5tVvmpAusoSxjejivUskS6x/8ugOpz7f5h2
jrtIfGxOu/+z5Do0FN5CyLeTtkB8UmlYWo3Z3R3X8Ru9podoNKa9PtlpUQnnf6/7
HgkuYxqqt4HaE83nCbnAsIYLE+AI3ah4O9c2XIhMBBgRAgAMBQI9q0DtBRsMAAAA
AAoJEGx2F4yg7Zgtb4oAn0iasOCEKzAW+LT8Or2Jj5AJq8IeAJ9q5YKV/kuZE8G1
otqKGK6X6iceCg==
=yns3
-----END PGP PUBLIC KEY BLOCK-----
D.3.26 Markus Brüffer
<markus@FreeBSD.org>
pub 1024D/78F8A8D4 2002-10-21
Key fingerprint = 3F9B EBE8 F290 E5CC 1447 8760 D48D 1072 78F8 A8D4
uid Markus Brueffer <markus@brueffer.de>
uid Markus Brueffer <buff@hitnet.rwth-aachen.de>
uid Markus Brueffer <mbrueffer@mi.rwth-aachen.de>
uid Markus Brueffer <markus@FreeBSD.org>
sub 4096g/B7E5C7B6 2002-10-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD20hPARBADzumxDOkMdttpWKphTxFC/j0+MJRW5UmFjd43c301LEMFSJMkv
06EukQSOVWGyGL70v/4NWx25BiLhLDIb4feE5SZccQTnjxXYCjkQ4LfcolqTAzga
L3GLNF356vKLQPlv6J5ah3vdZHa8Djh8q0s6CHAPi2rhEVbO2x7IcRW6MwCg/0+E
KmRtdsifDJ00iBEMpJAApccD/As/bzVXI4FZwjwIMdep9+He7rwL/xGK+ZmRUEoN
iiIxfd2oOkwDXZuFqTGftONd9Apao+FefTbcpEfv7sBVzHCJBn2bTr5mTjDwuA8v
hGQ/7+QyKIFPmsL5KZYPkBcRA195UBSdwEPdERGH+aWvDTVJieyetAiD78WTd5ez
T0V1BADwVnc1ABRMz6e8HK+78G/4vMHKPPEC7YbSmOo25FKR7XimUIlvGfj+CNO5
w6QSDJaIRo9yOCPEacMe91NeZskPlEEXN/KIOlV11vTZ/pVDMETnzdarNo2B7J2K
4HQzTYBzfFHdCrKP0tExSCy0iN2lWzSI57S9o8YxgnwrmuJPN7QtTWFya3VzIEJy
dWVmZmVyIDxicnVlZmZlckBwaG9lbml4LXN5c3RlbXMuZGU+iEkEMBECAAkFAkTZ
3xQCHSAACgkQ1I0Qcnj4qNRBCwCglhvWAuZ+9bWZ64EXP9wHLiQYT1sAoPGL96ae
YBK0wnq1TWjE9GPTYFXAiFUEEBECABUICwkIBwMCAQoFGwMAAAAFAkTZzskACgkQ
1I0Qcnj4qNTguQCdHFTLRplJE7g607rCVSxDCefYw8QAoIMaWQv0Iflm5aAR0F47
3WrjQplWiEYEExECAAYFAj20imoACgkQbHYXjKDtmC1WawCfUZkir7Dy7wP3hiNA
X8yo78CpuFYAoMJtyYVOf8fayYICxujAO3zU2pjViEwEEBECAAwFAj53axIFAwHi
hQAACgkQT4OMtyagqBYphwCdFiRae7gCvrB/jFA8ceyXaEP44doAnj41sLHZFGWI
ZUmQmNTiNfZXYoQQiEwEEBECAAwFAj53IYwFAwHihQAACgkQdROiNhMQLPXCqgCf
SgcJhp/6tnpjypjXWH9t6uKHg+MAoMYnXWc7iXVFvi99BonJW15V63uptCxNYXJr
dXMgQnJ1ZWZmZXIgPGJ1ZmZAaGl0bmV0LnJ3dGgtYWFjaGVuLmRlPohPBBARAgAP
BQI9tIVmCAsJCAcDAgEKAAoJENSNEHJ4+KjUCJQAoMsgaMOze2p3Iaz0/fK/Xmeb
654IAKCDmJpex0C61bzfczSdaxXPPyIbJIhGBBMRAgAGBQI9tIpzAAoJEGx2F4yg
7Zgt0WUAn1WbgrMzw02LdGQQLBMzY5CYXKxTAJ9uvEu5kTB1jFhMa/rM7r04dipM
cYhMBBARAgAMBQI+d2sSBQMB4oUAAAoJEE+DjLcmoKgWxiwAoPKtxw1TpXp/6KTr
YZD67bOTJA8+AKDzxW0tIl7ij/nnNE9gob7cSeCfuohMBBARAgAMBQI+dyGMBQMB
4oUAAAoJEHUTojYTECz1ZIwAoIW7tPHgp/AAUso8L1C62O2WF4l6AJ9jsLQ7cBnL
81TJ74C3Zey4iU0PNLQtTWFya3VzIEJydWVmZmVyIDxtYnJ1ZWZmZXJAbWkucnd0
aC1hYWNoZW4uZGU+iFwEExECABwFAj4kssACGwMECwcDAgMVAgMDFgIBAh4BAheA
AAoJENSNEHJ4+KjUzWsAoMhZqjpybn0KgRf8Br3eExRIbpcfAKC+OlKaKZLRSgbz
+6Pig+YQiPnOK4hGBBMRAgAGBQI+JLiDAAoJEGx2F4yg7Zgt9j4AoPUVdFwcegkz
/rAuVD5T3psicMzIAKDgKHpuYGnx9WLeK0fcIS9uAMrVzLQkTWFya3VzIEJydWVm
ZmVyIDxtYXJrdXNARnJlZUJTRC5vcmc+iF4EExECAB4FAkA33goCGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQ1I0Qcnj4qNSSjgCdHF9CzCm9j6uX5aCpJ5Cg2qG7
ktMAoMhccEzyNtzKGskfzazD1oTJdTjNiEYEExECAAYFAkA34C4ACgkQbHYXjKDt
mC1PfwCg5bAwdeUZ/YgXy9UF4qpEX6fH6BEAoIS2DnUx4qlcuuhBUp9RXnST2G2k
tCRNYXJrdXMgQnJ1ZWZmZXIgPG1hcmt1c0BicnVlZmZlci5kZT6IYQQTEQIAIQIb
AwYLCQgHAwIDFQIDAxYCAQIeAQIXgAUCRNnO0QIZAQAKCRDUjRByePio1PgQAKD0
YBsRWZpJv+i8MS5yTzympEWFOwCg9nEzWeocm8GIKu/EWjoCX+G1LOiIRgQTEQIA
BgUCQDfgMAAKCRBsdheMoO2YLRWlAJoCSpQjOyb69ZXMoDKx7naBi5aNAQCg+Zl9
IW0wDSUhTsHnwOf+Tf5sACG5BA0EPbSE8BAQAPkYoH5aBmF6Q5CV3AVsh4bsYezN
RR8O2OCjecbJ3HoLrOQ/40aUtjBKU9d8AhZIgLUV5SmZqZ8HdNP/46HFliBOmGW4
2A3uEF2rthccUdhQyiJXQym+lehWKzh4XAvb+ExN1eOqRsz7zhfoKp0UYeOEqU/R
g4Soebbvj6dDRgjGzB13VyQ4SuLE8OiOE2eXTpITYfbb6yUOF/32mPfIfHmwch04
dfv2wXPEgxEmK0Ngw+Po1gr9oSgmC66prrNlD6IAUwGgfNaroxIe+g8qzh90hE/K
8xfzpEDp19J3tkItAjbBJstoXp18mAkKjX4t7eRdefXUkk+bGI78KqdLfDL2Qle3
CH8IF3KiutapQvMF6PlTETlPtvFuuUs4INoBp1ajFOmPQFXz0AfGy0OplK33TGSG
SfgMg71l6RfUodNQ+PVZX9x2Uk89PY3bzpnhV5JZzf24rnRPxfx2vIPFRzBhznzJ
Zv8V+bv9kV7HAarTW56NoKVyOtQa8L9GAFgr5fSI/VhOSdvNILSd5JEHNmszbDgN
RR0PfIizHHxbLY7288kjwEPwpVsYjY67VYy4XTjTNP18F1dDox0YbN4zISy1Kv88
4bEpQBgRjXyEpwpy1obEAxnIByl6ypUM2Zafq9AKUJsCRtMIPWakXUGfnHy9iUsi
GSa6q6Jew1XrPdYXAAICD/9aiTfaH5Vs6Ms4bUQIeOLvadkQy4eVVKIXehBRAJ0X
SVed1BNBwyBPUtuphL2BvX7Vx69418nwd5heQMAaWjps91W/3tXq6IseBlVGQcZ/
K3ICoafLYS8kp5i5ksX+2jvCF/H4KtDzODYBQOnC2TgVY3q/UncJDKjOS0Rfellh
a/PI4wd8k0i2PKB3iqZ2kgetMD7ioU9hSQz2UHSsx3t88vj+QhuXLA/PsIBso8py
X/6gxAUhGZKFMOJbqAowUXxQjyChVi9Rr08tM4PvDN2SD3XYhODrCLeNuGeKnoYG
3HkX09xJglxLUHsTU6ZHx7EK+vkEdTd74RzzFf4wJnMPnT3TKNX1u5P+DOZ5bjBZ
2O0ze3qLk9fBZxpiP2ev7GDMnQAeqb8Ox7lmGFUH1UARXhaicIhWTnfq3kJsCY4a
DI7yHGu0Q1pg/R7V2ZGLgBTamItb6mUWGCBE5AF6AYVJQ1UU4We4FAfMmaiEb2ZE
Gi60ff1jAR1PxAnEDHvb316Wv5GXRf3r6EZUQyuQSnWiIhgCs3EqbBUzbZvCVtHZ
vLX7HZ10HzpHEdwNVpFAurUyP1DgRCCt1qKeDLui+t4N/WgP1EdQXpkmy+79Kcq4
ny+HLaMgYuKSk+khJhA/l7xfMk3JNwlp1adMS8/FgScU/NS629UPsK0fJ1Mwlk5Z
w4hMBBgRAgAMBQI9tITwBRsMAAAAAAoJENSNEHJ4+KjURHIAniigU3LNmmT0gemQ
7wb7L8No/lEcAKCDziXLMavHZGnIuNydVv7D1XEllA==
=rJ5H
-----END PGP PUBLIC KEY BLOCK-----
D.3.27 Oleg Bulyzhin <oleg@FreeBSD.org>
pub 1024D/78CE105F 2004-02-06
Key fingerprint = 98CC 3E66 26DE 50A8 DBC4 EB27 AF22 DCEF 78CE 105F
uid Oleg Bulyzhin <oleg@FreeBSD.org>
uid Oleg Bulyzhin <oleg@rinet.ru>
sub 1024g/F747C159 2004-02-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEAjnDYRBACecNDd39vZ9wnodFlATK+xvhlyX4M3FBEV34t9eVZtJz4916yb
nLZmHwY6awt+nm6FGciSPucfu7stBCqvPURWEThJgAyXbxEVNyXmXrZ2F5OyNMyM
EcbuqLZTjYxxN5mxUYswtiNDmdWn+Ivmw46wTOl5Pu+B7W2KVl8mwwbAjwCgl9hA
puTWWN0zFklDJIuLx9eVxnsEAI+QaACe8H2l3XFpNkp6n680ZlW7FBZDDOYjCS4z
nhFg7Bca74t6vnn5Q4miLnDDyOPkZqMBD2nLUkcK/kMfe5uqDUWf/i6sFDwv7d6I
9Ag4tUWLkhxAqaqomesfI2yS4o+QGTJgQdGU3IUrOnMJD7Ascwj7304lYuqYcaqT
KQHSA/9eTg26Ihn9uBpGit+slgkmTHmKgAbg7IaSHSEYRbpmnc0Je794zeWns/oI
vAyGNxEFpPQMVrSXHnFmK9AOcLcfssE24a3zw7So33asH2Ha9yYBrfKGrTCPZAsa
uUGrKbGmXQ0oXDjjqV4anvC2QI5pEJvMbHJ+Xyq5xQN73ttJxrQdT2xlZyBCdWx5
emhpbiA8b2xlZ0ByaW5ldC5ydT6IXgQTEQIAHgUCQCOcNgIbAwYLCQgHAwIDFQID
AxYCAQIeAQIXgAAKCRCvItzveM4QXzXVAJ9RD4kKNcvV8UmuBM66osVfZ/7yIwCg
htVf/ZfKdcob1zQsBNNpmzkpduKIRgQTEQIABgUCQCOgsQAKCRD9LjUgMMgeateB
AKC0iX0NNspa5EnBYGE/eEe+LxRs6ACfUqA0s50e2goJznaIcLTgZXtDECGIRgQT
EQIABgUCQDIZWwAKCRCF1FBFa2kbA7N9AKCbDyp3g6vRN7dQKBb35s7gLp8yIwCd
EH/ivmrxZSaHlrOMJjt6rnmuFqa0IE9sZWcgQnVseXpoaW4gPG9sZWdARnJlZUJT
RC5vcmc+iGAEExECACAFAkOMPS0CGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAK
CRCvItzveM4QX+tfAKCLk3zeTyzbbN6TqYpnqocno4H9kACePQaaDytLX+zk4plw
sywqPLv67SG5AQ0EQCOcNxAEAIUR6Uj/bLAu0/FSGDSCXfjuThVT1lh1rCLQkbBw
TxNiwHPHHSQRa654aoYbQdi9x6M7fzE6Uzmdj1Gs/UBYZhhsrlkL+Ls/xuhe3Kh3
E6lho11qPhjYXmFHk42VhtVlOcikZ/Azgqgycfql81H3bKWv6jA0el9SnX4yk5qf
tgZTAAMFA/9T7/ty76bNeP3/LcY9ZL9KYWB8v8pJ9jEt/RfBXB0GTuV/H+bzTjSc
PwhT8Fam9Fo+r02tUJfqA+XlOJf6IXPlLPRfvzHhiBJSBPuMvB6vYs5zrlUzkgNE
VFHBr+TxpUWBq4ZtI9K8YUbPD+s86irYn9fHlnj9qnYsod3ySvU0xYhJBBgRAgAJ
BQJAI5w3AhsMAAoJEK8i3O94zhBfFzAAnAg+W9rkVVdYu33hNqpX8E1t2kShAJwK
V8DuSaXJtEgVE7Wp5CeArqtwUg==
=/2pb
-----END PGP PUBLIC KEY BLOCK-----
D.3.28 Michael Bushkov
<bushman@FreeBSD.org>
pub 1024D/F694C6E4 2007-03-11 [expires: 2008-03-10]
Key fingerprint = 4278 4392 BF6B 2864 C48E 0FA9 7216 C73C F694 C6E4
uid Michael Bushkov <bushman@rsu.ru>
uid Michael Bushkov <bushman@freebsd.org>
sub 2048g/5A783997 2007-03-11 [expires: 2008-03-10]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEXzleYRBADIqilbqBfzstvMByOY3QlvQD9QIGQLwZbziOMByQPwgzgBFk6x
OA7NOfSKONPTsLtIOSc+CbuyEfw5jJiXsQ3Ox71Zp2JTra/bTim/WwJKC5Kc+egl
CD6KO7GMTCBb102m2x97G+rNjGS8n7Uf7ITgoj9QtxBjpAC3K1ZcPoAcjwCgobcT
q5MUrCqPHrnlZ87BnbT/3m0D/15hcV+qndPCShIqFTYbTSG18X7lBNTONZXmCm04
5dRcJrz4qLvsCYkBrmOCrKbYViQCQWiT7/G3Jzc+WtGFirYibU1TxBprZuP99gX0
Hea3gvgodlje7eq3Dz7Hx9uFgN8pfw2wWlEgdkuYk72s3lSJN6+TGWzXuWnRYYJ1
H8XtBACpByr9qcCaJ9yNAwDbDZhj03zSeZoIQz6d/3tDv7SkzDlVyxErJCO7CiHg
JlxN0+paX0gW06xkLmwSESerJVbxEIoejdkdxebqPEIQN+9Se6Q2tkefMWd93IwL
MP8sXgUBE6PEmFZTwI1/Av+vR7aI1pPk+yIrKTV2KyC7yCULMrQlTWljaGFlbCBC
dXNoa292IDxidXNobWFuQGZyZWVic2Qub3JnPohmBBMRAgAmBQJF85XmAhsDBQkB
4TOABgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQchbHPPaUxuSKCQCdEAIOx9JT
lAxIOwL6ApsukCI1bgcAnjkybnn6t4WWYy7IvmwMMJJ17oe0tCBNaWNoYWVsIEJ1
c2hrb3YgPGJ1c2htYW5AcnN1LnJ1PohmBBMRAgAmBQJF85xpAhsDBQkB4TOABgsJ
CAcDAgQVAggDBBYCAwECHgECF4AACgkQchbHPPaUxuS8xgCgjJ4lLhI3wDP8Rnhv
Iy9UW5BuBEYAoI22XNE3OHvBdsmUyUvVji8yKt4auQINBEXzlgAQCADnAWwYquUZ
mbrZ9/UO4abD7Nm0vipplm/O078SMdonir+HKWZStjuvIHhpPDGI0wCpg/v24B3w
QVGiQhXWRL1cbvjDmiQG7GFdG6u4c1+2S6Evx+fp5DCjUMaoygd/KwF5tmxE5M2R
7SOYueuuxcDiYi4qJs9lroNxnwG2/VkrcPxlek1QbRVjs+TuRnzTaUzXbU7kli6y
PUhBucf6nB0cPHG6VVn8N0Kki+HBaQjYOxtBCO2B5E0uRq0Y25l9Vt9s/0TfYnYb
E0/sLj0XSBu8WWmXtW7QrtLPN0Tb6XrTeIaWW7HLy1ACVlzniu5oeumVKiW5nsW4
uJ/6kF5Fuu2PAAMFCADNuQ0Irmhub799B7h+FJVtNu1IxptmvJnD/RoWXhAtVo79
c176MEqS/8tghzdq/zXhr4DPMiTDWf1p4ynKFFkpQaWkHO28cvu3rc0tdpkI2d+s
zKT6fFNn3kqQ7Eq5xgijSK8+aTWoUhqFvxkhLIcColuPK2TmQ+uIxjtu62lU52eZ
DDePyHFGVWqtkZ99k1vGxZRf+vVXaKTBkGY3Pek04knpP5ROGA+JjL/Ew5o4SWfn
FeD9aJ+xtZ9VqTUyl+U4XwIYlRcWzbqsbGp0D0jgry5Xhiggngd7xtNSB9/44HuU
C5EQWVi35HKNdXMq4wsOMG68DCTE3XOABa5yPY7TiE8EGBECAA8FAkXzlgACGwwF
CQHhM4AACgkQchbHPPaUxuQTrQCcCfrtwSXFegD9D0DpYWa6iIy9glIAniDIOvRb
4L8/nn1Nbu+PBNHamCHi
=zD+p
-----END PGP PUBLIC KEY BLOCK-----
D.3.29 Jesus R. Camou <jcamou@FreeBSD.org>
pub 1024D/C2161947 2005-03-01
Key fingerprint = 274C B265 48EC 42AE A2CA 47D9 7D98 588A C216 1947
uid Jesus R. Camou <jcamou@FreeBSD.org>
sub 2048g/F8D2A8DF 2005-03-01
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEIkZzcRBACrskMO6BYlK30ghgpDYTou1UEgp0Y4QdghWeEP5kppuDy7kf87
CoKVvE/u+pVd7aFoTMa7ikqxKH4Kh7wnDEbFnzeZGtsf0Fzw5oHgoaQQlZHGRtr1
49UuyFnRWVKyI8IXS25Ie5p6ZlbAVFINOdJuP81gku8SffsoifnKIiWrTwCgzhTU
uS1rg+TpKkiRnkXXtpVF9k0D/3/OADlTo77GAWMXl6HBTaB3BXB53Q4PozvGDter
lWGKbx6uYvLq3ZPX1XBUapzJ3eoEfCsA++FeSzK+tue/ulbLiXmFhXSQWtXoRo5D
I75uOoXlrc45uLc9XkOpeZ5dF4a1iJOGHe/hD4mmyrWIM+E6cy1lL4EetM35ZiEM
lHqDBACehJoEdCAVMOcfQLs33/iTBRBE7Z6fN9DCH3kTvoYcgpZsFAX2WQFz085/
zHJ3NVFSH8LCi/6ck5ZeXCasAS3L99Q/io4WwmlqDj/b4PBdfoefInLJkroijcQ5
B2I2cH2Ss5kkwqj9PovanMWNY6Irv2szIViIeThB+l6hiuzaK7QjSmVzdXMgUi4g
Q2Ftb3UgPGpjYW1vdUBGcmVlQlNELm9yZz6IXgQTEQIAHgUCQiRnNwIbAwYLCQgH
AwIDFQIDAxYCAQIeAQIXgAAKCRB9mFiKwhYZR31UAJ91fYdpk0PNNr14jtURyeeS
upTEEACdH7tOg9LmYNxAi0iKWVInoA/TNmW5Ag0EQiRnPBAIAIKVE+F4De4BWuab
6LREy3VmvNQgHSF8lHJm4TWKYGEkNhG+sIRFdJExqKG+N+El9QY4QGgezdogQIYk
RBSg7nWzVrs7DiHJqC4PB/f23bzJl24Cg05jtxvZBz7t4lNXwY9G4kTmDb815FXd
1p8gwa1KCNsTlKVRJxbaku9gHsO2JZigLMzzF1Zt1vGtaSHX5SyjhOdMOFtjuLed
NAgl9vgAoMpXLf2Saom38Lgv/jnWz9OfST0P+OA/JmqN5DqeRTlyVZdQ8i8bduYX
xmtbBPOGHWxwUDxiXMULkdjkLLrY1UaizR6/ULI6+cPrPLZFdnr+5GK6ZoTXyJ2n
EUUxpGMAAwUH/iPguYUdGVnwKiwqojHq9DzDb09qvPg+UIEjwZA9mPExfMPLo/1b
2NLgOF7pqeluXfiN84i58sipi4/ntlsNSzCYKCH2t2Wmfjdfpa3N4JaVptLR650x
Lzj3egnWJKpHVSO+v1U7BSYBnaVPGfOMQVlSO5ra41SiVyZq6laX30PXXIFP6Ocx
VWECVLmTR+L1g/5Nvq/L6NPv3ziuSLbSpvkLhTxLosaQwYFwPE7mLKgERUKDNc1u
EXqyf8No4LKyO9V6VLckMgG4qbjQZhm9ozCmEYoKFZLafsq8czdNIKi4JV/8aUjU
CsR5Dc8XAdwzPq6DBcikn1UBnvotbHtAFNiISQQYEQIACQUCQiRnPAIbDAAKCRB9
mFiKwhYZRw2hAJ4mmNxtlCe9yUHRCzxsUxl36gQYtwCfQZ3f8K4dxPU2ClJ46fTf
FqQS584=
=KYGd
-----END PGP PUBLIC KEY BLOCK-----
D.3.30 José Alonso
Cárdenas Márquez <acm@FreeBSD.org>
pub 1024D/9B21BC19 2006-07-18
Key fingerprint = 4156 2EAC A11C 9651 713B 3FC1 195F D4A8 9B21 BC19
uid Jose Alonso Cardenas Marquez <acm@FreeBSD.org>
sub 2048g/ADA16C52 2006-07-18
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBES8etwRBADeB8shuQ3GGp/AozsOggqLnSmFwCS8nGN+rnE+4LHuRzkL4Kh0
pgzalpPre7DohKjX2uzq9lTjjmsrTKZLM+yaNZ9fFMHC1uHxZnV9/c7tC97oQQXl
FjMmemGZGA3VMhh5jEtjT5EJIvPBB4SBVhVhBJ24ananUD9KmUHTyP8GrwCgxMJ6
+NrGKVeu5QYVLo9oVo26J+0EALkWeeHI8PE3f0jOqS+Voym3jQPLw7pvx+HoySw1
X0c0YRa9uJVH2e8aFMMsCzT/sP492IksJvtRNpzDSJJyYM3zukzH+l7J2vwDvKgD
YknZJE0pAS0GRAVbZQ9u6bez2+CUrGZW7Bvablo7r3nBHyhI2SpeM6naXlS4AJ6I
9dbaBACm82l0Uwip/WoJM0r/lB6eXMz9tFeRgfnPY3+G0Y9pFpdxTX0q5M73L6u2
PeXbWI2XPyPqw0wqda5YNlcRylXJmzLFGQzR6opqIbOEzRE+IinyQwQlcAv3qzBU
p7qCplhjblcyAhWTlM5XsrAWxXHyNFrSCCPDgW296+8b6b94s7QuSm9zZSBBbG9u
c28gQ2FyZGVuYXMgTWFycXVleiA8YWNtQEZyZWVCU0Qub3JnPohgBBMRAgAgBQJE
vHrcAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQGV/UqJshvBm6wgCgqtDd
lyjakeTr7YVdNmpaI/UxpG8An0jtgTDD2M+CioUqGN1SNTkA/6cWuQINBES8euQQ
CACt+RPVEUX/qDk3Qh6E1Zrm410mAJLfgG70tz02ApDXhW6aZccW97rH3pec+RDW
fZVaSW4xHjUQMu1JaXK0dD++UWifuhYF+GUfi2NQflcy600VjM4v1HMZulTE5/0n
NfPU4s2Vu0w1JcuXryjy5O8+ur10wQ4HFnL+qSDmXY2UKKTHA7vVrBTmysELDuj5
N6T9+xxuR7EJG3lwTREgPnr5nRlyZBxgAd6k/AJ8i2X1YiGix2KI2fk/HYdgl3FL
xnLXrLE43mAwQjcmkMruNkebjfAAnp6vKvSOLZ3mqoPNhP6SPGTPxoskcHqHhvXh
L3Y7/Qqga4sg+P8tZ4YTx4SHAAMFB/92KAG0TePM8+gtp64oOp9RuUELjT35f5RZ
0ZJZ1JromyMjOc6FRh1a9HiVzY2Vq99S/r8S5QoNH6vppxGjSL3Vs6vJg79eT5Jc
ODdEZhoSzqmc/TwTHfOeHiFJJk8kAtX33CIHBUDM0p3OaJDj3weYi0TUWcxcvlFg
p4RIYHCkmJj1/sI+0U8Jw35nSK4uNwW8MCl9a2hwHCtfnvQBfotybc4+YuwFesT2
SDRit/mXxYkmi/a5GPB0To/e/QSBuk7MMNtLv0oF8LCrfaN76XOmahxjaSYidA4H
LUFNqtRL9J5/T4VSZsrSl+Gb6HQIaMoGPbXmFk3i6FzNP7VDViZ2iEkEGBECAAkF
AkS8euQCGwwACgkQGV/UqJshvBlwLQCgqDaWuJOgfV0r5li2gRPUMI5XCscAoIG2
pLZLUWFiL2unIMhkFZSQbZZj
=I2hD
-----END PGP PUBLIC KEY BLOCK-----
D.3.31 Jeremy Chadwick <koitsu@FreeBSD.org>
pub 1024D/4BD6C0CB 2006-01-23
Key fingerprint = 0EAA 5E65 44B4 43CA 3016 48B5 4534 937B 4BD6 C0CB
uid Jeremy Chadwick <koitsu@FreeBSD.org>
uid Jeremy Chadwick <freebsd@jdc.parodius.com>
uid Jeremy Chadwick <jdc@parodius.com>
sub 2048g/1D3235AF 2006-01-23
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEPU2YIRBADrQbBypNoLNbEqDQO2r4vwOX4+R9Hpz0wHT5g/mCme7K7ml55O
p1s/fzVEqCqyqaNlyiEJvezST1EF2e6/YDpxW3r8hYf6phg6z24ZhaA7MdwUzmkW
tHuCXIsC8REvD7U85qgf2+wJM/X0svi8/1xucL7IOTGVj/MDy2K6Sfq7iwCgl8gk
UyFvGLKlsHyLv1J5EhfkWksD/Rh/AaO7JF8f+mKMwENb4BWdJcY1cNnxgo8PK87N
RdmLjjJan9cw/VLGXGnI0GFDVKxSG0WcHgIZ1B0bvyU/KNFcHKibLg9/NiR6QZhb
vXoCtBqHMHevil62fc5ZCkuRkEUqRChiMGHOdDr+xCqCYiiF5pA4OrKvWHhE6Oxn
kn4CA/9zcokFQZprp/fHhivF6PUExYLWLH3t2IM4MNa2PGiTBwf5pLIITfisD7vO
zfIc699ndGGw9bJyPp0/gN96nXLyTs3GdTqJOE/0WTriCQ/xhNLUZKDBKbVElwoj
dbgjutch3pAjbPx9R4+hrBvcycPQmIBM7q0xZFST3kRwHRk0GLQqSmVyZW15IENo
YWR3aWNrIDxmcmVlYnNkQGpkYy5wYXJvZGl1cy5jb20+iGAEExECACAFAkRbCq0C
GwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRBFNJN7S9bAy4uTAJwLME4QTJHn
gE//AWqZBfhV+Le+HwCcDu/DxXKh14/9/POabQv3OKGQPQq0IkplcmVteSBDaGFk
d2ljayA8amRjQHBhcm9kaXVzLmNvbT6IYAQTEQIAIAUCQ9TZggIbAwYLCQgHAwIE
FQIIAwQWAgMBAh4BAheAAAoJEEU0k3tL1sDLSjEAoI4OUjvpOrRzXrDP6XnU7mfP
7keIAJ0f4GFTXAToTLj4kf0Ai03ItkWTZrQkSmVyZW15IENoYWR3aWNrIDxrb2l0
c3VARnJlZUJTRC5vcmc+iGAEExECACAFAkVW+y0CGwMGCwkIBwMCBBUCCAMEFgID
AQIeAQIXgAAKCRBFNJN7S9bAy0t0AJ9KblrW+FBhNephh5QX6H/C7u5UNwCbBJqE
FZMAp4B76dZwxF5lGuzNmH65Ag0EQ9TZnhAIAMCHbTZHDt2QvPyQFg9hGYh+WO/8
3wz3yiKjhldi85NDygwsZ5QP6wvH6PEA6IdBW11eeK7swo3k0ZzT1HhfIF5S8VJI
XFrJ4u100/NHuIHTlSsAg9vqpmqMnfALlLd6Uc4BF6vMAOpWpJPeVDnGTHETcLA4
gt055u/oTEDkgZPlS6oKsUbtExhn+4TBU+gj50Ac4V4qS4j+gyxlH10hx2dgg0c2
WzQA/USBEoMKWrXGrb9YhgTYwI0wLwh1W92V+EAcbFYOWRMWlU25mlyTE1U7Q+gO
9mpchILpf7ndgxiYV3L6m3Ha+DxIXfcRznli8b1aWk+VRvXcb68nRiRcKLMAAwUH
/jPvFNL3I3XPmOTF8qz6XZbEe5jcPC7d/5G9y3bbPYfS3rSKLdrhf+Vo8AbpFkF4
c9fnbUVehXwKjdWRxe/RoEj2V4AuNmFwcrHU4Wqj+yWln5ceNCm0WUVtTStq8nS8
HjTWx59RtQKi4sXPk+MyyM1STzaZ+XfE0jJAnuLgBSciQz2sXuTiHRiVbdnYR5Cb
Y+xrmGrT7vifsW6Zr+dw5ioSRkJJSId9zZdh3RSSWdBWl86XW+SQlj+c3T1wyKhw
UGsph3hhClNRr7osNS2pOK3PhUlJEDiKCIOCZODfh6k2lfyAhI+us/GJ7dG3/5BT
OzARiS2j89nB9ybRsNHeFR2ISQQYEQIACQUCQ9TZngIbDAAKCRBFNJN7S9bAy8VR
AJwIN6fqIGekk5E2SwEz5eIHUHJVSwCaA9w4hDEr91A+bhJPh+sarsOV9ms=
=7o1B
-----END PGP PUBLIC KEY BLOCK-----
D.3.32 Hye-Shik Chang <perky@FreeBSD.org>
pub 1024D/CFDB4BA4 1999-04-23 Hye-Shik Chang <perky@FreeBSD.org>
Key fingerprint = 09D9 57D6 58BA 44DD CAEC 71CD 0D65 2C59 CFDB 4BA4
uid Hye-Shik Chang <hyeshik@gmail.com>
sub 1024g/A94A8ED1 1999-04-23
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGhBDcgZmQRBACk2gJB6utE2SYUGkhm/qHI6OoQB1B1cZxxjsUBmQZG8jHKj0Qd
D5AZZv/x7C/2eyhUl2Jpp5Q2t4DIlivhrTYYM2VQ6YV6xXfjKrUjBmRc4i6IpYq/
t03ncDTyS3Bn56WcY1t+hAOlfQ/kTLEn0MLHPHvI1FDVV4VqG0MzvsV5+wCg5so4
M6YC+F5Tstp0tqOGCbe++A8D91y8JQitroVJ6bXmgCLHHEZqZLBrzs4MIPEHZld+
qaZlcbvPvmJqBjXVs0cojROEG8ZZgkooTZIZS42gKxN7sM7mVrQp/u7d9ZiIs7EJ
wlYDHL1pbNJBZ6jk3aqrWtbVClzo3R/vjm1jo4kmQn3c2EmRY7n5vVTPvmLuSXvp
KusD/2lMBEiTygcjg8MiJN0acy1s06def6LIxNMMivVjlIFxpq0YU2omzVFljbgy
gAAcZgA/VhoGaSCKsoA9M/51tnIE7tcCQYsHmhoHsERliw7NPr4frmRPuaA3gx6h
qVbwjUk0/gFTPuxRmnJyUl9rjn4sCze0eoMTraCTb81ru+/FtCJIeWUtU2hpayBD
aGFuZyA8cGVya3lARnJlZUJTRC5vcmc+iF4EExECAB4FAkD9H94CGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQDWUsWc/bS6QRXwCfWQyDrnHKErxj3jZWfMgTTSUR
+HYAnA1S6EfWVR+xI4d5V7K1o4U+JYh/iFwEExECABwFAj0XTZwCGwMECwcDAgMV
AgMDFgIBAh4BAheAAAoJEA1lLFnP20uk4r4An3KSrVlQU+03cu7asDiAUu/0YA2R
AKC/LEXgIKDd1tlWvJBi9WHOJWeyq4hGBBMRAgAGBQJA/PiDAAoJEMZRom5Q4jOk
Nc4AoOpk2HLqrrw/RX/go6dgg4BwX0GCAJ9lXnFvF3MZt15axDDqkW+vBwsgtYhG
BBMRAgAGBQJA/HFKAAoJEMnox5XjtG7/usYAoJRmWL6X567c4ypgCUI+pcivVwAE
AJ99/qwsMdZoLfvsCeUYOrvFI7+Vo4hGBBMRAgAGBQJA+ph8AAoJEN1CmnbjJqwA
XucAn2jHHc+u6KC+1eNErXNPBaAMEZjmAJ95rB5dvzS/p76Rn/85ggOfo7gEQIhG
BBMRAgAGBQJA+mR5AAoJEBi5Be0l5MBmFq0An1SsywvJPu1aIWMbV1hgbvoKra7n
AJ9DN8Czg9Xvl8zfxda//syHfiLeiohGBBMRAgAGBQJA+j2iAAoJEHu55xgSdy2P
cqMAnijMYmWiJrkWM5PZrLFfM23V306WAJ0TsSRl3bsFuNbmuptu/1ALTUMkL4hG
BBERAgAGBQJApQYOAAoJEEsqSJfTnaDjuNUAn38B71Jd+bTa7e4uTNgt+ygpoT0E
AKC5FiPN1e/5TTQpicpxm/+ifqzFl4hGBBARAgAGBQJA+8H7AAoJEE7mpWgbFYrN
qq0AniWfE7RcLFWX9YgrZLVWxLvxpOrSAKDTgNvLoVKeUf5rzHs5f0XN6NLUhYhG
BBARAgAGBQJA+8mAAAoJEKeszx6Ol9rhrbsAnRi+1LRKX/vPwT4Rn4SMc2pEbBel
AJ9ZxYTXsdEL57O8EBSac4287806vYhGBBMRAgAGBQJA+otFAAoJEAG0czTg1J6Z
YzoAn238Nt4AbFVJ84l1Oce6W8zl6wmiAJ9HXnuPJo/m77lHAbNP87sDor9kgYhG
BBIRAgAGBQJA/SO1AAoJEDJYHX6m75tjC0gAn3u72LSZiSPnz/Tg4Yc8xxaibjCu
AJ4sWlrx6IVRVRkchxjmg2R809M5oIhGBBARAgAGBQJA+rmNAAoJEFRMMhzhlJHP
MlQAn31bJlo3z8eq3dWQr+Yr2kU39HL8AJ452Y3ec6wnz/i96vWsGhbprIJSTohJ
BDARAgAJBQJA/BMLAh0AAAoJEFRMMhzhlJHPs4YAnRSB6EvlonTWNksKakaY0FUB
rvUSAKC4WPXWmntGmJTTovnlrSpUuhmP8rQiSHllLVNoaWsgQ2hhbmcgPGh5ZXNo
aWtAZ21haWwuY29tPoheBBMRAgAeBQJA77SDAhsDBgsJCAcDAgMVAgMDFgIBAh4B
AheAAAoJEA1lLFnP20ukzCMAn0Zzt6A68IUmA+pKZYeLSM3x8BvPAJ9Xay3AvXHq
xkCunjqOBq0EFtRqGIhGBBMRAgAGBQJA+ph7AAoJEN1CmnbjJqwAEswAoLi6L+2X
oyIPqW6tddaBGsRfrFoiAJ9uXR+C9lQ+E9cKuDZFIsvixRJFa4hGBBMRAgAGBQJA
+otDAAoJEAG0czTg1J6ZFfUAn1m31LtNatUVft+HATP3Suk3BpQUAJ9c1zgpT0iL
1M9lEfopTLuYqFIen4hGBBMRAgAGBQJA+mR0AAoJEBi5Be0l5MBm+NYAn11iZAAH
L/NiaBxDdqJcfdL7uKy9AJwJ2MTxC5rTVB06OONBYE30/47ENohGBBMRAgAGBQJA
+j2eAAoJEHu55xgSdy2PbggAnirZz0+jJsmx4iU3imFWNNFktY8lAJwIMSvQdKfk
+92fXCU+DBJQkQA7VohGBBARAgAGBQJA+8mDAAoJEKeszx6Ol9rh4LkAoJmF/Dq8
WWPmabYwhn8hADnCuOPhAJ0dc0+pjPCXwHgKIMqYknfL3ojxv4hGBBARAgAGBQJA
+8H2AAoJEE7mpWgbFYrNwv0AnjWWP5WrOka30jnmD2f4ZfuUWbC7AKDHUbhm5JkS
fP8qudaVwot45xIuNYhGBBMRAgAGBQJA/HFRAAoJEMnox5XjtG7/DLwAn2VkM+5z
WmykJRGbT+Zh6+OHmxjpAJ9DGPrpTXyiIP5EEd2w7+EXiGKpJohGBBMRAgAGBQJA
/Ph/AAoJEMZRom5Q4jOk7+EAoLv8vwveEEdPYNQJ+5BzZa+gBvT2AJ9AS+lvI+fV
/JQ2hVaP6DradoicaohGBBIRAgAGBQJA/SOzAAoJEDJYHX6m75tjle8An2npGKEv
5zx+plAXJalZH0l6kADhAJ9bHoslJAfKMD6Rk52+MG/hwgnPVYhGBBARAgAGBQJA
+rmLAAoJEFRMMhzhlJHP/tUAn1ruy6bmP4IUFFc7HQg1fIo9qlvzAKCcvCq3RPF2
v+hGi1uuu8w+Bfxcb4hJBDARAgAJBQJA/BMKAh0AAAoJEFRMMhzhlJHP0Z8An2tb
hT67xHXlxeH73zslpXATFqUzAKCX99jd1jD26cqMOMYMfyg2JieeHbQgSHllLVNo
aWsgQ2hhbmcgPHBlcmt5QGZhbGxpbi5sdj6IVwQwEQIAFwUCQO+5MhAdIFVudXNl
ZCBhbnltb3JlAAoJEA1lLFnP20uk6LEAn14XT6cU9KyAGwropJxoWR95DPRYAJ9k
TOe2ot/MwOLI4pD7A36FcqfQXohXBBMRAgAXBQI3IGZlBQsHCgMEAxUDAgMWAgEC
F4AACgkQDWUsWc/bS6SxfQCggiWV05oDrtdjts6FdOn2H692y9IAoNeCpx91wOkw
Vp5c894CrLroVT7giEYEEBECAAYFAkD7yYMACgkQp6zPHo6X2uHldQCdEJw4dYnn
SuIcb/S9aHR7GZ0YLQ4AnAmLOBuiU8NKBkzlDuGukCg1oE2juQENBDcgZmgQBADW
3laHi0adLD3j4Obyjqt2ssI1XGXrFNSW5n+t27iioOw60wy8OzBxOhr2P2P9cvQL
AmJ75IVJ6aUF72E4bOfF03xr3b8vCHIoejy23h7Zu7KUW/5PDAYEbFnafjrSN23q
LpMkv4nZ0JZqJ/VEr5hQeo1BDHMqBpAx7LfNkBggXwADBQQAmUdEgo8xNr7EGhtW
cUyldHyy+PZMqxDny4F+A/lecZTIjv7S2JM2zGwmC8V/vrFIGihMKEFhyf95FDUK
ID2IviKFmkHRLnI5SCJg1CnNaC/epuLSMYOppaWcI1F6COVeQEpNcnO3qGQNho2t
ls4HklbPC7T5cQjw3RPIqNgzwZSITgQYEQIABgUCNyBmaAASCRANZSxZz9tLpAdl
R1BHAAEBjhUAn0OG9og9prEffO/nwJCrCRjIPn+gAJ9r01feaU5vSZZ7bCLYtkoJ
b7AAzA==
=dqQP
-----END PGP PUBLIC KEY BLOCK-----
D.3.33 Jonathan Chen <jon@FreeBSD.org>
pub 1024D/2539468B 1999-10-11 Jonathan Chen <jon@spock.org>
Key fingerprint = EE31 CDA1 A105 C8C9 5365 3DB5 C2FC 86AA 2539 468B
uid Jonathan Chen <jon@freebsd.org>
uid Jonathan Chen <chenj@rpi.edu>
uid Jonathan Chen <spock@acm.rpi.edu>
uid Jonathan Chen <jon@cs.rpi.edu>
sub 3072g/B81EF1DB 1999-10-11
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDgBZiARBADgByjeXtfBseo67ZhVuyAMTk4vWu+bh966TDx29E+cS2Ud+mYe
X8eQYKfiCQXlAzspXFVy4nmqsBY6KJKGFek5lPoCKhh2xpftYq+M+2N/oznrMzK9
GZvMdd/zhVp/HvrdpLrIxjMVA4dai5p9pYB1kgr3EjV5ed3onKrWP/soLQCg/3LP
TAJ8ngyQvH+YieZpZRJn/IUD/2ZQGOSSPhJTiYmPR6+dI4Mj+ep+NlrC0bel8RBh
ANV5eaIbh+rKFPPj1Pdei+Fbkixft7Ne/jH4s3d1li4L255T4Zapw+JMCOQf0+Ps
7za7uE88ofBK6nxdmJSR8vLoVKJLSD3cxyJs+BmldqZTzOuh945I7ajwyaqnPEiI
GG6vA/9bRbnqnvUgMUml0kNq9ItjvdyUM4fgdS+sICjnFtwuPC29+0/FP2qmiEm0
W7GyQNBqDHlyiEe+R/G+3hA0/ey2dMVeOI7ti5+oQXYD2dccrQT2ixHAyko+N4Nn
XVy8nIzUWNFprXLpC4WPfK2VjSJpp0nrm2DN07LDN0NcJMrQiLQdSm9uYXRoYW4g
Q2hlbiA8am9uQHNwb2NrLm9yZz6ITgQQEQIADgUCOAFmIAQLAwECAhkBAAoJEML8
hqolOUaLYDgAoO6YPC4qnUXmHkRA7p4e8t4ZTe1GAJ9Yv3qqNB6M+/60uN0MCshb
a35lsohGBBARAgAGBQI57on6AAoJENN4FMlqzsGqwIkAnR513+/0KzDMUI2GLsG7
R5q3cpqjAKD+IOPgbJHgIK0akA9GNA1z/P0/v4hGBBARAgAGBQI57opmAAoJECAV
MdWEXf7dDMgAn1djbz2wTeCG09TEdvSATrPmj3eWAJ4/syRYBR/qLqBdiyLW238F
BQ7uuohGBBARAgAGBQI57o74AAoJELYkBuZbwVKh+g0AoIxeOw1l0FGdy/hKdluz
9mrb6EexAJ9VOHWxZKgTTln8+ZyfxBd5ruFB8IhGBBARAgAGBQI57o/JAAoJELjx
LUz3PH1EZS4AnihF2U43bwiEGWkT/JLLy7TSfRjFAJ94xSfSt39smgMQmVeYMBHu
HSLMrYkAlQMFEDnul3dNVigheQUMEQEBKw4D/iWjX6ZnnmDStbXxWmEH+e2M7G16
R3nY2TuOCpjXsZqqRe8XHS15DKspNJwUZNHh+Zjr9U2sRqalmkIFt2nB2X8CdMyR
pHFf0SrTwnapIYRHEZ74fkAsu6qb7YatSNhzwcmALx4mzgLX7ARsrau9NzUgrY/G
RqH8GOyB5lHPFpAdiEYEEBECAAYFAjnvJEQACgkQGPUDgCTCeALPGwCfeoJCW9cs
4K6OtnvLJIiB1oqV6FEAoN8JjdYrOwgykMjyq9f/PFRm6WiOiEYEEBECAAYFAjnv
JFcACgkQiOF7HfzlZWFTxACfTQ6LjXC6kmyqBEjgSQvc17Ypaz8An1Ab704SKRwR
r3eLdUOBTFdDXbU9tB9Kb25hdGhhbiBDaGVuIDxqb25AZnJlZWJzZC5vcmc+iEsE
EBECAAsFAjgBZmIECwMBAgAKCRDC/IaqJTlGi3A3AKD3HgdSlRjb2PNY9fmpEeYH
4lFhpgCgocDA03BR5C9wuSKhaBVFULlm8OuIRgQQEQIABgUCOe6J/QAKCRDTeBTJ
as7BqsDJAJ47uf3WrmN057AwozmuZtb9vMm5EgCgsykRluwbCgC6ZewHezoaiOow
jzeIRgQQEQIABgUCOe6KaQAKCRAgFTHVhF3+3bZUAKCApjy6fQvR7tLP1reuVofJ
oeTofwCfetmE1PO1XcTZxUer5PN01sqA0TmIRgQQEQIABgUCOe6PzAAKCRC48S1M
9zx9ROChAJ4zQm6DLDcRdU6Tuk9/OCdKnHMnhACgtDI6x3Jw8FPXci2P2tdRtKN3
B1KJAJUDBRA57pefTVYoIXkFDBEBAUr7A/4vnr99JzFe44a674uECQbpoEQkYYnH
f/LLbUMhQkmp9nRwI/pS4lpEMxPhKBPtOjL3tkpXfhFRGClMKbRLB58Qj9QNVzHq
nnN9MV83+fhH4fYU5isO5sVl817AN8NJdE6OsyL7LZWT3n9Ri5+qgeMa5rjMLw60
hUAISXJKZ1r16ohGBBARAgAGBQI57yRHAAoJEBj1A4AkwngCApcAoKmg+EZV4ev5
RW/Y8LqjShfezs/QAJoDCln4Q/DTjxMw0JqaGB4ueI6CwYhGBBARAgAGBQI57yRa
AAoJEIjhex385WVh+ygAnimdjrEtTQA77QEZ2PF0BEf9//V8AJ0S73bH8sBgmy12
ke3p9QDxZDYHi7QdSm9uYXRoYW4gQ2hlbiA8Y2hlbmpAcnBpLmVkdT6ISwQQEQIA
CwUCOAFmeQQLAwECAAoJEML8hqolOUaLDKAAn0Qd6pBHUKZwZ4PNnVZFBagD3mQ5
AJ41koGIb6g7Q1Xtu4HEBQZAvsgpKIhGBBARAgAGBQI57on9AAoJENN4FMlqzsGq
u2kAn2POi/O3+sJ3G7mN4rBkHf6S7eF1AKDjdY7lbIjkJ8+fUyIrvuVigzAQRYhG
BBARAgAGBQI57o/MAAoJELjxLUz3PH1E1Q4Anix3+MKXfnwrgUmhkReBQS4sp6Qe
AKDN04ovFaX+oElfkglOxltBumSqfYkAlQMFEDnul4pNVigheQUMEQEBX2QEAIQO
PgnwB5rBnqA0kNW0jNy4fq7UgikOYKjps/NVvuGhR4cfn6uZQUNPeO7S3BKL3JPu
BlGm1cSwLZES3xTDpnq7dEQWYyc8c+/U/mUrSDQH1hVVo0rZwYFqr+5ZL20M1Fw+
ve+XgfV8RvrMBXtphnVl4Qo6yghuWmf5pBEpElp9iEYEEBECAAYFAjnvJEcACgkQ
GPUDgCTCeAJSiwCfT8ClDVDP37K+RE0wI+0o+YTrCCAAnR1pTuctZsNefOKbSWXk
8BiHHfW4iEYEEBECAAYFAjnvJFoACgkQiOF7HfzlZWHbuQCdFwi9MWCX+1ppGDcu
YFwdNYfNn7wAoJSIogi5+KgCWhyoQWogYlgCs4WZtCFKb25hdGhhbiBDaGVuIDxz
cG9ja0BhY20ucnBpLmVkdT6IVwQTEQIAFwUCOe6N+gULBwoDBAMVAwIDFgIBAheA
AAoJEML8hqolOUaLEEYAoPHfT4twSf2tKV8moPhqgQFgN2hxAJ9K7Lhc8HWSpvgh
4jIaHaM8eiJnookAlQMFEDnul7dNVigheQUMEQEBYvAD/j4EQzuAKhSdaJ54F1hH
8PMmOwxM9HJ4U8BvWY/wQJa0Hgkxg8UdQE9O7ZFWj/KypTEheSEreV6JWtkCdtpg
KADWPRwKEnH2oz4y0/GjwoHfpyIZFlAC9WYYo0+glKLnH/FQSt7W33eJxLkepE23
2hMOa6nEO3OFbik5PxaxpkzciEYEEBECAAYFAjnvJEcACgkQGPUDgCTCeAKdJgCg
qtwHztlKh2pWO5FlSpMZ3ilXLEgAmQH9OUO+28K2b6DYqGPSn+UDWfi/iEYEEBEC
AAYFAjnvJFoACgkQiOF7HfzlZWEi6wCg3uFRxhC+wR5304Lq/pJzX2HuqqUAnicZ
7taSto90zR/xwcYEdcSaRHRAtB5Kb25hdGhhbiBDaGVuIDxqb25AY3MucnBpLmVk
dT6IVwQTEQIAFwUCPRgU4gULBwoDBAMVAwIDFgIBAheAAAoJEML8hqolOUaLXVYA
niQtgvTgGqxqsxRkd/aFegjCw9zIAJ95e7tBtTbBFgWZ/TeMIpLVAgZJUbkDDQQ4
AWYiEAwAzB13VyQ4SuLE8OiOE2eXTpITYfbb6yUOF/32mPfIfHmwch04dfv2wXPE
gxEmK0Ngw+Po1gr9oSgmC66prrNlD6IAUwGgfNaroxIe+g8qzh90hE/K8xfzpEDp
19J3tkItAjbBJstoXp18mAkKjX4t7eRdefXUkk+bGI78KqdLfDL2Qle3CH8IF3Ki
utapQvMF6PlTETlPtvFuuUs4INoBp1ajFOmPQFXz0AfGy0OplK33TGSGSfgMg71l
6RfUodNQ+PVZX9x2Uk89PY3bzpnhV5JZzf24rnRPxfx2vIPFRzBhznzJZv8V+bv9
kV7HAarTW56NoKVyOtQa8L9GAFgr5fSI/VhOSdvNILSd5JEHNmszbDgNRR0PfIiz
HHxbLY7288kjwEPwpVsYjY67VYy4XTjTNP18F1dDox0YbN4zISy1Kv884bEpQBgR
jXyEpwpy1obEAxnIByl6ypUM2Zafq9AKUJsCRtMIPWakXUGfnHy9iUsiGSa6q6Je
w1XpTDJvAAICC/sF510YKnZ/qLcx8LfgpeHXSwVzk6/wZnnplNMAr5CvgYWa8fWJ
L3DcbYUsZ4+eG86RULQ7WwaTXvuRXxiDsc7Rf3pKlZJGgOdIPS+VmCasO26/ohlE
tWZ/5VoOJD1fRdoI6gttwhBXURY2ydl0cy+rCv7hLBTEOLunCWiA0fiPC8mw06vK
ckaEdbhsB5WfH2XVEpF1db2zliNLeCAFEjxoo429/2JcaKaq91hqxa/ylAz8W4ku
jCxTifWF9Ef8qz7wE9tyAplw7/j8E4lo/xSAOQLL7sh99B32bPo5sXCVS9IdZQCx
GRsZM1JIlSbhdMKWrWaKpJIxWwNxlWHyVIHCY8PiZr1GB+qBICQL8egBtkurQoB1
mBPBjjVtYS9VUXx2GtG92mLR4QV5obkqz9O3ZM7fVBjpCVHKdf5s3g8IOWPmP6oX
0IgOQXC8PDOcpSYhgccap0PcEwh5wWaTCTFlxRG7cUesFODM1RnP9X4sFygNCVOy
TYxI06oLAc40TH2IRgQYEQIABgUCOAFmIgAKCRDC/IaqJTlGixddAKC6OtCIquKb
qnfGSEooSVFz5kPTaACgtZYK1PfljVCb4e0xoy8XkArq/8s=
=cJgh
-----END PGP PUBLIC KEY BLOCK-----
D.3.34 Fukang Chen <loader@FreeBSD.org>
pub 1024D/40AB1752 2007-08-01 [expires: 2010-07-31]
Key fingerprint = 98C4 6E6B 1C21 15E4 5042 01FC C7B7 E152 40AB 1752
uid loader <loader@FreeBSD.org>
sub 4096g/9E53A5C7 2007-08-01 [expires: 2010-07-31]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEaws50RBADNBWbMkteeLSMkyQ2Ff92gfFCrsBL0ZTXWjHR73PqorwIlS5j9
Y0zGazjblbGcyzQj0JDDJdQuIeA3BW8aCYgacORI77aOWxIfDiyuXumYOSct62Ss
TSxjsv8WQcFhGVZ+Ou0zxboB519US2JBpRTVA+F75bJrxX/Ax5vrws5zOwCg4WSM
jQP/H52YYVdyQKxGC9C6F1cD/A7ggN8X1zu7U+85gjoSq4uJtQwsYoOTI7fnhVOf
TOmvCJILPouK4mU0gtaTG1jwfhrOf8reN4taOLRqbEnBsqLPTKsUpvMEDhab0gZS
klyqrt8qbWIvdyZXTlsEgiJaw70ys2Bw3zd06o6w3UDsJu2wMIqWdooUxFL4a8WP
q8NrA/4u4o6RGXYbhGl6dtYDLJADQ7C+8x44c6fiDK0d6o/M/2Y7DEsyqPW2oiNf
g+z72phEAzi11ry05StdjO/5k+BskNbiV+cBXuO/u2bHBZYpZAvtNE0D11gUh+Fy
dZXirJ2LSs3zH544JVk4aQrgkpZFTVpVNDebqEeI2lC0bBdfm7QbbG9hZGVyIDxs
b2FkZXJARnJlZUJTRC5vcmc+iGYEExECACYFAkaws50CGwMFCQWjmoAGCwkIBwMC
BBUCCAMEFgIDAQIeAQIXgAAKCRDHt+FSQKsXUkLcAKDdxtPI9LHkHDfz7XcZqJI8
pvUfvACgifp5pvc586B2Dk4f9gzqV2USy125BA0ERrC0RxAQAI/lyodTlM4iOXcc
L6Zf//KQdy0RaEtomRzPBTJT3OKgua108ms1aiJjtUGjTmvyU/Szd6LUBNknQPnR
PMsn2yh3Gf2yeHodqz83C7lsRVm9cUFSL0j6SGofuXzypxLH1EV2MUoWSb/wBykg
N4nIVYIlHWGTBxY4u0+OM2XsAEysgjH4u8zSOKDfdLco95rLHVw0VYZftOCVoS4C
4UWX2sxKJ7FMli2W7oMdaqb0uskQz4IrqtGjnSycQ6ygjI5NQZSZiqAW4/op94Yb
JMh//u482cqWRCifFbdo5Uvc2xUhaii5GMgcDZ2PsIMo11C8amtQnMZVTbeHILP0
1Odw2jV2oVTiDCHkQZvuqtmrVkF8yYZbra4amI1Aqh2TYOvqR+IaLUqmv4Nr0kUC
2U5mg7gjJmZghvErfo3Vibj4MPrh0RS50BxkcELNiUu2XYvBGbhTvWIMXTv0MC40
hp0nnUYZWxyOzlbz1vVtL8BLBw98d0J2r39cwXh8yKM9mtWZN76sG9Vco5ITv7HZ
zd3EBrljh5r8JV9RmnboPnfKsMYvWVDvko1ZnOKitbkB+wuH7W715BvdZ2nBm2b+
XagBf9BYDAd7wnzoxq92YgQy/ziSSwcYevM8mcoxiZXTAxP6THCYUbsmRS8Sfo7M
PoLcPMzDTwJWGAj/mha+uMOKhNdzAAMGD/9dgn/ZEybsplvJQbtfD2ChCW1uaodT
8s3HCJfQ36eYCqhQ+53jjdkQ7me9P3Kw+adVnaH233qUgF5pRBWuH8s7k54/nfMR
UZWobxC5gjxAiqA0acSziDiCZXA7Ex3ipfWnORphZEkJ1cgjSbLGY6cPXMPYylyN
m455+S/d50kc/prmMyUq8KefREPdLk2XTm4SY29WfDHPvD0tvWWPoUwQpKAWXwEE
2fgTRZWEF1hS3MMh7OUduKqoa58RORj6jIzJkfFoeLhuiEvA2NvKFBWbGKF90vVq
St7QQYUHcfL5SmS/twD7WQV26xmAjwztatBH0rN6yQKOYXalhACiJh166x8azhky
VrfpP7NWhR0hXWskQzUwWhJj0EKVDQoK/9ph46N/zK8rL7X6gKX8RMnGZKupcXtt
73C4eUmJcD2KCqe9ZBhCxkLpCHLQwAylDSpiIMh1EV0UA2lhsJI6ldNwRs8yHO4P
XOnnX164YuGCPOqdlOUmyz95VAxSW+DCkI3AZMzuNwiIceUD+Kijv268leIJ34ui
JSVwJC47UjjNT/d18QpwlST/olfMGk7Ay74SdAxRtH3Cvv6vgnwSQdECdLZ0n7jU
UOEfdxEb+2S5XV8A7MxdpjUv+xG5f9uTBp82soI3lnXxV1X4+JU08dTzsgmahTJ1
ESVS7AA1nBH3Q4hPBBgRAgAPBQJGsLRHAhsMBQkFo5qAAAoJEMe34VJAqxdSNKAA
n2Ho+8xBe1twvEDxCnG18lXemKXtAJoC+BnKmNeJPBBPlhtPxEqTh4S/mQ==
=PrOy
-----END PGP PUBLIC KEY BLOCK-----
D.3.35 Luoqi Chen <luoqi@FreeBSD.org>
pub 1024D/2926F3BE 2002-02-22 Luoqi Chen <luoqi@FreeBSD.org>
Key fingerprint = B470 A815 5917 D9F4 37F3 CE2A 4D75 3BD1 2926 F3BE
uid Luoqi Chen <luoqi@bricore.com>
uid Luoqi Chen <lchen@onetta.com>
sub 1024g/5446EB72 2002-02-22
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDx2qBMRBADYSjvWKVcUxUb1aR1VjHTlFo6zc6PHMK8W3CRin7lY3NgsYsmZ
n0IvGQIDEHhTpOEWLS0S6A/bseaGUir52X6spZ8i5hfd7Ps9RmeS0oHx0XDS9JTJ
HXFE5RjExHbLnw4DbsaqR4Fl1V7NJU2U/nkiJILJd/PGPZsdstKYv5QvnwCgmwr7
QZlkTV/m61MmbMAEpEFWaecD/Rp5Qb9S5NGVplNeNqub4fC+Ydarkorr8qBJN9Va
xu1Qgj3sOAoxmuOnZ99YAgXhs9Bqe4QsrQfs1cMUVzZsl3FIffh92HkrLmdJlsjX
8lrRT694cIP7+ELNGKJ/zaXI3j2cnQPVqUO1icVfijqatqDg8bgQS8C8CGQX6e6h
ADKGA/9cIY450gMvrtbR3/bqH+IgvBCUog5RXv0y8c80sJnzeqawx2BuziFvv6mZ
Kv0PJ2vnWok0NHcyuBHkkEt+ujYlMQXHZ6wRykYxIUzM8tl+9129tSNEK+GdcCOZ
rfbwm8scs+VmzrHXP+saOPcHPBr0e/KPPixNN1I5HB3yI0ILSLQeTHVvcWkgQ2hl
biA8bHVvcWlAYnJpY29yZS5jb20+iFcEExECABcFAjx2qnEFCwcKAwQDFQMCAxYC
AQIXgAAKCRBNdTvRKSbzvmmrAJ9FVK0lT4Qym+qzj0EA6TP3V42cwACfQl+ClPzJ
zngykscMJW07MBXkQ9i0HUx1b3FpIENoZW4gPGxjaGVuQG9uZXR0YS5jb20+iFcE
ExECABcFAjx2qpkFCwcKAwQDFQMCAxYCAQIXgAAKCRBNdTvRKSbzvkEwAKCRteUw
2X3XbPsVDCBZarrkf113YgCeIHmhkDHbauw4UlUO1tYNVObn5dO0Hkx1b3FpIENo
ZW4gPGx1b3FpQEZyZWVCU0Qub3JnPohXBBMRAgAXBQI8dq6XBQsHCgMEAxUDAgMW
AgECF4AACgkQTXU70Skm876CUQCggJuwNIJy6f05Ka17RYn+j8hEQhwAnicDXnsy
5SEYN6amlHdqN/HwXCsbuQENBDx2qBUQBACifA9hUBBYNqCcXTs8Jk1MCcToMFob
vRt/SK2EcwjZ9aF9sIX3tJFrOHEe/bIcDMX19e480T4+BBs9MyHdnKgPR6vP8ZEe
FvT8+44Wd6psLB1LwsE8UpJ3CbLjkgafTpJIlh4NP5iM2p+2ugUIRM2ZaAG7MOMK
Ec47KOEb6yI9ywADBgP9F+p+zQ1Z/qVekBooIKU4xKBryGb/XIPJi/Pgapgr3oE9
kKH4iObbvMBSV3kd4a0+FSEXSZyRnMD1AG+dWhAHgb9rbjtICp3hZOKCMfdZxFVg
QStZO8vP5EhQYYtIXiNmOvkkBPqb+to5RgFFez8oIdPlMUq2Hf9MBIY6XDoNJl+I
RgQYEQIABgUCPHaoFQAKCRBNdTvRKSbzvh9GAJ9K3KifYIBOHlsmRLF75mgKQk/c
0wCeIOeVykZkImOxs0pEQMR/4g47Wjs=
=RNuY
-----END PGP PUBLIC KEY BLOCK-----
D.3.36 Andrey A. Chernov <ache@FreeBSD.org>
pub 1024D/964474DD 2006-12-26
Key fingerprint = 0F63 1B61 D76D AA23 1591 EA09 560E 582B 9644 74DD
uid Andrey Chernov <ache@freebsd.org>
uid [jpeg image of size 4092]
sub 2048g/08331894 2006-12-26
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v2.0.1 (FreeBSD)
mQGiBEWQwPURBADoLKvU4ommBNyZyVO7L2S/AzCQ7qZbnnyP06JfZAD1gay7rcT0
1n9ncCIUF7+zJkkOyAM13rbImLqGewIxFkcI9z42qsLiLA9yCuig/5GmyJQK1Zce
FyKkR6ZkpuuXUAZnoiHJ5mGuY89rWGrM5FrINkbaJkFuJjIUkh7pSk5OBwCgvzbx
BO0ye9X5e3/Uz+FOE71qIIEEALGhytNWYso6b3rznuPxDJhniApNEPbgnZBdP9xL
+/TahRwr6C93SJZKhYYmsgUTR4h6oP5dbMsOquCxOuej0lLYWV/Uvu6OPwqRlXzC
lyU45pre60zIuKS6QBV3AKagrwJcw52B5c8FxUOcF8QLU//SjvaiVbq1eZLjSUne
/xMABACtrSN6ERQ9GEIoc9AlbCcYoRJq2rp7k8iZz07FkUNSAoWc/Jei92DVxn1n
oHQtUoyIWi+pC4f4u0u7jz3VIQZ2SGMlZJI1WLxNCtnmiKiqqVE4A2glLv0GI80Z
wSH8C1QbR+1aHLwT7xQ73TdbUrkFEEjS3OvY4CypZjeDSgd9T7QiQW5kcmV5IENo
ZXJub3YgPGFjaGVAbmFndWFsLnBwLnJ1PohjBBMRAgAjAhsDBgsJCAcDAgQVAggD
BBYCAwECHgECF4AFAkWQ4AwCGQEACgkQVg5YK5ZEdN2TQQCgmyQ6vMXc3Ta+L3k8
vWC/4D8vFAwAmwTJzrdsnGKgct8fx7raPc2AHg41tCFBbmRyZXkgQ2hlcm5vdiA8
YWNoZUBmcmVlYnNkLm9yZz6IYAQTEQIAIAIbAwYLCQgHAwIEFQIIAwQWAgMBAh4B
AheABQJFkOAGAAoJEFYOWCuWRHTdFl4AniwFl5fZI3oC7h1NtmvHThsgEZdXAJ9F
A+QmsvfCrsnwb08hJPFqpgb8/7QfQW5kcmV5IENoZXJub3YgPGFjaGVAeWFuZGV4
LnJ1PohgBBMRAgAgBQJFkMXuAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQ
Vg5YK5ZEdN1HtQCgq2ygofSezn9ndQ+xDogdIDBsSOoAn1AiFeAsKcFm1i6c7tI+
Yo4SVJ+Z0c9Pz00BEAABAQAAAAAAAAAAAAAAAP/Y/+AAEEpGSUYAAQEAAAAAAAAA
/9sAQwAMCAkKCQcMCgkKDQwMDhEdExEQEBEjGRsVHSolLCspJSgoLjRCOC4xPzIo
KDpOOj9ER0pLSi03UVdRSFZCSUpH/8AACwgBIADwAQERAP/EABwAAAEFAQEBAAAA
AAAAAAAAAAABAgMEBQYHCP/EAEAQAAIBAwIDBQQGCAQHAAAAAAACAwEEBRITBhEi
FCEjMTIzQlFSByRBYnKBFUNTYXGCodE0krHwNWNzkaLC8f/aAAgBAQAAPwDXh3C9
AhcjLIgAACMVpUKc8XhmVLGNjToBYfFOrj9A8Cvc3ttar48yIZGT4rsLWF6W8lJ5
6d2lfsOCzOVuMncNLPI33TGchGsRso0QBBD3iOIlVRyk4gAAAxCxVuPZmXMMRvC1
uVJMjH2jp0lyXizHWUWjVuOq+SsUbjjuLvW1Sj17up460/8AbvM6biW5uk0NMyfh
Yybq51frilLrKrsRMxGwzUNGjRAGnv6qOFUmEAAARiJiCb0GPfOkcZns8L87i+dF
gX/yObzWchl1Q20OiP4d3+pzryvJ75NCWNYjOCTkcrayuxGzDBg0QQTUIfQKsOHK
TCAAAI5EVrmumPWcbl79Wu5WjXWsK9NfdOZvsjK/vvoMiRhEYnRh69YrKMGahjSE
bEY0aIIIB9BjhVJxAAAEchYzr6Tom1dMaL6zzXMXsXaZNhOhnMKeV5CIkjJSRdAr
MR6hjMQsM1DRogggAe6JuFuFywhOIAAA2QgkfbOL4ozicqWSVo0aUpu0R6Uoz8uf
Ln9tKd38eVThb6fen3Cm41SZRdQuoBgzWNYjGiCAAgHtiXaF2CUvRlgQAABsp59x
pxLOl+2Pspaxxxc1lrTzavdz7/sp50/Kv2Vocqqb36wpTxlXSO2hdAaB0Y5yIiZh
ojDRAEAAPZ44ULtrGaEJaAAABHPFL3Xd5K4lVdWttZPSJooG8SNzNufbEMcYjiaS
QjGuNIRogggAAAewQ7pdgmNO1YviAAAQXzfVZf8ApnierY/GRPcEMhtYXD3F/byS
QxVcsS8K5BXoqW0zEE/DWVt7as0tq9EMaZdBWYQexANEAQAAAPaoyRS/Ze0NEAAB
SC69jIeG5Gn1yVPvlU63hjhV81YJds+iPcrSnOnqovLnT8++nP7OVT0PDYmLGWmz
E3Qpo6BrRIZWR4fxt+vjWkev5tJyuS+jqlaM+Oue/wA6JJ/c5LI8PZHGN9btmVfm
MmUhEEAQAAAPcOziaS3j28U1AABQI3PHeL7TsHEdzFp0rWutO7lTlXv/AD+P8amI
x7HwJFSPgrG93e6O9fzkav8AY3gEIxDGz2js/UeXZK2j3XMqSEhZBggAAAB7M14P
gaaf0GrZWuz1OaICCgBCch9I+H7XiUyUK03bSvX8apX+1f8AU8yPaOCkaPgvFK1O
Vdirf92aptANYYRy+g5XOXLvHtyHI3sWnWY86lSRSBlGiAIAAew2KdplOlt7dIk6
CfSOAAEGsw0bLGk0TxS+iQ8Rz1hJictc2cn6tuk9qw9u1pg8fbSLoeG0iR/8hbAB
jFa5eNPaOchnZrf1LOvUcreXEfuGZIQOQuhHpG6RukQAA9nwNo0cvUx0iCjgAazF
eWdI/WKkmseKcfxpho8lncLXRzrJOkMvd5prp5/lqO2cQAMjI5/H2b7bTq7/AHGP
PeIOIJrqZ0Sq8v3HPbrjdQDRo3QN0DGQj0jQEPedGzOX1H6hwoDGK9zBuxkGOjZI
OsuCla4gSW/s3f3JC8IUb++W2g9aajz3iLie4mk20nq9dPKun0mThcTfZy6a3t27
vU7sdJJwD2a3aRrtXqtPlOavrNLSTQVleAl7HuR+GUpoHQiABukhciGiH0DcD4X6
CQi7VHr0ayyjCsNGsU7GfeeVflLYpk56S7ha2mtp9tUq1W5Ra/8Af2lCzzmVtZeW
Qx15NC3Ku4lq/OnP+FOVfyOitbu3vrfdtZdaGHn4pJOl9zbPPsrjux3LKbP0f5aC
yyFxZT86b9F260pz5tSvl/X+h6Bdw79qyHmfEUE9JX3NpU+6czIa+Bpc3MuzbR7h
tTYR5I+voOfvrHs8zIUmGCELkDDAPf7hfCJbdOgm0mVlrbcZNBftOi3QkZxykdw2
iFzAxt79cY6BBwEUE/SyEsTapH6Dn+MMjHaWiq3rfvoea3VzJOa2FsYsXbUz18y1
okb9mgp3s8laVovd8O/mTzcW8R31rK0VIoY4vXt05N/WvMwLya9uvEvHdipFbvLP
o0az0fgjCz46OS4uI6puU5aa+Zo5eWG21/eOByVzuS9RkTMQiaiNyuw0Q+hXUsIo
4idRdJBPFuExk8QXOzaaTBwNN9zskHCMY2ayM2ORKWcaTXl1IsNrE/kzt8f3UNpV
2YNDvuP77nF8X20l3MrKYdri/D8Q17fFzywIm1uRJ7rFl+CIZ6o1ZtC8vdLUPBGM
jrTd1y/GrNU2LHDY+wbVa2qRlqVtEZw3E131+o424m1lRmGDdRGxEwgh9EkwDWAY
OY5riuGZ4V0egh4ZoiP1HUAIxFFaxNerduitJF7NiPJXWzEYk11G5mWreL/yjrcZ
HogNBVAaxnZW42YDzriG53bg5uVyFmGahoxhggH0UpIKNYQQcV7xEktpDmsXH4x0
6DhrEnoQ5ria97K3r904e5yetvWX8JlIt6OOf0npFovglkaxG7HO8QXe3Aznnt/L
47mRMQjRBo0APooVCQAI3KvafE9Al1P9XcysdHoY20HCx+0HTHm/GM+u70p3nL7E
rkfsnPTOAM6uQx7WUz0rcW/lz82T/wCnVkZSyVzsW557m8l2iRtM3SvTpOYuJSrI
xENEEEAD6N0jR4oCMQSR6zKu02xtpIamvoG7pLBJ4hm8RZmPGWvPpZjz1b2LIXbN
PJpLWUubZLXbgki/kOVmkNngHfbi21rBq5U1blaV93lXnzPYCtc+zONz1++4jaNR
xN4/j6yjIxC5GIAggAfRzERIg4QZqGkTx7pnzQJDcdBZ1dAiEN1LtnNZ/Fplne7n
vntqKvW2nUpgycK215Yy3eEytZ47daVnW4j2q0/etfKtP995ztzYz2dzszJtyG/g
OF5My0bTXFY4WatGrSlNXcekYjD4/B2+zYQ6NXqk95yxLfRw9begS9mXsWtDzzPX
MjXTRfKcxcMVGIxgCCCAB9GMNE3RrXKfOMkuPC1jLeffFa3EkmS3i1ymNFc9outw
0PcH+glsYdxnnf8AkOU4xuLmzunrDNXRKlaMlTiLmdo7R9mRvE9cX4T1K7wOPseH
nt7O1jh0Rd76Kamry861PO8XxBeYS7qiPV7Zn5vEb95xw+zXYReTU7v3GVPxXI8b
rp9XkVLfiKeB9OvVD8hFkL3tXiGPK5CwwaADRAA+jiN0Mi/t31a9ZhTZB1udpzch
rrgjjJL6fscPhmWmcvGfTHDqM7JXGRu7ilJEZUNDGQshs6CrMzoaWIfXZfhcyeKc
OuRio61Zap51pT7DgbTDVv8AK1xjPtSTI1Inr+0pTmp6rPG93iduRuqSE8Zytk1p
dyI5mSMRbgmsmilCQiGgIAggAfR4hFNHuHBcUY+4tbnfT2ZucKu1zYLJJ7pS4oyV
I/BXzMuwziR+pTctM7bzfq1NmDZuI9yESl3apG8kkyIYeU4ow9nPRWZpqN51j+wk
i45wEMXKCs7Ur31pSPlyr+dSGbjuyejbVq7fiqYdzxBjpLlZ2xcDSK+pa18+ZpY7
6QLZVrbz2O0i+isTd350OTz17Fe3cky++YcpVFHBqEEAQBAAD6K1GXl87a4r23Ux
xWV40vpLrnbPtx050pSgtOJZMha7V53nU8KSR/o7RG2o5Did3bIyGRbpI7mvj7ee
OTrOqwWuIwOJcDfvl5OyJJKs/Vzp8fgVovo8zFwuqa6tIKcvJqs1f6U5f1JLP6Nb
ys1FuMhHGnPvZU1V/KnM14/o3skp4mUuX5fBFX+5yPFOLhw+Rra28zzU5eb0GWmJ
hvcNbT2cvO+aRklhZqfZXurSn8KlXJYq/wAd/jIGiKDoVXQaNAUQBAAAA98ucvYw
6vHj1/IeYZvKvfZCSR/5TKGySnW8A3rJM8bNXka2b4fkvLqSeOvdXv8ALmZVlD+j
ZvGNqK5tbh/vGxZ26IaSj9IsY5jzbj6yb9I1npTuehh4N7iN57e0aOkjaZV1rz56
T066t4M3w8lZUSTci1L+I8kydt2a6eMz5FK7EYAAAAAAHf4zA5Orx3aRVkR68+dG
KvEuKms7zekj0K5hzMVi7j72Syn3YjtcRxnbOm1e0ZfhXzpQfkLePKtu279Jk8pV
uuj3DrcJI8keiQ3oxzsOA5fi+kb2L+Hrqp5qsuzdJKnuHqHCOUjv7GWHpWSGStdC
/YtTh+L1t0ysyQNqrSvecq5XcaAAAAAAB6JwvxRXHL2e85vDWvdX7aHY0vcNnLZo
HkhmT5HMPKcC28sVa4+4ZK8+dEk6l/Kpydxwtk7aeqXEVEX9oaGP4T7VZO0e5LPz
6dVKKtBU4Ou4eu40d3ylq13sXcLFL7Nzbezi2+0F/EwbbGuKo9gY5fiiTQjRfOeZ
3XRKaPB2WlseIInpXmsnhuv7i/xZYsnEMzx0bbm6u85a4j0SFOUjAAAAAAA7SnD9
63uCNw9k459SatRs2eG4h2qViuXWv33qa2JxWdjudd7dx1jpXy1c+f8AQ3H7Si+H
oKyWt40niekiucRLO3WyDv0bIsejWXbK12epy0SKDDY2MjiC2WW23DynIp9ZM+F9
i83EPTL+n6RwUN0q016PgefXyeKZk5CAAAAAAB9A9miJFiQk0iiCgIKRzzbCdZJE
DlNHaLKerplUlyCa7WQ8gza6b+QxpvWdzwjf9oxb2bt3rTmpz2bi27lzDlIByIDp
oGgAAAAfQUbdZOAAKA7QIUcjHuvFGXUUVzBys+xfQy/I5tyrrjPJeK7StrlJFOcm
Nbhq6a2vl0uXeIY/G1nNSkGk6W2wlLS/x8kaVuI5n5VrWlGpWnLurWnKtKUr3+fP
01LXEeDhRt+3Sscbe63unJvGRiAAAB9BwqWUHkbDBR8Y8YRMPFY5ziE3rZtdpF+A
4j6SLPqgulp6qaa1PPZVJcb4d0dfkbJ7qw3funG3Mehyq52nCV9HNjXtmrymV6Ot
fiWM/dPHiLqi++uljhHGIomkaAAB7lS+0SF23vo5CxukU0+gWNiQVZCTWIw3bMzP
XktnYts+ou2EvaMdbzfPGZXEqfV9xTVx6NHjrdH/AGZi8cQ0lwTfdY8odSS19sei
4iJJcV1nA5pES8k0GQ5bwl21pkEOj4gfdxkv+Y48CdfFIniIhAA9fXWaNrCW0cTb
1knoJ9Q3QKg9ySH2BQy8W9ZsWMfHtY+CP7gXMCT+0JzE4s/4JKeR3HtBIG8Q6qHN
dnxW0rd5yt7NuuUmGo2iQ6iOXteJeBvk6TlRwatBYdtcZWYaAH//2YhhBBMRAgAh
BQJFkQLHAhsDBwsJCAcDAgEEFQIIAwQWAgMBAh4BAheAAAoJEFYOWCuWRHTdZ1QA
oJnXXFVCmO+dmna7MxZfmouwaHumAJwKEBA0yCMyAWY6IeT+cRI8hmGhHLkCDQRF
kMECEAgAqm0YR1tf1oO5eaHkafgzPBqDJRCIb1pv4raUIKMrrlEnXkeyCIP6iOIx
jxXOdSiI9BAbx6V2rZHu2J/n1OF++BGZSIksLGdG/nOTso2uE/goH2vJFzgBtS4r
fQLKnfWfjm3QOQfNU0wcxo4HKV2Sqpopj3n2zkE//oJdCCnmogpkars61iAKFgSz
zEPXkPEV7zKaf6UKuVqXSYrWaZ7MN01WiljpR27Wqx8FcdvxcRyhFCtt968mm1oL
mydgvOzY6UdNqnv9XOCmE36ArcvrPCygUy/mCru3YgTHNeQdB8Sc4FXf+UwC469M
4JjJFVmDzyFrz9QDtdR/O/KnfS30dwADBQf/Y37iViqLut2msclQWOnFftG2P2fu
xXf2rjf/DwHYutN5NFERe9gZYQMdBWAD3ANUr1xiaFwWJFx1azzzlxz+UtoHd/F3
mAWc/IpoUNn91SPLMWCwFqKCa8lSAR/n55IKeBJxMpyTpb7G9BKTQ38N17UUVuFw
Kl/HHGgDp1tYnEDD3J4sssDXCo+H31VQz6vW/IGdc6OaGFWa8DZcz/pLh+cPp5BT
76ZFEe+pmz5SkaqXQ7n0fGDTf7hG0HdRUp5Q7Y9U1IxIDEjdBTem7BeLQQB7xH9G
/L6CW1EryKpYPzjC4lJWwaP/H9n1Q8eaeB8Zj5/TYf9l5mAn8qsJ7cUcYYhJBBgR
AgAJBQJFkMECAhsMAAoJEFYOWCuWRHTdg9QAnAg82a7K69vHoDfSFMjp2trLswGc
AJ9RFN/fKYunmZzi/STcxm8mj4AJRw==
=XTXc
-----END PGP PUBLIC KEY BLOCK-----
D.3.37 Sean Chittenden <seanc@FreeBSD.org>
pub 1024D/EE278A28 2004-02-08 Sean Chittenden <sean@chittenden.org>
Key fingerprint = E41F F441 7E91 6CBA 1844 65CF B939 3C78 EE27 8A28
sub 2048g/55321853 2004-02-08
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEAlrEIRBACQ1ZZIej0e8esRdDxmuSv96bv1NTDBaEx7P649JM8a3afUvnQl
JkA/ryZsKAnw1OeIK907Cs5HdaG1lD9ttpQolG5ZN23K01CuHUvq6yY+evwDV31D
rKwYfALKfdhtAaymxM7RRsNNV8OkXLg0SEtBit4lbdY79vqiVC3PeWYvIwCgyOlb
7dw3f2mNtm280LybDSjn5KcD/2gWssJVtQgssnCi0Jto8csULw4OKyJHvXX06Qkf
lnXKcCJTBMgXZf0cZpYhuyqMUZfsVJaF0lMJ85J8zD+Of3G/KwuCqW7jqpom0zw9
mgsmhZ1rZCbf4cG1orpGSSfmsi5IFoe+mWEJgHwIKlLYd/XDfT1q81swa2AlcjbE
Pod+A/0cNSOWz4rj1ZjcxYsxg0sZES5eFEHfIJ+5g3yMbNPcvbQhlSClgDD1Z46p
6bEZA4+vL2kJH+29E1Q0M6H4OB2rY/Co5TypocuazZR1kwkJY+bQtFqPrcCm67Er
GYl3qcbtV8Wgn153k6DnMUc7by2iTrJiRjWw4LNVhRZn3/dj8LQlU2VhbiBDaGl0
dGVuZGVuIDxzZWFuQGNoaXR0ZW5kZW4ub3JnPoheBBMRAgAeBQJAJaxCAhsDBgsJ
CAcDAgMVAgMDFgIBAh4BAheAAAoJELk5PHjuJ4ooG+EAoJP+RzGsCHKYGaLhok0/
B0hBnIKtAJ0YTlDINuquFtqFTeZgwTUg4jeHFbkCDQRAJaxTEAgAqKA+B8+oo31g
N7Q6uw1rR5F6M2fFBwPrYU9w6bM7qX6e/oy3epL8BgtzdlHyzcux/hLGDHGP6mku
lwH5wGSjqfbk3guI1ogl+e0EjblIeUEAA1R/k2o8xt/HINhXiCjQhY6AJL9cljGz
NQY/ecR9d4HEvjc+Ticgyt4h6WSGMTpjjY+Y0bWrxsXi5ZAsCNYEuRgdaRM52aXR
gGkSqMBOKSKAPGc35Jh4nzvPSKjXmkXutCnPNcO+qPoro5j2Dx53ZkfB7Raj6CiY
C8VQ8PDEpjELTq8fuOqqrl911RDYAOECWEqyim78qROuhgq5750w1CJj3K8o2FDE
Qap5jNPiUwADBQf/bk9Es1QDyDTPLC7Look1OS50vhotrHce7P+uab++khm03ajq
XmNuTYifQY0kgzzEBaELw4+isBf1NV1vvPK9P6k6FCx+1mcNYzItRLBo15MtcXlB
IqkD3v/BnhVgT0PqJT6jO8glKCmhEq+GurXqydIfEzWCbz0+snVK769Q9rJHHUf8
icDKfUI1m7javdnXVrpA1kKZM8Omis+BfO17XDBLYZuVW5rAJDzG42YM8H1mrqBa
GL806X/3i55d2RfgrljiZvXBpdOZRnM21w6hxNuj3OaVxqrQn9hOgzBcVdSZWc9b
vxpmZ2j1vx7i4xNq5dzcBqxMKDcAcwomLWgjHohJBBgRAgAJBQJAJaxTAhsMAAoJ
ELk5PHjuJ4oob8sAoI0szWtufl86pHsG0AwxjsykDS38AJ0SAW5Nr1N1HlZlrtlG
0ev24JoBxQ==
=yGes
-----END PGP PUBLIC KEY BLOCK-----
D.3.38 Junho CHOI <cjh@FreeBSD.org>
pub 1024D/E60260F5 2002-10-14 CHOI Junho (Work) <cjh@wdb.co.kr>
Key fingerprint = 1369 7374 A45F F41A F3C0 07E3 4A01 C020 E602 60F5
uid CHOI Junho (Personal) <cjh@kr.FreeBSD.org>
uid CHOI Junho (FreeBSD) <cjh@FreeBSD.org>
sub 1024g/04A4FDD8 2002-10-14
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.0 (FreeBSD)
mQGiBD2qLwkRBADbZ6Rsv7guMTzGT9lj4eIE29vj0ZZNWFepFEqEmWK0jMLAATX0
koXkP/qWsuGBhVHcSyZtVG+MYTwAzo5nBszx12CNL/GkEokQ/9FXi+cA3W5TJZTE
ssMq0PPwqCB7+s/4DBmc3uI22TCOI7J26XkftuwkdihCMG/gk+cgKkzZ7wCggaBp
02a96DwV/78wUZy9C8B6uMMD/j5jAO2HOubn5CRZrOpko3za+qVsk6yTCmq12z+t
r9veYORoVohxVTIY+xpeHQVlOe5URTiKO0Uvu34Tl34x0BbSLBWrGU8UTMA4+hpl
QTUK1GI1DheFPGGGxbt9w40nslRVw2Or7GA/XHexCDwx5KZpJNtO8c/MqdlzAae5
CuYQA/9bb5T8xhamrsOFTmdLY3wPM2efnp5d3luwA2Fe3SdC5Rkoa2fDye5w7fy1
9YX638Nw0YU6P/xmygdBjqxKs28/6evo79KAWONL0dl20pEYoj3yVz58C3YGLEFe
p9ggrBf41MjnnMg+D7NdBOHtISfOrU3TtB/1DiGE3+QpMwuOHrQqQ0hPSSBKdW5o
byAoUGVyc29uYWwpIDxjamhAa3IuRnJlZUJTRC5vcmc+iFkEExECABkFAj2qLwkE
CwcDAgMVAgMDFgIBAh4BAheAAAoJEEoBwCDmAmD1SyYAn3JBBPs/6lAQ55HLjew2
suN8XP8RAJ9OBFQhUphqmQ/shjrwbNRBsgDbc7QmQ0hPSSBKdW5obyAoRnJlZUJT
RCkgPGNqaEBGcmVlQlNELm9yZz6IXAQTEQIAHAUCPa7Z7gIbAwQLBwMCAxUCAwMW
AgECHgECF4AACgkQSgHAIOYCYPW9MgCeOYgOUTCIsagnCymketJwQoGBEpsAnik+
bL1lPnomVghlMMUgU8wxB9sQtCFDSE9JIEp1bmhvIChXb3JrKSA8Y2poQHdkYi5j
by5rcj6IXAQTEQIAHAUCPa7aJwIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQSgHA
IOYCYPVI0gCbBZEg/a9K4BAY5HQ7wFOp6u/G+nYAnRgb4zUmf2M57dxEx2hm93pI
aKP/uQENBD2qLxAQBADMGxA9f5QYLFnR/XZ+Hqa/YCeqFMZ3hC4KnjWBDDXfI0Cv
HMLBIW5027NPIDeN95998T5YJPDm1TY5Cort72CTDS3eIfoG0iGwIzzLfXrZB7Zc
1BukNV5NMFeKPO7pX6k4R0aQr0SQUmcdYD7t6V/M4xswVOwcECk/W9BuGA/9NwAD
BwQAy8LmYyssQdjImAASQABcpdOua5orv0ojYMu+edGmjd0WqhXToUHcDfQgL6YA
kO/4g37ysvGwlpj8U7cZwabMO/zwnryyOEeGEA+5aCsji4VRZHOkdflcuBOXj0nR
9yHmPFfwWTxLtV9ajLCP4vXqKPrKciS8SbuLYzvx+lnUiCqIRgQYEQIABgUCPaov
EAAKCRBKAcAg5gJg9eZZAJ90E4gu6VACob81uH3MxWmgjpG2iwCfeNTe1Wz7EO3K
z54TjDmC4biJg2M=
=g8A3
-----END PGP PUBLIC KEY BLOCK-----
D.3.39 Crist J. Clark <cjc@FreeBSD.org>
pub 1024D/FE886AD3 2002-01-25 Crist J. Clark <cjclark@jhu.edu>
Key fingerprint = F04E CCD7 3834 72C2 707F 0A8F 259F 8F4B FE88 6AD3
uid Crist J. Clark <cjclark@alum.mit.edu>
uid Crist J. Clark <cjc@freebsd.org>
sub 1024g/9B6BAB99 2002-01-25
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDxRQfMRBACvHk6znTM5boH4k+2+anGxRuPxPPIJgo6Ny385v60FtJjwLwDh
9LwvZZjpjXi7MM/0FRfUE4bqzrdBtUm6XXGC8v/FTH72TemXR54yr2zuCTcX3jML
e7wjrO0SO1cttASSeb8OsVQEqiMT4VRm94AYdQvS8bNxbqlog9PYmhh6lwCgwDYl
Br/IhYSKQTugPEb8nSyP3e0D/izp3mt4NXcULIp0PZFpvnGZAMLq8moZ3cYa+8nM
kRCWd/1/94lCd1YM8f3lQsaEvRuWaw7rT1ENknSb5TZnEMsTvV03CM4DMzH63Zde
wgl8Xne5lF/WyiSsjUeSkmvCExFA83fz/Cv8/fk6K2O2Ajo0b33Rb7WLH/gb4U4s
9ZkEA/48XB6/s0vGFVnELRSXbc6wCHbnhG0/58ewSbJ2XjyIFFFmeqIF2bpLhuRT
YTBz3styfrjeAqsi9t4gtcEK3vyvF83ql5b23u5/V/+O/ZLwk3kceYmjM0mbETil
FajrLZjaWXpTRQauL/tsqxItBI4BNuTvnh9bizQY8V7xzAgMwLQlQ3Jpc3QgSi4g
Q2xhcmsgPGNqY2xhcmtAYWx1bS5taXQuZWR1PohXBBMRAgAXBQI8UUHzBQsHCgME
AxUDAgMWAgECF4AACgkQJZ+PS/6IatMaGgCgqdklRK39OoUma5sl44pEl7R3GhAA
n1680hBnTGdIR4wxFY39uX9zK708tCBDcmlzdCBKLiBDbGFyayA8Y2pjQGZyZWVi
c2Qub3JnPohXBBMRAgAXBQI8UUKgBQsHCgMEAxUDAgMWAgECF4AACgkQJZ+PS/6I
atPX0wCghHE+X/oyrMbMrCsdwubBf1WudnAAn2WHoVNZpzgMck2MhFdwa/1rAJI1
tCBDcmlzdCBKLiBDbGFyayA8Y2pjbGFya0BqaHUuZWR1PohXBBMRAgAXBQI8UULc
BQsHCgMEAxUDAgMWAgECF4AACgkQJZ+PS/6IatOKKACgsnfy7ZCxEWmdnY+c9KLm
x0V1Zy0An34Ky4kzHxDYDTIoO6XRS48+/aljuQENBDxRQfoQBADouiAUldDORJkG
K7fN81SWvocuySMOL/dEv6UQnBgR4lmjmaLog3QMbGIsJqiPRLDDS3PMkYf1dgDy
6hPmMkWF/xd13Vpk4S5sIjrqTBGoE9f0SPbcDPIjRj+htXFcI+qvhvdceYi24Zvs
xGX90jb+fimZdrJNtobfEqJaYOkrDwADBQQAsCwtAczuP/aM624+UYBrNMCmHpRS
ZAOAnp7Hz83GafkWynaNRDYan2KsBrZJmbZ3MJ6kyUj6k37Keh1c7pR5DsY202on
9haB3lTZv+j2QooPyj9Ityd985eqiRwAMBuOrpaCpot7zYlwiG/Lx/0P00RZ+Jdz
hyidSKrsudGAp0OIRgQYEQIABgUCPFFB+gAKCRAln49L/ohq06htAKC7SFr0uQmS
9fjEOFsF9oPMMxgFwQCgjvMA6reNmNAm0i6ycFh3QVYEUic=
=C4zW
-----END PGP PUBLIC KEY BLOCK-----
D.3.40 Joe Marcus Clarke
<marcus@FreeBSD.org>
pub 1024D/FE14CF87 2002-03-04 Joe Marcus Clarke (FreeBSD committer address) <marcus@FreeBSD.org>
Key fingerprint = CC89 6407 73CC 0286 28E4 AFB9 6F68 8F8A FE14 CF87
uid Joe Marcus Clarke <marcus@marcuscom.com>
sub 1024g/B9ACE4D2 2002-03-04
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDyDmj4RBADa/Icz5Xl+cJUGNxC/tWgXWqcA9VA8GN+PeqKhXS0BnVHntdsQ
xbpFUUKK4ld0Zex/Rec1jgC/ikExJHHIee8ZVcHqP+tsWexi83/ZvEdzI95diBp2
Is5fYp8P8hdIBNQSOoc1jVYrTJUaZgJK2uBzbkh/WbipwsQbueRzXqPORwCgsPNr
StLzqOpjrA7FdUz/JVQf5+8D/1SiKAOFiW4TxY+fS09lqiLs3mbXjvw23iQwLxje
4vBd4+b9iAUWOsSretSKv6OE9ZlD4FYea8HmMgEkuKfXGc8GvTq4J1uHZ0gcVbrB
GmxAUBPPaAENYEJfJf7dcysKVAl14ZQVIvzAGJAZHGuegD7uekGKnOEA61R3ze4a
M2zNA/96I77l0qiMc6J7gXmiD5uxC7FsSCFj5sqTYMgBqzIYEZjU/tTUbth84xcR
i4X0WNkaILqq1mOcBfmzQMvzG1n1CydmJU6iF1ewle6cIui9TQYg5CESrJF7xid4
vVXRz+xi6hc1+0bSaoJa3sfpNrSSr0lKGdWHZozWdQjOvTMCXbQoSm9lIE1hcmN1
cyBDbGFya2UgPG1hcmN1c0BtYXJjdXNjb20uY29tPohXBBMRAgAXBQI8g5o+BQsH
CgMEAxUDAgMWAgECF4AACgkQb2iPiv4Uz4c6rgCgg7XXmcYqcIlJdDl0aGU8r0Dl
kfYAn3W4oHUReFhATFkj2d+7zu+Rsu2MtEJKb2UgTWFyY3VzIENsYXJrZSAoRnJl
ZUJTRCBjb21taXR0ZXIgYWRkcmVzcykgPG1hcmN1c0BGcmVlQlNELm9yZz6IVwQT
EQIAFwUCPK4tTQULBwoDBAMVAwIDFgIBAheAAAoJEG9oj4r+FM+H7U0AoICIVoBe
9B8bo1lrvHh+UF7GY/WaAJ9C2mCThFrmqxCr2bCtR12UoPCPqrkBDQQ8g5pAEAQA
qk1J4LBDLeWs6ZOkPDYYcKCSAu0qlzEf5YP/TcSeZcjJyXILgesFXcayoy1v7ILP
QSXj4p5uzRyn0fuGqiTvajjxMZz1aSkvgGyS+gc+PDmi4SJ2N/tX2isrul8MK+NG
eUsLuZaM1JKhgKpq9yuu3D3ELG7ESga7xsOs1V/sSd8AAwUD/20XByIlsUUC/65K
G/DQ1WfX2gNuy5If9tSPQ6h1Lno5Hv3ow3ktybIoQSxbcBo28nA/Gzg5NFGVkkqf
OkH2xtS6V0K/WjzsrloBHCPFiKp2yHpXfKubxl8yefQPTMj8hLwlBKrNiN1fz5/6
29TIkEwDwrUwHxQreE7FAzPMqHORiEYEGBECAAYFAjyDmkAACgkQb2iPiv4Uz4cn
uQCfX1zNrahRTWz/HRpF7ms8qZqzdOIAn1uuu6Jst43pDzanBHUOBzUP6ymA
=Bu/6
-----END PGP PUBLIC KEY BLOCK-----
D.3.41 Nik Clayton <nik@FreeBSD.org>
pub 1024D/2C37E375 2000-11-09 Nik Clayton <nik@freebsd.org>
Key fingerprint = 15B8 3FFC DDB4 34B0 AA5F 94B7 93A8 0764 2C37 E375
uid Nik Clayton <nik@slashdot.org>
uid Nik Clayton <nik@crf-consulting.co.uk>
uid Nik Clayton <nik@ngo.org.uk>
uid Nik Clayton <nik@bsdi.com>
sub 1024g/769E298A 2000-11-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDoKphMRBACXqpAlgcW54cNw4RBJvlbX5GZ4+VGpV8AyFnkkrKelwH+qgViL
L96W7iXCEQqciAAQ2Jw6AMskSdVbb24Y70foITKGo1VEXBKJci3sdKvuPWkHNlJq
zGKIrikVHLrD5Yixt1b6SVntWiRJaddiUaI21Zcuechaap3isOAdYrNR8wCgluEV
qGB0ng92wVENiIaooHiib28EAIzfn+czzPm19gtAM03W/otZJqsHsIGWuuoIC+Wn
Gr9aGVFGB9NcYXHz+jdwSe3o8oE84ohWBI/JVX4K+xCt1gXBqRax4F1QdDse3np3
o49bV79VFbaec8htk88NTp6Xwd8b1GaUFXFbtqAN7DbZEz8oB+57E+2q+ajFQTx1
X6NgA/99QvNMD+SWc73a5SbicKPw0DDktkhHlE4re255nfvgnqjpmxWYyT80Ra+2
rqABKUrgGgegv1I8/w5zbGBd8h3lO9opMQ1qtt4oAKv/incBh0OouMGyQRINQIMQ
YQHcUmOu1ds5ijS9B5QCfn89TO4aCoJiS17FRxpJmoNrx30/LrQeTmlrIENsYXl0
b24gPG5pa0BzbGFzaGRvdC5vcmc+iFcEExECABcFAjq7HT0FCwcKAwQDFQMCAxYC
AQIXgAAKCRCTqAdkLDfjdSENAJ0b+qcfohYNvN4EcyltP+bcyW2QLACghCW8T6Mk
uTs7EkA83E654PfgJSOIRgQQEQIABgUCOm67jAAKCRBdUhyM5rFQFmTqAKCZAG/9
xzh3ZhbTk/vD1RFDFhEjtACfY5oFGV5jon4sJHsZRQ/+fv5F+JCIRgQQEQIABgUC
OzoIGgAKCRAgFTHVhF3+3Q8sAJ9UXDBTCKXbbpGrYIVmh8+AbFlpLQCeLdXz4Rvq
ht35oJdscZIBXlEqs/mJAJUDBRA7OgjCTVYoIXkFDBEBAUYHA/4sxrvsZe5bZqPc
tFoB1KhhLDhVIWMhOrMLN5MPQAV/OHUebDZaOUYn0Rojybh0kQnFhkySvCy5z6vu
IXiNQF9kwdL4l5mCAuY6zoLQ05ychnUQDSjAR1vRW8AuY/9zLqsk5IscIWoUpIvL
FscLp5FzPmRIe++UteR5s8lQdrexg4kAlQMFEDs6CTwO7bznZmp0IQEBlysD/RMM
m8HEnqlCQ/psnaenXQFcKEkNPFWu6fmA2XDYUsauvFYWriILCu7SmGZVPfGpfUGq
m1nvvrkRim3+5kpIEZQnFkW6o7DsDhFQakcIt/+tvam4sRUxzJ/Dxl/lmaMfJ9G9
0KidfQ+Peh6Sn0z8j8A/9rFCk0nf+EaUfOhtk10IiEYEEBECAAYFAjs6ESgACgkQ
gb3TxA4fm3lJWQCgih0UnLvUcL/miI7K6A+1tuPG21oAn05R3obifoeLIsYBGe0b
rf2GCVQxiEYEEBECAAYFAjs7PmIACgkQtNcQog5FH31wDgCgkMLrbEAc3q3wqVfQ
UB+Mw7SvsMgAoL1ffYtAmbQKknRfgv3SNAeMfST5tB1OaWsgQ2xheXRvbiA8bmlr
QGZyZWVic2Qub3JnPohXBBMRAgAXBQI6ux1ABQsHCgMEAxUDAgMWAgECF4AACgkQ
k6gHZCw343XQqACffoEs3DQRVH/U+3Hcp0P3+p+39rwAn3DZHvQDAoPGTHvcfwJv
JiNyzU02iEYEEBECAAYFAjpuu5EACgkQXVIcjOaxUBbbcACgxf69HGBrCBjoCJm0
8uMzStTFdk4AoIwTRhmZKdF16GKxcCavvw9aHRz1iEYEEBECAAYFAjs6CB0ACgkQ
IBUx1YRd/t1GwwCdHVLbDTjY3/8ti7uMv2y7gOfVDJwAoI1hS0OT2XHvp5vsK7Vp
aAOf2HYziQCVAwUQOzoJFE1WKCF5BQwRAQFqlwQAriB57Dl/IZX1CcrxKXGsZJUi
Pqh1Pnzg0hhwDEmzlo8GqS61IFFchDQLXKRA8jHHy9DmKNQUVTjFkiasj6gp0xDE
+S4jLt5+CVCSG/3/rCk1m4d8pE4lfB46gUzKxD3TPR+fpzElaUaZJ9bAYuXpCGKt
7q3Cljp/Ri1/dBfhq5WJAJUDBRA7OglBDu2852ZqdCEBAZezA/4yUw6AZEleESFo
HGwHKyoqeqRKm5V9FgfJ2QDfiqp27HSQo4sLht/83yl5mkYs3dB+JJNWQkgC/62r
xyInPK2zNPnlUoHL27NI/onXpVFgPwLiUGF1S4s8VSliiL/mcaEKYSr+F1IZPeEy
/Rwx54eQ4qOvh+JTJkwpuJ8e8+yanohGBBARAgAGBQI7OhEqAAoJEIG908QOH5t5
8FEAmgNqpoJJax89oWyAUBF+iZR2hRIdAJ9kp8cVFj3NNWZ7QNfKfIB/xbHEwohG
BBARAgAGBQI7Oz5mAAoJELTXEKIORR99g8sAoL/YU7ZZi/21I5xcsIa5iQ7yEVq2
AKCn7/iYCoo/aCxEuzQRL3VJ50A12rQmTmlrIENsYXl0b24gPG5pa0BjcmYtY29u
c3VsdGluZy5jby51az6IVwQTEQIAFwUCOrsdQAULBwoDBAMVAwIDFgIBAheAAAoJ
EJOoB2QsN+N11V4AoIFS6k+sbT58GASOpQXyDQleuS7GAJsHiHyt1woHN7mOxpo2
KiqoT3d/CohGBBARAgAGBQI6bruRAAoJEF1SHIzmsVAWDrEAn0AIgsTVcu0FFhv1
0syvJpwVqqm7AKDBJ2MZAt1EeT7WR8JKfB47g60StohGBBARAgAGBQI7OggdAAoJ
ECAVMdWEXf7dV5AAoIIbg5nm3XE1Qk9Nv66nVZZbqm+eAKCCBQ3YptghBWkPwLUb
/7BO94GvX4kAlQMFEDs6CSNNVigheQUMEQEB/h4D/3gjPGl2VBCgKeq7wxccGXqD
G/1tkgkSaujnC5ORad5AkNg6ZrgmH/h3b4CUymVm4ddoLwzgaq83Uo7nvA8v4vRU
9oKhczr8+jfqhSUF2wWUuNBDZreeFWuVJr7CJyEEPfv+wYTbNLNrPRTT9NLweq94
V3FGu3c0T7z2VCiDnS9piQCVAwUQOzoJQQ7tvOdmanQhAQGm/AP+L1f1FWsBHaaf
gVLxN8D8jNR0htpU/xrW9vTp/YvLrNkx8ihGH3y16lyAZlXON/ZiLIVIdKXBkuE+
zxfzY87s+ZJBEQJgj87khRsetL4qoUZIObgE4AIv0szu1bwXiK+RcPo7jPnpg2Q4
cYc/jFpMM+lkelmHp7lV/Kz6MhN+dd2IRgQQEQIABgUCOzoRKgAKCRCBvdPEDh+b
eRZqAJ9Fp7+mNG54DqPDV1J7qP4HctZkXQCghjz28SPd+DBkzT0nLNsbJKQ8db2I
RgQQEQIABgUCOzs+ZgAKCRC01xCiDkUffQVFAKCanD9OqYtytjpgJPwS4QoRc2j8
lgCghRujIjNIsb1jAC8mchBbENHfDM60HE5payBDbGF5dG9uIDxuaWtAbmdvLm9y
Zy51az6IVwQTEQIAFwUCOrsdQAULBwoDBAMVAwIDFgIBAheAAAoJEJOoB2QsN+N1
uCgAoIwsEXnbbmB+PLB3TPW6gU/BhKp0AJsEJIq5VF3qH+mjqiKxgtq+vNQ5jIhG
BBARAgAGBQI6bruRAAoJEF1SHIzmsVAWpPkAnRq+OwehLht3RdZ0eEMaBovxgre6
AKDU2u+ORxySutpVAXqt1nbxg2wJoYhGBBARAgAGBQI7OggdAAoJECAVMdWEXf7d
jmAAn2tmOwfDfggEKVuIOl6BnqdPZYLKAJwK/sBvu+n1hoFldXi52uR0FVgQc4kA
lQMFEDs6CNRNVigheQUMEQEBzqQD/1ZjUFZkyCJIjHhITiaFskyFodgk3fngLihn
vt52cTHZGk8F4aoLTAIhWmmvBkk9rNWVm4yAJZZRAHbz+vtyKGYAzBF8oWgski8X
QxLp/rU05BcwOQvVGh5OY/VyJY9un+DJ2cT+7TvL4VjbCqURSuA7fBBu9SYE1H2N
2Ef3jnrEiQCVAwUQOzoJQQ7tvOdmanQhAQFXNAP/YbFNaL7oKn3TecpmCHnAooT6
VnTecdTfEgbrPUnaucDMgmC+uGxLOtxVhx/X7KxMIX2WEit+bnJHH3mOCzEOnqWe
7XvW02jAYnPuie5BL6a0CP9Hi2/TXtz33obFVQH7KyGlN8CHfuGhMBuILZ5qN1pz
KTlU2V/7D8cM/YO5dK6IRgQQEQIABgUCOzoRKgAKCRCBvdPEDh+beZI0AJ0SJ6bM
9HKt05Hs7VSf4jzRVpt9+ACeJLZbuklMTIYc60RYx3MQeIJ/AOmIRgQQEQIABgUC
Ozs+ZgAKCRC01xCiDkUffW5GAJ98fM3fg05lK3Qkt+/qrfJ1vR3WNQCdGD441Gm1
Y9y6PYGN6ix+3raAV6O0Gk5payBDbGF5dG9uIDxuaWtAYnNkaS5jb20+iEYEEBEC
AAYFAjpuu5EACgkQXVIcjOaxUBaMkACg6uMcI7/L4Dhdm687gDIuGAhcBHsAn387
0y82CP64+tNmsYIJyK4xbXoBiFcEExECABcFAjq7HUAFCwcKAwQDFQMCAxYCAQIX
gAAKCRCTqAdkLDfjda79AJ9reEvg1IeU+fK7dvwNG17p8izWSwCfQitEiQEgZejn
712syoykKXBg0pOJAJUDBRA7OglBDu2852ZqdCEBAeH0A/9anrxTdxUye7niuosZ
sHtaklLA8sVgcZjGrW7Kw+islIT0qHhIajL/KPfIlKrzdoJT8MJGchvZdBLh53Qi
DVMJ8U8sJN9Fnmre5QkNXtwR1fyG3okU0gmw5pQELRtBfdKs1Vn3XbgYwEAlXmOQ
VS947nLloaHtOVlDL4xqtj2fGYhGBBARAgAGBQI7OhEqAAoJEIG908QOH5t58WQA
n3kDIa6CF99xuovvh/p9cmSWVwdjAJ9fabaZj3FFr2ZBgLhKdvnlBl35dohGBBAR
AgAGBQI7Oz5mAAoJELTXEKIORR9944oAn2lz4goNkImYgfUFquPOgclQ1kxFAJ4s
ER2eLyl2lWQoRsOds+SX2ikb+LkBDQQ6CqYXEAQAkEkfRicoO8I42BfA1Tgaut/H
eUdWWLO/nGx6hL2FNkQ/vBhjinsvi3vd6+4eUE/O/3deTSGi9GtgXplCGxaDuF/n
r9JjAobOQ0f5TFLiILdy8OL2SZE6VHO6VfCoGy1N7Eg3jvzJ8pFNxTdVww8HIlAr
nNn8Kqww57uustQYISsAAwYEAIFghSt+tj3C5koFh7IXPLNHrux5XsDMaCUcDTsX
jpEQ7WywzHUVgL2QHxeTbZ6ZMp6BkPklsgPdNpFEOCCaUFzJ/z/1/dTGXPMuWgGI
nuy0bFA5mHdiisjLYP+tvRY170mVSjB+qVRErM/fzrO9eQtKkaYLozWXPTZCN5XK
k4sGiEYEGBECAAYFAjq7HZsACgkQk6gHZCw343UoNwCfXnf91HKKcZe7yb7h9rJA
PbUkrewAn0exWATudMNC4IQf18YvII1t4Cn8
=9wNg
-----END PGP PUBLIC KEY BLOCK-----
D.3.42 Benjamin Close <benjsc@FreeBSD.org>
pub 1024D/4842B5B4 2002-04-10
Key fingerprint = F00D C83D 5F7E 5561 DF91 B74D E602 CAA3 4842 B5B4
uid Benjamin Simon Close <Benjamin.Close@clearchain.com>
uid Benjamin Simon Close <benjsc@FreeBSD.org>
uid Benjamin Simon Close <benjsc@clearchain.com>
sub 2048g/3FA8A57E 2002-04-10
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDy0zIgRBACh/FYaouoKpVZdsPe6buzrEmX4WcsR8iPjQVmwQ4lgsfZpWq1o
sMhiL870bhH/79xyvnatqU1yi9+kwgE8dZu3aSOgazjx+NVOD8jES7ADXzfi20Pi
Rvjz3svuys+vB9dIpl0LORxSTE+k3SGH9PpMb7wZMt+vFVdExYheLk9xtwCg4uCg
ulPV+AArye1TUaKrTbSw2IsD/RZpbYly4g/eck63e3QualpecRCWHpiVshtgjz/0
IvKxT1PXSYw2pk3WRFQ/VjBX0fh0KS22LfudVbdMfeXboj97Jw6VFToVDTNIhs6R
olpD0RSTNH89dBRtdxijgL53lmAs7pMico2vs2h+nWKWLhv604tDs5UFbJ5BMtQn
9se5BACNtLS3XCo9kDib4wMBPxL/9TWPAYXLAqSrJ8bwbcuVBUu5f4e/5Y5/iawh
v3yiluQkxxuriWBkR6H9cyZPkKHWvWwOz8opx+DTBu87JdqRxBl4kqz+zCAi1Xt+
k0kHtdH3fx8IFlk28weUX3k2re4Oxv8KuJPXv2a/pJ2Huwm1dbQpQmVuamFtaW4g
U2ltb24gQ2xvc2UgPGJlbmpzY0BGcmVlQlNELm9yZz6IYAQTEQIAIAUCRdO57gIb
AwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEOYCyqNIQrW0wPQAoIThGdS9li5S
opcG4sIpSvq+LP8KAJ4l9dlSK8TGzOYQNQXtH1nG1VgVnLQ0QmVuamFtaW4gU2lt
b24gQ2xvc2UgPEJlbmphbWluLkNsb3NlQGNsZWFyY2hhaW4uY29tPohhBBMRAgAh
AhsDBgsJCAcDAgMVAgMDFgIBAh4BAheABQJF07qeAhkBAAoJEOYCyqNIQrW0+X8A
nj6vcRrZAym/K50Oh7SzAjpIPPAdAJ4tb10v8+NIKlOWtlJTfymWWclrw4hGBBAR
AgAGBQJFtrC4AAoJEOI7fnC0Z/C/9BMAoKyQtUy239PRDHv3tCArmgILCBkOAJwJ
HQnXOY8UerFlsojuQUOXzjO9CbQsQmVuamFtaW4gU2ltb24gQ2xvc2UgPGJlbmpz
Y0BjbGVhcmNoYWluLmNvbT6IXgQTEQIAHgUCP0XAlAIbAwYLCQgHAwIDFQIDAxYC
AQIeAQIXgAAKCRDmAsqjSEK1tF9/AKDFyCSwKZHqpvnnb6nexV1hQv0VSwCfVk71
pMjm3TldaUvv0qXWIM93pVKIRgQQEQIABgUCRbawugAKCRDiO35wtGfwv7P+AKCp
Tyc8C0gvNlgXXGVC2uKYKGp4NACfd4lgKHvkWGEhkU8uKgqSZWb2lg60KkJlbmph
bWluIFNpbW9uIENsb3NlIDxiZW5qc2NAc2VuZXQuY29tLmF1PohvBDARAgAvBQJF
tqbCKB0gU2VuZXQgQWNjb3VudCBpcyBubyBsb25nZXIgb3duZWQgYnkgbXkACgkQ
5gLKo0hCtbRfdgCg195mpBKyK+E//F6a5Zm8aaHl3/MAoNdFYmNi/EuNVc3q1pDw
9H9AHAHkuQINBDy0zKQQCACQzjhHd5xdiSkXCd/LAIm5vmbMZKm658hJMOT833hb
k4dKvdNYOkgNSVTr67vUlqt3o9aR8EDchXLvi0I/OtDFrwE0tUgoWjMC8bcSq2Hb
uuVvxhD3ZQi0Bhy2dYijj8FGrVD+PJ3XUj4t2F1BheZ1pkar/cj+OEdgRAEnZzQS
mjY34P73ijpwiTv60jynOFTA4dX1hHFKdi2fsl2cZOrMstvCFS1XkC/O7kZKhrM5
v6/5fulfNNAa080lUuXfDOg9G/JsjKpmugrSutphxwILWElfiGiRfXdokFvXqbXt
sEW0l5r9VSSqMg7UTaWJE03mEnLjb6jrTpm26z2aawYzAAMFB/9ESYyVMFCLDeRC
tCcq3nRzMFZCYLE3l8Y17mcyx5GZGkK945jqJRcenG3xWJCqrXlHA3tbZ7+Gc4OF
kr3BNBs3vK0CFdtVFFKJT1aiuEEXlHalRDI8eAAAkG91OKMCb7DWudK/zzNmFWTz
oJS5ar4Ymb8g42bsfaJ4iI7GsnlgvRQk8HZJAggMdpEEXTIqOLS0L7mjYKwCHdNp
se/DgXdFhrbfCT8QF6vZonSfDzRqm1HqGJxR8iIZQJFr+2mdrcPsXkMQ9pX2YzSn
ucTolTlqBqES0a1RrnFuzi7QczFk/JzGHkz5O8JQFBdcK6gAxWI9p62LVvR3b05s
mdFTJMLKiEYEGBECAAYFAjy0zKQACgkQ5gLKo0hCtbRuIgCfXvphwuXuzadBStxj
djDr44BdiAcAoLK+kkFZqHGI0YmMDuKMtYDmU05n
=/2rY
-----END PGP PUBLIC KEY BLOCK-----
D.3.43 Aaron Dalton <aaron@FreeBSD.org>
pub 1024D/8811D2A4 2006-06-21 [expires: 2011-06-20]
Key fingerprint = 8DE0 3CBB 3692 992F 53EF ACC7 BE56 0A4D 8811 D2A4
uid Aaron Dalton <aaron@freebsd.org>
sub 2048g/304EE8E5 2006-06-21 [expires: 2011-06-20]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBESZZ5YRBADZ18WQp9eda97kmLEVNkYUkTbWn90/9ViXP5lWhWDvdIwXXa+S
byVbZI75QkYrvhhyDQPwK2pwF3v/nGaBhQvO666uWWyqBAC+FTjc6GQ/tVTe67Pp
dBVlY3X2QadAIWOYHFWNhG58jAXDnuz9po/w/h5t/6wayVElamu/jPBwBwCg48VZ
4q1oQ7M474YPBsyLfmkLEu8EAJwdgos/BxJ0a39PFtI768+6SS4e+B7qt5UDd30l
87rvKoW3gXuf4Vn00Y8m+aK+mUjsWeQfDCF6Kj7/ecGNSkfvwmsEDnRMujyapX6J
wuJ6DzKgrc3zEBXVK5g+JBrSZDGetkdl8jndG0lmxIqxqnx1R+uxiWNs9NAdeP1P
F7vCBADAPoKaAEW0LlsOE0zIylP5e+LTBd6MQeZ8zISlNqMHDX9F174Fo4CFH/pI
nW588yf/ChScuONLPIPbMBkvoC34yLEGluvjZov0cjySqzcTN/TkZ7iH1NrkYe71
/z0Pe6jWY8p4KjK6C6dKok8b1ZI/btmJyuv6bkTzM5kQlxg43bQgQWFyb24gRGFs
dG9uIDxhYXJvbkBmcmVlYnNkLm9yZz6IZgQTEQIAJgUCRJlnlgIbIwUJCWYBgAYL
CQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEL5WCk2IEdKkTFIAoJwahC11/B2TXIk8
9PioqX0c5nU5AJ0YGkpXIzDzF6QskMWWQq64fMuE6rkCDQREmWehEAgAzFoPIPXW
+sMFJs/DzCYMzHglYmNzHr8wCfvNq3hiiHUfk9EtcUaMnVI6TMkoEEF4mXMpf7oc
uCjU0+CZMf2GV+bLkxs2rNePyjzTuoig1vsl9RFA+1tMfLrUsUKwoPjLZUbHHApl
S1x4k+TaLanT+tSQar//WNuA5JrmxRXSyYXu/2y5VSi+niaNKupNYXfqr53SuW2J
xh90I90hzgBzQypWNNDEIN1c/lkgIvWm7RbbBliX9Y23iUeFkzmLbOUcpLSy3zj3
9I3eCshQdFv5UT54N8rMAg6hGC5jfeqy4mVpMLWst3Y/Od+DBv/F9xnaquGW7LYp
Pz+H4fJzdC79hwADBQf/XyMpsvO4z1N+8DaVybwMedLd4ExSkIAsAI3MTS1mtNu9
mFm9GQULWvUH1YXBFnVVidibc7zdTwVEAPFhc/uZ5unxqzbUAj5whkCBUF53ZpVv
nsskZZ3aUEh4hEM6S1t1kc7+HptpMgaSxEcjy+ylybMEzBQ14Mh38sEavfoeDvfb
aP1AtLQh/+ehQZHeA6px3PvdDeevM6zLoAY6yEKtd5QaSrvhIuP91HKeQjPgM8yy
IZTWM050axPzKZOCf2VsB78QUNVGcfFrbScleBvaVbdOh/ZgxGOgD7LOhhgivV1m
dLQ+3W66/GuUVDHap5hdzPuoUgFTodlzilfqjpaekohPBBgRAgAPBQJEmWehAhsM
BQkJZgGAAAoJEL5WCk2IEdKkNGoAoMBfaOMRp7+OtWsx8pkGGlFszVCDAKC0rEFY
lBcUW4xcel1cl7I40JK+lQ==
=bsX2
-----END PGP PUBLIC KEY BLOCK-----
D.3.44 Ceri Davies <ceri@FreeBSD.org>
pub 1024D/34B7245F 2002-03-08
Key fingerprint = 9C88 EB05 A908 1058 A4AE 9959 A1C7 DCC1 34B7 245F
uid Ceri Davies <ceri@submonkey.net>
uid Ceri Davies <ceri@FreeBSD.org>
sub 1024g/0C482CBC 2002-03-08
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDyI9msRBAD3ChWTrd6eyVBO/p8CKWvVwR2nHBlwNzjUwLhXK12wNXpzIOkD
ZoRm+eh23B06dTISQhfCJEdC6nhb2Tu/q7ZdTVZ8xsuEQh0AYgxDfaKbDkOQ5UXb
CbymX6LEarS7yt/WNTZYZ42wKfaaznW7k9/pf6BiqkSOeXyYAhqgHty7KwCgyqN8
2In5R/b/DDAN51vGrFWcD5UEAJwcZ6zCpwZKKRNbWziKGC+avf2AAkc94uwU+qzn
3oea4Fp/NCSwoLghisKtMM9PDWk8Kkt0HUcv5n88sD3HfXzYQDFbx8VxLXqdaIyA
NYtY9JJ6ErX9FlUaUM0qwbxI5fahKzmENFPn/1322Tq7UpuVcLOdqsHZG3xMAv4s
ynzmBADBf1z7t9xBlbbLOZ90KxH9+TAbfap62fryCmr+a0cQVsynfPMfM2vdgUi1
UP26yE5IqpIliNTdxtXCei5sWsWkA/N4sEMREXzsNjiN/IAerU9aw7MIW/On9oC7
vNGBiVZ0sX0mMnG+m39wPP/WFsWogHehM2ZDDLQCgkcxqJHpqLQgQ2VyaSBEYXZp
ZXMgPGNlcmlAc3VibW9ua2V5Lm5ldD6IWgQTEQIAGgULBwoDBAMVAwIDFgIBAheA
AhkBBQJDWLjtAAoJEKHH3ME0tyRfGVoAoJ8MM1InI2UNV8psbz7ohl2H3IIiAKCl
fQwvDq+57wOGwww9EHjDnrQbjYhGBBMRAgAGBQJDv9fmAAoJEJnvMgrELySdmKIA
oKLyqXKtsSbNFOdz9LFOpd7EqmxOAJ0XgLeoxhXy0X6sWvuOTuD67Oel8YhGBBMR
AgAGBQJDv9gIAAoJEBCXnKrAf8AFNLIAnREnzXhLjkUFyLOMwEsaNl3RZ0KiAJ9S
p8RSGaditiGbCXA3F068K1l6wohXBBMRAgAXBQI8lfbaBQsHCgMEAxUDAgMWAgEC
F4AACgkQocfcwTS3JF8B+QCglZ+/NH9oWiL7+EyJ04KUFF6NbtEAoLWBDEfP8E0E
X/KdcO/0elAnMbRaiFoEExECABoFCwcKAwQDFQMCAxYCAQIXgAUCQfDJJQIZAQAK
CRChx9zBNLckX8waAJ44zndecthUv9HmKavugJaUxWakBwCgtkSI0X6VOe65y1lo
PAcT/i2Q2m+JAkgEEAECADIFAkU/jngrGmh0dHA6Ly93d3cucGFlcHMuY3gvZ3Bn
L3NpZ25pbmctcG9saWN5LmFzYwAKCRAmSeYoxdNNBe6vD/9Em8nePer24Ldnzqzc
0tqLMm4pXn879IUur7SEDek5+mhOSuBbosKH3WdOTCPTbBz7LL3Q4JsQtAFZiPkB
RGxl5ppoHtpd3XiJK4Qh/A95l8IQV0jdwOc20G/BVxXwEE1yplL8x8R83Wv3+FHi
b4KU9dAkEV4b+WxC7BxPAw98btlFI4T1MTTdQcybe8p1KgkJGcM+uvM7R9dVFk73
6XBBkkDSqFgcWeanFlqkTF4x54rfBlnmlne/HdnKNVs3G0YdSrSBVT3BRQ3n+D+V
l0wo4wABHo4tjh+QhmQzoqJHyPRgIjqFWTYrCShWrWXdW2IuXyJpKYmZFgFqnmPJ
4zOUMxPTkkJ25H0l0n+BhxMm+sdktQT0XdiNOQ5e4swzv5F184yzi/gCKSOW36ds
OK671ywHEzksXRVeWU1LHKuoNSth4Qk1yYV4V4fDGMcPPqGmMyG1aYPcKduPHgiJ
dO97lE3Ca/dvEcErg/a0MkoufRoWaZorSJn4FlxuCOuHdfi+ZBA32V5OpuwB3IQd
rUaP+fOoARtxqU2OzTT16u1u6qCsNG1pNMqc2RsWYb0khinjIX7VgPOVQi4YS/d+
Jst645CHzkghQNJyKgyt+ajqFwrEXyW4mMcCHmrx60k6i9Beph1bp/iJGI3ybHk6
U2/GRQt7J/137V6rJZRUm+8FjbQeQ2VyaSBEYXZpZXMgPGNlcmlARnJlZUJTRC5v
cmc+iFcEExECABcFCwcKAwQDFQMCAxYCAQIXgAUCQ1i49AAKCRChx9zBNLckX4xM
AKCaf1vxHCMlKYk2J+q/OReX4JM51gCfbkro32QKPmOO1mvqkpYfc/nlvlOIRgQT
EQIABgUCQ7/X6wAKCRCZ7zIKxC8kne8tAKCeIFCa0cTyiVOKB33VS/nXEDqEyACf
XcsUq9wkS1FRrLfMrQlH7xKPap2IRgQTEQIABgUCQ7/YDgAKCRAQl5yqwH/ABf9j
AJ0UgYT2rWfqq/3OXTpAsDWHBeYmVACfdITIbUJhoZp7fIUw50iHkUKrHJGIVwQT
EQIAFwUCPJX2wwULBwoDBAMVAwIDFgIBAheAAAoJEKHH3ME0tyRfJUAAnAyFm8Ba
Iss8LLQl/ci6H8V6F/DoAJ9PgtXQFVPkix5PGt3l0oqqn2WiyYkCSAQQAQIAMgUC
RT+OhCsaaHR0cDovL3d3dy5wYWVwcy5jeC9ncGcvc2lnbmluZy1wb2xpY3kuYXNj
AAoJECZJ5ijF000FryYP/30PjjG1GvSvoKg7BGoIQMnhBuzwko9wF8wT2AqAGTk8
xkzb88vnghcnDIcQD0pwn7de5SqSalj93Cd/OsEi8TLQinfXbbWYvKCmksQ6uiN/
hbDvfi69e9AQIubGLh+CYIA26HC+KtKxQ54ynEJdAksDMr9M8rS6Np03Y9XcavRQ
iLFaShqTqzgtQbqL4ZGDlnBVtCkl522sB/iXGPdpnpxBPx5WVkfp/bZtdzZI3FP/
FQGeuSXlca4qgbuCRYSAFhZG4Gvr4O9B7uSqK1Ved3Oqah2mo9i6WrSIsehXWARy
S6Mm9/v8ED1LQRxSPmQUkQoNgt6Pxb29IW51mNomHolHORo4OEaaVmDOUNeFPjNF
VL/KSF8hyHdNfRjxIq0lI7e+XOIeEJeOo3llw9828TSlUhLmSKi/8Xb4zqcHVolP
iYxGcLZRgRaY7kVFA9T3v+uvVDofWhum5+YzjuM0ii0uqMEuC+uE5g9lIuRYngJk
OGK7XQdg9m5HV67qvA/7ouEd/WXiifgKtBVCWC2VU2HHponmObCdQu9XS/QQn0rF
BnbFD6iVUFRLWZt5sJZIOneh/4Ee+iYTYFAAPqF72uXjv5/aZEpVNjlEonABDEft
yBHF8yN3OM1ZNR5UUcOxBl40pUZ9BsRUAKZ58E6yPoKmu7kSPssbQgHMOmwyxvbr
iEYEExECAAYFAkO/1+YACgkQme8yCsQvJJ2YogCgovKpcq2xJs0U53P0sU6l3sSq
bE4AnReAt6jGFfLRfqxa+45O4Prs56XxiFoEExECABoFCwcKAwQDFQMCAxYCAQIX
gAIZAQUCQ1i47QAKCRChx9zBNLckXxlaAKCfDDNSJyNlDVfKbG8+6IZdh9yCIgCg
pX0MLw6vue8DhsMMPRB4w560G420IENlcmkgRGF2aWVzIDxkYXZpZXNjbTVAY2Yu
YWMudWs+iGAEExECACAFAkNYuRoCGyMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAK
CRChx9zBNLckX31FAKC6gO5VL2KU9Vh8rc1pOfi2ipJH6wCeKR6IVcfeECUGVpez
txhfdeWcTvGIRgQTEQIABgUCQ7/X6wAKCRCZ7zIKxC8kneJjAKCPw2VIxxa0CKym
p80Cw57MtLHJMwCgl1EH5Qv6Si9H4pjfacnRc8KxHCaIRgQTEQIABgUCQ7/YDgAK
CRAQl5yqwH/ABVxbAJ4h4/60PjUD7J06iImyadephKig9gCff7O9KnCzcd9wg+u1
T2uDY5sNXk2JAkgEEAECADIFAkU/joQrGmh0dHA6Ly93d3cucGFlcHMuY3gvZ3Bn
L3NpZ25pbmctcG9saWN5LmFzYwAKCRAmSeYoxdNNBaEWEADDP7OeY8z8kBDNAodX
uajjJFcnwpT+58ap3y0v/1U9Cl/Xko+EuoRKzooqbr7iWecI5tQM4Jgt38HPbAjv
eVa/Him/GhPQHmnF3maYUS0GkYT9Cp4DwOdqat9/ZUJNtxdt9MqmhSN2+YWuRRVx
YedP6GVIuaWgONAy/daH31Cj6gcpXno/vRyZRBVFKF3pVGpK7vW+HRVFEebfTsw9
POzPTPgIsu0bXBOvJWDhL5NaNj/j0hCwgQAst3e895An9SnxB41EhdUcisx8+8s5
3+lxV4jDI7XihFL1iebqPc43JrC01GjVnnAGmq6EvjF12v6dKVZvg9EL76g2tl64
jwKpJpKlH27r9/Aq3RZR9ORRM1dRqdIh4PyDKFAr1YLEck6l97VNzlD6VRtoHgZN
csb5/jdlual1yAN4pWolmg2Z9DI/rntuPzxEPQVtzXQlhqbu9Oy5TmV/+p+0deHi
vWdppnLPjEUroSqzUI6MzsWvCI8uE0t56ginWMgUn8a34sNsmoFr03i33rVbwL4T
FxL6IMniiiIU/2yLTULhUj+InL9am/RozGQy/20lvl9RgMJMbqxH+JHfYhbAqyNc
j6pEMfCz6cDjz5Ax//d61Ucz4Y5ze71RDS9CFNQhUnT2Nya3hZszp7XWwwFRzF+z
rgmRG3SthRsAx1JLqXGSjrhn37QkQ2VyaSBEYXZpZXMgPHNldGFudGFlQHN1Ym1v
bmtleS5uZXQ+iFkEMBECABkFAkNKSicSHSBObyBsb25nZXIgaW4gdXNlAAoJEKHH
3ME0tyRfmbwAmgM8RxlVNuJ21w+vNOz9VRTixYWUAJ9on0q7U7r3DoLrlHR7AERZ
AnNsT4hXBBMRAgAXBQI8iPZrBQsHCgMEAxUDAgMWAgECF4AACgkQocfcwTS3JF9K
DACgqcXLx+lstujUIJ57fYfX7DpaTlYAoJr5CpgeNfVK69NlZSLw0tszxd63tCdD
ZXJpIERhdmllcyAoV29yaykgPGRhdmllc2NtNUBjZi5hYy51az6IYAQTEQIAIAUC
Qzc4TAIbIwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEKHH3ME0tyRfbR0AnA0x
3FNcN7QZFCMjyUIq+8SU+H8lAKDFIjKSK3zdW3wkVBtPmXuhSm6d34hGBBMRAgAG
BQJDv9frAAoJEJnvMgrELySdoXsAnAmfR3omQLViU4jJcBG9nL7Hb0GvAJ9OpEcl
x0GKtnXg2qO17ScNODs7rIhGBBMRAgAGBQJDv9gOAAoJEBCXnKrAf8AFw5wAoMP1
76cOsZzQhAZJYGuqmn2GMyE6AKCsY5bWd8ziA6TnumebNo8nqdfIhokCSAQQAQIA
MgUCRT+OhCsaaHR0cDovL3d3dy5wYWVwcy5jeC9ncGcvc2lnbmluZy1wb2xpY3ku
YXNjAAoJECZJ5ijF000FE0kQAKerd09AdfoAL03XNWMZw/cxRsftj6VYlBw3Z05I
Gz1rzkrU2zpZoiuDcKAj1olabd9xDQTMq1zYt0rROOcs8gu3/nzXo8LwyyFv+PrY
UtyzT1LPmFmWiikHtOatSiStDk9UkBH+b0jjbO01oba92PqMGLyCbH35PhbutOOa
na4FRKva9n8ZazkzMy8cRCFyaBUiN7kfgtzZa1TuSpd1k2y4wi4nu0A2fugJbY/m
gV1Mf0kSuVs0cx4X4KH2bjKwwYsXmztavpD31j6PPmtJarpeCi5fBYie2JDNuEQv
IfOPYJoPF1XNfTKfHSr2cpX1m60XYCGLTLNNmBitlgABkgAQs0ionC6zkuNwgnJt
qK1mgZfAj4ms7/ojV+QUC7bzfR875Zsg+S7nIHUT48bAY/5fWQbYjGLu/uCBtEoF
0QtRWbBlRsSkVHaNhzOA1Eb1J25LVMOHBI/POC9M5ozTxBDXzim/MnrwwaX6l3/e
ZPlrmqad5P2sQ9BlThbADR2elLargEH6WPmfz2XXNuFs3KK1wgBxFNjv0gg2gcTJ
pU8TZIX6JxFusA0xfyV6hwyjwWyLRkS73G7t+jit17xaDfcuaId3uYqFB0q06sVJ
+1zuaQqtUKS1Lz7rR3/g7Vrf+GgLSXQSaph+Y3/olVloqGsyKtKksmHV4YCGEwrA
CMMCuQENBDyI9nMQBACCsXTESbCbETBauHz5lsLGPcIu3Wxxm6q03eu4ssivMNN7
eYhkxoHK4bE0iIMl8iFUjeIzvGXBrdPIbhhrmFJ6gIfQ0lwVexTZkpFDQyn84CY+
TbzWXNOdkAZsq+hQugw1yVKn4FO6cGxKdB4qNSaee/7TTBWXluiOblwU3B3fSwAD
BgP/RwKczbedj+27cYLvuk2jpDs7hmhL2BLha9HmnTyPFYDhW97s7gHjHn3nYjik
WssTYuVGllsn2DXRUVOeYJMzC9KaFHwRM+iLgPOKTNopEmvvDCVi8ZeUvyquowH0
l3sigHyF+vPaQph3ZxHvO5bI6eaqtffLMagtl0rlSKD4kheIRgQYEQIABgUCPIj2
cwAKCRChx9zBNLckXx4mAJ9kE53878kMY2jHiJ8ElEzEWbJOsQCfStKMIHgOPO05
CJbsJXq7OYX9wSM=
=gvRl
-----END PGP PUBLIC KEY BLOCK-----
D.3.45 Brad Davis <brd@FreeBSD.org>
pub 1024D/ED0A754D 2005-05-14 [expires: 2007-05-14]
Key fingerprint = 5DFD D1A6 BEEE A6D4 B3F5 4236 D362 3291 ED0A 754D
uid Brad Davis <brd@FreeBSD.org>
uid Brad Davis <so14k@so14k.com>
sub 2048g/1F29D404 2005-05-14 [expires: 2007-05-14]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEKGCoMRBADKcY+c0DClCJ6cqBHMdye/IiDENT6SMUV8S1T3Iz8UDUrYjtbR
JbM5w3ZrV3+h7HsUZaNGL6hFwxqFFQrnzBU3+BzpgTTTCC78hAX1HIoYWcfNnqjI
zrIMjhU7wcS7hwFTdJ25eiqXSRVpoMWEpXo8JSWVTUNIuGkQlg579CZ8JwCg5alM
xDHxzIugCp9nuFWwavjus5kD/iznJW8yKOstdRrnosBmhA8Ijq3cv1H2NfEfmloV
nw/1g3mY0DtBUnzLGZ3uNUUZhSe82zKI1984dYSKoCCry0y/g4pCuyTswqpl/WTc
hc9rSUFleVu05MXKoO70WSSMQGLPYLnd4VrGShz5hPtZKq2CZIQvwiAcacUwoOGJ
J/ghA/9HD9/z7QeArsR0KfkLrZ34YH0o5e3Otz3dub3B7M6rU9MuFZ4uThhp5GHo
0E1puC5ay0mpFlWuxikWPCwzOK7kiVuea+89iFLs6u+blUETGI3SM48FbrMKQqDh
HZMjBWg6caY9GaWsehNxk3TuGZpA7m7Kf8Udtr9YJdRHr/HifrQcQnJhZCBEYXZp
cyA8c28xNGtAc28xNGsuY29tPohkBBMRAgAkBQJChgqDAhsDBQkDwmcABgsJCAcD
AgMVAgMDFgIBAh4BAheAAAoJENNiMpHtCnVN7MwAoIjFptce5hIVjXaK9LSalTvn
dVoyAKCohVZ6DdmG3Sr+sM5v4HyhDA0dWIhMBBMRAgAMBQJChycZBYMDwUpqAAoJ
ELTXEKIORR99yq0AoLMIK5LVHVy1o8AppyDgO9PO7uMsAJwPwYYvsMPVPYQ0Jkga
Ic28kaEUwohGBBMRAgAGBQJC9Yx0AAoJEBeO4nT4FnLF57YAn0j2eYcBonvvlLwb
qM1q8b/sYr9oAJ49V4iPXZg98bnKD027ikQdQhdY7LQcQnJhZCBEYXZpcyA8YnJk
QEZyZWVCU0Qub3JnPohmBBMRAgAmBQJC8/u3AhsDBQkDwmcABgsJCAcDAgQVAggD
BBYCAwECHgECF4AACgkQ02Iyke0KdU3tVACgwpWP/1oXrmtcFHFzcliHa6fIXGYA
n3Bx41u1X6JnbJrynlwT1ArY9kR/iEYEExECAAYFAkL1jHAACgkQF47idPgWcsWH
qQCfeR97YtQHwn2yDP2k9oX6fZ9Pt60AniZRZ5BMSkyftCpR3zx6Jxl99wd0uQIN
BEKGCr8QCACsjQLDvnrcRsGno7O4sUoDRj7C6tAS6ahv779OodNW03c/EL1U1thD
qhrNvN6M/BSG+tzuJyFFnSLHfkJXxEn3XQVYcF7dV4HStotxRMSBFRFqFizf4VGX
72mqArAeKEYW3W+mmEGJTqjRvvMxEfl2XRtGUASkSGkKvrXuq6CeJdYPgPLg6PtM
NcQ2RlwdvOV5zutUa76zHnKZeQ/fzyR8w5HZNUxPltgjSU2NeVIOLTCakXZRWT8X
7BnUlCUIamRLmLdxTlizW/bHIzHZ0Zl1sA/uDCea90NgV/0s8gz2HFIKnNJQ5332
DIQvtaezFVLT+0hTyDKb/P6QRgmK3TEPAAMHB/9j3bI+ifWv4dp2NzfxXW64P3l8
zcA1nms+EYYn0HlswwPARndsi6zlb7nF+NRluMZYkyqkNAH/0fdUQONQw8U6A4JO
3gS9YQ++mSubtQcLCT8h+vzscS+GVoKsSl7FwuY0IP1cFx6bOuN+lNfZHU/AZDzQ
Jyj5OfDvpupbulT92gqUakMSgmz5uqX8AbIDLnqJzJTW1UgJ5Ft7RrFVCFAufJcy
nl7grHRf30e8lVL0KqdqsLcwWKNY8ZceBOij6OQwbnFezZlTGV5KyshCur6pyby9
H697clLqFspFH7euqjbq2hICPOIXD/SEl99lgTTGB2LCaVhxTnjgMTttQDgciE8E
GBECAA8FAkKGCr8CGwwFCQPCZwAACgkQ02Iyke0KdU2EhACg1Kpz7UjdeHfItxjw
5tLzrlWIYFQAoL8SctU9Ok5BuEfjJ6eBsLObTXTH
=2qOu
-----END PGP PUBLIC KEY BLOCK-----
D.3.46 Pawel Jakub Dawidek <pjd@FreeBSD.org>
pub 1024D/B1293F34 2004-02-02 Pawel Jakub Dawidek <Pawel@Dawidek.net>
Key fingerprint = A3A3 5B4D 9CF9 2312 0783 1B1D 168A EF5D B129 3F34
uid Pawel Jakub Dawidek <pjd@FreeBSD.org>
uid Pawel Jakub Dawidek <pjd@FreeBSD.pl>
sub 2048g/3EEC50A7 2004-02-02 [expires: 2006-02-01]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEAeUYARBAD2RoYfLkSt38R06MpFesDgXVvgSb7q2GGTiMLZE7iJ8iKQU7Rx
DkpW7EkpJ/YGPXro0KumkIGoPCsMF1eLENUhGhyMosN5Yb9Y7DXsOv3QcCKIfBlM
P3Y+Y7By0GvSYPvYK9GZI2ZvSXyTraxB1eO/7c+aqS7wdwx3bCsVKnyzBwCg+nXQ
izSD3wmwDYxffxN4dawiD2sD/00L95dq5XhM9nISjWJOjGsPJqyzoZZH2pemOgcq
SeNimi0yWOWeZh/bxbjUYI5RXdBXGdwQxW6DKFU9o9NFe4se1jZcbPjuRtkbBXqz
Mkh4kv2pvZ+rHu41kqzOZ0z+rbZld2U28R76xtx3RI4OXvJ8z01RHzAEwJ1G6s3D
wI6iBADy+KSjJmfgP1rAcNPuwW7T7L2H9fLNTp3mmWZZDj6n4fykcwM9Jtz/K4QE
i3GHNB2AnmR8yiPE2m87ObsKV7d8UK4WP0OLfbr7d7TZ0jDscBhlyfYgKYDFHaJH
8O+L7df2oQU31wYEvYOP/mSTPO7F5TJZm3/Pygp/JkKnPDCnY7QlUGF3ZWwgSmFr
dWIgRGF3aWRlayA8cGpkQEZyZWVCU0Qub3JnPohkBBMRAgAkBQJAHlGAAhsDBQkD
wmcABgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEBaK712xKT80dOwAoNjy2Xrebr+p
AQroKNQnIzaR2QysAKCXRA9XldUcwxSOzRJNhDktAKQbZbQkUGF3ZWwgSmFrdWIg
RGF3aWRlayA8cGpkQEZyZWVCU0QucGw+iGQEExECACQFAkAeUbQCGwMFCQPCZwAG
CwkIBwMCAxUCAwMWAgECHgECF4AACgkQForvXbEpPzQudACbB3QlE/GfSY+umOHI
y+3UjdMKuGMAn2JC4vrcEPwg8XMF5iEIaEZ0tNmVtCdQYXdlbCBKYWt1YiBEYXdp
ZGVrIDxQYXdlbEBEYXdpZGVrLm5ldD6IZAQTEQIAJAUCQB5R1AIbAwUJA8JnAAYL
CQgHAwIDFQIDAxYCAQIeAQIXgAAKCRAWiu9dsSk/NByVAJ91gG7VGmIK1H1LyHnW
ZPI8T7WRBwCeP644asOCGfje3+NjA0F9OHoL2z+5Ag0EQB5RhhAIALfZ2Kq/Yd1j
X4+kdVgCQqHP9tEHjYLwGICL3Y1i+whLqUx/X+MZmt4vNZLaoaqRXhMD8A5c9tN4
06ODB6afzS0feQE/s3j0bKRviTvUedg+CLvt9anqf092gRt1MnKAAWsw+WNqfCNI
xsONpWWS5LL11PLyEOhxqsEvcx2IpswjG398MINFwHo7dUielCDpAPgu8tCVLpWb
GqUBiWdqzq9jxvIS7obYUmr0VBqElP16LrcvoUs8W+AGvkfTZW3iX6yPhfpnycKy
OnStwtO28Ud2BlRrp1YLJWv8oZcYDP5p0GyhbmCbj6qG+BrA8XbIgASFZHK65CWr
++Zc5tztIBMAAwUIAJVrsEErdqxbj7qdJXVebkQZLe/hr5fFOGdOwMmvNbsI2nHj
0B/L8Gfw1v2N6K5ST68mSH5gPpDDkLqDfqY6OcN2LBhVvOdEGJv7kp8x0XK/vsbj
jARiO6l7ZrtH4E78oiHzYK1yGFNMi6c5zpO6BXRUAVmKptL/BRu0UPRMfScyIbnP
gT0dcOiTazJ5U9Ol+Mjk4S/YLqe/05JQvmzKzSht6E8BbgiZxwsrWB+CLpLwglbg
f4NX+BAjApvoesbhkLOY03bSgP6CsRbL7izgVmfAHbOJk5eIYjSEIOcqIMyg3cp0
kZI7omon6uhjl36Ad1uEwjkW7jPgCz9a62bLr3eITwQYEQIADwUCQB5RhgIbDAUJ
A8JnAAAKCRAWiu9dsSk/NOa+AKC/grZ0DrDsO9LtCEQKwTcP7EQYBQCgsk9ZmVug
9caBiftOC/+/0ej5qqg=
=/cMH
-----END PGP PUBLIC KEY BLOCK-----
D.3.47 Brian S. Dean <bsd@FreeBSD.org>
pub 1024D/723BDEE9 2002-01-23 Brian S. Dean <bsd@FreeBSD.org>
Key fingerprint = EF49 7ABE 47ED 91B3 FC3D 7EA5 4D90 2FF7 723B DEE9
sub 1024g/4B02F876 2002-01-23
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDxOCiIRBACyyyoMk5OyGdOkR0a4fj8zPJ2AOielQ1BYv7JlIWdNeMHdQ0gj
liTgXwDimeBnElw7sNrmdfocfwKbmX33exFPa3AkJgLflBcuH9+xE3ozgzMl6t76
QL90PPIc24Er670NnhF7Smvubus4IdckvM24kuUTINmiuFzVwuwWdXdwvwCght6R
HPpuFeiMZHRJAiHmu9AkKrkEAJRLmRGgdqTQ6RRIQobqGS+1grl6AsXHzKfvjx8I
//12yrFiUcXE+167I529OW2i4ilmVjBmnwwe3750ZKBIp8OUBkMkfMuTSyCCFD22
CX4N7D68d8eCJiCqv0jMZGnoWoMulmWzdyplcg/FhdLzUfpXLWX7/9gzy9k8hKBT
Ou2UBACRLG7zwgKcYx4yjHhsCxuqGOeKtcfF49ghCp1s+wPsnXy8b6ZAY3wFeHC5
LFyUsQFarizV0aeqJoOXEB296xZYPpgW6C+rajd1WVi7zhPxsfYedldX8HtGDMKm
FRN88P75OGjMdFOYrpXTqUAJnoTUN4UynLV6WbfM7Cne0syg9rQfQnJpYW4gUy4g
RGVhbiA8YnNkQEZyZWVCU0Qub3JnPohXBBMRAgAXBQI8TgoiBQsHCgMEAxUDAgMW
AgECF4AACgkQTZAv93I73un4TwCfWqT0UeeEn9qstLTycDZF6oiKUusAn2dZRiNX
06KUv2qJk2g88nUsBXgDuQENBDxOCiQQBADXY+I+CYMmiant5TBMzh5JfqhW2FXa
aZDgi5XTVAStL6AaygeLIaVSSUUuOxiD4JB7vxHYB7pyVg71/lg5moud8NP2HNKW
YR2mZjCQ9bHRQRqqPBTMrSHJpq10cZ6grxvVmte/oC4cI35wL8HEe2WwChZgk0tS
YrA5PRt/UGWLLwAECwP/SxokqxcRa3lZqkpdwLgLWpyx1KNBg7wIJYLmALI0UxpS
ezweD7OukikqZ1BYlaaWZ7N++r4sNDR9WTIv0ySNovxJnnlyo6FzD9RD7ijQbAvp
nhpikigC+GvdnvmreMXYztc9WvFeJT/S8LGDkDHcm0ECmBDo3EA8W0+sOQsZxk2I
RgQYEQIABgUCPE4KJAAKCRBNkC/3cjve6eroAKCCMN4s5AqvTy38BWmspFvSu90I
IwCfTGutfs+PGUY9JJoabnnfJhfIgNA=
=MFJO
-----END PGP PUBLIC KEY BLOCK-----
D.3.48 Vasil Dimov <vd@FreeBSD.org>
pub 1024D/F6C1A420 2004-12-08
Key fingerprint = B1D5 04C6 26CC 0D20 9525 14B8 170E 923F F6C1 A420
uid Vasil Dimov <vd@FreeBSD.org>
uid Vasil Dimov <vd@datamax.bg>
sub 4096g/A0148C94 2004-12-08
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEG3FBQRBACTPLU4+bnd9eNmB/xp17OCQdMez/lpGrFWcYRh6w0RqUEt3AAL
o2dhleKR/RgaQtkLmNvJQnMVUkrH4dHCTDcPDF7jTUIDxxSa9YmO58Q8ITV9XrjF
8H3bhY4xYA2VGhd13GrRYHtexGtVbBLtAex9Q+U0DBTmKO47C4cnw2cZiwCg44yq
qn13lHY4WlhJ7WB75n6t4x8D/2tazzoHbKUZF7gxFaeeFfIDo7Qd2S4Sq0UZgy2b
J6Api3TAkD/aL6Znh8YEn5ZyMBQzCrJEt5Fizw//nnUYKL/DMF0nVR2WeU87WnQM
wxKSoS1qNHpXRj5y5cDHHqiOSLdDJeBb8VGb9EE9oxG13kX91F5uwRj2m+YcUl7M
rdnoA/98GJVhBQLfCT7AIu8AeoWgMYdjUVsBQ7yZfMntrumfDqy47r2gFNEGMgRB
oN+wITfGhRW+GPtP/TCZr0iqZkz+H1gqnuK+h0j6Jhvq9hY0kEI4O6JgaoozgvdD
9pZEaN1q8/FiSinUOjJLfnja6RYhxv/P+3fWq7GPdK6Bt2kDlbQbVmFzaWwgRGlt
b3YgPHZkQGRhdGFtYXguYmc+iF4EExECAB4FAkG3FBQCGwMGCwkIBwMCAxUCAwMW
AgECHgECF4AACgkQFw6SP/bBpCD2FACfao0eHQOosHyTTKE9ClYzi4xsoowAoLZj
QYqpUePBscVIoXHwmXcTkN9wtBxWYXNpbCBEaW1vdiA8dmRARnJlZUJTRC5vcmc+
iGAEExECACAFAkPPwzoCGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRAXDpI/
9sGkIJwpAKDMIALqzizC9vo+vts0rxFYmPZsCACgzmPcOFXV8+xtIx5vUKQTuPiy
sT65BA0EQbcViRAQAJbrD3+6HrMUYIlEXlkKm6QrCvwNS6JkxSjisX8rMZHfo9PS
kGEg50sDpzrQPQm9/3SyHjmFdrvKLKoAscz1pkzqRq7/Gu3/t36vQ8DbCddwDwf0
hAwpB7ZMUiTkPvCv8C2ZUYdvCZEiDHJSIr2jbdYjYXwU/Ry//aUNzPLoFMwmDzl1
IjUPMLL0FufcJpVH7vJSOTxDAVTnyrXSZbKlKUWYVCxSxoHO7zFvWQ4s6QoIct3a
ouFmZIVlySDE4G0MDshDoHOD/Z53d4Mfn41zhPYgEPAtR7g4xcvIq93MVHlFndys
d/cSJ5uTOjcRyHmvL0KrApyXUA6f2Qek9XfXIH9bYdAtvQNvDpxKZNpIPEWIoN68
N5en8u/RfvbacQ/WBYvoS9qMqqLmOA1oxHZwnmi0o8pA+CyUcy2hNoVmySj8Bg5w
LSMosUHQXYEeH0hUhJIbHu96h+mcy79Mcev0u+zeXM/UN8HLAoHH2T1R6kEOVFba
d1Ib4CY1zFFUyVwCbYH5CBDXKEND7CI11T6jmPzvX2WFOPnw9irSnafSyL/Ndebr
VyRPQQWLe9uE2Dd/gQagxoaGX2gGVAPkJ9rEToZVtvV6g04RQSdk/31+aLepaj79
4bvt0LJmAa24Cyh9XFC9QNieuz9QxUKD4RyJkfN5HLU7dCHRrdQXbDnFMaTHAAMH
D/9hLUMKLDasVD+5L55mWoCep06YexBCt1QLW0uMPNun/fH4TQtVakDC2YM8bufh
JzR1zBt8sdfpErWGqQ/+TN4P/9lzr0uDs3p/TQEzaeqEs9ChjccIUFKC/lp2xDYh
BB7BqvsKWbvjktZ1HN7ZGHM4YIGxOK/hcQua1ov5WbJ6V9DXEmi6EguVsq2uEtQu
V/8DwHtv4JZpPUUQmqL6VKkGPc1uLmiejjbq2aUJmbqsLMZfx7cAe4UbeR7ILaZn
+UtQaNdNe04D5OH67E4Ntk4VaZz32uvdJ+v9Yx9TQYJ2nadWd5IuHm/KaPlFzXbk
8vlyFZS8e4hE2Jvaopuzx3fecCg6MIQ6pc5Jxko4EAsoSaGRwGNodQWQGPc2DZxb
Isy1BIZO5XrYXU4MzSOkhR4iJtap3UxFJaImxRBeO/z0//MI7BxDOpNw3zUDWt1w
lAR2DY/Eyfrsx8SK/MdS4ds2j22rJdFGhuxO+uHJ+eZC70pccVRqRPMMs4uDA77r
TpDB6VHEsqC9MTMzkw47Bt5My/qzrn/DbAAw3qkI4kPfynmYmoNwiegtD8fYD0XR
JVlvQ7mnU0ZCHKcEh9Gjwqpg21/4kewaPxwlF1NXescn/proYpLv9uUwgVHCHVfy
ntTKlGc22bcHlUXrdbCaC7d4Xj8SdhKER1Fl4wqmDGJdY4hJBBgRAgAJBQJBtxWJ
AhsMAAoJEBcOkj/2waQgxQEAoN8d1808ijz/VASozvQNLAKOgEdcAKDA7JkB9MnX
XmPkHj0KHckscg/fYw==
=Yp1b
-----END PGP PUBLIC KEY BLOCK-----
D.3.49 Alexey Dokuchaev <danfe@FreeBSD.org>
pub 1024D/3C060B44 2004-08-23 Alexey Dokuchaev <danfe@FreeBSD.org>
Key fingerprint = D970 08A4 922C 8D63 0C19 8D27 F421 76EE 3C06 0B44
sub 1024g/70BAE967 2004-08-23
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEEpzAURBACu7RDb0dP0oorBa7j0Do1auzG1N2wQgTMIHoo7DhspaGjvN0RJ
/dozO04jqyWopb/cA7iWMqn/7gX9ckHrKa1ugQRb8P7AhIZNmfc0B5AOCqeGo8gi
o9y/XBhFRS3Osxxe0j2bIoL3pk0EBjHaa477yiZyWNjq5j8rPf/h7DudtwCgx14M
iEwmKZ4hWMzeaKYcOFTIn1UEAJtUMrBbxMxchDnIuAn3Oz3ESpGpxSDVcTHUxoIl
3A+mizXetzWX8lmEP8GM2oM1/dRCiF+l2v5tcnBO52PT1cFst28W6Ytyf1PamIFC
GNL2CZUz/ZVRBPEZb7CfXJYupYd1AiYNCoSyh9bOv4Fin3Uhm+Ds1n6x3yulCFyo
PJ9pA/wOMpGwCNSpNLcfz3gG5dh7PR2rhh0D0w7jZbO/l8D/81inThfBRb7B4KIP
v1Cl/ynm+M4XS7Fy3xjfPHbUvHY/DNr9rqI0qsGU9qTubuBO+I647tjLFem8gaue
yESeoU4okXMPblPXh8r93JIfbmi/rMcuddblJ5kw6U/IYYGGS7QkQWxleGV5IERv
a3VjaGFldiA8ZGFuZmVARnJlZUJTRC5vcmc+iF4EExECAB4FAkEpzAUCGwMGCwkI
BwMCAxUCAwMWAgECHgECF4AACgkQ9CF27jwGC0QXdwCgwTxjqqG9DppWUVvfQklR
7O7d/QoAnj9qF7prbDCAq43MQJIJ1AP6x/4UuQENBEEpzAYQBACsVmYX94l7jndx
byPUZl5SlKLJFSTIymPGLebcdNg8rF86aq/9d8nRrkrqUWtpQtWeAZw2GZn0n/vz
kRbmaqMaHkmdg9g9xT2qstOL0rZhCyvLWVeNYUjgkNWi7Be3yjb11RLPOanpug5z
Rfu6I/7qjOcVEoa3cjlahdK//xleWwADBQP9EWsXY1iKSQ1k1B3N3+EEWbzuOzaH
upo7fLwamIVuX7K95YIqOawMlhERBD8MUxfrzJkOIbVI/81g802Iq1D2Xv46hvCP
J8oszCeFjqixsOkg3HmdUyvTHnODBHsQMoy/37r5voAElx/LXc4Dm9DSR0rSTpXh
mUdHtM0Y6XYEcoCISQQYEQIACQUCQSnMBgIbDAAKCRD0IXbuPAYLRD9GAJ91NEgg
OHfLL9Taov5GEDVjEaD8MACfeTqtFRD4Piuxg64CGOdNBCJ5+p4=
=abIH
-----END PGP PUBLIC KEY BLOCK-----
D.3.50 Dima Dorfman <dd@FreeBSD.org>
pub 1024D/69FAE582 2001-09-04
Key fingerprint = B340 8338 7DA3 4D61 7632 098E 0730 055B 69FA E582
uid Dima Dorfman <dima@trit.org>
uid Dima Dorfman <dima@unixfreak.org>
uid Dima Dorfman <dd@freebsd.org>
sub 2048g/65AF3B89 2003-08-19 [expires: 2005-08-18]
sub 2048g/8DB0CF2C 2005-05-29 [expires: 2007-05-29]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDuVKxQRBACAKP3+q7GJT2OMujrs3EgY2hdrTtLatgzpYGHsyewpckAhMPv0
RGyVpcmXdArWQFMfBdO76TO3r6/CKRTEAAW7UieQwCqflr/qRWfaiMkqIDxll6wU
ZdayDmuLPlp76xN7Cvy4p34lq91VNdrZ3FesMXH1xTPrnaJX4zhFEd1/QwCgnmvP
UrU63yhExZOs0Cpo9ruLa8ED/0t2nNIoOM2cUghN6Lnh45cY1O+jnjJ4QMOi7bEs
XwS4sIZLzZ6F07RCTTbcyRkrrh+WqX89z35ppi6PM2GZS3Zgz+W+gtzvrhhBcIHm
0INVgsJJE8Afa2EzA2HIXsKl462Rojo8hmFXO34lCnQTe5khzLZVlUSxVpdoucvE
ew/OA/0Sdos8xBWc5cFz7iycKpDCNjEuvMroPaFH0I9wPAX3ZBQeyHVLsUYDZKFb
xDYlfLPfRikkxolxF+kuzqejgPMJe8aBZfPK8fIhn3IJw/5mOETGnaAPSQDCuN81
jIQ20Dancod59Axoj53VB5bvUW49Z5lapV6rGLb78YuYxxQcUbQcRGltYSBEb3Jm
bWFuIDxkaW1hQHRyaXQub3JnPohaBBMRAgAaBQsHCgMEAxUDAgMWAgECF4ACGQEF
AjvcEb8ACgkQBzAFW2n65YJotACfQgyy6ccNJM++ogr4UI0QItTsSPkAoIYl/xWT
hgWobGIOvCQzU2AV+NUgiEYEEBECAAYFAkKZC0EACgkQbDa6AvWDdPy/XgCfVqbe
ZkvcFSken2EtrJ8I6husA2cAn2EsQdRTMlE+6A6Iwcg3gjPB6h57iFcEExECABcF
AjvcEb4FCwcKAwQDFQMCAxYCAQIXgAAKCRAHMAVbafrlgvGXAJ0ZLXbxOz0dDh94
SFIxkRe8KE8gVgCfcHnXtUP4oWpyHZ61Ptg/vbv+EMyIRgQTEQIABgUCQHWoBwAK
CRDsbL+biYKsuZgQAKDQM/ws0qDgBBl78R3+bdiBepazCACfcqjBRkMtZRFL5k/T
RD9PZHKVh4G0IURpbWEgRG9yZm1hbiA8ZGltYUB1bml4ZnJlYWsub3JnPohXBBMR
AgAXBQI7lSsUBQsHCgMEAxUDAgMWAgECF4AACgkQBzAFW2n65YJTVQCeN8TR8YIV
DYcq40EP6zU4UkwR1YYAnRsA1eDMeLWTtOW1DY1ajeoWY5N2iEYEEBECAAYFAkKZ
C0QACgkQbDa6AvWDdPzaUQCfSU5c41XaVSRSnB+GbfjwWNksL8gAnjHNveKXl6s1
bFK8FmUxZOQCVfRViEYEExECAAYFAkB1qAwACgkQ7Gy/m4mCrLkHyACgl4+J+DZB
ugNnNwBDLvvptU8wS74AmgM/8NVgFiD+lV6xZeqqOecUPfK5tB1EaW1hIERvcmZt
YW4gPGRkQGZyZWVic2Qub3JnPohXBBMRAgAXBQI7nKCzBQsHCgMEAxUDAgMWAgEC
F4AACgkQBzAFW2n65YLOxgCfQb+DcmfgjgC65ecR/JGVHooiOloAn24vuwXem5o5
5Ghiu8IOXmucO4jMiEYEEBECAAYFAkKZC0QACgkQbDa6AvWDdPxymQCfbffQmqj/
8wkxEmExYxVeiXEUp7sAoJ+D1qNrbFeKnMo8QhzG6BqYtcuniEYEExECAAYFAkB1
qAwACgkQ7Gy/m4mCrLl2+QCfV1iY/JPWDYMiC6SYtB5T4v7wjeYAoLqi88pkNlBo
OwiKsYETI24p/yWhuQENBDuVKxgQBADyhmTjQD9dOI/M4X9sF+Nvt67rQvAu3j3G
0stq7Pu8jtEdbRaz35izFxfwnY+/RHK7PXCVoAHze5yfZu6qxMxKZd/mcy+1C43Y
WQ8C0M/pXg/YX3Qm08xTqUm7G8Cx6AS8/1s95MaSuc71E7bfMV5I6ja6+AjcMyD2
hJiu8gewOwADBgQAl5YGq9pqpDqGYpGDFuc0Lwyu/vmEMS46EesbYC2CJGyyPpjs
eRx/yitJe0lzURA96Kgb6qwz7OTzZOzyE/Qb+fNLwh3MOwgSbusqeHyRIC0w6ElJ
rikyJwpmnGdPPU3Cwerp0oTHpqGRENjbcYOaaHE2iWk0wrw0869ipHnOQReITAQY
EQIADAUCO5Ur2AUJA8JnwAAKCRAHMAVbafrlgrCeAJ4nDFNUblhVC9rNBzOMaKJA
wqM0lACdGZS6w22ACrd0nHQcl8u34qGcy+65Ag0EP0H2xBAIAKGqfY3rPRteNSuJ
c+0DJq+Rlp5eS5gIXI5LZ73WrSrbTuu0gx+ZTm9bz8WnAN8lM0DyJ3JkJfy0FOBR
VLh0K/ksQ1NNwKqWrx4ZS4cKV2LMtAZe5IOsLxvYuLV4cPOrCeNZku42ehVV+n4O
FR5UjxmXLW31mYdbo2TeNtABUCipszCvOpJ93L1FyBpAFACuBzMEO1DOMvtijXzt
DJHDvOISFQLivOnPn9G99TPNJr4IQas7HPkCOqto8Z5kl+AbywYIWqYBJTEPp9f4
VLwEegEGXZXRsdlIRPavwaw1i4pDT1GKEYKr84uw/MEm+LMzNiBKWIe1PjGUWmXT
+qMC6bcAAwUIAJsJaBPPPFbO2Jhup4rkt11ea5spnACnte3FLWU3QR3Gm+9EbqHu
BhkF1FhMcFNIzJMxbBSCPCxA6tgbw3C0frl6BtraNZDW0FThYcV+xundkZZN4zQc
CWk8AS+A1metHy7SFldRo8ApBC8jWsUfdUw57QzKIv6lJoJhUV526pYcMwOkh824
7aIwAD9Aq+QjMFBxvIsQSK2Spoag0/PUSi9gQ5Gs1GeqHHQ1Z93z+xn5y/fuumOW
rb16/7b1lWYV77dOU3GqSgR3AlBqiU+zX+J7DEUs1w0HshGwZKOFYEP3RXqn7ePh
sSQT2eHhyi5kb30Cjcah5emKagnUw+kcUnSITAQYEQIADAUCP0H2xAUJA8JnAAAK
CRAHMAVbafrlgsEXAJwP0lOmgpEO/a658GuZPDFWDF/5WQCgicjIwyEShBkrEKX0
Lwi7CPdGAz25Ag0EQpkMrBAIAOWN8f2FC5Ms8ivOr28XdvkDmUXEoDd9RDmJXcue
4icY2gikIg41w2AoVAOtBO3B24kZaMIyPiprFoQg0S3HKky7uC0h6Hrwdh2BRdgb
QSZ7X87yfBwvyKzcwv8vHM3/yQVdz0wXL9lnOJc6TZnATK/NeVJg94Hh+yk/tfOL
Mx/NGvdJqzar9ZHP1fRxRRJNdpQfr1jO5CMCI7VQS6M/bhXJZyP3hif6BD0kg20n
R1yv1pl7IeLl9XTfkFOrLhezCQCt9zQ3fVF1fDVi+MfDXEaikXZUrHqeEhx1QZcf
hpTn8T7ooOrOm/Uv1EgPDsEyrFe9cwbcX70M706hitlFoUMAAwUH/2fd7p0HcUyE
qbo0upsnVPsVrBk0ea1TKen+SI3p/QVp7QqoQoSrbQtfk0TbH+xhEv1ZI6PJsafa
LOP3z/2ULOj6f9O4sXh4bAMuI8L9Ay4+s4RouTSYcEYr+IDnj0S7IgkHpOJraM7U
6VE3nmoe6TutIAbkvyTVs+AVuPiBCutLKe6inIGGUM8+afdDm8rymfVyJDPpH4jm
afsVGIXcKtGh0XdG+cJ3KzJSJp1gwFXBPmcUWuwBpD/MuAXQgkMvh6Eh5BcZ61Q/
evjDpUENG8r+U7qvWG2ncuhrCEWj0qKp+7WFXazoxF7WRPRL76fUpckuJP0nZhYd
pOWpB9BV7zKITwQYEQIADwUCQpkMrAIbDAUJA8JnAAAKCRAHMAVbafrlgrQ5AJsF
SdOjEfuDShMW+extgDK2AHuqVACfSooNbyT/XUaU6pQQdj4pH0p2+u0=
=hGAK
-----END PGP PUBLIC KEY BLOCK-----
D.3.51 Bruno Ducrot <bruno@FreeBSD.org>
pub 1024D/7F463187 2000-12-29
Key fingerprint = 7B79 E1D6 F5A1 6614 792F D906 899B 4D28 7F46 3187
uid Ducrot Bruno (Poup Master) <ducrot@poupinou.org>
sub 1024g/40282874 2000-12-29
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDpMfbARBADvuMgOIlEdTWlb4XvAu1YEfCijox47muRNbkA0yb0drMwYnV05
tZ5cOK1uVELQ+gtGK7lDS5rQ68LPpXFMVva98skkVimzgfmQiqDOXiYW4BVE1qmO
THpb5dIpHoXqTDILTLVomf6d8Z2re+IJUNvbrBFM616wndIQqux/O5LHDwCg1Hky
KrYDoOT1lcDgSGH6RcqSoAkEAI+D4y6JpBctutEGWNcgijLv36g09LYNeC/gD2aq
0bS/4c44eoPkMCBBn8MM9AIsK5sfne2GuglHcUM2U82s5UbZcQl8vzcyG9AVGQGl
aoO/duxFKPQC70/xEa26Bwjv78cVWm6hLHoMZRXvsprr3pQpuZHmzPWwwxipqXkY
gYApA/wMrLwdewzd4yEMB5O6y9WSd+FUA/y1MS1+9epdbzPnpUszR2QKlA+XblfD
8KdxxUjIjt6WOXEhQ0GCWfRauB0MAZHTMkA/NVnmR+pI6FSJ9LJ4s6+BoFRbKdDp
JY6yJUZzqRgxgo7tIcpRsRuXP4zu8KYlCPL0Al3gSW2DlKYxirQwRHVjcm90IEJy
dW5vIChQb3VwIE1hc3RlcikgPGR1Y3JvdEBwb3VwaW5vdS5vcmc+iFYEExECABYF
AjpMfbAECwoDBAMVAwIDFgIBAheAAAoJEImbTSh/RjGHWXsAn0/3nHkOH2WxLdWl
ANdjJDzkMLywAJwN6CBCDKSbN7OzfNHTx3XAEVUUmbkBDQQ6TH21EAQAiEIQKsg7
Pi2k3L9fFnDDAcFgh2oL/MpHgN4kKYx2aoTr02O3rBmK3ADCIBqj3dlWMavIOuzu
1DvmvsloIcDwsMsc846bjQq0R20VaiNz4NJqZfhS2/xYPzJo9sPTncJOGQowjv+J
GqlkmvLVSLSzYPh7OZjdw3SxS3zFPEQg0ccAAwcD/iZIddUIenySJdgs8WIe26X5
r34/0TlyxiwtlzefYpVHHYD8CzVhYPD+iWUpDv/10HC7c58JTxNUGyN2UGcaDNRc
g/VJqRahYxz9LokB+vRPmCyoP8bhLkrp0fHZFnFpH4IY4WQecLBfYJZZF/K7TLLz
O5tine3BIL/LpM0nhVWJiEYEGBECAAYFAjpMfbUACgkQiZtNKH9GMYe/7ACfTNKi
dschnmutxCWw5fcsyqP9oYcAn0Cf7InoUX5AUFaj4dFZ4IN+9L/m
=LTGr
-----END PGP PUBLIC KEY BLOCK-----
D.3.52 Alex Dupre <ale@FreeBSD.org>
pub 1024D/CE5F554D 1999-06-27 Alex Dupre <sysadmin@alexdupre.com>
Key fingerprint = DE23 02EA 5927 D5A9 D793 2BA2 8115 E9D8 CE5F 554D
uid Alex Dupre <ale@FreeBSD.org>
uid [jpeg image of size 5544]
uid Alex Dupre <ICQ:5431856>
sub 2048g/FD5E2D21 1999-06-27
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDd2Z60RBADHdQ8600NP2/sBbuIW87WqWXZyzDX0Q6AA/czBlV2PKiEhCgTJ
wZCWJMs/iR0GgfS3LKYd/eWW48LYj2V/0YjafV/A2B6+1QsVGltXunvtYxC4GnCS
tzPqsI624jgtwZ5sb8oowOv5ykEVw6lxneRuluymOq3YFxhRfjJ3koNYUwCg/9ou
KUPZ3hPNklVoLPAnN+dF3gsEAIxacljfmb3KQ2bnngkhvASu7g0Ipjql2k1AiBwC
1oWnsMIYX5qNBLA+6FtAGFYqrT8hV5qROJyNPVeVKj3p+wt23Co/t/w0gaLccu2J
lI6QBFerCNFcqNMgzEAbQ8ARxSrLW/THpOJ8i32z0AKEtx/1LdYlcFB+l+8FLuKg
EgXMA/9RmwjhPmZ/V5xUXW6mrkSfRDtxRsEegaixqUI6SmskgGgsQybjSc0fxWtl
MCKZ4sIqtykPAlf5fGeX+FjYyR6iFnjfJwRFxilLGokqaDEZeE9myB2Mue9YnFoS
GB12c6U8HRf4R86uk4tWwzMO70Gyt3bSp2GTXeMiuy7dibKIRrQjQWxleCBEdXBy
ZSA8c3lzYWRtaW5AYWxleGR1cHJlLmNvbT6IWwQQEQIAGwIZAQIeAQUCP+1QiAYL
CQgHAwIDFQIDAxYCAQAKCRCBFenYzl9VTRTeAKD1MQaPbJTcdkjGCc9UWX/+BfrF
WgCgr07J+hRd6NOpwuceEBOJiyUXtYyISgQQEQIACgUCOdIfVQMFAXgACgkQaJiC
LMjyUvsYTACffZ3C/DrsfrhU194Kyad5hj/jIjsAoJK0hql1FpySpNsboLyEnHM7
63b9iEYEEBECAAYFAj0+wBYACgkQzN3ZssLok5SIwACfR/1J2H+j0Mbtn7qUGRUc
QvlomPQAoOC/koTFa2Bm5THjlBfSsk3q03deiEoEEBECAAoFAj2hfjQDBQF4AAoJ
EKuTOEU6hQh2UHoAoK7PchQCfxOc63B2ZBMyMldeQRSyAJ9k9sbDyykjjFHvFLz9
ntJKhK8+HYhGBBARAgAGBQI9oYFgAAoJEKmYWQA1rBephm4AoPkodLvw0WC9ZVku
M78wklL7g4gNAJ9tj7M2vz0p/OVrZbwFCL8T//xrJYhGBBARAgAGBQI9oTGOAAoJ
EBEucGQpBWq5rzQAn0eQ9lGtm59BT+Qo/5bwSEvNW6bhAJ4quX9bKP+3wDz+d2Ea
/Ieq7PG4LohGBBARAgAGBQI9oogEAAoJEOHp7vh9u29BFVoAni2SREp6+ruUO4ZY
vnyp7X+9rRGLAKCCMPtYqrfl52ahVtpur0zRv0s4ZYhGBBARAgAGBQI9ox/uAAoJ
EJPzaUMH27/PGpAAnjutHjHxcVsTFtKnoi7jwOhhmR2GAKC4OLDkwcGgt0gCBE+k
9d6Xa9lPMYhGBBARAgAGBQI9owbBAAoJEDQEO2gJfT9V0bIAnRINee3pwDzKigGF
kf2IwH6d+Su3AJ9U8Xe4PabdhuamjxIfKo86utT7f4hGBBMRAgAGBQI9qZI8AAoJ
EKDr0i7FpXGj904AoJ2soZyUwjiS6a56kcqD4c4I9YZbAJ9IqMPAbhl4FQoJ01nJ
lHsh+/dts4hGBBARAgAGBQI9qaH2AAoJEGJ3j/Re/FWCNw4AoPQ53owxWbWi/cQE
NJ+G2rf7o3l3AJ0WtU6+W9CqVTbdacQViMRlHvM4uYhGBBMRAgAGBQI9qV5sAAoJ
EMqTo2QBwKB66goAnROzJ8axgpIADNk94ZIf8xP5XTX9AKCCTxnmt0XJsjoZD1qY
L2vibQBx5ohGBBMRAgAGBQI9qe4UAAoJEFeqDLyJce6Rz4wAn2grcZUcXrX9LwJE
Ee8MfVu5tVGVAJwLr/yzfosZJjR4wr54crXDJXcje4hGBBMRAgAGBQI9rboSAAoJ
EG0hDjaqcofL+H4An1ptz5qMc7AV5Vvc6EsXcgh7IghvAJ4xSftp1serlfL4Db7y
+byfSiKSb4hGBBMRAgAGBQI9snvFAAoJEF+WLsuuYRIXJCAAn3c5v7n3R8JbeXB1
wWOPw/FgKK+YAKCn6/JAH6sdvOjk5L37GL4yU2XfEohGBBMRAgAGBQI97g9qAAoJ
ELeAlgoS+UxGpXYAn2ZslcTauBi3teQwaYm4eDS2R/wvAJ0Wnik+nIQ/1g64kKNB
qcV6jF2HVYhGBBARAgAGBQI98IXPAAoJEPgxT+wsuUSVSXwAnin8UZGwOp4jPX1Y
TgR2SCGpdY9kAKCDzavGwkIO4K55XOorf9AYgQevA4hGBBARAgAGBQI94MTTAAoJ
EPJCAIGCve9067gAniBPlLk5hPyCu07/VUqyr1p0Bv/cAJ44pGuWMDYa4zQVaYET
a9OoeDxWwYhGBBMRAgAGBQI94c/QAAoJEDSlil2NzYH4SqMAnRq/1EZzJ8WavHrN
mwcKB7oGkz5rAJ0Y0sQ2SZhSti18ySsiEDVMRBpWVohbBBARAgAbBgsJCAcDAgMV
AgMDFgIBAh4BBQI/7VDwAhkBAAoJEIEV6djOX1VNGVsAoK25N6W5QR36bIlLLWUW
+804OwylAJwI7jUfJFIBynGVECAjOxs+wJdqn4hGBBARAgAGBQI94qTkAAoJEFi1
akDcxXWWdPEAoNBPTsEzXYrY2VRigz+GJGoeb6PRAJ47kv2VhtXa35UkkcoXeNAl
KKpNIIhGBBMRAgAGBQI/yNdcAAoJEOMfb+3S0Z1k3QYAmgLlP2DsKqu8W9SZZewC
j6y5Q4TnAJ4z8BKu3WW4+FgSgzUbfxeRm1R704hGBBMRAgAGBQI/yN8NAAoJEHqF
Mmo3kYje/MgAoInyoeCKWiupv1nPAc7WNyPRUTlyAKDAKk0re0Tv9NV25axIsRcA
lXSH2YhGBBMRAgAGBQI/yiw0AAoJEG6MV3sbsXFonjwAoJX1N3984XUOQvjtvzgm
yEMsPpZ3AJ4xb5W6wV5Jx2Zs6b6l8Gfa5bhGGIhGBBARAgAGBQI/ylqIAAoJEL6M
vx5iDEDttdkAoIHhltNYjyqdRqIDe3BiMh6ifJnWAJwK7CsN2cILS03dnOhUI56A
BmcbfYhGBBARAgAGBQI/yocAAAoJEJFrGm4xw2cfaZYAoJljeDokelUmoqJ5nSAr
LlM4BcnQAKCkMKAOBSltS8WsH84J36hmPdC5XIhZBBARAgAZAhkBAh4BBAsHAwID
FQIDAxYCAQUCN3ZnsQAKCRCBFenYzl9VTQiOAJ9HfMp2sdOYktGhv2fL5QD+8IBA
ogCg/2bYytgwqGBDoUK4vQmvNf3OF7OISwQQEQIACwUCN3ZnrQQLAwIBAAoJEIEV
6djOX1VNZkAAoLemkl7kpuOmYOxx8UXH4M7qohPAAKDs6fvPTjg55xwWuODRBTZm
Q64u1rQcQWxleCBEdXByZSA8YWxlQEZyZWVCU0Qub3JnPoheBBMRAgAeBQI/7U77
AhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEIEV6djOX1VNK0oAoPp14QWuw+em
oL7+q0L9RCAtw+15AJ45PiXh1GNC7HPj7xEzLdU0FqNM6IhGBBMRAgAGBQJABqTY
AAoJEGiYgizI8lL75sUAmwSDPuHjpFlqPDLmZ9CYh3Hb82lqAKC3BLlS9vSv8Dzu
hQVIUSh0Um5WsNHU+9T5ARAAAQEAAAAAAAAAAAAAAAD/2P/gABBKRklGAAEBAQCQ
AJAAAP/bAEMABQMEBAQDBQQEBAUFBQYHDAgHBwcHDwsLCQwRDxISEQ8RERMWHBcT
FBoVEREYIRgaHR0fHx8TFyIkIh4kHB4fHv/bAEMBBQUFBwYHDggIDh4UERQeHh4e
Hh4eHh4eHh4eHh4eHh4eHh4eHh4eHh4eHh4eHh4eHh4eHh4eHh4eHh4eHh4eHv/A
ABEIAJAAeAMBIgACEQEDEQH/xAAfAAABBQEBAQEBAQAAAAAAAAAAAQIDBAUGBwgJ
Cgv/xAC1EAACAQMDAgQDBQUEBAAAAX0BAgMABBEFEiExQQYTUWEHInEUMoGRoQgj
QrHBFVLR8CQzYnKCCQoWFxgZGiUmJygpKjQ1Njc4OTpDREVGR0hJSlNUVVZXWFla
Y2RlZmdoaWpzdHV2d3h5eoOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3
uLm6wsPExcbHyMnK0tPU1dbX2Nna4eLj5OXm5+jp6vHy8/T19vf4+fr/xAAfAQAD
AQEBAQEBAQEBAAAAAAAAAQIDBAUGBwgJCgv/xAC1EQACAQIEBAMEBwUEBAABAncA
AQIDEQQFITEGEkFRB2FxEyIygQgUQpGhscEJIzNS8BVictEKFiQ04SXxFxgZGiYn
KCkqNTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqCg4SFhoeI
iYqSk5SVlpeYmZqio6Slpqeoqaqys7S1tre4ubrCw8TFxsfIycrS09TV1tfY2dri
4+Tl5ufo6ery8/T19vf4+fr/2gAMAwEAAhEDEQA/AOJFx4keL/hHrOVYLJmS2eNd
qGJVbK5IAyo78n1Oal8U+GtMdhDout2etXkUgjuIixxIwQMxXbwcYbIzngnnBrmr
qO0gLXl8s9sl1GGE7XJ3HoPl5yWwMcc9Saz5bLUdPvRqMAnhtY5VXz7iMxg4B2qx
K4dyCQD1xnNedC7OmrHkkrGddqNP8QajaPF5UUu2VU27cKRnjPbk1Y8OXMMOv3mo
XSpKpOY2mG4hhjkVX8RTzvrFtesx3RxGMyKXbcuTt5ct1yR6cdKwLq/dZWAZV7cd
MVvGnzb9UVKUqbsz06+1+zu52mTZHO/LSqBlvw9f8aqQXLI6lJo0jCgAMACBnpx9
T+def2l0wIllOB29WNaC6zs2yHYNvQMev41p7FJWM3UZ1XiBY72c3jQxq5ULvQBs
qM//AF6ztOkhs5TIJfKLAfL0HA4/GsCHWn87MZIV/vBGIBP0rUkltDL5ctw4bA3L
Iu45x/8AXpuCa5XsCbWqN29vk1eVXubmOX93sVDgk/WsXWNGmjurC4XN1H1mRCAQ
BjIz9O/aqN/Yny0exuFTPzZGav8AhbUHtJA15JkjK4JwSDxnnpQoKFuUrmc7KXQX
XbrT73xvZSaRBeWdraRRgGcrI+9ed2CcH+Hj61YutRu7ia+mu9moRlFR4FTY/wAo
5IHsRn8TjtW5BPpE14tz9lhDcYcKBjn1HXNYerQvN4quLZ75rMXABtg6bond2xjg
E88cH35HGc6ilOWpSlCC0NrSILDxLo88ekWxsZpEaG4hiOQqncFcHockOCeDgDjv
XMeMjcx6dYeH7RCYNFsFnuBnhZ5ym8/hlR+NafwivToviGeJpIpYZJSkgUMyNsyM
N0I5J+bBAPOKm8bWsOnaZ4qvIt5e+u7fyy5+ZFDgspx7jHHoKulL33F7HPVTSTaP
Z/gtA0vwc8P26uUaSzba6nBU/aWwQfbNFL8GLj7P8MPCSAIF+ynezHpmfP8AWiux
njyk0zw/xpr0rWUekwwOs0J80AQ7RDyDxkZ6d+MfTrfl1nxLD4XlttQFrNIfLmRL
uFHNqATGSq4Chu/rk/Wj4h6Ff+HvDcepHxXqOozwzJBCLhEcAOCpGWBPTPGa88i1
PVLi5gtlvGUh1WMoiKQzMB1xnuazo0oUY8rVz1ZT9rJzR0/jWTRHtdmjXV9dTLO3
nSzbfLZeilcfU9a402jGATbwQXGRvB4/Cuj8e2kFr4hudPsJZ54EZQXmkLszY+Yk
/U1m2seyE5AI3beOqjFQrK5reU0nJ3GSRRfZ/LjQ8HIGef8APFZd8yqqIxOcYGO1
Xri+iuAYmjKRg9FJJHuTVSW1ga5R2fcvXPqMUlcTV9ixozLCUuZl3shOxd2Nx/wr
YLSXEcoljiSUqXjaMEEkdves7SYYJ9QjMi7o41ZsZ64U8Y/Sr7yGO+tZdrAh97KT
94YJ/Lg1MjWKdiXSL4GVSyK0YTI3Dke+a2Looti7zWaTbxlHAJGPU9cVx+hMst/A
lwStsAGkwc/KOuK14NakOomW4yIlZt6L90IRgD8OMUMlXepfsbpIx5SBTjGFzjNb
zQJqNvb7WZbiM5inGSY/Qcc9f5VwF5L5N5G6ufLlY7SDwAPX8/0rq/DN9Gk6wNGX
KtldxJJNDlbUajrYT+zr/Sr5XvLgXE8pJ3gYk3KOSw9Dng9/rXW/GPTopvh/p+q6
XHMsARBdiSUMWdWAZlUdFyynnt9KddwxuY7mS2hmnjGY1kGQD9Oh79cihtW0jULS
4tNZD2kQspo7eNIsxCV1IBIXOOTnoAMCoXM2pIK9ROKhLdGnpKapd/C3wlZ6NL+/
hSKV4sZ85d4JA5HI4I57UVieA7qK90/SdJn4WKHy13swB2sq9jnrzxRXVUi76Hkq
K6jfjxIU8O2MBfcJL5TkHg4Rj9O9eX+F1U+JbIuPkS5jkYn0TLH+Vd78cLlpxo8G
TzJLIR74UD+dcXYRLaPLI5KvsYoQM9RSnLU7KMfcLOug3d/NMHx5shbcfTOc1lyS
rauRCrFc9+9E120cQba2D6nP61WSVZ1MecE9P6Vjc6klsQzW7TSO6oVyMrj1HakV
DCqRbhJuPP8As/StOGwE7cHa+OQDjP0rSs9FkYKDGdzgYYjijnRfsmc9p8l0kmVR
yxGOR3rQey1CVfN8ttxUjcBjGeP5ZFen+HfBscqgmIYI5JGc/wD1q7iy8IWsqlUg
BI45HFQ6iNI0WfN9hHLYXcSzQlkQkHKn5lIwRWydG821a5tCWWT76k9D1/nXrur/
AA4ujI09nbD5Scgrke4xUuk/DzzLRi8ckMrEBFToxz1/+vWU66WpvDCt6I8EtrOW
adopVK7Pm644z29+a6vRtOu49s1uN4GRgrz+PpXudv8ACi1m0Nr6S3WW4RA5VRhh
x8xP0PQd68be8vdGv5YICYyOACM8f3eaIV1U0RE6Hs+pu28s7IUdATHg8HcOeCB6
evFZmqJZSzvKIl8w8Fl61e0SdZJZFYDc3qpI5OTWfrlqLYmLz45SDncpBBB5rpoa
SaODErRMp+D7ldN8XQruAV2DR5zksCD/ACU0ViTT/Zb6CfzNpVxgjr17fhkfjRXW
rHnzi7mj8Vpi+vafEDnZCzfm2P6VFFZxyeHlvJlDyMX/AAAJA/lVbx151xr0F0Yy
sAhWJGJHJBJP863rEA+GILcLkmLOSeucn+tc71OuL5Yo89vpYwdhR+PepNBiSXUI
4uMN159aTVIyszIw5DYOKt+EQZNbjQLzu4xWMn7p109Zo9O0Tw1amNWeMtjhST2r
o7TSLOOYP5eTxgk5xTrD5LQKMZq9bxynGOprgUm2em4Kxr6THGmFQYB6YrsdKUFg
UABI/OuQ0iFnlUH867LS02MADwBVS2CC1Ox0a1R1+dsbuT7V02nwRRIqgqcHPA4J
rk9FfdKi5AB4znrXW20exF5ya5ZQbepyYu6la5NPaQy2zRPuMR+8oOA3Ofyr5B+L
ugRjxfqTRhdv2phtz2xkivr+RmSImvkP4yaolh8Y9TXA8soJCvu6A/1rSlpVsuxG
Fu4SvtocjZi5trV1ZSJdgUEnpjgGsWS9ku52W5K71LxOfdTkfof0rctLm7vLE30k
Ugib92JSuFJ/uj8s1yesl7XV7h14DiO4H1U7X/8AHTXr0Iu3Mcld3lymT4sUQrEY
pMsJVIxzgUVqahBvHzKDn8jRXRqcqsWPF1xFPJZ+WWwGckEYxwK2baC4S2jiWJ8I
gGfwrJ8Y+a+qWkUoAxExCj3OP6VqvNcykbJ9pBPbBrE0a91Gd400P7TE11p9uqNa
kJOqj7w9fy61jfDiNm8Ux5GVRGJ4716Bb3awWGZ4/OeZ9rgHlto4/nWN4V0xLLxH
NJGjLHJFvjB7ZOCPwORXE5NJxZ7jpRnKFWGzOwl1eCxXy0jeaUnoq5ArOuPG9xCA
IdOkznG5hgCm69bahIfK09Nu4/MxOAfx6/lWDqfh2RDbSO9w8vHnh3wuQc8Y42kf
iKKEIsivOaV0dXovju5Y7mhBYEcLXrfgPUJdWkVY1zIyZK9c183T6faW+pwLYSuW
WMb5N3V/bnOK+jf2eyv9pmScjcsX/wCuoxC5VZGtBycXLsi/4on8QaYJJQ8On20f
PmTNtX61xVh8R/ES34htPE8Uik7drI21jnqCw/ka7X9onTHv7C2vI0nmCN9wD5FX
HUgd6888LaHp2o6zZS21lFEIpVaTdhuMjcNr/KxO3jcOMnrWVC1SHNIqo3OKcY3b
PY/DnijXbmSGC9u1WeWPKxyQFA4z1UsPmH0rwr9o/RZ4viZHqEkLRxX9mhJxyGXK
4/ICvpD/AIRTTZtWXVbcpaoWEgtIP9Qrf3gOAG9SoGfeuH+PGlm/v9Mu1t/PFmWk
kOCQqjaeSOgz/OuenUaraChyVHyQVm1r6nl3juZbPw1o3hi0h2QW8X2iXb1LsCBn
1OMn6EV5T4phZVgunJKq5iceiuMH+lepfFu4Mniz7YMI11aQzSIBkBiuDn3OM/jX
n+tL9r0m6t8bi8Z29juHI/UCvdw6XskeNjpP6zJPo7fcUY7NxaRRuxkZFClsdfwo
o0W8Fzo0L5BIXY2fUf8A1qK2scfUXxNFnxXbW+S58pPfq5rQuj5WFMqj0BGM1qS+
Fmk14aj/AGgG27dqNHz8vbrW8dJh8pfNCySddwUdPSsrFuaskjldDtZdTW5sZZ0j
kUpJA6nOAeGz+OK6eJ0k01AoAa3xGwxgjgZ/x/GscH7H47XyU2LHAquAOTnc3T8B
W/cSCSUJBEzeZnzDjjGK4sRTlzaHu4PEQdDlb2LEMfnx/Ss+6053JG9wDxw1aGnS
KrgEcUaldQwox6+prGk9TrlFNamXY6Hbxt5oALDuRXqnwSRV8QRw5K5U/jXmGnXs
1yzBYyiLjJNei/CiYW/ii0LYCsOT6ZoldvUuMbRaXY96Wyt54vJuIlkjYchhnFcr
ceH9Htb1jbwIjZ9K6szPFLsC7hnk+1cp4jvGt9WUSJhZR8no3/1654tR9083CRqS
m0mdNo9mYbXJcHIzVW4jgezvftaxmzJP2ov90RKuW+verVheR/YN6tkYwK8Z8Z/E
iV9O1vw/Ba7WmuHgE5YYWPO1sY5JOD+ZqadP21RKC23MXJwcpzdjyHxbdXGu+Ib3
VChQXErNGpH3Ixwi/QLgfhWDLBNGOYwQD2bGa6G5ljhX/Vztu4zGm7H1qlcKSmeT
nnntX0SioqyPJlJyk2zh9Ctbu2lu4ZoCkXmFk+YcD8PbFFdLcJ16Cige7O2eW3Ug
SOo5xwR1qTCSIFVyTkZPb6VYmiGBItvH5pwd23/PaoLpdRCk20aNlccZx+FTa5By
Vm3m+NdTlQqRH8i7h3CoP6mtxIpW+63QFchOc59azvCGk6vDd31xq1o0TXLs+Q6k
nLE8YPTpW/LY+ZIAjty+WWRMhvbr796SiXOWuhQfdG3Tvgiq96isu5jwOnvVy+Ty
5WHABPpiqeoJIbQSW+0yAcA9DXkrSVj6dSTppjoDJDG3lPgN2x1rqPAWtBNat0lj
2kMFz+NcJa6lfQRbLjTg4AyXjbj8q2/D2raY77buzuoc87gvce9U4yaZtT521ZH1
VZ6kuoM0yuY8DaRgAPwB9aq+I7SHUbNY7lCjA5RvQ1y3gfxBBcW8aWun3dzIU/u8
nHfjpVvxU/iq8nsUtVgtYHkzNGRucLnjJ9T6Yrz5RktzneGlSraaG3sNjp7eY+UT
5i3qAMmvmm9DT3Mt0/zF2aQ8c8nP517r8VdbTS/C5iG4zXWLZMDONwO4n2Cg/iRX
iYnAGHVc8dRXpZTC0JTfU8nMKjfLF+pmRl24dflHQbShH4Ecj3qG6KAkCPcAeD7V
bmld+cdDke1VXKlM8j6mvWv0PMSMicgA/JtHUUValjB5bbn9DRSLO9EttG7FLU8E
bi3btk88Cpd2YwnmEBhlSB8v4U5THDGqZI/iDBe/4mnShPMDFg4HIGOf50iCBEXb
5cgCBm4IJz7fSoLi3REDCSWMg4G0b8+uc81aYkjeQCR0AOSKjkLOxj8p1LDnAGMe
/NMDB1VEM0iJkKcEZ6jIBrNt3AfY556Vr6opF2R1yo7/AFFY1zGQ4deGHb1rxqml
Rn1FDWjF+RLKi4O0YzWh4bdVu44nLKrNz6VnWs8TgK4APcV0nh6KAyKwwFB6GhSa
R0U6sotWZ634Eu4LdV8tnB6fert55I9hmcAALnJ7VxHgkWpRWbZjv7GuwDLezpGC
GhjIL46Mewrza7fNuc+OfPV5n8zyv44s0cOmQyMUefzJCMkMB8oA/wA+teZiSKNk
VwX7MzHB/lzXr/xnsxc3tnOxAxGyjPrkGvLJtPaNhueM85btn3r38Bb2EbHhYuXN
Vbfl+RRneFCrKr7G5BAOahuTGuQ20nHPGKWa2edj5LYIPy8EY9etDRDgSKxAPbv7
c12HKZN55ZPyZyTwaK0XiiXA8sk5OA3OKKCjszCky5zjHcnIWmGNYidspZz82QDz
/T2oAYoBnaCOCD1qWIbDtySMdCKRJCoeRVPmKMnBOeR7YpJbRod9xNLtjA+YsBwO
OKke8trVmOWZgeEABJ/w/GsjVr25v2Hm7UiHKxr6+p9TWNWvGmvM6sPhJ1n2Rn3M
4nneQlsZwufTtUEibsY5IqREJLA96daYLFT2/SvKvzO7PoklTioroZ9xarIysh2O
OMiuz8A+Hb/V7aVI544xjG4oSRWDPasrjg4PSvQPhndSadayx4X94cjNZ1XJR0HT
tJu252PhDwdJpsZF3rEk65+4kW39ST/Ku3tYI4ogiLsUelYOmX6zzLGASc9K6VgF
jANcDu27nnYuU7pSZyXxF0T+19HdIkzPGfMi9yOo/EZrxSe3VH2mNsnPysTkH0Pp
X0rInmAEDODXIeL/AAVYaoWuIwLe4I5dRwT7ivVwGJVJcktjiq0/apW3R4edpYja
uQeqnOaoyNGjGOV41AOG+YcfXNdvrXhHUNOyZbfzFBJEsYyvT8xXN3UUMKEyvGAu
C7dgOmfwr2IzjJXRxSi4uzOfusvGxgiBLcLIRnvzwKKsbbe5ceT8uceZEc5Iz1A9
fp+NFUK5/9mIXgQTEQIAHgUCQA3BlgIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAK
CRCBFenYzl9VTUyfAKCPzZcnNkDyHypU+wZkicPKQuWVtACfSCxA4/IVY+oWI9l2
x6uSkR7p4GiIRgQQEQIABgUCQA3JIAAKCRBomIIsyPJS+wPrAJ40SdQR/ruPWkBT
Q+kqpz7fTvW+LACgzYiB60Djrdg1JfZy6DAoresN2U20GEFsZXggRHVwcmUgPElD
UTo1NDMxODU2PohYBBARAgAYAh4BBQI/7VDUBgsJCAcDAgMVAgMDFgIBAAoJEIEV
6djOX1VNKTYAoLQEAZmjiD/bwfaXfgp/9MGDYLwCAJ47WxftOqTrwo+DmLMs5eeH
cB2R9YhKBBARAgAKBQI9nynbAwUBeAAKCRBomIIsyPJS+wsqAKDnsTnj9g3poCL3
rXQAa3z+cLSINACeKHPJHJFeAMlTth+exCsjzHvWwqqIRgQQEQIABgUCPaAEEgAK
CRDM3dmywuiTlMgyAKD2OL8xT2F1Tca/IdDITcMmmTMtAQCgpYddO1+uk6KD5yZ1
T1r9CgczFLiIRgQQEQIABgUCPaEzHAAKCRARLnBkKQVquU3wAKCf2VNbbdf0NjZh
MWj/2MUJuj8OmgCg4Yc3NusQXoYQpPqNE9Lq3JWnkA2IRgQQEQIABgUCPaGCJAAK
CRCrkzhFOoUIdniNAKC2Vu0JZAhoYcFJgg5f88ug/uJM6gCg/NBi2E3lD3AEwTmY
YMEHM0Eo89mIRgQQEQIABgUCPaKUeQAKCRDh6e74fbtvQSmoAJ9HCY8UdGJidzNF
KwZfe4hPNSsyxQCghW9jw9YmOJkL0khM9T/ObBHRsYmIRgQQEQIABgUCPaMf8gAK
CRCT82lDB9u/z+FgAKCJhJtQJL/IWuEHrwaMOzCciaNAwwCgo7JG3LwdKXuMDd9U
IIiLdDpo4tGIRgQQEQIABgUCPaMG5AAKCRA0BDtoCX0/VQwDAKCGdknfi8LOrA9d
/DZ1bL+ziinH7wCfbzssDMBl3lk2XOyYxHu9OwOUG96IRgQTEQIABgUCPamSQwAK
CRCg69IuxaVxo3QzAJ0aPnSw+fmsrjeUvbxxm/hYiKRpdACeJ31wyzywkuGDmkZR
jUtu9FjGgvmIRgQQEQIABgUCPamh+wAKCRBid4/0XvxVgsnqAKDbDwEL/0LIAeFN
ksQlJMKJvmL5fQCg49d63dzlf6CGBzOEyxi+oDbd8ESIRgQTEQIABgUCPalftwAK
CRDKk6NkAcCgetZaAJ4kzLKNGJNUec0+xpIpT6tTfxC8zACguXnsLsNZ0+jBMKOY
Ieqza+3AyNKIRgQTEQIABgUCPanuLQAKCRBXqgy8iXHukSxgAJ9Ro+qXA8/+x+TH
1u12UFr6Lk/CuwCfZPgS7RqYzbX8zUpR2b4+c6mf2tqIRgQTEQIABgUCPa26GAAK
CRBtIQ42qnKHy9TFAJ49cIxTs+m0pA3VrYFjsu3hOMnpFACeMp+Evlkit9ddvrP+
m0uNV+qqDG2IRgQTEQIABgUCPbJ7ygAKCRBfli7LrmESF03KAKC4gi8VUcmT79ls
xDQTrsZ/8TTGugCfVQeNotyTsLhPlKZw7rMzhfij6ReIRgQTEQIABgUCPe4PcQAK
CRC3gJYKEvlMRsN0AJ4+BCQsl1w7ecPJdBpBXhz2zJqttgCg07UpF+Mjxz2kIHHA
hRBgVh7AhPWIRgQQEQIABgUCPfCF0QAKCRD4MU/sLLlElRVWAKC0iCa3eREcovyT
TLKO9/t3g303uQCfW07f8XhJ30HsrgBXRGMBMFufHNmIRgQQEQIABgUCPeDE1gAK
CRDyQgCBgr3vdEyhAKCsTxGYujlcC5MFwwIvAdF0gkCODgCeOyejN13b8lDwqTIG
GWgcMNYhZCWIRgQTEQIABgUCPeHP0wAKCRA0pYpdjc2B+P2OAKDELljFrGV85WHW
4kBU0kQAZEDxEQCfW7QgKSWcXMSXa0RidcsdBn+TJp+IWAQQEQIAGAUCP+1Q2QYL
CQgHAwIDFQIDAxYCAQIeAQAKCRCBFenYzl9VTQjzAJ0cpYi+A6e+c/5XYiysLv+o
/n7BjwCfWxYKnGdMKGUD8GBNUSLxFCbIGYqIRgQQEQIABgUCPeKk5gAKCRBYtWpA
3MV1lkbEAJ9KMWQ3p5+ceSJsruNGRDsOntnTigCfRMzcsyzxzT3ncqeX+SwKmbMQ
vGKIRgQTEQIABgUCP8jfDQAKCRB6hTJqN5GI3qofAJ9mHIJvRB7rf2urP4RaT4PP
+4vg2wCgk6/GZEGaRngOXhdeanvVcMxGltiIRgQTEQIABgUCP8osNgAKCRBujFd7
G7FxaBs3AKCEHQxpUBGAed8pEdhvBNGsJgUfwgCfacd+t+J24XMrzLEHF+CWDSj8
scyIRgQQEQIABgUCP8palQAKCRC+jL8eYgxA7ZGFAJ9yThe7M04jK19RJApmUIC6
oQ0gfQCgpDhCiTf+C2EBzS0bwRBrspZ/00qIRgQQEQIABgUCP8qHBwAKCRCRaxpu
McNnH6a3AKCoUBJDcp332uW9cd6gMSJr7rIbEACfboFIMeilqey8vI3rktNso2xh
81KIVgQQEQIAFgIeAQQLBwMCAxUCAwMWAgEFAjppb9IACgkQgRXp2M5fVU3GFACe
Pwx0Beh0P95n7+QfmVOzlGsxKcoAoKS2JixAHziI6WR49MbyhZ13zconiEYEEBEC
AAYFAjppb88ACgkQgRXp2M5fVU1A9QCg2BJLqwfN8oCw3QNVITUQ3QgTKNMAn0Vr
mwp7qqRYqdrKlQ9UxXv1jscQuQINBDd2Z64QCAD2Qle3CH8IF3KiutapQvMF6PlT
ETlPtvFuuUs4INoBp1ajFOmPQFXz0AfGy0OplK33TGSGSfgMg71l6RfUodNQ+PVZ
X9x2Uk89PY3bzpnhV5JZzf24rnRPxfx2vIPFRzBhznzJZv8V+bv9kV7HAarTW56N
oKVyOtQa8L9GAFgr5fSI/VhOSdvNILSd5JEHNmszbDgNRR0PfIizHHxbLY7288kj
wEPwpVsYjY67VYy4XTjTNP18F1dDox0YbN4zISy1Kv884bEpQBgRjXyEpwpy1obE
AxnIByl6ypUM2Zafq9AKUJsCRtMIPWakXUGfnHy9iUsiGSa6q6Jew1XpMgs7AAIC
B/4iOQRTLPaimmNLii/gU4Zh8u4iATtDnkMY9ldInQ0QT4qrK9/bRe/jnpHTlrTm
aKd48B+wDBoUjU19EbFl0FN1e2Zum2oOBKfEwr8Up6tmBY9vsxCsqY65fP432P3s
ILrLh/k81wqVXhuEvUxpkbZMtEePLLCl39G6RXD2M8qe5LsIgjFH+a8uCRwdUWgF
Dv/R4HpwKNk5U6u5Jmh3XWh/OoHPshWV1AfbUFCVSwuuu2r7g2VzVhBbWqdlTfLs
Cvf8JBbmWwBQOj09F1IQN9hZzXxa5+K5DdaSuFXURglTpRnONTwbkPwM37526h/t
VAf3gSKBEtg1jPveLVdKxoGKiEYEGBECAAYFAjd2Z64ACgkQgRXp2M5fVU3vzQCc
CC/qqMn8MWKJ0CbiXiTSu7dpojYAnjslrpODNzSntRQ5rK0SawJXsWWk
=CMdE
-----END PGP PUBLIC KEY BLOCK-----
D.3.53 Peter Edwards <peadar@FreeBSD.org>
pub 1024D/D80B4B3F 2004-03-01 Peter Edwards <peadar@FreeBSD.org>
Key fingerprint = 7A8A 9756 903E BEF2 4D9E 3C94 EE52 52F7 D80B 4B3F
uid Peter Edwards <pmedwards@eircom.net>
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEBDlWwRBACjdnvu/rCOVEjpYmlmQmmmYZ0hbUdustNozm8dtKpg2w+zED3z
9kHcoXEY2i1jxmJrHd4PPcvMutJB5AuYU4NiBmdMgBgfZvW7yaD+tHfvgozNyEKa
3Gcddamy/ENCFKoSTEuCDxH77zf6DXh/B/Ekjav0sZnGHPqFhUdKzwh21wCg57uM
Z3aL0+sIhiNYEJK93yjXt0sD/2F6+T7dj7wjdCPsb3mh5YSTjGeSXjnXHfeFQmmA
/dPyOkWOAuTo2uR3AeVRrJ6rslKLqyl773HX+eM5b52gIsFZ+CzSEiHSrHEqOR/o
3jzzGWhZb3Q/dbeWsPrtw32XUOdiijH5h2PyfKQ6reu+lpH8oKTbvOoycguHnsiN
8zt/BACCRoxdjw3f5L4RMfbdxN8/9GLcDzjv27s4Jn17snXuOyNzWxky+hNW5InM
wG92m9/a4XtZX6viK4sY8kfFLvAx95vaRiPJOPdUIx6Hk34HHsXdQ6XbUaadlBuG
Mxr+aT2o01qzxi+dS8+SWXjCBwT5mRVdOZq7RFYd73I+FrzltLQkUGV0ZXIgRWR3
YXJkcyA8cG1lZHdhcmRzQGVpcmNvbS5uZXQ+iF4EExECAB4FAkBEXVYCGwMGCwkI
BwMCAxUCAwMWAgECHgECF4AACgkQ7lJS99gLSz9lewCgtKJX8EySD4x42LoZ8imS
gYzQ2AMAnjAlfeFF6q4Lqiv6ikUW7uSGu2WitCJQZXRlciBFZHdhcmRzIDxwZWFk
YXJARnJlZUJTRC5vcmc+iGEEExECACECGwMGCwkIBwMCAxUCAwMWAgECHgECF4AF
AkBEXiQCGQEACgkQ7lJS99gLSz/1ugCgwj+RyWcUk2WtWZlox7rmTG9ymDsAoJ+r
ckrEYUJfPdH0GKonpipJQwL6
=73v6
-----END PGP PUBLIC KEY BLOCK-----
D.3.54 Josef El-Rayes <josef@FreeBSD.org>
pub 2048R/A79DB53C 2004-01-04 Josef El-Rayes <josef@FreeBSD.org>
Key fingerprint = 58EB F5B7 2AB9 37FE 33C8 716B 59C5 22D9 A79D B53C
uid Josef El-Rayes <josef@daemon.li>
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQELBD/4Zd0BCADEH+EDDjEX2ztufB5dele5Bt4XBg3cYncvlTsVEDLR89xtwmFs
3no9Hs0ImTQwplsDgbixBL3DXWi46dwVK0MGYIUycJxLfsgFdlWngcXYkpWF3O8g
v4YhytcVi9uSBy8oNB7huiY8IXh4XPgiOKztgCVJZbIgi8ahoif04eHTT9YGOL5x
Qu+n7D74zAcgzK0XO+O+WXB8EoO/saJxzcCIeEGzfCjq4VyL6JB+1c9CgWlrpI7K
LOpFqrN2qHygIMxCicp/163AdxD9I1hUtlF/sZYY9BpkbweLLqxKf4qtDYAMZLuS
xFGfIG8f0imfFeTXt85FgYGxqLMlmdjFefIpAAYptCBKb3NlZiBFbC1SYXllcyA8
am9zZWZAZGFlbW9uLmxpPokBOgQTAQIAJAUCP/hl3QIbAwUJAeEzgAYLCQgHAwID
FQIDAxYCAQIeAQIXgAAKCRBZxSLZp521PM0PB/91jWBC7yI2obxE+VGsItduiPhC
0x+Z33suGP8f7ewGBlztKC8y5N9jCGCfG9auwkJ9Xo27zCpMIkba4CfbRqyLxWoh
ZluHQg5uge7AGefmsdfDsfZq5mPNtUkB8uVn3tXGwVVsxknw8PGtw25wbDCOXTCi
t6L70v1gJfK8UxFhu0VCdOxbRAuQoIkE+bSO6g8bJrt6JFzhVpuHdgxwJbziWYSp
nEJUN4Eou4UfCteVQrkh2O7ArHMmAEb89s5xbfNrQ4NdVBXHfsrzEDhWOqgiQ/4m
o2DAs8iy2aCbWRaKG6G57g+uwhbqEN3gkeDfjhcpBMLqQy8drqx+erNGVYnKtCJK
b3NlZiBFbC1SYXllcyA8am9zZWZARnJlZUJTRC5vcmc+iQE6BBMBAgAkBQJABsPr
AhsDBQkB4TOABgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEFnFItmnnbU8miAIALbu
Y15l3+9kNlv4Arv26aYrRcIYEUcCLIGZnD93NPnyEza4WwsUbCvYgNpKb/wojAA3
xUdzHtRUfDp++eQU72S7DcRkkTt5vrnwKnH9kMsr2/hCIaO3ESiOVoPeJy91fHEF
I9K1qP5noJQjfjr1w4ib86spyVb5LH3QPEnyvDX/UTBYiYu8UUYonitLZ3iHk1Ku
x9SQoPszvkxdM1+d25pbG1uSV8JQRym6TsPQp3RwpbCy5hnwMbDLaWl6fbRwtAxZ
i6A0cppdbgi+DDrOFoFKuU25YKKOKl76Vy+cpjYPBPRH3mOTYd/i2xliEP56dTJU
4QqDJPpnJdmvXiCFt5k=
=UfKm
-----END PGP PUBLIC KEY BLOCK-----
D.3.55 Lars Engels <lme@FreeBSD.org>
pub 1024D/C0F769F8 2004-08-27
Key fingerprint = 17FC 08E1 5E09 BD21 489E 2050 29CE 75DA C0F7 69F8
uid Lars Engels <lars.engels@0x20.net>
sub 1024g/8AD5BF9D 2004-08-27
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEEvjRYRBAC1jMkUf5HrEQcNSLSK4NogjNTuwxE9d4PjgOiJ04L/haKeUAaB
x21REw659FNCOW/HDuCzNH4POFQYoe2dyS3lV4xk+YsoJ50NuoCro/tiigBztKB6
u/Ukq8bReroNwjP1Q2TnCHWxzDIq2HJ2FQtbXXlWKe7ZBu/LFwAsHLenLwCgzkp1
i0gxqzxWrzIApMiKWB+HORED/3Jjom3MOEZfr27aYvY18700uXui6GAkcxTj2/6X
s1MVpQt8F/BAgKYkw8Q3qOgoaJPHpnBQXMIB5TXCkXxZYwvUFlLHMOghpZE6/eHn
3+UdvqsxHGa59Ym7HYzS1IExBVNfof4MVsunQtnGaHyQDMrKt2zF2MmTgASzITWW
GyOjA/0Qc0K+hUBPsiaVpNcCZs6vPxeU1qSZamyZlVIjfQgRkTGN94bJD7l4qzaK
hpmOLF8eD6+pA936HVhLfmPsNFkpFgw10oQQVYIVx/Thj5tOX2o7VbXUdQEkdTTO
t75c2UqZIdPKet/btF+NPnnT3P8u0UdVvpvMeq7thLuJLkDDo7QiTGFycyBFbmdl
bHMgPGxhcnMuZW5nZWxzQDB4MjAubmV0PoheBBMRAgAeBQJBL40WAhsDBgsJCAcD
AgMVAgMDFgIBAh4BAheAAAoJECnOddrA92n4OuIAn08LIWiZX5vZ5GvClSsa30Wp
2LG5AJ98fEToSwavm0tAuDHU1kPoDhPSqohGBBMRAgAGBQJBL48NAAoJEI90JpT7
YBR5I/kAnA3vnk2qg91m3nocHy6nS2tShMUzAJ9RQ1orEGxFGukfgtY9iTTG4Tpg
/4hzBBARAgAzBQJCVYkTBYMB4TOAJhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5k
ZXgucGhwP2lkPTEwAAoJENK7DQFl0P1Yg9UAn0/WHYshCUKP551shW3EtjUFvSF/
AJ9EhPPzNRdgS5cs8Hifvd29McguHohGBBARAgAGBQJD/deEAAoJEAwB9WIgsQYJ
9lYAn3MTmAp+MZn64phFp346NFhy1tRwAJ4xd16I6dRhDMSiNVPQPybwAZTfirkB
DQRBL40XEAQAobWOOZBUJm+Twj/sGj0bUdlZ5H1Qos5uWEEjamcElcmN4dG6Dyjl
X+X4dmcAQADm2JH5aajdWKKDjDNaTRbdV9XCe/iogYD9UhbPEQuHovTuDaOQrRsF
nSCcXH1GABWF+Cp2JA4FVS1gmHykr+u9DZP7CsOosI6PWmOYwySidHsAAwUD/jVL
iRLUj2qR3ejYTa61ATT5wb6UtuIohpvBNFj4t3V+LWATXmuOP1mYhy3SmoxUcmFj
uULJ2GHHb+wNnP8YpGdxRVFkBV2grnpKqPdCkcm1ON707w2d3aDCEl9KGzhEvg68
c4CF0hVkLGIs0qeZfsOwxE4jdYpPl8YuuRZV2ah3iEkEGBECAAkFAkEvjRcCGwwA
CgkQKc512sD3afjgrgCguloybHuwhKsmOnnD6HSp1G/s4mkAn2VeB3Euh8fg6W/9
gcKK4GHoPC8/
=T+Zj
-----END PGP PUBLIC KEY BLOCK-----
D.3.56 Udo Erdelhoff <ue@FreeBSD.org>
pub 1024R/E74FA871 1994-07-19 Udo Erdelhoff <uer@de.uu.net>
Key fingerprint = 8C B1 80 CA 2C 52 73 81 FB A7 B4 03 C5 32 C8 67
uid Udo Erdelhoff <ue@nathan.ruhr.de>
uid Udo Erdelhoff <ue@freebsd.org>
uid Udo Erdelhoff <uerdelho@eu.uu.net>
uid Udo Erdelhoff <uerdelho@uu.net>
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAi4rWsAAAAEEAM1u8Y60omElX7Wtrh75P8K0L2Gp6omV6iDuwl9kXYhN94jF
DE1F4xpkRDWvQxsWbYeIk2F3VYGuN12BhbRNcNqoyniQt2XMmbdEmp6ltumH5WbG
jR5Xg0LkJ5AJmxvjJXXA9q+/eTfmyTfPjnCL70cTMWHdUl+EBUPoh1XnT6hxAAUR
tCFVZG8gRXJkZWxob2ZmIDx1ZUBuYXRoYW4ucnVoci5kZT6JAJUDBRA0K3Q0Q+iH
VedPqHEBAe9vBAC+el5mJpqPkC/+om/SSE7mxyuUqHAx1tNUymL8gTuV3mFB0goM
xkxhUOMMYe9z2zyi+RXrECfLT2OqqUA60EZpl6Mgymj8SVZSv4ZwXdU8cgynYNfX
T1pC57mN9mxL10vTTJEix7QsrVz0W479/IkBrhW9nTidQtORW1Si5T5IA7QeVWRv
IEVyZGVsaG9mZiA8dWVAZnJlZWJzZC5vcmc+iQCVAwUTOwzFWUPoh1XnT6hxAQGl
eQP/bLMp1qSdkt2/BKchpx+lhOemCmT3LHQ1sNzelb7dBwnsvE3Z9lOycH2pm1ro
j6x3vmcDAqZ1yh2eFEVNK5abfhuI3QH+9QdgvMcSIQgF3VIMer7JXxNtFFX8JRKm
+YfLfDifcK+B2HRkpMt9ETY8b3/cYz+gbdKNe4nVde5KPT20IlVkbyBFcmRlbGhv
ZmYgPHVlcmRlbGhvQGV1LnV1Lm5ldD6JAJUDBRM7DMX9Q+iHVedPqHEBAYHUA/4l
j98KC7y8cjapO4Hi0r/eO7gUwDujvrBMYbWuhmNCO6xlPfwRNm76tnNiTFdqVLat
XSrQwEUys9Mq9xe2F2RuqSfYWjmHKX3/gNW3gRJbnBqO1QN6CDqo39a7LgllqFf4
yFj9V6i1c0WSBiOeWy75DHpsfXHupMxZWPPRWh0TnbQfVWRvIEVyZGVsaG9mZiA8
dWVyZGVsaG9AdXUubmV0PokAlQMFEzsMxhFD6IdV50+ocQEBzqsD/0nX9rV5cAcd
jFTayQvoAjb/nIN+TJVHumuC/Glp9fKHlfTjMnsUawma+iQESjUB8XgyeJ0WvR8M
vQGEMowYr1YTtFiYfFOvrzXZmhB6NfhFV3s34ZLDeBnncUqkas79Pi9G9AP2Y/Mc
c//i2owj58xTfocYNT5IxVVYjB72Py+3tB1VZG8gRXJkZWxob2ZmIDx1ZXJAZGUu
dXUubmV0PokAlQMFEzsMxiND6IdV50+ocQEBBJsD/1SVP70fNa3ShAn18+yEXOIL
TlFYCUmGaBIeAsd7r8tXFYbf5STAOEOiqBB9Y7V1tV4IriACru+9wo5wBQoCLBT1
RNj4NhwVvkGReTDsA+Zz/vUULrbklVKO724DktO0+WRbn/w99trttuUTGvTHRER3
BjuOfJ/QoLlnLAsDBMov
=TCJD
-----END PGP PUBLIC KEY BLOCK-----
D.3.57 Ruslan Ermilov <ru@FreeBSD.org>
pub 1024D/996E145E 2004-06-02 Ruslan Ermilov (FreeBSD) <ru@FreeBSD.org>
Key fingerprint = 274E D201 71ED 11F6 9CCB 0194 A917 E9CC 996E 145E
uid Ruslan Ermilov (FreeBSD Ukraine) <ru@FreeBSD.org.ua>
uid Ruslan Ermilov (IPNet) <ru@ip.net.ua>
sub 1024g/557E3390 2004-06-02 [expires: 2007-06-02]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEC9nOURBADtxz6jwoFt/gIogEFIebDz4S/7jef4ou9prQaWJKTmLYAe3dB0
b3iZaeUZAN2HnYrtNC9QUlF8ChMpVLsLp00+nL1A7wO8qfPdHXee5iQ30JgsozDG
vdoAB6zA5mCe4+maZ59R9CCNrc2aB7binqOxKfiu65h46DocCzLVrBC7BwCgnyWr
IQp7gzqOy6L4GVycyOwBArEEANgdO6O3CO2w6ovxe2cvlHV6NiqbEWeCRzCVrCiK
ApB69ltrOqUmPn0cHV5+8KPXu0AaBBkmwNjuw0W/etSFq2tachIqY1qMjVFxvk1v
qxu+1fq5mB0vTNALJ0nDpG3j4TkKejlqsXOgAYh8/8aYxVhxgxgD5Ni6C4UTBb/B
sw+HBAC4UJozMPg6gsSdhYYqY9KCCc+xntaOxFKj4ir+o2EZ9qJ6Yg/FDygDxULP
tfCG7MdzRyHAdpMBOXlp+2VB5HbvM+XCiLh+Qfj47HZgT2jR7GgWM8HCNLMydqUs
odh3/8NJT/Q0AaYBKDKvEQPrv9siRvNLYfM9fFQ570Nr58wExbQpUnVzbGFuIEVy
bWlsb3YgKEZyZWVCU0QpIDxydUBGcmVlQlNELm9yZz6IZwQTEQIAJwIbAwUJBaOa
gAYLCQgHAwIDFQIDAxYCAQIeAQIXgAUCQL2d5wIZAQAKCRCpF+nMmW4UXr+4AJ9i
Rv0F9CXB6P9s7VxgagGiRgnKJgCgm9ONcZkKiRJz4ThM8+lUVn7/dvSIRgQTEQIA
BgUCQYJBHwAKCRAiylhMenujwLSuAJ4vH3muPfL2j7g0i3tBxANH19HJnACfUqbj
KgRULoLdd5Xd3xv1TQMtYCKISwQTEQIADAUCQYS5HQWDBNx+SAAKCRCrL1pbFSVp
kLOhAKDo7/Q1gjtWnHNj4KkJc0JwrdjLoQCYny4YEuaH0XQZmli1JnYDiezQf4hM
BBMRAgAMBQJBhMTSBYME3HKTAAoJEID3vqaVM+drOnUAn0+1xLBukkS1LUENeWwI
FkO5+xqCAJ9ML9gITzyOy5XbQzOG0MyH/YkfH4hMBBMRAgAMBQJBhMW+BYME3HGn
AAoJEKBP+xt9yunTpSkAn3YtJf9DIdaO4YtRtnPNlYZt4CgHAJ9vnB4AM1SAahY3
pgrhO9z6XIw3qYhMBBMRAgAMBQJBhNROBYME3GMXAAoJEIfaXA0nNZpRPpYAmwXZ
/pIjOqugDXN/MQErc8aG7pVwAKCaZXtnm8CT45OWVeVAIu7uDmY0F4hMBBMRAgAM
BQJBhPV8BYME3EHpAAoJEL9L0OYEnbh5Jx0AoL0vfYGS3iWE5u66RasB94xyQbIr
AKDY22dEDqObs5DwrjkQHX718wiKQohMBBIRAgAMBQJBh7rjBYME2XyCAAoJECRx
EX+pUQLB8iIAnijUZVkQloDfwcbVg0w6xuOFiCbOAKC9hggzd3ujHQ3vVnYEoqS9
lv+rYIhMBBMRAgAMBQJBh9AWBYME2WdPAAoJEHPeaYzHFAWilFUAn2MLzNKhtam8
L4s4h68T48QgHB6vAKD64I+m0Z61y2OMH59/j7JYbsZFNoiiBBMBAgAMBQJBjJBK
BYME1KcbAAoJEB9/qQgDWPy9MoYD/09F+lAdn5JSk+QE8WOyPO7ZP8uqVoiCid9+
FQynmcneq6PsjhO5KDyHwK+nIxWwsghlKqG5gmCuN4/YF4wkxx+6mVt1O5WFhlSt
x9y8lrN8csLMUCQzLaluD7hpYyScT1uGOLI0q6HgZ8pP2XQ05uIGUIfjt17jYbSp
DKphh+0ftDRSdXNsYW4gRXJtaWxvdiAoRnJlZUJTRCBVa3JhaW5lKSA8cnVARnJl
ZUJTRC5vcmcudWE+iGQEExECACQFAkC9nZsCGwMFCQWjmoAGCwkIBwMCAxUCAwMW
AgECHgECF4AACgkQqRfpzJluFF4VOgCffv/mngzbhP+88uSHERTu2BBkefIAnA9H
hLGo5SaCSeWNwuqdgK3GvwDqiEYEExECAAYFAkGCQTEACgkQIspYTHp7o8CVcgCe
P/DPle+jMtpgrrS7tnk5jeluAg0An2r5PK4eajYFLcIOoDk4aXThHEgviEwEExEC
AAwFAkGEuR0FgwTcfkgACgkQqy9aWxUlaZCofwCePa9l9dsyD9k9tV2dm8aNYywD
jEIAoJBiWx3/1gqZYmjed+zV6vWa0cKgiEwEExECAAwFAkGExNIFgwTccpMACgkQ
gPe+ppUz52ubhwCbB/EXTvUfSYc4vFaQMGa03naiDK8AoJ7rBjM0S4MrH/yISFxF
PYQgC+RyiEwEExECAAwFAkGExb4FgwTccacACgkQoE/7G33K6dN60gCgu6O//jpu
JSok+bBc4X+AZKJK+qEAn0LswtRsAtUMDkA9jvKnBWCNAxQqiEwEExECAAwFAkGE
1E4FgwTcYxcACgkQh9pcDSc1mlFARwCfXf65/bOAJHXeKIKgyvpbpQUSCk8AoLAK
v42dyiYsLhzUH903wR+OK3LCiEwEExECAAwFAkGE9XwFgwTcQekACgkQv0vQ5gSd
uHkgFgCdEqxUdKNkt3EsPy1MaHEJWpKbjgEAmgKdjeXG5Q5syxP6AQtgwmm942zH
iEwEEhECAAwFAkGHuuMFgwTZfIIACgkQJHERf6lRAsFo4wCfR9sK68UaZUGInWsP
jOlbB1RlIGkAnjvuFzUSF2a4PdxNJXTFbps0sa6EiEwEExECAAwFAkGH0BYFgwTZ
Z08ACgkQc95pjMcUBaIWYACglNKP7iXD6a3kC5ezCidQ9bw7atgAmQHVg/78odHo
v3XEMz6hSYiA7ZB9iKIEEwECAAwFAkGMkEoFgwTUpxsACgkQH3+pCANY/L0sQwP9
FwLOugh4xHDwloS4nfiCVEB4tGcUNUNvyWAirweCorPcAWz1h56EUDM2bEEQLNvN
7KH//KLFl7P7w6HBg5OIsOxOv6pwM4cqFYSfZ1tCrqSVL8JSz2CEuqeBO63vwMIK
Zuz5isBHWB3V9jR/FARZFK64pj5jqOdrhXlEsclw/hi0JVJ1c2xhbiBFcm1pbG92
IChJUE5ldCkgPHJ1QGlwLm5ldC51YT6IZAQTEQIAJAUCQL2drwIbAwUJBaOagAYL
CQgHAwIDFQIDAxYCAQIeAQIXgAAKCRCpF+nMmW4UXso+AJ9A1bzRrRjjeVPejggh
dSb2MBtI+ACfTHHJ5L5tWTM4DaKE1zNslFcKJGCIRgQTEQIABgUCQYJBMQAKCRAi
ylhMenujwBtyAJwPbdhli6lM80ElaFp6Z4k26mFmXgCgwOwFHhG8JmphwsK2EuOM
IYtRL+qITAQTEQIADAUCQYS5HQWDBNx+SAAKCRCrL1pbFSVpkGDTAKD9L5kXDMJl
oEVg8Z9WjA4YZ+DkdwCfcvG9fxWmuFbCieKMwooQhZPjTTiITAQTEQIADAUCQYTE
0gWDBNxykwAKCRCA976mlTPna5OiAKCy1RqGuaaV2KEckQfu5qY4STRbpgCdEESQ
rQjwdC53+itYYSYjl24gi02ITAQTEQIADAUCQYTFvgWDBNxxpwAKCRCgT/sbfcrp
04YRAJ9KXOH+0A2gRhQaBpG9wYtycCMPmACfVVrj5SccNfCLfVCagLtwkrPjRkKI
TAQTEQIADAUCQYTUTgWDBNxjFwAKCRCH2lwNJzWaUWIQAKCyzJw3bO+6tD4lz32/
osDpvZnClwCeOFWWxTJWZmXa07c7rNhH8co562yITAQTEQIADAUCQYT1fAWDBNxB
6QAKCRC/S9DmBJ24eZFFAJ4/0hvCrenteNbwNeXt9d7EsuJTIACg+3mOLi1EJX/7
sahoqtQzZaxL1zSITAQSEQIADAUCQYe64wWDBNl8ggAKCRAkcRF/qVECwQzhAJwK
h9jknd1hm8SPSdePW5y0feAytQCghhaLXPEDYmwIRUYAIbdJMD2hEuiITAQTEQIA
DAUCQYfQFgWDBNlnTwAKCRBz3mmMxxQFordLAJ9kzuLcEMrYOwdX/ctHhOuwj5XG
YACeLUfYnnx7CcB+KUVZrEscniV1eoaIogQTAQIADAUCQYyQSgWDBNSnGwAKCRAf
f6kIA1j8vS0NA/kBfiCUi1miZl3UjuBICQT3tWZHrMuMUQ6MpMnjshiT0vrSvSOG
eCGEwGkrBCl1VuFpHO93E9shjcLgzNwPSbtiasK/kzJL32Hyd1+Tc2SGoKrLSXiv
4zJMTxwWBYzFCrniIz3+/XrU9D1WFGtBYc1jsLCvDKEW14RP59qs8TKNV7kBDQRA
vZzmEAQAlY3mpmNBVkekHNNxs7W/ansqON4QUvAR0q2BVUvhHunVd02XNyQZTCWO
SORhXX5jH2QIzr+igTWLGzm1I4Q6x1519I8N+rZMaQMsflvdNNOYDdfj5jbF8w2h
vWcKfi7k4lenw+loDDaQZbEfdzR8qs1sR12oz2ZRc4Lwqxi1d68AAwUD/Rt1poSP
2/xiYhq6yb+dPKEnYSdnAYVYtvH0+qztdSbQyYty5TSnuqJx7fT7apRLJ2g6I455
yJpzyBZR1H8K3AQsH/VixMaVZl4xUUUwxbyiaZLM++WNDl58pjgJAvJueYPRTl/R
/QPSo36OBYbqkzlR+U/TDxXnW9OvxSmA9hG5iE8EGBECAA8FAkC9nOYCGwwFCQWj
moAACgkQqRfpzJluFF6l2ACfWWiX/0QlAZ9NU7g1wtD10jNJviYAn1qovdOHVYwW
xfUIyIEOONF8sN1I
=tea/
-----END PGP PUBLIC KEY BLOCK-----
D.3.58 Lukas Ertl <le@FreeBSD.org>
pub 1024D/F10D06CB 2000-11-23 Lukas Ertl <le@FreeBSD.org>
Key fingerprint = 20CD C5B3 3A1D 974E 065A B524 5588 79A9 F10D 06CB
uid Lukas Ertl <a9404849@unet.univie.ac.at>
uid Lukas Ertl <l.ertl@univie.ac.at>
uid Lukas Ertl <le@univie.ac.at>
sub 1024g/5960CE8E 2000-11-23
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.5 (FreeBSD)
mQGiBDoc52gRBADCgyiLgEDhBbalLQ1VGkvfbdazaBHQRdGjsEPwPEG1xSI/5FFm
0497ZJEYkUG4rXbgaNATSSS8yrqJ5i0rX2t3Y1TYOVim8gLq5ntUQtAdhHtnZD3n
GbiBLRNRTD/HYd73ta4V789JMheUrQt192IRZZG8iKMjjaW+YQ5Z7nQxZwCglyEp
33kslkv25cFVFWEHUhLvck8D/2iTzX35onmQkXdYEk8S8sS71UoSBgf0q5/4D6aq
/Oq4zUYiChC7WGNNMjLSWDPsvt4U01SHfZVMOmbgJXmY6gE88tv32pGkLaIW+f3v
BkKLwO8le5GvnfTA+xTyADcrqiZBdtH0zDd1jY61XCsAFyJmMnM+xbwT/dXa+Jtk
h3CZA/sFdlpJrH65GHcuyuI/6bGwUkQqpTMCmYeXQjcEsTt2bWQ+knaAFJ7q2+uZ
fmmzlhqNuPZ45TTd6BdRFtJFFOndi45yEZsSN7XNBcHGx5MshL4jCEtqQEDfUogd
UbwkJtgK0URxFyZ906xhVwgwvX8eW9CzPj0wYsbYLZtGZ4zVobQnTHVrYXMgRXJ0
bCA8YTk0MDQ4NDlAdW5ldC51bml2aWUuYWMuYXQ+iF8EExECABcFAjoc6IYFCwcK
AwQDFQMCAxYCAQIXgAASCRBViHmp8Q0GywdlR1BHAAEBbQcAn0oa/bdjZ3ofFKf4
1GT/UYftjziKAJ0Wzsy8sDahkaJbyWzKupp8Q7Uzy4hGBBARAgAGBQI7oHuHAAoJ
EKkf+mOb7TNKOesAoIDjx0iq2xsnFfcECkh/zheU5HShAKCpROLbXal5pK3U2XC8
t44oAXDL7IhGBBARAgAGBQI9S8/aAAoJEBBfSR2o12TYudcAoNufp4D+vHXyCX+g
K/RMOpcLQmFUAJ9TbuD0ghWzqYY1VGdxrDusUux8dIhGBBARAgAGBQI9O+wTAAoJ
EEUnYQZfFVEBfVsAnj/sw5aUDA2vEghr6ZgwzCmzPzeaAKCAMiJxQpog5s1HD71V
3ZhLgk+KWoicBBMBAgAGBQI+sYSdAAoJEC3GaJzjyx7FiZkD/1H+Y2A1iZLXGBb0
16UTUb7Dk2E6VO81SPtviliM8mx4onuvEHHJq789gi8N3TolhLPnPj1ZfEAGslIX
5/JQRx71qhk3hDnGNaszxrgoTkYHQaaoxgZyeoWYP2wVHYF3eTXFLjh3Q8ZAZMGX
yNwsYvvdMTIEP9kIQV/5oyuI4H+eiEYEEBECAAYFAkC9Dq0ACgkQ/PmauBrc0r5s
+ACfetNYnG+BDKQzDeVgBsP/9depWVkAoI4Ey+1kZmeIdMAwnHOSV8b2TF/GtCBM
dWthcyBFcnRsIDxsLmVydGxAdW5pdmllLmFjLmF0PohfBBMRAgAXBQI6HOdoBQsH
CgMEAxUDAgMWAgECF4AAEgkQVYh5qfENBssHZUdQRwABASlAAJ497mVoCv4YJtvI
begRpjXIpnPRhACffoiU3BSc8pN7gUlWtGZDB8Y1Xh6IRgQQEQIABgUCO6B7gAAK
CRCpH/pjm+0zSu47AJ9KbtPOqVhHdF5APDbrc3olf7lyNACfc4M3ZZLSXzG2fsoH
LoVX93P4xKaIRgQQEQIABgUCPUvP1AAKCRAQX0kdqNdk2FxfAJ9WA+1axtpqoafb
5KAMCZB0ALSg/ACdFFizbtQM51ebXiNVhcT3rmVorCeIRgQQEQIABgUCPTvsEAAK
CRBFJ2EGXxVRAcQuAJ9YP7X9N3xWPpgWF91eHfOtsCS0OQCfdKlgYCv3vJfFNjFj
H9pNkBgjrtmInAQTAQIABgUCPrGEmAAKCRAtxmic48sexRS4A/412GhjArnp4sER
F50HACd++Dmajzjbaycih0UyFk9Jhx7lkpNMFV0EyNKJq9unBfvuX4ji8kuq62ln
I+p/avkjBkpqN9XH0YIQkCYh7X/I5saVWTSqUJGZMPR0HrnJziWyOAiQWEfJc4/A
yY6IuS4HMIRvlcVql9MgMWUvsiCwiYhGBBARAgAGBQJAvQ6tAAoJEPz5mrga3NK+
5uMAmgOksIQqUnvIB9AA/egOVWPNTIABAJ9iWClWufO9VSjm+uKCXFoEZbBAfbQc
THVrYXMgRXJ0bCA8bGVAdW5pdmllLmFjLmF0PohfBBMRAgAXBQI6HOhwBQsHCgME
AxUDAgMWAgECF4AAEgkQVYh5qfENBssHZUdQRwABAdfRAJ9sUaTyswjTHMCSqZHN
ZDAsCVhyDACfehlPEYgA/zu0rHhQW1fFxRlkhTaIRgQQEQIABgUCO6B7hwAKCRCp
H/pjm+0zSh21AJ9sa+U9/NyXhVUm+HjhpV/bL0Le7QCfVc80UHqb3b0Dcen+jov7
tiJ3eraIRgQQEQIABgUCPUvP2gAKCRAQX0kdqNdk2A3wAKCR+d/9qrGqzpGoBLQA
b9SRAjl/BQCgop5t90WbPwuJm/AVdbE+N6As2w+IRgQQEQIABgUCPTvsEwAKCRBF
J2EGXxVRASlFAKCFlpd7McKT98cATC+8Sd4RFNAUVACfRHTANXgfK7hmvvD0pWr5
nofT7p+InAQTAQIABgUCPrGEnQAKCRAtxmic48sexfwPA/9WyE6OAshMZUuCjHvo
nHt0G+qomn+6CrPrps9il0ofWAWHEDMM57OkUYu8O1uY4G2WDfcUGx3XrzHxqsch
Seeb5/aD4z57ZQzdGz6zRyorJxHJ2S4vTvLv5QWSKCBqYUEEYgPC22C+JHCfvTcx
76bDE41skqjwcJNNo0sPcMHAMYhGBBARAgAGBQJAvQ6tAAoJEPz5mrga3NK+qYEA
oLuLq1uPXXdYnrJ4e+c3qI3Te5FBAJ9lkHFlMp+6lcQ/fN3kSxWMrH1ohLQbTHVr
YXMgRXJ0bCA8bGVARnJlZUJTRC5vcmc+iF4EExECAB4FAkAmTJ0CGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQVYh5qfENBsty0QCbB6IgEk3WC8br8usvNqWt2t3y
93IAnjwh2DGgCRk9AH7fdNoSF+an6CquiEYEEBECAAYFAkC9DqgACgkQ/PmauBrc
0r7yNgCfegCimXz8NHxxTnfsz3UU++dz4jYAn1nPAh8hwYPh1rWUjHh/ATX356x4
uQENBDoc54kQBACRE1IriFYgaKg3pDeBPDM/BUflmZSlC50NIgCadloOGwu3AFcs
ooWwN9nsVehbN9xjfZa34/xXo09Rn14o5kTKYGSqzYY0XbsNjZl5uj0gTGFRmjS7
fNoWpdsfh38xXZAJOghxd/KFRV5fdnKoEPz+ARNo2DRZpiiEJUa14e6lpwAEDQP/
TvA9mc8OEa9dn0AzCRwvITqx80WBRBVBl9bC+fx4R/CCt0O+gtkoPBlAdY/r0+XQ
ZhCeOROXy7e1sbAMm0U0QHgckne83VgzV9TAWHtP2dfGgtOzUE4PlUVBerTCGADP
FTN+kcvV6U/O+knnJGmnxxOq/9qtkdtEHvyAzWjehPaITgQYEQIABgUCOhzniQAS
CRBViHmp8Q0GywdlR1BHAAEBIkQAn19uApjyy6+M+JD7Qt8inbcYjk7cAJ0eNltS
Fv2s0kptGIN2izILm1myaA==
=qAVp
-----END PGP PUBLIC KEY BLOCK-----
D.3.59 Rong-En Fan <rafan@FreeBSD.org>
pub 1024D/86FD8C68 2004-06-04
Key fingerprint = DC9E 5B4D 2DDA D5C7 B6F8 6E69 D78E 1091 86FD 8C68
uid Rong-En Fan <rafan@infor.org>
uid Rong-En Fan <rafan@csie.org>
uid Rong-En Fan (CSIE, NTU) <b90098@csie.ntu.edu.tw>
uid Rong-En Fan <rafan@FreeBSD.org>
sub 2048g/CC9AC94F 2004-06-04 [expires: 2009-06-03]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEC/6qERBADMYBi8aUI5zAFh1Gix53UN0EyjbxzDxrDvUweitnVYawKbxbUK
X/HdtY6ExD7f0QccAtcbhAWNaxeJFMW5my5Hb7HWlrC1x2wnr4juaPaJXz5YoFoR
5uySiip50Bjb3V2f8YglVKGi7Ssz6pmHxm2bGBv2sWngcu/9l9VI47o9zwCgl/m6
9ceyzMejhJw7qZV0dwzzGPED/iOoqKBCpHaGOOBYbBkeqwhc0UFlTjcULcCNg2dT
/sSPnPSun477YYEdPqNZ+20bWhZimh6UNad53hChMnvta2kzA17YML4lnZi0eDaZ
Ws6uZBXtWhomJF3hkJfbRk8jfF1O7L2RIOnlRNji5VTwlqFMO7s78XPDXC3//9nQ
hfVbA/918ya3FYlyfpSmoyZRz5B4mbIInd6QC9G0CtQE+VQsxD5wS1zm/Qm2ToEz
zGlyW3toAv3iqfYEMOftrGR6tAyH+t7upQ6rTkllfUJxAdsOu9bqcmLjDLO8Ym4L
1gsvwPfSwiG3yeucSJDPcPzDQd9oeKkFgoucjB9Z1+oty4OdVrQdUm9uZy1FbiBG
YW4gPHJhZmFuQGluZm9yLm9yZz6IYQQTEQIAIQIbAwYLCQgHAwIDFQIDAxYCAQIe
AQIXgAIZAQUCQL/s5QAKCRDXjhCRhv2MaFg7AJ9Im0OLuvOKl9rVieKeme3kafKr
twCglF6TsB5KWLGqPP4MHzCI7lP0B5iIRgQTEQIABgUCQMxqrwAKCRBCpksL8/QZ
yLG2AJ9SNd95Tma/PX+H00lN+9o0G04btQCgjFm2EboX4o/CSxx0gXJucSrdOVaI
RgQTEQIABgUCQMxsbAAKCRD5CLzYwf5OnnkYAJ9fevQ4aoQbS5hNT/7ZCdpNU16M
IwCgri0A+QbNv+uNptSGOo4NK5mjXD6IRgQTEQIABgUCQMx/SwAKCRAFvPnN1LJI
gih9AJwKAe1OSAT6xtEjBUDCocJEDCswfwCeMZbZebbvR2a+dlPN3RniUQh5krWI
RgQTEQIABgUCQMyGxgAKCRDkwHVW5ykoJTu0AJ9jeSasEBNkKOkMJmRx3RLKXa2p
1QCbBUjDO27rfMBEedeTDBNIuibbWt6IRgQTEQIABgUCQM0MKwAKCRDPwfyGIOvG
QVA4AJ9kFU75ANquB7eOpLFnpQxoJRNlEwCgw1qopsGCmVp0ErqfDo/s0WGxxDWI
RgQTEQIABgUCQMyBwwAKCRAJAzu3kHaaEPxMAJ46xzMOfMnNQ0FN5pUUCC7+saBE
iwCbB4pv5x8Vkc/xzXWWhyEzrMA8u6qIRgQTEQIABgUCQM6ejgAKCRDjIEwfXSux
Gn3JAJ49bO/za8L+m3MsFShzFeOiJ6lweQCdHvkytNgUCeJN0vfnrDUG2G1XbayI
RgQTEQIABgUCQMyEewAKCRBUt7acd9Qzg63IAJ9sgYplGxHlnHIGxMSUGMjqfZM8
KACgmegztvZWAOKLMTMu/0IN5eWJW0mIRgQTEQIABgUCQNCjBwAKCRBDZXPuA1v3
XL/SAKCnRdZJPFRl5YNNw/mXUPZgId2f2QCfZdc0ddzixI/wRr5MQizgkocQgwCI
RgQTEQIABgUCQdOcWAAKCRCsxgFlEcAjgsHKAJsEAyb3UqbdK3mXhm2y4/0Ddq0y
qQCg5kBrc5rqtAw2qGVK1npz0UHXGKm0HFJvbmctRW4gRmFuIDxyYWZhbkBjc2ll
Lm9yZz6IXgQTEQIAHgIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAUCQL/s5gAKCRDX
jhCRhv2MaKNeAJ0dlwH0e0QxS9fwC65JICkf24RUjgCfd4lXf3Jj22m+vC4HNoxe
HKRsUtaIRgQTEQIABgUCQMxqswAKCRBCpksL8/QZyLTsAJ4ov20tMw1nqbONvfi+
iJ9fv268RgCdE7wqSDsf1AkB0YBCvw/noRatdEyIRgQTEQIABgUCQMxsbwAKCRD5
CLzYwf5OnmQmAKCm5T8I1Vaf9lwE3yn8DBw0XQr7mACgrTsVIpECqIlQYb/DnSNF
BDcgNh+IRgQTEQIABgUCQMx/TQAKCRAFvPnN1LJIgqXRAKCPw+owPogvwPdjoVOX
DdchRn1nZgCfbbyAv1gsa5k3gxBetzUhM2QhZg2IRgQTEQIABgUCQM0MLgAKCRDP
wfyGIOvGQbDzAJ9Wr9+diK1i8LzvtdfxT+RzPKdfnwCcCm5s5nSrHc/1NstAxOOz
BOITimOIRgQTEQIABgUCQMyBxQAKCRAJAzu3kHaaEDEwAJ9VKT84A1QXcTZDpH5u
JMe5mQ4f7gCfSRrTUk0k5HvB0KyOM6CHflwRnleIRgQTEQIABgUCQM6ekAAKCRDj
IEwfXSuxGlggAJ9aCF9Wa13C3aUWIRbHcALnAoevgQCeOuwd7rdItcPq3D6gP8U7
/FIKY2aIRgQTEQIABgUCQMyEfAAKCRBUt7acd9Qzg3sCAJ0azL0SUJXJx7NcYdQe
6VBBBaIzLACgnyfZ68crJwlv+fRxPhlxdFhgLgaIRgQTEQIABgUCQNCjCgAKCRBD
ZXPuA1v3XCeuAJwPrsSVVCrC29F3Xygr6QB3MS4a7QCfeOsqHEfwiXuxt2xjcF09
r0H7/96IRgQTEQIABgUCQdOcWQAKCRCsxgFlEcAjgmKeAJ9dWtZYU93qkd6Cdpo8
jKbYq4y+BwCdFbqSBm3EwGgfzQZfvF42tacT2pW0MFJvbmctRW4gRmFuIChDU0lF
LCBOVFUpIDxiOTAwOThAY3NpZS5udHUuZWR1LnR3PoheBBMRAgAeAhsDBgsJCAcD
AgMVAgMDFgIBAh4BAheABQJAv+zmAAoJENeOEJGG/YxortwAniGXfizNBB0FJqxY
a9fwjQXuCqhDAKCVopA1UMEswlv/osv41TXWwOzS84hFBBMRAgAGBQJAzGqzAAoJ
EEKmSwvz9BnIi1kAmJSIHlwK+ZixVVenJzWnw2E+62EAnRsRvLeETz7aikmh5Yvd
pWUNwHu0iEYEExECAAYFAkDMf00ACgkQBbz5zdSySILkrQCfeAXv6CFk9GijNtYW
L+/GPwkdmLIAnAgNUUUChGlslG6gcjGolSdY3zvIiEYEExECAAYFAkDNDC4ACgkQ
z8H8hiDrxkE56ACfRTItJiynItOoNSOt9fZQPOo6SpQAoJGT/lO7RlCYmkeiP62A
X7sX+DmViEYEExECAAYFAkDMgcUACgkQCQM7t5B2mhAlqwCfRFillUo/5PB7QzvY
YmflEgSWCoYAn3u6t8jni4PEltvRVn6qg9CF0pU5iEYEExECAAYFAkDOnpAACgkQ
4yBMH10rsRoW6gCfZ7o0wkHWbPgEkXV/fwzGHIvhI9QAn3nkgqFi7Fo2gbJrfhn9
zTdIjrRTiEYEExECAAYFAkDMhHwACgkQVLe2nHfUM4MgUACfb8BW/GER+rQe49Xn
CCM06HZPlcQAoKYldHWK4QxhTZbSIZ8qwqcj1l3OiEYEExECAAYFAkDQowoACgkQ
Q2Vz7gNb91zzqACgoLhLxEyI6Kf49QHgc34KzqYGXxUAn2hHOlDEBvyX8IaI+TaK
svFbGsgLiEYEExECAAYFAkHTnFkACgkQrMYBZRHAI4KJQACeJhAYTXUCUiQrcfcQ
ntCi7QikU3wAnj4bgydk6k3zT+fiFytJNCIdAIOXtB9Sb25nLUVuIEZhbiA8cmFm
YW5ARnJlZUJTRC5vcmc+iGAEExECACAFAkSfQfQCGwMGCwkIBwMCBBUCCAMEFgID
AQIeAQIXgAAKCRDXjhCRhv2MaEwHAJ4oy/obTSGCioDxVB5c+51TU56t7wCeNjIE
k7aOCyrrNcByfsl0FNcuIee5Ag0EQL/q2RAIAPXcIiQWiDDoGQoP1+l6i0VnMTwH
UrBsuqviQE2FJ53a9ZjtUD+22vO+xuWdxPs3FLfH1yQrxM1QvvR4Tza/gkHFs6xc
AOJeT0VLziqdWULvFK4WhFMg7ZE74ywgkg6TChb9dPfNFBpLZSy6hnAop/95rxSF
7N/6+d423PDUFogEXbUvhgKQBGCzjhl5ScJhGoM3t/7LlVQqAD9wTkMXHDs8q9Ex
/ZBMNmWwLv0p8qgz8v5uc6RytWaovlEItjXiQBpg5l8nRLbkvJZwrHaNz17OIuvs
3DaBJ99JhKcyC+Bv4o/7g3ak5DHQRiXurbah762Pcvar+sl49R1+gy3MFGsAAwYH
/RbgiCMc24EIYFusPEJ5dCV/D+ttWsTTeVzPisxcTSLkTACCJWv1JetFey/7jHJy
vqpnc7wm2krqzFOg5t5h42V4MnJkoX1k0A9MylxwCCO4V6YeaJPachmSMaQ5WNcn
Z2npke20ExRHkkVVXjV6LIiy1bLK7RqI/+PVzlu8TI+A9i1hKWIfBCE1nL0mMC55
vJsOQ3i/1VVfP1i3LRNWqCwv2evQo2mFOXNN6egFFE5sCYFdigKV1ISvA3QC5i0P
fj5mfWaw/nm3xvG/JAK1Yi3ASM9esPTka7jF1FLXdFdRvK1otgUlJCWD9eTeIodu
1gNOHz08MiGY9RsOihGmgUOITwQYEQIADwUCQL/q2QIbDAUJCWYBgAAKCRDXjhCR
hv2MaNQsAJ9xwOgnX1DE7kHQEhae7kOvcJ/JsgCcC9yPXelrbRzgga+1zZCnD+O5
6D0=
=ZFgs
-----END PGP PUBLIC KEY BLOCK-----
D.3.60 Stefan Farfeleder
<stefanf@FreeBSD.org>
pub 1024D/8BEFD15F 2004-03-14 Stefan Farfeleder <stefan@fafoe.narf.at>
Key fingerprint = 4220 FE60 A4A1 A490 5213 27A6 319F 8B28 8BEF D15F
uid Stefan Farfeleder <stefanf@complang.tuwien.ac.at>
uid Stefan Farfeleder <stefanf@FreeBSD.org>
uid Stefan Farfeleder <stefanf@ten15.org>
sub 2048g/418753E9 2004-03-14 [expires: 2007-03-14]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEBUhZkRBACOyBTXaf9n0gkvq52yhACaPjUpAY4c+Z+xDM5jZZNpcaEyuU5N
ipJdvlKIIkfB+Jka5TxiUBskSo6cegPW7k3G9/as+39SeOexEw5aH1WROcrqD1Wq
iBTJ/Ey8eVleGTP/3vpbUoT3gcNZuus00J75OmJV06xyTA9M0tSy1/aIxwCgrbCJ
Xr3wLOPYiGXf5WbWfy08DmUEAI2xYIycYgZ7ogcqFcu6gShO/uTcXkZL0xOIC8el
rAC/HciJagmvYPjQimQeKhqyX+uvnhguiS+XZYx9yqegOG1dSOVWw6FJTYgzKeT7
6tHmaplB4JQLkUSBn8p2fsyXAaIA4M+2c9fYf59El5+OyfOhGfAEJNJv1oGLYWic
Bbt0A/98H+rPmPwtv4ntIvCq5xkvjENzmG6WerNF5dXHsoG6Lnhe++4jUquHseEI
+u4ou+v1it5vBTnPI2Wz02WP1Oyz7JC0cPAbrTGz+eaaNV+M1wD7yqj1poW74buk
4hJ+myIqC1dRrliAyrr75xHl3pr212+8Cty8RTiNF9xgICtH3bQoU3RlZmFuIEZh
cmZlbGVkZXIgPHN0ZWZhbkBmYWZvZS5uYXJmLmF0PohnBBMRAgAnAhsDBQkFo5qA
BgsJCAcDAgMVAgMDFgIBAh4BAheABQJAmCd/AhkBAAoJEDGfiyiL79FfqEoAn0cP
NQJYvSLWsU4gD/cffKUtLEKiAJ47lf0I7dFdAJSqqxSCOrw7iuWhTrQxU3RlZmFu
IEZhcmZlbGVkZXIgPHN0ZWZhbmZAY29tcGxhbmcudHV3aWVuLmFjLmF0PohkBBMR
AgAkBQJAVIenAhsDBQkFo5qABgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEDGfiyiL
79FfeOMAnR6XllE6b+BKnoRjBOC06PXfoK0jAJ4yDtL0vkYkW9LRmoFkWpxJYilU
ALQnU3RlZmFuIEZhcmZlbGVkZXIgPHN0ZWZhbmZARnJlZUJTRC5vcmc+iGUEExEC
ACUFAkCYJIMCGwMFCQWjmoAHCwkIBwMCAQMVAgMDFgIBAh4BAheAAAoJEDGfiyiL
79FfwykAoIes15zWxNJ7iQr1n4rP+x1LidM5AKCDakRpNHAdMiaJJRNrHt9I1kOu
FbQlU3RlZmFuIEZhcmZlbGVkZXIgPHN0ZWZhbmZAdGVuMTUub3JnPohlBBMRAgAl
BQJAmC7cAhsDBQkFo5qABwsJCAcDAgEDFQIDAxYCAQIeAQIXgAAKCRAxn4soi+/R
X//IAKCmPHdkW+JyvXq8Ph/4AcoSYGltQgCeOyA+WXLvjD8s36h1ITQXleLr0Ju5
Ag0EQFSFrBAIANrcNEggDb7bS/TkhZg5CEw0HP0bFOogCowNgGZ/9EzZA1SvABYb
vun0RyK0Ceh51Vr0Lb01i6cIDTH/cBVMqXX75YPusncMzsEuMdBCzMqKRPCpimUD
jFmMIBrkbtu8OTwaL+Xy1j7/SyfYv8fV6q6ibGWgN4pcyDmItTWYRNnR1G4EdIvl
a2CgQr7AgzWPGeeZLrUqUuLjYKwZ5JUqch3ooU4e+eFkYjovMyiC5E23UxZWyDZQ
DA1aOizxH7519R5l1YDsrqjZdVz3Ks7iCPYZ+T2QMGM7oUDjbt0xAhQCt15yj2K7
f0m6KtmHWzwgf5Dagcph00anBMldDQ1RqscAAwUIAMReNMLnk1jhYUYoitYNDJTO
Pp1X5bk66+b5yHW2Ul9DDboe9tp37AoSJf1hEI7eyB1qkKO3bt9nePKOuAe64ft9
jMYEm70IS3tmo3hHyTbLuOpxF3f7ZHmai2gXPdDmIczDqkE1PneX9gJQadQTqvky
4PVHKVUGTBScI0S830ZBbIsvoYimjGCPMuz4UT0vKR3XLay4RjwCYC6waqRuJoBq
rfm/vmx6/GNfb/jwZgN3QYPgTptx65eAdEAy2C3Y7RbMrbx9qqvx5TxaS2yVFy6X
6gIrSmFSFE8rplPDActw1V4YMyuwnyVvGe93pYwYfxzM/BxN09V9QBQUhIa7TMiI
TwQYEQIADwUCQFSFrAIbDAUJBaOagAAKCRAxn4soi+/RXy2fAJ99u5jBvCIXuEPa
rLB9utH3lU/ymgCcD/fpfY9v7wyOrivOy6Wz3ZWjdnQ=
=9khA
-----END PGP PUBLIC KEY BLOCK-----
D.3.61 Babak Farrokhi
<farrokhi@FreeBSD.org>
pub 1024D/7C810476 2005-12-22
Key fingerprint = AABD 388F A207 58B4 2EE3 5DFD 4FC1 32C3 7C81 0476
uid Babak Farrokhi <farrokhi@FreeBSD.org>
uid Babak Farrokhi <babak@farrokhi.net>
sub 2048g/2A5F93C7 2005-12-22
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEOquWMRBADPeAMeFy9OMbD3PxFjNmPIuY9CMb/fP9G3KNugVwLoHj29pXHS
QDo9OGHmA6udL6ZjZt/cWsU6CBwrVmr7nnqIXwOFGsvv4sT4cQJd51ypMFcvrYvi
UmdfnNZWeggviCMYdZErMqVdH7QKZyZ/7xB1IBV/66Bu768nQlSpTmqTYwCgwpUr
8V37ACzVXUZ/1CPqtadIe50D/1rlR4GTzMnmJGBbqY4c2nNtaUA2HEzI11QsHvFp
jTEcHI/RdhLv8dcFFAD0PmLC+5W7OydXvQXBfWzVXmrEPzFprwOc79wfCB+JzOt9
JzyClVDYvhYd0f2kxrXOR3ddLaBCMU9A/NxvDL05TCE8b3rSuV2VRT6E6A45/88t
aKKvA/9ewMdS3zicyyK33FTYTecGJc6Kt1ke/spq6jo6k3+L94Z7eZrZrhXGMRYg
Ibbm3VuxoPeIqyY8SujHwNNzP7PqGp8MVefjzktldMyvbJex8oIyB0NMrHTJ2JTp
ScJAetOE/mXYhMSACgWbebu6uBEigmaz1D4WNU/ITf8xuX784rQjQmFiYWsgRmFy
cm9raGkgPGJhYmFrQGZhcnJva2hpLm5ldD6IYAQTEQIAIAUCQ6q5YwIbAwYLCQgH
AwIEFQIIAwQWAgMBAh4BAheAAAoJEE/BMsN8gQR2iM4AoKXtRmdbGhmrJ3cW6lcd
gP4IUfUkAJ9mqLQk3ztstsPzzovhwV4sIH2VgbQlQmFiYWsgRmFycm9raGkgPGZh
cnJva2hpQEZyZWVCU0Qub3JnPohgBBMRAgAgBQJFUO2LAhsDBgsJCAcDAgQVAggD
BBYCAwECHgECF4AACgkQT8Eyw3yBBHZd/gCgmHXJVgY+AwvJvL2v2qG6+P2EsP4A
nimm5LNueFg2PbDsRb+Iz53zw8d6uQINBEOquXEQCADPKrfxmpqJEbVpJV1PfcLJ
KpvF/0s1NEhvrXVnm0GhId8R96n22E9oD7QYTw/+TkdCksw0dcAIvFH2y++HNQoE
NVgoyVW32Rw076Va8nizA2icB6hEJwKiI400qKjZknj2pnILPHORq+Zl43sHaXnB
imchl5U9gZI4EXCRC0u87oLd0IHuFMUGYEfhsxninLpmFNPjS55zEhPDIBTuFFiN
NFZ8aLxq6APGd1lbLJhYnQIYZJreaI3lXc0VYqjkaB5WBeYXKNNF3y39yNY3SXFt
/dwIP60IoaIAjARFLqvUNYOsHpjsVAItxxMdTpAlX28VYWsr3quGL97Xhd4NfDvb
AAMFB/9ep1jcpFocEOurMYZkIrPE0CdgdeWzlhHhW2F38cZTj46WxoAY21QOfjRx
tCcGDrKNNwoHO3TIsuPrEI1OtJ4y8b7Pj2zuv/kUAEMUjl5dutg2kIDz5cs5zxI6
4HhUx17vQGTOK3l1I2JxoNrMKPcDKxegHqYqpzb6vEr3gsKT7GSeMBREq0rvfZfQ
ZmZTLfdy0AiQ6KsVt1YV9wUE7Kq5OmhjVZNovhZtxO/tzppQLNX/62wdf1OmFZIn
xWrYFHeH/N+QGBmMRf0NMb0oOn4nEMem9QhSRcW9UcyU1K7Usa3m3WG7qrmcq+ri
9RVM7/8wJCKNJD1ej35rMQYVrolIiEkEGBECAAkFAkOquXECGwwACgkQT8Eyw3yB
BHZy+ACgqz3KenkNoTQKFv4nrGUHnAqMm5sAn2Z+BhMOzEhuimOTVLXVzKuipov0
=vL0B
-----END PGP PUBLIC KEY BLOCK-----
D.3.62 Chris D. Faulhaber
<jedgar@FreeBSD.org>
pub 1024D/FE817A50 2000-12-20 Chris D. Faulhaber <jedgar@FreeBSD.org>
Key fingerprint = A47D A838 9216 F921 A456 54FF 39B6 86E0 FE81 7A50
uid Chris D. Faulhaber <jedgar@fxp.org>
sub 2048g/93452698 2000-12-20
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDpBP9wRBACTXnvtFjxGYNH2xj0oZ09ggebJAzNOz6FiQKBkYo76EtyhFU2U
s8F6HJmhAVJVEodJiA2V+mbVVI9wG1r+yFxgpC4JCdtozSt2cgKHlfFcrAUn/bVX
p3ZiVio4/tWVS4kcOZcN/gfXxykG3Z6IgeMct4P/v+Yby5FKrjFcHUXrYwCgpTuq
u89HjAet3e4MOkJ43QDOqf0D/jQTRdivb0N302svCzG1ccc1y7YhiLN7GEY6VttK
Dkb9psNQFlgd+GNOpQqXXvh0EhzC0sA+lNo6F6rWZsrtQD/i2vAubzmtvgsF+UIp
268IbgRs1RHW5ZOqzkvDjMN+8/Kk/v4qQ+62WAuP2/iZn6bAjAfBPd5SGa97SZ3E
d0sjA/9o+3jTgxhNz56fxQb/e2B4lqPxuIsorxB28hmXliOVRQBHwx4e8XNvN2Xz
WklapX3AWKP/D1ZyzxNEaBezu4NBFpl9HqudFDyFeRzyrhGSD/f3XtlDTHD5hv31
+LSprexLW8nxbsKKjX94LnyYItRGcf7gU5z1V73amT0vedaXj7QjQ2hyaXMgRC4g
RmF1bGhhYmVyIDxqZWRnYXJAZnhwLm9yZz6IVwQTEQIAFwUCOkE/3AULBwoDBAMV
AwIDFgIBAheAAAoJEDm2huD+gXpQaPQAnR/EryK6lqRdUFT3CQkf9a7mds4SAJ9b
Uh/4pgPEMHVqh/mYuabRi+D0vYhGBBARAgAGBQI6Zft3AAoJENwfuC7pkT1X3MwA
oPeTrHw/8GFopppT/LtI41zM4NZ8AKCEPsKoGwmtolGYwCTGc4sZje1lTIhGBBAR
AgAGBQI6Z05CAAoJENh2/K3Z1dz40l4AoLHYYCgZoCWLtS4ybw7MZK5ZbIkXAJoC
C5q0lY5Kg+UReRewOH1vzz/wyYhGBBARAgAGBQI6gqxpAAoJEJ0r034T/C2b5uYA
oK8oK8CubWexgX1rJoKRINWBjEtoAJoCOat7l1Q6xjBN1E8fqn7f09Vfo7QnQ2hy
aXMgRC4gRmF1bGhhYmVyIDxqZWRnYXJARnJlZUJTRC5vcmc+iFcEExECABcFAjpB
aRwFCwcKAwQDFQMCAxYCAQIXgAAKCRA5tobg/oF6UJDOAJwKrq6xPbruIKSiL3O0
0Npnq1h4yACfXIkxgKsR5KxKk6kr58ZxZd2Dsn6IRgQQEQIABgUCOmdOSQAKCRDY
dvyt2dXc+AxbAKCzZ1Rvjn6P2kLaCo7/2A6LOetihQCfdL8Wo82cTXSpsGTJg4LU
FjlE9XGIRgQQEQIABgUCOoKsdgAKCRCdK9N+E/wtm+CiAKCCd05PPCM3ffd85LKm
+cRR3PTybgCgu5y+kYYTJB3hBchxggLCrJ166wm5Ag0EOkFAfBAIANHkcMb9WQWx
1A390MV8UFdR8eqiYZfuFHaNwgT3Ou+0QcawP6uC9gbeqEpNnlHrE3giJvP7BrNM
zut7Y2Ca5FJ1oy0m48OwmZY5AP2lN1CsIoU1bOCQ48R3KCB6Wb2dE442MEdMen73
+HzNnLiFGwifqn5yAHVIzfKilhpRUFr5lbZJkBk5NIc+Ny+ZK1JHXuJZ3jdKFBu/
Gusip9Dpd+UANyF8Tq+S3YfP8lFu7zA1JAHu5LnDOo/K1gZ6EZJxc5hYUu98Y6Xv
6EJLEwjKHNZLI8skX2uXR/0zQsZNz5FbSVGdQfYJlq9q3eDZBBoibc4Pf8LPOXLM
HhKyj39FE4sAAwUIALTlJVYI4353pzebM8D9mtqXrXY1qusNqm63pWHosPuG75XT
2hOmjuFFyoC7TEsMe57BUag3HiWyNR/CrVw9AppqZ1s4O/zAo4HlkJbZ9rhv9IO9
FiTR5FWtNCArAQJWpflRMYuVthZVVTGEM+zx2BTNhBdU4LEtRMz28E/r+tn72sMc
ypZv6/FSs5Rn0/rO4zYiIisk3ZLYCbJMHQIxjAIdwH2XJBYbbuyN9GbCLVOcIlkt
sbdwCNIQXY7rBX7g4Br16NCo0g35p/92s9QFFN6GJIzdOpbq7JVHnkZhMLfJgGhm
JIS85paJGy0bbb4qPnE+Tmi3apYe3tZ8FjkKRfKIRgQYEQIABgUCOkFAfAAKCRA5
tobg/oF6UKe8AJ9QmSqCD+d8ex1kMxJ0SZZqIcSO+gCfUUTrdZCUu9yC3KJIjvzH
6r7mPk8=
=R6MH
-----END PGP PUBLIC KEY BLOCK-----
D.3.63 Brian F. Feldman <green@FreeBSD.org>
pub 1024D/41C13DE3 2000-01-11 Brian Fundakowski Feldman <green@FreeBSD.org>
Key fingerprint = 6A32 733A 1BF6 E07B 5B8D AE14 CC9D DCA2 41C1 3DE3
sub 1024g/A98B9FCC 2000-01-11 [expires: 2001-01-10]
pub 1024D/773905D6 2000-09-02 Brian Fundakowski Feldman <green@FreeBSD.org>
Key fingerprint = FE23 7481 91EA 5E58 45EA 6A01 B552 B043 7739 05D6
sub 2048g/D2009B98 2000-09-02
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDh63HoRBADnIWpOjAts71A8JG07tKjUYV72Ky0nWN9HAtS8FJTGeT1eXwGI
Wxgl0mTrmb+fUWuEt1xyB+0h9uzwbWgrojBiVEyPbfdORFvOlWQ5VXub41vxz0Es
AvQt/HptyH5UKPHCtK/5WbgAHPZldlp5rBPA/E9OnsfgVeSf23eyqkup8wCgi7g5
nKKJ1LaE0Y1eVhGLaOSYP+MD/0j69SjwjUpIAe47u1SJLsx/K+vP6Mx7oqw2gD1v
Ap6sJnpNVx9vpr+DozYGrGFb+LnnML2/JqU2OQswCBRWmqkATJDrrdg+VyXIdyXV
slk/6paQ/qPjcnyLFXWgQuyoL1me+4e36LFCxFTRVcfvO6kidOXGmDQ2ue/Khjef
XLRWBADK40RjC89IrGX4PuapS9fOSj++GfWHZsdxuxSYT205sZhMOiTECR+DPZ5p
06si2rPf6GbS/3zPEYd8J5wzHTS5kk3venhpxjze1ltloDQm6hD7/yJdK9poBa8P
kRuEYqM8RNWpwNKu1x8SsqyyYy/JzceAAXs1zAs3g7CoLHGag7QtQnJpYW4gRnVu
ZGFrb3dza2kgRmVsZG1hbiA8Z3JlZW5ARnJlZUJTRC5vcmc+iFwEExECABwFAjh6
3HoFCQHhM4AECwoEAwMVAwIDFgIBAheAAAoJEMyd3KJBwT3j9EAAn0c1DQKEVawy
t2zfgVxyIYsw+ca+AJ9CrtFiZ3yQIp0Y2alhcRBhM+13I7kBDQQ4etyeEAQAhBiJ
oc5q7eotOiSkna9BDGxlxg8fM2+wb/MBTrOUZ+BkbsVYRNBQnzzYtczS7uwXt4Fc
Oy0iBD+uOEhVDZgXNQLFg6HxyN+xikgWiPx0vKjQVIfKB1R1Uqh2VIslGc90TS8f
WTo+7gkcwR5Kjq6m8rs8qeFa0GqrtTP+bRBoj9sAAwUD/AvVkkCNJK7pRWDWVSJk
NPmvEJ/8i+YahBLcUkg+4H8nSh+fNdhI2ED6CN5ZU7yYiTN5iAc9HJLDLFzHRIDX
KyGS3JqzwrT6+HKTaS2fVKFVeGVgzlTvczWizabEZAOMQOrV3F46ei4STqBjM09/
nNhGlL2ce641KZ6zgdtCG6PaiEwEGBECAAwFAjh63J4FCQHhM4AACgkQzJ3cokHB
PeNuVgCfdFUKo5EQLwqnGxcw5zAzqDnFVkcAn0o58BEAPRr2RoAHHWWJn5JoyJD1
mQGiBDmwog8RBAC+zE0IpGNV1naZh9os6S//ct1MfEMBoHH2TQhajIfLVraWA1I9
AbOTuYYsPgxqK44ZnPUnNLmgIRBeVJXklXsdvjtMrh7QMj7evAGneT4vVdVj/9aY
7mEBuQephgvE4bUM7RPvOc/paiY08+HANljrvxcmMhygDTP5SEp/QJn7zwCghB66
YVHI5u4xBAcHiHbyJWShmekEAIUWEIL4I33C9/yuenYogKLLS2/wmMYMCM5uMTkF
jls9KtfW/TQz8M8ZU6xdVBQjvDpw9G96l78amjiMN9Gm32C8m3HJaN0V+4SGJjiQ
fL07gu60LG0phnk1CtWLVQnH0LuIyB8jJeoaeYmS2Xv0rLLeMQ/hgUcQB8xu61Z4
n1shBACf1w7B9ivEhBGWBsjuX2gTfW2eS4Mprs7FD1/8f/wbdvhitMdjZOFjOIO8
yi/2W6B6T3suTcUgdC2qFmXkiWUun5kpGp/KRvrYm2eKpfveOL0HgD7juEZtBJcT
zV4oMel8TlZidIjIgLUeTbGfxbYPm0gONEGZHsymlZg9/7sDS7QtQnJpYW4gRnVu
ZGFrb3dza2kgRmVsZG1hbiA8Z3JlZW5ARnJlZUJTRC5vcmc+iFYEExECABYFAjmw
og8ECwoEAwMVAwIDFgIBAheAAAoJELVSsEN3OQXWVdUAnR13DerFrFdS3xufFox/
m9T+VKs6AJ0Y7mgJalqPTTalJB3fbWUeIsZBsLkCDQQ5sKJfEAgA5LI3C4rGWWbG
cGZMLDhuBhjcoSFeWnrVVVZAPEm92+LcrfoT1Slp/2+KcKTJN/uQA0EpNmgUFBYr
3vSoVoVm10xBxBIX0zP7uPQNYKoJX3gLBiRZ3xOo4A6VqEpRbo5yjj3rshN4IO9B
T9zqx0ZoHSSsCds0Ax/m+0eSTghl+Shle1tbJstgcoxf6peKa6XcOAJWtQ+r6hZB
Z1tpjmIrfaeG/26da858C4TcogNhi1cpbyfQTZA7070JBnpRjhcQpELT4hRsJV2G
BX0dZn2hJOb5J5zl2M0N0Yx2BHM6mVT+oUc4EvfRn6fuhVRwIuckxwXaA31vWNPh
v+S9VD5BqwADBQgAjOXR9HNAh/teG0p4ynOlWx5G+tBWSfqWAKOSpi9SKb2Zipjg
bVNjmO4zNYhdAK6YbyQgrDrwUVPWoc8OieUACujklkY11eg8QFGr+tJow7iCMOPL
ES5vW1sBUl7dN+4tf5QTg5q9EGHL2rTndEVeutFbcKPR8YQXdu/U5hdO9zha5fd0
RWjG7zLTaukO4mT2bTuojgCrnsvZ4D0XRW+SUcfXZrbKcsoFiU3q+EvlOuWg0W5b
FcFfAXSAzC2CpZlQV3hhSDkgeM3cbnb0hv7feSIizFpqFbNyOgarqymZIU07HcX5
c44etbO++GQ/tMI7oCPUb9a5jIt/YqPvIvmPDohGBBgRAgAGBQI5sKJfAAoJELVS
sEN3OQXWr4MAnjpZdSq11IEN34VjwhD+eBMcxjqaAJ4yDvFd8u5ehurCY+KjWSXo
uPPUsA==
=oR1w
-----END PGP PUBLIC KEY BLOCK-----
D.3.64 Mário
Sérgio Fujikawa Ferreira <lioux@FreeBSD.org>
pub 1024D/75A63712 2006-02-23 [expires: 2007-02-23]
Key fingerprint = 42F2 2F74 8EF9 5296 898F C981 E9CF 463B 75A6 3712
uid Mario Sergio Fujikawa Ferreira (lioux) <lioux@FreeBSD.org>
uid Mario Sergio Fujikawa Ferreira <lioux@uol.com.br>
sub 4096g/BB7D80F2 2006-02-23 [expires: 2007-02-23]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEP9+FkRBACKcQPLBb7vcUuQTM+Zqfwsd44vzULREV7qHVvTqJWDsFyQd4hz
/rX86mmHiS/fOh68SonP6QdXO2i+d+LshgLTVPBlW92TXsFYP09FUWWx2dm0P249
P7xoIcQ7slhHnSVuPDObzm5T7yDXL02OeO6qonN62IjjxB8xzFo+W6SsAwCg2BtA
gvPq1hyeXVXlbItG/9Hbul8D/0yjvmED7dj7eQpm6LvjswjkMoRdg6cgR+/N9LdP
GIdjGHkfFnW8hRg7QAPzmstkhtY1I3zEjVVCcYjJrIibaqBAUAx0v5HszLKKRnrI
ZZm4IXKFpkVC2sV475FpFTPXIiHmyzq1lbpgAQXX71yFNJ7hsEuYx1z2Ihblz/B+
KHJ8A/9UNVEPc4s2YgjntQSDWRY+Vcr6M4bN/+ogCJ7XYN5lcHjB+gUD8kAWupEH
1hDV3WFahpG1i0MusOZM+dggTXSshd76z0JlOJjbywEv2Z2nb+1b1GU4EY+2RlTi
nP9rO7EqtPhHjNkpXfsSHFOC3qfcsDhphXOJeOFwwhMhkxmkHbQxTWFyaW8gU2Vy
Z2lvIEZ1amlrYXdhIEZlcnJlaXJhIDxsaW91eEB1b2wuY29tLmJyPohmBBMRAgAm
BQJD/fhZAhsDBQkB4TOABgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQ6c9GO3Wm
NxJtqwCfZrWhCzRFNX2TkVEW1zMS0mw5aLwAnRUNKvayClkvdqHMLksYTFtUu4RT
tDpNYXJpbyBTZXJnaW8gRnVqaWthd2EgRmVycmVpcmEgKGxpb3V4KSA8bGlvdXhA
RnJlZUJTRC5vcmc+iGYEExECACYFAkP9+lYCGwMFCQHhM4AGCwkIBwMCBBUCCAME
FgIDAQIeAQIXgAAKCRDpz0Y7daY3EiNhAKCLZTyIxlE0tU91Cy6YxRKCu1Kv5ACg
rbLcuizHmkAx/du+XaG+aveC4Ui5BA0EQ/35pBAQAL9uIr9y2BwxMeHbj6LLmoPC
DmQnzXWWWIZPtEyWlUv6ANLvtNX8M0ZWzfy4Z4EXof6/m3Z8KsAEZf22AObR+CA1
mgRRmDxVfWDU3fYYIVwMTQ/IqjWz5TPfldXySqxtW/Zm16ODYv3c+tnu/KX/M/WQ
1l9pLfIB9G3NlnHwHTWBdIQhomXLzurW0yuq4LXobA/nQmOWmrQwjXNk1zzO+p5t
v18thaXoF9pGObS86oCCfwaUMg4RD6PtizVUSA+frFmcR0/kpNGAWw4gIqHY++9c
Ri+Tjvbii0ZhBZNb3l2spqhg7zMAqzQ/wR0kJt09FegN6vClMLDBJW5Rveb7u4XT
e01JY5E9h2Nt/RaJQ2RgaoD0bNLx32Zda0GOzidFAK+0QzOGvfMKimaye3YkWRXg
GFZFHH4k0FIcRd461ta4aN0VMKbpRbYxZP8oxmN3VrJdrf91Qqton2Ljrqk4ndQA
xb6zbtJeobx6MiYlDf4GB4Wgm4g2L/BYH+ObV5QqnTnwMIjP6Y3BvP941d7eX6VM
cpJq3ueDK+FHbF+KEozHycvlZrj+el5SuWXtNdOVma/DUQjHJ1DHMmciVqZwArnm
Ygg7f0G7dMxBi4n4OdHHSkJXwth4ojbZf+zDDQnHmt7J04/EArgEvBKxOGEh8EcR
evS6bR8NvH7lfXjl+7AbAAMFD/9DHsJNi6bx5sciwo7xvwx9NZY2MTHBxaWV3iWj
9OIoiklZt8Ca8a4ukDc5d2t/DrGr/rtKsUyQ7utEhfdKr17TYZH9mW9ZzOKp5sjO
aWOcmFCGMjemejPedAlH8sBD4I4zg+Ph/tMRgAjyw/ZkhXlUbVJ4ooibU1uix5Wy
AcxXSyrCOCLbVfpcCphiXCRlFsVuyiTkjM1D3STr6M6YSq5vTpbWkUvHs9c1pgqh
51SoGR8tcyUM3JUvY5fTos1sRlIS6XexXEvmBe51jcuV+4I9cI2cXWVpWU09zBTE
mF0WSgs2pXZftMpbLwaTSjzGA4VNQQ5jocsfWUP58HgBCyO4x8G+N1A9PWYtKUoB
WVcjjl2ak8G0mbTGb03QaIDAy2CVkeKYVws6ZTQBZtfKiO8Vz2UQcklRNTPTxYHo
69kIY47+6WW44huXc81ACGx2GXXDZtqxasysRtzAzl6U/FKy2lHE7Buyjh7VKYI1
7IncPhl/XyEBWTESAppWvd3WiCdT0zq6wpwxrdpLprWblqxLRttK2Emwe2KhvDk4
3jdj/KOlMi2OUa600mbRfjX78MbNHisLUEG1ceMXaQY3quaerb3Q1N8Rptn8sT1U
RMqbVlP4fxFwJg9F8nyLYzBcVm1H9WGFoojCqQ3htuvI8kca6I/UQxHG7V9Meqbm
uFqP7YhPBBgRAgAPBQJD/fmkAhsMBQkB4TOAAAoJEOnPRjt1pjcSt1UAn19TWL7b
atBvRWIroNaSp6+y2jWHAJwMSHg8w1dVEw3XxYR1fhEhE1hBWA==
=lXvC
-----END PGP PUBLIC KEY BLOCK-----
D.3.65 Tony Finch <fanf@FreeBSD.org>
pub 1024D/84C71B6E 2002-05-03 Tony Finch <dot@dotat.at>
Key fingerprint = 199C F25B 2679 6D04 63C5 2159 FFC0 F14C 84C7 1B6E
uid Tony Finch <fanf@FreeBSD.org>
uid Tony Finch <fanf@apache.org>
uid Tony Finch <fanf2@cam.ac.uk>
sub 2048g/FD101E8B 2002-05-03
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.7 (FreeBSD)
mQGiBDzS0/URBACREmlUnPeSzfnC0m2oQV4eSzgYjskiLfwZ++Ql3zErPw0AphH7
m95dZwAscTm3CQRHDDd/RYxkJMAYA+jmw8cVX1rXtQ2URRmzy2/I+qBU1NCPrqBj
KRqrav9uhLCLGvEwdqWg2dqn8TMwNdlETbH+R0QQ/1lK8XtW0NiHC8I+NwCgj/8A
v8ifdpVSnFp1QesTAVwdTbMD/icRYOZ5I94DSRk5GGnmD+lyhfj+ejYbuVEgg2ig
V9HuXJMnBKTnuwriuskTreeNQBvBCTltHrRe1LujAtlsbixooTgUU5jkzY+J/PeN
fLd1J9uoqTGQ7GjT4SMfKuetSRBhcRZYvm9FM+54vsumKcXGK+qBfPVBHo1bk8go
JxgBA/9tnrAoLIUPvs4d4ce9h5BGA2yG9Synz3w1l8Zr+4coomUjbJFV86ZWKPM6
nyb2RhDb20ESkZnCoDxZY+p5t9c3aiQJKQQV8Gj0tj3c7/OKoyMePgabH9752Q6u
piZ5Ml3mfse/Kja4THRoPEjkQzAn77jxfvesKiEh+fu6gsJ3cLQdVG9ueSBGaW5j
aCA8ZmFuZkBGcmVlQlNELm9yZz6IVwQTEQIAFwUCPNLYkwULBwoDBAMVAwIDFgIB
AheAAAoJEP/A8UyExxtu8J8Anixqe2bmDbJpcPb0IoT84nnhJ3kvAJ9sOLAQjWYv
K7SdJyMF10YX0CIfHohGBBARAgAGBQI9c+arAAoJECm+XSJo/VSfOQ0An0ygDe/V
bqSTjYJwlIE8YYpty4jLAJ47UkBPjTiVre6ew5VF19jMKvdsE4hGBBMRAgAGBQI9
c+V+AAoJEPbdMwIQ+kzRlegAoISM0MmY8lkBCBTsow3Joc7tLgn9AJ0QrUzWpq7N
YPnlJ0lcd41pGeMTqIhGBBMRAgAGBQI9suQtAAoJEAtcZfDlrYLgTkQAoJNPNMs7
ScBAN/nLDgzNue3K8KvGAJ9ss/muSiHvLiFfiITYIrMb3iDD4YhGBBARAgAGBQI9
szNDAAoJED5DhLnTnUHhMXIAoNb0MSJWURRoRUBuzS3IqGjeBckJAJ451qIIzvpv
0BPv7IwsHLalwHN0p4hGBBARAgAGBQI9szLjAAoJEHw7eXCIx8H3AfoAn2d2BuYF
xAiBrtgQINxUFv0f6uO+AJsG4UaBDFeDfYWuy5ewplYVeKEiCohGBBMRAgAGBQI9
suRJAAoJEIhoz/fZwesRGRsAnihqruuppwzOavzHgImgw880g30bAJ0QG8O547sJ
CaSeppCiY9Yy/wQBh4hGBBARAgAGBQI9sre0AAoJENUEeBB7Yyy4xn0AnA7Ro8by
KFrC60C4/dHOqU/+AkeEAKD2PCSVlEx8ycBVnWMk0XyXSItDsYhGBBMRAgAGBQI9
sgLLAAoJEOdNKbgr4W0BhsYAoJVB/mXnINoaGdxDp2NoHNLOyCkvAJ9iN6Zhoo2C
4E2eLDhoU93f4F9AArQcVG9ueSBGaW5jaCA8ZmFuZkBhcGFjaGUub3JnPohXBBMR
AgAXBQI80ti2BQsHCgMEAxUDAgMWAgECF4AACgkQ/8DxTITHG27ATwCfQaJHzDZc
MzhOrYjhobphXayiTboAnifEwKJ1DDVZxPxxWvxNoTvaPwm2iEYEEBECAAYFAj1z
5rEACgkQKb5dImj9VJ8CPQCdEcZ3a7bXQyNZLg3KQ1ZvBfaGIEIAoJKdHTkC63GL
fT+osKfdjM4UZ01piEYEExECAAYFAj1z5YQACgkQ9t0zAhD6TNHaUACdHH9+sG2/
msrvhZ0FbGmp1tKsotgAn0y/a+fx5rh2/FTVcpYywQj13jDZiEYEExECAAYFAj2z
Dt4ACgkQC1xl8OWtguDpOgCgwPUtE7jFzwXRzAs1svxg5YXU3BcAmgJLcKt0G+FE
YL0O0stYX2ea03SHiEYEEBECAAYFAj2zM0sACgkQPkOEudOdQeEXPwCgnJ+9OF4H
22joPbsKqJjFN9hfIaoAoNJDV86nE1d6/CU/LuKH2uvAhv1biEYEEBECAAYFAj2z
MucACgkQfDt5cIjHwfcLsQCgi6NITOb5mKFKbsjjxj0LFZ/rauAAoIiJoS55pdqH
RVp5WgUikc0YJiWMiEYEExECAAYFAj2zDu8ACgkQiGjP99nB6xHghACdGSHyJofq
RXByL+rSxSlV3OosmyIAoJn/bRX4LGGdXqj8OUpvZt4ViIWJiEYEEBECAAYFAj2y
t7cACgkQ1QR4EHtjLLi5nACeOt3CWse7n/I4D4z8IH9+foodbEcAoNKDnRE1uR0o
SsnDqCVBpVwpGX5ciEYEExECAAYFAj2yAs8ACgkQ500puCvhbQGtKACeJ2FG606O
sLLjrzGmeIjZ5xzvK10Anjv8e5eBab8M2cxd5IdieOi6PfNitBlUb255IEZpbmNo
IDxkb3RAZG90YXQuYXQ+iFoEExECABoFCwcKAwQDFQMCAxYCAQIXgAIZAQUCPNLf
LAAKCRD/wPFMhMcbbieAAJ99oc3W8UA0Peqdc5cX4Lbis7hI5QCgg7U7yZqSbW1b
RDP8kufk/86S5g+IRgQQEQIABgUCPXPmsQAKCRApvl0iaP1Un6hiAKCRNZdsA0tc
0oTdJ/pkPkhyRWQx1ACeKRe/CfJF/xWBi8jquecKf6gPMkyIRgQTEQIABgUCPXPl
hAAKCRD23TMCEPpM0ZNrAJ9pF8Jkhu9JhU9naYgwAmYX5iS9NwCeOCi1gW7nJx/J
dN55WbPIyfzKw8qIRgQTEQIABgUCPbLkMgAKCRALXGXw5a2C4EwAAJ9goNYWpdCh
RnPzdARqPkIl9BBcVQCeLVknYrZ7yL0wT/DGabOtE0y+qXiIRgQQEQIABgUCPbMz
SwAKCRA+Q4S5051B4UqkAJ9jWdqexFEJSzT+idX58XITvse0jwCg0lOck6/COkYd
8aAwqfIdyH4QJWKIRgQQEQIABgUCPbMy5wAKCRB8O3lwiMfB96UCAKCIyFg+QCTB
0f0VQPOnHFVi3CT0qACcDqnzRgYu3Tz/kzUSr3hWzhnBx+2IRgQTEQIABgUCPbLk
TQAKCRCIaM/32cHrEahEAJ92I8GNwWTl02bcQ1vMPHtnbbCf/ACfTilFKvw5z64/
XubRaVr54idRUHKIRgQQEQIABgUCPbK3twAKCRDVBHgQe2MsuMfUAJ9HnuPn+dd3
TgMwr+VCfvox4Dw3ygCeNWvusO4oy5RYuRej36qzPe9nLGKIRgQTEQIABgUCPbIC
zwAKCRDnTSm4K+FtAfExAKCjbHa1kgHxAC9FoBJGk0DYBziZMgCdGO25X841oHkq
kfXEH/bhoKy597K0HFRvbnkgRmluY2ggPGZhbmYyQGNhbS5hYy51az6IXAQTEQIA
HAUCPRc64wIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQ/8DxTITHG265qgCePGYX
+2/SUFlhIlTtJt+cq1BuP+4An3OThP4AU4PT/9Qv+VBQusMz17XciEYEEBECAAYF
Aj1z5rEACgkQKb5dImj9VJ8fIACfbBiH1K+OnrBefDuwiQRnk+l0Q90An2eZDyVX
69irU3BQGTnfSSC0oFOFiEUEExECAAYFAj1z5YQACgkQ9t0zAhD6TNFNCQCfRE+X
4BB27oPuIrcghqF8cwAH07kAlAxSx4k8w3cRL8zg3+pj7pYgYNmIRgQTEQIABgUC
PbLkMgAKCRALXGXw5a2C4O42AJ9K2vWLCYfeNf3486r/I2Le+gslJwCgyuQ0LQeX
T1gzsZN0js913k5tb5mIRgQQEQIABgUCPbMzSwAKCRA+Q4S5051B4deJAJ9QJuZs
+TE6tIX72XF6gUhwumxL8wCeKL3F4GkGbKD7oZdAmxyKmXO1mEqIRgQQEQIABgUC
PbMy5wAKCRB8O3lwiMfB99OLAKCxSmibXonC4pzcM/wXjWGFdXcITQCgqVk0Wghb
V020dqzH92iBgXDleRmIRgQTEQIABgUCPbLkTQAKCRCIaM/32cHrEf54AJ9EOwW3
SLucyv4vGDTv06BeywcYpgCffv5ykOmLpd/OJpeB9YQK1nsiX3KIRgQQEQIABgUC
PbK3twAKCRDVBHgQe2MsuJG/AKDjdNIMYpdwcn1/4/U2EBJNAsYWHwCgnfzGdKSc
jX9iz+Kxlk6+5ol8X7CIRgQTEQIABgUCPbICzwAKCRDnTSm4K+FtATW4AJ90Xspu
Rd+QhrXweG3haragq2CQEQCfe+/ll3/HjfrA+9883jDP14owSAa5Ag0EPNLUFRAI
AJtkhGBrUaEVP2fO4wQpmujYfPc7+GT+Q0naKCXrMQ1vDK5ppsghiSr9TdVB3kdk
ev2oGxgsCfy2uPC/JuewQByYBmtKJuU6GDaRVXgMhpVwhcRraaDeYZm0GIDQEX3f
WSlL07xxbzSZnewlSqUEAznHjLGN1pq9mvPBczq2hrAsd9TPHo/IB9JsVmHV9GYa
sHUSbVWx1S6ntU2kV2TyKpBS4luF1Z7y6yIWS9pwiZjTlWdUGSfUkkTu6sM59dBA
xv9S5Q8TY44TUQfhHQhcLTz84UurU96i6cb99ZmN5uq6IP6NPIumhOJAqPvHSqly
+Ez/oSzSyUoyZ0Saj35E1C8AAwUH/0tkQh1bn/BhIyBO4S9z5wQfI+ZpR7npeKZ1
aYQUjFzbULb27Y20HRujvXljFPoWB1oJO+oXULkCaNWI+72TYXzKRDqYWMaubwrY
e5dHJ4hEDpmpqeG7W425rItDfhz2wKORc9vk+eHMHGZZhKamurmeH7hrVpe33BRf
ts5yvYWofYonWGF+KydBcrMp3AMbKGQMSOwcBiSpIJVn0HYJFIOWmthtKIMqfVmL
WS2sqFKITbBKHBemP+97FVAc82dXxj6irB7/jBjdPX5/5B8HHOXWeEvuHSjZ+6ef
XFrTVbeh2u1alB0aX5kz4cb8Fl9Oziqc2Lx5HLgfkKiWgDAu4YOIRgQYEQIABgUC
PNLUFQAKCRD/wPFMhMcbbofuAJ4k3jgHTXOHznfpXNRDIjZqPPjJEACfXAql73R3
KnkOqXNQ7FzYXOIPK74=
=7TEa
-----END PGP PUBLIC KEY BLOCK-----
D.3.66 Marc Fonvieille
<blackend@FreeBSD.org>
pub 1024D/4F8E74E8 2004-12-25 Marc Fonvieille <blackend@FreeBSD.org>
Key fingerprint = 55D3 4883 4A04 828A A139 A5CF CD0F 51C0 4F8E 74E8
uid Marc Fonvieille <marc@blackend.org>
uid Marc Fonvieille <marc@freebsd-fr.org>
sub 1024g/37AD4E7D 2004-12-25
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEHNnEURBADK+anixdFH+aSxIGLw1soiwMXSiVPD56dmoA/VAFqrE3XVo/y6
bPqpSNwvvhL8Um2v9G/7EDMorqekYErS3sgUOtrA05NSJlOUJk/97ZFzAlGZ4/u3
CwtpFBdiATaCvAdMocWhxVkyIFvo6AqVNz6RkTldJUuwVzGelXWk9IfI1wCg586A
r7CU9HIsVJD7/vIbIIsKDncEAKYh6XKEBHWI1pF3Ony+rPhlXCV9W3yraiBb/YXS
XaPr2Wy3XC86ufHZs8ewug40DqcSfRobj7qV5II1CMoVrwhUuJ9Y087ETjt7xC9d
xI4jrkVZlaRt0m/LUKLLfz6L9KaLWRkBfFhOjJH6TAv779q0n/KfaiU48Xuue6ff
KNDtA/96/oTg9+NWjm47zCdQeyZGzEE27btvzbrLZuG6TcP7gAV0F6udGbImgw1f
mKrQZn4ZtVKCKS8IzTn/UM/P26Pn9JOzDKd2voPE9Ee8D0L8ywg3mxmBdm+TY9vs
r2OEV89Nc2sJZm5CeiqEvfACI8KwbExqWy5TW7Qz+zLi3zk+ErQjTWFyYyBGb252
aWVpbGxlIDxtYXJjQGJsYWNrZW5kLm9yZz6IXgQTEQIAHgIbAwYLCQgHAwIDFQID
AxYCAQIeAQIXgAUCQhzb7QAKCRDND1HAT4506BdRAKCaBqu+lvdAp3fhgIJxL0XY
YG6vhgCeIyaLMYFzQfii5s20wePEhG3rfMq0JU1hcmMgRm9udmllaWxsZSA8bWFy
Y0BmcmVlYnNkLWZyLm9yZz6IXgQTEQIAHgUCQc2dRAIbAwYLCQgHAwIDFQIDAxYC
AQIeAQIXgAAKCRDND1HAT4506PmiAKDanV0mSeUSRJuDmfA13o4ELsQ38gCfaEgn
LyzKfRawEhJdqsGPWW/fnte0Jk1hcmMgRm9udmllaWxsZSA8YmxhY2tlbmRARnJl
ZUJTRC5vcmc+iGEEExECACECGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkIc2/AC
GQEACgkQzQ9RwE+OdOisEwCfY8xxYIhN0w9CSUbsN1/EoYp0D+gAoLedf7wiwvmQ
O0XpcJaXgtlO4x6fuQENBEHNnEgQBADPHKv6eOKxk2HPrm180rVAM6/d3LQkBEGL
Ma4QuSXXbTDXpzfrt6YOLi+ILe/hu5DNnGbQyvkBB1lLdmqW03lat1ape9wytNoA
kHOX2C4kom2WA3FvtAoxojmylEn8S0koH7RUuhhTM29rVBap0W+UpwpnxmtbGXEO
NciLWy5CzwADBQP8CSp5Hh4+7uXIRpp+RQ8PKJ2vQVnf7c+QTPDN5MLXEv1UK9gK
vtb4sms2yr2IuBMP1FSAFN6DpedjoZSKimxqCyMNbyy0io2pMrNDCpqCadKOyLWN
gJhJTxE+3kYeZqzZExvf8q+faQqXp91bbS4XZ4JzgAkT3B0mvQ1OHlVlAauISQQY
EQIACQUCQc2cSAIbDAAKCRDND1HAT4506PAVAKCWlLnQdfJsRZtt0Q880glcLzc8
SwCg47K+qs1q5klc1cCIaCj+/TtsLCk=
=rg/z
-----END PGP PUBLIC KEY BLOCK-----
D.3.67 Pete Fritchman <petef@FreeBSD.org>
pub 1024D/74B91CFD 2001-01-30 Pete Fritchman <petef@FreeBSD.org>
Key fingerprint = 9A9F 8A13 DB0D 7777 8D8E 1CB2 C5C9 A08F 74B9 1CFD
uid Pete Fritchman <petef@databits.net>
uid Pete Fritchman <petef@csh.rit.edu>
sub 1024g/0C02AF0C 2001-01-30
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDp2C0ERBADDEONsb7B2tbhvATFEmuw64H7A+W9Kk6NMunEF9kp1VguwRP2w
pjtAon2QbvM7HABE7t3IHnDhhS61kLpN3Zxdxwt994s+jRMZ1s/p/XIP5/eIx5ds
BgKZk45sm2qdg0vRKAPF+On5voQttbBvBdOVMWOmr60Fc3I+BTNuAgaEHwCg++GC
1P4Upv9OHJCQ7JI7gKa3qQcD/3HWzaGMwyuvcuzWFDLpfv2kuYxNutg75+l0K83p
hCFxorUVw16+j4r1/464GnTAhvfp16Z7ReODy53NOlG9/fQXAE1nHZp93kFnkgLF
uIQZQKTiYsHP5eqt42gOGmX4lBRpJlpTNsdlSr8CC9VUvzqZ+H6wG4epDE2jUnFD
+kmRA/oCBoq5k3Hm4gyi3Y1F8cLUGU9YFDzhzTkDQiZc1Wqd/QlnvMW6vci7MRKv
eeeZHQOpzOSxzuPo+b/Prn1ssluAi2IIPObxrq5Gcz9lQ7/xqrvQH5EosbpH5zQM
35ku8psPGcRqcRKG7OecAoYpioLLWc5UJ/SoKAoxqzecICf3qLQjUGV0ZSBGcml0
Y2htYW4gPHBldGVmQGRhdGFiaXRzLm5ldD6IVwQTEQIAFwUCPCEaTAULBwoDBAMV
AwIDFgIBAheAAAoJEMXJoI90uRz9hSgAn0Yp/3lUexQCv3MEjwm7l7XhZi5IAKC8
Qnw/RCmcFjahkHQTXXZmW+rSwokCFQMFEDrzKkoSaX0gm5SkDQEBszoQAKvEeQYp
zt242YB6MVU88HavNYkonemSqA5s1fbg3dwA4TT6TTJ/757W47vbFnzjb/AmGIJb
r8moK8rC+6mnSC2IewsaFqkDRFSRp42XLxyVdwdkJKY/L0Of8rOpWlUsW/Zk6dIE
XFUs+5bjSEO9DiMQjmd4upPTF6r4o0jddW+wn0thrqNk+3ghd35q4HjtFnYMruMv
BKzLUYfyLkYA16w45nOF9Lr1Tz6oNzdVEJXrubpdHsHMs2sFQlrnD9A6EMog/ouD
g2N1ASr6UycE9s2nyVXM5W0WVahAhdMosrUCuzDlhGWv6mQqjTNZfl27/+LJd5sM
QEv0MQoTf/fzOI7kJdPsNGTibnnTuE99atLXpbNhsKj82BjYgAAeycutTw3Qy6CX
B6fpdWa1PE+BNSdOUbiAtxyV4XPcw84C6rvk7mZepYVBYPKUrupPM9OY1d/mCEE4
zDFv6o9UjiZabQmzKq7T8wKZgV+Pl14dpHcR+xd7tZP79duLdyIkxOe6Z2xbnqY5
NlOar2AfMNtes7GIkknx1p+2koRfqh+W1mPH02Vjgi09ru+kY27jzxHmswRlu67q
3r69rGouXBgIJQ1OnyOPXLKY/iglgkRIXGmAoU2R3Ii/X0lsQRYA5XdtiBodezQd
gCuJ1XfK6W4xWjZsONGmEhNN9RezUJKoMSeziEYEEBECAAYFAjwhG2AACgkQF47i
dPgWcsVClwCcDW2kRANOyFNhbBhDE4OHOPTAau4AnA/8TasNnyJLhAxeYFiQhpuI
fiRDiEYEEBECAAYFAjv9fJwACgkQXvSymrg2XlXuQgCeNou9DlCKpHZF7os0/9K3
xV/hva8AnjNqFXvpIZPylro1vJkzgHh3I4SkiEYEEBECAAYFAjxOdVEACgkQ2z94
QKW3O1wm8QCgx5i66wSVMIhs+Yvb0He27mJFW64Amwdkruw5+oN0NUm8HHHCAqFV
S4HitCJQZXRlIEZyaXRjaG1hbiA8cGV0ZWZARnJlZUJTRC5vcmc+iFcEExECABcF
AjwhGlEFCwcKAwQDFQMCAxYCAQIXgAAKCRDFyaCPdLkc/VorAKD3J94O/gJeEgYW
R+adK3SewjnB6QCfQK+70Io6Jlz3GmoS8+/c3o2hSUyIRgQQEQIABgUCPCEbYgAK
CRAXjuJ0+BZyxSERAJ4z//S1Bzb2OUl7ozm899AYR8W1LQCbBkDibniWmMf6Gwy7
fL9Flyks7yKIRgQQEQIABgUCO/18pgAKCRBe9LKauDZeVd66AJ44EAAjhGopDGym
iCGXJV0EvKo01QCgiGW4Tr5DZG2mY1aqCtBgl9UIz/qIRgQQEQIABgUCPE51VwAK
CRDbP3hApbc7XBD4AJ0Q7a37xCQKlc/m1uxQ62JxgvgHWgCfQFAKfveCwE3W/Fpy
+glLmP0/ZTe0IlBldGUgRnJpdGNobWFuIDxwZXRlZkBjc2gucml0LmVkdT6IVwQT
EQIAFwUCPCEaUQULBwoDBAMVAwIDFgIBAheAAAoJEMXJoI90uRz9gnoAoPosyzKa
niM7FvhR4xLDLaazqe/gAJ9eE0hFz6NDr5h9nRZ1qfU8BK6NM4hGBBARAgAGBQI8
IRtjAAoJEBeO4nT4FnLF08EAmwXdi9L+Yq3liDz2FYledwRRqO8ZAJ9hax4xk4ue
E2B8IogV9WHnnRSci4hGBBARAgAGBQI7/XymAAoJEF70spq4Nl5V7ucAn2K6WfjX
4vncJacQLGLVuh3tMCAWAJ430sgOCEmwY2bAdNfu/+WYe6YxwIhGBBARAgAGBQI8
TnVXAAoJENs/eECltztcBPoAn3zovCq0kHyFqm1x0QPDtlAkRG4gAJ4gCD4Le8Rq
43M+s91wrrTyNOutobkBDQQ6dgtUEAQA3sN519zCh7owShpNYRObr//qeAZnPcx1
69ZscNuVDy4EoKeyiLletkmnwNes1IDpq1RslCkHa8UOjFy0jby9cjePCJNo0b8Q
5qG/4iJf1020PT8AMxvL/H/SZH27ueF6PxkpSgDSsz/e92c7CeYpTu+n+xBYsLO9
GtNi5asTvKcAAwcEAL+HRDhWp0dDD4AxTa5evEl7GFy22y5sFVDHA9eukt70/d0d
nAi5d14uA/LbAIWyLCE6KC23MAJOgrQSc2PbOa2O45rx3dDw5RoqXDqyn9xPM304
hFzXgllOFOTYKMy6G4DBOv5KWKgVOx03XyIPqAVAObw3rHzewU0wXhD5Qk/QiEYE
GBECAAYFAjwhGssACgkQxcmgj3S5HP24HgCfdErc/JU9fVJIH/iLTbWo28vu5yMA
oIDNzwMAwpXoLZkEkk/dMUDTsFCy
=ZbG1
-----END PGP PUBLIC KEY BLOCK-----
D.3.68 Bill Fumerola <billf@FreeBSD.org>
pub 1024D/7F868268 2000-12-07 Bill Fumerola (FreeBSD Developer) <billf@FreeBSD.org>
Key fingerprint = 5B2D 908E 4C2B F253 DAEB FC01 8436 B70B 7F86 8268
uid Bill Fumerola (Security Yahoo) <fumerola@yahoo-inc.com>
sub 1024g/43980DA9 2000-12-07
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGhBDov9skRBADzrOg1JwL+kHv1dTePFR2lNrErbMe+WVeP1sdGuKcYTP15VQyJ
WV/6ZoUGsihAmFGcGyJuhcUJbvlvqRf4ZlwD80a1y33SNxxsqe8n5dm4Wy9FElL5
bjs4L0kGJlSL8KnYYUTQKEDBcTch3+GTjgS4NQBZWy4h0W6EWqgxr7CZYwCgpeB3
tnDcY3ELA5EP6Bx8wZN97zUEAJo972g6HplZyuyjqqTjdztXNgD+DlsyNpNkEfqs
AnZcr4aqEeyMNtGl8gPIc9JwPPSlX5OfmjCm3zWtEjwrHway6YPggXqX8efuY3lo
LxVfjRt6NLI0TuV0FhojgHuJYB9RsXQFZxbYH8A/j6jQHbiN3wTyYHtaAJJ/iELg
82oWA/dTeR0kjvjgrfB1MiFCH4AL77bZWuxSv1CvV09DlYtSxfLpyBm4OHvDZmOv
V6zT9COM2+f2/EMI15cNllYXB3WnwfYit9tZtEFBl1+OshqYBbcNkser1pBd5jP7
fDAkpDYGx5OgpqAS8hz4XLPZdS/HXSegodYKinU0p0Rzza6KtDdCaWxsIEZ1bWVy
b2xhIChTZWN1cml0eSBZYWhvbykgPGZ1bWVyb2xhQHlhaG9vLWluYy5jb20+iFcE
ExECABcFAjov9skFCwcKAwQDFQMCAxYCAQIXgAAKCRCENrcLf4aCaPIbAJ41RzBA
OuxYwZFUSbMbU5PHENe6ngCfcnVzDC5+lkssh628m3GTG0EjINS0NUJpbGwgRnVt
ZXJvbGEgKEZyZWVCU0QgRGV2ZWxvcGVyKSA8YmlsbGZARnJlZUJTRC5vcmc+iFcE
ExECABcFAjvw0YEFCwcKAwQDFQMCAxYCAQIXgAAKCRCENrcLf4aCaMcVAJ9brBw2
LPC2RcZpsm5S//dETM/qFwCgiuPpVVwBP7ibzn5xQVNAdB12xOa5AQ0EOi/2yxAE
AL/FYZQw0b7NrD04j6dxrp7wBjgd19ux4zQocXgXPlzpBZxQ4A4/icGOLnIU+vDu
ltbpf7aMTd/mJokJwx9pE82pOgxk6i42c5qKkwkmjhO2/4FFk8HXco2DJ9roRi0n
eBJztXskUY4cVavKdXNeJY2JUeBYvmrnREWG1W2/0ZMzAAMFA/4ytkv46phPokQe
s7yy67bEeHiydjvf3uM+v1z3xWoLw5ZU+8hLdFkESpZ7u+qA1mj3i7LNBZhfA5Bt
Cgl10v9DWX9cda2HlMjyyI9p3dfPlOcAh69PMwexJ1VYPtizK4ZkC8dNk0rTVPOf
SYftSsFGdDbUAq3ZokhjLkVRFY1LxYhGBBgRAgAGBQI6L/bLAAoJEIQ2twt/hoJo
ewUAnRRikiShfD9wCuyMazVJ9+FZLWiiAJ0YFgos24sNEFq5rA4I8UZU0LZ5Iw==
=y5FR
-----END PGP PUBLIC KEY BLOCK-----
D.3.69 Daniel Geržo
<danger@FreeBSD.org>
pub 1024D/DA913352 2007-08-30 [expires: 2008-08-29]
Key fingerprint = 7372 3F15 F839 AFF5 4052 CAC7 1ADA C204 DA91 3352
uid Daniel Gerzo <gerzo@rulez.sk>
uid Daniel Gerzo <danger@rulez.sk>
uid Daniel Gerzo (The FreeBSD Project) <danger@FreeBSD.org>
uid Daniel Gerzo (Micronet, a.s.) <gerzo@micronet.sk>
sub 2048g/C5D57BDC 2007-08-30 [expires: 2008-08-29]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEbXBHMRBACh5wwMt0bmOk2lR4xDsjHRiJI8lIOUzLDmSW/1DJHsKQ+ipDBw
lMg9cIx6Yp0JS6GQxhd14pFkJ0VKVVt9oVcXWc0OYBcnrPtVcRFietE7wTG6fcrM
Iw+ZQLuIn/UkFUhwN7254W2k+krFKjq9EDGExL0s3P8FwWkGuBKAM3HUpwCgvuW8
jn5wGoIU1pLDmIYzKCxXDJsD+wfuIQIUMW5GEfFwkEl1i8C64fkCjVXv5y23J5uE
PfBHEJK8dFv55re6fnZKqAJMnARHAFY0Z2IH/538wZc787P7PULYxsGrB4DQgnlL
af8AWgpcGFm6mz6QA7mLj9h8zv/PwZmcrfawV8YDJNiow4CsSGB5A1UUZUU6lSsk
IP0jA/4wjVIOamzJZUJyVPIM1WqMUag2VBieUFmgf6M0sn8wlyR7feAUJbnmkeAH
j24T6DPd+A3HgKKMZrfRqGc253VsyxbtX/M6F+85mmsecV0vmRl0oVJgIg7Aq+bB
0TMBtANZR50ouQqWs1uLku0F5VhODoVUDw97LZPv5ei7P/p+a7QeRGFuaWVsIEdl
cnpvIDxkYW5nZXJAcnVsZXouc2s+iGYEExECACYFAkbXBHMCGwMFCQHhM4AGCwkI
BwMCBBUCCAMEFgIDAQIeAQIXgAAKCRAa2sIE2pEzUlHJAKC+SEfHXVuLZ+lghF3I
MU+e1em9cQCdHcVupnW+57s9mcD5NZuzDASBHcG0N0RhbmllbCBHZXJ6byAoVGhl
IEZyZWVCU0QgUHJvamVjdCkgPGRhbmdlckBGcmVlQlNELm9yZz6IZgQTEQIAJgUC
RtcIXAIbAwUJAeEzgAYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEBrawgTakTNS
fwEAn16FpSi/Lctq/aV5Mh1XpFD0ses5AJ4z4w938apaw0vzw9RiqDEBvbHqBLQx
RGFuaWVsIEdlcnpvIChNaWNyb25ldCwgYS5zLikgPGdlcnpvQG1pY3JvbmV0LnNr
PohmBBMRAgAmBQJG1wiAAhsDBQkB4TOABgsJCAcDAgQVAggDBBYCAwECHgECF4AA
CgkQGtrCBNqRM1LpSACgh1YZQWrHaL4asAutBLgbuR5q0CsAmwbzvWAC7MZvRvKF
oE3NWnDztIwutB1EYW5pZWwgR2Vyem8gPGdlcnpvQHJ1bGV6LnNrPohmBBMRAgAm
BQJG1wijAhsDBQkB4TOABgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQGtrCBNqR
M1IX9ACdFDZd8fIFjkuVujkVlgvHn85h+n4AnR7VpjT3dETOfjCqKrqB7O+OmzGt
uQINBEbXBHgQCACba+8VX1EqhOGaDuZSu+PXgk0W0muTckSA3l+tPvpjeiTqW8mc
JBwE437fzy/cVYx8m+fEoixFo4D5kcDORm65e5M4B9ECiJjw1hojXoVWF2aliLhV
cjyL6v5VQ4SKuYny4cceX7igyFWb1Jcx4zBzC2TGLprq6v2JJyyPJsiksjMQZiZv
otSkbc4jFDkJU1P8mst8hAYe7aZdjO0ccFw3Lii2NlXAjlM6XYGHUCEeW05S+NkP
S8dmWCFfKdAGhYXC20Y5F/MrYTpP0mKUPAuVlL0Qa+scqBcceHcXgPywID3df2pe
2WdcEojzW3BEtLGVZw7LEexYBEQz8ngGUT+fAAMFB/923hvNPjOEG9EA/5GaLivR
vZftvACEUxzZc7nCpEqWXEeH/Hh536Lj2SKi4MxzXHH44KpfzjAoa/NBk3VrSu1w
zZPBv+/lJvAj2HOych16CNpwfx57BTWYBpilcQ7j8BeWB9F5VsQ4ffGrnW+xZRfq
JTTG+sNKG7LMGhvuHB2NAdlEyoEX+XrzJw4WzA+eZo7g9kzLOGY/hdK3V846Nl3b
pA3iSpVOaI7gprhmjK1ESz58/fLFVyFYh0ZXradk80K1cxiUV93Zo79Uvw5K8tde
gr+9LUWouND7BXxRJ5AiaiwSwa64D6Qq8OREYF4c8qIl9cwWmE6qlR86Yc+C7f3k
iE8EGBECAA8FAkbXBHgCGwwFCQHhM4AACgkQGtrCBNqRM1L9mQCfb+hnPmlNyP3H
FyIZslqXMLP79BQAnR09l4FnL36xldwsMrqll6kRxh+K
=z5Yc
-----END PGP PUBLIC KEY BLOCK-----
D.3.70 Sebastien Gioria
<gioria@FreeBSD.org>
pub 1024D/7C8DA4F4 2002-02-09 Sebastien Gioria <eagle@freebsd-fr.org>
Key fingerprint = 41F4 4885 7C23 6ED3 CC24 97AA 6DDD B426 7C8D A4F4
uid Sebastien Gioria <gioria@FreeBSD.ORG>
uid Sebastien Gioria <gioria@Francenet.fr>
uid Sebastien Gioria <gioria@fluxus.net>
sub 4096g/F147E4D3 2002-02-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDxlUM0RBACvTeKRqOnxJ6rIhOdf9vCoPA46hxkjTRgWCd14oxC/P5SxlC6D
kGDg+Cd/FeY347+C0fwmoaEJrzQcUMGIBdjOa6UywIcbuYFUY42T2+hsMVr2SSK+
qz8hmpnmgX2PRmN6veuXI5L1S+3wEUDv/wpJLaPhnIs8Zt3OuwVD+oxmxwCggdzr
SyxiA+f0tOqFlREV80qh9mkD/jCaBzww4rfSQrXsiyEOzDVP3v/EA3vYmkwyzm7X
//+3ouHrUTPt4w7s7EbGF9xyTj0zi6J+6PADjt4yGgO85BfUyIiOp7oqLyu1lc+v
lfgfOUSTr95/jfMfI5QXVoswUqLzAe/kZK8yH+mmd9PNDEXqXhSzWQd0O3kBrvlX
KEEaBACB3SslcYkfdh7/kAoC8fyT4eDdJUPXLMgfjks+W4wngu2sHv0fCMhJuW8i
5fhcFUnMNNuxw7LJ/+3NIYx0yacfx3DPeWEtYAlj1AggQJPiXNUIH2hKEh1Md28J
JyvfGg5yjFk0QkZXEr/UIjCi2ooUtXSgI99HYn2soOxiKI6cBLQlU2ViYXN0aWVu
IEdpb3JpYSA8Z2lvcmlhQEZyZWVCU0QuT1JHPohXBBMRAgAXBQI8ZVDNBQsHCgME
AxUDAgMWAgECF4AACgkQbd20JnyNpPTrhgCZAU1wpIXOP+v2CsyPYGcIC03GsDIA
n0qxuR2OP+YyFrsnA+yogEETkzbktCZTZWJhc3RpZW4gR2lvcmlhIDxnaW9yaWFA
RnJhbmNlbmV0LmZyPohXBBMRAgAXBQI8ZVH0BQsHCgMEAxUDAgMWAgECF4AACgkQ
bd20JnyNpPQGWgCfWL/2Q6PBPbDB7xMz+uV18ovl96oAn03b9L6/soWmPDnNN9rX
GO0esJ5xtCRTZWJhc3RpZW4gR2lvcmlhIDxnaW9yaWFAZmx1eHVzLm5ldD6IVwQT
EQIAFwUCPGVSDQULBwoDBAMVAwIDFgIBAheAAAoJEG3dtCZ8jaT0A4oAmQEQvmqK
s9Y6EaJSnNLD6Qy2MKtHAJ4yoimf+lPR85jP4jKoQaMLeYpvCbQnU2ViYXN0aWVu
IEdpb3JpYSA8ZWFnbGVAZnJlZWJzZC1mci5vcmc+iFcEExECABcFAjxlUiEFCwcK
AwQDFQMCAxYCAQIXgAAKCRBt3bQmfI2k9AMpAJoC9f5tZH0s1LBDksqJF+yDY55Z
rACdG+9SsE2SJUOUE8Zfh1h0L13EOWm5BA0EPGVRxxAQAN/O6Tfq3h6bKUDyVtPJ
m4qmkAq2dMF/IwTjeiLCgGEEGK9lDxLWtXCZi85NdDqQjM6Az6bqNnj7ZDkxkhXo
PBjLbfKH1ZGGYKaZqzDTTX90aNXS5ZkyJ2vTZ5UDv2G3BPzuBkfLoCfieo/ygqs8
2njdJWS7zVYx57ZnYqpSwc0BTl6jeoFXFS0VWnGzHjF8glaDlJbcsveM3oe/kOB4
Cdi6Qw/2XFqxZyTGiDaESbLUw1bMgNXe+sowbx9o4r0IoM/QO8mhe4vVhh3+KuQR
wOfuh8FHu3uJ1uEdK3sXZJiyRnFhDokPimiHHI2XOZ+U2EigwvEO34NDgHMz/ax1
vvV1GkpEm2RGjhIaGl3sbytpp/LIzQh+cVEqcrGvRMJ/web+P8W4NM/ygxtpEpJx
lpBsMrmMB2jYF3Ry9oCSDBwQSIbMoS+akSR+dySoBlAP7bvseHdPjEG9k7DljcKF
y6Bg3X1lcg/Ire6uxLaHfXjRKz5YAvaNJZl7n5uYpvnBh9izYzWxp+EucGqRrz0y
+5MB5mMa5czKQ5Bn/qxJEduLNgaM7DgBDaJ+0m6DuJvb2Vd1ifXWeqDhxi9T/ugt
drZjvk+FCfsw6JdV8Te8hB2W3NXjsYke7TapAM5sLh7tJ3S2fHHKjgdXIyl3wVr5
CAzHkssJkVT7oP0feryaG7TnAAMFD/928Up+8kdlvOCD48eIwhNeOD8dV+2oLMap
S6vsMKUnS7/hIff/gntk5Fiaf3pjio7qJK7GRKvOTvkGd5AnRgvqbYzIqB63OrGI
dnUJ3NqZJaNPcHxfMCu3RwgBiKjLAaNhK9PUo1N7FaU+4Gb7MGPdduWFncgX/n5u
CxIfY8lkOr74MXwe+gJ7Ybuk5DU+s2tgj5IcI4Qe1VEmD7npv8eekf7VURi6Ga91
Qp5uNDyEAkqrHGJVPEWUZJ891kqOhhheMb3y/AIaeCw1hznOQaEdxlR9zzLP9LeP
Wio6XnTLLbRhrk/uDCfjQ/mlZl96WV6SiZzF92jTJhJNRidtr1yENwNMi8cDVG8D
D3d1jvBBZNIrB6CLHVAhRxPB11ThPwQuGkVNNrP8VquCXuoOIqJGGX0ivpCmemWi
nQ+e+2ASx55rqweUz7urwyLRH5l0JlcOWuTCblwM6ZIqebQeiVm+pZ789fY8FOdI
B5TawBkoAHgvSiWLv5iz5d53B1BSV2LigrJ6I+30DXAsbkldvtaeiYKAPRLnk/yn
TZZ9nbNPhKTuRXSsUiPrRqgndtVdhWPS5RFJUKV0duSC5qwls3AxUDKf9p2Ci1vZ
XmK9iohF5JhGiMe083CuIQITp/PY7xwPgleV0xROGWjiO1MC14wRK+uSRf585yRJ
lyGwkugKgYhGBBgRAgAGBQI8ZVHHAAoJEG3dtCZ8jaT0onoAnRqetkw0IQGEHDis
P2T/ZtaLVqp2AJwOwHDdKXMLcfeuVe0egqgkY48Vog==
=U7Mx
-----END PGP PUBLIC KEY BLOCK-----
D.3.71 Marcus Alves Grando <mnag@FreeBSD.org>
pub 1024D/CDCC273F 2005-09-15 [expires: 2010-09-14]
Key fingerprint = 57F9 DEC1 5BBF 06DE 44A5 9A4A 8BEE 5F3A CDCC 273F
uid Marcus Alves Grando <marcus@sbh.eng.br>
uid Marcus Alves Grando <marcus@corp.grupos.com.br>
uid Marcus Alves Grando <mnag@FreeBSD.org>
sub 2048g/698AC00C 2005-09-15 [expires: 2010-09-14]
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.4.2 (FreeBSD)
mQGiBEMpwEsRBADcnD1kRdYoPvpKLjT1w1T5p1fT/LAimANGHXVoZxusjNdJjleF
7SNfN6V+sjm8bdUjZb3VJr3oA21sdwIKXzamhtbaDRAAvKdYIRecTaLId8SqI3dO
mZtLVo0A7XNkjVMtyLn8lPKpdiHPOc05/x8sVLNZ2LR/xFJnbdT5bomy2wCgmIOF
EaoJmSuh5trZRiKIAeIodfMD/3zaTMjI7eLziJG2IWdxceN40vUX555gCpeFEQtD
DfVV++32c7BN0j9o8VFl3W1vsQ3Elhm9GRlb5hZbRo53Z1YTJEzogXTGBVipJGID
cDo/bCmRuMSarsT+M6R1NF6uToSBeVZyCtA/DDbJHNvYD5VeOJKsdaQ7hYtctoJ6
ms7hBADD8AeV5gLZOjOIFTAkX1ibEksxz/P8aUFjnj0QmPe98/RI02e/iYVVdPgz
HgrTA+gF0X7nIicn+KhBgOT0MTx6bf9DFzmk1KaFBA6vnQ9alw1WtRHGsIm0OgD/
Jn5tRQFriUS5PWQP8FKXcUfmqOd0WtLebPicX66nOba+NKdU+LQvTWFyY3VzIEFs
dmVzIEdyYW5kbyA8bWFyY3VzQGNvcnAuZ3J1cG9zLmNvbS5icj6IZgQTEQIAJgUC
QynBHgIbAwUJCWYBgAYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEIvuXzrNzCc/
UUwAmwVe85K4Ljml9AgBKbNn5juVRkr7AJ96PWlTFr/IdKq+1m3Zw7Hyt93cf7Qm
TWFyY3VzIEFsdmVzIEdyYW5kbyA8bW5hZ0BGcmVlQlNELm9yZz6IZgQTEQIAJgUC
QynASwIbAwUJCWYBgAYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEIvuXzrNzCc/
6koAnjbYaFve7vZz3DW2qTBnYXp/n5IAAJ9+2EStzCP3tnKb/hjOxotstQufCrQn
TWFyY3VzIEFsdmVzIEdyYW5kbyA8bWFyY3VzQHNiaC5lbmcuYnI+iGYEExECACYF
AkMpzVMCGwMFCQlmAYAGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRCL7l86zcwn
P+oFAJ4tcY+w4DVH+x7euh4K6ECBqM73PACbB2QBuJrDOtTxoYdmiH3XdHCytT+5
Ag0EQynAUhAIAKD52CU2Xp69qfo/j/1aLgiMhgLpx56ySAb9SzZySUHadyptFpJR
i3glUnoUh9dfU1jr8Y0f1oChCmm9TOZnQJWR7LOrO+av3gxnRtVMkvVr8eAPG3o6
C3VZop7FPxR05Jmy0EtIxweEgNGmCX/p58T9LAM50E9FacmwYAIn77O5zXcJVnBI
m9Ih05Hy4nGIoyF4iBA/NZQL10glMnwc6p82AiMj1FI6i6iDdPYBeiHKUXkyZ+Q7
Df+HkelT3zot4DPKBeGBSFyQENOjHCp4wl27DsfiJXViy2NRz5lzrSFgvc0ZIUus
Ia5d9nG+OE67JKU4qT5xgJL5+eOe1lXsHgcAAwUIAJKuSmq6lvF4NWN8HWDimXBE
Ol8jNHf+miaLgMxOhAOeD4TQHpqgEhnf02koUbGDbli/AS1oC6WGhKSekgYKZCkf
zmvRNEkCJCOMG3bOcKEokHiujcyQHWf8k4WmBQe0hGalrE+oaLti5H2/jAqUqYFi
tHWRUeJDgfwOXRalI3YJJyjfBzE6ckE1kFWoEeXDuZdER9kusWWVrX38mdniwoKj
7e+GtfYo+riB4Nb/TSuQjw45DKVaqYNi13P2P1EmHwmrSjnL3Yrck3x/vDrCKa0c
2+BAMAaLVnOGdaYT1xsaMBGcgSkybQoOmvMm5hdtxURqi7k/TbaNhV/etSzfB/CI
TwQYEQIADwUCQynAUgIbDAUJCWYBgAAKCRCL7l86zcwnPw4iAJ9rVaOA1zKrzwRX
CLE2Xxf/FkN6JQCfZU7PjkJvE9jqgsBVfMhi6S6kNZ8=
=rDV2
-----END PGP PUBLIC KEY BLOCK-----
D.3.72 John-Mark Gurney <jmg@FreeBSD.org>
pub 1024R/3F9951F5 1997-02-11 John-Mark Gurney <johnmark@gladstone.uoregon.edu>
Key fingerprint = B7 EC EF F8 AE ED A7 31 96 7A 22 B3 D8 56 36 F4
uid John-Mark Gurney <gurney_j@efn.org>
uid John-Mark Gurney <jmg@cs.uoregon.edu>
uid John-Mark Gurney <gurney_j@resnet.uoregon.edu>
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzL/8IwAAAEEANuX7fcIa0S5fVATYQCGwgBJo9DxRr0m/QjrP4dJh/JEIjmv
h37FMs9qsMPtyAZWlRSnbVFyQiz5ptFuL1irClW2UHzlLvd5s+pKMfIkJWDTnrvp
0jFebYQt0chZeLcKT9s5sSo9ua+fUumOfaWyubUZPIqmDYqy98Em7wI/mVH1AAUR
tCNKb2huLU1hcmsgR3VybmV5IDxndXJuZXlfakBlZm4ub3JnPokAlQMFEDMBDfTB
Ju8CP5lR9QEBmnsEALAS5dZyQXxsDAROz+yHizsbgV1Ok9vFwE5en7QnOGcSkQX9
pE7MzzlbpP63toF9zWLF75dbXE5X0yYLoB0pvNi1NXhXqA0YbDeAi1Ed6uBXbomW
MDdm0s+O0Y1NfuS0uKiFiJUDOjdBrgEbnmPZM/77dhr5UbmAtQUHFftaQfY6tDFK
b2huLU1hcmsgR3VybmV5IDxqb2hubWFya0BnbGFkc3RvbmUudW9yZWdvbi5lZHU+
iQCVAwUQMwF753W7bjh2o/exAQGjjwP+MKiFH9EfOGS7yr5NQ4+vWXuHe1N6fi9N
jJsFfzT/RCM/wo/dNG/xhTgdCoCWRt0gKkv3SLEPYGDPDtC3Nf7HV/66wOiYYnxD
3cmjgpLn5u/Ju0oS5xxNb5Ly8EZnfz967lIHjp/qhbZ9o7kO7Nkb7bUgozNqBaRy
9Yo81fVAtrOJAJUDBRAzARCXwSbvAj+ZUfUBAeUyBACKoIXfYBpsKqmmnTg944Tw
5t8lAFZ8qJz42Fjw+hswC6c+7b87imwaH3AjPnFmsA6f1ES7xDHG8RQleDtKsyik
gHc9Yos/neVqwfrr4zSV1PdNPPpG5uNT/jI1k1M3pH8kwYdKiwaIHQb5+sGUQsO1
ZoxCdzT7HJq4jJtBGVIRULQlSm9obi1NYXJrIEd1cm5leSA8am1nQGNzLnVvcmVn
b24uZWR1PokAlQMFEDMBEHfBJu8CP5lR9QEBak8D/2V+1pP6zA1dvhRLcO2pGldn
Q/dcVAAtZIZ7AUUap1pKXZF/Tt4gWKMtAHj01xUbwU1fmI6DF1p4AVjDqOxJDnoZ
RD9gv0RiZXdUesXL2UBNHc/7f+amAJgmXNrP/m70ejgzPluniR5hQm76fKYjkxV1
opRhhchTjhrFndoQ9nvQtC5Kb2huLU1hcmsgR3VybmV5IDxndXJuZXlfakByZXNu
ZXQudW9yZWdvbi5lZHU+iQCVAwUQMwEQWsEm7wI/mVH1AQHxMgP8D7VM+qUo0qGM
uFUKqxoQcDPVKt2W1X6wWTHdj9cxo3oW1tlLEZ24Y2v5v1pzonvseaTjsse134dP
a9qjcwXjs/zxXzHoQs3B9BZB2qXaR4T3YeuCjq2qIXGwsrrY5fkoch4OLg0/FOui
dmNbFjVQkIma2rIRPa8GhXZJtGl+UEk=
=bUtb
-----END PGP PUBLIC KEY BLOCK-----
D.3.73 Daniel Harris
<dannyboy@FreeBSD.org>
pub 1024D/84D0D7E7 2001-01-15 Daniel Harris <dannyboy@worksforfood.com>
Key fingerprint = 3C61 B8A1 3F09 D194 3259 7173 6C63 DA04 84D0 D7E7
uid Daniel Harris <dannyboy@freebsd.org>
uid Daniel Harris <dh@askdh.com>
uid Daniel Harris <dh@wordassault.com>
sub 1024g/9DF0231A 2001-01-15
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.7 (FreeBSD)
mQGiBDpjbB4RBADW+4fkXvVjAZ0A1X4wgXJQ4Eyes1LH7sTexP/Zm7sg1D/R9zV5
w2kBwOhICRX/hxVL76YZv2MTNL/d3pV3ZW2yV3Z6H7Pq7s4oVn2q35owUwLQZfSI
SBTnBiVN7NqMZ/kzCCdWBwg/4G2FVNFwc7RyuOFQL3ly1PBtgbANbpCyfwCg3QXB
K6AtFaEP2MA+SWWHQD2dNxcEAI11cbOHbYU8asIxbqYYyPOMgPsaLlPiTh6JQOO0
2OiGxoQlmZvkhlWf8B9ahCeYoKgA1zPqdHA2C9YMvOV2LvN+/Qi0n3hpqkfM7lLC
QMJgm1KxIzccWY9Iz09GRlIFm2JPaCVLsKh1QPW50c3yO9TMSa6lXwiRgvxPz76C
JHniBACa25NHH3x8zx5KA0FgMM15Wc481777CFVsKazNay00G0HogSICZ5lHffdi
1O5u+qQHchVKL0Lbe1zhdbVHdSAbEqnKTqseVMQ6I1TVu4gO89B72aY1RxAnAYjh
PAb5W/RhZBSR5NDVZyANnqaGE7U7KMqn4/E0lC7w1TzoIZvDMrQkRGFuaWVsIEhh
cnJpcyA8ZGFubnlib3lAZnJlZWJzZC5vcmc+iFcEExECABcFAjpjbB4FCwcKAwQD
FQMCAxYCAQIXgAAKCRBsY9oEhNDX55peAJ9NKai2qEcFLxzC14qDz80zBGwP0ACf
YhsW5qhTw/Rck1Id2W1alUEXMre0KURhbmllbCBIYXJyaXMgPGRhbm55Ym95QHdv
cmtzZm9yZm9vZC5jb20+iFoEExECABoFCwcKAwQDFQMCAxYCAQIXgAIZAQUCOmOL
hgAKCRBsY9oEhNDX5wXyAKC6VLe3svRc+FgmmjPS/EWvi83sDACeOpmPRbViajOw
4MUhKA7hxnRlBeG0HERhbmllbCBIYXJyaXMgPGRoQGFza2RoLmNvbT6IXAQTEQIA
HAUCPSJfQAIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQbGPaBITQ1+dSxQCgsBwM
uDviakYEKswiv6zMHfYBBCEAnjMyu+oxjKOWOo+of2qmtQH2LNg9tCJEYW5pZWwg
SGFycmlzIDxkaEB3b3JkYXNzYXVsdC5jb20+iFwEExECABwFAj0iX2ACGwMECwcD
AgMVAgMDFgIBAh4BAheAAAoJEGxj2gSE0Nfn6bIAoJlPaQlqk4wbNGoscjigAp0R
B9ooAJ41JxSh9w2S16mFTGNKvVpjXw15BbQyRGFuaWVsIEhhcnJpcyA8ZGFubnli
b3lAZGFubnlib3kud29ya3Nmb3Jmb29kLmNvbT6ISQQwEQIACQUCPSJiFAIdIAAK
CRBsY9oEhNDX558OAJ9iOqCDUX4cdNMSZ1KBQg1gfTn1yACfZNL6BY+mYC+XV83L
7DXacstXHlSIVwQTEQIAFwUCOmOLtgULBwoDBAMVAwIDFgIBAheAAAoJEGxj2gSE
0NfnaM4An1YVu3iDtrG314UIuZoTw3zd9ucxAJ4yg3vWB6ceg06KuyaGTJSdZ1Oa
p7kBDQQ6Y2wkEAQA0RSR8vkmX33oyYl+LwlOmemSKbSQFZNImw5TDcRYX83fa1Z1
4oIgJSk1h5l2jx/+29chVR1nTNqPYlRQEDMxVby9rMq2RAnjorM6oDdtIQIBNJ63
vmUcUiORGnKhC0waajpmZibcxoUFk1KcLyfxOT0JTOLgsJfqdqUENIc6NqsAAwUE
ALaLYnBOoIr5Wm/KC7wRtS4gHeeOeskZyyoa3+AeBorDl0VvpgYwlNdAaP4xJrx+
