
 |  |
Chapter 10. XML
Contents:
XML Terminology
XML Reference
Entity and Character References
Document Type Definitions
The Extensible Stylesheet Language
XSLT Style Sheet Structure
Templates and Patterns
XSLT Elements
XPath
XPointer and XLink
The Extensible Markup Language (XML) is a document-processing standard that is an official recommendation of the World Wide Web Consortium (W3C), the same group responsible for overseeing the HTML standard. Many expect XML and its sibling technologies to become the markup language of choice for dynamically generated content, including nonstatic web pages. Many companies are already integrating XML support into their products.
XML is actually a simplified form of Standard Generalized Markup Language (SGML), an international documentation standard that has existed since the 1980s. However, SGML is extremely complex, especially for the Web. Much of the credit for XML's creation can be attributed to Jon Bosak of Sun Microsystems, Inc., who started the W3C working group responsible for scaling down SGML to a form more suitable for the Internet.
Put succinctly, XML is a metalanguage that allows you to create and format your own document markups. With HTML, existing markup is static: <HEAD> and <BODY>, for example, are tightly integrated into the HTML standard and cannot be changed or extended. XML, on the other hand, allows you to create your own markup tags and configure each to your liking—for example, <HeadingA>, <Sidebar>, <Quote>, or <ReallyWildFont>. Each of these elements can be defined through your own document type definitions and stylesheets and applied to one or more XML documents. XML schemas provide another way to define elements. Thus, it is important to realize that there are no correct tags for an XML document, except those you define yourself.
While many XML applications currently support Cascading Style Sheets (CSS), a more extensible style sheet specification exists, called the Extensible Stylesheet Language (XSL). With XSL, you ensure that XML documents are formatted the same way no matter which application or platform they appear on.
XSL consists of two parts: XSLT (transformations) and XSL-FO (formatting objects). Transformations, as discussed in this book, allow you to work with XSLT and convert XML documents to other formats such as HTML. Formatting objects is described briefly later in this chapter.
This chapter offers a quick overview of XML, as well as some sample applications that allow you to get started in coding. We won't cover everything about XML. Some XML-related specifications are still in flux as this book goes to print. However, after reading this book, we hope that the components that make up XML will seem a little less foreign.
10.1. XML Terminology
Before we move further, we need to standardize some terminology. An XML document consists of one or more elements. An element is marked with the following form:
<Body> This is text formatted according to the Body element </Body>.
This element consists of two tags: an opening tag, which places the name of the element between a less-than sign (<) and a greater-than sign (>), and a closing tag, which is identical except for the forward slash (/) that appears before the element name. Like HTML, the text between the opening and closing tags is considered part of the element and is processed according to the element's rules.
Elements can have attributes applied, such as the following:
<Price currency="Euro">25.43</Price>
Here, the attribute is specified inside of the opening tag and is called ¤cy;. It is given a value of Euro, which is placed inside quotation marks. Attributes are often used to further refine or modify the default meaning of an element.
In addition to the standard elements, XML also supports empty elements. An empty element has no text between the opening and closing tags. Hence, both tags can (optionally) be combined by placing a forward slash before the closing marker. For example, these elements are identical:
<Picture src="blueball.gif"></Picture> <Picture src="blueball.gif"/>
Empty elements are often used to add nontextual content to a document or provide additional information to the application that parses the XML. Note that while the closing slash may not be used in single-tag HTML elements, it is mandatory for single-tag XML empty elements.
10.1.1. Unlearning Bad Habits
Whereas HTML browsers often ignore simple errors in documents, XML applications are not nearly as forgiving. For the HTML reader, there are a few bad habits from which we should dissuade you:
- XML is case-sensitive
- Element names must be used exactly as they are defined. For example, <Paragraph> and <paragraph> are not the same.
- Attribute values must be in quotation marks
-
You can't specify an attribute value as
&<picture src=/images/blueball.gif/>;,
an error that HTML browsers often overlook. An attribute value must
always be inside single or double quotation marks, or else the XML
parser will flag it as an error. Here is the correct way to specify
such a tag:
<picture src="/images/blueball.gif"/>
- A non-empty element must have an opening and a closing tag
-
Each element that specifies an opening tag must have a closing tag
that matches it. If it does not, and it is not an empty element, the
XML parser generates an error. In other words, you cannot do the
following:
<Paragraph> This is a paragraph. <Paragraph> This is another paragraph.
