
Chapter 9. Database Connectivity
Contents:
Relational Databases
The JDBC API
Reusing Database Objects
Transactions
Advanced JDBC Techniques
It's hard to find a professional web site today that doesn't have some sort of database connectivity. Webmasters have hooked online front ends to all manner of legacy systems, including package tracking and directory databases, as well as many newer systems like online messaging, storefronts, and search engines. But web-database interaction comes with a price: database-backed web sites can be difficult to develop and can often exact heavy performance penalties. Still, for many web sites, especially intranet applications, database connectivity is just too useful to let go. More and more, databases are driving the Web.
This chapter introduces relational databases, the Structured Query Language (SQL) used to manipulate those databases, and the Java database connectivity (JDBC) API itself. Servlets, with their enduring life cycle, and JDBC, a well-defined database-independent database connectivity API, are an elegant and efficient solution for webmasters who need to hook their web sites to back-end databases. In fact, both of your authors started working with servlets specifically because of this efficiency and elegance. Although elsewhere in the book we have assumed that you are familiar with Java, this chapter breaks that assumption and begins with a quick course in JDBC.
The biggest advantage for servlets with regard to database connectivity is that the servlet life cycle (explained in depth in Chapter 3, "The Servlet Life Cycle") allows servlets to maintain open database connections. An existing connection can trim several seconds from a response time, compared to a CGI script that has to reestablish its connection for every invocation. Exactly how to maintain the database connection depends on the task at hand, and this chapter demonstrates several techniques appropriate for different tasks.
Another advantage of servlets over CGI and many other technologies is that JDBC is database-independent. A servlet written to access a Sybase database can, with a two-line modification or a change in a properties file, begin accessing an Oracle database (assuming none of the database calls it makes are vendor-specific). In fact, you should notice that the examples in this chapter are written to access a variety of different databases, including ODBC data sources (such as Microsoft Access), Oracle, and Sybase.
9.1. Relational Databases
In some earlier examples, we've seen servlets that used file storage on the local disk to store their persistent data. The use of a flat file is fine for a small amount of data, but it can quickly get out of control. As the amount of data grows, access times slow to a crawl. And just finding data can become quite a challenge: imagine storing the names, cities, and email addresses of all your customers in a text file. It works great for a company that is just starting out, but what happens when you have hundreds of thousands of customers and want to display a list of all your customers in Boston with email addresses ending in "aol.com"?
One of the best solutions to this problem is a Relational Database Management System (RDBMS). At the most basic level, an RDBMS organizes data into tables. These tables are organized into rows and columns, much like a spreadsheet. Particular rows and columns in a table can be related (hence the term "relational") to one or more rows and columns in another table.
One table in a relational database might contain information about customers, another might contain orders, and a third might contain information about individual items within an order. By including unique identifiers (say, customer numbers and order numbers), orders from the orders table can be linked to customer records and individual order components. Figure 9-1 shows how this might look if we drew it out on paper.
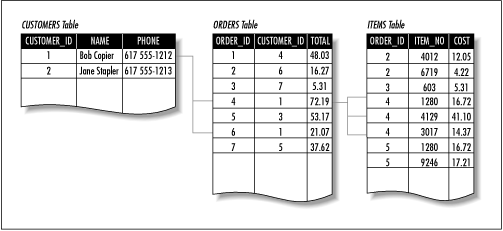
Figure 9-1. Related tables
Data in the tables can be read, updated, appended, and deleted using the Structured Query Language, or SQL, sometimes also referred to as the Standard Query Language. Java's JDBC API introduced in JDK 1.1 uses a specific subset of SQL known as ANSI SQL-2 Entry Level. Unlike most programming languages, SQL is declarative: you say what you want, and the SQL interpreter gives it to you. Other languages, like C, C++, and Java, by contrast, are essentially procedural, in that you specify the steps required to perform a certain task. SQL, while not prohibitively complex, is also rather too broad a subject to cover in great (or, indeed, merely adequate) detail here. In order to make the rest of the examples in this chapter comprehensible, though, here's a brief tutorial.
The simplest and most common SQL expression is the SELECTstatement, which queries the database and returns a set of rows that matches a set of search criteria. For example, the following SELECT statement selects everything from the CUSTOMERS table:
SELECT * FROM CUSTOMERS
SQL keywords like SELECT and FROM and objects like CUSTOMERS are case insensitive but frequently written in uppercase. When run in Oracle's SQL*PLUS SQL interpreter, this query would produce something like the following output:
CUSTOMER_ID NAME PHONE ------------- ----------------------------- --------------- 1 Bob Copier 617 555-1212 2 Janet Stapler 617 555-1213 3 Joel Laptop 508 555-7171 4 Larry Coffee 212 555-6525
More advanced statements might restrict the query to particular columns or include some specific limiting criteria:
SELECT ORDER_ID, CUSTOMER_ID, TOTAL FROM ORDERS WHERE ORDER_ID = 4
This statement selects the ORDER_ID, CUSTOMER_ID, and TOTAL columns from all records where the ORDER_ID field is equal to 4. Here's a possible result:
ORDER_ID CUSTOMER_ID TOTAL
--------- ----------- ---------
4 1 72.19
A SELECT statement can also link two or more tables based on the values of particular fields. This can be either a one-to-one relationship or, more typically, a one-to-many relation, such as one customer to several orders:
SELECT CUSTOMERS.NAME, ORDERS.TOTAL FROM CUSTOMERS, ORDERS WHERE ORDERS.CUSTOMER_ID = CUSTOMERS.CUSTOMER_ID AND ORDERS.ORDER_ID = 4
This statement connects (or, in database parlance, joins) the CUSTOMERS table with the ORDERS table via the CUSTOMER_ID field. Note that both tables have this field. The query returns information from both tables: the name of the customer who made order 4 and the total cost of that order. Here's some possible output:
NAME TOTAL -------------------------------- --------- Bob Copier 72.19
SQL is also used to update the database. For example:
INSERT INTO CUSTOMERS (CUSTOMER_ID, NAME, PHONE) VALUES (5, "Bob Smith", "555 123-3456") UPDATE CUSTOMERS SET NAME = "Robert Copier" WHERE CUSTOMER_ID = 1 DELETE FROM CUSTOMERS WHERE CUSTOMER_ID = 2
The first statement creates a new record in the CUSTOMERS table, filling in the CUSTOMER_ID, NAME, and PHONE fields with certain values. The second updates an existing record, changing the value of the NAME field for a specific customer. The last deletes any records with a CUSTOMER_ID of 2. Be very careful with all of these statements, especially DELETE. A DELETE statement without a WHERE clause will remove all the records in the table!
For a good primer on relational databases and SQL, we recommend SQL for Dummies, by Allen G. Taylor (IDG Books Worldwide).
 |  |  |
| 8.4. Running Servlets Securely |  | 9.2. The JDBC API |

Copyright © 2001 O'Reilly & Associates. All rights reserved.