CH6UYnxrMgCXG1l4dupkGXOCRPlAcM2ouEyDIGHRTVqHy40khZnWzN7xfZhKNcVd
FxeHqOG61ZrhcMboxZrdJC7hK+sYrbngeKRiDs4VRoOuiEYEGBECAAYFAjpjbCQA
CgkQbGPaBITQ1+foeACgme+2LKdFkytbn/JUhBqPYVAD8KQAnjP+IDVQ3PDEKRkv
AFGJ6i5SrWJ6
=j+GD
-----END PGP PUBLIC KEY BLOCK-----
D.3.74 Daniel Hartmeier
<dhartmei@FreeBSD.org>
pub 1024R/6A3A7409 1994-08-15 Daniel Hartmeier <dhartmei@freebsd.org>
Key fingerprint = 13 7E 9A F3 36 82 09 FE FD 57 B8 5C 2B 81 7E 1F
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQCNAi5P5owAAAEEAMIKNuDnLGiTOzk3kGMmz1ii9FbYEM6fKdf0jSi0YSTxSWAn
7EZbBehJ3yTAYuCaGSEGXEWismycc98LnH2Fb0uI2EsJ0CVLJqxsOL3DK8XE0YOk
HjSKUpmJkh/BKrMAmUnqhbD6YIBiKnZh3ABt9+a7A+SakJQxvtQ9cYxqOnQJAAUR
tFVEYW5pZWwgSGFydG1laWVyIChMYW5nYWNrZXJzdHJhc3NlIDE2LCA2MzMwIENo
YW0sIFN3aXR6ZXJsYW5kKSA8ZGFuaWVsQGJlbnplZHJpbmUuY3g+iQCVAwUQQGso
RdQ9cYxqOnQJAQFBSwP+IIm2bFprpayabQ/VgXp10OD3sgIEtH8c99sU91LyotNT
ySif8DS+ujliDk5wVnaOlzqrV4sga8d2ybM81hdW0nxI9dNxLIp+ti90OecZMF6M
4PlsdkYGnqZDzXlFg4o70GSAWKjL9RTG5JvNnYWS453mCjYc3O4dm+1zzADfgcy0
J0RhbmllbCBIYXJ0bWVpZXIgPGRoYXJ0bWVpQG9wZW5ic2Qub3JnPokAlQIFE0Br
JFTUPXGMajp0CQEBkqMD/0D1K1hTJc8u5K3gpsk9LrnOVYpP3zHbSe94oLO5tHv/
b/Y1626xqcMKYfAIk435asuPnGRkMjgpsxPUKksfWMlUqW4aIiX7di6aMuWkgSBI
BXguu1Dk/qRImOZkNzWc3V+/CQ+PIauy2rZubfW2+oVkW1iEmmO7I/nPqDxDBNBI
tCdEYW5pZWwgSGFydG1laWVyIDxkaGFydG1laUBmcmVlYnNkLm9yZz6JAJUDBRBA
cX8u1D1xjGo6dAkBATkoA/9aDk7yNvh6urP9EWcPv5mjJt0yYIIjGpV7VH2P+mTa
dK14ah24HSaTjh4psJg/uFw4egAs2XxDKXrf1SHCaaVajC3VQGvKq6V2Ytmgw6qe
Rtt+NtrXVJn5EUnMY3+G8YCXugulym6bUWaC1x6PC0Y2IEzRkM3H5Et78gd2zujB
o7QqRGFuaWVsIEhhcnRtZWllciA8ZGhhcnRtZWlAanVuaXNwaGVyZS5uZXQ+iQCV
AgUTQGsk+NQ9cYxqOnQJAQEV6QP/ZFHefmwjiex7zEU9uhzjEdZhDlM0szKULUoo
TB4x3yiXiYlzK2aqppXbV+vl+t2VLhd3McH+SKSiKwoBVWrdqsXguruIjUYGMAJI
aE+Zh3OGUs8sZhtQqn3nE4+VngpyXwPwXPrDhQiwwJRxj+01lupNwS0Z6cAPmD4A
W1L0aSc=
=HsTV
-----END PGP PUBLIC KEY BLOCK-----
D.3.75 John Hay <jhay@FreeBSD.org>
pub 2048R/A9275B93 2000-05-10 John Hay <jhay@icomtek.csir.co.za>
Key fingerprint = E7 95 F4 B9 D4 A7 49 6A 83 B9 77 49 28 9E 37 70
uid John Hay <jhay@mikom.csir.co.za>
uid Thawte Freemail Member <jhay@mikom.csir.co.za>
uid John Hay <jhay@csir.co.za>
uid John Hay <jhay@FreeBSD.ORG>
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQENAzkZeP4AAAEIAMKg3LRpUCJdg9V9Pr0KIdvaQeItf5Fcrbh0GE4skfNPKeTg
TQifwdG/GrMPYJBPHU8JnFqumLUnd2VSoFEJ/6W5SOZP2l5ZCq496pGCSekpe+kR
dN3Ra+GoR+cWVLKuXj+IxA0Ziv2WEl027TnMhWGf/DHLdoWvSwJdVrGnk0KjBJGr
HwWE6VGlhBSoOWMa9T0tb3sRVTEIJXDCn8f12eixx8XCzwIQJSgWC+ThrY+ZO/hz
FRR5yl+izJfffQiLjc4yY0rXqDu9K3i+/0lWywcbnqMtRj8Pnr3j3Lzft+xex2ml
qX68fE6dxof6Tc3GQCEqelj0IOAb8Zqy2qknW5MABRG0IkpvaG4gSGF5IDxqaGF5
QGljb210ZWsuY3Npci5jby56YT6JARUDBRA8TDj/8Zqy2qknW5MBAeMwB/9R+Nvd
bPPkvll4Qaw9I1FwM3iaMDM4IkqR6r+Gsi+RYIClYmRBU1HXZzKyNR/Ysy0thnIe
YO2yg7U2nYJ00ysSZl1Hd7R9EQBuYZk647PMKbQ+pQ4k9KiO1ObT9JivWz6u6R3l
gJMnCUEi6s+xW88eeTDBO/AKE9eUUBDZ765M3WcVmGfDYNpW/D3tX7taGcFT80DG
VXKnFHAP2Um8IZeHXKGqh/jTTNCqwz7oj3GfVzzGEnmwI+goZScQWUl5J708MnOf
uxiuOMBs7SLsvg1d7iEkO1oCDClv72i2Sr4rPuybIPMMPIpx/DpAZAIiMYHJ6PdK
nMXSYgk0GOjx72pttCBKb2huIEhheSA8amhheUBtaWtvbS5jc2lyLmNvLnphPokB
FQMFEDkZeP7xmrLaqSdbkwEBzGMIAJLwFCCICbR+kqejjFh2BznIOT69PIfE422e
C2yD23fC/lqZ6LixxGrsZK5TxRycWw7fq06h77kd/RX8UMFErphMTkIapt+wLLoX
qGLcY1dVyNhW34SutdHzXkMFo6T8COAautpnAMhrSh4dBw6XQUreVqc1BsyXL4vT
LyI1/E8E3wELJZHldWQ7ldvXPUOaoJp5PJ0FIV3Nvme9g8U0BrZT/NjH06mYgsKW
+40ZjeRycvA9Yjh+ONAOdX5ijn7QbixjSehFsmdpx+KdNyZbp6iAIurf7ysEp2Qm
N6K/3EukEnVvy7Nn1L8+7K4IDkK+TocpG/m/P67w1AlrW0tNAMe0LlRoYXd0ZSBG
cmVlbWFpbCBNZW1iZXIgPGpoYXlAbWlrb20uY3Npci5jby56YT6JAJUDBRA5HN4y
wnPlMN5G9U8BAQVeA/0V4alPthF5+FVL7GJ14R7IQee3NkepbsCQrWfDl11DJkyn
DxyISqzQd/ur1v5gziOMppQ35rekRYxqqmcKSg8oZtcQ8WFfrMPOYDDn8uTXmwX4
OgLuW2EnJc0y1JiKuew1tHRQuoObZtO9yePRKkq+cPgLn+yrjPjGAJ1AuUL56bQa
Sm9obiBIYXkgPGpoYXlAY3Npci5jby56YT6JARUDBRA5HOfE8Zqy2qknW5MBAXAc
B/9QuIZEQJDfYJyv5Ztu9mtEUZoFfavYmLnLvbUz0rwZOzv8/krEQtkdVvkWYWQc
JSal11h7L1EyY1YzrTnANkq4KUboeiR3X6RZ+z0p1pg5C0imWFdMpqnY3croHkQy
0zU/d/kDd9mU3xismVbDa9xSJHbFh5KDpvnbeRxh5VIXcdiJ+RbM9VNqsMmZwCBS
DgY/pyRuyiMM91L9IfWlOUwllAEHwedQg+ja4/M1gyiGKr7rmiE5LH9xbInvRR2F
rQKDtmU49MS7ybHoLfZ9GXKo8iTNOuXE7OGOx8kIuapiNwKm2wayng8utIxGacoO
hp8D0uj3dgTFUZ3pcMSxtjWEtBtKb2huIEhheSA8amhheUBGcmVlQlNELk9SRz6J
ARUDBRA5HOgL8Zqy2qknW5MBATYEB/90qkiF+JTQZMN2wwlLkXiadUd1uHK8Um7q
f19t1pI2Is0BNxtBwVY1OlrkpFkSkpSUHEmVKUVhHjsHVV+r+EdJ4dTcsT6c5cCJ
i7avfz8duVbym09yDLytnBGr3te7tkmalwk3JkjXJhiMuUW9w9woCuVWRexlABDm
Md8JjvyLqIe6bNkIcE9GvHhQQUYegYqVhDqzKH+cme1olSYDDjt458yMYo6UXu+x
g7gESluIgGpK5hKI/MAw3r/XgOliBa9igg816jrTFiX1oZT6dgDKlzxNS7J/O/EM
GOmNi8N03Qx819oKlUaMHAFPNeUfdT74bqVYbDo/GJptzaQtUiMv
=l5Xu
-----END PGP PUBLIC KEY BLOCK-----
D.3.76 Sheldon Hearn
<sheldonh@FreeBSD.org>
pub 1024D/74A06ACD 2002-06-20 Sheldon Hearn <sheldonh@starjuice.net>
Key fingerprint = 01A3 EF91 9C5A 3633 4E01 8085 A462 57F1 74A0 6ACD
sub 1536g/C42F8AC8 2002-06-20
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBD0R0hQRBACPEDZc2XKdvIq9F4ofeq/EUB8ISFQ6kaVPcb5ingy5ND+0MUbz
K9U+q6Ik8d67KfHHvqGn7XTOXxGu2WS6rIa4ElFHtG/9lpgYtOFRZJxM8nv5+zCn
elu18skUNup1y3uIwvhNUY3OPSzVkHC+tUPWfW/8DqdJzud/l8sDFDRtBwCgtixB
FHJ2jRXInApVzwLcjpgVJq8D/ixzt0O/Zg2p62/qyAHac7M1sEc2QarCAGwRbuNw
jHRtglxQw/GT2NACWqy7lVHKd37ciCrXg9QrTjotJtMcoJbCitYvbQo2RHfEeIyN
yw7rffTQ4CpB51KxNhUWHcUfe6Jhx2hgHzehJg7hYnbtSv5hJcn2DXMSHHyHwBri
hpldBACI7iJxl2MtFUHBo3XW27WYDzTNTh2LUaMcIaowMW/+vIDds6EI71dCAjuU
Ai8DcNacMtE0xRdtNzDMS8vgYWBVLkHv2ENVdLfpxhM72iu4tmPKGF5AXK191dvJ
qPge41Z2/57191Xt+keYtuSQDtXwZfSu1uLOHBa0BBvmppBOtrQmU2hlbGRvbiBI
ZWFybiA8c2hlbGRvbmhAc3Rhcmp1aWNlLm5ldD6IVwQTEQIAFwUCPRHSFAULBwoD
BAMVAwIDFgIBAheAAAoJEKRiV/F0oGrNMRsAnAlWdC5LkmEF3hZjNAIA8gMxkfnZ
AJ4k6LXdmHMSSPbd48MbDYq67yzOG7kBjQQ9EdIrEAYAib54xuFqjHpvLxXmqFRl
qAgAD5XpavuJisxGjfm7aTVWIpR/OOVFYkW59YInHM7dDHL0Y7tQETeEKf9pj6kF
TMyWFoBjtdazqSmq2YXOvI00N27IKT9eqxJ/qR8QgIqBMNkraP9QKi60ASDIRUtl
OZSfokSbAKkZMTyS086CgWw0bCPXRCvQLHDjga3KCbht0AjrZFkGmi6r4+rXFnT6
D3JrNSQ0Hj2qFEixHtZvXTsqgsEkOEtoe5taMFSygM0jAAMFBf97Ip2a/kPkXNt0
p+2xmWIFEDim7J9Cwl5viTb1t8fOKx69hFDQ2BwPNDZd1HvlrYTpuJ23uTrDOZsw
IT/wVc/IQ9nn4+mkxOmq9iTHCBS99OXz4IsODT3W1sgzUfl+mdqJP8xfEnsyqy6G
ivOoR3QdZg7rxvOU98HhDQ1iJX3rCtLNFGisrovDF33oHMEE4oHvSMXeg65JXWiU
EpEpioINjrA3P+TL+fMv1tb4+wSUPqTWX34Gx4UfDKnMedxl6j2IRgQYEQIABgUC
PRHSKwAKCRCkYlfxdKBqzVtaAJ42mqzwmJCpk8fdsfkHUt5uGTN8sgCfdmDni1OD
NWQi1mhQOXZX9oGgyso=
=PTeT
-----END PGP PUBLIC KEY BLOCK-----
D.3.77 Mike Heffner <mikeh@FreeBSD.org>
pub 1024D/CDECBF99 2001-02-02 Michael Heffner <mheffner@novacoxmail.com>
Key fingerprint = AFAB CCEB 68C7 573F 5110 9285 1689 1942 CDEC BF99
uid Michael Heffner <mheffner@vt.edu>
uid Michael Heffner <mikeh@FreeBSD.org>
uid Michael Heffner <spock@techfour.net>
uid Michael Heffner (ACM sysadmin) <mheffner@acm.vt.edu>
sub 1024g/3FE83FB5 2001-02-02
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDp6LpYRBACHINF1K2lJiWCFAgY36X+NFDvgbRe9U7BKy2Q8ZPouMOi/GIwW
iocDyVwRnK8tC3D1BM3THs3cFW0aPsSOTGngZE8rTs8lm53UWi1UApTUztjH3odp
OynMb/Dj3k8SOWkq5mYYzl+38jsz067tRDlij4s4I3EjwcBQJOhnUUWV0wCgpDBc
wAx9TBVCSY9H5YLtCrJbnOED/iwQH58xpFLxQO1FDYlUCZgZaASm0luft13HuCrM
Zj2oDgJZOcuP2AshoJXnKavDjwBIvgf/p6cPZ9CS0sF8WI+v/LHN/EUQQoXXNzD5
ZujgMh1w35nMvl7fSJRDaie9HggnUx+ODtWimmROpiicDXb849asCrUUEcpU0V3G
wYaxA/96OWzf/TCr6CZABFBCLq2VwX3Run3ttBiXOVI69gEDj95mfeDUxPQH4JNt
/hI1B61Ab3/yDWmjzrW7Kb2i9URK4OKw/95YjoC2g0t/CFrmFi82UwMsmUp4mIqJ
eUrQ202IY2zCqCEtHcTbUdXrP1eFkGmi77s+KzzzknO63+efXbQhTWljaGFlbCBI
ZWZmbmVyIDxtaGVmZm5lckB2dC5lZHU+iFcEExECABcFAjp6LpYFCwcKAwQDFQMC
AxYCAQIXgAAKCRAWiRlCzey/mTswAJ9uujS3rA/mJcR8TH33q6SRhZSeFgCePzaT
lOAkDv2LVm0F+V5CBex2gkqIRgQQEQIABgUCOs49wgAKCRDCpSwr0i8VsUrfAKDi
Cffo5C6Ei5xHtWRA0DpHChOoOgCgqwDeqC4zLU/lB/jKYdGX37VPMQO0I01pY2hh
ZWwgSGVmZm5lciA8bWlrZWhARnJlZUJTRC5vcmc+iFcEExECABcFAjp/gWcFCwcK
AwQDFQMCAxYCAQIXgAAKCRAWiRlCzey/mRbDAJ9BS5FWb+Dj4IHlRYsr6IHCXxet
LQCgmpN9GwBWNxzBlbAQEw1O8anp5xiIRgQQEQIABgUCOs491gAKCRDCpSwr0i8V
sfQXAKDW4IsDEKGr1rYpO4IIZPMl2hVLJQCcCRUr0Mfce6AXKUYBfjAlZmddN0u0
JE1pY2hhZWwgSGVmZm5lciA8c3BvY2tAdGVjaGZvdXIubmV0PohXBBMRAgAXBQI6
f4GRBQsHCgMEAxUDAgMWAgECF4AACgkQFokZQs3sv5mRMwCffitElKCHTC+tF8hQ
R9Tdb87+PH4An3jlIX+TAD/u6CjyAZ9fR8nEXeVUtDRNaWNoYWVsIEhlZmZuZXIg
KEFDTSBzeXNhZG1pbikgPG1oZWZmbmVyQGFjbS52dC5lZHU+iFcEExECABcFAjrF
NgQFCwcKAwQDFQMCAxYCAQIXgAAKCRAWiRlCzey/mTbAAJsEIOjmXPBxqyrpS0QF
lrJtDENffQCgmWgC/5AezMfJwtu+s001BNw7oRmIRgQQEQIABgUCOs493QAKCRDC
pSwr0i8VsWB7AKCZe9euDml2vgJAaaPt34ptUl4UHACg4SZK21iSMmLW+cI6L8iw
gGvDcPe0Kk1pY2hhZWwgSGVmZm5lciA8bWhlZmZuZXJAbm92YWNveG1haWwuY29t
PohXBBMRAgAXBQI7RpsRBQsHCgMEAxUDAgMWAgECF4AACgkQFokZQs3sv5m0ogCf
RV9e/JXy1ixgKCVoqzaIQ3j2MBQAoJwtV25V4gpucQxysqRrWTB65Ja+uQENBDp6
LqIQBACFcO+vvM6/ItdzUhX3vIihiKENou4FchXwc/u7uchsLs589+PwaYWXqtPH
E9YSjXYo9y87Sl6ciOagBL6rJZ8oNKc/ylRmx42iSTdAdEKCgK355kmXiWgaAm/W
CT5YIETaY+D9TrBDD+c+ofB8vhekxAlr30FAnX6VmUJFi5xfrwADBwP+LiUdpsML
kdJj0Y8PmbB3Gxle3X9w+6hBkoP8Z0q5dzG3Y3mGYpgLd4Ytf1KEKUm68BDJgcvf
41B2Y6Ptp7mSRAufbymIRihNKH78fleaziWsux2CYJGZvsJzuYrlzgwuTzcLQKL6
MfRXZHPyt+1SwQeV6pIE0DBZLHg9a0Ak5sqIRgQYEQIABgUCOnouogAKCRAWiRlC
zey/mfYtAKCVze8DK+0HP1fTQyDajO7o9RTIVACeIwhXBEbRN8cH0BsG/8Qn5sZo
2Q8=
=/joR
-----END PGP PUBLIC KEY BLOCK-----
D.3.78 Martin Heinen <mheinen@FreeBSD.org>
pub 1024D/116C5C85 2002-06-17 Martin Heinen <mheinen@freebsd.org>
Key fingerprint = C898 3FCD EEA0 17ED BEA9 564D E5A6 AFF2 116C 5C85
uid Martin Heinen <martin@sumuk.de>
sub 1024g/EA67506B 2002-06-17
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD0NjbIRBACZTF4rK66+y43uXsV8CHSefx5lRHaLPFMNga+sUBRIFcwu9WbS
KSP/r60Gf/mNK4EUX3/+3gVljrgpAbQL9X9MV/SO50aZM8JMrUkUwjuzzzFKplT7
bdB2zWhexWemFsE0F1G5NpxkqMg/E0aiZb5P9MVJyGLlF1hCwhWsNG0OewCgzQ/b
yAEMk03PPk3DOaM4d/Vdf38D/j4O+TJPSjMf58wRGkrT+BmLCvFvg1OsUOMgyQPC
Y07yO6WmSiZV5ynqb4bS5m3jfQmG1I2wK+dIf8SHyaVgqZiUpfqrsFV2qwfZXcod
C8a8b/kmEbdMk1j+jZ8qxSScrKCHKqdEs1UihCt/F1kVVd8gqYbWouICxF4GoU4Z
ANmHA/4xVNIInKVghFk9lMaK9lDgQs02laaTWLWzcSfe28ADds3Jdur0Ox06tgeU
zdktWQvRYpIjqiQCCFLN18l6Lc5qyTg6fnx2yWpWJMb/xumUz7A79X0TBN8WG71n
zfJLHtn7fCjsi5009s7Ahu//Q7pGN8FvkrZHZ3xNw+3pAaoawrQfTWFydGluIEhl
aW5lbiA8bWFydGluQHN1bXVrLmRlPohZBBMRAgAZBQI9DY2yBAsHAwIDFQIDAxYC
AQIeAQIXgAAKCRDlpq/yEWxchZjRAJ4s0v1VXJmkm7kj3kMM0Z8xMNoJaACgkcMu
T1ID/2v+A1X7+suOzrWMr5aIRgQTEQIABgUCPZGohAAKCRCteU9X9uLnUzW3AJ9T
0Hzs6ZZq3HAYuSVkLReaZEhyGQCfb7goCt5RLbxx+3AMyyX5uh1boQmIRgQTEQIA
BgUCPZGlrAAKCRD5Ay7lt7i0eYdWAKDEeKMbkRTSZKsKelQwiD+T3me3tQCfVMLi
9mkjolOAXpAOVX3Igy5QHUS0I01hcnRpbiBIZWluZW4gPG1oZWluZW5AZnJlZWJz
ZC5vcmc+iFwEExECABwFAj/Q6/UCGwMECwcDAgMVAgMDFgIBAh4BAheAAAoJEOWm
r/IRbFyFjSMAniK+uu6ts+tLchT7+npgPJ0wmyCXAKCmCmXrSUTnPG5DwiVD66h6
aL2GHbkBDQQ9DY20EAQAh4G77oKy6pQB1+dhbbLsfb3UeRWv7i/w21Y1tSriZ5gm
HhofJRuczvrhI9V23wRVOKs417TGJzytDIfp/huycYMigAQXikmFBJSqIC2ktJEi
0DGhhne4XBdJENiHV8rb3/mk+Ffes/88DmoU45fpAwY1YN1jH8WO5mEq2aKCjHcA
AwUD/jBsaAoUeNO00hwuZuWYNM4nvX57nptObVzP54/TfKs4GmdWzcfI2JB+5eFp
rjtNCK+tosTQd73VzMWKk0fwiIew+GsB+g/ibK/WJW0lS6fktW2nPG2mGRblLtf4
8W4ZmtZUqFTBSbmZOcsxQ/LahRosX82NbQyFPwuFMEBqYho5iEYEGBECAAYFAj0N
jbQACgkQ5aav8hFsXIU0ogCeLnzxBftyPv5iS52Ear+q/mPZL7oAniB0B6mFArQV
gtLJNL6KejWqSh3V
=Z84i
-----END PGP PUBLIC KEY BLOCK-----
D.3.79 Niels Heinen <niels@FreeBSD.org>
pub 1024D/5FE39B80 2004-12-06 Niels Heinen <niels.heinen@ubizen.com>
Key fingerprint = 75D8 4100 CF5B 3280 543F 930C 613E 71AA 5FE3 9B80
uid Niels Heinen <niels@defaced.be>
uid Niels Heinen <niels@heinen.ws>
uid Niels Heinen <niels@FreeBSD.org>
sub 2048g/057F4DA7 2004-12-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEG0KFcRBACgVFt+tcJtDzCAHLta1UxWlT5ucTeSfsNyhfYRdoz+IBtJ7bE+
8ydX/y8ZG9Rbb6SCP176Cq/sHj5hDlxp62k/7csOcLvjqPC5dbZG8hgxerygXLE4
b76zjI5KLOyCDRyqh+DEBO4uuopZ7ACoJMRhCWyfgqJomlGy0Mr/BzfffwCghsiF
7TsOUyQcV0vlxSXBF5bZ5I0D+gIVZSjLsS8IXUIZiK3dRFvHm4aWrcxwlGKsfJ4J
wGvOMR5laNHXINUYaoEBdiUaCWW6J5lesluX7/g9+X8t9mvfMmDrVlrJKoc8zlhM
o29TB4oL5mM7jHjy0Dw8q/n1i1ydWQgu8a3v7giuoYaOKX4N58qWDDGBbd1jOkol
bnqIA/9+kVIr92q211LsR3GJTFMMs/f6nbDwiyZdpzxE7b2Xu5d175wjX1wqJT9C
pgS+8p8+Puj+KyVJCGQTw31Cba7W54bOxfbJ62rheh/xVBwfDwdus3XH3WEH9KRm
pLXRowTqliAzl3CEu+iFqJKqUQ5AYe0PhhcT1Tbf6PHp7iQdTrQmTmllbHMgSGVp
bmVuIDxuaWVscy5oZWluZW5AdWJpemVuLmNvbT6IYQQTEQIAIQIbAwYLCQgHAwID
FQIDAxYCAQIeAQIXgAUCQbQ42AIZAQAKCRBhPnGqX+ObgGqSAJ4/ld+x0v6/64Up
+1IPobpSdvjgzgCeI7Kp4K1Td7QNQG6Afc9nY4WTj+60H05pZWxzIEhlaW5lbiA8
bmllbHNAZGVmYWNlZC5iZT6IXgQTEQIAHgUCQbQrdgIbAwYLCQgHAwIDFQIDAxYC
AQIeAQIXgAAKCRBhPnGqX+ObgIDjAJ9iqh9KLsBXEl3T9U4xsLpqKHoPugCfWm4T
jRLWPt0TEGm+0nmtlG1dP4+0Hk5pZWxzIEhlaW5lbiA8bmllbHNAaGVpbmVuLndz
PoheBBMRAgAeBQJBtChXAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEGE+capf
45uAc5kAoIIA2lj2dycq87whxsoWq/vpdb6sAJ4iHMxJ8xN9QiJ+NiFZkNds4+iZ
uLQgTmllbHMgSGVpbmVuIDxuaWVsc0BGcmVlQlNELm9yZz6IXgQTEQIAHgUCQb1m
XAIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRBhPnGqX+ObgB8fAJ9xsptfCNqT
ceHQzE6KvCAGUvTSQgCeMNrLow2tqvi1cbrKyJHNwb8uace5Ag0EQbQoZRAIAMCB
AJMtUeb1EZKoeHhMiaOoIfQP1u9CAEeLEcv6QhqqY/8qQdoQXLpdfjXkKV5K1DcK
1nYzBatU3DIHqP0qVD1Sfm8tqV55Y42wKmMlA0nM/ryJrf+9b2kx0p3Uff6PIErU
6KA9BE8a07j/bJKaA5Qfr2WNlzsV7Pvj7kyx/wCOB1zCPlZGDIlCW0vYrT9rRmz0
EINBEPqJLYAFBZ3eJ1+0a8lWf1ERhmF2nzz9Kr03nN5NA1iiQj3G6M3VgCMcC7XX
DgDVycSt7ipFV7+2fUtRxKFJgIwvvkaDKsWb2vpzEcj+D7rAoGEiJmfwBbFDMB81
N9lBLHbAQ8fl9pdaHiMAAwYH/ReHUkVakaHWhC02VAwYudIcTIwJ8FnZ6afU8av8
mHSZFoL0ytUguxeJW4009z4TKU/9EfWt9V2HqnUQpff98YI/ysHkWuGLwplIe0N+
l2TNpIBYoYkyQwjHygqR+PaYG6X7ncICFqJTgbjFDjCPu4v+um8CNoT3dlzqYXIH
T2AX9zkS7600dRLqE1Zl684atsYQduYWdVPwh9fzER5zjwRk3My61fR7uYGpxwoc
SxZOQOU17s21G/pgqv/oZAPqLdUfLXQ2ZG+naMfp8xMpsbJpWPF0Fnqklx3VZKM8
Zx2MStJaqeoPVDjlvAbLPvOioFCUAcIO62N0IcK4yV69YJyISQQYEQIACQUCQbQo
ZQIbDAAKCRBhPnGqX+ObgBR1AJ4itGc8L05AY6C35TL+ilvXDp1uagCfR9Dxmg2u
9RkYrA9581ilMd2RCkU=
=x4MH
-----END PGP PUBLIC KEY BLOCK-----
D.3.80 Guy Helmer <ghelmer@FreeBSD.org>
pub 1024R/35F4ED2D 1997-01-26 Guy G. Helmer <ghelmer@freebsd.org>
Key fingerprint = A2 59 4B 92 02 5B 9E B1 B9 4E 2E 03 29 D5 DC 3A
uid Guy G. Helmer <ghelmer@cs.iastate.edu>
uid Guy G. Helmer <ghelmer@palisadesys.com>
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzLrzf0AAAEEALuGJUgTVleE9HeqPAi+AqBDMMfa76kC63xx98Hqv1N9TlT3
jlWVShX7Da/9h9WgK98wkb7613Ur7dPl2qVcSns5w7MCustbtt4YEaQwXZ2jOEZf
snKt82+DYxZRyfUlY4h/8WA79R8BwTGd/l6g3kDoQuD/446BT8c0Yd819O0tAAUR
tCZHdXkgRy4gSGVsbWVyIDxnaGVsbWVyQGNzLmlhc3RhdGUuZWR1PokAlQMFEDLr
znbHNGHfNfTtLQEBxIUD/2Lk7Ds8Rt5ZPVNB2Xv2kzEByndv+r1FUDSDcWUn7MaG
HdgIqfkNespNzv8K7ORW+qrgIAtCRGXhc0Z1q1/Mb3kzC0g4UW5BuleZEur8Ys7t
lc13ZV94Wb/rVEnY5wh2s3mCmMeXVA9CAiNBzzI9O1RKVZrLLYJk62ysSoq1os+A
tCdHdXkgRy4gSGVsbWVyIDxnaGVsbWVyQHBhbGlzYWRlc3lzLmNvbT6JAJUDBRA7
8tH9xzRh3zX07S0BAdUDA/4poipXJFYG6r7+Hk32P5unYZt6dJZ4qSwsnc4+DVuk
krv5L1jC8Wg/Ojerk2hYTyArM7xQkw0tELOADL2KBUlHp+Ipz7UuO55n/9aOHnWr
YJLjT3+9eliYkPqJ4t7sHqlCeuyKc7HkoaaN1ErJTmLLy/Jfcx8BsyVsgihI9V1s
VLQjR3V5IEcuIEhlbG1lciA8Z2hlbG1lckBmcmVlYnNkLm9yZz6JAJUDBRA78tIj
xzRh3zX07S0BAXQ6A/4zKB/ROfSAUmVQGm0tH1IC4lZX1qV/PZ4z2KUWQPmXP3jr
jzYFdlAPaUNIwVqW8Mwj+p9njnL/Ltd3NzAjTP2I7bSzBtg4NcEBRNclOOnbCamX
B4mSGt07WgfT1QGCY8HyKXNhUBbqvPShfeH1OM7iyooLWU79V/1v8utB/mHxYw==
=nrvZ
-----END PGP PUBLIC KEY BLOCK-----
D.3.81 Maxime Henrion <mux@FreeBSD.org>
pub 1024D/881D4806 2003-01-09 Maxime Henrion <mux@FreeBSD.org>
Key fingerprint = 81F1 BE2D 12F1 184A 77E4 ACD0 5563 7614 881D 4806
sub 2048g/D0B510C0 2003-01-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.1 (FreeBSD)
mQGiBD4dlrYRBADhXves+DDbhv8dD1LyC7e+RIASp8rEN0mJDVarhEy45KxRZcD2
hE9dLXZU/5hcdK7yfatneg5xGFiedFJ+u/HcsMkxeb60+RUcF6Ec5L8PJmCwIQl3
3xP7UmC203YufvyidQSayOk4LDyg5WVGEXiN5KuShJC+feAwvtAao5eHnwCg5CmE
y6rO8Bh/K2MQxP8CXCoLG80EAINd8twMsRIIqAxtVWeG0yudtgYdvhpbGrNKoq2b
cxmfunLAQmHim1jL5run1St3ZACyuP4brckPiBAOxVoRcIMOGPk04Lw3blKQ7u02
6aOKKlGvW2pF5/Wh6v/q7gzAucn1HJYcGK7Xc8IvfdIZJl/tTeCo0/smxND4EWhU
C94zA/0bvNhgntEwLF8x6UJnZXfQ8/LGl/NkSTyTMA1QqRrrik1oN4mYOAHE05Y4
Oija6MSgD8YDRcrxxr8Dwh4pqS/+FlEsV5y4A4OoYbPW5L6FAbEpKO86jbE3FK20
lX9Li5+woBWaTuLRcU2Tk69WLeOTdOrs+f50S1xWB4DJKBjmu7QgTWF4aW1lIEhl
bnJpb24gPG11eEBGcmVlQlNELm9yZz6IWQQTEQIAGQUCPh2WtgQLBwMCAxUCAwMW
AgECHgECF4AACgkQVWN2FIgdSAaZtQCcDxSj1KNFQXWXPl+U27Sl2/IbKEgAoNDq
Yn86zUh4NPJZJb3P174CFRK0uQINBD4dlxYQCADaMWMhYNWemjrdioJoZU3vYkup
IcQg422OZoxWYcUz6zKVHZuPdXSAFO+Edrt8QwvYrjhSiOSF9NNnFgNGMBGmqOg9
Kfk5rIKnENNQP8H8CZtzlDjJXVoMAeTfaeV9+ztHwWKk6XagjLApl9Fx42Quu4Po
JdvJNHhq5Bf299jecRsWmSo7DtpNnzGC2HFWRkGdkkNmpK7hFe9m3YsFuP3nCFps
RXCFMx9t2Bneh1eM+NqogjON+vyZzOUB32WY+x9Kz6Xf29auU1PSNYz+1LC7JAYk
f4CrFA6wexQHKe/nXwlik3/JeFSPAsp/VsmvaHOenZTOfmtBT4ruOwqn8DGzAAMF
B/4tHAo7/sAMgvkz0qHAxV1DjOjB5AQSs4phksYWYN1uaJq2//oD/jjifmmkhAq0
JLEeKDquvuNot9dtJ/75DF/XNa0Upt4Hq509Wm4o5NBN/CxRzMn6oU+K86S6RF1x
JidNNI+CsTfdkNnCn0x6OjRsG0j+CUbwRrs4CJ/7ZWkuMCclLBKoI+rAwd5YM4eI
noSrSZ4/2Uct7CyVm2aGIh5ofR75L7k92qZ/D5hN0wwKrL42bO8gJqPGPgsCtr9m
OcT2DtOxkS9ir2QRyD7SelKM4pmSbxvk8S/IzrNS7dvKiO0xQXsvf+sG9rZOJ2vF
i3in0uB9SeXAzsqNCqtEkSbeiEYEGBECAAYFAj4dlxYACgkQVWN2FIgdSAadQACg
z3dGbsy32PBhRn/t1lXp1120VrAAn04hxsFX0HEKt6sqAcpIuzdTVrEM
=8gWX
-----END PGP PUBLIC KEY BLOCK-----
D.3.82 Michael L. Hostbaek <mich@FreeBSD.org>
pub 1024D/0F55F6BE 2001-08-07 Michael L. Hostbaek <mich@freebsdcluster.org>
Key fingerprint = 4D62 9396 B19F 38D3 5C99 1663 7B0A 5212 0F55 F6BE
uid Michael L. Hostbaek <mich@freebsdcluster.dk>
uid Michael L. Hostbaek <mich@icommerce-france.com>
uid Micahel L. Hostbaek <mich@freebsd.dk>
uid Michael L. Hostbaek <mich@the-lab.org>
uid Michael L. Hostbaek <mich@freebsd.org>
sub 1024g/8BE4E30F 2001-08-07
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDtvujkRBACVspBVp8gaHUZeh35hSQiKdKYiA5zd0Qez3eiRrWFIilZLB5HH
reTe+wFwBOMEsgwA7e4v5GWnsWySWVRe3okPQ+Nc3CTmF7JGlnHklhExFtQ4EGCq
Z2BCj+QfusUap4vArd+hOW4MS8bCnV8GvDJLdIMdbOBUI7RAl6+JRxQqYwCgz47A
a3bnV0/c9E9nuRek+XRQfDUD/1fsX2sK0w1fjLvBDcrhlPFUDj4P/G9QrjnWJbBl
RaDpYaSEklbb+g8TOVtPEqprtFPQvqB9kWS9IJfmd+WRSJYXBtTFPJaYAy7hlQi5
jw7pqIK934cMbJEIMKDfkScpKrC3qplRIUN8oRtpYONF9TnzfrA3RkLvG1Dk20kc
RIU8A/9uOfhXSgKgTqSZbW3QbWdE7VyVOBLANeWgHY3MOhh4qKsbM2v7SK2lSVu+
cY650DmZNJEpD7mE5wje7eFTvmrTbB1bygBrpxlithpNkqlFp/ePmU+sal3VTzJ2
SOpDkw6NaGTMercnJe+jWObfPMphEKL18zM/BFwOWg3ubGYlWLQsTWljaGFlbCBM
LiBIb3N0YmFlayA8bWljaEBmcmVlYnNkY2x1c3Rlci5kaz6IWQQTEQIAGQIXgAIe
AQQLBwMCAxUCAwMWAgEFAjtvujwACgkQewpSEg9V9r7TyQCgjH3eMZ0+irDBZ+eS
N4S9vV2eC5IAniLYcMk66do4xiru6g3Qt54B0beAiQCVAwUQO3JisgDy2QnruxtB
AQFYBwP9FMPDSv4DdSWaGkCXSeSLfyMsTflkVRa0gRljcqEQQ8iEfYKaum8eI8vE
Et2h+bMVe8q9PnCB9Fn++pukaH5wrggg3O5o+2gSh2Hoy0/Ter1E6gHiH8aWoV5V
4yB2J9hEffTrzzG0X4G77XVVWCiAqyp52gRMl6ftbOOXU8XDat+IRgQQEQIABgUC
O3MMugAKCRCjLHqb4LuvBA+BAJ9Zrf3OInzwdjeMthjZ6kYtSYysZACeK9vXzmNn
PcrKw/W/6M7egoZIeouIRgQTEQIABgUCPmxk0gAKCRDdEQhXRChuGuaeAKC9pThr
yviZ4bdM8X16xVvd8RDrZwCdHOPEdLM5xJrMyi52SnqVFukInMqIRgQTEQIABgUC
Pow66QAKCRAATVS4OT0kackyAJ9v60ShjVJHiu0CdRf/ylAid9w2yACeNrFJ5axk
lXLO1sqje+YW9goFCkKIRgQTEQIABgUCP2OqBwAKCRCgT/sbfcrp02A/AJ9ArfKX
XakRN3oiBpoKtocwvVNQ9gCg9VbdLiQ5wcKpKuftk1Bem6PXAM+IRgQSEQIABgUC
P5ebXgAKCRAi5vKQUHpCI7SeAKCW6ufJoaUYFz3frGo2dfWzjNwygACglQFhJGPI
BOiIaVwZP92CBwPUO6uIVwQTEQIAFwUCO2+6OQULBwoDBAMVAwIDFgIBAheAAAoJ
EHsKUhIPVfa+a/cAoLJDt6PWCv2PbCf12owCoebj5USrAKCDPAiZ+er8CjkcKnZs
G3JUPl9KO4hZBBMRAgAZAheAAh4BBAsHAwIDFQIDAxYCAQUCO2+6OwAKCRB7ClIS
D1X2vg9PAJ4iPqRoS7R5MLHf/2NU4YVR0EjICgCgvqkehhBxgdV4PLn/ahj0Qt15
6c2IWQQTEQIAGQIXgAQLBwMCAxUCAwMWAgECHgEFAjtvujoACgkQewpSEg9V9r7m
igCeONqh6+GxitwdVEWxdn97jJk5lWkAn2E5ygo1qdsEYizcGPY+RAQa5lsViEYE
ExECAAYFAkGEstMACgkQqy9aWxUlaZDr+gCg9bKPJc+3GQz4wsybaOpXsNRR4HEA
oPbWzHK2TkOneHvX9yL+y/5NuMUjiEYEExECAAYFAkGEtrUACgkQv0vQ5gSduHkk
1ACgysndAyCMjx7wuT1EnxXNHcJjwr4AoMMtFh2jP2oZiCL9j1G0sM8HA4zmiEYE
ExECAAYFAkGEttQACgkQjDKM/xYG25XyfQCeLbZwZdPR7muhBCWYOG1xqbvhlgUA
mgN72X1hceIs2a3v/+wlbbvdkicKiEYEExECAAYFAkGEtx4ACgkQFdaIBMps37Kp
mwCeMD98R8Pd5wUIsvlNiocZATBhFAYAnjso1MiYY5r/vm+gcaLxYCeGAyjoiEYE
ExECAAYFAkGE2O8ACgkQFGWX3NzDmcfFZgCgzKhe7nre34c0yZGDRcfzXlREoiQA
oPx4pDwJr8UZW2b9AjEDiz5mKavhiEYEExECAAYFAkGE8vgACgkQP6DeCKDTkWhp
XwCfX5Ct56AL879/4bI23egU7sst/gAAnjJ259f4xG66pxv0c3ZA+3yzby9EiEYE
ExECAAYFAkGF+m0ACgkQc95pjMcUBaLuFQCeMt4CFIkaLmCbwTdhAI46oO6d6hgA
oJb0CqzkjtMv3mGBQs3Xq7GcPAK7tC1NaWNoYWVsIEwuIEhvc3RiYWVrIDxtaWNo
QGZyZWVic2RjbHVzdGVyLm9yZz6IXwQTEQIAHwIbAwIeAQIXgAIZAQQLBwMCAxUC
AwMWAgEFAj1t+AMACgkQewpSEg9V9r4uWACeLnmepDc1dzPMmQAxCJNXSMRoBrgA
niG2FR5ttJuXfcHofVwrN5qTk81eiEYEExECAAYFAj5sZNUACgkQ3REIV0QobhpD
GgCeIIJ98azq2OBixZd19bthwdBY0loAoJqUDsnkxwzGFWYhMeSp7pVysC0NiEYE
ExECAAYFAj6MOu0ACgkQAE1UuDk9JGnA6QCcD0X7Y+h3SrmHrjG0a0RM5bbP6CcA
nAkceK9Bo7FCIZOfyJiTgRimK3/biEYEExECAAYFAj9jqgcACgkQoE/7G33K6dMy
EwCdF7OWVKtQZRyowf6pmI22A4DCbgYAn1GHBFmblK4G0DZ35gmFxLwcXWcfiEYE
EhECAAYFAj+Xm14ACgkQIubykFB6QiMJzwCgtNxJpyZgWWD4/UKfPRwmnINAYD8A
n1Y+CLQxCAuLkPe2nFAPGUFhFBGYiF8EExECAB8CGwMCHgECF4ACGQEECwcDAgMV
AgMDFgIBBQI9bfgBAAoJEHsKUhIPVfa+hdoAnRGTkvkhCKxB0Dl8UiMT74sxwRpU
AJ460yVCwW+egzvup6E976k1wpa5SYhfBBMRAgAfAhsDAh4BAheAAhkBBAsHAwID
FQIDAxYCAQUCPW34AgAKCRB7ClISD1X2vn/AAKC5d0k4mJ1AvKIXV+STb1t2Ygw6
UgCfYpRFyocSgo6KpK12YEyO0zQtCaSIRgQTEQIABgUCQYSyzwAKCRCrL1pbFSVp
kGQ3AKDj72l2upUff57ThpKbD6b5yHgN2ACglno3WKcuZxvdhTV+uzz9ihjvQdOI
RgQTEQIABgUCQYS2sQAKCRC/S9DmBJ24ebQDAKCZ5omgIy7Ps2BE+6ECGlZWdRDT
SgCgv/iA5FuFcdQJn2/ScBeMiV40NuuIRgQTEQIABgUCQYS20QAKCRCMMoz/Fgbb
lboaAJ9/vvhxWtUnRQiv8c3V1iDCDFL6uQCeNrvMsVmoOBo1Ffa9qiepLElBQkeI
RgQTEQIABgUCQYS3BAAKCRAV1ogEymzfshF+AJ9n4m0OMgqYSCbyMV1ZKF9aFDHj
5wCfRY84mbxPr5lnwp0jS3Y5ZWJ3ipeIRgQTEQIABgUCQYTY5wAKCRAUZZfc3MOZ
xz9lAJ9AuKYrFFw5WjJnhDn5kCaQBWy14wCgns8BUwJtiEnAmlrunzxS2ZbNkH+I
RgQTEQIABgUCQYTy8AAKCRA/oN4IoNORaJmRAJ47uMWxyt0OKlVH3SIRT/tuPN3E
vwCaA/sMCtb+ocVxMbaqskSJLSHjsb+IRgQTEQIABgUCQYX6YgAKCRBz3mmMxxQF
oqP6AJ91VYhI/uMUvRos/eT+xsLiOtJpCwCg3tFVZhHgpOCbljAEwbSRbM+YMT20
L01pY2hhZWwgTC4gSG9zdGJhZWsgPG1pY2hAaWNvbW1lcmNlLWZyYW5jZS5jb20+
iFwEExECABwCGwMCHgECF4AECwcDAgMVAgMDFgIBBQI9bfibAAoJEHsKUhIPVfa+
cIIAn2NHuE79An0zOAe5Eb6U/wmZXAvSAKCv8K0wgLvlNPjksWEx8t2G3e78uohG
BBMRAgAGBQI+bGTVAAoJEN0RCFdEKG4aswcAoMBnOBIIHYdUEJ4WMT2sDzq7GHio
AKDd912ew00eGfdnEwSlkRuhGYl6CohGBBMRAgAGBQI+jDrtAAoJEABNVLg5PSRp
NzIAn0T3AF1A70ENm7gxLzjgQpdfEyyMAJ4/H3SBcNQSoQQnxAdrSmzCEBtllohG
BBMRAgAGBQI/Y6oHAAoJEKBP+xt9yunTLRYAoMJUuXFPYZaVmAym0xqsdUnHNaq0
AJ9JLnudg19UlwZBmauji/tdfWxOk4hGBBIRAgAGBQI/l5teAAoJECLm8pBQekIj
SzsAn30cbHvSF/4PIEKPZj0LO44679iwAJ4xXCaCrpUjJN8UaoA6RI3O90YgHohc
BBMRAgAcAhsDAh4BAheABAsHAwIDFQIDAxYCAQUCPW34mQAKCRB7ClISD1X2vtTD
AJ9xoKScCZTRjE4nAoQPxotRcryXcgCgylmTpQCdAXm2b2mCEMPCrdBh0uyIXAQT
EQIAHAIbAwIeAQIXgAQLBwMCAxUCAwMWAgEFAj1t+JoACgkQewpSEg9V9r7JCQCf
QaHiclxq5DTYIV/aLt3LbTht9LQAn30zG7XaHijFGLdK6dBJILPsCeTGiEYEExEC
AAYFAkGEstQACgkQqy9aWxUlaZD+VQCgqZN7CJgdZf4ZCuSoGi7jr6XXPmkAoKTH
8r8wQkbO9/DUhr1Coh9arK9PiEYEExECAAYFAkGEtrUACgkQv0vQ5gSduHm+7wCg
6kyLSRHu7L9l7htBjHBIaWME8WkAoLUJ5M8enb2DDjwlm2BqtZlGNA2QiEYEExEC
AAYFAkGEttQACgkQjDKM/xYG25WobACeP5EDN4t3GOEyou63pI657mB/du8AniYQ
kQvpWYIgY0dyMSk1HatP22iPiEUEExECAAYFAkGEtx4ACgkQFdaIBMps37LTVACf
fik1GnfLzg6KbwS6SZKThTeKAj8AljUT4+LcxFg6SgsC+tvATUMDn1uIRgQTEQIA
BgUCQYTY7wAKCRAUZZfc3MOZx0wSAJ90OL9LyJnrEmgXDAnl1KyV80OgPwCgw1RQ
KMCDeCXfn1q9uzKTFWGEl5WIRgQTEQIABgUCQYTy+AAKCRA/oN4IoNORaDmmAJ4g
AtnkP+wrNu8ALK18MZczQQKFIwCgpUTdqJHlB+NxfUoB5gwtcb7rpQ2IRgQTEQIA
BgUCQYX6bQAKCRBz3mmMxxQFov+JAJ9e37KaIc+H7v7imwtKxiE7qNNVOACeIaij
Sx+ca3H4BKQ/a2GvPhM48ya0JU1pY2FoZWwgTC4gSG9zdGJhZWsgPG1pY2hAZnJl
ZWJzZC5kaz6IXAQTEQIAHAIbAwIeAQIXgAQLBwMCAxUCAwMWAgEFAj1t+LIACgkQ
ewpSEg9V9r5uBQCgskCQeIaWBjnmd/Xnh0ZKX51xTxUAoLcld6rVHA+4e2Vz3FQ3
T73d2r4yiEYEExECAAYFAj5sZNYACgkQ3REIV0Qobhrq4QCgqnRha2c0Vh5h/945
x9cl7TSYzZYAnjbWNvJbo7sIo6TQxEZKmdnvmsHbiEYEExECAAYFAj6MOuwACgkQ
AE1UuDk9JGl9eQCfTcakGDP/BEmyuEA6GDM5aRb7vS0An2TJiDW84eHxcxHQHPzy
rz2FB0/PiEYEExECAAYFAj9jqgMACgkQoE/7G33K6dM5HwCg7mDLpb4JByHaZHtK
zRQjQzjzJWQAmgLnvaJKlwv20zvAgz0hefi+Q2isiEYEEhECAAYFAj+Xm1MACgkQ
IubykFB6QiPtNwCgotfWEdrMUvjldC/xcvo1joaccxsAnRnPAc8l62wttcvZCWh4
ZpsozqBhiFwEExECABwCGwMCHgECF4AECwcDAgMVAgMDFgIBBQI9bfiwAAoJEHsK
UhIPVfa+FNUAn3R50AIVQ1LceP8aMoGyOBbL4WZaAKCwLyjDh+06muXuDNcu3s39
SvUO0IhcBBMRAgAcAhsDAh4BAheABAsHAwIDFQIDAxYCAQUCPW34sQAKCRB7ClIS
D1X2vumaAKCaU4A04bFCI9oOVUGo6ejx57ZCDwCggMwl9wIKt04aupwmIgira6sW
yuKIRgQTEQIABgUCQYSy0wAKCRCrL1pbFSVpkL09AJ4kW8Ajmif23gAnM+Nc0MQL
7GwVbACgysRq7spf7uxiu9awbqx8By+DwniIRgQTEQIABgUCQYS2tQAKCRC/S9Dm
BJ24eRzHAJ9x0WS9e9hsd+Q88J/koRcheAmHJgCgpb61Cd2og0AE3HosvqSguHmU
u0qIRgQTEQIABgUCQYS21AAKCRCMMoz/FgbblenRAJ9lJ+FVcaADxVBp6EyB+YXE
kDAYJwCaAxa8fGK/1WrHW2jC43mmoOGNFAqIRgQTEQIABgUCQYS3HgAKCRAV1ogE
ymzfspOJAJwNipmOK7ocbWNbRQSCtUSkDB+U9QCeP7j7GEujTO5M5R9YtJQWF0dv
STKIRgQTEQIABgUCQYTY7wAKCRAUZZfc3MOZx36GAKDhFbMLKArBw40n9iDqKSYs
9yw5DQCaAxoSVaAPfniFAj193AAcTcQTMZiIRgQTEQIABgUCQYTy+AAKCRA/oN4I
oNORaIBqAJ9a85JXuUr6vj82HL0bxPVtQOMynACeIJUyjZbdoLX+GVLsFIXUGHzM
GsyIRgQTEQIABgUCQYX6bQAKCRBz3mmMxxQFoqWWAKDKwqQTeMsPEfR5rn7VLbsB
FGCW+QCeMrfldx7v5ibUgVQLZwW7y0Hu4iK0Jk1pY2hhZWwgTC4gSG9zdGJhZWsg
PG1pY2hAdGhlLWxhYi5vcmc+iFwEExECABwCGwMCHgECF4AECwcDAgMVAgMDFgIB
BQI9b0hiAAoJEHsKUhIPVfa+sZkAoIlIoBDtL4BAInfH1oiTVbWNHQhDAJwPeBUX
sa2F3cU3+Fksg7n6sDIYYYhGBBMRAgAGBQI+bGTWAAoJEN0RCFdEKG4aTxcAmwa2
jsIaacyRb31elEKZdSWMfZbSAKCy+LiAAemcmXzGUnvSM7/M4w1J04hGBBMRAgAG
BQI+jDrtAAoJEABNVLg5PSRpfLEAn05R33B7SPNsIHEPt+cEINb+JexQAJ97c3MU
uDW8FHq8GnY+AM26YzHa+ohGBBMRAgAGBQI/Y6oHAAoJEKBP+xt9yunTHyIAoJgB
MltcxW2Fsf3mJxC2zPf2JtuOAKCOydWeCJITDRK5olxPzIAn3ctrH4hGBBIRAgAG
BQI/l5teAAoJECLm8pBQekIjv+oAn2sjoFPJgB+jG5rC22bktfYpFT6PAJ96z9ho
K4X1Y9jkv069GDEifHu17IhcBBMRAgAcAhsDAh4BAheABAsHAwIDFQIDAxYCAQUC
PW9IYQAKCRB7ClISD1X2vsxLAJ9HVuI9Uea+mqAWSYJEy7ZHoPQtGACgq58A8xhV
qphW0P6DOYdBhR6HYwaIRgQTEQIABgUCQYSy0wAKCRCrL1pbFSVpkAknAKDC79+b
reyVTbhWRcyp8UtIUBJA1QCfaXqiKIfEMmSAy1H3vjeNktY75C+IRgQTEQIABgUC
QYS2tQAKCRC/S9DmBJ24eUBeAJwKHyAILuk8oRPuTPAu3jsUmvIWAgCg2frzaL1x
nxN+wdhZQvkkPJhrEciIRgQTEQIABgUCQYS21AAKCRCMMoz/FgbblWULAJ94zCGb
qB4vCnbxADeZCSlbY8CqQACgjpg9ARbzZK1GDMWlHnfeBVY/BJ2IRgQTEQIABgUC
QYS3HgAKCRAV1ogEymzfst59AJ0bNqnso3f8CMhJEgTSsdk26pSgwACffO3NMpnW
lF7Kt+yVYqZoB1tsBPmIRgQTEQIABgUCQYTY7wAKCRAUZZfc3MOZxwrZAJ40y6Ql
edj79oaTgj4csejdGdC7mQCgnhRfFtmzMsHNsTTNW+NVQZjMiEaIRgQTEQIABgUC
QYTy+AAKCRA/oN4IoNORaHbwAJ0dY9HwXDtQrLrlfZRA1eDt/0dmTgCcCLN5OcqD
qqJzT1oTcL/4pebrPcSIRgQTEQIABgUCQYX6bQAKCRBz3mmMxxQFot/lAJ9EjEc7
BWpV2pX/OZiF4N0oiuZe/QCgm237ZWa+5LgxwxhYnjRNpPY3aGW0Jk1pY2hhZWwg
TC4gSG9zdGJhZWsgPG1pY2hAZnJlZWJzZC5vcmc+iFwEExECABwCGwMCHgECF4AE
CwcDAgMVAgMDFgIBBQI+t5S0AAoJEHsKUhIPVfa+AakAn3Sa7A6PXq6Obvcnjljz
MjupTQi/AJ4/hk2rna5a2IVfO3Fr1qd0xdySSoicBBMBAgAGBQI/Y3i5AAoJEB9/
qQgDWPy9RF4D/1t7oN8vrY2zqWsE+P33mp2n2cw+lh53/AxWvyviy2eBhmTCqv5M
OFHC4Ytpm2wO4ogLuWB9sD3YcpRm68HBCmL5RWZ+2O0zWzM2ldyOt5ILwk2D5CQD
F4eC3zjjpxnpop5I683Y4HL8HUxB7wjmzh3Nvu9BWt//5yyYYV2TuFLciEYEExEC
AAYFAj9jqgcACgkQoE/7G33K6dOXigCg6ifuqnvO1X7ev2MITz4UMavyC7sAn12W
5YjbsctLpXOFv68NKS1z/UhmiEYEEhECAAYFAj+Xm14ACgkQIubykFB6QiMeXQCc
DkBg7qBuixrrUZ0ggK6DdninuWYAn0f7rpy5x8zTm4iOdGHyU5BbdaHeiEYEExEC
AAYFAkGEstMACgkQqy9aWxUlaZDb8ACg5FbFbPdaGLgzmE4QqaL0zT52sYYAmgLk
F+gEiEzKGMyyP/9GhB/nNO/oiEYEExECAAYFAkGEtrUACgkQv0vQ5gSduHnEWACg
7Do4GC0Xly11Q/I1LpdCAaTrScsAn0eweaomvm5DDke1Yup8nwtRwPoYiEYEExEC
AAYFAkGEttQACgkQjDKM/xYG25WuuQCePmHg89cl/KliQJbDEdb4gro30IEAn32Z
Z2EqGyX4WaTM94aLJx6fwjwxiEYEExECAAYFAkGEtx4ACgkQFdaIBMps37JQ9gCf
QUi1yI1vibCmr947dQOnRe7GfMgAn327S9U7RlNvrvG/nwmwVMPJv7rPiEYEExEC
AAYFAkGE2O8ACgkQFGWX3NzDmccWMACgwqLn776Ly9PvHMfe1abvSJhxNhgAnRKj
9a/OfIvdUGUTLnuzRlLv8KXxiEYEExECAAYFAkGE8vgACgkQP6DeCKDTkWiCaQCe
McWdZWqBeqAAC2/hsdvRyPSaa4cAni31b95jB2/xpWh3Ietn+LgKH83MiEYEExEC
AAYFAkGF+m0ACgkQc95pjMcUBaLrpQCgn5t5Yh80emZx8pBKA+eJqIzI5e4An2M4
pil7LSgCf2VdSIgHRPo624CWuQENBDtvujsQBACFt7tjPWjHlYZMEml5R+o7eZTr
UUw0tAtcMcwV86r5xmvllPhsjar/LMAY+VqLPD7Z/KwTwrRfdf236sPshB/v5BoR
u4RCDW0yy6Q5xOLCj0LlOarUfTYUMhYVfv2FNKNm5FSk9/3NEkwNi/PxGAV5KNIx
QXDND4YskIjGiJUZMwADBQP+LVrKJYCmOM3iq3qfcuONwpBvhJb8Z7AWywUyl3H+
Gy5/PF0nWzN9nQNHcb5aqiszY4tvdqAUW/ttIRtKR09BXDaAkct55YywRf+mM5Eg
KxWQtjPW7THXzsPrSCJ9V+lYMH3wHw9+qs34fA1I2m0P2QGw6b1ZcESbH58wM4x7
ZQOIRgQYEQIABgUCO2+6OwAKCRB7ClISD1X2vgovAJ4xjmcdulAo4ML4T8TJ+alY
nQO5zgCfXsb8wtA8I0ngWwOQxrnRRE7+Smw=
=j3Mm
-----END PGP PUBLIC KEY BLOCK-----
D.3.83 Howard F. Hu <foxfair@FreeBSD.org>
pub 1024D/4E9BCA59 2003-09-01 Foxfair Hu <foxfair@FreeBSD.org>
Key fingerprint = 280C A846 CA1B CAC9 DDCF F4CB D553 4BD5 4E9B CA59
uid Foxfair Hu <foxfair@drago.fomokka.net>
uid Howard Hu <howardhu@yahoo-inc.com>
sub 1024g/3356D8C1 2003-09-01
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD9TDBwRBACs0PcLGuginQVidy1QScHuKS9G7gd8smYI2FcSsk/AkBhqIkWv
hieu+iXlpxyZYCDDPKPhieDLkTHc9hYOGG7oTJhBMXUrUqBIk+sqeeUAl/eh0grX
wUU2khj8EkYC1f6p9AKu25zoyXHxjnKulMhrZRIItg7jVJLaFQn2A9KCkwCgyVeF
jCegTvZWikBuoXmDI/K3OuUD/19Za3DHV+H0dmfAG7JdVwTW7mJ3nCWJFvlpTSSU
9Di4VCVj8kUGmo/kRgpZ6gwlCaPmwh/wWiT/vHVQqdd+EH/k/ITs+zWrPOnWCxLY
zV0BEKtW4kdaP5H9ttNh3Wj1GRpyxh/FrMP7zJfdgze2WoRY57j+H9Kuw2s/42RU
zYDAA/9wIriNXAj6pFB+J2sCqYXIMNDNDQh6lYFNFgTS/WPYJoA8PWY62oFc0V6n
ES8GOXjyEya428vedVy/G9kj7cB/IiTTy8Hj7JjhUk/rSIPXMMtNyvM6vQ++f1IV
1qSzR9sijpmpk/M2RusUQwBP131PnCzSCmAZB8gvcNSlbA9gnrQmRm94ZmFpciBI
dSA8Zm94ZmFpckBkcmFnby5mb21va2thLm5ldD6IXgQTEQIAHgIbAwYLCQgHAwID
FQIDAxYCAQIeAQIXgAUCQh1SIQAKCRDVU0vVTpvKWcmhAJ996hkp7RKzCsO1R4wh
81QBqxZ87QCdH2JXwcclPFAF/XKpS5kbQbKdW8a0IEZveGZhaXIgSHUgPGZveGZh
aXJARnJlZUJTRC5vcmc+iGEEExECACECGwMGCwkIBwMCAxUCAwMWAgECHgECF4AF
AkIdUuwCGQEACgkQ1VNL1U6bylmL+gCgle9BEVLP/FKDTEsz6pYH/hdVMzgAn2kg
KyplWAdJKjQ4AHlKOzi1DKj0tCJIb3dhcmQgSHUgPGhvd2FyZGh1QHlhaG9vLWlu
Yy5jb20+iF4EExECAB4CGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkIdUiUACgkQ
1VNL1U6bylmacACglEvdvs5wMSB3EEP4qp46uKdXlt8Anivwqzf9dhjw07omH35k
Ll7D5wGouQENBD9TDB8QBAD+sEewy1REDPQWycqdZVWzxmiS1X+TzSAgfcc7/QKv
AZEsGADvhHcvaACTBuYRVr8DyzUxFUxeNByWSkLe7N5Hmaqauw681zsI+2osfXbW
Jkp3JUybeFSIN5pacLNP5+DEAOzzphCF8ALv9H/MB8J9dRhZwDkY7SKt/cSNh4Cz
xwADBQP/aD4exhzoF1iXR4879xEAAsRy3CCaoiPNeE4Aj9mWmjqEMzWYOjDeZ2zF
W8Jrn2i+tOVGFpg2FKwtuqU8JRs/lqbedYUlM3UQl2pqGSV2tAziuLKKkzPnKWo6
79hIhrjQCEPk1MqipoL6l8qZb8vbBpoCee5NF772jR85ai0ZdGmISQQYEQIACQIb
DAUCP3rhagAKCRDVU0vVTpvKWU/OAKCE4tEk79yRFtmSNNa+ddafxcuyagCeI9MA
byQOCAi708pPSIquH3oiM8o=
=P50z
-----END PGP PUBLIC KEY BLOCK-----
D.3.84 Chin-San Huang
<chinsan@FreeBSD.org>
pub 1024D/350EECFA 2006-10-04
Key fingerprint = 1C4D 0C9E 0E68 DB74 0688 CE43 D2A5 3F82 350E ECFA
uid Chin-San Huang (lab) <chinsan@chinsan2.twbbs.org>
uid Chin-San Huang (FreeBSD committer) <chinsan@FreeBSD.org>
uid Chin-San Huang (Gmail) <chinsan.tw@gmail.com>
sub 2048g/35F75A30 2006-10-04
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEUjcNoRBACNcrOsDaRrFQMnMjnNViPfgBakMnwy28P/tfZvg+vx/5iRt73p
5RrBE3dJZyAIOg+3st7sgtVuqeymh8JmoRlVFqLKEpCM1NNqq6TNHhlLBAuIYtTL
hqN2knPM1m/IZp1Y4a5Z1OVnM6/fqItkxql4SX+GJ5815Lvh+1lokr8eMwCg9w2Q
HgsgytJkYiFGJpkw1YOfwFUD/2oALyshDDCQIshX2xHPk+zLTMQva7uqDy8AUJLO
o0DfaofDhkGjZnLpuFrc16eyfaYZw+mO149WTMpWrzCi+SmCXje6MSywINHneql+
X6OzJCazYCGUfkSbwtAH89gIRKJiQKQfi4xhDrn8Iu+x3YtOKKxnrEVGX2S8fKka
6YJ9A/99q0NX+543o6/kjfOz6Q44xzoyalBXT36THsFm239AaOejufu+HeyTZs02
rvrF7IGgga1eUeQwx9gvRNFX65CkUc3AOTVfK2Tn36QJcGfm6r3ZYFWKjAMJ3haf
aElE7Bs2zGergI0KNOid8rjC6osA3NVYSGI4mKIuQcBoxUNf6bQ4Q2hpbi1TYW4g
SHVhbmcgKEZyZWVCU0QgY29tbWl0dGVyKSA8Y2hpbnNhbkBGcmVlQlNELm9yZz6I
YAQTEQIAIAUCRSNw2gIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJENKlP4I1
Duz6zsMAn1oP0sY1yRMo8jr7iCCdGtw2FuISAJ9crrnri2tcPS3281HX/4xk66dq
c7QtQ2hpbi1TYW4gSHVhbmcgKEdtYWlsKSA8Y2hpbnNhbi50d0BnbWFpbC5jb20+
iGAEExECACAFAkUjdFgCGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRDSpT+C
NQ7s+pzxAJ98bMcpWM9Vd/YvB2tx2tK3zH89GQCgqOGeoJQvB+MWFM1oVbP5jmJS
wDu0MUNoaW4tU2FuIEh1YW5nIChsYWIpIDxjaGluc2FuQGNoaW5zYW4yLnR3YmJz
Lm9yZz6IYAQTEQIAIAUCRSN1FwIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJ
ENKlP4I1Duz6QX0AnRiAfY8Ngh14cBzYH193/LSIuebEAJ9wY9Gz9WQbwb7QlJEX
cOmrejGiTbkCDQRFI3FNEAgAsPAXITBR7gx+9AyYwzvtIUjzo+viSfVHusyZccu8
82qzPKYF3J1QewFczrL6GbPCNqw2c/IZ0Sn8leGgVw5cwP+eUNtcbuQIa8Hpgl0Y
Ns5WZlr94NXTdU8+mO8WXugzsumUnScnKFhrzEQQKYbbAIavBAzVAoj8Bu2UDaCB
fCc4S6OwHgUTuLHDRA0b8YXe4Zc/VbblSIZFosga3vishPOCuj0YWjLjdkXHFZ+Y
We4oDxnMT/yPBcp1/7wqEhTid1dgJvu9R2N9IFSxHTxoHiEsEFa9z619/imVPXGF
rmcoJb5vG/NSH6cMHr5KP60H4ze0pwMKJ3had+YJSIJGBwADBQgAm9eGbCZ3RUin
Kh/AJSsVfzW0snA4V1sv3ovSOekROs9YoUkalx8Ywt4fZkGHFWvYXLVb1KnmW3+O
juhfrjsgmaizQhSMHT47C21XJSvAWuXXZrF6PaIiPAo6q56wjfSS62ycj7z1UlSS
SDEusPgFG3LfYBuM2wjRYYXZ2plAcxhGt2oM5Mf4Tjom1Y1GHp4m9VOIa+0D0HZI
+oNYlOteR6I2tWg90bXJcAd6VlSwYi25b/KRkzYyHlU84o11UJnBnG8HgaN6E92w
QAQTtIUd6PxLWYBG0ni4vtD2ZwyGKAH26QJIUC4bLYdfoZ7V7/MbwI4JEliGjZCl
INqt4mrYsohJBBgRAgAJBQJFI3FNAhsMAAoJENKlP4I1Duz6TJkAoNRkeWHFV+q1
WHzk4XJLFtL8cNyBAJ4u3Mfd7xo3Bx8pAs1vSTWooWb7Pg==
=IROz
-----END PGP PUBLIC KEY BLOCK-----
D.3.85 Jordan K. Hubbard <jkh@FreeBSD.org>
pub 1024R/8E542D5D 1996-04-04 Jordan K. Hubbard <jkh@FreeBSD.org>
Key fingerprint = 3C F2 27 7E 4A 6C 09 0A 4B C9 47 CD 4F 4D 0B 20
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzFjX0IAAAEEAML+nm9/kDNPp43ZUZGjYkm2QLtoC1Wxr8JulZXqk7qmhYcQ
jvX+fyoriJ6/7ZlnLe2oG5j9tZOnRLPvMaz0g9CpW6Dz3nkXrNPkmOFV9B8D94Mk
tyFeRJFqnkCuqBj6D+H8FtBwEeeTecSh2tJ0bZZTXnAMhxeOdvUVW/uOVC1dAAUR
tCNKb3JkYW4gSy4gSHViYmFyZCA8amtoQEZyZWVCU0Qub3JnPog/AwUQND7kZgis
sbaj1yqUEQIhvACeJ58983s/0jjThuj6WeTP6hLZNHgAn0o2KINvhw+Oc8uQk5m2
aTiVgVQxiQEVAwUQNcJNdAyPjrKngh89AQHA7wgAg3QnT0BcF/zp0VRMUZwAysRC
o4Xkgv4oaisCPO5jERGEp8NlXuMD6wJCrGRZ9xVwTbSRXJVirNkiSKj1rnNc/pPA
DbjsmQ+3nhLU+YwNgc2VEhiVpeU2iOL7ircc/YN8epdFPbzn2timb98b+/qlaSiz
m+g8pxnY4USn1b4CnzyirD7mvHhV61k0mrUSmaKzgg2Ppeo2qPzn4w44hgT5/jjm
iEMzoH8zFrN3pwcUYYhH5rNWNnqUIMwuPOEHn4Wp+sMti4yOqQxNHnP0Mv6mxS8+
UKRhtDXU0Ra0SaIhaNRw0k0YLEbO/lteTRc+7cAPBs+QUTa6xbVxIzsBAWLC7IkA
lQMFEDF8ldoff6kIA1j8vQEBDH4D/0Zm0oNlpXrAE1EOFrmp43HURHbij8n0Gra1
w9sbfo4PV+/HU8ojTdWLy6r0+prH7NODCkgtIQNpqLuqM8PF2pPtUJj9HwTmSqfa
T/LMztfPA6PQcsyT7xxdXl0+4xTDl1avGSJfYsI8XCAy85cTs+PQwuyzugE/iykJ
O1Bnj/paiD8DBRA0FhC0XatM0mFMec0RAgaSAJ4kHkYXQO/74W5m/7ZvQa3CPR8E
/QCgpHafK/S6PWQsSOChmVjwrZDVP8qJAJUDBRAxe+Q9a1pnjYGyp3kBAV7XA/oC
SL/Cc2USpQ2ckwkGpyvIkYBPszIcabSNJAzm2hsU9Qa6WOPxD8olDddBuJNiW/gz
nPC4NsQ0N8Zr4IqRX/TTDVf04WhLmd8AN9SOrVv2q0BKgU6fLuk979tJutrewH6P
R2qBOjAaR0FJNk4pcYAHeT+e7KaKy96YFvWKIyDvc4hGBBARAgAGBQI1f/BdAAoJ
ELwCvAMsr1lwqUEAnjOz1VWwJeI2QZMNEHO8RLURWHSYAKDqG+S3NzCeiKM3RRzc
FubwdsfYLIhGBBARAgAGBQI5ZAxAAAoJEMN1Z4b84RmYUt4AoOtidEj2yIZubvvT
kB+moQ1+ZscyAJ9dhz4GLNev7zNNfdAKi8JqoqfMlokAlQMFEDF75Qb1FVv7jlQt
XQEBdn0D/0X2Auka6RU2R46NqrFB0kZNL5rGH8BuTRz+cqEATLGkCXknJDeJ9iTo
EeE++VOL0utmhcYDyyT95Th5FNlXO8YQLgb7Gxq+UT/HOS7zznlBMs+mQK6dSlB6
7XDNoitRQTpmOHTmKYVsljJA4GBMWm6pawKuxSmX7aavwgYjEbmsiEYEEBECAAYF
AjmtSQAACgkQLKRaTx+AVKjiTQCg9FfHlNeMts2GcXWplPQya7GEQtMAn0nrzupn
fRNx6+Gi0Km+WSlUQkMF
=ZyVN
-----END PGP PUBLIC KEY BLOCK-----
D.3.86 Weongyo Jeong <weongyo@FreeBSD.org>
pub 1024D/22354D7A 2007-12-28
Key fingerprint = 138E 7115 A86F AA40 B509 5883 B387 DCE9 2235 4D7A
uid Weongyo Jeong <weongyo.jeong@gmail.com>
uid Weongyo Jeong <weongyo@freebsd.org>
sub 2048g/9AE6DAEE 2007-12-28
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEd0e+0RBACwYdXNeIplh+WEQ9ywP1wJyTpGe2rVvkOLlJNpTJpVX7JT508G
KuYI2B+Rn/V+1+AicL9tsUAnWX/tDma3bYw0Ls68LvD/571k2GYG3CMTy5FSrrtp
3v3N75jHDsfulUzHL3LHsa/CA5qzuL819KIaUfTKY0A107vcI3m0v4emEwCg2BaW
OyiO9pic/WnPi4tuFjLpeEcEAIzLSKzAiZZ7U8ESKAtonwYqdu0BIRFpp0kedXqD
M9cTts8VjqjdMOm55xvI7h9EGjH+crFZBlZD0NWXD00NrrQdHifulSrv5l3Wtgn8
xilqUhiYUcPQu2DHSuVlShvNZO6/rYA8R45axAfQv8rFo8NV0oElH+bvGq1mwRKY
ciJ0A/9lN68t6G3LKmaSfWz13IUJT0E2qy27NnSb4RuKE2TuqyIMFzXh5+jjnp3U
zRDX6KrYLju5Ire9GGJEMsGs28B5r3HXUPADqVIS8i6dW/npZlyizU7MfoRDFiRe
btMpnYx7d4qnpKMpEm1J15JF84YrNGvkE55z7+g5zG0ua9KZgLQjV2Vvbmd5byBK
ZW9uZyA8d2Vvbmd5b0BmcmVlYnNkLm9yZz6IYAQTEQIAIAUCR3R77QIbAwYLCQgH
AwIEFQIIAwQWAgMBAh4BAheAAAoJELOH3OkiNU16VAEAoKnaR60kp0PF+O70GH7y
v4k26FJqAKCycX2eM5PzjVzbAKHq0yMRj7tkbbQnV2Vvbmd5byBKZW9uZyA8d2Vv
bmd5by5qZW9uZ0BnbWFpbC5jb20+iGAEExECACAFAkd0fKQCGwMGCwkIBwMCBBUC
CAMEFgIDAQIeAQIXgAAKCRCzh9zpIjVNenkDAKCGZSCJTG2dSCbEH3kLTpYdAnfM
gwCfay7fmNNMrN31IhC2jddWylvSDlW5Ag0ER3R8ARAIALZoci+sXDkhF0ahtePy
ZszOeKUg8MHIac5RID5CfjGsTsbfAv7eM7TBocAJOKBxhD/suqsdomMBMwoMKYdv
R4tKCosDopYGwNFNtryXrOQctNKxIf31kc8UnqGfgRAwjABorBRJCQdBZEBm+93k
lDl0azEWPFuwzZ+dA12dw0jF1/n7TAIkvaA7joFfNvZ8a2WAfJvoal0/nUqmJCmB
ntaWEdZP5rOEUvVBn117W8D5B8YHp//TM7T3eT4M4Lp7wUQIiwT7fGgRWCIfIrGd
GZSEykjB/keyIip2Hh//0Ft0Ot8D+4wYz9YhH/RRmfBDMBhW898B1rEewhc0wmjH
txMAAwUH/iB1/HLYV9ckHT6i/UDl8lEsw5CMxftnEI6wY2i9MWqTSTiuoNE+PQAA
kicGwxrxxtvLccdFE4WOOQsh9oyzbOeWWBrtxzloRBzaxC9dx+tQaOzzJAUjaEaV
wneSg2x62naLiztaQ9U66g81BwSyT8NF7uYjsCyvPsrHwDELNcPdDXQ2q0GKj0I5
tSgqMOPwohYRRS3hYfoPnYZOshdwYErtMCola0hZn7LXJopRByQyT/x2N6WW0zGY
YxJemF80JqLrf9RtZVSsTeqT7Sd0+kcgPq3wcoqDXKTEQ+K4yjcE7c3hqhowQU72
2S6S4JjYQhKvdJykZRuvynQGeuT8H8KISQQYEQIACQUCR3R8AQIbDAAKCRCzh9zp
IjVNepJjAKCIgdGxVdwuToMZ7z1n2mJEulHr8wCfdimx3iKjNLlAE154wBx3v9Rr
trI=
=5yOU
-----END PGP PUBLIC KEY BLOCK-----
D.3.87 Michael Johnson <ahze@FreeBSD.org>
pub 1024D/3C046FD6 2004-10-29 Michael Johnson (FreeBSD key) <ahze@FreeBSD.org>
Key fingerprint = 363C 6ABA ED24 C23B 5F0C 3AB4 9F8B AA7D 3C04 6FD6
uid Michael Johnson (pgp key) <ahze@ahze.net>
sub 2048g/FA334AE3 2004-10-29
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEGCy1ARBAD/K2SbL6XiTJ3Rn/weuN/L78ROUltIoRGOkZE4971fLcAbtIsf
nANWDrpDqbhLgEbZLeCn/EIWOPqrYyKpCGu/IoZ6kx7UPtUH4eooJBarrrQPJVV1
mfW5ktDry3AoiaUH+jL47AxFCb/bh7Rc11vrhLKdnc74wI+nu2cyk2llkwCgwX78
nlN2qTrbXxOEAPpJjMontfsEAL+4sS9DOay7NkZq2B2p9AZnSsXQg6/r8Epqznqj
yPQBm489UcIZy2FiBwaUR7w0fMh5xNX0FE3xFiTd4VUTgUJUSqpYtdfI7IHvJXml
P/VK14CtgRY2B24wpDPMae32hGBFUwSE9Frb5NiKlxMC4+fR71wZS7MtxTnwJ1v/
MoVaA/9FyoKCAw3Dqnf5W89dj5W5x35jLKSLobEhhUB2S2LPiwBa5A79euMvgtk0
gKeh6IslXKOmCO148ws7HSaErBIBVBDpfOsqcQJTcd5lvEbslp+z2oCKeQK3pgQ5
aEHp8IJ3YgQEHz+YityOF0jCMGNJTFAz18U4RzVxSe55iyT/17QpTWljaGFlbCBK
b2huc29uIChwZ3Aga2V5KSA8YWh6ZUBhaHplLm5ldD6IWwQTEQIAGwUCQYLLUAYL
CQgHAwIDFQIDAxYCAQIeAQIXgAAKCRCfi6p9PARv1oW2AKC0xjNgjhL1EHPtFOXH
kGz24lF4QQCfQxkoJBq0CkLQrYvdA3MLP+IJ6ba0ME1pY2hhZWwgSm9obnNvbiAo
RnJlZUJTRCBrZXkpIDxhaHplQEZyZWVCU0Qub3JnPoheBBMRAgAeBQJBgtexAhsD
BgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEJ+Lqn08BG/W4JwAoJaU6MbisTlg4EMF
jfE+wNptwO4kAJ46A0W6SiLWbK09gu7YlgfLgdYAmbkCDQRBgstcEAgAvD4PzCsh
muLtNkPVKSlk2eZbqlIuyapbuIo6rHk8fo7fkfqVOOrnGOrAT5/sflmnG3H0BLvF
4pkk7tyRtg3hz8qGACCA4SRf48TxRERpIUoW5R2cVBsMBTnpspRaFu8OdBL0dwXs
LmH797gxDXCGXzSU5xKBSQN4LfoEuLr1qQmPbuPW+Rdi3hrdk1eGsJ03rU5RExzQ
ck+J7a5VWsyghNCSj1Rzuw+0OVGBijJW51FD9QU+Eqb3seL7E19mWC3FMU34RFwn
5lbxolY43iPV0jc0MFcV4POHUSZ8ot9xbQpcAClTyXZh21QEIFzYjJe9ZeVWKOqH
UZS1naB4k98G6wADBggAnRlPolzcjJvqvv5Hfv7oDeDARNxqeKTj+fPXIHR0Gh34
8HMfmxsFzS6nsrrVc43Q6Iaso5hbdP4UvE0/HzhPALzCTeZGpZF54pffg9Pqb84U
p+D59I+b88RDBvvfwF0OBg6du08Rdkv9JfG3R+QZembK+IhUa5yxhtfbQmI6Y01r
phtx4FAKZw4Xp2eb7IBoZWktfcOE99UJcl9hUmBHJXRznQoCHz5OwAKA6a/0b7j7
B3bPxj+tLlQksdmRbEJKVBa3LQm09PkxfZj8iahvQbp23p5VSJDKzNDrgmsqaCpV
CFNgMvYLvtxC2xA0uNtaRpdZRLS/11NUj3oJIULv8IhGBBgRAgAGBQJBgstcAAoJ
EJ+Lqn08BG/WFK0AnjdWWBxG7slwI8u1W+7uRsuh6NXMAJ9r+6Br6mlEtsoWrMel
IlhG1mVq6A==
=I7wA
-----END PGP PUBLIC KEY BLOCK-----
D.3.88 Trevor Johnson <trevor@FreeBSD.org>
pub 1024D/3A3EA137 2000-04-20 Trevor Johnson <trevor@jpj.net>
Key fingerprint = 7ED1 5A92 76C1 FFCB E5E3 A998 F037 5A0B 3A3E A137
sub 1024g/46C24F1E 2000-04-20
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDj+agARBAC1AfvgGQEVdLwS0dirwaN+pDDWWiaSWBNRNo4T4KKG2vyhhnUi
f2PcjPx8rYLvbokJFltoTWos3lS8hD8PZGBDlImOPzffdm/GYEmr1mE8fQvzjdKD
iOTqQi5IYYhLZIMmUpBTK7XN2zrM8VrkgCpb5TYtBrQUPheWs/SZ31EvLwCglUPA
T54Joolfvk0Y8I6dSGYctpUD/3teZiYwem99CE3b1tsqavQ1MUfjwSPZQq8wjVe8
GZUtwaeExugAxNjXIJeXiaCij7S6JSTS0ytyxZ5/O1QFmBhuD/7zjNFD8yB8nu8x
slma7mVhMuhqkwU06hTkp6MNNJ7kRItoVETtLqR5mW+0UUSZyePQFIH9U7TKPG3W
vYMIA/9btsMQD/7QA9p/m5OP4sfdVdNCZ32tJ534bMjDYyf/P8k7QzvDWU8f7lbk
3vX5pSmHplws0PwSZITmRarMdEH9ucP+24m06MQ7YmDYyLlUCestT2gAxnB5/X1h
fJnmdCLi/Vt19WrVM79ebddbCqCaoz0xv+1qOQmPue/vKXIH87QfVHJldm9yIEpv
aG5zb24gPHRyZXZvckBqcGoubmV0PohWBBMRAgAWBQI4/moABAsKBAMDFQMCAxYC
AQIXgAAKCRDwN1oLOj6hN4YuAJwOTOURcLpgAx4HT43jNxDYCsT7DACdFdGCwsi4
w5ZiCeoizmoBMFvYTa65AQ0EOP5qIhAEAMAerdyvcs7DOxpsli24gkKJxCwHSq9U
23k283XpZHOp/0eS6WEJMHMyQ7BRrx3X6mkSgBEnHdO6MetBQjOHdjSb8ycotrJa
H9eMkZ/Iky6dbiWpPLI4ytS4Q8Z4oEGjUTm7pJiE/pgmaCX/kv0WMs/35En+42sY
VoVU9bDI+X+3AAMFA/435RbM6ywO/kL8D3lhwINGEIqmxWpJDlXPPJf2pLiWZZVK
MLGkHOTe2kUdd+E6WcoRZdGblOKxLACrlKpJa91aw1ftQT6rt0k8GDCGLT/33FWx
2IRSf5sHmz8IOm6L8TcZU31hdWqpDLmiIj+IjUCx8+eAUjZcVRoj6BYnWc1Z64hG
BBgRAgAGBQI4/moiAAoJEPA3Wgs6PqE3PKYAnikfYo//UA7/jrDuTXzqPmi/Un5f
AKCFsfcXDbLGfWaAqe2YzeDR2Z55/A==
=N4HT
-----END PGP PUBLIC KEY BLOCK-----
D.3.89 Poul-Henning Kamp <phk@FreeBSD.org>
pub 1024R/0358FCBD 1995-08-01 Poul-Henning Kamp <phk@FreeBSD.org>
Key fingerprint = A3 F3 88 28 2F 9B 99 A2 49 F4 E2 FA 5A 78 8B 3E
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzAdpMIAAAEEALHDgrFUwhZtb7PbXg3upELoDVEUPFRwnmpJH1rRqyROUGcI
ooVe7u+FQlIs5OsXK8ECs/5Wpe2UrZSzHvjwBYOND5H42YtI5UULZLRCo5bFfTVA
K9Rpo5icfTsYihrzU2nmnycwFMk+jYXyT/ZDYWDP/BM9iLjj0x9/qQgDWPy9AAUR
tCNQb3VsLUhlbm5pbmcgS2FtcCA8cGhrQEZyZWVCU0Qub3JnPokAlQMFEDDmryQA
8tkJ67sbQQEBPdsEALCj6v1OBuJLLJTlxmmrkqAZPVzt5QdeO3Eqa2tcPWcU0nqP
vHYMzZcZ7oFg58NZsWrhSQQDIB5e+K65Q/h6dC7W/aDskZd64jxtEznX2kt0/MOr
8OdsDis1K2f9KQftrAx81KmVwW4Tqtzl7NWTDXt44fMOtibCwVq8v2DFkTJyiD8D
BRA0Pu7GCKyxtqPXKpQRAhhSAJ9Z/WCnDtISX4FU9bF/5QKEvmvtGgCgsKyY1mk7
0ow22bUmdvPOz9zJxQOJAHUDBRAwIIYjCn10cvEMm80BAVrEAv9+1GycVrDVEVEX
cNTQ3CX+HiZKNXsNWruNcrU2+/djtR4l069ZysWvx14NPtnefRxspzlUH6CrRMNg
R2pGJTUDZNZs58RsYv+BdHE4V/oZifP1fMI7ZuW0NIRjHhUIweGJAJUDBRAxSx5c
H3+pCANY/L0BAY+TA/9YQPISXYaS+5r0I60wCJ+i3a9PC69Zak2ikgTHQi97LhpV
tEsP3SAYInDw4YMS2oU9w1XxoiLLd9hUpcZlmO8Ip3vNF+E2ZCfR4sNzKarY5fdo
+sxzatGWRPgnHjbm6RHWCw6qJACDD3VpaFjx2XD8QrOTyiObnbHhWBdoEAIyNohG
BBARAgAGBQI5rUlcAAoJECykWk8fgFSoTiIAoJa59BqzeoS1ytJdiFLzK6GjEl+c
AJ9AErDKZKYLaAYa7LSLzt78zlN4+YkAlQMFEDF+jX1rWmeNgbKneQEBCrID/i/r
i8/eXUXRJp2fqJqzvrWGTP9Ix1O4vMguah9IILijgpYyOJYkezZKijjVCVmLX7Ew
fNXfYkqLAWUa08eov4QfJfJDgfe+Z/3/UoX7RcJoy2AjTBZQzOI9JMkrzFdtFGYw
Mr/QXhOdVVpSGeZ/6Hkrs7pd2Z6MNNrRf81ZyJyYiQCVAwUQNBDRpnW7bjh2o/ex
AQG7ggP+NcUV4mCzYx1MM05kz8Vt8OEjirEBthSypLf5FrXrJ3xZ38CNX4gckTY2
iYVaXxStSMIaKdeLDM+ArU58UmtL06DXBAu8CXRfzgEDwxM/0FCvjDvoj9FuSyBR
KtUIg7wwnCXJ2NI+hxYYF5eVWNtnFfPK4mTsf5Mb7O4jkG4Fw0iJAJUDBRAzBiva
s1pi61mfMj0BAeIhA/9fG0FYVdoFGBUsSFE2lLTth1T4uxkaUs5l6E30vhSckUdB
A806kx7LaAXtj3loE7Dn/XFLm+VCnCZEUKe1ayb+Cp3Mrqu6V+vWvkDL3gs7lMAL
q5w27f3pji+jVPIPVJOdELjroqW+a1C0C0UaBeU5FYsv1REvNxEV3WEPTJd31okA
lQMFEDjGXEvKbyuD/AwC1QEBMcwD+wWwOmzXE7wpIEZ1p5KsRiVBQ4F1VEo4LviQ
kE0jUx8/i0/Y+kRpb3sZc+yh84qYA9vrRe8IDqc1a66ZvGUPZOsfiICpJoH4ftPz
8xMLgyfHZrSR+wICStXNAKok8Oq6a56+Vxjh7wpNDoObN5XfYyAr23yNoPh07pP7
dXNRfGKiiQCVAwUQMTlDoO9huekR1Y7VAQGy+AP/Rzp+UGtJavbSiPx5EnXOXxkA
/+ulXQgQG9vdkWwewkvxDNOzHW3KkUWCGtPtIMENznbFj3QlYB+USIaf1ogvlD5E
dXGPDfTINpE8CX2WXzajfgYFpYETDzduwjoWDZfEN9zZfQqQS62VgAReOIz3k9BL
708z/+WUO0++RLGCmImJAJUDBRAxfJXn9RVb+45ULV0BAXJ8A/9K6NT6VLZZC5q3
g7bBk5DWuzBS3oK2Ebww6xzsD2R9edltoz1J3GPngK0CWpHh4kw5iTaRWoC2YJYR
NG6icnGvlMAl1/urqQHJVhxATINm8oljDKsj1RBJ6VKBzNbCJIHTVpX0AJoqUQX2
Idi8goFr0fAm7cD2CBb1JhoAdzEfO4g/AwUQNX+5mPxGGtR+MqsrEQI2aQCgmSzO
SfQxEtKMshB0VJCgAi9exqgAoNosC8C/0kFMiGI8djBrxiQ1O2vpiQCVAwUQOa+C
q6WQ7KI7msylAQFqcQP/e5kOmx+qu99qwEkrwpTWzpfpgGl1BuEsKDIRk6VOmo7o
egtd8kzRjL+S2OUgUWA9l6i4uUXsTJWIDzqPOc8i2vI/OfelnKIGu/uTZ/A2Az8V
7+6hhPhIZ+JHZ3ep5rTd++4+SyCFLXWiCl8NmQwdhmJpsWUtHavEsC3NBgW+5rOI
RgQQEQIABgUCOe5/HwAKCRAj54bpvu2UbkMWAKCLrzhdCCmJoA1/ljX7HbXDuf3u
cACgrwhPV6ZGrKEn1Hkl7Z88ICwAGXSJAJUDBRA57n6ATVYoIXkFDBEBAficA/4s
HQMoCC4q6OHVor7iZt33ypvjvaKRiS58A/SgAc0Y8P60GqpuAEcLUl07V5/hAcwW
WKGGX1LwBmRxvhbNn2tHUVAj3oB7UM0KSUa7KvltcaqXFYIyjYkAROkgm7oTWMaY
vN5H6JucyOJdlkqzvAACtagXntUEwxJ4ptHxwpylJohGBBARAgAGBQI57nf5AAoJ
EF1SHIzmsVAWoJgAnR/1FVW1EE7BnHJDt/GpIR5mq11kAJ9RmTUUaedL+I/xCn8g
OViHwwcea4hGBBARAgAGBQI57oQcAAoJECAVMdWEXf7dOzsAnApDRHpSZZwB7DbE
03ZPUqZUaCV4AJ9pGurLhFjYo0jVR+CH1MrqkjxVWw==
=GwRf
-----END PGP PUBLIC KEY BLOCK-----
D.3.90 Josef Karthauser <joe@FreeBSD.org>
pub 1024D/E6B15016 2000-10-19 Josef Karthauser <joe@FreeBSD.org>
Key fingerprint = 7266 8EAF 82C2 D439 5642 AC26 5D52 1C8C E6B1 5016
uid Josef Karthauser <joe@tao.org.uk>
uid Josef Karthauser <joe@uk.FreeBSD.org>
uid [revoked] Josef Karthauser <josef@bsdi.com>
uid [revoked] Josef Karthauser <joe@pavilion.net>
sub 2048g/1178B692 2000-10-19
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDnuWJERBAChyOg7jb+Cj5UDqGfChHZDAN5GqF28W0GwrvV0RVWqlGx3pn+S
XzDur7ijNQfj3jAAGgFErCptXWcDz7CLzS2GxddaMAaQcPWP9hDjJtUJ633xwjU6
H0U0VPdLcWtJJCva1LvKp67ICkM4Wx8OdVHhCQN4akvNkYzdt4AG+s9vFwCg8Ddq
naF901g4VlK1IUqWTxPUtocEAJROiv4o3aIWrXvD9YBxkwIrrvtR8V+QaB6drOer
AU9NC3T2Vkm90lgmUpP+HCmpZt/T2v1t5a4HHjyf2ljD5ANeznAZORA6SowuWRhv
ObmYoN9B+vzHCitVTXLNksJCK9kpEvbS5shzbU6UsecCUTohjCU4po2RrsSSILqE
oXYjA/4/j3Qg/w0RabnS6RJyGDls3FBqS4gyVByaJpH81snvZUbw/y9aT9xdo1YW
gUaLcEW09whi00M50vaMzXJ0KYcWHZzk7LrhOqcIiCAUm5Dfve3dwk0DbgVD6iCb
LRI7NuB1Tm8YyvZRRqG2ZcfYVPZgVm3zj748sRaRSPWfb4wGgbQhSm9zZWYgS2Fy
dGhhdXNlciA8am9lQHRhby5vcmcudWs+iF0EExECAB0FAjpsFVcFCQvE8cYFCwcK
AwQDFQMCAxYCAQIXgAAKCRBdUhyM5rFQFnG1AJ95ZZo5g7AhYtfJOrmrP5fboYCV
XQCeKruSz2WhPM0ss7qsTA/e94XlAeyIpwQQAQEAEQUCOe5hEwoGYWRwcHJ0bXMA
AAoJEDGmPZbsFAuB22UD/Am9JP6EHolhUPH4vccPMoaZ7u8ng06npVXXYjnLGbC8
UsKlQsoLxMsC7c1A3iumQ4geIF2/R8Ihj4jpOXYbcx6okDjhZIyqB1gv+RighsW9
uwhsVF7fhk1uRc3asswNZgi9sBGqNnfCqMF351UMTvfBXHnqzDJ8vPMOStsWDzCY
iEYEEBECAAYFAjnuhiUACgkQc4fikq0QxsR0aQCfZF8RKRaKqR4emQjub87fAVYo
Pk4Anj0WaSOwC1CX34RUN4bxzNi57xReiEYEEBECAAYFAjnuhmIACgkQtiQG5lvB
UqHYbgCg8AFs2jQ6xhKIziO/xhupEXT9ZZUAn3IpjCum/oIZOGUELJoajAG3Gckj
iEYEEBECAAYFAjnuhusACgkQIBUx1YRd/t11SgCggKU5NOYpsG/04L1LkCcV2lT5
V7UAn3d0EdAIb8tMvCgL1npDSYphoSzdiQCVAwUQOe6J0E1WKCF5BQwRAQG6MAP/
YMLUSid+HBJtNH5AjuZlX52Z0Oh1AInqX6igHrQYutSG7j2Sd8cpk3j6vT9V03rm
be2IAK3CRdnkIRQt5nH0acijgjnAyUqJ+q5WYTUksFh5b7i3qbhNj7fw/6Dw3A5O
dGlhgTzMSpPSSXuxeeognqkNKUmWw9yjrr2q0Gi3UK+IRgQQEQIABgUCOe6X9QAK
CRCI4Xsd/OVlYTzDAJ0RX5Vn8KhP+zdFBxdlNQcO1/vNywCeOlwHD7oY36yog46R
iVjyTV+s2EmIRgQQEQIABgUCOe8i7AAKCRAY9QOAJMJ4Ai9JAJ94rFed7/tJJgbm
9qOOMAXdC9MW+ACeJLRW04xTW430Y9G05+4mczcfUbmIRgQQEQIABgUCOmwoagAK
CRCTqAdkLDfjdctAAJ9ikjH2Q56jO48RqUcK81V+QZWu6wCfTXXII7m9DX77OJZ9
MK/kXB45OfyIRgQQEQIABgUCOoShAQAKCRAuIEybiwa+dYnRAJ0T1R/7noje9yl3
G1X6XJk2q93QFwCbBXaSGauZ7sYH7kc/iR2yQBP5iTOIRgQQEQIABgUCOe9xLAAK
CRDNC4o1+1fXk/gLAJ9jzY1qmkpPqzb9lIzb0Tlt7pCRQwCfe+R8BoGODBcVckr3
jdP6/rTPECW0Ikpvc2VmIEthcnRoYXVzZXIgPGpvZUBGcmVlQlNELm9yZz6IXQQT
EQIAHQUCOmwVXAUJC8TxxgULBwoDBAMVAwIDFgIBAheAAAoJEF1SHIzmsVAWgm4A
mQGnViGPYiGgaULvlYM35mN2N/TrAKCDsiQ4Gwlj+NgPHwQKa1bQUbyqiIhGBBAR
AgAGBQI57oYnAAoJEHOH4pKtEMbEWs0AmgMYEMEB2C0+7x6X7BSfb49c8NbjAKDc
bL+B37ri/JXth2rMWGUAHjAb/oicBBABAQAGBQI57ofcAAoJEB9/qQgDWPy9HyED
/2rdYa4tS4wXcfx3M1+okMZZERrWaO8rtYORLfvrZY72EJ90giB6bzw5kuUJeeWZ
oZsJVnd7ITBtXolBWrOt+s1B4SdV4gt02G4L/lJ42ok1sOlQLVh0UDZgGxc7WUag
z9l8F0OsVFLxjlEFI+NDogbv+kz0a2bTMjiWLLAu14ixiEYEEBECAAYFAjnuhu4A
CgkQIBUx1YRd/t29dACeJTWyfb0Df5fPm1XPsswweYLjGDQAnjpMDUHOFc5fnNMV
qJop9jq/AF5JiQCVAwUQOe6J3E1WKCF5BQwRAQFhugP+KQYQsQKeYB+gPoSI2egK
EynZMAJG0YiI5cA5Co4hyNY5YIbIMeo4GixHvwQcnTH/3PzZFcmDzXm22oc654po
+hryLx8X7dZnCN8RmvoyMaJfx0664PXWq5zLnfaJnr3gV/IvVHj0uVbDaizWUyK7
dLLe9nLE3nP608/AKuc06dGJAJUDBRA57oYKAdtd0pfmON0BAU7bBACXXkeG3A8b
DMLtG2QlmF279GbeQ0ZBG3HojyTzUbk0I6nlM5yeS9/SBkWWeWxkWZgIDhN6FWuR
OF9Vh1jIrnZ0wihWitIVsytHdwET4MlfYh0sH+7GW1zUi8syiyGPCd89zBL3EVs2
8pJs+btK/kD2DGQkRWHZN7BuNLb0yM3/R4hGBBARAgAGBQI57pf5AAoJEIjhex38
5WVhw64AoNaWiodMqbzSGBs1Xp/6mDr7rsiPAJ46bAmdjezkyTDC2z6fa6Bzh9o4
dohGBBARAgAGBQI57yLvAAoJEBj1A4AkwngCtqMAoMdXR32u0WIfAE7me3+CucX0
GNAQAJ9daEBWjNbT+VlRQ/Jc1iIdxSBxHohGBBARAgAGBQI6bChtAAoJEJOoB2Qs
N+N1zm4AoJXqvlK1b/8LgNxyqh961iRMxsIsAJ9T8aXUpFGCaL/r+109xHrXWkig
F4hGBBARAgAGBQI6hKEDAAoJEC4gTJuLBr51GuEAoJSeVEPTlr8zVC0A0fL9zSQ+
ZWNGAKCMlkL3XhHZ/tKaAbJtlf+jymTW7ohGBBARAgAGBQI573EyAAoJEM0LijX7
V9eT8bUAoIOLIiocVylJa8udF+9Q/+AorbkvAJ9sI+JVeywpgFZchlHyb189aocw
FrQlSm9zZWYgS2FydGhhdXNlciA8am9lQHVrLkZyZWVCU0Qub3JnPohdBBMRAgAd
BQI6bBVcBQkLxPHGBQsHCgMEAxUDAgMWAgECF4AACgkQXVIcjOaxUBY5YACeNT4b
YadZLhfd+UVab4JLmH6ss9wAnjTBYX5zCu30yWfszSeWGd2p5TbwiEYEEBECAAYF
AjnuhicACgkQc4fikq0QxsSzVACgnCcE565FTv9LhGJmmxjNZi4jNzUAnAkJn9QV
DkwFp54Vtl921duYZQX5iQCVAwUQOe6KFU1WKCF5BQwRAQEUagQAiJqlq1zf+Irj
iffxGzKP1vcCkeaXRiPyBHkS0yCSy6OBxPhdUsvOzT93qgRUqPGBB4Q7jM7abSuM
99gZW9uQN59nwbBFzWRKK/Cz8xHMlEWIdMZHUXupWUTDBHdHERaj4NaZvE6RXgAd
k4saIRT1IFLeWejpaBvLMN8XQXHL3XGIRgQQEQIABgUCOe6X+QAKCRCI4Xsd/OVl
YY8eAJ40vquX/AaE+KslwUBVTBmNpQo/UwCgvAbcnU4rzYZ+TCBB4ZRUW+MpdhOI
RgQQEQIABgUCOe8i7wAKCRAY9QOAJMJ4ApoRAKC5Wcxx1y8Dr9u4ePt0SA9IhZ22
sgCfTOrGFzNJcy5nI2qDz1VoZPVJQOuIRgQQEQIABgUCOmwobQAKCRCTqAdkLDfj
dfNDAKCNnoZlc3cI19gPeP78V+mV83sVFQCbBjBaWkwYqPh4EY2E86U20STnb3KI
RgQQEQIABgUCOoShAwAKCRAuIEybiwa+dQ+QAKCoRMM/CeUdTbKrF+Z5W72JlXbq
WACfQtCaQuUBN1ibVKQr6HimK1z4cRuIRgQQEQIABgUCOe9xMgAKCRDNC4o1+1fX
kx/UAKCf6sSugsIEgu/PD36fUKjmTCa2EQCgzkMVRzIuMcIA0G0493IeecKply20
IUpvc2VmIEthcnRoYXVzZXIgPGpvc2VmQGJzZGkuY29tPohjBDARAgAjBQI7i8YN
HB0gSSBubyBsb25nZXIgd29yayBmb3IgQlNEaS4ACgkQXVIcjOaxUBZdHACeP4xT
8uykptHJHuS94P6bwuNeek8AoOlLQUlfadwu/7sdbWtjdWI/0iysiF0EExECAB0F
AjpsFVwFCQvE8cYFCwcKAwQDFQMCAxYCAQIXgAAKCRBdUhyM5rFQFsGhAKDCrR9J
n4qKt8Hqljofy9M9xT4lMACcCcSKt0PKE1oL/UaNgUVn7tAu/ymIRgQQEQIABgUC
OmwobAAKCRCTqAdkLDfjdVxZAKCMp+S6JstAa8HtrAfh41j6LHNf/wCcDq8dJ9nq
wEHqP2sFK6Z/NtPu7p2IRgQQEQIABgUCOoShAwAKCRAuIEybiwa+dSOPAJ0cMSzB
Jy0H2UGSiVGNK3m19biG2gCgum7/cxqt54aEM3V+SbTYmrkipgi0I0pvc2VmIEth
cnRoYXVzZXIgPGpvZUBwYXZpbGlvbi5uZXQ+iGcEMBECACcFAjpxdZUgHSBJIG5v
IGxvbmdlciB3b3JrIGZvciBQYXZpbGlvbi4ACgkQXVIcjOaxUBar+gCgxUakd2xJ
oUH6+D1mRfndDAqzjkQAoKLSTYReJMHwhXZc2OmOTTH3xsy+iEYEEBECAAYFAjnv
Iu8ACgkQGPUDgCTCeAJiSgCg50cRCYSeXmnBCPR/r9uhcT9imtUAn32umZNXmL/y
XcfXg7bXzku/DKSJiF0EExECAB0FAjpsFVwFCQvE8cYFCwcKAwQDFQMCAxYCAQIX
gAAKCRBdUhyM5rFQFk3LAJ0Wpi09EOAOMXinfOseIOD7Uv1vcgCgoYHE/liKe6p8
2akulQniyJvXnHCIRgQQEQIABgUCOe6GJwAKCRBzh+KSrRDGxHASAKDDqv+grb04
Y6qIx70hBmr1BN7ICgCg1JgK1HW2sJ8xfEO+FSmfwpqwpnyIRgQQEQIABgUCOe6X
+QAKCRCI4Xsd/OVlYVDyAKCC6wlp1qGx5/Tu285+eALovxhumgCfVu30XvpgDrFB
Jin09OMykkJkCvOIRgQQEQIABgUCOmwobQAKCRCTqAdkLDfjdeDJAJ4mMYP2ItaQ
FEOrtC7a+3L1A115FwCeMYSBxtUHjngsaU6Hsdkj7dIQEu+5Ag0EOe5YuhAIAMun
iz0umurHI9PJ71ETF+cZLsykYDBMTnUirUoBk/eRJL2nfj4NBbClTLDT2xCUOHya
bDEtMYdubzjfs92N6yCRK4v+318bT7d6XMHG6B5vBHCcMhS7O0luNX099S605NWR
F+G25B3v0opmJ6p5hsnCfsEOqXe5g8Yoqql4yjbOFVM3L3gfxg9L0tGS610Vqx/Z
nHF1rd5BBlmEO+t0U3FMWHidnEMBEE42eKA43U1DqmOUPHeIo46UipGVARO7sW8U
N0dRKSfxLwZQEiYvmMTABER1HUi+H/0M1N0IYFMqQ8hpfjocsZUNYfcCoblboCau
XkybB/gLAURTapYZ0kcAAwUIAIwxcA7GU1mxYIY1uA4WRjpGfT4w0qRSbonO5W+p
JZ/TmM+1cuqe4QetAe+2p599TLckisDvz17ZxBnMZs3adxr18C8oPDlTgReqeVY0
UA/r72AL+i0PXSriFusD3AH3YwsSmNfF48qZ4RapdZUWPGO8L9TNy7eTz07rD2Wr
p0kDng9vGBeMMNGGbyTnpYHdSNW5mf3+2VT70HAzR105v8cBAn4wx46yQPEINeTW
XnsNbYy6EfJ2iVAyNAnrQW77NJhFBsI8kg86L9S8/o2UFCSXEHAsd7uEXBPLJ3m+
IwA8they6czCm5i8pufRRCveTJUBPsJ5IsWXLrWtScFau8yIRgQYEQIABgUCOe5Y
ugAKCRBdUhyM5rFQFhseAKDdFw3usXZLVrKHo30sPv2jNdPM+QCfRqjP/hfxMa+T
p5J1gj4xWykgTuA=
=U6zf
-----END PGP PUBLIC KEY BLOCK-----
D.3.91 Vinod Kashyap
<vkashyap@FreeBSD.org>
pub 1024R/04FCCDD3 2004-02-19 Vinod Kashyap (gnupg key) <vkashyap@freebsd.org>
Key fingerprint = 9B83 0B55 604F E491 B7D2 759D DF92 DAA0 04FC CDD3
-----BEGIN PGP PUBLIC KEY BLOCK-----
mIsEQDQwdAEEANxnThVC8GNO9VXTjWFhJh7XgMLHf9jDd0B1804WUqc3c76r8y/k
AXZ8e3kNH1rpa+VJ0rYQnurQg5BeFQny8TzU6PC9QSdqNKSCvhai6B+w3t15sKJK
nGZ7DwyoyuShMFNMVF250KS7dEZnYy8yrtopCIWJAWzuzuQQtmUYk4B5AAYptDBW
aW5vZCBLYXNoeWFwIChnbnVwZyBrZXkpIDx2a2FzaHlhcEBmcmVlYnNkLm9yZz6I
tAQTAQIAHgUCQDQwdAIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRDfktqgBPzN
031cA/9ZuwCRbYhTHWzOhQuT8dm7Bby0wEq+KzkULXd/ExgxCu/54t9M7csD378X
/Fg2erLP2J8cYIcVXmdtIJO8AwZRw5GgmVP+h1sEY+KT8jiJNlX2hB/9qCmng3FY
ItLBY2t7XVmTPMw8BLANE7PJ1LKT/OoUHEk0OjK53KKGNU2oUA==
=VzLE
-----END PGP PUBLIC KEY BLOCK-----
D.3.92 Kris Kennaway <kris@FreeBSD.org>
pub 1024D/68E840A5 2000-01-14 Kris Kennaway <kris@citusc.usc.edu>
Key fingerprint = E65D 0E7D 7E16 B212 1BD6 39EE 5ABC B405 68E8 40A5
uid Kris Kennaway <kris@FreeBSD.org>
uid Kris Kennaway <kris@obsecurity.org>
sub 2048g/03A41C45 2000-01-14 [expires: 2006-01-14]
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDh+mV0RBADir7YUHYRLlc0EN9H9OwMtvatKsJGA/BSvvbcVGdXxcDZODZb8
5UNUDltKTmfgOxMxz5Agadl9M9TJwAUyhRjkc5Ua9LWskx1HnYlsPx6/saFYU6IZ
SLrBcfpX62hvpS5x+GJ8VENoRcIc//YFG/zEA5XRQEWG5mNg3KSL/DZRiwCg/6tF
0f8E7vABNKqDRFx2JEkeERED/32z9UUXbg7y26ziUz6oXaXDknCD9HeUdA1lmyjj
Vovy7Hmk67OrbuuD6t3p3SI5vUvxfOnzpqMk0lAPtkZmSCmOhvmyGYqbrpIGLV34
wNlLwcNRTUDtfUGu4JL0PMOtpOQXdxhfXGI09VwV0eavq6Kzg1Ce/CFD7k5xdWzy
F0J4A/4/eUoXG6KGd4gCTp9werF9ZnUdrtIMkXCgx3D3mrhEIYEBiQ1jeotLK7wv
TCk/u9ki7owWdKgvLkMNI3nLp19+NgivoGWklVvhs7URn8Wxv1gMyvJM8k+ZRl/P
RQP7V84s2qDQuOKLR/U0gOJeLmHA9leLLeAjxtN0zr4mjV7u/rQgS3JpcyBLZW5u
YXdheSA8a3Jpc0BGcmVlQlNELm9yZz6IRgQQEQIABgUCOfDM9gAKCRAgFTHVhF3+
3YO7AJ0ZJwzhG6FohqEaSFrg45j/GjS9CgCfanJh6tPlubkjpOSFNnJqJcSef2qJ
AJUDBRA58LyFTVYoIXkFDBEBAVrXBACxSj5Ou8meYSixH+tPBUPgdbqTWQ6JgdvG
zQSQK7q0OvRt/QbM4ewXEr7DRZlJe4pXlQqMn+CUieETjk0vaOsGYrMOj1NWp5jY
Kft2xFg+5HehlkM3h7/tXKrz3Bc5v2romFfR/6RebtbWHyf1mg6CJ8AbIRHjCj91
ca6wEOIBAIhRBBARAgARBQI4fpldBQkB4TOABAsDAQIACgkQWry0BWjoQKUFDACg
vnqlh6u1d0xcsPF2B4fbo0sF0MoAoNF7E6y4G47o7oFWoL0HCzaXsRkuiD8DBRA5
IjpBhqlMgi1qJksRAqL+AKDIm4mvwS568j9ZkKqI86XOySm6oACfd6RDWR+crZ1u
lKLEkSiQCLlFPDCIPwMFEDn8wmF3zinFj6EuIBEC7GgAnj40RzKQEJK1+Lw40ojV
/Eav3C0ZAKC7b4D63pTGOWitAWOtpEGV28Yma4kBHgQQFAMABgUCOjKA2QAKCRC7
7G7kaPPBBCLjA/9RQV0lMtKqHQLag6spTWV6DUADkNPfgs56WX6JsATO9B95oxcl
ehhMzeP+mbwZgJjR5GraAdoWXYbnWzpfPaKcztYrt90jtDPDcAuAJis6CHGAmych
FKeXoCr2m2OGcaQ9V41NNORNm79dX6v+AMyIL0oxHZC1f51bXHamlbyaCAP7BlZ8
K8TPbpYLzQCiBZrszhTlnuhQ7+gSyY77WH9pJRklFqCeFNxDb5988nxwHL7QioRY
OAkbgEFzCIdzjtEWjnlv0ZkhXc0qds07ESnGHaqK2r6P/IrRbtXWwsiiY451R113
Bglm7OF+KP9itMJi9Vg8cLj+T8wieTwPd1Y4wpyIVwQTEQIAFwUCOmFZqQULBwoD
BAMVAwIDFgIBAheAAAoJEFq8tAVo6EClvYoAnRmzFfvkql3W2b6TQH+nvi7T6cXW
AKC5eJxh21XWyRYiD9ZxIVgONzuZzYhGBBARAgAGBQI6hHsWAAoJEC4gTJuLBr51
YY8Anj5qnIMIoyHAesDA7f/sAIjzQIPBAJ97gyIC8sm+vZssS9yusnyWb/oLgohF
BBARAgAGBQI7r66LAAoJEIwyjP8WBtuVA88Al34X1C28UykPaRha+9fqLfmuiyQA
nR3vk6YF7kIeq2b96dxIF24/reNqiQEVAwUQO6+u12fCgI8zwWJ7AQHIFQf+NW6I
Od9DJWW8jIXYrnwp3B61C1emDRrRbEMdW68s1fng6j013f4NF68SK6RLcl0GzTl1
IjxM4tn6akBjqkvIk5FiPJgs7i8WW0Xq0jGqaSaJnbTONRpemCk9lwJOhKa1LVRi
c/wHnXP6IXeEwBjJ57H3YUjFc9AW1smWMpUZ18sRBzCp2BHcfTCACz7fFseDtYdA
+UNJ4NWSqIJOct5cOGOsumP781JWLSsDiuRFoghYQqUR/xbk1aKHXuRlUYrTY2gk
+Z4yzNB3MMCdK1G9jQOMtsN7LZL7E7T8MFU9d6WFIh4h7/xE63AMNlv5t/m5ps07
/ZDuPaxwCKhCA05L+LQjS3JpcyBLZW5uYXdheSA8a3Jpc0BjaXR1c2MudXNjLmVk
dT6IVwQTEQIAFwUCOnIVfwULBwoDBAMVAwIDFgIBAheAAAoJEFq8tAVo6EClTaAA
mgLzJd8N1dIgO7yB3oL1+y9egIjqAKD5ZipcQcBa1sOTs1EV7czWAkHvbIhGBBAR
AgAGBQI6hHsZAAoJEC4gTJuLBr51aD0AoKVQAAjIJ/ZUeqDXcStPYVEjXbQqAJ9w
dU4rJbpmPzrDNxVjA/XsxpCAQLQjS3JpcyBLZW5uYXdheSA8a3Jpc0BvYnNlY3Vy
aXR5Lm9yZz6IVwQTEQIAFwUCOnIVKwULBwoDBAMVAwIDFgIBAheAAAoJEFq8tAVo
6ECluiEAn1rxQ3Zytp5ewztR0Nx3WZ0PZ8j0AKCvalnlLFWNZvDg9+WHRU8rSy2r
+YhGBBARAgAGBQI6hHsZAAoJEC4gTJuLBr51hQAAn35wVfmGgyJGaK7SymU8I9tI
GuDNAKCLXoshUwSFXMKcgnGh2WU54FVLWIhGBBARAgAGBQI7r66jAAoJEIwyjP8W
BtuVa94AoIcrbj8nl78EMmq4npDs7k7hdJR5AKCYkC2kiIaCwaNyWFOJYeVfTBfO
mIkBFQMFEDuvruhnwoCPM8FiewEBQB0H/AnWue1FzgheVvRhdIIWszOvgamNjkum
OxbaWFdTOzYkunMDq7zHEP3Z05ZbP8QnfHaXyH0/Dr0Vz2/6W+EMLlW1PXWKJhrz
F6GwxvzZpvPmuZkxmngvS/evDVaibXcLSw35mIgRSu18DPb/LxxfBQ6pjMkEBTco
+55cgCISAHjGrtlJUZZA8M33Mpbm1Mn62x6tM9jHG9n2Yhyxx4ME9C0PzjywG5DY
XaYT1c1WdcO1HrNMbgFch2E7bo/V8IvSsAu198aRXMgmqgi4ZYQI8Wq4XBVIVmMk
TZ7bIRvvj6MHqiSk8eIQQL5fNEioUSuPtx1XhaG8M04Er0OFyn/5psa5Ag0EOH6Z
XRAIAPZCV7cIfwgXcqK61qlC8wXo+VMROU+28W65Szgg2gGnVqMU6Y9AVfPQB8bL
Q6mUrfdMZIZJ+AyDvWXpF9Sh01D49Vlf3HZSTz09jdvOmeFXklnN/biudE/F/Ha8
g8VHMGHOfMlm/xX5u/2RXscBqtNbno2gpXI61Brwv0YAWCvl9Ij9WE5J280gtJ3k
kQc2azNsOA1FHQ98iLMcfFstjvbzySPAQ/ClWxiNjrtVjLhdONM0/XwXV0OjHRhs
3jMhLLUq/zzhsSlAGBGNfISnCnLWhsQDGcgHKXrKlQzZlp+r0ApQmwJG0wg9ZqRd
QZ+cfL2JSyIZJrqrol7DVekyCzsAAgIIAJ0sC3USd4/7JuScntlGrqL71IFH0Vj1
r6jMSitZyLrL++eDASLf1rFOPDGJMvOGhrV9CvhUvsyLFI1fwoPmwp6pmZv5BU43
MgSbGKYIgkCZ2pGBYg5sTl4iiy8A8Vp4EqrUQhhk1lk1Hy6+Xy+wB4uFIRKuvRiB
wGd4MXjfBtzg9vL4tj31kAG0KZ0R92U9qiWkbmAgBHB2wbw+WV45hYNA2Xuurn+S
WjSCHrQr08SP966Cl7j96BiOFFg+gJpfjmQTrvB+WuPe7wT4xEQ4Tv2/vTVgO4q9
c84Bi2/Rc+N75MC0MOp+0BVa00cD8DsQBHMFlwea1GikqzDUIcfQb66ITAQYEQIA
DAUCOH6ZXQUJAeEzgAAKCRBavLQFaOhApc4CAJ9ZFjZXo1Lex1rHoXZH+LgxlekQ
xQCfdkWHAEkV6UyZ98vsnu/ZlHcDwo6ITAQYEQIADAUCOmFZxAUJBaUnZwAKCRBa
vLQFaOhApcsjAKCcLm6aVjFIGQxluSHDt/OT41pPEACg0shCNM43tvfaRfzrgDb5
8fGalkiITAQYEQIADAUCOmM/7AUJC0qoDwAKCRBavLQFaOhApZDuAKDZcYc9bnZl
iPF6/kmr9BBQtr2aUQCfb2ycB69cTi+09jXD31k8PffbIis=
=nTL1
-----END PGP PUBLIC KEY BLOCK-----
D.3.93 Max Khon <fjoe@FreeBSD.org>
pub 1024D/414420F4 2003-04-29 Max Khon <fjoe@freebsd.org>
Key fingerprint = CE1F 29CA A6BF 2F26 13E8 1B61 62AE 6B8F 4144 20F4
uid Max Khon <fjoe@iclub.nsu.ru>
sub 1024g/6585039B 2003-04-29
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD6urdgRBADQpkTC4vQZ0QvJaenfB5vMGNzpxq3shsQD5C/ExNtZ2PTrPe8A
GAcsNUmZD2O2d0r7VSDmPWQ2zDB8bE+gak1pEmooOZ+lb9t+1UwtkzDWK5MEgbRj
8dlNEagiWZ70jwbm+q8P09LMmjB2ez3OFpDzROjvA0/rU7FMWlo893aqxwCg+0P1
d6tf6xfiE0Dgz0h7aoOBNhUEAIds+i+l14zzp5Dg8nVcrp8GhsDhGUERkpmnu4Ks
iXRAbgnhv7XD1qD4EKagITMXmHQ1A6IXVqGjKuEPW3otOEhOMkfOrvI9TCcp4s7s
6d4eHt0wgjptmWF4pV8KCjj6hAkakFuli/ZjVMNiGAb3cXVocw/Q847Df6jNI5vp
OfPtA/9kGOoNIssPPa1Ni0k5MPAXB6jm658pmQShlHv1GCG+tbbzqawvimwcal31
m20DwVc/ocRQFf0/2Rqx0h9GfU/QtB+uq2qk6HTEvDfzGv7SRpPwx43fscF3Sn8N
K9VXs4Xtbrs5OYGJAMFOWg5SHd9jddTnViNtJQPGD6Bd12BB1bQcTWF4IEtob24g
PGZqb2VAaWNsdWIubnN1LnJ1PohXBBMRAgAXBQI+rq3YBQsHCgMEAxUDAgMWAgEC
F4AACgkQYq5rj0FEIPTqigCg2Qe8X9Qw88N7mk9llaZqs+3A+FkAn0Hy5JfEudVm
/3rXsNKkDf95Z9cmtBtNYXggS2hvbiA8ZmpvZUBmcmVlYnNkLm9yZz6IVwQTEQIA
FwUCPq6uzAULBwoDBAMVAwIDFgIBAheAAAoJEGKua49BRCD02zMAmgLFdtcfQwJ3
ctRFpJf8dHyClNQZAKDzqyItbtqEsWQGgN3QsG9+dpsbmrkBDQQ+rq4AEAQAyLyK
nyVL7VVb7oJh3n8H6CMXcBy/5OV4bATxxCJLQIP/eJkOWv8H+feYnv8Z1LpMI6CT
qhtVpobIpejR1CA/jo0NStQ5phhejvg08K+wgLMPFEOCCI/RUdHjNGHW4CXmhy6G
Pm1PPwBiIJGG2AvZie+7NdYjnyd7Q77lE/bFQV8ABRcD/2B36PEMQJu2HpivP/hU
15sVnYim3phBpGeYTV4e8PLhx1TFDgxnplBkCrEB24hqIFge5zjDVvJyE6t4Zlkz
IilsEanYbzBUkO/3qYCnwrUefxLxmzMx3tkNVK9W7Z22j3H6Dtvcxb17kMuJNHoV
KIufCJXylZFXAp7t03T3uo2miEYEGBECAAYFAj6urgAACgkQYq5rj0FEIPSc0QCg
3Jjbq8a/pI2C+MXDMrW1sC/PhkQAn3vNQqLa/nntV0b3V4lWRI3wk3k+
=AcmI
-----END PGP PUBLIC KEY BLOCK-----
D.3.94 Jung-uk Kim <jkim@FreeBSD.org>
pub 1024D/BF6A9D53 2004-04-07
Key fingerprint = F841 0339 93EF D27D 32AD 3261 9A56 B2D5 BF6A 9D53
uid Jung-uk Kim <jkim@FreeBSD.org>
uid Jung-uk Kim <jkim@niksun.com>
sub 4096g/B01CA5A0 2004-04-07
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEB0LjQRBADyOFyWByWl/N7zJK77MuFgYAHFOQ9HDqMipzzW7JbDSNVXroCJ
w1CLcVBtO/6yKVjwPg+7KpVpGyrOrrw/KMk74IWVkmp8b2ryGjB3ab/tUVrUjU7o
NiZKh2EEEmHVnJOVMuAwsucTRzLycF66l2P4o86bhpeZ3fdv1EQ5ZJ3qewCg17dh
7zXMa1VX0i4HJ7djf/A//F0D/2BirJpyyucjQjUtDm89tnMR86fLCNkXyIp6blGy
2OIr4Xnft3zhJr70y6SSCOIV1wYxLakFdta+76XdTYWYfe/OR8TAHzgfRX7PMZe0
Ls5dDZH/p1nFFCkq2xyaSh0VbY3ghp9VSm57Rw3y6+YjHt1CrHB+dYv+1PUHPgvu
ZC0VA/9jCEdgEXat2h6cGh7krWFt2qm1qQmBRIzas1H9aoMuuZnYnYg3uE9FHF2/
ydUnNHNEwt/moyaqABz50Q0yM5yxzcyIlQzR/J1x/I06wysyogbOFzGHdIFP4iWf
rMkF+5k8aOWXwQv36UfKaZnDB+TwHQRhm+B6ys3IxUaNFKAFsbQdSnVuZy11ayBL
aW0gPGpraW1Abmlrc3VuLmNvbT6IWwQTEQIAGwUCQHQuNAYLCQgHAwIDFQIDAxYC
AQIeAQIXgAAKCRCaVrLVv2qdUw0UAJ9U39Ld6/P24bWQEJvaLlzcJ2++lwCgwlcD
KB1H70S/jrz312P4NoBxirm0Hkp1bmctdWsgS2ltIDxqa2ltQEZyZWVCU0Qub3Jn
PoheBBMRAgAeBQJCzE1QAhsjBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEJpWstW/
ap1TR64AoJ0EdTKGipigFVuFLuk0YaDSLp7TAKC8Br0vNgDhnChL/SpLfle32RRl
/rkEDQRAdC/ZEBAAwS09CBv6wqTt2Ng1Zt7doJamAytRqv0BdPWXOP4nNhMMyGJ4
wZnfIueXbbZCGMhv+m9Y1/oA54RuRPwtzEjtzwAWK/ChK2qoTcHoLXYm/jn59caF
wKkcSp00paiHVcN7mnULWRI6L+qPaEezcan5ZXe2Yc+hFxAYgne1Os8lf15t/ES3
kdDTwSL6DFOdD6wA9LGX7A8rYhb1Jxz8zxq7IKzmS5M3NXp7horLyF/qtQbTqX+e
6mgYYtyEwJxTtQbBkuyNOriM0Mm5kaYUz6pnJ0ja1y2uq1MJnZN4TrOTJNss25eg
uZ6pFIHWo7pwfuE/wjNYYYbIPjqMeNhFVK9KvjEMJFEalgi5TPUazrLSsO1O63U0
d/14uyZM7WcDv2A95L3u622Ybw6ZTCc0EEl8ppZT66b4PfSkiSHOWngRaKK3heKt
SXtEJg9plwd9nfbza9FptMH+UIKr57ypC6nEAva0nPP9CoSjHfhQ1f1l+L6rUbjT
t8hnyzi0IJUc7YT5R0dduIKnYvfljQ7a5ONSY75vSSnW3aVA+zOKboaDA3ZXmyFL
+2DWY1XPA31I3chR9juG+8a0mJ3+N/5DQQwmIdFH6YtAppaFQxlRmY8zmaoHhas/
xpeuuXFh4iExEilDLd8KwhJF1iUPvtI7vj1CJaU1gcpnDXy3oEYyikkX5DcABA0P
/30/RstdIaYdF9x4pJsvla4cjkdy9k2jFP9/vt0zmGVj6K6ZNu2Fj/zJtlp13oyS
Nd0y0NDi8lrilh+Iay+aK1j4lQyJD3t3K20CeYgO76frvuplZiGv4GnouzfGJYpl
ZqrNVQukzg/uGkarvORTSM1lb1712kbbwMRRdJ1fs6PfSiPilRavgh7ez8vtfoBb
c5pEE7/l/QpvH2oM60OGQ7FxQhJO433U3SJd2JuDlZ9fPz6Sxqaho8HOsg8XQ1Pu
gft2xmH1qV1PJNw5ExzZx5RuxIjkVood+MxdsfTCFwO/uUOyGX2RbPHROmj1Q/Nr
dQzNcbxumpjd31KtDuW0j/iIl0GbWTt5vNBrLdI0K9/qeOhwDkUWBHZcuoztrYp7
Lv0MSjzClFNlbMJo6GjPWw1IQ5rCMyWlj/EtNhSRsCfGoU0mVie3tAUQ3VZTADY/
yF7vazIAqIj0lOX2Kh4LaKuZreO5CVwDVf2x+W3unVbTMcVhGS4bw6RFBJfzqk/u
99o/hL1PHyMjjTnqK9xtOSCX1yVmsuOGG5mqJVJzr8xLBbEkp7f/KA4gYFrQx+Hc
d5Qc6Je42T/l75HkuU6SXvqtk2CJ5Gm/GJqARefBx4u5JWGDhwD91bFGrQE3WHsC
rYMt8RcmMO1YDy3XJarUCYlrJl/L14xYm+j5rjP5+3dliEYEGBECAAYFAkB0L9kA
CgkQmlay1b9qnVPWVgCeKtPuz4H3qwApWbMhtyGhn8L5UQQAoLKugvMVvthNKOiI
E5Fbf9wkC8rs
=HTXi
-----END PGP PUBLIC KEY BLOCK-----
D.3.95 Andreas Klemm <andreas@FreeBSD.org>
pub 1024D/6C6F6CBA 2001-01-06 Andreas Klemm <andreas.klemm@eu.didata.com>
Key fingerprint = F028 D51A 0D42 DD67 4109 19A3 777A 3E94 6C6F 6CBA
uid Andreas Klemm <andreas@klemm.gtn.com>
uid Andreas Klemm <andreas@FreeBSD.org>
uid Andreas Klemm <andreas@apsfilter.org>
sub 2048g/FE23F866 2001-01-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDpXnNsRBACosqQnFwHgBcl+H2TXLWG/uAAdcZ3d4vlC9tKIPif/WovfOTuA
CM5KMb1Of2uAQm5S6KpSCDSudZIZw2az3ka5ESQt82kgd/1Ue8FJDdPkGY1RZrEp
Zq7VDPfENAM8NuYCXIdVYpd860tIfongUbpgHq9dA/bgoDDHXlaBQzUMNwCgurYO
XH1FSx7vApyBFqaE9ZKglRED/jbd0UeQ8E2Y8jvoHgn9kDGjqgTxNerLK2g7gRgx
o0U2do7kjKKWoUfij/x3RRpGUDzkB9xhibyoPQKuVim4NVNdoUoqjuSDnoDT+XtL
B8bYGXAAROPXu1AT1r/P5k3kSHDExu1qfLEk9Sch7CKrVdNaZHsrknbmFPPmhdsf
zz17A/oCfA5tXthQ4YOlmyjJXiMmiD/aX1fQovjayQDD/diNYQ/z3JUuaA01Nhw4
02LDFCk0xO2T8wWIC8Ox9J7twKKBT9Ep1MpZw/mY7XlpTFP82ls15pNIshogjlX8
23aBC+xrRda6SqTAnqsneyxGujSkS4sNubUWaQf0UUfcxZpA77QlQW5kcmVhcyBL
bGVtbSA8YW5kcmVhc0BrbGVtbS5ndG4uY29tPohXBBMRAgAXBQI6V5zbBQsHCgME
AxUDAgMWAgECF4AACgkQd3o+lGxvbLqQrwCbBNMKCTamyfzbL+69hya4MTApyOgA
oIBKu//LaM9gC+rfYUSFRaVY5PJetCNBbmRyZWFzIEtsZW1tIDxhbmRyZWFzQEZy
ZWVCU0Qub3JnPohXBBMRAgAXBQI6V51BBQsHCgMEAxUDAgMWAgECF4AACgkQd3o+
lGxvbLpvuACeJLJc2HBP42h8lVDWTZwV3qstGXUAn3yIgz/FK7+//Ax2ceO115u9
T76ptCVBbmRyZWFzIEtsZW1tIDxhbmRyZWFzQGFwc2ZpbHRlci5vcmc+iFcEExEC
ABcFAjpXnVgFCwcKAwQDFQMCAxYCAQIXgAAKCRB3ej6UbG9suq2VAJ9TDD3a6fsP
E79VBmop25fpGRsmAACgobOH43x4KJJxNSFM+sOY2QCv+rS0K0FuZHJlYXMgS2xl
bW0gPGFuZHJlYXMua2xlbW1AZXUuZGlkYXRhLmNvbT6IVwQTEQIAFwUCOledhAUL
BwoDBAMVAwIDFgIBAheAAAoJEHd6PpRsb2y6vC8AoIPWrHd+jYEXzo838pxFoJ+x
v0N5AJ9kyfJz4y0UjGdwMrfLCRL1+h/OwLkCDQQ6V50XEAgA7nyqQb43D5Nl+4bd
pwt+JqTn9/MnmG1Cw0h3++JAMijW/WTGGrpgpuFhtvfjs0nJ3FZMlDjdRfJ2LKa4
xR4J/2gIkYzvuI+JaiojvyaKnO/VZC10zH+kQmEfAZTSONucKPOPPrOX87fJ/SLC
RRPJdjR/kcub/yR7lZ9jI+5fKmv06Vgdx5agvL92eY14FdEhg4BiN99CKyOIdTPF
xgj2bCultqldQ0FhB5Iw+IYwqV6BJsRewrNJNoXcYLeHkOyf3ULxYwYmu/wh24jW
ibfotTy/hvRO6CBG1+r+Svqxj161T8vtFWEDdlMW9Efog3O7zjI8lXWF2pOgGWt3
7g99GwADBQf7BlcqJ8R4BrI/Z8cJbvWWBftMC/dx8F63ISjq65PKc5izq4fSlJWb
AEDyTv59Gv7qDSQ+ECnjivw+FBu//BY993kXLIE2KB0AY6jgMz7F4JsBhYofGMSE
uCFgvh9c3EO326RtkgsQKM4pOC6LFZRAedjo6LZzm9k2JZK2Xv8fsLZIW9dSEtqG
ch32Uu9AfThrFnZ6cApeRnxWZe3btBXbgxK2w3jT16j+CtIbeJGWdF8NN7IZ4+4v
PzdDAVBwAR2iUz9vn/d0fGhVYLHBFekfB0jyl9gfgPLkXyMorDOhJ1nhdAI9Jm6g
7FThPfNDzfgEPEgSyVuMqEoti01u0dw7AIhGBBgRAgAGBQI6V50XAAoJEHd6PpRs
b2y6l8wAmQHMTVyf5sddE7j9+RCEC9L3VluJAJsFafICjeu6dBMwi4QQaB0zqja4
7A==
=E/l3
-----END PGP PUBLIC KEY BLOCK-----
D.3.96 Johann Kois <jkois@FreeBSD.org>
pub 1024D/DD61C2D8 2004-06-27 Johann Kois <J.Kois@web.de>
Key fingerprint = 8B70 03DB 3C45 E71D 0ED4 4825 FEB0 EBEF DD61 C2D8
uid Johann Kois <jkois@freebsd.org>
sub 1024g/568307CB 2004-06-27
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEDetekRBAD7mBgP351FCNnqp360OUy+ZKCr2IxUU/Tyffqyrrgiol16kTEO
bpImo5cgZcw+y3wTSgGxwbb+UmUcJhLDO0olDNOCOYdBzzKfTyZwLzgVaC/XZ2dE
LQa+3FnIp0btyU9vermk7GqWJqvVUTnMSjinqWS0MfgrcuEXjXTQ1b3b6wCgutKz
BhEasg38JthFvIownezYwHcEALNJsxEnsfEMm+DQXPUvWTiScu2QR2v0BVVzfg1w
DMaEnSjw44NF+cyyKXfqx3hYkboRw66GMvcbfl7AYh7ThfDjof5MHfBbe6aeJwd+
pyVS9BRiXMDbwnuPm31K1zsyCr6XeQquM204Jb1fdMiFEi22A2VxQxAY4cjenvgx
2UIFBACBHtPfsK8QyAXlNtTQqvMEQe01pXm3u90pL8DBoWsWR9vDIlnJLaMgi2jG
xBNQp9UP9ZxS+BiAoEkUficsoPvoMkzQBSnfcDJfnyCXranBuuhsF4mzvEO8uLJw
4NwT+7jij0udeWe3Ymd4ppWHEADhx7PLdYdq4Kczuu0XcGqHarQbSm9oYW5uIEtv
aXMgPEouS29pc0B3ZWIuZGU+iGEEExECACECGwMGCwkIBwMCAxUCAwMWAgECHgEC
F4AFAkGV02gCGQEACgkQ/rDr791hwtgJbwCfeBGfFaR0IIUhvfVy7GYFQUjHuYQA
nR0Vl/9xS9SbGpk9nqDCHooXgrCPtB9Kb2hhbm4gS29pcyA8amtvaXNAZnJlZWJz
ZC5vcmc+iF4EExECAB4FAkGTw+cCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQ
/rDr791hwtg4zgCeNkjhClKqeDjTWvoSuh805WDuXnUAoKFid8813Hg7HATB4UwD
3KvmHBIFuQENBEDetekQBADtrxEvnshp47wNGP33Vwas4RtDVp40lC51yVFj9Ior
zXhq9SD20gz8qPCwG3a4Srhbh3rgjPvzzqcjSE/axk5+LwJ2KHySlpfwu4wTtddf
o6JzlJYWtQE+bcp65vnd6L5DGJsm1KmRTOZOL6wWxTXft4lgxfg1MEbzOKcL5YnU
BwADBQP9FCPfDZYwAsZya5h3aAd9yg6dvDsObs1D1MMIiygr54/cmGUiPcI6zaga
hTfDiDGanlBk1idFVKh0A6ZEza55NA45lJ02W9amWvrjG+PB8wTX4IWRAmDN4ql4
QuahtHsciUVzw4BtHhPtM1+DpT+C6aPwclpmxX2Az8tHDjHKdq+ISQQYEQIACQUC
QN616QIbDAAKCRD+sOvv3WHC2ICsAJ0fvZ0rq70bwTIWfgYq3N3fSZfR6wCfdrgZ
/8nwcdMpTA2LAo1YbndxFW8=
=VCND
-----END PGP PUBLIC KEY BLOCK-----
D.3.97 Sergei Kolobov <sergei@FreeBSD.org>
pub 1024D/3BA53401 2003-10-10 Sergei Kolobov <sergei@FreeBSD.org>
Key fingerprint = A2F4 5F34 0586 CC9C 493A 347C 14EC 6E69 3BA5 3401
uid Sergei Kolobov <sergei@kolobov.com>
sub 2048g/F8243671 2003-10-10
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD+GP80RBACjmIRFKqJ337zOjW51eExucWRny0pu5fuGaxuJmGSbKaJRAORU
1jx9i/Cxcw7iwrnbR5xeyjWLDb7FIAemPltBItt0tE9H4pQXgP8d8VL3eehguMda
o0yfP7WUm3U9uriJEJ8141Yql5IR0e8isQa+YsYbkd2RmDdCMDdC3W0Q9wCgsquv
jc1gvAh7ypvhk8VLhflAeZcD/jQclE6S2zLZ1DSP2Q5mmuMS2ouRV6Z+fbWKF9XF
TSxdLevWcXmPqvsXFT75cz8pcBIw4c/wVd8OsPU2fd+1LZCFdms1PqLjhUfXgVbP
Q1Pl8zCAyriSnR2+BDwUMGzEgidkTjmjlbwhGzPsSJ8rv4i18xYs/JbmkeAV/ZBA
e6jrA/wMU3ho5aIJ69KxZb3bmPVHYrqL8Q3n51uYausLxdHDMxVvjL06VAGWbF/h
TdiFJ1ngMKfcfzI5/awpKwb9FPbERuNvmT10MDKumFW3xSAJMRzxh7O61u8N7dmc
xLdirICQMRN2jPo3v8T2ANsdydVTn89nqdpg4Bo9Rsz/Fdnrm7QjU2VyZ2VpIEtv
bG9ib3YgPHNlcmdlaUBrb2xvYm92LmNvbT6IXgQTEQIAHgUCP4Y/zQIbAwYLCQgH
AwIDFQIDAxYCAQIeAQIXgAAKCRAU7G5pO6U0ASlRAJ4mnVHx0rA5dhw0scFGOddP
cH/w9wCdG6HPWlDpXFB5nkpQalMnGzLAkka0I1NlcmdlaSBLb2xvYm92IDxzZXJn
ZWlARnJlZUJTRC5vcmc+iF4EExECAB4FAj+VJGgCGwMGCwkIBwMCAxUCAwMWAgEC
HgECF4AACgkQFOxuaTulNAHJ7wCfbcMzZiTmwuTD7wLTxvzC35OQE1YAn3et7KAt
aLZuVXYIDROr33RIlfcUuQINBD+GQA4QCACIrLJbs3SkUJpuvYC1N/iykFYGHKPM
L+XCCK3A4HL6f+GyCpvajz62cjUfuXv/pkLjcYANnqKKPJu6Bj2rFmOG785R/RPD
o2dl+zlZ0fggQAv8zZqIP2KyQRSVa44Pxc/G1V5odcg/QOcKU+FZrkRXoz8SqfDU
OEfarQP687+DU+Th0Nwn5M20+0ml7yw0/y9DtggWXzlWyIdYfhU+8HckvzgXnUFA
tPdfDUzUxEjvVBUwZ5iHtUlId6sHiiTCS/fbnRzwJA1Pu1E52B2AfsLxFrwV5cRC
ASfi7IGhZazGCctqZi4hbWQCB/+ipEVGct+bD9BpW9yS/JiMAxcwE0ubAAMFB/9F
k6mZUzBbxQkSbXP4w1VSxf2m/lIV9v9M0LCMwjmcsJzsdLUG/i3Zo+hAjT+GznMU
DVzPHq55LiNs2MKC8WKHXgXFCB2uoZvlGu88I2JjucoeibtC7zbKmVOntuY55zTk
uiGkGRawIIKC6oqVFV0EGXxrcJ6v3/0vgBQSva08reETZaUFe3ivt0rU0NSbhVJ0
1WiPXk9wFY0ccemUVmdcX4hhC0yyBB0px4qbEBY3+mtHpFVh/r24GXvWXkbLowGd
nmKeigX/tlRyYgPHLM2goUHUYe0erbKp2fyeQhockLOWY0DBFcFRK2kSx9HYdtcI
N45tvtkBza2O8C7uCtwgiEkEGBECAAkFAj+GQA4CGwwACgkQFOxuaTulNAGwbwCe
P3RXUuqmNGYCM0IXPlop9XLZIcQAn1B9zRfHFJm7tgMI0A6Avybs7V8i
=EDjf
-----END PGP PUBLIC KEY BLOCK-----
D.3.98 Maxim Konovalov <maxim@FreeBSD.org>
pub 1024D/2C172083 2002-05-21 Maxim Konovalov <maxim@FreeBSD.org>
Key fingerprint = 6550 6C02 EFC2 50F1 B7A3 D694 ECF0 E90B 2C17 2083
uid Maxim Konovalov <maxim@macomnet.ru>
sub 1024g/F305DDCA 2002-05-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDzqHSERBACUPYN18/fnXdsI3CsH/UgX7CL1yLSgTCTbEA7p/jPA78svM0Kt
aHdZG+mhZH9u//SaPuKPoF6OST7pb5ee48bppzL8v1+zYIAUWib/ImR/ZEGi5SzM
mYtNCrK3YTblaHoeKKSrVwYvFi4HYQZWG3hcXaozhZRVQTnGnDdQYriSVwCg24Pl
UzXu1n8lw+4zDlW3eGIkxEMD/RpnH5n8maXO5MYRvuBpGGTF7x3iV0somnLhQ1Th
1WD/7OhRRzfRpXarG8ObyxyPx52et6tGV9IjSdO+uuVgtTUFRKsr6QYk/y49blnt
pGtd4kTHMy99Zt/GP/CBBWn7dQtMGABDobA0ZU5ILkSlZ+DHtZLEkIXljhxIyhbw
sIQzBACKTwIrcF0trhi2dibKMOWqy8RYP5iKe1vXy5SCdcU7HxicHGzI0oRdlCHT
jh0pik8YWI24d18UdHDhvWHxbF/QCBbW+RAyiNASzzdsiIswo9Zvras/NZbnagHB
tP80kBhLVC4udmO7GKYxKjpgsuqihaFJdcpoxx8J6mv2sTxK1rQjTWF4aW0gS29u
b3ZhbG92IDxtYXhpbUBtYWNvbW5ldC5ydT6IWQQTEQIAGQUCPOodIQQLBwMCAxUC
AwMWAgECHgECF4AACgkQ7PDpCywXIIOv9ACfdAHOpcAmtGrNB7f73DIYjZSRt+8A
njYiaKCJ2lZpj9b4JEa7C2uIoFVJiJwEEwEBAAYFAjzqOncACgkQIkYMagPC+y3J
ngP+OjIKj3GrGZD8LXE7mK++WiAqlVyC79x5g28q12EUkZYzLGIkGuz4/NA3wcel
d5G6dvV+7JEzEf3sAT7/iUcIgYhIepEWFEUhngvNhi+qf/FqVuT9bYz4UkHEL2Z2
Soxgk/W+N914SgLWiSKE+hClD4NjsN/h1rT/kA3kEMKRkw6IRgQTEQIABgUCPOo6
HwAKCRD31D6TzwF+V9VbAJ0alq+w7D5p6jk69ApdFv6qWHZ8pQCglKhTRm9d/78N
gZZxXPyTY3qYAs2IRgQSEQIABgUCPXS68QAKCRDc/7Ca5SeztQNbAJ9XzTZBQ6wY
X0UKVtj8E5X8CVTMmQCaA/iZu8kibLfaFPPSeTjocghSdzeIRgQREQIABgUCPPI3
LQAKCRDkwbNJgRZkuSIXAJ0REQ1xY6OFvWLLY7vtPhSkEbsXJgCeJXaVc7+6A/l/
P7RGJoVA2aqqSryIRgQSEQIABgUCPjwGgAAKCRAL8GQSYLofR8p1AJ9NLtBZCdpd
p8oG67sSD9EGk3+hWQCg/KkUjHGmVSGmQU2A+CX8MN80lSKIRgQTEQIABgUCPmtE
jAAKCRBOOAZa8Q9p19UWAJ42kJIpDGF+/PoSnZ2kKXev6Pwd0wCffoPGbdkFDn4U
1QkH1LfBS1fzZ9u0I01heGltIEtvbm92YWxvdiA8bWF4aW1ARnJlZUJTRC5vcmc+
iFwEExECABwFAjzqNHkCGwMECwcDAgMVAgMDFgIBAh4BAheAAAoJEOzw6QssFyCD
NvgAniuAmAatY9m/JXsO8Pf4Gaqn8sdDAJ9w9iEjbVIrHicNoGig+JZ2MzoXaIic
BBMBAQAGBQI86jp6AAoJECJGDGoDwvstnBYEAIbMNUUVHnlBJyylGD9ILRi+6hM4
3OVjUMtSi3+wWxSX8iLnC8wfSUClEcbhEsgLo88IH9KARIMRP5GVZd4IdfQ944AC
O64TgKe+Gywk5LW5BwVJOMpXLlrZ13nEM48hoiLipn5c4sx7fKBTJKQkz1KOrNfh
IvL1t+wZ4XMUCDiWiEYEExECAAYFAjzqOiIACgkQ99Q+k88BflctgACgnBG5BoSe
NBw4L8ZU1sgm+ioMzboAoIprTOjAbKoE7JP1Lp4sw7yQ3s6hiEYEEhECAAYFAj10
uvgACgkQ3P+wmuUns7XTmACgghrnoPXCydTbuzTMvihKf+YFMv0AoIwLXMMrcZfV
E7VisZO7LHKPNAsZiEYEERECAAYFAjzyNzAACgkQ5MGzSYEWZLn4mACgtfoD3CAL
hinoyXOMFMbGrZhBXVAAn0iSmTDzGG/ez7IhxVfxDgronhLQiEYEEhECAAYFAj48
BogACgkQC/BkEmC6H0f6WACgj0hsYBO/cd8yReuHn7G2Uy8ITXEAn1gPWD0th/V5
Z+3evG91zU45tYOoiEYEExECAAYFAj5rRI8ACgkQTjgGWvEPadefrACfa6HcGH4h
P7H1OYrFtAspVdWKYmIAnjKIN8ukxtmZUxBo6XH+Aomk7bDOuQENBDzqHSQQBACC
eenGIATI8xuuYEWX4Q+6RD68CY8exYlHgBKug4rkjNFu+S7FjhCzklyCJ4txdLfE
HI8rqTvH56nQT/SRAs4oeTyGJoRxH+OvOK0SMJGuSduegNEPR6wShdgJcsEmeeqb
GuZjWxa9p79biD9reWXCEhFrGjwAZDLMDJvoWAu+awADBgP+OsRhHT1r+PeD2tWA
/x2wAMgfePG2fEI2QQg0BZtyEK+NBA5uWFZZTQUqO2MPGOxqfAKPlmBBE+tJBAbQ
E16+IzXJZ+DUv1JhlV+/b2vJDD3OcwEJaIk+/IQpDkGRwteevdRxDTfqaRI11XbD
YwM4u2aJPTjxyXHxXiV9P69wrmSIRgQYEQIABgUCPOodJAAKCRDs8OkLLBcgg0I2
AKDEBTYIFJjK1nTwXRYfHEx4ietiLQCfbMUkZi0uCFW71DQ/w6Sq7ZuUwgI=
=WWB9
-----END PGP PUBLIC KEY BLOCK-----
D.3.99 Joseph Koshy <jkoshy@FreeBSD.org>
pub 1024D/D93798B6 2001-12-21 Joseph Koshy (FreeBSD) <jkoshy@freebsd.org>
Key fingerprint = 0DE3 62F3 EF24 939F 62AA 2E3D ABB8 6ED3 D937 98B6
sub 1024g/43FD68E9 2001-12-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDwi3FcRBADkiWSSJSOX38CIPgbUnnDQ8S79eZ0zQYnYn5aeRMi7w0B4SnQP
1DcFZ/EHNtQWJTCaQBWQZZWvL1ZjdK284YrpSKs7gfoV5BufcFqKatewWZUfsUad
FEKTXLXlZa55151UtFy9erkA22VWHmqkauDFYl4DiOtaUWCX1Gg8xCvB3wCg0sbC
/VtANEu2XbxUp5pGmReNn50EAM4vLWfZk3T2woHN0VBOwEk0BM216zfJQGLFUFqT
nLKezO/QqoCCcVpH7rwV0V6NI1w6YOSx14CU+s83iyyO0KlRypoptWKBoA+cjs/y
3Iy05K147YfWUhgkKcyw/Qwx8wCDaetG+qZCX4nY0EByezFe504uDkcxk5BrqBX8
E6kzA/9vSG+J4aejKRw9z7Ku5cLV9ygXCksu325uY2t+J6b+48cT8eFMOpgUHyNV
m5ypOL31KYRPkOzK+iiDoTPODh4Zg8YZLsgWdTrC0ZQW2nWPNd3Zv+tLAmiwVjIV
x4XqtFXh4nhI2eM/PXhdN37R48OKB0DmrvdH819/2+9upNvO/bQrSm9zZXBoIEtv
c2h5IChGcmVlQlNEKSA8amtvc2h5QGZyZWVic2Qub3JnPohXBBMRAgAXBQI8IuKv
BQsHCgMEAxUDAgMWAgECF4AACgkQq7hu09k3mLaWwQCbBEeFWt8z4HlnAys0FYB8
/U63eqkAnjKz2Lxj14N8QYtbtFThZRB5fq5cuQENBDwi3GIQBAC79Y5tcPi18bZd
REXZmDOnLc0gHD9y6PHgR92BUCWQuafcxfQqqY2ESF/JQ0dFfBEkCAmYU2YkPZA5
A7skmv9zHun/bXAP02hrvMU1Gt0ZHIzDV0EaO+uxY8eSKg4JuxZzpgzWCIxI/6uh
ZhOuEF/uql7IDKMQcOfsvVrF8cZfNwAECwP/UvxNG/RUOlOHdRo3hY3H5l7zmaCi
AwUU6Z+LxDn+fwERX7wL5rasafi1r7/9VvGADfelpxKR0kZM1eKYPtri1zS6Zm5a
CC+QVyyoTcb+x0mWForq6FxLDf7+l/O0TuEG7VOH4RgLaT2N33yoScEvxdB/Qo4w
KnT39F7lYjbzBvGIRgQYEQIABgUCPCLcYgAKCRCruG7T2TeYth30AKCzp2KXBqsa
N6wOyM+tHQ4DKNMasgCglJCipoxpnnvCsGiZJv9AgNQFDGM=
=a9D2
-----END PGP PUBLIC KEY BLOCK-----
D.3.100 Wojciech A. Koszek
<wkoszek@FreeBSD.org>
pub 1024D/C9F25145 2006-02-15
Key fingerprint = 6E56 C571 9D33 D23E 9A61 8E50 623C AD62 C9F2 5145
uid Wojciech A. Koszek <dunstan@FreeBSD.czest.pl>
uid Wojciech A. Koszek <wkoszek@FreeBSD.org>
sub 4096g/3BBD20A5 2006-02-15
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEPzlGcRBADVxGiWQYCSd/HJfQi958sIFwxgfaFLyKaD4u8yhdG6s7SOz6mR
0jTdoMfg90n8CUvDIXeHj8Hhot2gLLmOK8BHXdR5/PBkvoOEAiqWjmFSsxUKyKTU
ntYgpIwNtitVVdunp/kBk/w36Ue5veNL2GtqbVRMgp//ebV3GBZtAr/QowCg+w6K
5vebaggZg2H4EcdAJ8N+5wcEAK4PGjLtf6KWwFh81TihtD91EAVIMjsZO6vzofK0
QpMdHDI0QZgvraCpsoLppYpj3dp5XL6mxRCCpFpWhhRP8aocR2ujvXYJY49qGi/5
EowE0UuIrdv52ubCHlUWcyYdrnIa/QAh9JpHJIGdIVlysjRujygctUH1HK6zZYSa
8R0DA/4o0up4kfwkdm7FGbFy5arNR/Zbe51dsgkA4aPPn3MymIBR1Tb4z+M0uHya
VKyER9ISP7gafpjpZ9y4D5lDWwL0m5oLfgm4PqMJ6/44D4chDRlnkM8w/l6VqSq8
XVmU9iKH0J+O3/jX0tE2Mbk2gL0pZKeBPcnkBHLSkLUHWNrETrQoV29qY2llY2gg
QS4gS29zemVrIDx3a29zemVrQEZyZWVCU0Qub3JnPoheBBMRAgAeBQJD85RnAhsD
BgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEGI8rWLJ8lFF8hAAoJemHjhjIrhB/WY+
pFmKwfqNWN4YAKDzV97FKMrQsq2ECzvWSV6hF7QMkLQtV29qY2llY2ggQS4gS29z
emVrIDxkdW5zdGFuQEZyZWVCU0QuY3plc3QucGw+iF4EExECAB4FAkPzlaYCGwMG
CwkIBwMCAxUCAwMWAgECHgECF4AACgkQYjytYsnyUUXbMwCgqqKc+pI+XY398xJS
phO65/Z5dQAAnRVA0RLAJHRzSN9aHy9RyCucN5oJuQQNBEPzlJEQEAD7Lq9Bd3jR
e4C1u6kZCnKsbkNl5Ogor3cwoowydWrwrP9KBis6s7e4Zsek4ylR1QzV77G1ar5/
9ecjDM+Vok/R0sGkufRUfD7XBI1mG1KJwnxZYm8aRYCERTRoXDThoJwUoHzwVn9y
Xi3gyvS8GRLCWlAXYwJrYHn5ccCKfrOSdQG10ZWEj45zDUGFw+PSRtAOfCze5cAl
txiDbiOER1/ryQaKutMPT3A0zDbTuG30/m9F7XDXsF/S+7kWzyfO0156xKORcJSD
pYMILFsadN4WzSJSJFvUTVSJ4b7ljomKEJCjZF+cbPDNoiNUobLedTAkMPpPigF0
KjVGX/yaUEaMR1GvDQ+UF7zf8ncyrdcOUtacvc7M3hL9Q5noO/CbHvqRW0g3Gvys
kHkQJNL215gd8wxCrTv0OWfDWhOOIHjiCFTA1JGukVh49wt1bYAzn0uz+QOGfcIt
JllvKP5vrvjtL9LpXsWgoKO96Ijr2t72ofuG+q702u0/E9G8oTNSzyi7t+KThxEB
5VpoJItTE7A8nmuqubArIzHKyVvThsQE/xMeTE5zruN/PmsdV5zWHuJU6MArtYUa
tNr5KXzK6UDsmdHG4bUjShjUh3wrAHLIodR0gRISM8Nnyf1l5XBh+iiCoqQmscZ2
+4la+9Z5j6FrRDf16CDx1n7bx6vTkMYG6wADBQ//SJf5I+N2pAKpV8u60B1LI85i
84JOGvCenEeLqnK7td1IRAkKkv0anyqMSpxTFdxect8tUPKttvTSkn8x44Seexx3
1bfwgYoCnUUwxNegu3kv+gLfCJwsIbXjXyHqEapPHNmbTPmlZKWa26TO1Cx3W5QA
UahlUkhFhMhbfnsxu4hJsMD/i6SPCGEhbp0jfHvXQc0VdUGJla8TOJXzfdPtwozn
skDrrmugYtt3x2Dzf3eYr+p3EScE18uMBvcSvbN1w2ZOz9jIaO/mQ6dGpFGejo9n
D+8KAb3ke/ZQ0ov4gnWXsKQLdQsVUuPt14cLsXfK1jhlaydtEmP8h24pR2CVUkow
2N2E7KzXsE0ZPc6na1r9WkI85Hd1y5qZ0zxOVijraFYu436LXewqgPSXvwlc0jMe
Uw2DgMEHK+AvMpNVwVGs8IYwVfy1EYLRguP/DR9NsmzVONEfkQxVSzUoGlk//m0b
bSqpA99Mbye+clfEjh0H8kgx9xOYmKTyygZRCC9sKD8W4WstZQ+33UxssaVu9qrf
m7qDl9+GYT+s8JDhzUazNvKi+xbiy7wJtIE0dShMJKN2/m2iP+PH6RE3GMfWaxjB
Pp0qn5VxJ3Ev/VFervSP6SnMuE3BqJ+aU/bSVx9mZMMLsrHuG+qA5vCC5vOtnHJQ
zJ7o8u8XzbuX+v2pq9SISQQYEQIACQUCQ/OUkQIbDAAKCRBiPK1iyfJRRZQ0AKC4
7SDQifU3JEpy7s5MsTtZQ+DuUQCeInUZzNAQW4xzNapS3xMV2mJ+6tY=
=sg8v
-----END PGP PUBLIC KEY BLOCK-----
D.3.101 Gábor
Kövesdán <gabor@FreeBSD.org>
pub 1024D/2373A6B1 2006-12-05
Key fingerprint = A42A 10D6 834B BEC0 26F0 29B1 902D D04F 2373 A6B1
uid Gabor Kovesdan <gabor@FreeBSD.org>
sub 2048g/92B0A104 2006-12-05
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEV1zhcRBAC4T9pbx3J+/0qY5k3IVGMGpI31SZHwtO0ijDBA3V0mIOUpty/E
2AnAQ/7GZEvWtMd3pE5xwoicgSQbPcnsHG9kqG43vvr2DdByY9lavqoXPOXKeQnr
U/Z5eYvOgT5Da6USxXI5obFdNsCwwKYt7Sbvfj6L+FVWSS8HW54f9xuqLwCgwCRv
TxVBZJ4xERWsk3nJH4B/GKkD/20ddbTHSTBuBpulmoOUNBcrnIEYPRCDvF/e07yz
sp3KJeMegdPEwBoy6bF9R8HkVgSEx/jdMSZNeMeAOpAKDlTUyTNJRgzVwqu+SgOj
GT8IzhLNFaZ7wiKoA0yRhGb77C3IPzjSbcOI9A3vn9DkStWfDtjTIOxh7FxF9+H5
c5z9A/9++LOF8L9VPHUNi4h/L/jE6CWSZgeTUIMkSwALrochNi9xIr+kS5pPxUPZ
MHVdG0+gK3wNLD6KGpBnHB65wWbb85fukY9y4YgEv0+TjpPwkbwlAbKtt7cf7RA1
mYtYStbOedPBAE8Y89cAcmQ4a4ViJFWfSTLJorAAy73pVns7ibQiR2Fib3IgS292
ZXNkYW4gPGdhYm9yQEZyZWVCU0Qub3JnPohgBBMRAgAgBQJFdc4XAhsDBgsJCAcD
AgQVAggDBBYCAwECHgECF4AACgkQkC3QTyNzprFGOACfYLDfWSz4Ke3HN+suyrD4
iwnZpycAni9084/VZ5iAadc6I1o81cGFX9GtuQINBEV1ziAQCADQBlmiWzgTaAem
j1rFzVhEe3bSRg4qmcyiUyIbVWj8Ecc71c33fSHdgjHnAqKGjxKIkf7qoSziLWL7
b2dxUiI/M7OUTi2Tdy3nJa/GJ+PK3CK4oM/oSMGOSUz7d3ZaKwZX4d/GmpCZ6U6w
XFPymLOQtlDRTyz31QPCQXnI2CD2yswSdrHID/LuBDx+24vA2NyGy7WdUmSSchnE
aw0fYTiHbjqI4xsTS6wkRJ4QRcHg8vyXc9Xd0/TKtaFBURWfHDC9RWNjisrhc6q1
89o0QHBW+UqcYdWPUgTO38hr7k8U8LNJT0a7axsgwiwLr1oSS8z/RjdiFwuArM5M
PQgkvMYLAAMFCACIMIO2gjtPL64mLy6If2TPBTqb+g+HaWWk4lxsUN3A7A5y9TXk
w3Hx2jcig6P95jIKyiTJkV5ZqcUuwtEWK/nK6M4o8x7QQwLAfH6x/wfsb9Gays+K
wT448Xhi05cOnIuKyFXXzaNRgGe/G+fxpxqEjmgP5y2NjB+KG/h4/Am25h9Ylm+P
EYq8QMxwYS+3TpfCMmgnqTymegNZpbQ32nJYKnxn9j58sLqgp7BjekgAYi79z+Zx
0HoeGPiehGLdymoj5aaiTCZfTB5CRMyn+dbvXUpl8hdAEG72q5D7JH8yicOANHUd
NdMIcDxTJcHnDQeXdSrVWGTQmt4iuwfweKlmiEkEGBECAAkFAkV1ziACGwwACgkQ
kC3QTyNzprFoGQCfZdGMd7cQFoCW1DBGMnNJ9AO5WmQAoIM4BtfriXvx3Tov88ES
DHOhFMi+
=jLzS
-----END PGP PUBLIC KEY BLOCK-----
D.3.102 Roman Kurakin <rik@FreeBSD.org>
pub 1024D/C8550F4C 2005-12-16 [expires: 2008-12-15]
Key fingerprint = 25BB 789A 6E07 E654 8E59 0FA9 42B1 937C C855 0F4C
uid Roman Kurakin <rik@FreeBSD.org>
sub 2048g/D15F2AB6 2005-12-16 [expires: 2008-12-15]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEOikikRBADU4oWe1rkbd6R8HeOR5I/Uw6gGk0zrBPNkyT9PAtNKFYgAOotZ
fJbo1czDlN5cstvqBOUKbmeOwqkMi3/DT1N0VjGq6eocBCvBhHZ/PIyIonV18JGI
/wYYQ2k0jAOpehd7QYYB6w06gi+siJ9UY6iEhVxrO8rF5Er7RYXICubDEwCgszsF
U/rIMr+yw52uGDe4d1wyICkEAKI7uw05tkwQutLzjx1ZOCu1o8zLepZ1QMRDn8io
EyMRY/pCvge7k1kjmm/6eZ3M39fPrvwcpfsRF/dlgEeQI9Pn0HDJWG7eU/zg0wrQ
VkvELJ6qtJvlQRKMh51EfLkR00Fy0HsBWfc4U82GvBLU5fPL1FujMeVLJtZ0W3q+
nHjUA/4z0JVp6vNCkPOr+BiJhdJsiAYkGUdqHR/mZcChcRD9jJVRO1JDQQSvP3o1
GvFqqRU5VsvYXKVKlVoWQiKGu0Hf/ZIOnY8ek49nTsUTm1MDPIFqMl182uxr3s40
DhBmKzhufDBkgtNdpC2SU0h5mwkF09Xo1goVMn5DTbQfRfNfF7QfUm9tYW4gS3Vy
YWtpbiA8cmlrQEZyZWVCU0Qub3JnPohmBBMRAgAmBQJDopIpAhsDBQkFo5qABgsJ
CAcDAgQVAggDBBYCAwECHgECF4AACgkQQrGTfMhVD0yS6gCfQyXa2JPiyfy0EFzQ
HGwWrDPjzjsAn0IJZGfMUiTegcmtpu0lNv6nMUiEiEYEEBECAAYFAkOjJ6YACgkQ
TclL2LcfYF1uNACgxXMrlmzdzmMwriLK+T4OKcffa/sAoOCL19v4pPw4R4KI3o7O
MOacY9bIiEYEEBECAAYFAkOjvw0ACgkQryLc73jOEF8XvQCfWcxEwIwZ4eZld/Qf
eB1hsxJeDxUAnA/ftOsZtbG4o299udw71y57GHMPiEYEEBECAAYFAkOj44IACgkQ
hdRQRWtpGwOERQCdH2AVEiuQohXgOX2PdCIZYiufCEEAoJgGONTdR1U3cp1X4Hhc
cuAX+Z1IiEYEEBECAAYFAkOj7gcACgkQXeTX/hlJ3IB1CgCfbgMdPkgLWLQ0HHKx
rR1nB3hzAiIAnjOwE3TRytoNLPAAuECgudqkqpnRuQINBEOiklMQCACBiZ5wcv8t
jUjCX2iZ7D5qQiWuJYPhMpBS4hV4mZXhM+pSjFctc9PFw+WHlaRFXn7zGYP404AS
tvqmnZBInBdal+L7r9OhPj7vrQcYDHJTMDflHK/YhfBwMj8/r2jkV4Ja4ji9nazr
Gbq1wJpP1jrsBuFU0Qy4HRZwSyKrFNGqAEsiZPxgMAY16fi3IuVbE78HlUq+0I6Z
C90z5MbGFGSsZRbWJSxSCOqQ7YxqoaCqxxNeF6fIYQdL4hatuH287dqmru6ST6j0
ApQF+mnmlwKnrLSzXw0Hbvfj8ZrGyAc9cLz2oCwVwvLsP+ohiNBDHc+FFXcBxIcy
kZi1+6AxjhXfAAMFB/9abRCZ9AoTa+Hd6ajC77l/Ul4jlj+R+DKQ466kj+WYOdeO
XQtF3e1g89cEX1S3lnjIZGS3uGZ9YehtxMwBXlOCIyyLhNxlRWS4YJeC2E1q1kZm
+xs6IC47g1E5yVpm3qcUp6HKwO0SGLQiN3ECSZfBtNEcEScAFGq802lLLKnMRBfV
DpwXP4jop+90NSKP4RKzgYdXXz3SAq3heKeuBOHl3biaTmvh/FSoZtcGSqWLPR85
d+5GZVJRzrwGqrGN/3zRvd1PbTpeJ/pbT/saFtsVCmlPoUOpKeyDHGlPotQo67gu
1cwcr8h0D+oYPMLlspZFuMXvLPxaNB8oRLyxVzUhiE8EGBECAA8FAkOiklMCGwwF
CQWjmoAACgkQQrGTfMhVD0wzaQCglkceiB8ksT3+rwFRApwaWTO8ey0An3w0Diff
8juSFfJ2ZBIPyPzTGgMu
=0i68
-----END PGP PUBLIC KEY BLOCK-----
D.3.103 Hideyuki KURASHINA
<rushani@FreeBSD.org>
pub 1024D/439ADC57 2002-03-22 Hideyuki KURASHINA <rushani@bl.mmtr.or.jp>
Key fingerprint = A052 6F98 6146 6FE3 91E2 DA6B F2FA 2088 439A DC57
uid Hideyuki KURASHINA <rushani@FreeBSD.org>
uid Hideyuki KURASHINA <rushani@jp.FreeBSD.org>
sub 1024g/64764D16 2002-03-22
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.1 (FreeBSD)
mQGiBDybt48RBAC/KCE5CLVZsYvpmgrbum7JHgIgnX39EPMQmL9Y3LmYy6Iwh+OF
iIjIqW6cDeCcxHoJBwbSUerC5ueriwZCh46gSnLVjnmBLlGFXyxYbSfFGetMVVSR
6OpiQuITp4ZhVw/UoCGloNsIFKg6l4JMwqZmsrZPdl+zUU79RV9Zb4XhFwCgsRIo
1mf9I3rNZ8f1Jv69nUR/lJkEAJB6fY1rtUNUwq+JXOnFGD0KnC8isQNyOeQ7Y1il
HQ9mGVKuUC3Zh0FzvdsU7Ks2ss9ynxfbFXnyyAOqXwTzU9pMuW5oLOUmjqwEfAhV
4S0xcnPcfGGJ671NNeqa8X4LQv6ECWai6O4CbA4aluRqhHNxT9dgEai8RN434LQE
tGxcA/4mIlvVoM2c2DRjD4+/Oj+i80ZMpOgE1RkuQmXoZ/DwLD3EHbIBX4cNffOd
FzxYrKCrXD50MehIw/IhFfHN/GdEN7NT87M3j/ydSYFluoiLv8FXO00mr8cDi3wF
q+LGbniEhVcW6wpUz9zVFmdLAp3HQi1uRAHqYmdSs6gqjl/+pLQqSGlkZXl1a2kg
S1VSQVNISU5BIDxydXNoYW5pQGJsLm1tdHIub3IuanA+iF8EExECAB8CGwMECwcD
AgMVAgMDFgIBAh4BAheAAhkBBQI+L/K/AAoJEPL6IIhDmtxXgj8An1YuXcp0iurB
ZYHiaYMzAb+lYhALAJsEAKTyeqO0plIvHBV49L5CErZo87QoSGlkZXl1a2kgS1VS
QVNISU5BIDxydXNoYW5pQEZyZWVCU0Qub3JnPohcBBMRAgAcBQI+OM7uAhsDBAsH
AwIDFQIDAxYCAQIeAQIXgAAKCRDy+iCIQ5rcVwyNAJ9Y5N6lIMXVy4sYCdgQvqDR
xkUN0gCgrsbQwfTOBcy8Mw/UmGOE4/fwrNa0K0hpZGV5dWtpIEtVUkFTSElOQSA8
cnVzaGFuaUBqcC5GcmVlQlNELm9yZz6IXAQTEQIAHAUCPjjO/wIbAwQLBwMCAxUC
AwMWAgECHgECF4AACgkQ8vogiEOa3FerLwCfRPWW7lC/pAVdD2Jo+8rcWTKQ1xEA
oIQ/on62k7YBO+buO+K472a/cW2MuQENBDybt6UQBAD/ZGmvwhzt9YWhF9q7mLOT
iEMzL2AzBryLzzUphejgDlJN/TIoDtaJfMyNkO16FbUq/WLQbKYFKfDunqx+eVSi
PsneeYw9nAdlcXVgHRjoL3vj5O7PIg4qqps2mnLKEOXLAH2PNTYY6+8T0NQicdht
YIraowzLoKRdINuDQrCpEwADBgP9H4CwbNJtQAHwS9ATmfL6F2Bg9LWe1godSWkM
N+nBxKvMqrajJWfxV09f9gzn0qmMZT9u2DwcADzRQLC3jkzgOD1f8UiAuCuDEE1a
vg1iCuyiI6m+MMWCkOCj/69wIu1ilmWqkn8SeoEwN+hwqHa20ue7vBhXreQanJim
sq38ZdCIRgQYEQIABgUCPJu3pQAKCRDy+iCIQ5rcVzT/AKCgYOyEMpIxXYVI5gYM
CwQ3hkJ28gCePnTu3Ke6lPoQsMAo3TzKkUO9Wj0=
=cXJQ
-----END PGP PUBLIC KEY BLOCK-----
D.3.104 Jun Kuriyama
<kuriyama@FreeBSD.org>
pub 1024D/FE3B59CD 1998-11-23 Jun Kuriyama <kuriyama@imgsrc.co.jp>
Key fingerprint = 5219 55CE AC84 C296 3A3B B076 EE3C 4DBB FE3B 59CD
uid Jun Kuriyama <kuriyama@FreeBSD.org>
uid Jun Kuriyama <kuriyama@jp.FreeBSD.org>
sub 2048g/1CF20D27 1998-11-23
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDZZXiQRBACWc1PcCjIpTl6aCyOMVfz4jlRSKblwib2s07TBwbgR1zMhbPie
O2K4ZJqTcG4EnbMLEyYMbYwvNdOfUIjMW3VI1PJhRwWthTcbUjubzTu8Zxw+sKME
ansth0xZW7Ax29UWQcTPxs4SRsCPFO8t+aWwZOm6z0fb5l1vMmKNJuw1+wCg3ZZB
qK93hQPaOObwglnAIrgNpScD/j0VCEeC8fTMk+ZIo+z0+bUGPGU5cq+4XVXABYLn
wMfR6Wr5Ys/3VCx4Oyzzgp/HBzcE5HxJukJ2ur3m9IE+uFfY4+HEFiwL++Ke4TWU
7rn4rKjJYhGJ6iqGFwuxwmHdjcBh/38X0kmrCxyPYpt6xO+sJBP+QOABw3PFlMkF
PUY5A/9RGU4mm6K7cteNdbHDI8yFNorQs8W8fRb8yP8bw1T8qB5+/rQ5jxAfA5sr
FCuZsKNFdph9z/I3eFYVW4P8+9gmI2FAAAocWheSyKttAFHx63JRyBqXq9xmHKST
kuaoQVXeFycSULAPkV67j0/zDL2mis6bRpPopINGgjkia16u6LQjSnVuIEt1cml5
YW1hIDxrdXJpeWFtYUBGcmVlQlNELm9yZz6IVwQTEQIAFwUCOmRRlgULBwoDBAMV
AwIDFgIBAheAAAoJEO48Tbv+O1nN4+YAoKeQztEcbPBbbX7DZAHOsGZLrZ2NAJ9a
WEoFGMT3keQDjtjUI9c8IMh/l7QmSnVuIEt1cml5YW1hIDxrdXJpeWFtYUBqcC5G
cmVlQlNELm9yZz6IVwQTEQIAFwUCPE3sswULBwoDBAMVAwIDFgIBAheAAAoJEO48
Tbv+O1nNMp4An22RFzdv9zdNLlcY9GLPFyUrniqiAJ9F9Rhic6qBaXynksNw51Do
+cLWkbQkSnVuIEt1cml5YW1hIDxrdXJpeWFtYUBpbWdzcmMuY28uanA+iFcEExEC
ABcFAjxN7RoFCwcKAwQDFQMCAxYCAQIXgAAKCRDuPE27/jtZzYFdAJ9BFckSo4/r
SMe9UqbRMPK+8FUumwCfYH1pt4t6jFlulLk+9wYA9wISL3e5Ag0ENllesBAIAMSU
hrKdEdKzQXHzkoE4Nzl3hb6dtDmjgYr+3X95wBkUvtrk2CeYG3RC1PNwd1sEFEWp
IiSzOaQDzxZmtBGpMkQ1It+CW4sC5Cs2TQ59VHLFw7HWSYMNj+RchWuWkhwipnX5
8wu6To12Mu2MnyLszX2QIUxrQme7UpKkJgCct60C1DZLoQuZmfEZEyXmSfJsizeq
eeJuusZwOWDH0ixuFVK/5A2RwaWFMftdhh/Vw0EkxdQnMJ+7zJ/hbY64VR7uz8oI
5smfjVe0yqXMACREUzXmqn+Dc6Pz6ESVTv2XwIy0UxqxiYk1J98Cf3ffi5+e/q1d
rej2PzArpfzaygu88uMAAwUIAI/IiiQJupz9BaCws/K6j4Qs5iWRiSB7vaZfgCr9
c6vx+mIXX1Pblity5TOn9qXMv7vUM/dgmWSBbkkrvfD++H4ybJjpcOZN+peeGd0G
/UfiQFMarsj9MozAmhzI5L00JqLOf4u/XBv0rh5HOX6t+M9MfZYL3C7bn/LxmDif
prT8jxoA2SC+lPGSzI+M+ay/mz8kDmGD7fCS+uAFo5T1kjU+ed2dhXnl16gRR8NO
6yAdURIC+xs6P+7L8uOiZfuk0gzn5RC6CYrEKiGZf9VqTRA2vcirPNEZR44jYXS3
nL7x9pIsHyCyxEvojut7iGWO6qbaW/c+MRjcA8jgp9OuFROIRgQYEQIABgUCNlle
sAAKCRDuPE27/jtZzZksAKDbznARmDIIxZjHfAry2UJFBPQbvgCgl/ERQfF++Uvw
hLaVfesP/NCIt5Y=
=AoU9
-----END PGP PUBLIC KEY BLOCK-----
D.3.105 Clement Laforet
<clement@FreeBSD.org>
pub 1024D/0723BA1D 2003-12-13 Clement Laforet (FreeBSD committer address) <clement@FreeBSD.org>
Key fingerprint = 3638 4B14 8463 A67B DC7E 641C B118 5F8F 0723 BA1D
uid Clement Laforet <sheepkiller@cultdeadsheep.org>
uid Clement Laforet <clement.laforet@cotds.org>
sub 2048g/23D57658 2003-12-13
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD/bH3wRBADoVem06r8ivhxQhCOEH06GAg5J6iqqlKIo5BmOiQ8IHo8JzA9z
TwFNbhUCMWzUusH56nNHKOTuFV7wHiR8nvK0y2yU5qTK3MHbfSeMVy4rFAKgyZae
Wf1lxRHU+W/EksFaC31ljkF01TGHVMtpKPzDSttgrrMtgstT7QKWTKcggwCg8bVn
g7MH9udGaSNY5hO3l9wIcusEAMD+erpSZgVfwojT/pliCwnvKRwNByhIWqz2y3Ly
M2+VR/IjFlpOvT4Ytrn2VC4V1duahdowNQh5x0vUPagRRYKx67OEbIcisKsGQTnT
m4FSRUfULKZ3M016uSsYNbuopctjrxHE1YJfskHmLnIHjnXhJjfmouQqOX8nQSh0
ryjCBADTi6z4ZvH3CF/C1egPsmYzJ14H2t51JUSHwEWWaj3LkILEGvHsywCIT7Xd
R34B0hPIn/ihsJF4XBEiqJlZmFhfFUmSR3/No4TYKOtMAzfo6GtMv8q19U/LQaVY
1wYY0rWCqfzwcH9vSLlpHL9afqNBnVK3XiBGMCmXZw+4klu+f7QvQ2xlbWVudCBM
YWZvcmV0IDxzaGVlcGtpbGxlckBjdWx0ZGVhZHNoZWVwLm9yZz6IXgQTEQIAHgIb
AwIeAQIXgAUCP9sirQYLCQgHAwIDFQIDAxYCAQAKCRCxGF+PByO6HcPlAJ9gLehC
AhRMepAZrGdPsPFoMB283gCbB6y04aeQlXaa9+xAm6C0ciAiXj+0K0NsZW1lbnQg
TGFmb3JldCA8Y2xlbWVudC5sYWZvcmV0QGNvdGRzLm9yZz6IXgQTEQIAHgIbAwIe
AQIXgAUCP9siqgYLCQgHAwIDFQIDAxYCAQAKCRCxGF+PByO6HT+eAKCBj8MXtxmq
l0PuLGLnR04gnauqPACg8Rtgb2XwCrgcZFcjS1Fl7/SmTE20QUNsZW1lbnQgTGFm
b3JldCAoRnJlZUJTRCBjb21taXR0ZXIgYWRkcmVzcykgPGNsZW1lbnRARnJlZUJT
RC5vcmc+iF4EExECAB4FAj/gQ+4CGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQ
sRhfjwcjuh2wLwCfZ0Sqh6DY5U2ZDj+JrdqX1qzEaGMAn30UALtH14r1jMPPq6xn
UuMfFjyLuQINBD/bH4QQCACbO8LantesOQKcxZS6WPSLhIoZerdMJ/b4DCd22GGu
IM4eoWiYPX73cTMbN9cTEObaA0hvXEdn8vWl9/RBV6aL/fYhAqTVGWhXu6MBJiAv
0zFeliJl2+7MqzZjjr8GSFkhM3tXEzFr+7r7/Bqnp8hdzMFUS2dLcL+ZTXJuq9s+
xUNnwt0+Qy13VQU9whTZNZy3PHHa3XRc5IbZ5FnqMM3D7twlt0sS6j253b3CXw31
qEREoLutw25X8pbQeYJW8st0xIEY9z0MikBOJvKPAUani5+eWjuJC0FlXYM4qSnz
zhBpDbQBuhQu5JgPPiXlBq+ta/prm6FyJjcK+EyJsMGnAAMFB/9DIGugG/5F+4XC
dTvFluD8zbP6zwqWRuHX9JmA+oso6ruDHiZ+Ckdz0xBfD8yoyENIRnLmBxx11uZN
upAlM2itsvAwHMm6zKGLwlN+74vhoCTzvDFtnyTSgC8as4kk4XCax2QMAueFpW+2
8/SSLqIK2UWT8/5SkP0QaN5qSFgRwhGxYgyVP8pflrjL32u+fEwo8EjNnOUHX4WY
uzdzq1t+0K2AnZH5TiUCPy9iLP8o3rBm89Qdh45wzqN9DOGePoc0v4opQK9+3TRa
vYAx6izrRajiGgUHLcYeL2nQxyi3LBkKvbp4Bw/dpxGTdmPhtyU8jYqdP5SQbrFJ
4DwXqs4biEkEGBECAAkFAj/bH4QCGwwACgkQsRhfjwcjuh3mfgCguHMdGD3Orm8e
pAU+aCOCPVkkx7AAn2yhe79FYbHDx5Dx2LAfRRRyfxjR
=lVoL
-----END PGP PUBLIC KEY BLOCK-----
D.3.106 Max Laier <mlaier@FreeBSD.org>
pub 1024D/3EB6046D 2004-02-09
Key fingerprint = 917E 7F25 E90F 77A4 F746 2E8D 5F2C 84A1 3EB6 046D
uid Max Laier <max@love2party.net>
uid Max Laier <max.laier@ira.uka.de>
uid Max Laier <mlaier@freebsd.org>
uid Max Laier <max.laier@tm.uka.de>
sub 4096g/EDD08B9B 2005-06-28
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEAnrX4RBADpu3Q03zK8ehNRHgNzTPCEVK/sWWr3hR39/hfFmdYcovwyMTis
OhW87G6uOA5C84cewrEP866l3xmkS43dkgYhcaLxPYFB94OWzSk95AEgFACohnw3
l7WgcmHyZbdfCbqtuew4RY6Vqf/UzMVzOlvrAOsla5c4ImpaFmxBAFANIwCggiRI
o0P2iw3gBY2y1aG+mTWKidcD/3O4LPoZItTzx3vWq2wQ5mwoF0n01wIhQk66UtJj
LvZV53LzEEuS6JL6LKkl/AlxKaUoS9OUf9D7nyJu/dDYHDKCj+m1UBo3AkKUcutn
FLgGFwHU4Apcy3CCblMm8j0w62EFnXjIjUoPBqgDUUrePvVfIgJbkFjl8e0LcnTT
m+KaA/98+/pHRh9EvGKpHWIUc2qHNF1BfFFmq2wzmzu9MCk67IstOWq4GiRChyCL
V9SYGJ5upRRPMvxAQD3DAclfuyMKk2a43rXM4DRbePPeqH7ZGi/yyzPOGvqLgLDF
VboM4bNJPa+Z0PX0QU6o70fyWPXQk+23suxDUgYvFrPEufATO7QeTWF4IExhaWVy
IDxtYXhAbG92ZTJwYXJ0eS5uZXQ+iGEEExECACECGwMGCwkIBwMCAxUCAwMWAgEC
HgECF4AFAkYBsV0CGQEACgkQXyyEoT62BG3+aACfbtsTiMA94ttjwscgLB9cr0qQ
PtAAn1j+sAozCf68cpUFjNc1YQyR47pRiEYEEhECAAYFAkES18UACgkQTVOzajVB
ZGAPoACgv7gaBQqC40XWmJI5CqvsjBKupPsAnRWFhc/QkldYxGG7Zchg697ohuaU
iEYEExECAAYFAkK+7JUACgkQbHYXjKDtmC2aqQCePdVXxOSZ/jEYuKnJe3HD2fl/
JXgAoOUsrK0IldUrazH9GBcxY4hl3CmbiEYEEBECAAYFAkO4ZKQACgkQ8nRzewv2
yFNmigCeJyZdNoRip/NXG7tNwXNQGq9npT0Anie+9MkjaCOWOWMO4XFyXBm0O8Ls
iQEcBBABAgAGBQJEALTWAAoJEILS9urEu56fkYQH/A+t3UGC/te9e7Ubr/iZ6hkL
tF/JANBV2YSBrM4O8wh9l0tjd+qGlq2+2VoW38fb6RmZVcAH+sXKm0BiP+v/EmDL
oxp2DlR9V8QRcuLIITsAVSCIEhuzpMG8EiPSDQvc+Rx0ptYdCYaUvvp+aLYhc8BA
cKoSDEygmtcOGo1tvAjXKoPnRqo4YFlfhguQB4UVfcf3jPUcGFRrYjGUu0NC33p8
N5fcCo0VxPnA/jdh87rYq4EWZYBThu6Gx9Mb7Jfzl+Ab8OJs0t/2nNFZlR76V/Ha
6NPM8iZ8qisVIRcUr5R9btXbjXxfFeNjDDv6R+0OTnuHOLvtEauJ2xAM8yaxvUiI
cwQQEQIAMwUCQdbJMwWDAeEzgCYaaHR0cDovL3d3dy5jYWNlcnQub3JnL2luZGV4
LnBocD9pZD0xMAAKCRDSuw0BZdD9WLjLAJ9zn1Xwr4/J4WAlJmRVg1FVaW/qgwCg
oAb8wcvCIk37Vc4ibHoaLDlnx02IRgQQEQIABgUCRHSMSgAKCRDYNLsu7fxYhyQn
AJ0dZKh3s95ck9EmRxwQhGHNZzE8CgCgolKTUWyAmMGfwQR4CTC+xKPwzKqIRgQQ
EQIABgUCRHSVJwAKCRCrGD+pQphAQSKDAJ47Qtr4yLOnAoNrO0CIq2hADRoYuACc
DMkwU7/tb4/wbhP8qPCayIEe6dWIRgQQEQIABgUCRHSgswAKCRA5vzeqwUN7dxVs
AKCaTRCe6EZjB44i5pVDPNIjg99AiwCggpSqIFnz/lls5BcaSmqBeRYcj9SIRgQQ
EQIABgUCRHSjDAAKCRCvZCSxPb07IB2BAJ4h74XSn/a5MJbif3mxZEi2arTRqwCf
UwQZc1DwKjaCzupo4Y7Oe9oiX4aIRgQQEQIABgUCRHStHAAKCRDieO2QMatLNiS/
AJwP6dD8FKsbHNapegEppE6kK+Pu3wCfWyN0ZQa06MLQn/xJunzze2w9RaGIRgQT
EQIABgUCRHSdvAAKCRAy22ifJoR+hI5qAKCO/nr4gFed8oqYUVG3Eg6GCXVh+gCf
XZd9Z4DCd71FaJQ5bYvLRjodWg+IRgQTEQIABgUCRHSlxQAKCRAqTbBO7XfqQzOM
AKCEWs7qjrLYe+FSsgKKTsqtlZUgCwCbBYtG4KsMNqlbs8nPHezcRYWrEiWInAQT
AQIABgUCRHSrOwAKCRAitKPqdki4FQ5gBACAqUEeFuLKCYHCRMkwWrCcMw2KRDLo
Pt3fJwDc//lUQsNZe0KpXCJv9K86+bgYNEByAPdGbxGC3ARED9dAg2WC6tF7UfGY
w+AsA4oj/s/O7HeTTzlGGab/nIpzeZI671KXf9bZoohjjGm+V2gWtcVcpfnrqrLc
7pfQoH01jJ7LrIhGBBARAgAGBQJEdMpmAAoJEM1qd61qq03bnisAoN/orlD1u0wK
dcptumJjoUnjOCwvAKCP2/K9c8xNqgQXBqgNDVKLLslgzYhGBBARAgAGBQJEdNZN
AAoJEAM3EQzGj6jtffwAnRfgHkJYCVA6DHvRx8JBJNokZY2hAJwP20A0C+vIEoN3
fsuKPNhQyI3Eg4hGBBMRAgAGBQJEdK00AAoJEKHrLLXDSN7Ik1kAnRC2aJGdtUWh
CfaHDvCXBJ6TAV94AJ0ay9Myhjmunw7+fPolmNIpCV90TYhGBBMRAgAGBQJEdXbJ
AAoJEOWLS9iqGXOkxJQAniacHefxA0jAqU2PAeEL+g7mlLTqAKD3Cr3QGtEnTirj
1h3RD2TCOIbIKIhGBBARAgAGBQJEdJUeAAoJEKsYP6lCmEBBj2gAoKdscfFF1obc
Oxy/645pZ7d77/XrAJ9syfxjyzPJGfgD+YV8ycOI/mGO6ohGBBARAgAGBQJEdKdG
AAoJEMuu3ahKVag6yegAoOhVuTF2b/FTzFC/hXn7+6J4ecauAKCZc7xvSMvRYrE7
PZDWW4kzl4hAa4hGBBARAgAGBQJEdWzHAAoJEJsk77nPF6IOP/IAn09PBdGa3z9u
AhVt52wO/8XOLSlIAKCJR+ZJDoOA3Mb4Wgoe0PQZ+QIHDohGBBARAgAGBQJEdu+e
AAoJEHvDNTBle/A9ekYAn2Pj+m0YOFwVX9mExNGCIPgy5RRAAJ9MK5Lkktxgk1pW
0E+uYLcd4T9UnohGBBARAgAGBQJEecXNAAoJEGII2gDlIth8IaoAmgK7bk2lh6i0
hqIt3ICN2+NCmEk+AJ9J9TiJU4WXnna8ua/FyvquDpElQIhGBBARAgAGBQJEedT6
AAoJEP4Sv5MWA2EcPaUAnRYYL2HqMzaolazxkoLqo7ONNbp1AKCaxl4zHvXEJTMQ
rryGG70jR+GtSYhGBBARAgAGBQJEeqbfAAoJEBS/1KonENpIoA4An3phAsRH8Z5k
cgVAt8YOGQ4Bs5X3AJ4qsndyIqer1Q5BafiL/HdqWUWXEIhGBBARAgAGBQJEeqbi
AAoJEBS/1KonENpI/nUAn0V+hM29bICBnCj/pn5PwzIDQ3UJAJ9+sJMC9YcQ7h37
Zh5lmTtEbnvuMYhGBBARAgAGBQJEfAIDAAoJEKVSUOZXTbpfYQQAnAvQZ9mqODTy
w4QbR7FwoP24luyfAJ9FsJGTayFl/uhmoPGSPT7+Z5cXgYhGBBARAgAGBQJEhE+L
AAoJEEdQmW/OAoFhAwEAoImXPk9xrkY0Eu7Qx+8RhH8Z2r/wAJ9735kIvFdemDKK
lI9LppKXu+Tkn4hGBBMRAgAGBQJEdXbJAAoJEOWLS9iqGXOkjSgAn3Kvup48ST3E
g5gtAELFhWoYHAexAJsF7O8sTSEGDpavTQmP6w+X75seJ4hLBBMRAgAMBQJEeetZ
BYMB4BQHAAoJECJ2djMwHcD7z/MAlRb+6OEt7kiit8QC7VBcs2U5jvQAmQFfsHH0
V5CTC4D+WSsqzvB8AafJiQJIBBABAgAyBQJFVLZnKxpodHRwOi8vd3d3LnBhZXBz
LmN4L2dwZy9zaWduaW5nLXBvbGljeS5hc2MACgkQJknmKMXTTQVkpw//fMOY/ado
SF4u0a7yBqLmHlJZnKqv3kH+ZwbRtHF+Avn4/GWXr/6NatRx5JZ8nljD1xUJWhcS
9hy3BprkvE2mANbIDCVO87ilZhBfTQCJn2SblWbBGBrNnRuVwGZ9EmP41Xb+ysjV
UFead61upEXtovGE2apova4es3JqLdNXYcarjMizycpcxxPXNcaZxL9zu1mWYYaM
weIl3Li9q0hCP/hdo7WxgX57ImY3cvbmHFtcaCOlx9OmgCZyFP/NtBfOMJw8cP35
B1n9ebgfwtuz5AbMirG2FdKu1wb2jaBxq3SMZ4LTkoUelu119cNgL8v0lG/ckwW8
dHBAKrwqZcYoJ23oRRTdtyrGyHHxSt/bew4Qsip/K3b5BpF9frFTqCTCuDWBWn1W
wwy4Grd0PrtRprf2UeBctP2xdqACbSYsvuQQHlCv6KdprzHLVM1/o99/Mn6eBspu
J581P5R9nWknEKSZwKIg2q0lkRX6Cg30LnbLJqKjaeyNEmbLXut81dA77L0PGRYX
gr9oK2+eGIXNYz0NjXkMw10QxCLACG6MUZbQc1iIIX6pnpIjNNzoEzWhGk80eQGP
fWRnOuD27U/RL6KyccjreJbQc0pCVz4Ug+ghQpkFh8rxuHrkD+W3FL2CHQufByJs
yWU6mDzkqYFnQB+mcnllzERymco7N/GvYquIawQQEQIAKwUCRrSXCwWDAeKFAB4a
aHR0cDovL3d3dy5jYWNlcnQub3JnL2Nwcy5waHAACgkQ0rsNAWXQ/VjrXQCfcfo0
Erz7IlfnYn7HIzAxF31nbQYAnR3HJjerhgDSzfzjWpgUCuS4Arn6tCBNYXggTGFp
ZXIgPG1heC5sYWllckBpcmEudWthLmRlPohgBBMRAgAgBQJGAa7JAhsDBgsJCAcD
AgQVAggDBBYCAwECHgECF4AACgkQXyyEoT62BG1kHACfYM3aVAFcAbb0vNL4So/P
27k6CbAAn3D+8gt3GoTL7Q+B0LJ/TkI5HM+9iGsEEBECACsFAka0lwsFgwHihQAe
Gmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9jcHMucGhwAAoJENK7DQFl0P1Y0tQAn0zy
sIJERZoTKY/rLw3e1C7oo39SAJ4i2BoH4lHdpW1oDnv1e7hlqXFTC7QeTWF4IExh
aWVyIDxtbGFpZXJAZnJlZWJzZC5vcmc+iF4EExECAB4FAkAop8sCGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQXyyEoT62BG2wxQCeIRPC2d5IdKNyy5CHsdTZ4R4F
RvoAnRWWKFoNd0I4Ing7oOetUH6wD/BHiEYEEhECAAYFAkES174ACgkQTVOzajVB
ZGAnVwCeM6pxzqKkDmkUP2+CtJZVw+fpxOEAoORU3tdMV6Z/sggWVvt+T+9xGRMS
iEYEExECAAYFAkK+7JMACgkQbHYXjKDtmC3MEQCg3/t3MX0hBoMDyum+kiGYgHSQ
Z/wAoLhnkPNS7wQkr4uTTE0xcmPsKU3wiEYEEBECAAYFAkO4ZJ4ACgkQ8nRzewv2
yFMr4gCeK1fA3Yhvln5VCaCoYLyqUZ+eNAsAnA4ZSB1wLhy1+KmGveraS0nxkFYI
iQEcBBABAgAGBQJEALTRAAoJEILS9urEu56f0hUH/A3zAQrzrLPPMWnNN/neJmss
h6eyLEx9eABX1EOrrwapqu3+g4MvvLDFL4t6IgKxSx1wdOueJhPNESLpVAZH6e+3
VIE0iyvrCT/nWS1IzLHiv+zF9JgoPhjOVXbyo0Do9Eix2gYSybIdTGkP28a4zQf2
0nkJr60hwcRO9ZbdECSg7Lex+0iNrEZGzWKxMp1AUMG5k00/+7i/zteJ3Am6gEbP
mttW4lwOjHxPHBmjKOvdABrTHeqtwbCA/NGl2PJ2MrRTI8NINvPIVpVOLvPGwyUp
7IQ9Yb6iTP3NBuGSfU40+rdQUTdGsWJYTUzLN2oY7JSDyBNNFSMfe3tahIkn4U6I
cwQQEQIAMwUCQdbJMwWDAeEzgCYaaHR0cDovL3d3dy5jYWNlcnQub3JnL2luZGV4
LnBocD9pZD0xMAAKCRDSuw0BZdD9WIaiAJwMr18Qw9ovub4LbTQp/UKQd6lQTACf
U6b4ZL3Ep3RmIVOH8Q704RUXlfWIRgQQEQIABgUCRHSMQAAKCRDYNLsu7fxYh/Zh
AJ93yDd8YEhcLn2cHY28l2SrWw9I4wCfdobz6wJxvP/p8+yPhZr2F7NDJ/WIRgQQ
EQIABgUCRHSVHgAKCRCrGD+pQphAQY9oAKCnbHHxRdaG3Dscv+uOaWe3e+/16wCf
bMn8Y8szyRn4A/mFfMnDiP5hjuqIRgQQEQIABgUCRHSgsAAKCRA5vzeqwUN7d9VF
AKCeiTDoLZ9owe8IlDKUW1W4fCNj9QCgl+CM244j+7y85/MG10JFwmz4g0SIRgQQ
EQIABgUCRHSjCgAKCRCvZCSxPb07IEQhAJ9Tug2UAZApuYyLwrjx3JQ58xQkbQCg
n9Qm1svpN4DPbEB7qGnk2ugVl3eIRgQQEQIABgUCRHStGgAKCRDieO2QMatLNsns
AJ9JjtQresPmW6OwfTnJxucYX0dmfACgu4ZH+pcWYdriAMt4IPJXexxXm7yIRgQT
EQIABgUCRHSdugAKCRAy22ifJoR+hAf/AKDQhZzsIQ+cQSC1Xn0HCxJWhz5aPgCd
HhfJQsQIMF1Oujrr6LtBezm61g+IRgQTEQIABgUCRHSlvgAKCRAqTbBO7XfqQy/V
AJ0TdStk1PeDZbPvZeJxyHgDRv6XDgCePGqa1MwyzEc9JNJxMbtMhOSrWx2InAQT
AQIABgUCRHSrMgAKCRAitKPqdki4FZRvBADsdB04GwtGs0nbsiMIp3SG0u3IYnr3
98i94hFd8wUnvUe4u975gPLqaCSRJkbPb779M9hzlF3BfzFaZWxS2ot0fVdhJwcA
RDkI5Jpvo40/4pE57oe5b8dnAJLOBnndYLVPo41RAGk4f6bp6IFlprZ54YPRs6IN
cBppqDcBaqHb/YhGBBARAgAGBQJEdMpdAAoJEM1qd61qq03b1hgAoIxTgdmUjPu2
3BlDr3ZQee7jrNs0AKDRQkQBTLswRXA7N+9k5j2QJh9mDohGBBARAgAGBQJEdNZK
AAoJEAM3EQzGj6jth44AnRVEkCik7krnfQP/JsDGcbIUSVhlAJ41FRQkeVJ2GthJ
LZOwKkCTVuEhFohGBBMRAgAGBQJEdK0wAAoJEKHrLLXDSN7IR7oAn0w/CnOKOa4b
+GC37OZ3hM2UG0L1AJ9lGwKBuFdjpIptrxkXqt/54M1GLIhGBBMRAgAGBQJEdXbJ
AAoJEOWLS9iqGXOkjSgAn3Kvup48ST3Eg5gtAELFhWoYHAexAJsF7O8sTSEGDpav
TQmP6w+X75seJ4hGBBARAgAGBQJEdKdBAAoJEMuu3ahKVag6mLcAoLjxXvtS4p/j
RZrUuJgtpUXNTc02AJ9Y4e7DMhiUj+7w1C69pMSX4kbuTYhGBBARAgAGBQJEdWzE
AAoJEJsk77nPF6IOy8UAoK1xUj5X6dzg+Ln1bYNhW3KHLKfuAKCAYZ+h7k+4WUh1
iP6CutcydStAYYhGBBARAgAGBQJEdu+bAAoJEHvDNTBle/A9G3EAnAtAByfabr6H
8Ah/jFjYBguLBAwUAKCAV7fnhHshZpnj/oQLDds+zQFenIhGBBARAgAGBQJEecXE
AAoJEGII2gDlIth8HUkAoIH5taCNbcyJxtpsHM25cfyucyKZAJ9liCQYp80BwO4z
nOgCVHspkJoVZIhGBBARAgAGBQJEedT2AAoJEP4Sv5MWA2EcTSgAn1ZzLhn7ENjq
8GLh+U4ZYZ1a8Qq7AKDT+LJnt/rMwM9F2GsgAnkQuIyeJIhGBBARAgAGBQJEeqbf
AAoJEBS/1KonENpIoA4An3phAsRH8Z5kcgVAt8YOGQ4Bs5X3AJ4qsndyIqer1Q5B
afiL/HdqWUWXEIhGBBARAgAGBQJEfAH/AAoJEKVSUOZXTbpfeg0An1Po8Xqi85hk
+veH0+oru+VQUlZJAJsFKAgGAp4gxrFT9wx/0eXpBfYtXYhGBBARAgAGBQJEhE+G
AAoJEEdQmW/OAoFhwiUAoJ7hb15pudkdCiWc1nibsWfIMeoHAJ97prq8n0NuIbKJ
oHCyhC3h4dMsWYhMBBMRAgAMBQJEeetZBYMB4BQHAAoJECJ2djMwHcD7lqIAnjAP
jyE5E5UnMBI/EaKR9kJLiCPPAJ9chDiiQs1etWET832850wSsDTDTokCSAQQAQIA
MgUCRVS2XSsaaHR0cDovL3d3dy5wYWVwcy5jeC9ncGcvc2lnbmluZy1wb2xpY3ku
YXNjAAoJECZJ5ijF000FIYkQAL4x6yQu/FZfI/aaCy7O1gr2B03i2yvV2GaaOaHY
gAmt40f3DzX9AYk/ISLWVB9zt9wEdt7S1Cm/DUlX3lfVfi5I9eEM9l3DDsRjxXz8
slgbIR5Rkfx9wDHaQ0FUPE/m1BLFArzyr16ek77TDxzQdo2jfWQfzfgfUGsIEUSz
VmqpJTExPfsxPW53I+vUhtQfrglnCtFr85A/CtYeq17qtKIZsUGgrWGqasJB3Dg5
u+tDJPbfbwq+ipu6DKJctt+E74mKvLskZAqq3aWtYWSax+xPBxAaLYLeEs3o3H/8
qxsBch9/C3TeN5CJKOtcMw41nq6cofTCBCEucsR25pjRGexmmmtX9boBBqFC8JXx
MyFWvW7t3lt2iKLEt/4FiQ68spB+VsLZeSTBt3xXg3yqRaMfSoJ0AzHegK6O7iz7
eFwWIgAX/129cUfJ/KAnvShtNrFZg+T0p/0w9nMh3dtOj/YEn6Kzi3J5+4ATlN57
ln29VH80238RjudDiHbDRNEaBQnBYKnJp0nqyK9yhbx0VeeP0dFqoQk0JmPojCm0
xixLQEzBoO+vDBOBZfBtqIfeV6QwTDdEu/XcAM1ka0eJxIxnyIs5hbkoWjpbH4Yo
Rmj2AIEwwNOUFCov2c0m4Sakl3qO9IJrggQPCURwbxWU95lkVEnsMWXDXInUS92V
g7XMiGsEEBECACsFAka0lwsFgwHihQAeGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9j
cHMucGhwAAoJENK7DQFl0P1YrskAnjIDlGZV152iILDR4rWOffMh9UE4AJ9acnJu
H0f+7Twsx+0kZLVarN6+eLQfTWF4IExhaWVyIDxtYXgubGFpZXJAdG0udWthLmRl
PohgBBMRAgAgBQJGAcSkAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQXyyE
oT62BG0dBgCfccJy3a+19YjynymN8l0Qym/hcaQAn0Va5OryzscQKFRaiSlgEnyl
C0XdiGsEEBECACsFAka0lwsFgwHihQAeGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9j
cHMucGhwAAoJENK7DQFl0P1YBrAAoIkmja1bQynop5qJ8K9p8rbCnj8UAJ0SqUf/
01aCH6xDxGqPTgwY3QusGbkEDQRCwU/HEBAAhl9u9dVzrISpDQv3tT9nQlQw6AW6
4uW6ZXMprO9Abp6j452hpC/t/LSbGonB322QpHxpYeFr6NQcKbk0I0XAN39tq1E1
nDqNBaB3FpqFgsOlpSNqULSn1y/t7XXu/hDd/J/s7FXKr2vko5stZDTHEW+9oR9s
8vEVWjU8DAHltY7vIsHUEZwebotIbGObfUEkiNLoG/aP+1Fo6Gm7HyPO66oUtEmP
vnrFcfGO5djvc0/3jxKNvpjdRO8fFE/B1996M+DFmevQbxXTupQ9QCY2Bc3sT4Ej
w7hBB1Byo6AbkcfLn2A+Kua1zSn8jdQ+BEInCpYoOqfyNjY2RmLGX3iSIiDeldUB
saa6E0sJhmR4PfQ1A9q31fLTIgw3Lnk5cWjIFIbxV1775B9JLNUKk70mGN0afPlT
0HUd6irME2yiASJk/pYC+O3aGYxQYfDCxIgPYgOVMyYCXnfp6OcvhkACiF1+0S/z
XxZmEP9WVR8zVKPC0tXxcw6k5nmcwe9pgNABrUdWvo8KifN1NNkZB9+ZxAs+1wln
DZvh08X6o6TjWOh8123R1G5gfPEH94huiQKZN70lpALI33vF/M9W3C/jzIZBMXLJ
+bSIbj3oSSM9tNWni8mKBMUDuTGKKqaUdSXC73YP/BoJ34KqRsmhRMhBBBvvGfwK
2sBO2EoBSFXMzGcAAwUP/i8dNzyBAZrqCQLU0/LL4uztlpIenZT7suFjBmX4ntZl
9QQndVBeMF+YbyrdO/0tkpeu3lz0exJt4g3Zao7K8hCqxUTPS7+QExTMusAiQpQv
te20zvJ2DbN63YXW3EGgBPlAmPQjtU0duzxa1dq4WHQy0dbBgBVWipMGBKpYj4mZ
itIMLBZYDVOQbb/0NNtYc9OJXZtpffw/txiPbkdbYIkm1UQ5uh2uUI/N7bswhxef
inn2ZHtMh7U+8EPXiA3V/Ved5gGjWDddt4AAYFDasKrHeb133kn94hBfPd/eyHJ2
tPMvgS2XBdhg5/rKpbL09YeuZGoW1QSj9a/1dE+5s15lhqCB2a4xA3Kyr7XWwt/e
ZFBK55Sk115Z+Dt6Q0ZipXoZ7reKIdeZElM4IRR2GyZLK5W3TmcWLDllboluD5nX
0FI/LLazZJzTEWfMb8F5WvzyceQSsjc3Ngdt+alWYyIgGqXhhVlnUlCN+9R2/+Kh
e9/ftBkqaaKph/O2+KImxJVgU1SNAEfsddDkV93sUFTpQ731l+j/1Oj+yopuR10k
Ny1npFXVkfpUEn4r8dItKVPm6AtI7UMwR15DBdNSDA/v1n12M/koGOLovF9IZPTK
88hphpkHpVreSixBSv/KHF0mUeSEqFgtGNKbZUM+5KyO0I5jYMKpW90dtdHs5QD0
iEkEGBECAAkFAkLBT8cCGwwACgkQXyyEoT62BG0ivwCdGnHCqBuQeSM/FBOB0h/f
01jfP2YAn3DLpgqbfVb0MZfxffpFg3K6fWkX
=jGQA
-----END PGP PUBLIC KEY BLOCK-----
D.3.107 Erwin Lansing <erwin@FreeBSD.org>
pub 1024D/15256990 1998-07-03
Key fingerprint = FB58 9797 299A F18E 2D3E 73D6 AB2F 5A5B 1525 6990
uid Erwin Lansing <erwin@lansing.dk>
uid Erwin Lansing <erwin@FreeBSD.org>
uid Erwin Lansing <erwin@droso.dk>
uid Erwin Lansing <erwin@droso.org>
uid Erwin Lansing <erwin@aauug.dk>
sub 2048g/7C64013D 1998-07-03
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDWcyFoRBADed0r7ei/q5DX2f1sKLuIaf71LNIUjHPV0npYNsZxodS800pTY
gqTJuqe1DfJKU+nw7FAKQN1myJPNj2aIsvm2sg80xV1uoJmWTloQulRGQ6C7C+Q1
xB20JUL7GIczUM5hDRajr44vCJcFSs7EVVHBXRWi2UVm1cja/R3knkevDQCg/2yz
IUJmOHN2ccJVuHttouGEukUD/Au69uLjcdPgMrv5vLwAg1Vg2uf/Qj3RbHiDgi0O
RWgG5urvRM/m1T7QjB6UKpF+oYACkmfwEZbMzlRJe1jtr7qRwOpAMW99n8fc1Jx6
YfdVtl0TxhnZBhI7/Wx+1DW7zi1CwbzBXFh1O8zdwPUn7g2G09NWDGEkDGb5Gz5e
pXrBBACipRm91E9z7AQD52ygXzcTsqN/S5vDFtLJ4zJQCRRQ+LLt01vVmbkg8yhe
sQVqUMjp/HGFI+CmPZpp4Oc1Y5ixlat5CsnIWxzjy2YU9mqBAx3jocf1+HuYQq/9
XoENs+ySHBkdNQFU6thEqJAOYD5lmIt84OByaOHrbc7d1yOcBrQgRXJ3aW4gTGFu
c2luZyA8ZXJ3aW5AbGFuc2luZy5kaz6IZgQQEQIAHgIZAQUCQmvBoQYLCQgHAwID
FQIDAxYCAQIeAQIXgAASB2VHUEcAAQEJEKsvWlsVJWmQvgsAn1UuHLp4NqY/YJsQ
0edVcH/e9eHUAJ9+AGa+PFqV6BsuKxbWL8Mea/8l2IhGBBARAgAGBQI8UYMvAAoJ
EA8SlUXOHPkKaiIAnAgslxPgz1agFB0iOXuICG7J56+CAJ9jyAUte/fimzHkBK8V
nH7AC4BeBohGBBARAgAGBQI8xpO8AAoJEDx7h1Mest5m3vkAnjsKf/RN/Ef+Tf/k
i+GRf693IhqhAJ4isfzDR83AgfkRNzxVgUyUNcLNZ4hGBBMRAgAGBQI+baDeAAoJ
EFPCDI4dQfvVbGoAoMm2lJYVPhweKl9sOJNJbyUfYv7yAKDwUDg1yCvW8Vsd2AHH
Tf0MvkDgn4hGBBARAgAGBQI+L7keAAoJEIWAWf86Zh+dOyMAoLqqTf4BvLqAaOPC
cUVXMZZBeZi/AKDcnlvMm9Nzxn7lrtqCoT1Xsc8mb4hGBBIRAgAGBQI9TuvRAAoJ
EO6eLCSHzT29quYAnihhAfqTX9dotFSxIgmocxOphbraAKC3CIUZtiWw2TukK2Mh
HcsDyh8MmohGBBIRAgAGBQI/OME2AAoJEKmGKcxs/75nm0gAn3vpkv/leixHZj7n
WgH8waf7HZZ8AKCmmKwWGT/Q4my/RU3KJDc96dGt84hGBBMRAgAGBQI+a7xtAAoJ
EFPCDI4dQfvV+iQAnRGHUlO25j/apxHB2dEic/GSCopiAKDTPCjzdRaZNvqmhhxi
oMtpC6wOEIhGBBMRAgAGBQI/OhVvAAoJEKmGKcxs/75nxQMAnRmdkFAUaqH9thsl
WxufDLXeE9ZBAJ0Uk9j2U03K9m0iqNpmD4gNxSiH6ohGBBMRAgAGBQJBGkL3AAoJ
ECKr8Oz5Vhwx3tsAn2J6i8g76WtfG1MLiWK54zC+GFRJAJ40DWi8Y4zgVp0Z8Hv9
WE49ItTSkohGBBMRAgAGBQJBhK4xAAoJEIwyjP8WBtuVJPAAoJ7pI3TdVOxgRCXL
r+T5Rxw0UK32AJ9Oe6NGjmFxaOB7emvF+cFduYZeoIhGBBMRAgAGBQJBhK5WAAoJ
EBXWiATKbN+y+xYAn2A6vlzWuNjIjJb3JVOT0i7flzEsAJ9s8bWfxyRtE1FkKzpC
FhSfgZCqz4hLBBARAgALBQI6pkV2BAsDAQIACgkQqy9aWxUlaZBhiQCggaB1IcrP
9WYm99SgbusvVNBxB/UAoOgcU3688rrjXwDYPK3FNYZWCRcfiEYEExECAAYFAkGE
wS0ACgkQqRfpzJluFF66zwCfVDh/Vc7sZT75Vzb+vIKY4FL1uR0An1lBKgZzhHzS
rAXPn7CgkSmv+KHIiEYEExECAAYFAkGEwtIACgkQIspYTHp7o8DwcACgmtRV9Rta
s/fSIH+UZ62C05PGQxkAoMna0Me1UFXDjH/uI1ZPN2OUE8ewiEYEExECAAYFAkGE
12oACgkQFGWX3NzDmcfo/QCfWZ/tnsLwBUlO8FtUkHlinU6w/xkAoNDkcOSSNpu/
LzGxvsW+UiNmxYQLiEYEExECAAYFAkGE15IACgkQh9pcDSc1mlEuAACgyOCf/+66
wHw/TA0yztuvNNp4ZF8An2XIs+v8MRbmWTCV6unD9PSJLgVJiEYEExECAAYFAkGE
wCkACgkQQC1G6a60JuVhKgCg6wxpjHQtnmQLdCfLERM+lEr7NKYAoKW48MoiwhWT
cb3fLi430j7xLWBYiEYEExECAAYFAkGFYYAACgkQewpSEg9V9r7DdQCgiK77PBml
eabsOmi5gknT0XZOxC0An2FVHPQT2GKVc6lIZD+FSCGTG+VliEYEExECAAYFAkGF
erUACgkQntdYP8FOsoKyJgCeM+Kzkx10EAhPSIah/AjSaHjC6C0AoMTh6aaIj+6L
EDl/PgLtiM+W6W/HiEYEExECAAYFAkGGA5YACgkQc95pjMcUBaICUwCgnPs8HXtS
R3ktcEaDXpJfWMrbu40AnjigpdY9jzsn5mLL3vysknU1d1vHiEYEExECAAYFAkGG
8N0ACgkQbHYXjKDtmC0WdgCgxBOPpWMTiYTebn4nGoktbj6h7ysAoJR/b6jLHrKh
6Ikl7yMCRAIWRAxiiEYEExECAAYFAkGHc+gACgkQfCLDn4B6xToaTACfbh136/Q0
l8CHkQFx/NuDSoA/j+wAnAs87/2N3+GLzOGs6XjerAr6Z0vWiJwEEwECAAYFAkGM
kCgACgkQH3+pCANY/L1pIAP+MXyWBx9sWV+/ftZqhUUHpsWp/3fJED/DiZr+HgPF
DNa7RjtFBOXdcVLKO73cZOI9YTZryIaDymIJbShEPXaK6ph2rHgJcb/+GHngNU/k
yUNyN+jUysAeMGrMjuK/Xp/KN7KHTL77E8RzJ3jkWYeIQ+mgx1akj68h/Gh3n1P9
s/GIRgQQEQIABgUCQmYTigAKCRC/5Dh+VOJ4+CSyAKCiMM6vak2XjnR/GdnqmCeV
0F9TnwCfcmoekTOFCPXuJBMGmj70ltmI7AuITgQQEQIADgQLAwECBQJAiAPpAhkB
AAoJEKsvWlsVJWmQ1rcAn20sXoGopOqL5ZhlGaQObJ2UCRq5AJ9HEhB4jAX8U82Z
v1bTDCZim6KvSIhzBBARAgAzBQJCc7ViBYMB4TOAJhpodHRwOi8vd3d3LmNhY2Vy
dC5vcmcvaW5kZXgucGhwP2lkPTEwAAoJENK7DQFl0P1Y1QIAoIa/DUGi5XV47DZv
ZgKM5YqjN05eAJ9opLmH7ElqmhTnBduHF1exco6wfohGBBARAgAGBQJCc7HTAAoJ
EKibO5Jib/8x3s8An33V3XRLVMxIfuJyTUwDU3nRhzo5AJ4x7v+PJfpFlpSbT4i2
zLB3bil8QIhGBBARAgAGBQJDhyD7AAoJEO0Yto0WGUVTKPwAoJYtrPmYXr95R0cx
yLqeCbGhMy0MAJ41Anrfc1RYZTY1kbgm1kCrjBvXbohGBBARAgAGBQJDi3+YAAoJ
ECHFCRYOSnh1sMgAoKU/t3OCHUd/ES11+Y46u2rlfHjNAJ94fXCmRfgXIXKiaE12
0Tf1G+WbHYhGBBMRAgAGBQJDjHZGAAoJEI1JTTTHDr1Q2zcAoLqYGgT4umKQ1wSQ
a/FWzni+7ksyAKCM4sKQtZaoOkFkyOD8CUL5hs9AmohGBBARAgAGBQJECbj5AAoJ
EKph7ok6g98yTF0An14SS1+9hYbKdKfefZEQLoI/1sauAJwKvj3L7tUqL2/3/CIx
YpBtZxoN4IhGBBARAgAGBQJEebYLAAoJECGmRpvR77qm2GgAoInx2YAyZkttMBMg
Z5aJq++a8mK8AKCbvxkTEjaAJVajH/YntvCN/uhUYYkCHAQQAQIABgUCRTx1OQAK
CRAmSeYoxdNNBRe5EAChxJZssLUnOz+rZu4xDIuZswugKOcih301uZV/JOfozPl+
KnqGXESbZkKPPSL40ISlKsgGR3oqDPU+nuLOGymArP1h0SOOxUg1Na/7Vm6j+5PV
aAPGpGzbTXu1e3Qdk1GjhoHFDXiifN5LmI/qgsHsIuvDMe95iNYloGFPxCn9JZBh
2qpvT89yVhQZvDGzfb0BzkAXSxi3PPoaeNBl7xO+WpS8Fv6nqCriQfghCTEP/CGU
IwxKU8ZJhebhQxINnXfj1uSnpxGmhnLsBJgh/21Rah/hjgHqJmqSaI+Xa+Pe09GQ
/9CuOLrpwij2fKhaYBGxFNeA24+fEaZyJD0ClNnVkrAY/DbC/GzySn5BL8ObKNmD
guleEE2wtoW/MxQS4IA9Nwv/jQFSScqpJ5L4/iqWrbNYRPL0a/cHnnJ6AfyhB4Uh
A4Da5Tnu1cP3/sexBvYbQtHAbDTMhmQpy5EpvjUrK6aOIFysmMqDK0rtJgP+/w14
i+xNHNJ9xI4YnMXwjKeHFSxuLyslezJVk1+REjAQWL2Ip+n/vzcsbRpxvyke8Zmh
0dSrDv2RMGbMbw3UVnhaW0OZRRFlT4w293uYE5iOvaFYdSfWKeWYXkBJ4C/Gl7mh
NMJcv9rp/WqumCu5HdVXQ3p2U0LVKiGMSFbw+2MM47xy+rN0drY9uEGce6wNmohG
BBARAgAGBQJFTMMKAAoJEFr0HlHjM6ocWYcAnRsN0j0xtS03LiL6/ZtG0+h/s1gz
AJ9gKqpLLCnIMBWDvhcz61hLZ/8814hGBBARAgAGBQJFTQDRAAoJEC0/fAt65FQ2
HcwAoKTbCJmjG9JeIkaokttLyJbPK4XxAJ9+JA6DywscMGyaxZ+Q6JLtODhZBIhG
BBARAgAGBQJFTQWlAAoJEB6o5aqXJfY7h1IAoI0gSOEBPbDmwyTePFKHdBlG+v74
AKCOBSaBolytGq5Fgpt50qgLpY/UrIhGBBARAgAGBQJFTuj4AAoJEBdynXf0qFEv
V9AAmwZ1Qyk8rDG2FznRi+nniv5ZyuryAJ9q9gptydskfF7ww8LnRaMmabXIi4hG
BBIRAgAGBQJFTP8lAAoJEF8DMJySFff3aKEAn0T2NBzZ11UPxLSBcBqQ22afMQ+i
AJ99CN25E9GIAJxEmTm9ooBZ7dbYTYhGBBMRAgAGBQJFTPZPAAoJEFxsTMBaeYkw
md0AnjZsYScBlito/5pQJNUki1CmkWHrAJ4gbNVKd3QKkW69DoBF8vyRk5GH1okC
IAQQAQIACgUCRUzoUgMFATwACgkQvJlvTb+wLG+v7RAAtW7Yt1le8hDzmmqi9R5v
5flAluX1uMLe3zR2fwdtcEticvAe6jyZ/t/5NSeyK/cMCdE3OH5DKszz7vnOCUM3
z+DQl9j/VUfnakKd7BBMBK1PUbAFXk/V53rFdI5tTFH2dCzAeiPYwt2J0fF6wbi9
cHdmqKDaDeCRDcXFGMIsnFcbSn507UDm0NLoweemzzCKTzaRVrkbST5ZOD+2TY8o
CZZfB25KwoAMbp2CjznTeDFj6WNf0Q9H9rebugV7caQxjReV2H1sRMQFsJAe1GTx
1K3qiiT98ageHtokLu7eYMWsB/IwljvbDq5OHRdb6ZqVt6TD32gG70wiLilZIXg1
ue5ZGb6u4qpqy9R/bQJu0NRVuocyxSJnrnRazGxtBqHKrW5X89XwA1Dtt7bGFYH5
Vbl9VpxlpAuRfGC0kCCwixhCX8ksiGgMgMTjVmcl6FvLu5WXaR0IdJ1SxGZhjMD3
C4mMIypECK54IQOWrK9T4bkUDMdLS+pIx/sy62dNZMGcBvz6/vM5wkhZV9kECF+C
uatGy8C0j5o+MFuiHGBZpxmSE2mtQYcyX+mPVtZe0U7z/JQ1Ib0OG3aPIjfoftDL
WLNSQ0zbxA7F3YGdKoX5dezan7EqedPCVHjThROtd+/N0rj/Vm1zR426VME+FfXv
X93GHJ8Vz0b4narlR6/ZQl+IRgQQEQIABgUCRU8swQAKCRBuafjdksOBfj3TAKCZ
V8TOZs/OPz9VDKRTY6fTE76YtgCeNiL185YNRO8G2L4cjC+M77l3i3uIRgQQEQIA
BgUCRUz/6QAKCRBc5cUbh+BXvjYPAKDU+MZkj4lVAzLQ+qroYBKYpqYMYwCdGuLX
NSLBkYiuHPVAPnzmrBDjLYyIRgQQEQIABgUCRVcZdwAKCRAcqVpjVrDKCC3jAKCP
oKxnZ/JFgjFwjOSxVs/6O4hYfQCbBi1AmkcinZt88I+mnS7++DikOJqIRgQQEQIA
BgUCRVhCAwAKCRCAPFo0hMg0c7KUAJ9752PS4BayFfOWWoBUzHbWfFJ4ewCbBj+q
OHlhxZ3xX7WkKc6q6Vq+fIC0IUVyd2luIExhbnNpbmcgPGVyd2luQEZyZWVCU0Qu
b3JnPoheBBMRAgAeAhsDAh4BAheABQJCa8GlBgsJCAcDAgMVAgMDFgIBAAoJEKsv
WlsVJWmQ+yAAn1iXF8SPDEYCjWUA1d54UGzqbSWCAJ48DYoSregWR2APL7U5f0kk
udRHcohFBBIRAgAGBQI/OME0AAoJEKmGKcxs/75n7vcAnRucgiwEmTL5MF4rZV8b
ADV7oGjCAJj3NWrf2L57HeZpNCaG8MmCHIk2iEYEExECAAYFAj86FWwACgkQqYYp
zGz/vmeqbgCeMcQgWXXlbHzzv2CzCdHVqQtyksUAoJ3UumgYBxTJY+IrzMtgcZXa
7higiEYEExECAAYFAkEaQwEACgkQIqvw7PlWHDHEmgCeJpwMuxTOH25WtvsoeU4V
ox0z86QAnjmNVabNvWEgUHh7Yvfv63FwjbxjiEYEExECAAYFAkGEri0ACgkQjDKM
/xYG25WSIgCgheOeosUHT4xVxxzu7mbQfG8+IeUAn227s7uYw0rppuksEVEVygXX
FhpyiEYEExECAAYFAkGErkoACgkQFdaIBMps37JFDACgjVe+ADfM9Lql0kzKajEl
kMVXJO0AnjK76wjerW8iQdbDZlmpRJdaRXE7iEYEExECAAYFAkGEwTYACgkQqRfp
zJluFF57PACePhkvrNkXRYT07XzWA2Eq+0g1FAQAni1abFzQeKqK7ClpbSUtFxh1
tFzdiEYEExECAAYFAkGEwtgACgkQIspYTHp7o8C94QCgxBk8HEIsDSuFeL0DmwVH
QxwslLYAoJcp0OCWg1WrdrPeC7lbnbpg7cTWiEYEExECAAYFAkGE13MACgkQFGWX
3NzDmcdZ/ACgrl/ByAsNnIi+0htJD04ynOUKxPoAn1f8+s5Wv0L3yv71xNVwtCPC
T+n4iEYEExECAAYFAkGE15AACgkQh9pcDSc1mlGRxACfbl6PdByO7o8gOAc3vDhm
CAd653sAn1b0cjJXOhOTLp0xeQ14LaR+tcTBiEYEExECAAYFAkGEwCUACgkQQC1G
6a60JuXC/QCg4uY80X4886CUM4/+1A2AaJNzkFcAmgMpn8ERGK7ZcCYSrWp5dTlO
2jfbiEYEExECAAYFAkGFYYYACgkQewpSEg9V9r5DXQCeICSss6kayW9wsJWeuUvv
ypMerG4AoIqQTG7EGWoUP2dMfwAVoGR4gpkhiEYEExECAAYFAkGFersACgkQntdY
P8FOsoL47wCeK3yF+YOxhhRdcOeg1qGkDz5TYlYAoLBVAA8ucyhfqsEOrZSMUJE9
Zl8ZiEYEExECAAYFAkGGA40ACgkQc95pjMcUBaKPBACglupjJH3xYHWtrOXgtEQy
YNCJ0QUAoPjX3HC45lVH3rTogGx0vTM3qtbsiEYEExECAAYFAkGG8OAACgkQbHYX
jKDtmC0sqQCdHE9qEiPTVxFrcPAhtRsMg/Q0SGgAoJWGuUpL/h+kfEPVDsLpNtmo
PYKziEUEExECAAYFAkGHc+oACgkQfCLDn4B6xTquxwCXcmrC4clMSBhS2MJB85vU
o6vNjgCfXxSwxeDImBJ1f/e6XmCKQP9dkL2InAQTAQIABgUCQYyQLgAKCRAff6kI
A1j8vYliA/4zmIpslbUEqqG/DBH94wmjAe5+LT8pKyd6NKQIydiMMuDCVgs3HjUk
UZ5DV83x0oi8sPmLO0IghpWPrtZEp1QZsoUQR4onvMVxLVwvVaUR1Ff/JUdLLCju
1zYd+Z2hkCttYjcD3YWRt5658fGr2X8KFQEkJwaBQqS5EjcQ2eVqr4hGBBARAgAG
BQJCZhOsAAoJEL/kOH5U4nj484kAoLz5tAtVgXeLEC3GjfI3U6KHP6wmAJ9poahZ
5NCZXjr+3Yrgbpmjg5M+a4hcBBMRAgAcBQI+3YgoAhsDBAsHAwIDFQIDAxYCAQIe
AQIXgAAKCRCrL1pbFSVpkG/BAKCF6+3C0qeJX6KHd5WkLCrj7SUmTgCghUCiqIvV
bfIwaFvqX0ALDgQ0wraIcwQQEQIAMwUCQnO1YgWDAeEzgCYaaHR0cDovL3d3dy5j
YWNlcnQub3JnL2luZGV4LnBocD9pZD0xMAAKCRDSuw0BZdD9WCT5AJ4/ggL6A2ZN
LWpDJQIK71cfc6UzqwCfekkCAxMeq2+oOpPuYoLURn+tJLqIRgQQEQIABgUCQnOx
1gAKCRComzuSYm//MUyFAJ4vC5bJE+eq+BPdxFFK4NNdnWaXTwCfRi/8TTb5UNr2
LnNzvG3752Bc0zOIRgQTEQIABgUCP5MGIQAKCRAPEpVFzhz5Cs5yAJ9NheSl2a+I
Q1qtO1vM72uvbf95SACfUzkvScIuz6SaY17LlcA8sk5bBzyIRgQQEQIABgUCQ4ch
CQAKCRDtGLaNFhlFU8dmAJ9+G11TVpFLQkNOxVtIvpwIIitf1gCgiCHfjd2E6KOt
BTXY0pqoNQDfRrqIRgQQEQIABgUCQ4t/nAAKCRAhxQkWDkp4dRGsAJ4gqCus/gYA
o9zh4tBm4n6h+lTiYgCeO9nizQH11GZLENyu9f/k39jvRS6IRgQQEQIABgUCQ4xX
+QAKCRChx9zBNLckX1b8AJ9ZSpf1t0LZY98OPnD1JArhMDwmSgCfRbsuOtkT1B1C
NuyLzzLqf/QnZI6IRgQTEQIABgUCQ4x2SgAKCRCNSU00xw69UHBTAKCsWpaf4zux
nZ8fgI/SJ1xzAYYVEACgq7c48BeM8/I7UsDF0wNYDrDhotaIRgQQEQIABgUCRAm4
/AAKCRCqYe6JOoPfMnMAAKCCa/yYfHywJg+fopBFWkNrncY5uwCfesDZsGNAfsPl
8fagEWQ3Mrjkal2IRgQQEQIABgUCRHm2DwAKCRAhpkab0e+6pj7lAKDdln2crHdW
acx1BKCZKytzADaHHgCfYDZ4LF4CNNnir1piH1GL/MdByJKJAhwEEAECAAYFAkU8
dUMACgkQJknmKMXTTQVuqw//bq5STUsGcwMOX6DhWvEObwHDuWFeur8ZZXF9uNPQ
+j03o2anyzE6wMdwZ7LYLHKk9KCzrlSUxknWuaGAGPlvbngszE0oNk7xzuA9VPB3
nzVUsLyCPtBN4YJRN7bgPvGABnoWZZzhh1dCLZ8aQe56U8yWZWAZnSSWt003V7sO
zg44fOtDeWNORaah7oSl2BASjJkp/iwNMnJ9cNF7u9McazHCQe55xCyEsmJQw/LC
YPwIDJ5zX/A7OWh1Eae2iq+wxHrngv5Rj5DStwviKpDD17ULdT37U2JsLiu8Gzm8
AtYxqcdlPKKEGGn2AqCmQkt1l41mMXmCEs7omSCjo5u7ygTBChyITlF2C+id5PfH
n82SYDT7CgNlVbB9+ieS0cwqJ4DU5oOgkvGvtkUr5mWb9w/7JSNReaEbf0Xneo1a
Upq/xYYwR9hmstBwdA85IBwV8G7dSHDkixtKBNqq4jhssgoBqdDpF5VX0SplLZN6
FUA2WPnsyeDkYq+XyJczsYvGwKe8RoqmjNCSqUYFypKXCao7pYDqDt8Jt0vgXvFn
KrNUklAM4RKHQx6yIlAgGZHwE2+D1gswxuJIOmdnuvmPR05vfBJso+jSBMwpEgE7
ZeE5NT+8pYavScLsB6lvibuBrKEj2k4lr+pamnNLkr/F+3+r2SMsESGyWRmCUPZr
PF2IRgQQEQIABgUCRUzDHAAKCRBa9B5R4zOqHEImAJ96Sqdl3j0ihN+PxLEV3HRl
gYsq6gCePpjamgJ9HClrsqlNJ34Gy9PHwSuIRgQQEQIABgUCRU0A1AAKCRAtP3wL
euRUNlQtAKCKM2nFOd06b3HK4bO/80uTDPRe0QCdGfIkL7ojuE8ZE0qeJUqh/ES2
5qaIRgQQEQIABgUCRU0FpQAKCRAeqOWqlyX2Ow20AKCoQm/HQPnMZAifuPvo9Gv2
ktsa6gCgheyFyuF9nq3f+4tBsBH7xCAzhS6IRgQQEQIABgUCRU7pDgAKCRAXcp13
9KhRL0kcAKCWVeaRTVHVCwuKuOJB/Ba0GvJIcgCfWRabGJDDuvSu+0tKdfs5+4fy
ypmIRgQSEQIABgUCRUz/JQAKCRBfAzCckhX390zzAJ9xQsSuaXU9Ytr1MO8PPGqH
UKiyNwCfZ3xbBZ261YUQYIx1bQcSm1p0LZ2IRgQTEQIABgUCRUz2UQAKCRBcbEzA
WnmJME+LAJ9z1PTBlOc6WNzkKosGHAoAp36anwCgjWzp65YtJulMo0xWqCA4hpRr
YCuJAiAEEAECAAoFAkVM6GQDBQE8AAoJELyZb02/sCxvWyoQAMwOQNqhwt9ix/5a
XJyC9F+Sx5vD0pbaxVN5cubz8n4+EII7qP6VyOw2/o1lNAcuz/5f2uoBc/NjrrG4
oVbKlpthXuoslgZ4EJIR2AayD1ANsAqlbUicVpQoQBAHN2h9FqywpQet+wLtaSL6
EUu9WI4lN6OAvaQyNhGnXbHB6PPjDXqmMOJ/B6icdFXVVw1GyB8ySDT7Cy74BF5k
IEisc9jYM06nKsK/TCRDp2glWw3pCgnCZ5WvbsResOX7Gpc520bTPv6ogwYF/fK9
HHbIeNc9G/TmeNAuIJrFwWqGnL4tF+4ozfBeG2Z71h4tK6ii6m3GV/7iPvgA+rTQ
JhGCA/+fLH/+4+CfUmQ/K5BpIxirE1KPJZeIjUz5y03OV11EfU/RpblptQ7NeJoK
3wHmw/TGEMo6gZNq8H1EXuGHCC63awozSN67h7WqBtyjycfvevC8ZkKA3LqFeVNe
C3Oom3xyiZlSvmB8C7BZpGRgbQ16qzeF5NOfJrHcH311BTf0r0iYxCWySX9xNkWL
B28oob2JJV09stvfYeBNKT7Z0bhDmkukPn0ZnsAz1LcOxzMK/GxVlaWfU4U+5xcI
QFfM2haty1jCjPhYPGqQ0+kaNmAIqHVIavplgmFI4b4lFVzfII6UoFm5D1PVSZtn
HbX2ZVcyi+FAHcbbdn3Udx9GrSLliEYEEBECAAYFAkVPLMYACgkQbmn43ZLDgX76
ZgCgpvu2JKZQmWwx3U39WehIQq9xadkAn2MrGkY3WUTqIGA695pBRl0zGEVgiEYE
EBECAAYFAkVM/+kACgkQXOXFG4fgV75MuwCeJp/jTC5pL6oRhcpgG8VpENpDlNMA
nieRyejTBqPwGMmE3aphAfpYEsaHiEYEEBECAAYFAkVXGYQACgkQHKlaY1awygi4
aACfRPBUzb406wkT73fMTHA5ZwnYpbkAn1f8yN0vlvFb0qUKir/n77xgSSExiEYE
EBECAAYFAkVYQiAACgkQgDxaNITINHPZlQCePxA4AWcW1QvpIwoL0eb02nDnA9AA
oIlgjXO3/XSFAUzLAWkTz77E9xs0tB5FcndpbiBMYW5zaW5nIDxlcndpbkBkcm9z
by5kaz6IYwQQEQIAGwUCQmvBpQYLCQgHAwIDFQIDAxYCAQIeAQIXgAASB2VHUEcA
AQEJEKsvWlsVJWmQHTQAoJE5kfCwSi6onVyrdiWDfMN5FlkOAJ40MIJMQay7HEKC
9H/uDhmIosb6fYhGBBARAgAGBQI8UYM2AAoJEA8SlUXOHPkKk50AoMjV8lYE28vS
cGYXIj1WebhzOB17AKCiR1/uxnZnZU9AxAwl+qG5CEQ9/ohGBBARAgAGBQI8xpPA
AAoJEDx7h1Mest5myPwAn02QMT5rCXuGAotZd8P803lwzaD2AKCqfzU5tK/L6FRP
oozAnUaYV0oVXIhGBBMRAgAGBQI+baDgAAoJEFPCDI4dQfvVpXoAoJeatp2KOxsy
FxhiRFuf+w77RgWkAKChudBj76hLzDhtZ2L6zpJVWolqiohGBBARAgAGBQI+L7ke
AAoJEIWAWf86Zh+dnTUAniHpRnfHx/is13fpGl6Fe5lRhrD1AKDk8OBCe8JVxAyz
SNnfLF3xQ3tE2IhGBBIRAgAGBQI9TuvRAAoJEO6eLCSHzT292PoAn2a+OPNw0s7E
1mMeUzde9U/viGvZAJ9lgoKpOeBrSB+ZUpk95rcCYW/XAohGBBIRAgAGBQI/OME2
AAoJEKmGKcxs/75nUt0AnA6sy+RHNStcT1MpgidSNe640A0MAKCk4qbC0p+B4MUC
qdeoguaIMGjv2IhGBBMRAgAGBQI+a7xtAAoJEFPCDI4dQfvVwQwAn3+qa8kJo2Vb
4S8XZJ2Gnqx5KxCJAJ9yGZ5QFTUTdRIZPrCyiSeM9Zco9ohGBBMRAgAGBQJBGkMB
AAoJECKr8Oz5Vhwx9J8AniIWVePJd7M+BLU5klT9WL4aBM6DAKCOL3p+FPELj+4q
vYOFXeMZNLC1ZohGBBMRAgAGBQJBhK4xAAoJEIwyjP8WBtuVymYAmQEUUwNFceBt
vnUD831RiPWge+gOAKCKKsi9+ZWCswEErMWHLEcB8XYeFYhGBBMRAgAGBQJBhK5W
AAoJEBXWiATKbN+yMTIAniGxyrvZ9pz30aOjNHsw7R+5pbVmAJ90y+dUSuTLfek9
ALBJdEdviKCG+ohGBBMRAgAGBQJBhME2AAoJEKkX6cyZbhRec5IAn3iOdXiE13/I
vrH7DMVr71Tiiq36AJ9203XcOzBPsDlHKBMGWLIAjom4nohGBBMRAgAGBQJBhMLY
AAoJECLKWEx6e6PAyNsAoI1b95CFtWrr33COVFC6M8P3SDqmAJ9tmLvqjQC/6hEL
JppxNmgwtLORBYhGBBMRAgAGBQJBhNdzAAoJEBRll9zcw5nHmFgAn3Y+JIwvYWvb
0msetUsRrBLbF43RAJ4q4ZIGjyP9Dbikt5Xyatp9EM6PJ4hGBBMRAgAGBQJBhNeS
AAoJEIfaXA0nNZpRuA0AnAjmxjpzKuIT3LIHTyMyWYIAtA1oAJ9pHBg8NeRrpr07
jkTM22u5gQA+iohFBBMRAgAGBQJBhWGGAAoJEHsKUhIPVfa+efsAnj34WYGG1sSk
nVp/W6lxGjbgEx6kAJICQUzmZPqte/DfKKkN28jaTjAfiEYEExECAAYFAkGEwCkA
CgkQQC1G6a60JuXk0QCfS6YnbJrJ8cY4ontKJ8OjW+5KzmoAoLvJb3qZg8NBEVlM
M2563Cg/3w7IiEYEExECAAYFAkGFeroACgkQntdYP8FOsoLdjwCgtr7SULq/vwBS
XWzZjaZimPZ+hKoAoJc0yOe+Iq+8YDMaZd0xUjR42x91iEYEExECAAYFAkGGA5YA
CgkQc95pjMcUBaIgkwCfQsNySmZoGyg1weVpOHMRwqvF1noAoMjJAnOjrbOvOG1W
IQOiNPqUcq4RiEYEExECAAYFAkGG8OAACgkQbHYXjKDtmC0L/gCfdVVMQseB9MRL
pMKs+r0YJOgqESAAoKrUOQSXOp7RT9BFkK2zlzgTmBFOiEYEExECAAYFAkGHc+oA
CgkQfCLDn4B6xTosTgCcCI5By3CCWC5IWlHbMw64IHV/masAoIbRyIcTVf2WSGN6
+NFQ5aESsfW1iJwEEwECAAYFAkGMkC4ACgkQH3+pCANY/L1SeQP+InjoMms2oJUc
y6TL+oePOwPYSSU3HCsoxE6ugr6TPELef/FJp0fQxSSN31gV3HAVN27N2Qa7QwIl
oPhLTgl8/xbLBUjLQvMZpjS8GltB+Mr2ksPJDAfJDuv8RwrAsHY8KvQognV2uQYu
TbKEI+yAnY0Ty5jhUL0YB6+VRb6CCYKIRgQQEQIABgUCQmYTywAKCRC/5Dh+VOJ4
+DRCAKDEwuWpSxGB1Ma4yHIvS8NyYZj5GwCfVRGzvbUE8jkp9VVSoX6jxxnHyqiI
SwQQEQIACwUCORRUmAQLAwECAAoJEKsvWlsVJWmQSdAAn1R4xzjkbTXR4CUJF4mr
amSs9R//AKCLvACJMj009dkQ9xOo08k/a+NZDIhzBBARAgAzBQJCc7ViBYMB4TOA
JhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5kZXgucGhwP2lkPTEwAAoJENK7DQFl
0P1YzXAAoJHRiZ+dCA8n6zuIwEwcwxf6uiApAJ96MD/fqLKBcsqt+VCBGY8pd2ws
V4hGBBARAgAGBQJCc7HWAAoJEKibO5Jib/8xJ20AoJmSwIytW1TJsG/Yl/bWUaw/
e21jAKCYTemeRe43/mMq6cApV7IgyDPlw4hGBBARAgAGBQJDhyEJAAoJEO0Yto0W
GUVTMw8An0yWW774gyTT2WN8hmxk3wl4IVjwAJ9m1qjKTEM7k2eTCV3WhS6i7zdI
RohGBBARAgAGBQJDi3+cAAoJECHFCRYOSnh1PooAn2y9MK7W1oqNx1bst2TKHd3X
mW/vAJoCqzXDXl2Ym+aowDbFEQ6A9NKF9IhGBBARAgAGBQJDjFfyAAoJEKHH3ME0
tyRfi88AoJIPJWMLO+4Nw+Hyb+6IaWinjueRAJ9kt/ruqrQCSOys7Z+OLC4nzvSz
uYhGBBMRAgAGBQJDjHZKAAoJEI1JTTTHDr1QA3YAoIS7aAfVh2dfySAb7CE2jNmX
xvz3AJ9f/M9ATXDB3Hd1TfDL5UBxB1HQYohGBBARAgAGBQJECbj8AAoJEKph7ok6
g98y+xsAoIK28oWpn9NuowlELxX3KwT3Z+8vAJwOZ+SpQKtm94lmjy3nWh9KuAUF
sYhGBBARAgAGBQJEebYOAAoJECGmRpvR77qmXJIAoOYgu7XkgMsB+ySlb3oUKQLK
fY2+AKCcTdGYQWpxZKX64KvxSd5C0PDD1okCHAQQAQIABgUCRTx1QwAKCRAmSeYo
xdNNBcATEADHV1TbhOsgzIDcB9//srNNz6vZJJVeUg4Y3jE/f5lcSOXdu9pdBwvX
oi0sqNnS7vsZh8/hNXUF9afV9WzsouX6a2bY0OQusw+HnHj+sSAQnQCOjvvoR+n4
nOpnmZ6w0/d3S369WVCmsTOYkHzaAsiDmJ6o/VkdSWPjxJ8wIDmlqhWtYo/jsosc
tZuWIr4ua/+j+bL+D47Lv7JF5U5nBLCXWBNUvPcTijpvfQD5yag3YlSyiBqqup4r
sDyMmzI96WnlS5kq6cHT4OYA4h0NpwPaaG6pn49hFoEI8qgrYk/G5rGWGryXpSS/
fMNH57qknvn6jMehmRjuDdOg9HWMzL2+iZdiKA0Ej0uSOczhGpDHrGGfnp3UZe4y
6DqJDbRFW1seYGxDXV6gAZ/Bqh3Q67wjDwvEsbUpYmO0ePBs0LRcVLPALJSVJzSP
/8oeGVzp/zOCmhI328JxtudGrRT1azH0Q9sD5+adU4LRH3Pv1F31J/hotE+JVCA5
1/D/7ucABk1KllxJeMuW77S8pSABABZCrq0kHASL+jS9jHQg9LOBlBPS8HRTaXAh
+KO9JdbT+tLNyKwskFyvnOfJV8rVe2gdsVbNZcoV1cFMerZXKIo1I66NHfgDQU52
zALSAzJ9cJSw6B4z9GscV17u1CoosWFZ69Xn15Qnke2t6fwYW+IGKIhGBBARAgAG
BQJFTMMcAAoJEFr0HlHjM6ocbz4Ani4RMafyfk6LXeYjfRuDxb+UZuJBAJ9zXex+
8PLpAND44cupT/NNk6zGpYhGBBARAgAGBQJFTQDUAAoJEC0/fAt65FQ2SHQAoIVu
jE20NuICWBzayQkINgakkMRiAJ4ijgXBDUq/kLNKKpndWgx9Ccoo5IhGBBARAgAG
BQJFTQWlAAoJEB6o5aqXJfY7umsAoKY3YI4QpH3YmLPljLIecVC7s5mIAJ97i3Ko
zX359cF3asHy+p9t4PWwD4hGBBARAgAGBQJFTukOAAoJEBdynXf0qFEvYTMAn1br
nGltGLkZQuwgFd+yKRduL+pJAKCc8ZgS8UObc8XGitOVp7aImacDIohGBBIRAgAG
BQJFTP8lAAoJEF8DMJySFff3vK4AnApl9hpU4x67uwLh6jD9e4vX0uAfAJ48op/E
IhlWCU8w3Y9e9rGYqrt4KYhGBBMRAgAGBQJFTPZRAAoJEFxsTMBaeYkwL9sAnRWC
1oF5wkdnkmmkZ1BYJ4dtDDjWAKC3RklrLt0FiCIIwpmP+aBjNCL63okCIAQQAQIA
CgUCRUzoYwMFATwACgkQvJlvTb+wLG/R8w//ZUIfMq7vnu9fFeQitY/PP/gIuN37
E6d0RIeoJv1oQ5UMWzF18tHqEkNCbND9Z2g5GCGpknyVzYXwZIs0v1LPJsXV4wYi
xaapTrEL4nyq9Jbmk03klWruTtsYdHk8eKzrJNERZwKn7PxPR8U105lO8JBerGKR
BLMVc39n3BCo2zAE5LLMpeMUWkG9+qHkSRDPA6dnnzaGWz22JZ5UAKjOh1DjfYDQ
sM2EG1m6Tjk4WaZNaIsMxKZbQKzCRJm5CurAJ1a/2tN+1as2ONI4LXEtk8nXkr3f
WP3GnPaXbPHg6btBCUSFVWAO+AJqi2rErCdyl74l+KQNW6jUxd6LoIufMqg+wz+B
fyUg553smveJLtuWjVjDnWGCOMRIUq908TAihdJ0EHpP6+AVXHVV7OKqb/3s6Sw7
SoHh3pDMAiOwSPfQBcoSWSQwhhd6GPX9OgUxt21PwTgvrFE0c9NItktg3hxaXzOH
LyKtQqN33HqlaZxreNmMMGXuBFsFrLLRQOCYwrO6WOc8oyvaVVCSRXBLPcIAnWcs
2DNtDyY+WGJvief7MUkP1LFLOt1hcQ3HOaJMCfxIW7tneVJFyAKM0eyOIJqLnucf
XlGXf5vK81lb+MFcGx7PeFis/d5kygjHNHd7JiWDJaCHJ6W3xUnvzyABRivFanou
LWwLn90Cp3cAyYKIRgQQEQIABgUCRU8sxgAKCRBuafjdksOBfsCjAJ9N1nO12EMA
0Hz9YViyR+FGosXvUACeL0TFTxMvdDzcOcmVXavtE27bkRyIRgQQEQIABgUCRUz/
6QAKCRBc5cUbh+BXvszsAKDBq3tSoMjfaGsN9ZQ3ee7K/D3T1gCgiUh9qx4lNMvR
KckxreMmcQmJ8QmIRgQQEQIABgUCRVcZhAAKCRAcqVpjVrDKCObbAJ49Whhz55or
91RCK+N3gQu+++LLigCeNrkZWBmkV4Z8VpebfpGaJXcKXLWIRgQQEQIABgUCRVhC
IAAKCRCAPFo0hMg0c/WrAJ9XD86Vw021j4JZK5iLzm3AyRFaeQCeLgQFW6vfoZ50
8M5E/4alyreAUUW0H0Vyd2luIExhbnNpbmcgPGVyd2luQGRyb3NvLm9yZz6IYwQT
EQIAGwIXgAUCQmvBpQYLCQgHAwIDFQIDAxYCAQIeAQASB2VHUEcAAQEJEKsvWlsV
JWmQiekAoKCzNzu4y/5tMtSf3JkfhVgSktKHAJwKEiGPfrjLt0O5V+8z08wikrNV
34hGBBARAgAGBQI8UYM2AAoJEA8SlUXOHPkKKeQAni2dMvSLz8w7RQ57Tu3c1+5E
nfwAAKDA/VmA69GXTiBJzmSa9Uu1EmeXUYhGBBARAgAGBQI8xpPAAAoJEDx7h1Me
st5mCAUAoIE94kKZaFArdYpjl+BjeP7huRTZAJ4yZkrCUb3Vn6U/pa0FqXl8EP/c
jIhGBBMRAgAGBQI+baDgAAoJEFPCDI4dQfvVRusAniyvDBwsUlQtXbLqm9rr1pxe
3oPTAKDdZAczoKFYmgt5s67tXYoeMMx7gYhGBBARAgAGBQI+L7keAAoJEIWAWf86
Zh+dx9AAn2R39qZMi+EZlGb+kwB8g9sfRkEWAJwLLpLcOFnhk4uIxjG74v22ecBW
4ohGBBIRAgAGBQI9TuvRAAoJEO6eLCSHzT29CDIAnA5oJBppZlieN2E08PU5fJkF
afq8AJ9RbR63QCdGsx4JGTv/jGCn3s/OWohGBBIRAgAGBQI/OME2AAoJEKmGKcxs
/75nZAQAn0f/QYyojMZhFXCcrY37BWi+Sp7BAJ9Wy+CosI5aKdh/aSvrUuZ0Kaah
9ohGBBMRAgAGBQI+a7xtAAoJEFPCDI4dQfvVUVIAoNBjBsakeYwmi3LYippxmb03
z4GGAKD+JeXQoaoQIjPcGz2bzLzNvB28mohGBBMRAgAGBQJBGkMBAAoJECKr8Oz5
Vhwxz1oAn1+9m9j74ZkJEjr+t8/Z1IJnzfpmAJ4ng5tev/5po3hQzGOxVVqdjGW4
gohGBBMRAgAGBQJBhK4xAAoJEIwyjP8WBtuV/tQAnjycpCEusqp9NMBMlpYmW/AL
HapaAJ4z5yzHpEvGTSXU2iYOIUa7SN0iqYhGBBMRAgAGBQJBhK5WAAoJEBXWiATK
bN+ydL4An0YyjPPDXPbA9w8pontXA50yeJdKAJ4y5TSAyfGvV1cf5fpCPeK+zNWQ
KYhGBBMRAgAGBQJBhME3AAoJEKkX6cyZbhReiSUAniPnfUnPuVcJNOrX821MxTEZ
4ljeAKCGypEU4H8LAwXvuGPZXumldzzmp4hGBBMRAgAGBQJBhMLYAAoJECLKWEx6
e6PAopoAoJWGelu4B6TKFCaqKBdkKCVx/h94AKDLgUU1uotqwJlZuyvjWwss+kNk
eohGBBMRAgAGBQJBhNeSAAoJEIfaXA0nNZpRNpgAoKKfRyPHpjRHGiu2S7bK+OOr
YvqpAJsEq7L/zF79OoVCKS8w7sOxG8YNiYhGBBMRAgAGBQJBhMApAAoJEEAtRumu
tCbl9KEAnjLykfQVkd0UQ03gCunaTWIPvuKeAJ96jf/PrLRHr+9z2X2myV6Snp5W
/4hGBBMRAgAGBQJBhWGGAAoJEHsKUhIPVfa+lCwAn2TJXJHk4Nfwee95LeYqnMHl
6Ek7AKCLjPUwtu9AXA+HC0BjY8VwnYFW34hGBBMRAgAGBQJBhXq6AAoJEJ7XWD/B
TrKCj0sAnjAAhoxIdv11cV/gYBX+p2YIwFqKAJ9D+XiZy+K8ZTn0xnYYJCz1Topg
KohGBBMRAgAGBQJBhgOWAAoJEHPeaYzHFAWiNFsAoI7zO5y3A0tckJVZUzmx59nS
M/r6AJwKopaux0jR8O3MEsaiyR8FejlPmYhGBBMRAgAGBQJBhvDgAAoJEGx2F4yg
7Zgtpb8An3JYvUCUMTIhLkHrSaJoefMBUFt2AKCf+nQemIp3CaGei13teEpxdK5T
HIhGBBMRAgAGBQJBh3PqAAoJEHwiw5+AesU6okcAnj63eadGg/BAfYiEnmdEB45H
qYi9AJ9AZ+Z18XuXUDjO1JkBx2pZUc2MNYicBBMBAgAGBQJBjJAuAAoJEB9/qQgD
WPy9jIwEAJZbmXvNRkkVKMnqE+9nhIAnhdlCaAH4/8lW2cZWM4Uk1Z8fXMydfmCX
+wP/amgoIpMSnhk2wUJKyHlu6wWbAasNGqj6k4DrZcmrWXIoRncGhiPXGF5mn2xK
yqdtec4/DPzyCUlprBW5zOwxRvQ1ulxHrqRmYWWoDl/+bioDrbo5iEYEEBECAAYF
AkJmE84ACgkQv+Q4flTiePjFCwCfSAJ180YxYcFMQxMlfWcGLVL3Zi8Amwfy4nd7
yX35LAB0j0KOElOYVPgriFcEExECABcFAjxQWGcFCwcKAwQDFQMCAxYCAQIXgAAK
CRCrL1pbFSVpkHiyAKCyUICvfnZj6MVBWO1zI5S2WUd20ACbBJPt4X+SpoPoEZbJ
NRJr14oIWsuIcwQQEQIAMwUCQnO1YgWDAeEzgCYaaHR0cDovL3d3dy5jYWNlcnQu
b3JnL2luZGV4LnBocD9pZD0xMAAKCRDSuw0BZdD9WHy7AJ9RiI71dwfyGticmk6T
A+1jAU+gtACgnYBaLT9R50GZVePcavlurCwHVkCIRgQQEQIABgUCQnOx1gAKCRCo
mzuSYm//MYM9AKCXMYOrvwofiJ5/nE88Tku433RHgACfYPDxicoa+brH4P+/LqNV
3Ouj7o+IRgQQEQIABgUCQ4chCQAKCRDtGLaNFhlFU0WYAKCgoBrZmF3wWqXwOn/t
Qz+rv3piOwCggOa0p/o/GnHT/+CCXqJwAmhV3TCIRgQQEQIABgUCQ4t/nAAKCRAh
xQkWDkp4dRlfAJ9kmScSnXkOKRZFc+ORZQ5ygzeOKgCfZce6y4Z6awNp/WL5Bity
cm1sEk6IRgQQEQIABgUCQ4xX+QAKCRChx9zBNLckX/K/AJ0duoosSJr4giiF/1Jv
YqAenMNyMACglI8DwuU2YYW4z7IAgoCEgtR7QfOIRgQTEQIABgUCQ4x2SgAKCRCN
SU00xw69UP3iAJ0d78uEjrR15VzAA5t//Pzie0h4YgCggdzPzKIzSzATirY66qbt
Z94iqgiIRgQQEQIABgUCRAm4/AAKCRCqYe6JOoPfMkBjAJ9O4qdVjcgs2jrpVMdz
MIBqKTEyewCePUM5LCwTaXT3sfBkQgSbuXGLy7KIRgQQEQIABgUCRHm2DwAKCRAh
pkab0e+6pq4TAKCyMkOqP6Vse6/xZOkQq6yJOZjToACg0xXk3Z7GySov8S+b5rl2
w/+yTkuJAhwEEAECAAYFAkU8dUMACgkQJknmKMXTTQUAQQ/+KN7nbgkbSlMbqoQ1
CMfAmCY5VN86yXMCOhwmuDkZjvi4FVGxfmvbapCpxz92keUYBwjtSdMKBTjilaUU
b1a5t5+IM073n33Qb5CAuGq0DvgEN8CdU0KVnkqyfAr5PpYSPlMssehDDA8Ugdm0
46Ngc0+rck/bNrm7riHRahcMBqZ6VILgy7JdUze2CjpBSg97BF1o2jjchZrEIaaC
xVg7PGVAbG3f6tcLRB5nW8UdzY6UhtVJ+eZ3SNMijxAXUJbm6n+qnQh94NHh6e/E
U7raEIIkncIzNsjXefMnrFjX9NvEqxVGaaSaqP07p9JE4UsMNrhutLwSzrCrtznu
0dyJ5UAfFq1z9iYPcQi/QjaAqcJfY9aTNBDv0YagCH6iXDexcP9UXFFIph5teSfd
cDutvBiLlNsnk4Nl3MpFgmIfHGmTVjTZz4+zQ+l4s8BzdGvoieczJuHGmnHggRnC
GD7Y3g9dRQZG2KyC/dAxHftPIlEjyGpnleV+b9NIJdbH3+FKicvj3DZZVp89IZIn
CBv0vt2UFvdALZ/g3b571nRUbDZVGg71tP1b6n6yvACEck/pa5OUdhwDZOieG7xZ
/1YZQLZ3USJMmheZ1L2sQytTwd1ENb4rFBtx+Dmuivi2hCBSJjZraZrd7YizhIT1
bKhXZc3KsQ2thx8vdyJ5eIKlBViIRgQQEQIABgUCRUzDHAAKCRBa9B5R4zOqHFn5
AJ9RCfeJdZ5fCpsVM37kUYlafVummgCbB1HPa9bOuSBwb55J605q79Y6lICIRgQQ
EQIABgUCRU0A1AAKCRAtP3wLeuRUNtuRAJ9OPbD7XuCLEiHrap2GTRqFaIylCQCg
nR0nFcmkpLyHa+3fK7izOK5gG7eIRgQQEQIABgUCRU0FpQAKCRAeqOWqlyX2O3IE
AKC6h/iymo1BHfbB6+zFq0+f7WoGPwCff6XUwMzcm3B/vreoFDMwZpEXVt6IRgQS
EQIABgUCRUz/JQAKCRBfAzCckhX39/A6AJ40UyjHT4ExUCL6Wa3AeQUbX29UQQCg
kC/omd7SUsX3FGnwnej1SsxBmqiIRgQTEQIABgUCRUz2UQAKCRBcbEzAWnmJMOfJ
AJ9Pd1ZLkEFnTO5Ii6OX7TLsKzl4EgCfWqooSbPgG6WUiSk929Mu1DtBZdKJAiAE
EAECAAoFAkVM6GQDBQE8AAoJELyZb02/sCxv4A8P/1AmxNWE50aRurPteeY4lqZB
UtKubBTzrjkFBfFUyV2b4XoCWOdHfCfsIDNHnkQgBf+0TJpQpiXyvbTB43N4wKYJ
tXYAjWAx+8dt7TUls0O1DZ0ct3S6y4lobNJF0Czyjes0eUy7Z/jxu9/dUj69DXt6
qbuefoBl2+YxYlYJiDnV832jzwqIjvOHUhY6IekAUsA4kDljvkIHcqMuYB3R9s7u
yEfN40MpS+ZW0rvBS03DNWW/2B9vDynajhW0+BKhSNBCu0YGVKskuVDVDfbZPE59
NHDPh1tFFs7u6fOoo/19D/0R8PlnY/ubpkBzj73EeV1TmX58SM248YgXt8VGnjha
0HUDVdC+wlWpSlUh4+A2mQtFRNJ0qYd1a2Hjr+iTcpvf1sTKJm8S4jQ/uYkUie87
vjBmroAgPgmuR0m/je3ySW/hnIHv46rMMauAunSpm+OjYuvUXMB/NnpaKC5KFQSS
MAnfTLzzauSKoOIJvsNJMVV/ql2V8+IPtSLnAymqCzNMRphUEHKu71xEUlY/h3dN
v4MfLYXumolIgA/uO2yrg/q+qv1Oy7qSIgFBgcqEVKgbamFTOtQjc2S656PTE9Ki
L4otgG6QxmrORZ9dT5jqsLZ2ffuhFUIUnW7ECzXq50GngjBoBTze70MXVzT1APUc
gwzPc2iFDOzgy0rUeaRxiEYEEBECAAYFAkVPLMYACgkQbmn43ZLDgX5WOQCfS6VW
ORmH874436h7+HKX6poDTLUAnA2gwb+yfxCfHokXWv42q3sOMFDDiEYEEBECAAYF
AkVM/+kACgkQXOXFG4fgV77lTgCgwC3t3Yb7jxl0czrqk1Hj9urQ1mAAn2cu74b9
V8XwwKLO6N17he3oOJNfiEYEEBECAAYFAkVXGYQACgkQHKlaY1awyggMLACeIHlc
TgQDCHvdQGFUTJ5Plo7ZklYAn1dlMOoO91wteVhzAbtyl+BruPyTiEYEEBECAAYF
AkVYQiAACgkQgDxaNITINHOcagCdExKFusdzzYJbOJXGFFu8fjB+5e4AoJo8Dk1F
vFSxKtT/tgZKi5siTz30tBxFcndpbiBMYW5zaW5nIDxlcndpbkBwaWwuZGs+iEkE
MBECAAkFAkGHbZYCHSAACgkQqy9aWxUlaZCOpACgn8JRrDMbxye+zWNMkh2Y2q2W
F7cAn1Vve00aKkWOydjU0whdiXtV4r5EiEYEEBECAAYFAjxQPkQACgkQIqvw7PlW
HDFPGQCeLj2Fh/uwdJzUeCS/AIX2DaynwH8An2BsSrOVm/90qtotUD0AHqRUtDuQ
iEYEEBECAAYFAjxRgzYACgkQDxKVRc4c+QqvmwCgnBG4Nbfl8Zn8E1ke3NlqrhZI
izwAoNpHT+ik/Jq1tw3s9gBwULesiDtfiEYEEBECAAYFAjzGk8AACgkQPHuHUx6y
3ma24gCgzklLGnzmcg1yC8MPS7UvHITceiUAoI6dS41+aTpBLTl4Js5ei18kM5pz
iEYEEBECAAYFAj4vuR4ACgkQhYBZ/zpmH50rnQCggyRhI2mqXoa0XcuJsEaWyjCn
a/wAmwV++yMXxgY7StofLXSjrVawntAtiEYEEhECAAYFAj1O69EACgkQ7p4sJIfN
Pb3GcACeKql0+dId5fBaXlkmqRP2oO3hIX0AnAwBJDbq61l6TvDJwFJ0ojbM2SPQ
iEYEEhECAAYFAj84wTYACgkQqYYpzGz/vmeWmQCfdzTW6AnxkmrrdaNsFq+sE1Mb
jfcAnicmts+pMl5SdBlmtf41udeFp28aiEYEExECAAYFAjzP1ycACgkQU8IMjh1B
+9WXcgCgvex+ssTmUrhRdlQfTLIKrNbFKY0An0lHxzoACx3pBrSgT1iaj+thOInZ
iEYEExECAAYFAj5toOAACgkQU8IMjh1B+9W9zgCgnerRPsk07mXe38KY7ROVTBzd
+RwAoIUDC6Glo+Sk3oqBN4Gk7B9dVUHqiEsEEBECAAsFAji2fj0ECwMBAgAKCRCr
L1pbFSVpkDrJAKC1WlePhbeD6bRNh6MnJcmNE+sBnACfcNAi0zk9GanptpO676xl
GZ6xQD6IUwQQEQIACwUCOLZ+PQQLAwECABIJEKsvWlsVJWmQB2VHUEcAAQE6yQCg
tVpXj4W3g+m0TYejJyXJjRPrAZwAn3DQItM5PRmp6baTuu+sZRmesUA+iEYEExEC
AAYFAkGEwTYACgkQqRfpzJluFF5u/wCgm2pBaOWTBsWTVjJ7bvck4SVqbbEAn3+4
wZ6fmdTiWWE9gIhY6otii2dtiEYEExECAAYFAkGEwtgACgkQIspYTHp7o8DpkwCg
lILpyP2D6gXtWNMrc7OOubHEQz4An2UhETLQ2jRBNnMKJY0oDxQiR7uSiEYEExEC
AAYFAkGE15IACgkQh9pcDSc1mlFp0QCfajJwztyiiKlZW9cw1tVINWzafJYAoJDp
rrFHiJlWriylAli3o5a1YlA1iEYEExECAAYFAkGEwCkACgkQQC1G6a60JuW6rwCe
LjDqXSzsBWbuxC9lpCre4rOTqEsAn31/bq8KC+aUJc7EIhfI4YEJK8zkiEYEExEC
AAYFAkGFYYYACgkQewpSEg9V9r4bzwCgspthYqiEkaO5yZ09NhVv2Sac9UMAn2by
wyc9o1pjnTMwFbMwlpBUuJtNiEYEExECAAYFAkGFeroACgkQntdYP8FOsoJ3gwCg
zhYLAlCJglsrF5eV/VPbK+7MKNsAniZfVu6+o4E2x/Z3s5/q8M2hP1bItB9Fcndp
biBMYW5zaW5nIDxkcm9zb0BtYWlsbWUuZGs+iEkEMBECAAkFAkGHbJ8CHSAACgkQ
qy9aWxUlaZDHIACdE9Z4mJvDo0E4rSlyeE4Y4MbVMHkAoJuWYHvacbi9KtWed3Rf
+Knu6Q1aiEYEEBECAAYFAjxQPkQACgkQIqvw7PlWHDESPgCeLzs11SdU/rLJZSDb
0m73k/72QU0An1rSn1Wmg8OdH2NM9KkcRtXPEfySiEYEEBECAAYFAj4vuR4ACgkQ
hYBZ/zpmH50YwQCeNE2NndbV88qlEfnnBgp4nceB7VMAniWOdzhrZtPkzzx/T9pp
/hw93NPOiEYEEhECAAYFAj1O69EACgkQ7p4sJIfNPb1dbgCgz8lJrVn3iNbrpVeq
oHPqInbKL4cAoM3/98S48nC91ew+S85KQNOSvvo+iEYEEhECAAYFAj84wTYACgkQ
qYYpzGz/vmcSvQCfUWUHDE82xLjYPDDkCe2mR35UAqUAnijNyHsnA5nSLLTY4RQq
lLgQAQMpiEYEExECAAYFAj5rvG0ACgkQU8IMjh1B+9WrHgCfUWnW9jXIPbHiCcb4
54yI0Xnn5q0AoKsOuxKu+gc3w3FoFct8U5oiShfsiEsEEBECAAsFAjdXfwgECwMB
AgAKCRCrL1pbFSVpkNw0AKCMxoK1oIE7uwq8s/fukIvFSMQIwgCdG+hdPNF+dv0r
/VCynCur7hSJz9CISwQQEQIACwUCODsAZgQLAwECAAoJEKsvWlsVJWmQw3QAoLlS
2jKJCpp8PPbnArIU/MUsJQ9rAKDMiY77mTXW76d3T2wWuAzOQ9WAgohTBBARAgAL
BQI4OwBmBAsDAQIAEgkQqy9aWxUlaZAHZUdQRwABAcN0AKC5UtoyiQqafDz25wKy
FPzFLCUPawCgzImO+5k11u+nd09sFrgMzkPVgIKIRgQTEQIABgUCQYTBNgAKCRCp
F+nMmW4UXsAFAJ9t9F7hcwmdUfFiKg3HF/NtES4e6wCfX8KegcTbAwNvnFljLmDb
GUWiLHyIRgQTEQIABgUCQYTC2AAKCRAiylhMenujwPR8AJ4y6rZs5t5/Vld9sb6K
6xS4W/UpiQCfbk6lrZANZg4awOkA3+y9q20FbsCIRgQTEQIABgUCQYVhhgAKCRB7
ClISD1X2vjziAJ9Cx/Df2n4FBEfCUtOx2MXCow0wUQCdG/SO1AtN2sGyNrKxsXWk
0fCb/UeIRgQTEQIABgUCQYV6ugAKCRCe11g/wU6ygjTUAKC/NVdOadJjFoX5cCCk
9TO91boI0wCghp0ULM92ElpkTPRwqQt/5gF+Axm0H0Vyd2luIExhbnNpbmcgPGVy
d2luQGltZi5hdS5kaz6ISQQwEQIACQUCQYdtAQIdIAAKCRCrL1pbFSVpkP12AKCu
Eybyz+BoirW2PrKbCanqX3JxSACgszK3bQ0rhu5WSXULUPnKN+ylxjmIRgQQEQIA
BgUCPFA+RAAKCRAiq/Ds+VYcMaYUAJ9tBX0ttayKcIciRYkqUrDo/K3baACdGW1R
rb8pPmuxAM9CzUoI4T4ee8uIRgQQEQIABgUCPi+5HgAKCRCFgFn/OmYfnQ5PAJ96
W7cu7KAZQzQGasoXJNATRsq7QwCgu5GDxFN2ZbpPgI5p2fPIBTCQ48uIRgQSEQIA
BgUCPU7r0QAKCRDuniwkh809vdXYAJsHwiKr5ZSTlYmSpp24/HbB/V3//ACgprln
fsdKiClaV15DLhS4Xbv9XqyIRgQSEQIABgUCPzjBNwAKCRCphinMbP++Z6MjAJ0U
tbiA/THqd/Cpq5PkChtJGqJZeACfRhXKwE5ZswECr9tXEPblQrR/k4mIRgQTEQIA
BgUCPM/XKQAKCRBTwgyOHUH71T1lAJ4lLWJZSeUY7Tk1WNKmt4xQz/h1ugCdFAUv
gMm51M/LXxtYAsonDKTvt8KISwQQEQIACwUCNnKTKQQLAwECAAoJEKsvWlsVJWmQ
9mkAoMj0J5HczxmUz5IJ9IrtWu+D5PEXAKCZgt8jApbfC6msFwjA56D1lwOXrohT
BBARAgALBQI2cpMpBAsDAQIAEgkQqy9aWxUlaZAHZUdQRwABAfZpAKDI9CeR3M8Z
lM+SCfSK7Vrvg+TxFwCgmYLfIwKW3wuprBcIwOeg9ZcDl66IRgQTEQIABgUCQYTB
NwAKCRCpF+nMmW4UXocCAJ9qCZfiWNN4zPqooip8dfWt/ZOkxACgg/DZZ4uX7dm8
BhxGSXEeeEI5BFuIRgQTEQIABgUCQYTC2AAKCRAiylhMenujwCnUAJ9dTHT62c5d
PT+8EEop/oK6fuPGsQCfXt0lla6+vFLmWbvhd6gaFiz2ogyIRgQTEQIABgUCQYVh
hgAKCRB7ClISD1X2vq8KAKCG1971Tz2wT0sBCsvunIFCpvo6LwCfclaIUISlVn6d
yTK1Ty6aai5Oai+IRgQTEQIABgUCQYV6ugAKCRCe11g/wU6ygotOAKDGTyet9nlv
0ZgvICeCB2n1T7CBpwCgk6gw3aiPCnA3ikN8dQkoPyg1tpi0H0Vyd2luIExhbnNp
bmcgPGdyZWVkQHhzNGFsbC5ubD6ISQQwEQIACQUCQYdtEwIdIAAKCRCrL1pbFSVp
kJOtAKDZMEtF0YqZCUfNLeX7spKMxn2/8wCfRcr8glJaJr8IjLSSQocitBXrzvqI
RgQQEQIABgUCPFA+RAAKCRAiq/Ds+VYcMXX7AJ0eFIs1Tjl5kWlWq6KjHlvw2a2b
qACfSDfMYd8UPSy3xIVmB/hbRvxb00aIRgQQEQIABgUCPi+5HgAKCRCFgFn/OmYf
ne9+AKDfQ8jozWpf5dAG4Nhzax8TJc/LtgCg9cTTW4wWYpWTRe917RrzRaOQCwCI
RgQSEQIABgUCPU7r0QAKCRDuniwkh809vSP+AJ9rxnbx6LH201rq/SvDlmP8r1d9
WwCgm6X++Nykt/9cSb0lETMpirLaW2KIRgQSEQIABgUCPzjBNwAKCRCphinMbP++
Z/u9AJ9RFqyLk8PBya6tZ1RXQM/1ZkwoVwCfUSwcsMkVqKviOGjaNvh+s/mcK8WI
RgQTEQIABgUCPmu8bQAKCRBTwgyOHUH71cqgAKCzm2ApsHaQOv/JsHGTsRQQhrnt
CQCgyXOx3aXwCqVXVHbR7hBQlfUftYuISwQQEQIACwUCNZ4soQQLAwECAAoJEKsv
WlsVJWmQgGAAnigFHvlWpAwlKBtqnt5SHNltEexUAKDeQc8dNb8lZ/lU2ndFTXam
VhOsCohTBBARAgALBQI1niyhBAsDAQIAEgkQqy9aWxUlaZAHZUdQRwABAYBgAJ4o
BR75VqQMJSgbap7eUhzZbRHsVACg3kHPHTW/JWf5VNp3RU12plYTrAqIRgQTEQIA
BgUCQYTBNwAKCRCpF+nMmW4UXiiuAJ48d4/wDfaoSqcn1ug2/X8UEawNLACfeYwV
aTRpk1owIe+5ZJS/LWttypSIRgQTEQIABgUCQYTC2AAKCRAiylhMenujwP/cAJ0f
9gtLRFGj390qp7PkvpOXKhw+IACffI7++4POkv8ykHysWxGktxrDSmeIRgQTEQIA
BgUCQYVhhgAKCRB7ClISD1X2vmxLAJ9KraGyd9C4OJD/um0UIqAka7gYlQCfUyQO
5+bWUF/0I+jcQuJi8DGRD3WIRgQTEQIABgUCQYV6uwAKCRCe11g/wU6ygnmtAJ9p
1h/WI/O8o0yFOOtSP3rx7bEsOgCeJvC5I+nEilNn1Z8mIWCtAiCNWXC0JEVyd2lu
IExhbnNpbmcgPGVyd2luQHBvcC5iaW8uYWF1LmRrPohJBDARAgAJBQJBh20hAh0g
AAoJEKsvWlsVJWmQtw0An2CrEFKvB950Qs/O9fZrgndEEzbwAKC+KpaeTih/C+O0
2hXZ5MA+RrFrN4hGBBARAgAGBQI8UD5EAAoJECKr8Oz5Vhwx6bEAnAytN9vThnHE
U5Oy/o6StUT1Kek/AJ9ikotctFbWKr+QYSA7BjK/fPU58ohGBBARAgAGBQI+L7ke
AAoJEIWAWf86Zh+dvZ4AoMJLkAid0uabgWErh43deMuUeTckAJsGKo/K4Bph1SrK
LEr3WcBTocQ/5ohGBBIRAgAGBQI9TuvRAAoJEO6eLCSHzT29XY8An187Huopsv4I
oxSd++VadevbTJ+MAJ0ZqeHWlwVHFBhc5mXrU8heyZAU8IhGBBIRAgAGBQI/OME3
AAoJEKmGKcxs/75nWOQAnR5VYLD81XC0S3rbtTiCq4LTnCl7AJ40swwZV7MpGGSr
/5KkJlULZEo2s4hGBBMRAgAGBQI+a7xtAAoJEFPCDI4dQfvVGKQAnRyFW/qODOvG
FOEX7MWVdTs+ymSAAJ9t3/istPKg3/IjoEE7oTENMOYc+ohLBBARAgALBQI2cpMV
BAsDAQIACgkQqy9aWxUlaZCUAQCgy8WYx3gr8h1vlDV9znZXkzDYgSEAoI/F8ZSG
RpZdIy2VfDlpqW4nPG5xiFMEEBECAAsFAjZykxUECwMBAgASCRCrL1pbFSVpkAdl
R1BHAAEBlAEAoMvFmMd4K/Idb5Q1fc52V5Mw2IEhAKCPxfGUhkaWXSMtlXw5aalu
JzxucYhGBBMRAgAGBQJBhME3AAoJEKkX6cyZbhRe/WkAn1o4LhKI/puqmsyryh5U
T+naj6gaAJ4xgigBbRNlSYwd0mWQhQK/nGp0zohGBBMRAgAGBQJBhMLYAAoJECLK
WEx6e6PAN18AnAr6fBOLivsarnBZz/rRYDi7XLelAKCR3WKCYSIXJY50osEVeqkY
TMJkdYhGBBMRAgAGBQJBhWGGAAoJEHsKUhIPVfa+7fAAoLhuEb81ilNPSlBWit0j
vb+J4IGpAKDEOTbIGwNCoJvtK44eXh8CxC0zFIhGBBMRAgAGBQJBhXq7AAoJEJ7X
WD/BTrKCnFIAoLg1kzs2NoAlVXbcsPuF8hn4dZRPAJ9Dyp4oBJiFoY68PhS9kVZ3
zbdXTbQlRXJ3aW4gTGFuc2luZyA8ZXJ3aW5AZHJvc28ueHM0YWxsLm5sPohJBDAR
AgAJBQJBh20uAh0gAAoJEKsvWlsVJWmQ6zYAnAxJo/Lv7iYohTSXIgtwGXuCFCP+
AJ9GTHrU5Vku2LT6LDCF/zAA3pXNRIg/AwUQNZ4oYJhX6fJqzulZEQIwSQCfZd+p
faGn6ZlKJFae0+hl5sgAHGQAmgLx679Ef19zrBIjeLe7+FL4sWi/iEYEEBECAAYF
AjxQPkQACgkQIqvw7PlWHDE3egCfQfmPTwSfqkvqn1JUFzR9cXx1Tz0AnRb+HrZU
GRPU8lgHJYi3m3XJ9Kd2iEYEEBECAAYFAj4vuR4ACgkQhYBZ/zpmH51Q8wCgy32e
xSGXuJnL5Af90DvHtZPhbBUAn0XsGDDOjvZrRqYMlvpKg6T8cKVaiEYEEhECAAYF
Aj1O69EACgkQ7p4sJIfNPb1zmwCgkUm8q76fMlMHGQP4usMoSEc845AAoKbhQtEe
sFHCQL8UjKHwcmhE2csdiEYEEhECAAYFAj84wTcACgkQqYYpzGz/vmfpqwCgl+SG
Zn/cWsYtfjJJrgFpVOxsn+IAnRFtkayz4PwYLFzWq6bjkIqHwQhiiEYEExECAAYF
Aj5rvG0ACgkQU8IMjh1B+9U/gwCdH/ZmwDFVzog3SYML7nXT7TqIHhMAoKUUP7sh
yrAvKX3u94VU5mZXFYEZiEsEEBECAAsFAjWeKAAECwMBAgAKCRCrL1pbFSVpkIXs
AJwJ1RNFjSxshCa4PhEb7Y2CDnY+SwCeJqUOQ3JY2+2OgZwVp7grsksmP9eIUwQQ
EQIACwUCNZ4oAAQLAwECABIJEKsvWlsVJWmQB2VHUEcAAQGF7ACcCdUTRY0sbIQm
uD4RG+2Ngg52PksAnialDkNyWNvtjoGcFae4K7JLJj/XiEYEExECAAYFAkGEwTcA
CgkQqRfpzJluFF5qFACglUgUkf0RxoFmIPMwl7nco3zggfEAnil27Ts6q1T+YsET
W87bewODfQWziEYEExECAAYFAkGEwtgACgkQIspYTHp7o8CxMgCdFq8UDXXVyjjQ
RBfzoPAQBIFcefYAniV5y+onQE9AqF3sScwS8+euiVUQiEYEExECAAYFAkGFYYYA
CgkQewpSEg9V9r4TwQCfVbt09+GayRqdzECqjs1IOIxJ5z4AoIaPbaCkO5+4ZZGK
3+mBT3maSuJ8iEYEExECAAYFAkGFersACgkQntdYP8FOsoKJYwCgyJJpsqmBvAGZ
kLts1MJ1OZ4c2lQAn0Yla/F6qFruAdea0nl7zATlRcZFtCZFcndpbiBMYW5zaW5n
IDxlbGFuc2luZ0BlYXJ0aGxpbmcubmV0PohJBDARAgAJBQJBh206Ah0gAAoJEKsv
WlsVJWmQlLAAn3NPQnFeqlqKwCAEdT05GJKhpNX1AJ904DWk/Ehhniqn+OyS6NvO
6ZUHC4hGBBARAgAGBQI1qhNwAAoJEEyZIyWW4dGNf/cAoLMKPPHktNB41rA+5zA6
RZP7JLmVAKC2Bhkg1ig0s76kTi6Ngn0LJPFTpYhGBBARAgAGBQI8UD5EAAoJECKr
8Oz5VhwxIEgAoJAAhNBLUgCTGTzITnqqqtza1V6ZAKCYW8ads9E3F6GoOWeJ/rkC
5ttMI4hGBBARAgAGBQI+L7keAAoJEIWAWf86Zh+dWe0AoNlEr9T7QVQajXHsHInw
vWyCUH0VAJ46Txh7sr8IzTRinY4csug62nxHmYhGBBIRAgAGBQI9TuvRAAoJEO6e
LCSHzT29DQ4An2rYMAMVtKyVFrnq6ByPbGf4Ty4fAKCLg/wNb7HfR6pA+ZBiK/f8
gJ1mOohGBBIRAgAGBQI/OME3AAoJEKmGKcxs/75ntx0AmQHsYViO3X9XtRkQGpiR
ZlDnZUkRAJ0ehP5SoCPQnIqyhN1z2IxJVKtx/YhGBBMRAgAGBQI+a7xtAAoJEFPC
DI4dQfvVPuMAoOIhyuJQBxL9O55Yccwqgqs1pYbfAJ0SvqSqbPGnMt9MFDdCfjkr
t9dQ0YhLBBARAgALBQI1njCeBAsDAQIACgkQqy9aWxUlaZD+JQCgoggHtgIyLoZp
nCbwouhjb2gR4dMAoPn5WJtFRgQJ2/w9aKs5IrxZHZv2iFMEEBECAAsFAjWeMJ4E
CwMBAgASCRCrL1pbFSVpkAdlR1BHAAEB/iUAoKIIB7YCMi6GaZwm8KLoY29oEeHT
AKD5+VibRUYECdv8PWirOSK8WR2b9ohGBBMRAgAGBQJBhME3AAoJEKkX6cyZbhRe
4FMAn3zDN4wRvOZaLZKtR/FCg2KixFaaAJ9QsVyUvOS3MYV3Ne0hqfS7LeWxG4hG
BBMRAgAGBQJBhMLYAAoJECLKWEx6e6PAo/0AoL99RV65lFNaneOw5uoJDGph2Smx
AKDJT2oZ+z7g2DqOxmnRL3jujXuTWIhGBBMRAgAGBQJBhWGGAAoJEHsKUhIPVfa+
9w0AoKB1MLg5Qvx97i4r9iIwdhsHlPNqAJ4gNXa/UHUFY/jncp55INWWZMp/lIhG
BBMRAgAGBQJBhXq7AAoJEJ7XWD/BTrKCfKsAn1dtvWeF107c1OYcTwjTjQWiAjYX
AJ4jMRTTtt29kPAZg0Trt13mPusdfLQmRXJ3aW4gTGFuc2luZyA8ZXJ3aW5AbXVk
cG9wLmJpby5hdS5kaz6ISQQwEQIACQUCQYdtRwIdIAAKCRCrL1pbFSVpkHxPAKCQ
LPGWpuFr1zd7vJ3E8efKB8GBrgCgrlmoGv2HWLyynP3Hfca4OgCHotSIRgQQEQIA
BgUCPFA+RAAKCRAiq/Ds+VYcMROnAJ9iZn+COygOh0P+PCAFRadbF3CqcwCfQt1I
bakPYw9WvKYbtdYcSpteG16IRgQQEQIABgUCPi+5HgAKCRCFgFn/OmYfnZsDAJ0a
zr492ZFQRj5I1BtIM6/ZnoJxHwCeJK0vzJ3k67cNw3iSQLnY5q7LfLCIRgQSEQIA
BgUCPU7r0QAKCRDuniwkh809vQigAJ4rH3+hCVN71xDTpw6dgzg39t2ktwCgvkWM
MyxhgbIirUXky19EtqgJVTmIRgQSEQIABgUCPzjBNwAKCRCphinMbP++Z/P4AJ9T
//oZd3aZQ8p0oOidUhKX55ZSKACgjS65xJCkXMMOXc7yMtrEbYlOcfeIRgQTEQIA
BgUCPmu8bQAKCRBTwgyOHUH71RAxAKDepXkjsDESBFsVymPbx6ONSTwrVgCg7fBm
3a83j7uyc7QBj6FC/UjPJ42ISwQQEQIACwUCN3ewrQQLAwECAAoJEKsvWlsVJWmQ
8n0AoLucVJq/1BBiFe54SNMCO4hD9qt6AJ9QoAcHwViH14wd0N8XqYFpT/ZVQYhL
BBARAgALBQI4DKFeBAsDAQIACgkQqy9aWxUlaZAZwwCfcFtAANZQz0WEzlgxlGDE
uZsXgDgAoMO11XAO6FcTRTC2hmyBoDiCU/VriFMEEBECAAsFAjgMoV4ECwMBAgAS
CRCrL1pbFSVpkAdlR1BHAAEBGcMAn3BbQADWUM9FhM5YMZRgxLmbF4A4AKDDtdVw
DuhXE0UwtoZsgaA4glP1a4hGBBMRAgAGBQJBhME3AAoJEKkX6cyZbhReJEoAn2+d
7TM3UUri0KTsdVDI2RcbdZflAJ4/oN6679dSIBbdjl898A8zIlZEzYhGBBMRAgAG
BQJBhMLYAAoJECLKWEx6e6PAXdoAnjSPh2zzbh5L/mRGiqMAAbQbgldOAJ9gGN1O
bO3kmBWOCOTQzcq3jyqQ+ohGBBMRAgAGBQJBhWGGAAoJEHsKUhIPVfa+tFMAnRhT
CMjvdsFQAH7e9139dEZzh9EVAKCe9OUrzN3OxepgcInuQnnZWVt+VYhGBBMRAgAG
BQJBhXq7AAoJEJ7XWD/BTrKCwKAAmgO+1eLV8DWLv6LwC6z6492Zk+ndAJ9mhjh9
OYCVY9uQIRa6DZVkO0tUD7QpRXJ3aW4gTGFuc2luZyA8ZXJ3aW4ubGFuc2luZ0Bw
b2JveGVzLmNvbT6ISQQwEQIACQUCQYdtUgIdIAAKCRCrL1pbFSVpkAuuAKCxgE7S
zbzu8L8GpcjoUDfpPXJTXQCfQ/Cw1ZYGMwLDbMCPPmOxgF8f2ZCIPwMFEDWeJ6aY
V+nyas7pWRECpzkAnRyS7MGnCV8ryuY51k285PPfK9GDAKD6h+CCG79agN8IV2H9
WnnGfAhihYhGBBARAgAGBQI1qhL/AAoJEEyZIyWW4dGN+uMAn0qVi28I4RYz7Ax3
ubPStUcsNRS7AKDyAA8mFvcywTpwB3nhZr1DMYjEA4hGBBARAgAGBQI8UD4+AAoJ
ECKr8Oz5VhwxBLkAn3YhHDMeaHKQ5gIv9Z3uKQXGhUfFAJ0S7TZTblmn5sQ+yDYC
l22cY9oo7IhGBBARAgAGBQI+L7keAAoJEIWAWf86Zh+djD8AoOUaKX0TZQgxWKF4
kWGdc6MTcA6bAJ9pvQtIridVI9p15GTEeHb3B+hEPIhGBBIRAgAGBQI9TuvOAAoJ
EO6eLCSHzT292EEAnipRpjk9Ks5Y2GfzvvFUyLV/vg+dAJ9V5Y1bo8NkiyHeXAVd
Nu1cCgItZ4hGBBIRAgAGBQI/OME3AAoJEKmGKcxs/75nQf8An04GKCtLfA3YyJ8+
uVEStt4MDYRjAKCNa9UiEnL4FjbeuMlPmMT7hTgTVIhGBBMRAgAGBQI+a7xrAAoJ
EFPCDI4dQfvVye0AmgKc33426gqBsOV22n+FvSqYrKbSAJ0TOJmxiMRAT2oYyrP8
UOJJfD6XoIhLBBARAgALBQI1nMhaBAsDAQIACgkQqy9aWxUlaZDd3wCgnI+6xVIn
8Qm4oKMA73Mzp6RSeM0AoLQS9WLKJs6QZ41IrEP2NMYe8fusiFMEEBECAAsFAjWc
yFoECwMBAgASCRCrL1pbFSVpkAdlR1BHAAEB3d8AoJyPusVSJ/EJuKCjAO9zM6ek
UnjNAKC0EvViyibOkGeNSKxD9jTGHvH7rIhGBBMRAgAGBQJBhME3AAoJEKkX6cyZ
bhReyS8An1BIE4oOvr9sRsXQxc8z4cMh/hHXAJwLRqsksQjStjQBz09iNugbPVDC
9IhGBBMRAgAGBQJBhMLYAAoJECLKWEx6e6PAXaMAnAogAeK7CK6mEAE00GspyVUJ
IgZLAJ0dY6KpMCOE6MEBAbGxxSxjltaKYIhGBBMRAgAGBQJBhWGGAAoJEHsKUhIP
Vfa+Rj8An39lqL+plHqqrDg/XdIrCYdbiVCVAJ9Nh4TRU4xGj86Nbxeii9PbueHZ
cIhGBBMRAgAGBQJBhXq7AAoJEJ7XWD/BTrKCi3wAoMiAcB2K0DqDYyRU2jni86li
uJjpAKCA6kILoU2zK4hrCatAtGOUmCXiFrQrRXJ3aW4gTGFuc2luZyA8ZXJ3aW4u
bGFuc2luZ0BiaW9sb2d5LmF1LmRrPohJBDARAgAJBQJBh21kAh0gAAoJEKsvWlsV
JWmQo60AoOXzWrUNklq0FfhgIwm05he+keJfAJ9sagIYEANwCOy/454yAx0ZDIiB
/ohGBBARAgAGBQI8UD5EAAoJECKr8Oz5VhwxTBsAn0B4HbejqjrqYo/2bPZstcCP
oiNRAKCRGtXNsLZ+JpFJQUOMtVOaojeZ7YhGBBARAgAGBQI+L7keAAoJEIWAWf86
Zh+dC8QAoN3k/xmEhNnvQPwQwhBrV61nkhGGAJ42PIlY4d72pc7mvSmZE47azxeD
5IhGBBIRAgAGBQI9TuvRAAoJEO6eLCSHzT29rrYAoLGs30SWF3v30Ks8bSLoVBSl
zmzvAJ9nOfo+Ie3Waiu4Y6C5z6w0oZHP4YhGBBIRAgAGBQI/OME3AAoJEKmGKcxs
/75ns0YAn22hQ2C7cBldGVOXI32tx71R7h4zAKCL4v/sIL4pU/BtOGnG8FrokQ4z
dIhGBBMRAgAGBQI+a7xtAAoJEFPCDI4dQfvVtHEAniGVczBZu9cD1gRPhwcH6Qic
GgMWAKChmWo0qe9WDn8K9u3uNua4fWgu/4hLBBARAgALBQI2cpLmBAsDAQIACgkQ
qy9aWxUlaZD7bwCfVOtVLJMeCNdTI1ULCH8ojy9eu18An0kueY0FxufZMyL3LNMO
9ut6BdOZiFMEEBECAAsFAjZykuYECwMBAgASCRCrL1pbFSVpkAdlR1BHAAEB+28A
n1TrVSyTHgjXUyNVCwh/KI8vXrtfAJ9JLnmNBcbn2TMi9yzTDvbregXTmYhGBBMR
AgAGBQJBhME3AAoJEKkX6cyZbhRectYAoJKfa8arFKeQz9CmoOILd5oZW1U9AKCa
k90SAN4Y56fxtQcKwpIWDICDj4hGBBMRAgAGBQJBhMLYAAoJECLKWEx6e6PA5X0A
niLig9MmPC/IHnPqysgALl/rQ7rGAKDf0eDVtO/O1RYwDHD3XFS1rAsTuohGBBMR
AgAGBQJBhWGGAAoJEHsKUhIPVfa+MVgAn2zBHK082c9nARnaIdnvmKwvHfF4AJ9P
mXZWbePZ+hPEZedCJ+gjav5eEohGBBMRAgAGBQJBhXq7AAoJEJ7XWD/BTrKCdQwA
oKCb5e6XYoIWBQS83dAWWbzRYHUzAJ4/AsV8w3OVx4gcfnc+ydNrqhep37QsRXJ3
aW4gTGFuc2luZyA8ZXJ3aW4ubGFuc2luZ0BiaW9sb2d5LmFhdS5kaz6ISQQwEQIA
CQUCQYdtcAIdIAAKCRCrL1pbFSVpkIJtAKCqYbfX5GaAPpGkr43CcxV1GOXXdACg
wGyhJx32OUxcKRX2vZu2V/04NUeIRgQQEQIABgUCNaoTNAAKCRBMmSMlluHRjZD5
AJ4/FIR7fPAn0FRsAdVkMYjjheQNagCeKS8BinUZZTmkCA7LlfGndG/I0DGIRgQQ
EQIABgUCPFA+RAAKCRAiq/Ds+VYcMRLEAJ0YESOK0XEwY0jf8Ux1THnMbaSTewCc
CjW95oATVX456md2CnYW1bVNG02IRgQQEQIABgUCPi+5HgAKCRCFgFn/OmYfnRdG
AJ9SZa3Rpok0KkfZjb47ukuJF4zZcwCgujNd99qa41I+DRBdk2o0iKFFHJuIRgQS
EQIABgUCPU7r0QAKCRDuniwkh809vcbPAJwO7q0t0IGv80t5jKzrvczuYtK5JwCg
rb9G5humttm57x97GkzEC+huQRqIRgQSEQIABgUCPzjBNwAKCRCphinMbP++Z3PW
AKCEz2tqA4eX4E4WnjyJi455CG0ABgCgpw9ubA3JRqZp0KBc6f/1x5XM8T+IRgQT
EQIABgUCPmu8bQAKCRBTwgyOHUH71R8CAKDFPFvcIkXGavodznq3PhCL0R8nsACf
dtFBd0Idbu4ETFbnY6u5dV7PFq+ISwQQEQIACwUCNZ4otwQLAwECAAoJEKsvWlsV
JWmQ1J0An1aSjsro67npsNM6hnpTiRImvgGmAKD9yopC3Wp031t0NYUpjQnaix0K
RohTBBARAgALBQI1nii3BAsDAQIAEgkQqy9aWxUlaZAHZUdQRwABAdSdAJ9Wko7K
6Ou56bDTOoZ6U4kSJr4BpgCg/cqKQt1qdN9bdDWFKY0J2osdCkaIRgQTEQIABgUC
QYTBNwAKCRCpF+nMmW4UXrkXAJwMftLYSsXOrrowltmLwDjmK6gujgCbBjUwYCYe
+JddzmYJhSgBCeG8TfqIRgQTEQIABgUCQYTC2AAKCRAiylhMenujwG49AJ4pRVcS
l3aJRpP+G0+XK6b1chw4kgCeJ/OZbjKg/j+w9sMKNepYuuvzvwuIRgQTEQIABgUC
QYVhhgAKCRB7ClISD1X2vmpkAJ9IylbgjXmZQtzBhZIBth5rqAl1NQCfSCuQUB9J
Fn10mxCqmx11ma22fSuIRgQTEQIABgUCQYV6uwAKCRCe11g/wU6ygj9oAKCF071C
L4ib+pRgsKRPHwgejhlEwgCgp38HA+uM5+IsDi70RdhX666oMZa0LEVyd2luIExh
bnNpbmcgPGVyd2luQHBjNjk3LnRyaWxsZWdhYXJkZW4uZGs+iEkEMBECAAkFAkGH
bXsCHSAACgkQqy9aWxUlaZD3lQCgyB10dufhfSuCkatEebukUy5RLhMAoOtcZsKU
ewZhyG92AZsNkSMAzfLxiEYEEBECAAYFAjxQPkQACgkQIqvw7PlWHDG/NgCfR7Do
9Z+kNonJIuy8VVgM0GLpPt8AoIFWMHIxw+418kj4LxK0vvqZFNs+iEYEEBECAAYF
Aj4vuR4ACgkQhYBZ/zpmH50x0QCgq74qp7DgYDTB5YfJ30ZoljVYRc0An1hJpVXq
jawTXfOHySRsmkHDy5kYiEYEEhECAAYFAj1O69EACgkQ7p4sJIfNPb0augCghgg3
pQ5Qt6zJtsGrCCfU+Y0vCMQAoJnaVSPg43bIvIVj2vH7VaA/mmoJiEYEEhECAAYF
Aj84wTcACgkQqYYpzGz/vmfw/wCgnbt0iGLe/YUfae2B4t2BD1pDnBcAoJrR0974
CMAw854d2trE2WGF33d2iEYEExECAAYFAj5rvG0ACgkQU8IMjh1B+9W5hwCfSCxB
gf5h2uMXA0iShz3YR7Cy4gYAoJnNSapdZvffToYB2MXYS6bH6AfViEoEEBECAAsF
Ajg+5rQECwMBAgAKCRCrL1pbFSVpkAVBAKD1ezQQbHrSCkuIuyGULEF+5jgjhwCW
N/sm9hkKGojS8r6XUrNXlJ499ohSBBARAgALBQI4Pua0BAsDAQIAEgkQqy9aWxUl
aZAHZUdQRwABAQVBAKD1ezQQbHrSCkuIuyGULEF+5jgjhwCWN/sm9hkKGojS8r6X
UrNXlJ499ohGBBMRAgAGBQJBhME3AAoJEKkX6cyZbhReqaQAnj7P1GP4DrbhgF4S
9+VqsJL0kRrqAJwLY5O+Ac3Wr4Zudna9d1YY6lYECohGBBMRAgAGBQJBhMLYAAoJ
ECLKWEx6e6PAq0MAoJ8DdLcBGZlluBPU41QIUPXN0HxeAJ453ZdHtaGlx1Y4U6K+
3PLNYlXf5ohGBBMRAgAGBQJBhWGGAAoJEHsKUhIPVfa++DkAoKewdz4RLGsa44mc
rxHUF1UpTdzVAKC49yZC73SWCFQfOfcAApdwQrnF8IhGBBMRAgAGBQJBhXq7AAoJ
EJ7XWD/BTrKC4X0AoMPaAM/o3A0EPqZkX6MHonh25d3VAKCNQcfl1S7n0Meh6zyb
GgakaHGlw7Q0RXJ3aW4gTGFuc2luZyA8ZXJ3aW4ubGFuc2luZ0BwYzY5Ny50cmls
bGVnYWFyZGVuLmRrPohJBDARAgAJBQJBh22HAh0gAAoJEKsvWlsVJWmQOigAoN3u
uJxUMioV0UMzDpbMKhYIyIGcAKCMV80SIelNG/Usi1XWIumqvaWle4hGBBARAgAG
BQI8UD5EAAoJECKr8Oz5VhwxawwAnAmZ+2P82uDwf8EfcUbbxcmE12dTAJ4lXGQq
sQ8Bm4Grvzdxl1/YWft6SYhGBBARAgAGBQI+L7keAAoJEIWAWf86Zh+d3xYAoIJG
bbGiCoiuxzDK8n9NBUjdl+xCAKDKm3OyP5rmo8mhyGSMTIhYwpCg6ohGBBIRAgAG
BQI9TuvRAAoJEO6eLCSHzT29ghQAoMBPR+SzJ+jvx746U50vS1w0+dVUAJ9DhTJb
/Uxt3FiSCAC4JzaoDI8ddYhGBBIRAgAGBQI/OME3AAoJEKmGKcxs/75nBh0AnRfD
bxd1dy6y1fNm0Pf8ND1045JWAJ4saYem5QmHJM0zL9GR02VRN1n+VohGBBMRAgAG
BQI+a7xtAAoJEFPCDI4dQfvVA34An0LKa0ne948MoZ228UfSxqbOYYSJAKD/aeVI
/HGF4bt3lAiw19MiDkanrohLBBARAgALBQI4PubMBAsDAQIACgkQqy9aWxUlaZCj
wACgtL3fxd2uvcDPzcHgQO4Ikb2MOEgAoMU+4U06rrOJ/9khHAQQabgNkl2hiFME
EBECAAsFAjg+5swECwMBAgASCRCrL1pbFSVpkAdlR1BHAAEBo8AAoLS938Xdrr3A
z83B4EDuCJG9jDhIAKDFPuFNOq6zif/ZIRwEEGm4DZJdoYhGBBMRAgAGBQJBhME3
AAoJEKkX6cyZbhReDkgAnifF4VgQUi7gMbpHcWcq9FzWLblOAKCZ96tc7hHJqArg
9lyf3App10Hu2IhGBBMRAgAGBQJBhMLYAAoJECLKWEx6e6PA5AoAoLGtM/du73uC
8S9U6zqivfaLdR/AAKClYHBNffrJvHxfeP91XaXp3w2duYhGBBMRAgAGBQJBhWGG
AAoJEHsKUhIPVfa+zx4Anjt/3lJD4vV/ZMOgm6HfUb58dQEfAKDMLIS3Bd5m/kk0
xubKqZcLoZYJLohGBBMRAgAGBQJBhXq7AAoJEJ7XWD/BTrKC3UoAoKp9k0OnAVul
Ikzzn1gLLuIUFSYfAJ4mcV8xInIIzMrutZBsAGnYXlDKBbQeRXJ3aW4gTGFuc2lu
ZyA8ZXJ3aW5AYWF1dWcuZGs+iF4EExECAB4CGwMCHgECF4AFAkKLFNcGCwkIBwMC
AxUCAwMWAgEACgkQqy9aWxUlaZC8ewCg3pxBUwV2nnOGQSV57i5cQpog97QAn1vi
qRoRVBYRkuJtw4nJiPYNQ8tSiEYEEBECAAYFAkOHIQkACgkQ7Ri2jRYZRVPzPQCc
CXaPlix6T0cxYRGc+iPefrk+rXIAoLDjccKLPWS1NSxBrdpyRtULLPukiEYEExEC
AAYFAkOMdkoACgkQjUlNNMcOvVB3AgCfZlLbTcb+aXowRwv1Av/IOrP5LScAnj/C
Rc0uFej+hf0k8eNOjKbPXJJCiEYEEBECAAYFAkQJuPwACgkQqmHuiTqD3zKgUwCf
Uaxt8ndS2r1xdSimSnu4HrD6RKkAn2FKGYHinNOGOQtc2KaqYm1v53o9iEYEExEC
AAYFAkOMdkYACgkQjUlNNMcOvVDbNwCgupgaBPi6YpDXBJBr8VbOeL7uSzIAoIzi
wpC1lqg6QWTI4PwJQvmGz0CaiEYEEBECAAYFAkR5tgsACgkQIaZGm9HvuqbYaACg
ifHZgDJmS20wEyBnlomr75ryYrwAoJu/GRMSNoAlVqMf9ie28I3+6FRhiEYEEBEC
AAYFAkR5tg4ACgkQIaZGm9HvuqbOZQCgz68rVWOElz26e7FtmFalcxH8/1UAn0Ix
YDMZqxnTaLZIRlrRY2YGCsKRiQIcBBABAgAGBQJFPHVDAAoJECZJ5ijF000FduEQ
ALVAB5zhkDAAZRtzIs1JdF3I5RI0A4zIn89OveL0DiIhp1GX8uyYXn3RBi4TWUHh
+UlGBmYNWW+r64j8JWLrKO4WHr9vvUP/J8O6/QmDGKJq7AbenNNXVbXP5Ul0ooui
WDXD2ZqUT6tz+XDimVhTtdaaRIVVrTRaOoCqfMNMArOa+COtsOSpwy9Kg0Rr2eWb
yp34yYUivL2AjisuEyDF8NDM894NNEsyLUhv12pD63/uzcHDjRyWmuv0f6bFtRqr
oe65j5x5BDV6AP17jdQDUqz1s4x23Pu/VZ3mYrrn+vPiT5zLBymjEZ5sVPYyAXG0
uEjjNZeO80EVed/ysjQE+O+FPi7vwKiX9MXCXyvAqMCUsuViw3XqxjyIjKfb3IfP
9YRkOWbQIpATJPV2I+4odf8aTLdUzEZI4UajeiE14hL2PMkyo8X731FHkPLG50We
NthqlLQVA53zBkjonYO+Rgf+PClgCbbM+ZtzULqXlP6cTVQsW6laCctSx6Zwxg1L
6YUIcigcJ51OqLplsfMb40cI8D16pjZWO8iTVL0hqY4VbFxciEWBfA5DwlXOWz79
sr8d0pn0TMq9+MGqqlpTDUNJTYMVrfiHw7Jlw0QjVSYYZL2lJzqtBJ5qa7Bv6JAp
nFqBFboVJx3krj5bPxXyWQ3BusLXeB95MAtM6pc1AqKdiEYEEBECAAYFAkVMwxwA
CgkQWvQeUeMzqhx1aQCfX+9VqMXjMNpyBIygWFahKA47EN0AnRZzE+rMbQOAqbsM
IjoG8T6FMuf4iEYEEBECAAYFAkVNANQACgkQLT98C3rkVDbEaACgkkx7PhEUNaDv
xHXVI/rHCaMTiKgAn1C3wB3Optd/e+TA9BAdBWXlXEjNiEYEEBECAAYFAkVNBaUA
CgkQHqjlqpcl9jtGpgCgu/3BuPb6SjW7wMZbY6Wf+VOkCn0AoL9DL9jEcC9JalyD
OCs0XFh8LmQ1iEYEEhECAAYFAkVM/yUACgkQXwMwnJIV9/epQACeNVLez/h6ug43
RShCHlLVKs9okj4AniXLx0f9om7jIyujZJvf0f1JTdDSiEYEExECAAYFAkVM9lEA
CgkQXGxMwFp5iTDZwACgjgaMUAvy+PQXTQVD6g/fQasA/BkAoMly96QAT9dzGwV9
PyLWgAdXDiDviQIgBBABAgAKBQJFTOhiAwUBPAAKCRC8mW9Nv7Asbyx6D/4205PM
Qs9gBO6RVTPzdmkQePKsz9b5QsvbgqxgWXIGqCvexXw86V94LqrnxkuzT7IW045M
nOoLo1sL6UcapB/C5dq7ggJoSGSZtWK3rnotDP5WiX5GYggBkOIDKDaTJVmQ827X
nRWZ1CAiqhELOdYWPmbLVNHaprv0SScwWmy+Iq1kGAPg0B21kajTEnaWqo7bqaLj
fAxcZeHk5MvWXW1SBOiEUIH1YT3xYHfuCC4KuJ8sn6Q+H+E0bl1SoPZDxo8gX2Ow
5YmUswEMyo5l6uwkeQT8y0RCF1tUB/v6AtTgEV1pCNPDglzmEqUPPrX/isntq3K7
G2ZaHYEs2eWSxsUeIHTVpKdzw14u6SgkjA60LVn5e6a/ckgqyhKxZxZ058NO3Yfd
oH4tTsU1BzRYms+KYtaiBfWCKgUI7HIbhFZzROXec8fnvxsooa79JvT4deJr4wAe
coW1gwHvhDrpfP2feyx/m0oa36TCH3V4BeRL7Lws2bOWOlYB6s66aJc3zmQhstUP
Qh1CkiD4sTHlraqnrWFDFDF88z7YHywaWOG+Ruwr9w+U7cc+HPgQM0sCYechOa32
KtFyFzgmumayFb5uJJMiGx1eA8lKWH1a1VZ/OI/jebc75BXOyuXrnA+PCXCIi59m
5HOcL1XHuCoSdx28McWbMd6xXoN2R6SF59893YhGBBARAgAGBQJFTyzGAAoJEG5p
+N2Sw4F+CoYAoNAwYwos7kSwhk/DZ/TYFpceyewNAKDEXBplBS/ztQH3OzYX4uiy
l4BXeIhGBBARAgAGBQJFTP/pAAoJEFzlxRuH4Fe+1NoAnRLhCq+5AY6lfawO7uFv
BBysDW2iAJ9AjO7V7jKJOvtXt37QTmTasVZq3YhGBBARAgAGBQJFVxmEAAoJEByp
WmNWsMoI/fMAnRP/M5WdoZmM8k9dAyrSJz3VwF62AKCKb1LqaSG/+K7HIdIED24G
Ax4QB4hGBBARAgAGBQJFWEIgAAoJEIA8WjSEyDRzVZQAnR2uPiOAVSjNMqxoyHuS
uXC2egrcAKCLwEvgs0iAjsbFJZmr7kIGScKOYLkCDQQ1nMhaEAgA9kJXtwh/CBdy
orrWqULzBej5UxE5T7bxbrlLOCDaAadWoxTpj0BV89AHxstDqZSt90xkhkn4DIO9
ZekX1KHTUPj1WV/cdlJPPT2N286Z4VeSWc39uK50T8X8dryDxUcwYc58yWb/Ffm7
/ZFexwGq01uejaClcjrUGvC/RgBYK+X0iP1YTknbzSC0neSRBzZrM2w4DUUdD3yI
sxx8Wy2O9vPJI8BD8KVbGI2Ou1WMuF040zT9fBdXQ6MdGGzeMyEstSr/POGxKUAY
EY18hKcKctaGxAMZyAcpesqVDNmWn6vQClCbAkbTCD1mpF1Bn5x8vYlLIhkmuqui
XsNV6TILOwACAggApddV0kqyLQVmeg9VJ6jXZZOG3sYb7hoJ34V8Jzq+2tfnAJcO
/T0xNlZRXnmMd6ZlHlzJcDPXe7UvVSMLREZXR5HA0OcgVkKiCDShY/LB+Dl21fad
A/mxQYEx2SNSPiKOUIBDRlDwCzFIBq4MhwpIhDQE7lNMMgQivUZX4uFW5sFUSw6O
VliE3fFPPoUKw4AU0OpUbF+V3/DlCiP1A7eWXJe6paE0cozi65VO4GvoI4ikQcs2
0tDgbcGBOpbOnBGjwx6KjV/9rv+xXPlfPbtuQOATopGgtZSMwctzIMH9ON3q/+OG
XpnzsMnCyUZ1oMS5C9JcDxdQZg79E9XkfZ/RPog/AwUYNZzIWqsvWlsVJWmQEQII
8ACdGwHYf/zHVvp15mWSdZ+Qj/YVM98An0x6CeEiPsRU/GWtzrHIcgHvzWiy
=5i3W
-----END PGP PUBLIC KEY BLOCK-----
D.3.108 Sam Lawrance
<lawrance@FreeBSD.org>
pub 1024D/32708C59 2003-08-14
Key fingerprint = 1056 2A02 5247 64D4 538D 6975 8851 7134 3270 8C59
uid Sam Lawrance <lawrance@FreeBSD.org>
uid Sam Lawrance <boris@brooknet.com.au>
sub 2048g/0F9CCF92 2003-08-14
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD87mDQRBADpSK4q7J5JpjHMPdlp4ieo4jJR9V63tvptpBOAk/nuhWnY3fpu
Z7pcxOy5I5hZDIu2kn2zkBv4CTsn9yxdWgJaSKU9nQMYpfFdCnajo0HTwV72+7eK
u86VDWZeWuuUIiHVNBUILClbOadmRFDxuCCjyE+V97o4CiUu350M28YdBwCg6LE8
dpO9NELy9LJxyhPBE51iS4cD/2CdsCXzmKaFTa+w5fCOSBzNv516qY1GEkNvmDrD
e3dgeyxaembidWjjU2vqOZmWFP64jgayvyFZChGMlRab78GKXH7DIGGrXWp9v7B9
JjCqDyuX3NGaxCDFUNJYR6nt7Q93sAT85oAV9EPeFFEx7Ksd4C1iKlGlohGwleb5
TCngBADX+A5DR9eI9E8loh9NmT4HVzvjk9kvk/vq9i0MqxgcEBodgRPibVKWTWOj
MR0T+3qOzLGiVjIL2FzVF1na27hGJmXupxU4dWoKVGR85JYNOoFBNuR2HZsim+iy
sX0gK6ejsxVhhx6Q+CQgCQ80TzuY/dD2qFuOGkda0P9Ro62yt7QkU2FtIExhd3Jh
bmNlIDxib3Jpc0Bicm9va25ldC5jb20uYXU+iFsEExECABsFAj87mDQGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQiFFxNDJwjFmBaQCcDJfb0SfPgEimiFVhsQOJccxJ
F1UAoKJrgMOoY10RAqM822JzOnn9mGXutCNTYW0gTGF3cmFuY2UgPGxhd3JhbmNl
QEZyZWVCU0Qub3JnPoheBBMRAgAeBQJCWzEGAhsjBgsJCAcDAgMVAgMDFgIBAh4B
AheAAAoJEIhRcTQycIxZWoEAoNefUsJBBCoZSmfVIPEh4g1oDmOFAJ9H6Q4/hfh4
hFTLxU7p2bLgbdjGHbkCDQQ/O5hBEAgA5LFaiwqsnyrdVB+Y7S511ZPmQOi8UwfQ
04PIWyt9a1MwGSYdUpzGAieMLe4KG6olMlLH0X/qxkVjbukwPyybeN7RNUZE1DD7
KGbVOWpyQHhAB4EPfzRJFYQEmT1x7tk0nVbF7emuK9iG+Z3et6Io58QjOgyEMLYU
UjwzCE2NYjJmMLEy1e+icfEkOs30s8XPrus/GNffVlsxmHEzxtsicw+AVnlrjLtG
xZ5DsNRqJM14L9X5qR3O0dq3BnKGZPOctIF6bRv0AC9lX9kQ1saFqv8iEHoHZ2vD
2eIplYu/bviD+lI+w6zrq/KgNHQ1n9ngzs/N14lN9C57dHTS7U9nJwADBQgAhWSk
YnYr5vUskZgVmf0joVgYNBqXIBKo3qXx0DYxGOT18EbKhtSYCar4Uhjob9fUhQop
nEd00GQVZwDTL3/STCXUUSaHRJhK9yCwgvQ+/q58yW1JvMrCA6uaca89y9DnfWxv
0lFbOdLJJQNrgLCyNweLhZcEjOSTQO6EZB5OX+z4Dgfxd/5DKWr19JKw54Qtus3s
9zZhVoQoXzWiDlYdtuGUjnVQvycegOxwjFN/TP9IQpQS8HFMfEu5GLTbRAQ3zirS
W4FtGaeI7cUqap6ot2BRd1prAXyThXHxYAARaYib/xvCLRDTfXCHgJXbqEiJ72Yy
FgGYqFTRrTTgxiXo9IhGBBgRAgAGBQI/O5hBAAoJEIhRcTQycIxZLQgAniGrL6cw
+rQG5xLeJ6hrbllYV+8cAKCmIpsp54t97HWvJTKN9GhbpQhojQ==
=iBxM
-----END PGP PUBLIC KEY BLOCK-----
D.3.109 Nate Lawson <njl@FreeBSD.org>
pub 1024D/60E5AC11 2007-02-07
Key fingerprint = 18E2 7E5A FD6A 199B B08B E9FB 73C8 DB67 60E5 AC11
uid Nate Lawson <nate@root.org>
sub 2048g/CDBC7E1B 2007-02-07
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEXKYeQRBACVxgl1l+IwFK3aZ96X+BHzeUuGfAAWSqzZuJq0rVXhUU0KnGy6
r2HLJKwGlSQ0tP7rsYy34fDZy5BB1JajHNUIhb5SJFZH3VltQuZ3mnaLWJajm4Q2
c3TRBVVFcm4y0x/QiCcz3JvCUWHaPUUWlpbrkt57O5NTVlneOtruZtYPwwCg+3Ft
WjNU4ppXEbbsLHsIri5gPCUD/2e7RFkq1KaaqA0wfwictFgxuOZX00Do1kIFfoE6
0jKSxU3P8E01H68vZs8vGuVOLVE1pXoWoJa68zVOWkLCTE1z2U5YJumZL1mDRRHt
VfqlsaHNBLIRd9qAZsj3F5aSFu1/hCOiUkgLWQa9e/BAv76L+mCIJ+g5bU0YTEhx
XoFwA/9dF3JFdQCkrzbhS9/BSjEIXDCl7e9Yt4/6jTg14fr9Pb5hyUYYxu6i5v59
TgSdxSFUd3MaZmH3Kewg++9oqewNEYdOu/gmx7GiSKr3k0FlX+aK7UsVDjEr55Gi
XH5pqUce7y8bmx03a/pa0Lq5WLvPnfUaplWeoCmmAXeYmRFYqbQbTmF0ZSBMYXdz
b24gPG5hdGVAcm9vdC5vcmc+iGAEExECACAFAkXKYeQCGwMGCwkIBwMCBBUCCAME
FgIDAQIeAQIXgAAKCRBzyNtnYOWsEUGfAKC9mTqJd/PjHdTG0YZkBr0Y0PLmCwCb
Bl/VHprr5SrFDBdZy+vB5GIEhme5Ag0ERcph7BAIAJKt5PBfx/CEqBDS+JkDyYLG
RA3johtfG5HPVPOX1iFJgDLx/5ZKIsK3oxJLkkZQDBjzJgU+GcffBwafaTObEbid
D2rtwtqfM2EgoSntvJhrP09Qfx1/MOZs4MVJbGEec9egMgFRzUSKZ2xiYNqKOWL4
dL0TOyeLg7HQne1fuOOFEJZJtCxHAm75z6Q8deYHr7bQQ6NZuYc2qsOLjBX+M6Ig
d+r5p3vhkeg0uUzkRR9bAmtaDT3BFfxfMG0b4iTBpDW5UQ2Cp0NG+SAEaXVCYNcA
kKHZGTTI9e6a8AimsP1wOKs1TsE7WSLsk0Y1U6E7OuHLdmGwZygipfkUXR5v/hMA
AwUH/jLrMCAzZaCh6m6mrJ2HYCASRSfGKAbmfqPymEICfZ3Y+FeCCFopeatMZPyE
R6gEzHyu1hlSHV6yTfxRDV+gO6Pl9snsucJtD//ZnfNZenKsFoGJM8qu758jBA5m
FY5bTlkySmFJYHGAtpMap85j32iA3B24VmgIZ+rE/YVQUbbkaFrKN7Crvm+PgH1u
xbLrkjypklyo3iZZQo75W7SobSvyqnG3LRXkXsS1U1m3QWcLqIjKZTrrhbV3IIRK
+A0rSRKXpDt5lOYIqbJ+PwwGexlgzb31vJa0+N8qjdvbbMZIOA7mDVauEYsETkU0
Wtl5Rc1M8Qx2IISH+K3AGXHqn3iISQQYEQIACQUCRcph7AIbDAAKCRBzyNtnYOWs
EcVTAKDj9JrwUwygZFNG+oWsOA3/ikA7qQCfQkYnj9q6E0Z21p/ZTDptic+qSEI=
=yO1b
-----END PGP PUBLIC KEY BLOCK-----
D.3.110 Yen-Ming Lee <leeym@FreeBSD.org>
pub 1024D/93FA8BD6 2007-05-21
Key fingerprint = DEC4 6E7F 69C0 4AC3 21ED EE65 6C0E 9257 93FA 8BD6
uid Yen-Ming Lee <leeym@leeym.com>
sub 2048g/899A3931 2007-05-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEZQ5iYRBADg09p5ljHhIDwhH8i265BFEL1AyW3EPEOb0CyFErp3K4H7+IpG
FeaHUrB2i4MYs2r9gAMHadBMTXZJv7ECq2AUQfm3vTKeBjVVz/N7jsEDcmH6bObY
XvfRlp9618IBRCDdcbD3Qs0Bv4tM+e0oNYBTsOWAO+bfpHYPk5wORxq6ewCg8DWN
J/THLd42Fd4HTfxTC4tTa6UEAMPz7iASUbyJr7//O/Uu+05MBKX8wuNdrH2XPUWq
MwLcgEpKSFl0xjpJUMpr3eWGvAg0Vz1UzxDUvZUwbj/5nXh2olNoMH2LQY0QwXGG
TPudevBeJ6W+UaEGCAH4Yy25hxxr9h8XI5KRlPCOjQ8i6H+EZbLRTLgOrvBWvD8B
Ob8dBACGxoySAQP+leHIe9nrKyZ00tkNI6WPEPAG+14yiCgWLJnWKi7maIHzjG+1
1Fz5+nyMUtHofmLvNyDA/V1e2LFXDjH3v/PcTCQON8EnHAoYmqSRAZMBMmDpU1Af
f/vbiOg1zwhwAhdO8y6GZHcJGJjJ8lJYs151ehSS2Oa+NRCfH7QeWWVuLU1pbmcg
TGVlIDxsZWV5bUBsZWV5bS5jb20+iGAEExECACAFAkZQ5iYCGwMGCwkIBwMCBBUC
CAMEFgIDAQIeAQIXgAAKCRBsDpJXk/qL1q9tAJ0fy0MkFt+hNcvb0OMqTRJvjYlB
KACgluazpF5ATo+dNtJifOd8kMBxB+C5Ag0ERlDmLBAIAKOlmONAuOtrVXvRw2gr
wYNA4bjQrv44PLCMGuicddC1S6+Ngp+F2bjq43iyDk06i4eXBop0uqzkGA56pCVW
51mSLThl5q/1dixiLDOSy/9Scuei57KuP5MOk5GpFBU/OZv0R+1ZaK+718+jI8/E
NGOt/rZ3ZaTR94rAn9yQzVp4prVw4F7r6Vrp9mVu2qgoYKpwpfuR4nw1kq80Z1R8
TxtUrGFYSY7nRTPI6FI6fo6BVPMAw01Xh3oKfDfrecaNtNNgM/DvkrBvZsVHu3NO
M2yAVL6LP/Sjv0uF1pK/WjP27hzvO3yha2KYS3oBu4zysyVbi7QuFvm5FmF0mKik
JosAAwYH/RWHzWWtpgXdbMUrPxFTmFhXCVVuyiHG0h3bMZigKtAMcjjYRMenhiRm
e5Z5si4VzzpaaZaVY6T7hmzM3cran4VH6dFdZy6qhBFzlJphpLwnJti/FMrF2CdY
1kthUC0fxeEDPBkYvV1izBrPQ915XYXuXdJjbk/ATqeIKsqEHWSmTCLcLLtWn9Nt
X8DWU+GHMbaMAbtEfL+i8vg0WIOeSE4tlQwIkvSzfXh6Rysr7NtOuYzADD6ORRkg
Q9K802n7IYXqWhZTWKijXpf+n+NzWdXC/1UZambcfo1gcS1fotmrO3Fmq3+FgJ/A
YPmudGbHwUlAXVfJ47Atxggoe0znf5CISQQYEQIACQUCRlDmLAIbDAAKCRBsDpJX
k/qL1tpnAJ9MKjKh4P+ePXeQ+yIwfPza+MnFcwCgvVONrkQ6Byi+tZ1ilTlKR+8+
xnc=
=XiOT
-----END PGP PUBLIC KEY BLOCK-----
D.3.111 Sam Leffler <sam@FreeBSD.org>
pub 1024D/BD147743 2005-03-28
Key fingerprint = F618 F2FC 176B D201 D91C 67C6 2E33 A957 BD14 7743
uid Samuel J. Leffler <sam@freebsd.org>
sub 2048g/8BA91D05 2005-03-28
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEJHnP8RBACRTtM4Fb2oRITEwfTLIKSa5Mk0m1A7Pitd1qkjtAyFCi5V6uF/
2FXPP3Ux3M8xzrvkQNnWkYvGh5MSgkkJ0nszUvh63m5Lp1Yr/EMQr03v1HfqGKF2
SALv7eVJ3XHEEGsYq6KOcJ+2n3FkL6bwGXkXSya85a+EwQ+/aBhpEOEKwwCgl4N4
oTMEgh2Z06ZkMJrqbf4/P38EAIAN93nvAN14v41zw25b4USFzqH/JFTG3utAVxiB
NgTEkD+OkktxJFoTrZxfxoU6Od4tl+yIyhKJgj/QlH5pA/mpMeaXh+TQ0/EQAzml
d/sw7vXV3WJ+zXIZeh51yuHBY817e7izcnfmY33UrOdf4DtcplmUrfQd1eVMSo45
K2b3A/9a0tg7NhdfkL06b97oyKb0L8F92Q1sO6J5sgsEjNrUVrFnNU0DIDgbi/0t
oBpnqIDa09hhBJ1XYcxU4KMxBLpuIeuk2cDCUCVeeEDmx98GIss3hKO8YWzB40y6
7vtdh5lveaNV4+CA2xL/cDXscl+poRQA5tR0efR16jckEaEcVrQjU2FtdWVsIEou
IExlZmZsZXIgPHNhbUBmcmVlYnNkLm9yZz6IXgQTEQIAHgUCQkec/wIbAwYLCQgH
AwIDFQIDAxYCAQIeAQIXgAAKCRAuM6lXvRR3Q7whAJ9e9jjfVscKVirvWN5IM2j0
60Q50QCglAppekJH6jWStTwoq1EroBFPKUy5Ag0EQkedCBAIAKmxNvJW/W+PrE+T
JjKw6dbqUqAUNIGWnr6xgL7KYBpx5eo0XH3RCVzvRSfboA1+nXauTn/FhOtWMw0J
dkHrMQhxKSDhWOxeftKuiRiVLPXxF7PX0JMOadxOuqNSt1VWcuTxxBB2wva2Rb48
JscdFbT2u7+PHNarDgUnEobobdvbzh4F1ACaesUq4s2y8jH+YJTaBqJJuZLjLwti
C2zv7skf40I5ldud4/7ARGuumpjTrqZFQeQwPKX975X+jw5SBUJXA1ckKcgTp0s5
Yk+O5+yUkt6yzDO+CAYEaZ/xfpOhwmqSIXtdo+ilm2q3y5l+nyEVidYncRWRWYyO
iaXOJdcAAwUH/0Ixl92WezOXBqMrKVaA+abCN6t6n9zxSnwfVo92Vlfqj8Huz3Hk
55e1in3P01xXdNKnapYNkCg70WbtNQtCh0nJdGGDEWVqJsjiqDDMYa7QLahV7HPB
RyOtoAXnTWPpyk0d5WEXPLJ3vPjxqv5wKTmav3JcvVahSVWi2wmWAgfQJXYRvCU3
EEQ5KqtCBrQNdBsSRnzgDsMY2kAh02VuGTbkVlQz/rI7HAYEOL8SoR489O/MTE+b
5HtUT70rk57/3jR3QtiH/3Q7OqnPh/ATjO+pnPuhfqHiQWLWRDigJNheH/B+1Hmn
sHiSWrUmlaI0bzyIVW4Xft3nu/wH3QVSSWOISQQYEQIACQUCQkedCAIbDAAKCRAu
M6lXvRR3Q1SUAJ45iX7Ka9rb5pwAmY+fyfpuO4qgJwCfW4VAl3+NLCCP4A0Y8wlb
UtEtg3M=
=kR9a
-----END PGP PUBLIC KEY BLOCK-----
D.3.112 Jean-Yves Lefort
<jylefort@FreeBSD.org>
pub 1024D/A3B8006A 2002-09-07
Key fingerprint = CC99 D1B0 8E44 293D 32F7 D92E CB30 FB51 A3B8 006A
uid Jean-Yves Lefort <jylefort@FreeBSD.org>
uid Jean-Yves Lefort <jylefort@brutele.be>
sub 4096g/C9271AFC 2002-09-07
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD16LoERBACHLA0g5LE31OgOwlPPpQHnOciC0S7/mTj+XBGMi3uS8ts2K2pM
biEm7+xsyakCP98ucTs/OQmCizSrqMRJbCSX6TW/qx2hWw+QREZWZhTL+3pRJ2eX
ip+wyuOuUjlFJ28fIlil7XPAv2ly4tP6umC41+jT2BTgQObegm+17uzsmwCggCZg
VopF7lI3hUtJd58PTatZt/MD/RLMBRG2eZYfOGpHLF9jg7AoUNouMFSMADyYRLwS
vlUrcR3HlwjqKq99WucWCAkneBym7yRuNDUeZI1VBxasG8/KQKL9mEB9iweufSiT
qF4v5Hk95wpkbE4v2jGvLsvzE1D0Jj4fJgdm+Oiq/wrFIYeL6R2gzbhLn96X313x
appTA/wJix+jwlo8cgvmaCrJMVcHlaCiSkDM1UlKDQSPB5VxXazeW4EvN9YpIr54
aWzQ5elL3zhGfJZwtY+KwqBWeaHrvE6VJ8kjl9Ol0+VP7MObgfxgb9VB1oktKGuL
zbeVnCVZXbaqkxeym9kB+VUJPYJJiLGOztUHBjvxGazIxTXhIbQmSmVhbi1ZdmVz
IExlZm9ydCA8anlsZWZvcnRAYnJ1dGVsZS5iZT6IWQQTEQIAGQUCPXougQQLBwMC
AxUCAwMWAgECHgECF4AACgkQyzD7UaO4AGqT/ACfRmyJHE6XFGGVvNU3Gx1E0vpe
scsAn1yHaROu1BCUra0S4BNPVidE50iitCdKZWFuLVl2ZXMgTGVmb3J0IDxqeWxl
Zm9ydEBGcmVlQlNELm9yZz6IXgQTEQIAHgUCQlv5mQIbIwYLCQgHAwIDFQIDAxYC
AQIeAQIXgAAKCRDLMPtRo7gAahOSAJ4qAsR/hQO7F1SZ8CrRqRQoz39GXACeJxqC
bP08SjMi0oW2ZGGQH7A5oH25BA0EPXovJBAQAIf12QdmBkGQYGGEBhmFUk9XU9Au
9fxbrEc94kDisD2zpXPRuOblVTE2lVNaxXN/aVdf1AJHtpexdKjc/opvIa4TJuTI
vBA5gZk6AEpkAgJYHme3joJIHJtyHEms4HNO+yvnYXBGmFTkc/ak1o+rBwbWkvUw
IbksCSBpUWolzyThbVrRR5P7+HNsp+RcKgo8dJsU7SaP6VVmAIBTWyObXZm+eRpJ
yJMnTXUxWz7W4ywvMu9OF6C/4e4x+ueBQJ5xYRpyZbEol0BdiVQRoxEnsc1I2S4A
c5YWZuMnzRtkQV4mQfhqWrPQ5nLfVc1V5yp7PGyeJRAwIZCbTBD4wNBePXhTQ+CP
JDVVaJW7W2ComgI/1tjy9K5IYMLSXSmbvCg+A/qxEuhQQHPhlvZA4FLhxZaTZpXl
EHyvxyLxridyRfRzmE6SVCA3eyr12ewKaTXimBmcRvP0vrt4nL/SS5rlKh6RsJbQ
k0ETLBi6Zq3y0HIcA/8He2OSusyhgEBJaO8de9RF2APUOCcbt7Dz0f40iVz11pGN
8yfFb5BW7XYwnprZbD43QXjB/N7lD7lTRghLxLl0QSLs7GoQj2fXQiGenOnhsMIo
pQ0b8G8J2jCJleBBdNGQ2tedBzyUVgap3zFuy6yPIoKsip8JJNOJEz4WcpZrBJPc
UE6VNqkUzb/MHcxPAAMHD/0f8AUCDh2x8Kv1YENpefaN8WCQw1NeSgZtLuPYg9Op
7znNk+Xkl7WpZROz9s0S8AIGNr5BCpDxCg/AtdA1+fsiQXi05bV5N63LPQZNtLjV
oAvsnyn+p/ZGVnW6JhfPedJQY62jDmty4dnYNYSZWvIXnVDdRILIgGGnPp1Or6HQ
nurqIdKSnGIO1Zz00e5hGMPUsylsNBvesrHKbbzKbgp59cwvhoHk2oet5aK0+Ici
aIcCaWyjCGH/d53YTIf5ZRx3glDWbgRadPCVZiaDGdNQenF6zAVyXiJOa912sW2x
WcyhEa86imh0lfYSm1KJFYgnXLv33hlmQ2iiF4kBVk8Y6qU4BIDRJYDcPToNjmEt
lOwA3m3gkembU8uxy3mpE1L/iNb73i68xwfCHlZ1LzCnUShOl8aw5fu7C3qcytUp
t3gaD0TeHuqS4XIYBgDjNRPILW6e7IlK+3yQE9cLgMb6+vNQuHfkYr4TuRSUTWlM
sWK2opEq/z7e3LWdJrU78yHTBTVV9Myf46JpcWE2KYrCRHk564329Jvfe+uByYSJ
lCXogYpFo3HbaAyIjmcZDgbDHFaYnJ0dq/NZmK1rFVbBm2Z6qW1laG1X6ke+KcNY
HoUwEqEkYeOsovwkH0veLxvfDzBGtp33V3OgVuYa6WA51tpJQH7KgTvh5ETJBHzY
TYhGBBgRAgAGBQI9ei8kAAoJEMsw+1GjuABqd9EAn3E2CMMkEWdOtVjwTu+wWhuv
3bMQAJ4soo0qCyPCVz4Y0Ly5jvYWToXt0w==
=kszM
-----END PGP PUBLIC KEY BLOCK-----
D.3.113 Alexander
Leidinger <netchild@FreeBSD.org>
pub 1024D/72077137 2002-01-31
Key fingerprint = AA3A 8F69 B214 6BBD 5E73 C9A0 C604 3C56 7207 7137
uid Alexander Leidinger <netchild@FreeBSD.org>
uid [jpeg image of size 19667]
sub 2048g/8C9828D3 2002-01-31
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDxZg2YRBADEFCcKKsa/VS6z7aq+04C4rJ925MPEdQnGo4EVKtRv38AnqUaW
M6w2CJuDQ4iS+FL+nWaSwRnfGufftkEx0mSum1FMXQQ6+buC11LkgUYcF2f0wlak
HGr6Vo48RGz76Vi7u5tcoEaLb6uYjJfOOAzYX1aOv/T+qeGVc+JJG4LhNwCggBHB
1DpYSy35o1I7EyVufjruQJkEAKp11sHwuPcc6Q4q5hSKG3VM5TJKHwRkdoRxgfjT
UJGecH9GA4Td7vh11dMyS22RnFNS5hcCdCdoe9PkDEvwp+w30pi8uNOFmpCF9TlA
FRgwFC9pq6VveHd1PHWSRgiTFxeTXgJ0Y/zCZSitURCtlqMXMg9qnUe1tTAF99yp
zmQZA/sFaFGTLzCbPrUY+2q13b5PSQsv2D5FHFGuH3FL/rIyPexKmm9Fcs+LAQM7
rx94ipa0OpwapUwCFPg6zNqQ+67JM4KCzRsoSQPsVtCNNcEODQRMXqx6DK1tYUvf
ymCAmXUqqqVXARyDh954uBqTfRSASsqPsVAxtwmVA7rceEcIfrQqQWxleGFuZGVy
IExlaWRpbmdlciA8bmV0Y2hpbGRARnJlZUJTRC5vcmc+iF8EExECABcFAjxZg2YF
CwcKAwQDFQMCAxYCAQIXgAASCRDGBDxWcgdxNwdlR1BHAAEBQuIAnRn2yTAmJACp
PB9Nc1WjeQpipeDAAJ900VXCYeRbwhfldpGMbiGlkj4Ly4hGBBARAgAGBQI8WYOm
AAoJEHninGCwBj/nkIMAoLd0ACBW+D47AAGAHLvbnoVOUcysAJ48WGg7PqFVvxq5
66+s+xtIsYOK1YhGBBARAgAGBQI8WsZXAAoJEPSMqBtpqFhziTsAn1jBAxq4biI6
ZMO9tPDjXdgGWCu9AKDW3KmsBTCEZomtitZtbKTPiun6M4hGBBMRAgAGBQI/jTT0
AAoJEGx2F4yg7ZgtPz0AoMP+vntzMwK6UNZiXNqnicGBn1fRAJ9gslYqStRTXgv0
GytGmbrqAvKUt4hGBBMRAgAGBQJCNujQAAoJELNT4Gpva4J6gesAnjrWpLWWUFF/
Yt4GUP7Dd2dCqTNyAJ9St58kCHv3XQPIOWScicMrGTebBYhGBBMRAgAGBQJCOoAp
AAoJEOMv2scF+1/ZKEcAoKssBpCFMaSAq5VWLCO4ggxb6WodAKCv2hiiV3dHswxe
I/l25PCDATjTSIhGBBARAgAGBQJDpJAeAAoJEIXUUEVraRsDpIcAnR2iRPpS1w3i
SCqV5/5+jJx5SyjtAJ46/73g9swXtLEIUgl7z+RGg1/IQ4kBIgQQAQIADAUCQ7Gf
MwUDABJ1AAAKCRCXELibyletfH57CACMkpmNhmUxfx9Bp9ifKhvZ12ZOvv0wYlBD
3XJsXEq4aHJ+Bq2GmQLyEFX8ryV0HwSl1UfDEVsJ7IRjds66Wmo218eZp33tHMbq
02QvrroY6nbaPHXpydhAaHmY0iZcFtUJXRa9VqiAUwTVlKbUkAL0r87RBTxhIzDq
xaNZC+MTxUJphyDQYnJ8OvOuHeeMRhLrwQZJEevtb8JR5CzyrjoIn351ff86hz7R
PsThwMXTMqT9T2w98GhuP5UYRp1bFNCbAlWJwgNiLKd+6AXdyQIOouCzY5tnD1wf
vPB1v+wTi6KnU6E2VsQ8yggFcPaPovO3uKkRRAkATgN/meGtDBYhiEYEEBECAAYF
AkY8hosACgkQ524iJyD+6d0B/QCePfnQ95VTfwRpSMHu0GxbWi5ZUlgAnjwAONqq
L+iionCmk3WCHjeFvv9WiGsEEBECACsFAkY/XkwFgwHihQAeGmh0dHA6Ly93d3cu
Y2FjZXJ0Lm9yZy9jcHMucGhwAAoJENK7DQFl0P1Y5VYAnAjxx4bU+zNPpIRO4QiD
gpYZ69ruAJ4gdxhkupzsuLeXEdoZjngqbtDf3YhGBBARAgAGBQJGSaS/AAoJEI2O
PuD3c7zgVlEAn1nKfTF8E16RhQM1cqV3YU1odL9zAJ96gPRqe2GHv8yEQLtJfTsz
NkXcndH/AABM6f8AAEzkARAAAQEAAAAAAAAAAAAAAAD/2P/gABBKRklGAAEBAQBI
AEgAAP/bAEMAAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEB
AQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAf/bAEMBAQEBAQEBAQEBAQEBAQEBAQEB
AQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAf/A
ABEIALkAjAMBIgACEQEDEQH/xAAfAAAABwEBAQEBAAAAAAAAAAAEBQYHCAkKAwEL
AgD/xABLEAACAQMDAwMCAwUDCAUMAwABAgMEBREGEiEHEzEAIkEIUQkUMhUjQmFx