Instead, you must have an opening and a closing tag for each paragraph element:
<Paragraph>This is a paragraph.</Paragraph> <Paragraph>This is another paragraph.</Paragraph>
- Tags must be nested correctly
-
It is illegal to do the following:
<Italic><Bold>This is incorrect</Italic></Bold>
The closing tag for the <Bold> element should be inside the closing tag for the <Italic> element to match the nearest opening tag and preserve the correct element nesting. It is essential for the application parsing your XML to process the hierarchy of the elements:
<Italic><Bold>This is correct</Bold></Italic>
These syntactic rules are the source of many common errors in XML, especially because some of this behavior can be ignored by HTML browsers. An XML document adhering to these rules (and a few others that we'll see later) is said to be well-formed.
10.1.2. An Overview of an XML Document
Generally, two files are needed by an XML-compliant application to use XML content:
- The XML document
- This file contains the document data, typically tagged with meaningful XML elements, any of which may contain attributes.
- Document Type Definition (DTD)
- This file specifies rules for how the XML elements, attributes, and other data are defined and logically related in the document.
There's another type of file commonly used to help display XML data: the style sheet.
The style sheet dictates how document elements should be formatted when they are displayed. Note that you can apply different stylesheets to the same document, depending on the environment, thus changing the document's appearance without affecting any of the underlying data. The separation between content and formatting is an important distinction in XML.
10.1.3. A Simple XML Document
Example 10-1 shows a simple XML document.
Example 10-1. sample.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE OReilly:Books SYSTEM "sample.dtd"> <!-- Here begins the XML data --> <OReilly:Books xmlns:OReilly=http://www.oreilly.com> <OReilly:Product>Webmaster in a Nutshell</OReilly:Product> <OReilly:Price>24.95</OReilly:Price> </OReilly:Books>
Let's look at this example line by line.
In the first line, the code between the <?xml and the ?> is called an XML declaration. This declaration contains special information for the XML processor (the program reading the XML), indicating that this document conforms to Version 1.0 of the XML standard and uses UTF-8 (Unicode optimized for ASCII) encoding.
The second line is as follows:
<!DOCTYPE OReilly:Books SYSTEM "sample.dtd">
This line points out the root element of the document, as well as the DTD validating each of the document elements that appear inside the root element. The root element is the outermost element in the document that the DTD applies to; it typically denotes the document's starting and ending point. In this example, the <OReilly:Books> element serves as the root element of the document. The SYSTEM keyword denotes that the DTD of the document resides in an external file named sample.dtd. On a side note, it is possible to simply embed the DTD in the same file as the XML document. However, this is not recommended for general use because it hampers reuse of DTDs.
Following that line is a comment. Comments always begin with <!-- and end with -->. You can write whatever you want inside comments; they are ignored by the XML processor. Be aware that comments, however, cannot come before the XML declaration and cannot appear inside an element tag. For example, this is illegal:
<OReilly:Books <!-- This is the tag for a book -->>
Finally, the elements <OReilly:Product>, <OReilly:Price>, and <OReilly:Books> are XML elements we invented. Like most elements in XML, they hold no special significance except for whatever document rules we define for them. Note that these elements look slightly different than those you may have seen previously because we are using namespaces. Each element tag can be divided into two parts. The portion before the colon (:) identifies the tag's namespace; the portion after the colon identifies the name of the tag itself.
Let's discuss some XML terminology. The <OReilly:Product> and <OReilly:Price> elements would both consider the <OReilly:Books> element their parent. In the same manner, elements can be grandparents and grandchildren of other elements. However, we typically abbreviate multiple levels by stating that an element is either an ancestor or a descendant of another element.
10.1.3.1. Namespaces
Namespaces were created to ensure uniqueness among XML elements. They are not mandatory in XML, but it's often wise to use them.