CjOBFiRykaGxssFSc4KSwiU0NzhDYnZ3g6KztdHh8P/EABwBAAEFAQEBAAAAAAAA
AAAAAAUCAwQGBwEIAP/EADcRAQACAQQABQQBAgQGAQUAAAECEQMEEiExAAUiQVEG
EzJhcRSBByNCkRZSYnKx0SUzQ6HB8f/aAAwDAQACEQMRAD8AudOkYzMI5aZJpe40
/tQhcbYwjuCCTtKCNQxGQxPaVNpUxh0ky7N9PG8skXtRQSu6Nmd1JCbxHlTtHIwm
5fcMF6FoVV2UwzSztnswxxBnSneSCPuzErGsJaobYr1E3ILSHAU4MaSyRpTgyrI8
0oqFkkkLLGzxTGn7UWNoCRkEKOC7KZZCTIVNuNWxijVIyvZVHppsJR3K/LKle9vi
JkxG7gf3XN0891x+q7G658MnHpYSzlGpnEaxTEsyRpmXLxw7ZC/tR07sjP7yEMBA
LyKvrpFoxZjMvajAhiijLPB3k3xBUO8qMAr3VZIo3b+8DPwpy/tHphpHMk6xqoq4
JVUYlqMCKdJTEpAjj7QMcMYLAJI8s5G8necQ6b708ZWnKQPuZoi0fKQrMMhEZRmo
yrIzlhGEUsucekQ1OSX8LZe5uvZoKBBGwLFL5GJYoC9NCLx+v7r31fTyDXhjP2XP
HRyKkbLBGZVVW2xPOYA6iQuAiqGkxhs4V4QVX+L0n59Ffm3E8VOpqJ4BMixROYyF
YFXZ1RmKsskSq8rqZizMSWwBJtdNo1HI7UW9ljnaGKRUnZngkkWN2V9sSKZT3IUZ
v7mWLuOzHaRVNo9pIpRUmplYzIspR1jVikcS9mNFCYghl3hdwgDlWZlKgFvnVzJS
YyKK3V+K2LfpksaBBLCubSM2/tQYVLlsq3dw1wHX9796otYw/rOnISNSkZOQHPYp
g27tqm4tsIkZmxtLM21EbIHtwqdrOnMafu0pwFRpQ+6EH99uQFTEqt3G7jPv2l2M
jKhGVYibcmk4IIzGsTDYuFRpNw2JMJA/bpnMsnHajUOyF5UeJRtXcG06hX/SfTWy
VV31RcEtlJTU0lVMEVpAkh2NGaqRcRU6NK8FKJ5ZY6VKqWOJp3Z0Lpl5rLHE9VVt
LtfaLsoIp81zRV9WINJCbRC2zivgteN1/A+yq+9RLqum7RxSVD00ib6p0DSZSMIv
by6CVT7ifbtSNsnCjYWB9FUnT9hGk3ZITYXUtG+VVgGYsWC/wpkZVUGWz7uUqO+r
/wDG5tvSjqRr7SHTyi01ddP6YrKOLT90gmlqK7UVDtRJq818jtTUjft6yX6yz0a2
2SaKne31C1ErVskVJXh1S/tD3UnVGjn0zo/QFt07WVUVrlrLzVz1ZuLV0eoDdrvT
UtZQV0LQWye3LBZKbtwxVkdIKiXvmSeNqdrH53llzj0+fLE4JxIkZXXrMjkrbIbG
VyEDhE8Pvkk5EZO2JIWljZEoZMQe/wC3v3340yvoaRpDsizv5dhk4wuAgYpsULsy
VUsE5JO5uSWt0XPjYYmGTMf3b5Kxxhsl2OCzOOAFwcsSuSPWdP6Ufxtq6k1hbW62
zVV103pzpNNbaZqu6VB/yg1abfRvJLdYHaOkFRX3xYqenqqanc2azrVvsqe88R0s
9H+vnR3rbS6Ph01qK1X26ars1urFm09T1U2mqSqnsK3m5UKaglo4KGrqqYx1NPNT
0k1TWJLBtq6SlaRQ70PqEiRhnjPDKbwSCRKCQbtidKjGJJDme1YvhjN5Hlxy4SQR
FYNhTSd90FWFDRxfhrajSSq7f5ucx8EYVQWdNzBmyO4UXG7cG2kjyceiifSpUndC
0e1faCpdtxLAsf4QoAwqjDYz8nmedb0v7mQq7x+8IdEjQJj9ZTcvb9ykZYKZCpVF
zkH0kq/pm6hjHGoEhXtqUZi4BdS7Bl3YXOS2QGBY5HySh5riyJF+2yaAYx/JTrcd
gFu4NqG20PEN0WSPTLih4Wmg6K4Ra4+effxByo03uWXeoEe5iCFwxK4UE4wAc4Cj
zjgAcH0QT2OXnZGApwWyADgA43bs4baPdnkDGByFMybl0+njDHYfb+gEAKBkYO33
HCht7ZJwMAYPPpDVmhpUEm6Jsr3CAwOCGHDt7ScEJkKCWIJ559Llq8cW7vr1ldbu
Tcicewx7EuLacjgnQPNP7s4q3rkrv9VfiKc9lYAr2iQzA7AGIJwMbiU2DjnORgc+
0+AEliYtlY1AIHkc/bzsfPA85H9B6klU6QdGK9rPkAhcFiP1E/Y5bA3cAbuSRn0S
SaWm3e2nEnAyx2pz9gCP0/Y//wAZ9Ijnxyblb7bdsZFFeoNgn7DipH68OkUoRjba
pxzX76rrkePFuFBSI6xSR0wTuNHPGrZBdZ4nmgMzMHJZI5BJ2vdsZo0b+JQbC1xt
GCm0syqgZQA6K5Z5WjkDBlJaUuxLIP0tyFwDQUZjaGNI8tuWEJuySowh3Zbakcab
QWbGNhjU8j0aU9H21dYFXcy08ERK7VXau3YADiJVXDzMYzI7FIlYlGQAJSipG/TT
GkropCqLjfsDEfbhTadvTKubt5T8l5rjl/fdeOH7NpqejmMksMceyfuu5LFUcFpi
XfcUiQMqIWHPGNxxg3jtqRqkPEchRIaeBk2SMgiSJRtO11YqVQZO4b/1AsSDB6FW
UQtuMJDZ2grvdctExZyAu1Ymbn3911UYcYKioaQ1FRHOwywZahpZA88n7mR1VAzB
Sf71mzvyXwC21PdxybdpGVHXsCFF8IPHwlpa1b4jyE3K+981zz/5puz/AN+Cb9lN
T0zGNGeXKxxxjLoZpAI44lVUY7AfIUlj+tcsAPRpBYZFV45RxJO+1V2ozCdYHDTq
2X7js392SFjUgPIGBX0phTSSGmRY1MpeREi3CKNf3EtPFUTFAxjiiJinIAZtoZRu
ZgkhybfTLNGpLrTJPR9wJ7GakglV+1FGDuTvIHjlklfcndGCxUN6jZMiqbh27U54
4JVzXfV9vIUtUgGo9i+/b7fq/wB1ffQ8+GrvsNJabTdLpWNQ0dBZrXVXGomqJxSU
35alhlqKmSpq1QinpxEk880xLsqjuOrqCvrDl+LP+LR/lX1KuNj6DGlq9O1ulNR9
PdVobnXS2W+UFXHE1PWhaWSin/bNlvMdPdLPcIJKWJBALdX0dzoJJYTtp+qu+3Pp
59NnXnXFgRFvuk+levb/AGVpoYmjpK2h07VzrVTJNIYgKVoVqV7xYsqRRkEuU9fO
l+lD6UL79aPVDW/VHqNXVzWRtRGtuNTGsAnu1yrq55qmMExCI9qmMj5dSo7tPu7m
GJE6zUafSw/qNbKtPh5lAUZ5JS24xavh3u2KN05OFj4tf0n5Jn881jpdNEnnlIjF
mVGMdrKcpFiFB6kb/EOqp8p9K6s1lJV3HEtfJCndqJJZt8yxb0Uyy7maVIleRfcU
Cu5OGLZHoprtEV9ulYziNVQqUydw7qsS0aHbh2QgK5I7eQQGbnG2K1/hcdA7RYXu
VJpGZSbc9HUMtbPIJlnG1XeOd5EaaPcJI5EjQiVAckRooiffPw4ugGma6pmey1Nx
EayIlLca6VooOS+2OKIQqoUgBhl1Y5YBTnIr/jjRwuMcU5QsYkdiohcds5xhUtrx
xKJJZRMm0lr0f8KddkIxx6jSkivuy3ZHZk3HAEGbXfL/ANq+Mn9TaKwZkSKRAF7b
Y5LjbyY1CrsiL7UwQ52e5izHIsn+gn8QnVX016/tlRrm8X7UGldMWSsTSFk/OXNY
4dQR1S1FLEae3iRbitwpZ7la4oLtT1tLHJVW4TGO3UkkJmV1b+lPpvAtVRWixQW6
lRJI4BCNssQH6X7h3MZAeVZuSTkgceqe+tfSqPQV/mgppmCxnu0rFissag5QgjBy
MhwQ2d2T8cTPL/qDyvz2Dp6ljyTgfbJkPuxkA74s45EmMilkKNbrqJWPqL6L13kO
NzTni1OMYxyONmAvMo1IjfRaVz/p4ZH0zfoC6zVX1TdCdPa51DSxWnWbRLPqPSiS
Wz87piOrimqrTaqqhtNZcXoX/Zy0Rlju1ze4ukoqaqmoFqoKCCZlZoGMxqJETAQl
QeTtwYkbCgR4cBmEYLZKAtLnn1jx/srn1JXKXrH1D+mrUN7H5O76NrtU6aoGNPHV
3Cqtk4kuUUUv5ISziOJ4JZO5WtUBd2xJYTI0O5N7PujqXmwMsRAxClFYwKFhiCFn
ZkyVeTLEy7mG0KMS8DlwuTHknucGWeNmXWSIRlCfqBKjKMUUSZKJxFZZdrsRizSI
hGE4wnEqtpJ2seDpYy67E5vqHF06exYkPZ4XId3BLEgHftWPcAFGzAz7icfBPpv7
h02R5GPYVd7QxuxQFo4pcF2baDt9mcAkMEU+GODN+sssCiUKgQvIqAsB3HUyqXwi
szBEDLtTcA8oKEqAGdPvp2NgWeEMsCRMfGXlkEpVQMBS5WIptHKg5LMQAFS1OZl6
ZUrF/JV5vlpeb3dBKPK36vEaLHjcXbXsFUPR3dV2/Fe3iv6t6Ye+RVpsR7twcnkh
yA3tIyz7AAoGfccAszEKkpum2+QssEYBA8rgcDHtAYAKPA4HjwPVgFTpmCQt7T+7
y8jPtJZKaRYygDNkg4fkFVEYLYzt9Jas0tT90MY2JZFOI4kKpyQEySOVAxxkYxgn
0+a+eOuSXRSwDnbabirKI8lo1uefHTHBbov9d813Se/76p6eBVopnemp5DGFaWGc
ZYxDYn5icSglU3PPJJkl235bJVlhVAVLTRdnbBBEC7Sxxow9zD92oaR3c5Puidm4
RV2DbwCQFoqNFAVihd/zH7oBeEjEwiRVkDZIwruxKgqxLlVwqqGipm3tFGgRDIJH
nUqAd8cCSqjAhpCEDRhlJ2nftAAJaTJo2xfUXXphJFI3SqNcMmTQ+9HpfaZc/wAv
dXwnxzx0crfv30hhYSiFRJUGE/v5JXXClwxj+M8LHsCKHZvYWKlyWVdNFIiKEQ5b
ZCdxLLuyFkIjGWIQq7KC+AG5fgkAZkMMSmNgjGRG8MQ7yOo2kAHnau1do9oCkYb3
elAtNskO+Z1KOI22oiHeZfB3KWUv/dhNwIBLPuO0hgkxj3dgf6QbmWU9NDF693/m
uPMvjg6eviuaoKVsv/ZefAmNFSSONVONkjNglS8wVFjBbcVLRpuk2BHO4jGz3N6O
IYGdg4p4o1kAO6Q722lmYEqYwzODIBtPbCEvH7VQn0Gp4og8TZnITvlyB20fgDB9
gZ8BgwwACEYFQA3pR0NO0siGQOwQllD/AKfcvbjXb7VbJ3MXdjjCgRl1YlHc7ssS
Ne9pHnkuLY3T6ktrlUUEP1Qn/wDDv2Oer7fDDfUzo2fXf069fNK29DLV6p6V9QbL
RhE93dqdL3GPhS0Q3yVO1tqNE8m6MuzIkatkK/DJ0/S2f6f7Wi0y0tXXan1XJWns
hJDNTXaehPd4BZkFMkfOAMY8Aj1uQFuhrIJlkiSSjdpo5GkfajJIm+VQrAI2935I
BUEluZFwuFjrnfeo30sXLXegdJ6h0L0v0dpnqV1YQ6w1FbZL7W181X1J1W9msllt
FMRBFLFZxS1TSSEy1BqIEp4XRXPqm/WmOUtHpoGbYz1JGSmWkIzQjCMWUp5GRCok
pNkQBR1//BrU49N57rpZMU8m3QuSEIMItmXFFueWePFCO2V7sk4Rq7VrxbRd7tWU
Vpip4/zP5SRYgzwthC7bU920EIS3KqTkecZPqLvUu108EMtbWqyyVgkYRSNg/AGG
IBzxufg8v/CPFd/0n/WlrbqtrKq0Zq7Xtl1XHFOTT6itOm7tp6J6WKoSEftCmqqe
OjRO88MQqfaiySRo7BpFyxv1g/Ujr263+o0VorUt0tdfU3Q0SXSlpZjWiNN8bw06
1EKmn4wTIY9y4UKPh8zlHL/V/wBK4J45wImTMxzRhii44y+7kjkhDKBFSmDIl3Hk
v03DW6X+gPMcKTx5ZenBjyYJZcuVltMJPFlniZSbkMMlbSzg8OR1dpNslXUYjEOG
JKuPby3tbhvOSQRyCQCT6pX+rvQd3NwpNT0tLLPZamJInq4w0kUM/JCTMFIiZlGE
LDBGOc8enovq3iw3tqXUzdeam/0lRDFW6unutZUWU1JC5kpaL8tJQ3Ggj3fvZAks
EkRba7cL6f8Avdvg1j0j1PQv+Vu6y2qppcrFJS1UtVTU5q1ulNSfl9rwiURpmGRG
aoZ+yhjR2Q95cPk2o02rx5TLjlkjHLGUXHHZlvc45Rm71WxyO+XW0Eug+ezh9QaL
VabLicOXZky4TC5Ms90GgyXhxoDcZsSWNesqieHg/ss+nVuH4m71M1JJUGydBup1
xSZQ5/Z7Gq0xQPUmPekc2YKyemVKhJYQ86yBRIkZH0hKigTvSZQodxkjQlAIomRp
JJZn27WkdEEMccUeQ8oAAC59fP3/ALM+bD0Q+uOTUnU6KtslN1v6b3zpH047I3rU
atud2tGoqeK77GElFSV0WmnpaCV0lR7jUUyTRIhMifQtNBM8jRAbJFE3caMntwLC
UWGIuw3M7OacsF2L7/e4C86Zi8wwa2eT+nnDIQkYpmNJEMkSEWJVx/J95S23IeYe
PM31J5XrfLtZgNZp8uA1Glx6jTOWE4Rz6dnOMMsGZcoqSjdDZaF14bOote6paTDJ
uV13kEO28gBE3rIyyltpbbtYBCCcuGBLU207QrxA9oKPcQsay7aqR3YknfKrRhIj
xt7kxbhsFz6yiCsuGbb+py53SAZ4YjBI5O7AYke1cljgJ2opmIYIp5YKxZQoXKls
MW4DFEb+7J/9oQDuyZVbYu6TcgeO+CFG1V4PjpXpKK2d/r56/nni6uv34a+ptTMI
w4wojMYjJ29yNAQkSoEcLz2pGI59uHPJHona1RREKBAParfv1aRySoJww/hBygBA
IKnPp1pKNd4YAhTs/eFcARsezM4BwuAkryHyu6LJc4A9EElDCSvdGCF9qqGfahZm
UMy8Fvdk555GfTcClLip3vjuKu+Wo+/bV3ZyvDloWD3Vnb18vXzX8+54Z6204hbY
Tuk/Q8kgy2ws2HkZio/zlFQiNQsYYIp3jB9H9EjGp7bMilTLLJk4PZIdIixxjDu0
ZVfb7t5O9YiACt4jSSVmDOu2fEjOu6Ry8ZQiPaB+7SOQo4JCqc7mYgg+pI5CaKmk
YMZFrJq6eRlVGVamoqo4pTIu8otIJFSNQinYsSlOAZzJ97qRRX80FX883fAtdJ4l
J1+67/s/Hse3fI8c+DOnpSn5aPgFp5Gwg9747ky5kJAUGPe7vt4bCIQFUejWGl7n
bDqFDNHUO28MV2MrLGmc4fcTmVj8OQQwjHoCJ0VYqsYnUB1pnxl5MplnBVAC4kPa
GxDhAzo4IC+jyGJVkYyzQl12oCHzFBvCuYz+8ZZJVk9m8459qKCxyneSpBY8+/pI
tKj7tDQUvCoNjMot8nJ+v2Ff/k9jrrwNo4FdWZ+cllwDtAJG3t8MzZ8ByxTc3ARQ
y5U9tggcJIgJcRogU+5FZI2WEHtgZKJKS+wsEMih2BUbSmnUGmMYZHeWWWeNSi9q
JD2yqlRvZyYYRJMzhAz7uFAHpaW2m7NPNL7pZJahJO2duXghiAWL3JkQxvIJDyol
dwCEVUAVzcfTcRO4xVpFtHu3hvi6pUpmqi3/ALX/ANttHt2L2/PzyrrXS3CzXGiq
nr0o6qlqIpp6KsrLfWdgiZJDSVdBUQ1lJOCG7c9JPFPGCjxSCQq3rIV9V30z1Fl6
x60sN+oz2rXrfU9ztDy29NS/+Tr9qKuu1JW7a2GoqIbotprIaear7dSKunCuXedp
R62NxQyiA9yQb1V5MDLAHD7QVVQo3FMLgr7VJUbgCKRPxGNMy2nqfYdR/k56ekvG
i6MSV0iRiK4XG1T1CVCRdsko8NJNQrhyXaNo3VnjZXNH/wAQMBPyqGrhCTLR5d04
Hp/y5sSVyOYbZfb2Sf8AqN4y41//AAV12HB9Uug1EISxeY4WO9QnHJp/82MYXTKM
4Syb4xbkxg/gSujrSPSLTWjrtWX61xVNwvjUs1VVz11qqrYKSCOmmgp4YaeOmt9E
IqiWpeQrHTygJSsXCSFHapzqrZYZes1fd77UikQ3WMVJQulIiJUk08jyCMtBlZOx
PIhCldrSBtisk7PqZ67XGwVstq0bfr/NqT81Uftq36dp6GsjjpZKRqWmp60yqakL
TyyJL26aWB5ZDLG2/dgUx60vnWmtuBu12td9qbDfJHqakXak/KVkoppMyrDTz7Km
BWdMjE0izBWQIQu31m/kkpzw7JRx6Vnjk7tRnx/cyGQ9MQmR5IYrHI3ZUaSL49Se
dZdBHGxMeXVRxZ45cn9Linlx4pwMcCTsJEYwlthJiJEjLduXa2PdQtF2GoslHcWt
tQ9VNArCpa7S3OA08iqq9qFpTCNwO4P22KodyrkAqmdE6Ygp5Iu1BGIaipjj7GS0
YR8h0CshVlKn9JHtVtoHO4IvoxrSm1Zo1rM8tyeOgpP3Irz3HgVCyyQJKwDmKJ0e
JFf3JtZCx2nMrOiPTu79SdXaS0HYpo4r3qe/0Vgtk80DzR09ZdqoUFDUyRR4kkii
mnjmlRGLsqhQ2CPQ/EOLJLTShWbDqI4yt8o7ZSK+27p2yAuNtTJcRt8BPONbpZaa
OoxMI48mn3zyJyRjGV/c4g1AZPMC653Xfh8fwjvp/wBT9bfr501V21JKbRvRTWNV
1blvNJQtSUf7M069Tb7PbYlMS00hfUNTarcXiH7yk/MSFXZD63oLCFXKuVjA2t3V
Z5ZJV2SO7nazsZZEBJDBSSU2gYC1jfhqfh5V/wBEGltWVGt9UWHWvUfWddaEuV10
5bp6K1WixW1nqaK0U89wjFfUmasqJrlcyY6anMnahTurTrPLadIpXYAm8sq7z4Hs
IeSQs/CgRrIccsS0RwpyBrv03op6DR/58Pt58spZJwtWFVCMHa8qR3zoPWyi8ka8
wf4l/UWD6i88xGhzR1Hl3lejw6DRZoRlGGcLzZ83+bjhkd+fJOEd8S4QjKHEuUXW
Uxkd2IilDtunYAJtREimcKvJ2gl1+MjtqudpHoqqaUtMqiBVZSxcOY3Ykrh96oMR
A9thEgyyq+3hXY+lhLBuL+z920wiMhYuziPlwqICqpJEqlWyeFUEYCqxe0KM+1FB
GY5pWcFnG5UGwAe2MvGg4flT/Amc+rPu3N81Z7rdHxtJe3HfN8+M3qr6Xs46/H4e
jpqyq6fCFqaM7gjRksFLMVXZH2s9uQ7mzlVlcgOV3OZECA+QQtQqjN+8MYY7gpqD
GSAAgbajL52cEgMR/LHpwp4s5yhHcUuFjZ/cqhZyrNglo4pYyBnCu/uRZGcYJZ6J
y4J7cZZFcoyxyMhfL7WYkksAwDDPByDz6VCIqSGRZ+dH4kKVSNrfFtcPCc+FLRd1
z/5r4vqvb/14ihQNL2UbvR47phDEqoqHaIRTdtQGdmZHyOSR2yBtJwyiFPLKwRmh
2tRrGpkULEHkmpYpQwyqtIImn2ptchgGIOAPSXt8kkQicHAhhkePGz2PKRsAIG0M
+xm2q3nYo5T0cQyTM+8uyOaekMAWQYRmDtLKFXOJWM6O3sLK8cahtyMPUjIG/pSQ
r3VpYNXKr/1S/mr8S2x449T7HyPF10HfXPx2tKczswCp35KSQwRZdYooomIRZXWI
MAoUPUyEA5aOZBhsj0oKWILTNGrl+2zBpIht7splzM4eQeO4WjTH6VVlBwrEpKmZ
aM1hUn8kn5WlowC4eeWBp/zMsjSe5tu0xYPcLSbyuN77lFTyrFRhtrZlqjlfcS0R
ZpZjuyoQbcxmRyAisxG5wF9cibYm799oxTgoQG5S2rubB49O5Y7y1/HZzfHCdd8t
cX+68KeiWZ/dGWiikCq8hXMkqiRUKxlz+4jdTLGGEedp3AZwxWVApZEBkcKrAuoA
DSqzIHADSF2jjjhVVkIUEK+3HhW8gqCQ7qcinWnYnuZUinkjmNOiIpZUOY5ZTuG6
F9jgtIAq1pJ3j7ssu/twuU7UUYJmkVe624mItud1mTJYbol3LsQb35LaHum6KvMe
Laeo+kY/6eeeRDw2Dx13R1XtR/D+/c4PCxp2yvCrudJak+1B7I1WD8w8jKzE1BRU
UoudqEqBk4hn9dHRufqV0PuNdZaVq3VOhEGp6anRRNV1tFHRSxXmhjQBjvmt0SSU
0Ct3HltkUaosjkGYsCSCneeeV42lnaBkTBX8pTSoise4oDb1ieVcntoJOM/xDleG
okaR9sUU6vKoYqEEc8RkDyNJhXAVyy5Uq29GUcn1B8w0mHX6fVaXPHdiz48mFiIb
SQDOMZVTGSZIfltltC6vwQ8r8w1HlGv0fmOkmx1Gjz4tRjeUZY0WEuvROO7HPq4y
kf6vGBes6M6MuV56i6wp6rUBv1xvb1IoaStmiiEccHdjp2pDMEKSTTTGOo7asjKo
ct2w3qv2/aJtGrb9crNdtJ6sojSzSzNJerjJLNWPHuWNEllqZ8ouBGwjUOi+MfN3
v4hVBS/Tj9SHU/VGnrBv6cXeulr5qKzU81SbPWFZt9ZTwRmQi0V9wjrgTFiKhqEK
RolJt7VBvU76wdKXa4LV2xPy9bba0ikpo27k4gmYrMsiLGj1EjM74LgyRlN3IYZw
jB5fq9LkzYMGSeolgy5dP96EJEsUoyccZbyVsZ11uuEJXEjKXr9q+X/XP/wuD0Yt
Dj1unhqZ4ckNLKWeGphDImPNkxSyRlEUk45xfukogeqlULrp3Q9xXTmn6KC2J+w6
eGemiVEMTpVPKzqoAlZ5nlf8xLI5MzsG8rzaD+GjrfS9v+rDoDUX4NU0K66tf52a
Jo1itwqO9TUFxrpJAUjpYLtLQyzOVYlULIAxA9UYaPj1V1P1JVX2SOS1wV0scUdR
MjM8VFE5YMUO1jJM7tK6FlO0IGOVJ9Wb9KHsPSazrUwVYiqI0WprbxUVCx1Urwjc
shnG0QxxMCYo4yiw4BVd2WLhpXR59Oxlvz48uPJOpEvu5yUJsCXJO30u0chZC2zb
RfN/NcWu0uqwz3Rnq8WfFiI7o/axZoygTyDSSIz3wjwsgvabt30fUUxgts3CTYQi
DdhwGVNzMzFmA2glsksThfv3eMjIKl3CozbmIXYr+1SVwBkA7gvBwVJZcA4bvwJv
xz6y1/UbrX6H/qs6r3nWeguoXU640f009XteahrL9XaevdZdpoaHphfdS3epnrKn
T+og1NDo+43Gqm/Zd6RbMZXobxQi3bkw5kMi4BXfEj5IKKGCM6qcAybUJy2AoZs+
7BxtGHftxsxhOUIZCPrajOO8QlGD+KCyIsZWSBFPM+r0stJmniZbyMpRMgVGW1po
5RJCI/p6fBa8KtKshkMj+514ARe5Cy7lA9vIkDbycgovgBz6CiAjZEO0FChiM7in
dLSOZW5XczcHJ3SPuCrjycZIU4jBJV4Y1bBZ+1lMAAcB1QbTkhsnjG3dy2e18Rj9
cZduAGCkYI8KEiXJ4HxgAl2Im4zixq5Fje6uOO/72Ld83w+B8zl+Pb+wf7V7f2rv
wmpaRgWaRc5WOOPtqDhVVjKoXc2ZJgNoyu1SB7NpOSKWnmeRiO+ecfu41IBHke1M
ZB8AeFwPS1eJC3bVMhAzAgsVEkJVQD8ARphNoIwwyQW59EToMjLvyoYCIAKu4biv
6jypJXn4AAGMen+mlbPkbr0e5Gniiu2uAPDdfxfp5b9+u0pvvnn9+IDUlVRvBC6M
ChUTIUCuPYxZO3uB3MFOYwMnABJ25BU1uqIVLzsO20URKE4dgzu7Ju5ILbmxgg43
7QvgemsFdBT0EaJ3BEshjRRt42x09IoADe1DDTQqm45MRLtjexJzT3SBIlTexLiJ
u0g97MWYh84zgxRoplOVjj3sMkFhIdvKyBuuAN1kQf1IeNv5cy+CPghKDwN9vx/K
X8f2q66rw4ArFkqKVAZJKj95MquU7dNErxlmYsd7TzOyR7Y1VmFQ7EogLBWwVUIE
HcnUiKJ1ipY1BWSYxieMPksZH/dyqq8ksfOMD00FJcY1lYK0RZ3cF4y2cSvB35AS
FZWkihjIOR+lBuBY+l3SVtPSq8hlHejj3YVtxwsILAHYNojOwOy4aQjbnbwUSK7d
3qOW1KS2hiXfbKnd/c8MyOQ5ODo7sq+em329r+FFTqLWmktBaZuOrdcagsuldMWS
hqrhfNRaguNJaLJa7fTxmaWpuVxrpoKSljUR4aSWZFZ8KuWKD1VB1a/tAX4ZnReh
1GB1sfqlf7YC9HYumWlr3qRLtUzK7mOgv89JQ6XZlkpqdJama+RwxiRNhZVK+sy/
9pI+vzV3Un6jI/o20jf6u39Kuh1Ja67XVuoKxoqfV/Um7W9LiBdxCy/m6PTVtraS
ko6SYvHHcpbnKY94hdMu9yuUz9sF/dMxwSTn3YxjgADnwc+BjjgOGlyZ4xlLOafH
uE2xhLIhtLJT3YyUldt4pNXOVUDK02kxsIyy8s43GO6o0JVo3Hd/Jw8LfGwz6jv7
Wn1lvUtbZ/pg6BaL0NQtG9PTao6r3Cs1rfpUZi/5hbDZprFZaGYMXKRTVt5hSNli
O9UOaWtb/il/iM/Wr1R0pp7qP9VvVKmo9X6ssGm6bTWhb/L0z0fSrfbrR2pImtGh
2sFNUU0H5gb2uRqpO0h7szKMin+JjJLzKxIbcWxg4U+PnPzwDk5Bzk59O30iv81g
6laDrYI6iorG1NQ01HDTbRMKqrL0tLJCSVwaapniqAxHs7e8EEA+k5tDh0+DNlMZ
mnHFPJGGacs3rC6GTKMCUWNSjHERVisEj4L6DFg+/ggQjCMs2OEpETiEpQjJ912i
8d8DTz41+9cPxAfpR6h65TRWldXVdbaukukf2TqfXl9t7RaK1HR0ctPbRaNP1lfU
petXXLvmWspqq2WmsoqhY6p46xxOjSq1/o8+jPWeirb1BorFpzXUWrLdBeqbUtnq
Km10LpUAusVuht1XBJB2n3w1Qqi9StTHJHPFCYzCmWvVxh0JElp1A1NWXCgEtEd7
lO6aWMK+YlH5jbUjaYiVRN7MoY5PqxP8Nrr31MqtJdWNH3mllfpVpK3x6wtt8lIp
qbTkz1C016ot00u6WmuMRS5zCAFaSroq6aQBq129YJ5l5NPUQy6/S5ckds4M80Mm
XFHLOeWONcUXZKS5u4KEYSSNyJsvV3n3lOl+n/I/LDH5x/USzYdPqMXl+fS4PvQw
anBHUpkyxZSgRxyJ48YyJeqUmPRNTXnTron0rsl0vFDQ/wCTthtENRPJNPc5jDEk
AJYmSpkY7Rg4ycsFIHkAZ7/qe+rq+9SbjctK6Hrquz6Cgllpu7BI0dbfUUlO7PKp
DxUTYzHChQyId0pIbt+nD+vP60KjrTfJun+g6+WLp3Z6hkq66B3T/Kevjcq83s82
2JgTTKTioYGYjYUzWbu85J+Bj4yfAyV4wRxkcnHjPOj/AEb9J5NJp4eY+bOTLqpp
LTYMsnIYI1uMmSM8iffk2dXiCJW69nnz6h88+/llp9Gxhgi7cmWDTlbqUIJGiItt
czHgTs5s1fV0VbT11HUz0lZRVENTSVFPLJDUQVNPIJoKiGaMh4poZVWSOWNw6sod
CDz62zfhRf2pHW+n75pHoh+IpNRaj6ftT2vTtj+oizWaaLVWlDSUyW6nqupVmtgn
TVtvqlij/P6ktVDTX6jmeStrqO8iWaelxA08+MiJe4xbG84EceODyPLgnBUD245K
8j0p6GrWmjUHLkZ9/wAe7LcDbwACQR/0c85ORd9XpIZyK+jJEPtZILFgr7xEhKM5
EYkZbzitskFqTsylZCMotCIXudp6Wt0aabK9hsUft89P+pWheq2jbBr/AKZ6v07r
vROpKOGt07qzS94or1ZLxRPCjJV0NzoJ56eoU7mjlZXLRz7opdrRNhXNO0oIAPbc
pvC8KHyruu5s4CI0bBgF43H9W7HyC/oR/Fo+sn8POru0P09dSTBpC+Sd+8dN9Z0S
as0DWVjAK1zgsNfJH+ybq0aiOe42KrtlbVR7Eq5p1iiVNhP4bn9qT6M9dLjRdLfr
isFi6Aayr5Ejt/VqzVVfUdILtM4gSSn1BSV0lbeNDVMojLQVVTW3awOe6Ku5WoNE
sg7JHPpY/wCbFljGR93GO3bHZbKElyYqXkDJ9vlnkKlIF5fLpiuKRkP+XrJ17cbZ
naMH1cBE9tbr97uMAA+5hsIzsWMLmWNQx3FpmkKKdwGN0smQcKDWUKWR3kj7ZVEV
JERQixpjwDvbOdzkks2fGMBP6c1Zp/XNhserNJ3m2ai07qS3U93sF8sVbS3O0XS2
VUSzUNZa6yjllpqqiraeVJYamF3idWRw4UejuNagmTswBwH2uXdc9xUQMFJdQVwA
QVG3kjyD6XjlGSTguSMvxpjzGW2Q9I2In8csqKFtxW6ESxFbs4eR74qror9eKnxc
4A0P7jYzIxjjlfuNHGjtEWmRSVjAVO0igku3kMw9HCX6jjhPaqDLVzhAcbgqqq/5
0yFlwsAJWJGJP6xtGX5QpqY3aQ7lXuPvaULhQm6R4Y4QCTuVWAZiDu/UB7hjhUXR
e60Y7YTYqs2cARYYtHkKu1SURSo5O0+Tz6KRxjR6o+l6jTzR6iIDK+2mypfi0FMh
0odh2+3PFnsvzzfPfhybZUxvxK6yQe6ZV4be7TAsjMGBcNJ3GkJ/hKqBt5MIvxHv
r30x9Cf066h6j10qVOvtTPVaY6VabLp3brrCshnqI7hPES5/Y9lRhc7tI429lIaN
R36uBfUl31BClP2odgCLsBPIaQksWIU5xhcKoxwAOD4wi/j0/VHdetP1l3jpxSXO
on0d0ItdLo6z0PeJpf8AKKsp4btqy5mJGZFqpq6ogtkh5aOG2Qxbvac/OByZIwSR
GTc9tfjQsYpH0sqAWJ+Ueb7TjjulGPfJ2XwJVhf6+fZr28U+9Y+p2r+rHUnW3UvX
t8rNRay1tqCrv2ob3XNuqbjc66WSeeeTaFVFy+2ONVWOGNVijVY1VQ11xmO6mx4H
aJHIwSeQT9uQc4Pn4wfXCvrO8wO4FmkBbJJywVR/UgAbuR8854xwrZd4pWO3OEHH
3B2nI/oM4AHIxzg+iMIRjxGOQpdterbSFbW5U1EFaqPVIeJ3VBXX40V1e3qirK9q
jZ4MaU+T4yccgHGG/wBmMBRjnI+/Hp9fpymsiddNDV2o45p7Rp/9qagqKWnAMtZV
UFuqWttGm/Cqam4NSxPIeYY2eQbtg9MJE4QlRj4OAfac5Ixgf0xz/P8Aq8PQSjWv
6g11ewHbtVjmYyEMVjepnigjnYKGL9o87MHeTjkZ9DPOdSaTyrX6kjO8WmyEC6Zz
nEx4uIvq9SA3FkNXyQbl9AeRx+o/rP6c8mk1i1vmmmjqZQYqaXDJ1GqR6P8AIw5N
rIapkFFrh9etSyXrWRrarMk1Q7TSOAU735mqM47Z2xtII/3kReRGRVRAmAoxLr6s
frp0on0/9LvpY+nahorBY7VoyhTqzrG0UkVDXX+8XWGnqrlpChrIlSeS2Q1K79QV
buRcq5mpUzTQyGor86818dLqRYI3Aqvy+Z0BAkiMhyQ4UARiRt0kcQUbUPJznEee
4XJJ4BJ/pg84zx88kKCSCCPAPqs/TfkmDV6Py7WZ45pOJ/qMGNvbLJK7y5Lefym4
jagSujitD/xo+oT/AIq838o0koH9LqDT5p4NuzFihh05j0cCLcHFGJHKXxX2vTKO
TwOMuSSxLFmHOcjH2OMk+eT/AC8H1/BsEs+Ao+TgZ8HAAHnkY4zwfQTfg7UwW5O0
FvP3J3EYJyeckgfp8+vO6FYbysh/hUA7EOTjj75PDHBH9SfV5ljix27SK8vq4UBo
e4sb7KRHckuTD2W75eIy6OVTteLSg+D2OfAuLeGkKBkjbDKmPnkM2D+kHI4J5OSM
c+hSttGcsQFB+2cfOeDx4Gfj+XJBK5ALvheB+piDnIOMAYOQCcn/AFj1+hLuw/jP
6MjgAAgPgj9RJ45+VI9Mzgh7sPTyxL4Y8wL3VaXwFRNxW3xz1J+/gqgq3kHqvmVV
RzF8GsczE8/93wc/zYk//wB5J55AM4K+aMjY5QDA4GD5x7scE8HHP3yfI9JqOXP2
znOP6AHA+AAcjzzjGfsNjfcwxhic5zyPgA5+Bn7DcT858s5fVKSRktzT0y23fJIS
Rdnq92fL6ZO5UGmJFmIFvF80X7170HCdHHG0f+y5/iS6603r7V/0QdTNRXbUHTq8
6Wuevuj0FxrJKl9F6g088EuqNNWd6lpJIbHqC0VMl6W1xsKWhudkqqijhjmu1a8m
1Os6/aap5e12ZHwpIJ2qcF3IGCc+OT/M+vl+fgUVFwX8SjoU9vB/dW/qWa7lti0J
6a6rSUyFRkAyPCCCSNxUZ8Eb/wCqvMzTMY5gEGAN28EkDkgAcKT+kfbGOMehn2iG
ScI0RJboMCExut7TtC03vHEpO2ylF+YQJaj7m0jvhGUuwu2JyIqhb7PdWr4SZft9
9ll2iMxgh9u5pI4zEgRvGHIQHge1eMswJJa2WRMSGVnbuKxxKM43sYowpYBUUMC5
PkZY5HpNUVdWOglklUQyuZyRKHDjfElOihhl3d3yrYxhS36ceiDWOtbXovTt81pq
662+waU01baq7Xu73SWGnpqSiooHkmeWWUpGPYmxQSSz9tFBY7SajjhjLZBEBVNp
bV08hdN1QF2/C5skAjyyrnk4Q75eOPivbxA78UD6y5fpD+my83+x3mW29Udcx3HS
3St/yctVAuoZoUevus52NSRfsO0y1FfSfmmEc1XFTxBWJIODK81PUfrfru4V0cOo
+oPULU09xvt2mp4Ki8Xu6ViJLW3a51Ip1aSUKiyVFRMUWONAxO1QAdCXWbqzqr6o
uqlm+o36ndF1GpvozvtBqi09INN2SpnuVP00pkr4qC1dRtWWCgAlqK+60VLVS1lX
uqnoIqyMGCKGnI9MzqP6b676OOpWh/rE6AxU3UDo/fKa4RX7TVmm/Omo0HqWi/LX
WSwVSb2d46GU1sdG+JEmplgDvE8kSg8/1DpdPnyYoRlk1LiZ6Yl/9DJkxwjKWD7w
7Y5JIcSb/HcwxpJv3lP0Hr82k0vmGuyfY0mTU6f+txQjJ8w0egy7dmudLOBLJhlC
Upk8TN2koEZZY5IRoAuENba6iqobpSVFFcKKpkgqqOrianqKeeP2vFNDIokjkjbg
hgDxgfc8GlPbhJOTtz5AJzlhg45weSec4+ePVjX4kXSC06f1fp7q/oeopLronqVQ
0d4pLhbQZKc0lciNQyTOm7bUop/K1QfayyIiEBgV9VvVjkOEUEBVCqCTn9P2znHG
fkk/f0W8s1+PzLR4dbD0OUqWMjzjyQsyY2NM4MZFG6wBfmXgD575Tk8k801fluSf
3fszPtZwCOfTzIuHOHX+ZCl2SmLYSTnwM/MFRlcgsBnk45APOfv4BA4ByRx6eDor
qaj0rFr3UFaUBpLXb4aZGx/nNVPJWqlHEDHIO9ODlXIAiWJ5TygIYR522rjwvB+T
gnP3OSPge0g4xwT65LUvBFMC8m2peOR4gfbI8assOVBALgSvtOPaHcDA59c8x0WP
zLST0uWUoY8k8X3kCjHiz48koSamx+5tYSskCqbufBD6S+pM/wBJee6T6g0uKGXV
6HFrv6MlTCOp1fl2p0WHPIQJx0+XUw1DC4k9mwrcTDm+3irv9zrbtcJWlnq55JpG
ZuB3DkRqTnCRrhEGCAoUccZKDLuGVJjTgFzje2M/pDeF8e48jHg+gzSMyhm4IwFU
HgcZA/8AefnOSOM8YOWPN5GOfOBnA8DnnnAPHk8E+M8efUmJhx4iEWMCESETZwwx
7AibZFhuIxitEijqmvajVZ9XqM+q1OXLm1GoyTzZ805M8mfLmk5MmScpLJlkWUpL
cmTbK+he4ADbwvPIOC2F8k5ySRnOVPgZweT7CwZ1JzjIz7v4eOSMYIHH2/l5I9AG
kwPjaRyM8HIwQAMfB+wGSf6j0TmJWbBGFxgnHP2zxyPgY8g58+u/cjujIWJOPKBO
yJXO0eOLVlV8A/isj7UtBK/xR4a4pW+Tm1q+LPBm1QZZVgU+0YdiPAVScqceCScc
EcDnwfQkE+SQQRkD/YAfPj+eT8Z55JqJj2jM36523H4wozjz8/Pz5/kfQ0zcYBz4
PPA8HA5wPOTyPnPj0m4XZuibo0UG6VlWbZBfK1Dh3Vu2xPDvPZz7MXlCy/e+LE92
74OzBZRkgkYXgHAwcDz4/n9zz/sMKNtzg4Jzt5zggYyQf58kfpYcHJIyPREkjEjC
Zz54zwRwOQT+nPg/0+fRzbg8kqKq8lhyM+ft/pHB84x4PpvJkNq+ngaSPUdt8hbK
NLSN/He7x0AvhfbuNUyj/wBVVdfN0Hd+NJ39nH6NXbUH1QdRutb2wnTHS7prXWNb
pIY1jh1XrquoaW3UkJlYF5msNu1A0wXcIUZCwHeQHY5WVUX5iQtOQSQeXZTyPkQS
CP8ApgZ24HgD1TP+Av0Zpulf0K0GvauNpLv1w1pf9YTAwAdm0WSY6QsdP3G97RsL
RcbkpXODcCECp7mt5qbgTPKIo41VWwQd4wxAY/oQj+L75++PADYZk8uR3ejckWQ0
kUicnPBFpR5f9JXiHqdspylJPyAZdUIFFJT2bQofZHwgO01NDO4lqJBHIGAjLAF4
Y0SNNxYkIgQsMEBdzNjx6zB/jS/XTYNaai0j9GWk9ZPbrD/lVYq7rXq2hqhU262U
9XWQilsjmlmY1v7HgqP25eoBhFmgpabDMkqLZ1+Kb9QOoOh30RdS9RaQvlx05rG9
y2fSNmulNUqtVRz6nuJp7h+UmWTuQ1Mdj/PIlRFh4WUPGQyq3rBnXXCquNXPWVk0
1TUzyvNPUVEzzTzyzNulmmmkYyTSuzO0jOxLuSTls+jMmeoyfbk7SMYs5EI3DK3K
rFBgxJG7iSgv57l4ftxyRntJEJxkwlN2zBFi7ZRmReRkV/yj0+NGPTttefQTVUtv
1FfU6+/RbqWoc1dTQU8d1u/TyO9FTDqiihgaqp3tpZ+/dKOilamlSV6xIIqjf+Yk
NVXbSej6uq6cafvHa6F9YYFrtMT96Oaw6X1DqFZZrRd9OlyFt1n1BLUxJXUELChp
q+oiq4FgE9SfWYLQ3XDqV01qQdH6tvFLRupjq7HU1kldp2thZdhhrLNVNJQTAqSM
9pXUfodTnLxWH60OpFJpGTp/qG22PUWm6Z6trODHUW64aehqpmqlobTU08rRR26k
qnkloaJqcikDGKnligSKOOi+a/THmWon93DLTZp5Jv3nGuklnT04p7YylEzY/wD7
kjJEzV637hL7m5+Qf4i+RaPHDT59PqtLhx45Y9LhzSn5hDRQQ+5p4amNZ8miyofa
xTwLo5xGMpwccdPInryl40vpjqb0C1S1Qj6PvVZqDSbTkSRC318qzVtLT+VEDViR
1dMqY7TSEKBvb1WFUuGmbg5yR9uGBH/24AxjH2H3mp1Q+qah6wVln1Dd7cItV2+1
i2XKeSmTN0jjpIoI3qZYyYpxI8Iml3qrMzO20eRB2qqHaaaSSN07kjsAF9o3Nn2K
oOBk4UDBC4BwfVi8g02fS6bNDV4YY9RkYSzMVmOYrG5IyuNuSMYWgeqUpWVTnn1j
r9Fr9Zhy6HUY8+njjljxS/GccBPfjhlhXpMbkniIre2Mb9V+OU00cbbpN2xP1KP1
MTjCr4yzHCgknAPj0FR5JJO7J/eNnEaciFOcRjHBOOWPz8HAI9cn/eSqWBwj9wAg
jdt4GRjd85wAM4+fXiyDuFmZRkn52jwQfIGMYzxg+7HyMHY/9rxdrtlVN28lc0AX
fIvdU0nzztCrGw6YjyVURPdD0vDZ4Fs2MgnJzuxz8+CTkZwBgfYj4x65bznzgZGM
Dk/68Z4wc8HHkfHoK77jkYxzzkHnGfPPz8Ej4wOT6/DyqoHuGS3JDDPJzu+B8j4I
4x9/TbKmlIsiLSrw8EbSr2o8tRp2kbsTulHkC7pp7XaPXJffBXHA8eBW4AZG4AHj
H2HGfjGSefOBnnIHoOzfmJEgyw3nDsB4QZ3EcZyccEZDE/fA9fgvuXK4JUg8H4+4
5PJ8ccf4+ulMjQl3kwXbAAyPapOQnPgZwTjGSRwdox9GXIOwkbSvS2HpXj1ltRA2
mQeROfHWUqH2qLe4UoP5t5ew9gfg1XYqrGp2qgAABBAx45J/l9iePjn13BGMHA4A
P8gOMgYySfGQOD4PkAsMn+LAgEgjAGByCeDnHgcjH2x6EK2QC3nHJyoHycDbx/uG
RwD8fNXFCO144i8ESI7niLtLoo+QqXDgp6eG/wDqsbauJfTT7t9SeOTNW5O18Hwe
fOAeQAcj+RxzjJ9Of0r0XeOoWuNJaF05SvXag1lqOyaXs1LGC8lRc77cKe20MaqM
5D1NSgORkAZ+Mlp4X5244yME+ScHB+Co5XAJJ44zjHq5D8D7olXdZ/xC+h0KUrz2
np1crh1Uv0+wvFRUWi6CWtt8kxUe0T6ilstImSMtOAPPqDrNR9vT5pG2ownTIkRc
iSxxpkFElAibbb5RadxO6pMT01V8AhH4ObURGuxBfG7Do/0otXQToh0r6N2dE/Zv
TbQdh0tG+3sGeS026Cnr7jOuQvfuVwNXWT7WyZ6hwHcgn0MqKl2mclAnJAQndtGS
QMqcEkHJwTgkgkkeno1RbZGV3VFEZjU5zhWAUlCcg+4jzkZ4UDwSWLraOFaqYNGj
MW3FmMjMSwDc7GYLgEALnOACfOSJ0Oa4G5GPNpueTg9red1KBygvFoy4yVBElyAc
PF/z/vxfy9+Myn46mo6qX6X9A0lKZVpK3q5RG4hawzxYg05fXo4ZIgAARKWKscDK
n5IAyY1MrRxqqgh3x8+MjBzj5xn+EYH88etbP4oekrjr36RNbbszzaJulj1rTBUk
3NHb638pXsucgLHbblVSyNkARoSTzj1kdlDvMfBHGOeBgkDBBx9wMEDgeCAPVs1O
ncepnEVi/blEhOQyJRjAWQG25QfTJ2vZXTA00mcGXIEkbqwor59J/Db12V4m1EjX
GD5ZvB8Enn/EH+Z8euDyAO5bnIPg+4AbgQcA4I45448c+vJplUe3k8c/zxznkHkf
c58Z+/oDl3OfJ5HOcn/b5JGcYHg/y9MJKAd2JKLxG1a59Q7gOVZflIONxKR1yyjb
6QpP7RDkic03dB00+B8U53bY8ICAXfdhiG8jJGAMkYAOCB849cnnw3GSc8ZLHGM/
IzgZ5IIbP2BJPoK8yw+1eWIG4knI5J45+TnOCDjPoIZCTjP9R58AY+QcnBH3PyOf
Xd0tpYBYVPbL9xlxQHIBLbES9p34Rz7LyLw/uP8APLXJTzV8UeB7Ts24bsfbBB92
eOABz45A4554A9SC+nz6e719QV9rrdBWNadO2aCOovt6ZcrT90sKamTKlDLMyM2C
Qqxgsx/6Ubg5PO3JHjBwfknHnycYJwQeBn1fj+H1pHTlk6OU89ZdLXT1WqblU1lx
k7wjrYZYMR08ci5CvDCgAkhqHCujlo1yCTX/AKg80n5VoHPGZGcpmKNVwNSs4Yxs
gvJEL9aBxa/o3yE8+81MOoGem0+F1OaIsCbcYxhJjztlKRuRHaNbXliTqr8Py3Wi
hlksOrLhW1MELu9PN+TJzztlj2xJvUcDYvuJI2sSSPUM9YfTp1E00JKmCjW7UiMR
+4ZoahcD9Jhf271wNyrJx7gBjxoz6h33oVpWklravX+krMYR/nlLPeaLtRMF21Gy
leplmRZgGZIYSN8m0JGDkCp3qh9XnSWirqu1aZpr1qaEGULWQUMdHbu7hl3q1bMl
RJCxyBKKUAqd4ySfQXyrzbzjWY1hiyZ8dwuUsTGxfRFzG2G6i+eaWStni2+ffT30
3pN33MuLy6TF2xxajndw39tJyQra+iSLXHI1fikrqGqkpa2llpJ6ZtskM6sjq4/h
YH3cY5xgY+T8CTJlmb/YGyB+ofPO054488/y9crveJLxeLjcjlDX1dTVktJ3Cvek
aRUZTtI2ghMrwBjGAMACtS36XADckEfpOf55xx5+39OfV4jj4tamoNn4zeEPyaXg
Lr4fYyaVE0hLdGLLZLlkl8WoeqUYp+NVz6Q8Gm/OV2455Iwc5OMjCnx9h5A54wT1
RyTknA+eSFGeBnBxyOPHO7GcDks7vPuPBxxzxjPw3wfH+JA9C4yOPJ5Hg+POR5OB
+k5GPIxnx6anGSPrkl7g27QiJzuRXa7liQZClkqKVFnL8pBdJbSSGK9rynHxx6e7
8HVKd0gHkEjI+fOPuRgf055OPn1uW/syf0qnR3RHqj9U+paAQXPqxeE0FoeomSMV
C6Q0jM0t8rKV5EBSC8amqUpWZCquNPI5LDC+sbP0w9C9XfUn1y6adENEUpn1D1F1
VbNP0sgRnioaaeQyXO61AUFhR2a1w1t0q2zxTUkhznGfqe9COlmlPp+6PaB6K6Gp
DR6U6aaXsmlrNTQQmN54rXSolxuVZIqhHr7rXyS1tXNs3T1U0sjOc+2t+dZp44Qw
kllJjlluC9kU+3uiVUZspMVY1tQHdHbOwQWPQl8e7Vle9PBd8AnFe631DRQVqgNu
KvPGsqxqCEgVmd449z47ksO7IbaFhIb25XDHXK1hayZKd2VY2KMI+4QXBJJzGdpI
BVR9lUAYAAD1Xa5MsYYR7VhDBNxVu2rqBIR7VBlcEhnG52ywDD2n0yFyuUi1LLG2
wAcq0keQ7MzNkkglgWw3nDAjJxn1E0ZkY+nkoX0L2FBbf6p5CukqKpxjdd29HL3f
s10/3a6LukS/2Kz6ssVzsN+WG72O+22stN3tdS+2mq7dcIJKWrpZd/JSWnZoywCs
pbKlSAwzqfWB+FtqvpzS3bqP0EW4ay0PCJa+46QkZKzVmm6Y5mZqIwYN/tlPHn+7
jW5wRJukhqEV5vWhGG7wNT9hTNFIwKs7JvcLj37AQV3FdwyWIB5Oc49GFPWbjIkT
x4KllBmTdkKqAPlRk7R7wvgcY851fVaSGpjFlcJx3fbnGNPRYnO/Gz7hJJXLdCQ2
xrRkcUpSgyGyy1JFnslB7WH+1+MJdTTSwzvHOjRyIzxyxSqySJKmVeNkYKySKcqy
tgqwOduMeiueoK+yIAMWAJ8k+QeM54PABJz8fz1T/VD+G90i+oW8z6v0/Uy9LNdV
jM91uNmt9NWWC/Sscfm7rZhJSLFXEn95XUVTC8uc1ME8v7wVD9e/wrfqD6R2y5ap
0y1m6oaStdFUXC41unZvyN4t9JSxPPUz1NiuTxzyxwxo7u9BPWnZltg5HoJm0mr0
3qniZQjb9zDUoLEC2yWWLbJmpEI8fcY8ykR1mHIhuceRaCTJ4UUKinHCcdvNcPis
ZMkljgkYJ5Pk/H3H3HOcfbBB8ZuT/COCcN5PjnjyM4z/ALDj15UpJTvKjRyBYpu0
SCsq7mTcB3IiyE/qIwMMufsQA+7Cpkgb1Y7A3K7WZCHHBBOM459pDbiCQYv3Iqf6
xku2NB7N1zVhUajH02fjwO3w07Zc1dm4SJ2oVdDxdp1XP9UV5pDGwAZw+dpPGFOe
eMY5/mOcnjPpeUfVfXcdpaz02obhb7Sx4oqCd6RfGGzJGRKVYYyFkwxJJBHPppqh
zPVuDkjwM8KABu+cY5+DxyefQyBwsYH8QGM85znP6QOd2PP+oYPKJ4dPkFyYo5Ak
7RSVIcNTiRikv9VbuDaWV4kabXarTEzBqc2Ayx2y+1NxsoJHdGU4u6UHuUVR96fC
gqLlPUMZJpZJnclnklleSQtkks7MSSxHksx5PGPPoqkmYys58sFU8EjK55B8j74B
xxn1xMnHwPkePkZySB5P6SD/AEznGeBcZGR/0SB4ycg/Bx8+0nj758h2wiDvX39V
FVwokyXN7bi0d9+GWV7ndzbYt91fF3fv3d3b34FMc848Z5z4zyM7fGPPg+Oc4Pr8
JL/C3uxz7jngeMce3n53DOSefXFX2njBGAR8YOcg4OM/bgH5+3r0Ng5PyT8/J+Oc
ZJyCf1f7OfmX2xP9MXdFXmPwB7WgqlG3cbb4RcXnriKhEu+L/SfNJ2hQeBkbgEA7
hxx4OP5c5245+B8ffHo1p33chRjAwOf6+4AYyPGMfHn7EquGI3beMZHBGMf4ZKj/
AJf4uL000s2tdfaJ0ej9ttU6q0/pxZEK74zebtSW4SJuyNyipLICNpbyPgx80yI5
G9sVlJfuIRiEnjakZNNlBEhXvfh6HqUenoLH8g4/mwaXcc9eNb39m3+iVIDqb63+
oFueHP7U6f8AReCsiCxyboxFrTWEW9SzYUf5OWuSP+I3oHK9vOt2W+CKKZS2IxhX
LZXuyRKcIPa5OMo0gXBLDwQCnqLPRfSGkOiHSjp50p0BbqazaZ0Fpa2aestFG0RF
NHRU4jlrKnAVXrq6oE1bWTyYlqKqpklkLMWPpY1mq0LyFHym+bazHASM7ju453zM
pUDdnGGPjmmyXPmlObJckxewicMYfjEKjQtUsZT43SfBeENkYl91fXMrP5sK46Kr
38KXVGqF2SH83jckuS3cTBUCNGQKFYAkgLvCjO4AZOQwNfqULUMEMk2RlnEaSYYM
y4LMxOdoUkcefGeT11FqOKVZXCqdjL2lBxH3DtYMxZlEhG7czBQgyckFgPTK1l6R
p3JcfywwAxk8+wkHJyc8eeBjBJrQaeO1jKC0tqrbcbk3V29HsDxUeIWpyyF2dEig
OOhOvcvnqjn+K9aqOgIJjR1/hIEjKFZufvjOCCScZx/gSxFRGRQz7lYjiTDZIwMl
sMwySOOOTjnx1qf1z/8AWH/gHoob+9b+g/3L606DKIyZXsaiBRxtOeX54LoKPYoH
miSjuoN2SEaCqJF9/r+C/wBeD8LIinY8jZkRzskPuQsS2A2VOfd4J58rn1EL69Na
3DRP0ndWqqlrZaOpuVqptPU0oqGjnYXmvp6GaKJhtYuaaSbdgcoW+PM0R/cxf6I/
8Xqsb8V//wBWit/+L9Of8c/pHmOpnDR6ooT7MYPZZlYR/ZYTbat5pjfELFji5sL8
yOKONrEPYH5pKK4Dxl0rOXJDEHcHUrwQQeCMY5BztORyM8Zz6LmqHBG4lwgYKGz7
QWy2PLDkE45+QPt6H13j/tH/AIZPRI/lf6n/AHv6q2SBCQe3wAcsoRi87j0k323N
HqHnwalKQR5/K3qJVbFOA7X/AM934/C+2V5CeXJPgkg/qPj/AFfbn4OMfveDyD5I
4yPuT8+ck58cYGPPPFvC/wBP+Q9eHwP/APfwr6axvUdsak7my+Zl/IWW8gfPsUgp
3NVt/wDCw4567976/b4EFh4Hxxyc/q4wvPH3+2Pnn14SD4Pg8jkgffj+fOBj/D49
fj7/AOkv/h9c1/8AEv8Az9Kmgb9px6Et9XpG+3+Kq/34+t3bb4NzwB1z8ddUdFe/
jsZM8ePB88n5+ScED+LwM48D1+t5xtPAH8/OB554+3+7+v4fz/2D/uX14P1yf6R/
3n0uRPHIgTscwNjwxliiMfVxd3I6aDgK8fM0aQdxd8e7t9x+L4rn/fwKiOWHkkkH
jO3BH2xjxk5JPJB5HhZ6SvlRYNRWC90EzxVVhvtou1NNGx3R1FBXQVcMikcqY5Ik
ZSc+APOcIqD+8/7Lf8J9GVq/vP8Auf8A5R6i5Wna8xkNlF+mMLbrteT/AJXopRex
37NIxbq/hCleDd/c7558fTe0Z1ClvOhtJ3zvhjd9LWK6FizIHlq7ZBUvORv9xJmL
DAHBU5GfQer1VIFdvzAj3gmNXycB9pMso3k72QAICCRuwqLwSx3Rv/0N9MP/AJea
H/8A0VD6UNz/AFy//R/429VvTYoyhCb/AKzqPG2iNc29bj46rrjwXnJser3PHFba
l/HN11x4O7tqFXAWSqd2JD9vcFwo24JjRAcEkcFuB7QNwx6Q8t5mZyUdtvgYaNB/
3SeP5/z9F1d/5zJ/1bf74/RQ365P9M/8vRzAuONxWPERY8SkMccuZc3TJrj/APdj
ckmUubepHLRzIriuOP8A0Hj/2YhgBBMRAgAgBQJGPQt/AhsjBgsJCAcDAgQVAggD
BBYCAwECHgECF4AACgkQxgQ8VnIHcTcumQCbBP+z4pnIHcDuPSxIsZlsngm5KjEA
n31uxCGN+rZ3vMWdpIk4HM8Dw1j7iEYEExECAAYFAkY9DeQACgkQeeKcYLAGP+fz
5QCgmajf8630aMQCUBCh9SzHXOfSY30An3zb2t3YMx14hRxGObDTt4YuZixliGsE
EBECACsFAkY/XkwFgwHihQAeGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9jcHMucGhw
AAoJENK7DQFl0P1Y7kgAn0WEK7x31T2HW7L6JH+hyYilpQoPAJ4nbljvJsEJXos3
3w5cIBzxGrQAB7kCDQQ8WYNzEAgAv7uBtwBXWw1+Z9Z3/n/Ny1eYkP2fGkADE312
HtLwV/46nDxfqrZtagk0YsuJS7MEvsnJBae/zcS0Sjz139BapA5f2K5kVHpixWo8
itml98Nx7JUaVdkE0ZIxRNv/PqJaki0PyvqPn8b+xWb7gGbxShJYaS7nfhVV5gJw
aIXGwRBVPtbccecTQmfkhowDKds2w0Ljhwcd7ZLbH3SMJLtebYqFfgkUOW0D4cAQ
WzT3CoXXlgKjglgZV3laI0nEMTVfb2IjnSCRGJmfFHd8M5gKw4rn+m7yHWPz9KBQ
xZG3oDn6veON+c+If0TCUDB273Gblee6XTj93fekjU2tShR56wADBQgAivI848cL
Na6EWe/D43z/cBg/CUs5CDwM8FTZqQBf2CMY7oo3lMqFtV+e0yk0RH+PRADSwNS6
zk9pNs9wuB0knI8Lx+F7sTFQyYFRX7lWFZwQqYJUSjaL54qvXG4WzUiHOA2YMHVX
jmfOFwAm9A0SSIXTcGSdQgHdyTnCpdAoa57S40HHRMk5ooR4GWt3nWZrvld9VeaC
29eWh2gi2IIwj8nDm6YAd5JCn+hwHT/XRTcrBE7clld1e/7HNo6CnVHYNPtLhf5O
zm9fuxGEwxFn1Fw42G8txU3m6hRiPGAuD6QzEl9FmuH8plLmCWfH4qDjFxJW5Pui
us7pV+ZXMBCMgohOBBgRAgAGBQI8WYNzABIJEMYEPFZyB3E3B2VHUEcAAQFE9ACb
BJmDy7UZOmvcCZ83fBsMArrC8MkAn3zKySx5vPY/ocOMjEcB099D7B/I
=H22z
-----END PGP PUBLIC KEY BLOCK-----
D.3.114 Dejan Lesjak <lesi@FreeBSD.org>
pub 1024D/96C5221F 2004-08-18 Dejan Lesjak <lesi@FreeBSD.org>
Key fingerprint = 2C5C 02EA 1060 1D6D 9982 38C0 1DA7 DBC4 96C5 221F
uid Dejan Lesjak <dejan.lesjak@ijs.si>
sub 1024g/E0A69278 2004-08-18
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEEj2LwRBACdxv/Z/TqPsaxTmKrXZSOPnQca8L9UksW+71kI7YouAkbnnTyB
maf7zCs0BDcUU6t2mO5ijJlxXe7Y4yMx/3mwGX9iWfWh5U9xobG0STcU8ET3ZQmZ
/AM1vSL/weLK42YHxyqSrudt/oWxH4iDZFz5I/HI1DRwZMFhft3ja+pdYwCggAu5
GwYrQlQJHJcCFbxnYUGJX/sEAJXyzea8rzP7dTUsaOYcLitIpy/eDI3vkB0aW7Uh
JSicWASPW2erv99f1p2gkVQ0b0lrpMwPrysotfN6wLLYR0fowCWHm7hnASgohFpq
VwB7aj0HDEHne7EIr6geSpnO8Y4QUtbFVWo9cq7HGzrB8NhwpLXQ5g9RgB+H9SS7
SzVXA/4qPOAoJ8Fp+ZSznd46yd+dgFmVpSJuTs3g+hFolSioEkbi66fHwPMWeifS
i02AkU8m/qiGMAXRwBm7s5jeLwQyJX38S4PnupPg8pOjZtLVYoTWaM19yuMGS5S/
ryF5MaCGtuB72Wnsp67aZIkaHjfS4QAKo0WVH8yucnyOS+BFsrQiRGVqYW4gTGVz
amFrIDxkZWphbi5sZXNqYWtAaWpzLnNpPoheBBMRAgAeBQJBI9i8AhsDBgsJCAcD
AgMVAgMDFgIBAh4BAheAAAoJEB2n28SWxSIfMJkAnjxPSokKlZtVhYhAcgX9as76
sadXAJ4yo003F9ilZw6avaThCBltR/MqWbQfRGVqYW4gTGVzamFrIDxsZXNpQEZy
ZWVCU0Qub3JnPoheBBMRAgAeBQJBJQwqAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheA
AAoJEB2n28SWxSIfOHYAnA9quQ97rU3eJHb1LzOTpwZVMSDxAJwJnLzSFQHfJu1f
seG9fTyt5UpBAbkBDQRBI9jCEAQAza9XDZevfbu9BYjDESbKo38SRgyTd5/lIgzH
IlF+9zGr2e9PH1WOIPr0m9m3LYQzkL3YiUm23UoJO7uhvWvCpxfChwVx3VFwM7Yz
WqWBV+W27aZNROEmh5KheJACE/m6j0R6UECiRHZS/EsHP8FNG8roWro23ApNR0Vh
zZ6iVNcABAsD/3glWDyCWMA/eX/YGPw3xN3hkENgruwtWKkK6TW6kYv94k4iD/b5
bRsmIvGd31AM5/Qv/IQd7epXb2ovDaKvMl6+jAJb1NMCSzOkCnoqcQoKB0ed33d0
JOVWuA34WCMZ2zHLFEtwuQkHZqmyNQcxRLGLkODo4WWsYNU7KeGHvAJDiEkEGBEC
AAkFAkEj2MICGwwACgkQHafbxJbFIh9+8ACeNr7M+KLI/eWu6Nig8877cjrEP3QA
n1Kfo14Pijwx26kysheLFV1jutrq
=IfeN
-----END PGP PUBLIC KEY BLOCK-----
D.3.115 Chuck Lever <cel@FreeBSD.org>
pub 1024D/8FFC2B87 2006-02-13
Key fingerprint = 6872 923F 5012 F88B 394C 2F69 37B4 8171 8FFC 2B87
uid Charles E. Lever <cel@freebsd.org>
sub 2048g/9BCE0459 2006-02-13
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEPxAWERBACkn7HyvqMEJbJcf5eSJ57WR4Xoo1PU1GIsAYhdFhDOvmeWRZcH
kwUyFyol4X3P7RyibrvZwnvc+nrqXqATzVeDHT2NhcTTeG7fq4E4a3VpdqR10uV5
nswMRw/Arci7vuAQnmHzOYfnNP1ng6qLjA/CUizQ01WakhQeHGtbM9Q5XwCg2GEW
H6d78/rWY2Lb2wo6cS+9Du0D/01cO9zPg+Mh2T43XdLMjnVp17jR99SuNajqJbBJ
pNehq8yA6wb3ahZPjKtXpgELu7YI7omxhqcq1mxKvXa262aV72qdWqWoqvZzX0hU
lOckg6Q6EO7qGvU/jOY02/tmHdzQy6UJzHB7JVsfZ9DGH5xW23AYmbD4WF8jXtyL
Ey2eA/91IZpxEK7guIBt0FE0qMSCh5VOOlzOQkV+KtLswzEVPOWw/93wGpd/uilx
jZESPZ70cSWuCWwY15FEFts/gs5gPhCs1h4asQI0Shft3sgQrBhE1/hg2uENccHR
y1Af75hwezkwFkE2DUXFQqLuUlGu0sOtG+b7+IPrYuaGAB/yBLQiQ2hhcmxlcyBF
LiBMZXZlciA8Y2VsQGZyZWVic2Qub3JnPohgBBMRAgAgBQJD8QFhAhsDBgsJCAcD
AgQVAggDBBYCAwECHgECF4AACgkQN7SBcY/8K4dpvQCeMv7yFBMFOPxa8lF15IYP
8LRYjaYAoJyIupvj/RgaM5zZXZdPUS+gro9SuQINBEPxAWkQCACPOzcRL0LbFubW
3c8aJODeBG91aQRPz+ndMItFW6/+CW3EmyCGyaG8uxdtY0SOx0yALj4PiSj35s8u
wqfsWFRuNixODl9lE8ihq4d5qfeiwpcAR9wVNwgnXD9boKXOOFwb70W+9pI/I4zX
igHFxZQpndROhIFO1RLdoBlB89vV5iX/qzPKHFfmbbIkY4zvAsvW2MCly1WiEC2y
GT5GJTFZgko5/VBFzb3VDvA0grCGGTbHK1hnfuuvouQPnbuawdSZO2XGMc2pFcKW
gh+fgdw5Y/oQZelJKhLaL8Lz27buTz2sj5O/cYv5n7wDD/kSnb7+pd//qagox3JZ
bGXKTED3AAMFB/42KW+FULr4keaGuhAZ07hrNs73Uw3QTTNIUYYOkSJVvgold8RX
HMP38WANIkHtB3LBaZBxhqAOp2R5AppIPfyDrp1q0lTOGpzWfsQNQd10KRsXZGkf
K6INVa6kpzQhNDxBUyLh4onp7hZyt9zXdZrfYJLexbxrxkP1LDRDNJJAY29LnVR2
vyDHPrB6mmgijy07S6yKwC6iJIRoU8w4X3xFqIQ+KcA6VBhXqtqxSjk7GQnwyB7Z
7l4Qg8iZvX5qj753w6BDEwDtXlCCbocDVsu5xcLRPwMN8BgH7XcYCwmZFEU7IgEk
RAhqiHsjpnO7al5a+HQJi/KMOs5aDfwdkI48iEkEGBECAAkFAkPxAWkCGwwACgkQ
N7SBcY/8K4fTZgCgiVDpYWzuROUmau+CUT/UVCatpHUAoIyg/KnHhe9PUB9Gav5+
/KWhtyRy
=T2Vu
-----END PGP PUBLIC KEY BLOCK-----
D.3.116 Greg Lewis <glewis@FreeBSD.org>
pub 1024D/1BB6D9E0 2002-03-05 Greg Lewis (FreeBSD) <glewis@FreeBSD.org>
Key fingerprint = 2410 DA6D 5A3C D801 65FE C8DB DEEA 9923 1BB6 D9E0
uid Greg Lewis <glewis@eyesbeyond.com>
sub 2048g/45E67D60 2002-03-05
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDyFNecRBACKn+4b36n2/e55yTfpLXS9a57gQNgx0WXBfbK9LMLf2D8otD+0
z1DW2eclAOwJVtPftjvYP0HKFVC8Pes9Wvp6Z0sIEPpdkL2NPlUuxXUyh1b92u7n
Bpt7Uwsom88fnn+BOPrvvPL8Arg3JBen+Jd8o9yRoABCYku8vQF6CEUDcwCgmHJd
9hZ/kRb1rLdSLssB4VMQ3zED/0/SVm+6XV+2ObXn9FKQpCC6sMSq+PCoR9NzAVRI
njTtkpyR0fjJZr69IN2E2MWPonv38Xg1tWJnR3fKUOnNqwiVHBQKKrKa9lGWsZQp
TrR+ihtJ9hC626dCq9JDb1Ls7TXn9ha+d0WNuqiwugto/myHm/GVlCANhGzUuDNU
Mo27A/46YEAMuhSQWOxgSZ/Z5g0ybgpswVePrxvD4sX2/AVfKClOYpPiNJe+S7YT
JmfIPkpP2P7v+87BaN/uWgaFmxlhpUOIuat44w52EwwGB+K24cGgq52XncZsYTYH
SrLitkRtt35tVdnn1v3gmDi83M8W/YunflpeJAgJC0QzxKuar7QiR3JlZyBMZXdp
cyA8Z2xld2lzQGV5ZXNiZXlvbmQuY29tPohXBBMRAgAXBQI8hTXnBQsHCgMEAxUD
AgMWAgECF4AACgkQ3uqZIxu22eCkCACfUuNYpGGlFboDl5FZeXlor/k/hogAnjyq
/Vw8amjEN34PGuqBPQpMnFrwtClHcmVnIExld2lzIChGcmVlQlNEKSA8Z2xld2lz
QEZyZWVCU0Qub3JnPoheBBMRAgAeBQJA/XNpAhsDBgsJCAcDAgMVAgMDFgIBAh4B
AheAAAoJEN7qmSMbttnguMYAn14cqGfabS626P1D4GMcSkSagzaZAJ9LyH+vMrfn
OI2x9+VLyaTSAvm4zbkCDQQ8hTajEAgAmuQukPFaefkzE7DTIgSDIc5vRmUHDs01
bGp36R7f5GEmXwNtCZ+Mf+H54QSzuNh1QaJ6Nq/iYd35LA03/I7AgUFwSX1cEc/n
fNjxqS27CAab6nIt9Syb9WAAKUKDMwZCjHBNv49CAPyVVb1aTUCJyUcv1gGSMNHX
r2bkWpa4nIN4+rqD3hifHCX1j/2XMkmYY8NCVTY52zqO4sCbh+ohAMfYtW2yV2Iz
z4ngppp0fUbmlGV6DVvTC1Mi61UCDkhO+TZFlE3qXeGlP5GR0SbpdQmPiI0Jpinq
Zs43gcd2xtiUBM7HAMoQDpyFirDuyDKUgMWJrtJtAwWa4cf4Luh/fwAFEQf/dqpH
bl48tu+REAPrjk9NWaGVqi1vv0r4LJXo8db9aGxwwAzKXDhwqHo69E6l4/Rd+hsa
sIJE7vGNbGK+uerTg/W3jot90MqraplXHuS54TjOMyzWSSG7S6ypmDf5YnK3xQE4
NfTYvC2GxphotkE+QmBzmeft/Mo3opVYlv3OOBqiQoCYB348rXczxEUPam3bFBw1
wp5XjA0kqYRcUbxNE5AK9c+g6R2c/jT96EnDZDpMRCNZiAKHFLEjtHy66BiVHKvg
tijWD0kxtlWV8KAKN6OhUpSSsCv53jsCIntNARAVENOKOV0RQVDfJgykeK+3eeNr
UdIjAWFAWcVOEw5TQohGBBgRAgAGBQI8hTajAAoJEN7qmSMbttngHb4An37mZU8r
E3SGCAlTJCLV1JxRDXVyAJsFBVshxisn1GycdT3UCwcJVAHJ5Q==
=bx2+
-----END PGP PUBLIC KEY BLOCK-----
D.3.117 Xin Li <delphij@FreeBSD.org>
pub 1024D/CAEEB8C0 2004-01-28
Key fingerprint = 43B8 B703 B8DD 0231 B333 DC28 39FB 93A0 CAEE B8C0
uid Xin LI <delphij@FreeBSD.org>
uid Xin LI <delphij@frontfree.net>
uid Xin LI <delphij@delphij.net>
uid Xin LI <delphij@geekcn.org>
pub 1024D/42EA8A4B 2006-01-27 [expired: 2008-01-01]
Key fingerprint = F19C 2616 FA97 9C13 2581 C6F3 85C5 1CCE 42EA 8A4B
uid Xin LI <delphij@geekcn.org>
uid Xin LI <delphij@FreeBSD.org>
uid Xin LI <delphij@delphij.net>
pub 1024D/18EDEBA0 2008-01-02 [expires: 2010-01-02]
Key fingerprint = 79A6 CF42 F917 DDCA F1C2 C926 8BEB DB04 18ED EBA0
uid Xin LI <delphij@geekcn.org>
uid Xin LI <delphij@FreeBSD.org>
uid Xin LI <delphij@delphij.net>
sub 4096g/8ED8F128 2008-01-02 [expires: 2010-01-02]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEAXU5URBACciR0AqkCQGUnebUYLAp04VdF23g9xE+OzXW0TsDYHqI3Ecwlz
B8563UsF5B/0im7zj7x1kX6qRML9L+g7D/QllRuNWIzfBCtcBk6MZHMsBMFRIGlK
gJ6GHZ6wgy47lUUqk0+vAquzoe6duZX0B1luo9aFiPOMbO+exFfihhjmAwCgjZ1d
vr1flK4XY2+Rx2KkMHbLVrsD/R463grAvf+R3SXo/LGm98XCQX6n+szpWM0FoZeT
NOEygnXSCtb0JSqnynM5AO+FNQtky0YGk1R9fJBXluqxKfyFrZps6+MDg4R9Cpbi
kC+b+aQUb95K+TSRCefZdI2r04DLo03FTs4qTBMbtBTwjjWiy+HVarp+AAw5UjNM
cH/mA/9dTAU1NnE51TKTt4oVnwH0wfTBYqLhgfDbwYl/U9XeZ3W0Rm1RU3bOsbAR
4vVJg24QGewm+KQa/4gA5cHa1Wvvrcu22+8bGVHpFSzIK1A6qmehAZJyT0VFGqpg
x7oTld1L156tRhL28onWY/YIU7X+LjjGXrM5Ptx8pwKgxMMN9LQcWGluIExJIDxk
ZWxwaGlqQEZyZWVCU0Qub3JnPohhBBMRAgAhAhsDAh4BAheABgsJCAcDAgMVAgMD
FgIBBQJBSZfhAhkBAAoJEDn7k6DK7rjAP+UAnRY65A52eP6ZGTHDSFfExsiWzMBp
AJ9xsyEcg8uKjd2m4DR/fume9nYTlLQeWGluIExJIDxkZWxwaGlqQGZyb250ZnJl
ZS5uZXQ+iF4EExECAB4CGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkFJlYsACgkQ
OfuToMruuMBOFwCgg3l/tGrU7yEToftGF7IlQYDWcPEAnR6hGG5tUkyVBSmlgRR5
qJTB11i2iGQEExECACQFAkAXU5UCGwMFCQG+7IAGCwkIBwMCAxUCAwMWAgECHgEC
F4AACgkQOfuToMruuMCXlACfZlNlasnVWs3NjIQhC8+z2akl7RMAn06w0yfXqtWX
4cKItTkE3OQ8yzxktBxYaW4gTEkgPGRlbHBoaWpAZGVscGhpai5uZXQ+iGAEExEC
ACAFAkPZ9WkCGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRA5+5Ogyu64wF1m
AJ9zQmYdz8GB7CM4dLzBNJL9pikcAwCeLgL/ROof4hhQUTPItYTvQxN9BUi0G1hp
biBMSSA8ZGVscGhpakBnZWVrY24ub3JnPohgBBMRAgAgBQJD2fV1AhsDBgsJCAcD
AgQVAggDBBYCAwECHgECF4AACgkQOfuToMruuMB3NACfYNsqmvghDCO0u354J6YP
uALLRQ8An1+4jfvnzEgNaN3jaQfk8D4Sb6lFuQINBEAXU9oQCACE9YbWNaP344Mm
GzEwYACUtCAghdXNhPImALkmg4iiFzlwcFGTU6gx43QRhmOEb1n9mROBkpn/axEv
SNrEqz6Vb9QpVvQwZfGvxyCiDfzmWXIHzXIy3frwx22O17UDVQ7rvU9oETmOhHwT
Aw0iKYsHRYgjBVtCgfzPxquocVb0Tt8fG8YKEBqxApT/FJaiISjz9xIhN3OhTYvn
KB1lJYOtaAxYViwQYZsN7CSgYnPGmOcUVP0RyO6PTnRUnSWYbrY7LNaUfjDQ7n/z
SbrEV/472R5+uGcyq0zF6g1FU2GJkfTUcHMTH9Ww9qKuCOFOpNZNjbg2NXpdU58P
jg62tB7DAAMFB/0UMAHgQjAgTgzFgNXaO8hgDft2WzosgC/L+kWxKdE8xccHO3EP
W+McNu3OXu8v0Yc4bhWInpIiQBi5G/WDX7rMf5d7v27//QF2W0ZemiTzIj5sIgch
8spvmZphup1Aya2xi0/YD7DmlW3P9g6VtWzt2UvRfXhE/FTdKFHqlkxCbxZnr4EE
VusclfLz0p6a/5RV3DC7tuawsjXslyDaWg1j/4OSTfRxZ36PgGM5KsDtb3ag9SiG
DcHsySPyJJjSjHXoMq26w+HRFymR26yvI6juoaXOhNH41S0QFqAP3NetOUzqpc4R
DYo+tv3J9AxFjbW2wnGZbLibx/px4t9hdvSliE8EGBECAA8CGwwFAkFJlsEFCQG/
U2cACgkQOfuToMruuMCA+wCfecrGHPe6Cu+9BnYkppoB21aHdXsAn0z7fNybhZk2
MRalPjAfw6hvkIHouQINBEFJk7kQCADFnWhgDH6XFSh4L5LGbH7dFtBLzeEbK3O5
CuUD7nLjh2pnP+b8lYbpfsLNFaEYnC0FDi9esSqo12lC19JUDRCnhZJhbMLeHqIY
SufcE6iNvcZZYvhJdFMV3K114ZsyOGmGm3FjE/Q/vcLCRndNqfcIznsVOBRX8Bku
oA5/5TtMWZkcXvovCT66XmYIe2CDeK6KF0OqKKZeSOuvIkqx/dEiYh6jDymoeO5t
LuE8m2bOjtnt2pPurOyPtGCUWs3HaRIVzUSPITZ/TGz1z0ebDzqDE7xOaxnqygdA
1B7bscCnjZkPSuw6lMgvDaA6qsPpMEUy7XDn3Nmwsx/risGknZsTAAMFB/wOwwmK
ZFxjQhpDAIiViiQOqnOViFY331uYzV8THRnLmfxWhoGJo3XvvBrI1C+da3DuFRnW
UnZiOpKs1xj8yjKtYyHYsiaWuoA7nI3XOziiD7nP5MEgE3xvF8+MkrbmOhTkseqT
tKbOlnE8/J9AG9IcjfvVmN3LzXEN1W99XmGXzrMhGYLaDp6W+rvq5XkOkMDFbkf6
W8fvdecJ5pIUpnGgKqDaRuJVP/+6gLgBPIiBzUyaqp3iRagqpdRNNeelYfuNZMLT
qfZRd7ieoBYgD9tU3rEcIO6LDNLJwKQqooBh1jUnjKWEDspzjPZuzqQ9YzvGD/GF
/YeCFa1IWl0xnjCliE8EGBECAA8FAkFJk7kCGwwFCQJuRAAACgkQOfuToMruuMDx
8gCfe7fK9K73XzecdjRrzBmIydx14WoAnRVg+CXSToxAw2FD+XEfLSJlAg64uQGi
BEFJlCkRBADcmN1wexDz/B7aog+tVnyEDLK4FT0Jg/cN0BUaOEsHbOM+ZnVQ+yYZ
yBBj+iGrnZUxN9h829p3ggV+X3pdflVG4V0lZ/733DIeiNbyjx1f81EZfYRdwDoZ
2M0USYlzgUOZC5SCXskblkx+vQ3SJrTkg1cdFwwElkbTKQVvkl5bHwCgkPEEudGR
jCwdiiyDk+lidptMavkEAK3dJiJkodmX1yluYR55bNRROSe0jXMx5CIuNBWs4jE/
tk39KkuVbQnpGARyskMeA8tNSRdEWvWVRB6nnastv9rLtADCJvo39yjOmQTiz3wq
EDQHOuOk6QMrWrUU03yhAljT9mLh08R616XZeX7wXbg9LxOhp5auK2zYiTsySWC3
BACO0quIEGGnuo8CTcaAy7+WYCj7tvW6NS6p2yi3a4qqVxgKsmJpJnXms7dbhC2h
hErxgu3N+/nzeVf9/uRiw04MGA1X6ezeCdF5N3N7mAzeSIcDwsrADakAivIcX9FO
XvhrehT/fpZWPuvhQUUq4SlDTPl61PK7BZVt+2VsESi764hPBBgRAgAPBQJBSZQp
AhsCBQkCbkQAAAoJEDn7k6DK7rjADHQAn0g8Bf9td6oQfX/EUNeWYugxNAizAJsE
M9CuzlI0rCGsnpNShtz31mHv0JkBogRD2fFxEQQAp7dJq2/6oTTHiw1VgB1rULiv
wuVkhLCm946JDArJw+s7D6T8IoTNH8cgTwCXz0Yj9vXFpGrwPJrKquHwqwaXmVqO
/5hlDvQXQkUFruxFWlfhKxoIaFfN5qTeerFDnUFaiikVTprYJms5rVP0ydk6ZCEb
OV66NNnw1z4ci8R2SzMAoO+ESGr3mRlZOigDEfIuoxeDvmvNA/wLVfYEHLfvM6Iy
FgvVAPZg2JdMq/Ul+eMW3/zOl08j1MT3cEJKS+hUZWMpLS1ReZBk2ntIq0UGzNrL
+0byfDoOWFWMt2F64qNxlscf0uwhq/jjpmMhfg75p/B9mpkTuJl2gbzn2Viijmzr
EovCWBhx5st+2Ynp839UOrOU09XLqwP7B/G3oOUwaj2HP6+cRsHpWc5OZUo7A9Dv
r0iTpcK9WTL/VyDg1Gl5CMAuxv+UfKVq5qPoE/Lklh9aCcgHU7lcw6A5ckBNnwNu
qLZnZ2NUavpLKaLq4N7eo4J37LAGZMBNbBDDWYncP/+U4LsgoYciPlcUdBg2Ua42
0YB6e+aombi0HFhpbiBMSSA8ZGVscGhpakBGcmVlQlNELm9yZz6IZgQTEQIAJgUC
Q9nxcQIbAwUJA6AgAAYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEIXFHM5C6opL
/ekAoN2XZbmY/7FFOuBVLunMBOCi2fhUAJ94Ir7mkbDz7uEXDmX7VLDX9TGz4YhG
BBARAgAGBQJD2fSKAAoJEDn7k6DK7rjA/OgAn3cNroZacvBoGeQyDxmmrYVQHw5R
AJ9M/xQVazulyRW+DDQRZeFpe8Ry8LQcWGluIExJIDxkZWxwaGlqQGRlbHBoaWou
bmV0PohmBBMRAgAmBQJD2fLmAhsDBQkDoCAABgsJCAcDAgQVAggDBBYCAwECHgEC
F4AACgkQhcUczkLqiktX2gCdFsgieYAamt7pLRxNflx8+kPYPyEAoNGElkv2pkak
B77SvCxwHhQzhQ5kiEYEEBECAAYFAkPZ9IoACgkQOfuToMruuMCHeACdHun84B49
kBQz4HZlEP3IqCvs71QAniXQD3mKb9vmDwRMHvolXwRMMtIvtBtYaW4gTEkgPGRl
bHBoaWpAZ2Vla2NuLm9yZz6IZgQTEQIAJgUCQ9n0XwIbAwUJA6AgAAYLCQgHAwIE
FQIIAwQWAgMBAh4BAheAAAoJEIXFHM5C6opLb90AoOAeTAyXSxXEG7yhewW3dcTp
TIgpAJ9xK07Ggca+fdV5QveYTcqj/jeFO4hGBBARAgAGBQJD2fSKAAoJEDn7k6DK
7rjAlngAnROyRMpBTb4Gduf72PavMmvnPwIHAKCErhTZtUZRgW/Jj+1QFR8/ovyx
PrkEDQRD2fKGEBAAmIes4Mx1gL9XByGFW3ugJ+rWyGyhCFpVoYAU9cBeKnEimeEk
QnmjK6UL5ZoVH5K9F9kf3eOdMLFj/DaM/4j1kr2ZOW2uqvczxgzLLfH41k9vOd0Y
iL4BL5705wkq0rsYfhpYY5OphhkduCDhWvjJdg1MD62xl/NBY54b8y/MPTu7fikv
vFezYR5wuuBiCKPrz77krrUltX2Lx9b+FxYQ+rX7IH0WukQ4Ih53xskYPE0O380j
iM2WwIqqMVIURBfwEIGMt5zFtll2KvnaPjX/l3gkXuJ8ZH2wKyHixA4732GMiWnl
DleAn+Vj83xZppbtAh/NE+hPbRZ9gsWZaZN+BUGst2refD0IRsit38hCehO2L94L
M7W8ne3yyTepQUqhlsD+iTf5skvD/O5nBT/ZDgxnwVwUh5RsToky3n81hGm41y1o
iIjsAhJrqkR/gXKfzdrUQjRehf+6Mgr9f81wqkoq6rBC9YFmCVsYdmURf6CGrm+r
XrRUSTWxojniJQvRqx7oN366BwLOwcflp3Mvy+kXvmR1ICNAZd7KPSCaxn2Gn6WI
E8k/vFYajng60Td2meZIsfkyYcna51LlHB1fzx8stViq/t/ba6BpQoSCuIIPMEgH
yEfRs/3oxfWqDAZYdkEjpal3+Whf5VCyCgVyf06YIPrC4ZvqyLEhXHw9pisAAwUP
/00e8AH7nxDMoOkw9Jt8x7ZHHM0L2H5Vf+apyp6yyHNpCsXG9SPL0Xk8RYD9txNa
uqwjXCX5rmCKX8dOgx1SBjdYSKBCUpsiG7+Ikzx+9nougKqtW6NLf/Ch4P7qT0Cw
i+0tsfOQY3x89d6hMU2VHzTYAoQkdzCY2HKW2trfM6oXebAoqBTRfCxLaPqyHths
1WHEPxzlMZ20rq1Pa2Pm9v6QKD2Im64ZMsjLBxYKf4HwqQ+OzGaIvGcBpNIDSSJK
K02VX91WR/GLzdSJAzQIfovrw1Gx47CclYgFwZCUcxgxE6TAuSkojMCYje2qjm5f
S8/KNho+gli6msGUL7LLpsiPemHxAMjoERwQT+Yjok6OQA4mjZ9iUrtx7Sp9ENL2
mW418mEi4EbGvPzxVag6Kh/lyVpD2fJC1XxQGUqrqY1RtctZ7ZSvo+SH/uLcnF2U
vRHgC4U44pYiPvvrYPEtVMwnnbCfNG+ZH2Au/n/x6IF6IxpB1FG2Qb3pUkjeNIfw
U4s65hZZXoXph/K4l3WHmoiFl4OyGubkizriOUAX7zFbtBVYKWsHMQTJkoeeM9Y9
HrVaXK41+TmlzTZ3mMtcnrH37kPulytPfgWQwctth/JsehxLCcl46FiK+Dc5J0iz
ksT/I+1euxiAJpd+uJAswn+yHbejwKj1GoejLRAmPl7eiE8EGBECAA8FAkPZ8oYC
GwwFCQOgIAAACgkQhcUczkLqiksoVwCgr37ag+vCH0UenSbvxonWenXb1kIAnREm
zqOMMNOh4KXMYi8ANHEpRZ2zmQGiBEd6364RBACJ0vvNmw0xG+HqL4dArFz0n9Bb
+Ekm602L5pR/vfzz3Cuh5IA4IkehbalqwPQzixnccFjhsR6NbiKEU4O4a2ZtT/Eg
ccGP3+9pdi9GeuBOKDWLak42DI2Xz7wsjsaL4hnnrxNDfnrFiS1hTTQr6/1FzhoI
wJRPcQMAbEPZzb1wqwCgw72dszamS3gDja5UVAu1YnA8Av0D/ir/87zuFO2ZKLg5
WjxoEelyT4GQcz0hcrkV/M6xQc50a8uZcnqIhbDT9WLZoDkCJpi7JCdC6x3iAfpV
TFQQBimXlNzNoYGB4TQHhJWynYI//HtS3Nww+VE2EPKOLPh8DBv3ZQVwf5VDU2S1
WtCv10+22nakQPapt5suykLiFvlcA/9zsPGQ4fOFiJZmgWZu/MbtQ0WlwYfyZjdx
MQaIha/OH8G3dh2qVdmPwkQnDI2eSggMEvJYg8ksq69be/rr7etJiDpLF0ku4uiY
LnDznQv7XTMO2ZbTje+s8xuOSF4b27Zw63FeReOSZkjJ25ux4A9e52ry+J9Crzs7
5TrAlM1+srQcWGluIExJIDxkZWxwaGlqQEZyZWVCU0Qub3JnPohmBBMRAgAmBQJH
et+uAhsDBQkDw7iABgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQi+vbBBjt66DQ
ZwCfVbXK1/4R3fsmbfmNMWtIj7p9resAnjO3wt+fpR/n6gZ7MY8r/CJ42EHniEYE
EBECAAYFAkd64E8ACgkQOfuToMruuMCJiwCfSKad5ZkyNQ0ibzTVLiKhVG0C/J8A
n2oUkI221ZqBKzoVT1IFup5yXfV+tBxYaW4gTEkgPGRlbHBoaWpAZGVscGhpai5u
ZXQ+iGYEExECACYFAkd64HcCGwMFCQPDuIAGCwkIBwMCBBUCCAMEFgIDAQIeAQIX
gAAKCRCL69sEGO3roAUuAKCsoSKbWhUDvL9+VA/rftEZu+CS1QCdHaN6ouokP991
Er6iUTzOmXQ6o0+0G1hpbiBMSSA8ZGVscGhpakBnZWVrY24ub3JnPohmBBMRAgAm
BQJHeuCCAhsDBQkDw7iABgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQi+vbBBjt
66AinACcD08pVY8meraP87NPo4dtFWLOEgIAoJyBjyrIfVoJy2aCYDpHB+TPx9Kp
uQQNBEd6394QEAC0tHEVHut18KCFl4zZOVws1R3U/Vk1/3/VjIjM84WxzPIBTde4
tus410NUR8CCEO8iO5MMQ81nOSyaImiU+GK+jfDEO2SSzaR/sieAB33wKa7tnKgK
GT34KqriZiBZNDYa+HcvB30+jBI8pjLsyEDsJb+40HMniLZXsPcIIu6j1Bdt7Nnc
y+VmIXnzFRvDlMMeBShvSueci6sVwquDVuJVkN6CzsvVgau6NrI4we2iBkErVmDz
1V6tt5SD59su6xV11wfq5Q7SS3T2nrT7ZVKeBabg7Y5F9obIJBA5P+RmFI4yuKse
pq6nh3hYEk/0wI1mYs/SkvudO0AYLDbNznp8pzsJVJJLaKXjFNW/QFyhTKgJzwrQ
zHfc9kzSkqHUKigV5vHsweAFSCBsL4W3GJ0Ww9EayIQFXitrJeuWYfS2fbpAAktE
RAlfISbn+we60FaKdNu9NOY9tksMh1Jfp/E80ZPJS/LOsdP8/6KadIHmM6AhwYv0
bVc6jFf90S+XGQaUTnwLGAJzRtPoVND0tII32SkbyOfgnFYaoVxQwLI1WrdiIgtx
beoK8dmVcq1TK3r0F8rNPovg2o4VAAUiDY052vSsx2WpULkMWBQ+AcSKxwL6fJl+
he7+dEAYmcQkg3/ebol54jXJtU/x24CPGqKRh7gA4kdkDCf1wA3XB/1rEwADBRAA
shtezZHa2YvDywFdyF+TSvKaPL5XK12Zqeecrtf5kdDXmQe4mWlJRuMIcCBJkxTK
+XPeYXbdlZDgMTY4htshoQaDN3ujItjk/ALz5+49ckTbp86H7FYyyqEHsKYXbaT8
4sOzNezR/ZMPFN5Jjskv/rju5ha3aBcdvRpyYDjvdkhGE4iuEnPcCvXKpzBKE0Zd
uNuFNlCS+qJpCsKqstn6pQju30xE9iX1flPMdWdZHAhg9fDW1Cwdod3iLaPh0clQ
IpSPYUvlsB9xXAWMN4abSnYpnalnV8EExt8knRsMr9YnNusVpdhnUkj7Lvk+RPKC
YnKXwEmd+BMxqJsKJZKJG2dVmHvXJJAQt6ELdLKf9nAgGo6D438Nmx582nAYnVq+
R8R1iQ75G5Amb8aS2pnAwnB7SN/bLEKIcS9XoZH+TLkabMsJ8bvilf4jfvlXgrTf
udNtCUwToWOHeKZvvvdX5PChqQsJ7R459bKcksuxpen7uCVfPzr3J/r2LtR+viXl
MUQCm5lfTnA5IEbFKH+A6x/TlLbtiFDPrGUiYiR0jf38/Tpv+EbLCgulpWIgU6Ln
zZvdjkTusJULsTQfSMCGW2+z4RzszZi0Mz2b4e+EiRg/b2zVkOplHvr6pBUGvn1I
O3GqsWcnmJe6vwvKV6LiGv9xf8KYGBnZ6EsDejmPqAGITwQYEQIADwUCR3rf3gIb
DAUJA8O4gAAKCRCL69sEGO3roELyAJ91GaNMnIJ3QfKCjzlZU3t8Uzid7wCeK4Ng
bnb9gHFGpH1QylHtTuqRnaA=
=Cm8W
-----END PGP PUBLIC KEY BLOCK-----
D.3.118 Tai-hwa Liang <avatar@FreeBSD.org>
pub 1024R/F4013AB1 1998-05-13 Tai-hwa Liang <avatar@FreeBSD.org>
Key fingerprint = 5B 05 1D 37 7F 35 31 4E 5D 38 BD 07 10 32 B9 D0
uid Tai-hwa Liang <avatar@mmlab.cse.yzu.edu.tw>
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQCNAzVZoYQAAAEEANP5N0PqWEDO1ml4yfxXCQ+hEhaXyaGyNboh6uLX7uNPXQTI
9veETXNd20Fu+8yuzVFJk+KmmGerUzduHLXm6q+szHBvEQoJ2ZGk9AL9jj2JjFRj
rCRsf6mk8SWuL0xDBTu04bZZ2ttNDxNiymNTqdBVZmX6Mdg/T2i3mv/0ATqxAAUR
tCtUYWktaHdhIExpYW5nIDxhdmF0YXJAbW1sYWIuY3NlLnl6dS5lZHUudHc+iQCV
AwUTNz0HC2i3mv/0ATqxAQGQ2QQAww0WfeHFmupfTBWWdmNSX9eCDIfN7Wsuiu54
DgCi7T7ixQa6reIsMAKx1KHNX/GSBr+t3nyHT7N12Ee09qKXywQAw9W2nrdMGE1V
nENHEFgJtvnoN76U1goANEfZGnLLhyuDoMyZGCZmVG6FiV6EoKrWxfwq+jV0Y9K0
3AI/Cny0IlRhaS1od2EgTGlhbmcgPGF2YXRhckBGcmVlQlNELm9yZz6JAJUDBRNC
H/ubaLea//QBOrEBASTEA/9H+78uZl6JvHwGKOXyZkrRCLTUgifJcR3thVfynGrM
AImheJwqgVP7FQojDk8xBCBQ1b3tpwpeRPwE0V/Dr5MkFLfiaVgCIfMibqcc9zuH
i4RYcRqKswiO3pFeDMyHiSxylURcHfx73CYijIDyG+HPiCQ4OGd95VJywUzOVddn
+g==
=jIT8
-----END PGP PUBLIC KEY BLOCK-----
D.3.119 Ying-Chieh Liao
<ijliao@FreeBSD.org>
pub 1024D/11C02382 2001-01-09 Ying-Chieh Liao <ijliao@CCCA.NCTU.edu.tw>
Key fingerprint = 4E98 55CC 2866 7A90 EFD7 9DA5 ACC6 0165 11C0 2382
uid Ying-Chieh Liao <ijliao@FreeBSD.org>
uid Ying-Chieh Liao <ijliao@csie.nctu.edu.tw>
uid Ying-Chieh Liao <ijliao@dragon2.net>
uid Ying-Chieh Liao <ijliao@tw.FreeBSD.org>
sub 4096g/C1E16E89 2001-01-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDpaoxQRBADcF3xUpV2Vs8pV5QnfwFvTzBY1fnczFB149fe1+plAQEARu5xk
Dn6dpnPw9CM49eC0ouEYwPByhICcSwlUGBgxKsOqGjlkIlge9vtQdwI9i4xxHv+h
OxTyhdHYI8hQjyFJaQNmzim7SdfX8bvx5bcuNV9n/sVIsKoy5rbXo2rWmwCg/+rX
A79Ki8IORrhyEGd3+JS/rGMEAKpXT8Z6MNOJa8xL2mrVd9ZlKDMSZXPMxYowddI3
hZQqjtbssHvB6qpmbrQ0geNF7aaBCIAnVR8tAMxacdSBpbz0ittXA9i86gyjMri5
6xSgd6CrdcbibDD5TIOSBeYcFBb+4UkZ85kQYil/gcksp81NZg53H5eI5Wrw6sBM
/nYCBACEGldPZ2DdUPPvsfNQme7N4Yd6jS3BvXbXhqCYfHiCNiRS09fcLGEnO4br
6mQ9/K8kLx7R7GXSNOevoMNLLJ5kc1DIFYXQeS1weB86HY596nNqn914C8UWhcoR
wZBv4bkgZpAirBGPvrO+Z9YM3B1N0a+xu1rZzYSsBya97wsverQkWWluZy1DaGll
aCBMaWFvIDxpamxpYW9ARnJlZUJTRC5vcmc+iEsEEBECAAsFAjpaoxQECwMBAgAK
CRCsxgFlEcAjgrpCAKCHxIaNLyp4tT6j2UrFEyINUY1apACgnv8EuncpGD+Zm+Em
o8HOKUG5Mv6IRgQQEQIABgUCOyeEvgAKCRBr2cjSd5gysdAvAJ92xR6Wv4jg8DBn
VMypazvpAM7fNwCfbsK/olkpB8NQGt5YaixPvu8IWF+JARUDBRA7Mhy1w33D30O5
lTUBAUx9CADDyga+ulzenkEpaykTu8FPJ8RS6Dj/2K1zROfdoKNPzTWZeHrGM9FM
bPsZ6Vg4tJJKacr9WblfRNiUf0KIStU4ogFMYcouEWJ7Fvc6ovH91zB0WOzACVGX
rjJc4TUNe6E33XotLW2fhpEWZoUNJxMa9uux5i6YRFXSpyXLcu+tmSDBGkjdyRZ/
VsNglwfQDFtI+MqIpHQP8NpJSqeTxDdrLLK3+bDcxNDqzqVmOZ4Y2Mlzej9pxPBY
RYbOs6aORQkDCOC8fhYixI/gu4+hZQTkr/Dp2Zev9THwo8wjg52Pd3KU9Y4OoMtO
fOdB6z0dLzGbWUXaealBJujEufBPPVCwtClZaW5nLUNoaWVoIExpYW8gPGlqbGlh
b0Bjc2llLm5jdHUuZWR1LnR3PohLBBARAgALBQI65Sx4BAsDAQIACgkQrMYBZRHA
I4JFIACfWI/enwLh44kL6z8mQtwE0Q+iSlIAniahZULNeHsoE3sNcfcsCFNafw8Q
iEYEEBECAAYFAjsnhMIACgkQa9nI0neYMrFpcACaA7k/1m9DqK0AvSBZsSLL0fwo
zmQAn03jRr8opZGMVdivbmi9hkHiRwAgiQEVAwUQOzIbycN9w99DuZU1AQE6nAgA
lbrIYTH+p+v/bflh9gp6o/KUQDVwx9TBZBVewogyWAYf2uDavJ+m90oXVgMu4H1W
DU5spmtn//R62TGoiS8vPOOltsfNMCgTCIrxKHEUQEXMa4rVkiI9NGRL6tdDnRgq
P3lpg4eP6/bF0zxcc3s1l2a2WeK7+WYtOOYU9TCcebsyiHxvWuev000rQtRUgeHE
jCdaAVuCUlBD6f9MUX+Ww6HbWwFJYXkMW2Ga931MS6qf5xcuhyh4JHI/YLwdiOoo
mdbUbXTkU+r+od0iB4w930sxwjnyGO2LfTxcIA7fgeALkmNhWwVCZjkQ0iGR4LEj
1RHvahMrU6qqX40xgz8/dLQkWWluZy1DaGllaCBMaWFvIDxpamxpYW9AZHJhZ29u
Mi5uZXQ+iEsEEBECAAsFAjrlLLsECwMBAgAKCRCsxgFlEcAjgq7JAKDwmq2mVJwr
pFHaVsrfJZXmRSqYvACfTC1DhXwEm8m1aFeRhe9N6LUPtyeIRgQQEQIABgUCOyeE
wgAKCRBr2cjSd5gysV4tAJ9Gt7y4bVGlm34MRdurQdTsEmQ64wCfRgI2kGaanklo
IySQ2tNH0B0s5UaJARUDBRA7Mhy6w33D30O5lTUBAVNYCACPSdTc+y8xnOTAO69I
GxWnVw7n4ZP1yAOFW0kWXDlSrzxvuBzkaYYe2q5tBiTjc38j8L0m/GvIAToFZKGG
XxNbY7IGhTP/sZBXei7960cUZEJqaTHIrJxALXeyYj7bQ8OBtLsuJpG2+7k4c3+1
M8t/k4DpVx2L9IgtvHTwIOH1MeJpH526IUXDipNFaRTPKUHE1exKOd7z1zyGgE7e
x0+X2cTckTFzy8NQgZFzAkA06HOYjQf8i/IOvp84Svozfg8NH2KriC4MA5a3rD4G
n6fqtecPgMrcG+KIHJYZvg3yToceFJkwxZFcSGtl43pprgSf/pqkZ1fodcJ7Llf9
gJ4OtCdZaW5nLUNoaWVoIExpYW8gPGlqbGlhb0B0dy5GcmVlQlNELm9yZz6ISwQQ
EQIACwUCOuXFUQQLAwECAAoJEKzGAWURwCOCLMgAoJGhtnPbzYhZWHm5S9Dkgmvj
QsgvAKDq9LzJ14Sojrtpxka5F5iViLoqEYhGBBARAgAGBQI7J4TCAAoJEGvZyNJ3
mDKxzzAAoJFFuWMLf6HHO0TiPdafPjuruVpuAKCC0eE7oh9t4xMlTb2SYWMpZS9p
hokBFQMFEDsyHL7DfcPfQ7mVNQEB9KQH/iLaexNwzgB9efMXg6RH+TtaWzxBdeEc
7CD9oxjG/1tsfd8S10UScnr+JHTDNn3eh5KdQDjPmKkedPngAIjKHvb/Jux7jcxO
OLmRnVeFD1kMyNlv5ggtJcHJ4QXe4rBko68qyU5ON9pvA/h7Xe/ulGw71dOCx0T6
jBlpmLF8AZlHW7z8OS+DYa7fJFI65cDbtd6c9hM+O4WNj8PK7p6MPgilIaWsnJq1
lS5fkaQK+dqaIaVEE4WqTt8v8xC805X58HZXRFma5D39yGFNd3LRCpu48mM5LDLT
Q7tfs9jn1Ru7iUHyjI1Jel0hvRGblL8iW/zvwmS/XTXPsh3H0U/WfWG0KVlpbmct
Q2hpZWggTGlhbyA8aWpsaWFvQENDQ0EuTkNUVS5lZHUudHc+iFcEExECABcFAjrt
DlEFCwcKAwQDFQMCAxYCAQIXgAAKCRCsxgFlEcAjgknjAJ47s3GGw/KsEHKDjjRi
D/kcOgiNZACgxKgabQRGmvwKMl8fTtNxiTbAyDOIRgQQEQIABgUCOyeEwgAKCRBr
2cjSd5gysSzKAJwOKSwO0ZIm9II4sjcxWPeNUHAl5ACfXShCxB2mVs6kRDsD1o7f
aWeuChCJARUDBRA7MhzCw33D30O5lTUBAaMTB/0S70cAqqqAqrJBZosRZhmXWixk
Ah1gMH8SkNVygA3BE3k4A9LC3LNyvlnbCGPFH8PYvN8ymcn3sSPu9nyHVZ31VDU0
mp7JvKeW49tWxBeoFWpNJeNxTv2aNpFCLahpiwcDt/HW8/1NC5dJirDrIrVTrhWG
85UUYeGmMX/5qC7bFh+Y5FC6HxnFTCWlxpZQDtWw4Dbf8r4dMrw/2I9Uubj6brEx
LeOG2gB5UAuSS5Brp/9eiAlJs6jRgLU883IzpIhYanz37nJcLV5MVHhbGiR1Yyhr
IQlO4pQ2f3VhaEpkUu63x6lxfyVVJsZZ+vZU6EvtJSFACWR1nK2SbszGt/FRuQQN
BDpaoxcQEAD5GKB+WgZhekOQldwFbIeG7GHszUUfDtjgo3nGydx6C6zkP+NGlLYw
SlPXfAIWSIC1FeUpmamfB3TT/+OhxZYgTphluNgN7hBdq7YXHFHYUMoiV0MpvpXo
Vis4eFwL2/hMTdXjqkbM+84X6CqdFGHjhKlP0YOEqHm274+nQ0YIxswdd1ckOEri
xPDojhNnl06SE2H22+slDhf99pj3yHx5sHIdOHX79sFzxIMRJitDYMPj6NYK/aEo
Jguuqa6zZQ+iAFMBoHzWq6MSHvoPKs4fdIRPyvMX86RA6dfSd7ZCLQI2wSbLaF6d
fJgJCo1+Le3kXXn11JJPmxiO/CqnS3wy9kJXtwh/CBdyorrWqULzBej5UxE5T7bx
brlLOCDaAadWoxTpj0BV89AHxstDqZSt90xkhkn4DIO9ZekX1KHTUPj1WV/cdlJP
PT2N286Z4VeSWc39uK50T8X8dryDxUcwYc58yWb/Ffm7/ZFexwGq01uejaClcjrU
GvC/RgBYK+X0iP1YTknbzSC0neSRBzZrM2w4DUUdD3yIsxx8Wy2O9vPJI8BD8KVb
GI2Ou1WMuF040zT9fBdXQ6MdGGzeMyEstSr/POGxKUAYEY18hKcKctaGxAMZyAcp
esqVDNmWn6vQClCbAkbTCD1mpF1Bn5x8vYlLIhkmuquiXsNV6z3WFwACAhAA4vXK
JfvHChbHRCc0z99UHVCluHwRUDopIFNfuBmiAOA7Ozz19dmYBKDgudZpDNZtbE4w
0S2eW3xVTkPUWdrhr0jDcibkhpdFI+Cp3x2zOhL16Yug1xFSqWDSOo3QX4eBVxMH
0sCHiZMlcx/QGl1bwZ9PpO10PttjloI2SqWGUNK9FGDjVfJoX8YMy5DG4rLcaS8+
m2IOb9BiYoRs2Dot9KZjWtL7+CDrFmLH4q8P6OHiE0RJy+7YoTvsHr0JU6suasHK
NPfzrXlWZ8C5sKX0XuZTJNkfKojMVucM6olzpaE04NAtKjDffHr7Rr0md/6Zy7ru
gJIOwClDyfMmVud0J9Sx/pLKlldakJl25Xfctcz/DXZJNGpvfeMm5+pzR/zulQc1
zDopdrSq261hJKE/5N6tPflXz9UreUdRm1mZV7SEgCKODMxSxexRfw51O0fk3vZ3
rfSjSgeIz9Fs3ypJHCd2q5C4LDa5XgX8vNSYxLKIevu62BnQXJVTKCyuvzUGOrvs
nhKzR4GjrMm2575e+pxojQPVXcytFqzn4CS3QTWHvm+J1EzFwhdpR2kXAmaarpye
JbUjuCDHDhJPegXY0oRa51lLhvcij1U6smqutADIQSck5JmyQKuC+x7Y8iLk/HSO
3uni8G44oFCf9KJG69f5Va0RHgjBUOZgKMAlKA2IPwMFGDpaoxesxgFlEcAjghEC
3KEAoK+jSxWG0hQa1aK0vkQ+IvD+Ag7EAKDahnKlbMifGmPSpYjK0zcUeojzyw==
=NLH6
-----END PGP PUBLIC KEY BLOCK-----
D.3.120 Ulf Lilleengen <lulf@FreeBSD.org>
pub 1024D/73087425 2003-12-21
Key fingerprint = FDC2 6422 3949 9965 0F33 8726 0882 E0F2 7308 7425
uid Ulf Lilleengen <lulf@idi.ntnu.no>
uid Ulf Lilleengen <lulf@kerneled.org>
uid Ulf Lilleengen <lulf@bbnett.no>
uid Ulf Lilleengen <lulf@stud.ntnu.no>
uid Ulf Lilleengen <lulf@pvv.ntnu.no>
uid Ulf Lilleengen <lulf@kerneled.com>
uid Ulf Lilleengen <lulf@FreeBSD.org>
sub 1024g/CD5F3420 2003-12-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD/lfxARBACrpdJye4zO2JikjmeUGzGYnVyCw3LN6oeksqtB/lUkUGDtkZe/
XThVT2Asbx7U0MgiYs2S0/fKStdkaRFSLWpNgao4+pCiEQ/hs1GTt7ScH4fLNTN9
YG/CENGOf9aSfeB/IZLXYXSXKicg6veLXq7VTsCcS9gELG9oCcZtUjF5gwCghzPS
Sm0xpC5tBM4o0IgS6ics/jED/1BtbGw+hHo1UZSb/KUt14Hr0RKsEEuqxaOXsT0d
5KQQkeBOsX7EtHD27g/mz5BFPLa1kMkci1V7ikuOpr0cMuxprpTIKir2T80bfpsh
xAF2a+sjonJje2msur1855/jnHluelBeJcQoeQv6V0MkdIIJI9TN15St19rNYzmg
iQfVA/4/XdKIGzJFYAh9G4QoOY1uqi0SrblEbXRvr+qpsGe1Ecnu3SDrdbB7VDvJ
agPx8/lD7e6E4jpbbiDIhPPuGzxrrdimPO/Bj1pUsWx+SnMAX7XRm/I53aPLMBga
fhuthR1dQ6V1tUknncdW4ZVYFmtdsYw9dzHeDwl0QovPcx1fKrQhVWxmIExpbGxl
ZW5nZW4gPGx1bGZAaWRpLm50bnUubm8+iHcEExECADcCGwMGCwkIBwMCBBUCCAME
FgIDAQIeAQIXgAIZAQUCQ4odFxMYaHR0cDovL3BncC5taXQuZWR1AAoJEAiC4PJz
CHQlkKAAn2IrzE++SBDcd6NYtc2bxQH3ncZ2AJ9WE9IKAAQcIbrz87f30IQRvbW1
XLQiVWxmIExpbGxlZW5nZW4gPGx1bGZAa2VybmVsZWQub3JnPohyBBMRAgAyAhsD
BgsJCAcDAgMVAgMDFgIBAh4BAheABQJDih0cExhodHRwOi8vcGdwLm1pdC5lZHUA
CgkQCILg8nMIdCXigwCeNKpq8RopSSXk/Ab9KOzviakGxEAAn2Sf33OvPqZyvspm
i6i9HwODXpNziF4EExECAB4FAkDmFQ4CGwMGCwkIBwMCAxUCAwMWAgECHgECF4AA
CgkQCILg8nMIdCWMqACfTS7hPMk6MsfILzd6WmqMakZryFcAmwesOd8mBVMk35+K
AbkM8rAnK3SyiGEEExECACECGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkK8LmoC
GQEACgkQCILg8nMIdCW9RwCggaqhKrm8o8zI8pzC+JNMePbGUq0AmwZMXH8Rx1Rh
4KwxG9l5z6Z1mKVJtB9VbGYgTGlsbGVlbmdlbiA8bHVsZkBiYm5ldHQubm8+iHIE
ExECADICGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkOKHRwTGGh0dHA6Ly9wZ3Au
bWl0LmVkdQAKCRAIguDycwh0JakfAJ9p1R6siiMj6SELxG1qMDg9MrUXHQCdH2LV
kvfV6LYfKMuE6cAS7xW7hMWIXgQTEQIAHgUCQrwuTAIbAwYLCQgHAwIDFQIDAxYC
AQIeAQIXgAAKCRAIguDycwh0Jba0AJ4tOVOMv8OsYwjXgNqKb4yiTdwd8gCfQc7+
clv5cX8fd/pZN69fnaQm+ha0IlVsZiBMaWxsZWVuZ2VuIDxsdWxmQHN0dWQubnRu
dS5ubz6IdAQTEQIANAIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheABQJDih0cExho
dHRwOi8vcGdwLm1pdC5lZHUACgkQCILg8nMIdCVNfQCfdTCvzJkgzNlMroWJrKLC
bc2ET8wAnjY1r/V9b5AB0bE2YyjmsrqKkIkhtCFVbGYgTGlsbGVlbmdlbiA8bHVs
ZkBwdnYubnRudS5ubz6IYAQTEQIAIAUCQ+U5zwIbAwYLCQgHAwIEFQIIAwQWAgMB
Ah4BAheAAAoJEAiC4PJzCHQlU1wAn0HM455aU7PaRK/ZZBTjyzLIMhw5AJ4313Uh
DxV2WIPYXBkcqwjX6glNH7QiVWxmIExpbGxlZW5nZW4gPGx1bGZAa2VybmVsZWQu
Y29tPoheBBMRAgAeBQI/5X8QAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEAiC
4PJzCHQl3vUAn1VYOvi74AI/F2uy5B8bH/RfVABCAJ45AKdEIOTB23oUu180WplE
YjJ2xLQhVWxmIExpbGxlZW5nZW4gPGx1bGZARnJlZUJTRC5vcmc+iGAEExECACAF
AkcPt8QCGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRAIguDycwh0JcmZAJ9M
a2kofa4Hhj4nu43tx29PGudF8QCfasClfuVlDbpnc9h29eI+H0rYzqe5AQ0EP+V/
ERAEAJPhbg/p8IX++4RejKMBesIcwIesMcBfKfPYr+9kxVDzgKVhXMumV4fF78W4
QGbF57HunU7aghdiB5AqGBQ32AAlmVQO2YpvxaQwWb0N92LfosQEWCC/c6/muofm
PyvfP28HxNzxI8V2/PuQTJkzMB/IrbNRM8R8ptso8sASLuOTAAMFA/43xIF7QGNF
XqageSnFfTfvpPvH5RMpp7+bd1ingnLidpEhFcUqu81Qhijr7qxIXwW6Lo9kPicq
v1tuRYNsroZBHbUpc7KHsJzXDm/J/g+QpFgFsHuZ7Z0Bm/UsItA5ugOv1d6mJQm7
jylV69XbpR7kKX4US8V5ikVUKCvOVC9BgIhJBBgRAgAJBQI/5X8RAhsMAAoJEAiC
4PJzCHQlH6wAn2w+rfUbxlNv37wBNGgZ1Y5WVoEwAJwJslKSlIMH+/Dqu3enqWPq
G7h35Q==
=VA4c
-----END PGP PUBLIC KEY BLOCK-----
D.3.121 Clive Lin <clive@FreeBSD.org>
pub 1024D/A008C03E 2001-07-30 Clive Lin <clive@tongi.org>
Key fingerprint = FA3F 20B6 A77A 6CEC 1856 09B0 7455 2805 A008 C03E
uid Clive Lin <clive@CirX.ORG>
uid Clive Lin <clive@FreeBSD.org>
sub 1024g/03C2DC87 2001-07-30 [expires: 2005-08-25]
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: PGP Key Server 0.9.6
mQGiBDtlTjsRBACWK06+7mvIGANAHlZcVtH8KK7jv4Bx5Q+eJ/SmHeyczNpVteQw
GljaasBweg7xd3b4Q5//YKFZ+U50wzFWHFcLcMvwCwNN1XedC6L0rq0Ra1YpIA2G
eWkr6MCbf8qtYOdayoC/B+oa1IKtwPmHpA1racXLPuAuSzyZrIA8JFIY9wCgyN3M
+2U5F8gjbDATfzEJ/BpvIeUD/R6R7711Q7zydbw1EkOEu+eqJdX8hNUtokzQDyJT
InrT0K8xKdOfbNsqe3wRt/YNxmqBZG0AQX9FPIYID3YouzTW170nxSB1cfvUDeh0
UzKLz4OGvy3eGJr6nab293zmCaqmf4MXwkxxAEdKfwCw22Z70CI4Ul7bgvDlgob/
LcuaBACUTJ9WEtchhGFsSTAArFNs6dfW8AuxTKDPZiV02PbrJPAvVTjDZiTCq2DM
YshoOoYpE3it+wIzlCCr0CeNZevwvsmM++3OqsWjlIv12cFVVbrAAvdAaiPe+gCj
E+zneGcQ1g37F+xOIdMoWuIiGuLfN17f1xJpPtVGXoUR2m/++LQbQ2xpdmUgTGlu
IDxjbGl2ZUB0b25naS5vcmc+iEYEEBECAAYFAjyRtiUACgkQvOLiI6moxGLXAACf
dcL0hKYyhJWxmABNhqbEknRQhT4AoOI+SEXos7jrce6mjB8iNqkJb8GMiEYEEBEC
AAYFAjyRtjYACgkQrMYBZRHAI4LHPwCgibaa5ENhSv/1g3CrLPaSaCM/7owAn3HF
p4cwse35MVoME1VNLIcYgqBpiEwEExECAAwFAkGvRH4FgwFeFqcACgkQWDJ/lrPx
jd7IJgCbBPZff90iTHboTlUWbty9UXdSdAEAoLVRp6reDdohgQRWK8lAsdzYlixt
iF0EExECAB0FAjtlTjsFCQHhM4AFCwcKAwQDFQMCAxYCAQIXgAAKCRB0VSgFoAjA
PpUuAJ9lRv8+TgjyKbfHnXWsqgB62tv2CQCeJnJFrxfIn2u5EndaQJWKoUGjZvmI
XQQTEQIAHQUCO2VR3gUJAeEzgAULBwoDBAMVAwIDFgIBAheAAAoJEHRVKAWgCMA+
LlEAnRgDkCttHGVycBhwp7ILIMtnCrTaAJ9KpHRfBpij9RR0bNT+sQC+j/49DIhd
BBMRAgAdBQI7ZVK2BQkB4TOABQsHCgMEAxUDAgMWAgECF4AACgkQdFUoBaAIwD5Y
IQCgi2s7J2Wr9xxEoMUySaDxm0tJRxAAn2AaD4P0OazPfEmAE6AD3i9DJbysiF0E
ExECAB0FAjtlVBYFCQHhM4AFCwcKAwQDFQMCAxYCAQIXgAAKCRB0VSgFoAjAPh0z
AJ9PT/hFIFfNnglKGrK1s2apjFCnHACfWfANsEucBTRcs4q1GkJdY6Zfr+yIXQQT
EQIAHQUCO2VUpAUJAeEzgAULBwoDBAMVAwIDFgIBAheAAAoJEHRVKAWgCMA+eJ4A
n274CHva+usxghVGD0ugR8wGuJ8+AJ9LhFlLEK5C0rZNnQFoBHl+9i7aKohlBBMR
AgAdBQI7ZVSkBQkB4TOABQsHCgMEAxUDAgMWAgECF4AAEgkQdFUoBaAIwD4HZUdQ
RwABAXieAJ9u+Ah72vrrMYIVRg9LoEfMBrifPgCfS4RZSxCuQtK2TZ0BaAR5fvYu
2iqIYgQTEQIAIgUCPXo30AIbAwUJA/YdFQQLBwMCAxUCAwMWAgECHgECF4AACgkQ
dFUoBaAIwD4mlACgsmIeQL9JztCnJ/YYs6H0D/P9P0YAoJRelusDdc9/9sLOulpg
xxeSEV3CiGIEExECACIFAj16Oe8CGwMFCQXXUrQECwcDAgMVAgMDFgIBAh4BAheA
AAoJEHRVKAWgCMA+bBIAoIXK5rTueGdQdEhmCgmczjJKPCUeAJ9gh8t1ubSSMFd9
ftqRBwqYNgYpwYhlBBMRAgAlAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAIZAQUCQSwn
pQUJB6gM6gAKCRB0VSgFoAjAPiruAJ9OUlr1G2+oZQTAnAnmJO1CoSsIEgCgnJJS
pV8t/Y3bcIGmociaJCnUuO+IZQQTEQIAJQIbAwQLBwMCAxUCAwMWAgECHgECF4AC
GQEFAkK2TiEFCQkyM2YACgkQdFUoBaAIwD6WMwCfRXekIZlEeJzUEo7XsUcztErL
t70AoKmJXG64E+WgGatl7exj+plQIDd0iGUEExECACUCGwMFCQXYpswECwcDAgMV
AgMDFgIBAh4BAheAAhkBBQI9ejyIAAoJEHRVKAWgCMA+1voAoJBm2lezo0KY9k+d
5T73BohAfjyhAKCPbGbPlub1MgR+gW22rzYWFZMy6YhlBBMRAgAlAhsDBQkF2fnB
BAsHAwIDFQIDAxYCAQIeAQIXgAIZAQUCPXo9/QAKCRB0VSgFoAjAPtmpAKCWeV0t
GDC0pD4zsgKhf/Dj1lnRfgCeKf3ZJWdckS8yK6FwZoK2cbw0NjC0GkNsaXZlIExp
biA8Y2xpdmVAQ2lyWC5PUkc+iEYEEBECAAYFAjyRtiUACgkQvOLiI6moxGJvYwCf
dYm0zYfOvSe1ARzrMSGcGhchCLgAn0rzSA5L2OKvArnMX+qdun1Vxmd+iEYEEBEC
AAYFAjyRtjgACgkQrMYBZRHAI4KIDwCeKWsXb4GLH8g8/gtiv+hsgOni9l4An10L
0LtQPIryuN0mr3oCmPi4erCNiF0EExECAB0FAjtlUpoFCQHhM4AFCwcKAwQDFQMC
AxYCAQIXgAAKCRB0VSgFoAjAPjUtAKCH2cH+UKJ0WjnuTKOVFQGIKCuW+wCeORfh
xAGeUTJAbecLqB0u0wVw9bqIXQQTEQIAHQUCO2VUjQUJAeEzgAULBwoDBAMVAwID
FgIBAheAAAoJEHRVKAWgCMA+b7AAoJMIHZEjleZhRTvAWxMIl6s577f3AJ9TDYGP
K5Vj06IayHUPhlcafafM/YhlBBMRAgAdBQI7ZVSNBQkB4TOABQsHCgMEAxUDAgMW
AgECF4AAEgkQdFUoBaAIwD4HZUdQRwABAW+wAKCTCB2RI5XmYUU7wFsTCJerOe+3
9wCfUw2BjyuVY9OiGsh1D4ZXGn2nzP2IYgQTEQIAIgIbAwQLBwMCAxUCAwMWAgEC
HgECF4AFAkEsJ6gFCQeoDOoACgkQdFUoBaAIwD7I/wCfdE93DKKLuL55htZTwJaq
PJ4A8xsAmwRfU4BMUvVKSYesk8viO7qdOPmTiGIEExECACICGwMECwcDAgMVAgMD
FgIBAh4BAheABQJCtk4jBQkJMjNmAAoJEHRVKAWgCMA+7U8AoK29KbFojuh7WEkJ
xXxZH1v0dZlBAKCfbfYiAF+zNv/GLvIM0WkMbqt1YohiBBMRAgAiBQI9ejfRAhsD
BQkD9h0VBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRB0VSgFoAjAPlG+AJ4hEd07UNmy
QzXMxvNb0TrP5B9u1gCgrrz4xQw6CoR6nd3rMLOABVNRj0eIYgQTEQIAIgUCPXo5
8QIbAwUJBddStAQLBwMCAxUCAwMWAgECHgECF4AACgkQdFUoBaAIwD6OuACgkEWE
w+ruNwOsymY+LdyKWhjfu3kAoLqI2LchjI9OI/CfwHzDb0u0qZO1iGIEExECACIF
Aj16PIkCGwMFCQXYpswECwcDAgMVAgMDFgIBAh4BAheAAAoJEHRVKAWgCMA+8GkA
njLU1EatPIYApFgB1fHkTDj0oPMwAKCeyYFkRP3Wn70hpMoCEDZIJHE59IhiBBMR
AgAiBQI9ej39AhsDBQkF2fnBBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRB0VSgFoAjA
PvY5AKCBVqePG+G36tBRoa6ZaZDhooji4wCgtV/HSmS8Ixqke4WoJWrw7dOUi3S0
HUNsaXZlIExpbiA8Y2xpdmVARnJlZUJTRC5vcmc+iEYEEBECAAYFAjyRtiAACgkQ
vOLiI6moxGIBjgCfYrqPteHie2FYxI141bEi01uADccAoMDWWg0SB0jiOBw6BzcG
A47TJgNGiEYEEBECAAYFAjyRtjgACgkQrMYBZRHAI4JvUQCgwyD6aRpYHebDB4aH
rhfJo2c+hTUAoIMGsEo1BFIvDg0xKeVRcJbhGzI0iF0EExECAB0FAjtlTtsFCQHh
M4AFCwcKAwQDFQMCAxYCAQIXgAAKCRB0VSgFoAjAPsHiAJ9xCGQ27FzKWPNWpZd5
z/ubhYXVRACgmG2DUKtDM26ZXqBxlh925EcVhCmIXQQTEQIAHQUCO2VUfgUJAeEz
gAULBwoDBAMVAwIDFgIBAheAAAoJEHRVKAWgCMA+Z4YAnR+i+7bm5D5LdEA8TISL
6+JNOStaAKC2D5VSmva73d7nOjy8ixv03Nxh8ohlBBMRAgAdBQI7ZVR+BQkB4TOA
BQsHCgMEAxUDAgMWAgECF4AAEgkQdFUoBaAIwD4HZUdQRwABAWeGAJ0fovu25uQ+
S3RAPEyEi+viTTkrWgCgtg+VUpr2u93e5zo8vIsb9NzcYfKIYgQTEQIAIgIbAwQL
BwMCAxUCAwMWAgECHgECF4AFAkEsJ6gFCQeoDOoACgkQdFUoBaAIwD7mUQCgtEcK
Vzpyj4O7XiP9WzNKaCPwVFgAnikbm6kCxVB2ufTvz5vFOVj4vC2WiGIEExECACIC
GwMECwcDAgMVAgMDFgIBAh4BAheABQJCtk4jBQkJMjNmAAoJEHRVKAWgCMA+vnUA
oJXIbMcZB9ZNfZudnUOPdKv3zrktAKCsy6geoCVCpn4HF45V4WCESQjTkIhiBBMR
AgAiBQI9ejfRAhsDBQkD9h0VBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRB0VSgFoAjA
PnZ9AJ0b6QgbMGcVvEi15nc/6UCkkQprfwCffnprsRmO+/e0WEcIdUrXXX0iPIWI
YgQTEQIAIgUCPXo58QIbAwUJBddStAQLBwMCAxUCAwMWAgECHgECF4AACgkQdFUo
BaAIwD672ACeJ2WFvKV43i+8TpWjTT2dJ7qQ//sAn0ktfTjXkymogXLtO0kdm2DL
+X7CiGIEExECACIFAj16PIkCGwMFCQXYpswECwcDAgMVAgMDFgIBAh4BAheAAAoJ
EHRVKAWgCMA+oqcAoJNgHNBwAAQZSClQv2YOzO6eoHi9AKCf9PmxceU/dW1a7Xnv
HDsZ7Q3/T4hiBBMRAgAiBQI9ej39AhsDBQkF2fnBBAsHAwIDFQIDAxYCAQIeAQIX
gAAKCRB0VSgFoAjAPtogAKCz7a9KK0GT3ebtxA8POzdUVOovTwCgyKHuKty/1sfo
xEu6udRpvvz8bmG5AQ0EO2VOQBAEALf8ssusqYLEbmL+VMjyhiftLcD3vyInzDik
5DBcYmUA3cKs/5tNrdznITPVGPS9Smpq1PfcgMqsX7PIDGyqoN0yQtUKYurDG9zb
0VyUA+YDCep7U7E8UWJ/zCdBUe39tq7LZLbLnZ8jyoKzZfdy+p940aCjwIieUUaE
6B2EgK7LAAMFA/9w3y9SiixtxIYXoEA6znq0omGj8hwL4OU4wfPO9q88mYKa3Lvb
y02C+EEtktj52uFjanG/Y/xIqRxhvkeI88ygd5ZAeT9LLgF7js4a2J1JhpzDifPX
RFQmI6V6xcsnuykSKiUgb2ZQsBeI+pETOGu5k8ErEWQ6/50cxbNbIh1Nk4hGBBgR
AgAGBQI9ejmxAAoJEHRVKAWgCMA+158AoIK3YF5vEu9RPSj8M4UJN4DrQ0VsAJ9c
tF/cItKqIqZ9RhFcg+IisxgUtQ==
=g51D
-----END PGP PUBLIC KEY BLOCK-----
D.3.122 Mark Linimon <linimon@FreeBSD.org>
pub 1024D/84C83473 2003-10-09
Key fingerprint = 8D43 1B55 D127 0BFC 842E 1C96 803C 5A34 84C8 3473
uid Mark Linimon <linimon@FreeBSD.org>
uid Mark Linimon <linimon@lonesome.com>
sub 1024g/24BFF840 2003-10-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD+E2XERBADU5F4DbwP8KaHN1H+yz8zaPjOSLJushNA8Qu0hN7GXqd5vgRDc
zzzeZIzVVxPVdrQ+I24UwSIYu4ww6nfum6kRv/i5khxbYM4zGGPG7s5pmqIECum1
tKvJ21IE823lcJtUp0C4qhCTZvoc3lADMn9cPgOSJClzHjAYDasOTy9hhwCgsTqP
aHntu6Uj3BYpurWHJSePWrED+QExF2asNPehIOZ4l7dwpaeGSTxeINH1FYnlF+J1
N8lvpFQ2H3sfSViVgAtqM27Y/jOf3EkQH0Wym0iCczOxEUFbNH5NWAm6IOVT9owo
tkh2PZgyfN0AJZBPh9d/oMN2MEKPb6wcqr3c67ZmQG7B+LGliBSVYhWDbd6E2YHb
bvKVBAC0pL8fzNldEQUUYDTTrWhMVCr7IGzwrd6cEhIZ6b5kqQd1IsIChVG3jCVL
wWGSgmXY4J7i4Ujsx8k/f6CluNLwmP5t9caycz32QdJAWkzQq2x4AQUy56HDbvui
QFOqD+PGWqvoUUyJqLbzoASI5dcV35OY+m37Z1Wxhsn22WBE0rQjTWFyayBMaW5p
bW9uIDxsaW5pbW9uQGxvbmVzb21lLmNvbT6IWwQTEQIAGwUCP4TZcQYLCQgHAwID
FQIDAxYCAQIeAQIXgAAKCRCAPFo0hMg0c5j/AJwO+VSVExRY8saToDKF3hVe4wNE
EwCeKFf5ysZjQIJY3pJ9tUzm8o3tX+i0Ik1hcmsgTGluaW1vbiA8bGluaW1vbkBG
cmVlQlNELm9yZz6IXgQTEQIAHgUCP4yK4wIbAwYLCQgHAwIDFQIDAxYCAQIeAQIX
gAAKCRCAPFo0hMg0c8c4AJ99m0hHLctAVXjfZYurZBnl2dUL7gCgiG83BXm30rBa
POtWm2AstMb6uVm5AQ0EP4TZcxAEAMQPPoRMfBR3cRc/T5NsWunFlZA6nB+3BkVd
p0ham4FoseEh7q+hqa8udARMpTc4LIIL4FU6lIa4L0s3Z77d4bXfJmwlUHuUMSk0
tnG003D4VDBc3HWSSX/W/CRyN+OBxPljJywTjI4goyXx9Lc31qwpGqYy5Ao8X6EA
TT9g3IgzAAMFA/wMgON1JxPGr8MSvSLHLMY/xn2PR8lSVZmOlbhNE5hL2FzyFME+
Pnc8hR31cohFjSXR7hb6SOWrZjYpdIVsa6qdqXIRDbcb5sKEGv9959W8yt+L/kNr
RlN3oExA2pkYpEQfLpH0HdMmbU61NR0cI6p4ZZly4p6JR0kEajaUOlq/cohGBBgR
AgAGBQI/hNlzAAoJEIA8WjSEyDRz9lwAn0pJVzrxxaB/PqtJsu034bH5PnlDAJ9G
axdzE7A6F/UPmrURep9QFDq70w==
=GflG
-----END PGP PUBLIC KEY BLOCK-----
D.3.123 Tilman Linneweh <arved@FreeBSD.org>
pub 1024D/807AC53A 2002-06-03 [expires: 2009-06-15]
Key fingerprint = A92F 344F 31A8 B8DE DDFA 7FB4 7C22 C39F 807A C53A
uid Tilman Linneweh <e0025974@student.tuwien.ac.at>
uid Tilman Linneweh <arved@arved.at>
uid Tilman Linneweh <arved@FreeBSD.org>
uid Tilman Linneweh <arved@inso.tuwien.ac.at>
sub 1024g/FA351986 2002-06-03 [expires: 2009-06-15]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDz715ERBACtUda6yExghzQAimIJ+aH4fKEXDYUXk07t8KURPZD+LOCuQkwG
DF71fklUC5tC/aYOXtHkBD0trw1rxtCuJxtdwSioeCi/gslrd0X4iTmsd6cPsJ0v
ZFmMcJpwy1TappXGeaZ1q67MS59itR/TTRv++z57mJBVtqPLYGLUH/H6mwCgkibF
7hxfeFLg5UEQP1EKw/JWZ0EEAISeVnxqgJDaf5VsRRfdr81bxTVh5G5DksisElrr
+ipHE0a68UicR+ci8Hg9mPxsJB9Qpr5fQ5NTd1UtEJx2C40LaJvebtFB2UJu7SEY
jwQ1KzoJtbU0IfnHUGIqog+l2iLFDJdwho319kJzsatHlt1HT6Kt2ZCV6w0G/PbH
+gDlA/9ocHK/4MuyM1bbHP2dYv+bbY9PgprgdNQYCowqRsjGFuuV12Oc1CJm5Ksl
tLunUsa2DupQUe19Fw5A7nyU1Em5sRESCNs0RE6YgxKb22OuoejPS+u5C9agDKa1
/6yHHm0Yk3FdsQh8uiCvGo04y32riGQZxwX8UHGQdd7KSSCDkLQgVGlsbWFuIExp
bm5ld2VoIDxhcnZlZEBhcnZlZC5hdD6IZAQTEQIAJAIbAwYLCQgHAwIDFQIDAxYC
AQIeAQIXgAUCQPwPkAUJB8Ke/wAKCRB8IsOfgHrFOtkWAJ0RM+cJJ3uaGn+PBigE
zfIELKoVoACfY599K2Iug+qpQQwwvHYYzOk+OFyITAQSEQIADAUCQOpisQWDAuPe
XQAKCRAdR29gbPDq9yDcAKCYjKuAJHQvnuf+1IeGScwhhz+WWgCfbp0k+pDYlZ6k
7TBi+7PmPPyhSXuIZAQTEQIAJAUCQJJ4CwIbAwUJBtJpfQYLCQgHAwIDFQIDAxYC
AQIeAQIXgAAKCRB8IsOfgHrFOl+uAJ457x4ErxhaO2Jy9adbBox5Z4wijACghN+k
+GyBdagYlYUWkK11hp/0ZSWJASIEEwECAAwFAkEksIIFgwKpkIwACgkQG2jc/MBZ
aCORbgf/TONOxTSoOtnjM9ykdLmxJV2RvyHSCLrGNKIG2rMsZtcpH5OZ0RY14wcg
UQBdcxwjyWw0cHSEvf/ceh1smlQUz9uwrFnfygKn+Z5kOvmFjR0lnli8KFbHqE8M
X0tdke7BM4yyViCh/Cg42ftIe4uZfoBjvGBTqHTJBrtybk+2Whpr+DsLLCiqY7O5
MGwMAo6njFopM48Cv7sMvMnyMGw9sNTD9j0MhHhCAjV2Csd6WgvCNxPvsAT7a81W
DHmz9QaxWL/DQ2j17aetPwYM9GoErSxLzDmpNqFVVrDehpvxPXJ2Ki7SCkF1hjy5
cSMm1/ZKwWKCLo9rn6FgWinKbmN5WohGBBARAgAGBQJDnFg1AAoJEMYEPFZyB3E3
cigAn1oWHCfS+l/8C9Wsh6wOmEch3G1xAJ9EJ7w1VLaHxvpjD7Hagn1BXVpN5ohG
BBARAgAGBQJDnF6YAAoJEHninGCwBj/nLR8AoMTfuesvwwrorPSgvQjuWfuzWE7B
AKCpdUEXuOVJPhoeF19AyDwn10KZFohGBBMRAgAGBQJBhOHmAAoJEKsvWlsVJWmQ
+4gAninkJAT3QPl6wVA1XaEioBWlRPOfAJ9tGh5oyJW4nYAdmpGkfPtFcCGawohM
BBMRAgAMBQJBhNcCBYMDOZ+OAAoJEL9L0OYEnbh5zIcAnj1LvAWLTiL6AdYFqhHm
UXoIMUr4AKDzb0KlFompnEmng3tnAqooIpd3WIhMBBMRAgAMBQJBhXr6BYMDOPuW
AAoJEJ7XWD/BTrKCyDMAoJ76QEd9ClEBrdH8m9IIEdhaQGL+AKDNFAIK0PvdxvVs
iqNaFgEjcMSbH4hkBBMRAgAkAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheABQJEkrEa
BQkNOnQFAAoJEHwiw5+AesU6+/kAoIrphPvC8zh2HQAVN5KtwiinqgUoAJ4/hj/S
pea5anGzLmQf0i1cTFKmZ7QgVGlsbWFuIExpbm5ld2VoIDxhcnZlZEBhcnZlZC5k
ZT6IRgQQEQIABgUCPQEmWwAKCRBnwwMIcls3xlbnAJ4mqyE9U2svn5pm7AyG/j5G
OyhOqQCfahDzCmIa4k5hMs5vZpPUlShqQAmIRgQQEQIABgUCPQH8LwAKCRCVZB9r
JT5Y42Z6AJ9PWRjpvTsdMirhUI8FPcifZdtmHwCdEOO9K/CNIpQyOOelSGIy1drT
tIWIRgQQEQIABgUCPQPwnQAKCRB4y7mVGlcnuRJOAJ9LS7+vS3boxnAKsrPYd0qO
6+2RHgCgsYwJn6OfnTm/cKC/4j+kLLRRa/yIRgQQEQIABgUCPQSwcgAKCRDOPNFA
dhcTZ4btAJ9wSIQYdIiQid8R6N2kP/x/pj2bnwCfbZNfkGKHvzGBPdQ70pLx/1L/
KUGIRgQQEQIABgUCPQTAPAAKCRBRrPatdb6Al8WrAJ0UGWD3ifEeDXhBYDkF2/EI
lfuMOwCfaHvJ5BzWEak/uQAEYUzWb1+GrF6IRgQQEQIABgUCPQTZhgAKCRDjd7Y7
dn78JOxkAKCKAbcYrsygWfCdxRvMnKLZWmkGpgCffubUsi7Xsb1Nw3mjxHCw7zz5
R46IRgQQEQIABgUCPQYM3QAKCRDu+906H+KB67pwAJ9rd+2ffHCswoNT5zFIGbMc
2qiuyQCgilA4iXbtYLDofNnkhusAnZ1Nxr6IRgQQEQIABgUCPQeqGAAKCRA60+bK
hIXg1wZhAJ9qENZjzGa4hlWBMU5fODifYAJ1GACgqf2BCJf7l223znEV7bfiev49
BVyIRgQQEQIABgUCPQp2zgAKCRBo7eMoW+RPkTUYAJoCV1CKRKzY/M5FlqXN3rq9
xdRajgCggYofPiicSisbS/otey5jWd4eAC2IRgQQEQIABgUCPQqPHAAKCRBc26rS
0UI1oNGxAJ9ExMVh/1WCpniFcHunE6eI+5J6OQCfUgopkzFkPg7+jGbvtBVB4Frl
FM+IRgQQEQIABgUCPRc7RwAKCRANYRDWc4/ggX4WAJ9eeEaBe2+ll/9CSagciyWQ
NgkaxgCfYJKYo/lHMJ4lZf67t0mDWQWDFeeIRgQQEQIABgUCPRojrAAKCRBJgeBk
iD9BQnifAJ9VmfUOZsTF6iElfMCc357hzDtYcwCgz9NrPqDjBjkGfA7rKJh9TAVy
2hOIRgQQEQIABgUCPRsZ7QAKCRD9n8P2kOHjRhv1AJ98t2dICzYBBz5HlGsCx2ZD
z7qxMgCgxETlcarFyob2qPD9nQQCf3pYseaIRgQQEQIABgUCPSHiTwAKCRDmTDIV
2hU/q959AJwLuccd2AAC9BJ+Q4XRfqsYK8rcvQCg2B/Ek/s9V7hs6cH0ZelLnfDO
CaaIRgQQEQIABgUCPSRdQAAKCRAoobUtGtp+LHUmAKCSBapTT6fM+UZH///UVFpx
vC4SlwCfb5nT+bUE7ZJpFeyh2FEuW0LbqUKIRgQQEQIABgUCPSdsHgAKCRB9n5GQ
byq7LbgQAJoDxrU5j5yyPtUZJ9HRpkfs5M02xgCgwlE4kNBns6e2o0e1kWHY7D6b
Ku+IRgQQEQIABgUCPxBYqAAKCRDW+vrdlS8//6PlAKD2GuYPlMhCzHVhSVj6UmwJ
4G1zggCgxmcpqcsXq9h5C6YC8zU+l6cVjC6IRgQQEQIABgUCPxNE5AAKCRDQGfXv
kCeriBq7AJ9OOIDoxlUcTSN4qNQaDXHyR64V6gCghjbBcdYPfm3ji+XuGYz7o40S
ONqIRgQQEQIABgUCPxZMXgAKCRBGzFxj8xilajZqAJ93aOMSC8aCYLI5Gp5qLFia
Fj/pigCcDvqx/OVATb1CQl64AzlEuI7Gnw6IRgQQEQIABgUCPyBAfwAKCRAo3bD9
Gcm2uqPUAJ4oei6IliN0HvGEFLmqu+NGo7OpwgCgnHTmKCpB/dqym6Qzm5+hTeC0
RiaIRgQQEQIABgUCPyi28QAKCRBvI4vCT9paDDSQAJ9LcGwoEee/F8YHf9ZFrVqQ
RyIEZQCbBIvQco54QvjGxbV7u+6f5UBpTIuIRgQQEQIABgUCPzX8tgAKCRBp0qYd
4mP81KmSAJ9t8h06cq38jRmkc6ZTXFJCa0lrcQCgp6skhSpFTj1sYuBW8tQb+WNn
ukuIRgQSEQIABgUCPQTfDwAKCRBxXtagfnuKyURJAJ0YPZBeSeWizylylUypUaIa
bZsNcACghS4ODcpZcWMWAo+V35lLaZq9YVeIRgQSEQIABgUCPQTnSQAKCRCP8RrF
3+gPsni2AJ9VZS7tSKFWzMVW93/zV4FsQPzFswCfbT0ebezV47Nij/nyFRwJd03k
Ha+IRgQSEQIABgUCPj0tFgAKCRCrZOBpb9Z/ZGpdAKDfSIprUnXBqtqMA3JaBOVI
iBj2OACgxdSzv7wcOT3RqPTlBMa3nz6cfsuIRgQSEQIABgUCPxcLSQAKCRB3+BUz
uw7ox3M8AJ9olkCVDUWwIrS4Y4tpL3cx49LlqQCfaszzGRh+rRhXaiw8J+LjRUKm
k+uIRgQTEQIABgUCPxGn/wAKCRDFwMXHIY0Y1ybGAKCpmb4NeUELQ353GQi7x1UQ
LsubEACgofaj+px3m0N9R4qGjk8uGgC3ZEeIRgQTEQIABgUCPx23XwAKCRDeeq9u
lMCcf2vKAKCyI6VAD/P3hcMidPLf5JjshRA9tACfVyzAbakRHuTmweeW7BfOaP1/
dbmISwQTEQIADAUCP4Mg6gWDATsdpwAKCRBNoCCKE+KQpNwdAJjdhBZZocAj/xdi
1ENBXLD3ALwEAJ9IJN7cv/1KOS+PJSkzUAlzZScCNYhMBBARAgAMBQI9BfV+BYMD
uEkTAAoJEBQRON2j5F1mtKUAoNxwRw6WaplUqcEhKzAiSyomODdOAJ91aXOruYpY
vf8GGfIulbhAMr/dIIhMBBARAgAMBQI9JxIABYMDlyyRAAoJEJwvxkwIVX/fl18A
n12BQYjFZRc0flDXRh0/L1QXUggyAJ4ueFZ0M3YYsjzYOl1xRkbnuzLzVYhMBBAR
AgAMBQI+DdkIBYMCsGWJAAoJEIn1u5RlyRKFpI0AnihfTe0/LSCKz8WM0eMNuQ92
ollxAKCoHQ624Zy2TMMWG8CqclX7WYC+mYhMBBARAgAMBQI+L7jWBYMCjoW7AAoJ
EIWAWf86Zh+dHb4An09CiU6Brnldjp/D4xHn716mFX99AKDUXlSha7M8NZwDWVxM
zkvNC+/K34hMBBARAgAMBQI/EU6KBYMBrPAHAAoJEPVrJqOmOZ5zH4UAnjQVGVhY
RU53RBkQKk53Q8x3yQX1AJwMkCRBqCb6gT4KE8b9qrlOOjjlyYhMBBARAgAMBQI/
EqbFBYMBq5fMAAoJENQ8swWV/so08nEAnA7mzPf7qoWbr+1MUgF5sNNHxqxfAKCa
HFaIkkUoswwg5wUXNHvsGQ/FlYhMBBARAgAMBQI/XEsYBYMBYfN5AAoJEFl7zE4S
QqbyjL0AoIfIAUAWr+9tpfCsOny5PuOK7xWdAKDcpNXGPzdpUXwsJgO4RJClI9G1
4IhMBBARAgAMBQI/zD8IBYMA8f+JAAoJEKC+nbo7iG59a7oAnRBuW94IM4IeVhvp
OTEGaB9Ppm7SAJ0bzy34Ye7RZsGtXkgWHso6NaqJQIhMBBIRAgAMBQI9BaSYBYMD
uJn5AAoJEDX2YXxROu/ZyuMAn0Xeltg5z7Jj6+ptjhb8lHxLP96DAJsFkF7vePg6
PJM3A1AKpWZzSEIM/IhMBBIRAgAMBQI/FQ9gBYMBqS8xAAoJEPS0sMx5fr+rWG4A
oI8UDZAJEG7chm86AAl/M5GZRM1hAKCAFzKTgfclqgT8NNqkf/DE76+T7ohMBBIR
AgAMBQI/F7MaBYMBpot3AAoJEL9BWVtzcqKlOAUAn3UHUjJQ8QCsL5nN2ajXcCgz
I0IAAJ49mEofhTHpN9KDArBaSkqil//Y8ohMBBIRAgAMBQI/HHQ1BYMBocpcAAoJ
EMgPdFmtwp7NnA8An0ECOACHfqftDrYbWo54e1blqQr4AKCKAvVRmQu0YNRiUNcj
cR3gR4inAohMBBIRAgAMBQI/HxxsBYMBnyIlAAoJEOdNKbgr4W0BMpoAoJ/xc4Yv
+lwsGK6lnUBPv/RSxSYAAKCrOJS+kYD4Zjuu3eEO8ygQVeYujIhMBBIRAgAMBQI/
I56XBYMBmp/6AAoJEBigzI1XBqS0PqUAn2EHSSJhOma/B84qFhL38hVjdorWAKDf
vHzdy4hroOHA7fJoxVF7Tut7TYhMBBIRAgAMBQI/J9+sBYMBll7lAAoJEJ/PLM0/
PmQmAfAAnRruc5kjtXi+iLWP70QZ9I6P4ykhAJ9c3REtxX1DnUhocojidGRVGjgQ
rIhMBBIRAgAMBQI/KF2TBYMBleD+AAoJEJYkg+FWYsc0YDQAmwddwM4E7w1dGDWy
PMF6PjcDSXQkAKChIYK6bM9inabfyldkX+toGHYsOIhMBBMRAgAMBQI9BeTFBYMD
uFnMAAoJEMoOFpwo+jiKKQkAnid/I9kd7DTXfhvn0lkJl6SLRVNrAJ4m0a+eB6Px
WCxtqQLBtiOWT7blOYhMBBMRAgAMBQI9BgvyBYMDuDKfAAoJEI2aPB842e2bZxkA
n3VO6NUbq3BLz7yG336RRGciJj3QAKDHuEyvYGsvsomRLRMIxtgxIy3IV4hMBBMR
AgAMBQI9BnBFBYMDt85MAAoJEBhZDH3rCzfcV8gAmgL6uqWxJo/y36fZB1GyG1VB
ay8yAJ9t3gUJ57yNxs7jW9xPFVs13VVsk4hMBBMRAgAMBQI9BnQWBYMDt8p7AAoJ
ECm+XSJo/VSflpMAoJBEiIHwl0h/nkUeTzV10Fm9TJckAKCA+MiM9TdThVSB672E
JvPCGiQ3S4hMBBMRAgAMBQI9CHZXBYMDtcg6AAoJEK4wPLMZKvd5UZQAoJvsUA8r
cNAe2dGu0+ysKrCQR54hAKCm19dKdKtlyMNdk7JwegDxX/oV/4hMBBMRAgAMBQI9
C7rnBYMDsoOqAAoJENS0NLLmdnFMwIYAoNrAyDonRQehoQfAdlJv9uJt2XAXAKDV
NE+78xgimxa17Q5JyrfD9iO3/4hMBBMRAgAMBQI9EW+FBYMDrM8MAAoJEM6KedeY
AW3HP/4An1xaReTAbNnADHug+9MjzIOZ9SjPAJ4zmmQe9ha5a0TTsrJu6sp8viyb
XohMBBMRAgAMBQI9I3v3BYMDmsKaAAoJEOZMMhXaFT+r3m4AnjDIQmnvm6MfBrAV
2hFry65muCPKAJ9o9+eFF3lS3hEoOoiF8mDUpyBTa4hMBBMRAgAMBQI9JrkOBYMD
l4WDAAoJEGHYUdmmgiFTtTIAniRboW1Zg0ecUEPQVU7ulTxnlLYnAJ96iR1Zfdso
seUqehBhdaqm9L5Q54hMBBMRAgAMBQI9W3nuBYMDYsSjAAoJEDFPepXsFSlCPBQA
nR4lEi7K3zrF1lDIpV64+zAGN1dtAJoCJViCgKWiZxwj7u3F3Z3c6xzGDohMBBMR
AgAMBQI9W3vrBYMDYsKmAAoJEBC7gPwWvXfGitwAnR3Xa96/2jNZiyQstPFjsGRH
BSVDAKDcEmlzhMV6GFa48419+p7htmkbD4hMBBMRAgAMBQI9alVUBYMDU+k9AAoJ
EPfw5w8wfVbt+YUAoIoAgq1XnKM+aFU/gKRFs2/xI2EeAKCAlTDm+9pFpiNEtjmg
nVYulnOjLYhMBBMRAgAMBQI+DmDQBYMCr93BAAoJELPQo/yz5a0xECoAoMfl+8NS
ToY83Rb//klcEYHl5GgDAKDpc2qj7s4/El7UwbxeRECXMLiqkIhMBBMRAgAMBQI+
EF3aBYMCreC3AAoJEC8Xh0DY8T2+H2cAn1iyu1H4bV5njeDdUoV50gUccyBeAJ4i
QXHG1aE1gVQuq16MgCkvbjDsrYhMBBMRAgAMBQI/DcASBYMBsH5/AAoJEGx2F4yg
7ZgttsoAoJWnjISQ+3PWFVouaFLEN/W3mWfKAJ4mMpvPD5E7A/lXY78Ed708ed0Z
pYhMBBMRAgAMBQI/ERTfBYMBrSmyAAoJEOGFItd8cSvLOhIAmgII/33+7m5dHF/m
CCN6D2iwRbBQAKCOcCNhtLai2Wsy/5Bns5uNi+/N5YhMBBMRAgAMBQI/EUWPBYMB
rPkCAAoJEOohmUEkd8r4OwUAn3R1Cix4VA3Ogc124P4lTHTlrrWLAJ45xPQneuef
kM0mrj+lQTjW3P+gXIhMBBMRAgAMBQI/EV0iBYMBrOFvAAoJEBn+2DzivqNBAdkA
n3JQWr+B+NJ2zWgpxx5dCy8RkEvpAJ9o4M9xhnDXh9RbgoNAzeiui19cwYhMBBMR
AgAMBQI/EaXQBYMBrJjBAAoJECjG9WuBfDVo1/cAoMuECNH9deehfm1Wgro2KSzE
oUhoAJoDPdEVdiZkq/TZVFzBLXckiG1gJYhMBBMRAgAMBQI/EcT3BYMBrHmaAAoJ
EL6cho0EYE64o64AnjSWNZwXMcuNdjKNYr8xIGWK36qLAJ9bdWa6wd6Wjl1uRFGK
k6Rbjy2i+4hMBBMRAgAMBQI/EpQwBYMBq6phAAoJEFZtNizuCXfoA2MAmQEKqVcc
UR1uroXVJ4JOS5GCFYg9AJ915tuiXoIhAcepGscWLWLq+i0YUIhMBBMRAgAMBQI/
Eyo7BYMBqxRWAAoJEJJVvZ/mhE25w0gAoMFrqFZtRisFazFvC630Xq+wXL3YAJ9Q
Qcrz8936/psyEwkVdxCUOwgaGYhMBBMRAgAMBQI/E/C4BYMBqk3ZAAoJEJSP1qDh
D1AuyFkAnjRGBgbHsCk/0r+A1moojSP3yyPFAKC8di2UMw9bvsBBtw/IuRhth4oL
johMBBMRAgAMBQI/E/EUBYMBqk19AAoJELR14ge6tYIpkjcAnREkZ7Qv+5Z89zRQ
8ykv/KXEAtzEAKDlrOZbHBj6uzBICO0OMTyL6xqHEYhMBBMRAgAMBQI/E/gLBYMB
qkaGAAoJELmCy9XA4x8dydIAmgMVncAjCwiLfoZMJncza4FrCrIIAJoDVxf607z5
NCTVonUIiA70zLYeXohMBBMRAgAMBQI/FShlBYMBqRYsAAoJEFgpV1AFAIOL5AsA
njS+rc8wvK/K8T4IsSOnavxyTOY9AJ4tyFFcimgcZgtHVvU9WZ6QqXEjCIhMBBMR
AgAMBQI/FWGVBYMBqNz8AAoJEJ7QeO9LOhNcQ5wAn2vPgbpsujhBtRg7TAzJdSXt
SHE+AJ9AePKh852E9VGAOoF3YS+601349YhMBBMRAgAMBQI/FWGvBYMBqNziAAoJ
EPAj+AsmhB1bfbMAoLMZEtJd+ugja7OQ+8ouRmqc3z74AKCzQaRPzpzy8XkEe+i4
ySZiqcwyaYhMBBMRAgAMBQI/FWvWBYMBqNK7AAoJELtVpH/JAcM+xWAAn0Ln65AY
tDAjdUuYIRyl97l5IS7xAJ95gwMbzt0RO68Mf/sKlkGQxoMnmohMBBMRAgAMBQI/
FcESBYMBqH1/AAoJEEvvJiQi30CHHzUAn26bkLG4z8F6+db6/WSa/+06AkTAAJ9o
BHU0WCwqgDKZM8toqojym0AfJYhMBBMRAgAMBQI/FoKrBYMBp7vmAAoJEIQs23pE
d54YQ2oAn1ypPOBspNjSI9dCzPt7YFMtvrTnAJ9rS7dS4M2oWnvIU+eFxmf+Uom9
zIhMBBMRAgAMBQI/F+AoBYMBpl5pAAoJEFO2uB3BPO4HWmEAnRDopJ7NNxg9LF37
6TQh+XldQInPAKCmaoOt8HGD3yiOV6XbRqx/Ul2gW4hMBBMRAgAMBQI/F/CHBYMB
pk4KAAoJEJEfSuaGoRjmkPQAn3PKt6LuqtQIB0TYwVH0q/RBhItoAJ9j4XtZnF/s
FXyeLNhb8hJVdX3m3ohMBBMRAgAMBQI/G9ISBYMBomx/AAoJENNbvJm8fQIKtDwA
ni8wx0LsC+0xDGuadHbwqx5GSdwnAKCZbh5U1JTn4AWf1Vpnv2hg5a1ll4hMBBMR
AgAMBQI/HDzrBYMBogGmAAoJEDu/z3e9iwUN9nIAn32veRRk5ZnmAGiBop/msWBf
FtI1AJwJVxuL1yTTejqUkAfoc2zn9R53jIhMBBMRAgAMBQI/HtB9BYMBn24UAAoJ
EPhZkLAkiutz9U8AniCKzevEPr4r2NNG4txGZ8HacwwNAJ42AEipnyAufuxPJWLT
y7gNQss9kYhMBBMRAgAMBQI/H7fQBYMBnobBAAoJEI+5tw+kz8luOo0AoOgvAzYp
HFKo5JgOzbkecpPj0oI1AKDSmtu55vcujKXgSasZ3xWt/PHnxIhMBBMRAgAMBQI/
IRZGBYMBnShLAAoJEIkhtdzNFaiD4qgAn0n6bVE2qIGhDNzbZyZrrqYHaXCkAJ0R
76g+bju3TS0Y6Vct+1aehA6ekIhMBBMRAgAMBQI/IWQgBYMBnNpxAAoJEPnQFPA4
yYWNyT8An24A20bUKiwTVvACBkTBQfQcR+jHAKC60/b5mckazlpLzAPXfu78eBt2
bYhMBBMRAgAMBQI/IWRTBYMBnNo+AAoJEF0Pf0ng5J80r50AoKaicxLX/Izmrf2z
Xdj+cPEnzKGPAJ9wGbApfwaL0BlybNPKQP/K/zP8E4hMBBMRAgAMBQI/IYCXBYMB
nL36AAoJEJSbJewHRHJSg4IAoMdQ0RPKOSFA8V2pLNAFYbebCM+iAJ4nf1kMZlzP
zkpoGr4p8q6cLb6iRohMBBMRAgAMBQI/JX+7BYMBmL7WAAoJEPK1Kl0KX7aHW5sA
oLslJOc/z6veNFyUP+BbAs+1vmF/AKCcoc1Ap80KGKxiqxXa7F54XwGIj4hMBBMR
AgAMBQI/LVUnBYMBkOlqAAoJECyYPlrSilXW/tMAnAqb8A2fwqqbV70PejvfrxSg
GP7+AKDO6USErOy2yrOJMoCYc9PWaB6JWohMBBMRAgAMBQI/NDKUBYMBigv9AAoJ
ELvHFNGcZ82WsCEAn2RLYgJCWyEp1tTPQqcZIOfdl9YiAJ494D2fr+XZh9oFh7/D
WdN5DeGFoIhMBBMRAgAMBQI/N+VFBYMBhllMAAoJEIB1JwBlqEHtoJIAn0lmI4/F
23nURAEZXhO6Je9ZOQA7AJ9NORO8Dx703EGWGCdfJo0PHUiTbohMBBMRAgAMBQI/
Sd+JBYMBdF8IAAoJEErxVCqWOlSwV6YAniF8OXsRECf2eWGEH1dG9WAimLKvAJ4/
dP2I6PB6QbUDux8JlDU+cz+hsYhMBBMRAgAMBQI/SfQOBYMBdEqDAAoJEKsQMCiW
lfJfBJoAnRGvqvZBpalXNHUIBr+GqBQ18BPrAJ9s5RMNIV2ymvLfCVCaLqVlYhkL
TYhMBBMRAgAMBQI/SgvjBYMBdDKuAAoJEO9inFQJsG4Qh6wAn2STkQsHy7++7+8t
PDhZQmIiTQXqAJ94cMjwPQpv6z8XP3gykA7xB7bdpohMBBMRAgAMBQI/Sg+oBYMB
dC7pAAoJEMBUgYZQY6CWRNcAnjAOywy6tSJf55JRj/+6k8Rq++4TAJsEV7Y7hgH0
Q0PuPOh7TU1wMEJI5IhMBBMRAgAMBQI/ShLbBYMBdCu2AAoJEG9iNrR7D/6F+TMA
oLi173b/7XbKN9WmqmJxWLceUc7hAJ47HuX6lM0uvKbw1qvR2e4W4YjhT4hMBBMR
AgAMBQI/SjPsBYMBdAqlAAoJEE6oxMIV7zzdPGQAoNljcC14Y4SANVwopcr9vwZF
rgKUAJ9bIHaD85Grl01Wbgbr58Iyy/z8aIhMBBMRAgAMBQI/SnmNBYMBc8UEAAoJ
EDtohlrYag0ZsIwAn3zy4+GYH4yZEMpfAG8XFBSVUZEfAJ0a0scTg5L3nVHPg9ss
47INoyPGL4hMBBMRAgAMBQI/UgrQBYMBbDPBAAoJEKUG5tTdTVCIx9wAoLLFuM5i
yiY0+bXGXdewBlxxlSXkAKCi+PaQ34LXRAaPt0+b0YYfFc2ytYhMBBMRAgAMBQI/
UlJyBYMBa+wfAAoJEAdlf3OihrU2kHAAn1phSiJdBdehHcXPTgfUsrv913fQAJ9P
OEBVlb6nPiP7/GAfoLwcjvMFdohMBBMRAgAMBQI/U5eSBYMBaqb/AAoJENY7cMkf
A6SKTBgAoJYZ77fSR5xWbgzOS/YEY6uNQRU5AJ9BX//P7+R6/utZWaNYcnLc0n5d
uIhMBBMRAgAMBQI/XytKBYMBXxNHAAoJELpEiomc6OesIAAAnjYleY6jz8ZLK7pe
GeOvTSMAbj+lAJ0XpF5jzPOYOZix1n1ECod8ilaZAYhMBBMRAgAMBQI/ZH3QBYMB
WcDBAAoJEGZmcXrbg1Z5uOUAni/zJASkjl3DGCpLXu9GX1RroKrTAKDcPU5smlsg
dTQ4MNSpO7hmEJ/8X4hMBBMRAgAMBQI/ZH33BYMBWcCaAAoJEA2WS2ZXDm3qlJMA
nRNt0k01BCj5re9lVvyjLsuhJWmFAJ9IQznEKnO2CS50FGqABGytU23EYYhMBBMR
AgAMBQI/ZH4MBYMBWcCFAAoJEE4CrK4d1rOABccAn03VdUI6Dx6wH1fbslxT+JB7
kTE3AJ0ZI5x/YbY5RfOlb3BcdC1R61aI5IhMBBMRAgAMBQI/ZMWbBYMBWXj2AAoJ
EMj6d5r1kZr4+2UAn2cfCAVkWjH9KD0ujjxw6dtMZhP9AJwIdeqtVvmjXW0Ud/Zw
pA1SHeFI3ohMBBMRAgAMBQI/ZyCNBYMBVx4EAAoJELMWfd6foB5+HBQAn0IfuQVS
roK+x/aQ5sdSxI2piHT4AJ9W/r1njeG2mr61pSq6IEpK9CC8GohMBBMRAgAMBQI/
dYOQBYMBSLsBAAoJEGEkmiEwk5yl7bQAnjXpJCPWfdybAge1iOpvrwSkJEi+AKCs
Mdv288xAANZdsO11BaSgSJ9CH4hMBBMRAgAMBQI/dt5VBYMBR2A8AAoJEBfCLtcz
eVosGecAnjEuTLe8jS6bgpABfU7w9o52OYuzAJ4v1BO1EMgIlzqxCKNWwy75uuFT
nYhMBBMRAgAMBQI/jxJ2BYMBLywbAAoJEBnKfwIxvJ3WxukAnA7vc/P+vq6asieL
K/QcnO6rFCpaAJsGn1o2bT53xJ1VorIZPjmIp/wBIYhiBBMRAgAiAhsDBAsHAwID
FQIDAxYCAQIeAQIXgAUCQAvaEQUJBtJpfQAKCRB8IsOfgHrFOhKiAJ9WATOU9sRV
wilgeqJDb/CM4A6OXwCfUt/joKNCRo5t2MQSyduYbUUUV5WIYgQTEQIAIgUCPPvZ
3gIbAwUJA8JnAAQLBwMCAxUCAwMWAgECHgECF4AACgkQfCLDn4B6xTotvgCcCTpL
zPaI6PcaY6bQs0sU+vx/y2EAniX01//zLLCf32/SFgoz+sKCCVdViGsEMBECACsF
AkAL2agkHSBQbGVhc2UgdXNlIHRpbG1hbkBhcnZlZC5hdCBpbnN0ZWFkAAoJEHwi
w5+AesU6XeAAoIAsTf+iRoJ2Ssz3I0NVCDq5C7sdAJwPk0jhHcp+Smx7JUf0EjiZ
IhlqDYhtBBERAgAtBQI985fUBYMCyqa9IBpodHRwOi8vd3d3LnRvZWhvbGQuY29t
L3JvYm90Y2EvAAoJEBBYFoXFIQl+sLkAnAhFTAtrsVGOk1PhWYdYGCUB3rKNAJ0b
6UcNJBcuDLsMWrhmr342rubgQYiMBBMRAgBMBQI9BRkQBYMDuSWBPxpodHRwOi8v
d3d3Lm1hdGhlbWF0aWsudW5pLWJpZWxlZmVsZC5kZS9+bW11dHovc2lnbi1wb2xp
Y3kuaHRtbAAKCRDehYP4vb/oOAp6AJ9sbAZYVOAK9KJnrXG6M4HyFIn7zQCgx7YZ
3lauFFTDeQtC6f8O/YqL6ZSIkwQTEQIAUwUCPyFXhAWDAZznDUYaaHR0cDovL3d3
dy50cmFzaC5uZXQvfnRob21hc2IvY3J5cHRvL2tleXNpZ25pbmcva2V5c2lnbmlu
Zy52ZXIxLjAudHh0AAoJEKR5zcRatGBqDhAAn07IqzEqiDQAq9ZuHVA9q/Se0BhL
AKCDNey4KgYxDLmHlccdugDvlo4RT4iTBBMRAgBTBQI/IWPJBYMBnNrIRhpodHRw
Oi8vd3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9jcnlwdG8va2V5c2lnbmluZy9rZXlz
aWduaW5nLnZlcjEuMC50eHQACgkQeQV2j3WE9djt4gCfZmdTVNllaafXbvEDqU76
dY3QKHQAn1P8Dr+OhFqTx8i8xse1R4dDKAa1iQCVAgUQPSHiMMRGkei8OaXNAQEP
rwP9E5Zt9bK6y9VYcIsbBFDvAYLhjhvT9IKOfQrHIzsnNgIfec6R0B8LRXGaOlUf
6jMTP1p06OvuyRNGHHusWDui1nVPcN+t/uXB7QT16UefXv11czXqmzCKtDaEDQHC
qAJMWAFGjL96IESNMTFGGSx87nMUgDmL5HJVaw+WLG5kcVqJAJUDBRA9Is6DvUCm
6Q/OhUkBAbbpBACdcJbmmeUz2kxRjtB2dBr3l0mVGpIMdVMC/NaKqHqk5gxRm98c
Onq2we9PSBI7H5xBmJSqX+ZJHRVUSDzoGaJ73A/yPFi8t7Q9MRMb/Xepw/bEx7js
vV7Lg+tXRedxG/gMQ5E8KS6CXRtQIprLUGQJ/rOA/wxylXPIUMGNaiEbmoiiBBMB
AQAMBQI9I3u8BYMDmsLVAAoJEMRGkei8OaXNks0D+QH0rq8qJNlZQIKrjHRPX8Bf
gN2401rOk1cRZF3SJ3zC+FK/uOM9NKfZI5E+SCaxHmzGamB7J8jYsdqMJIAMnXTj
aPpXRgMs01GMBFmOiGNJJtZ/e0589n+kkjmDah1SedId48bHJQ+bBwYh/tTnQwgh
8ss1f4C+ustiU2y2YWziiKIEEwECAAwFAj3aoBwFgwLjnnUACgkQ5RUoJTMc2l1s
vgQAk1Ep1LH00RT/M7baFu//UnQ2gal6jtTcKQlkpt+5LHqcHQRc0eritnByi5Uh
HRlz8qkotdmUpbk4Qe6pi2py3PXyDcqIXiNj7WqVmrMiDVhuabjG6rz7TjTBvCkb
/cOwKA/E+Wq9EYd47CDFYhaeCaJibtaaJAgpACjLwdOBtJiIogQTAQIADAUCPyFk
iwWDAZzaBgAKCRAbsIu/KpIyJbiKA/9tGaHm/H1E8+nZbVNLycF4XHysp3AIfThF
ycrtF76BDzUBhMJP1wqIFoTOVpNEZyfcaRdxenBuFdfevylp0S4HKt5Njunck+KF
YhwHE313f4Khx5tfVji4PCtdDqDTKaDnC8+bkMBlz2aN702bQT3JYVMd++yMkUuD
QFdFQ1dBFYiiBBMBAgAMBQI/SiLRBYMBdBvAAAoJEJugaRW/hasxf3kD/20udTH6
KqiBG6O25k3furoU220pjInNW4MLl9gWwx5pffmx0ht50NdP3W6Zi9Bcmdto0IbR
luIiuBKMIgkaN6GJfy+BDs+Q4sPfvFYbt29Gbq9S0+5GbTRx91cAlcx5nffuCQL+
QDle2tQQWz9buIDppqkcz5Ec0SK1U7Dtk+DbiQEHBBMRAgDHBQI/FpZTBYMBp6g+
hhSAAAAAABoAY3NpZ25hdHVyZS1ub3Rlc0BwZW5ndWluLmRlImh0dHA6Ly93d3cu
cGVuZ3Vpbi5kZS9+YmIvY29udGFjdC9wZ3Avc2lnbmluZ3Mvbm90ZXMuQTkyRjM0
NEYzMUE4QjhERURERkE3RkI0N0MyMkMzOUY4MDdBQzUzQS5hc2MiMxpodHRwOi8v
d3d3LnBlbmd1aW4uZGUvfmJiL2NvbnRhY3QvcGdwL3BvbGljeS92MS4xLwAKCRCr
HktgRnVrHmr/AJ40BMVSZ0DdOYNUzMjA9DinC6rJGACaAvMqo1iyaHhyjSetEUGy
bb/xM5mJARIDBRA9A+0UlWBhpt2TQTkBAS1UB+ICtY+/MOSiz1j5xqhC7STAxOPP
QD18HmO3AHZywXr3G8iOh7iyJU3EphQID6B43Tvu8VjaX2mvJur0rppMlHqGDJSv
k1J8diwkuhb5jwmKBBTOoPdh6QEhi8GanAizKd/rnppwAfzeP0CmiKjzQQJUiAK/
P4KLhd0ObpjtfBu2D3azTLinMURTI8vYmlyK8kVgDG5fsnnL0/ksnsKw990znbxz
7unlnGCL+MSyt43CCdoaIjiaK82pt7vTVf6K5yIXbRAfphsyG4KG3ZO1pvsFygD0
sRs+NSx8Oij/zXQUhELw0/zCTF63zNDIe0w5JRcUOXdK9a8Q2j3HVJ6oiQESAwUQ
PQPtFJVgYabdk0E5AQEtVAfiArWPvzDkos9Y+caoQu0kwMTjz0A9fB5jtwB2csF6
9xvIjoe4siVNxKYUCA+geN077vFY2l9prybq9K6aTJR6hgyUr5NSfHYsJLoW+Y8J
igQUzqD3YekBIYvBmpwIsynf656acAH83j9Apoio80ECVIgCvz+Ci4X/////////
////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////
/////////////////////////////////////////4kBFQMFED0D7Q8BVbrioJTa
JQEB1xwH/RyMspXEKjRWrceEwuCwfFb7jGo8twuLcbFOSIJKQkJZMb+zgS1GsU7c
4tFGk7sy9aIDTq7g+Q8/7FOVtbxQQzdP52/xYIrwj5UGVPMF9/di8GSfgbMlXmDU
jg03iiwMWHom1z2Bq1wV/oPe/4LbFYodnQBX4JQebnbgkBvf/5+JGR49p6gqv+jG
Jsib+Y2ic9C6nsoE5+kGygdJ4Rpj/sqiAqKeJXZ0LOHm4uffNCfD8wcqQmsWNweN
kXPOOYNoL22KRdRxjYaxCD5Knhe/V+mO6NP0Eogor5qi2wb9Vnocu+ZRoVjdbh1D
0+rmMWcQ3hXOJ+G0opSi7wFPiNokxmGJARwEEAECAAYFAj0nlkYACgkQjPZsgRPd
OVBIHggAptNnfiAYXEBl0t3++ByJm/lBe8WwvrEtCYCIWvW1243G7pOYa1QN3Raz
5YeNNyRwlM4/lHHrY49BhU6fJsKKMGXYI20KAKYYsSdIQsnjy1ZcUJiHsuZEphzu
tNUnh4i4x5OJfKxNbvtquk0IGNW2rCTMNLtac6iMlyDiGRwycKJo3et4OvjTviWz
wzGvg97q+4SZFnCmja0VUT0yXplg+zwCSz5jMsqtwF2RQtJySmm/EtgFLssXQi0s
JC8QkB1yKryJqHKZ4p8unqv9odlrfS2dBtgYbwRFwPWESUJxMIQ6n9RhSaI7W3Rs
Spm0OlZedWS4E/aojxW8ISwxs4/UvIkBHAQQAQIABgUCPSeWfAAKCRD8uuIMohH1
7WYeCACJwvBuFlEe3xd6bi6L58poGqJ7nbJvdbyxPB9unygFDI/ouC57NxQqylCo
LCKhOspCe3IphaudKjuxFQDhBwNtC+5rgk97srlFYiXsuKQ4licZ/YEZJWMG+wD9
We9LIP7wmaVqR4m35s4dzVfoqrQP4gt/pr9DOPoPesZanM/+IdcEeDRrmcFYjuYh
W4Ja7dl3ArtDIr4vR4SD8DVdDA8QFEF8qBmtDC0q3gAYc5R9oAnqKZRVYGrkjeRY
iv1NbyZpFjb7gUFpa2/ZlMRNWC4wmyZ1Wvqq7nGYAZgG1sYcWaRDOLqPVvwlcmLP
gK9654fcd5WrCznyM2os4JW/8XpyiQEiBBABAQAMBQI9BMOsBYMDuXrlAAoJEAnp
+QqKck5FrksH/j37K8wcFO78HG/GO2SjKlOG8mgq2zEQNctEodT0DegJuXW6OtKa
EcLrgrNYWogBFJ3DLBc1A6esFjYqYanqv9ckYVR2dFZqPS1SbpJpdd8kx6MX0CX3
gfSsH7/DwxCm3+6C7OXoOTlfLYaw3mR/wAziExU0WeEa8b6zNCe8nJlyqLOm8UwO
arwaYt5LAeFVrxuMw2lmkQr8VWGByXg2JTq7Ey8nKiWPR3kUny2E732Bh7SkEuvQ
JpS3eBGzQ24enFHvTZ4ti+Ty6Tom8WQeZP9u60+pJY5vmUZjbNBl06yW1Cl0D+60
zDv+w4YBh7+MEbRzdrqObF99lKaByk4WlViJASIEEwEBAAwFAj8RDoAFgwGtMBEA
CgkQQAYVDkAJ6u1hUQf/YtTZirwiRKNadHBL8pbFJ+N4eWdhtZE0DRi+gPZXHPr7
vD+uQU+Bewnv49jyzhTfeKPD+02XNjwUtkWtmazbmRenPDdXw6Wzf3zB/jCYY1E8
wCHYnFXp5TdAlhmitmJ5LN45EKsQ40whhI0GkbASO4/usAapNtHKZp/DFZODGO5U
8bRv1BJSwoLpsH4l4vDSi3GKAelrzEpHRyE5x4OR9xOtYIlrOAgSdlKfnILoqWoq
s0BR2nzpGH4nbLmWeIumvXFdspZecMIS2rCW5fVvk9dcELnakKfCv4IQ+QdEEEro
Tw3qtQKFg+S9U7AMAu5nLPHEVxUHMgUhS0tvm3rjCokBIgQTAQIADAUCP09yDwWD
AW7MggAKCRCloGDCbsJmbfnRCACAW+HHNo7IJ0we1csKVQNDeBanMY/t4jN7VQyS
WIsHXF/Wr87OwsKbwrza3RpwfRbnunFDrcKj2/DriD7hTD7CRj7M48yjDQMnTMTL
bJ1sY8B+CmsHdq17DSMUiP3AIOXgFzKPEf0QhdCwRJ5YUxVAYtmptY1t1IbLYW+H
H0vUwftyFcRZV8DHdyeBlRGR59A/3fWdOQFfcExO5qbONYnfoGjX5sRRY5zjQQn5
j5vV52i3DUMSaweKCaHSCjdeftnnUh6bVB6XXt8pfXu/IychY7KYdzr3PEA6P+6F
RY0+wCckbLY8pmcVPlmUc5WytW4BRaScodVhtyo/ew9gc2wyiQFpBBMBAgBTBQI/
IWOfBYMBnNryRhpodHRwOi8vd3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9jcnlwdG8v
a2V5c2lnbmluZy9rZXlzaWduaW5nLnZlcjEuMC50eHQACgkQ+Xz54zpLf11dfQgA
rPGTSsMP8QxQpksXYDm8hCEkvW6e0pXnZtaF1vt8sumTnK6Ac5Yz0J7waBD7+kNb
nirrzFuoxXUqIQ3p91p2lp5kfSsAFMlg2z40Yqz9KmLqXh717qyWfO7hgb/J/Jlj
2z7pZQsEJPAmyd9AF7g+qtKg008TiwAOxgD5DuOZ3a/3n7Bl2r0YRncwfpwjT+sm
LbodlLB/NJ9jLzsAaD4uM1b+InozBnqc6K08IckKQ6+i9G1KDDfLOa3Vc45PHdNR
LNmwXfFHQ2BY+gIAAN3HtkJ6z3E1akrY0o/zQafiJ01ruYgsCUzh/n98cB21TZVL
bAhj/K/uFB1MfShas4juFIkB3QQTAQIAxwUCPxaWBwWDAaeoioYUgAAAAAAaAGNz
aWduYXR1cmUtbm90ZXNAcGVuZ3Vpbi5kZSJodHRwOi8vd3d3LnBlbmd1aW4uZGUv
fmJiL2NvbnRhY3QvcGdwL3NpZ25pbmdzL25vdGVzLkE5MkYzNDRGMzFBOEI4REVE
REZBN0ZCNDdDMjJDMzlGODA3QUM1M0EuYXNjIjMaaHR0cDovL3d3dy5wZW5ndWlu
LmRlL35iYi9jb250YWN0L3BncC9wb2xpY3kvdjEuMS8ACgkQGaJoCYg4/ZQ2Wgf/
ZA+qzqf1y3r9j+jgf8M/BrI3aXSgtL8ZDfek+rYdVcPMRKLMfnBuqV1mhOa1vPsE
snUW4Q7LWKZOcCrcQcS+eGXi8QyjHED0Tu5t5jF6laq1qy52kVav08oc+0dDuwae
sIxMKvFW/qO4kM2lL3CPK0uEBkrcKMN8sasjr/Cb/O34q0v4/TtdPgz6e6OIAAsk
fEi785Ld0JWykmH70IYAGKmNKqboimuax3NlZrh3BInH8VWWjubIKji/AhPAu8zf
4NMC006t9BJ+BRFeNlS7Xkit5fLDyZ7JaR4LWkrsEdBmIVG2Dm42WKKRiQJoJHiP
1CaJb95p0+z4SRLYOMXfaYhJBDARAgAJBQJAknnFAh0gAAoJEHwiw5+AesU611MA
n3ULEacZE+cuEpQ0oJTvfgUgNQzjAJ9BAeF+jToC/Rxe0Ic+BrxDxPLU0LQhVGls
bWFuIExpbm5ld2VoIDx0aWxtYW5AYXJ2ZWQuZGU+iEYEEBECAAYFAj0BJlYACgkQ
Z8MDCHJbN8btKwCfSU2UKty39Piam6JpXhWbY6MIJOkAnAshBsejr/3qNQFK82Zb
y600y2uziEYEEBECAAYFAj0B/C8ACgkQlWQfayU+WOPKEQCeN+03m6Ueah9FB33d
gYoMlmhsC84AnRNPqKH0SJL58TXHN9hOFXagVpGMiEYEEBECAAYFAj0D8JkACgkQ
eMu5lRpXJ7murQCfYyLs4CIisOCdQ4NDpNiuprjbNRsAnjt4yxhRQ23HUltvX3NH
QvFhcJRciEYEEBECAAYFAj0EsGwACgkQzjzRQHYXE2f3VQCfaf8ar8a0IkcUbp9Q
QoY66doC8c4An0qYBmAlpdBbfgbAzaIeNIb2npiQiEYEEBECAAYFAj0EwDoACgkQ
Uaz2rXW+gJdXwQCg4sN6gqDm/GKDgCyP77Mts3IscosAoJnJFmOdAc6Hbb0n2pQK
wQLSikzeiEYEEBECAAYFAj0E2YMACgkQ43e2O3Z+/CRh3QCfXKPrcbqPuGwqQ8vO
etHSMfWHpz4An3gyt8ra1+CJzJuKieR3AL8gqUkuiEYEEBECAAYFAj0GDNsACgkQ
7vvdOh/igesWegCffmypH6riziaIjgmB6KO/BBvqQD8An2TjBiiidYpJBo0VYmgN
WIKb4oeKiEYEEBECAAYFAj0Hqg8ACgkQOtPmyoSF4NciCACdHZV+M/55urDisMjC
iwaks0CCzpAAn3vOFAuO5CtJaGRdzfMCGXSKutX0iEYEEBECAAYFAj0KdqgACgkQ
aO3jKFvkT5EBGgCgivHRlkEfPNujOmvZKo5zUor07ekAoKBT47Y+Xrbn0spYdHzJ
5hZ4rf2PiEYEEBECAAYFAj0XO0MACgkQDWEQ1nOP4IE4ngCfYraj+NUQhproQeBC
o2fbuLTApO4An3ngBIziwZN1rIceMdNIMx2Q4gEaiEYEEBECAAYFAj0aI6kACgkQ
SYHgZIg/QUIlCgCgpyZ6iOlSe0/5qnrro+A5OG6BAOAAoJ6vG/ClrmC+nHatZDA+
yCnCk6NPiEYEEBECAAYFAj0bGekACgkQ/Z/D9pDh40aOdgCfSOMQ+nXBNbenRHxb
WBE2eDXBubcAmgON8zew01UA1H1g6Sk45WPJAK22iEYEEBECAAYFAj0h4ksACgkQ
5kwyFdoVP6u5AQCg0CDaKFCgCj9bPRtq4XnZxymzJmUAoIPB+Hz6ONTwFTPUrPVJ
H7/0aukFiEYEEBECAAYFAj0kXUAACgkQKKG1LRrafiwYXACZAdAast3PEsIECoJf
zMxKBGKa4rUAoIuvOACVKNJpzopyBNv5d5BdnjXpiEYEEBECAAYFAj0nazsACgkQ
fZ+RkG8quy1MkACfQjgCCf/yZBnC64jIoMW5PrHGOcsAnAsMHXWyBR0CHmmfkYAD
vJenJwP8iEYEEBECAAYFAj8QWKgACgkQ1vr63ZUvP/983wCguGUzZUugjLkLIJEZ
YVlmneF9U0IAn1YJ5hcTsDAJjAt4lIbxk1p7884biEYEEBECAAYFAj8TROAACgkQ
0Bn175Anq4hh9QCfZRisrx8FcwzjucellQawseqEXv8Anj52roEfefohLpbCMaqs
G27sEweLiEYEEBECAAYFAj8WTFsACgkQRsxcY/MYpWoe3wCeP+yPkfAlji8TUFsz
hzCnZsxJruUAn0W7SPgZYvzr9XU3QkiEAapQViIJiEYEEBECAAYFAj8gQHwACgkQ
KN2w/RnJtroH0gCfY32tS2FHKxO4GRnSTfCqdMI40coAn0aS3XwE13f4xFZCBk+t
9IjQkazLiEYEEBECAAYFAj8otuYACgkQbyOLwk/aWgxR6wCgmiX2MCBokAAejejg
x/2QAGzcne8An0pb8DWUArtTvJsEXbn4uvgrfF6KiEYEEBECAAYFAj81/LYACgkQ
adKmHeJj/NQlbQCfRftS8Rmprq1Mg8ve0hxXUrJacmIAn0TmVO4uxcjEEK6PH7R/
hsR0kNaQiEYEEhECAAYFAj0E3wgACgkQcV7WoH57ismkwACfQ6xHjAP5Xi5kvOwK
gwPzS8IrNPsAoIFFbQI8kCRlJsNe1PZnXXTedO5jiEYEEhECAAYFAj0E50MACgkQ
j/Eaxd/oD7JtHQCeLz51hglehiHIhv3IKTHlSoZbLL4AnRKb5BzAmXHMP7AsByMb
UPFBCvrZiEYEEhECAAYFAj49LRAACgkQq2TgaW/Wf2QS7wCfZt8jtactnpu4qawp
iiQy9/W007YAoICc3mtB+qeBbOegZBHmooK35j3NiEYEEhECAAYFAj8XC0kACgkQ
d/gVM7sO6Mf6SACghNIzLkQPgOllFxd27Q1ZuIds+loAoIopErzaXaxIaM6d7pFG
CYxDLNULiEYEExECAAYFAjz72GAACgkQEH3do0kMxDrnuwCfS9cRsw+001r4bwdl
Y3AbG/BibpQAn0qf3XPy0DI/OWMQhD3Ygp9liu6TiEYEExECAAYFAj0MrmAACgkQ
GnR+RTDgudiUXwCfWoc3XqAMPMhOa7kpjsJxJJCR2hUAoNoTTUxlc0OgP1L6MunU
gYb46IMAiEYEExECAAYFAj8Rp/8ACgkQxcDFxyGNGNcwTgCfWg3hQyTJs7s8CPi8
AxSCP7TYiYkAn3DZ8v5qWeQqMTc4R0aYh9Dh5g4qiEYEExECAAYFAj8dt18ACgkQ
3nqvbpTAnH99rACaAuW1DdP8Dnq3WPi50tc7oaycyEwAnjyuSeR1320YGklEgf+1
Bg62T5mQiEsEEhECAAwFAj8oXZMFgwGV4P4ACgkQliSD4VZixzTuUACgpcyfQjoo
/PK1aH+Rerf6UPBYd7cAljAkax/eOKjz7PFQCI2vmVmuqZ6ITAQQEQIADAUCPQX1
fgWDA7hJEwAKCRAUETjdo+RdZojGAKC2ZWUvMRagUn3K6wMuW/QFav2+zQCg3I7O
vwjBeKoFiBISXNuef/M8u+6ITAQQEQIADAUCPScSAAWDA5cskQAKCRCcL8ZMCFV/
3xDlAJ92rS9kDmlMWIdEKY6yQ4VBToNOYACcDUdj5slAxG4APKDotAM+0RvM6qaI
TAQQEQIADAUCPg3ZCAWDArBliQAKCRCJ9buUZckShWmqAJ9D14l967llRy9rCKm5
JJHEX28eZwCgkrMAE4H03Oq1qZ4VaCYFNPUQ1Z2ITAQQEQIADAUCPi+41gWDAo6F
uwAKCRCFgFn/OmYfnX4WAKCel12J1+fYnLOPFGq7Z06T4QLIJgCeOC5cnGdDEvRu
8bkleDqQMFcOZoWITAQQEQIADAUCPxFOigWDAazwBwAKCRD1ayajpjmec0waAJ4z
r6/pm2FTz5Wdiqcb3jC7/5NMVgCghmDC5WEM6x5EYWCTZKiN+7PnBeWITAQQEQIA
DAUCPxKmxQWDAauXzAAKCRDUPLMFlf7KNALWAKCi5ovQdQZPEbDSJNblIopKvdpX
mwCgoXjtD3LJousL1sKb+a+oSLMTFU6ITAQQEQIADAUCP1xLGAWDAWHzeQAKCRBZ
e8xOEkKm8hQjAKDoIy8kKR2bstYfmgR6KRlZo/JLbQCg1hXGrf0j8vEgHwpO/+WC
Ps7eIpCITAQQEQIADAUCP8w/CAWDAPH/iQAKCRCgvp26O4huffc8AKCNROtcV1jS
barPz7J7O7mQ8wQAUACfQKvvvjA2VMbsOwQsSFRzdEjKMouITAQSEQIADAUCPQWk
mAWDA7iZ+QAKCRA19mF8UTrv2QbUAJ0RYBKzMEcuGDRrpRgw45Tyoi4WSACffVbI
rg7MLNtZOrUc89qB/akLjKCITAQSEQIADAUCPxUPYAWDAakvMQAKCRD0tLDMeX6/
q05MAJ0R6B6y59win9KWBZ1pp9C9lTWPYACgi+txoeQi8rzdxifstczqJyyD/++I
TAQSEQIADAUCPxezGgWDAaaLdwAKCRC/QVlbc3KipVT2AJ0UmwPdtrPj+j7JWUZ+
FGrKzIq/9QCgmZDzoG3QrcwmsQ8U+P3cYZu4snCITAQSEQIADAUCPxx0NQWDAaHK
XAAKCRDID3RZrcKezbT9AJ9TvuhQhlFK/ZKr2YnmM4/ignavxgCcDgglg9H+ix87
BkVhjVZsRjm/DgaITAQSEQIADAUCPx8cagWDAZ8iJwAKCRDnTSm4K+FtAaJNAJwI
JijrD6sA1QRh3gNyJrNo/tLH6wCgwK3n2bKTW7tCFAGhIvdDQ5UA7GSITAQSEQIA
DAUCPyOelwWDAZqf+gAKCRAYoMyNVwaktDrmAKCY8yOGV+S2kd9n8hMZhvQeo5aO
RwCfRaWVGoZmOD2kUNq36MAB/nvqKJSITAQSEQIADAUCPyffrAWDAZZe5QAKCRCf
zyzNPz5kJpVoAJ9bRa0fWY0aPfyVSjX/lS5DVWnP6ACdEjMBjxuTkuWFj3cIZ/GU
4asoDRSITAQTEQIADAUCPQXkxQWDA7hZzAAKCRDKDhacKPo4iityAJ9aZij7lqY2
Qsfe5o2Nyqb1kxotzQCfb1x2rlwmjedsLRsPr5I9iE0TMJiITAQTEQIADAUCPQYL
8gWDA7gynwAKCRCNmjwfONntm/o1AJ9FSqHTkIyW2VVxrKcGiAl0Bxb/rgCffXQ0
2gFA5F4AgwSFh05HKSyrFO+ITAQTEQIADAUCPQZwRQWDA7fOTAAKCRAYWQx96ws3
3CnFAJ91rADHNjNPPuLXzT4wBhSDybWXuACfaWWXiupFFxbx1MvpwveBTKAkZVmI
TAQTEQIADAUCPQZ0FgWDA7fKewAKCRApvl0iaP1Un9zwAJ9427nh1GyST65n26eW
5xlDtpVggACgn4Dq9eM3dCnK6C2auLLe5dyOHviITAQTEQIADAUCPQh2VwWDA7XI
OgAKCRCuMDyzGSr3ebLoAJ0UUSDnzAt3nfsJl2In0HsaHczXYQCfdkm8496UTnqm
Fu7lXsCHXhk5zFKITAQTEQIADAUCPQu65wWDA7KDqgAKCRDUtDSy5nZxTGOtAKDa
ZEM9cQniPaS2+R0UJrHUYQoHdgCgi7G5aXG9am6M9/pp/zaweyDKutGITAQTEQIA
DAUCPRFvhQWDA6zPDAAKCRDOinnXmAFtx/S0AJ0cD5hm7G1vvyNGdrMOE18h0gCg
xgCeMhD2VBl30SEKCdyWWySbDNkxyq+ITAQTEQIADAUCPSN79wWDA5rCmgAKCRDm
TDIV2hU/qwDaAJ0QgttdCgHOdcFWZeMmA8QXkOmJMACghFQ9vNTe7qLuTv4w6/NQ
lsphi96ITAQTEQIADAUCPSa5DgWDA5eFgwAKCRBh2FHZpoIhU8t2AJ9D20Y3N6Vm
FlYV5j/92Nb5ScnszwCgwG9URDNJIyQaLdbBbLxNTA0jhmeITAQTEQIADAUCPVt6
4AWDA2LDsQAKCRAQu4D8Fr13xsWjAKCPxwwTakafx1WNhAabMjSrN3tKZQCgs9Y8
kXyYPLmubNzu+vFPk7Jkwa2ITAQTEQIADAUCPWCzCAWDA12LiQAKCRAxT3qV7BUp
Ql1PAJ429UFbcOerZlJFaYgjZOuYBUmKJACdErlKoq8qXcmKtV8t0Vwq9fPYcsaI
TAQTEQIADAUCPWpVVAWDA1PpPQAKCRD38OcPMH1W7RC/AJkBHvyEtg4q1kk9Jr1I
7CStyW1iLACeKEgJQvAsd/HwSonlQU78mAAu5yCITAQTEQIADAUCPg5g0AWDAq/d
wQAKCRCz0KP8s+WtMbKkAKCRbHIOa1fVINVdcuGvOR7zvffXtwCg2HzEP3ikiAC6
FBgMzMm7/EC+juCITAQTEQIADAUCPhBd2gWDAq3gtwAKCRAvF4dA2PE9vi4MAKCg
4ChwZoDC3PGedXl6ykteIdRTBQCfUohzbMxJr3CAINYYNJBvZLQskpaITAQTEQIA
DAUCPw3AEgWDAbB+fwAKCRBsdheMoO2YLQDEAJ4l5777aBZzv9UdoH2PsrDROG+u
bgCgjuFF7qxIo9x6RfH1jZDz9gObWOCITAQTEQIADAUCPxEU3wWDAa0psgAKCRDh
hSLXfHEryx5bAJwJpv7ws0dcJxN8aki/BhDXycdlHQCfQ/0oksxXWxtNtVC1Ight
8JzUnUeITAQTEQIADAUCPxFFjwWDAaz5AgAKCRDqIZlBJHfK+J1JAJ9PB5TMHAjE
6/M5EdzDAowru+nRCwCeN2UvMesN7fSLpbLDl/7PQXsensyITAQTEQIADAUCPxFd
IgWDAazhbwAKCRAZ/tg84r6jQf5sAJwLhkhC1NdlY46NzSoRCy9kSgmQmgCdGqWy
P28C67BtK4N/FQl6+PXXpWqITAQTEQIADAUCPxGl0AWDAayYwQAKCRAoxvVrgXw1
aI41AKClGXSvMX34dJkd6OV51kjIFa2VDwCfQNfg7GIW38C7njuGC5xQcAn3E2yI
TAQTEQIADAUCPxHE9wWDAax5mgAKCRC+nIaNBGBOuOcyAJ9kK8Q7X+MEUUnD5Or5
yRyQr8/xzACfe+UE3dBBqy21EyM7uSw+gWDl0hOITAQTEQIADAUCPxKUMAWDAauq
YQAKCRBWbTYs7gl36GEnAJ9p2WJUghe3csdJO+hVrTFKJ2fMWgCgs/nsPcZ9XRhN
6+qVlG1VV8PWBPWITAQTEQIADAUCPxMqOwWDAasUVgAKCRCSVb2f5oRNuVfkAJ9L
ruVdHUr3SEsxIZK2OyNEnyj0MgCg5+e7GqYKsUHUrVvQEYgEqV1MFtyITAQTEQIA
DAUCPxPwuAWDAapN2QAKCRCUj9ag4Q9QLhyMAJ9gtIUDEqWbm2NoU3Yuxt2A+lUI
AwCg3paIwgN9+/+fsoshzM7LgbpBv9KITAQTEQIADAUCPxPxFAWDAapNfQAKCRC0
deIHurWCKZYXAKCUOydHPJ5pGQ7IhW73glhlloaNLACgmHQTNv2Lek5mLWSz91b0
AKnWQhSITAQTEQIADAUCPxP4CwWDAapGhgAKCRC5gsvVwOMfHeCGAJ0ZXNzA5I5j
iW/SQVgso43T9880CwCfUdJ4ZryDNMkEVB+G3K1R8l2lePSITAQTEQIADAUCPxUo
ZQWDAakWLAAKCRBYKVdQBQCDi9M7AJ4waTyAGLRbSRpu1wXhqh7GUgex6ACfUT/M
OkiC1mREYeHhByez3hJZYTmITAQTEQIADAUCPxVhlQWDAajc/AAKCRCe0HjvSzoT
XKhLAJ0XsDm2Wv+ECgLvclxe9dHiub17swCfVMkZDmW/lTxV/ZSk1thAeferKTeI
TAQTEQIADAUCPxVhrwWDAajc4gAKCRDwI/gLJoQdW4iuAKDmKOz7a10eUd3aJsCY
VfR/2kq1igCfdn+p4L21zTR9P1txpMcPfXzuMZqITAQTEQIADAUCPxVr1gWDAajS
uwAKCRC7VaR/yQHDPrWGAKCxa+R8faYRmeqd2kctIZna1nXQdgCdHQqnQY57Z90G
eHDAFxUcl8R2zWGITAQTEQIADAUCPxXBEgWDAah9fwAKCRBL7yYkIt9Ahy/DAJ0c
oX3RhYQ7+fOY21jHsDi10Z42XgCghj4VRFmYdqfzefsmNa9ZWbq40SSITAQTEQIA
DAUCPxaCqwWDAae75gAKCRCELNt6RHeeGO0VAJ9ishuIMGxhoNpxzcR9A8WvUdkF
1wCgo0Bdw8iJ+MmJaEskG9Qtmj8QUBmITAQTEQIADAUCPxfgKAWDAaZeaQAKCRBT
trgdwTzuB5bJAJ0dYXSAyclET4PFXAXJll39jkxaagCgzKHhQd0vqqFzDpWnm3AE
1GiYGWmITAQTEQIADAUCPxfwhwWDAaZOCgAKCRCRH0rmhqEY5vWZAJ0YkrTrncXC
Y4/WiZjo1SWku1XmMgCgmVaVAk4MZG5KknjaQyxt5xIcWQiITAQTEQIADAUCPxvS
EgWDAaJsfwAKCRDTW7yZvH0CCpHwAJ9pCojV5NH1mV16vAu/v82QVrkLqgCgoDGW
wJT3ksW6KmlZiLfsVokQGk+ITAQTEQIADAUCPxw86wWDAaIBpgAKCRA7v893vYsF
DbLSAJoCh/HiqezPTgfNk6IBUgCcf0adkQCgjVhfNP5HUW414iv1Sosp2fdVqe2I
TAQTEQIADAUCPx7QfQWDAZ9uFAAKCRD4WZCwJIrrcydtAJ4mcVCBTWzTPlHXBsnw
NuM608iMRQCeK63SERX9wYUX0lU4FZTMcn2nAjyITAQTEQIADAUCPx+30AWDAZ6G
wQAKCRCPubcPpM/JbvvXAKCSt7vm8sP36kypeYvF4QQyEm6RzACg5EewFjUL7mh3
0oyiI9Us+9CEHUWITAQTEQIADAUCPyEWRgWDAZ0oSwAKCRCJIbXczRWogwu9AJsH
C71EyEqWLc7IEqmxmWUTI9nPTQCfeKD4OI0An/4C/THbKy0JDtEWikKITAQTEQIA
DAUCPyFkIAWDAZzacQAKCRD50BTwOMmFjaLdAKCKnEm8cWaO8aZVrBe/DRsKqTR0
jQCbB+MyVOqpp+u2+LmdXTV0k4QkBhmITAQTEQIADAUCPyFkUwWDAZzaPgAKCRBd
D39J4OSfNGvqAKC01BJ7+mPN2WVOKEpwnJDcL8Ja8QCeKGY12kaalGnKuI/ypRyf
vFFyVkiITAQTEQIADAUCPyGAlwWDAZy9+gAKCRCUmyXsB0RyUp+eAJ9OABoYfKXV
cTWyAtqLpGsHzcUu2QCgg0tAZijgpYISdPtb6FhKvlqKcRyITAQTEQIADAUCPy1V
JwWDAZDpagAKCRAsmD5a0opV1kk1AJ9EnK9kkqIEelIaLwxLOHgo2jN5GgCgyshB
FU2OlulhxHCSL3EV0I7fSW2ITAQTEQIADAUCPzQylAWDAYoL/QAKCRC7xxTRnGfN
lrCrAJkBQu4RDjw8+IqUEUMbx479tdRGVQCfdIvBavVjbhHmrsyFEYGiSEGsrniI
TAQTEQIADAUCPzflRQWDAYZZTAAKCRCAdScAZahB7c8oAKDYTFwWzTAsGI3bp6BQ
H49J6XtjywCfaYFHPsu3RlxKHbM3AbR6Gf5bOlKITAQTEQIADAUCP0nfiQWDAXRf
CAAKCRBK8VQqljpUsAovAJ9b4ZIIXGuTYPf7ICGSxyihjwvx+QCffqblEIgt9ong
pTBrhB4g3pzNnR+ITAQTEQIADAUCP0n0DgWDAXRKgwAKCRCrEDAolpXyX6iMAJ47
XNF1nknO8qRWiJ8Ie0JR4o9MsQCfYDZ0GjVYOSdPANDehlsuxZN/wdOITAQTEQIA
DAUCP0oL4wWDAXQyrgAKCRDvYpxUCbBuELvwAJ9KRqTPOq2m0NfjTrH4oEEKGYR4
qgCeORRG39UNCwOvw2Eup/iuYvDuTbyITAQTEQIADAUCP0oPqAWDAXQu6QAKCRDA
VIGGUGOgllLJAKDEfrSL1ND1hzriuTZ8NxD5+vsNmwCgoi1ZkacF9lMn2WKbEFWz
svVit/SITAQTEQIADAUCP0oS2wWDAXQrtgAKCRBvYja0ew/+hZGpAJ4zWrfWJGVi
DyPHmYHC3jFb9ftCegCgg4MujwgF4cl9TqfH48yizSBWBOCITAQTEQIADAUCP0oz
7AWDAXQKpQAKCRBOqMTCFe883dLZAJ9zi7ccFtdakMlxKxE05/BWCExYHwCffuPC
Eh24Ki94sH0QIJhFMu4zp1yITAQTEQIADAUCP0p5jQWDAXPFBAAKCRA7aIZa2GoN
GUNQAJ4+EaSnr4xGbK+siI9W4YYdqT2orgCfW1+TB5z5OeF79ZXEy7FYhPEEB6CI
TAQTEQIADAUCP1IK0AWDAWwzwQAKCRClBubU3U1QiHWKAKDgEmF8GJYmUaBYhWwn
AoSuHPl51QCgx0Dtqvd9RZaUXoLbhiUphMDQPxOITAQTEQIADAUCP1JScgWDAWvs
HwAKCRAHZX9zooa1NjsiAJ4yOFmGZnvXW7wwtlQQnrlvXXjm7ACdGHL5oylxCcEo
6qifAB5HaOXRApyITAQTEQIADAUCP1OXkgWDAWqm/wAKCRDWO3DJHwOkigKnAKCE
JOvgjpXvCillonlzuRG2yGnjBgCfXZLux+M48MIecaqa7M1MFDR58G6ITAQTEQIA
DAUCP18rSgWDAV8TRwAKCRC6RIqJnOjnrEuWAJ0ZiCFgshA2cIETpdz22Z7bFkYN
UQCgghhHAm8JvbV2NwdI40kYSrdq1WCITAQTEQIADAUCP2R90AWDAVnAwQAKCRBm
ZnF624NWebfbAJwNCa0HHOttuD9FjlhOjlXmOCzQJQCgkQLKzTtry/nW/cilJY6d
Lqi7gRGITAQTEQIADAUCP2R99wWDAVnAmgAKCRANlktmVw5t6mUIAJ90A7GoBahT
QhMKcE/dXlNVRLXDlwCfXZptMCmAgzHs+sLWZpN9zc6NfEeITAQTEQIADAUCP2R+
DAWDAVnAhQAKCRBOAqyuHdazgEb3AJ9efRdRS0xCRtpH/Ga9tgMvC1xP7QCfUYWe
1QjIpEJOzBeRqUYstoBUL2WITAQTEQIADAUCP2TFmwWDAVl49gAKCRDI+nea9ZGa
+KS3AJ4lsZ8yKdW6FVP+xwOnw1e0u8K4OgCgo0uUNv+nab4VimANBu32SEAywtCI
TAQTEQIADAUCP2cgjQWDAVceBAAKCRCzFn3en6Aefk4BAKCSGqI3yBJep5XvaqTP
0yGFYiZHIwCcCxxS79hY0aGj3ijvQS32qdE4w4qITAQTEQIADAUCP3WDkAWDAUi7
AQAKCRBhJJohMJOcpYvCAKCZhn4G1wphZnYJRTXHkOWwbopQiQCgteOHaLxP2k5q
Lw2ia81yCpiRcw6ITAQTEQIADAUCP3beVQWDAUdgPAAKCRAXwi7XM3laLF1CAKCT
ljFgyEpaGm1yxjxVtwJlhO61OQCeMoOIsDf/LGRD+UeNfrP34G3RmjSITAQTEQIA
DAUCP4Mg6gWDATsdpwAKCRBNoCCKE+KQpD5zAJ0fbYjfWpiMWXrROAPtGcvKCPgC
GgCeJ7U/YeWWJ9ZB+z99tDd3c4KIzkCITAQTEQIADAUCP48SdgWDAS8sGwAKCRAZ
yn8CMbyd1qr0AJ44zhJOMRGOHT5ff+NvfV39MHoxFACffU/M83+Kvu4g9y6nz+5f
91h1LA+IXwQTEQIAHwQLBwMCAxUCAwMWAgECHgECF4AFAkAL2hEFCQbSaX0ACgkQ
fCLDn4B6xTq67gCffqgqlDCuYUFLzAu8tSqwdH7nslEAnjeMkSNEh4krsuVQsc8f
mLeEti0oiF8EExECAB8FAjz715EFCQPCZwAECwcDAgMVAgMDFgIBAh4BAheAAAoJ
EHwiw5+AesU6eD4AniXg8BZgz+FOOJBnYlOD2e57f/ngAJ9dnQSgf4FRljyNDjN6
VzBpowkGRYhrBDARAgArBQJAC9mlJB0gUGxlYXNlIHVzZSB0aWxtYW5AYXJ2ZWQu
YXQgaW5zdGVhZAAKCRB8IsOfgHrFOslUAJ91ZD1UvplEZjoex4ZLAiNHRuLR8gCe
LqYTaUelXjL+4qr86BiuSHnxavCIbQQREQIALQUCPfOX7AWDAsqmpSAaaHR0cDov
L3d3dy50b2Vob2xkLmNvbS9yb2JvdGNhLwAKCRAQWBaFxSEJfs7aAKCmKM4Hx30W
cwzBgka77dKmrawX8wCeNqMZAlB0vc3VU9VVlnx7dh/cqbWIjAQTEQIATAUCPQUZ
EAWDA7klgT8aaHR0cDovL3d3dy5tYXRoZW1hdGlrLnVuaS1iaWVsZWZlbGQuZGUv
fm1tdXR6L3NpZ24tcG9saWN5Lmh0bWwACgkQ3oWD+L2/6DjilgCdEkk7NvpsXr46
p2p9eADs8ORpkmcAnjZcBlDIj2c0O1pPEXOKs5BJSfQpiJMEExECAFMFAj8hV4QF
gwGc5w1GGmh0dHA6Ly93d3cudHJhc2gubmV0L350aG9tYXNiL2NyeXB0by9rZXlz
aWduaW5nL2tleXNpZ25pbmcudmVyMS4wLnR4dAAKCRCkec3EWrRgalC3AJ9178Sp
mCYvZ5VbpNH64LUegUTgRgCgtllyIHMjemzT5g7r3i6qwR2uRTqIkwQTEQIAUwUC
PyFjyQWDAZzayEYaaHR0cDovL3d3dy50cmFzaC5uZXQvfnRob21hc2IvY3J5cHRv
L2tleXNpZ25pbmcva2V5c2lnbmluZy52ZXIxLjAudHh0AAoJEHkFdo91hPXYu6gA
n1a3sukcIHGqXltKgB3x9ktToAF+AKCXZGKayZGwC5Ir0Njxhsx3zwKom4kAlQIF
ED0h4ivERpHovDmlzQEBFtcD/1qUujCOYiJQVN3SzyXzR6fvnHqcpc6+J55uN7+L
XQVBdW7tjc7vOcClBzKI3V1Y6a2V6VQSNX1yxGBaB+ftoCog0OyqanYgcNR+3iIv
MJ4Z26V28Mptyc9Ub8cd60pADHKcWM0r4f5/5UNugnwCNg/EvjdkHg2MLqKpA2Jj
w4YqiQCVAwUQPSLOeb1ApukPzoVJAQE8lQQAiCSul7FIad4Pder4RTB8ow2nE52U
4W0G0mjD78CBaETZOHGJuO8llrqnx/rYDS7rsAL8Rj/v5YrsYOBbPY/6s94W6Jy6
iWijwccQJRw91CtGueCTab9EsQE6WQnp1kxDyJC3FMytBchVE+gLmcn/7MhPnWj0
5xA4wLS5N0maYEaIogQTAQEADAUCPSN7vAWDA5rC1QAKCRDERpHovDmlzaE3A/99
qZ1tpSrkk3Mp/Hkbwdn/cbKpYtkMfm4yQyjaeRL52CrOtVVK68DobMTaRz+KYTOh
I9QMhkwSn3sxFpA7YmJ5NcQbw9lp4UU+42+KNj5szfEM/C+tDOyMHjBw4sgBXvsy
Y5w05SLXMN9KU48OChg8TWKyLCaGZybsl0FG3D5zC4iiBBMBAgAMBQI92qAcBYMC
4551AAoJEOUVKCUzHNpdoJgD/iTuEAKeayuvv9jrK+8dpFt44/Tk/094H6xVIYui
06ywdD+S5+fTNohceNNAwexSIeS81sc9TsJr+hSAKoH/K9eTLrVM1EsgPR3yVwjP
1NglCJbqZ4NcYV+51Dn/049qQL3ekeSLNeXJs/AmYOIxLhcB8Qa734PBOBpSfs60
wRMdiKIEEwECAAwFAj8TM04FgwGrC0MACgkQtGuSO22KvnEuPAQAh8oEB8HrrihR
nt0ydhBQRDRPj4rtAEJ9Ft7G1D6cY32LsGlQgBRRy5IH/YmI9Ktwpi6ltX7qULUU
vjPeLTxbBiKEcZgI9j8a+oon6L61T6P001uD65DHw0W/Hg8D6vzKDZyI0OTqAi/0
MTir6otSNWB/TDhbUWX9NfABiBJ4rA2IogQTAQIADAUCPyFkiwWDAZzaBgAKCRAb
sIu/KpIyJe5QA/kBgBlYScZSjhj9g/v9o+8vl/PuBu0LceqONiJ8kKu04CId1E3S
bJx8hiQqWuvYaSJMZz+WmcYM4r8n8T1yQ9QLE7c2jIbU86irykBXKixX+af1vDo8
4B4moPZpvTs8jHBJDTWsBuGlWxxd6GHgOP7L/u1K4ZE2PC796zuSlegRNIiiBBMB
AgAMBQI/SiLRBYMBdBvAAAoJEJugaRW/hasxDu4D/0DGiGqNXNF/cSeoAkt0hywx
HKqEjzjGb1DTtJ4kLD1x7hC98LE4AaOAocDoK4FekUPbVgiyy0PtD3mNoJORWz28
leSxNXowWz3cPIrkn/Y5wrmw7Xy9ZJXJNv0h8tcxRJgUgLVN3BFrS4sx3sSjFMLb
UH8znaZjxI9Et1iRl6VCiQEHBBMRAgDHBQI/FpZTBYMBp6g+hhSAAAAAABoAY3Np
Z25hdHVyZS1ub3Rlc0BwZW5ndWluLmRlImh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+
YmIvY29udGFjdC9wZ3Avc2lnbmluZ3Mvbm90ZXMuQTkyRjM0NEYzMUE4QjhERURE
RkE3RkI0N0MyMkMzOUY4MDdBQzUzQS5hc2MiMxpodHRwOi8vd3d3LnBlbmd1aW4u
ZGUvfmJiL2NvbnRhY3QvcGdwL3BvbGljeS92MS4xLwAKCRCrHktgRnVrHsTuAJ9c
TEySl64e6UJgYUVyQ9FUhDBT7wCghZWaFgusjbcUY/8wh9C/OvsSCp6JARIDBRA9
A+ZYlWBhpt2TQTkBAQY9B+MFdy8EKYP1mgbIXhZC8sScs2sSUsLhF0ZpSq6JcAMG
IqjZZRSPfvDgt9Aqe8GnG6AtZ7NXdfYARBq301Vaf1t/kNwVK0zcL3TswpGZ/j9A
o+HhJFA1ivPHb3zrazrmEluFHbbPHZ+33Lvx1APLw2AXP2ise5XmO/Ra52I5TgeN
P9HJs1R+Qk8Pt+Pir5EfgegoJngRgdySfvcFFo9O2Kinx1sV3a/KTzmP4kzmygsk
2zVjTN9uLv/RV7U/MheTshFxIfQUxCFUofTz16Z5/nPEt2ePOWXQGPZrcW8grx6j
QA3TnNQpy45kpBns7nWhvJAI7UWzBBdMaBwJUjLUiQEVAwUQPQPmUwFVuuKglNol
AQHpUQf/Rw37iEBl3wVsGFQqsz3n6tqrfO9ZGKG/EHRO+l7iCPHjt0UHwUWLPJ0d
vE6wHbfNGFjBzWcIukJSnv7erLPgTgIv2mClN+uyMLXttYBL8OXAxG2uCsE98VG8
E5fio88T5V9a6/NqkQQYlIQj98JO8SIMwvs/EMBFD2PzEUVj/pEFONl8Wh6cFE9G
untvx3+7nUPNC3lw9dbmdTjYKTq/JHJ/rqAW0qoRbzDNSB8tTWitQznLe8srQK3g
p5qq+SqGvy5L6U2X8YusQSGm730QWEwqG0ek67TwIhq/TujYopw5VhXUJZukCGSn
+ASABCVregwXgZnhyrvgeAxNiE6U2okBHAQQAQIABgUCPSeWQgAKCRCM9myBE905
UO4VCACdm9qniy8LWH5uOktlSqHKbzoI/qTofUmLFHuzuh5idJl/JXImM/516u5r
3uZBmRpnPYImOi8TetADuwLjLTIHpxkfhVA3NRtrq1HwtHtice2K8cHUYne5RC8B
igRv/M+AP6EmgftoQ8v4mbTgT8jf4IwggJz8GX9m70zpGSMXgCkcltLfJYYPXuDT
u4bw0g7OOeQi2hjDlxm8b/stB5xJ9Qw3+TyhdT4z2msmt2h0UBDr3Ejs2Iaj3Vr3
KmN3hhnClcE7dXQNK7ry1V2J0JBBSOO2IZeBekvLHD15iwMxPL5SHz1L/95B2Jfh
M7V+QMadsQaaEYnHUh/GXXCc6nSziQEcBBABAgAGBQI9J5Z5AAoJEPy64gyiEfXt
ntQIAJYAw+AjUbAot7HWUhfqYXcw5Q6F36TY7VjNk1aD+Bh6WjKxwNUVPZH91fjw
skCZ9hDqrwJs/KciU2zeWz7k9KhFj/1PGtfducx1k5zwJUB/HmgtNk7dsUJ09GjV
+Sy9a+SdwLOgjizIl+jDY/YUAs3V2f0eOEmANdUntXDvhyiu07uo3aN0VdhB31T6
pakGObK3E+oAh/jkPw1I/dWBdKoKSHEfFeU1RgC9xBaJmoKVfCxedo3wFhZa7klg
HurVOOs1WWLwUagqGRq/kQ4+n8B8mRQNTlXtTjkL3pEMYmesP0UwmNlBFL4fl4Yu
nu5wFpB4LdXrNLWLpM/0WZfA7GCJASIEEAEBAAwFAj0Ew6wFgwO5euUACgkQCen5
CopyTkVHggf/XyO3p5CQ+sqbLVr8IyBGBReqgXgNV98UbhngBm+BL9VFNJwJyb+Q
qaJGQZxBvn8Ng13cRBDgGIlzPzUWccs66zOuZoHkR9IeLnKYQud2VWG1bGFfUrq4
p49xZsV/bD3kzORUUNF0zzTzc4EK2/xHgooqrbcsjCXsCS1598uaDOo8nzMnQBO9
tRiiyYNE0gIAYsG766ZhdUHkIWJquCK+A1U0PljBTF4HORVruJfViaCvYguZCP22
vyYbpXmOZzGIWQ//m0yXJ40mhWae2AjtJJyQEm4zRLsWv6TRwa8+DSW2OMKM/uXb
z/nLV4OSj64IEF+VKdznwRpcVVHkAKPRjokBIgQTAQEADAUCPxEOgAWDAa0wEQAK
CRBABhUOQAnq7RL7CAC3H+vBpE14/d06iAiGV1QFIuiNF3/V+REu5/bbxqzuGY6X
CmCmS8lXva08Rr29yoShJMUsvbtgQTbF80wQ5ZUlZpdlxkH88MW522rmkWD/PzxC
F5tR6hBOW7p0ccbbAns5s4BoFh7bHSU7tDmaTrVZ5t5hcHGoXFfFvMOIRbNoxvid
pxQOiqPbVNPqUUt/e1JTKucRjCaC91hXgPtCGR5Nbc4isImlUrMIfHqebsUzPxH6
6vW4ecktSCJQhRY32KBDs/fY5AiPZ3FMfN5QcnLPesJgvK5BkQ0DB1uDbG0ODL0Y
nilzR4HZYtTv3kbCg2Kyz068ql6+Z16L5qfJC/11iQEiBBMBAgAMBQI/T3IPBYMB
bsyCAAoJEKWgYMJuwmZt67wH/if3kjo34L91/rzgIwlyimeM4ncnzfsCGG6q2fjT
MkIWH6DN9l7geF2T3IN2VeC2cXE6n0o+7T/pA9pw4MnwqSxfgw7yiefSaLKlWt8f
p+XIVNN4egyQ2AEA7wS0j0rQdpGt1j9P989F9iSh5sxdqXXF8NiJSLNk/6Qc3CBP
+7JoOh4Z532jvx7/q1atd4qYXhFx2b9vA20FLUQwJOyMbpYoiG8d0a3uQ0xivTUE
RUkOrbHkum1Q1b7R81lDYSnts+Z2PtThb/RW21BgllkLhqwg8xQKjTQ0S/Y9UdYu
bffvegMXuUAT9RMyuwKjxlPnACE81oPS/nS5fdvz0WaXf9iJAWkEEwECAFMFAj8h
Y58FgwGc2vJGGmh0dHA6Ly93d3cudHJhc2gubmV0L350aG9tYXNiL2NyeXB0by9r
ZXlzaWduaW5nL2tleXNpZ25pbmcudmVyMS4wLnR4dAAKCRD5fPnjOkt/XSZCB/45
brff7zO0wtcSO55jnl1ef/ivPg4jTKDRRLtTo9BEGf0NDYM4laaeFV2DAP/upFTG
7I3vtRG20W64jCxzuBPto6Om8DobzCWaqr4vnuwi0sHFpqeX+pULRHFodBPv2PMe
vLMDHTq7wVIh62hzJrWYPrX8CP3Fgl7s9f0O8YeoGIWQRTR+oJ9qwDqY55uVzKfh
alrxoC/MWz+Au8HAcdDJvZsTN0jEF7byIuKjnL0BQXjuMiEcIAmNZ8G+mU3F1tZa
MaEkvIC0VuhgbuuUc8CvuSdSeu2jtVdAR1T4+o7JXl7T3cMe6VMRpIZSw8S9c9oY
ANM9W4Fv/CcfXjM0YZGViQHdBBMBAgDHBQI/FpYHBYMBp6iKhhSAAAAAABoAY3Np
Z25hdHVyZS1ub3Rlc0BwZW5ndWluLmRlImh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+
YmIvY29udGFjdC9wZ3Avc2lnbmluZ3Mvbm90ZXMuQTkyRjM0NEYzMUE4QjhERURE
RkE3RkI0N0MyMkMzOUY4MDdBQzUzQS5hc2MiMxpodHRwOi8vd3d3LnBlbmd1aW4u
ZGUvfmJiL2NvbnRhY3QvcGdwL3BvbGljeS92MS4xLwAKCRAZomgJiDj9lNvQCACU
ffB9VWqHksmiZ/5q/zKBGtWBGChdc1KkjzrMcfwZPijE5taUdS1mD04+6naJ+KgS
bIiOrtk4GsCuHJSLBIhJy9dtpvaZMhmU6kKp1ItxXfBw6VqD3bgllDPnkWkb5q03
4BOAmdg7Y4jXeD5iCdUNpIGemKlF1S1GNYnYzYnTKfRIcqgZ8G4QA8Po/vDaoPw4
2XbEY1p3pjUjwfuh4Uhqb3lZtM/PPCHhSkogT/EW6DdyB40YfZzvDQj4upYfS19j
wbrREo6xsFAMeQ60nZFqxjbWD34BIIqnWGOGM3vU+4kTDJTH36MOHSmcpteXz4wD
lBUTstG9MS1/zMPJcRt0iEkEMBECAAkFAkCSecMCHSAACgkQfCLDn4B6xTpECQCf
ZWMSiTQL3cODPJmeK0lxfmtRSRoAnif1TCQIIBHuzdUVvcP6g+yVqpm9tCNUaWxt
YW4gTGlubmV3ZWggPGFydmVkQEZyZWVCU0Qub3JnPohGBBARAgAGBQI/EFinAAoJ
ENb6+t2VLz//zDIAmgM8Pn8fyYwFN2SxP9nhxCQ29iJeAKDcePVaMco+0a3ECEdC
8K9f1vrgNYhGBBARAgAGBQI/E0TkAAoJENAZ9e+QJ6uIuX4An1HLngrffGbtzm8q
mS7pwbhXe+J5AJ48LfmHJ4b97S5pU5Z9idOlXZsY4ohGBBARAgAGBQI/E2yJAAoJ
EK3sLNEalTfnUnYAoIZNqErG88a1q7YEzIGxrYJOnNptAKCLDpceIDQ0aEhmPsUo
Fp6whg6p14hGBBARAgAGBQI/FkxeAAoJEEbMXGPzGKVqolMAn0gx5juuveK5cXOE
12M3eoKH9DLNAJ90uBOT0ahOSTPBNaYRNrG1OttHGIhGBBARAgAGBQI/IEB/AAoJ
ECjdsP0Zyba6a+8An0AOYFxPrdDD9arN1ojCR4diAecHAKDYiwxv3h5hoLfoJa+p
eG51Rarwv4hGBBARAgAGBQI/KLbxAAoJEG8ji8JP2loM7hoAn1/RkGr3qSul/9EL
ruvomxMJ0+QlAJ0Zj+Y/WUr96hetuIemzO+0o/Aj3IhGBBARAgAGBQI/Nfy2AAoJ
EGnSph3iY/zUPaMAniSEyLKVjJYEFAIzgmpxNuAEw/8nAJ49LyrQk/aHobbXe+wT
MC2N7fyGTYhGBBIRAgAGBQI+PS0WAAoJEKtk4Glv1n9k3kMAnAmgrI3zeE96a9hb
iYNcS+Ic4YwOAJ9zUAVGV72EnzLEA8JhcNZlI787M4hGBBIRAgAGBQI/FwtIAAoJ
EHf4FTO7DujHHE4An1R5B62WCOIqVajJ0a26vRVhzKEaAJ47Xe8rLMAdtYaz0rEp
yfCNjqIBzohGBBMRAgAGBQI/Eaf/AAoJEMXAxcchjRjX9lEAoMSwB9XomN8VtVSM
EGu3TdF3CrPyAJ4wXuds5QQPmhHZN9MIisUe10ZHhYhGBBMRAgAGBQI/HbddAAoJ
EN56r26UwJx/I3QAoOiYfXDSmN8QMsUn+Lu9JfwjxptbAKDiK2CGjUoe6yFpV7/Y
CYKTmv2si4hMBBARAgAMBQI+DdkIBYMCsGWJAAoJEIn1u5RlyRKFYgQAn2W5Elwm
02FoW3p52bma5BBKqhJ6AJ9yXbNJm9Cz3sPDkF6ul+j7HxiWNYhMBBARAgAMBQI+
L7jWBYMCjoW7AAoJEIWAWf86Zh+d0LAAnj2BIGUJ5uSdAVkf5Z/m5g0t7CC7AJsF
kT+BqKhGqdbc72389zzaKH5DqIhMBBARAgAMBQI/EU6KBYMBrPAHAAoJEPVrJqOm
OZ5z19cAoIe9jY+hXbBcpbHSdHub1f5KlwcAAJ0bHhMRIgDcZHuzWXzsDRDfhO4w
l4hMBBARAgAMBQI/EqbFBYMBq5fMAAoJENQ8swWV/so0YwAAoIVHtCduK36WcMoO
CzS9w6VobjTHAJ9lRYJYRAGn/CBtYgN+etlHTG+LNohMBBARAgAMBQI/XEsYBYMB
YfN5AAoJEFl7zE4SQqbyBWwAoNRdVUQniCjD7CxcJuQBUFmc1komAJ95FJ/s4Fl7
dm9jP4abpGQt/SY1y4hMBBARAgAMBQI/zD8IBYMA8f+JAAoJEKC+nbo7iG59Q0cA
n1ZFrw3Xh4+REyGOS99VqERv8vI6AJoDamcmhbHVTSpNGoj6n9GWA+eYsohMBBIR
AgAMBQI/FQocBYMBqTR1AAoJEDX2YXxROu/ZSVAAnA37DEH3NDy50FDJgM1GPtuO
IEL3AJ9Wh+7WWKw0Gy6yeMeHuGH0kpHyx4hMBBIRAgAMBQI/FQ9gBYMBqS8xAAoJ
EPS0sMx5fr+rnDMAnR/lCUGtwQRw2AA6sxBXrLBCsBVxAJ9Q1VXzLTyNLUybQfp0
nE0dkgojXIhMBBIRAgAMBQI/F7MaBYMBpot3AAoJEL9BWVtzcqKlKtcAnRyiBTKX
OFsBMeuj9vCUWK5Fz1p3AJ9BezD99gQpPFiGPMGJKPyJEz2EaohMBBIRAgAMBQI/
HHQ1BYMBocpcAAoJEMgPdFmtwp7Nn1AAniRAYjILIvZZIyLlrEiUY0KVx2UNAKCG
QvevCi/63MLAjsNuzVUlIwEL5YhMBBIRAgAMBQI/HxxuBYMBnyIjAAoJEOdNKbgr
4W0BbpIAn2Znv2gS1TQ0H0GLmTDoDW+PqbqQAJ4/+woVBzSm8TIjOXux+Lp84aqH
KIhMBBIRAgAMBQI/I56XBYMBmp/6AAoJEBigzI1XBqS0JOYAnj3FF4xQrt1YYEVX
Gv8o+92TWoSjAKDECfrO/zk7s4U2d5NJVKEujlnK2YhMBBIRAgAMBQI/J9+sBYMB
ll7lAAoJEJ/PLM0/PmQmkdUAn14LPbXz1IpbKxI80lygvhKF7sqAAJ9xifp9t3v6
UHGOqx1Pu3+dsehD/4hMBBIRAgAMBQI/KF2TBYMBleD+AAoJEJYkg+FWYsc0E/sA
nRSoytDaYe2pOj1Ps+nst5+K4tqdAJkBnKjq/W0RsR7O8ufc4qkRTFVBiYhMBBMR
AgAMBQI+DmDQBYMCr93BAAoJELPQo/yz5a0xCekAoPZAWjnpgCe4y+DKRaiNp+eS
YDcAAKC1dr61GbLTIY1mlVbD3dfSbhNNaYhMBBMRAgAMBQI+EF3aBYMCreC3AAoJ
EC8Xh0DY8T2+bEsAnRLlQRY2TaLZJNRikUXCVQyKg0Z+AJwMoaIkQNA4gWh6lbLy
Qo6wGDf3UYhMBBMRAgAMBQI/DcASBYMBsH5/AAoJEGx2F4yg7Zgtvm4An3wyWfq2
7Xj0iViHJ1RqUTC0AraGAJ9wkqhE2Ot+ixHUINz0J5S11cOLuohMBBMRAgAMBQI/
ERTfBYMBrSmyAAoJEOGFItd8cSvLt2UAn1gXsNtrbWNwpXBkmSUp5GjKbWYlAKCL
vka8RR/RurU/5pPyqupQXvhOvYhMBBMRAgAMBQI/EUWPBYMBrPkCAAoJEOohmUEk
d8r4Xn4AoInglVmYwXkbnbx8Rz1ll9DW1chlAJwINTwjpfb5daxWwwSJzWSQZFqy
u4hMBBMRAgAMBQI/EV0iBYMBrOFvAAoJEBn+2DzivqNBuzIAniLwKsG4cmYfXOhW
7ZiS+kxCB/DgAJ9zpH7oBiKbGx1FLeD+N+pze0ChpIhMBBMRAgAMBQI/EaXQBYMB
rJjBAAoJECjG9WuBfDVo56gAoJ2wra1YqRblCD42Y9dNkgeuViq1AJ0YvU5vWdPo
gzRM/7x+4zj5aZ/QqohMBBMRAgAMBQI/EcT3BYMBrHmaAAoJEL6cho0EYE64KzgA
oIU5sgmYV8kRHBjYeLAcAWxYa2UrAJ9PbRrqaQFNu3xVdyjYPMjdVqhaPohMBBMR
AgAMBQI/EpQwBYMBq6phAAoJEFZtNizuCXfotD8AoLg6ec9wm+rQI4doDZO5CZok
sDSIAJ9KYqHY2qZ22zanR4wdXswSNGEnPIhMBBMRAgAMBQI/Eyo7BYMBqxRWAAoJ
EJJVvZ/mhE25UPgAn0WXM7fl8mzkf+MpCCxjcUhswbNeAKD7HzIU0GUL4gpQK4C6
eemICjTSP4hMBBMRAgAMBQI/E/C4BYMBqk3ZAAoJEJSP1qDhD1Au6ewAnRrZ80AK
Hcl6mM9OVrrEyLsBQ9uNAKCYYPqAbnHy1homEXoP0Q5tuhBfNohMBBMRAgAMBQI/
E/EUBYMBqk19AAoJELR14ge6tYIpEJUAoNk0rAxP7mHEWjGdKstOj9f3jqR9AKDg
agq+e3G8FT7EA5Kj48+K+jIgmYhMBBMRAgAMBQI/E/gLBYMBqkaGAAoJELmCy9XA
4x8d5FoAnjDfn85K9De7ANkRBcbIWnpDnhzeAJ0QE2/FjyXipFxmm6BBNmaIM+es
1ohMBBMRAgAMBQI/FCUtBYMBqhlkAAoJEFGs9q11voCX6bgAnR312mY8VNJP9YOD
oFmPcmY44dtRAKCKshRU+IxFUjY78P13KhPrbfFwq4hMBBMRAgAMBQI/FShlBYMB
qRYsAAoJEFgpV1AFAIOLMCsAn011oAS6xU63aVT+LwkINDALcZ/8AJ0Wap52Jw7X
6uDubnDyPG9c5RI65YhMBBMRAgAMBQI/FWGVBYMBqNz8AAoJEJ7QeO9LOhNc3+oA
nAqSpWtIhWuYcGTbpKyHHgM0QQ2tAJsGveq/uaiz7mzdFKqmABfiTNm9KYhMBBMR
AgAMBQI/FWGvBYMBqNziAAoJEPAj+AsmhB1bdrQAoIgRG8xxV4pGqlx760ut7+H8
jNSTAKDhvhjmEkmEPa/yCPZ8DBNgYneXiIhMBBMRAgAMBQI/FWvWBYMBqNK7AAoJ
ELtVpH/JAcM+ceYAoMsBPHJnYsqk3wjKXEKngzAIPnoQAJ9v3RGynzW/IuJfylDK
0Y6yBcGFJohMBBMRAgAMBQI/FcESBYMBqH1/AAoJEEvvJiQi30CHi0UAnRtGW3yv
F7YQ9vMwOWrMc9dK3tTOAJ4shFG54+h7ubVV8JqKfQMZPiEaZYhMBBMRAgAMBQI/
FcFOBYMBqH1DAAoJEJVkH2slPljjqwMAnjnB3a/OiOgdTHRURDdNR66ahez0AKC5
EyJIB4OdJ4dKVHZ06hpoObTy+YhMBBMRAgAMBQI/FoKrBYMBp7vmAAoJEIQs23pE
d54Y1oUAoIeQLaS4L/f3FWD8IT6ERhamwpGtAJ4kaX6TnBnZ9ArBmqcy8ozkNJRa
MIhMBBMRAgAMBQI/F+AoBYMBpl5pAAoJEFO2uB3BPO4H5JEAn3uuJ/N56IylWfnZ
7dhkCdARbGgVAKDQV9NmqT0pXHXsWy1FotnToP9qG4hMBBMRAgAMBQI/F/CHBYMB
pk4KAAoJEJEfSuaGoRjm5K4AoNq5Ru8wIxer6sFuzqPq4T3uVZjYAKDVzdNA8wHl
uNAkjJdhMmN+LuGVoIhMBBMRAgAMBQI/Gm2+BYMBo9DTAAoJEM6KedeYAW3HdmAA
njglckkTKxCK/wal8Nm0aAXucvTcAJ9heBSnOsv3zAwfyD8ChtxWF0xheohMBBMR
AgAMBQI/G9ISBYMBomx/AAoJENNbvJm8fQIK+VgAniEcSCqX+OpU+Kkt7xiKgfP4
Xy3RAKCuOBzA+s2aBNZVgf9Vz9MQpgUM84hMBBMRAgAMBQI/HDzrBYMBogGmAAoJ
EDu/z3e9iwUNUv8An3YFNdNWdZejyZZtKoRbc98CSz/eAKCyl7WZloLgtpGNESBC
bNTkJTRzZYhMBBMRAgAMBQI/H7fQBYMBnobBAAoJEI+5tw+kz8luA2sAnjesTopJ
iWaSjVhKNX907zt2kGeHAKDbqP00K1DeaBuRElQZj+fUNVMJJohMBBMRAgAMBQI/
IRZGBYMBnShLAAoJEIkhtdzNFaiD0z0AoIP48cktw9bPhP5q9bK62nzSun+tAJwK
YPrdoGcrnF36Z2vy1zemIeS1sIhMBBMRAgAMBQI/IWQgBYMBnNpxAAoJEPnQFPA4
yYWN+V8AoJZFB7EWeEt+xl8hoZfx/6vbuoSIAJ4gXEOv7vTzjOrJ/8rT3gWlZKGP
BYhMBBMRAgAMBQI/IWRTBYMBnNo+AAoJEF0Pf0ng5J80YvQAoKxAULsxPpQ/5fOg
k411KxstMGZFAJ9ZFP5EYlrpUPVR152YZiczTFVEcIhMBBMRAgAMBQI/IYCXBYMB
nL36AAoJEJSbJewHRHJS8ugAnilmk2Wt0F3/z2moFxlfBLRrEDe6AKDAfTdySt+H
gg9ZympSU3HBXs83fIhMBBMRAgAMBQI/JXFIBYMBmM1JAAoJEPhZkLAkiutzCmwA
n2U2twcja17dJCX03QY5BYWlRCCiAJsGjM0j1QAZR6K5//vXPSQsUZ0tx4hMBBMR
AgAMBQI/JX+7BYMBmL7WAAoJEPK1Kl0KX7aHY5MAnjE+hWzZEGRFicmLf9o9bQHY
SZa2AJsFnUFVNFiHObXW8qMDdTkDEEjkyYhMBBMRAgAMBQI/LVUnBYMBkOlqAAoJ
ECyYPlrSilXWxawAnjCiAHSdJvomFss0MNWBmNYuzP1oAKC0FlgKmy3FuGVmsGm0
PZIJsRAF4IhMBBMRAgAMBQI/NCMmBYMBihtrAAoJELvHFNGcZ82W030An2xEMzWs
m+KBYPSy7IZNKT1K/iWKAJ4+3Kh1/FHw1QjipDp47/7oalcXb4hMBBMRAgAMBQI/
N+VFBYMBhllMAAoJEIB1JwBlqEHtwgEAoMEyieSHLwT7lWKybgj6QUHATjgoAKDV
/B9zo/jkfBm93bWgawD+34iUrIhMBBMRAgAMBQI/Sd+JBYMBdF8IAAoJEErxVCqW
OlSwlbcAnA1qUTXG6WB7+RjGR5gGGg+tZ1nGAJ0YmvOW2DeiOvMLzSskCzdIeD8j
R4hMBBMRAgAMBQI/SfQOBYMBdEqDAAoJEKsQMCiWlfJfPcEAnjURziuJ9uyTAcSU
a9vaqoyGIl0UAJ42dx3x+mq4FLZSyUw2+INqprcKEIhMBBMRAgAMBQI/SgvjBYMB
dDKuAAoJEO9inFQJsG4QbrIAmwWpsreLsZzXSPuyaEBED8jWD5N9AJ498cL9xzpQ
1u2B1ta0PmvBK08FzIhMBBMRAgAMBQI/Sg+oBYMBdC7pAAoJEMBUgYZQY6CWflMA
n3bEY57lWc2wZNlyT4ThIOemWfVlAKCtmkeQl4talgSzYXfMJ78+IjUhhYhMBBMR
AgAMBQI/ShLbBYMBdCu2AAoJEG9iNrR7D/6FDs8AmgOQiWn7b7+ON+XKb5LCexCC
BrCbAKDOfFrCBt4QPZW+4AJd5vC9EFrvkYhMBBMRAgAMBQI/SjPsBYMBdAqlAAoJ
EE6oxMIV7zzduvEAoJKmFuzxJxxI8UpDIaut5SixC7PHAKDI8QK0+Zksag2q4UjD
bXJuxx0kNYhMBBMRAgAMBQI/SnmNBYMBc8UEAAoJEDtohlrYag0ZLDEAnjialvb5
+Zv6aIxQ7W+dNz2VFYtRAJsFV+bljDbapUGdU5ezgh5iRbx7gYhMBBMRAgAMBQI/
UgrQBYMBbDPBAAoJEKUG5tTdTVCIFA0AnAxdRMSvyxn4I6JY+/LyiPd1d82eAJ0W
0I3aGhqnNkgh6bcyTKWVD275hIhMBBMRAgAMBQI/UlJyBYMBa+wfAAoJEAdlf3Oi
hrU2pMAAn3jX4tP5Fkmrmrw9zGbtWttJgx1BAJ9mNH3mCgrSoT1GUZpbKRJgPz1u
l4hMBBMRAgAMBQI/U5eSBYMBaqb/AAoJENY7cMkfA6SKBLsAnjbeg0hdzEnXhiw7
4vrZZuYuA7ztAJwJS1iql0K4CCMhpmkSQvOvg9x31ohMBBMRAgAMBQI/XytKBYMB
XxNHAAoJELpEiomc6OesQMsAni79sCahaHwYGCw/5arjWNWWlBTBAJ4ghyFiL32s
+DfQX87jjftmxvEL2YhMBBMRAgAMBQI/ZH3QBYMBWcDBAAoJEGZmcXrbg1Z5mK4A
oL+qRlvr4rlM/Csmai6dp8lXsQuhAKCAP1wxNS3McENWR8V6jTOhNQ4PQohMBBMR
AgAMBQI/ZH33BYMBWcCaAAoJEA2WS2ZXDm3q2HYAnRulowz/E7vbymayGUBrEQlE
HAF2AJ0cGZBa4tOCxNCk/fU5rXbY2R6hMIhMBBMRAgAMBQI/ZH4MBYMBWcCFAAoJ
EE4CrK4d1rOAsj0AnjuttX2QaReGs4X0M203acKP7pcqAJ4/HhmzmW4GkY4ypd/6
w8kwa78tQIhMBBMRAgAMBQI/ZMWbBYMBWXj2AAoJEMj6d5r1kZr4uBQAoIL+r8wG
jVmPs9ZVCFjFuwqe60e1AKCO57osJhwRkHX/V0V4D3a8XhLhzIhMBBMRAgAMBQI/
ZyCNBYMBVx4EAAoJELMWfd6foB5+JGwAnjAt0r3T7nSU7yGy9N2AiiKeBimUAKC8
RJ8BW5n4BK4l3CkRqV4sVIUwjohMBBMRAgAMBQI/Z35CBYMBVsBPAAoJEMlPfflm
8tnG/gAAoKNNWKg6/a853L964H0oiP8slYtBAJ4s6x8gzvT/HS6tg9v7MvZgdDbV
fIhMBBMRAgAMBQI/dYOQBYMBSLsBAAoJEGEkmiEwk5ylZ+AAoKIAJXyoxoPk9vtf
sKnp0Yito20LAJ9WJ2azDAfLAcWAwesTyGkZ0Nwg44hMBBMRAgAMBQI/dt5VBYMB
R2A8AAoJEBfCLtczeVos9EMAnir2nU+yKliFfYi/+752sPnBOsC2AKCiuKmXw75r
dDj4HuteorVT6yqUgohMBBMRAgAMBQI/gyDqBYMBOx2nAAoJEE2gIIoT4pCkzQYA
n1nX4diOXWc1gZ45lrFoHQBCjRLIAKCDUuJa7efN29sMA7JMU5DRUqmnaIhMBBMR
AgAMBQI/jxJ2BYMBLywbAAoJEBnKfwIxvJ3WbfgAn39ogXp0+YDH1/9yzj+zlyZO
hL24AJ9uzyVUwnKGCh5n7OoAS0FsXdfYLYhiBBMRAgAiAhsDBAsHAwIDFQIDAxYC
AQIeAQIXgAUCQPwPkgUJB8Ke/wAKCRB8IsOfgHrFOm1eAJ0boiU8exzWwueG259F
lMmE9O34GQCfX0DtGbMndyRtcwbXqX5ih14WHd2IYgQTEQIAIgIbAwQLBwMCAxUC
AwMWAgECHgECF4AFAkD8D5IFCQfCnv8ACgkQfCLDn4B6xTptXgCggbpZQyKe8BvY
bC1NUXc9my720h0AnROeWBYTqf5E64r2kr3LEzijdJhbiG0EERECAC0FAj3zl+QF
gwLKpq0gGmh0dHA6Ly93d3cudG9laG9sZC5jb20vcm9ib3RjYS8ACgkQEFgWhcUh
CX6JWwCfWBLfY0MNvg76j1aFNiDSN0+Kc+MAnjyL6sZi65007O2iMN5ZrpizKHEg
iJMEExECAFMFAj8hV4QFgwGc5w1GGmh0dHA6Ly93d3cudHJhc2gubmV0L350aG9t
YXNiL2NyeXB0by9rZXlzaWduaW5nL2tleXNpZ25pbmcudmVyMS4wLnR4dAAKCRCk
ec3EWrRgauA7AJ42KOLGN/ovjnxEdHD7xzzRcHktAACgkyi3zR2G3oL5a3nit4rQ
vihA+xCIkwQTEQIAUwUCPyFjyQWDAZzayEYaaHR0cDovL3d3dy50cmFzaC5uZXQv
fnRob21hc2IvY3J5cHRvL2tleXNpZ25pbmcva2V5c2lnbmluZy52ZXIxLjAudHh0
AAoJEHkFdo91hPXY9CcAoKrjRA8ND3y6T1aQSgRZeJeYu/LAAJ9sJeTFMk2uR098
SDRCUcfTeKC8xYiiBBABAgAMBQJADIE/BYMDwb/PAAoJEL/W7lhX938JNtkD/3/2
RKm28v6btjL2UrCJg8LjxoqxSOdU6N5SLplZ2YOef3+gZUTZSsYT1K4XvPoBvPif
+6zd0a9bFp+fP2j7SGMrlhHTd6+aDQ/BHaEZzt4dY2dfFcDNyvqIKeOTXw8/HR+d
wryHDNwRcEMOb00IPVjfVirOcdPNbn6jYP1LYnPniKIEEwECAAwFAj3aoBwFgwLj
nnUACgkQ5RUoJTMc2l3FHAQAki+C6EKYQRullCePZ2GMJ8SR54xI42JaPbSBzxpb
684J/jabcr8WHHJvGXlapUmdl3vqlks5tatn5iFJvbE4qAPOdo6C5NXIpD5OSbHA
ocXj43QdrftuMVF7w1fyJBkWFoMrMZoa4FxiFLENbm7DknLebp1Bp282O/XR9R52
PJSIogQTAQIADAUCPyFkiwWDAZzaBgAKCRAbsIu/KpIyJW/MBACnClO5+acvjHnf
aUd53tcKfLkb+vWzMXWKNt37RG1d04bKqlkZdzJKT+noMBqflVf91rk3goPPJPDj
wUtm51gGlSgPG4mPnhQRrUHwC8BM0lGiuB68Z1QdxF1iUx8B623GtPrJbfufCexr
AxIL6La7KosErbR1JXbjS9+d+M1p9oiiBBMBAgAMBQI/SiLRBYMBdBvAAAoJEJug
aRW/hasxbHUD/RqcGxjUaJgELwAfNcTpm86BsNL5tu6WJFe3DdIIzQTb27GGgbOf
j5NRLFnk75xgQtk8lnKqsXQHMC6hm+pwh4ZGISBZE7NIqYokUSYDT2mbplDo2kDP
yO2V1fWf8P5f8rI5e2QYIvn4kNFWidfQKh1Rw86MlZVIieVf8eVeS5qCiQEHBBMR
AgDHBQI/FpZTBYMBp6g+hhSAAAAAABoAY3NpZ25hdHVyZS1ub3Rlc0BwZW5ndWlu
LmRlImh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+YmIvY29udGFjdC9wZ3Avc2lnbmlu
Z3Mvbm90ZXMuQTkyRjM0NEYzMUE4QjhERURERkE3RkI0N0MyMkMzOUY4MDdBQzUz
QS5hc2MiMxpodHRwOi8vd3d3LnBlbmd1aW4uZGUvfmJiL2NvbnRhY3QvcGdwL3Bv
bGljeS92MS4xLwAKCRCrHktgRnVrHo45AJ0dD92uCPhsjLWrVsbhMJfwmkVOnwCg
lKPYurVXyo6uXC/Q5KdueASb3iWJASIEEAECAAwFAj8RTT8FgwGs8VIACgkQCen5
CopyTkVorwf/ZHfXpigg+qo5D9nzURNgsckj7d5F6M3QfYUSpE7Hl8826m80iVci
BIkZEo9R2H9mFOf8CJFBLqcbz6vxRC0Q+xMbZSw8o0tRrfVTEPyvdh5ayIwKsV1m
gFuxJwyDPN3zy7LejqsLQUA2IGY+pCz2kv7P0iWRvK4uaRO/z5qaF1QLd+aYssol
kidmcMnkJph3+/UiN8Tvlr6UAcsAolj+ZShPM1whJ6aAOL1EnDmnHScVVmGIl6Qf
2q1jtPlF3qG6CY9CyIaUSxSudAEMaGthTeM+MjP108aJcTYVF1PbyHnKy0e4tJlU
/MW5OohVH3/KEmIj2lT2AvBUHbCYL4NW2IkBIgQTAQEADAUCPxEOgAWDAa0wEQAK
CRBABhUOQAnq7TmRCAC1UpdCGBG6ahH7Rmw39bsX4YqExVEuCHnTvMe3RvVqx5uV
kzsvHQU5wNYm6g+VOpMH1JMpQ7EsI4IUELbBAHfVHOOS4xWVYuPsP95o+uSGzJYs
67p42cEcrHHvHh4BFYKOMnw38ghfizR0hTlQyAWsJ1E5uI/T2Yl++Iav1tmhj2nC
p/mrNDy80iTLuzLZgn/6XbPUwVS6E5YUV3AOPqOj/eDpDD9GDEjS3v9AavkmoECg
LScHU25khmXwp3fogXU0LBMglGJ47yavnpzWYCk1nzR3kWGwwSb6MgN/Ryono3kX
IuCow30IZ9RAw8/6vZkK+dHF31sWA/i181nhepJ2iQEiBBMBAgAMBQI/T3IPBYMB
bsyCAAoJEKWgYMJuwmZtssAH/3ctJgr6Mh+JctTcxzMdMtVAsP1xe2CGzvVbryCz
tpeCQLfq/Bu3m16dfKurzArT56FQK+q+3uGrKe/tAYbzF5I+J8f+DdFt6Rvbsdf5
jxfa6VqvYUXI23B1OyKs0vFamkvm1YCLhm/fUU+GHqPZwPYasL01xUSj8yJr/bgk
Xzy3A+Ddp1IFFnFBdhonANYFUOhoSaxgkTky7dLPtJS5gla5E/z4OmacV7qIGath
hxGT6gVIj8kW4Zs+BrWRxhGYzGDt1fJzIDJB6ZO5bodnUoQycyKKn37YE5s7kEdK
oRMkZXWZaJk4bdF1b9EQZxlDvCBIRDPyYV1HQyk3R7az4S2JAWkEEwECAFMFAj8h
Y58FgwGc2vJGGmh0dHA6Ly93d3cudHJhc2gubmV0L350aG9tYXNiL2NyeXB0by9r
ZXlzaWduaW5nL2tleXNpZ25pbmcudmVyMS4wLnR4dAAKCRD5fPnjOkt/XUa7B/9E
12tRF4ZZ6zu04Ml0342x+tMNCW7BNNIYaY8vzGv5L/1XbZnUsvMbODbswjtUIm7f
TMd4QUlM0Onl8Os2jIKpk879oAptDdDZ9qW2aF49Y2xshn+OAMdnqg/siiQuHIx7
bQBdM0y0hxlw86be9ioeZxSeXPcsOfEoig7f/q2nepDnrJCOqf1L5G98v/Wur7iM
kPCoB6hb1VG6lwoATTeTqcQnBVKbxAYkNrRlzydQFMVyC1S26tkxebwURCCQ21gI
Uv1WtE/dPwffygd/GnwIDnRaTq5GqkylB1//x97Y4dUy0Im7QXqNN7E9eRpSKOZg
Cz50g4AL4vkIWiBz5NoeiQHdBBMBAgDHBQI/FpYHBYMBp6iKhhSAAAAAABoAY3Np
Z25hdHVyZS1ub3Rlc0BwZW5ndWluLmRlImh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+
YmIvY29udGFjdC9wZ3Avc2lnbmluZ3Mvbm90ZXMuQTkyRjM0NEYzMUE4QjhERURE
RkE3RkI0N0MyMkMzOUY4MDdBQzUzQS5hc2MiMxpodHRwOi8vd3d3LnBlbmd1aW4u
ZGUvfmJiL2NvbnRhY3QvcGdwL3BvbGljeS92MS4xLwAKCRAZomgJiDj9lDjmB/9+
xx4CERYCnN4lFiVjVFzj+kf8CSIypWi9eV4Cgm+KD4Rzp0mykx9RaOPS80YGxNoZ
nWs3rLou2HZDTvMSFRewgkOcqC/FHrgGidboA+rUKTqswfoItSHnkk405mw9WeZH
KIzuqYuTPjldEXqXt0Q6fUR34S2c539ddSST2fmZWZihKo7wTfVYr1tZf4I3tgzk
o4RbKka1kTCNaN7brJ1Lnsxsv+qWpZXkkeBxzFm+ci1whREIRlCRd++KZ10UeBO8
efZjNQRJ6MtZaT2l2NjAMtOtUVYoQQp62U8MaGSN4GYUlx6EeGliVG25BxIp25aq
FxE1aoxR34P5xxoo/0u4iEYEExECAAYFAkCUK3UACgkQiwjDDlS8cmN8qACcCXDT
1uoHqpYBqUwQXGBrIG98OLMAn3fDQD+PxIoQRnl2mTfS7tvK+5NSiEwEEhECAAwF
AkDqYrEFgwLj3l0ACgkQHUdvYGzw6vdwmACePDgvHzOP08Y9YIeCvHDdrxovnFAA
n1Drnt2s/TrU5WqQNcskN73uo7b2iEwEExECAAwFAkCY7TUFgwM1U9kACgkQ7YQC
etAaG3PpewCePfTDRDfn1Lk6GfcgT696QNyH/JQAn0ROZC6OiyRop2WDPsloq/cz
qckkiGIEExECACICGwMECwcDAgMVAgMDFgIBAh4BAheABQJAC9oOBQkG0ml9AAoJ
EHwiw5+AesU6pr0AnRh7cno052HUBE0aa818rs/8zlAnAJ9Rpxn1PNy6fHDfggn3
CvfNoY4DfIhiBBMRAgAiBQI9rbqaAhsDBQkDwmcABAsHAwIDFQIDAxYCAQIeAQIX
gAAKCRB8IsOfgHrFOiX4AJ9GHkeHPIbS/6NGOjYJCszIux9zRACdEW8bvoIWBtpP
qk4Ea+hzDwPAtLSJASIEEwECAAwFAkEksIIFgwKpkIwACgkQG2jc/MBZaCO9nAf6
A8uZ2u5TNZyJUSjevVElgUO4dhwF8EDMm5aYqTZeLU4/PYGVREJRFwfNqXQ1MFCy
8nSrB3vDBC21MoRPTnfvqZHTNwc0SHoZA6gYi5JhzkX+NJwds7M1VXFnKesrjNsn
f0+NYeMkiMNRj+ZpqXfhXxcVnSMeDmHHOTtxO5LDAn68irrAIg1SJWanRUL9cCl+
7SOPa19pIKmjNKIWEtRnhR92w5TKvm+r32PwWUXyecqsNKvlzNxL+YPrPWOWtC3l
GPATg/m9g1QJjsQbFSUM2cATMJeYXN1OA9ih+SctVQ5N2/OLHTapW20pEqZ9apZ4
5/PuKOuQyN67GU9rHvSdVYhGBBARAgAGBQJDnFg1AAoJEMYEPFZyB3E3RikAn0Hh
f4umlH98ndhjQs6w/QaZWPJ5AJ9X2T5BRWQfbgXjkEHSUTMb7xS4HYhGBBARAgAG
BQJDnF6YAAoJEHninGCwBj/nWTQAoJDd1azU15qBByVSJyVquMpBeUqPAJ4gdBiJ
cT7t4q4Kq41DkqKTH/qD5ohGBBMRAgAGBQJBhOHmAAoJEKsvWlsVJWmQ6QoAnjuD
6c+ikcJpbTYpgaVKc5ZODGtwAJ94pw3P+iiFzIFRGEDMdhIZ8r/nvYhMBBMRAgAM
BQJBhNcCBYMDOZ+OAAoJEL9L0OYEnbh5jzEAoMxd8I4KIYqynGu94KxD6aKd4MaD
AKC/FqUbbkk8idPDFgSV+w5ZHRwOzohMBBMRAgAMBQJBhXr6BYMDOPuWAAoJEJ7X
WD/BTrKCmuUAn3GD2uLP+/cUz4mUqrwNVz7mMnOEAJ9fJg394Vq3GdEvRRjSI9QY
z3fMvYhiBBMRAgAiAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAUCRJKxGgUJDTp0BQAK
CRB8IsOfgHrFOs6mAJsGHngnJ1kZq5IO5L3UpBFuEq5i6ACggtf4QGMcgerJF+xH
g3E/w86rzB6JASIEEAECAAwFAkKA85kFgwFNTXUACgkQ9cMgCiOcY4T/Ggf/Q56y
b8M4HpS4WetZGeoR3jJy+TH0cHtcrScN9lICvJNdUYdql+Ghatc94xf40ZhROhkU
j9XUhabvmEIz0ieayTurqzvDshV5ID1cOREZW1sclPxP/cEH9K34Nv33TrCzpKfK
jvrL8PZLdvdVklgb8O/DHh2BFI53JBoWGLr4NGxTIwqnsGcTxz+vqsYEUZSOtuAK
5rxu2rhmiyb6JQ44vXXOkRaMoHZgyhXAeqGWQn6bDETOYkqJEUCaupHDsQvbkqtE
uRd5KgacWl/ws+2sFgqRidhyfCDOiloZ9w2dz2ihbxVpDHzreiF0DArs+7oSz3of
cp/B3hNPsa2n1O+VULQrVGlsbWFuIExpbm5ld2VoIDxsaW5uZXdlaEB6aWQudHV3
aWVuLmFjLmF0PohGBBARAgAGBQI9ASZbAAoJEGfDAwhyWzfGBLwAoKWnsa+E24L2
9Y9VyeXfZq3pg9k3AJ9hEEh8WO5fj4Z073lvgHVPG6qyB4hGBBARAgAGBQI9Afwv
AAoJEJVkH2slPljjgrMAn2TgIY+ZB9r9qR3HM5I+T1fLYmveAJ9QOWDtqooXNB9V
caFEHmZjWgYUvYhGBBARAgAGBQI9A/CdAAoJEHjLuZUaVye5V44AoLB91plDEM+i
o+/BzmYfzfwypybJAKCFpbbrLHz0Ne0ff4ntBjoKgzSjPIhGBBARAgAGBQI9BLBy
AAoJEM480UB2FxNnQy8An0ZtsEQIU2LXngkTiTcy4DU+n/cDAJwPZEkWgSLvqryJ
DSz2PsnFEYk/YYhGBBARAgAGBQI9BMA8AAoJEFGs9q11voCXsWQAoMGOsUvlQqY3
DWpxCUSIshlu58bWAKCf5Hpb3MRH5ocAAQinqe+i8+ktK4hGBBARAgAGBQI9BNmG
AAoJEON3tjt2fvwkrSwAoJSNjWNY6KP6vzZ6bhbAwrQ0o3BfAJ9WKRdj1VkSIAO/
eYhAKx9GnPyq1IhGBBARAgAGBQI9BgzdAAoJEO773Tof4oHr6+MAnjSOOrmkCiQ/
mN4IbMMsfvfeS4YRAKCJkwtAYHRAdfa8a4Dk/lEf05zU1YhGBBARAgAGBQI9B6oY
AAoJEDrT5sqEheDXDuQAoKz49XgLPKaeDx5DfmpxuU8nDP2FAKDN37rcyuRmedDX
dxyHf3ESwr5aj4hGBBARAgAGBQI9CnbOAAoJEGjt4yhb5E+RHsIAoI9tNZAqnMt7
KgiOQJQxYoHhNCLoAKCENv2GGaQxDrhkUXQNhRJawqjKTYhGBBARAgAGBQI9FztH
AAoJEA1hENZzj+CBgJEAnjHQY7cG1ZvhWi+KYhonI2qfqK1/AJ4sILeTb9pI+PJi
P5EKv8tdV8ugzohGBBARAgAGBQI9GiOsAAoJEEmB4GSIP0FCdoMAoJl9WNhjT/R+
kuh/5djYKIrJUYf5AKDBGfIqseJ9B3WZTcxMCVyO0muMBIhGBBARAgAGBQI9Gxnt
AAoJEP2fw/aQ4eNGnwgAoIWRlm8mc7+U+JsUo1rT0pR/dDg9AJ9efo0Dd7L2l7Iu
uS7JAoQMX0IDmIhGBBARAgAGBQI9IvmrAAoJEOZMMhXaFT+rw0cAoK7Bf5VxrTrU
7H03wXYVGKnXKpblAJ44b0LpOydOn2r01e0U/TBa1Z5clIhGBBARAgAGBQI9JF1A
AAoJECihtS0a2n4sp5YAniDzAcgLH2JzCUQu7JJJ6SHXXsAoAJ98ZL3vsNd5hRY+
a4zOdCiGikbCCYhGBBARAgAGBQI9J2yfAAoJEH2fkZBvKrstv/MAnRua4ZlkudQN
YjDpybeq/NHUi+MLAJ9uB9meu0zTRQbR1G/6lmgwd9jK8YhGBBARAgAGBQI/EFin
AAoJENb6+t2VLz//IlsAoPd8nnhb9Gd5ljRv60Z1L/xzQNOLAJsE3vXwN9ZlWfVd
yETSIuHWTpt5R4hGBBARAgAGBQI/E0TkAAoJENAZ9e+QJ6uITRoAnjTDdSGCNENj
pKFDcOS10vUM+0ucAJ9kqmFbEsI8suAH+FkXRrt7eAUzF4hGBBARAgAGBQI/E20O
AAoJEK3sLNEalTfn1KYAoJGkFf2ysgJePueqZXs/qz092xenAJ9In1C1rEIm9o+W
gyrv0t1qx42DpYhGBBARAgAGBQI/FkxeAAoJEEbMXGPzGKVqetoAoMQSa/Jmc7JV
TuCgTrNTnHTTvpbxAKDF5DJ3RTwqnZ52xmrHBrDjMoj4JIhGBBARAgAGBQI/IEB/
AAoJECjdsP0Zyba6xlUAnROCRo1o4y6bgSdefmO2SFCjVI0mAJ9FGyb0u/OQEgMl
Wo18agiuPcMUPohGBBARAgAGBQI/KLbxAAoJEG8ji8JP2loMKGcAn3mUyhLHmiDq
sjzEpr2PRu1uAP+5AJ0ZfqdHIjBMf6rpNszrJYucdPZsV4hGBBARAgAGBQI/Nfy2
AAoJEGnSph3iY/zUVM4An37YGrDwvyAD4XDKz3fMHg+2D4pUAJ45TOZyzGNP9EpR
NpbhHzXtE6ZmhohGBBIRAgAGBQI9BN8PAAoJEHFe1qB+e4rJhZYAnjt5sWZTVPzy
yO/SDo/EbyOGyN80AJ4sk+glDv3/OOX1V1FGnB89s9XvqohGBBIRAgAGBQI9BOdJ
AAoJEI/xGsXf6A+yMtAAmgPwVlVpRF9bz+BMX777WDdijvZ5AJ9bvWlFobbIkzHP
Hx7mx0KyL97jfYhGBBIRAgAGBQI+PS0WAAoJEKtk4Glv1n9k44cAnRRvfMvfjL6u
/bPwjdqNmM9VBpLmAJ4xSf89b5Tj8ddFxuyNs56Jpij/04hGBBIRAgAGBQI/FwtJ
AAoJEHf4FTO7DujHnhgAnAn/GuMMoYUsje3I3KNQbKdV9S2IAJ95UaULEP6yQlAA
td7hu0bqEpRU7ohGBBMRAgAGBQI/Eaf/AAoJEMXAxcchjRjX4IAAoOBsz22Ebc4a
VrqQHDHBW+NdH2iAAKCd0PgbPaRYZjoKqWAzp+5M9R42+IhGBBMRAgAGBQI/GEvn
AAoJEBp0fkUw4LnYVCgAn1hKcCBrKMwVwKqOWDsKtNuhwL7TAJ0S7OTgp8WBlY2A
ppo1bqyYggeRlIhGBBMRAgAGBQI/HbdfAAoJEN56r26UwJx/kd8AoOfESY5IadAC
DT0/chs+1lqUsn6ZAJ9KO8HLj/BJwKUfF7wKLoa3g6et8ohLBBMRAgAMBQI/ZH33
BYMBWcCaAAoJEA2WS2ZXDm3qKFQAnjN1CdrS7+g80+VqFAXf0UwpBsrEAJiyp0qI
xbLiyWVLj79axYL/KT4PiEwEEBECAAwFAj0F9X4FgwO4SRMACgkQFBE43aPkXWbs
gACfQCPFAtb6OBdqD3sJhCRgG7BWNUkAoLPcP3sw+yD9RkygLR6Ruba9ahGwiEwE
EBECAAwFAj0nEgAFgwOXLJEACgkQnC/GTAhVf9+upQCbBE1/lDppNQ553+Kr+ld/
NZQ79wgAnRZq4CqIuiWDQkTJLpl2CVYQubpNiEwEEBECAAwFAj4N2QgFgwKwZYkA
CgkQifW7lGXJEoWiowCgs030BbhZmv8hTnzrZY49coEwkEAAn2aw3ioCblMYsipM
s2tOnG8LSaPgiEwEEBECAAwFAj4vuNYFgwKOhbsACgkQhYBZ/zpmH52/RACgmRcX
wHRPj6vCSvXK0RKYFNqnE5IAoPW97ijCfLTMcc5TQ5zad+X4CNVdiEwEEBECAAwF
Aj8RTooFgwGs8AcACgkQ9Wsmo6Y5nnOqowCglD4JoBSpW/JNY5s92E5xM2Ek5nIA
oLpkhk67yA6t6bN+KpohkC9FTleoiEwEEBECAAwFAj8SpsUFgwGrl8wACgkQ1Dyz
BZX+yjTNgwCfdfAIjcF2wInNGcPi2MO0VOS4h68AoIGpGBGw3SymVwUs56PhbZ2D
iHDxiEwEEBECAAwFAj9cSxgFgwFh83kACgkQWXvMThJCpvJ5UQCfYx2eQVspTlBh
kSR9eI8LvmTVWI8AoOOu/JvRlg00PwwQbPbbRJpUn63siEwEEBECAAwFAj/MPwgF
gwDx/4kACgkQoL6dujuIbn1DOwCeMWKi/vfEr9gGI9tPuaWrvsQ3uUoAnROVrB9G
bygdg60AMcC8UCr3JeIqiEwEEhECAAwFAj0FpJgFgwO4mfkACgkQNfZhfFE679nN
wQCcCDeSkIBkaQ16086MGkdfNuKiZKwAn2tpwhoXtEbgsHpCF3zAs/Cc0as6iEwE
EhECAAwFAj8VD2AFgwGpLzEACgkQ9LSwzHl+v6sElgCdEc6+HEIZZg/ByJVW0dPS
HgtnQ5QAoIe96t2+ltWislwGMLZw4YnA9F/JiEwEEhECAAwFAj8XsxoFgwGmi3cA
CgkQv0FZW3NyoqXX1wCgoeWCnwb2eqYH0BIa2QOS0PyJs6MAnjemG3u3/F+2YAVF
b/j/hWWd58FRiEwEEhECAAwFAj8e1cAFgwGfaNEACgkQyA90Wa3Cns2ydwCfT+Vc
qJJwikWxzMf87emW4Cscxl0AoI6g5g/915iiYsIIVn4vrvZD+ayoiEwEEhECAAwF
Aj8fHHAFgwGfIiEACgkQ500puCvhbQGgcQCgnXRR9+lFagxrQDaqGxfvKJS6ZCEA
oMaIhJSoTGR5z80flj32PYtYPtp+iEwEEhECAAwFAj8jnpcFgwGan/oACgkQGKDM
jVcGpLSFZACfSQV68pbho5g0ZD9GtgH8+Qya/90An33f2uquYtYxlQjo1ELSbv9I
L2JoiEwEEhECAAwFAj8n36wFgwGWXuUACgkQn88szT8+ZCagGgCfabFI4Mrv/Gn1
OdY1r8w+QzfIgbYAn2kOQu7q305cZnSXc8clrS8TnM5aiEwEEhECAAwFAj8oXZMF
gwGV4P4ACgkQliSD4VZixzQNwwCgiDHqExihoeHDgXd71QgxWuQrMSIAn2EayYYb
Q+gC/OBIrrvQcY00oBBuiEwEExECAAwFAj0F5MUFgwO4WcwACgkQyg4WnCj6OIrI
AQCgxqSp3Cd9N73uID+EXcDx+48h0hEAnREExhuH9gdoAzUR/+uLr4gyswXniEwE
ExECAAwFAj0GC/IFgwO4Mp8ACgkQjZo8HzjZ7ZvpPACgmnUwYbCPrx4vK2n7RqUI
NYIZ3rQAoLAACVRv/E4FzIkuLOKviaxWPeldiEwEExECAAwFAj0GcEUFgwO3zkwA
CgkQGFkMfesLN9xS+QCeKRxfqyWwPrBVU9ETPrsFAy2jmoUAn0xuH8yb8CRAdLWo
FS79H4Ab1/iJiEwEExECAAwFAj0GdBYFgwO3ynsACgkQKb5dImj9VJ/jywCgpttI
iAh63fliMUB78r5pVv9DzHYAoJivMe0CxKyB+DN8Qw+eureHowTsiEwEExECAAwF
Aj0IdlcFgwO1yDoACgkQrjA8sxkq93mm9QCgn0vLwKwAoRCzvGqa0mzNxXBb6wgA
n2KkgwjLq+nBpiCD3aWpBGcIanPbiEwEExECAAwFAj0Rb4UFgwOszwwACgkQzop5
15gBbccLVQCeNWwobWCzXLEMNwyCDECBVY7SfHUAmwee17eZXkXnd2EDopndt0ZI
nBDkiEwEExECAAwFAj0je/cFgwOawpoACgkQ5kwyFdoVP6vsCACgoHXxPcl15mkq
C4UH3N0wF9hSKB0An2ogjtkkg+lripBol6sSQzw8wHGliEwEExECAAwFAj0muQ4F
gwOXhYMACgkQYdhR2aaCIVMrDQCbBKkp4GNfJx+WHC/X5Xce/8cNb50AoNUhrB94
/7q+iQ0GaUGTsKw6IAfPiEwEExECAAwFAj1beicFgwNixGoACgkQMU96lewVKUIL
eQCgoLmUFS1YgDn47WTIHB3S8eO5a3MAn1L+l+O161pC/zvUYH4aoa+9Xuy1iEwE
ExECAAwFAj1bfGIFgwNiwi8ACgkQELuA/Ba9d8bY0QCg69LH3fDaDaof3M6peyRH
v9PCM0EAn32I0xguBCMVsbv6gxTrXo4w4YW6iEwEExECAAwFAj1qVVQFgwNT6T0A
CgkQ9/DnDzB9Vu1xDQCgkdM4WfTBxAZsiRe5PLYP8jDR2/AAniCW+Gu2EQJwLWRj
PqOvcJIb8LRFiEwEExECAAwFAj4OYNAFgwKv3cEACgkQs9Cj/LPlrTHw9wCfQQgL
hOC+QSldOYyu8k8S5B8cerYAoMYxqUTD8tMcpuIo0xbgDC3J9a/aiEwEExECAAwF
Aj4QXdoFgwKt4LcACgkQLxeHQNjxPb61nACdHwt9jEnJ4/eyGOrUfpp/yea1ouQA
oIaiPCXMlbhNNzc4m1BpVEsw453aiEwEExECAAwFAj8NwBIFgwGwfn8ACgkQbHYX
jKDtmC0V8wCg9hZEI0Jt6J15qMqGZKAAfqJUMqUAoNQU6kNI7AtztvjCcUnBriIf
e0dfiEwEExECAAwFAj8RFN8FgwGtKbIACgkQ4YUi13xxK8v5MQCfZHDuXl2cWe9a
4P2p9lZZayYb0cAAnAqkSWW/oIPxEU+5Ya8F6DYYKmqTiEwEExECAAwFAj8RRY8F
gwGs+QIACgkQ6iGZQSR3yvhkggCdE6qxVswXo9p5atPVqrWoPaGowPMAn1pIEWd2
z2OyP/doUZq0PLCnHxzZiEwEExECAAwFAj8RXSIFgwGs4W8ACgkQGf7YPOK+o0Ef
KACgt8l6AXLZgdRmqyz5mw4eGAxvSJ0AnA7bLnASAzFiUiEfYiwvMbrTLnV3iEwE
ExECAAwFAj8RpdAFgwGsmMEACgkQKMb1a4F8NWj5wQCg08+K6aBDNW4gJnvnY0xm
iVGi01wAmQFvQQeBim3pUKxKsvIDQugLKPG/iEwEExECAAwFAj8RxPcFgwGseZoA
CgkQvpyGjQRgTrigBgCeKmovouIibT3kajx402LxQDugxQoAnRO4kABG9/VGz5ng
1dI71Ufjz2GRiEwEExECAAwFAj8SlDAFgwGrqmEACgkQVm02LO4Jd+jLcwCeOSyW
pikmr/dTNeMYY9C1FLSFHPcAn2SunmQ+n9lUWiDCJnvegKRrtimXiEwEExECAAwF
Aj8TKjsFgwGrFFYACgkQklW9n+aETbmlrwCdHEVACJoo5yeeK5Ozh9iitnufUv0A
oNfh9ufMiUgYZfQ16zgesMCegEaOiEwEExECAAwFAj8T8LgFgwGqTdkACgkQlI/W
oOEPUC6HgQCeP5asAMsRB0y+ddSMNJPwx5MYi5AAoLR/0Q006geBNJ4sWPBogmFE
TjxMiEwEExECAAwFAj8T8RQFgwGqTX0ACgkQtHXiB7q1gikf4ACeO+4yvB93TI3t
EonLL8utG4LqK2EAn0pkNIbWv5BTdMZ9UtiU4lLsggS6iEwEExECAAwFAj8T+AsF
gwGqRoYACgkQuYLL1cDjHx1jSQCcDMX5auJPO0Vez3BsZUL9hvrdGXkAn0k1QGkO
dPGpQ0QTmSrUzm0UzleUiEwEExECAAwFAj8VKGUFgwGpFiwACgkQWClXUAUAg4sb
AQCdGtxPKJGtuMoRf3vBOrrO9IlzrScAoNxpmn34YkF1KduyFV7dTo8jy/M0iEwE
ExECAAwFAj8VYZUFgwGo3PwACgkQntB470s6E1zLtQCfaXZjYQ+sksgc8hMzCtFA
EAifnfkAn005kOQXSZuBkK8ugQCpuy8k5hS5iEwEExECAAwFAj8VYa8FgwGo3OIA
CgkQ8CP4CyaEHVvuigCgquvW4X6eZygYwZIS38S+aZTI/k8AnRtPX45jHE+d0/M1
EQbCwuaoVAlxiEwEExECAAwFAj8Va9YFgwGo0rsACgkQu1Wkf8kBwz4SvwCgw0pB
5XK7POsJ5UECjCykQs9sSyEAoMvLACIRSjrgRebLvME3UULl2ioPiEwEExECAAwF
Aj8VwRIFgwGofX8ACgkQS+8mJCLfQIcbNACfYMXgGmMRtYNBQAHWdKIBgIIhrCMA
n0iL8A3SQcUws9/twq0K3GvlK5+yiEwEExECAAwFAj8WgqsFgwGnu+YACgkQhCzb
ekR3nhgNCgCggOiZWqKGDk5hRulk8LIZNXRA8p4An3BTkDYeJ9gWLGeF/zZWnJI8
3pnUiEwEExECAAwFAj8X4CgFgwGmXmkACgkQU7a4HcE87geD6ACeOTFMJgZhv6KM
m53JGifaNUh/bDsAnAsZ0K7CEYfZ0n0nQBqyvWjqxz6TiEwEExECAAwFAj8X8IcF
gwGmTgoACgkQkR9K5oahGObhMgCePUlvpiRZbl6etIGryTyLYR9gqroAoJkCK44/
Ib0oXCZKRUIgvDJlxavtiEwEExECAAwFAj8b0hIFgwGibH8ACgkQ01u8mbx9Agoy
UwCgp1vVNdw9MZEhYYkmSdeJxJYvcAEAni/aQxlebubW73MgGUbvvUzJtAypiEwE
ExECAAwFAj8dgj4FgwGgvFMACgkQO7/Pd72LBQ0AFgCgjDNuyTmuSCL6pTZG0o3J
/SCDxdQAoIhj/wunPLECjvio5a0rLuQMUywliEwEExECAAwFAj8e0H0FgwGfbhQA
CgkQ+FmQsCSK63NuyQCdGFZvy8aWzu6uQkSu30OaAzH8mDYAn2M/HLdu+6bL+Oq4
129OUTXTq+JDiEwEExECAAwFAj8ft9AFgwGehsEACgkQj7m3D6TPyW48LgCeNvU8
GJ4LdXqQJ3u/OLw9pBekg/oAn3xsUyp16m5rUaa8Yelm/R6ZhLaXiEwEExECAAwF
Aj8hFkYFgwGdKEsACgkQiSG13M0VqIOyQgCcDSXFE2JqMkFqHoSznM7UYAadwGUA
oIXFr2/jjvTA7KQG/6Kcq3WDwBcoiEwEExECAAwFAj8hZCAFgwGc2nEACgkQ+dAU
8DjJhY1JFgCgk4zLx2cNZbEWiDKQI96ExJeuqZ8AmgJjiKd83X6fd6PbkVYcmJrq
13ZuiEwEExECAAwFAj8hZFMFgwGc2j4ACgkQXQ9/SeDknzSGXACcDbHIGQM/WB+M
PU24ZGrPL9SWJ6wAoNog2GM1VJq+yB0J9w4qkRkRQyptiEwEExECAAwFAj8hgJcF
gwGcvfoACgkQlJsl7AdEclIYYQCgnUSABSCmOQfzl9+6SeUCPPI+PwsAn1RAW8oU
D50odE4XXcLa2Rl8NLoHiEwEExECAAwFAj8lf7sFgwGYvtYACgkQ8rUqXQpftof9
LwCfa1J/jVUGC9bb6fn+zrUryCAKu6kAoKfUBIDGq7u3sTs7Z2d0fbDrw1IriEwE
ExECAAwFAj8tVScFgwGQ6WoACgkQLJg+WtKKVdZCYQCglZ4FpPbpXjhu74bRCVrd
eAJ5nQAAn3d76InANQ0LAGb/S2EpDpW1o5d+iEwEExECAAwFAj80IyYFgwGKG2sA
CgkQu8cU0ZxnzZZG6gCfRHGq4yOy29gdqadB55XeJbxNGZ4AnioTed5Qjk7Sgi1R
esxqR0XSHEXTiEwEExECAAwFAj835UUFgwGGWUwACgkQgHUnAGWoQe0mVwCgyaAq
pxyq9vksU99ejBktUq3E+WEAnjiFFEBu/tPQetz98ielQsAAAxx9iEwEExECAAwF
Aj9J34kFgwF0XwgACgkQSvFUKpY6VLDZxACggedehItsokXuyb+/K6XXXZ/tcgEA
n0gPVSNunp3pAfQw4dbKuNsx+qKbiEwEExECAAwFAj9J9A4FgwF0SoMACgkQqxAw
KJaV8l9w7QCfWVJMXScGJJk54wuMl4N4kFSuQHwAnjcaGApmVlAQO4bF80i/mXWr
OpuziEwEExECAAwFAj9KC+MFgwF0Mq4ACgkQ72KcVAmwbhDR/QCffs40d2Ixbgjf
AbPh6wMSsUUF1IgAoIMa44KQki6w3U8XMuC2YC4cwa+6iEwEExECAAwFAj9KD6gF
gwF0LukACgkQwFSBhlBjoJah7ACcDaBeP0NPcYYnCD/Hh3DaqUSvUqcAoMPUI58V
74Myg62EooU8xlm3F8dyiEwEExECAAwFAj9KEtsFgwF0K7YACgkQb2I2tHsP/oWf
SACgzmpTH5UXykE3Vcx9bf7LSOoV8bUAn2GhraKmGbZTUq6etXO3A7MPwIawiEwE
ExECAAwFAj9KM+wFgwF0CqUACgkQTqjEwhXvPN2RSQCfX8eXBdrlgbXTC4qy6hiD
0XTH2eEAnAnpoTqfbuXZPrQ3aTSsa80+kZOpiEwEExECAAwFAj9KeY0FgwFzxQQA
CgkQO2iGWthqDRnPPACeOftkkQb2E/kCuS3vCuXv9fHU+uIAn23ZP5CNcMFr7gSO
GyJWWa3RYxWQiEwEExECAAwFAj9SCtAFgwFsM8EACgkQpQbm1N1NUIivbwCcDaNB
9KPvUJzwsVwMB5e6lF6oIaUAnjZAxd21hgmacqAU2GUiWDLQf9ytiEwEExECAAwF
Aj9SUnIFgwFr7B8ACgkQB2V/c6KGtTYgtACgh9uIe9rhr2inzR+l4AKqGTXkQ1YA
nRgJzGhsUXe5L9pT9j/tGdVia49XiEwEExECAAwFAj9Tl5IFgwFqpv8ACgkQ1jtw
yR8DpIr74wCfYzvbGpvLtZlTEilE1GLDvuuqrqIAn2e7kNhLcjKIYf/Ew2ebeSU1
NAVUiEwEExECAAwFAj9fK0oFgwFfE0cACgkQukSKiZzo56yENQCeLoQpJ6g2G/Bb
Pvs7GY7yQUBUY3UAn287CLpTknesBdp2VKP17/+QXKyeiEwEExECAAwFAj9kfdAF
gwFZwMEACgkQZmZxetuDVnnmRwCgyzMjyidP7kqGwHtuNKvZxch9LPQAn2PgLZsY
58xHx3zJwQAuMtQbxnIPiEwEExECAAwFAj9kfgwFgwFZwIUACgkQTgKsrh3Ws4DW
owCfSivVhD6KQrYQKn6WKLhzX7rPrUYAmwfRgUV/TW0YJ+FdxHYnQTq9vP8NiEwE
ExECAAwFAj9kxZsFgwFZePYACgkQyPp3mvWRmvho1wCfcKaPcAmKERyMMGzC2DcI
Sa1N0XcAoNjA/KX7Wb3TfHrDlgVoJj3Pz94HiEwEExECAAwFAj91g5AFgwFIuwEA
CgkQYSSaITCTnKX48wCgln9QeNOwxvzirYVdO1JiJRVPfooAoJvbuUGz3JgYlcfI
Jv4qavEQxTBhiEwEExECAAwFAj923lUFgwFHYDwACgkQF8Iu1zN5WizjwwCgg64U
kRnhVE/LWsV9wKDom+APiusAoJXiKKcZX6bWxBagwGrmKps78T3JiEwEExECAAwF
Aj+DIOoFgwE7HacACgkQTaAgihPikKTPegCZAaWNKXI1gVzLzfTQY6OfbdrrMkQA
oIwJ4T7oggx0nuQZIOuOhdPEWSXwiEwEExECAAwFAj+PEnYFgwEvLBsACgkQGcp/
AjG8ndbEGQCfeqdzppVd/q5Ge3ifa+oGb8vpM+UAni3C09IIhlFrAl2cExRU/v8i
5EF1iGIEExECACICGwMECwcDAgMVAgMDFgIBAh4BAheABQJA/A+SBQkHwp7/AAoJ
EHwiw5+AesU6oBAAoIWVMgus2P28XPTOPNVtwwwEHNfZAJ9wa67ar46OySJ5MGUy
45zcV7CG2IhiBBMRAgAiAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAUCQPwPkgUJB8Ke
/wAKCRB8IsOfgHrFOqAQAKCLHe6ZQtrvqlMj45q1MzzljkcQAgCggt8dWLdgjW5m
Kx+aBq0b9+V3ry+IbQQREQIALQUCPfOXzAWDAsqmxSAaaHR0cDovL3d3dy50b2Vo
b2xkLmNvbS9yb2JvdGNhLwAKCRAQWBaFxSEJfi42AJ42PjJMjXqUqTVmXbxU2PEJ
4svdcwCfRPxi46JV2VDJ4W63G1DaUDiWiWGIkwQTEQIAUwUCPyFXhAWDAZznDUYa
aHR0cDovL3d3dy50cmFzaC5uZXQvfnRob21hc2IvY3J5cHRvL2tleXNpZ25pbmcv
a2V5c2lnbmluZy52ZXIxLjAudHh0AAoJEKR5zcRatGBq03YAn2agRerjydLAVZj7
1bDEOOp+x66RAJ9ShytdZkMoPvUd9CV/8H5HxooLEYiTBBMRAgBTBQI/IWPJBYMB
nNrIRhpodHRwOi8vd3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9jcnlwdG8va2V5c2ln
bmluZy9rZXlzaWduaW5nLnZlcjEuMC50eHQACgkQeQV2j3WE9di+ywCfasORltrD
CeqxTVRCt5ApJnGqJ+wAoIHdbs0xxl/6vW9hya8xiNLH6bv4iQCVAgUQPSL5m8RG
kei8OaXNAQFIEwQAjU0nYZWZedJSmP1p95TXWPHU7H5EK63z/pNlbVzHyxiCwR2M
6OacN7sEIL/PndMM2R0wVbfjmtEogotpKeghoAxnHzZiFJPT/VSjk/pJ0Vskoi57
VlsXztfiaShSbWN2mXe2bcr5ypfY6EMNKyBZno2nSUZRdZ8pd0tZWf3JzbqJAJUD
BRA9Is6DvUCm6Q/OhUkBAUbCA/45odKyNdrcQ1n6i1aDW+LCw8lTxsOikdW5GJQR
hHr8CX38zQG9I80Mc7OqspyVCiJ7RrbJB3q8i/QSauaWBGw7Hfxi2+KL0kkYnLVz
yGwinRfH9jH2N7AV4c5pK2T6qPIqAlqvbahpiBgW3N7F23yeSkQmnZf77bwCoZ1E
GBksoYiiBBABAgAMBQJADIE/BYMDwb/PAAoJEL/W7lhX938JWHQD/0KGlDZTHafA
rjeelk1yI0Em+7wRI1Qi6zqhsewE6O8DVobsOOeEWpc+sTsBCxignllpVq18ovEQ
1uqAGtb7mSKmS6qicn23/WgEE32ZmWInkZTAra2a0UPaSZl/1AYVEXrEEYRT8c55
pbaJljPCmMeTPv4bOZ26jlnRuP1ZHnu4iKIEEwEBAAwFAj0je7wFgwOawtUACgkQ
xEaR6Lw5pc1InAP8DiZIr+zbc88sTKSIAta6rJgXOen9D3IfF1uf31chOcwtXqXA
ZgF3PFoQMUUvsnF2nR0FdxKYx81u+DhUJf8LEzSu7KDscr1fQfnEHY8XQZkH28Nf
5A4Pvif4SokGIFXPJenvivZvRXm3w3vDxWsXNDeavEwruCLwTKIQFKW/7kaIogQT
AQIADAUCPdqgHAWDAuOedQAKCRDlFSglMxzaXXqEBACRD+dGF2xlUYAuWPS1NrK8
y9TdelmV9j8JkRPyxoFOUjTJima+I1mBIpvKw0cmcRMrXd1QBbgjL10PhpYZUdF3
hHOqpSmG1HptytFefLb/STybLvixEeq6UGJkkAZB+nwR4Wv05fW9/o0++/02xO1f
qyQgG2+3zk0id6nVQyo16YiiBBMBAgAMBQI/IWSLBYMBnNoGAAoJEBuwi78qkjIl
2BQD/11SvcUGwoDdPSv1OzKIdLM8u57m2WA1FAOtlJYjDbra6p2n5ClbpNwQ6phj
75Hi09kcEatm2WgM5zLD7laFk31ZTPVnRK8C65ZfJ91oH0Wlkz4eojSaTag3WHKq
EcvaEBK6Mo1iiXU4o0pDq5IGuVMJeOE87Ly11fB9QCuOQacBiKIEEwECAAwFAj9K
ItEFgwF0G8AACgkQm6BpFb+FqzHE8AQAkMxtg+wV+VOJ3NNNiouacu7qllxp9N4W
gKsdRLJQDV+hcnIMnqhOcwewKS8/ievIC1lloZ1bIiTpwtkli9qLtZMvXKYETj34
YEwuc4sB9eVkxiGsh8t56s6ERgKEQMr872ZZ10F9YRqjs31whrMwylRrBEU2SOLm
5RMOzC2V8GOJAQcEExECAMcFAj8WllMFgwGnqD6GFIAAAAAAGgBjc2lnbmF0dXJl
LW5vdGVzQHBlbmd1aW4uZGUiaHR0cDovL3d3dy5wZW5ndWluLmRlL35iYi9jb250
YWN0L3BncC9zaWduaW5ncy9ub3Rlcy5BOTJGMzQ0RjMxQThCOERFRERGQTdGQjQ3
QzIyQzM5RjgwN0FDNTNBLmFzYyIzGmh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+YmIv
Y29udGFjdC9wZ3AvcG9saWN5L3YxLjEvAAoJEKseS2BGdWseDesAoKCjFDCU3jIC
6z+0nRKimHPzV3aoAKCrm+owZ1w6bBXMB6tZc4ZwRLbztYkBEgMFED0D7RyVYGGm
3ZNBOQEBq+gH4QFz5MNM6veSfl4uzf3ftMDylYkMjJknlg/DXVlv0tKShrJf3MSl
QQjf0x+RpAxMSOFj3OeUhTv9l+F+rnQljg7sqaey5DbJ0Tml6JVOQkqaMMVKbqo5
XJMcFqvrvk4U3gSQVsMy6aIFCbUIiHDHaZgecbOnIVynPHnodPxehO1yzHXDXXFx
gFdtVQAfbBZ97x9b+o4HuJkc7wwe7cuY24ySPP4APEvwbgobn09LBTcV6df4RZBJ
NVBhrdi2vAyoM0cNaRTbjoH8NpTkLp91QuIWk4bbHD2r0EtxSlYx3RfJeGpBQ10X
Jba7oETBXy5K4yU4R/9zFAscXcjnUPmJARUDBRA9A+0YAVW64qCU2iUBAZ/0B/9D
SJD5LUeMmra4zZ954BjdkY8UxXkMbbNU6Ea1FXjU0qEBQKCzH3ROaJeqn1+nq2Xl
VW0Mp1xno3SgqXXduwWkYGWjhZobvlU5KYVDBbq4lhsw2tU476X8+XofbbSKC00v
+tyjpSS7fuo8Sl8U1VwQJGOLD674qCP+wpNuCSxJPrnERH5Q7cCBAsXNautiCzqg
qSyuIMOZGh2qtpPA7dx878c2JVUf9jal65kESFWFzP4fe6U7U+9ReTQs6alzVXEl
3Sb7tCkJo9FbRQ1TvEqK8IOVXfful/QXVDh9MyxIJ4Qm7AiUgLn1r+z9H8mpua+0
55j8Z2r7loh9LfRTsFS2iQEcBBABAgAGBQI9J5ZGAAoJEIz2bIET3TlQ2aoH/i8C
2dL0xDBUqoXkSIffJgqpZNUt3L2z4gDn/MvNk1ml9PjxDz2SBWOHcnwhA+PmhyO4
umlNBGHNkktKHt09cPwLwij927yOQz2YT4izoiWxkdkWMtOTA1yX9A6LoCXUYRFo
pjqeLmJ6l4v9sgMT4P0uY86rnF9kVh+Mt0J+no4KwGNW64xgRJp6CdJ74iWWqlB8
VYBjK3zQ3MS7GcsDBQ3vFAfZ0QxUP6i5bFdKiLPi1bxgcDOnXV009Wd+o6nwq80f
VplOAps5l55QUhRKI4aui0Z4p/03keadBvcAy0IlgG0vBK1k+mzzI9TIInS/cTmD
6PU/3MCLmznJRKyair2JARwEEAECAAYFAj0nlnwACgkQ/LriDKIR9e3aqQgAobyh
smVVEqLNKySVwdbk8wYmI5Jig5XBpR9LNg94RbDFRU5wFEJNAPo1BYPwE4YxZCn+
WJ57lXEWNA9kNnWnF/QepyQvVId7tH7HOhqZ0YpfRIWvdrL8TrZUrNaHj77LBo9x
rt9dduMllDpgBx7DWnx72fJK59MgvAcwEew6qqSSvGQILiSEudfHy/6sYPBjLgyX
yQIh6/Tkn1kjf0rCqAl3qMrcIuAJ/JotSxkjw9tr6JFVuebsaf/W6zKXzsiXxTfA
8gDzC7ObL0vDRP79pMT7jfBFVm3y7k/PLSwMgVsex2UFO2ko2z0lkCPcRKCi482V
WM4R75r/rdBISG5c+okBIgQQAQEADAUCPQTDrAWDA7l65QAKCRAJ6fkKinJORT7w
B/0QLriSr9e8qYg9LKzZ9dRvhJgoNpVnCgHXiWDwuz3Yy8IfCwoC83aail+I/gEc
53vdYpoz/FL+IKW15HRY/WQV/JDujTOEr1bGRivYdM5t+jYZ5Cc+8azPCY8aKFBT
ppPRssQJt7ibBIFJg+AfMq4gEz/KFfj9AszDhEBsrOTTv1nk2oV/ktXE+VMx5dH1
1ilyJJf+yuRQVfJvUyQaIej5l895/+DeYI72WR6mKTjR+1Jxkl/qn2u2PQJSWQ32
bzIu/vaOXBVJ2PouIvMf0pqmv617tMryNEvhJGu2aYBGMCN5hv1MklMkwF2azwir
LvnOAulpumomlrdvAw/Z6yZUiQEiBBMBAQAMBQI/EQ6ABYMBrTARAAoJEEAGFQ5A
Cert6LcIAOC3o4H8Ma/GD2heMQ4F7cgMgO5/jfeLzMkuYRmxYTK/tc4xGTVuK/o2
pfEMS9MYs0wwjzcYq/JWKly0/vSW3D2jiEUzfBgvWuuYPWfliexNwsMnPaxIrnc5
Q07k9byyTsyCBLmZY3oI0hbyP5GSDRo7NLqXkhTdL18pHP/roEIuXNe/58K3Ony/
SoAm4rCb7BoKu8XkU55uFyuy/4Fi9lfVoHWAhXwnNOd/Vm087hawu0OTV+2KF/1l
yPSMPHNWmgZEa5lGPw9Z37EnI12rpNy+qJc8D6aNNLfNYqUBwcd4xAFNAeRF9+mK
KOXLjruvCBge3d/4edhSkx2Hc8L2PVyJASIEEwECAAwFAj9Pcg8FgwFuzIIACgkQ
paBgwm7CZm20cAf+LEy8ELPU4wY8XrWmxPJ+7E6kBejGw5ImZAfIAuRIhmYAkl+p
WjLO5LKCH15fWMr6qch6pcq3KG5sIT1j69fK6Sx10wlKj7LY9/ybiP0GIUjJFPaz
ChNRdWIltSl8bX5if4HKnlJPlLt61O03aziOR9FkV1xXC/xw37y7bmQJNZoFohn7
GK6EQPMWrZL7+ywh4ty/0MzfXNlWQssZU2pZQRyDVUl+EBmkGlXmUu/dQHBLlanD
YlVDyBUy3iWPINDoDdba2ny2g2oRmvMXlkh+4MbeVkU+B2cE5MMe+K3uJKP7vTbZ
KCWPUFJ/SyPju7aoM+D45BylEpzlIDa53DlkgIkBaQQTAQIAUwUCPyFjnwWDAZza
8kYaaHR0cDovL3d3dy50cmFzaC5uZXQvfnRob21hc2IvY3J5cHRvL2tleXNpZ25p
bmcva2V5c2lnbmluZy52ZXIxLjAudHh0AAoJEPl8+eM6S39dkwwIAKjo94Mz7+ry
atxk1pmMylgu5u77qqnvJ4gwOLB7lvYJCLou/QAyyy0I5iwKSQpnWJmkzV1XZdnQ
/qqvMSH9l49cgxA/kQTM5laAXf4JXCM+JdLqcWlvoNAApJB1T8uQzi3+vU2RdVKJ
gl4HehvyTOAS4fWMqQBhz1ha5xaXUdPFrnC6ih3bflmWxFxjK6OtEOi+q+sTlALf
PZ5S7tUazNCHXYSjtC2AncW8zq1tp+TYMJ9/Cj2j30M3752HW73oXQAHW4E3cgfi
NWlxRY8eC/9XR7PpnZYV9s3gbHoYrn5vkbxOmzW+bbw//y8CBV5vtLdJo4J2bR1Q
ueKjIAv6rBiJAd0EEwECAMcFAj8WlgcFgwGnqIqGFIAAAAAAGgBjc2lnbmF0dXJl
LW5vdGVzQHBlbmd1aW4uZGUiaHR0cDovL3d3dy5wZW5ndWluLmRlL35iYi9jb250
YWN0L3BncC9zaWduaW5ncy9ub3Rlcy5BOTJGMzQ0RjMxQThCOERFRERGQTdGQjQ3
QzIyQzM5RjgwN0FDNTNBLmFzYyIzGmh0dHA6Ly93d3cucGVuZ3Vpbi5kZS9+YmIv
Y29udGFjdC9wZ3AvcG9saWN5L3YxLjEvAAoJEBmiaAmIOP2UNN4H/iI98ocmrlSs
XKH4kvKrAXdVR6Zt/eWN7bDhufaiCq5gPpkySvANnBSHv083bor6AoK4v77Otwl5
SiTnK9A2YkPqfk54mYzX6Wyd9rkXfvq7gx1FZIv7Ad8Ht2aJqAhGlSZWQ9DE7b7l
DtCDwrDREimWAdGozy2sjNsqPYyF0R6okrHfkOVheXEw9ogZY8hrPQYENabv4R5n
Ig0QsK3P5QA9c6uwcEPYvz9YLsJNPgub5PnU9hWwhinttwq5byt5f787YFF+61Lo
Gq94SBEG47NY+j9++vvf9YCJLnMVzmZqdE+MZyu0AjcdXNzBIByBeaJFVzSyxQcn
u9EjayJMWcCIRgQTEQIABgUCQJQrewAKCRCLCMMOVLxyY6bmAJ0avxrzQD1efLks
7SmqyWL+q0sMrACfeWLTlQcgmuWDPagEG252YLLmsSqITAQSEQIADAUCQOpisQWD
AuPeXQAKCRAdR29gbPDq9zR+AJoCQLogYVirW7v9e6ueMN7GfeNpVQCggcuTNnj8
MC54QqRu3aJIoz1D/2yITAQTEQIADAUCQJjtNQWDAzVT2QAKCRDthAJ60Bobc/CE
AJ905qJBRThmUHPhUypx6mhm6ZpBbgCfcbCpxMQjLIhCTbl4Xra1cze07JqIYgQT
EQIAIgIbAwQLBwMCAxUCAwMWAgECHgECF4AFAkAL2hEFCQbSaX0ACgkQfCLDn4B6
xTo3OQCcC1SaePSF5++9T8ih4uDaJQ2zcNcAmwXvuFFBzUZn+aXbifdQ2Q1wWQ0k
iGIEExECACIFAjz72QsCGwMFCQPCZwAECwcDAgMVAgMDFgIBAh4BAheAAAoJEHwi
w5+AesU6LrAAn1b1v095d8SjY2t6825yYT5KsP+9AJ9OhFAQb0IjZSkn8JFqhKE1
SX0FP4kBIgQTAQIADAUCQSSwggWDAqmQjAAKCRAbaNz8wFloI8tiB/9z5rOW+Y11
TCqvf98SdL+uuTamCL5ZG+pvClkXR8zHEsNRZiQWOmWzXhGi9bwGNn8XKMs4W/jQ
FuGy/cqWySSKgH2y6vgvIVSeZAJFCrD4ydIKXIopHSeFG/qV3TKBYa3/wPkptUlh
IpX4sFjglb+sIPlV2kSpjcKJQkQqH0E0+SkXj4ewzXumiWVpgOr6sjJJA6HKLRN2
r4EXswUnAl8/KwpXca8yR61KYKpbbdAOL9pLTWatUHP1qahtaF3Bt2skfjklKbtD
Fw7fIyYo1RGNq0ZoGLqKHzIZHIdgvxqlplxjZUDfZx01OoKxUd7JRyaXuap+zI4q
WmV4QgTshwXOiEYEEBECAAYFAkOcWDUACgkQxgQ8VnIHcTe4jgCdE2rlxafeb54q
g/nIA2c8tdxqt+kAniB7RIhtf+xdTlAAogvgsoM5jeweiEYEEBECAAYFAkOcXpgA
CgkQeeKcYLAGP+d8igCgnQyD381FYrENuvxVk+r94mv73w4AoJOhtIELKg/p9zHz
xjZGEVviyWiaiEYEExECAAYFAkGE4eYACgkQqy9aWxUlaZD/DACg5m7KcnPh1RUZ
X3bpBAOqQl7sOGoAoOPe9A7f+H7qsisjD/5epkWMAR0fiEwEExECAAwFAkGE1wIF
gwM5n44ACgkQv0vQ5gSduHkDPwCffv3kuJ4se5SmysEPCG8cx1E8LRYAoPUH6dJc
k2XvpcfMu/rAbOeG9UfxiEwEExECAAwFAkGFevoFgwM4+5YACgkQntdYP8FOsoK+
VQCeOjjFdC79gzRcrgbBfE8VLp7Rz8wAniAYG48/1SgkIP49sEhYhZClkvOziFUE
MBECABUFAkOcgIEOHSBTd2l0Y2hlZCBKb2IACgkQfCLDn4B6xTqaGQCeK74DmNvQ
lBEG68SVnC/Th601ZecAoIhif4+AgTgttXMY+L6yXPArk1ywiQEiBBABAgAMBQJC
gPOZBYMBTU11AAoJEPXDIAojnGOEbP4H/1kHozS44ejLQp8hDQPaPsdd41aoWs7e
VZSfZRPBVUKD/m4/LanazbRqAD472raEpv6VvqQV5j97H45OiKOANs3gZudS4STK
c0vDGi5xNVdhgtkl6wZfeSRZnRZZnP8MkP07xeTkVW2PpC6nFyG2ijWMMmsTLbXu
ouHa/qpp7Wl7sM4GHzAJeNmXo6a5uMal3xcWhPxP/o5qsVAOx/Kdy5oHa9JUrl94
lEslEE1U2MjxP4LhSgvSc2UDZJV69zBrT2yCSVQUbWCgw025wRjvuaPDsbW0ceBo
6bY6fVMJBzhAzONUtbm4ayVzE5hWnaUUXWUjPzfjNEBYIix0dlcEGeC0L1RpbG1h
biBMaW5uZXdlaCA8ZTAwMjU5NzRAc3R1ZGVudC50dXdpZW4uYWMuYXQ+iEYEEBEC
AAYFAj0BJlsACgkQZ8MDCHJbN8YKfQCfbqneeSuRkRWo8Pt5AJJhu68fH+sAn2hV
hwowNTFTnJ+VWLoYINmwNopViEYEEBECAAYFAj0B/C8ACgkQlWQfayU+WONzFACf
QBGpIsi42s3iqv4aAzpXzlIJNjUAoIfca9XSUulrYQecXPL4XT/yhK+biEYEEBEC
AAYFAj0D8J0ACgkQeMu5lRpXJ7lbtgCgm22+HVBwhSTprdZHLeBLDEG39NYAnjcN
Ht8/vz0wknxJwgPDHV2Py39LiEYEEBECAAYFAj0EsHIACgkQzjzRQHYXE2dK/gCg
hXxDtBFfvB8475eJOFVlg27jCpcAn0SpH/URRBBmkDrN5hWVog6qGaeziEYEEBEC
AAYFAj0EwDwACgkQUaz2rXW+gJdRWgCfbh8pq+MMhNhDjILn9xKHDFDtuf4AmwSu
fZRxbspp/d6dL/nv8nAd9q5KiEYEEBECAAYFAj0E2YYACgkQ43e2O3Z+/CRhDQCf
fdw06kcOoGkHmvs8FSY1qQf9rTMAnit6fMF4c77nQv+vbe2G2MIm7Yy6iEYEEBEC
AAYFAj0GDN0ACgkQ7vvdOh/igesu8QCgkQkXs12wkOF8rN41B/n3bwnmcHEAnAhd
rBhdplJBGRkCaIUYcn4Gy7tbiEYEEBECAAYFAj0HqhgACgkQOtPmyoSF4Nc9kACf
W1XhTP5Rga2k93b7jK6jVE3J5AsAnjs7cIp+qJNkRea6AyRb/wkAAQewiEYEEBEC
AAYFAj0Kds4ACgkQaO3jKFvkT5ER0QCcD6qA6BCPAZT4JKiszXSAGu2iQ+4AnRzh
DrzkkjzzoEjTqnMOVIOrqAOviEYEEBECAAYFAj0XO0cACgkQDWEQ1nOP4IGOoACf
XhTkM4grPfWJyzsLsl/97L+/wg4An3IJz3967t7OQZ8aUV0PTTGJKxTEiEYEEBEC
AAYFAj0aI6wACgkQSYHgZIg/QUJPrwCfZz0LEX34+GYtSynWGsOXOvhoUiwAoNrr
jbgNpUX+EXYDzFjJGzlALW7FiEYEEBECAAYFAj0bGe0ACgkQ/Z/D9pDh40YMEACg
wV4/aYYQDpd2MIA3PSb0hx9Ek9AAoIkebLS5BvVjV7ckhj3w4juPUSMUiEYEEBEC
AAYFAj0h4k8ACgkQ5kwyFdoVP6uGlgCgpxDw0SSapnFskycdn1K8aB2CqJYAoMQA
fxPe8ZNM1w+AiVjysaXZZjW6iEYEEBECAAYFAj0kXUAACgkQKKG1LRrafiw0LACe
MYS6J2YHXD8ZrRNMFkjiDMYwWRcAnR9DOJJnegL3rpU2kkMGownx1/uBiEYEEBEC
AAYFAj0nbSoACgkQfZ+RkG8quy1MzQCbBMwBpJ9Vr6ZcRDR/6eweor/Ne7oAnjyl
jwUI6q3tADpARXloSgrdD/0tiEYEEBECAAYFAj8QWKcACgkQ1vr63ZUvP/8shwCg
/INT+NtdjmmU4cd2EEXNfvIaNCoAmwUBxlT/upFnOCznvrgR7EkGlDDTiEYEEBEC
AAYFAj8TROQACgkQ0Bn175Anq4j7owCcC6IvBcliL4fcqalvpeOnl82BBJwAn1VD
eAyKJFwVzHzV2NqNmVjwtosziEYEEBECAAYFAj8TbTkACgkQrews0RqVN+eK3wCf
clp/TQmEBuaKZs9pGdvF4pWPBgMAnA6TK8qytbqSgAPJkWfq4Raazl5/iEYEEBEC
AAYFAj8WTF4ACgkQRsxcY/MYpWomWwCcC90qEAvElCqsYoD8l8MpGwOSShwAn3DD
YubPtqmiVeZUkXhbhBC17rhPiEYEEBECAAYFAj8gQH8ACgkQKN2w/RnJtrrK0gCg
pp8nlqXMfiPIVq/2ZUX4LosibaUAoOEYQs5O6lYVkyBuXwV/6hp9XcYaiEYEEBEC
AAYFAj8otvEACgkQbyOLwk/aWgzMQwCfT2wwq4+HNMrcpFKQPXg5YOAA7skAoLjo
TH5vxmTdd5K/qSobIP19FsiUiEYEEBECAAYFAj81/LYACgkQadKmHeJj/NQ94wCf
cYwDcDUyj1TQ9Zq7un2yevABhjIAnilnW9RWeronC14woG3YoLczY85PiEYEEhEC
AAYFAj0E3w8ACgkQcV7WoH57isljZACeJ/9V6UMcN1EfQq/PnhfrDWw25RIAn2gD
H8AS9N1bFQXPy1LymrgBLJMoiEYEEhECAAYFAj0E50kACgkQj/Eaxd/oD7JjVQCf
WHRYcwZ5hsrQp3b5eZaUJ0nh3wMAmwd9/DReuYIn4kDjdlFtFiCz6u4XiEYEEhEC
AAYFAj49LRYACgkQq2TgaW/Wf2RCpwCeKywwopn+uH9zprjPfXQS9VTIwn0AnA5G
T11+1eJf2zXCqq3luNe69DGhiEYEEhECAAYFAj8XC0kACgkQd/gVM7sO6Mf07wCe
MIE1z2CpBuMUthivy9xgqJNHLEUAnjcDmd25kzxjhUibiizLOqZd1U9miEYEExEC
AAYFAj8Rp/8ACgkQxcDFxyGNGNfDlQCglEfBQSSgRWyhTUZXZEf2m2RbbakAn05Z
an/s6jcCsWlqqhUjz7DruenSiEYEExECAAYFAj8YS+cACgkQGnR+RTDgudib5ACc
CLJkrUNZFiyygQO5ETFZ1WLoZQYAn2QAwGOfsaBhRc9Jl0ZcGwroBgIIiEYEExEC
AAYFAj8dt18ACgkQ3nqvbpTAnH9e5wCghywape/DcgyzBRmh71DhbQ68gyoAoIXF
LxtLNwPqB9aZ1U/bhYUY/84miEsEEBECAAwFAj0F9X4FgwO4SRMACgkQFBE43aPk
XWYihQCfYo0cYtGmPQWeN8EwWD+ej/8xy0gAl1Mu0DSPleoxWNuxjx3cdUjO6zaI
TAQQEQIADAUCPScSAAWDA5cskQAKCRCcL8ZMCFV/37qBAJ9X2kW9GAdwHjuVPl2j
xcS10MPUbACfdaOWvDyDuECpmZZ7bKK99KD2L8+ITAQQEQIADAUCPg3ZCAWDArBl
iQAKCRCJ9buUZckShWXRAJoDIPp25Xfd9O5433Wx8D4kLj88EgCfYwL7eWnmCbNj
QT0cjJNovDmH//CITAQQEQIADAUCPi+41gWDAo6FuwAKCRCFgFn/OmYfnVFFAJ9l
5VXxX1SMc92HXZMgDT4Vb/zskgCguGT6udrT0DNEMszUXRrilmCHQz2ITAQQEQIA
DAUCPxFOigWDAazwBwAKCRD1ayajpjmec1UmAJ0Wjx0gUknf4p4hBJvilBJ7k47P
YgCdE6COvpTO/A1Lr7efk0cIhYTDxxGITAQQEQIADAUCPxKmxQWDAauXzAAKCRDU
PLMFlf7KNENtAKDTjnTQIVO49T8GHxB9RmwASfXynQCfXlm7npIUQcPGcfyYHZCz
A75MYDeITAQQEQIADAUCP1xLGAWDAWHzeQAKCRBZe8xOEkKm8v5sAKCOrp/QeFe6
ng0mEBms6uN2moWSnQCg/qp7bj4601GhNYu6/gazU2hL2i+ITAQQEQIADAUCP8w/
CAWDAPH/iQAKCRCgvp26O4hufTMHAJ4kz38xM6QBli6+PMfdoxLiTCH0FQCcDOZb
CEdNQQSP8K2jga7PEugdVOeITAQSEQIADAUCPQWkmAWDA7iZ+QAKCRA19mF8UTrv
2Y3+AJ4w6Z9kTvk6Dj1R5dKdICifFfO1eACfR0YPBn0OyFMh5UleA5qAj0KA0JCI
TAQSEQIADAUCPxUPYAWDAakvMQAKCRD0tLDMeX6/q4qqAJ0auKz+AnGqjqrybjLd
GX54yTCDOgCfSxpFnMbWySwhXVAmWkwM4WWQgimITAQSEQIADAUCPxezGgWDAaaL
dwAKCRC/QVlbc3KipS4PAJ0aUoeUB8kQ3iWVHytOwFszrnvXfgCgou2nEGLLN9E6
cw24b1U5LINhBiuITAQSEQIADAUCPxx0NQWDAaHKXAAKCRDID3RZrcKezRD/AJ9r
4Nek0rLWckKINAPlxMkg4l0fwwCgjiasmCjHalTP/GXY/mlDUZAmQ4qITAQSEQIA
DAUCPx8ccwWDAZ8iHgAKCRDnTSm4K+FtAbcqAJ0e7ZAizJTL7/GFNmbTwflcUgKu
uACeJ5IxsHThZV4AcdePQiNYeLAX+HOITAQSEQIADAUCPyOelwWDAZqf+gAKCRAY
oMyNVwaktJKAAJ9Dlr+CFkvHVzogSYVpW+R8JiBMyACZAVvxtJaMqAc0bYB29hph
hd5W3P+ITAQSEQIADAUCPyffrAWDAZZe5QAKCRCfzyzNPz5kJpSAAJ9XdjKjg7uE
oESuikEhF6c3GXliGgCePSBoz4IPtn1mQH+3gvoaBM4Lk8CITAQSEQIADAUCPyhd
kwWDAZXg/gAKCRCWJIPhVmLHNHESAJ9XQniwRzVmgHyIz08GKy4/61rLJwCgkgJb
QeEgjd80CwjRxQ80ptzc/QWITAQTEQIADAUCPQXkxQWDA7hZzAAKCRDKDhacKPo4
iqgnAJ9FEQ0wvy/gouoH6U749fHISfeSNQCgnOFFzWtBkj7jVQmgkiMgmu4O8HeI
TAQTEQIADAUCPQYL8gWDA7gynwAKCRCNmjwfONntm+LBAJsF6XSEGS5y/3s5E2k3
6LR7+4vh/QCg1QRAZ9qRD630zqK9x8OYoZHD2QGITAQTEQIADAUCPQZwRQWDA7fO
TAAKCRAYWQx96ws33DLLAJ40HfHpwH4CsJv7WhwwRDTAE0V8SwCfU0dg/1Djrdqc
e2wdxIz03uS6vEWITAQTEQIADAUCPQZ0FgWDA7fKewAKCRApvl0iaP1Un04CAKCo
a8LGBAkVsBGYicxkD97nncgW+gCdFcFwKlJvwTAsvCcBZylrnX1k/RqITAQTEQIA
DAUCPQh2VwWDA7XIOgAKCRCuMDyzGSr3eaGiAKCZy9RsqauGkx8fezUbMnnags6Q
IwCgo8CyAP8EaXIku8Fo54vKi3VSt/GITAQTEQIADAUCPRFvhQWDA6zPDAAKCRDO
innXmAFtxxw+AJ4x4rmXE7Vu2LsPnSEcTx2VPGofpgCfdqqYC2uX6IIrKvM5wwk5
uCPvW12ITAQTEQIADAUCPSN79wWDA5rCmgAKCRDmTDIV2hU/qxlPAJ9WyClD0K4S
B6gXUa459zlhAfKYEACgjK2qLAFGTuphWmakm9D5iAqmQzuITAQTEQIADAUCPSa5
DgWDA5eFgwAKCRBh2FHZpoIhUxdeAKC+qu8EM7ItPi5M8dpfAv3KBPxTQgCfRxhh
sJA5rcltAl2/EcgOPD8UYlyITAQTEQIADAUCPVt6fwWDA2LEEgAKCRAxT3qV7BUp
Qk1qAKCV6lYEBeQi4J+2UhmYMYoxj3JlKwCfZBO7tuh7tKwOyRHux95Gpk/iM22I
TAQTEQIADAUCPVt8wwWDA2LBzgAKCRAQu4D8Fr13xhKzAKD3hyugDYn8jsnM3Da3
I35XYcZM7wCg7/VZJKr+wQwo9czyUzGE0idOo3qITAQTEQIADAUCPWpVVAWDA1Pp
PQAKCRD38OcPMH1W7e3IAJwKPumax/MaUlUPoIJWmWKm8lxqBACffhny9+NmphVF
WCPvYLAywqmAMcmITAQTEQIADAUCPg5g0AWDAq/dwQAKCRCz0KP8s+WtMaplAKDr
oFWbTt0+JWWzTrbBIvlBhObRGACgm1IPny8Er9Y5Kh8/SnNYOIStjeqITAQTEQIA
DAUCPhBd2gWDAq3gtwAKCRAvF4dA2PE9vvZ8AJ481dRbt7rufrsqC9WP60lbSJwj
sgCcCdxB6kbSsD460nSp08fegQ8+ux2ITAQTEQIADAUCPw3AEgWDAbB+fwAKCRBs
dheMoO2YLUEwAKDYM3wVZ9LykpWK2ubnMJ0Pbpd2cgCg2C/Wx3Mg4DuxO5yTs0/Q
RG2HKISITAQTEQIADAUCPxEU3wWDAa0psgAKCRDhhSLXfHEry8hTAKCD2fusVA8P
4iSI6mXphTh4nAXWMgCgiuCLmP6T6gQSCZjig7v0JEamZU6ITAQTEQIADAUCPxFF
jwWDAaz5AgAKCRDqIZlBJHfK+J/fAJ0eMVwhlROyvaROKtc9SYCkXFYeEACgj1/5
XSeLU2crObQwvaIrjEOzb92ITAQTEQIADAUCPxFdIgWDAazhbwAKCRAZ/tg84r6j
QQqhAJ9QW7TWDyrDWSm6SmYyVfO6rQPo1QCgllg45VMJvLOVuRisfqAY9oFwhqGI
TAQTEQIADAUCPxGl0AWDAayYwQAKCRAoxvVrgXw1aJngAJ9OFtLu0DifRGVRhMOC
iKEAQ7vNWwCgpqqCFCxvI1zFrEE20efpGW8PBF+ITAQTEQIADAUCPxHE9wWDAax5
mgAKCRC+nIaNBGBOuAm6AJwKJtlKYlPWlOW1NSHlLFlggnxLpgCdE02ERORBV6N8
mi30PGhp8gZFJwSITAQTEQIADAUCPxKUMAWDAauqYQAKCRBWbTYs7gl36C6UAJwL
cG5gSCDPyR1weT0PEBnFTvTWaQCeM2iyo3bLqfKEwBCRkGMne199n3mITAQTEQIA
DAUCPxMqOwWDAasUVgAKCRCSVb2f5oRNuTy6AKDGmDHdMEzf8LfRcrEjnJsfS17i
XgCggATe7Ote9uX2Em3o4+jXKWyzjsyITAQTEQIADAUCPxPwuAWDAapN2QAKCRCU
j9ag4Q9QLkdrAJ9C3bHsqC4PQ5UfNL6N3pmdktUMGwCg72FP36yRDlU1dx+rSitN
AYksmaqITAQTEQIADAUCPxPxFAWDAapNfQAKCRC0deIHurWCKeQvAJ9lci9Xqd+E
NePww9Pk4Td52fEhHwCfSYWbx5kwn+28IHCYqo0dhAX02xyITAQTEQIADAUCPxP4
CwWDAapGhgAKCRC5gsvVwOMfHfVFAJ9SkFE3/eVmkQocvP9mqX8mS1xpRQCeKbkP
+T5wbfMQV2KaBTBIYcZ4/saITAQTEQIADAUCPxUoZQWDAakWLAAKCRBYKVdQBQCD
iz2ZAJ9IOx5HuWB3I53Ga0tRmjMZk7eqwACcD1TGifrKa2m14PaxL3WDeFnYLZaI
TAQTEQIADAUCPxVhlQWDAajc/AAKCRCe0HjvSzoTXLs6AKCJEtUnbv28e9EB5nC7
qr7KWd4PyQCfc+6xQxw7swhASGlew7G7jTjbJAuITAQTEQIADAUCPxVhrwWDAajc
4gAKCRDwI/gLJoQdW5xWAJ97ZuU2cX5f3v0zGck8Z/uCHDdvtwCffmJFcQGscObI
rUJV5GKkUk8W33+ITAQTEQIADAUCPxVr1gWDAajSuwAKCRC7VaR/yQHDPiZzAKCf
+fvymPc0OM3jDJrT1xxT2XMHmgCg2bTwNEhGk2zbpsmYIjE+Lpl9fCeITAQTEQIA
DAUCPxXBEgWDAah9fwAKCRBL7yYkIt9Ahx2OAJ9jupuyyUNMLVEIi8W6Jm9Fh1yr
CgCdGFgVRGv5zOtrhGgGxr8BsWiNST6ITAQTEQIADAUCPxaCqwWDAae75gAKCRCE
LNt6RHeeGLtHAJ0deIAH5ZODFB5zxUY4H1unmL9I/ACeIWsHysqfMfA/M2Ri8/DK
LMG0IMSITAQTEQIADAUCPxfgKAWDAaZeaQAKCRBTtrgdwTzuBxYdAKCcS7JTHCvN
c1dG6zxowpxNcdH91ACglwmlKKpzxjhOyEw8YrruTpKWdU2ITAQTEQIADAUCPxfw
hwWDAaZOCgAKCRCRH0rmhqEY5k3mAKCyNYs9Siy8l86r3Zl4GhF+jH5LCQCgzk3T
oVNYatJ0FN4qXdmsDN2Mq8aITAQTEQIADAUCPxvSEgWDAaJsfwAKCRDTW7yZvH0C
ChB+AJ4hzioxiUZYSTAoQw1VCO1Io1JwhwCfWIlpJCYrKoWKoMPOqDmLgKegQ7qI
TAQTEQIADAUCPxw86wWDAaIBpgAKCRA7v893vYsFDWk6AJ9eLME7oqPbh0LlACT8
6FnQsn96BwCeM7IKe+X+Y1CKC95UPiCFNmnvLISITAQTEQIADAUCPx7QfQWDAZ9u
FAAKCRD4WZCwJIrrc7caAJ42wyTjO0DGITJumOISdCEtQRuYQACfXm0/V4EmxT7R
VE9soai69OKRGNeITAQTEQIADAUCPx+30AWDAZ6GwQAKCRCPubcPpM/Jbl8YAJ4v
y6wmVKqiuIS6DQ0c1T0XdwKCeQCg7RxmvUFDasz6fdRQG+rbW3t3GNuITAQTEQIA
DAUCPyEWRgWDAZ0oSwAKCRCJIbXczRWog25tAJ9+YpwWX5o/oL5cwMSK8iUE5Yoa
QgCeNJ/MVk5JMtPLAagqCk4jR5LMKm6ITAQTEQIADAUCPyFkIAWDAZzacQAKCRD5
0BTwOMmFjbWEAKCaXT/wxD/wTW+rnw69KmWHk9biRQCg5Ud/R0rFHraReqdtjV8J
jKQ/S/uITAQTEQIADAUCPyFkUwWDAZzaPgAKCRBdD39J4OSfNPl8AKCHc7F8LiIl
tDMoTRrn/ybhSOkJVQCfYph3Yx8qzaqfjm0a6EK1gI4UKFiITAQTEQIADAUCPyGA
lwWDAZy9+gAKCRCUmyXsB0RyUtxVAKC4VgaloS66RTXiPimzonxRnBAd1gCbBNMx
1vCKzLoPs0m2GvSzvqd2Z0CITAQTEQIADAUCPyV/uwWDAZi+1gAKCRDytSpdCl+2
h/lsAJ9hVgt4Q7X5+Bppg/u3jlDgNMKzfQCfeFJjsbovCpcSdkm6Gv/iCuGXSwiI
TAQTEQIADAUCPy1VJwWDAZDpagAKCRAsmD5a0opV1pofAJ97A1RdbctQJHAv9quS
eeCJSUs5hACfXZI+Qpjx4auCdryo57MdLGAIAtKITAQTEQIADAUCPzQjJgWDAYob
awAKCRC7xxTRnGfNljVTAJ9HNCMZKVwPisbeR371bFdt5yTU0gCcDwW3A/TOsFI0
UhuE6pAqn916ZKaITAQTEQIADAUCPzflRQWDAYZZTAAKCRCAdScAZahB7eC7AJ9B
r/Rod/wvHWytq33XYcXkbqrqcgCfTcpol8zraccBa4jSkJKx8IpRZ7eITAQTEQIA
DAUCP0nfiQWDAXRfCAAKCRBK8VQqljpUsEYrAJ9FTP7kMx7Pi7ivQPejwVfFqpUo
jwCeLA8iCDBByboThi9iqE4YG+uJkHSITAQTEQIADAUCP0n0DgWDAXRKgwAKCRCr
EDAolpXyX/7DAJ40IOWUvR8AUMUToKCw79+TMJXSNwCcCOCl8wqdP6a+G5x1HIgm
MhbfTK6ITAQTEQIADAUCP0oL4wWDAXQyrgAKCRDvYpxUCbBuEMTBAJ99BE/7Q2fz
Ne50DHDU4QYW5U5qQQCfZKqszvlNnsFnjFRpv18lL4ORJi6ITAQTEQIADAUCP0oP
qAWDAXQu6QAKCRDAVIGGUGOgluOrAJ4hRvobuMAb0psWVFnPB4UR12wmVQCfQ1vc
nX1p1F80lAT+jk8is9WMeI2ITAQTEQIADAUCP0oS2wWDAXQrtgAKCRBvYja0ew/+
hf2zAJ0Tf4tB97+o7nDtDhd5U0NhrnXUwACfXH5W/YP8xZ/tAa89vOapxdmixRmI
TAQTEQIADAUCP0oz7AWDAXQKpQAKCRBOqMTCFe883Ye9AJ9gw2pYh9rQqyRZOADn
MlK/a6FaIgCeLFgbNag3NUCcXCV4rbhSkwSlPzyITAQTEQIADAUCP0p5jQWDAXPF
BAAKCRA7aIZa2GoNGX7nAJ0esRu60r4pPq8niU112+lVYUKCxwCdHX2JxK0sieYT
vIqITS9Vm1Kj7UOITAQTEQIADAUCP1IK0AWDAWwzwQAKCRClBubU3U1QiAkwAKCJ
OSwQKlxTwI40iAQzHhu689N6mQCgr8Vmo50HMet8hRpEzY3dinggmE+ITAQTEQIA
DAUCP1JScgWDAWvsHwAKCRAHZX9zooa1NsWtAJoD56zye/vqwtO2+TwoISwHue0g
1QCfdvtTgaNFo7tQq3iCE3R7y7UF3LiITAQTEQIADAUCP1OXkgWDAWqm/wAKCRDW
O3DJHwOkiieyAJ9h+clMF7BXqzZbRfSN5YyJUonTRgCfd2oHU6S3RBcebu3xA75n
SpwAVKOITAQTEQIADAUCP18rSgWDAV8TRwAKCRC6RIqJnOjnrLiPAJ9B8FvvkGZQ
id0GvUVk0y5M5E+BfQCglN2SBDSxhAiVU/E6zXFfpA+mDXuITAQTEQIADAUCP2R9
0AWDAVnAwQAKCRBmZnF624NWeRVwAJ9G+7kCaMAU/KqD+0k14CmTwm2uBQCgt4ui
ufVBgYdKG7U1I8v2fLD9Vh6ITAQTEQIADAUCP2R99wWDAVnAmgAKCRANlktmVw5t
6jU+AJ9g40cdfBcyd3NgdIVAlc9Plf9G8gCfTL8lP2VXHx7twb6V0Fy9q5AWhaKI
TAQTEQIADAUCP2R+DAWDAVnAhQAKCRBOAqyuHdazgHAJAKC3aakEn/4P46A4/uN+
d5XYBR3AiQCeI+f7i4LVleBCtsg8vokOpARCeJWITAQTEQIADAUCP2TFmwWDAVl4
9gAKCRDI+nea9ZGa+DiyAKDe5hs5WLcl38vFpY8S0tEdbFVojQCgoDKXTQklIY2e
IwpIEhhfNGyjI/+ITAQTEQIADAUCP2cgjQWDAVceBAAKCRCzFn3en6AeftyWAJ91
snOgAdruVaBkc38qZaTUyA8gzQCgphVF/Ru6iuEOnXYmqSSigpjTSJeITAQTEQIA
DAUCP2d+QgWDAVbATwAKCRDJT335ZvLZxkIuAKCYUTzwZOs8iyGxJNMTi9eoFjIV
IQCffWdrw2O9/yOyj/+0m4Tk3y31yuqITAQTEQIADAUCP3WDkAWDAUi7AQAKCRBh
JJohMJOcpVkFAKDQoU1+5Wv9S7sjdV8r8VifAacvCACcD6RxgBW2B4V0U7Ev9j+D
3dBJtLKITAQTEQIADAUCP3beVQWDAUdgPAAKCRAXwi7XM3laLNgUAJ9zWJFrG+En
7x5DbGkghswwQIsxbgCgllCnCenAthiMlmHgRLX9fcghCkKITAQTEQIADAUCP4Mg
6gWDATsdpwAKCRBNoCCKE+KQpC6mAJ9fO5hOgikqezGgjfDlpE2m1Y5KeACgm0H6
OTRDRtuEQGHEJOk3EtrZJrqITAQTEQIADAUCP48SdgWDAS8sGwAKCRAZyn8CMbyd
1hcmAJ9V0ozCE7xJ33WmuaOsze4hxf6JvwCeLAWIo0GbICcXDO1aeI/CnZcUcuuI
YgQTEQIAIgIbAwQLBwMCAxUCAwMWAgECHgECF4AFAkD8D5IFCQfCnv8ACgkQfCLD
n4B6xTqoNgCfSm+e6Dv4s4Wtr73ovH6Lbs1TUAkAn0QKGHaINuoDhsxIfNOlL9lb
rCu5iGIEExECACICGwMECwcDAgMVAgMDFgIBAh4BAheABQJA/A+SBQkHwp7/AAoJ
EHwiw5+AesU6qDYAn2zcDnGt+xqpHa0UV/spcQZNacwUAJ9koQddSQY7o0Qd6qX+
+yU7yz4REIhtBBERAgAtBQI985fcBYMCyqa1IBpodHRwOi8vd3d3LnRvZWhvbGQu
Y29tL3JvYm90Y2EvAAoJEBBYFoXFIQl+suMAoK9wMiePGVWghspdqtP9CzYpY/ZG
AJ0bZJu2VkMvAWRlGOzRgT36eZA9uIiLBBMRAgBMBQI9BRkQBYMDuSWBPxpodHRw
Oi8vd3d3Lm1hdGhlbWF0aWsudW5pLWJpZWxlZmVsZC5kZS9+bW11dHovc2lnbi1w
b2xpY3kuaHRtbAAKCRDehYP4vb/oOGeJAJ9Fj3VCUQIZk0qd9UGUEJIXBH4m2QCY
xLYupcwjq5IpO3TDnf1pcPonSIiTBBMRAgBTBQI/IVeEBYMBnOcNRhpodHRwOi8v
d3d3LnRyYXNoLm5ldC9+dGhvbWFzYi9jcnlwdG8va2V5c2lnbmluZy9rZXlzaWdu
aW5nLnZlcjEuMC50eHQACgkQpHnNxFq0YGqazgCfaWuFD/Y3mWHymdnU3CL15fZu
daYAoMYSpXJwS+IQh7rsdske4ac4u1oniJMEExECAFMFAj8hY8kFgwGc2shGGmh0
dHA6Ly93d3cudHJhc2gubmV0L350aG9tYXNiL2NyeXB0by9rZXlzaWduaW5nL2tl
eXNpZ25pbmcudmVyMS4wLnR4dAAKCRB5BXaPdYT12CdDAJ9wa2zL0+9ucn4EEYye
2ewY2ftnLgCfV0GGtD6qqswRXSX8xg1uVT8BvTqJAJUCBRA9IeIwxEaR6Lw5pc0B
AU7xA/40Pz2+U1DqLqhc9q+gjGYaKbvB9cp1XD7TdtaZGQflFatqzjUWMFx6moDB
NpH2ewJwERxaLFPIvl80RwhcBVOanPYXS/Tk0AGwhsXYnNmSXQz5esxe9UIFk0Ng
ZNF8je9vMOgD7+sNVu+3NPQc45XajKsoRq6i+vOiy48grLPrvIkAlQMFED0izoO9
QKbpD86FSQEBPwwEAJyHvOQPxpnXgPRkcH+WBATeDfYACi8wRtYqpBHrUWo0i8x+
05V9QWEaeJSauaKEhEoF5zjG0CQ+FZ77gWcF+W2AU3sBXXt3yK7hu2yVDu0dZ4V1
ycN2d4LvV9s2X+Gig+lnF3m9n+hE7XkR3kjcvlToi7D1rAtQg4G5xJFFVxmPiKIE
EAECAAwFAkAMgT8FgwPBv88ACgkQv9buWFf3fwm2fwQAsZtoL1euv11o+Jx/BSax
ObERXUMTQ4WQHRh+uZSTWdxM0H+lLCvhBpquwZ1bTRKFnmb1JZTpkefUJ5h/ZG1M
WBP8TA3vQMzVhwu5VrDiWehp8OK5hliRQKzXy7qiup30DbSB/bDo/70+jDGU1Scl
MdVWIAHB0RZ4+sMz0vm6LfuIogQTAQEADAUCPSN7vAWDA5rC1QAKCRDERpHovDml
zaUUBACDoo52K7TgUbPWPP5OCCSXu3gq0MmsZkGa9ri/FQGErQB2UyxJlldsih1J
Hs9UDsxvcvi0PHS2d4UgAL7fYp7BY64JfC1XA4lkrdrGD3DkYWDjkaGHwdzkXUzl
TKro29bJvuqLtdSaEfmozp6oNyuG8I5NEIsY8Fczynj5or9PRIiiBBMBAgAMBQI9
2qAcBYMC4551AAoJEOUVKCUzHNpdilQEAJ2mlcltB/DyQtNOneX+qAQJe2L6fusQ
rfQxDg4c10Wk+66Hp3mvooRORBJFOei1V1elBSrqwkihrioKVubPpHVVMSACsdbx
f+OnCzp2xcEAlTca60RCk3Vr7HovwC3ok3FQYenOsjN1mim671DrEuShZdcXr28N
mVbS/BxXdeBqiKIEEwECAAwFAj8TM1MFgwGrCz4ACgkQtGuSO22KvnGBFAQAp5y1
TghvnXEw0D7SVExX4YBjBc4WkjdYJNcPGv+e+lzhBQr4omRWfaXyJ1QI4wJhIOu9
UAaeXncBRObPTawsD7bROf9kCois/pPxwq8U76O7jHc0U1o243izjxloa52vlUVo
lysBTQ+9wbtB79YWCL76AxBRjZZ8ncq8IZ8AbrSIogQTAQIADAUCPyFkiwWDAZza
BgAKCRAbsIu/KpIyJSKcA/sFG59sCKxjoDnvAIy7tKe5zETyZg9esDUP3UE2EcLm
P/ahWMPwAEU1Fm43WhKf96vLH94Td7rZisji7zxlU/6/g5z+iUA3zFBTJQ6O5WYV
KGGRG/P2MfZlmAEUTIYYuPDn8Wo5lOw/eJF2jOAGAi7ILPeHhXxjjn72X1tqQuJO
W4iiBBMBAgAMBQI/SiLRBYMBdBvAAAoJEJugaRW/hasxz+MEAJE2ZbBrCenJ67wV
bJzITCAIgbC5s8K7DqHhEIxIRG/O2DbU1g3mgxbV+6PaAonnPvl+HEF3k82g217t
PkTXYJuBrt5T/NgcwxzlkMZ3xUKZybz50KvxDAnKw5OIcpSnh2E7+Ja1AkBbzF5w
/rYMdVKdlj11CUcEY9CVkwQgc0KriQEHBBMRAgDHBQI/FpZTBYMBp6g+hhSAAAAA
ABoAY3NpZ25hdHVyZS1ub3Rlc0BwZW5ndWluLmRlImh0dHA6Ly93d3cucGVuZ3Vp
bi5kZS9+YmIvY29udGFjdC9wZ3Avc2lnbmluZ3Mvbm90ZXMuQTkyRjM0NEYzMUE4
QjhERURERkE3RkI0N0MyMkMzOUY4MDdBQzUzQS5hc2MiMxpodHRwOi8vd3d3LnBl
bmd1aW4uZGUvfmJiL2NvbnRhY3QvcGdwL3BvbGljeS92MS4xLwAKCRCrHktgRnVr
HlyZAJ9DfCRr/epketGKHgFJqEtUpKY5HwCfV2vAA6M5/ECBMbzYgnvk0AyXR/uJ
AREDBRA9A+0klWBhpt2TQTkBAXlOB949F4PDm6NH+kr4CRk1ZBe9XPvpDwi92dtW
8XbnSuQeEiTyuuhsh6hxznc0E6hxp0TkSyyQQvCkM7jdepYUz0YTcrv/7B3l8PcS
m3LptluQmsuaoE1DNh9jrngLwjQlF31/4DIAAb8R5FDA2E2Yes6S0EwPHH3jjvae
YT16+krw3Lt2cja6vnmslelegCc8HvxqPRvOQAZJKg2cOwQyNz30yYBaFEcEKCFD
msAKPd95/pOHzaAAkYlDHrzlNBQ/9ieuApOGnWe5zrTJ4U7zmnJk1wSOpVQtzliO
j0nRdVtPGSzAy71XeiDkwX1ZpuJs+6WnAsJysZRF7xSe+8+JARUDBRA9A/EIAVW6
4qCU2iUBAXx8B/0VFgPg08KC1EjdkdTmruI5RRhnurqrEDNuh9zhGoc+DIx5OMBp
Kdv/FuBMLvHy9s4rpg2q94Nb4fCoU2vz8KJMyFvDIPlLwixriqBBeITPqSdJmGQz
h3bNOJ7tBoSBzRg+TDCCPyI3zWnoZpnv5ASu3nDODiImcBaMEM8XlvR4ciiv44kg
16C6d8TZ1KlYUyYzGmBA1AiwIuPnZdwkmHL1OOgviBZdopLUNdxMmuSpoZC7fkUP
AgvyHUIXdaIeHBsO3ddQADWmEuaA+dt74CZJ9kooZwFIiVLsA4sFja1yvmLO6YO0
D/xTGYDj4ptoKO5/EiBLCJgXXD201rZI0LG8iQEcBBABAgAGBQI9J5ZGAAoJEIz2
bIET3TlQgzQIALkMyL6w/Yy968ah5KswoSokkuCsJj7VfqHBXcS3Wd85yXG0gIpb
Dsp3WhoMs5F375UkzdvQvZW7quInvn6wthKXeX7WxqhM0T8quUYcH1SDHDYRwsSv
z9l+PaUdr0ynwhCMVyz256k76vHQspnYktlFfH1rGLsgTRonFMeWZMp7BWRuQ6l9
hwsKEC+rggdkhmaz6Iqq7MotVdC/nqqm1I8bzMIZXyZWcRre1eGCGftAteHwB61k
yt+WwGSFE6byeaS+Y2hjsWi5XCg+wOKAdP08ZU1w7BRGY9guaRrRGrRed/RGG4+L
zwl93EtfCVUharteVIKJdJVkQc/32ACrzuaJARwEEAECAAYFAj0nlnwACgkQ/Lri
DKIR9e1xQQgAy3tOBRcTiaoO9WFAKbHU5rMVwaxfeAxgaozaWiOUDlbi9XfZgPzs
MYxItWMhv29jbIfVRQXhbw9l++2h6aIUdf4aYIVTBuoZvvdeOby63DUTxorPCg9n
IRBKGQRWPPZ/WcbSfJD4+iMed6ynjt31Yjb0UDVmXMhzFT69VQTHuG6HuINOgbgR
+Z3OVqp+LZl+mWG0l7eQTufEt/lpN49LuzhFbx9TgmhPbdXG8o4zgR1sHSiwCMKu
nWrw75YU8FToBY25KGJYiBUaqEhSmcD74myVWQ9vMMDZbAQSSI51Z1YYB+4PPmUM
EZ+eAZxof+sh3A71k7gh2exatVglxj9HE4kBIgQQAQEADAUCPQTDrAWDA7l65QAK
CRAJ6fkKinJORUrHB/0fX5mNz9MO8jAEnEOCWJdcDLP4aYyfema9l3RAWZd1wDt3
yumhl+v9KXbGb5SO7UMeBuQq7DOALBsaag3FHjmpxmWvKSOk7rGHvVMxhB+krlZZ
6owSSmSv87cjr2oZunGFk3fZ16/nVPWFKCC9ddKThNBjCZ8EsEk39PEE8w4KayDm
FT7n+rsdiIAH6YK1ZgXRJb5hYQrF1MqhZA1IF0adWUJqjru0CTfG4blw9MdTZSjF
bZzi25RtO5kaCnXwwwu4eJKnMl70vEpyw2sLZlRVXQUZiyCYhbKhgyl38WjibUd2
0p9gv4ywYXZqGpMlTQXPlHfDciXV95bLD9yyGtijiQEiBBMBAQAMBQI/EQ6ABYMB
rTARAAoJEEAGFQ5ACertgsoIALQ/lqNTA0s/L25U7SSqylj0/95pa3KbVLUA7efX
7EG/0SLnMTjvi2XCEBn4KjS9oRwKoXB3swiynLUgD2UAfKchaCeDMmUYbdEGI9Ci
ZAMmedbfpwD2XmDICSMgeIxwBrdd0A9wamt5GuF9oPsCu8aLemPUXseHcesvOfpY
GrLt7KA+fj2zjWfHMjRpnrP5Vnw+iKoEdMcCJ83Oyf3Xd69PjOP5PmdJ9PapT7Yh
0QJG+NRGWJ97j+xHJk+/qCej1SLCzfyxLNF8+/DQmCU20xK4yGNYV3iuXWSkwXTt
59n9nw5dRATXS8KjC+Ub5SSv3qL7GZTT0LnJp7RjX97sRS+JASIEEwECAAwFAj9P
cg8FgwFuzIIACgkQpaBgwm7CZm3RvQgAkSZMs8C728vT5beOQBrJHNDHeR9hZHyT
FNKZ/I80C6FUki0JvzryS65HWoFAuyxumP+Pg5/QpHzwPg/QmKZePAlULltrokA5
ETClu5EgJSuRP0NgQybXqZ0Fsgwc2WOsuiXMAYb0G4galH/i8yS4ExWsSGsFFggT
e6xuaJzVKLjIirKgwwjl84Ln3E1/W45/edvfijl67wRfZhsyFwtAjoLx6xcFnvPM
AGKQe5YKk3I8OqLcvlpPn02Ah98W2oUBgwWdcqrLnQ342CZPW4Qpbh8WdXsk/XDP
dvJRmf6c404HayWCZ4w4LJNCpm2tNG6zVn5x9uVtbL5NaiodpYIGAokBaQQTAQIA
UwUCPyFjnwWDAZza8kYaaHR0cDovL3d3dy50cmFzaC5uZXQvfnRob21hc2IvY3J5
cHRvL2tleXNpZ25pbmcva2V5c2lnbmluZy52ZXIxLjAudHh0AAoJEPl8+eM6S39d
UcsIALNb7+dIiLfvPwvEt13ay/Nx7c8snvFdzj2gXRJ2h65makFGj7gflmHsdlDU
ESxEEnKRitIhT72k/kGJbVNoiTpAFRMjAjLekMa/Ij+gakk9Vr3BzVmiI2OF8rzI
Ndj7PRDoolFpvqds7KaxmjaZF0JDgRWj5i9jyUD57zi3UL0lvMGyLvKoBPd5Cv47
1Crwjgz6+XNU6riJap1FoZOrygbQKG6ZCFsU1fBasq78Dk07MsW4XeXe+Eyptskk
SP8Rml2yzyTKryNM3iVKy429/kPItJvOPYg4kxE3+FI+sGI62uIyvlo0PDQAMrng
BRPLr5pvW0yI/cdz8U0cUnX0X/OJAd0EEwECAMcFAj8WlgcFgwGnqIqGFIAAAAAA
GgBjc2lnbmF0dXJlLW5vdGVzQHBlbmd1aW4uZGUiaHR0cDovL3d3dy5wZW5ndWlu
LmRlL35iYi9jb250YWN0L3BncC9zaWduaW5ncy9ub3Rlcy5BOTJGMzQ0RjMxQThC
OERFRERGQTdGQjQ3QzIyQzM5RjgwN0FDNTNBLmFzYyIzGmh0dHA6Ly93d3cucGVu
Z3Vpbi5kZS9+YmIvY29udGFjdC9wZ3AvcG9saWN5L3YxLjEvAAoJEBmiaAmIOP2U
CZ8IALz2EVXVA8GCZl76kXlvGSmV3hz8/q4bBIlnYy6aLzsauR6wpyWmdqZMPU+K
st0mo78V+ervN04nxOmoBZVdaeMlRyTyiqWQ0ROVNao12qZPyWMhiio9RMU/mno8
APLjGeYW55Jk9DB5xduJb96VdzV4dbc9gu5rDeNu2yjryjtxTXdx+oTOY3mfUcqd
eLFPskwu/B2BuKQYYiAOrFceu/XX8VtqUR5dAv48X13DYbS6BdJPQ6WtOSxKHIS/
k2qbjzStLwTrjFchpr/gpv47BT3HogLTJX9f56sm8r7qxhxKiqmq7tOyRMwGM28R
JquO5Q9LOmLcvCya8pR34EytUQuIRgQTEQIABgUCQJQrewAKCRCLCMMOVLxyY/vL
AJ4003CSouFl94u7OVa8A6nnBnS85ACeNFSQ19KQEERCs1SuHtEIfbgjf7mITAQS
EQIADAUCQOpisQWDAuPeXQAKCRAdR29gbPDq96o5AJ9nh//vF3E2avfO4IAq/+vY
xgtSBgCdFN+7wMBiqBWOPoN8KW3t/ptHZ1CITAQTEQIADAUCQJjtNQWDAzVT2QAK
CRDthAJ60Bobc5K8AJ9nqIQdRzbAYh2C7ugn7XZgZ0tQPQCdHvklVlsUQfcvs0Sn
XPLRO4i4vMqIYgQTEQIAIgIbAwQLBwMCAxUCAwMWAgECHgECF4AFAkAL2hEFCQbS
aX0ACgkQfCLDn4B6xTr+iwCdFReAd2YstulCrK0fu6MSfDh2E9sAn2X8hpotkUZ0
pV4keeMIfgm33P/hiGIEExECACIFAjz72OgCGwMFCQPCZwAECwcDAgMVAgMDFgIB
Ah4BAheAAAoJEHwiw5+AesU6kJEAnRpLqrALiiXPw57mofAq1xmOITmdAJ40/DKt
kXOF0Y4aTwua/bPhRXUxGYkBIgQTAQIADAUCQSSwggWDAqmQjAAKCRAbaNz8wFlo
I+TBB/9jaJxHG07h0ZNVlYPkIaAScGZxCmK64Z4+clO45KgfTkLzB3EYK0zFG1KC
rqaY1XDvQuK1H1X6p0Y+KH/sTnHVpOOIHw0fDo06QZ8ieBKiCI8Hq+Ed4O7IFUiX
xi6Q8PY5WMT8bQnWmJa397Xg3QBqW3kHJ4T/LKjekavM8weNkmpfbvRyeGcTgv2W
dQFZu6q4BHgvMBVipTGtvXbdXCjvE4QezvPiMVkzUPZhh0EWUSYL7BY/suBUkmai
N7stoJ/J7uvLaoOB77s2BlsNqIPvTfu1WWAcVEC4v4EuDqsorUGQuqbMf4D4l0OS
3kRzBvK/hKwS3f8HuZ8Txs6hHH9ziEYEEBECAAYFAkOcWDIACgkQxgQ8VnIHcTe8
BgCcCdlqgOwA7SruyzNdByzePkURMuwAn0wgtGD7F9Q45RFP+A16kl7Sdu20iEYE
EBECAAYFAkOcXpUACgkQeeKcYLAGP+cTkwCfW7vjVRbEvmw8v2lKTR4w2y+S3hIA
oIk6/sxL3JFwk7qqSi601fGqJwg9iEYEExECAAYFAkGE4eIACgkQqy9aWxUlaZBi
PwCg4l5H3ffHBuA/ygkKyM8aQTAiGncAn3HMm8Uf3ZyiB3anGTGWOW7Wal1ViEwE
ExECAAwFAkGE1wIFgwM5n44ACgkQv0vQ5gSduHm7TwCeJaYSaZNoV6e1dASO/rvq
M9McWmUAnj0mIGnVHh6OllqsL6i1wZHLx0v8iEwEExECAAwFAkGFevoFgwM4+5YA
CgkQntdYP8FOsoLEjgCfVdwTAizDRszmNixXrGLBQDKJ04QAoIkVfdO6qoPGUx7T
oE+KYi98nPZhiGIEExECACICGwMECwcDAgMVAgMDFgIBAh4BAheABQJEkrEaBQkN
OnQFAAoJEHwiw5+AesU6Q5wAn0YI15RSwrNSz5yZpOnVWAyC/ObfAJ9LBDDtWpsy
enJXDQ2wrpyjl45b74kBIgQQAQIADAUCQoDzmQWDAU1NdQAKCRD1wyAKI5xjhE0z
B/9n7/SYsD6XaJaC6bzgVIUBeZQ0+GE9gGgwT2tPuBBFucFXGJsj5RB30uruOtNN
vF9QqNKpHrtrdn2lA6AMT9eOXLutzfADVNuaec/opoZ5itz94QVDPK+C6BWldHH1
jwNmD/2b374d45lRXOC7CUPGxY+kpNhfmV8RREDGuzCHTUFq/hpB6PbHgKFcC3II
+2Pno6LlEex51LYNXp1RGeBrIO+95SWP1kEG4OApAI4LdjbZpBrTetk6tZsQaNzc
pGfyGUvrOwbHnwNZwUH+7pYiVPVICVwwSGeacauZ59bNiAv+XTBoO95Hm/xGabhr
ENXpslalKY7y3Wy30JcLmfTXtClUaWxtYW4gTGlubmV3ZWggPGFydmVkQGluc28u
dHV3aWVuLmFjLmF0PohmBBMRAgAmAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AF
AkSSsRYFCQ06dAUACgkQfCLDn4B6xTqy8gCeLB5DwbYGbYe1628MTJ84w6Y2ICQA
ni8Sk4vctDxphokObZSYO9ZfcyAniGYEExECACYFAkOcgLMCGwMFCQfCnv8GCwkI
BwMCBBUCCAMEFgIDAQIeAQIXgAAKCRB8IsOfgHrFOsBBAJ9lae6Yx+hYnhQlAL2V
6hKj6Cdy0wCfTI8qVP3GSaczTliaRgswukbgZGO5AQ0EPPvXkhAEAJR+JXp+B5wZ
WFu2EzCwEH7rHNiXcQ/pnonR7NV2gbOUZ9LHskHn5jq6NNZPEfIwBJqs4RwoIb1R
FNGkyx01qjx3yMUtORy2SGENCBBTH+c9kkrL1Bq4MnbR6tWtAcOKjefsZDjBE2Sg
XTPW4Jy+yrRfhhxa637by25Wmx8PHlwLAAMGA/9dRrwk/jXPcGvqcyz4I/dsTM9I
hCxyKvPJghBxGNTAmqHYn3WWR8H49cHfi3XW8HMNXl+tk4IULp7GA8akmKw48d65
oqd9KD468k+UkagdO83P+Uoehtv8ROCbYECF5AkPgtk8px8N5EgHE2PANrXTL0EB
/TFidNLdiJu+CUsDGIhMBBgRAgAMBQI8+9eSBQkDwmcAAAoJEHwiw5+AesU6LdwA
nRhxmaBZPZAvPnVKH1f0zQtstV0tAJ9/Lmae00iLauhYyxp8MMchBykovYhMBBgR
AgAMBQJA/A3ZBQkHwp1HAAoJEHwiw5+AesU6i58AnRe+qm3OPPNQ7YWBXfZyZ1td
ruMgAJwNyw8d86KrivrJY1qjtQn5lqr+tohMBBgRAgAMBQJEkrDGBQkNOnO0AAoJ
EHwiw5+AesU64V0An3ZTjvq3XBrYD8hRyD94P7Z96Wf8AJ4yt9R/Vp88vZV+kxEO
/DCnBQED8w==
=lqQ3
-----END PGP PUBLIC KEY BLOCK-----
D.3.124 Tong Liu <nemoliu@FreeBSD.org>
pub 1024D/ECC7C907 2007-07-10
Key fingerprint = B62E 3109 896B B283 E2FA 60FE A1BA F92E ECC7 C907
uid Tong LIU <nemoliu@FreeBSD.org>
sub 4096g/B6D7B15D 2007-07-10
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEaS8qERBACaZz5sEl2I6ZKN0bcqTm2G2jrxPKmX7jBxXhlwonMSfX725Jz6
fiYxo8MN0709R1xk4tKLJZGM1cxNItFVi0+8bdfdqc88u3cabTM9qYd1hoy3uJtO
Z8YHGbwzcQfU81r0cs/7xHYROjU1DjM7ixa3aVqokoq+N0nIHNztsDzNkwCgjQrV
NoU5rFgzsvxbzNmrLSMxpckD/39CGIg1ic4qeuNHEHoTRIGgCffFGr/VOW1m1zYL
h5nX0qpE8e3y3c7YwX9yxueJtVTZV2HSP8/yILkBMb48ggUcYLaaPFthGAnggx7g
XB0bLw1TYxeykQoV6MIUf+LXVggJV8js2lZmpC/eUwnbGtDj8ShidE4RlqyMvwtW
/K7BA/9ZrFZkf/2KysdzweIV4HJG3tntx/bOJDGN/ndp7s7E54iTpTIQLEaXs4r+
Fb4tEork0p/BrsH2VpDp+O6SjsvpxlOxUN94BkUtwvNj0v2rAXwjEz8RNCXWPoVJ
G8juOTAtLmgG5Bj+8JOHlHdO1nMZXfAzxYWwVAjE9K1z71kEFbQeVG9uZyBMSVUg
PG5lbW9saXVARnJlZUJTRC5vcmc+iGAEExECACAFAkaS8qECGwMGCwkIBwMCBBUC
CAMEFgIDAQIeAQIXgAAKCRChuvku7MfJB2bKAJsHeFHOGni/1CmTS/IcyOYMmChi
rQCfSjwIUFej0kqsSo0VqLTAjYO0Xxi5BA0ERpLyoRAQAMrvUD7fP2937y24s55C
MmmGiMxUsutflqt4mIpGf5Ssj0//h2bjFxknChyx7uc9BhnxXPMc1zN+V1onm64N
eDMZon6LL3ThZvIVFbrjkRv+O1Iqh82k66HNTSl21/FQ8mL3/0E77yfrd8uZSrTa
cQOdFNYMN5qUbG5U3R6S76CaYX6oN8ctJFXN8PLO2CCn5KBAJ3CWvdcmoadWq6rf
w7qA0Q6FNXYQq+PxvxNKei9w6xcnDc0DA0/TzaOm3lUQnIQWivgtMa7zkM98LfRu
wAV7Nn2Op6IeQv2e1i5zT9tL7Au7hUiDXzO2upae3D70tPcUER7k6J7NfWaBfsZA
CZ9X+jNxECL1RzZnsNRtLMHfIE6YJCc6Onw+PuBE8147hF4bNv79+5JX5XkB7UBd
8KMHkpCUA4ANo9WTt29JdhUi2hChdATXiIKodWLuUjXjOczDe1HA69BPA6w/RL1C
OChSEm0M6rYLx8a2X2rpIE+fONE1l9gtWPB1OBOs3/yKO+ozknnbUpMIZpCdq5mP
BTuLaNAEWTpQUVEJ/32lLdSf0qYtqpn+WycSGXYA0cqRWXYCldTRaA5n4kYC+9ho
yIueGCwW0D68QGXo+s4VuSaRwTu3kwkQ1H+srwK+pd1wMSabzaN3YgOT6g/L5lrI
el3jspkgLpEHXYCk8WIZtaCjAAMGEADAsLKwES5Ig7Z3+LFMTFxK3rGMIoUizQpW
kHUAcwO58jud6t0pxyz5RtYyoAXeCxEGYt5xhYgdcnbWDjraEN94ptOdLeFRa1IG
y+LIr3+oWF4s4aJqe2WiFd8Fbhlw29YH+CF7E27m6byeYiH6mSB/KuBH9cFicG9B
mSf6li6ZkL8NGNZ9l1ouOH1TA9hePO7RsHjP38unUFbSg6l9gfiaZF+sNXddZoQc
qcstmQ2VJQkatqAAPTLwMEIYJvjY+DeKZAHbHfv97eMIe9F2aQ1OdAmL4lyownVk
fILsTGZ4OOI6KvJD8QcQxn9g5bUwoxIoR1y7AoIYUe84sX5xqo7byzOqlcGQIa5B
ss21LvP+0gJxrxb8Y1+jDqn8Y3wEe7V5pEchMU9BsTpPD6MNqdkZSiUCA+Yz1P90
WgO3UbzlDTp19XeOmfCN5srlI2irtijkmKnzLmJFPU3oVnS70vxTZ6JghBERuxa0
8si44lj1uPztWIc86BmYfEPZ8yuaVve8bI0Cmr/IDUfHlX8/wQ59TV+utMvPrx+e
ukPoY3Ybxg1r/M2JSEqUmh8czViNrJDqWtEdOYf/oriSJ1mtenq+mEyxwlrgJR5x
ZAFB/X2eZm/vEnlXttxgRlhT4HBAw6j8ju70BXbUm2boDlQDyQnPG2jA4RbTnvUw
2aN3vWATPohJBBgRAgAJBQJGkvKhAhsMAAoJEKG6+S7sx8kHi2gAn2xTy641n6vL
QzMTDTvTKnwMTWoMAKCDsxLiKzQoXpl9Z24xb9BxFdIgLA==
=nL7g
-----END PGP PUBLIC KEY BLOCK-----
D.3.125 Juergen Lock <nox@FreeBSD.org>
pub 1024D/1B6BFBFD 2006-12-22
Key fingerprint = 33A7 7FAE 51AF 00BC F0D3 ECCE FAFD 34C1 1B6B FBFD
uid Juergen Lock <nox@FreeBSD.org>
sub 2048g/251229D1 2006-12-22
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEWMWfERBAC6P55NRPt7PWHQk3e3cp6yAYpxsNH4TyMZUNKFjE9E+g4GDe1F
fd1ebE/as+qcZ7rnIoEqXMYyXW/8X8kdE7FJVoJBmH3RdlaJhHSxogrAHZJ87PWH
yGC4mP7F2zvLjUqB2fUC6gYUJybmYi7F6run1zPKLr5A5Polx/SpqL52IwCg/5Kq
vo2Lc3ceBT0L5BKOWFLHBWMEAI/OIOXhv4Hsu0k0Ol+Zdwp3vkw+geBo0MVHp0/P
XItW5TM5Xi0iqQAcBU2KmPKUinaIJEEPAat5sPMZ/0BUsdmhlD6BqIp0qC8LXm9g
Tqmenm3WpiJPsd486lW6dxzFqOZKdb6qq87SJ7ajnPB12SykRW26VkyHzNCqiETL
LigDA/sFPsm499ccL62BwkRGax93iYylhsrV7zXT8FXAPIS/S7JasvaiyHTvRv8K
u9XSO453WZtzN7TkNp6i3Vw1SSxbrwCRZZ7nspEdMXWF9ZdTtSq8mpA3R74X7dKM
SXPbbsTFfQ5JR9v8x5T201nFiM/jPteU6WbfyQc1MuMCUqwzm7QeSnVlcmdlbiBM
b2NrIDxub3hARnJlZUJTRC5vcmc+iGAEExECACAFAkWMWfECGwMGCwkIBwMCBBUC
CAMEFgIDAQIeAQIXgAAKCRD6/TTBG2v7/bkFAJ9/NodQJ3G3mLhNkT/rv4ncgpOV
KQCdGm6jx53ESn4s8YJAPKWgym0AKTq5Ag0ERYxZ/RAIAMR6vbusFDGVMpB6AWhC
cru/N6Qz/kfB6+Ufy2nXcYMMaD2c4MiSUSV6pF08s+xx8oqh6DiGdPvdJQ19ZAdw
BJaD3tc2EeIv7Eh0upHhC7CuRk3eHHd+KaKFquLGU4HNMEvxXkW+DZ0wWrbVIu0N
vRBYXJlil7B3RE9+9yQLdoK1IA/N7DtUvbezVC3Px/ZuNe+cnI5neXZVnm9ks9E4
qlghKSdb2LLghwfBy0JRqssZnvvqS+kRz0LJgKIX57pSrHfx0L5Rwu1JWqvmWKYV
hkCogZFXpn31ArmmJ54O5KEP4hYNR2FcF8hwNjMqfij29QRi7xpxDLQYgUjM/kTl
g1MAAwUH/2TJn6E3LtPX7ceMUKVyJRO/OsS7/r8nX8hPRmX/cnnoHTtYOQ1S2F9J
0IFTZKubxfyhp9ldRx55GiDWyRvGhhjCOuUH7VCSPMCURbMOHi67EDfqbHPzhKcZ
1lmeqpETmPx4SbVQ9vQ1802gsyZzNy3BQcoK9GIw1Bg6KLYVQ/9rcSDHAB+ULVF+
YkthjJcPDQPdcn8Zy+xGDuciav9HPaeRXK8nXvx8ERDti99GiuHI/S5+t3wDeTPT
dZuMiiJYsVc3QuuEN4eMseohFUX6R/Mnm2L0qFc43k3h0vmOoTu65dMEnYZdsKiI
wXTiy7GaMXH69Iuq9QK5wAQGHwTDbJGISQQYEQIACQUCRYxZ/QIbDAAKCRD6/TTB
G2v7/Z/1AJ9MfhLFFNtQHDgvIwjgQa2xJX+N5QCfQKUy9vBwNhrVvrH86hoDMhjV
d1Y=
=E5fg
-----END PGP PUBLIC KEY BLOCK-----
D.3.126 Remko Lodder <remko@FreeBSD.org>
pub 1024D/8F494B77 2004-09-03 [expires: 2009-06-25]
Key fingerprint = 575D 8AD6 8646 E6D2 1226 0A8C D2A9 0DFF 8F49 4B77
uid Remko Lodder (Remko Lodder) <remko@elvandar.org>
uid Remko Lodder (my FreeBSD.org uid) <remko@FreeBSD.org>
sub 2048g/6BF55109 2006-02-25 [expires: 2008-02-25]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEE4vPoRBAC4dNWQ87nDcZoYBN06IANIh9vEomUme0YimbljsIozq+BLDgZi
6A6iQXWpoEWSCOHX5nCnQDS0selxJ7easE8tm2NXHIKLOCStDh9Jk9/dPpvAPAKF
ZRyRf6emtNFewvQqxaP16Rs3mlvyfzKDWhIp9QPz5SohpgrpsNR0HcU63wCg34zJ
uXgWapznE1e/gpFHVSdao0MD/ieMQBXiusNFj+ULjm9w+XossGiSuk5t9n5YlLtl
Y+wpfeXq0bAlAjCHMmL3ZpPsksyTcJT4NEYyd+JUKBT9YVOitXHUfW005qHDFXBw
5hMl8SritJLxNY7OfEvVeGM06Ipeaw2IwxrSBiN9vmPMpdO9hZl1Vbj0vJ+CTgnb
l2fDA/9rsMfj8rsFNZipEprRo3tJQ4G+SaZAIvaHxwFC6ecTrIJ16qYfSPOB50RU
Yuiz2UTQeVUHYcUqzpcVmUAij5WX1gcIrQdYL9BC3Kpp+POc2IPlpHcqcijhHbi0
WlbRyaMTkARVJ6NTU6wFChvS7WTHwApo7dUJJEYNSYkggksiGrQ1UmVta28gTG9k
ZGVyIChteSBGcmVlQlNELm9yZyB1aWQpIDxyZW1rb0BGcmVlQlNELm9yZz6IZAQT
EQIAJAIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAUCRKAV1wUJCQrzXQAKCRDSqQ3/
j0lLdzhiAKDXhajHOwIGMBW2fRE9kspcC0pfugCdE6uMVulTQyHVUZ+gdV5ngPLS
axG0MFJlbWtvIExvZGRlciAoUmVta28gTG9kZGVyKSA8cmVta29AZWx2YW5kYXIu
b3JnPohfBBMRAgAfBAsCBwMDFQIDAxYCAQIeAQIXgAUCRKAV2gUJCQrzXQAKCRDS
qQ3/j0lLd+PcAJ4oQDiFAGq0gCH0hcNu/yvRyeuFOQCeKbycSr2jMe2m9LR++UQp
QaaGq9S5Ag0ERAChRRAIAM6a31FevymHZ79ZCv/oG5DjsSVGtM1cYbWvA4C+EStc
vEWZL/tEMqJipi3tjaxyHPfuwAGd8NyagY89i+YXrpe97OxtbXk8DUDL5KHJH92H
rLvm40uBIULeQgdXP23RQQxLt6UYQ7nmAMbbU0NKkErNG4KxEc7wX5XFtMoRn06o
s+CQ6ynS1XYH5yaVRFAOo/kiC0DsQUE/k1e79UvVo7kq++Zmx20bQ8EN8fJWCjpz
gnXbNArUw3w4Srsbq0mOQqtlLQTuZkwnDdPzmTa7AREDLE3NrEt4xXdCT9iHPyIg
yqikm5YR/FCLJ3trEq1l/5YLQLC8ygvg4dd6aBm27a8AAwUIAJUg4wJvh6F989Er
h3bsnlrv6rlo5Ij4ktJeptXjkzT12uI7mBhM5UuLkjrwN2+XCq1qnKtjaYW4yt2f
rUYXLMQ0jFAH3wus/9rX1AMQMjErDvUj2lZWyc77ETFo6cJQDyy7BQb5A/5fOSv0
astxip4m4xDAyeiM672jwEJ0H0vIRMXIIfVXj8bmg7da2mylTkku2gsA6moTLKx0
jBg5P0Q5XmFO+H21Am4XFlIJEyeooaP5CON08tKyE7GyQZTrbRWJe/8G+rNs0jbB
cpqPHa/0n+G3E7G0zho7QCYGtNh5iIn0/IOXhhoP/wQhh7Ay4Gi4BxtsNfgNWwoq
q4hHxY+ITwQYEQIADwUCRAChRQIbDAUJA8JnAAAKCRDSqQ3/j0lLd5WJAKCiNEXw
yNgsPsGLogwW+0OZLjrMsQCg0i8S8DLj+bQdZtkh58Ifdq3nXlQ=
=jkQz
-----END PGP PUBLIC KEY BLOCK-----
D.3.127 Scott Long <scottl@FreeBSD.org>
pub 1024D/017C5EBF 2003-01-18 Scott A. Long (This is my official FreeBSD key) <scottl@freebsd.org>
Key fingerprint = 34EA BD06 44F7 F8C3 22BC B52C 1D3A F6D1 017C 5EBF
sub 1024g/F61C8F91 2003-01-18
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.1 (FreeBSD)
mQGiBD4p5ccRBAC+tbiJm4bc9dO8oaRhVGqWmNhYfi2GnX4AM2h+L7bcIU/7jWVn
uWGe/PFHDcuOpEov/XRw1gmgoNh2DopTxf363DVMevmGW3R1842YMmLvCYZ7C0Rd
0GdbHW1xXeRSygs6peLcPGQ/7ISK0BHMudFim5FrpD0tq3qrqRmuGgls2wCgyF37
u+ZoP3xiP0wANhoWJtyBWQEEAIeYSHvIPKFIo9FG/+wckx9Fc+hLXPKwoETBPof7
Wft9zXiYyowuGj6/ydb6v229nI3lJwVPR8X6Ptjf6rO1vjf7uUED9dNBLr10vdW6
jYClBT8lqJAq3DzEpDk2kOlhYwtrykyld9Ys/7vgliuBB0XRUxGVNieqDck7PZWL
ewz5A/947m/ZrlZbn6+jsshGk30/pEXZUhcDnUBwW26GuFk0TGlXBha3N0NFwqz3
a7qnJcvSTKfeZJY5NCwqzCo/rLpmaNd9JCUrgwSd1MI9Txrbj3lDRy5dj4FZBQ2N
BVgni7SRKaiPw1KeEprSOR8yiM9ZjbV1g5zPeZ2bZhSMCP7mdbREU2NvdHQgQS4g
TG9uZyAoVGhpcyBpcyBteSBvZmZpY2lhbCBGcmVlQlNEIGtleSkgPHNjb3R0bEBm
cmVlYnNkLm9yZz6IWQQTEQIAGQUCPinlxwQLBwMCAxUCAwMWAgECHgECF4AACgkQ
HTr20QF8Xr9fvgCfUMy+qlN9qQtwMFAKWViSllk0xYgAnApLMv95d6Ecrj7+U9Et
liAwNQXWiEYEEhECAAYFAj4p8nkACgkQtNcQog5FH332EQCghR98TNpvYGdrsg6Q
S3BngO5n3VgAn1zo89iPy8VMP/kXq2jlzs/74+i2iEYEExECAAYFAj4p9igACgkQ
2MoxcVugUsOwsQCfY34hwJIc8MapwIy8fWmCeLs4T0IAn0aVpewWF99H6SapelNP
hvDzTYLIiQCVAwUQPioA7mVgqaw0+fnVAQEUHgP9EJXxzQlkaN8VsfRJo/UFmC4z
wGkwu2yatUjMSZR58VpS9rF6CH1rzmNFtZZmIh6ItQ/mPaUDW2yObWBRL2r9vkVx
e+DPcpcZAebM3ibjsOg05cftcphv41rLak0C2Nec3MXnxT15O7fcO6aO+d4oJ2Yi
oL7YJX6RHrqNCTQn6/65AQ0EPinlyxAEAIGtuZXdf7K51Gb9jijgdV1NMPKwujoq
K9f1PZocpDve0vwXN6AvzJ1L/LTrZPvBZ0UCAJR/zVtz4H2bnSqalbd8j8bmxfYx
0SA3QNAKJhgBGNlnK4HvAGJCs8oXYp+6Ph9WWlTcPzkfscPFc42VcUEdfL/5kyLr
OvGAUW6D7iCnAAMFA/9CWXarz2QMrkduiasc8bhSmv2lVOfUVcIdz9imc72Z5GUk
FBiQJ2kuqJrxMUqAgoccnJ9R0QVZwCaQyRNakEQEcENBKq9Haa5LLo7nD3CAiqIi
URqloJORSzXoQCrw8OelbBp9RaEqVdCecbNqAbA8Ru4NIwcyZCgvnX/bUTKq54hG
BBgRAgAGBQI+KeXLAAoJEB069tEBfF6/XBkAoJtQ4ECj3ntS2xlODgB8N+cKIsdb
AJ9Lwk2EEIZhvzhwvhpwIKAhWhHcmQ==
=C3Jv
-----END PGP PUBLIC KEY BLOCK-----
D.3.128 Pav Lucistnik <pav@FreeBSD.org>
pub 1024D/C14EB282 2003-08-25 Pav Lucistnik <pav@FreeBSD.org>
Key fingerprint = 2622 B7E3 7DA5 5C53 2079 855B 9ED7 583F C14E B282
uid Pav Lucistnik <pav@oook.cz>
sub 1024g/7287A947 2003-08-25
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD9KJ7ARBACp3MjNRANlRjkeOgYwxQ+wYbuWeAwY8/G6ZMJ3eVffTpVDU9/I
P+d0StwlRTb7nenXOU0Ukvv3THskI/8D4qqeRKD822LFui30gxlv6uXficHJNYfl
4zlicKl5TyfCbZTMoCjCBeL2Pgk4OPuYn4pudjlaSVYHM2n4dMWdLlH7zwCg0E8z
LdrDYapLdgezr2TaMy/QVksD/jk6s5FBpESnRr1X6c7giSbTaXPPRw6/tvaKhPXf
1SpToswyB315eXEKNKKPRwA2kiSPcNciUjLdiJFOdrTpRUy6XfOhgDBa4IpnMfwB
bOj1w/0sjy0Mgzlj1ae1fVDFY/5dfzfqa8gcXCV9u+QRELtz29S0Yivk4BlqH8wQ
GFnoA/9mUd+OLIiy0NXNkEwPiKsvKyEPt9ERY+8ODdH6+P8VATTXBQdIBWGBAnhO
PBKQ3t8WiKZU7OwAeb0geyxaF6mlf+nXp7bIs/osguF8U1oawnc/459Xlm5JZSqM
4vSYKgZbl0fLpeQ+7gCnV4v2VOK+CklrZoIXXYybLWI9uRIZ6LQbUGF2IEx1Y2lz
dG5payA8cGF2QG9vb2suY3o+iF4EExECAB4FAj9KJ7ACGwMGCwkIBwMCAxUCAwMW
AgECHgECF4AACgkQntdYP8FOsoJcBACgwvi5aF1TB+VUnfn1aoMEpYyJbloAoJ1o
ni5QjI3rZIQ80Mkrtj9lwzcfiEYEExECAAYFAj9KLMoACgkQc/PxpRAQX0iWNwCg
3cFfsyCqXsbomDR6FDO7vc36ph4Anjz8ZqU/uAELMcDeAu+G3V/szlGKiEYEEhEC
AAYFAj9Q/0wACgkQt+DSc2Q4lGbmdACfbOIMKBRX4PDwTe81OAi0m/ImVX4AoLGr
grkkSSn9civs5o2ovlfYHLO3iEYEExECAAYFAj9U1FkACgkQhc9768l+pLaMjQCe
LYtORcg3I/aNa1jrrhx3f2DJawEAoJsr4ilP0faolpeCBZ8F4uDFWZ2IiEYEExEC
AAYFAj9+zBwACgkQHgKKGreJP+TI4wCfSxff5PaKtfwmkW8ZOh/udslWmNIAnAtQ
JCKLXjfR8pVWAdKNhAXJ39rRiEYEExECAAYFAj+KedwACgkQsB/XvLG2RNKEEgCf
dl3XBRrq5+/Il9AEspiC0n9xijsAoLTHNvM9LXcSga6LBnwk6rHsdshJiEYEExEC
AAYFAj+Kf/wACgkQu/rQsBCtaKI9WwCgjlKegmtbMY6+r8FlVdWuM2HPQrEAni+s
fKobgdKlfHt2M/ZCAXOnR/hJiEYEExECAAYFAj+VN/8ACgkQDsZnm2KtQhc++ACd
G/HfvFMi4LXagZzLFLPmihKO1LMAn0ix+S3usm5aoVkuvqn7ik1cVyDAtB9QYXYg
THVjaXN0bmlrIDxwYXZARnJlZUJTRC5vcmc+iF4EExECAB4FAj+yp2MCGwMGCwkI
BwMCAxUCAwMWAgECHgECF4AACgkQntdYP8FOsoLsqwCfeMIFltsrDkaPZZ7phSx7
0u6E2tsAn2fFlP9U2QT1SUebpaUaRbnRKmuzuQENBD9KJ7cQBACWoRj6p3M3mx1n
6FvPV6EoLFXH5dSRS0HIGwe0M41mZgD9VcRfA8OXYFYCzlSn35owkHxCmjjOp5XD
1u37hl/rEPCsOtMFxzjyj5Ujwu7E/cAAqAqB2u9Zy5juful59d0U9pGhaAUALtaE
IMdZJTXHX9trbnpAyUV6L8TU3s/2XwAEDQQAjb5WxBYKAHRykalp4QdE+Obc8ZS8
rqf4KY0R5PYYvcni6lBBNdKgTRHThZZxUybU+pww95RKXRv1PtLb2jW/BKwV6qum
SqQZkZzpUtqd69DDGilC8J4BtCPJmB4QpzTZjzeGi8MDjkX/btP/wY9z+f/3Cguj
500udi7+fT9CRuKISQQYEQIACQUCP0ontwIbDAAKCRCe11g/wU6ygh+iAJwNtPbJ
zULbTUIEZ+C2eXcB4+jjYACfT4aN6ETBfBYNij1Qmd6TjOXcXgY=
=Jmz+
-----END PGP PUBLIC KEY BLOCK-----
D.3.129 Bruce A. Mah <bmah@FreeBSD.org>
pub 1024D/5BA052C3 1997-12-08
Key fingerprint = F829 B805 207D 14C7 7197 7832 D8CA 3171 5BA0 52C3
uid Bruce A. Mah <bmah@acm.org>
uid Bruce A. Mah <bmah@ca.sandia.gov>
uid Bruce A. Mah <bmah@ieee.org>
uid Bruce A. Mah <bmah@cisco.com>
uid Bruce A. Mah <bmah@employees.org>
uid Bruce A. Mah <bmah@freebsd.org>
uid Bruce A. Mah <bmah@packetdesign.com>
uid Bruce A. Mah <bmah@kitchenlab.org>
sub 2048g/B4E60EA1 1997-12-08
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDSMdS0RBADQE42S0MDRcjiuM4mPH4NL2m60OMHgq3mYuIzrNkRE4jSzZJiG
8jBMl5VysnTkdvL61gH4aihIqioULOUq3L9XEtlrLbx1HDXEEdAdhARzqPapD4x2
FbHpjb0wjxQ7RmXXvLHDlPa8x8K48BJjZ+9WhPs6TKu78+I+9cqZ0u1KKQCg/2ls
GAGht29FiOtHrHFVMKl3WXMD/R6wl33Xsb7mwFROBWoYxExqSAZ9xeI5KUtQ5f2U
eYSbUfxCTkcBIImjf6UhtjLTs6Rc0ouYLHOHu7wxVVzA0x3UpcEWUkNXWsy4PO+S
j7PdzKi52BzR2LY62DoBTUARAaIsvp3fV126NPBHR2Isflo2OlEvwKGJ40IJMLGN
d3xBA/43QdXUcxa/FFAeCroYr/BkWPYz7Oh1HFBTa9xxrKL5sLDJChp/yLFoVhsG
0t4w595cbD8L1n1PckcaKVK2Y8vjafJKL5k5Ea/CnF0kO7+Q3RaydqzOcS2yP0n2
ZLQ+sorNz1huY6hrJemH9SjWnYKg4xbxfQzRBcfRxGQv3usvC7QbQnJ1Y2UgQS4g
TWFoIDxibWFoQGFjbS5vcmc+iGAEEBECACACGQEFAkLy8f4GCwkIBwMCBBUCCAME
FgIDAQIeAQIXgAAKCRDYyjFxW6BSw/IGAKCXkxrROelKd6498dQuBhdVBji7qgCg
/eUqq6mKA+R+P1MD4YjsyXy13pOIRgQQEQIABgUCOe6NVgAKCRCI4Xsd/OVlYVW/
AKDVOmtjLziEZDRxiyeimOQy2cQ0pACffZ1KopGDjOi1Hwi3diH5dSmOOwOIRgQQ
EQIABgUCOe6NXQAKCRAY9QOAJMJ4AkinAKDIpaIXZCpCK7ysX9PW+3/tL7nNawCg
ngynY5TWPwEdZ1aedPev6M/3+HmIRgQQEQIABgUCOs5wJwAKCRAJ/r8QgpnNs4gP
AKDjAHY+qf+Li5WmAXDzQhsZ0Om0dQCeNJ706+74vz2NLze1Ttc4EHmDXEWIRgQT
EQIABgUCPQenhQAKCRAgFTHVhF3+3UHaAJ9bd79S/Sq93vH/bQbmGuoUFR4BXwCf
a9bJYAT5gz3SN6pxqRxZyqb6EqSIRgQSEQIABgUCPQetSgAKCRAh+cW892qb9Z6d
AKCQqaiB1Wh467OWGusGvrYQzXlq4gCg4FNg/xngvZeJW97Ntn1BJza6s3SIRgQS
EQIABgUCPNl+gQAKCRAqNrG6CC7PxbswAJ4gLnUa0Jx78YupuQjIPRB5r3puggCd
GjYiK4n0b9LbI7jZhgJsEb89JoGIRgQTEQIABgUCPQernAAKCRBG7a30NX1l+4fl
AJ9Dz+M2C2doo92UtEmZK+DYzJ16AwCfYga0raO8/sIAEd1Wrp+3IlgmrcCIRgQQ
EQIABgUCO+moHgAKCRBVlt0M6b9lPaakAKCAhO9xMc+3ldxsPUnGNhTZ6HivgACd
EAzCr/VbLp0dG2/hPV5Om1d4aA6IRgQTEQIABgUCPQer/AAKCRBdjovp8jga1Bpj
AKDDCZG5Y5HLe729yr1PP/Q0vf/FRQCgiXZX0DhJj5Pa/SlEKHn0FqJ/ti2InAQS
AQEABgUCPQetLwAKCRB8S2dtoA4VY1BIA/9l02ueCOR++lCobMBgOBcFOO5NiE+M
x2osDI6r1cZFMYJXOfxR1nbvzT/yGZv2waF0XECMvbjUSdcRPHalVGDivaLR98z8
6p7mFzr2g7LHpI/brauPIVYq61EHtZK1LWzKFAK6HEpx+C4JXURsA0d8i66Yu8bx
jVJVn9pP4WEiI4hGBBARAgAGBQI9B58MAAoJELTXEKIORR99m68An2c0YEMO40sq
UAJNrmCrox4RlAXUAJ9PvIK2AFsFRj0CYqjc1F7sdX3VCoicBBMBAQAGBQI9B7fI
AAoJELaE8XzBCodN+R0D/2fWf0Jp2gJy7Pq5v3GZBxiE4Jlgill6C7iFU+wv+V6Y
fp5KFBfTNH+myn8DP9I2PDhSfH/epN5UqkuTzqyz4DLpmD0Q/eK2U3SmWrfQFojh
BUDGLDSsSMcsUQOc/kYYAZ1Iqpe+2F6+UBNq66/DWbS/9hm9uqIL0ehRb+x4Nl5W
iJwEEgEBAAYFAj0HrTsACgkQ1uCh/k++Kt1d5QP/RZ8QoiVv3yqpFDOogmHGFqoO
3PWJKMzsP0zvySlSM0Q9RD3bSTRGYg02UxHm+EPS6hy42td452YUYMMK4lirRQty
wcKjuM2P2owoB7H0AuVjDsmEdLihxVq79/Mh2WWytabS0OVxvR51JW6HT8imv3/8
vSU1JXA3BZnTrl173dSIRgQQEQIABgUCO6jZ4gAKCRCeHQdkN4IiqFUkAJ4zDQG8
i+y4+nmrEDHtewizXX8a/ACgkOdRDTFhrElHzO81thsR6BnDh2+IRgQQEQIABgUC
PQep0QAKCRC1UrBDdzkF1ic1AJwIQLg4bt4zXyc79PsDRm3esGh15wCffnTIMDtR
9b2kRuFVRLnDBxA0IOqIRgQQEQIABgUCPoN1pAAKCRA/fNKRRvrNxw2cAKCJnEPh
KU+w4MRdVyOsI3m1puIm2ACfX1+ehJ0wkRuSKN1sE9XpR74PqTKIPwMFED6LNcJi
QObrltOfCxECiSMAoMAwczTW4s2rMJzvEsSxVUMgH9ycAJ9ztFJbYsjP50gMjWbx
8IFnHLQKPohGBBARAgAGBQI+Yp0KAAoJEOGpmw+ppg/j5NcAoM+A5luHR+h/uGFy
CnMScUMV2mH8AJ9oBLhulGjW4otlfO8Sm6WXTJxEvIkCHAQTAQIABgUCPy8b0gAK
CRAdYunJN23Ox1ytEACnpieD6dwAgESgHR+Iw04YYbmLB1rynuI65AqfBRdEQnqG
5xXjwZmwJ+aaSFEraKLz6RQLpv4HvKoXyvZAhzSFOPmHvV7GgmCTDZ1kVJNg22F/
8AdpBdfrW4RPbK7MeOS1MXV7xzr5mC5NWimIJVrsn2TLECbciIu8Kpy4c7wv3EF7
wmZzaTOkalQLL9XODpWhm2X1ASJ+nl4P9J4IElR+lwy/KqRXLljA6/v9+wBs6kmV
idbzeXTrKttX++EJ0PxyMMX2j0CAVZeXTWH5ieafn6X9uU3f9QA1ZF6w23Z8JTp0
ggoOvqYJ5+GqmDdn/YrY3hUizlCy8OnAOs0cpN6VgaRrVgmIWKdK/o+VE2iLlbSb
cXaLSN43BIWpnFrypxRZLN8YZQb3P1/A0ukOM/GHf8qE+0SXJlL6CUP1N5GsgRej
JOc8YEuSkanPA478KvwaY0m5vXnc+weUHSrlkwxKrRXzENz9jGimhbK+J8OSPqTV
up3Mjnc04zglDYtWbttlc20zZtB+I29uTqarLLRPG+LpKFxSGvEJivXMiksWzR8e
Py2VRGCo7bSbjT54nTJeBuhMYylNc3tDege6vDiyAJnFOWCF19b5coyStLsSc6xu
KXRe8cUcuxeHoiapXlYdwso2i6jhKOuTUspA5gK4kBe90RDN4kbholz5wUiiAokC
HAQTAQIABgUCPzFIvQAKCRAPJ00hlI+PBvVuD/wOSFsStty8WdpxlG0gXk9RWWaC
YsNjBcYCpHTFoPRQ+fZn/wQWWH0EVZ4pmPJB9f7COADs6gnoRWUFl+eApNi5bgsC
8XUvcSnWJpPrZwmt/2c0mTd5rM5LvmaGezMjBKYepTvMWG8atd3Vt0O2WObt3/1m
XVfzEr/EbbcTZ1umFyjUmh+6Z0LsCt910Br8D77PZdxjB4BmiVxWQKsHtuSNRTYF
RPgGZcsKzu1cyFyI5DE6kwh1b1UjQSV7vCPRsCiNXflbejjZZCtSQ1OBrM7R/4rP
sa0Tkf9MEBq7Wsj313KMZ0oPhEcM5so4P04VYhMHqABTijeF7kZ+GaWdiKZxVhDz
aFryG1IunTLr5HO+yFa1NgsFtBbsmuploZYcJMeWKuo/z4DWvClgES2sTBKfRfVO
q/65juxImaDxc1Qy1yyRBYl1Wiib1aZSToK/X/OsZwPVo7QAPAqbDQcMkrc5JJ80
c0N3TJtu+ymidWUnZ+gvFe6c3DTV+trItxrwPjhHfPD4+oHH1tFb+ofcAa69qt6j
LIziLMjS+Tyv5/8QP8xshscaiCDQUpjWwsjkkDfQBBd2lpry5iUL1dLVfSDprRtt
dTpIe7ZXBsss+7XGBx/A4ApW2JAxoPo+A7obZMzt29jge6RCIwSXx1r6ltrqnYcV
O2RFRKEXP/IJ/Iexq4hGBBMRAgAGBQI/YU+6AAoJEE8s09gnk88taKEAoLCFzYQy
gC5TNFi9g4jPi53k7pAnAJ9MBgAycaj1QFLnFwFb9rOZIHyR3YhGBBMRAgAGBQI/
YnQoAAoJEMiGpCvVsvD7NQMAn1ckw60nFYwxjPIEWCFVXzO4Vw5qAKDFeA154HBx
NDSvbzu1LVz5HjKx9YhLBBARAgALBQI3e6BCBAsDAQIACgkQ2MoxcVugUsO4/gCf
flQ3GeCupyHPgKfFikkzF1yhbwMAn0DqJIZ9klHdcWGPz2cWHA7PSPGCiEYEEhEC
AAYFAkAyi/MACgkQK9b4h5R0IUKRQQCcDqpDaOqbpozLjhEmbw3GkvUkM+QAnA64
PuM7qnvvqyYnARyZCfXI2AomiEYEExECAAYFAkC0G7MACgkQ/G14VSmup/ZgxgCf
XJq5zF9MRHkSh09MQWnqOYv1S6sAnA+9CRUiZU6A/AsV8QQ9VpZa1OSDiEYEExEC
AAYFAkD4HsQACgkQoE/7G33K6dPbiQCfVxLCAXYMOoBkhncGxRMrCrHjlnEAnjL8
wI7YWfJxW8ZGhxt0+5tq8vG6iQEiBBABAgAMBQJC0cfBBQMAEnUAAAoJEJcQuJvK
V618sIYH/RKryJhK9oyyLDJVOBp65U6ViVC07T2hlQYfot48p62GmURoxba9dF9A
jjFcwGc1D8vhnnfIQz7pnu/SI5uWdAonMAJvRMwIpwt+mj3W2UiPVBbqvcZjRvay
RVxyQCGJwE3zR/0yden80GHNPZuDACWrPJ+MzuertkjOclMkXadCI+nWnZ+usVqT
FEtC7N5F5gRO8tyZZ8a4CCadkHJlXtEXbjnbmHVDQP9E0PVc5DuN3wwA6jFyMDKb
TWHH1SWJJL5VZOvTj1D6ToBlccS2vGhOqhPOWzIMZOERplyx+PfY7JjLOOo19ggn
HTUzQUwvsJNhk7UW5YQqmEJE8iZWoR+0IUJydWNlIEEuIE1haCA8Ym1haEBjYS5z
YW5kaWEuZ292PokAlQMFEDSNdJeozjotI+wmPQEB2sAD/R79H8KT20AvdLfLK3hU
/jm0Zc2EkJzh1fl2HKotAyfp22WAfutAsz8R5HIYX6i4tM7DWG6pX8kwiWmzEvHd
5+GlUZHvnjKQ/FMLARnHzoPtx/WhX7DQxfaguOnmjdmRGzKbDGj8xDL3b8yFmOaR
dbs4ibPoajzaZ3Tr/W4PZq/qiF0EEBECAB0FAkLy8goGCwkIBwMCBBUCCAMEFgID
AQIeAQIXgAAKCRDYyjFxW6BSw1EKAJ4qGuAM4xTuFXXIRdujkCQEUqr1hACfb5+G
KrD7r2lZGxjg/lGThLZYvZaIRgQQEQIABgUCN4O3TQAKCRAhPF408YILVTFSAKDW
VZm+TtyL320Ys3xjCWSY0dZ8ZACg6+bO0WQFvgmjLgpww4zf9A953DSIPwMFEDeF
EjyvogFJ1jl/pxECv0UAoP0N+A/su+EsG7AyqtTxc0SkSG1MAJ4i8MbiIzk+Picf
+hm1H+gXxWn1Kog/AwUQN9n/OWlM93/mX/l7EQLDZQCfaV51kpxPgnf6Phq5748s
gmarZroAn3NskDMAtcSHqTyYfFu7SNOxgWIdiEYEEBECAAYFAjnuh+YACgkQIBUx
1YRd/t2hWwCdHqfPJWb2wVx4VoMtod5RRtQ9tF0An2ec1YSzFuep4DB6dI23LP04
voQ4iD8DBRA587GDd84pxY+hLiARAq4zAJ0SMRRA74tGwcGLWGwAxBbpVmPM5wCg
sH7yO2LFTpDA7ZOJxLlsCumygsyIRgQQEQIABgUCOe6NVQAKCRCI4Xsd/OVlYfzc
AJ90xj1zsCx/77XSTRhjOth7YuT55ACfQJZMfNge3GcyXVSRAKsP4TQ9zYqIRgQQ
EQIABgUCOe6NWgAKCRAY9QOAJMJ4AvUZAJ0fzv+uIaG2+DHRCoSYI6ahOfvjowCg
hg4JNSkzdscpeMLb5q16DM1wI9+IRgQQEQIABgUCOs5wIwAKCRAJ/r8QgpnNs9gE
AKCkwV3KND32VVU/8XZahJoianhhxACg5v5u1/2R2enqkLWZUWFL28qu/o+IRgQS
EQIABgUCPQetRwAKCRAh+cW892qb9YsbAJ40Xm8eNqn8rNDzw0OPYNllg3fp3QCf
ZjLQcRY41X1pBDw/ANzaB/VMKqCIRgQSEQIABgUCPNl+fAAKCRAqNrG6CC7PxdY1
AJ0SC7aH9Xl9Jd3d97YA4Dkik102yACeJ/jBytsYC2I5XM4rM23KXUyWcPKIRgQT
EQIABgUCPQerjQAKCRBG7a30NX1l+6nXAKCmvl6WMd8LGiDIjoCFftCNCjWtKwCg
qkc6y4+xT2+xliwJJpbLYuauZmeIRgQQEQIABgUCO+moHAAKCRBVlt0M6b9lPcKJ
AJ9Qay/Wac7u0Xhhv2gEcjoPDhjN8QCfbpDwH2kVSzDVywWQeYmNl0tWRPSIRgQT
EQIABgUCPQer+QAKCRBdjovp8jga1NnSAJ9f82WWtmBwykCgd3sxQ7S+UXDE8ACe
K/OC5oWwkQ3d25iL5KjAevFBCtmInAQSAQEABgUCPQetKwAKCRB8S2dtoA4VY6P4
A/9GQa7Anvzfqg/t8lz2ZWS4DWOXcpepN9NwyspwOCc2InJ6COiNqsFAWltbBXT3
Ik7zl7UvFrNrMQcWK5CYNbtmfxC260BSsS4jECPt4UKLnKNGLsyaQTI8u5uvzYP5
L7zn6fnLYbRNLIqEu21dAwPgrRnZKCMlyfs1vxBI35ULLohGBBARAgAGBQI9B58I
AAoJELTXEKIORR99BOAAn3MBIytcvWun3scv1Xs0CTptuRW+AKCZ+pUZ/59HUo4l
qhSmcyn+010UGYicBBMBAQAGBQI9B7fEAAoJELaE8XzBCodNS2gD/Rs2mgQiCmQQ
zqlldque7spyufObyYyXAcBgcRs4Tp+Dk4CpQZyUB1/wn4xEO45voG2kp3twCyYN
BKDrwpZYiLg3QWJRnGifYAiwW+W/ldaLydHvmCJzxRngVYSfrOi74gcqUDlFFrFn
EUpusat5DOYSUqk+pnhHKXmtVWQxrNGKiJwEEgEBAAYFAj0HrTgACgkQ1uCh/k++
Kt0z8AP+NNkS3RA/2uhPsdpOo0Oo7arbTP1zk27TRW4pGj23dga2XaVtM7nSUf5U
Tf0tTJ5dDhbTobrm+GWQ2ThBB+IbY/oigeI9FLE1Rx7vn2IEakjiD2E4kafL95T8
ooBrCkbqDPxigs+mYAig9E9I6p62Dm3nBlOEAnq+6t98rsi/yjWIRgQQEQIABgUC
O6jZ3wAKCRCeHQdkN4IiqDWxAKDAk9tST2QaFszZPH2gVgushcOo/ACfVwfxrBj0
4HEBwa+w3WL00RU7dMOIRgQQEQIABgUCPQepywAKCRC1UrBDdzkF1tVlAJ0QGe/T
0YYoSb3+Va/nTjqD1aA2qwCfcikASWvi1DpX7pyGD08xylln57OIRgQQEQIABgUC
PoN1mgAKCRA/fNKRRvrNx18XAKCuAnmaHp/afH/D7qMyY78c8O6OFQCfYI2Do346
vvcw6EupU1XxDXrK5NqJAhwEEwECAAYFAj8vG90ACgkQHWLpyTdtzseEbQ/9FkHq
LNaxRNXCFKyyBakKuOfxdiCA/WyNTm+YKW0tu8Yzqb6gL8u3dKjF3+W6UGzPxyRU
YeQ0khy4UeH/Po87HXo+Eu8mTWZUBxd6KKkdVH5v8Gq1x0m7qZHJ+46X+HsLlEz2
7omXEK/npgXl6sa1wX8OjbG85c5259Sezr9wvUgmbBd2U+xITRmmxGwvzzP6iEoI
bbzNYjZFwqlOXeC6Hehiw/AB8eZ+qMr0FtTIONV/CK1aaGHKwV6c6K3zjmhnLPi3
1kvqccS5uoY2D2X3eeS7+0IJXTiefRm3YJOilLMsEj31X05+1aZO4X6LTbvTGqCh
BoHuipylrwuCZeJP4LI2J3iIqpBsXCK/zCkhSPbPSa6napw05BLT920cSEkZB1cE
SzIdHFao4u5G987wzKM2xcSfuwAWMxd0OVHzNlH7fAblH75ot96cR0VzWxXosB98
iU5BFBxBXgxPxNw5qCOZuqr0eOLfmoaTVP3mueeP/w4okVw2JdQ8xhFiSdW0hA+b
QYtbjOpmBzTvQ5Txl6YmhqmsxkV3q38JM+/3DNSiULvK0Lw0tIdbLejmduxlWmBu
p5DKi4f4WniXDRG5cSyt7ozMGmbStU6WasK5FvoZm54u+IoVMcnBu+H3a/JxGCNH
ndirtbgdez6xZd4vaGRToxyy/fRUnvA2xdY9vumJAhwEEwECAAYFAj8xSMIACgkQ
DydNIZSPjwbwHRAAtrOgbcw4tAl2YRgfzaO5eTOr5vM+nOsdOkwmk7XuMKwnQkoA
dyJ4wp2v6jZe9b9mkZX7XAzLls3EF+pfAXm7Mie7mjOYR8DH6p7bAew+YBIIq6bU
FjM2qYBC3FYoRQLPzB8Cj58QC7wLVAYndS5+z5nh4/JKIB8uM2KQxHewPRNRN7RZ
HXlJTdmAqcb/n4s/HDe5mTh+vuuzoqrOJKFlBmnVhojDDkRqSAMMijMYNPV9rkQ2
RZ/ti3xKR1bIUz9jlReqVXn+T+oIw+kR8uPyAKQNdov6uvShAqe60V8/JAeorfNA
mytt54mcB3rTPsj76RFnrPC4k+G08YWuW+vmmezRx2FRNlG61WeWGORLpQ0T9yfU
nPoH5KyYnod91n90VXEcyEQyYTLOnDMJ8U7jOlnLVzGTMiMX8+gKmoGmTYzbxUan
0YOGiV5KR4HaAQzl953yhYJ1J431iRdjOLVXT1Q4IuiFgyIMxTceeiXtUeFMpbco
8GixnCCWKBJL40gU2xAy2hyPNC2s9krgQ/XGbzKGjoqY2FbRU94dtiwpIEx7hRbW
cSdj1Ny1rNC/KFkn7dUY0wbwYtJPkVadmqTe5dDe2FT1SBqzAXm0312gMden8bly
XoYXuaEU4wG3hDsDUeSGoyvcuuCVZRlO/nHXueSQyeOArOv8tNCqALbcSC2IRgQT
EQIABgUCP2FPvQAKCRBPLNPYJ5PPLbpAAJ0QgWty4BWn9xzLNVqexe/zT2f0GgCg
xAi3vElatIil4AEH4bEOLe9dzKOIRgQTEQIABgUCP2JwvwAKCRDIhqQr1bLw+1Wp
AKDBDqSDEelvLAHy+4Eb4xY/cHg2KQCcDWibvRs2L1bzNyOoyE/hPfbgNjCIRgQS
EQIABgUCQDKL9QAKCRAr1viHlHQhQvoHAJ97600f9vsYM5UQ7GhJJHl7U6pv7gCe
Iy8kReROsRKjVvwiEG2K4e+aqxGIRgQTEQIABgUCQLQbvgAKCRD8bXhVKa6n9ivh
AJ0cAl+cKCKFNX89rRWFp4hCn6rPigCfdeUcPsV+LqNS5aVBV9Q2w1slfv+IRgQT
EQIABgUCQPgeyAAKCRCgT/sbfcrp08+pAJ4mDcrSKQ4uvERV+uEfxlaSccHCaQCf
du7kJMl+QQILLzZywsCCn1C8nQq0HEJydWNlIEEuIE1haCA8Ym1haEBpZWVlLm9y
Zz6IXQQQEQIAHQUCQvLyCgYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJENjKMXFb
oFLDMwAAnjfLmu45IePvR151wwTQerqUgrnXAJ9LgGdXbdZL0kzfyhlfVs/pdPBL
Z4hGBBARAgAGBQI57o1WAAoJEIjhex385WVhjEUAoJ/rPEgZs/YUnfDnmMGLIxdF
hz2mAJ9EKcQ8233rt0pdt4xvRXziLvLG6YhGBBARAgAGBQI57o1dAAoJEBj1A4Ak
wngCxVYAnjhh80GEvKsG9kdUb/doJE8p2BIbAKD1azZoxMi+pIH2hs4plL7oyqf4
94hGBBARAgAGBQI6znAnAAoJEAn+vxCCmc2zE3YAn1pylLDv1Bbsyb+hjT6CSr7o
o2LaAKCavkdw7lb9NpR9lOc/qaEWyjcRyohGBBMRAgAGBQI9B6eFAAoJECAVMdWE
Xf7dH1EAnjUTYP2K6jRcSMUl40P4S67KMl6/AJ0YfKTHo/RhE7AvyE4zERaETylA
WIhGBBIRAgAGBQI9B61KAAoJECH5xbz3apv17EQAoNs0ttUBYmDgMHRNviLjF04F
Hj9tAKCACgUpqyaeJJGd7glBp33Kgp60KohGBBIRAgAGBQI82X6BAAoJECo2sboI
Ls/FfegAnRMPAfMfhwf4/Hmn12hJlw7YnLLLAJ9GiR1jUOtKMulsOjCZYVW74h0F
94hGBBMRAgAGBQI9B6ucAAoJEEbtrfQ1fWX7FRwAnjoduMj4hoXgi/X0p+Q6nsJW
1wYGAKCt6IZ053pq+3fljhclARAuNJTIr4hGBBARAgAGBQI76ageAAoJEFWW3Qzp
v2U98CkAn3iYu+I1XQKAjEXji2bocrMjr1kMAJ0eA4VZdJk+JTWnPntk4Pg1ITGS
2ohGBBMRAgAGBQI9B6v8AAoJEF2Oi+nyOBrU+rsAnAjUV6MJadAnXe8VJsOvdbTH
N5yaAJ47ve5A8HLOxkn86YaUEm20sc1DPoicBBIBAQAGBQI9B60vAAoJEHxLZ22g
DhVjzDMD/RcE92t8k5xx0pUiQFAOlCjJfVuh3f3cof26plw+hncy+hlle9rGPSVY
YhtTGgy3InVS8Kp8x4RyJ/Ymy19I7yrsRQK7c100zCxd730pUwk1Yxvyiv6Djs7r
OcsHF5suU1rDUBmTOm5HzleCm/fzVkHcXst//RPCCIhumOhoRONXiEYEEBECAAYF
Aj0HnwwACgkQtNcQog5FH3179QCdHeCmWzl2nEqI5zqrxo87MPrPVs8AoISl2sGu
Sh8Y9gWwj5AA/eHoLuUTiJwEEwEBAAYFAj0Ht8gACgkQtoTxfMEKh02PpgP8DJ+y
XkLsYnUH7BhnED0PYFYsOorCe/tPg7ocMc+XGKUrags9IJQk+nZpfmFOR/pycQBU
/pZsDYYSGAKVFNI2ElPoTfUFka6EHFFag9Xs9YPeiCkcr4sbTmCx+6uVidvCnboa
E5c4Uczws3uck6QVB7WKHzjBdvO/OBnmB8zOP1KInAQSAQEABgUCPQetOwAKCRDW
4KH+T74q3RvGA/9JJp94uPG2AehKliTnkT3r7U9gBA1LzO+7TJI9a+i79+484EM/
EZwwjnks+S+vS+m7StUDeOYYFSe/d4xsg47cAN6cEleMJzunNh4vKH7cducWZbia
bUrYrZH6cIJU5Vy85h+yhx+tjdexRPtLxv24JZVDqxa8IWtIIKiKmUVPb4hGBBAR
AgAGBQI7qNniAAoJEJ4dB2Q3giKo+x8AoMpsdaJ93u6oIDYHziPGbQy9VcMJAJ4h
RXG3LRdvOsm+0ZV36s6qQHWAvohGBBARAgAGBQI9B6nRAAoJELVSsEN3OQXWTOoA
n04Y9k2OHyDGieYAHJ11n2rnPhdGAJ4i2yIXGgDaBeXP/op4OB2CHbbmfohGBBAR
AgAGBQI+g3WkAAoJED980pFG+s3HzR4Ani4cq+i8iqN4pEsR4zDG+hKgUi8BAKCu
5aNC3ElOlgyXY+Jyw8zhgmpeS4g/AwUQPos15GJA5uuW058LEQLfuQCg4Hgl1aA8
PULLwKIolsalL9A+RYsAoMt3oXAnVMQwmDvyYulm+oxKJllHiQIcBBMBAgAGBQI/
LxvdAAoJEB1i6ck3bc7HMWkQAKo+SAjy5D47D/eOt6ikqcUbxF74pAorSbthtj4r
U6DMDoxqX8Ap5NZry/3w8pUZL5zRgyzYeT9oXoUk8syjenxoZb14lQEGd1ZSy1/D
I2yHgnqzNLlk083Evvq1tdJBoJ11OB1RoOTZj5PQHoI6WWti/S9w87071Chuja98
4p/U0RBWQgb78OaWnv/dCHYUynikHK+x6+arZo1ci5pDFktaSHzQbUgI+vW3kIZK
4s34cbGmBjCdLtI1wqxkRnWYYmYYj7NiRdJT2OnQot5QyUA9lZFKUickFyfWuNFk
Exo6licEcI21JWALTBq23V+AyaEIoIN2PdY3BbCcinHMjLbJ6vni5EJVhjNIF/wL
oAmip2xWcDQJqE5cCNG+LleyNoGCuQ+5q1/4mdrl/FJvzhWLJKEvJcd8xKqt5mY8
cVioJdIwJHDZrWnS0Tum8Ye+0HbV/UqX13KbV97cTGGIGelB/Fh//v08zApho3KI
fNz57TrqHinmpdVDgMTZC4jZCti4njHYOITNhNUu8H5OZysVzn71YQdg8e7dFeJ9
8sTVQS/YQMg9XZEfInu92UP//t7hha6yp7Cns+H3k1VaGsbCug2iiagjkvZgfqmM
e8zugg4T7RLTy73jPL6PDgNBrl8Eu+1ysmCKdOAMC6nDKwPWto/fMQ1rt/0gcXot
47eWiQIcBBMBAgAGBQI/MUjAAAoJEA8nTSGUj48GIvUP/R5Grvaxae14cnW0mqJz
v9F2Jm2+FbILYZUTRFgcHG//gOcdW3ehhRX2+85O3ndr663O7yYPcj5wtObRCcTp
9bdrETSi0oNmkZbf6DgDDQl7Ywpnw2qwznwSHVy0dNZ4ew8A5H/JhD+gnRjyiw+a
i8Xyn86QcRw6MN6FHhDr8TmKYbLnblL+6+n+5fXDCqEPcXDOtIkzWyFiWpq5w9J0
JbvEukbhpjieJzd8zedEUOGZGQ54YhISl9B9IS+PCBcxMhEvPjd6zCwbJtJGsVt6
SsLIBlygjfQFqPNn4UX1/rDqsQ32Gw4cMIil2RYRtxfN1QHCH4nid0ZdMTFtodqv
hqV1MZpTF5ut8kPtj4RtrtJaGNATZr+N5+wukiSdo4MTuphb68sBJbD/dV3eTiQA
kFb2+0Of8/wE4RfPgD2RBMa31Nukk4JKLoV5qlZE9F3ZGRT4FzCQNxt/mmMCJXtW
O33oQEzuycPSUw/eqKskBbXkx41wMXw/Oa/CrADPWOVRpqkOq4zVW9JPNItkwSZ1
rCpp+fXkSO3v9/r8UMWuz4fNacqQCfm8+1Shs29DMuonYzuxcRR3MRGV91UlQ85+
jiP96TCPdcOdErQ0EOHkPF3r7sUUXzRhdoa3UpvFoMbL5OufP56R0IyWNtdoHqNe
vDmJ8jcEJj67RXzGKL5eAGfHiEYEExECAAYFAj9hT70ACgkQTyzT2CeTzy2GTACe
J4BppzXByYFAwbOx8PzgmBRK3VYAnA1nir+/+EHDdINUoIXzVHiV7hKWiEYEExEC
AAYFAj9icMIACgkQyIakK9Wy8PuX4wCfbeVNeOT2afD9et0eGqnHZ3c3RyYAoNnX
IzOwmWru+6fhtsEYvHFCL8/+iEYEEhECAAYFAkAyi/UACgkQK9b4h5R0IUKJVQCb
BG4/YtxPFGIy9eOxnQJyRwrpwsgAnjdD8XOIrOp+U70uAY7rnRGaLni/iEYEExEC
AAYFAkC0G74ACgkQ/G14VSmup/ZltACdF76yPp+CugnQ+RkKhSBG/+qtIowAniLG
I5/n/dPJhLWvW1Ykl7Bdh00eiEYEExECAAYFAkD4HsgACgkQoE/7G33K6dPe9ACg
kWdHnaHveLsWUkoON+xt8MeUnUYAoO9Jan+db2NgoEoJTZs3RC9kgn51tB1CcnVj
ZSBBLiBNYWggPGJtYWhAY2lzY28uY29tPohdBBMRAgAdAheABQJC8vIKBgsJCAcD
AgQVAggDBBYCAwECHgEACgkQ2MoxcVugUsN0ggCgoEqyQSfW536+C0hfHEpOp0EL
LcQAnAl6DvzwpoJwrWQc0h9nykKzJcDDiEYEEBECAAYFAjnujVYACgkQiOF7Hfzl
ZWG5gQCfQpNn6yvqdu84zzBBst+l6hhZaOQAn2SJTy4RJZetqZNMpgoQfJF+MRUb
iEYEEBECAAYFAjnujV0ACgkQGPUDgCTCeAI5VwCgmS7PLgTE0htw56cO6WS1Tw/M
oXYAniBaB0+h60Yqt2+9eW3ORmYYRZYQiEUEEBECAAYFAjrOcCcACgkQCf6/EIKZ
zbM5ZwCfaXlx0KKbiGiwDcmBMXFZjzw2fVIAl1SZjmhnPvwLnlqdy1Mt7s9FT9uI
RgQTEQIABgUCPQengwAKCRAgFTHVhF3+3TsQAKCNtV6GyUY+8PibM1MvXHv+S1/N
WwCdH7NGAtuhVubQX2Jd4PIFLQYLA/2IRgQSEQIABgUCPQetSgAKCRAh+cW892qb
9SXgAJ9n2q5gskfp2ApR69WtRrQ/DzFvrwCeIq4JB5XrXdZnsVWDd9rWEaJ4VuOI
RgQSEQIABgUCPNl+gQAKCRAqNrG6CC7PxcTJAKCR0VIdQWPR1/30X2Dbdu0hn1LU
9wCcDeidUYkMXBtY69YdwjU1w6KHjICIRgQTEQIABgUCPQernAAKCRBG7a30NX1l
+22SAKCY1RIGfp9Q4ILM6iJwyQo4ZMkXVQCgvwQ51yxCftq97nMtOLqx0s4pZcOI
RgQQEQIABgUCO+moHgAKCRBVlt0M6b9lPbZuAJ9Yjcs3fJXQThwDkhcTTo4pX0BZ
IgCeIN5Mn6hQaqR8Z5h6fiXqdA9zxr2IRgQTEQIABgUCPQer/AAKCRBdjovp8jga
1JbgAJ9fKWmuJGii1EQV0a+3i/VshRI47QCg3z5ml7DMd9xwkVXO5CZajl8qi8mI
nAQSAQEABgUCPQetLwAKCRB8S2dtoA4VY6NoBACFoqy7IlJHqvu6Z8q/uw2qRcGq
E17krbXviSlgxb/7Usl4u3KlMBAWnCsj2Vnv8c7DrQGDbXNfEUZvV3zz5QfVF3z8
T0n/GptHo+ORLwLQpV72ucoFWN1zYgOry8K6Q8ObsqwYDRDtfMGtNBnzjg57rsI/
A7vWaqXIodtYn7ivuIhGBBARAgAGBQI9B58MAAoJELTXEKIORR99CCMAn0jK+gA6
vktC9wtCu67SiHEXDoyEAKDLHPnn+xcoYLvZfsur4OvG1uTo3IicBBMBAQAGBQI9
B7fIAAoJELaE8XzBCodNPM0D/3Re5qHcEzUTmNO1lgZeP+q/yWsIocT3kcidLeu3
7B7CsH7o1Zf2P8KCiEnx1SXYK3PN+EtUyg/9Z9hqXiMoGtvkb+qFgQc5TGZmAtWn
3hyiHzVdaI9aSo30M4pH3VRaSSTWcLYkC5t5u12+SUrlOtq0ZQjLPOXpCL53d8i7
ROe6iJwEEgEBAAYFAj0HrTsACgkQ1uCh/k++Kt1GwwP+LnPQmxJxuS4V3AqmwbQ6
Fbf+QyJODI6xApsoPcdq3cRTbFE86yxgJDeQeXN9+KXrPp0QU+SeEekVO8Z4ilJy
hmjVEqjyRJF6BwfRXOUq1UTVo8q+W6Okkpa6fMg7PML1hKKcaU2uRbxG8OVEQ+J0
ekeBIHyLkaHmPG8ZKrqVmw+IRgQQEQIABgUCO6jZ4gAKCRCeHQdkN4IiqNH5AJ9L
jFgED45Yg1HXKtcIa/1DKii/6QCgyk4TnvuBUiMov/XiRgykTbMiO2eIRgQQEQIA
BgUCPQep0QAKCRC1UrBDdzkF1mFFAJ0etxVK+m50IJboRSrGtAx6owvRpQCbBkbn
0dZX2oE+3ZbpfVWiisXZ0hiIRgQQEQIABgUCPoN1pAAKCRA/fNKRRvrNx1w4AKC6
GxIOY/HaH3OJyP6jLxaB2ScKXQCfX9js5vL6d8qD5HtpZubv6ff21+6JAhwEEwEC
AAYFAj8vG90ACgkQHWLpyTdtzsdHnA//fKus4sLo7LH/5O0ofCM3IQiIys9LBcH5
h5NSNb9cqevjoMeVzEfKD8vyt19fDzd4ILgqTeWKngkj9ELshnrYauWa810Xo9H2
Rt9vVAaGzHwPtGF0GvHq1TK2g4E+LGNlG7jhkFbWu8OpD2isjlDBq6tncI7z8dJY
aw6wJK5TrkNCLMprWQovyoa6OS32PGLNON+FEeAa2ENOEsBXcVEfutc1BHogvr6G
i4XwaqB54gk2lDvVol4LwlkSZhMJw1I1rSEeTTsYWiTAnkNhVne4RvbOYCJuCrRb
3Kga74rKiGwG7fpiUGas7Bkiz5FerPsCI6bCIiCLAKcuUqkoUDEDD+D1ZsmCnHQV
MS4ucS/5AA3tuF/6I1qeQOIXH2SOZYWxQLEgIai8gl/jOfhICeMXS11sgQmG9OKb
wXhWxJPHLWkrVGAitUHYw/fj56S+CQdo9JGzjLsJj8DJxXSnr/ah56Q6UV72uTfW
w+5yYcyI+QlvThOZ7zL1ktQQbigQAZcmTpgS1ldhH9pc7WurlyV9bV6ROYeiqIe6
j98rMblFeaiU4CgFY0lIqPKA1OJKK7d8DesSAYNLP8D3W2xRbMgafp4yxJwm5coV
an+fmQnnPe50r9puWSaOugi/Pka4CP3XOy88odUZ05wC28Is7/QcMQzHAj5UdlUZ
/JNwTiFlBYaJAhwEEwECAAYFAj8xSMEACgkQDydNIZSPjwbVlRAA0UKZE0bBtMse
S7gVtz4AAeIDVHi/VL9LX2AT/Rgi9mxtB2ul+2ubEr9l+pIeK2bt/RN6eOKL/N4i
NOZcQr0pbRlecj30iF8SwoCd/IkUXH5Q5o/7uKNoGBNXOX3r6+aqdhGMcjAe0R20
u1RVFl92V3EYxGZym+FwL2yRpEARvUBPmeyli0DSTDzCUed3KtWZO3LN5lfJ/teo
ZGaTs3ETYvIT1egco9DG7juA8hvaJq/YclE68E9s8GTX9V/TXq3g0FkT3IdOXlWN
bCzAbnAvRjqcusXH12f4DKCUhz/WcaF9/wU85ExWF+rDfnxDEVtcJB83JdbxC4uC
jMY5S6GEtuvDbTJW73twkrdwBzTMwi4aUC9SYWCVlvxLrod4y6zm2UGUYV1egaTn
wdVVgXjzy2UzWHcUWbw4AwVMUXs3Up6wncaVe+gMKeMhMk9eoEgATU3swbigVQyz
6x1O350qZgx2j1D+3LMHcEpZ7jbOPFhv0zT5gtuQVBhnBoxF5F9kGQd0cFDgUCTR
emZYnrDjtyb90gbwOIUz2GB1obgH9TH5uGPccyxX9or5qmvXZ2Id2/pOmxlHj/CN
/IGcaIU6tm6/uoigAPYoG+W+gjmlH5msf1MuMmBnccX8+hqWsOsV7Bd3Qb3Tjwql
8pHe5pA/xZzuXejGH+/Ouv4yLmgXlzSIRgQTEQIABgUCP2FPvQAKCRBPLNPYJ5PP
LRHhAJ46SbLH/JorxxTNVSwsXJKLHfivhwCcCUUskOCuw1QU6FqoqyHvWgAtvmWI
RgQTEQIABgUCP2JwwgAKCRDIhqQr1bLw+0sbAJ4g6hW8GbPktt7jmbVy5gcw5ThO
nQCgrhwQdg+8dnurDKVJFoJ+DOxGlkOIRgQSEQIABgUCQDKL9QAKCRAr1viHlHQh
Qop0AJ9Gwf2GvrRDretOKpqB6WH7q+xwbQCggDf6k/gCp1SgEa76CmoM9bmLSQaI
RgQTEQIABgUCQLQbvwAKCRD8bXhVKa6n9iplAJ9aKQTGIJWZO6XJu4eOfIKugG6i
qQCfaSMIbwewKVcADXOdy4RgjW8gqVeIRgQTEQIABgUCQPgeyAAKCRCgT/sbfcrp
0959AJ9oyIL8hzxku3V7loeKJniMQuJ9WwCfTPsTs6s2DdhOyMDXeOe6gMFjsKS0
IUJydWNlIEEuIE1haCA8Ym1haEBlbXBsb3llZXMub3JnPohdBBMRAgAdAheABQJC
8vIKBgsJCAcDAgQVAggDBBYCAwECHgEACgkQ2MoxcVugUsPnoACg21dsNct4vizn
XTB1izxCmKe0aKgAoP3yBmPcmUKDDseXPAblYLLqn6eyiEYEEBECAAYFAjnujVYA
CgkQiOF7HfzlZWE0dQCfVIdGmpefW6qr8TOrENXM39HolocAmgL5DdG/nYUfUUP6
LrS5u0/A2BvEiEYEEBECAAYFAjnujV0ACgkQGPUDgCTCeAKmmgCePVbkQ9AsnCO+
sqkZ7NYcdK5LT9UAoNU3T9jgMvnW5gDKTaJEy8477q6FiEYEEBECAAYFAjrOcCcA
CgkQCf6/EIKZzbM9tACdE3IgDQ/y/f1ZhuyIsud2baKg6K8An2r8w7cEAwfWye7u
3I6sr3fJR8/eiEYEExECAAYFAj0Hp4UACgkQIBUx1YRd/t3U6ACfVd5fnfsai/K+
duMDi0WKa2k38VEAn2p0uGy85e0MQ1S0u3FdGSLfkN8XiEYEEhECAAYFAj0HrUoA
CgkQIfnFvPdqm/U3ogCfau3JPECPX6A/RI4UWkUKQ+oowGwAoIpLlY529WaVqbbV
bVYacVLVbdFBiEYEEhECAAYFAjzZfoEACgkQKjaxugguz8Vf4QCfRDfaMqBSxK43
gurEuy8OCFKwqGAAn3oqVlkd8t59MZBw18KZbaPbly1diEYEExECAAYFAj0Hq5wA
CgkQRu2t9DV9ZfvzrgCgiTbsoz9DrF9xDC2Z78Z6gLbAv74An1Ym7gkuCUcjHTxw
XXNzfZ1CiY8KiEYEEBECAAYFAjvpqB4ACgkQVZbdDOm/ZT3/xACdEGJfn+fp/0WS
aMjNEb1EYkUXYdIAmwS7bOv/UjLxJ3HcY4ooG/BexGd/iEYEExECAAYFAj0Hq/wA
CgkQXY6L6fI4GtSrDgCeJVw1t8/ud5C7P+7VDoyIXv47M50AoLg3I3TP32lGXqF4
hFe6VfeMppj8iJwEEgEBAAYFAj0HrS8ACgkQfEtnbaAOFWOYXQP+IJH2o8bGTLrZ
p7Nc2Bs2p7aln3COggZKfk2F88VRA7Utsdjj9KysLp8EiNi7tR7mj4LHuRp4wBNv
2RDSWqk9OZSq6IW5ZpmlECCJ/H42wmn+jt3gS4bBQyQlUtr74hDqfqgY1Wd21bJu
ZpCTL9drVICxN+Dof8MJH51anQAsI3OIRgQQEQIABgUCPQefDAAKCRC01xCiDkUf
fYP6AKCm90SLG+7bnqIVykONaB/sFtu+8QCgn01PJqvV4duJEAkTmHs385UYJ9WI
nAQTAQEABgUCPQe3yAAKCRC2hPF8wQqHTbR3A/97W+V7e/4rowEAh5l7EOKXxTLv
wfrZDvsB0nFBLv/RCb7jtQmwtGijb2NCuOTtNW3/HOGeeYNMwPfYf4jRsLRtlOIk
waULx5RgmK4NITJXHiJ0D81wduBfPoZO+kP11AZpQF2n5okOMqoXLceg1ue3g9ll
LPMJZveSjQnSi0kcV4icBBIBAQAGBQI9B607AAoJENbgof5PvirdMVMD+wTxQSvm
qx18J2uYZj6ujUX3lbYPwK1ggM4w2MmVKUD+X9RBjaW1aSp9YnQLL4j0lFOkYssc
IlGSFRGeE8cF8DBis2ape/lg6DWSON9qHgS/44YRC8xXZPXNB1wwQM4cUa4L3Mxz
AfYWJwAjMO0y5owDebKEnZjYeGaRD6hwhkbriEYEEBECAAYFAjuo2eIACgkQnh0H
ZDeCIqjgcwCfYuVM7kgfbmALOd/umBDLHGxx6HwAn00+6UqhasWTl+G2oCydp7sM
kguSiEYEEBECAAYFAj0HqdEACgkQtVKwQ3c5BdYilQCeM1Mft6Kwxqo1nbOLzQ5v
OWlRbSAAn1IyIuMAmJylg/cMqesV4McXYXQaiEYEEBECAAYFAj6DdaQACgkQP3zS
kUb6zceUJwCgmyXUHKLSZ+3DwHQQIBnSkouNJUoAoKP/GwrD+mo2LDKObb10I5xw
QYVwiD8DBRA+izX7YkDm65bTnwsRAjB5AKDQcLYt/6PjoATMIPe3izHDsImhVgCg
79BeGlQC3H5R6kecepRKFeK5g9aJAhwEEwECAAYFAj8vG94ACgkQHWLpyTdtzscy
aw/8Dz5mVfCrrTCx4J2/h9/HgXCMCwyMdG87e7CgQCaqsXo457G9thSA+fSxZ5rj
DDqs+go5K0QGE2U7UgRJ+YMlemCxrywRCIfoO5qW+fWc3juHwEVehrfSfsa9Xk7B
izoyETeK+1ggx50hNN+DRKG7jBokwzOsMYH4CJgPRBz96DL8Dgaxiys6cPKx8bmV
Chu9goZEtWSNbTXdeCZRDe043IFy0Yhg7CAYKOIm9+L6iqQ3nYxCXOdHRBvGVpZM
6ZlBCsJD5DDSTqSb5EEuiybO8YYzaDXnt9/Fam/j+arS7eJqfYXsI9CBA5SCZkaQ
ERMkFm0uk1uiQZa00VBU2tJHaAPqmc/Nuv88Db9056x8pvS1LPdtZ9cL7xqZRXzZ
Dl4mRljYL1Yn8xU+OmeVdPVVfUjSe0lxog1d9ya5DNNXySVT22xqIIYK8I9d1VHR
hGtsPiZ3Hlj+FXnvc9KWFuRAwprkRclOXZvU2i8F2joxPvLyE06tjTOj3VNDJPd3
Q0LzTtfMHszoom4wt8RtxNvQqkDuoJ5VHyshdWRcZg3mFIeuEq8QHgP26YQqOG19
N1343ao8k5rLhN59ZeGo5zzM/zklOjrdhyenfRH/8BQZe1TFeDHuD4jURekDFFOV
KM/j4Bf7Y7qxAkzWLdqWsFnOMUy+Sy2IyEotVM9Opsd3IVuJAhwEEwECAAYFAj8x
SMMACgkQDydNIZSPjwZD6xAAtsGfhze/SOnRJtGrz9zPrt0ZT7e+sWCk4k8hDt3J
qGjuLUsH7Cu4IcVLrmNLlKNxrN2T8oxMcibDoQj7er60iocsSifIgwpwnJXhJ40T
k6OK1aSiVIwQ4ff9lywSqaEY4wnYymxg9ADpPJfDVIZkhjARdLVfdLhkFwBiLVj7
T8KfY++qG6XZDCk0WdQ+Uh7qk8fLwdihuKK9+ySCVOwLIuARAmBtGOS8VOzgm1kV
oVs/RjVn7o5Wu+ckbYBkvWkzC5uwTR/U8MRs15V4MmxGL2omjO532ZogiyGNhbI3
nkA9byWOKQayLPK7/Vf9jYEzEUrCfX0oU/Y/tK2tUKCI4GX0Y9s+8D+xmo/uKMmV
0Rh79rMNZAhnb7Y66qn7/VYJjyBxZoR/1dsLn0147ouuF0NISHBtSocPH/5/b4Ad
+7jUn9WZe4H6jVGdjjrUIGk3C0IB2fUW7Dp3Eda8J1rtMMeo6ult7y67Q4A4g9wc
sY5cJBwkckroU8wQraLaFGutClWeyoHneb4nBL9TJwjw2DlknIp39TFONIE6T0lJ
vapOU16zTB8IZ3rixVuMl+IcJi7uNuCCmDsh6auMG2QMIIe9B5wGQ4cPS1CmoG/O
5G1/D5e0Rncvsy/KdnwnA2xCGVH7YgCM98SfJGLCI9bpCqq63llKPd+rCzlLU1Sc
aliIRgQTEQIABgUCP2FPvQAKCRBPLNPYJ5PPLWSmAKCvdbstKvhG4XaDxofWuWz1
WoAv1wCgn2JMIKqB1r/fgU+cSAMKLwAoWbWIRgQTEQIABgUCP2JwwgAKCRDIhqQr
1bLw+xzAAJ4vlsWlhklfv92GMCEY4E7fjsrgRgCdGLfsBuxfTkUToRGgoxfiR0i6
03KIRgQSEQIABgUCQDKL9QAKCRAr1viHlHQhQsD2AJ4unwkMZtCqZQxKkG46sJyo
AeCFKACfdt1c5n1zk70n2jTIEBmyRMQTBjiIRgQTEQIABgUCQLQbvwAKCRD8bXhV
Ka6n9kurAJ9mlD485VMjlFMhjvpgPUmi6lhRvQCeMkvghXcy129LJ8f6HrMbF1nY
d0mIRgQTEQIABgUCQPgeyAAKCRCgT/sbfcrp04KkAKD0WGdrXoOL9O7PU59gmvsP
QxfoowCeKjqCwWNSvfc3hvaqL6lqQq1Y6Xa0H0JydWNlIEEuIE1haCA8Ym1haEBm
cmVlYnNkLm9yZz6IXQQQEQIAHQUCQvLyCgYLCQgHAwIEFQIIAwQWAgMBAh4BAheA
AAoJENjKMXFboFLD7oYAnRRTp0GejwRmem9u8GQV6VLp076KAJsGNKqwweGFa8cO
91bpzUemGWQGU4hGBBARAgAGBQI57ofoAAoJECAVMdWEXf7dN58AniqC0HLEPpB6
ESefyQKpRVlpTcC+AKCIy2WFq1lAksYB1/dYMU5+wzxikYhGBBARAgAGBQI57o1W
AAoJEIjhex385WVh9oEAoKmQIWf+hxmJf7IskYAzXUEUi1wRAJ4zFYwo04eKV7sb
DHXPHR13pfZW0YhGBBARAgAGBQI57o1dAAoJEBj1A4AkwngCtb4AoKY5S5sCQCbn
19SraaSTPVBmImyfAJ9fG/FSYHCMNt194t9uixewoBCLrIhGBBARAgAGBQI6znAn
AAoJEAn+vxCCmc2zF+UAniGDl8pHwSOuJxDril0p8Ko/O7gUAKDaRn6sGz5erDxg
Rr6A/hDaNEyTxohGBBIRAgAGBQI9B61KAAoJECH5xbz3apv1uekAn05MpMaRgtCo
o1E6pI6boqBpxeUmAKCggEAPwXKNmS9m2unaphEZrXbcpIhGBBIRAgAGBQI82X6B
AAoJECo2sboILs/FqOAAn1DgPNBWkQJxsWCDYAWG1TIi6LkKAJ9302UjWqTlrRUz
zFEpNb3/7tdtvYhGBBMRAgAGBQI9B6ucAAoJEEbtrfQ1fWX7W1AAoMkkgs/Dnrmd
v3jS5D5bZWDiF/0xAJ0ZlQdE1a6x9FuBE31sGPbZJFjaG4hGBBARAgAGBQI76age
AAoJEFWW3Qzpv2U9er0An0G5GRcbYPhxGXelUZA7i02+OqeqAJ489xEd+M9/8XCl
ot7bYcaAIKPiwYhGBBMRAgAGBQI9B6v8AAoJEF2Oi+nyOBrUFPEAnAx7C6fu2geu
1x+EtwtnIQehhLhBAKCrTji0qZFeVXngqiW+8SPpAodFpoicBBIBAQAGBQI9B60v
AAoJEHxLZ22gDhVjGKQD/1V1M+nOmEXulqfoNynqnFKN7oafzPLPzyEvJQFc1X60
Agx3te5E9OgJhYLqleVC4tPfGoiqCT68f7nemh6QAMu10iQoYUPL07ux6jIMmEPe
o14rEb58AH7RS65qJdpK9v+18kKP+a8+huLERtYRPzGffMCReZ7ertNfidK1EDHm
iEYEEBECAAYFAj0HnwwACgkQtNcQog5FH31WnQCgkmbUrptpXjcrPmkP3rROGHs0
TycAniYxzRdqIWx47Iaj7dLuxcvTHR7oiJwEEwEBAAYFAj0Ht8gACgkQtoTxfMEK
h03OSgP/TPpnQyZVwCgSIoX/Yz485VgXNfEIyoojai6TMwnBLCkp++nNoIf5Dcba
xHx97g1ojCqFZ8hvOAs70JBFQiVhgREn3GAcHR8VXLapdm5CTnOwF1GPfB3dHcxp
FrRIHwNSbM8gyx7/MBYOCOpxArdDZLHSLns3CKEeq3JzgahbcfiInAQSAQEABgUC
PQetOwAKCRDW4KH+T74q3Z1sA/4iwg4lSmpFBG3GIjreoth2SMtRYHvnK2QpklWl
0/Waz76mzUCZOW8xz+QqFvhMPy7pVI7w4QWnlZI7BMfLUWDX+jlTIg9Vq1f0jXaw
4j5ESYej6X02Dwbly+kOMuCNf9l3BFTBqGOWziPsZcAHsZrqhgOT1korNAW86NYc
D3lFnYhGBBARAgAGBQI7qNniAAoJEJ4dB2Q3giKoFjQAnRb/8lYs9iMgAGcq3SxI
ncT76jcCAJ47SFXq25cZHXv8w/40OVk7ZMZGCIhGBBARAgAGBQI9B6nRAAoJELVS
sEN3OQXW3KwAniOhY0yPMPcbq8/BaqcEx/cvuyioAJ0bvD3UIQKHdzJlusms5sjn
njzG7ohGBBARAgAGBQI+g3WkAAoJED980pFG+s3HyKgAnRjkDaG0eDnjpYwomKYA
GXsIjET0AJ4o5ak1vZNDAqI4kg1v2C2kerYybog/AwUQPooWdGJA5uuW058LEQIL
SwCffrvSiLVs4zeJQKDCZ5/txijnyeoAoI4vJa0WBSMP1Tb2o0ANYe+4GHAUiQIc
BBMBAgAGBQI/LxvdAAoJEB1i6ck3bc7HARIQAIkAegb3UmnTmQXWE1EqFNokRvzH
kJ3LRszOZBv1ZTq1bPiyeSAaEgRJWYLf7q8nkREckqzBQ3ISXn8pj+l2S6z8d3FL
nLotTFRQZPemwasw6XRvaIdL8MEnssAyHGTnQsQEFPFUoHJrb1L55I24NFoMLDlb
S2ar6Gm1vWNRuIw2z+uh6zAtosMUWMp3B3LOhSjuELIeulojIzPY6FL56Lods0pb
Sc+2UzaKUcqqaczijaC6uzdoR3Zt+xZk7GWsa6zfugBh5UcU8kVr1l5YvfMlzGAP
s7QKRvCfgJN+YINcw/CazGE95ixdY0FLQGIfskeQUtkdiJeD45wVNUsYOBAbZX2l
KHE3wuGO8LS2JZZY0Bj7T0Pw0JdHVf0AvallMPv0xiFZf/TfghBiA/RG8euwdIqN
0Q3hQKHFSxjvH8jQE/sVPiwL8h14nUd5XwfgJgIgP2blPn75yGpAXrVHnjDEH1VT
DGfcbKEGSeqdYmK8eJOOFbs5z+XgnylOAJvwDn38Kn1K0hI3B5XyVlH4PzRRNvRj
2kppJBbNTgwdlWHjHdyUGASMSAlr2jITuO9LwO35mFhSdqk9eDNBukXv/KF7+pz5
agJx7Lu1PLB8ia9rgD5ntAUr1MJbi1R0+r993+7ngvu1ROjiUrs6zolXBHcB8G2f
JVHjWPhAC7TJFbQmiQIcBBMBAgAGBQI/MUjCAAoJEA8nTSGUj48Gm9kP/3SJUz1x
ZkngYsVM05hcICWzUX2bI4QtX0FRjDEC7gK6ta/pgM1ZMzorJ99uT7gZk0aLcnLo
Rbxn85iEZmg/bPcAp2oYkjF/9tbFBeTcHHQsiVwf6vyskVAQhnyRgHamhcX7RxNL
pQTUKEG9KLEmU4rf/FwB8RCMbSWZUFgUMgr1GGcR+Sa9Rb92OH06ihrsINJrV8hL
LQhoSj9JhOolTvf0gZ/D/YqopFZfmcB4QZefaQWNVRnv9lCcT0d889iRQLGWvkZJ
9+nbWhjlileo9soTGg8ejb4Q/jLRQhYD6oYYqJ49pKf78JX30TEzIo6dQIv+rTK4
ngcMEOUaK50+YGDEorVS8lZQbGYYq/SMfprxqfh5MT5YfXus+ur9fhLccQK5uQJJ
ebDWZKEXDdObEECOLWSS5Q2MQiyXQ7qWe27kW+dZWmsDZh0AUtvnoA5F92EGpDaT
SXCdTWMqpPQyhsnRwxlZp13SXGGd81ghePYvjOQTJC7eSGHSmMROLFQZk8h4dR1Z
1HOsBCUktAvxnq6cxzVWf3hOzQz4W5nuBFiIhzac+5ulDpV0S090a5tKkLrbXd7d
5rFg5DyCnT851Tp140vxOmEQG8HbS5c0Z1hgWZ0TKnvred6xZQ0DCXmCioypAhZY
es70lOIxj/cGT1rgBFtLbxhc2r2b2YDcnZMtiEYEExECAAYFAj9hT70ACgkQTyzT
2CeTzy0hBQCdHyJJoRGvB3/u/iIVqfi2ZM57ddEAn0He6pc/KPyGKaV5d5xOicLx
25oNiEYEExECAAYFAj9icMIACgkQyIakK9Wy8PsEJACg4gEPwQZasvNK4uqjoo71
1FJhKwMAoLKbekzTQVTpvOZZKxQGm9cDXgthiEYEEhECAAYFAkAyi/UACgkQK9b4
h5R0IULLXgCfVXab0tlOszHsKgX+unjuB9b0YGsAn1edz54snUroRVUozB3n2ge3
gyNoiEYEExECAAYFAkC0G8AACgkQ/G14VSmup/YoWQCfYz431uqel/Mn2pW0jjZo
MTQPka8AnjrRTE1UjHjccclw/mGTAtLczG+giEYEExECAAYFAkD4HsgACgkQoE/7
G33K6dMULQCfTzkkq/YAIfoz7OHd4IuFwa5t8K0AoJxlmUIYArFopHXPr2KmcYNI
nNRetCRCcnVjZSBBLiBNYWggPGJtYWhAcGFja2V0ZGVzaWduLmNvbT6IRgQTEQIA
BgUCPQenhQAKCRAgFTHVhF3+3dkQAJ9HV17gMTtF08GgPhzgRwno/rVDGwCfcQlt
3xdrwf7fSFutTLT7gBVjvQiIRgQTEQIABgUCPQernAAKCRBG7a30NX1l+wnzAJ9h
MZblSxpSVfJpV+53wT4uCXgjCQCffIRsBwN7ZXoP7mzL+LhrHIza3IqIRgQQEQIA
BgUCO+moHgAKCRBVlt0M6b9lPfGhAJ9/dUFlRYJ91E8FzLkXn/SgZKQICwCeIjWn
VYKiUB+Y6FSR9sCKuwuV7xqIRgQTEQIABgUCPQer/AAKCRBdjovp8jga1G10AKCH
E0/UNcgqwCPsZJLNkCGpmuv8OwCfbYofO75CuMTpzLwKdzZCYDTD+AKIRgQQEQIA
BgUCPQefDAAKCRC01xCiDkUffWbuAJ9HUq/wpxw47yFLDRZ/2HtPBRVWyACgzFng
1nf0U4jm+y/5+G5Qtcf3x5+InAQTAQEABgUCPQe3yAAKCRC2hPF8wQqHTXt4A/9x
WSjFPrA9rKYKj0Kn70gnypK++fHMWnohTiTA16D0BPIITNnJ2ZDgpw4e31GjbTgc
NcNAJAZD4f93YLLEnEXN9ihXIFbrhisRe8rnq6zWjZvPUMf94SNCCuGVRj/V2M6H
Nx46mA8r5Ejk0bVScbjD32e660m1hOYc7ye7dtA0x4hdBBMRAgAdAheABQJC8vIK
BgsJCAcDAgQVAggDBBYCAwECHgEACgkQ2MoxcVugUsMDkACgnWY9xvPaJXivvJrg
VgA8VCW8OBcAniW2PlA9621xD1dar8JGR8T6xF0miEYEEBECAAYFAj0HqdEACgkQ
tVKwQ3c5BdZEMgCfVGP+zxgVXC2/8ifhVX6QT5fxzIAAn397V9V3sEq5XVgHksV0
0meCdlHEiEYEEBECAAYFAj6DdaQACgkQP3zSkUb6zceLVgCgh9HH1APmMYyJpMQe
RhYNELOVANsAoLAl3qmzleaa+3qxFlsrixYSy7g1iD8DBRA+ihYgYkDm65bTnwsR
Aj3zAJkBvIdL2keRqSuM7m+MRNzSTSfbfwCgqRdVGTfwdEat9BUNgiAUH+GySkyJ
AhwEEwECAAYFAj8vG94ACgkQHWLpyTdtzsf4gA//dii5I6XCQ3khpmLQyNJTkGfk
uTRHtAPMDyf6mJHnv/15WXA9ID4ORFi8qAAgvYasc1sfTa+Qd8oL8R6JmnUDV8Mt
dlsFqfgYnltBERdx2NSxnDV0QyVIRApiwqCgMYsTB8mARXRTfo3h0oqSEOvSFzx9
WCpU/Kb283qHPtvKh/ZfjdtNVHqVS9oNfg5db36LRx1ayWZxDNW4dq9Q7pohlcR1
kDPfcgdWWiCPWZSqBRHXAq9QnFPqKdAg4ctIUPu61CCb7iHqMEBc6qT+XcMyXAWB
L3T+6qmEcZ9AgQmRIkFtwG/IoS64uWZYuLh1EmsnMOKuEgtyI5Ujt2b86zz26wga
hGsUSH7TCojVbQG8Agnr7FsjNoGPqs61KmRN1L8CA/Crt5/unUMimWlDVMLP9CD4
ChgSDLK5zMisF55GV51j//IkeGuJz/ueXBVx0r0bgFvxCyR7G6NAA4H/AoQ3rrxF
f4QYNuAdXGjAmuHc8VtTAchWlThACieLp1fn5GcnO9z8l6j3fzW6R4XgzWfm+vkf
C93iAy6ZRLTMt21ZSJV+BUZL4/lKCIz5SxLYnN49tZgzqrH622Kkt8eT6pxDuUxk
MGs4n9bu2FheKOZRAXlCbQyA6B30TN0nHVpJFRDZRsfT51LbKD0623WzMwXgDyhL
RRO7OY/vtLWWlXUl3d6JAhwEEwECAAYFAj8xSMQACgkQDydNIZSPjwaG4A//W231
JuB/SFIT4hfo4k7cAt8XItRbnechv+7JNxkb8D/NiflXzqOjsJMFFPifaGnfS1d+
S1sdpFQ5riHZR1GZyXPgO/zlcNus+4u3G1Uy/AnO+vq4o637k53dXYXedm7VO1fi
I9S44VnTF1UZccvrUxrNIlewpODNqSUnQ1B9MCviDQHM2B9GHvLvGfAYxrznFh9Y
rGWfz+vPHFvTtBf50rjMnlBwK1/obqk7DmtKz1wFnp0xWndSGkccrvYzAL4yOI4G
5C97LC9YNLnMnptJvf70cqGM90hdRy8l0tIvcEpxz2uNZE264w7jzsFxYBsGUu7a
oOLqDl5a0zXnKGjBQiA2Ny4oT0ClQDUQXyg1pgqyV6gjeQUrU9kYRDugPvohItbb
s4KBx48XF2IJOtM8GJ58uWc5RN2NcbDzU96a6aEWq1lZpIQ3dedLLQ62aUyjuBgw
aYYOmPXcCLHd1KJ+Q8nM5VWISdbvLePg21w1zMMjCn4x3r9NWRvgU7RmE0dkIAJg
3fYntkMEhKJd3UOI/tKkPXumoSeh3ZeKY9kX057km9SMbd6Ta+2aAmh+j0XsECg6
akZiIdTNuENHbKozvsYn/aVIV0Xa1EjoKZmNmUkwOHO21N8chOtNpF/q7eVTjN30
P4Byvv+qLgvDRv/ttIJQR6JwL/L3l/9+RC3T3mOIRgQTEQIABgUCP2FPvQAKCRBP
LNPYJ5PPLeiXAJ9+oDmohcfCjbKbXHnszOR3dEacoACeJ2MC6nhSrqZ0H4Mqg8TX
GoXZBOqIRgQTEQIABgUCP2JwwgAKCRDIhqQr1bLw+/UmAJ9ZxwlnixZ9FrIGoaQp
f2y9oH0UkACfX2gN+UdkicK//Te5SLwjHkdvwmSIRgQSEQIABgUCQDKL9QAKCRAr
1viHlHQhQv30AJ9FzYF3Q+psI9uajSM/MdomZpxB5QCfZ7jyjoqsDeyyj8FU/cDl
AylXwVmIRgQTEQIABgUCQLQbwAAKCRD8bXhVKa6n9lVaAJ93WH9Plcc3xGGcOYQR
16lRm1B9sACfTSdPHcR6MXYeeLldvZU2n7/tOWWIRgQTEQIABgUCQPgeyQAKCRCg
T/sbfcrp00t0AJ9FGpwRmL8LbZ6CcCXF2lZSJMWcjQCfVnaL3r9G5CiIX9sUgJRs
xwYImd60IkJydWNlIEEuIE1haCA8Ym1haEBraXRjaGVubGFiLm9yZz6IYAQTEQIA
IAIbAwIeAQIXgAUCQvLyCgYLCQgHAwIEFQIIAwQWAgMBAAoJENjKMXFboFLDuzQA
oKEZtOMMcFKq7ixTgwkHxFrm6nJkAKDSDBEcYqitXwC0MRCu2edscFFO6ohGBBMR
AgAGBQJA+B7JAAoJEKBP+xt9yunT3tkAoPwLI9DEnGWnH/WEBino2z2kiZsWAKC6
hgXGRwa8Hhuo8gbEFAYM5jvVRbkCDQQ0jHUuEAgA9kJXtwh/CBdyorrWqULzBej5
UxE5T7bxbrlLOCDaAadWoxTpj0BV89AHxstDqZSt90xkhkn4DIO9ZekX1KHTUPj1
WV/cdlJPPT2N286Z4VeSWc39uK50T8X8dryDxUcwYc58yWb/Ffm7/ZFexwGq01ue
jaClcjrUGvC/RgBYK+X0iP1YTknbzSC0neSRBzZrM2w4DUUdD3yIsxx8Wy2O9vPJ
I8BD8KVbGI2Ou1WMuF040zT9fBdXQ6MdGGzeMyEstSr/POGxKUAYEY18hKcKctaG
xAMZyAcpesqVDNmWn6vQClCbAkbTCD1mpF1Bn5x8vYlLIhkmuquiXsNV6TILOwAC
Agf6A0oIHx7GA/Wg+7Xy+rZVKyrOQ+bxzDQbpNNwDBP5mZ4NoG6tgX9LLpLkihRl
mL76JsNHhQxaSHOU9mjmuAZgNVlYRE+O/fTIlLkRrBkgn0colEMy0EFx8/UsTPu8
j/RBURcrAD+ony+vXyl9cb2HEfpeUWhGQC/WdIhPwRKCK2fIZ75Szjkd4tgD9+yY
UEfGCbpw7bRwqHRDEdVy7qx7nHcTH5Xq+vdqJ7ZlsaNMNhDukS3RunILkTW5q9We
W9eabSSyY4uCY81YP2bRF/U/FPM/mYbWNUELgSmN/YkSwWLGgfjcCObTwgd0FOW7
XZuJ71R7ytBEn5kDt3bcvULsB4g/AwUYNIx1LtjKMXFboFLDEQJ3lgCgpRxakeNI
vUps4fdR3nZq/MRKTsIAoI5BR4LrbaOwqe1M5HlH1W/jDLIp
=D0KC
-----END PGP PUBLIC KEY BLOCK-----
D.3.130 Mike Makonnen <mtm@FreeBSD.org>
pub 1024D/7CD41F55 2004-02-06 Michael Telahun Makonnen <mtm@FreeBSD.Org>
Key fingerprint = AC7B 5672 2D11 F4D0 EBF8 5279 5359 2B82 7CD4 1F55
uid Michael Telahun Makonnen <mtm@tmsa-inc.com>
uid Mike Makonnen <mtm@identd.net>
uid Michael Telahun Makonnen <mtm@acs-et.com>
sub 2048g/E7DC936B 2004-02-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEAj2wYRBACHexVRaQ9QldEPYx/ukn2dcSi1H0ZFByRZvdB4ukm+z4FxfhWt
mw9gaq88mWLySchgnv7tkJDVGeZa4PLxDTdOpnEC1dDcjOCJiHAlo6gmBKGSP4hn
h5XfpEvyS8EQqbMD47CBAYstj9upnLYwpGYfU8x72tUUaJv9+mww9MC1gwCg5xYP
/iBwPb87nkOdB93/pQnxLW8D/iGeIKt0Zw602CTQvNnFjB/0RcO3JpwU7wn0ptCr
5/1OAKWEyYGfHGt6DZtNPzRLJBXmLmlYpCXDn7ZB48sz4Xgrf+05j0/lPHsAdrPK
OKCz/CJR/aGIPPTLQNTbMWg3pL47F+cfFhDwgQ8yzzYdQZlyDSv3ANPm+YZQKXKr
LhwLA/4mX5+hW2ntcnPXUOfnya6/KIufDBqjl620heB6cbrFLv9IcqVvDiVfICYH
jluYx+wqtKMVLa35fs5nF1Qv+wLelLjay+YdlYpeCCG5MzA3w5WJOK28vk5uAaDi
1rSep5ePi5ENmhiWRprvx4qPZef7MDWQ6rTR88781J/ENdV2JLQrTWljaGFlbCBU
ZWxhaHVuIE1ha29ubmVuIDxtdG1AdG1zYS1pbmMuY29tPoheBBMRAgAeBQJAI/Zg
AhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEFNZK4J81B9V7aQAn1mBnIqieZIE
T0IJd3Lk168oZKodAKDVaBuIZerbQDHPIPaJUSrUAe1NUrQqTWljaGFlbCBUZWxh
aHVuIE1ha29ubmVuIDxtdG1ARnJlZUJTRC5Pcmc+iGEEExECACECGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AFAkAj9w0CGQEACgkQU1krgnzUH1VdiQCfcLWbaIY470p+
h04RXpg+xQm4I5cAni9caDZovhablGxWXnMYcYADz7W/tB5NaWtlIE1ha29ubmVu
IDxtdG1AaWRlbnRkLm5ldD6IXgQTEQIAHgUCQCP1xwIbAwYLCQgHAwIDFQIDAxYC
AQIeAQIXgAAKCRBTWSuCfNQfVXYXAJ96JaLB3DA9YSZU6Aan4Sej2jb8NwCfTw0e
Q3zx1z4ckf84ZHO6+U5tGeO0KU1pY2hhZWwgVGVsYWh1biBNYWtvbm5lbiA8bXRt
QGFjcy1ldC5jb20+iF4EExECAB4FAkAj9jMCGwMGCwkIBwMCAxUCAwMWAgECHgEC
F4AACgkQU1krgnzUH1VKpACdGThHL9XMCCm+XANPFsq8JJL7uPIAmQFoL7uMxJFX
ZkmGhFi9jN2DadQsuQINBEAj2xEQCACtWPMKOwphtmOC82oyZf3PQRcyhd0BtDl3
P8EJg3fonvnZIKkiIdo5QMnFlCUd33lqkiLaduwk64SYBHHHkMGCtaViRC+1ukcA
ehJuv7QaybNCpPUdXXA8MUm1MqSflIKI164OpoFNFHIC2aWG65QNaMOkbHLcAu17
5czXYMN9d5iXeZSur9DSrCLz0vRxjaWZ2ksr0jvijFasXsfydiCB0MXE3reZ8Yln
koRIMCsLcPOGZVi/7Gn3FRWpCd0H9Z3UUVRAHLDfNySwI3+NqZWdUwk2gu/jZ7at
3b/PmGR12zHj2sL0OPg+f7rDSfOZfeR7YnM38McGhhd/XXg2+4yvAAMFCACSzNxE
ibtE9JfVIBhA3UD4qE8jFug5Uy13/NM672gDr7lnPY3d3pZeVKWnWEqQQhrKF8Tl
G6vOT/noCeTLO1Mcz+JeUY2WlTj5AGktehT2bLgV6PAGIUUP0zifqR47kx32b8qA
ZSwTUqus1QFD9YIbSfqbZu17FLk4AN8BSeUfM6Ktq5nR26+5v8WqMsGfXPvZSGRG
GqwTN94sW2B2GV2ep4OghClycSdl9CBfhawpaR1NjNXadtEWv0Ww8ctGfojR8Qoo
SVWPeXcmMGIF84gnmzeCOdAZU2psqBJ5XCus9HArm09enyVReMxrWAgcKxroRK6V
KzjDkeYkYI7PySStiEkEGBECAAkFAkAj2xECGwwACgkQU1krgnzUH1WPyACggAOh
k3grQGtqSllXt/GlhTaCdogAn24UzgrsnW6yzrpNeoWcmyDFJ4nR
=TuyI
-----END PGP PUBLIC KEY BLOCK-----
D.3.131 David Malone
<dwmalone@FreeBSD.org>
pub 512/40378991 1994/04/21 David Malone <dwmalone@maths.tcd.ie>
Key fingerprint = 86 A7 F4 86 39 2C 47 2C C1 C2 35 78 8E 2F B8 F5
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: 2.6.3ia
mQBNAi22tqgAAAECAPARUB5VpJvYQyHAzL0WITkJmKG1lpwFMPz4jenjJRplPr33
OvKxQcXh1bAWNVFiJVDJsWwnfif94wQdVUA3iZEABRG0JERhdmlkIE1hbG9uZSA8
ZHdtYWxvbmVAbWF0aHMudGNkLmllPokAlQIFEDCwQ4yqxsuiiP+uKQEBricEAKAE
f18kbKpFKU/DPRVhVYlLHCkzXLzZCiTxBUGjMaXZswKwrjVLF2l8mrNQhqC9L953
AGyUYNfPLtqw7b088v3ATCIrZ+izWyE27IrjZWSS57GZiDtnkm6moarG79yANBql
LBc0sK077cHEC+/gDwXNBLg0NNpHkaVXPxixt/ETiQBVAgUQMK+p+pFKk8pIl/up
AQF0QQH+ME6vPoS2+FgSN1q9R1hwmwEPAaYdyfhv2lj1/6KYDEaO9Lhw2u57nW7z
CDpir9gNN0X9U3XrIxlJ7wWxa1k2PokAVQIFEC7vu/zjBB1VQDeJkQEBWFsCANX+
qJO8J6qeJW8gcrmxMBA0l2MjEHcu8XNky6YT3yS6So72yL1lZbG78Sew03fXnWNS
GyhRrPz7sURNLtJDNDo=
=wpn4
-----END PGP PUBLIC KEY BLOCK-----
D.3.132 Sergey Matveychuk <sem@FreeBSD.org>
pub 1024D/B71F605D 1999-10-13
Key fingerprint = 4704 F374 DB28 BEC6 51C8 1322 4DC9 4BD8 B71F 605D
uid Sergey Matveychuk <sem@FreeBSD.org>
uid Sergey Matveychuk <sem@ciam.ru>
uid Sergey Matveychuk <sem@core.inec.ru>
sub 2048g/DEAF9D91 1999-10-13
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDgEenYRBADgT1f4m9S5l4Eu6t+PAji9dZbgMDbxE3QFh2H86bneL3ufAuCk
aBX8YnBrgXc9c+R8RLwdXpUjbt7i/tbQl7b/iaOcJgpo0yAWObpqxdmn+k7nkksd
1kMUQCi9X0mK44rbYAgCIKvXQovaZtoS8FhTdEci/6IhQf0WuJT0pN1BfwCg/9WM
KyzUPqB2LNLDwQetKhYcoO0D/iPI0UOVOeQUyYmu2i5JQD2K+A08jwIs+r5N54hE
bBbWQQkZnS8zfPh/HEudW9C5HD0a+BB/Lbq8aFq5Fh8NtU6k8sFqNtKXP/8mcDbt
rnSnoG3XRdtBioDG2sQUgHjQJmV6+ZYeqMe+4FIr9UIijm91RmKKQ/1pcUfxiK9Z
JO/hA/9DRRdTRDz1B5ttKJ0NQBfsUOFwwBAPTtoFDao5qJjz5QhVGlxybaLMwcRo
i3/5qPH8tCiQr8e7RlKGOccoROr6zvEgLERKCCtALVNPfZUA0avH8ORZz7KUopTv
8gaVOf6zSuxDlbndAhngU+RBh+EukzTZAsQrFDsVVC6irWm+nrQfU2VyZ2V5IE1h
dHZleWNodWsgPHNlbUBjaWFtLnJ1PohdBBARAgAdBgsJCAcDAgQVAggDBBYCAwEC
HgECF4AFAkOfCa8ACgkQTclL2LcfYF3sAQCg1tnkwCjzX30YVnXXa3jm8Ylsf4gA
n2b0W8dI/Y/1uXrSDu1uz/JYRDNuiEYEEBECAAYFAkOj/coACgkQQrGTfMhVD0wi
gwCgp9iZjDtysUtACZze58VROjl6r18AoJiR2rnEvcHQDsBv3PJRE5XCmBBKiE4E
EBECAA4FAjgEenYECwMCAQIZAQAKCRBNyUvYtx9gXZXjAKCzqI2PzQRRFWlI5veV
4U+x5Lc7lgCeIONnpV1VJCkCkKGHKvpkTrZ2+GyIYAQQEQIAIAIZAQUCQ529rwYL
CQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEE3JS9i3H2BdsagAnjcGi6aqhDzX76mG
QSSzhE9os8/WAJ4oAA925eHCvzUJ70KuzOd/ur6KBYhbBBARAgAbBgsJCAcDAgMV
AgMDFgIBAh4BAheABQJDpoPmAAoJEE3JS9i3H2BdAfkAn2wNyDpu0mSzknbTiwn0
ZtULGUzdAJ0YTvvLi0fJwMKpSVRk9M92RxDep4hGBBARAgAGBQJDoaY2AAoJEERt
DDCMkWQoLHQAnjPyol0c+TwTcwmKmhx9m2q11hmjAKDEnF/ZMvEK0DA+tz7bcIQd
1ZpoU4hGBBARAgAGBQJEovYVAAoJEKkX6cyZbhRegKwAniqOkIAm+pPxZeaqLM8w
Fae7PtPHAJ9/Cv+mMbOuukx4D9pBtFTUgyQZjYhGBBARAgAGBQJEowRwAAoJEGwD
cmOt/VyaB/wAn12/XGsruhluMLWeGcZ8P8/w0KZkAJ4+SfQ9/kPGZy9bMdvf/Kow
ZW58aIkBIgQQAQIADAUCQ7BQKQUDABJ1AAAKCRCXELibyletfHV5CACOuLT1gjq2
g4Tm7hMbGpC9NnK78HWHZr65dr25WlVekwapDmvO75kixqhwZ3hrDRfDtQsUrrCa
0n2zS6jbGWWkFUVjEHZaKZjLF8HbLJbU/J7AHx2im9RUVx+eD8VI0T8iNvW2ODo4
bL2CqEYz7k9lUGXi3RZm31Y13dOislyEA5dO4lqh56tXynYFa963xGOXgulHX+vz
SCbltc5mQt6uZ+bKmUsl/ffA3bzZ/aM/DInD5RKuU024eibxOQ0QUPlHq6tF60Uv
xEofeYRdZo+hdyOvmRlpkFJvcpBSZ0U7f/r7IwwqMDKTImbee5DtxgbKLJNR6IG9
INvjWLHdxoMPtCNTZXJnZXkgTWF0dmV5Y2h1ayA8c2VtQEZyZWVCU0Qub3JnPohj
BBMRAgAjAhsjBgsJCAcDAgQVAggDBBYCAwECHgECF4AFAkOfCbgCGQEACgkQTclL
2LcfYF3TtwCeMK4gZteXRp5TTj+wc1mZIinw8RIAoJbG8NI+Sz70Pd6Cs1TEnj/C
BXA3iEYEEBECAAYFAkOjvpUACgkQryLc73jOEF+NYACeNUDUL7kHITLt8KaEW5Rd
lDQ88OAAn2WCdl6evL/PYG0rJJvpi/PNphzziEYEEBECAAYFAkOj42UACgkQhdRQ
RWtpGwOABwCgnYyAqsVrdLU67vXl30UhR93KSC0AnRNCks1LaxSlRQ/0FUCiBYoe
rPDKiEYEEBECAAYFAkOj7Z8ACgkQXeTX/hlJ3ICndwCeNwDoLdZ/uQPAmZWU7w9x
4LvGsMEAn0/tU75Pnk5htx3aKgHNZrbgC8MgiEYEEBECAAYFAkOj/boACgkQQrGT
fMhVD0x5kQCgon3OpWC9aDJTiozvGTiDE5w5hLQAoJq2i4yaC6kRT41B3aOfjXKk
SLjgiGAEExECACAFAkOdwYoCGyMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRBN
yUvYtx9gXZ/NAKC9I2cSvVQrE7IFrBSatdxwMHzMUACeL8+qkqtWdfhEJpSJFcln
Xw6tW5mIYQQTEQIAIQIbIwIeAQIXgAIZAQUCQ6K3EwYLCQgHAwIDFQIDAxYCAQAK
CRBNyUvYtx9gXftKAJ95Qiq5aPWFS9UnIb4w19TPIq7OKgCg1o3+/16rNohsn74a
1zlK+JkIJSeIRgQQEQIABgUCQ6GmOgAKCRBEbQwwjJFkKObbAJ0ZwW3xBEGFsZfF
tGBveNQjLzURDgCfRIqdpUtPlcHLWc2n8YUx6FpFaWOIRgQQEQIABgUCQ6Z7zwAK
CRBEidDtZ5uBGQQBAJ0VZPlNoataRuQdzULUXyc+iSfPewCfUZYcvAOpaQ1z+eJ7
/H11zmZ2mSqIRgQQEQIABgUCRKL2EgAKCRCpF+nMmW4UXv5NAJ0XVv2BGFs9zhJW
jdD3xbkZcG/YSACggDGixZ0HT9+FAC3qnJzxYjER0U+IRgQQEQIABgUCRKMEZgAK
CRBsA3Jjrf1cmmk3AKCRv6qI+NOMGiKIj3c7RzN/UC55ZgCfaNfE8Eeym+wUJGH8
a5lMOEBDfHO0JFNlcmdleSBNYXR2ZXljaHVrIDxzZW1AY29yZS5pbmVjLnJ1Pohg
BBMRAgAgBQJDncG9AhsjBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQTclL2Lcf
YF1AdACbBMS809aBX96UVFp8cqx4RAg75bQAoKBvCCEBY3hJ2KbrXu+TfGcNGfCt
iEYEEBECAAYFAkOj/coACgkQQrGTfMhVD0wGxgCgrZA+my8MDGgaRF57rnP60Iqe
oRMAoK5UbrYtXL23ao8O6m9S5EG6g+pWiF4EExECAB4CGyMCHgECF4AFAkOitx0G
CwkIBwMCAxUCAwMWAgEACgkQTclL2LcfYF2HYgCdGLs9tjadS8Samc2GGMRAeP/6
R2UAoLVh92UM7g2o9XFIOTVrPraOwC0/iEYEEBECAAYFAkOhpjoACgkQRG0MMIyR
ZCj8nACfbLM24O4P/h/V3A0Bfk2se84M644AoIqFIZGr6T/BTkRjtONJyVmKAg85
iEYEEBECAAYFAkSi9hYACgkQqRfpzJluFF7rFgCdGsz/KQy4veazVW+VDfstOdRd
3R0AoJmXvEXiXHyqWEKNxQ+CKBQsJdDCiEYEEBECAAYFAkSjBHAACgkQbANyY639
XJpCxQCcCFudoNU7Fztnkavjsli0Dsu8ptYAn0qgc7RJVmWV8sW2+ypTK+l4VWkr
uQINBDgEenYQCAD2Qle3CH8IF3KiutapQvMF6PlTETlPtvFuuUs4INoBp1ajFOmP
QFXz0AfGy0OplK33TGSGSfgMg71l6RfUodNQ+PVZX9x2Uk89PY3bzpnhV5JZzf24
rnRPxfx2vIPFRzBhznzJZv8V+bv9kV7HAarTW56NoKVyOtQa8L9GAFgr5fSI/VhO
SdvNILSd5JEHNmszbDgNRR0PfIizHHxbLY7288kjwEPwpVsYjY67VYy4XTjTNP18
F1dDox0YbN4zISy1Kv884bEpQBgRjXyEpwpy1obEAxnIByl6ypUM2Zafq9AKUJsC
RtMIPWakXUGfnHy9iUsiGSa6q6Jew1XpMgs7AAICCACewsZfxk8RG2OlA5Xwu2qv
tTq6dyC6sPQQBZJaPrd9ZOC4xh6mY8ymybkHSjG0sUbz98l9WaFHGiEv53nHQIJc
hOF0pBGhIuVPUAB9Oj3W4xk3xOw4PT8MYWbjExMLwUuNVDQCWeB84GLxmRJslDMr
ZFv+/39J4reVXdY6H/bLGknWs9Gl06h8dsL8Sc+PBj2Yfjf+BBdaKCl26Jw2trVm
yCLlm6QY84veNoDpsK+hT6IAAi5h29bITYGiWT3MLFmplDT+gtqaJifCBGh0VgUk
4mnWhL1jsEFrqoEpzOkCWEwLwYvrdCMElc80c7jk8pVeJiZGFgaRckyjGeacXe2V
iEYEGBECAAYFAjgEenYACgkQTclL2LcfYF2z4gCeLX+cbR0xy/B7v2wFZPABVHWd
/CYAn14opUDUCjxXXd3vrkwzNCIrYQ5i
=iDu9
-----END PGP PUBLIC KEY BLOCK-----
D.3.133 Emanuel Haupt <ehaupt@FreeBSD.org>
pub 1024D/90215DB9 2007-02-06 [expires: 2008-02-06]
Key fingerprint = 741B C70F 100B F360 0B52 E92D 5F01 7A86 9021 5DB9
uid Emanuel Haupt <ehaupt@FreeBSD.org>
uid Emanuel Haupt <ehaupt@critical.ch>
sub 2048g/6DD0929C 2007-02-06 [expires: 2008-02-06]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEXIhOYRBACqxbx/nLwG1OVuFs1wt2zASY5P1JbyZ+DA0+21YKpYz6EjRIcn
j3Y1FFJO5T6pR8yTMz47rEaT4K9OLigYZkwWg8G0WUqby/CJPylEkAwrhg8do7ys
kwTJMg8nOlSyv+m9KFK2C8mhcp/dGqp/Ev91iAKE9M7wCNxYzZGk/lHnVwCgi3yc
rQReRXDrXkOnJr0v4g93T58D/3rrIQJoFa90o0iUCatDJxvQ5eG0vxVPcERssGF1
vUAWFJn83cImWHltpOEWyBgOnfjfkFKZolG7QXBejJEPXYdSKzinDT5yqWXQXCHn
YCQxtO4OPxgtlV56sAlAeZgytuGfmkNfzkhoN8nRD3YXBlVWrhQwhVdmv5MBi7Pz
RFdCBACk+4WuKIVkRCKualPZocELQnAXuD30AFqGP3w7EAac8dlXumsgdQsP667G
R/RaBo2nks+tA8L3LXkMCgSCHFP3y4F82BFaNufkf5aTGDk4KOeEOLa4Wn2kyAQb
kxIApsN1T7y//EFu/VoRRIx7sU91ep1O4Ww3TPhpaqm92OGfsrQiRW1hbnVlbCBI
YXVwdCA8ZWhhdXB0QGNyaXRpY2FsLmNoPohmBBMRAgAmBQJFyITmAhsDBQkB4TOA
BgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQXwF6hpAhXble+ACeL4FCsn3oEeNo
3OSZGqK7HyeSTvAAnjSUwB+7Fi1OIiOzQVIKo4a76IyJtCJFbWFudWVsIEhhdXB0
IDxlaGF1cHRARnJlZUJTRC5vcmc+iGYEExECACYFAkXIhRECGwMFCQHhM4AGCwkI
BwMCBBUCCAMEFgIDAQIeAQIXgAAKCRBfAXqGkCFduYUwAJ4gfS+qakG4VbU4zMW4
uBMXB9jg9ACgguQQkvNLpX0HktmO0BvhVRkGUsy5Ag0ERciE7xAIAJzXp5NhJ2vr
E1mxRlgeWrTzQ9/W2D1+MAQvH/nEZLq3yS1snyLvk6KQooRN9MP1hftWMOSsAs5u
cvrnKJOxouK2bIAdd/dk4dwVky9kq95PHow1NNiVEdWX+CxjmZXZ6uzr5XpXqSVl
A8aaZTaSoAT0hzDWnQ59HdwzbEDwNGQrSmLmxK4TxmYsVM//KyPnG2tGb+lrIsf+
6j7m/QrHrf/5j0hv5OGtnD75f8no7BpNZ6nKfusM8j1qECf4GA0rQheXLsMalst8
MwZecaxWdvdHugiJUFbyRrBFWYWK2Ne0wyPTx9mK/CP2ayLJro9vsA7Tix6d1S8z
4kkFShsxveMAAwYH/3EnNUO2EpN/R9uogeEUobHifbTz3Da/xe9/+k3iMZbW+6TF
ntw7aFzemeAYVabFPwqyn9FfzMAsOlz0u7djn8X+lp22Nvr+eYjfnSyGfGu8Uso/
KKdg4QeshrCcIDVdYBa314aatPRIBUO0qPRJISOhXC3NV+6QDaODT6p1xtsDSfdK
BDct6uqntgHRssTzTlBZzwoZeoC0RqcIipG1Ly+y/yoTou1MiOoN1SvLMsJtrENz
3+oG4p2yoZY5zodvJNmus3ArxHyVpn/iM/8onOufSZnftgDay3XPqxUIBVlpXLZt
CuKP1XuWS8odKzGYrFAuWq4TW9QbkuRY0rwpCs6ITwQYEQIADwUCRciE7wIbDAUJ
AeEzgAAKCRBfAXqGkCFdudl+AJ9Ik+uq4ank2SalIwfF2iFnNb0ATwCeLqLQIWnM
2KoyQBvRCcKpNGcqYUY=
=8Iic
-----END PGP PUBLIC KEY BLOCK-----
D.3.134 Koop Mast <kwm@FreeBSD.org>
pub 1024D/F95426DA 2004-09-10 Koop Mast <kwm@rainbow-runner.nl>
Key fingerprint = C66F 1835 0548 3440 8576 0FFE 6879 B7CD F954 26DA
uid Koop Mast <kwm@FreeBSD.org>
sub 1024g/A782EEDD 2004-09-10
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.6 (FreeBSD)
mQGiBEFCGHYRBACI9ERMi5j2009Juy2kpXS860i9tJJ10mM9TNuCZVYcPRRTiSWe
Q+YySmBtR9TA3OZfd6BA9EqusEgcwUJpxjZ8zjGzirj/OjcPtKwM9ZO6dadeMNaE
wT32bJDUw//2ky2xflJCsjg+TSO7PxQi3g/YEWfau6Istg8PKfzHQan0EwCgxwrV
6JijZQ85jIgQoceJjkwBLHsD+gKeeSUG7g2CO+NJf2d0tBj+l22QzmeAtlnuUskd
nHKDAzzty80e4HXkUYw8IMueR7Fe2Tjx20OvVSkzMwiZYqevIJHVhiouCFZxYpSa
JQHPYLpMXMVZ1X8d17tjbFRBXWmNrDcEhb4m3WoDKfQD/qbMCwBErsQ0t15dddnQ
BVyqA/93dSzMYRC+Zm6Hzfk5Dz2MsvsxEE30ysSwFjIZ06RtYPKlN0x3ABCGba8f
o5H0P6+gobJRLTQfK4xDS4J3G/d7TWO1bZGk9MPEzCJDexTt5yfKsY2jZRVRrikE
fIbdSUgLnczBdUno5qC9IyMhGNa8O92GsjleDm7D+p+wkkoyCrQbS29vcCBNYXN0
IDxrd21ARnJlZUJTRC5vcmc+iF4EExECAB4FAkFCGHYCGwMGCwkIBwMCAxUCAwMW
AgECHgECF4AACgkQaHm3zflUJtqlWgCfWKIRLzsvZjBjuck31Ep8sEDP0GgAn17m
X0hYq8W+2gbHbmYeqIFefHs9tCFLb29wIE1hc3QgPGt3bUByYWluYm93LXJ1bm5l
ci5ubD6IXgQTEQIAHgUCQUK9MgIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRBo
ebfN+VQm2sH2AKCnwIQ3C8+62/uQh05mqXqdzAaU8gCdEkRN+L9HY1OwFlSDi6Tc
OAWLTPG5AQ0EQUIYdxAEAItGBQMO4f4rHYh9zc4fd62RhBfMHJpY1ex6HeiHt3pb
i6KfBUai1zRYxgq9F+8qR9WgBLF1VhA4O0nCU9/FKOChc19W7xKa2auvE22Kq1ta
xjCszahtPTDGIBs4K8u0fH/Gx4VSikQcfIGNd3IK4vALbLfH+iK/1RJNXPzQ9A4H
AAMFA/4+UBNqZPucstZgmEwVB2H1Bt671fQqODpWj2eOMIYJWXKraUxdIjUqzm9K
QhC7LBj9ihsn+LRsO49oWIAv5bks4zC0STACJ+Lx+FMb1i5ayAp/03DoZyrjRnGb
SIY8Dtqonut2nic0NQ4XD5uqTkx2t7xlKJay/n4Nop2uqwajOYhJBBgRAgAJBQJB
Qhh3AhsMAAoJEGh5t835VCbaOZEAn3wkQ7xISlGUox1/aiPU1CafRrZyAKCXgDLa
wlCa23ftqh2DPxkAXtCnEA==
=FIQv
-----END PGP PUBLIC KEY BLOCK-----
D.3.135 Makoto
Matsushita <matusita@FreeBSD.org>
pub 1024D/20544576 1999-04-18
Key fingerprint = 71B6 13BF B262 2DD8 2B7C 6CD0 EB2D 4147 2054 4576
uid Makoto Matsushita <matusita@matatabi.or.jp>
uid Makoto Matsushita <matusita@FreeBSD.org>
uid Makoto Matsushita <matusita@jp.FreeBSD.ORG>
uid Makoto Matsushita <matusita@ist.osaka-u.ac.jp>
sub 1024g/F1F3C94D 1999-04-18
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDcZe6YRBACDOZSZ5cWE6IvNkx2Ht6S/VdIY1OXFU8n+cOVxNIHFWXPUOrFG
F526VZoPfjURnslubdxXC8TKGspX96uc1jdROHvEwsxUUELyzZ7G5oJ5wd4jHwjq
K5zwV5FZoNm1SHdeN0FqZB9rlJdOt0kxVZS+b1PUc0j1i4oDNZz7+8rc0wCgltLi
c2i5RQzjuvJvF9P8OYGujHcD/3Tq02ov/aNX+jIoO58uuOBZpYFL7ZfbCeiMs+4A
dmvjTI9MpfLBP711iu1asuikx6HLQts9UTVk36qP9ubNmFi54kDHsej7Ce8m+dOu
Cjcjle6Be71MGLq4YUxd9xZmGGDPhEFnHWbB/QPP4n/m3DN3hblWBgP2PsgmqDyK
518dA/0bhL5pvw5LSaRtGxxWvFBInfWGzC5EuLw4ERZW+bEFB0To08ZnocLRN/E6
tZ2JTr2O5aMLqUEM3jgsIvs9EOGUBwPRzyOQXpc2uQemn7J0pL6PQfuBIaUI/NOu
ULM0gQfLIV3wOP6Y5gH0FBcLt/ofrqdYys0C6zTq3LqDW5FdQbQoTWFrb3RvIE1h
dHN1c2hpdGEgPG1hdHVzaXRhQEZyZWVCU0Qub3JnPohfBBMRAgAXBQI71CCFBQsH
CgMEAxUDAgMWAgECF4AAEgkQ6y1BRyBURXYHZUdQRwABAc3PAJ0VtHlKCmR8IjdR
KJxY0C5fdmaDGwCfecy3f/dYGQsljHhv0Wr2PxciscS0K01ha290byBNYXRzdXNo
aXRhIDxtYXR1c2l0YUBtYXRhdGFiaS5vci5qcD6IYAQTEQIAGAMLCgMDFQMCAxYC
AQIXgAUCQ5F4YAIZAQASB2VHUEcAAQEJEOstQUcgVEV23p8AoJKAqle5nC6Wi6yO
TZtcr4axeBnAAJ9ABx4gqACagCDc/OMk3pmtb4sy1bQrTWFrb3RvIE1hdHN1c2hp
dGEgPG1hdHVzaXRhQGpwLkZyZWVCU0QuT1JHPohdBBMRAgAVBQI3GX1RAwsKAwMV
AwIDFgIBAheAABIJEOstQUcgVEV2B2VHUEcAAQE6EwCdEPG7N7vmhgYEqmZqPLm6
oqjHOpIAnAr1FfVDPXpfE2SmXUZenG7+5MwntC5NYWtvdG8gTWF0c3VzaGl0YSA8
bWF0dXNpdGFAaXN0Lm9zYWthLXUuYWMuanA+iGAEExECACAFAkORd40CGyMGCwkI
BwMCBBUCCAMEFgIDAQIeAQIXgAAKCRDrLUFHIFRFdraSAJ91gKAjNH0XzAKohpQV
vo3uT7LNvwCeJSxDm0hpmaOpa+LCcabNP91SyhS5AQ0ENxl8HhAEAITl4uP+i5aY
Wr7mPBLAaWfoQ4fyT3pUThtStiymqsrEDFKhVqA/KD3PUV1CeOBc9oq69x1+pUlk
VYz3vDrvk0hP+dy6nerUEbkdGtMKLvGzakdond55jgSTZ6CPHxqyLva06QpY8tj9
CODunFUE+MPVV4Lf9U4wMeEDZFEYvcajAAMFA/9kKoDY1ur1mAPJRWAcEONxnwiW
qe7l++fg/294wra8IkAbF760iMnqq63qavsGT6xStMi9EwZC687p86sFex6KF+uv
P04CTAyt+FAph7oa44AdWJo4tJ4SP8xIznOiZS8clWwxTaqv9Ncy6LZwbZf/P427
egF1zuv5A/MTO3KD7YhOBBgRAgAGBQI3GXweABIJEOstQUcgVEV2B2VHUEcAAQEr
7gCdHJTTs41XBpfprQCErm3tGXwRrG0An1zUSEtG1AA4jFXNgIlud0OO4aMm
=aY+v
-----END PGP PUBLIC KEY BLOCK-----
D.3.136 Tom McLaughlin
<tmclaugh@FreeBSD.org>
pub 1024D/E2F7B3D8 2005-05-24
Key fingerprint = 7692 B222 8D23 CF94 1993 0138 E339 E225 E2F7 B3D8
uid Tom McLaughlin (Personal email address) <tmclaugh@sdf.lonestar.org>
uid Tom McLaughlin (Work email address) <tmclaughlin@meditech.com>
uid Tom McLaughlin (FreeBSD email address) <tmclaugh@FreeBSD.org>
sub 2048g/16838F62 2005-05-24
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEKSlvMRBACEIyrOE2NlPjwg7bS3nUC4S/D1nPV22eEJ0ga9+LNHlQnsJON3
lGOU6iMGa6QaBoqg7Qw3aL6FaJlogNQfIPWZCRZdfJjlbw0Yd6EzCpMqoowB+4y6
XuObOhie5bdHFK8NVk9n1BZGUELcnPGMdhPPIQ/UHq7Rlhbqh8qkcA0imwCgzNEV
oPAY1SeozW0kBE6YUXXGQXkD+wRzl9As4+1CE3ZgxUWtoNqYvZMNWYTbO0ZWMx6i
YWJ5GkLCMdVqNZ7iCteeDBVoRzLEbD/FyVzazPm7FBSxzK71EC+C4Ybt2IQPWfBK
Q0GI+2ghQ/HyLh4gLCLP5XEk9aw9DwXGJt2q7HngEJli5o8LFVo3Qiu5X+QeC7QN
r6uGA/9/raZnDF33jfAlx1jrHnFVEa1xzs81q2LK2ii+RdU5bvTJQchoHFRKZMBW
HszbXB4f+wqkSkj6B7od8hBINJwdumQXdjO6nybh2abkCT2f/nyK7ktCcq027AD4
BjWWFltUZpvspzq724SOEyBsbYJp4YTB2wys+gcyDF/ugaJCl7Q+VG9tIE1jTGF1
Z2hsaW4gKFdvcmsgZW1haWwgYWRkcmVzcykgPHRtY2xhdWdobGluQG1lZGl0ZWNo
LmNvbT6IYAQTEQIAIAUCQyJDcgIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJ
EOM54iXi97PYq4MAoJeuQSfnGZsPBIpzOZ0vHmf/ZV4ZAJ4kKyQrqbxup6u/vMWG
lS9JqYlZj4hGBBARAgAGBQJDnF0IAAoJEMYEPFZyB3E3kccAnRcxLZQIxgo0T22x
GUDB8tkAUUOTAJ93N4aVydp/zrDo+OE1HStNFEsWvohGBBARAgAGBQJDnGKmAAoJ
EHninGCwBj/nLhoAn3sa1+X0ccAhA+iPHo1mypN2uKUqAJ9B46J73q8E7PU17U6k
RHY/7eCLaIkBIgQQAQIADAUCQ826swUDABJ1AAAKCRCXELibyletfK2IB/9GoKeE
G2qDTfQbwG2Gbj4sW2FjaeNryneSTxXRMpK5dBwiMi07iM8Ze+8NdE9KlOzA9I1r
tkYgR32UCfteyQXU8YvsKf6Q4wRqKbpckqI43zXMdvXyzG23P6/gR/Ozqh96Z9vA
i6WdnvxjZaY6jItk357LJPQDP6zQncKFfcw7W+QAPx2N8BrUUy8U94kW6URhS01R
d3NP8JylEXqqF6L7cSxcmO3A2QAVjzDpmfWu6AvREuYY7dkSSZWGK9hpoEjPN5GS
LDgwRaiYZKHYz8Bx2UUA6sqaoebqAHY09bHIZ4fMiEkm7SSf5PsoS0emb9O0q5U1
tHI8+6LkM6Zhs57CtENUb20gTWNMYXVnaGxpbiAoUGVyc29uYWwgZW1haWwgYWRk
cmVzcykgPHRtY2xhdWdoQHNkZi5sb25lc3Rhci5vcmc+iGMEExECACMCGwMGCwkI
BwMCBBUCCAMEFgIDAQIeAQIXgAUCQyJDgwIZAQAKCRDjOeIl4vez2IaCAJ98fPNG
gmITFIYH+M3UBkw1YTvfAgCfQdAkDAFJxVrvDZBDliO2NB6jAu+IRgQQEQIABgUC
Q5xdBgAKCRDGBDxWcgdxN2PzAJ9d7HmdkCyM5CN7cgG6BaZ87AHY5wCfUjblYg9y
tsrTj2+ip8f05PC7zhCIRgQQEQIABgUCQ5xipAAKCRB54pxgsAY/5+exAJ94yol5
HuRwmESdxzjj9S70GoYbsgCgxad9osFjtuxHHX37vaxUgJyLEbGJASIEEAECAAwF
AkPNurMFAwASdQAACgkQlxC4m8pXrXxT7wf+Ji6vtaE5wjEI3/puKsHfGJmmHklL
UBkcl5acntPLPxhXa2Z742ZZW+3QXeUyyXnqU1/BSn6/NBYO6I8yUJc5QptnlCvQ
sJpwJlnTd7jBhSzN+L1xGxxvmmq2LfzLIleW8ye27vBOW4JDPDSgz4gVTKRqc0JV
1EYULkWCGpfDA/xPP+4Lhizz57Q6EqLVurxMjNLE2mqV7feIvYoGLxOX0RxbNSpT
+uJ+6ydpyE8UhykkQwgN0vhaokwSHC1KWWFH0ET38hcdFvaVrWZsrG/GwGg0T0mG
23CvIdBUGH9U0roJjUa6CDDQz8ohR0P04lFpVsgDi9AVPEFWTX4gcUwyILQ9VG9t
IE1jTGF1Z2hsaW4gKEZyZWVCU0QgZW1haWwgYWRkcmVzcykgPHRtY2xhdWdoQEZy
ZWVCU0Qub3JnPohgBBMRAgAgBQJDIkMNAhsDBgsJCAcDAgQVAggDBBYCAwECHgEC
F4AACgkQ4zniJeL3s9hsCQCgjLOKwwiG6bABO6ue0mjHpvR6nhUAnidSAywDgVQa
nv8Ev+hIv4/QpD2PiEYEEBECAAYFAkOcXQgACgkQxgQ8VnIHcTcenACeNyN5PiZU
TJ72eTxbc60q6PpkVOIAnRInAWvK8iW8I7uGOMBmyYtZWfu8iEYEEBECAAYFAkOc
YqYACgkQeeKcYLAGP+czFwCgkAtsuKGoojwfo/Rg6p9RCazIUjYAoJ0xxWeuZ/df
7lkbyqcRGJOfLeBBiQEiBBABAgAMBQJDzbqzBQMAEnUAAAoJEJcQuJvKV618rKkH
/1kUl4Cqj3n9a+acjUnl5gH1r6SVUuNK6pPJPVpBXDOGWQQPfVYl2LTtFfzIh+e0
q7J5os8timFbi/6HaI3RNV21XoqrDVgmRA8lApxM3dfB0hlJ6jx9eoUjHgi4n08w
nX3g43I0zoRc3lQPHFc0jV9yRhgAln2yHmrvdcW0SUb8Zv/FvyG26W1gyEvl0cPE
/AvKerTr2oP3aKnWtQfylovIw6Y+MmP3AynlvYghY7qw5QSnw3PhITvoFh4Lg4hI
c/AoY69TAdf4d+kHtbo9vssMoT/NAIaAN3K8hdzSmJ0Ifsj7/K9+qtYz3r3c/+Qz
1pH6hqz1u13upXLo/slPV7S5Ag0EQpKW9hAIANJJ8W4+BYSzM6ihW2ElYyt3h2hp
WXptNPnrZDAoqx7YtCyPnUpn6dJrlsz2NTJiW7ahdsCQqrCyMTRCzAZAbFN1s8Se
0hlREeHxGBIw+trapap/B2u0VQHDfVEL/9ib+jUFm+Gp3izgcgf4y3tvJRmmPCgj
Y9fFcFu7PrntYsK91OkgungUriZ1fbjx0OkHRaz7nnq+On+dVElFh2iTwpZKrG3L
7Qws/iVWamLOSQ14d3fzWN/Y7pF09QjOo5i/iyN1QEYiOffYaUthWr7lJ35muuaH
yEMeodSNkKCF+BqpmmWKgJohopQ1/f36WjwlaVKaRh0zCIxcpX5xPtSoMzMAAwYH
/2OiL+gBLaaTC5okydoeHAE+G5TobT4CI2fw2P9htDWVYf1eIriTRYKywSyjF+YS
nCc8hleBDCwrUY03GXCFEOq0SAR97cfRhzxlHps3n3iAuZp9TwcGDiskL0wAaNS8
43AKNHlKRNWxXoCE4oBlq/t1+DV+7BnjdI+MCAUe8h4y/jACIxpxnRKjmAcN2qDh
THauJKvmUjw5W9SvgDU8sHNXRAdTbCrDj3iEAvZ2bTUMLmh9h0tKhwmVD14IMpDp
7ZELqCgJgtHjv9kAg0Yz/Dy34jdLgypTJzUreQcJYvv5Krp1QLRTMMtoMtkop56+
oKcUsj5bqschZLFzuL2hj3WISQQYEQIACQUCQpKW9gIbDAAKCRDjOeIl4vez2KQu
AJ999gXGK70qxOzC8xOb3luxRKE/TwCgleUyV4VszS8i918p+td30+xsf1M=
=DTOK
-----END PGP PUBLIC KEY BLOCK-----
D.3.137 Jean Milanez Melo
<jmelo@FreeBSD.org>
pub 1024D/AA5114BF 2006-03-03
Key fingerprint = 826D C2AA 6CF2 E29A EBE7 4776 D38A AB83 AA51 14BF
uid Jean Milanez Melo <jmelo@FreeBSD.org>
uid Jean Milanez Melo <jmelo@freebsdbrasil.com.br>
sub 4096g/E9E1CBD9 2006-03-03
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEQItSoRBAC0Dd1LYWYUcjRH9XabIefY+5q+Mwi7iBdvUjq96c/LgGZLXbG8
ZlK92kraOdWvwrPcYUCjYQwwesOmjXryXPoS+AYiz9iVs7AR/A9drFECh50wfaiL
J7X4kSpR9zDgju/yVPyT3rhE4ZEZ/81txqdu5DSG5+vD8dLoXdb3EziXFwCg8Njt
Lcb+ETI3MvK0M4A5HpuBvTEEAK2H7mNZ5BoLCrB81244e1BFwd16raITUv7DiF11
Wl4kFowGt0K9P0d6QxmL3bEdeud2wfNaVjAuiO2B32XlV4xskZmfalniN6fsX9b9
jnzJzpFvR4tPeZdpw07ePYJXh5vZjx4Mkflv9X2+rWafLiw5vkmwPnkQPcnhWnD+
Ia0UA/40hZZvC9h20eH9hAcJA865wLxzmUijzgAGHjXVjhNT2oYGneNeY70auub7
hGVL7GwsDSYc76W6IhJOcAjgHcCfa3uGerFR56T9se0ysmlBrONiYTokVZ3vKFp6
m9ZceaPiE94RtHsVVkDa+F2KWeGU1As8gskVBP8MycodYb8XgLQuSmVhbiBNaWxh
bmV6IE1lbG8gPGptZWxvQGZyZWVic2RicmFzaWwuY29tLmJyPohgBBMRAgAgBQJE
CLUqAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQ04qrg6pRFL/NCgCgg1C8
cFGpWahx1wgZ8IQxsmCSUV0An2YnP/Q4w10WTe6qp+I+H7c7k900tCVKZWFuIE1p
bGFuZXogTWVsbyA8am1lbG9ARnJlZUJTRC5vcmc+iGAEExECACAFAkQxmpoCGwMG
CwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRDTiquDqlEUv6McAKDC5MusdUU0kl9T
/ymavKEu9a349wCfXWEu9GgVb0CCZ8Agx3BHHIuZNo65BA0ERAi2QBAQAPB4mj53
L9vbS2WLCAPMMn4ZGDYGXbe1pB/mjRbZlTGnUYWE3NO1fLYXEaoilRsvcEKtbsWp
Ynuk8Ou4DaNoVyX9I6I18rs5KMZBiLOvQZFYCBbJYSIn/nNycOqsTy6Nw9mz7mrw
I6e6EhiYh/AQ+MI3zID3iYnbQlQFZo4gLMFTLKklpiV+DaPoDiEkQPGn+0mmLEIO
pmCqiDTxCIrig7feExCXJa2+CXLj2OS+r6su38O7WJiGMq0i9nCeu+4NnezoKPwt
+s5kVYAjOSzDRybWz0UDzi9M7Kxu9tFoxEQUikLDMdqSklPfRs95TEmpXIvksn3A
lub2Vfum6/kdRNkxPPbUuyEvtzeCc87LB2cLpP2+EXcfHCe7MdrtowWleRqXymXa
Lyun7uKk2etFpEIfAqCPC1Yd8Jf2coyVY/n+a6yotWzCtQ4vogO2dTTKmj17kkcW
1CXZz4W73Jut9ixZmYL/zOJj61j+2S7K7VLfSNrP8H8SACH0oHxYP89BaqOSOO2N
0DtvyhFfS0OsxAEBa/EgtCAZiON4nZdQGPyDvq2/uQ1SGxbykTCvgxElAQfyUh7x
lctdQQ6f6MEEPHapdDwpnqX5TAcdY7v9eE+/DZNTeswUBc03qtqxee1II3K3+Rvl
4R+DuGn/oPdgksnX0kX0wtHgclXRsZ6x+wEfAAMFD/9S7Z0ee7WeH4WwU9Mf9gSp
3JGafoInoJZNSRsKAl4VFC8axivUGyUzJdTbADoRXDR6NfqJE94u+pP3vx4AAvVH
cvzfGj10GlUOwQGbQxaYGgYtqVgQ6MKeS6A3xaj63WgBFtx8bbt3e9XTnjPto2ZC
U/pM3lmwsvxHoJGgisRvEfdQeWW2cJlxcBfpqat1/2MFBK60Wd0WAr0x6A3m5xpy
ejftkcUa08BT4LSiGAsmuNKtUYULA9OrbvJreUa90lrM+6sZy2Edh/kulNmXgS4Q
Y+OVptuhHSgBeME+j/fM5+p3Uyyaa45xmCFxnx5u/XBWhzMiPvi/m+qYkXPECFLx
CiZ4OC7Xso79UeMmYq+CTDMWR6pe6iGVQZhRH69ShA+c545Eic/RoOv4ra8se7/U
R5BU29AWWtapMq50/h321Oi+JmmfJHrte9Kd6RdyahuvtlWb7bgnKPwzpaRXYtbt
H9SskRTdESK14AwH2eUVAP66Dfr5xBoyuS2g9MkRxxhjHWmMi4TAyh47VgXUxOPF
Uh1eFsIqVa1scXFaimmicdnbg7N5iVoqIIiuc2Q5P1xIuTUdxw1SjXOInmjAszO7
Ckad599/WaNFS/pkDOgt8yfQaLOKCqVuKkimWa8YuZkm0g/aY1n1cE7TvNpxdrS+
dw6TU3idxbY/DuNsWfHfrYhJBBgRAgAJBQJECLZAAhsMAAoJENOKq4OqURS/QrYA
oIelyoPYInm4v6UTBo3XhOwNkHWbAJ0XXqE5J3Zv8FCqjQsJTFCmmNSoGg==
=CyrL
-----END PGP PUBLIC KEY BLOCK-----
D.3.138 Kenneth D. Merry <ken@FreeBSD.org>
pub 1024D/54C745B5 2000-05-15 Kenneth D. Merry <ken@FreeBSD.org>
Key fingerprint = D25E EBC5 F17A 9E52 84B4 BF14 9248 F0DA 54C7 45B5
uid Kenneth D. Merry <ken@kdm.org>
sub 2048g/89D0F797 2000-05-15
pub 1024R/2FA0A505 1995-10-30 Kenneth D. Merry <ken@plutotech.com>
Key fingerprint = FD FA 85 85 95 C4 8E E8 98 1A CA 18 56 F0 00 1F
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzCUT6IAAAEEAL6dJExgqBvPOEKuRtkeb1b+bcUkMV+TtiT5GPXcYlYeYuDH
Veh5BK+ib0sULahN2lGdgIWEwcnyGokELvc9ZwWyjgcopWRCoY+VkCzz4YIqtiHy
T8VUw6bIidslytDjG6wAp2zDtAR75uOM0bLDMsoXQ1s6sP0HMRv1TA4voKUFAAUR
tCRLZW5uZXRoIEQuIE1lcnJ5IDxrZW5AcGx1dG90ZWNoLmNvbT6JAJUDBRA5NLf9
G/VMDi+gpQUBAf4sBAC21xtMkZsdR/FoHzg8fppFN623p/ALXJVBEA52W/FPfqVd
4tAJeViU6UgtFBxvu1J7ctXM9O4r+xd040ZTtWVDZSRhssZN3hBGx31El66niUIU
IfJBco0nkfUreuKw3MX6vrZkuNc/WGFaQo96JCsYTt7OSzZQu/vpa3gLH5kThJkB
ogQ5H426EQQAxAaz+YSEAmOES6KLRJW0otN/whsuTPIbksydLGrRUpvGivG9Ohe6
khLnXE0ApknWxb2aqvP5oRHfB2nx0ZPpm1hdrjMgD/574GT4gskyTdRKd9hdCUrc
lcS0WohvsI8si7kKJawa5F0zy08pNOIFstL1YRdQBzfFYHl30aGAXFcAoOnEpqZ6
ffE4E19IexMDmb1KA+s/A/0ctHXLB/5vlUjOpGB7bI3yHHgTT6r1C56WkXQ49SV9
Ad2sN4nrvNKdNBJcN1oAvPh49WBWcSAwTTpub87rl5B8vQEoUHOBWQMUrGCU3/yD
KopmHBvtROsP/3KGiCfrteWCdy6aonQLv4TXOeqYMstbU0MjNBVgmAItoxqz1237
CgQAlO/5jMCLdxricI+1f7Gd0zwbxHe1JUV7kjLqMx1JZ75LlxuIiQbJgMpWVNXu
j0O8df5mbhh1+G4K9O/p+Cg19+r5ghc8Ms0YOEkYRlKp0be8uzrCu7qItGfLKMsP
t1eU2RJ5YPkD0bOjcVxlFQmXkQ791jncpOdrz2O1qgMLpr+0Hktlbm5ldGggRC4g
TWVycnkgPGtlbkBrZG0ub3JnPohWBBMRAgAWBQI5H426BAsKBAMDFQMCAxYCAQIX
gAAKCRCSSPDaVMdFtRS5AJ49YIU1IAJl2cs1g5gDgXPoY/RdsACffJZMBGaXpcfm
ZpRRIAtzq+Vv5Yi0Iktlbm5ldGggRC4gTWVycnkgPGtlbkBGcmVlQlNELm9yZz6I
VwQTEQIAFwUCPE+i4AULBwoDBAMVAwIDFgIBAheAAAoJEJJI8NpUx0W1RBgAn01T
zuWhCWOShHSfKM+sXcD1YrwPAJ4jr1tE0c1rZ1Lnz5YYZefpSnt2mLkCDQQ5H451
EAgA0k1+aZvnxXw7WBcuEcT8VRBUfdYSrXVEi8R7xjKrw06U92cDSkqdA16rImto
u0SSTFTnUXXHLdAuf2nsHplrzjEAgrMUWTtRTtaPKrtCwWE9Tk6lSxOO3+HA3mGn
I3Hl1KgTErIbqIAIhftJXpW63Xt1CZtJ5fOKCyNAL4obe+gkmsyNTPwYw1iEVG1N
exIdkm4Rr8TWohJ/b0ql3rEv9y/nKRj23OYGDGKKGY03svz5Q/TB1CdQdlfXhtEN
Uz674NimuiP0NyBp0Un+hPnr9IuoEILuQhAYOnji3G1OVEQCBFONGT6CLugoPrgQ
0/KeCgIxB59TVkLm41yukcukzwAEDQf9EpA2dTA4k5rr451jRPbR1a19knOAz7Z9
J0tWWbySXGw1ZMLMf7BA7bnnIqDeuKLkxIwc4UGQqiXmmKbbdy0pYPQSC6dxIsFE
8vnL7RLZKhTLi6bFPj6Wspik0H1GnmvRwlaJ+Fn8g7pG6Pi1B497dTmZU3TX8s11
XT09jftPjHLeziCBXu4OE/a0Gqc59r0A0bG94RbaW1rVmnX9KuvMpv9Wfx1AN2eB
jrfpDPoMd8JU5Fn8KATvLlXPkSqQ+iQxOvYs6iXhoDrugPuo5bEF6sJBc/iC7ZmR
kuy9zUh6K1uAYJoZferxiaglJH+pyrkBBDLjj3Akw5pSmJesekGwsohGBBgRAgAG
BQI5H451AAoJEJJI8NpUx0W1UJMAoIrd17bhiZx3eYtAgi+1IwaTx8QeAJ4plmqJ
sGDiYyJDVnPYxZcEN0h06w==
=CRmh
-----END PGP PUBLIC KEY BLOCK-----
D.3.139 Dirk Meyer <dinoex@FreeBSD.org>
pub 1024R/331CDA5D 1995-06-04 Dirk Meyer <dinoex@FreeBSD.org>
Key fingerprint = 44 16 EC 0A D3 3A 4F 28 8A 8A 47 93 F1 CF 2F 12
uid Dirk Meyer <dirk.meyer@dinoex.sub.org>
uid Dirk Meyer <dirk.meyer@guug.de>
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAy/SKTUAAAEEALT9vGQnDIzghnYdH5u7zeRqZPXH+2Wbq0q1FD334xciOQMh
S6DtELkvVzA4x1PoTvDminXVoPQHtNKs4iMSM6uT5c9JxmdTlfrTfN0JeNi8Jz0E
f0NxJk05cjhBKACGrD/AMvnQetUhmbSH3ss/XXfq4kVb+an+0eUVKCUzHNpdAAUT
tCZEaXJrIE1leWVyIDxkaXJrLm1leWVyQGRpbm9leC5zdWIub3JnPokBFQMFEzTv
E1PcieqTvCHCLQEBDvwH+wWxG5ANk42zjlbZGJ7QqgbfB8t5O5VzlJ4TVL1HWZXv
AbLNOYeCxRJqQoJcrEjuWM5T6G+NFZuvjV3+aByNuASc0a97rdu3qfMcQFnyhPbw
ljmQjXg8I7szw0KtWahx32WaSZxZRWs7EBZkOkZmR4u53zLWUUz3+bmADsYHjtiS
j1zssOyujYaViTrR0xZ3jY3KXEg5LRGI87mzZvzB1HQw9T5/OEGjearU7O/nCsbC
4CbexSHGEKnk8WVOfIq7J0wS74/vjxvAJnIXiEd9hAVCFIFQOjWFduKku1FDTBWk
XfayxciiQeOZEOk02r09LoEGO9rX9u30P3r5j/+C2DyJAJUDBRM0t7aVH8NrVijL
5/UBAbxiBADKfom5wJ/8VphpWalKc3iPVLo3cmehaD0kvdtmhn88bQ9EG4TwL5FH
ceN+yyoEUp8jCDp/eiBbMy4MgZPF9yqUxSSn+9dE1a9Q4GnWDSW7S1eiIWUpPwaA
kGMF0XrWkl5SADudf154fGdKZ6R2wFd/pjPmZ9WcjuGeb4D0Q+/I/YkAlQIFEDSz
rDMZnmx2bOkyOQEBx9kEALJ4xJRPH3F5DmrmTTUdkuRGcaf/jZh20Uzh4c89rVFi
fafcDn7iZG6uw53Ybla8rgb5w7VIx6T7rvOTAip8F2v0FbghoA+lRARyWiLokLtC
XpiuSJaEx0NehfvGuNxNmSLd/h3Ky0ekoyo6QJlNvKh79Zv/GmZYc3hwGZb3tFJj
iQEVAwUSNLNeSgnccDk5839dAQEUrAf9GWjBbmdXaFjbQkvn6EAUv3FzrYXfB8in
LQhWTydTdEc/yDt6b9aU/mihtvGc+M0+r6aQypbFaUTmj09d871quFU3McwfUxh6
TsrH0nJbToru5YBlnWBlK7A20etMJl+AfQuFiFPGeKKh9FS4oAMVfMFwOiLgobZr
zv2buYv7w+MSHXwEYDcVN+8ohe25WinOZVoZHx7T0UeRftEfvkKPhf8PR6bWQivn
24P/ZXKGP/7C5zJPt6lligTAHZAVms9Tj3+iDWKbcbHYQ/Ct4+qws5aGszHHtRVL
t4QPr8kSvvW/LKrz4P2Z8eAXgAeOdHf9r1y6TnLmmRWWSE9sf13/FYkAogMFEjSz
XjqRXk4s2wiTCQEB3w4EZjgibaU+pTKDNeiwQyTZZ/VcMUaNbNEFvDlbbaTx+Cgo
fxKO3cueJHKLGs2pyq0MioXFJbzoKI2gloQ+ay/f8OWU8gvSW9dhPcf03eBVEZQ+
asapi81zI+IigVa/Us0H3rNOScC5nd+iyjQAjXA+wwbbTblxvZiBLe+2aUSruhqX
no+F1OLaSYBCpCQMUIkBFQMFEDSqOAC+po5/hTEyfwEBNQgH/jF7wbWP781ByIsX
n0xNdMuXZ2E81Nvt4vfnHAWELXhCyG3CL3iYwFwlk0ZC2evO+niZxIwVHJVtS8Dy
OFfKCr38ElCrIvv0B5kLvpeY9DLicM+Hrhk3viUJj0p074qxC4owUiMdGT+Q5/qr
8IM3MACq2KDFfcVnEI2FqDZnygkAQF/7iA3OQanb6BXKWAalgtmDbB0GZ+6rs+Wg
RplysITEhUOUo5RMyNEzD43dVNoE8SEk1UBwr4K8W/RcscfoZNukAq+KjHXQ+933
W0O8SrAbqaYhCNGS/oUvui8YZjG4N2MCaJjVYCatY2kIVcuGqzZzu1HiE+GyJ5L9
hgFLyhyJARUDBRA0sPB+nnPrCk1Y7lEBAZprB/98cyhTMyelbeDgpp3b5/W1Y72t
c5aP5rCslih7iu+P69SLgxPoJ0hw2Ur9PpCkDWK0N6UQluVwAMtNEImaAEa8CbLN
bJnXqV0n763xC+VnGEqVkub/vHQpcahliJxx5PoWSmOOwvH0kbZZkgnnJRnB+BCz
aKvj1A4dDxijX5drHLRWl2kV3pbpotfXXiN/IRZd8hIb0axrEjh7P7M49DVdRLKG
lfe/U+HgsHDcOD86X3yOxtOcf04Fij6+Z4FQ09gei7vhVet/8KFLMaYNUU/Iker1
7Ngmf0un+Hk1NrHfDpalmVz9P+32wozcctaLFQckpTBhszbMRA1+0JUSNnFiiQEV
AwUQNK6LFg/TsrJXDH4ZAQEROAf+IvqgnpqrITf7gyTPsLnQxYiV4Be1FWboLmRw
izTyIqyUOMPPsbZEsrIsKnAqkgk9Zk45FpI8XoiE+ZqqR+Vki94UdSQQRVDabe33
NxkjT7WuZFwgYi5h3YFKGMSuS4HNU4dMUyqG7lxDRWwrvV7QFA88MtB9/YzqSfJF
fKCLCi7K+9dsv3ThJ0EE862sAW7cU0/853UAnKPlI5NJY40TxUyKE1VREHszrU5O
LKap9M2gHjeMIyzs7sj9ioOZcfLt8PZkw75kE5ttPzokD+LiiSo8YM3U22sOGD7I
7JjkU8bibtSZTmuOcEtedd1p0KzDrqGCr7hC65JNSt8qkezzOIkAlQMFEzSr343Q
7XFfk08SzQEB73QD/iZP1T4KRyr3VbOdbvuvEb+qCuj1Ty6D/oD7v3K5/gu1zrjw
uEfxHNnh8LeBkVR0lc5hVKrGrpXKPJnq1GYLrWOtXFgs1tI7epoWKmXd9lxc2fSf
x8EUoxikpvp4NTjWnViRC6xHQ9VMvbOi6ZyzKc+CeStQUWiS3znIsOWZcA8siQEV
AwUTNK1HDhhutKVJvbM9AQFIkQf/ZI4NwJwoK3xB+7sp6Fb03pwzcEDGc/swvi/z
rvYgQd3asQTPkurrCjef2QKQbeKtylW2lZ45GrWLSB23oSrZkziyIsnt9/0xzMsm
1cGeT9MIrdpEMmriQzD2MqDJFBZaB0l7KVf/aLaGXuIlzt+P6Ubh+QFbGEwdlJtc
oKbLXNqAOEv/bQtqAqDzeBKOHzHGhym7u5BfKXhwBFnj9BDigGCdrn7hRvQOcFnQ
AMqA/ySQxXGzAWqJJV0YXhrnyPDRHWTMp8JFnB+IbfxuDtHpwpkECTPh3J75bmRR
Wkyrhwwxg4ATplJpRhGOqgqdZQWd/PGz4Bb9GkeP4D42jPQlTIkAlQMFEDSqirHk
Ybn2j84RhQEBEpAD/AyaYow1MOxmaH5bCtVAHG6J2fsvBD7y2s1C1+GHaL/h981G
NP/JjMjOZZJEIUgQQsaXKihHlk3c9UN4mSMU3jEA5YJhfeouQqWirxlf3jp6fzOI
McY6qiF3lnqtMMJD7xAYkHHFLcDSrXMr37+X8l5NMaX7ecDxZhX3ci9LIoIZiQEV
AwUQNKmVm37wWOhDIxQlAQGJigf/S0Az1YtdUQAitCx6VJ/9/9LRZ9bA1NQLe6OM
waztjSOvTa98upy3Rra5WPYsv6QVM8YnvVZGyOmXy6UmvaMUErg4bw77wM6sPjru
rAWJwQNR+ZQzdYwA6vk0OhNxvBDSVAMWBDkhMMRZQ/ttiuG3MmjMetXozl7jnHTa
X+1hKxcJd3mr9wPByICxd7CGe7MDcrjM6wb9M0uaequ/VewHLUMpF/Y7VoLcDCj8
twBvdEPlS0LkFbAf8athcNhtepOheUw3KkZQ4KoWOexfszhFJP8iE3OVxMgp9GaN
vEQQbk3iVUrvqt7ofF45OaSnIpzek02aVdpfqcurZQjeOLrYvYkBFQMFEDSpFJA2
fBamCi+H5QEBAfYH/Ry4jHhlY97Doma3KwMzSO61jkw+6uaLZmA885ltZJoEkS7n
Ojz6zYUmJOvgA0Se2OcvJmUCnK88Qu/mQ6MduK7r4qQLIG6JjHGLzrpHMmJRTPJf
jiCHGrgIT/wWukaeNwv+NGkOlrzcIp2SJzF2zb4QzHiqqwUs4gqCZxGkaC1QCq38
DsbyQ/GIeIl7g8WxzCKVJVvGTFR2/VRb5fVPnkCZJa47nev9YpxTnRDv9A+RKSG0
33OwKbZCK10sUHtEndK6HCozFpwtf72Q7CK+vuY9bl5d/WoWkEQ7s5QCNih8K8TQ
4Swi2Cba1+/QqFgyt0SFLYTctiZzk1eTnr9hPRyJAJUDBRA0U8SOeRaPkdpiClUB
ATabBACJCOFjgP2Gv4hGVykF6OzytbmjkTQ9FoPNucsQe/KTKUyUiAyBxTIqU+b4
T24BPWXK91ecP+Kv4qWT+1MHiVrIsLJe8T4RYONNdpystIaoqLvYYSNlUA0H7daW
9hS7hvUMCfvWQlUZF19L/5TS9516+t8r2IVh3H4ba6eljcxLlokAlQMFEDPzSFOo
bpJgSifwFQEBzH8EAKK4F5vNleLRLwE3Y1fha74WAUEQJrzhe5FMWUl4ViFwO4hv
l/zEuFzDXJAF0CAkrgrs5APK2cLV9evKUokk4K7/WcxtVTEFkzj+AlLUKeIEh2V+
TJe1eNUBQz94aW2xtp7HXX2Hce+Lgj9BUjEmS5N4/vMxcaQXfn+3rK3BssS1iQCV
AwUQMZEKf7UNAz+kLonRAQEhhQP/W0IcgfWlol6R7hxADisr6RKo+Y4YvA/lkVJj
Ka9D466vMOA0pBiyOkzSjj3VBbtRILrv6AWrbt5vp1/ovn06+PeHNb6Ta8yj1DPD
Gb0xMe93xbqSXgCAv6SPTYIZH4FN8S7wfy27vEs4n6AKLqDg2OOBOT939C+iK2rM
DDM015KJAJUCBRAxANRNOaQJrWw8XmUBAc1cBAClLLFbYVVLyewtsdKzPquf2zbZ
btPG7Vv1jeWCoKusWQHMlu4wFZXaTGZOQ0mUzxUlZcu6bAl+VwbvAtIxHunvNvN2
QtGuWp+Uk4HFSBvhX8fLfIRjKj+Zv/bffi0kxepQXSxh7RJXokYRhe2b4/YmjIeO
Rm34eShgFbdY6+MJXokAlQMFEDD920zlFSglMxzaXQEB+aoD/ijK1ER845SQhw7J
SKZnwOGiTRMnoefn46d5NorVbFU+Btp9I4Twz7Skvua9smd9CCeIgmPCAkEZBi7j
JOH4XZGNCEKkJ41Zz9Q8fjnl3W/4i4lCgtnQnCq2ErO0UngCaqZr3k4ATytZD+02
YO3ZJ0KWJRuqRQQ45prwt/Gq8BBctB9EaXJrIE1leWVyIDxkaXJrLm1leWVyQGd1
dWcuZGU+iQEVAwUTNO8TntyJ6pO8IcItAQFQ2QgAirJqlbSJdRm9uA6kuqrd1jDA
UjYjCagLh2yBVdG+SIDyZejLFROrpQRCPbdh1N/V+jJY5HQHqLz+Jpi5QHOn3+VJ
evGfa63/btCd5LwhZi0nwRCmw3xhHulm1Nb2pQVJ7+172zd3AE38lmdnnzMt/1F4
3vG0r68jWkr9WDIXvsrtC7E1gyfvotPnmAk/PG0cxf+cgMprBJpH8xnbWGpdtQbj
sNo6tijd2KYR0r3qWoeMEdk4JNIdPWd2JW9zGIlYVsHeTBZfjwO+IbsZ5voS40fk
cZJXRQqMfxnp89YUYBHJ1lMFHNflwHHxzuAvEa5NN73jQFfumLxJNdnKlHDEvIkA
lQMFEDS2lkvlFSglMxzaXQEBSlgD/3PJnW9pwAyQewA4q+wmQ8WTucGL4pQXC0lU
mbGoXh573Kz7NzKPoW6HhFcgWa0jcBJ1UKyLBppuS2jhHe3V9a+fPLX7fYzzQqOT
D9hLbp0fCGwZzE/QSvKA3AHhUBTppSVIN+vRMa8Pw4kFOu38mgJFh6LWQRGK30dT
hz/smT9GtB9EaXJrIE1leWVyIDxkaW5vZXhARnJlZUJTRC5vcmc+iQCVAwUQPEvy
rOUVKCUzHNpdAQHDMgP/f6VLtoGILhjPafrfeE4009BC3JCjdi+B1voxbXRVyb6X
2oXNGw1tpm6S13vrhS3T4ob4MW9+uyj2idyHQlQXkZmTs5P3mEoGXq4HzYC7WHZD
pQ1GrF+sshid1XDjej7bCKiVUjJeMyrdI3uD+cgu/kWDc5GC0HFy8+qqutUKFyQ=
=b0g6
-----END PGP PUBLIC KEY BLOCK-----
D.3.140 Yoshiro Sanpei
MIHIRA <sanpei@FreeBSD.org>
pub 1024R/391C5D69 1996-11-21 sanpei@SEAPLE.ICC.NE.JP
Key fingerprint = EC 04 30 24 B0 6C 1E 63 5F 5D 25 59 3E 83 64 51
uid MIHIRA Yoshiro <sanpei@sanpei.org>
uid Yoshiro MIHIRA <sanpei@FreeBSD.org>
uid MIHIRA Yoshiro <sanpei@yy.cs.keio.ac.jp>
uid MIHIRA Yoshiro <sanpei@cc.keio.ac.jp>
uid MIHIRA Yoshiro <sanpei@educ.cc.keio.ac.jp>
uid MIHIRA Yoshiro <sanpei@st.keio.ac.jp>
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzKTzO0AAAEEAMVsAcUX89qHkwlI03RlAYBqQa00TFmgPwZs8sWvNUqTGtlK
kOXcN9WNBvwzMYtEk/u5C1HukqISnFkDW7ZKYm+Um1sQPioFHTwDC6R2HRDZBCV7
0fROlQpb479iBlr8wNAYDhOs0rl25FpE/uAXYThW9Ik/apgXN4rTGxk5HF1pAAUR
tCJNSUhJUkEgWW9zaGlybyA8c2FucGVpQHNhbnBlaS5vcmc+iQCVAwUQNu4ch4rT
Gxk5HF1pAQHYiQP+IoxOpfpSPg8Gr7MUtoU3WZPY/5IuKoOwnFNFcSyuhrgn/OOB
pbxkYjTO3MLh7Xa+9sPigevHy/sNA4vVZdjk05sjRfAZxIWPrinRy/kzva0KOY69
u1QfX+Vx2mfq/EfMJMHP/Am0H71nOfAZsscKlb/jmuo1TxIpCUx+wWmNn5+0I1lv
c2hpcm8gTUlISVJBIDxzYW5wZWlARnJlZUJTRC5vcmc+iQCVAwUQOY7IlorTGxk5
HF1pAQGQBgP+MXSjPfcnNhNfUmeLu8sM63DnrFIfRP9E+n/yhZT0wO51r2LmF4ZX
YI04IJCywJiPjEpCFXNAhqDfypkTXWcbLTxX6gE5GNqii5iq+z+UuO4panpJO5OY
4H0/90cH6I/zl93EZN9wfZJghn66vgL4tDTgILdRPekIOB23JQIXsf60KE1JSElS
QSBZb3NoaXJvIDxzYW5wZWlAeXkuY3Mua2Vpby5hYy5qcD6JAJUDBRAyk8ztitMb
GTkcXWkBAf3zA/9sDB0n/UlsH9hzaw4r2k0FT9F7Ixtk2i/vqmHDUUcrlEqGaeko
/3Q+et2KzepX981mI7N2jdClqJgjlHapGoIQWZL3Jy7ocgCXDTYwGU2cFRF7kzkz
h3FyYotm6bMi5F53GamkVbYZfogLo1MW7jmqIydJNdT1oseDbrwkjvXwdLQlTUlI
SVJBIFlvc2hpcm8gPHNhbnBlaUBjYy5rZWlvLmFjLmpwPokAlQMFEDKUUFiK0xsZ
ORxdaQEBjuIEALtVC6fjyDiRnZ3ReckdTO7k83VUTZiQH+2cMFNd8gi+O2sZ3YnW
6veQI45VB3oHD9kzMjol3B1ld7iKcQzHC6qUEviW+mTRRN2Y26DB704FNeUrqm1A
LO8NPL6iNKFvUNsu3T0ZRY7oX9a9nMmcD7M2bm6jxrhckS8hY7x1D0xftCpNSUhJ
UkEgWW9zaGlybyA8c2FucGVpQGVkdWMuY2Mua2Vpby5hYy5qcD6JAJUDBRAylFA5
itMbGTkcXWkBARgCA/0RBudh/8z/HWdX0GC0m3I0zIAOiGfmnJMPkzLryXuOQsbE
dg28b193QnwTz6/ASF6PLJkivcd1vREXCz3C+jHz6OGs5jUKcSf5c0ZaIE4T21Hq
LPKHSj0cYxgiC0auwY46m/yfO8I0bdiM6Ki3fSBTlTmDlNhWxOQ4Ic2RamKNNrQl
TUlISVJBIFlvc2hpcm8gPHNhbnBlaUBzdC5rZWlvLmFjLmpwPokAlQMFEDKUTtSK
0xsZORxdaQEBjWYD/i3EOU8lEoje9jTBHfQaps9BQgviFSaHk0G41emKszLSLnGQ
BeMGZTyWda6sTSqeLKg56HEmmVGzC/nHlhwspC6bdYaBmOpnSmmzxVstcYq8oiXI
mlfFEcL5DJEau1VTBP56Fk4GCffaibCTRGYrQcJz4yLfATjYsni5Y8zXqhWItBdz
YW5wZWlAU0VBUExFLklDQy5ORS5KUIkAlQMFEDrvMx2K0xsZORxdaQEBTgAD/jO7
tb78V3muNw+rfD8tA+yWXw8IdC4QHCa+Ga6Uwf9nw0WD+fuuz0I2La4iaC3FPtTs
1hz1QlmrztffL3tfsePDeN59nz89m+WPW/Cu+mLY2Eim2Hm6AWKVvtxtndunOSls
xQLr0uhvNN5BOzEqv2V+l0MrwadPxUrHG0izqmGJ
=cmvD
-----END PGP PUBLIC KEY BLOCK-----
D.3.141 Marcel Moolenaar
<marcel@FreeBSD.org>
pub 1024D/61EE89F6 2002-02-09 Marcel Moolenaar <marcel@xcllnt.net>
Key fingerprint = 68BB E2B7 49AA FF69 CA3A DF71 A605 A52D 61EE 89F6
sub 1024g/6EAAB456 2002-02-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDxk42sRBACyzSSCLYA90zaZoMlg4zhMXhciG/YuiBZ005q0s9W9cuFFxwOM
0mLFbBHQKj5TG5TNswnf9VreRg8lRPCzgQ63atc10RU2tfa88hIjWZ4G4WEFDeXS
hlj4dIA6KO93UEoJmIyR7hswisb086mK4dM9hq9FxJT7YQ63PkUYmd+pfwCgjX/y
xM6+aPj0sXuOvAcVVmrnp8UD/2pEd8kxAKIaWmxOm9aGB0/E6vjZWxCk1+CO7tgG
4gInFYUnqniPB4JOXOWriwBGPx5IqWYwYpgeuoi/KeE/Wn7bRUEeCbBGEmJkHO9l
3xJuPX8JKDkGuTNDvR3SINKSzx7gb77eGorwxV7e4FXBeXOyXLxgDqDhh7Sjv5/4
ikr2A/99b5t1akHlNe1ITpuEETDNRcfu38/KW/nF3p1IKQ4Q+exSlEJzPFupYNoZ
O7uD3A0YCNf3jIY52ufkZXqhqfsp6aRLetbqDcKVrZWSudAzGAEk3Q85a6Ei4mUB
tfv4dmXQOLzfAFHezhCQIt5LIPJ5Dmz/a26+u0DmlfisgP5ltbQkTWFyY2VsIE1v
b2xlbmFhciA8bWFyY2VsQHhjbGxudC5uZXQ+iFcEExECABcFAjxk42sFCwcKAwQD
FQMCAxYCAQIXgAAKCRCmBaUtYe6J9pN3AJ982m/rtLgyiuHl1IM+/xfsZ460SACb
BM7V955SU4T2b+1FW1ieOuuZEKC5AQ0EPGTjbBAEAKbxUKuiOJsAQnGKTXtbyRdR
Y6BZQK9tPNXEIjIUZ94Crs9lVq/P3kyvpR/ziL+Yt3agUAELiX+cggUZ5KRzKBmo
PJ6ZdWOuKLRN2+PfK1QVOQayeZV11XZAsPwyHI2v/hvjJnFvQNTEXWLZsBNnfTdx
0zi5RBNhf5Gt1hyuT4cvAAMFA/9xKQ7aKkvi+C7KafwH6B5X6lIQxRbTQuaZaqKL
M8pDmVLqo3er7S1ullwMWfarQLHtlwirX9IOQN833TCDev9QeeYZZ5g2MpWO5nx4
kxEOAK6Lg+QBg4RcoLK9CpHUpLoChGQzNaDudztUixwVaaigj21O4PXFr9pmLLZk
vj7AN4hGBBgRAgAGBQI8ZONsAAoJEKYFpS1h7on2XgAAnj0B9B7g4XPMXjizKVNP
YLC2BYjgAJ4tZI/tGYxHex5RCeFv/fG4wN593g==
=R/4a
-----END PGP PUBLIC KEY BLOCK-----
D.3.142 Dmitry Morozovsky
<marck@FreeBSD.org>
pub 1024D/6B691B03 2001-07-20
Key fingerprint = 39AC E336 F03D C0F8 5305 B725 85D4 5045 6B69 1B03
uid Dmitry Morozovsky <marck@rinet.ru>
uid Dmitry Morozovsky <marck@FreeBSD.org>
sub 2048g/44D656F8 2001-07-20
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDtYTkERBAC9AbWM/ZdPmvE9Fq9NkLKrhuVHQnKhmLUUS6aQI+XETRY0v39X
2f68rVcazOuqZQ/Y/011VmFLsS2dTMeVoXobEcGPo1wgogn2MHko7dUlcb/ra/4P
vq0En66bqgDwZgyXgr371E0tqROl+92sY7+Pzk2EpGO4cWDg20ika//ZmwCgnyy8
v/e91AQ/+6ItDJ4iLpvlua8D/15W4Oq0iwhVvnQu+3ZyyjXLaRKzfg/kmun0NeTb
O3jppzmizaG3OgZfNa+P7N75BlDZzT4aUGUebYSmruLBncmueJE89EEa6iaewiAa
akR64JByffhCYjlknpKiY8r76tsrSyAEdGnttFbJw3ez0Yroy2QKnxTt0RmNhgDZ
u5BiBACzO+P+O2y8HTgFL3P0m4WSnjkFmjd3fsNhkap5hzvAosi2Pbr458zreQVb
AKomKv4Kq7kFWJGrDfgO8eZRE5uvhdUzlhRoomOECgSUkJv0mib0M04p6ZlRCuIt
B9fQ5WUCZCsBOqulxnPxVtAChsrgU7kLln0P4iCfCLTnRRykBbQiRG1pdHJ5IE1v
cm96b3Zza3kgPG1hcmNrQHJpbmV0LnJ1PohGBBARAgAGBQI7XBCKAAoJEPTmR373
xeGT+cUAoM+v9P+SeUiitrLtEM5yqNOVROdwAJ40tfqN++jDwAqcHeVoL9iau34B
KYhGBBARAgAGBQI8RdG/AAoJELP9zVSEUUVRvtAAn1pLD3cZw5QIqRrJXeIfceBk
C3X8AKDnGkwPGbxalnqrz1G1I3QdIyIFCYhGBBARAgAGBQI/FTaTAAoJELQQOaJZ
OQTM4ykAn3HBhIBJdK1goaUYWv4AxawOD/X/AJ4q10Ec4hwj/OCvoPr7EDE16AYn
BIhGBBARAgAGBQI/y1k2AAoJEMf1dctQ+RB40wYAnA0yCRdWCtSJwv7CvlwIp8us
wpe4AKC04wFQwZPL7+L6hxCQbVLco9O0y4hGBBMRAgAGBQI+NrGXAAoJEAvwZBJg
uh9H+lAAmwRw4hwCBa/ZwyKIAVtC2NeCClkRAKClBZwTy0caL7jZHvNDLvAf7WL+
yIhGBBMRAgAGBQI/oUvbAAoJEP0uNSAwyB5q7DYAn3CpM39q5KG1ulFk4L82jG2x
iD/3AJwNagRgnXhxD7ZaKVznH8A6EMvsBIhGBBMRAgAGBQJAXxpfAAoJEIW3bC3X
1V8aH+AAn1VJ/BSzXSso3tCNWLRGj71TbZVNAKCeyZ3GK9ACILe1VcrAsWgsZlZu
4IhXBBMRAgAXBQI7WE5BBQsHCgMEAxUDAgMWAgECF4AACgkQhdRQRWtpGwNTVwCf
dbcojqkUhndOq/ZfkVTNFX9K1BMAoIL6h6UISe03zCU5jHr+PLbg1+KNiFoEExEC
ABoFCwcKAwQDFQMCAxYCAQIXgAUCQRiOtQIZAQAKCRCF1FBFa2kbA3vtAKCFAw0k
iZXy/fuffZr7kUIQs71z6QCeLDZN56uJitc4wLcMYk9f0YK43oyIRgQQEQIABgUC
QzlXMAAKCRDs8OkLLBcgg3JLAKC5uDXWztS4CxW6UmrKQeOkZ1XVsQCghHlLyHNF
U3mx5Ix913OJ0YreweuIRgQQEQIABgUCQ6MnMwAKCRBNyUvYtx9gXQRVAKCphrJW
1l08vJYBcHB0L9SoXEY6RQCfVnaF/AKywtO+F3N3rQ8oUJ/pLKeIRgQQEQIABgUC
Q6O8MwAKCRCvItzveM4QX26GAJ9ZeSEVqy3oPTTSp7N6m2IuE07SbwCgjV1XK75E
7SA1RzjHLhaHR5TXX1aIRgQQEQIABgUCQ6PrWgAKCRBd5Nf+GUncgGdOAKDdxemx
LNS0vyMrHaL6BaUBB6GZNQCeInnCSHypThU3gje6qzK7wvzhadKIRgQQEQIABgUC
Q6M/oQAKCRBCsZN8yFUPTKCdAJ9LMRYELC2vMQMpKav2FZpbdW+uCACgrsdtdEmD
u5NGs8tvsEN/RZJJ62KIRgQQEQIABgUCQ5xbHAAKCRDGBDxWcgdxNzsZAJ0Y/y/V
tj7SiUFFmBQf5X213PdsRACff88PGBewTXnWKXGw5QS5UBl2tdeIRgQQEQIABgUC
Q5xg3gAKCRB54pxgsAY/56UOAKDI3Bd6w+movMKVGzZNZNp3c+VtvwCg3NZ+/o3h
CSYSliA69FbO91G6e0uIRgQQEQIABgUCQ6Z5cwAKCRBEidDtZ5uBGa29AJ47BnH1
jsRMs1Az3/qXw+OID0GdIwCbBgpLoBudHg4tZ9v2mnPel8huOFOIRgQQEQIABgUC
RJMPyAAKCRCpF+nMmW4UXgVsAJ48LTkwJc7H59xQE6xCH38czbBHrQCfXirFC4WS
rbLTvdyenUWrlQh5Hse0JURtaXRyeSBNb3Jvem92c2t5IDxtYXJja0BGcmVlQlNE
Lm9yZz6IXgQTEQIAHgUCQRh3SwIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRCF
1FBFa2kbAxEQAJ9p3vcTJCOwssNVA//wiyUximGelgCggaS4vscpI4GjDjz/5MAb
pZdk7kGIRgQQEQIABgUCQzlXOAAKCRDs8OkLLBcgg/fwAJ9sGQoHHykSPO9rFmiF
fspjyPgLmACffJ3+Z4wJXNKlmY6D3fqVTB4vkHKIRgQSEQIABgUCQ6G3KQAKCRCF
t2wt19VfGhdOAKC2gfth4x25oDhO5YKZuJRwTRIgUQCgnXHO5/rWDoYeKDxRsWze
zczDh4WIRgQQEQIABgUCQ6MnOgAKCRBNyUvYtx9gXX9kAKCR06Nt1BSKyMd07wSl
sWc4mq+N3ACdGLm3hFxWV5NhgjJyE/VRVPUAseyIRgQQEQIABgUCQ6O8OQAKCRCv
ItzveM4QX35KAJ4jsBq83Vo1/brrQn6h8njUoSe7PACdGW13bPB3zu7QEyL3Ur/K
86q8IsuIRgQQEQIABgUCQ6PrYgAKCRBd5Nf+GUncgAPQAJ9l3qLexbzF4JMoxoEo
flkuHwXpCQCbBK6bS0nJnmfoNGXDpRRo8qAEFSWIRgQQEQIABgUCQ6M/3QAKCRBC
sZN8yFUPTBYeAKCf1oHL86oyiPTxopWjzQY0G2v9oQCcCd5tbZrhAuo87Q2G7sS1
ALHyUPuIRgQQEQIABgUCQ5xbHgAKCRDGBDxWcgdxNxpLAJwMZnLXTD2xOMaUbEWF
dfl0/YFUUwCfSAtJPGN9T5cP5Zy7cWvlNqt3UHqIRgQQEQIABgUCQ5xg5gAKCRB5
4pxgsAY/54NzAKCsNx3hhz2XmW99A2dGRQPLx/v2LQCdENVtUKrjb61O8spFe6uR
QQ0CFvSIRgQQEQIABgUCQ6Z5dgAKCRBEidDtZ5uBGYTwAJ4vw7oifyiZ8Y2AgZhV
Z+kVTIf2IACcC1REuI07XJzwO9yiIZOsk+dvLOaIRgQQEQIABgUCRJMPzgAKCRCp
F+nMmW4UXkIhAJsG3I2+u3s9FxBlcS2swNLS3aPqeACfSOHu7LH2vZhZ83h4ctGr
Rq8tmoG5Ag0EO1hObhAIANX5TO/cDWaKqIaSRz4NyjTpHgtIDQpzT8D94KOnRmaP
0B46pcNxP62+zRXIP3iHFKTGits2EoGqsw/2Y+S4RxtL/669ykxb4W7TtBwHG9mX
EsgoiEol5eylKhNHOe2ZUwm5BIq3PTPywueehMMB7A4cqg+k+PDLyibzz6lvYKrp
oVvaXezfX8k6vOmiRIWyazhEG3KOjiS3fnzI+qYXHUiiWjGx/CM+DcBzcuvebW5e
j1ewB7O0qjIvxzuJep/KYO6n748CLYqLzF5mkSa0SCBWcK2LvfjlOjxp4mCSslIP
eJO2DbGeBsmzhCWV10DqZdds9t3T7tBAKr56QAswUHsAAwUH/3Un3UAEi2tgn7Cm
lOuM6l2iyxm0dT4xrzUzBrhPHUKpY28vUv3CFn+3qvhv/F2S56Oe+jbjhG2gljfP
E16MUSbYwCjCuLpU76ZgFpQL17TLn+1hehhCjihqSIL3mWK09W95Gyxj9xrzG7fM
gLgzwsZk/r3qh1Y2Mef+47FD4Om5conFeoqdJCyH59LJQ0zZVG8Ldr/tYYvcKvTb
pxqGjaYQ3eOAVgVJPvqHpMeWETA34HUfOVDZHtM2w03KeHR4Tlxa/opdIrmZchzk
0ETdYPy/t6AfbJ+avbIbH8rJUd6ifblrKUqGyrc+gJ5435T3YowGVGpVVRZQyyfg
uRP+CIOIRgQYEQIABgUCO1hObgAKCRCF1FBFa2kbA5t6AJ9B0laWrFnyRvVGo/NV
QHmv6xkKhwCbBo5yKzSSgAUpfzjAw5PKW481T6g=
=Zfaq
-----END PGP PUBLIC KEY BLOCK-----
D.3.143 Thomas Möstl <tmm@FreeBSD.org>
pub 1024D/419C776C 2000-11-28 Thomas Moestl <tmm@FreeBSD.org>
Key fingerprint = 1C97 A604 2BD0 E492 51D0 9C0F 1FE6 4F1D 419C 776C
uid Thomas Moestl <tmoestl@gmx.net>
uid Thomas Moestl <t.moestl@tu-bs.de>
sub 2048g/ECE63CE6 2000-11-28
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDoj/ekRBACnO84k2i5lLHZKscyV8tjQSkkr26hasdbc/uyV7HTiPhMUjEAz
Pamk+bDmy/Ls8k0SJ1l0vILBBd31G5VYtKonIrgp4vZ9gV0fBdCyFDXb8bh11Pk3
pEZiG9vJevq40OPvsThLKHCLNhZ5zLPp6gd0IHwRJ0LU94pouFXd33MzrwCg4gTJ
K00Dw0w1hFtUsq6WjNC+1B8D/2WiEuzBMnO6gz0p/eJ1eZ7mvrBXLQZ0u5vJ3eg2
CCPrtS1ZITq3ICPDN6biEiMgtRmlYn/VYvDQqxwNE0X2yMfB/9sdah45zma9EeVn
Iy8meaCFDLhm4aIYc1foUuz3WbCNlJFY5xYPXCMXLkC65xdybHKng5TXh6NOOWf3
PfCWBACPMotTRKttAuw5YcZE5VDrSXPYHu/jm2CpIVmrac7+kDj9pGH9sB7BdUxw
vczqtAT0jk7MrT+u3FH9wBtEFTXl7ksGTmDOFWJgYn3ZOEaVaX/OqD89UNhrOA2v
ZOaaoKMYxK/pszPdr1Ghd6BQCmYKtLBlFYiTDRM5UMVHTqN7VrQfVGhvbWFzIE1v
ZXN0bCA8dG1vZXN0bEBnbXgubmV0PohXBBMRAgAXBQI6I/3pBQsHCgMEAxUDAgMW
AgECF4AACgkQH+ZPHUGcd2xMLwCfdEkPZVBgEmYnlyOKfyTSslMhud0AoKDKZNXA
huNslb4KF8yKWBNRwfPStCFUaG9tYXMgTW9lc3RsIDx0Lm1vZXN0bEB0dS1icy5k
ZT6IVwQTEQIAFwUCOo01FgULBwoDBAMVAwIDFgIBAheAAAoJEB/mTx1BnHdsOfMA
n1xd4f7iAe6id42DLg4W3fibsCwsAJ0cT2lf08RhHkT+zLVoubyIDoY6ILQfVGhv
bWFzIE1vZXN0bCA8dG1tQEZyZWVCU0Qub3JnPohXBBMRAgAXBQI6pO9pBQsHCgME
AxUDAgMWAgECF4AACgkQH+ZPHUGcd2z+7gCdF5fq/lebn3/gp40O8xP/J0XFbiIA
oKJP186L04qpSNamc/qG3gs7h3DGuQINBDoj/wkQCACl8M8ObSTJaOY4SgoQkKgB
CkJJP5ScUpfYV9w3dxKL/77cyfghfYsnAWuA9yXJcjA0F+u+jRf8gS7OaHD9H9Mm
pMGq54Aa0KUQaDbL/Jzf5zrKS/RASHzl1vYXuZB1OIzPfeAIx9u3UaziVEGXJha3
1KgTur+TU+F94ZFTi8uApq2VoNT6sFi/V2x79bxlLFr9M9yD/0+kMZKovWRODy6T
gWJzzcdd//dkvKp22tNf6C2wq8Bu60cWR81+awgG2otgZjCPUs2Bwhqa5opeUqGn
J+f+PXo6+m2UF21m1vLARENuumu6SXf3XqGIUiQbT6jCdJORzwaxeCiMfu0qNnUX
AAQLB/9u9gZN0N0r21ZjM6ZRmDC/REouCdYHEj49+f9g/xLXCfacpWVcrK9lIrcg
hxRE2mQ/nlQLeHroC3Dp1AfThKSPFX3PRD/9CcRu480imT84ljf+6vonAZ20Edm5
vVO+UoJMZQ2G+rWRRf4bDfwFoyDw3DsNmUL4yH8m2RpTxXn0pQtD2riJD8CBCXEP
K95TYT4MomJ7Szg7O5/QLngfw0q6QdKRm1vEIP7r6t+UbVNp9+5g9qvz4aqm3beY
pw1QCDHcqpDITnlTxTdV2SgNpF8JPg7joaOa36AxWwRzfLFyzyw/JGQE8RwJa8BN
iTu0IrKuiF1biRxqiYO887GBA/8QiEYEGBECAAYFAjoj/wkACgkQH+ZPHUGcd2xN
TACgkS0AGqqd2nLtWhpbE72tD660tv8AoI24cRkUa2op32mti5zfLLMsM4AZ
=76WN
-----END PGP PUBLIC KEY BLOCK-----
D.3.144 Alexander Motin <mav@FreeBSD.org>
pub 1024D/0577BACA 2007-04-20 [expires: 2012-04-18]
Key fingerprint = 0E84 B263 E97D 3E48 161B 98A2 D240 A09E 0577 BACA
uid Alexander Motin <mav@freebsd.org>
uid Alexander Motin <mav@mavhome.dp.ua>
uid Alexander Motin <mav@alkar.net>
sub 2048g/4D59D1C2 2007-04-20 [expires: 2012-04-18]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEYouBIRBACKCnll/QyL7oh1g8bNwX4mX4QDz26jOjGW624VOCOb0jarxzV/
s8NF5V7ddCLMbf8wqA2QqeyrNm+e0FdsLbxVAN6NtF6hRCK0Uwc438toERXBLq5j
Ss6Ofc3n9KBdTbUDfTp3t9Tda1oajF7JqembMz6cIWXmcU5P+7a5b48KCwCg6dhG
X2f8H0s3WZkFi4gDXkUOMMUD/AxfkpYNv3CMGZx/6XVAlNltOoNRG2j41tn1Bhkz
3xgPueod38HbXewTESMVm1qPW3IdNLCrVXg8/TxeUw97h8d1Xa3wfX2DEDfUSCWp
IyH+gAchvZxJebdf8UpGtXMrJPzVznMHmChs8pavhnZfqtJ2tplFEf18HLbvzU8r
0GpGA/4hNHGvKtts3CTV7XoQlQrWqhl9okjAUarLjrf2iCVsUhyE3UpXmp0il5bq
mhfVv5b4FHUkrSipOsJmVSLgoc0muL9G0BNvLkMi3/vUi/6TOjANYOCnUF324cKv
9o7ojNylp6eTh79wx80tHt99ZgNh1butSlQAQSTXk0aLLbOSqrQjQWxleGFuZGVy
IE1vdGluIDxtYXZAbWF2aG9tZS5kcC51YT6IZgQTEQIAJgUCRii9JQIbIwUJCWYB
gAYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJENJAoJ4Fd7rKBAsAnR3+WbuhVRDu
7AVndqKop+Qwg68hAJ9W8/4LOHr2XjLT37RQyxPgtodbvrQfQWxleGFuZGVyIE1v
dGluIDxtYXZAYWxrYXIubmV0PohmBBMRAgAmBQJGKL0GAhsjBQkJZgGABgsJCAcD
AgQVAggDBBYCAwECHgECF4AACgkQ0kCgngV3uspZMgCfafiI8rCSzlLwyWRXCpyH
smEYsgcAoMuqcyGJ9P1yzcddYw9SZUjkoj1dtCFBbGV4YW5kZXIgTW90aW4gPG1h
dkBmcmVlYnNkLm9yZz6IaQQTEQIAKQIbIwUJCWYBgAYLCQgHAwIEFQIIAwQWAgMB
Ah4BAheABQJGKL0sAhkBAAoJENJAoJ4Fd7rKJFoAoNe3pxIgHjKb+mjocFUrzkAn
O5pkAKClil44JNQKWePpy+xNRNG8ko5487kCDQRGKLgSEAgA8Y2EXU8EbnSyZ5AL
RyHn7axmxr7p2qzEkDI8EidMlJOxfyCj7b3t+5QbIbieb/pnDMGuXPc+7lcK7Owf
pu9DTvWPdLRjvXNFJbuRH5mXVUdHS3j7GnAqqgb8ydTbUrKRwY2BijJaU8imXibc
+ujXgO/ZVrvYpiXtZx38cwfoIDA+LFpQlLBUUkV7GRpBYcrkrVEGMrLBAPht+l71
Y/IBMht4z5VBFMxJ13TogMseOKKDrRVsxmMqbBjr/S23pVZqpjQYGwkNo96+JxeD
pQGlbbbRftiuObXEZsk4yGp56jXTieZLUlq9L1ELkzHIjPhNoeudx/tdtgZPSwsp
I6M7SwADBQgA2eUilFtIbEsAizp1Jd88J+2Z/dZ3M0LK7rqZuBVQdeJZbpYBfL9v
+JEbjw1e8HV2goYtwkVgfP3tJX/xqzmwIZxd3wLLzDucPrtmQJfDDcD3fDBVvCeZ
Z+EjaGp8/rIE/h0LCk9XXHjK+JOZaKt8tsCtkpp5nbAMaPRBrCm9sGB9Oyt0rrU2
/ryvMIf4W602iKDka5oUl1fhNP7R2lnkLRK8OPEPdboVxOrzzdBB8XN67B3kzDRt
+nBHqFZNn6GafIYpvoJS1jqAskug2IjmEUIxDxEuD2EhIiayLAuwmGnR8d3iPVcJ
/KF/URy/Y7PBtkE2amogd725uRTxXOXAA4hPBBgRAgAPBQJGKLgSAhsMBQkJZgGA
AAoJENJAoJ4Fd7rKMlYAoNZbw8I7WBascnxVyObkqE5rLKxJAJ46TGlVlvBS+PXT
L4EaOMcBYbTvTg==
=ZML6
-----END PGP PUBLIC KEY BLOCK-----
D.3.145 Rich Murphey <rich@FreeBSD.org>
pub 1024R/583443A9 1995-03-31 Rich Murphey <rich@lamprey.utmb.edu>
Key fingerprint = AF A0 60 C4 84 D6 0C 73 D1 EF C0 E9 9D 21 DB E4
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAy97V+MAAAEEALiNM3FCwm3qrCe81E20UOSlNclOWfZHNAyOyj1ahHeINvo1
FBF2Gd5Lbj0y8SLMno5yJ6P4F4r+x3jwHZrzAIwMs/lxDXRtB0VeVWnlj6a3Rezs
wbfaTeSVyh5JohEcKdoYiMG5wjATOwK/NAwIPthB1RzRjnEeer3HI3ZYNEOpAAUR
tCRSaWNoIE11cnBoZXkgPHJpY2hAbGFtcHJleS51dG1iLmVkdT6JAJUDBRAve15W
vccjdlg0Q6kBAZTZBACcNd/LiVnMFURPrO4pVRn1sVQeokVX7izeWQ7siE31Iy7g
Sb97WRLEYDi686osaGfsuKNA87Rm+q5F+jxeUV4w4szoqp60gGvCbD0KCB2hWraP
/2s2qdVAxhfcoTin/Qp1ZWvXxFF7imGA/IjYIfB42VkaRYu6BwLEm3YAGfGcSw==
=QoiM
-----END PGP PUBLIC KEY BLOCK-----
D.3.146 Akinori MUSHA <knu@FreeBSD.org>
pub 1024D/9FD9E1EE 2000-03-21 Akinori MUSHA <knu@and.or.jp>
Key fingerprint = 081D 099C 1705 861D 4B70 B04A 920B EFC7 9FD9 E1EE
uid Akinori MUSHA <knu@FreeBSD.org>
uid Akinori MUSHA <knu@idaemons.org>
uid Akinori MUSHA <knu@ruby-lang.org>
sub 1024g/71BA9D45 2000-03-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDjXWqERBACDCxgN9+yMfpm3yvkYp+P4Uw6xxPdcZ9RvnTRkBX9zXaRgSPmM
zeZ63LpB99uVphVZrv/EdlyTf+cRdz6VXXRcTBloA/FsyY86IluBnWCH054WyXzr
7az5WB9yDbPnlwcSL919bq0UqTuQUlQswdQAoDQG5LNNZNa0T01ydYtNlwCg3weS
I/nEJrGCXGy2wrjg8LiwQ28D/Re2JHQPTYqDEZl6wj5U83wT55ChnTrjPRbGmr/C
UdJP6CZQg6+DXYGYulcp3oL4btcdFDRFglJzmQNkUYmqiVC20SMVKUctrOCAI60P
7VE40UtXz9EounPSRQQ1lSdMNeRwrZ9o7IcrSj0EBw8lw3d2WxyM2Rs2crZWfOI2
mu8dA/9LbmAw5sLk5Lo5i41nAWP76pyuGxSia6zMRdML6ynoC5kmyrI9TwW5LNU/
Lsq1Ru2XSA+CwSBpTt0vdwS88dDwPGxRuUHhWVpa1M5t7K7uYODB1cD5AyNoNnR/
lHpxfPZOJNdA3OPgfssN9K+PIuhbBU5xONCoAcdC9TEqSezfUrQfQWtpbm9yaSBN
VVNIQSA8a251QEZyZWVCU0Qub3JnPohWBBMRAgAWBQI411qhBAsKBAMDFQMCAxYC
AQIXgAAKCRCSC+/Hn9nh7n1bAJ4vkEQX0JkcYgltt0Vv5qkS3bGqNgCguxfhuEzZ
vBzpAW9/XdstjA/DSPS0HUFraW5vcmkgTVVTSEEgPGtudUBhbmQub3IuanA+iFYE
ExECABYFAjnly3oECwoEAwMVAwIDFgIBAheAAAoJEJIL78ef2eHu7RoAoKn5Lw0y
C+/lju5+pV0WI5dmxTzxAKDJRtsRSTBcJ7ohvzztxZqyjfSK+bQgQWtpbm9yaSBN
VVNIQSA8a251QGlkYWVtb25zLm9yZz6IVgQTEQIAFgUCOZGiowQLCgQDAxUDAgMW
AgECF4AACgkQkgvvx5/Z4e4t+ACgnr8RmYw81/oC7MKS2CSoFb9cg6sAnjKay6ho
14iMG+YcFNbjxwGvSE9EtCFBa2lub3JpIE1VU0hBIDxrbnVAcnVieS1sYW5nLm9y
Zz6IVgQTEQIAFgUCOeXLZwQLCgQDAxUDAgMWAgECF4AACgkQkgvvx5/Z4e5+zQCf
Z/09J5FOgAqw3UrTTAzR6QWicG0AoJdlBcdUltEO4WV+q3FRlw4RVnA8uQENBDjX
WqwQBAC09OxAmKbGn9FETdMA/5abvOY7JgNcFhQutEVnJ90mF/npBucWkCRbOr83
t+NB0h5Te+lV/c+mjPyOemfWdAK4R9zQsat+ZqATv4Vgiy0UbJ/5TPfSraNK+QkX
nxcDrhpcJXZhX6VYzbWdRSn8xSZzPT19qq0BFafz9UhZKXnLDwAEDQP/dpZe0jWw
rED/Kbyr8CDoEKuun/5gPi5xmNz9iJlyvcsdOgok7yen0HHWgdaZAGX3GzjpB5gA
aISX/kK66s+NeM1XQ7YXpcI8naf0jPa6N3SNWjLf3xPxLbMk0SyaGnrnSQNikk/H
Bk2Nqyn0kcEaaBbdfrgkuuQWPnBDrq2EdOOIRgQYEQIABgUCONdarAAKCRCSC+/H
n9nh7oxxAKC+gMyhZmSZdTvT3a2Y0RDOx5kRLACeP3JEvGZAZuo1sJeEw504+jr8
1Xo=
=M+Al
-----END PGP PUBLIC KEY BLOCK-----
D.3.147 Masafumi NAKANE <max@FreeBSD.org>
pub 1024D/CE356B59 2000-02-19 Masafumi NAKANE <max@wide.ad.jp>
Key fingerprint = EB40 BCAB 4CE5 0764 9942 378C 9596 159E CE35 6B59
uid Masafumi NAKANE <max@FreeBSD.org>
uid Masafumi NAKANE <max@accessibility.org>
uid Masafumi NAKANE <kd5pdi@qsl.net>
sub 1024g/FA9BD48B 2000-02-19
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.2 (FreeBSD)
mQGiBDiuMYURBACEgL3d4mL0pojugj8TZFEQef+MKkXB3lazrqV2ahgWqt6K24qr
5fZrGkI8vxmYR4VkI1eLfe0Q4LoBZifL5nJYEvMvWPmdLuYjp4iwjgBdzLnwr59+
k8+T/fohGDOqx45voCdq68Jmxg283zFGQ4FChMP3ZMlOPmFRIp01C84xxwCguNFG
BVPeuM0y7JH0ucRygUqc4acD/jfe/UEjGBWxOCfZYOnXEp4NXWis3xRyUDO3cuoG
8M8MEmg0dX0onFuNU5yrEBFtzPw2GO6DMM8h5hJXdSWkiyusn05PGk/jVSP9/MD5
TYyqKL1tG/fKUgtevZSi7o1x/N0bgIBqmzd30Cqx29p7juVV+SBcKCRT1qloz6fc
a5B6A/wJD5n3HOAStsWpZ6To/Apdb4A3PD4+ePfQxSICsHCFg/M04FkrG48So2qc
7dSq6UH3xLsoiRIUonwCQsT+PaQQMrZNKjfal9xlEFfw1TV/squ+oNE8E24Lkzxt
8Kkn86Ec5uiUlRulSMG9HJuWM+9Qu7TF76FWP8llVp6ELkYCGrQhTWFzYWZ1bWkg
TkFLQU5FIDxtYXhARnJlZUJTRC5vcmc+iFcEExECABcFAjv4RDQFCwcKAwQDFQMC
AxYCAQIXgAAKCRCVlhWezjVrWUEIAKCgwVSawCg1Lzrbf8uZdMAfeOWFXQCcD7EF
tsdhbEV62AOUeQQWPr9de1O0J01hc2FmdW1pIE5BS0FORSA8bWF4QGFjY2Vzc2li
aWxpdHkub3JnPohXBBMRAgAXBQI7+ERfBQsHCgMEAxUDAgMWAgECF4AACgkQlZYV
ns41a1lUuwCgsIhWJdtPBebkV6w+NQ/8jlkJgrwAnj9lZkiTAgl1E/vcF7yPbY7f
HlHetCBNYXNhZnVtaSBOQUtBTkUgPGtkNXBkaUBxc2wubmV0PohXBBMRAgAXBQI7
+ESBBQsHCgMEAxUDAgMWAgECF4AACgkQlZYVns41a1nv1ACggYgtKhaprmMs30oz
yoC0NatFJ44AoI0XSPh2G9zHEjF8AyYAe6sVCLqvtCBNYXNhZnVtaSBOQUtBTkUg
PG1heEB3aWRlLmFkLmpwPohXBBMRAgAXBQI7+EljBQsHCgMEAxUDAgMWAgECF4AA
CgkQlZYVns41a1lYRwCcC8l4PdrwHKNrZlTW6vod6kYgR3YAni8iLUZW5Se6nTH9
WuN0XYPpZRG5uQENBDiuMdYQBADVzBBn5+1UQVCLS51y6eCD3TidT/uJAr+eeiWZ
IbTmXrltNm5rGs7OT9QYNLhCFFPYKJxa9hFbrGpgserEFnqBfxcbMLa/wyIm9m/l
MI+NNCAU4IpgDWtgjf1kjzwnJPwH69YzcqS2jlEKIjkCrEa/Bpr1Nvo4aLvqlTR8
tJh+1wAECwP/YBMEMx/zgTvS3Jtji6nPceRe8icGRHb4SD7MVF/WxYu5VK7wlmuw
9I9WXnHyYaL4c6Q49FAvwhkppByqJFL0txyJ8+nNa6H5mit8m6dcsCMG3NzyvxBP
082h/MWbJn3Xdg89lp4UG3UP8sV1oWyIchd8rqxFk/EVB7fVQWNz/gKIRgQYEQIA
BgUCOK4x1gAKCRCVlhWezjVrWUlcAJ467I5lFNlkwcENe5vND+DPaWyreQCfddOu
6Va2/bf7Ln4TKyl17uRro7Y=
=VmY5
-----END PGP PUBLIC KEY BLOCK-----
D.3.148 Yoichi NAKAYAMA
<yoichi@FreeBSD.org>
pub 1024D/E0788E46 2000-12-28 Yoichi NAKAYAMA <yoichi@assist.media.nagoya-u.ac.jp>
Key fingerprint = 1550 2662 46B3 096C 0460 BC03 800D 0C8A E078 8E46
uid Yoichi NAKAYAMA <yoichi@eken.phys.nagoya-u.ac.jp>
uid Yoichi NAKAYAMA <yoichi@FreeBSD.org>
sub 1024g/B987A394 2000-12-28
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (GNU/Linux)
Comment: KUHASIKU WA http://www.gnupg.org/ WO GORANKUDASAI
mQGiBDpK8uIRBACY5SwFQXiqzDlO1k/syoFoiFIFl/Dp+QmwK2oovIvlBVo/1gbx
EhXrKRrfC67KSxxdUsgN290v/VVTmq8Opy1/RF+RAdxM3JrUfkcm5+IBWbSUfXFP
i8OXBVgh7wNENVtwwD52F+0CFIWZXkClaif4DGkf38V6LJ6hBIycxuNDQwCggXTT
Kj5SP2hFC0ueyQtPDoJEgbED/0bPL9R08io82IQqksOR9IUy0OdFJkLVWLnollEY
LGjXa/AHgE8L8oWU/2eF1WM4JrtVRdcKe0Ja2e9LuH6IonGAdwqUeeAOwA/RdGj3
63EglH5ugv4rZZKWZ3/piuNXvtq0bhAfl6zBHi5iUB4bgPVoVJGn3VyykPWxdqfX
sT5+A/wIml11cFMogN3RXy/2Y3JRWeBtUCfdoRjeQPgK8++krm2Pr/AtHgcqNSjI
W0slX4cLou2TEhV3BHb/4npsdaY0BzYgL7V1YggCv0Pu1s2D53Nzi30V66SRP0BZ
OlNTA88WdMfoF3ttb04swSenG9X8dbpyYEdlvxNbbKKbUiBORbQxWW9pY2hpIE5B
S0FZQU1BIDx5b2ljaGlAZWtlbi5waHlzLm5hZ295YS11LmFjLmpwPohXBBMRAgAX
BQI6SvLiBQsHCgMEAxUDAgMWAgECF4AACgkQgA0MiuB4jkZz3wCeIi857V2zyRA7
gRVsx+DcoCLeC3YAn2G3gFd+v14iZHXrPaqpd1gSjjayiEYEEhECAAYFAj2pty0A
CgkQFwU5DuZsm7CchQCfdD/itI8d/uhmH9A0upJYYoYS46YAoOAfpFKvAGe/vBpw
dy40SxBG/qELtCRZb2ljaGkgTkFLQVlBTUEgPHlvaWNoaUBGcmVlQlNELm9yZz6I
VwQTEQIAFwUCPai4HwULBwoDBAMVAwIDFgIBAheAAAoJEIANDIrgeI5GKx0An1kh
KzDAfR7Fzba/V7DHq2BRLcRQAJ9nZFgBncerxFMYAanwJruIYtPnJYhGBBIRAgAG
BQI9qbcxAAoJEBcFOQ7mbJuwe4kAn1E2VVFpLajGFYgipCmMgpxRXPmxAKCUa/ee
BEW5LPNf8xhaeIGlAtPZm7Q0WW9pY2hpIE5BS0FZQU1BIDx5b2ljaGlAYXNzaXN0
Lm1lZGlhLm5hZ295YS11LmFjLmpwPohXBBMRAgAXBQI9qLhMBQsHCgMEAxUDAgMW
AgECF4AACgkQgA0MiuB4jkYrnQCfUgkHO/ioUTHeBtYJHGeL9qthlnMAnikYzk6K
gDV8cHI/ETcNoh542Q6piEYEEhECAAYFAj2ptzEACgkQFwU5DuZsm7A/JgCgvX8u
hjU7WPofTfM2d11+j+ywHm4AnRS8iRNMqbP9+crcNzCRSQ7OZFqluQENBDpK8vEQ
BAClmz0m/wuG01nst/7X+riyNgZ3j3oRurb9Fg2pb7wkci6nlhzCHTcFNCZiY1nS
Vp+/3tRkC7HQPz3zhYo3ieCf12NUweJ8jhbZubp1fYY9ubKoj12I+LXTfZf3kA5G
UD/n1nkAqxH2yP3eVz1BpKUc+Lz+5USiDo+XfrvfxQcZHwADBQP9GejakrIdVKcA
/4UTWnMh8HK2b7tDLwLKyJg/8lagBkIAH5tPpCXi1qXuvHe+T9SjbdwW/lyxSARV
FAz1ejp4QEWsAGQ/pchjb+S+iYvNq0VfzkZPqFFllLMaQc9mo6blgGgSEqLNpba6
gDmVTJZ5jAhVxFBhRPwchSdPP3ewVRWIRgQYEQIABgUCOkry8QAKCRCADQyK4HiO
RpwtAJ0alZHYWdBCXaPF9G9HCl/T40wzJQCdF5K4aEEsIG1P0WmNjbY4PEAVndc=
=NZ/b
-----END PGP PUBLIC KEY BLOCK-----
D.3.149 Edward Tomasz
Napierala <trasz@FreeBSD.org>
pub 1024D/8E53F00E 2007-04-13
Key fingerprint = DD8F 91B0 12D9 6237 42D9 DBE1 AFC8 CDE9 8E53 F00E
uid Edward Tomasz Napierala <trasz@FreeBSD.org>
sub 2048g/7C1F5D67 2007-04-13
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEYfTV8RBADcVRh6fWX1XI43cTrdJBctCOxf9jZ6eedmhajkpMRhg7b0JPPL
cYL6H1x1xqKbXtKxWE+BzQfdDJNJhwjQIwaXityWHihnkw5XBCRMuCGrUuaW/pPQ
31EX1Am9d8k+ckUK8tPMNuWM8+ZYjXTJppLg20pIPBRwvmRR/hrHDhMvbwCglDGC
ZfTHYkv36MFnkPHJH4iaQIkEAKoy+bcyOiJK0iuAx5KeF3CxP53Nd4sbsHKcbibP
OsWJKKUHPlVTts6bUvM6RH+zUHOeWpXmgNvZTsvmoLU/E0I80BN5ngdOwV7oqeAk
V03iltsBGIeBv5B0xxYDyQBuo52LV5CGZ7F65o1jGF8LWfZbtPh02gTmhYymmLeV
QryDA/0WbmKavL5Dh7L4Ugz1JVIC6miD399IsLV+XewJjcaXnnngIplz0ZjK9hHx
kuG4w3pi450z6gMTmpY1IPC7R158j/fLhygYLhB0sffXaGs50nizBlBoZNR/RZRJ
7Ik1Q1E4dV5kVhgqBs6qPCfAdVMKGTWpM3xF2uyFT5xbuVPxIbQrRWR3YXJkIFRv
bWFzeiBOYXBpZXJhbGEgPHRyYXN6QEZyZWVCU0Qub3JnPohgBBMRAgAgBQJGH01f
AhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQr8jN6Y5T8A7L7wCfa7dxDhHm
WYOcaZ3PiBCxbMyMeW4An2regIquPmK4ZyrJkfXGd7BmmgGKuQINBEYfTV8QCACv
/cPnRLjvnYJdozvbzoBqC4m2sAmBClDV9cRtIGXu//ULZ0CnDmEByfp7W2Aqlm4a
+WnDBlbKaP4td0uwvly3m2hNH3DS/7/aBaDYhPUeetmIP3GZrelGlQHqe1ldJuwD
KEiR0ANagAikuSiO8Fv76YY2dFmUSWh6mNd6+/F6hYahByJbDXrsYNSMI7BtpH/C
fPaSew66982uu86IGIZPREfKSYouLuuHPUwrGRbcwyeIL5y/0i6Eyxi3JuPHCYSa
a0jX5VQ8Gn3P3SukTdK+rWaJQMlzjbdaZknB/GeRDEc6ND3eqdmQa/PdnkGVwHeI
S17IutKHDCsxDqSJgak7AAMGCACJtwmr70SqnOxtHugDB0G4tAEN+poeol9zfEnE
A1nZImvDNLUoX11YZRLHCc9nz2V7HIzTacNL8ue5DenmtSs72S3zHM/DnIhXjx8r
hBFrSW/DdJB80LLcC/NhRcl3U6sof4nzYuipkgr7evAeoZqWpHiYcuag0ZRRH5Jv
4Yh3R8zFYAg2NSKs2Q3CCX4c0vs1boZ1f2x4QQhxTpsDkjJxGPJ8OEAR7W5BjDOY
KZBL9+02bzJKnOcbrtRkbylGZAQCxX9DoZDGHSCqaUBZMJZzWauW6xcwd4s91pMQ
MVG1u5WHvZlOEo1Cg3Y9QSyehMKkcLwyuBj2zP+ijlkIBuFhiEkEGBECAAkFAkYf
TV8CGwwACgkQr8jN6Y5T8A6VnwCfZdSh5TaDbb0wjcyUkVYAWZIo4n0AoJOfSvnF
MeOHsJ51PEblZGwvjW0k
=hc/r
-----END PGP PUBLIC KEY BLOCK-----
D.3.150 Alexander Nedotsukov
<bland@FreeBSD.org>
pub 1024D/D004116C 2003-08-14 Alexander Nedotsukov <bland@FreeBSD.org>
Key fingerprint = 35E2 5020 55FC 2071 4ADD 1A4A 86B6 8A5D D004 116C
sub 1024g/1CCA8D46 2003-08-14
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD87tOARBACkfv0/19ar/kUNsj2vL+APjo/cx0A0bubEmaPhwNuLOjtafdNm
/pUULYi28lDVDxQJ8UM1voqrCcue+finCyy+k2L0nR37tlUA4t/+GH4gq4y2xL7S
o/D5DqHDA0cTDAIQCbdD/rj3Z7nJw2Vkn3tAwZ6NUXV7OdLS+csbpJIjmwCg0HB1
tzahpgegUe5XauCly+NXNMMD/3UcnNA7kBKSZMcuOVq7TkqYYvQZPoroK3yYcAZL
Yo4WoPEyjtlD/ZpZVysQiSMxLXRHjsEbMAMZL7Tx/Sav01XUiBHBGDHXaWWVdqmg
efxtBeoG7MZxAAXBLfcSeV0bjkd9oGWW/inHrl0NgEljZQqo1kbIEb5asooyT18v
vZgjA/9l8xZdOlSJv7Ct+VGrfMStMmpBCn7IRSjeJRq2pNe0pbJtzXAnAwyrB62X
gF6n7ONKdLk/WPihRdfrc4BZnNIWZU0q5P11rOENQEnToprAOYebhmS6cY0lx0SR
M00HVTTgzsNVWDy9h+uOobicBSHPh2La7KGnFRtMb6pZFg5Y2LQoQWxleGFuZGVy
IE5lZG90c3Vrb3YgPGJsYW5kQEZyZWVCU0Qub3JnPohbBBMRAgAbBQI/O7TgBgsJ
CAcDAgMVAgMDFgIBAh4BAheAAAoJEIa2il3QBBFsAUoAoIGf7gn1DPL+Miw3/2W1
YdJPT3TjAJ9LOVjgV1mZks+FjRdl1IETcJ4fPLkBDQQ/O7TjEAQA9yIaEvU/Vbj0
L1xFjIOGEyM5vFvn5xP2LibOI7hUH+cMDaWkBgrSLqsI7k6P3HSTVWpkKUTl+vJe
OJnIx1gFE/WJDPK5trnjzHQI9kWf6j8EREXCFuuvDy3QhuJiHTjB+I8IVYh+oiXl
6SNo0ekvQd6KZlkPUXy8rczb8Y+A7GsAAwUD/iPYrIWC4xSX8kL6HFjaE2fS42EW
iyfyb7slFSE2xtRf+xZyBa2Mu5XQsg+vJcSBsjrxpYdd+OuyTLuYRsYvuLZnB65H
tTli1/ous2J56useJyeik9wJfFyZBlOtmw1QFLxELly+XgKiyGRNkTrws+smyFjC
GWwhlhc40r824oWPiEYEGBECAAYFAj87tOMACgkQhraKXdAEEWySXACgwFVr9ZgH
TYnmgWGXAmQWvJV+xAQAn2HlGDmOpuTDzfO5PvXOOWnFjvIt
=bcPN
-----END PGP PUBLIC KEY BLOCK-----
D.3.151 Simon L. Nielsen <simon@FreeBSD.org>
pub 1024D/FF7490AB 2007-01-14
Key fingerprint = 4E92 BA8D E45E 85E2 0380 B264 049C 7480 FF74 90AB
uid Simon L. Nielsen <simon@FreeBSD.org>
uid Simon L. Nielsen <simon@nitro.dk>
sub 2048g/E3F5A76E 2007-01-14
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEWqLYARBADUgEaHYK73qi4nXVO1DfcVKqzWZw0lDYXv3mVQO74Y41hP7QV4
IyvRuuWmKK0vm+ibh4WQTRGhqeSr+tDrgUIqs/tavDVx27DdBeOi5fQwFiyM0s3B
1o3VOzfmW3nOEAEEfAd/zQJVrz0GG6ao22zFSVRHEpJle8QD/HTsZ5sWIwCgiYNX
Ok6oK9IdCky3kl0xwE/wkpMD/jKoZaj2/rc7t8ZtwBf9mQFECou+SsM5YFFMx2JV
nHShx/6z/d1PWu59fnPOP/t+QkqBa4ds5msot4wJFqsFwuTmtCYySsK8j9yBbh6B
KH2Iyjwnr3IFU2PopIxzscuGT4EKbLes925X6tjCfx+r4uGIVSJ6Xzu+9jGXK0KI
TZshBADIuS+wneCYZ1Wnc/cwaG3SMXaVTOkThQS+l66o3BfXX77TN0HbjB+/CmP/
lWjcUv4tTYfmI5kQg4pRA7rSEsMBwec19CIy+mf9QD1HDVNGex1tGdGNz7oaOvwm
oT2nug8mCt+77q4ESQOmfHzLjIQqKh9D8zX08atp7EVhHw2sH7QhU2ltb24gTC4g
TmllbHNlbiA8c2ltb25Abml0cm8uZGs+iGAEExECACAFAkWqLeQCGwMGCwkIBwMC
BBUCCAMEFgIDAQIeAQIXgAAKCRAEnHSA/3SQqxOqAJ9qfsJx+6hT6qXy9k0Hkuto
pyh+lgCfS+cAvWkzwcTlZwmj7xnVMqex1T2IRgQQEQIABgUCRao0HgAKCRAV1ogE
ymzfsoOMAJ4qsIQaHkhYT6FB06o9Hjd0JElbzACgkPVfATTcp5dDhiry+UMCPxfl
4Wu0JFNpbW9uIEwuIE5pZWxzZW4gPHNpbW9uQEZyZWVCU0Qub3JnPohjBBMRAgAj
AhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AFAkWqMP8CGQEACgkQBJx0gP90kKtq
rwCfc6UlwvCI+OQ8PV4Y7xVVNK8ZWLsAnjAOOQET1C1XacStkK9icK7u/n/fiEYE
EBECAAYFAkWqNBwACgkQFdaIBMps37LD1wCgmeJUFusBpliqQMpOYaP3KL9/HDIA
oJox4FwHo8yhvqG7ww92FMeknNCxuQINBEWqLa0QCADNQVSiZOL9KwsEGkCLtUGQ
l7hmf9iuis/GxokTE/9aPYiCKx29wjo4b4pURS/gHdNGU70KNfqli96Q1zlS9CGY
KhQoce0ZDOxpO/6ZZzaOtLw5x2/8M45BDJU45STx54+F/7Lt3hZMNMlNvjZGF/W7
f5vcsPHqGAyFjDkjuL8QQqhsbaPsCTlqngFYh8/4F06+cd4GM85xGu/LM9M91TP6
9ulvz4H/5TiUNvDjt1e82soRhwY9bwHxq7b6s3Q4Wgwo9l2Y2oW4T+TVpcCvgu2D
vUSXo4U1ygPFl/CQ2Mz5IEp7e0aanzOU5FhMeEoAkJewRq5747noEcnygiPUuoOT
AAMFB/9KyjWpXwovVjmNITIB1JPuZSO7NLhA10SpeFz0YXJVIiteQcHnUHOUn+7i
tO8XbOg79a2Pz/5tLuX8YqNQQjODFKpFnFymlFr+aPpzEJPoXWHG1FkcM7rjmLpy
gj6eokmEdQdr5CflY+IkJMNC0DxDfhsI17fQVAsaScWgnmSgfCNYT7uPFw8K8omH
WawyIlZuAKa+l1Q03IFt0oDLqLrcMK7DnSJvSkyM7WcH+3ObsMaCXVziD9LOlW5B
M3mZyXS3Z5A8/menv1lRYm7kxCt17HEmhxnHM5waqFyK0y++X86lNpwmBQZgzTN0
2bCE2wlPqyT1LCVu4s9RAyET4hy6iEkEGBECAAkFAkWqLa0CGwwACgkQBJx0gP90
kKt1pACfS9WAfr2P8Vx/ps3WYdd8QYumnQsAnAwoaIe1d968x4FIKOewpptF/JdB
=ggBj
-----END PGP PUBLIC KEY BLOCK-----
D.3.152 Anders Nordby <anders@FreeBSD.org>
pub 1024D/00835956 2000-08-13 Anders Nordby <anders@fix.no>
Key fingerprint = 1E0F C53C D8DF 6A8F EAAD 19C5 D12A BC9F 0083 5956
uid Anders Nordby <anders@FreeBSD.org>
sub 2048g/4B160901 2000-08-13
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDmXNAsRBAD0WcmPy11DRvDsEpadBPCATmPrvAImfj5XjcxBAJlBJoc9fiq4
8OcnipVdId6STdVKvB3K3h9aNsb75+rD/W3nMi8MumjyXJoHAf8d68cnjppizcPd
uQPOy76lkbiyV9OYBtaNQqmU8hE8MTr5Kew9NBCoC4SB4NX8kVh8iglrZwCg8J4F
ltBYDz+Z5ZGoh54fnYN6IAED/jO7ISCvWbFtnzCw1FOghcgueqrWoy0OYKq8ZfuO
m046fuIlHcswJOKLLexTajsYAC0WWe9H3SvKvv1etexMh5SsrgWTsSuIvlPfG4oj
D5vIYqvH5NiqJdh9qiFEzGsv44jgESDVy9qaErbXRVe9htuRZqbtEPnB5cRRwTr1
WhfuBADW1VLXj3UGw4OeBBd5KPIYXCx7RKS4nfrlBCqMcIaiD+K42U+7PXEJB8uM
2sJ6uRYs0j4tTLBbDC2TC1QfT5NIVLG5wWkIh+jL7PODH+i4LF8n0pQyuLwJOFAx
s6RIHNPB2fdI5sqB9lMIBszlb896wVJf9PPWFAt/5Aekw7eTLbQiQW5kZXJzIE5v
cmRieSA8YW5kZXJzQEZyZWVCU0Qub3JnPohXBBMRAgAXBQI76xZsBQsHCgMEAxUD
AgMWAgECF4AACgkQ0Sq8nwCDWVZnYgCg4fzk40pYLg3iNayO9dDNp4yHS/MAoLi/
WCYhNOS0TMpap9SQXC/2e0MZtB1BbmRlcnMgTm9yZGJ5IDxhbmRlcnNAZml4Lm5v
PohXBBMRAgAXBQI76xekBQsHCgMEAxUDAgMWAgECF4AACgkQ0Sq8nwCDWVaoNACd
HR57Uuyyti+OqVr4zaVEIgg+bYwAoMcFR3xdqArQmp561541p+k1IBUWuQINBDmX
NGsQCADRkDqg2uW9mn5YCXlzx9KlhAfPRny6kF4+B+ga0ZaIzJng2pY8EsAxKn88
yH6ERs/PYdsy/AyksG8vzuc9CalW8JFEc+kvtJIL0HhBonlInaeUWHPixGEcOPcW
ab8dPhW3zfEgOqquky21d8Zg+G3Z29tmKGcYKSQgt6W59z7vITK7+gv7tOGp2IpZ
1kGqPZn+JqvB3n/uWo3rTxOGA/tduMwfESA5gHmEzKmU/17yIkE0SflKOp0VIGdl
Fp1A1ULJDDVXjtDkxFvZ1I+WpqF7p9FCgy/OHUfUa0py3uHIEKMahqpAZ9e8D+GI
nGizPR33ZY5PfM72ABXeGhFnweP/AAQNB/9HPBzxoJJFJNLyosSlI+Wkmh51K/nC
EawQG6a+tgL6cPHgJQkgthPUywkI+2g7SUSurgPz0hRCPg2PjHP3PwVhjKzUgfAj
y9eVnu+JSpst/a0Y5LEQdNnwG+Y+Cs0q9xj4T1VXw8B9fA3y1wS1a13zCQjfLrZP
ziIGjHIBvpOFrSU3ML1rRaVfQpm2wQXsGHzjkaZq7HQy2EOVLzik34XkPBY1DrnY
nSEwSurfjTrKTLNYsN53xCGwJ2w2347qXr04j87XhRmGCJQ/Nrrin4z4LQ/zNm5Z
bErlts8PAfR13kqP7rx/H1n5obhpOoXUqb4Rm94c0r/s9JRah9ppgADRiEYEGBEC
AAYFAjmXNGsACgkQ0Sq8nwCDWVbTvwCcCG0X50Tq7V4NeGgREttltmR7UlYAoOgK
1OFsIdCCq6JjrwvfN7ry3pwc
=clge
-----END PGP PUBLIC KEY BLOCK-----
D.3.153 David O'Brien <obrien@FreeBSD.org>
pub 1024R/34F9F9D5 1995-04-23 David E. O'Brien <defunct - obrien@Sea.Legent.com>
Key fingerprint = B7 4D 3E E9 11 39 5F A3 90 76 5D 69 58 D9 98 7A
uid David E. O'Brien <obrien@NUXI.com>
uid deobrien@ucdavis.edu
uid David E. O'Brien <whois Do38>
uid David E. O'Brien <obrien@FreeBSD.org>
uid David E. O'Brien <dobrien@seas.gwu.edu>
uid David E. O'Brien <obrien@cs.ucdavis.edu>
uid David E. O'Brien <defunct - obrien@media.sra.com>
uid David E. O'Brien <obrien@elsewhere.roanoke.va.us>
uid David E. O'Brien <obrien@Nuxi.com>
pub 1024D/7F9A9BA2 1998-06-10 "David E. O'Brien" <obrien@cs.ucdavis.edu>
Key fingerprint = 02FD 495F D03C 9AF2 5DB7 F496 6FC8 DABD 7F9A 9BA2
uid "David E. O'Brien" <obrien@NUXI.com>
uid "David E. O'Brien" <obrien@FreeBSD.org>
sub 3072g/BA32C20D 1998-06-10
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAy+ZtI0AAAEEAMPph+5fYQ4pUXUCgsXGqWi1LuxtqSP3WC/20zlqOUq35T2e
/3dEqFXB1Rbzz7rhI8hraDyGybexiO9OcQMbxSKBha+BnMyqhoTM7bmzSZCRSWtI
Q3ugC5Q0O6RUkrHL3k88h/Q/9IrqCXIesMaeeWOIit7tJ9dYgWVgqaw0+fnVAAUR
tCJEYXZpZCBFLiBPJ0JyaWVuIDxvYnJpZW5ATlVYSS5jb20+iQCVAwUQNmQ3lT/Z
OshBzgmJAQH1XQQAjUh3qkI0ZHl9qT9cKB0luAA++27jB5muW56NhcgobAje2T3Q
JRosYrHJ8HeNfp8bsYitsfxMiLs7PvRGFbYopFnkApEfGoxh9MVzih/lvDLp9UbT
fUvB7SVsV+T38/Cxzs4k+mPh8CZp3ACCG2NzfmIW73fVwJdpejkPHLkq6wSJAJUD
BRAzFpK2Q+yGnRNLITEBAT2wA/9Oq5mKzG/0P2q25cc2fQzqcLpLL/QqJRf74Xns
Qiz8wXKrasUNpYun9NglgER9+D9t4AuZtsFI+yOfuS7zDoNUhYpkq5Zr4PGYYHyi
LxY8Gzxv4Oa1atP5XMjRkP5UzyQLERAcHJwYZK/aE/wXkUu7qFspDeDTNNXZ8ddr
qV719IkAlQMFEDKRATFlYKmsNPn51QEB3msD/jOwXQRYrOMzXux+dfgQNIt+ckaM
tXn4+20u0Aaj3rPqMU6QIoTvsMcG147q3TYwq7pXYvdujQpbPjC3ErBnM1gh4Xvq
Phqf8aaYzfUF+0rxwVbUh55VLnMC6YHY+KzjHD41SMC5B/eScGog1tojvO+qxri2
3J+6Bk/t1sNabBAxiQCVAwUQOXHPRKRQkCwJ0+ZNAQG2EwP/R3igrGUwGF2Fzadv
U6trHulGwvEnLy6JF8tBstifVOubJWxzliHpB77Vf34onzG1a1yezRqRUsrzSeyX
2StbJtG9M/3hYVVSuexHzsItnqcAcfggzQs275XV+EJ2JtK/zYp0QiusmPQJsA/R
C+A/dSG+7xEtyNq9p0h9VHi32f+JAJUDBRA0didEq/8HtEbzIS0BAf5oA/43tqeI
pgkuyKvCg28bX0YtQBSJo64ohFsSgQN2FANfpghH8dhfQt3/AXH3jOisHA7ESTNx
ZT8yxPl3T4ZhZ3VILlldeuAM4g1U/ZDS+IPJMu7Rzwt4XYy725X+fLVeWoPIuIgp
vX8+8hc7v6NkV2nwBMgbRGoblAzas2K79skXvIkAlQMFEDa+UHHKbyuD/AwC1QEB
ULYD/RgnK84Wf37e+5WGQbHgzUkrXXxzfFpRTEV0owBSK5KA7+qlGVQVFZJ/Qz4d
EwU0EAHj72uaxVuYAa+fCaOzD/G6VOv+4r9zout8dxPYfK1RLPMg/5hn0Jqf2Ce7
33ibK8NUYtjMY5z0F5wjEdiieSsLIsT9J4dB2ZODT2Hfe7briQCVAwUQOXHPFPLl
ZUzmDiptAQHgMwP9EdDJkh33cF7UQu/76hKFMc4FkTOQgvQYx2qnl4ZeYgjs4saQ
roj92c0WlGbdsUP9U6lE1o0CkuMKyxsfagc/5SQlqgMiVYyr4QKRBiHVQYQJpSdD
6ldX9mmtHdaawPw2BuEke97MzHA30S1pgfsHb2x1CQ1SCEgqSU1yAm5IIzyIRgQQ
EQIABgUCOA0WMAAKCRD168A8ggVe99e0AJ963AhynrQYwfkqgywJpxN27blObwCg
m2LOJHiX/iBG1JYeuE8bYpdhlKy0FGRlb2JyaWVuQHVjZGF2aXMuZWR1iQCVAwUQ
MsRyh2Vgqaw0+fnVAQEnxwP/adrTqBG3BsYkDcG2Um3r0LgjcrC44HSNgYrA/rDs
OmeoK8pmCaefqhvEshmI/TukqmfCKMZM7DAoGCV+20kNqvsqSP5AG6ctBoM6bQxj
7oMkjLIl/F4Ryob2zsJW9ozR1lyTbo7mWiMjdZqC3JQzKOPUmJECN1UdnYNzbpAO
vgu0HURhdmlkIEUuIE8nQnJpZW4gPHdob2lzIERvMzg+iQCVAwUQNmQ33T/ZOshB
zgmJAQGrCwP+NNVRnjjcNo41qkTsRW8bhqhbHrHBOlAfq+3kT/gM1xUAcYsQOKur
gBGNMAr3wew8ApsUz7QgatFLTgxBNX/vS6/7hUuqNJhBAwpCG6i4lUFmJKONY9YN
D9tP6VhNMdBLF76yUhxORPu4vcxPOqchN/Jgkevjf9ONnIYDeV/hySmJAJUDBRAx
0fuQZWCprDT5+dUBAczAA/0fq4ncYY1FqCSqQH3nLO60kz6vmo8IlTI7cpL/e521
TqRTOK6HLXYrnVBI49D+oN99TLGTlUk+jOrHc7Y/js0IRLZkKcNUsl3JVIGith7A
PaKSFkMVNF7BrIjqHIWzyPuHs1w7z3h4BmFUTQ7hc29QYlW2rgE12qvxwesQ7B2o
HbQlRGF2aWQgRS4gTydCcmllbiA8b2JyaWVuQEZyZWVCU0Qub3JnPokAlQMFEDZk
OCo/2TrIQc4JiQEB22UD/0LP2Xn8Pasaq1IoZ3GUSEG25y7KK+GtJ9pR/XDU7Eil
NB+GvKw5amL2vjxQNbphb1TqJ/dHaqKvAunMpLbOMUUSqzzZ34orPqLcB4LCq8wy
Djch1sZzPSHPxI2zrAB3AQgbS8MXMxXoFjYFmxMtBSFZc3JqrkcTvu8KMXluTBB4
iQCVAwUQM2kkQ1dBBKOknqTZAQHwjgP/Xtg4VaOoHkqVo3SF4r9MkAtgG79k7pz7
dlIlMaYGJB87flG5PpPHI9o+9txWQH4vkexaGzUsez+Jgna39lhM2h3Vi7ekRK+t
a76lHOYq/6B4FD9TpLYAFIcukyVDJJcsxDZD0WRtoYkG3z0GFRIeZtV5nKdxnpdH
oop1rotiL/6JAJUDBRAyxHKdZWCprDT5+dUBAenWA/93EfJZx5fuarjQ7AnQiPAj
Ai95v3Rlh13+N9vC34+C7RMi9pIj6B6PnWTNbVhg8RY8S6hB91J6GrN0KVLD8yDp
Y6+U08Yc47fOfSWhPopNDfqgviGw7ONmc2QCWEKpcH4c1VD2jJIr7iewfVgJAiKd
EB8kQhrutuQNDNNX1dCSCYkAlQMFEDR2J1er/we0RvMhLQEBJB4D+wUr53bKlokg
6LAa57g9EfeCLZSSlLArf77vwLoaLKzsdoWLQ908VNmQZQbUt5kt3O0Htdx/zRTP
kqzV2tKW0aA7D5XDWJyv1lfBuv1g8C162s5voiMKz6WyCynP8n51nRlXaSHtxWql
LBBQ3IIzJXGd4AekQGBncx8o2XSYdQyLiQCVAwUQNZF2YbNaYutZnzI9AQHCzAQA
hFX2gAvH07D1kO0b9Mt9p7b1MFJgSKc+P/qfx36FAOJfjWtDicsYItx2AG0g0p95
DpZRwFa1YH0qrF1pXXTlBSFwRSmozArlToNkEOKmO7LiLrDsyXQEta2X98A1zfcg
+WcUB0Og/qzege2hEs1bSvIOTiDlt8WczMX9f2Fl1MuJAJUDBRA2vlB5ym8rg/wM
AtUBAfAgA/9oGE45DxXJLVSpE1+8NjtEN6O8i826PWP1EkbJvoFTDGY2e0IojtSx
peiCIikbSSF4uOT3B7WIEmZVyn5ajx4RCKzoRcKVfgu7i+Y57wExoZSx8VrjS05T
wFQ+RbHSXThyO1HZCYdfSaaYVfrrLv5ooTBRHzP5DlSXk13nddBOE4g/AwUQOT3B
NOMeMj1ArjBSEQKxUQCfY3XjdW3Yun2hWKmKaPpXDBKonz0An1Wr4nbjBvlsovrs
eysWYs1ovDgKtCdEYXZpZCBFLiBPJ0JyaWVuIDxkb2JyaWVuQHNlYXMuZ3d1LmVk
dT6JAJUDBRAw9rraP9k6yEHOCYkBAZjmA/9lczxVp0UjLAXM3jfErQv2dzpLDAiT
QVp10pi+a8mAzPVCnmCfcNy4fQJbInAfe5FC8gxBe9DnsjLfHh5vlZzDHANpbq5P
MLW5C2igBoAg0Im4RpevDhD664ZgYgB6HXHhPBSB3Gaarnpx+R6JpfDBolSg6Boi
IN3q+kzftlTaDIkAlQMFEC+a5SFlYKmsNPn51QEB/tEEALKURfb7Y7metDHx5oV5
LybWyV8cTJKINUllX8HDnz6zZQ7bMYlQ0qsqRqEIDMpMk1tojT+/HI4te21uW0T/
FCemdm7leZM6g38Ne358L8jY/34iz0bIFeZjDzLoOKW5C8wtG/N88voiE0grVR3e
iFEmtwWT5lRaV+DmKYQ4kXxAiQCVAwUQL6UVDceLqoSSZB6ZAQFokgP9G9xfWcKj
CxbEr9TAEDsKIsNkKQKEFlfqGuAjSVWOBqEIyG0Wb1pZEQKHI379aEK9nVNSsQ5m
Qk/E6JRvYENt9q5uJ9mp6+wPUVYt83YL7uv1YJJSy788tdr1esutgiAeLNmNMmOg
Rw3vz8iKYJozmSyDSK/HwHS7zZ2Q9K5hpDCJAJUDBRAvoGvwym8rg/wMAtUBATFj
A/9h8jSR5py9wPy6WkjsYQbml8B2fVjsLzoQbMI+b5IFYeDkRYLTnSLJKzuK8zHn
1aFeXIhD0CRY5PC9jMAu84I59iE90x95uLPAH00rSJam2gEqPovRYcinADluivOT
XGAn5qN9bKlmdsFNLMIFs/rohnIFab7wG3+t+i+8YYY2YIkAdQMFEC/kX5DT8j9C
J2rqEQEBOFcDAKcdXpMcMjw+uSDwNc0pjOEYkfnpaW6MKnOo0qbwALmuSn/l21+J
eypp1kr9VeWKn9tcUHucBHyTzswxeu21jI/KUUIRzuQsupgnop5LyNNrpDjxbQvN
uiBIX+jAVQvxsbQoRGF2aWQgRS4gTydCcmllbiA8b2JyaWVuQGNzLnVjZGF2aXMu
ZWR1PokAlQMFEDH/SvU/2TrIQc4JiQEBl88D/1d/WSV3W6RwZQUnbSp1GELg5knB
87imzxf3t328/vzRRFUgAeB9qcW9fYRwdhZDs4ffUASm2fXSbXocnRdGDJMKaFZo
oJpYK95vZFc0irLhI92w2RjLH1tF/W0TCopWMLN4KuqYX3PLMzQEcj08w3BcwWXw
D0UuVD91d4WeljRZiQCVAwUQMfQd+VdBBKOknqTZAQE+mAQAsE8nykNNff0IINOC
NIBLSQoldsWtZrO8aTlUI9Exf683zWeOQc2zijraJbEhj+9nXY6qYI7Gf+4N2eFR
vN3PkAyVcBAaVHtQ/Q1/HBCjEwY2TiU05hktBSEa7M3XZyy3+YKjQlj2JSJqvA0f
DI7Mv7xrKLZEi3yrO7HZ8xO6NJOJAJUDBRAxlKZbZWCprDT5+dUBASQDA/wOt72i
yCcgku9VCU8tu5ITF2sbz6b2Zp7y9plW4UkWCjXHfvahpmiTRXFkc6S6WykLoyjQ
Hxw8IjsGR/J+2EcdnCHzcWv4w1/COIb8lAShu9pOiT5pTdzBCPNqdCQFBlf9/S1j
FPHv+1NbEx5HfkJbuwhiACy60GEpI8YLhUB7zYkAlQMFEDR2Jy+r/we0RvMhLQEB
NkMD/25QwNJRTtAB9fw4b5XNcpTxBpkMNBQ5Xc+NDeJ4uXt4ET3U8tNwFqwg0DF+
8SyeWXfRzgPiIj5A5I/DkJAPVlKz4R4QFDMtsodj0p7dpiCfHb+DOXh+B+iCT4zL
us9PFL5CnV5aXfSrtmkYMrIVfXRxVYpDAjC03ZP4t0SAKWNIiQCVAwUQMpHsW8pv
K4P8DALVAQEEkQP/cxwPYVHiztp1Znd+6Z3T+NCWIpJS8sPZmqc+MR0PG7BFXREV
0OjHVTT2uOo9UTNVXWTCO3wZSvWl/nOxlurMMxBQtXlrVZ83jDIeOjBEC5AKGFTh
UVpFx/YcxnRFXGiZ/bErqEPiohbu9i1TYOyiSOr+PArlinqdB+O54bij8G60MURh
dmlkIEUuIE8nQnJpZW4gPGRlZnVuY3QgLSBvYnJpZW5AbWVkaWEuc3JhLmNvbT6J
AJUDBRAzZsMLZWCprDT5+dUBAaYZBACu9COxVsyXxjJrXo+4DdazJYgcbH8cZstQ
2VUlT9E+8ZJ4iL4H5qIqvtkp9eIiZdi2/ovv9wA0uV0MZdPS3IkqumKrz4UGbwLk
Y+VMTDtJwuMztfia+qcVx/HLuZMfuTAB/fyuJLW5i9kb7X3yUSbr/9J8p+4da0R1
YMj/mKuserQxRGF2aWQgRS4gTydCcmllbiA8b2JyaWVuQGVsc2V3aGVyZS5yb2Fu
b2tlLnZhLnVzPokAlQMFEDJmySJlYKmsNPn51QEBDVED/iaXSckzmJmSli4El3+R
QwsKy/eT4CmwzEH9kFlYJ+qYYE3tIG7oVMiBkKMLj95Qk9wt0xMXo1NsD4PsFDOJ
XfyUcJ+jl3jwGraGroVvu2Lb/0UiC9qXPmNKeYopQCrswdx5EUkAmLXA4lgfPS1g
EeEPQQVKbMc2DBXhUDubqbdztDJEYXZpZCBFLiBPJ0JyaWVuIDxkZWZ1bmN0IC0g
b2JyaWVuQFNlYS5MZWdlbnQuY29tPokAlQMFEDNmwyRlYKmsNPn51QEBwT8EAIVR
LR03d2nr6xjGFNq/1B+o6lZv9rKHBxQqjG6j/hzUhQNnywKQA0hEucVSMLyKsXSg
0Prso1Ta9lZFqrAnqCFAiSt9Ed/BQdFYBygTUAXKkeA6cT8pe7CaqSocWYTjGmfQ
7Ol1zBz4o5JQWNOgGCkAjBxl8gbd7yjV7R2Pg8kPtCJEYXZpZCBFLiBPJ0JyaWVu
IDxvYnJpZW5ATnV4aS5jb20+iQCVAwUQMf9Kxz/ZOshBzgmJAQF9QgP6A06oVvhv
XESbd/Y8FogfjOKw+sr+6ok+VC5cdC5a/memKPejSj+UCVe3J+trgmmvDEorQHat
P7ceDXwDFbfXxM5wLHSUXpDef+FH2g4kA6ffiTVkgNiXeLIxhSBtDSJjV69VHIki
lg7M4iN5EZkoeysSLGqbV2JFZr+N5E0fn6aJAJUDBRAxkFNfZWCprDT5+dUBAV7O
BACntPk0/VswGltxwnstBRS6lJwFEye/aHme58nR5teMIhntDyxY42cFxv06hGNC
ndoUqPfAFALp5TIs7c56vB/m3ii1VACXEJUc7yW5APwjYSoM/Mjoz1XKo7Y5C4+6
xENKH2jpRKH+q2hjblcC2VZ+pJ/Mv/Wej+fBGkMF9n+0dJkBogQ1fjNOEQQA1ynh
Qpl7E31casIlR7+zFqD/bs1LiC7be0CAxi8hFnYQ5KlF6lMfcqx+gdcuKt/FyO2d
jhYeihFww2cjkfZ7bANERffofnvdkXzegqOhd0jsk7gbgEPo1fh5dJm4e0qo5eUo
0zI09wLx5yjNtWWnNM5o4YVxaa0kiC3DKdRwXIcAoP+4T5LqLm0FMXR+Uo1Sq7Mr
LVn9A/sFkOT8Ss8+JSwxtk2QIAg+QvmvyGl5xmL14zn3NpLSwocFSMX+2fXBAEQz
lhBz38JI59DhIbV+7XlIjsd+Id/8CFTzeSH6oR1QnBFEE0fmcGAGAAqn4oX8mHc7
bVQxrxzJlMFILts69fTdqJURKjwNuYZbO8OxelJTeHfjxc5Y1gP8DBwxtuZPVJw4
mymwl0DoQwEbrC+mKBTdyZ3gOMv0zN64KFEKQZJPfdtfLy5Wks9k1x+53vp8ZXV/
CIoDf0hvbuiunlifyyklLi8nqNa+KMRmnws7XkEmgQTrkIV26V9sRCt8EOuDXZ15
QWXwcuSRGvt0lqUztokAuyTbSNJy45u0JCJEYXZpZCBFLiBPJ0JyaWVuIiA8b2Jy
aWVuQE5VWEkuY29tPokAlQMFEDm0v3AA8tkJ67sbQQEBlVAD/igpVJFYq5HGrOpV
ZgL7WgAzvf5cU0hmLi+C+Tm8kF2xL3rHNlUnzzdl6BxhLXfJ0xTEADsLUifBJPxQ
AwJyG+Abbf/gciaYwZn3GFwPKbRQJ6dmzBX4buq2cMzs9oKANTAIQACgkhFOSs1H
FcIDaa/VNeP9ox+xcnp8WSGM49CGiQCVAwUQNX4zzWVgqaw0+fnVAQF21wP+PK9M
lfIcaOAuQVMgQhsDWqlj/DdxtsxT1GOnlHp3JGxdThyxdBDrxmiU22a6216s01fN
5Ac25USeKRCcSVyG0+G/Xd3VfWDCEQCLNBwblAGKW9BEZfJhS1xOuTEYxgbmuvrl
LTdvWm+MwPetv8kayhD1LM4rVovMxenaPYUub2SISwQQEQIACwUCNX4zTgQLAwEC
AAoJEG/I2r1/mpuiz/IAn12Jm9/9Dv/b4gIauJlzjETOxhMoAKCQkYkZoX8/OMgg
uxkmPy4tgYut04icBBABAQAGBQI5cc+lAAoJEKRQkCwJ0+ZNB5sD/3NrN8ZYP7Wi
q8Zb389Qwc0JFHB9+EyFimhPHrLGgFBrZXM98YWd4wnkzqzeRKHuQMnHVdBG6z3u
SJEU8Rsl4KepiujxjTeT6SLjUwAR0iG03O81GU5/otBtsqTIiJJdJD5tSPqHkuXx
i7ruAF3eKlobaNFNzQYOjtdF2Oz+UfW0iEYEEBECAAYFAjlxz8MACgkQ5r/NLxCB
o3xeGACgnDA4cV3ts1eueZlof0vhnhtOtVsAoMxzJZorbcesWEuFDr7/MONCn5Ca
tCciRGF2aWQgRS4gTydCcmllbiIgPG9icmllbkBGcmVlQlNELm9yZz6JAJUDBRA5
tL95APLZCeu7G0EBAZECBACL36sVALZfqAh6Ku3b2g9EKMBOCzHv8hJmFHCw1uUH
4SU6dM2DeIJo2nVBaxtK4/G/0f2Ed7bQJ78C3GM1oF6LZiRQzEX/QlwZQSS8cyPT
C2H1j6J8ZnOMnbytE/NFbjLZDSTktKd8+4GNe0oDTB3/juqva1OBmSsnj1NhpMsR
k4kAlQMFEDZjny5lYKmsNPn51QEBkUcEALYsZckj5fs7uUzjSgyzF/2RrHJ5gGrp
NBwikiy1+wdZ6bz8CQ6kcYC3Dap3iHSc9KWTn6sK5ZvYXcYD9k7is8V8zuitUrrS
GWpY96qmNsCTvPSwfwIcyhYSIJYjdqmv4EnKo2mwkY3zqOV9DT1ABFLSI9Eyy8IL
euhrm9jWEXs0iEsEEBECAAsFAjZjnl0ECwMBAgAKCRBvyNq9f5qbor96AKDgZmSA
0aJZLBG9IjT+Ol/eqUbFPACfZ0z5wo8X4/aD9MEAbJRJQEvGsHyIPwMFEDk9wNvj
HjI9QK4wUhEC9wsAnAgPzultU4+iO6c0mhJMBgFyAwriAKCZBIHKp2TaXPl+JYk/
k58afcSTh7QqIkRhdmlkIEUuIE8nQnJpZW4iIDxvYnJpZW5AY3MudWNkYXZpcy5l
ZHU+iQCVAwUQObS/ggDy2QnruxtBAQGIGwP/a2m02NL+cJ/BoIFINK9HN+mOubYU
To27NN/uNyvIqUnvN3JiOv8j5/cJOUDUjEPbZve1y5izyDyw/4HxBk6OKAKWJ4tG
SZOCEndBe01m1e2rczkjw0wPM4VcPVUXyt/432e44fo+pMczvtUFWQdz1inx1auG
REqu6xad7P5nj4uISwQQEQIACwUCNmOeugQLAwECAAoJEG/I2r1/mpuilcMAn1Vu
g9cpssNgJLaNhmD5ftmivVk5AJ9X673ovjPGPXRnlseGkldpeyrUCrkDDQQ1fjNQ
EAwAzB13VyQ4SuLE8OiOE2eXTpITYfbb6yUOF/32mPfIfHmwch04dfv2wXPEgxEm
K0Ngw+Po1gr9oSgmC66prrNlD6IAUwGgfNaroxIe+g8qzh90hE/K8xfzpEDp19J3
tkItAjbBJstoXp18mAkKjX4t7eRdefXUkk+bGI78KqdLfDL2Qle3CH8IF3Kiutap
QvMF6PlTETlPtvFuuUs4INoBp1ajFOmPQFXz0AfGy0OplK33TGSGSfgMg71l6RfU
odNQ+PVZX9x2Uk89PY3bzpnhV5JZzf24rnRPxfx2vIPFRzBhznzJZv8V+bv9kV7H
AarTW56NoKVyOtQa8L9GAFgr5fSI/VhOSdvNILSd5JEHNmszbDgNRR0PfIizHHxb
LY7288kjwEPwpVsYjY67VYy4XTjTNP18F1dDox0YbN4zISy1Kv884bEpQBgRjXyE
pwpy1obEAxnIByl6ypUM2Zafq9AKUJsCRtMIPWakXUGfnHy9iUsiGSa6q6Jew1Xp
TDJvAAICDACbUnOQOcw3s+pOH+FYx/GmyXVbPBDQt5wH/XlQQq+pRl5EVxMI+H/q
VW8kvrgrY7iZXBNSdfj0RgONxwr8NBASkQndd863+8wYVBdc7x+uPi6XF5JABqh2
asmx8F7F4shq0WJ2QfLmk37l2mdBmFyhGuOlsr6Z272BbigiZQoicVXuYilUUrax
hCWQ/nZZm4/Be2RaOhqX7jegPu8Zmkh1PqKoIj+HAXrhs/o21tVFojeZtc6f5Lap
0t/lhFE4Fq9VrvK8GtnuU6nvVoZv1OOk6nE9aghK8qP27OEW27OH6TwAG/SE83IX
eIpoFZp40RWliVHeE66iNwsb7r5f8ZNsVtwXF7JttqORySwizWg1KlFo2odWmAGx
s3n3DtOa9rrZsvPZHlReFuZG6q9C6MDBPb7o9wPVFr9AbVA3Kgz+V4uEuM6NAZn5
K+XEOEOyBf5bdjVBdfd7ZRqXhzUrqK2C9HTaEo5H4g6X4gUHp2x3jtyPKHTG6Eqm
OwSwTfpoWTWIPwMFGDV+M1BvyNq9f5qbohECA8kAnjryv1dFUQTWTQGJJ29hn1Uy
lSVmAKDF3kyQAZDAyz+21MQJnmJ2O5dFJg==
=cMCa
-----END PGP PUBLIC KEY BLOCK-----
D.3.154 Philip Paeps <philip@FreeBSD.org>
pub 4096R/C5D34D05 2006-10-22
Key fingerprint = 356B AE02 4763 F739 2FA2 E438 2649 E628 C5D3 4D05
uid Philip Paeps <philip@paeps.cx>
uid Philip Paeps <philip@nixsys.be>
uid Philip Paeps <philip@fosdem.org>
uid Philip Paeps <philip@freebsd.org>
uid Philip Paeps <philip@pub.telenet.be>
sub 1024D/035EFC58 2006-10-22 [expires: 2008-10-21]
sub 2048g/6E5FD7D6 2006-10-22 [expires: 2008-11-17]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQINBEU77U8BEADNopKL65b7L+pfgiiY2zp+5RS93iScvGA8ZOqcXei1FgT0uOtL
1xj68c17EsNmBif9q/h1I5PDQYmn9GrqyITNevQZ2ZMRScSZ0I4Ly4nZtJdgsT8V
lEnObIknaoERyEtNabC5h6PsyZpIFIi/oYpoYT6DEeUudVUJFi5pY96XNzh6fdPZ
cfw6N0mED13V2TH9twV4MeorwYBSE6mFE09vM1yPm12tiHFE2+EprGJpXttyrzrz
D1KGKeOSSlZim0L60P/TY+WW66xz+aDX6QLIw3AdUjE62KmWiYfjhkRA2biZX2LI
m3tFCLwpMIdpy80Lg0vlbh0zLVilX0ZE3iZSNzb1hP4q1QxqblSiNZSptSxMClcX
h1J7fk6laCX/cAXzTJpFcEVxGlb4D0ryz9xJ+oP+AiRMmm4Wenxik5m5vJWPX0n0
lqRC+20xBbgrBcD7/mKMZYmGB4761OVjRbZNceHT92zslfAaT7iS25m8sccNF0PV
pYIySpuLHJ7q5W8FFaTelJtG54y+9/sHGFsRnpwPNEtuDGp+dGJ6tT7WOaE+5Agw
Og9YdhBIXXuyUTISA4289378aStGoEn3KOoGXG16eLtnulq0vPcfjPmwTcpoViV1
DOTfbzKFAr0mtlg2GEqCuRGBYUGx1PhDYVSwGaEj/nzINC2NVdC7NaxTVwARAQAB
tB5QaGlsaXAgUGFlcHMgPHBoaWxpcEBwYWVwcy5jeD6IRQQQEQIABgUCReH8KAAK
CRDH2TAlnf+q1JyIAJdIevuhvBW5sXOijprjLtIv3i17AJ4kJ56ezA9aaN0oflwI
qXS0vKh7IohGBBARAgAGBQJFO/SsAAoJEL9L0OYEnbh5Ck8AoLAjjoaNef0Cdvar
C8lXWCGOevl4AJwJQFdIeNmniWpwZPZTPEwaqGZqZYhGBBARAgAGBQJFPHD9AAoJ
EKsvWlsVJWmQOK4AnR9xGIGcndPS0DZQbJ/vy0KTYqExAKCc422e0G0jwo8/HeNn
nIgrSMIrDYhGBBARAgAGBQJFPHIFAAoJENuE1HYSbUfAMRwAn2vvGIgDa/UTsKd5
wMWzvL+sL5DHAJoCicwubB8WeBVhYt/CWHQsG5VCVYhGBBARAgAGBQJFPI+XAAoJ
ECakfGr+bYUPblYAoKOCYQ6u02bgTI/OJ3al3QIoTSblAKCD57JVvjVRuZxyhUB+
tHlVDKujtIhGBBARAgAGBQJFPKjmAAoJEFZBJvIp8ZvRllUAn0YLwcvyhSpzkHop
lDmIGfdxeq/EAKCDi8M9K3nk+lvdZbmMbg77Kv6Xi4hGBBARAgAGBQJFPLNZAAoJ
ENdZXTdLcpYlUZUAn0jBnTySxCvpC2Xh+7iTvYWxmauNAKCSfc6A04CXvx2T9vCo
5aMoNAGdeIhGBBARAgAGBQJFPPEoAAoJEGjhJSt9pcU7MxEAn3WXA5R9Vq0F+/Di
JXnOjdK9SduSAKCrGrW8rzc928ME1db/AR88MuhlOIhGBBARAgAGBQJFPPepAAoJ
EHPeaYzHFAWicf0AnR58NpBrEpcyGzRCQx1XyFx2S/2pAJ95mn84PpNwE06FuaQ1
arcDadeTOYhGBBARAgAGBQJFPSghAAoJEAbypSJtCNehRdgAoJvyUbWo7/LlrfpX
7kbK7yVzXV3OAJ49quz/eGaMnQNrFg5i3jJ1GnUAnohGBBARAgAGBQJFPecQAAoJ
EKrPs4YhG27vYZEAoOf3dDXEugnfPgNtNFc1qkl1GHXOAJ9Ybe47cmctcok5BaYr
4L+3tKthEohGBBARAgAGBQJFPhw8AAoJEKkX6cyZbhReKkoAoIc/7kY7769HMeql
mOhM2WGbOcePAJ9ZglKFonLbLitjG68SXC3VnfQKgYhGBBARAgAGBQJFPk8GAAoJ
EC+VFQiq5gIu5HoAniq+J8CPwGuz/WiatImkxDLfPjo8AJ903msFMWw6SoCE0pUW
Dgt7pxnREYhGBBARAgAGBQJFP9EbAAoJEJRq0wuHLLoEgRIAn0B4af684NXZKUjF
ZVDoTa78lds5AKCfmJRQhex03mJaZCICvNUL8HqQXIhGBBARAgAGBQJFQESXAAoJ
EOkjWjUYLJeDWCYAn1FOzG/SYzZ/wk76LcJtklcC9698AKC+v0hsGWHVw5brMFPd
w3Vj2SeLcYhGBBARAgAGBQJFQGdJAAoJELcooz9Fd1H3jfoAnixGZx095t/nYrmc
MWijYQw+k3NNAJ9XlD6jw9YKpkkHvk1gn33dqJmHrIhGBBARAgAGBQJFQm9mAAoJ
EAYGnPKWlFfwdPQAn3fWPnheVKy667yfNiVD+fOrbua3AJ0f3jKynS76pFt/UeaM
i78dS0VA5ohGBBARAgAGBQJFQnYBAAoJECXSjMWVfVjPSNQAoKYiFBK9HfgU0PoA
bxM76WzIO4rrAJ9hmFi43RN4lauVjPM+DiwqHsQCt4hGBBARAgAGBQJFQ4W+AAoJ
EGx2F4yg7ZgtCWsAoLuKmgM1YlVaKu7hbsHhsU6bpxOFAKCCVePorSYrPdNUN5lz
+4+ceq8+4YhGBBARAgAGBQJFRb/8AAoJELPOLSM6q/mS5zkAnAxU1e7gs5izUWYO
/tIXOYRXw+xMAKDU+K41+y32vYVhxmEbULQqwVbjmYhGBBARAgAGBQJFRhoYAAoJ
EMo5dFnlGy6RZ2cAoITx/oTtU8iP+4LeYWqk1bAWPI+PAJ92M4fs1JKkf2ZxfoUf
AQgimQ9UBYhGBBARAgAGBQJFRiJKAAoJEKBP+xt9yunTeVoAoIR0g1LmHVszgRoB
0pwE1DU8n9SZAJ9ACNW6ICsEJJhaMkKgw3ihDy1GqYhGBBARAgAGBQJFR4KiAAoJ
EJfO5hKrjj7VcygAn38UiWJd/Z9aObV81A9XIcZmdHSOAJ413JisZ7Xx4sprSkOG
7xKpmlk5VYhGBBARAgAGBQJFSa3dAAoJEFmm5/To7k54MvAAnA9gmtoxGZT92qnl
El1yZfLPqeCMAJ96DgG6DgFc60gRRQbFBzIo6+sUU4hGBBARAgAGBQJFSxxGAAoJ
EKwhViahIYdXXTMAn0stK4yLRAgCFhXbPIJcHSs3iL9QAJ9SHU3xK356wIxAZnjR
6sSR0rlah4hGBBARAgAGBQJFVGbqAAoJENjKeKUexWvsXCwAoMU/UV0hSkqCAzez
lzN24IO/yzRHAJwPL+7MW8dVm3uQ9wKIJmfAKJXcUIhGBBARAgAGBQJFVdoJAAoJ
EBaK712xKT80Ca8AmwU45F6J17RtiBW00muUiakva6L/AJ4uKhPEkvPCJgaxCKVJ
9Js0TraXq4hGBBARAgAGBQJFVhw2AAoJEBypWmNWsMoIntgAn2hh1rNlByE+80oe
x34HxhLXKa9QAJ0Q2j97jthjVlfmP24aYccG0yuZ+4hGBBARAgAGBQJFVxuCAAoJ
EBXWiATKbN+yZjcAoIQabGmBdoqm/h95xSNlNBNLbJPuAJ4ig+Jlj+I9NvBRInUq
Ayqpamv6+4hGBBARAgAGBQJFVxuaAAoJEDDUOm5k6+IgqQUAni4Pc1wYJmzdZnck
S/I8YuU/4WqBAJ9TqJ/yWIYrak1TtMqqnBdG2nUaWYhGBBARAgAGBQJFVyqzAAoJ
EL/kOH5U4nj4388An2ppiH19Js9Gu3mfJlNUmu6sOeMCAKC6jm3AsAo6OgSBZoRf
0KGFRe6e5IhGBBARAgAGBQJFV0kZAAoJEF2Oi+nyOBrUccsAnRH8NZuK85b2m4z4
b7eQ9wFWMi8lAJ9CRRNV9LLRhs2HNreUinhbIQeuCIhGBBARAgAGBQJFV0nBAAoJ
EE+xyIscE5vFHB8An1e7sohUFrzhVuqZu1K3IHkC1vn8AJwKx+KYiPdUSxBNdmFe
C2dyW788uIhGBBARAgAGBQJFV0sEAAoJEDMRJG1RR9z0j/wAnRUiytdSTQyphXVX
6keyuEhNixdRAJ49zPihwFu564OiNUotXBYeeHwzKIhGBBARAgAGBQJFWLI5AAoJ
EBdynXf0qFEvT10AniWl5EzY1e8paryrq69o6T2aU0xrAJ43/tKLK9ZBgMfd5p2n
DJpUnOfuOYhGBBARAgAGBQJFWhETAAoJEBRll9zcw5nHEp0AoLTanGw1c+kd2be5
GoOwMQRCIV3HAKC86gjb5KQXJdnc5PTtAjC4J7cv1IhGBBARAgAGBQJF4ZPEAAoJ
EJhL04CsX3AMU9sAoI8kPwa+N8pprHg4mRIox4Z6Z+N3AJ95DxG1xCABXDICvgIq
yyE5GvJO0YhGBBARAgAGBQJF4bTBAAoJEFAC77GWLjiQSJYAnRb8s9u6SpA5s4JS
AxsvN1kyVjgrAJ9uuMjEcECzuxBXORmWe85DQyk154hGBBARAgAGBQJF4d3NAAoJ
EE1EwCDFwFuu7g8AnAjYIh3iY80dUTh1y7/EK2BS5nF2AKCurITgX5MqpC7p7hdE
eAxm7npN04hGBBARAgAGBQJF4eVJAAoJECV+3BMl8VmUCI0AoKC677Qp/QSypd5B
d5aKVhh7b5FpAJ9NXSjm4KMPxARNPV09sIin51OPCohGBBARAgAGBQJF4enCAAoJ
EHhn1Tx0eTXdDpkAn3xDac92/uQH9h3x3sjRIQbZohx/AJ9yekb90xm2MjVgtLVm
O/SCA739l4hGBBARAgAGBQJF4e0/AAoJEFiD3l2iIpt4O6EAnRlLTZuD40S30q39
CiNEvVRCK1zKAJ9Yhy1MGxC0Qc8xH3WoNB4ueqKEKYhGBBARAgAGBQJF4fJRAAoJ
EFUVYHaRYekR5OEAoLagvPT+4HBwSty2XZZuS29jNGRtAJ95lKp5WUe3ER2sYvrk
r833OuDU9ohGBBARAgAGBQJF4gQeAAoJELOx+BoCeHiADYQAn0reA1SyGkNmiyQ4
0cVn78rptU8gAKCcdvYM7j0RiMaDjEC1VPynoAchpIhGBBARAgAGBQJF4hIQAAoJ
EOVE3gebfDKNzWsAoM9JTs5NQ9OPJo2EZ52x7WPnCXMyAKCEdLV0A3AXhaHlLVLf
AEgtEQkyAohGBBARAgAGBQJF4iIYAAoJEH5OpU/Qq0B1KNkAnimT7/3dHVhqEoq/
iIdWTaESQ2PqAJ9ANUnpHL2EH6QenQh1GQQwLmFQbIhGBBARAgAGBQJF4icOAAoJ
EHZJQAVJruv2rUQAoKP4K1CKRT0GGC+ZL0Rofre9QySSAJ9ddZckKCNiRfrB2pN1
My4oAeejq4hGBBARAgAGBQJF4i9rAAoJEAZVrBDy2EYvAewAn2Ie8313KZzJs2kQ
6naMN27UvsLuAJ4oyPJG8gSWd835wR0bh77IrO7WT4hGBBARAgAGBQJF4jI0AAoJ
EJzL2hYB+otKQ00AmQEvateRIFwRkE/Ta/HNRZXqdgwtAKCcuGJqtwDFoDaapUxX
HdAZslCJOohGBBARAgAGBQJF4lC0AAoJEFuTwC+eSpyd0MUAnRs2CUtPqqJVqJOO
EXOoZFWUInSqAJ9uneS4FclqLsAH66mJW+VTRKrGyohGBBARAgAGBQJF4quNAAoJ
EAMlcIRNIxPVLVEAnA0Ke4Rw2f1ZgaQhLbT/9cM0Xs+6AJ9X36YZGeCvpcsXceSi
y90pMI+SpYhGBBARAgAGBQJF4sEqAAoJEHMcr9NTwaMviCcAn3zC+aD4qvxydYaa
aiGKz+l7Gi2sAKDALKqObGPqy4Z4N5RfKuPO7JV5TIhGBBARAgAGBQJF4ss6AAoJ
ENoZYjcCOz9Pb2IAniTFUorVnGjEKdO9w/TJJIAdmaGRAJ9kpYcxnGdIVD1oAL2W
neimulkGs4hGBBARAgAGBQJF4vBRAAoJEItKxIGsHnFe/VMAn15Zp8l2sMLW1e/1
AOcakClQQlEbAJ4gpj7FIS1aOhMr0+mRJvxnBT14zYhGBBARAgAGBQJF4wXVAAoJ
EDACjSRIE7X+74QAniP65Ceim8Q+qbKTTKuNmXpSu1SfAJ4ygzPKrlgObMsQquxS
NH850dffY4hGBBARAgAGBQJF4yUWAAoJENOjcASuTRzUdQUAnApK8bsdAPd8PK0G
otAbGuuIoa95AKCie6nNpKWs2Vfs7Drc6it9HaD864hGBBARAgAGBQJF4yu3AAoJ
EB9/MmoS7vYql0EAmQHwplArFeZx/NwZ1DOni2Af/308AJ4yLkNYgBrE39FqKoyW
Cy82dcY3/ohGBBARAgAGBQJF4y6qAAoJEDiaVjzCcqEmi48AnA8jMLx3DFvCOcLg
SUIrmsTqhDkkAJ47e0GhQXBb3XnqyMesEKCFWsCwT4hGBBARAgAGBQJF40jJAAoJ
ECGntTuACWnvBYsAnRfL+aClyOhr5ZDiAn9VSA9v7wQPAJ0cOWhv/nnrTukXDZGe
L8iEGzlueYhGBBARAgAGBQJF40l9AAoJECic/8DmPNbWSr0AoKdXTD2BKi4KhkfS
j0rHOjgSX+EjAJoDmxJe2PM3aZXf/As6Y4AtydiPH4hGBBARAgAGBQJF41TLAAoJ
EErbH4hriFRDYyYAnjlE5pKGLD8FhireIHVJvtmVvzzkAJ402lHg1aq59DULHp+7
88MkRtXfy4hGBBARAgAGBQJF44RnAAoJEM8SNHyWi9WHElQAn3S/CXYOM50Ektdj
D31voZ79YxCsAKCBLTRPDbfpVbTaaNHFxi745LQxmIhGBBARAgAGBQJF45cyAAoJ
EDhzTXeHkBRSCz0AoJc2ytd1OY82O9zpnTWUd3EP+afcAJ47nc38YAM7E0ngqlWZ
0Aw4JowZVohGBBARAgAGBQJF5MADAAoJEHCyAyE69Z0W7YQAniq90lxQsl32RYYC
0p/ElRJ0gTAaAJ9ifxBOG5XfXYsDlyJM0fNtb4aUPohGBBARAgAGBQJF5XYBAAoJ
EHkOjJRh/9qr0L8Anjnah5s8iGbfQXtPLwFYgR6ihcmQAKCEuhMMWCm9H8EF3iJx
p6qnckpZHYhGBBARAgAGBQJF5amFAAoJEM6A78SRpwfkT6sAnj6PfrZbsd/nrMNx
IurtrQRjkyQ1AJ9An/37xHEptMJqGTihE/tYisX394hGBBARAgAGBQJF6ZYsAAoJ
EBVYlEWZ6B2gF9IAn0YPyBVK4M45P8XPoxzL58eysxBkAJ46R5Zw3l9poc2M0bcn
POTtM8tmZYhGBBARAgAGBQJF7dt0AAoJEDBp6SG3mocce+AAni00fXGE7PBdiVmM
q92/UVt6RVuGAJ0Rykv22dJlM+WT1r/3nkHwrwelB4hGBBARAgAGBQJF8c+7AAoJ
EGnSph3iY/zUSFcAnRQ0UDSzzhMriRkX6PeRJCC4t+ZpAJ0YlHN22zumq4uJ+H/d
x7LTsnQIU4hGBBARAgAGBQJF9VMgAAoJEOpi07Zqq8KhPJ0AoMgnZk/0N2WJVeWK
uCwOoS6vqTo8AJ9o7Qp7TXxyx/2m74XYT7RbTYJ4iIhGBBARAgAGBQJF/zH5AAoJ
EDqQ/8EUCNfxqyQAnAga162iTQEL9rLL5rAk9nsuFYotAJwPKGDcj5iOZqdilw4i
u8IyFbZeoYhGBBARAgAGBQJGCjo4AAoJEIpncZwt6CezZX8AnRObeHOWVT13y4Zw
LRl5tradePJZAJ45/5Ex8w8KZx5tdQMhhg9EoQgxzYhGBBARAgAGBQJGCokQAAoJ
ED2vVKIe71J2sSAAn0NAQ4kPjXPGI3p2XvqWjiJD7Pj4AJ0Yo4QAObH5IPemFMv+
etS3Knk3cYhGBBARAgAGBQJGT8yxAAoJEGBl1TP9wgW5fzUAmgJOWwsGTgoI/9VR
hk2sBw9ZHgnqAJ99mnO9BZDU8szanUANRPQzByT7DYhGBBARAgAGBQJGUm2wAAoJ
EEjJztxXHuSYePoAoIo5wQTVgNLMFuw4BUfx/2zRFow9AJ41Mv3DIEIZPkePaAS2
7B7KqhJxCohGBBARAgAGBQJGXE+3AAoJEHHOr6zsoorb5DoAoK7gpZ+xhDilBJVJ
eHoqi59qSoTkAJ9UktPiosJXdvgXF/iewKWsg7YnQYhGBBIRAgAGBQJGUO1nAAoJ
EHkDg6l0ZuZTD28Anjb505he0sGqsvdtz/j/b8qAUaTXAKCo6vqdfjHM8xNPDsEM
55h8L1O+MIhGBBIRAgAGBQJGUO2nAAoJEAJJTlL82leHczUAn1A3wUTV/giLfS8c
SMMy63UYDLSJAJ4y7LI/n2fRPY/iUrb89cvvoBtDqohGBBIRAgAGBQJGVLZQAAoJ
EDKI3m16FCTGb7IAn3YIYeqNJgaNqo3uOHaMPXyhdHl3AKDeV7gZ6NTK4hlNgcG7
zTdrMUldOIhGBBMRAgAGBQJFPHw6AAoJEO0Yto0WGUVT70MAnRIt3nIRVtrBUUf+
ARdLi6WgF3h6AKCvMfNhSQ0lgTGRfnjCWJNp0hH2JYhGBBMRAgAGBQJFPQ5PAAoJ
EDsr5WIUkTiXF+oAn1JmYTdo0R30VxyeAq9OVupZ8A81AJ9xnEyqRYE5JTFQSnyC
naiasiA5AohGBBMRAgAGBQJFRc7/AAoJEFYhzLq4BaQWt/EAoLpx4NHJdK3XvP3F
D6IBYG9YXENLAKCpOVYBi+jdcACcn005zCu9OORAJIhGBBMRAgAGBQJFSmQUAAoJ
EKHH3ME0tyRfnVgAoJ4YEiYVNCBmgSADowgrlyaOV0zZAJ9XOSPHY1HZbt2naFy/
kQL54COp9IhGBBMRAgAGBQJFV02LAAoJECHFCRYOSnh1X0wAn12H7QcuHUMjTpCv
b6n2Vda2bFoPAKCkKnMgXtxRDaqpgFYc6UOG6I/ROIhGBBMRAgAGBQJFWZnQAAoJ
EHu7RcYqQ9NMHMoAn1S0SoZDx8cGEYKwuLsbiS3isJitAKCevJ/SHOs+1mlHoyss
cK8zeyTZ24hGBBMRAgAGBQJFZgjJAAoJEEIUTAYlN20+ir0AoItayxh63ybLdMFr
wt9Qo/g7uJuHAJ9n3F+9y039KuQ3id3k+ZxIZS9w6IhGBBMRAgAGBQJF40+tAAoJ
EIwl7g8NwLfWWTIAn2ETa9VtV0Z1vpwANwjGXr5LQ3U5AJ90iQY7RbxmQ2glTnNx
XqMeSNp8C4hGBBMRAgAGBQJF6t/KAAoJEEHcHJByRJcLjZAAoKL5E/cHtkurk2G1
y2a47lJn0Q4QAKDj8xIcynNIImkMjzZLpNXHFu6NB4hKBBARAgAKBQJFVLM1AwUD
eAAKCRBfLIShPrYEbQ0wAJ9YALnp+0soJem8hhB7IRisycI+YgCfTnCivHZs7bCI
e/PY7V/OL4i/nUSIjQQQEQIATQUCRfGDJEYUgAAAAAAOAC8gZmFsY29AbTR4Lm9y
Z2h0dHA6Ly9mYWxjYWwubmV0L2dwZy8weDAyMUM1QkQyLTB4QzVEMzREMDUuYXNj
AAoJEKd8S94CHFvSqE0AoMZdrTi08D4+5/lPWx453a+0L/xUAJ98czUXanYtiJaO
fkfj+5PM5TV+pIi8BBABAgAGBQJF776QAAoJEO2iHpS1ZXFvBvIE/3GKB/i4+m2R
mBqyxhWShO6Fz7Hj2vmqqsKaKVUp/SYXftXmTDD14IiVxOFl+7riaU/ubGIn0cn8
dpLVjth+rS04QkS907x9afMBx93Py+Na2fPg/FFlKmEv9+Yl8yMr3omKh6VzgRFF
tMNRNDA42TZa2cUsRvAGs4GQZ8t9HgI1Janmnl2Ec2EBoESyhgL2uZqfSez51HfA
l8RtrT+2K2WI9QQQEQIAtQUCRT5aCIcUgAAAAAAQAG5zaWdub3Rlc0BncmVwLmJl
Imh0dHA6Ly93d3cuZ3JlcC5iZS9ncGcvNDI2NzEwMTNGOTRBMEFCRUI0Q0U5QjZE
M0RGQzJDNjJBRjc5RDI5RS8zNTZCQUUwMjQ3NjNGNzM5MkZBMkU0MzgyNjQ5RTYy
OEM1RDM0RDA1LmFzYyImGmh0dHA6Ly93d3cuZ3JlcC5iZS9ncGcvY2VydC1wb2xp
Y3ktdjIACgkQPfwsYq950p5ImQCeJo41Qrs93qfxYgL+GsMhmoV1phAAoKT2UTKH
OaxnC4TDwXz67uxbP+0EiQEcBBABAgAGBQJFPLwpAAoJEILS9urEu56fXz0H/jGb
lglqrcuH1KX12m3OTCWr8exda+NQ9fqaLd42xMHw8l0wEjq1hB14J+vVEQBLqcaP
NA8YUT6rF5feQwZCSfvTIZtxIYiufXuLPnl8xmNGWMVMjqraSkg6eYlwAHYD//R5
YgOXuY8byDKM2OyRYwAHSCDGGQyObdxlKBnBTiPskubLgTEKtluAiYRUPlLJOWC6
TribgLa4o/+1P0fnb+qUOelSE063CX0toVfxZGUptMraSxm8M5AWnYkFHtqSN6/R
f8zBkqM/R0cowKJOco1eSx2YQM3qrBVPLNBV5Eyf4w22M+5g83TpDocZJ438Vlcd
Yz5JxFHPl8avzRi9eD2JARwEEAECAAYFAkVXTTYACgkQLtRdZmGgc+nvfggAlq4o
amMXxVclsWrL0O/BSmqyu7cvONkT77IhAs6olFvHJDVjpMEafrXCe2NH3/OWbxZv
8KK3into/X1ex55ht0vuhNax+hR/GUYY/MF+C+snZgWiyvYAmv7zQw4UQG3RB30A
tODe6jPozNwzzVzGCNZ9w5G1HqIIFrYJJs+nLpvdIE9CPpoHVcZdZG3vx0QpIUob
3DpihUnRje/ieIioIoD9e878g7KvkbOMqdCNrgrgEl7VvSqnoeWiJ5bpAm5lOAkJ
eDE7vEtqSHhI6oE/UjiLVMb+qAbmnF7q2Apg2Wpg09tR6my2PJj38hwkla/MX9bt
meG4gV8AM+MZ7LqnsIkBHAQQAQIABgUCReNH2QAKCRDo4GL2DcsEMV1/CACcggZE
u0pl6VGj8O3MJITaRI8MPT+5n1pu7Hx4rH7dr9CX439eCP5SHRka9WGOVSSc4FAs
Z6lp6LVUMiABNOhsWAU5qoEt99pAZAHapuuDdqpUDO3R6j2EJeVc08kHWqvLYEGb
YSxH3HlRSzEuRH9SaHDi4B39TQNvGwvN0nNNQFYr+ZkbRdFqRiOO4o6WyO0UGN4F
bYoCNU2Vkk+oEz6xisp828KWGTE+So3zLRZS1sAQqCxTO1jmSlnP83hFlVN6TxiX
FhoL1LovwcbHpth9GH70wApIGSX1mddd9MVlw9cXFcdHVeUqb5kB8rDx8iRp6fk1
DayjtyODj+7sZwC9iQIcBBABAgAGBQJFRK4iAAoJEFeTDasLhrBn0CQP/ioOq0lF
2spLUyE5eG1y/epjjhtq2D7e2pR3S6G7zuTdIP+xvL9XbyACgXf3A8zxg4qVHgq6
D3V7zH1REAgvx/VNzAgbCksZyx93/pccsNXBbHJem6R3OCmktUwQxjSs4gzd9j/j
OsOL9f6DCKi3NAUmTIDTBgHwh9Qn+PE3gRpO4VQUDlI1Ji4FO7nxt5En5NPt2akI
98i8V11TKfGvPyCglLrN+NB/qlSWKefOXaSyrs3cQD6JQuTsuQtyJ5k42m4nX3go
28IHKQ7zk8btEKpN64b/WOFL1kvGn4GI8gWMQDmNtdRluQ7hbOkMBAiUAgGLk6NV
+724bH348EDjVm6O3hMMfkQogu6zKyWdUuomlP7RKIL5293mJm4XaMm9P6dWbI3i
6a66vLa5mFx7U8fjPstOVMJQjJfnn5GU1fOdnLm8lJxIe3TyjPh73496Ymz7gGdz
VNnT35IHFgxIgcsk4ui7809D6xCWv23GiRt/yiyy9no0RmUnkZ7N1YkAyRzupnbG
w/MlCttfs0LYd7+ELAa1YkWk/486X8IU14yOuv1vDhcN7Yne735EGBasvRdfWHwx
H4xtEBx08hk5qbYxvH98dVb7vMOjj3B9qxexa6F9N3eTEsfNfeq/xn6UWfXEWij5
cjSb9B52IuPnCQOGsPI1s6SjV6O00aaYMaU0iQIcBBABAgAGBQJFRRquAAoJEPJx
4K5ucD2VziEQALBdBNdOG6m03hj/PeSLnkALOwbXdn8R3hxIj9AizfyrC5Qty2oo
DRfL682Rz+zTHBfUQ9JHBhuNw53eFtgmy3KkJxYHM62ivpKbuvBUfyW4tIan5LQO
yuuxNM0UmfxXR57JeUMx6eNJLaGoGodIWXyNkxO9VynZ95vdY39DEUNPgcUY09qU
KxyaaUsNA1+FvZjf3aWSwAGGk70GfR5G1k6JJAM/Haw/PgWAPq5aPo62lGKyhrjb
lx4p4ptSdF6NeN6AOXUT0zPda13lVUGGgadAckGcUZ95/pskSWfU2MNH2qOFoKR0
5t4mrDWoAHwlb6XIq9R6Z3xQmqtDarcoRH+u7NByodSd+FaU2kHE2R5RuYB+lpG9
BCD6bLYwP9n6nVT7byPAt7jb+cERCnjLtpueSIlkUUMnvaSlfuq+p5iSeGkUsShs
hKAv26wGS3XmrFIOLPAloNid78bYoMMjOuD8Rr8kTNt+IFP/gyUOZNd/Xezt4Dmn
jXr+ZzsJj4d844HbdOKFFPQv2tGaS1P4JE1TKfDW9C9OhnRl8FTmyYoL7m+DEhF+
EsTT5carSFwbvEt93N3G+gXWkZirdGYXr1o++I48Y3wxzYOIGUtt9MCZzlAxyjPF
XOSgQzDYlxElZMbwYbbFlHslFd+1hNUaVxtS2eCHy+hDutrOz4AZvGcdiQIcBBAB
AgAGBQJF4sQ9AAoJEFIiU8PXJzmB6X8P/R5sXaiwxmdrBSy+ldfDemn+lw9YejAq
w+Y9jLCfqgOly3Zq6CnB/M0a3C5KM/BjgD8bNSNJXmNQsVAFUTWaBqMoofCqoOVx
vGalcj/12DCuzsWsSrGbuO4eVubVipEbMac8rMS+qTlI8WrBrUSB0iC6q96QNRRV
UrSFJ213fP6Sqo5tCqZn5UG4NafyU3/g/1IkNVdtqhT8MfdfN9rZ7942KbPKdves
CZ1GBHuZl8ufeh/L9hmQx0Insxs3GDj3Mn1pf4Hy9VDjVIJaRSJRWGHKXf5a53aV
vveLPzWnIZMYSAVm1YR2WJWdnKy+521e2/6LkSGnqELaQzDjvhOwBHzv7TOx6G5B
4vRqlosRGvc/5y6Iq+jAeR0YW1Yl9xHIE7IB37slbQ1zrkVKQkw8MWYJq9UYmQts
xvcdNDfQkLXLEZXWX8vAN+ayxKxExfCBRaOYdzcjWAdZ9nCBpU8g3KspEk88qh+u
YTGkPkLitcZqodYxkn8YaTJvtX56nsgvIWTK9bTBYaYGP5JgYm/3RIqOZbIJLCYg
Zak2qMxPSxZFL3K4+bLA2l6Jt+4NgJFe+2Q7E2FJvAPTjPfWCFqPZXBnp/FwpzlO
bNtp9VVuTlQk9QhFCFl2UzXNuYJiopl0Y4oK3PH1g+Rrjf1bekqTx3HVwrAxFlBS
OxaaPN9aAHTWiQIcBBABAgAGBQJF4vyTAAoJEDOWFYjhwhhFU2oP/R5xJrDZXI8a
ZKRExgl8/GZz1EIBSN2sC/QOVI65oc1s3Ud0lFm99B6vDkewIPYZ+BBcm3fWUAe3
uv35oNMMlVVwCNWjvj0HhOww1fk0kPQNw4xMpxWmc2fh16SS4e2wsZr5tXDMZk65
kyjh+tgiglwrTddJpeCR0OgW9GRL58nG7yPlA6/Ym6YehTKaWsKBhwXob9ANbGNx
IMtPRztAYxHxkPD+EpywN8Ncpty0XmGkjwnkTNGtSOC3PlgI70ZQPo1cs+/TsbBc
ectQG5MFFR4jQ+9MfnB0ie1RuaAhaNlnOTqmkD5UlhZYQV9GNmJKCMVHC8C0wsdH
XSJt4MXWxyF2K/58xFSCrC4AWM1NKQ0io1FnbrK155YZe/WPGrEHPcn6+VENuYMb
eiNE9Mt/3s3cT5baMW5R54k2bdM+lEi0ZRpA5zkZtSeOPkSiJHni1T8U/WXwG+hE
1F8QIEw3exeOIlKC/se4JsT8Qb6SYvr0HyPfK/MiZoQaLk7l5Od+p1DT2jXiKswb
xTOUmMvwY21SUIiGseMNZwJ7s/JI/gn2vQpre28gHhyvwiKOHsec22/H7fhowy8a
IDW3bK+JJ/5+XyRwyQNJObNct8kdQKUnqVBJo3zVQNwqsiD4qPYcMVKiPHmnNdLu
UCxhU7XrF/b18HIQOXvQunw2CTsK/BTniQI5BBMBAgAjAhsDBgsJCAcDAgQVAggD
BBYCAwECHgECF4AFAkU788UCGQEACgkQJknmKMXTTQX+nBAAwI9lmzy1FGauJ684
78m8sAUzB+gSxxO7I4Z+lhH6qlFyH3LRml1L+lMpUvItOsXsDLNx0s5/Kx0bBkdE
P740WZSSRSf0Cvv7VrFePlMfmJqrMZMVG06iJQqaDT47fEY13/+oRnhYGGw1jxSZ
HVAejUFAqSe4kAIJfbdcAtroSWqZrvLU/fF714WPRRRqxNm0GAU+4mrpXs9QIXcA
61gzFR01FjA2l+JCyV/xl0Mzk+z8DO8tP1CJa58ufipASQ1GFXAm/AqiW4tKW5WE
qIXDjGxrPEW7n+erFydy87Pijtk4imfsTJvWTii9LecYahB7xhmD7pzWEapFnU43
dnN4u1AAduBeBSaN/IqWsBwRxywa76q2KwQjfiSBMq0pXYhrBVhbvKv62a7MSE1a
BEdXJHMQ/AIyEFehRdbO65xRLqY4NB2DFUkCKtcz0SRDqO8QhKQD+DpOfgWvf45s
yz/OT58bGZvbUTB6WrE1w8n/yxFMMJoiO1oBHCMt/gQ479EDjlKmLLqGDxBfKIew
SJ8uq0tKgjdzrIIQYRkWTsRVFCcKfCNAviyONen3rIFFXI6YJ9QAOiGQhUSg26w1
TmtdC5q+14s76/TP6mNnTa22fmqTN+fiS8awBB63GnYNMqgRh9N5ZfNss3D44llO
I4FuiFi+M6T13Xe0p1W6kWiXhrSJAkAEEwECACoFAkXtt6ojGmh0dHA6Ly93d3cu
ZWxoby5uZXQvY3J5cHRvL3BvbGljeS8ACgkQlXlS1880AanQrQ/7B+4J6/6U/61J
YaEnWvAGJlCeHEtS0jgs9a6c+SaFybV1Sk74SRzsvNm9Otpsm4yCL9bOljO5zaHk
gFAR2vsaABJ4ZkbwQq7AS6PwEKtHH2jDJYH1230llchtWvJHuFlikWdcTV0X+m3C
PPjPioFyDyQrT+WivONAyE+PuJS7OUpMU3KVCr1637qmYoPzMFj/5DRoKtv5+9Nz
fnoLxfx5Q19L6FKcv1bcFziLUq7fqbaFtdXkVMUTsjW4xswNWyZRsUJiNTSCNVGH
QhgJfFGU+FwZdTF+UIssjAS9k6D7VavlgFclHSHJuiOHmhDqp1LJVSa5nVHSAN2K
q3aPz4fkmlsRYAocCdO66pKb936/tgful29NvkV3ApNJrIVzblR4XoooXlU7MGRR
PtTm33N9mBSGMP7g82Lge+U99WZZeAykjOeIIBctNTKuW9y/RXPQ80FNXjMkHXyT
n0BQrjVKhh69YNH+hW1o80S0XuTXELZ+Os7z8TTsQchGBUWCGWKUZ5LwOp4Bu0pO
q9jOKm+w+aQ0wBycWh65HCUdo/ieaWHFvSw3HWc2mDnHieBSSZGQHwmbGUxaCKJf
XxJ2JiIm6inRKhTVRtYiOqD2pK9vuHXQasxx8/MZD4lZHAHayLFIQLG0kJao3bVL
e4fxzASbNGCppzCU/o+tBptVkBtmTMaIRgQQEQIABgUCRlL7mgAKCRAiGMgejnwD
/3HRAKCMWyT+ub3ZE1cWl9J3qSQ1NdUt/ACdGodyPLF78MatFaX0bIvXmbXkePmI
RgQQEQIABgUCRm6AxAAKCRCPqYpv7u1w871iAKDTYib1IGYIDm9V0mTRC7sIvPpD
swCbBYyOTGHWIZ5AYG1Aw8sGbrUgxtqIRgQQEQIABgUCRpH24QAKCRCptvcwuD12
HJs7AJ4xzjVe9QO871rEX4pAZRQuHoaomACg7lQZCYjhfLcr+CIhBn38mlIvfxSI
RgQTEQIABgUCRp7w9QAKCRCYYg1FtYEYLABhAJ4x7fxoxA8iTO3oKm1IAnfWFn8n
WgCeKZHZ6NaPhIvSR/52hDx0Z52cqGKIRgQQEQIABgUCRqSyLwAKCRCYtF5mZjk0
FTnTAJ9ezR2YerTsAGAjLy1l9hbPM3x3JgCgtJPspmRiM8I4osFxp+gK8g8Q+yuI
RgQQEQIABgUCRqSyRwAKCRCizvCpOtm9pysDAJ0eahajHngfpWlVNhVhWE0M2iNm
VgCfS19llnPU+Tc+MB3ovhQ2KUniYt2IRgQSEQIABgUCRtGrbQAKCRBJUOEqsnKR
8qwcAJ43TesNd1YTBXJXd/egSzyQqIXTsACeL9Egpil/u4vF3jlcD/mR9HMmQE2I
RgQSEQIABgUCRtV71wAKCRD2yOmcZ2gdPN8dAKCI9N4AnVNk6//za3D77xc6CU//
UACbB4mmh5whweklpiSWzI9cRMNHMKe0H1BoaWxpcCBQYWVwcyA8cGhpbGlwQG5p
eHN5cy5iZT6IRQQQEQIABgUCRT3nFwAKCRCqz7OGIRtu74ySAKDIS/hlAg0vrGqY
6sWeKY20maS+UwCYnNbHYs4kSJg2Ja0eNogKZpnhvohGBBARAgAGBQJFO/SyAAoJ
EL9L0OYEnbh5mNcAnAwkoLnJV+/TS6U/SjPH3I+k2UKhAKDKurvGJ+XkWCtXPJ5b
MzEogNWCyYhGBBARAgAGBQJFPHEBAAoJEKsvWlsVJWmQLJMAoN3yTggYXattX44Z
mh/INCV7i9ipAKDypZlZ3Bg6WW6skVBE4E3zj0P5Y4hGBBARAgAGBQJFPHIOAAoJ
ENuE1HYSbUfAFy8An15WkJa5ETk57AGUE7NDWWQFBYfEAKCOTMnFQEM1X4cfm40d
sOktbJ05p4hGBBARAgAGBQJFPI+ZAAoJECakfGr+bYUPrLcAn0Lrw6/DmaC1fxsL
txbSDSpQ9Y/sAKCa1C4Vpq7d3Q9jPeNwCH0FEVrmhIhGBBARAgAGBQJFPKjmAAoJ
EFZBJvIp8ZvRcLgAoILw/OaAHFfCIu1MP18tmOTm5MWOAJ9hOrE3KIGLYBeWwnb7
3mF4KVHzo4hGBBARAgAGBQJFPLNZAAoJENdZXTdLcpYloS0AnRIUYeM6XfswYqAV
7jEfFwDS23X2AKC7ldStOoj8SXlpKEhdAlmHiUHl7ohGBBARAgAGBQJFPPEtAAoJ
EGjhJSt9pcU7B7cAnAptO7JnxhjAauHk5Dn96iQBMLQtAKDLoINKP210BYUTNzhm
HD3PACQvw4hGBBARAgAGBQJFPPe0AAoJEHPeaYzHFAWiKdIAnjGaZiTTok+85PmD
NxAuAYrxHYT8AJ9+JGD+Et2wc0YdUOt6uMPGoCDxyIhGBBARAgAGBQJFPSglAAoJ
EAbypSJtCNehs+IAn23Bp9KTylEIC8Wq1muEfLnW7uLLAJwIOMzO36oVBfzl1sL1
QbVBpGRPNIhGBBARAgAGBQJFPhw/AAoJEKkX6cyZbhReHM4An0hQ7lRlF2g3c8Nb
TPl2Tv0QCObaAKCIYJjQqr7ZnypSJraY6w8gZO5dhIhGBBARAgAGBQJFPk8KAAoJ
EC+VFQiq5gIue/IAnjtOn7RWk5xe8PgzpQMNEufDYGx2AKCwuOHmnHLyNR451mkb
lJgg82GVA4hGBBARAgAGBQJFP9EiAAoJEJRq0wuHLLoEOYIAn1go0FF9IZsdB5Yj
Wdwk5FuRgutcAJ4rwmwJUTPdbpgoRozDRlWFGJ5KlIhGBBARAgAGBQJFQGdTAAoJ
ELcooz9Fd1H3PXwAni/9FAABc1RxGG1cCA1wpxXLcXNsAJ4nQLHp11WTkbc6vvYk
busdenwPaIhGBBARAgAGBQJFQm+PAAoJEAYGnPKWlFfwRqsAoIAcfQyKLH1VZtvE
hyX/paB5+kTSAJ91qmuQ1rFQPrtU7CQdUJz87/Hw6IhGBBARAgAGBQJFQnYHAAoJ
ECXSjMWVfVjPlUIAnAqBmuALhanEBUL41wMKS0Dr/WDLAJsG0pL6woPJbmXSzTVX
AXtpH1qZ9YhGBBARAgAGBQJFQ4XBAAoJEGx2F4yg7Zgtc5YAn3nQlgiaxUAz2qFO
JGgpDeQ6U9DiAKCw/wyTvsY0AuJW+7KbsD1GATd5GohGBBARAgAGBQJFRb//AAoJ
ELPOLSM6q/mSfL4An2HOm02TrhKaelmSpAGaFkY9fd9IAJ4zeBnhoDJJ3ZigA0EU
PNy81DsMtYhGBBARAgAGBQJFRhogAAoJEMo5dFnlGy6RJdYAniYUdAhNRCkuGL13
PxFeBcq+Xab0AKC1v8TM7/pbUMn5N5ta/+6eaAjyyIhGBBARAgAGBQJFRiJOAAoJ
EKBP+xt9yunTdLQAoMxdl4jziP5j5UNkqDnjGI2za7wlAJ4zqLIRGGJuvGISWrdB
tg3TWemDjohGBBARAgAGBQJFR4KnAAoJEJfO5hKrjj7VL0oAnR2Xu0T7phI7M7lW
dTw1DQg9AsgQAKCe0BnJeAvidIaCoFFLT68Jq5xPhIhGBBARAgAGBQJFSa3gAAoJ
EFmm5/To7k549hUAn1NHIS4vIfdU4xF/yhfmVO9MHp3vAJ41qzvLBDUTOWWwjwGl
Jys5+SwA3IhGBBARAgAGBQJFSxxMAAoJEKwhViahIYdXh7cAoIUOM7TFN9YuKIvd
zSunNSj+CnxtAJ0VB1HCe4JhoBXfNUKRFtqGq9eU8ohGBBARAgAGBQJFVGbtAAoJ
ENjKeKUexWvsQS0Anj3R3LbjGD52bJKNrx1DVJ5si72yAJ0Vd6zb1/XzWcHmDFDY
K36wCnUmq4hGBBARAgAGBQJFVdoPAAoJEBaK712xKT80dVQAoPjU3nvAZ4UppiEI
xX6yMI4JK2p5AJwPa7cYp9CmaysplI9yS18JCvjKCIhGBBARAgAGBQJFVhw+AAoJ
EBypWmNWsMoIYdMAnA3RVRV3CU+uiUvmu2LfTX44daSjAKCIx3coX+NiFA3ptKrO
kIghwFJ+g4hGBBARAgAGBQJFVxuHAAoJEBXWiATKbN+yMeIAnR3PVrS4K6jhaAez
AiE+qD2zAG/xAKCI5sFLrSg3rMk+enDC/KlKX5tDr4hGBBARAgAGBQJFVxueAAoJ
EDDUOm5k6+IghD8AnRisu1zBnILtzb+lBlNwoQsLXY4UAJ95vNDzT42QOLRdwl9U
B0TW7Iux6ohGBBARAgAGBQJFVyq2AAoJEL/kOH5U4nj4LccAmwYfjAOL1un2sl8m
9e57s7Cynw01AJ4tWgexBkIRa+Q5wjD4LDjl7x/UEohGBBARAgAGBQJFV0kbAAoJ
EF2Oi+nyOBrUnJ4AoIColqxf6CnbtKomTeGrUCYuGMOVAJ9erlr/ND0TjuRRhjC2
6JBGeIY79IhGBBARAgAGBQJFV0nTAAoJEE+xyIscE5vFllUAmwf4TY7SjHiGUs8H
/lTQlVhnSr7pAJ9RmQZBU149oLGNAkaRTHDsqzpUj4hGBBARAgAGBQJFV0sKAAoJ
EDMRJG1RR9z0lEsAn1Oa4UbKB6Ccho/q4FzSkH6slG8lAJ9nU11fYt4qkV55nbEf
vy1A3QYfEohGBBARAgAGBQJFWhEZAAoJEBRll9zcw5nHWk0AoNMLrViej7h+jYnF
bRei+6wEPUFRAKCaNns4o2B/3GrXvyivGeSD0t8YS4hGBBARAgAGBQJFWzPLAAoJ
EBdynXf0qFEvfQwAn3BglZn3Oi838nSiZB/xcNsYAKGEAKCFaeNpU/s39LA2RGXl
Hw5LniGfn4hGBBARAgAGBQJF4ZPJAAoJEJhL04CsX3AMu84AnArBs2w/5gJDYGn/
GAJGKJYqQje6AKCGEuyxdTpgXh0+Wf0fsQlHKrH7VIhGBBARAgAGBQJF4bTFAAoJ
EFAC77GWLjiQojgAoJ0sHq64UJxufSx+iCJO6HXayMniAJ4lDBdxnNRp247nDyDr
ISl31l6lkIhGBBARAgAGBQJF4d3SAAoJEE1EwCDFwFuuhGQAn0Yw18xC/O81Wg6a
1jWwf84husj7AKC1XCAFI9K10E8s2FP2WQLwBICby4hGBBARAgAGBQJF4eVOAAoJ
ECV+3BMl8VmUNx0An2UL4930CxO7y/KB1BYC6313841XAJwK61IFYs3gNiGrGi2d
7WigWNCyU4hGBBARAgAGBQJF4enFAAoJEHhn1Tx0eTXdTiUAoI0W9slpj2mVjaSw
rYp4GA2nMNt9AJ9uLpKbjtdqpLCoIsN1ThQ4dUS2g4hGBBARAgAGBQJF4e1CAAoJ
EFiD3l2iIpt4fCQAoK7tvorh9evu3ASE53R8jx+HtdRcAJ0Uq2dRqd4sTRYBhaKA
aLONgX9rlohGBBARAgAGBQJF4fJWAAoJEFUVYHaRYekRLlAAnRQYeGA28TuOFnhO
N8tAP3NrIpgrAKC/bvEnwmlgpDdL+UVk2au0M/ofjIhGBBARAgAGBQJF4fwsAAoJ
EMfZMCWd/6rU5xEAniHhdHGSLMdyipyWVirWkmQ+FbzGAJ9Lt/EM1YFJs/F8ebLO
F9VVx1kruIhGBBARAgAGBQJF4gQlAAoJELOx+BoCeHiAXosAnRSOpO5WVUB++0Qo
Uq26kHMLx8nYAJ0WAzM2KSM6c01PwthMZ/lx2b0MiIhGBBARAgAGBQJF4hITAAoJ
EOVE3gebfDKNoR8AoJZSpxUZIb6vBiTQof8yHWyFZZjnAJ41FaoAoUnQyUOEaF2S
IOWkoyz6ZYhGBBARAgAGBQJF4iIbAAoJEH5OpU/Qq0B1VukAnRL7biIL/d7FRYuf
mBfP75iCujG8AJ0WkYYY2xkGiHN2BiR3yfXrmxz9dIhGBBARAgAGBQJF4icTAAoJ
EHZJQAVJruv2Dv0AnRWeNN9gnk/9qyJl6P+pgMOuPgAvAJ94n9DTgC2SIzh1HpZO
lVN8XuMAZohGBBARAgAGBQJF4i9xAAoJEAZVrBDy2EYv3CwAn0ny8FWQnlItQvzc
E0iL/kZh/xlYAJ92KeuYLcjHgKgqpuoHStZvkDnoBYhGBBARAgAGBQJF4jI4AAoJ
EJzL2hYB+otKzekAn2cCHy0/Lm2USjekF+WFRGSwFVcXAKCWuq+oS5cfaa5mc3eM
zBaxcGDyFYhGBBARAgAGBQJF4lC7AAoJEFuTwC+eSpyd8cUAmwdgp/4TQEEpm7Jh
tzETnLmn7QhPAJwPAvWwdyQ1rDnYfBEV2W5rq9jvgYhGBBARAgAGBQJF4quRAAoJ
EAMlcIRNIxPVzlEAnjLKmcDjH0qKWsBU7UXx4UMpDhjoAJ4rsQZcFLGQMlDwxH1v
BQewRGy+CYhGBBARAgAGBQJF4sEsAAoJEHMcr9NTwaMvFIIAoJXc223Mff4PxfOQ
HvIxnoLnehjAAJ4020TtDXBxcZCFkG4DxIUQxo1pXohGBBARAgAGBQJF4ss/AAoJ
ENoZYjcCOz9PDw4An0rmujXmeLrbaJSYaAmgIMu7cy2YAJ9bvM34Kk2U+Oq6V57y
n/KnEUE+9IhGBBARAgAGBQJF4vBTAAoJEItKxIGsHnFekngAnRzniv+lS2djP9yF
J+UN7EbX47fyAKCaJ8NW22EdRZKcwsoPlCjPoJ1qNYhGBBARAgAGBQJF4wXeAAoJ
EDACjSRIE7X+skQAnRm06bfouwS7Zw5oPh7EsBifSkvWAJ9r7IfBDTuVCtPNfdqq
fK+AjjcVHIhGBBARAgAGBQJF4yUZAAoJENOjcASuTRzUdbMAoJnGu04YTskDX1cA
xdbdtROfyTUcAKCjlcBalaTR50AIcA0eXF358Hrn/4hGBBARAgAGBQJF4yu9AAoJ
EB9/MmoS7vYqnPMAn1CL+zmEIOJ0duujr6/NA5yS+bUuAKCswh/7TyrRFXs9fYr5
1Nf4j/cV6ohGBBARAgAGBQJF4y6tAAoJEDiaVjzCcqEmF/4An3pHxn9oQKC1kr2v
oM5B+C13aq0LAJ9WSOGetdqS8uBFzPLVbFczHj3RAohGBBARAgAGBQJF40jQAAoJ
ECGntTuACWnvyIQAn1LbgUFyHuT1XQrZz1RYdtLMcqMtAKCF1Nk7A9hoHEJR35oi
FwyZnIMRbIhGBBARAgAGBQJF40mEAAoJECic/8DmPNbW09QAoLHKeijGh99VaOLb
yFXqpKLG8n6IAKCdang0Lv2FPL0XJTKONWUB4WoTz4hGBBARAgAGBQJF41TPAAoJ
EErbH4hriFRDZiwAn26iX068ncR6xyKq+911DOewrUMTAKC+/S0BuPNu7nge4Lwm
4OeC2SrMRohGBBARAgAGBQJF44RnAAoJEM8SNHyWi9WHWEMAn3qi62iyvcUqv1R9
MhE8tBj1JNMfAJ9vKwzFVm8QxFpdVthwfINO0NRmm4hGBBARAgAGBQJF45cyAAoJ
EDhzTXeHkBRSGjwAn0xdHrIX7GATUTPBqEyTbA+x+cpgAJ98bm9Okp1Fj2V7/XMk
smrdOJ9PKIhGBBARAgAGBQJF5MAGAAoJEHCyAyE69Z0WiPUAoLXrJAGFYLHgHS1T
kOTBZibCAmzMAJ97NzWQfveMgIEzl9Da5RaALsSUpIhGBBARAgAGBQJF5XYDAAoJ
EHkOjJRh/9qrCYwAni7WFJy5WMBkTjLs0teVMgdTlxygAJ0VojbrWZZ7G5GW0myo
F4IVR9cV4YhGBBARAgAGBQJF5amFAAoJEM6A78SRpwfkPJ0An11dVvxIOPABpQB+
bIkj22FX6hX4AJ0Wcf2FCIVOaGZhjhprihL1C9KabIhGBBARAgAGBQJF6ZYvAAoJ
EBVYlEWZ6B2g3zkAnihnIjmaXSpZKMPM8HZ0dw9AdUqhAKCWJYJKIKEw05q2nbYm
AHnVStyHaohGBBARAgAGBQJF7dt5AAoJEDBp6SG3moccsRoAn07atXeoAtQ6D1cb
yUMZglXkF3KMAJ9cWamfogKQE2Lx+Y16b6XjFzAPTIhGBBARAgAGBQJF8c/UAAoJ
EGnSph3iY/zUsEwAnA1H3GDfUVS2NwdZ2UD6gRPw1MEWAKCrxsnE5nmPH+vl96pn
uEM+vVwdLohGBBARAgAGBQJF9VMnAAoJEOpi07Zqq8Kh+YMAniZBHuuNTd84bWbF
fvIsLbOj8FMkAKDNhwvWOSPiBOLV4FP1hC+CF2OOvYhGBBARAgAGBQJF/zH9AAoJ
EDqQ/8EUCNfxOGAAniAWwV13RC1SjbAoWg6r4SNtBsxEAJ432yu6xUQyaQjBktjG
dEt6ipAh64hGBBARAgAGBQJGCjo7AAoJEIpncZwt6CezvZAAnR4CNDXOc4opdVSR
4AYC27gC0gf1AJ9z05ppibHrnedt43BurISQteEc7IhGBBARAgAGBQJGCokQAAoJ
ED2vVKIe71J2DMYAnjhVuAMNh/6CGYaF6kXrSPuYvM8gAJ95ZR+NS+uroMqp8uWe
qQ/9nbEN9IhGBBARAgAGBQJGT8yxAAoJEGBl1TP9wgW5y1gAoMXwFVo0k+CIIqhN
s4msXvi2dyROAJ9JFBK2vESyCMqRady81hRlUZRkt4hGBBARAgAGBQJGUm2yAAoJ
EEjJztxXHuSY/uEAnio9w++xLz8Ocyc1B4g5Mf2GojsaAKCJFD98zrvF7aESzF3u
vAjNEumpo4hGBBARAgAGBQJGXE+3AAoJEHHOr6zsoorbCG0AoIz5tRkJEdqUQM/w
n70EpvzfwVrtAJ90Oe2AY+PvID0Xbhn7vdArLcb1PIhGBBIRAgAGBQJGUO1uAAoJ
EHkDg6l0ZuZTblUAnjHEoAeo4GQI+DPNsOKmvC5YWhS2AJ4nSTppQlUxv0OSHZMJ
Dm/TRn3EVYhGBBIRAgAGBQJGUO2sAAoJEAJJTlL82leHzQUAn2QM32nG+XE3ukf0
tlaVnw/Ow9mLAJ9GD5mOwTaFiPKMwCOAvKlZkdgVP4hGBBIRAgAGBQJGVLZQAAoJ
EDKI3m16FCTGscQAoIKh+i7EqSW26+e1JB79eb2h0o8WAKDb+8RWXTF7ORnYsSy3
2DNVoW0ktohGBBMRAgAGBQJFPHw+AAoJEO0Yto0WGUVT5c8AoIkR8J8rWBQEiFw3
cHYqHUAI1lSPAJ91G0LMXPIcd/6SvU15RCOy2zfNIohGBBMRAgAGBQJFPQ5PAAoJ
EDsr5WIUkTiXAcgAnjtmrnKeVkxJ2h/ajRbLzGMRCn6/AJ9oIu0qS/83WW3bEfgM
ZFlsdE44QohGBBMRAgAGBQJFRc7/AAoJEFYhzLq4BaQWDfsAn0djhYV0A1195f3N
iPHlcCUONqDZAJ9iI6QHftf5X43AFCSAfIvMBSUdRIhGBBMRAgAGBQJFSmQcAAoJ
EKHH3ME0tyRf8y8AoJ/q1PqmyvEkxySpJXbNTkHtYolsAKCgT/bpsP/yWr/79h+e
DMqZMRvgMohGBBMRAgAGBQJFV02UAAoJECHFCRYOSnh10uUAn2ezAN0+I3dUjkhd
HZCAa5r75EPHAJ9Q7EBC1k8QaXJeD2+nZVHD8jDlzohGBBMRAgAGBQJFWZnQAAoJ
EHu7RcYqQ9NMn1cAn16BP5LMMC9OXGm1PYJCOmsf3f5qAJ0bxM+TfSmz8eS4MRWQ
eSUmidfHQ4hGBBMRAgAGBQJFZgjJAAoJEEIUTAYlN20+ESMAoKD3f3VAttEfuI1f
YEkU7ucnP/LmAKCDNJaUcrhvO12AbT8dEKzLDJ3v4YhGBBMRAgAGBQJF40+5AAoJ
EIwl7g8NwLfWYAsAoLq+OAImI6LTxtiUrrAki4E5vUj7AJsFMhAr8ag/ik/9ZASV
qykQj24mXohGBBMRAgAGBQJF6t/bAAoJEEHcHJByRJcLlCoAn2JzVAARDE7hSzyd
vtcOZrSaClzSAKCm6DTZAXYYd9Zlx3W5E/LK0gQJqohKBBARAgAKBQJFVLM6AwUD
eAAKCRBfLIShPrYEbejZAJ4/cA1B4JmqR5g5jvooGSZvya8liACfbzZLKezZAFdp
F2HfYJKjA6NVQraIjQQQEQIATQUCRfGDJUYUgAAAAAAOAC8gZmFsY29AbTR4Lm9y
Z2h0dHA6Ly9mYWxjYWwubmV0L2dwZy8weDAyMUM1QkQyLTB4QzVEMzREMDUuYXNj
AAoJEKd8S94CHFvSBbIAn0O9v7RMedOfOOm6MrjqrHfDgaNuAKCTv7WyO28RpxHP
OwVelEHUa1E2ZYi8BBABAgAGBQJF776SAAoJEO2iHpS1ZXFvHjUE/2qc1qF9Vx2g
hTH5JbSqCeIK+mSol74wRmRb5Ry2ZzUwcx3Qix+a8vCw0ktVIq9uydaGugakcpqz
4v4hDj9z8id9D7ZyBTaVi56p8k1B4vkpdVa9+7DxOwsM7z1Y1ZFrGo8CaHzOarSD
dIy9l5gYd9ShNqYJsYgV0/olO0P/smvm7QD9VDU20cU6cqfJB4vEqJQTpVyqQKsf
BkNTT6Q1zdGI9QQQEQIAtQUCRT5aDIcUgAAAAAAQAG5zaWdub3Rlc0BncmVwLmJl
Imh0dHA6Ly93d3cuZ3JlcC5iZS9ncGcvNDI2NzEwMTNGOTRBMEFCRUI0Q0U5QjZE
M0RGQzJDNjJBRjc5RDI5RS8zNTZCQUUwMjQ3NjNGNzM5MkZBMkU0MzgyNjQ5RTYy
OEM1RDM0RDA1LmFzYyImGmh0dHA6Ly93d3cuZ3JlcC5iZS9ncGcvY2VydC1wb2xp
Y3ktdjIACgkQPfwsYq950p7y+ACglRn+/KomOH070ny/dYKfw64G9R8Amwak44Dv
Ob5zW1Qr9OEAnUsDpg8fiQEcBBABAgAGBQJFPLwsAAoJEILS9urEu56ffNMIAIK5
ZdSglCpL6lfgJfqB+UpZ/1nhod8eiO1omWju09Ct7d07ZgH7lSkHKJghU2CCuTwi
bScecvgLC3k4SZYGXVTHvro0fUi5ZBaDjDAE4y2XijY2vN1hfbf4BmxGWc1Aj+vV
v0TYcHMOujUuHW02QEDrU6kZM6b0x+t37IBGqrwaqRJgBwMW0CIy5phNhoISOZwI
rJ6GuOIctcYFR0AvYYwrKqEXUXJCaEvDVaI15oOipbhUbN2s7cgCruWTO3b/ayn/
5aiyXOHTTyuS169laiVNZp2o+NzzmdJSs61Ax48bQyVkvpwIwl1Mr+BZgD1maifY
wWZWIwOr/++MNXHaPLmJARwEEAECAAYFAkVXTTwACgkQLtRdZmGgc+nh7ggAzc+m
fRlpS1YxHtT3L5/zJvyKjRAdfk6YrnIfymZeevBjPuM2ZtftLV7DYd9vp3z30TDq
2kjrN+lOmJX20bKWfEn+cP2gyImJLO7EVysPQd1SuTrSH89ZyNzNnCSO1sN3w/JX
koKyqRkm0iJxR6ALwLG3YUgFSxqzGQcqPWO58bOURKiWouKfBaGHvTuLhwv+icy3
W7BUo0m5ziW/8jEt6QcpVkuxsNtBSe9vZ24/ZC54sKp1FC04a1vETCayfudQmVwJ
2oHDL/OIxvQABlg6cSf5QpEmYpOUm+zY8jNGRstUkB+ZFMqeO1Mj9096SKzVFOT3
UOyG4AchGRuDUzAVvokBHAQQAQIABgUCReNH2QAKCRDo4GL2DcsEMb1wCACjYwVZ
c6vkQwcHXFTITf1BHrdYjxKME8EdOUx5DONuFn4cWvBV5UIJUMWtrRwzNQ9pQPlu
Bhp0lUTZNEtsBHQYoNHFsG7787BXs5A7Iv9fncZfpcrOUiLd8HiyoiJZYdwGbO75
N4DCkgLDQu/4WWvP+FGn7V6kjjkTzxfYJ2LW0xKVEEK6XmP/EMd7ff3O7SSbsm/f
YiwbY2G4dqgIvK6Y0ndJyLZsar9ZepOPFSVmKvky05GnfBfKAzJny3GioT7tHtq7
zuWIZYrBqIxTeymgAjlFfA9stz7kfafaE/2jLnJf8vyIR1i92/vSDeDKUeYr6r9l
JxRNhFWCPKPgLK0wiQIcBBABAgAGBQJFRK5KAAoJEFeTDasLhrBnsSEQAJ3Op+md
tchU1TwBcpAwEnBcedNV/ra79e3oDCFTZiIlJQri3Gn1kL8riQG7afpUpNk758Kc
enrEWde6jXuId3QTlXzFSX2Xsz7ssaNq2LMy0uebGRGF2p/WQvQ7+7/bQk+3hP7M
pWQuzSolglCfnKOj7jUXzgkMN35N04ARXkReDyHGf6AMdumLIDVA2zCHmF8RBq4N
FVXhOTFVaPIsPZKK/0OGt5+Sd27ajCH1mDo2kigYoxPfesHMRvTqp2zGG6+0UsVC
nCT7fCIPy0F10k5Dwmlo5i6a+pEbMhJJBvNEk9Z+NFeI+Yh5uvML/doVIin4QRvy
5Ap2IoYaI4U+OlJch3mUvBmeWfSWeMI1fXgNnJKQeLUKQhKT7R/h17G8ojRjlIzi
pMp1PwbgAvL7QOg2ptlrqd53CcJJSmF5fnKGfbNi9jl16WR21v5Vgipu3tr7P+ks
N0siGuqhexCvJY4+wJ7R/aInAJF9cio4fFMoFLQTGYbSP8rOnd98pqxNOx2iNpbm
GcGGXCylK6RQx6inKSsl5EYN2Of5JqgrHOjvfWKcYFKi6xbUMPKSmoRcq9gx7oSH
XfVuSN7T4jLlSvjQNwp3bX8axqjU1IxOmuGG4j9L2naR1mnu+mkdyCYCwKfZ1huG
mUvmA3dyE73i8gDaR1HKi7O01Vjw3fK3hmPKiQIcBBABAgAGBQJFRRrDAAoJEPJx
4K5ucD2VYNAP/2ftYzmvi1rGjen5LaOdCMF5Vy0uJBPr3tnCRt4lY6M4vqkBkgRg
32B6IQeJj+peeUmpSQsMY/LWyd1KXhXq5uxIfLS3sVN9a8wMJo7LDb6FgIdH24n1
cauw0Uet00utJfzfukdYPZbwE3AgZ1FM4Fjz5mvFvAdKw5qzACZnvusvGL9B801a
kese5SgGhsZKZrCluRFzamcK9qOPiIbgryg7p/qg3w0X8u/gGVPMNvDRh0czjnn0
10EAsfiocdeNtTDcnJE02PktF4u1SS0l3/aUxZY8aH/IyEh/ykodR9LkPKpA/NLQ
kGvnCI9SSR3GQJplWc1JuCo+dpjjSFuPGm/sm+K+nZcxY221Q/FrNBDJqLKNUz9R
KynphsrRoQWfJuzbVqJ48V1mfzz4kXrUyPii0oPBSbwNEuMqTjPzwCHOxYS1yd0w
HDeTIFlFbxaBPHEQfhPx6hPLw2u4jji4ri/8mXY47sTGJtmxbra/1dDIeMw+q7AZ
5rXDp3DfFVaTmJRYy6PeIPiRorjW5e1rdYzr6BypiNFJcoO9yNAgcyzNmRAv/oyR
EPpAW60cux3rKT1pVDopJl4+rjNkDI85c0v1u6nF4apuBM5lGRbW6NORlNtJ9SU9
YLaRalLyxC1myibOBpj1bBu4b/U6c52HsPkfENLBFSBx2b5hZFRt0WgfiQIcBBAB
AgAGBQJF4sRDAAoJEFIiU8PXJzmBVZMQAJMZD6+UYpY8YNMeDBGJPvM0KFOOT5rL
VpuQqlmrM712t2i1r50z5OD1cIKLaGlLkRGeiLnvSJ/ZE4ofJu6DTgIVcr/oboe/
kvSpIWSKLR7AuZTVrWq7aiDBv0lznp90FPXT816XaIY3Jpt4fzuc4b6tXTPIWk+7
5dzaSJiE9XUMkxm/VtJDRMxZ8w0a7askWdM3q9hJgEvF4TH+L/3pYaGNuedhtvC0
Ya9t18pR3ZlYQOA+H8618HEKNVfmpnw6SA0us6JCPbLNdLcWaEt7TyKgUu47IsjI
y9XX6CepRZqhj7usPeYS1Ripfv+PNVHNqDm1Lm5LchywfkH4fYwwBS/KW2bGjRwj
qZXPTjkjlzClUT6hZnxQE70VWLAJggFkM8oREpbevCO7T9vq9mHXLo4CyK+/pUPU
VVajg2Y6xJRevYJ43nlJswxmiyhKGzMdg0/R3g1a3HEMgyg2t2cQrWrCOK8KyvpS
YBNaL8TWbSTF6sDDzsQq5HOuSrS4V1va57DefNpN9wLsVw5YO9RrPgHXjavBDLRK
3RNP69ZtB+NFp09ukZk1cXqtERw/jKtlTNy9DqrkKne4ISQfb+BwfKlAtgEcXCDF
Oam+snSTCa+zErXqqVj+zxG2p6dsmjC+c6THAsX7oWMjFZ0Y1JvWgeaZKqKghKcQ
a2sfDZS9v+OPiQIcBBABAgAGBQJF4vyVAAoJEDOWFYjhwhhFdf4P/10k4QjHh3WD
SX6jWNRPcNsMpHGbmwNl+D0V5ve432rcxwbIuQsZpxayyAfyCKKQd8vZgbSBDY28
/HARikKK7hrtZXGj082u4pL15MRGkqBptyfxMtBcIg1d9ctLxAKbr6qKGD+PTTVi
NB2ZyDl+XaigzmZ2ERhPzzZ3IHxeiGPpJjbZZ/sOg2Sez/R9vw7TsHkYQqqX0YT0
FOq06/n108OVszaO9pwzZXg4jZlA7zK/O+Yf1+kc16rK2Qhah/lQMrELlb/U4izD
ryFb00aoRaCOtref6uOBwRuvoXBw9JFlNSH2e4mM5uc+Wr0+GoEwQc6MkSF93wvf
D2u/GnexorH4M/2Ss313c4WPdmM+BEAOgApXeO6ZZXMTdmzQKNTFcdjcWcA7kk9w
zkYXQQXlBuKJAp+LkqvAP+G4vq6Epok82/PcGAW8QwL76yuj55SCxL16B80hRZuS
uf71SFKD5Qzwo1GMXNMWT9JEF3eBdxyR6wIJFimiKRVc7zEu7EHbgM1ZmOAh14Mv
nFdOQ2ImBlPCXBfpn9YOn5U1pw1Dj4MSKn93Z//xZzg2XehZUyM8B6QmozJZJqT3
iOgDArxQwQMW6TOwO4Y1fqMmSzLFDd8bZQ5UYz97dzTxqEWlpOsDeG5AcfFvNap/
MVvrbgA4UP3ghG89gvE3hzjFPM4XlEb6iQI2BBMBAgAgAhsDBgsJCAcDAgQVAggD
BBYCAwECHgECF4AFAkU788AACgkQJknmKMXTTQWk0RAAp7gfRroEfPo34D1QHN9x
jxjM17yn/Q/HLbj1WfuJEiRyFZvI4oV6ebnVdCL0P3RGBlO7p6KX/ZhD9OCz/JcM
UvhG6k27Eg07aWJRXHhXURvrmniRWn4cEMyteLq2HpVh8jJS0tZtw8uNJdY0rpj2
iuL/7J/+BuYc94py1lFeC6hovrhcebr6oKJ9c1B3Q4a3++GAp/XvprhuV+5bmH5v
tIt5BJ8JJPwaWa4CZ7gEXO9yyo+mnOB+yGZfyWpdMXz6t15l2/7yWpoJbt8F1VU1
BYaiN5gBQc2+T6Yrrgm3eMj6Fz95HkoxFloOa/YGcGABL0kUjCUhIBJzj+QFzR/s
qhsZi5T9krSpq1o+jO/rCAARIpVB1uYwdwN+5Sir61DNP6kT5wlopRA3wbr/2Cqz
K6XAEvabUzdgH6sJTbcxKJLhrL/F9kEwNvPSVffcOC2et1yst43vujQcNKO7B3Pz
wzhWWYVvfib9+EwFqbzIuj2YDduDVsa+AqdtOWKPtCfv99a25S43gguPSRU2zeMF
zmKPz9HD7EWjtJzTgaYoLnHoAeJlPdEoouMfazaruN1pGBb+0Zse44Dq30uc/eEc
LhJNmc44T6I11319wkCnSjWg91hVoWsSkcxnFQjcQ0kBkO3DRmXP3ggmfENJ3zSg
54bvWlANrPtvBz5YiACVDumJAkAEEwECACoFAkXtt6ojGmh0dHA6Ly93d3cuZWxo
by5uZXQvY3J5cHRvL3BvbGljeS8ACgkQlXlS1880AalAFA//av4EmwRVeaEzk9Rh
1NO4ZmXxsSS4n1tImGetNWdDaVh9FNQYljS9IjzNFSUXVD2LKb1l3jZRl7p4gttS
1dultVECgPATqYS+tRO7wkep/uAyg3NAgybFlU6bbeoLEz1Hx0RetOwgr4Yc4crI
IgngdS1TnTl9ulc1NCCWVMREVj3ZcP4oQf8J2jwD4s7PmANCP8/UDelLv8GHa1Hi
kUMZXZX8s5TIKMvjXlAqEe8GN0x6PWujx7ZWkIbkQtLLaC2js3+DZogT9Yx/dBT4
dTU0viedTy6X6nZobdQUiSRb8cvdkMAlIJ5IMkLvo4ypLcsb3zkMdk/bRYTSbpz1
mKGajaFzVY+FA9ebY8AZ2ipU6Rwzme/kUGeUMY0enm9B5WtwXPxgpLARTyFSdRaE
fRgXbrzz8KZSS31NahI13QJ/cHvy9uHxnOUhZEAezIgAZgayxYOI3gX45h2tCDe3
lo3R5fsd1O51NboVSI09II/GsPYNXs4m3uGrXB5SmufwbgfzU9zNCqgAL6J321hH
cHb8yUDFRdj7A4Q7r1KCdByrSgLVMrnPHI3QoD6E8FUt66Lrj0Yj39HAu3tGfo5g
4Zh4hJ77JabDhWZWZOOr68ZnS9VyFUNosvdCfexIsE0mabnBVQafSU7quBrieILv
6vY5ejFWiQrxDKq2X2KCItg1+G6IRgQQEQIABgUCRlL7mgAKCRAiGMgejnwD/1YT
AJwLtkhNjE4R8Ayy6w6eU4FxHhFw5QCcCD+UPTzBorZkiFa3cyLk5143Q3eIRgQQ
EQIABgUCRm6AxwAKCRCPqYpv7u1w8+qzAJ96kn8yD9uXDkPUP0VHxBMqCgfLOgCg
rkBDEZxWa38AyBOpcM+LrUwIeXCIRgQQEQIABgUCRpH24wAKCRCptvcwuD12HLHC
AKDr0XFic8ENRSfR35nOfsTEuDC5sACfUQO7PQndBirDPaGpDvxc249WXnaIRgQT
EQIABgUCRp7w9QAKCRCYYg1FtYEYLCUVAJ0a60czq8Oo1q/oV1crz05u/g2eXgCf
Tqq2xdvVlRnpJJXsw+7FEShehIaIRgQQEQIABgUCRqSyNwAKCRCYtF5mZjk0FcUj
AKCWM9pe03j8SzOsqGoGYdTSblRRNgCgzJDCg8Wj2gIjvmEnk6VppS+iGMSIRgQQ
EQIABgUCRqSyTgAKCRCizvCpOtm9pzWWAJ9PJWhMB9ys9xWKt2fUr29oszgzZgCf
QdsX5dXHFbMnK0Bez1aopGESegKIRgQSEQIABgUCRtGrcgAKCRBJUOEqsnKR8s81
AJ9wYRvq6RPKmTm2CbSGCabOkA9J6QCfY42idtkMptQIgCnkI48ZBJKfDveIRgQS
EQIABgUCRtV71wAKCRD2yOmcZ2gdPG46AJ4wmjjzMNUlBYC8GKDvtEdY3rL5ygCb
BrsMKYx+ZRfGZGzNfGHh7WblVTK0IFBoaWxpcCBQYWVwcyA8cGhpbGlwQGZvc2Rl
bS5vcmc+iEUEEBECAAYFAkVGIk4ACgkQoE/7G33K6dMcKgCdGLeeko7j6DLXBbk4
jFrHMH/8jhAAlRe3O2B7oo5O90xJ1DpBscKRIMCIRgQQEQIABgUCRTv0sgAKCRC/
S9DmBJ24eYgIAKCpABivri9q0ouEti7UrJARP0teZwCg9DoggmWio22GdVmvmooV
69jwPcuIRgQQEQIABgUCRTxxAQAKCRCrL1pbFSVpkN58AKCuBFWt0lkhURle+hQ2
hi6vujYCtgCcCOnSX7qISRcDij0ARj38846/cj2IRgQQEQIABgUCRTxyDgAKCRDb
hNR2Em1HwEPgAJ9q1ehLlv5iyDKFX5gL6LND5pWUogCgktocpyzeQTMYqhh9sJ8D
xkqSM/KIRgQQEQIABgUCRTyPmQAKCRAmpHxq/m2FDxcOAKCFKO1XDdXLp8I+8cwD
Z7HGvw0fEACfS/8tg6kuLH85D3k71QLNoGNW4DGIRgQQEQIABgUCRTyo5gAKCRBW
QSbyKfGb0VKUAJ9YEd1tNcZ4yIKPceOV8o3nhNwh6gCfXl8xDxnhIWqeDDcmS4AV
EgJjsc6IRgQQEQIABgUCRTyzWQAKCRDXWV03S3KWJclKAJ9NMZHDBnab1P9c4KYG
2dTwi05E4QCePEyiq6JCKXoSPzL5XGw3ctceSIKIRgQQEQIABgUCRTzxLQAKCRBo
4SUrfaXFO5TRAJ9jmLVYNNIZZaZtNEPAUWY8hVNXowCdFCPhRDFZMT4yxFMIuxVR
SuDMM42IRgQQEQIABgUCRTz3tAAKCRBz3mmMxxQFotiAAKDK/+/dZpw/Rc5uFxas
2VOdr34wKgCg60I+ouYII+vxD8Uivp0h11iBNTyIRgQQEQIABgUCRT0oJQAKCRAG
8qUibQjXoTLXAKDm0ZMR26zN9P5oc89Dg+ZWcVDRgwCfS9vUdy8BowvJQDwEH3el
Wxu3urOIRgQQEQIABgUCRT3nFwAKCRCqz7OGIRtu7yVBAKCPv6401zic5zCzJOp3
ubYRd/SyBACfZqQKiGat7k6DFuDxKAiBEa+ZvASIRgQQEQIABgUCRT4cPwAKCRCp
F+nMmW4UXmGCAKCH5o2w8Ip9kFYh+paSDNMlKLhpwgCeJaoF7Lvo2txuvXDA8tSx
5p9IkguIRgQQEQIABgUCRT5PCgAKCRAvlRUIquYCLmO5AJwLgnj0aXbJsjpDDLhY
GrYpNnm1mQCgjY5q/jviQ7XpVKsatMvMeCkeX3mIRgQQEQIABgUCRT/RIgAKCRCU
atMLhyy6BB9eAJ9tJ+PunHGkk7kMnfdhCXzg//VdwACgmOHdfUKIVybFBWMvEjsu
P+WwnlOIRgQQEQIABgUCRUBnUwAKCRC3KKM/RXdR90GyAJ9hMyoohBERtXZl5/gv
KzVo2CkQ9QCdEbKxklk6luobukekSj3u5v3YZ06IRgQQEQIABgUCRUJvjwAKCRAG
BpzylpRX8KRBAKCbGa9HuvuAq3tDLEoCi90Vntr5OACcD7RquDackzxYJXPZaQ6r
OoV8FdCIRgQQEQIABgUCRUJ2BwAKCRAl0ozFlX1Yz9DXAKCbhpNSrREsyF4M9+KL
Km7UCY5cAgCfavBI7CeQdqppPJnGlxuEk6CkaB+IRgQQEQIABgUCRUOFwQAKCRBs
dheMoO2YLcw2AJ9S9e+bv1e3jgonsrrMSCgzzQd3swCgs/6ha3BXZd5pgOpyZ42w
j6uveoyIRgQQEQIABgUCRUW//wAKCRCzzi0jOqv5kuehAJ0fQxi24t/g3K0v4lWe
GHI9ZTIzrgCdFGfdBADIhpsbTTpLP22Y8hqdmw2IRgQQEQIABgUCRUYaIAAKCRDK
OXRZ5RsukX7oAJ44mOQnZ9volfQo/OiNIQgfW1+BNQCfSAE6Sf5Tzp0MNPBmcQSe
6uDMh8+IRgQQEQIABgUCRUeCpwAKCRCXzuYSq44+1STmAJ4hZzvoaxdzLdR/YRG5
0ZZPDQFH7QCfUkhpKMI9nIOMn2D0oaywhc7b20GIRgQQEQIABgUCRUmt4AAKCRBZ
puf06O5OeHLWAJ9xC6PljIbI6Cf5np677ASbnS8i7wCffWuzb9ArMYvANR1lzkC7
OVPd/02IRgQQEQIABgUCRUscTAAKCRCsIVYmoSGHV7fTAJ4smo6IQv8b60FEBuSc
8SSCQmoPkACeOAO3pH+iQuLX3NBokpdi9R0wlICIRgQQEQIABgUCRVRm7QAKCRDY
ynilHsVr7DuQAJ41SDq/023GqnSxExUk1e4Kc2Xg1ACg0OWABS1JV+C4LKw4YpD5
qr/GAkqIRgQQEQIABgUCRVXaEAAKCRAWiu9dsSk/NAvSAKCjeYR96o5CGgctA4VK
4CbsFd53TACgro5bhEwhfuYZjfUtwLi6yxyQ/jOIRgQQEQIABgUCRVYcPgAKCRAc
qVpjVrDKCO+FAJ4mGfISIyPxJfjU3ydnqCpvlHBAKwCfYPBamkUXuuMqMJfzQa29
Sr6qe6qIRgQQEQIABgUCRVcbhwAKCRAV1ogEymzfsrVUAJ4nNH3u7Eg5bVGABUBG
izONQBAuRwCePywht4RfWabjEhkIIFfE0vU6Us6IRgQQEQIABgUCRVcbngAKCRAw
1DpuZOviIP21AJ9cXvKovoySlKhqiJTc+rNGBRJsXQCfWkVdUMfd5tGaHeQ7U73R
DaM9RseIRgQQEQIABgUCRVcqtgAKCRC/5Dh+VOJ4+AYIAJ9UfoZxitZNPjHrKzLQ
PO2rWp/n+ACgmdzrLF8uAnqswHe08BxqA/WHMU2IRgQQEQIABgUCRVdJGwAKCRBd
jovp8jga1Nh2AJ9MbgIeRKmU3nlIikvS0z3ylELQhgCfXMB1WymTjd3jUY+XbeC6
tBRSwuyIRgQQEQIABgUCRVdJ0wAKCRBPsciLHBObxbCtAKCeokhwVXCmsb5VuUi+
jslTMJpZ2gCeLWSMeUylMGHRMuSH00v/PQECxX2IRgQQEQIABgUCRVdLCgAKCRAz
ESRtUUfc9HwJAJ46dL9UnfuaCpmitcCwVauUoP1P5ACeM4UVocIKTI1fsO6jnA6p
0TvM0q+IRgQQEQIABgUCRVm48QAKCRAXcp139KhRL8dEAJ9aESq6uitTJ45DZtfd
UkFcEPAmOQCeKt6zl0sGrHtMudP0NaOFXqIbOgSIRgQQEQIABgUCRVoRGQAKCRAU
ZZfc3MOZx/RbAKDw9+e6i+LEpxWgbXci9GwJaC7fwQCg6gZ+3vwicL6fyiSNlLs7
Y/FTSZiIRgQQEQIABgUCReGTyQAKCRCYS9OArF9wDFAxAJsGT4Gi+7uYYFA0ftXD
nTpyH3jVRgCgihDk7JbnKMXJz9MJj+ccSC1jCy+IRgQQEQIABgUCReG0xQAKCRBQ
Au+xli44kLxdAKC+H1Pz5mtA6/+0cUF7KIQjK8O8SgCfXJtEByuiuyDOM/EHwtma
2/aE1w2IRgQQEQIABgUCReHd0gAKCRBNRMAgxcBbrmd/AJ0eCXMKduMg2FyMv3I2
FMB7n3hyhwCcCyade/BatZXZe0DkfK75+GlnvFmIRgQQEQIABgUCReHlTgAKCRAl
ftwTJfFZlATrAJ9TTFchApXt3tOgJ/xKCCKBK8HAvQCdHQMZ17FOqrxv9Wku7mLz
QjzLwD+IRgQQEQIABgUCReHpxQAKCRB4Z9U8dHk13RFtAKCYjkMgZP5UHB27yAPp
aB9QlW0IhQCfQO4XVmAFTwymJYKjcsGziSXQ0IyIRgQQEQIABgUCReHtQgAKCRBY
g95doiKbeCQnAJ0Q2JsjTBvJifBy/T91yu9JWmfh4ACdHMbdwkW9zXYuVPwrf8fb
aMEE1buIRgQQEQIABgUCReHyVgAKCRBVFWB2kWHpEezlAKC2SWWg1AvwMNzNtetB
p1+LsXFzMgCfR7IJ11EcTsev7ManV9xPHAqIo7GIRgQQEQIABgUCReH8LAAKCRDH
2TAlnf+q1OCQAJ4wHaVopYwpK6cXVC8HDzmKsKs2TQCeKO3Qx1VONG3KdUO2/b+U
/DronYmIRgQQEQIABgUCReIEJQAKCRCzsfgaAnh4gLhEAKCiDT8ENwWJo3I3D8te
tE2+w8KyawCgln0+a3BU/MlXxA9UYkpdMtjU7O6IRgQQEQIABgUCReISEwAKCRDl
RN4Hm3wyjWQjAJ9in86MOMvnRjUUH6mQL3Z1rVtY5gCgwLdTL/0ya1zne1hoWnCf
ZmQuwneIRgQQEQIABgUCReIiGwAKCRB+TqVP0KtAdT7eAKDNfnwsXolp+wWq9vAd
JdQPQo5nMgCglJIh3U5TVo5ictr0t4JBKa/ZGPKIRgQQEQIABgUCReInEwAKCRB2
SUAFSa7r9oF4AKDqnajpIS+mT953uCNlCm/cGT1NTgCfRPoH3RJnLdGDC0XtI96q
hKqfkQiIRgQQEQIABgUCReIvcQAKCRAGVawQ8thGL8pfAKC1qsc3CmRv2oe9jCC7
zDZTXNXDpACcCAlSrEpyHsxw6eXtZfMNNS7076+IRgQQEQIABgUCReIyOAAKCRCc
y9oWAfqLSljoAJsFZYS19CCjtCz9zOEoFXaNJ7VzfgCbBHnthl0H6zbPVj42T5D6
OKNQruGIRgQQEQIABgUCReJQuwAKCRBbk8AvnkqcneIDAJ9R93U8dtIPS4C60tLk
TG3DtAnm4ACfbKWMHd8sLNL6BtUsoXFZoHR6A+2IRgQQEQIABgUCReKrkQAKCRAD
JXCETSMT1VjzAJ4qHG+dgJ4s0kX4sDvA+//n1yAuSQCfQJ0gy1Xym6wujA8z/P8o
eVbLyZuIRgQQEQIABgUCReLBLAAKCRBzHK/TU8GjL7IAAKCAnlLXyisAn9hqCDAx
Ng1Mv8YK8QCfUeiXeLftuCc2UHZufu6y3MGKftiIRgQQEQIABgUCReLLPwAKCRDa
GWI3Ajs/T3MkAJ9q+X7vXXjWRB5plBfLPVP1V/Np7ACfVT4DhTrKRs/4gg5Me4ql
YU/0UoeIRgQQEQIABgUCReLwUwAKCRCLSsSBrB5xXmSVAJ9qjx5hc0X8M8IuFs6F