For example, let's pretend that the <OReilly:Books> element was simply named <Books>. When you think about it, it's not out of the question that another publisher would create its own <Books> element in its own XML documents. If the two publishers combined their documents, resolving a single (correct) definition for the <Books> tag would be impossible. When two XML documents containing identical elements from different sources are merged, those elements are said to collide. Namespaces help to avoid element collisions by scoping each tag.
In Example 10-1, we scoped each tag with the OReilly namespace. Namespaces are declared using the &xmlns:;something attribute, where something defines the prefix of the namespace. The attribute value is a unique identifier that differentiates this namespace from all other namespaces; the use of a URI is recommended. In this case, we use the O'Reilly URI http://www.oreilly.com as the default namespace, which should guarantee uniqueness. A namespace declaration can appear as an attribute of any element, in which case the namespace remains inside that element's opening and closing tags. Here are some examples:
<OReilly:Books xmlns:OReilly=http://www.oreilly.com> ... </OReilly:Books> <xsl:stylesheet xmlns:xsl=http://www.w3.org> ... </xsl:stylesheet>
You are allowed to define more than one namespace in the context of an element:
<OReilly:Books xmlns:OReilly=http://www.oreilly.com
xmlns:Songline=http://www.songline.com>
...
</OReilly:Books>If you do not specify a name after the xmlns prefix, the namespace is dubbed the default namespace and is applied to all elements inside the defining element that do not use a namespace prefix of their own. For example:
<Books xmlns=http://www.oreilly.com
xmlns:Songline=http://www.songline.com>
<Book>
<Title>Webmaster in a Nutshell</Title>
<ISBN>0-596-00357-9</ISBN>
</Book>
<Songline:CD>18231</Songline:CD>
</Books>Here, the default namespace (represented by the URI http://www.oreilly.com) is applied to the elements <Books>, <Book>, <Title>, and <ISBN>. However, it is not applied to the <Songline:CD> element, which has its own namespace.
Finally, you can set the default namespace to an empty string. This ensures that there is no default namespace in use within a specific element:
<header xmlns=
xmlns:OReilly=http://www.oreilly.com
xmlns:Songline=http://www.songline.com>
<entry>Learn XML in a Week</entry>
<price>10.00</price>
</header>Here, the <entry> and <price> elements have no default namespace.
10.1.4. A Simple Document Type Definition (DTD)
Example 10-2 creates a simple DTD for our XML document.
Example 10-2. sample.dtd
<?xml version="1.0"?>
<!ELEMENT OReilly:Books (OReilly:Product, OReilly:Price)>
<!ATTLIST OReilly:Books
xmlns:OReilly CDATA "http://www.oreilly.com">
<!ELEMENT OReilly:Product (#PCDATA)>
<!ELEMENT OReilly:Price (#PCDATA)>The purpose of this DTD is to declare each of the elements used in our XML document. All document-type data is placed inside a construct with the characters <!something>.
Each <!ELEMENT> construct declares a valid element for our XML document. With the second line, we've specified that the <OReilly:Books> element is valid:
<!ELEMENT OReilly:Books
(OReilly:Product, OReilly:Price)>The parentheses group together the required child elements for the element <OReilly:Books>. In this case, the <OReilly:Product> and <OReilly:Price> elements must be included inside our <OReilly:Books> element tags, and they must appear in the order specified. The elements <OReilly:Product> and <OReilly:Price> are therefore considered children of <OReilly:Books>.
Also, the <OReilly:Product> and <OReilly:Price> elements are declared in our DTD:
<!ELEMENT OReilly:Product (#PCDATA)> <!ELEMENT OReilly:Price (#PCDATA)>
Again, parentheses specify required elements. In this case, they both have a single requirement, represented by #PCDATA. This is shorthand for parsed character data, which means that any characters are allowed, as long as they do not include other element tags or contain the characters < or &, or the sequence ]]>. These characters are forbidden because they could be interpreted as markup. (We'll see how to get around this shortly.)
The line <!ATTLIST OReilly:Books xmlns:OReilly CDATA "http://www.oreilly.com"> indicates that the <xmlns:OReilly> attribute of the <OReilly:Books> element defaults to the URI associated with O'Reilly & Associates if no other value is explicitly specified in the element.