2WT7FoUAIwCffhS4XIiZKV/4/k/DpQLacLm8rSSIRgQQEQIABgUCReMF3gAKCRAw
Ao0kSBO1/prAAKCWvgQ07kfa1CoY1VyvfuROms3VzACfYAHKxOyMQ0TcnReTol+u
WckNkIOIRgQQEQIABgUCReMlGQAKCRDTo3AErk0c1JavAJoDabpLADUkxFPvaVLb
hrlgWk46FQCfRbBFlKy44eId3WiVorrgAQf9IWeIRgQQEQIABgUCReMrvQAKCRAf
fzJqEu72KocdAKCnrDTASsV4AecbP7VutAtikJaQzQCfVi36fJU+g6By9T59UwR/
hl0uF6uIRgQQEQIABgUCReMurQAKCRA4mlY8wnKhJnuuAJ4vQBRZmYWjTh209/rU
sC4qrm2oQgCdGu+4N0yIG5snr5dwsrW/bxYs0EuIRgQQEQIABgUCReNI0AAKCRAh
p7U7gAlp71YnAJ96+4XfOmcrnWXvlfiaWcbKxV4TwgCbBnKtyp+wV29P5IhYpdp/
GbH9BT6IRgQQEQIABgUCReNJhAAKCRAonP/A5jzW1j8kAKCAzU34mrRBpuU7eNnq
3I/zuxmkwQCeIB1zRpyKe86Nad60o6ikeMXuk22IRgQQEQIABgUCReNUzwAKCRBK
2x+Ia4hUQ0yeAKCX6kD+qkg8GI5+tiOsmQbMp1d9QgCcCjhG8HEKHQqwZBmnIklj
2xm276WIRgQQEQIABgUCReOEZwAKCRDPEjR8lovVhwAOAJ419OObAhIDSxhWonXM
1CFvOHlhQwCdHQMMz5ymFMxg6rzXNDwjoFOMnQWIRgQQEQIABgUCReOXMgAKCRA4
c013h5AUUi/nAKDYYQeV28qUDu7kHLOuZmw7UI8nIQCgiqj3/zfaP9zI35MHQSzh
VoZmYEaIRgQQEQIABgUCReSjhQAKCRBJWJaXG5zC6gN/AJ9j/Yf2arjhnV0AM/g5
C/vS/m2fKgCfZ6yuPCQ14omI+GRThiE5mqXVWlGIRgQQEQIABgUCReTABgAKCRBw
sgMhOvWdFntJAJ4r68kniSSlOzzNYCGUb2oi6d5I9QCgiZ9kHy7qKL/rj1KnZdZl
QdNO1qGIRgQQEQIABgUCReV2AwAKCRB5DoyUYf/aqyFWAJwPmaJ+yYS9iJgxVbGA
K2798R/VGgCcDhZMTwapsi9zr3sMrrCDrFPpkuKIRgQQEQIABgUCReWphQAKCRDO
gO/EkacH5A5pAJ9GMCWvJn+R5nz8SQE7vGCrMkv4MACfVkvU7cv7BLUntSdsChOH
36Uvw3mIRgQQEQIABgUCRemWLwAKCRAVWJRFmegdoAA6AKC6KcQHq1CJyiqzsekt
mkwMpTBSPACgmy0ftV2GHghZvY344Hmy9zRdhKOIRgQQEQIABgUCRem4LgAKCRAu
Rz/3HXOENNcMAJ0ZaT6MeAhmP3DcXAGGw+oPILVbawCfVfXe2+TF2+ASMwwRidiv
h9/IOZaIRgQQEQIABgUCRe3beQAKCRAwaekht5qHHFRDAJ9K6zs36IkW/UNjwP1r
1nvVMCJQlQCgtIERuC5Nki3/n0Pr61I1jJwf/1uIRgQQEQIABgUCRfHP1AAKCRBp
0qYd4mP81NP3AJ9f6hInx1oJoyckKYSlJLUXGM9A3QCfWvMiNOAeWRWtE2iqS52z
xXTyBzCIRgQQEQIABgUCRfVTJwAKCRDqYtO2aqvCofQHAKC25Xfz4CrXwxNUQ34W
49/Y0IPOygCgnamO8CNK0oFd/14NFslm9Fv6bUaIRgQQEQIABgUCRf8x/QAKCRA6
kP/BFAjX8fRIAJ9/QTSnCY3IqvE+W5iYJhJr2R+V3wCbB8E5KsOWaSISBUR6vCdJ
4EiBN9eIRgQQEQIABgUCRgo6OwAKCRCKZ3GcLegns87/AJ4jHlsMdHa5OxXd/VJ4
MesaRk9HlQCZAT/20jp5Ia/jQdDhkRl+XaJiXVqIRgQQEQIABgUCRgqJEAAKCRA9
r1SiHu9SdikRAJ4m50VRHk9DxmbUWzORZm46DicPQACeMsfNHLMZlQflbWsMIiZR
DwfnX+aIRgQQEQIABgUCRk/MsQAKCRBgZdUz/cIFuaoJAJ46fnubRA6OzCleZB2n
Me1ODCjMNgCfarPbbvW8XxpP/x6/JQyOXZrxGuKIRgQQEQIABgUCRlJtsgAKCRBI
yc7cVx7kmMsGAJ9j+zY1BUuLgLg+hVvsiC2X4iNk8ACfQZyKwg9dGftF5vObhBhG
JS2ShYyIRgQQEQIABgUCRlxPtwAKCRBxzq+s7KKK22R0AJ0aircG0i20InL/1P+R
HRe0pJ3QygCcCxPlLddNuAG8qpsXJzlFgLTRp3KIRgQSEQIABgUCRlDtbgAKCRB5
A4OpdGbmU6pYAJ4u0DdWd1xXTAqtkyrpVTzUYtiBJACfQDG7SwRmURThuphiU6AR
b6NxacCIRgQSEQIABgUCRlDtrAAKCRACSU5S/NpXh5E3AJ9h73wQ8E7A14kX3nd2
uy/yXbUmQACdGsuIZWsAaH4GO2lLreO1ULe5246IRgQSEQIABgUCRlS2UAAKCRAy
iN5tehQkxsSdAJ99c3v6SZ6lXFaUbilVhfViEwhJUwCeMbqcRDeHM4rSCbU8WmxV
1/zeQWOIRgQTEQIABgUCRTx8PgAKCRDtGLaNFhlFU4yuAKCpLgQ651p3y9pftDAn
M+z0g6ctVgCdF/TCZrFhRFiXQemSKo+jsZnCJJaIRgQTEQIABgUCRT0OTwAKCRA7
K+ViFJE4l5MVAJ9vd40q/n3LFVwWgv/u7SkoexiItgCeJ1fHwTxyDaoVTPNkjcpJ
VOnGmQqIRgQTEQIABgUCRUXO/wAKCRBWIcy6uAWkFhqWAJ9qqlfIrt6Iox3Qcs/i
hRpOF+kOGQCeIJxCCV1z777l7og1yWJf8nvLtVOIRgQTEQIABgUCRUpkHAAKCRCh
x9zBNLckX9FOAJ47phf3Q0vWiZTzBnbiBYbLV3OlmwCfTKZLuj32n76PPHREDr4s
QNVW6YmIRgQTEQIABgUCRVdNlAAKCRAhxQkWDkp4dVawAJ0Qi/e/AJvrrZfbJsC3
jkR1Kft/GQCfSzbVMAdXdQ4NQwQm3zVhfK0nnaCIRgQTEQIABgUCRVmZ0AAKCRB7
u0XGKkPTTHYrAKDM7KsXxNKk1XcD/60H0heHtyOt7wCgpTxEoam8z77FBDVVnWHS
+7wp1tWIRgQTEQIABgUCRWYIyQAKCRBCFEwGJTdtPtvGAKCcU+LVUPpFQyDEt13x
WuGarKiCyACeLnBpN8ILgG0Ix3A4CPX13TUCMouIRgQTEQIABgUCReNPuQAKCRCM
Je4PDcC31oLRAKCN4+UL+bNbezmMWYiN9/h1nfR5pQCgp1d/qP8QsaYBXgQ1I2ZZ
RF6vnJeIRgQTEQIABgUCRerf2wAKCRBB3ByQckSXC7KiAJsG2V6/MAW2b0IJgVrs
eZB7eDw4bwCgj7pvROowKRuixAqI8fOqKAE0la+ISgQQEQIACgUCRVSzOgMFA3gA
CgkQXyyEoT62BG0z/wCfUz0NkUHdQFAByg0Z5ld5qsZXC1wAn01/a40+PqeYLNlp
CSba9mD88sLNiI0EEBECAE0FAkXxgyVGFIAAAAAADgAvIGZhbGNvQG00eC5vcmdo
dHRwOi8vZmFsY2FsLm5ldC9ncGcvMHgwMjFDNUJEMi0weEM1RDM0RDA1LmFzYwAK
CRCnfEveAhxb0ozMAKCSkVIWJt4NxkHOwMeTL4nvTKLP3ACgiR7dwRhFOLF62UHK
uOpm/P8/6eCI9QQQEQIAtQUCRT5aDIcUgAAAAAAQAG5zaWdub3Rlc0BncmVwLmJl
Imh0dHA6Ly93d3cuZ3JlcC5iZS9ncGcvNDI2NzEwMTNGOTRBMEFCRUI0Q0U5QjZE
M0RGQzJDNjJBRjc5RDI5RS8zNTZCQUUwMjQ3NjNGNzM5MkZBMkU0MzgyNjQ5RTYy
OEM1RDM0RDA1LmFzYyImGmh0dHA6Ly93d3cuZ3JlcC5iZS9ncGcvY2VydC1wb2xp
Y3ktdjIACgkQPfwsYq950p4mugCfVjyHTpSiCMDnkggcdLmJTFDNrUAAn0Cm6oc2
yjPEcjt0FzuFxNwsmyfGiQEcBBABAgAGBQJFPLwsAAoJEILS9urEu56fudwH/0Uj
WYWlAtAfg9OnKzCH5KnwNnNiuhCWrXJvXO5lx+VS1ypJKox+8fNMDrQ4txis2Szs
ApMJZOnfPHiEqcfXQTIqcVFJSamAvmvRTFjGmYHC3exD7g07qpB3wh0C6T5DA1xS
I/lz/E+Kbd6XRtWvnqBlHc9NCsqUs9hZOuMpc53dVxxHXsZVvyOBNWQJVhJnCxDa
G42q14iB83LySY/RkFywsTvm+h/THsNDgS8XCWSc67q3JaOzYTcIdCUhMJKAe8Uu
o3q30p3W3ioOpidXxppoZMr4XtPP87+Gcsz967QKwaiauLDyd8wl/4KqpH5ukODj
A/LHGggrOfcen3bmz0+JARwEEAECAAYFAkVXTTwACgkQLtRdZmGgc+lshgf/U66C
+Oog9mGt+ZPv3kFRCc6UbTV2WegZEorJpFmNdabDRomBckybige9rPIPgQIo/F5l
58sK2WLpM+yHR8FmtGr5DBkO5J3uQE59utvVE270Mvf3HkrU2Zlo6kz9foNhEQzJ
lzPN+HEopmxSQQltUmZZUQanIUwQbUqwS0aJgTqrhIWvsH36XpjERuxe3dwERhbF
xuKFoDldwYirPifj1fGo6JQtYw6u0563cvhWzmSbp5MHRpryhxlNUJ482VevfoNH
czon94CotYLK4q3Ht2DEE6WsiDbdw2SnWcPZItwwq4s6kyVOYYbmPyRZWfG4+BMF
g212NTHn8uM8GTafvIkBHAQQAQIABgUCReNH2QAKCRDo4GL2DcsEMadlB/9Me2M6
4+EQDhFZJgZedeJvzqgQdvvhH7VoQgo/kKWtXYno2SqJe//sWHf+qvP9s10yB6Ik
SgsNWi3x5sttaqBi3Yn0J6R8C4dDWcRtjG+CPU2mDuj4ikYpZOlq1uABPLNC84fh
lCuLXvv31n+JH+eIYCZMVfp5HRFyXDdX0osUoKwM8ldaYoV4FfkqUgbtqfRbPuy4
bkBI1J+3haJZJ/GhOCFNNH/9c/R49eX0w1j6KgmGaLSohgXyaW4hGO+VDewMcsNS
3dCPj+tPQeQEzHrwQIY3Kgbp1d0GipV/UxJpyRmH5WQBwGDz+VtH3DoGkmbZe8eG
9EJAQ6i5CwnxjqaHiQIcBBABAgAGBQJFRK5MAAoJEFeTDasLhrBnU6YP/2GdaIVR
kmW2srw5mnXt8AKSmQpq+GQnlV/7zLQ81uoPKiMIHwFa7RwNpoIrWRJ/LtzKlqwy
93eFTTRxLp3oU3wuedV8PpQOKt/stctyfMCCeueXO2KQ2wUVBVvIGjKJSK8mWSc7
Vv25Y6gwiP3DFqoDWN3WZJhnpW67M8WEO+ZUQIRKLtwgtKRdz2O8bQYKpZ6AHP70
1QAKkqVlK+MtK6T3OdWR7IkoUieVs1PqdnnGC6WvwKZ6xCtjRRtbdSlcKCPlCEgP
VaAT3m9YnmBexAkt9Nny/4/1H0FGhXFNi+GSrZKK5I9kUf6UZ253041gAmVbkkiH
2JmdUnpA095cR2ZEmpZQ2JLHASbHxmbWLeDAljul21BbWy62psZBUt29oCqZ/4pp
v7rnwVL1iZ+P1YDOjxXPd4RmUNLaakOxGfcGMMgaDVyQcaR/B+b0vAC0K5Nlfbk/
p+28bahoWhSD90ynzebTWRQ1ZhGG5k9JBWa6e63J4xC8BHlLusqmboaAWV3rn/Ng
KtN47Zt/MN6ZfPVaYMDrUO67Uh43t2GrCaiDa7qnFrZEJlVDcj26zzHG7CGpTjFF
SVBqnYVyLWC1BS9qifkkaXQDCJ2reQyEt2BUIYk8goGCXxZWIE5VLdDaU/YyImhh
fmR3Rrn2v0qQjFlFs3nr3uwuQeJllm0uATt1iQIcBBABAgAGBQJFRRrDAAoJEPJx
4K5ucD2VDcUP+wV7mrkU+6FhrK0jZVSydUyrs3AtqRu/noyMI9PRBybIQGKgIBUl
pYjF/+ZfVYrRpBgF3CIIQaGERBVELOJ2bqYdeZ79QWdkKDp6oNA2/1MoJ2r1QYoQ
qD0FfesKgbm+scps7Ufawj0Iyyuv49xuGylM2Mm25Ep4ovyOXF2Z7EwR9mnD+iJO
GX+ENp9Lj5FwtgKHupOXdaTwT2TGf7agYEGXXJkyFcQ2mly5eWAmHZf8ETKuCVn2
0g0kdHL+bIhHBtqq1h1yBPb5IAOmBC0hJR46C7ZFdxL+JxS+gUuMJtl5M1T00Qoy
zMpelKJBxMsF3eKqm51b+V7DZjJ8TLAqMFgp2FwFhJVVtRys6VbYnIbyYdeNuOz6
umE325H3jdpPD09ijpNxBCaxencdocOVdDTYmT2dVe3sFfhE9/UgwXmxivBJXAky
mbDHsJ7UyuQJLA0qIon0qIMiOXrn/laW0/siEvOC23DVMGv9qHkac0mtpgjyhSxf
kWuifKrfFsYPgUUBxtQ1MysuLP80BHwfuJjIHyPZ645rC6PwWVwLK9Wp2PD1yq6x
qPScC/AdaUWa3nnKH4c0pIsWDT5qYy2KOarl10c1dq4cCsAZ1z4qN9qah7b6D6aW
9JX8gecpfKXreKQGAD0Vzno8cB3XG/PjKoV0Dfgh+aPMxRyWLrvymOijiQIcBBAB
AgAGBQJF4sRDAAoJEFIiU8PXJzmBjxoP/2rCnGGcRsRoF/exd2MsZnoNse4xMK6u
XkaJfxlW1Rd3q0Bs27E/gKcYjk7+d82JfG+4P2eaLjbZCYM+P67Md39UufmCcHJ2
GjzUlpIP+3mSPDv7YG3dY9j3jjG/7DYV0DSeTksI0bjplNJ6+MJ/WKPfCWtSZeu7
VL8XmsaVPMeQbrsMYPAkWUEhGHvN440bs7HSfBQUfzxxKF6jsp3SbA0YSLgesYMK
DzLgqJK3gVnooNYQGbyCKSpgaWp5Q86uSetuMR+5tKIHEsiF33rB7B7ABXE8//PG
CC4wrlLnT51gKowNY5W+sMkAGurkt/A0HU5gZiW1fqtr3xYQ+A/Yardp1H1a7fbH
/zSAsv5l+816ArEhYkAXsqxLfYyLrSiPXe4HmYrm6Z2cEWXI3vkn14MF5JbkAAwv
YlXugUfB7cvu+qTNqJKgrEvghgfoZKP58ZWlAyNiVTwVCkQbPlNjZLxQBYrBYflV
HYRzTIZAZ5kczLyMt+/0mlUAnM0ZMZXtdY3/Tra+sxR9+4c7gZoBaT9qiWqKSLBd
wElXkg6KaRvSfAPZzNuTys5ZgMIeW+W99sHpeg1APjCzRH/mVP/RBMJrQZ8NHTnF
URxskzvlp14wKDx4vGLuA5M+zzIo/3GJSU2csY2zrkQmv/WqPfvsG+ZdA0A6Azh6
zAh7YMZpgaSXiQIcBBABAgAGBQJF4vyVAAoJEDOWFYjhwhhFg18QAIoCtnXDD1Wz
P/lUo3APc18HmOCWR9JA225ih91YeXebWc+YIAJwt73tcFIgpVjVLBTfavUv+Flh
IxSmqCChCer5iFJ7W+nMMkPx2nhX08+93fcSELv1HANlp2aEqwus8QRJxUGxuVa1
eAEz8M88PEHg1oePC0xt1cmw1xbxcbRGdv0O+qzzG23ehsOrFTXpyJBURPECXQNP
M+EeAWb1BedbSZo8hOgI4fmStdE4b90R9fo+tYp9jqZ4gML67KoksUtyzsbi7+sf
Gic/ieQcdp5GdVx0vHD9RmTVEPAdrChEsQsndGBJGgFvmLs0lnNeaB3L40jzI78d
dnTaymtiBb5lT1nNio0TVlSS+JiFRUZX+NJ9ElUbxLgInKgpoITuwRTT9PqiGq7C
MC4BVU6rL/vlGtvGykli2DQlSB9hh3O8V1wy4rp3/Wu7FuYiDxZ5Ao3+Sgy7jZ2N
ldgfykUBShbr/dy37lVPGNAx3Zl/JwQipesRn2cuHtND/4/jCrNhG6hoIoECAxFe
bW7ZFohtRhQuw0iHXAVequeJYp6YX3APn2Z8emxQJXJOzHar69t9ygKLF1yHBYj1
K1MJordxnCPqGn6WTs+iRLxUatTFODQzb4YCx/7EkA5fgI3JUXPw3/wMwqSIfOqh
4yhhdSl+Nfa9bD13mkeRcipoVBS6XCKBiQI2BBMBAgAgAhsDBgsJCAcDAgQVAggD
BBYCAwECHgECF4AFAkU785MACgkQJknmKMXTTQUTPBAAuoXbG2AnDlaBpM/Y+Qzy
1QWMWv+eOIix8rvdReNKnT8UO4rJI5q06MihTsvWbP+dt5fbMHO/3hXHdXQySMwb
rGLEVpTHUZZG53aUmDIB1W6A6BGiaswNNQD+oSS+OGUP2zw5X2wJXgdZ0fYezWTm
ovsEPq9JsknwyoJ+M+UcFWwU6mbgmh80gJJtu+hPU6y6g+m2cheC4wVm5Ds0+YEw
dKSN0IJel4YCxjLpKTI7v4Vx6r2AUv3FHrR4aeyBxUAH1rhoRD26WMK3/90qF/J/
U0wCeD9QDwykiiykeJsl/Ga2WFE/anjW9arko03rJgLUN1WTxBCPNn/eoxw1WJwy
Th5YvUAmk/VpY56HCekiym3CSLu7E8WeCw05I95HziSJfaWQQTaJFURbuvU7UTH3
1h0XhxKNZgoVwEenDI8e3kE7achjX378hCXMddZ5KajRYkoq9i6wBT0+VxJ3axZu
ORrePVKpoFW/ZJ3RlPeG0RZob7DBtbD2sQuB7Stn5G56mjLRAgKR7D+jSK1NPe9y
sWzlAxAlStSDn3Y+6vR7/HY6+NC6ZZMplD86UHl8RD24cFOC8UmiZtH5V0rBfCgQ
Oxw9XasK+SogO1q8BTlx9MxqTW1lLXYa4emxky1AXDIbJ+JqNCHoL8fNZrGWX5ne
06mjbzJ+QEicd4B3OM5FABWJAkAEEwECACoFAkXtt6ojGmh0dHA6Ly93d3cuZWxo
by5uZXQvY3J5cHRvL3BvbGljeS8ACgkQlXlS1880AanLqg//fqsVeJPJfp2FA//a
4s5Ai+sSilWuOaHZ3xgmNq7pCF3DWnAT5tFhnUjAxnJb9CbhHuhoYx2BPDEWDrhL
1fBoDcW0gNRg5/8gSdz/IElbykKXUjWB/mTtKVDAUKW3Xpdp+JZfjkz0aLhYDWSS
nS0RI6srHlhi+fEovv8MAIAiY8FD4ToV8m2afK62Hb+eWJlSFfIJr5Ydhq3EDG2G
l8FIetYA/UUuige1FhiyvcG49aza6IeteLC/OFzX7VdwLYw0MTRVCLOREclVIzwk
GPSgtp/RYN2fBn2rQn+fe8QXxbdtW6qq8Jj+75wvnl+hkzJl/zSEr04rUT+0o0QT
YF6dgzIXkoqxzy/uS0mZhJBOGeEvXlkDQbNnS1DnPSeVMKMm4LPck/Bn0rbGoAox
tB7uHXDhHAaWBOuc94XYyqjV4DiY/PbVu8rv4RSHsTlGEnYIh5KYM9AJ7koWUjFM
K+Oj+AVMuy8AJ7b22byZSc2AAnGeo8dGLZe3ttWHkd3/yIq88+G4+auVD6+O+2gs
4cdLkxmYEkoWlMnoCjfcnl6v9gLOek9YCtu9LhAZPFXnhiarHF6BYVw18n2gTEnG
8QQ75U9EyWYj6PSJOrEUr6okm68CoFgy6KScErL5eW8JKUeHCjEa3yJiO5kIa3D5
qc/dtS+FDDdudgSzeXcIsQDc3FOIRgQQEQIABgUCRlL7mgAKCRAiGMgejnwD/9cI
AJ9OFbYDu1ZYgwq3yyMY1etSslNSNQCZATvgqRVLX77SkdvpcwbF/dFDLZeIRgQQ
EQIABgUCRm6AxwAKCRCPqYpv7u1w8zGJAJ96VH1HN36XdzK+fUnZZZXMY6M2lQCg
3dWoKEatkH5VxaK8MoTSg/zsDDeIRgQQEQIABgUCRpH24wAKCRCptvcwuD12HC6Z
AKDGSqcb8afNGYCCH4/vjZ7PHhPpFwCg3zhuxS54H4vy02R+L83J6dDsaIeIRgQT
EQIABgUCRp7w9QAKCRCYYg1FtYEYLFE7AKCShU9RBetlhxp5SvN7qp8q7A6/QQCd
EaesE7em/L3or45E1nLzcS37TCqIRgQQEQIABgUCRqSyNwAKCRCYtF5mZjk0FRMH
AKCyXFH8t21KZ29SFHuWnKGqgs5GbgCfZuK60wqkdMYYflL2qwhT1+5mokmIRQQQ
EQIABgUCRqSyTgAKCRCizvCpOtm9p1M9AJ43+CWBqUWrUbLWqhk5IRWJs8pDJQCX
d8fvnI7Kb+139T7YzW9a4R2DKohGBBIRAgAGBQJG0atyAAoJEElQ4SqycpHykAQA
n2XOzEDvnkVIworYUsgkc9aDHwpUAJ9GAHuZ6/DwOFfl9YAYiR9yn9HQmIhGBBIR
AgAGBQJG1XvXAAoJEPbI6ZxnaB08sVwAoKpUkF2sYhb4Xa9JpcNo4JK9ln1+AJ92
WhalBpLXFZKcViM3meic+BHr/LQhUGhpbGlwIFBhZXBzIDxwaGlsaXBAZnJlZWJz
ZC5vcmc+iEYEEBECAAYFAkU79LIACgkQv0vQ5gSduHmmzQCaAyEk96XHpYdXvY3j
pYILjdcibswAoOKRGSIPdG3lno9nMma3haVrvURHiEYEEBECAAYFAkU8cQEACgkQ
qy9aWxUlaZDBTQCghiiYrQ9qF4SN5LC3D4n35mNdkEYAn0xgXMxI8HYx2cNzJQla
0k5chpLriEYEEBECAAYFAkU8cg4ACgkQ24TUdhJtR8BovQCeKyvrmAhSRCc9hhZG
TklONt4bG6gAn24SXgjDsfdNjjt4vrtZg1LtD9mPiEYEEBECAAYFAkU8j5kACgkQ
JqR8av5thQ/5GgCg9WAQKyyf4NNng4+SgpvZfGM5RnQAn0bxrzynlhbwXsCEJjCd
94Wn24riiEYEEBECAAYFAkU8qOYACgkQVkEm8inxm9GjyACeICWIVgKS64NoacEt
yDNHU0DMWUMAn2WYT8gdfFC+XFeVI2HZyXUBpva8iEYEEBECAAYFAkU8s1kACgkQ
11ldN0tyliV7DgCgnQPlcAiI8qrEr7egdCfSSrvyagoAoL2kAFMf8OE+uRz/Ilwg
Q99Wb0h7iEYEEBECAAYFAkU88S0ACgkQaOElK32lxTsmgACfbcZ7Wm2tMQpL6bIN
URxtf8agm+kAoNqRbHLpgBJO982mfixeLzeLOTqNiEYEEBECAAYFAkU897QACgkQ
c95pjMcUBaLcFwCggnKLgL1S/aVQ03Tn8oqkASx3j8QAni+OCqoZP0cVRByrXb3D
9pXhUzE0iEYEEBECAAYFAkU9KCUACgkQBvKlIm0I16EyCQCbBSJ+SuT6CnRLO/+Q
B51vzOQ7qJcAoLM1mH9U6bCfOhSnKrScIcsibz3ziEYEEBECAAYFAkU95xcACgkQ
qs+zhiEbbu+cBQCg6Wv7SDsq/frK9SrthO6Kp4t+iKAAnRMKitDx1ZKkgXmLB0WS
/acb4FJkiEYEEBECAAYFAkU+HD8ACgkQqRfpzJluFF7Y7wCfdc/W0x02JyWFTh8M
IaeiSPYjvpQAoI2KhTzIpsgjFkWNrc/WYQCK3MHtiEYEEBECAAYFAkU+TwoACgkQ
L5UVCKrmAi7/SgCdFJdKOUcZIgcqF5cSkNlcBXV8lS0An2Bo/p6RPJchVjATSrzh
tjMLwGm4iEYEEBECAAYFAkU/0SIACgkQlGrTC4csugQsfQCbBR946oojKKYE5kYT
fHBR6cK2QEYAmgPuxHv+seFHWVkFyxEFs6xDJ5OSiEYEEBECAAYFAkVAZ1MACgkQ
tyijP0V3UfcycgCeOaDmmLkJXiVBhUfwxyi12TCb6p0AnRYUuZEwClECxD2KQKfI
zbGGzCdHiEYEEBECAAYFAkVCb48ACgkQBgac8paUV/AqhQCaAhscxgtnemzHX+gd
ce1g9ezfDfoAn0H7K5BKw5nKQoldQDoYyCNtVwg5iEYEEBECAAYFAkVCdgcACgkQ
JdKMxZV9WM9mlwCfQUIYLc8EKz+PA+luhY6dYCXOohcAn2Y0d7qGP02HPcXxuub6
UnmVf9i7iEYEEBECAAYFAkVDhcEACgkQbHYXjKDtmC0iIgCghwkSGaFEcJ9PfI1B
R1BVJYl47HMAnioswicq7Mnz5bNUMTJt8cFFI4ywiEYEEBECAAYFAkVFv/8ACgkQ
s84tIzqr+ZKWoQCeOPv9+2futZN2DQ2FI1/E7YNQoe8An0F4H4S20Rio274q4eRj
u2LamAdviEYEEBECAAYFAkVGGiAACgkQyjl0WeUbLpH1ggCeKvVEqvoNmJnMkuzK
gmGgmMYvbDsAn2EIs+9zg2vgJOiU/vXxWxblRNGOiEYEEBECAAYFAkVGIk4ACgkQ
oE/7G33K6dO7HgCcDzOZjYJ/0TKpoW/PquXStDQQvUAAmgLcse6JKtxmPN8zgqmP
1wVKPRbxiEYEEBECAAYFAkVHgqcACgkQl87mEquOPtWMWgCfUuXnVpDjeB+zj+KC
bT+HL8abt/AAn2WxNIQNon1AmZdtADwzS9U5g86uiEYEEBECAAYFAkVJreAACgkQ
Wabn9OjuTnjI3gCbBn7FlAnZRhM4+rkcX3Hxceaqk4kAni2FR5xXPK7vylFozJC+
98Lk5f86iEYEEBECAAYFAkVLHEwACgkQrCFWJqEhh1eITwCdEgxlrLXD460UYHmk
rni24DtlUQcAniudz8sY6usMaxb2/wn8bF1A8bAyiEYEEBECAAYFAkVUZu0ACgkQ
2Mp4pR7Fa+ym3ACgsQmGP0Yd7KxoguOvn7lqfTPNV5gAn3fqaxqEsoAT2/2lR3iD
vE23MBvZiEYEEBECAAYFAkVV2hAACgkQForvXbEpPzQjUwCgzh7s68u6zqhfijKb
jXlU4AycD8IAniV7gc3XvQFtAOImAQZQRBgNxkEJiEYEEBECAAYFAkVWHD4ACgkQ
HKlaY1awyggt3QCfaS3m6v5ikKl1nKvQb4AlrjcmMDgAoIQaO3acjZa13nm0ad9o
RRa6MEaYiEYEEBECAAYFAkVXG4cACgkQFdaIBMps37Ks+wCgkt+KLSCZPh5lPmq8
iCJ/w5jB72wAniM1TyyLqxGKe4mRH2gTA/4YJ2tIiEYEEBECAAYFAkVXG54ACgkQ
MNQ6bmTr4iCHWgCfZrZMUNndKLUIhNyXR4sRm9BMaegAnjPbpvjiWT7Dsn+IcX8D
Wp7LFBKiiEYEEBECAAYFAkVXKrYACgkQv+Q4flTiePgZmgCgif/Xh5fAWrpczRw7
4QDSYwSO5XwAnRhcn78tLU08Ih3csa/feNffFSNeiEYEEBECAAYFAkVXSRsACgkQ
XY6L6fI4GtSKFACgoccy4EIqwMqnhUh0h0K9hzYt2S8An1Q/6IC/8ovwY+65e4rm
NuEAihPdiEYEEBECAAYFAkVXSdMACgkQT7HIixwTm8VbgACfZBLqnvqmE/dQ9Qxj
2NGBRa6CXosAn3x/KmkctYEwKbovua/TQVkWjj+KiEYEEBECAAYFAkVXSwoACgkQ
MxEkbVFH3PQsNACeNbYqL1kamDXmGolcsCVyAWPGrusAn1Ld435IoJ1vBMUzS/YU
UGWmxa5oiEYEEBECAAYFAkVaERoACgkQFGWX3NzDmcesQQCgpuy2XcY+s+ydAIE9
/a6zR5Ft10wAoKOYp0b0IeqOuLKmZXkYrQ8+Ym8/iEYEEBECAAYFAkVazuAACgkQ
F3Kdd/SoUS+RdwCeLg/HPHTaFq8Te8wKjSE1wD84zCEAoIO4zWdvSwAlUpNq4LLM
yXi3RieHiEYEEBECAAYFAkXhk8kACgkQmEvTgKxfcAwPogCgxQmp0asZTyP5Cv73
lZv8PyysTZAAoL5m88A/GvOeWRXRBltO7h22kxcliEYEEBECAAYFAkXhtMUACgkQ
UALvsZYuOJD1qACeIulDnAmIToH3bP+CoyXnFwejunAAniS6PUjwECYQW1FGE36T
+fyBWUX5iEYEEBECAAYFAkXh3dIACgkQTUTAIMXAW64xCgCdEPDShmxLJNORmIEl
w7bUngzpm1EAoIO1ZJNtcQgyvuD0oPE8jJxJvmRpiEYEEBECAAYFAkXh5U8ACgkQ
JX7cEyXxWZQeUwCgsqV8HaGPXcsMtDXDXJg3hp5OGYQAniXxGpvmEfkqx1HEdljJ
WvSMoWEFiEYEEBECAAYFAkXh6cUACgkQeGfVPHR5Nd1mhgCgjbGiBrG7cJfs30Ut
ONTFgdNH9ToAoMkPVLyb1i0XXt2TOq/ULfcinJGGiEYEEBECAAYFAkXh7UIACgkQ
WIPeXaIim3isSACfRXolP+WWaUj3KrENKspNZs5G03gAn0a3kw3qJ+FZ7vDV1NQc
sonLGRh0iEYEEBECAAYFAkXh8lYACgkQVRVgdpFh6RFe3ACfT3BjBY/FknHR8L3p
0WmU1T6OFCsAnR2y9lGRx+f3XNeT7pJpAavYLD+7iEYEEBECAAYFAkXh/CwACgkQ
x9kwJZ3/qtSdxQCfXXB7wfAJq+DT4UoET+6xzQL0gB4AoKSX+PVSstlfTyKNCERx
2J6oV2KfiEYEEBECAAYFAkXiBCUACgkQs7H4GgJ4eIBUSwCaAq4jYXojtiMgpBsZ
ztaTOzUngKYAoJBdEeOZveU8hr3lEpHJiPyDEnusiEYEEBECAAYFAkXiEhMACgkQ
5UTeB5t8Mo2YOACgxfpVt8BCn8RbMWwWWO7F71ksNX8An1qsp6CTwUsmJIkPDjyX
APQofl4XiEYEEBECAAYFAkXiIhsACgkQfk6lT9CrQHVTQACcD09PXdi6uw5o/e6B
UThYOkS8bPIAnA3Re9Pd8y63FAshTav8yByMtF24iEYEEBECAAYFAkXiJxMACgkQ
dklABUmu6/Z/lACgueQz3y5wlyVRThYh30Doj5JQHYUAn3dK2WQ5zjNbHeLBAP4I
TrzV6jVtiEYEEBECAAYFAkXiL3EACgkQBlWsEPLYRi8pVgCgoaBSjJ4c2iGnk1BZ
olOzwLR+sk0AnifR7gGQzqYO8irzDcWIeCw+JRiDiEYEEBECAAYFAkXiULsACgkQ
W5PAL55KnJ1O4wCgic6wnaQenjfTEf2meS6jYEl73ZEAn3St8VyKK//g9yKVqQ7+
ADinP5jWiEYEEBECAAYFAkXiq5EACgkQAyVwhE0jE9U1fgCfaL77L6cAAOAi8Q8e
yWA5zYMDtTkAn3AS0EgskYq8Gf7hQoIxhaZ6erHwiEYEEBECAAYFAkXiwSwACgkQ
cxyv01PBoy+0bgCfTxXfzF3JrRWSweU1Jfwm7HSYSbEAoNumyFsdNUe461pReeu5
Xg70YzQHiEYEEBECAAYFAkXiyz8ACgkQ2hliNwI7P0/A5QCgmJxf2IwQcnSYWlT6
L236EzxcJy4An2PQ/HuiSeYGe6wZAQplAAoSMmpqiEYEEBECAAYFAkXi8FMACgkQ
i0rEgawecV43hQCghhc0TulpPQPZ1F1VwK92e3R8WiIAn3UqbmiaKS+Fji9gOnYo
Kc5aSSCOiEYEEBECAAYFAkXjBd4ACgkQMAKNJEgTtf6qqgCfaOJUjXBfNaaHEpWY
fJkHrr+2xBgAnirKEbvhYSPOnNbNdqIL6khZY67riEYEEBECAAYFAkXjJRkACgkQ
06NwBK5NHNRSpgCgroeyoe/A42VQ52Cw7jSzWIT5S2wAoN7y5PpW+kKLIvUybc7V
CgC1CkskiEYEEBECAAYFAkXjK70ACgkQH38yahLu9iphcQCfRl6hY15rkdL+YuEf
rTuAbKWUbsoAnR97XdzuysxFJ1te3MWKxHb4Sl5tiEYEEBECAAYFAkXjLq0ACgkQ
OJpWPMJyoSZLrQCfW8hTLnVFEE1ocUAC49DadLj0REYAn2IFns9NctORQGHgCYtt
2XDjKmjxiEYEEBECAAYFAkXjSNAACgkQIae1O4AJae/G4QCfYOwKbO/q8qNzPuQu
0kR6TQ2j+ZAAnjecEaLLLhYyPHIH72g0HgF3CTaviEYEEBECAAYFAkXjSYQACgkQ
KJz/wOY81tZrwwCcCwotjIsh17iknyb5tw2jQdq02E8AnRnBY6WbT5i+wlo6QBPg
HA7PX1wNiEYEEBECAAYFAkXjVM8ACgkQStsfiGuIVEP2FACgwYetOw+WWRx9v3R0
IdM71Byl5EQAn03AGcFBtNZWgkTDcvRaENFBlY86iEYEEBECAAYFAkXjhGcACgkQ
zxI0fJaL1YdnJgCfUzKFueLc0irdhNZqsH0uCzGyZMwAnRVk7k1YSutV9dSth9kK
LfBEFU2WiEYEEBECAAYFAkXjlzIACgkQOHNNd4eQFFKBqwCeLhtFig4QyYSOC8cQ
TVMzyyGhau8AoMIcAhUeF/AUgQQsidP33NITK17fiEYEEBECAAYFAkXko4UACgkQ
SViWlxucwupumACgnUvuuKQPAOE3gGbnbXdMtpDeOIcAoIkzED+79ImQu9NFx4zy
bS/pjkCliEYEEBECAAYFAkXkwAYACgkQcLIDITr1nRb9pACaArVVdHkbd0juT8fy
2tgemy7YJc4An1h4HoefFi/NJYzekAAQsEMzj1BniEYEEBECAAYFAkXldgMACgkQ
eQ6MlGH/2qu5SQCgg/5E1munJEyn7EzZQiCgbwZDmm4An22MO43/Djh8MBUD6t9u
ln1+9UrOiEYEEBECAAYFAkXlqYUACgkQzoDvxJGnB+TPyACeLA1G1uswwVDKoO2M
r9Vm4U6hMfMAnRO7cVTrNw+lmHKk/MLZcMVfX7Z1iEYEEBECAAYFAkXpli8ACgkQ
FViURZnoHaCN+QCfWVqziWZaCMt1cwjs0q1PegNFTfYAoJrtDQs0j8Mr718bSifZ
ARsnou8TiEYEEBECAAYFAkXpuC4ACgkQLkc/9x1zhDRQeQCfRAXmlJ9ti5xVBhk1
mlPWOIqyW88An0fRJVYnLI84CAAOrGFwhxrSrfo2iEYEEBECAAYFAkXt23kACgkQ
MGnpIbeahxw/CgCeJNBfyAvjDPhlqqrkmd/PTT+ZzcwAoKsyBz6XLYejG5RjQZey
PvMIfyeIiEYEEBECAAYFAkXxz9QACgkQadKmHeJj/NQ6mgCgihm439eDpdWf9C19
YGKFKYwJwysAn0UWP5RRTEabxscB0n8YsaQoEUuBiEYEEBECAAYFAkX1UycACgkQ
6mLTtmqrwqGM1ACfXYoemJ0wtG0UJrTAdw83Ne4bTjIAoNxP/fwmOqZ6DWZ2xdxJ
jFgLcHvkiEYEEBECAAYFAkX/Mf0ACgkQOpD/wRQI1/H7gwCeOxawK2PWFPUlzPr8
FBWde0nySOcAoJcfuJmx2x165GCV7brPJulxHsn3iEYEEBECAAYFAkYKOjsACgkQ
imdxnC3oJ7OSuQCfaGITyALXZe74lD/6zTeVFGkCJ30AnjqCnlt77KWGHgDTha6I
ExUCvFI8iEYEEBECAAYFAkYKiRAACgkQPa9Uoh7vUnZu3QCeKSdhH76uoNEDFD6t
JLhxxvNItjoAn3MF7mkibWqTEjIX9DfzQF0f5LbaiEYEEBECAAYFAkZPzLEACgkQ
YGXVM/3CBbmjfgCgg3yJEuwDvE9R8U8I740RiNFuFJwAnRH3g8U4hFQ0OV2cBohC
zQEPB5JviEYEEBECAAYFAkZSBygACgkQFdaIBMps37LwHwCgn28rdcY6wyDYiu8m
KLcKnJ99OKUAoIk4P+rSzWGtQSZAkeFRH7z29V1AiEYEEBECAAYFAkZSbbIACgkQ
SMnO3Fce5JjT8gCbBqwnvXiBYESgGiv+t0ZrrWDYsIcAnjn1mSDpfJ2QjArWgN3p
2YJjerTAiEYEEBECAAYFAkZcT7cACgkQcc6vrOyiitu5wwCeJeqA1qQyeoCPN0Rw
hsaSDPb00RUAn0wr34TI8CZgWDujoWKDk2ltNPGliEYEEhECAAYFAkZQ7W4ACgkQ
eQODqXRm5lMw3ACfX8c2SE352xAdhOy4eQINBMWro0sAnieNhqEYZWrCww/Yr+I6
U6AxkElGiEYEEhECAAYFAkZQ7awACgkQAklOUvzaV4dlaACcCN07xQXpNY+D3/Nl
JuJYUOPb+8MAnRckOZvaNDlG9C2ug2x9EWnLuAHFiEYEEhECAAYFAkZUtlAACgkQ
MojebXoUJMYZ6QCfcxB2x+T05nX4Pe6SNPKLTqGIqTkAn3WVyDikk5xT9FGMxYVu
p5JmXm6CiEYEExECAAYFAkU8fD4ACgkQ7Ri2jRYZRVPhtACbBhF/A+1iln68OW+P
IBVwojt3M9YAn3U5xGwempO8xNUxaw7nL8EEJ5loiEYEExECAAYFAkU9Dk8ACgkQ
OyvlYhSROJfLIQCfXxVuAm+Nli3ChAvJ87Ts6tpTAJUAnRwZB5nURCV3rh+MW3DT
JUd5SjIqiEYEExECAAYFAkVFzv8ACgkQViHMurgFpBZHlgCgsQT/b01et4dtMv2t
Gl2BQ1mj6o0AnReDm8nEXJ3kDgKfHlfSwO5lYVGfiEYEExECAAYFAkVKZBwACgkQ
ocfcwTS3JF/jzQCgmM72wJO4Soo0ie4QTVI9dZOHYxEAnRH7Re3ogovLCM2Gn15w
N1z0DzKwiEYEExECAAYFAkVXTZQACgkQIcUJFg5KeHVDBQCbBbN+Hg20tuIPnfmB
Mx09G3NG3WkAni2OG8FTQBtDWQEq1qBuXJdJ8FJtiEYEExECAAYFAkVZmdAACgkQ
e7tFxipD00w5BgCfZETUIlxOdn9AOVY6Q6oI1RmdUgcAoK1hPdszkxR1epNcbqh8
HuEv7hptiEYEExECAAYFAkVmCMkACgkQQhRMBiU3bT60gwCgjWxCvbu8mMTGiJAb
BLrvhf8zA/kAnRmPXZtIb4QHEKAwIW2/HkLsQTK4iEYEExECAAYFAkXjT7kACgkQ
jCXuDw3At9YTpgCgw/PoZTSqOv5MqVimGOUkpm0dxooAoI02BdH/eweFxzQbzPRr
AZTKYXyaiEYEExECAAYFAkXq39sACgkQQdwckHJElwuNNACfXvKR/6bT5EE3b9SP
VRbgzbIvqDcAnj+F+7xush+wnQczGl4oS1VG9B52iEoEEBECAAoFAkVUszoDBQN4
AAoJEF8shKE+tgRto1UAn10JJSSYp1KLzxHE8oOF6f0zUIFhAJ0VGEmXIDr6kLHq
wpqztu/pmV4sC4iNBBARAgBNBQJF8YMlRhSAAAAAAA4ALyBmYWxjb0BtNHgub3Jn
aHR0cDovL2ZhbGNhbC5uZXQvZ3BnLzB4MDIxQzVCRDItMHhDNUQzNEQwNS5hc2MA
CgkQp3xL3gIcW9JVRgCfVU4aNqWLlwYFAFw7Y5dd6k0hLXQAoJySGsIbgBoEZ+Gh
Z0km5dISlMJ9iJwEEAECAAYFAkVVzKsACgkQH3+pCANY/L2QuAP9EgKkqwfjWozW
a3pdl47roBleOjQ7XIH02XldIE+IT5GznAN8syF4VtuAA7CF9O/AziDt4GItvRTv
sM/m4Ir/yu+wijCElibAlppCtzhLNC6Igep7bbJtQ45w/rw0FGjMBK55yDbeGWZw
028fPQjoiZflCXRCmBPlFhLG6l6O6g+IvAQQAQIABgUCRe++kwAKCRDtoh6UtWVx
b08CBP9xgVRDdGx08+mJ3OqnTeG2zLHhGP3W6AqYxJDe5yJQqY52kl8Cv0+MTh5A
QyD+rUoc7EsaU4eOlh2U2AY6wRkdcgbI0Vsp0LLqI9vf+6F8RZdwpUwSSva4o31u
BDfEwdHcueaojCvz9/vbJhfHQxdg3lN+wN0baCeV8ICOZZ5kOF2gFHA6cR0LYjoS
HZAoKVuAZK7ndX9JKySmWvKkyf++iPUEEBECALUFAkU+WgyHFIAAAAAAEABuc2ln
bm90ZXNAZ3JlcC5iZSJodHRwOi8vd3d3LmdyZXAuYmUvZ3BnLzQyNjcxMDEzRjk0
QTBBQkVCNENFOUI2RDNERkMyQzYyQUY3OUQyOUUvMzU2QkFFMDI0NzYzRjczOTJG
QTJFNDM4MjY0OUU2MjhDNUQzNEQwNS5hc2MiJhpodHRwOi8vd3d3LmdyZXAuYmUv
Z3BnL2NlcnQtcG9saWN5LXYyAAoJED38LGKvedKenTkAn3QOdXkMFPfJhiBm4i/o
hXqO4F2pAJ4n7zcGVpJQsAbveLYY3c+8tyeNUIkBHAQQAQIABgUCRTy8LAAKCRCC
0vbqxLuenwG3CACYPg1kOuAhcWcfMUutsWbZZcQkNGke3IsP9lCyDlr8pk/emtg+
jwTosrGFZr13smjdcKc5nHqvNT7JgNc7xs9p6MTjSdltYT8ouVLgl9lH40bL/3+G
xj01R5wBxpoyiVg72Qi1USivu683xsGgC6rrYKOTTrWdUn0L308178fFPoBSuItF
KYF/AZI+FLdei8gmEogo6cP+4Q0K3nP7XE+yYEp/od2RYcnuVHqHcB3D9x0FHubQ
nQ0jMZZYOmoeXFO1WcIb79Tb8Dmw6sVdekn37o/tfpFFYt9roj6RtMGMxDk/Uwi4
1VdQtrO0ljEfxQYUeFAq89Ul8aDf11C2sPcriQEcBBABAgAGBQJFV008AAoJEC7U
XWZhoHPp+iAH/0i/659z8DOqqARTdl5mT/KB0pDYxoNMse3KCze6g1Tamo8hIEXW
Y3xgzPyWVbTW8OI97/vVfWu5qTmy6JBu3Umc//NpmhNWJWnvcG6wLBcH28eOJxAE
9Vfmt53F+87LBnFHBYQBSu5INCsvldXvBlNvoPNHQCcnewMSkt56SSy0s/SpWMht
rkczpbtADQZd3wuAhayJkOM5EjAW1d9Y+qNJbnBs6LmIUggol++ucASsY1ZpTXvp
TPYeh/qPukC+lLqrDoSHt1+GZwoQ2gXdNKQ/pb42RpYpZ87C989ncq6Q3mHXxJWg
Xae5WmrpfsVvIBGAAHleVrVDlKZMaAcLo5mJARwEEAECAAYFAkXjR9kACgkQ6OBi
9g3LBDHylgf+OiP//ZkvyAAJifMyiKgqL8DufOKCCj0KMTc2oeMvIGc/xBZe1XW4
9n7TmaiIvIgk/AOgbXabJxfF3dtBbIAFWRiHXsRHKzEBg3PLjG70UEXXGKhdz0z4
dM/NjuX6XBuNeyClG92vGmCJCQHjcEuw34ANX1D8Es8nMJJiyIp0ZT9c14x94l2f
PLDvjzLjRxuncsdPkBA0RxzHiNgPQ3i7ncxdIXa9xoEgoEnFyuYD3DwddfRkAYzb
j5+4goykQvi7ZDvkow1qN/KlhAA2TRkjdIm/SsyunRU3olzJE6YOqi+LCXEv7tAl
/nFZl1DVA1J15W8n5D54rOqR9NiAQfiUt4kCHAQQAQIABgUCRUSuTQAKCRBXkw2r
C4awZ5auD/wMZRz7GdpX8O+v/HNlmAyvrqP/axss1qNJsHzkoMqyeVyErkMqJhrM
ViX9GwBPlmCeEKcOQXpakCkimx5tzBmYPWy+abzmB6J4qWH5GOJcykc9DGJrRxB3
+fT7kBayGvW/MW0vgN2bU9Deq7cXOgCHlW5EXK+JigkVt+zas+d+Z2oOgT0Ew6eI
I3rxjhoOyQJXdqFZVYRlcud2liNQfdTFCUtP4Ncx9oFtvMNFERGpRw3ENKssVS87
qrJQXcNuOUlQ2DETQ559clJyO8gcHU94kz8OM+WENGwB7GDFbq+GJNmJf4sxkvdG
7xEIno+mzoaGkv51m3loifCCSJBvZPwh+6YINGaxzTqIZ0s8FdjZsT4hftunUaUJ
Mc/pYrL4d2KVTSLlRcaPrATvrOhb30wHfa+cRYJNMZHKqO118cleQqORX1xl/szm
Eay+palKc2y92UXkbBodRXvU7WDYMArHavpibCGERyv2dmt7HVB8iYyPpKsSNqOH
iNsMfG+G6eWaBxChkLQcXq0mGyUqGsflPUqTRUs9fRnlFmBrLPAkJUZEwCdxbHkK
LN3Z1MPy4gp4EMaQVi6yq4hBgomS7VkPezChF5ogyih80own0VEnW+dojkEzbVY4
saRiyoUNSi0iTkxZYHb5mMx8VLa0ws9gwRglsivxOnAnUoQLC/ABh4kCHAQQAQIA
BgUCRUUawwAKCRDyceCubnA9lXhIEACQUzMjTCdoe/vYG6FudwT8ID+1N49ZyVFX
uM/HjY5yOMF0rIxLOGMeb0rOcDKZbgiLLUCKXGuwacK6bUJP1daBZOHLUnaYJXEl
bnFHKmX6tJYzxDG3ydpb6nqZvnviVmYqxQa/pGztGMIUkxuRPtOoBsaIzIX6iamn
IWxWj2luYOk8iCXk+6yQKkPy1LZIyibld2eMZh9GxPgM8r/3HYhgwiCYkJYhwbje
A1VjXTcOJotMvfkf8xMO1EIuL9rpiK4yMAHYLPkTcB+dzmz4fE75/iFP87AzYlIk
txAuRUD2KecRUBZI98+iudGlJKbaFCqdZS7jsv3xsugVy3lUFXq6pwO8VPihQiF8
u2qppSwskPA5D/3yLeEmfKokMAv+EuFuI+ZOuwev4pENn114uXaapQ5/h0Ss+mfi
bWOGLRoS+eGU0ME1FSh+TdT0XacSAFiN9LfgnR32n8lCeR/X051uIArhuBY/D3Bx
jyPO0+yNMl3vivKXDBF/UCJtEaaSVxFMTyxkNfnn6gyi7k2pD2RpPMTb2A0yzD+3
3Yi/6HtMWSFNYRTWwdgGBD/032eygrff3n+TJ/ebOBFByF2e1v1PulwrUiXocFQk
JbKgxKuODbyWHMMPqUOwDaF8ob3gzSaasH4INdbRFSyG2aZITigAJpGUFu0hyo+s
B3xn1qB5+YkCHAQQAQIABgUCReLERAAKCRBSIlPD1yc5gWKuEACQO6TJ8nK3xKYK
nH58bQBmn3m0xCX9twx3As0QS/ivyzJJVgQPE4lmQYBry0rNaM3Kv/gCwwm0t8bq
mwpVTlxKkLDJMYD/HtDWO58/dih8wlw3CLt09BsLaOrsg+G2WxBTFuZ2du86WGEb
nWVOX+QWJong7EHooaZRcn05fRTE40CMnV1MS9sMAyanQbJHpiqGEzciudmYwnxZ
48EyNzm2JoWkpQ5SprYHVgkpgRyWU3rPB4jNrCcqd9+zvYLeS72UG20uIqRe8CKg
d/cvHqoSKlsxGAYhgLaqiNhJfNaB9gsftiZrWO7+wtPJQ86HJFIoJ3BlWbl+WprI
kjv1zujp6UIXNJAeJjFvfmrWzu4oU3AC3BUeLzbv653hEir7rPYsC5wbhEw+YxF2
uoRVRsueHrF30wMEec+dNC7jdjy825MDllRBnB9f8wgsZ04tdZhRrvV1vCVpuW72
l70dfC/8IVjQ1moLFG+Ua4pnI0SzKOdmeRpk8Lf6DbM8s2ebNV9aVcRGQMDeve0t
ZZst4Cv0GNYgIi1AlpFP3wOyzL8IuE+Ox0S/9EIA5nhXPYqkg3YbkGvsvqvWBHbM
SXsi9CTfZj6EbaZnnpBIu7F+iXl2JDTOoiM6l6+O0Jf/HqS2dBx6wGSHYJ2ONU5O
fe+7nBEHnoL3PSh2MdFUwIEFFCvLXIkCHAQQAQIABgUCReL8lQAKCRAzlhWI4cIY
RS25D/9DPeR68+SD4LSVXWDcN7MIgClC/SKXM6A/rRFZbfbSyzJ1YO0oZqa8+OI4
UTgbXiLrWNk4j2spk2GRJR/p6dG0zJlzdGDbYsl29+/DAvsTOc4mkR35G9TCKqy4
HAqwvAA1519SB5/NFIpeebt04a3EVrEaC8PYjfCEIabMqv/S/mnf41+foI0mOXLi
be44y2RXn9IBDLs76wYrqEzi1sJlYt5uYa4JkqNYmgVbeCay7+lKpsruUGGYBXff
asTvlwO07y9wsNzbTmdwH6oIysItaOAae8Ve+ll4FlypC+ryuRpuqnmItwnJqnKd
jGctFSmg3OHimmxOYUl7FwC1wpomUqwMdRv1+gg0uMCXpySlzoF0GqmMDCuCwBR5
snFouHLuGNh69lgpOl3JFqlDLWnJxd4oSeke2qMNa5PVEAL7R1nFV664q5QSRWw9
TPOuk9fnefky7YeaP/VM1hlZbw8Y2jpYpdVxx+6MWy52TP4uiiO8u3qC9ors2P4x
ZX/0oykQWWzKs8uH8xkcKiH4v7N2wDgqkRHXgJP8nQsl5qDvLDIgJFeddyAXJf0j
4LGzKbFHxjQAFcX3i9nW57Lu3CjH0zz6qIuT3giupiXVi7K4j2plMDn0XmRycvxg
2NCogHoRxtbwSrms+yKUT7edoHudm9z+zZfUeA4GiOecmWSPBYkCNgQTAQIAIAIb
AwYLCQgHAwIEFQIIAwQWAgMBAh4BAheABQJFO/OlAAoJECZJ5ijF000F2LgP/A11
x5cTSYZMtVGcQUw/SX2CXQn7nsutoe6nIoIJFl1Tg3fTCCbSa7RYsAC69bACjfvn
kY52rg+1S3vi3bkY4bSkhk/9ovdjSXPAxsWW205WpgOlXSdEaP1K5D11QPU2+U74
gvmrotNODebw1S/2t2ld0nZK+3DWhVThWonFmK4LHpQmR5SxL0MvBwV2HV9WPEWb
Ezf9MZxKJOXtbPiwWb1/QxxfkR5m3thpjejQkG9pzRjdRSmpcUkRl1M5OFnQBAXv
k85sU/Fm+mjfISGY6QV5daaOOQIEYdvau5DEboSmwlDl/8Ljh+oweedS08ky9JIT
qxGJfzQU/EQrHALFhtWsr1/tbbL7WCVRs3g2POTaMLzQkLLE/p7A9fueTSRJzCXt
2oDYKllH2xnQHqtE88u1tmGFoP3pnhLZR0vRUOk/u+p4MV4MBe1nRDhSQTQNBQim
YvMp2DNBaQ+lOdsxQhW6fwfgjNk/QLNhL+XlUTKaDl/Kkh8VlJfiMo4bLVvnkUaW
l89ggXu5ODwjlutdmSGht4HvXoJg0rujmDXXPE7TC9wBwveji1Th36kJTwApirJ7
fFFmzsYwihe0t0MRXQZ85Zp+XQdJwI5hUAUm8RLXYdypqn6NpXt33qiv3U/0ktJ7
vT8h47Wu26ATXSCrma3+sXWRMurtI9N6X0BYwALxiQJABBMBAgAqBQJF7beqIxpo
dHRwOi8vd3d3LmVsaG8ubmV0L2NyeXB0by9wb2xpY3kvAAoJEJV5UtfPNAGptAMQ
AI65u0iFjIwionEuOnFcYqL/8QxytBLel12aek0oCZe5TnJQGI2gigy/FsxrP49a
2IN9NGspRDYVqf9f2CO6LzfIDwgw7obhJnxDaReeYRv1bSAiiJERbwGj35zCqHi4
xjz2cd0BfXVICLfY7NaaaR+eReCdYJkoVih0LKkiUL6s/SIpwog9EjCnbNI6BZZ4
XFoP2zAG3iXQ2WzdRcwE98CmNcZlebcnfK9x/NSnEnLIHvkfyUH/e1qCaw20a7qY
Q6tUbbqmBdCH7z0aMWKbYyCUgovoV1veYwWRgCPS2ZDEJFxj3dAGZeHRJHMo3Qw5
Ax+3KHJfIab5RjIkWrAN123TTSyf61SPyBMN/xQrpeMC55uhNyUkB12Gu+SyAau/
8AXLAsILkiaLnD50HEi3B0oz9ku35JTwbhBVdEct2N+J9TzQpC7wpsdwSosTXhFi
oMwNz374gXhZqoAhnyOSau8Eo1CGiClCe5hIC5vXgLrX55hhahSjFLDSXpDqdplI
HXVVqD1rKh4EkMSXoP2QKSuQcm1cADL5cDupUU8SOaKnvXEgdyCVe3DjTFrkoSP5
mQaDCzuC9k2Sjmn8FETHklp2S6BrTY8V0UAXZkQQV8Yr+SKzFXptjyI3u4hzDzDW
1jpkiz2yMjxui9SC27JevUptw0RIBKUzV/HenLpL04PliEYEEBECAAYFAkZS+5oA
CgkQIhjIHo58A/+s2ACfSh2lrybtTXoCECYOxVIhNDr6YfgAnj6wZFddpyAFukxp
Gf908WNJYabGiEYEEBECAAYFAkZugMcACgkQj6mKb+7tcPNtOACdFUd9T0BcxSkB
NM6GWQJkYyd9180AoKElZP/leQMZvIW4+wFA3r5Wdia1iEYEEBECAAYFAkaR9uMA
CgkQqbb3MLg9dhwwUQCgrYTG5N2AZFSPctGES3o7NYkQehkAoJquSURqg+tmCsIa
vVMqpPAvu4D3iEYEExECAAYFAkae8PUACgkQmGINRbWBGCz+IwCfX0H4rQ7WY6Vt
JYDnQ9MAxFoHErIAnigbjnobAWP+w7KJDBsspQiJ9NtliEYEEBECAAYFAkaksjcA
CgkQmLReZmY5NBWpyQCgpMwLmu7xPUaAdU5dcg3HUt3Eb0YAnisdKeooJqbhGLZQ
GzIf6d4dF02AiEYEEBECAAYFAkaksk4ACgkQos7wqTrZvaeIjQCfQc57J9xErBQE
VRUXkEMXLDUFpJAAn2leOk20mvap8KHBq1cX5smLTLN5iEYEEhECAAYFAkbRq3IA
CgkQSVDhKrJykfIFAgCeP5dmvQ1uj34eZ9wQwpIyK4j65AkAn3AWpE8wE4h6A/5F
FDRqbBJUpXehiEYEEhECAAYFAkbVe9cACgkQ9sjpnGdoHTxxCgCgqDVmqFjHFSUC
IEMwjldmjzGhhCcAn2RFPiO+FgY1AmtTDZf1BoxUejBntCRQaGlsaXAgUGFlcHMg
PHBoaWxpcEBwdWIudGVsZW5ldC5iZT6IRQQQEQIABgUCReIEJQAKCRCzsfgaAnh4
gLVQAKCJXYtPtzFqAiuHiLRotJITJoNv0wCYmEgP5Zor3XPgGSvYjz/zICZSiohG
BBARAgAGBQJFO/SyAAoJEL9L0OYEnbh5gzsAnA5n7CogvFO1OXbGiUfe6f7HIeKQ
AKCA9O868uD0lJg0ASbjR4E4RyBMDYhGBBARAgAGBQJFPHEBAAoJEKsvWlsVJWmQ
kQgAn38QavQ3Dvf8xbSD/eRpNW39tLiIAJ9/qaYvPn4cqEnoQl8OsMw1gYIdBohG
BBARAgAGBQJFPHIOAAoJENuE1HYSbUfAvBoAnj7lPGECsJCVGJFK6KgUSaHQDJZZ
AJ9erfuPtQRVlFC1rx6eqMNEEiGPL4hGBBARAgAGBQJFPI+ZAAoJECakfGr+bYUP
Ua0AoLh9tVd5CxoO3kQVkol45v5bwJigAKCPaiFuiYeCtJ2f9XOfuEB6QMhBF4hG
BBARAgAGBQJFPKjmAAoJEFZBJvIp8ZvRIBoAnRZJOlbXBil4qBIhwzO2ldl3HBWt
AJ95zPx6h+j1+1CJrhiV8345ZgmWuYhGBBARAgAGBQJFPLNZAAoJENdZXTdLcpYl
PzQAn3T3rzZAqu+91FpkVo4E57QxQoNRAJ98neRkIUUGONDFwihd3Trvd/gohohG
BBARAgAGBQJFPPEtAAoJEGjhJSt9pcU7AyIAoMiHI8HvrJmmRk+EkWb20uyBf++a
AJ9c0ghIgOlHS7XOcwxjgv1iya2OjYhGBBARAgAGBQJFPPe0AAoJEHPeaYzHFAWi
GaIAoKGRcsMC3E5quygXUmQ6nL83YF9wAKDJVHHkwsV3bWaWq2ZMkHCbjDNI34hG
BBARAgAGBQJFPSglAAoJEAbypSJtCNehibsAnREOeP8cMoTfKSR0fpzdY/k6Xxc4
AKCzCdnW9Lu6jSFW7GJfvhx9JsUngohGBBARAgAGBQJFPecXAAoJEKrPs4YhG27v
wtwAnjP45zwtCHx+lAUw6+QjMTHWaM26AJ9Lsw8wvbathJc1bjcBcCUjDh3CyYhG
BBARAgAGBQJFPhw/AAoJEKkX6cyZbhReysQAnA2mSrTteoKb+j6bAuXy6oJCRmO6
AJ9TYUGUuODUwNoNnHY/XnGQEBCOvohGBBARAgAGBQJFPk8KAAoJEC+VFQiq5gIu
xFcAniJLINm+Ucvq3MxzVxCGt+Ps/T8bAJ9ve/fKDbX23xHrwSMTqxeAcL2OVohG
BBARAgAGBQJFP9EiAAoJEJRq0wuHLLoE2TkAoOUJjnaDAqVgNbCeHvF1bVYtEZa3
AJ9HdPkP5XDwTtN+w96ZhOvigjZnf4hGBBARAgAGBQJFQEScAAoJEOkjWjUYLJeD
muQAn3WsqZXjWJAyZ/Rb3I3FoRVnyXYHAJ9DabsluDIehmSXI7zBcd7AzIAn7IhG
BBARAgAGBQJFQGdTAAoJELcooz9Fd1H3S4sAnREA6ddcG+zotHyoj4xzOt6Z6Qdv
AJwJ7Ec9EriQopBYySHlo2VPQE+ln4hGBBARAgAGBQJFQm+PAAoJEAYGnPKWlFfw
z9QAniJ11YA6B4lKzQ+3yDBkUC51WQ86AJ9QSb+Ph8/v5QnlDAAfirjzxkS8HYhG
BBARAgAGBQJFQnYHAAoJECXSjMWVfVjP4YsAnAs3C9OBG1vcKhpRLqZEpvcvp/Iq
AKCJUm6Qev1ETSO+GfOe1n3q2sRDQIhGBBARAgAGBQJFQ4XBAAoJEGx2F4yg7Zgt
RvEAoKeYNaVfauAg+FjrI/ZCUF+7a1Z2AKCnmbcVYAh0BJA0luq7U+O954my44hG
BBARAgAGBQJFRb//AAoJELPOLSM6q/mSdhkAoLOGfupG7+DNsCrxHg7T0lTGgG5f
AJ4mB+IifrEEkWqyVV1fwpEDTg8ftohGBBARAgAGBQJFRhogAAoJEMo5dFnlGy6R
eP8AoITozfb7cmo6BOekL21FNC2woALLAJ9M3+8DFS9lj/yctQu5S1189IVPU4hG
BBARAgAGBQJFRiJOAAoJEKBP+xt9yunTqXEAn0CllfaW7kL9Oz16Cn1jBIvEeyfI
AJ4mDFypOdRGruaxLrsYhoCxf5LfbohGBBARAgAGBQJFR4KnAAoJEJfO5hKrjj7V
rOYAmwQIGHK+F2ZssP2bWit8afR4ZU16AJ9AZ/AOUxfgmIlgNujqolE6bkFaHohG
BBARAgAGBQJFSa3gAAoJEFmm5/To7k54RxkAn1T3GaBNC4E2rZibFTfe59YxQ93i
AJ9ZRSeg4a0XEvLhJJUxYJNFcFTGJ4hGBBARAgAGBQJFSxxMAAoJEKwhViahIYdX
fFoAn2RNU0qGszvgAvFC/0RETOmanm7uAJ9ZmExSPe4l4nl1s+oQzlu1yIJ+u4hG
BBARAgAGBQJFVGbtAAoJENjKeKUexWvscPYAmwaLzRYIHpD887f14Ir8plggwR7J
AJ99cr0ZNeZXGF/UuETX3m+oVn0JoYhGBBARAgAGBQJFVdoQAAoJEBaK712xKT80
FkQAoOm0Z+rK/rckzp1txCEsB1GcZTJZAKCtytptvKOiDlwkiEBY90fhszfV5ohG
BBARAgAGBQJFVhw+AAoJEBypWmNWsMoIs+IAn1xHq7mfG4L6XV6yYMMkA3JdyHL8
AJ9OrVeHfizUavzXW8/j0MkAu8rmm4hGBBARAgAGBQJFVxuHAAoJEBXWiATKbN+y
6tQAnA/BFffVAUrJDto+AhpHx0rZFDGkAJ91jTJpQEsFQBNkJre2mL9YDI6PoohG
BBARAgAGBQJFVxueAAoJEDDUOm5k6+IgoXQAniRtYZ9EXDl0xl1GwgBeENA90jEP
AJ9ohBGFZCZyTLpStZ0he+bgl6XOGYhGBBARAgAGBQJFVyq3AAoJEL/kOH5U4nj4
Q0cAoIx4x8xr8WKlFyZsGfLqg1XQtfZUAKCAcZpeoP+qja50wwPISFZtGmSS14hG
BBARAgAGBQJFV0kbAAoJEF2Oi+nyOBrUTbQAoJxr/hcdm3Am7Cfke0p3vUznu0W+
AJ0Q1+DOxqHbnEAo/UJbLzw1ALeX34hGBBARAgAGBQJFV0nTAAoJEE+xyIscE5vF
ZVUAoKVHbwTVZjPOz/sobBDLjVoropirAJ9VDL3eKfI1bXyPM9Er7SLNKNd+RohG
BBARAgAGBQJFV0sKAAoJEDMRJG1RR9z0jvMAn0iyqW1JYHNohwNQMBt1fJfxdtrt
AJ9zZwIixKRePaIjSSJo72oseIRWVohGBBARAgAGBQJFWhEaAAoJEBRll9zcw5nH
mdYAoNtJblpHYqIa9xVbsPZRViKvhA35AKD8/2G5wq2HKNDlREsEcN+PG5PUV4hG
BBARAgAGBQJFWzPaAAoJEBdynXf0qFEv7c4AoIsCrBTwcUP5uyGiCvzqb2rhsNzc
AJ9Ar5QHY7tzCYllc/PjrneOGOD214hGBBARAgAGBQJF4ZPJAAoJEJhL04CsX3AM
qAkAoK68n/ervqIL4uNUqJBwi9Lbl6DLAKDZtmgWjrXONTNkrPDE6GWAS0LSIohG
BBARAgAGBQJF4bTFAAoJEFAC77GWLjiQ6SgAn2/8onrUShnZKu0nUV0myun+n5nt
AKC1RB9U3Z+3uWIhfguAC94eWCtRDohGBBARAgAGBQJF4d3SAAoJEE1EwCDFwFuu
1GMAnj7Kc4nDWpABvDOmAo0bV5dk0pnaAJ9rXu/tsdbunoyjry2SY7RXxlwJEYhG
BBARAgAGBQJF4eVPAAoJECV+3BMl8VmUsZsAn2cXD6qVZdGwI7KuhjSSeq3L8FGC
AJ9+usMPqivjOMWSY9m0oQdPjAhlY4hGBBARAgAGBQJF4enGAAoJEHhn1Tx0eTXd
eIcAoInCDMNmceRzifNetynJIJo9i6KiAJ4x5cVoxc3J8hS5OIO/5gGsverghYhG
BBARAgAGBQJF4e1CAAoJEFiD3l2iIpt4bTcAn0zc1Haim5UlWuMlO7MpinLCbEWQ
AJ4jYpEaeKlXFbxIoLuyl27jHj7SzohGBBARAgAGBQJF4fJWAAoJEFUVYHaRYekR
s74Anj8lFDrs49QHTkL5raA/W+1ycMOlAKCWOdiOsMZHFDdnxgybrF0UUzJg1IhG
BBARAgAGBQJF4fwsAAoJEMfZMCWd/6rUW0gAoK1Qqed3rEqzSgyZZTOzl0liIXqC
AKCsMlbYnFFguYDFfoSxqP7ON+LfcohGBBARAgAGBQJF4hITAAoJEOVE3gebfDKN
7I0AoL93/cV8keYDSEZmSa1mODK56d2bAKCdOTEwCTs6o/51TnmZM1SIM9jYwYhG
BBARAgAGBQJF4iIbAAoJEH5OpU/Qq0B1jTMAoL0LxQyVk4uGVgxedzuij5ckZceA
AKCjYV1+1tatqwOiI8XapjUWokxtRohGBBARAgAGBQJF4icTAAoJEHZJQAVJruv2
yxMAoKU9CCwhdoDGSUfZsSB+IoB76uLXAJ93huh3WknzFQ1iW2wi+H+QALK4QIhG
BBARAgAGBQJF4i9xAAoJEAZVrBDy2EYvhUwAniJdE1GWR3P9FoojOONehI08jNd6
AJwKuU1daJLPoZgo72pwSvcaUmWYSohGBBARAgAGBQJF4jI4AAoJEJzL2hYB+otK
cj8Anioc3GLnDf0YawMpqWsowcD9/XwbAJ0WuB+0Va8o39kC1F5IMs2sH8O5C4hG
BBARAgAGBQJF4lC7AAoJEFuTwC+eSpydJfQAnjX+peY8X6e9nJedob9/dsYwA4ET
AJ9Hsi8Ce+MZk2NSHN1HcOgUJbzH14hGBBARAgAGBQJF4quRAAoJEAMlcIRNIxPV
bnoAn1DyL4EkQ6+pZB1RYSMN0S4b9htSAJ9oo8KuPzwdM8WjSqmattkGyCkczYhG
BBARAgAGBQJF4sEsAAoJEHMcr9NTwaMvwmYAn2PH5sjrHb0VT88ErYznzBL4ZXJg
AJ4yOVxkzaK7iqRXIV0l26tMM5sAAohGBBARAgAGBQJF4ss/AAoJENoZYjcCOz9P
wpIAn1UjBcm9EFHzUWObqGBwX2nczEhQAJwMhbsD4qEtEHTcDVywTLug57iBt4hG
BBARAgAGBQJF4vBTAAoJEItKxIGsHnFeNqcAnj+Yeq0a+1CgEantO1cjoLhvtQ6f
AJ9O03hx69+qstjquG7dTrNqDNI5OIhGBBARAgAGBQJF4wXeAAoJEDACjSRIE7X+
PcYAn26BnUwub3JSCecTnS9gSQo4EBZnAJwIul+SMuG/YM36r8VUluyC7YClaohG
BBARAgAGBQJF4yUZAAoJENOjcASuTRzU2NAAoJAcsSeUjPlfbujjWmtsvj5uIOOZ
AKDiEpKE16mOWsZ7zwLfW9wPVZNaNohGBBARAgAGBQJF4yu9AAoJEB9/MmoS7vYq
l+sAn2ecFoUfRzu/3wEigdKRkcGOH7XkAJ48YAAkCCjIOR+aiX9FLtX9K1tWb4hG
BBARAgAGBQJF4y6tAAoJEDiaVjzCcqEmEcwAnjK09CsyyX9dDpBQJXpEIFk0yUK1
AJ96t2NdegULETUY+r+DW/6Y8uEX1ohGBBARAgAGBQJF40jQAAoJECGntTuACWnv
638AnisMM2+3GQPg0OpsObUlvdmRVqx/AJ9kaOckJGr2jtzHXGef9ZnaQ/yRuYhG
BBARAgAGBQJF40mEAAoJECic/8DmPNbWpPUAn2xc8z7TPuCdnh8TQextfRMeMDRO
AJsG3nNlPWj9zBNOyP22jiWeCZilrYhGBBARAgAGBQJF41TPAAoJEErbH4hriFRD
8A4AoLEGqZP/neKVYDhEiXKyBUQtaXJHAJ4xr3Awv5A8cuVuZ4rj2FP45NdCh4hG
BBARAgAGBQJF44RnAAoJEM8SNHyWi9WHEEgAnROvzuohiDh/BhVrVWOJ2JBl2MK4
AJ0YODYTxsJOcwzfKbS3+HM9ghhEsYhGBBARAgAGBQJF45cyAAoJEDhzTXeHkBRS
CO0AmwbPl2bhWqSV5CYAItRh0Um4qdfBAKDWAYrjPjXOSOBzvJHFIcU7XGC5uYhG
BBARAgAGBQJF5KOGAAoJEElYlpcbnMLqomQAn19wOSzE5yBmfFh4StGu/VGcaurg
AKCC15Xntiy1Ewnf8tQtUHo0hCgkSIhGBBARAgAGBQJF5MAGAAoJEHCyAyE69Z0W
dGIAnj9IL1a0fMXbzudaSShnERyhNTzTAKCdv/xIrtZPyDx0yBzHXy4OmcRqV4hG
BBARAgAGBQJF5XYDAAoJEHkOjJRh/9qrp+EAnigR9G6GYL8Ap4M1FfDd4gkFpko6
AJ9mnEJ3bBUv52xxxlkJG1fA1BXL6ohGBBARAgAGBQJF5amFAAoJEM6A78SRpwfk
xf4An0ttYREJj3ZKLvDWXJqEHlmQf6JBAJ9wLSO50uIsvVBX/93XDQheAxlIp4hG
BBARAgAGBQJF6ZYvAAoJEBVYlEWZ6B2gglEAnihv1mKDuM/qOQ0hpriT2BQbBZ6y
AKC6J2WUnOa8WjdwL+j99V7bIazFeohGBBARAgAGBQJF6bguAAoJEC5HP/cdc4Q0
2kgAnjeE08UKUyMGshKJRUYS5F/waIWjAJ0ScRc8vdnaa0NJWdcrPokvtX81n4hG
BBARAgAGBQJF7dt5AAoJEDBp6SG3moccEqEAoLOQc5HtKYVOVoS4qftybido1S9h
AJ90nwckHEhrVnyKQwZF5AUCODXonYhGBBARAgAGBQJF8c/UAAoJEGnSph3iY/zU
nBQAn21J+dXT5IJMHlMJm9IfeI71oTNOAJsHig7GkV+rZCWr+omRD6a9bw0iR4hG
BBARAgAGBQJF9VMnAAoJEOpi07Zqq8KhPkwAn0mutpDpcNijnM/xQOQg667y8A70
AJ9WhBjCtO3a10iuxx0Z1qmZfaL0AohGBBARAgAGBQJF/zH9AAoJEDqQ/8EUCNfx
aMsAniRWYJiBIinWds8qw9tmKRA0LUb0AJ9bbVSLl9/zYcywFUrsaJOGrOu4XYhG
BBARAgAGBQJGCjo7AAoJEIpncZwt6CezLL4An3aKnEiu2dVp440y01ZP8rxcj4cy
AJwJMOmCFz1AqDxMR90xSBpgnIMxZ4hGBBARAgAGBQJGT8yxAAoJEGBl1TP9wgW5
HwkAnAuWw6uhMZvsAOmIQp/s+atlz7V9AJ95SMBlRDbz46ImhmXySoyIa10aqYhG
BBARAgAGBQJGUm2yAAoJEEjJztxXHuSYqowAnilqJKq8lwao8SrROqNcP0vtagCO
AJ0fvgNPgn8PysSp9yFNe/42ichy54hGBBARAgAGBQJGXE+3AAoJEHHOr6zsoorb
Oq0AoJ+e7wcR9S0lzhnuSjiUjKqx04jbAKCpemhUuiopwBtJV53+foMiTboYLYhG
BBIRAgAGBQJGUO1uAAoJEHkDg6l0ZuZTTOMAoKqsNYXvMPYTsdwkOxh1QCZmoFpo
AKCEehXFbR+bvKoEszZIb70p+EnUHIhGBBIRAgAGBQJGUO2sAAoJEAJJTlL82leH
lyAAn3wjRcViWQ6IwlhW9LIgjAQN5zVAAJ46SM2y96DniGgz8bN556O6JwL2a4hG
BBIRAgAGBQJGVLZQAAoJEDKI3m16FCTGyasAoJmdqIcRdKx2a6Xz/ClWX0E6ddtZ
AKCGVydv/D61OQXeWT532qBWL693+IhGBBMRAgAGBQJFPHw+AAoJEO0Yto0WGUVT
gToAn1Ofb8lJN3nrts8ksRmXc+MWQyOyAJ97mYxhxnclhzkQPZdxMsOrmA9+z4hG
BBMRAgAGBQJFPQ5PAAoJEDsr5WIUkTiXu4MAnixh9KErRv8GtHneRc4nRnAW0oV3
AJ98dj0xQMmltzJAB0UOMDahjmBijYhGBBMRAgAGBQJFRc7/AAoJEFYhzLq4BaQW
a0kAoJGFUM5iyFzb+VLDOxjDj7YuREssAKCdNU10F8mzzs3gf77/z7EOv+Qs5ohG
BBMRAgAGBQJFSmQcAAoJEKHH3ME0tyRf7gwAnirlU7oMQWk8t0zXfpSkKJKAjIxV
AJ9JByHZFw4JE2YBZp6j1Nn4/p0dX4hGBBMRAgAGBQJFV02UAAoJECHFCRYOSnh1
Z8IAn2Q1yNALKj9i4XWsNZjizw4xSB0VAJ4yqVaUcRzj55M6Fcw57GqO67FskYhG
BBMRAgAGBQJFWZnQAAoJEHu7RcYqQ9NMRmgAn0OJGibBGfdjrpnKDgroRFiOdV/k
AKC/34An2i/kc0jrIWgGizzKd9BO74hGBBMRAgAGBQJFZgjJAAoJEEIUTAYlN20+
5xsAoI4Sr9+55ZsMJIOYn7QNq6+7oeS4AJ40PNcnsnMBniacY37FXuGf9O70rohG
BBMRAgAGBQJF40+5AAoJEIwl7g8NwLfW0YoAn2zNQYcAyrHdZn95gtRCx/KsUAnl
AKC4BX7jXX/o5pj5oavzBgstYfpLrohGBBMRAgAGBQJF6t/bAAoJEEHcHJByRJcL
SGYAnjeLCAj1bYyYa/05jFW/py2NmSFpAKC/v/BkHy1Dr5n12iwv3YDkwskBFIhK
BBARAgAKBQJFVLM6AwUDeAAKCRBfLIShPrYEbXH6AJ9ig0i2ffCooj/teQH4+CU/
s+NxkgCfQlAfDOKsNZ0t8mDO1n6yuUAKcCSIjQQQEQIATQUCRfGDJUYUgAAAAAAO
AC8gZmFsY29AbTR4Lm9yZ2h0dHA6Ly9mYWxjYWwubmV0L2dwZy8weDAyMUM1QkQy
LTB4QzVEMzREMDUuYXNjAAoJEKd8S94CHFvSXnsAn1x4MXGs5pvzaojpcqE5pdvG
5neNAKCB6f/sWrWfVcm8PDNNB6mayvVw94i8BBABAgAGBQJF776TAAoJEO2iHpS1
ZXFvEHME/2id8ZhcpQQ8Go/P5Wu1gWV8cyvPQ+AT2e3Bzqd9tbkH+hSMIt9ubVl3
IyQWdiZzZzVQaUapMirKxFdiQmo+JkrOEs/mcUUVq6XnDy8lJdxCQOz8ZFenUkGQ
aovNuHRQAVvd1GQppK35T7x00lRwu4jhdgiF4GJ2dyV7T8NTN7O2ADEDnXClHyCG
B6EWy2QsdOtKMckN16UxC4sajo5/VRqI9QQQEQIAtQUCRT5aDIcUgAAAAAAQAG5z
aWdub3Rlc0BncmVwLmJlImh0dHA6Ly93d3cuZ3JlcC5iZS9ncGcvNDI2NzEwMTNG
OTRBMEFCRUI0Q0U5QjZEM0RGQzJDNjJBRjc5RDI5RS8zNTZCQUUwMjQ3NjNGNzM5
MkZBMkU0MzgyNjQ5RTYyOEM1RDM0RDA1LmFzYyImGmh0dHA6Ly93d3cuZ3JlcC5i
ZS9ncGcvY2VydC1wb2xpY3ktdjIACgkQPfwsYq950p52xgCfXZth5pnHae2J5+Kc
2EohMYzW7X8AniUizIhcHb3zAim3F9zYAj3tGxQXiQEcBBABAgAGBQJFPLwsAAoJ
EILS9urEu56fmYYH/i0vpRRvs0U4yC6mjQTCYCnRRK0F3WXaQaPQpd2qI45KpMnV
S23Bko/OUPSwlgSIkBkvAaep53EpAMNqbzDjrxYvungQdG5yckxVsuJPCfg/bEW8
Eq5uJ2T+2u8x+Xns5keaEWJVe1MqOtyxe1v4r/gZkyowe3rHAS54/rZZH/KJTA5K
WW0R3XqRJdWmybPmwdUqdA8DotHthF98sJ6gpNeJcVYYjB/yJEexji1EbiTX8HJJ
/+dkrKg4m7SUzIOgF7pW4JmK0u/CE1Ds9QT4mjocNQIMIXGmZE+0p95+5V8H1xRR
S5RUJjj13bCDBMhn+FygcllVbg04RD/jqFWEXraJARwEEAECAAYFAkVXTTwACgkQ
LtRdZmGgc+nkzwgAjYIAVqbrUywYgywoww51I5pr6No7eacWeo2ck6yzK1EkVcNE
YwEAifFH7QbTLq5irzaTbhqWxzsturv4BV1lN//bVS/e0wlJLo0LMhwzpb6rSHRF
k8d1Y4JtQFORmML0Nv/bSOfN1dAZ/vYt/mf9WzWU70zVZCX4jZaiQka1YXrZUnD9
X1ZPwm7od8cE1AnhN+DwW2Wlpc9dYS1p2DS6SFf9vuTo5URC4R2qx71lZNB3Bg+n
LoMrgRoRp/5CBrj8gfpvvPfIgBXSB4DpBRGyZqxi1ap2x/SfGH6jxRrAGZ/hUcdd
/s9UBA50WVGQBGo4kR5VLtm0DcQeMuuQ+CAZU4kBHAQQAQIABgUCReNH2QAKCRDo
4GL2DcsEMUPaB/9cw9jOdvGOaRsaShiPqVnid9IC5dntKZQ3z7+nvMDFAXT22ceK
6qHRjA+h0Z2VaPd2UsesN+ivJ2bAVxnLhUt+LrT+PyXCY+X+bMTdNicjKPsPwzKk
uQksZ6qy13eouYD2m/fHYhwfF0DFf0y+xD/VQrbSmxuliN+NiqiRQ3JKjBzDRZv9
PnjV79uqCWRTci9CW6tTvrjeehQQYU6PTvghaY6DB1NN35L3PPILaPkZkRdgRgrR
IHFjZNtJRzHa4GToXg7hE9JHZx5TwF/gdGhZqjnO6bN0LP5eyYjKVR5TYpPSUQCr
rNpMZMpO7YB0XfajWjGqQus847id+yIu00KFiQIcBBABAgAGBQJFRK5OAAoJEFeT
DasLhrBnTvIP/0gXDHu0sfAmFYF8X0Tw9cJzeDGXF+HbjFxpeJET9zVVDfN91bfD
wBebV1aYx3rmrJiuXIvAn27MMiR0xnAEScC0WrKxF5El6HgXjDhM3CdB2Gdp9Zn4
/PFid/ZtMHFt6YkqDw2RaPLtr7UFZy74kcNHfld9Zzks4g7iYDWIFUidx7yG21EU
KQz78YWZkRJRgfzqHl7P6XdHh2N9/zCVG31RtiOLAYHXT9fMWKhQSFBEj6DEVwao
YHNhhjLKTW2OiQizqv9qEMLAuKt9Xtsp8Oo8W8pnzYQoCVAGxSuoI7y4VDzXkvaK
P3QCxv80wsVbFPEMKDiOtiPT4suU/OBlaLXaXTU1kykAzxJRmAKWapoGv4niR3/9
omsnRYPio4aB103OVmy/aFO1oOhCfsUnxSxdkc4WLJeqzblqiaUySM/ftuf6WNXC
LnQheUwzq0OhviVLATOZPHkzVYEq3l6GYBf60TQYDAmdfAIwO+m8nuA8it/utgZX
pppPrZI+nH5KQzDfwKmY3U0Jw8EMgCdDKwMi1+w7+zUtOubaNFp4ovQicJOdAcEF
xBvL+SiVLskfrpxEyF4abohfiVv5KAoWmSGQpBiZtTaQy4omCHrDg6s+YcLzl8ry
RbPxWLCjPr0RmkwkCpMbhwtQDfDcLY8VEAFoluT/m9t0ODjcw8uWEDGwiQIcBBAB
AgAGBQJFRRrEAAoJEPJx4K5ucD2V+JQP/0CPoOt7yUdKS3ayVfg5YlE5qnIO9jCT
GQIxKzHzQjOB9ga76M777JWCNhZHabvUUC7jNPtiy+yQ7BXdcjy6v2b9XSrm7uKl
JS/dReYXzIgOQotAIM74vUJsAfUZAaNGvaCQ3ZyGD0v4fNUpXvpho9au1Xx2f9uX
Wu6XYZ8EmiNlNs2BBEzc3lpyZTex49vnInys97QO0NLwTtbsI2K5VWIPpkRUSK+t
tdtCvy//Fc9rK1ohLzftXSapNbODXUT0DjOqe5MbT67brk+aUqZUFLl5+QpnsPsJ
dokXwp+tAE/0pT5gBvaEMWeEdFU4T5CV9qCIHDghhSSdcvHcuSAzLwe1kDNSGNlY
hRErPKuguHrOK4Mx6NEZEwm32N/VxBJNN9zWXEF4Zk+pbc0mqNiw2W5bXX3ATKft
gUfzOmJBGly7HfRc2epU6nXfBik1R9gvXxu4hhE8neR8hwJrBGvhWjOICN0y15eb
JWiPipkooeo8Z6Fu3jVDTDXYotmqh8M8/Va/WfZZ85DLebbEUMky/fwVZ9rSAacP
gWpNwIlJ/zbxRUqsVzq2CaCx2W8gOR13WJZ5W1uqTScyZ9ad/A/+s/2gaZXJ9+M8
v1AKqdogWjdKzjuVoYNz5VcM/4b8fDWf9UKa2UjWeyb9upyVq2FoBJENL+F2m5I5
StvEMQV/0nVYiQIcBBABAgAGBQJF4sREAAoJEFIiU8PXJzmBclAP/jdQ+4ItFSRg
12daZSmiuzIAFpgr8MXB8hiart7mt2wPZlzLlGkki6cViRKxj0pe2ViTYResRqPF
tWsBSDtBxhqk2Ywmqo7EPze9R7Jm9SBYupSYtuQ+8oJJohuveHIWmF8JcXZT3tTi
H8e4M9DKAvKcTrjLTl40l6FwxOnH3NCUkYWyQYIp7Aoln0ClhZdh8WXYyncyJBZF
sjEnGnpCUp4khOYHxTZEMuesgWHKkW9s7ub4T6ZQrGG8Zk9Z7bIS2KXtLQTdKP/J
225LGw1ygiZjb7hwiSDF7yIDf6I2OJpacJA2WCizjyWYm9s3r/EVZAf0Dga9/247
gVHbhxvg5NOe8a8CKfTfVi2pbPkqiyw+Gjr1cdyDr3K73GE2kZCButbDNnWG3Jzx
eHzjw7xK/suJ6M0CCrLcZha6TZVccqo3JNckFwLDArFiL9NTqbW/MR266wP5h2Rg
xxV2H1drdRzosSXfeePdWhTrLWnEcJrmCHPq2T4DfDmgDP71hpIvAKO2qvyFeRi4
m6eRugZmHPzJGOHiI3fqVJQ/btXgea7tXGgbs58omAW0MDgOS17Urvi6Ns+xsB8h
7Mm2qZxVFO55J82IN9c6IXy0eSwuFByg+29u7JcD9Ejimi67PY5L1eo/5LEgALM1
dXZ2p9xjyN++3y7WXOoQpAS3MCQcXJCIiQIcBBABAgAGBQJF4vyWAAoJEDOWFYjh
whhFGa8P/0hhU2UvKEHkAS8pQOVKJ6KRte+vpZdCMqZqhwsPaBxDoZndppwjIFzu
VX5YtuWmA6OAerBCfuQiC2ndK5/0VHPKrvF/XAKhFaF3pevDJ33z2W2oHn2Nim/f
fXNhin+lmv+87kadGfpB7FtW5Wdc/NwImfx2Mn4lhHwuv+R8KYbayAdIJ9uu/m/T
TZ5CYldpxWBVzFIpKtdb+JiTBnT4uUo/eGjrNIaXGpW+DYDWFojpMplUnMzGbFOg
SbHl17gGfY/2QXa3ZZ0McJo2mB+ZjXjqKgV088Kvs9P9qgJtXLpQiWVwiLoMJnxh
gRhEQ/JZYiQRPglQ1xRClJuT0+B1ETSaLhtRuKpTjxc4S2/IWyq8ZtpDXs6rMLND
kLrtvUfEde/X231nS7qeWQbJ0X84gMWgbCVKCb70Zm0CZtXpG7peDfPEmIHXinG6
SAnKuEixDZxZuePt0rT7LRRSVySq+0q7/UkjaCkIyfCA9gOYZPv+R2ubV33MS2wl
xu4hXFdi/uIjcUwUY5mpSiFTkitUjBkP31U+nFpB6Fz78LzvVguuYN+9Q0gP9+Q2
CtXMGAfwQykIYqDfQ34Dtslj2AP/IqBqNZFe10+2v3GbdBcCw0y/lqIebuLfyUf+
Dw+eCZR3358m6IvyERA50nX5JuSJu0avkEv/GqBJwvG+KYBvddTQiQI2BBMBAgAg
BQJFO/GVAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQJknmKMXTTQVRIA//
Tfy3qDEgrayTpBbhCzWvo1jiazBybfC9CJM8aDHg+64SD3GezaioieB2AlcB1sfV
otXonACpbKOqnxmSkNutGJV0/ilHBumGjorbzcxUc0BAQoDo1d1dZcqSebLwWuoo
tLbcJQVjNH+e6oHQXGmnejOK5TgOR2NzSMLKagEgL4qOnmUZNsfbCt0UbKSgZrsV
PuY+1FOgyfyVUTNYHP+Jovy7GccF5dvMtyo5tBI+pbUfLdIg4B1bfY4qwoYPTI/S
5xvta/AU6HwsSEfRll+45H+HxuLBKiccJ9T8QGAfgbcBE89gMNIxVemBZ/iEPatL
kK103JxlzZnHMgf+vZBecYLj6rmv1L5PBXXknA2szuGLr1K/q+hEtdaWEw5S2cA+
E82nDHRQN1BV3JhPazmk3YBVCaCm2Q+DIP0ZlxJ6mu1Q7WVvYPFbcVF3ujopwpKZ
44sC1K8EraZoz2diivdutm7cmSoSbvtIDOoerq402ipNbSv0pNqyqAomNU+BbqiH
rwVXozq9ugYamiJMCf00VbCZEnSXEUhx3UQHzJmT/sXxeAk+JpEWUpFT8o9WogtA
TGikN2a6fAMqi+RubgtYv25e+t37dEo0E26aeXBy9lzRtGlqAZfmQKxL5CsEvtKu
PN2IbY2zCnuDuRZ3zI9D0PNI6FKvNAlk0jeoqNyKcRaJAkAEEwECACoFAkXtt6sj
Gmh0dHA6Ly93d3cuZWxoby5uZXQvY3J5cHRvL3BvbGljeS8ACgkQlXlS1880AanF
Tw/9GkHtKOjItr0NBIOnLBbZG4AFF/6jZwzcSDaGTLLfsaPIjE/sjihXo2Z+a/rB
UMjxj7tI2sAaKj07lpegNeECql384QcaB54N8xzzAs511ejf0qwdScDwEHJZjQyu
WkyHtEbrVXU6PWdGbPk4SukYgtkk+LCzuezysk88wcsG6PrV9XO/D6o5wyXTfO5a
6ZwqbeJ9nGhiP4QwNaltSk5TOLZxJBHV6WBvpoZ5eGBYRV74WkAUTZgSZniuEKZH
hq613SNo3+lTTn0pNkXQdF7doOMeGWq6Vt5c2NzbJ+J8jrrvcmpq/5PUE1ewHSFV
aFncmOlAdAnOvv6SX9vC2QtgKiVmcl1GaAWxb44ELyUpFHfLmGiBcaxtpxcyANq7
ABGaxMFOmwXY0Ot7puHQVeh4KJm8IP/3Moxq8NJ/Y6SRF4IBaSFcBnYSdCWIa4ei
JMVfl2yvxWBI95IGAAk1GEAZn6wNxKOpejaR5ii1C4o4yMw+AWibNtrP9PacJ/r2
jpuayoCjK7DKlw6OpzJzOL4HCKZXj6/k4rSTRDcVJOOy/uat0o8bMIK4qGsz8gbI
EAOrJhp8lwRottCILkwdZwP+/1h3IdSYFSLwFfkr/XWY7TDEbjQZA0TuBDm0+ZIW
7ju44A9y4LeJ/Zqn8xyF+3jfx9vZwZVzreXtj5+R1/f5doiIRgQQEQIABgUCRlL7
mgAKCRAiGMgejnwD/57ZAJ9mjneiMCa8AWc+zgL+1aCh0czE8gCbBKI9io1lerOM
3t4mS3j1JIdt3KuIRgQQEQIABgUCRm6AxwAKCRCPqYpv7u1w81LGAKDAb+LuBFW6
zi/bqRyWGQjJn07U2gCfRBs8xi2iAK4zWSMjjpoRHbr4m3WIRgQQEQIABgUCRpH2
4wAKCRCptvcwuD12HD7RAKDeYvFfE2jl8cbxjTxSgObdp41m9QCfckXfzzIPRxbE
58rqlg9n71mr7j6IRgQTEQIABgUCRp7w9QAKCRCYYg1FtYEYLAgGAKCSYwo7ZuQq
v5E8HMubFcympcOWRwCfZW2zfJDhPWnvZrXJ2+ajtSXHL72IRgQQEQIABgUCRqSy
NwAKCRCYtF5mZjk0FafkAJ0ciaGNgeok3lcU7IRwvnMTaM3vUwCeKryEW7+UU3tk
ReodznVm6kCIK8+IRgQQEQIABgUCRqSyTgAKCRCizvCpOtm9p+jZAJ9aX2DmrcBP
PHPV5kMMZurK1U5sOgCfURUhiGFxiZIkK/rXSvbOpxWjzW6IRgQSEQIABgUCRtGr
cgAKCRBJUOEqsnKR8itjAJ9KGxol5F74rsx2e34B+XD1ER6wGgCfXo5dARlsBDpv
vbp9rJBEsfP4d3mIRgQSEQIABgUCRtV71wAKCRD2yOmcZ2gdPBeiAKCg+cslZ83O
hZ82riRvO7USlZ1HpwCdGmxQD5eKKZjUmYVc4OXKkp7TfSK5AaEERTvu5BEEAJ2k
cOh3hPoLBOmDYyY/oSCLC+vBrOYN432br/IQ+brefwgYvbbk8LpTlOojIRwPIgUd
6cfhAqO1MnGnYI+giQsGNqH4JKcUcfcSH3u+WejSzUGGe3ch7QdYg/+SEwrUFWHI
wu8e2R2KvyDq6NA4nvdRm2iG+E62O4SQocTlJBazAKDeU170FwpVYezd9TOrkALl
/ug1UwP4+srixmNJgmN3bh5VCPhV+vd5/1ugggsd2dqWC5QNeYdaOEw4z7WlzJmT
vSvWBi0Zif13WzSpWoCVQhxBgkgpx4u/B79TNtrDBKqxUyogI0JsBRiduKVB+A2f
5veghl1VkqJadsrieJxymH7QFe9+dlkq8izUN/xvCVQ1FkwTQQP/c4Ln5ZbXQD1W
7loFY/iLmrtDwPEULJvPptbIRNhAvs4ROj0J4wNcGMRYuwPbpIHJGxuCoQRXLagJ
Ka4+PL84Ckji188Vh+Xm7rji0JqKt8+3nXaHY1tA563f4BLMgl2fXC5wTv+a5Tfa
0ln1GyTBJaE7hPVN+x0iqeNa5WFJGkmJAm0EGAECAA8CGwIFAkU77/cFCQPCaBMA
UkcgBBkRAgAGBQJFO+7kAAoJEC5bvv0DXvxYT6kAmgOJ3an2K+vXXkX7p3qCNR8b
Bg7gAJwPzbMfQ9chVhUcKEg5Zofld/M7yAkQJknmKMXTTQVPChAAwPI6Sa0bo309
WzvVUmqM3W9truAJgUhItFJwD1skgUwGqaeRbVPpsACA+wBYFkpITkm3YJLzAolB
MXj30qvfglibkhaMjERPcJoNE67o7bJLAxC/f5dK0Gy/41iuqOTt9w3XeT7vU1G2
/tDHPS827qL613aJZ4Y8l+I3nds3owHkvdZ8HZeHYz64ybR28PlxAcFqfp0VY1j9
lT9ZBfdx36Uwzk9vTXGM6AnqMDdZHqwXRawsUBvVSfiseQyIn1pX8U+NkqHHP++G
Q8BTk1ZilwFmZFfoaIx1PIC016t3GNJF/IBjZdIRcHzaETEhJfBDhIlDsFTtJZe4
JrfhfH4lHopKSAa+Xl8aMZ+nFIyK9Lgtlx5+zrL1pBKQg3NlgKlCb50wuNHF8ZA5
euy+NWCLSPPGwo/pkLXGuDR9byoCVpzLQRcBkA+z+wGLX4iX5Nl6Exp4muTdPuyW
rOE1fP6jNBETD9WhQuNMVv+HEtG/1MYf9EQ6FyZ8+Nf16UCNgcHY4XxJMZyTMrVI
WEMkrdrd3ExnWAmYuxqrPMSrLi9jG6BKVG3NLvglSLGZbJ/ohGT4cl9AYIFoaNud
KFO7lDgyKjcoVs/s/OolF1GYcHw0yUvSNe6eJSvthlHuhTCk3rGr4qHvzYqXk+P+
70ufBDuxfPsVXkTYklJYumbGVIIyhWy5Ag0ERTvvVBAIAPsiJx0zJ+LAEFg9RsSp
lJ09c0E5lfiIBn/pVOBc7k4RJDn5LlZ0oJjUse0n/+KreHlDcD24CH259KU0q0Oc
0avLbCaWtpox2g/Go2O5gm6dhkDhivu6tmMgjLvvtpKqqHxN9n9C3pjSlgF7Isq8
NnR04ogkl/8/ZCuOQt+z3KhdUNNTgtbTrLCNLV6OrW6ZtOV+lZliDm13yiY8dnk1
I2zbFOj/tBC5q7QrYxrp/ql0msE2iXZKFdsb8P8FjtytDt/oaohBkXBHs49w0e3S
ttqMpt31E4ResMdWOdDGOGqGvW6wWrtBcUGJgxcPjgIYGMh3DBRlVFNXNvcLFgD6
bB8AAwcIAOfu58CZviW+Ov9WDsCypDdpitVDwNWOY93DkdEQYUqBnzn2Wy+GKwr1
ble+ryvbtABkA3cKFQxJKOnREO8pN8MmFGXt9/qwqZLevk++OC2DmurOHW8isVOg
agDK1wGYqWx9ki6jM3Uwy6oXgbMEoPwTUza6YGE/NbfC00jSPlfj2lpq5X9SBB7O
5npWc9O9+DrR7glppY2xwgvLKgphPQ0eNOeg0I+b8Hykx0n5qEcclTigYW9YknRo
jANDidIfz2FxYnR6AEjJQ5g+vi6eIj6Vsfvwcvo9awPbiul0k+IrL54W6p8SHZhq
UXYKPKoeXh3j69dFngqmpznL0dm0Ju+JAiUEGAECAA8CGwwFAkdAIbEFCQPlZdEA
CgkQJknmKMXTTQVS6xAAv7T10muNrIkY9HPh88DPIQ//YL+MTwJU571SaDtNcqJ7
5KeFUb1UxNQiNeczQjznMSI6mmKvjf/qJjA2XkjsVjTFgYz20cQ61r7erStEsnkk
WGL84PTf7BszSdAHpJ5qARBuSqaIzoH5I4w6KnytEC5FJORUSkk0bGTa0AlKak3y
vxBhSl3N4pElAT3SsPrPt6y+Datb+k7IJFVK1Lw/UlF6if83+/P090oipA66Qw0A
Dr+6hmxOK9Ruxni4BgSPOdBVYEFxeJtxAWAoYOd3gT1X9qj4qZBjGD8DUX131BR8
9hbTsNj7fyCgvEL5ht4N7/Afk79DkVD4aS7rJ3uNkiYud3Ti2g4rE+zpYJd49b+w
J1mKhrs3LTrMTMGiG3pHPpm17uXN/qQwuAIL79hIoLwDwc7Vetx0wt6e59SGf9do
+y9OyckXTAPU6vtZFZ94mgbVpWq9+gQtxzY0YjVsLk15e7NR/XhiKKzlqGJrwryp
TwdxsIsaKMzc50ObII56JfyfbwxWa3V2UQrK6CxoS7FGbLLv+OBypECPlMZEizBZ
7R3ofwLpDpICA+3l/kd1o0omdKY2kGg49istjnr2bpMDPq4ldL3JBZMn4sC5FRvK
oPkoLD2LT++gbEfnUNaJHTYPBLBEvw9QF7g5iJQ4wr1jp3XGnlRfI8e3XmYIfpw=
=hU+Z
-----END PGP PUBLIC KEY BLOCK-----
D.3.155 Hiten Pandya <hmp@FreeBSD.org>
pub 1024D/938CACA8 2004-02-13 Hiten Pandya (FreeBSD) <hmp@FreeBSD.org>
Key fingerprint = 84EB C75E C75A 50ED 304E E446 D974 7842 938C ACA8
uid Hiten Pandya <hmp@backplane.com>
sub 2048g/783874B5 2004-02-13
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEAscLQRBADERe+RX2eJpYLoaJ7d29B8YcTYzNlsfzghM1R1/Dx2RDy5poKa
Jn9j+Iptq1qS9GkTHXFcQh8LT2K7wnE/MZTCxkZvg2ZkfQbJ4Z+0z3A1A6Kvg0tH
X5aqmPUeLXvnps7nqZxkhl2ibcjhH/VYZK3mdRikd1wtJD1EhbbeqaR8BwCgkQAG
vdJHN9gfjLLcM12EitkjoUcEALoo1bPoULWd4YhVH7W5L3Qp0dr1vf5pYC/V7FQ+
8yPXZtGzMvIld8iX1sv/zsw4EoXXsaRzJo/ixdCS1WYBPowryu0G/LX5w0RTTGHc
ihcHLm6ZmyNuIsTQ1ifLNASJoLkNBlQAuA0VG4evAujrmaWyEHbbIDSQKUJOjL9u
jb2HA/9pycrr3+735Aa7B5jThN6p1XEC8GQg5MDx23QnTPj9QHXH4qs7s+hwxZq9
3WkVFBcJtDBi8PeEVqfD/QPeU3ewbnNnfaF46miGV1iG1mzU4zMq4n5oBdijf5eL
cRRdOJytYKTvlSCe8gf0MzfaB3RqD8+Cjcs3PtQOy1VT4aQiv7QgSGl0ZW4gUGFu
ZHlhIDxobXBAYmFja3BsYW5lLmNvbT6IXgQTEQIAHgUCQCxw7AIbAwYLCQgHAwID
FQIDAxYCAQIeAQIXgAAKCRDZdHhCk4ysqEPZAJ9ByMndfTtnnVIbsyHc2NjDp5F/
vgCeP6o87Lw4aHuGo5guA9yeWwtwAla0KEhpdGVuIFBhbmR5YSAoRnJlZUJTRCkg
PGhtcEBGcmVlQlNELm9yZz6IYQQTEQIAIQIbAwYLCQgHAwIDFQIDAxYCAQIeAQIX
gAUCQCxxDgIZAQAKCRDZdHhCk4ysqLchAJ4+01/uQVdqdDeESGodcvgKsrieqACb
BIW7HMvh85WqofTeAK5pJu7hCM25Ag0EQCxw2BAIAPXEkkg6lSxGRmVH1yzRnSKr
/M48xyRXYDrRPaVVBFkC4Af3CR5MjncJtjbzm7xH82glC67cksRTfTZRs7kJsid+
g62V53dAu1Uoj8ecSDhblb8yW3rTLKVqGcliGcTRFivcm+ZFm0kc0xCQE3rd1COX
NLEomMV6xuZ9PVzDAbJwAoGdpCYsCl09eZrTErueQ7pEVsLx9/0zQSmC/uDFEVZ7
23GsJg23+EUBT5KuTxQ4i0k++Ccr4HR/OiUy6KmyXSNsKsBsXwm3map3Debqqqx1
ssrDXa+PHkKEUrONQBoYbZ17DpPZb+NKWibi0Vp1HKPP2vZl4NZQC0GBLXbEudMA
AwYIAOYhwVTWKQSgeEZUNe4PwvHczx8/3VNjYZGY6/ZRjgmfO3+MagjonZqfxYha
GpsEV17NXm4WIg6HWtI43JwIWfkUybsdxQVH4i5lWYuA26wD6UtNXw9laPHKXonR
DvmKDC6K0iFbSxTqXRZVQ//wMxh58/Yw/fX+fYtmH6u6kPaL+CPRkhQLezTzZWHj
2wF6v+frdglW1/LpwpCFndb1i5+36ogZ5ZudG/iz53QzlOF0IZSGHIb9tlQ+4gUn
KfxpQloI+5vAyqpHDKIH9K26wTBzKsp5Mt4W6cLfgjXs7TNc8BVT8d4rmmbGpGnG
pSjj7b1q6EhpIVBkAMLw7qanLlCISQQYEQIACQUCQCxw2AIbDAAKCRDZdHhCk4ys
qAuZAJ0VNEtJSZOAGetxBJ/BMWahVD8xeQCfVKwTHdPh83Qcf28xx81icY5OKY0=
=rF4D
-----END PGP PUBLIC KEY BLOCK-----
D.3.156 Andrew Pantyukhin <sat@FreeBSD.org>
pub 1024D/6F38A569 2006-05-06
Key fingerprint = 4E94 994A C2EF CB86 C144 3B04 3381 67C0 6F38 A569
uid Andrew Pantyukhin <infofarmer@gubkin.ru>
uid Andrew Pantyukhin <sat@FreeBSD.org>
uid Andrew Pantyukhin <infofarmer@gmail.com>
uid Andrew Pantyukhin <infofarmer@mail.ru>
sub 2048g/5BD4D469 2006-05-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBERdJJkRBACMPYQjOqisztbRuKcG254kVS+eoBqWqFKY98x03KtgEYn2/Em2
EU4sPfhr1PYabCT5oxmaIhmBRuwryM2V/Py4Gl+dfJ4+cmRt9/LXQPyWymSlCXj6
U5mTqCeOId45PWU4lis44vN7DgAKZptu5GoUAWxnfh7M/K0UQGU/MNOPSwCgnt26
U60GErf8Fao0V31YPjRJko8D/1F7m5LNW9zzEMF3WFQURluoOxrmaAnehfYA+HgX
kcM5t0SZFnsdOCbsKLMxl1E9qgbF9mAwTU2MfJFNhEuCUWZlYs7a69XSbr9HgI7p
cqeHFhpbKTfWT65bJ863jnsMwS9/mRHNka5CeNFh2Pz06mzV3JherOQIq3lcBAri
TnaEA/4st0qZe6VawiZgGgGbamLtS/iUMxhmC0SAv/pdYVieeXmXi0E3b1mA39Mi
oRvFL3gT24UsVEaazwcwqnnifOqlApCGubSitYM+OPa2DyoYDUoCP0A9DgohSrRr
/+yCES6zTQOv5fV6DoX8tvEQ+2+3DictO2FLuqUC5joBu1+42bQjQW5kcmV3IFBh
bnR5dWtoaW4gPHNhdEBGcmVlQlNELm9yZz6IYAQTEQIAIAUCRF0kmQIbAwYLCQgH
AwIEFQIIAwQWAgMBAh4BAheAAAoJEDOBZ8BvOKVp4HwAoJZ1Z1SB73vCYs9cxyuP
mhVV47b2AJ410LsvceMdtc+g7LZ5Qm6jHNmCaLQoQW5kcmV3IFBhbnR5dWtoaW4g
PGluZm9mYXJtZXJAZ21haWwuY29tPohgBBMRAgAgBQJEXSYbAhsDBgsJCAcDAgQV
AggDBBYCAwECHgECF4AACgkQM4FnwG84pWnW1ACfV2rsfdxtJkFxl3xClNRoTZm9
llwAniiNDnbJXOjId704Scb/LDYymESptCZBbmRyZXcgUGFudHl1a2hpbiA8aW5m
b2Zhcm1lckBtYWlsLnJ1PohgBBMRAgAgBQJEXSbFAhsDBgsJCAcDAgQVAggDBBYC
AwECHgECF4AACgkQM4FnwG84pWnbLACfQ5S3OAPZEJj/7zb3z3Xr/1AP4PYAn3LF
f/4tcV8P5NZw0wxqYUMmWtHstChBbmRyZXcgUGFudHl1a2hpbiA8aW5mb2Zhcm1l
ckBndWJraW4ucnU+iGAEExECACAFAkRdJxQCGwMGCwkIBwMCBBUCCAMEFgIDAQIe
AQIXgAAKCRAzgWfAbzilaVj1AKCZyDzhFFyymsLh7ykuQLQnLPy55wCePzG4LA7y
mwPr3zKG/6BTOql0t5y5Ag0ERF0knRAIAMGIx2+t+/Q6AEVLhSeQ1WHUBbjsuVDB
qMT4RZaiMq/UA2QSWFTuqylpV6rlvLR3d54MOvn3hlgj6zzEnoIj2WLFFtcJzVuF
VbrBRLCjDgAOC75Kt1LJEOIcJwyZ9c5gGau4Ng8zyYkbYBJ3qmhtnjF1+m39uRc3
+4CPRdlLTa0Dc0cbQ/hEE1VzWwXM61oxWKwHBk2hluv4AAhzjrenT9yUqmemc/fA
U53feBIZrWNS7dzyL/L+jc516vHkvhNeHqyzZcmLktXshgfeLTe3qDsXnt+F3qr+
4M+nTfkATdRQvSfs12KNAke76Bx6mjArNXh/sazc1nr4SJgZQ53b/dcAAwUH/AqU
YZNJzrMDW1JBJtGvjo41T46WcXjw7pHQvzciOuYRVsclc2reXEHa8aZ62Q1LsThz
d12lm47R8NQcMO8n+avrIuomuBooANf6QruKf8MMFlRGxs9Gryu+839NadbZHRsk
NcfJG35WiKMksl6MSfMxSdhl0BhBk4pgPPJT1t+FY7yDf+N4DgCaDuRnXnTLPrxp
LukXPTCtXjostVQ1Mv0kcTtnUu9yGeoBNhpUWQrOy5CI1Vqp8K0xMDbRojDSRni7
zl9gfnzxO5V47llfhoNTEjLsZZ/8n3Od6KRMMUTgClRFe2la42u+R0CDAIRkNkI+
WCPc8mM1TsGgw43LxnKISQQYEQIACQUCRF0knQIbDAAKCRAzgWfAbzilaRRRAJ9R
iYtTvkXAj78Xt8J5FMOoiCo6TQCdGj7U+SJHD3NDwqmkvfMc7Vp/iqs=
=47um
-----END PGP PUBLIC KEY BLOCK-----
D.3.157 Rui Paulo <rpaulo@FreeBSD.org>
pub 1024D/0493CA02 2007-09-19
Key fingerprint = 8E4A 0A83 680E ADB1 96F8 402B 7C3F 0CFC 0493 CA02
uid Rui Paulo <rpaulo@fnop.net>
uid Rui Paulo <rpaulo@FreeBSD.org>
sub 2048g/D0851F30 2007-09-19
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEbxejARBADbFk7g7VmkWH7doKstfPCcbdBzoo6JZrXrYWXtgkLUeE89E/LT
I2yAqDYHgUZu0UMI9OJWg11LOzqAPC+ToKSqbYWYG0PnL7Rq+47L86Xvqc2Ms74q
Z2bXw3bion+EVOKcUsV6slcPFPuRPZPkO34E2drqZSlrUX0SXQwMBuuikwCg4/1O
7L0+ui0yvMZ6Pt3X8z6IRwUEAJWx6vGV1QCs+4tlmZZCv24Lrxx/4RVQ+TBLdhG7
ryM9PbCDAexlkvQCl6s+/jbW3o/NXk1pjcdS4SC4Oz0jG4id7meVqAReDP827pBK
QyjdS600ZX3znaQ9Bu5j/SpD+h/AIEysuRnkecxZmbIEynqMjSIMHjvum/97i5g0
g2mwBACnO4Li799RCtv6A+pQKYFzKPFnAyAJoHmcU68h5jOgW7EULHfuyByE4v4w
hyB62j9kw+/W6ZfQjaPHqvxHhAwWRfxhlCtFXYm0zzzioKQXSh8m2H+3ccOKbcms
nzD7Rmp5TVHg1CeMqtqgvv+iF9b/EmTMugPh0oaWdsNI/+yQf7QeUnVpIFBhdWxv
IDxycGF1bG9ARnJlZUJTRC5vcmc+iGAEExECACAFAkbxejACGwMGCwkIBwMCBBUC
CAMEFgIDAQIeAQIXgAAKCRB8Pwz8BJPKAkKtAKCK1kvvihrs0VCzN1IEusdzozli
lQCdFvctTgbV7vy4DwtITeM7AtHNziq0G1J1aSBQYXVsbyA8cnBhdWxvQGZub3Au
bmV0PohgBBMRAgAgBQJG8XqIAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQ
fD8M/ASTygJHYQCeLmU9ughT2PEnhRMaKlTtMQeenbUAnRdvVGOOYtPPk7/U0gam
XUgPFZb5uQINBEbxejAQCACVmIHUutWQPeHUwArYN9v7F7ynduQCWvroFa6QVBM3
YA6kBAGOV4LAaCyVSIAQz9yytMZT2pBpZb+daH12q0myif2OPbAMFMkld3zmxm7D
P7Gek0mtM7/U2IP3L2pL47SSYipEBfUM6Up3ULL1qiEVnGDUQUeHO0CdhsJiM+Zi
GEpDk1B8G9yYWYLjcTjOyiy7MvqnEl+ZBLyIwl2Veks6Yd+pnswpQi4LS+9CpMRR
UZdpRO5SbydwNZmupdIgA0rYHwArL4FG7aWPPNhG+JjWf05KNo0AeAvbfQGp2H8Q
FfW3GqzPbWOBirY3+KQ/KRAFMSx/6cYQBBdanu5E4KvzAAMGB/9AY9tCVnwp2r23
UbNCJlVOb6Aa0Uv662h+eQjm3Oe5zUbMH7D+Jz/8vUHLe7gdpbYs/+/6bbithQTz
wWk/n1+rvtOxNt/nVJXDYAooZOSMB8p9VDxslrhsCJFHnR+P5yONhFrGWhKrN3gC
UGd8/y1j1e4b2xdI/bvuQaDOJOMo0w4oYveaxPvyiox4Dx5ZR1ZxTXK4yoddIUgq
rwOyfcrPEs4o6f4U15dw0TSfUQhPzTXlKFmN6d4YPI2r3vAP8uBJA5DQuQPDuUE1
WsHfK2IWnz7heC+cH101qV48L+gNSV/jeYcyslTx7uEBaI/O52hC4IRcCMcwf3tY
7mABsIyViEkEGBECAAkFAkbxejACGwwACgkQfD8M/ASTygIrEgCePXhaDztEZx6c
42RyssmLKlqelLwAoN/WxnCCqQon6L+pEZA1wW0GdgEM
=DGcG
-----END PGP PUBLIC KEY BLOCK-----
D.3.158 Mark Peek <mp@FreeBSD.org>
pub 1024D/330D4D01 2002-01-27 Mark Peek <mp@FreeBSD.org>
Key fingerprint = 510C 96EE B4FB 1B0A 2CF8 A0AF 74B0 0B0E 330D 4D01
sub 1024g/9C6CAC09 2002-01-27
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDxThkERBACPf5/QHmyM944qrl3hWlWvK9fZZR2c37rhxAeqDJ8WsEMPBTZK
WPn9BsMk+2d8e62FkzYo6L5juekd8invwd1nnszFFJdTDWx+vpMMgYuHBmme0QuP
OnlU2FwJUCknw5Ed5pYV8F6azGgUNjYKIIJi/L3D9S2qDZ7l+3DgD0knKwCg4o8Z
ZE2vd9uQw0AZ7lIa+li3hB8D/jHrVZqHxhOuUbxIXoJG3g54mH4i9GF8uN8ZdhA0
9AxLVLzjLr4CQd97++LdSLagSvgD9N6OrtMPeqge4Frr1anJ+LRPDeOQhd0meJZB
iCiekil4DSOsowqgmIG7DlAJx+PNV66qO1ExX1fv1ugyoWHJqYmdBSF9x1fHU788
GxCtBACC9DLBMmMVu1Fsw3rnkZaR7xX1a1Bu95ZUu6TKJP6qUS5GnQOxF7dDjuwX
/uRinkQ7W9vR4UuVvcV+Ct5R/yq7e+SfLb+YFQ2BmWeGNs5AVLxIZsZ0ar16fwB9
XdxxHU/IkA3kYo4JfTvi3QXjLn4mbYUuBIVGAL63UO1kx1c8crQaTWFyayBQZWVr
IDxtcEBGcmVlQlNELm9yZz6IVwQTEQIAFwUCPFOGQQULBwoDBAMVAwIDFgIBAheA
AAoJEHSwCw4zDU0BXeQAoMlSoeOO5WtFMyC8viNAafpPcT6hAKCcjmQyI/cI0id2
PMX9ZOfrKd/ma7kBDQQ8U4ZDEAQAw9gcDj02cAlUh8G9bLIQazPLJnX0fah7KB3O
kxh8wFn0LliP7W7HLB+nQNyO4TfNgI0bhVyKDQQbKI2xJ4hylo9Z1K2R7GilgCnB
FUqIp0MdqAswX2Dq7KXoyYAZRBOnQounUMaQ+6cfRI37mWc6dC2uY5qHne4zmLML
/lVOjVMAAwYD/1ZArkN4IDk/VALPnzW4VYcCcT+101DMZfIMvHK2MiwWFmO+Er/K
gIo9DrybHNQ6+bVQh/F6PSlxDrgWey7dQbHQSssC364v3RPOCmuBJCMTEszaais3
VekHF9i9NMsUzbGpowaQv+YKMFQu4Rtlwaq7NUp/cD4a+jaxto9ij4EliEYEGBEC
AAYFAjxThkMACgkQdLALDjMNTQHvuQCg1PrMlcafQ3BUaXAQRlGoyvF2WcQAn17c
HA1RAO/MXM99nT62+AKLlpeb
=mfY+
-----END PGP PUBLIC KEY BLOCK-----
D.3.159 Peter Pentchev <roam@FreeBSD.org>
pub 1024D/16194553 2002-02-01
Key fingerprint = FDBA FD79 C26F 3C51 C95E DF9E ED18 B68D 1619 4553
uid Peter Pentchev <roam@ringlet.net>
uid Peter Pentchev <roam@cnsys.bg>
uid Peter Pentchev <roam@sbnd.net>
uid Peter Pentchev <roam@online.bg>
uid Peter Pentchev <roam@orbitel.bg>
uid Peter Pentchev <roam@FreeBSD.org>
uid Peter Pentchev <roam@techlab.office1.bg>
sub 1024g/7074473C 2002-02-01
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDxaTyQRBACmEhDX7pW9oQY5krlJO+cKp1/dTOsyonmmSftVKayUY5rdWckq
NzNW0z0q0Er2AuyojL+Hu1b8FsKATQrPpAZReiW+2t6w8RZpj3xuxgpapQUZnC85
VTclNIkGrHMVrMz8U6TR3eY5rvqDAeBTDd0uk7Ze15t40A/H2qR1PeNpcwCgx4ds
qeZc66EfIRQAzI1JB5D8jTsD/A/qzG3t6qnJ4wUVn3nJBZ3evClzk2EWcB8Krg3i
NG3MRfRDprAZdnnj4HAkBgrpJrKexqEEIMYlkL/UFR7pqwoWJQWJDcHlfsQtxIDA
wM3bcQrZ7dokBdZdVJXuUnuT8YWYW7cAlWtPfJohjiIK7EzW2GntojLTryOHbNiK
J3ihBACT90mof6uXHmntNAodatIRJRxQOBK6iZH2x894i41jEOcTFbwqpV50wsnj
Eyav1RWeGVZwB3XdSBj7DfvfxaoRKVsoaRUiJza8fCksAF4TCsRNIks1fDamM/Q+
HKP7pl1UjxVAxM0iuLlQQo7dm5Nv1eWJ++HGgq/05xjoogmm6rQeUGV0ZXIgUGVu
dGNoZXYgPHJvYW1AY25zeXMuYmc+iEUEEBECAAYFAkNz0hwACgkQZFEgnhWH++bR
MACfTTNHfo1BnhSsmABRX4CPhszqBCYAmJdci/hnDVK4ZGYwPWf5MD0u/EyIRgQQ
EQIABgUCQjFmywAKCRCGoKrEFqtYxJXxAJ4hEITQluViVT7M8uPXm0VbX4hvmwCf
ZzbG5Rc6cJDeRyRy+nEsWB/Ah3WIRgQQEQIABgUCQ0OkYAAKCRAk/V5km/QrB2Xe
AKCDJOGbyecQ5ywrnb60qhJb9upL9gCdE+REnXDRPlQh36KbX88UoeNPgneIRgQQ
EQIABgUCQ4RqsgAKCRCPxop+lmt5yhLJAKDNBmcjEao3U1rM+P0nu2hcjB3ZRgCf
dvIezBGCB4wIyjzEGa1R/+lV6kWIRgQQEQIABgUCQ4wKLgAKCRCrL1pbFSVpkLQw
AKCFL0eRhk3o4CqprcfJGRoJEx1XXACeOlj8uQyqEbRtuWnbpeJXBUQAS7+IRgQQ
EQIABgUCQ42f9QAKCRC/S9DmBJ24eZxlAJwNaq9+MxKskPdPNh1T9Di9OwpvtwCd
HbntcgvVxPbRff+Dknb29NZ3WweIRgQQEQIABgUCQ43bXwAKCRCH2lwNJzWaUWsg
AKCt+KJ5X2ZA1aVl+YI8+qxm7YMjmgCgh8V+K/wT9ptHoEhha5Cgp5I1Z42IRgQS
EQIABgUCQhH7RgAKCRAtP3wLeuRUNl1jAJ9ZWgAtHADJ5cdToZ0wVJgnDfDJGwCf
RFttUxNacQ7IWTGJYa22QFMydseIRgQSEQIABgUCQ2UvBwAKCRBfAzCckhX396UI
AKCOshtaDWADkQIgSbyBby2gfiSpsACgkHS9GoQpjkBjpaKIzur8BuJDktCIRgQT
EQIABgUCQ0OWmAAKCRBcbEzAWnmJMEyTAKCai/2mwMxJL0Hr5utUpJHguW3LRQCg
vf8iCA7xsPgSVnhs+J5LPQ3E0jyIRgQTEQIABgUCQ26i/wAKCRALrfXLW/Xwcxeo
AJ9VfYc1reW8bqgyK2mOJY2quEAcsgCfWNVKuGY5aheFQwK+4YZxIuFqbyGIRgQT
EQIABgUCQ3IW9wAKCRBc5cUbh+BXvn/dAKCnk3kZBtmH56viIjHkCIbrM3vsvQCe
IcYVgc9OqKtYxq+3fUAoNggtqv+IRgQTEQIABgUCQ4x0twAKCRCNSU00xw69UFUc
AKDpRdPXpBVG8BQcz5qWnKi9Pc3TVwCgjAnOkj6O67YSrezj+FgErLcQHYaISgQQ
EQIACgUCQ42gxQMFAXgACgkQoE/7G33K6dPpZACgtszV5Xlx1OXdCCDb2kY9rAMu
4BcAn3jutO9V53pvbf1qx8amDpbd/aQ+iF4EExECAB4FAkG4+OwCGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQ7Ri2jRYZRVPlNQCdF4kcGEXVU44KqoMnQ4RRJlVl
ZxAAn2gRa0b8PfhpGmfjvSzCW8ItTbJOiQEcBBABAgAGBQJCsy5JAAoJEHllsvFS
c+2nWr4H/1kIQxlvy2dQ9NSRUfONwK/X5n1RoKNN2MdoLxz9PmavJ/6UCcKodrni
qzsYXJigW2TnPyk7Ult/dddwTStpBc2QM9AdNKdsps43OiUnGTXXeguJP20g/TVB
Qs2oJkpyU6p1PzSsjKI3cJxWqinzWHUA2Be4tCfLpJXUkBODDQfHNlCShR4m5RZI
6tOK/QJwnMt/c2e1bupNnBSRoWRDsYXSJknHjqCBn5cj4UU2QiIFzxQDY/4HwCU6
IUaJaKGQEL9J3wOwshyWqcedAWAnb8PVU0NhLrXZZMEEKgSCKq/1r7+CY8KXuM65
iHn1A2+/V/AlFhonH1b71SuXNDXngsSJAhwEEAECAAYFAkMxG6kACgkQjFFfxEuN
tSVWaBAAqJZDe1e044ZK37Fx2leyjprZkdhSKuq1nQCaEVUAn1zd9bqFrn5fuYqp
nLYjcJuvrweXeE6bc85jGtYOfX9ozwczexo6QWyMwz69qBMe941IN4L2M0TRPuLs
RAhcaQ0O1BdBzPIOCbONsr2UO00DKae+aDwtXXRlZv7yORpQAENBQNdqDoK/KCmq
4iDv4T7XUITJVktA+ISFtz+LYrkQYUZVOYGMYY6e8lC1Ng6w5jn7koU0tOVNHgwc
8tEtPOVWGnixO9RTVQVdg4z4Hc8E7JDDeBr5yp6u5N6bXvin3L8wh6BZ3l488UKK
zI170okywkgB2+xIo+kGGik7yMWZqgLMheIAKYYZ58Xkn5QlLII78t1uURorUYXt
dce/77exr1bPQ1l+7OaAXHmkDvk8LN/1YW/317sd4SEpcZkeK0ObFOcOWEIKaLdY
2rfs13t8nWf/SiV/0SQmgt7nQIARnJ3N7K1b0PaVMkYIU10b2Zf4+9GUXeOTGmq/
Vhqfby7V8w2+AJmWHXKfZc/YRRzMwIXi3pnIXeo+PSUKlyH0yqRPSwK4yq274p7U
6f2EBbi186W7P5A3Qh/fX5KigJTYa6LU/rpqssNGtZRV1wT9sn+c1vmxWFTuv5qf
zV9QIYzQQ4V1zl5WV064luuBpbiBj1tbBYE2n22E2RZSQXV4CviJAhwEEAECAAYF
AkNCeVQACgkQHFcMiQ5L0Ku5CQ//WsVhKm3Fu1rdEdkBRGSP1Om0RWnlBia6TfS7
0ldIQ5wzjG0FSECLglUjiKNf0kz9WSNm4qms/zbDWwnYmAs0RNGKs9xq7jooshf8
FcRkq0zbHFsWbJZU7sM14MSNdgjRx6DnvWM6nYdHsjSQR2IhmG3SObBWPYGGbAmz
57xCspvPGdvmeaYyUNQZulnRPkyeldHGn5YINZoxoD7cOd+3A2tNE4V4MpNidYyP
BaeZC2gjC/kkwjH0ArmAFU+BaLL2y8Hokj4h8qnVoSOXA86GvU1ayfD3QOMc5h/8
YSQRUlKKTR5uYZgMUIusLbAg1XAfAqDCJKx3kYEohdTPcgliXE4Fs39n63jDK7Uw
PEkVlCtEDgYKQfazON6laB4Qb+g8uyk+syTeoXJlIZHoZxHptJTClQwnhCEXiuEk
S9W/DcmktOSQzb3O1M2prZm4IyoKz8oWXCebBRy0yOAkV7ZW5Fv8rkOz7yyuK7Po
v95+Go6UsU7ps4VkcHkVWAMya2cQkWc+0Ag/sqXsUReUrNbH8mFIdtj39nyg24Ze
poWHisyaqqwKLjes69p90ZtIzdTe3OXFE6JVHTT3unnwfOlLdVOFZ33U95kkx31g
zadgA6HSGm7aKAdejY6K3on7J20aaEPOca1fIfKdm+aB7x6odZJ0jszpsw7+rOoO
125q5YKIRgQQEQIABgUCRAcNCwAKCRAvlRUIquYCLnRpAJ9rI3QnHunvilzHydtT
+EppDzCTsQCeOVjDinu0VlrWpNLBUFFHUMkfRh6IRgQTEQIABgUCRAFw4QAKCRBo
81j2wTlkfO5OAJ93x4TIiKfh1dZsmwNlAal+5hhtaQCdHIL0Ji7csZZOxky6FXCW
Pgexi5yIRgQTEQIABgUCRATJaAAKCRC1Hif1GeoZRuL9AJ9Jbze4iRGuLPUHwKll
UvX3zUEg7QCfbs5rhmTd2WVtis2TilAxz83xA4+IRgQTEQIABgUCRATogQAKCRBv
P/EQeiz/bNJ2AJoDF0eSqOry3PS53iT3g44Le+freQCfTWRig2ehiObqRAlAGnCH
nDEX9/SIRgQQEQIABgUCRAHjngAKCRAGBpzylpRX8D04AJ9Ipdt3uiyY2wbbme0x
lwTTeSBvWgCeIthp2D8jeguDVTZsqRXWYP+u0DKIRgQQEQIABgUCRAL0SAAKCRDl
RN4Hm3wyjWTZAJ9U3LOudX8qt3f35BLDqOdQeKm79wCgw0bvnMyv4hyPxjBqQ2SN
jD84mauIRgQQEQIABgUCRANgXQAKCRCboJNrWjX9QmYxAJ98dkvZukAjvzdlyTPH
q+FpNqhDoACgt5PFMpENeuv3BhJpRhp4UZBRerqIRgQQEQIABgUCRANhnAAKCRAx
SLvvHu8m9BsDAJ4xKyarpIkz/fdwHZq8HsYe37D9jwCfYpqHNqwjVpO1cyZNbbAF
EQ3LgX+IRgQQEQIABgUCRASMNwAKCRBo4SUrfaXFO+iQAJ4rZ3WcEkSJnp50rV5i
n52NYHjH2ACffNaMgfuXZBVwUWSdi4kvdjEjMxuIRgQQEQIABgUCRATE7wAKCRA5
TcWRDtcE6iFUAKDZ6F7gh/rJqmJKNBkf70KWu6LE/QCeKBiGckzAe56fvQkj/ZYb
wuoqPGuIRgQQEQIABgUCRATU9QAKCRCBWPsu9Rce3hArAKCVPPszyFqSmNCxfsdX
tbZLHnRCnACgtF3WTK+uRvDn9ksHsFgjtI3v5+mIRgQQEQIABgUCRAYgEQAKCRDz
Ic2Cj6GPC9yKAJ9Ggf5JLlu9SkEdwYf4uWntezyRqgCdHnjaf2dCWOM+avMblKLu
/5L6XjiIRgQQEQIABgUCRAhe0wAKCRAeeK5vqIdVR1z1AJ47VBLDRxUBH8puTHlo
vp8dxJvtKwCgiOMrTUw17ZvdNxYjwUNtmlTO2/+IRgQQEQIABgUCRAhr3QAKCRDO
gO/EkacH5O9pAJ4uXytKDmH8htoDuYAssoimPdwCRwCeMWmmDL9MF3eHLg54SBBU
sy5Xy0CIRgQQEQIABgUCRAhySgAKCRCLSsSBrB5xXpzpAJ9U4oBc996hDI3qin1W
msRH1p+cMQCfSpCe+rUYEQCFa3YaMZyu82uvvviIRgQQEQIABgUCRAh6aQAKCRC2
uuo9QeZr2SlRAJ94+Kbbu/LkewOZXCrdekYzSn47NwCfS4qij4I9aNrAXncNiie8
8LPCLOWIRgQQEQIABgUCRArhnQAKCRD9Ibw7rD4IeWPgAKCrdOUMejcUpv+kkp1B
9Oqdm2hSmACfa8r+ABC3e+sw3lqL5wGLtz9c49qIRgQQEQIABgUCRAtWGAAKCRC6
bFqii/PSADpUAJ9o4F6Ey3i71ewtxAXbP3VUO8EfiwCbBI7InWcldR2OJDIEwTAy
3fxW43+IRgQQEQIABgUCRA3BtwAKCRAmDDVIiPiPj7V2AJ9vo8Yve5MVw6TE2S4T
iuQyjW0v2QCfevU12udOXkkMLFRcFnPAOXgC0I2IRgQQEQIABgUCRA3CXAAKCRB8
8/WvKUmfYcDnAJ9jppAM6tN8mU3yj3kFHNsuVraPNgCggjP4xFX2CBKywGaNvN/T
D5bXCa2IRgQQEQIABgUCRBV6JQAKCRDNYDtaLs+YSzdSAKCClxOjvKc8aP/zE5wO
5pVEXUjAJACfU0r1gE0rESnGP3uaR+rE/+JEioiIRgQQEQIABgUCQ3HtKAAKCRBc
5cUbh+BXvk8rAJ4/NxVC502LLMd2zLqsO41BoeSqCgCfVuGTZRa+WiM0TmakGYDD
eVoJrFOIRgQQEQIABgUCRAb3UAAKCRCyOtu7DpH1zGkhAJ9rtkF+JhX38Z7aDCsJ
eYJTsd30VACfUXmRzdy5VmV6RaLUtFbj/kELILaIRgQQEQIABgUCRB20/wAKCRCy
Otu7DpH1zDo6AJsHDa3hb05hmmkgMqUqCQfdqsrT2ACgy2DqImpO2shf8SDiuxSI
v+Pef+eIRgQTEQIABgUCRAuJsAAKCRAzoQRHKwBWgfe2AKDDPQW3VKQQGEk1Aafh
F4wUJC2I5QCggYl6mh9gGBaXDt997WFzAMYe3qCJAhwEEwECAAYFAkJC1mkACgkQ
HFcMiQ5L0KvPzA/+NHAElbGott9PDv6kUKOW24VyAecqzlvnjwZDB1XdE7vWy7Ym
EK8XwOHOKeukUsrotz9ZhUlsqgDDdw6ZrfjcIVi0f01XEM7sT39Lm2CLEVOWkPN8
YdP0h6GOmnt8V47Ih3twLqiymupHPU3izyq1CI+F3OAMl4W5JCGhj3BnzmISFS7J
cG8yue3xLxH0zPx0hB4GKR15xAKFssxdi5Mii56+eJ423ch90ICTnTVM1sQMABCi
K5Qo2wp3fzPvjCB9uDmGuFdyOiWG4lqHBnyaWg2oB5tDcJW6iwwCq9Dre0yuCQ2v
tcjHurLOgd0uEu2cVtsMs3751Wi7b3GrbpueSGKGmeJ/vWe9I7a3x+jB5QjXOHCK
1JC1TIkLbvE92YhQtB+SjZHrI9h5/8hFOkqi6GoOyZGZDOKh+IP3e1xsNTWI/86Y
coJfJPp6rUTGG+fzrMf5jggc1b+jfSbcvW0T/poFiUbybZyBMwoi8TS3dB8y74UB
DVN2idBFNGZnJq+siaDqPwNU3Sm0LnBin2jsUXoywqaUQgS60p5eEE/idDCrfU9X
SPe8D/M7Fnvo5eh260BOBDiPxyAb/8JNS1/Y7hc9JUnh/QwoUCk8G0+ey4Xv+cxG
lkvIZNuakEnWzki3Mv2XuS5yaJB2WXUw4PNz30xUJhH0jl4Q73HuDvKM/ymIRgQQ
EQIABgUCRDQNQgAKCRBu6hG6hiZ4prQjAJ9K5H/Ck9rtqkIVO5pMYijiclBWfwCf
cZD9PvgXY8Bbi66v8L3ouX7S39C0HlBldGVyIFBlbnRjaGV2IDxyb2FtQHNibmQu
bmV0PohGBBARAgAGBQI+L7kFAAoJEIWAWf86Zh+dcOsAoKJBD933Uz0BaJc7c1Tk
Jq7t8iQoAJ9aIw4ORey/3+z6JfFqS0G301J8HYhGBBARAgAGBQJCMWbLAAoJEIag
qsQWq1jETngAn1CCIfGZcQSCrjfzW+o5pX1aIVRsAKCksfRv/qbagOkCOd3dF7Wr
ljrzmohGBBARAgAGBQJDQ6R1AAoJECT9XmSb9CsHXdAAn12GG6ghh1SUhMPNPQeF
p77ZmF3CAJ9iJuxbWa3FhAYkE+hUxSbeDpwxrIhGBBARAgAGBQJDc9IcAAoJEGRR
IJ4Vh/vmnl4AnA8QGs36fdNm6O23nRWd2r0/8qe8AJ9wzO+jC+QRUwI1q9IxVPZ8
jiNCsIhGBBARAgAGBQJDhGqyAAoJEI/Gin6Wa3nKvlkAn3aAr1eVqEvTbsBLn1yN
wv5X4FdpAKC0C5FuaEUD42SkuCQ31z5NBDmSs4hGBBARAgAGBQJDjAouAAoJEKsv
WlsVJWmQQ0IAn0hVD1hPwzrO46TYZx2kKvGw1QFTAJ9IjsyzpwolHzSpLq5z6voq
fqINL4hGBBARAgAGBQJDjZ/1AAoJEL9L0OYEnbh59+AAoPMNXp+aC6mU+yrkEWa3
ssJB/EBsAJ0b7A8zQ/rBVSZgnM76/1zNfgtlGohGBBARAgAGBQJDjdtfAAoJEIfa
XA0nNZpRcA0AmwY4YcfvDI6T3fWHp5l9KkSPQ016AKDADTVUqybjFv1Ox1b0VFh0
wH0doYhGBBIRAgAGBQJCEftGAAoJEC0/fAt65FQ2nUgAoJ91fV/9vXTk/szG9DS3
QCHRjfPkAJ4/e8ntb/3iL2v9PRDg2Z2avAMbzIhGBBIRAgAGBQJDZS8HAAoJEF8D
MJySFff38FkAoIEkAJ57RwR2gdNAZ/7yhUJO6g6mAJwLdGPjTPsDDwqBNqNTMYOe
ZPv7s4hGBBMRAgAGBQJAkDZiAAoJENjDuVLpGrm5AhAAn0soS8assellXLX/d2ef
AEE8N8QmAKCQ3+7QVgQhiZZ7vnvt5mTtsljGT4hGBBMRAgAGBQJDQ5HfAAoJEFxs
TMBaeYkwCYEAoI1gG5EvTgmfF9V06zvLywcPulthAJ45Fx3/zaoCHECRVbywR7z9
Oo2D9YhGBBMRAgAGBQJDbqL/AAoJEAut9ctb9fBztV0Amwa8CPIeKeyc7abgntZZ
M0kvvJA0AJ9p45+GBwYuaVLe1SsFkMd/pW0PaYhGBBMRAgAGBQJDchb3AAoJEFzl
xRuH4Fe+7MwAoNdhe0887PwEyt0uVRPby3uBzZ9OAKCwsy/Nxnxn5tbKFqq+Uk7j
IUalnYhGBBMRAgAGBQJDjHS2AAoJEI1JTTTHDr1Q9KkAni3if79R76kEEkIpliYC
wue6XsQwAKDf/fPFVKZ20tfEu2NNgqKyo9FHuIhKBBARAgAKBQJDjaDFAwUBeAAK
CRCgT/sbfcrp00VSAJ40hWJbZ0qgECbtFZcYGpYq5Y7HcACdH9/VqEDMnSpvnV/D
9bSFsW7mJteIZAQTEQIAHAUCPeHuPQIbAwQLBwMCAxUCAwMWAgECHgECF4AAEgkQ
7Ri2jRYZRVMHZUdQRwABAayvAJ0dZJSw0QTG02XSgRBquy80z8oGzgCgo0k9FtYw
SZc5QzoHHBmk3Qu47weJARwEEAECAAYFAkKzLkkACgkQeWWy8VJz7acOUgf+PUlj
Ke28YjQZo0htM0qz2kg0Xi6NJCrxFs7EV/HTdtRa+6wVwlnyplm5RgJwqU3nS9IU
Ce2gCQNYtcfrI1/tLsONHC9Zun21GNyBG+wO/mD+ds3hhYREToiV7/KSVs8V+5Xo
pSJsypCky2KJ3NbDjs0nR3pK88Cd5ChfdF4m18pEUTA03VD4Xdb1cBR+1YjLzz+U
hjfm7QVdZ4671G23UpQjzrgbpgofe9PbSem1Bde2COPmIKxk6ON9CNqYOIBFeyNQ
k7UMIp+oYBSJ132nToq3AYxZKryMepwzX5cPRq9vHmc++X1edjlU4DGD09HFrNnn
EE0yQNKxZm0AwJJAZ4kCHAQQAQIABgUCQzEbqAAKCRCMUV/ES421JcEDD/968mTI
0beJUzZ7VlIhYDFocz0DLzbZ749K6jotCaClrYkDZhiIfroBTbZ4kQwS4g9RTMPI
I2Mri4sVG3IiyJq76EgcAw+FRwAeRYTl3+vhmf4dsqHuc0QqSv0KbrASx/HA644y
7Ia63xKZ2e0WMDKrKs8abVver10le+yB2B2O8Xr9+Mlc2HueicQU5FpyW2hhhwxa
Mz3xQz4pdJTZpRjGjVc/I30Yoy94bqqv7rMh874TPby9vrHdT4lapiapIuOIkKzs
g/ONQILz2E5RbPXCDmr9sfe3MFZ9V6juZ5SBpAIcA7eJjFyuOeY1uBWEhF7iQ4lK
U1SDgA6M+P/LGzJuje1qnFGyn3aZgRH206+XZNZxnHtbgzoFMvnngd+KLnfFUlFK
luqlo8rYAGrbgGVe5tvESy5KLg12sb8/bn5NEbx6MlVHrH/0APGtAxs3XfJNp2Kq
OwnyId4IAUez7siPZGxpAetX6TZJQIce+gmGi3aFqTJIjfgilsuRHtOM+OYKGWVJ
5OkhS7GEIXh7+hHVTq5SOe9X3aOkg2GUHv9OZ3FwRpR24n0s2fEbCrhOTvZ+gOuX
cmVW1nZD4abgZaqq5fxdplf6u+itt/dr5pwJILn03TRRi4zKzp2NyCpWwF6KToj2
ORY4qINe/n2z0ZPberKQ7gMXeYisMItO4H4OvokCHAQQAQIABgUCQ0J5UgAKCRAc
VwyJDkvQqyupD/4wTW4a+Pidbq3pn3p7nUh5YCAeJCZ0slIpCIb1/We0p5GVTCpM
TPF631QYbrEX1SheUorxPESC3QbyClStdDePwuGGPgJ+ffqU7ivKbiny/hw9ck+z
JGamYnnzbj9WTJpsDtxA1xR+kRUX9D0oZc2thXZ1UzsYgxWOuj2yuR6AiFYcoiC3
76giSn4HP5E8OucEpzcA9657tnfywqDauN+0JRLSbEUjTVm54Fzt9/rnD0zrJXIl
5TYYGJoCbt1O7WSK88IWSISZ3i/1c70D9wE+SS7uv28epZaJRi1UoTHzavk1ipzV
3CXEYD2UPwgvZvNhdWeMh8lDX6OiD7xgILF/BG8b0YODMpzpTxozf07h3dwPBF2S
VpBW+ZA5h7IyWx9ED77o0wAO/Pcq0TEzM7DzsjlxwVG71NjFOqslN00tXUQ0DQ99
rEOCKORbLtAeiqeBUjKtSymXC1s+RjQfljqln5IM4pxEtvBxWFvDFE8x2M6aOz4i
inSivNQUYujIW4NYCG3mzQPmOIHuXdoUSNeK3n0uN0T6OTj637sZuc1x2dmKcVAo
sR+KQjoL08W9Hm5Y6ooGeXB6jPjdIHZDe7SDr8CoCJ4jSTYyuthCDsFZPiO+eW2j
CIjFtqRcZ3JG6WA4S7t3/9IYj7X3qZbmmaE7OqD6Eyodg/Ciplv18gm5SYhGBBAR
AgAGBQJEBw0LAAoJEC+VFQiq5gIuM1EAoI15xPlspNWWakxeVqP+1TJSS5LHAJ0Y
k99ZUy+rA4UMg7DwaAX2QQNxSYhGBBMRAgAGBQJEAXDhAAoJEGjzWPbBOWR8Bk0A
oIZqObrXvX5O64k0Y/7L5A03hVpqAJ90UcBaUNNr8OI/Y9L8PM6Cczw9JIhGBBMR
AgAGBQJEBMloAAoJELUeJ/UZ6hlGqLgAoJvux24SWuY9pxtPOFGBivsTjKD/AKCN
rtCq7N70BDt2KKNfetNAuE1vp4hGBBMRAgAGBQJEBOiBAAoJEG8/8RB6LP9sH+kA
nAwSk8VyvrzCNTF2OdOw/ojHggcXAJ970pmz35BkqAhpIvFxXN3GrcGo+IhGBBAR
AgAGBQI8YlaPAAoJEODvog97wFGlnkcAoJkOQ7gySM5qFZ7TKau3igJFQE7dAKCS
NNMhzTgdzzyiWYqTgRYvKS2u0ohGBBARAgAGBQJDce0oAAoJEFzlxRuH4Fe+5FkA
oJd7SHXnHO4D3K7Trugsz8eIhnefAJoDlpMhOdtWirhkyCBV3JhYy+HJMYhGBBER
AgAGBQI+V7j/AAoJEE0F4QDGxFyVzv8AoJ0KTXMofgVN4ujfUN+O9AEkFO6BAJ4s
62iGOWy4pDJDzX0iMm1qIP+EBIhGBBERAgAGBQI+nX+8AAoJECopZefBlHJhq9YA
nj165KPT6I5H9dTeDJ3f+5oOzCS1AKCLo1K3Lj1JtI3tsYHNel27AD0PTohGBBMR
AgAGBQJEC4mwAAoJEDOhBEcrAFaBJhQAoLcS57jgJ5BruuqL81C0gxZsDYTJAKCM
eizmBGG55Fn+OuVLRI1r5jvVq4kCHAQTAQIABgUCQkLWZwAKCRAcVwyJDkvQqzWR
EACJR3wovPhpRW3INKmmpMhnwhdRhpFBTBVv3GLSH6J6K3fiqZT01uNoqK+J4cbU
blJjrvKn8my5pmkUbuEKTknMsFvKJ45EiO3tu0rwb2MD5TgUmRPqQdgUvxRHIlki
Zuk/Dc56jFYfI91ZXiPQp1sX9p8b3o9rd36BIvDfyCw+IUnjvZtLg2rAR/e/oXTJ
2K4aMS/N68BycchIvB+X79HZCF+EUtpsf17L9gsj/wVHq4FQbX4Plvgv262Hdndv
QKv25EJw/1tgVg8j5WX51qtpkPY8deWBFycc/ZZ9jsAKZHd6+X8wnJaBdL9XoIyK
1OOFarjdHEaA/WyMlUk1YUVv47ojQdsFE+7gEfwRNnSOsO36Hn1JDirixLwf/bAX
kodSG0EZDBA9am7k/pr0jTJhzmJd5t/W6CCyDw3lWPuOWQcosAl1RPUelLxNqbqu
BIU6NIMW1q74AWMHaxp9sOksWvxPmBPh5MZXH0RzzSa5+mHGEQ8/oU2Ausinekq/
hrqi+V5NuniOusl9cGoLwVJRmGyk4p9v2CdbJi+50nM9uw30pW0MJ/C0wxUWbkrq
u6Frbeqg99QsRfMKoqvjVmlg0LehVie4UA91tcTqrnrE6M3UP/Mxe/Ys8yW2XcSz
tfwS+Zqt2hKO7s+LmuhxNFw/4v47RbgM+HGWXFB89331qohGBBARAgAGBQJENA1C
AAoJEG7qEbqGJnimXeQAn2I4/JYNh2RYW3XkG6Jk01SL+g6nAJ4w4r5GVjZPyF+M
Ol+ZXCGKoDbiabQfUGV0ZXIgUGVudGNoZXYgPHJvYW1Ab25saW5lLmJnPohGBBAR
AgAGBQI8YlaTAAoJEODvog97wFGl9LUAni77ZvB/YC8ZHhroc+u3KcvwLKINAKDR
nKJHJSzFoT5l8CPNUi6Fy8/aOohGBBARAgAGBQI+L7kFAAoJEIWAWf86Zh+dmdoA
oNgPuuZq0zIRm7au1cTIRXvBiVJxAJ9FDcQXTrJeyUIEVYeXbkdkERE0MYhGBBAR
AgAGBQJCMWbLAAoJEIagqsQWq1jEBXUAnRdNmay/rDPn+ds0ySqG1H3ZD9ItAJ0b
AgPLLAIalv6xVQxqbbbOYN9Uc4hGBBARAgAGBQJDQ6R1AAoJECT9XmSb9CsHpJ4A
nAuMXuhMfkmQ/IZWvE4skNMd9vT7AJ44TYzHQDajDR5bABGnXRxeokwsh4hGBBAR
AgAGBQJDc9IcAAoJEGRRIJ4Vh/vmUwoAnAiXMOSfJ9bKGCxbLabU+qbo3FGjAJ9I
+mhsyeADUFuh8Q6cZ6Kb2pVQ04hGBBARAgAGBQJDhGqyAAoJEI/Gin6Wa3nKv/IA
njQXEu7Nk/LYaTH4A4BtxUvoilhDAJ9EWDXgwhIG1w0K5Piepci6icybw4hGBBAR
AgAGBQJDjAouAAoJEKsvWlsVJWmQGNsAnRegA4HGA/Rlx4iZXeRz1AF7RXRGAKCO
Td6I1/bQsbdP/YAsA8Nhhgfh94hGBBARAgAGBQJDjZ/1AAoJEL9L0OYEnbh5CbMA
oLVS53dCiG0+bui4QTf7qPtjkowjAJ4mtxZdJXDwFrOED5QI6a2hguFP5IhGBBAR
AgAGBQJDjdtfAAoJEIfaXA0nNZpRQOAAniITpz6LGQ/aXgF2rVk1FWCfp1V0AKCs
xhvUG6nYq8b0e0muIWdcqjOTKYhGBBIRAgAGBQJCEftGAAoJEC0/fAt65FQ25nUA
nij9VuRB6oDm9cWK65SbM4lsVLO+AKCDTYBIk10kk3lHgCnZOnn1ljg+jIhGBBIR
AgAGBQJDZS8HAAoJEF8DMJySFff3tjsAoIpdaa/X/q93Vg5qjAUV6K5rHBGJAKCd
xCoh14FHPfGnSYBmA/8oCbK+d4hGBBMRAgAGBQI9CCw7AAoJEGisKvHPFzcTgnQA
njk7cbns0+g7mWID8YpluuJVo4z9AJ4iFP6Xs1TIuoiVOVUwpsEnqFQuLohGBBMR
AgAGBQJAkDZiAAoJENjDuVLpGrm5vdYAn2F4nWk0KzrczHdphqjlakY1Z4uQAKCa
wPQkznZli4veAlf95PHxw560RYhGBBMRAgAGBQJDQ5HfAAoJEFxsTMBaeYkwZZ4A
oIb/gFGqX4jsvmWpAVTmGX02uK0gAJ9fEQMF8zBT7x3kWv1woR+sW4KVHIhGBBMR
AgAGBQJDbqL/AAoJEAut9ctb9fBz1VUAniCBgOgBP1Y64Ku9E5sOQqSEho4bAJ4j
27K3nGaXmGHlH3g+Hl+R5IgZcIhGBBMRAgAGBQJDchb3AAoJEFzlxRuH4Fe+NjsA
oMDOBhk7fKQMTw+KP8oNZTooKpP/AKDOoQHTUW/Gz8Cer1kOdgXZqY5L4IhGBBMR
AgAGBQJDjHS3AAoJEI1JTTTHDr1QJCoAn2Zi0GAbZrMT1z+gwrtMZsV6dM1WAKCD
p5S1Hd7o9y2N2cC/7esPmd/9zIhKBBARAgAKBQJDjaDFAwUBeAAKCRCgT/sbfcrp
06qUAJ9kbqkkAcchmD7vP2ipNHVJBrhz7ACfQQ3rtvYZ9BFwzY4RC6WGS4BUcgqI
XwQTEQIAFwUCPFpPrQULBwoDBAMVAwIDFgIBAheAABIJEO0Yto0WGUVTB2VHUEcA
AQFLwQCgsuswra6JwVsi0ET4jhXbUt2NBtkAnRFMQmcBicyJGFE44lqlWgHwEFZ2
iQEbBBABAgAGBQJCsy5JAAoJEHllsvFSc+2nUywH+Ns7t1VAl2KuMOtmUnCvYANh
5ECV7wN4NdzFhtPDDseAYYqjMJfVAVsyFR6376cf4HnRHDwObrqbun4m7EgGxEag
YBJeTgg0quzf1SSnvn4goSQqi+B9BOqYuhm46qrvJjc9XWHJdyfvtcE1um7cGHAD
2NrZQZwKtieW9D2bVg8JuUd9pG9zLlhziAtHT73IYuZx6Ny2abJpU6fXoSE7+F6a
zibOXarW8QUxs4TCsjRR9+8beqU83V/2k5yE6T365hrkHE2iBW/YdFpFxyWIpNNw
isfzIiSoEg96Yt+cY1R14qzAzg2xSUDTUYt1nbIlIwEzkGkJsvo4wt2a0xtmCokC
HAQQAQIABgUCQzEbqAAKCRCMUV/ES421JfddD/9++jYHPb8IJMsr3QAAhY+7Hvqk
Q/HuHug+BcEwYAJ7lcWXxrilHxjJeD4yJ3OS/5PJ4WBKQWApSdxHkzlAW78qr6lj
9auS8tyRRnSNntAu3vllMyUyBNlg0dtjsujo/jjsvMPcMGFXgTwq0ZRIdb5iJp1V
UiggtatJrvUxMvRqUeT0kGiDBhXRQftC01ecY+56uU16qKxrtHJcAXRgzAkGn485
CqEhrxLRbcxiE8PFIyz2IMaXRp55FklGVdazq7vQa9/erX+x3TVPDq4W7ayZyIq4
5C1xN1UH7kioD429ie9bWfzrMbZ86IUrDiHlCC/yulJoK2fzjw51/YS6wKwmvVAo
xMSPL9mdfcOfyS9qPBRMkblZZCB6tvnsuHCTG/1tQI/J58+htZP9TVDxiK1C14sj
LWp10pCMh1VbvKhxOYteSKmAMVzPdurLmmyrYm5br8GvKSNuYR4btnAQ31JCupoD
H/qvqIB7BxJV+8QqStYHOZqvNIuuNPhmMGCougaVCIJVGN7Eu5t5yTAspKCujUkW
uiqyQRLDyp6tCVQ+Y5oS/EpdY0avNRatIYtguAFMfJkFYql8yM7ZZY4DgmCC3Xaj
pCsPPH6eka1zYumfF8chWyb7+INYVzFAlKWusWrakEXkHeMeBrrKU/csIP4IFZZg
yWCUEfJVCzgThpULz4kCHAQQAQIABgUCQ0J5UwAKCRAcVwyJDkvQqzhbD/4tMN4k
nnAwiwZwBbBWZTSa/trzKx8hREa8dkLHOjJoFZzZZ0PxenjX8IUAmid5n+ltpvhc
WsmLqagHZLio5Vj2/95N58HHHroNZuHjRLOvXkOOtA3PdeYVHQrRpEQnlUZQlw9M
9/amYHZucQcvPM+Tz4QCv2fYCQpPdLvVs51/IYrsWIdUCiKzoZN0pjfo4P79t8b0
KtPT0EuLD4Oh5YsgdVhq59K2lgl8eXQAQnNtZ2vUO6/aZVo/NPDcUJY9UZSpfibm
9kdxovHseknYQ+7Tj7p1wo1JNVKdc/ezqAmdKQ+X5vczyuqyKYpWvsXYLCgSwAU8
Q9me70EHOOUetLmf9gqtODET1f1vWS4K2TPY1Kctx9mvtC9p/W62205CzWNUKyPM
6XFY2xcOG/n358NwppzkJ0W4mAwNLsmwdxtyuu/pLDd4u+zc2SXHpehAs0uZwhD/
ETGxe3JR2bhyjjTX3B0rqs0DQaITe9ExznUL8Cbosp6Q9n182cRrhDweY3u+bWlu
qUuLgZ9GaPTJuevLVNVtTMpMxkbXa141LDXVYRfNVmLZjz2LtiqBxfX5hv0l0KBq
T+xWnDD9k2jYqK0/i1JruZKg6ZnV2KbFls7RiMAkgGZilIBa5+jrmloOCUowrgaz
POCAFwkA3OBITvIrkvpCVWaS6ZB86JS7lhpXXIhGBBARAgAGBQJEBw0LAAoJEC+V
FQiq5gIutG8AnRwURaopy3G1KjZvYVRA2Snn5CSFAJ9h7vRr7S8irPgeX4TzdkCZ
alaZRIhGBBMRAgAGBQJEAXDhAAoJEGjzWPbBOWR8wQkAni3HuzaBK0gvRUPxjB3z
BOaffCW1AKDVUZjpNdp6BIx81HSK/WSuHEnPRohGBBARAgAGBQJEAeOeAAoJEAYG
nPKWlFfwVkAAoIPiu4G0o/gdsCE/yOriAkBlsRvsAKCMfWBjYZ1V0MwkVG6Q/zrh
fpcn5ohGBBARAgAGBQJEAvRIAAoJEOVE3gebfDKNSJIAn1rZYh/rgTfXYMRocz5p
DvKLDdDRAJ0QpKuP3U26cJ2rqmGbdPKQkMyPgIhGBBARAgAGBQJEA2BdAAoJEJug
k2taNf1Cra0An0GBlNKSDvACSCfP11g27isQMDKbAKCyO2BYvFw8sNCy2hLj2okz
+tsulYhGBBARAgAGBQJEA2GcAAoJEDFIu+8e7yb0V8oAn1xQYywDTaCJ0piEgIqd
3hh8nNZkAJ0d3VTo+2ANL5KBiipZuqDBPtBiOYhGBBARAgAGBQJEBIw3AAoJEGjh
JSt9pcU7LN4AoMWFv6qVhRfVGZAlx5AtVJSacmBpAJ97QLhdSPXtA0sWGfzyoTTc
GeKILohGBBARAgAGBQJEBMTvAAoJEDlNxZEO1wTqSeUAmwavdks0n8EO0nj7DG2z
WmLoLB9CAKDJSyUL5o/247MWwruMqnjrQfIogYhGBBARAgAGBQJEBNT1AAoJEIFY
+y71Fx7eB7AAnR+rg1Xt7X2LCzvPS+9hohjWP8gwAJ44xQ6ChJ885yEm6UPfm4Cg
k6GCPYhGBBARAgAGBQJEBiARAAoJEPMhzYKPoY8LxREAoJsEpUj/jOEIDXQ8fgQt
Qq/shO7pAJ4lafsRA28wsvnoepVjg9o1e4BW8IhGBBMRAgAGBQJEBMloAAoJELUe
J/UZ6hlGwAoAnRatKEqD5YI/WGi1xip1ou/IHpfiAJ9xFsD2Fe7ouc4yulfvN3qv
h7+iAIhGBBMRAgAGBQJEBOiBAAoJEG8/8RB6LP9sYKYAoIfif8T1wS8fqovZSxAG
0fh5s/edAKCbwMawTtX1nV7vGPZO+66XzoK7XIhGBBARAgAGBQJECF7TAAoJEB54
rm+oh1VHlMEAnRG/f17qWbf8ww1QIzyfojBNeIkPAJ9Pg2vXYJx7sSvYZuf7eWFq
yDpmmohGBBARAgAGBQJECGvdAAoJEM6A78SRpwfkuxwAn0CtP/GLIEQk/rCDvLKK
UK68ZxOEAJ9RoOH4tsoKxz9804uzePjmFSV5zYhGBBARAgAGBQJECHJKAAoJEItK
xIGsHnFew24AnAh6H7wB11o/xo6b0zF7PclpvSdzAKCE21F/elkHSExOT0SxsHC8
vvlalIhGBBARAgAGBQJECHppAAoJELa66j1B5mvZjBkAnRkUrCT6ERSZxai4f9Oy
Kr6cfj/FAJ9TAVIdAe+UtmAJ+eo6SYuDAZbThohGBBARAgAGBQJECuGdAAoJEP0h
vDusPgh5pLoAni72qaA2Qj6ucObfzFh2f+NPfdyxAKCQjPZk1kbnFbwJFRT4mDXX
ommAAohGBBARAgAGBQJEC1YYAAoJELpsWqKL89IAKSYAnjKi2OXfFNGmO3SFF6+B
JJDanQcmAJ93g0Qox3z3igteMVAXGUT05f+bTohGBBARAgAGBQJEDcG3AAoJECYM
NUiI+I+PcGkAnie8WnUwptmuz2ynjaYc1HxUkwBIAJ0SiSWPNBtB+z6QfLEbPaPB
6r4GnohGBBARAgAGBQJEDcJcAAoJEHzz9a8pSZ9h3TYAn0e7Cz4VoobDvpIbVcAW
hSGnJqFWAJ9priR1q2bGD/wZJxfuNMtjsjnXSYkCQAQTAQIAKgUCRA81bSMaaHR0
cDovL3d3dy5lbGhvLm5ldC9jcnlwdG8vcG9saWN5LwAKCRCVeVLXzzQBqZqCD/9c
IB6BCqSOatrnKI944U/A6RFrUn+5bZx2xrR1hlGWUBJ85PRxkKFxZkd8szmca/6a
5tT8Df4KMA6H8d6Msc2XFQJexwVX55I/jcHevwiyGdTJf5u2+FdP5uBdSrlXULPf
7lCfrudgB5w40gU3keStiOq0Arp8f2j/Srwoc+TliF8QEdLPG1+xOwWsJ8Lgfexn
NwKaZgrYz5m65/p+1Jdao9c+3gUKx42SBXszXEGT92dCGjRb1kSeFxgPy2/3TJhM
suDDYEM6z5q2LAK3yebUVpdqMsvoD6PW255IdvIO/5hxRYY4gusml80Wv7xsfEy2
M7KuO7I+w8Cvxf57nNWZH5lBqTbEQUBAEr+N4sIaHRFnM2sl4f2sXha6A99W/u9J
KkhMQwb3z/OLZtCNX441OA2eXvS7V2ydwAx+i3UJd5q5VRK7RzNQih39syw0/gI0
nrdEtFpeiFhU+wj6RB6556FY0C38rtyYRvJZifJnTiKEwLf2W3A2DuxsLkl/+8jB
VqZTp6kZ9ZSC72DHt6u78/JuTXpMjCKXVlM5gFQTpdLvj8+EFFegko1aqWCHNdu4
QIVPNN7Ka8Fe40MloAhIsaTNOP69h+CqKUMmIGtIw6JT8XLImghY/Vjmy2Qw0edv
+sJiPIkpJwDh1bATpf+US7antYFZJ0D3KKGcT7edHYhGBBMRAgAGBQJED2sQAAoJ
EIwl7g8NwLfWNHQAoIs50RQPeQxtcx8oF2kB23A31UtWAKDZQvHkq7ig1CVpdbli
kj63V/XeCIhGBBARAgAGBQJEFXolAAoJEM1gO1ouz5hLJB4An2j/2f0pMJBvhITo
qIEMzigy8uXLAJ9hCyIz7Z3JYuqdrIM6wUn2tHAdxIhGBBARAgAGBQJDce0oAAoJ
EFzlxRuH4Fe+nA0AoIHR9lcWPNe+xAjuvs6GAmqwQxJtAJ4ptrEd0zflpvH8rMAI
zMg8iyfUn4hGBBERAgAGBQI+V7j+AAoJEE0F4QDGxFyVHc4An3GXrtS/xMPuVTTg
olIGtluy7eIJAJ9y5yjlGBIlRn4fqwDHGqXywKu8d4hGBBERAgAGBQI+nX+8AAoJ
ECopZefBlHJhDZMAn20bMfzoYHDG1SqSDwVrOJvrKhYWAJ9YberNh0iR84GVC3pO
kr4tXM/QI4hGBBMRAgAGBQJEC4mwAAoJEDOhBEcrAFaBqYIAn3T5y/tZrgES0/uV
Clqa8WA8ZIrkAKCZe/a9E5jJiZXFDtUIv6zZ5r+tL4kCHAQTAQIABgUCQkLWZwAK
CRAcVwyJDkvQq8MoD/9nU6EQO1N6jgqBzr7mFCt+/ccvSBkYB3k+GTh/u+vtEqRo
OoNCXteEAe/01XsNaxqP7i0toxSXg39FRTkh8UP9bH4zvrkJNzolpjJhMBmyg/pj
0KGT6jaghCYJ4+LRcw8iw4dNQGnRH042uVK8UmL8Lqx9WwLaqY6beiskHNNNL812
HUseiaYWUYNW+I+3y7qvPD/jvnxJ4G7euE/HhiNlR850YZ67sCiiNi3O/7S4vWmm
Kt/01k/+zUjewiCbC8iFwLuTyJIBPjQ/Vhi/N0g6K5gl43BsttOdvnqBPvQ0SrW6
wo+nBbimPTqb0E0EQCjHihrVmpXwg9UJru9tQUts056hkvL3uaZNOISTFXm+un7e
SYOcEn5XaTxqfxB9jMLOBHTW2miKhzQzjdZqIE4hpnhketidk+J5D32J3cI0K4Zj
YPNCrv/J/NDLUHMAy2GwK2ji+lhZY3E1g9TQXwkokXjphSNHqSjrwpsHsHC9k8rH
YMYMIu2cU4dlGFyM4Q7S9F0+Udaqvko5AMa2ZVHE8+5rra4hSPyDEvGeWBT3jN2E
122HQZCrxv1YFioW5YMHaiY0t2cZdhuZPyp0ZfhriwFukqoKl7fWSwQ2giyfZxIS
alkSr4drOuDkip7ShxGI7sQmzdyuQ8ZDWtX6bcBROPbFNXwEj01Gg5z+SWdZtohG
BBARAgAGBQJENA1CAAoJEG7qEbqGJnimgikAn3LXHYYh6HBC+WiNeqrz9O2qXWMz
AJ9LLPTUTGHyWzjMUjlwfBaD8sihEohGBBARAgAGBQJEIpFVAAoJEElQ4SqycpHy
ZdEAn0aNs0twwSjbahYGrIMTgGJir1jGAJoDYC+SQ40czCqFJsNH0qzx2EE637Qg
UGV0ZXIgUGVudGNoZXYgPHJvYW1Ab3JiaXRlbC5iZz6IRgQQEQIABgUCPGJWkwAK
CRDg76IPe8BRpcAiAJ0T/n+UbSZzH51HRSlpXlKwnTdeoQCg46wupQiXMNCbVMyE
cyOd2w8zsSaIRgQQEQIABgUCPi+5BQAKCRCFgFn/OmYfnf5FAKCIAu/ibl8FRFfy
DfQnU4XlmKKUTwCg4MquGS1xJyDyKlYc5diBak7pPf6IRgQQEQIABgUCQjFmywAK
CRCGoKrEFqtYxJD5AKCzAh3+VGDTildAmeRLjuIRpdHhIgCgjRzot7kCbGTI82Ly
Vq73qjVLQXGIRgQQEQIABgUCQ0OkdQAKCRAk/V5km/QrB24mAJ9kgV59kO04U/VS
sIcun4k9VMyn6gCggyQtm3ms6Jup9j2CdwWj8/SrvoKIRgQQEQIABgUCQ3PSHAAK
CRBkUSCeFYf75jb2AJwI9ZSjRJA3uf+rkHlzDPZ4xo0OcACfW1HTciYRxell/fyu
kjZsTUP019eIRgQQEQIABgUCQ4RqsgAKCRCPxop+lmt5yheEAJ9Y4HUE5YvIpBUO
e5LZptbHCwRx3QCfVQUHLl/8enB9d48aGFS3VY1LBqGIRgQQEQIABgUCQ4wKLgAK
CRCrL1pbFSVpkH6QAKDbnKA4ld9Sp7IVPeFnrTM8sFo5SwCfbiU9ewsGE4gwdUPi
DIKC/t/05neIRgQQEQIABgUCQ42f9QAKCRC/S9DmBJ24eVCWAKCxtMUdRalAH/VG
yUZmW0eZvtazTgCdF0J4taUeAsWlbv1sgfpPuPFAZf2IRgQQEQIABgUCQ43bXwAK
CRCH2lwNJzWaUTueAJwJNZzlNSOlx+OdoiyR0ZRBi6gKSgCfWR3BojS6X1sJC+uQ
2+squc10XZ2IRgQSEQIABgUCQhH7RgAKCRAtP3wLeuRUNqG5AJ4tPfLkOHLlAPgc
BcUMuyVrE46EFgCeP4Y89YubmdN4ndVaiqeH+wIxR0aIRgQSEQIABgUCQ2UvBwAK
CRBfAzCckhX398o2AJ96PA/LcZ1o2ZtLTEktM658ugb9OACeMKLi6d7Zx0vsjRWY
EwTVe9mpxCCIRgQTEQIABgUCPQgsOwAKCRBorCrxzxc3EzgqAKDfbqPMzsYHu56o
7hsoot6qKH85UQCfR2UCDprRfc/JMn7wk99JzgXGK4GIRgQTEQIABgUCQJA2YgAK
CRDYw7lS6Rq5uX6xAJ9Vaz9IwHcLMJJap0W2wA1mA5qxdgCeOxcNtDh4gah1mHqB
13C/sNOnv4qIRgQTEQIABgUCQ0OR3wAKCRBcbEzAWnmJMNATAKC/4OocLVXpqowH
zwE0YWLhNeG6nACgjB6ZENZgZPblX+l66uL/lqeOSlCIRgQTEQIABgUCQ26i/wAK
CRALrfXLW/Xwc63rAJ9EsUW9O2Lh1lDYSQxgg5MqZW6NrQCgyU7u+L9iYApjJrAy
Y5KuNFqrLAiIRgQTEQIABgUCQ3IW9wAKCRBc5cUbh+BXvhvAAKCK5pCO+m+MDfzS
VdHVOluEJP/usQCfePcQsb6to73kfoFmawlot00Ro2yIRgQTEQIABgUCQ4x0twAK
CRCNSU00xw69UFDtAKDDrtZwFHgcZOho4brjj6olvUaXCACg79e6Wt65/5JQEkjG
DldMr3VUzjuISgQQEQIACgUCQ42gxQMFAXgACgkQoE/7G33K6dOgygCg6MiXAWAo
hW/mrqcIfkvk+W3gc/4Anjrh88FuqCS0i/TSkvJcGJgywyowiF8EExECABcFAjxa
UXMFCwcKAwQDFQMCAxYCAQIXgAASCRDtGLaNFhlFUwdlR1BHAAEBPDMAoI/aqHGs
Wi3sYgXe0ijU751zU/dHAJ9L4exiV1AyFwy1MvAru5MEJwOxqokBHAQQAQIABgUC
QrMuSQAKCRB5ZbLxUnPtp+j4B/9bbc6sPmANKL6vkmxdhBKTKOzs4MTcSR0CBX2U
3DUYSEwg3CHFJ4z4dTmCtpGectF1cz64sqAbY3OgGK5az6zzYrHjri0OlKaDUU5w
q96riarzg1QhbfeyOp8WQzRaqP14o41BdkJlx9dk8fginwCyiZPlJbcaymmfyXBY
M3PTF7zbrA7tjY/3I8AF/FTFkGAE7fo6pPpi66XX+YwZ458kAeJlXATphK4zXsIU
tyR5s2pjiA5Rlq0DbAb/f4FDCB9b9vj4dHIgnvIk/i/mP8Pjwmw+/TgpDuCNuIyC
netzFHkWcEgQwsp1gji9CAtYJNSS+x5Gyytw9xHQZVROgxlsiQIcBBABAgAGBQJD
MRupAAoJEIxRX8RLjbUlu8kQAKfAbr8cxs/PnsCXVDu2q20U8uCVMn5pRc/fl1oH
f+6QLaja+ArQbgVFNUmdZa7/rOgHGaAmIFCmObx29pwmovsGPduDTKwd4BRFb0Tf
Y9aEVyuUCwsh6EFopIVcPgHlHLvVmo9I725mQhszN5ZxFYdMKGIhl6O3xxx1pKDs
6xZsDPAkrWinY5Z662Ww4L3/l87oKdJzWpDlfeKIeGn7r6+fuyeKncTqeRszOKaN
cV0Fwb8poXTHFk/TqM32+YjLIhyePfL0/yKrnlAR/QlNBV9tc1DvGYlJignIWs0e
kt7P2HhAtbJC5rhdwcm2WjukpsFnJI6qu82agDm+oAwTmwxj0W/9A7unfMF8j9ir
JtFPV3fwV8rOsQ2IxkF15zyvcsQ8RyqlCMH0gcW/n5fkkkc521+fuMn4SYhe+qgK
lks4knHEUkscuPoJ6SAZkPHOGMIuqOdL/dlOrtnqVaG9nncawXMKRV/IwIOF6zPh
6E4L63Fbd54e/qAh85hK0OA0UHjc+OI6hzhnxWSFGP3hXjYidYQfSb3dGuCmkrup
lhPCHpFKgNKPkp2sKlSRUxFMfPQRjJ7O/fQGRfJr6MsQtM+ukZrHtikFJ0Xy9ea0
gyoSz52kg+wVnWr2lbCwYp2TMFWwIoYGP0oEmbj/8ZoIESyCdgODHBEpSLEnbnPK
6RCviQIcBBABAgAGBQJDQnlTAAoJEBxXDIkOS9CrvxAP/iFIlQh/jNbmNT07wd2i
pwuuNlkMFB42nIt7tbTyrTwasfBk4T0JXRmmEqkTsD44XJKyaLsdK/KoeRiXYPZn
LykJwgAse5fhob/uWQaKJdQajBlrbGr0b/YvpQHCZC5wnU8LD+xXKsKU5r2lpsEy
5oybQM3VJfvibHfuwhF/nu5c1vCPo9kMmy8Ju6hy3RjO4JRV0BTWJAEfqR7Ndrt2
vPJc9GQfdsaM0EA6bv9aFCzjEkvpjwXlPyUgmsb0xh6ftj+uP0ReGeV3PI7cDzgQ
UOhcVxDRJhei7WOjLzd6nnb1tiHOE4iP1U5Y/TbVrsZD5/mz4xTSxqG2bYBD/KSS
71su2KYGnxXJbSFNzAJXjcWufLe9x1QjRNq0KqqygjLnrzdK6TBNDEKuy0XCdmW2
p6jBiYNHA4olhx2yUxMR1uOXFHdAaq7U0FtVQrf7CgJRxZ6d/qaoo15E6RYHMEi3
Xo5UxMNdYGyexLgiUswmC67B6MfP1DlpvjEZ4tqdlcT3DEfrhfIaC/hBEkLywsqh
Cwpizoz2dSgtdm7X0V4UrnWUIBN5SGMHF0KkP/N0c/hAkDLDQShTbTNMufxrShCx
LmhHAYRBx6qP7lIoRlPACFHMgHE6840uXPkpZL0U1AULSenN9ne3wueElhP5omOM
0YaqCs5ugK4O1U1MzE03wLQ6iEYEEBECAAYFAkQHDQsACgkQL5UVCKrmAi7qiwCd
FJzZznOyxnt3XNdvn593vvz4HJIAoKF9WMogOJoNdRfAdlNdqOaoFIdliEYEExEC
AAYFAkQBcOEACgkQaPNY9sE5ZHy+FQCfR/o1SK1u+kb10i101lFVKtkcPSoAoMZk
Bzb94IWJtq/5B5NT3vY+pZ3GiEYEEBECAAYFAkQB454ACgkQBgac8paUV/CFmQCf
YQsrKB9dVLacVtOuMAurtSRXbIkAn0iWRZAOTacjaHqN0joTqToddb+PiEYEEBEC
AAYFAkQC9EgACgkQ5UTeB5t8Mo0TjQCffS9xy6fXD8kIgBDszYkoBeLzHtIAoKsU
e+/b9myxWSqPFNbs+zVPnGQ8iEYEEBECAAYFAkQDYF0ACgkQm6CTa1o1/UJUnACg
wTwZkS7kKIvQu1KUEUjMgOaJuoIAnRCRsffdT9Jnent4M/z+SVzgrLFQiEYEEBEC
AAYFAkQDYZwACgkQMUi77x7vJvSfaQCglqiYfVaozXk78Q5Lorn4SeHJhokAn1mF
T4RIe5H3oV8HtEDJdCpSh0kXiEYEEBECAAYFAkQEjDcACgkQaOElK32lxTu5igCf
fJJyA8Gnx2DB0UtUD4oHiQYNTPIAoMaz9KFx+GFVKuK9i0J0Vd8lF/dqiEYEEBEC
AAYFAkQExO8ACgkQOU3FkQ7XBOpoawCfcdltQ/ApJtYMTaf0JPeZrjTNOkIAoPtf
yyTvuXi+dByEjm2XX2Xz5xK5iEYEEBECAAYFAkQE1PUACgkQgVj7LvUXHt5MvQCe
Ou+V9BdXJlDj0/FL2xyhlByJ0nUAnRER0rJZbaWP15MrVJCz4B0j9ulCiEYEEBEC
AAYFAkQGIBEACgkQ8yHNgo+hjwsO7wCfTxzkBzvUbPwRtZAlPMwRKJ2QcgAAnRjR
CEDvupDkt13VL8UG1QCZQSyciEYEExECAAYFAkQEyWgACgkQtR4n9RnqGUaQDwCe
LC1QPWJXY5BJOcw+h8GKHqNanncAoL/aIuta2WCLP2kAh2X4XVb37ec6iEYEExEC
AAYFAkQE6IEACgkQbz/xEHos/2ytiQCdE6mpfFhalCs/FQDgCv6iFpvGZHoAnR92
nqd/CMNruhcIhl4JdXXYElYSiEYEEBECAAYFAkQIXtMACgkQHniub6iHVUfrsQCg
hmG5adHg/IkpfWby4MoWxx8lTFgAnAoxQeYFPmZstEdjJlh0tb70tFgRiEYEEBEC
AAYFAkQIa90ACgkQzoDvxJGnB+Qk4gCfcn36+yzosbxS1a+NFuRZoHWgng8An2LM
XDz91FDkshrzB6VWHu7SB6H9iEYEEBECAAYFAkQIckoACgkQi0rEgawecV6QmgCf
arnPnnsQZAsBqRmG5ESHspvHbdUAn3vlzJ8xUtrTQwdDtEPafLbrBnFhiEYEEBEC
AAYFAkQIemkACgkQtrrqPUHma9l2KACghSi5v8Xp/gL7k96agQOAcUWxL1kAn1YJ
f7Oc/NhfqY3Ts3Bz9mOviKHsiEYEEBECAAYFAkQK4Z0ACgkQ/SG8O6w+CHlaHgCg
iwxy1BWaRFDKb/8exFk+nAJz/RUAoIMoesNO2zbu17FTK/NGAw5TiHZfiEYEEBEC
AAYFAkQLVhgACgkQumxaoovz0gDvKwCfWMN4qCwYLZ99CNOPB7cKXOk4QZAAnRJd
TSFmcv38wy/83/a0Cv5PiafsiEYEEBECAAYFAkQNwbcACgkQJgw1SIj4j4+a5QCe
NehDDT+AoJLx+P1Ba2g+ZNBalssAniwYp71KQTfXgIxqfFL10dGwHoBEiEYEEBEC
AAYFAkQNwlwACgkQfPP1rylJn2E3agCfV52BefhPGpf1J2EL3M3UHhcbudIAoIOk
8tkpeV70JWHkjcgqLz+shJ/HiQJABBMBAgAqBQJEDzVtIxpodHRwOi8vd3d3LmVs
aG8ubmV0L2NyeXB0by9wb2xpY3kvAAoJEJV5UtfPNAGpzlQQAJdnuqWRvcnffTw2
9j8GaUWk2Cpb1RpKfHZIP6Rmg1jCewcLFJgpOv3DbeP8Mp4REVMndiW5gOy3gCO8
9RhFq5eGs1ElPtPeUWZqUoggfW5325gj9yntIVmxtHwQgVskECA7S/2Hedd1VI9y
V6K60nJlJ/01SYs9/l+ExigXiXMZvBXjcerVfas0I3qPkNZNegj2wM9bnXEF5aav
+dd0wcl/rJjF+qkZYnmsldNrlFe7P0OkwD+KQjyyZwv0zM/mx5JsMlV4NZt10Fm0
iCXoy8TT2s33jlJQvSzaggFRmfGn7XKLZf+5hjbfnvS1fKGOW/xWLs9OMfjzIt8f
khzqLB3bfnUY7oDKl9LWNHKTddRQV9cY1XP1yRcWKghhDpPnjAvaCGR0o/vbGZtj
LAxIuEKc9o7wQQXJ5GiMNW9W/1SykhhhPSpEU0m+MACCJTTki6yuJLdhob7GRGSC
+ezJZSKHh13pYaoLUJylA1r06A8uZWowQRgIgjPpXYNVmC6wSuTBGNCIamoaSEUH
TLsi0drJCwfbrsZDIdGeM5dtRMa+hbkOpfrnLIsEjvDAJGDk3pZw395ejtAmhFCs
x61OGEaIZCSfIsJSGPIN2waQHSegfn7b8K2PGtQrHzkoCLmD166igJqoVYyt0U9H
GWBVQV0N2uuQdhTRoIQbuOo0OgcsiEYEExECAAYFAkQPaxAACgkQjCXuDw3At9a4
+QCeMyuKw4IdP8sHq2s/O15Rb6APjq8An0eDiJq5Dna0e2ABvKOkzGma5JIDiEYE
EBECAAYFAkQVeiUACgkQzWA7Wi7PmEuFjgCgmheKCIvxd4x/VLFnxSgMvQfq42QA
n03NN0V3vHyjLezoI7xOnUcdChc3iEYEEBECAAYFAkNx7SgACgkQXOXFG4fgV74b
pACgjQtAp+yUaV9UH7O3g+9KU3R05jAAnA0aIi99ZSFznt5c5mSXO9OLp5sFiEYE
ERECAAYFAj5XuP4ACgkQTQXhAMbEXJW76wCfQnCP7s8Sz95+SkvjuFO9gJ2e98cA
n2afW0dzYqgxthTK05CCr/VvGtHHiEYEERECAAYFAj6df7wACgkQKill58GUcmFQ
eQCdERkcZxu9PcFLwTCFy/z7BcWICkMAnj156KXYcnzwDuF5FYsC4ObdVlzOiEYE
ExECAAYFAkQLibAACgkQM6EERysAVoGrIACfU7nW+Xk4RJDKgdsUxnSX4VIlsz8A
oJyH8K5JryLHPFyPAs9v5A6rcygRiQIcBBMBAgAGBQJCQtZoAAoJEBxXDIkOS9Cr
uygQAKON4KH2hwCgYsCFz+JOa7uDQQ07qWMnj9iuCElybhrhEl2OJA5hLpJm4fQW
XI6F/RVTWGn8js0hy5noMWGTsRDtrS2phxGCXfQ+cUg8sTK/mykxT+Qak0eKyN+6
4zg1LnaWZp+mMoDyY5ma2y4c+3V7S0Wcb2tIte5UZpcEbxPDPLlejfnh+j3r0DqJ
HFCnnlRJq03XV2viYR/Aeth3I7Q2yBwKmzlgT5nlQWe6wQz5vv9dGch0oPaDsINC
7LlfYfz8SCx+NXZt1mkpNpxR5fDBF7wJ8dYou35DoMolbUl3RJ0j+80fDw9oP/D+
9sVG8oVEmLvgWtq3kChfmUvNn8IiWVco8T4cDQQYEfH2d/NzPL9CGhUdkE29+i5+
2S/cHUEEz392vYBqK7PYBFeX3gL7HAlsFhRbz3riE9E957P+r5Jp0K+fmMPvWQZy
KcWDEQdxWKamTWvyVkEE9pQ59yAOKZVWyI4YqYHBPRUHNc/gTvrKcrOZk0/Utui/
dsNaDOYdfuQ7laHAiL1+Jl4XIbsMabsuh7uAq6HiCTfhdgvfhIWXEPeLo79EAd8R
ze6omdZDFxKoeamKVchb9jrI555GS/aL3F0vNSuFekZclDVLAiZfjZHl5vaHxLmC
pR6D+quiZ1m7QHOFGqZqCM9V7afH4Uz1F+OkXqsuh/7T0vt0iEYEEBECAAYFAkQ0
DUIACgkQbuoRuoYmeKYFowCfSI/BZvvQc/ACV2l9GIogXKeW16AAn2POGmvk/3/1
tPC61FUePfYe3ED5tCFQZXRlciBQZW50Y2hldiA8cm9hbUBGcmVlQlNELm9yZz6I
RgQQEQIABgUCPGJWkwAKCRDg76IPe8BRparTAKDTd6CiC2uYOgcwiQBQBTwk4iF/
vwCgrRdmqmxj5spPUVTrVd90zCmnJ6SIRgQQEQIABgUCPi+5BQAKCRCFgFn/OmYf
nU9pAJ0UwUSVVGxFmcqU2lLmw7QuMqg4xgCcDFKTxUw987m8ssPXR/aJWekJpXKI
RgQQEQIABgUCQjFmywAKCRCGoKrEFqtYxCAsAJ4pj4Rup2BUOD3tv6TGJe/qWaFS
7gCgzXEsDxHTOGCtJO6waob5QrQy+ZqIRgQQEQIABgUCQ0OkdQAKCRAk/V5km/Qr
B6rwAJ98KSIk2hbsOZ/DuZ4alXH5ebQDXgCfeFGApPGS3Z4hdEmp+eNs81A3TQaI
RgQQEQIABgUCQ3PSHAAKCRBkUSCeFYf75swDAJoDoEu1DH5y4tyL7TiWM20gXOuh
dwCfYnINWs9IeB6lfZIUkdSBbL+zJKiIRgQQEQIABgUCQ4RqsgAKCRCPxop+lmt5
ylLkAJ94zNKo7uFH9Pa1p/35ZRc4tgOFgwCguS1QU6OrpTuqu+f3qMPogxPg5a+I
RgQQEQIABgUCQ4uCMAAKCRAhxQkWDkp4dRU5AJ0Ux83cbxVivy2gnMtPGvJycJYL
kACfUlIKkhBOgO4rn51PVtAlcf7SR16IRgQQEQIABgUCQ4wKLgAKCRCrL1pbFSVp
kBVuAJ9LqPm7DTUjZPaaTIWVXVfpUdIEbACgkJa1dnCHetT8bFjy9tEpac/ry4eI
RgQQEQIABgUCQ42f9QAKCRC/S9DmBJ24eQGoAKDHj592qJ64WV6hJIxJt3MExX4E
YwCfVsDtiQSs98Osd35e1SeZ2puF54aIRgQQEQIABgUCQ43bXwAKCRCH2lwNJzWa
UUmXAKCevl8FIthq9yS+DqRxfQ8Rdo9lyQCeLux3hH2YBIshRi+aSo3c3GsGHn2I
RgQSEQIABgUCQhH7RgAKCRAtP3wLeuRUNhC7AKCSNxyqMYbI0r2numoyMctQkB1o
TACgle4jTYqMMqNEWS91rpN5Bj+KpdKIRgQSEQIABgUCQ2UvBwAKCRBfAzCckhX3
9x+6AJ9GrhvGCnB9GYiiJdLVhcCtXuEomwCeMLYIgOD7vfesRzigr8xxnrpMZ5KI
RgQTEQIABgUCPQgsOwAKCRBorCrxzxc3E7FkAKC46sBJLEyxSe+iAQQ9NXWGuEAw
8wCdFs5nV+iGD2Ggt0r2IbshnZuwQ4SIRgQTEQIABgUCQJA2YgAKCRDYw7lS6Rq5
uREfAKCwKjGqVGMg5p448WK3pqmMTejelgCcC4JA75HK5X8F3IbEpyEyPJNjF1SI
RgQTEQIABgUCQ0OR3wAKCRBcbEzAWnmJMOvLAJ9apTal4f4ukT0wxHEho3FJkpOu
9QCeITS7Yc/lcfjTDxXGHP5CyC/teKaIRgQTEQIABgUCQ26i/wAKCRALrfXLW/Xw
c39yAJwMJpYXrBqhCwlYud50/4A+TGUhjgCfdJoOingptjEYMzQtcruK/BG4hLOI
RgQTEQIABgUCQ3IW9wAKCRBc5cUbh+BXvmusAJ46JDI811dxacPqXV2Tv99r0gjU
LgCglPfVY7LTiWB0XlOH44PK/3zfCLeIRgQTEQIABgUCQ4x0twAKCRCNSU00xw69
UEd9AJ4/l6VQ0+ifsUg99UlSp0BQbTenFACfQI1N3Fks9duZDHmd1UTtqSNfUwKI
SgQQEQIACgUCQ42gxQMFAXgACgkQoE/7G33K6dNnRwCg6UWZTD6fhf2jE/k2HXID
cjdrr7AAn3sBh9hP3HbS2rzEa3C/zLl1OBj5iF8EExECABcFAjxaT5oFCwcKAwQD
FQMCAxYCAQIXgAASCRDtGLaNFhlFUwdlR1BHAAEBbEQAn1qdf8upTthni/JRrLG7
czyYz5TiAJ48oK5kIAR5y7jet49yXs+nlNGA84kBHAQQAQIABgUCQrMuSQAKCRB5
ZbLxUnPtp3uCB/sF9F+S2hEvzxJuaCAYx0v+/lGZ0+dw/sweOVn5eEhcLxTqWd/P
0bYNTndc4tJETzdeYT+RqhGSZHoTYnVs80NQeZ82Wy78Uql0QoVqJe2Hc7lzxq0F
OJkQZ5xgcxuIWWMhI7Rv3/xtYFL+ckMfJx4HG6QdmOXV6LeqGC1N75ei2zOPhCNA
5fmNvsr4wIQYfhUDhjEj+ksD2JSY4hY61irPXVZB67lusRWFTA0GfLM8RDxVa60+
JXp9MerlX9UBQrzC4qtgOeEYi5YbXgQZyvlPOlfRYXq7JsxQmxbQ5Oopv3S9vCpt
n7Yrd+eW6TyadW5N1abLiZH/wrXUnXQiR7M9iQIcBBABAgAGBQJDMRuoAAoJEIxR
X8RLjbUlK0MP/0/vI0o2oArCXHOwgtcAdXxriR83IzWTmHV3mmZjJCK1vkDqD/oa
m1WsjAwBeQRt8Fl+nahcVktwms5hxOvvBQN9a4DVnvWgjDpJc8VWdBXLwrkDVUJl
f4Dx5JW9tk6H7/92Qev2dWZHK2bvyBaH5Y4ZnVHRs+PxdAZg4oPPjqh48Vz9c0Bp
jyQCWt+KsOgbUpwK5ai35+Ys8zd2boRaCTRknwkn8/RUKVMqsGt7CknIFFfHscMY
sIGkTN8exhQIbPHTtlv2Cz4NhhbgjC+LJs4tC+FJvOjVHDJ63JJiF3195aG2oljy
/XtfGlaMHIBPDxtxu3cdU7gMyLWHY0HnKTk3+zm65/kkPP1YR3x8uuE2pc+nQocc
HKI3AwrrKiihRytzang9L0VtVZrtXrf9xssXi3KGi/d+jCyVNO5q8MykeCBdG6W4
7ZOf+29bVYFlo8pgDc/pmKVM7bxVkKm0Dpc3lCgSJguu886Mo/Ps7oI53Jdly0PC
K2eJCQAkUzA6cHvhF5HCLCZbaXD4K2gMw5MO1oV6LrW2nvkpwHq3FLkddCI2Efmp
pro+Um5k9u+RFsEzH2l6+php59BGZkFUKIGz/xoaAohUTzJCSAVrb7ug1Ye/7ra9
+dBDeoyOndb76cVwIbrI7fAv9UQEhcg2XJtEcgh3BHLNk/GmCRuzVqr4iQIcBBAB
AgAGBQJDQnlTAAoJEBxXDIkOS9CrsCgP/2dgWTrprCikjvHoy3K4wrdcbrK+q2yx
1Pc5hNLaRgeWDUMWfvdWlqaScVzQ5D8TpxEP9O/042VPKYi1z7MqUWM8RLceUTIj
2IgiNxv5UN3WTMdh5latyDmDsq0NfMqzGyPnpcCrAFZME/oh0srhwXdLpOBxTxDv
PIaMIYGafKwPgoag7MsmmpZIaS2+k6AbBCHzhb/NE7U6aOfNIZBeeKkgd/ZYcQiS
fgqlV1VYEMM1CjmZHdIXA/+qkvgci8q03z6mIub/LNUjc7ZX0iLR3yA4dn11M/A/
H36ENujpsCbLOsp7Nd+EWpUaY1RZKZsV1K+2D2UJzUAFuuTWx8DbS9XSH4oVkrIM
6hzPhVt+kEjpR8946UOkAU6T8JjTy0f/9I6dH4fcyl4eTxekvuMxX60HU1+zInRi
3XMmiTikw05legDws/LMLGNZZazNZGVAIWENegf0UPysNAhzrjzfmdXuDxfdcnTf
0xdaZdSe8NAG8IeEeXi/4jgj33W62Rg+fZr3osbh9pYVCI4UPaygPUqKiiOS2sB4
nMr3lJO2vRZlT824RCYKdEmnm8gOQpbrlyfHGWaZMhNwB7e06QOqId4dMlrHurM+
G2NOh8tlLzfqHI/sf2r0mQgvy9YsmtSiS1FXJNuoNza5uuw8un7T0BVVc3IAE0O/
1XsrJsniKtSJiEYEEBECAAYFAkQHDQsACgkQL5UVCKrmAi5xiQCguH0sdXfqYVAj
fxWAbwPaY6NaXkAAn2biSu70M1dlx+jlgmjag+6gJVIMiEYEExECAAYFAkQBcOEA
CgkQaPNY9sE5ZHy6fACff7eoEww1vP3JTzyBOB3tz7hzudgAn2xZkWpKtX1eRhJV
rkop7yM8+uaNiEYEEBECAAYFAkQB454ACgkQBgac8paUV/AsHgCdEs9sCniLjOPE
PQT9zr95rdN2/lkAn0XbVRrv+0YXRb61vJT3xssp1LyViEYEEBECAAYFAkQC9EgA
CgkQ5UTeB5t8Mo21+ACeN07gUrZfv2hmaXh++ykgcGg4LB0AnjXNAFi20EEq0Oc0
iqYiWs8enJ12iEYEEBECAAYFAkQDYF0ACgkQm6CTa1o1/UKXWgCfRXmr1U83fZIn
4D94emz3SWKpCeAAoIqSDiltTDPLKlaPV3E0ItiOT3mbiEYEEBECAAYFAkQDYZwA
CgkQMUi77x7vJvQUAQCdF+kJeAzYrc22Qv/iGdvubMq63nAAoIChcqTTX74ZkFCt
M02DmCyPhN+NiEYEEBECAAYFAkQEjDcACgkQaOElK32lxTs1KgCgzicozfi+tuwQ
ZBQ79E32pw6TAYAAnAwWB1HURGRJZ8fZnrFkmJGAQXYuiEYEEBECAAYFAkQExO8A
CgkQOU3FkQ7XBOrnNwCgtnfIKzLzBBrR3FFQYC6tBUpLp1AAn2TInihf8cQBszJN
gykLVkDNVLydiEYEEBECAAYFAkQE1PUACgkQgVj7LvUXHt78GgCePj/cMylCraIn
nDcT38N28y3bzdIAn38euVAAhqtpZPC6yvsJmZOGn7QXiEYEExECAAYFAkQEyWgA
CgkQtR4n9RnqGUbhhgCguSMquy9Jkq+8xUnk27cPtBBhGfkAn0UakO2BJYfxouHO
R9Uk37ckChEeiEYEExECAAYFAkQE6IEACgkQbz/xEHos/2xz+ACgpNpG60c6fyLQ
2h8jdMG/vbePbfIAnRNgwNlJcq6QJ3hVOFrE5VZFvoYkiEYEEBECAAYFAkQIXtMA
CgkQHniub6iHVUfCcwCgkl4HWch/zhbmYUGXemnBW+8ED3EAoKMYe5Ki3WeHCSi4
i8b26U492GG+iEYEEBECAAYFAkQIa90ACgkQzoDvxJGnB+T9UACdHPRxdQBNsBMq
D8On4aCIBT/1aNwAn3yYE4NIPdjkJQTzOkX9Cpkmhrn4iEYEEBECAAYFAkQIckoA
CgkQi0rEgawecV4S9gCdHOIpr+YYNrDGPCOwl6lZKV+KTB4An2+U+Gn/X84DwPE9
/z4touVKeAp5iEYEEBECAAYFAkQIemkACgkQtrrqPUHma9mWtgCfc/mEUZSdbFBY
lT/DADFndQyxz9gAmwQuUvWkND5u8AQuxgsKF5KU3hbYiQEcBBABAgAGBQJECZ0v
AAoJEOCEDD1mKW6IsUYH/jx7scV8I3m/Kbvq114Ao3uU3AX1uMn8IJ6onTWM3USY
fgCjyPZ2ipsjiBJE2jqX0vZcOi744d+7eiJc6Xdf44WWmPFq65l3bm4i6fNsScp2
4+0F1MirZHwzOiWhGvTFjSQnbkMTLHqG57VOTggGh+7ogcYZ/LgzRgj7bZmveHSs
EQdzfJVrqitenNFs+lQREvmfaTqXY6USyX4MEiD9XtAEIO4AfBuIl+a2XQMESDpo
aL39GvTRudYn4H+i/vBq+5s2yYpF8WQdR8tqi7jl3wWOSzI1ejHoA9Na4kenikQ4
fYWubrMZaSwwcaQG+iddLmGjuvHNx7KangkECUJSmiSIRgQQEQIABgUCRArhnQAK
CRD9Ibw7rD4IefinAKCiRVaaGLE1E/fpTvv2AivkcGuhwQCgqdxd0VLuGWeYBWD3
rrVa+aAMiz6IRgQQEQIABgUCRAtWGAAKCRC6bFqii/PSABymAJ9AkyQ/bYxPuYdM
Dv90wTuF8xc6OwCeLAv6gZduUKgAKIqUc3MFxnqei8uIRgQQEQIABgUCRA3BtwAK
CRAmDDVIiPiPj852AJ0dULqLRK1nS74w0RW3y+ukxIN4MQCcDayVGyQJ9wRdVAWy
zGmm6o5UOJOIRgQQEQIABgUCRA3CXAAKCRB88/WvKUmfYTqAAKCmi2A/TkhtQVcj
eOLGU077G+ZIjACfSvU1/WbxY9GDhm4iCGx9bquhl8mIRgQQEQIABgUCRBV6JQAK
CRDNYDtaLs+YSwCBAKCdsTtxEF4evQBn9NOKo0NJdkbPgQCfTPieLa5IpwS+N7Al
b2mWkLAIt4uIRgQQEQIABgUCQ3HtKAAKCRBc5cUbh+BXvlvUAJwPweID+RnmWBLE
ANm1YQIA3B84bwCg1eX/I3Kjvoygc284RgRx9amgxqmIRgQQEQIABgUCRAb3bgAK
CRCyOtu7DpH1zEtqAKCxr6TSyhUe5h7R08YGNATpBDwhoACdEJggQgf2TZWc71AE
xLV643w9exSIRgQREQIABgUCPle4/gAKCRBNBeEAxsRclew1AJ4+QWbZlLSR2MfU
J7K/TcvS00WLtQCfTknJi5rxAknT6Bkand7KwRWrHi2IRgQREQIABgUCPp1/vAAK
CRAqKWXnwZRyYfSbAJ9mMcCbzxUILq4Q7ZtztaxRNhyNowCfdw4C8mhmJlYwq0cI
7bI4SHNn2lSIRgQTEQIABgUCRAuJsQAKCRAzoQRHKwBWgYU4AKCZoZrYD9AtCOwT
tgjI9C3vxQbznACbBGEQdin/rAeuvVimy+DqlEjqWBiJAhwEEwECAAYFAkJC1mcA
CgkQHFcMiQ5L0KvmLA//SkLWAwdD+Jf8nv6zl2fk7SI1ugN6dRktE7WVGldnP4U7
FGfNsEeK3gLKITLiVlfqis1c/zcinJMubz5JHl0Tkd47dB+fxraYk2COy68C1vKr
rGvHaBcWcl0bGiCv10CnUJZDMuBLuRMuwja0PxqsefknWvyURONse2xzUNE5UeJ6
AezBSHJ0+15Tq6ZYcxJ/u/HxrTOqrc+Y3KEXKTwWGVB9vS+x+Wb9xRz8EM1idoez
qG/abgRqNWThyJZSM7wP7eMv+Eq2HWb0j2hPMqbMwXb3hv3QIH6I0ncoQ3Br84Pt
Vnjzp1Iy0iR0wC9F7yRBoiRbwOeKbnjIEiOGjoazActKCghl5ZzVQqOKIgZXyBla
xHDzQWFsFhKZovqFKQ4Nq4NZbtOeRFuYxituFSxa1w+fOYtsYxufrHjodtQLHLJC
5m2J9FqPuJw+pBS82DkoUcy5JKIWUdbkU65o/WGLPyQ4hAJint6x50bIcG78Qjuf
BWxlFUR7bsajW2lm1LNM4qWRdrTEReB1ml2C09712JIMH8PXmS3ngu/oIbjN5QH4
nOe8K/A68WVkQEaP2+xXN5xOgQJ1eaXe/1qeiGExYRFf+rGk8Q07dQT59k+2rtPQ
l3KYficMSugb+y22Bsp66/+CcFuoQCxInizqKY0M9XFr3yqwvCwdTogDH/X7HKWI
RgQQEQIABgUCRDQNQgAKCRBu6hG6hiZ4pg8zAJwJ+XUv9oVBll5aLdThv9mKXN6f
nACfXqSUrG5A8GM5A+aiuKFpqApEp1qIRgQQEQIABgUCRCKRVQAKCRBJUOEqsnKR
8nxxAJ46sM9lLfcH/X8UWkLOJZTJ2uIDeQCaA4XCm9WgDbHpRBv5I9U2Ki5fWVG0
IVBldGVyIFBlbnRjaGV2IDxyb2FtQHJpbmdsZXQubmV0PohGBBARAgAGBQI8YlaP
AAoJEODvog97wFGlnkcAoJkOQ7gySM5qFZ7TKau3igJFQE7dAKCSNNMhzTgdzzyi
WYqTgRYvKS2u0ohGBBARAgAGBQI+L7kFAAoJEIWAWf86Zh+dmrMAoJL133WDbnc0
dl0VCNBjEcg1G79dAKDkgmXth3RhDbx8i6PeHR5z/YiL2ohGBBARAgAGBQJCMWbA
AAoJEIagqsQWq1jEu08An24cevpiPgIw/2PYgvo2V+UVGTSrAJ9B0G5ctLg3iKtR
3coqXPTGgHbTb4hGBBARAgAGBQJDQh2BAAoJEB6o5aqXJfY7KfEAn0Ejy72YsEwx
oEUTWSc9dB26zshvAKCP2IvgF41eO0IL+3mCoSFu1s3XeIhGBBARAgAGBQJDQ6Qe
AAoJECT9XmSb9CsHl00AniRnA3zQBygz8EQie52Vw95K5a8fAJ9oZtam42q8KKRV
Qmhp0xrVCFTO1YhGBBARAgAGBQJDRBJJAAoJEEScxw44vyGJdqYAoL/J/sE30VGb
CUv86wItTMuvlZyxAJoC7+m4M/2qHoKt2Aidc0mj426Ov4hGBBARAgAGBQJDc9IZ
AAoJEGRRIJ4Vh/vmRiEAnAuFj4jLYJiL9IgeY7BegSXAwWHhAJ0cmNbcUWx0LDm7
/30caou8ebYRL4hGBBARAgAGBQJDhGqpAAoJEI/Gin6Wa3nKgEAAn167cq5GupDb
Aykec+jBSyZu2yjjAKC6xTlHB6mZoIy3zHijmkB2ikIbZ4hGBBARAgAGBQJDjAoq
AAoJEKsvWlsVJWmQkE8AoI2BttEdFFuNmdxVvMatZORwIaxYAJ0Q5YbshSp4vnHz
DtleOaQa6dVyL4hGBBARAgAGBQJDjZ/vAAoJEL9L0OYEnbh5i1QAoOu2fHvOd3mV
Jujqo4NFu8cb06t3AKCx6qv+FAF76nSdgfIfyYvmeSWBtYhGBBARAgAGBQJDjdtc
AAoJEIfaXA0nNZpRGjoAn3MIFp+zhy6tsLFaRqdb47XBJkhBAKCGyl7Z29M9U0bK
fLdlgCC8KUZwhIhGBBIRAgAGBQJCEftGAAoJEC0/fAt65FQ2FBwAnAuPMhOjXDnW
zqx0KIjf9W6IqvWvAJ9+EpGoZ0ad/+S3OWNYTbl5BaW/K4hGBBIRAgAGBQJDZS8H
AAoJEF8DMJySFff3Sb4AnjCDmCjR4BbSM+D077UizX1yt58/AJsFFxWeq5R35jw4
QE+q84teinPzGIhGBBMRAgAGBQI9CCw4AAoJEGisKvHPFzcTBS8AmgPR/1dTfDcQ
92FOcYocoL47W39LAJ9I4OtRUu0yOGVT+OynI5v03sLsBIhGBBMRAgAGBQJAkDZg
AAoJENjDuVLpGrm56fsAnA3OX7JImSPfPfIrQBlzA8wY8uKLAJ4kw0+5MWr5QqmF
6DfF67zW01pbvIhGBBMRAgAGBQJDQ5HcAAoJEFxsTMBaeYkw2wUAoIKoADw6xXxm
cKg+bPHHdT4aivjxAJsEPtI8Ijh+dtr5+vXm+bPhYcK1d4hGBBMRAgAGBQJDbqL7
AAoJEAut9ctb9fBzG/UAoLNQVe6W+9ZEjgb03LGOkfN7IpOAAJ0bpgdAfVl8qt0w
A5AbqHK1MkPb14hGBBMRAgAGBQJDchb3AAoJEFzlxRuH4Fe+jlEAn3gWM+BmmsoK
ghlek1hDkKihZJWGAJ0VAea0ElDuk2PNYKLFZldKwqsgB4hGBBMRAgAGBQJDjHSz
AAoJEI1JTTTHDr1Q5JoAnRoUPNu0PbTsPaW4L+JtZ08TORRCAJ47NWRFEb9/+Vo6
Fw3BeRmi2JX+pIhKBBARAgAKBQJDjaDAAwUBeAAKCRCgT/sbfcrp05BCAJ9dXNXx
qLUvYHOmKer6oNzty3J+EgCgzkNiB5xidmWrqnHbQWWznhk1uoaIWgQTEQIAGgUL
BwoDBAMVAwIDFgIBAheABQI/TEhYAhkBAAoJEO0Yto0WGUVTzbAAnjhDQZVsxs/d
jZBpZ4daDXGNjOIBAJ9RVtzYJ3BSOQc5hpkqvrpiS8zc8YkBHAQQAQIABgUCQrMu
RwAKCRB5ZbLxUnPtp/tNB/4mr58qb9jocPbvw3grGTlF4TQmV7U0c4YIF7YxFEms
jg7sJCSxzzy9R/bZkHIAjFimnb+1pyrjoetrVpfjaikAZKLNl+8K3YIaiqU1W5cu
NyO9OxnTCkU8wVk3PacCQhf4RicLVDB8mkA8ZXGVbQmBxeCpFSZBNhjlOFQnSLqy
Q0wX3C9OHOuxnyvenV5hNLUUwLXSNq+OuLGM9kHKzQGAG+8kyd2/mmF3VIaOuney
MACipJQpAgF1/mGzavSxWlAtqQTxpyon2TaTYMtWGMIfGNZ1Hc4bowE5sfZnYiJu
Ck6YthwJEFfASTLpB84wtdjdK938SnEZt+0UgphNGAo/iQIcBBABAgAGBQJDMRui
AAoJEIxRX8RLjbUlpgIP/ip0jcz+95wP9SxtmIHJDzzBLUDyE3WB57LnFRsToBEf
BFM3jhAJ9ONHMOyUIJpT2xuBEk8yL02JU6px0iB5KUKG5yGgZJf+ORp05C3m3vGB
KZXxijgeS++1EFVlMgl6vOdL3l2p948tKQKjCYEn3SwdhVf1ieXuOuH29FmcHyGB
ZP9O8ARTiycrNwYjLVmucrGiwV6mrNbCQl9LFhxtAtyvIlpUR1kFLSpWNO3dTT5H
T20cu+0gNB/2ZwAy5u/RHpwvtvKdjE5ePOIp6E/hLidz6VPUhvd20mSVXSoLEEy9
eGxQnSfcDLr5Id1Ua3J0ETC5HTf/wN6oXkAjMCGvHib96ncktfddHo34Bm2/HRLd
ECW9XWGWmsLq2V0UFRCgzzB6LSf2QHjD5SvHflt/fqPDfreEF5d0H/qdnGSZ0o3F
azu90fa1akdwI8T5sMchTN/BpLy+sOkkh4au1Wxjt9EaqHrKwpS3HR3kXV9p4NOF
MbzKYUE78RuZ/Wlc70dwCjiSlOB8XXy/E8J8qsEcMHghNl6l065Pm9asGGs7Sczw
Ny0+ODIgqjCqFt405Dgx69rtMfsJpSBqsBu2RTBfODO2/n7HmtWYwo9608jjP8B4
CWgmUWDnlfG1Lw39LqvuK55/L3/WDsQRhJ+fyxekfY40pjQKZ1LAS5aqeuuuiObt
iQIcBBABAgAGBQJDQnk9AAoJEBxXDIkOS9CrFu0QAIQasJedzjXHXR815XeGdVJd
/p3o47k0M4bYZ59Ej4tEB444hzvhNtMOCdvjxfn6vlLXKePD8GMyTmyeAszgHEcQ
HwZyjb6TtGLUL4V/uQ9Pci2N/sz7H9MTL46Fbxn2n21Tf23/2QFxHNsjaVh6aliS
9Y4xr+I5evmftspTLMbTF+CJ/rzoqaPMOUfFnsNUt4Oi8FFV3NY4Fpxq7y99MdIC
6HrBd33lINVVwG785GgIjXdsaZPP3kL3sUhYDPF0KhQ73pbSDKm2iF2LKFPykKTN
ou/CL71wjzIAKH3JmyUBeQWM7aOfcoQOb1ejzxVuOmhmrUEm+zP5Qw70CTiL7Pz/
j8Uqd1u2pH5oRQH7WTAJSuJy5dwhWo923KvAX60q/Vnpexj4au55KKh7kGwkm5pO
SirdzzcUhfLrI7DFXyCFkoB3mlZ9ujWu9DZ3wgYyvpWCtuJ4fNIrufph+th2SBNR
9jCj150lcPaG/03cSAE8Vf3Tgsid/s0v98MQv2C+E/N9v6j7pWzcOH5+u592p12C
ISs3vJO0QDMNYi2DHDx4DRSZzcgNd7tSV6ysGy/rRQHSEqhaLOKdb+zguRdWsHJb
d6+rCiS4Y/lR0BnWdafqhGFHuFIhk+p9wKm4bmHTMkW0I3ctLnfLZFiBv0w6YiTm
AHZkPweKNAr55PfPvn5TiEYEEBECAAYFAkQHDQcACgkQL5UVCKrmAi4tOQCfeMPY
QP07ynqLxnxVpNjMD+ub+HkAoKep9NSzweEFVmDWMqAMU2VNdGCyiEYEExECAAYF
AkQBcOEACgkQaPNY9sE5ZHxBEQCgx4FvNDLeqYiiv9TBs4qqzTf3tSEAnA2YraYp
rxgDqTLu3w4uQihgMY7niEYEEBECAAYFAkQB440ACgkQBgac8paUV/CuQACglt2d
SLzJZOYwvCP6DieWjA87Qq4An2Ellp1M4bqPGuKzcXPnJZDGmyc6iEYEEBECAAYF
AkQCKwYACgkQdklABUmu6/brbACgtDXKKSH3JJDNpc9Iy2KRHVTmPEYAoO1R79yg
nBN2NVQ/Xq8KknbUztqqiEYEEBECAAYFAkQC9EAACgkQ5UTeB5t8Mo0KsQCfRlFc
kKugCQTnevnRf/z1lNPFnXEAnRaroINjoYXSH59f0rqQz2G2VG0YiEYEEBECAAYF
AkQDXrYACgkQjMOH2gl/VGh3PwCeJO83mYATOFcE6cNp/r9S5Rf7Rt8AoI93/qxX
3jylN9uW1TvZCwUy0V4iiEYEEBECAAYFAkQDYFkACgkQm6CTa1o1/UL9hACgmDYC
AtMhWz4S9neenQhwPLaKPFQAnjyq0JBa/qE9BNp4OpwxEZhrfMoCiEYEEBECAAYF
AkQDYZgACgkQMUi77x7vJvSRFwCcCTXnvq/48q5Qo7kge0Me5A54cS4An1dOdV6W
IcQiMAlW08kmw9D+6RshiEYEEBECAAYFAkQEjDQACgkQaOElK32lxTuBtgCdGSh7
VMSE5S8/nauCDYoJXz1qC2sAn2a8txu4skprIvuOuAk1jSen61qriEYEEBECAAYF
AkQExO8ACgkQOU3FkQ7XBOpjfwCfZXC510EVtp1af+CkxGG96DCzXgEAoOCTmqpg
JCtrNZSgpZokHAS/GRuFiEYEEBECAAYFAkQE1PUACgkQgVj7LvUXHt6ppgCghNTS
m0kLUcyvMFl214VLp0FiUagAoKuT9pRH3WpUOMJrhq/vhvtpaxLZiEYEEBECAAYF
AkQGIA4ACgkQ8yHNgo+hjwstoACeNjzRhjcfXjafn2+kLu2A5xoLdEsAniLrnaBz
qntUzbnz3e4mXuMyX91AiEYEExECAAYFAkQEyWcACgkQtR4n9RnqGUbT/gCgn1PA
hD9+6TgeWfLYZk9MZKkkyT8AoKZIgTu9y+XM6NF+06fDB15gMxWKiEYEExECAAYF
AkQE6IEACgkQbz/xEHos/2yZjgCcCx1EXe51of8shNN73KPbJnpza2sAn2RLIb1D
Ua0b2iLxG5NxS+VvJxYYiEYEEBECAAYFAkQIXssACgkQHniub6iHVUdowgCeJzAZ
eINFL0NndMzW35QzlFvGmD4An0/YGJjpF98S9J8obBFIqaTa+6JkiEYEEBECAAYF
AkQIa9YACgkQzoDvxJGnB+SiaQCfU9apJWLGQyThMy+ookKtXsolL+cAnRmoBBHv
qJIOqbFcAHz9+cVv+vf6iEYEEBECAAYFAkQIckcACgkQi0rEgawecV4iuQCfaBS5
FRbZVMftQ1y86zsd3i+Btj4An2zfZ+uEzYAkdT79gSI5EBkPKmVNiEYEEBECAAYF
AkQIelwACgkQtrrqPUHma9ncewCeOLNRFMoov8JEe02WfrFVxSob+ScAnRdvxVS7
AM/SQgkPr298ddK5CKTCiEYEEBECAAYFAkQK4ZUACgkQ/SG8O6w+CHnaMwCeKZ8Z
HXT6wvwDlMscguzmRh8VoxkAoLKF5NeNemUwVhtqZh0AEB2ocOHziEYEEBECAAYF
AkQLVhgACgkQumxaoovz0gCP8wCcCO0gEysb+DsLwn0+8dAHylY+gu4An0MhV5Ye
jCJbYsA+jtvooDhiLd2TiEYEEBECAAYFAkQNwbcACgkQJgw1SIj4j4/hywCfbC/+
Gw/uRcFc7He1o4sgqexJ5n8Ani7sK2VVUfaIzbjY0SNFz7ftoiUFiEYEEBECAAYF
AkQNwlwACgkQfPP1rylJn2FHIACgogtACFvgYPOgi4Ig+hicwBGhST0AnibZ98+i
EvEXqou/aiELa+zzRt+MiEYEEBECAAYFAkQVeiUACgkQzWA7Wi7PmEu4NQCdERX4
nvVlYZB8vDt/xatvb0Px778AoIPP9MtofA3iWPhxsSiRnEnrisGtiEYEEBECAAYF
AkNx7SMACgkQXOXFG4fgV76ajgCgyTGGBikVDYAMk142Ggldi9NwpV8An2pjMkjM
NOX6C3Hi/nfEQCX+i1SxiEYEEBECAAYFAkQG91AACgkQsjrbuw6R9cxpIQCfa7ZB
fiYV9/Ge2gwrCXmCU7Hd9FQAn1F5kc3cuVZlekWi1LRW4/5BCyC2iEYEERECAAYF
Aj5XuPkACgkQTQXhAMbEXJWWKQCfb0lbUKHXc7mfPSx3O9lXa0tKNdsAoLpOx+h+
DCG84aQHWxnJ94DFOebdiEYEERECAAYFAj6df7QACgkQKill58GUcmFbLQCdEHMI
SJ1gkvWG8Xdvyowx1nohcv0Anio/3kEVxQzSZnrXjqcxMFAjkBp5iEYEExECAAYF
AkQLiakACgkQM6EERysAVoE9uwCeMNkZHOFu+vcXiEQal1/umQVyAhsAnR0tTvJ2
ZGvhv8RaEMCTcycIOb3ViFcEExECABcFAjxaTyQFCwcKAwQDFQMCAxYCAQIXgAAK
CRDtGLaNFhlFUxNwAKC6cpksorKVDpnYKbANRcV/6qkBPwCgxTPm63Wi+G/i8L04
1j58TqLCTa2JAhwEEwECAAYFAkJC1kMACgkQHFcMiQ5L0KuqMxAArq0Kt5PeHucB
UH2jaZNZRHoF5PGQJIHdgQv+qTOBEYstYmf3PBimBQuoAnZomgOtwbyycRjoB7D4
mcrfhxK9tTX7h3r7qhd4cn1NYSx8L1TgZY1qm/oNinRpaJY5tYQRM9dtIlLGgJ27
JBJ5+KN9/Uf+Avha2G54hNHfmoZ9vLpXenR5r8WrrXUPU1KKg+LA3MZ5UwJriYLk
xlcXLkJLpv821APPz6+8tksxXAt5aOeflpDn4vWIuCSN3XRq8n/vmXoQO1d3vogm
OIR2mDVMXKcrgay+JHMr89IvCzq3KWhjMBi22xeoxFqienVnFAEAGZb5dp8vxAhN
g8v3BNCmOcP6+26JokfJxF+/F8GBbAjOtGQjaxl5tVxmE49MqRGPRePYRYQEXaLJ
EsSrLAtx/Om2HkicSp7/UAIrCCOZ8qc4bVlu6rZphfiUGHbufLWcNsRBZKVoNnZq
qHVUQ+1Yi6pI8K7cdYi9LPfWrAbFt7E0TXv4Oc6tSjPM1BzQVs40KqrRB1cduVjW
tKyiWHw2Wn/5zEV5cisUa+lPZH3Sa3A8uTaFpfZJW7j1K2icgB5QDlQXr/h9k1ke
7jtXLcFRqK38VKwN58Sla4M954i6i/oB2tJl82EfHRyvqVnEW3dgl1nEbQwMVLJe
fNminfa7VlrzwRjITY3cto2Jhe/yEoyIRgQQEQIABgUCRDQNPAAKCRBu6hG6hiZ4
pkfTAJ0erD5C/YAs4CkE4Pnh56tA6KI22QCcC2hWuJ1YsNfbs4veyWa2+ysr6jeI
RgQQEQIABgUCRCKRUgAKCRBJUOEqsnKR8gCYAJ9OSSvkC34cjXk8TBwcebw0zBPL
OwCeLDxiIuKcfjBggVNEdNu9t8MT58K0KFBldGVyIFBlbnRjaGV2IDxyb2FtQHRl
Y2hsYWIub2ZmaWNlMS5iZz6IRgQQEQIABgUCPGJWkwAKCRDg76IPe8BRpR1ZAJ40
swNOlEpnU6VHbFie/Ab60vqzHACgv4OBTed4SGR5KVHngYgUHahzTtiIRgQQEQIA
BgUCPi+5BQAKCRCFgFn/OmYfnfvMAJ4ylcUJiJm+xyihpIo+mfSlrrwmsgCfZ+PW
Mq0jNcQWtlhoT4k7h5kUWp+IRgQQEQIABgUCQjFmywAKCRCGoKrEFqtYxII5AKDO
niNN/n0FnPw1A3prhWqC4jXoFQCeM1OohOoBrF1/unQzRDjpo7gor62IRgQQEQIA
BgUCQ0OkdQAKCRAk/V5km/QrB+GJAJ9yw8zIHsl3LbwnHpFOUgkbUjGTcwCeKvYK
AVIltUTmF9e9uScUSl8TrGWIRgQQEQIABgUCQ3PSHAAKCRBkUSCeFYf75km6AJ4w
QH9zg4I5db3mSDysoTnhiCiE/wCgiZjd61TEAdSu+DHTQHTDME2mPpSIRgQQEQIA
BgUCQ4RqsgAKCRCPxop+lmt5yg9QAJ9r+dwCdumFxLAE3IGu1t6Ae/FPNACfR9XS
G1H/VcMxrkMUNPxG82eayOSIRgQQEQIABgUCQ4wKLgAKCRCrL1pbFSVpkKE3AKCl
/9eoxxK1WXEIHgRUKWt4HNA74QCfQwhwlEo0WAM7WPkJZXCbqsRGW8eIRgQQEQIA
BgUCQ42f9QAKCRC/S9DmBJ24eVf1AKDQmMaKV0OiY8PCrXgJ9BNolcwa/QCfWXPj
wjWsrWliR6ocKmfi5wPJYW+IRgQQEQIABgUCQ43bXwAKCRCH2lwNJzWaUTIrAJwM
aVN2hKL3zkludUBk+PQ4yXDbnACgoFh4LNwUPyK5s/62Dp8/tsHQhKSIRgQSEQIA
BgUCQhH7RgAKCRAtP3wLeuRUNnMSAJwOp63WfYWPoQ9vKkydg2lds/TSPACfRILf
UIjB2lVllVaw2checYsNg3iIRgQSEQIABgUCQ2UvBwAKCRBfAzCckhX396TjAJ9o
h734I583nyEK5EwwEvOfqZlHQwCgnMhTgGn4obYvHNzCD/b+AMLD+DyIRgQTEQIA
BgUCPQgsOwAKCRBorCrxzxc3E7h7AKCkrQD2JomIF+DqsVVr9F6w3S64XgCg3hX2
4DO1bNeC0P/s/M8Pq3WgL9CIRgQTEQIABgUCQJA2YgAKCRDYw7lS6Rq5ucDxAJ4o
W1L8SSWPv4FZlq0Kcgg2q6M9swCgtK4fr9vt0c2IJ4X7LmOT6zmgKICIRgQTEQIA
BgUCQ0OR3wAKCRBcbEzAWnmJMPiNAJ42YEeH/umvShmwSwerF3/uJyp79wCdHZB7
zBy2xXljWQqNAOk3tcZARPyIRgQTEQIABgUCQ26i/wAKCRALrfXLW/Xwc15DAKDK
hqb7JbJATFOxikjITMcln58T1ACgwlz/erdPqQOR3S3CUTcvN76qDfuIRgQTEQIA
BgUCQ3IW9wAKCRBc5cUbh+BXvrz2AJ4qI9k3MilLi013n504xq8BgVvTqACghOOF
IL7LfUwNJQxW5goKgn+L8+iIRgQTEQIABgUCQ4x0twAKCRCNSU00xw69UPSWAJ41
md3W5xXWomsJQYcB/pR81RTMwwCgqd5nAymkeOimG6hDGvFxI5KFzSaISgQQEQIA
CgUCQ42gxQMFAXgACgkQoE/7G33K6dOUMACfYSFU2b/DmgOFpE5ORc8znh4T54kA
oM50rfFGF1KXqhXJ0FzZyZyYuANXiF8EExECABcFAjxhYMYFCwcKAwQDFQMCAxYC
AQIXgAASCRDtGLaNFhlFUwdlR1BHAAEBJc0AnRlGc3mhcl/V0tgRtALHDAIxwbRe
AKCqI7yIS0+BAbTv79i4w1Q5JDrunIkBHAQQAQIABgUCQrMuSgAKCRB5ZbLxUnPt
p2+jB/4+BAlpvEbN2Zk7WYA8gXpiNUbTlm9TETkavWcoQprL3MOX2KlgRinPHC2q
ZBymOgBmv6vwJD5387l560K0/tn6lt2Iflw282/pSFray3xmFAPI4QMuchMuyYF1
zseJLp0rV09lhpPuCtl+GCStib99pCz5kuKDAuyX+bAUrXvUmvCiq+hL1Onbz983
jUGXbQv8xarjkcqTrG25pv2cZxnXXQP8fjQ9ADMQ8dYRKbvKeX8IU7mky6U2YhRd
vSWqlnqdOJOJruGfbhFzShp6rYzlXI5o4FNV4xXedu0aA5unLzL6iMJYPJAw1SSx
/aIUIj8MjIOLKoHB8RiJOA6uJ6OSiQIcBBABAgAGBQJDMRupAAoJEIxRX8RLjbUl
bycP/i/IjD7kvQBkbWdnU7EeEd2/6O9sd3QGgcZArnO8aUaO8nK0kZY8ukXYKZNp
O3X+gd3g76B0J78jWB+SKYRJ5Sj+1yVA9aSs75DzH+LtAR/yxSQxGONxXnHPIKrz
9qz+7+fEwgFMumJWYPOngRLL5SEZ4WzStdpXS+UBYTqo6izChu0fD/GTXG1sgeN6
hqLayM0CN2YBz64JoA6AWkoLtNJZWIgG5KODvKAKW4IwuJvKxjW/FAuE2AxssoNm
ZkwnMLJ9Jp9FMe4O25ukFSlKmj2UCj4jfiTxumZhX1LBjo/90B8lzIHPn+azE7lp
kuoMhF2fQEwSpXWhO+YPfclVUjyMbJrzDwHUt1HKSqxnflOX+tMXdODPVJjfQh7t
E66bTY6aKo56MuzS+8FdQp+yiO0YGlg0N6q4WrZIvXEKQJkDKFkF9ly5gHcqyoga
bqDVCSxQ3S4KJUCjM/clZ6nomMCO+sQkeyon4MAFUDiosn8+DBRUJFwC9nzRXQwG
LpA864OXw/nwaUlD00FVcu0L9LunOBhq18rsL0rfJnnIWYvlCjzstNW1Wj4vZBGt
mcmenytDkhE42bpLHQGtLs/Qg3rJ0GvB2f17bKtv2MLq/YOwKJOHFGt5Dut3Ei6y
RgtjdQHrAKpNnp2UnMlZejf02inCSu4OYbXs68KXyosJK775iQIcBBABAgAGBQJD
QnlUAAoJEBxXDIkOS9CrlL8P/1XwCnSlp3khOrFUQRAuidOx8zKTsnoKIX3EOg5o
Y+FuCH9fStaQ2A0sXZIAWDpeWjhKglBnvNCOteeEUaC9sy39zVZxB6bXYDDschqo
J0UaTV9ecqxFtVGD4NkjIkr+CBIeQRH4iDPTjeuUFiXWeiT1ucyIZRUF/78aThCo
ZamxovgrS5vXT7RpOkusF/ZU55Hg0bUT31CTmCgdDrWqekemiK7bwth4U85izG8Y
CksTV6JZ+2keevafWZcV0MDuJZ31yEnf4fqddzVLvx27cuhWtJTTm4jksHGKt1iX
UczxS+7WBnYPbVVCKHc888Me1/dMJW7/3GFnjzokWpL96/LUDBtZH83JgiPBn6hK
T5OngcPXUDL3tPxEqutSC9IukCdirKUL663e+2EZQvccD/0+dX+mjo8GLgPPlJe+
8TmfVzgN+aOhUeyD7vHBU8wcuxBYSAwwH/DV6fHI575ywlVcgQfL0QjiCzmwQxLR
pN1irRbAyw1h0ib4/GzCBdwKGr9tROCkilxTxyWHp3zzqfcvePFHYbZkHtZMEwgq
XndCQthl7qrmtz/jbxycjWqQbpRfdILWT371hgQDsbi4jKqaOFSUpAFtF9ckotcl
QrwX7oHhxwskk+ZdgHjinoLECHxcv8HeYldj0O4ib56jRVyNSQw9S+g3SwXL0Imh
Q0G6iEYEEBECAAYFAkQHDQsACgkQL5UVCKrmAi5m7gCgkd+Z5Xyeq3FsbmRhloJl
AhIik6kAnR5YAiOyr48qKUQZ3T5gvRW/ez3eiEYEExECAAYFAkQBcOEACgkQaPNY
9sE5ZHyToACfQRwMGBwqAbNKyJr5HJ3NiuQHRkgAn1DVKLos7m315zz2h+sDWYj6
3SmziEYEEBECAAYFAkQB454ACgkQBgac8paUV/APwwCeOLeuHb/8H2j5OE5/ry8F
Ia/8haIAniXz1riq+Ad36rmwHbihuZnv9ez+iEYEEBECAAYFAkQC9EgACgkQ5UTe
B5t8Mo1A2ACfXbMSi2Pqde5yRVBYJwx/FBHmV6UAn1nuk23yVGKnYSQG7S0UyJ0P
HSI2iEYEEBECAAYFAkQDYF0ACgkQm6CTa1o1/ULGOQCgrlDAnQd7phXbtqF1m6U1
YleO45kAn1Q34zOh4JZdCdEOhvusFhbb1NfFiEYEEBECAAYFAkQDYZwACgkQMUi7
7x7vJvT2UwCfeakjFNF1JqDV8f3MjFBXh+7Ov0EAn2CuQU/4ZwzL+cpOxON6QAs0
3NwAiEYEEBECAAYFAkQExO8ACgkQOU3FkQ7XBOqsOACdEvU7e/K6F3Kj29s1IlHH
VairGFIAn31oDe1J6FatcU3EnrwGBqebFQpIiEYEEBECAAYFAkQE1PUACgkQgVj7
LvUXHt6slACguhzq4j49tiT2JVkufd7EYNjzzhMAni0H7ZB7uKnUBjyttmBI01Lw
/IpRiEYEEBECAAYFAkQGIBEACgkQ8yHNgo+hjwu8TACfcUcMhjrIBHlXiMSzSfvr
TJ6K5ysAn2yuZ6tFE1IlqG+IvaUWDfAYpWeQiEYEExECAAYFAkQEyWgACgkQtR4n
9RnqGUaodACcCEkdC4sV25bzbTUBx/FYTrSdXg4An2iYasFVTk4Hgx0PoXrax+NH
NxkaiEYEExECAAYFAkQE6IEACgkQbz/xEHos/2wongCdHp2BagvK7KX7AAf4CxiJ
rICQrmYAnjsyV/xJ12xC82N+c8t4PRYnS+SriEYEEBECAAYFAkQIa90ACgkQzoDv
xJGnB+QkWgCff1GCbAKC8WsyIOMivdWu9rMUyBgAn35NDEHzrbnWdnPfFQB6fDKV
VIjIiEYEEBECAAYFAkQIckoACgkQi0rEgawecV4tTQCfYSIrrIgGY6ucfjNCebvy
q4uGbJgAn0cBZN5J0ETYSN7uBa6QSSd7RfXwiEYEEBECAAYFAkQIemkACgkQtrrq
PUHma9nOrQCghUk6NO3JvwIEqOHNYxOO+/rlm2MAn27yYlsV1UPw13eu3pLw+OES
EkBFiEYEEBECAAYFAkQK4Z0ACgkQ/SG8O6w+CHlH/ACfYO4WAfEnFkdcOBIrEU7x
mnWfsqQAoIsSo34ApwlsxD7oWA9m1zDoB3iDiEYEEBECAAYFAkQLVhgACgkQumxa
oovz0gBDjwCeOb1dOE44KwIA31tC0P4II1TfzQcAn0Gfdfejtla2x/fgzT9zr6xe
gamKiEYEEBECAAYFAkQNwbcACgkQJgw1SIj4j4+WiQCeKcWqyXbCiXyKb80GxZ7+
yKuH93cAoI+1DYZCIB5YB4i9uYGXQw2n/eq6iEYEEBECAAYFAkQNwlwACgkQfPP1
rylJn2H5rgCgmBEDkiW93ez4giZn2MvazB/7bXMAn3Ke3wb22JeUGFZ3hwQhvxkP
IimPiEYEEBECAAYFAkQVeiUACgkQzWA7Wi7PmEv9bQCgkCfbRGS9f/UY2NAoKItS
3/+F97EAn1hpSOjSNxOyjordENnXgll7CjjaiEYEEBECAAYFAkNx7SgACgkQXOXF
G4fgV76H4ACfajAHzDNZ3sEp8Ag2ohrQU5YKnKQAn0bG9RJs7wACwsB6nskUmlAL
vuyOiEYEERECAAYFAj5XuP8ACgkQTQXhAMbEXJXXgwCfaXMWeVeZ2OB9LJSJiv/W
ENjWYc8An1o1bMPlVuxev7hmK7XC9KzBAsDFiEYEERECAAYFAj6df7wACgkQKill
58GUcmEX/wCfTmwquWB1g6ULF/Gov8Hcr3GUZH4An3LH0aNjKq4MPXh1nAv8wpPb
Nd5EiEYEExECAAYFAkQLibEACgkQM6EERysAVoG/0QCgnSJTFiBG54b5f5cO2wAV
hCClYPAAn00+o8El9/wgex1cpdBaWg5tb+QniQIcBBMBAgAGBQJCQtZoAAoJEBxX
DIkOS9Cr0SQP/1D0Bq2j+scxI23BRGse0Q8dZf8ro7qyJn3IovXWW3Mcr/pDNciR
kSUBhCvuLF+p9x0gCF3N+dyOQSkKHj0Vdxsg/WCxUk4nGj7gr6bF+O+jC9eovVM9
drnlx75ajKT9lL0VGVrC3hB/4ZyWB7PadOtw0MboCm8/e7mCCEYhTK4Kc6EG2Ims
cOqvVWGTXMyT2zRK6pHPQGHtzvXgvvhZJL3KjLGEVYXwElDsKWd/cxAVCr2ixmZv
QrRLBkoJ5iDSgWLfGLZgTt87gtP0/fIh/8bzfYsUJlbZsNjJxhr0/Bw+TiKatVm8
7miqqeLWtZIkBVZOSZsw36I6NdAaOReIeddw+hLPkUF2bzki4CeDzkGqPcrW6cEA
Zou12sMp/oJFPex2oHh2e7qomnK5FVyRDGHuu8yq8SREls9sZHcKaOoGpABxde1I
LaNUnRdWccfa/b+UeQ0dnWKzKj+ChI42xOH6YpUrAWyGC1pMuq2SD+5zzmfBFIqg
4rlC1vdRVrhrqayWn2KwuBBMZLrBmdo1WlJVx2mVeyji3MuGeteJmyMnZRaOMdPN
KUvQKd/uIpLNXFf3dYZUzTVB8SxFCzrMItLpaRKOc/S97OHFv2sdT9T/X7m2fyQM
qF+UrgHXqIzu51W5cbyQQXEpiLcT0j5Q+wNXbQXRFsBKy92dZvyc8imSiEYEEBEC
AAYFAkQ0DUIACgkQbuoRuoYmeKalWACdG/6ZDCiSt1fk9peZcbLVsun2WbEAniQx
jD6OuumBAiKl36aE9Jzc53uViEYEEBECAAYFAkQikVUACgkQSVDhKrJykfJeBACf
cEhfdoz2ZQiuQTTPR8W9dfYHIfoAnjGEtcG5pSBYtWwb3ftzwbqZ6LwxuQENBDxa
TygQBACrSxqbUTQcb4J6322MJ+uZlZ1eKlap1ImFEXwga+0RV5CINvdJYCymYoh/
g0JCp7sYTiMKM+Fq0SHdlrTxj0V0aBKa5JfYW/MiN4jVfs1NToPEFBwkRwUd1elG
TsLjP9ZdEtKOwOxwRgVUKMWEED404vWLg5EhXcAxkE3Wy1jRxwADBwP/QBmuGEV+
HhsSpxWsQtEmilqxzBifRbaTRCuL62E2RXFc9HqytIBtI16AfCvfecexEO3Y3yz+
YmW1otUz/50ZIyDlWpuWpoTAfywWa+aOqTWbfbE6aryEaZwfA2kcmy30/sfALbNr
D24lRztyq7wxacQvXhldDkyz77aoPLMcXxKITgQYEQIABgUCPFpPKAASCRDtGLaN
FhlFUwdlR1BHAAEBTiEAn0ukT+sYt3DxU7pKhu0bYmvtRoUyAJ9oqBYcuxutzmjY
svk0OHOC6GZbyg==
=2fQZ
-----END PGP PUBLIC KEY BLOCK-----
D.3.160 Denis Peplin <den@FreeBSD.org>
pub 1024D/485DDDF5 2003-09-11 Denis Peplin <den@FreeBSD.org>
Key fingerprint = 495D 158C 8EC9 C2C1 80F5 EA96 6F72 7C1C 485D DDF5
sub 1024g/E70BA158 2003-09-11
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD9gSfARBAC0ZC5VEuEzqk8KQ3tFam5rugDTaigVzYDmT6XBrQuVwYrFY5zj
gz3o87e/KGmvh0FgpulhoJpkOW9l7oPQpp0wvEm45WRq17+7quW9VppgVCzs79FL
Cc77A4g5LAuO27i1yygfMfPrr6J/M5bM2FyuUS35QvKBTlkZiB/Zt1d1QwCgzJML
PdRvozXQdg6/bPc+M3Wh9AsD/0NxL7cwGExg57hnxA3oNB4M7IM1MwbDDaEQvJbW
Ls8c+x2UMzdE4XHMhr940GiwUzEa1lyy0M7FmB+cdFgqhJ1VFjYE6VyGkyYtticL
my6Im5S4Pfvx7pO2qLmYW+OnbnC6FFgFPbsAZVl/1fy4hN7U2zQIMw3kIodFBnyN
RMsvA/9uzITCim3ov/9x4OYX0BfUNNmczIZMvXbmcuDH+NfwkGu9pmRitx/AWHGJ
chOv4vMuMnBHU12TV1dstlWrb+Q5DVrnbVUq90mUbxg2emvlv+xK2oZ9EBKjAv/z
NFqySi52vd+OmgopbVI6bI2+VdKrKeNcDByt/2zRGo9Y9hDULbQeRGVuaXMgUGVw
bGluIDxkZW5ARnJlZUJTRC5vcmc+iFsEExECABsFAj9gSfAGCwkIBwMCAxUCAwMW
AgECHgECF4AACgkQb3J8HEhd3fUzKwCgj1hA+IDNLHGdD+ua2bs3nPcL+vMAnjR8
6CwsvOZIL5cr0EyveMsGNWqnuQENBD9gSfIQBAD+YKY2v46TD994B3h0KtAI8/Zd
aJ+K1yUNIDxjueo7v+c3jKaWPgX1h+Cr/O936IVnG1zg81zEF0Ly6NcwWrj70UDO
deA4tvx8HQoYfjwRA2kYAv73yvt+UG6WS3cGkX28dcLb8/JEV5M64AYKhgqRX12m
VJWIKdqMYzho8n0mCwADBQQA9WcaZB8RVj22I88DA6okYxiU2vqAN+QUvZfX0X1/
7Rh3mB8iAXBuASEw6NbQnGtky8RlkTDgYu1UJt0aSV2U2CXKOyPCJut0Ka+YYtOM
prdHmnNSksNvwThju8F6js51nrf3D/7L9SFhc+W8JTfa8iz9Zfgq1HQkZ3foSO5J
W0CIRgQYEQIABgUCP2BJ8gAKCRBvcnwcSF3d9Ut3AJ9WFh2gFxmqE8O3B85dO4yx
z/OvxQCgsQynjVGZI9JJn1W0KOAYSbihdu4=
=kQUf
-----END PGP PUBLIC KEY BLOCK-----
D.3.161 Colin Percival
<cperciva@FreeBSD.org>
pub 1024D/D09347FC 2003-02-18
Key fingerprint = E0B9 3FEC 01CD E1E4 C79A 739D 32DE 1ECD D093 47FC
uid Colin Percival <colin.percival@wadham.ox.ac.uk>
uid Colin Percival <cperciva@freebsd.org>
sub 2048g/AA35B966 2003-02-18
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD5ST1YRBADxgAihxhkd5+87xPxAD3OvMzKKrAhWX9VPaABzjrQmDJrJ0cyb
Boa6+aHlnaFZYEIv7DVDylNg5aUDRRDJOrKeWnSXs9Kizg9+ek/3V6202Z5mZiBG
YjShN2nhApkTHTN0QfogOEXmY9BHzJzHix75fJZ5wk4q4X28FKVCReoeAwCg/2p/
rgnDBQFkJy/0Lnj6MZQw2KkEAKQ/nNK/KlKNlfA5KAuqS16l1WQKgOP+ispUoaVN
arhTU7NCB+UKBAJHPQVeVAe+UvgeUhjh7psCp9C1Au0hmxnpluF1ljknRUzF2WlX
ql38/1cHT2RxHr9i/fG8hHQCQkRLp1k01n7rVTzXX3j/K0V+CVbGWIJK7h47ceEL
4tk9A/0T7H1vCeuiu50aMDaigCOmd1XQb+dZlEs50mzLlC1mwtTodRBLqo3Ol78R
nZ7DN73AHH7w2197kJ0I10dA6Q5MpScfXKUtnUuItSxv59E9O7SDus6ya77L0lCR
cooYL49EuB/pwL/P+c/p+Ki9TmzauGE3Wji6gDH7kH/aVMFwwbQvQ29saW4gUGVy
Y2l2YWwgPGNvbGluLnBlcmNpdmFsQHdhZGhhbS5veC5hYy51az6IWAQQEQIAGAUC
PlJPVggLCQgHAwIBCgIZAQUbAwAAAAAKCRAy3h7N0JNH/EDpAKDEN7HNTjpDEf0K
hlVxk8c868mrLwCcDDQ7TEi4XqeonghuoWYRE/oooq+IRgQQEQIABgUCQnhSngAK
CRAV1ogEymzfsiShAJ4yFvxZXVWbuzG9lyZLgoUVeQ55FACfeVwS0Clf+93BByQq
U0E8HE4rXsm0JUNvbGluIFBlcmNpdmFsIDxjcGVyY2l2YUBmcmVlYnNkLm9yZz6I
TwQQEQIADwUCQSYZ3AgLCQgHAwIBCgAKCRAy3h7N0JNH/JU9AKCZEbOE4KD5FRmz
xUhoJRJOKS6prwCeNNqyRB+lTg9006K7LAgMLYuUrDuIRgQQEQIABgUCQnhSpQAK
CRAV1ogEymzfsivAAJ97Vk22Grq9IrmnKfQY3DHlReLBrQCeO7KaNWoct9y8t2FG
pAiqEM02Kl25Ag0EPlJPVhAIAPZCV7cIfwgXcqK61qlC8wXo+VMROU+28W65Szgg
2gGnVqMU6Y9AVfPQB8bLQ6mUrfdMZIZJ+AyDvWXpF9Sh01D49Vlf3HZSTz09jdvO
meFXklnN/biudE/F/Ha8g8VHMGHOfMlm/xX5u/2RXscBqtNbno2gpXI61Brwv0YA
WCvl9Ij9WE5J280gtJ3kkQc2azNsOA1FHQ98iLMcfFstjvbzySPAQ/ClWxiNjrtV
jLhdONM0/XwXV0OjHRhs3jMhLLUq/zzhsSlAGBGNfISnCnLWhsQDGcgHKXrKlQzZ
lp+r0ApQmwJG0wg9ZqRdQZ+cfL2JSyIZJrqrol7DVekyCzsAAgIIAPIwHNo3BY8l
8T54p1GbRXqGxw10B7/wuxc6XgdfDfJOMOjn48+O0LNwyWXWLPR5apGaqlubzG+O
okQNP8okLQ5W6vRh09/Y3XfAlHh5nx5bwEFOmrRJPKvyZIY/KjvAA8PAgCIRKVfH
IzUqvXbjESrzMuskkxoVRVyrx52FHx6XqQWGY+DJJV9VFDSxzwfq9K4JHQ3yRm7G
75hrPXUB8VC28mOLCEwwkKNyh9PQj27PEwjErPLJ0gKkkK0cfnvcv6pMBkRAHfL7
RqM4Z4yqqfaofS3B50Nr6dvpPx2Xyus3y03Zr9QZuKfFVYJ6Gb3oZuJnRXT5XIwD
5Fiw/V3xaD6ITAQYEQIADAUCPlJPVgUbDAAAAAAKCRAy3h7N0JNH/BntAKD/JPN0
g8NrWUVUfiKonbtL1vgMEgCdH+G2T8UJC2wyRTdp4+Io42+tsA0=
=7ABx
-----END PGP PUBLIC KEY BLOCK-----
D.3.162 Gerald Pfeifer <gerald@FreeBSD.org>
pub 1024D/745C015A 1999-11-09 Gerald Pfeifer <gerald@pfeifer.com>
Key fingerprint = B215 C163 3BCA 0477 615F 1B35 A5B3 A004 745C 015A
uid Gerald Pfeifer <Gerald.Pfeifer@vibe.at>
uid Gerald Pfeifer <pfeifer@dbai.tuwien.ac.at>
uid Gerald Pfeifer <gerald@pfeifer.at>
uid Gerald Pfeifer <gerald@FreeBSD.org>
sub 1536g/F0156927 1999-11-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDgoUi4RBAD7M4Qt1tcqVgudo8wH0X5XzTQQioy3VXyOqASWq0dMA9b8Rpph
UsomaXQSrg77B2jwFDrXi6/2qTCTBrkApHVJcjsyJ0diuQATVVokkyIVA03TISC9
YVzTrfrnfj/XdDHWJkCT2Wsaso+rCjHQJ7t7yKEWEokWrh79Wit6+3oJEwCg7qFd
GZrHnTJy6fxiwsV4ZP8tMpkEAI2C6lMnTDWtmrf5cPxAht/2mD8lkV/K6k47TjdN
NmwbrPT1jBSldWUFjTjK2Lgim3JmLUS5As+xOlWB1H7zd1Acq55G9qaxvjXujn+E
54iiwI2WylrWAMrpvkkCk968mhddh4Vyrs7HRpwa8K8Lz6mvv5zRWMNZCIuJS/n9
dpX4A/9fPSAxH+JmHgQFKuZeMXShjPL4my4SZkASIBCiZSjaeGnh70nS+HCwAx9P
RL7M5xLCwgwYnCRy7ml+9UZM9tSx4BaI2OPEZuES4aOhSTAg07W/pbKmuTxBJCHi
1bNO4Lb0D+4aemSAX6BjP1rSo1EQnu4QOCNWZ6hsT9IbVx71I7QjR2VyYWxkIFBm
ZWlmZXIgPGdlcmFsZEBwZmVpZmVyLmNvbT6IWAQTEQIAGAMLCgMDFQMCAxYCAQIX
gAUCP2iUxAIZAQAKCRCls6AEdFwBWtFiAKCHxW9pSs6Rh68QVAiVc88YcUoPXACg
ylbP/VDvg9Or8yDqiDS+mst3zmaIRgQQEQIABgUCObOkOwAKCRBb+b9fGxiJFV7T
AKC48O9QhvbXFYiIXvL9TyYpXhQlmgCeKVyl0WMrlY+kJHm2ru23JWFbaA2InAQQ
AQEABgUCOg3EsAAKCRD175d9nvVQ4dEKA/9//meSO1hlT1Ipeg1QYB2EbphIoaFT
8Y5M/EBmMlhB1aBvg5xHQ9zLbbttqong8GLMCjBIKkiUIck6mVbddtDJHWEfAGmu
1Wrx+R0xJwRxNAGrWWaKfJn69iT1fi53uRb4lFMiU/58x27W2MPr5sC4BVTxhyd0
3YrfY4MFgzbj64kAlQMFEDoOxeAzdR0edTxGXQEBosQD/0gL1aMJ+/KmqEpzIZ2E
s8CsqU5SwlyAxzRXX2TCS7d/wZZFMCOrcjH4vRl6rsrfnyW37JhNAXqcsG1PV/uq
HojUKpo5lGLq8qR5P0eyClZEzEGZ8yszeA/o1FH5u5klAh0oNKWo1DhL7EGS3XHc
1MqRDMFQ3Dp0g2OwIp18Nqm8iQCVAwUQOhJilaQZRkdEqAW1AQGSFwP/eYA1/y/t
atGQRsG8emjTArNVucrOW5yH+PUhX/oAgJml7Ck4Cb+MuVKZ4hy7JNrsrtAcussy
t8NKPfjBVjtkzOucCvIa26MMM5LeZIzWHh+NlRE1JdVyV4DKvwy022aDm1CHIvhl
k89R2ZNmYNH6jP5aEr5gIs9BtwhacJwdLhaIRgQQEQIABgUCOhQAfgAKCRDi9ji/
EcZiIchvAJoDrt35vTfCbrva4CTvR/Yz11Pm3gCgo77F3MF9N5wVBcrO54mkPH+p
85uIRgQTEQIABgUCP89MbgAKCRAXit9IPBD6Og7qAJsGEow9qMUek+SzZ/x8pg6V
S6XKwgCfdn2j+e8qJ4R9P0EwMPkfvt6m10SInAQTAQIABgUCP8ey5AAKCRAZVE9k
aJXn4XztA/wNx8+ODQ55LUfbz9bPHsEFop/d0tMW2BL9BD4i88jyIZdaKvSN9cNs
xkLAQOp7N5ui4b4PYGSOFVLOTSXZ8T4ZnZ2bOGW2yniIH/WTtYe8LoTAPMz+6O4f
oHdEeXWXg+PwiLASXDbHeRB5WEkQURvx1+CtNkB5JdFWpxTo77w5LIhGBBMRAgAG
BQJAdWqKAAoJEDiaVjzCcqEmUYQAnRSjFhTCufkZ2rA3N/oWwPHX+j+KAKCTzIfI
OP5xAfL0U7LZFrP4bWjpSIhGBBMRAgAGBQJAdWohAAoJEEgc1JLnL9XFdyUAoIU0
YZw1iX+UcYuarbRI9QHDmZNhAJ4m/hZX0TzguE55uZ3AtVQrgEOIRYhGBBARAgAG
BQJAyFxYAAoJEMVYWQiVq/UMg6sAn3/Cr9dBomQY2QGlXYcEiQDk0DiJAJ0Q1LRj
PrzZGuT7SqzaSdymFFUEOIhGBBIRAgAGBQJAw1FlAAoJEKZJAleFDuzMfegAoIr7
yvqjFMHZoiOm5VLxW/tmMvFdAJ4sv3F3tBFeEhTy1DzSTKBr7fmI0IhGBBIRAgAG
BQJAwHDqAAoJEJJF5/16WIxiJe8Anjck3ZxGnjiFkGDrluldATI+NeO6AKDDVGw1
OmHFBVS1SykDnU7IR/blOYhGBBIRAgAGBQJAwzuEAAoJEH63kt8ZH82KmEgAn1vV
wSm66N1N+oF21+ZEOi9Zsr23AJ4gzXZDy3IHlUtdabhuCx3/co8KdYhGBBMRAgAG
BQJAwd7LAAoJEGzbQ2xyBIUlkOIAnjuJ+dbpiaghrCP3YSZMZlHxfFCWAJ9hYxGL
oDTrtWqjnaUzAQsgD17JxYhGBBMRAgAGBQJAwNuoAAoJEFOfjK8M4nEdMeEAoOXk
JQ/HJsAxDjym6+9zfNLQXbGkAJ9y5g4g23f0z5993+WscA0cuKivW4kBHAQSAQIA
BgUCQMMIhwAKCRBMJa+4YC6DGY7GB/9JF8e5KziC6zaMgo4Q8cP7dr+W7H6ozptM
LNrmcXwRWQVWzrrQIMtgdt03MZ7P6HvWEcUmSP0EJa92CjLEbFR/Z7D/cT/jYUiy
pvqddrtaBmGpyDC6F6Nu1NYWdS9U28P+8I+yH/30BNxXvyNuv2p3ZGcIgWl7pXvF
BUW0QLSIFrWHWj1k1T9oviUtlSq6xkEZ+g9nkQy245TDpUpiG1jBY633H8Kl2Mhl
EOmnei80N3DeNvASIkXwO4pVzmuDM2BQP6c/Ji7XJnFExm9coI4OdWn0yr27ONHd
yvn795NRfN11UjG9Pl3EtBLb/wd/1AuvAPLsyUG9BzsQVkMVsqEdiEYEExECAAYF
AkDF2V0ACgkQPiH2BEeFMRNjZACfZfVVBIRqp2X1AvRlPq5scCXJ6vcAn0i88k4R
HIDq9KQF07S2b2pLkEZviEYEEBECAAYFAkC/tg4ACgkQNW1gNO2uDNobKwCgp3MW
8IiXAR7d7Z7u05kZZtJOHDEAnRCoVyxNTXCyAQaGyz56GdsFmILciEYEEhECAAYF
AkDEXHEACgkQLiz2e3eWpguvSwCfSRsl96/Lwf94pVNnIXemfB1K6rcAoMwuunmz
PYeDHRHfg9q+Iy9jnDjziEYEEhECAAYFAkDFPG0ACgkQIhjIHo58A/+urQCfVCa0
HL8n7qS8yad1PKM8UPgNve4An2iRgUH75LUBOneK/A/n1YF9A74jiJwEEwECAAYF
AkC/6tAACgkQHlgy2P0zM5nNuQP/bC+K331bmxEKPBf4wIj7JY5gvU4BFejK7DRb
B5uUSslDNxC5fMF+Sn8ao4t3XpOVAgj8p1gjpz/iHZlODZ0BPy2gHFi3G6MJYlWB
nCOnIBNxE0OUdSbPl9nNJm7vfHaW85WvfBU6BkdsB/iKcVWZVz02vF+//t8kYs3n
WaMz0L+IRgQTEQIABgUCQNC4zgAKCRAcub/coZFOEVMNAJ90L9u7bsfqrzM01cnJ
gLjk3oxNrwCdGvdCIH5JkBnn//VdG/xxg9ZqOXSIRgQSEQIABgUCQXqU+AAKCRBu
A49e4KODd5rWAJ0bC8c8YsSzgjLdIIB+DHOUX35eKQCdGDezowPVtT9I+UI1z+Sa
RW3q4hOISQQTEQIACQUCQTKQwwIHAAAKCRAKBOKp97E84UGLAJ9kWAMM9ym4x0iN
ijl4/ztlJB4+GQCfc13Kgv7ls28SSD63ZYXUiZzvQK+IVQQTEQIAFQUCOChTpAML
CgMDFQMCAxYCAQIXgAAKCRCls6AEdFwBWiIIAJ4/fLSxytQ5j7k66kDrVM/TsA/Z
iwCfTKi7NSUwCZfvvvzFsPFKxBWukqCIRgQTEQIABgUCQoC0YQAKCRDqe/OXAXVi
Po+JAJ9KQS7gXT1EbO7bdGJZLP/OzXBqOQCeLegHWqTNdBCtrD8yafqAz27/beWJ
ASIEEAECAAwFAkI99AcFAwASdQAACgkQlxC4m8pXrXxOwAf/e5bGb0mLR7HQJp4W
q+/bC3ISbugTRcILDHK/iZI53W2wdquEZ/TXM549YJxzwI5HljK31jfKf1B1+svg
VwVD+UqMe9g9lNi8DWHn8tVNRoMShDUMyJFknh26EtpCqICdo5cBY7U+xu//gzuA
pBoWhLeadpQYvOvctFpG9C2gHVWzwjgFmIdvB/V/Wy2d2UdTH16Q2D+/F/701RS4
m5SXTQb3Od95QfAoppHPsEwe81/IQvPQHtHf1DNGL7QA+oLNdKC/J0T7Ik0TdpDa
VjnKNBmIFgoAVLaez3/KwzezFjA7KLzBEV8Dh2+h1WkdmRcpp1MsvuvMj0VLD8eX
QTgZH4kBIgQQAQIADAUCQk/C9QUDABJ1AAAKCRCXELibyletfM3VCACrlXvXMhFc
SRQT4dtOkqmxCl783NTqxZE8aCAccXfEbFp+Hf4XPRjW7b2kWj8gdtgs2C+YU/yb
xkVn/eBp8b6pIh8DTBato+19DRs8MUTB9dP1mP/7OtvS7pz/n3WvrUmlq9KJCLzh
zo2mnKq/5yll3nrWy4evz+dDBSByE95NWq9FdZVbpenQEx5PKdKsPAAj02fO66nL
XLf0uG6q7373Wb0RWK2djrk422xjkg10QJLIMJ8H6hRdYmmY7nznf/kfDxTdaG/a
eQopc2X7BvRvpuqZSWGrQ0G4razNS2AA/bBlDb0vYniR8fSlIvkFWTd6sWuJhxdL
8IGPJOujt+YbiQEiBBABAgAMBQJCYi2ABQMAEnUAAAoJEJcQuJvKV618gM8H/Aqo
knW5ps1BI73kntrDw9g4leD03CvklS0pDxtWTDRZwbuS6gHNacIkjFX/SY4GiUvd
Mqvs986uDxzfekkgcIEwJ+eCkcm2xYB5Tws0ZA4BDKt69v2dtPRaS95rwOfDJ0bs
B14q/FY7sD1PWVxpC9UOMR0jfykh2nVpkxwq5wwUu+fdLbItadIxO0pcqF0ZhONc
K8k9q3WdyKzTY1IClgc+jppaMtYuGSlfxicPKzU4qcGkLHNNZdTEAi+IWIUxq6Ul
4EjnNAp4GfsoFCUxYC+SkfcQoAtHw24Dd2QmnwGft4NgWDSdXZFHkjdKnl74MkJa
kYaEfEAyOPDzYjcXQMSJASIEEAECAAwFAkJi1fEFAwASdQAACgkQlxC4m8pXrXzn
ggf9HkfgTVyhrzeipwQc4bwodwCVJbk2A1LijcbeADdTLRxrjBXmobyLunqQULSf
GNCKt/ZaIZONYU6v1NqEZTRUDGl3mHYKEHSQ8euZIE8CuJq2ySKrp8aLRj6o14+y
tipHMPNu0nnY5WZPy3pm30PHcGB4/JycxoZaq30B52yTdEsDCNN1R1DXFa1asOU0
+9fjxKuzUOT0M3w4r3nKX8vE+6eYv0Z6DKdr546GEblkeNnCev0RygqXywzARq8p
YT3oSU62GTnUInSNlBIgpjIqAZgnvyltovkbqRl9lVRKd5Ou2q+CAa/x6FOhAPq2
uGAIiyChCilG41+4ePNQ988GUYkBIgQQAQIADAUCQnVEWAUDABJ1AAAKCRCXELib
yletfNpKCAC/L9Ty+4s4XsgbFHRwJCzAP4nGsAwmCO1qZSMABNtANIZEdQ2CXG/B
jSmo1vRKjZYeUNQl6d38hDuJwhQXua5xMDgccSQRpIixzbqyAajcLedZIUWuTQJi
hDcKVtrw8w373573Nm66s0DIIp2OWzAGLXWooijR+Urm6tALrvazRLdinkO5qvBH
zZE5+W8gqNnB8KhnogDDQamkyLD4nPC4+AqIlLNIj8h/lx+dxs5VWoIeiSxrjhoT
gTEF791ZCDnMBQr1o4oTRrx2CVB2ffTZWIbLtgIRddRcIYbJZ1JvytHGLT6XpNQ6
uTzuGz+Y1e62hiSahUPOBgTXbeORlwaoiEYEExECAAYFAkKDvRoACgkQI5RDGv+B
Nc7P9wCff06hcnYlMBCwduxC6r5udeyOrK0AoIPGAZ1THA8MOVPsjTnwGlwT81iz
iEYEExECAAYFAkK7de0ACgkQcXN9pvjE0U/fyQCgmdoaXVaOiDIx+UxbvKi33wCd
y0sAoLrXbwX3vH7/qcYzf/hwo1aANAPPiQEiBBABAgAMBQJChxtiBQMAEnUAAAoJ
EJcQuJvKV618X34H/igN6ewRtdrQ3h20JufA/AJlrwvBCAgkJz/ppmhC2EodskNn
mOU5i9Q22zXTH5dfQjO72HcLlHYFPxRhoCAQlehorS+9oYkwUIcarxpnWh1++Sbn
pMcWi/SVZyOJoxhffWuaiKYx+OqO5U5M22NIb1Ek+IPPCQdBCNTLKjBdi+1UG+J/
EQG0w6Il8TTjIxqznEIAJ6y9vfjw6GnQqCvU5oZz/eKihi3Dg85J46wWTOLPSGUj
MgP8Bd4/o+jw3D9nKQWPUHdvBJMnmi9+q3kr1d2QuykfeBR7ipHxv5sPQIdr7DrZ
Gvs6ld8S+XcYeiPeINpmjvYSLltMX+g96+E0dleJASIEEAECAAwFAkKJw34FAwAS
dQAACgkQlxC4m8pXrXzq/Qf/Q8dHWxAPST1F6S5rurk1Ik+S/6zjR/Dq/zFBrPX2
IyuIpGxlEcBABYoOyOXNHTMVT6NKUGb+cM/VuEYXmDDRjcxzTLKll6vLsS4O/QBZ
A95J5uzM4NGpkTm9HcKQ5W/rcWJgryxwK4fvgkpxXidVC/YYi2HsV1vWxDPo1K7J
yEvv1qAAlxzufrO4Ejn6NWIbZCYyhZn/U7+Wjz+9oOCwZjze8CLbdT6Ns+BrfXm8
PCqhq9+46xDO2UQ1B6CEoZoyhA57UQdimyRpYjpSDghxkOIDmQwd1SkKEJ+Nq3Hu
Kl8d/cYfkhWpUuqHi9nPO4atiivOMo0Au4+RXeNhDdWIZ4kBIgQQAQIADAUCQpzg
ugUDABJ1AAAKCRCXELibyletfPnICADIbt6yc1QyeXWMq+ozMu2L7c+59tjjbD3q
/i0XhBj/YiIctungC2T1EOedPkaW5SEmQNMFyRTrIHqLXTmVOu090HaA8d/fmFnj
9itNLjfATgXGalPyKiHuTeUBT29NwKaXPEhbAvTtcqFyY5wcjYYGZD6vps7Y4+SV
fJVARxhVlxdAmoGePmysZDLesgtZQrYybJMqKlQLPDp81jEmmy4YUYc3ccdwffSi
SwUgAInvhxnjbSWKMCoklmZMHH+D+SqMu17HKfnBKqj1u9P+U0a3O//Xu3p7yHni
YUHBXxWrY4IuAnPgvqfJKdCDO0QzofBdTftahVOQjrTCI7rGDRiXiQEiBBABAgAM
BQJCt0S9BQMAEnUAAAoJEJcQuJvKV618L5sH/08dkNneXprVp/UqNhtlOOjP8Om9
y+hIIWN1apnyDpZ7R3soLjXuIBH5CseamGVFXgxeuAAUrwKD9xK6AVipLDKm5LCU
kHwURqTMuq3aQUQsy0m9gn7XzQBuJHn2leI20NTyBabk+OwDDO1a9vJJHL1mOmsq
Ylv5d1izubrPnmnl8/whqYHVy3QcgmCu3fMbjn/kAf0AvdYXuBbJgY9QPw2FwwuI
6oFzVxP8OvBKLp86BN0QrkB8DAX2FrXu3yO3OQuYfLIKlhtGs1XgwJdPm6bVv/o/
Mok5X4zqOVXA9qY9D3WBonzxWRU8doTnlKiPRjagWPdWNBuAhG7LGbtdNGWJASIE
EAECAAwFAkLRBtcFAwASdQAACgkQlxC4m8pXrXwkowf+Kl5ikZIqOnGblvKWZQRE
+F5LtC5TILcWrJ2BjxvKFYASnkMzA1YjZDi24nIqbN7x3jekPHkwNGPU/G20xqfY
poWCR9F5QaQ8VbO2Zya720DwbvmmYm0WbFR2LzKbTHy0B44vrLb1kg+sX/yLcDsG
ysU4Hzn+iY09vsZjD5aCwkg1LgoHm+p33/seT12qBIJVqn9MHEho1OYTJUdGwlEW
G0a70usCN8BU8DZs9s0JRJ5ZMM68D/VeHHZ8csn9AeFcS3+hQBgJJzYW4MTWjnCc
U5Ldhwwm82qbcJpYu7yXqpInSh+B4zy/8g9xogzZ5glXzQkdoE31qCyRzfHadfnC
j4kBIgQQAQIADAUCQtGsBAUDABJ1AAAKCRCXELibyletfP/8B/9/izlWdsbiHJvI
UFYQfcQlr086R19srS20ri+2+d78x1565CC+cdwRH4KYxyATQNlxpxF25zT4Snwr
XdAC1dyehzOnrMkZQsM/mMluEL7a+aVrPiXjDhqhTDEBmSHItpm7pR+l1i5hocfA
tNyo9vygh1a3OkcCzsvIbRGToG7fMg8pxcnsnKpwHvVSMTKyq60EKMChrkrEc0Re
wnFanMV3IAfSBVWq01hqtFyg6oiVL3ZMt5HQLYyza++lNzZCMI1weq9v1txFxqRP
3KpKXL0JEaxEPvNCrau8n3srIzVC1UWbG+2ZVLfu414OpMiqJyf6bRYBLUp/5Lo0
f0vcc9SniQEiBBABAgAMBQJC43X8BQMAEnUAAAoJEJcQuJvKV618M9EH+gLFwBz+
GUq9BxSUjveXOP0fAeynBykfKsS6fOuQy6dCsioJujiwulkGOcrq8Jdj59rYkEGl
WsixyG9ACVx8YadFDaCKbNfoT/FH+gqlhV46+veySzLaRcjb7UdSYcUiEgCwXaCn
iDZfpl9jbz86vLkfPUXmWfscsQKP7YGQybtdK41X40jGbOSeR8whBNEv8mk3hODo
hj89mYT0DsHL+P5von71KuUXEtjgOpkLLsZEhSXid+FZsOswC7DNsRpeJnigAuvP
ECz+FeNgUr4te+vn+j0kINpAU/zno/Hpk3F6rLx3nf21ANcAEe5i6B2MDdCD37R0
uZ70kFr5ebPYpzyJASIEEAECAAwFAkLstAcFAwASdQAACgkQlxC4m8pXrXyhkggA
pIuydE4OKh4elrmFHE8Vz+yGIuCt4Y8WjMqSxgbdWHow/oVvUuvssBJHlauDEWuP
C6GP/2NuN0hsyvu1mNJzbkgjADe9cVm24/gYaZXcQlxDha3Rw1BfZLfveAAACtJu
A6HXi0HU8bA+8kFu398gKkY5MX0YkDY8NzQoBMx0Q0b2suDrM0hp7UqNzkUP+uSM
mEOgKban2UQny0Y4PwgEnQS3nZgI3RkJK240F5fB8eLj7GwXKnq2mAthgfNhWw8x
5fmYwUu4No5kHwpPbmkeuF8cLOi21ywDKoEpt8cmXeLR8ve0JFWwOxnKBnJpfhZ6
MXSXV0DJZZItdLt9TroDGYkBIgQQAQIADAUCQu1aLQUDABJ1AAAKCRCXELibylet
fNBbB/wNX2ReMcBn9eywE/RW8H8lJo/LTdMjdRhHqAArTonVccskqS89WI8ZOpJE
wabLApF22AJxnf7S7L4yqiT2RoL9RtqRaytM9ko///3asEuBwcegbmX+D88886WL
dfgrHIgzwYSppkPSYsoAWQq3MnUhtX/vRBp38XmzQZLdFBHJxmwIGXw2ihUmGFew
vHpE9OlppyCsPDYuwKGabe8804/vZtJKi8I82BDydn+qPJFK7ZDVJ0Vcpn0poQ9V
8SBRI4Au8AN6xM5jaO+gE8day9Y6CH+/aXnTaFxozCgXlCQLO4XmYYghoxsXsxE9
huV3xPhNq2q0lmuQVH3CmAcW1lW+iQEiBBABAgAMBQJDBc9CBQMAEnUAAAoJEJcQ
uJvKV618NLMH/2otDctsw4+IKqP+ziH5pl/VkUSDEPG00I7+vNe4uHAGbOFGr2MF
DzsDe0ZhGldDaLOUBqFut5aejqhBYrcvXeejrmKxj3KRxUA0wkuLhKk3xKLD+AWG
hlV/Mqv8DfKdsSiPLyV/jCABwtr7YxZPpQM8CeaX77xwfjwRnl1bNfL6Ek9nNVm+
n9mzkWdzgVhhMIY7HEZYDqe4b75tnXFvMMEU31w4gKLvJXvvW2aUfBTHmaJejFY/
ODAuTbHALS8Hj098uFdM4FM3V82M0WRCMB9r06wjqcV0WTTLactO0tOETxZjdSlO
su2VazK8v0b/bKkUpjzoFzMfwBBplxbfDemJASIEEAECAAwFAkMIchMFAwASdQAA
CgkQlxC4m8pXrXyzOQgAtQbNRsf3W7/TEf20x5HPjtJaXIj5tOCvxSYKyOPWiAJs
n4jZEPx5DpGLsyVRJwCMpWwcgFzb3cMLq8DUbW/kVeFovVdVt8qXB56pchWkIlWE
cus4NRSGs0q9T05Ye3VKykmgEmXIhGyUhcRg7P973NCN4QiRc9LPbX7/+OghlaGp
GKKlnvxmvBJPKYaIAPNPFHagDor3ZI+qoHcB/uRvFXWNpiBtTq4n+CUWdWk6eSAz
V4iKMsvhjPePp57nAQQm3A/zopIEyb6v1eEhyjdvSSjgpo8kNG6qz/mBFYHciw3x
VXlXd7OXAAPEobHgAqoO1wATSTYWaktnBjEM/Q9+TbQnR2VyYWxkIFBmZWlmZXIg
PEdlcmFsZC5QZmVpZmVyQHZpYmUuYXQ+iFUEExECABUFAjgoXSsDCwoDAxUDAgMW
AgECF4AACgkQpbOgBHRcAVrUAQCgsFUA3scdTjNKQ/QnmJPBQ9zU/BIAoKup7wek
DSFc3r5fe2MAmtms213ciEYEEBECAAYFAjhUMpcACgkQpy/2bEK9ZF0w9wCdFQx9
my8HXvokUIgea9tuZRuNopYAoI3ev0gDt+sWZb6H0img8B4g+auLiEYEEBECAAYF
AjhT3rcACgkQDF8aVkjSn7EbIwCfaD1FAv0uB7iLZN6BGdobEyF4gA8AoPhsPt8s
BgPYPYbJKYWT5b8P+mfbiEYEEBECAAYFAjmzo/UACgkQW/m/XxsYiRVa0wCghcrE
dfVZoiDjAjC/KDUV0bSUBYcAn0f/KN7H2c7RpxeSdnJuAcVU92f2iJwEEAEBAAYF
AjoNxLIACgkQ9e+XfZ71UOEmAgP8Czky/oHEIPjooam7GhA+Jt89Ds4aBHDIyMFD
haq9UfEx2tUdexE1vLvTx4CWEoB5kDKvDgyvufQebZ7qsHyN0hG7xVeAhcfsDDWd
k7at87y1dM2yp+c2Jhb+yFY1hVLwV+v8IiEHEjL+e+oc5zxHm9J+ryLGSwNiCXwh
PTNKBYyJAJUDBRA6DsXgM3UdHnU8Rl0BAbNeA/9jHfCtSpcFep75oZLlt4EOghyh
o3lYAxja8GKMAUh1Jk/JTsTQoOCEIV+H873455u9Ukk+xcOThnSRBkTw3dWLERX8
l5wNrW80cop042zxHyAz7Oy5TlT6l1xvN4XV0twvxUnXfAeHc6t0LSwa6HIydF3U
waBkD3cR0cZ4vxhhq4kAlQMFEDoSYpWkGUZHRKgFtQEBaZsD/i9ShtXM2IJMPKp5
xjVUsDpsbVHnvwyTaNCTtwGOWzCUI7tMPFIOGl1bKYs2AoFumhIDbJKIZrM5l1h5
wXw72Y++PYoqfporMjHGPsFgCoCn9TFpBW+YS/Ksxpe1t90CrrWc4FkBuIfRtUVl
HtK9uyNy1puC807d5L2FB62sHspsiEYEEBECAAYFAjoUAK8ACgkQ4vY4vxHGYiGn
jgCfbmF2uwRMj91WXk13iP49SzMwDkgAoJyblGzFHeUVMraz3khPWqmnHY+CiEYE
ExECAAYFAj/PTHUACgkQF4rfSDwQ+jqhUACeJTyqDM6h+roU7Dw+cxXI9ZrQtCUA
njoEQlRHHR61PqnitP0F6ZyEuuC8iJsEEwECAAYFAj/HsvIACgkQGVRPZGiV5+Hb
EAP2KUS4WucsKOBnZTZEoB9AlvmJ/4tFKvgPBaZ5ocWYvBb+4PW1fwF4DZVOsehM
DpMwustJnUF9UfsBPfR5nJOmhHoiSYHHcValOebAaHFUYLGA+R6hgigHZQcjYXcE
YLUSNTuYSwFA+fyPiGwYrdGHFs4IkeNJ+Z0DtAoV2IsyuohGBBMRAgAGBQJAdWqM
AAoJEDiaVjzCcqEm60cAn20aJ68+99kaXuSySZtuc7OeyIRxAJ9uqNOimGLIKh6S
Mk6rdjVJ77ivlohGBBMRAgAGBQJAdWopAAoJEEgc1JLnL9XF/2AAn08rDGWWX+y6
/n2HhUbiSritomh2AJ0U3I6Mgat+fl8BR8/GlbmHAb5MnYhGBBARAgAGBQJAyFxd
AAoJEMVYWQiVq/UMkXAAoJ00yY5dofbFwz1DHMXfhlp5fjZcAKChiGIuFkPKH5ce
iIZcFn5fHcvItYhGBBIRAgAGBQJAw1FlAAoJEKZJAleFDuzMHHEAnR6EPRGi/zAf
iU5cv5pLMH3mZLlVAJ9+Qw+fzs2t7B0c8pk8vvm87ynS/IhFBBIRAgAGBQJAwHDv
AAoJEJJF5/16WIxi9JcAl0KXSLQcbA8mAuEFGBPWp3d7f4AAoKImHiT/gZMgx0kq
OWvueIz9P/JBiEYEEhECAAYFAkDDO4YACgkQfreS3xkfzYphTwCfY3l2T1tPiFEB
olBPesWTy5qxrpsAn1YkbGJ9HtKu/W8Eo90XUWpWlVCWiEYEExECAAYFAkDB3ssA
CgkQbNtDbHIEhSW3KQCfRU5PAL+xXrMeheshn5FH5mrhlU4AnjJZef7kheZQ+BQb
IulBJv9U2R1ziEYEEhECAAYFAkDA2/MACgkQU5+MrwzicR0zYwCfVJ8kSGRR9Zjy
VVAdHqApVA3coikAn06gQflVn68PMpsnvJua5H+f4lWPiQEcBBIBAgAGBQJAwwiK
AAoJEEwlr7hgLoMZ8R8IAIXY/wecJSWQ09Kvd7T9Ynzd/u4EqFjErIdNxPm1DAuU
O/h4dfMeIzLimVek7oAKRPNV0CEFxciOYJTr9VXZbUtxNzEXVIXsVVoQ3I55xM6p
meG6ddGeCIspglt+NilvecCFQeeY5xBW+iVvCuP5QfZ/MHOdXjPqKraY32yWA0M/
SppyhL/RiVdgolsH1+n1JGYQyQlT5n64SFAKeAPNaKqtG22+6zLsBFWC5+MD4AKC
KLImKlWsMlwj7GwVewvwlNft1T24lOV3NAjt1PVcVs64OfCm2KPRVmeIGtUQyRzU
4J2K/q1O1jBxuOMDva1vH93eAE3EY6icQLcylw9EM7+IRgQTEQIABgUCQMXZYAAK
CRA+IfYER4UxEwLEAJ0fr3ngS8uo52J4lwu0rNqiAQ3T4ACdEDaXjNNKfOhBYax5
apnpRQTrd8yIRgQQEQIABgUCQL+2GgAKCRA1bWA07a4M2hCYAJ9RSFzV0Lfbjby7
xrtLLTo0qOtkxgCfYcT1b5yRi/PvLgMHzc3ZtLwL46OIRgQSEQIABgUCQMRcdQAK
CRAuLPZ7d5amC2PRAJ4+F1/zwk2dhFhwJY6jQk50YXDP5ACcDyzajZKIQwYct755
IzYcw55JG1eIRgQSEQIABgUCQMU8bQAKCRAiGMgejnwD/+CDAJ0ad7IdOWukYwoF
fGG7AWExvnTZcACfamN5zhTyRO/1GFs8PlzedfWWbOCInAQTAQIABgUCQL/q1AAK
CRAeWDLY/TMzmdAQA/9fCyUTrkVkXpqo+Z7Fa9ABK2UFnOQ1byoN8KQNR+4VQ/jk
kbGpsWnP2yQXXD/DfZRH5VwI4/JPY/VfVusrFD8OjdG1xM0s/H8AbT4Kn8UHbH0o
jEEmP72zeDoucwdd5XDw7nfNz+i1LMCj+QtLJcNRMXM8XuGiqgadxUYjlC/RyIhG
BBMRAgAGBQJA0LjSAAoJEBy5v9yhkU4R57QAn2C/Xa5HOoOPNaHNXGr6bsLQZmBZ
AJwMjx3QLKdGIdz6KBiK1TDKgXrTD4hGBBIRAgAGBQJBepT9AAoJEG4Dj17go4N3
JDwAoKvUOYKlx5NYqRVBt2z6T5mHX298AJ41+quE5BtI7/yI9aK6y43m4jXHtohJ
BBMRAgAJBQJBMpDKAgcAAAoJEAoE4qn3sTzh0pEAn3Iny5GHj/VYldpyZPF7Ax9e
eNMmAJ4vtxs4gddzSekNEMW7Hh1bvMtaa4hGBBMRAgAGBQJCgLRxAAoJEOp785cB
dWI+p7EAn1/1VkbZU6ct360YuCj0AqtEniOAAJ9XPInr2gXmN6bV8FlbdVdO2KGF
XYkBIgQQAQIADAUCQj30BwUDABJ1AAAKCRCXELibyletfIdkB/4n7QdDzPgFFwfv
Aiiaxd/vZPA2ezfT0IEas3KXkxgwAjiVzXhvCHrjoChDumHVTNOF2wwkklVI/+DX
XsbrYRzxSsukyS8E4rIG+4fJzx9HDsMuqjdqJ5Nbgl5AXNzpcVxuJLvT84BAPnoe
t4pg7JQbkDlpQSJns3Bh9gmKGNwS3zWaEderw98iLFHBcY5pK1DfjDIdUyEhK5kO
PmcppwEdhM6g+j/Y5fVznttRRuL0oNhE16m1aoHTR2oqUusKaJo5x9O5K57btFQ/
UKyrcwHMg+7TH1G3q5c0H3p91oEanjL+AWRBkAp3/PL8661xgG+KSmhS+4LIWM/o
KXKnqGnwiQEiBBABAgAMBQJCT8L1BQMAEnUAAAoJEJcQuJvKV618ixwIAL0Hoh6u
G+Dn9uTT7biu8k8cItJtQ4viaptKXdMhB4TvzzU9ikBE1W88h/duSb9O8RjHcgo9
j1/tIgSsYuk+PheGvkZCnqKFZaw+Hx5lGoS3yM+DxFfrVk/jp8UY5yrGGIosWsVl
zh2atXdPEMfaXafUjuWFb6A5+CLZIAOt1rqmrNY1ic37gxR1lsxkfyTLnAquVea1
hwKn4IkY5iEjzbK+nXyqZMoaeLrN6rMDEBHt7oEqkIukVm9VG9o/wVeEMx0+lerK
4pgGw5klD9yk10qLmHJq6kvvO5CqeK6QJI3CsfLX5rwvVB1u3TkTdG2me9oqJx6n
4ylHc4RNpn3Qb8WJASIEEAECAAwFAkJiLYAFAwASdQAACgkQlxC4m8pXrXxatQf+
PjhKsTqbIjqZXQOWGtdoLJRuOKrJJv8SplIicYgBJseEdKcBMB0DF2BXEZZAyR6a
cXBgl4uc7Dl1K2jFAZdHZKfQUJk08RGKMTlN2eYN5MqW0AsjZ/9hHu+2LLhAf8R6
vcLeifjyp9/S8GCgW/JLAvBYpZYmUOvIqbRHzsDEmlF5i4kOVzVQxxkfw98beAu/
2p3w673XyUqH+vWWPONBRo7cKdRw9nGtI4Y96toJEzWT4PU2ZMotedB6vXmpsZIV
aa8T9WZtVRIbgZGCOaVQXiswffhewnHt3hHh5exdhc2OuALQz9/14wnkDeb82fE8
AePBI//GEkOf19WEMA/WWYkBIgQQAQIADAUCQmLV8QUDABJ1AAAKCRCXELibylet
fOatB/9qvOyfGlK7hOZS096MrwA448MMWXQ2e7OwrLnuXsxKsAWvMvyHRKW1roBo
grkh5LEXq72kuB7v55qg47QBKYzWKSp4/N78doRQHSoq6GzRV3f2m4TKpG1bvCnP
m5N8Sh/oGmOMQjecGctV7F8gFwaZWxRTf5UZ78/maTBP4hFfJRyios7HiuZsE4ch
8Cuemx88x+vD5X9J2b6DZyQ1901+MiKQYtFgsmy0GrUdTuWf7LFLkkNqxDmtKrB5
WjfklIl8A6w+yB9ck8eiK+yBVcxCcw/RYb/1a7yNaO9FTJSMpLHK/iKqeMTYVEvg
8r0ZTvHalPNWhMgqW8IrZW6gyP9riQEiBBABAgAMBQJCdURYBQMAEnUAAAoJEJcQ
uJvKV618UJUH/iT2TnNDxsil5P14kvotmFKBB2NGOKlQL8cpM4Wimoh3iaSw1nif
jJEn8RglJTMhWQT1f+nhV6B8H/jEOeS3QmTriLhANPHf9aiF+5BA/CjOLBTwwWrA
e0WQHk0shYmxUMcWnmwSUSyt/SG6g9vwLY4if9GVVTB5ruJk+GEK7VrluHjNWuNj
SRSkfRykhHzxCuSPk2D9/S7v7ik7uxnNezxYL4B3V+Xr4VWefer6UiuWihb1gbee
DxkX127cYwbMBx1clKshIGte0UDpej9MHoLxJQ5ezc3Nzixrk3Tr6KZmVLPzp5fl
dkUJv1NaUhkbYbkv6bi1tGrXpuUq6DXYdbaIRgQTEQIABgUCQoO9HgAKCRAjlEMa
/4E1zhqeAJ4vnrpeU4L7AngL0nCERuno5BVz1QCdGSIpiArIXeQEh+cYekfJse6f
O/mIRgQTEQIABgUCQrt1+AAKCRBxc32m+MTRTxyiAJwPIRxjjDxJwArKrwcuG25r
Yid1QwCeNZA5SNCK+hN3/wz8k8E7DETKDpyJASIEEAECAAwFAkKHG2IFAwASdQAA
CgkQlxC4m8pXrXywEwgAtFta8pts3sGkmd+gRyZVGrHzKsdInkf1cs6ABj74aslT
/qPK61f5tM+2Sa53qXw8VhKBXIUQwGyHPVdc5BVnx1gfqVfTaWBCWyRiCjHfwRy6
vpQ3QSO4nBLg3ugM4FtFMQL9VdG846dljMGXIUqC93x7SvF+eMffCbj/ANrHt7a6
oSuwzqL+PmKEuni3E/o8oayIuwd+JJeMXwxQFQjeAPD1Gxr2+bLZnlfpIH1kDdbN
l5p4QOQX1UW/qxC6xsBBNQiM+3WQAYicohwR5C2GaH9CNul7xi3bfpKL2FR46Hfz
2Pq5VQM6SIj5nvA9/Uqj72K6j+9WGkD2ENA3C0p+W4kBIgQQAQIADAUCQonDfgUD
ABJ1AAAKCRCXELibyletfC43B/sEK0XcFOjl5FG+VtPHrN2Y3fF0PFO/ia0VXH4g
DGsybYP+zZ8YoOssH+Z9RUpvLj+BQqp9U82lIPcdUm9mwyywIuadYnsbZ99UFuC/
Rt95s9XY4tO4SXLLxL0tkVNv7Y19s0bhR0K6xZMGm5+xIj/jyJlCx/U0+oNtpiVm
48XYbMJXDJc7mn0YHRzPlVShWDENbe2Zwvf5yFb+1GF2M5No/aZoD9Xr6MaeDjmn
G4bllLBBtRgze/XFEj9MXPkmW8s2oLFkWVuTZvEZHje1aMLBzu28l46+2ph21k5y
DSH1SOZWzBPvmklBn8WuzORzYw56dFrVrVWhxjRQ2rd6zOcJiQEiBBABAgAMBQJC
nOC6BQMAEnUAAAoJEJcQuJvKV618S1AH/1LI+6jIlc85vPP1KubP7DRfhOZxqH7B
BK5pAJ9gVwelRQKkUejemsUenAp+wN1Ckf4liQwWuxy+pvJRaeJq9Sc/aK0W6lPD
euYgt9pcB/bdJvHpn3VJL8fGgePxPs+Cnkwn0TfWPj0neJyXnWKfImaFrCBd/QG6
CiDt0OeQCQqtxh3oIIkFFs+0f3KqMegOAlPIZORHVmCgiYSSPs11ivgP4ubCnIWr
zm1gFRdimmaGGzlnFmhIUQvqrjdIvOf4rCpn7C+71HFfb9K+gLIRMW+hOM0pIqgJ
hSmt+qLEuJhAvdfcWvuEeT74dxuqtM4X8Hs7zaJliVyQ4i6Ug5u69o2JASIEEAEC
AAwFAkK3RL0FAwASdQAACgkQlxC4m8pXrXy5Fgf8DAX/2+g+KgSrz1fZWZPCcdy2
4xoODQeOf4RA0yoqTOfH3TV9nrygFpM0nX/1Z6XMb0pPdTRSTnWhr8fn+sEe/zhZ
p/x805SnSu/BEsJIBxCi1vBtjmKMcqkVI0AyAo7CmJRMAZ+jqCIgKbb0vRkq9Mzo
UyVqsTCZt5drPtfJmRIXNhBvg4ORLD68Btzvobq1jXIykd/0H/LJK993WQizbdf4
c643G5LJaXjR/JzsuHBLeQ3sxFdNUZSdLJHsXUNXw1/v8fT3VDA2giFhD+/MZ+9k
EsQU60uKU9L64LChDu+22iFbGDTdpewkB+D4CJAJ/Q4jnkhF13f5ToXGMnWpVYkB
IgQQAQIADAUCQtEG1wUDABJ1AAAKCRCXELibyletfHMUB/98zISZRXEuoI0IcHaa
jQq+5qk+/ZF6yZ4lTNnFWcBO4BXTUUTSBpduCPd8plzRYeaPbTLhr65+plF94kNp
ygTsdZk+41rnMrsHLkDrBrJM1TJg9rx1l7duLNPkz2tL6Yy2jcZeo8Lw/Yi9AjTY
TEFZGVxdJSDiJDo3EqhBZlUCXeFxUDVU26071hhZ1W3U6TaJ3v1xOI62aFIOi7Pp
hW+aNhUJ10Oxd1GpvVNHkYCQRA6pgu5lNqjkr9D0jHQonBAjgP7QtAz773ODFijG
d65Q5Y67K72EE9IsT2H1B/jfTSj8j9aTHdO+YshlCAFsDHsRWCyebk2kobs5rU9R
yGk1iQEiBBABAgAMBQJC0awEBQMAEnUAAAoJEJcQuJvKV618DsMH/iZd0xNSs/Dl
GGQhobLAAjrAhg7VIXO4xpg3vtTeEm8bnywlx59YcCtG93wMKR7HHXVCnokY/rR6
eyPFkYrZgl0n4eOfa7L5N0CuSKacKsiA7/o0k2wzOPruH2TCZhlxK4ZZfpGGN2J6
Qjqe430MRXrwiiQNQBMQ9hh7Wn6Zzeql6jtxvz3Whd1Ch8GZnsBuwzwXOWgKjy6W
PD9DSd57BSh4YOMoQPAsmwiXrb7AHpGbkQxoSGktpZCPoQ0QwxCQMH8Pn7IgsGMd
RFYPj1k9adtQiviFyRY9Vd9OZb73NilvX1Ew5f9TAVyrcu3H+KndzPlZPV3ywUTD
xpzD+1Jtfh+JASIEEAECAAwFAkLjdfwFAwASdQAACgkQlxC4m8pXrXyW0Af/XZPy
kda8q3fJEB3IXle6o7VIlBrmwxmCJCXZ0BFyQ6LntEAJ1tWSEn8qte+31AXyw+F+
dU2DdTa1vU+/svbUhtc0cmFxgPvWq5iS8RaBlKt/3cK3QcRtZBO2AmdzN2HJRqR6
KtYpM7LVBaw1HTPfriM3P2EpRcI+wgbvu8PTfrrGVHqUNGNxF1AHgIs0t5S8gK5s
+Lr5pP5nmLeAK+qidLzqydBfdXXWMUmjt8TWN8RUwgKuwmqCtaUxwPXDsvwA+k3l
4eSA4dn1hvB2IRNb6oq/1YRKDgCXGFPmJXN+PVk0VTukpB9vOvZ9II0tF0Wy9pE4
vNJJywshC3pJlWvUwokBIgQQAQIADAUCQuy0BwUDABJ1AAAKCRCXELibyletfLp7
B/4xv4ljJKg0vRKhLsPgSqBej96IwZzW9QM+kwR4XD18I+IE+IvikHKLvd5S7e46
ThIyVvQ78RyfH4Z0/rJHCT714BOcQu0a6ScKmGINPPOznKMAlUJbZceHt9ua4U4C
2ScKwViqGEu4fM5qQ5KE3Rb6lGM6Z6riPcGY2LyYJoqAtbE6skS6qvj925AjUUgS
2CxVjtZ3Z/e6XyWItOqd5sHYbuN/SacxBDiJoQt30Ljt3bmQSo2Nt7ONRE9Bwtn6
grLLcsP+bFa2KqIHTnxxUQUWv87taKfE4xsBC+f3GLPdlTc3OjuJmrFOhUmgMIg/
MFP8pCSA+43rC8y9JVrUyTnjiQEiBBABAgAMBQJC7VotBQMAEnUAAAoJEJcQuJvK
V618HzgH/jRE22fwNlcte+iXbmbY5+GKrU+i8CrtQUroAovVenAarO0bvSLUf3v7
/zTLmhO3nxNeWSFWeesrOl26vzh9H0ur2kJqWMIAvf9F5heV93me4UumJniDs5Cp
OV14xrckqqu1+wVMjBv/N8/Amn9Ibgg9uxHr99Gq/RbP1h3eR7Ggs/SQdmw/V/Ox
d6+B7qW7NrjwPJ2Fd4556JFHVOSYyUFQ4oWjlx7F9dJuGLsTBzkgIsD7+IDHhb30
5x0zm00HKzSbh6mOZ0z3Rs83wiSWY//NIWl/xeC93cdCEvpAFEUdknW0VpveMijK
UaV5U9a8kB+f02apR0xWu0KJiaYwHjCJASIEEAECAAwFAkMFz0IFAwASdQAACgkQ
lxC4m8pXrXx6twf/WsoyFnhC5GhgkTeb9wdnUXiL8TQjta3vWqlJtHo3lG1t5FjX
5hiTwRvRdzIVv1HVAWL9sN3UttLk+0AG18WKYlds3jpQt5oqMWerU14Q3QLfm0oF
aBdfJ2DCnFxx4uZ8FZmB2qSwAlyA77S+bz16stwO0EQGF4jEV8AxKm9rea3m1+5a
oN9XF5eXJeTsToNutIEF0o03yQZ1WXsuIBkDk4v9er2bwieCV3mxYzOts9w4heSX
pMjqlKw1jdcbTZNlU2TUzFmveNdRd2qwCp5guWoPn6qgEMF4jxLOqZtdM0o2Fv1P
8x0EJnOeJkq0+cQ6Z+74Wd6kxCAIkGLf1maojokBIgQQAQIADAUCQwhyEwUDABJ1
AAAKCRCXELibyletfCIYB/0WuwtRvj3wnKn4R99cp5/qkwTgGbftTRVSLv+Yg4Nf
MUg/DKETfBIuwnbYP/WV1bTIvy5J8BPmI5+radjMrussE9eWHTx0ooE+wk5m6sba
zpWcrlI9gtlnPDRN3w4qUXdlZv4uhqLCdzRv8t2FleN/Da86pJoqFy9A7Wi0IgnJ
OnDJHWSGjZLSIKDDhqREx3kD8NmZxUS419GXwzjVcyNJr2R5wNwlIF0GZ35xVZvh
SAz3RSNUqxdkxbfcAsHHGcmkLBWQ+YbhkfTKo8oWD0E8YsTs64Kej/Xy837i9Z0p
Mr3if2QuT+HrbIM2/ZxxcbQmrPTzUZbAPy94sCPVmpQ6tCpHZXJhbGQgUGZlaWZl
ciA8cGZlaWZlckBkYmFpLnR1d2llbi5hYy5hdD6IVQQTEQIAFQUCOChSLgMLCgMD
FQMCAxYCAQIXgAAKCRCls6AEdFwBWsc4AJ9g0Pdvci2rahpB3RnchpraoAHNswCg
4o+2L8GWF6pCbHMmIvLLtCMcKGmIRgQQEQIABgUCOFK+LAAKCRAMXxpWSNKfsSdT
AJ0Z6SWrVX1lW7E3MI86ur7vSkZ1kwCfQKXUp8eH7+/CHE7PsoZwni+yGf6IRgQQ
EQIABgUCOFQylQAKCRCnL/ZsQr1kXZSGAKCDAnRoxmn022rqoourcTNtLT+27gCf
UBcpWgSNlCDeoI8XZx2x7xyKD/iJAJUDBRA4cLbRLYGOhrpqUw0BAUNxA/9el9bb
nsDn+yoczvxvisCmblxt9isXmoZ++EaT/XF8bOGZ9zP7sw4Jgl+nitZ1S6av744m
bs08jjkZiYMBYyGyBn4OdmoB+etwOe9R4uvw/LcKshmea3TIETUl1+KiHmc7+koo
ZYSsz9zPy4gnvWfvo17h+6mPywtv2bRcfZ6C1IhGBBARAgAGBQI4g5biAAoJEN9y
nLrmWD77ryUAoMumDG4a0qITLLOJEjfpDhf2ly42AJ95lSe2w8HuI8TkVPx+f16U
pHkWSohGBBARAgAGBQI5s6NMAAoJEFv5v18bGIkV8SkAoPD9yQb582rYVEZizxFB
goNbuve2AJ0Ua8xmtr1keg8nb2bnYzi3NQWgZIicBBABAQAGBQI6DcS0AAoJEPXv
l32e9VDhlZMD/A8Tv3mjCopoO60ItVfvc3CJISyTtW3DeqSw1JrtuSLpm9n9+dt7
rPrEIu/czIgAfnSuXJr+sjBc74LsGSjAOerqrHiWi/6qsC/sJLiNM7Zx6oiJzHbr
6ZRVky0sIvFqZBIHu2NMb7AsvUzBLtz7KJpSTJh5fa/oM7DAIgb/ae90iQCVAwUQ
Og7F2zN1HR51PEZdAQHAFQP/Y44E56pK9b7FkHZVOOHdDAsQuQ4B0vA7e8CuHGLs
EPSFNff3Zxg7i5R09wUVoNvLdb9wnV3xo59KtyKEhqrIgAifymtcrv01/qaf6EwX
z7NcYrqzLEEyPD68b30wjHvcySPSzq72Nc4DSWUzaF1elb9mKs32xniSoeSLa3OG
TsWIRgQQEQIABgUCOg7vvgAKCRDyDbWHvBhas2AsAKCcm3eOtDv1/g74jC1Wvf85
bkpGpwCfYZh8Nylavejg9T/RjEHrx8JAIyaJAJUDBRA6EmKQpBlGR0SoBbUBASa+
A/4pu6k2U/ROIDTxbjfbM4rkwhUBasC5GIsaBx/RTlNmQTXUmUIqR2UK6HCrln2d
0GCJ4X+HWBOKrV4EKkFZiCR0mpMdW6et21glW7iJhiQFUi14Z62AxwqkgyxucWhE
Mf0hD/yIpkssLTsmmHpe0iMqLtSKTTcXFlxh9VB3iAMAHohGBBARAgAGBQI6E//0
AAoJEOL2OL8RxmIhW80AoL5vq3sU4HWoDyiWpnrFV5FTlSO3AJ0fa75iv8wNFeO0
8mm3CjhzLxWlLYhGBBMRAgAGBQI/z0x1AAoJEBeK30g8EPo6LaUAnjYae7nVu1UP
Ef5vINSGyPRLjUcbAJ0bGF53bsfUN3vma+T9rYuWlyo5W4icBBMBAgAGBQI/x7Ly
AAoJEBlUT2RolefhPCgEALe/UfphQ9LUa4t0FbKXOeF+y0sunnmjgD15WvFTa9KD
5Oju+Qurnm0ZhYfhNwTdz9ZlSszBNr7W5Q+YfQOknId5FD5In8VjDADCyhNp5yiF
uIfx8dbg2DqKVMsxZNRJucZTv2uQcXav9dMMBuS4PQU4UggiJlB0BRYCR5eNlvFk
iEYEExECAAYFAkB1aowACgkQOJpWPMJyoSafmQCgimzmBhpq6Xwmnz7IYyDoFJ0Z
EwUAn1Ch5jPvj20D/8Ubep37CgeugWjciEYEExECAAYFAkB1aikACgkQSBzUkucv
1cWW+wCgnIixnqVcEyE2YV1DftjaBiSYYEAAoLgq1CtHe7TgaeiErQDe8uLAsMHX
iEYEEBECAAYFAkDIXF0ACgkQxVhZCJWr9QxnfgCgqhAeP8lY+Xo/LRCuKE+t8Gwv
odAAoJBQwAtXcbkBgT/OXSsP8Ji7AQtViEYEEhECAAYFAkDDUWUACgkQpkkCV4UO
7MyEpQCgnn9VNRVpRG9CBewWj9ihCdoxjcUAniMAZNOB9V/dQb1dRVHaQmkHMFrK
iEYEEhECAAYFAkDAcO8ACgkQkkXn/XpYjGIm+gCg3oL3zlntGnZmlpLopCxBRQAI
WNAAoPWbaX6g2GNNivzYzEuRy61Hgwo1iEYEEhECAAYFAkDDO4YACgkQfreS3xkf
zYrlhwCgge9sNBu7fwon4fybWiuvDGugAy4An2sXvzFHmZG76M4y7b1hE3niBKWF
iEYEExECAAYFAkDB3ssACgkQbNtDbHIEhSWqtgCg1Gm5xyCkiuJbMbXeHXpP1E9T
bP8AoK4AiBzoORI5Z+fU0et2JisHDev0iEYEEhECAAYFAkDA2/gACgkQU5+Mrwzi
cR1P2QCgh6g4TYHrhewPIfQvDaaJmZWd9Z4AoI2ASXgNDchT+vwmpJmaI2DgZv/e
iQEcBBIBAgAGBQJAwwiKAAoJEEwlr7hgLoMZaP8H/RHEQsue99AYsCyfUdlb6bl3
r30zB6W9ocRCzN3qBW3r1Z4OEjwGjO3KW9LZPVL+xyP6WCTzrVXwud+e9/htS/8M
z6i/k3ylKZkVU/bUkVFOC749IXIi54mJC952SBMdZdHQbnLtNIwOZQ4ulva+O020
4TS8OgAbIpZgbKUdLnDEtwCguXbz84xI0ITmyc3Y1OtZc5FRP28EuqS68EAor6k8
+UVXa1g3vuxUemHYGP4o9dtmj9XDymLs9QA/NAhNx17x2zsYFXXfE0551XLaVxq4
8FRqvZRFOdcVHQNhC/QqLOkgpnA/E/thNAz/ZUykbsCeqrHm92TQr05cFTzEpneI
RgQTEQIABgUCQMXZYAAKCRA+IfYER4UxE4pPAJ45StglrziRw4x5IcJdp0ParUKO
3wCfb0GAdEXscbptTlvtKyfyPFGj4l2IRgQQEQIABgUCQL+2GgAKCRA1bWA07a4M
2gCzAKCZYdEzm9RF7DOhPmsE1eNnGxDEPgCeOvb4rebvjKJ1ht2w5bYmqFpUasWI
RgQSEQIABgUCQMRcdQAKCRAuLPZ7d5amC784AKDhuLsVNPw5VS3EXiImBYZ9j8Xx
UwCfeje6fMBBS47tII4JYPqkMI3fD7eInAQTAQIABgUCQL/q1AAKCRAeWDLY/TMz
mVBNBACH/gwRXu1Ivl0KIWAF65/OnQocCVwQYamHxO2dQroslDl/t8JaC/QPt9pN
4sSB1rCqZWHbVZmGZ9TdoEJyPGS0qzAd8VNew/SxHPV/YX7+qsUd0TkEHHgmprde
Ne6geRgx8kQoBQkuH6K22wDwhnQPFKfvbNruhDqQr0e7We5ACIhGBBMRAgAGBQJA
0LjSAAoJEBy5v9yhkU4Rnn0AoIYKkfevWc7J+wmbV9oLtr196BZiAJ9gpjWK4e+b
99Ln98erqQSpjQaMdYhGBBARAgAGBQI/yjXNAAoJECDU5cPQ/fnV+QkAoMcommMI
z2BPD+pHIoblxrUePIQgAJ4mQwE24nFoJRC4VXgmHZt6OfQEx4hGBBIRAgAGBQJB
epT9AAoJEG4Dj17go4N3//AAmQH29o5BxyFpfE8VAW04Y3CVrU2iAJwJ7TlzjYvd
GOmFJ53zIH4+0QxgtIhJBBMRAgAJBQJBMpDKAgcAAAoJEAoE4qn3sTzhkigAoImd
sKqT6gBZxQNfwa4a8OpJLkIZAJ9G+wsWGyQ0nOxRB6ijho8akhCz84hGBBMRAgAG
BQJCgLRxAAoJEOp785cBdWI+wSsAn2kowHwVCzlCm3THliCFB09j5StaAJ99EFLy
lGmscCBiEVN8L0QmnO/VZIhGBBMRAgAGBQJCg70eAAoJECOUQxr/gTXOHlYAnjzu
gYRFvI4JgcnG9Q7zPqtjlg2QAJ4u3e7KMhbfbth6MIa6f9UbQzN4W4hGBBMRAgAG
BQJCu3X5AAoJEHFzfab4xNFPTBUAoONYxYxzi/hcBKgm9RSgXdz/axqgAKCya1AP
YWEFOnqAUIl1gAPmEABOPrQiR2VyYWxkIFBmZWlmZXIgPGdlcmFsZEBwZmVpZmVy
LmF0PohVBBMRAgAVBQI4KFOFAwsKAwMVAwIDFgIBAheAAAoJEKWzoAR0XAFahZoA
nRwpDNnCbhQPISWQqKfUtyUIMg4NAJ9dkRyxI9NuXdjQSSHlEslOFgxJLIhGBBAR
AgAGBQI4VDKXAAoJEKcv9mxCvWRdU84AnRm0ZuxMTxeDS5ICvX9qMGE4XuMbAJ9G
8APS9xAObPgUW8T2hucWg1wXP4hGBBARAgAGBQI4U96lAAoJEAxfGlZI0p+xxO0A
n3AJrSIPyyYyG2GVmTNAJike9/ruAJ9kZOmz1fUClenONmsR+3TIeMnGeohGBBAR
AgAGBQI5s6OqAAoJEFv5v18bGIkVGmEAoObJZ2Q/3JRAmbOpXnM2y40klMz6AJ4l
ZYG0eKEwyldhg4lrdO4Rvb2IwoicBBABAQAGBQI6DcSzAAoJEPXvl32e9VDhGXoE
AKx2rQIHzZhtdRV7nJVQwb4bGzg0wwTWghfrgSTzCppOKbOa2cJL5VClVmlXRS5B
2zcdP82KU6jKANtgXrU9OVm2NH4XYX7l/ToA9agwYwadKhwcL38GV6XQc0EZVtoi
EGCafFk9npqKR3bSbLD8EhenuTQ0Z6iLRZaYQlMpU++niQCVAwUQOg7F4DN1HR51
PEZdAQHOLQP/c1pQTtDFkWR3AuneCu++U3muQudiBBLI2PfN5hmF0CvPaRdf2LPd
hQs57acUzVybU5AmukpeJSbZSII/CyopSgynEDvESB+JJ7Mtf240hCjGA9CHp0s6
uDc8eo8fS3qs5KBYPAfJEOg6rsl/ODh8dhNQArwH8M4YxZGj5nzJEv+JAJUDBRA6
EmKVpBlGR0SoBbUBAWffA/0ZRyHfjlOdKUQjKqzHLNwwoQvojLBP8IHwa9O3rEcS
sdiLELoj8UDbNUNd7H+dYqIe/96Ytqe5bpTv0aViOTNZga2QVsO7EcJf0m1GhBCx
eY8U2y+cmHF4QxSSr5C8uoHoSGDp2m6S+wHXkh1FjupYVQiDxXxp247iFsq4Y1uT
yYhGBBARAgAGBQI6FABTAAoJEOL2OL8RxmIhUeAAoN6SS1xlX6SQxYmmSkBJgJ4F
QjR2AJ9IA4UHjsRX7rU/m/Xw8iPxoUq3oYhGBBMRAgAGBQI/z0x1AAoJEBeK30g8
EPo6DU4AnA0nrnDyO9TsG52Xtgq2YmXB/b2KAJ47M0uOl+VViMsCnXhYLrROHtVx
DYhGBBMRAgAGBQJAdWqMAAoJEDiaVjzCcqEm7BQAnAqv6ZES7GQtqg6Rt2+WVSV6
XtpOAJ40qzwHcR7OX+NSiRjl3WOTwERt0ohGBBMRAgAGBQJAdWopAAoJEEgc1JLn
L9XFbwIAnjJ+IwMJ/71KehsLvxv5r14nIHmCAKCwT6SXfz7HNGz8cmDL6ZN1rrtr
iIhGBBARAgAGBQJAyFxdAAoJEMVYWQiVq/UMcE4AoI2bj/IuuRk8MZG7XjwO/vo3
2tE2AJ4gxBDve+9MJXokMaryjywbkU6VkYhGBBIRAgAGBQJAw1FlAAoJEKZJAleF
DuzMDjAAn2kz8mCuw7uIViAD98dAEB2HFI3nAJ9GnzCUN8NXJuRUtg5VD+tJdhS9
VohGBBIRAgAGBQJAwHDvAAoJEJJF5/16WIxiNSwAoIjmK0RulCjSnKSkVd9WhtPU
aRgCAJ4x/uoJcg8htdb1+OgiZ9EmF/1GNIhGBBIRAgAGBQJAwzuGAAoJEH63kt8Z
H82KJ8kAoLDx9KGXap5ZWP8Hsj7h9Dub0gZAAJ41Q4E3h+MjUOUu4NlfpFFHEv32
TIhGBBMRAgAGBQJAwd7JAAoJEGzbQ2xyBIUl7EgAnjxeRkWAw9IEE2WvB8p6Esp/
TeTQAKCz3THl5H9Bmwgadju982Ca5hxg/4hGBBMRAgAGBQJAwNuuAAoJEFOfjK8M
4nEdV2gAn1vD87zQNrFCDRKeoWfMOeOjztWQAJ4nO6LaSa0S8ZJDbznsnIuFo2fe
IIkBHAQSAQIABgUCQMMIigAKCRBMJa+4YC6DGYLJB/41oFJfyT4Yj4W51N+hlLVS
FMMzzsPipEhh5LpQzTjua5yKfbW4a2Lc5UldozJaWcl5QB0yyhDxtFytbxa2jfrH
7xNajUNYspArQ+eBdn21OEJoIRq2HZY1oi/nEnnShKf8cxSDFCMdrmxJkQKQphHr
VSS/zHI7ald0A/gS1ultib+SdFUlJ+E/67nieMgfTG0HclwvQcw0vZCk3hSEBKO9
V89jMJV9CO16SRZtRSDsXhVMzsaBUIkciCWTScqfEecVvD8ECwmivzGR6OFEYXUC
kv50DpOZ44+RpGoEd3FOCCaGtYLWweTsin3ICA0joUX45A8wJ0oqvcPgHoQzQB21
iEYEExECAAYFAkDF2WAACgkQPiH2BEeFMRMy5gCfYQzS6DDlRNigBgUPsr8T4NjC
Xe8AnAhvngQ7nD0e0AmtP6/7Nz/28tGgiEYEEBECAAYFAkC/thoACgkQNW1gNO2u
DNqn+wCghCynuaRQNYRVoySZSyAsVElZEZMAoJNtKQ07FkYzI4RknrdT5W5S6hiH
iEYEEhECAAYFAkDEXHUACgkQLiz2e3eWpgs0XQCg0tSPUPAvjIk0tyrx2UDcyvk4
8zoAoJ4tpb5Oj/5+Kh09R9wHVezldDqZiEYEEhECAAYFAkDFPG0ACgkQIhjIHo58
A/9LuACeNB/7nH7GsQfh0po6dFVDHPnXXycAnA2jet8NNpC8lT4Xeh1+zeYYurpE
iJwEEwECAAYFAkC/6tQACgkQHlgy2P0zM5k7OwP/ToNua99PBI1eauM5WHm/bJwI
kzTJrUT7KW/xgIrsV+13b1Chtse+XwGDMSajFvl+GEVpALQx1geY/sGetrL7pKZn
kkXmvbRtz6AP47HDsljY7fU0DdfptLAZhkNxRmxaKhbRphzD4qRDm2UTxG7haEzt
XaetWDC9dJS49d31yBGIRgQTEQIABgUCQNC40gAKCRAcub/coZFOEYxxAJ91XK8W
hZxmmrAkeu0IlPfG2pW/7wCeMgObqDgNwECxZkEgimhNN10DEZ+IRgQSEQIABgUC
QXqU/QAKCRBuA49e4KODd6DsAJ9laTzyxecAR9GQGQcMPD3JgfCUUwCfZBwkbNno
/3azXMCVgh3xaBwIeDeISQQTEQIACQUCQTKQygIHAAAKCRAKBOKp97E84clcAJ4n
cotQp6C3FxfKwvFIk9peCV5d0wCcDhnaj0uv6S4U/KAkQYhOm2FLkWKIRgQTEQIA
BgUCQoC0cQAKCRDqe/OXAXViPrshAJ9R3snPtQUcNtSlRQZh9XYdebJfgACfVjmW
q+Fj1KuX20yrEEwrX4mhZsaIRgQTEQIABgUCQoO9HgAKCRAjlEMa/4E1znDCAJwO
EOMpr8w7/8UxXMKq1XYJlDSskACgnNrfQo155BuYwBWJ0mKKixAiHmqIRgQTEQIA
BgUCQrt1+AAKCRBxc32m+MTRTwgoAKDNiuQ9daEdqT1kIZNDLtsIKyHuLACdHKOE
Q2KUEko7glpLDA5+rBqy/ya0I0dlcmFsZCBQZmVpZmVyIDxnZXJhbGRARnJlZUJT
RC5vcmc+iF8EExECAB8FAkOcnV8CGwMHCwkIBwMCAQMVAgMDFgIBAh4BAheAAAoJ
EKWzoAR0XAFa4zMAoNe1CtKVmT8hhG2alfDPwGRugClZAKC5+363+cotJEUEA5Ta
QV9O00DodrkBjQQ4KFLrEAYApl6bTQjQZc1Qof2x9ScrF3KQWAlzVHcrHeEQo+5Q
7mvXlCaCWU6l0UhXUVa5c/aKqGJz+GPJYoldEcPzrRNEcS2TtWb2dHeY56gs6qTp
HuU6/z7I0cezjqMMA26n737ikiA1pyOQD5LwXjHPw7wluPliHf3TMgFIXdo9rM+G
U1e+inE0h0aH6puVwtoAlfuTg/O1dbCmjP0T9VROK0BsXRDhZtRM9BXT/xeUEDyT
1wAYolOwtsX7IiAS0yT0emODAAMGBf9kjrZvxwTBYItADVPSARwwB9PfgZt3tFn9
PfmGc/hsDqffLU+CNgKV2vQW+NLc0Uo5aenwu8wwQgwTLWEjarw6Y6s+4sKEFN4J
HZ6hCxucHAM+x6UGDf7F02Cw4mt+kz8R9GCbFR7xhsyqTZRFnSUD3uEitkkYk48h
iTVnvqKFgXWacCDYO902nZKwd7SKRrHabe9vG83GEAMdyaNxG4fcwguJH2En//NL
G9AUxL7H1mSA/S2Mf/Bwf11YHS5g0RyIRgQYEQIABgUCOChS6wAKCRCls6AEdFwB
WurwAKCgw+5FenbnpD9I5rerbCXeo7/7EwCeOvTpUh2KYkATZ1D2yfKh57GRxcw=
=3Uph
-----END PGP PUBLIC KEY BLOCK-----
D.3.163 John Polstra <jdp@FreeBSD.org>
pub 1024R/BFBCF449 1997-02-14 John D. Polstra <jdp@polstra.com>
Key fingerprint = 54 3A 90 59 6B A4 9D 61 BF 1D 03 09 35 8D F6 0D
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzMElMEAAAEEALizp6ZW9QifQgWoFmG3cXhzQ1+Gt+a4S1adC/TdHdBvw1M/
I6Ok7TC0dKF8blW3VRgeHo4F3XhGn+n9MqIdboh4HJC5Iiy63m98sVLJSwyGO4oM
dkEGyyCLxqP6h/DU/tzNBdqFzetGtYvU4ftt3RO0a506cr2CHcdm8Q+/vPRJAAUR
tCFKb2huIEQuIFBvbHN0cmEgPGpkcEBwb2xzdHJhLmNvbT6JAJUDBRAzBNBE9RVb
+45ULV0BAWgiA/0WWO3+c3qlptPCHJ3DFm6gG/qNKsY94agL/mHOr0fxMP5l2qKX
O6a1bWkvGoYq0EwoKGFfn0QeHiCl6jVi3CdBX+W7bObMcoi+foqZ6zluOWBC1Jdk
WQ5/DeqQGYXqbYjqO8voCScTAPge3XlMwVpMZTv24u+nYxtLkE0ZcwtY9IkAlQMF
EDMEt/DHZvEPv7z0SQEBXh8D/2egM5ckIRpGz9kcFTDClgdWWtlgwC1iI2p9gEhq
aufy+FUJlZS4GSQLWB0BlrTmDC9HuyQ+KZqKFRbVZLyzkH7WFs4zDmwQryLV5wkN
C4BRRBXZfWy8s4+zT2WQD1aPO+ZsgRauYLkJgTvXTPU2JCN62Nsd8R7bJS5tuHEm
7HGmiQCVAwUQMwSvHB9/qQgDWPy9AQFAhAQAgJ1AlbKITrEoJ0+pLIsov3eQ348m
SVHEBGIkU3Xznjr8NzT9aYtq4TIzt8jplqP3QoV1ka1yYpZf0NjvfZ+ffYp/sIaU
wPbEpgtmHnVWJAebMbNs/Ad1w8GDvxEt9IaCbMJGZnHmfnEqOBIxF7VBDPHHoJxM
V31K/PIoYsHAy5w=
=cHFa
-----END PGP PUBLIC KEY BLOCK-----
D.3.164 Kirill Ponomarew <krion@FreeBSD.org>
pub 1024D/AEB426E5 2002-04-07
Key fingerprint = 58E7 B953 57A2 D9DD 4960 2A2D 402D 46E9 AEB4 26E5
uid Kirill Ponomarew <krion@voodoo.bawue.com>
uid Kirill Ponomarew <krion@guug.de>
uid Kirill Ponomarew <krion@FreeBSD.org>
sub 1024D/05AC7CA0 2006-01-30 [expires: 2008-01-30]
sub 2048g/C3EE5537 2006-01-30 [expires: 2008-01-30]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDywg58RBACh3rn8lR6mEBpFzQUN6oRmHo2mlkzY2+Pz2d5luRyE51WVVOlO
0juFuR2PIz1LXPy0Mucz+lGjZ3FPejU4PaiVe0WOeV57UaSeGvB4D+wc289fO7EA
ZUiI6vgSGnK55FbA5YN9eDlDqr50zh9/XS++bOovtu0VvBQ9CbXGz/O8UwCg/dHO
aHTyTA0pE2rQq/7c82+xl6sD/3etZa4LnesLIEHfZbueuAJ9x3CGwNn/vdecjv3Z
i5rb9Q2i3jTZDWoyRSwusP8ayTh7lslkAAVlARJ9pF8wbJ/V7l1DdglVovvHuH2C
1Zf4GvzBCQcVvDhuTqTerxmwe2QE6r5bwPOP8hSguvfzaR4+6uGlsJZdoN+vvmhB
wNnhA/wKulV96Cx8KDX4g5QY0+xD3v+9fnA2pPIdVOXmEfYEyN1oG3LTaF7VSxc7
XQimrpCwtRB+1bYa/edezf+PitI5994zqrd2HP0x45zwhiKoWZ/terUrGCkXbHB0
Z9cxxO/yG72uq1De7EuNkHPQ1MdW+G4LV/myN3ukSQ4MDmvrRLQpS2lyaWxsIFBv
bm9tYXJldyA8a3Jpb25Adm9vZG9vLmJhd3VlLmNvbT6IXwQTEQIAIAUCQzvfnQIb
AwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEEAtRumutCblFnQAmJOgPgOtUK3T
nqi1fGcdDmQ+DXcAoMRbUwjle2JCQTrxi09rAenIfV+FtCdLaXJpbGwgUG9ub21h
cmV3IDxwb25vbWFyZXdAb2Jlcm9uLm5ldD6ISQQwEQIACQUCQzvf3AIdIAAKCRBA
LUbprrQm5TFSAJ94r2JZk+NGBfm7EzXQDJS9mqV4DQCeO5BoipB1cdjx59VmCRn3
2AurMMmInAQSAQIABgUCPjEUowAKCRAiRgxqA8L7LcJgBACe3mnRYBFsxbQZxPEF
MjUUczKG3r6Ih3KJlL6cmIWRmsDv8vI5t6PGn8RQkkaSsu1UaU7Y/P4aR4dpxh2o
FJcWihGvy/yafGutqX/DcIU/9F0yLoCBU+4fATSj7QBIi3TzwWPRzds5fDCuM1B/
LQvX/LNBOTCiUpEN25HLUwcyTohfBBMRAgAfAhsDBAsHAwIDFQIDAxYCAQIeAQIX
gAIZAQUCQOb6jQAKCRBALUbprrQm5dBdAJwLZBpW1uqk4vnlusPLVFNZLU+obACg
yUlbUXvZWYuVttMHdXBHSLb4GwqIRgQSEQIABgUCPjEUjQAKCRD31D6TzwF+Vw5W
AKCNttrx9eqoWj6A+g9EeigFvaQQigCfbegIctSzNceC0Xk3FafegcECZyqISQQT
EQIACQUCPjo3awIHAAAKCRApq9wmu0emN3zXAJ4kyIOyd2nbs5kP3dee8uBKGHjT
iQCePnMuPcuH28UhpfQ2aJckKvfS5xGIXAQTEQIAHAIbAwIeAQIXgAQLBwMCAxUC
AwMWAgEFAkDm+pEACgkQQC1G6a60JuX5TACcDWhNm3jRvGl6QzSfLJGg2AKYJf8A
oJNeLlYGBjnWKCHoZRlNwJ2hAMddiFwEExECABwCGwMECwcDAgMVAgMDFgIBAh4B
AheABQJA5vqRAAoJEEAtRumutCblCMgAoK/CR1Xe474X4BZFGMBliy7O2FfqAJ94
GPSa6CkvttlrCin30W25O1U5N4hfBBMRAgAfAhsDAh4BAheABAsHAwIDFQIDAxYC
AQIZAQUCQOb6kQAKCRBALUbprrQm5W17AKCI1UI9O/mT5mfNdGLQbCqidpRsxwCe
JI8QrBYfg4d6iIgANSnhtwWlrF6IRgQSEQIABgUCP89DsQAKCRACPu77/rnef70Q
AJ9KMo7bzzW234IulQ2O4IEFMmIPTgCfZbfO3WWWNn7BpquKVf7uuHu7SriIRgQT
EQIABgUCQYJCwgAKCRAiylhMenujwJyKAJ9FX0TwJTuIp1selT5xsadto4hdVgCf
Z8emg4RJr/B6r5Eut72SF8fzETKIRgQTEQIABgUCQYOyZQAKCRCpF+nMmW4UXpKC
AJ42BIE7TOH+yCbf3+17BpW1Fp84GACfb0Ilcg84ZnMKguWzalkiwAE+K6+IXAQT
EQIAHAIbAwIeAQIXgAQLBwMCAxUCAwMWAgEFAj1iJO4ACgkQQC1G6a60JuVz2gCg
jGNfdrIPH+bPGVt5Xi68mq8BOF8AoJ7Xh0B/iF/E8M9yWJADeVtUZFqJiFwEExEC
ABwFAj1iJO0CGwMECwcDAgMVAgMDFgIBAh4BAheAAAoJEEAtRumutCblbVUAoN21
SsteQ9dwvgr/CFJvAqLpJnhiAKCimyFDDWaQZB+ZzUpFtvbTPoGBIIhfBBMRAgAf
AhsDAh4BAheABAsHAwIDFQIDAxYCAQIZAQUCPWIk7wAKCRBALUbprrQm5Vp2AJ9a
2uCo3MpXBJ1PfUZUNYFTKaQV5wCeLkLx8V/bzG55wI14WPg02YZm+USIXwQTEQIA
HwIbAwQLBwMCAxUCAwMWAgECHgECF4ACGQEFAj4476IACgkQQC1G6a60JuX1cQCg
mXQygEurSCm92i/zfzMiCFz1jFIAnig2u+V1fZ0FSttJRT1jtoeen/8uiEYEExEC
AAYFAkGFe0oACgkQntdYP8FOsoKFWACfWrXTLi9uiSYwmyIINer9dJs4YmYAn21A
GHaOXHZ5vC+UOC5575qECus3tCFLaXJpbGwgUG9ub21hcmV3IDxrcmlvbkBuZXRp
Yy5kZT6ISQQwEQIACQUCQzvgBwIdIAAKCRBALUbprrQm5aWZAKCa1sk42yaYjCBp
685gHFsijMJGPgCgt7FxG9z7K0AGf3qajYufF+Zy7BuIXAQTEQIAHAIbAwQLBwMC
AxUCAwMWAgECHgECF4AFAkDm+pEACgkQQC1G6a60JuUODwCePGW49pmVaSjX1GjV
mvBAWkZFAvwAoNW1uJ7fFAEbfXaRwakBgRElOSFSiJwEEgECAAYFAj4xFKMACgkQ
IkYMagPC+y3CYAQAnt5p0WARbMW0GcTxBTI1FHMyht6+iIdyiZS+nJiFkZrA7/Ly
Obejxp/EUJJGkrLtVGlO2Pz+GkeHacYdqBSXFooRr8v8mnxrral/w3CFP/RdMi6A
gVPuHwE0o+0ASIt088Fj0c3bOXwwrjNQfy0L1/yzQTkwolKRDduRy1MHMk6IRgQS
EQIABgUCPjEUjQAKCRD31D6TzwF+Vw5WAKCNttrx9eqoWj6A+g9EeigFvaQQigCf
begIctSzNceC0Xk3FafegcECZyqIRgQTEQIABgUCP6d+UwAKCRApq9wmu0emN95m
AJ4y8/2ZJoQaECoYdaGo8ZSNtbpf2QCfThLt4w0bRfYcmhTF/4QCZ7Fz0ueIXAQT
EQIAHAIbAwIeAQIXgAQLBwMCAxUCAwMWAgEFAkDm+pEACgkQQC1G6a60JuXRDwCg
hGV2pc5fTdA9cIiVJyglpUcdHhIAoL7T8XJosiNxB+DgBd21QiMIuKT/iF8EExEC
AB8CGwMCHgECF4AECwcDAgMVAgMDFgIBAhkBBQJA5vqRAAoJEEAtRumutCbl424A
n2n34YG25f4KegjUUavRc5SPtUSvAJ9vh1VvX5H05xi8jEs12IibgHkzPYhGBBIR
AgAGBQI/z0OzAAoJEAI+7vv+ud5/Z+UAoIVi8c4sDkHCNrdKzdAoLrBuVmdLAJwP
96LFaYaOMcHnEPD8+Cz9HZe004hGBBMRAgAGBQJBgkLIAAoJECLKWEx6e6PABTMA
oKgxR99yRHNApvrvOUmiQtAKzyRxAKCCqOJ+ZyMRHsLEC2W8DZOEEXkWwYhGBBMR
AgAGBQJBg7JnAAoJEKkX6cyZbhReyq8AoISXZwf9atA4+X+TZowHl+JZ7nIwAJ9W
JNVoIVYPX9gn5VVOmVZW3mgnbohcBBMRAgAcAhsDAh4BAheABAsHAwIDFQIDAxYC
AQUCPWIk7gAKCRBALUbprrQm5XPaAKCMY192sg8f5s8ZW3leLryarwE4XwCgnteH
QH+IX8Twz3JYkAN5W1RkWomIXAQTEQIAHAUCPle8qwIbAwQLBwMCAxUCAwMWAgEC
HgECF4AACgkQQC1G6a60JuVCWQCgorM+0KdXDg45pjCoUb+Wi6KAyAAAoLsoEOWK
6eGqHdhGfCoSdd6eZi8HiF8EExECAB8CGwMCHgECF4AECwcDAgMVAgMDFgIBAhkB
BQI9YiTvAAoJEEAtRumutCblWnYAn1ra4KjcylcEnU99RlQ1gVMppBXnAJ4uQvHx
X9vMbnnAjXhY+DTZhmb5RIhGBBMRAgAGBQJBhXtOAAoJEJ7XWD/BTrKCzwsAnjaQ
1B3xIijhfU0bY9+ciHECAWSfAKCM9qCT7HU5gyZBlnzZakoJ8sFKwrQgS2lyaWxs
IFBvbm9tYXJldyA8a3Jpb25AZ3V1Zy5kZT6IXAQTEQIAHAIbAwQLBwMCAxUCAwMW
AgECHgECF4AFAkDm+pEACgkQQC1G6a60JuWD9ACglvGqYhfbQFtmUllo91eLDkyP
tNYAoIKaONf0SDGy/KXOJs3MrxLRYVO9iEYEExECAAYFAj+nflAACgkQKavcJrtH
pjdDdQCcDeFqdZf5xo13MGSntJYqeRYgo4sAn1wW6Jc4YtkTHomgGOMKZDmKmevQ
iEYEEhECAAYFAj/PQ7MACgkQAj7u+/653n/AQwCfaET8Jm26uA408mc26UmP/Ouo
RLoAoLJxKhLAfPuSshj+7ABwwOj57lYkiEYEExECAAYFAkGCQsgACgkQIspYTHp7
o8AWGwCePjXyJyFCFygVuY3iM2BV6/W0EMkAn1K79ljQfNng7EhsaPDGDan19782
iEYEExECAAYFAkGDsmcACgkQqRfpzJluFF6u+QCghB+5YspNSN4sbOPXuRLcQhpf
2HIAn2u/pVDphblCDMs3jc3+BSe9ZO3MiFwEExECABwFAj6YESgCGwMECwcDAgMV
AgMDFgIBAh4BAheAAAoJEEAtRumutCblSzYAn19J7vtDM8wmVHp1ewEsfTIRxir3
AKD21tPp/AUKEWyxYv33jJfxGQHeaYhGBBMRAgAGBQJBhXtOAAoJEJ7XWD/BTrKC
xj0AoM/PvuVaHrER/GWAd0vCtqHtdTwzAJ9N0fS7w/W9ps7nmfkyhm5TbdqM6bQk
S2lyaWxsIFBvbm9tYXJldyA8a3Jpb25ARnJlZUJTRC5vcmc+iF4EExECAB4CGwMG
CwkIBwMCAxUCAwMWAgECHgECF4AFAkDm+pEACgkQQC1G6a60JuWuCwCghzLuoJla
zCcTUdyTr2ucyCGs9B8Ani2RMiTeHHgZ0biUq7cxPpsa6d7siEYEExECAAYFAj+n
flMACgkQKavcJrtHpjeQqwCeN69PlhJ6+evCdm3kuYFjNTqM5MYAnjHWWcFXdjdp
noC0IFLM9NbaXTJuiEYEERECAAYFAj/sfmIACgkQSypIl9OdoOOXdgCgpL1FyZpl
uMeKr0lBh0dkRyoOsC8AoNbO2KwRBJQX4qihiYA4JLyXMcamiEYEExECAAYFAkGC
QsgACgkQIspYTHp7o8AAMgCgvaiBzwONqocWYIfT+gm+aOFcdgYAoL/TKjNZL5xf
AQkCYnHanTYdoOhiiEYEExECAAYFAkGDsmcACgkQqRfpzJluFF4BSQCfZQHleSVe
sP3Zp4N1OHRzIOdexMkAn1rUD1iM2a/+s4zuHHbdUu3PMtLeiF4EExECAB4FAj8a
/hYCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQQC1G6a60JuXBVACeIesPvX4O
xrCyEVg4EdWtaHVSWU0AnRVTx9ozo2I5JY24AZpbDR5BHYmBiEYEExECAAYFAkGF
e04ACgkQntdYP8FOsoIzhwCgo8+i6YtHWQndOyT9d0byglXLKEcAoJqOUHg04hSY
50PZq61GoRvjspJktC5LaXJpbGwgUG9ub21hcmV3IDxwb25vbWFyZUB1bmktZHVl
c3NlbGRvcmYuZGU+iFYEMBECABYFAj8c6qkPHSBubyB2YWxpZCBtYWlsAAoJEEAt
RumutCbl3rMAn2S90LgLYaI8Mq8eYazFBuKi+AMZAKDt7FHkTFxnW2krdPsbNyp+
31fbZYhJBBMRAgAJBQI+OjdtAgcAAAoJECmr3Ca7R6Y3rbEAn2vsY2oejzqXeHWQ
rtnRWgM6oHBRAJ9pJdFeeHgspUQzs/KUv3w0tU8OzIhcBBMRAgAcBQI97yBdAhsD
BAsHAwIDFQIDAxYCAQIeAQIXgAAKCRBALUbprrQm5RAcAKDnHNqUhX8CYuOZcwf8
V+3y1HK3xwCgiM3TddgGLXMsYuqVzw80P4UEA6uInwQwAQIACQUCPjk1jwIdIAAK
CRAiRgxqA8L7Lbm1A/9jVq2A0HxK7lyUeliRCPnmnenb2YUWHfiUIx4vrvB+6DOf
xKxzLACnDkO4lgIHSYS0VyoxP/DOwAQurOnGxAIr0qhw3lmYnfdLwXamqR2Q8a70
vBevnA5eK2YUz+OeZt1IAaYqtFZH2P1NuFClqQ07XG6oty3wHJBsGlA9qDJEmohJ
BDARAgAJBQI+OTWSAh0gAAoJEPfUPpPPAX5XzVAAn2Wmbk30E9/MewUZKgFO6bm8
9bL1AJ99Pt7/TRkSmAmixHoaH5TMnDsyP4icBBIBAgAGBQI+MRSjAAoJECJGDGoD
wvstD64D/0960yPzqfTRCybADBCszlLIn8CiboKHFymC/NtVXeO8EGERPtVmxhoT
+o3BplvOBsrDfDRUClgN3nxH5jtv6VN8U1a1b0RmTaPx3EA4KSLsGAIF9ewa3FN2
J5VpKLDSeO3doISs8p6Uo9J3dMC78cfS/+mkIirgxvysSxL55ZWriEYEEhECAAYF
Aj4xFI0ACgkQ99Q+k88BfldDYwCdEAMd2/9SBL1eYn6RoxmAfS5TiBwAn3o3hX5N
MLb3hR/H7I6yg4+/D8p3iFwEExECABwCGwMCHgECF4AECwcDAgMVAgMDFgIBBQI9
kuNkAAoJEEAtRumutCblbKkAni4Ij1OFr+AIeKeabUSn4heCvQ30AKCvqWMHlMDN
Sd50qKD8ZhAKqFp2O4hGBBIRAgAGBQI/z0OzAAoJEAI+7vv+ud5/nhMAn3F8y8SF
eG9gB7nMjdzSRQFZxd1KAJsGrgdih8ipPitUEnTK40DFeJYjqbQvS2lyaWxsIFBv
bm9tYXJldyA8a2lyaWxsLnBvbm9tYXJld0B0LW9ubGluZS5kZT6InAQSAQIABgUC
PjEUoQAKCRAiRgxqA8L7LZgnBACI1na6AlmmQtnYpi9PYpOrrjrHQ/nEGKejU76N
9NygpHWtM1OwSzREbSB9b+HiHOd4SCFWYEYMiEkckJwry+LnLosuNLjS7J4az7lR
v0lpwAAxarpXyl+C/VWMNdlAJR4MChEBOnuyRk90By8QvUkoWR/C9ZQ29Pw3YYeU
5MFYPohGBBIRAgAGBQI+MRSKAAoJEPfUPpPPAX5XqzAAniETW4ZW7lPtGZ1O0fzn
zI2Gw562AJ0TRC53/cyjm5V8vPGxGngT/Hyi9IhZBBMRAgAZAheABAsHAwIDFQID
AxYCAQIeAQUCPLCDoAAKCRBALUbprrQm5WSOAJ9JcURIAP88Y5G3uCZFYuMlXnps
AACgyfJXskNyB/d6PmYO3juzndVdNE6ISQQwEQIACQUCPjk0KwIdIAAKCRBALUbp
rrQm5WBmAKDhsv833kIEsJAABkecn6T6Vis7hgCgxnnbyUSRzLRKUZfGespCfjO8
5FeIXwQTEQIAHwIbAwQLBwMCAxUCAwMWAgECHgECF4ACGQEFAj4476IACgkQQC1G
6a60JuX1cQCgmXQygEurSCm92i/zfzMiCFz1jFIAnig2u+V1fZ0FSttJRT1jtoee
n/8uiF8EExECABcFAjywg58FCwcKAwQDFQMCAxYCAQIXgAASCRBALUbprrQm5Qdl
R1BHAAEBbYgAn1486u2jzX6/5y3vGlk7Yp6CqTtYAJwKj5xDJgCXxH6t+XQIhDpV
j89tF7kBDQQ8sIOiEAQAvB19+liKQdIpwXF7FYgfXBJcoNOwETDUJ0DWx4cv8O5z
MlNuMvERiSod4+lDO0E51TAzTJY5scjSDgXgDUrhE9BriwIGCtSR6NezsdesGsUO
tuvJAWG6WK0P5Iq3PB6c6bhVcYrsTTCzZ9G1dsG33aTOQBRL0bY6NYdbraln0W8A
AwUD/RJtSNbtdSP8CEK9rJ7qlpJvQIOgmBN+F5QJDPQKfFfTU0YC7VHRuglLlMFD
w/uJ3CjTzUAK4Xi/G4iqRYCSAPZLuwqwnMsNo1QKciNXrA2R3SoP4nPvU6yBuFdf
kTLuzqEbPCBpPFhpvkVWZ+UZQ2Uyz30dgalfnk14+38qks0ciEwEGBECAAwFAkDm
+6wFCQYXq4oACgkQQC1G6a60JuUKfACfXEg4tAhXdEK2szWGva4E00ABdsgAmgPg
ggBoopYQ6DmFkRrHXMFQi37ZuQGiBD43+FkRBAC6CRBHzVwjw3b0789Sz23niUFz
Kw9NtWo4VtHg1CdlA3/7+hrXHOmxcAo2SwaB8viHczQrlYkXaAQbtdGZdFlD1Y1l
UNbJ+aruP+nvH3FBvEAqNb0vNpqeXyQshD+PYwRuozfK4wxprWdajAXVYVyolieF
xqyYRKAGqaL9wVcVbwCguIC3no2xieR7PROKzOq+V+QkoBsD/R0rItfbrTRoj44C
A6U6AoUjv/lmPD2HY/mkNaeJxZ0llcyzEFeEFAKbFYg2UMfqaGPVPiCxjd2UyFtn
8Im8SLjgPQrUT/0/lPmxunFuRT4gZRbNAR23O94Bg0Vy3ENrvEGz0GwjfC+VG2sY
Ie86WTgXT8eV8SEoHy3FKpJThZSZBACfkNAM5zNoozsG+6Wy3mFqtGTlZxu3HDN/
u3oZx2iTyp15vk8i/BZwgQ/9dhUlA+ZJnsLDptxlxZ/ijAl4lay28BuOD9e7pkCS
lkTsyppZQgrLxcc0qUSlUpHq8njNfVdBNw6frPZ1bahnFswkK8fYudExSb86b0G8
isz8uUmL5YhUBBgRAgAMBQI+N/hZBQkAdqcAABIJEEAtRumutCblB2VHUEcAAQEJ
JwCfVNDbmFGAmYfovBUdHECf3wgxSPkAniqYGRFgyTNE2Xd69ZSHBQqTeb3iuQGi
BEPeZqoRBACTA7MjMMsGG7etACeRtt/PXAjaDVCU8BbZir65iauH4eT7fclN9KWZ
PD0TGtM2uvk11qmlKqStNzadBtztWjspC/dYj0nYZXSJlW38FUwTYHNdlS2fd6Ng
BDJKeD6jkhiM2x2ItnQ8DBmFMH7Ht9v/9NPLgwd6eZn0NYwOctWNqwCg/JsIvBzq
QXEAi+LHZgRKCOQJkckD/0Aa4PeMPC0RLsL4/I3/EsgaQu+h6Bdf2QdQ2Gn79qzx
SU+EofIVpwzQlvxSQVNJ+RX+vWXM0zYJaeEt2i6oYcE62TkV7vYhH6Fyu8E97DM2
l5FeoOnIaRGSjgy28xzRf2lXjFkgcbV2+LgehAJB5y9CbiRXBO9xa5HdySLDeZWZ
A/wIHmRInOk+t4ifo7SSvV8DA96sk2vBF5n7h3+zoZIz7I/kePcpFXYrqUeTWBT1
EfUgOZdbwMGyYXec+BBR6TUvYEBeJE1nSAfrJp3NRXFRCekMuIs5laA7vXFveOSg
bhlh3pSS2QCalwSyh3wf3j1fj1Zt55JtauWZYq+a4zoNaohPBBgRAgAPAhsCBQJD
3mkjBQkDwml5AAoJEEAtRumutCbl6v0An0VQkbwR/gHNcmqLZZe5XseezcSJAKCS
YShlk9jSrQJY/yGMh/SVSf/MsbkCDQRD3muSEAgAg+59j6HezJydLmHIPEyBD9Bu
8f8gKjHaoQ5glrgFMYKbLdEOOqzOejjnzF3BJBhFlzlFIQWCkUlO1Yf6tiG8rX4T
QFochpx5jxEWSW7UCx1lYyztkOw7LmHTk7zhcs4MWD/YjQIfZ/M+/ZXNACYwr3Lx
xTOKz+tIgPix/ixl3IVRteM3pej5PlBvcyiODFsFBpUXoJiL3nx2fQFtWKsqooIG
VrrNsscvC8sn1pvGPZTc3gpyQYyzxkiVR1djz18NmOh8yXe2RYxJjhn1tQNpJgPn
Tk1e4caJcS83aTS9sy+j7MXyV4WGVcJ/4MH1Qq/ehPdKMXAs/VV5ooocsYrr6wAD
Bgf+ICK3je9GpUf+ZsDRhv3CQmwbvRdRY3wY2bUM5DckJw7Lx//ozE1po9SDB5yz
h3+P7UqBHi4z1ShTN/S+CBGzQ6+ikZlPpbzMppEDf6+0SQnJYZSlvAD1/Qud0ff/
aTa4WBbACpg1bVKENA6p8ZwhYPXUyrYkLSTMLyfkvn2fQ8la0/ojXqtVbMq3OPc6
L4wv+5CQgZRmMXMhkUVg8QYZSi3pYKC7fg+aR2OY4fUbWt8Dr2p6LVDVOdR7F12c
G45gQfEdycMVUrmdQvaxphTUzxo7n0x6bI2m2O4IY9neEjbm1+osY2IGmJVDy1RK
Ya78PZp3pb4F7NsT2LYoghixNIhPBBgRAgAPBQJD3muSAhsMBQkDwmcAAAoJEEAt
RumutCbl+OMAoLl0iDfAr3+Sek9FeA/LpkozE+ctAKD1thZXB7RPP7lZehP9cK2v
6MXOtw==
=3Md4
-----END PGP PUBLIC KEY BLOCK-----
D.3.165 Mark Pulford <markp@FreeBSD.org>
pub 1024D/182C368F 2000-05-10 Mark Pulford <markp@FreeBSD.org>
Key fingerprint = 58C9 C9BF C758 D8D4 7022 8EF5 559F 7F7B 182C 368F
uid Mark Pulford <mark@kyne.com.au>
sub 2048g/380573E8 2000-05-10
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDkY4OYRBADvB+3Uh68SGrlbrq1MTAN/gnVaj4ztmA15X13bunGYdLKLEJdq
rd9xFv5OgxGZXJ+sDhbKomJ7yrBGtUwC5kIrKXN+MPbO60yy30+kIVLKjXIv1d+c
MlWhjFzHra7WGFmvhzYnbOI/zjlOR68iKHnwxhtKFOK9m2O3voURWLEuqwCgzK/S
j4UGrPUmZf9XOZcKdnN07nMEAJrNh6aoVgK1xwpyO9uTURuCppqAUym/fr4xNQqh
mngblwIACnV9FpBi1ogtX1iDo4YeQa7t7ALgdwTBbU8upVFYzoVByid9ibNu3OKv
j9JvL55jUVg0wv6a8bEWjxnNK/zVa/HCzTbAzHob0CSgH9WmEJJEUIqI2/PG2dj+
ZX3QA/4y6Gon6iya2wk0Zs7mrTj80kxLRMnuPN6geTGVNTfrxat+sA1PVpT2WWSo
qOrPoyxcpUBbJ3VlFmuYDDgld4lJiGD/2SG5BkD6OoGlRnD5AMgUxQtQFnkloao0
3md8UDucIJnJRF94pttQtv4lVKaocm4z0Fx6cWC4Ysupj1AG0rQfTWFyayBQdWxm
b3JkIDxtYXJrQGt5bmUuY29tLmF1PohWBBMRAgAWBQI5GODmBAsKBAMDFQMCAxYC
AQIXgAAKCRBVn397GCw2jxyVAKCbPwK2rDZx/oahfd4M7XJ4GoF0xQCcDExtL+DK
wOugUQwfVIExB+HBM3y0IE1hcmsgUHVsZm9yZCA8bWFya3BARnJlZUJTRC5vcmc+
iFcEExECABcFAjse9k4FCwcKAwQDFQMCAxYCAQIXgAAKCRBVn397GCw2j/OXAJsF
bdYQGgCs3sXMOdb7pNUi2DL2kgCdFOFSojmWV9mulpzH6ceb/fKgoJC5Ag0EORjh
UxAIAMrmc2VXtnp/WWhGne6yTirnnWjR/c+rSK8ixbAqTkdYnocY6gtBJliR7LSh
Cv2RD8TaUc0ZZseHC5vR7VZKXobXUF7QqB1Rgzz/CpsFeEmxxQxZrVKNjwcMloSt
wmH17yW5tBDg8+6KhFwHj40oV88/49L8utVMEW80gh9O9TlYw5qCAp5QKqkFS52A
hO54xjTNdEpv/9yXpwQfgUqkAHM8MQhsaxmKCIQXUGt6Lp13aHDAYtMizED0LBjV
3P3qCoc03P9k2nWwGGU7dukncYNNuLDW9xwkAfV9VQuPYCHEBiPTcRnn99imyvNz
FNhOElHDttCyKtt1FdZZVAQzXusAAwYH/18mnEMMv4rMZglYb0PRCxaxwQYkxESt
KyXEclTc0kgyaZnf4Vbdz1rroxxZLIf+16p/MVNFierz/7d5FbJYggCDSsBAaj4r
Qe2/Os3oCnHyyQY+zF9Ac30CsxzgDxMYxYGJHr6x+s9cloZ3WwBFAO0bMoS/9T/9
/S7L0d0litecox5et2yEw4AqHdCslGx5mX0os66uh99eeEwW2EQHSLklwUPReb7U
6m+fNyWxq5w+qTPG+zcXdiW/117T1aONVmg29tSNW8S/syha2PCJ+IoordBus4mU
kfa49yCuXyZAYDNLbkiqMVTDCqrH2+n1mbUuhRBaSZEvgqVfVLZzRziIRgQYEQIA
BgUCORjhUwAKCRBVn397GCw2j7T3AJ0ZDGzVqNQBE07ntRKuzQQmou8YhwCgibYR
ZJyP31xlO+Lt5FgzzeqcQwU=
=DKp2
-----END PGP PUBLIC KEY BLOCK-----
D.3.166 Alejandro
Pulver <alepulver@FreeBSD.org>
pub 1024D/945C3F61 2005-11-13
Key fingerprint = 085F E8A2 4896 4B19 42A4 4179 895D 3912 945C 3F61
uid Alejandro Pulver (Ale's GPG key pair) <alepulver@FreeBSD.org>
uid Alejandro Pulver (Ale's GPG key pair) <alejandro@varnet.biz>
sub 2048g/6890C6CA 2005-11-13
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEN3W2YRBACt8uucrC3Gv8Q2PoAppL0Gdmy+ufJkvp+e3QpNnEvYPU7jivtZ
MBuMVzadeiE2FMfzAhD90bLOxomZSwIKAc+uiMqqXrciOGMEBFFcHNOgHGI48me3
fBvzQ4weJjGQrdUVOuQOtCNEmPHHdXOG0Vks+2ZD2czYDmixUkysso1gXwCg5ETt
H/u9qXgKHxwQN1znhppBHu8D/2/ikj7Y8S5evZauwQ5m1qBMz7GS4FyXH8LZPPC3
KJW9AHiNSOl4a0g6bH17OTaa6OOljyO0MzbM0UQDJON9JvGLH4q3ML0QQ145yfvQ
fxLbFMU0B3MSOgFUkpRrWflbsleBp0BH6MCUNzdhDVgyQxyLkyr+mdX6m7N+EiF1
m882A/9hz6+cmex12xdJnhx/frVL2Ji2deY4JntneNcZS7FBCWCe5d4weYUlLUJa
sAZuwe/8q5BftMfHXeJzwLc+8zJ2EU6HEX7QdJTezSb7Mjh8Py8T/7TkyjK9LYJ7
hg8BSx7hQ0xo1KJoDx057GjkE2PGW+ngUyAExGvZHc4Gos3lgLQ8QWxlamFuZHJv
IFB1bHZlciAoQWxlJ3MgR1BHIGtleSBwYWlyKSA8YWxlamFuZHJvQHZhcm5ldC5i
aXo+iF4EExECAB4FAkN3W2YCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQiV05
EpRcP2HiqACfSVe9jQLEj8zM/iMLO3S5aLY6EawAnjIo6VapDopNW66BjRzFKQ+D
P56HtD1BbGVqYW5kcm8gUHVsdmVyIChBbGUncyBHUEcga2V5IHBhaXIpIDxhbGVw
dWx2ZXJARnJlZUJTRC5vcmc+iGAEExECACAFAkQy/PwCGwMGCwkIBwMCBBUCCAME
FgIDAQIeAQIXgAAKCRCJXTkSlFw/YcLPAKDTcYP8Uso5mQls/wFYuOsfruyyXQCa
A/xZlNpAz+akVuPQZRh4qqHH0nC5Ag0EQ3dbdRAIALqYTavt1809JFOCuiaOZBeC
/qK5Hvi70rgyIyUJj6q0RrC6FzEOTKGQIaLZSdxhG50lw2KFOCkq0ARfhdrezR0a
0WQApeSb63hd1lvOz8ocyPkUI1IKc7aD0aQfcplaf3NmQJ6HF0rEzenRUoxy3mro
R1yddUO/HosbvaeSCRabM1ORqx/G3WFfmX6dHuLltvbModDmOr04QbQ4+gctmplR
qtk7eRXAFAG+Fo7lkhF0z1KUFQF56kL3rDXaAQzE/Vv6Rgk9vOYGXLJQdngNIXhC
KVzrkqrZXj4El1gfSR1Dl32AzZtY6acGF2GvMGm2R2udTHsYeyCYXKlBRu6xakMA
AwUH/iRn8SsuszctzdLqNxideej+9FQ+nHaMBw3Y+N1tlkHeDVmPDNiTotOzYo/V
aRhW3bAebwEQr5bOs/6bnDrK86b2PUuwC/XtE9nXF9f1QQvApIyKzW6VG/FsQIpd
+5lNWfRDKmoUZpMeKg9bQCjeFk8tFXsnp6kn8NhEAMCCeDwiWYUl8pcFlNIwPs1M
brkZ7QCbA8OFAK0YkzUqYmvKPIS2SjpMA+uPJ0674v8kMuh9VhcQj/1RKKR0q2Fm
sUykWFoGEp1FAVpMkKa2cKS3vYgpobMjVYeMWhsWXAFM9hZT9gI5oKVo7ECUZEBO
f9dufNDZ1UHAHlAojMMCW53/fGSISQQYEQIACQUCQ3dbdQIbDAAKCRCJXTkSlFw/
YY8XAKCxojHrj/8OzUI3PFFTS1/afkj3HwCgz5wfMMjyDZG8rUt9ZFbUVN/RPs8=
=iWC8
-----END PGP PUBLIC KEY BLOCK-----
D.3.167 Thomas Quinot <thomas@FreeBSD.org>
pub 1024D/393D2469 1999-09-23 Thomas Quinot <thomas@cuivre.fr.eu.org>
Empreinte de la clé = 4737 A0AD E596 6D30 4356 29B8 004D 54B8 393D 2469
uid Thomas Quinot <thomas@debian.org>
uid Thomas Quinot <thomas@FreeBSD.org>
sub 1024g/8DE13BB2 1999-09-23
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.7 (FreeBSD)
mQGiBDfqEAgRBACWuQA8w3jSz2SOXCzzuggBpkXadlyswhNi5Jce1auOqiRVw8gD
cTlIWLpboHFyJeF/d5A1UPjgmiexRuyyukyQn30Z3bx5MaWwojJb/K/4ppguCwg0
6hXIJoT77FpOex8WySQ4nGK22+EHp74utDJSp6uj4QxWYhXJ+/LraUyhUwCghdgF
ByPm2qwPYbiNJaeLyJNN8oEEAJEOxTHuXlB5HUzFSOPOYFIxzpsFkbUvpqEt2Ug9
mgorHqgcmeP98YWLwMFznLXehyAjtvoqRYWWHepHQwaeqx6ZpwHdStPXTi5mb3ih
Rzz90yL+2ctf7nnd7rc8bveN8gzlRAnHKjyjSkC9DXpBWd/N0P53XPoqdm+WlMu5
XC2IA/0fVbpYQfcbiFf9O/FMym1gWqF6xemtP3ClEG82yhAU2kyYnmdBQj+OYaJO
eTW7RSptEfx2429HgOU51JHn4JGEf1U14Qe67X0I1jzIPKHxLACWwVxezbbW2ljm
snPDX9S7QhZgZFiQRD4hvV9h+cK5EYb0ee6JW6rX1fK1FAyt9LQnVGhvbWFzIFF1
aW5vdCA8dGhvbWFzQGN1aXZyZS5mci5ldS5vcmc+iFgEExECABgDCwoDAxUDAgMW
AgECF4ACGQEFAjfqEAkACgkQAE1UuDk9JGm9TwCfQu87Wzf0dxpjtI8FsCGpeZsC
aL0AniDJcaMKrNDhV2RYGhVWnS2QMgU5iQCVAwUQN+oTTN4fokUTQBLdAQFCKwQA
qYJH3xn5saRMS3vCd/OSgho1sYT/VpqSRKqqK+++TwnAiddP4nIjJ801qi3xmj/x
asZXY/t6t9c6F/V+zyi+605FiWd1zob7jCCk+NGmSCcBdfu2QDJfbSnQEkkDDyIM
gDFp0a8yTChd3khAqrEyKV/nurTi0CFuHHUlLNZvJGOIRgQQEQIABgUCOH8t0gAK
CRDNwlt1HkPUTkfVAJwKlx7U/PIDLugWOC7y4ezhd+8L+gCfVQN19+VQjW99tlCJ
UTrCe389PpmIRgQQEQIABgUCOIBuWAAKCRCBvdPEDh+beVnhAJ96FGBEcsxgYqjg
HOaGeRKtOygYaQCcCreBXTmJ4kjI6hwEXLIZEOriL3OIRgQQEQIABgUCOIAAWgAK
CRCCvws+sGjBN14fAJ4s8KTGnb5CEOih8rlPXPirmH5CUgCfSEOhLs0Moo6v0JzD
9aNYpQ/85iaIRgQQEQIABgUCOgqtWwAKCRAOp1a1FEhD9ZcFAKCAtkdn9HmB1AO4
htYQ4WhU7wbpfgCffOzyPPNIEQEorZg9q6fSAhMqirqJAJUDBRA6GWTqQGOdg4uP
VMEBAQJtA/9K/+oQfcjiLtasv2CWsRj+ueQJBCqnsScTgQpKSZX9xZhqLok6o3XP
xeM0iJtyz4rjAwI/hZioc6+o6K/K1OKn/1Lyfzj4KtdW9tevtAtwYFcetQNxEtlB
33GgIBo+GgJ9JhNzXnqPZdV13WQRdBntpJGkezIra+T4nES+rptdwIhGBBARAgAG
BQI7HkUGAAoJEDoapjWQmlQGPGMAnA655jvZwLDUWTAH/5Xhl6LyMGGtAKCffcLQ
2mHerpCwXzWKNPs8me2bs4hGBBARAgAGBQI7HpFlAAoJECwYoCq0xfN/GZkAnR9x
NWIvk5tqG2gwREX9yRuj0b4RAJ9xtyb4+Md0hYbC6Ygb5ezH8ZAM8IhGBBARAgAG
BQI7HmMFAAoJENyRPZhd8DFn5BIAniJWbZXPO5OoMAdBeS72QriYbAlxAJ4m7HmD
APcikpX9MV/o9HqxR0Nd64hGBBARAgAGBQI7sdvrAAoJEEClvu1y0Dyxl0AAn2jY
qYDskpmBvkuPYC59Tl9fzQmmAKDGF7+cP2FUvtxmZ+l8iTm/g50hBohGBBARAgAG
BQI7uInSAAoJEIYHkD298KrQUCMAoJs159fBsjZh7E0sGWE0IAEdwH0gAJwIcsJp
U65HrsSIbVbvmD+lbwa2tIhGBBARAgAGBQI7xx4sAAoJEDBZv5LNN1b0SbwAnRdL
ZcYR9OuhqTW8rEs0OpcGTVCVAKDswo+6NOzugNZLqZIfF52RjkHfK4hGBBARAgAG
BQI7zVoPAAoJEFPlmVtRVTMKRYIAnjgLGrRo3Zh/Fl/+ODaABypF2Re9AJ9U1h4T
FINLAY9569j0rqFNr5gD/IhGBBMRAgAGBQI897wiAAoJEPEzIkEbgK3mUvIAn10j
BuF/A0y+gVesLfsIDguzfyCcAJ99K0azFbXYSUZ5/XJSJlBRhZexhIkAlQMFED1i
DHoA8tkJ67sbQQEBzUwD/jLSmpWIglpBi+F7G6OSXXE57BHldGBoLWTjK4oO8rvO
4zBoC7QoqOQSLuC9NjrjRFlSWNWR5O/xOH7I6hSE/GSt2mmIdUnEAfgplJ04r9qJ
kBTE5ix/XPc02uBSkgQv3TGdqr8SNu8trSa0AT7vw78kKOj0TVw9Ap7DCcKzYsTG
iEYEExECAAYFAj1h5oYACgkQiONoszDJNIpI4QCfeqYp+usipwxyPtDNKsb/JjlU
FekAn2GxcLbSsS2kW6m5fqa3V/Tw7k1PtCFUaG9tYXMgUXVpbm90IDx0aG9tYXNA
ZGViaWFuLm9yZz6IVQQTEQIAFQUCN+oTswMLCgMDFQMCAxYCAQIXgAAKCRAATVS4
OT0kaQ/MAJwM8fztZzPR2wWY6uNbBeZhe3J2NACfUWj1hvToUB6cFPY/Eer4mhJp
wziJAJUDBRA36hPT3h+iRRNAEt0BAQK5A/9er+qYqfrZRJCkXRwT8YNpt4Zi087Z
jyYMZR2kYAZJUA8Q/YBoJuPqkXlsx3kWmyDe6K6jP1eMJiWNbrcH4m96IeUEbhlD
7e+LGpwqYjTbp+7pwfAHkpAQXkB/vvo4Gitcb5Pknvj+YYPsEDuSMQxbBL1rWAhc
1JhROiaWE0vdR4hGBBARAgAGBQI4fy3YAAoJEM3CW3UeQ9ROYR4AoLUZJtftjz4n
+wEo+H2hCN+UN9duAJ9Yb8lWmH/ZIJqLMM9PiXU0OIz01IhGBBARAgAGBQI4gG5b
AAoJEIG908QOH5t5dbwAn2A/LWelybp46IxdWKYjBvd3m3PaAJwPOGcJengwi4St
b0SjNXaxUq4prIhGBBARAgAGBQI4gABeAAoJEIK/Cz6waME3UFcAnj4lGBYFE0n2
8R9GA5iRf+gcT3j7AJ9ob/SnIaS/TNI+YM3QhiAV0PWdqohGBBARAgAGBQI6Cq14
AAoJEA6nVrUUSEP1KkYAn20CoeTxfh+w+DuohpfN4G7b1NHVAJ99wSZyYcMBZ/fb
O7cMKc7q/c29HIkAlQMFEDoZZPxAY52Di49UwQEBK7oD/1kkDsmY2V0/eVpdsB25
Ua6YmOe81hm1/jDSe0869wDWDwwdyzgpVciifPDqVIAl+2uzawrazkJUJaYTHaTh
WPJe49pEkrfoBlymefaPfzxkZc8VTsiyecvjB8yqgiWkVKIOoaTnfsaL28YX5VR+
oMQwR8iZmTdyTqvBOyaK0DRyiEYEEBECAAYFAjseRQkACgkQOhqmNZCaVAZyIACf
c4DWUuct4pEosdStBnb1nTrgBNAAniFY/KV7LQUOK6Cd5fCg28T3ZFetiEYEEBEC
AAYFAjsekWwACgkQLBigKrTF83+UQwCfYxx+gCEwSQVS1Wf99OI71i5Qr/kAoM1Y
pc0h8oQW9eP2qB7i5OmM4RY5iEYEEBECAAYFAjseYxkACgkQ3JE9mF3wMWfwNgCf
aOsZeRQ55p5AxfH6dNnUFztuLQEAn2OVaJq9x9nlNaVHHhtVvBSy3e0JiEYEEBEC
AAYFAjux2+4ACgkQQKW+7XLQPLGvjACgzjpcmwMr8D70XsAcKzRlGBs+LBEAn2E1
s8k//sWpelo/XZtdIN4FJUe2iEYEEBECAAYFAju4idYACgkQhgeQPb3wqtDMgwCf
d2qtQCT/RP9kaJntGJvdXWMZYLMAnRDRPUjUbHVc9gMaH9lLKX9rHJ1CiEYEEBEC
AAYFAjvHHi0ACgkQMFm/ks03VvS3yACfaVpSjmAOPFwvtf6760mrf0I2Sf0Ani9/
WYGG3ARZiike52mMEEkhAdQQiEYEEBECAAYFAjvNWhIACgkQU+WZW1FVMwowNgCd
FMw/T9fCkIzXC9GM/VYn+FMVb5QAn05iilPJu0CpcLfsXbJRS+E9JK1eiEYEExEC
AAYFAjz3vCUACgkQ8TMiQRuAreYX5QCeIqv9hIM4ta/kt2abewVyqdMDt/QAnj2X
YppdAV7y783u+hBscbmr2hHPiEYEExECAAYFAj1h5osACgkQiONoszDJNIodbQCf
Y9l9H+W0hQyFTER1LcCppFTTTBMAnjtsPJDc9eq1jKwXhTIUkWdBCwjptCJUaG9t
YXMgUXVpbm90IDx0aG9tYXNARnJlZUJTRC5vcmc+iF0EExECAB0FAj1hgngCGwMF
CwcDAgEDFQIDAxYCAQIeAQIXgAAKCRAATVS4OT0kabNwAJ9hD8FZ7SFnQio/uHYs
sc+k6gU98wCcC34bEYJ+XVKB75WUMleshVtmP0GJAJUDBRA9YgwHAPLZCeu7G0EB
AZhgA/9hC5jSb/DCB5dMWYRenA/aJkDsSsCMgAqmbFGLWzUZRgn2Bqc2uFKdT+ea
TeeKapnSl2ppxac+odSUPTY5PWF9Q5+OsNQLOJkcLy5d2XSGoYiicVXe7smUHl1l
tlT3+twbiwCe/3qdlsMOPEhJfUKyYRVzlsNLVlLaLjFRGY2h/IhGBBMRAgAGBQI9
YeaLAAoJEIjjaLMwyTSK5xsAn15xwc2IBpNg6/TLBL5QzwD/KLmlAJ99rGujgTt1
rjWreFrHtzJivbuJaIhGBBMRAgAGBQI9YgSRAAoJEPEzIkEbgK3mscIAn3PWrHtn
Smt+NrxPPf4fJRdmzx5GAKConDEqaPYmi/DfAw1mB2vLF1lhQbkBDQQ36hANEAQA
ija4VG1y1xjhazkHAyK/ux2AVYC1b4wEkUa3kos7YaoQ24tfO9Y7l7EA0abBM5Ca
9v2rWb5k3ouXBuyI4C02muT/dUUfbZb9atkvZeJHWzFoBjHu5RHkCTT5Vfb6tJZr
e/njzwQEXDXCCbEXS9JLQ2vQo4+o1sKnmb8XztsrSfcAAwUD/jxXIq3DoUgrPc/A
c16hgLkgI5Reu7QkRIpOO/ZuBZ5ymwdFXHb/4l/0ti9H/ONUag1PAHC2+YMuuZoO
NhVkFw5Uxm8QEoiS88I1Tu+PSrFIG9J2uzOcaVR5cWlvszoitxicR2IQIkouy9Zv
oS9ihhkhW7P/VXoxfLFwBD0qsPdsiEYEGBECAAYFAjfqEA0ACgkQAE1UuDk9JGne
lwCggGkRGKsB/L4LeCilJ1DO96kNj8UAn1ofH9VS6wXK83zRzJ0NJpwVsCs5
=mFN1
-----END PGP PUBLIC KEY BLOCK-----
D.3.168 Herve Quiroz <hq@FreeBSD.org>
pub 1024D/85AC8A80 2004-07-22 Herve Quiroz <hq@FreeBSD.org>
Key fingerprint = 14F5 BC56 D736 102D 41AF A07B 1D97 CE6C 85AC 8A80
uid Herve Quiroz <herve.quiroz@esil.univ-mrs.fr>
sub 1024g/8ECCAFED 2004-07-22
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBED/zxERBADJcZlF+Rzm8wL5lPTTPA1zLwa9u4ZZeVheS9vRGTOC6Sfi2NV9
feWCM4TR9CVtp2tAcVlrXjBzvhbeNajssCPn94qUh4z8ERJKT1R8n4zlilTcMTSQ
qZ9t7mIpcpsmpCO1FvfozjfexpUSeLHONKlwHhXXQFdJm6bw3X+kZKUeQwCgut4g
ilrxtY66n6pzC7jt8GaM1ikD+gLzk88lPNHA8hZurRaYoRD2cD7jOMk0WNuuRZLA
4LsG+hJUyrPU5vLKou+2iXl6MBvjlYwY3FS5wc1PZ9tRRbMNIq71xCTXmSapks50
M+/cVYhJhQTVWCFhY+HZLDJpiaeMEkTHqoXo6ePVSMgFDQXADv/hMIPkNheXzmXM
yhw0BAC75FBSMcRJz8jOaHXSZ7AM9EdMhH4mru1YyfLzwqk0DQS7ToXc8mEpo9SJ
c/rYfSHf6Egx9856sncCfLvoTScZDwWXvB7kJPOfXK0u8KK1uZBDAqEacmm2oEHd
Xi0KbfW1zyqIPnLKjgu57OqSGyDBKzC2XuQvWcNk7Sol/Yxp9rQsSGVydmUgUXVp
cm96IDxoZXJ2ZS5xdWlyb3pAZXNpbC51bml2LW1ycy5mcj6IXgQTEQIAHgUCQP/P
EQIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRAdl85shayKgHKNAJ9/qmkJgaMW
zOFnMUGcH/fc9ksrZwCbBhYIuo/nnHe9tC53mIlqDoXOz/a0HUhlcnZlIFF1aXJv
eiA8aHFARnJlZUJTRC5vcmc+iF4EExECAB4FAkEOc8MCGwMGCwkIBwMCAxUCAwMW
AgECHgECF4AACgkQHZfObIWsioA0SgCdF2eAlmqyihMQVf/T8r/x6x385vIAoIhZ
hhYxTsWZ4dUA1XmbEfZxMQPvuQENBED/zxMQBAC8M+1oDgxVjVnYlhapOHWNMDlU
1LolN2B9sUm56K0UaCpnCsrm2Jc/kzr1egmjqxGkV1dIih65W+oPZQOBqq4mAvPI
SRlE0MrcPCeRyzN4zSwqwu1o0rcCWaacPpNxnG5icluD1RPBDucRPhc8gFMmcfEq
5pgw3LU58ZIrvB3FLwADBQQAjM9l/u6o0CVwRZ6XshuJQnc7Kt+su/xyZjkYqURp
sZ8Q9xWgKI4Tv/x+IbgkU5D2vCu6FyfDpBMWsNnSxVJ8FaHCWDKLpDHxB0+RUcme
HRcpvV+HnLvJtF1V0dRB3XVtD8h6TcGuntFlKHFTKKQk4H5X+fbsUdq4ycNwgNm/
IfyISQQYEQIACQUCQP/PEwIbDAAKCRAdl85shayKgJrjAJ9S1aS1G9Vpq0kYjZHp
pFmvrw+CbgCeIgeeepmX9+n+2YEAuWfJlX2KZCs=
=Snnd
-----END PGP PUBLIC KEY BLOCK-----
D.3.169 Doug Rabson <dfr@FreeBSD.org>
pub 1024R/95C11771 2000-02-27 Doug Rabson <dfr@freebsd.org>
Key fingerprint = 20 BB E4 38 5D 89 D2 D4 68 A6 2F DC 0A DE 10 3C
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzi5GEEAAAEEAK2MWoFtSEoa6/eVi1dRiebsF+F4DnoxIaQATYfhynrLDLDL
Zvl0pfgzMWG6VvtsC5c2u549BdYsbs7F95dUUAe2JG9V3m8YeLuzC5uTpac5PeX4
2pHpniY5DDRRlgv0BpCRDOF7JmnMSp1yv5I+EFzTdGYv1CdcyFfJuUqVwRdxAAUR
tB1Eb3VnIFJhYnNvbiA8ZGZyQGZyZWVic2Qub3JnPokAlQMFEDi5GuIB213Sl+Y4
3QEBIPMD/Aqz0G5OfPjsHo+QgqXgwYfsdl5D2qEoQGj/GvJNW/+I5MeV4YuydZGJ
PbJa6dX0C9jdhlPd6BUtDKBsY6/lQns+VIufraYhalinWpExFdDYi8ONu9tPzgab
7HCvgz+Ecp5UFdbIdfBvgelfwJBgJ1486VUsC8H4TfAjp0ZXlxRXiQCVAwUQOLkY
QVfJuUqVwRdxAQEFqwQAkREhyh+Eu3QYxDkhhGwxHWl8G3WLEth/6MRUwLY0L3dt
qPfZ5MByKqhj8EqKoso4KnBzDajeKwjIeM2mzlmOdRH6ElR4WtoQpn7Ru3O9u7/O
l0ojq8PDUw0KTNKcLYuvG2qBKHeLYzpTEPRbKiRprZtB6bRSYE2mM3rY7q9LU8k=
=pQjj
-----END PGP PUBLIC KEY BLOCK-----
D.3.170 Lars Balker Rasmussen
<lbr@FreeBSD.org>
pub 1024D/9EF6F27F 2006-04-30
Key fingerprint = F251 28B7 897C 293E 04F8 71EE 4697 F477 9EF6 F27F
uid Lars Balker Rasmussen <lbr@FreeBSD.org>
sub 2048g/A8C1CFD4 2006-04-30
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBERUw7QRBADJY85JY9QB4nxv3rXAPnlW59gLmWzuuVNnKBrQsoD5jq6WrDEs
fqqU2h/JwHB06RZMm/VUSH9MnsrxpGGKbIuJ9bRn9zA4qbgP0kPCMoyb9AmyGEYx
bIp0N1PeYni64IQH3XGaycloWNhNDDLv6o+c6e+wNnRfUv1qygKhM8vf5wCgyN3/
KgxrTIo27FnrLDatjxYgHeMEAKtOpeyGk8VhkxXX7t6/sD1HPvDiuYLfM/14VKWB
ZXaWcOzhytZRFbu/DDG2sMiMFdK8Xu7a1Zsfa683kmpgqHkG0FYcS14Y8yHDU1IM
GpCRz18v8tZwW4N1npJ/vthpL1B4Hx0SUhGo2HgE85pRHdsDbhp0S6pZW2ff25wZ
ljhABACI2/zM6SbfibbyRsvJcyW/TOfnEOxHUFfqT3SFYAP79hRBsqCN8v4fSR54
Tf+jHv7uYVH2lK3zED3sXn2VCgjD3jJNLkeGB6qY/WnWYCB63YwUXk2igOqGijJq
XEVplNG6ExaQIco5vilOseqWuW5ONJKMM+iEi5TpfV1cPGFpAbQnTGFycyBCYWxr
ZXIgUmFzbXVzc2VuIDxsYnJARnJlZUJTRC5vcmc+iGAEExECACAFAkRUw7QCGwMG
CwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRBGl/R3nvbyf/xeAJ98F2AdELJxK6Po
3rTPUqnJK+GZawCfX/0jvc82JWnGwbDcpyp0+xUJ/xe5Ag0ERFTEKxAIAP2AWduS
+WfuTAqZlD2aIzyvzZPOJ7a8ZDmUtBDxbxuBetLMqC3oFMoZ1/857wV3J7Jvxx7u
LFbpdYS/0zXTjyKE/NWqeHIuGH9fDOIDuUKT1ZkEh+OzfWQaUihYTib330LwWP1s
9J8zLCJM1SdQSHVDOG9m+28JXH4ITmK3LkR3zdb/QYEOyFmHfhSqVQpZ/KEBYZ1K
Kn0gItwqDILuk4v8BvR3ioWF1Ywod6JEMAgJvwypyDlyglvVVvav8UcOYIYfyv2i
6g2EjIqmCpzaEa3m/RumCWaCLIIeZUqpM+rIfQyKcjgU8J254dFMqFYFIX7iFGnO
FVhT8tyNXolkKWMAAwYIAPrna0LxXoNVdwCyAW6pcNR9LkWsalQ+cCTS15jnguq5
V6HmMHsbAIwcXqZn6benX5g6Gx68gIrSS/c3iBMS3jiauIu/bjvhdTMLr0v/jXpp
7HjdOkgwfdE184hxVzsO0w3UeWFVhmb6sW/Wb9OtdRTj160mHj5UsCycg7Q75R20
2sBke5vP6o22CCNOZQxM615oFDgotYO/D5I8h/x08IQHlyxzgG2VXFbb/vvibOVs
iFA246TaRzxYjo4pJ7apRKhXWX9Bm6Tl/X3X41idqbkZXXcdOV8i1jjJ+8hvmUXX
BTrU4DyOHeRrKD2GRBGMn8WxhPL0DN+w2zBRpRdM7sWISQQYEQIACQUCRFTEKwIb
DAAKCRBGl/R3nvbyfw7kAKCnpl/jNh5Hx0mkJ6BEDWlmGzuvMACeM95BWxxghmcn
J6BmOEuZ+TPmHxc=
=6byw
-----END PGP PUBLIC KEY BLOCK-----
D.3.171 Jim Rees <rees@FreeBSD.org>
pub 512/B623C791 1995/02/21 Jim Rees <rees@umich.edu>
Key fingerprint = 02 5F 1B 15 B4 6E F1 3E F1 C5 E0 1D EA CC 17 88
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.7 (OpenBSD)
mQBNAi9Kb+IAAAECAOaa/3k5Zo+9i/fUPQfU4fzrRFwNifp7ujcxLNFsnMgcWeJZ
XMd6iGiomTlBSlIHeNKa+JMGPmBTRrL7I7Yjx5EABRG0GUppbSBSZWVzIDxyZWVz
QHVtaWNoLmVkdT6JAFUDBRBDA7AqRrL7I7Yjx5EBAQSTAf0WL+tTm+n0NFF2xQUO
ZfxpuqnERjNQY5KaWQuC6qk4UOVCwoBNA24ZxY7TifvhsNErMHMc6HTKGvzhyGyV
q/pGiQEVAwUQOhrmBjZ8FqYKL4flAQGcEwgAwPj2xt3ITbeUWf6HiqA1u6FiIy+w
T+GZC2Mit4UQNdjKuNJad7t56Wqem57IhOGDWGYZJoZki65y9jD0BB7MixjuQhhW
CV/vjdiX+pDxa0HG/75CNS7PVribIuhpbTFR2tG/EZh0sl8yMUpYho81yUDMeHVN
UV8YqerlqntgqVra2cfPanScFve9YYXVgEbM2wQyWnEG6q0wPL+upmoZ8ppozHfr
dVYiOonwl6QrgtzavI3tHTHtxDajMJpnQLC0rWHQRmY0Xd9xs+YUpaoUcOQFUH8L
PEp7d1OQDd6KJOV+mQ/Bf7tZwl7as3cl/16nCMZoDJVGNGCuug4vEeV36IkAlQIF
EDMEqXeGvtRXff+FMwEBX3sD/1Uf0sqHFBfFtuphKG5ZK9cz12NRANLpVf0welRX
Y/Yp9AIL9xGGiEFvlma1TN8IA50Gxgxq7cEiHDWT2Zh4Hps0VWmuH9vGwc84D6PW
JXuuPV4sdfCZnJUj+g13P7ypSlPSS8WIDVET5vG+K5m8jOQJ0NPsWGaZMGknXfLT
ZDWDiQCVAwUQL8yKYkDqOE5/AdFlAQEmFgP/VwyNP37Vaunu7DdvBblDMpfMStds
9GY0Jmhe7q1EkkGjwSJHtkn31yPwdb/93d25puCU6rZ1+qw5jKMY9qa8RvCOnnNF
vN0fOqGso+We3q2rGamjBYtVnihYBni7jCBTJ1lvHixWM5XjyGkIQsRBoh3qNUNA
I3LeH1ArE3IHzDSJAJUDBRAvxTnlxS1HbQ2/kG0BAeaxA/wPKsCrDl3qJsxrLPUP
tMfXhGBeOZWPMx1rulCknHpTgfjPpA7soh7K9zi9LAatR08sotD7oAFWslP/OR/F
DsaLWztFjSmu1laZyU5E7yCIsHgILX0aIsazYW0UoYqCm87FDzHP1kjXs7c6mgOJ
g2YIY6o3UH4azIigo37B52J6Ng==
=O0QA
-----END PGP PUBLIC KEY BLOCK-----
D.3.172 Tom Rhodes <trhodes@FreeBSD.org>
pub 1024D/1B9EBD43 2002-01-15 Tom Rhodes <trhodes@FreeBSD.org>
Key fingerprint = 2D4D 1D31 A5C6 08AA 1075 C963 C0F9 A089 1B9E BD43
uid Tom Rhodes <darklogik@pittgoth.com>
sub 3072g/F7A606E4 2002-01-15
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.1 (FreeBSD)
mQGiBDxEXywRBADtQr4venVgd80wgpOBWwSLvYrw7YmFRMcTP5aw7fRHhxmhEyRE
/1jyqt6I/uyS9irePzRyGcX/2RY1+APWjXN3dFtrcYzF1zNLld5flVzid//0bBt6
WkxH5DzCd18B0iZMVKYkVhlFibS2vp6opqoOAd5SU+oDx4OY82r1jDKavwCg/7FU
VwL7iSh6PmnzBWuXIaeFjeUD/2E5JlvQXbcCK3AbEZJg/1lk9vfD+JVl8ZcOA+Tb
JyH9MXJ+swS3wvFesjwIwIQLIx2LsecuHItmzybBMmYNLSd8RTsI1gYPLl2zqUaN
FTpgHeh1bKF3oi9nn1KywxxpZxI8s9ClmdIeBW2hNWOGJf87vwAYf4uglox89xWf
tztCBACPVVdNrAb2UOcFlwjvtcC11XkR7elLSrImJ61uZkCFQ3SNJ/nyppjzg8KS
KDwehl4X4poqDBBShyh27PF8DtaZ0slatZuMz3CcmR5+aR6b9+5gHoekNwtR/Rra
gYyTAMwdlnrh8zOd0fcpdmUW3NN531zy4Atu77rMb9JvWEz3sbQgVG9tIFJob2Rl
cyA8dHJob2Rlc0BGcmVlQlNELm9yZz6ITgQQEQIADgUCPSAgAwQLAwECAhkBAAoJ
EMD5oIkbnr1D2YYAnRcFECq5cm4t4mBmbsRnk3CCqZ3RAJ0eIsczi5W0fVRaut93
lnnnPH14frQjVG9tIFJob2RlcyA8ZGFya2xvZ2lrQHBpdHRnb3RoLmNvbT6ITgQQ
EQIADgUCPSAgAwQLAwECAhkAAAoJEMD5oIkbnr1DsyEAnR/iu0Ijqv+yqCBsiGQh
hZ7JnhQLAKDBlIB1Xka1xJBCS11HitB8QiQbn7kDDQQ8RF8vEAwAzB13VyQ4SuLE
8OiOE2eXTpITYfbb6yUOF/32mPfIfHmwch04dfv2wXPEgxEmK0Ngw+Po1gr9oSgm
C66prrNlD6IAUwGgfNaroxIe+g8qzh90hE/K8xfzpEDp19J3tkItAjbBJstoXp18
mAkKjX4t7eRdefXUkk+bGI78KqdLfDL2Qle3CH8IF3KiutapQvMF6PlTETlPtvFu
uUs4INoBp1ajFOmPQFXz0AfGy0OplK33TGSGSfgMg71l6RfUodNQ+PVZX9x2Uk89
PY3bzpnhV5JZzf24rnRPxfx2vIPFRzBhznzJZv8V+bv9kV7HAarTW56NoKVyOtQa
8L9GAFgr5fSI/VhOSdvNILSd5JEHNmszbDgNRR0PfIizHHxbLY7288kjwEPwpVsY
jY67VYy4XTjTNP18F1dDox0YbN4zISy1Kv884bEpQBgRjXyEpwpy1obEAxnIByl6
ypUM2Zafq9AKUJsCRtMIPWakXUGfnHy9iUsiGSa6q6Jew1XpTDJvAAICDADBjQ3p
OyWSFGSmZagEbqS2T+KMs94IxwdEXqLIfsS1XvPl7D45kKTN4ThEzuz2sz7gWvv8
pWTiV+XlKSgzjX+c6mu64DJTLiYn2Vdgk8VqxmDMWlS4r7nQtCuUg9+cqrfDE+vl
Cqpfy2hDI4rNwC9vIY6RomEEeq68ixmUWJsUSoitXtbVxTrq7iPJYzFmkBqWT1iK
WUekmfDN6wY94Lpbai1I04kR+/vxKdkmMAMOwv05W6+llXUz3twwuqny5ipQcPj5
i/+Pe433UEFmuNtkUNk8lX5QhuBnyhFK+nzlOScld08AL5zcqKm/yew7zSREXnHu
IzMjzAsO216ufFWqI9UDE0tg6US045P5GeY/uXRfDNb65DuGxFeisDyH/WtoST20
hn5OcS+RAv0fjKGhwTeInc9Qdl57cd8n2Kif9oBlQ9wnfWL3lxxZfMOpHJNy6+D8
dCem3EdjUI9ScJyRiwfo6fXJyZ630n+3I1UtGQhqG2TYDiPo4yqw8rMJm1CIRgQY
EQIABgUCPERfLwAKCRDA+aCJG569Q5/eAKCTPO44fSJpxA3pKV2T3D9tmLpWMACg
m9rVxuLvsLUuy0UenEK6/bBsDsk=
=C9cS
-----END PGP PUBLIC KEY BLOCK-----
D.3.173 Benno Rice <benno@FreeBSD.org>
pub 1024D/87C59909 2002-01-16 Benno Rice <benno@FreeBSD.org>
Key fingerprint = CE27 DADA 08E3 FAA3 88F1 5B31 5E34 705A 87C5 9909
uid Benno Rice <benno@jeamland.net>
sub 1024g/4F7C2BAD 2002-01-16 [expires: 2007-01-15]
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.7 (FreeBSD)
mQGiBDxFDgwRBADSAPXXRSDeS8jX0younPZ8dPSW9UBSCn9GKgyV37q6rrwaHlSm
CspUTL/92h92nhosLkNa8Xq4P7oZJ1NUijPGIXAxuwOjkE2lxBP+0Kxzkjrc0FF/
ZQK6cqpVjtrTCGBo3+im6v/dw2UnmILM1GrV+TpcmTvyGMJjXT4VB+xtiwCgiv56
PVM6qCrd5p3NXlveaiYoXwMD/Rza1QobPGHlpX0hkj7bPS0YApNEY8F82yZ0vArY
NHiQ7lUW+wLWL3+/+h/O8T6tjE7FeKdoI9+U/EQ+3tIbUVpDWbURJtJVyCE/rD/M
9kDjXxp/74aICSIlRxPMA8AGAP2Zv7a4GZIlhBVmDu3tKlDvatUiRU9HPACOZqQU
FpR/A/wJRDr64ICA5/N0qB3e9Rgxg66LcjFl40jwM1Hd/8c6JlLE/vcdowcqxHPd
yEgKZoJoKYN5Y7WXnQUvrkD5O3b68MGfJRjlvxCML+yedD0lDntzJE2O8NQdATnB
cj1CraaXHvtN5sddw8Gtih6/8p835fcsQyr/V1BKhoTGCTtkpLQfQmVubm8gUmlj
ZSA8YmVubm9AamVhbWxhbmQubmV0PohdBBMRAgAdBQI8RQ4MBQkJZgGABQsHCgME
AxUDAgMWAgECF4AACgkQXjRwWofFmQmD1QCggnxa96nN9TOz2aLsVQ2qszwzBBQA
oIHKFC8JXYP8FH0fA91zLnceWeLDiEYEEBECAAYFAjxaJggACgkQo8kg3R/NoURX
hgCfY64+KES+rcptZLiA5hoAvX13gsAAoMOiUC/0Non6V/srofbjO8HFM/IziEYE
EBECAAYFAjxYkvYACgkQDCFCcmAm26bQlgCgjapRIU7hMjz5HBnZgNr418+JVRkA
oI2DYOP10H4gBZPwT574rkvlrXiKiQEVAwUQPGs/CGfCgI8zwWJ7AQFkGQf+LQO4
gNf0j9z/LIyKA2mCT5C8Zjh0h7DmRxiiU+4N+bIUuZy7hSVlyWnJMG1JTKMiK1Ss
nUReCTkNM70rBnxOQV3BlcHksb9ZsrECy8icfslRJGpQmQlrUxppHSyb7UJh5d69
C5xpDEFUBpTgSZw5JKDOui8gZL14TcthoP5vuj9geo+DWWogyYq0umiaZSDzGeSa
ST6+ebL1ne+F8hVdxSHcTChFVfrHDWdgAhkGBantTsfbETTwnBHH/k+INu6LxBkC
JAZMw50vKs739Z+Zxx/gSRd2CDnSlUsoMgJGKLX5MGWmCqEPw8uyBT/T9t8GOAg+
sx5XjhBhe3PmVPTKNIkAlQMFEDxrQDpVLh4uc9KIpQEBgk4D/RaNrMtwjUoITVdY
UwNLGdh2JC2d3pM2b0DUoL1rcXwctmc5z3I5co2c/r9k00PGzWv6D3LYboTd/bxk
lPvn+6uIYmisl7CknFnCLO7lbILkEBGpQHE/8Z7EAI2zUZ/bi3VKcKAFooNPv+2p
HteKkkVc6z82BWCI0bzH+v/Z0Yu+iEYEEBECAAYFAjxrRMMACgkQUgAclY4JAiON
BQCgiIf8HrEU/qOoM9BMRwW/1RYeVhIAnjWu/jgHWJVvdPpfG4UIJKpk8DaliEYE
EBECAAYFAjxrRR4ACgkQjDKM/xYG25XSygCffF0SdJ+WNXkxspiC2BzQAldql78A
n27raDOotEaHxv5/qatznaWJja5UiEYEEBECAAYFAjxrS7EACgkQGPUDgCTCeAJj
kwCfa3fOqwWcLbVO9we8um2rkZl4qZoAoKLH4FUXz3qldvVyRvhbSlDWGwP0iEYE
EBECAAYFAjxrS58ACgkQIfnFvPdqm/WWRgCfaGeUlRGzWSQQZzg2pMz+eC/yFuAA
n1+qQO7UVEzxTnoD3hAg1T/mLsaDiEYEEBECAAYFAjzPTrEACgkQzerIIuwxO7XE
yACg5rmr96yl/M/qQ3DIFrx/Md6eJYAAoOStOGPS/9Fly4Dv7T9Cx7Dsz4QDtB5C
ZW5ubyBSaWNlIDxiZW5ub0BGcmVlQlNELm9yZz6IXQQTEQIAHQUCPEUPdgUJCWYB
gAULBwoDBAMVAwIDFgIBAheAAAoJEF40cFqHxZkJlowAnA4n58ngka4X6ycZCpXo
YNRu1R8iAJ46BzE35MLJtgJQztGSnWngoLhCVohGBBARAgAGBQI8WiYKAAoJEKPJ
IN0fzaFEho0AniKI34jtQurc2v0PlnTAze7AKRmmAJ0Qfp0DhFEbuWqv2dJbJCnh
9wYOs4hGBBARAgAGBQI8WJL6AAoJEAwhQnJgJtumuDgAn2NODtyfzrThSVz9xls5
A4CrpDvHAKCywVtdpH4aYFNtHZPt48wxar+mgYkBFQMFEDxrPxRnwoCPM8FiewEB
nH8IAJ6w9TU1kRNm4ifVR9yp3/FMBZXNnor4FykOjOZISowfFGY3wwNWGnbCSa7B
5spkDiqnBFwMwbcTQXo56OEWNAir0hAkUEQD7GUMcZmEWy8ZaQIedN3SHhydfR6X
aNar7uHyi0yi19sgq1/Jnu8DLsPio75gSv1h95anIvoGE1YpkTNGemQ6SyGs7rQ5
7QuYXqN6P60cJLC0kwEZ4YbcN1OuZ6iSj31TDVp8EzDCkFm6eMQ0wI6UPpdlymxE
gfFAV3oDlj4ZG6pzNw/ZcvQFeqMNgM+c0j+omZsFlPvW4wfZAV+cevVV5ATosYSd
PMas2WxPXG7pAwhyRIgyq33/09yJAJUDBRA8a0A+VS4eLnPSiKUBAWl9A/9kN+3x
nxr8iU8sZMef8PpFMUNj4gp5ARDw/Q3Sx7jlGJEyuLGbeH0Zu/mTvpV6vQzcm3NQ
EB51WQx8EmizIbtX1PfpyRgKLOXGll0M8D0c5JOdZAAAXYVa6AtFm36rZ9dbM2UM
XGNClNt9zXUXK/sufCVC1z6vm87I+RJOUhF91YhGBBARAgAGBQI8a0SzAAoJEFIA
HJWOCQIj7r8An2XwJ4WHnootgfqCUcIfbr4y70QgAJ9ngcIvPy1q8UKMdLk/Y5Ti
V8TlE4hGBBARAgAGBQI8a0UkAAoJEIwyjP8WBtuV9uMAn0BBM8hO1iCUp9UD8bQ3
Ptp3xrC1AJ9Bn+yVzTVl1x55X71sglUWxtQixIhGBBARAgAGBQI8a0u0AAoJEBj1
A4AkwngCupEAoMzM2E10s/451EDjYkdr1fKo9tV/AKDfSYJ2vOJx7JzciRfj5hQJ
v+81GIhGBBARAgAGBQI8a0uiAAoJECH5xbz3apv1pQQAoNKsi+LOvlXM2GGkzQoY
Pz9xDxs/AKDgm87TPdaMYhI2P0AzCTHJenYalYhGBBARAgAGBQI8z063AAoJEM3q
yCLsMTu16gsAn2OJb5oK/QYgO0EpREcYF6EVOLegAKCipUzr16GCumxYGj5cEngb
7ZkFfLkBDQQ8RQ4OEAQAu5zqbppTM975ccYXxCUx2OECAdzxoSgsJe3kunbvZOSy
i28t4V+H1+54ks8AOlihN5XBgZAR0ohJ7RTe/5l/EV9rZcY+Tnf75UskLbjifzZP
Qxd9zYZ2sUbv9oJnX8ORiphIRKlfVjbe8tqdaexQ382FQwUVcC+yc1u2Ye5vffcA
AwUEALlq/J7TvHXtjeY4BgKsApAxGzyf4roPuXADurCLoaXrUclUsU3KWOFOToW+
rxQQYAjz1T/lXSOGVzDCaQf6IVIWBYEVu3ZWTI8/amp37hoLdiiU/x0VWVkgjyfX
VTdIdsmnDaoTAVq+r+JyIubzRcr79SpOEIo5bPl+km/6R/S3iEwEGBECAAwFAjxF
Dg4FCQlmAYAACgkQXjRwWofFmQkGSwCdEHZJnes6qzSKL6bXiBr0veCSQNoAn0PD
YbCuiDguaEN052KDrSoDvk4S
=L0S4
-----END PGP PUBLIC KEY BLOCK-----
D.3.174 Beech Rintoul <beech@FreeBSD.org>
pub 1024D/68B487A6 2007-06-09
Key fingerprint = 2B77 2860 7B8C 1B09 663A 6951 EF89 03A9 68B4 87A6
uid Beech Rintoul <beech@FreeBSD.org>
sub 1024g/018C35E9 2007-06-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEZqQhQRBACP052+c4mv7GwTbGp5vICUWvoH7a/B6+SnI0cbusi5tNbxBXis
Qdv3Qzm7hqq3FlEecvtOx+w4vxbUJ6tOQkVwY52viEAi1phpkgu1ZQVxzY4Zv54m
46DhdkfayKxma+GcV3dkxZb7uGI84ZqC/gee7wuAHIhhX+1WGRcHTZk6PwCgjl9s
38m0OJNsmX6ZCnIZFZegz1sD/0i+A3d0sxS1lfT2dXM7fITWcU48dFuD0mifiv7u
jZUqWPOTeNYH2gFCoteia/rWVwykPivKcgAgisQjxjClqYON968m0L2mv9EkvIGZ
wqUR98RKkrOSztf3hoKl0NRaIsL/TzoHR3+9b3fmcuW+J6+xAI0sjlLpMtd9Gfpz
XMnQA/9gxZ/I6A+ceAgZ7mIlBmbVbcquQbd95sVFV6yu8bI6YBLHiO3MwJi005H5
OI95GiUYr63m5ziq5xRr6ymwUX2ytiFBPRE62GiyJ6YVmd6+GwYxPKXdH4KwtRdB
0WynYlmTQAHTZFcDNJprCTWbJ7d0Ov5/thVY9jl62ucAOLw5/7QhQmVlY2ggUmlu
dG91bCA8YmVlY2hARnJlZUJTRC5vcmc+iGAEExECACAFAkZqQhQCGyMGCwkIBwMC
BBUCCAMEFgIDAQIeAQIXgAAKCRDviQOpaLSHpvdwAJ0XqKSZtg7aIRRYdr3tSSz5
ZNO8dgCdGH9GLC1voQezIm5OuAo6BGMAdRG5AQ0ERmpCGBAEAOJB+GUbHoawxI91
gCs6kY8+LPXBjCimr6cjPyfCJqbMx7rKzRfGsLjSIo4zoPnw7IlWDGy0CYUG+OAJ
qsnxTV2afDgCF9fKA37B9Ngh1BwWrOU9JdwoqRZkELGn03LhaNC1SODKjST86hnh
YyfN8J4tmFvnS1rAHSHUsWeBXkU/AAMFA/9dvGq+fpA/Nqkf591NjbsJwvVvFcq/
5U6QaVT77zopQR6N3SgoOz/S1eldXOpOtxCQ86KO9WxRfrodH2iQiBrurK4hevVn
sJwzzc8414k228u65F/PAjjwM1QbI+ttq+SsW+mphONRyVD6HsFYcNOgc2if/CUb
JmM9UBpnWF/k/ohJBBgRAgAJBQJGakIYAhsMAAoJEO+JA6lotIem+RwAn2SyuyLf
uA+fyTtZY7w2HSdlJDDnAJ9/RYdLgoCwn7S/kXenWETJa1pOxQ==
=HmLU
-----END PGP PUBLIC KEY BLOCK-----
D.3.175 Matteo Riondato
<matteo@FreeBSD.org>
pub 1024D/1EC56BEC 2003-01-05 [expires: 2008-09-19]
Key fingerprint = F0F3 1B43 035D 65B1 08E9 4D66 D8CA 78A5 1EC5 6BEC
uid Matteo Riondato (Rionda) <matteo@FreeBSD.ORG>
uid Matteo Riondato (Rionda) <rionda@riondabsd.net>
uid Matteo Riondato (Rionda) <rionda@gufi.org>
uid Matteo Riondato (Rionda) <matteo@riondato.com>
uid Matteo Riondato (Rionda) <rionda@riondato.com>
uid Matteo Riondato (Rionda) <rionda@FreeSBIE.ORG>
uid Matteo Riondato (Rionda) <rionda@autistici.org>
sub 1024g/A040570C 2003-01-05
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD4YMjkRBADOT7Ua8/jbuJnPDzHt/HQu07sfRHZbf+WmX72K58Tpjz3kswox
+3LpnqZf2B0s8PZzLkeFBH0fdSybFT27CnQ6YrMhYM4rM+VyN035xmnvAWmkiYp/
iyTYWFS6hHRy0hGZYDcSUHou7xfoHCF7bl7hsONArYadf9yS9v/NYlfrewCg3NDN
X9gtr5/3LC52PYscMIwG4F8EAMJe84ycNFvlcuwiO1BPESKrYjD++8pidYGk66iA
FjOMUBtcbgQ3QBu9/lOM8S6DHa1Cs12nvbibZJtURy7IJxCEv0MepJBWPNimoHz0
hxV3ZF/BIulRre5RZ+pFpeYCKXVge3iQ/okjuKHod/VnHrxEXjWw0LQYWNyQHUZt
eH8ZBACFEieAhOsM7XC4MJJqxuwnFLBLmSPwaJZs5CfRxmnRp+up1Ez/aN4k7b/r
rl0dpCLOcQ+sI9rikJm3Rkkdlo23UQb9kq1a9FDEUjkfz/sR9RIlxUbaOaGBEJaB
OItFpjXMKKeYqKVbvP7PBmJz4jIim3igre8FxwGbmk3YDW1w97QtTWF0dGVvIFJp
b25kYXRvIChSaW9uZGEpIDxtYXR0ZW9ARnJlZUJTRC5PUkc+iGcEExECACcCGwMG
CwkIBwMCAxUCAwMWAgECHgECF4ACGQEFAkbySp4FCQq7S+UACgkQ2Mp4pR7Fa+wZ
PACfevfrVK+lGi2HF7EFmXiHSeoQ83EAnjfzxq3OTEZIu12R6dS8KGbHGRjSiQJI
BBABAgAyBQJFVbmJKxpodHRwOi8vd3d3LnBhZXBzLmN4L2dwZy9zaWduaW5nLXBv
bGljeS5hc2MACgkQJknmKMXTTQWxxxAAgHEDKMojm0Ri4FjGuXcIuF4lcIRzm9Y8
fRfQA9whGfcrFbcJ6D3JzTqk70lc1bs4aE1ApBGgLKGk67m5RzK0yFoNw2iqgUma
iOSBwsfzqLj40cti2b9MFcQ+SE5ncPAOhQoSIb29ELMi++71vuI+1eiKNSBvKbht
kEHSlvrCufGujefZbfWwn+0NCMlCAuABJcR+WXLjjzaKo1FDdue5MNuko6s3YovE
TLjsGfVQZbYdvVD8cRpPlRfd6SR8rWN0EhdBIz/mqsathtlxdDtm4One1Z2qXRsg
eB/orr5sG+eiBXpnQjQIZ8CnBF+j7uoxPA5ewu9iiIytD0LTbxxqtHZkbZ/4ZDXv
gIPTKXE4EOSSBdcp33oTxGiLidobgun6i1at0H4dZX0n+iqSkAe+emEUVsXv+xh2
nu4e34Llke30az7I7UZFZ5e5DPgiv/iN5tAfMMosBnuaICScnZKCyT3xhdHTyj5P
YAtpq/NJYqoAbvu81bddTqRCZN5gIfKfrYWreYWEDawQVGxET7/LnJMDAgXlRj+i
qSsjP9tKlrr1LowfNdM8JEJvdsLVRlTloyAG6UzyiCpEycPhSy/pyzfbIGz/FpFs
rvCzkUk+FQvXt9u0zmzmoOC/HFkqk3SNIOMkKpg28KCvbsyMdnv953L7EVLqcQDX
zWxZ5UeKnbW0L01hdHRlbyBSaW9uZGF0byAoUmlvbmRhKSA8cmlvbmRhQHJpb25k
YWJzZC5uZXQ+iGQEExECACQCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkbySqMF
CQq7S+UACgkQ2Mp4pR7Fa+wMYACbBLQZlgUtb93h7HhziBKj+NbBoPIAoMJAvSGF
Ve/2B1cyXxpSkx9a63veiF4EExECAB4FAj+S3TsCGwMGCwkIBwMCAxUCAwMWAgEC
HgECF4AACgkQ2Mp4pR7Fa+yRagCdHcaj5oQFCv83U4TS4nVKibpkocQAoMBsgZpG
zD6ri2FV0s2WykTXD8HciEwEExECAAwFAkJveugFgwDghfcACgkQymi72IiShytp
jgCg22Fo57NbaMAtspNIK/jmmsqPpFIAoO71KJGE9W/PceZcXKOKyjyFeIJhiF4E
ExECAB4CGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkORjCMACgkQ2Mp4pR7Fa+yX
LwCgwKpb012gu08aAQGGdX0IIr7zrPcAnAk9J6YWMDy7bmXfnAu7iyupjvaziGQE
ExECACQCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAj+T9xEFCQNc+FgACgkQ2Mp4
pR7Fa+zWVwCdG70X7pGA1SCP2T55DoQko5ns1nMAn1N8hp1preGr0EgP6wXReBy5
KkixiGQEExECACQCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkF1ZOIFCQU3zqYA
CgkQ2Mp4pR7Fa+znIgCgyYpGXQhqvi18tiODcdtXVo8UUekAoNPXvmATDr3UPXEj
iyvZSyqjV3R7iQJIBBABAgAyBQJFVbmHKxpodHRwOi8vd3d3LnBhZXBzLmN4L2dw
Zy9zaWduaW5nLXBvbGljeS5hc2MACgkQJknmKMXTTQX7SQ//eSi3Ktcgnm1Spn+g
ICP1S26EEovi39JFCC0JXp2U/6IGAn+/bHMMVbu3CkWo0CdfPnpmhA7XKj2SQ0AJ
6ndd7zOEPJBVOTsMTeoOEGj5yE35POrD8ZT6SXTLKPPnWMjTfB25D0+/tSOCONwR
lZP1FZrSu95tvWH1b6zYlhcydje7+F1pmdrwEFrqFhHF8GIUBSI+lIAOj1GlWvT/
QII9XExwcMa9a1Ay/MLVaNoPIXLBj9nFf1FL39ekU0ou8uo90rsbgJEPMdmnUU4R
j7BkSHFiFaDOsUjNMUhiLk6xFs85JOedeo0DM0RDV7gisf7utVATl5m8mJ8ZTU+F
oLiGYCM+yY93jph+Dez0s329eQ3uxlQaZzZ6/thynflkVQ0JkqLuXo2weyGF3fEI
l72tf0oqcTsnQE1h2zC8AwQbsj5kdDNjYwf2MfBZ6jHxe8Y6a6WlXMCjcgNsfT7g
B/YEnAVYt6hpXHrMVuEeUFyLvEaoc+gRXd0ePMTK8Zc4T+Y3/rs4DnJHtNW/+Rt7
wIpXULF1ISRbtKdxiVINQD6+y5SamZPYJwysbmScbHwUu39Y8zQa00PxF/pw+Xve
yeRrrCnijRPfYJlDHQSvNUu+texd1aix0mK3T92LAcI26uFBGVJvfZ5gJTLB53gb
tgktN+t3kcTmnvGjVJ37+DGlpTK0Kk1hdHRlbyBSaW9uZGF0byAoUmlvbmRhKSA8
cmlvbmRhQGd1Zmkub3JnPohkBBMRAgAkAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheA
BQJG8kqjBQkKu0vlAAoJENjKeKUexWvs59IAn0tZPGloXvFLMhQHxbqYhVXJkVPz
AJ0W89l12gTGlB+MnQeC1VchQBgTqoheBBMRAgAeBQI/kq+KAhsDBgsJCAcDAgMV
AgMDFgIBAh4BAheAAAoJENjKeKUexWvsWr8AoMQFD7462JRnnXg2caQ7G3EP9hgy
AKCayAdgWjzEbAJbcOYNfudR4V6uz4hMBBMRAgAMBQJCb3roBYMA4IX3AAoJEMpo
u9iIkocrhV8AoN4CvGLukd5oJNCfHT6uZvXqmAKmAJwNFLS2ESp/hZpC5DuB6xHW
WLo+jYheBBMRAgAeAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheABQJDkYwnAAoJENjK
eKUexWvsqsUAoMJOzTLaBjIE0KQHhbJp8Z0K7DwVAJ0WXsmiuIyyiDMwgqVrp3nb
82vD3IhkBBMRAgAkAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheABQI/k/cUBQkDXPhY
AAoJENjKeKUexWvsfiIAoJyiBsoQQTfYRfDg9gifeiRX5jHwAKDBH+Ye+8EntSyn
bNDcGXd3MOMuq4hkBBMRAgAkAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheABQJBdWTi
BQkFN86mAAoJENjKeKUexWvs4VQAniVyUG2RohC5hynspp6EPOi9etLwAJsEuoEu
09YwMJOtyKy/l3V9/h83iIkCSAQQAQIAMgUCRVW5iCsaaHR0cDovL3d3dy5wYWVw
cy5jeC9ncGcvc2lnbmluZy1wb2xpY3kuYXNjAAoJECZJ5ijF000Fk8IP/R51/Pq+
TOcmQCHuNnw3gA5RykFkgDli60uaf6WVCob/acJ20lgEXgC1to2JdgNqDOrmZUcm
5AErwoPZgB0rS3WOpJeS1Sl/IbOWZpH+G1hwlgOjLK19wwCvU2HH9RdvtsKFIExn
bVgxUI/79VJyan0ufua8jtd7HRnpX+WDTIZZIYQdrKsKYsP3Q5vJigvuLHZ6Kb84
uF2GPcJYaHuryxdhiBliQJ7gUtYgs9Dpel9lDthqv/+TH/+xhbJ97+yu59UK6p/3
O+/ozgMnfZj6ckUT1keFJGVTwRK6jYUjBvlUH9RL6Q10Iig02K2IndKbyGeX/en7
e80sJ5vrtOkpbWPFI5tZloAEpIIKvvyVakgAPTzA9YatDNVexFu/23zGEQZ/bvD+
WHn4OjEMaFmAz0EmjnSRxEFVVUfm3zvCest+Qew4kxDl1cG8EsQ7vbiZQ4i1rSWB
u4lA/0wIT6O6WrCeGXAHIhLY+iRDWuSo4LyySpkRj2WGISf772dRKEPWc9AwzXTU
OZ/ZzlefpdLs7QIPhVew9J4i6vsGnJKIxaWfSb/0D4QyxTbs+pORmZn1dTqYkxYT
m9B6/Bz3SsZX4DrOIJEp/yHKN+qIH73/7cHL9H8PcX6q/q5n6GyIPAbz3aPKr/ec
Y5Q0DP7gGItSTAzpjfls1dps/DTq/YvHBsrltC5NYXR0ZW8gUmlvbmRhdG8gKFJp
b25kYSkgPG1hdHRlb0ByaW9uZGF0by5jb20+iF8EExECAB8ECwcDAgMVAgMDFgIB
Ah4BAheABQJG8kqjBQkKu0vlAAoJENjKeKUexWvsK3QAoMZl84gOxoWEN9yCxDKi
wWfwwbO2AJwJIJTsmvJWMqN8O67ykXLUE3B6ZohGBBMRAgAGBQI/OBUqAAoJECGd
tTlfS2RLHnYAnjevlZGhqb0TGiwacsVa0kP8fTXFAKDFtE8lcNjmPoFUsY3Jd29S
YZmBXohGBBMRAgAGBQI/OMYJAAoJEBcHKSX3WQ6BYkIAnRyaV9rOSacwSmiJqsG2
JogEc+5qAJ45G4hGEZ+M3PF50B9TdlNChe1/cohGBBARAgAGBQI/OVROAAoJEMB3
A9Pg6wbU6x4AoLEH+a5o3f8VgazKssxOo/dWANQsAJ9Mb7pvWLO80U9+Genk4Ppf
1Q0NO4hZBBMRAgAZBQI+GDI5BAsHAwIDFQIDAxYCAQIeAQIXgAAKCRDYynilHsVr
7F/zAKC13N4TYIfRaDrde9bVstyFmuj1fwCg2rnQElfuX50qo40uUHjyc9VW+giI
TAQTEQIADAUCQm966AWDAOCF9wAKCRDKaLvYiJKHK3whAKDu+rK7djTGSL4PvnyM
4OuyuE3J9wCgsvrckqSARKEYK9t2vrw3YDFtdUmIWQQTEQIAGQQLBwMCAxUCAwMW
AgECHgECF4AFAkORjCgACgkQ2Mp4pR7Fa+zCUgCg14T+K5reEK2My/D8FyAeAl+W
UewAoMv8qnGVp7UWwNuez3F1zx+mW6QMiF8EExECAB8ECwcDAgMVAgMDFgIBAh4B
AheABQI/k/cUBQkDXPhYAAoJENjKeKUexWvszIEAn1IOi7barh7DDNvdtZ5nQ6V3
1XmDAJ9Lh/KNe/dgiX6GnqA5ti0fEwB8N4hfBBMRAgAfBAsHAwIDFQIDAxYCAQIe
AQIXgAUCQXVk4gUJBTfOpgAKCRDYynilHsVr7IKJAKDU1KY9xWJZmmoLaHnOjNcM
t7OsewCfVaLCIj5OI51InSN6rube6W5gmtWJAkgEEAECADIFAkVVuYgrGmh0dHA6
Ly93d3cucGFlcHMuY3gvZ3BnL3NpZ25pbmctcG9saWN5LmFzYwAKCRAmSeYoxdNN
Bcf/D/9erGdyo3vlqA2jUIOQRPQMNCS/71J+2CFBSmJ2I9WmeFDR/aMFSVrd8AQ8
YmgaeC0qA9Ql0IYaT0dTfd0FSb/vwFlPsd0JxBSTAtnNVxwFm70WT/Ny11MDqveZ
wbG2/k/JKICDQ9bgfe5CVwTybrtl4scvTPDSKIPUG73BDMurgRsUF4zHXbzo9ltE
O/b2++sq3Y0f+V1IMMMGGWMU1NF1SbkbQyx4T7jGJUPbDrMF7lmdZKRW89EIxYQ3
jLPVB9A5zksSrc7oWSQ02NUjLffju4wi2nbp4SVYmkaL1rDP03j3QrCVHA76wtNg
3A9Z7pwPmau17dcvFxmrc8VTiiaIwz0ssClKMcf19qeWNDvnD8Yx/4xUL5QpJe0Q
pRzY0kI8IWhiLqZAB0NveemmIZT3OoeDBXDMXa8d+WD7N8O8LZkjWqKDAP6aMAlZ
+Vc6Rr6xkdvQlZejMWqNIgQTnfi+DbEGG03tCFTiH+ymssuph1yz0EaP3wwwmIqL
O6onFmemVfStgfww7jRifnpeD3jWKicgL7PY6k39Lsn1WTBHXrCM3nIfHGn6toKd
oPMUsf7tCKcjEcdpzWih1lEbBwRK9GExXeKw3FtEToJJtyCEWVIaWPR4js86/NwQ
OhWpIZqYLaGMy3OtNdTYfvDSKQmoOhfU9Ma1MdgFreifHUYrO7QuTWF0dGVvIFJp
b25kYXRvIChSaW9uZGEpIDxyaW9uZGFAcmlvbmRhdG8uY29tPohkBBMRAgAkAhsD
BgsJCAcDAgMVAgMDFgIBAh4BAheABQJG8kqjBQkKu0vlAAoJENjKeKUexWvs02wA
oInfOAKEsujbPvxHyAoNefHdiNY2AKCVtKm6Vjqri0BeL/h8Zj7TlbwbJYheBBMR
AgAeBQI/krBsAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJENjKeKUexWvsfGoA
nAvDjfIQkf5x9in89dp9VXfRmSZNAJ9QApyIuk13CyHMPDqxhqlQM0s7TYhMBBMR
AgAMBQJCb3roBYMA4IX3AAoJEMpou9iIkocrkfcAoJUuC5O3oOh9dEj1eSjRa4TL
CqGQAJ9Rxi3yVAt8CQKEtEDaGfkKUWYJj4heBBMRAgAeAhsDBgsJCAcDAgMVAgMD
FgIBAh4BAheABQJDkYwoAAoJENjKeKUexWvsLe4AoNosKkNksqXhyibrBRFoXKeS
hvngAJsG3JbaSNkEaGAlRjANxb53RgOF7ohkBBMRAgAkAhsDBgsJCAcDAgMVAgMD
FgIBAh4BAheABQI/k/cUBQkDXPhYAAoJENjKeKUexWvs0YkAn3Ze1qRLvkLEo4A/
akWlR/Y4uBHMAKCxeuxG723VrkVJfPAdHlkulZLQtIhkBBMRAgAkAhsDBgsJCAcD
AgMVAgMDFgIBAh4BAheABQJBdWTiBQkFN86mAAoJENjKeKUexWvsETEAoIZu0GS0
fCx5PigYz8m0lWZihOgBAJ97TOswN7T3G4Tx5niJ0+cW++L6TYkCSAQQAQIAMgUC
RVW5iCsaaHR0cDovL3d3dy5wYWVwcy5jeC9ncGcvc2lnbmluZy1wb2xpY3kuYXNj
AAoJECZJ5ijF000FHjMQAJklF/IJJx+XyWGTYjbJ2FIMEQRxweqpK91sQO0nOKhw
XLcCEagGbhKWz8rwIOb3SOCeLlPEzHQz4uTlk4Kjd75DLwCYhbNXlMye2UqZOKCV
Je850WFWjexj9VuK4kKl2y6Jv91h2W5aSrJuN/aUdDc4Tf9dZNa7ljP0MBsdzUUc
PuSCazbTcM8bDAPWjsEBC8CR3uJkc/a0OmuzAtoxgOapySNzxvNtTHtrJuL3fTGy
CisNTX3qNhLGA+NLCEGph1YVxE7Gwh41KGbtaPDlKPONCjjVQFguDI+E12i5qM9o
oBWx0jAjzkvvJILRjh1isWvttO1MFTu8d7sxcK9Pbw9rWW+wZoN9SQnbbV5NTBpW
IAZSkkgh72DuqWPEao3QKWY94vS5bam8UYmgFkWSf3jggTjZlvMAfJKjDIsOfWSF
uLRfzLWa1Tk9JeswRGP/4Hr2pqWovt59Wk+oG6qaF0MusgK3idvEYLtu8KhxJAvm
rz45OqjZuybGQash/DTt2rdfnEDHn5Syf9hscAf6cg0b8b9ORrd4MdZ5fYOP61F2
JY22KVAf72PYxEUPsjMxXDXWyqV0AgCecbM8Vv5NEaMqxtSK1idlD4f70TXyighn
5Gdq0Fr+jbGLp3dkYxZCxrkBTIJIMCuiEStQZ78y68nNE9ThIoxIORQR5KmNXBjN
tC5NYXR0ZW8gUmlvbmRhdG8gKFJpb25kYSkgPHJpb25kYUBGcmVlU0JJRS5PUkc+
iGQEExECACQCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkbySqQFCQq7S+UACgkQ
2Mp4pR7Fa+zQIQCgrG4nyUqDXlwZcM4EBJ2P7oUv81cAoNa2aYB53U4FQi2gI0Bj
5fttZQlWiQJIBBABAgAyBQJFVbmKKxpodHRwOi8vd3d3LnBhZXBzLmN4L2dwZy9z
aWduaW5nLXBvbGljeS5hc2MACgkQJknmKMXTTQXp8g/+I154/0tWtidEDAS5cYZJ
ywFGY2LLjmCrT5AKktJfGJ4/YnlZXsxsS57iMRDSJ9mvKgMwwd/iHvJI6m0cXws+
ZDyij4nYYk+48//MNPkhbe6s/3ttaEwAT5OZL1CZ9YY44GGsWDEndgDhMvdZudWU
Ydgm9fdH76ixEFVwqcBVxqyDIOYu8klow93jH7rhgNs3IjuM+y914BpYmyw7wpEr
Ob+W3F4ZzYB+BhlBUd5cLRekEsKQ7Q13N/u3vqpDy6Se8NZDDYZwb8BWOOtBt1gd
g7UOa+FkWZpNh5DEvTm1+PXBCcApIDM8MdVmc2pm1D/xNn3SVhO7qBNgEjcDENSk
DNt+o9elcuSyxPj4ENJFVEKDjbPmGY2B4lsL/ysJOwGlbVu/dvqllzRzk2UhJo21
DrEBrRUmjQoGIuVXRxsbV3r6CG7yRZe7KOz/RJgLzkedM7JXsDeg65H20cNEqaKW
WHL1CD5O44fAy+2GtBtv7Uwrz5wenDPqlG1ZPb4QldzLHtdXz3EQihE/TBuOTusD
D4YGZQJ05dc3WOslKLXknfj3tYTV+eRpTCifThuI3/jgHr1JDgcRW3e3hiZnwhwI
EwJL/bLvZRfwfVmu6KLGrokvbGa3eDl606tv8r05ilkQdvY7stgVZjqzFC3/dDXp
3VE9e7qvslC880Yf5wQLy9u0L01hdHRlbyBSaW9uZGF0byAoUmlvbmRhKSA8cmlv
bmRhQGF1dGlzdGljaS5vcmc+iEwEExECAAwFAkJveugFgwDghfcACgkQymi72IiS
hyv7pwCg9RhZbE1Fa31gcBbJPpK0Lo5UePkAn1ibjShq1wbEnPE6NOItONShONbp
iF4EExECAB4CGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkORjCcACgkQ2Mp4pR7F
a+z0TgCfUJ6QjuOAmFbmPFyhuj+ZvKY9i24AoIP7KXnjHB9RHCgu875J6BcddZCP
iF4EExECAB4FAj+SsIoCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQ2Mp4pR7F
a+zkIQCgqEU9XCBikHsADZ/U1zSzXnV0g6UAoIBNduGdRhi6rzB5N7DvLCX/kpCI
iGQEExECACQCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAj+T9xQFCQNc+FgACgkQ
2Mp4pR7Fa+yNhgCfV46eWVAYlCl2d70JQtkx7RGzwFIAniU8lKj6gqc7CJbf2fQl
MDmic0qXiGQEExECACQCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkF1ZN8FCQU3
zqYACgkQ2Mp4pR7Fa+ycEACeN1Gu3C7DgloRXTx/pdJg5k8T1bsAniDNS1BHtKvs
1fAcj//3zOJiaOQsiGQEExECACQCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AFAkby
SqQFCQq7S+UACgkQ2Mp4pR7Fa+xMxwCg2fS7iw7ma8MLNEKpl/LiF/j5f2wAniU5
ZIi1EBdSmYS2K2CXe+1fJQc+iQJIBBABAgAyBQJFVbmKKxpodHRwOi8vd3d3LnBh
ZXBzLmN4L2dwZy9zaWduaW5nLXBvbGljeS5hc2MACgkQJknmKMXTTQUmOQ//R9AF
t1oVlCDWvnZglRBHnhDmmuRGBiZo5xVVLBXLW6Fh0OJjdfTkad1zMI02JxwAqrEw
PUODmlsDGOJdGuRSA0J7pVFj7frld/xhFHSykrZFuTjRyLqSETQ4kdwRGyUsc/x6
V1m4Q2UVdiVfb5hBOIXT/vrqE48d8Bz4VSk61MMQpBf6J7sQQIE4DyGcBM4QaXM7
xuN0yQGIE8fme4GHGkAL6D+GqZzJHFBOBtW+/Uxd7UKod31H061Z4TqNYp2OApV+
gvLWeUA384/vtCx3z2nqKXkJ5z6ul3lKdslh3bR5va0kOGkT+xlnl2rJEovVMf9W
iEosXXwuZw3MAsI43I+fGNlHbpj+B0atphULa0A3Td0YJhUtiY0MXkXBhllGbUDd
CxsdPDsick27Ju8Ubebq5baXT4dnjHHsOVUddUC3s7EOYmPtkXNRv03EynvGItim
Ix2RngIJSk2LFNVCjXLXBxZyIEPXp44a0gniwAVzFWZA/eORVxvAyfRqBDl2D/sH
0V/mSZ3yRYZd1+hisXWO0HKrQjae3pE754ij1S16PN9/6om1MVk4GCFoU0dsna4Y
HiwbGqIBkEMdCtynfICb1AoEWkvD5L924kGCeAU42jbGBA97vf9tD9D0WAuoeUVs
xXATHED+QG3uKOCETOQVIBaVOndG94lFuD287rG5AQ0EPhgyOhAEALj7rmdCarMP
ZyjXxYtC5PtujHo2JKovJnEFf/320shI4uekmwWzpD7wwKZ5K/0kEVpSsleiRwl2
fbMHkpIWtNv4hmyp0tiNBKes4ZEU2n5v/6mIfucinb1/dlOAZ9A2Vt8ENvCv4LlX
G2cO+BXWX4rUCuw/IBgEwDbyQ9UlJ/sHAAMFA/9MpblWU1tWOBEvj6EGiKglizo4
PoWWlCPOmszeajjq36qinjf6MSU1mjVD6VZmJtQJ1cRJ4/SFP3lc2BfwgdKGy7Zi
Y083WueT7DBD0sbHRL9d9OBJKyjPl/sgs9Lq8uqYmqoEbjjasI98AuLq37FXCQwz
zAbR4UIzMqiJZLseL4hGBBgRAgAGBQI+GDI6AAoJENjKeKUexWvsmBoAn3+rzz5A
2dHLRi6GSO3ewVr81E5hAKC8A34OSriV6EA60sWrLIz1hwzVEQ==
=budv
-----END PGP PUBLIC KEY BLOCK-----
D.3.176 Ollivier Robert
<roberto@FreeBSD.org>
pub 1024D/7DCAE9D3 1997-08-21
Key fingerprint = 2945 61E7 D4E5 1D32 C100 DBEC A04F FB1B 7DCA E9D3
uid Ollivier Robert <roberto@keltia.freenix.fr>
uid Ollivier Robert <roberto@FreeBSD.org>
sub 2048g/C267084D 1997-08-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.4.2 (FreeBSD)
mQGiBDP8ElkRBADQrtDGMaOawsdVCxQTrtCoa+VFeSebgBgIdfrgduTTOteV+bqz
RYa94GBx3Df/LCxEtb8bgcL6DlD/B5nCjzMfwzW+JkqXDz7g96oVWW48jUIeNrYL
qBZruvcopUEmH3iBZU8ig3lpJ5/XbN+IYGP474E2rnTNfaY26E0iWkWqtQCg/wIY
KQKifk4Ibn3nbOlGoSQw3lEEAMPKAcgV6SgMYUE/SQXbSrrsKLQXDFKD8nAJ9+cF
QCtxLwP/qwt5aMQwl0KAZ4xR1XEWAq6KGOGjPpm0SSjfmAYXgADTLAnx6zI1O3yq
2SLl5ydH4RBumWXAMssVCLUJJzXxL/NY7e2x5Zh5RHbYA9m1ntGhiWENk2G6zOlD
HhzmBADL5zYL4jbgd2D+bzkiyCq5ncJhq39ycs7h2DijQGa6jR1bvcw/P2cBLleH
AKy1g4padSlD6CZNDDpe2C3J+QihewU4dF7fHL6Glh5+pBQMQJEPMsxZJcJKapY6
lND8AdwqZiO8NNqPBvcMHo0Hzdvq+KsfjyaDNS5NXnvGwM0IY7QrT2xsaXZpZXIg
Um9iZXJ0IDxyb2JlcnRvQGtlbHRpYS5mcmVlbml4LmZyPohGBBMRAgAGBQI9ySgw
AAoJEPEzIkEbgK3m4DUAn0A9ZuA0IR48JAhy+/IcRHPBoiESAJ47CkFzHeccD/Zl
y2v25wz2T8Y46IhGBBMRAgAGBQI9yS5eAAoJEJvicC70esLLMzAAmQGlBgF7Q5jf
crpp9GGHA1+3G71VAKCExOqdAB0Rqgd8qRxhg8C6BXXEo4hGBBARAgAGBQI9yT+L
AAoJEIG908QOH5t5MEsAniiaqjRQiCQ09ZKJGtfmsLS4dOnBAJ4zbIKEWqC+ng3N
8S7UiWJkDdzRZ4hGBBIRAgAGBQI9yUAkAAoJEI1JTTTHDr1Q/IEAoIGiC9SOtXvn
KG5mSx4Cq2d5NpD1AKDngtHyCe1yr6+TdMVHybxxCKk/qIhGBBMRAgAGBQI9yVTw
AAoJEKK7+yQM+Vb3KT8AoN0xGEPLGMa4dJEnt0FSQBcb3PqZAKClO4W9ENPciQn2
vPsWIYCb5BuGw4hGBBMRAgAGBQI9yhfJAAoJEIjjaLMwyTSKukYAniAgCxmCqP78
NlodNAVNjP4RZPuxAJ9I4b2Peakjj9roUMp4eFuZORLPLIhGBBMRAgAGBQI9ysBH
AAoJEABNVLg5PSRpensAnRcY3KrMkUudI7BKHx4tJoqOCUxOAJ9o7vWcVE2hOPgQ
slTVegpgxmWZU4hGBBARAgAGBQI93ml3AAoJEEU8RUkCMNYC6QEAoN1GvPyOeFD6
8ItBoiV3XjWys0YgAJ4u8QBSj8cm/MpUcgmC7p/lbXAHM4hGBBMRAgAGBQI93mXq
AAoJEF1SHIzmsVAWPiwAoMoKxMWxibu6mSxNvnhMXSH67YqDAKCW6+qKKI1j4dtf
aW+Ge7a+tiyp0IkAlQMFED4q6FxlYKmsNPn51QEBGFID/jX52YDyKAtA/n60wUIe
iyKSfDPdnh6uaka2JyWVs7JvKySlT1vCe2ElLdolFrmarqpy/W1bKvxOB0rqeqUl
ZYPd9Kvx3p+ScSrLpEYVyiZKsKU8WwD7Ycib1L78829/WnexoRIfexNtymb8BdPk
r0n7emlDEWxJ/+oJe6JbruPZiD8DBRA+KuiGb8javX+am6IRAtR8AKC8y7ViP8wc
gHJxmjosWGJ378rxrwCdHTfZm120ICfsZK6S5cect2X0JHSIRQQQEQIABgUCQoim
4wAKCRAMy37+CzCpOxxyAKCFtkuLw2zaXQ4frFl4KXOwqAkcpQCWJPQhMqRS79d6
T9YkNXsfUZ+gq4hGBBARAgAGBQI+tlhNAAoJEOHfd7dqs2nrqoAAn10Qmw/K3VmS
RdPBtmR4O5BXg9hcAJ9ILRxSJhvBPaxbUaGdduMxnEwwxohGBBARAgAGBQJCFKEW
AAoJEOaKpze6bBYw3h0AoIYEuIZeMcr5k17B8gU8bl9mLBp6AKCPy5U0ZPx2UjhB
yAy0hUw3TUGzXIhGBBARAgAGBQJCplR3AAoJEGBl1TP9wgW5hqcAoOxebmX5YNAu
Aq7Kbe9DHTCZR0/8AJ9VyHep9WNv6k+acQPWQNVR2lehlohGBBIRAgAGBQI/bSvw
AAoJEBj1A4AkwngCG40AoPPOgbemGcB3ifE+KTCjehB8guo5AJ9E5dR4ZpoTaDuF
/MUmQlO0el/V9YhGBBIRAgAGBQI/bSxSAAoJECH5xbz3apv1iFEAoNfCMznA3Qvf
XavAC42bKofklYnXAKDiyRuqRFKu5uwSoiDtxy4Wwp6IQohGBBIRAgAGBQJCipGD
AAoJECIYyB6OfAP/XA0AniEGBqs+gIzfEUi41oMC4UbiZrAiAJ9wmh2PToMfNCH0
j4Ob54Ze2osi8IhGBBMRAgAGBQI/Y2bjAAoJEMiGpCvVsvD7HWoAoPOvjo8FWbZz
Nalo3On2GDQLYweTAJ45vDzjByOJuL8b+4AJ+DO7xVXGq4hGBBMRAgAGBQI/xLHS
AAoJENTl7azAFD0txQcAoIkG4Y5tIrEXPI6CYfsK48xXzaORAJ9HtOHNJVOD19ze
EJo2DWOAscFeO4hGBBMRAgAGBQJBg6+hAAoJECLKWEx6e6PAgBcAoMwUE2+9ZNHJ
c1DVbY/DO+fq7zrgAKCsMwG7Ch/rAFMx2mLXzW680LbTiohGBBMRAgAGBQJBg7Ey
AAoJEKkX6cyZbhReuz4AnjjUu+GmNWcg/TxE54ezgmQ1R3RPAKCZFi7verjEMQYT
NZO1ORXZtG/KeohGBBMRAgAGBQJBhMphAAoJED+g3gig05FoCfQAoI0RbGfROzQw
Umr/SfF27faNVZwyAJ4w9zlIyNYbZM0Hs1kB2QWkqQww3YhGBBMRAgAGBQJCdiuW
AAoJELXIbIQxfSjWWV8AmwVn8B4P6GIfvAgMc2qSNtZU+pJhAKC/ML+AlAL3pwAj
2k2W7RokgJWYlohJBBMRAgAJBQJACRKfAgcAAAoJEKmGKcxs/75n0qUAnjqpU/o3
+ZCJYuHJvfqgJhawaltpAJ9x1cIa8t10NXhZc/CWsecabDHEA4heBBMRAgAeAhsD
Ah4BAheABQJCkaGNBgsJCAcDAgMVAgMDFgIBAAoJEKBP+xt9yunTVH4AoOUsx51j
CDpDx8lSni7UU72x/wYRAJ9RPbjQNuO+84PUR/3AcA3wBanRkYhzBBARAgAzBQJB
r6TRBYMB4TOAJhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5kZXgucGhwP2lkPTEw
AAoJENK7DQFl0P1YqX8Aniewyq5pu+VpYWOBxSGaG/Ju8pYZAKCY852Nokp+m6WP
dRB5rNHeCaLICohGBBARAgAGBQJDjZegAAoJEO0Yto0WGUVT3dIAnRmf4j0PYP5q
4VnW2Cgcd1slgMVxAJ9FcKd3Buna12uiBdLzIXQfuGnjfIhGBBARAgAGBQJDjhLk
AAoJEL9L0OYEnbh5XtQAn27QDNPREie4dzbJs1xfn84WTlSjAKDqFol/VRSFFaWF
5zYyeTfFddQCu4hGBBARAgAGBQJDnFx8AAoJEMYEPFZyB3E367MAn2b2dVjeFKfj
AxBN2prx/+gS5tpgAJ9FU9XTf8Eqrk/iMx6XWoy/4rTg4YhGBBARAgAGBQJDnGIz
AAoJEHninGCwBj/nbOwAniR6ff8HXR9oEc8xHlEhqhXijiMiAKCuW6bP/wGaCnlP
1DdGsFGURGQ1C7QkT2xsaXZpZXIgUm9iZXJ0IDxyb2JlcnRvQGtlbHRpYS5uZXQ+
iEYEExECAAYFAj3JKDAACgkQ8TMiQRuAreaH7QCePRYEO8RMLHDmrd57FYphIa4v
a4kAn0UPl914ueYGYw34KLcxzLD4Q0MwiEYEExECAAYFAj3JLl4ACgkQm+JwLvR6
wsu4KgCggJASzyWfkWesNMc9kUNgIAkbsBYAnRx423nCYCHJiNrOaWV1BdmerKo4
iEYEEBECAAYFAj3JP4sACgkQgb3TxA4fm3lYywCaAwbFQOI2aXp7tfv+pqf526zZ
LJMAnRKTmQQKVloVXXN/y7WDLOlq6qyniEYEEhECAAYFAj3JQCQACgkQjUlNNMcO
vVA3kACfT2ly5cUYk2qjEELxl3+hzf+XqZMAn1kenkFnkuVApbW3f2lUoP4Pb39Y
iEYEExECAAYFAj3JVPAACgkQorv7JAz5VvfbxQCguY6CTwwA0iBtWEpmp+1jpCDP
iGgAoIqH4hctM7NoLZlZWvkEPzOiRcrViEYEExECAAYFAj3KF8kACgkQiONoszDJ
NIqPsgCfc+DIiligUx0NDSDCln0/DcUeG88An2CWDf2vVgwW1HJplO3sEiSOWAPo
iEYEExECAAYFAj3KwEcACgkQAE1UuDk9JGnuXgCfdAC7Qp7nxLgI3X9fl8Oc7Y5d
FPMAn1pZhYPy7Su1FMh5zmXXlLduBU5qiEYEEBECAAYFAj3eaXcACgkQRTxFSQIw
1gLr3gCgjAkjHYWwlTcd1A+0fyB8JI/9jtUAoODFgUVz8aEveyKBDI1R/HvLxGKk
iEYEExECAAYFAj3eZeoACgkQXVIcjOaxUBZ+OwCdGOz5aFakC25wy9qlVyBcrRDL
xF8An0OOgBzf2LfNbIrV/kVzmwy1kPYeiQCVAwUQPiroZGVgqaw0+fnVAQFEkgQA
q2mNr+CZRLW1MXjsOEb5lVbQ/rYbppplgqdaQcWAcBe6u80lx1FLB9qdOdWpa83y
f2GIrFQ38y4zwaMglcYIibb2lrBt7oJN6RHXoMH9jyIkbKQBfNaKYzUijkOgM6gO
5AOeq63P3kDIrMOp7f04+a5pFEy9u5mS8MamWCPs/HeIPwMFED4q6ItvyNq9f5qb
ohECsSIAoJ9jMqh5LhFx0BndwI2+a91ONwsAAJ4v7BD+Vs0/KC9Yg2BWIXKwqy1C
+IhGBBARAgAGBQI+tlhNAAoJEOHfd7dqs2nroF8AnR81QajE3UPYjvlkP9RXZFkZ
QNjPAJ9ekwgsXv6hciSae8RwjDUWkc8z0ohGBBARAgAGBQJCFKEWAAoJEOaKpze6
bBYwUL0AoJ+WGaaalw+VLnY2MB76ok8pW/PiAJ95BBDBW2qXh4jp+oJJaLWBaifE
CIhGBBARAgAGBQJCiKbjAAoJEAzLfv4LMKk7peIAniTeBbEKP3Idmiwj7VCoyIMM
qkc3AJ498LtX3QTK8pE+qK4xiN8/EdjQMIhGBBARAgAGBQJCplR3AAoJEGBl1TP9
wgW5c50AmwRYgmZ0YeRSXdwvS5vxJqaU6BJVAJ4lvoodgI+IaBtBEROjxUGDeJbp
OIhGBBIRAgAGBQI/bSvwAAoJEBj1A4AkwngC89AAnRMFi4o1cPo0w5JPq7Sk2nll
vYJ/AJ98wkZAn3DaGQNi03+q5sb3pyaAs4hGBBIRAgAGBQI/bSxSAAoJECH5xbz3
apv1b9MAoJ9uJaDHQAO0AbDCrLdzSAeaNA0AAKDL1UrbR+aEqOwsidDL5XgqOPBM
YohGBBIRAgAGBQJCipGDAAoJECIYyB6OfAP/Jv8An1xG6xU1KHc+XgxAr0bGw23h
1W1EAKCddeP9XOAFWJSRcU3w7lDI+9h6f4hGBBMRAgAGBQI/Y2bjAAoJEMiGpCvV
svD759IAoOD3BSx8l/LCyovzJ9fNpYBNcEHuAKCLieus+f4oMAskH3v5DLcExvD+
sohGBBMRAgAGBQI/xLHOAAoJENTl7azAFD0tJ6UAnRqIab6NwOPVT0SJTdppJKrJ
FBEhAKCyguyt5Q2004G28wbIHk2y6Zj53ohGBBMRAgAGBQJBg6+hAAoJECLKWEx6
e6PASg8AoOKARTsKJd0nTlRgJMB5eLjfu9hpAJ9zUDU96KJ3+Nprbyrcr3Gx9wi7
SohGBBMRAgAGBQJBg7ExAAoJEKkX6cyZbhRem74AoJnUhPida9HLE/JKdb1FGBrB
OCXpAJ9+hRhbWueKQYskzYpRIvQpLmFc2ohGBBMRAgAGBQJBhMphAAoJED+g3gig
05FoRIAAmwWRQoHTmYAbybkNFNufHwbQtbnGAJ0SGuGWAafa0BSVrp/7hr+hucse
QIhGBBMRAgAGBQJCdiuWAAoJELXIbIQxfSjW+msAoKSlPJraYn0pMu4t8CuIBvT4
oQcIAKCVTFioI/TmFgeQstcdsuzDEOSREIhJBBMRAgAJBQJACRKfAgcAAAoJEKmG
Kcxs/75n5N0AoKECf++T17PrTicv66Rydb8wMrcEAJ9gewO5e/Qo7Q6Y9e6Gilcy
iPUUC4heBBMRAgAeAhsDAh4BAheABQJCkaGNBgsJCAcDAgMVAgMDFgIBAAoJEKBP
+xt9yunTbmYAnAsbsZUh7gy9WAxZsS/y1dgBcoHDAJ4wwcKDMF5Ar2Fk2k6JAGEz
HZdkKIhzBBARAgAzBQJBr6TRBYMB4TOAJhpodHRwOi8vd3d3LmNhY2VydC5vcmcv
aW5kZXgucGhwP2lkPTEwAAoJENK7DQFl0P1YrxcAn3U7o83wbcJ+uY2pY1LHCp2H
pTbpAJ9DkG/HETpcmU6peT0zDHYCRkIKXIhGBBARAgAGBQJDjZelAAoJEO0Yto0W
GUVTGD0Anj6dtF2dWPDe6w1tEK5qHtyQ9gfnAJ9bTq6bK0OsuUQ91RFg796Amjwd
YIhGBBARAgAGBQJDjhLvAAoJEL9L0OYEnbh5obcAoJCoIjGEaIceeAwuGrNoA4M+
L2LHAJ42o8fW/GjP//e0tkFhsqSMUCJ3Z4hGBBARAgAGBQJDnFx/AAoJEMYEPFZy
B3E3xzIAn0Jj3Ide8Fj64gwFBOS/d80mbdf4AJ9YcIKfyuiw89WGxavknLA7cF/2
0YhGBBARAgAGBQJDnGI2AAoJEHninGCwBj/n7t0AoKMSLdLS08bVWH9f2v7DKbvw
fdzOAJ9GBFT2xo7wcNu1G9G1HXzgSAl3LLQoT2xsaXZpZXIgUm9iZXJ0IDxyb2Jl
cnRvQGV1cm9jb250cm9sLmZyPohGBBMRAgAGBQI9ySgrAAoJEPEzIkEbgK3m94MA
n1nbCsgPM/kKYtk0XG5XtLjK4vRxAJsHvzOZtOn8ckuz7AlM2d/wUGR5QohGBBAR
AgAGBQI9yT+IAAoJEIG908QOH5t5bi4An3OjFEBI8mRSQTsj0Iz56PMbXdbAAJwJ
OBi6u+nLgEfhegQ5emDd7eK8CYhGBBIRAgAGBQI9yUAWAAoJEI1JTTTHDr1Q8wgA
oNro206RIz4pDvzRphQrDpILy9IGAKDSYEgSUgv9ohMps/xE/O5tBi2UJYhGBBMR
AgAGBQI9yS5WAAoJEJvicC70esLLjnIAn0YIZMq98VFuKst/c0q+zfH7e9Y5AJ4u
c5lUWaqliZfEY5mhIzaG+fg6RIhGBBMRAgAGBQI9yVTqAAoJEKK7+yQM+Vb3YiQA
njlTSW/hnjpWIfqwurmvWOz/yPcRAJ0Vs5m9CP2OEm/8cpUMh+CQjUaD4IhGBBMR
AgAGBQI9yhfCAAoJEIjjaLMwyTSK5FUAnisMJFdPE6zo3GcTXDn7GdUTOjdbAJ99
syT6ijQevXcZcCB3t9EwEHfcKYhGBBMRAgAGBQI9ysA/AAoJEABNVLg5PSRpmIwA
njHR6d01Dxaq2WhsbuGUfc8ULvRtAJ43vLlCP4B8NVG7WHhKCGV8PaayzIhGBBAR
AgAGBQI93ml1AAoJEEU8RUkCMNYCLFYAnAlLX/rgFBSZY22HIevPsThLOjMuAKC7
dOLmD28hTAi/2G7vHzRoXHQs74hGBBMRAgAGBQI93mXhAAoJEF1SHIzmsVAWkxUA
n3fUf5wZirpDV95I+Wm0xp4o32TWAJ9fE3cHi8r2IOSzOSj1+dQMPjNZpIkAlQMF
ED4q6HBlYKmsNPn51QEB0rcD/i64mEtVvMzY0w9me80jBp7D32XV6MGnjIrWAu4H
piT/u/FJyHPObrhj2WC7dugIAL8pVLT1ZIENKdCiR6VlJiq+bWhKQ6gwNc0K9JYZ
S+PEvxb5Es4xfFZZ+de2I45lXAZPrxbbFNxoAgpEI5ZpGOotUaPEZThftaYfdhW6
dkwPiD8DBRA+Kuijb8javX+am6IRAnb/AKDTxkJ8J4l9kaZe6TXdwvR8pQl4MACf
S3loHiIsKtmhuKKLkdTgWJqGLKSIRgQQEQIABgUCPrZYJAAKCRDh33e3arNp64OM
AKCFmT5MIBmCu5Z58dQ3bC8UgImJBwCfZoBsemSDqv0KDyDrnjEW3VoeMceIRgQQ
EQIABgUCQhShFgAKCRDmiqc3umwWMHwZAJ9b8PvJoDW/oXnHOXcD3TjsjqNzQgCf
ZOE50e/NtVGIiKvK27twPPl5IKqIRgQQEQIABgUCQoim4wAKCRAMy37+CzCpO6lF
AJ9Pm5PdwFlLA9M5PxXXXdndwQ2cjgCfRmQXcHciHPMpxa/1efhNzbiWTiaIRgQQ
EQIABgUCQqZUdwAKCRBgZdUz/cIFubJCAJ0QRVsPxwY1xdy/H85D08vrS3c7BQCf
esZSo9ArkEbtZnz2A5vhaciFc8OIRgQSEQIABgUCP20r8AAKCRAY9QOAJMJ4Alt6
AJ9CDPSaAA3DexrMcTWEeHrLv9x+EwCg5IQX3ryzCbElLMFRgj6qZa4uNRqIRgQS
EQIABgUCP20sUgAKCRAh+cW892qb9ZKHAJ94OVNGsu7OqpWu7GQd0Z7tRlAjewCg
h2v1yBeKThJZnEV8s3Q9vNLjI66IRgQSEQIABgUCQoqRgwAKCRAiGMgejnwD/2AH
AJ0cNorSyiUk1wN4M5Ux745YvS/X4gCdFspMPgPcQQ1fk8wxXyav0Yyf/bmIRgQT
EQIABgUCP2Nm4wAKCRDIhqQr1bLw+2MpAJ9rzeaWTW7e3feviChNz2Bz13Q6AQCf
d29M7b4R/cxZc5vGJeAM1LhSIeSIRgQTEQIABgUCP8Sx0gAKCRDU5e2swBQ9LVs4
AKCOLBCnY7MrlEUYR7mRBtTbW8tx1wCdFR2ejf9UqS3CXzSDnFURmFXPLcuIRgQT
EQIABgUCQYOvoQAKCRAiylhMenujwGpAAKCmdUSpKSoCs50ve0MZkCPpJjgzGACg
g5gVL5I3uI5JDJE8ian1XYjQ9i+IRgQTEQIABgUCQYOxMQAKCRCpF+nMmW4UXiNq
AJ44Che0zSmkF4A0Sre1HF5Cbe3gNgCfWkQtIEbfsh+iyCqGaBLawK5hl1uIRgQT
EQIABgUCQYTKYQAKCRA/oN4IoNORaHy4AJ0fcWhifFcQGcimG8EN4jfFueOySACf
R7zsrt/lXGc+RAc/MtT2e4pNJYKIRgQTEQIABgUCQnYrlgAKCRC1yGyEMX0o1nBf
AKCGeYbrzQ3Tu1EPpBD6wawMRpEjuwCgx1tVKGFIUdyfzPwwH1fAokXwy4uISQQT
EQIACQUCQAkSnwIHAAAKCRCphinMbP++Z1aYAJ9Pn3Jd8Fc4wPBaT/KPM+Cb1Y7k
iACdGyDWjt1n8XFQBBJVPiOwmbaz2VCIWwQQEQIAGwUCQpGhjQYLCQgHAwIDFQID
AxYCAQIeAQIXgAAKCRCgT/sbfcrp03HxAJ9ia/GqsKoz66Fq0wQsFJL0jaODJgCf
c1gjWadqJ0j7V0vdvC29GyozLVKIRgQQEQIABgUCQ42XpQAKCRDtGLaNFhlFU9Cx
AJsFdmjRQ2usIlDoGMKSJqEGlU3aCwCdGBg6a68hGAQpxmBZbDObpMlfF2OIRgQQ
EQIABgUCQ44S7wAKCRC/S9DmBJ24ebckAJ42nev/IdqFD7/MZhKLi/Hf4a+hBQCf
bC9kM9E/omH/CdxkGk+6b0fzzzGIRgQQEQIABgUCQ5xcfwAKCRDGBDxWcgdxN/Jo
AJ9WidFb4zkn2QE4aujCQM7T9wF2sgCdG8f+3TAw2mJYlCmsDD5J6cK5NcyIRgQQ
EQIABgUCQ5xiNgAKCRB54pxgsAY/5y0FAJ4vNcYrOv8J4TToEuf1Z4a/ONE6OACZ
ARe2KYkTJsE/HOoMD4xZiYsQC2y0JU9sbGl2aWVyIFJvYmVydCA8cm9iZXJ0b0BG
cmVlQlNELm9yZz6JAJUDBRA+KuhrZWCprDT5+dUBATv7A/9GBlRMHaWB9qvyH2/A
P/T4ZllxxJB9kXAB4rsaWtGZfyc3blhNnIbKovya4OdYK0mMXPFuJbq+gTV8IsPo
jg6+kuTH6Zi3CY+SKrYt5jn/nbQVjfs/Y1AOpzMcFHy3wh8UNgi6lj2X7QLKr0e2
gsQFiNZ3yxntFoa7V3K/OjPPpYg/AwUQPirokG/I2r1/mpuiEQKkVwCgiQ0gH1F1
gSkIjGcuesVZysinQFoAnj8EGkwABsIHci4e9nBXA8FqSqNtiEYEEBECAAYFAkIU
oRIACgkQ5oqnN7psFjAQJgCfSPY+/IS/2onJLzAKxukX4nuRWE4An3eHvZRkuXld
nFM4eRQqCvg6uxXUiEYEEBECAAYFAkKIpuAACgkQDMt+/gswqTvRMQCfSh/x+PA+
N4ZgqGfIsGPDjja34xsAn1aLw6GbRoVPc33XPsC9ujou+6cYiEYEEBECAAYFAkKm
VHMACgkQYGXVM/3CBbm+awCghcKwOa6/+3N+7mNcVhRLP5wlb1YAn3AQHkjupGzS
5tnei4bmDFPsOWquiEYEEhECAAYFAj9tK+0ACgkQGPUDgCTCeAK53gCgk5As66jL
jVv/KTSg8wSV6nxLvKMAn0BQsl5LA9Ge9h5JRMzk6PxibFX8iEYEEhECAAYFAj9t
LEoACgkQIfnFvPdqm/VY6QCfYhfrj3UHHF+fzo2EUpP3h37lCfUAnR53fy8KAOoL
tnvmna+1GmscmssfiEYEEhECAAYFAkKKkYIACgkQIhjIHo58A//98ACeMJ3jBMQu
KSjbASNrZqyhfo9dVvUAmwQeixlidb2QYwtjLD4d/v9LPcPZiEYEExECAAYFAj9h
5esACgkQ2MoxcVugUsNZawCdEIbKXEi2c9j7LF6vjpSBb9vBfXQAoMWWtOeXkB1v
KKH/RyNSXgICH0JSiEYEExECAAYFAj9jZuEACgkQyIakK9Wy8PuCpwCfXeDHOuhz
rll9BSUj0ZAV5VlbMwUAn2QopRHYTTlj+D/TiTYT5UoQ2zTgiEYEExECAAYFAj/E
lngACgkQgb3TxA4fm3nI8QCeNVFDp97NyzJVDMLVs/+UZ8rUylYAn0kEAbd6vtpo
gy9GueW306H1o6MRiEYEExECAAYFAkGDr5sACgkQIspYTHp7o8Cg3ACfdgZmVJZf
OSTJBXbBbkGa2n00ia8AoKd/kk6T5rKrcw34+pTrjEHMEKzOiEYEExECAAYFAkGD
sTAACgkQqRfpzJluFF7DiwCcCrE0tWfvZGr5rZYwhWfZURIVrLoAnAtK+9tMrzSX
+Vf257vk5BKe/FhDiEYEExECAAYFAkGEylsACgkQP6DeCKDTkWjzogCePHSVBT0F
m+cSneywiP1Kvf7gpmkAnjKIDPQBLarHmivfrXwa7m3hTNdAiEYEExECAAYFAkGV
UjoACgkQRTxFSQIw1gK9egCeLLeYprEea1EanA0/MRBLgVXvSkQAn1tJEaEi94Ov
9G+zh3aStpk4U59kiEYEExECAAYFAkJ2K5MACgkQtchshDF9KNYXMQCfbYADtpto
pmn6ZUdV59PSh2T6vl0AoM0Fb7nSmuEEwW8902HXci48YuyCiEkEExECAAkFAkAJ
EpsCBwAACgkQqYYpzGz/vmdDQACdHbNc3D0moGLnnKeswvD+YAbpjWQAn37bLsML
JkvHfpVGLcrWtcUmxDyKiF4EExECAB4CGwMCHgECF4AFAkKRoYIGCwkIBwMCAxUC
AwMWAgEACgkQoE/7G33K6dMFxgCgzErY8QHIOAqNJVL1UXGWhWw7WSwAoMhrAETI
R0Q7PMPHDUGKemvHG+P+iHMEEBECADMFAkGvpNEFgwHhM4AmGmh0dHA6Ly93d3cu
Y2FjZXJ0Lm9yZy9pbmRleC5waHA/aWQ9MTAACgkQ0rsNAWXQ/VixFwCfZc67oREi
MhDg4LZMk9knDy1nJWkAn1bgX7xLF4dyvStgV939/A+GeqJoiEYEEBECAAYFAkON
l6UACgkQ7Ri2jRYZRVMQLgCfcj752RKJYyTg3HpDaY+udREzaZgAoKtf0m9bujC9
kH02TAf0/fzcDntViEYEEBECAAYFAkOOEu8ACgkQv0vQ5gSduHlu/QCeMAim1Dds
jMTUESgNQBhNXps3VX0AoMT8lS5DULf+bCX9DK9h/2VW+MR+iEYEEBECAAYFAkOc
XH8ACgkQxgQ8VnIHcTc6fACfSMWwCe5Q5pnx817dEQE029OmNWEAn2W2pdR5Mr5y
twKU7qUZP+yPzNOziEYEEBECAAYFAkOcYjYACgkQeeKcYLAGP+ccfQCeKp+Oq2n2
wCjtVyxCLlSJGBPg6XYAn0YsQHWSC4rUH8pzWPuJpE1wyH/CuQINBDP8EloQCAD2
Qle3CH8IF3KiutapQvMF6PlTETlPtvFuuUs4INoBp1ajFOmPQFXz0AfGy0OplK33
TGSGSfgMg71l6RfUodNQ+PVZX9x2Uk89PY3bzpnhV5JZzf24rnRPxfx2vIPFRzBh
znzJZv8V+bv9kV7HAarTW56NoKVyOtQa8L9GAFgr5fSI/VhOSdvNILSd5JEHNmsz
bDgNRR0PfIizHHxbLY7288kjwEPwpVsYjY67VYy4XTjTNP18F1dDox0YbN4zISy1
Kv884bEpQBgRjXyEpwpy1obEAxnIByl6ypUM2Zafq9AKUJsCRtMIPWakXUGfnHy9
iUsiGSa6q6Jew1XpMgs7AAICB/93gJFiuchJMmENS5jIlSVFM8N1x/33SQpHw9Yu
c3SKelU3Nm+u63HFMLEzMnr+5msl14hlA63WgC2cCuyZw90a9sSs5Cz6HZNdPgjf
UaCRyhZVvGOqlSQBNgx01qH2VYekNmsn6Fuum6cyZ/cwd2fpBlf0DWL0FOq1NzkP
TKh6Y2y95DcpyRNl8abW2E0rhofxkWB8taKomv6n5N8pLMK7SHLSv3cQXzU689cz
ejNyHm5FbtcXxPrTMTwpgDmwbSubVj7RbkkmImnDGemOFGjv9uQjcuJNATJJgfK6
IjNWyx9kgPmoN8qMNeo5bmzkN3SZduIrZITyQGImglPEIvfIiD8DBRgz/BJaoE/7
G33K6dMRAnbxAJ9H2TXdTLPZQ1OUZCnoSA0tSz4M7QCfdTT4428ML0KH1ozDZ3Ip
izq3ic4=
=mgE0
-----END PGP PUBLIC KEY BLOCK-----
D.3.177 Craig Rodrigues
<rodrigc@FreeBSD.org>
pub 1024D/3998479D 2005-05-20
Key fingerprint = F01F EBE6 F5C8 6DC2 954F 098F D20A 8A2A 3998 479D
uid Craig Rodrigues <rodrigc@freebsd.org>
uid Craig Rodrigues <rodrigc@crodrigues.org>
sub 2048g/AA77E09B 2005-05-20
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEKOK8MRBADOO9VIucM2dGygVera0+Hcu9ud2f3MrcfVgsB7/awfE/MgIYtC
CFtCJrD1Ml+p/spmiuzJNDSamT8NHywsG5R+GO0EC76+mfL3hwXvGUJoQV+NcDu6
99s6OUWTimi5OPOURzG7lXYpO0wVysx3R5Nzg7tIC06fmXNXuj02JvCm+wCgqkPx
nZgCFoqq2mHoiLL59CUExbED/iOnglDOuZsncR9xRZJfbSLUJf5z9NE413FXAx3f
THY7+akGk8kWChrOeyIvLvSGmkHHFQXgh1umG4fFd7TCJ0Sexh44s5q0ROjEK4ge
nwAsS0iheMB6JqW8ibBfawr2iwu3ZAkqfelU+NSbHm4sEeHxEGyJtZKA7rOPGDm8
YOBZA/45n2E/Z6hv6D4Bm1xEDGNICK28uTqzXh0wyCJJtVOortd4CmKZZrZJj7am
3aDdtFUZ1yZc5FW2E0xLa7Oz8HUj7eMT7Ljfd0c5yNna7WcNjqWNAz6WMhHByRZv
nOPiUMQNvCbyrKw9OsFKNNbrSnjQcc/5yy0SiIMVm4rydXzK0bQoQ3JhaWcgUm9k
cmlndWVzIDxyb2RyaWdjQGNyb2RyaWd1ZXMub3JnPoheBBMRAgAeBQJCjivDAhsD
BgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJENIKiio5mEedzB0AoIXeENkxV41KlJMV
z0ozHJ/q1ESdAKCimzfOMwz7Qyauo4VHs4rk7NEPerQlQ3JhaWcgUm9kcmlndWVz
IDxyb2RyaWdjQGZyZWVic2Qub3JnPoheBBMRAgAeBQJCjjVzAhsDBgsJCAcDAgMV
AgMDFgIBAh4BAheAAAoJENIKiio5mEedT6wAn0IjcGqARj8Qe+JZThbQCQbH0ERp
AJ4w1pYLdsKphwaEB8GakvaeRsrBTLkCDQRCjivkEAgAo5DHUcjEBK54Vo2S403y
InnfqiiUDXqb8Oof18CICB6JgA3NjP5g9BE5+7dI8relt4Q0ILg2IJvISIlfmyDl
+GuegA3dMo1IrghmtI5+IWN2mm1iNy96jpJ1TQhvHTFDlETdV/BE57CcO1ZnKHiW
m9G3GjnMrunVyLMEY+6TJ6ykqP2VzYBsc847iCv477LdYFe1+vedZb8Bk9xpeeZJ
tuT3O+JiR+B/SHISpycxyM3ei+C7eRRC8wV+khOw/8xirJ1Wzyg3GrolQPtJsTNG
mqg6DXIYPY5wbF3SUBT5ZA7pLPxXhUWNewU/8mXisuM0hp7nz9VLQ4JfbMuvGF2j
wwADBQf/SCUw06q5l8qdJ9G3WFfPOE449mq5uXHGlfeamCkjx9/SzI/8yldrxwdF
5XiAZWRpeQoksUbPI+tmxWqi8NDxt+KLDNhSCg0+C8KRFBY0ZI4CDmUg+MX9Mix2
ir/RK6eoEYNXdt32raX7MzQP87LTL+cnxJzbQ702HYpVqrJUOgSRwQ3posbp7hwV
djfiE38r9Hd/E4ZxxAIT3GafZ12KzxQZ8dSxoa/2tP8VfAfe9jt/XX4F0QD2yIGV
2wJMd/CZWTZgDfNW1anGR+9AyV9dT+8cYi36fkgTQb5rN25rJKzHd9RA/EGJXSU4
l1hNG4gBpYjF5gD/UTuSgGI6XInycYhJBBgRAgAJBQJCjivkAhsMAAoJENIKiio5
mEedTS8AoIa+gNX84jClqNvPR5lMlQGKeB4HAKCaEmhTA9kGSY5JW3hsfDiwfr0a
PA==
=hHZm
-----END PGP PUBLIC KEY BLOCK-----
D.3.178 Guido van Rooij <guido@FreeBSD.org>
pub 1024R/599F323D 1996-05-18 Guido van Rooij <guido@gvr.org>
Key fingerprint = 16 79 09 F3 C0 E4 28 A7 32 62 FA F6 60 31 C0 ED
uid Guido van Rooij <guido@gvr.win.tue.nl>
pub 1024D/A95102C1 2000-10-25 Guido van Rooij <guido@madison-gurkha.nl>
Key fingerprint = 5B3E 51B7 0E7A D170 0574 1E51 2471 117F A951 02C1
uid Guido van Rooij <guido@madison-gurkha.com>
sub 1024g/A5F20553 2000-10-25
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzGeO84AAAEEAKKAY91Na//DXwlUusr9GVESSlVwVP6DyH1wcZXhfN1fyZHq
SwhMCEdHYoojQds+VqD1iiZQvv1RLByBgj622PDAPN4+Z49HjGs7YbZsUNuQqPPU
wRPpP6ty69x1hPKq1sQIB5MS4radpCM+4wbZbhxv7l4rP3RWUbNaYutZnzI9AAUR
tCZHdWlkbyB2YW4gUm9vaWogPGd1aWRvQGd2ci53aW4udHVlLm5sPokAlQMFEDIE
1nMEJn15jgpJ0QEBW6kEAKqN8XSgzTqfCrxFXT07MlHhfdbKUTNUoboxCGCLNW05
vf1A8F5fdE5i14LiwkldWIzPxWD+Sa3LfNPCfCZTaCiyGcLyTzVfBHA18MBAOOX6
JiTpdcm22jLGUWBf/aJK3yz/nfbWntd/LRHysIdVp29lP5BF+J9/Lzbb/9LxP1ta
iQB1AwUQMgYGsgS4QK9eGvw1AQFKxwMAgFh/hThe6nT9YUONHIdxWNaL8zUx5SEq
7WDCOTYqUCJoXJzwRcIlyHaZOO1OubsnOMyNWpR5PxDEfoXyV58UY1RH4cXiP55e
yAgEtWQF6RtAvl7ikZmRxFr3QAVQ3QxmiQCVAwUQMwYdyB9/qQgDWPy9AQFtiAP+
Ob3Ee5S5j6JcOQ7OkJcFgAJgRkNX3XcyO3IECZpWpihGHkcWKaQZd76sKjvwBq7S
Fznt8UxOwmqe5YSpW3cZGrbyFIrUU5nueL39eJsdyY2u3bK6CXeFikKWKOjiesMv
U3GJttqaQZb+8UZyWNLSOpfPo0NVsbHk6jscEHLEHLOJAJUDBRAyCihxOgN22FUM
Xy0BAf1aA/4jgZSy5F/J3R3EziV+yA3bFa2MVlY+SvTrwm+8JTTYgqmTaVpWJ34n
tBobYtxKOb2o+Ie8QGdN1sbU5Nan32oOa44Qo/AUvr0SynANb3CoA6n+DsCPNx4z
QXxO6+5mDdnWh2dx66MDAZpOAxX0lndZjhT752ZJbjTOXoXGgV2oSIkAlQMFEDIZ
rVY7f8e8znZrHwEBblUEAKbFVE4oE+WFo0APTXeWdPmv6FbWacsOWTpYyyT976iX
TGuk4nYX3GrYx2xU73ucdXZoxYDF/zEE3fM3//l3HMvz1+PpZyjaT3kn9WOGivhP
Ch5gRnehs1+giG6MhmC0vXt5BpzdOhdgELWi8iRYEO9cEWhrsipkBhcE5+44im9W
iQCVAwUQMfgT3jz++eS7QkvFAQEk/wP9H0du7o2mP4e+vuIJ7ZvLeEw/05+S60XC
67B33YahMq8BTr69R69FYHDcODG3Qmi3fCXfbsorhVWzdB+X87p0mI38E3lUOGiW
6pcSxdBOL7IKoHInCdQqF4WgWZOknN/mORpaxqyHvm2oWvNfe5RmtQsnBEPBGBnQ
GtvzA4ZIDLaJAJUDBRAyEOLXPt3iN6QQUSEBATwQA/9jqu0Nbk154+Pn+9mJX/YT
fYR2UqK/5FKCqgL5Nt/Deg2re0zMD1f8F9Dj6vuAAxq8hnOkIHKlWolMjkRKkzJi
mSPEWl3AuHJ31k948J8it4f8kq/o44usIA2KKVMlI63Q/rmNdfWCyiYQEVGcRbTm
GTdZIHYCOgV5dOo4ebFqgYkAlQMFEDIIucpYl6t82lyyQQEB5KMD/0dAWjf8yKCW
+sjcX2hUUWAwbfWVYJuabBqMdrdaqSkDvQRzm0KXGVQ3BN0u2WRmr6q6JSzuWdFL
438rJwS9Dk9g+BVvveiMdXCQ/v4S1ZlPO6B7j8b+CnRg+GjdWcqbeGAH6V3HRlvB
oC1B45yAyhxK7pbdFetgfVDyKoMQs7XSiQCVAwUQNYZ89VsBgeyXi/ZpAQHohAQA
oM2qlrfjXD30cc6wf7rSermdHLGjDBIHI/kl/jYjXfoxVlPzuQ2gWLBMJJqmIMhA
M6go7Ub40tHtmrLWQJKTurcTT4qYhBkFSr1gV4JfyjqEKWWa4LtA0tCwng4XiIx4
QJ1/yj4F6vHMtQQ0p91UQcteLNGqLQ/cYkeXZVTAWqeJAJUDBRA1kcBzZWCprDT5
+dUBAXDdA/9OoqwWqtgdykcOm1j7TuBqEiilg4PE7wEq8gADjkpvjkU8hCJWbmT/
XMcTckfehyOJYlkcN5U/JHJYMMpu7y4qZwDxq9lvZUghL4cl1B73KbgNcV2drTIh
DX5i7fGR4u2CK0dztyuQ3KYBpJT179ERRDw9ZjmCgd3sri/uMz90oIkAlQMFEDGf
WDRrWmeNgbKneQEB9DwEAIaVZQHN2TPyjk8sAUofM1ilZUpN6v8xp5O4SZhU4Z5Y
R9e9t/lplxPGgDyYvlVzliVBUIMBCyekfI0lNqr5NptVVsmEqkSr3FUUDKk9sI7L
NBhNTYIO7TK5ER09IpexNscSG/LzKyMJnZG032KgVIYRp7Fjx2R6uzKANf2/qyuw
iQCVAwUQMkRC8Hy3DmMtBSL5AQGP5AP/WMRtE+DdMZMHLiYNXquzOd1MvfeylZbE
bM9xIqTiRWqHkIMknSxZOGQWtmI1p3HspMnvwS8LcbzGZGxRdkIh7BdTX+9We+Cr
qTevGPjY+3yO5eN+EAVwwyXloLbYrPTnwWES1lXSjoHN6EOn1YouJNbmdbAfKJNC
j+7TZALdNAuJAJUDBRAx9vzphNbc3Le3wi0BAXBCA/45ftozyOJdxKYLpVQLpwSc
9bUyyPctpJCwzc2u7nFpaT7zdPzDiM5fgR6Y+EYGgjOIsSArHTvP52S9cwh/Auv+
g8WRIPbNxvwqq3DTqbC+fObhXeQnZZvpCYXQ0EDmosCv/Z8BH+Ley8m5o7misCWS
fp7GXisg4MR3k3fg2/KNk4kAlQMFEDIEV2eOAs27CVkM/QEBX+4D/0GthUuUukWC
ht62Gp1gA1Xv4pBVdpcbjNWs5Vm7JpY17ylVhnunFevd50uZRhgI8ZW3dgA8F45Z
DYb+ORy1hZvTxL3jvSY6+rTLl1bfDdqcYl/tTy1DfQraYUyFO2H457Oq8mWX8Bh0
nyMTRoubmtkqF4YNLL2mJ8R8V5jrR9uIiQCVAwUQMgYuMpwp8Mbst+fhAQH/DAP/
c/TYArdPFIp2AFpHbYcMix0MlpWvH/Pm/5GBsWvH++u8FYVR1VxQ6w0cnj5bUeAF
M90iISE7Q1+Y+sTQQqiMeuMsFy0dcR92ofRG3p1D3PgbfRE74fI0DzGGNJY9f8rL
wqVD2QbcV1M1Jw8M9Fd1XLUQHNND0gl0kNVqm2vHW4CJAJUDBRAx+RRbpFCQLAnT
5k0BAXu+BADAbMQ52w/XLiOTHxf0HkzRBuASFVGbQJA5nuBIO877D3dw3iSghnjY
4glmK0UwhsGglszEJPv/jDpnZCOjppfgCLqyS6B3Hh0vYz9Ys3T+3zdo5HXiUgbI
sbp20FrVBJUoDkEOIheZKsAYcbTnxD/y/ULKMnUTEdcgeljw++R+1YkAlQMFEDIZ
+N6v719yl27X+QEBRkQEAJcjgLLAOai5PlqZOeAp8ffOhERJ7YKyfTxdwGDZoLrT
8B36+4JwdhwgaWWmlfsHko0wwWp9BKYju6Q+LGfu1JmiDyarUD2q9WWw62hk1Tns
yK0TjCmr+ADvi8tNaRwUGQRJVyuoltKusm+SCqs48RSLQxOmYk7KVcD8F4WOgG6y
iQCVAwUQMZ47zrNaYutZnzI9AQEQQgP/Z88RStJfdiSPlMk8Vn0w1fSUSjsAdiOc
mARs0jiliboLc+cyWxh8JJAMe5eZFAcA5ZJ3A4u8KQ0Xx4NoXczq7S6uB5Un4pVS
dPPb4tmhmzXZdJkoK17QfGNu8+lYxNOtjKKYZ7Mfv0KaANWOwdpg7HcRcXSecOa1
e6saKgSZbUmJAJUDBRAyGYL01ocrpT8NmN0BAd7iBACc/G/qpW6OwxgKmXqPV5qk
eQKCl1NgiTIatm5avRd4h+whgLcPJ1K7zHCpOA+GOAQC8MLGnJnxJVAdsiZjgkqy
ZTHez5sHUiVjJpuk/yaaODT2g0OpYCkSIo7/0uagg1SnknvWWIgMr/TNd+HE3SIJ
/wipVc5wLNWE6r3orQTmz4kAlQMFEDGe9eHcgPKm1TJ8uQEBhMMD/iYQqUg/8RRf
ZmbGCt38lAGGpxCWROsEBoM6c6p7/ih7AwpHvJoynO1iEmz3uLTdW7d+CguEOykT
nmigR4ePSvhw52JZ9gOyNIVRhI81WFbg5Ku4wDdzb3Kcyo0cPuGmvetwI9SLsnZG
dyhw5wKOMrYFBv/0gBQ14rgL2A/EwRkuiQCVAwUQMgJKVfKmgBGt1kwZAQEX0AQA
vkt5G7pRADd0iO/wPgP3bZfQ32Xs0/QuEkQRrJdnJUBTBiF5jEP+7+5S16ykO1Ns
1W4DX1PLJsOYdrwSC+n9T8nsUpnN5s/SWOHq/CnmaXH+h9K0pB5fone0xdBr7k3T
TxTvIXPRJ/hhukBzqm5AeDUWenMLX8FDIZNhR1wZ4xe0H0d1aWRvIHZhbiBSb29p
aiA8Z3VpZG9AZ3ZyLm9yZz6JAJUDBRA0FbDyH3+pCANY/L0BAcaEBACWu8AG7JrW
rw1fl68fcGmSS40OXhOsEDICXDG+sjNxFXQojPq+TSZYuJ4u1e8MNOTxsfd3y10r
vztszJvFy8mA+1zaFrELqzGR/mNeOLSqycSxzJ8mBV8jLqb3ikirOz4uB9EsZBu6
GrtvgKmusULDg6ZvQruIJ8q8ODSYE/04uYkAlQMFEDQWoDw7f8e8znZrHwEB4+cD
/05quZRK3E/eCkeHl3oCU+J0TAar995WS3gxloPM6vj/taeuAeRggVLm1Dq9MqmS
hFhg+VwdluiH9uz2loK8Tlv0Sgx8fEMPCHFjBqVlb8pIJDRQ6WufUDZ1OPNI308J
0k95K/LeYs8gvH1/zSIMmeyr5lVCtZSNU8Y05iji1brAiQCVAwUQNBWssLNaYutZ
nzI9AQGp3QP+OKSZpVgmBY7Z6IkQq52t1U4gTEYBgOm+T+A3ZdlrOo2ACURL+ago
4W8BMA0rPyhGRpAWH4OH5wTX31nBnYuUeXz/CKQckiVdQA4PN61Seh2Y7msi6V47
2kuc+Nt30ofsWrrSBlh5yU+iQXMx7kIU6Ampvwp7IILjSBOlJfcE7tGJAJUDBRA0
Muok3IDyptUyfLkBAT5fA/4rMfz2D2WYm7ujXquY7Mh+eTVQ0cjxxZoQXge0209d
fwwqZDnxqKWnrfl1FIwCrL4NLvwOkyMXxX+hQKf5CY7HeiAt/O+9L+7FidGYnDHD
Y7py9q5226n8HdxgCYAZGF/k4/rbYvdI49FAJNnwTAi7psi1EpQo1raruE4yVmqn
EZkBogQ59zBkEQQA4jWzhgsNeyX9UkgZerRQdJZ3OOuCsOHIdR5Vf2fIMCgJ25zN
51jCuxbg49TVAowcvi2ajVKRqtYFmBw8SLT/a5untxWsXH5EmPq3SADeZaHMRRrt
TD3TA5zFoFqr2H2ZJBxym7DehVhKqee5ScGwxdplWakSQ9m5yndYHLNaPj8AoNCT
CXyS6KIVHjSpcxpT8Zjjwtt1A/97HBr224IZ2+So2tFbPNVMRVwKt/U7JlVCsOjo
3xF9GUSreDT4LGrm8Y67k+pAAcoR+KvE0NKGG1xWchmm+NGF7U7+9XUfHWAmFz1t
6OGmZkUIZSaHCWda9VUT9h61iU39PMhXV8ee/M2tK4wF/L/cl1LfaSHWsLKFgx38
HvHH2AQA2YsTtaYpNF0jSxKxmATiMH9sjgNlz/JFijibQoj/jtyU+dfHf+oPx/DA
NCXpi1CCKmbeT14Q9n1mc2msa0tT1qJqj0S2Mm2gH4SxO3rXj4Zb/cnPrAxZZyxY
FjkqBoeSEEdLxJwb0HUZ7gOs+aPqqz0+l+JyMuW7t3IoGsjwEzO0Kkd1aWRvIHZh
biBSb29paiA8Z3VpZG9AbWFkaXNvbi1ndXJraGEuY29tPohXBBMRAgAXBQI59zBk
BQsHCgMEAxUDAgMWAgECF4AACgkQJHERf6lRAsFl7gCfWqmRNrZDTMunpsdSLD1i
rohDJjIAoICakbb+lQ3jlSkPgiTZOe3L7yv1tClHdWlkbyB2YW4gUm9vaWogPGd1
aWRvQG1hZGlzb24tZ3Vya2hhLm5sPohXBBMRAgAXBQI59zC2BQsHCgMEAxUDAgMW
AgECF4AACgkQJHERf6lRAsEhwQCeI/mR3pH7oMN59R6hTiIGjNt7X0kAnjVUZFiM
iYWkf5LeymkDrxWy5t/3uQENBDn3MGwQBAC46iYEw3jtA6oWtCD+VfNcR74eDT9W
JCJ2vxJD6bN35fDXYjzXk6uyvX5Z0ag0yjKqbqsa/bPOuTTIeoxK/3zr/jh+x2L3
dFY88uK/Dit7FY7NM2+jDoETXZoJbZuNf3eiTWmI0JrSUBMHXJdTuBO0LfAY65tR
OqzFwCgztqF2NwADBQP/TDM+25v5c0njS8NMofBsun5dtywOHjmbMedDgaZRGsa4
P+4/owb9jUBjk7GOtlL2edUSKBNuWYbKjDkW2134W6rbKDZYlnkXQ8Z64XIm5STB
zfUEiu0sEFB8Cfe4oX8kHXa6kv11NOzK9qSv4zxmJTI3CMABi9fOu3R4F2XsuNGI
RgQYEQIABgUCOfcwbAAKCRAkcRF/qVECwUUEAKCElDCyXmWq1T82/oT3eFk4WeFs
jwCgnb++jBLoAgqu7BiWMBVe9sCLfMY=
=qL8T
-----END PGP PUBLIC KEY BLOCK-----
D.3.179 Niklas Saers <niklas@FreeBSD.org>
pub 1024D/C822A476 2004-03-09 Niklas Saers <niklas@saers.com>
Key fingerprint = C41E F734 AF0E 3D21 7499 9EB1 9A31 2E7E C822 A476
sub 1024g/81E2FF36 2004-03-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEBNxyoRBAC22NnMqcH1hXXkz+jC+U2QGzOJdGHZtLRXDRpS4blFtRgAf4ab
tZY6LJUMnjmdgaPP3Mc7YE/ITF1hGnzYF2jbJazNm17nMSP/66dGJt9dK4XAE4cc
5nYo3GnEkacAa1zUvM6e9OGaAIkndBDUW6+a9aSQNcNyMnYL1/APv+wdIwCg2G4C
N221QrjrGbxVQPiBM51lY98D/11d/h8aOHYkf+nirhIj9GvRmXJfD3RANZUDjOsj
OKGgUNlXm/AT6I226v9urfdtrhMg+5zdO+I2p7dZMad/RpnSYo0GMdLRzOlN6aoI
+4JYoACq2C7iR8pmItb+L4Nl5nNBwmcLBXD+HaZebGffZy9Uvy/A5G0ty08I8LKm
5STvA/kBMybZhX+RTq5v1Kzau63bMBJR8MPHyWYAIBW2wTMJM1ndW5RrbIMJ71qC
8DFFTHFJd97s/fqBMQ9rj094CdDxCYQJUkZy5+qiBkRta//iSlgsi54Xhj9prgPj
nBMWxUjAI5Ih0VPIp3/z/q5aQRvey8Ro5JWmduzH0KpLv2Qe17QfTmlrbGFzIFNh
ZXJzIDxuaWtsYXNAc2FlcnMuY29tPoheBBMRAgAeBQJATccqAhsDBgsJCAcDAgMV
AgMDFgIBAh4BAheAAAoJEJoxLn7IIqR2/y0AnRetbhzvjj3kKOV28bx2Qt+YRA/j
AJ4yY9wDPJpwq63IsGeo3BYXi32zPbkBDQRATcc5EAQA2SipeeJJjvrzqqILHNA7
X+m/PAJonO4QhyIEXXMhzNGdiUVJ7wli23gGVF0Cj3V97Yw5KFGco3qOvvsWkO4c
CLwd3NHbVL6OHKM36LcFd+a6RiJO9qAGGixyqUIkqYeWCmpObihrkZy9WADsSJTc
/qOrLghJ0GyR4Ga8CoFNT/sAAwUEANfA3lWeTj3QZcDnJZYejt1aJWt7oUBQ/KOc
HhTjY/A7zkQsAdgbcmuhzSiIH6eoofTwNOl/Kl0ieSdIyFMFfVxrmYEN/HUUUI4q
J+BgWZgppinaeUEabnZPfY03T+ZanJ3DmB8s8x4HdpFi3jgtWY0KfDhDfHtNIeRu
CYmLAzjYiEkEGBECAAkFAkBNxzkCGwwACgkQmjEufsgipHbIOQCfSaudT6wnsh4G
6D9TZkji6aDqUBwAoKqxWnOya/v/MqcgrXGSCih7phIL
=Hz+C
-----END PGP PUBLIC KEY BLOCK-----
D.3.180 Boris Samorodov <bsam@FreeBSD.org>
pub 1024D/ADFD5C9A 2006-06-21
Key fingerprint = 81AA FED0 6050 208C 0303 4007 6C03 7263 ADFD 5C9A
uid Boris Samorodov (FreeBSD) <bsam@freebsd.org>
sub 2048g/7753A3F1 2006-06-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBESZt5sRBACyDUDxsmkdq0XNNJfbsdVO07/vtUc+rP5hBEdMzbetPnLdujSX
JtwzS2b5kQFk1ONAuTs9udlcZhhq5T2FIyhqpvgLG3tnt4gDabRgFsOL6oB4dFKv
yL5emRwnch+wYlwfaoWXsXpWfdHQCwFfL39lsYLIR/aXcMwjXF1wl9yl6wCglkCt
NECUgmsoUYE1iOyC5PnqHkMD/088reqeJuH2hWHupCOihIOOddQPiKX3EY1Y6piO
I3aQFxOq8BdYw+3WAlBs4vegMmzk9MYEwP2STsVcPE+eu55m1GCRRds++oyv9tQO
TFZVsYEuvJALvHSW3InTGHWfhQPrHcdodyRjhgo2bKY1RwO3RHYDRRQj5i8LDn/9
kRSiA/9Y9Cl8Abr7kuPbgw7uWb8lRta9/le1UWQXpU6GAZHXEgppHenDaRqvbaag
MhXXiKuuFAz4LNHf8UDqyQ4fjjfR0EajIivV17hpzagPWIzzEdr4j3RBpwHMYLbV
1yfyml5QT46amMd2Vwq83Zgn0cUObu8E0IITqTMkweEvH+soOrQsQm9yaXMgU2Ft
b3JvZG92IChGcmVlQlNEKSA8YnNhbUBmcmVlYnNkLm9yZz6IYAQTEQIAIAUCRJm3
mwIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEGwDcmOt/Vyam2gAoJHvCp76
i+XiNv4R3pJgG0ZxTCjOAJ0S46VswPDByVJZNF95pfy1qEDb/rkCDQREmbekEAgA
vAUui6QrSn//3FHeSvH1smd0432C1r8IHvR7m0Ki+F1cRolkWF29y6JMpoPcXrWC
D5OpGfZaZQ9SwhedFr776xAwMDWAHlrHEpPC4OE3RPq7YWENc40hL+ZKfsZhGA89
H8fiU18UdDlARgg1PDBbVi+F4ZFfKSyNcTUO3brIIpUy5OfAdTkgl3JFKERlqZic
ZWjS9PXjsyaeTYn1Ny2T9WZqbk9Ghsb2/t8bIyayu9KNnI+vRSafRtaomeUEsKme
YZyU4pLutea2Zj6u8BtEVyxp9Gcy0Whn/HwQc/FZE91Z6UzViucBqKmFmw3A/OHF
HV3DAxd2ctkBrt5jzgJA2wADBQf/dD7RVzfD2ea+jpgqJW5EFDqYebjPLab5GZJ6
uUWWZu73ynDm92lemzcT67JYirU0H0sQ6QmcZ9ZwqqdW/taCjvpsXPFb88B9AL9c
aQD41otxgpCF/zMQwgS24DCrdtPXiKceTjHNEAMOM9xS3FBNAWjy23Jz6rIt3ROD
o0X3iAta9cT71Q6/u6BYo1YRuLIAWZ1rpkELb06NUxsVuEQmBKGMBKf00LEw+AV8
0FkaEukzFuG1u3k2qkeFJEZW0C6d04JT5jsskRiTrIzkd1FTyaEdueaZoiPBQybX
KE9GyClXn1RMWA+dzAjjNvJOo556NAIpebgvXMd1rHSRxumHdIhJBBgRAgAJBQJE
mbekAhsMAAoJEGwDcmOt/VyaOikAnRQNCxBdrbQSOLIxrChaMU5tNejQAJ4hpoO4
tGfWhh+Ib0+vCD7UaSphYg==
=fafd
-----END PGP PUBLIC KEY BLOCK-----
D.3.181 Mark Santcroos <marks@FreeBSD.org>
pub 1024D/DBE7EB8E 2005-03-08
Key fingerprint = C0F0 44F3 3F15 520F 6E32 186B BE0A BA42 DBE7 EB8E
uid Mark Santcroos <marks@ripe.net>
uid Mark Santcroos <mark@santcroos.net>
uid Mark Santcroos <marks@freebsd.org>
sub 2048g/FFF80F85 2005-03-08
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEItZGARBADLwd04ILGjaq1OV/1cNTU36Ggwx2fKt1OQSFgfzkQDB2Ff0R/P
xXLBhx3mVEcTt/vNcniqyOA3Pdla6nVtxFFMDcXhEN/d6Xsv6UY0s5B6zoJ6tx9J
2lpP2YQeA0sCGPnl6QjFYX1pbehPO7CSen0ApDBmfJx/B0J8AwCh9utzmwCgwmBt
KvC79obIrPNdTr8quYyYZf0EALQbGGXPhgZN8A8u+PebwIajKxMTxqPnJbcImwRd
GOjdRQ79BT2Ze3g97ReKjQCCqOFY0Gz9XMd+OGfG5MfDwe4pGXx6DUxOYOJqL+2p
5MjDbpmcmemtIaC1AwchhCsqcQVo7jbH4ewsxsb33cIktX6lidVxjUZQaTioPcah
t0eABACy2edSB2D3KXk7zoNMnfo2ew++Aot8EsL4TOVOrJkx9p0gEKKgL4ED+y8Q
4cw6chINnqQWIQ4WxyTHeVjw/SIgVfOBEFhvaZFtC9wfDTk+1G2DeMuyw/KDK7fi
J9KOUhAtKPKTl4D0nZN5rOULgPDgq5WaTjxkWLcs9UjcpDCQhrQjTWFyayBTYW50
Y3Jvb3MgPG1hcmtAc2FudGNyb29zLm5ldD6IXgQTEQIAHgUCQi1kYAIbAwYLCQgH
AwIDFQIDAxYCAQIeAQIXgAAKCRC+CrpC2+frjrUsAKCWZHuLZGVk+bWwOh9E/eH1
I5FTzACeII0hwrpqPwlxOyNHMiF32+SYc9+IRgQTEQIABgUCQl9moAAKCRAVEq5S
cndxfy5TAJ4o2kmigp9+7Pg8vtGQeJwSgk9dSwCfXo/xBlHKAF1q0MF24MDcLx1q
4m+0Ik1hcmsgU2FudGNyb29zIDxtYXJrc0BmcmVlYnNkLm9yZz6IXgQTEQIAHgUC
Ql9s1gIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRC+CrpC2+frjsirAKCdbg00
iJcryV1H8H7POuWA5cpqBwCeJC7RbQcBAU4hg5kY3Q6yuVLYD9m0H01hcmsgU2Fu
dGNyb29zIDxtYXJrc0ByaXBlLm5ldD6IXgQTEQIAHgUCQl9s8QIbAwYLCQgHAwID
FQIDAxYCAQIeAQIXgAAKCRC+CrpC2+frjqw4AJ42EWPG0JCtzDpUx2fCWM73SJ0x
NACfRxkme8yMSHLPRDYFQ6up3y98+VS5Ag0EQi1kixAIALfhPatM8pRDvjbMuw+x
z046aF+ygNF3Z+jQYMv2+TNx72MUa2GMM8WloInYu/sbJLuv6yMXKbtGx2wQAAkB
Ayd8Ink2dniabAummzHuRPLycQ869QJGg0+xCq8pifCsUXh3Nec4IFjkVs73hn3+
fcyN/bSO5uVzAsLgRczJX1zhipi0joFijFW8V3hk61VPDuB3UM0EzqelA8VMsreu
wrs6N4BCRVcqDvncTrV+8CAPdRuBMk1NFffQTM79G68UIq64OZSs7uJTOsqLj4uh
EE8V1rbqoaxNUq1KKIcQxIOMtyMbXnDuM5fXTqKD+2MEmiJE1D7nE2qzmczOFJ+9
qZ8AAwUH/Rvg8dNLeZXrsYL5A249GjKZOdv9NpmSpEBtjp2mMeodZBVO6u1KlcfT
N078WY3f/Z3vTt8mqg6woWS4M3l37mDbNb7508HjVC8rALC3ZueCRb/COvTssxBV
TCvRcJmDYdhGxGAAIRGPiYx+9UF94AE37UgxAiLbTHCCimJmMn/tXvNsX2Qr1oKL
oYI6kINNYE7uZ9oqZ72zQoJdCBBxyBwRRHj0axzNgtXjK55yUrHDYDnLvu1dr23K
85Wje6ZVWbKp1+qbZ0tPmPPWb7QYH728MDHzkdcPp+B/QSiJPBxv25CXn9hZBLYQ
sAUeOwsaps1T4OJoybYNQihLifueGC+ISQQYEQIACQUCQi1kiwIbDAAKCRC+CrpC
2+frjhtvAKC8dlrD4umaE+9r0LyOx/+il2rXeQCgvUTSvbtlZo87oKp0EtGn++rf
IdA=
=F4/l
-----END PGP PUBLIC KEY BLOCK-----
D.3.182 Wolfram Schneider
<wosch@FreeBSD.org>
Type Bits/KeyID Date User ID
pub 1024/2B7181AD 1997/08/09 Wolfram Schneider <wosch@FreeBSD.org>
Key fingerprint = CA 16 91 D9 75 33 F1 07 1B F0 B4 9F 3E 95 B6 09
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: 2.6.3ia
mQCNAzPs+aEAAAEEAJqqMm2I9CxWMuHDvuVO/uh0QT0az5ByOktwYLxGXQmqPG1G
Q3hVuHWYs5Vfm/ARU9CRcVHFyqGQ3LepoRhDHk+JcASHan7ptdFsz7xk1iNNEoe0
vE2rns38HIbiyQ/2OZd4XsyhFOFtExNoBuyDyNoe3HbHVBQT7TmN/mkrcYGtAAUR
tCVXb2xmcmFtIFNjaG5laWRlciA8d29zY2hARnJlZUJTRC5vcmc+iQCVAwUQNxnH
AzmN/mkrcYGtAQF5vgP/SLOiI4AwuPHGwUFkwWPRtRzYSySXqwaPCop5mVak27wk
pCxGdzoJO2UgcE812Jt92Qas91yTT0gsSvOVNATaf0TM3KnKg5ZXT1QIzYevWtuv
2ovAG4au3lwiFPDJstnNAPcgLF3OPni5RCUqBjpZFhb/8YDfWYsMcyn4IEaJKre0
JFdvbGZyYW0gU2NobmVpZGVyIDxzY2huZWlkZXJAemliLmRlPokAlQMFEDcZxu85
jf5pK3GBrQEBCRgD/jPj1Ogx4O769soiguL1XEHcxhqtrpKZkKwxmDLRa0kJFwLp
bBJ3Qz3vwaB7n5gQU0JiL1B2M7IxVeHbiIV5pKp7FD248sm+HZvBg6aSnCg2JPUh
sHd1tK5X4SB5cjFt3Cj0LIN9/c9EUxm3SoML9bovmze60DckErrRNOuTk1IntCJX
b2xmcmFtIFNjaG5laWRlciA8d29zY2hAYXBmZWwuZGU+iQEVAwUQNmfWXAjJLLJO
sC7dAQEASAgAnE4g2fwMmFkQy17ATivljEaDZN/m0GdXHctdZ8CaPrWk/9/PTNK+
U6xCewqIKVwtqxVBMU1VpXUhWXfANWCB7a07D+2GrlB9JwO5NMFJ6g0WI/GCUXjC
xb3NTkNsvppL8Rdgc8wc4f23GG4CXVggdTD2oUjUH5Bl7afgOT4xLPAqePhS7hFB
UnMsbA94OfxPtHe5oqyaXt6cXH/SgphRhzPPZq0yjg0Ef+zfHVamvZ6Xl2aLZmSv
Cc/rb0ShYDYi39ly9OPPiBPGbSVw2Gg804qx3XAKiTFkLsbYQnRt7WuCPsOVjFkf
CbQS31TaclOyzenZdCAezubGIcrJAKZjMIkAlQMFEDPs+aE5jf5pK3GBrQEBlIAD
/3CRq6P0m1fi9fbPxnptuipnoFB/m3yF6IdhM8kSe4XlXcm7tS60gxQKZgBO3bDA
5QANcHdl41Vg95yBAZepPie6iQeAAoylRrONeIy6XShjx3S0WKmA4+C8kBTL+vwa
UqF9YJ1qesZQtsXlkWp/Z7N12RkueVAVQ7wRPwfnz6E3tC5Xb2xmcmFtIFNjaG5l
aWRlciA8d29zY2hAcGFua2UuZGUuZnJlZWJzZC5vcmc+iQCVAwUQNxnEqTmN/mkr
cYGtAQFnpQP9EpRZdG6oYN7d5abvIMN82Z9x71a4QBER+R62mU47wqdRG2b6jMMh
3k07b2oiprVuPhRw/GEPPQevb6RRT6SD9CPYAGfK3MDE8ZkMj4d+7cZDRJQ35sxv
gAzQwuA9l7kS0mt5jFRPcEg5/KpuyehRLckjx8jpEM7cEJDHXhBIuVg=
=3V1R
-----END PGP PUBLIC KEY BLOCK-----
D.3.183 David Schultz <das@FreeBSD.org>
pub 1024D/BE848B57 2001-07-19 David Schultz <das@FreeBSD.ORG>
Key fingerprint = 0C12 797B A9CB 19D9 FDAF 2A39 2D76 A2DB BE84 8B57
uid David Schultz <dschultz@uclink.Berkeley.EDU>
uid David Schultz <das@FreeBSD.ORG>
sub 2048g/69206E8E 2001-07-19
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDtXc9MRBADg4tN94el8rq0ZMUqB2jEVACg/UfYjtsaboDL4HBBUH+P+Wxic
9JqotcTbT8pJGeRpeXbfO0YHaAFnUfilhoFkeLyAgDvnUP9Z77DjFpliLAKlvuCz
Lxi4UxgQXRdedNCg3omrxQWx7Yx067GT/yw4RgvogOuYBX0l3AJ25/WBxQCg/6Dj
TMTu6iYR2Y6dEL4NGs9PnBMEAKBlhelAhzYoMpcWpk2VITUgONMW+Oi2JDTmwDd+
1FAUDc1mHSoNBKPUrCWyXiwfzL09/ROlK/KMR6YoYtV6d66zZ/dQNuzrMhsis+Ou
PCtvcaR5NGln49THgcw7/K5gTjwrG1xA/wcwnvUp6sxjh4p88meI/LNBAstixb3z
FiLDA/9pAqn42B9ZBL1le98DTiLDemHvQFgXu8Oj20IIF0umyJRBfKwDY6iIx0gd
1rUKua6XnqMSEg+LmHmSfDBaAOsFTdnL7wVU0tLF0V9goxU4qDZjw5EeMEqnk7tg
/6REIvtdOA/GLOmr/Q0WA4JEukcih3AQ9iFnwg7WAp0S4GF6gLQsRGF2aWQgU2No
dWx0eiA8ZHNjaHVsdHpAdWNsaW5rLkJlcmtlbGV5LkVEVT6JAEsEEBECAAsFAjtX
c9MECwMBAgAKCRAtdqLbvoSLV78JAKD4iJ2kNeTsYQnWZ2DeytAeqVaKFwCfTIQE
lFPZyaQr7yjthREE+8SPZCG0H0RhdmlkIFNjaHVsdHogPGRhc0BGcmVlQlNELk9S
Rz6JAEsEEBECAAsFAj5S1iEECwMBAgAKCRAtdqLbvoSLV4b5AKCljokqRgi/pbDa
ZebYLluQCIkbgQCg+jSKAIi1r+CZiaCJdqk193IZVnm5Ag0EO1dz0xAIAPZCV7cI
fwgXcqK61qlC8wXo+VMROU+28W65Szgg2gGnVqMU6Y9AVfPQB8bLQ6mUrfdMZIZJ
+AyDvWXpF9Sh01D49Vlf3HZSTz09jdvOmeFXklnN/biudE/F/Ha8g8VHMGHOfMlm
/xX5u/2RXscBqtNbno2gpXI61Brwv0YAWCvl9Ij9WE5J280gtJ3kkQc2azNsOA1F
HQ98iLMcfFstjvbzySPAQ/ClWxiNjrtVjLhdONM0/XwXV0OjHRhs3jMhLLUq/zzh
sSlAGBGNfISnCnLWhsQDGcgHKXrKlQzZlp+r0ApQmwJG0wg9ZqRdQZ+cfL2JSyIZ
Jrqrol7DVekyCzsAAgIH/1AtvAGCJchvLFoaR5KNocKcoUMe2NrpRrFS3DsYOsXU
0U95pmAHJaMt+wv4UDs/wNzOzC6stRML+3lg6sYnSgddH+N/DA0b5jQSAyNWlL87
j08h3ATaPeDD6qhqFRe3uzpQMAJJWbeTdyiT2vwgglgcaJWuVjYSfkkxX7AVDFHw
C4IOuZ0aQhHyHQsGQURTg+sotMx+kX68o7oGZqBBOcr8VdFyrlq0Tq1b/i0fJnn2
Nz5hY+OOXbyeoJbaY0KiGnnMwHmeZ2eJWk1cCHUZnrY5WOxYQHail2KHXxhYuPoI
xsL0y+XdErX+lc2BiEbvXROs+VxEo/3/BVJXAIar3nCJAD8DBRg7V3PTLXai276E
i1cRAsj2AKC26JMJWsvd93UUWRXDKmU46MgLggCfTOIjPheQwY9VCN3jO9YROzij
QVE=
=qhh7
-----END PGP PUBLIC KEY BLOCK-----
D.3.184 Jens
Schweikhardt <schweikh@FreeBSD.org>
pub 1024D/0FF231FD 2002-01-27 Jens Schweikhardt <schweikh@FreeBSD.org>
Key fingerprint = 3F35 E705 F02F 35A1 A23E 330E 16FE EA33 0FF2 31FD
uid Jens Schweikhardt <schweikh@schweikhardt.net>
sub 1024g/6E93CACC 2002-01-27 [expires: 2005-01-26]
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDxUIHoRBACGAbIspofa2HTwV0Y81ZgrizVgvsHduKRMYmu9scX6eFSQWC2a
JLXXnMJMK97LG2m6qX/hzjxZKU/n2eNpHa3h9zLYQ/8VdN+AFHGZtgmZ7xe7UpBI
V2YohykdmgKqg8WuVQGrNTwbkaAFeLnG3yXhR83qukRvv+qFfXbEF+1S2wCg6lLg
YJ6U4J1pfTO95Rd4hw5v6DsD/0hUfa6C6C6xjME6P7r/ORd91+nJsfO0pcV1rK0s
yCMdAy/zdUlKpsNF9vS0qhCFonuOHWxMEe7D8L80oUAwlk4RrFBm+Ch7RoBGYGru
aEom/7JGNoRqUD2CKbFnkAYi9HP6XlXcpgm3GO4c4VtIcEbgywjw7rNhmNoYLrZV
YUb0A/9mNCqpPTd8ngm7kPyTTMJitYEVaBPXEdiPueYJND+eI9AQkcqYhs6LWq4c
jgmTNeImQ+kR1UeDj3dOwUDqhGmLPN60nD+Q2oHHBif8NJOu47mx1dgdriM9FsTN
3UbeSve+mY8Z8zcPIYKl2UJLPZckWgq4pZRrE147cnKHSHHM9LQtSmVucyBTY2h3
ZWlraGFyZHQgPHNjaHdlaWtoQHNjaHdlaWtoYXJkdC5uZXQ+iF0EExECAB0FAjxU
IHoFCQWjmoAFCwcKAwQDFQMCAxYCAQIXgAAKCRAW/uozD/Ix/ZB8AJ989jyDH1G2
T1KMoNd7gPk9tAw1VACfXJgkrI42ShC4cHz37xrVLXeJp9i0KEplbnMgU2Nod2Vp
a2hhcmR0IDxzY2h3ZWlraEBGcmVlQlNELm9yZz6IXQQTEQIAHQUCPFQ+0AUJBaOa
gAULBwoDBAMVAwIDFgIBAheAAAoJEBb+6jMP8jH9P+YAoM72fnNwxxcDjb+3Mv3A
CfbHonYCAJ9lfK9fIbkgfAHo+2kwnOEN4yWxzLkBDQQ8VCB/EAQAzzIqOgms7u+e
UKampP/5U9G78HA3GIkVLcAeq5FfpFtls4NmSKz240zNxXmABWTSlBmOQvMdhB08
vRbzEsxPoVdNaF+QvRZYEr5+2bOM1pnHqYYMyUKwN83LXgTDnXxas4mtrkgngZTe
tGdFQ3PIVqW4jV0MmnEmaqde0nMJ6XsAAwUD/2z82PDDwFBu1Ogogh63qE69HSQt
8weHX+Skmi75jE3r2niUlx6B0IfLXzFqP33vyrsov7QHgAuOjNficisbC73o3gjp
voJ2RYB2IfUCgeFvipLpqY1TWJ3bF52TYnJg4rrEWd5OWs4FB0iaJ78LVWgq3WsN
zfgcgfQ38d+scJu4iEwEGBECAAwFAjxUIH8FCQWjmoAACgkQFv7qMw/yMf1PIwCg
nSP0i+q9jhEf9T5xA0+qg2yYB/IAnjvd/tA+2/5bP4pObE/oRNjIVZBZ
=YPu9
-----END PGP PUBLIC KEY BLOCK-----
D.3.185 Stanislav Sedov <stas@FreeBSD.org>
pub 1024D/EB269581 2006-05-20 [expires: 2011-05-19]
Key fingerprint = F21E D6CC 5626 9609 6CE2 A385 2BF5 5993 EB26 9581
uid Stanislav Sedov <stas@FreeBSD.org>
uid Stanislav Sedov <ssedov@mbsd.msk.ru>
sub 1024g/B47898B1 2006-05-20 [expires: 2011-05-19]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBERviT4RBACarPzU6+FIZWe1FBe+jNdft8htAFmrVbwJQVDNmx6MNb4+TABU
IhNBvsG0yi5wKr84PPI9vhduhegN80TT0kb2faef9qzQb1gtTng+XS7Dw2uel2S4
XXyj/Aoi8a1mvqbOGFYgwNBSRZHil2fYq+fXM7zTVNV54oJ8UhRDzK+mEwCghaha
/nhSJm5n7B4UOUY3u1Fi2McD/RF3lXVd0q54Jb6Uz3Sq5KgSId75G7a7UKKnWN85
LVM6G6VBgd76/vA1By0X5sY9JxbGc+SccODP5Y30eTfM8ATIVavaJt5egoPPHMbo
onbDgYchc8GDhthxKomYL01j4rbZtVoTKqb66Oj2yH9toz8dx/NqyxXoI/x9xrS5
uUVbA/940a5tL+uwZ4ri3aC1B7rLqHw8PQU78RlljW+XTNFwK0nxPw4ibOR/q+cj
4T329Ts2e8pwHW/mouO1V0G5hfsc9ieeFeuZwFtcp1HcZ8NQiy9kD9oJeou3D3DF
MfelXs6u9oTI0mQ91b3SSQ3P2EQyMeCfptqAFPu0UdJraNvxsbQdU3RhbmlzbGF2
IFNlZG92IDxzdGFzQDMxMC5ydT6IcgQwEQIAMgUCRQ6enysdIERvbid0IGhhdmUg
YWNjZXNzIHRvIHRoaXMgbWFpbGJveCBhbnltb3JlAAoJECv1WZPrJpWBBXgAmgMo
cJCpg1WO81PtGQWRPBdmOiM1AJ0c0S2tT3fiiWy3YxGX/Gg5xa9ZVYhmBBMRAgAm
BQJEes1cAhsDBQkJZgGABgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQK/VZk+sm
lYGy4ACeL2/uE1wfNoSX3s7r6rFH/4XTn5sAn1FrlcGP3UqWL1PnuDcFr326I1dz
tCRTdGFuaXNsYXYgU2Vkb3YgPHNzZWRvdkBtYnNkLm1zay5ydT6IZgQTEQIAJgUC
RG+JPgIbAwUJCWYBgAYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJECv1WZPrJpWB
oBIAn0r8P82jc6Kckvrl6NAvMZTUyTxCAJ9HdqfKdpZX7T68vdKEt1DiwBemA7Qi
U3RhbmlzbGF2IFNlZG92IDxzdGFzQEZyZWVCU0Qub3JnPohpBBMRAgApAhsDBQkJ
ZgGABgsJCAcDAgQVAggDBBYCAwECHgECF4AFAkUOoFkCGQEACgkQK/VZk+smlYG5
4gCfcNonqxmYyMPgX+/bvQ51bE60f2EAn3hJ+odNmcWZpUEGDyVRBGoJanZduQEN
BERviT8QBACA+7zeO4/5Os+DiAMsmADE5sMbuq96tQX//IVK/YegpFZS7C89a8wk
ZdQqxjNul11Qi0ow3abEjkf8hw7XFHR/EFM5L26ZIflFJfyNsBRVh58qzoiUqDnV
Zrvtld4OE0Xy90G3RtsIdBx1SIlW/9haY2mhPtuMIO2IazX2P+uC8wADBQP/f/vA
zrNU7Jymo+rExfEn4dNEQXn+tGWSxaPWlD9/eJCMYVmXCDymKvpxDbBs9+485/Pb
FgTkqDSz422avxM51562FgFES4Nb9WwI8hZajzGNcBUFdBEIpIOWbu8AxXbqAam5
jG2nulcyHpVKeQx1/yFE3vxQnHPeQWDJochx7b+ITwQYEQIADwUCRG+JPwIbDAUJ
CWYBgAAKCRAr9VmT6yaVgcV0AJ9dE8CfMFLLmQDzDXyectDxX4YsagCfQUrPSKzU
6ZOB1kr0hXd13pXQdVA=
=g9qV
-----END PGP PUBLIC KEY BLOCK-----
D.3.186 Johan van Selst
<johans@FreeBSD.org>
pub 1024D/7DA5C53B 2001-03-03
Key fingerprint = 3021 482B 52C1 3FFE 4752 4D57 68E1 252B 7DA5 C53B
uid Johan van Selst <johans@stack.nl>
uid Johan van Selst <johans@unix.nl>
uid Johan van Selst <johans@gletsjer.net>
uid Johan van Selst <johans@vrijschrift.org>
uid Johan van Selst <johans@FreeBSD.org>
sub 2048g/EF1C75DD 2001-03-03
sub 1024R/355F8408 2005-11-05
sub 1024R/9AF7EE88 2005-11-05
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDqgzyMRBAC63IHIDuA+G0pBYRlR0s9FUXlMKiw8f7RaipaqNviEzoOdgFDm
0BnUXWL0FGEkhq6+aTgvm4a9P7ftraAis7kZzokHej2tzQdbyGcMURrY41COa2iZ
/I+/qMmx4++/u24mIqg1mY1T/AfAJj922mHES0Q6CSee23zqZWz0+qvqQwCg3gfM
19ZwrPBtPVh+uxnQ+klQKEUD/3PullwjgE1e35qf0ncWHzLm8zJprQPu8yDnqXpu
HGSz6mEBZIFxSm4CZJHulFFBgwB7vKfoa/ZfJU3KXu7eyvmRk7aS9rlJcu3A0+vA
U0bXO/OmKr8YYiD88XrTd1gfrawvRAgRWu0VjIEp24yiEYRjjTr1h+XRYijuwLXE
xTT6A/40B0bWO38roO0ewMEWHwe1/YWhtCl1bTSRDDivVHDarSY0K6y6d4nkXA3H
3CqF8Zz9Ivq5FxHFapHVyagUt6IWBf21YovDbEQY2Zf34wYJHcOFdxtDxmyLbntW
J711se012cgxjEMiW7vxTmLesFZfqwcnY5v8Vga09CltFgfICLQhSm9oYW4gdmFu
IFNlbHN0IDxqb2hhbnNAc3RhY2submw+iH4EExECAD4CGwMCHgECF4ACGQEaGGhr
cDovL2tleXNlcnZlci5zdGFjay5ubC8FAkN7P1gGCwkIBwMCBBUIAwIEFgIDAQAK
CRBo4SUrfaXFO2SxAJ9ZDv9fK9A9BMpRCduIyLn/HIeMTwCeIZV4tMVFy/ghgkim
Nw+KGD0DG5yInAQTAQIABgUCOqDrcwAKCRA0V/+EtFw4haC2BACzKePBL7ZyOBq1
PevDPQjtahjcl7USnXZ5HoPBJKBnsnXn95Aemb1jg4vP45om0oS9tdtI/CWDAf0j
w44j15nY3eoTe9CSJV995VjwWirnik1SKxqff2/qErLNy25Raa4xJKPGI1r2YZRz
a33L1an14sexHMSR9okd/fwj8qWB5YhGBBIRAgAGBQI/s/uqAAoJEDYDstQq8oA+
p0QAoMCgqWKCANDl8L3bZQUbGp3VpfDiAKDFyrunEBvvI5ylRQnQlT0gTcejFohG
BBMRAgAGBQI/tAwMAAoJEOU3f22J7zgDpqIAoMnA4Xa/0ApljmApPjJmLDFk1I+W
AJ48uNGGO0uk5PODNncwzfgbJk4LqIhGBBARAgAGBQJBbtPYAAoJEEkHjynsEEJZ
MusAn23sIAb2U+xR+SvE9SfQKQLwWbAXAKD0R6xT8yPm/JUBlucf543eOV9hh4hG
BBARAgAGBQJBg+VkAAoJEIuWKUP8JD88YJcAoJzsA7Ay11A4eU7AnLkT7SytmzcL
AJ9SLjZ2L+mgxArjAgrsps3ILQ0UGohGBBARAgAGBQJBhjh6AAoJENXqFJCyXWMP
rG0AoIizfKejmmfr/YsECLmNS/VDEj7mAKC+sGym7Y/PQtBP4qzkjUkEY6g2aYhG
BBARAgAGBQJBho2yAAoJEIzaH2BlMh10nGcAoM6MAiQFWhFIRwq6P5pd5RH4AK3n
AKDYsWzcdimHyW/raIk0ioPRbgkIMYhGBBMRAgAGBQI/tO48AAoJEHs456GxToKx
mIwAnjhXR43U2pBU4VsjA2VRYaS3Zm3tAJ9DczdaQ4DDvmsAOj8/vF/Aj3mORYhG
BBMRAgAGBQI/uR75AAoJELOADYxWullRn0YAnisenY8tlHKsw934iQB8TD1fyfMx
AJ95iwHx+QwKU8htwYYA8UpP7okqqIhGBBMRAgAGBQI/xJIkAAoJEAYGnPKWlFfw
tsIAn2fIBgs/JVlrSpwEeLFHsBCxzB0XAKCFKMO27oqFoVjUoC713aLv/bJuPohG
BBMRAgAGBQJAm6D0AAoJEHGDEjXFDlqXw1YAnjmABBdchpySWsYHRsYb0T02jvx/
AKCkhHQ5wZ2x097XkIWoT39yqitbk4hGBBMRAgAGBQJBMJyVAAoJELBm8e7pxDok
FEUAnRcVm88ihgj4vAyluWqsABhQaTQ2AJ4p0HowPl+82XJ+gMneLu49yjWtzYhG
BBMRAgAGBQJBg6hQAAoJEB2vUOZ1/FDzncwAn3hZzKgrZoEK7kUR1N882bZIxW9k
AKDNLvF4PopZ2jxzp4wPbL1jw1kyFohGBBMRAgAGBQJBh67cAAoJEIHlYoe1zlSX
s4cAn15CTrNzvXXXfi7a9/zirZLqrcu2AJ0Q2Bdzn6lXe0fRP1szD6RYi+8KR4hM
BBARAgAMBQJBbtPvBQMJZ1MAAAoJENeMvOVmp0sxRh4Anigg21EyEZB5ghicDkQZ
I+SA5v7nAKDzIRQoXCoVrEq6jFvgqiwHVVoG3IkBHAQTAQIABgUCQYeu7wAKCRBu
P/ZN+VwvbZhTB/sEc39lKKv7+Hpeim7tOOFBqROAFOo8Yhc8oQai7V87gql8fPli
vd7sPHRmoRtvzx6QCcE0EvI6TfQyshAZ/FhE8Wc0jrSm8HtBHOWWQG00b1rygSn6
u59tlZIMHrsGDfaJ38DtvnGk9ls0zvYky4QnPUVTFoQZbjJWd+TVo4jiUUSXEc8A
o6O3dFpvnc5X+UiN/krc1CXy1YkKRnQA27yAYpf3wryFJ8swMhln9f8TomEtr+Sy
n6ZumHICz87gTZwX2nbvSQjfQqAJtaRZVfLUo3nWDvX0TGmEjSkEi4X7yyEoUP41
O+1/SwEjdFRjdkNbzgs4Hu2OaBZt+adLKd3/iEYEEhECAAYFAkGIkRQACgkQiuaz
jU3Kfl4ApgCfWAZ4OS+8t/9JHpwjV3/1B0NzsSsAn0LFPcFhHb4+iHgjGG7aer8T
obSsiEYEEhECAAYFAkGJ7ToACgkQFbyd9tifJxRL8gCgn9zeusB6xMScPPu46q5k
Fo/ykSsAn0YIuVPC17di/j4/ohh0rXuqjtOjiEYEEhECAAYFAkGOixgACgkQWhGi
K8Wh9zQ+UgCaA89IhxjQMfvKuwXZLaVat1xttPUAnA8N2tdJLw/dF+Mz4/Hv/N8G
OLeviEYEEhECAAYFAkG2C2gACgkQwkHCVWdvs1tHjQCg0LO1slVVJ1lat0jYCMab
m5GkqZMAoNFOr6x8w1oo+7ujeu1XGcqsqEpyiEYEExECAAYFAkGE2KYACgkQvFLk
IaQsuSMFygCgnvzHB8viNK/wqeWEIH8wQ/3580kAnRXARmstGbmdF3+Z0jDslXwL
ZJbkiEYEExECAAYFAkG18PEACgkQWQuVF2gdUPXbLQCePdCTZsEKuQak9Dpp5sVQ
7/Dnh88AoIGO9q5J9PTiVFovWTyhXd0b7uU3iEYEExECAAYFAkG2CGYACgkQIKvY
3CcpIaj89gCgiGDD2tAvLQPfkcZUYd4N4oPHzIwAn01lIFsE92u1BzoVBrPPJtM+
SD4siEYEExECAAYFAkG2G0wACgkQUQInX6gT1e5gNQCfUM4H2Cqeq8vpp4DJnc3I
SSmtrtQAn2Z9FF9jMLDB6SbU5X5aNRMURt1ZiEYEExECAAYFAkG2PxoACgkQ+gB9
UUaNYshSuACcDsNiUo1Wz0ZUBwM0/hgxtvw5PrUAnj4GOUjF8oWZa4CP98fEaA5p
0KU2iEYEExECAAYFAkG2T3oACgkQJ2rV79NnXwg5pwCfamTrj6RvrScGe7VntRok
84V9QawAniFlDeAlW9IOMHm2tP1KnkBVxkX1iEYEExECAAYFAkG3PwwACgkQLuYk
QekiJq95JQCgoKfLViQaF8j7QjvMHI0KTjPEQb4AniYpxd/jFaTZs+KS3l8SgC4U
UsGJiEYEExECAAYFAkG3WNYACgkQu8cwf92DTLvLDQCgluwobcXC1zt1lG/7m/On
8ShKgMQAn2LNrDsaD/tW7p06K4xA3eSRj3wdiEYEExECAAYFAkDAnssACgkQUA/p
QBC2uR2JkQCffcg665G8CrUeqNyeyWA6Mc4CYAsAoIzYK4OwMNJnFXykFjJDXtd5
l8xaiEYEExECAAYFAkG3aFAACgkQtrrqPUHma9mCBQCeKXdjy7HtlMdWoYppvDrI
2/NZeOgAniermnqPl6AaLj+4pAqg3ns3FpBeiEYEEBECAAYFAj/Ekx4ACgkQX3bh
eojG7fZgmgCcDE3IbsDT4t7BnbFaHiKZ53INW9kAoKC4wCDe9IgVdtoCH80hwUad
euEmiEYEExECAAYFAkHNyHUACgkQt1EUCfwV2+ySHQCgs271fqEHSrnU1qPsVMi4
w633aGgAn1X1E0p7pjt36eJWlIAOLcGjpwooiEYEExECAAYFAkITOgoACgkQZvDQ
qp1gx6AUMACfeBFQ2pGHx2ZyaRowp7MTdLWgtKYAmwRnWLxrWP8RdZBxy2x2vr1+
x9o5iEYEExECAAYFAkInPncACgkQub27dH8SNyvQ+ACfYz+aSmdLII+7Vv1Zj1oU
CUx+5uYAni6TIyDK2GFykcDNu2mNy4/mc+x9iEYEEBECAAYFAkKYjWQACgkQxLEH
mIV5aiNaDACeJ/BlVmI++WqHz/+u3/Zgu0gcdX0Anjr3JDTLwBfnfR7FA2SwrtjK
Zdj4iEYEEBECAAYFAkKcuLMACgkQgPe+ppUz52vTfwCfeldCNdEwTMBzRtrZiNQl
xlJLqXwAnAix8SiJd7POKVsU9yuwmd2Iv8aLiEYEEBECAAYFAkKcxmwACgkQi0rE
gawecV6e1wCfYy8PwBHLy+nR1ih5hTxRGWF/aIYAoIFA5RETlsIOcEQMORzaUxmh
N55MiEYEEBECAAYFAkKl/3sACgkQikrfrk5fuEuksACgj4WIUKMYASwPg2wU/ELk
J/cIIqAAn379IGoI+nrCHPLtjZj3vG++Y6CGiEYEEBECAAYFAkKmAhwACgkQwxUT
VxAWYUkutgCeN0KDng6OhqBEjDScHYuP+th1nREAmgKXrQuxTXI0rP1Lk0XXwFoH
57p7iEYEEBECAAYFAkLBNxIACgkQQs8/NhzPMwe7kACcDfPjLauFMFFlobhdrPS/
7vtai9AAoIWkW9fYqwtCtWQhkjGEfOg5D4TyiEYEEBECAAYFAkLBu7AACgkQmVI4
SHXwmhGZygCfVzSkz4VXPbSu1VYD/OUU2JYFHQ0AnA1V0NhMkA6BJ8Ek4gUQYm5O
Pun2iEYEEBECAAYFAkLCOI0ACgkQb3O60uztv//3tACghRqRK23a5mkzIYWyQOmb
eoyWSe4AoLXcdntwgaFEoJSNSAOJjxUUg6/+iEYEEBECAAYFAkMkVEMACgkQ+NyY
g7UqchbcSgCgmqexfUEJ0gkpMqCdcGalPCKDrw8AoNNcnvaAjQDjZBaoa6JQdFXu
gbgRiEYEExECAAYFAkKWQkAACgkQqs+zhiEbbu/c3gCg4DWuwWYsXLl1AjL3e7hh
UawYUx4AoMF9qGAGkpeEnl5aK4ZLiHaw9Da2iEYEExECAAYFAkK8VJMACgkQZuYu
UFqD3LQxtQCdGsiBzq4M8Cn3RPXhztiSdCb6QscAn3bOE+o4bVLUKZGoMyqLXUJ3
1mgniEYEExECAAYFAkLBlVUACgkQQmt3qm6LsCFFAgCgr4WL8laoQ5MfDygKDMV/
M0km5tMAn0Bt/GsIF+5hnPWt9/NPyNTPmiR2iEYEExECAAYFAkLDkJQACgkQX0su
YMpJLSZQygCgu7UgSYRITK6zxr+zNKlpAXpaFCsAoMH0jTBHXSs7FIyy0/ExP18L
CE2hiEYEExECAAYFAkLSyp4ACgkQEswLStuK+XgZKwCffY8vQxpXjkOCgg6mL1En
9b05WtYAoO402j5Bwg5W2autlZi0QaE69dh7iEYEExECAAYFAkMll9sACgkQDmJr
rRKYwrQ0IwCfRJpT/qPAB39IwxsMOxwr7feLfjQAoIkCm0XL6pjIksqOxNz0ZI5a
x8TpiEYEExECAAYFAkMtLO0ACgkQsZPEIupCY8bwQgCePi7YOzrucHteAxsAjtQi
1h/dJPQAoMG+jgSQemUNK9KWgdlcnM1UBz0diG0EEhECAC0FAkMjz1Immmh0dHA6
Ly9waW5kYXJvdHMueHM0YWxsLm5sL3BvbGljeS50eHQACgkQOtb4EYMAzAJusQCf
Y6eC88JKO7oaucktGkNoHcebaegAnid6DlTY1R1TG5s68TZ2vm7ALezEiHMEEBEC
ADMFAkKwZOUFgwHhM4AmGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9pbmRleC5waHA/
aWQ9MTAACgkQ0rsNAWXQ/Vj6QQCfd1Q5tNDFtnSh52ml4wxRpXAG6b0An2QNrZXi
jVN59E0Ywgr5LF0JdVZ0iH0EExECAD0FAkKWGb02Gmh0dHA6Ly93d3cudmFuaGV1
c2Rlbi5jb20vcGdwLWtleS1zaWduaW5nLXBvbGljeS5odG1sAAoJEDAZDowfKNiu
EPAAniH9rqMlAW4P64a2MpnOWhxVRUR8AJ0c0swHteieXAhnjiJZWaCHDsIUJ4ic
BBABAgAGBQJCmI3EAAoJEPiGFmXZhxNYjbwD/2ffZhFbOLY0rmC1dvsPjZ8JsWpA
lLeHx/cS2WpxaZWdUMoVrIgpxUVz6mcIxN2JxgeVy8Hh9EsDpu/iUOT+ppa/p0H5
J8vEOMdo8FQIvP3fyHR2aDK7Ge99HU0Sai0HmORbxD7qLrrZ0ACTGe2gZ3YyNxBW
berlz5Y+2A+NzSy3iQEcBBABAgAGBQJCpgLmAAoJEDnPe57sL1gRPrQH/i2ldfez
HphWDBzuVv6oFzDNGuZcWH/jDz6gj1AktYeceRET+857GpMV+iWPmnHUhnA0+5Wa
Vkt5u6iAgm87KseE+1TnQph4W/RG7YVHj0hNKEy1mxTWoeg+2HWH5ykW4ZkW3VgE
gsEoI3c2kjmILKAjk8DzehY/21Td6ndOikLKafLZIs0xCjVRkEL8Fkz8p5arj/Ig
sKFH5tCIPk+v1SvV2PmkCjCqIh9Jc1VLZ/VkJmXXTpsK0JNHkNV4mYRm7Jpmv9eP
fpPjysVwXgUTZTLMvgor7naTvq3xQfAPxRP5hO/OQqysh3Dn8QjrsE+lBj0JcN9B
N7Z5sbmrlpFUQIuJASIEEAECAAwFAkMbSPMFAwASdQAACgkQlxC4m8pXrXz5rggA
ooBxDMGI0nucSp+uBlNfCWPh2X45Pu/MHFYDUme/MqGzuMcvRv3u3njJAhHOcS1O
KISh90HRODCrIxc4MFviWDHNjsnfzHnRGHFlpoGBEGcsoN4+m4Du5LbedSo0KieN
Xo1DrnK41FgCyqjYHIclkZhjMSt8c2Srbem/wcr9Uf76qTZLZ/wFEsebfDrEFOyx
7oysF0Lo9ELsKs9UTyIQXD3rcjldmintrbKtC2DdqaNoiaiFb/QBgU1dRIkTPtfq
dgcZ/EREgFFEBdW1tfl0XZgMTinSgaidOi9abtCmXi/F2zAlAPuC0poijbS8mj5c
q1vbajNiXv99H851xBsdg4kCHAQQAQIABgUCQ3Yd7wAKCRDu1XFrB45D1Hi1EACc
x52HrRmNYhsGccBx6ryNJA5As8wrJUyAZbcNm3rYhppWpB6JUsZffW6KgJ4CIxg7
acYvDiW3Rp9kj7pF04yveDHjQeuLAZ4nA1/AUvGzzMNp6gC6Bc9nYhFzlq49Asja
IQHtyXbdzu9mwiPMkga2ZlPXGhY6CuIIANFwHUTFEGU7+knpa5fWe6QJvYUu2bGB
n/NuU3digxHOixN7zCqvGvcLwVqvjnHqDb5Rh2D0HmsbC0UaoeuavAYgEoBlJXpY
ZFflTEAyyqnZmQMZY/IuugMEiFeDn4eyhjNOh7YMQqCOatqLrQ0WZp5bJxPwG7Qb
1m7wGRnuttDUL+5qjN+AHq9poYqVt5M2X4U4GEzf5gL5ZWf4ZUTT1s1AzqrFK6kG
iypA4d/8astmrbk/Ajv+q2umkC7PRwy5pgWeGMXaj/aOpzfI+TWP3a1DB9eMzpge
VcgwWrpbID8U3BOOMMRTxWWDM7qid8ASKEfQo8EFlaMwV0Njq1yZkzc3UeOA8qfa
XmNgT3helepQoXWJlTVpXPnHcrE4ozv0Wvf07wkBnZnjAm4X05J6YjC1Jc1s2Q9W
zx7EQnOGNCmPK3YgWxpJzqj/676uWhvJVLi32z+pOCah4UDifZEKR8pleh5PRzJN
EC/2HbShDTipwFOmFzAYRIkvud7wQnIkOEi1Kdi0M4hGBBMRAgAGBQJEAW6AAAoJ
EGjzWPbBOWR8uowAnj8CnxREirHoYO2/KMMoNdxI6cMIAJ98iQf1qJ4N66N0zLmT
6OzpYvR/rYhGBBARAgAGBQJEAu+zAAoJEOVE3gebfDKNSB4AnikmZcp3rQWeKspU
w0Mn30zL/xdmAKCpaO4UnAPyb3LXE1GuCYkQ6TeTIYhGBBARAgAGBQJEA2IpAAoJ
EGx2F4yg7Zgt6XsAn25YZZImnlLTz4To7sWE8iTSYAofAKCEHCsZUP5XUD8j6HAu
+1YDMaot/4hGBBARAgAGBQJEA4u8AAoJEFP2f3RxX8bXtvAAn0/tjJPwFU86MNSb
jfP+xokcANCGAKCDsV5TeNluQ7atNPHYg/TwhRnze4hGBBMRAgAGBQJEA4sBAAoJ
ELvHFNGcZ82Wc2UAnAlWnIbWZiAJM8Cf19Htc6nRbPv0AJ9oYS5ZlGa2M+Qq36Yz
vY7BlHakhYhGBBARAgAGBQJEBj8YAAoJECILyIMzDEp1rpkAoInS8NCDjz2S5pO9
59GcD8YPX/++AJ9j333d1WYWSK5DPlKu9dAU37a+0ohGBBARAgAGBQJEBvZNAAoJ
EC+VFQiq5gIugAEAn2PggstnTcSUSebwtLkcr6+XIIU3AKCBxxOPeD+RuV7bErqT
FizE5I/VnYhGBBARAgAGBQJEBwicAAoJEO0Yto0WGUVTpJAAnipmnYh9ORB/D1XA
o0xQiU2ybwdfAKCUZf/0VP1KrbK0mz7E8YtRNSJO+YhGBBARAgAGBQJEB10/AAoJ
ELcooz9Fd1H37t4An13PTEh9esPaqru2l0YTWyLTLfMHAKCBNQ2crjDTd6fx/8Q3
BS3KSwBLqYhGBBARAgAGBQJEAKWHAAoJECdchlElUOfjbzMAniyaPmk3kDZFj/N+
4e3D7+ou8FcNAJwNyfEfd8RdAm+QLDjGJM7sL0dufIhGBBARAgAGBQJECBF+AAoJ
EALnf9mIHIXEAmMAniij+2ji9hUzP4rUMegrFYhTc+RAAJ95YtHN//DGFhOrdT4c
bf0tTHvZPYhGBBARAgAGBQJECJ5kAAoJEMcpqsa+jGsuZrEAnAsXUMxbnFaWQvOM
2PuV9jfx284QAJ4kdal5xEUcC5lSvzWVrfwjShpsF4hGBBMRAgAGBQJED21TAAoJ
EDOhBEcrAFaBm0sAoJ+npjcSje0bGEENQQjivdCihO+tAJ9XmnRqj/dg3WLRKmPP
Q+csQabvGYkCQAQTAQIAKgUCRA4sjSMaaHR0cDovL3d3dy5lbGhvLm5ldC9jcnlw
dG8vcG9saWN5LwAKCRCVeVLXzzQBqUX2D/4491WbjNgBq7YAvuCONi2VdF329bDb
bEXweSoUmVM/VLwYwB5ulmseR6475JzTMzb0UvqSDpV35gi7Fa4Nu+v2HoBGftWC
DWSuLdtxhch7UmuiWcHjYmtA9uGZqeIkK57meiaggrSOBzhCoZmf0mtTOm2fgwx3
pg9m59v5Th+sUeAUc9qjFB3qsIvYVZlDhCCR0f9r2hEmJxQ9C8qzpSZHNSQmToqQ
XZoWY00jEuuI3q/J4LCy53B2NCVH02pexkBpMpYsL+QZw9d/RUHGW4eZidzdrgyw
CjwW00Q+D8H2qdS1VVV9Zol3BcvAhylgTbEd+m2E1wZ/NNvSb8ecqdg0I/7bdXKr
jNkl34kCszJgHAQY5h5pei9sOIQDC4I9GCDHY32kMTQaofP6Zx7p2KVE6XjGideR
kqSHMSR1DnNWLC7oOodOT2GEkB4WuhclDphPBRSb4ijvsoHSNotv9TEXKr+0J+5S
Pw/tD8Dbuloo7z0iiCMJXZd+66swC3+1HNpx1w6sjvGWiy8xUgojWTus6jgLoxcj
bB8QH4ADc90plO5HwxKjL0djO8uK+G/dvHteWZbk0z08DBhYy9Z+NKgpnpsl/vuj
RCrOBrzTeWNBWbps/5h7XNuL2x1NOaycbvq4bP2K7T+p+AZPP3G8gB/0E1JrIjxN
BTmykVZxS7h8ZohGBBARAgAGBQJEEe4AAAoJEMXAxcchjRjX9zsAoLbzK/XgJhmV
xa2z88goWCF101Z2AKCTgFiCYe5spDvoctIj7y4Us4z4bohcBBMRAgAcBQI6oOtC
AhsDBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRBo4SUrfaXFO9GkAKCPd/nv5nmDa935
dATfxOWbAf30CwCcCcPlO7jdlo2ZY+efa8euRG4tBHaIXwQTEQIAHwIbAwQLBwMC
AxUCAwMWAgECHgECF4AFAj+xG0ICGQEACgkQaOElK32lxTtBrwCbBOjFMVeh4xAY
y/SVHdnDFlxd5PsAn3EOLueFYa4JkTJoiIsBGXJsR5x3iH4EExECAD4CGwMCHgEC
F4ACGQEGCwkIBwMCBBUCCAMEFgIDAQUCQ3s2nBoYaGtwOi8va2V5c2VydmVyLnN0
YWNrLm5sLwAKCRBo4SUrfaXFOx1wAKDXLFHPWXlNnFPx8LG80bcAz1rzhgCeMYKh
QVjY0Zqf21JENHWWRTRrDUSJASIEEAECAAwFAkHLJlIFAwASdQAACgkQlxC4m8pX
rXyInwf7BUf4XchhrstPZaHQ0BzDPsIEqK08AYvwpQDHnkWb/mIS4DyAu/Cc9dwu
aZghfx6ayvzfrZSeqg8YGKXMyprqFkKv1LzBAkKVAHu6CEjTFE3KqAvYDb8gOgKe
BMReMx/GAjm85YB6Jakkc8mrlauDzczqDeiNk3wyYZfwscq+8Nk4jaGwsf7Rndym
+ZKFi/Sdq6oGLHtbKgapZg8yttfEqliD0tAAHd266UO5xNrPXFRoUogXSYx0Qmu/
QHPG9tZNOxl6M8t2Ut6tgOLUbX6GaI52C1NOQaw+h3XDcT+JMkhPHopV7cbvoR+l
sMBStHZN415oOJ8mRkBoV4V0EBJSmokBIgQQAQIADAUCQdz0XgUDABJ1AAAKCRCX
ELibyletfNesB/0b8aPK2MHoDvPitXI3Uso1q0g/np/3sdZFQdFoMSNF0VZMuKd0
ILPrmz15KmzPKOzFTP2F0HAPAoRYuVhTCzyq6DLT2EmIZT0aPAenaGvlLGrfrrBJ
XnX4ghuVxzp4TvpmOnf7RK4/3cdLfBS0BYK5dCM+ZsDCNcazNJRxr/SNP+DqmiP0
l7eIwTj6niInloMNaFS9bsGBJavr3rvYW9lNpCz+lo9nZmedd4hSZwi2Kr9sMvR9
qWBQHkP4NkSwGlNa4AxLRRaZ0KXpzNfXiMnwzt+SYKcudxEDRHr83/wO+rduqaxK
ZiagnMS2F687/Pl1HktmgIoMC3TOem04EFRAiQEiBBABAgAMBQJB7r7sBQMAEnUA
AAoJEJcQuJvKV618QdsIAJw4TYzNlKTpWyBRiDmFHN9Hr1Hm5pOzUQCu8ohwj6Bl
hr+BrnAOsM6dqlXkkzz5zGww9ywopOJxNWtIRYvFqT0mAKrrLJZqvU6DJaKige29
+GpGD9q+KOcL2JEQ+NoURK2jlTkk4+Ap75myMNESGOfll3SqobNh261IPwSUjxWy
a92MncXjULKCb7oKg1EBLN2mEilFC7tD9Z7cTgNTfnm0HCROz/KIhzijOFO/0DDt
O1jxpIg4qFcoNiNhOjz2ID694yLkHs0ks1h3/+I7vMoiJy95o+y/VksdHxDLeW5y
RAQOY0HBECPBXGKW8mriejCTy6PGVYnKNmUuY6aHDeGJASIEEAECAAwFAkIAi6cF
AwASdQAACgkQlxC4m8pXrXzDBAf/Ya7NU+fuUQLY+ivOP3H0snB85vsL5lsQ/PUk
ml+wy2XkbbrtcaDCzgQDx8ue5/CpxElix8CMdaF1Y7VCieqpQiTqMLgTd4o/Hz2I
3ImzfWdr7ddDjLYdsu3sZtO0heJFt+/oOb0MdtE8jnZprR+AqFBk9uC/+PtURTvp
Pu0mZRKXNyGhF2LAF5k3qjVG0vEvmYafqVw6vUG2hdWtHfy1HfMogqILO57ydn9R
ci5vJnTG/ryaM8/x/a4YXmbFPL85kmU0wN0+5q8+k3m3Up/EoZTDpELjzVW3oYdt
+ymtrjTf99BdFpKP3RC7ba26AXk/3f2oG1oIuQWto5Ih04q0I4kBIgQQAQIADAUC
QhJXogUDABJ1AAAKCRCXELibyletfKobB/97KeQCoFacXaikdrwWKyvADhbUAKb5
t8KaEQgf/XVwIwIPcVG4UX6COaXWcPtmL8X4BxlN8GvtTr/stbQaJMj7qFvX1ER2
k+QcI2Yfq/xq4dsNvHnwWwqQxebXE449PQhISEmkk86q6MRUQ3AvJnbcNZn/QBZs
SVjC/PnNowAdttTbSwQ9O0UJTqePA1BHPeIkNtkxLU2W2EKSzh5OHAwaME8ZbUl2
erJpJKZEPmYMsy5vDUdqa0oFVaAHjQ5iu/aE7wdptrPkZTbCLtT34HVclQXZI4T7
7NtijHHMkXuTnl6N9+HnCEAdqBm8igpt0y+bpOcQc0zPDPNcEk6PGSA6iQEiBBAB
AgAMBQJCFqTBBQMAEnUAAAoJEJcQuJvKV618O04H/3I7xQ+p5NVpk8F3eNj4PUXQ
E9MxQgggmBU9j/Jsr/8OQuKyR7VhEhbLfAuWw3xElI0ceBu0Xgg7s5Wy0s0aDBQT
Bnbw2q72jz/7IAxi6Finn8CCbbTf9gnRCqSQK3JQIoKWYRwg6NDodfGxFR6iA4Jx
zVrDDqbgtWD/SUnK1Ej5q7GJ9yovPhRGC9DMIGf0WDRSJEhDif5b8S7s2JPHqGG0
gxEi4ZRXhQ+3oExxZPSi8c3+tqO5CshveH2/wiHZGMu20Tg44FCpmevjFCR8ThbI
VGCng3XxG2La84iT7lyrD0y/uVS0QIREDX6LSlWkM9mhfas9n5QVTEEBUpq19KSJ
ASIEEAECAAwFAkIphpkFAwASdQAACgkQlxC4m8pXrXyZ0Af/f8VcLYQnN7DB6791
vlZkyGUKdQzHliQxp3hnRxQelBVM0Tp2P9lsUjhqhLpnk6KQiUV1ggpvDwqU8yc9
nRueWLpIpeFCPpuPLKhG2/ZVXYM3nZA+aV8q6unnXc7sIYkngqINrSqp6GIhpRzR
zBN9ctA5IyXXElkZ9YaoAYQjhR8xHriUHNnBIwGhfrcARVUhlhcsGnXEfgk7ZZJl
k5zX6FjmZdQSDRWuq++c6aXdM8/1V5JYMnpLpHrxg3hyoirtrG7gonYfB9ZiEFtD
B3wIPykZZld7HS/FM8NoPjQFYt3DerUS52I33M2vdlgN7556otlMqzyQsT60x2dj
SJIwhIkBIgQQAQIADAUCQj1A3gUDABJ1AAAKCRCXELibyletfBGsCACVZAFjysMP
vqCHVrsZDHk0JGW/L3cHnNQi2F/w0EMsJeCQxWS+svz60+G9f85Xc5PSwDooi8fq
6NBvthKZeSfw01fDSiYKHQQUcic5uvSQzyLvO7oWie4HZhUj3eQbwQGXFmm0FrwB
R7OXC0xe17QqjBYdILxyD0qq0t1O3sxC6uY85k3jYNOPNNNBcGPrr0jxdrihaGVm
99cosC5KScMPoDhnQxbHx+lbIoSgQGxDWV5QKTRx/Ppaw84aZksEFGIQClR/j+SU
Zvom9+mozLMk5703VkK2dNJfG+SszvABg/vDknLs8iHLgQZ9EzyX9PignnnbkLan
Q+X+dy+tFPRuiQEiBBABAgAMBQJCT7bTBQMAEnUAAAoJEJcQuJvKV618qnAH/i0D
uqKkIGOfLeq08lDIUnDwRrItl54AARmZmUHg4iJzL9EmEfLPoXM4zI9yzZRF7QwC
ADH6m8Mnzagp6oaHJt/8ajHKkZ8PRPpEr5JhIw14qs/5Q9CnOn99pFk24jKF7ywI
zIdJYj7B1M9bUD4A8LuKvMoYnzd0tDDyqE99c2AuufjI419425MZWQ6YFrfMVC72
SMTXobdgFa1OGgM7KNYNGXmjopI1p9Dwx/EPT8Y7tc8V434BwTtsCXclHo7jNt35
d2YAnwsNzZEgQ9Viw7wRtVrQo16ocdytq3Cdsz8yx56JXTlbkqGNNczeKRY3BaTf
/bEW6wBZhVCzzhmXRkCJASIEEAECAAwFAkJiMeEFAwASdQAACgkQlxC4m8pXrXwd
xQf+Po/YCwZSwCTxluV+BrAZDJd7CHcMJ0JFFdNrtlIU3rNVqeMQ2Oq7Ult0+Oi+
RHr6SNkNqLUaEdMyKv8sP038vHN7wuloEOVw6HiIcZq3PFEmzzTdf0oimKJdBX6l
rtZWf7wFibgOc9c7tithD7cauL4UB157R8Qc/wS2h+x0qN7XBgILqspm0O3CXArJ
iiTzkuOHbv2sEJt9YtpqVhY/IK+Rm6/e9uUtXMvKUGjxefT7tYzaQvT+dOakUfUT
6tVr6IL2IDA/bRElLjX+RGvc/AFDkgvQWfKtGIILd3o/L5uCwVedc1X73BHyyvY4
JFt+QdPM+od9QgjdvmN8mncyGokBIgQQAQIADAUCQmLaNgUDABJ1AAAKCRCXELib
yletfKa2CACUTrLga0DS0viIrObmQQKMY2MuXCtahzUS3PwPhuxuGnC7inGyf869
Y7O0pWwTsr5InsI3tvgRkFKzEjyocMG7q1yfVAVfsylsDOqjPn8uaYaJ1e+rDgPZ
q9BEeyimhSfNyHeb9sij/MLbRpvqIbXkVcA67P4vQQh966ez2z6LAQUqA3RfanZl
qA4Qdj9hXGl/ruQ04S465oRdHa9bIKblI3k4JUJlib2TaRDz333+EFSRnay1Lvmy
2mLaEzLYIThcx2t1SSOVWluB5iAY9YGknE/cUD/U/H4hVj+MatIynZJk/LkZnrPK
i0TOxHv+NrX7K45HvMzYjhWAvrtFuogViQEiBBABAgAMBQJCdVmNBQMAEnUAAAoJ
EJcQuJvKV618aDEH/iCTgrcJI8amU4UGPfXHNPNvmc6/Bge2skCyYsw1mi/PoMT8
NcIJPRv8ZDOihmXCsaQ4W7V9ToZuBtHGr5LY0y+sdR02FZh5TOPkuf6gdfadu5dS
MMQAsXs+Y6ieX53I2fIH7XQpQmTOiI+CTywhtMpjwO2JbWUmxjxFrIXd7JHqMgyk
IfDXGO29/LxqpewzeeDtU9glwcqZognOr1Qv7IeUy43wDvb9ml4ntgefthzGbKTB
+iJZf5fOec3pxS+Thyd9dpDINv+2QE/doNMAF7pyu5s2g/sktrUz4pI8WzlOXnME
akbDyelbFWURPLOEMRM0+Bz3EXvSx4Ll/mbJ7rKJASIEEAECAAwFAkKHnZsFAwAS
dQAACgkQlxC4m8pXrXzRTQf8CffP8aKkvGv7vcOgvNFSvx+wRdF3Yx8qZcKD0Rg0
Z9Obk28wnOVrEv/uJnpdFyM/55k43mse39oz5/myYpBRng/d6pQrDvijVPg6oQ1b
9St07yjBjauuCeYZJk/1CB9tTTFOCN1mmjoZRn1y20dIv2wYytTzJMJVvl2KwFCv
YP4Y8IFAz3Ue4dwRqp85w2il9SMaT1BH6aJqzjvqA6rT/jR1/BW3yqFTVXwflE6j
2T1snF6Q74cKMwpZmksN1/Py//ouc3XdZ6SfWXb8WwADwac+c6BqA+OBgyuM55iI
URCc8YMa6mwn9TtjEAYEbG8qM4xf+PmCGnGf1XKQWXF/YokBIgQQAQIADAUCQomY
BAUDABJ1AAAKCRCXELibyletfDTHCACP0tEf2ECWDRF0zfDgvkoXt/7ufAjUWe5G
2HedFACoshFygyX9uvrUpx3wF9KatXtBQB41TqH2vOVldxfLVEQ1i9MTfyD0LFMV
Rll6H9FCVg/A4ixu7xVXUbMN//0Mg1Fq/ApLn1Xfae+j10njwbSBZ9K9QyjmCyt/
OEeVJ3WwjcuMCCGh6mIn9t2OSASvJY14Ekqvu5/FIJLBQYp085GmZJ5zEVuKN0X6
Rm5meLD6bE0ciIpMYK4DUSJO7Qk+SvsTgy0vavAUw7sVsaM8ms/hMkW1dG1wdAnx
ru92qAnYUBBkNXq4aBFg1zZ8yeiB43VJf5mfGStm90OYjJHcz7WiiQEiBBABAgAM
BQJCm2OvBQMAEnUAAAoJEJcQuJvKV618CWcIAJDFE5VEY8WTB7Q6/ZEvyz341kOa
BwH5l9L6F/HqfihBemqo/Mfn8fQTGttVmuONtGG1LlAvY/N904Oz2uy1S9JH1hLQ
1MB5soNjVxQtbkAuKKOFjHONKiJXy5itTJa5XrvmvaC9WKadKvqoqP2SR//exJOe
f9losXmjytwZCOBQnh8HkOofo3npwsve9Ix5BktxovviBuDJPAuuKo+M4ICFczB+
V6RwUDLtRIZUu2MSjUtxMxqfAlvz/E7Sg5tuJD3akTuwLuccmPfbu3jvjBlKUZWz
cLO3/KrkJd92YruKqOzmVFtFMxbEh2FNSLz9oZlyXu1/0jS/igWZHNr3VoqJASIE
EAECAAwFAkKctSYFAwASdQAACgkQlxC4m8pXrXyHSwgAtVxV9RB0i7Hm4TVQ0Khb
bf4hTjVLawvQW+WjE2rW2LdDFMA5VfG7a29xrrd5sinGcwEMenG4Da6SlXq0/Lo7
I5Q/AeN51uAvOaGpwnSWGIsX+3YksxpVN8O7+JrV9Oo5gq9oJGtfBc1qxdrmVGfM
Egi4FrOK1Rgyb0J1HWud8Nq43l0B3DCBbORNqNYUs0vRETDIgtOAHp058ZYxV85c
rzv+to15m5atkHB1eD2JXcPcxF4jazVV0yLrQGG6zImfFvb7LRCgeWEKrfy/KVna
m7D8p+apDGZYW/RmLNp6iuk43cxbA791yGmny1eJym/9FzMV7KaztWDdI1lT4twp
S4kBIgQQAQIADAUCQq/S0wUDABJ1AAAKCRCXELibyletfMPzCADJhoVuvr12dmwO
qBeW4U2GUySBvrffjt7/zrRyJk45Fsx2YcVHqMG8tD+eVafps/pMt8RXHxsNBZaE
ok1CcpklriUHX6C4xKYJ59e/rbHCHbszUZpvbIQHgxQYrq9Jgovq7UuiBmeGToU9
9scU19RCCnumBIBRFpP7ripj+VatspT6yIYtflsr6vgmShJESUFjkOHL3c8hP6cV
304ZWV8GbLksXzl6CUmYpKhht2ULX+kI2B5fQ3OYD8KBnrxdqrXa2TJEPtVZxrI+
Cg2zVwQRO8sKtjFMbVuAMs3UzFvh90J9jtcYobt55z5HFlhmZK/b+NiGQuy9Xcsw
Bl95x3YBiQEiBBABAgAMBQJCtRnFBQMAEnUAAAoJEJcQuJvKV618UCkIAIBlPaL/
kPIzcIVDoGhwff67Cfhy7VTsqbVvurb92SqGg1KJID3WePlZL8PZZEKPOy9qZ9g7
PeEybV7JdaENGdCbD0MGkXuzI3Qc1XEu+iC4OrAn6plpmHMCoOJBHURQy98R/30k
auvRVZUdfU3jD8dbQ57cX6sPorTE+53DhbuOhtw3L0YPzdlUZESYW6F7Gc63dg9W
m98K2jkBQvBDXKj4AtbbUP1rJIARlniw1dB4EH7teIg766dwdVbNc+YW42lAKsgY
09cxoPfXztd+WB0Z+sdUsAq5a8zlPcutc4LaxSnZPMJuaI+Ayuq66t+RmZpF2v3I
7Xw/bJJlPCmPszOJASIEEAECAAwFAkK3FQkFAwASdQAACgkQlxC4m8pXrXwm/Af/
QmfJF9Q0s+DyAedUXIXdpTOwHyX2L01qYnYfTVZ1ODnynSN36tTRxxywelzW8pxZ
nFH1AIoM5E1gU5DFzKzaoO4c0mrs+WShfZQBBZfjKRFJQCqYQwg37uCb5gFmZKsL
b+FgbYY1vM835r4xxZdksYmgAuAKL0vPbWKkQtHDBw8HcDbDG20HaxcHs2BzP8CA
kHrpOp6ryySqP7p+chdfS+LaSEfT6u3lFFv5H/1TMYjy1JgHFaVwgh2zKsaywOUl
1CRla5E/xh0H+59D8VbQ+QQO99/0cbITDG2ziONvzMFSkP6T+hKRc1eplPze00uY
ueH1ira95q+kQvSBdfjdnIkBIgQQAQIADAUCQsjh0QUDABJ1AAAKCRCXELibylet
fJR4CACGv20uyl9rGyDBYEeOzd0kfPKqhQvZULbV8Xx2W3vUV3d/51IIlTU0Pxgt
6Ck0Hxr+4QJwJ8+TzZxrtz9f+BPvasVJ1i3YtKeYJ6PjvdOetmQeoDmTMmy77q3x
zzuLVayPT29AFXjBmtfK0fyRuA7v3CQ0fsoy2uEQrvUOw7zUCZtML+2xY0+OlFFN
85ZpEnpcUTn1BYM36FbTfxHw+9D/6AzfMarzUbHsh8k5GCQqQfJWKIGSBJYiayjD
ybh81FHbR6+FC2QB1BnlOCGp8bqFbxkCPlevTUbpz7DQqJ7bKIkCJSlzUfDiw4zZ
SOXRMXBSJ8AgyD8xdmyEF9vkNPaViQEiBBABAgAMBQJCzNZeBQMAEnUAAAoJEJcQ
uJvKV618NKIIAKj6l4lECmOYl+Qw05Hf3mTgUL64K/f9oEEhF9Bt7pS7FPfJfnPB
o3Suk+AtoaCeo3ly+X89fsV5KSii0secrxhD7Vobm70yC2/e3M8DGDvOuDiCImUn
OEA4xdsq2p9W+2cLgoCnyCVnH3oi6L5RkBLaKKVhmV9ytv6L8IGy9Tk2dSYJVPKn
t1BrD8mUaU+7irt4elxdxRmkCyAYIWNoq4OikdxD0GSwImEpwCkDc3GuD+IcdZsl
tBnAhftKo78hmu7VKc9X0dOOWfcyEa0Vf2qkXeYsKVRATw544Gh0w0QwhHr4fmk4
OR5dtvLoOaI55yJo+e8WaD2i1jL+KETbnFuJASIEEAECAAwFAkLRc78FAwASdQAA
CgkQlxC4m8pXrXyGLgf+O3xrFAsxljieg0mac4nDcS/hU/DpAABb7pKjXH5mZveo
sVNgoe0Vj19b5NdNjwlpKJBW3acOtqtjEqzimrMLqeb5lRux+qEYNxWWEsHDuOP8
PJ34SRm/9qsKDwLaUaZ5J9U/tQweGQFoO7dZ3W8bcmXM5X2HvX2Ul2NrpQ8h8KKE
N0XzwRdA9oz2ozvXVi5NP/vJgex/E+S9u6Tc4iMWhP8Zt6jbORxvS1CyLVHP5bkV
J/74FVIQUfD+AyeYnNF3JEcLGhr9ftAea8Y1v9nftV9ykGmzk1QJGE8hZpdFwGiY
sgpnH5EwVqUbZkd7GyiLutw2XuHuWGv3F3rwxDsCTYkBIgQQAQIADAUCQuNAaAUD
ABJ1AAAKCRCXELibyletfBM8B/9WovTYWN9iO8SDZI6uNN00YYqHRBreR/tQTKrk
8+9CoBIEEdmGqIsWrwRwS2dI2shmKTiGQDr1oU6PGURKkHJkoaNheHYsQx7v+o5X
SyriP6+i8KfzGui1DEEyZ971D7An3KXnSdQxWaQuQplcgrxdjBcjuoYN3HgQxsA+
WEXI61ecuHbfjS05tdG3kSpCn1JAca7ZMfQcmSNUQtO6trDODI3smkvouAabIzyC
7tg9jPPXOUmh5P5ANNLDUsk7VuYEcVIUDptrCP96oA/hvPDUOXMQOvwlAd/DpCTm
D82+kjLv44Sl0FGfeE3SeXtR5QAbLWh4+uWgZz1ZjeVkmlXfiQEiBBABAgAMBQJC
4+hzBQMAEnUAAAoJEJcQuJvKV618U4cH/0grAMuChN6gi/VQOtCK+4jtmp/lDNDb
u1vZfXwluolqxhNwAi4vx40gXVAtbda5N4XWChyZpZ/9PtDVFg7gOsKRqxvc7QwO
n9juRA5EnC7UnzqnINNuzZFHmXuTQ9jwp7nIVWE1JiP7WzniIfliPINIi9+KEqLK
RxDTBXWyJ71z/T0uaxFzsg5Fy6QAPrgoUqf1TcYzfhldiwYXE2j5SzSDNViSAGap
PFwG1wkliSdTZD/qVkOZWawsUq1DStoaiHwKnMfWC/fr6zKojmT4qnpojkznC0+L
CgtLcVerwBjKfWMI/VAJnFM0ba5ESDbAdB5Go45lL6a9hMxZE5XXkfWJASIEEAEC
AAwFAkLp2AMFAwASdQAACgkQlxC4m8pXrXyFUAgAulRQA5p6v44XCo41Qj69egMT
5B3qXiFtMsNUTKrhaVEXrRjsSficqTugqnSt7+zyOarNyGi+IwNJoMmCVZDYBkd1
c/FHwclsrEY025t/4Bflgei2JPv06vTIPPiEqoNXjUk3BdlKhR5so7FirV90WunW
dZMv5WrXXEfR8nSQbCCXEJn6VYomcbyFmfh2dO735Vnw3SJ+uS2VE55mwopROYF3
Uwueq7qaJOwRM2QJspDwzl9WNrFYvxcfHzfbgl3PvtV3aSVuJbVxmgP0dl5zAz9M
3yzyK0y+kvks7ByiUe8fv45YxGyliDXTogB6kLJX9FS4M8r5rX+u2kzi6bbAlokB
IgQQAQIADAUCQu0jNQUDABJ1AAAKCRCXELibyletfBdOB/9JDptQJhHIhyx9Fk5p
FWoq/kC0o2LNDAKyX46qaqgVtt0LzWkpmIBpVxdjNYJcqYf/+0U85ZcpjzJ+JR0K
vnwD63+/6NK2CbwjBFDNf/P35X4Isgdw6Y3v6G2oKq/6mM6II+NohWHUvNktHj2t
TFA32oNXVOZ4+ufRX7/xLQ1/V+Fll+3YL7zVuTamn7qDx2+5D/NVQKwHBLurOZod
DKxnLHzVFHMAUGWA2ehHbo1VCiYF7nEMYwiQOldzeURgGudO2yijAqaWB0SG4Ibr
UkSrSGmYZwEKIXo4s+RpX0+q6flZhRdjv2/3C7Mwt2ULJ4HxMkK96VVmAH5rUizN
Pzg8iQEiBBABAgAMBQJC/5ifBQMAEnUAAAoJEJcQuJvKV618WesH/0EWnKW9bcvp
plVyRmIIlMyFuLM1BdZuMlj9hgVv+gFV9dW+UL4hAdQcx0lfhfV77u4d30mgwLpn
LSxg8m5rP5Fq2dolk1sm8NTgp7JBUsOG9bJSVYSVccUt5OouIBqoKLmM5IRlT+jY
oAYH8qyVfOnJbIqjtXfZmdbhXzi085QOec9zVJhqLM9fNyABDMbP17W9BIzsBsSB
9/7sejyzeaGSauQ7DymyI7Q8DBjTK6RKmtfyf1UEF0TA7yRcF5Ra+2puweCiOmhu
0doMfNcw0sjT2GI/KGdXye29RYAGPnDtIdXekdbIcbboEKhl3XyAo2apvGa8NNyJ
YhPpKp0Z4HSJASIEEAECAAwFAkMI0yMFAwASdQAACgkQlxC4m8pXrXwpyAf+ILvv
wCotjGrpU/cqUsfjIPhUFBya3d8QjKINaZOhyhL2p2Jwsif2DOLVt4AYzgrVADU5
btU49x3jZHeEY0g5PqhA9nnieYuGsuOYeuTybhCEbE9KlDNDv/K3Nhx4SX7FiPMA
ymXAHh1m5loQl7lwFS6XW75UbiUeUwg8hfOM2w0MyIsv2fXLIiGmH4/ntqYehLI4
GCZm92nDjVikUln8xhAarXZqraz7vOJkOaV2YzL68K3ORUml7vGBRfdWJLO5lPip
OCwj2ANyqoDdBhrS3Ua4plbCogB9a7umDvtK3RCsEQsSBza78uWWOsdO6iuTuBNB
LlG4MTdrYCWLU7ebEIkBIgQQAQIADAUCQwwgAwUDABJ1AAAKCRCXELibyletfEB/
CADDp6IoyHIHMER5Glyfg09dfGT+7Fk5RdSU6OhGW2FfV56VmA81OWrWs+HQqq3s
rnQ3uWVlT1NXjm50fJWRRGnIaEqPoBif4fk3rXSQ+bOdpaOAB/093ZYZdb+VU2Rd
kWoTbvXIPMmRj7CeQFNLWmnb5eyZmOxg3ThQfk93mfVKDy0VZPeRWTvRUHy8MCI9
6C4jkpePoU5KhD0uaGYjpqyQJjtEB0tSzYSZEW/GylSstHD/M2pCdPrA2cG53qyV
Ihl7QW60lPwAhBRjk8Ye0UZ4Bg4IkGrzeOb0PVNo9DAAWbRAj+e+5a23v2Afx5BH
5zWctvTDJ2qeEA3nHRlHNVamiQEiBBABAgAMBQJDELzABQMAEnUAAAoJEJcQuJvK
V618d9EH/jB3TrGQwa5XzBgGzRSnGZZtLj39cUKMekhEvqC1r4X/9HwEbvHhZ5Tr
bb5cA3V/E2xyfYH9thYMHMu4/jyFC1e/KeUvtkbZfg4cfOASWWCXTmB2lLDPPRbM
9/rDvC7ZD38G0WiFk3BZimNd4AmDyOFcka4IjXLCkGQv6Wa+FDygacLBIowwpT4v
4SPVe5j3Ud4go7R265h0417YjhwbjD+Wn/HYQmgpcNUb4UCPxK0wIrNOtxOWRtU2
XDxLG2Bbu8kppQe89+BEopBck1BouhXqQ86HPHK9tEBze9UE1heO4+XCPF1fnOQb
bkJCbYLqPRdnKI7xcudbZgIU/6QyLmyJASIEEAECAAwFAkMTX/0FAwASdQAACgkQ
lxC4m8pXrXxp2Af9Hh0ADOBTayjzn3EbMK6+UQPVJthppT1ys2Ut4C0D/gOXatgy
mLk/KLuawSC8dRAdC19DwHcUbKKxpX5VvZArXuKdYzts8Xo7OhKAm0w1z542YsnO
47JWmJwedwwk+fOgTEqCJmrB/SzwTPp69EM5Dj/0Kf6nBxD6ccbC1Jg5YPqXoAEk
eBBKrzvJS0oZsa4lkBMFlr5pYzJurw8hfD3maa5RqlqsV+Aqjl0ouF6TmMs5+cHD
jZF8UnyCTAAb9vUnmNGQk73euGIzujgrZUhkUq+gxAbOLX6dGKwAra+eAFCCCiSk
xcOq821FCYpxeKJIEoKrH+jOoG/a/Ygij8Et9IkBIgQQAQIADAUCQxQI8QUDABJ1
AAAKCRCXELibyletfL1RB/42vPZlqNC96OgdvrMiTjSiAAulKJAofBMeNtFYzSI+
5uEYc53T3hU6OcW1fiMB7gpJjQOc2+e+WoS64ow2TJuBt2PgGh/pVtRCixGzAcNn
gA0hFOK45GZ4udsIZrrPeKbmOpuoUhXXX8xBb+ZNAmIkAnRHmYGyUouSMdIX8mP9
h8oE8k8si7sRAr2ri+m8DFiSVnrDIteK10DLdREX6cHGoxxLpPMJrhywYL8Zdv6p
NNaJMTtMq4CVdICbYZeA3bFPrM8Mx7CovdojL/AqM9huSTkHIxYvXcKSAW+ZvCQW
p+mEILCaXnSVW7NdPxUHKAzYRxofcuo4c2UogVvRnzvMiQEiBBABAgAMBQJDFLGa
BQMAEnUAAAoJEJcQuJvKV6184rQIAKwkoqZgpFQr9tE6bYkau5TmOEMbSwCpnpji
aiUWPyL3CVmzAEqcKFWuF0IT20j7dtbl0QN362GKXYQgizdOnW4v07hdIerC+7bu
C9AFp2O6GEY77nOQsevHTDfJq+ht4sdl+2CeAPbsnZm9YN7HdRrpbFDCj9iTjFp4
hnkeQ4xs8oaxKGsIXRirCRFnOgTiyRRJV5Rn5Eeipt1PW5bYyMoB2Su4kto8sNVY
e188iiwKCMM4SsHAi4Q8mSlseKtsko4Oye4guADgo+n9vRShIa3srTLKUt6fE+B6
OlV61Ls2XM3vvavxSrVWgIJ90H8UsQm5tMheVIMkIF8eAbBasAeJASIEEAECAAwF
AkMWAqcFAwASdQAACgkQlxC4m8pXrXx3JAf/cbij6duKGCz94rVDL1Gk7I+AZait
uDLUlReDs375kUkhsPjGuaj1QjCCYCsf0MYyJ8IGnrkZSa1tWwhMMreekfyqFo3q
yVis3ZoQSa5XNXXCryWd+h+LmxiuPQHlokKXQDWTExJLU+vaAvoV9iI65I8wtxxC
V5UiMm9QhZfCXHdO5ymF/DpKftAmEQTFui8GfLMMg9TqdUxK0PY+OHt5s5hXm1O8
K1RheO2vFVJFmljazOS5b3oIqwNKb38nbj6AANXQHZ+4WA+HjtQ85Wpk1ObbvDlo
A9DHRT/8lGCJ0Y3yrUWPpSpBx0DJdD7ca+XXFuHmYj+vGomq9d8BVL1lCYkBIgQQ
AQIADAUCQxdUtwUDABJ1AAAKCRCXELibyletfGJACADFNxLaoAnuq+eDWfjildtC
BRD4OexcIimzwSFhv4qio+G/ndzX5FIgCLEtRa3wazaW4sz0YWvwQ3boAGsfCeg7
ZN7WtVZ08jroa0k+rx/9l8HeaTC952Si9qykvc/ADOKrBFBc/NNzRiX7F5r/ABjI
w4IQTYyFlniRNlg1vo0EXE10ZE8JG+zDAEbnUNyk9kP585n8LfGT/zVllrGGSOwf
s1cNxMcnSkPLdJ9EtMhfbaJSIax91dnjP078Qx/AIiu34IQqn+tlQJqwI0O73mWL
TqRSah3vTPX3eTorNtg7acWhlO3Y2Tr5UjKNmgHRcUvQF172JPgXaal36/Oq9OSj
iQEiBBABAgAMBQJDGKWsBQMAEnUAAAoJEJcQuJvKV618tQQIAMdyeg3WbtRDqZG4
Cr1hWNEF4+Rthe+sPzep0WErliDXMO6S7Y0DBDnuuA+Xt5YqsQ89nODJGEpTKrGW
DFrYW3wbr5sG2Qi75fSQoKV2q43PjQT1ITppAkhXvN15DaheLJ5lcYBBdeJjwDkC
5JHNJn8GWAmSuz+qOfHJFh18g9wYK1rf/Mw3Pw7ra4uo7saX5SWa5A8A2H5zVf62
dKu2RBFClh7EBepIpTQglFTeFNtvuZQ7ke6xCQCX3+B2YwDjxwJuuE40ZuIT7CGI
t5hC90upcV891osn8436MC6g7X6CbBcHkhTodas9wSsqkCQeY17ulSzYS5L0U7BK
tbOQFkiJASIEEAECAAwFAkMZTu4FAwASdQAACgkQlxC4m8pXrXzrIAf+L/Jpl47w
1L7pjmfBo5bp9dNSAJT+wQDtFmO22jwHkGfGhVIbS1BLzOuaRcjEgEQ2xUZs1N8N
Zm7AN9NoZ2pPHXo0riiuUy8+oJ2GcDOCLWiK5EAH8jMm9QC8IU8QhhvEb54lqtF6
HN2ZJX79BTtCM25X3OPmhIBnTNQfvJH0gzp7G+z6T1NaxL5W73HvKp/fQSldYI++
Suw2mGxZxeY1foRUpyjRoLQ9XIRCTPqzvVKre+GjzQ6rdJn1B2xs/BiWUvH9D7Rw
/ab5TkuwkecNuxsZmIlarx7JGk5hfFDZmXgMxHn6kUnSZjWVw/vpqIFOdUVVCG4L
+nTnSEYOiDIpRbQgSm9oYW4gdmFuIFNlbHN0IDxqb2hhbnNAdW5peC5ubD6IewQT
EQIAOwIbAwIeAQIXgBoYaGtwOi8va2V5c2VydmVyLnN0YWNrLm5sLwUCQ3s/WwYL
CQgHAwIEFQgDAgQWAgMBAAoJEGjhJSt9pcU79hIAoNf80+re6chEhpaVihDGtKc+
QaDaAKDc8F6wXUJjHQLT3d1jf+MxQVYgSYicBBMBAgAGBQI/s/ZtAAoJEDRX/4S0
XDiFRRYD/2YTuRhvOYUNzlU8xyfS5x5qZ1Wz4ikCHSdS6LvC5EWYbrP8Pz1PEpdr
nEtVrUXO2qGtENT9AjcW/NFQ3yV347+1mW/OmO2Lljk2ROtH8nbQGZp1zCMvNCDZ
WUAu+w+kMlaIwA/ulO0jNxLts4cmLfj4wRew9h26TXLj9/ElOfpXiEYEEhECAAYF
Aj+z+68ACgkQNgOy1CrygD7xkQCbBlBddc+dc3DjQyrXuhjXx4JeZ0kAn0sKkp+8
kTCUMkTvJTbcJMyotjjaiEUEExECAAYFAj+0DBMACgkQ5Td/bYnvOAPvHgCgqpm4
s53/vZf+8PJyIafnSd28wPgAmM4mfOo6j0C7RgqLkPvGXTLPVq2IRgQQEQIABgUC
QW7UBAAKCRBJB48p7BBCWbtgAJ0b1XkbTc/4hQTB01PMJdXvRmXDJgCg8vdWb8ma
rd+A522qNkoAm/ZvGuGIRgQQEQIABgUCQYPlaAAKCRCLlilD/CQ/PLvVAJ9wkmQh
l2Sj1AFLRGxwsJ+C97WMiwCcCMF0zRI3YCdg0v8rbpC3dTykyzqIRgQQEQIABgUC
QYY4fQAKCRDV6hSQsl1jDw03AJ4q2BVZUJkMtGo6ABtrXXdFNbCN0gCfdIu2kXEn
634ylKR1jfUvb6PuRzyIRgQQEQIABgUCQYaNvgAKCRCM2h9gZTIddJ1LAKCJ3GaA
4Dr15fIXm4WgGwUF8W4AAgCg8Z/NQeVdCvR2zsydA2ADbo8ppl2IRgQTEQIABgUC
P7TuQAAKCRB7OOehsU6CsbFvAJwKSZmZ/HY6OnMRe0HU2VIIkWVBSwCgl/Ncb0Zl
fNYTY4tG4UNuIDPAkQqIRgQTEQIABgUCP7ke/QAKCRCzgA2MVrpZUUGLAJwIEA4R
QEjAPpDxvFmqbAAtb5r62gCeIGnCjdNKE8jIathsZXgP+/uKSHuIRgQTEQIABgUC
P8SSKwAKCRAGBpzylpRX8B9sAJ92en4wlU2CGLQ3HymJOH1Py/XZ7wCfRW2+flHI
PNJ32agL+L5CjPlOLuWIRgQTEQIABgUCQJug+gAKCRBxgxI1xQ5alxcrAJ0Zvb3j
4w3xAhccJAU7qxF2BeyjRACgosN/eb+WOKmXsEpQ7uKBPhLy7yaIRgQTEQIABgUC
QLzjuAAKCRBvc7rS7O2//8AWAJ4k8nW3+kB3ilx199yub1Qfy61azwCaA2NBWLTA
Koibx2zpLtvT8enLA8mIRgQTEQIABgUCQXAO7wAKCRCwZvHu6cQ6JOrXAJ9s2mYp
2tQd5v2ATmBHLkligbiYCACePSqFJ6O+NQB3UT+GMp/ShICyvvmIRgQTEQIABgUC
QYOoUgAKCRAdr1DmdfxQ8xqeAJ94ONNXc5Lth1pw2AwmxpLF0meq9QCgnNoJjHsk
WHlGxKPRj5Ggs9iGy2eIRgQTEQIABgUCQYeu4AAKCRCB5WKHtc5Ul1DzAJ9YvdgA
X07v7eQEdvE0rBpCjGP5IQCfaIltU3jrUkehRF9aMmHSBaOYGymITAQQEQIADAUC
QW7UGQUDCWdTAAAKCRDXjLzlZqdLMVhJAKCeaQbFYrkjF9IO/0ZMqBoXpSSjhQCd
FYCzGmUmsa9pE8jTjWzndjhsdTGJARwEEwECAAYFAkGHrvMACgkQbj/2TflcL202
JAf/Yv5GyJAgfQ8JLSjUIRwU/TL4oV+cMEfqYSvQ2TBaPcMEIOQgoA2gpKxDEyAh
fxz4fUyLVBEXfqHIm7/VXDNlFTTfwzvzcmN1XGRqHCLKlWaJ+4hwvTif9py667NC
cITtU4jlTfYfsRbTjeVpGH26P2s0IQdc9Guzr0elWS73SdSokucq/mA0HQVyxt1Z
gD52+GpiZG6r0jYj1Xw7cehop/bbmhqo2CsIES6d+e/XkywMMEfKCK3MazFO3Sds
LfjA/y+WMPicLK0CGAa4Q9VKs3Hh/C3E5dR5vsl2RgyC91pIrQGJNl/uQexp5RwF
aOObFSoxX8eEhpA28MZB0SWNHIhGBBIRAgAGBQJBiJEWAAoJEIrms41Nyn5eUmEA
mQGVx6TcxmqP8ZL4M0TkMe83+POXAJwNl0BRxiLfCvoe90moxu/WM2wuaohGBBIR
AgAGBQJBie08AAoJEBW8nfbYnycUemgAoIbkE1LZ6tS/ZZs6W6HNpm1p+AijAJ98
Kw4IxNpkqvZznZ+DVL+JWQ8xlohGBBIRAgAGBQJBjosZAAoJEFoRoivFofc0JFwA
niVQECS7cwk/+bjbcZM432gkmWjWAJsEMQVhOvlGbOXkp+jjmJFSpb9ZGYhGBBIR
AgAGBQJBtgtgAAoJEMJBwlVnb7NbmHIAoLgR0s3yqFKTJuiAypuxlEebYnAfAJ0a
SVCAVyR5AY+zWBSaaNVSA6KxwIhGBBMRAgAGBQJBhNirAAoJELxS5CGkLLkjdWsA
n2S4XVLeGxpSnJZqHMRz3MXZzhddAJ9QWz4QNCVgTRocgpA2XopJtrMuB4hGBBMR
AgAGBQJBtfDzAAoJEFkLlRdoHVD1J6gAoJIK1d2J2JySqmI7z8oGL12fB6dGAJ91
FC/JicTc2nY+0/gMtVf8/8s5VIhGBBMRAgAGBQJBtghoAAoJECCr2NwnKSGoCGoA
oL2gU12meCTz98lOj+JYouuZSbdPAKCPcGXnFLb75Uw4m91NfH3TjuBquIhGBBMR
AgAGBQJBthtZAAoJEFECJ1+oE9Xu5BsAn0AI0JAJoWHpYc2Z48Uco7V+Jq/gAJ9F
jkRFUbuWXcQPrAgGHZgD9FdRaIhGBBMRAgAGBQJBtj8aAAoJEPoAfVFGjWLIso4A
nijFTEVa8du1UiBeTAj1rLD0FW/LAJ42jFAGta0UyxbIZWGhP4DvFBuNeIhGBBMR
AgAGBQJBtz8QAAoJEC7mJEHpIiavD7sAn17qk3jpnVklZZF8sYo+1jMr/pqiAJ9I
3zWMDR0Z9YB2CeYT/1VO8vZDg4hGBBMRAgAGBQJBt2haAAoJELa66j1B5mvZkmAA
njmkvISleTtKYFblou1d1C5q3SPSAJ9ZJ/cO3uXTMbaXFrVLujxapA/HCYhGBBAR
AgAGBQI/xJMlAAoJEF924XqIxu32lBcAn0soNtf4ekys7iKEHm/wITZ2OedNAKCK
5BtwL8zd0ml10WEvb9M/5gNZp4hGBBMRAgAGBQJBt3CvAAoJECdq1e/TZ18IZ9YA
niRsNMxxf8EO9g4N8sjh3LoAOE8LAJ9sMBwm2bYcgapQfrR9Zj5I7qku0ohGBBMR
AgAGBQJBzch5AAoJELdRFAn8FdvsvNEAoIkpGMij2ytgwnn6EGNv4V87adnnAJ0U
TUxRhVWPbmP3S0lDJAByAFJmeohGBBMRAgAGBQJCJz55AAoJELm9u3R/EjcrkMIA
n3snGF7ybvutJl2ESXkg2OmtX919AJ9Cb6wPF+/yWIy2qYqSWa7hEJoke4hGBBAR
AgAGBQJCmI1oAAoJEMSxB5iFeWojpsIAoJWjzPkS7GPOM69BvCAQ1Mv4SKdaAJ44
o1aeueepGFHRztead/r2b4OdhohGBBARAgAGBQJCnLi1AAoJEID3vqaVM+dr6LIA
oMoIVbIu19hUDgonkOAP849FQXWrAJ9a1XW6IMvoj1i3z2Yit3Se8PsMM4hGBBAR
AgAGBQJCnMZwAAoJEItKxIGsHnFeJ80AoI0lCl2CNcycO00bNG7WUnDblXHWAKCP
Cte0wO5X8MHAepdmsQxeX4BHuYhGBBARAgAGBQJCpf+BAAoJEIpK365OX7hLko4A
oJX/j9wKwnRg4jL9/MKUbSXxev8bAJwKSlomPxWyeHUq/P0HkkpQToPszohGBBAR
AgAGBQJCpgIgAAoJEMMVE1cQFmFJ5oAAoIv8SXGlc/vuZBVavl06XsPm5zGtAJ0Q
jphfkOj9Az8FPyHDoMUPnVV+yYhGBBARAgAGBQJCwTcWAAoJEELPPzYczzMHk5EA
oICBwI8NR5ipiZLtHJg4EOUKlhT5AJ9Ta8CjJI4HqD/ub1EVeqkIrVPw4IhGBBAR
AgAGBQJCwbuzAAoJEJlSOEh18JoRL94AnRa4DjsWPE69idhx1OtYA6o3tEQsAKDe
WDWJAsqQCbYFq8/f/GMmtFj2wYhGBBARAgAGBQJDJFRKAAoJEPjcmIO1KnIWzksA
oM2crCp4rRZPd90iTbtGI3ENKO2WAKDrV43iwBDKixkPfyR65lHk+WM7RYhGBBMR
AgAGBQJClkI5AAoJEKrPs4YhG27v5KQAn0958PhC4+SyDqS5Tv9NTYiJs4oMAKDA
c2WahlwBZ+sOS9Kahjt8Os39CYhGBBMRAgAGBQJCvFSWAAoJEGbmLlBag9y0GDYA
oO2NzoxEG+ThKqDL4JMKFmCkuM9+AJ4mnoyW1PVJXPqMj6y5z+/qKI8X6YhGBBMR
AgAGBQJCwZVVAAoJEEJrd6pui7AhnG4AnRCJQYoXCw8cfd0+lyGUeIV3aD+gAJ4m
/ULCPgyFp44+7VB7pUhqn4OfoYhGBBMRAgAGBQJCw5CUAAoJEF9LLmDKSS0mL80A
oORZNuUzNXWq0uJ+1x9VfcRlDWSmAJ92MgDRn/sGu3oYkHSWjhq6T4WVKIhGBBMR
AgAGBQJC0sqiAAoJEBLMC0rbivl4lKYAn2sS2V3W4rnG1ANMsXr53Z5Gv0z1AKCz
Hi+Px4Lpsq2TY+NjE8OhgVaMOohGBBMRAgAGBQJDJZfhAAoJEA5ia60SmMK0LaAA
nAvWVhK8Qjx4zqG3wJ4u5LIpWrwKAJ9BViTt8OSU6Sj61hHGuYI9tpwTqIhGBBMR
AgAGBQJDLSzxAAoJELGTxCLqQmPGVeIAoLXIMYANKBy8tdalWzv4CNO62FRSAKDJ
kBZ/HQzmRKb9iZDzADtdEQw7q4htBBIRAgAtBQJDI89YJppodHRwOi8vcGluZGFy
b3RzLnhzNGFsbC5ubC9wb2xpY3kudHh0AAoJEDrW+BGDAMwC/RwAnR/+3e35w7Aa
cg6p8jlSYMPiFCYDAJ9LB0JByPVhz0QadOXxJwNIuNL7zYhzBBARAgAzBQJCsGTl
BYMB4TOAJhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5kZXgucGhwP2lkPTEwAAoJ
ENK7DQFl0P1Yf44An1yAmZTcjCi674lD+bmPX/lLiRznAJ9wBmFXB+rTRUwbed3E
YmA1DD5Kr4h9BBMRAgA9BQJClhnANhpodHRwOi8vd3d3LnZhbmhldXNkZW4uY29t
L3BncC1rZXktc2lnbmluZy1wb2xpY3kuaHRtbAAKCRAwGQ6MHyjYrhAUAJ9cKos/
XooSgKDw0CLd2gwDjReFAQCglC0CUjdFO+jmQIWK6aKWwZ6AB/WInAQQAQIABgUC
QpiNzAAKCRD4hhZl2YcTWBN/A/9BTBcoRJhdewOEQ2hzWyffi8Iu8lOTHHnW7LMQ
j4/mQsYvzjUln3dd4EReW5jucfsEVhV8PFhmzNO4lxBV0jqFDBnC5iJWP09ZKxsF
yMN7b4pGBbiGMzv4Fy8Pl0l7k/g9Ph3IJ8uHzMLzbPgZVjLknIlO0Yg1smYMNBmh
CuRp+IkBHAQQAQIABgUCQqYDDgAKCRA5z3ue7C9YEXnPB/0enD+VFEyowOFZYh5z
OmiQlFKVIn8dLEgLFCRDoyBr+ocyXiLHPu0I/2LlUjwsU/yWaE8ctjM15RaRvLGq
md5z0C2By4pEKD0ClGQcsU4Qw6SoDxD2DrzeHaMVPGGqagaxG+kP5BFFMngkwAJX
skzsQ7XyiTSJrspVOBVcOpK+YgNX4GRsAjJZDeD5cG6gCZOiNntEyF3E1VI9LFBv
V83M1PLDm8vdzJG6e85NYl7SIZA85x+EKJz0LMaxpr8bCaEvtca7xZKSl5Bd+Dg2
ocnmZjRHRtvizh0yGu+JWVupsYjD1x8fgxCLsg0mmI/J5BYFT4cF9x3tVw1ZLly5
jK1MiQEiBBABAgAMBQJDG0jzBQMAEnUAAAoJEJcQuJvKV618eaEH/A/U2EHZBnX1
jEmXtfZGW5IHeYY2aPdL1hvaWrMrsVvcpJFjmwM+dej84VMW44LgxI0iJL7kbxaL
f8AQRGwRYECFWsk4Wplcmj06UOCP7v6VzfpLoGD8Nge8lQ/1inrJHuriMKb49qR+
+9QAWdZG2N5LPqdNr5jlZPa1XHvczmn+/NJL7/xF+p+xLvTvTKbJk3gOtC3yaDI3
1/zFaOKNje64G1oN63boI3fjYwX+5l3N+Go9/1iigVDIVo+Xt2xZo8kBAU4N8MLC
WfvOAWPANNLzc3LDpwbb8hwQ0jAgxaiG6yXxQIAP/ap2wKK+DywUIbtorTqZ8MwR
4ZlJSsTobnGJAhwEEAECAAYFAkN2HfIACgkQ7tVxaweOQ9TRkA//dtspX/X7/BDA
ZfUeKIF9Ez9a+8zqPX+XBY2QrEjuSEO36wfuqd8dVLZBlpanv/HGstlOd/CDMSuA
Wg8knh1et4VM3fUcRnBwjUPqGwDumI61BQSk0ywCEeMziBbbCmCElrOIpxWxJOvl
z5bdOcflIbeyD5yI26QEV2soQQqk61ZrglHAX0bVfDXQpcMa0jCe3MlKWn/Z878W
aoLmPIrH/Nw8aq0p38mORqODFLVbn5nqhVlxhxx4TnJkpvdhwMuCGC4jqRFOv8T9
AJEmf4DpTlNHeGTvHuYuluolNzaXzxoT2RQTmK1yKqV5V7f7gPni42lO6JRMz34h
Wn7xGgHr9veG3BcM9y90lYpZY2XCoKoqKRkqlAj1A9b9njo6PYZH1ePWHQU24F5I
RdEFf3nXeohK6TDBVYAos/tI+ZrMjTSZGpQU+hOd0xj9d/maN/FZGLxCJPzM63Kx
Lzm/V/lIHDbuOOO3nbbYPVDkmWUY58kNZEceZt/ghjQ9bJQpTOrqwCcHE9s0n27T
29DKRE/VB0um8Q0YOYX1kpeiLgIeJrfEevl7oLA2IG5+B4O55veSmSitIrywNxaN
XP5SKk2/ARkSj6EU6+YUUvUOcWm1fIBcFhMIN+msn7eCbPBYXPPlrkdr2ZvSMgvP
FucdsVZA5iQvCRUawxBqyIvdhlQ3ghCIRgQTEQIABgUCRAFugAAKCRBo81j2wTlk
fB4FAJ48oJHm80m+YuIhljJ30BErJYu1EwCfRWXnFzG+F2Nlnn4/M//7NJk+ut2I
RgQQEQIABgUCRALvuAAKCRDlRN4Hm3wyjWD4AKCwyI3Er0OaSZdQ8FaWLplhv24w
fwCfc3hejxy3Xh+Oi75gho2Rr+j73UCIRgQQEQIABgUCRANiKwAKCRBsdheMoO2Y
LSC+AKCoHKtuB8b+QN6mq51bonSgKttxjgCgroXeTqvZI+T6KhMYitHECOO7T3mI
RgQQEQIABgUCRAOLvQAKCRBT9n90cV/G1yedAKCZ1TluuUWW30uqC1lgO8P4FFGU
lQCfYW03cKl4ltytfqoCSgXGvrjdYOSIRgQTEQIABgUCRAOLAQAKCRC7xxTRnGfN
liNhAJ9/lLuLNftqEjfVV3bLM+BnanctcACcD/KP2gS1Tyo0yWArSZMSndfivmiI
RgQQEQIABgUCRAY/GAAKCRAiC8iDMwxKdVr1AJ9WM3S3XQL8omdD6mi1y/AuN6be
0QCeNWv3ZSCy39Q54RA0PTg+O01EyC+IRgQQEQIABgUCRAb2UAAKCRAvlRUIquYC
LluUAKCDARRexkJvPK65ajap2zC0chyZLACfc1nt958ndLrOSpbilWhTTtVHsmOI
RgQQEQIABgUCRAcIpAAKCRDtGLaNFhlFU7OpAJ9KAqY7LNlmjCjl9VoVj+TJ+mUY
8gCgwNb7SRNlB8vzNY5CFR0sIopshyaIRgQQEQIABgUCRAddSwAKCRC3KKM/RXdR
9/jGAJkBMfWsVHmjtVBgOzXC7WLFWPIgFwCfabkpgbPILf67aFl9Efbydc1JvhSI
RgQQEQIABgUCRACligAKCRAnXIZRJVDn43e6AJ0e6mrjMGrYyIF9MlNiyJ2ZiFB1
6QCeIFHpa0Z49xGyodOP+0TPrL5lKI2IRgQQEQIABgUCRAgRgQAKCRAC53/ZiByF
xKlSAKDJLfMbgeEh6KV7rN3bwpFkTq/5DQCfQYuxMgniNtrPCBn4dpjV5fKLVxqI
RgQQEQIABgUCRAieZAAKCRDHKarGvoxrLmHqAJ4p0wA0UhOSdhFHmfFrhQ/Ib/0d
UACfeoM1rMr6H8BtbZWyA13O1hKK/8WIRgQTEQIABgUCRA9tXAAKCRAzoQRHKwBW
gXykAKCO8keEC4hyUyRFF4kNdLTPc01OGACghsx+IX70M1hvFk+5rwyBSaqIjfaJ
AkAEEwECACoFAkQOLI0jGmh0dHA6Ly93d3cuZWxoby5uZXQvY3J5cHRvL3BvbGlj
eS8ACgkQlXlS1880AanXIBAAoda1LdDpp+Ui759Abx4eJYuba/ryn4qZI0fTwwrV
D1NTUZEC/xlT7aE0neNWCVjDS1bSMdR4qepFfsLskirMNRaZeiQpbdgIkACvEhUo
yfYrLxAxEcyMb6R5CpwOlhgBRapBsgBAfQ68etCdvvTtmHBPiBLfOV+iELN0LRVl
tsP9aA0ymAp7xdqPoILeIV0PF4xq5K7QLlWE4SHBVXeY/MUf08UAkiU9d8MCeQ/F
iqprFcld+uweUMKmjK+XIMsMbx3E1Mfv1p1Z0cr65UqE7RdAlyoDmaksviYzq2Js
Qs+AOQ7WZURY2XEdlqbNTCsS5e8H4jqKyLGdmJFMTvFqMBEW1pUnFqCaU93BhVhN
Le83f3gJU8DuZb8heDlP4CIxB1IQZEUME2YYHiOu7Y6BktH+ayfEKCeOI5e4lHqn
NKpGDM61GJBXiVcKYA57WQ+CEDfsLad3twXsXSREU+l2vbVfEIBDSu8G1SXORcp2
zNJNy9U2OXteT4Y4XFRBjxb4/SBiFbmLiTann4lOvGpfOrRhQFFcU1rK6xCs2ShY
NT5wNQ6NVvrggkCefHQidYJI2qQUHkXieVK+nzmH2fre997f8/OESdBkFxGgWJqa
V08rtqY3qUv4/A57ROw/3UOJvFYmPj+TbrvEBSeTENSVlZkeQhi/hwbdTzHX/qK1
WvWIRgQQEQIABgUCRBHuAAAKCRDFwMXHIY0Y17bXAKD/EYFwbhY1C/hAqqwnz9CN
pXWNfwCgjey4bUbJEDrm4PX32PuvCpX81vCIRgQQEQIABgUCRAb2TQAKCRAvlRUI
quYCLoABAJ9j4ILLZ03ElEnm8LS5HK+vlyCFNwCggccTj3g/kble2xK6kxYsxOSP
1Z2IXQQTEQIAHgUCP7Ea3AIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRBo4SUr
faXFO/CTAJYmwBuTxoNOipLTKoeOpi9U24NHAKCGQk+tJgv86kOfF1JkxIgCzLEn
Koh7BBMRAgA7AhsDAh4BAheABgsJCAcDAgQVAggDBBYCAwEFAkN7Np8aGGhrcDov
L2tleXNlcnZlci5zdGFjay5ubC8ACgkQaOElK32lxTuO7wCdEkq3IxHToimnzxdE
FjsxukDuCxkAnA845EwGhBlBvzCm7dMkjWkbEhmkiQEiBBABAgAMBQJByyZSBQMA
EnUAAAoJEJcQuJvKV618JeUH/1Q4yL8kPkn0ceEtSvsKW8w6kikun7kR4AyHF3+n
J9nzznmHc25pRIseUrUnqnR4yL6SaXnuVduj49qt6VvMt/s7v6ilofOf62m4DHKI
57HDLQdwCEFttTQWRXUUI6PhYnZZer82JykbC3V4mfOtrNs/sS1HO+4ipUxLidxj
oCEqYytV1/ttaKWR+o6P0N40dz/+R5hT+Z4ZGRyy8i8EA04Khw+/jw/jSsb8XO+M
ABMoJGvlCWIIoETkhTvl+Mi1886FcPywJ69wm+qy2UGejSr61LxAOnkfNUm4EUDf
h7jNjkYn+ATpgKEdGPSkJtIQzxJ1ELixHs1rqoAOM5rIZ5aJASIEEAECAAwFAkHc
9F4FAwASdQAACgkQlxC4m8pXrXwb1gf/QPbHWt3CfiRjUGeN2qpZX/uu4ZK5CRuR
rFoVGXD5L7suX+NXJWJq8HeYzAqCKQEOG4KWO3aJbvmeJoeaCragLYrldllqsNZS
fjnw8lKSDhEPQO8E1g8h/vXzTs+zRqou4QPSgpwv7DxvfK5ozcZxEiQ/CbM3v5XT
SAyD8UQCqD/Pzg3U4EHjVYkEg6UMeNu17Oyv7Q3wjFykxYnsszDF3aw9oGIMVxs4
ViW3jrZS/yODkbNFdbKZAgk2ZtNyZbzyymgp2V/p0rRQS0VkGfqHMbmeiU8HLNSk
G/bWKDyZfvfcOIRA+ktB0585xBP/TRUaya7yrnZEoKtacAAELXSmA4kBIgQQAQIA
DAUCQe6+7AUDABJ1AAAKCRCXELibyletfFUAB/sEiUpKx60XjcJ50p6u0KGlK6UE
1JN/CljGOQgd8jS9VsmQ1rjnJTTR80NGywKcHs5dBp4uc9/qKptsxe+4q5Lc4ht8
n7uO5E8px1XlLjsZ6uM4J9R548CVcvo7EE1oo8kaOdgaBwoDHsuwwRJz1mSotYNk
kLrbSLgCZ7xUq2vviAF8z2MGvHgc8t8oOW33LGcjkImHKAWFG5vyZcpR2cJKFOjf
Q06q5ENryIa7RQbdwnLHOlf0G3jx96ivrZouk86mF50YyJQRepRx7bMRyyxjBuK9
Punt4Daoygftlr/0h2Gr962s2ZkSQm5H5Jt5rmiOKpORluVkD38RKkYLvzKOiQEi
BBABAgAMBQJCAIunBQMAEnUAAAoJEJcQuJvKV6189YEIAKrrAKrbBLYFqoWh5mQZ
1dlqHdpzkwGvfa877CZMoR60MYJasVVO2Ep2VOJxdgUt5nL0J37n7+LlZZxPER4y
rEo/1ArYWUtgzdSuExmSNhv/NYfH+OlCRWu3D+8LIMQ7ZVaDiQXUZ9UvFqtepZQx
6DEH0uIzC8kUBDhiuzT2bPwMIgth7jM4pNHJZGvCtZGSEYzNHIRaUrRQH6Ag0uSG
If2pux9rnShuZ55/fuL2dCsV10b1dGHZkjtu/MSiEmQynAtxSvFgvpbzbk8rCypb
THl2mpHrdEIPJV/Tq0pA1DzAScnoXP9pcA4B/+JAAowvNL0aN/JhXQx/f0dfGGoJ
k3OJASIEEAECAAwFAkISV6IFAwASdQAACgkQlxC4m8pXrXw3dwf/UCLzzm1M5PWv
zHs+NU7GZDdHobdJ8yc8H6qfX4rUND4wBPe5eB698iFWn10+y0/SG5oHyv1iM3Vf
en25o2KXv1uf3G0miUzuLDBQjuJHgCjr9J9ZQPjY3P1dpC5jB8zcQ8JmjBODP3CX
rnfKEsfX4RHOmA3/e0eHYR7EgtXX4s5Wq9xT9qt/Lzgjn9+/a6Zgz+/zE8VPbpTs
b6kRfo2bhLycuW6fuHud6IqpHHUeNFZyI9RnSp7g8MwZ/uku2xeVlXXJZsFqkwlB
71WOUppSpT/fiSGBKjpD06ukP/9OKD6C7CQskJNwON+qaobD+IYdlECZM8haAgS7
W+nJH2imPokBIgQQAQIADAUCQhakwQUDABJ1AAAKCRCXELibyletfItLB/9XgGad
9EananYeeyJ3AGzReM7icDQ0/Xv3GSRGMNIvh/2jzRWyGlc86uvXCHUDeSCS2i6C
x96H4+sUGU5jmf1wYZKSsVDVYQ8QkSYan7UF51j5SpNiya5DlzqqHSzB8tsTCbff
GlcVYbN1wbQi2xnRPVpCOT+OCIflDF6xyqpiNYpJHNQ392y1uGWVthE+FT3i5TX4
QKVb34UgE8L2/45ht6Kuup4Sn8gnZwPHwPHW4u9TIA3td3sWlVvVnvtAFS2/IRdQ
axKSdg7yY62Wgk0yUCU+fmyz3p1Fasd+m61VumauJqO7SX4dZMXk7gZDOgoHGb8g
/ijXKHlz8RzZ1YJoiQEiBBABAgAMBQJCKYaZBQMAEnUAAAoJEJcQuJvKV618+0AI
AJFbre/JYTLcJ4zbHYkBVN50XyLiXI0gDl8TdvcrO1aLNToriZom0Dk+phpSL08/
BZqSqL+GRaBaU9Zud9y6+Ux40sa/jn+eUi+A2RvLjtAvo5XGlukL4JiuSccSMSLq
VwY+KogsI7kgExCBD24kLWz5Tb5zf0qPvoK4YAWcW9DJbmSgcYvCzj/kc7RAuuHr
M0HdBl1o1H6qPYptvMlsTIJCU7hy8E3BMx4F0t74Z+oqThzRG8wSnAByuJvI1CqX
hVTfsZgLcUEFzjpmGqBqtOTHW4+I0BXFDJaZuMLaYfOg8RSA11juFEGPdl5M/t5o
mbowl+AQzxR67HKWkdiolkiJASIEEAECAAwFAkI9QN4FAwASdQAACgkQlxC4m8pX
rXxGeQgAmfJi3dW2R+JLyY7b7+M5aXEIwcec6n7zSNfq6F5BL0rTGjt84UepvbU/
NN0V9AoID/iejB3UciPAg6P+ZaMtJP6rLFmb1fLO5zX2b5oBxkNCJ6/pijCBJELA
/LEL2VDc5LVIsuG4yo2WNMiNWxe3F6yx7nzGonOKKg2SyrTE0quwnOzcb4bZlfYs
L192OXNquYODsIALicqc1fA/ipEF7+U8xkcPMueTjElg0+4709nv/o9RO0/jOp79
8HK8a7lIE8z8BsrJWqQ+xjPORgJnM1LQlJwmBe0v1ydsmN4RuxtFW2x07Kq8yow5
wGd2mXFPhbtZdftsxUmjUwT/7JHwC4kBIgQQAQIADAUCQk+20wUDABJ1AAAKCRCX
ELibyletfJdDCACpw7o/2gMDCmzE3y/BhZRONxHj8/bZRwD/EQpfaH3f88EEUu9t
ZVzxQRWHZg2MbvmN1DQ13NSWgyn/vzshwFYEEjUxoroZwhTspy2pZrZj2JRcnrq/
37mu3KYDww+Kyu4r61VOBcpGSAy7rm+5+3VuRZ/qx4id4Y1ZXAy6/HIhoOBXnDx7
TXgVSK3zeRbZ2TN/SP83lVJ9dsXUkX7RmtaPx4cSdlUq+mNJ127J6RoWF4BWrRc4
2I2oDQJvrgxPwfO9CLfZO9WiP/9BJ92fQMs7G7UqdWDpX63+7kckCwLQevMasnrw
r0Qs76a88/mquvm1TXyfuq/N5fhVPUkPNC4wiQEiBBABAgAMBQJCYjHhBQMAEnUA
AAoJEJcQuJvKV618S8AH/0U9re64WpK4EXsVEXdLQQnRbd4rynmoByzFgtgZLE3N
YviO4V+gYbak3znRMXBAYQvuwRLrqekTbLFnIPgcbzgEvo+UL9yL60KZUzfIi0QR
bPsnkAO5XNJBjCGFCeHxkS3GmRy4gfIU31J8egy13KVBRAfqDPaeWIeRHdSa976l
WE2tGOXbGBi8rSGrsVsaqo0zGc7akAktaxsSTuQcnoYI+8TCjPv9jAJrzszelcaz
w7N6hsZwbXvS3ot2Atg2LItgz5FJj/qj+71oUkZVrQuhszk/zGne2IcbUXCs7avY
eEHa7cRHpQUiPrnLy/8BcMEyaRfSoV2IlrmeNL2cajqJASIEEAECAAwFAkJi2jYF
AwASdQAACgkQlxC4m8pXrXxOBwf8Dy8/JHfk/ceGJ0gXzh6YRu8XuaTFlT2TMLQm
uxlL2/HEuoPgAU/LZZ/h0DoROAf7eWDj4wQrpq3aFpcC9WRHiblfw18rMAW2g9FT
NgyfxsTmqUBiTjYeC+o2rgjpgJYlMwjCNnjjy9Q+d0lQWyrwgrRLYKGPbV51avp5
GqAxzMXo/OTc69VE+zVP7jL+wnetSmhaab8uF5uEJ0y31643jqlN88eAuvUqMFqK
WOLnmZfctLQOitbA8efMqLpjG9BnIQShUWWPDTVz8k5o3VNOPz0aC/oAqMA9DkUT
8rmzDl7G2RwZfbd7LGHmkjoXRGocAAhyKJlFtlzrf5H83VGtIokBIgQQAQIADAUC
QnVZjQUDABJ1AAAKCRCXELibyletfBDsCACnfM95eVVv5HOtxbHoPoAg8rk2wpsV
jWn+qKs66pOKbITC9J1E1ljkg+Efj4gMHAGnuhUxj2gm/08r7o4uad4xDxB6PtM+
3409zcarL9SMNVTU2DTKPE8G/zIOIqXJrtLPK373vFwgDnqWG9zdKI36mlsMdhCW
yzODBQwY581Y3lKBN4TNxfUeC7wtfZcYyrLQRKMH2xr1n1r3CkORJCgHkXo5arfX
BZvzXCd6LVLsPhoUGDavi5R8zWPyabpyh5ArftCZwt4U5jll3C+ppitnUN+EQfiM
kqtTzAEJ4bvjQadt1nKILVwMsGfU16MKvkIINVY0kDZmss0yVGfDGXi1iQEiBBAB
AgAMBQJCh52bBQMAEnUAAAoJEJcQuJvKV618lUQIALXxMCPaxwqtG5ZyMR2K4yUq
dYM1weC1X11riPHmLN6z4G4LTPCoBIui53HG/+SdCvn5gKcieMwiZiwDTd8aQ5Rg
0pxMC6GTTiFOJ+8PwxiuzPPxcebLHjUNRqu/IfvQcua7YyeUEyoOm7ReHRig3pSe
zpdpwqOVbjkR0VnLfbBNMztc+PfoKmOYn5lwhN//b3YQTUPKArTjOeLkuAftbNC9
/WRTNDM37nryaMFgZZvg2vDwA/jlnFC6wqRcLQp3YbqcKzq5aqaA9MrrlKu97fke
8uivsLdPXEUwKACRAVmxg1f/7fi6SxD6nWt1+ami5qs41cZsJhRIsZjI5CuP0TGJ
ASIEEAECAAwFAkKJmAQFAwASdQAACgkQlxC4m8pXrXzUrgf9G9tGRtcA0DbzC0T6
mR242JmLq25DSNeWp3M6rX1p+j+sWPKX6cragRn2C97KMAJQ98w1GVQaMmoHjCgj
gbMZtt3lA2Glg0fWu2esD/KguM7MXT6Xc60rDcAj76k1dXZ8kAWc5OAO5Uj58x2+
SODWhBx6vsUhtyAt9A7rd0DIHC8w+wfwZ3JBsEldZ48T1c2idwkRhC5QXGkpuSTf
T1gyZVCdLFEvV/qGShgp2fl2Es+CxipTPs0dLwh+l2YOMr3TmQg1Ey+ImMVK3tS5
SsRJsJPYtLtTEU7dnvW3+J8L2GPLML2lV82fD4fk8W4YTkQr8TwJwRP73pkT7NTK
ffVyZokBIgQQAQIADAUCQptjrwUDABJ1AAAKCRCXELibyletfNOBB/91sVfszrMd
Zfm1nHlrNmshCW9jXjC5qxUHl6Six3L4iMR0CZ4SUuJQmkcA+uo/fG3kwB9RK+JX
yyj4heiCDuERptY98tNo3OFnWEXaEIhZ2RD/fLQ1Ulm0lojpUwv6z/Dx5HJQ6pjh
FIdgMeypqVXicSaHuBv1438hGC5BjEThAQD7DlhTWB3DeP1LHlaHwYcINk8/Nk+g
3A++ug3fRpnJOXaRsH6McDpBH117C93gFARdTD465R7Mt2DpMev5c1b/bfD724mT
fnbtx4r2rRtlGmThvWZmeravxF9O0e8IPSdd2vV6ELwvB1aEk2/a5qKwYs3BTUQ1
B333j5VpgpE5iQEiBBABAgAMBQJCnLUmBQMAEnUAAAoJEJcQuJvKV618yx4H+gMH
9bEUEMy9ERFlGr9eNlz3Aut2RzBdJZZavySDmNBKTHcj0UyKxGBclKo/9cx28yTl
FnqYX76mmrE6DFxo8jKjSr0Q/VXTH18+t6nUpDjojmY+L8+VHuiAyMsnPHrWrGk/
AjkTIN4Rv4VRaCo8rSXKe75mGOao+ZVZlZ7tqoPqqFoFWQhU8GIiXVjMp3a6hOMw
QBG0uGQQV+ntFFNq4+ICbioBjAT9IwpHoEsbKpvjr2AQd1fC9pPeGOmkhs/KNpw7
4Sn/cI5zLbYoXE4ckwDy6uEbzpjhOOlJ0+hHdXYEvFcs7UxaRdGxIuGyK2EcjraT
8A0Y0aoXjWoqvKiFxsmJASIEEAECAAwFAkKv0tMFAwASdQAACgkQlxC4m8pXrXyH
3Qf+NcO8xswRXQA7wwezylOZmILKPHgPnqJADGfM//D/B1bNbrbObYfdsdAb38Ow
hSOjxL4ayfTxgre4IWmOu/MHYYCTikaW4Dh2wRdP4dW8ZJUOGG9DCYG5gHGBeTEE
57Qxq58I7CK/yMLN+1iQNcQ0Gmhb0+JbuT15qw2uTfRfQTHJqxZmm+PNVcR+7F8u
P+gXQ71QngR44cPUHMRjUSKFEwhC0vI7n9DK8PkQu5Vkfd/dNnqFZVo98DuAXu6x
0wETKSIRNAQZFdkd81QqK2NueFF6FZGETGpyVqMdhETEUwjnqeDmjEnmgMhmG+al
oiT62yGrUPsN/nCqrMFH3xVSb4kBIgQQAQIADAUCQrUZxQUDABJ1AAAKCRCXELib
yletfF10B/9lfi6E7QjhFPp/7LJek04Ja+XU6dF5gXVsKJovt5ynsIgva8/4NlyB
KwdRPtv4F8ltuJOuJEXZ5vnLnatJH+bNe5AMgy2IhYMuDNMs3Mrtrv/7+iqfbl5K
Jz4/7ANkIfpPrVIYP87Jo2aaApCEabyqwFfVcUFthUC8pm87hyVUYQwkvdpTPYL4
OFKeYTNcitQXKLlsnugBzvqUPtUzdBD1bU+zQFQKWhU1YGU3B+CQOK4vw0bw1PRH
7lOk4xYMU9T1Iq3iYynEmtWYhTjel6OqgrtqOK+zmiLlP/oSxkIQN2/Nb3Tw793B
Hl9f9/csqsuRN8elG+JoYEY4AHOEJ9+HiQEiBBABAgAMBQJCtxUJBQMAEnUAAAoJ
EJcQuJvKV618lukIAKeD4H96Ic9Z8QzsMXBB/F8Skt1uNxZ1ObkQi7Klk93uPqyN
v+O18p0Ao7giVdtA6w/xubEYYSCrl5ZDud1r63LdDYiG8VvhHDwYXi8rYfGmUEwn
ZPKIf6Yn+RgvZvb8/YNZCSN8ZG5omUYi1DGUz1mEttpukDrjOYYKbKcHSuGXznAQ
YfJQubAr0TDhyuFnT7qNdICFhkgbZKs2hdmyUXME2ir4LqXEEz8+dn2Zz2yuVzNY
Vm7ezABuEf9KdufmsvHx8c6KMQJPfwyD/4UUuF40YeNmAvYR/aE4paqKzKUCHxxs
3NIjSpZRyrOP+Ld3dX/0g8OV/FUU2KJfwjQmSDSJASIEEAECAAwFAkLI4dEFAwAS
dQAACgkQlxC4m8pXrXw1uggAk7cx6ETqp3SkUL6nGyH3CjvMqImgp9mH0F4tHKNB
KtaXSUImDxn9w2cqe1XAz4u8Rgk9NhWzxhecwiTeY68OzB9IV787GajMW6zGKiJd
oXI4p2cLpZ+HuEUENaMTNQdaDXLtd3/MRq1ueCanql+zcF2S27YZ29CCj9wHCZ1C
n9VVeaI9uYCuFk9BRSnppjq+HKOol5uKjqig+Xm2cqMamgTWij/wlOdcq+R6X86e
3OuOpNGILX1yrfrfLHYkuE21MoJSe3FqWUuP1dh6QU1XdA5uMmcyts/UkbAG+kTt
WGmwcMum0X1VxqhNx56mNDdlwrOyLYAZs89e2I0YsA1e0okBIgQQAQIADAUCQszW
XgUDABJ1AAAKCRCXELibyletfCwJB/9A0YS0sEAxSa60p0/W5w7b1QyN4f+g5m1R
7N1Bidf6o/cuhg0/Xct1vP501caDnrS6wbzAiSak3w2PBIsMZC+XdjLkopejDEDZ
OV7OMxjeB1JgX7dfrnq0kS26wc6Lzmpx55SZQ5H6UreERvpl3R5oGqeenJHozWDH
PpzmR7M7Zlk9wcbuhTiadZQxIeHnsDAXZeghoqrUiduHuSOBIhYyzu3AEcbm5/Ok
ls0E437E36Ha6zQe3iufm0iFDCGiTHd3AjGGfJ0i25/D/HWwzNxOfchkl0qwsaTL
cjmF1WPVuDdaBekOTSNpMsDbNp0zUkavxx+uBaUrBG1meEwJhs44iQEiBBABAgAM
BQJC0XO/BQMAEnUAAAoJEJcQuJvKV618oaEH/jh8gSE3V7XyQd7mdHjuyzE8ut4e
hIZRZZAUGQQmZunmw2UzoxldcKoYBXOwdGSiVzg4iVQt7hu8+Vf+RjwA/c/ZAc22
fYLFRgv2aaaaEioercgY7O7wlzgqsHtK7RkjXxvG0ZCRcBpuw2sEsDRfGuzBISrf
weUQ01nKBhdv/pbJFRkmmccT1sojOpNH2WokvKWBRRSSLwZRrcboFXbtaQCW/nvs
4WVR8Zw1+qYLenONmvRcRkgBCCZcEcpMjvadPUwHv16TpxSaFIhXqjE6uPYDM8iJ
Uy+WShfR+D85xRzx07pNJM8xTa89CrubBguxmTsh3Ex8qvoqxJIo3jUAubuJASIE
EAECAAwFAkLjQGgFAwASdQAACgkQlxC4m8pXrXx1+wf+OvjfOw41K7bTpGpZeLbZ
brEUSZlUnZBwTuLmoZ/5bp5/IOJZlcj9q0a4RxwERV88Dxa26ZlkskSFS+t6vxgW
K7hk7QLZSH3AADbTGJwiWdc+Rc+cEmt1ZQJR+Y1EKGGIeTfE+nTk0+XEDmbDv0hD
hZ3dpLfNyKoL7SZ3s0t691gpNsNJPNMsz3gBcHPjx23gX3MBV1dRRwYQmbhbO8jc
onll7X/gTzazZWAAVOx0ZPJ4L2mQ74c8pl4anA0uH4yGCRvjNCbo87gmqhH4emw2
MHnUU3lqBhxRXCzLJ6n389Mp2jMo2NOE5xp6+wodBgSOwJdfu2OMbIDiPuuAOuQb
/4kBIgQQAQIADAUCQuPocwUDABJ1AAAKCRCXELibyletfFiSB/9W6pOZ9dpkIspI
s5OeWQx9Wd4DdR0PfmmOJETEmqPwtdk6myXsVwXGfcSxAl2h517SqS1+wVlbWy/5
wFj2h5VuBhKGuYbqoGEh11YrM6872LnlK3E+9XwDVgmtQsZD3T0tgYa8uvK6cNhM
6ln8Yi0xHiOg7lTsuGCu0HVhiws75aZ1HMkyfGPKWw0QcGqyODDC8gf+uGbf6bBE
AWEIq3mXKNkGGMle+4rAvwnmcrYGzCxTQjChWLCa45W5rmR5bdY2i1lPn5MuQxsD
kWdJ1A7wzwPEna7Ft97IpUq17l1UeELUe6ABtP8d3VX6okXjJV7khvV04jjN3S6O
ARnk8UFZiQEiBBABAgAMBQJC6dgDBQMAEnUAAAoJEJcQuJvKV61827kH/2FKnOq8
rWPuk/3a8ORK8ddqweimE9Z3jlR2q+YsGRITdiL3b/D4JRwtEKLWsTDLJjiGxqdQ
vOAP1xvatSrCRSEPJYBymx7d90TZ4XRCA4+VwP1T6Dn5gnqr/FpOqHRzzkuZbhLk
zJE42tfylVMLIgUBFinMDPIwFBmCkG90Xxkj/ho5A026p94eQ/I9TKUZhRzNY1Gz
Nfzd9etjZz4AvKUDQqi+YJmpiQ4I3CmG4eTifsrSZuJZ3lN/4KVphw2rcKxNXnhL
LvHu8YqMmWMnu3y0HGDNjCzX1V/4cTrmq1z+VCiRQDvGYqT4MBv94S3VfLIAW81y
AXiu2QESEpjA8ICJASIEEAECAAwFAkLtIzUFAwASdQAACgkQlxC4m8pXrXxkjQgA
nxR2ENZFFsG+P28aIEV3Ae5Q4W1Kz1bWMHah5UFxNrT40lbYA6oohx0I9TdjiWb9
/hFuwgUe/Q/fOxfEcQj8jLblGUnaGj1WRzXQyHOk2Q+BYXoIgk+8FF7iqF1L1wuk
oWAEB7OZXH/0YiZBw8Tw5rb9fqlt5y5OYmGY+htWIOl9rh1/4EQOWb9lUON9kNNC
G1s8tqdsWzsRd7QfxPpAosaA1I1uzaXspEmVxJgWSzJCHc5e/HVjdB0TaTo8w5ev
SRWYZ3p4dcLHQpnbZ/fT0litI0mJtdeJtC11iEvTi4JPJpZsS+iKbiwcHViezR4W
SAXK0N/Ig4RV9n3+rvSQT4kBIgQQAQIADAUCQv+YnwUDABJ1AAAKCRCXELibylet
fO7AB/0buPKxGIsWkYDs0GFW5qR6H6jtSGEHsLg3wnwCGi/junryULq8DXbAnNPA
B/FfDByia8ESYtZmA78ZYhsz2cjWRk3EetoYSreSIU/LOVJsyD8oMGIyOfiD/RUf
FSjnfeWJRbv+Aip5YjFsrBr0yWeGRMKTm7JR9DLZB00/GOcElOXczyk+Ob03gDOK
VKVvb1FHm8z8rT14CS+3njb+8P6kYLFSnxyRm2rG7Oe2PpgPdSW2YLoZUlyyKgPl
tTVqCdqC82wK5FBa6iXRoG3h16rtCG/x37dLx3bCxi3V2E9/qmZ15aY1gnCmZfb4
4OMFiZjrOGcysQt1OfgT3/0NVv3YiQEiBBABAgAMBQJDCNMjBQMAEnUAAAoJEJcQ
uJvKV6188hsH/RnA6tHYA/4gevSmU6+eqEUHGtYXANHpjd5NB3UkioSuFe/nTRyY
kTNUJjCVDEC+1KEmUyzTZ8v774ex7XvaUQNnhqOZGGmA4I/Iy2gwAeyn4b2TH8+X
nBDFu0ggXEuTDVCDlUIoKYqp0joQ6E+xRTmim+fx6Z4nc6JVmcUJ7eBGAw2vb6nO
oWLZ9IzS8l9y2GRhudxQ9QYN/bxJVBopVwN40bOqU5KnUeOi7ZNFF5ljIS3VN7tz
7vkgEwG2qQBz+EsjcmlcYGYWm5l6WHZdI4y1jouyuM0b9vaaIOoxTCr/QSTJLRE2
uzeZxAED16smPFOtREZLQ/puwCc9388MxV6JASIEEAECAAwFAkMMIAMFAwASdQAA
CgkQlxC4m8pXrXwwRwf/YGEza16+E+Jt10GDb+grpZ//bO3hBU3BmbllbrqANKU+
V8ZkD/eGOYMs2TMq9NvrWCO/VsX9T+MbKo4JlrfIKlOT0iLrp5BABI5ByPP+YYUH
EAO2WdIgOIW0zYAYIc3XtIODAi6dBJlLTGDVxc3B40S/UqpCqVtvnFsIgQo+f1Lt
gsM91HOTChH09MIdWQcrcD15QcOmPpMKguD4pseT8h30SLNsojo7JotXfsi93t7q
xoQ5wX2XbwWA4sZcESLrEC5yeoUaBPFMVFc1XZtsaAduYyvMesHj2yD5Gnz7S6wm
5yyVLP8K0vj4L4lasCOu6XNMP9OHmvCvi8+3+TbqvIkBIgQQAQIADAUCQxC8wAUD
ABJ1AAAKCRCXELibyletfOftB/9cjcpNmURVbgq9UzElanI2pljOGsCXvKSVlNvt
oAGCQT0j/utdryquckax0OmIX8GwMb5Br1jLIeR61t7/UjrbSozQ8UWPMxyH67su
EPgnwVjgoYhP6CR+G5980HbWBW5agIWtFgX/1seoXrKrpAplrsJ4g7i4WwIMFE3/
oAWpOQgCKH0vZJFEmTaEiTvUt/jLBIjxhMPJ//OJFBqvP/HoJJ9ty/OR5QvXK2Jk
eEn8F6IVJ+mMLOznzFIiEYuOhsKyABVFkKhCDr9g49C+KJk8TBaRwf0uXmOOgb+N
+QtIWj1HGZnzkHS01GODPLLQSQ1CEtsnk+WH6ZvdQU4tYMLniQEiBBABAgAMBQJD
E1/9BQMAEnUAAAoJEJcQuJvKV618SGgH/01SqteRCfgjWv8vPezSvii/bAQYSke+
EbV8WLpWEdSRMZaIorfv9qSCuDTWhgTB42tYzPNFnpIhqkQKGvNFVhRMAQR69jZ8
jyiZs3uj+PF8tZ/Ci5kJvkJ3K9f7Yl9EZEBZox+di7CxG/qxhlFTNYPT8QX+QHC8
IpGFx6HNbKbD7aLZDstDrGnFjlznhQ2PsfkiIfm37rOkus79cxxwdOAFrySpXaaq
2OVmH1/nkwDi+9MpAW+CJqW66IPHQ8r06XFbNsddj7HN3Sq0josgpVeeBqRC8NAv
6eDxFtA0nZ76lrVK6aAJTrTYPtfBQgSfcstQ257b1Xq6jpQo/59z3uGJASIEEAEC
AAwFAkMUCPEFAwASdQAACgkQlxC4m8pXrXys6QgAoOBrpt4BHnu25kheVL7yEY1N
PXDOyq0/sIKfFePIEa888fcim/h0uLr3BqrCCjZ6pHREIpYfjsPp7Yjx8LT4yG6F
4hUUtP8iX3faJ1JynKxxxI7UMyjgaYZSEt2Lc0HJ8sLD8Hr46pYY/FEgU6bNzAb3
y+PuZAFhsqixLmnlrHsO44DjPqCnkBynW+b0nq3ZdtCU/hOTnXKBbrCdodEI8NFa
nTA+610hm71DtPdB8lNWdcuor16/b5b75cxdoRjdN/DYZWUSsforBC07CRl8niCv
U17oN86Vw1kYtv7+iEPL+K9Pjb3L2JYOdHaWYsMUj4EFDBi0t0dYgn4hKWEIK4kB
IgQQAQIADAUCQxSxmgUDABJ1AAAKCRCXELibyletfApOB/9tRyj8wuMIXcmoSY6O
HLL9BCeGmZutgxRzASipE5DkSz5Nmf7TxdjdSmrceyNWqCe1+JDWsl/2czoXyCFT
8W+WHRo5KiVhT35L0LmdgMAQd9n5ZhAGyhrY7b60+B6e/1UTGD+hc2zAT0U8bjOd
2uwibuKKAPu/jZPRVV2oIkQecIg5f8UkYjNX16+kZwoQm/jjVVZxabHf/0z8rQ5v
ICP9msRd0LRRaKS9ufyiSNtVUuIepsYYpE06JR+9vJwG/7rDf/kP4rPWQO/IVlC0
WGYarJrDtbGETL7hOejL/ZAhRrEzksr08ryL17TZJZHPab7Y/uIXIHU3oLMEG+CC
k2i5iQEiBBABAgAMBQJDFgKnBQMAEnUAAAoJEJcQuJvKV618V+cH/06bvPc40C1L
oO0lAD4A3YXzloVnSwLa8c9Qij6DnVUMFbm1tMyYmNEaM3VGvmL5oUYsjJiGMRHv
Sov2RneyKB2M0jagzserNnbS8q8MwdmjrTqTjwrejSJ26JtymoF3aUo4/CJuwCr/
pQTHLwk/Gj7IO5oxy+tI3UQAZXNzY1l+bt76dD8gl1Fbok8PXTLAWzHkqpurucb7
9hG1dXkrpEA5YQJgFwTIkPJS/FuPTlMj7sjQM9I9jqgHRa+UtIqp8nTI8G8XreSu
/NXQCmZ8uHHHiL7GiCdTi+b/LEl7uDz4cpbcnZO546URG+3Z+asrLU0jV2/0zTyk
9qm5u6QjpsKJASIEEAECAAwFAkMXVLcFAwASdQAACgkQlxC4m8pXrXzgjAf/VVF9
+iZ43BRd3FNQNLCz0TlvugI/RmQQTl4ynUSEsPHk5Rc52WCB3FaoIb/Y8W35xyqX
534aMKRgucS1ZtqOhBpzcu8jnUYKZI2bp0UwW4nOFOOKTcvIJd/3y//Cs0BONrPF
R4rm+cC4kYptzEXMYHYMT8oEFsa9tw3vCZ/D+jgp6QHB3qnhu6snFo5gt/smnKsi
kB3sMWEOHhDEbGc9Y/UsTSdNpzk/1P5NugOsaeP+zntj6TFLZrvF+psOyu/GumcB
6StTpgectUtZj1ID3woiFx9FnQUQPv0esOGTH7qTg1BuRpyHcqONIdTE2Q5YWs7r
u5S3ZRIaQTrwj7j9qYkBIgQQAQIADAUCQxilrAUDABJ1AAAKCRCXELibyletfLxD
B/4rz6BhFkpOcMiHXvWFo0cJt2yH3b+3aB0Dx6DmfIctR/giLxtf4rrxce98JtKv
gsD0jE36wUukrKaQCO6d0uqY+fDwlkQlKVkWNzhPY1VW/H5g2Z3mRW8ahCe4uukN
1rHglV27ekepFlbv3aIK0mJIZBGnVwzaPm4A+IRxGrPs4szoXDJpwuiSgtpPJdrf
VDmu5aOgThzUpBlEgwGP5s2CHCd58kRtfgctuyUDYhMk/hkhnzrJsA1CJuHqTUCj
/cCvNI1HaiESGyk8p+DWka95uc5Yn1gQVVSDxzLa54OBzjTV5hKR9uDuxRqB3C2B
bCJJA9aXzyd+OEIogaMGXlDZiQEiBBABAgAMBQJDGU7uBQMAEnUAAAoJEJcQuJvK
V618YWAH/22CGrrBDXSr7z+XWD6iFigyZF2nkQTMlj8tLvf8rpME4IYNLVsWCQG0
VA6ufdbKKvMIVujdHPwBz9KsK5PjleNkcxlPrAn/73LwkWiVLcpdjwDK1uU+7nCT
0PTwGpzbAnljJpS9AG04KM0ht/OYp6bTbBUK7FlS4IIdKfIdQuL9SNnMnmE1Z1X0
EuIZBhMpP74MrJjWh3rKcdYqygyl1/RaS+kh6Sk1YZXxvFoiw4DMqvOVFma1s6gb
6Km+2A86ThTxgjf5LzCSyWC9CC/uNStssoBwkl1LBgrrjQq+15cKMQA5kPZFQ5RC
qACL0cFSb8Fofz6xzQnejEhrG0G7Fm+0JUpvaGFuIHZhbiBTZWxzdCA8am9oYW5z
QGdsZXRzamVyLm5ldD6IewQTEQIAOwIbAwIeAQIXgBoYaGtwOi8va2V5c2VydmVy
LnN0YWNrLm5sLwUCQ3s/WwYLCQgHAwIEFQgDAgQWAgMBAAoJEGjhJSt9pcU7JvkA
njlWyGE0FHHoGAAIeyOY7/NLVXwkAJ0UJXVLrQiNVbcoTQmASyFiXFi7Z4icBBMB
AgAGBQI6oOttAAoJEDRX/4S0XDiFqqUD/RuibKtsjGZb9MeKHbw2S6jXJ4FwGaBg
0vc1jCouziVMukHZopsrUHWh4wrPZT/7rATCcd++p2tk1A9A8osgV0xirp5XRLND
fNXqerGNmAwAcD55tBgS2sDrK99MzJcEa0EZ3aw32UB33HQruew/dM85G3R5BSEW
vicQLtFoQmqwiEYEEhECAAYFAj+z+68ACgkQNgOy1CrygD72vACgohMnVDl2V788
EdQLN7D5iVBf4dYAoM/6N3tHBQ8dG2utOWwva+6/JxcTiEYEExECAAYFAj+0DBMA
CgkQ5Td/bYnvOAPJ1ACgoPrLqTeAzlBI8pobepn3oWyvoqQAnRMMcsZ3IE+2v6oC
bF35AzC7dngMiEYEEBECAAYFAkFu1C8ACgkQSQePKewQQlm2WACg7rrL9+RRHlsr
EzL2ECQVdyyt7ZAAoLyOu/a9cEaZJVqQU55I1VWEZ65jiEYEEBECAAYFAkGD5WgA
CgkQi5YpQ/wkPzxT1gCcDmG40pbSDqUWATPODkNBVxTDip8An1MY3NvxBXIL6N5/
Y3dU9G2XAI2OiEYEEBECAAYFAkGGOH0ACgkQ1eoUkLJdYw9G2ACfatZn4evwWqDl
n6LOM6tdqJ4S4sAAnRGVYr09Cw2TYia2J6hi/b3aNEn0iEYEEBECAAYFAkGGjb4A
CgkQjNofYGUyHXRYMwCfQtpBHoSuVtds/Y/xGHWN7EFD/zAAoMtrxMvWE7W8Ngif
W6ZV+JaA+d2AiEYEExECAAYFAj+07kAACgkQezjnobFOgrEXOwCgxZsXyQA6I231
uo/0fKXlK40/yykAnAna5fUKuekobljwEUBGABIKGF5MiEYEExECAAYFAj+5Hv0A
CgkQs4ANjFa6WVEZrgCfTfSGXzmPMAfjG8DksXhN2Hk3c2wAn3aH1QPdMqCkphYk
0YFqygjxfgQHiEYEExECAAYFAj/EkisACgkQBgac8paUV/BhdACdHzVcYAn0VHG4
uCMuGwYj4ImUSJUAn1UboCXwVfM8zAAqSqkppEH4gK7fiEYEExECAAYFAkCboPoA
CgkQcYMSNcUOWpdLtACfZ/lw6CEIs9Hhuf44+wMQ/PnBDAgAn2fOWgFpG34TTcuO
bMfbk86dwy3WiEYEExECAAYFAkFwDvcACgkQsGbx7unEOiR1LQCfcdRA7L042NUz
UKBZyc9xbtcllVIAmgPkakTSccFPgi5nK/8olKChyEjoiEYEExECAAYFAkGDqFIA
CgkQHa9Q5nX8UPOXRACaAgFwkJ1jEK/LSrBllVsOaNtUK7IAoMU/sloxzQKtoJRw
InmWpRqXXkmKiEYEExECAAYFAkGHruAACgkQgeVih7XOVJfCAQCfb/opuMBBbfiN
V7gODeEgrrLt6QcAoIsAGJ3RkyXAGbhQQpnXv+JklBQ5iEwEEBECAAwFAkFu1EgF
AwlnUwAACgkQ14y85WanSzFYsQCgoWKJAYxGSIizh9kng12BR1JeIs0An3MoI27Q
k+1oHRUlpcV9VKmc1e/xiQEcBBMBAgAGBQJBh67zAAoJEG4/9k35XC9tZPEIAJBR
X5M4+z2alg4sMMNVZ5haa3kqng/dNZOjNbFEuD3kKy85ua14mrG6g/b99leZau72
iVuDr/YCEA1dRHUzZVc8APBygXqNPo7cZT6TCuvAn8xhbfN+mYhI4/XhWgLf7UXM
mm5Kx7/bIVNPu1tFhEUcyrbt41F35PnSwcS7k4pezgBYqCxu2mUW5Vj3jibjfJZD
2p00oQUnqsBokwkHVlbk21QkZKNZcYuwPvWCSjsHutnfs/G62DlIGDmGmxc8BmLX
7+rIfBI93ae6fD/AjTLJ1sOQsZMlc0fy6AQBKWDfoZzOo3OkFRqzr6Ef1VXVx8Gd
nFAb6+Bkt1GlSvPs9dmIRgQSEQIABgUCQYiRFgAKCRCK5rONTcp+XrFwAJ9PMACa
YXsjMHDMrKpzM0o2/1KvzgCfbruwKfm3WwmKsPfi/MH6yASGh1eIRgQSEQIABgUC
QYntPAAKCRAVvJ322J8nFLPPAKCmEDknO0HdxWvhrCAFTrjosWNWMACg3eIRclcj
rDeD7iNT4txgKNp52+CIRgQSEQIABgUCQY6LGQAKCRBaEaIrxaH3NAb7AJ9oDH4W
m64JYf2cC9G4VAzHwelNmQCcDdnkCtXCqRyBAO4slAj0RDekgX+IRgQSEQIABgUC
QbYLaAAKCRDCQcJVZ2+zW9WbAJ49lYmghMnQInJ7U1VC9x7/FWPThACeJlsKHGoW
sr1zJR1YrBe9PsYzPtyIRgQTEQIABgUCQYTYqwAKCRC8UuQhpCy5I39lAJ9hanxK
sHjNjs6CnyW2ZQGdmwu/hQCggB4sXnm5QiQGWiPCa9xGC6/D/lGIRgQTEQIABgUC
QbXw8wAKCRBZC5UXaB1Q9QA4AKCRgFUVk5XkPyRcZlfzzguwmE+PRwCeMfobviCd
ntNbgwMd2GrYXpaj1tiIRgQTEQIABgUCQbYIaAAKCRAgq9jcJykhqFMuAJ4vPx9W
TST/FpBaR7uyAmuoqgF8lACfbPHj4AL7QBgChQzdQ1nFOd/iiGuIRgQTEQIABgUC
QbYbWQAKCRBRAidfqBPV7ouDAKCGH34OSFgOs4XqQEPlyvTtayrtSACfanoc6nCm
fpdIKrrps7afccHK61CIRgQTEQIABgUCQbY/GgAKCRD6AH1RRo1iyAv1AJ9tvDYV
MFm9/9dM53dvtJJNHbuG7wCeJ/yjaJB2GjD2djx9SoZJvP7qebyIRgQTEQIABgUC
QbZPegAKCRAnatXv02dfCNo+AJ4g4ZSrUbxQMnkpXXlAMtf6mfN6XACfbbV99mtN
2ZfwL2yccgp0oeSMrOOIRgQTEQIABgUCQbc/EAAKCRAu5iRB6SImr4TlAJ4ty1bZ
LJ0XgLNQpxwwUtt5VriA5QCfQos+4SVeXSfdj5sOL3V1+AsFH36IRgQTEQIABgUC
QbdoWgAKCRC2uuo9QeZr2RO/AJ4w9E82TF+p4J7ZtoOuMm0/sOCEzwCeIOwQJ5X8
PsSt1lAmNj19w3ugiaeIRgQQEQIABgUCP8STJQAKCRBfduF6iMbt9v++AJ0X3jSf
OW732yeXjYXLgn49Yl7BPQCfYaOfQwYaxsuXBpywdJWnzj+xrKSIRgQTEQIABgUC
Qc3IeQAKCRC3URQJ/BXb7A5cAKCaXaoVBh2JSsR04l7Ux04BrgeRMACfWJsTSqWb
kJOK0moubs7gieEnyLWIRgQTEQIABgUCQic+eQAKCRC5vbt0fxI3K7YIAJ4loaDs
DASZ2TNm+ZSUFVw8wrnp0gCfe/5ue8MRqBOnqGY0QznLPI90aSKIRgQQEQIABgUC
QpiNaAAKCRDEsQeYhXlqI4qhAJsHwturk6zkxpNKptt0csHAichsPACgzxZDcWKZ
dnJ45Mjpxq41X42WjG6IRgQQEQIABgUCQpy4tQAKCRCA976mlTPna90QAJ9jUlvG
QDOAv18oXuF6dkvjsctwSACePJkZ2mXjY+WiV875W4EWS5J+dt2IRgQQEQIABgUC
QpzGcAAKCRCLSsSBrB5xXt2OAJ4jMoBz7tsPOf3Jm1BDBWq4wslLNACfc3SE66Hp
7v/qjK8//hCF6sK3AmWIRgQQEQIABgUCQqX/gQAKCRCKSt+uTl+4S2BoAJ9B+6ty
TPdJpt/jJMhPGItBBoIEGACffXG+D8qz4GsG+c210UlECKXP8YuIRgQQEQIABgUC
QqYCIAAKCRDDFRNXEBZhSaFxAJ0TNsh0WY7tETIXntuUGJZ6tMa3VwCfTLnriHCo
0yfY4e4WSms6lE2lSGyIRgQQEQIABgUCQsE3FgAKCRBCzz82HM8zB0EwAKCayn4B
3Wn1VPt695/aFZLJAKw0LgCgiN1nGJjMU7NgCpVxgQ2HRYTETd+IRgQQEQIABgUC
QsG7swAKCRCZUjhIdfCaEaqjAKCDv7Z6lx3z91XMqCkTQBdUGfY8WwCg5kzvddhR
Si8nIdjCiLq5XOZl4uWIRgQQEQIABgUCQsI4kAAKCRBvc7rS7O2//1AFAKCqh/1S
0t7t8CXP/t5eCqtpYkrxFQCfTAnie+Hr6ajRiVoeGU+cX4FbyFeIRgQQEQIABgUC
QyRUSgAKCRD43JiDtSpyFoQrAKCymtEKuL/55pa42q73DFdU0CpoogCgwHM2X9rs
sBS0XbSSlFvJdUj86QOIRgQTEQIABgUCQpZCQAAKCRCqz7OGIRtu71m3AJ9xy0Ad
WpHl0C9U5UXEz98JxgiRbwCghV5tTJTHJ6fYrxNT1R8cFwoldmyIRgQTEQIABgUC
QrxUlgAKCRBm5i5QWoPctIzpAJ0dWeV7NgEseDdtPN3/xkKUgznQVACfaExDDE9o
+ZNtBNN5GvvT0Fkpg8yIRgQTEQIABgUCQsGVVQAKCRBCa3eqbouwIcG8AKC5N8hj
oKcwykcclYGdag5ubxM46QCeMJV8w6VZsJbcE2kxzzdW2iiaHRaIRgQTEQIABgUC
QsOQlAAKCRBfSy5gykktJkkXAKDhdCayc/wmo2Y6gdaMUoAJYE/TvgCgoRS7arf7
CU/qRDfZTUA+8g5GD+GIRgQTEQIABgUCQtLKogAKCRASzAtK24r5eJ81AJ9ziMPZ
fLWIiOQzdVCuZtb51Ys5+gCfaEVRXkfyFmcvxoKtwyIzfmbSC4OIRgQTEQIABgUC
QyWX4QAKCRAOYmutEpjCtB0bAJ4iNA4fkDFv5ZimFAPD1eMBD2m22wCgg5w4Jv8k
HawfbjbAZqWZx6LwJAmIRgQTEQIABgUCQy0s8QAKCRCxk8Qi6kJjxqtKAJ4/WHgc
y06tQjGPot1m1B/DfVCnwgCghVGD19Lyo5QULBY7+h496EF4HSWIbQQSEQIALQUC
QyPPWCaaaHR0cDovL3BpbmRhcm90cy54czRhbGwubmwvcG9saWN5LnR4dAAKCRA6
1vgRgwDMAvbbAKDFl/kYFT7067M7U2OM6tevdEJftwCgokfPUPtul2PPf3Hd75mq
TZ1xU+6IcwQQEQIAMwUCQrBk5QWDAeEzgCYaaHR0cDovL3d3dy5jYWNlcnQub3Jn
L2luZGV4LnBocD9pZD0xMAAKCRDSuw0BZdD9WNVtAJ9mt9kYGDR6Y1YrYWhGnFAu
FYe4XwCePxbIYwDOGNmXRcHCPTx7uZbFFTOIfQQTEQIAPQUCQpYZwDYaaHR0cDov
L3d3dy52YW5oZXVzZGVuLmNvbS9wZ3Ata2V5LXNpZ25pbmctcG9saWN5Lmh0bWwA
CgkQMBkOjB8o2K4TngCfYbg2Ida8pJwT4me3Mp4ZQBR5ewsAnRXRRSWVS3/uheER
BFP0GESaZHhKiJwEEAECAAYFAkKYjc0ACgkQ+IYWZdmHE1hiCgQAr6J5H5Y0kdAj
7opic5cjiODyU8jR/k8TPDAVrRUs4/9TGcx1MxumzHXEnVTL+e93cTvTqeQ0OyN2
DX//FOOgciAgqIYXn1TSuXznQo3DqmEClP1FReHyTJhWhGRLW1M++0KG6BgoLEyz
udlNQ6436UsB1aLc/b2otg/k1/FdUuyJARwEEAECAAYFAkKmAw4ACgkQOc97nuwv
WBHEyQf/X37BFCG6rifJm9FLfCJ94sDs15ScrfHYynBLImbnh6FcklZDS2RJLRi2
YqLoN5O4zdy1Thgl/h2fDrD/ziPgKDLADRN4IzobWsdtQ+/lwWZfvIZw2Ja0OTVY
G/h7f7R3o15gYm1wdpKeuZTC4x/fkHcP4puW/vItrl20xxuAv9/VMxvcrTaLumse
Pf40OuHOA9BW4xacluNmz0EtMoZeABgxCK/lHBdhbxe7Dsz6IMYlxc+/0bAwmQot
3boRORKZWHE1GKEMOUjaBBMF5gN0O94zFOAJV6rRf9I405okf+4EYZTogH/0yjw3
YH6LLHmo7esSkacXmX/oVphh3+6KZIkBIgQQAQIADAUCQxtI8wUDABJ1AAAKCRCX
ELibyletfB5KCACOkdciGM9MnsVUaVPrOosS9bBxLK+gk+AeQXyCK6r+aQ+7diP/
azakAXgF1hhrZaYO697htWCPGhvF8QwiZmFOWE4Zx0Fjw82UJpi1BLCgH4iFpcO8
U1M+Nt28NmKr6Tenbn7S+1TWxlUkddWwp8iF0eqHlHqcoLmRI1CeyizDthgptGRn
d8x09sj75DmYOLgUNhh4tNdaVM5pyckNFpGEgmh0bFQUc0gnG+AWiaV7YjS6MaBi
phuMvTtH9rTcctcp8836Qd2fjKJpkoBar3oOAg8Bb6cVB3PEgSwbS0/Th5kxI2rK
58SthLpvqdhC7iupQ/ToBh8nkbjcsNbCIFz7iQIcBBABAgAGBQJDdh33AAoJEO7V
cWsHjkPUXekP/i8GjtHgEjQzKrSa9yzO17+hk64EQMz9Bm/l3kipYiNeCrqRMBOT
mF7Fz8Nu6O8Xka9/i7MKG5X0FCn/JbaiZ2ljVEzPU/PHmJ7q/WiN8tRSDmU2HTIs
LRdoNSj6DhbW8Y5XSKJOo71939hRrqDiWuRh9mlnhdwBqBncDpBEgpvB7RjxE2cM
mWCRhqdqAURiMtrMtMKIE746j3mfCNLGU807Aha9UvnNpMfSgS+8PfneU1smZ4Qa
1inA129ttsVeGbr3c7xKA3nMC+sSJzHFec5+HNzEsjS8gCDfDRolKbV0bFD6KPRf
bimWBMSBTTt3q/fGm+36971OGx9zwKO3HYfablfPuO2zwXA4UIM2xmqdScDzR1eC
pyW7bJYk9jjwC2x9J+snHfMHCjFGnk1JRZoCRm6qgk2jBSwE1j1UjaCbjcRyd6j6
RG6Q6U3dnJo6XyYBjw+8Ik16ADuFRZIXUleqG0HcK/cExnV5Rje1/KD7ArNq2WVL
86wO3Eff3ZP+k4T1G6uQWNDyKbODaoDi+TvOmySquwUUfk1Ro14p+Le4vEdDhymP
0sLGY/pw8DqQONUWuEe/eDsHxNkbd0ECMB+rroVH9RanJhVaVjrMYis3mDwxG1PH
q6OT4btESEDj0GqwF8r0LoonrdQGJUgcEg/CfzZSnEab1rrgY9kCg7GbiEYEExEC
AAYFAkQBboAACgkQaPNY9sE5ZHzUwQCggf9HfQqZ+ij4D0MEB8iCU2xYXfsAnAg3
G0iRVXzqGFsSpzJibC46iO8ViEYEEBECAAYFAkQDYisACgkQbHYXjKDtmC2iagCf
eTWh8maRO6BrFDb0QJ5+OIVywhUAoPeRgwUpjilas6ijZWARKNU1gyzRiEYEEBEC
AAYFAkQDi70ACgkQU/Z/dHFfxtdqYQCdFbY7MJSQCVvFu9SulNrtB8ZxsPoAoIMX
A89Ou/BEcUyI+7eR8ksWl8xBiEYEExECAAYFAkQDiwEACgkQu8cU0ZxnzZbcZQCe
NcqwgbIRckDPPsmJCNu/bE40wlkAn3zDHmMB7MUtZu//oDB9qV9JpL/siEYEEBEC
AAYFAkQG9lAACgkQL5UVCKrmAi7OZgCeN/jcJpdELyqC0oFwP8SlkxQNY6wAoL8f
s0Gsk89of7036oEk0kzoJTUgiEYEEBECAAYFAkQHCKQACgkQ7Ri2jRYZRVOsrACg
riAxEFf6ZzlwFkdYnVKkONscytQAoKgljd4gg5wfOeJ7QOquJ1Nx3HN2iEYEEBEC
AAYFAkQHXUsACgkQtyijP0V3Ufe5QQCfeDZfH76Y0s5ErfvdoTJguMAx8LUAnRyE
zDLOr29l/CDO7jLBvF40hRyFiEYEEBECAAYFAkQApYoACgkQJ1yGUSVQ5+MWewCg
kRW+r0KP7JbarS0G5o/c48SE6dQAn0eJRNjP4I+vFFGGuuboJkCKNRB8iEYEEBEC
AAYFAkQIEYEACgkQAud/2YgchcTA2QCfZDeXxN2WVygILzAHRM7QEM0YrRQAoLVz
5sQW+P6nv5rBorKWdd+OAQ87iEYEEBECAAYFAkQInmQACgkQxymqxr6May5DrwCg
hrorW/n4ceCsWuKm4yWN5I7T77kAn0Y4N3HTq/63L8Atu+nNKZOQUxPFiEYEExEC
AAYFAkQPbVwACgkQM6EERysAVoGo/gCgj63xLu8oNklvXbpMnaBnoKTWXR0An3SH
5dtRtWfYFWV7GzgAqfxVf2+ziQJABBMBAgAqBQJEDiyOIxpodHRwOi8vd3d3LmVs
aG8ubmV0L2NyeXB0by9wb2xpY3kvAAoJEJV5UtfPNAGpFyYP/A6/NuojqKEdKpLY
DL/vtVp2nWCGqUv1UhjqRaa4Z4eDmIJbBEDVMU79LUjtOQIZ8CG5BFPaBErxPlQN
eTAuLH92XOvCZd8KcjlXKMaepXmzNnNUgme7hyfwATN4xsa9U6Z3BWudwDkH0UkU
fgPqyFVuqY5y8pIyrZojoap9GAoEkIZu/qSdGlOqv1vpCBcsZbVlBqFHzLYAnEuO
ZVxdEwh6RoQrqoEDTsYT07H6zgYMHqvVTsroc4AXpe0mK7T1DnFnDoq+kfmUblkg
FqIrpPlu1qRwb4sXFkf3I/bFufspaFItcjbGVhYfgIvTlB2qAO4kYPtwrDdqKq2l
uqMOEmV4hkdT1rjUgyuoQWZNxdW17TOVxFvYhGhiGRG0SOu9rYroEKOB5B/uFwn/
F3lqkzXAp4kmkVuRhqquJU+/ryGEQ1wPeoMXp4lyMuQsBNJuiYVdH3MXNZnmhiF8
WTO0iobFd+Iia3l7qPpAhEFPFLsw6vRmy/JQHDTW88meRSvjy2iOxUjT1KUU4u0F
jiujBHbY19pj03J/UsXDfDupYZA/3vbF79Qdlla4jRkCQyrvozp2zSBS2loYRzem
UQC3AUaLy5d/i/wPje4l9HmA92YbK5lfWXuG87rlcsrH+XD9/0eLiPc5z8rt3Gaj
XD4kvZHCa3hfr/3bHlTNu2EUfEzJiEYEEBECAAYFAkQR7gAACgkQxcDFxyGNGNe7
TwCeJh+8jcLP6ljLy+WFgUqxaWg77/kAnjy1oHJLvM63dsAzUglCPlkGnn6ZiFwE
ExECABwFAjqg6w8CGwMECwcDAgMVAgMDFgIBAh4BAheAAAoJEGjhJSt9pcU7QF4A
oNSlvydnK4Un0+zkR49VPoU8EgGNAKCMekJU3qjQe/L8NsVaczzSQfSFvYh7BBMR
AgA7AhsDAh4BAheABgsJCAcDAgQVAggDBBYCAwEFAkN7Np8aGGhrcDovL2tleXNl
cnZlci5zdGFjay5ubC8ACgkQaOElK32lxTtFEQCcC2An1AQ9vmrQyKJ9lA0f2vft
FlkAoMVYmV5kaKRMWW0nvgHNPXPQCiN/iQEhBBABAgAMBQJCYto2BQMAEnUAAAoJ
EJcQuJvKV618K/kH+J1V3Y7+Om7bMfjcipBKOCU/oE6AtR7YKRofb6Y1hfZZBTRb
15vNjTe1Wg158Lv8UxQB9qvp7PEVQvEotm1Z0GQoXEBHPMJkLGORk1Z6Ei6uBRFF
FqdRWxVCaFY2OOvCzo3L0je2idnUYrciuwIABKVY7wSrV8S8HP4gbmXOLFordiFU
Fzi9PL0BcMGThgWb2H3EWxijpvH7EzwhWRkXkyT9JjwsSvEmYWio83Jy9C+PO6Q/
fhOXcUBMQVjnKAhcMzy87Gtyb/y4t3Bg0/AYzZ77pw7OTJXgjp/yLkoLWKarGPXC
OseTlez0K66Ux01X9GTNPkZzgupX7lPyvjDPi4kBIgQQAQIADAUCQcsmUgUDABJ1
AAAKCRCXELibyletfNtEB/9ZoDGoMDIIOQvy7wLAgueQs2asmMJ1xVgM2Lt8mk08
JuezUj7+k84bSg1clVknwolGm8Z3AxQ4LKPF5+G3SFxD+kcbhpTFs6B3ehvb3QCk
gKihKpkPED74YH+1TtpiNU6+fSyt5U5Avj8QmmBwpcHOrmSEmheE8j1JdJwfrYbT
ZbNLr0On4PIhPps3rTNkD57Ir6a1eWq45APKD+uGTTahLnHPxtDwaHvdXbmFaojr
zJKfXx2B2Algax0gvf9XJvK3NvlSSFS1HRA5Qj80HAymE7iX+uQzw7VOzEGcoGPK
Fkg5MmIxGvXG5hTO5Z3tQtKMO9/0YjbOzcA8wtsZsx/FiQEiBBABAgAMBQJB3PRe
BQMAEnUAAAoJEJcQuJvKV618jTQIAJdplgkrcTjiYrN33jYAge1XL/cq3BxOTiKe
kd2vINjNNOgwvj1JAuKLCu5Opg6P7wH1UjPsxx2UYJtqr5aA238j8hLly22qAfNi
2GyhE5sR67HxHHOqrY82QviEed11y1yltgeSBY7o4/ErLZI1MCW493xosd1ziZRb
PrK6+HaZ/7i/UnPbN8um5pT3Qr+9QDC/twd8uAsty+U6NOqTaOgIjrrwQzj0vJFP
Pvj8sWjhJHd1TWD9BSmYyLKow7e4ri1irW2vbaf/G4cHdK4VjiAPhzDaGehAO2im
4IoyR59a3zFTh9W4efyHpjxdrqpuboneq2+UA2/eFsOLtuGxw8qJASIEEAECAAwF
AkHuvu0FAwASdQAACgkQlxC4m8pXrXxrigf+KlWElpPqVRjQC4TKwkNr35PA3zak
G8+u2/hhPpaj0WP4wjsoLZdLAF+47w+GcmqoiSPKr7xNP+8uWIcY6PcP1iJvTW+6
/OcPA1Jfi2zdkKu6jQhO0r+CAvB7gE1tYxK4iBoGG/y6yyeyzDTOahkeHFsLf5iY
5VPC29h//6FIiwV6x0UI8U6ZdyOH8t/YBV4xvVYIrkhFuRN9tAS2+fONs2zrG3oZ
gcqRR60uJ0QgdY5VDTZD16C+cgZ7/0dbh26CtJgSahojXjYk6WTWu9/dbaJhBbWI
4dkNOsm0xOXL47h+rlItFRzDQIx6bbroEWbXNBbCNwOS6WG7uXXv/b0GWIkBIgQQ
AQIADAUCQgCLpwUDABJ1AAAKCRCXELibyletfLdbCACKViBV3+18s8UJhUlNssFQ
Yy+0KzKTjFoNFGgoRt3cqg4NNHxTJWcz10EGKD4PJ8CjJYoetKZRZVrchgL7lur6
y8BVW8Ks6kSivaZK/RWZ9WJhf/mPws9GvpGiniULu3aY4ZLLMcBNes8YJgcSBdtH
prun3lu/9PpeEnkk0VCQhycMXzYCp0SvNs3pfZmwY5XzpPhvovg5xLI6OZxcPb5q
4/ZPW5QRtWvH6eAubKHSNa7cgK4okB3h5TkvlVNdtdu16TAA/mdJ8kNamsGHLg8d
Gqx6OUyQ4xWQ8KEOjHjvLfYT6s+1oOKWgm2ZIakaOdoN2lviI1GwIAWKcPEqcDzA
iQEiBBABAgAMBQJCEleiBQMAEnUAAAoJEJcQuJvKV6187RMIAKv0OUwdAsuA3Hpb
kCxyFzztEaQVDP/5y6Scio0c5ScJoCYDxK7btpZbo85yRbs5O/u60rIbXmdKbsl0
/qJivgJR+mnZ1ys6GSIsA0+bdUPB0wngdhdLqZBAkRxGbwoE6Pjr4ryBM0POaORb
VObYK8IrH1kKQ+Y/nBJ0ReIZq1PUv3aIaiaty79wvmWOTqPgcYbzkNHONRCPcicU
4px6a27XmiKFO2zXvx7mSLTxACahM38i2wo3PLWyaKBmJfuxl4kSJZgWy1t3gdyI
RSKQH57oKgjP8STx1+Hj/Jh062Y9okeucNLEwAKJGuBvr3H9A3pJ/37NxepI3Dma
yn3y1tCJASIEEAECAAwFAkIWpMEFAwASdQAACgkQlxC4m8pXrXyaEwf/Q3WIsZLn
RPDDshyt/vnu4OMKb9w6dtcps4CFwYspKsU3f+6wkA0F+kCIxrQRQbirKKTXrkFl
rSlwzx8AKM9MXpNcXF88Cioo34VIasIYYQG2YRRwx81v/XosN48RqTEVCVjwW59v
L6zeZP+AM1WzKKp9dYeog0CeIaaWGZdPka9MS+CCATqnohLV/AG+VdK4FW7crhx1
xXefbmrd5ucQ8F7tWfEYMcadoJJvmsEnI3T1bsmqq6wobMYMef3MWP682h4tyaXC
bHaXx8kfnrJdnNKEYUoiJzY7vdxcMMryA8asQfr2mLC+njMbw/j0SUEBODcnPaAn
wa1qZFYwfbvbT4kBIgQQAQIADAUCQimGmQUDABJ1AAAKCRCXELibyletfHRRB/4n
G5MHBqpuFMgU7qJiz3ACijOMzCBWXzG7p7zsdKCn5eyyxue0UCE6wwDcJTS7dHy2
8BWtZ05eWP4TExF0dnEZArR/+dRCmnffy6/geqCpl25DIwfi8ZaejP23Hw7jIRg6
lji1csHDBlw2hlUNzsPwb1JHAR/iDR9bY5hfOMnFINQbGBTMFc8iW1WdGIOpUrWC
PBTfaZVGyEUuDLOAvClMpn0Wvj7w3zhxPYWWUL+2+uuDwrZDm0tTrFDYq3ZakM4l
6q5qW6r2pI7ShB5jC+979JHek5QwZxGWpiATRlFPGLRxRQUClPjl9pXt6rRAMY/z
xX6cD+xMlO9HTvkJVagziQEiBBABAgAMBQJCPUDeBQMAEnUAAAoJEJcQuJvKV618
aDAH/1ZwVoVJK6PbQiegqistXTfxdIpknnbtt/JgTHlisBqyQcEKXmdUlkfTEAWO
x/+PIQ1AmlzeA9ZFjGNx20zlMH5Y9X+T6GI6z06XtV+IWdIJLfC07hwkbK8zQWwR
mwSVZbTku3R0EvmhsBBjZnCPs1ynC9zjsETFIhNEuo2JrJIaURAu45SZZcoykbpE
nX4yocc1iUF4pDxblxHcSQj0N48rC77w7PLd+Jyg/SokBjl2W0JnmxN9Dt9JvHvo
Y2LCesXDxbuhD4wBAF+J8kZDTQJ2UroKrR23j7P2IdwuhFSXztiOvjTgjEGFFv6t
Oj6LP5teH74HpzZXSER3lKnxfqeJASIEEAECAAwFAkJPttMFAwASdQAACgkQlxC4
m8pXrXwdtQgAyllahKJq+JjBTX587F8jHgjBxTaB18x1S8xUGmnbs5RNeQSUv5yN
fCA+CfX0PqVWeCxEhhLaIPCUML9aPPQm4flMyhdEBDw/Q2rukFt1y2Uq/t9mI/+V
2RDhWCM1k36aUabnEW5IGa+zAEfeNhoHDHy/MyH92UQkkIsQQEQdns2LPoIOXXKd
jAkVKBjbkZasEtr6lcCII+phMiMECbRKGZF3dfITzXMrCBMe7IcCeXoXKSW1v9/V
hGfeFnzVC9x9IL4Zit+fORXmKYel1zKQctqiaflqPPZNzZGtMKPqa/rJB+43BdMv
L/JFvsoa3K+yXw5KckPgZT459Phep8pZDIkBIgQQAQIADAUCQmIx4gUDABJ1AAAK
CRCXELibyletfOqkCACqjyqY3tLEFs0W1g1RudEvBI36+3tAo9gxcvSHZnTNmGQg
a6InosK8EoMA6gEyZVYFMJqoLMEIGettur8tQE5X8ySeQXimdY1AwUeY57uAT4Nb
rmql6U1E7r7PY0rXs4BSdlMsE+iQqE0g1WmeQClGPAh6TRJRzNtMORnkIBo0O+3S
Zv4qXj7QrWk5Ajd8zWZAMfNHgDAqGDwW6Ilok2uRP4pXW/mJo1BJY9qjjtBNENfd
dN/bbpvJXBzPsV+xwl62/e63lgQskmbJblvl/o/ek6UIrCeJwadbZnhStJ84Eqhq
vy50uzJGjedFMCJPLHgH7xj0wXUqNsnrCJblB9PWiQEiBBABAgAMBQJCdVmNBQMA
EnUAAAoJEJcQuJvKV618D7kH/j6nM+B7XQNiAlIYbECu2Loyy5adtmdw6IU9Mt7v
EY8iaZQsNsq0QplrzSxGAmr6tcLcwQpQ04i7Vkv7bo6IafXtiEkoeyQVtyWrvNH8
3mfpOU0dTenGzePDSN0T7/3RwxaW6yyo6jqUPDyOvIrBOCGwv/qA6MO63AxqwES5
Y4p+F7+6if6F54iladQLTZS7QkInHnhR0V/syvd/yTo9xHD7+tAbAh/7Fxu97NRQ
POZ1bNPMZkH8tYzlvUuczgq64ahiEFPHzF4TeU1mA1ASj6t30KAlk3kM/euAcbKI
V3KEGDn7Q8mt3nZ7hK4NbpJZEd4fvEjiJm2s8OmfVZyH5e2JASIEEAECAAwFAkKH
nZwFAwASdQAACgkQlxC4m8pXrXyqmwf/UFV5zX+c73c4gn8W/MaEgdScyAhLUH5I
56zR/VS37o5HW5wQvW++xXUhcGvxJe+f6tKbsKLNV/HKLXuhpPtsWT00XD48geLH
IbmH3QVuO/FlSTt+xIIfCpOouJBWGpAWpyececUY/naxK1xoNXqNkaSfdGdQ15Yc
zSIWX98DOUFZgiShhAyin9JJ6W41gRrDLTpM2OmPxidR4CcM/KIXqRE1i03yuSlN
/kpK9ABUme10cdH+6gzjCn9Ez10GWTwHM53Zz/xgL2ovTTXEqL6tiIkNYb0Kgwc0
+AI1bmZnVsYHLuwFNFyYb+wJbI4JmNrgBtOhbq6Ae0SQj5kCs2n2UokBIgQQAQIA
DAUCQomYBAUDABJ1AAAKCRCXELibyletfBeWB/0S9taAsm9/TWQ+KcIgzYENPCdu
780DY5UMnysIbjAHWsR7/Ad5hSelD9PFYFG04yG94ipuQc6usAta8kEP/LJY1b7S
yyptQiAwTHWaTeammSliOYzLzyRIHZz5kC39JIOjP+0o5fCuXJl1z8QlBfFi5Tzm
28vpk7qMwQc8djVyfT5/FxpCG2pI8McGyFEd5tIueBqeJOOofYQGkDCZ7hYvgo/6
GcdvbkcEYRF5ENMsBXqVMHFWE6BBgREJoKllay35BriV9O9s+GwS/I6wqNF2vHch
1xsFAR1TZUj0+tWlN8lgikxsxAYXbWf8v43+sQIWqIJ2aW1G4dN2mB73RdvkiQEi
BBABAgAMBQJCm2OvBQMAEnUAAAoJEJcQuJvKV618srIH/1aRQsiKqU92PKduw6Xl
VxJHSO56LAGyNZiHQ0vUATO2Ta5hGK+ueDModqfgQNx5hJV1hqrqaTkL+602qMi1
EmRO/sUoBvu7xqBsVxdSz2jAzt2az26Vh08e4ugyN25RotzbEDeGp5yYkZMrBSgY
nW+fSEZ0uM8izVYxo2GPnb0KLGYJ3m+YFb44AEROaTPO0TEbYi4TbCEYJQIApgrk
NT1QNal/7V72kWhepN1VaD2d19dI9+XvhdTwiO7YTSySPydDfHXN5GnK2jhOB0ID
oyoCX6nU1KwTt3+NVmRd95ageDZDUGiI0b+y7VZLtPG1gKdn7QEUjyYLTA094Z88
y7yJASIEEAECAAwFAkKctSYFAwASdQAACgkQlxC4m8pXrXx5VggAjfe0tPg/GsFX
OrjbCy//GUoAWYZoQAxuuicQ3akLpn/be0F12qOm6aWAtUBYbALY276YVEKFHGGE
2L+BYyFFgdNu9M9rGWrwOJOv4wuJNoDPGmVSBPsZg92fqJEF6EoFFRaOaGyZIrlv
P0z6HAOy5tVk/6PVSXiLp83VxIfW10oNHxSUxc5fvRST0lCRDUCsTmqGQSevqu8F
K7AFpSmaBY3uBdM0kJLUHGBaSwMskzoXbyOcI6B/4r1bF2QAsB/efiSgU4qdpD06
t/6qCbzP0XdBGw9CBXQkx9biJotLavXubodnow74q1vPL9Kvn2E1fEE29UDGf5cl
od5ZoTg2NokBIgQQAQIADAUCQq/S0wUDABJ1AAAKCRCXELibyletfMZFB/sFflNh
0LbYcfS7YXGsyiwef+FsBOI6ro1sEuGG9I8oouuAmOzVipfXn2JxS8TLKwV7vUrT
KNk8pUBRzU3x7DrE/sf/Oz+pqb2iBrEtVuQ495MmYr/Z3z7TnZAXUPNF0Wdw4s3T
KyOS8kPzTmLdXMYeBNy9Z/ctyt2/ZvXy5/sGf/iH809cFcaLuC4CaPm144onOeGj
7n0HykdsrM3J9bSn7yQNW70r7/PZdXxIbkoojaI/Yz2TlZpx4lHC3p+udGbYZd4Z
r//W9nj2U6AD0e/gAPbOgpxAkltK5DY3tIzTIVK4vAxAuqvHFD4qSOyhHLihzlxK
YljrIFKcOJ9u9UxRiQEiBBABAgAMBQJCtRnFBQMAEnUAAAoJEJcQuJvKV618Br0H
/jMKzWfktErhcRiydzOaVwo7v9am8EEX3DpF3H//vZKsnWnOR1YzuKl4uE3mBX72
sVz8oC8u1i6BID6Zv4UNBaVY+X81du/wKscje44kz10KI2zlenb7upIvLc2KUo/W
N/6/ee+l9dL2Fcne1XxKuJd32Qu7H8ScSfm2y7gR79RSj33lOFd4pGX2HQMETBOq
5HXe9TBBRLY6KzZIdXGsIDd8wgXYZBWwKWfKmDzK72XsRB0HxP1IPWRZctsOlRto
cvARjfcUzFxpt7w1qh6zJK0/BztLfEhlmem/g0SVc9VOrVjId5+SewKe5xjzJ/nF
Dmu4AJnHh5JlvuxWcHUKVISJASIEEAECAAwFAkK3FQkFAwASdQAACgkQlxC4m8pX
rXwMLAgAueFvxnwAlATmIzphSMjRrYTRYgfX+TygLjTQrFN3RG3Os5JuOmV2ixwg
iAHWkvKsfTVErd/kIxZWNqRADZziD/1xc2ahvtUxotQTJXJ5E4I4amLfTVB5bbvL
qdwTuIqMPWWGssD7ADhLg4m5wCnX+Kcx7OuGnKHJtMuDJeQMQ8yLn9sWGDNcjV5x
onWBA97dIRWJpK+ow80XZoCLmUUoPP1YRK+2AdN8zQgv4WFPmCltrMVKWvTCk5FL
EB5D0FV7qqBp2cDojqppZTYKwH0rMYXUy3MgWZKrfD1oAmbDhQy0WbGqb9L6dsUv
ZyVyQt66IcdUzY+eaJYFC1mOTxMKg4kBIgQQAQIADAUCQsjh0QUDABJ1AAAKCRCX
ELibyletfPAiB/sHVq9TmkcprOktNVvNN9qs37vJnaUH7SIdwAh3FYnV70VhN/0H
sTwInVnLEKBQAd/AMtdmXDJP0T2a0g9X20wedaFKROoFGMZ0VMaACkokm9XDmcx/
bBZs0AwDCnIPEmQDv0VGdpqCxUaspKgKDNSUOD8bQYWlmu2bzyGFWpDSsRZHoE4R
JPZ3zH7s9/hDtHoAXsXdl3W8t1Pn5iU0C13Y+Rx7sFizAXE5slQAZ6PErFxqzama
uxgcMGn3tpIqNUzrGkNmTs7DyQi5RguIW4PrsmZilmX3/rcKve851vQ9U6nJ7nHz
6PJa3QBVExsXoPguDyQ3PLodFV/8xR19d9ZKiQEiBBABAgAMBQJCzNZeBQMAEnUA
AAoJEJcQuJvKV618GWoH/ipBl4r5T/8/7IQ7BpjbdgtNZUed5ZQnuKTLxBSl6fzi
GhXpoQP59yPLAmtwbLPplh36mHZ31JiBjRyDcwCYHCySZaewtkuOTLdkHC7Tx3KQ
3+lS4piUVArdmF1QaB7Blqy59EXF24sqBYaHYBY4h5nq3kgOqygFkZ8BHAIE7gST
sONoUdsi3iFA3eDzY1spt8jBLdyEhFi710ex1tABSdV1i/yL7X/WJ0QrwkdWEVXq
U52AdKK6dF4erx6+yHO5gTCOXOSekISfU+r15dTSeoS6vOeDMotgvRraQKpJKUEr
tCQuzC2C7wduiVUANqwiI/7gZnTKmrGv3BeZZbspEnyJASIEEAECAAwFAkLRc78F
AwASdQAACgkQlxC4m8pXrXw5lQf+IxjIM4TL6gINPnQ49jEQX7yI45gFO3XcATl3
HNxyZDtjmEyzDRyvautkDuHcIK6uV5DagIVoFz3o9lEXxtB2AeJYL/Sz9kroLT/6
NOiPekr1ue1+g/MTisGOJDwIFx60krG+YpPrIHrFP5j4VNh7X4yX7M5ZfzsAH3nz
FsREnwFIP3o9KOA/0LitsobNfF42k9e8836281VyT7WFgCAOwpRKiYtaXxq+pguV
M3KwizaJNcsDgzffzvlXOQqFFGh7TWbts3A6k1udV5WE7QOq8sIrWFDEuGEqOxs/
KpMfeRUtzGySGi/FELKSMF+wzfQSxsP7RS2P/DLQh66poXTn1YkBIgQQAQIADAUC
QuNAaAUDABJ1AAAKCRCXELibyletfFfpCACEcLBKUMXaF++ye/1M4zUNN616KtA+
FdreJ4ctqD2s5bxHYU6lKadxYX9ALp1epjnEBGZ8/SRNrecskATW3hfNLwYguHGE
2o21JP19XjbQw04UGHf5R/uanEQr3GprS0rCK3oTmlX+iRER7GCjr+tDrpL+8mZc
yFAvY2oHhzCFLm2rs949uDsqIikTjO7Kp4mzv0ZZWf99xK8tpPc5nZjY4THBDq4K
EdoYoN6aytl5SXSDYvgOgVzuBqMmcyxdAub7U9pBEgDgRBwOArQp3tk4lIrDDLdo
7d+L0aI8hRLpCJgrPoObnk2OBQvmQ3040DwHAx12RXmSRyNf3hAHrO+4iQEiBBAB
AgAMBQJC4+hzBQMAEnUAAAoJEJcQuJvKV618QEAIAMNJYMHKPbMvBDUblcn3ivzc
StN00u8yNd8EQCRECnO6Whk4IjdWFVUlFcvoEheonzwv+Vz1PKMZySFrT91/AdKn
FUBZc7nc9iOENet9RXNVMNx2KNpgWtl4EvgAd19qdUjuolnTDCmBgDHUBXtLepAM
9HEqSeD/oCegVVAoIQbUuu9+toK025WpttRBxHyyY1eagk8UpIF3cTtFye8+Vq52
qk/4fhEIfEGQkdNVk8YZrH2/ceQEErmpoNqgQQv+uq8bi1FApYY4HVEdQujT+4V6
wOjoGo2nlArlvcXsbfKJ1nGTzTrmOGbmKrE0K+wRs6L4dP5zIdapkr8lb8ZwNnqJ
ASIEEAECAAwFAkLp2AMFAwASdQAACgkQlxC4m8pXrXyTXggAxg0VZrNtRiEgj5im
oRzTpEkcxAgeIGjBRfPBVkshObXnsNqP7JxaOpA+1xs8AnAzjmnCFJ2at+gSJoZH
jm8jccGU+tJ2BpqVzC5wI0FQ3nn7VT+Y+UJ3QCFZLmHOPciRorimDOKk0RLJDsYP
K/cNe71ddPwqg3OzTC4LarBGWlGObYWtZkOu74KR2nOhDhrjl7/G3ug2W0LziO0Y
im8XKcxCsUfaKOoP2x/A/8hxtkunQ6cOrgPyePFyFxnlydFnXr3mcgtEjoYYuTb4
FD1xfryXZiRPsH6hOELjxmPbCVO+JiwVu0C7xgRegmAX90cbWad/l1U30D08LrAR
UKskQ4kBIgQQAQIADAUCQu0jNQUDABJ1AAAKCRCXELibyletfB7rCACOFwypSkkz
kVSGqmDX3/pdJQw8PEm+z321ppNIYw9GEtsL6f96OCigsm+I5CKaoQKJfWnlckd+
SffdfpjlrZXSTNA1zN9RTljefWB1qT2gWORskWb3ykL6eTLfAvlgGZBik44bcDP5
2ocXO5YhnWfRNoeBlvVCFTaMQWxMvHwHkQW3eeNmY1kb98wrwmzsMp6BcmBdLjvi
uvJ74B2jWABB7W8Ygvt2jRk1FWFA2tsUvWX2XtTX5MlIqW7+3uBzazHeD+Z8X1Bd
oJBg8280SQTbn9Qd9TYCmoAH372B3xVv41u5zaR0+2nfqicVV/ZK2p3Ekals3kr6
mtVHqXiIdYfoiQEiBBABAgAMBQJC/5ifBQMAEnUAAAoJEJcQuJvKV6183rUH/Rf7
VUitzlRhK+A++SC0BjUxVD4DYrV9pi44Au4nGk/wvcbkpulj9eiq6zGXNWyDmzf9
gW9lFOlE/nWGhsibALWdTkAACOwXJW5y2mRSoVAciQCQ4hbXv9W+Kn4bL9z4W+vd
AuxirHL2RnzqtfqWgbGlPHUnJun6AJS1u/t3dPtF947BJfm4u29Mx/5TLaTjTMmK
dYcYHxRPl7WsV61ghX+krBCzBYNuAC/lxqDFHZ9qvykrLeH4nc7hYFLg32cVzUvU
MEpUfKTj3+jFONa9muTnIv82lZEOG5ullQOI1mnzYcBAWCgYy7ln5XClS7C+NK0t
MYoY0NSz+dHiuu3zDh2JASIEEAECAAwFAkMI0yMFAwASdQAACgkQlxC4m8pXrXwN
bAgAreidFZxC0mzh18YkUWEMs6Ox5U+fYDBv1RRJ3iUFTxsnO4Q7JT3JeDFv24QQ
0M8rVYNddIXoDMeUMObgmZNEztpn4IaInnbNXkJZukSLYJhkqCKNaNFyliDH8tju
K5lXANTO9MF5yplYO1qqotZSV8YXxgneVlOByVRUbVDvMRWuRwEYzRSYdrdexC7Q
SOkEZbGKAE46H2kPbpM99krpZCXPyvhwrA5OxYumvWlZ6kSxE2n4QlPZYDP8YmPI
u6hqp6f+6eiusScl2Ww0XGj5ownm5zpf+4g7g3TC8Kgt+xu1ClQuypKjYv5Flt+T
WIQIKOTputX3AAC2CTAtqb61AYkBIgQQAQIADAUCQwwgAwUDABJ1AAAKCRCXELib
yletfNVZCAC/qPD3Td/tXQ3xF/IKWTVzHin7InPmaRBU+oME6cER9YmCy8zOHQ0/
kf1kDIuxlQTJMBzFDymP/Xn+h75aPRr1iNI61bGk348M6qKOZdqw98x26zC2TtKM
nXxdgyaCSJ4Q2KqTjdg9C8W3ZO9QJJmXEoOzimHCQZO/kQoyJbnbQHA1BJlBmvu8
y9Bzap/RqhEXbkrWw6QPaz4X9N4ZRkxZJ9DAItfRQd3ZP+PShm5NoOJXM+m4XLCK
fqENP//F2eulOxOU6O9pB8tVKlhIIw/6sPoq//TkYw4DQwE2G8q9t2jvaqXhKfHv
KICtryn7MEw63ZFtsw/G3IB3yhQ1i1zDiQEiBBABAgAMBQJDELzABQMAEnUAAAoJ
EJcQuJvKV618+yYIAKj7ah66h8UvCe1VDOM4DafBbhGyjjp/GbQFrj0R5OGUYjCO
GclQBGVzNHQmSAtjndukmBM3Jyg4mwWN1Q6lN089GJBpsKn+C32cVptsiK9i+rT5
SQMWZbU1KxzA1TGBEZuyHRjrmamAE4hVJlmK4JSUuH5qpeiqAQBNjWJrPqZRk487
rs8hDdtGeiobAxC2hAipbCBYuY1s0bRDMqCMA/yHwLrxSoadZC6MG82zaRhiK5w+
eFp8pVMV3VGtAVsXVg/jBwdgbKd+NaIpbWznGyrTx2FHKywD9KOIgJeJNSDEGI+h
mu7qHDljgOvzwB126LQfDtqsAFyh+VBQk/sWsGOJASIEEAECAAwFAkMTX/0FAwAS
dQAACgkQlxC4m8pXrXxGjAf+OaC6hTuLDISFeaw3N2haZ7XxNgAwEkohT1Y7Zd8c
LQxVG44lKR/2xRCGqqW/IIeeImk2ugnNIIHwTyYo52Ixeua05F/UQLkfynveuFVY
bjkjxSSQsF+K1gG7Z9mNabbB6gVICkw4dqk6U9OhYIl7fx6RaIX5yRr05xTCOn6z
nBchRMS4uzP/koVGQZk8cWtfgH56ftmKZaq/XtVl2KG7BbxoRkq2ArG0gKxzbgc1
HtDGIPp9vaQCFIhCpbjkaNE044Q3nXV8EEQQ0/wZK1ghjdJmmsRctucHvkk7t1IS
+I002wNamLaf/AmlbnoCLTUR+C+4Y0vl67C6RqFntztYYIkBIgQQAQIADAUCQxQI
8QUDABJ1AAAKCRCXELibyletfD8yCAC1SQF6Wv/8UIfXpXzi0XobFp7L9+A21ezn
04q0VqdtdBlnpo1ezhUNkzoKdUtWICNArAxXFfKeJQyYH9NxxBFrS409O/+dftgN
2N6MHZF7km39ErlWj2Qc1X/lui+FGIlY9LAhgAmAQ+Swq0zPThMvmXaG2L6UrZ3s
j+fy9wkHhLEPJq5ZM6E3563/pPbucaTTtQUvDfAvNteD3Ft5jAYZ8tBw0UdbmV3g
Ud8kyBGdZoyw2NK9RrydAYkWTgDRg/ksWGP6wZSEnKyk4WacC1WSjiLtxlG5QfoC
+ZdNwUQlcDKzRN6WLEhD7uIUSUZuFth+x3OwOjxDVN6m4Fb+GtnQiQEiBBABAgAM
BQJDFLGaBQMAEnUAAAoJEJcQuJvKV618da4H/jvSESO9bN0m1ODDpTeXP6fuFESM
k4gujAHZ/x0iZu/lVaI61Prd7z+rifps9J9T2BAUYgUcIYUtd0MlbkneI4tPHZhS
74rsigqDJczC0tHqX9x/TnBrAAa0p33brMx5wNTHrpVp1u5y2AKTK0dQaGLrC47J
ci1Xqi1snRh1Op9WVtvXTCW0A5DmFPubTqrcMfmwUvSvpEvOll8gY14cXDXGmRQ0
eCAyobu5GpC1EzuMlSb3t0dYTG77gdhrVr/PVrL1tfruZIm4gbUwCgnmrGSbPkqG
sAcNZ0bfK1vh3AC6lgEo0dSz9HTMQIntxbnvE7Qasqsguo92r7c6l688j0+JASIE
EAECAAwFAkMWAqcFAwASdQAACgkQlxC4m8pXrXxipQgAijF0zveXZ6LkD59C9iQd
yHeQgYjX464YfWz85AiTnAJaK7bLF0/CXYj4liEmg/WR5P1WVOoMlAA64N1Xyxfy
7cdQqad992cuF5TNVCtqWEJyJS4qDBs6Ihpmqa7Y+8MUapqRGPCsmDbS8pPu9rG4
Z7X1bzeuYuhc8ltHdcyl8gvP1cYwbIHOZA5AqJToqt5lEFd7scmXe/5Yd78FNNkB
Z1k7ezD7gvvQBKUc/fLitIMqH0GjkqMn94hnA8sHNtlmAIBn4gqB3Jpyf0Hu9zKo
UoAoFXerHt2N8T4UdHK6c9UEh/e990KsiShN8zFk61LCHolNn4Www+/S0mQL5mDE
24kBIgQQAQIADAUCQxdUtwUDABJ1AAAKCRCXELibyletfDDQCACKaNmgD5ZDboQN
2YFT3RItxz6EKko1SzU1n73LD9tYAP18ERKnkJNIjNmbxHQzrZQS901rmAjzyGE4
FDRHUMeDaesZva8GOOa2zQCyJ44L2p9wdcVl950eG/cgDwp92WVKz8s7OwopdqzL
qbd/MRWlv8Qecik6o+pG5nalz6PYv5d9ozzjQ5CTtxG34avNTfAsXc3aM8YsDVjD
75r74xsoZsGMOeKjP0vdUU3nyhrO559JBhBm9KAMm4zizPr8EMdLM8RfY5CQfr9E
oU2wEl3lEh1nZan8gMWqUhoIZZPHOkoKqsWBIfSK8me2gH+mUaBPL8WS7utd+/pu
Y42Ssjp5iQEiBBABAgAMBQJDGKWsBQMAEnUAAAoJEJcQuJvKV618ebEIAJI4nbeF
LOtXwXdePSXdsr+AMAOcANmKgaTgxdPdMEzXq1ArL90qqs/Aj11tnjuhNO4S/XXy
PqyFrdtphRn+etEvYgLahANwhtcSxINrjC4nNGZEl5ut2Iz51IeTrhJmGhoj/R2P
fhcsG1l3SmCkY1dOYCJtV9e45JQ2i364eAzpH6pUkbO1lKYkWz/NopuxOLkD4CPF
NZ4b05/aqHoQmT9sfubOypl5p67Da4ISuqDWwyhGpYy1t/V8tAxZkCsuroY1EpqJ
ba5ILMnB6s4rsEegPiZO/1HpKpc8lbU+wee3A0s27zBQ6q4yIhDQAGnhSYlVX6gl
BuZPoV23XVHQTIKJASIEEAECAAwFAkMZTu4FAwASdQAACgkQlxC4m8pXrXz4hwgA
kPEMgM5PUPvfpTg/hOq8kwYKbzmAsGIu0Vi/NKRGz4NIQ8AJGkteNvJj3gMlJO2a
fbfkQZQ/Aa1tzf/HLGgsqMMbS7HlUCx1uz1B4D2S9HLNQBgGWWGS0hst2v3xfQAu
D6E9GFfZWego+x3+jI35WX4E/Haz1WOASA9h3hZv/WYHvrm1lYk+o2/6mY3+UQh3
BiMeHQfcKRRil5rBdiS17+hjWMFaEGrG3qdvBXjW+QCJ+MQ1xcssVoWtJU64lxer
2mGtFrEXaXxcXlmrKcfDGwb1S+pJpb+HEIxVPsBgrJO5ZemH6ZVzPDnRv1MYqPWQ
3TM+0dHRoN5wBajNq8Ki97QoSm9oYW4gdmFuIFNlbHN0IDxqb2hhbnNAdnJpanNj
aHJpZnQub3JnPohGBBMRAgAGBQJBh7d1AAoJEHs456GxToKx1m0AoKA4eNrNUPeq
3sZtVrtP10in3MpQAKCNgt4Q5AtPdMnoxSpLh7HOKGC/u4h7BBMRAgA7AhsDAh4B
AheAGhhoa3A6Ly9rZXlzZXJ2ZXIuc3RhY2submwvBQJDez9bBgsJCAcDAgQVCAMC
BBYCAwEACgkQaOElK32lxTugpgCgsaRofJDeSDfNnnPYiNrNikgFNOsAnRokWclu
YqtrptCH1LTnUZsjWImfiEYEEhECAAYFAkGIkRYACgkQiuazjU3Kfl7UYwCfbSVN
RDdshqwcKoQL0B6WHyphOE4AnR/zYpIWCkHEu2dsNMzhRft1daZriEYEEhECAAYF
AkG2C2gACgkQwkHCVWdvs1snjwCfQH8R2UZhi94mmYMIvc1YKCa9pUsAnR+hRG4r
8unEeAwr/TzVi5bIGlETiEYEExECAAYFAkG0v9gACgkQs4ANjFa6WVGFegCfUDzY
yXI3Uc3wgmaJl0t+6zoWFa4An3bp9P1FmpBwDro2fxp+QOFJH5J4iEYEExECAAYF
AkG18PMACgkQWQuVF2gdUPXsbQCgwFa5/OlEk02dRmPbRJlTHM9d3/cAoLGOTbZ2
GQVDHQEel3RUNvnQVHx7iEYEExECAAYFAkG2CGgACgkQIKvY3CcpIagA6wCg0sp0
WaIYM773E88phBQECERm+P4AoJutkD7WJMPCPzhajA7ZNJ6ZdJr6iEYEExECAAYF
AkG2G1kACgkQUQInX6gT1e6ajgCeNjG6U4kqfQM60RJf2joerLr+EqEAoOBjqZDB
FnahqDXcdLiM81zKr4S1iEYEExECAAYFAkG2PxoACgkQ+gB9UUaNYsiDzACeLqRC
W/NfpMLY7zf3LbbFuubuu+YAn3bn0dzWdzAKbG9PWFrxvKTDY31QiEYEExECAAYF
AkG3PxAACgkQLuYkQekiJq/7RACeK7nFryQ9L6uOqPHY/WIj0nsNY5QAnRNPH+TG
1QPu2u0Ypc7YblLrAUfMiEYEExECAAYFAkG3ZDwACgkQ5Td/bYnvOAPc7wCfXijR
dlPbuK5DQw5nE2/Cun8YAoUAnRqpoFKIx0yEoROtHwCC38R7CV0eiEYEExECAAYF
AkG3aFoACgkQtrrqPUHma9lfUACeNW/OyAw6l3uni3A60rLdEsxEAVYAni+g6yc4
WvwgmixpuCI9f+OtmF3jiEUEExECAAYFAkG3cK8ACgkQJ2rV79NnXwjrqgCgkJ8I
w2d5WlZLkSSFCYV9Otb6GNIAljFLzPvw3YfOJtez2wZEeGhKOQiIRgQTEQIABgUC
Qc3IeQAKCRC3URQJ/BXb7KaQAJ407IJLoRuNPYpP8EaFlejNRgFooACfbkgJjsIH
4WghowKkMqbDSKlGCOmIRgQTEQIABgUCQic+eQAKCRC5vbt0fxI3K7NkAJ4+Pals
2v8VO9YZYovtIvjvnUEbsACfRZZ/MP3e3dbpwGBjXiY3lLHoHBaIRgQQEQIABgUC
QpiNaAAKCRDEsQeYhXlqI91pAJ4+snCC83SZbjsrrq5XFobkgQnIhACgv7o1H4cW
dTSafVPCmr2shXU50dCIRgQQEQIABgUCQpy4tQAKCRCA976mlTPna/XWAJ4lc5A/
4IUdtYiGu9AmEhNLwG8gVACeMhH5uKNb+mhIOPykGcS9ckyNXOuIRgQQEQIABgUC
QpzGcAAKCRCLSsSBrB5xXqB4AJ4mHu3OvClwdFz4cu+Euh4X2bXMLwCfbAHMxRyu
/V9AzbeWJ7NHWWwQyXKIRgQQEQIABgUCQqX/gQAKCRCKSt+uTl+4S5TcAJ9tskao
iuv1b6PPXWuJhsX4cKHTuQCghBY6zjOg7MD/LZfokwTMD2H90fuIRgQQEQIABgUC
QqYCIAAKCRDDFRNXEBZhSU7LAKCPwMU83xa5347n85qur6bm5M/mEgCffPtwG4os
F2ek91d/F6vS+gf96VeIRgQQEQIABgUCQsE3FgAKCRBCzz82HM8zBzC+AJ9wQC9S
TQD3QLECuSYWj0Ufq+wohgCeJY0fM2xO134eU3T3a5+nQ5SCMhOIRgQQEQIABgUC
QsG7swAKCRCZUjhIdfCaEVIUAJsEdlKCN2D8hL4zIjMfSK+yOd9JAACeObJUGssj
MxVhpl9TQZYSA0SrqKyIRgQQEQIABgUCQsI4kAAKCRBvc7rS7O2//3XXAJ9dLwer
DTwegqwNIUhtzwqywRU5dwCaAoSNofmXobn0nt7Jb7QXbImU01CIRgQQEQIABgUC
QyRUSgAKCRD43JiDtSpyFvRXAKDX0K05RGj5I6W+J70Sm0vCTB1s8wCgkx5rYFPg
PQW2rxSjUbEdG03y9sqIRgQTEQIABgUCQpZCQAAKCRCqz7OGIRtu75HIAJsHoW+q
cHk18z/3r4eGx/munMxNlgCg93WaPtcd2F2DomvZ6T/xaXZEoK2IRgQTEQIABgUC
QrxUlgAKCRBm5i5QWoPctAbFAKDiMqi3WDcpQlF9jv+rVtiwl/PMJgCfVd3MtTxg
nBej64vdBZcu3S19HOyIRgQTEQIABgUCQsGVVQAKCRBCa3eqbouwIWdYAKDAqb+E
IGjCuTNTi4VGxzauor4bBQCeIENNRqFYKYB6C7aanzupr6Hv6f2IRgQTEQIABgUC
QsOQlAAKCRBfSy5gykktJg/pAJ4+cKvV3/e5dM/yE2pDnpNFZl4E2gCgggZr9QiG
pg41Sr0BF2A6+XQhlqKIRgQTEQIABgUCQtLKogAKCRASzAtK24r5eP+/AJ9lpYyy
qG5HSAOmoQaEbu2PyzBUmgCdEDq7E+7kngHNuw2JsFeUXA5at4yIRgQTEQIABgUC
QyWX4QAKCRAOYmutEpjCtJgKAKCFOAZCgngys4IWN3rdP/lfcCxVpgCfezzHcCkr
SAE2abQfSXwya6mxF/WIRgQTEQIABgUCQy0s8QAKCRCxk8Qi6kJjxo3vAJ48+5Q1
hXGJ8xlEWbTevRs4/QLxtgCfSlXcYk+PQlLHtN+UqMzWvZ8AfDuIbQQSEQIALQUC
QyPPWCaaaHR0cDovL3BpbmRhcm90cy54czRhbGwubmwvcG9saWN5LnR4dAAKCRA6
1vgRgwDMApiWAJ498SsnqtCgBVyA3R9p9jKmQt2MuACgxmIXq+BM6qbPTxhB8Xpl
27ieZfKIcwQQEQIAMwUCQrBk5QWDAeEzgCYaaHR0cDovL3d3dy5jYWNlcnQub3Jn
L2luZGV4LnBocD9pZD0xMAAKCRDSuw0BZdD9WN9xAJ4z3YvBzGdxIuOqh6/+hN78
Gs++AgCfbszyfw8GeCXqkxCF1WRZ7gFsScKIfQQTEQIAPQUCQpYZwTYaaHR0cDov
L3d3dy52YW5oZXVzZGVuLmNvbS9wZ3Ata2V5LXNpZ25pbmctcG9saWN5Lmh0bWwA
CgkQMBkOjB8o2K71EwCdHVsuEtMXVPXuirAN2pbFMy3wWjsAn0PUtvpTNW0Amk+f
8dW6UuLJvfKDiJwEEAECAAYFAkKYjc0ACgkQ+IYWZdmHE1ioFgP/YOMAPh7V+akF
A6ro1JR0eYMiGcNMgLepbRzxG0GdU+pAuQ+4EDrlz20ZrVGoUfVUg1kx59f1AQZE
bt/2mz0/5oZMM5WIup4T8ExHMywsozkJwhsUaF5eJAL2KRiyk0zIVAtDGSyg7yin
B5gRlehTiUf4O2f5QSj9j9Zsi0VW4T2JARwEEAECAAYFAkKmAw4ACgkQOc97nuwv
WBHNsAf/WbJp+c24yrrNiiCjkRZC5geqk4pg9H/q6gUWfK2Q3J4dLx/CExwxWrjV
bwG2RAp+fG8zQGfUfoyrFQWXqQ4Mr14/LpLyCYgWRW3/DCrd7fypDqAGOy66aSMR
HOIjmZI7EqCWGk+JncheMRPf79PIsrUwh7hqpBjhhRv8/cenQy7O7Ab+nkQIoSkM
IPH+Ast4SbWf8L7npRDaGGZvz2mGdN+di1NUQisRbKOnpIYusxN0Yhr4wsqt/MQ5
y66BOkhOhQWHjXOf6Ya5/8XC0Dr2pn8ni/uAjMIAlrV1Ug+ITkebdjcVZRrlLjKr
78wLYEvlvCbTCL3W0Pna5TPn3sZtsYkBIgQQAQIADAUCQxtI8wUDABJ1AAAKCRCX
ELibyletfMxKB/0asiP5I6/fvD/waZlLFwVr5b55ZoF9SULiloVhVbVP6lvqJ6pR
3UFBdc7qt/zj9lTl8M4UkCwI6JNfG8HfY9XWHM67b1tionfh0xyDXs3R6kh3WqX6
LSHVSfa0ksv9uand82sTV3nNxO8OBnYygvLpvoXS/Xpkrq657oj46S7V3k9P5DnJ
RRa+D45UDHgJJsdTMvpy0LIMfhElyFdFvWoSrjpB5r+Wj+pGNThceW67YbYSLPYI
PObQZFybtXPu4cTC1t9lWG3l6n/b0fsIP73d7DYp6Tsp0MYTqDsgtlls2CBXIYvI
vMI2mRMUb+F6lkyrMDAeG+qLL7pUv0iweuxwiQIcBBABAgAGBQJDdh39AAoJEO7V
cWsHjkPUHMAQANtHyK75RtFoZ9DrLvmZAtUZSUOFCmzLw3oCMkJ3Rwf22ERWTcZ5
eCvjsc8A+ORt8zcDcxOHJxAFRB7dwtEKYCkFXH2kHkAqJN+qrPLflYEcGUorAK2S
3CgIcO7ZjMwHWC5dGdqtrv/kGoSgLc4OnsmPeHEA2pgtI6mwznbHzh3sj2esZoBa
XSKEryCvESijYc8JL29oNF8xR5hQ26ETPlnSH2ODtLAAw9gHhYyfSPV5BkYcDLeD
WRIpPE99T5u8khRQsGdWQ18cvlE2CY9bHGC8DodX4N230hDXeuO27FlDXR4jWhbt
K0a7A4+VPoUfFBEwtGFCAv1QS/Ut1WYYYqCG/kw+7y9+C5dUVE41S+/7fe8GwEKU
fei4m9qsiTbg99+2mNi5fNFLqlgO2zjQ2GqHmJjm5VHTq82xg7qKXO6j4cbhErAj
fj4Su/4swjZgyLyN4D6xvtylvQ6iRfYcaEsxILJ3W+lv6oiwbNIf6fhTW13jcFVk
D/zQnuZpv2Yi41J9WeYgDhsgXzdRiNoN+xGmIMe4Zi1jzt/W5RXffST2R2uivJN5
TYGIZfJQktjg2eFghukpHuqxjRvDREp5cuSa3QZc+d9Yo5yyUbufjlLsrN2S3SzX
Xcfy8hrFZw9oumvj2t/NUh06nz0H5asa8bUX27SewtQ7nn6W/7G0RPyBiEYEExEC
AAYFAkQBboAACgkQaPNY9sE5ZHysTACfVtm7L0Fp0p+MLiVyighsvdrsrlsAnRRO
ZSfYotxoME7bG0U/m41GCzfdiEUEExECAAYFAkQDiwEACgkQu8cU0ZxnzZaTeACd
Hl+Uj08AL3fW3+UPxEbCInCNdskAl0ngsdqh4aIkGnhuom8pbz+m/uiIRgQQEQIA
BgUCRALvuAAKCRDlRN4Hm3wyjYbSAKCTMp57Yrmy1bXPbxVcPMWTxkRx1QCfaMyP
xGs9mFJd6nkREZ6mC7T/ylWIRgQQEQIABgUCRANiKwAKCRBsdheMoO2YLbbcAJ9b
1afPZ2UN71/XLYkicOf1g+yccQCg6wYfriLGECBqI2U8WVeiRz+hwMOIRgQQEQIA
BgUCRAOLvQAKCRBT9n90cV/G12PlAJ9pRTpJvBph2Ky55yRI/944B3QfYACeLf+9
J8FdPoep3/ElBTE0zRnXvXKIRgQQEQIABgUCRAY/GAAKCRAiC8iDMwxKde+uAKC5
dxCYxWznBGiDNK0uNfNbG/iW7QCfYvdrYKULFfTzig+PT0/upcxSaHKIRgQQEQIA
BgUCRAb2UAAKCRAvlRUIquYCLvuuAKCO9xAaLBX3I2EvcYRLZrVfBT1FeQCghsNJ
5GvpAfoq3h6MW5tVxzDEH6qIRgQQEQIABgUCRAcIpAAKCRDtGLaNFhlFUzcHAJoC
+Za60MH+mep0dgqBbsZTMwEeIACfUMiVsK/Oc0GZKlxprS/dpaT8YqeIRgQQEQIA
BgUCRAcsdgAKCRAGBpzylpRX8FKAAJ0V0X/zyWHkf5KG1SkzSYMJndgp3ACfTrpf
i9m389u7hexvL9ZiF3ExjamIRgQQEQIABgUCRAddSwAKCRC3KKM/RXdR90bjAJ0T
xVo2zQmsJd1gICpjLpA6/zvjqACeJEVhdvCrYsiLoZ+Cjd+25CpvGCqIRgQQEQIA
BgUCRACligAKCRAnXIZRJVDn46a+AKCDQgyfAqp5gC0xrhEqSeAwllxJ/ACeM+17
PJ8V/uG00xcSTAPt38T7M5GIRgQQEQIABgUCRAgRgQAKCRAC53/ZiByFxDN4AKC0
mavLWqcZJB1HUJhD8SxAI4yF6gCgvdxKjIVUL8twP/80xxzYAOseSriIRgQQEQIA
BgUCRAieZAAKCRDHKarGvoxrLlizAJ0QSDR1i0RJEkYxLcBjeq72AqHYywCfamxJ
tfjkmWXVcajPfY/SewPnsyWIRgQTEQIABgUCRA9tXAAKCRAzoQRHKwBWgZfHAKCQ
LKwnZVMSxOaXwMfNo8Yr2tHSSACgpubXeeMvvDf+fBNBnhDWF/FpZTOJAkAEEwEC
ACoFAkQOLI4jGmh0dHA6Ly93d3cuZWxoby5uZXQvY3J5cHRvL3BvbGljeS8ACgkQ
lXlS1880AampPxAAnWvkndvNANPq5C8y2rgBx1vSv2+BxzYknV03k/vXbb2kI4KU
r4SaFpBRLT/jaSeKCqIN7/zMpFSg73kkgDz4f5XS/UEJe2s4YvcVtFCXhyLRT2Ac
Zkvt70RDKFhsGsNPBwodVA2zXL8mhlsdRvK02cc8wsIw+0Mju0pD/DOCXXJqtKQ4
Pk8pAevf6Us6e8igcdY2o84VBS34U+p6MCIqYk6gsaRgYOpT5w6aOowITQjGJsZB
8Yd/q35QX1iQTCTTgtZpilUO6Dz5nkXvvvNHTMyhOZrVaVxjsoE0jBtGLDHxF/PD
m7Pus0wfrM7Z113MVLzcIb/LxlSdqQZIxy7GUe5gqt5FuBSuZJtIRDbDG/C8IlYL
sNy9J7Dd51bEUXztl8VePXeVqHlGoP1xIZ6hXzfoGe+/9EETIaNej4gPTFr/LlXN
2yoNiH5N5Az0IMeVVzPiSiYL8rqXw6ZRRJ91KDAj2N/2YN89PIXGqkFjxDnGKVCs
pIJKAlRkz6QrQWsdg5JzseFpnK3DVKEsTD+lCq4OhcOwy3k0FdaSgpAxQvwRwuHP
wh2Vfg/579GmUP0D0LjNSWiyEnR3ypTGCYLhF9FaVX3Xp8jEIgJ5DEE63RieMB1p
NCuo6cIrTew5ZgxbBErzkVHrjVLZtLznox3Y75AFlceHNL7GPsi72UPFYM+IRgQQ
EQIABgUCRBHuAAAKCRDFwMXHIY0Y18WYAJ4tWHecKceZuJVwio1raFLBuLKZ6wCf
V+WgJ51gQ/KwAUUgDjpxN9vBuCKIXgQTEQIAHgUCQYO1DAIbAwYLCQgHAwIDFQID
AxYCAQIeAQIXgAAKCRBo4SUrfaXFOxBQAJwPLVyCBCWZREeYB9xYHAf4xw611gCa
AgzSoFLDFqGU0wT8DtXKrmlf1zGIewQTEQIAOwIbAwIeAQIXgAYLCQgHAwIEFQII