The XML data shown in Example 10-1 adheres to the rules of this DTD: it contains an <OReilly:Books> element, which in turn contains an <OReilly:Product> element followed by an <OReilly:Price> element inside it (in that order). Therefore, if this DTD is applied to the data with a <!DOCTYPE> statement, the document is said to be valid.
10.1.5. A Simple XSL Style Sheet
XSL allows developers to describe transformations using XSL Transformations (XSLT), which can convert XML documents into XSL Formatting Objects, HTML, or other textual output.
As this book goes to print, the XSL Formatting Objects specification is still changing; therefore, this book covers only the XSLT portion of XSL. The examples that follow, however, are consistent with the W3C specification.
Let's add a simple XSL style sheet to the example:
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<font size="+1">
<xsl:apply-templates/>
</font>
</xsl:template>
</xsl:stylesheet>The first thing you might notice when you look at an XSL style sheet is that it is formatted in the same way as a regular XML document. This is not a coincidence. By design, XSL stylesheets are themselves XML documents, so they must adhere to the same rules as well-formed XML documents.
Breaking down the pieces, you should first note that all XSL elements must be contained in the appropriate <xsl:stylesheet> outer element. This tells the XSLT processor that it is describing style sheet information, not XML content itself. After the opening <xsl:stylesheet> tag, we see an XSLT directive to optimize output for HTML. Following that are the rules that will be applied to our XML document, given by the <xsl:template> elements (in this case, there is only one rule).
Each rule can be further broken down into two items: a template pattern and a template action. Consider the line:
<xsl:template match="/">
This line forms the template pattern of the style sheet rule. Here, the target pattern is the root element, as designated by match="/". The / is shorthand to represent the XML document's root element.
The contents of the <xsl:template> element:
<font size="+1">
<xsl:apply-templates/>
</font>specify the template action that should be performed on the target. In this case, we see the empty element <xsl:apply-templates/> located inside a <font> element. When the XSLT processor transforms the target element, every element inside the root element is surrounded by the <font> tags, which will likely cause the application formatting the output to increase the font size.
In our initial XML example, the <OReilly:Product> and <OReilly:Price> elements are both enclosed inside the <OReilly:Books> tags. Therefore, the font size will be applied to the contents of those tags. Example 10-3 displays a more realistic example.
Example 10-3. sample.xsl
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3c.org/1999/XSL/Transform"
xmlns:OReilly="http://www.oreilly.com">
<xsl:output method="html">
<xsl:template match="/">
<html>
<body>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="OReilly:Books">
<font size="+3">
<xsl:text>Books: </xsl:text>
<br/>
<xsl:apply-templates/>
</font>
</xsl:template>
<xsl:template match="OReilly:Product">
<font size="+0">
<xsl:apply-templates/>
<br/>
</font>
</xsl:template>
<xsl:template match="OReilly:Price">
<font size="+1">
<xsl:text>Price: $</xsl:text>
<xsl:apply-templates/>
<xsl:text> + tax</xsl:text>
<br/>
</font>
</xsl:template>
</xsl:stylesheet>In this example, we target the <OReilly:Books> element, printing the word Books: before it in a larger font size. In addition, the <OReilly:Product> element applies the default font size to each of its children, and the <OReilly:Price> tag uses a slightly larger font size to display its children, overriding the default size of its parent, <OReilly:Books>. (Of course, neither one has any children elements; they simply have text between their tags in the XML document.) The text Price: $ will precede each of <OReilly:Price>'s children, and the characters + tax will come after it, formatted accordingly.
Here is the result after we pass sample.xsl through an XSLT processor:
<html xmlns:OReilly="http://www.oreilly.com">
<body>
<font size="+3">
Books: <br>
<font size="+0">
Webmaster in a Nutshell<br>
</font>
<font size="+1">
Price $34.95 + tax
</font>
</font>
</body>
</html>And that's it: everything needed for a simple XML document! Running the result through an HTML browser, you should see something similar to Figure 10-1.
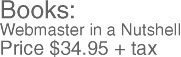
Figure 10-1. Sample XML output
|  | |
| III. XML |  | 10.2. XML Reference |

Copyright © 2003 O'Reilly & Associates. All rights reserved.