AwQWAgMBBQJDezafGhhoa3A6Ly9rZXlzZXJ2ZXIuc3RhY2submwvAAoJEGjhJSt9
pcU7lA8AoNyEZp+LdM2tC4SvfrZzI9vWECPwAJ9FW4XPfmpeHUYr/ApIcfE4CyJH
94kBIgQQAQIADAUCQcsmUgUDABJ1AAAKCRCXELibyletfDK8CACG89dn8qtfpvPu
+w7zIGEAUfDDOWBdkp3neLxOgwvJv21aAx49CK5M4+KMRRjXFj0SqcGoa8vtco15
UePKX8s51v8KoW6YXrSGBSjONXRwN8lTTXG1jDycLwxurHd7/3921LTD7SL22Zjl
l7/DZz846BZba1XrhUFL18C7D69rxvohQZHiUdZzcR7JPTanzCbSUkwNbBTjTggB
48lPXLc0MzzM4p35q/cQ1jylD6sfuz3ss/8Rdnborc1OHel1fmGxLyPN0be2Pj7H
uQ20G7SBDfiWqSBAAqX/Mm8BqBxTVCNCpcupoT80vLqiFCNYTnQ+87lvB6eBvl/Q
9ClVHs/yiQEiBBABAgAMBQJB3PReBQMAEnUAAAoJEJcQuJvKV618roMIAMlRxR3X
LO6gPJADzOzKblRd2qBv3KdJHwf+VdENCDJ7aUIstHHqoxnievs9ZwPSsIBvyEx5
JVBft+wZloeNG8Jll9Wk2g6fWf2QGokniL3K3nRK0lI59p4edYq4eq/npBSdr7dD
4EMmfXruasurRfLb8Z8PPhHtPYI4d4F3zxSAbFLjN0mVHbtBEgYjvaTguXZKBg82
dl44HKdx/PW7S1ew01e994LG64nO9TFYcUZ98o7OfyzZ96DBXc6gScQfhhEkGZrl
oBOloRRVW6gIqWXhDuI9dB7tHGVFHQ2E45YA+wc2K5O2Zl1s4oBgBpxpjlZl/Nta
GbAswHv1YGz2L2SJASIEEAECAAwFAkHuvu0FAwASdQAACgkQlxC4m8pXrXxiDgf/
bo1alHCnx5ru8K1zc/+aCsnqMGsoCChr47LIc1DBPOt7cqDczVldOKWFYtik9ghT
M/2dq0EVS3sV+uPXsQaQ3D0L1N2JFC9IYHvTqKiH6mbVX0MxRESlmFTAVRaXaH2E
3AyeB42vM3KCjCFitH+IqH3b/u1Alznk41UHzg9pWRXnokSO2cDBs+g4LEketeDn
tnSoM7ofQtJu1vczHj3KaQ+uIbLTyaRmolpRYQUsmrDClPLP+vx8X5M6Y31GT1ia
s04xtcIteLq7VuU0xzDvEwXipuDGfHMniqy7BZeeNTSfNA2vC/2l/qNxS0gpUlFw
xNGh9gAoqd0684vJzTzRCIkBIgQQAQIADAUCQgCLpwUDABJ1AAAKCRCXELibylet
fJY6B/4qgo9Bh3LbtSF0uf3/StXfyNeO0kocwGdT5luVhosl8OgnTNKPsz6pKhp2
Eq6gQ9pMd5/AJzuEEbmi9jnzSel4Knq7RxuU+WU69aApsA7zc7edyBXRSQSlsP6b
k3GnFCX/EwqdH7ewGiVpIvDqwrTg9c4+UVa6JO5ECFjsqHEWbZ/IqlBvF965D0ni
vFA7fv6cNrJq9jja7XgGFUoJElTe2g7VIZ8seG3kFV84uEQN8C6qGCOPP/DMdoa6
LXKCQqx5TGtl005uG40loDX5s1asRJ08VkxO6PLiZeboHCNC5lEvyiIsWRjDpCuo
bYgWgFZdCSziq/B4wxZOTXD1MmBUiQEiBBABAgAMBQJCEleiBQMAEnUAAAoJEJcQ
uJvKV6187hcIAJWB9Z/7p5oA67u5zeyAoevNsPtVA/fXlnfrNB2OBKL41hfCTwhe
CuE3OqfRGZicpPgB5QTJNfROEPMXByl2C/N+RFe04epJMokjHJkfSWZPZgHIkLex
sxnQ82DRIFUxz5KFnptmBy9l/4+vOpOWx7CeksWSRar2Jei4xus3HdT7TpLKlTGb
2l/E3hCQbeE1BvSQKbNQgFsWM6VFqpq4+Cq0XyHWfPrgEUKVZGLu8DEuJHeDql3P
h+LIIwGndfD9f5H+nvdt5E+YbhZuaZYA/spdWLBv7ut4IIMMtO/X/UEc3umv0xsG
7v3M04Y2bS2h0b5bwUcdAh7wA40yTycj+z2JASIEEAECAAwFAkIWpMEFAwASdQAA
CgkQlxC4m8pXrXwNoQgAryIxGBCAvhlcrQLoOkiADp7MBW1XoURKcPu4mqVmQvU+
lZUuZmHJxdQ6ILI26KiQseU9uCxZWhKHESJhtKli9jrKAtoE5o/0w2cVWuvPCpUT
WygG3aFI+BVYcyTlNRYYo4cKSWHZTrJ+pibSrEyy8dOrj0OMQ16A56TcyrB0MDPg
dvNv392dAgT9sJIBMropyBm5oKUbDPQk6/UsgaVW8+z/pIylE7U9vHR0aczMy7Ev
Ix6FdX63Dv8EiNyn6qe+O1ODwLtzgv1mmhNdsDGVGyXYeKtgyS7kn1aNT7wdpzPW
u26u0P3UeQ0eKiWww2Syn4oDGJdpj+34d3KgJ97LsIkBIgQQAQIADAUCQimGmQUD
ABJ1AAAKCRCXELibyletfDbaCADB5GUWYO1p4yjE4TWiu7JX4cWbtMt9rG+kGY/2
lTc7LRW1MZ+D1kFoYKMr+Mm2FOeV1WRby59CtQZKyeHJeoOKaU/PkNYCpdOi6gDi
ysq7oyekj6Bt6G/j/U6sRKfQFJYumXlcxQVeTxMSqAi/A67qQ3fce9Nh+/l8VoNF
wyYaSsL2ijMIcm1FVk7Yx+piO6XX0NtWloVTExyb4ornD85If6b3TpeMHpNpfukt
f4cuRjLzGQ4Qvu74+LrH3V+HaXzrVZianMXgE+6nzcRF1rze+jpkP5dyJwEs+wlQ
XMsBGPDwy1Jm/b4mJ0CfvgGfnVbNltw1MTrfTEvrzhHCMl9/iQEiBBABAgAMBQJC
PUDeBQMAEnUAAAoJEJcQuJvKV618YU4IALKhn2hH2Shhi5VpBnwlaa+jeDWyvPnv
+jOcGA6XsLJNmFo0iyaD6K6i/uTCRxfR7aXWxOEunPnENCl9aPgzm+dy7ENMEj+h
oiiMBtx+wwU+5/8a+0qOFZd41lcdjQrD09XFY1mxKaeGb5OgwkQOpuY1YmPFY4cH
ASpz1f1gWf9MAEGpFJG0K//nLKuZv7uEFzjYYHIjduw/7gfwHdVBzsmilPRMzvPL
GjsR8VWwV7Y/WQk2kFM26rQS2SchjOB6WowzcQe/XFxgkPY1gnW8PPurvfBd+CLq
S+bJGZ/T7Zd/VIiKYDLQzxC0AzcKnCfW6cq9BtgN2bgmHGBzgdPyIrqJASIEEAEC
AAwFAkJPttMFAwASdQAACgkQlxC4m8pXrXwtdAgAgs6L8cegYoklBTVuHrD2Ctld
9m5/49ztjMPj0gjc0e7WHPp4m3k9XYawfoRGRRMzOFUyhaoJGWxneIoCB8zUOca9
FP5/VVVDtUcO9JpyhlwQ6iUsWvEaDPSYnlDM5nCFgHzW0IbgqodiF7RL/2mYN036
INN4yArwZqrQgtS9/WSU8J58HlpQm2lhy/+A1bOhZf5zgw1KuwhRxNQeRKSnR3H4
0wyEKCDdfXG7BJt2iril10bja/6KjUpDKb0dWWMryeORN82H/EX4k74H0vWzMuBb
LrFZm9v4LOyl0FS7b1Z9FFOlg2TaBeZWQoUqcdM7xk7JoVmlUy4sm14QtaX+FYkB
IgQQAQIADAUCQmIx4gUDABJ1AAAKCRCXELibyletfB5FCACMOM3z2cvG+GZpAA+n
JTSAIT8QosAx4rmQtOkKJ80Ogcaq9LBa5mjQMr0ODSL0GyqbIfPtrEc7eJqv2e6x
WpebrEiG6jejmqztSAh6gLpgLoav48ZxSW7t5kZvnRBgxBv9t2T4YirZHS/EdNfo
Go0U7DzkYxb6eIjmuhpTTzi6iNnVw3ymcYElXUlSeNWqKLXNdZ8wf5z8mZUn46n3
ekEQm+hi1Pfmyc20qlJst/jhhY59VETEPF0wePaNqgsHuniaGzo3IrZIsA0AAGs/
qOPTsEgnHb9ZDj6SVI8SDWK3MLspwJFTc3VDx6Ke+OMIRHTKGKNcgEQEuZ/UqxyH
IfX5iQEiBBABAgAMBQJCYto2BQMAEnUAAAoJEJcQuJvKV618PtoIALcGybAyUv3V
GOQYymy+DShiv0p0jgk4SG3nFYYdqapT/3AfyxdrsRUjHBIwNx0ytH0Kbwq0mRz4
rPQxs+oIpiovkNrPjFlpNoQPbfnxWZEHd03j6aPLNkzKdKavZIn0/xpLxoqaWWrS
9u+MM5X+J3byIOJldFK84u3bBAWQVNtcc0menqvKc8HME2Nh7WJkbFWE53/Lzq2k
+3Rs2oFi9tZfmO0NMzLZCPwODi5DXiXY9eyieLHqYvjotprHgSLotZ/Dju8q959i
nOTqu7pqeWyChKtunULqlGmDTvUWGzCWEBAMQZVXSo0ha8NKtec5i4SEriJQzYBk
G3MpU84T9KOJASIEEAECAAwFAkJ1WY0FAwASdQAACgkQlxC4m8pXrXyK9Af+PEx7
ah0KsDVzXIP6ezzfpA07Qj4FM+CKbLzgXU4KCt0nlcZNOrb6PhvM+o/tttdPWrwI
7St3baeAzc+npVYwGBKfjfd/haS8ijkyjWUJX07z0Yc0j20IMEd+jNvlg3I9Gz+w
jNxoQJia1q5RS8YDyuUt634l0t84oELr3BIsPZanNFETO6xZKr3n4HszctlLVaC/
QZr0a0qkzLBb+q+Rj26M9Md0Mjwy5otBYjbIWJ8xNfQ+iRd5RI372+ZAuS0HUy9G
7gJRvfzCsAY9sS2yGdw7Y4uDjatcPJFY3NBAJhpd11hq39c878XOljhfyl0G/XBO
GLLBUVW0jllLVHVk+YkBIgQQAQIADAUCQoednAUDABJ1AAAKCRCXELibyletfIXu
CACVB3nZWyCB2L5RG6pktgSN2M0oTRo7oUQnXP7oL3qWh+WWyw5WTG/QNnkFFBT8
jMy7x4qG8jBKooutpfszMXeKpCM3o7QqMxfGDpMdW5ej+l/kdcLaq4VykI1d9pH4
sUvUCsvM6P+52k0nGYfR+y3wAGlOlTju93p1rTIXcGxuSO162n8blc9p7Hv18Krd
9amSlCb07fETXUhjhiska557U7k/Y8aOekVVtDBW3CpMXpUFKfE1Hmck0fG0Sh6M
ML4CEh/zptyVnzbilzl7DO7l140p/BbeSgtXrQOv2w9+y+hqPBLCt6z+1fXQu3hQ
dA1b+VefBdnJsgBugWCgnO4EiQEiBBABAgAMBQJCiZgEBQMAEnUAAAoJEJcQuJvK
V618xM8H/RwZlEcdVhE0HzugnbYk9WT1S+mnfi9POFWj8WzJKThSthDR6rgtqHHL
Iz8vtznQAYPaE68Gk0yYvpNDrQReQBnTaTrXv7kGVg0Iik6ohIxij6kJJ+e4k37B
JS8BvWQ2YK+b6592GNMC/8nEke6NcpX4ku0P0KhWjIKvvj2nFYXEIeoqPAYr3dJm
ICBOi5VI/zXosYsHXnXuwDpTWjogOQrnh2l3qctDgWJ/2zC0J3WRYDSSP25a17Fw
55D4YVn4vv2azPh1CEOXqkt7ipk4lexiMrf1+QyEmmN7bapdC8lea3VwQkccJGx0
oRyWeRstvm7wJBu7PoY3+d2eHLO+FXKJASIEEAECAAwFAkKbY68FAwASdQAACgkQ
lxC4m8pXrXwCwQf+NU+c1rWLLuKjwC/cM9KaB9C8CrLNo4B9F14gRKCpLWtWsGwe
ElTlFBLd4rx2Oj/nZDO10Bm7rGlM3wpTRnJqIjluH6oLMeNtbAmTHrH4Xl5JZjAN
CHz9dX509tPpUhGhH3o/kTeNguFN+vYJeH0yX2BPlMKP8Dg17wBSBz8o2WWYFb5B
VYTjw1gzAWPWl/onTcMUgC0MrsCyCR2p08Kc2ca43ZcxS4dx32y73y3wAwBhcMKM
k5/30rXIm4kPZ4tAv1CzZaC8IVY4ehnU4N6nGk5Gzw9JrnQebDUw3jZ470Zv7Tcw
HfcXtkPJnNnMyI4htjrvFEaa7ooaqshzqash+YkBIgQQAQIADAUCQpy1JgUDABJ1
AAAKCRCXELibyletfKqSCAC7EI+c1FY4pVLEQXkDD5JxUQHI+g8RFv9Qezl9ueqv
x7ZNnUbYl9JXVFt2vnq/XxMmEi+gLA67CbSlKJ5CgJLlGkif4/+YYlBQFCNN9obk
Ahm4YhycusTTMcZVuFy5VurYgqyLd3JWHZm3TejKyKcr7f6SjUNir8DC1szQpHrn
X0e9BBk4ux9W1vd4ItHHdCKuloT2pHUx8SzzrTXkVb4gZXMqiCU7pVMgd97Ldflw
QvPKcyqbdFHfxmX5Vtp6hfXOXqJD+ZNV4aHvKwbHRcZmL9u7+sdUhB1PFgRkYz9m
7d1+E3CThnsy+Bnwym2NNW905Te+a0oHB5zZ+8rFUHT5iQEiBBABAgAMBQJCr9LT
BQMAEnUAAAoJEJcQuJvKV618MWcIALhiB8owByNCVUNPi9XianjcB79QpVSVjs13
dVZTf5N+zX03X0Im1ZMNonclV73cO2zHyXO0gMH9edPSV0lE/u7Ejz6iqGvqVJqO
2z2haVL2GO7T/CEjPIDE9VPl6N4JpJ7VaDk9NgjEMp36p/1g2VbvZiteQ3F1Qw9x
l7rj4QK7HhXEsS+IP7o0f692KhLKCXL+wAhmoR9a9w5vtYfPzIEebEBoXTuy5ali
3v9QLZI2TTv0Jnb0/1OYbUncwydtsQlomKW6Sk32HAMaJQNUz+EpIE3VaAW624Db
Y/88CSIerfDtEvl/fl0YoIWzfJc8I1GjP9GgDa7oHAhMlhTxLAiJASIEEAECAAwF
AkK1GcUFAwASdQAACgkQlxC4m8pXrXwUGAf/YCpluFliDzRPUwYijqhp++XmQDjL
nXiox7t13DV4g4JZhLHSB77BWL6Hd9WFPRDbTwcxRNgkKl34FQ2k2IiF6zBzwrJ8
YQShhfMHbl1J2Gd/Nt7TV1tQP4QHuKWdQGu3lNNNTOH76Dx8ny3DUnoplyDGaYlt
2YNqAWM3bqQb3MCq4tZFYFxIJ/0w/G6IT1dKVvor17f8kS0j2L7liGiurMXCmXDf
DQxpJ/LfVUE2rFm0MZuxkb8LiL3Jp3iewd45ZtuKP3pZv+VYcA+Y0+FNlb7syx/Q
5rPaFk+uetDHheILFFoFdy7qYOGLmQqQgOvhjBImFpQstZ/rCIRjxWUxb4kBIgQQ
AQIADAUCQrcVCQUDABJ1AAAKCRCXELibyletfIIhB/4o5A+PxLfqALC7QxBjN4bk
97W9Y5Miu2ZqtL1OahjAxFL1Ot1Hd24YaRg2arGo19c3aYAxeZxkvm1cioroh4el
aN5zoeKQMKPH2uHvm51MFj3Eamqe+k7y83SpwQ7/OWYHB3Lx5BvURpkeLAjgP98N
zvFbkV9Nmh8MlbMe+awm0GN26KfCWpuQfH76yjjk38FlRiAnvAIxmqQLuyDBoNBd
jG1thY2ot5QKJtyGevQ2Y86j/dKaSOqvJaZQoTND4/0L98xPJKQNj7diM9UqmyLB
XRyziLoe4yvXys6U9tTFCdIeLpy3Wt2QHmb3ZjKaaocHhKct5QDcB2CTZIIR9m9R
iQEiBBABAgAMBQJCyOHRBQMAEnUAAAoJEJcQuJvKV618y/QIAL5UPaIWbk5K8ZYj
NI4qRoHAwrZVlO9XH4KrKu86gvKbASNSnZc60q0UxcXFLy6/cPrxhUJEASDEq+3F
AJYecU/5NhedNovd6hQ3O+sjxFiYeURGH0FGonEzlhGaMS4O+jEHpmxstbYHTmSG
U4k8mJkqlr9KULVhKHLUT+ftk2K2xUKVbugPy94d17/5bKbv/HTcbbS7wldrBw0u
1U2uYW+S47NpowkrEVjtjw/L9clG0w8b2yiTpV/54FL0sNZIvoZgxh7yU4jmPjlU
etabg+hep9WCFMMQSTYl0LjEjEd2XpHDW7eRzlFqRmjoVV7Cz+ltjMT8Sg0XEipK
jVv/QMGJASIEEAECAAwFAkLM1l4FAwASdQAACgkQlxC4m8pXrXzu6wf+PO3v0r8c
b6fHwStgjeosHJY5J2T/v5CREtRctrFNNFZcJbMMAeVhj34hCRfosEp4qo+HpJs+
vsuVmoHjJgo9NNx5UrcNokYainlUcPGXWN3clZ96ugSheI5ItKEa6f6X92hZrZ1o
taowZyKP3L437xmW4qIiiTEhLowlG2eW0op616ZeoO5sWxiN8Kw7FkIO/UuF8NP/
Ocl4ueQYyg1FcCSqMGuHa44ZyaMLnkBJRPvEV1h7ZddEss4p24itetg3paoW+i1v
NTPq1KYNb0GKSuhj/zqcu+3AbWCUozLzytUcQYScB6ur80c1y81/0JwW61DS3JIM
aOl0JUp9P0cfbokBIgQQAQIADAUCQtFzvwUDABJ1AAAKCRCXELibyletfJ7DB/4+
uz3R0qG8xrgR2oxSWl59IAy23PapYm5kpqucGoDYERVmxS2sMzH9VW3YFOVqEJ1g
7mTLk6rAJ6tj99MrRuq6OQL9tcgRK2/T3VCoU0/1Nlok/IfiYmWNMdJdRn7FNQsa
pQnOKYm+wKv3DbOg+ys5zKdz9YNowzViklkGygzZkbz0Vv1z45kO1x6/asYcYbCE
V5uwJrzDetZh5ZbuRzQ6YrpD2qNTkJgfNZQA8noDJrlQloXfdt99dvFKa5hmynzJ
IJfdUOWIYGGWjS4yQ++BChGZLDKnQE5CGxNawfIT/an8flhGEay4vD0c/fCWMs0q
BeQ9h7Y1s+rZOMiQJji0iQEiBBABAgAMBQJC40BoBQMAEnUAAAoJEJcQuJvKV618
+mQH/3/FRwQlSCTvU1dluWs6QCpxUJkjIUP2jUz604Vf2hGIJA7iqByxl+acQjD4
Z7WZ1qK/14gyiiCWQBqi9h+fnLp8w3yuj61jNjIpEBOvh929p0XqMmAklwvnhQE+
308XVAPr6S0QvMWc/sKjhM3aUdIO6ydyzzS95PiR71U8zmm7QXSxL6WqfPL78Zqv
QG1zKFXt2gyr5hygYVNmEASrbCUKe0dEnAXhGOkd4lwzCwcoSt348kZJNGkwisa0
I7OYuI3ic2RabN0dwnEBfh45FaAd9nmjabb4ybxmi980O9qPJoln9HYKAiUbwEJ5
InlHTKhGRKSCDEg3bIIllT/XWjmJASIEEAECAAwFAkLj6HMFAwASdQAACgkQlxC4
m8pXrXyhLgf/W7YjXgs2KwfRvyFNFlpa0pp91MsZZf8+cVmkg/MoEwUD5XuS67fS
BptilCL/8ZkSXlWDsxN1srroCTYNv4j0kV89D/IP9T8WHCukHmHfb+Dh3Hsh8dk+
tcqIGt+YIhAS9TppiJNNFfRRprDeAXTovMnPvIv0eZnpsvNOFffdH7l0HOoOL0J/
SEa65i86xOAd4KDwAKR9t9Dm3sn8qOnS4QyX6SDz/EYWxsNeAMoY3B/90UgCfi8J
PEu9E3CgVWizn5XoX3Cys4pun03GVWxS/5rj+5ZIWI39jFXMcBvQSdzj+/1ld0j+
n6Uafsg+SAhWzmo2C3QYie1TC6thokc4K4kBIgQQAQIADAUCQunYAwUDABJ1AAAK
CRCXELibyletfNndB/9zRBAJSMR+lmnKyuQl0dS7xZbTh65q3hcoobPZX12CQEdH
xdiI0EZBhzIt2KBhrRx4nw7NM14pkBM1uugCZ/3b0+LCryzHaHOX419XCUo5kjS9
Iift/UrAflq3BR74Xpygl2PVlgdM0rQg/rIMKrUqSHqRcFFpcjflvabLn5LdGcwS
rtxuJQg4GeR39ZeizZ7PvYB5U2oNwSkB5D3x7rbM21PfJMNK3oxMm01P/DrstR9t
z2lnDbTgT1HZlzru7Nt6MGaXyXj40nEZVMdx9KIY+WBWW/2zFQGR4/PEDBTQaTN4
ptkReUrbLqgq3BqhKPv1t3V3aLsgdE2SwCnewzXoiQEiBBABAgAMBQJC7SM1BQMA
EnUAAAoJEJcQuJvKV618jTsH/16mr74Uz1pCVq1jSY0oNeLGx1Iu7Ff9tT2KTpih
Om+36gX+Is/GBWZpZwvUmf6ZKhIZ1UxOffDen+DtkMhHiFbRUeEpLQkY6UPW0kCU
ON3wzPlAqMid+cOYhPhTIB5PV6S/a8qOV9wtl9UyUWcWy3V0mATAGSELNlB1KAZA
Jq01mRMHEku7uCJ6dHUHm9KexVAKGxJHcqedT22cmq+4Aao3YSQ8FRe7nSkleRS/
SKPloulbys6SgaEDUVdtpINdPfBub20q1EkswQnX2fWeQX79HTY8gWeuJZswQhcX
9Mw+xx+ArHfel4UmgSCWPVzSIOo7xh8oCea7rrf2LqGoxeuJASIEEAECAAwFAkL/
mJ8FAwASdQAACgkQlxC4m8pXrXw86Qf/atBk4CPPxd9s8yr0hPbuaRmWD4+hoOOr
wsQ7HZ/KYZ5WWBnr8ZQgpyfWh509I9VoihwYHLE/vOHvjxfy84e2fDEOLIA+1U1W
h67of/xlZ05ZO3B4QIKghKVPqs/gl4vAElIise2ubrnmx7i/5wc4QrghVtVvEgDz
DtFgPt+7csP9ipmo/Fuo8RNUyxJklGtD9SxzByVPTfmvjlHxq51rLDtcn4/EiBf5
GtswR2JvTqygdCbXxdwa9+bK67/EhyzT1iLfmvYNWN/e0NCjpH9AOrtp+4yR8XxV
w6uX4V8CWnfcPOyJQlVmpKPcWz3ValDPiMihIR+tj+JBRkFU4YXj6YkBIgQQAQIA
DAUCQwjTIwUDABJ1AAAKCRCXELibyletfFtxB/9mJvb3utl84kFHVlQMNyorUXCf
kqY7oOrJTmAItlmGXhSalEqaKoiVEVomKpeZzH+I9DmWRh3yKthwp46oEnEguQEd
xVQiiPLm4PzTcQENitmin5kbgsmG/oi9J0bEe1GTAFwwp04IHy4tkxWl/ilTB4Qv
IbDjlRMSk7TWGEEypVxMMR5nz5sXSdwIMzLlETT+/nXiLHIQNMwdqedN6LIkOaD1
UP1SQnn8q3RcwjMUxJyAQ8IHX6SOw6Lev72e98hRtYXFJLmihDQNO10/hz+ZLXzq
ZYB+mF8/vG5knz9Jb8jYztPr2y2SZ6y65+T3M7CIxwJaYIIPC+d60S4fHWoTiQEi
BBABAgAMBQJDDCADBQMAEnUAAAoJEJcQuJvKV618UkAH/RGQWhbl2pEU1YU0y202
eLtMdqq2RTlaM4obw+5Al4sGsMqG1zPgWkIYRzQedb/F7snPzgvm5BSNkR1TKBhY
DMkdYcJBhOU0s2Qmpg/wOvCvXiMskEgP9gtz7kCKUB3TMJ6EAawciz+wgWtqpAzr
Tako+gFAbttKmzNJN3I7ln/Rj4Cd/mX1xtwFLoFks1dMRKm9/Zbbe53Ihdf/u3FA
AZQAxoehbKWCw6CxgZLPOa83/U/vDAQHGotpPma4TnKuwWdQmxbMLrU0l/7NEKqe
i3C2VqgUdkjGLPCkoVwJef5rdWpPwuq56NCsnSK+k+Xa5+CSnPKa1tnybg8djf2m
kcuJASIEEAECAAwFAkMQvMAFAwASdQAACgkQlxC4m8pXrXw+EQgAhvcOSeLYtmtt
pPZ3ku4frEdHXqBIWX6MGYHV+zjbNvcHrgFbYlC+YaEWhgxjZ44G+znWe3KtEJyb
s4pO8Vrh1POFqAd+mIOWPNH+unUs/LPqveuWNJJ3DVR6yJTE1LONmqaqLUCkaGe2
xeMa12m6NbO3paWHV7RxqbhXHkLkNnMjS+MX5dm1d9+yXBm0iS60ts9yk8pV7NvK
mwEzQEIK5g0DIycmHRlvFzdT81Td5TkkltlpLP7W7Yn52kIL3DViRY5RgvX8zCdg
V8HPmZgyHnHenIm7LzOOvAv+PlzYXz0JK8O71RC6SAQ1HhIwseZz4cgBosNxFbvf
ly070lqzSokBIgQQAQIADAUCQxNf/QUDABJ1AAAKCRCXELibyletfMBdB/40F9kl
9AqWm9dvCXh5EcsvqFN/m0Ue0Uo1fEUHBJp7iaOQdB05V3Syk5bwFXOk5+vrmVAp
LYyhX0Uaaz8N9DKYlRaWbGHqOXuHF0WPTrdxUzoSo256cQp/BjG0BD6nL3JWnXsp
1hWQWFX8mK8Rs6F2shfL62LxOLCLZKgDyGggjc1wr8kkxHKVEdrSfiCOcZzBbo40
qfYpzbjj2sX+AsElWUKMtjIemlyAiY/qRVcSRR14WiK7IZf+u+OKf/2uXanVogfj
5GRDd99xMLDL+Vb3Vy6FJ9vbYipgKrhbcxvJ3yLJg9KTUpF3fZdfxtZ+34njLVR+
8ZWuNYETQAupBHPWiQEiBBABAgAMBQJDFAjxBQMAEnUAAAoJEJcQuJvKV618N5MH
/3/2K+8TNGqALmv4gQJzLoJlB20v1DKUvySFQ/UnWIZMhHIv+Rpw71LvMuTO/Y6L
1pTqn4mOXlNyOW0lGEvG1jhFOOfH0ALYjw+BURNkm2X6ShVoM7aIbOsLWMIWtDY9
PqyHSIZ6VoyUgBRgDcrqQjH1Nt40jrXd20FGS+t9Fd/dqxJZki4eTMXsVJVy+ua+
6k0xGF5MyQAHx+Z7GfVZvjSCIO70j7CAcsKvs2SnNyvYw6SbcdBFZor02iTLZl1y
Un8xDZJrvV2253h9H2jILUE6lX2wt90H4aJOlahIpPB+Eiv04di0V5d6zDnxrVfU
U+FWzvYWS1S4jTsJG2Sl5BaJASIEEAECAAwFAkMUsZoFAwASdQAACgkQlxC4m8pX
rXwTZQf+PfrcLh8BudEjyOUscqMOTeaosmRitOObeJ1MYlKPKG8QHKz6zf3Q7MFz
preRkt7X71hZpY/Be0rSLarQt8Y+Lnl40Tudg8ZArBx7ZhIcs4y/oH7cpmQbeT6r
NHJ/uMIL4XYEmybOzCBNy+Tmnna3z+UlsnLIXiPBYsy1NnYGWUZMhPQlOxwo4A0l
q057AHyowA33SzhM2SXXIFlM9ROq18bFQby2wSk8dkork4KeOUI3hs51hMZ4w7+2
3+KnYeBkiB9pdi94AmtXI0mkPKiDuDsozjXdzCewJl+nX4XVhW1DYmQO2y4kLEtb
u6QTWhRmi5mSiwPRrKUcj3oo9JlNWokBIgQQAQIADAUCQxYCpwUDABJ1AAAKCRCX
ELibyletfBlzCACGxJ9E6Nvntc7BXKU+q/1gWe91SbCw7pCy94Fn/0uHAyNyKTHM
WHtzicsYsrJRfrGMt7zoaUG5aGCU/WjE2CrIV3NBZw4BaYx1fZCo8935vb0HIQd1
QQcqa6p2tQfHtu7C8T2VhKIVdqjOnHekgZ5pYOfSKRWf65uPD6s7QGCLsNj+pWjZ
bYvqYAvGLHslu3UIcu+rHuAT1SJrRzuc3YXYHGBDNLuD/6uFiNKy3waImjlXPYY5
XHa3ZpniMFLkwkM5423GMWpOkscER4VBDItLcvzthIgfLHkpSHA9MqYZ1k09IagI
CnGi50Peo/BmXlmALV3J/iWZnDAmrtuDO9FJiQEiBBABAgAMBQJDF1S3BQMAEnUA
AAoJEJcQuJvKV618/kUH/RXUea5GldyfuGMTxnoPBTf/W2NKM//bCTW9OT45ffdX
N2L3UXKDVouEMsMS2inraHZGRbKOcpRD+4LyqCWOFPRH78z5Xpkw0uzNjQ1XI0oG
zRVQPcXWNFwXqYYqZJRIYVv0TNCITt/XH9DZd/aceYSuMP2Xr18aX/jBLUR1ZIta
tyS71Ny/Zfip1Hfxi/czOkUHs4kO5jIneRsEqxxDv3wsjSFW/SDcdVeo4QO+k8g1
4CWYspjEWvYkhz5hLF+KWaWvjdxGdAR/z9x1ee+fqbLPqjWf+EskliRhLX41l9vi
Na9MALpjKMfGPMrgYTjkrW0rJgDZSmnhgeR0DKICgRaJASIEEAECAAwFAkMYpawF
AwASdQAACgkQlxC4m8pXrXzu8QgArBhokoBTj7jpbWa9y+LLzciEr+CeZbu0GXlc
iPoIYXr7K8aq7PgmqWcskWJEOsT8uEKdWUWYaa0p1VFcdj5SO9XHnsQZKtBm0nFz
WRaStmfK5qtm41uXNLnYgn7Eo8JZmdxzulUSqgvPqFz+EIfsG+hqe2HJwCdrvfwY
tiUDVoebr05k7bFKpvpcdAmf/RwUqVe0uHCg6DN63rCFWCkRWgrDbLp1b/ejqGZd
NhRFh3pAVsd9MiJBYpHfK4UwsXS4Y4r4La16JpQWhlKrV6K1PBltvX0UzvfgqaJO
c84f0XUZoLNJzsvx9oKEocyxxtrPzPJJojqvQm60/UlopihPpokBIgQQAQIADAUC
QxlO7gUDABJ1AAAKCRCXELibyletfO9PB/sHhcRxy8tYkeINmZ3K3OESffg3uu/Y
vdOTQVtww3sGTahvrbA6M2Jy1jtYg8FbPF0GoIygcD+AJKmjJjHKBEkjVd5y8ARl
71l25NvARm2Frq+J+PS8mbuuJgPJvhWVTuKHtLhYj3ySxihs52hnwWKCVN8/alZW
C50lgNBzqsun6EI88qPwZH8OekvA8AW/Q3a3E6wvoMjlcjehkP8DLD4wOenZiutT
29/v5qxoXAMEhH3Fvzz9SWtLJVHnuepH9pc4dDgKRE3zIuAZpzm+5ud7Tz2rv732
a+BW+QxkDnYv2KMQBNzMcqPQF8E8iBr/vDZV6/7DhRh+76dUPmOthTYgtCRKb2hh
biB2YW4gU2Vsc3QgPGpvaGFuc0BGcmVlQlNELm9yZz6IYAQTEQIAIAUCRC6tBQIb
AwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEGjhJSt9pcU7lakAnj3CTYSvv6sV
7w9S+EGjpy4mlXgPAKDUl2+qZJ6uGLrNNR6DuxzAVwnRlrkCDQQ6oM9SEAgAljMk
uuoda12owc4YL/zpoDAaclB6Z6/0LJZsetZZAXuZG6oqWS+er/Jwyah3za+BMN70
7s2Jrqu7GYT/5r/uRsajj0fkzJUOzaunLGEr6uqp1Kmb9KdbJXlnw3ehLBX8erW2
Lw/BYmAkLIJpRa2+3n5DeYoAUCGH9FUFeSu8Lg7YtaWiMCIukzt2h9YXFABUjDf5
r9KPmMrhKS9ch+9HeOfxKqB3P8BuakyuFKji2fGogtCxGE4Sl/ma4/9xv/QYhaaI
isXAnn6XdJemBVFava8Bg6+DXudZiCEvbtG2htSCBkmYUBi9H38b5aUqTsDPIVBn
vdNOsUUyx0psL9QWrwADBwgAiCzJRcScfOuPTIBCraNXaD1yF0B+iadC2Vsbr83N
MNc5KBGQ4BGz3XmTdEZ0wDb/1tGT0Vhfqj27HGXhVSuASvvIVJwji33aNfw7fSHu
HLpzJ70cCbRi/eo0ipwvORopEqAr50QO4TUkQa16z2rpbFrqc/kE90vzBLbtwzM3
wQvDWcLSC2XBF9KxKvMCCWd/BvMwNN2ASR5iTfDmEguSH8Sdh4qHhW6t216Xm85T
jZJEL02L3Oe6rX+q/Xrs+ndfMNq4MAjfnzqVXqJDKXz0vRXBqMpF5XaM4H03JBqm
OMvvF6gpt+GfcyqhUCoVIcutLy7UAmgG/NVQdcBmB2O02IhGBBgRAgAGBQI6oOsc
AAoJEGjhJSt9pcU7vE8An3Z/LhDMOs15ThLnVUAEWVoCmVznAJ4l612mBTj1oOIV
Ox4pu7YIuLsCpLiLBENsE3sBBADPdlR/215byfJANkMhUrwEVzGeOmVh55FCkNrz
3TWPxLF5yortB2tnkdyYuMnZFysswNt3MxYFgX53YcF2nG3Ymsw//RSj3gGdsD1j
JMvVh+qVaS7bMB9DroJTGFqQ/YhiecX5VAMtLsE/6te7C/ueIDj8A0eTzV6j665X
vkDHVQAGKYhJBBgRAgAJBQJDbBN7AhsCAAoJEGjhJSt9pcU7HsIAoMbWuf0CgoPT
oe5YGYNJYqfCL82hAKCnGH4To+V9EMawsmGP7Z1h3DzMariLBENsE5EBBACk2XWW
OTbP0W5wxeK3aib5XULVK2JM8mJIBCGWttuKI4HrVbyZIKoJ9Z65bgbzFdYSAuxn
WgqmS/5sKfPY1dHmsZ7nHOtdcB49XdFRNSvhwBf73GBWgDv0Z5c5bPoQaXTIA3ar
vJQwRoTX3HUQPBOEh/FgD8b8rf3XE5/zaAyZkQAGKYhJBBgRAgAJBQJDbBORAhsM
AAoJEGjhJSt9pcU7x6kAnjvPVNGVZgF99DRPLxchjRBwTn80AJsFekBUcvM00Ina
mt1yi04nJIim7A==
=7U0i
-----END PGP PUBLIC KEY BLOCK-----
D.3.187 Bakul Shah <bakul@FreeBSD.org>
pub 1024D/86AEE4CB 2006-04-20
Key fingerprint = 0389 26E8 381C 6980 AEC0 10A5 E540 A157 86AE E4CB
uid Bakul Shah <bakul@freebsd.org>
sub 2048g/5C3DCC24 2006-04-20
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBERHS6MRBAC60MHcIa5gqGjSmHLxJeZTkLTDK0zEo7MRJuMeF90Py7wdP9Fy
jmRhyBS/tYfOtPrpHwAdn5FIkVzajEklv9L0/JiUx5WDrmJFWqIgRLdRPYw909hE
7pW3uTs2qotWjeA8ecefzlTX9gdZVgy2uPhihMG9cn7pL1aXluca8AUsIwCg4lUf
8pL0Pn6pZ6xP7nG1hEvkzr8D/1LR5Bm47RboJ+dvoMf9lwlXiEBP0m40100urcxR
7e+AHDX2yr6s4edx7pPRCq2ubPgzK2rYv4NHN943AY8EYbrazp5F3EItDOLHmIus
JasvCgPTb7HYWO7Q28redJyUIfBUTPgVVk2z4EuCb5QKDU2/2DyqWThrLEwTCTRh
mR82A/sHQE/xib0291VjMxGKiatd2Xm5hu7dSzCeZwc/5uF0g33OYcd02fosyERd
96SWmGigFWLbQ/kFiAoN0OAlQQoNPuWjGzIJVrxiy9y3Fw2hnoiV3MAWAGr43+UI
FR+XB/MxOKIozYrMouhZHtmw237fKVH6Ewe/rFkthkgm9P9BpLQeQmFrdWwgU2hh
aCA8YmFrdWxAZnJlZWJzZC5vcmc+iGAEExECACAFAkRHS6MCGwMGCwkIBwMCBBUC
CAMEFgIDAQIeAQIXgAAKCRDlQKFXhq7ky+oMAJ9Cth9LlPV2on7lTedInW/6T2mh
YQCgm6bY4yyoJbjUxop0bcuKYGVVuSO5Ag0EREdLsRAIAK/+InMhz/qJB/+Rwq08
K6TtPPkAs5+IcFQqjShCtFWiaZrvBqvcTPDqVIMu6CAnBf6QTOKQc+L7lSUE6QdI
0mE3jiieYJ/cDzSqntYZBkC5glW0AzemgyllQRlqKrIawWu8M+SwZipvKb0YCIFo
rmhoHCjzK/DKlSi0MOjPVTbsyS/rTvhAoXxodogKfNzRpb4MwDjM4Lda9mO+hKlI
93CsBCzNZaOECYJ/1vkpuGqOBhvezrLtNCYFmul2JtVMyCb86mOIJAeiwn/hiZu5
eU3QYdvcCOfYh//B8AZOVSW1x8HYzMFXuznVtx1P5ygvtWY3u+uIlXC274XuV0aJ
NNMAAwUH/1rSg/fSdVGEG3ge+sGtFKHPOaGW014dt5nHCePrhLwHIe/udyZPCD3a
axp6RVlx5Yvw2+nMBWiW65KACBUQslSHbeM5u2aPH6HaAAEYCJ682vKUWyEHGljJ
zDBBANYKThYwle1xRxiE5MT9B2Bz33z2/BQnCgo21KYAU/2bwi2qVG0jyF0i6ryP
6r5w2zZbZA/0IINcwENYRhYdtU+QtyB/HqX//nshVnxZFgG0pIPET5ltq9VM+6Fj
hxJ2RXwGOxBJW3+yLw5JuDVrqoOz2lAOulY2uiQY1Nk9xHDBKZ1U172BugHuOIbW
EAgbLB4QFuIE0HF1h6bNSISULLt0/yuISQQYEQIACQUCREdLsQIbDAAKCRDlQKFX
hq7kyxbGAKDdITbPvXRBxINGLWTcNxtRqjXl0gCbBVmMqSG99Tl8uB7wTZRDjtCX
5DU=
=iFzp
-----END PGP PUBLIC KEY BLOCK-----
D.3.188 Gregory Neil
Shapiro <gshapiro@FreeBSD.org>
pub 1024R/4FBE2ADD 2000-10-13 Gregory Neil Shapiro <gshapiro@gshapiro.net>
Key fingerprint = 56 D5 FF A7 A6 54 A6 B5 59 10 00 B9 5F 5F 20 09
uid Gregory Neil Shapiro <gshapiro@FreeBSD.org>
pub 1024D/F76A9BF5 2001-11-14 Gregory Neil Shapiro <gshapiro@FreeBSD.org>
Key fingerprint = 3B5E DAF1 4B04 97BA EE20 F841 21F9 C5BC F76A 9BF5
uid Gregory Neil Shapiro <gshapiro@gshapiro.net>
sub 2048g/935657DC 2001-11-14
pub 1024D/FCE56561 2000-10-14 Gregory Neil Shapiro <gshapiro@FreeBSD.org>
Key fingerprint = 42C4 A87A FD85 C34F E77F 5EA1 88E1 7B1D FCE5 6561
uid Gregory Neil Shapiro <gshapiro@gshapiro.net>
sub 1024g/285DC8A0 2000-10-14 [expires: 2001-10-14]
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAznnjPsAAAEEAL5gfaY7RP5vm89lqmjGAJRBFLM/qzHJKrYkRVDASeLZ0/JI
Bfypd8N1vQz80tnqzOh7aLgAskgluyx0O9EuZXTJUwm+ew6wA8vh8JA0kpI5g3N5
wjXQNWPxSCeNIz1hbgAPtRunVLXXoaxxCQziU38bd2RvzlvgQdbgof5PvirdAAUR
tCxHcmVnb3J5IE5laWwgU2hhcGlybyA8Z3NoYXBpcm9AZ3NoYXBpcm8ubmV0PokA
lQMFEDnnjRPW4KH+T74q3QEBKlED/1F8UjkufYD0G9eV7X5ujAVffIBl6nvHVw4+
/m+lXxnUmOInk8AUmHIxK62BJ9CPWHegf91BsGNMVA7cQiF+atdz8Yy4h1Snt7FB
OsL2Ak0g2WUrIDfB+N5SB/EjdK0BdURsccYbORGVIveveUNmxuW4jUZWcInCkDx4
FTGRxzAFiQCVAwUQOeevO3xLZ22gDhVjAQHAVAP+NWdTbxipCQANnRf4BNl492mG
VN51MBZnlsy/lyMu2yckR3eacaXmp3zKardwex7Ajle5XC6sJ1H3twYv8g63eqJ4
XuxC9Uxmer2mj7wibcO2srtwv2hgLMNVjJrClALolQ6WT7/6L1YENP0Ef26eJXnw
pwXdfaXurbwnv4tyOOGJAJUDBRA556+fvdqP1j/qff0BAVUtA/94+oMC9pJgXi+0
tbwUsAu/pJqHByjCjO+LscH+gtqb4VhfxdEllHTVj5Cju7o+HcYZdtTRdggx2FqV
zaCp2kq1kbEGuQCJzwNHkG10I8C5YlyXUaYGwX1gEPImzTpOI0C3Any0UvK4KQsl
Crj0UmRARVwzulGYE7hxknivvkdbw4kAlQMFEDnnuKvPHrUDIjJ6AQEBL3gD/0CL
e4R+dknr+zAUfldFg+cYzjzjGNENjWNuz1hqw3SMC0RPPdXtysSNQJGzBTtt1PEW
whlPDKA1Wg1y0BLt6wDOe1LIIZUe+nv3OELd9M7D/2k9ctHilyqSdON+pPiCmUVK
MtA8sfP5GdVsS8G6qFVFFvXzBnNvlcsuVjTA72ZriEUEEBECAAYFAjnug20ACgkQ
IBUx1YRd/t1J+QCXQKpkZ5rqZ51SbcgRaFI0yyab9ACfXujgbkNmaxHGnOCxGzIp
VJDnXOqJAJUDBRA57oZATVYoIXkFDBEBAWL6A/4/LJE/dP2EcrCAFn+GKhLJjdtq
ks6UpyZ35UlEYdgBldTX79TdJIFUte87SZ7b3RVDpOMHpGj2jpOgRfZj7+nGCeLZ
DstPcAJJSHc7qvdrv7egu97p8dw6nxrMw3oR2VRptivQzIbNkvU+lIQ2exkVHkgR
WFGrNBkWJqVHYN3Sq4hGBBARAgAGBQI57potAAoJEML8hqolOUaLCDIAoJ6u7b1b
vPN0yh++SWLsBRL71woLAKD7MhDamaYfKyJwjbZbSHevr17tjIkAlQMFEDnugJUf
f6kIA1j8vQEB59wD/jBIsmEMqCTKTefHfng5B978SCIkrVq7gTOhafidFKD9KEme
LVYJYmi+L2Rpa+vwfUqt/gWyoh6svM6PH63HVb+7Fjv1nmEQM+mSabNq/kDgmpjg
9QPHbMjcCU/vLSMu3tdmCAzZBLAmTBIZy1pnV8GkF/gCxwR+Fjr00F+g+/siiQCV
AwUQOee+9y1ZDtHS0qyNAQFJFQP/TYnSKTs6X0Re/1CD91w2pGRzEeumO+hNs1aX
sWHQ2VL1JGI3lRvGf8CkduPVScGsPENN7IYKieCToKfL5bBAyojqN5ZqFV0J92ZK
Tk28HQplz9B0KsgXLRwK9q26zyFedMJhG5A4Jp4B53cGOpHXljTaSVyvBq4Kk0Sz
Qe+wbi+JAJUDBRA557s4mAfmW9hLWSEBAdb9A/9u6umDds1HMyvwsoW1MLwlexhv
/74gv/K/Z64YGdYGJcIwgQihJg0AEXjVg3UtpCLpJase91DYfNpj8u877MeAxuZv
W4l6BF5Pess3NbphHMpUjsBXhOJwb1pHTwOFk/qjOVvRZgD8tbykzcxF/u8IUhBd
RJG6fUrjtIzLQBLiM4kAlQMFEDtV12F8S2dtoA4VYwEBHacEAKKsLSNwV7aoyqf3
yrbdOu8H4/WzYjBLyPqlGFHa3kSH6VPO6Hv/+2/fEgL9YiuxwONAPjeMUqhyoQts
eLCR5G3TwA5WW0VEvkOjFJjRGNqlQ1L/1OAJGaHexKLdAEamzK2tcr2S69zHik2x
4p5KIMx7KPNdJlUrQwQnYSjGtEXyiQCVAwUQOe8PYqjOOi0j7CY9AQGLkgP/ZaS6
jBnmL5Rniqp6acM3q3C+63YP+e37R+vcbGHrAMuyOMmGoKwq/955Rg8VRDPNrDpL
M1PlWBcmitrxXr1+NaEuN9+5NKeKnpPEf8MXXwgjUe8vl4MZMbSOSoYGOy3x9f2R
LwkrHQ84Ma9+DYHD9dpt2fGXOpsSMM2xP6qVsOSIRgQQEQIABgUCOrotcQAKCRAD
EujDXYzae7/qAKCPAntk7ReoP991XUYDqVnDlWnyOgCfRUHDScDh+nOlsyBBZ9IM
BLKRcjqIRgQQEQIABgUCOrmLHgAKCRDSD9QFytUJxsZhAJ9iaHp7M9Sz/fVbrdxV
AYj8IgTpzACgkLisMWdl06CWRp8/WlQ4wIUInzqIRgQQEQIABgUCOrozZAAKCRDa
1acZvMEx3qFNAJ0RMwoNTlUc65TnsCtrIRP07aiipgCfRYAeTFJFAde2FHE/cfXL
XAbUYZuIRgQQEQIABgUCOrqeuQAKCRBL2KFeEWrdp1JyAJ9XiSLygWe4U9dYZL+U
6XqXqbVMgACfa1NwVeHLBjb31nLlus8eCZpQOdOIRgQQEQIABgUCOrqeOQAKCRBq
g0XINN4vLwikAJ0dfdqA6A/KbdETee5vtrYRfgxcvQCeNVp+Bz2iD8ZmDmIRCLq3
sZuCOWaJAJUDBRA6ulth9u84uPhDcHEBASgyA/46x3K3rPzitwnwFLSwg12tdjVp
t/rl04rScdA2WPAjr9TooFJCMBN+DBmcIt+y9puE4kSHYuOqsDgSBxPJlDa8U3B0
FwJKBxnr+FEVqpfsvUf0Y1WT/3nD1z9aWUwoKpoJyvHiWJwagk34Dzv0FFA/3s2t
Cm3PjQ12xwztcrrdSohGBBARAgAGBQI7VLq+AAoJEKK7+yQM+Vb32AUAnjXWXcQ2
iJ/wQWfEY9JA5PDXNreFAJ0cLQESRA1uii0bHFIfdUr07PhOq4kAlQMFEDtXQW3h
1PwU5tB0cQEBEMUD/3g7h8wCNzbbtLh0/l7/1WlFL4eeRPkEVLdGIQfB25Q3qZ7B
eSZNef2LMtTUqoQtpJTiHWg6BDsr0Sn4zIu2m66POh3wEbc8zbBci4zLr8VFQ2b9
U6+ABGeMtNrBpJyftZVZwtCD3f7i6N+wAEi3hcOq46THmaxNuHEW32l9rDJBiQCV
AwUQO1kQagZ+Xti/tWVpAQEblAP/TECpzEAdlLRZUSP3yvE3jeqbVi88UbNrD5Xa
/AvBCctlXpFzA9AIO4dILyztXykFHXrVVTY8G+2EZWrsiCBPrMrYgORPX1n9x4WV
RoTvCGvb5rs+wStsHAJXNEX8co2C34qc4jpLIs/NAtIzgI6MoFcf8Qld9oMbwQSo
lNlc3YOJAJUDBRA7adA9I+Ri1L97pCEBAeecBACdFGVUzCM7q2uiDPInIhPsJKDb
51Rqt9UBTvXJ3o2Ztt+9bcWwIZ829VWcAE+VQ616jF7an1tzZlRrLx1dh5pcIZOl
h2Mx2aMaFxwKGnDlixwGio536dUKuMfAvZnTqW6RdapySOUjD2lDYuyfw65ns5jp
7DTTaEazd8Q2ZVBlOYhGBBARAgAGBQI6uZEJAAoJEJ213TFSWb7JAEEAn0gFmar8
1oCz2p5mRLtio0ItmNYlAKD3dmsqUAgdd+Mz4G7ax8JNelfpN7QrR3JlZ29yeSBO
ZWlsIFNoYXBpcm8gPGdzaGFwaXJvQEZyZWVCU0Qub3JnPokAlQMFEDnnjPvW4KH+
T74q3QEBMeYD/03sPgJ0QKQXzSRGyiVZBkZ4frsFj6nH2IP9+zCTRUlX0uyo6f1Z
2RC3a++MbaKFR/LUmdZ8DkOfOTcvsoIQJ6BOQO1/XpOkppvhrYRUU7a6C9wM7ptW
EJvx5IcmWk5oWxmx373ecPb5MkhiXK85/NRxhlS5PG5kcz2ajJ7imYnuiQCVAwUQ
OeevZnxLZ22gDhVjAQGn2AQAta7mxgLMyGKhq9msyQ2rITAhEvhoYM47OeOgyq5F
Kx0b0rEmIjC+sDx3YOsbauw/Z5bAYzZnUmhe65KKA76eITqlnMt1ykaDu0jQLGKc
zXjuLCMCDT/JCZStoyt6XhG9R+R8PnXk80PtZlTJjHuJyghBq5fzrIKs0k2G7eVc
hnKJAJUDBRA556+nvdqP1j/qff0BAWVdA/9m5bMpkhnxDcfApaDp6mF2hEdacuHX
rMXOzsrTuFiFoJhByXfMbMDM1T8Hq3FU8TJ3BQ/ydgoeiuvWJ5j0clBegCbxS7tH
/FvlnZBikNeARFTD0m5HhmG+vzIwhe2sjh7/0dqaj1RMwLPxrQVyukHGnzyFodjc
DJy1jWEl1Onyt4kAlQMFEDnnuLHPHrUDIjJ6AQEBNF4EAJbWN0TBkhndWI0ZwzYB
ecji+VzV04rCZzgg+XCX4p6YfZn/T9GmP+11kLg2M6RZMxXHhDoGyySaJnRow3wS
0JHvpKH5nWqeroWhGjWdXbtrlh4e6NbH/72e+xcBCFumuYRntZUlq5tjrGYa4TUI
F87ibvNipGJ+12Ia2xg3biwIiEYEEBECAAYFAjnug3AACgkQIBUx1YRd/t3ncACe
LGaEhnVagJXTiufqtHb0ukCwBdsAnikTuFqH49JGFZ1X62vtOPWzrg1diQCVAwUQ
Oe6GS01WKCF5BQwRAQH2CgQAlplYPCet71rkFQpsgzzcZR5YtQS+PIeNLXTStuOc
DPtTK6069s/1MmAYaNoa4B0nYXw8iUjuBra8W7mL5bWKj1/nAYMsdIvt+QJeBjCM
5b4KfCdFxpm0LPmGHP9SIHgJxptJJvGOsZ/doYYJh8EWFMuaDnDKxyF6Xf8TeJo5
uPqIRgQQEQIABgUCOe6aLwAKCRDC/IaqJTlGi8jjAJ9SwrJ1diaDEhfhxfXz8dLz
pmmolwCgqf7h4Y78pGRPi3V9m+tfcGk8MaWJAJUDBRA57oC0H3+pCANY/L0BAUOa
A/90Zs74A/fud2gsqPPW1XXxLd6XHD3s8UK7xgVxshq/0+Ufa1uOn1JioAOgYf5m
qRe8qyN7j8V1q9tvOeUIZKDYg+nYgMqHJ1zVHx2F34ihbUuRwsdgHZOh4srwqVXQ
O52FB0kDKxRYtUwm2FdZGR01QJoG/E87BGNb1/XCppz3dYkAlQMFEDnnvwQtWQ7R
0tKsjQEBnI0EAI8u3KxjyA+GwnIY7rxw48CuefYn+XjM31D3glu06mW8rRpmmfMR
Haw16uXuc5JB96HiXt9/yWqi9guxK8UOBzEUjwr7UmzlNWS2K3/MeEJeawUXrRFl
7nKTutX+8pL19xjWjngZYpiUFJ2KN0p+/28wQZAcumWfXDE28okPR0jUiQCVAwUQ
Oee7RZgH5lvYS1khAQF7TQP9GqMeOk+PEzYdrf02tIRgZqOK8vPA0ulVwVZ9kI8w
mChF0Y/N2+BjqJRv93BeNc8WzzI3rQHdQi+Nksd+RPNNUyVoicyGrl+UBVO7GHPm
RQuQz4XC378WTtGUyFASmxgvo28T9QJaar40Zkq0I+ZIaggGAr9qtKc3GC9sDsgE
rs6JAJUDBRA7VdiIfEtnbaAOFWMBAfEpA/4klnBk5rcdlbIM0OfJx53vsLCxGBXz
/zxpOboHGQ7pQvmqDbdOxsl19i8IPlSZr7QXMCsYsBfGpaAbWE/FccjloNhGqmsz
7v6P4vuzoOsKF1Z0IFx975KX2txUjH2sZvbC4w4XTWHlMSaKvEMaqeHyTR8SmKJQ
Tway6eZ/+7Ca7IkAlQMFEDn4b9qozjotI+wmPQEBF8gD/jnr7OlRpSBUz5uHIT2s
sOhNJ8APU2fpAsZDko2xnsHLm+5Uo6UDph4C8cPeCCJB9MqTicb63NKeXYdBbH/6
i4auD101bIf6fvdawBYQtZUS5wLNhFpOWfRcYOnazzUwPntERmB8b1jCnClsIOvd
8s821d8PS9Rqb/c6sMxcfgnqiEYEEBECAAYFAjq5iyMACgkQ0g/UBcrVCcbRDgCg
lD7I7eyTlt+ANPqhqlCyGI+fynEAnAgwUVTnA9PvxQdqbPwAi8TeINY/iEYEEBEC
AAYFAjq6nsAACgkQS9ihXhFq3afcqACfU3TXiU1hgK0dZ0iNcBbo1wtfUlUAoMhA
9AUjaBuGCSkuQwyrwvGkv2lxiEYEEBECAAYFAjq6njsACgkQaoNFyDTeLy8SkQCf
bwG86aNwQS186QsKeJLdx8Fj6YgAoIsiYdN/O0bfiizUZYLRSOEgLt5LiQCVAwUQ
OrpbY/bvOLj4Q3BxAQETBAP6A3C3azOdu+A6UyX9f8yGHn012ibI8mxUvR8MRpbM
iVaIQ4hVUjyK/3pcw1qF6a2Cfzw2+l2kizKbI8U0PUnZ3ki5dq1MAmWmxI7O2T/d
6ZHsRPrj671X9ya5yblLEhfhd0uGejLBV76tJCxdpeQdWgU5HwvvUZobHig/54/5
Q8aIRgQQEQIABgUCO1S6wwAKCRCiu/skDPlW94J4AKDkHDn9SR9yOyVCSDiFppmF
ptOkvwCg0xYLoZI/b4O9ZiSMRFb0ktY0CFaJAJUDBRA7adBOI+Ri1L97pCEBAZ8b
A/9rlgIM6+dyJI8q1HsziqZWUYIQ9w2ol5l3ZCVXqEYP/ToalP9Fe+LYclZgbifB
Lydz71ZED0EtS+q1s7/bcUzadRPEZqoy/RGFop2SO5Cxam3VOBt2MiHOxG9bRlbp
D7l6ZLmLIDGOH4xv9Q1iS+7BXwCxoSjjeQF4piOY8i3uuJkBogQ78sGtEQQA0PGj
ByXgQDy4N9gbzxhtwOXrcnSN6dSBhM/2bYrnSh3lYKevjrt4EaOQHdnPkyigNYTI
QndGsh8SQqaeNKo7tl/mXPe7LCBhZ7Ds+ltMveEq/B1HmksCaPXqJJdS52XfJUAS
hXIv30pRstGvISPvm5bfBJWKKFAp8TSDC1xlhj0AoP/dcbvUb123NcRexBqIBAIL
UrQdBACbeYy0dBiOMA0nhx94R5BOGJJ6k+14Z0a6Qz+WeBJTia6f7inokr8yYHVd
zelpTTD7QYCNCqq9LmomjeqtkZBPFfj29tbLeZ8NwyuE2XFz12JPTfs2QUHw6WD0
uI/jwcNECxeDQ8VxmY8h75Uvoex5JkYCJynyHExkmdxo+hjqTwP9HxTm026/BA/M
bc4sJUHU7zcXoG367vikJkOC2kS8uum/fp62bDey846DVyF/EryddRVg7pqXZj9k
VFJ0i1CEXr3IsjtWi3OZb7/dVD5DOKqFDhr7OJQZbulPHgiackLPRXQSngt02UB6
qMvru435E/m4yGI5DvtjWIdcjyLioYe0LEdyZWdvcnkgTmVpbCBTaGFwaXJvIDxn
c2hhcGlyb0Bnc2hhcGlyby5uZXQ+iEsEEBECAAsFAjvywa0ECwMBAgAKCRAh+cW8
92qb9cxuAKCcmeGEGidQC5RNwE2sDaiiD2RlUgCffZOb5sf3hsfBgLRNJBX8LAU2
D3WJAJQDBRA78sLJfEtnbaAOFWMBAQkKA/UVxp9iAa+RBlQVK/SxJkYhvXwdAWmL
tI5f4ggVxO85rt3tMXzqynxf0NKT+8QmyevkQgFELptW+d2fnC2OLqlYHDGYOIZC
EBx0x/OIcWBtdEn2zjS7peFwwOmS7qE2O9bYYxL0k63u0+mAuN2zZtq5h/LUuLvt
tC3fIFXC5ZnQtCtHcmVnb3J5IE5laWwgU2hhcGlybyA8Z3NoYXBpcm9ARnJlZUJT
RC5vcmc+iEsEEBECAAsFAjvywgMECwMBAgAKCRAh+cW892qb9eHMAKCnO9VJJuCH
tr2OX1tzPCPN9vx+sgCeJ7I6BLfajCcqdKnDLV2pvp/tRSyJAJUDBRA78sLUfEtn
baAOFWMBARQ8BACuOOFfK7qLFipRdyXL/UEMulH7Jf6pr2rnxGcXShEob8H0HT14
CMfeShmGezrgLmPU7hqwY6fz48XjASLMo2LVtcdNxsn/f8+CSIhYjCue5AwW+CRK
WFEgN5MUsjkaK0ikBi0+OELw23qsR3RtEzEsURvyVf61bbdJJWYZ3Cva3rkCDQQ7
8sGtEAgA9kJXtwh/CBdyorrWqULzBej5UxE5T7bxbrlLOCDaAadWoxTpj0BV89AH
xstDqZSt90xkhkn4DIO9ZekX1KHTUPj1WV/cdlJPPT2N286Z4VeSWc39uK50T8X8
dryDxUcwYc58yWb/Ffm7/ZFexwGq01uejaClcjrUGvC/RgBYK+X0iP1YTknbzSC0
neSRBzZrM2w4DUUdD3yIsxx8Wy2O9vPJI8BD8KVbGI2Ou1WMuF040zT9fBdXQ6Md
GGzeMyEstSr/POGxKUAYEY18hKcKctaGxAMZyAcpesqVDNmWn6vQClCbAkbTCD1m
pF1Bn5x8vYlLIhkmuquiXsNV6TILOwACAgf/ZjIISPnsQx4SLh66JTExKgs/PMzP
7OOZNu7OdqwzELAGG6UIs5v4SgrWZ/VGg0lFxwhPF/FgOL4ZVVhIfHrBSta3j3t6
Qtp4AZGoxGyKi5aoO4+uj+DiFK+/1PHLW4sHwFyghy+TdAglOEKkr7++z5+sZKBU
k0ik8h+LJwMl44UqIjAqGlqdLmE2xU9q0lgjJ/UERpNJV+FBR6Lxu0TGyUc3cVu0
ovbJ3Hey7Dcr4lvPaj6GXZCfck8QqPCZvEc9CfwPXOrrdSZ9Cax6qyYwSuSy85iA
ymFwQE3lEbKhf1LXcgDDBXF5eM4dtF5bwAW7ijnvYG+4GU1Kg3b+zQkZMYg/AwUY
O/LBrSH5xbz3apv1EQKExgCffMvcS5FKHNfSwc2GOBLFdRYDjTUAoI3Fpxi7re/C
hdiB/lsBOHxjhvJOmQGiBDnnrJwRBACXxbriCa+0S4JY8rFJe9U160xXZ0hqJsvf
IZtokLGDjC21G83K4pTJRhdWlWa04HrehUtMIdT/EXKfUJCFl7vk/WGWT3/1H3xx
EUQzxKu3xAJWQXJs8t2r+Dkj0csrpLJvRyuZ5+mzzFbzFSIaWohlY8Q1Ou+39jOR
fyVPkGjizwCg5CzrVDcXH2oTF3vMHsw/Bhfz3bMD/AhY8q/jmUiV09hCKb7XG6f0
C+qpmBeByk5G/JFmTRv5T34MkWQJodaUOhJtzoOsOjKQSect3c+XncIMADAGCnGP
GP/6sxfuyLOgsuV6TXSxUvxi+E99zKTmKPFRTBuJCVATrTmHHAiLEqTZzE8DeJ6w
K9kT1fRVnCKs4yczI7diA/44Ay2OW4PAuri2lJm7yXsiP54lNCP0eMXOQ8RSWBZh
HKQl66o/pm+FsT9GK5XloJrFa7+2XuiVoyNiva18dZkCFJzychda9pwfkkHjtidM
RI97ACdUCPPQFVMB7Dqr4wXp+qQ+tXScnZT3LMeotFwuiSfDl4VeNOswEw+F9ObC
UbQsR3JlZ29yeSBOZWlsIFNoYXBpcm8gPGdzaGFwaXJvQGdzaGFwaXJvLm5ldD6I
XAQTEQIAHAUCOeesnAUJAeEzgAQLCgMEAxUDAgMWAgECF4AACgkQiOF7HfzlZWEO
hwCePNxxTa/16SShRlkehXsG6CzWeksAoMCaDOmhTexTrNfARBURWr7A+lkPiEYE
EBECAAYFAjnnrQ4ACgkQGPUDgCTCeAJDSgCfdyHzyykKAQpt0xJKEEHiVmDXEcMA
nRM6JG3b8P2ScMYr8jHnzyd26/9viQCVAwUQOe6GZE1WKCF5BQwRAQH1ZQQAiASZ
8t3aMWxJBGqzfmfJwhn+toAO6MlNx0vTagiO1+X5DG+0Yv2R28WYsetAOvJLQ5+c
oGm9YYlC1IyOfbwgdJ/UZ7v0wndZ/gNSOKVK7Av8oItXAbVWni2Faym3jWg1M4uf
rTBGkCouN6VMN6xUfue+3BEyWVQ9+xgwLS4nCZOIRgQQEQIABgUCOe54gwAKCRBd
UhyM5rFQFkLDAKCagGDgxsIy5/CaXH7EQ9DZwAi+tQCgrTwg1ubGAvy8xYWDdbHa
1aUaRdaIRgQQEQIABgUCOe6aFQAKCRDC/IaqJTlGi+BQAJ9TZw3/MkTZvwyeJx4r
EIOYfU8CMQCfc/Vdt1wI4gPwpy/ebNLV49JWmYGIRgQQEQIABgUCOefNIwAKCRBA
/7Kvxn29cAXfAKC0z9J9EY547dJzkBWYyjcm4eGAfQCg8gGsyHJSN/HsWdIXcaEr
PdshIWW0K0dyZWdvcnkgTmVpbCBTaGFwaXJvIDxnc2hhcGlyb0BGcmVlQlNELm9y
Zz6IXAQTEQIAHAUCOees/AUJAeEzgAQLCgMEAxUDAgMWAgECF4AACgkQiOF7Hfzl
ZWGS0gCgy8P4iM6tbH50nfGZX51Wb4Ge7RoAnRtI8BzHhw+lH+l4dAUk2tmCzARH
iEYEEBECAAYFAjnnrRIACgkQGPUDgCTCeAKMWgCfTmWBF0c0pp2w6FbpH/o+Swf3
wNoAoKTkPKf3MNeQ5ndu4AyefA5E6ckYiQCVAwUQOe6GbU1WKCF5BQwRAQFRAAP/
RVnv8rhjaUiXmZpUvvCyJ2FLj8wlI5lS6vcjqsrdoWUkEnbBssNVBtac8LAzXGV0
TGcqgNckV/8avwhfKqFvUD+RBVgYP/3TBcAKjNK7TSgOmArFGJ2+N2Yzz7ihpyzF
vCf0tCupXQALEhyDprg+p5dnvC/0jskjaYdHeAuVChuIRgQQEQIABgUCOe54iQAK
CRBdUhyM5rFQFi+NAJ9kmSkjeLlthNOFMbi2dNgJVsMxwACgyyu1Xk6FCjEI4hJF
OwcEBR8SlAKIRgQQEQIABgUCOe6aFgAKCRDC/IaqJTlGi0hLAJ4uplCrccwi4PK/
vUaXpnFgrlqZaQCeNlSO2SfReOaMZDMedbMEUDIrlzGIRgQQEQIABgUCOefNJQAK
CRBA/7Kvxn29cExzAKCG5NPGwqrBI0fDTjLrlwyC/QoH6ACeNjQPM3dHVPE7ogif
gsYnPWRPBXK5AQ0EOeesnhAEAO9L5G1lA3oDYFq62bifXtKS/zM2aiKND8yONxRa
EuhcSqroNY5FrRy1wd4t14SA4/LzZ34DsiuNZ2+h2HD/3KTMDQ/qE/FBblNwE5ZH
9cQ44a9WwGsWFDRgtuHV/7dHlZClPpwD+tFVI7UGufhv+PPKAG3tTfRvWY2lReqV
wsc3AAMFBADlrsLDoQFnE2ieS5pn3pB/aiMF2Z09U6fVTY+mdAdAU43xifQFGMi9
vuzHNzwFGtJosK35BhfSshHTER3cT0yN79HifRAAwKP+KIoxFhfgudZafG6BaaIO
UlhPW8s9k+FtN04x6/jgRq9pz/E6MwVxW0Rf6V5XAIFWWN3xd2JH5ohMBBgRAgAM
BQI556yeBQkB4TOAAAoJEIjhex385WVh4UgAoL/9Yqhurdv28afXOQFO6iYYw9rd
AKCbvUNf7ygAueM3OPl/j7AfQK1X+IhMBBgRAgAMBQI556yeBQkB4TOAAAoJEIjh
ex385WVh4UgAoNUFbjJY+EdQx+mry6ajI0O1OzjHAJ9rspd2xHuO+r1fEZyn/N6k
LsOLmQ==
=GprF
-----END PGP PUBLIC KEY BLOCK-----
D.3.189 Wesley Shields <wxs@FreeBSD.org>
pub 1024D/17F0AA37 2007-12-27
Key fingerprint = 96D1 2E6B F61C 2F3D 83EF 8F0B BE54 310C 17F0 AA37
uid Wesley Shields <wxs@FreeBSD.org>
uid Wesley Shields <wxs@atarininja.org>
sub 2048g/2EDA1BB8 2007-12-27
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEdzy+MRBACwXYsfLwZzbzYru+XqMIFKVIIszXJK61UejvQqcuaZRNLSQyM8
Fc5dI6AfciZV9tH8LDqYmd/vDtzjmBp/h2SPqQfiVuREQ0+c+aplvWvWc2TjFQg6
CZbb730TtazPXbObZvSMRvLeRM32W9Abj5L8DXoQbpMtC8cllG21fsY4hwCgyngp
xK9e32zih9ddXk+NgjK627MD/iPPyo0N4cb9omNwOCot8YIRpdJhmvR/yPh+8rmW
NUu61gV8jn2XB6Ldto8/dR7chqqbBU7bS+hsk/lmbOuLNe2XkQA3e7dd0EEHSYYf
mx6zjw/dEb9EBANAWI6QOyjNM9npWb/shZi8Pehcty08t2eytd4M7wPI9zLAXsMV
M3nUBACgxIoW4e9yXeNQ3CI2KD/Dbup+SNha1uCEmzN5A0VfPJzyi4Avdtl9URGC
HUFnUAs5B366yQTgmkjUcfcWqTKBicp4TAZ2KbuDzMX6f6cikb9bdbl4P62vN718
5iclN77KfTfc6j4aOdIbnc6J9GStvYY0R2eZRKkr3CsqSuebxrQjV2VzbGV5IFNo
aWVsZHMgPHd4c0BhdGFyaW5pbmphLm9yZz6IYAQTEQIAIAUCR3PL4wIbAwYLCQgH
AwIEFQIIAwQWAgMBAh4BAheAAAoJEL5UMQwX8Ko3juoAn3bIDWeVAWOfi1XjXdaA
HN7HKkMKAJ9RJ4F67NZKo37U5E3UnnVSRLCZ27QgV2VzbGV5IFNoaWVsZHMgPHd4
c0BGcmVlQlNELm9yZz6IYAQTEQIAIAUCR348ggIbAwYLCQgHAwIEFQIIAwQWAgMB
Ah4BAheAAAoJEL5UMQwX8Ko3KPQAoJYfbksQ/n/1FitmpqJb+AmpOmkPAKCVXF0g
Clk43/Af2rVb3Vm91NmuvLkCDQRHc8voEAgA6Tped4TSVLcdXmDMeHvt29i/9rGw
EO6lbwUZfamHGasMALyhWC2/nWhoCdo6tTP2XT9guEX5eu/FoN+nAEIKKHqNiiuZ
6jyOuzUFD/d6n8pUkjHRLqLxFznbgW8f0aaG4rNJTQEQy6+X4/yKEvzRxjroNbZQ
l300+liw6Q5OztzgMjhkcva4Gxf+aVhVMueGVuANj1QhPPqvIT2roRsBY6PPNCGY
AaymLWBq51UbvE5j2jtCF2nfxYnajauqnJpZK0tSkLMkxWd/Khvv7GmO4v47qx/U
DTx6iQP/i43JZIqSg8zSGjY9Lr9XJpzxr4FVyW/rs5X3Fp9ZCQxF3Sty5wAECwf/
Zs93KXphXLWhCal07JQsu0T2y81+EXRue7QltZs+VTHvGZuc949dgnZrq6iRckpD
unMRJUXNrKP6BFNOJuDAVRVOxxDQc+ydVGwpQFzJes8/9C0TYOaw0k+ayCZapfVf
L6zktK+g8oYOXVjjdo8hX9xsus5ie69x73Csve59VmGgCwvywuLUcjCWEgMZGRY0
hBL9ec4uRDVRIdsl15hQ3NGwdxiDEPkJu8QzQv/t4cde+omnI0UdH+Ywk6FZ2qxj
62QaoTvFhuNfWUdmnEAbIkfRCFnHVEL5KcQs0Z9CM2V6qS4kdD9wzthhYtcRgWjS
paW/fPyNYLmXuYgvfyk8XIhJBBgRAgAJBQJHc8voAhsMAAoJEL5UMQwX8Ko3AxYA
mgKQnqx2baAJtOI7VsgWeTBFEi+HAKCaIQDFpsRsUtsuEYpqj+/zH1bwhA==
=kNwv
-----END PGP PUBLIC KEY BLOCK-----
D.3.190 Arun Sharma <arun@FreeBSD.org>
pub 1024D/7D112181 2003-03-06 Arun Sharma <arun@sharma-home.net>
Key fingerprint = A074 41D6 8537 C7D5 070E 0F78 0247 1AE2 7D11 2181
uid Arun Sharma <arun@freebsd.org>
uid Arun Sharma <arun.sharma@intel.com>
sub 1024g/ACAD98DA 2003-03-06 [expires: 2005-03-05]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD5my2cRBADKOgeJz+IX/4UT65iwvAMoR5SMctMAEGNHvTk96H0DSYmDmqPE
6D4PWxjiAmbFdMmxGvmPlZDGRk7IpZhrvmsAuAvwImA/UyGb3Qnb0zOoOlAIQiGz
NXRvum8vzoTeW5r9ghLOKkBuze1qi8PZdT+ztreaYcPPZBI9zPNfnZd29wCg4Sqo
eWA46NgWICUsOpC3dkhAmdMEAKBUmh8p4kOZQq5LPv3y1fo+5MBI1gnawiJoO955
nzVuisH5h1yaNjz0nkB5VtEG2Ub2mhBjckze4EP4FzPgIpOhSMdGfNh67rrByvv5
DD/SBwjULSEGbBlywn462QDb1X0PxFX5C6IYK2Q6i/vbWkOFMI2dVuQX0PUq9zjN
D5QJA/sFeXR7NcutCUaLknFCaV1cBTITJNurKn5Vm3QQq5s6R2cFTxdouHcSNkto
EbhcAvMapxlWl146h7mAtLsXXa5s3wuMWq+igOXUk0wkcm8CqvSQtnVYl4Xy/Ll3
zXKxtzKHZ1YxAdYQXGkesBuaSafCN6VYDFFSEwChHrwe1sV9obQiQXJ1biBTaGFy
bWEgPGFydW5Ac2hhcm1hLWhvbWUubmV0PohiBBMRAgAiBQkDwmcABAsHAwIDFQID
AxYCAQIeAQIXgAIZAQUCPmbLaAAKCRACRxrifREhgYRWAJwLdcAEvjkJf5bHy975
R7q7Rp4KUACgq214dvKu35ysWriNNxu2jtIj1he0HkFydW4gU2hhcm1hIDxhcnVu
QGZyZWVic2Qub3JnPohiBBMRAgAiBQI+ZsydAhsDBQkDwmcABAsHAwIDFQIDAxYC
AQIeAQIXgAAKCRACRxrifREhgVrxAKCXiBsYhu++BPQX9prGf2BeKNYaswCfaS2Z
eNyZsxSNedBb26k8ARWrZzq0I0FydW4gU2hhcm1hIDxhcnVuLnNoYXJtYUBpbnRl
bC5jb20+iGIEExECACIFAj5q4pcCGwMFCQPCZwAECwcDAgMVAgMDFgIBAh4BAheA
AAoJEAJHGuJ9ESGBbWIAnRAlo9PVZzdar5pmWDGspeyGk63ZAJ9X3x6ZQSD7uYeB
ajKe61NpPAamJbkBDQQ+ZstqEAQAkgu4UWlgyF1IeMM+vwHQ43zik3Rn6nhpJXRb
Arpg4QyVHQNQshVT4XsmSvcgw0TSUub0x5m23dqnhcoB/mk0kAIymVQiEaa4SLjI
tTXd93yRvSgPd8JEUNFwcSE43ZJrrmSAqIc6MUJ0hI/pAeCFvRWYQ80+82xx30Vn
fJLOJR8AAwUD/R2xFX5geJ7W8OyLtB5XQirkL1YPGLNNx4lyAPXFJc1s1KwfZ90q
LYNw2qLRIacYKmY2X9BrWADXPrEZIDKljn+Awz34lSwerLHWwYDDoeyjfMt4Mmra
MsV8UIjaBGO1ptbqEDSVeb1tiWQGa622pT5YaZp/r/OFdlmg+JvkAzHkiEwEGBEC
AAwFAj5my2oFCQPCZwAACgkQAkca4n0RIYGWkgCgxhDAezhK5kiSC4N74g9ifsF2
jl8AnjujFRJcMfV2R28jiZ2BS9mnvqjU
=klyl
-----END PGP PUBLIC KEY BLOCK-----
D.3.191 Norikatsu Shigemura
<nork@FreeBSD.org>
pub 1024D/7104EA4E 2005-02-14
Key fingerprint = 9580 60A3 B58A 0864 79CB 779A 6FAE 229B 7104 EA4E
uid Norikatsu Shigemura <nork@cityfujisawa.ne.jp>
uid Norikatsu Shigemura <nork@ninth-nine.com>
uid Norikatsu Shigemura <nork@FreeBSD.org>
sub 4096g/EF56997E 2005-02-14
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEIQ08kRBACP8kqP9uJbHt3w8lPR08oRyvhkUgDO4ZtkragusqjwQ2qfv1GM
P/cr01I7QH5k8cexhrjroWoaeXIcMUvNtMOODgj+BhjF+9mj66FG4ed9RkVxvqo4
3v41Hed0bX3z1vrnTNC4KBfS2HZChIZr1ZnQbosW+MRAcvclgOkF4RFYZwCgtdPh
WQv9+Lo5QHqpt2hgz8tWklUD/RXBD2HpVfbQX0zkwKUYrHIoE+0oMizzFTdQe4RP
HsGiCfZ19msSb4Pjewm1K+Rhg6wUq9hCE0gX2U9J1BUtXtqAoy4xY1JSPg40bigo
+kjEAIJ6mA/a1UJXpJ7lDMBzKtwWfxc7F48M2iIJLUaXQzSVyWcZ/V5e9y/1VBsS
MclmA/9+1Zr0zrpl8/HnqLfHiyT/3CNGKPodqfEb6qkSP2M9RtYRTmeX9BBVh9of
JyfAlkD3XlDyT+wmLSZKTRvAVeenBe9ApvJIYvShVU3m0R6nfDtREmWtILtFf3Jf
fwDvNJRoRL0UwkR3AbbMEkhe+6fzUHir5jRCPlV2EiJYrurEsrQpTm9yaWthdHN1
IFNoaWdlbXVyYSA8bm9ya0BuaW50aC1uaW5lLmNvbT6IXgQTEQIAHgUCQhDTyQIb
AwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRBvriKbcQTqTkIIAJ4vawXwVjgwFZGT
wx+99FNG27QbygCeMaOv1igYzwl3AR2Ex5DQA4kSHPi0Jk5vcmlrYXRzdSBTaGln
ZW11cmEgPG5vcmtARnJlZUJTRC5vcmc+iF4EExECAB4FAkIRRbQCGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQb64im3EE6k70XQCgkVmB4DE5TioLKXQjDLhFarws
7VoAn34rlYTkNXPKyyCfYNKnFy4Kvtd9tC1Ob3Jpa2F0c3UgU2hpZ2VtdXJhIDxu
b3JrQGNpdHlmdWppc2F3YS5uZS5qcD6IXgQTEQIAHgUCQhFFyAIbAwYLCQgHAwID
FQIDAxYCAQIeAQIXgAAKCRBvriKbcQTqTka+AKCkKxW56I7qwivXmENPOmIpSCoq
kgCgkXJC9xya2xLdpejt0QHA5vKdqDO5BA0EQhDUlxAQAL3egLJ0c9xHZnD4u5c5
xVixwR7I0AvHynNRNqbXKPg2sPBAwDjh/zN8EUSR6tOL28WGlk35x6iYopvixb91
NKwFzk47Zv9k+71JGKtaSVpxhttI6gO8AabD5mkpxXbaZZhj/mw/7+pliDLZQXRW
aDJgCwD7XngxVIVkUetTmLT7Zchmj6332X/B0NdG8zRDXoH8CStJdJJdegwJ+zQe
U0MRZRl9VoHjSAagL2Hk9rrlDwMUN00ectEGurih5CA6qVWAL18GIConndLwD2KK
a9J854xf1y/VtQKDzU2I3f7eQfgUZs+f6XBGm4mqFJg3+h1dEx+i7wgVZfEN9b9o
i2JyVk4kHNvuHQt6Eg6oL42Y58v/sbqIrroxtVPciBvYaw2bfQfhfzOS7Ho/P53O
TXGNUBznH2RIW/GWhJlT9zgfqnchn2D3YUZ2Fa63gItvUwVYoRDPygxMhGqxGRsr
HIr0envWXjpmozE+aBV89rsWk8f4bt1mp4jiMHKRo6Z8/50wkzWDBtSSguzig2ac
gMDhGG2QWEKTuOYS7EM6FEz4vhX4KZKk1DGVNkpK5736QE6MNqILlcsPcfGsT3QU
+7u4DFHQHGg7rdLFpBnKH5KtzHaJugChrxKhJiRTuriM8GzFYvKwOMVrtfThsX65
ZEzXsIirWKNmDoetffGx9MuTAAMFD/42QLAegFaiqHwjiK5ju+YUu0kme/VMu2/O
0rXIHDFruxCV9wWzICsvb5Ung7DBFgVTumI2FVLepzVkqXjhye0XJE0IiFdyydMc
2ahcuwoKsTlCbGzqqsgLcVXmSbrSyDZUjvfPnuOWZjSy3QALssLvbWl33bFl88H2
VvxRjk4AIDkJm6Q9i8fTp7tbyJfdtJqCFMU2MHK46vPVP8jQqg+mLhh/hPOhoknU
mlE9DrTGLOqoa8A9hOXjyrZuNeIb8+PMc8YPytFaIOL1Kt93qjJrF1wauzEaeZx2
fQMpHW5Ud7x+CwSrDK3QV4MLWLMFzP6bb4a7bf57Y9OLn30KWx6ia/Ff5ZYHANH/
4fK0fgaD1TropYUMkTXn+CjN8GeaEM3tz6FUWYUBjqa2n2coLfFR5kSBK/sO2MmO
BpFXNqcUiZ198exbqmaF6fpbBaIn2eo3LGGbw4gK4/nmGQb9wvoBPwJFcMXmhN8R
ymYE+jOFvMJ3W+9DHnryYK9t3b/+5Us3BC/oQKu13e+snXAAcQhtgNTjExU7qzcJ
CsEwOOdwZF8Zf/0aPgFmkm/PXghZYJfdbmLLbhEdSOmikm3B7pBx2S1ZTAAoXIuB
uofutdCctHUJs9Qj3ZRE8L+vRWlnzufhX2knX//WegDRpD0wdc94g0BqZpOT0Iuq
fBx0K+foFYhJBBgRAgAJBQJCENSXAhsMAAoJEG+uIptxBOpOFfoAn20qdgTPaPmI
Dx8oV0GpgT6zW3ITAKC0fDtfsq7z1vlOerBQRbCc4Rtmeg==
=/u/r
-----END PGP PUBLIC KEY BLOCK-----
D.3.192 Vanilla I. Shu
<vanilla@FreeBSD.org>
pub 1024D/ACE75853 2001-11-20 Vanilla I. Shu <vanilla@FreeBSD.org>
Key fingerprint = 290F 9DB8 42A3 6257 5D9A 5585 B25A 909E ACE7 5853
sub 1024g/CE695D0E 2001-11-20
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDv5ys0RBACm/dkRFFWNFb6pafzsHX3YHfyYBQAhyoT5ZPvvh7e6RdHYdxYc
tYjgtOid4jL20Uz7kXYwT5OVYo/l9j/AqknacYoboO5AHcJrfO3QjfztJaorUSqv
w9dv6DSOQWwTmexeshp6v5aEsOpDbfPtUnFBwcJe5lOBsokk2CqkzI/XqwCgv49G
uNLbdtIN87CrUwyiLG5nsSED/35/A/9b/KNwjBoBbheCJDByHNPd9svQIpVWTuk5
i5RKVQQET4ZD5tPQWPnSZ95ztkkwcjjOak+esHK85yTYXXjrfcP7JiE3HIZhyj3S
dxWaOFEbSE3Xc0BT+8BOAPFfb2WMSdCQFowkRqbMiFudLnz4tZnBmTQcuxqp4G7S
AFh8A/4jBhhkKaw0KeWtkFKugVgUWZNWZ54aJhUaLg5wGbSTNME74YLO0Xc+wkjY
id3gG5ayJyecZXCMUf175/ZaSPeNRCBOfMjDnl3G05b/huBFUnXzxTkWCcmopOwW
5tz4C69UVP1UHg4XMu+f6D48srIaFu+DOMTwniL95vqcGkCUJrQkVmFuaWxsYSBJ
LiBTaHUgPHZhbmlsbGFARnJlZUJTRC5vcmc+iFcEExECABcFAjv5ys0FCwcKAwQD
FQMCAxYCAQIXgAAKCRCyWpCerOdYU/oHAJ4kKjpX6iMF1Y0FjPMyFiyUlgjT7ACf
a3czQMrflxJC/VNuzMAmzA19j3y5AQ0EO/nKzRAEALHq1lBY0OBQBeV7sGOvTaBN
itMZeVDrGDYUQ9xunaDsEHfz2fD3jXCZLaUayv4LZeWzRr4DbnK4F0AmZLR1v5h3
LxBuvqHPRma5RyyFRftwTNHM+DWu6TSqnE43QS7Ci+z8ua96CmcDa+PnEfubyNLE
dco8gfE4oHDqni1R2qVfAAMFA/4uVSYj/DvIzckbZ05FjG+pg4HKsyxyFeFsrm9D
8JD9tC26k4YxLG5FPBdKRsDrN/lZbnLWHTtZqhE3WlX6DRlea93T9Vi2skbujKcN
mbao5pyVXWl1dboFquP8ku91CRTZvmdLF6IBnPo0LfOu4jD6DsD5O0UZ7lD/Y+6p
8WcDfohGBBgRAgAGBQI7+crNAAoJELJakJ6s51hTsJUAoIB80SN0z90ocSdxYGwl
xkOSm2cvAJ93DigXb3moOsw3BRLlLPQRS6TZxg==
=aR5H
-----END PGP PUBLIC KEY BLOCK-----
D.3.193 Dmitry Sivachenko
<demon@FreeBSD.org>
pub 1024D/13D5DF80 2002-03-18 Dmitry Sivachenko <mitya@cavia.pp.ru>
Key fingerprint = 72A9 12C9 BB02 46D4 4B13 E5FE 1194 9963 13D5 DF80
uid Dmitry S. Sivachenko <demon@FreeBSD.org>
sub 1024g/060F6DBD 2002-03-18
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDyVYkARBAC2Z/8odq3zwRIQZ9XOF4ZoQ8ITJRrTUwwYjwOf4Kz6gTH+zIGt
Q57m5w1Scse3J/fDdIZzw0gJgH0XRpKOonWi23di4B3Oyvrdr1Zm6OlqUjoty8CC
7jo5WlLF/05Vai2HCUmFeqiukCN0mfm3Fd8S+hf1IpE1gaIxCKNvYaf14wCgpoVG
Tqi+lIMCktV/vxUf3h7KgOsD/3nBeANz3U+Izr9g/AsF/FnHXeawl2m7USaIB7b1
4CFrQp8FDl6TCAtPHQyQ6pdnh0HZ3h+7cfPB1poRaXUvDimQZR9KHZO9uIilpC2n
MdBjbkXmvVQ5FhOJz49cXw51Lck11n/+OuP4N4TcIHdt0DQJoUrGIB6X6Op9aOrP
Ob70A/sFsFfebYdfH8loLsJkHU8VbB2Y0KZBXSnhysQ9muvj1HqT+n66o/3SliCE
R3cNVMgg51pqxzUC0o6qTVKJbfOrI5b2tbYjvx87ejugQwafhKu8t1liDuUYQK0Q
S549pzLKUr/NUvJaYU//6QlFIPNSzwB6x4wjrWAKBv6Vn+x0c7QoRG1pdHJ5IFMu
IFNpdmFjaGVua28gPGRlbW9uQEZyZWVCU0Qub3JnPohXBBMRAgAXBQI8lWJABQsH
CgMEAxUDAgMWAgECF4AACgkQEZSZYxPV34DFVgCfREoIUfpKaEeGyzl0zKThVC7J
XccAnjiB85SwuNAxMraQuGDJXojukUfwtCVEbWl0cnkgU2l2YWNoZW5rbyA8bWl0
eWFAY2F2aWEucHAucnU+iFcEExECABcFAjyVY4cFCwcKAwQDFQMCAxYCAQIXgAAK
CRARlJljE9XfgA6GAJ9RFwXlNqYap2SI14IPRjX9ZAzvjACeOC/Elh0HkwQ2HZMT
edpgzOuknUK5AQ0EPJViRRAEAO4VdFfYGd/amgG2MDGqD269Kb5vTFbS5mDczgjM
6gXZgOjhbvj3x2auo+Pfos6M/bOtHuIk7QFOeOEJ1wcg8wgE3L3kFQPeEPeOgKBk
/eA1ExIW3hiPeuwNxT3iWEv0GF/rvCSeSK3nuuDBNmkSpJ4LHIyO8Kf5YJNp8+6D
yJ8rAAMFA/4jaulRHxSsWlFIm3gpBR9aiXGGX1pZTuJpXqjAQcRzDa9cuVatiSJS
H9wzfE8R4353s5HpaY3AkVRjY6s9AB8bygGdUCQjuIuifTS4+tG/wmaXNgyqBqaB
6V9gTgfW/7XqcJUGeLLMUpccSRZhlQvHd18aTfPWPB49xu2+arw6P4hGBBgRAgAG
BQI8lWJFAAoJEBGUmWMT1d+AYlgAoKZWZs7rDLdQbn2d0CVwmWb6hQLhAJ9E/r8N
n3jf2PI8Psl2wtgvWazpaA==
=mkxU
-----END PGP PUBLIC KEY BLOCK-----
D.3.194 Jesper Skriver <jesper@FreeBSD.org>
pub 1024D/F9561C31 2001-03-09 Jesper Skriver <jesper@FreeBSD.org>
Key fingerprint = 6B88 9CE8 66E9 E631 C9C5 5EB4 22AB F0EC F956 1C31
uid Jesper Skriver <jesper@skriver.dk>
uid Jesper Skriver <jesper@wheel.dk>
sub 1024g/777C378C 2001-03-09
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDqpHqIRBACDazER4MfiNd6QrTZ925IKM0HuYP1YN6uodGYhCuBGb1a4cFnt
0Xuw1fuaGqahBnNmBg7Rsetaf7b7/w90Of286mRBgIJIr33VxaKd+lW8l6ORQK9K
bDR8/IpgHxjt8LXNdBr0/Eddj6mOPojooIDOmoGyj0XOlRb5bq+xWlDtAwCgnjQa
KG01en2qMUwrvPPZzyWg/qkD/3q+NyOVyi0MAgXdYNxI0tMrDPsRzmbvG8wxZQ1S
fGHGJEvlKhksePCteX3cLicrxRZazfIteiBXL+0iEvSauF7JZzhG5OfbLTQS2MKr
d0rFCSmez4VAJfx8nqJoA4C+yTphxAlyP53JKF2BmRbfSuz4vIbi0e+zsc+kZehS
7Tw+A/9tanL63z5D8qmPZAE1JqRJfyDnTthzUPPY9h1CEZN4jtcdL/FLME2TmKva
5kcgp0WTAGK0tHsyHvij7KZDAp8Z2R8/456DpS0Rk5vTBy+WKMWV+j+RlRlSAr1U
bkg6cEtMKCImXsprST8UImfJH0DFUXt15gQ4ogog2xPnuvk3/LQiSmVzcGVyIFNr
cml2ZXIgPGplc3BlckBza3JpdmVyLmRrPohXBBMRAgAXBQI6qR6iBQsHCgMEAxUD
AgMWAgECF4AACgkQIqvw7PlWHDE3ugCfa3zgBbxwCmIGGlSrwWPP0q+IGsAAnjuy
GZPJgHaWjAn+SrRftnZu9M0biJwEEAEBAAYFAjqpRasACgkQH3+pCANY/L0+bwP/
YrW19JdTDG7fDCYbwgn1ngA1y+nRT25G+ozBUJt5q0H8VL6nrWwcbfk9Yg6jWkIx
Qs2SF1A9yv0YXFqN1ihGYk0iTU/peZ17wP/TIvd+zkcrzXpdHrfrOy+xgalbi7+c
v52W/49xYvqBsmk0CDRSkdkYt3VgvK4Bo7xoBF4IEl6IRgQQEQIABgUCOqoEkQAK
CRBHg9f1XdH7jORAAKCxXIkp49PFrGbiM+JBIsMS+Ig2bwCfXeekX2maFMz4I8pf
AorI1IepXYaIRgQQEQIABgUCOqqpywAKCRA5SqH23klAVvt2AJ9kzNRR0EjI09CQ
TQ/m/Rr1/LCjCQCguXoX2XJHP/+HEFs2THnDfoLU/taIRgQQEQIABgUCOqzL6QAK
CRAKdbF0qMx7Ulw4AJ4oKf0ufrvJ5tus51E5w8dRFTx4PQCeOfwDs+ergM+7Rp2N
Borm6mrF18qIRgQQEQIABgUCOrIYawAKCRBMkXPzcEhgNMzHAJ4oa4hCoZOp4bG9
+9pCThBAKY2NYwCg7tQ9eNJdqMCEXGK/4m267Ln9QfGIRgQQEQIABgUCOrIYegAK
CRAwsbGPZ4yL3Zh/AKClN3cei8gFogDQH61mdjagTzuGBwCcDCt4N+tz+Vwb6zlF
vrUUqSdTMe6IRgQQEQIABgUCOrWzFAAKCRCykdjYZOuTLtrtAKCXRt59ypkFvQQc
f1HY29CrzPvh9QCgmpBh23D7Tb11yoM3i0/g37vIQ4CIRgQQEQIABgUCO3lDNgAK
CRDXYxq7nko3rv1CAKCLUGNAVyZsp5TXrCuse0/yF96vSwCbBl4Tm2/MZj/phNKC
UwjGw2eTN4OIRgQQEQIABgUCPBdmcQAKCRBJ9Xw5GLJJGyr3AKCZx1BGvYveU2GT
TaZ8X32klZsx9QCgzO/N422XbR5PIpnxt0FXKqSMFxiIRgQQEQIABgUCPEnw/wAK
CRBUdQxFFW0hZNZjAJ4tMdQoxwZQj3il91ndSrGUD5cWUgCePQueyaYG8JCruXDX
KTB5f1YZN3G0IEplc3BlciBTa3JpdmVyIDxqZXNwZXJAd2hlZWwuZGs+iFcEExEC
ABcFAjqpKJgFCwcKAwQDFQMCAxYCAQIXgAAKCRAiq/Ds+VYcMazBAKCMqcWbk7gC
hYm53EL6HVDoxaeDOQCfa6bEjXrcxW/EST0FlCMcs2LKoXSInAQQAQEABgUCOqlF
vwAKCRAff6kIA1j8vQA+A/4+e1LpjSu8NFfeky2GG2Mjk1xqzb1nzVDQlKmaPXY3
dLtqw5tVHA1FLNaSFXDg05NowqQj6OIfavs26orerWyRrD3OJZQBBde5gf/IZBVO
bk4WzE0hZmHQvchrWR/gDiHJRYnSw+4Sx5MnKBlgccZbIPxabHudUnx12iuNtTl6
O4hGBBARAgAGBQI6qgSmAAoJEEeD1/Vd0fuMdi0AoJdRZoDG9YwxVyp3wb+e/e0r
UPwdAJ9fFipa2TGSkCjO61unpDtawmJCLYhGBBARAgAGBQI6qq0MAAoJEDlKofbe
SUBW+xcAoKmJ3XWnXwJyFMD8CZfNABbBeYNvAJ47O8mk5vhbl7rl9LneJMNEMama
v4hGBBARAgAGBQI6rMvsAAoJEAp1sXSozHtSFmUAnAqhsMdq6Ihz1LQwrNuKXS0n
eaO0AJ0dIWyChTlqADHbW7Kfq4OZw7yyfIhGBBARAgAGBQI6tbRMAAoJELKR2Nhk
65Mu8CEAoOhXx5OkCJtIOBUbobpphx3QxZQFAJ9BZ7bxk3VdhpQUrEdlZp9vP3S/
xIhGBBARAgAGBQI7eUM4AAoJENdjGrueSjeuDXEAni1RAvL4LqDhx2GT4QLH36Zg
VoGZAJ4qq2IR+g4plSyfFC+DxfXgi/ASQohGBBARAgAGBQI8SfECAAoJEFR1DEUV
bSFkYvgAoLXHkVuyK7iXyhYrSTMeSZeYp8tNAKCloJ4rZB/E51xD49UAH1P5PV7v
orQjSmVzcGVyIFNrcml2ZXIgPGplc3BlckBGcmVlQlNELm9yZz6IVwQTEQIAFwUC
OqkorQULBwoDBAMVAwIDFgIBAheAAAoJECKr8Oz5VhwxEjUAn1QJFvqeDJ8gU8rt
gz3CmnjlsAAmAJ9BqfYvV5zxGvgkOKRyMu6i2Qa5m4icBBABAQAGBQI6qUWXAAoJ
EB9/qQgDWPy9FkYEAKwpmiuxudlg5EK/ZJ4ClDDdL+Nr9TXY0sKLSwJdDWpgqBAj
jovInON6rEeqa7CSvSlDozqzf97IdKRjBQFkogPbVSfvgamz0zJZtWkfE7Hvw52X
8U7PyWthoTwECIvzYKH35+NiecJQqXf+AfGRLF0pCSBLSXR2zi3Bqee3nZ3BiEYE
EBECAAYFAjqqBKYACgkQR4PX9V3R+4wBdgCfdPlMBWMvvNAcseruEfvAoRpkVGwA
oOGKx9zFdxeJMh1g+y7S5/9fRbf3iEYEEBECAAYFAjqqrRAACgkQOUqh9t5JQFbO
owCfXo3a9iJoed3J1BlGTxmGmUJj9coAnif3VT+yBgedsiHlhQSgtGzA3JnAiEYE
EBECAAYFAjqsy+wACgkQCnWxdKjMe1JWqQCeOyD7vywbVSEtL50PIpKC/OLOpWsA
njBP5yLKAJESHopfPxDbn2FKBN/2iEYEEBECAAYFAjq1tF4ACgkQspHY2GTrky4n
kACgpwg68nagqKErqB9OZD8yqrUqn/YAoI3YNI2VWY518f8pW2G06+a5nmtfiEYE
EBECAAYFAjt5QzgACgkQ12Mau55KN64LuwCfU7FdiOvvFKloFqFNKnypvZrh5H4A
n2giMNGYRQ5DYUPPcmmi5I9vx/JhiEYEEBECAAYFAjxJ8QIACgkQVHUMRRVtIWTJ
ZwCg8nPl82ZIFs4+2Opuoeg1AobzO9cAn2EbkcY5WfaCFO/cpflXpEgX6V5quQEN
BDqpHqoQBAD69+DjZ00uDr48npfWtrVxuDmZb2jzS3Tdt0p6V2gVuengjobHNb1T
6o4BIjPu/yQ8qDlDOb+OF63wfowMCIU+qNBBtmoSDKmQu0M9hREHA9PeHjIsN2dk
wpIAnM7kXHAE0T00QlBCLzjvef/xooKGdcaA4Zse+wLMixgwJbto0wADBQP9Hlh+
SI7YcYZV+nOhNnPdBG98UHNhDiheklrZ5BQMLzPEn+qHkaZTeX0SrEbPmm4D7nRk
UGTh1H2CIL/YaffqVYVKw/8HTIJeXZMgJwdq+j3S5P/Vnc/g83uZpuzdW8PNp6A2
u1JHPq9M1haoszxtTirQXxo4Ht4/DWaY1DtDkZWIRgQYEQIABgUCOqkeqgAKCRAi
q/Ds+VYcMQbsAJ9J+QGEzdNcvYY0lAXZAnLBnW7lDwCeNJmcu4gVYPvBDLe2Xu7Q
Crfzumk=
=Ru0+
-----END PGP PUBLIC KEY BLOCK-----
D.3.195 Ville Skyttä <scop@FreeBSD.org>
pub 1024D/BCD241CB 2002-04-07 Ville Skyttä <ville.skytta@iki.fi>
Key fingerprint = 4E0D EBAB 3106 F1FA 3FA9 B875 D98C D635 BCD2 41CB
uid Ville Skyttä <ville.skytta@xemacs.org>
uid Ville Skyttä <scop@FreeBSD.org>
sub 2048g/9426F4D1 2002-04-07
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.7 (GNU/Linux)
mQGiBDywu5YRBACKxY/5WzdUtpL2aK2Yy/Yde2spYiEP2vKj3bs+ovV7a9129lki
ldCu8PhoJO+x+96+AwbrR/T5FlXyQrInMa9U5os/8/HQjTXtY/oeq+UNDNFZrnMR
Gu0zYICbzgd1rW/tnZJBkB3X2Ao6k0hSATGmP5/sowT7EBSdaM7ZhhqOywCg5A5n
J7+062MfzdS/3KoSn+Utex8D/2BN/BMLvrItQBUjy0tn8Vsomx+FHbFKOm1cuOeq
smhsOmsANwIafiZnK4+SnQlVbXJLM6exNTqSimH93y7Q9BX7hmWYl0XVpUui0mBR
UrVG00PEa0jTLasOkvlyYBS1En4gZ5J2ArE2cYFPkv7jndqJ/pAAZkG+tQnXJ8l5
g0SLA/4tJHLJ6kPad98V3cVbTfhY2Dn/i+QbHvzBbBj+bETLEUdqOKzADGrWoJeE
fADfxYi24wHkpH3U781p4SldZpOUvkyYj7YmjqZP0AH6SsKI3i52z1BDQF49gRcD
uc0sSmv57yvjKCk1Cehen4/qaVcqXWTZ5NfyGb+hbHLtA2FxSrQjVmlsbGUgU2t5
dHTDpCA8dmlsbGUuc2t5dHRhQGlraS5maT6IWgQTEQIAGgULBwoDBAMVAwIDFgIB
AheAAhkBBQI8sLuXAAoJENmM1jW80kHL8KkAn1yTiwsMLq9GsqA44hkh1Sk0etM/
AJ9BiDSqgX0S/wzyXAqfYcsmxS96qbQnVmlsbGUgU2t5dHTDpCA8dmlsbGUuc2t5
dHRhQHhlbWFjcy5vcmc+iFcEExECABcFAj0dWzwFCwcKAwQDFQMCAxYCAQIXgAAK
CRDZjNY1vNJBywFtAJ9NCVHRa6GxtfTxae+6ZkTh08xQZQCfcGNMwhcSGJUyjKI2
eYucgrkwp2C0IFZpbGxlIFNreXR0w6QgPHNjb3BARnJlZUJTRC5vcmc+iFwEExEC
ABwFAj0di4oCGwMECwcDAgMVAgMDFgIBAh4BAheAAAoJENmM1jW80kHLzoYAoLqR
3unds+O73Z3EppJna4gECkQ0AJ0Uye7ZXLMTJo7pNmZSBSz6bA/qFLkCDQQ8sLvS
EAgAinenfe1g5Cdp8bf72+idBePq0zHyPUOpCuFGkiKXecXpgQUHCVYM8IiafB1M
Or9V97vy1H56sr+HaBsC75mpuPC7lnltoY+zq0zIkNbi20+p/546W7A5MV66xtTx
D6uUSyZ3jksAaVch+6yQNNxr3CDWiNSjomkK1ExPsjaPAA82L4yExAJJGwUYAPOS
B1Gw6N3dUtoNuQwJdcw8fjsaRektXsHm6Nnm++3gB0YJ4/x3gcvxlNlONHNp5vdW
msQAJtWj4isSMfqi6Y4SQsw2MWOKrYr8Lt++m4cQC6/VZXafTR/TrDZCqYhwovyX
vgLMdKfxTZLqsyZwgWDxFKOEewADBQf8CCEh65lRfWQG3MopboOs2fFp3BsfVMvA
stV5AYktLHvwGXTW0rx7sCdb3kBtKjiuNFob3gis2Nd05NUxFrzrZsyaktyDiZmT
gjmEL1LvodDg/mXLRQgl3QDzUL1nlfFQRkcKqlDfCYezbgYFxCy4EGsC86cf8s8F
ZI0hyXXY+zir+xJ/w4KBtL+cY5LJExh0FyPfNnL+tXUthRuN9wxZwVyQ9I4RTlkv
ybb8VTWEgzkIf5BiDZalvcOJNAujptlgz2cLnV4Kzu55Xy7jOi5YfYjMbSDa6W5c
vO/wbcAG3gwZOoeHBRjwTNkn4iBkDPq71o1LDDxHvWUVAO+jU3TrZYhGBBgRAgAG
BQI8sLvSAAoJENmM1jW80kHL1RMAoNsmDIuxlUf3YwjAr/fSqBOKWgN0AKDc0CBV
uZAqlAL0tDv8Fiz3HvICMQ==
=mEvy
-----END PGP PUBLIC KEY BLOCK-----
D.3.196 Andrey Slusar <anray@FreeBSD.org>
pub 1024D/AE7B5418 2005-12-12
Key fingerprint = DE70 C24B 55A0 4A06 68A1 D425 3C59 9A9B AE7B 5418
uid Andrey Slusar <anray@ext.by>
uid Andrey Slusar <anrays@gmail.com>
uid Andrey Slusar <anray@FreeBSD.org>
sub 2048g/7D0EB77D 2005-12-12
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEOdg/YRBACkP7DeG+wypqbAvKYmIYMBHsYFCmIf5928MvpCgwO4idtg76IX
Qd/AQH0sF2uFJiikI9NiJuq3OUXsyRk+7xltLLrgzl7/0GTT6jej8tWFH0AU1/0r
nYhUJ/svVe+QNNEbMOvCCcZLslv4/fuak4Ilvgcb/SAir8iUL+nfNzwLwwCgw+fG
2DBpULmZtyMUMZYwyi2UQ2cD/jycHnx1+AHLt24OajcWBoBG88DlcK3ERpg/J+D3
PYoNfs4qcEhU4UVQw5vhMXBnWxD+BiZf6yrh/GRay11oqShMWl/B4UQrZZBwXBVN
Lvx4aY6LRA/DAUd0R2CUIwsjaaeBQ2gmvISau4UjtE1ezNI5s/E7oFDNDKkv06Z2
hrucA/9G3+UlrLhDWd2+VMt99O5FFEhtHbClMUXIhXYwFS/41zy7cGf9p4wA+IQC
SeXns1bvdZYBxPAYTgDK0XGP8yi0TMpICcXB4v9gkqKIIuO3scB3mH+We66RG5mI
7sls5BoJ3ARfsJuidRS1Uu0TXqCTcj2NTCtDNWd82nRarNpDwLQgQW5kcmV5IFNs
dXNhciA8YW5yYXlzQGdtYWlsLmNvbT6IYAQTEQIAIAUCQ52D9gIbAwYLCQgHAwIE
FQIIAwQWAgMBAh4BAheAAAoJEDxZmpuue1QYMTQAnRGPeBTIOHdEj4nOmVtECGhv
jpqsAJ4pcMFoOwSyCqy5YXoetkQWrsq3IrQhQW5kcmV5IFNsdXNhciA8YW5yYXlA
RnJlZUJTRC5vcmc+iGAEExECACAFAkOdhSwCGwMGCwkIBwMCBBUCCAMEFgIDAQIe
AQIXgAAKCRA8WZqbrntUGGMkAJ45WS+CK9Uh2UYk3kGG6/jmx3kVFACgl3ALZehS
E1Z1ifNha7XLh8C+U3G0HEFuZHJleSBTbHVzYXIgPGFucmF5QGV4dC5ieT6IYAQT
EQIAIAUCQ52FUAIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEDxZmpuue1QY
MzsAnA1T9Wkp8yaxQmPBuuvZNrTdJOBjAJ0TJrwVeQW/+3zffBICU+rptKA8xLkC
DQRDnYP9EAgAjavYUHgBttL7+qFwfeOJ3oW+sNVNsMp4VGWvy6QeVCeFvVK+Kpb/
eN9ScAFJM+8wzhNHv3eyXFht0jwSadX48a0FzcYApm+pP3OH6y4Osxhz27P2tc2u
yzKMV19nZz28cikY2mtH3Y2GtSyn8pOIL2Ar4sc+hK1LnszGTPf6YgLSBlJSnGH5
+TMg1Pxq/CSDIq4zEv9IyBLlbuK+w1/fqDzLBT5L51FdKDUpsCBZNPaRiin+ZkBx
LI742GusIYz+aIcwsRBDONnWdemAHbtSFDxMup5SSEvlAtEU5O0gO6bZx3tv+WZT
6EJ66QsE5IszzTGkw0qK/H/BrsEbyOPbOwADBQf9FOrU6qF1Zj/ONad4vzbjDrn5
nI1vnrBkJ2QJnMM/d6V2ItUVjz9myqXTgteERmwN60DD1jrTqsw5xWHJ/rjJCoW6
mUHWjVkUram3OL/HO96t8zmTZDynrGXfnzLqykkLgJVsVmoU/1OCusY6h0CMAiWr
altooE6mD4dpBQq1svwJEe98/X97LJix0J8W1QLOwOi8lD5kApFf6feTRCzJKcOy
Szr3NiiwYGGRyHDQhe13KiGoJZQbhoJlbpS7krBTAxyUll6RRtQmlITLF5wmP0jV
JWPN2tZ5BdmqYEqOoH4h6Dj+D1glXT19YN6kh+CV1w/d6iWWiB1lDXwDOQMtFYhJ
BBgRAgAJBQJDnYP9AhsMAAoJEDxZmpuue1QY+tUAoK4RQLo2F+0c9PlfrfUOYpOk
GAzYAJ0dMZ6xeDy4UKlIBdDq4KPZk8IGzQ==
=vOBB
-----END PGP PUBLIC KEY BLOCK-----
D.3.197 Gleb Smirnoff
<glebius@FreeBSD.org>
pub 1024D/1949DC80 2003-08-25
Key fingerprint = 872C E14A 2F03 A3E8 D882 026E 5DE4 D7FE 1949 DC80
uid Gleb Smirnoff <glebius@FreeBSD.org>
uid Gleb Smirnoff <glebius@cell.sick.ru>
uid Gleb Smirnoff <glebius@bestcom.ru>
uid Gleb Smirnoff <glebius@rambler-co.ru>
uid Gleb Smirnoff <glebius@freebsd.org>
uid Gleb Smirnoff <glebius@freebsd.int.ru>
sub 1024g/A05118BD 2003-08-25
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD9J8QsRBACUyUv4bahsxZl2FID6EMQWhx0jTm3USIrxLV/Gc2z6k2gpFPtO
V6qVzHSVV8uaIRGf+7Yh+uJINWeMJpmljvB2bjr4kSJcIKPA9O6QwlCS2eCEKLRw
pLz5T7NAE3+unm+jI+cTEF6E+oBJX1AoRDdxxfbrwKwHDs4GVnvw59sWCwCg5gc0
QfYCexqGbOx7s+xjcXRxitMD/1ueSCsb2RLvV9hZzwsFOV3p6lahZPyC/TZaL+5D
5xwQnEvU7VXFhgd+G/XcQ7RwNLYkNVK4yhSoKK1WT36zs16/1elfqXWmslJpquIE
OL5AEeVapZMrY6Q6/W8YzsydZGvt+t4vQmswlHurUW5kt1KrCNw0HcalN49Z89bC
DMLOA/9JNuDx7FwK9IotF+HStr10OQP8pFuQWdFJp1x1+Pj6EzZgP73997uyQKx9
mVHCWmKRR6vbhGvczoPbZtJH15XBmxhkKL8lXUSTkmCM5uOj++lSIGExIyfF4WY/
pq5u2zx+n5iDUPwGEQ7pYKg1imEUztdlbtQL/JHFaRNE2uZETrQjR2xlYiBTbWly
bm9mZiA8Z2xlYml1c0BGcmVlQlNELm9yZz6IYQQTEQIAIQIbAwYLCQgHAwIDFQID
AxYCAQIeAQIXgAUCQ6PhZwIZAQAKCRBd5Nf+GUncgGV9AJ0X9u5RVsjPEDqcbPW1
v9m6L8Q1awCeN9KlEFA98q410EuJ4p+jMagRF06IRgQQEQIABgUCQ6NFQAAKCRDs
8OkLLBcgg0NtAJ9C9g0IiwqcovPX8OxitOfNBKr0/ACeK5tVzTjtD7CPT2Te5Lyf
PRrrI76IRgQQEQIABgUCQ6O9hgAKCRCvItzveM4QX6Y5AJ4kuc0XU3IVheKTg4xW
t6tHMfonUgCeN7ZI83DTxTfMcwD33nB1zzCckE6IXgQTEQIAHgUCQZH1iwIbAwYL
CQgHAwIDFQIDAxYCAQIeAQIXgAAKCRBd5Nf+GUncgBajAKDbr8m2RKDOHst7XIq9
E2NQhrtJYgCeMjfzpd91CuIC+PvwBHT0ZIonfH6IRgQQEQIABgUCQ6MnVAAKCRBN
yUvYtx9gXT3uAKDlVBFtR0zYcr0fdINqd6b+ODLleQCfdTdeGLPZ00pKhHcY2gkQ
WxgLN3CIRgQQEQIABgUCQ6Z13QAKCRBEbQwwjJFkKP60AJwMLagg2dbRBFmL91Lq
7gMAZxGIBwCgvVmdmtCF0ylHW/+2vWQjhyWQQZOIRgQQEQIABgUCQ6Z6KgAKCRBE
idDtZ5uBGfiRAJ9Dwj+nR2yCDvxQDZZWtfFghEGalACfb+HwuhwJY4W7UT/mSOkP
gi4UBmW0JEdsZWIgU21pcm5vZmYgPGdsZWJpdXNAY2VsbC5zaWNrLnJ1PoheBBMR
AgAeBQJAWvJaAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEF3k1/4ZSdyAjkoA
oJ5ea7eNHe4vharPD78tvFGINan6AKCc1hQkVgHHBdR34MUr0A5DoqtufohGBBAR
AgAGBQJDo72OAAoJEK8i3O94zhBfAt0An2aVzRpj8MBKY2KpRg1F7vVH0DXRAJsF
cLlvUKbwmvtLfKGh1404feJY4YhGBBMRAgAGBQJA9O+8AAoJEOzw6QssFyCDpm4A
oKCLUgrLqtoOQnTZ2jo3oPTVaUWUAJ0TY4St9fqkzj2H6bmS5W7XN8EP+IhGBBAR
AgAGBQJDo9qbAAoJEIXUUEVraRsDHdAAnjsiwoMw44Eub0p9wvvSBQ5WAM1nAJ45
F4vuy6gvEfPng4xwbP+sCsbreYhGBBARAgAGBQJDoydbAAoJEE3JS9i3H2BdseUA
oId88tVAMkRBmfOOrcu8vm0KQvnBAJ4iZxkQ+bDX9bAdpzQCSdG67VfTCohGBBAR
AgAGBQJDo0CRAAoJEEKxk3zIVQ9MrVgAoImcVrxzUswMYPbksKQhrzsnQ97mAKCH
EDAK6j1Axj7R8RAG0mZCN5/fhohGBBARAgAGBQJDpnXfAAoJEERtDDCMkWQoIeAA
oKZPAIAIOpgUovspAgkiUU/Ua9U9AJ9LI35CcROscoeQjXDABe6huL/aMLQiR2xl
YiBTbWlybm9mZiA8Z2xlYml1c0BiZXN0Y29tLnJ1PohbBBMRAgAbBQI/SfELBgsJ
CAcDAgMVAgMDFgIBAh4BAheAAAoJEF3k1/4ZSdyAQ4wAn19jlTy/RWdg/IgWKWwi
l92sEwCJAKCQf469ekDrV4+eaymvdQM1L6C7zIhGBBMRAgAGBQJAva1mAAoJEOzw
6QssFyCDUWUAnicFUWTy8f2WXoC7syzLcGg+tIjYAKC92GZTmBwRkXQznOSxjMKK
2itlu4hGBBARAgAGBQJDoydbAAoJEE3JS9i3H2Bdtx0AoIYk/JVyc9014s2W0oIi
bIvxej44AJ47/sn4X6fxkk1txEqlVrVs+exZTIhGBBARAgAGBQJDo0CSAAoJEEKx
k3zIVQ9MI24An2SXKlaCgunwPJCaxJ+8BzDlF9reAJ9t5xRmP/wW/C5b+h4+I42C
WbB3/IhGBBARAgAGBQJDpnXfAAoJEERtDDCMkWQo45sAoICPZ2Ri5oKwiAjDaMLQ
9Lj04GcMAKDUTGDadWWVzaLZYrMjzm/J25nDDLQlR2xlYiBTbWlybm9mZiA8Z2xl
Yml1c0ByYW1ibGVyLWNvLnJ1PoheBBMRAgAeBQJBkfVmAhsDBgsJCAcDAgMVAgMD
FgIBAh4BAheAAAoJEF3k1/4ZSdyARMkAoJFGLvMlavwswwN9yYwsMGziPz1WAKDU
1P4aVnRFTtSbYLoY5w6WXkLrH4hGBBARAgAGBQJDo0VDAAoJEOzw6QssFyCDCqAA
mgIGi9xU3k22UCNWG3Zjr8IbSrzXAJ9nLy69HxBnI4xPL3ILe+89rIqfYIhGBBAR
AgAGBQJDoydbAAoJEE3JS9i3H2BdyvsAoJmuBspiBZZpVXSfHMcDg2FW0tCWAKDl
B89Ie4J8fhN6CrN/B5vPORcUsYhGBBARAgAGBQJDpnXfAAoJEERtDDCMkWQoHbMA
niIWmZv1IbFMfyb0ndvFvFeVZ8fsAJ4rPKRN+jOB/lDK1bNjynHHX4+F57QjR2xl
YiBTbWlybm9mZiA8Z2xlYml1c0BmcmVlYnNkLm9yZz6IRgQQEQIABgUCQ6MnWwAK
CRBNyUvYtx9gXXc+AJ0X91Ts2ljW5yDy57Ruvfz9sGahPwCfVg6KTHU4wstwvjvp
T2yj0vUXer2IXgQTEQIAHgUCQPQ+HAIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAK
CRBd5Nf+GUncgJPGAJwOvaGydsrBZN4rSUfF2hqkkxjs2gCgoHcmbWJeJyLauhqF
mVJKDetjjXuIRgQQEQIABgUCQ6PaoQAKCRCF1FBFa2kbAxrPAJwP9olZAbPB+1ts
I4aPR6YGoRVfSQCdFwRSbPGCKApOR8N5b0JTUM3YpKCIRgQQEQIABgUCQ6O9jgAK
CRCvItzveM4QX0zmAKCRfSo7dn+i+dxE3D0+oYWbpXI31gCgjCLObLKX6ZwqjNPw
Gk8zlL+tvfKIRgQTEQIABgUCQPTvvAAKCRDs8OkLLBcgg5Z5AJ0Xj0lcwfZaHtPM
TM1JE0wCDdAIqQCfb9QnwNCxEr8YDm5Pl8jLSAEiRIaIRgQQEQIABgUCQ6NAkgAK
CRBCsZN8yFUPTAiRAJ0SzL9vooMSHAZT/oTLdaFjBE6eSACgmfpIxb/mowK47pt/
6fIKDQip4oCIRgQQEQIABgUCQ6Z13wAKCRBEbQwwjJFkKCzvAJ0eRuYgFjTDCESS
WrVF40q5pgGYkQCeJzo4ME7343Kx1qZgHcLp3vtbAsS0JkdsZWIgU21pcm5vZmYg
PGdsZWJpdXNAZnJlZWJzZC5pbnQucnU+iEYEEBECAAYFAkOjJ1sACgkQTclL2Lcf
YF1QQACeIdkowF59NeomERMsof4r0bBYKK0An0JLvDq2qZX52MPrE70GB+lQf6xE
iF4EExECAB4FAkD0PnYCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQXeTX/hlJ
3IBnHgCfakd4r4KTQPcsXoTjUmdu0ACRIbcAoLxwGA4grxJt5m5icZHttw+L9InH
iEYEExECAAYFAkD077oACgkQ7PDpCywXIINDKACgksXrxU8Y5nSO4kUvp9MdzPvV
qxAAoLJm3mqmv/JD2ivoaGtUTjPF8hiQiEYEEBECAAYFAkOjQIAACgkQQrGTfMhV
D0xQIACgl+zgTpoAgnNhv+3RtzDJ7lUSB38AmwSHia3NXEcpC3UC8DwQfmmOugm0
iEYEEBECAAYFAkOmdd8ACgkQRG0MMIyRZChu2wCgsiuqKHtAz2IUvz+g15tMyVsm
21kAoPRIOV2CBf93Vx/n2zYDBJS9S6MKuQENBD9J8SEQBAC9eRKLwb0YDhMAzaCx
U4dSMuKCX0feG8T947PwVDTiCL4TUccqEmuV0jnvs8HR1O3KJ0sz9tIPFS/rIEQI
TN80rE3mznJJJRqaNfoFYsloUfiwpI056fwEe7/zpPR3N45q3t5QpvOTHE3V4T67
Q+yiJOzu621VkFsqrXUQ1xejSwADBQQAlRwT36KGswvQEQdGxGJ69i3OC6bE0q1h
xqJOuGJlqEkcQiwWx92ePYuShzox8jaFFBCnNvsha3j6ArGSZakx0LXW1p1G/Pvl
FLu1P4npZJKvFwh3WVooaV1cUsdE68HU0k5bAxvBgMJ/wWp/OQcurnhWeV0H1gmh
dBwhppjd5ESIRgQYEQIABgUCP0nxIQAKCRBd5Nf+GUncgEglAKCjiJSCDTn4IOoO
7JGkyCRerJup1QCcCec4su8W7fondrpubUDLX6B7Z5A=
=buTJ
-----END PGP PUBLIC KEY BLOCK-----
D.3.198 Ken Smith <kensmith@FreeBSD.org>
pub 1024D/29AEA7F6 2003-12-02 Ken Smith <kensmith@cse.buffalo.edu>
Key fingerprint = 4AB7 D302 0753 8215 31E7 F1AD FC6D 7855 29AE A7F6
uid Ken Smith <kensmith@freebsd.org>
sub 1024g/0D509C6C 2003-12-02
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD/MDZIRBACfyWbQW/cZnu504r57DAQbCbTYNG7V/TgfZwphIPyC8YnLtmJv
vLdtl7+ToiG7UJUJsBE9OJdb1qA7JP5+jha/TlzIAUMW8doWNyI52nM1zHzBAZVE
aB4Gxy7pib9yBsrGYiLbuV5YfB7TUyea31OXpZ4jPl1E6RxlYdVuzEhq0wCgnOeC
SuO0cJZMXisY7DhoF1Q8ucEEAIALzShJ6bbjABbcvMWmoRwXvIcBsAcjKSdRcIp0
AP+9i3PSZkNXV7rfYM3+SydTa3sJIVBbdXChQakcZqu9+rmfL53rErErYuRwKqhX
mkp4+3GO7cKm0Oya1xLF9es/OfkKcQ9LxkEytNEnU7xlUNoP8fkCMJcBIwagzPfY
7UAzBACEwGP/o1e0R36jOAjrUZsxe63Zopz5138bYdZtmsqwI+QHK6+/tS5I7FCL
EQZL6fEjR7gF1lcj3gC2nypjO1aqodx0hShlNnz9d3uJ0q8EChjJuc30UhjgTcbb
ZQv3hssKHkvTJ5ch0x+ohYCfH+Gcd8jbXCZvvS8PcI66DRaz3rQgS2VuIFNtaXRo
IDxrZW5zbWl0aEBmcmVlYnNkLm9yZz6IXgQTEQIAHgUCP8wW5gIbAwYLCQgHAwID
FQIDAxYCAQIeAQIXgAAKCRD8bXhVKa6n9nfpAJ9MHcwNehlbFRJn8B9tlLBE2JvU
aQCeLuore1PhiLZPjHriz0/npGn9xDuIRgQTEQIABgUCQLQblAAKCRDYyjFxW6BS
wyFIAJkBI9/2PBvvTvB0FZUF2yd3JEQJMgCgpWVGTdChec2z/YGMQ/EeTgNDThy0
JEtlbiBTbWl0aCA8a2Vuc21pdGhAY3NlLmJ1ZmZhbG8uZWR1PohhBBMRAgAhAhsD
BgsJCAcDAgMVAgMDFgIBAh4BAheABQI/zB/pAhkBAAoJEPxteFUprqf2oVkAnj0Y
vcFOkVU9JWyJJKieWL/+OuNSAJkBvi/uFt2RgkNgUOvHR61SxZrGeYhGBBMRAgAG
BQJAtBtxAAoJENjKMXFboFLDvxkAn21uVgtvwLN82vOpKTvBzwAUVK/gAKCKEQDk
vfyMyQZayoFeC8cMagaUCbkBDQQ/zA2UEAQAqYnqd58qHyrKfsw3SrTE74/4qneU
ra7FY74jcUhGhrxOElG5hXrHHEHo+0M+0zFwhqedecj2GZbrzGEl5SxVsme3slAf
Gt5OaAk/ojOY5d5rTezG5v7jSr4EX0JKDkdlve8RozHsutXznsXmUY/BfO1qACek
herQeczznycJPZ8AAwUD/1MF+jo626W+4/gMgjgCQ+saOiNI6AnGlS879MUjV0Ef
j6aPfAJ5Xi7zNqkM+HdNBxjPtyxIK8RqmdAjHDMR8FjlZjf+svwuL2CfXk4jCk02
OXD4dxJK74w/ZTK2kSW1VW63+5K1lgsRmZvnTpGZ4ijxj4H0r2bJFQ7iUd2kNxpO
iEkEGBECAAkFAj/MDZQCGwwACgkQ/G14VSmup/YeOgCfcaCQpDfKaEvYiw7XJryW
b4OXclEAnArceW10G489Csi2QR94q7clHU0G
=gLKU
-----END PGP PUBLIC KEY BLOCK-----
D.3.199 Ben Smithurst <ben@FreeBSD.org>
pub 1024D/2CEF442C 2001-07-11 Ben Smithurst <ben@LSRfm.com>
Key fingerprint = 355D 0FFF B83A 90A9 D648 E409 6CFC C9FB 2CEF 442C
uid Ben Smithurst <ben@vinosystems.com>
uid Ben Smithurst <ben@smithurst.org>
uid Ben Smithurst <ben@FreeBSD.org>
uid Ben Smithurst <csxbcs@comp.leeds.ac.uk>
uid Ben Smithurst <ben@scientia.demon.co.uk>
sub 1024g/347071FF 2001-07-11
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDtMtwMRBADrWbrHZdss5Nlj/VpLW92lUpmYdmw5l2wYRtTTeHXrfvUk++pX
dJ0l1bSC829hokrlQiJZJdiPqu0fGnhxXoeA5QMvrtjMAG8E+MRSLIUaay08SLeJ
NhQR/ymiLFmh5ZyzXyG+qhZj7/xw3ynHLQ/KHPhRJpAs9ef0x0rgMZxJQwCg00Y2
8eIQKg3mikkLllnK7OHgMYED/jEhj6G2BLjKc/QliKn7KZZ2Ev4MMKUj36LPgzqH
VTEhliqbRylW/nCFWhMyxbqzRjR0t6ng3PJYlSltcwwJheySHRogxV/gUvYMwQau
WKkyFZfiO8/OBZkbuQotLI+4tU2cQFzBTuFIogh3Eg6PRDKUFx6g1AlbloFgmimX
mdHABADTVFYFKHY9YuUTfpD0S0uLFQrtj3xyZGfA4tjXtc1xCgSmkxIVUoTzg09u
EtcEvo8FzmmH5JQQV7cM8TTZutSFcHuCftwbhoMH562YkbuY160TCDHB9xc7hzk3
uzij7HKskm0b6QmMCI6LAYHhAuTk1IKY03DwLBIgEX8g68wyBbQjQmVuIFNtaXRo
dXJzdCA8YmVuQHZpbm9zeXN0ZW1zLmNvbT6IVwQTEQIAFwUCO0y3AwULBwoDBAMV
AwIDFgIBAheAAAoJEGz8yfss70Qsc6oAn2Kxzsk/d1GDM4VssT3U3jaHDX5FAJ9l
jFv088oFIgnhUiBOmoPEcwnozrQhQmVuIFNtaXRodXJzdCA8YmVuQHNtaXRodXJz
dC5vcmc+iFcEExECABcFAjtMvDsFCwcKAwQDFQMCAxYCAQIXgAAKCRBs/Mn7LO9E
LEV6AKClm5AuE0PobuyUVri0ZPT4Qzn/SwCfUO4Q/dz2kXJfcoi+svIdboVWsz60
H0JlbiBTbWl0aHVyc3QgPGJlbkBGcmVlQlNELm9yZz6IVwQTEQIAFwUCO0y8XgUL
BwoDBAMVAwIDFgIBAheAAAoJEGz8yfss70QsqkIAn3CdGD3kdBP8cNCWB/mmdlJJ
2Ba5AJsGjmI0R+adewxQuNIGxPuwfuhqSrQnQmVuIFNtaXRodXJzdCA8Y3N4YmNz
QGNvbXAubGVlZHMuYWMudWs+iFcEExECABcFAjtMv/4FCwcKAwQDFQMCAxYCAQIX
gAAKCRBs/Mn7LO9ELCM3AJsF3zHJhMdP7zGhP1Sbwh0vOA8WYQCgxONfpOQhAWu/
WwnZZnwNjUcnbh+0KEJlbiBTbWl0aHVyc3QgPGJlbkBzY2llbnRpYS5kZW1vbi5j
by51az6IVwQTEQIAFwUCO0zAYQULBwoDBAMVAwIDFgIBAheAAAoJEGz8yfss70Qs
txUAoKltbmA6D+5e4f43LWOOqfv6P/jOAJ0eUczvTczRuBzg+7fs0MsrtYtteLQd
QmVuIFNtaXRodXJzdCA8YmVuQExTUmZtLmNvbT6IVwQTEQIAFwUCO0zAkgULBwoD
BAMVAwIDFgIBAheAAAoJEGz8yfss70Qs57MAoK3vUyOUBVsEoHitX5eXJDos2JnX
AKC4pG7X9x0EziSKSi/SFmRRNhx267kBDQQ7TLcHEAQAoByKPA5d5RrBOmmVb6cA
5T0sQvYBsgHpn5INcPr4/B3pAXROzu+SveIh1yg6f5poE4LhxQ0Yva0sCPVI3WPU
YDpOSu4l0BikO26sQ1WdGYpRiTxuFaqzKLapIiDOz1lpY4o5yChEKtJw6t94Hckr
Ss6dPH9uE4hoaWxdbvquTrMAAwUD/RrkuvBBqAjN7flRrnNuQA04j8Oc5/znRiHQ
Ojq8i0w7t1qrT5zCNbd1S4Avo8hc5+G6ap9nv5KA3G9TKsgBQjcCB038k/k0pzRg
JZhIOVBXpbPb8ZahMk7Tdm7nGgILJzfW0cg2AwToKpEcxEVrhdtTjc11/J4q+wBO
07lDXfYgiEYEGBECAAYFAjtMtwcACgkQbPzJ+yzvRCzdZwCZAXcRSox3VdhHpoJV
FlnCmFbg4FAAmgPfaRZc9BE1SF825LsiKDAvUzs+
=D508
-----END PGP PUBLIC KEY BLOCK-----
D.3.200 Dag-Erling C.
Smørgrav <des@FreeBSD.org>
pub 1024D/64EBE220 2006-11-11 [expires: 2008-11-10]
Key fingerprint = 3A1C 8E68 952C 3305 6984 6486 30D4 3A6E 64EB E220
uid Dag-Erling Smørgrav <des@freebsd.org>
uid Dag-Erling Smørgrav <des@des.no>
uid Dag-Erling Smørgrav <des@linpro.no>
uid [jpeg image of size 3315]
sub 2048g/920C3313 2006-11-11 [expires: 2008-11-10]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEVVy+cRBACQ937Evm9hWTrWo4PSxJEs7Ce7g1iMAAa1aZwAG0iUBupM0vcd
eag4BxPWZNcWE86IB08tM9vdrXAS/+lKFPuKQDhBfCSPrvVHRdFokTaPZ8lekMCc
vedIojkHs2v5hdXwud5PmLiBXIrTzIkIwKeSO5uZDE8fxvpCsD+XgBXnvwCgjTJS
oaFH9GnwFvPZi+3chQ2T6fUD/AoFlEbJw0pqEopbYbIun3CBTl8G8sCrn9X6IpKX
Lh4CwzlJOV2+3hKUnK2Pv00R7kJmGI+0TrGjF6O0zeRkl6eNXQxgbhxrY3QJpTlC
PBq6bMcstlqRn7V4YCndXLRUxUNApg/BAiex3Jk78YUR02Fm8Yn5moKa8aYI+Kg3
q5HbBACF/bIV/T85Jzds6ShS+OpzRXeL/v0640bdoJxjlcCvuF/zldp4ynB7mz5t
+JDY4jBi+051uOMNGPsUbeSoc7/SXAoh3KnzO1GpX3hGzgXPg651TiJYSUx5AKvS
h1YsRbkew6JzEdcjSRgEROYNfk1n4Vqy0t8sxxkogaEpT0dVJ7QmRGFnLUVybGlu
ZyBTbcO4cmdyYXYgPGRlc0BmcmVlYnNkLm9yZz6IZgQTEQIAJgIbAwYLCQgHAwIE
FQIIAwQWAgMBAh4BAheABQJFVcxYBQkDwmdqAAoJEDDUOm5k6+IginkAnAhVjjz8
rtrJGvX072L8g5sR3dCUAJ0QjELqG42pdZuk2vAqxGUfnLthiohGBBARAgAGBQJF
Vc56AAoJEBXWiATKbN+ycOIAoIOoNuBhwUECQ8gLCbZ0UM32KYTuAJsEFe+fTwfm
ke3z1EyqLw6hI9kRT4hGBBARAgAGBQJFVdEHAAoJEKBP+xt9yunTmIwAn2ZYsSEN
JuXc/RtkiyfsHd9V3r+5AKDjk6T44A8yt1rJTxAafISkWnfqz4hGBBARAgAGBQJF
VdLFAAoJEBRll9zcw5nHLMQAn2owiwjKy9KHQPUrxdPLlu+8wzkjAKDTRxKO95jd
q4ciRH3OytDQnNAWX4icBBABAgAGBQJFVdThAAoJEE1WKCF5BQwRljgEAIhEqAWq
ANd9TRbaZusKCbebxj4KwryatvRFnACdf2+QdQPlMWXLFT/o0mOWLfO/ZXp5PR8q
yh5SLS5JzBvtfqQ8CpXlu7d9gQ/huDEYIbfOHeQmURjh0xz7eNeOpo9aI873o988
ZWY5xerzBLpI2KMOW4D8FE3+3BBRimMJ9PquiEYEEBECAAYFAkVV2iUACgkQMxEk
bVFH3PQ6qACeMcmmhoEdyUWqJD6XFRtoWnGQAqgAmwRlgx/5K9EwGnkVfnUr5rfZ
uEEziJwEEAECAAYFAkVV0YMACgkQH3+pCANY/L3LcgP6AqlGo3DYeCAyAoNM2rZ9
foI9+4/601jrEmiTMZ9fCc1KQ0bs1vg3Q3iZlz1NaE08zMN6ub14tnCeWSzTMaKz
741lm4ZxuHWnyQdEjUGqcnCSykHsyyZxl4urkWJNO/3Z+o6MT+8Cg1Q8Tsz0iSJ2
kopIJC+1PYuIV35MR4CFhSW0IURhZy1FcmxpbmcgU23DuHJncmF2IDxkZXNAZGVz
Lm5vPohmBBMRAgAmAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AFAkVVzFEFCQPC
Z2oACgkQMNQ6bmTr4iCLbwCffkTovf6eg0tYwfDzZG1K4HdeNYAAn2SOy0S1cAXj
k4ci3x00pisEE3U8iEYEEBECAAYFAkVVzn8ACgkQFdaIBMps37Kv6wCglU9/QpZD
u2Hj9UPHjN/0uFLHyqAAnisZb2MNvsS9KAegVN7zUpnJl3itiEYEEBECAAYFAkVV
0REACgkQoE/7G33K6dNA5QCg8aTnAQKQVvazXOU6fdWkxIUumzcAoLyiGBpVQrYw
nWXMccFVtVwW1sDxiEYEEBECAAYFAkVV0tUACgkQFGWX3NzDmcct5gCgw3kM7D69
rLbMfq25L/Tz+NelmGkAoNZ23I0g7krjj4L5OKVCXZu8mtcIiJwEEAECAAYFAkVV
1OsACgkQTVYoIXkFDBFEbAP/Sojn7y3EoAZxa/5Y6kiXUk6lx9WkZxV/8Q7pf+HK
nMrL6skQPUSjXqYNcM88WAzLR6VGAHhM0YKG0q2cHF3xNzOXyggd60haFYD+iH/8
3MQc09/rn2oYWtPrzXlmnPpcydmQfKHwd6e9+FIc3213KIchzE1dncNihUmjwPOs
X6iIRgQQEQIABgUCRVXaNgAKCRAzESRtUUfc9KgUAJ4j6eaNQsKeaL6xSBWuv0xl
i10PjwCfYKdih3+QEPKot9zYa+MfzsH38peInAQQAQIABgUCRVXRhwAKCRAff6kI
A1j8vWCjA/9kzjUYKAIk1ZUo3v0IXS0qvFLHr40yNk0CnJPEU/DqMIarg65Y946p
E+GZJ1gTDtnzZga44AE1wcMTQPlX81sWkTBB1osNRU66NurTHf5fPO7gehv/Euzi
BER5FsgnnUk4HuCCbNOxsscpBjkUiYSXVoZQa+XgA5BANmW+IaFU77QkRGFnLUVy
bGluZyBTbcO4cmdyYXYgPGRlc0BsaW5wcm8ubm8+iGYEExECACYCGwMGCwkIBwMC
BBUCCAMEFgIDAQIeAQIXgAUCRVXMWAUJA8JnagAKCRAw1DpuZOviINXPAJwNOWfH
J+QUI+oREvQzD/7X0x/WAgCfVO9uN1bna3u07QRB91J2QSqoRV6IRgQQEQIABgUC
RVXOfwAKCRAV1ogEymzfsu4AAJ9KNsOzSiIbLHJyhvebODRgPiOe9ACfSVHbJWV5
Gv6j2Ee7uMBqGDmm6VCIRgQQEQIABgUCRVXREQAKCRCgT/sbfcrp0y7FAJ0XWB/r
gkcjG5dZUGaNFvcvBZXgeACgl8FJS3gJP3WCS4mwiQ2YE23IQySIRgQQEQIABgUC
RVXS1QAKCRAUZZfc3MOZx8IOAKCUm2GhELKFMKQf/J0APIu3YjzmQwCg0a7UnQcw
h5Tyqh5tsBP2dIKvVumInAQQAQIABgUCRVXU6wAKCRBNVigheQUMEdbcBACT5jwZ
WMTZApWUXksb+Br/4AJQuyl/ioSM/QKN+ISUoL8z15u3sMyAeRtxRPzdyzM70qF/
pil2EJ973IGONRbsgDSkxXeEnQ54NaJSgZb43WJu/PgARN5PV0Bv5lovGYW0hbMx
MvlE8nVufXrrJnHLhp7ZMDRvfLXPf1adNBoxJIhGBBARAgAGBQJFVdo2AAoJEDMR
JG1RR9z0MFYAnAmoO/9oTt1qNQfmEvHiMpCwC7MMAJ4/lhNKKx/5PZeIw2AGkG2V
iiu92NHMRsxEARAAAQEAAAAAAAAAAAAAAAD/2P/gABBKRklGAAEBAQBIAEgAAP/h
Af5FeGlmAABNTQAqAAAACAAHAQ8AAgAAAAUAAABiARAAAgAAAAcAAABoARoABQAA
AAEAAABwARsABQAAAAEAAAB4ASgAAwAAAAEAAgAAATIAAgAAABQAAACAh2kABAAA
AAEAAACUAAAAAFNPTlkAAERTQy1WMQAAAAABLAAAAAEAAAEsAAAAATIwMDY6MDg6
MDkgMTI6NTI6MDcAABWCmgAFAAAAAQAAAZaCnQAFAAAAAQAAAZ6IIgADAAAAAQAC
AACIJwADAAAAAQBkAACQAAAHAAAABDAyMjCQAwACAAAAFAAAAaaQBAACAAAAFAAA
AbqSAQAKAAAAAQAAAc6SAgAFAAAAAQAAAdaSBAAKAAAAAQAAAd6SBQAFAAAAAQAA
AeaSBwADAAAAAQAFAACSCAADAAAAAQAAAACSCQADAAAAAQAAAACSCgAFAAAAAQAA
Ae6jAAAHAAAAAQMAAACjAQAHAAAAAQEAAACkAQADAAAAAQAAAACkAgADAAAAAQAA
AACkAwADAAAAAQAAAACkBgADAAAAAQAAAAAAAAAAAAAAAQAAAB4AAAAcAAAACjIw
MDY6MDg6MDggMTA6MjA6MjIAMjAwNjowODowOCAxMDoyMDoyMgAASt+LAA9CQAAt
VOYAD0JAAAAAAAAAAAoAAAAwAAAAEAAAAEYAAAAK/9sAQwAIBgYHBgUIBwcHCQkI
CgwUDQwLCwwZEhMPFB0aHx4dGhwcICQuJyAiLCMcHCg3KSwwMTQ0NB8nOT04Mjwu
MzQy/9sAQwEJCQkMCwwYDQ0YMiEcITIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIy
MjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIy/8AAEQgAlgBxAwEiAAIRAQMRAf/EABwA
AAEFAQEBAAAAAAAAAAAAAAABAgMEBgUHCP/EAD8QAAEDAwIEAgYFCgcBAAAAAAEA
AgMEBRESIQYxQWETURQicYGRwQcyobHRFSMkQlJicqLh8BdDVIKSk7Lx/8QAGQEA
AgMBAAAAAAAAAAAAAAAAAQMABAUC/8QAJhEAAgIBBAEEAgMAAAAAAAAAAAECEQME
EiExURMUMkEiI2Fxkf/aAAwDAQACEQMRAD8A9MQhCB0CRCTKhAQmSzMhjL5HBrR1
K49Td5HgtgHhjzO7v6Lic4xXIyGOU3SO0jIKx8jpJnapZXv9pTGl0Ryx72/wuIVf
3S8FlaOXk2aFmYLpWwD1ZG1DR+rJsf8Al+K69DdaeuJY0lk7Rl0T9nDv3HdOhljL
oRPDOHZfSpoKcE0SCMJUKEEwhLlChByRKmldAEyo5JGxsc9xw1oySnErjXapJmbT
NOwGt/yHz9yXOW1WdwhulRTq6p9TMZH5A/UZ0aPxVNxJKd9bKABnPRZs5uT5NnFj
UVSEa3fn7kx4wd1YHuz5Ic0Y2898pbQ2ylqI3SPb4jmPa8xzMOY5W82n5jsrUjRn
AGVUcMEY23XKk0yOKkjTWm5+mxFkoDamLAkaOR7jsV0wVhfSjQ3GmrAcMBDJf4St
s12QMLTwZN65MfPi2S4JwU5MaU8KwVgQlQiQCmFOKY5QgxxWUM4qJ55wQQ95x7Bs
PsC0dfL4NDUS5xojc7PsCylEP0RuAcFVNRLpFzSx5bJW5OcJWtPtUT6iKPOt4AHM
nokp7tSSO0sLnD9oNOFn8fbNRPwXC0jbt1SYJCfqDwCU5zw1hOM9gmbf5BZWcMHd
RPaNJJ6Jkle8v0+hT+QcBn7lEalzjh0bmjuEqR0iCuj8akkaDzGFqrBWmustNK45
kDdD/wCJux+5Zx7RLE5oPMbK7wXLmGugzkMmDwfaP6KzpXUq8lPWRThfg1rSpAom
qULSRlschCF0AQpjk8qNy5YSjdGmS2VbAM6oXj+UrL29xfbIXci5uT8VqLkSKCbS
4g6dz5Dqs9Tw+DSRQZyGsDcqnqXyX9LF7WyhWXGjoXFjonTzAatDRn49AqdNxFLO
4n8lSRx4zk7fDbf3LtspI4s6QBk5JPU+abLHCRkkvPQeSrRlFR5XJc2ttV0LTTCU
hxaWgjOlwwUypqDG5xDdWNwAE1mluXO6qOZ7cjGyrudcj1CzmVd4usOiSCmbI07m
MMcSOxwOatQXd8+htXTOgc9oIO+AT0z5roxMjwMAtPXBwpHxRyDBw72qxOcXD8ex
Kg1Jt9FUNIwRyKscIRiKa45IyZQ0d8Z/EJsjA0Bo2wi0UrRXskjOHPlc5x9hOymC
TUk6Oc0FKDTdGuapmqFhUzVqoxWOQjKF0AaVG5SFRuXLCVawA0suRtpKzscgcwOB
zuQPiVpKkaoJG+bT9yydNJGGvYzGGyOAAOf1iqWp7Ro6P4v+y2W685J2VOWoy/wI
dgdnOSV1b6PTEt+sfsWcfdqqXLKalL8bkqhKSujUhG1Zpo2ZIDjt3UVRFh4aDkHq
FlKOpvTKx7pmTaAdwQSPcn3SsvBna2ljm0h2C4NIUaTVHStGmiqHxSFkh1xjqei6
LWNxqaTgrEQ110gjLp4SATg5HMLQWq4men0jp08kItXtYJp9o6Djk+9MsE2moZGM
n13HPlkkKGomEUbpHO2G6ucNMMzIpXNxoZq95/8Aqdh+aSK2ZpY5N+DVN5qdqgYp
2rYRhMehCEQDConqUqNy5aCQuWFu8brbeahzBpjeGyMHQk7EfEZW6cs5xbRST2s1
EDczQZOPNpGD+PuVfUY98GWdNk2TV9Mz1yqG1Nuc7qw5wFSbb6qOOGqppXFmMyQN
djPcFcue4NdRlhIwSNXm7yXXtNyJgADMAbAkrIUkpW0bqX48FymrKZ+RJT18Lhnc
Pa7O+3U9ETVVKyIfmq6V+nJBc1u/xCbPcJGE/o0T99i3qom3CR+l/ocYz+2CMJjy
qhixru3/AKQNts1VPJVufLFT7+HDryT3KsWiZlJQmVwBdI7bsMlVrrdnim0McA47
EN6bLiw3A+hCLVhocXux/fmuHO3aFyi6pmjq6h9aWU0WPzjgzHmScL0Ckp46anZF
E0Na0AYCxPCNL6dcHVcgBjp/qd3H8Pmt41aeix1He/sx9dkuexfRNHyU7VFGFM1X
aKAuEJUIgIymFPKY5SgkUnJVpwDC8EZBByrDzsqlU8Mp5CfJLlxydRVujxniOgdb
6+Ux5ELtx27KCmqsNaAA49Qey2fEFrFypgQMvac4zzXnlQyehqNDmEb7ZG6yJw3c
G/CThyb2lmjbSB7nZPTAzhJXvayFrg869uR5BZKkvM+gsbDr08zqS1l2qzE1zoS0
A7lxxuk7JfGh/qx7sdcKolhHiYAO3ke6pW+CSeTLi7Q48wMquHTVUwLgQM8lqrJb
5TVBpa0RgZJI69l2ltVfYq/Ulf0egcLUwpbToDQ0lxJA9gXfYuVaNqVw8nfILqMW
zgX60YWof7ZFpilChYpgnCByEmUIkIHOULnrgX3jKzWFrm1dUHTj/Iiw5/vHT34X
k/Ev0kXO9F9PSE0VGdi1jvXeP3nfIfauewnoHEX0j2mzyT0sBNXWx7aWfUafIu7d
s+Wy4nCfGFVxPPViuljZMxrTHBEC1obvkjJJJ3H2LyGR515yprfcKi1V8VZSv0Sx
nLT0PY9kvJDfFpDMWRQmpM990tkaQ4AjyKzd8sPiZkiAH+3kuhw3xFR8QUgkhcGV
DR+dhJ3afMeY7ruviBbnCzXjfTNqORNWujzantWl4zqG+dLTzSTW6WR3rRta1v1d
t1un26IvJA0k88JI7XGD6xc4d1x6bGb0Y+3WTXOBIZNQOcADGVr6WkEDRth3JXIq
ZkQ9RoCc5oBycADmosdAc0Uq+/nh2mbVyR+JSiQCYD6wB2y3z3xstHabxQ3ik9Jo
J2zRZ0kgEEHyIO4XivHnFUVzmbbaCTXTxOzJIOT3duwWetN7r7TVGahqpIJNslp2
PYjkfetPApRgkzF1LjLI2j6hjdspmkLyPh/6WWksgvlOG9PSYB/6b8x8F6bQXGku
NM2ooqiOeF3J0bsj2HyPZOTEUdLZCh8T+8oRsB8mSSue7c5TM7JqQoEA7pnLYp4R
jKhB1LVVNDUsqKWZ8UrDlr2HBC9Dsn0pFjWw3mmL+njwgZPtafl8F5yRjkmnHUYX
EoKXYyGWUPiz3mk4s4drgHRXWnaT0ld4Z/mwukLpbS3P5RpMefjtx96+csDzTsH9
pK9BeSx7uX2j3i5cacPWyIl9wimkHKOnPiE9tth7yF5lxJx5X3wPpqcGlozsWNOX
PH7x+X3rJ49qUD3LuOKMeRU9ROXHQDb2qRpwEwDCXKYJJQ8jqula73X2ipFRQVck
EnUsOx7EciOxXJ6JwKgDef4qcS/6iH/pb+CFhMoUoNsYhCEQBhLhCFCAkwhChAwB
0Cdt0CEKBGndAQhAgFJzQhEAqEIUIGUIQgQ//9mIZgQTEQIAJgUCRVXNiwIbAwUJ
A8JnagYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEDDUOm5k6+IgXsAAoIgKM28/
7QEaj/dniY60Dx05HmGBAJ9wzVU81fZOsy1zhQXjqkXR86SfrohGBBARAgAGBQJF
Vc5/AAoJEBXWiATKbN+y0swAnioDHaWcqqjBIBSN96Sj2Fc9MdKjAKCI/DI2x/9U
S+oLQqbmWuIM+f/WbIhGBBARAgAGBQJFVdERAAoJEKBP+xt9yunThOcAoM0tU4B5
nYu/BEThw303mx15tQHXAKCxEiYipngcXVCL2SqmEL5yQq4vT4hGBBARAgAGBQJF
VdLVAAoJEBRll9zcw5nHxQ8AoMk8FXQ8FRPZmUmSMrgH/rn1W01dAJ9JoGO73MIJ
qKFyHBU5UYYeomGmOYicBBABAgAGBQJFVdTrAAoJEE1WKCF5BQwRSqMEALRtvzYB
tj697WhppxWqZ5zVV1nAgbdbJ5zHWghMoYiod69OZ/3ZxticAmLEF+yenp4OeItk
3ZjPCBQAI7sT7YPHEkwzp8vCUrqWp5XkA4OvSgI6p2ajuZhREdCvilRPtuIf0jTV
sOK/eklxU1Sd6KUPzBI5o0ac9zQsrY5oFqeiiEYEEBECAAYFAkVV2jYACgkQMxEk
bVFH3PRIfQCeKG8J5xyPZJF3e6b3HovW8eiAVzAAnRCcLkhgrrNA0BYKWUJAKWv3
deEhuQINBEVVy+wQCACAJNIBtl1krYP2kKBpS7VRAaXUH7kf2FmxKmH51lYBbBwS
JYFHJorMSAWNYZBqY5vrDwy1K6hAxz/B/shQEYWYY9aVEEffmUUxcKF4OZpqUP/j
CcgJOqUcXL9uir9uYHc+tSnGEiAtJZ9HjQ4gwfXQ0qNmrdPTI8PbDR8ELoRYuQLm
4c4HYBO+/C6PRcwHiXSg6uO/NyUthZWz4ODnwPV7dJllPxwJTTgay6sKJ3UhgdFH
pGb5U5OW+fEA2tEsv5sbszDvSgSugWAUCQxb7Js7REY1fcwGFXP9lAzwkUicMJZo
osuqvIrusK9tL4DJWbkIz/5LAsPeRKJNXQ/j6yH7AAMFB/9v1FJtBebXV9PiahIP
W0/fiB5Bcmp2lj7M74a0rPT6fwG+p/NULicBBAPU3p3vPzAsm3BJauOPBDH9XFrM
iaQ64L0ijQoHhZhoD3tVkGihT8L2SHanhGXoFJTHb8CIA8yh1Sq18U2twPZjCK30
0lD0ba/qrfm3902miKMXYSlCszosjpfqoX3f/WDQXrOgERMdPkZ34Q8bNk5VD+95
j3f171Lmn08/c8IoUWGvwMhsONJHDQYmxf+dJi8M6zU9HqyTy4KJ7dSufRuOLcpO
zEfBrn/Ii0sxgeONSwUgeYLtjXC00e/XrVGZtJwUVSMwinuwxY7KF/pyaWrEePRr
gp7jiE8EGBECAA8FAkVVy+wCGwwFCQPCZwAACgkQMNQ6bmTr4iB+XgCeJAW1mrjx
/50jTLN0kTiQXnmd5dgAnjGc8V7Ovynb8ZannQ/Q3nYwCFw2
=R5bv
-----END PGP PUBLIC KEY BLOCK-----
D.3.201 Maxim Sobolev
<sobomax@FreeBSD.org>
pub 1024D/888205AF 2001-11-21 Maxim Sobolev <sobomax@FreeBSD.org>
Key fingerprint = 85C9 DCB0 6828 087C C977 3034 A0DB B9B7 8882 05AF
uid Maxim Sobolev <sobomax@mail.ru>
uid Maxim Sobolev <sobomax@altavista.net>
uid Maxim Sobolev <vegacap@i.com.ua>
pub 1024D/468EE6D8 2003-03-21 Maxim Sobolev <sobomax@portaone.com>
Key fingerprint = 711B D315 3360 A58F 9A0E 89DB 6D40 2558 468E E6D8
uid Maxim Sobolev <sobomax@FreeBSD.org>
uid Maxim Sobolev <sobomax@mail.ru>
uid Maxim Sobolev <vegacap@i.com.ua>
pub 1024D/6BEC980A 2004-02-13 Maxim Sobolev <sobomax@portaone.com>
Key fingerprint = 09D5 47B4 8D23 626F B643 76EB DFEE 3794 6BEC 980A
uid Maxim Sobolev <sobomax@FreeBSD.org>
uid Maksym Sobolyev (It's how they call me in official documents. Pretty lame...) <sobomax@portaone.com>
uid Maksym Sobolyev (It's how they call me in official documents. Pretty lame...) <sobomax@FreeBSD.org>
sub 2048g/16D049AB 2004-02-13 [expires: 2005-02-12]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDv7rWERBADAnp/1Nc02OyU3eiXisqYDw2CaFNG7CpTNalQbJCX9KDuCzNbh
RKS7slRG0Cp/IsCIoJ0WLugslAZHBtLigl5XxdVeTYKJfXV1gKXLBnzW942oswUu
zMeZzpcrCYHK7AVaTtZJEQTDf/SIx/ZYu8DJPv/7m9I7aY3EYXQsHIqj7wCghRzg
vhbpzqR9KiIsH82z5ctlGHUD/AixgJJ6dCf/bxIq3siaijMs1fM1JNLTIL5W7i+I
LWUjM9PJztfasAZMj4kXjimZl9345CW+0+jV2oe7y+AFWGZUsQHKb3azruH9frZc
a6JSUOwvy4mQjMwtQC2ngJsUQGqrfGl3DLaa4hJzlgQ6i0PHTN1ljKvrMNgtgnZg
dypDBAClZuCCjn1RffnM4FzWuDZLYL/wLhqbtzMNvQXe5gwnDeg1QM1xgfUtaaa0
7f071Ayv+K54wVk+7XIRZLP0Kbgo07kJlXw5AzznzY4167RkcrifLPtG4nbDQCaS
QreYjUG902h8T7ckkmTV6VAPGUEh/ms9aAeFxAg2XOXiwCaYerQfTWF4aW0gU29i
b2xldiA8c29ib21heEBtYWlsLnJ1PohlBBMRAgAdBQI8INsQBQkB4TOABQsHCgME
AxUDAgMWAgECF4AAEgkQoNu5t4iCBa8HZUdQRwABAZRqAJ4ypOHGqZA7mf+m+R1k
kUCSxtirZACeIXLS54rLLTauEHQtuHfNKEQolCC0JU1heGltIFNvYm9sZXYgPHNv
Ym9tYXhAYWx0YXZpc3RhLm5ldD6IZQQTEQIAHQUCPDcdsAUJAeEzgAULBwoDBAMV
AwIDFgIBAheAABIJEKDbubeIggWvB2VHUEcAAQEdMQCgg67lgOG0NlSy6RlNxeqT
mREvqt0AnjoRX4MwyfWsHmD63XoByM5XjdketCBNYXhpbSBTb2JvbGV2IDx2ZWdh
Y2FwQGkuY29tLnVhPohlBBMRAgAdBQI8Nx30BQkB4TOABQsHCgMEAxUDAgMWAgEC
F4AAEgkQoNu5t4iCBa8HZUdQRwABAYJvAJsGythE5SUctWSmAYIxYHagnEUU/gCd
FQv6AywESIEMOLK5iaONMFb5NGO0I01heGltIFNvYm9sZXYgPHNvYm9tYXhARnJl
ZUJTRC5vcmc+iGUEExECAB0FAjw3HwsFCQHhM4AFCwcKAwQDFQMCAxYCAQIXgAAS
CRCg27m3iIIFrwdlR1BHAAEBbJQAn1tcab5GD07XKi33AdcyP521kGhHAJ9eo7wb
PMLk4e7y6ZiQEeMd4DF1/5kBogQ+e3iWEQQAsxiirVfUk5G6X5YyhHT3pX2Tt6n0
F5hj36BLxU/Cbn7viUMP2x6qafIolWC5wW3JEklsql3wXovUl6Uuaah6S57XD+45
YNAztjJ2rOp4wW9KD6i7IWkbtgz0eRLQBNzEvcvdMfGqH/1XujGn033Q3tpgT8sH
WfbT68DXuaUTJCMAoJhav+twkmoLhT0o5KSjSgcmtjOvA/4oJZ9D5H4rSRKWhQNG
5A5FZlNX1q7K9/WYcSKWsE6R+jnOFigZOt/wEXA4tUiI1b7SaVnSPNgQ26iMPDIZ
uauEmvjQmVDSdO0ZsS545VQ9xJtksJdHZXnTVKWyTNiRWGHWT3ucR2XFJ40U+so/
AxKch0N5CqtYy9A27aO6KLqBOwP9GJUvIE1zB5plWP70d9Kii6Gf9c84VwK8sYcd
w45M4DozPUJqMUcfP4ycvK5AY80MRvNr+UP0VgfpuKElh2JCUpgj9XTE48vuAdyd
3q6lVEC4SpjZu29oFNyzcX0dILPHy49pTaNOUK7EQgdS1S7OWksP6XCWQ+Fmd8E7
vtcT+BO0JE1heGltIFNvYm9sZXYgPHNvYm9tYXhAcG9ydGFvbmUuY29tPohiBBMR
AgAiBQkB4TOABAsHAwIDFQIDAxYCAQIeAQIXgAIZAQUCPnt4lwAKCRBtQCVYRo7m
2FP7AJ9QC+MpLfOgfrBZ62ylXJbgV9rSfQCbB+djelAeWNwsPCSI1ztdLW71gIW0
I01heGltIFNvYm9sZXYgPHNvYm9tYXhARnJlZUJTRC5vcmc+iGIEExECACIFAj57
eW8CGwMFCQHhM4AECwcDAgMVAgMDFgIBAh4BAheAAAoJEG1AJVhGjubYpG8An1bD
+5ViByos/wyRoQ3fL5eRnPbYAJ9orRZWWPheXO7sO4kRB4p0tUGZQ7QfTWF4aW0g
U29ib2xldiA8c29ib21heEBtYWlsLnJ1PohiBBMRAgAiBQI+e3mWAhsDBQkB4TOA
BAsHAwIDFQIDAxYCAQIeAQIXgAAKCRBtQCVYRo7m2EMFAJ0SKWhO8mbbRHNjJZhr
Z6gRvtM7RACfXwBb7dbxG1ZEcJHfvaJxo/VxF2G0IE1heGltIFNvYm9sZXYgPHZl
Z2FjYXBAaS5jb20udWE+iGIEExECACIFAj57eakCGwMFCQHhM4AECwcDAgMVAgMD
FgIBAh4BAheAAAoJEG1AJVhGjubYeiEAn3Ni+6g6qIJABeTEveO+vjXa1lTRAJ91
k/l575bXLqs7r1IIDcKs2q9WxZkBogRALSX9EQQA2ZSfrH+e14MPQbrgS6foZgvY
CkNR2N+DlTq80oRkNsNOvdCE129HrXaEgiVbLjnr19pNICMCst2nGCjTMRXCeqEs
bAzUgX+9YKAzXYxrBz1YXABursMSx9OJW2CNQMIlZWh9vD1eovnRtSrI1kaOXroO
YWsFOxEVVh3UaX97r38AoLp0c2Fjf18rpMrHJRl7hejRJH0tA/4lPatfAvWdRtPM
TONotaMvjmp7c6XJd+hdEIJgCQgJT7ccdGLoCk1JgZYp+xoJH+/U8TpyUYeGCedN
+eduSu30PWKY9UPUaEe661bSGXvdSveV0xgkXuddsN+ziPVHUV75Cd0MmbBpD1Oc
48U4jAl0ToANUTmtDM/1Ayj2nZSsawP/UPdzuNR8DSa96lcEZN3nKN4hv3YLUta+
Jw8U2PRnJZ7y4R1bKFW9fZzQM9a54uZxqP8o+rRyxyYuRqguoGK3FKTiMwe37HA5
O2CaBppTUfhc4L+y92EAim4k4KipHkEtIKLDWpzFs0UsR55fjy6HrR+D2FaUi54a
Gw+S9KlmN4q0JE1heGltIFNvYm9sZXYgPHNvYm9tYXhAcG9ydGFvbmUuY29tPohn
BBMRAgAnAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheABQkJ3tdxBQJApfwoAhkBAAoJ
EN/uN5Rr7JgKW6kAoIqEr2u9gwwpTeDvaI/0WS84KejUAJ9DgBhAvpdS65GWQ1iz
LiNmbDVPwohGBBIRAgAGBQJAp+soAAoJECIYyB6OfAP/2kMAnitEcs+VooxoMqeu
ndhwYZymjyM2AJ4tIu44PEc5NsfKdTYUqf1J/yG9MIhMBBIRAgAMBQJAp+CkBYMJ
ZBzKAAoJEElFpTfXe0P7t6IAoI6h+BAMLfvSRLcie++SEYrD2veaAJ9OARzgMah+
XzwPsh7xghoKYZB/fohMBBIRAgAMBQJAqAa9BYMJY/axAAoJEH29C5XtjCBCWUoA
n2nMTvMwkzXxtbNib5KABdl+bJkOAKCo0fuKEmFjO2279gJRJ3ABwIyGl4hMBBMR
AgAMBQJAp+bzBYMJZBZ7AAoJEBeO4nT4FnLF6s0AnAnqzJCQcOaUTL9zxT5EaDGo
iDGkAJ9LZnWrjrraf2OAOzNWP9EGlGBJgYhMBBMRAgAMBQJAqA8KBYMJY+5kAAoJ
EAzLfv4LMKk7oTAAn2ubbSjM6i7m/vI89mq3iEW5b94qAKCDLgTA040qeKuNP472
VgL88HOFZ4hMBBMRAgAMBQJAqCfeBYMJY9WQAAoJEGxj2gSE0NfnKuQAoI6QF0P2
iVb4XyxGJokP3j8R82WLAJ4pNr1tZwERERNPN+tx7GQabv4oCrQjTWF4aW0gU29i
b2xldiA8c29ib21heEBGcmVlQlNELm9yZz6IZAQTEQIAJAUCQKX8FgIbAwUJCd7X
cQYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRDf7jeUa+yYCnHAAKCOveBgrUPA37AF
QE/RXskb1Hk4IwCgmGYBM0giWFy6feo55wSGSkq9zLmIRgQSEQIABgUCQKfrKAAK
CRAiGMgejnwD/+hlAJ9M83zihFrokQ6etoUbyXOAUndkwACeJwDSkdi8SYbJYKDF
KCtZFCkkiNeITAQSEQIADAUCQKfgpAWDCWQcygAKCRBJRaU313tD+51VAJ9x4/ke
+qsJLRaXChYzKw7IeMjXeACfRrjRs6+JEEu7YD+JEsmEcjw732OITAQSEQIADAUC
QKgGvQWDCWP2sQAKCRB9vQuV7YwgQik6AJ9TN++UJJLQBewwk44sRkDFX4HqbACd
Eb9IWxjzZVU++brh0t7ZzUWiVraITAQTEQIADAUCQKfm8wWDCWQWewAKCRAXjuJ0
+BZyxeyWAKCNUgnimNLNPwLYnZA00usYzFmtUgCeJY6G6WCvTzTzORl02YQRjX0G
E4mITAQTEQIADAUCQKgPCgWDCWPuZAAKCRAMy37+CzCpO2kUAJ9BmGuvf+7Bz1ka
Ks92vEvv+3B69ACfeIer9qirOJQD1Knd3bJmbG6ptq6ITAQTEQIADAUCQKgn3gWD
CWPVkAAKCRBsY9oEhNDX51cwAKDWXdgVIwMFvkX+UWrIAcELPQK3twCgp9SYhI8o
eSuWQrtI1NrH43dnz4a0ZE1ha3N5bSBTb2JvbHlldiAoSXQncyBob3cgdGhleSBj
YWxsIG1lIGluIG9mZmljaWFsIGRvY3VtZW50cy4gUHJldHR5IGxhbWUuLi4pIDxz
b2JvbWF4QHBvcnRhb25lLmNvbT6IZAQTEQIAJAUCQKa8vgIbAwUJCd7XcQYLCQgH
AwIDFQIDAxYCAQIeAQIXgAAKCRDf7jeUa+yYClbbAJ9aRpEjLDKXtVhjVmf8pIJF
MDuPAgCfdhkF4CGjhAeitWxpH+WdCRlE20CIRgQSEQIABgUCQKfrKAAKCRAiGMge
jnwD/166AKCIm+EGRyBP0tR9EoM0nihlTE4+GgCfTfhsfPla/Nfi3MlghP+N6BrV
42+ITAQSEQIADAUCQKfgpAWDCWQcygAKCRBJRaU313tD+6OGAJ9tE7s8HjQpdGFR
7yxTHvN6MMpZXACdFQvd0G99F1du6vK6THJt/TuMwP2ITAQSEQIADAUCQKgGvQWD
CWP2sQAKCRB9vQuV7YwgQgrfAJ9T7R7Q3FJZaNqAtHMUHFyDuEk34ACfX1y57LUO
8CZKqHl7ZOot3RB2VoGITAQTEQIADAUCQKfm8wWDCWQWewAKCRAXjuJ0+BZyxUrV
AJ0cZ89+YM3lbETeVlvHprOug/gWbQCdHbHscPfjx7FVkTTUe6hkd9J7fwKITAQT
EQIADAUCQKgPCgWDCWPuZAAKCRAMy37+CzCpO0YUAJ9dhzywfm3VmhTQr2Gh2NF9
EtISNgCgg3A7wVmhphaBag4PqB1D/NcCg3qITAQTEQIADAUCQKgn3gWDCWPVkAAK
CRBsY9oEhNDX53yAAJ9xUFCI5G7nlOZTr7UKVP4FR0EPUACfSOnqzKyyp1OSibmx
zW47Lz72gES0Y01ha3N5bSBTb2JvbHlldiAoSXQncyBob3cgdGhleSBjYWxsIG1l
IGluIG9mZmljaWFsIGRvY3VtZW50cy4gUHJldHR5IGxhbWUuLi4pIDxzb2JvbWF4
QEZyZWVCU0Qub3JnPohkBBMRAgAkBQJAprzZAhsDBQkJ3tdxBgsJCAcDAgMVAgMD
FgIBAh4BAheAAAoJEN/uN5Rr7JgKB1kAnRtC7GHF2GLbDyqJ8b9QDNCeUC9bAJ9G
igTUYVWJua2Fa64tJtKJ/JIonIhGBBIRAgAGBQJAp+soAAoJECIYyB6OfAP/UHIA
n3V0lGZVJWAvdbpszkOq4jSf0JWwAJsFunCvZqn4AyRoFlCfF0DBNOugvohMBBIR
AgAMBQJAp+CkBYMJZBzKAAoJEElFpTfXe0P7gokAn1yPJFfgJ2BxRjpN9NsivQly
qObUAJ9pLPMloXK/69udhQCi/hQyD+YtGYhMBBIRAgAMBQJAqAa9BYMJY/axAAoJ
EH29C5XtjCBCFX0AnAzukQp+n6mOl6BWG4+wPZa3s4cHAJ45ugwVCuSLa+Cm0xRy
QwXFAobKoohMBBMRAgAMBQJAp+bzBYMJZBZ7AAoJEBeO4nT4FnLFBloAn1hZu7BO
zljw+6etQuwu7nW5Xvb2AJ9I69B/Xr8oEsnQ7VLuRDQypak9qohMBBMRAgAMBQJA
qA8KBYMJY+5kAAoJEAzLfv4LMKk7NSwAnj15R9lyjrqK+BXPMpCV87MuJABkAJ9a
mCwv0S6UTti7BgGUOmunycJgL4hMBBMRAgAMBQJAqCfeBYMJY9WQAAoJEGxj2gSE
0NfnAkoAnRGHimIOvkNh1EUTNj0z3gwayCUbAKDZTgsntCr5VOPZZYbLrJQl6vlh
erkCDQRALSYmEAgA4I82XMqjiHHbgYea0nF5OoNHXENTmpRIEpE7RZdj0UrMAJI1
fWXIjl4JS7OgvIG+thSoyC5ueveK5j8gw9gIlQi7ANcQndBRnse+COnue9Z4L8J7
NpfhSop5Gskin4ReUwnRAFZPb+aEVpPph4S+Zxg8sCUGojvTDuRCUk0mNov9W3Mq
eFwUfK8nc2n3eveGtfp4ygyhq+E9lMpzbQ4Flhbm2x3Nmqe7VCb6Si69JKZQrWaw
1yHMqt3AQr4RgtgIjpX2CmV8j/Izc8WVAbQDqvDM3NaVHYVzGuui4RYCbvMrrabL
D5zmJjsRDdo66NYWs9y4Aky6SPkp7+sDNQqbdwADBQf9FCI7TFHFeVaTqSAK6vsQ
nkbgBmoexaoSofJfJAaby8WeZ5AVGHRavglgAxaejZZqMHpcO+hDnTBj13J/wQMc
ocgfOYPRzvwIZfx7Gc6uF3NIgUtn55DT+cZmjq3sZcUtlmpy22kLpDPy+x0CNzqv
lMILIxiookXJaLGqeqjGXwQOcyj/ziZNb7ZY4nJLOjshnzER/YMY8xvnJnqQ6PDe
izwPbuP+Ej9E7iAJhDnz8et4kSp2w3Mb5Zs5pu4nYySi/GincQ8r5gUOJXmMLPrn
N+3qG/WP0GIni7hF83GgzvV3hjtcMuFf5AJRKJeq0AAgm5MiZlCFM7zWhffrWCx6
oIhPBBgRAgAPBQJALSYmAhsMBQkB4TOAAAoJEN/uN5Rr7JgKItsAnRFQomWrmkKL
KMzwh2yhNHGuxYtOAKCQWvphJCOXG2iv+epUwNTl9f24EA==
=Z1Sd
-----END PGP PUBLIC KEY BLOCK-----
D.3.202 Brian Somers <brian@FreeBSD.org>
pub 1024R/666A7421 1997-04-30 Brian Somers <brian@freebsd-services.com>
Key fingerprint = 2D 91 BD C2 94 2C 46 8F 8F 09 C4 FC AD 12 3B 21
uid Brian Somers <brian@awfulhak.org>
uid Brian Somers <brian@FreeBSD.org>
uid Brian Somers <brian@OpenBSD.org>
uid Brian Somers <brian@uk.FreeBSD.org>
uid Brian Somers <brian@uk.OpenBSD.org>
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzNmogUAAAEEALdsjVsV2dzO8UU4EEo7z3nYuvB2Q6YJ8sBUYjB8/vfR5oZ9
7aEQjgY5//pXvS30rHUB9ghk4kIFSljzeMudE0K2zH5n2sxpLbBKWZRDLS7xnrDC
I3j9CNKwQBzMPs0fUT46gp96nf1X8wPiJXkDUEia/c0bRbXlLw7tvOdmanQhAAUR
tCFCcmlhbiBTb21lcnMgPGJyaWFuQGF3ZnVsaGFrLm9yZz6JAHUDBRA3DAEvDuwD
H3697LEBAWRHAv9XXkub6mir/DCxzKI2AE3tek40lRfU6Iukjl/uzT9GXcL3uEjI
ewiPTwN+k4IL+qcCEdv8WZgv/tO45r59IZQsicNaSAsKX/6Cxha6Hosg1jw4rjdy
z13rgYRi/nreq5mJAJUDBRAzZqIFDu2852ZqdCEBATsuBACI3ofP7N3xuHSc7pWL
NsnFYVEc9utBaclcagxjLLzwPKzMBcLjNGyGXIZQNB0d4//UMUJcMS7vwZ8MIton
VubbnJVHuQvENloRRARtarF+LC7OLMCORrGtbt0FtYgvBaqtgXlNcKXD6hRT+ghR
bi3q34akA7Xw8tiFIxdVgSusAIkAlQMFEDgdNQU/ZTB66ZtiFQEBBL0D/3PZ1au2
7HPVMN/69P3mstJLzO/a95w6koavXQph3aRbtR7G/Gw5qRQMjwGrQ4derIcWPuON
oOPXWFu2Hy7/7fYgEAsQ004MskEUImJ7gjCZbmASV/8CoJHtBtNTHC+63MRfD++Y
U0XXsN832u5+90pq1n/5c7d7jdKn/zRKniQQiD8DBRA1On7BSE2D1AeUXi4RAkb7
AJ42Ss6CTanh4hGyCU4b7/1/C3YN4gCeMr/leUdkWUOMtfZw4/oPXw3wAhCJAJUD
BRA3DJamZ0o98VSxcbkBAQisBACa6S/a72KFyc7ZlpqTbrkj6BijO75uICeB1c1+
FMYx4TEXN3NDxB7sQm6AykgMSQmraChjfmwaK0P6iBJVYQKNxVscgA8za71rEUaU
rt8M6aaQfZlYMy3DHYjl1mmzeraD2ZjY70DPliiSnsZbu+JKlZcdNEfE6y5jprN7
vVTtFYkAlQMFEDNzvb1sq+iWcxFJBQEBfZwD/R3KNFf9ype9Dea8j1YIeNZ1E3e0
3en1I8fMj6EmS1/L1WfFzMnfFCxZs7JgPtkBuB3CqP8f+LOdDt6PHPqNakmI9E6f
iuGfJZ3jFZYATXa0XKuIoxIJNKhqkpbF8ixJZFTxFwAAwVYM3+sqr4qQ8FzVc5en
txjyxPFNkwJwRWV+iQCVAwUQOKl2j31Nxs/Jk7xZAQEidQP+IADd17yiXIV3h/pr
f2nDYgO/o8bQI5jH0oyYmiJXWHWgPREmIlw2pj28EM7mjDrJQN7oR/ltLTTfAG3G
kO8KlnijdVmexxT8y1LmkEyYaIjU3VpmimZIcYgzRgOcnCQVyORcFG9tkGgfEo+7
u7xFwaTKPvsxHDfrOoWkmwAfMOiJAJUDBRA3FKmdnWdBAAxuEhUBARJtBAC9mwTX
OL6cT64NwE3Wfz3pKS+pWI97PaQX/H+3mC16uN/AP8sIlpKy++IF8XGdhMvQB2Vv
q2yT81G63zAID97lqG3krw8ikaNcLSp02B8vjhCGwSBw5iFLity+yrqQX+1gCOOk
O358s9Lcb7Ua7g4736Mpff00kXyCnGsNmiDYe4kAlQMFEDNt51zvs7EFZlNtbQEB
W0UD/jZB6UDdEFdhS0hxgahv5CxaQDWQbIEpAY9JL1ygd1RWMKUFGXdRkWZmHEA4
NvtwFFeam/HZm4yuGf8yldMyo84loTcVib7lKh4CumGxFT5Pxeh/F8u9EeQzclRF
SMhVl0BA2/HEGyjw0kbkprI/RD3pXD7ewTAUrj2O3XhEInLgiEYEEBECAAYFAjVq
LOEACgkQ9Xj0ZDU8AgY18gCfZBmPr90sGIXz3HZoHMfyY3QfLSUAn2acppnW/NjI
ZBnCYCs7EI/l1dtgiQCVAwUQNq9AjPafnz58Zbu1AQGDmwP+NLOUsBKV063jzu/A
KFBRGuWeG4MsZKU+wVW6upv6ELSudPV3tjNstF0y5HfOqF6Y8isxs1qvE+mUyjXR
ffuS4UtspScrXT6tQIw5NgaHH31l+PqV50T4gul3DXWBokC/Dkx72REmEA4h3jH8
APFnTMxStUfNJyTMADWF4ySay82JAJUDBRA3Fjs4H3+pCANY/L0BAZOxBACTZ1zP
daJzEdT4AfrebQbaU4ytEeodnVXZIkc8Il+LDlDOUAIek5PgnHTRM4yiwcZuYQrC
DRFgdOofcFfRo0PD7mGFzd22qPGmbvHiDBCYCyhlkPXWIDeoA1cX77JlU1NFdy0d
ZwuX7csaMlpjCkOPc7+856mr6pQi48zj7yZtrYhGBBARAgAGBQI57mEkAAoJEF1S
HIzmsVAWneQAn3ZJ/mSszOjEwTjTPX6HSO/nLIJ0AJ9/YB2Q2XX1gbTx9JlIIUwG
6QeZOohGBBARAgAGBQI6t00oAAoJEJOoB2QsN+N1KscAnR2mEU5khcQitC4h85l+
iC/WfnW4AJ0V1yY4fFz7OPzPmVcS2Qa784xgHIhGBBARAgAGBQI7Og/KAAoJEIG9
08QOH5t5UukAn1fovkBjEEzaoj4ese1j6+N/+ePCAJ9tXJA3ZiV+xpwEX99wKD/9
UKdbOIhGBBARAgAGBQI7PHfSAAoJELTXEKIORR99J4sAoJvjOirmZSB3ugyyCq9B
K6ZdWTwHAJ0dhktheUV5yo8/8t5GytZe4ZnsULQgQnJpYW4gU29tZXJzIDxicmlh
bkBGcmVlQlNELm9yZz6JAJUDBRA3FKWuDu2852ZqdCEBAWVJA/4x3MjeQKV+KQoO
6mOyoIcD4GK1DjWDvNHGujJbFGBmARjr/PCm2cq42cPzBxnfRhCfyEvNaesNB0Nj
LjRU/m7ziyVn92flAzHqqmU36aEdqooXUY2T3vOYzo+bM7VtInarG1iUqw1G19Gg
XUwUkPvy9+dNIM/aYoI/e0Iv3P9uuokAlQMFEDcUtWOdZ0EADG4SFQEBzwUD/iDF
JROA7RL0mRbRuGCvbrHx0pErSGn4fxfyc0rKnXHi2YMHLon23psO/UYb6oadAsqe
5LiNpBzt2tfZGd2V5Q5d1Q4ONUlf2eS8zcPb2mSrhf77RmpLTo2nOROWs51hiAOX
M8LEYMnRDnHfDlTzFDK3TVkSOl0TrZ22WkUsJg/GiEYEEBECAAYFAjnzuKEACgkQ
I+eG6b7tlG7fygCfWp+4d0XMF2h5Z3dF2NHRQZ5cKt4An2Lihl29VXso2OY+bV5s
9JRiTOeTiEYEEBECAAYFAjnuYScACgkQXVIcjOaxUBYtiwCg6uHe9RAfPJDy7fC2
gqEmeO9hR8gAnAw8oGTuRxpX+0kdbTpxZl+5UxuWiEYEEBECAAYFAjq3TSgACgkQ
k6gHZCw343UihACfUdslW43QrvELZUfojQpfJbhKgZkAni3t62v1mYDyre3zlctw
vB2gpVefiEYEEBECAAYFAjs6D/QACgkQgb3TxA4fm3mcmgCePiFNuSQzZJSwQenj
pZUaP8zALLsAnRT9r4JmFy4DbLdT3ora8aNspu7OiEYEEBECAAYFAjs8d9cACgkQ
tNcQog5FH32f5wCgsrKZ6IV01c0R6IvUH8pDuQ64Tz0An06PzWqgmCDoeoOjjzS2
ngbS4k7gtCBCcmlhbiBTb21lcnMgPGJyaWFuQE9wZW5CU0Qub3JnPokAlQMFEDcU
pcgO7bznZmp0IQEBczAD/3b7bI98gQvrHosunwf50vjZygaH39xJL+exbGa2hreM
/Z+LFutXssGokc7ipYR6qwxNe0kymnwTmldTbZe47O6IOSBT1jZVYdXCvrKQ5neu
eQ/KcrIc4gxen0gLKhn059+cZdt14zttDDCuOI+COVeqxMlAwQ65l+PSeejhZH8G
iQCVAwUQNxS1bp1nQQAMbhIVAQFDCwP+P0H+WSW0h2dB2M6pH9t04GAkK1R/3TnL
qQP6TiRvF5PVgBoDrkonaj9mP6L7r0Xb4FQn/eRgHumsrC63aHR6TVm2dwbGgCxB
0UnklJ4yTBRnmq0Z4KZU9vn34o+redTqndEjwGfvsXMr/9DL4hb9YVUlt//o0I0J
vJGJGM9saX+IRgQQEQIABgUCOe5hJwAKCRBdUhyM5rFQFuJEAJ9L+13u+bX1qzjz
7DGfEpv6qh8tKgCeKMA6VwcAi1NPmyNySaLRhqz9oFSIRgQQEQIABgUCOrdNKAAK
CRCTqAdkLDfjdZmPAJ9IMUAaCOyeEW8IZBQ3KUhCWW1Q4wCfYdWfp2mrQZmkejFg
c6NKZulIBeKIRgQQEQIABgUCOzoP9AAKCRCBvdPEDh+beRQtAJkBD5tug9hw8McZ
4FmCQdoww8lgGQCdHxrNgFDuqQNBjj+2tgAxR1aYyhWIRgQQEQIABgUCOzx31wAK
CRC01xCiDkUffd0sAJ9DoGfZSslJWJ+jmFV8wch4olfuzwCfdSm+Fzi+1rg/k1sm
W6HWhlmV8RO0I0JyaWFuIFNvbWVycyA8YnJpYW5AdWsuRnJlZUJTRC5vcmc+iQCV
AwUQNxSl5A7tvOdmanQhAQHgcQP9G7c2PBY7WCXESItPNGlTfVGHUjPDWWFUxUmQ
sAYHD2J5KSO90iS6GpXWL5bjAoEKVPRQ4TbwqOlZsEo8UgBJFjM3jJLCmmuwbkfj
kQVCiyi9gb8c9wzNdTYYyPSLBVPGcyrsjygfnzwTEep8Q3YBEPeeCYHbj32u7IaX
bqlb8F+JAJUDBRA3FLWcnWdBAAxuEhUBAcYYBACos9nKETuaH+z2h0Ws+IIYmN9F
Em8wpPUcQmX5GFhfBUQ+rJbflzv0jJ/f2ac9qJHgIIAlJ3pMkfMpU8UYHEuoVCe4
ZTU5sr4ZdBaF9kpm2OriFgZwIv4QAi7dCMu9ZwGRtZ3+z3DQsVSagucjZTIeyTUR
6K+7E3YXANQjOdqFZYhGBBARAgAGBQI5/MjzAAoJEFq8tAVo6EClLkEAn1UHGexD
Mj/uZ9oHoyu4GJW0PkKrAJ9YRLH5YPux7txOymktvIYWdACg7YhGBBARAgAGBQI5
7mEnAAoJEF1SHIzmsVAWn/wAoNcd1PwEz1sXKNJ64sJHqBowtcg9AKC8SzrUiHdR
kABWV0rVfmxMnKpt74hGBBARAgAGBQI6t00oAAoJEJOoB2QsN+N14rMAn0tkxYzI
ZR3q/TTVD5pl+4x5wUmSAJ0fayzjxJlBNhI/g+OYTaOJGAyhXIhGBBARAgAGBQI7
Og/0AAoJEIG908QOH5t5Z34AnRiddtVRnUC8vAKi3JfPD0SjlSRoAJ0dhcomVwh6
GEfod/xwEsezfTvv0IhGBBARAgAGBQI7PHfXAAoJELTXEKIORR99aQMAoIhrnIaq
fSY+OTkytI92T8Jk+WhYAKCIwO6MR6JUn2QIzHKWUiIQ2J4Px7QjQnJpYW4gU29t
ZXJzIDxicmlhbkB1ay5PcGVuQlNELm9yZz6JAJUDBRA4t89HDu2852ZqdCEBAXM7
A/9YBm+45S+GxfCMjVkYxWBAlNIGS6n6TBlRTNQ0B+f3RhUvCAksSRZnGnTm6PcU
P8Lc1bzvrDj9s8auGjT1OvQ6ypC1jR7D71nsjRIaKvgLAbsPGjFSMKTwZFx+LbHC
zBEvRcSb7tYnJg+gtjXbVcztlSzCbWtv4qRnVhrotirh9IhGBBARAgAGBQI5/Mj1
AAoJEFq8tAVo6EClHQYAn0WVMv1mf/ybg8Q570StT1Bveu6BAKDWIeCnyERzTB2s
AToRo4F4EXkxp4hGBBARAgAGBQI57mEnAAoJEF1SHIzmsVAWfwEAoJTnt1WNtilj
wWBW+j5LzhHPLmH1AKCsm8orE0M6kLK64DsFzFiuCkqhkYhGBBARAgAGBQI6t00o
AAoJEJOoB2QsN+N1B98AmQGyos7+2Z38cL5i75N7ppn55gBkAJ42Qc9LQxdR7pOL
E0R8IqiaUXrS2IhGBBARAgAGBQI7Og/0AAoJEIG908QOH5t5V64Anj9wAS0UicwC
8pwP4upADVFjddTjAJ4iGkDwrvXoig2Ct+xzmJyP78CmPYhGBBARAgAGBQI7PHfX
AAoJELTXEKIORR99JYIAoMvPy9WeDrsRADN8ePg0UWjQ30yBAJ956M19BCWSuXAR
jVwP3kTqaFKMlLQpQnJpYW4gU29tZXJzIDxicmlhbkBmcmVlYnNkLXNlcnZpY2Vz
LmNvbT6JAJUDBRM7OhMLDu2852ZqdCEBAQTZA/sGHilPXF7QfYTFwk3mTh02dI4l
iBwQ2Bs8OuNAXiQyD5wH91JhEgwNUYa5lV01zWvgZznMJUGmijAXVUs2uRwCV/nQ
DDZs96JVRLOk8t6UUjPG47CeECsw4RXTXtPOsS4AubNdnplXFD2tI5lBKgn5xewO
+0prjIKHRpZw/YXlsYhGBBARAgAGBQI7OhTiAAoJEJOoB2QsN+N1EkcAnAsDn+4J
uBSsw3EVvTRUWL2ulZK8AJ4mQQhfapaafRvdWbN/kR07k1Z2nohGBBARAgAGBQI7
PHhgAAoJELTXEKIORR99lWgAoIWH4tk6xJzxwtN+bUQHj8u/DwNjAJ9TTH1Uw0tt
3mPjEgv3yQyXxmScDQ==
=g4uu
-----END PGP PUBLIC KEY BLOCK-----
D.3.203 Nicolas Souchu <nsouch@FreeBSD.org>
pub 1024D/C744F18B 2002-02-13 Nicholas Souchu <nsouch@freebsd.org>
Key fingerprint = 992A 144F AC0F 40BA 55AE DE6D 752D 0A6C C744 F18B
sub 1024g/90BD3231 2002-02-13
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: Pour information voir http://www.gnupg.org
mQGiBDxq4ZARBACJSN3t0e7d8A7LNfvsKsNNfMWbANu/f3vEhDEj4D4X2QLKyk8t
Ti5/wO2Z7HJiT5QfI3zeRWetvHMWXhAYc24GrTUMdCt2zhUjufi5BdysmcbLiZFt
9wjJpJITW4A6W7YP55ORkZs6ye/j4Luf7YN4xISWvM9/kzpUtU8R6txC3wCgq28H
0tdFPUDvyAwr+97vHs97z/UEAIFPSIAsrH00DuudiLpqZB0LE+BcDsSKgxBQsZJT
06EQQaE9XMN4f46nAtxzFhSbGZL4qIBUO3Ny1Pp0rqjCfumuwONLXZSK829LaaJn
WfZ5ux9ZjvfYJ86NgUV2tFnwZm2UYQXc4234FfzfebeiSmYI27BMvLJ28xXU+pNw
vUvhA/9uPu+i3Dk+ha+0UaBTp/HNTAveoTKH6lNOS12XhCNNPQUL0gonJTeWThRO
z4YttxgLa5I/MoNsub0+GtNrlyhLyHKzjBBHEqJHJp7+zkyfCODnJaxUqoKskUSD
QF5VX6v6vEQl5UBjGwonHmzsrnuqTb9pyYhfPTch9n22eS6ZqrQkTmljaG9sYXMg
U291Y2h1IDxuc291Y2hAZnJlZWJzZC5vcmc+iFcEExECABcFAjxq4ZAFCwcKAwQD
FQMCAxYCAQIXgAAKCRB1LQpsx0Txi0J7AJ9q3/ulyXnWjGWlR0L+3QtfPKI5EgCf
WTLlr+SXYF+nrW4VvQcJvuyzZyG5AQ0EPGrhlBAEAKQjsjIRO+kHT+9qCYsw6HPi
BYzH++xP0i5143trUJ66FoEfqOl4UqHwNJ7GEXq9MWgzBH9wDL69Bb4kSKQ9vKwD
EgAnXObS3FOUPLK5AMXc5jy8rRaUru58+cGs1cNIg69zgQ3FQyWF0FHI7kGsAdz9
8iUZhXL22I7+EVBgd9DLAAMGA/9oK+Xjo7xdLZvkW8b4nNIA7Xyml2uMLYjg/OVg
qRkVU5f7KM2oHna7+VtvdJrIl9bTVc6mrTl6GY1/0GYb1edgSu2Axg+msj3fVkGd
8hWuNQ/T5v45kgPcoJxWLzaWWkDeLQAf5tq/QVmN8hofl6UsrsNDvYTBbl7129uo
3BJbG4hGBBgRAgAGBQI8auGUAAoJEHUtCmzHRPGLta8An39UVQwz3OgsZQ5e8upC
VEBCvTUmAJ9/8mbmXF+Ii/JdY6STmU1MMfmQvQ==
=A6my
-----END PGP PUBLIC KEY BLOCK-----
D.3.204 Suleiman Souhlal
<ssouhlal@FreeBSD.org>
pub 1024D/2EA50469 2004-07-24 Suleiman Souhlal <ssouhlal@FreeBSD.org>
Key fingerprint = DACF 89DB 54C7 DA1D 37AF 9A94 EB55 E272 2EA5 0469
sub 2048g/0CDCC535 2004-07-24
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEECPOARBACeiKSpedo952tApwSI+rrDIrp5LOC5FG1crAiTpAqy6aP+n60z
c2euoVDGjH/ncUZ+TxUK/MkzSOFXTjU0TETFgq2UMxSzZCLwPrmQibfHbmnF08+g
0EjlslsszccPgTEZz6F85aZGYWjU4dhQ1VYP+y5Im88CgahggCB6J+8hHwCggMu3
f51egcdCrodzFvL8poUYKi8D/i644gOjVN/YamHS5QUGNPJ9xkcq5G4OfK+Ubjq8
6T1dd7UkJ22sePpKGtRhPNATeEar/HwzLB7r2h+UAD4Yrl6+//EwWB73BgxyCqcB
X57s57K3+UMblbLR3NWJAD/HpxIBFxXfj55VPk6aH6GX5LzayMxfZVYccMyWOcsK
UZaNA/0aJkearTpmitBL49fOhz8Je/QIF6riigkdOuyx62yAtYRNrVbDrQvvornR
Z1CLUp+mixUc3bT+emLFpz2ZXmGqCr9BMAqENh0gayGeekyk8IYLQudFSidL3yHo
WErc76neXoBE/5M/v7jZCrQS9loS0vITFsui0Rv95BcsNbV0iLQnU3VsZWltYW4g
U291aGxhbCA8c3NvdWhsYWxARnJlZUJTRC5vcmc+iF4EExECAB4FAkECPOACGwMG
CwkIBwMCAxUCAwMWAgECHgECF4AACgkQ61Xici6lBGkj0QCbBe+RP2fX0+t1fiU/
oOcORVeRc3UAn3Y7M2TfTKmSh+5RXsaxcVKWDqZauQINBEECPPgQCACOxltxnJKq
MHIW1P1u4pjby/v0ZsVWbhqmPzW1L/o0SHbBdPkLn+NZmOKG3sXFkitq1nnXQMq0
pdWwEK55rN3+iYMpq2OJgubsEDJbo39Lom49w3xXs3ElHKWmgjNUMmiGi3yA3Q5P
p9E13ze+ZBTTZrlj9xtTsXYPCkoihcjA8iD1G52CJYuVQOCxeKo3d8EZi4sFXhTs
yGfK7ipLN2jO4H8LSrImMlT5z/ePmhTgo59A+vsIShklJpRlHqYB861sMobUlbCd
0n7Fng8pD9jIG63usHJgU32AVEeZ9BMaZ5Gjsm7KvIwJH+w8DGnR7016hleSXSEk
wVbS7zjXKfAPAAQNB/9GQcWpnuKYlVa7olq9XOVHe2pHrnK20wLy14ormB245Aip
gTCN/SEIgwc09nF2QXXXhzZrxsFCPphgJh7CT8g25LCJ2rchOhCpShNS43I1ol3d
II4nK0DtXUJc/3qG5PgPaNLHHyskwIIyfL2rKRlufTgByzF3AKXHweJQ9suxGkGS
i2+l1NBwLwsjee59gEyKXT/cbfkV/IgA+NBpj7QaDs0yhsbPSDAJszbo53aBAB9U
sZjWP9tkrzaP1eoSbl+LFttLtrivG/v8HZuPlI4lELeRboslI1aUUfZVt7xx4A6P
u3L1DWOYm9rQ0q1KMlhGQKa/JBtaKy73wwzZujSWiEkEGBECAAkFAkECPPgCGwwA
CgkQ61Xici6lBGnrNQCbBljRUNo/9EHyCk0D07YM27DYC+8Anj9wU0uuZE798XZ6
n4y0m1iMcuSh
=Fl75
-----END PGP PUBLIC KEY BLOCK-----
D.3.205 Rink Springer <rink@FreeBSD.org>
pub 1024D/ECEDBFFF 2003-09-19
Key fingerprint = A8BE 9C82 9B81 4289 A905 418D 6F73 BAD2 ECED BFFF
uid Rink Springer <rink@il.fontys.nl>
uid Rink Springer (FreeBSD Project) <rink@FreeBSD.org>
uid Rink Springer <rink@stack.nl>
sub 2048g/3BC3E67E 2003-09-19
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD9quKgRBADeV4lxkbaQyNZMKsSxS5DJHYKbIy150H97+m+J3vYI9IPhBtlc
oqnlQTaIpoSn3N8ExxwMADRmevRhTHLhXxgfym5iDEAlIAr5uDMKPfwc3yUPPjkG
CKKUQhEZeRvrPZyE8D/CicuSDtunnsXttK+7xLsWAS00gCr+cHsMPebivwCgyMiT
z4YpZ8AlVx1ZDxHIR1CgZMEEAIIcBI4MB9cfOhu9Mje++qIHyAz2jsK6d7/Xu4ua
r2eyDKb5zsbQCwALBRi/vXdR8lt4XvDjvmHQ36J5vGDnfA5t+KtgmQ3EXInggk0M
ZTEvnFL1q3H+bHCKsf436Cb4Nq/bPQMCznPQ7IQjiMBWJPRd6Fv93kowNKdtEAlG
cOn3BADGc8z7dEq+xwNmeXvc0jWJpZXTzT+9eRSQK61wqyJH2gWu8wd1T37pa32H
Efp3Wod5IUFaS7E5P7kthuoMwhKYu5YJJBOA/iV4a1BAKjTJO7sGPwXXIvKMpoYS
wcnicf1rhZ1kSLmX06PA8x+2GFPK9ZSBU0XXhbV09JcpTSbScLQyUmluayBTcHJp
bmdlciAoRnJlZUJTRCBQcm9qZWN0KSA8cmlua0BGcmVlQlNELm9yZz6IYAQTEQIA
IAUCQ8tX5wIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEG9zutLs7b//Bm8A
oKysvuif0y9iIRSvLA0KBBDYBA1MAKCWEpH45Gv3c5lR4keGHo6O1EuFv7QdUmlu
ayBTcHJpbmdlciA8cmlua0BzdGFjay5ubD6IXgQTEQIAHgUCQb6gRgIbAwYLCQgH
AwIDFQIDAxYCAQIeAQIXgAAKCRBvc7rS7O2//ygBAJ9uO+LYKzNfgcKAv8EwEmKg
UWvd+ACgstc4SYQz7IDk2V9ELXsLZNJHu+G0IVJpbmsgU3ByaW5nZXIgPHJpbmtA
aWwuZm9udHlzLm5sPohhBBMRAgAhAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheABQJD
y1ntAhkBAAoJEG9zutLs7b//5pEAniSKnGBZhNgxgPI4xFrBefn1FX1nAKCJ7l21
9H5w2fIng8oy+Mc/lipRE4hGBBIRAgAGBQI/un1kAAoJEAahzEOamxxah3cAoK6L
o2tmYvVDKzXSuyODzWGMIPO3AKCoqHpnLbHUVCK6uNCtUMsP10k4EYhGBBMRAgAG
BQI/unuMAAoJEAdJki0OPZOdHooAoIY0GBH5xaMQHLT7U/H4kEJoy8gqAKCEFO00
fn3ipm+gEe1xpp+B4ghWOIhGBBMRAgAGBQJBdq2kAAoJEOU3f22J7zgDoi0AnRHx
J54/6qgkzk3XYWytM8kORJ8LAJ4kbjFKaxN4FMrfmCXyiobPAdFX4ohGBBARAgAG
BQJA30+nAAoJEMsdesnWoa8+Ql8AnA7jacrDH6VeCyCVPG3bCehRJGFlAJ9cy75M
r+7vyd7HiIDkumKda0v1yYhGBBARAgAGBQJCLf29AAoJEHs456GxToKx7HoAoKDH
l2h5HvFTNZR2yeHfjMr4XKqqAJwPng1h5Oq444Na6toMTxeYmfiQCIhGBBMRAgAG
BQJCLf3cAAoJEGjhJSt9pcU7QtsAoJFIRKi0yuJBTyaZHUYc9/CspFwOAKCv2fGI
ZYVRDvIILnXZayCVPJbtsIhGBBIRAgAGBQJBp3poAAoJEFECJ1+oE9XuIDMAoN+y
gQsgchoxgjgj7xvc+phiXrx0AJ0Wrk5qkVMxH4SThHTmUcWtgUy08ohGBBARAgAG
BQJCoEL0AAoJEJlSOEh18JoRhu0AoJM7SvWSprG7QDHKOnEXf6naqFjoAJ9r0RXn
b38Vh6C/S1mkkvlLMhrObYhGBBARAgAGBQJCwePKAAoJEDYDstQq8oA+VQMAniJr
UHQpCWO9Gl7P2U9mSUM9bmXGAJ44+xRxWgmcbaB5MfNxc/+EhttYoIhGBBARAgAG
BQJCwln/AAoJECtXItZQPuZ/ie4An23xXBcj8uubd0RH4T4eytcsT/APAJ9UVS4C
+A6oZ2syWMhLwhM8De7aaYhGBBARAgAGBQJCwl/cAAoJELm9u3R/Ejcr/sEAnAmt
TRDaCx52VtTFUCZ3gqdJJ2nNAJ9LiD6qEUEsR78lj8KtHIFd3gJyXYhGBBARAgAG
BQJCwl/jAAoJEO0ktfyslxhcw1kAoIeAi1yRgvSjscfriPPLJsfItirAAJ4svEJC
OZRTtcLaPTCGljgzNHe1mYhGBBARAgAGBQJCwnenAAoJELa66j1B5mvZtVwAnibO
IGxb784vCzraDVqA/eewItNfAJ9FqdOZYw/CovHLAj3w2nXFTsGvx4hGBBARAgAG
BQJCwr9aAAoJELOADYxWullRPjYAoIJm0zbOeXuCRFTtpHMyjVb1VLPQAJ0RAtgr
Ms9M9CZrOhojTARULOlEYIhGBBMRAgAGBQJCwZauAAoJEEJrd6pui7AhX0gAoMAp
9Xqrbmk/RMZrNc0l1qo7Z81TAKCfroUBS3Ecih8v1jGmTgPUSkTV8ohGBBARAgAG
BQJDHqqEAAoJEAYGnPKWlFfwIZ8An3dUfKJR8MQkDF46pY7ehQzyjoyhAJ9I4yiG
pkBKVRlQnl83NxXeL9jGuYhGBBARAgAGBQJDIKKmAAoJEF924XqIxu326E8AnRSy
bi01ic4Un4XXDT7zs9BX0GtCAJsEgPknCSS/yYPgK+Duk45J3jdf2IhGBBIRAgAG
BQJCywt8AAoJECdq1e/TZ18Ig28AoJbmYoCkCeUozLToGrESAo5OuhWGAKCYdOzJ
9sPgsvr8x/xa8whXrdIB8YhGBBMRAgAGBQJC0F7lAAoJEBLMC0rbivl4Qu4An21t
BQWlJyrHZ8ZxLeWb3bLC5RjtAJ9zdPh+fDYt4/Z4h9twvCe3nKfAeLkCDQQ/ari1
EAgA8g7iohL/Ws7gm0fHBa1iStYxJxK6p9oy5zvuN8vfgVsj4Efjm/eS2l1RH6lP
jw27XdtAMBuEctGFAhtBajgdYhryBhOKeUIOZo94QkRLMRf2mw1gAM/yaTVlixTt
imq2S8KfLYLTKb8T/ysQQLhaGHuI37pN4BIdISskMiFpDS3vuquN1Q7y6i3cmUUa
8z7km9Gx98uQfPesUPn+pcAgkL0f5LBH5smNeobJ2TbVTfqKm8070NZ4md8kYtZX
9YvF7W+6CT/gK0mYwbMkoJdyiGHXLmzbWwnhf8LrOH4cB+2SaGowaNwNon93KHX5
gyTo5Ok/VSWqtacxKg0i7JBT2wADBQf9EDMyjJ8AoCH2/fGePWfpTb6y+z465AO6
UA0LUNcMjVO3Fm8KrgvIf/k0SFuEkXfchVPmeBdR8uGR47+A3U/49wJObRrnKjNJ
BtNZBxqW5rtWHAO470MQ1B89c7Wu2f5SJfqu4HJjy7LAWNCJ//KQ+tsLYrhVawbZ
/fmmt1cur1qJA/C0OqNhay3CBw00dr4IE5nzUw1qjXQ1Oc1h82JMV3IimPG/Mqkr
cmwbg++OY0U21uEcya002rhfWSNiNLxlAthFHqK1LNDd5EsePRHkUbRXKM0TWvV1
8fSN39nNtd3O8nMZn9KvmFyKY6uDAYegHv+Qg3L47VJu2UKVrVVhYIhJBBgRAgAJ
BQI/ari1AhsMAAoJEG9zutLs7b//78UAoLxcADrltOZuLTJMieSR9zw7nruqAJ98
hpneRV17ciF5APqU2SSiDrugQg==
=Gfya
-----END PGP PUBLIC KEY BLOCK-----
D.3.206 Vsevolod Stakhov
<vsevolod@FreeBSD.org>
pub 1024D/213D0033 2005-03-14 [expires: 2008-03-13]
Key fingerprint = B852 0010 761E 944A C76D D447 A25D C12C 213D 0033
uid Vsevolod Stakhov <vsevolod@FreeBSD.org>
uid Vsevolod Stakhov <cebka@jet.msk.su>
uid Vsevolod Stakhov <vsevolod@highsecure.ru>
sub 2048g/786F2187 2005-03-14 [expires: 2008-03-13]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEI1ezcRBADE9OSKYo4FwkV9/HZCsEuq3afu/4cEiRlaS/pod5b5/tv1DGAl
QQdQeNxW8nzDLrODbyCtmJDxvOib4Z2qz2NZOgjTujnlHeKecJJKkXg7bYIgMWy+
JQNX613fcsgQicUQDyi0nMKcvd8BcKuzDUCGEuyMxEE5UyBPXOKDuPLZNwCgznDP
rjh6cffp737SBR1ViasIresD/RYo8N+aMdwIQwqWXYXuSj6sCDutU2MUsRe9RxaP
iDE+XvLuxRa5BTAitMWrDJqKdCjysADTXl6Owic6+Y9ppk35+VHDq7vsow3v4HrI
znJVb5ZOl7nyaBtsd7v/nRFjQEcko11PxbmAAY8UevbGSmUsOmyT2ZMgYkNgGrvl
jsGZA/9UtsG0IaR9+EGAuvOGey3Rh5AfNVontxJ+FXpCyHgKXWFrJIzbFPJ+iaYN
xd2uUnEcAeGkY6UsK3z6MAvAorJC383tcRyfZQ7nAYhR2tmPVjFCNU/wPLT6MiZQ
LgPbYh+SBWTpofpnAcVmVRk18tqtAXuH3kb+m+JG1EppxT4WMrQjVnNldm9sb2Qg
U3Rha2hvdiA8Y2Via2FAamV0Lm1zay5zdT6IZAQTEQIAJAUCQjV7lAIbAwUJBaOa
gAYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRCiXcEsIT0AMwPVAJ4z7YKxK+3XB8ic
Ml40/9QdnfzA8QCcDbtrLjTHVfMsLZls+CpS7SVOZLK0KVZzZXZvbG9kIFN0YWto
b3YgPHZzZXZvbG9kQGhpZ2hzZWN1cmUucnU+iGQEExECACQFAkI1ezcCGwMFCQWj
moAGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQol3BLCE9ADOu+wCgvhaDI/qqW88t
h1qkpZiSoj1QGhAAn0aH/9Ln20qZlzOzflE+RMNroro2tCdWc2V2b2xvZCBTdGFr
aG92IDx2c2V2b2xvZEBGcmVlQlNELm9yZz6IZAQTEQIAJAUCQt/YkgIbAwUJBaOa
gAYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRCiXcEsIT0AM18MAKCYLPaRezw9CggX
0WGxZ4V2AO/H4QCfe9H8leQkgkf81O3xijejFh4yo225Ag0EQjV7RBAIAPegYMuM
CjkzEiNYAWZNa+IgCrfWTZWuiCkvfvbYlnx2CLCMhtCi6kDIGm8k8ub0MrgI7JnR
z3dVaKUi/ky7lbTCkl5lqLdJCX7lAOmbXrtV8Z/w4ke/9aoA5mRcA5U6IDKemkr3
2mfEEDY6ZOYltLaOh0oPcX1M3v2NIeJhITi6QeDLOpprcCB2fBaZLNC7elgExxaf
4Ij/Y+QYvZ8ejdOG+AOYHm4DOhWXPyfhhHLRG/U8QY40mYY1BhXZnm8ki/n6ATNn
5/iUzVZVYYOFuuOhl0B4TG01TlDuhvzm3nBblXx4TkXmlJGY+jy9pzyqyI8OpwpF
b5/+Q68f2OBltX8AAwUH/iaq0BjgK3Rk6Z/0Efw0ZVk4oO/RhQWcY0f5QDzPnoBk
DgQcsraDpK+fMRAbNXNjRA7qnTDzyVSjURHEJluNGpXQVXkrO1j5+N5yJXZy7Y+8
nlUm31UKp8bgzCSck5LcluV9dOQKSD4FvgRmyrt7Zf1Ge824/KkoQaw8MqXGd3hL
vWta5S3YRJZ1xKKYdld9P7GI9PkOSsD1f4fYQpaHiHTQB+/LIsLiiEWzEnVvWnqN
CJoatLuznMB4uTjAmKMrOAjVw85+x98Iz/tgIjA/eFO1OlOx1+3UpwdpAibKXDf3
dIxbuhsp6xy2G7xbYr+ErgZcpOePy+vvnOxc1gwS4q+ITwQYEQIADwUCQjV7RAIb
DAUJBaOagAAKCRCiXcEsIT0AM/LDAJ900L1+vJyKrr3hP0al12mE3cy+9wCcDeQp
6wzJCGiOCfCGViOv+39ADh4=
=gaWL
-----END PGP PUBLIC KEY BLOCK-----
D.3.207 Volker Stolz <vs@FreeBSD.org>
pub 1024R/3FD1B6B5 1998-06-16 Volker Stolz <vs@freebsd.org>
Key fingerprint = 69 6F BD A0 2E FE 19 66 CF B9 68 6E 41 7D F9 B9
uid Volker Stolz <stolz@i2.informatik.rwth-aachen.de> (LSK)
uid Volker Stolz <vs@foldr.org>
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQCNAzWGPsAAAAEEANfn/N113UfsP+wON2IJD1Npij5AKnGs1V4bXkxjcQd8Uxa4
AKoCXtdBqB13f9xaWKI+yHvzYvxSpVD3eU8e0VBnO/PVgkl48XGWqydMW4qF6bA2
cIOAEpytVR5wWEPdmO0LQ0zQx1lTl88maQY7s0Vi2o03yU4tMBLpPok/0ba1AAUR
tDdWb2xrZXIgU3RvbHogPHN0b2x6QGkyLmluZm9ybWF0aWsucnd0aC1hYWNoZW4u
ZGU+IChMU0spiQB1AwUQNyb/0968PY9qESIpAQGJcwMAi+c5BcVhXuXTv3bpbsLU
Ftt9Pp+WCFw1SVsUy02HIkt+NTfyW6gf/yuQ7gjMRSUtp0BVXV/2NBCT01ysTpX9
uQMa/hz5pxHESkRJBxvBPt8RsP3EYMYbtwPTMcix1d0piQBVAwUQNYdqcEekbAQj
CIb1AQFsogH+K1mszKG+DSo72s0YNpV63NCj1Bil5wUNzRe6u3ajd4G5PZuHmmWd
Y/uAJz4zIO53jBPYqMXGM0JHHKHu8EaLd4kBFQMFEDWHakmCXfx719L9vQEBlEoH
/2myvoUi2Np5bujRVI2h+uKSxwWMN89fXqH6nh5XTLxTcO6VEMHAaOlV4PEXzbuw
Z3QRD+ovELzJNu+RCXmAXNjUI+l0H/MHTtSttDa9mGXH2WRw0Qinm66OIbsprOCV
cAunc3WKItGennhpJ9z7iXIy1jTMcZ5suljM+qFFgVZUoD+dcc4Xu4FjT3GB50dX
MOwWWPGdSemm142TfjkvdNfNcqFw1Dg9/QLTXlXzqEbYVWgEFnVVd7Arspuo10+4
IqA4i9bpW61XZ5KGPYr4IYyZ4RxiwPCTE9GkgxQz9Cq0rVmJqyjTYSt1JJuKxrWE
IHSqRYfItXJjs9oNRtXFkwSJAJUDBRA1hj7AEuk+iT/RtrUBAfqVA/4lI0dDnQdt
bkGr0fMssdso0BOHeYNXzzc518ne5/+juCoHap+348+KvHS7ppSqaCEIi65qMAJv
fi3DT3KmToQMkE7XVfRv7V1XbQTEsw3D9xq+VxLWFdlOMbRtK29UDIyuNSDLeVgu
PAsfZQVqaMfhOqo743wmcUpswgIRRBk4jIkBFQMFEDhaWABJ6axjeQoR+QEB6OYH
/i/a1aYox20Qn4vNy46tD7c1RH/Ub7HfU1D0CsW+X2mJV78roZg2VyPLo2nfFpN/
BHDR+sUCjL2sURhEdVPDktEkcFGs4V9mCFp1RUQvmKBQIGuUFadJ8n0bKtTEwH1F
zYqUzgXNdjYc3HKINb9q+ZfICVCcyM4a4M1gH74giKnHKMN7nXKTbWbBmh4b6iEM
nr5w46VmToAKuAdgG7unH98dJRnV+lhTfmKJ1eFMjnz1BCcvbU3oLJylDMw0Tk+8
gBv3HVfb66YBaMJOLJ3Vinh8KAhI6JrIwn+wAFJ4V27hcRIoB28lQXsszY7WsUEK
9tslbltr6Ll9bwpeRZ71IvOJAJUDBRA3hDNlQL8ekR0N0LkBAVADA/9a/4x8k/Y0
OnwHaMTPhTHeIzdWaCchY28dQs2x8voRu7kVGNEC086VMuvpbxXDphJvzYcr+gW8
7dtWI8gvrABmNYh4CAqASl2byN5weA3Vq/JfFNUyLJ9iv1N0JhyQOOkrws8WqryM
IRlZgC6+9oaZyewijGKy8AFN81CLV2DHEIhGBBARAgAGBQI7SvgIAAoJEOpKzVz2
XGjNKJYAoNqWOqq2PjUUCtl+LKRRbZF+JZCNAKDXYaXtG6qbZAaEWE+m7r1LLe+O
nYhGBBMRAgAGBQI+QWnDAAoJEAcllNVHsDXr0fwAoIUVE2QqsHmX5fIeyAOSsGG2
UJlVAJ9GPk+28IOjqJO3jw15LkvX+4JvoIhGBBARAgAGBQI+SBHZAAoJEBDLp9/8
BqUt2wIAn2Nnv3RldasDKub8ciJHsepxBzaYAJ4giqIRIvlxLKc1Lies9wxkXScc
AIhGBBARAgAGBQI+QEyyAAoJEByNJ2SEN+Mf8zcAoM57AaMFNyq6XGMsrI0O3cJ4
wMioAJ92FrujzmnW2/WA6Soi5DrF2JnA44hGBBMRAgAGBQI+RX6WAAoJEC9KXfQQ
64+oh7YAn0e3SZfP7bThkHK5TVVjdyLHfDKVAJ9ydt9U+MpPY55NoJ6Uo8a5jxLA
SYhGBBMRAgAGBQI+QOblAAoJEDmjyUz9xKj9kWsAnR6jJOxeY4rKP0n7Ggr4VSnu
ycg2AJ9o+NRr4q9yyM7pfREFZcoV1XCmI4hGBBMRAgAGBQI+QWndAAoJED9XzG+e
a3bfC7kAoLWacSdLLJhBuuTBN+BvHnWBLnCUAKDIj5H1oxzJ76sP/JfZsapEGF/N
sIhGBBMRAgAGBQI+Qq16AAoJEEAMHraiSM5jKhgAnjgBQVtp+LTcCnT2f9oYwYsP
u4qlAJ9uCN6whxSETrv0S9YjjEODzNPK+YhGBBMRAgAGBQI+QX93AAoJEEEY9vyV
JunFRwQAmgLVw3LkbX8KIZlnDWL5voMRFw6gAJ99I8+6GZWfDhbZ/c2iF761bn/A
kYhMBBARAgAMBQI+QV4zBQMB4TOAAAoJEE+DjLcmoKgWLNAAnjPWg4SYMj5INI/Z
67KSORgK1FCTAKDSc+zGbjao08ECfJs3g0I875J4/ohGBBARAgAGBQI+RbPbAAoJ
EFv8diRAZaHaj20AoPhVj4LSdtMGbyzzCKFbWEiXfbDuAJ46sEmDEUKW9LPMpIfw
bPA02N1XvohGBBMRAgAGBQI+QLCOAAoJEGJIS48bSI3qqvIAoNTk9lKbvIjCxjYu
Pi+6QyWeMidrAJ0b8421ck7IAE5ByeOGhMcWTXvmUYhGBBARAgAGBQI+QFwQAAoJ
EGoCMg2CoDJemxsAoI+pJTqzr/I9XifXmoxAmGmywwnZAJ99zT1A0X9vyMhfEj+v
S4PgZP5CTYhGBBMRAgAGBQI+QYUfAAoJEGumFqTBUTsMwecAoJFSJuJHQaqenIet
6YYF2RQMG67GAKDPRW/Whv1ocOrY2kURdIKvtKoLfYhGBBMRAgAGBQI+QC7AAAoJ
EGxG8ZwW/bKYr1QAnj6fbgEOmLvusBd0xl1QNjoJSJMEAJ4lZbc4ZfML6rLKLcjU
SiXewZJG5ohGBBMRAgAGBQI+QaANAAoJEGx2F4yg7Zgt7/EAn2LA73pPdic7lGbw
4/zIM4Ccs2RUAKC3A0wEFXh84B60ov6IqOjpw2Ue4YhGBBARAgAGBQI+QXqTAAoJ
EG55RQKgGXnANT4AoMFVsGRuUnRv32T9gbU2cswWJJ8+AJ42FyyYKF8UkchrtkTw
Vuog5aYATohMBBARAgAMBQI+QMp8BQMB4TOAAAoJEHUTojYTECz147sAnj5UikFV
tMJlzb2myMZQq1WwVfs0AKD2rQAKLMqYguwPnxZgTqdjkqweKohGBBARAgAGBQI+
QFe3AAoJEIBnEocjFa+jNXYAnRBBVLZRL+CcoIKkSOgfHxWuwCP+AKCmdgS6N+Cp
yuB3RLpLZwdmgfI3WIkAlQMFEz5AXimGoAgbIrKVHQEBt7YD/1u5NM4zHgXdQaWC
zMT4jUq1vL0s97I/QVOLeSxaTe9eDM0teOjFq9jE8ZSCf0hCeNEQENylewUKPb3l
2Cnk2iECjhA4oz5Y2EjsDBKMxYqIeTrs7aX2FmmuUS2V0rXAq/IlZVKEpGYkHeE0
iTfV08LiX+BVzTSN3nH219xV5JM8iEYEExECAAYFAj5AWp4ACgkQlI/WoOEPUC7T
7ACgqAw/1qBb2L37c7fGos8+Kga+7j8AoKlugMVba+7iFlppj8uLsjrd026HiEYE
EBECAAYFAj5AJZMACgkQladE0noea19+JgCfTFPlMzDdbkljKsApRIhEJ0MgmAQA
n3jpS7f+9z+F2+VT1EODr+qgN/TviEYEExECAAYFAj5IaJ0ACgkQmpTNb38U76R0
yACgq7VUA+Ge/O8925P/vjgU/J+inkYAn1IKkDq4BoybzuwNbIViHcA/Pw9/iEYE
EBECAAYFAj5Gx3sACgkQnvV2imrOP6y1YQCcCxXkvBMxP+QZHp3aGEcPS3BWFpcA
nRpba/mx8Igvy54P49U0iytSDRlYiEYEEBECAAYFAj5BeqMACgkQoxjOxLJuarl+
egCeNgMW5NhVX12rFBQtBw87rRRL+mYAoIfJOcdPK6KribOYa3IVPzEDDACviEYE
ExECAAYFAj5AtroACgkQrlHMQSNGevH2MQCfe20+1ceoEJ1f/tBmGMk5L+b5P8YA
nj836l/Q+MFUrSkui5vFnLl9+8E3iEYEExECAAYFAj5BckwACgkQsMS595oNgqkL
8QCcCX9cJDpF5ndPPql3dMQ2TQOw+z4An0Q6b8/w3bmcv1vK/FmC8NK38G85iEYE
ExECAAYFAj5BaoEACgkQtHXiB7q1gilw0wCcCB2TVfy6ngP+U2gBmRJrrN/pjGUA
ni2MxhPJ0UjF0yT2ybRN0dhCHm3NiEYEExECAAYFAj5IaUgACgkQv7s1Bo4lI/3w
sACeMrgVkwtcYBLjgz1j+voZc01ghu4An3tDEXZj/ZC84SU2qjeUvTonx0u3iEYE
ExECAAYFAj5BE6UACgkQxzjfyzWGunEZTACbBcFVKaKo05O8gqcNHzaqoDRad3YA
njo4qXL5vZe1+Ca+Udc3v8j1cnGgiEYEExECAAYFAj5BhRAACgkQ0ORHvREo8l+1
SQCfUTClW0oDQpulk484vp4zxZuq9m4Ani5fkDVe5V5v8tErtl2emrbN/PrCiEYE
ExECAAYFAj5AzUIACgkQ1VamYIjj71fu6QCgmgFAgW6sCcX0Wq3zD67y1jKO/dkA
n3Y6+LXalg4va79fuR84qwc8w6FEiEYEExECAAYFAj5BI3gACgkQ3DZ0N+WqyzT5
kwCfdw6c5A3aV4Mnw+TXCykESqZHvpwAn1A6AZXB1SIb8/z6cAyJnREj8lgbiEYE
ExECAAYFAj5JZVUACgkQ3uEZ6Jp2yaOHigCePMi1gAsMcFUxX86yTd0l2NIcec8A
n3SjLh8NXgnAkRvUijWniQKg59fyiEYEEBECAAYFAjzSTagACgkQ32cuVxwi+uzA
RwCePk17Hk+BRidQBbbRT6rS0w5quyYAn2ak/VAfJC2036TJGk/agMeIffY7iEYE
ExECAAYFAj5BmsAACgkQ8CTvgjVRnqhXcQCghTsuu+lr69KxozYDfUnStj9tGycA
oJ+rgBsQI2qsKVKCGHUGdSiP7H0TtBtWb2xrZXIgU3RvbHogPHZzQGZvbGRyLm9y
Zz6JAJUDBRM7HgBlEuk+iT/RtrUBAVGYA/9O2enRF0aTJMCInSA/JMAn6JYlIBPn
dpRmRumHOQodkllBKkoU0DextJIqRRfHnBfw4C+6XeM8ynZWB3oGo+W2QjJqt/Y3
+H1E6c2Glz5/k8m9ftXVZW5MW5vTNoz1JvTq5Q6CugR9Blu0V93yJL37TQ+S32D0
Dx6Z4NsZZBDI04hGBBARAgAGBQI7SvgLAAoJEOpKzVz2XGjN+Q8An3Xj0J21Ksg7
FRqA93rshe5ZZXwgAKDRQl/BQY5AGZlBPO2H+2fOv8AsZ4hGBBMRAgAGBQI+QWnL
AAoJEAcllNVHsDXr9kMAn1okZvtPT5VXSzzVkWR6g13OtJ1PAJoCIchW88twLeog
z/Nzg3mq240nH4hGBBARAgAGBQI+SBHZAAoJEBDLp9/8BqUtUSkAn2d3mERiipeA
HziP5R3grI9uaI4TAKDE3qE57joBG8A8qCmYJPSOVldbJohGBBARAgAGBQI+QEyy
AAoJEByNJ2SEN+MfKWIAn3ivxpA/uKUHl+fm2KPLmRNYI3HxAJ9SOoqQX8C+bj4p
c8oelneVlsPY5ohGBBMRAgAGBQI+RX6bAAoJEC9KXfQQ64+oYusAnAoryTN3Qttx
HSnYsUmR47Dies0+AJ9ZwrkvSzCK00AN4BlcbYYmLfU724hGBBMRAgAGBQI+QObo
AAoJEDmjyUz9xKj9bIwAmgINDAPAQomDcgOfG5Cu+htujHCjAJ9N1Uua6NaxYy8D
v1tbsSGVmRLmV4hGBBMRAgAGBQI+QWnlAAoJED9XzG+ea3bfZGYAmQHndOs/EP9y
TpMe7dsnaUqMRPWbAKC7XKNVqX9d2q/gfMfYA3sKpyiZ14hGBBMRAgAGBQI+Qq16
AAoJEEAMHraiSM5j+NoAniMCeL3nPdSdJeXyDuGHg7Z0euPKAJ9KPSZu3rw01sel
8uZ3hHCHGcRALYkAlQMFEz5G0L5Avx6RHQ3QuQEBcrsEAL6SAiCyBNDmnBR+xHUO
F7YpbkcSJPd4dDgJi7eKhD9o55wGdLWjMZJlKJNRWQNpAGTxx3bSZSiZPTBlVBXZ
OcCnkbZfKa3dZCKP5HxHl2vAEcroasiNQQI9iLF7LvaYZ0+g1EmlO/Vj9CWHB8ZL
ur8dZDBrG27il95aQFrtWTBDiEYEExECAAYFAj5Bf3oACgkQQRj2/JUm6cXVaQCg
maKjFV25e4MDarIJeRrd958rk7QAn3xiGFmzB4hvIKxCd5phuQyWCE7XiEwEEBEC
AAwFAj5BXjMFAwHhM4AACgkQT4OMtyagqBanRQCcDIf7Yqwk9DkEj2NLwQm+kgX8
oo0AoJzBj8dOY8RBCteUwL9A0LoxBF/XiEYEEBECAAYFAj5Fs9sACgkQW/x2JEBl
odpkKQCgvdFhFeBj9KcsCdGqkHDGfv1SDdkAoOcL1EqjKaz2vzhp3cxEU/kLsJDL
iEYEExECAAYFAj5AsJEACgkQYkhLjxtIjerTHQCfYxaYQ5o6bxRhjOPv5lTVxeMj
ikYAnR0YV4wlQBYYGGt0nKtvg8MuBLSGiEYEEBECAAYFAj5AXvUACgkQagIyDYKg
Ml6O6wCg2FJOk8R831/RrP9CCv8VOaj5KtQAnAnfo4+TXJUwkMXRM596KiSIL72l
iEYEExECAAYFAj5BhR8ACgkQa6YWpMFROwz+YwCfWH1UcIp9H3P1mLwKeQHZzDwi
6f4AoNV77nh6CAd/AFufaWBQt84obYAOiEYEExECAAYFAj5ALsIACgkQbEbxnBb9
spih2gCfY91bcc/xnKMnOICBrS/MFr6M7v4AmgKEWSakagyDY7TAT403SE7JYWqn
iEYEExECAAYFAj5BoBAACgkQbHYXjKDtmC1h5ACg4pxJxfj3iH9VKMKhSSaxQkUL
6HwAoJOMhoSLcSBcwRhC9c6br6HJ8ZPqiEYEEBECAAYFAj5BgcoACgkQbnlFAqAZ
ecD/mwCfZiPgPhxIZ2uW+3yCVQpxHDJKbqMAn2zfdRalO5+nvLweSKLfvnn0lmEW
iEwEEBECAAwFAj5AynwFAwHhM4AACgkQdROiNhMQLPWbJwCgqiqgiND7vrvR7lXZ
+RU594ERmO8AoLU4pU1mboIwas06Bxt69i9fq/4ciEYEEBECAAYFAj5AV7cACgkQ
gGcShyMVr6NkjgCgoiVSCaInsoV1mmdckUF2b897HiMAnAnvDrvMi9MBlZ7u6hor
F6Lzw4REiQCVAwUTPkBeKoagCBsispUdAQEPzQQAskLYlBnE9LDF9LOVAl+uxOyt
P+ygRCke2xddkRQMMno0o5N1GDZ19MCC1gH3LHfpfRBX4qqsd1jhu6x00jtOKZdY
ZBhR0pI2toIg4G2gcIApUW6gwvm08vTgEadsAhctF5eYF6X//jZ+KD6NPT0vQhtO
BnsEZFgtaUGmdKGhmA2IRgQTEQIABgUCPkBaawAKCRCUj9ag4Q9QLrjHAKDIkTqD
wxhdTKtbO7E7Av3qXLun4QCfWM1Gbgom3IvDOO0cjOmVrUBWVY2IRgQQEQIABgUC
PkAloAAKCRCVp0TSeh5rX9JOAJ4tNwWBAuCK3rQH85vMEQMyhGtFKgCg04iSA7Tp
qmhKWSewlfazudSHtBWIRgQTEQIABgUCPkhonwAKCRCalM1vfxTvpCZmAKC4/759
p3jrLj7x0RseNO2ZTeNnCgCggulgV4ZH80hp3l6+ACGCCD3NO0aIRgQQEQIABgUC
PkbHewAKCRCe9XaKas4/rFJ4AJwPRY59Vsh2jIRqSotuByuQCyZkPQCfUBtv6IyW
k6RXu6VUrAxSOxYodNGIRgQQEQIABgUCPkGB1gAKCRCjGM7Esm5quVn+AKDIgwUw
NacdRUUDelaMrFe7F7nzIgCeP00xg2eFHI1V/GO4KU1ar7TBFtyIRgQTEQIABgUC
PkC2vQAKCRCuUcxBI0Z68X2WAKCkvSW+1xOBeUFaZ0W48QnrdXXgAACbBEc+oeCX
Gd6r2WqEh11Doly4aVyIRgQTEQIABgUCPkFyVAAKCRCwxLn3mg2Cqd7/AJoDZDUX
3ULlwyxcHpQTnV15xJVYawCeKZ7criCJsxQG+1BxK3EFLgRePd6IRgQTEQIABgUC
PkFqXQAKCRC0deIHurWCKTRFAKCkojFse9VrAdDHVxR7fUguPPEsTwCgnn5xJzVy
fyecWDEL2INvKmMcmx+IRgQTEQIABgUCPkhpSgAKCRC/uzUGjiUj/SQ9AJ44o83x
XDeyU+DfT7sSnw6mI5tFNwCeN8n4xEQeQ3vDjr9k/zX/hjZUSWmIRgQTEQIABgUC
PkETqQAKCRDHON/LNYa6cVLJAJ98aJ4kTcVL66TTiAkR9IfI48x2gACglM18GIGK
Ix4A3ji4yB7BBEwYxnmIRgQTEQIABgUCPkGFEAAKCRDQ5Ee9ESjyXzhVAJ49HvGH
ufeXvVqpqRzpHS7A2KhAhQCfa/1HEiUW3BYRPxS/rzRL1KfmaxKIRgQTEQIABgUC
PkDNRAAKCRDVVqZgiOPvV+vKAKCUhQqUVlMR6XaLJQ+Agd3R/AZvIQCdFxfP68E+
3Qh2HDlkCtnqhXEvZY+IRgQTEQIABgUCPkEjfwAKCRDcNnQ35arLNMyAAKCw9lTF
nqIZrigS6FL6VWd8IK40FwCfe0DKJVTC1K3qBZNZmWwREFcC9juIRgQTEQIABgUC
PkllVgAKCRDe4RnomnbJo/DLAJ9X5mdgo0D9jrzYPUHedIBgkanj8gCdFqkVMbgq
QWB3lOx2qa+IeCsu+QyIRgQQEQIABgUCPNJNrgAKCRDfZy5XHCL67N2uAJ9hPkCY
wRtgpj+I98LNUu0fdU/qzQCfQNOpV5iFSTsvNOhHCAc/Cgrh0h+IRgQTEQIABgUC
PkGaywAKCRDwJO+CNVGeqMPqAKDAHnMpI40Le0QBsOfy+Asrx26bUACg06SuKdXy
/xAdj/loIt7VviUgxbe0HVZvbGtlciBTdG9seiA8MTgyMkBmb2xkci5vcmc+iQCV
AwUTO6oqNRLpPok/0ba1AQGjhQP9GAmJYWAEwJK9UTQjmtM49YKCI6qyRfEOrVW5
/RbL67I19Lzd3wfXkNaKyb0uG0zbGUN/mE7BYkPt9cx3GPxLTNmwMjQxTO6K63y1
Uqpw0nzOub68Jyy8gTsrKODUf6Qq9PJZUOklUTlUuTibyLn513kHaIByvIYuBLfn
2swrq3yIRgQQEQIABgUCPNJNrgAKCRDfZy5XHCL67CojAJ0er2B3hH1shIaSGkNJ
JjRRgwrcxACaA1mQVC/GXakpIv3yv0ldFLWTYze0KFZvbGtlciBTdG9seiA8c3Zv
bGtlckBhc3Rlcml4LmZpLnVwbS5lcz6JAJUDBRA2XsjAEuk+iT/RtrUBAWeHA/4w
wfmxyl9v8sJesoRqvJBH65DtRLhFTwHgvQyVCUMbIMkkyf9TC+YvcCoSWe5gIvVt
S4PyurOcbw97iJBtH7aQYqwQztMp/I9iGpEqlEMmISl4nLdMI/pehqfUyfD9AQo1
6fSka2F/5tj3UbFG44eu3gbubWU3CkZnY3vSaFmnIYkBFQMFEDf92KFJ6axjeQoR
+QEBd4cH/iOmUttgV/O/kkXLzaRdH/uGXnqAOx61wC5p/wsiw8oMvkC/zFPlHMna
k8m9rXdc1NyUwXNI6yLc+B25+LJLVvx5iEnEFGCTT34Epg0HDLdCcfwBwmcBTQOn
4HNMo9ZEH2zzSYq4vssIc0IYQbqcbBuqmgbsA4F8sReg+p8VukH+55Fj42MuLOiy
tZaCrwaLo4j3ZTmsEPSQEUCQduSxyz5es4ri6JB+QM1TLPzmtNx3Zfbjq8oDhx6e
zZgpvvWTUYoAakTokLrXd1IgFtEqETbkBGHYDOf4FxgZLwvvtEQ8cuW2K81/HY+c
yiP6WX8+Tif9Ts8ytd/qJRzf0xU/U1u0OFZvbGtlciBTdG9seiA8dnN0b2x6QGk1
LmluZm9ybWF0aWsucnd0aC1hYWNoZW4uZGU+IChMU0spiQCVAwUQOFZPzxLpPok/
0ba1AQHfMgQAgE8mUY5piHY53O5wSlpDmadpQ24Iz6jBWtnZHmHOOzK9tgBAwREa
rAkunLMnX6tInHS3QWcsKw+rpwkeRYjhwjuyApmxH+UABv2tun9A8FbA4mNuI7rj
ClROv5CP0g7oE79xq25L9VSj37JwMAyYrPquIaNqd8JOvjAg5T/ybumIRgQQEQIA
BgUCPNJNrgAKCRDfZy5XHCL67JIQAJ9qZqQ3TfEoTrRQ7EOTYOnPWEHwyACglPIA
wTW3pxbq/C+W+kO/PNsZ3PCIRgQQEQIABgUCO0r4CwAKCRDqSs1c9lxozRWKAJ42
Xa6HftDxF4bImBTLp4bphkg3rACgsiFJj48b731sTUwXzUoJ1Vk2JSO0OVZvbGtl
ciBTdG9seiA8c3RvbHpAcG9vbC5pbmZvcm1hdGlrLnJ3dGgtYWFjaGVuLmRlPiAo
TFNLKYkAlQMFEDWHpVYS6T6JP9G2tQEBUJgEAM2ioA1zLsOGL8k3cwoS4rWlKmiI
hqlI6cc8ePfKe2fbregQiQ89/lQVTUWiC5MA7l9ERT3dUIjYmTsX+5OQLJY/UQQU
fOcFsrwiOqMZbkAR6vgKXSj3GsjrPuPhG8f1INXAeB/GjFrfQpuwCliC6Bfmt8yD
aFRBjZgfnE8eH99xiQBVAwUQNZS2FEekbAQjCIb1AQFJQQIArqkTioNBIq8p9Ybk
Gm4ztbJHCRxOyOyoKz5HVtS2Ra08LXMDYj/7SCVerFbE3FmxYEniRGRRJX9CzidS
zIC/OokBFQMFEDWKCt+CXfx719L9vQEB3qsIAJq2iP74omWhzvwWiIa4UJ+Yt8TU
ZXHRgk1q/D8iV4LUgMgdRAP2tuO0aX6pHm096EA9H8gNeZ1woTSnLgw8Z4ySJk8J
36jahk9wYDbc/t3L1jm563eU+idUcwpOBwbAcNdKTayPTD4Peu0CWfCjTWQ6L7Xz
hH3cW+WuKqoDlVL/5qTtfrG9eUAieJaB+1ytuq58V9w6P+QB9sWw1kS7YUdxyQqH
4IrlCO1Wwi4FVDJ6a3QUsRtDpDPj+XOiVZasFMb/foWzi8ZH2vih4Hb9JQET7vQc
54UUAFK4vo/znsfK+AbgypuiLGYnvh29egIo5GADryMT5jlRwk5Ppy8wMcOJAHUD
BRA3JwXN3rw9j2oRIikBAe6PAv0Y1/tuA+Uqfm2IyM+OyjFP5QAumPWSvQLovJ1F
u2Q+JdXzBSRiKsWmWQPb+HHC5EMGDXmggEnWCi4blFtuosms7lcX+pwD9xUJj/Rp
mc9bIR/vuosYR3QAAqK+IqabG52IRgQQEQIABgUCPNJNrgAKCRDfZy5XHCL67CQG
AKCL6bVRdJJNWM/prg0+wZkrUhlY5ACcC7L2EFVlhL35V4MGMVUefOC7N3eIRgQQ
EQIABgUCO0r4CwAKCRDqSs1c9lxozQlBAJ4hArrfK6uPBNk50nCeJAyBTeA2RQCf
d2EysIPiSy1VJ5LpSFL69vKSnFK0HVZvbGtlciBTdG9seiA8dnNAZnJlZWJzZC5v
cmc+iQCVAwUTQEm7TBLpPok/0ba1AQGKAQQA0+mRB+Z2eU29OIaxQ1+nUF2PSNmL
3cwXW58tOgS+EEq9AfKTPFGYgMymB4N7igZhZEaFkp3kl2UC1lqIfKq6RraxnVKa
KW+WC/qdXAuGQZ8AMPAcP8DLEVqtFgUing+6U6JWofXhtB/SnEjcQWX8uEZ4MJcc
G7oQ/NdFiVk5IOo=
=r3Jh
-----END PGP PUBLIC KEY BLOCK-----
D.3.208 Søren Straarup
<xride@FreeBSD.org>
pub 1024D/E683AD40 2006-09-28
Key fingerprint = 8A0E 7E57 144B BC25 24A9 EC1A 0DBC 3408 E683 AD40
uid Soeren Straarup <xride@xride.dk>
uid Soeren Straarup <xride@FreeBSD.org>
uid Soeren Straarup <xride@x12.dk>
sub 2048g/2B18B3B8 2006-09-28
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEUcBVMRBACN3a/+siykVNlKvwCmd4HVMogG+Oljeu9wyLsI8dJ9Y81bkY0h
fi7ve3Tfu4GeRcirnrc2FV9Fcsv4dt9DtYQ7PQTPH8kjrSXr3kQoiHE4fGGJl4IK
IVIHj+iC26JJgbqFcSU7CKGdvZIOJ17IPPh/HhunKBv9ljNJ5MM+WL8kJwCg20Ez
J3CRnHM90EFk/nfAlJRvXk0D/3rqR1ODyY/8fFDtpOIjkApkw7k2eoJsfqy7tbtX
YwdMKQptAvz2NxW4Qjfo3NbgGbfN6eAlhoy9Srcfm886KPMA22ZAvCWopFNbqAGX
e2iOEwbU4JflSq5vLsIhOVz133W6mK1c7VJ0cf2zl+iRWtISES4fOY5s9rEacIjA
NcAHA/0ak6bks8LqzC64zFdI6bj2FfJbOoTrga1/FQEBSw8bET14S20G/713ZCD+
tQXXrs8I9YjBQREsKYmy0ixFYFmxMvG0NxkIyrwD/GEqpBbNdkJlx7pUhqv3zyRY
rzvcmca7jIguu6K9nYi3t45nmCVo4ku9EE34YHzvgFQ15+1LdbQjU29lcmVuIFN0
cmFhcnVwIDx4cmlkZUBGcmVlQlNELm9yZz6IYAQTEQIAIAUCRRwGPAIbAwYLCQgH
AwIEFQIIAwQWAgMBAh4BAheAAAoJEA28NAjmg61AFysAmgIisxdd6032Jk2xeI17
gcHuzXvuAKC5z1x4XxCwELWC9mk9HUlVTWcMW7QeU29lcmVuIFN0cmFhcnVwIDx4
cmlkZUB4MTIuZGs+iGAEExECACAFAkUcBVMCGwMGCwkIBwMCBBUCCAMEFgIDAQIe
AQIXgAAKCRANvDQI5oOtQAvaAJwIhTZcNVO1HKFwW5+hfnpE55hAMwCgtgTvelBA
dhl0HgdkEN+HWtZzEnC0IFNvZXJlbiBTdHJhYXJ1cCA8eHJpZGVAeHJpZGUuZGs+
iGAEExECACAFAkUcBtACGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRANvDQI
5oOtQBgzAJ0e+6mp3n17yH4hAzcE2toJ/CPBPgCgrDC3mRdXEOD8Gegm80agUykc
Fq65Ag0ERRwFhBAIAPf3jtvf8pJMZoO7SQ3/Et3jla1POUcJuk9T70om/Fqi9Y1b
mxTXR7yu5Rue/ZSN20laoywnJQAJ3BENx7mZHZwCzZDfEU9QU6WipPykt7KbhBG7
DjXBONGY34wl4RearvGn61FuL77/pkSA1XQ4+5U/hWIisTWnHRufxoykhlyo7QTN
x/S1bEXA6eTtfT7acA8sZfMRiqb8opOtJPiSMO7vBEYHfkleUGhSJwI7R7ghux2z
y92Sp1sFO7xb7ZVlKVPo+edqbu5mKRLvhykLiA7keNv/YGkfVjPgLthAo14JIL3b
95dOkGV/iI+DlYWPa/sDOM2KL0S/wJ7dXMtMVO8AAwUIANqJ9nqvDnWMoiJ2/Zuc
H9y7CMmSZEdzQwKqaJysyDqiV6LAK9TXsxzzl1UXximPMCb2qwtVGOaRKAPR8qjD
9GQc0Lb/BCFQ213o0eb+pvq7fFmUxrt7kMUvbwRGhiRbHyo1qf/z+VA2bntosYmW
9YSpa9eoE3iXr3cF6wQVw/nUF7jm6QQ4M3ak1MiaoICxxCy1x2WzW9mrUePPWz25
x0Pj0+R3mnWMTewLC6kk3QFM3usdxudGXJqDVch3w47BHV59WgSnzYPshGFp0VlU
xeJNWJYu0DM/8WeOvRdf/5VdxwJGDtxRyQSDX6niYHWg6tL2Bx1cCxJnnzLLnXDp
PziISQQYEQIACQUCRRwFhAIbDAAKCRANvDQI5oOtQObqAJ4gRDoYRjl6DWCd2DgO
ECDwvMM5wACgiAYFjP/BOSY6RZdSBTxOSdyeVdk=
=Dgd4
-----END PGP PUBLIC KEY BLOCK-----
D.3.209 Marius Strobl <marius@FreeBSD.org>
pub 1024D/E0AC6F8D 2004-04-16
Key fingerprint = 3A6C 4FB1 8BB9 4F2E BDDC 4AB6 D035 799C E0AC 6F8D
uid Marius Strobl <marius@FreeBSD.org>
uid Marius Strobl <marius@alchemy.franken.de>
sub 1024g/08BBD875 2004-04-16
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEB/3xIRBADGjxOPVRN2LvXTd6jXqKf4/6pPVPQlKqtwpOZj9JgDVE+V0Elf
kjvwfCXA0gqt7kkal8i2TU9v2g6IIKP1eUoNpBy/s15Wc8JMlESB6CkfFPNkqj5o
ohRSoKuB8dud0KR3T531rPfQNmsVRWtxrPYigkrtYZHiTPSZFgL0e+RiBwCg+i3+
p9+1JBby6tthOolOGdr54xUEAIYounibXk8p54DJeunp0rMbzKYvbXYTOyc4HbD0
t9kOH+VI3BJ+DlEuCejgwRkxkisjhQbSTa4+EGROKYcVIBBTtsj8JGHiNyRVSQ0D
+A1KDuZQh7iDwuyatT0xvcvFw52In0dj3RK5hDV2ZX1ec1WiEMKdf8It+WdTSQPT
UUF+BAC1WEPU92FZefdEDIQQHu17xsCestDOyd6xUBpxyPV2dyUwm8k7OhRalNuk
nAIXfbZcVVZ/+RWDdfiftoSxQmODQg0JtzhtGEQO2q/FozsCy4Bx8XPk6CQmPMJk
x/o8MwR50qDlsmcMRR2NDF+I1QOyRpEmugZ6sO+WXm8bkj1J6rQpTWFyaXVzIFN0
cm9ibCA8bWFyaXVzQGFsY2hlbXkuZnJhbmtlbi5kZT6IXgQTEQIAHgUCQH/fEgIb
AwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRDQNXmc4KxvjaHxAJ9+D0jNIIFzozzz
6n/bx6N+yV2rwgCfZRtKVbN4QNEBod9tfer2TgmRlqGIawQQEQIAKwUCR3O7DgWD
AeKFAB4aaHR0cDovL3d3dy5jYWNlcnQub3JnL2Nwcy5waHAACgkQ0rsNAWXQ/VgC
ywCgjtPLCzZAAgOuFiLwNw4vF6ZXJBQAnRPxbc9SwccyaGrkk8kiCX1nxVmFiJwE
EAECAAYFAkd2QQ0ACgkQ722CQfCBGV1D4QQAgo9MiuMFTfyjZn/qfQmSenruVgSW
GpKiz6DTPhmT767GqaVqaaChoWqPY6/PGPTbk71NleF1v2HU1Orzoj3KqgzE6vVM
MMfmMXJ7y/A9hg+xImKuThiwMzfJJQ+nrvCc1beJIiMxhJJLHxmBJZve/mbMUs3V
HC4tGEcdrGecFY2IRgQQEQIABgUCR4ekWwAKCRD09yJxgsm6KU0pAKCIgvYV8BNI
ES5/8AK02J2lApE5kwCgxetWv8ToTTbUhW2AhaIEHlg8KQi0Ik1hcml1cyBTdHJv
YmwgPG1hcml1c0BGcmVlQlNELm9yZz6IYAQTEQIAIAUCR3QWxQIbAwYLCQgHAwIE
FQIIAwQWAgMBAh4BAheAAAoJENA1eZzgrG+NU0AAn1xgOlGk3+FpLagxQh6/O94Y
8iz1AKDvu7Im3yfxj4LRh5UVKnNYMIJTtIicBBABAgAGBQJHdkEIAAoJEO9tgkHw
gRld4JcD/j52TeNiPNJ4hDyd0QJUItk8RXcvBtrg2dSl0TGmNs2f1+3fjZ6vdrE+
5Ry0qh38ywsxs7sEFURPavre4i7EbdOWv6NawUfaIsgXp8Os91bQr+UrXe2esAEC
SICQS9hHI3qEl8hPqay7rPl/lXM3ivofmrRXXfBRCtxUqy8+CFoeiEYEEBECAAYF
AkeHpFsACgkQ9PcicYLJuikeVQCdG97q3ZUAYRy7za8JihUzddma5wIAnRS7veJj
ENbiKHg6MJc2BMFGZ9H4uQENBEB/3xUQBADFOTE426iijaR8FaZLMIRaSexGfOvc
nPJFF+rkoktpQzP+9BKDwKvt1HmlDXaiaeJfwEfQdK7/oORh9+ynL9ag/KaocJtT
8eAqhVnoC240NF+PhMlX7YblUwa9+M5MfNmDkNEV92ZFIJ8QjRAzn/G3rQIMo6ax
BmsF+1P71QEIgwADBgP+Kbmf5TjcU45Wuc3ceZCAEm9o7VMhsU/tVu69x6QRu379
HqJ9RDuAOdcBWQ/67Jw7blSbe3yWZpqhxLTWwYELJG7/XSNnIsFl3osF34lm0Y9M
lJl+XBQ3UV2kPgtIMDTXDuklzuhdhbIlhWOXJJf48WkSxeB2WGnnlVvBCjBTx3+I
SQQYEQIACQUCQH/fFQIbDAAKCRDQNXmc4KxvjWiAAKC5xnCwJYOHHwqreNa98Dah
W9e6+QCgjchyumMlSJfpEEnGG8vU08TmXrs=
=QOvV
-----END PGP PUBLIC KEY BLOCK-----
D.3.210 Cheng-Lung Sung
<clsung@FreeBSD.org>
pub 1024D/956E8BC1 2003-09-12 Cheng-Lung Sung <clsung@FreeBSD.org>
Key fingerprint = E0BC 57F9 F44B 46C6 DB53 8462 F807 89F3 956E 8BC1
uid Cheng-Lung Sung (Software Engineer) <clsung@dragon2.net>
uid Cheng-Lung Sung (Alumnus of CSIE, NCTU, Taiwan) <clsung@sungsung.csie.nctu.edu.tw>
uid Cheng-Lung Sung (AlanSung) <clsung@tiger2.net>
uid Cheng-Lung Sung (FreeBSD@Taiwan) <clsung@freebsd.csie.nctu.edu.tw>
uid Cheng-Lung Sung (Ph.D. Student of NTU.EECS) <d92921016@ntu.edu.tw>
uid Cheng-Lung Sung (FreeBSD Freshman) <clsung@tw.freebsd.org>
uid Cheng-Lung Sung (ports committer) <clsung@FreeBSD.org>
sub 1024g/1FB800C2 2003-09-12
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD9iAJ0RBACJHmAyofYftDx6hFkYRkCrM999YrKxfYGybHI+MoN2fFPXMvSh
idYzBGhij1a8E7DGuZ2fGwSxdUZXcUA9PlDPuTmxs/xI/ZgX/qnG4yPgeT7KfZ5g
UqRpm0/gz/7g5UsvNBw0iUzSbI7tTXprErflhUXX6cC1bPHTeEQbHe+nSwCglpMT
cpcV93CQpMX+GC16UvwC8MUD/2TzigXSQ9rJNoTLuhsibSK9fh0vzq6rhCrzy2Ma
G4M9kLvApu7+8YEk9ydVk9EE0PxHTTXGAxnpZzTW/bCCcLubhBqv8eXs2GOOxzHG
YXb9Oyo+FDe0EAEZ5Swmf/V2eAHV4bYDmXzW9okxIUK6skXtFxQ70DxqcmtAxlxa
QLgbA/9plT+d5g2s1c11Z0p5CQbxa8sJu4nLFT36DzhR2BmhTEM/X2wSARGe7PKu
LdWI1WfU4Avoj9sWehSF531tMekMSZ4lp0gb0rYOyzGTqTWjq32mkqep8MDP9cT9
6H1UaSU96yyc1sprUdU7XDf7TA4jZp2LSLlOEB2UCOa0mBL9QLQ4Q2hlbmctTHVu
ZyBTdW5nIChTb2Z0d2FyZSBFbmdpbmVlcikgPGNsc3VuZ0BkcmFnb24yLm5ldD6I
YQQTEQIAIQIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAUCP4IzGQIZAQAKCRD4B4nz
lW6Lwc3gAJ91P1UQoV68L7emHnjqlf3nK6qzmwCgiVtWyaqQJq4fayifeKfFmT2U
0EyIRgQTEQIABgUCP2SPxwAKCRDm4NvoVAvGHGhiAJ90wTMq0zYb41tG8M+RoMyv
oVsgtwCdGko61SUEB+884zRD2bHhwFMg+OiIXgQTEQIAHgUCP2IAnQIbAwYLCQgH
AwIDFQIDAxYCAQIeAQIXgAAKCRD4B4nzlW6LweOrAKCRWdRCC8hQYwWCa4/upt6N
hc+SRgCfVybP7alAFua8F010HJiSfXdNtFuIXgQTEQIAHgIbAwYLCQgHAwIDFQID
AxYCAQIeAQIXgAUCQSQbpgAKCRD4B4nzlW6LwVB9AJ42/CQFoYKDRYz+XmCqBou9
Y+Nm/QCfZv19FBbMSOfvRW6R7nJTSkf3Uj+IYQQTEQIAIQIbAwYLCQgHAwIDFQID
AxYCAQIeAQIXgAUCP+GGogIZAQAKCRD4B4nzlW6LwUZ8AJ9q3BbkGIsEuhnp6rWX
uSkcXYkWWACeNSCb9l9g/650wnXPEHcHsRpzBLK0UkNoZW5nLUx1bmcgU3VuZyAo
QWx1bW51cyBvZiBDU0lFLCBOQ1RVLCBUYWl3YW4pIDxjbHN1bmdAc3VuZ3N1bmcu
Y3NpZS5uY3R1LmVkdS50dz6IXgQTEQIAHgUCP2SMCwIbAwYLCQgHAwIDFQIDAxYC
AQIeAQIXgAAKCRD4B4nzlW6Lwb3bAJ9mJttWnct/3ej1XlvmnAxRq6ZkOACfdZDT
sLSo8DN73ZKDbiP73KqDPdmIRgQTEQIABgUCP2SPxQAKCRDm4NvoVAvGHONyAJ9t
QrXQSZDkm71qAw+6HiERQ+qsEgCfWuA857Lrda9ZR8X7IJJ3XLO2HPi0LkNoZW5n
LUx1bmcgU3VuZyAoQWxhblN1bmcpIDxjbHN1bmdAdGlnZXIyLm5ldD6IXgQTEQIA
HgUCP4IyxQIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRD4B4nzlW6LwecsAJ9F
HNrKHPsCJ6ZesY1gJI5HOVijvwCfb5G6dT2YW8TH8GNRFe7rWPXO1E60QkNoZW5n
LUx1bmcgU3VuZyAoRnJlZUJTREBUYWl3YW4pIDxjbHN1bmdAZnJlZWJzZC5jc2ll
Lm5jdHUuZWR1LnR3PoheBBMRAgAeBQI/gjLeAhsDBgsJCAcDAgMVAgMDFgIBAh4B
AheAAAoJEPgHifOVbovBz+wAoIJhcDpcOVIACy+wboHG4nGOQfiWAJ45qvE09ckd
IX+MDl7xez7OMqDU/rRCQ2hlbmctTHVuZyBTdW5nIChQaC5ELiBTdHVkZW50IG9m
IE5UVS5FRUNTKSA8ZDkyOTIxMDE2QG50dS5lZHUudHc+iF4EExECAB4FAkAoN7AC
GwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQ+AeJ85Vui8HhdACeNn9owhjpYr2y
cYCkOFDv+q3xIF0AnAijfOOUq2oT0d0+B9sALIz0HHrEtDpDaGVuZy1MdW5nIFN1
bmcgKEZyZWVCU0QgRnJlc2htYW4pIDxjbHN1bmdAdHcuZnJlZWJzZC5vcmc+iF4E
ExECAB4FAkESZaACGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQ+AeJ85Vui8Em
ywCdEDYOgC1/YxPHqyvEXGs+JTFFqfkAnjfkTpRPM492elqZkBlQimFGLeWutCRD
aGVuZy1MdW5nIFN1bmcgPGNsc3VuZ0BGcmVlQlNELm9yZz6IXgQTEQIAHgUCQSQc
2QIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRD4B4nzlW6LwZ4TAJ9hByDD2ep6
ixTnazmBJSg3epv9tQCeOM4JaWNwvbOrF528n8PQcgpe/3W0NkNoZW5nLUx1bmcg
U3VuZyAocG9ydHMgY29tbWl0dGVyKSA8Y2xzdW5nQEZyZWVCU0Qub3JnPoheBBMR
AgAeBQJBJBoPAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEPgHifOVbovB564A
mQGePiZdxv8qVwvtdyf6m9SvosGoAJwPuv0oR/D4PIDKFYtlTqfYN35I47kBDQQ/
YgCgEAQAwHkhKy54M/yuuJgb4Gcit2+fDnlRZ8yRJkGe8OSl7qx9Gaz0+kwe1Gir
V+DQFGC/W3gJqjEN12jh11ZUabE3Seeofec94rDZz/YBkf5ofMT1+tN1kwr+ju7C
lQdZCwNewaS2p6C5PsXCUQQ8ZHfgs8YB7Ze/TY6GvpOoDKqYHO8AAwUD/1ZvVV9P
e36FE4RkHg3P1YLkMNs5fxleXD1l6LZ8ElQy1V0RVg8sD2W22xh0wP2W9RplsDYj
UwFKuRtxxoEsdXvDNLaUyG4hXmNUVBz3b3tmZSvENiuj5EchJWO85T+AFT0g7ap5
wWlxOqmvHC5NZRiAP1fpKpwoSvYTLP418YSsiEkEGBECAAkFAj9iAKACGwwACgkQ
+AeJ85Vui8E94gCdEqq8xPwuUc/LJQyc1ziacZJ/FmQAnA41/zThbZg2nf994Wre
OT332jJ8
=EtCd
-----END PGP PUBLIC KEY BLOCK-----
D.3.211 Gregory Sutter
<gsutter@FreeBSD.org>
pub 1024D/845DFEDD 2000-10-10 Gregory S. Sutter <gsutter@zer0.org>
Key fingerprint = D161 E4EA 4BFA 2427 F3F9 5B1F 2015 31D5 845D FEDD
uid Gregory S. Sutter <gsutter@freebsd.org>
uid Gregory S. Sutter <gsutter@daemonnews.org>
uid Gregory S. Sutter <gsutter@pobox.com>
sub 2048g/0A37BBCE 2000-10-10
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDnjW8sRBACtLAIsIja7+4PNGeKl3CWK1BDt8mJrNTU7yIpIFyU7kbGFzNDc
nKuTGXwFlI/1N964p17uvwVBq49dFTGFOzw2AEvgwl5Mb75Wsf5ztYVSir8ng0b7
123nb09ZExWCQTMMbD6RXEVfTrIUEHazYMDIhuIU+/WkYVhNWuiaACvpJwCgjuEx
/8BANLXa9UkQt5ztgWwUUdkD/RvGakaQr4gAhVcm2mfDYjxLtm1+BxbzsDV9U2Nv
2nlXSfCyxvbTjwX+Bq4/bwR1a0KDIPvjqYAm2tQY+bsPGkjwBL0DUrHVTRK2PpPc
K/9avIFk+PYkpakPQx3saE9b67UbGk5rUCnbHU99mvqET3MtU5yRn9B8hu7owROi
EXFPA/92vhsPhcPsvTq9Wi4FlWF8MeDyZsEKA/lLUTl1A4QnbiRtC3bBvxOeoPPu
jQP25DskCdtWWcOuvHRZ6kE/WncID38oc00dqaB9xR+pi/ltnXZpOCjvU1Q0yMd5
QcoD9Im6fLN8zo4gr2f2cwWC7TQ6TLxTYpifGK6sbC0ATdnFkbQkR3JlZ29yeSBT
LiBTdXR0ZXIgPGdzdXR0ZXJAemVyMC5vcmc+iFkEExECABkECwoDBAMVAwIDFgIB
AheAAhkBBQI541vMAAoJECAVMdWEXf7dycsAoIewU3SxZCQWxKFdQ7444Sm4qd/w
AJ0W8T5xXDLYlW03TjJuLo5JnENQsIhGBBARAgAGBQI57nu4AAoJEF1SHIzmsVAW
xCYAni+wfeykRrWXDjx6LEbwY3/tJ+vFAKDkDFVK859XVpmHin5cwYESpiWEuIhG
BBARAgAGBQI57ovLAAoJELYkBuZbwVKhP9cAoJbEJSB3b7Gs4fhkohykCTdN6ofK
AKCGSbPBOt9GK7r+XVOPBVJBpZwHYYkAlQMFEDnujg5NVigheQUMEQEBxocEAJOV
MLs6IKMMeWX6OiegkmdMaox86gHOOOS/94n78ClwTJ8kf4MVPF/qz9oLvCNYcSP0
IevlMAAMgPQx4amUwwrdqO3lUWx01jrxO3L7r7PKLCT61gIfoVhjJSRvA4wVdGRB
OhDFZ18qzTkqUORDbjohknDSt6Ydxh6RwEKQM8EtiJwEEAEBAAYFAjnugY4ACgkQ
H3+pCANY/L34TQP/e6VCd8sZhz8pqlaxk2zHmyCKR9gKHn1P34Fjd/wt+mMz16T7
aJbr6V0qpdvZdCkcmoQ9Q9btX9uu+GAQLUHPHLCn8bg7icw20d46LUmm1b3x3N1v
OdBk0AykVGei+TuSs7QLFQXWqwQCOfBWVk62Kw0fL1hMBVPKS0uHPotRqBOIRgQQ
EQIABgUCOe6NMAAKCRCI4Xsd/OVlYdj1AKCjZ04lHm8Dk56adtZkzdzBCx8C5gCg
q3QsF46O590E55SsokQd7YD8kASIRgQQEQIABgUCOe6NOgAKCRAY9QOAJMJ4AlwI
AJ98qRCL2U3KnYKrbPc+p8bzZxbTZQCglbkX8ciJVvy5oHzJO/5f+HIg0k6IRgQQ
EQIABgUCOe6TegAKCRDC/IaqJTlGi2/FAJ9l+bY/2GWpmUxtZYs0hdnejFC4IwCg
ivx3tjij0SfNTP79mbYFX3oJxo6IRgQQEQIABgUCOe6OpAAKCRBzh+KSrRDGxCeI
AKDM83nigOH0/v8H6M//+bS1LV/A0wCaAqGb5Nl+D8pnYK/hEER/YUCgVMKIRgQQ
EQIABgUCOe9ejAAKCRCTVeV2USQDllNdAJ9gmpeLdhkr5u0pWuO+o9GdUppyywCf
QWuTbYI1gUKl1z+19+YUo9+kJzWIPwMFEDnvZ0rjHjI9QK4wUhECp7YAnApxxvTZ
VLi4bsBqM+VDVnbPyVHfAJ9vj8pXkv400Zm7Mq8warkniGN45YhGBBARAgAGBQI5
9HwcAAoJEBoX/tg15TvDXCUAnR3ymarKUUkgdFBMzq/H9paGWz6xAKCOLwiMYhte
cwGDJX6s65DkkK1V6og/AwUQOfzDgnfOKcWPoS4gEQJPAQCgnvIv2HFf1nX7Kool
PVvVNYS7y+IAnA073e5i5N1HQ6+ZdDPMCm4G1wPgiEYEEBECAAYFAjs5NIgACgkQ
k6gHZCw343VmYQCfRIJqA7Le/8De5lsxUKJCwofEiE4An3nHw12vlBB+pD3Isp8t
IMBO80T2iQCVAwUQOzoLUw7tvOdmanQhAQF2wgP/STr380FN4cqHKPo9YoFPIr3w
IkiX1HupMBWvp7yqU/0VzWeYw5/SPhtL1u+4OLQw+JzRTXRWksleBSLft5aoj3Is
6sry4ICNXz3nQepGSIarhtjZ1MBSVhmRPDvRf/aQSC/nNhq5w/GesQBPHYqNU+8Z
c6mIbSpSGSxneQuhLEOIRgQQEQIABgUCOzoRrwAKCRCBvdPEDh+bedDkAJ0R9Gc+
sVy6QbjbbsCD+XbI/zXqqQCdHeMN6+yPD3qKKQajYzKYIqRFyhuIRgQQEQIABgUC
O0AKwQAKCRAXjuJ0+BZyxUSAAKCPXKa1+HidCv55P66AvH+DAnCaTQCcDPrzPjxd
IJ4RUQgasMK2ptv8k26IRgQQEQIABgUCO4hBgQAKCRBSAByVjgkCI84UAKClNjgb
0DPRySH+kL4zOS6xaNT5nQCgqEVDEw3kBWey7LUtyjxPS8TK4L+IRgQQEQIABgUC
O+B2KgAKCRBeakKSkH3ZZloOAJ4r6my3qw+c20aweoKXCF4cpBZC3ACgh1CoA1GH
hvq/drP65s2woQE/Yk+IRgQQEQIABgUCPBEtuAAKCRCmzd7uuzvZuEMLAJ9m9zor
3WstocNvkKInbcv5TAcYcgCfVfLYd7GKUBA9ZBGrUx2s/Cezl9OIRgQQEQIABgUC
PBE9FgAKCRCj8j9oMUUU7sgSAKDXFAbnUvT6CBZ7z71sOKw0LlfTGwCeLRVAnUfS
ZLV2CS1/3JKM77W6CYyIRgQQEQIABgUCPBE9NgAKCRB0bcUgGn7VbSQOAKCiIWkt
ZvGQsgcHeR4oSrqB/vqUNQCfbDptGRJ0rVlbjJqYbq/CJNTd0E+IRgQQEQIABgUC
PBUX4AAKCRCsjdSbXIj/ndegAKCYFii+lsT2fgx8/4pKB98N6bKGlQCgqLOch91n
2HH/2NA4zCjdfKVR/RyJAJUDBRA8FRfn/R/34dzmziEBAZdxA/0fn5+SAO7fMctj
LsKfpMY4f0G9sXVeBH6yJr1Qqg2vAJSYod5EXJmpLUIhMC7WR0WEfOIg7xsvgDhO
s1ggKiGTmAN+0v11w1TXxsY0LXlWVtVCq4Kou4o+ZHtydXFxfUSLV71oovZrPAbe
SnE0OTCqLpUzYoBV14djD1iKGMF534hGBBARAgAGBQI8FZ17AAoJECBlfewSPsYx
BPAAn0XJg0Pp8FBkV0S+/Ssd4GSRSJbGAJ9x5FYDB97/mijlRvQaHRflOKeTb4hG
BBARAgAGBQI8Hd9kAAoJEHw0tOFM5PZV3yUAn3nikj6Z4cQ13g+zDs+rvNx36fKx
AJ98vb0if81tw1WVazH8XsJbGK3ICohGBBARAgAGBQI8ERs5AAoJECILyIMzDEp1
Z7oAoOQilHqP/vFzz8p3j4fvZs7Q8v8pAJ93Pj+WEtRi0H/k/m9sYIQ/yH0hiohG
BBMRAgAGBQI9B6kvAAoJEEbtrfQ1fWX7IzkAmwQw4TRYchaTtTkT8QJ06+XmAU86
AJ0d5Gb9MtC0XdvMPeCKWwgdq/3F/IhGBBIRAgAGBQI9B7BlAAoJECH5xbz3apv1
fukAoKPv5i0h/ID1XiEnUhuyR2dJAAzVAKDURVTZzxDY0ehVTQCPxfpNg6hsrYhG
BBMRAgAGBQI9B60qAAoJEF2Oi+nyOBrUNzIAn12QHimN1BiKppLknVfVTR86BbuJ
AKDcN3RN/660kLLsfKOAOmFoViiGIYicBBIBAQAGBQI9B7BEAAoJEHxLZ22gDhVj
gvAD/00EB+DgmbuAm7vJsD2IiqRiFzTWUA+ppnoYPKfO6w1Xy4Blf6XjRwSAiY9z
ctFSpQ3oTiHBkyJ7+IZ51NsJdaj4GiDwYuuP+F1E/ThQFunc2yxJKRDLgs2E8mSz
Ecz5XQ6+7AJIT2mUHB7SDvhqaLYhKHLBSJ+edThpKISlsODFiEYEEBECAAYFAj0H
rSwACgkQtVKwQ3c5BdZOyQCdFdmq32OIrMwVes3EBVzIrAJKyIQAn0jxtW7INcgO
oi829JPBFIYyUZFIiJwEEwEBAAYFAj0HuVgACgkQtoTxfMEKh02L1gP+KzfNZO9J
Fcp9oFMQ7rQXGkhg0OzGxYMg7EUt42wGm5J3BI/wdbMRg42lX2GSu/HoEm1jSP6Y
rSIXxaUnX48xuBSWd6GndVdCIVOavruU6hUjdhg5G0APC1lk80DK3Ib0g+RQnodQ
gTva9iWzV2/8OLdaT2NwD0JP5Eh/nw/NewOInAQSAQEABgUCPQewWQAKCRDW4KH+
T74q3Yk9A/9U+KDqW9l0CyDbad+sVExgAml5jXzyRYfWxLMta46yfgHodEXZnokh
YZpsIiMOswZw8HsjMo3aKCwU4eV1robkeqpgSqTDCU7RRLJoUDDEqq0FWAf1CEuf
58zIkxXb6P2Q7fsaOyOO0cel/wLhmcJfxQL2/Z+C1Kc+MNwyuW0tJ4hGBBMRAgAG
BQI9CCHtAAoJENjKMXFboFLD118AniJmQTVOYlk/ji4uM4zPwF/nZXVhAJ95SqkF
vdR7dyQfeMGfzXH0eq2mPIhGBBMRAgAGBQI9yzBOAAoJEG2U2yGkQUVxhUYAn3pf
cwHeK8aQDebwyN0mWzIClgzYAJsE3f3zW9VsRfMAuQgwXwNGyVto04hGBBARAgAG
BQI99uSvAAoJECnk97b03b+uobsAoKBPMtrUUyOUz3q21mZ/L8Tw+jaSAKChwBjX
hcivV/+ayoAMbWOoNnjkkohGBBIRAgAGBQI993/lAAoJEIyjJ9tDO6CH8s0AoIVT
7w1OuVpUoMLi3kCx0fYAeDhHAJ4qnzEC6GezG+m9bwO55341uYMAUIhGBBIRAgAG
BQI99386AAoJENfKOrov6HXMU5oAn2kRaA7dqpcD3yHxwly21YL4EQ/GAJ9tThrS
wPasv74tg3zE25FqdnrTcohGBBIRAgAGBQI99vi2AAoJEP5PXn8DpeEIfhwAn0HX
rxH4jBwNFEWtHyRhnnq2KsfaAKCEtWUIiP9uVPNtBArpJGRLdY9Gm4hGBBMRAgAG
BQI994cWAAoJEFawMV8BZ8o4QTYAoJ5zFMMHcqi6lokiZ1rcoc4EkvDcAJ9SHvm9
Cc/yLvym2+d7xLaGfFRpL4hGBBARAgAGBQI9+AZ/AAoJEAkitBQQRHddPKIAn0lH
5rDr2OghxOBKicUCQYAd8bICAKCTZjUE4ECNt7fWPXHXOrxNikAqZohGBBARAgAG
BQI9+D7QAAoJEMhTz3PoZU6X3GsAoIxw+xOEleTOtul3KtWeLSnDx7wOAJ4xJCr8
D4PH0+h9xFijiKQdqsQDs4hKBBARAgAKBQI+KO3KAwUBeAAKCRBuiJudMebjmKHt
AJ0X20zqwBq5ktgrzyyCt2zmU1AtIACfZWie6QR5eA3QU+U9HZ18FPxD0ViIRgQS
EQIABgUCPpJNTgAKCRBh9A0v3SE9uo7vAJ94we2LUiG7sY7eg4l3AOnFRAQ8cgCe
JJb38AMvB0VG9JjqTaSVc9TfEfi0J0dyZWdvcnkgUy4gU3V0dGVyIDxnc3V0dGVy
QGZyZWVic2Qub3JnPohWBBMRAgAWBQI545CKBAsKAwQDFQMCAxYCAQIXgAAKCRAg
FTHVhF3+3a8YAJwLQwRdXo1/0RK3G4EFklG6TXXZlgCeNMTkt3JY62CMDqftWBAC
hiTgiP2IRgQQEQIABgUCOe57wQAKCRBdUhyM5rFQFmk3AKDtT2hQ5pX+6RZ50ORX
lSxQ1BN/FACffkckE+GkCPt6zOMa4AR0D2ouO4SJAJUDBRA57o4pTVYoIXkFDBEB
ASQ0A/4yzORAMwz6ZxNobN5ULmtD0iVnXc4Rai5jq+Gvpbo6GE9hW0TYqMGelvKm
JTNy+Ug+uPPCEzT/QznQRBfXXaR81WeGrpqEEstTAc6oBksLDRq08khCttGm+Y01
24Sj/ECLpUtmSG4XVUzt92vALHw2Ye56XBChsUA5FcgT5b4VsYicBBABAQAGBQI5
7oGoAAoJEB9/qQgDWPy9BzgEAI6sCXiG8h8ynlpXyWQblT7gFBWkZ/pim/1flIwv
fzb9NDizeKhK/7Q2yKKAi0WmEVu4aPO8KSte5w0RrcL/PN0ntKfwHItyJm4khtRw
Lf9xjCLfInRbCogXqWz3l0lS7c6GboVMZg98ckNMHkBIz0WkAc5IY5knzN32+Q2l
MYgNiEYEEBECAAYFAjnujTIACgkQiOF7HfzlZWHhwACeJGcU/uPxHSzFcnBv7SyX
l6zx7owAnRaUWXQmUAePv6BrnrMoU9H+6126iEYEEBECAAYFAjnujTsACgkQGPUD
gCTCeALgTgCfTkrdc2jsG5Gp1Lz015mDUDV5GrcAoI0Cct0/fKB6Is522b4SblU/
wS42iEYEEBECAAYFAjnuk3wACgkQwvyGqiU5RoudFACeLusByZnXwg2b23xUxquL
H/wsVacAoLdFNOvwE3jjMZD+6JD5cG3DYGYEiEYEEBECAAYFAjnujqcACgkQc4fi
kq0QxsR6ewCeKOFHSlTZH4NPY1HssXShRafcnQYAnR2dDd0EhcKCe9gNdzrSqDcM
Vuh6iEYEEBECAAYFAjnvXo4ACgkQk1XldlEkA5ZS7wCdFUYiuNyhDK7FMdhQ85gs
9MeRJR8AnjrqyQgu2dYTMFRiKj/Q++N9JT4MiD8DBRA572d04x4yPUCuMFIRAkDe
AJ0VdYlBJWvJcBNMNBoVpZtpBldqsgCggs9FcLWIJrV3najTOUOA+V4XCpiJAJUD
BRA57oFKAdtd0pfmON0BAekNA/4/d/2ej6u0l64BtAIuQOm+MGWBSI5KlcCEXy6i
V/KMj1Qorre3aei/nBVzX5bY3oI9ofZ/qn//GZky7vqIJfm8htIn24uwrSRomApE
m/jo8+zDomH4zia1UJvhvtp3mMUXRDa6fQ9mR20G1NLt+wrnV5bj+zwrn/3g41Hr
IUJIfog/AwUQOfXYC9jKMXFboFLDEQJ8dACg1/Sj+bJIeFDHmKmT2Z6WnGlqJisA
njTZsQNGEL3x1WoVH98WnL08PT14iD8DBRA587Rpd84pxY+hLiARAv4oAKC99cE0
wgQlaO8GWEztUP+oTs7XrQCgvny5h9Ydsq9UkHqCBmOKnaZIUSGIRgQQEQIABgUC
Ozk0iwAKCRCTqAdkLDfjdTlMAJ9Ssn3nGqITEzAxIwIn2DgigpLPXACghRW6Sot6
CS4ZaXLkEKr6Gd3ygFSJAJUDBRA7OgtXDu2852ZqdCEBATmTBACEUgUzk4KM9kPY
vQrbhqz+1Q7pafBC6E6EwrQMofbzSxdF+bIsFTgpy72q9gagYOvw+ntY5+pDyCJZ
4dgJcQUtm1E3EfBTPvZuCiObphhDwO5X169bRDGJ6Lvu+tSWPseXh2kLhqtQJaat
4i5N5sndSa5A/Jy3r+63krG5jqL2pohGBBARAgAGBQI7OhGxAAoJEIG908QOH5t5
Ey4An2hvIhN1sIosvxYabATE8nu0emxqAJ9f5E0q1ov13smU++lXTlR3Tz/QYIhG
BBARAgAGBQI7QArEAAoJEBeO4nT4FnLFx7UAnAoAynRfpCr4b+OED6g2zJAR7vhW
AJwN2u0xZBC/rAjAOA8VvqF6TNXoNYhGBBARAgAGBQI7iEGHAAoJEFIAHJWOCQIj
KesAn0TH9Ai4JTTeWmmrbVgBhCdu9FaQAJ4sgcVaajqDH1KSEQ6xq9pLxUW6N4hG
BBARAgAGBQI74HY4AAoJEF5qQpKQfdlmCTAAnj/saNHLzGlaNw6XbmMTkdPcwqNq
AJ9TwljvnABJBi2MkIdnQZxm6wz7oohGBBARAgAGBQI8ES3AAAoJEKbN3u67O9m4
c4oAnj4HIlHFQq7EyunfxEmZsFeUpgSQAJ0T+kdgk3VYyEDAJvWY54JTXXP6rIhG
BBARAgAGBQI8FZ1/AAoJECBlfewSPsYxN0wAninRjUaNmTOh9HlY7D5gEbHDUNcN
AJ9dMWK14Qza2qnYKAuwpcxPhFHfAIhGBBARAgAGBQI8Hd9pAAoJEHw0tOFM5PZV
VQcAoN190LU7jsPqpvOsGhav/2Vl4znkAJ4yISiCnc4H6vx6leTC63jgk6kc1ohG
BBARAgAGBQI8ERs8AAoJECILyIMzDEp1ZbwAnAr0XsXG+Cyo4p2Rbf4rGhp2Y/5G
AKDERRea6EGP6jL9Wx+zjXmTqWvDJ4hGBBMRAgAGBQI9B6k+AAoJEEbtrfQ1fWX7
TW4AoJNqI23+6z8F9or177Ue/RADwxyvAJ4xFL0LVOa1e+yqIgo6IKmD4qpuiYhG
BBIRAgAGBQI9B7BoAAoJECH5xbz3apv16gAAoPhAHTxwPcVb/cYx1om4KrVVDfR7
AKDXlXnV8pHxcTSlOsmCxbXZo2kGtohGBBMRAgAGBQI9B60sAAoJEF2Oi+nyOBrU
FvAAn1cepW/byih3/Lzt0AWotEXdM8KrAJ9HdXHE898p3xWFRv9HRpPZMoIzCoic
BBIBAQAGBQI9B7BMAAoJEHxLZ22gDhVjPigD/1FQ/XJrg9wSMYF/WA1/7l2S9lGP
7b6htNOa9CUwd8hJFDJe4bT+e0z/DnBKqxtoQs1XvhXzroIohmBtQNFfwjlu+I+4
eMhzLsDD4h+nuE+nm6yltwLl0ct2TMww+PX/28FRl4ftAfFuLhuYkxgUvs4x10XC
d5A7hFoHusMv3aNGiEYEEBECAAYFAj0HrTIACgkQtVKwQ3c5BdYbxACeIc4DpFve
lsf1Zn+pKlk2TJq0HjwAn3cU6Xr+vSlD30lmZ9/YynIbjz82iJwEEwEBAAYFAj0H
uVsACgkQtoTxfMEKh02w1wP+InvSnrYzUgdeqOeiTMDavDKwo3qyeFgSopBun+fu
l7o7QotxUr18BtczPpZzv/q3yh3WVUuT2s3O0Kkiyxjp4h7xSZ1XEMhbhFjOfe3e
E1YFD/lwKuS6TcBjrODhnrtwAbssoewQsZMmSQHRiB+VYxgsm1Q42H+ay4uDQ86h
p0GInAQSAQEABgUCPQewXQAKCRDW4KH+T74q3RyIA/kBnsF5aCKMEHm9nHZ6j4ER
9Q0cHbUeKq2bvwD9WUcqlsD8u3bK48lxZqsGszsIpGuFFFgiRSMuPhzI1uqbvcHi
Hwre2g5s1n0uizLS+a/+ZOR/lPrZls4E6ATxIuaxY4BM9Q0rG5hb/nmWodSjA+3/
isvxz6uFVRHoNyb+BgTx+ohGBBIRAgAGBQI993/vAAoJEIyjJ9tDO6CHT0gAn3G2
WZSWIjaSabw8aofRpZ8tMwguAJ9a0oLpChBQgFyOu/JtiZLYHu6MsohGBBIRAgAG
BQI9938+AAoJENfKOrov6HXMvFkAnjortNOFTeizkCIFzmwYzQKtUrs8AJ4nAD6U
ylwidkcAcUcWLVkZUg7rXYhGBBIRAgAGBQI99vi8AAoJEP5PXn8DpeEIEVcAn1cX
KkITyYWR8UQryNUoIJRKaLI4AJ9dO8SCYTTqkUCHCWs7l7UDz/WpBohGBBMRAgAG
BQI994cYAAoJEFawMV8BZ8o4DkIAni+T09CG4T6J1sPw+cVEWjcrvVL9AJ4gZ7yb
KQhskoNksw4OlCHNiuyNrohGBBARAgAGBQI9+AaCAAoJEAkitBQQRHddHUkAn2we
Ma4NX7LzmUb1jdk7c5ztdttxAJ9tqGAOlhmrQ/VfApGwCQtlFiJicYhGBBARAgAG
BQI9+D7SAAoJEMhTz3PoZU6XpBAAniwwfqVSeG5b1vV8zUrk4ayDj3fxAKCR52+R
V3464Dqp8e2kkouI+4c4aIhKBBARAgAKBQI+KO3NAwUBeAAKCRBuiJudMebjmPj7
AKDZoWLp1mJ9ByddGJnwuP8i4hwYDQCeJh2n2Emrz0Gv5HQQMkfNxB9XEriIRgQS
EQIABgUCPpJNVwAKCRBh9A0v3SE9uq1cAJwKHc2rmuRjF/vGGzL3bM9dhQFYsQCc
DO3xXCba1Rc+QPJfwlJhuVTtKau0KkdyZWdvcnkgUy4gU3V0dGVyIDxnc3V0dGVy
QGRhZW1vbm5ld3Mub3JnPohWBBMRAgAWBQI545CpBAsKAwQDFQMCAxYCAQIXgAAK
CRAgFTHVhF3+3Z9AAJ4sw5jXvvpvaTU8KeSRdps35YE3kgCeOzr50psCrp6FIsqv
t8VBhykU6LuIRgQQEQIABgUCOe57wQAKCRBdUhyM5rFQFj2YAKCyih1PKF294baE
WHLLmh7CNivUBgCfd1nv2q6lFFlFbeptQ77d1HA6f82JAJUDBRA57o48TVYoIXkF
DBEBAVSZA/4jIjk5o+S5DH4TsqvBozosE6bod/lyleqkoFnulUfAVqMiDSDtWDYf
in1mSmC+py8jcRfRw3Yzn0YNf3aWpMWW2pdQeSlNHBxHkcH3tiXfiaWpXUv8skYJ
X5AjGSlqOcuSOKynaLGLsJt3lSVhx8jaBX6Q+2ND7LIirXDIMWe7HoicBBABAQAG
BQI57oG8AAoJEB9/qQgDWPy9DqsD+gNnPN8++meWpLFEwtVlUhf+AmCgSnc0TROM
9rgwtjsEzLBLuPmXgAI6/0FOwfj8kwFuZ5JUSMfdRm1QM+oHkqfjKi3RsCiShX0l
HF5FPbhMgoxFuvTCnfUn5AgxRkzzMmH9VMJx/InbN9H3CmoN2eqhyqzlaQlanc4G
iKfw+/NfiEYEEBECAAYFAjnujTIACgkQiOF7HfzlZWENIgCgzZ4DHX3MxzoVPPKi
BqQ7olfGoZQAoKPZjucBMaicCbpgk9QpnZDe2OG6iEYEEBECAAYFAjnujTsACgkQ
GPUDgCTCeAIeqACgoP6bZ2VuQQbXwSNKV4crNLqm3BUAn2l9U5vZ3K5ramSJtT/d
lPpI3h0UiEYEEBECAAYFAjnuk3wACgkQwvyGqiU5RovYdACgj0wQ2fZyFF1qPLL4
lDBsOAzSuOIAoOS+IBCrAFn6V+3KvylHuiMtik7ZiEYEEBECAAYFAjnujqcACgkQ
c4fikq0QxsS2egCaAy3ys+YSnZvuQjTJYxyqUpPVOikAoJaZ5auYk8LX8qT8VXQ/
i8RusaPHiEYEEBECAAYFAjnvXo4ACgkQk1XldlEkA5YumwCfVpQ0tHjaiJ0SvxBK
SSrYPm9Xgy4An0rbFL1h7748ZxP5AgeYhNxG8ZKSiD8DBRA572d+4x4yPUCuMFIR
AhrxAJ42B68gBbQg01A4oVdFfOa9RX1GgACfdzg13CvXxaiMs+UbcLl9qqNw47uI
PwMFEDn8w7F3zinFj6EuIBECrnAAn3k95VzUbZSSuA+sIAkHGGDVw68RAKCPnEHx
foKb60Za3UymkINn/aBdfohGBBARAgAGBQI7OTSLAAoJEJOoB2QsN+N1wH4AoIpy
XfE9yypNjA8Cr471UqnHBH7NAJ9KVU2QFmF92Biki5tamSnU5lnP6IkAlQMFEDs6
C1cO7bznZmp0IQEBY20EAKODjHE6v+pezQW1OMC6AAJC0QacePZCnwwrrzOVWzDE
zrniXF4kF0t0ctsObP2BwBOrytYFIr/85myAI4zb+3ZNim6L49aEkoVuo/HiOBAe
Ip4Tyc5ETHD8dd/IDsMtse/hN8FNN1LKXYGEwh29n903JaLKxup7ZQdHF6ltjDVi
iEYEEBECAAYFAjs6EbEACgkQgb3TxA4fm3nPwwCZAZFP8ciAyFFp3XZZlJplsUcG
5EkAoJODgFF1sWesgv4NDmK8sZI0Jy6EiEYEEBECAAYFAjtACsQACgkQF47idPgW
csW5JACfbdnrXG9XpRNVsQ0zJT3tIcRTmLoAn2wJWVVLNTPZcKVnWKVR8H97ztB+
iEYEEBECAAYFAjuIQYcACgkQUgAclY4JAiOtOACfeV0ELu6l2OALf6pOgPIdjnus
qykAnj5Atp6IXwLawebGavHP9zvQsQ9fiEYEEBECAAYFAjvgdjgACgkQXmpCkpB9
2Waf6ACfUiLMyxhdJdqxMhV5YriU2RZvGq0AoK+C4YcspsDsS+l8vPgvC99peQzY
iEYEEBECAAYFAjwRLcEACgkQps3e7rs72bj6SACdGtdNYF20ahnd34SOdkK5AyA2
6NYAn0tSBYUgbsWXEDfoJy3uhjnmbN5PiEYEEBECAAYFAjwVnX8ACgkQIGV97BI+
xjFUywCeMRgKKTs+rkZmmVS7xo65W+LR3i4Ani6c+nHLWyDUXukkZhCp9rAZu+8P
iEYEEBECAAYFAjwaYOQACgkQfDS04Uzk9lWHNgCgrH8XRSCnuhkINCYKZ6wb7dZR
sKUAoND0H2E/DgTwdisbM5mIfG+pOjzJiEYEEBECAAYFAjwRGzwACgkQIgvIgzMM
SnXXEwCgotD1jJLrop9goqQUlTCRKrQT2JAAoMWAfd4h1FvrXWvbi27+i0XgrC6v
iEYEExECAAYFAj0HqT4ACgkQRu2t9DV9ZfsjrACdFny/yvBNPZBWM1wsQTWabX5C
9wcAoJBR8QC95Z/AvZVHFhT2V1fiCLlwiEYEEhECAAYFAj0HsGgACgkQIfnFvPdq
m/VgwQCdHGT0CGAvx68hQq50i2tUhTgOKakAnj+2W7ERXafEHYtIZtyFYWXXBm97
iEYEExECAAYFAj0HrSwACgkQXY6L6fI4GtRtUQCgtRjmmIXXuAIkyhdgN+ShFIyq
EGYAoNYJeaf2J6upt84scuzSA8SsuowLiJwEEgEBAAYFAj0HsEwACgkQfEtnbaAO
FWMqjgQApA2X8w9q4mdDEjX4/cZrQ5IHG+rKq+lmVKEtgRSGb6RDUy8lkh97RhVV
+0o1gNhs+H0q479hgPJ9TRzTiFhql2QgnuGuiT95K23ZnChXKyULWIJc4077swZA
ryDQT6nWPNviMhwS6/BvbEoLtYja+xW3/SfPVZjwW+ZghTLT/s6IRgQQEQIABgUC
PQetMgAKCRC1UrBDdzkF1sAtAJ9vmbuvxHxqdCqJpUQf6+57Ga8fCQCeO3Ke9avn
rBfR/EQv0E51zrx5ULWInAQTAQEABgUCPQe5WwAKCRC2hPF8wQqHTSzSA/4+uR0o
v55XDEdgjsPs+oRZHDI4hIKdSFRMDRFU9Vjuhyi257SCrmEGUpuuw8chgDOtynaa
HkQZ80lrq0qZg9g9eBRqGMEwblzBGsRResb1ubB+fX+DpntJw5eHtBqv8SLYe61j
jsNZD0yXRenL/dXfkH7Tj25yMof8WYxO7ZkKzYicBBIBAQAGBQI9B7BdAAoJENbg
of5Pvird5tgD/j3D/jrB+9ETGlBYd4BVz8rjhHBKpofx9LZPe/X3Z7dHYattyl+G
Rnq/lr5w/UPbp3QVO72p1LWYE9qMeB8usmMe6c6RWe1Jhx0q9yUS58VQ9cnnVaMH
QAc91OKre1P+FoGuaVCxAZrPjI30Dg1H7lncZaDCQDhscDrg2znkniVJiEUEExEC
AAYFAj0IIfAACgkQ2MoxcVugUsPIXwCgtMf+88LGSwUW4Uf0Qmn1l6xKTokAmIM6
VPoIaqXGCXJtsd8N7GMUQl+IRgQSEQIABgUCPfd/7wAKCRCMoyfbQzugh8IfAJ4p
qA1enwsfEgyMptD6MNdKfJ+gogCfczxia0yt7Dxx2SecYlcvADKxXhqIRgQSEQIA
BgUCPfd/PgAKCRDXyjq6L+h1zAjBAJ9HRwiZTQB7m+/qGzm28VLDFj/c8gCggUzx
D+sixRdljlssCmdQrNdyEXSIRgQSEQIABgUCPfb4vAAKCRD+T15/A6XhCGB8AJ4w
Me9ipP4OwstNYls+xiJN2UrRPACgkjU8oSj1RX8PbMlL1MrhHn0gIEmIRgQTEQIA
BgUCPfeHGAAKCRBWsDFfAWfKOAoPAJ9s/CFR00kFrpWkaODbT7ea31bLuwCgqYDF
BoqYVwDVBrwqOGr3DA5rs2uIRgQQEQIABgUCPfgGggAKCRAJIrQUEER3XbCwAJ92
zZZJyC3apJKQQVZA4ieo3iRsEwCeJyOC/0/vr/VKKM8IhiFPzpqyegaIRgQQEQIA
BgUCPfg+0gAKCRDIU89z6GVOl88HAKCdVdrf6IyR98cmR1Y6/h/THlJWXwCcCQVq
Nl0sM6UXl/dyfpTOw5v1xmCISgQQEQIACgUCPijtzgMFAXgACgkQboibnTHm45ih
2gCg+SBttC1AUmuZgHSiRxze1XR+FMsAoNkynSxkrAO0twkG37t/UzF/0bUYiEYE
EhECAAYFAj6STVcACgkQYfQNL90hPbpIFQCeM9foqwKsqgScULlMoev/USnOb3MA
niLeVpdpf6MAi9gLOhUI713BM8i8tCVHcmVnb3J5IFMuIFN1dHRlciA8Z3N1dHRl
ckBwb2JveC5jb20+iFYEExECABYFAjnjo2kECwoDBAMVAwIDFgIBAheAAAoJECAV
MdWEXf7drtAAnjgr0qNs0XbNC/TIpGuDWJWkhxxwAJ4+TknZClBKlKZNjn8AsmwI
PpWA64hGBBARAgAGBQI57nvBAAoJEF1SHIzmsVAW8mkAoOx2QR1iXggQIknHd24B
NGtXlFp0AJ9by9b0IqB9jY2Nq2yl9G3xKMElCoicBBABAQAGBQI57oHPAAoJEB9/
qQgDWPy9vNgD/RhKbHVRmORUKEGr059QexpgN3YZxcE+k7T+u+c4g6n3u6G+qlYA
avdtvxEagBgGilYT3ZQk5Pt/2ss2+hCYJJECh1+Eo320wPBrjxOClOwi7Nw+lIK5
acTtAt60zxHnLfIp8MJlrQPbIJ53ZACtlq+hZjGR/DdzFu1vqoUQ+9XNiEYEEBEC
AAYFAjnujTIACgkQiOF7HfzlZWF/sgCgrA52wER511iftFEbpNvltT1dxDcAoInq
gtdUDy8FFkqcLDkJ0LsBNZmgiEYEEBECAAYFAjnujTsACgkQGPUDgCTCeAIYFwCg
iAls2rG6XYsQirh92R4Ixv5uBiAAniREG9/kPIRjFjuw1m+Aqne/WjbfiEYEEBEC
AAYFAjnuk3wACgkQwvyGqiU5Rot6/QCg4bghKw6sGeX3x4UvWEglw1in7aoAniav
YOK9NfyRNPl1VYpZGj4Gk7CNiEYEEBECAAYFAjnujqcACgkQc4fikq0QxsSM8wCg
2g0eOvOUy8kX+K3YFFKQb/V0p2kAn0ViZPCMdrdKsP6yxhr23HNX5y6piD8DBRA5
72dW4x4yPUCuMFIRArKNAKCHOuqkD2knDjGWd5JNQo4aQFhcWACgx5nDxSqmXk6R
TGMwZYbmoA530yuIPwMFEDn8w4l3zinFj6EuIBECPKsAoJYAg1KKOh3iM2O4IkyY
7n3CK/qeAKCqcfr7CZ/uld5ClFzIxJGZIzT99IhGBBARAgAGBQI7OTSLAAoJEJOo
B2QsN+N1bu4AnjQDseKJXvhSL7kPBk6oDuru/J2OAJ9vYrahks6NoBvRWZ8B7H66
DymaeYkAlQMFEDs6C1cO7bznZmp0IQEBXscD/1X1sTB3Ag1w8aMJxLhpxeBrPikd
8mbs06FTD26CTdK4SuQrO4nBlDkoaxItfPuIf3SyTR7NQijH7MFo+75Lpat4FjSr
QPhZleWKj0U78KYLaIFaUTkoCZMhJEKFwvS+gKbP8FQR2TI3jHWjGJnRcMMA/PZ2
COkyGZsL1UgPBw2diEYEEBECAAYFAjs6EbEACgkQgb3TxA4fm3m9hQCeMtzB3clG
2FLlU2k2UtY7NHyVKs4AoIzNSzMvtSQZGhB+/jM3E5GzAiYMiEYEEBECAAYFAjuI
QYcACgkQUgAclY4JAiMxiwCcDq1QzMkLiyTzuS2qYuSIBibYdVkAoKfAJBuR1EiZ
NkqHoKfviFeB4NHxiEYEEBECAAYFAjvgdjgACgkQXmpCkpB92WaNjQCgpxoHhw2C
418T2DWOOTbE19okarIAoIBoWrPD4aid+OVJYIZ1iRLho1hIiEYEEBECAAYFAjwR
LcAACgkQps3e7rs72bg6YgCeLAM2vcwu8g1Nz9UdSyO+tDHbMHkAn1RtZ0hCMFRA
J4nqL47vYiQ49ISciEYEEBECAAYFAjwVnX8ACgkQIGV97BI+xjHPZACeM9xZiELl
COKdFLZC6mGrGj0uh44An3derychCV2kZHEkxXIextWHOWSniEYEEBECAAYFAjwR
GzwACgkQIgvIgzMMSnVABwCggRqlrHTDwkzJYpPMU4t3+JHl3uAAn2xGrUGxKATs
ZdXDu171n50YJa5CiEYEExECAAYFAj0HqT4ACgkQRu2t9DV9ZfsFBACfSZrFGiWn
XxwPAXZfnW69QXtavNcAoKLpt6/U+ms+MJk3RB9XuKe7lo5liEYEEhECAAYFAj0H
sGgACgkQIfnFvPdqm/UJJwCgogtFxoob1yTTa2tnqzchLAGLnTEAoInj40lhkcjC
+VMl7FM+mKWGPrTdiEYEExECAAYFAj0HrSwACgkQXY6L6fI4GtTFBwCghZ9L7nxV
qQtMHtqSY72OXygMO2MAnRebMkouZedp4rFVCxqFOkoTM5NQiJwEEgEBAAYFAj0H
sEwACgkQfEtnbaAOFWOCCwQAqiQnXTXABp4VrIjCCTdrdn1O/u4GWW/OUfQXPOIK
Ig0eOfCMM60SaR9ZyddmrLLYeDk8vkPbdIAxdaQz3WyqOwLWCqu/9C3YPS7mIzDk
HN+eJbjvSPG97mQnu1uuL0qu52sQKGe83WAS6fioz1YTKEnoDKQCcDCU7S+K7Eud
wG6IRgQQEQIABgUCPQetMgAKCRC1UrBDdzkF1naHAJ46joUFFCOBBx+bwSP/d0qf
1Kl62wCfRdKyAp88it85PW4gecYx6kRKfyCInAQTAQEABgUCPQe5WwAKCRC2hPF8
wQqHTV0uBACCzT3oYFZVvfaeB2gu2ja7SgG049T2TscWZR+vuI0GTnpW9DQwJu6D
wiQWcu5s3rIUCY/8vDKfYr6qYUN1P+cvKIfTNEfNcHqknrujRBlMG1/42Wlw+jqk
tWIsKXDdbGIBs6k7hslFa1Ho1k5eF/sAv61E8OBJVlIbk+lm2yzcQ4ibBBIBAQAG
BQI9B7BdAAoJENbgof5PvirdiuQD+Ln+qrC39iLPhu1JWR1g8cVrRq2kMX8Rgk/o
PMXvryWNeqbUyFr19/5WZYWKLLUpQunaASjh4b2MFuqADmDozRc1MQcG1kNW8K9F
wNCCJ5OdmIgoi3LXvBHGwaqta8A9ckV/Y94Y+VYPU0UQ4KQCDW2+Ke17vefTrYNH
OGk9chaIRgQTEQIABgUCPQgh8AAKCRDYyjFxW6BSwyOiAKDbGsOoZZ18LRdx8Ljz
SuQID3cRhACg4xYcTXAhrvonBObrLEV68+c1mkaIRgQSEQIABgUCPfd/7wAKCRCM
oyfbQzugh+lRAJ0VJk3+EjuXmmZi2t1kSX+fJcsLPgCfc76HizlZy99CVwl7JNsT
x7S9o9mIRgQSEQIABgUCPfd/PQAKCRDXyjq6L+h1zDLUAJ9CgUMXNkimqDjC8hK+
4mXTWY+8VQCfcyj6jSqQNGjfUuaYYfFNRn+LiwyIRgQSEQIABgUCPfb4vAAKCRD+
T15/A6XhCCd6AJ9CLo/EEozb1hkumNK+hR2V4Ca5XQCfTurbRsPFqa64XGvViPiF
tm5c7V2IRgQTEQIABgUCPfeHGAAKCRBWsDFfAWfKOJboAJ4+u0ACS2bHcCMk4qAl
3LM+vyPDPwCggM/gQhV5vcO8U+9WGHGBJxzMpGSIRgQQEQIABgUCPfgGggAKCRAJ
IrQUEER3XcjQAJ9YLe8ARydx5sgE2NF3yt79Ra14xACcCYzFuu67d74lpm+BR7M1
/0/fFH+IRgQQEQIABgUCPfg+0gAKCRDIU89z6GVOl5IaAJ9CMlhQkY92ybMBHQZX
glrAyvXO3QCfTdGWgDvnUJyskQyFGZ9LnbtrxWCISgQQEQIACgUCPijtzQMFAXgA
CgkQboibnTHm45jAewCfaVTRu4IRnQ/RPSIxMEEbQgRMazQAn3fN8DVoVUlZH7uo
TN7vIJT5AwUHiEYEEhECAAYFAj6STVYACgkQYfQNL90hPbqvbQCfUstEQfLQHA0l
0Y6+Nz26QsBuc30An3BfepjYD89bUaXODn41Na+yiPKpuQINBDnjXC4QCAD0UBPS
OUsYU8KA9uFCN/RNUtKzx/W16jjpYxqvCdKxbjb3pI7cbmMQtwLHgIcwTC/jSHGx
cJB8JcVHQeaf87XvHt06Gb4aOZAX+oAELe3T+nzSdQ1HttSplWPqzkH0AvoMdCf+
ZmM738cTLrUHTIkgc/yGzUyXiV+m0bCsUBYgDSLgUwS2hCl96r8ELxPqAVVHrDJa
6GPVH+zfywkWaQUknn1TiVnM8JjQiC9x7V+tix9xisysGAG+XPH+jYn9c4q781Nc
psD/hLG8IKd1AjlfSnxS9TD+WOg3g2VdzfcTy64e1z4o6XC/XJssQQlPQYmsnVvx
3LnfIZjlJSO+aTQ7AAMFCADKSxl7M4TC9nEkt3xzx9Wl4qc73J1RqF3+tCNlj2Et
zcbKBxynifjY/m3FJdJcDvbsaJUubBE3Kze+SZih9gU35yZU81++Wq0KhqcpDK9L
qnK3/+3YKqiXV64+Vq43dQXu1C2nsgzQ4vPZ15dgeRLbK+4ez/Gt1fm/YJ86EA6t
UGiZZo37N7wodPoBLfrL+8xRimC2kFK5vOCdsU50HZv4v55t2oHRi5FRWJN6GGUH
eDORcCvzkeulvNxomKaAOyRMMLwzch/kF2eQs36veVwzENiKDub28PCuhrFXP7ke
q/Ybz19GIsJFSd7lemnzuTSkMoQhPjXmlshsLXhi3Km6iEYEGBECAAYFAjnjXC4A
CgkQIBUx1YRd/t15/wCeK53sTVsgjbjDv984yiaHxGzKz9sAn1jpwcaKsxGC0ayc
sTEQABKrEX0m
=fxvp
-----END PGP PUBLIC KEY BLOCK-----
D.3.212 Koichi Suzuki <metal@FreeBSD.org>
pub 1024D/AE562682 2004-05-23 SUZUKI Koichi <metal@FreeBSD.org>
Key fingerprint = 92B9 A202 B5AB 8CB6 89FC 6DD1 5737 C702 AE56 2682
sub 4096g/730E604B 2004-05-23
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBECwLW0RBACY/obrnveQb489t+RYYeX4nXBW31V2DeDxv7YwEy4lA1K1ExoX
lcmeLh/uQT1hoH9woQW0BXIM5ilBkrf55DVfrjJ6usonwPVoBoiShdWy8jOJ1SAl
l2jJsWK2jMrPSqu4NBZoqpaJQ4pofLsI7WFtqC1zV5CWFcl8vMbNrZZT+wCg1HCw
NXUwCl5TYkrlTNCZfGh/QrED/RbVx2hctxSwy2FpG+xxKKpahtGrSfHXOotxFz3R
nx8ohWaBEnUjuT0ahJrFsa7yxmPNp78+0a7BgaxIMLEe0z2bprcAEqz9xDgwS5qG
rxL+so/837fuqMfMyOC9TNgQ4UzzFv7Q/MSP/vgxWZdjtSWZGyduFkFRzNmNLdRA
wlGWA/9QuX7ob5EQBGsAMABhcMwLahjKuXNcFDfa3He8km4fnzxFL7ySePKioxZZ
eVt9zK/QDVCYTtHXPiLGDQ+FphIKWZy0lv9fSuwH/VWE+QBTO9CUCuiFBRX20tPN
WSHiZIlbZc81dStuq8EZp0HL+1iHhtftHWHH+Vy708g74cXYUbQhU1VaVUtJIEtv
aWNoaSA8bWV0YWxARnJlZUJTRC5vcmc+iF4EExECAB4FAkCwLW0CGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQVzfHAq5WJoL1tgCgt1IVzmHVdA3C5YtLbxOqyo5p
k/oAn04MSF3ffr2jxFjUvCoPIVu/dOGXuQQNBECwLi4QEACR+yJIOCf/CfQOp2yY
Ny1QpBm4Rm+NnkJLaPX0ZKxxfa5cHQpqRQl0anbbihRYA3x+TlmD7zR9rTX/Hg+z
nMLdVE9mGz57Mex+GZMUa5RfXBP6RgGsnDfXVAXBjqW1ZAZ4zFiO4vQx8SCwGK6r
67etzvTM+iujcPK2lzQippkG8AmaBNHlhL+vhV+ILplP+OY5Z8YY617DZFLB58ir
dxO43vL5P1vQjFCpD6gJ0nIyAdJO0aT3ALUtrtXoIn+6Cf7sh/qtcNbR6I4FIutx
Le1ujb4nniziZ1iOTW1AkNxqwwD0eYQjxZrHEK0CTkEOBmUsR5iQp3Zghq46yVYv
VdFmbdZJ2rjGZJqZDMqUtNqpaqK3rPLknJt30IzOuDWoZ5ttNf+XmfM+4mrEuHTV
0xpAbW5AL1BpUskMBAcqM30/aEBarDi4cKoVkBNs3m3FM/KGFMjGZc781DGKLhyr
aVNPj6Bmvk1z05f0o+UHhavLhz8becfDRA+9ue2mmtFdZXdGMz6LL8cPKRLegZlo
4vbQ4hz/9UZGBUJVWJG8X85x6fhtrkRglTAGentGvZdOTmOPMODMoECtALPSJKXd
P3iJlL2iaPaMUNJSI6449aku6aT6J77/OFTWcNLaYNtF1goNLTQiTBjKj+ESwfVs
WznjFNx8+boTYkXj/HjZq9KtdwADBw/8DDW5LTYmzCvpZk8z0vG6lKjdPurn+97b
epaw26XlbQvXnxAg40ho1Maki94vDzPHtxj9rLaAv1xtoShtzBfKXum2umFxA+eo
WTnQwGaU+t3U6ndDU7PIqKgjl3x7ufaDT9pjR5BnfWmg59uQ0sJPCdMFpe9MIcxa
dS5yU9fyPcadmSvfFPr+4vYe5IWFdijfTDc89eTAeR6eTKvhRyAwrJPOpjeytTfM
yYwmflv2vZ5RHh1BmNfVVQ35PmeySgGKCbu674m4MLeNsyyoLtZrnhGt+UfB0oCr
ImbmI/OIggehV7jJlGdNQtZXbHJpr2R4GiJSFe0V3Dh33jkw3xS6iroG8+n2SMCg
E8iuOM1S/9rrjSVtmJi9ziaqdPtZuX2GHFBfDO9dXCF76Vc+c2JlDM0w7ZWyzwgw
W7IQtnX/ld2TkBcWq5bCs7/G0YOGxwWF+5PGE7ajwNtnEDoFVHRdbiFQk0i0Ve+R
/yKEpDsCGI0LenCekQiefNSsTVJ2KkF5u5WZew/hcmtlKzQ+Iwt7OxpriEeak/y5
UJn/e2nX52BWQA8x1x2gOFwVoyeXTe12AxLpLKcIXZTi2IT2wK7Xs/rJtypwIOkv
j60zDWQpu0tzKcPm8Bl7SYTZDD5NhoHD19io6IAw4VCaUsne+VQgI42KPap8XJnK
fOCo/EDR+ymISQQYEQIACQUCQLAuLgIbDAAKCRBXN8cCrlYmgsupAJ4iTiPj5Eh8
HfhJj3uNv7V2KbhIOQCfacugQ/nUetHWqzg9Pv5WEbCKjEQ=
=xwme
-----END PGP PUBLIC KEY BLOCK-----
D.3.213 Gary W. Swearingen
<garys@FreeBSD.org>
pub 1024D/FAA48AD5 2005-08-22 [expires: 2007-08-22]
Key fingerprint = 8292 CC3E 81B5 E54F E3DD F987 FA52 E643 FAA4 8AD5
uid Gary W. Swearingen <garys@freebsd.org>
sub 2048g/E34C3CA0 2005-08-22 [expires: 2007-08-22]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEMJW1ERBACGUsHdqFuQjrrtjpvx2pQ7GpZYl+HS/jVPn+0MjMcZwRtk2T+g
b0/EzS/0oeOqv1biX/aZN19T31JGdlSm8FumpTc9zPgh830omlJx8V3g8wi0ZHzl
UjGa2MkmkaCEVeP5bX/NyRljP6fpnOy+5h4F0WcpkqwlXRuhOzM8UgpXlwCgjjPk
0CLI2jSVsnqIKtMdunOfsd0D/RaALnZrVkGtQfDX6MDo1Ws+ADGj8rGtmdN5TIoo
ivJvilG/5HSL2nsqOcIKWA+C4lZqzMIlo5iPSz3BijMc1Ni6LaQo4E4zvh7ID5fs
fXsMhiE7H2KNSGTjmmL/8Weq8Zgpu9TBD8CHUZLD6BU4Wmm9I/R49A16T5Gbylgs
fEwaA/0VYP+u8TEechtQKLuAfOwL2ruFE0YKmnXq2S7MixFvSNaRilB/t41I1YcZ
mcWbRlIBezvchln5qRommEKfp/sWVcocR+AuSTcLT3683SkeJ+9205bFx9xXJnrE
PBhqjMmRNNlmijcBFZHk+W7tCJQBbLGJkpLfqllfVkJ+rY/NVrQmR2FyeSBXLiBT
d2VhcmluZ2VuIDxnYXJ5c0BmcmVlYnNkLm9yZz6IZgQTEQIAJgUCQwlbUQIbAwUJ
A8JnAAYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEPpS5kP6pIrVGPkAn0i58Ikn
S9M9e7cMI9Fis6lXDoAxAJ9eRxZEgPn3aQ4DZ2ObnuKbKSqcw7kCDQRDCVtWEAgA
7jU7l7ssKXwc+/ynNfiLAm9nvCY4jMw+CK6hwhtuOmrgFH14jeEY8wRVBrOUkVi9
Y13Z3qkTk5DD4iX9f25iK8PJELU5XJWStuX64hIEyqowRZ5KkvsdydHjQ1x2koS5
oTW5kD2nWChnBKI7iWPgRnFnfthrXE83ZY1sV+/OBRZH1ZS5KVxOzClcoTiTE5Q0
Q4Py1vlS/Bw95Nhejef7gSf6fN+iV2DQn8KDF81+MIj1jTWt5LDa80G+T5yGWeuz
asAZVzBfPEHbWbVmRjT9Ajmump1D/0gUvxSr0fpnVfPtEFJ/MbLdcV1kyTtI9YLm
EWnov/J31bGCDlhGjYfaLwADBwf/TBu+b48oClOPFJznnNGVVJUdD528hfVor4Wy
3ph3KXSfaysOmG1xo+nQ3JpdzbC3nXgfVGM2wGvFEgq7ogBZ9YZNzwSP0vseJlwn
oXNKvKKDdCyVJC6Xi0Pd6L4beJRTjxf0LPQUjYdQbwrk2RqHXZ/RUapYjlfOWS2l
4ZqHiMoO7ZIAj/bdBKxySu8qVs3zmu59SE+ZQgxSXwxw2mF09XWOLgXsKTfhXlkl
ZyKhjcSlVfjy4SXiXy2zFCh9+T0eiCeEzz5kS0QkA3npOooIFftI2q0IKbHOExSA
YwOocuVEW7eLzeBfCoDa0SoapeXcjyF7KbiDwQ8xu9gEIUkpXYhPBBgRAgAPBQJD
CVtWAhsMBQkDwmcAAAoJEPpS5kP6pIrV3wIAniAehy9Ttb00FbjcevJetKN5PWe9
AJ9XhpsYKAyHxoZLFzGdR3EGBJNAbQ==
=EQll
-----END PGP PUBLIC KEY BLOCK-----
D.3.214 Yoshihiro Takahashi
<nyan@FreeBSD.org>
pub 1024D/8394B81F 2001-10-15 Yoshihiro TAKAHASHI <nyan@jp.FreeBSD.org>
Key fingerprint = D4FA D8CA 2AED FCF4 90A3 3569 8666 0500 8394 B81F
uid Yoshihiro TAKAHASHI <nyan@furiru.org>
uid Yoshihiro TAKAHASHI <nyan@FreeBSD.org>
sub 1024g/B796F020 2001-10-15
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDvKlwgRBADKGTPgNos5F4dobTyIhNN1nVHwKtvdTM06orzFj8VccmdZlJF7
DLp1UH1gwiVGLu1NPOrQXKeaZmK3iO11fTV0zbCUlUnfgSQsJJeGUFMx7/tgu/F3
L1qe1p37txNYN09SSEBJe7rlTLhM4VWa3LeEG58Td0d2qP/fJeikz9HIVwCgzIJd
aEclfjgNmsx2lM8jn6qxJXED/jyqV1eAgTD8C6MRPGYcqyLUZoIy7SwdhvQLKlT3
rAI4yHy5m8Njj0bk1oJM+2PAhZN3o16tpsjQEJuWoIGWxe9P4AX2Rr6htpidn2Gc
UOXaMFZyy0MX4ULfph78FEzRC8WGEV1hWLW9pNnzaASY/RwNNvW/YnGyKSCq9ilC
YG9mBACfcmN76QnFFDHd76otrltwwjj1zTRoHEnBgfj/EldDeOaU5cBG0HiV6cbv
94MYUi16AnN6462qG8RHJmSPblsm2Og1e7aaZl0CpVgOq86QBwqDHFXh0q0UtgXU
EQChaBe68ydZRwd9TScAknuj5iAXfXtwAeyhWbzmVyJH0Kk8QbQlWW9zaGloaXJv
IFRBS0FIQVNISSA8bnlhbkBmdXJpcnUub3JnPohXBBMRAgAXBQI7ypcIBQsHCgME
AxUDAgMWAgECF4AACgkQhmYFAIOUuB9UUQCgwTQSPrbTxhJvi1DdGsYhHOsT0PsA
nRNBwMyeLPQPhLxw8EPLgyno7+EHtCZZb3NoaWhpcm8gVEFLQUhBU0hJIDxueWFu
QEZyZWVCU0Qub3JnPohXBBMRAgAXBQI7ypdXBQsHCgMEAxUDAgMWAgECF4AACgkQ
hmYFAIOUuB8q0ACfTgzsn+Q6wc4aDQ7nT3+M4HPWXhUAn3nhtyq4Ucu2A6oHXvVt
1oAhhGyPtClZb3NoaWhpcm8gVEFLQUhBU0hJIDxueWFuQGpwLkZyZWVCU0Qub3Jn
PohXBBMRAgAXBQI8VVkOBQsHCgMEAxUDAgMWAgECF4AACgkQhmYFAIOUuB/XmgCa
AgHmONlOiOhKdY5LtVJoDi0+cOgAoK4wJFYzstYbpXayj0LqbgmYiY3QuQENBDvK
lwwQBACBBH7cM4WCT6D1w1XAQnWgL4eE/fMcR3aPiHBDd8eDWFFOhwSPh3W6jZ5T
STUEZCF7lgD3k+QJtDhVKE0U/hha1ZFMgdTTbhEW9Pl9DHW3BYxPXxq/SURwpGFg
0GriV65Hx3Dq6cxkBfzGZzrZA2JfRwb3pXisNSGDILAtNRw3jwADBQP+OSbFQWL2
n+KrBX4dPbp5cuFVL1/NNOWhSOwU+IsR8jDaCYpLy+Zkn7Bn90bIee7zsdWOkGWf
/qV0qm6dY7xLs/hoCKgk+0jPPevVcCayfCTzBZ+d76qPjWQtEgKN7/LJZn8rMCBf
B4kHxrcclf9z3OdI+BzTNrPZaCeHLd7nMKeIRgQYEQIABgUCO8qXDAAKCRCGZgUA
g5S4H1r/AJ973EUo0J+SF83Sj/hL0zDTQBKlKgCcDy1o6LmSduT3NE28KB3Iw10I
kqA=
=eB3G
-----END PGP PUBLIC KEY BLOCK-----
D.3.215 Ion-Mihai Tetcu
<itetcu@FreeBSD.org>
pub 1024D/493A297B 2006-05-06 [expires: 2008-05-05]
Key fingerprint = 9FCA 0857 A2F2 D136 5402 A986 057E 9F8B 493A 297B
uid Ion-Mihai "IOnut" Tetcu <itetcu@FreeBSD.org>
sub 2048g/8C6A1D3F 2006-05-06 [expires: 2008-05-05]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBERdMV0RBACBXzhIJhng84GgNX8gjQLANW/NzCMqE6gOtlQx3bV8Ndw8DTSv
X9BH1IE1D/Rb3XB95OqLrGFyqo7C8rhpq9opki31y2W5ZgbZu3zo+f3e7+B0wJ5s
FZHSPpf1nP5E+ZiayXWj1cJSeoVEgTnxgWPxU2QN+dJ+z2Wmfv9rxYGE3wCg25UG
PUZRtcKvgmXvm4d+/GKK8jcD/3XL/81+07PFTI7Jh6SmfBi8Xcdj2oanOaG+Gmkb
QLG8NJLwpobhtM9NBI3bX78zcSegNR7CYvnTB/wSsMf7Arde+LuwLetnQV10S/lS
gO1FynyqRHlNYmn7pHosoa29Ss3xjwrbNnFDyWCYZVdYZxiroyW7Emv0m82KwKUJ
PRvgA/9F+R8vdx4jfaMp9GTin3xNjlpeSe0Rq7JkSU6hJ1jnuvAeSvbZ09oxbYHj
IVmkH+Svu8KsR3KEtxZjD6I1oo/CzLs23wx1qeSqJ74uLlHyLZLa0H0VsOJV5rde
+vC5b4fNxIlAVQyGETeZr9zyv/UXmAVjVYlnlApBjQfrSI+BxbQsSW9uLU1paGFp
ICJJT251dCIgVGV0Y3UgPGl0ZXRjdUBGcmVlQlNELm9yZz6IZgQTEQIAJgUCRF0x
XQIbAwUJA8JnAAYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEAV+n4tJOil7jxoA
n0FJlILfDY4jZVQD3QXD/aAIBcYRAKCJ92+PJ0MDk3aOLlY/Dtiv27cMlLkCDQRE
XTFlEAgAoyPS5bW4+0FuIhu50q8MzgF4avUVpVIzuMqwm1kq3igkKkw+ZVqGisWK
IveNSccdmA4SThLObEqH2neQBbNzASCpeLuX9WDGTVA3fFcxgvzjbRgck/9mSCpd
xqivySFo6m5wIV93gdIMfrR1lMqBjZmwjlhOpPnjJ6OgcEhJ9bMW6l6ylUFajfCd
a48vCs83O2TQ0xPF9VMtdOdJKiOUViU3UCNyibqgBBZ4nQkyH2MrkGdww2smB/mk
qoaC874l2M7+L1a78/uBHT5PNCQ6e8E4CdAaWxwPQGRiM1N/Nhnz0T0/IHH6h9c+
hXL5f8GO0uLeFyhw0IStUB/ULsKGPwADBQf/bYmTiAKPHD0S/6OlTyjobRPYCD/k
xa5av+OjKgS2kZKZzO7IRvuLQUrcH0vRcwP7Jqv/cH8TMiQcN3Q1ldL73TcjgCp1
BxIn0ONGlHCuqSLKwsfqgUGJOPfR1xuzpKtgrMR8fuJ46xn7WCzxxkLFJ+m2fY2K
XTrbZW9/sMCgGUgbxi50YDmTxQDnTaUAobn0kZC00ZZAdZ+ABe9N8wOHtrJvFlcJ
xiW6S+h0f4tYhHdfhfFqpFC7J1LTu4+e0j96Xqwtgpz5jz4cUgbbqZuV1Lu7OOHR
NbCuvSnw6/Sc3Lr78OShCg84zv9Cz28T7RzB4bBzhw/ub5l0r7oY8GJeDYhPBBgR
AgAPBQJEXTFlAhsMBQkDwmcAAAoJEAV+n4tJOil7EWEAoMqcMXtEKwrqleoNPW7q
5qLPplADAJ4+rvjlVQ3BjvYWHHOEYjKkP0eY8w==
=icNv
-----END PGP PUBLIC KEY BLOCK-----
D.3.216 Mikhail Teterin <mi@FreeBSD.org>
pub 1024R/3FC71479 1995-09-08 Mikhail Teterin <mi@aldan.star89.galstar.com>
Key fingerprint = 5F 15 EA 78 A5 40 6A 0F 14 D7 D9 EA 6E 2B DA A4
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQCNAzBPh/0AAAEEAKiF0rNVbbuQue8Mo+knlGKtZJXWkLOhmdzE+FPxTSRv3TOS
OHOfFbEbTlcuplvYv1US6o4liAyyx6vGLGa7ZW0zLFAtTOJTfwW3GPmcMTieOIK3
wwzJtjH+wi7VeXIQCU/mOcLC9A8QaLqhJ86e3m9FODSFMIluSoucrgI/xxR5AAUR
tC1NaWtoYWlsIFRldGVyaW4gPG1pQGFsZGFuLnN0YXI4OS5nYWxzdGFyLmNvbT6J
AJUDBRAwT4kMH2ldntvsCqUBAVAcA/4x53VCfOx5Bm+BtneQNEvHgV8aqWW0tM4r
31KtsSjMwuHF3kl7PJtCfVk4OpRvog4u9V5G7gtUhUIOi/Qfuia2YHvvxIh3sx7Z
Gg22e4FxNzNob3qV+YiPOr+Aa6EoYfHB45eHSLFXryCBS60a0CfZies+CSzcHBy9
/Zu51dCtnQ==
=f57V
-----END PGP PUBLIC KEY BLOCK-----
D.3.217 Gordon Tetlow <gordon@FreeBSD.org>
pub 1024D/357D65FB 2002-05-14 Gordon Tetlow <gordont@gnf.org>
Key fingerprint = 34EF AD12 10AF 560E C3AE CE55 46ED ADF4 357D 65FB
uid Gordon Tetlow <gordon@FreeBSD.org>
sub 1024g/243694AB 2002-05-14
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.7 (FreeBSD)
mQGiBDzhleARBACRg1KdGeSzgkTXaRoBCqnjTjxoBZR8HzRn2hs1hS3CBJVGfAKQ
NOCyKFQWWqYIlKDIEA38767uW3yyKNSnQQI3Ad17ifWp37M1B4wdgGGmEAiyE3Z5
v63120MJgRhejyZph2d2CfAPiLPq2LXy6UIUipuYQl0BICZnL6rDm+QAwwCg164x
uMUutYhSdB9/hBLPECwtXeED/iE9eyJVcXvdambHZfcvySg5e5+z7Y8FMWQuhcO0
svBIrhU/gr7S9lkwudOj3LPIffwCUBNerVDGuDUhu7iR0YIRDX6aN+LCkHFXK9x5
ScLHIj0HHpbQLJeCeGAZnPpuIluFjRSaklVERHvio9gR2cOlo+iXRku/SbzPEzA4
BTvYBACCKxLHWNFdyiZLIMsSVn4pJtgUzIfSw/auBALMft03fvXD0cNOm2RfhJj2
Yc5U4k6PBBtoTTAaKVQ+D7CRHBhlg+Ls/aJSk7Dj8XJHdv0w1AkGz/OAJlJIDj9M
RRCPyfhTq4nlsbFOrJuTcq5XMxbdd+voohkhgaiz9Lk+KNCQX7QiR29yZG9uIFRl
dGxvdyA8Z29yZG9uQEZyZWVCU0Qub3JnPohZBBMRAgAZBQI84ZXgBAsHAwIDFQID
AxYCAQIeAQIXgAAKCRBG7a30NX1l+5DrAJ4gSRjBxPBeGI8qjBCAEFlKA8MOawCc
Cm2cEju+gP+x2a/op28O02bg7NWIRgQTEQIABgUCPQegzwAKCRAgFTHVhF3+3ahu
AJ0S9r2mcQEfQ21ZzacV6sTyJkXtoACfSxld9fOItvrLPh6C52JecXfraCiIRgQT
EQIABgUCPQeutAAKCRBdjovp8jga1Je6AJ4hlXGQAixShrEIb5bwTPWNKpQEbQCg
5XcnCDTpR7MIjRHd1Dg1Q9DgpvKIRgQSEQIABgUCPQeyOAAKCRAY9QOAJMJ4Apoj
AJ9Dp5QAmcAR6LVlPdE0usEtw2bgwgCg7pXfhaGhtMDvjJOWIardnhtKQ2eIRgQS
EQIABgUCPQeyVgAKCRAh+cW892qb9Se9AJ425mHg4dJf88ye13TsQkMAsSgC4QCg
jbqcE3gINIe3HJLam4stKTGcknCInAQSAQEABgUCPQeyQgAKCRB8S2dtoA4VY0ow
A/9gHpO8ZsTMx17LtBEL0+p2x6Uf7QzWJRilbgVr7/nCiMoj04rdbft27DnQg1pU
xu/Lzv32kkDLsWBfwV4bR9efa6Q9N5o+/eJZUuNVypxK1QHCrJ/oG2yeTtvVyixR
zXoFGAGiQ8xJplAJ8keY3NKjYHssFogU2GmYc4EIak9HDIicBBIBAQAGBQI9B7JL
AAoJENbgof5PvirdwdkEAKM7iNtj5DGZ0yOLFgumLiRr2a9IwAHu+su08Pjb9lj7
oUO/TlMIKf7Y8xG61ydotBL7t4eZFAWyT9ej+UBp9sBh2O5mY6CLeBLnXlka41mP
JyiDjK1hhTf2ccrkwrlCSDx19R1RQrjsndaTcb4AA9yZQdoetslI2FNqvXfsvtyO
iJwEEwEBAAYFAj0HuzwACgkQtoTxfMEKh015jgQAiZAHy0Ql+xB5zTRTkRziZSt7
uqHwF9KALoUd0UByFJPcqqtv0sWNcYVPu/rAAQFveG9bqi9rDPmxIuuEGl3TAyx+
ZKtXQ5re6E4G0AoJCKOpUAZaRQHak/iJZHgpl1Yyy2dB56kt9xz6Q+rCPS8O3t7e
giQzGOF5csFv465gB52IRgQQEQIABgUCPQewBQAKCRC1UrBDdzkF1ujVAKCAJrrj
PUzvNvCSuGMNmf9Dyua5AQCfTEJusbNkJKgu7CxHqyzTMvVlQtyIRgQSEQIABgUC
PQggAwAKCRDYyjFxW6BSw/5SAJ972HfP7sNl9poX8YGE0T3vN8apBQCg+WiUgSJO
ZeYEQMiZKLwAxoMbape0H0dvcmRvbiBUZXRsb3cgPGdvcmRvbnRAZ25mLm9yZz6I
XAQTEQIAHAUCPOGhOAIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQRu2t9DV9ZftV
aQCfYIv+czm8hMN3wjxF6sA5D43vrMQAoKRTxRmyjxDnRe4QoAZRRzogt6stiEYE
ExECAAYFAj0HoNIACgkQIBUx1YRd/t2B0QCbBG60aRGEgrQzMkpodzJbU5Itys4A
oIS56noACXYphdM25tdfKPS+QesfiEYEExECAAYFAj0HrrcACgkQXY6L6fI4GtTj
FACgiAuFsZW43/A3A9EATgD8s0tEmoMAoLHpxQUAQkvYlHobnsU2jSEImhDZiEYE
EhECAAYFAj0HsjsACgkQGPUDgCTCeALbewCgokMlypquzasL3SExbdbXS27xCwoA
ni4XvyoNd3GBePs4fy4yUjKyOTJqiEYEEhECAAYFAj0HslkACgkQIfnFvPdqm/V0
MwCeOBidsDe/z1EzCFK3LJPDkBvQCP4An0UYz4df9J69dxmP2Eqn8JJsdUdIiJwE
EgEBAAYFAj0HskUACgkQfEtnbaAOFWNKxgP8CfH/yozXDafD//91tmXwS6x4MSTX
stkfOGfOT6dLqla201Z+CDsHayQwfwVzJdcVYU+5Xe8dwb/sK8JjLiwb2ASnnhZx
nZLeHZYAi3U0oNscxrPZJ7Qz93KFrNf/No8HrmryU9TUFzhSHKjHyNeBH+TJEOj6
PRLftHPubEkO1q2InAQSAQEABgUCPQeyTgAKCRDW4KH+T74q3YoXA/wIaJzGfsFF
d3nlZKK8hfZD89eUSR8swV/Oy6Ctl8qOSk4XWFxtjRRzNS9BM/TYjd7cJBUOQDQK
u+wQFMztJdKdmntwoBTrdg7HGMGtKnR5Ppzv2XuGOKuoXy2y3yDgRsZc3iFEweZR
Ao42FBFU1wtDCV3+B1X4Gj6CJDMT9R3ItYicBBMBAQAGBQI9B7s/AAoJELaE8XzB
CodNgcgD/RYAFt6mLWS+CGSk2MdB4eA1McDDJY3d+On8c672z1BdQjPeYdd/zWHj
aqeMoc1j/ctisGogN1HUwujoI+xo4puraFnFiYyJR9lKFK9uMBVw/eRvp+29QYa7
RY/6U/OD7cfUo0BMBS9ZhZHNg6GMPSlJWd87pF8N3mFrwRK1dVOziEYEEBECAAYF
Aj0HsAoACgkQtVKwQ3c5BdYl0QCZAQrSvVWxwmwJq4qS4m9FgdWTucoAn2Dea8HQ
oOPvLRj9IRh0jdzOWk45iEYEEhECAAYFAj0IIAYACgkQ2MoxcVugUsNSiQCgktJN
6aCAHnusQajUnJ9expOWxYEAn18BPBKs8vdWvTJjNwqI9BAe6WUduQENBDzhleEQ
BACPsAZpNNdGXIlKMXJhYOeg/CuPG5dt0Ucaq9YhmmUJw8tmuLL5D839BC79qaSr
B9UTcuKdi0Kmaiu0nTas3h6ThDu+nqLpiGAUqkSST8jhJXF7e/X/ggMLatkBIvNs
nDf4owUFjzsm9nmb2GPPecWGsyArPkRGCmV+nfEYvhBo+wADBgP/QZ29lUpgOu4b
nhgE2LP3641zQHjMqvYrZKnHbmHVYUjZwuV2YUvdFPI21OYWlsAYyid8OUTN9RKS
+CcDcHZhS9SS5otQLG9P/aKVh/C9H2mnRU0GbSt8hf0HX+y6nuzPe3iwE9O5rbxe
S0c/zhrPuz3ZK0Y3e0Zb+tdd4NpOVxuIRgQYEQIABgUCPOGV4QAKCRBG7a30NX1l
+wSEAKCHPJh+3QRUcI1DG53fij95oTDMaQCfU2DJ5U/pKSfJFjFvN7XRpacDZZI=
=1nJ4
-----END PGP PUBLIC KEY BLOCK-----
D.3.218 Lars Thegler <lth@FreeBSD.org>
pub 1024D/56B0CA08 2004-05-31 Lars Thegler <lth@FreeBSD.org>
Key fingerprint = ABAE F98C EA78 1C8D 6FDD CB27 1CA9 5A63 56B0 CA08
uid Lars Thegler <lars@thegler.dk>
sub 1024g/E8C58EF3 2004-05-31
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEC7Hq8RBACUBh7OsXzgLr6Hz1QigRoSr5nWAUdj7Z9wNIcoE9t6J61MIUtP
qGL3x73LspmwBGu/aC9muJ5b4Ont+BBBkVkC3Cdl7pKSvT70/ZB7TKw9f9HA9S67
jK/NnrgG4R9amixfd0KyycNpf3yvug2FV5VZBiUqvuqWipqXacOxsD8rAwCgksWW
74+msARYAf+mTeR7/NCEH3MEAJFfoV3APPGGECWfwrDmQT1IiBhObbjsVKbo4z7w
yHxK+3Qm9nCG/sVthRll96C+rtAJKf+FEN8nvIx/9Z1UQ3Y7zTMgzlbz83BhhPnZ
lAZEZI+EfmWsltzmyjJHnsvShRvjEp/YQ+0tfZV5uAPy2yrICw/rvozhCmqTox5l
zOgXA/9mfbgbJR8NS7IwzcVSH+YEW06lyxLHjEd31aIj6wgX7O9H7JdXOytTqbSR
VXN+5GjJhEaw9GmAd6tsvusHMy+1GBgY7TFFUNYO+JqHn6FKGzfPiFyxDyvyrF01
QL033peqiNVxTS5nvJzmKQCpftlU3S85R+K62Alv6xO70HyaALQeTGFycyBUaGVn
bGVyIDxsYXJzQHRoZWdsZXIuZGs+iF4EExECAB4FAkC7Hq8CGwMGCwkIBwMCAxUC
AwMWAgECHgECF4AACgkQHKlaY1awygj74QCggWeR8IRwgHIsxVv5zItpzdtnkSsA
n31ytm6noxfetU5J/5NnR6bwV4WetB5MYXJzIFRoZWdsZXIgPGx0aEBGcmVlQlNE
Lm9yZz6IXgQTEQIAHgUCQLsjTQIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRAc
qVpjVrDKCPikAJ9a/Or2be00A9PeXyoo+b7VuLAzhgCcCX9kI2DduTtitld/mY93
vZDnQPO5AQ0EQLseuBAEALDSStxYn/CidImaPKwDZoYVpXpHucmBZ/nK/rFwMNh/
/RZD8ZdBF1PEDf3EA78qTxEk7PfSnoEWcxmcNfiMSALiTkehI4nWQH7j0ZSwqC/5
Du4lP1v1PSeR35IkC58n8kur74olLMdoYxlpVOwh7jGR9W/3MSEjQ7NJP9AZ4yw/
AAMFBACv3/ZxNdO78IPVJ1kQsfGUnwfpiw9syDqK+CMA6FyTCI2VUc6kY0Wc23Qv
uoGv8ROk75pa2MJxEH/GQJNSZerJCSzLqdCyEW4tuxxJPQ7celSZ7PL5QutBzytL
4rUQ5bUlYQBFlCx6aOuG2+zQqiFbm1RqX7RYdOf3LnlRmkaTDIhJBBgRAgAJBQJA
ux64AhsMAAoJEBypWmNWsMoIibYAn1x8xlAkuQC2ZlUID9ORxSIgEMyjAJ99nQWi
rCVB/qZMKoL16f9mHKvJ4g==
=OYqV
-----END PGP PUBLIC KEY BLOCK-----
D.3.219 David Thiel <lx@FreeBSD.org>
pub 1024D/A887A9B4 2006-11-30 [expires: 2011-11-29]
Key fingerprint = F08F 6A12 738F C9DF 51AC 8C62 1E30 7CBE A887 A9B4
uid David Thiel <lx@FreeBSD.org>
sub 2048g/B9BD92C5 2006-11-30 [expires: 2011-11-29]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEVueHgRBACBqHSbbyc8BoznmojkguHMrDQtqISv33b9tpIsNSHDgz4Wpoqs
MRwMPZpStu/FwULPzRUkceoYFIkyRyBwyIqTAD3uq2nisPR23ffDKRe8Q44Y8ccz
sAtc7zPz/XpoI+2tLVGBCZyk9UOuIK1HkrmEjJ8uG2/eqyuckjO39oA/3wCgorer
I3uzG/mJG7V0hHaCEkhQVx8D/3/i9YwqVVf2kqfKEGUASik/PXDpoeHfC/v6GFik
Ss47TSaiuMOCoxF92m9EcOSoYCHOmdkJ1l+AVAWCZvKHKDM6J20dRr1zNqvR37jf
FlmbF5B/MhRcjaSvrOLnZsP1wlz5sRkdAOdHNN/J/mwqkaatkFwtf7XcFMheB2qi
1XvRA/kBi8lvPw7/PGibDIZXBxUmWVHLCU0dtrwKjbHE1HIpMwgjbTFrvh0pjmXh
+qjn9VTcduP50Lrd/J3bh6WSgdc16xT2zxSAg9G8nJctDSJVgOJiYFUfLBpPBeLS
O5ZN3GHw3TyLnDV/NvaAfzp1GXaGUB4kEuIaiaxxNugT82R3OLQcRGF2aWQgVGhp
ZWwgPGx4QEZyZWVCU0Qub3JnPohmBBMRAgAmBQJFbnh4AhsDBQkJZgGABgsJCAcD
AgQVAggDBBYCAwECHgECF4AACgkQHjB8vqiHqbTvNQCghqU1WwfsIQgI4bQn94M7
z3PY/ZYAnRPT7soJ0GrlKAMRplxFoRWH1C1TuQINBEVueIUQCAC2nNYNyuKG/uCP
l6/GUoumFRE8tcbH1jW5yrFbi8ahcoi71iCQ6Ozdx+XM/qIu13/iEJmTOvoVyOFf
0pn0vVjgJ6yWek2oZmqh9Loj0WX2bRvV2uemOfvNwqUvDLCvbdftHgQAHOff5Tij
GJxEBzDylhkAlF7MlZbCejiIJ7Of9fMC066Yi5M1lg5wAX1gPG27PiXJLMjcLI1B
BsaIEtJsInd+UWsgjUE4tq1xoFhCeDZZWHCAyc7XyI7cy9FFQIII7SWkZ8TkZwKO
T4UYyIHKtRFtgrMTkcXAc/Eul0LEo2z2e4L/G+8vF7q9LicIyv3/BF62fgx3iCKe
HkJRWueDAAMFB/4lX+vF95ESlWuZ6DH1orSDKMzWlaJfl8ImE8nCT+QN/3ZauO7Y
4kQ11jy2Q+vURzltl5r1uMgAheBR//qDp4OTlqxqSyYFx49iysd3rjP0vnc8WGD9
BpGobsbcgw9axW6z278IZzJ7aroYBaceOHkEM6nNboZ1aKCn7jYqxFyzNUuJqqEY
0vxx82C2wHIPb+b9k5LCz+kMrq8fGDPERYYcFFKHMuKZ9oyide/8hQ83KadXbvJB
/GAqx+prMs8axuAMoGgksMRV7Er+eRZNqYyeCr31j+Oh4qpUbe1q3UPzkoUg9OMI
qJXvBn5S1M2B8epkggu4y6HDsbVXqgT+NCaWiE8EGBECAA8FAkVueIUCGwwFCQlm
AYAACgkQHjB8vqiHqbS5dACfWGE7OYOJs3lJUh0fHYJEYGfcOKMAn3Spx9LXSIcR
mVETDDKHRmZTSiZX
=iAPM
-----END PGP PUBLIC KEY BLOCK-----
D.3.220 Thierry Thomas
<thierry@FreeBSD.org>
pub 1024D/C71405A2 1997-10-11 Thierry Thomas <thierry@pompo.net>
Key fingerprint = 3BB8 F358 C2F1 776C 65C9 AE51 73DE 698C C714 05A2
uid Thierry Thomas <thierry@thomas.as>
uid Thierry Thomas <tthomas@mail.dotcom.fr>
uid Thierry Thomas (See <http://horde.org>.) <thierry@horde.org>
uid Thierry Thomas (FreeBSD committer) <thierry@FreeBSD.org>
sub 2048g/277D65DB 1997-10-11
sub 1024G/8866DD0F 2002-01-26
sub 1024g/36DA7AF9 2003-11-26 [expires: 2003-11-27]
sub 1024R/C5529925 2003-11-26
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDQ/z88RBADp8valPHNmMg4IWqAuVoPAPDDt1qbEyDwIoCoA9I/IaPOGt+58
WdqWaOiRq3RgpGlYTmO5TXDo2AtSJYj/Pp0JJ9XGgCZjR6f9ulrjijTEMEh3YyUz
Qmor6iV98PzIFT4DJ5EC9i5/H8wBVX84ZsfklrsxY8H/Rw2VgvF1wfdF0wCg/9Jt
ovsn3xQaWlrcNZX+J5Yj0f0D/2Rc7FNG0sWiNpd6UmuvbK+/gwRuapXcFBk/2QUy
DaXeTpSUdfWiDbOZwi6y+XYPZTjx1TPZeG8qC0D9U2DsVOCV3t7kD+K7wU+nJztB
4IH5xy4BPuxm7S1QdMsMEL0VqWpx+PGl/rP40gn/tCZHepqc3ngEOC0fQwobhxUB
xwiYA/wJDKlof23mVQJ9XeJ5w5kVjUzRsA+SoHqkwT8MrnbGBV9jgZTXquM4Ahpf
KE6jwB9lUdGrHNqVw3axMBm/OfjV5rQ9k9ADvSjM+T54gjG6njgwySE2n+OI858s
MBq7YFCL2RTFDUUen6kSW/MXLiOryoUQKpkbiRGt7YKJfnf04bQiVGhpZXJyeSBU
aG9tYXMgPHRoaWVycnlAcG9tcG8ubmV0PohWBBARAgAOBAsDAQICGQEFAjkq6iMA
EgdlR1BHAAEBCRBz3mmMxxQFovyRAKD3X3+Vq9iJioZfCq12iGqHAmRk9QCeKPzO
IsS/hIQJ16gbRzXMkRb+0AWIRgQwEQIABgUCO+3N1QAKCRDF7Xcg2dUNinGtAKDC
ZYkt4NG9Jw/EFEy9UkQxYgsHKwCg8yjleXQ0NGYA+zBkEjz+kNj1graIRgQQEQIA
BgUCO0cPIwAKCRDF7Xcg2dUNijdmAJwN5xdY85Iyd+XnD7O7A1mEDQ2D3ACgvZ4k
B45mTz9UE1lD/KW2qp8sQliITgQQEQIADgQLAwECBQI/sCevAhkBAAoJEHPeaYzH
FAWiQJkAoOcly5gKj2nH0aKf/MupqmbPIT9PAJ9gU77mSvtG5TaKby4UIPRElpg1
w4hGBBMRAgAGBQI/p+7XAAoJEAOz4dZY2jgd1VoAoIp8m2O9vLbHCiwdXZHMAQSh
1ZjlAJ4vEGGF0zO3lbIcZvsVhLYwav/GFohGBBMRAgAGBQI/qNxaAAoJEMEPdCHr
F9BQhNoAn0AU9dp8bClXno+t60eRRy/cmBIlAKCrDR4N5faT1bLSC73NZNAAs/tC
1ohGBBMRAgAGBQI/rOcGAAoJEL3yoiBeNhnTuJMAn0nWXCj8ylOD6BGuW/e8Xtio
LNPAAKClNFkI/anyi17CG69By5YZ9OIV3YhLBBARAgALBQI5KuoiBAsDAQIACgkQ
c95pjMcUBaI6zwCeLo/Gf/OIZeajcQJQ7WymzxTp/kwAoMlvS0VhJpCd3dGZMny+
/kWQDNzgiEYEExECAAYFAj+ws4YACgkQ8OAIYAA+1wHIewCgpTH8Yt1qG3B/3859
02z6O3n2wXgAn2gaxrfSUcPpLZ6dAtIrM7sOydeAiJgEMBECAFgFAj+wuhJRHQBN
YWRlIGEgbWlzdGFrZSBpbiBteSBzaWduaW5nIHNoZWV0LiBJdCB3YXMgc29tZW9u
ZSBlbHNlJ3Mga2V5IEkgd2FudGVkIHRvIHNpZ24uAAoJEPDgCGAAPtcBCQMAnjO0
4mg/bpGSJ5bjEuGxTz9CxM6SAJ0deoMywdxdQbrQJ8S453ywolNFarQiVGhpZXJy
eSBUaG9tYXMgPHRoaWVycnlAdGhvbWFzLmFzPohZBDARAgAZBQI/sCaIEh0gRG9t
YWluZSByZXRpcsOpLgAKCRBz3mmMxxQFooqSAKCjo5iWvw8Kwo6lMuRDPOvPuidQ
IACeO7otKuVjA0j6XYPnHQO2vbVfUaOIUwQQEQIACwQLAwECBQI5KunwABIHZUdQ
RwABAQkQc95pjMcUBaJvIACfRC9dPLhgJIZ/1422dVG8sxW3lNoAn00ez3emqW6r
U0jnkMv01aoMrhTziEYEMBECAAYFAjvtzd4ACgkQxe13INnVDYrnrQCgpVq4aC09
CVIgLqU47ZlOuQe5miAAoI+s1L3TVl2C5FTU/HaJ7N9pcJsXiEYEEBECAAYFAjtH
Dp4ACgkQxe13INnVDYrL0wCggJz5HkyKwapahU0ZmbUHuMlqNfkAoPS6ijluGNB8
/IdkHlBqWGjUCtPTiEsEEBECAAsECwMBAgUCP7AnvwAKCRBz3mmMxxQFog9rAKD1
zYHTIVo0AE+s/Lb0ilgbVILcSACdF/bg/fgspOzIrviuPpex3bUUsVWIRgQTEQIA
BgUCP6fu1wAKCRADs+HWWNo4HWQLAKCNk/pbWIzcoWbEjWXy/Hvu0wR/XACgnCZ8
0VK9nbb1GMYCiN6XX6JMgHqIRgQTEQIABgUCP6znCgAKCRC98qIgXjYZ079VAJ4u
oHMI/eUD1vS6vzUL9YYXG8pGiQCfXbOy+LnqCt3XYnX7GcCELXDNWUWITgQQEQIA
DgUCOSrp7wQLAwECAhkBAAoJEHPeaYzHFAWiuJsAniMUs8+aEWP/+aSkHoTZj8S6
Br2aAKCrKHB8ITgMBxC4haanXLeu884yuohGBBMRAgAGBQI/sLOTAAoJEPDgCGAA
PtcBCPwAnisbpFD4u+Zsx7Mk7EVKUi5z2r74AJwJa4RkfVj5vTPzietTdfyyG8Up
4IiYBDARAgBYBQI/sLohUR0ATWFkZSBhIG1pc3Rha2UgaW4gbXkgc2lnbmluZyBz
aGVldC4gSXQgd2FzIHNvbWVvbmUgZWxzZSdzIGtleSBJIHdhbnRlZCB0byBzaWdu
LgAKCRDw4AhgAD7XAb6sAJ4jQcrl7nJWsHCcibJiQj5mP7e0+QCgpV38HzzsH58a
NdZOVP7F5oYOaOG0J1RoaWVycnkgVGhvbWFzIDx0dGhvbWFzQG1haWwuZG90Y29t
LmZyPohTBBARAgALBQI0P8/PBAsDAQIAEgkQc95pjMcUBaIHZUdQRwABAVpvAKCs
auN2G/q/1jJi+p2JUh0lm1jgugCg8KAeC/olsVcEV/3Vm5QsyKrUyGmIPwMFEDRF
EhTMRPvJMiMiVBECI0UAnjgwfCDHvkAlopzSRS5DuXA3iijTAJ9/P4Np8UVKQ2TX
b54ZJBVd+NH6sIhGBDARAgAGBQI77c3nAAoJEMXtdyDZ1Q2KvtoAn1NBYZxsrpYd
B61LGLULeUevDshhAJ48hxbwLuXKV7wORRGdY48pGCUB44hGBBARAgAGBQI7Rw5+
AAoJEMXtdyDZ1Q2KlpoAnA87N9BmNMzQVHXSUtixsl3CEcuXAKDKTDfho1J8PQja
TfFlFzxqj6Y/Z4hGBBMRAgAGBQI/p+7XAAoJEAOz4dZY2jgd29QAoLCs7eNgMt8p
MASK9ywrrFbFAsRLAJ9IFffzLhuuwasYVqRurxXTIAY1AYhGBBMRAgAGBQI/rOcK
AAoJEL3yoiBeNhnTElQAoJBEFxJqWxTa6qzHKefINMMSjfhvAKCA0onGgSjcpF3z
cKAt+kHDLHNNy4hGBBMRAgAGBQI/sLOTAAoJEPDgCGAAPtcBhR8AnRuA4AdkEBPf
Fuk9AIbBKcMNH86IAJ4uCSIxFdzmvBMIHKTPqpw0DryDe4iYBDARAgBYBQI/sLor
UR0ATWFkZSBhIG1pc3Rha2UgaW4gbXkgc2lnbmluZyBzaGVldC4gSXQgd2FzIHNv
bWVvbmUgZWxzZSdzIGtleSBJIHdhbnRlZCB0byBzaWduLgAKCRDw4AhgAD7XAd1q
AJ4gQRvA+HwjyZe/iXtfurbtsx9auwCglVfRAM4L0L3IPzXrBKhj7vmxRh+0PFRo
aWVycnkgVGhvbWFzIChTZWUgPGh0dHA6Ly9ob3JkZS5vcmc+LikgPHRoaWVycnlA
aG9yZGUub3JnPohfBBMRAgAfBQI+9iQmAhsDBwsJCAcDAgEDFQIDAxYCAQIeAQIX
gAAKCRBz3mmMxxQFojubAJ9ATTvB+Gku4kj05MCj6x6vKD0jSwCeKvnmQ0ZV84fW
N+XWANOWEFjBoouIRgQTEQIABgUCP6fu1wAKCRADs+HWWNo4HRHaAJ9KCiMPJ6NX
XuHZwlDfGrwOO9xkHQCfVIndhp48NebhpsdxlDA/qV1UdbqIRgQTEQIABgUCP6zn
CgAKCRC98qIgXjYZ0+j6AJ9yUTEIHsm2QUTDYgU+486LjPcT+gCglykyVeD0q9GH
dLUKi69FyoALae6IRgQTEQIABgUCP7CzkwAKCRDw4AhgAD7XARjyAJ0WnMAnGmvr
fRUoc9Jc09J5dMkCWwCfUpNO1AwMGHz8PN/NExgv+Qn/p4WImAQwEQIAWAUCP7C6
PFEdAE1hZGUgYSBtaXN0YWtlIGluIG15IHNpZ25pbmcgc2hlZXQuIEl0IHdhcyBz
b21lb25lIGVsc2UncyBrZXkgSSB3YW50ZWQgdG8gc2lnbi4ACgkQ8OAIYAA+1wHZ
rACbBulk0H0vsEH7yxQD9jj7mcRS0NoAn1Ti0eZ/zE1UNdBuTl/8q/jd+cYItCtU
aGllcnJ5IFRob21hcyA8dHRob21hc0BhZG1pbmlzdHJhdGV1ci5uZXQ+iFsEMBEC
ABsFAj+wJh0UHSBBZHJlc3NlIHDDqXJpbcOpZS4ACgkQc95pjMcUBaIjkQCgzGUw
Yqul7je6LkSPVhP1YmdVGroAni4ReNynhu3TUQUJo4zBcwVvtuQEiEsEEBECAAsF
AjdcPS0ECwMBAgAKCRBz3mmMxxQFog5aAJ9XhE7suBxTL6kL1btLfB5p7E298ACf
SB4FjLwlLjo42xQ4M6DRQN9iB7uIRgQTEQIABgUCP6fu1wAKCRADs+HWWNo4HVI7
AJ91ogIm/rIkkQu7FXa6e6uuycIDVwCbB9ZzTCjNxjzop9gWytRhvFRx5YCIRgQT
EQIABgUCP6znCgAKCRC98qIgXjYZ01EfAJ41f2OfyM1FY4pua6DBLSLBHPNbaACf
VT5iZbK40auCC7b6MUG34NneUEyIRgQTEQIABgUCP7CzkwAKCRDw4AhgAD7XAX7K
AJ4m7GehLjTQpywvncfcrv/5MTSvgwCfYUorT/WTsDQoOaMoE2W/F+uDQYaImAQw
EQIAWAUCP7C6M1EdAE1hZGUgYSBtaXN0YWtlIGluIG15IHNpZ25pbmcgc2hlZXQu
IEl0IHdhcyBzb21lb25lIGVsc2UncyBrZXkgSSB3YW50ZWQgdG8gc2lnbi4ACgkQ
8OAIYAA+1wHbEQCfTFgbXTT++vxhYU6jT1ubnhyDQ+wAn2Nk8mRcTvFoxT1AEeYk
/7lUMihHtDhUaGllcnJ5IFRob21hcyAoRnJlZUJTRCBjb21taXR0ZXIpIDx0aGll
cnJ5QEZyZWVCU0Qub3JnPohfBBMRAgAfBQJAVOPNAhsDBwsJCAcDAgEDFQIDAxYC
AQIeAQIXgAAKCRBz3mmMxxQFos4vAJ9mk4ywY/DBvKv/mL+e9sn9SZRoQQCgikxq
LhFlaeW08KXi+sWa8L3fFw65Ag0END/P0BAIAPZCV7cIfwgXcqK61qlC8wXo+VMR
OU+28W65Szgg2gGnVqMU6Y9AVfPQB8bLQ6mUrfdMZIZJ+AyDvWXpF9Sh01D49Vlf
3HZSTz09jdvOmeFXklnN/biudE/F/Ha8g8VHMGHOfMlm/xX5u/2RXscBqtNbno2g
pXI61Brwv0YAWCvl9Ij9WE5J280gtJ3kkQc2azNsOA1FHQ98iLMcfFstjvbzySPA
Q/ClWxiNjrtVjLhdONM0/XwXV0OjHRhs3jMhLLUq/zzhsSlAGBGNfISnCnLWhsQD
GcgHKXrKlQzZlp+r0ApQmwJG0wg9ZqRdQZ+cfL2JSyIZJrqrol7DVekyCzsAAgIH
/11g00L/Fo10wPfhTK36SiPTICreJc5w3f76kNt858uucmPiCqeqUscqXR//pFuN
1E5fAydUiR2OvL0GZNYsbhNhbGCyKCXgNnf18cdljV7IC9dmWyB39w3WyArMMJxj
ofqWDCFhafVTKHNc6X3pRlmjRlN8l+Xma/i0y5aUyulCbOW+y7VC8j85T08AI4OA
MC+ZcNDMoO6JPTZxObBc9nYPASXq74KTw6I7Ts72QEG5ft/iDzkLyLVl4VyGdFjP
F+BaBokmsAFEjpmwTNNtPjaRBYixjcSQzzfHAc9nZuI4hwDC3M4QzN9CZpOITzsK
bsDn4Naq/ZzIwb1/DbF3fVGIPwMFGDQ/z9Bz3mmMxxQFohECX8wAn1/QaK7peizY
OIX9h5010OBgeQqaAKDTnqu1lJrjW5HDy7Bh8OHS34QUsYhVBCgRAgAVBQI/xHyZ
Dh0CRWxHYW1hbCBidWcuAAoJEHPeaYzHFAWiojoAn1seFxiuKdd6Acp02WRuSS0Q
PwgHAKChTHhjtuzIthEwsfu7BTbx7LdhBbkBDQQ8UrSXFAQAv3OVaKReKWz1Dr7N
1lMCMaf6syyw18eAWRwUA2TIHJJLi9Dh4cz1pvQec6jcuK37jnfMn0IK7xCx4Kh5
66Fv3QVcS1NPQbogfmjH6E1szfG7OgTjRrsJqDvr/KQB4C9CEqTJ4KkiPBqmHro7
EphCTpseaIwfsW1lN8oMP2PY/WcAAwUD/Ah4vjY66jR0jWohyntjWvUXJ2hns4/9
eqnpnUsLJNiCqnHxYC65KUjzBz6Pj043GZeMKB1NTCjO1gLiwZB6Fc0OOwNBNTUq
sKY3fFTn4vBUos/hDyyM6AK+AA//uYYLsIv2Xb0gpT29YQANnujMYg3Qw2iwsDXQ
3oUaMjJS7AKNiFUEKBECABUFAj/IXqsOHQJCdWcgRWxHYW1hbC4ACgkQc95pjMcU
BaJJVACfTzxZpMTum8hbatYNJT1LW6s/W7kAnjGB67AsK/ZNztT8YYGF4IvpNMtw
iEYEGBECAAYFAjxStJcACgkQc95pjMcUBaLO4gCgy2i7oC1CzXynfTVSSJeHUhUR
Z4YAn30gYAZ2SBnJbFacUKp1MVFF0KeeuQENBD/Ee1YQBACirST2KYveRvVMObAr
JFD7yr09NPTUFQVfM2Txov/ujuuuelgppQezbVMev0u8AXbj9PBK8aSmxPUQAoNg
Dd2o4aaKTP0H0C2NB3tvlBdVDWZ5S7B67+i+WehmjT0dZ7kqf6xnqRWGJdOiAMkD
lrZoQsRov4DbSeHtKqtLXbrwdwAFEwP/QJ2ni5rydS+KCbChMdGB5QzS4iOBcYDz
dZKU2txkZVDHUgcF90w7/cQv0AOAI+FfHlpQ0aYffCuW5QkM542J6ISrN78QWiO+
KP2jbsmLVHEYtYQ+efAvHX2Vgxnf5ccrmkaMeEJX1hTdTw6/J6zLdTLS7nPORFKH
FKx71Q5f96CITwQYEQIADwUCP8R7VwIbDAUJAAFRgAAKCRBz3mmMxxQForwAAKCM
kS7lIeQthoWkWMo9XoNI/UtNQwCeI2l+7zCTQnJcKWM45BJraPxu6MC4iwQ/xHuV
AQQA6UDzUqOVS4Wr/19dCAokjyhVW5vdxQQ6/9Hqi0t40MFa2RpFHPrf8mOln4JI
gbbLovtjCwWCAOM9R+rsHre7bxGUiNdvbPe4WfaUTNORivNHqQEEwb32HQlclyXf
BP+Xv5KRRW4Nchr2Q2GZ5SVwnI6D7HsaolnqWbAIH7Q/gcUABimISQQYEQIACQUC
P8R7lQIbAgAKCRBz3mmMxxQFotXxAKDN1cC52HRuCXYlDldt6M7ar2uhFwCeM9WW
IdiwCcBp7/H54lrLqyROdEk=
=UF8E
-----END PGP PUBLIC KEY BLOCK-----
D.3.221 Andrew Thompson
<thompsa@FreeBSD.org>
pub 1024D/BC6B839B 2005-05-05
Key fingerprint = DE74 3F49 B97C A170 C8F1 8423 CAB6 9D57 BC6B 839B
uid Andrew Thompson <thompsa@freebsd.org>
uid Andrew Thompson <andy@fud.org.nz>
sub 2048g/92E370FB 2005-05-05
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEJ5esIRBACGrMoYYIu2yCvXUOUgySagPjKetJ5zKOCFDa/Gl65tFtCcc3YR
IjSDCvKuxcuS/qPo87pNP1sHPT0gVhMr+zcTrj8rgLWfC+CTzV3FPTdIA7LhVwer
+evZ1jSHo/MY+GHTYBiDj/GiDkk8zBk6Sppo0OdzqZ0O8IW6tvh9n7RNZwCgrPYX
rzBYHlAZxmZfQTDhgi8rPPcD/jH740waoG4l564X9hfkHDbxe2mrwKrcxfUbNi0h
yIOTyl3glTULTno/xG6zxh4qG/COxIWhjC3Nkwllq+VzWqzYFoPIV4E/nvPNrLLY
5a4/19ANLLkrw2kiLxNKLPu+SwnAF6cLdnbpPrGZSGOg/DhquXulAs8foTxv0SVN
F5dAA/9O9GFOk9IcZ6D77A7Unysoxoa3WwqNHikJTo+bHvENJJw6BM1e93keLXbo
bljw02y2cBXMz+cwd0S3ysj2tEPvEWpUJCVbCk7bB565R1TBb8SJB08MQ7PuOzbh
PCCc9nB2TditjUTuL1yTrOW4qki1fHMA8ySNuYBiw/iUOkHgbbQhQW5kcmV3IFRo
b21wc29uIDxhbmR5QGZ1ZC5vcmcubno+iF4EExECAB4FAkJ5esICGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQyradV7xrg5vQjACfboFkm4m9zZmor2J1+T5IknZ2
z2EAnjX7sCxeTxGAUp0gv1+ijFir8Ju4tCVBbmRyZXcgVGhvbXBzb24gPHRob21w
c2FAZnJlZWJzZC5vcmc+iF4EExECAB4FAkKUyikCGwMGCwkIBwMCAxUCAwMWAgEC
HgECF4AACgkQyradV7xrg5tJswCdHh+UXADhzk4yJKgLuJlLYsSCK4YAn26SPktp
Q2fQpBC3mGRRUYVRowhZuQINBEJ5eu8QCADgBVHTfrvthg1lDFvuZVlSgZueFEuq
dBn0tyJULht4MyHAYzY1fBkKtRPxp/c+sGKzd/nXZ+zqQIJRYtrAviGAi9CyHTiI
URcpMACCvofuRoMJ8djl35UzioL8O+icL2aoSq1w0MBzzkwTDcmaiceWVIC/RZka
U0/irf31HSzAxGYO1wXtZuYp6BrEwcRezDZQUkO/riGKT9+UUppnTFVBbyelvVjt
D9iyeRnL3GEOH0IvXbPRo400EwOHs4ieOZhNO4xyzj2qexMcbFq2nUis/qctukth
lynv0mYVstLgS+GQiX8+VsbmK1QkTfKTY2ufTQDPJTcAa7Kneb+luDYzAAMFB/wP
UyXix1pw1+qSJS6m6T7m6wmPj93/BoB+sadJvmjdaGcE5yKtCLdQYHZyI8Pvl3aA
uktn+k/IxqSwLgJCSHv9CQ0AwN+kuIPHyy+hsJk1w5C8Qd4q8sYWecyt+aycYz7X
Op9EB2rpKgg5E+RHFsuyx/X2dI4/n9XsF0xTDXmvBYHLw1E22rliiS9WlJ1C8UHn
gjVZ8nqd4bI9HcwQMadtjXj0EcyarnJnrqLkJopzmLSJfOtnQvXyaTzwfS7fyQYs
lnj+k/jJFULvgolWLmmfx149+3ou9c6c9KItAE8kfl7dSaEwOo4oE9cKluzhFHeC
ezponq9OPdSpXUwBXjJgiEkEGBECAAkFAkJ5eu8CGwwACgkQyradV7xrg5szjQCf
WQNYMndCd/TFxFqNF8k6Nu45/lIAn3oxSJ0Gc09OwQB4oiL6kHscyL/z
=SFfV
-----END PGP PUBLIC KEY BLOCK-----
D.3.222 Florent Thoumie <flz@FreeBSD.org>
pub 1024D/5147DCF4 2004-12-04
Key fingerprint = D203 AF5F F31A 63E2 BFD5 742B 3311 246D 5147 DCF4
uid Florent Thoumie (FreeBSD committer address) <flz@FreeBSD.org>
uid Florent Thoumie (flz) <florent@thoumie.net>
uid Florent Thoumie (flz) <flz@xbsd.org>
uid [jpeg image of size 1796]
sub 2048g/15D930B9 2004-12-04
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEGyCSARBACWd64iJ+56C42einT4AIwy9qon61Lx+LO4BOMgeaQTGy9/fKq0
XqQmPddhp9awRtm0+QoeZQ00q2qyY6ufmSZJCr9iQg2a1b/fG/UKZSIKBguDuCCk
O6acsAd3H0fmZRu8jAD+pMsJb9gO5T6YLIHK9p8uVPG0lRKzulTXm5zsEwCgkoi9
h+S/dIPXfX94thtJgVcUeLEEAJK9ZO2KFfGx+YRKDpbj7ocGgjqMlhkDFw13Lycq
jopPipNwpey4ZKjJa2w2fmIbcqpUZW3EH1Ld8KBOt1bhGlI92uqvrssalNH82PGL
cbiuvYMHXOfE05tOWD2JgxJE5tY0KtED4SDaF77RAcy4z9nFt4og4YknB/seOQZ/
5oSKA/980pHAvnm3TFK7jQN+AIckWxOS3mXxvwHmvM/MzQEVUrFAPp0C/aCh4JJF
7Tvy54cRKEUJQpXuTeyBT0pMU0ataaESMfk4hM/WDhvlV0AXebah44uJfBAcHwJt
f/d3c+1I5eRkWuN+ey+6FfBCooW4KvqVCnrWC/Kk16VqAyn9UrQrRmxvcmVudCBU
aG91bWllIChmbHopIDxmbG9yZW50QHRob3VtaWUubmV0PoheBBMRAgAeBQJBsgpP
AhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJEDMRJG1RR9z0Y7sAmwT9GkO3Wcrl
y9KcPtsQV4x6dvJhAJ0cGtclPmdOM34jMC7U5NQol2bV/rQkRmxvcmVudCBUaG91
bWllIChmbHopIDxmbHpAeGJzZC5vcmc+iF4EExECAB4FAkGyCSACGwMGCwkIBwMC
AxUCAwMWAgECHgECF4AACgkQMxEkbVFH3PQ5igCgiRkJPRjrvitfZOrvLhx+oScK
3moAnifC/FHLFLr7hG/NlgLbF2yjN7Fv0cZXxlUBEAABAQAAAAAAAAAAAAAAAP/Y
/+AAEEpGSUYAAQEAAAEAAQAA//4AbwoKQ1JFQVRPUjogWFYgVmVyc2lvbiAzLjEw
YSBSZXY6IDEyLzI5Lzk0IChqcC1leHRlbnNpb24gNS4zLjMgKyBQTkcgcGF0Y2gg
MS4yZCkgIFF1YWxpdHkgPSA3NSwgU21vb3RoaW5nID0gMAr/2wBDAAgGBgcGBQgH
BwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5
PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIy
MjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCABgAGADASIAAhEBAxEB
/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUF
BAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcY
GRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqD
hIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW
19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAEC
AwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMi
MoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElK
U1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaan
qKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6
/9oADAMBAAIRAxEAPwD3Fic02nkAmmleagsSiikJ496AAnsOtN3Y7ivNfHnxL/sb
dY6KFmuwcPcHlIiDggf3m/T8a8b1DxL4h1KYtdaheyZ6BpTgfQDgflTsGp9W5z1o
zivlTT/E/iDS5EaDVL2IKwOwTttOD3XofxFe1+BviNB4hCWGokR6l/CyKQswx/46
evH5Z6UWA9CDetOqPqKkpANY9qRetOIzTQMGgCbuaKO5ooARq4z4ja3Jpegra28p
juL4mIMOyfx49DggZ7ZJ7V2bV538Qrb7brWgwAH70mT+KZ/lQJnPaV4Ksrq1iuNR
V5ZnAJTdgKOw4rbTwdoaqQunoAePvsf61qoViVRwAOBVtCPUUyTl5/BHh90I+wfj
5jf41y+reC4tMzf6W7L5RD7CfTuD7V6XK2AefyrKv4i9tIigncCOKAub3gvWJtb8
MwXV04e4BaN3wBuIJwSBxnBXPvXSVwHwwR49Kv42PCXRGMYwdozXfg0ikFJjnNLQ
aBj+5oo7mkbpQA0k5riPFbef4h0pYlO6DzDIew3KMfoDXb1yWqwka60jEY2Zxt68
Yxn9aBM4nXLHTPtDTarq00MjD5c3GwD2VfSm+FLpk1CS2t7me5t8ZSR3yufyFdjJ
bwzYLoG+vSoEt4oZSYkVQPTigk5HXdUl/tUWZ1A2MQ+/KSB1x3Jqewto/PWW0125
uwD8yvIrxsO/QcH8eK2PscN3dN50YJxwatJYW9mC0SBQeTgUAaXg2OK2/tKIMPNk
uml2ei4XBrrFOOpri/DsSt4huJDnIhI5Hrt6V2QznmgpElBooNAx/emsOc07uaCM
0AMrP1GyEw8zdgqCenXitCkcAoQfSgRx7/KccYNZl3aiS6SV5nXYCFXdgZIx071q
XjYkePHy5INZU1haqv7u0i+gjXH6igkr2dmLSeR1vHm3ndseTdtPt6fStNnDKM1m
pp9shEhgQewjVR+grTtUFxNFGCBvYLQBvaTpotR9obG+QYGOw61r0iqFUKv3RwPY
VIBigpC0GiigY8/e9qKD3ppb060ABGKgunlS2kMADShTtB6ZxxUjPmm4oEcZI0rf
vHGHYAuAO561WZ2544+tdHfaY24yxZZWOWUDJB9h/n+lY32dZdwXkg4IHY0EmTNO
FHzH8BzRHLIq+bkrjlQDyKuSWaLy4PHrSJYSaj+6tvmUkq0gGUX13H19utAGj4H1
u91GC7ivyW+zyBEc8kgjPJHX8u4rrwQ3Q5rI0zSoNMtEt4tzYJZnbGXY9Scfl9AK
vD5TkZFBSLVFRCQj7wz71IjgnigY5+tNbpTn+8KSgCOipKYRg0AJUE1pbyv5kkMZ
fpv2/N+fWp6PrQBntpNizBntkfHQSEuPyJIq2iKiBFVVUcBRwB9KlwPSigQzAowK
UjHNJ3oGFNI+bjinUHoKAP/ZiF4EExECAB4FAkGyCogCGwMGCwkIBwMCAxUCAwMW
AgECHgECF4AACgkQMxEkbVFH3PS/SQCggF9s0hwG9YgT2YoPMeDIusPHRh8AninU
7DwI6KO+MKC0H1ORHNA1JBtTtD1GbG9yZW50IFRob3VtaWUgKEZyZWVCU0QgY29t
bWl0dGVyIGFkZHJlc3MpIDxmbHpARnJlZUJTRC5vcmc+iF4EExECAB4FAkIkR+QC
GwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQMxEkbVFH3PSJigCgitESQxggf7Da
JFyrE7EnrNUogzkAn1zo1mdvA6eSCgI9365H/eqn0tVluQINBEGyCScQCAC6HHO3
jSLdJyP19/3vvIAaj3BAH4gLjq3elkLLKRwaxSheJ6gxs55itXPjd6f/HODVSHBx
puPZZ+QU11kenX7ms0cvfqROdk/5WPD8NYEjAz0nzQURK+hksFdIQdz2gZ3PyCJX
T5JoQ5DRbQMadBKjtvExGGXwojmw5w5ftYx8k4QTigvXWWeMRnLtm+9Y93RTcHwR
cx3tb3kudexpElECH+cYq6ZRzdjLrVupMHHFQYD1Jf6G+NEd+jbKoMi5WJISQBy0
LdGeJN3OxRxomwuLbuxGEBtp1kz2pKToxU39+WCbDP69ZtfIRAMSFFRS4WdDejhE
tcPKXJHf1mLuoiLTAAMFB/41HYky3Wbr46vZxBV+glPXrS7hWgLUiriRPGKNUW0j
FV8HmQ7AyyVpQl3FFBRvnvhSS8wKFkyxHGA0yg0WuIP6u9rDlJRGUNcMBGobO+rA
i2VOIUVAcKULtAV/AHyAC1zClXMBEbNkfAjX6AXFJpyHQyFheOepoHbZ4LwGUakt
D4+Au8ndr4RlLemr2umKGOrNzRUK3nT5FL7H56QcTmGk5p7YPJxYE2DOx6LV8GzD
BBREXfrFx//ESZJB3guiiJZslIQ1LFC58AsRLIimxgDTJj3WJ7fWO3QcCAQuY1KU
DKflsjiw1WEHDzHzg79eW0esg3QRUQ7gty8fWileLHrFiEkEGBECAAkFAkGyCScC
GwwACgkQMxEkbVFH3PRfkACcCAORPSVW6fQLJfJn47Qnp+ctFlMAnRrXkXik0fku
YhEx5U7AKdGZ55po
=hxwJ
-----END PGP PUBLIC KEY BLOCK-----
D.3.223 Hajimu UMEMOTO <ume@FreeBSD.org>
pub 1024D/BF9071FE 2005-03-17
Key fingerprint = 1F00 0B9E 2164 70FC 6DC5 BF5F 04E9 F086 BF90 71FE
uid Hajimu UMEMOTO <ume@mahoroba.org>
uid Hajimu UMEMOTO <ume@FreeBSD.org>
uid Hajimu UMEMOTO <ume@jp.FreeBSD.org>
sub 2048g/748DB3B0 2005-03-17
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEI5K/4RBAD0LiHx/Tl4UyaX8yFUGjX1+PvATTJloNZGXl+jagSUQxCOp6Hv
emDinSPskld/viupoAxjRImlkP905Y0Q6iDMne4s5fM/75lpeG9ztKRSgDQrQLTL
HhXPXKNMtDV91yDqFEkwptS+0MaTMY0KrlR29RtGnpjoa347TU2BzU6TcwCgw+SL
YdOWeSGs/7LKdUIyYlrldjkEAMqIQwnDl14vZBe9EOCrjSA4gHv6g2IQP1TRCpBu
+/Fpi2+xcj117xO++uqMMzoi3aWwsqarao0/VSJ7ZD81by1H56Hnsp1d0r67neJy
PKsyh2JfSQww9cxVkQjuZAjZNN1SLzDeA6xtSZrcmim+f0GIxlz3JFS9za/scs8x
mGqzBADRF2My4V5HEMeScREj2hoquRv/uG727Nw+jftwiE+7TB7+JUwwyakAStNv
x4+YEFAVSpKxyWgOeMqOWYd9bOSwJk40t9y1Gk6TTgV2C6sYwGHMSNOWYZbhYX7c
84cxm2PtQFIq7g4Q30IkfAhYFzEwKmPJ8eV1zO0uNIhE+SO9QbQgSGFqaW11IFVN
RU1PVE8gPHVtZUBGcmVlQlNELm9yZz6IXgQTEQIAHgIbAwYLCQgHAwIDFQIDAxYC
AQIeAQIXgAUCQjxiFQAKCRAE6fCGv5Bx/qe3AJ99w7Ipfxs4CF3/+eCf53HO3FuI
+wCdF/xyvVjjNdAYXCMxCHtUF85bD++0IUhhamltdSBVTUVNT1RPIDx1bWVAbWFo
b3JvYmEub3JnPohhBBMRAgAhAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheABQJCPGIY
AhkBAAoJEATp8Ia/kHH+3c4An3RGo6JduyjPTZFh0eCBezNgzxdnAJsGRRE6ERs8
nyORm56bvSgRTw9VKLQjSGFqaW11IFVNRU1PVE8gPHVtZUBqcC5GcmVlQlNELm9y
Zz6IXgQTEQIAHgUCQjxgkwIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRAE6fCG
v5Bx/iTtAKC+8mS7jAYMz3QsCe4dJeIPaJcFGQCcDQITgNpJcUmBZ5u21Jotvp1X
T/y5Ag0EQjksbhAIAP1+LeYSauTBi/ST3343W0lkqYr6HgZMNS7RtoCGFWcjfiYU
99ybRgr0XwH5yJrn6JASp27f/ve5cwt/7ERLZ7flcfFi53AekeuRjFDkThLx2N4I
s29ZQZsYubdOKHapnMflnFE3PQfkB7Og1MoFxkp0kOAEP/rOyuLMc9CbUaWczxWo
FS8bmZDJ5ZNzAQ2vQFu5ExxomOENApy3ZCm/Z6MU5YJ2trsP3dkYStyG+1pT4NsU
R4+TIbQfFzwZjowiC5w8rM4FIV4FMQ+3YvIEVkT+M/93hLGakh5tQENsitj7JsrC
VA2mkomV4Hnjj94YCxUiPu59kHgiKGgXbdnceX8AAwUIALF64I+guwCaHbjoRPVg
HWRuU2NzuKN93xii+xyIpImf+S30aTbFy0D6ZTQRSCs34oVNMSkUzySVcVn9DTG5
+KVCHCOnGMH/Iv3dRWlHZ3HX6Gvr/cRyhDfWYDEec7KCDGT7Q87UbmTZ9cmOh+/h
M4ND0NoYU6/EaaOqyRH4D8/LAeg0YsEpilClYWhlXT7VS7noOBf1JuB9Q0nOGycR
DstkHWJf5om82lH5FzAuh9kEAduv8JdBdsMh3Zh4N80tCV7OyBQFWHV0UgjARSLY
msEuelzzaFcfR2vIrmpYIElr6JzHGBiux0XK3Qk98kexGRdbrDFpaxbrsjs1/8m9
MVOISQQYEQIACQUCQjksbgIbDAAKCRAE6fCGv5Bx/mRWAKCAQQ67iDvQq08n+bHa
QkK3EDOmqACfZmJe9AepCkPAUkvp0ketnOPBXAE=
=QZ8N
-----END PGP PUBLIC KEY BLOCK-----
D.3.224 Stephan Uphoff <ups@FreeBSD.org>
pub 2048R/D684B04A 2004-10-06 Stephan Uphoff <ups@freebsd.org>
Key fingerprint = B5D2 04AE CA8F 7055 7474 3C85 F908 7F55 D684 B04A
uid Stephan Uphoff <ups@tree.com>
sub 2048R/A15F921B 2004-10-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQELBEFkBF4BCADC9kZGlvNJcktMfbT1e6sp40J8qNWM9B92GpCo84BzTyKxvIiV
HGWMivKMS0BdiE7pPVJXtsYFjNDues6drUBOtsUNlsK38sdxPT9UDupHVIXSxERb
pyyn6ELPEJmP+3UwYzNM6DCfPm4ZorcvkLDE7E5XfYGZxMveuNIu2qmOYeKaJKiK
t579i3co2YX7PXvUdbd6nw4vTyU7tC5KCFxCzs9FkNz2j2FJlZCe4AQCjhsv4odz
oyppj25QhG5rXavOOOBcORL0BqzXGRozZ37K7u9CuPebxj37LFzChZk1s2aH5kzM
fw9QZdUhJr9fkIv3FIfTVUvL2zXlpzmzsQBrAAYptB1TdGVwaGFuIFVwaG9mZiA8
dXBzQHRyZWUuY29tPokBNAQTAQIAHgUCQWQEXgIbAwYLCQgHAwIDFQIDAxYCAQIe
AQIXgAAKCRD5CH9V1oSwSr76B/wPoFdE6nFJ63egXDUHNUONVVqyHOWjoowq1f+C
G0IV+07RmChOSccyVBFn3NIjZ1E7YMQm37SUhvgqY0XNF3usNkxBdlHpG3ixQEq4
53HvI9JNHU6BTHVtGjDFW9ZhBFaOYVbCKHM2N+jq/RmZ+liD6QUC09jRo34ytDOo
wsmccQ2p+8cN8aMizhxseGUS0Vo0oKIzSE4rKGXalcarG5vnZ4stP+acMMAiTiCV
lMVHDtnC6Ca9e2H4ePmUBL0sHnM3r2+0e+SAb20yvi2PICOQ8vSEcbMt28WZPBxc
0qmFkemVS4qHgGmd8Pe2a/OvPQxgujJ+q0uPwPfIJ05+24yOtCBTdGVwaGFuIFVw
aG9mZiA8dXBzQGZyZWVic2Qub3JnPokBNAQTAQIAHgUCQWQF2AIbAwYLCQgHAwID
FQIDAxYCAQIeAQIXgAAKCRD5CH9V1oSwSlrjB/9Z6KcBwseAGY+v1TwtI9I4bZ+z
Vb62nKcYgFL7tJ0djIhrpl7l+lLr+RTvCG3A/vbERIxeameaOIHjUm/22KKRJEfK
DJ1PcAVs8ApB//1/X8ahH3GZvPvFzH+aYBxCHEw4g+UrkXFFgwmogviwP8QT6mh5
xtO9/fwnoHtCa0jZtRaOCCcQjAc4Vng1tGrKVE/E59LwmwlDErnqoT9jlSONDdx+
T5K5/dVwCiDdKJSm6lTBY+bj4Z1k3Qi0N+0XQtMviuZ8I+ew0H6DF7tBRxrlBLSc
VGUwILAUfbcFWMxbaQxB1PJEaThi6lSFJ8Pd0uZHZKeNoHJ5fcLxSQhudhcMuQEM
BEFkBO0BCADQJijowH7QvQPpo+DqAv38fi8DxgwqbwpUdiA2P1eo5awU9xVNs49f
XKG+QMMJHx5S6Bu3anOTKWlqZKfbOlTvlnW5anKRSngcW6kdoce2yb7wK0ovjFFB
yFTBe7QOR4G4wOttU2Fa6lVUOApC5pvuubs3nWW1ovB0IFYitPTG8lcBkgJCCOPf
/auv8ZxLYnaA55lvOupmh5WJjA8sqcwZneTTA1ATERmCRO0Y3Qp/jAiPb+vlnA1A
PdOpEpjbDHpjfjoBUGo3oKiNJuFZ+XMzlcBcPkcyY25cfgLqYKo7uoR9x/itirDS
CmBnXiimERYkaiU79+epo2giTtvHMCgnAAkBAYkBHwQYAQIACQUCQWQE7QIbDAAK
CRD5CH9V1oSwSrHcB/4xXBMPUVZukcE0+5ok1ZxMN+kwFP/DVOdmrteI7H7vQ//s
iZ0Hdg3RC4P6wYSGBbmIA695B3OUuRnIe4Xt1YcOkmSrPGQDvxbCLXTyxx8Ftv4D
UhqSu3DFUwlIiN/qWdSHSie3EPcMYEMS4HDHlZSaZgrKXhMHLVI2oWDz5fT00sf/
PLMpJqhveCYKOEi7Zu4ot8bDcfDt69I1MAhKSoAkni12+/fykvZXrxyvhwrKi8v9
lbionqqljQ3/+q6olZcXDsgwUf9mXYGs/tz2DDx2FYfZAyh4Fso7q2yGOfu3XAo1
0nKYeR0L8piSpZBWMKD09A9vzTbSSLfdcACIItS5
=93PR
-----END PGP PUBLIC KEY BLOCK-----
D.3.225 Jacques Vidrine
<nectar@FreeBSD.org>
pub 2048R/33C1627B 2001-07-05 Jacques A. Vidrine <nectar@celabo.org>
Key fingerprint = CB CE 7D A0 6E 01 DC 61 E5 91 0A BE 79 17 D3 82
uid Jacques A. Vidrine <jvidrine@verio.net>
uid Jacques A. Vidrine <n@nectar.com>
uid Jacques A. Vidrine <jacques@vidrine.cc>
uid Jacques A. Vidrine <nectar@FreeBSD.org>
uid Jacques A. Vidrine <n@nectar.cc>
pub 1024D/1606DB95 2001-07-05 Jacques A. Vidrine <nectar@celabo.org>
Key fingerprint = 46BC EA5B F70A CC81 5332 0832 8C32 8CFF 1606 DB95
uid Jacques A. Vidrine <jvidrine@verio.net>
uid Jacques A. Vidrine <n@nectar.com>
uid Jacques A. Vidrine <jacques@vidrine.cc>
uid Jacques A. Vidrine <nectar@FreeBSD.org>
uid Jacques A. Vidrine <n@nectar.cc>
sub 2048g/57EDEA6F 2001-07-05
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.1 (FreeBSD)
mQENAztEWGUAAAEIAMeniH36Nfiwf/XoVWcZReau9V4Q0taZs9J0WSAmT1kuS1OD
X1r8SAvQ5/8yDHy5rL+jrUpNw6p4YH5ll3ZNolLuWbEVyAOpJDalg28VOC8pKrC/
2Rmdlx2Ri0BMXAZW4hf5UrBSf05PgoMbHEM4IIbeZijv1dgLMlq8tT1TLimg5CON
wW0rDHr9syGYMQFLpmyoWha43B8xnJj121mGB3AE6Fhz+G1wYKQF1/KZucckJctu
eAOjw5yj6Lr008yvAhP8Wl89BYNwdGmaY2HUPtey2XxahqJI46/u/GXkkEQqk2vW
sNz4bIvzEArUWzH71GIj9NCiUAKGZ8KAjzPBYnsABRG0J0phY3F1ZXMgQS4gVmlk
cmluZSA8anZpZHJpbmVAdmVyaW8ubmV0PokAlQMFEDtEaoo3kYU/CUckqQEBkawE
AI7xJVCu7nHfHK0FhSQGSK6FtcV1sFK1KmIR94uyVQoLbtRWCd6od2U1BuMi+9/c
ymc7YFQ6ZeMrx0aUwSmb36+cOpLUrPs/B131OgBX/0O6EseXZ2FPrsD38/oOHHLv
ZoPWPiP/utQIkHpdmGaZfbsT3Jk64iMhl4IxKmwhDsoFiQCVAwUQO9CR+VUuHi5z
0oilAQEmAAP9FjGpHibt7uJTgYoXIPA9u4tJ8Ry0cLOZX9a5Yq5NfPMTA8v+8pY2
+IrhqhRHWDND6lIoc9aZkjFAX/XnCyZaA8aTSASXC4k5PbEvHoTrFXtpSKSMtZ8R
4AfqkhvJ8I0r0yRXvZxpx3EAZpy2K6jVhz8bwiQuk2fJK+79AQyRTHCIRgQQEQIA
BgUCO0RqxgAKCRBdeSLkcaKMc97QAKCIeXaT+tII2hgCz1JaN+tp6Mn8RACgmxRN
+9k+m97qhph1ES8GFeQJVsKIRgQQEQIABgUCO03CgwAKCRBmgG8dAPfQeiznAJ9D
klpWg02B8JByK2cnyim5ohqkBACfZZgGEMXVYxctKIB9DearNWhxCySJARUDBRM7
RGdBZ8KAjzPBYnsBAXFKB/90kY7ts9wDI8g3Bv9Q9PjbzSpTrnIIUOCuMpd/wvzg
xr3ERnvJeoSJWE0guWQ6+YIeaPBYIyhV3yV3YhHFQo6uYAt3FsgB/z+kiRMhxnic
2Xxqvws8i2Tb7xpYI/yJIm9fZZteHOJ/jOacHX1fdzXVZfXzfUX31biE2LVdkAiT
rny1egGLbN+blylNabHha0CLFkfaZ/UuenuS1rbI+oS+cwWGHZZxvp9+m0E7nDGi
Y7VDvzMLBq/0zUeTOLaOYqqCym9UGoq3yywkJdvcwykkR/BS8vYP1l+rTqVv06Fn
xQYONObU3hILupLZ51GaP+jkkTgIzAVv43lZVbZ6/XjoiQCVAwUQO0TC6/vCP42x
MxQ5AQFItgP/YwO035pYdCTUNprIXtnPkhMJU3m+ST3XGl+vTxD5M8PSpxL95Cvx
fYmvCaPkP5lXPPG1vi9f6dfYWkmL40t7U6+IlC3EaXD0w8/VTWMmeuC2rigUx9wR
uO05RR1Ks7/X5rADQSok/30Q8TiQ9BodmemEPmcMDL5/1dJkq/oFVEOIRgQQEQIA
BgUCPAv/6AAKCRCMMoz/FgbblWfXAKCX7bfb/+cEBCbrruEksFqbu4JlvwCfUYih
DTpbY9otgZZpt6xCbQ51gDOIRgQQEQIABgUCPMQ7SQAKCRCMUwqAO4GCft74AJ0e
H0zWlC1Ikf3TDpjH3+JbFc9ywwCeMsXor788M9Fj0W+4eo4QdM6wRdCIRgQTEQIA
BgUCPeId7AAKCRAV1ogEymzfsmjLAJ9nReOMPhBn0Z6/cuOU/C0ny7vCUwCfaHCW
bBmS8lIv+hQmh+j4Ku8S3hC0IUphY3F1ZXMgQS4gVmlkcmluZSA8bkBuZWN0YXIu
Y29tPokAlQMFEDtEao83kYU/CUckqQEBJ18EAK9VTM8litmppmSW8RpCTkCku72Z
PTL91tueutRw+PGgD4rL1BSuAZ/I/H+fYzy0w2Haq6tG88CkzxjzzWiBg7NoVpEE
4kv3U3FfkgXXd49Q/CRufsQWZL1qxV7Qpouk2M3VeZ9lJf1kI1GZHsDw2g0fBbIs
SncAn7p9j+H9j8v2iQCVAwUQO9CR/1UuHi5z0oilAQFMxwP/V3yvPwqm3vZj364T
/++VfcEkc5ZLFj9oZ6utO5Vz+NdjpjFhDKDMGBTwjXTnXFDTJDDUMlWGVKJxORf2
7oS4BvqyTzhPfnijJm9WeE3TNPgtx0vMzVuFuiydV9z9uT71pqmbKbtY2v5lxSBG
lJX8pHY0lrRtNIY3ICH3SV0e4nOIRgQQEQIABgUCO0RqzQAKCRBdeSLkcaKMczUU
AJ9b7ImPK5sckKVvnyt7lz4Hk2mIIgCeKoAl6XUU558xIu2AFA8fzma1zneIRgQQ
EQIABgUCO03G9AAKCRBmgG8dAPfQeoWtAJ4rN91CFY8FQDuZvLEIGW1QQuHadgCg
r+bq33V0rM/wF2VPrqu6th+f1sSJARUDBRM7RGeeZ8KAjzPBYnsBAZjqCACyAxcc
G5bI+hKjumPZS1W8WmvOgPHs0Q9poaKLTbC/bZPXnqeIslIfv1xm5FjNhXlpK08E
mjEiC4kGOFSkW65qNjWdRKXoUzq86v+dphDLpxd0FYXVViA7ETb3Hl6hv/7Qr5RZ
O/yGOI7unf01hEonTDUI5Wfs7dwc1wzSVAC5dc6rOlTGquSzcuignQM/rxJzx1iX
NZ2+G6h114/M1CkENBdS+gs+OrQFCp5D861b5gXjPX2z+5MpInFlgTLWMOBGYaPQ
AJZ+abF44iG71idEO9J+ywwAbOVKXxJzGhuqd1iDfoy+KaJ/B0+n5aAH2q8dmpOX
Uwh4F473DE9O1c5BiQCVAwUQO0TDE/vCP42xMxQ5AQF4rQP/TM7vbt5uxTpSFXcC
OWaG4GCgvxC2vftoo20klH3hcacod95GhS5xtvtNFVzCXM5LQEaH+F3g3NxYbPMt
qWAU7VY4GSkbHsKu6min5wQGy6///ikyS8oDYBP5QO1uXA9kNYmSsCm1ulrCdx7G
fD8yEyxpGj1e3q9PfNx+ouNF+T2IRgQQEQIABgUCPAv/7gAKCRCMMoz/FgbblejF
AKCGU0Uxm9gODWu/9iVrAfiGTxSGIwCggThVGpYk3bwgKI5v5UYsRGoKi02IRgQQ
EQIABgUCPMQ7TQAKCRCMUwqAO4GCfrDUAJ95BWGWG/6A69LVFnG7QVl95VbQ4wCe
OyNkM/aKnhMp3yWkp1DyKuHh6/+IRgQTEQIABgUCPeId7wAKCRAV1ogEymzfspG+
AJ4oTlUWkSpNcEWrlXhI1XxkXc2VqACeIOqoDsfljL+6J9agzgavXQT0LeG0J0ph
Y3F1ZXMgQS4gVmlkcmluZSA8amFjcXVlc0B2aWRyaW5lLmNjPokAlQMFEDtEao83
kYU/CUckqQEBjS4D/iuKIplzePrW48YhcgOcdNmVv0f7oLzGYo6plhp64gRyQMok
wfO4Qozzc86PZlwiA0O9th3TRNKy5U/CAKzuJIfVjIOiJg6O4LCPwb6A5Bn6G0Pl
Vqza01/sPex2EZHlMh2JmqapaN2BtZrtNrfOcp3PNkg1Y2hePwEbC7V9hyZYiQCV
AwUQO9CR/1UuHi5z0oilAQG7/gP/WljbKpJyNmAw1scRWFoP3PDd5zjHdpaBakTw
QMLLa6YlZr38it59dTWGVGNYDNvD9Y7Jbn039HEhQFDjIu8nGSD0+YYvZIXlTpnV
XujFrLE7wCVSt/0OtoOBguWSDLFgu0PpGiZhOZ0dqvgInV5rfwIdIbpnKoLqpbYj
xymzo1qIRgQQEQIABgUCO0RqzQAKCRBdeSLkcaKMc9WhAKCKtx+b7msbnZ+3hW6M
JxUWn92dVwCgnXTO3EhDI8U6Bn4mrmIf8rYoIWGIRgQQEQIABgUCO03D8AAKCRBm
gG8dAPfQeiYgAKD8yXuTqgdxPHWWngut0yhJ1lDTWQCeJF9wrOlYhv3GBeGJxAZh
y1q9xs+JARUDBRM7RGdaZ8KAjzPBYnsBAQsrB/4rxhQORVVCRfx9k8uQVVIKqCEW
OJM4CDpX0iBrBpuVtYsV1A+FdAMoLmsKUeEreBRU/pedIm+Of07/vLSeRULQwB6w
I6dJvel4m3n52LwO37uERyL6FuKSNKpRwqhFg9lBj0G5r0ZVR7RlwEIgwnq2h3RC
5jaPBQo7/uNoCCgGW2QGTTHBzdtq+7R96Yqykwkrrj+j4BoaEvG9vOisVvDX2VKr
tcOvyAekL/rgCmcNcqh+Wmn3ojXneDSI8hnVqStSsOyeRnCSdw4AZYcheOAJ9Tyo
dqRcHW/zoPDXe80greaL3aVThGyCSy0alAW/xX3HyaDWTgrc/OwJC4OcXnXtiQCV
AwUQO0TC9vvCP42xMxQ5AQGPtAP/QIilJ0/zVOiRupmyWdz+pYaih7zjTKA5aUyD
vtZZG1ASC/tcEf5A6udd3RNhFekVQzT2TxbExgkD+R7f4Nyd91YMzXjPDO9FWcto
jseAkgI8K2FfUNse2BX0g/zYTYEhCegLufgRZgyhLFib9Nl28MhxlOH45USHSuY1
uLCO6eWIRgQQEQIABgUCPAv/7gAKCRCMMoz/FgbblQggAKCRzjeBCLmlDUqAelCh
hyOYu7Z4FwCbBxUNPrFAUSZDXtTAdsk6oDbc2zqIRgQQEQIABgUCPMQ7TQAKCRCM
UwqAO4GCfnZDAJ0SFZ8j0d55VeDpYZCGqai9toAagACgjPwvNS0iTHEHEYGy1K+l
5QMU/lKIRgQTEQIABgUCPeId7wAKCRAV1ogEymzfskBQAKCE1RFp7IdjP+TqPbpI
UyX/5QhrIQCdFKzelL8uRrxm2wFcmk+Xt95KZnq0J0phY3F1ZXMgQS4gVmlkcmlu
ZSA8bmVjdGFyQEZyZWVCU0Qub3JnPokAlQMFEDtEao83kYU/CUckqQEBHEgEAKUd
LyDA5dUIrqC9cd+noesEh5GE4PhQ/KWOtYlaKtIk34bG4vX3TCsUsEsyfP7xD0I3
UPrKHctWfVQBj+iNNl9ZTK5FMJVt4N//f95ehFmmAnbUzyKXI6m6tgSvraxlSn2j
v6tXwgZWyzAewePMwNqhC0A/Y1KdCNI8ZuU7gDChiQCVAwUQO9CR/1UuHi5z0oil
AQE6FQQAjwd0zW2wT5XbKOMggHnVR9qHQa2hP++Sezu5/bZj0HILcVj+1matIpzS
2wQpHhkJCAsTJKfVuSPH27vE9EK1JVc4C7tl2b+0KWmKXJ1wjQypH1CCImMO7Zqo
h2yTGCd+vmj1+QoFANp8/RfUGYzAcvotfkBmLIqGSCeZiMoDB3eIRgQQEQIABgUC
O0RqzQAKCRBdeSLkcaKMc03oAJ9qpsHxaTrBUGl/CZTIE4iK4H9YRwCfUoUWszi2
hkdDkWWPCKpyJZh0xlKIRgQQEQIABgUCO03G8QAKCRBmgG8dAPfQeledAKDvEdli
OUOAhcPBY0CjUrXOaZqLzwCguj7bNyAO4opEU41LH0JrVY/AiZCJARUDBRM7RGeM
Z8KAjzPBYnsBAcFhB/0ZLLi878axVM0555fQA/toZyaHB0UUDLHK6GnQ8CO2bgsR
IWSqujq2/z+1ylEfH1HOO7oYyZih3f//OUCoabtUZ0fGxEaCUec3pHd/UqRR++nM
WVQp45lph1yhcYIj8NGEC5W/M4L8IQaac3aGP3sd0ipaQPrIm4wOXgbOG+TXywEE
mcR4VL2eF1ozuCBVtZ2MxSqsh24Zlrdns594OrG+gCQKe2Pnv6JA1HG3/66mse+y
BkSsv5wBJwjOkulheFOJiOIsJm4/V3/2QHNSsH/fxhHMOZXNiYPfPf/5kQhyMFiY
s6SMHS4XSzNSaI3p9PJM7fsXJqILOx+McSymg8D5iQCVAwUQO0TDB/vCP42xMxQ5
AQHsdQP/WabwUvXt5jKw/pqZS4Pqbc8qsDLSuN5xH5JgewwNuZBNpVHzenI4hdtX
g4t1U/Cm50264hBTTH2YgALEduxjXFj13oVN48JSPJXWyFQSUi/BBUAw2JpVk8iJ
Vdginlezc9EhrSEZxDRBIQVtlBBHGZdYCD5P+5y2NVpkhES/5ciIRgQQEQIABgUC
PAv/7gAKCRCMMoz/FgbblXuwAJ9g2+D5ZBtSHCqfI+ngr+O0EaaxjQCcDwgR2mZl
2Orrh5rXYXLcTQmW/VWIRgQQEQIABgUCPMQ7TQAKCRCMUwqAO4GCfsvLAJsFIm39
rRd5Q43XfFHmLWCjTf9OZQCfQSUgEK6eMcEVvhpiHIS4W20Ke26IRgQTEQIABgUC
PeId7wAKCRAV1ogEymzfskx+AJ97BkmjdjqNu+JfxpH2e4DcnPk8ggCgkerLDhkS
jWet2EWo9Tzc4ole+xC0IEphY3F1ZXMgQS4gVmlkcmluZSA8bkBuZWN0YXIuY2M+
iQEVAwUTPAv/fmfCgI8zwWJ7AQGrPAf+MlOC2G4Z9sb3NV+MA1vFoxQAl6HeQntA
ousZDBkyMVC6AGnLWWAOyYQnWOTc2qRY2kWKh9HI1+eKGKTLNeMrodT4DM6OvMeY
38KGqqAIjcwlxphyAtaRqGqNzlXCpdJVo2WSmcTkio5szLgMqDGVuuLRdxLubAcW
/r+gSio3avkw0f740DnU8Uv6Q/SiThkUY9uz8C6W70K8TCpV1u6L8Rg8Nit2Py6b
bAOMpYwb30IObHbyXTihrWYMLKQ9I2pzSpsdHrnsn2XEFMlVUh1aIwTc4UYB1i73
DvsY/oYkYiQikgh3oKfqUIYUi6FY5VS+VUq0gGcuFGvkP9sDbCbHzIhGBBARAgAG
BQI8C//uAAoJEIwyjP8WBtuV/FEAnAmm4E9WUNCs0cx3arrfqQ7ERXQKAJwLQLb/
lj/fF+ZEU94mLuAEAwyEiYhGBBARAgAGBQI8xDtNAAoJEIxTCoA7gYJ+uLAAnRgp
qwaG4PT/JcGjNeCRJbPapKGWAJ9K62TrGtp/2yAl7e36z3HKj05lcohGBBMRAgAG
BQI94h3vAAoJEBXWiATKbN+y2CwAn0ORDmsnZIBM6n1n3N9/Z/8+0Sq/AJ0VkDUD
0UjvrtHSHSC9LPL5vNhSBbQmSmFjcXVlcyBBLiBWaWRyaW5lIDxuZWN0YXJAY2Vs
YWJvLm9yZz6JARUDBRM9a6LPZ8KAjzPBYnsBAYt2B/4h9obwPHLDTt9HCk9wbqPS
YPdxY9aWfVDwspaD0ZkX1jdYxDx8DW4On080sXxpdKIpx9gfIa3R+efLVEgu2TRW
OyZ6dnDERYbtpRa48et/BcmXhW086TGg3jWjziMDsJ3mv9WTuXe+CQ6cFupi6l2m
ukOWMnIy+NJj1cD89hrtVXvFdGquAsMYvOv9zQUgvB/n+zOFfixbo+lIZsqgoQfj
BHG8QuZrO4Jitq1a3eUe19OGKzEfNyiXb7DiHxx+wNhuWzCT+Okk/ERHV/DV2l5I
dS9yDcluCXbfrRB1ibm0qrQ6MHg9oN6x6Dgy8b6+GtozOrH4CCRQaWBn2hA+Y5XD
iEYEExECAAYFAj3iHe8ACgkQFdaIBMps37Lc0gCghDvXaxJjcFJj7MZlgpopCakU
lc4An1ae3VlInvowTEFcKQ63796tz2vLmQGiBDtEaLYRBACaGs+hkBuM3WpcsUCp
I8RXdp3096q4yDePWTA+L6j7iLvIiTkFVH2JIx/lbN+0JKZYnXop4Oby2gcrbvPN
dCBwQERPOGmhFvsippfBcNJ/11duHA1/jbsATZif2LD8tCIg4ksfE2VtysYzRvJR
KZ/ZUkRoH9eLszOHNEYb5a1r7wCgoDzgurI7FnQe6OLpaEgdaBx1ZasD+QGy55D+
aWzXS0+Mu3l5rDz836oo2Gen3GIgd9ScQNN2iyEC3wA68jkDICkOYpF54vSvZ3/V
d35tEZsJaW0LpR40ktE3wdWL2w+dScGyK3BlTLw03RqnfuJIj+WjA54FDLzsEOLG
zE8Y0z2nRPgoKIWKAx0i2mSPLRKikHTyFl9qA/9N2CGdyzm3ofQ4Kff43GedwVBq
aFXzDVE62KuOZGRqtQcS5/o1LNO+TdQzXXXe/C2JRedx6Tn7i02gJuYZA1yT6b7+
H3UoYYsBIdTeZYGZwFWonAkzxRwSSQ6kuxfS/o+kBnugEzO/tLHSgY38nVNdILHV
yh5YHT9QsDCdXB6L1LQnSmFjcXVlcyBBLiBWaWRyaW5lIDxqdmlkcmluZUB2ZXJp
by5uZXQ+iQCVAwUQO0RqpTeRhT8JRySpAQHWawP9EODkTCa/R8kv572zaFOxGuqC
NDXRa+WeetPxru6XZcFBv4tNaXFw1Zwcmnxv8tQSbzhbtBLaJpbNpCcF2ps7PSgB
biIsm+pPc8Si/s16bmcs9MppFtosPbwo3EgbbEY0moQUSxab6+siYtnmAZDWcony
eZs4uLzsHQ2dQYxa9aSIRgQQEQIABgUCO04PVQAKCRBUthZ5gKoR2E5RAJ9gqb2i
R9yVCai8N0dt956SxlQJ6ACfa3P+EValFi+wbnVJ3KvYs49O1U6JAJUDBRA70JHh
VS4eLnPSiKUBAS+uA/41y0R3sTCK5NdgDdQmZDLxycrLux35wSQ+E5hCOHm562/U
+BuBiXJkwJcaqWx3FdybP2+bQdbryhwheZluTB2cNaZlCzTWA88lMRVciDLfWC8e
X27qT4sC3M0I9mLLQ7Y+4n/rx7S+UDyhW6rzlWBc3tBJvukV+rokMvLFcBCM8YhG
BBARAgAGBQI7r622AAoJEFq8tAVo6ECluB4AnjEoH+0liWGI7Q0svCjZduPToZUl
AJ4+rQe+/fyWLPO8W3v3NhNhOYw9B4hGBBARAgAGBQI7RGraAAoJEF15IuRxooxz
yQoAn2zE/YlQ/CjNNpfZGrBFtpgIZmslAJ4nD6g0U5ten60MPQlYNiKOkDuFBohG
BBARAgAGBQI7TccpAAoJEGaAbx0A99B6qPgAn1HHgEo+PIw8SbmnK0ebxhi5yjIq
AKDFaU8qf+hfdvs96SoNJ2k56j7RiYhXBBMRAgAXBQI7RGi2BQsHCgMEAxUDAgMW
AgECF4AACgkQjDKM/xYG25XNOwCfbdlFl2we9Gbl6dk1g3ityn8OXMUAn0rkuWS1
6SovViXzqFYwGxxGE24riEYEEBECAAYFAjtEz80ACgkQx5UK+27R3D+e3QCg3RVE
AxETxzYKHiXWhSvk0WORaigAoM/hjGI6B29WF6tqNIwK5ntxNqUTiQCVAwUQO0TC
tPvCP42xMxQ5AQFzBAP/Uqv+WX5jhfQ11QGoCKNgj37av3+PrV8FFZl7oYk7XWvb
xrkV0VEK4Hyyd6zJI1I9TIM2EBmeWBNVay1tGCpBWkfJooFwsb5Uo3edjfFrn/cA
PjQj3OZnG/5Gyw+Dl5udA4vr8Iskhj5VHvrJvJJSryrCfOavGs9qzP7IMamuIHGJ
ARUDBRA8C//QZ8KAjzPBYnsBAYnZB/97gr9wOk5XUnREHS5JH3/5GyGIkYFznocP
nPS/6jK67Vs68ZLVuQ36Vy0TJ58zeqckG3lRGWBMhTfBFHfnTTUFKrqxLY5chN3U
6Jap1aRMHp3QI+lWJP98mzqLW0puV8O8BINSswjBkCp4EOW3va8/vWVUMLzjALM1
txRurZ7Ae6jficJudkmdXdSvc0A4UWYgArzLbMSitwwsU15WtWzRFew0H6MXxtLN
1rHRN3P+aQE0T4aITZIaCUIMOuQKBYwGwT8SF0A/DGAFi8vb8so62mzYFiT0/bQo
Y4hif1bf9nw7v6zli9DpFYPWWB6pWmpbUXQlQTvryBjmD4qxB2tziEYEEBECAAYF
AjzEO1QACgkQjFMKgDuBgn5dcACeNKmOz08/aVRqXjVuVXdfhiFY8r4An3iRW9zy
0M12RZpIBflZBC2KzhvFiEYEEBECAAYFAjxrRSkACgkQUgAclY4JAiPzZwCfbJ1u
zPkXv4APOhCDgDpMTsiNtusAn05p419H/Ql9MZhhh0Z5wERY7u9LiEUEEBECAAYF
AjxrPs0ACgkQXjRwWofFmQlyLQCXePnxlsQw1akWQUV5pDIAHHDQpgCeKqRa23t6
PHM7g9PdEGc3Gw+QamKIRgQQEQIABgUCPGtKIwAKCRAY9QOAJMJ4Ak4kAKDO4IVw
V2KASZV0DblLDTkfuzow5QCgodm/YPiTin0FNCC4Nqyt6jDxbaKIRgQQEQIABgUC
PGtKkAAKCRAh+cW892qb9bXbAKDA7r0x7nVqfgyb3I+hl3aGnZpQ9wCdF7jXSaFn
2zqjjPXXAbifCrhf5byJAJUDBRA8a0nNfEtnbaAOFWMBAfNpA/9ZA8Bth1GxJfI3
pYqzJWbuCDLwrMRw4HzKgrh8VXps1CQWScJsF2zZdCKQAz4tmH9Nug3pnuuiAYE/
dicHq16KpvLRNv4ZrAVR/th3P8EwQpX6XmH4D6ZbmhGeawhf3naOkl0ju1mThIPh
Wwlfhoq7DvhCelRBEbGbDtAGFHFMj4hGBBMRAgAGBQI9YRbeAAoJEItfRiWnAR2e
K/sAn0112EJ0oLbG+ibQMLrQkr2SJPfKAJ9+TIz8znCNoFcnkN47ebUryn2vk4hG
BBARAgAGBQI72DGeAAoJEDXUoEGQThj5qwkAnjum+a2F6IhY7uVagRM7NU6whhsR
AJ9voaLZaFoL268/N0zM8DD+rBaWX4hGBBARAgAGBQI7syQhAAoJEONzzsALTc2x
zCUAoKMgX5GGoZ+JoZod22wau64jZCiLAJ92Rjq7g5oBb6bMeeYSvTX6OpgaEIhG
BBARAgAGBQI93JFzAAoJEOztoYZagVwfuIUAmwe+bcssQDeQmlUTpUUbQ1gqBwX8
AKCjHaDJEmVJQbJGgWJTaCYqpK27GIhGBBARAgAGBQI93JGGAAoJEPNELzbWbIHk
kfoAn1oehPwL3vSRjxRPhR0V3GeKt7wVAKCrPb9J81C3+0OrHCGB8hoiGR0II4hG
BBMRAgAGBQI93M72AAoJEC1ZIA9jNXaZkN4An2AqN/FL+RZDsDv2a3tOO7HH5Uv+
AJ9Fif9cBUbjcl6NcJ/CoxLI10+qfohGBBMRAgAGBQI93M7rAAoJENrdQe/OcRgo
hx4An0P0X7CGinnSIHgtkrSnnHLYJLyxAJ9G+udL3igOviHkJqlCUl9nopTge4ic
BBMBAgAGBQI93U4nAAoJEOHJS0bfHdRx4SoD/jxrpZKQGQ6HXP1sg2zGyR33QI4b
0iLjYtxG3QSf55FCdP0zXcaD6uOPlCetR1DZy/u+MPNxpvhjvLfE5DQ0gF4AFcar
nsMUtlJH74SRFUAkehySpvOmsvMh4Al4HPmr6XpRjVOsLyrJN+mtcl3vIKxMTau4
aWWxxjE1skahgnUriQEcBBABAQAGBQI94HVTAAoJEBUCTNN0nXiJWbkH/1rsVVLj
HL6Vxadz+eO5tiLahdj+R+i0+zjGWvMaRmbo3rg9U/NVURwJdEclLG9TGbQY6L23
LcQHjSVqavnr03RGwGSAfo7ai+tr81YszXh9ka3uLsQ1CaeotpZNq6XIuXhxTjaK
AAFXsQmdfAMiIMm0gGTqme/6y3E862Bx8M0nTpH9KjmYxy7OTbptw5/Y9vTX5oAd
xRzGRuR4PR+43YlEz9vN4DynJm3sV+miGPRTj+jXJZ/jMmTISlRPK5xJx5hZTqvR
v4ZyhmSA/R+vDNbSMccIBisqBB0OoDnWEZXtD2Yvus0vOheU/DE2gtDzDpxDYsqf
4RxHuHv9ignnlwyIRgQQEQIABgUCPeB06AAKCRBI7x9bLi9mjudgAKDFm3AQ9AIr
+k3VVXdh/RNR+A2VrQCfRPGGpFniW6qYhD3B0BlMG9Fs4DiInAQQAQEABgUCPeB1
HAAKCRCmw4BP83aBPUexBACnsxJmRRl4rHni7bBERkfKDWzQBm/JHOWOxUyAn7VO
Ny3MfXotFl9R/uPPqnD2W5d34CaNLvOYCC0/sqy3t7lcvty5DfX0rEAcvIhq1khz
p7wOgg9RuWIgmTr98WLtStA+imNTfpkPKZDKxQGF1k0V4WsNUsPxADQduwY1Sq4Q
+IhGBBMRAgAGBQI94h2AAAoJEBXWiATKbN+ya2oAn2oNRt2SrjZzsFn1hSwjsbUy
EnqbAJ9q8XC7gVuAQNI1/usdsNLgyx0gB4icBBABAgAGBQI94svGAAoJEI4CzbsJ
WQz9oC0EAJczia/ZAWFGZ0/hVyB1G2wKn/v32CQVba8aEObj05dLklt1v8kIzWSr
kfquAk+Zdn7rhwusyNwDxsHDCkFKUsFS0jjDnkUcveZuiD2qvp7CoyBeu8VyEVGW
OIrcsiTI7I7pnskFQox+j5+Ose1Lnjum5q/6aLM8iwqRUQUzGR7FiQEcBBABAgAG
BQI94suvAAoJEJ53fDCLRgihuKAH/AyGz8uzPCgo1PBsF2Y7hxnJfFw+JM/V3tDT
iQiPqww2wSMs+pIMaHqz4TUK7ZUYy2vg/qjViyRRhj5+gcBqnBkIe1L82hlpQabY
YclIl69vS5VJIfiqp9T99z6RKu4kQCB356vg9bFeiYaSJJ2XFQ+z0OxHiJIMQ+0/
j/yX4t5R+zmfN/va6rZIwAEh3D6R89Vq6Lt4+IuqPvzBhq2pw6d+RqHIKyGGtC8l
YYUszLs9e9UD/FXEpDb1wjiZHNtEkJocsON81sE5Gf6iyFutMsEO4yHQF6SY9rV8
218eGsS7goxX8S3knirQonrQw8jRS7ohSc7ZYY9zQzUxlasJHA6IRgQQEQIABgUC
PeLLlgAKCRCesuTzaRbIc7EEAKDeNWwCgPaG0C62amNgOCm6dcCvpwCg4ZZ049Fw
tjD37t+gN4ZMJp5H5Cy0IUphY3F1ZXMgQS4gVmlkcmluZSA8bkBuZWN0YXIuY29t
PokAlQMFEDtEaqs3kYU/CUckqQEBfesD/1k/cdGF5vgVgtq23cGwRGSy+cgeTItK
4TJyfvacZJsMWWXhBgEPvAltOWmFSUxCJQ4FV0il7+wEfrCCba3Xs2AFuPPSfNk1
t+Rb1hK478J26DSmvkVRHnyErKuFqcrHb/OZ48sF3b3YGupp87NRCMsAyty3jrih
tBOHcWf8x76ciEYEEBECAAYFAjtOD1cACgkQVLYWeYCqEdg3OQCgtakH61ognpYO
T3hQ1ujxkhE1TJsAn1HWyiLNzRW0NamY0Eq8MQzmo3rIiQCVAwUQO9CR41UuHi5z
0oilAQEbUQP8DG6SYPQ/ItCqVPf01deS8ORc4jKBWgDI6Dybo/WDMcdE97sWU0r+
dZtXzv7tv7IE2n3WVUTmB623SvTnvmpdun4+lyk993rz7H3yng9jPqzF7DmzVRUy
9k7i5PC9+gbaAYOrljuYCx+5nlOxQ6anTCRng9RaId8kHtnKPz0dRdqIRgQQEQIA
BgUCO6+tuQAKCRBavLQFaOhApeTkAKCB5AslGwamxbrSFnOWUAVWZojEpQCfWpfa
cu/L8ErRLS7UfHO7bBx0tLqIRgQQEQIABgUCO0Rq4QAKCRBdeSLkcaKMc1DAAJ90
/x6QGPJhi2zugTmyxAbEeitVlgCdHO1Cb3ypPotsYL1luknVjJRJgCaIRgQQEQIA
BgUCO03HLAAKCRBmgG8dAPfQeo43AJ4q0i93iOQS/BVkI1ZC6Wmnc9M3eACfTnIm
BUKj189tSh+k5SCzGOeMjLiIVwQTEQIAFwUCO0RpYwULBwoDBAMVAwIDFgIBAheA
AAoJEIwyjP8WBtuVbEkAn2YN3IqLxnAuWJLIFI4z/P9XafxeAKCB6B2XSUd1iG/W
/ULYIVRgKEexrYhGBBARAgAGBQI7RM/YAAoJEMeVCvtu0dw/Gm0An34P4fky0FGA
eXxrq0YAADFql7w9AJ9qLmCm3YGPHyk4U3/rozhkip7qUIkAlQMFEDtEwt37wj+N
sTMUOQEBbEkD/R0v2RM5Mw6FUMDyR3n2XEbyvP4MhVVWv7O59b008sNz+ZcHa3oh
e8DuvYtiVXVFZXtS6Gqsocn44mEoC2zt2vEcrRPbBnwmIIwYtgp8nhIfT8pENJcP
s5UqIN+3Wh95PuscwVUOv5+oKXFpgDBQWTEfG0liY2i6Eg3xAkI4PF0iiQEVAwUQ
PAv/1mfCgI8zwWJ7AQEaWggAlFVTQmcCPoareWkF84hco1hc33h4lYO9tZAy81Ya
tdnl2LNwwUS0uOC3O/m65K8dwz37AE1MxQJ2I4L1bvH5jrMfEAv774RPWA0dSa3f
IXd5mq2iDD+loc6b0yA/+/MZN+HJ/H1XoyJWKvvGTYcuW4bI7aiZxWj+8TvOgCbF
5Vj2cmNFJJoF9abdSQG3TGBkQXZ6DY09WX/9EiQC8beK1c4IBDbpp25j7LE4FLLQ
opvVq9q1bRlpzMSx0lB9u7jmA3lrtGw4XqlQ/uoORZ7mnWnTiVMDYHWKmVnuwhq9
SlHyRTKOf3Tknj0qQxmkS+lNucxICaL+SUubZo+glARKOohGBBARAgAGBQI8xDtW
AAoJEIxTCoA7gYJ+wxAAnifDVrWySv4oKNI0Wr8RNCD09i50AJ9Y8Jr0ydg8UehD
/4ggkGqbmEGn2ohGBBARAgAGBQI8a0UsAAoJEFIAHJWOCQIj6BgAoIyiZ5Eo6rqj
2vqT2rA+3YUNXpamAJ0RGOhRMpoWZ5WV/VcFwIUO+jBVJohGBBARAgAGBQI8az7P
AAoJEF40cFqHxZkJ3JQAnRXqtLza55yZNE55IBInaffxY3Z7AJ48C08nltPWYMKf
bw3t5bupWaB27ohGBBARAgAGBQI8a0omAAoJEBj1A4AkwngCvsoAoLTJncmFM9Lb
ymucsNfBR1vtA2qeAJ9x3YAQsz6rzGDbYbT3KgJNzXIlBIhGBBARAgAGBQI8a0qT
AAoJECH5xbz3apv1XogAnR1+vz6EJS6jsvjqqQ1EkcdluvZaAJ9EppEkv5RNb7lf
F9Bkxw9nH58Ao4hGBBMRAgAGBQI9YRblAAoJEItfRiWnAR2eyDgAoIxU6Efws6ID
4xuQN3fI6/rZCwYgAJ9CTAOKkaM5MQ8oRKQP9T3KjgUYwYhGBBARAgAGBQI72DGg
AAoJEDXUoEGQThj5ENsAnRZbRK3hpYeoYt4MGZMbPW+MSFv+AKCAPer45W9FEkhu
jyw2WknyZBPIwohGBBARAgAGBQI93G+aAAoJEGes8cJc4y/MOpkAnjzJVR+TY15h
3fT2ym6tU6PNBaNzAJ4qCB6PzYdpN+cLucFs6NyD5yM4gIhGBBARAgAGBQI7syQj
AAoJEONzzsALTc2xs7QAoJYoLXySZzFvWupjz2GCH/J5TtMeAJ47A+OwZlHjeGbw
rILVWRjvHq6uYohGBBMRAgAGBQI93M77AAoJEC1ZIA9jNXaZy6kAoL3yOGfKTngk
KSHucyf7JG6rorIrAKC4cOQn9rwDnN3zyiuSY+KiZWaexIhGBBMRAgAGBQI93M7u
AAoJENrdQe/OcRgovFUAoIrMY85jRh4geZJKVIeBK5HF5aBcAJ41ygZmhaqqs+M8
6gxuKtkUbDY2ZYicBBMBAgAGBQI93U4sAAoJEOHJS0bfHdRx3zEEAKSZqpe+aNNU
8Bw+R9d+5J9kbJzUMQbI6gkYNDfTg/Cenpu516s257b41frAKOLV0Y938OMB58ob
EiGt7OWeKmX1Y4jb2bbfu/qyHIbMZxTOB6W1FGkgA9D1K47zvUho+HrScYXH9mbt
pCK8sSjAjzMS/rAWgMPX/wlFsu5zcHxliQEcBBABAQAGBQI94HVaAAoJEBUCTNN0
nXiJhxgH/0hJ5FLoORlV0cvRSxC9j6Mvv/y9WZMLEcv2MH94zc8LJ6O+JDRwx7cV
6Q9blzl1cLGc6YOwGkmYWu1xX3+VOia6M6HaEJEdlXE1kCXNK0gRfPC4uXpynXeQ
OVZ75YAO8SrIwza9D7vm6i+Z+WQnFQfz1LzHe9LQEy0YWHUjyjyjAaBN7gmig6gY
mK7JxaGJZ/epEecxPA0rvLx5BijxxP/exRMDcadKNM76daIDNITTyU+ItToEtqG7
fCaInan9yC9LjCpvlhRKNcgl6vBMxa4NuwdXVvVk1rc+IikKlyQ0rQaeB5VLjzCe
3Ah8DtfJrgwwuRvx2OX3uCHwJadQ1b+IRgQQEQIABgUCPeB07QAKCRBI7x9bLi9m
jit0AKDU/qHgKEvUnVZeb5QAIi/+dJv10ACfa0efpT24cyMLmWPwzJxRK9blVyuI
nAQQAQEABgUCPeB1IQAKCRCmw4BP83aBPaVxA/0UFpyWupnx75NXJ7t7f53c3h/1
RryODIRGOndNqwd5Bgpcim05TrlGI3jFt3wb4g5dFSwH27NvwXJvqJ5f1KbBqvRw
Zy7+XuAVj7ZDzPclN/4m9iAiwpQX9SR7fZ3pxsXcFKVvGSyRUwARJcAxFNqhnFvJ
stehSGSY8mLsPoGsyYhGBBMRAgAGBQI94h2DAAoJEBXWiATKbN+yEo8AmwS5cd21
lk4+zhl7XbgFw7NbvJoTAKCNFJXE7z9mroZXgfDiPJ+XdaIdm7QnSmFjcXVlcyBB
LiBWaWRyaW5lIDxqYWNxdWVzQHZpZHJpbmUuY2M+iQCVAwUQO0RqqzeRhT8JRySp
AQF54AP/etVik3wRU5ubefl/pzZmvMm0ue3lnyOoURbW3kxaZsyfEjdiQy3zypTH
m6BnLmyrvxSRTQY73Y1++1apCnn90zMf1wT8ucjm4IAKFyUbJVgvMTmvRnTyJ9iO
5BuOW0nKwkoBW9J5W5Jpk+RYpZKrds14VYTht6QPtT9Ey1Qe47WIRgQQEQIABgUC
O04PVwAKCRBUthZ5gKoR2FvnAJwM+7W7fyma26ueEo+NoSFqRYxPcQCgn0dpaMbB
4qQ17wVpuSxC9bTOOleJAJUDBRA70JHjVS4eLnPSiKUBASuSA/96koGDlUBVjy4U
aDBHFN/+TZHxsxkO5GXhizMSSKHBfjw4nLrJL0EyGeZfp+4z/KTp4DrOUUzmBgYY
lgfe3LBVTj0nfsb/tcab3c+UTYndbIJO1b7Gq/xfkzRNV7p/e1fCIFUTQzB1qROL
lVkUBg/mSGzHPndRqMWIPm5B/6c3VIhGBBARAgAGBQI7r625AAoJEFq8tAVo6ECl
rqMAn0qAn1JyspmZ0zMTEJqAagxP6QOBAJ9SZX471Y7fNs+3OQbSOOsTXTrjuYhG
BBARAgAGBQI7RGrhAAoJEF15IuRxooxzlt4AoPvyWYaAA4WGAekoRO7JNU9vvbKM
AJ9Fea3AL5SQGQ72niIozb0C3SKynohGBBARAgAGBQI7TcP6AAoJEGaAbx0A99B6
VY8AoOU7J84qyiixa80nOWZJeOHY8xNPAJ0dMJhYKvLdl+eqJ9pgrbqTQoXQcohX
BBMRAgAXBQI7RGklBQsHCgMEAxUDAgMWAgECF4AACgkQjDKM/xYG25VrcwCdEGYw
4MiKXoorrWjnxVa3xyzUFo0An1e4xt3fX8eZVZBdWvsciNYV38RGiEYEEBECAAYF
AjtEz+IACgkQx5UK+27R3D+10QCdEFqssbv3ZreVGeUUJAQ5x/EU6FMAoLM+GPdX
grOVIOIG9i+S8k879u8uiQCVAwUQO0TCxfvCP42xMxQ5AQG7RgP+Ou53E+ydlbOV
FAaW0Eo3AXJ7ynsAL7mVu3qrD4QXSImIiVry6RzaOwqc66hjImuWN0LFMni5pJE5
dphTsJc4MFdSbjxty/XWd000HiUs64Ny2LgnH82QKTAjIw9Ua443krIeEipcL+MH
mdrOjBRdCT0no/badbbOQusiwQE6i46JARUDBRA8C//WZ8KAjzPBYnsBARAFB/9e
7C/VMWyO6M04kINBj4TSavohQWUgRwC4rLPR/+8Y3JtrZYRJLH3v3ZkSI4NTymgg
qHW7XBuyHJeSEH7NLZ5N2sHdUU+Tkw4rb2S293AYGpkQ+koywNaF2Pod5w7pMnwz
8dkhEizfhndOEIIig5nc8QORAZPJ4zm6fDgwAr8saiXN14wDu1TSZzqAIkwavYAh
qEQr4CfzYEO5r/xHWeerKhF60iIIkLELppvXo9Qzpy+eWVG04TP0UD/lOCOiGoGy
g6TlRyYAnFpjiOahDYDzO2Bk2t91mQLzcsdKc1RoDT0ncfUfltsy9BFftjybDpY5
jcmCsrYKiGcwRZ1qT2wdiEYEEBECAAYFAjzEO1YACgkQjFMKgDuBgn5BMQCeKkl+
fFY/rnDlS2tQ/ctk7XQB2+cAn1o30JgvZn/7bTDBt51F9D3vtQ0miEYEEBECAAYF
AjxrRSwACgkQUgAclY4JAiMZdwCfdA6uA0OnSoSiMN3Ak3S1Iqedf8oAnjEw3XYg
/XGXb4mDYMLhZ0r/F0VhiEYEEBECAAYFAjxrPs8ACgkQXjRwWofFmQn9KACePOL6
SJNkNA5qa0PnLn9hZBuA5qgAn23GsJ0VyBeMoO/lKzyMO54udJtiiEYEEBECAAYF
AjxrSiYACgkQGPUDgCTCeAL0awCdHW3HhtXWkwmCFH2fJvEH8z0WvsoAn2UNZR0x
0+sAH0f39A1SftEYF/0TiEYEEBECAAYFAjxrSpMACgkQIfnFvPdqm/UADQCfV4/W
Yj5/cNOtONx+fuPkLtE9sYIAnRr1nGxBRllnx2i6FiL8KXI8ixVWiEYEExECAAYF
Aj1hFuUACgkQi19GJacBHZ602QCeOFIfjWvbBeBx/59rAsMmbzys3N8An37vTNi6
MUtBd3PdDx6n55VSD96QiEYEEBECAAYFAjvYMaAACgkQNdSgQZBOGPl2BQCg3CBk
oHj8DwrUp5/6/lhY4fc6eTUAoMo6PCoonSpTPKN4LcakUifl7KEaiEYEEBECAAYF
AjuzJCMACgkQ43POwAtNzbG/ogCfTu7fiZ7/NWrgtUe0c2KSyhPflLEAn18stV1A
16ppYvrcF58A3Itu7ldHiEYEEBECAAYFAj3ckcsACgkQ7O2hhlqBXB+e1ACg0oHI
T9sNgzbyT9QKV8yP82ovuXwAnAxLq1yUuXJWr/qI793aWLlIhwtDiEYEEBECAAYF
Aj3ckaUACgkQ80QvNtZsgeRndACgr9XvLsdhB6O6+binbjYDWHqTmTEAnjtsCw39
ASPG4Po6RAV4Zjc5IuvliEYEExECAAYFAj3czvsACgkQLVkgD2M1dpnyzgCeMMP1
BPTXYZU9bk/ztaPdSE4GBDwAn3Tr8kd4X7euramTXywj8IxRfUMjiEYEExECAAYF
Aj3czu4ACgkQ2t1B785xGCjLQACdEHoqBw5Ssh9yVfPA04IEPF3pvToAn3FIUFB2
1PdJA2GPPG5lXy0WsSFViJwEEwECAAYFAj3dTiwACgkQ4clLRt8d1HH7oAP+NeWR
zMSJGZoQLKZ506Z3f7/KYVltls8rzRkMz8sXqvEyFzhGO+vutVgylzN3NPhlnREf
vEBdJGgT6rcvu6lQ+oYkgAhmNv1Ovu/JAK3MkUp7Bn8OhEFpigFl247Tlci6V7Qm
+OifPBcbZxH2JpyL5uuGbzoA/S0nOvUNe5WN/SCJARwEEAEBAAYFAj3gdVwACgkQ
FQJM03SdeInQgwf/cNwYy+WbV/i+jODKBpc3IoBC3ZL8dhRgU2q78MYQvA/UM6/I
ijg8nYff4iywDYFrENAjEUhf/T2Zb7rBNXxG1LuWRLbQuvB6YcaaiKitWC57PvAG
HS92lnRpwTTsTYblYncobTiefuu6ZuzTanrVzQVlqA9yQOey4aMDu57MsWgKQYn6
f16tCQFxrhcrXpUT4i9c0TYKQYGI4vRN/vRFZiWtHNYbVMVKdAoSz8NuqxkF6B+G
p790TCRLkfHiBY2ZkV4AdagOywwPQ/QZmz1I3BNKzs6DiHoW+uT09ba+Y3N38QmD
OO8ZXqeJqhUrcwAnz4Hdeg4aKibqSkepa34grIhGBBARAgAGBQI94HTtAAoJEEjv
H1suL2aOK+cAn0Gp3N+YsU9+juW4g04Iwn9y7eghAKCMmk0hhy4cau+Trxpi77qf
bL2uuIicBBABAQAGBQI94HUhAAoJEKbDgE/zdoE9VmsD/3pUOJT2z5Vgmqr0Sksn
slj+h6dvO+GkohGmECMN//aj2ou1+VETutAUz5Yx8f4kfNioxbsZnpfRY1v7VPuk
QYlFIRNaUzesesobQ+1gbO8dcVuuywNPwP0ZzjrOYfnWKNmkAHzxYRj9eKPGszhX
zntwuGi/t90JmjTCHU3DMACviEYEExECAAYFAj3iHYMACgkQFdaIBMps37LWmwCc
DCxFVe246xj2ZxB207ScmVc6bNYAnAqoBWi8+xW3MKpu+w3/BPhRhOvdtCdKYWNx
dWVzIEEuIFZpZHJpbmUgPG5lY3RhckBGcmVlQlNELm9yZz6JAJUDBRA7RGqrN5GF
PwlHJKkBAb87A/4kgyJTnK3CM+W+l27tbLjFefLFEuEngcVLHiInainv9/x3ZnZA
gsE+pr4QOMPHg0946CzyfCZ4taCkmtGRtULoGUlPppdjw8psUiB5yq/g8ac5/o97
IRbbQqNTxcoS2svBfXrPrJgtWC/BLZK6w4z5Zr1+wFSDu5SfoFteRFIeGYhGBBAR
AgAGBQI7Tg9XAAoJEFS2FnmAqhHYlpsAn3edJn0Wn9CtgQOa0b5Jy+iEH7E8AKCJ
1taCxmTM3jHtP/66HrH62RcpxIkAlQMFEDvQkeNVLh4uc9KIpQEBk3wD/145GM1g
+bgW31n+XA7MuE7QZA5BAvHU44fs9QS/nCm1ZKYbMql5nXzL/cS1OQEexLwfhoL1
5DCs5rc0JSMGB2SYfpdcNT6dlOGfrFcXKppDKHXPyjPzTUhoMAAM5o/660E2RQvz
xVVAmpYu4XRTMP2XMV2ibJLbUBiA679mu8JgiEYEEBECAAYFAjuvrbkACgkQWry0
BWjoQKUf8wCfaty+zDtvN5Q7HxlBr+CkUnZGd6cAnAkDWPthhGdqmXrVD9KTo0YG
2ZW8iEYEEBECAAYFAjtEauEACgkQXXki5HGijHOweACg3ZtrY0Zci1HThx5/uEPB
uf21cL4AmwXhrY3zlqHbigRQytFlM11YjaMciEYEEBECAAYFAjtNxywACgkQZoBv
HQD30HoVMwCfXU5l6znuIsF9/eCIwd9ZLsygUH4AoPpW/6P6QTxk5QgTN9iQQSb0
g6EziFcEExECABcFAjtEaUAFCwcKAwQDFQMCAxYCAQIXgAAKCRCMMoz/FgbblbRw
AKCf49lsY4UW9FHt5eelnV/NvjTTHwCdE29Cq7qaP3NDP6XFNSKjI/E9dAaIRgQQ
EQIABgUCO0TP6gAKCRDHlQr7btHcP0KgAJwN4doSyAC/KQjzCa+RfIT79oORRACg
lK/FnLEV67zc7Pu48k9mN3xa5WmJAJUDBRA7RMLT+8I/jbEzFDkBAeDBA/9YmnOs
zmK2n9M3Q5qpLXDSN8m2aDJ6grJcq4swaWCSwFqUNufdIsiPAb7MwnqYaZriXpfa
qJGp6ilBEd+3GlGC1I2M3uyQhsgmS4HdH1sIq/P0WlSYE0wawQmubszpCc2yeaKG
cf4D6EIafZGwOYv1gK1jngHG39bs1oR4LaP4k4kBFQMFEDwL/9ZnwoCPM8FiewEB
C3UH/1mAPNA8r4IEtg2m9H0fNBxJsE9DUFcNvAcPg5y8al9RfdUKti/HPqqbZdGj
A0tQteA5GEm5JbzYweIB/gCFxTqj88LGbVmF7iFseF5/pIabVtThI2mS8YOBomfV
SkV5VgSaeTtqPOzHiv8/TYvOIGku2FRY2BVKADYrNdASIPKoiisLd0PJ8REEOqhe
D/Ze2eH5UWV3VNQjrAnikYhkwoBh5ajGaz8PE+vWchsIxjmIMmu29yLZj9Pm4q+Z
n5auoU8RTiOIahqM7bdDWpfBmilU3Ew5kVACPx/0ZML9JpNzReL+srr+j3AJUuLS
CDBrRdBYEI8B00kwTnb5MfnlzeeIRgQQEQIABgUCPMQ7VgAKCRCMUwqAO4GCfqWN
AJ9Q0SoGwPMt+IhwkAWpxw9XsrLFJQCeOzNSi3pYtKXzD3D8/FfZE140nvmIRgQQ
EQIABgUCPGtFLAAKCRBSAByVjgkCI7bHAKCJqSm7cDdXH1BRJafFm/DGVG+KFQCe
P6BfCJBqdFjACBNV6hPiN8lAudCIRgQQEQIABgUCPGs+zwAKCRBeNHBah8WZCUTC
AJoCImRYfAFIl2pSsQVqcm4dkhr3VgCfeIDnHSrgrRKkyA/dbwo+wZPx766IRgQQ
EQIABgUCPGtKJgAKCRAY9QOAJMJ4AgX8AJ9IDMQ6un1Xc0VxI0ZLuPqhqMPN1gCg
whzHC46/unSABA4Nx7xEoM9YWBSIRgQQEQIABgUCPGtKkwAKCRAh+cW892qb9fKa
AKC3KdjW2F6WLCJIbnQ/m1aunGIFqgCdFLmAt2v6JaoL4X1i8N7oi7AGzgqIRgQT
EQIABgUCPWEW5QAKCRCLX0YlpwEdnuYXAJ0YNl0ntsypaCrVna9x2PJ+myby+ACf
ZxQZnNrs+XX/QjllIakyh4ktHhyIRgQQEQIABgUCO9gxoAAKCRA11KBBkE4Y+R0w
AJ9Qc22wrFOkbW4TvPW9mE4JNQC2ngCg3eR8wgVlU3yKIuSMaEK9uLiZAi6IRgQQ
EQIABgUCO7MkIwAKCRDjc87AC03Nsfg0AJ0QIEHU88JB20zVqwgvqvqZvJd0dQCf
WW2FeCHJl0BTrO7NNnFph5tOyCCIRgQQEQIABgUCPdyRmQAKCRDs7aGGWoFcH1YI
AJ9QUFukKkDPFsZDZqAgN+HD2/HA0QCgvS3luA1eAHnCHCzKEdmc/9woa5+IRgQQ
EQIABgUCPdyRvwAKCRDzRC821myB5DkzAJ9Xbtaml5jFP3usTYX0e3mcojhh+gCg
wDABH6TY/OBywmKgy2DUNyvRAOyIRgQTEQIABgUCPdzO+wAKCRAtWSAPYzV2mU0S
AKDvx6fnJu0rcgrq/Q9peWUFmeT2UgCaA3II6kd3R9n6WQPfUS6P2W7Q6L+IRgQT
EQIABgUCPdzO7gAKCRDa3UHvznEYKMhkAJ9qL8RJqohyanQ3H8wL+XgE3T2GDQCf
VYaEVBwInmSJx7HT4zYEKO2/mL2InAQTAQIABgUCPd1OLAAKCRDhyUtG3x3UcfDq
A/0erLJkJube07ZpVktxJ0bak9CaB4X2AG55I72gLGfMueJYTOxzCwiVEz2hUYYq
oTS+i0/3IrN8eJ5iJxyCkiB6NBqwGTYF0w0oD1IG0WMmYUhtGVywqRnJT/3IUD3C
7soekvWb0NzJjWvUp03w5M5grlzX5G6FwW7hkytBIDLTtYkBHAQQAQEABgUCPeB1
XQAKCRAVAkzTdJ14iRODCACe4SgdO2mDPLWxpHtaNwpOoL/OoVbj5UfqIFqzsMz4
PJtAc94Zc2VQjq76w6uDwLomzmoHuLhPe9INIbgEG+2KyVGTyrVisIcSjAP/j4sS
Exz2DkXYyKwuyShnB0sT7MIRUDkFu+evo7D1Hfdqu6fbc6RuNTlF3R9ewGQNZRdQ
Z97ZASMlhbrGsb01RtcZhVGR43gDBbTLXDx4f3b55bBBQkBdnySKSjstk09aj42M
LSLMnd3h3U6sn+LBaHKTNQy3CfbYF5rOtVimYAxKcNQiGgBa5scA405WuPdOWTdz
LsuhpjXVucGcyqwMTiTAMUNzllk/K3QWPuza08/KsNlOiEYEEBECAAYFAj3gdO0A
CgkQSO8fWy4vZo47uQCg6mAfbnN+f2zuzbz7KN9t6UyIBVUAn0+tA1TcWb7WNnja
CZlM2cy16k1OiJwEEAEBAAYFAj3gdSEACgkQpsOAT/N2gT1J4AP+N4h0hqm79tPM
oLPKBD/GIKNCZT6xkpLIMco3vxd5UEMmO3+5OaKCuR/gdONtdMNCYU5hkAjQs0u2
DHjf2NIQFYvRvPoL//22H6EzZNt375MSzCDB0VAPVcIjZO7Jrs79bezXobb/aISZ
IY7Mlr7Z1d7owP2WNyxhBkgTn2oZ8V6IRgQTEQIABgUCPeIdgwAKCRAV1ogEymzf
smoVAJ4vu6BeS8Fs4VwsyW1Fyi4MicTP0QCgjuCxrAMaW6ZpUhUQQ+Rb4lrQqk+0
IEphY3F1ZXMgQS4gVmlkcmluZSA8bkBuZWN0YXIuY2M+iFcEExECABcFAjwL/2AF
CwcKAwQDFQMCAxYCAQIXgAAKCRCMMoz/FgbblUiGAKCeCQaiDh0dnEPi8vw+qzue
I0T9LgCgln2n+ZN2GDQ2HjaAy1wSLTtod1SJARUDBRA8C//WZ8KAjzPBYnsBASBh
CACmLJ7K1mBNMn7UJDCsqnrnAsM3syxQl696+eYZ77jF4DZzXRli7MzF7ZCCnHBG
GprsxWaQ1VKVGbEiLeRdUY53Ck1mJbzynjsz0m7ov5zkwJgu54zYrWJljb/JhjJD
S61bVaNYz7sjUnzpOZIDrdyWPHeuVzd/aYWCUeE4w7RxC1IHeTXERuAQQTQ1fvRI
bX9ImpEGgSN1jy6XpRLDbGFJ9QdQNwbxS0WAGhdrDejXgICen2Fi5i3PdQ2fEY/t
SzbyDuxm4H04hY98V1iSfzn9renwPRoFsGLnNN0+31uJRXs8b8len1B7AwITCbFy
VJZrkTZPU1V1ePu3MJ0PQytWiEYEEBECAAYFAjzEO1YACgkQjFMKgDuBgn6juACf
fl0byV9hWncUSMftJ6XWISAyDM4AoIDW3zsrRbBoD0R9qEVVTJBAkrEGiEYEEBEC
AAYFAjxrSiYACgkQGPUDgCTCeAJlHgCgvBttlVqACXF09IDDQPqhtCNdxQUAoLrJ
oPsjGlmtc81S9dP7uthWVDpbiEYEEBECAAYFAjxrSpMACgkQIfnFvPdqm/V9SwCe
OaDuN8ZHTdORvZlTgiVyrKGHEK4AnieZj1nAE8YSBGQKsBw/cyXrDjBTiJwEEwEB
AAYFAj1g/p0ACgkQVS4eLnPSiKX6UQQAn2pb1S8nxEt8TPV+k4zL18et/AUX6JeT
Foa53Wx4eHYnXtLzcTN7OfC6x6bnOsj1J7tnjrszyJOkfC9+w8env6fu/5yIOJA9
JLfcEyfAIGrOIS5RS3H1V97i1c5+8oxHPXuUO9K82BV0gCTs/JHskitplEbc1Imd
YIpOtgHMk0aIRgQTEQIABgUCPWEW5QAKCRCLX0YlpwEdnnoAAJ0TgRrEvx36F6eN
vKUrc5xJeok/3QCeIeaBdUReQ32GMFHkZfYee0ZWMF6IRgQTEQIABgUCPdzO+wAK
CRAtWSAPYzV2ma0EAJ0Vbd8UEj30UPPt/mtSIfVgGLVFwgCdGrgcQYgXN9HgIEiC
gpxce9GJCFiIRgQTEQIABgUCPdzO7gAKCRDa3UHvznEYKGGQAKCEu3lu4DoHcqMc
rafVKrai0ZqDeACeL2m2zhRBwQWvnc74ts27Ft1IJVuInAQTAQIABgUCPd1OLAAK
CRDhyUtG3x3Ucdw+BAC09AA2r9qp5DQZEfPWG/JaIA/C/UDOQsfxW9ADaAuNWcj4
UoXpU5w7RmcpzixxOXfklQxxTjHnnsrvTWOE2oDhUlVaBNdrKliYfIL0WsFl7/xd
tk3T/gGGpoXrpWt/XXZrb66goUz5AEiMhsiH6guozp5nDgDWlPA3kxeYNYjTtIkB
HAQQAQEABgUCPeB1XgAKCRAVAkzTdJ14iYD2B/9Vu1KMZZpjJTYia9DhL2u1gb1H
seFTehbbHlIJ0Il61VhyD/u/4oVeZ4MKNb5bMEDS0cp2XQN1/ZA+cGcTlL7Ccv4b
glODBuMwfHg1vJuMEpwxvPRaCEweXbC9XpQoniOlSvNV9Z/v1SZ8gOMR4IwgO3G0
sL4zq3IOdq9cGCmKUeNVyI/euhzij7G7XzCQzXc+KPKWPmFWrmgLnMtRurSv18m6
P1c68tBkyceJUGPvhDsvwsgLeAPLYDaEIfXU/jacMWsxmr1F9yKSBYDCBS7NmsfK
VWbM/G+iF6g4oh7Wl9UWCRC+UM3rxXoBWeTj6XsA5nTtDt4FAflOJspKTEd4iEYE
EBECAAYFAj3gdO0ACgkQSO8fWy4vZo48tgCfbTnEwudD/TfU1jfsiebUGnDBd5AA
oICicrt+YvnjuIxzu2fB8wmlqoERiJwEEAEBAAYFAj3gdSEACgkQpsOAT/N2gT3x
SgQArgw+nKBTh1dkwdx1+qgoQp4n958i1dPJFlZ0why3DncJKafSnsmSdYSDwjU5
wuvnCm3eeT/7AZxdpQ4oOxhquR9l2hg5czoAHQ7fP7mtPGwJvFdmMJUROsT3JX60
+LKA1GGnhjKU6kOzksqL0bmN85fewTDPEKLVeT5tJXkYnN+IRgQTEQIABgUCPeId
gwAKCRAV1ogEymzfssQ0AJ4g9DnMnhGTvaQb+8Ksh4f3jwc+WgCfQp3jpFMfRaKd
zaTejKJoaOaiu6K0JkphY3F1ZXMgQS4gVmlkcmluZSA8bmVjdGFyQGNlbGFiby5v
cmc+iF0EExECAB0FAj1g/icCGwMFCwcDAgEDFQIDAxYCAQIeAQIXgAAKCRCMMoz/
FgbblXs2AKCJI2mkKiMjb3LbN4KlNVasia3sygCfXrmHuvhepOcV6u/jaWs/6B7X
dlqInAQTAQEABgUCPWD+ogAKCRBVLh4uc9KIpWkDBACItSCi+GsK3Nfm3agPmhf9
mEDxeaQwQJ3bqt+xDyAfkj6Bi3iyHSfxs8sdtqRK5MHEaAtEsrfMHAZtOz7dcX5u
ORQ/xpJVH+A5ZnsPNUdr5tF0LTawv4khteqeZsRF18McwFjWewrkGadDgEAuuT4f
UiGW/uOfaNYmFnih04XXK4hGBBMRAgAGBQI9YRblAAoJEItfRiWnAR2eJyYAnA7g
HfvG3k3nnSoKtW5SQZCejna8AJ9tVvOJ4tvEjZ25VrSuYB0v8EOrk4hGBBARAgAG
BQI93SzxAAoJEAQcxk3XwniUWpIAn1aQweAk+GdKIsZ5nX038wRviCzEAJ4hWfKt
tHJh43PvtcKX1oHWvgcp4ohGBBMRAgAGBQI93M77AAoJEC1ZIA9jNXaZ3vMAn1+e
1I3KoLX+cIcCStEPaVBgwuGIAJ0f1Xr7A8KmG0MW/YZjfhPm0C88q4hGBBMRAgAG
BQI93M7uAAoJENrdQe/OcRgocs4An0dwHEujgqomQu7FgQXenEtA2+WpAJ0fd9an
sXz9HQ+E3ONkYg+KRi9oBoicBBMBAgAGBQI93U4sAAoJEOHJS0bfHdRxuq8D/0Y1
sJ7Hn3LnGIcX9YWZYNPtvsJ663v95A/ZiaaQEluInD0r24EC07+dbIe5j8PYjo3w
hWl9SQKx+N+sWeVWfb5X0oJ47YUSZu9q7Xh/we1DUV245GMmamnPpOK2pazlExhn
ZtK57eBQd4o1QNByLNouvn7mIb6Yz0dHS1c22mZTiQEcBBABAQAGBQI94HVfAAoJ
EBUCTNN0nXiJvDcIAKFcrWdPM9EsLwBSXglTKBfdG9bAxD/c0FEGsob47XmctP4M
DHZvNU2KWOziqZsovk2xaWUp6WKEetQHU9n+RAzUEl3kZrRvRVSdZmy6rEs4VGUC
uXUT5TdaXBy4Mi6mbVX6FfrkhLXISkYHC6pvuE2vZFCioDsA5B3Yjw3XhHtV/3Nv
43a1f6JZyIqn7YnraJF6gS0vos4BGwaRRA3DZWDj8WK6wsSRsv+XEkONCcSWHCOi
w5TiFCn3/VNbuKQ/hzn/w62JvafsQq5oF95CheXTYzo6zY5i1DE8uStFNagXMqsc
vBpRiC6BBRAq40YPONKtHM58aveZ/ufNj/xUQROIRgQQEQIABgUCPeB07gAKCRBI
7x9bLi9mjmbiAJ49oWSAmySGwwgPaRrzAk1Ic3tSFgCg2KgCtmIXHXPTScLlTVtD
eprPlyaInAQQAQEABgUCPeB1IgAKCRCmw4BP83aBPU76BACki5Ho7/oSVGUaJ+Tj
8IqvlV6GNTOF1C/yA9xOXWUX5d9UDkUOgTyFSR7zx0nLo9YxKRoQhIdkBaeZMDwP
pWa4hR9EMEdEkRXbE65PpTNpbfX5yRtqF07KQMR649tlO8gqIZlF6lAOecMtDtaW
73g6QnkX6JDKtT5nXs+Ykl0guYhGBBMRAgAGBQI94h2DAAoJEBXWiATKbN+yX8IA
niCrUN1j2Xv8b/ey1g+hWAvEhtpUAJ4gUVlH1PnwbmVkmjfeM1zMTUZCr4icBBAB
AgAGBQI94stXAAoJEI4CzbsJWQz9HK0D+QHvaJN37U7GqItRca34fWhnJvDllJJk
zF9BGydZnGaOhTH5ou6qZF4xjJ+UmsCYhyGvIjH6gmqw4fe/oWAY8s10zIK8FhLr
pmYm7CQe0Ewh/3zWxlX3/OLfRMRJFjeKqjkyg4+LvpQAFIFkz6Nf6hHC+crAZ2Y+
xhINCkId6auCiQEcBBABAgAGBQI94ss+AAoJEJ53fDCLRgihudgH/3Y35hMF9/js
sgJq6/4CqSiXTtlrqN5+ELlGNy5uv2d3YNVGHOXGCLVVHTOvTsxRWyFAPu8DDiNJ
/3yrQkkWxWbziHMsUyownqSw5REcYx/s10NO+UYRGamDr/5XTGss+Cg+LDN+ewpQ
Fs5dmuq0yAXbQ/MOsAAqDVMvvHPZKbDTOTHGAai8bzspexQGBR6Xe0HhPDlJzaxT
0JB1HVXcBJN/UKRiHpEF/XbHFgDYrHdjsAwxSXr7dWq1b4BItwSkkTLxXkcZ4oku
hMoYLpEbH57Zm7UnMxcYEIrzBInJRVDzVj1Y3doucMPtnr2KPa6/66mYz0hvwO89
FoApwq+Ghj6IRgQQEQIABgUCPeLLIwAKCRCesuTzaRbIc+5tAKCxfRem+hT8rE9e
M6rj1nOEzIr4PACgoio3VpFqx2zfDYsCz46U4NMSDrWIRgQQEQIABgUCPeex0QAK
CRABuRx628rLXpcOAKCB1zqxeFY/hRlTtwKITlBucJayGQCgy/DqPzqxNwXRr/GH
xQSsp/s/tjW5Ag0EO0Ro7RAIAKzyK4A+9fcEZOCtFx6tdC/SSRw/qvyfEeb+8LJE
wkvnJnuVmrpd22JUvnyI8dvP+dFpMDnaSrSj9XjYwodlSa1nrH0tHvDfGIod49KD
eUY3IUs6fg2smHmhbczfNUqQ9e8s4wrCQeb9p7Rp/V3jJYj2df8/W3uoDNsVCYPy
YFwPbSkEYiKSdc/peS7MbX2dQ9Xr+PtLWeWctg1GG/UJQ04xPUw7RDr+QtRnQcVc
yd7d0lObroUTUXRSVLFAW/DFUS/Qfb4rHe4vhyjpeuMmnddrLOQzJRqxFaa0Wm+J
RKVemv8JqlFRK8zwP/QIm726wuRaYg27Tr4+zC9PJZIYl2MAAwYH/i6ptMz9BJF5
S5kQGnyl/PuCX3R0G9NvG2Urmev1yULSZwSYmU/KTM1o0s9l5PgOPtG7TQi8oZio
a9RcuNmsWcolZlEk8vfUjKonmILYcj508LNWY0WnfWvEnGDuHqpb+L0YQqarHcFn
3kHl5WYW2UhS0Vi4ViQE0gx9jSKqdAiQyTdsM5bQlgtzfvGpp2t2sIURlvOe92Hj
yDw094f3etzLapIR95HoUcOwiOTxDqxcjVcZjPw6AwaaAdG8ARRANEGfXUtRoZ3p
MNOF5yfJaGHG9sgntz/KRMtumtBrj5wXCgJnWGY4ce7EBZRclzfS1yElq4GqVth5
oRVMAVIka+CIRgQYEQIABgUCO0Ro7QAKCRCMMoz/FgbblSZAAJ9R3lBoVNcgGuYI
mYuoZPQc42S78wCggnIdM5gSdDdYXWr4UZZJfTfdDkk=
=lY5L
-----END PGP PUBLIC KEY BLOCK-----
D.3.226 Nicola Vitale <nivit@FreeBSD.org>
pub 1024D/F11699E5 2006-12-05
Key fingerprint = 2C17 C591 2C6D 82BD F3DB F1BF 8FC9 6763 F116 99E5
uid Nicola Vitale (Public key for nivit@FreeBSD.org) <nivit@FreeBSD.org>
sub 2048g/4C90805D 2006-12-05
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEV1n44RBADfkt4OUwHA7c8DbobkvhyXCRHC6w0NDQER6Q/uAE68nvEgPcdO
dAvGXUpNNWFXbKEnIc7ANCm0V7F2VDfwANAzePY1wBfVM8UQBLuSV2WIAfs1beLl
MZzO7sth2oeMuF7l7WwM31qwgRLTOOzXs7zG+m2uh1c1nMTKG9wgQ4rz8wCgmT5i
oJ25GpzaM0kgX3HQWP/MkFMEAK5GUSesXqHc37fEnO4WVvdB5afc4RTDJzvniXBm
nXkHin6uAWw4HSJOEOLPv8MtRZuIxOfznukjBpHnz19R0fEvWdRKzmDoc3Yn0BW+
FdszOxY9Nt+LtY3/ZdcbgAtWu662/t3SvgWULgCQ7bvi0Nu75Zn3nui4j2uU5fNf
6v4KA/9x8FXQ18BPO7EuYe5ewQwVaGWKvzrMmz8NsiZuRs4oxWXL1x0nSCumetKA
03UHxGAQli+vuMNDcDXg5zpaGN7hIqS1N1fR7XEouvkgTDTUPsjjQUdmQ98lnEBf
URB5D+qDq8nq7H9R/4rOmxKdiA8xmBzadnolJ69Iz9nyJ4mvb7RETmljb2xhIFZp
dGFsZSAoUHVibGljIGtleSBmb3Igbml2aXRARnJlZUJTRC5vcmcpIDxuaXZpdEBG
cmVlQlNELm9yZz6IXwQTEQIAIAUCRXWfjgIbAwYLCQgHAwIEFQIIAwQWAgMBAh4B
AheAAAoJEI/JZ2PxFpnlNbMAoJWh5Yg1lOayXo3b8seKn09ers2UAJQLxlE9lS9G
qzU9FITOFNllI+duuQINBEV1n5MQCADqyPgr+kjhfCz/2N8y3FmWr4CSE0b1S7rH
i7fy27u0QcNK3vN/l0Vbj6dsacfP9DC3+aGw3W8uY8LK8q72AIAwLh1aoYtJfzMs
v1kqY4shMAANF55VgcAb7lyHpSymFraVZCai0nzNyccjJtSNQgC9s1BkXeUrRTS2
su078DDYVgbXs1S14PkZOyrZ+0R4y4M6QKvD8Th46K+mZMaXdcn+wlIvOISFQppP
1htkyCnHexg5L6PE/VsdobiCyZ2zNKd+d6GUillVuO2Qpkq1dlLTPtRgFMnpjhRi
L0+a84b8rs6TE9g/ZLKNOmfmbGTTk3u4vQ7u6Mky6GCGO8W8WHW7AAMFCAC9NGWK
RU0l0hfHY3kjLll9Ygcnt42nAj4ipmnzMp0jAPV2AgShnzDJLZ1KHmJcUfby4I6c
HDKrI5lt6B8OD1hAWbHaAJ1Js1vfiwGDqisra5ZvkfJQMY1CDv1orXeM/ZnWzLSp
+PqVXA30ei/NtngXFYlw+BJHnbB18eKw25jT6n72Ls0T9xZscwgseAmSKZsrb6M+
N0tjZkkueWRbvrFum1i8Hf+VYhCgRkQFcTtEEo/Ulb6GRDXaFLPZzklfQMvjgWel
yfWpv5Qg6knJFGbQyZrJ/jNBAi7aM8XAuNhhjC1oHVyNlIRM1V+1MybvoheREjMY
qcdWjs5YCrg43SWAiEkEGBECAAkFAkV1n5MCGwwACgkQj8lnY/EWmeXXJQCfW3pc
YuXRQYv5d2NC5AfgnvxmjnEAmgPFcYvU/gGprH9Hz/bvXp3KrT7M
=NcNR
-----END PGP PUBLIC KEY BLOCK-----
D.3.227 Stefan Walter <stefan@FreeBSD.org>
pub 3072R/12B9E0B3 2003-03-06
Key fingerprint = 85D8 6A49 22C7 6CD9 B011 5D6A 5691 111B 12B9 E0B3
uid Stefan Walter <stefan@freebsd.org>
uid Stefan Walter <sw@gegenunendlich.de>
sub 3072R/6D35457A 2003-03-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGLBD5nXBoBDAC8weeyNQOMLmXMQ9r5UyPNpdmEsZa8bYmU9RGQ02Yb4R/81ucL
AIT1iZzot9feJq16YowWxl+BeSv2XQEjwKFB+KEz9p8HLG2Yj5XX3jO1wPHtwW4y
/zO5BwFKhBeEu/69eTw2JY3Q0cR/iQL0QKht7sPwS9aBqbWyMjaLpGQdn///P0B/
MxNZ7iXHpAQR6sKq2MUbiwWtpdlLEKLbUiPqvLGg7C88CkACqXc4NGJrWL4eXtgL
JmMv05JLhdI6nQhVNo+9WwBvcyqvEAd6i0FBTazh0SfrvVH8zQJ91QwnbsMLKo21
83GkH/p0zt19oilrt18C4IpW3mWBheTaffl4PBVH6lvcPIRkEPhZZ5tkyG67rwfR
r/vEo+//99XAwxwzGaiVKRlW2r0mVqmCLAjQpEkvfT2JiJt1okGwzCaWnjYAqk1r
EDuaCBKwxPpk3pyb8MelybP3awbR+FrkYJzZf6LqzihS6StyERJKW8QbIf/+71PF
iVciJtQ8at8n0dMABim0JFN0ZWZhbiBXYWx0ZXIgPHN3QGdlZ2VudW5lbmRsaWNo
LmRlPokBsgQTAQIAHAUCPmdcGgIbAwQLBwMCAxUCAwMWAgECHgECF4AACgkQVpER
GxK54LPAQwwAjA8bv7DeyVbTEIq1yyd+RDCEGwSRQPFxUCQW0tWwJoN0p+lNioIO
zIYy3+cqQ9rr71EMMEl650NcYibo3ECPFZrjkN9mie79gNa33hGfAaG+2A8LbkRa
HUyfRpFPmWPZ7XaXQHr2vRc6w9EuW1KGEVEEYElLM7YQSXENAqi/dN4DWQU/UFD6
wMrOLDfftVhnJaeL9z6wQLN3+lY/EvBf8vzKFr6D2T0isx61tpqydMA+/hOcZOw+
9mMJqYGWBSCp9hARDmd8wnL5O+jgiMAC7aXUWEk5uiQVVhCPxj2PN31j2YFwzEhl
2NLVOHuu0A4dFpXH7wIXT6cEIltRis3/ReE7VuTQ5oplAXl24/OPp2VZKYOf0LX9
NL6Z2Ea5rjuIQdVmXWtyJ2jZnxWqfiXiIKZoCMXHkE2eN+D+dpGWpWYWX87T0vUp
O4Wo/m3PBN6Mvey99nBgRfHWICzzVkKGBoSNSYjN0w6m5pU1F6t0W/WFI6Jq3CcU
QcJGQ4RK1zbCtCJTdGVmYW4gV2FsdGVyIDxzdGVmYW5AZnJlZWJzZC5vcmc+iQG2
BBMBAgAgBQJEXbEzAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQVpERGxK5
4LO6sAwApkJmvdlJwP/cBDD49IjKbUwjYRq5psU4dG9srDet0eLoUQtlI2KjdmSR
aXAX995xXxzaO5jMSKNPQYIoSU3Ne+TaG8/yz9Ckb9uBgPvA8kJvcr2cyIwierz8
ztvLEUV8/TAJTLA71Xzo5GBoM6wVoRXjYxZX+6ro1GagP5RJbotamn9q5Au66Ixi
J4r8xeTQAKduQKgLwZadD0b5VJr9mJ4IsUTGQYmcob9UaHorU7ja6Q7WDtZYVfqT
8CJxBBntmzlniYJXFFlvDJgiCxTcIFR3hlCPpvZ4X6YZ7uWTiK+UWrdJkJtwHu/t
qiE4EN5dn+wvRVNX4iBmRR130tswGHfzA+O8wFqlMnYhkkZt5l5sHrMalSyczyEO
3XfZEpRAcxxGeFTrMloeDWMIPBDUsKJdQhHniJ9HmjIEvh4c5IXnkUYd+pLZVShx
ggXDyUVNaWjhVvwGz853mkWsto9DAe1dib9cn6xwa+WIxhlWnt+bjDzv1KM1gVh/
p5LxDPeXuQGLBD5nXIIBDACletuXpBWOf2+nP4h+uU4gNP63bRh0bBznGnTORDJg
5vQRmO2KKt3GTAWGC5pgWqF7GULGB494uSMX7WvIfwSYhzgZ0k1DT33WyPgo7whl
JGNVyyyk/STEqijZCdzbti3zaFartl3oRl8UxJXMOC+jmt6XTnVl0WLfUkVFUIsV
shXdqVntMJkoB/iGfKsn7KvzT/tQ8pNe476uuOQvzOFcZlipzWvFmK8p37oIjeZp
ngFAleClsotOVL2VoRAdAmT6P+OxHCzk0Zcz6vz/3NA+WBxDPy/nk26Sd6suU5jb
sT5hD2IGVcjZ7PuErJkAkvVJU2CrWpH7mw0mFNM6LKwFEdPkjlbndUMqMAn4z0W6
hraotI9RySLoYJBpABjD5H7wjhf8OWu1i2ZiQuIX9hpab/RTm0jGNViothyNV6Sl
udihv2cSuCSwVdOC+v6MDKsvWwBQteMO6LG8e7OTSRCF8r+EDdfw/ly7mGJJrx1G
kwuSCQn+sbCFRxMXZ6BYomcABimJAZ8EGAECAAkFAj5nXIICGwwACgkQVpERGxK5
4LPiHwv+L+BP/SknUreGZHfnNR0tEafVQTmQdbULOIJ0herPJzoLb6pPEe0GvsWp
qQH/26hQusFrUtazAc89hYDFr3nLgdq4xiXY024ecVY2bU93Yz5K6GoiWcNwTJh3
4IcP6xr08j1v9LjgEHwFo4DkBKe02JjhAr1WcO0Gt74lJIDElIYuKZW81DT16Kly
45EPHdfjlC2PyvrhXk9fphB2T59H4DEkzlHrRK8EPr4zIXefDb82FFjVS38nD8TX
grJAG7Czq0/wCcKsnOvuhT0ICNJsSSz/QVboKCbN2upUvuWyTti6NRevaF6FDbYf
TVsdukZSt8/UBNHwCInbeLuorIMkPwcVr8r6oLv/JhWOS34y2V9OA2Zlx69cYQrp
ssmXJmwaIJQ0h6E1MQzTUD4y4VUaTvdgvEN4vC6t8NfC1AN0xErjCGrwuZebE7ph
8fLm/wloEhZv5v+UF/J1kOcxyFSQN/A/usPWgmUmmpghiRM4+Qk9nNbzoKRyfP0o
Sjk9E6QR
=iXXA
-----END PGP PUBLIC KEY BLOCK-----
D.3.228 Kai Wang <kaiw@FreeBSD.org>
pub 1024D/AEB910EB 2006-09-27
Key fingerprint = 3534 10A3 F143 B760 EF3E BEDF 8509 6A06 AEB9 10EB
uid Kai Wang <kaiw@FreeBSD.org>
uid Kai Wang <kaiw@student.chalmers.se>
uid Kai Wang <kaiwang27@gmail.com>
uid Kai Wang <kaiw27@gmail.com>
sub 2048g/1D5AA4DD 2006-09-27
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEUZ6yURBAD9qQ4Pz+LEm54dEtrDII566La8mVjMpZfp/xcPSY4Jsj9Rin4o
XiJ4cevwTiAr7KBGbO4uJ/hRwOQMlql8vzwO+Bc66zLxwQfGpLniTvdEnsRmiwXn
MOlc6Kd1SwxOk4rV/B6p1iJLZ6sXQPx9IlDskyJ0OhIYKBaYx4sjN4W3wwCg5QB7
QSrzEldBYnrxVFLHfmQO6ikD/3sW06q+gAdSFwFCFEZmE0kaCVzQUrTwnyKWlRPx
Fvk0PftHhbofybxiv3OFp/zHZMHRlcVqcYf7WRLww+QXRgFh6x5kkOoAFMVJzhYH
xKcXSnqPph6M4H1GvRVo4G1FkdqEZ5z2hRwiryugSfuzRRHil4ewpZQeB4am+Llu
H3UeA/wO4eqG62W13pRephwYO0ramQai+WV34z+DUGoKY2EMpsbE6+J85aiySvor
BTfWq1Lh5Mg3RYGWLmLay+GDQE2YIc1EUrCgHlUpB+vB+3pqPq+5ssOixktylJna
R40BAqOP/gO/sSBnCZpI9nNqtKDpONfS8xwDArEKaoqxxphD2LQjS2FpIFdhbmcg
PGthaXdAc3R1ZGVudC5jaGFsbWVycy5zZT6IYAQTEQIAIAUCRgD96wIbAwYLCQgH
AwIEFQIIAwQWAgMBAh4BAheAAAoJEIUJagauuRDrMosAoIPJziIJtz3GBALxa4SG
nIUGNliZAKC8yMp144zGxaumG1n4HZLNdaMwVLQeS2FpIFdhbmcgPGthaXdhbmcy
N0BnbWFpbC5jb20+iGAEExECACAFAkUZ6yUCGwMGCwkIBwMCBBUCCAMEFgIDAQIe
AQIXgAAKCRCFCWoGrrkQ69oVAJ9gWVClx+v3Hhvw2AjOyFaDT4hpnwCeP2ppw3M2
nNkuXRtTI3uY+jwCSmm0G0thaSBXYW5nIDxrYWl3MjdAZ21haWwuY29tPohgBBMR
AgAgBQJGAP2+AhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQhQlqBq65EOtj
DQCfZOhljB+TJQncoZWMf/CvbT5I/ZYAnimgyJtouIZGXSTqU172qsr721aTtBtL
YWkgV2FuZyA8a2Fpd0BGcmVlQlNELm9yZz6IYAQTEQIAIAUCRvwuFAIbAwYLCQgH
AwIEFQIIAwQWAgMBAh4BAheAAAoJEIUJagauuRDr8iYAn0PbQX8TzGfG4VJkI/W1
9Y2lQruoAJ4jtv0WxAV5CxIbBccVErg9rEdBdLkCDQRFGeswEAgA3/ArJRAwAXv5
AOSioc12EGWSX9bpYWfcODoJL5ggaBLQKE8SiA+evSXgvfW9AD8S9T5ltLSAYXUb
pbIWw/Nnp7w9+hC81fQI7mHoDe7oSsJa1mnyzibnqRczxy3V23cjqPLeZiRr3AkD
mhBkONQron7mk23x1lTsHCgFmxBZWxNdnkIprmN37YkiUB0ky3/x3s7BVdat3hqQ
ot3OF3i/6ugqW3qH8+Z3uEpWZr2yx5KwEJbUQNvgQqONlZsMDCp03jJuPIgnR/kA
iRFIUmGLocgOqfL3JL+l7MflVQFFlzZNQqKK+WK2kXOc/C31AsVY0YJ4CsjTQyBa
775LqpnTtwADBQf/WOJ8AztEUxh75zndmMV6tsUhq8K+cfaWR0e96zOP0eiO5IRW
Z4muIXIBC7FxgyR628XAPm3a/IbMpD0Usure0MIQkmaza5ktGXG03KCpQYYhveJr
3I69jJHUM7Vvrcl+a9wY3Ni5UgIfmWQzdpsVW707/SjZDcD9e3MWhASOThKb1wIM
II7zgKICwGBr4VSwNVdikdHJ2wNhziuwJQHFxQs8rsXTLzHeJcWJfpZ1bi1P4Csw
lsWosIFeKESAHoPsbpHHcS46cd6CXbOTLkonsUDqW5DZoN959MI8txkh54heZdXv
al72Ksb969EL5ef//lDo/ex8aaVYaYwiI0H3VYhJBBgRAgAJBQJFGeswAhsMAAoJ
EIUJagauuRDrkbkAoIe8dlhn35cPrbpcy4AtUGFlR0HTAJ96MT6WOnFqjfJJxo97
Hps0V71KXA==
=v7/U
-----END PGP PUBLIC KEY BLOCK-----
D.3.229 Adam Weinberger <adamw@FreeBSD.org>
pub 1024D/42C743FD 2002-10-12 Adam Weinberger <adam@vectors.cx>
Key fingerprint = A980 3F2E 80A8 9619 9D1C 82E8 A3C2 8CD9 42C7 43FD
sub 1024g/15D67628 2002-10-12
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.0 (FreeBSD)
mQGiBD2neE8RBADgkTfNUPbm3AVnVPn/Ds5lDO89yKowW3ULixWqJ6Mti+7sIQ6y
A4v5/dlUODTH0sdL4Cl3q36pCOP13IIq7o14h4YOjMhdMhsv43678VYK0PvR70hK
/PxqIRV3lQsP2g8LihKLpRy6sHleIXu1hRLbIBI6/iJTmFcENQfivyHpBwCg31J6
6jew1OrTLlB76aWmmRJIlVkEAII7j0gAqV/zjR16sAsfiCSHSg9A8RGBmC67zUfK
PxnrLiw0gqyrt77YnXvANGWDdIMHEZrcDBrb8ciSO8agBO2+/7mOVDVDU5I/SJRi
rfJTQvFphcnOe7F3MaxdfA/vZE9woXq4JLXfnmcgUAey4iYB2QbV/+v1HBo6wys6
qyDXBACMsXFWZbDNDwUZBxGVS66bLwpZ/UhWqkrAyvK/7M/HQjkFTUUX2fSTPnWh
AkcA82asPxQFTdbd7BOs4JnXUY4m+wfP3pzGaCbgL6WYumRjvmvkmeyZtFD+2wxL
nu/F3oO9PC2f4mGa6E928BLy2bRCV75L0OMmbR5Fd0Z+95k3kLQhQWRhbSBXZWlu
YmVyZ2VyIDxhZGFtQHZlY3RvcnMuY3g+iFkEExECABkFAj2neE8ECwcDAgMVAgMD
FgIBAh4BAheAAAoJEKPCjNlCx0P9I7UAmQGWPEjqlXfxptWgb5WKskfl+rkkAJwI
OSvOdiBFM7/EBBgn9pUQ/6PVUrkBDQQ9p3haEAQAzc17FQj9ePY4tW2+nWiQzj8I
GVG+8fsVwFhDb4hFcpJxPiR3/J07tU4iyKek/qUiOQdW/dI30vm3rOSIUa3r9iaj
OaJilRVDO3ErUCdcrJjGf+fTWZFa8t2TLwOooyV8tJ5IUYLwJ8s7/3OpwWh1pfCQ
qxGACCiXeKQo0a9jxJcAAwUD/35x0sm6jV2OZaHxX/JteeLu1hJOE4hc8oRqiE93
4j8frz33jIsRFpKJ+H28LXtRmVXtVTdq3RuHll5JRCMG+IPLT3Tns/d0L90twpOj
4r+2BFIK6SYE6JYngf+J5clwve3vE7Y/b8NbSawEApvVxdrpsevGH0Sn5MSdiukm
EkJviEYEGBECAAYFAj2neFoACgkQo8KM2ULHQ/1NRgCeJ6ZJYvc1oOUBdEKd7SoH
rFA6N/8An3A9ukQlZm3lPMutMia2vnsb108k
=0qTN
-----END PGP PUBLIC KEY BLOCK-----
D.3.230 Peter Wemm <peter@FreeBSD.org>
pub 1024D/7277717F 2003-12-14 Peter Wemm <peter@wemm.org>
Key fingerprint = 622B 2282 E92B 3BAB 57D1 A417 1512 AE52 7277 717F
uid Peter Wemm <peter@FreeBSD.ORG>
sub 1024g/8B40D9D1 2003-12-14
pub 1024R/D89CE319 1995-04-02 Peter Wemm <peter@netplex.com.au>
Key fingerprint = 47 05 04 CA 4C EE F8 93 F6 DB 02 92 6D F5 58 8A
uid Peter Wemm <peter@perth.dialix.oz.au>
uid Peter Wemm <peter@haywire.dialix.com>
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQCNAy9/FJwAAAEEALxs9dE9tFd0Ru1TXdq301KfEoe5uYKKuldHRBOacG2Wny6/
W3Ill57hOi2+xmq5X/mHkapywxvy4cyLdt31i4GEKDvxpDvEzAYcy2n9dIup/eg2
kEhRBX9G5k/LKM4NQsRIieaIEGGgCZRm0lINqw495aZYrPpO4EqGN2HYnOMZAAUT
tCFQZXRlciBXZW1tIDxwZXRlckBuZXRwbGV4LmNvbS5hdT6JAJUDBRA0OJBeSoY3
Ydic4xkBAREgBACBqWM1pZHF5MqOpsxyCeNdxsp8VXUSoReSmaZPeSY5caIV0NgN
cUw4AdSKPOu2jDeRSQNzkUk7+/PyK6k9dunZJS4Dnze5QqvTUgi+rHYnEs+DFBRT
CcMERiSftaP3gDqK3XyWgXDvLXxAkhiWp9yd/QsnZ1+ahz/qACVi+JxdB7QlUGV0
ZXIgV2VtbSA8cGV0ZXJAcGVydGguZGlhbGl4Lm96LmF1PokAlQMFEDGxFCFKhjdh
2JzjGQEB6XkD/2HOwfuFrnQUtdwFPUkgtEqNeSr64jQ3Maz8xgEtbaw/ym1PbhbC
k311UWQq4+izZE2xktHTFClJfaMnxVIfboPyuiSF99KHiWnf/Gspet0S7m/+RXIw
Zi1qSqvAanxMiA7kKgFSCmchzas8TQcyyXHtn/gl9v0khJkb/fv3R20biEYEExEC
AAYFAj/dD9YACgkQFRKuUnJ3cX9ejgCfbm0bT5x6nuCY4BD2scsMVKV8Pb8An1lj
aVb0KRqDjPRrd6FUZoMGWT/3iQCVAwUQNA+txx9/qQgDWPy9AQGHRAP7Bzyo2Hvu
049m44kNFgH7Kkg60SetOcYWzGKVe1nEEvBKWCMgICCfh5nHY1q/xv7pQjCBLQS4
tfl8gFBK9s9kyCS3qSNRposFeHRAIPOweGBJxXFSWhdxkAklSoa2x9xPbcOTGUSd
gHyAyIl4DiXmplB3/cOpDSH2hmPwp92+Erm0HlBldGVyIFdlbW0gPHBldGVyQEZy
ZWVCU0Qub3JnPoiNBDARAgBNBQI/4zjgRh0gUGxlYXNlIGRvIG5vdCB1c2UgdGhp
cyBrZXkgZm9yIEZyZWVCU0QgZW1haWwuICBTZWUga2V5IElEICM3Mjc3NzE3Ri4A
CgkQFRKuUnJ3cX999QCgmUQdMERtr8TqSg0FRMmOilnHEcIAoJtnsVDKUAKfdtep
mV92lCYIxEtCiQCVAwUwP+M43UqGN2HYnOMZAQE6PAQAnTVrljiWVWjKinJS3yXJ
5aRuymGUww1KyrBuuR6rK585tPhSDun7ADXhv2irpvV0mJvByXAZGccvkasxazi3
GsgvDHQ+Xa7OB3LV2tBuVc+3gc8wSmLV1bjp2L6/F5j9udR2ThGxLAM22XTNlcdV
gbg29tovg/44SOIRyo5Xqx6JAJUDBRAxsRJdSoY3Ydic4xkBAZJUA/4i/NWHz5LI
H/R4IF/3V3LleFyMFr5EPFY0/4mcv2v+ju9gbrOEM/xd4LlPrx1XqPeZ74JQ6K9m
HR64RhKR7ZJJ9A+12yr5dVqihe911KyLKab94qZUHYi36WQu2VtLGnw/t8Jg44fQ
SzbBF5q9iTzcfNOYhRkSD3BdDrC3llywO4hGBBMRAgAGBQI/3Q/ZAAoJEBUSrlJy
d3F/lX4An0WzfBUeF0RTqfr3BuK5BOZd2zEdAJsEfC2B8HKf7u+izDDf9DuwOKAv
hLQlUGV0ZXIgV2VtbSA8cGV0ZXJAaGF5d2lyZS5kaWFsaXguY29tPokAlQMFEDGx
E+pKhjdh2JzjGQEBtYsD/2rUV2eeTi6ekZCwbfVBu2vgDNpAPmb8kcjiBGZKZuPq
W4kyA0bd+k7ToZ39nu7HIIkHylOy3ZrwL+WM5hnFZP7m5LORBd4yLlxhwjWxltSm
Qe2ao9brbeGvU8HdksDVMhxNtBb43MmzFDU9zpcb18aRP1ZdBbdeF60A/6O5VMCE
iQCVAwUQMwWTcXW7bjh2o/exAQEFkQP+LIx5zKlYp1uR24xGApMFNrNtjh+iDIWn
xxb2M2Kb6x4G9z6OmbUCoDTGrX9SSL2Usm2RD0BZfyv9D9QRWC2TSOPkPRqQgIyc
c11vgbLolJJNeixqsxlFeKLGEx9eRQCCbo3dQIUjc2yaOe484QamhsK1nL5xpoNW
I1P9zIOpDiGIRgQTEQIABgUCP90P2QAKCRAVEq5Scndxf/DlAJ42mhP1IL7KSLcu
XzLycYhfZMF3GACeMpnznDS81f6WxFoZMk0NX8WJzdm0JVBldGVyIFdlbW0gPHBl
dGVyQHNwaW5uZXIuZGlhbGl4LmNvbT6IdwQwEQIANwUCP+M4HDAdIEFkZHJlc3Mg
bm8gbG9uZ2VyIHZhbGlkLiBTZWUga2V5IElEICM3Mjc3NzE3Ri4ACgkQFRKuUnJ3
cX8vqQCeMnLOym0UOXg67aQWRLKRdmk+ez4AnihpiTT3k/FSD1D3ufrIU8b6jEfF
iQCVAwUwP+M4FkqGN2HYnOMZAQEryQP/SViHEK6K9A9kQrFvTxXdPEWSKPLOz1ML
y4pqGJ5lqKgrk30b5DyqdOITaHKy6JUbqXa8yYHYIcGxavpghMaNqf19O4zakL03
j+EIpgkM3m0kkfOfgSeQDpNS4QecP0ZUtqvZAPdMH7252gsIWhXufYuoXR6Rz8Yu
+Ueb4KSZa5CJAJUDBRAxsRItSoY3Ydic4xkBAXQOBACpjRZY/ERfR0LKCN1Gm572
KgFjecAsBAeLvmX/M6ujh4nNt086CtUj5ZknQRNXV10Bkumog5C0/sTnXnsDbO53
1CHB/wwY0rpJQDicypYlz0FuxJLijcMuHquW5fo9xwdu4vlgV4Z+jmjTUGOu+Cxm
keNRBquOFqOQE3CInIoP84hGBBMRAgAGBQI/3Q/ZAAoJEBUSrlJyd3F/2noAnAsB
UsEvLVczD6f4yWR0Hr7aW7RFAKCCv30Zh8Xz29ZiePY5rBfRNs5p4rQgUGV0ZXIg
V2VtbSA8cGV0ZXJAZGlhbGl4LmNvbS5hdT6JAJUDBTA/4zgjSoY3Ydic4xkBAWEI
A/9M3nKAv2c5QVVed5uhiElOPt5P93R2JigQJxHps/eMDcI9ZMqbyi2XsSQa6MjE
RUyqaa7MVtoODWamaLxRx/86YaFJ58eVMvlmhPE9zBSliwnRflP43ilwsGOTdBOi
NWil5QpxgDeWVsjpxcE9QgN3oUSWp10IABzdZRgQUeHwN4kAlQMFEDQRBydKhjdh
2JzjGQEBJkUD/RF80uSrMZdUWgCkWZxpZbLxeI7JHyDdb/yt1dZwj6a2UdR4zYZb
uJUiqBVAP1/T9Sp5JiuZYapuOu4xcMVfz7k2u42FUWlYsQp1/iH6mceABdXYjUuh
2NQvH25i1OjQv1awOVp75bSOKUMF+4fDRDb9EV5UkutJG1XkguvC74XktChQZXRl
ciBXZW1tIDxwZXRlckBoYXl3aXJlLmRpYWxpeC5jb20uYXU+iQCVAwUwP+M4J0qG
N2HYnOMZAQEB1wP+LA9S3CJngcL/shPRsero2O2U0XgIdOTSZMoJmTyQZzOUy4ez
o7ZltMYw38WpPBhbC7emTuuBLD5LOW4/G2RHP1ifB2gZrXq7LG89ZZITPGLyIynM
iF+IYHx+E1gLCz0fVBO3EVT3nChxXYndj/utPKTw/7v78/k58liosWLg6UmJAJUD
BRA0Dvq3SoY3Ydic4xkBARsWA/9HWzohwzoCupAVpdlalGOAaz1og07bWcGHiD54
5ziuY0qRU44F0W5P6b+TlclgRxeLlnmWHvugfSx78uthRgRXVVQdLjjq9jHZ0sCV
fR1Xq/KtBiHYrhcEvj0O8facILlZwrpYdVNGzP2jlef0iRimVDJ9IJrqmItZMTC0
nB20gbQoUGV0ZXIgV2VtbSA8cGV0ZXJAc3Bpbm5lci5kaWFsaXguY29tLmF1PokA
lQMFMD/jOCpKhjdh2JzjGQEB8PMD/j3//QRFuCrF6bZ+Y2DbuW7Niss9aZ+EC1Fp
ZVgZcW+cMLXXWG0U2x6bt81f5CzDmvAtdgAWAqtBusZ5CRIij4E7mRdqTTpxuncp
bno5tlEiHtWPrJJh17wAPDQhSj+PhaZJAuSege6Pk6fmlJFd7t4X9US4Ao+c7xoF
PU+Bf/kqiQCVAwUQNBEFTkqGN2HYnOMZAQEbxAQAuQ3kMgykHW5VdLu+QIE4tlhs
Zrqz0c5AWtKcmp3p917qusaENeOciuZucVeDPQrvEoaIeRbbGAZSrlvoZmw8gDyY
5qakVvd2bqee4QxpIVGGldpwSxas/xKN02ZqMYLLyyO4z8Zj7oLaFGtLnooiKXFd
NHQZKPZ7NTkNF6scjOWZAaIEP9wv6REEAPJ+eB/ATOWQ9xhudn+Q4RCP7JNN8yXL
tUIpP+TrISKWVwyxbA2Nia4cm7BLoMXuNvcePtQfePKgQ9VjKly+wcTdi2DMtGom
MqbKxfPeR56aX8GtjAL2OuGcUViHDdqj72nHtxuW0b90NXI2kmdQ602BJc2tdB68
wosuvd2FQXlbAKCj+CZr//uspel6cVTMj5/OYDcSYQP6AvUVKqB48ClSUHeAn4xv
SVYdwRx0XOveoovjzO76FAGSqZyjmS3u346epqchopUDIZyP+gQPgnSgIE+a7GJw
aKCWVDDG7A29rZ9yxfGbChN4JhQwR029jIiXbC7+/g7a2hMs+JRa8kt1upRyQnS7
xN9M8vkNxNCy1DcI2s9GrUwD/0QGxLawN03i4FzxWXNVbkoHDnjoy9y6OMHcyCc+
9fpVo2/dLkP6mmM6jDtzPmhRB6sQiiwt8nmPEQNyJ0t2XaCKV7H/0EnzP/gvGkPk
jVanTs2TKVmJ6HKEz71VtlNe47YjexFWjDYC75oL3qAliIVZBnBdFcOwOVXnnFkO
kPdKtBtQZXRlciBXZW1tIDxwZXRlckB3ZW1tLm9yZz6IYQQTEQIAIQIbAwYLCQgH
AwIDFQIDAxYCAQIeAQIXgAUCP+M5sAIZAQAKCRAVEq5Scndxf9QyAKCINvg2tANg
tPj9gjP3yds3IjLDqQCaA+t0nyL1p+YFkA7M+kOuGIIvhyyInAQTAQIABgUCP+H/
6wAKCRBKhjdh2JzjGUPCBAC4/X+gbycm5wlXEllp2zLg3GQX2MpQ09hbf+uvzhdv
7kSliLEkDlwe/i3kJGDrELhPwQiMlSHHTpRi8qSjB1fiJssOCT0bPc4ZgK8seMGq
kifu8OAjZNU9aGa2NxS5h7UrVWhwEt8G5LtMYIQM63h9DqsnE+o6FcbeR5AgMvr5
PbQeUGV0ZXIgV2VtbSA8cGV0ZXJARnJlZUJTRC5PUkc+iF4EExECAB8FAj/jOY8C
GwMHCwkIBwMCAQMVAgMDFgIBAh4BAheAAAoJEBUSrlJyd3F/qcMAn3QcesapMg30
ZHO66AkrCJXU5RODAJY+rXGUUuZvkGBlLvoY/RRVNZ0PuQENBD/cL+sQBAC8XvjG
8k6ZmwcTbymtfdUo3HO4I8vPXyAl2yca1srl0Hg743hI9YTkyrVaS5F2jtQLzOkr
8ivhiRCy4jFGMUPKMCnAWNCT82UW14xPvBrvpNwQw9o91IkuaB0OCu+UWdqgdD6S
jy/3govRbKzkwFt8p7prjPYiAaCAa/2Xj+nDnwAEDQQAk0EKWZQ3Ehzi4/xDCiGi
daIGuebke9JQdKIT6qVHFw7IgljTlhOe771JyxNVq3NUF9XsWBirbELQ3/Yn0Ts4
Dfk/i/8fT7OMv2h4/btQGKF6cawrdFLqB8bJicv+use//gWE95+wiXX2XM216MGd
3C8f932CcSTYXYQYYEwnkgGISQQYEQIACQUCP9wv6wIbDAAKCRAVEq5Scndxf6Xa
AJ92UAmSdqxsLia2QHbHRcLfifePfACeO0dqdCjrEkyPGGahXeDcVrvpO8g=
=7AWH
-----END PGP PUBLIC KEY BLOCK-----
D.3.231 Nate Williams <nate@FreeBSD.org>
pub 1024D/C2AC6BA4 2002-01-28 Nate Williams (FreeBSD) <nate@FreeBSD.org>
Key fingerprint = 8EE8 5E72 8A94 51FA EA68 E001 FFF9 8AA9 C2AC 6BA4
sub 1024g/03EE46D2 2002-01-28
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDxVl7cRBADbXnR4t/xRvvOSiPuGPnOGeamrphPbpPXsWD8Nm/pjfN3fhSfa
0gv3Y2n/IyLTg93gWZhWloMznkdg59Oj0oPSUxjgPauVw4q6l3JJIcurJNlp/Q7l
DH0KLFJ8GuL6zxAz7Jcx1BpAIEu+G2SnI8+ZuGvq+YwaDxPFavfCqmVaBwCg/iPu
OI+84/W54yZXvxfUN7dkDmED/3CxYLGeWqPqE8B8Eq8BlmgfP/FwaqXXb6xR7jsE
XBaqNOIita6Iz49sYTYKYY2rMv6dMXjX1FM13wNW3rS73xkNvuJz0WU6sWl9Hw1e
kjNjCN2oIqkqB5/1H14NMSOcUPLqERP7goFIK7OAJejUmm5Nc3KjG1S2G97xxjPe
39mlBAC0QFfa8J0Z6TORFa8Uqyx90pC/Y+I/S+y0vP/59ReP/PnQq/aUdDPLt5OZ
edtpz7M4A2GtoVkWtedPRsw0hYK+Q3CtOMemQSnlfVjTZq5edL05Po09N89M/WMz
hB9aRcdY7IN/btsQ0H12ZH+rEj+O4Adu+qEjsWePfW60Uj74GbQqTmF0ZSBXaWxs
aWFtcyAoRnJlZUJTRCkgPG5hdGVARnJlZUJTRC5vcmc+iFcEExECABcFAjxVl7cF
CwcKAwQDFQMCAxYCAQIXgAAKCRD/+YqpwqxrpMSwAKCVuyt4B1Pc1tAwRMEOmmZw
2nGIIQCgyRvB49snyBl86TikYv97ZifyLmK5AQ0EPFWXuRAEAIghycOZtElvBhfw
r7TisjtVtzKhbF0Kj9cGg5brCC8/bJLK7PxNe48NSdlqMJ7algumsgYR37b/QBmq
sOSEa2wXCnvCSD0ol+bdPn+Psb+hyi+AVNmVgdlJwuxHUHny0lWQnxeQLrt07SAw
Ye/Nnc+arH6GXzBwXSpsQ2sOaMajAAMGA/9Hzjkv6HmJkPlKT2TNx33mbLaDk8xv
vAJXxogxDcUqDDwqszWPcqShaW0IkMZo+grZfykZJjA0/8QUCaEUwhnYIwHMQRdA
uNegCF/D2x4yzkF4d9gKYCCykDUrwvFDztIhGkinyzu6+xwe9qFcL/esIxnnonz7
Wx8/3e7pRvS2QIhGBBgRAgAGBQI8VZe5AAoJEP/5iqnCrGukuikAnAt8uA1EIv/5
WDCIpvNp0lgmwes9AJ4vD1R35+Db6UIw+R5EJaxNBY84zg==
=xbGI
-----END PGP PUBLIC KEY BLOCK-----
D.3.232 Garrett Wollman
<wollman@FreeBSD.org>
pub 1024D/0B92FAEA 2000-01-20 Garrett Wollman <wollman@FreeBSD.org>
Key fingerprint = 4627 19AF 4649 31BF DE2E 3C66 3ECF 741B 0B92 FAEA
sub 1024g/90D5EBC2 2000-01-20
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDiHU3wRBADX+GS3fClPc0K3s2RePf2YeV+w7X3cmnWb0FLhAekfIzjLSHl8
PWxXXQRtFyjR4KpsiwpGusX/nIJmaEoAdyqROKvpqYZPa3CjI2ldq1t1mj8lUOLo
+ktQvgR/fZoveOl+HT1yIRZDsLrQWYE96lC8Xx2Iiip/16whzhE4rJfWvwCgyb+G
a2jW0JaqmVRmyEqwzudoeqEEAKNUV5lmGRcs/GxwAJ7JRcxMI5QtoUBTfDKYyJZi
t6pudVC9STIpMoEw9m4c5KRFixdiHno/dbkECvSzpTA1qAHiC2WxeTXAz91ySTfk
iGNVlc670A+eC7Qi3ZGYhWKgKAvm0hOlYxOrU83u9naHKA+l4dOIGCQoZ7ElcfdO
77T8BADQG/nzZcaoS0o9za11YcYMAWDiEHX2JyWF7+O+qJc7UmAGMZ4YHeYOBTkT
6ybzjn5JhQtSr9YQglweYFjFYdeOmQAYow1MJxJvh0e0eoXwzOgdwJ8fzbxpHeAQ
W9uuI754sm3U80ag7RvzgeWRX7HdETCtbFF8ZCWHSE7sj29ZB7QlR2FycmV0dCBX
b2xsbWFuIDx3b2xsbWFuQEZyZWVCU0Qub3JnPohWBBMRAgAWBQI4h1N9BAsKBAMD
FQMCAxYCAQIXgAAKCRA+z3QbC5L66jfWAJ9QRUBS9u2D9s861txzAAGDur0x/gCd
ELqxcKVno9Q/l0DFb6c2ZIlkTT2IRgQQEQIABgUCOIdUpAAKCRAj54bpvu2UbtDT
AJ9anhNRzF+bPhzGsoVJG1M0+aqsWgCfV6grZerQHY0jrzh7AcGCMNNDNYaInAQQ
AQEABgUCOe58UwAKCRAff6kIA1j8vYq/BACbNYb6vCIi7/qEYF6dcBrEKf3sQ9mR
U+ign91BqI1XR6KWREzMb7C/j/8ClreLp+UYpzf2dGiMtg6wo05VM9/wNTgQ9XGQ
lm8VHRuMG6nKMxzMmugVhoKM16g4ongkLwV2GP7i/UULLl/YtBY0HHeZrvX5dFTI
e0I71GmWy38WDIkAlQMFEDnug1NNVigheQUMEQEBX6EEAKTQbXGBs5XC1NuI3UdO
DRvpRnzwY1KXlcJNWEUBFnwKqNdu23XyWT9VoMSHQwntTH1LkdYrrZJDQIlCchHS
bRoobiveoUEqqHtWx9enhADBbSyl+SeDanOd1rx3jieplg8rseeqS7j2k5EUCaus
wsk2W7zn4mpRNR25WuO8JOhjiD8DBRA57ojmGPUDgCTCeAIRAvbfAJ9SwgJaBMEF
FYpRIoNsgvnHRaBmvACfVf1DdCW4EiCwtstuphmkZU9uv0aIPwMFEDnuiMGI4Xsd
/OVlYRECVBkAnRJA6imAt+d9i2csxiReRI2xCrC/AKDjL3Wlp0ustkS1SkXiEZmX
OcGfk4hGBBARAgAGBQI57oOaAAoJECAVMdWEXf7dfowAn3es+GZFfAzNl1BY3IdA
kHBkpybbAJ0SghHeM67I6UvsD3OY4aKDu7D/g4hGBBARAgAGBQI57pd1AAoJEML8
hqolOUaLhLEAoOj8APJHlYELhru0tPRZSfZYovDmAKD9rBzlJZzxeN36SfwkYiNW
nnl0A4g/AwUQOfXFQNjKMXFboFLDEQK0OQCg2TuAY5h0Q7dgZgDe3dW/1zlLjskA
oOFLVMM9s8oA8sTCTGAMqnca/3GduQENBDiHU6IQBACjT3ldbYOk2zYwEcaYhxom
HuhAht9WhqRkBstdrJbmHw04zMNdRyodfbZk/DunKPnYPjSXVL2m3aXXdzPLXmMJ
WTA7WykvMxBZX9A7GONMwWKOoZcEJheNagfgOa+be4rZ/S19AnUDBXQGDCgbXlYa
BCrSRuAmfOVQ4VLW+3OovwAECwP/Z1P1kKWACm9Ual6GAlk+R1pASGOJS2kOyYkt
0VvV9BBfYaxD+4E1xp6T4FEkdQk2Lz+91q/b6z7CA0Ed/2yNtm1HmVGyMc5yFRoj
U38i0Lrxf0fo06g+ewwIXXEEuZrdGEFaxQpWTZ/uCFiGe1wtnGT91B4FDENxuIQ/
IbrSxgOIRgQYEQIABgUCOIdTogAKCRA+z3QbC5L66mpDAKC1YD/4KeNybL31f9B9
iq7OH/kskwCfeEvJINcMBk0UEdjpgO85woB6QKI=
=stB+
-----END PGP PUBLIC KEY BLOCK-----
D.3.233 Martin Wilke <miwi@FreeBSD.org>
pub 1024D/05682353 2007-02-23 [expires: 2009-02-22]
Key fingerprint = 0015 BE4D 349E 4DA9 46A8 4BB1 170A 7270 0568 2353
uid Martin Wilke <miwi@FreeBSD.org>
sub 2048g/B3BEE707 2007-02-23 [expires: 2009-02-22]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEXfb0URBACpP2zumJYTzhsHZyKsUnKrMNHjt2b9B+pOWxWJuxyozdqqdFew
zJo9s2odwMhAjyeM8Ad5Z4vjIaPAhUbIfNBuh1TYKKtAPhGpGJlwfo6yw5IIO5yy
2jW8Eg9ui5Q4PW3VvCSftHYLFgRIQiKINeHLvd61ZhQ7nD9Kelj/AzVLgwCgrqtO
Iio/laByeyAA9aXWiV1IAkUEAIWJOj1tIcn45jt20TVw9j0qbRXWstFkwuNxy1yU
zwO8aGPIKO3osqMZbFJ16qK27z6d6KsnVVY+Psd5TP6t9lnt6wz4gW7CnuLgBvyw
xhBbAJGLKPeqJGhM7cUFdpQKMxM6o29mJX0uKF8VtjuXD0gCiYGJ810kP8YV5Yg8
8I0zA/9UhgHcHfSREd30xRR3fqd2HTvUnHHnDXMJM4X3hORC63B07r9Xh+/KT6h9
/lD3HSQtFB+aPtuRagEjnofS7z1OV4pwZorJ3w1h9pLvLaMD2QZanVz5NMXBhEge
NjB+qIxeUrtodjNREGkub4eIt0btK8ZJFKE8PTosGgh/VgBiELQfTWFydGluIFdp
bGtlIDxtaXdpQEZyZWVCU0Qub3JnPohmBBMRAgAmBQJF329FAhsDBQkDwmcABgsJ
CAcDAgQVAggDBBYCAwECHgECF4AACgkQFwpycAVoI1OMBgCggnTYBWo2PBRGtEN+
3LTfB2cZK2oAn02cm3rjpYnoK9xWrmufTmGDEkgauQINBEXfb0cQCACe0r4ipQiG
NyuobvcNK1YvSIE4l9zMZSUIxkSf47Z9i/+fLkzjh0V6ZORZvFXFewzHXqugvmHZ
c6OkNJV/Wi/SumVfMZjhfetRBxZVTyMKj5KXn3VEhY8/xlktbpCb3/j9xYSP7Isr
vpPrN/uV0KuJBOxYv+/L5nJVb+JGg6Hq4GlsvlrCf1FsZJH9rtIZqN3Z3573bGR7
zilrD1soG5VnQRWlhEfKVbdUu7s+8tA0zBCineAUvO35pcUhuDjAz0MNPkTRDQb4
zahe3oCwFNZtneoloIWir7N645gnU8wlaEaAfLopfRlZajieGSQbtbGJ+61OXrft
DBz+hgKg3zpPAAMFB/9qerazeS79oy7bRW7T5OvIrhmyR/YIL2FB3BCpIFU6djRM
PVytE18MMhXesEq0GsPNvAunZbTrVZXoGqxhOagIaRIPoe84PwAWEm7rcUSFXdea
BQvaxjgYpsRuJRTrP1q+EzjVc+AybcWw+GPbDS8FBVCCGWeDbxw+wrHpyPJzJog6
vgGbpR5Yx8a91MXp4vNFoYIAIwESAx52CYMPGO566EYtLRzsyYC6sgvq/7Cz66Dz
yPhZ77cNi9UXBzl6nKcA7zSrwchG64CC35aBtB5Fvyoh9X8rU/AHAsIMKZfOABdD
bx4SPG1DZSiANQA6+3lg+u5OC2ck2UZL+E7Ml3w6iE8EGBECAA8FAkXfb0cCGwwF
CQPCZwAACgkQFwpycAVoI1NjeACgh5Oy3aAD8a7JteBaP1aatIcJlB8AnRw68QiI
afk0yZjXS9DwfZ+NfvQO
=4d2O
-----END PGP PUBLIC KEY BLOCK-----
D.3.234 Thomas
Wintergerst <twinterg@FreeBSD.org>
pub 1024D/C45CB978 2006-01-08
Key fingerprint = 04EE 8114 7C6D 22CE CDC8 D7F8 112D 01DB C45C B978
uid Thomas Wintergerst <twinterg@gmx.de>
uid Thomas Wintergerst <twinterg@freebsd.org>
uid Thomas Wintergerst
uid Thomas Wintergerst <thomas.wintergerst@nord-com.net>
uid Thomas Wintergerst <thomas.wintergerst@materna.de>
sub 2048g/3BEBEF8A 2006-01-08
sub 1024D/8F631374 2006-01-08
sub 2048g/34F631DC 2006-01-08
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBEPBdXQRBACT86OgiQJqRNqy+gSXuAmYH5Cpqz1iBuv6o+uye7O3x6cTLg/r
5JKnhu+rgW3fd1QgAZn07fwjcJQLAx5BcS/3R3aGYS+r7IH0M1+NoENjwXjOed2B
E50r9DYyZjO+GtxqAp0SQI59aZOTaA3UDV0sRzM5xn3i+7P0GoBSHTtszwCgwVYb
ixCmah6KYSvA7sy7RgEk3bUD/jhSchFtQV64L7AuUbci3plpwFYweSWYliFNjlL/
g41uPjhIP5L38yG2R7sDY7sjdnvJ8b9ZTB43uCe6/HxHNTj8zX8i5c3AP+KxS87D
NGnrcAYS2eR85w+EdGGQWcDMtQj6/JoW8BF8VdmDgpOmVMlqxrtGcQcY7fxUat1q
slJCA/41xOy+1aJgWak2JRhOMEeyb+k0bTFKWUIZiVHIGk8RbegW0isRa20Fj8r7
hT+oNEeCtIRyO16z3koVzZ0gLA8+JUPn0wEU5VuKpNsqiafFLjYy/mjaxlt7Pscn
d2V53y+usYoOLFQs7GQooo6PPh6GluTBooFqmLea3U0CTs8MCLQkVGhvbWFzIFdp
bnRlcmdlcnN0IDx0d2ludGVyZ0BnbXguZGU+iGEEExECACECGwMGCwkIBwMCAxUC
AwMWAgECHgECF4AFAkPBgKICGQEACgkQES0B28RcuXhHPQCgrf5qxNn53vvWganB
OLg9rU482DoAn398pRFSUp5aFo7Dz9+1e0wY+JGjtClUaG9tYXMgV2ludGVyZ2Vy
c3QgPHR3aW50ZXJnQGZyZWVic2Qub3JnPoheBBMRAgAeBQJDwX1AAhsDBgsJCAcD
AgMVAgMDFgIBAh4BAheAAAoJEBEtAdvEXLl4uEIAnjRG8femt+4gnF68wbKZJKnF
eVcOAKCFNb+kdu2S2iU5yJehGPC2Yfi4VbQSVGhvbWFzIFdpbnRlcmdlcnN0iF4E
ExECAB4FAkPBdXQCGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQES0B28RcuXgg
6QCeOPFerndygwnAqnSgBEOXKl8jhpUAoIPLowj1HWWdva2jId1LfiuIdu3qtDRU
aG9tYXMgV2ludGVyZ2Vyc3QgPHRob21hcy53aW50ZXJnZXJzdEBub3JkLWNvbS5u
ZXQ+iF4EExECAB4FAkPBfOECGwMGCwkIBwMCAxUCAwMWAgECHgECF4AACgkQES0B
28RcuXixFwCgjqi4KzU5QCpXPIAxX2pI0SIIBGAAn2qA0BNdstMGSPqCKuk2aeKK
qr7dtDJUaG9tYXMgV2ludGVyZ2Vyc3QgPHRob21hcy53aW50ZXJnZXJzdEBtYXRl
cm5hLmRlPoheBBMRAgAeBQJDwX0dAhsDBgsJCAcDAgMVAgMDFgIBAh4BAheAAAoJ
EBEtAdvEXLl4n/8AoJddHunNAucAY+h66q2tF3hVIkwxAJoDvR58qhnLKR5zMIBC
dgXKrtddILkCDQRDwXV7EAgAxeuBjuCZYxu9VwWjra5SIuPSBvGtDXFZ+8AVl6YZ
12wi/KtEQvB3viClH85CYu0CMi7nV0DWjDsqvot3NitKBLMnzxNWp2NBM8btCIRW
m1/nmM/dHDrbbEXDQeLwP5CTcK9Lq5x2psoLYLuuN5dxXGAuyOekfRpO6rVuLAvU
r5lrV8Yr2T4Wwhe/uxZU3JRww7JqPjaEHT/AlAGwVLqbtPLmdgwK5Bb8NRAvxEmm
Dea5ypFUsLQC3C297kKZ80I4cBXj14iBEnceB+M/kHH66aD+6oecTadCtlWh3051
15nZFVZC+rRbf/VazjgXN9KdUsrxJ4hPAK9dCPjV8Z7eNwADBQf9E/Q0/OGNmGA6
bdJSNvPSBD7i+RXkVRI4AiWhYLTw3sAvD5Zb4DPuSACwsoZegNqUqHH/aTqrb7Jg
yQVgCBXUHsu3Kjjdaz5VgzLI/6v5nE7vyVaL80cU8xFnRdLKLCZ1S76bsGGnhKHQ
7APJTTXX3TusdVKFo0tdx3o4oSBwRt939p74N33/PLp6NTpg2uNa2R29O+d8Ib00
F68GuUmUMgGFpK+RVMgHO0ON/DGQjytTb5C8reethVstFXRnw7318bYdloN7wp5V
KMuaVvR8sHcUIqpC+eYXJw7GxZO+4YRMAb3rkVN+AIgeoS7EnU1GbgyM6yXWV/Qo
2xHt2gIwNIhJBBgRAgAJBQJDwXV7AhsMAAoJEBEtAdvEXLl4r40An01vu+UirSJP
ABcaIIYdh5NW8fFOAJ9AosnjpsIlvpO2Rblw6tBoAvdxvrkBogRDwXyJEQQA7zb7
/Lc8rllk/qKxtSK5USD9qc21tjV4oH8cX1pAzVfh67OqK6EWofRBejKs5z4wuIGU
pi8I9YQa6o+TBe4Z/w0ZupWwoNxFtSKXedWPFplJ/GkMLZtIoG5n6Uec4zfEXMNV
yeIMDkioZE/9AiZZXK2r5uKOFrbp2jutZIfIPGsAoKF+KSKZLfSukvQGySH/vVTt
MwzZBACWeSOP/Iay+yK/oL5u+9ALiUpcWglFMHwaNbGUxGEIFptO7Zdk/K4uMrQh
mspPzGT3FndAMoamA0Wq/OxUBJVjrUvSzckR/G5/MpIXuXjgYwrCuqf8B4PYOeRo
2FKRHRcVpBRlQBC/pDbmvgx0Vy8OFoluOk9tgvWezOB5DC9GpQP+PsmlUePAbGI6
/sb9tEfbC+8cjsaRZL+LGCSfXOn4q2jFhVxdY3941N0wwFu5cSzxp7iXFVAiGI9H
qk1RapQ6gW+GTO/K9hVbccLXB3tdllpHJKRM27HXNieXe3DJ7tJxCFFfhGoPWpcF
kQWy45AVPOWzSAWoLC6ecj9Ukouaij+ISQQYEQIACQUCQ8F8iQIbAgAKCRARLQHb
xFy5eHBtAJ0SPgJdqpiKhzRCduBUr0vzOHqFoQCdFG3I2UC0Pb6Peszs8HZdVeKm
NaC5Ag0EQ8F8sxAIAMi89otKQxeJCb0LKBtlrq3ogt3RCQPJ1sPir3D7EBm/VkKC
WhlbliF75VTW8qWD2HA4DqPU81N9o7ZjCMX4Q2LwzfCv8liJ+ZXlHZsPuXlLmZHV
jAqKBtc3zuE1nTd5fHQP4GtaGQKG+3v8p0t3JfpXgit4OGYANFbF1i3174Rfpp9T
3LxRHX1iPDsj67FP79Ycr8w4tmdPBw2Z2Gh6M58hp9Z4ytEFfBUU1gD4tfl74L02
IAoSpkH56d85z264k+bRK2D6aBnxCKU7BLztG8RAK/9GCAOqxv16I3oByvZNGMx7
ECd13dkh4r3kXNliLg0bF3oMHaN0uqFt0Eoqif8AAwUH/2t7GFrqviBQwtr2em+o
1Ac/dyqj8F/ciYPnlaomOEypdhI/M8lMFySkH7M54xl7e0FVHvWvxhHu2D3CWgxh
0FW0gLS97HBbNxjYQCIFfNbT5WmRMPvihG5ym3TCOdo9UD445a4+DSqSLo/SZi8z
G5lUuuI8OYRJQ/43ka4lzbdUAI8YjJnyk6YQlZ3t7eYTkeHWmOrlTCSz6c7jQoNQ
rbIxrrkVi8kewd91853OekuLFZ6oZQtU/YLYFicacz8HE/r42uPsG2azeqqd19XF
NJOFuTut4fdAYbVeztIN6xYdgx+tI/LGzTSoMurOYI/U5kk65ABqxC3kgyG0ad+W
AYCISQQYEQIACQUCQ8F8swIbDAAKCRARLQHbxFy5eGGAAKC+QKCN4M/grwaBbTer
B5lKgt0VCQCfdhlL5hMDBDoaMdMtBZXFL4/Vn10=
=ArNG
-----END PGP PUBLIC KEY BLOCK-----
D.3.235 Jörg Wunsch <joerg@FreeBSD.org>
pub 1024D/69A85873 2001-12-11 Joerg Wunsch <j@uriah.heep.sax.de>
Key fingerprint = 5E84 F980 C3CA FD4B B584 1070 F48C A81B 69A8 5873
pub 1024D/69A85873 2001-12-11 Joerg Wunsch <j@uriah.heep.sax.de>
uid Joerg Wunsch <joerg_wunsch@interface-systems.de>
uid Joerg Wunsch <joerg@FreeBSD.org>
uid Joerg Wunsch <j@ida.interface-business.de>
sub 1024g/21DC9924 2001-12-11
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.6 (FreeBSD)
mQGiBDwWI2kRBADM4C4YlBiLozC/bZDedK12BMLyfnv9yOppj/doC1cOEaE+xZNQ
7/aDZfhi7FNQzt+ehh52DLihV91G7gOsACtUk3gLR8G+0q6U76dBY/gvAGzCYUu0
bJwlQCcPMysF4sNEwvsuct1fIVAHa+660X6Q+WI+eADIwZyN8wR1GrEqswCg3uGM
xm85EYtxPFx7tyxfA8q/d+MD/i+SPmt9xEZ/KZOMbQVPw/vYmeWW4lVZGG2HLKmH
J2FiAW4YjryoNqhpbbqlJigxf6staqgnQL4uuzBrr6v+OIjbljTHA7fs0WA4mtTX
u7YcAKPXBTztw/O+f3tZz08Ep+AHJ3Q+pTbbRQZpikGGdOpjfLcEyAQBh1rNA3zl
/MiLA/9IL7yfpyiA6cjX+MuUCqlqbPW2awQOCsmDBOcpXdOYC+MsBUhlT7IcFtQd
BUxUiqdIKlRtIT4l4LnqzhL2HASv6Zzc06zGS+tlG6BlpCGlSxz8fp4asbTYdJnp
d7lqme75jOUNjygal5lxJApincaLjv+4IaNUWCC5RjQuRsd3t7QwSm9lcmcgV3Vu
c2NoIDxqb2VyZ193dW5zY2hAaW50ZXJmYWNlLXN5c3RlbXMuZGU+iF8EExECAB8C
GwMCHgECF4AFAkGkelUHCwkIBwMCAQMVAgMDFgIBAAoJEPSMqBtpqFhz3+0An1WU
SyLW5PtVk8AN2wZOZoIbdpWJAJ9UZjNCICVixY7lc+me/lfu7+nCsIhzBBARAgAz
BQJB4lonBYMB4TOAJhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5kZXgucGhwP2lk
PTEwAAoJENK7DQFl0P1Yu+kAn27zpfl6Angb/DIsaV6srJ6SB/hmAJoDHPErifuG
2L4KGF3NcagZRoUl77QgSm9lcmcgV3Vuc2NoIDxqb2VyZ0BGcmVlQlNELm9yZz6I
XwQTEQIAHwIbAwIeAQIXgAUCQaR6QgcLCQgHAwIBAxUCAwMWAgEACgkQ9IyoG2mo
WHNIRwCgnTUFJ1krhK0XISLLossxl68fS0MAoJEjQcOZTKtIp8S4Dqo7/VJYUVKF
iHMEEBECADMFAkHiWicFgwHhM4AmGmh0dHA6Ly93d3cuY2FjZXJ0Lm9yZy9pbmRl
eC5waHA/aWQ9MTAACgkQ0rsNAWXQ/VjuVACeKGyJ5VTFr26fxsDgqrlfXjksoBMA
mwRwLuhmlB2Pn+40rvnL2pletnCFtCJKb2VyZyBXdW5zY2ggPGpAdXJpYWguaGVl
cC5zYXguZGU+iF8EExECAB8CF4AHCwkIBwMCAQMVAgMDFgIBAh4BBQJBpHqjAhkB
AAoJEPSMqBtpqFhzMlgAnigTVSmOOtxzyVwJaZDDxeg9aQB6AJ9rnepmNfxu7F16
wiaVo6US+2p0SohGBBARAgAGBQI8WsL5AAoJEHninGCwBj/nbsMAn1LuO73ckkBj
VxG/Qzy6khbyelOHAJ43L5JMsDGyhodaCwZ/Xc5AKAm+IIhGBBARAgAGBQI8WsMg
AAoJEMYEPFZyB3E3MPsAn2mgRnF3H7gjW814bjWgoWFBmPdEAJ9FQuryfHAGylj2
lZ5R68k0JWEY+YicBBMBAQAGBQI9JF/ZAAoJEHW7bjh2o/ex+jkD/RNY+vvEo2NW
RcKfCV53bYQaYInBBaMyLHjulxrDrUPfTjW6BzFMlEf4h+hlz2bV+uVBjhiJ2bFp
qL2vE6HEHzkloVYfk+4E8NDTVMPrUjX/Nd8Y2dsfAWPzx3tvdHZiyzrEQhDtU/fJ
gBOds8eKhxIyjwxTD5smbbqpJyWuh7kZiEYEExECAAYFAj0kZOUACgkQYQrfI5Z2
HYyemACfRtNZdqGCp6FSlz4EAtEys+B4w5AAnRmk9vN+kS4hPBU9a6F5GgZCMpti
iEYEEBECAAYFAj00IUMACgkQah06FlSR5oNAMACeJP8yYszO9wkRxZKu7fovNzgk
+bIAoMQBBw7DtYtj/KzJKRXmoX277zRriEYEExECAAYFAj/GOYYACgkQwAfeuzCC
U0VBbACgs3OzHeay5aoOwjJutpcFBx/yKMkAn16kZ+r522qJWbHMJuB3ukiWxY0d
iEYEExECAAYFAkGGExoACgkQFbyd9tifJxTfsQCeLNVa4Ns4iq42JGfwVZvb5gRt
YrIAni02UYsHBVESxl99372haKmgH4HwiEYEEhECAAYFAkGGJGkACgkQJHERf6lR
AsE4kwCgzzgFZvvk4tdr6xM7s/p1gmgBosEAoMA6Ib7qfoOuSrrlUBvMte33EyNL
iEYEExECAAYFAkGU+XwACgkQkgpJOuNBnRoxuQCfTKFHVPqSutt6CqKpsLGWeF4f
Z7AAnAxEWkhRLMAk6EYKcx1LRTmN1B9giFcEExECABcFAjwWI2kFCwcKAwQDFQMC
AxYCAQIXgAAKCRD0jKgbaahYc2QDAJ91rDkVGk75blkHwV92zSeUGbFFAgCffenL
K+whbH3KD0+rhLtOTkv7AjyInAQTAQIABgUCQYyQfgAKCRAff6kIA1j8vfC1A/4s
yV9FHODYYlko5XnMZG5ZQ0erCpF+kYt70XxzsiNSWDYUXX2mtNniJdWMBBzg9wL8
1CBt+5koVclllxeWJmYIemXEXcdC1o+aQ10b+JEUQoYDuEFfLTAV/zrMhBCP2qIh
Z/lpqdQu/vTCgK0FGA1HZ48i/q7v7tE57nS4A+AT/YhzBBARAgAzBQJB4lonBYMB
4TOAJhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5kZXgucGhwP2lkPTEwAAoJENK7
DQFl0P1YqjgAoJuop2gK1sXFJsd7XhVtRCzXK70dAJ4zywlp9erDWgofGE7Kfuzn
vkFheLQqSm9lcmcgV3Vuc2NoIDxqQGlkYS5pbnRlcmZhY2UtYnVzaW5lc3MuZGU+
iF8EExECAB8CGwMCHgECF4AFAkGkelUHCwkIBwMCAQMVAgMDFgIBAAoJEPSMqBtp
qFhzgrQAnjpusj+cjM07WYmSXgjY8QXUWmkUAKDJN9He1N83pEewpJ4p7HnxJeSk
SIhzBBARAgAzBQJB4lonBYMB4TOAJhpodHRwOi8vd3d3LmNhY2VydC5vcmcvaW5k
ZXgucGhwP2lkPTEwAAoJENK7DQFl0P1YMUMAnAzE1fKsKB3GP5bN/S+qkhv+Sqzc
AJ9km5QT16De3Ramxa8XImxg+rKpNLkBDQQ8FiNuEAQAnbGJUHM83j9CulgGV2kj
OB2n/3t0sRM+d+tZijBrhsOqSv2c4ld2rPaWyHpwF40ZvgAqYw/XtbTS32kS+DOO
4zHQM5yI2OYf68TaYU6TQrApCYJVPmZcQZRCGl54RF63gPa6GmteYoEUnA03leyQ
nWzV69A6xR2vwbfXo1eq8TcAAwUD/3/ITIMjlj8eJDzGHPRaBsoYspKF6nKCvBn3
rfduyZm7b+yknZKpCYDr/E3jvwM2CfnMJgGXH6xKnL/Nn10Spah2WjDvZ7Mppflv
BWHwL3J+qz4alKtnZDFg+PQnkZCafQI1YOU9Faduttb02fxWp6WKq60RmVbnW3rW
Ovi1AB+liEYEGBECAAYFAjwWI24ACgkQ9IyoG2moWHPQWQCdGAwIL50YjOPOsZVl
623Rq5N193sAoIx+WM012DbKtxLlfiAYHjoyGvA9
=SfCl
-----END PGP PUBLIC KEY BLOCK-----
D.3.236 Maksim Yevmenkin <emax@FreeBSD.org>
pub 1024D/F050D2DD 2003-10-01 Maksim Yevmenkin <m_evmenkin@yahoo.com>
Key fingerprint = 8F3F D359 E318 5641 8C81 34AD 791D 53F5 F050 D2DD
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.2.2 (FreeBSD)
mQGiBD97XL8RBACC3CMLdwZY/RcLw4PM6h2KYj+cG7TNSfNWszZO5HdQYrd6HZKQ
h0cL7cyW1Low8a2ZulxtEjM1SfofzDlhNaTYhyjlO4xBnJM13dMFchmM4j4qF0Mu
al1MEeO3EbLntFsh/aDX2sOKEavz5id8eKmAZKez2O5Z27bymkFf4o2UbwCg841B
WuuWHsy4O1zrac0WidkS3G0D/jeVbYA09gylZA1KSd3djHE55lQDQrUt3+2xWxjG
Lg60WIqys/yxei6nVO7/Wr6Q1WISiX0bYXAxHCZZQrT6cuNtEBntPPa9PnXRewUx
8xwVCBIuSLK5Kw2WZ2FMuQWTzfd4fwt8P9vghJlaV3h5Byw3e6/MdoDID9Jkg/ml
f5FuA/9kZBwtE4zKJvx3Pv7EG6T0w82QA0SFtcFyRnNarUIfqyUsFXNkr8hoQT3Z
J5haO/lW2HW70KMr26GxK61XcF8LQtfvphv9M+4yF3+DZSu1YxUM1Vs/q27EQhXa
3Cs4kJkKdzW2xDbIbuD5ZJQqFAzWX7IiTTNXnEGZStPTQMYZLbQnTWFrc2ltIFll
dm1lbmtpbiA8bV9ldm1lbmtpbkB5YWhvby5jb20+iFsEExECABsFAj97XL8GCwkI
BwMCAxUCAwMWAgECHgECF4AACgkQeR1T9fBQ0t01FQCfUR367fJJ37Wl4HvZVBoF
peBX9ZEAniaaK/D+n/JttkgY8jJf2ZvjF0SSuQENBD97XMIQBACPpJjDdDw42++u
vPMW/R7Iwqdpgs22T/bzVlFxDGx2uD9xaoNKI03jkOyUWiFlHbuifMRhxTwO5Vyg
nj91Y0fk8hdd9bjT0ee7lJuQ8PBqzb/uEVGFIC+56/ocFzuBANdN5fzEfxp5AA0o
zAPotyGEmLLK8+3ApZmAbsnQEveOwwADBQP+KgIxPzWAxYSn/MFPK2QBEjHuCCsS
JB+VOShc/QaSn/wFEKc8Brjpr1KeAEi7dFrK4Sa2Rn2+k9tRSJptxi1m3Hrr0J2z
0JofnF6cKkvmIsCse5OGCK/LJmuWHuNVqYI2X9Q0am+soHEYsRaqB/BDLT5Mw0mE
5NO6455cKEcyizmIRgQYEQIABgUCP3tcwgAKCRB5HVP18FDS3b1HAJ9ZjWomBkE4
1vaMSXyIopmSQNVxSQCg3J+fBmk0yhD2A8CIfxhpSRJDwus=
=wV5Z
-----END PGP PUBLIC KEY BLOCK-----
D.3.237 Bjoern A. Zeeb <bz@FreeBSD.org>
pub 1024D/0E4A7875 2000-02-04 Bjoern A. Zeeb <bz@FreeBSD.org>
Key fingerprint = 5E31 F886 E2EE BA7E 2AA5 DDD4 21C5 0916 0E4A 7875
uid Bjoern A. Zeeb <bz@zabbadoz.net>
uid Bjoern A. Zeeb <bzeeb@zabbadoz.net>
uid Bjoern A. Zeeb <bzeeb-lists@lists.zabbadoz.net>
sub 1024g/6139751B 2000-02-04
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBDibVJ8RBACD4GHc4Ptsvx9fzbshr9KKwRDEhreLAYhVk31aaI2q1/k7X0Jy
lSBsoi67YeoYpGFl9N26vReq1mHufTfbXjBzYkodcbTe5sZlP50HlHvXrnB458k9
xVsrqphq1C7oXPjoTsv+WS3zgR6kb74fjCCyIY3iKFnuBoNmhBwwGqr6SwCgspas
IibQSFclUc3xF1gwrTPhHeUD/3BVc061ZP1lbJEB19j3CGdreqxF/2dR5EpeT/ck
tc2vc9pNRVikzY7DDG3d8xJKqSIcGjhaEmDx+BXBp7a5BvTx8utOzaT8SkzWcCtm
kGVYnfXb3AxppFJ0b8s4feUX3sGw6RJhuJ5o0mD+YsffGx7BGhAPUQg8opLqb8VA
SzjgA/0desJLuSbrJ3emIAOtOHjXhcge+FHzjemM5e/b7W+to32EdsjDtmLU3Ozd
OC5KRAKc+bIANb29FlCEerGIxnrZkI7InWP2lceCJVrvGVBS7ZSrPudtansupSde
9xVQEK9/fAbhRjZAFxPQld/h2niM9a7DKsk/5jj9iBeH37RxoLQgQmpvZXJuIEEu
IFplZWIgPGJ6QHphYmJhZG96Lm5ldD6IVgQTEQIAFgUCOJtUnwQLCgQDAxUDAgMW
AgECF4AACgkQIcUJFg5KeHWLNwCeMqLNZ9qGaTMevi8XD3aX29kF0f4An1vLf13t
Tixyfdavnf7yR1Vzr8SciEYEEBECAAYFAjicHKsACgkQ8ZparKdkcvLXkACfaQVR
7DFM0uYOBRvPdXHEbioYysQAn1rF2T+2Kw9hNFIDecPc7DSY3KWUtCNCam9lcm4g
QS4gWmVlYiA8YnplZWJAemFiYmFkb3oubmV0PohcBBMRAgAcBQJAmUDkAhsDBAsH
AwIDFQIDAxYCAQIeAQIXgAAKCRAhxQkWDkp4dcldAJ9wYabXnkHowzLuDNhOE5Kc
vKNZmQCffOLEN2vwaWXGUMvOopweeHTRvQu0L0Jqb2VybiBBLiBaZWViIDxiemVl
Yi1saXN0c0BsaXN0cy56YWJiYWRvei5uZXQ+iFwEExECABwFAkCZQQYCGwMECwcD
AgMVAgMDFgIBAh4BAheAAAoJECHFCRYOSnh1WSsAn2p0jqshOQAJRMV5k6KX0ZOS
24fHAJ0WNoHJc7NunSYF8psmgnq6vyQf7LQfQmpvZXJuIEEuIFplZWIgPGJ6QEZy
ZWVCU0Qub3JnPohcBBMRAgAcBQJBBsEjAhsDBAsHAwIDFQIDAxYCAQIeAQIXgAAK
CRAhxQkWDkp4dUzOAJ9sIESTxIqvcbNn7IJym3QS3yvi6wCgrgQlEbTAinEmw5vI
YnAcZ2slxG65AQ0EOJti3BAEAN7GWKRvB1lJ3KsV+AiBLk5eCXlgV/NySuE849bZ
3KHi1aUjrmY6+I6Ux1dThT3vKXWpyswToxPwPjM0zUHfn1MTi+yxfZPaii8XEb0J
xIFh954WKeqvw0OfdJPlQF5i3rRNVaCBmFGU76f5Iy7uADFvCXQ/dyGzZczIKv1j
dfiLAAMGBAC0PA7svDq2S5GNjbUoZHvR06ukh1IRzkbfY0aX4OyhwOWzN0s3BazY
8K0PxynCv5fGMqWjm85vew0E4Qe7GYZrzupzX8M3eiyHRYzHSgfgLWyokRjgL6R/
lyDLyVm10VANoGID8V3tgseXC/coNhgyATwKXIETsXBq9oG0hGwSdIhGBBgRAgAG
BQI4m2LcAAoJECHFCRYOSnh1U/EAn3CxttXeYdVQnnuIl5OWefQjeiQUAJwKaSgq
Aw/UmkgmwF5uPEs7MyhC8g==
=RhVh
-----END PGP PUBLIC KEY BLOCK-----
D.3.238 Alexey Zelkin
<phantom@FreeBSD.org>
pub 1024D/9196B7D9 2002-01-28 Alexey Zelkin <phantom@FreeBSD.org>
Key fingerprint = 4465 F2A4 28C1 C2E4 BB95 1EA0 C70D 4964 9196 B7D9
sub 1024g/E590ABA4 2002-01-28
-----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v1.0.6 (FreeBSD)
Comment: For info see http://www.gnupg.org
mQGiBDxVhBMRBAD20EH9hS3S3gy73E1s//vYS1yo4GmmvzUzMTJo4HH6OMFT/MVn
B51RXK5YlQ1cau4MWt2sifpWsG2hmmmPtOIaC6Mn4X8cEXmzy6qW5m+3RUdXB8rM
pFSEVVEGhE9Sq+pTI1wB4VUJ5mhQtvWVJKsmuyf1YRa/zrr2zbZTIXg5EwCggloA
GdcoFNm7p+cW56HJI1jZTpcD/jUyc4KLeimo+6Fn3z6NZh64GS+JmmCDe7mlcK2S
XNPVq3tXXP3ZUKdv3faoMAgI1hSi82/32GINDkhiLPc0Q2tQZRDYKvyY/swgJSnV
1LV8jlpk2VsmsYOp9hW4SJLAQUaejpZe4CwHpOfJWbPkXE83nVygA0lnN89dfhIH
JaB8A/9VottMl88+CLzqF3AzN72R5tFWnSFMWumaODis+UvLW0XAMP4AHhvux/FS
Pl+m2YtilHhib6lfMYuGalN84H7VxOBxjc9L4qORV9jP4cWEYXpxx0DTmmtFfLae
xGGTyYNM1RiqmScXMF28Am1I+WhnLTql8DVFWr8XoZUbususg7QjQWxleGV5IFpl
bGtpbiA8cGhhbnRvbUBGcmVlQlNELm9yZz6IVwQTEQIAFwUCPFWEEwULBwoDBAMV
AwIDFgIBAheAAAoJEMcNSWSRlrfZ9yQAn0bnLWBjo47dKrS82X1VvbuokkNXAJsH
oANWk5PoOZzySJ7st8/IyaLBErkBDQQ8VYQXEAQA2cEOpYzl8L5y8TErdj1lfpHt
gxm1QFETl8HvZGb/hTRWVhIcUhtOLA2uftk1oDHbnp+FPsJuFTxanCaCSQVdtMEE
I1zK/Qy384FjS1B6L3yq84yTKn+Gp8SbMX3ZWT+dVmy88yJpmo/yFiiN9d2hYy1q
fCUWhbAoWeD7sqSeGL8ABA0D/Au95rpaYunrMhu5nVdvZpTbNEIEDLOTS337GWy7
n1E9RG72ujCLFg8tbEmjEUFYfCZ/cW+6+2/Nj7zoGH9xXH6bRTfSKXojdKgNkUvL
SLynpmFpUlFKc4fzSxx5EkCxH/zog9X2CQjMvxHmSD1/x+LeD0v/5WMsLvIdj6Op
0KmziEYEGBECAAYFAjxVhBcACgkQxw1JZJGWt9nbrQCcCvSJho7n1r4+1PGTlcep
ABxplbsAn05jPrtZLjln7aKcavCp8FICJ2TY
=GYHE
-----END PGP PUBLIC KEY BLOCK-----
D.3.239 David Xu <davidxu@FreeBSD.org>
pub 1024D/48F2BDAB 2006-07-13 [expires: 2009-07-12]
Key fingerprint = 7182 434F 8809 A4AF 9AE8 F1B5 12F6 3390 48F2 BDAB
uid David Xu <davidxu@freebsd.org>
sub 4096g/ED7DB38A 2006-07-13 [expires: 2009-07-12]
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBES19gwRBAC+gBYGtS96dDvWP3Tu/F+YGwMHVF2uKC57wDuIUK6FIQXCsHcV
LjPQEF6JE+fWZZMb2pb7YKtP6f1glNUxf4LIQlpTBqQGxYcOQHnu8pgUhxNe8kfE
Pi9l+O0pAipQAnu7vj/3+4uxHgDXtfJphew9nKQWtCKdz13YVUhxZZV9zwCgyLb1
D5sAWB+FAcF87qJd4jeEpO0D/1YvKgd2rV5yQ7jT2Xxl7dpq2u3vEeI15ZNxmMCh
sS+4CxBpCcX1GSNVqxJDahBLwsSoJQaDoaV20DlJkQZYSNoW0tUtEA8Gy5cMPr/2
oNIjPHRUU/R1i3rzA3k6so0QhJardwj/q8X3PQ/+N4vY9RDFxk8xTlaFL05Yipv2
fGVXA/0fFL6EmFG+n/3pc+HkeExXUZytUg4pCLugdLdIpQ/PcYo7suvXuVourLX1
6AhLSwc4lHjxl7+BlxmBYCdCJsjSKJi0A4CgoypcSP4sMvm3QNhfwIp+6vs0Cqxb
3FLsZ8F/+iP/IAgm9DmUp0EZhzpLC530d0c8hwFEoNX85eNp+7QeRGF2aWQgWHUg
PGRhdmlkeHVAZnJlZWJzZC5vcmc+iGMEExECACMFAkS19gwFCQWjmoAGCwkIBwMC
BBUCCAMEFgIDAQIeAQIXgAAKCRAS9jOQSPK9q1GfAJ9pk1BZz2y4RyALL9iJbE8U
mWKYUgCfcyq5jIrFHEUMEtdg5ejf+a9I+xW5BA0ERLX2KxAQAITsM+U08mC2ZU5v
70C9i2HtI/kU++PdENYnwsvk0PVd224zFJ7llWa6HT6k/Wv3ZqvphJ1Ebg9f1ztv
iQWbNUt+xGVqoaq+wQPFreHUpenF8EzjCtE9fRexC5uO9Q1w1GbBw9nw4kjD1dxV
wnZM88ZJXjdz58DN02BP3u19ugTM/jTlZvWfv0jplQZ5DzL48hLKTQiPGM7OrryS
VQsSp9Sk0xuYPz+whUqB/PVPYYz3N3rBZYAF4sjGD0r3FSFilzIlQYqyGYYKDOML
slI9OJhbMx5SEGdkZHf7DX3SVe8RiX29ghn2/q8SwsMQgoow4v6XG2vDRlXOHvNG
zHMgqYvsNKWV+KpBH1d7qj10och4uOhwou9dTtEpQAtrgj189SQGAWwi0Z4pMior
/jloMpjngtLeTYdk3O6Xb9Btel/0vISbV9+fwfAcZFd+XnRrUVjzQm3ZgipT3Fyu
ZCDDwKJnw0oMtyhiZbVAzgfNuflr92P/Hr6B2OajsLLqRdKMv1OTBluQrSWyA0r1
ZxZtaO19cBXseEVIBSShUH8XP2mH8Jy0LPkCeq1CAUF1CUwZaf0dNj9IU9DOO66u
4gqEckmDqLqbQ2nvO2eOkuUV7ZNK+6PrsVcUu6WssoHw8N95mU62t2aa0bh0JLdp
/Jy4Y6FYnHN8/PXPtz6CCnFsR1XXAAMFD/9TRC9ojYbMrgBxPP/yd6wjGuQ0p58M
fDn5atdzYFAljTIgGJGUG6LB+bKOkpitdrrWh/gc4Fq6ZQYXHttRx7ZE68I8X5eP
uv4C02zi2CC3CXy68W1bng31Wndjx9vAfUVXJjLwL4+SvSk9a4zGDG5a6FMoIF5I
4PDwRz1MeTIpnlAkhjjHkFlfC5a35O1Qd27/HUyf7hQgwjYr6plTBruK5nZR7zTl
x+0oo3jVakRWq2r6FcvFYRTgAFapmshdLYVR7gUNQ3CeCuSvIb+F1r1u7m7ZNVev
dkq3GdJOOijgwUBASYvj8u6c18VbfFoUCFSK8Dulq2ih+Kp0yv9x3GuA4mJvuv32
tDjcPie+cvKgsbYujZmS73aiKTMx1qhrb9ydxWd2wE9zRyB7wOw/5aSJu1HOZ7LN
Mjt3xyJayJnAxmyXjB/kVzsheDv/L+CLnqoYa5kkytZ1rEn5YZiAJE22Z/Wlo8ld
D50ukvVMRRjblKjess5Z9nRqHZD77049NvunclgCq6rKv/ofuQwtaHpiRevkMjfK
khY6vUHeqJyBdsyJowHkckGbTzmHn6SobNqM9rPNeL1jROuCjSJinjXAvzGWl+F2
DLQEXxIt7Vh6FGGH7ayUqOVQZ2r0Yq38+2bw0eFEDOcVNd1I7YqKvhfK5UNmuQZL
Y7rUo93+DfEEtohMBBgRAgAMBQJEtfYrBQkFo5qAAAoJEBL2M5BI8r2rM0oAniZj
Ck9uJx9JEVrFY5rzx5zoYMz6AKDHL9jTBoVfHC5flmdVzuqJ9IpDCg==
=jyox
-----END PGP PUBLIC KEY BLOCK-----
D.3.240 Randall R. Stewart <rrs@FreeBSD.org>
pub 1024D/0373B8B2 2006-09-01
Key fingerprint = 74A6 810E 6DEA D69B 6496 5FA9 8AEF 4166 0373 B8B2
uid Randall R Stewart <randall@lakerest.net>
uid Randall R Stewart <rrs@cisco.com>
uid Randall R Stewart <rrs@FreeBSD.org>
sub 2048g/88027C0B 2006-09-01
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBET3848RBADitK8bahB8Ftqi9wtYsFRGfdm645cTF5fAnxFjC+ouPfLk+cfD
I6VG1Vib3T+SYTTJ3xPm7tV6RLLlRsdAfSE4P73o5qVe85Dq4JBKYgdCms+0Z7B+
O0yB7B0KClaXhZpsQtK8yLtROjiJxw1WQ9uOS/me5AHi2cZruoOcYxkzbwCguMmd
tOy1SL5V2RLfJiQKAFQ23M8D/3m42RjkoMB791fuJ/pH3i98EuXhCwrSv7eZ3xYU
TY93OwMEwPYaABK3jSygMETj9hu2pYFbrAFKSHQVPLcUBrKYw9+Fjd4XTOOxYZeI
/+n0xSRk4W+sIQX97jCbvCrtk9jqIz2NQt9IlKxG0Xniio/Q8PsNNbO+jd5HSXqE
ja2oA/9+r3LUi3jKH9rpY6x4Qz/DBpcNK4v5Fz24mtkwTfjyfC2nTlG58bSbmulE
1tfOLDL5BHmGoyWIqaFzIVIA5oGo9EYG2RCx7Vr+WgsY6jr5tX7HlhByoE5Wemoz
YN5CDC9KCKe7TCpVJtlq57c02kE0OT3gqYsflidfV50Qzt9jI7QhUmFuZGFsbCBS
IFN0ZXdhcnQgPHJyc0BjaXNjby5jb20+iGAEExECACAFAkT3848CGwMGCwkIBwMC
BBUCCAMEFgIDAQIeAQIXgAAKCRCK70FmA3O4suHBAJ9kvtlm5qy8c6qSizjcvuzj
q4gFJQCgqthVasQ5jNFZf1p4vM+gD1T84M+0I1JhbmRhbGwgUiBTdGV3YXJ0IDxy
cnNARnJlZUJTRC5vcmc+iGAEExECACAFAkT39KoCGwMGCwkIBwMCBBUCCAMEFgID
AQIeAQIXgAAKCRCK70FmA3O4slQYAKCNWFpgxPkfqz7PoTUcobiXbu7EAQCcCj0F
mj5AKPyuPbwP3JT7Cyf4Fs60KFJhbmRhbGwgUiBTdGV3YXJ0IDxyYW5kYWxsQGxh
a2VyZXN0Lm5ldD6IYAQTEQIAIAUCRPf07QIbAwYLCQgHAwIEFQIIAwQWAgMBAh4B
AheAAAoJEIrvQWYDc7iyy60AmgLBwWw0LjdY6+zyUyUhRm9s4vZEAJ9F6dw61khm
NQlfhpvoBh24pl6GTrkCDQRE9/OUEAgA7GAeZ2BgjNDYa42+GV6uo1FxadTNppdN
gG22xgg+4SXnWZ25O8dofrHIwP9rk/qomw452MoAlVevV20uYthVqAXBWRGEhO/q
zKfyZxTe8aCOs1mjCKu9fPkSgNUDoCl6jCac/5mDdcLdVT3domBJvGiqqSQ/B1JA
3YWrYCnnLTUN2a2aPW0ZK14zCSjaWQFDcm8kPi1WwKu9yldGnAPoT03+JF4KN0kB
YkdmfEAFOJ4kjm2UROJc2aVUtjeMH3nqvdlTmuw6c6cmMMSIlXkcrTO7gRLmnx2J
HgSdukq0vEtgND6O/o0n9Rnr+UccOCCz6EJkltL9knjKwutdQz9x8wADBQgAkEfc
D/VQ1sUCgS5xyrer45zxW5NdeuFI+h12D94MKopczr73p+7Tc1bSDZK1M4e432qV
8hNy8Q6gYowhuuBqxI0LYcEtrJld0ma4cnMraRjkId2jmyK82c+O/K1w+vcGUsYu
nxYBiGwtTTo/R+202kp6VGD7jnIxGQs5WsMmnh8EL1m4BXeFm6BzfT29SuV4bdoZ
6/YHyPLGVgtnPBCNQUjLvXqdaOlk3E1wCBd4A90pC1dDiN1rsAxOTcxwgyKfasXx
CZsdBaXEYYUIfm9WrAFc1S/baV613184I1duBfCJWMKxGXMSr68CeFQ+I1036lsZ
IdHoq+Y3nZ5jPRUIYohJBBgRAgAJBQJE9/OUAhsMAAoJEIrvQWYDc7iyXiAAn3XC
FR1XLpBIlAr5dn8ozSpbwfoHAJ9ZDFSqbQt/EDawxqaoYP+4p4Q85w==
=jM4N
-----END PGP PUBLIC KEY BLOCK-----
D.3.241 Sepherosa Ziehau <sephe@FreeBSD.org>
pub 2048R/3E51FB42 2005-10-21
Key fingerprint = 5F47 3861 7ABA 8773 9E32 0474 5C33 841C 3E51 FB42
uid Sepherosa Ziehau (freebsd) <sephe@freebsd.org>
uid Sepherosa Ziehau (sephe) <sepherosa@gmail.com>
sub 2048R/7AA31321 2005-10-21
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQELBENYRSgBCADNXKEOqPFvo//r9KnH2BzwJOB8h8TmU3zS4fogC1HjYQfZmFRa
MCguECmq730ulxo2hnBSq9VyLfwnL0W1vz4b+2vMbcO5v9TkvnPlL3OW/mAHjrAL
u01ui5VR1TKxD12q/KIEQ49+Ir8z4THImm4WgKaYo37xrNMAZc2BSCHK30I8lda0
2DG8hzDtlCE79ZbqNAPmQYewflaU/ga0kzI/MftFeIZA7K26krXBLlOIY142ckTd
iB3wrC2s0tqjQMxQODQTvWyxoTLi1TGMY/zbXdc9aoXnuX6qKZEzTh6P5NU8cRto
BDlNVTV1eFYvFy6NNkNVE4Jj3yk96xWwlRJdAAYptC5TZXBoZXJvc2EgWmllaGF1
IChzZXBoZSkgPHNlcGhlcm9zYUBnbWFpbC5jb20+iQE2BBMBAgAgBQJDWEUoAhsD
BgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQXDOEHD5R+0LrJQf9FD6NUteiA76n
GtJ3FRPUbEL/GbDtg/Ad/goeOzQIgw60QSan+nuDIcWz50XWcxfnjkThRQP0CWwk
wkpGlOQt0DsPpFq2oSaR8yXSqfUAPuzSohmuArAeAs5aNlr6FYaXiOsvSmOM1pGX
7JkTvajjxcXcSLSTqJS43xbI8s/+gEqTJbOErNeWxdK6uHHVhGmWexzu1wrUzjxT
+4SFEEOsL/ScF2ITzByPZO6oBTrZveNKcC/nOBZAnkfjqqc7jRMggY4zGvFtFgsl
dbHwMqkWihoJvhqspoopCeGwt7sY1NFsTUFNOZp073C7rIig1vgHEWnhevleq+cK
ridbUbY+YbQuU2VwaGVyb3NhIFppZWhhdSAoZnJlZWJzZCkgPHNlcGhlQGZyZWVi
c2Qub3JnPokBNgQTAQIAIAUCRgkgdwIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheA
AAoJEFwzhBw+UftCiZIH/iSSBM5Nv3G8Y2cS1ui1Xc5KpChSt6CAqKTOiYxwWQ/B
U6clllym0NvzjUxiJm4JuV0N8sAy8nhhs79SNRfYfNnGeHXmLS58MPszhnEnhgZm
yuZFQdZ15T9Axf5gLmDqA8TYpcUYxssSm8PcJqoCGnbk28okwbRuwTUm9T/w4TXt
28w7SEXK0GFBG3ZlKPZh1er61CSwM7l/aoCkyFoNHAfGssFd/t0OCD8ugfQf9zvk
JKXsm15vQAhMJrbcIhMGPWKoLN/z8bQTHSN4AP8nGM7gq3zUKZwL5jrzAUtHGqGs
jtIBX9oPT5GLCaXZNotcLh40aS8qtemVthLqFS+pNu25AQsEQ1hFXQEIAMQRgCMl
1tgeNZlj6fN+JC4LU4DC+9R28tnzEXWFGud5XQx/EzNRQVDuiDqQKPmc86Ps77dl
7iJNTxapBs+Ki+3VOP11/ZUzHukER4iWZRXwfYtCE2tu2ht53WtYqoqwt40rsCOh
uzC66FIiZ9Woj4omL5br0lKj8kVqS+OKfLt452bWg0mV39lokA3Q0xVfhlL3Nuj0
S2yJcP0G8kesu/Ol1z85EK4GMlrOfZOaaz1r4f1u3FwE3Fo8anjvnUM9UC+ImJq0
Z6gZwbBQ0tk55Z2Bs2sSyNp5cDnNyxa9HPOpvNqEE4bD4pMzsRMlEUhgM1kTOe1x
AwBsQscqG1ovCnUABimJAR8EGAECAAkFAkNYRV0CGwwACgkQXDOEHD5R+0J/WAf/
aALJbyEU1nSvyeVp0mP6U9xRFnXM1G4zQ3mrFyMvYcQ0a2A3gr8E+Ejl5Lpg/7HU
t1UvLSqn00dqXuI+BIm/exDmpfLKXouBLVGtDcSQ/EQl6SV3mkJrvH8rDkCakCOG
Fho5cl3Ge8YThQW1jdjbo+zXJfC9+k4ienh7DC2Yd8cwpcYRAKeKFOdveSjW+Ox0
NFmZYc0F+XfKZLJ9d1SrFH5/ytQRAVvMbkLo1nb92ZXBrSbTN+tsLZrEbcmuuuZb
pP+0i1PJDqfCRVpYFnlPZsNzZU5c5ihABZ79/uSScAyuxlhRdZAVHSDc6cRyzB5w
AshLLfnD1BoaFl+lzNnL2Q==
=F5Wg
-----END PGP PUBLIC KEY BLOCK-----
D.3.242 Tatuya JINMEI <jinmei@FreeBSD.org>
pub 1024D/ABA82228 2002-08-15
Key fingerprint = BB70 3050 EE39 BE00 48BB A5F3 5892 F203 ABA8 2228
uid JINMEI Tatuya <jinmei@FreeBSD.org>
uid JINMEI Tatuya <jinmei@jinmei.org>
uid JINMEI Tatuya (the KAME project) <jinmei@isl.rdc.toshiba.co.jp>
sub 1024g/8B43CF66 2002-08-15
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBD1b+Q4RBACetpZD+bWytVmQ3Itmu0ZBfSDF6FVyUQuKS3OZmvsZHxxqq1+u
erHNhmyte/aCI/YrEUzHPT5LU+9LMpRQD0AwSs3Ot2vUzokSiTu8ZqhoWBcsosKK
eKM73V7NiTgBGuJ3UxVmKNXzUZhRjGHuekB/ZCCv1pDg9B3HPL8ty+2M6wCgu02T
+vMZW0VeByn79Lpmm2nu/F0D/3NN4e8ZtLTbUJxJb/hHhLzOr8XahZCqsNF2bj0C
0u2SzkelDa5iVDWwiOkg7xI154REAALOG1FnLyO4bRPkcQ/EO5tbzXoVn0I6MPWA
EiwBfVRXzP10MDHhqH0NvT8pyA4ex/BflaeFem9HItRjfojdqEUYVAACceAdLQLG
MknWA/4hfAAp+dPcU8iHmd7AemuGoOhu5AAKbp2S4vwozJEFiv67wD/+WFXVggUx
wbQ3X7oNiOLeg9OASDV5qtbGPATHikYagWVjndqmvxO1FiL6BnQBnzAVzOEN3L2K
Ex566bUw/2R/dr/zhOc3BKxCV50T2Xe4u/cEiYkUbLj6+Y8V2bQhSklOTUVJIFRh
dHV5YSA8amlubWVpQGppbm1laS5vcmc+iGAEExECACAFAkYDPqYCGyMGCwkIBwMC
BBUCCAMEFgIDAQIeAQIXgAAKCRBYkvIDq6giKEOZAJ0Z/iUCa6UrrsVmKiP4a9qB
0jFUCgCgn/3mQxdtXTA6SOlFFsisaxsIXIW0P0pJTk1FSSBUYXR1eWEgKHRoZSBL
QU1FIHByb2plY3QpIDxqaW5tZWlAaXNsLnJkYy50b3NoaWJhLmNvLmpwPohZBBMR
AgAZBQI9W/kOBAsHAwIDFQIDAxYCAQIeAQIXgAAKCRBYkvIDq6giKBtcAJ9DRqXt
h8WEpjgr+sD9OuaYqmV8nACfSdo2Ml+Qfz2Rad9OtZodmELCCi20IkpJTk1FSSBU
YXR1eWEgPGppbm1laUBGcmVlQlNELm9yZz6IYAQTEQIAIAUCRhkdkgIbIwYLCQgH
AwIEFQIIAwQWAgMBAh4BAheAAAoJEFiS8gOrqCIo11cAoIJT7N2GMSNXAujnuIvc
HnBtgk5zAJ4qDo/En3ic8E7h7zc4lT/WQQDhRrkBDQQ9W/kQEAQA1Q07/j0kScL1
WF9EeXVEyLpTxHZ7owTI+KrRcQ6Vc6KABu1cwhE78ANVfn/CkWVXHyDEnWEIvaz2
QYwz47sqOxdOg/AmHFVd8xouengw32KNjViVBMsW/l8VzyAVvvGGNuQ+f7zDZ/P9
v9WwwRcrgL9g+uAnrJJo/wttIBqhSk8AAwUEAIqcIez2zlkwGayFeLqgwuw4PCbd
kGtXs0l2mQljv8GWuTRJ5D8aD0nlM9MNaSLB7xq6igMriP/NyfIVv0aLJwRH8ilx
RBYosGvm+nEmUtakhU/77uXcLtipoUGi+y1reFRVSoypJil6lqDTjKtWQlWA7xOG
QzGMdgoBC1d55jXXiEYEGBECAAYFAj1b+RAACgkQWJLyA6uoIigNBwCgsUFgZMfR
sEybYW4cWwBNhNTqE9wAnRf9BFkzpn3ZyD+NBkjx2INcitoD
=ISn8
-----END PGP PUBLIC KEY BLOCK-----
D.3.243 Thomas
Abthorpe <tabthorpe@FreeBSD.org>
pub 1024D/D069F2A0 2005-07-06
Key fingerprint = 62EB 68F5 C1A4 8FCE 5A87 BE22 E469 BF8C D069 F2A0
uid Thomas Abthorpe <thomas@goodking.ca>
uid Thomas Abthorpe (FreeBSD Ports Committer) <tabthorpe@FreeBSD.org>
uid Thomas Abthorpe <thomasa@tbaytel.net>
uid Thomas Abthorpe <tabthorpe@stthomasanglican.org>
uid Thomas Abthorpe <thomas@stthomasanglican.org>
uid Thomas Abthorpe <tabthorpe@goodking.ca>
uid Thomas Abthorpe <thomas@goodking.ca>
sub 2048g/16752D82 2005-07-06
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQGiBELL6gsRBAD6ahgX4ShNoBnFlwzDGSznhJPNGBDmR5nWwzS3W+76bHf5INnb
wU3EKazu3nUPpMkoCzt05K/1nI+WvDa2l5qdGJHXghbJTaTzRAvQL5tUcQyaQS2A
PGGlk5xvQXowMMI4BTeUspr4/FXD4ApvA3WJDDa5E/yRH5DsJZhbt8uo6wCghzcO
F89BOjIk9sunQkG+UZenTzUD/i7PIKkiQybeNdBeJJLYV5+yceHmSN/9tKZzjBKQ
HG3PYogdrtKnd+38SLKl1qtdyVn8ve25rV3qUO1MqlO7daoYpKFEe4zKFSNu56RM
0w59cuOfqR0f8N213T3qp4ZLaSh/ZI2+wDVDra0/YuJm2vs2s7wYZuoFhX9v22vl
03TOBACsyqxIFSw02jbi5wkxR82oUvgJXFwRG51G8SWRE0TxuHIiJkyWfHPz5YXn
VALoO8UeJd5UHHiVMGef78sqY00Ay56Jk6O3rQvxgPv0GO3iZ75UrCndotzZsJqe
uYOfvmSGlDjdyCr9ttEU6I7NRLfegbSDIBKLH1tDx4tjgmAlrLRBVGhvbWFzIEFi
dGhvcnBlIChGcmVlQlNEIFBvcnRzIENvbW1pdHRlcikgPHRhYnRob3JwZUBGcmVl
QlNELm9yZz6IYAQTEQIAIAUCRso1hgIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheA
AAoJEORpv4zQafKgzscAn34Hn7pXzy6I6yH5LJk5AzKPOWr3AJ0anvtz4le0+d+3
8pqxgzc0LIez8rQlVGhvbWFzIEFidGhvcnBlIDx0aG9tYXNhQHRiYXl0ZWwubmV0
PohgBBMRAgAgBQJGuSP4AhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQ5Gm/
jNBp8qCruACfTnIPAG5u90p15gmJOQH2jHN31iIAnRfdwkMTxRAfnM67jyqqFS/k
FGZRtDBUaG9tYXMgQWJ0aG9ycGUgPHRhYnRob3JwZUBzdHRob21hc2FuZ2xpY2Fu
Lm9yZz6IYAQTEQIAIAUCRrkj0QIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJ
EORpv4zQafKgqUEAn0hS6bXdGyGjuMzh+y5tjxfiWJpIAJ94Z2V4ADOHh0xRA30W
I8QEey7J5rQtVGhvbWFzIEFidGhvcnBlIDx0aG9tYXNAc3R0aG9tYXNhbmdsaWNh
bi5vcmc+iGAEExECACAFAkWdOV8CGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAK
CRDkab+M0GnyoMILAJ9kmeKGp7urxNt30FzdJgxb6avWmgCePcu0exog2kn8zZzr
i+f0UT2i2i+0J1Rob21hcyBBYnRob3JwZSA8dGFidGhvcnBlQGdvb2RraW5nLmNh
PohgBBMRAgAgBQJFnTkcAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQ5Gm/
jNBp8qCmKQCdF0Kyo2cVcIp6uLiFuyzJT/zP5CUAmwYxG9hTClBtyXoHB0jakY7B
tBsAtCRUaG9tYXMgQWJ0aG9ycGUgPHRob21hc0Bnb29ka2luZy5jYT6IXgQTEQIA
HgUCQsvqCwIbAwYLCQgHAwIDFQIDAxYCAQIeAQIXgAAKCRDkab+M0GnyoEfuAJ0a
M3RzuyYugQMOIHRSJKxp7pwuzACeINi9MHxpn5Z/iar30wYUk5AufkqIYAQTEQIA
IAUCRrkkDwIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEORpv4zQafKgAAQA
mgL6eGO3Vlbn+W9b2WXD651nJLWkAJsE5JfBdP5XLai+RJLk67jrOnJM+ohgBBMR
AgAgBQJFnTofAhsDBgsJCAcDAgQVAggDBBYCAwECHgECF4AACgkQ5Gm/jNBp8qC2
fQCffjgd3bSt5RaNwumtyj39l5HgaqsAnRzZeCeE3v1EX7IcvHhT1e66LLmjtCRU
aG9tYXMgQWJ0aG9ycGUgPHRob21hc0Bnb29ka2luZy5jYT6IYAQTEQIAIAUCRso1
sgIbAwYLCQgHAwIEFQIIAwQWAgMBAh4BAheAAAoJEORpv4zQafKgLXgAn3s28ZTC
snfSuwI/65d6E5rEEWLmAJ9YjAEvMaio9Hexbt29U8o8RYv2rrkCDQRCy+o+EAgA
n8BQcPust0IZTGSb+Nwj9T9wRlVoa31bjstnPhXx/GWlfZe0VDlc6w0veB2HGoz9
WJkIbIOkc2ZzxnHB0knObxF1fcuplwMuPz0XK2CBJRrExI3gEJ+ao/TvBmMk5uZx
VIZ7yP1mzkCF5y8M8AkxxRTFfZ4H3SUAwxlCr7Jx1M4LvLjcKbKfy+ro/nkPoO5z
5fY9eLsF67aiAtgX2IvnFZEP8BUwlO3f+DeBM/3UlHl5A+XAZ6IUw+fdGfljlSzE
Ej3RoKcU1O2eRa2XkVWd7ZIXH0iQDYfr+vN9YhfL+zSfvEeLsMzzAu9HNSNAHF9h
QEPodMo6csY6e0xUecurywADBQgAnB1TOsQpvmryF9qHUHUviGaJJaMm0PQPbvGr
gu80SCUfOPnttjdd7+KtY3uM4rbYvFXnMl9cHyGaOlRtJZj42TIpa8iH5dEQXB3S
+jv2ii/x55PC7z/klLmtyC2u669WOd2bqlXk3eVgklFQ5yDZsds6RCPDuADYBrl/
08cnhFzEaO2OcsewN1yyd5crj1QxIepx7h6YRJZV4fCKELKfInMLguEpRrQB9V4R
oBXzosIvebPW87X75nPAuH+YtzticH7uMrG6VITM3vkv8aS/sE02uMDZKQh8gjan
ZGBtEB/xhXaBJIGabMhQWcM5CbcdshHG13gx8W8DNafN2bCA9IhJBBgRAgAJBQJC
y+o+AhsMAAoJEORpv4zQafKgEUgAn3uI606CD/ws/V8PCt2/EnB548tBAJ9YDJze
1jo7nwtF4D34H75dAUWU0Q==
=taJ2
-----END PGP PUBLIC KEY BLOCK-----
FreeBSD Glossary
This glossary contains terms and acronyms used within the FreeBSD community and documentation.
A
- ACL
-
See: Access Control List
- ACPI
- AMD
- AML
- API
- APIC
- APM
- APOP
- ASL
-
See: ACPI Source Language
- ATA
- ATM
- ACPI Machine Language
- (AML)
-
Pseudocode, interpreted by a virtual machine within an ACPI-compliant operating system, providing a layer between the underlying hardware and the documented interface presented to the OS.
- ACPI Source Language
- (ASL)
-
The programming language AML is written in.
- Access Control List
- (ACL)
- Advanced Configuration and Power Interface
- (ACPI)
-
A specification which provides an abstraction of the interface the hardware presents to the operating system, so that the operating system should need to know nothing about the underlying hardware to make the most of it. ACPI evolves and supercedes the functionality provided previously by APM, PNPBIOS and other technologies, and provides facilities for controlling power consumption, machine suspension, device enabling and disabling, etc.
- Application Programming Interface
- (API)
-
A set of procedures, protocols and tools that specify the canonical interaction of one or more program parts; how, when and why they do work together, and what data they share or operate on.
- Advanced Power Management
- (APM)
- Advanced Programmable Interrupt Controller
- (APIC)
- Advanced Technology Attachment
- (ATA)
- Asynchronous Transfer Mode
- (ATM)
- Authenticated Post Office Protocol
- (APOP)
- Automatic Mount Daemon
- (AMD)
-
A daemon that automatically mounts a filesystem when a file or directory within that filesystem is accessed.
B
- BAR
- BIND
- BIOS
- BSD
- Base Address Register
- (BAR)
-
The registers that determine which address range a PCI device will respond to.
- Basic Input/Output System
- (BIOS)
-
The definition of BIOS depends a bit on the context. Some people refer to it as the ROM chip with a basic set of routines to provide an interface between software and hardware. Others refer to it as the set of routines contained in the chip that help in bootstrapping the system. Some might also refer to it as the screen used to configure the boostrapping process. The BIOS is PC-specific but other systems have something similar.
- Berkeley Internet Name Domain
- (BIND)
-
An implementation of the DNS protocols.
- Berkeley Software Distribution
- (BSD)
-
This is the name that the Computer Systems Research Group (CSRG) at The University of California at Berkeley gave to their improvements and modifications to AT&T's 32V UNIX. FreeBSD is a descendant of the CSRG work.
- Bikeshed Building
-
A phenomenon whereby many people will give an opinion on an uncomplicated topic, whilst a complex topic receives little or no discussion. See the FAQ for the origin of the term.
C
- CD
-
See: Carrier Detect
- CHAP
- CLIP
- COFF
- CPU
- CTS
-
See: Clear To Send
- CVS
- Carrier Detect
- (CD)
-
An RS232C signal indicating that a carrier has been detected.
- Central Processing Unit
- (CPU)
-
Also known as the processor. This is the brain of the computer where all calculations take place. There are a number of different architectures with different instruction sets. Among the more well-known are the Intel-x86 and derivatives, Sun SPARC, PowerPC, and Alpha.
- Challenge Handshake Authentication Protocol
- (CHAP)
- Classical IP over ATM
- (CLIP)
- Clear To Send
- (CTS)
-
An RS232C signal giving the remote system permission to send data.
- Common Object File Format
- (COFF)
- Concurrent Versions System
- (CVS)
-
A version control system, providing a method of working with and keeping track of many different revisions of files. CVS provides the ability to extract, merge and revert individual changes or sets of changes, and offers the ability to keep track of which changes were made, by who and for what reason.
D
- DAC
- DDB
-
See: Debugger
- DES
- DHCP
- DNS
-
See: Domain Name System
- DSDT
- DSR
-
See: Data Set Ready
- DTR
-
See: Data Terminal Ready
- DVMRP
- Discretionary Access Control
- (DAC)
- Data Encryption Standard
- (DES)
-
A method of encrypting information, traditionally used as the method of encryption for UNIX passwords and the crypt(3) function.
- Data Set Ready
- (DSR)
-
An RS232C signal sent from the modem to the computer or terminal indicating a readiness to send and receive data.
- Data Terminal Ready
- (DTR)
-
An RS232C signal sent from the computer or terminal to the modem indicating a readiness to send and receive data.
- Debugger
- (DDB)
-
An interactive in-kernel facility for examining the status of a system, often used after a system has crashed to establish the events surrounding the failure.
- Differentiated System Description Table
- (DSDT)
- Distance-Vector Multicast Routing Protocol
- (DVMRP)
- Domain Name System
- (DNS)
-
The system that converts humanly readable hostnames (i.e., mail.example.net) to Internet addresses and vice versa.
- Dynamic Host Configuration Protocol
- (DHCP)
-
A protocol that dynamically assigns IP addresses to a computer (host) when it requests one from the server. The address assignment is called a “lease”.
E
- ECOFF
-
See: Extended COFF
- ELF
- ESP
- Encapsulated Security Payload
- (ESP)
- Executable and Linking Format
- (ELF)
- Extended COFF
- (ECOFF)
F
G
- GUI
- Giant
-
The name of a mutual exclusion mechanism (a sleep mutex) that protects a large set of kernel resources. Although a simple locking mechanism was adequate in the days where a machine might have only a few dozen processes, one networking card, and certainly only one processor, in current times it is an unacceptable performance bottleneck. FreeBSD developers are actively working to replace it with locks that protect individual resources, which will allow a much greater degree of parallelism for both single-processor and multi-processor machines.
- Graphical User Interface
- (GUI)
-
A system where the user and computer interact with graphics.
H
- HTML
- HUP
-
See: HangUp
- HangUp
- (HUP)
- HyperText Markup Language
- (HTML)
-
The markup language used to create web pages.
I
- I/O
-
See: Input/Output
- IASL
-
See: Intel's ASL compiler
- IMAP
- IP
-
See: Internet Protocol
- IPFW
-
See: IP Firewall
- IPP
- IPv4
-
See: IP Version 4
- IPv6
-
See: IP Version 6
- ISP
- IP Firewall
- (IPFW)
- IP Version 4
- (IPv4)
-
The IP protocol version 4, which uses 32 bits for addressing. This version is still the most widely used, but it is slowly being replaced with IPv6.
See Also: IP Version 6.
- IP Version 6
- (IPv6)
-
The new IP protocol. Invented because the address space in IPv4 is running out. Uses 128 bits for addressing.
- Input/Output
- (I/O)
- Intel's ASL compiler
- (IASL)
-
Intel's compiler for converting ASL into AML.
- Internet Message Access Protocol
- (IMAP)
-
A protocol for accessing email messages on a mail server, characterised by the messages usually being kept on the server as opposed to being downloaded to the mail reader client.
See Also: Post Office Protocol Version 3.
- Internet Printing Protocol
- (IPP)
- Internet Protocol
- (IP)
-
The packet transmitting protocol that is the basic protocol on the Internet. Originally developed at the U.S. Department of Defense and an extremly important part of the TCP/IP stack. Without the Internet Protocol, the Internet would not have become what it is today. For more information, see RFC 791.
- Internet Service Provider
- (ISP)
-
A company that provides access to the Internet.
K
- KAME
-
Japanese for “turtle”, the term KAME is used in computing circles to refer to the KAME Project, who work on an implementation of IPv6.
- KDC
- KLD
- KSE
- KVA
- Kbps
-
See: Kilo Bits Per Second
- Kernel ld(1)
- (KLD)
-
A method of dynamically loading functionality into a FreeBSD kernel without rebooting the system.
- Kernel Scheduler Entities
- (KSE)
-
A kernel-supported threading system. See the project home page for further details.
- Kernel Virtual Address
- (KVA)
- Key Distribution Center
- (KDC)
- Kilo Bits Per Second
- (Kbps)
-
Used to measure bandwith (how much data can pass a given point at a specified amount of time). Alternates to the Kilo prefix include Mega, Giga, Tera, and so forth.
L
- LAN
-
See: Local Area Network
- LOR
-
See: Lock Order Reversal
- LPD
-
See: Line Printer Daemon
- Line Printer Daemon
- (LPD)
- Local Area Network
- (LAN)
-
A network used on a local area, e.g. office, home, or so forth.
- Lock Order Reversal
- (LOR)
-
The FreeBSD kernel uses a number of resource locks to arbitrate contention for those resources. A run-time lock diagnostic system found in FreeBSD-CURRENT kernels (but removed for releases), called witness(4), detects the potential for deadlocks due to locking errors. (witness(4) is actually slightly conservative, so it is possible to get false positives.) A true positive report indicates that “if you were unlucky, a deadlock would have happened here”.
True positive LORs tend to get fixed quickly, so check http://lists.FreeBSD.org/mailman/listinfo/freebsd-current and the LORs Seen page before posting to the mailing lists.
M
- MAC
- MADT
- MFC
-
See: Merge From Current
- MFP4
-
See: Merge From Perforce
- MFS
-
See: Merge From Stable
- MIT
- MLS
-
See: Multi-Level Security
- MOTD
-
See: Message Of The Day
- MTA
-
See: Mail Transfer Agent
- MUA
-
See: Mail User Agent
- Mail Transfer Agent
- (MTA)
-
An application used to transfer email. An MTA has traditionally been part of the BSD base system. Today Sendmail is included in the base system, but there are many other MTAs, such as postfix, qmail and Exim.
- Mail User Agent
- (MUA)
-
An application used by users to display and write email.
- Mandatory Access Control
- (MAC)
- Massachusetts Institute of Technology
- (MIT)
- Merge From Current
- (MFC)
-
To merge functionality or a patch from the -CURRENT branch to another, most often -STABLE.
- Merge From Perforce
- (MFP4)
-
To merge functionality or a patch from the Perforce repository to the -CURRENT branch.
See Also: Perforce.
- Merge From Stable
- (MFS)
-
In the normal course of FreeBSD development, a change will be committed to the -CURRENT branch for testing before being merged to -STABLE. On rare occasions, a change will go into -STABLE first and then be merged to -CURRENT.
This term is also used when a patch is merged from -STABLE to a security branch.
See Also: Merge From Current.
- Message Of The Day
- (MOTD)
-
A message, usually shown on login, often used to distribute information to users of the system.
- Multi-Level Security
- (MLS)
- Multiple APIC Description Table
- (MADT)
N
- NAT
- NDISulator
-
See: Project Evil
- NFS
-
See: Network File System
- NTFS
- NTP
- Network Address Translation
- (NAT)
- Network File System
- (NFS)
- New Technology File System
- (NTFS)
-
A filesystem developed by Microsoft and available in its “New Technology” operating systems, such as Windows 2000, Windows NT and Windows XP.
- Network Time Protocol
- (NTP)
O
- OBE
-
See: Overtaken By Events
- ODMR
-
See: On-Demand Mail Relay
- OS
-
See: Operating System
- On-Demand Mail Relay
- (ODMR)
- Operating System
- (OS)
-
A set of programs, libraries and tools that provide access to the hardware resources of a computer. Operating systems range today from simplistic designs that support only one program running at a time, accessing only one device to fully multi-user, multi-tasking and multi-process systems that can serve thousands of users simultaneously, each of them running dozens of different applications.
- Overtaken By Events
- (OBE)
-
Indicates a suggested change (such as a Problem Report or a feature request) which is no longer relevant or applicable due to such things as later changes to FreeBSD, changes in networking standards, the affected hardware having since become obsolete, and so forth.
P
- p4
-
See: Perforce
- PAE
- PAM
- PAP
- PC
-
See: Personal Computer
- PCNSFD
- PID
-
See: Process ID
- POLA
- POP
-
See: Post Office Protocol
- POP3
- PPD
- PPP
- PPPoA
-
See: PPP over ATM
- PPPoE
-
See: PPP over Ethernet
- PPP over ATM
- (PPPoA)
- PPP over Ethernet
- (PPPoE)
- PR
-
See: Problem Report
- PXE
- Password Authentication Protocol
- (PAP)
- Perforce
-
A source code control product made by Perforce Software which is more advanced than CVS. Although not open source, its use is free of charge to open-source projects such as FreeBSD.
Some FreeBSD developers use a Perforce repository as a staging area for code that is considered too experimental for the -CURRENT branch.
- Personal Computer
- (PC)
- Personal Computer Network File System Daemon
- (PCNFSD)
- Physical Address Extensions
- (PAE)
-
A method of enabling access to up to 64 GB of RAM on systems which only physically have a 32-bit wide address space (and would therefore be limited to 4 GB without PAE).
- Pluggable Authentication Modules
- (PAM)
- Point-to-Point Protocol
- (PPP)
- Pointy Hat
-
A mythical piece of headgear, much like a dunce cap, awarded to any FreeBSD committer who breaks the build, makes revision numbers go backwards, or creates any other kind of havoc in the source base. Any committer worth his or her salt will soon accumulate a large collection. The usage is (almost always?) humorous.
- Portable Document Format
- (PDF)
- Post Office Protocol
- (POP)
- Post Office Protocol Version 3
- (POP3)
-
A protocol for accessing email messages on a mail server, characterised by the messages usually being downloaded from the server to the client, as opposed to remaining on the server.
See Also: Internet Message Access Protocol.
- PostScript Printer Description
- (PPD)
- Preboot eXecution Environment
- (PXE)
- Principle Of Least Astonishment
- (POLA)
-
As FreeBSD evolves, changes visible to the user should be kept as unsurprising as possible. For example, arbitrarily rearranging system startup variables in /etc/defaults/rc.conf violates POLA. Developers consider POLA when contemplating user-visible system changes.
- Problem Report
- (PR)
-
A description of some kind of problem that has been found in either the FreeBSD source or documentation. See Writing FreeBSD Problem Reports.
- Process ID
- (PID)
-
A number, unique to a particular process on a system, which identifies it and allows actions to be taken against it.
- Project Evil
-
The working title for the NDISulator, written by Bill Paul, who named it referring to how awful it is (from a philosophical standpoint) to need to have something like this in the first place. The NDISulator is a special compatibility module to allow Microsoft Windows™ NDIS miniport network drivers to be used with FreeBSD/i386. This is usually the only way to use cards where the driver is closed-source. See src/sys/compat/ndis/subr_ndis.c.
R
- RA
-
See: Router Advertisement
- RAID
- RAM
-
See: Random Access Memory
- RD
-
See: Received Data
- RFC
-
See: Request For Comments
- RISC
- RPC
- RS232C
- RTS
-
See: Request To Send
- Random Access Memory
- (RAM)
- Received Data
- (RD)
-
An RS232C pin or wire that data is recieved on.
See Also: Transmitted Data.
- Recommended Standard 232C
- (RS232C)
-
A standard for communications between serial devices.
- Reduced Instruction Set Computer
- (RISC)
-
An approach to processor design where the operations the hardware can perform are simplified but made as general purpose as possible. This can lead to lower power consumption, fewer transistors and in some cases, better performance and increased code density. Examples of RISC processors include the Alpha, Sparc, ARM and PowerPC.
- Redundant Array of Inexpensive Disks
- (RAID)
- Remote Procedure Call
- (RPC)
- repocopy
-
See: Repository Copy
- Repository Copy
-
A direct copying of files within the CVS repository.
Without a repocopy, if a file needed to be copied or moved to another place in the repository, the committer would run cvs add to put the file in its new location, and then cvs rm on the old file if the old copy was being removed.
The disadvantage of this method is that the history (i.e. the entries in the CVS logs) of the file would not be copied to the new location. As the FreeBSD Project considers this history very useful, a repository copy is often used instead. This is a process where one of the repository meisters will copy the files directly within the repository, rather than using the cvs(1) program.
- Request For Comments
- (RFC)
-
A set of documents defining Internet standards, protocols, and so forth. See www.rfc-editor.org.
Also used as a general term when someone has a suggested change and wants feedback.
- Request To Send
- (RTS)
-
An RS232C signal requesting that the remote system commences transmission of data.
See Also: Clear To Send.
- Router Advertisement
- (RA)
S
- SCI
- SCSI
- SG
-
See: Signal Ground
- SMB
-
See: Server Message Block
- SMP
- SMTP
- SMTP AUTH
-
See: SMTP Authentication
- SSH
-
See: Secure Shell
- STR
-
See: Suspend To RAM
- SMTP Authentication
- (SMTP AUTH)
- Server Message Block
- (SMB)
- Signal Ground
- (SG)
-
An RS232 pin or wire that is the ground reference for the signal.
- Simple Mail Transfer Protocol
- (SMTP)
- Secure Shell
- (SSH)
- Small Computer System Interface
- (SCSI)
- Suspend To RAM
- (STR)
- Symmetric MultiProcessor
- (SMP)
- System Control Interrupt
- (SCI)
T
- TCP
- TCP/IP
- TD
-
See: Transmitted Data
- TFTP
-
See: Trivial FTP
- TGT
- TSC
-
See: Time Stamp Counter
- Ticket-Granting Ticket
- (TGT)
- Time Stamp Counter
- (TSC)
-
A profiling counter internal to modern Pentium processors that counts core frequency clock ticks.
- Transmission Control Protocol
- (TCP)
-
A protocol that sits on top of (e.g.) the IP protocol and guarantees that packets are delivered in a reliable, ordered, fashion.
- Transmission Control Protocol/Internet Protocol
- (TCP/IP)
-
The term for the combination of the TCP protocol running over the IP protocol. Much of the Internet runs over TCP/IP.
- Transmitted Data
- (TD)
-
An RS232C pin or wire that data is transmitted on.
See Also: Received Data.
- Trivial FTP
- (TFTP)
U
- UDP
- UFS1
- UFS2
- UID
-
See: User ID
- URL
- USB
-
See: Universal Serial Bus
- Uniform Resource Locator
- (URL)
- Unix File System Version 1
- (UFS1)
- Unix File System Version 2
- (UFS2)
- Universal Serial Bus
- (USB)
- User ID
- (UID)
-
A unique number assigned to each user of a computer, by which the resources and permissions assigned to that user can be identified.
- User Datagram Protocol
- (UDP)
V
Index
Symbols
- -CURRENT, FreeBSD-CURRENT vs. FreeBSD-STABLE
-
- compiling, Using FreeBSD-CURRENT
- Syncing with CTM, Using FreeBSD-CURRENT
- Syncing with CVSup, Using FreeBSD-CURRENT
- using, Using FreeBSD-CURRENT
- -STABLE, FreeBSD-CURRENT vs. FreeBSD-STABLE, What Is FreeBSD-STABLE?
-
- compiling, Using FreeBSD-STABLE
- syncing with CTM, Using FreeBSD-STABLE
- syncing with CVSup, Using FreeBSD-STABLE
- using, Using FreeBSD-STABLE
- .k5login, User configuration files: .k5login and .k5users
- .k5users, User configuration files: .k5login and .k5users
- .rhosts, Dump and Restore
- /boot/kernel.old, Building and Installing a Custom Kernel
- /etc, Partition Layout
- /etc/gettytab, /etc/gettytab
- /etc/groups, Groups
- /etc/login.conf, Limiting Users
- /etc/mail/access, sendmail Configuration
- /etc/mail/aliases, sendmail Configuration
- /etc/mail/local-host-names, sendmail Configuration
- /etc/mail/mailer.conf, sendmail Configuration
- /etc/mail/mailertable, sendmail Configuration
- /etc/mail/sendmail.cf, sendmail Configuration
- /etc/mail/virtusertable, sendmail Configuration
- /etc/remote, How Am I Expected to Enter These AT Commands?
- /etc/ttys, /etc/ttys
- /usr, Partition Layout
- /usr/bin/login, Quick Overview
- /usr/local/etc, Application Configuration
- /usr/share/skel, adduser
- /var, Partition Layout
- 10 base 2, Stand-alone ISDN Bridges/Routers
- 10 base T, Stand-alone ISDN Bridges/Routers
- 386BSD, A Brief History of FreeBSD, The Current FreeBSD Release
- 386BSD Patchkit, A Brief History of FreeBSD
- 4.3BSD-Lite, A Brief History of FreeBSD
- 4.4BSD-Lite, Welcome to FreeBSD!, What Can FreeBSD Do?
- 802.11
-
- see wireless networking
A
- Abacus, Abacus
- AbiWord, AbiWord
- accounting
-
- disk space, File System Quotas
- printer, lpf: a Text Filter, Accounting for Printer Usage
- accounts
-
- adding, adduser
- changing password, passwd
- daemon, System Accounts
- groups, Groups
- limiting, Limiting Users
- modifying, Modifying Accounts
- nobody, System Accounts
- operator, System Accounts
- removing, rmuser
- superuser (root), The Superuser Account
- system, System Accounts
- user, User Accounts
- ACL, File System Access Control Lists
- ACPI, What Is ACPI?, Background
-
- ASL, ASL, acpidump, and IASL, Fixing Your ASL
- debugging, Getting Debugging Output From ACPI
- error messages, Fixing Your ASL
- problems, Using and Debugging FreeBSD ACPI, Common Problems, Getting Debugging Output From ACPI
- Acrobat Reader, Acrobat Reader
- address redirection, Address Redirection
- adduser, adduser, Administrator Level Setup
- AIX, What Is It?
- Alpha, FreeBSD/alpha, Disk Layouts for the Alpha, Booting for the Alpha, FreeBSD/alpha Bootup
- Alpha BIOS, FreeBSD/alpha
- Amanda, Amanda
- amd, Automatic Mounts with amd
- anti-aliased fonts, Anti-Aliased Fonts
- Apache, Who Uses FreeBSD?, Apache HTTP Server
-
- configuration file, Configuration
- modules, Apache Modules
- starting or stopping, Running Apache
- APIC
-
- disabling, System Hangs (temporary or permanent)
- APM, The Configuration File, What Is ACPI?
- applications
-
- Maple, Installing Maple
- Mathematica, Installing Mathematica
- MATLAB, Installing MATLAB
- Oracle, Installing Oracle
- SAP R/3, Installing SAP R/3
- apsfilter, Automated Conversion: an Alternative to Conversion Filters
- ARC, FreeBSD/alpha
- ASCII, Troubleshooting, Encodings
- AT&T, A Brief History of FreeBSD
- AUDIT, Synopsis
- automatic mounter daemon, Automatic Mounts with amd
- AutoPPP, mgetty and AutoPPP
B
- backup floppies, Can I Use Floppies for Backing Up My Data?
- backup software
-
- Amanda, Amanda
- cpio, cpio
- dump / restore, Dump and Restore
- pax, pax
- tar, tar
- banner pages
-
- see header pages
- Basic Input/Output System
-
- see BIOS
- baud rate, Serial Ports
- BGP, Building a Router
- binary compatibility
-
- BSD/OS, What Can FreeBSD Do?
- Linux, What Can FreeBSD Do?, Synopsis
- NetBSD, What Can FreeBSD Do?
- SCO, What Can FreeBSD Do?
- SVR4, What Can FreeBSD Do?
- BIND, Troubleshooting, Overview
-
- caching name server, Caching Name Server
- configuration files, Configuration Files
- starting, Starting BIND
- zone files, Zone Files
- BIOS, BIOS Drive Numbering, The Booting Problem
- bits-per-second, Checking a Serial Printer, Terminology
- Blowfish, DES, Blowfish, MD5, and Crypt
- Blue Mountain Arts, Who Uses FreeBSD?
- Bluetooth, Bluetooth
- Boot Loader, The Booting Problem
- Boot Manager, The Booting Problem, The Boot Manager and Boot Stages
- boot-loader, Stage Three, /boot/loader
- booting, Synopsis
- BOOTP
-
- diskless operation, Configuration Using BOOTP
- bootstrap, Synopsis
- Bourne shells, Shells
- bridge, Introduction
- browsers
-
- web, Browsers
- BSD Copyright, FreeBSD Project Goals
- BSD partitions, Using sysinstall8
- bsdlabel, Before the Disaster, After the Disaster
C
- CARP, Common Access Redundancy Protocol (CARP)
- CD burner
-
- ATAPI, Introduction
- ATAPI/CAM driver, Using the ATAPI/CAM Driver
- CDROMs
-
- burning, burncd, cdrecord
- creating, Creating and Using Optical Media (CDs)
- creating bootable, mkisofs
- centronics
-
- see parallel printers
- CHAP, Assumptions, PPP and Static IP Addresses, PAP and CHAP Authentication
- chpass, chpass
- Cisco, Using pppd as a Client
- Coda, Network, Memory, and File-Backed File Systems
- command line, Shells
- committers, The FreeBSD Development Model
- Common Access Redundancy Protocol, Common Access Redundancy Protocol (CARP)
- compilers
-
- C, What Can FreeBSD Do?
- C++, What Can FreeBSD Do?
- FORTRAN, What Can FreeBSD Do?
- compression, Can I Compress My Backups?
- Computer Systems Research Group (CSRG), What Can FreeBSD Do?, The Current FreeBSD Release
- comsat, Securing Root-run Servers and SUID/SGID Binaries
- Concurrent Versions System
-
- see CVS
- console, The Console, Single-User Mode
- contributors, The FreeBSD Development Model
- core team, The FreeBSD Development Model
- coredumpsize, Limiting Users
- country codes, Language and Country Codes
- cpio, cpio
- cputime, Limiting Users
- cron, Using FreeBSD-CURRENT, Using FreeBSD-STABLE
-
- configuration, Configuring the cron Utility
- crypt, DES, Blowfish, MD5, and Crypt
- cryptography, mod_ssl
- CTM, Synchronizing Your Source, Using CTM
- cu, Installing FreeBSD on a System without a Monitor or Keyboard
- cuad, Serial Port Configuration
- CUPS, Alternatives to the Standard Spooler
- CVS
-
- anonymous, Synchronizing Your Source, Introduction
- repository, The FreeBSD Development Model
- cvsup, Using FreeBSD-CURRENT, Using FreeBSD-STABLE
D
- dangerously dedicated, Disk Organization
- DCE, Terminology
- default route, Things You Have to Do Only Once, An Example, Default Routes
- Denial of Service (DoS), Introduction, Denial of Service Attacks
- DES, DES, Blowfish, MD5, and Crypt
- device nodes, Common Problems
- device.hints, Device Hints
- DGA, Determining Video Capabilities
- DHCP
-
- configuration files, Files, Files
- dhcpd.conf, Configuring the DHCP Server
- diskless operation, Configuration Using ISC DHCP
- installation, DHCP Server Installation
- requirements, FreeBSD Integration
- server, FreeBSD Integration
- dial-in service, Dial-in Service
- dial-out service, Dial-out Service
- directories, Permissions
- directory hierarchy, Directory Structure
- disk concatenation, Access Bottlenecks
- Disk Labels, Labeling Disk Devices
- Disk Mirroring, RAID1 - Mirroring, Data Integrity
- disk quotas, Limiting Users, File System Quotas
- disk striping, Access Bottlenecks
- diskless operation, Diskless Operation
-
- /usr read-only, Running with a Read-only /usr
- kernel configuration, Building a Diskless Kernel
- diskless workstation, Diskless Operation
- disks
-
- adding, Adding Disks
- detaching a memory disk, Detaching a Memory Disk from the System
- encrypting, Encrypting Disk Partitions
- file-backed, File-Backed File System
- memory, Network, Memory, and File-Backed File Systems
- memory file system, Memory-Based File System
- virtual, Network, Memory, and File-Backed File Systems
- DNS, Hostnames, MS Extensions, Using Electronic Mail, Mail for Your Domain, Overview
-
- records, Zone Files
- DNS Server, What Can FreeBSD Do?
- domain name, Things You Have to Do Only Once
- DOS, Prepare the Boot Media, BIOS Drive Numbering, Kernel and File Systems
- DoS attacks
-
- see Denial of Service (DoS)
- DSL, Filtering/Traffic Shaping Firewall
- DSP, Common Problems
- DTE, Terminology
- dual homed hosts, Dual Homed Hosts
- dump, Dump and Restore
- DVD
-
- burning, Creating and Using Optical Media (DVDs)
- DVD+RW, Creating and Using Optical Media (DVDs)
- DVD-RAM, Using a DVD-RAM
- DVD-RW, Creating and Using Optical Media (DVDs)
- DVD-Video, Creating and Using Optical Media (DVDs)
- Dynamic Host Configuration Protocol
-
- see DHCP
E
- editors, Text Editors
-
- ee, Text Editors
- emacs, Text Editors
- vi, Text Editors
- ee, Text Editors
- electronic mail
-
- see email
- ELF, How Does It Work?
-
- branding, How Does It Work?
- emacs, Text Editors
- email, What Can FreeBSD Do?, Synopsis
-
- change mta, Changing Your Mail Transfer Agent
- configuration, Basic Configuration
- receiving, Receiving Mail
- troubleshooting, Troubleshooting
- encodings, Encodings
- environment variables, Shells
- Etherboot, Preparing a Boot Program with Etherboot
- Ethernet, slip.hosts Configuration
- execution class loader, How Does It Work?
F
- failover, Link Aggregation and Failover
- fdisk, Adding Disks
- fec, Link Aggregation and Failover
- fetchmail, Using fetchmail
- file permissions, Permissions
- file server
-
- UNIX clients, How NFS Works
- Windows clients, File and Print Services for Microsoft Windows clients (Samba)
- file systems
-
- HFS, mkisofs
- ISO 9660, Introduction, mkisofs
- Joliet, mkisofs
- mounted with fstab, The fstab File
- mounting, The mount Command
- snapshots, File System Snapshots
- unmounting, The umount Command
- filesize, Limiting Users
- finger, Securing Root-run Servers and SUID/SGID Binaries
- Firefox, Firefox
- firewall, What Can FreeBSD Do?, Firewalls, Filtering/Traffic Shaping Firewall, Firewalling
-
- IPFILTER, The IPFILTER (IPF) Firewall
- IPFW, IPFW
- PF, The OpenBSD Packet Filter (PF) and ALTQ
- rulesets, Firewall Concepts
- fix-it floppies, Before the Disaster
- floppy disks, Can I Use Floppies for Backing Up My Data?
- flow control protocol, Serial Ports
- fonts, Running the Mathematica Frontend over a Network
-
- anti-aliased, Anti-Aliased Fonts
- LCD screen, Anti-Aliased Fonts
- spacing, Anti-Aliased Fonts
- TrueType, TrueType Fonts
- FORTRAN, Which Conversion Filters Should I Install?
- Free Software Foundation, A Brief History of FreeBSD, The Current FreeBSD Release, GNU Info Files
- FreeBSD Project
-
- development model, The FreeBSD Development Model
- goals, FreeBSD Project Goals
- history, A Brief History of FreeBSD
- FreeBSD Security Advisories, FreeBSD Security Advisories
- FreshMeat, Finding Your Application
- FreshPorts, Finding Your Application
- FTP
-
- anonymous, Anonymous FTP, Configure Additional Network Services, Configuration, Maintaining
- passive mode, Choosing Your Installation Media
- via a HTTP proxy, Choosing Your Installation Media
- FTP servers, What Can FreeBSD Do?, File Transfer Protocol (FTP)
G
- GateD, Running GateD
- gateway, Gateways and Routes
- GEOM, Synopsis, RAID0 - Striping, RAID1 - Mirroring, Labeling Disk Devices, UFS Journaling Through GEOM
- GEOM Disk Framework
-
- see GEOM
- getty, Quick Overview
- Ghostscript, Simulating PostScript on Non PostScript Printers
- GNOME, About GNOME
-
- anti-aliased fonts, Anti-aliased Fonts with GNOME
- GNU Compiler Collection, What Can FreeBSD Do?
- GNU General Public License (GPL), FreeBSD Project Goals
- GNU Lesser General Public License (LGPL), FreeBSD Project Goals
- GNU toolchain, Installing Linux ELF Binaries
- GnuCash, GnuCash
- Gnumeric, Gnumeric
- GQview, GQview
- grace period, Checking Quota Limits and Disk Usage
- Greenman, David, A Brief History of FreeBSD
- Grimes, Rod, A Brief History of FreeBSD
- groups, Groups
- gv, gv
- gzip, Can I Compress My Backups?
H
- hard limit, Setting Quota Limits
- HCI, Bluetooth
- header pages, Enabling the Spooler: the /etc/printcap File, Header Pages
- horizontal scan rate, Before Starting
- hostname, Hostnames
- hosts, /etc/hosts
- HP-UX, What Is It?
- Hubbard, Jordan, A Brief History of FreeBSD
- hw.ata.wc, hw.ata.wc
I
- I/O port, Common Problems
- IEEE, pax
- IKE, Step 2: Securing the link
- image scanners, Image Scanners
- IMAP, Using Electronic Mail, Accessing remote mailboxes using POP and IMAP
- init, The Booting Problem, Init: Process Control Initialization
- installation, Synopsis
-
- floppies, Creating Installation Floppies
- from MS-DOS, Installing from an MS-DOS Partition
- from QIC/SCSI Tape, Creating an Installation Tape
- headless (serial console), Installing FreeBSD on a System without a Monitor or Keyboard
- network
-
- Ethernet, Before Installing over a Network
- FTP, Choosing Your Installation Media, Creating a Local FTP Site with a FreeBSD Disc
- NFS, Before Installing via NFS
- parallel (PLIP), Before Installing over a Network
- serial (SLIP or PPP), Before Installing over a Network
- troubleshooting, Troubleshooting
- Intel i810 graphic chipset, Configuration with Intel i810 Graphics Chipsets
- internationalization
-
- see localization
- Internet connection sharing, Overview
- Internet Software Consortium (ISC), What Is DHCP?
- interrupt storms, System Hangs (temporary or permanent)
- IP aliases, Virtual Hosts
- IP masquerading
-
- see NAT
- IP subnet, Introduction
- IPCP, PPP and Dynamic IP Addresses
- ipf, IPF
- IPFILTER
-
- enabling, Enabling IPF
- kernel options, Kernel options
- logging, IPMON
- rule processing order, IPF Rule Sets
- rule syntax, Rule Syntax
- stateful filtering, Stateful Filtering
- statistics, IPFSTAT
- ipfstat, IPFSTAT
- ipfw, The IPFW Command
-
- enabling, Enabling IPFW
- kernel options, Kernel Options
- logging, Logging Firewall Messages
- rule processing order, IPFW Rule Sets
- rule syntax, Rule Syntax
- stateful filtering, Stateful Rule Option
- ipmon, IPMON
- ipnat, IPNAT
- IPsec, VPN over IPsec
-
- AH, Understanding IPsec
- ESP, Understanding IPsec
- security policies, Step 2: Securing the link
- IPX/SPX, Stand-alone ISDN Bridges/Routers
- IRQ, Common Problems
- ISA, Configuring the System
- ISDN, Filtering/Traffic Shaping Firewall, ISDN
-
- cards, ISDN Cards
- stand-alone bridges/routers, Stand-alone ISDN Bridges/Routers
- ISO 9660, Introduction
- ISP, Assumptions, PPP and Static IP Addresses
J
- jails, Jails
- JMA Wired, Who Uses FreeBSD?
- Jolitz, Bill, A Brief History of FreeBSD
- Journaling, UFS Journaling Through GEOM
K
- KDE, KDE
-
- display manager, The KDE Display Manager
- Kerberos5
-
- configure clients, Kerberos enabling a client with Heimdal
- enabling services, Kerberos enabling a server with Heimdal services
- external resources, Resources and further information
- history, History
- Key Distribution Center, Setting up a Heimdal KDC
- limitations and shortcomings, Mitigating limitations found in Kerberos
- troubleshooting, Kerberos Tips, Tricks, and Troubleshooting
- KerberosIV, Securing the root Account and Staff Accounts, Access Issues with Kerberos and SSH
-
- initial startup, Making It All Run
- installing, Installing KerberosIV
- Kermit, Using pppd as a Client
- kern.cam.scsi_delay, SCSI_DELAY (kern.cam.scsi_delay)
- kern.ipc.somaxconn, kern.ipc.somaxconn
- kern.maxfiles, kern.maxfiles
- kernel, The Booting Problem
-
- boot interaction, Kernel Interaction During Boot
- bootflags, Kernel Boot Flags
- building / installing, Building and Installing a Custom Kernel
- building a custom kernel, Synopsis
- compiling, Compile and Install a New Kernel
- configuration, Configuring the System, Kernel Configuration, Configuration
- configuration file, The Configuration File
- NOTES, The Configuration File
- kernel options
-
- COMPAT_LINUX, Installation
- cpu, The Configuration File
- device pf, Kernel options
- device pflog, Kernel options
- device pfsync, Kernel options
- FAST_IPSEC, Understanding IPsec
- ident, The Configuration File
- IPDIVERT, Kernel Options
- IPFILTER, Kernel options
- IPFILTER_DEFAULT_BLOCK, Kernel options
- IPFILTER_LOG, Kernel options
- IPFIREWALL, Kernel Options
- IPFIREWALL_DEFAULT_TO_ACCEPT, Kernel Options
- IPFIREWALL_VERBOSE, Kernel Options
- IPFIREWALL_VERBOSE_LIMIT, Kernel Options
- IPSEC, Understanding IPsec, Step 2: Securing the link
- IPSEC_DEBUG, Understanding IPsec
- IPSEC_ESP, Understanding IPsec
- machine, The Configuration File
- MROUTING, Multicast Routing
- MSDOSFS, The Configuration File
- NFS, The Configuration File
- NFS_ROOT, The Configuration File
- SCSI_DELAY, SCSI_DELAY (kern.cam.scsi_delay)
- SMP, The Configuration File
- kernel tuning, Kernel Tuning, Kernel Tuning
- kernel.old, Loader Examples
- keymap, Console Setup
- KLD (kernel loadable object), Using Windows NDIS Drivers
- KLD (kernel loadable object), Installation
- KMyMoney, KMyMoney
- KOffice, KOffice
- Konqueror, Konqueror
L
- L2CAP, Bluetooth
- lacp, Link Aggregation and Failover
- lagg, Link Aggregation and Failover
- language codes, Language and Country Codes
- LCD screen, Anti-Aliased Fonts
- LCP, mgetty and AutoPPP
- LDAP, Security Settings
- limiting users, Limiting Users
-
- coredumpsize, Limiting Users
- cputime, Limiting Users
- filesize, Limiting Users
- maxproc, Limiting Users
- memorylocked, Limiting Users
- memoryuse, Limiting Users
- openfiles, Limiting Users
- quotas, Limiting Users
- sbsize, Limiting Users
- stacksize, Limiting Users
- Linux, What Is It?
-
- ELF binaries, Installing Linux ELF Binaries
- installing Linux libraries, Installing Linux Runtime Libraries
- Linux binary compatibility, Synopsis
- LISA, Which Backup Program Is Best?
- loadbalance, Link Aggregation and Failover
- loader, Loader Program Flow
- loader configuration, Loader Program Flow
- locale, Necessary Locales, Using Localization, Setting Locale Methods, Shell Startup File Method
- localization, What Is I18N/L10N?
-
- German, German Language Localization (for All ISO 8859-1 Languages)
- Japanese, Japanese and Korean Language Localization
- Korean, Japanese and Korean Language Localization
- Russian, Russian Language (KOI8-R Encoding)
- Traditional Chinese, Traditional Chinese Localization for Taiwan
- log files, Log File Configuration
-
- FTP, Maintaining
- login class, Setting Locale Methods, Administrator Level Setup
- login name, Assumptions
- loopback device, An Example
- LPD spooling system, Synopsis
- LPRng, Alternatives to the Standard Spooler
- ls, Permissions
M
- MAC, Synopsis
-
- File System Firewall Policy, The MAC bsdextended Module
- MAC Biba Integrity Policy, The MAC Biba Module
- MAC Configuration Testing, Testing the Configuration
- MAC Interface Silencing Policy, The MAC ifoff Module
- MAC LOMAC, The MAC LOMAC Module
- MAC Multi-Level Security Policy, The MAC Multi-Level Security Module
- MAC Port Access Control List Policy, The MAC portacl Module
- MAC Process Partition Policy, The MAC partition Module
- MAC See Other UIDs Policy, The MAC seeotheruids Module
- MAC Troubleshooting, Troubleshooting the MAC Framework
- MacOS, Generating a Single One-time Password
- mail host, The Mail Host
- mail server daemons
-
- exim, Mailhost Server Daemon
- postfix, Mailhost Server Daemon
- qmail, Mailhost Server Daemon
- sendmail, Mailhost Server Daemon
- Mail User Agents, Mail User Agents
- mailing list, Rebuilding world
- make, Compile the Base System
- make.conf, Check /etc/make.conf
- Mandatory Access Control
-
- see MAC
- manual pages, Manual Pages
- Master Boot Record (MBR), The Booting Problem, The Boot Manager
- maxproc, Limiting Users
- MD5, DES, Blowfish, MD5, and Crypt
- memory protection, What Can FreeBSD Do?
- memorylocked, Limiting Users
- memoryuse, Limiting Users
- mencoder, mencoder
- mergemaster, mergemaster
- mgetty, mgetty and AutoPPP
- Microsoft Windows, BIOS Drive Numbering, Using Windows NDIS Drivers, File and Print Services for Microsoft Windows clients (Samba)
-
- device drivers, Using Windows NDIS Drivers
- MIME, Setting Locale, Shell Startup File Method
- MIT, Installing KerberosIV
- modem, Modems and Cables, Using pppd as a Client, Prerequisites, ISDN Terminal Adapters
- mod_perl
-
- Perl, mod_perl
- mod_php
-
- PHP, mod_php
- mount, Installing FreeBSD on a System without a Monitor or Keyboard, After the Disaster
- mountd, How NFS Works
- moused, Console Setup
- Mozilla, Mozilla
-
- disabling anti-aliased fonts, Anti-Aliased Fonts
- MPlayer
-
- making, Building MPlayer
- use, Using MPlayer
- MS-DOS, Troubleshooting, Generating a Single One-time Password
- multi-user facilities, What Can FreeBSD Do?
- multi-user mode, Multi-User Mode, Drop to Single User Mode
- multicast routing, Multicast Routing
- MX record, Email and DNS, Troubleshooting, Basic Configuration, Zone Files
- MySQL, Compiling I18N Programs
N
- Nagios in a MAC Jail, Nagios in a MAC Jail
- nameserver, Assumptions, Things You Have to Do Only Once
- NAT, What Can FreeBSD Do?, NAT, Filtering/Traffic Shaping Firewall, Overview
-
- and IPFILTER, IPNAT
- and IPFW, An Example NAT and Stateful Ruleset
- natd, Overview
- NDIS, Using Windows NDIS Drivers
- NDISulator, Using Windows NDIS Drivers
- net.inet.ip.portrange.*, net.inet.ip.portrange.*
- Net/2, A Brief History of FreeBSD
- NetBIOS, MS Extensions, Global Settings
- NetBSD, The Current FreeBSD Release, What Is It?
- Netcraft, Who Uses FreeBSD?
- netgroups, Using Netgroups
- network address translation
-
- see NAT
- network cards
-
- configuration, Setting Up Network Interface Cards, Configuring the Network Card
- driver, Locating the Correct Driver
- testing, Testing the Ethernet Card
- troubleshooting, Troubleshooting
- network printing, Networked Printing, Printers Installed on Remote Hosts
- newfs, After the Disaster
- newsyslog.conf, newsyslog.conf
- NFS, Network, Memory, and File-Backed File Systems, Quotas over NFS, Network File System (NFS)
-
- configuration, Configuring NFS
- diskless operation, Configuring the TFTP and NFS Servers
- export examples, Configuring NFS
- installing multiple machines, Tracking for Multiple Machines
- mounting, Configuring NFS
- server, How NFS Works
- uses, Practical Uses
- nfsd, How NFS Works
- NIS, What Is It?
-
- client, Machine Types
- client configuration, Setting Up a NIS Client
- domainname, Choosing a NIS Domain Name
- domains, What Is It?
- maps, Initializing the NIS Maps
- master server, Machine Types
- password formats, Password Formats
- server configuration, Setting Up a NIS Master Server
- slave server, Machine Types, Setting up a NIS Slave Server
- NIS+, Security Settings
- NOTES, The Configuration File
- Novell, A Brief History of FreeBSD
- ntalk, Securing Root-run Servers and SUID/SGID Binaries
- NTP, Clock Synchronization with NTP
-
- choosing servers, Choosing Appropriate NTP Servers
- configuration, Configuring Your Machine
- ntp.conf, General Configuration
- ntpd, Overview
- ntpdate, Basic Configuration
- null-modem cable, Installing FreeBSD on a System without a Monitor or Keyboard, Serial Ports, Null-modem Cables, Serial Console Configuration
O
- OBEX, Bluetooth
- office suite
-
- KOffice, KOffice
- OpenOffice.org, OpenOffice.org
- one-time passwords, One-time Passwords
- OpenBSD, The Current FreeBSD Release, What Is It?
- openfiles, Limiting Users
- OpenOffice.org, OpenOffice.org
- OpenSSH, OpenSSH
-
- client, SSH Client
- configuration, Configuration
- enabling, Enabling sshd
- secure copy, Secure Copy
- tunneling, SSH Tunneling
- OpenSSL
-
- certificate generation, Generating Certificates
- Opera, Opera
- OS/2, Troubleshooting, Dedicated
- OSPF, Building a Router
P
- packages, Synopsis
-
- deleting, Deleting a Package
- installing, Installing a Package
- managing, Managing Packages
- page accounting, lpf: a Text Filter
- Pair Networks, Who Uses FreeBSD?
- pairing, Bluetooth
- PAP, Assumptions, PPP and Static IP Addresses, PAP and CHAP Authentication
- Parallel Line IP
-
- see PLIP
- parity, Serial Ports, Checking a Serial Printer
- partition layout, Partition Layout
- partitions, Disk Organization, Adding Disks
- passwd, passwd
- password, Assumptions, PAP and CHAP Authentication
- pax, pax
- PCI, Configuring the System
- PCL, Checking Printer Communications, Troubleshooting
-
- viewing, Acrobat Reader, gv, Xpdf
- permissions, Permissions
-
- symbolic, Symbolic Permissions
- pgp keys, PGP Keys
- Physical Address Extensions (PAE)
-
- large memory, Large Memory Configurations (PAE)
- pkg_add, Installing a Package
- pkg_delete, Deleting a Package
- pkg_info, Managing Packages
- pkg_version, Managing Packages
- PLIP, Parallel Line IP (PLIP)
- POP, Using Electronic Mail, Accessing remote mailboxes using POP and IMAP
- Portaudit, Monitoring Third Party Security Issues
- portmanager, Upgrading Ports using Portmanager
- portmap, Terms/Processes You Should Know
- ports, Synopsis
-
- disk-space, Ports and Disk Space
- installing, Installing Ports
- removing, Removing Installed Ports
- upgrading, Upgrading Ports
- Ports Collection, Installing Using the linux_base Port
- portupgrade, Upgrading Ports using Portupgrade
- POSIX, pax, Setting Locale
- PostScript, Ports and Cables, Checking Printer Communications
-
- emulating, Simulating PostScript on Non PostScript Printers
- viewing, gv
- PPP, Synopsis, Assumptions, Troubleshooting, ISDN Terminal Adapters
-
- client, Using pppd as a Client
- configuration, Automatic PPP Configuration, Final System Configuration
- kernel PPP, Synopsis, Setting Up Kernel PPP
- Microsoft extensions, MS Extensions
- NAT, Using PPP Network Address Translation Capability
- over ATM, Using PPP over ATM (PPPoA)
- over Ethernet, Synopsis, Using PPP over Ethernet (PPPoE)
- receiving incoming calls, Receiving Incoming Calls
- server, Setting Up Kernel PPP
- troubleshooting, Troubleshooting PPP Connections
- user PPP, Synopsis, PPP and Static IP Addresses
- with dynamic IP addresses, PPP and Dynamic IP Addresses
- with static IP addresses, PPP and Static IP Addresses
- PPP shells, PPP Shells for Dynamic-IP Users, PPP Shells for Static-IP Users
- PPPoA
-
- see PPP, over ATM
- PPPoE
-
- see PPP, over Ethernet
- preemptive multitasking, What Can FreeBSD Do?
- print jobs, Introduction, Making the Spooling Directory, Accommodating Plain Text Jobs on PostScript Printers, Controlling Sizes of Jobs Submitted, Checking Jobs
-
- controlling, Controlling Sizes of Jobs Submitted
- print server
-
- Windows clients, File and Print Services for Microsoft Windows clients (Samba)
- printer spool, Making the Spooling Directory
- printers, Printer Setup
-
- capabilities, Enabling the Spooler: the /etc/printcap File
- network, Networked Printing, Printers Installed on Remote Hosts
- parallel, Ports and Cables, Checking a Parallel Printer
- restricting access to, Restricting Printer Usage
- serial, Ports and Cables, Checking a Serial Printer, Configuring Spooler Communication Parameters, Accommodating Plain Text Jobs on PostScript Printers
- usage, Using Printers
- USB, Ports and Cables
- printing, Synopsis, Printing Jobs
-
- filters, Installing the Text Filter, Filters, How Filters Work
- header pages, Suppressing Header Pages
- Process Accounting, Process Accounting
- procmail, Using procmail
- pw, pw, Administrator Level Setup
R
- racoon, Step 2: Securing the link
- RAID, Access Bottlenecks
- RAID-1, Data Integrity
- RAID-5, Data Integrity
- rc files, Resource Configuration (rc)
-
- rc.conf, Core Configuration
- rc.serial, Serial Port Configuration, /etc/rc.d/serial
- Rebuilding world, Rebuilding world
-
- timings, Timings
- resolv.conf, /etc/resolv.conf
- resolver, Terminology
- restore, Dump and Restore
- reverse DNS, Terminology
- RFCOMM, Bluetooth
- RIP, Running GateD, Building a Router
- rlogind, Securing Root-run Servers and SUID/SGID Binaries
- rmuser, rmuser
- root file system, Mounting and Unmounting File Systems
-
- diskless operation, Preparing the Root Filesystem
- root partition, After the Disaster
- root zone, Terminology
- roundrobin, Link Aggregation and Failover
- routed, Final System Configuration
- router, What Can FreeBSD Do?, Building a Router, Filtering/Traffic Shaping Firewall
- routing, Gateways and Routes
- routing propagation, Routing Propagation
- rpcbind, How NFS Works, Terms/Processes You Should Know
- RPMs, Installing the Necessary RPMs
- RS-232C cables, Terminology, Standard RS-232C Cables
- rshd, Securing Root-run Servers and SUID/SGID Binaries
S
- Samba server, File and Print Services for Microsoft Windows clients (Samba)
- sandboxes, Securing Root-run Servers and SUID/SGID Binaries
- sbsize, Limiting Users
- scp, Secure Copy
- screenmap, Console Setup
- SCSI, BIOS Drive Numbering
- SDL, Determining Video Capabilities
- SDP, Bluetooth
- security, Security
-
- account compromises, Introduction
- backdoors, Introduction
- crypt, DES, Blowfish, MD5, and Crypt
- DoS attacks
-
- see Denial of Service (DoS)
- firewalls, Firewalls
- one-time passwords, One-time Passwords
- OpenSSH, OpenSSH
- OpenSSL, OpenSSL
- securing FreeBSD, Securing FreeBSD
- Security Event Auditing
-
- see MAC
- sendmail, Securing Root-run Servers and SUID/SGID Binaries, Final System Configuration, sendmail Configuration
- serial communications, Synopsis
- serial console, Installing FreeBSD on a System without a Monitor or Keyboard, Setting Up the Serial Console
- serial port, Checking a Serial Printer
- services, Starting Services
- setkey, Step 2: Securing the link
- shared libraries, How to Install Additional Shared Libraries
- shells, Shells
- shutdown, Shutdown Sequence
- signal 11, Questions
- single-user mode, Loader Examples, Single-User Mode, Drop to Single User Mode, Reboot into Single User Mode
- skeleton directory, adduser
- slices, Disk Organization, Adding Disks
- SLIP, Synopsis, Using SLIP, Kernel Configuration, slip.hosts Configuration
-
- client, Setting Up a SLIP Client
- connecting with, Making a SLIP Connection
- routing, Routing Considerations
- server, Setting Up a SLIP Server
- SMTP, Final System Configuration, Basic Configuration
- snapshot, What Is FreeBSD-CURRENT?
- soft limit, Setting Quota Limits
- Soft Updates, Soft Updates
-
- details, More Details about Soft Updates
- Solaris, How Does It Work?, What Is It?
- Sony Japan, Who Uses FreeBSD?
- Sophos Anti-Virus, Who Uses FreeBSD?
- sound cards, Configuring the System
- source code, What Can FreeBSD Do?
- spreadsheet
- SQL database, Security Settings
- SRM, FreeBSD/alpha
- ssh, Access Issues with Kerberos and SSH
-
- sshd, Enabling SSH login
- sshd, Securing Root-run Servers and SUID/SGID Binaries
- SSL, mod_ssl
- stacksize, Limiting Users
- startup scripts, Logging into FreeBSD
- static IP address, Assumptions
- static routes, Static Routes
- Striping, RAID0 - Striping
- su, Securing the root Account and Staff Accounts, Using sysinstall8
- subnet, Gateways and Routes, An Example
- SunOS, Building and Installing a Custom Kernel, Choosing a NIS Domain Name
- Supervalu, Who Uses FreeBSD?
- swap
-
- encrypting, Encrypting Swap Space
- swap partition, Swap Partition
- swap sizing, Swap Partition
- symbolic links, How to Install Additional Shared Libraries
- Symmetric Multi-Processing (SMP), What Can FreeBSD Do?
- sysctl, sysctl.conf, Tuning with sysctl, Securing the Kernel Core, Raw Devices, and File systems
- sysctl.conf, sysctl.conf
- sysinstall, Console Setup, FreeBSD Integration
-
- adding disks, Using sysinstall8
- syslog, Maintaining
- syslog.conf, syslog.conf
- system configuration, Synopsis
- system optimization, Synopsis
- sysutils/cdrtools, Introduction
T
- tape media, Creating and Using Data Tapes
-
- AIT, AIT
- DDS (4mm) tapes, 4mm (DDS: Digital Data Storage)
- DLT, DLT
- Exabyte (8mm) tapes, 8mm (Exabyte)
- QIC tapes, 4mm (DDS: Digital Data Storage)
- QIC-150, QIC
- tar, Can I Compress My Backups?, tar
- TCP Bandwidth Delay Product Limiting
-
- net.inet.tcp.inflight.enable, TCP Bandwidth Delay Product
- TCP Wrappers, TCP Wrappers, NIS Security
- TCP/IP networking, What Can FreeBSD Do?, Prerequisites, slip.hosts Configuration
- TELEHOUSE America, Who Uses FreeBSD?
- telnetd, Securing Root-run Servers and SUID/SGID Binaries
- terminals, Virtual Consoles and Terminals, Terminals
- TeX, Why You Should Use the Spooler, Formatting and Conversion Options
-
- printing DVI files, Why Install Conversion Filters?
- text editors, Text Editors
- TFTP
-
- diskless operation, Configuring the TFTP and NFS Servers
- The GIMP, The GIMP
- timeout, PPP and Static IP Addresses
- traceroute, Troubleshooting
- Traditional Chinese
-
- BIG-5 encoding, User Level Setup
- troff, How Filters Work
- Tru64 UNIX, Initializing the NIS Maps
- TrueType Fonts, TrueType Fonts
- ttyd, Serial Port Configuration
- tunefs, Soft Updates
- tuning
-
- kernel limits, Tuning Kernel Limits
- with sysctl, Tuning with sysctl
- TV cards, Setting Up TV Cards
U
- U.C. Berkeley, What Can FreeBSD Do?, A Brief History of FreeBSD, The Current FreeBSD Release
- UDP, How It Works
- Unicode, Kernel and File Systems
- UNIX, Permissions, Assumptions
- USB
-
- disks, USB Storage Devices
- USENET, What Can FreeBSD Do?
- users
-
- large sites running FreeBSD, Who Uses FreeBSD?
- UUCP, Troubleshooting
V
- vertical scan rate, Before Starting
- vfs.hirunningspace, vfs.hirunningspace
- vfs.vmiodirenable, vfs.vmiodirenable
- vfs.write_behind, vfs.write_behind
- vi, Text Editors
- video packages, Ports and Packages Dealing with Video
- video ports, Ports and Packages Dealing with Video
- Vinum, Disks Are Too Small
-
- concatenation, Access Bottlenecks
- mirroring, Data Integrity
- striping, Access Bottlenecks
- vipw, Administrator Level Setup
- virtual consoles, Virtual Consoles and Terminals
- virtual disks, Network, Memory, and File-Backed File Systems
- virtual hosts, Virtual Hosts
- virtual memory, What Can FreeBSD Do?
- virtual private network
-
- see VPN
- vm.swap_idle_enabled, vm.swap_idle_enabled
- VPN, Understanding IPsec
W
- Walnut Creek CDROM, A Brief History of FreeBSD
- Weathernews, Who Uses FreeBSD?
- web servers, What Can FreeBSD Do?
-
- secure, mod_ssl
- setting up, Apache HTTP Server
- wheel, Securing the root Account and Staff Accounts
- widescreen flatpanel configuration, Adding a Widescreen Flatpanel to the Mix
- Williams, Nate, A Brief History of FreeBSD
- Windows, Generating a Single One-time Password
- Windows drivers, Using Windows NDIS Drivers
- Windows NT, What Is It?
- wireless networking, Wireless Networking
X
- X Display Manager, Overview
- X Window System, What Can FreeBSD Do?
-
- see also XFree86
- Accelerated-X, What Can FreeBSD Do?
- XFree86, What Can FreeBSD Do?
- X11, X11 Configuration
- X11 Input Method (XIM), Inputting Non-English Characters
- X11 True Type font server, Displaying Fonts
- X11 tuning, Configuring X11
- XML, Anti-Aliased Fonts
- Xorg, X11 Configuration
- xorg.conf, Configuring X11
- Xpdf, Xpdf
- XVideo, Determining Video Capabilities
Colophon
This book is the combined work of hundreds of contributors to “The FreeBSD Documentation Project”. The text is authored in SGML according to the DocBook DTD and is formatted from SGML into many different presentation formats using Jade, an open source DSSSL engine. Norm Walsh's DSSSL stylesheets were used with an additional customization layer to provide the presentation instructions for Jade. The printed version of this document would not be possible without Donald Knuth's TeX typesetting language, Leslie Lamport's LaTeX, or Sebastian Rahtz's JadeTeX macro package.